
«Как проверить количество запросов по ключевым словам?» – Яндекс.Кью
Добрый день!
Количество запросов удобнее всего проверять через https://wordstat.yandex.ru.
Только перед этим моментом советую разобраться с операторами, так как ключевые запросы можно просматривать:
- с точными показами
- с показами с учетом вложенных запросов.
Для более удобной работы с https://wordstat.yandex.ru можно использовать внешние программы, самая популярная и используемая – это Key Collector.
Для примера покажу разницу по операторам:
1) Тут мы видим частотность по всем вложенным запросам без фиксации местоимения (без оператора +).
Запрос — снять отель в москве
Частотность — 1481
2) Если добавим перед союзом «в» оператор +, то увидим, что частотность изменилась. Так как мы отсекли все запросы, где отсутствует союз «в». Например, такие запросы как «снять отель москва сити»
Запрос — снять отель +в москве
Частотность — 1242
3) Оператор «!» используется для фиксации словоформы.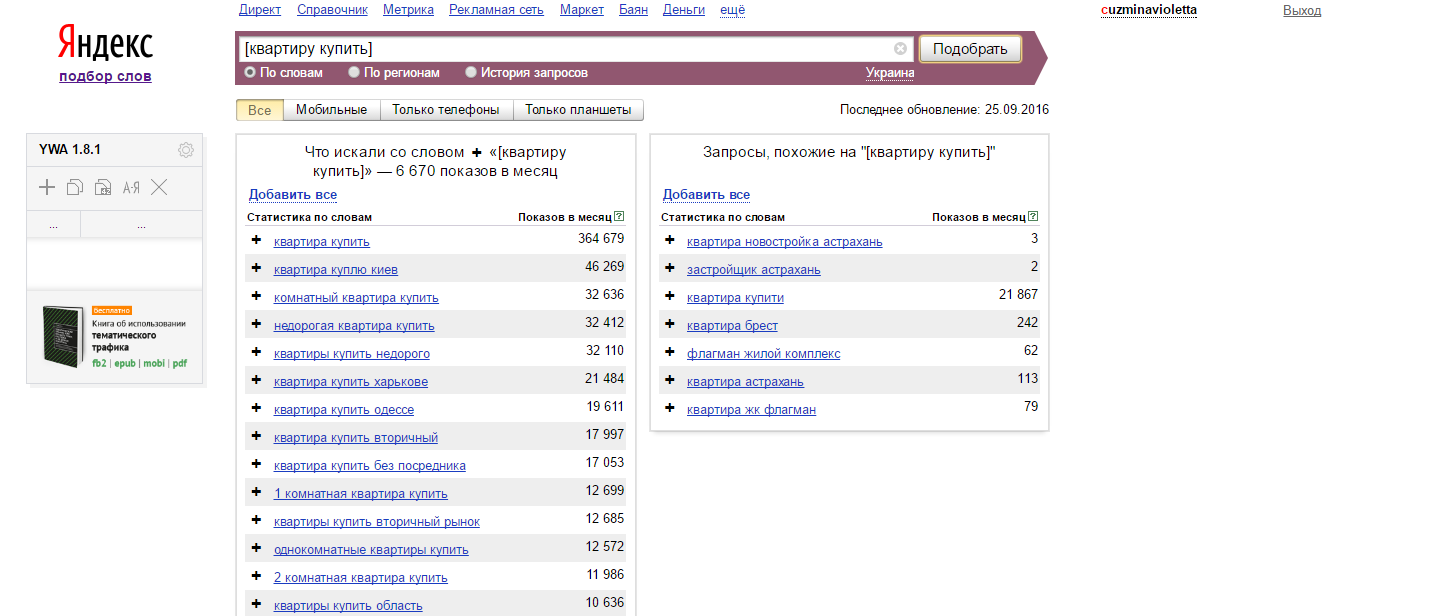 На скриншоте видно, что, при фиксации слова !москве, в выдаче отсутствуют формы слова: москва, москву и прочие.
На скриншоте видно, что, при фиксации слова !москве, в выдаче отсутствуют формы слова: москва, москву и прочие.
Запрос — снять отель в !москве
Частотность — 1094
4) Оператор кавычки «» используется для фиксации количества слов во фразе. Если Вы вводите фразу «снять отель в москве», то к этой фразе не добавляются другие запросы типа «снять отель в москве на ночь».
Запрос — «снять отель в москве»
Частотность — 187
5) Если мы используем все вышеперечисленные операторы, то мы видим чистую частотность по интересующей нас фразе. Запросом «снять отель в москве» интересовались 181 раз.
Почему есть расхождение в количестве показов с оператором кавычки?
6 показов, на которые идут расхождения, это словоформы используемых в запросе слов. Т.е. пользователь мог вводить «сниму отель в москве» или «снять отель в москвА». При использовании операторов вместе в выдаче мы получим отчищенную частотность.
Запрос — «!снять !отель +в !москве»
Частотность — 181
6) Есть оператор квадратных скобок []. Их используют для фиксации последовательности слов. Данный оператор подходит для использования, например, в нише доставки из одного города в другой.
Ниже приведено два скриншота.
На первом скриншоте показана общая частотность при введении запроса «поезд москва спб». Там есть такие запросы, как «поезд спб москва», так и запросы в обратном направлении «поезда москва спб сегодня».
Запрос — поезд москва спб
Частотность — 6476
На втором скриншоте показана частотность при использовании оператора квадратных скобок. В выдаче запросы только по направлению «москва – спб».
Запрос — поезд [москва спб]
Частотность — 1600
Запрос — поезд [спб москва ]
Частотность — 2921
Если Вы, задавая свой вопрос, имели ввиду точную частотность (её обычно используют для анализа трафика в SEO продвижении), то Вам нужно прописать операторы по примеру рисунка №5. Если Вам нужно выявить другие вариации частотности, то можете воспользоваться другими операторами,Яндекс сам подробно разбирает этот момент в своей статье: https://yandex.ru/support/direct/keywords/symbols-and-operators.html
Если Вам нужно выявить другие вариации частотности, то можете воспользоваться другими операторами,Яндекс сам подробно разбирает этот момент в своей статье: https://yandex.ru/support/direct/keywords/symbols-and-operators.html
Как пользоваться Wordstat — как работать с операторами Яндекс Вордстат и статистикой поисковых запросов
В этой статье мы расскажем:
- как работать со статистикой поисковых запросов Яндекса с самых азов;
- рассмотрим на примерах основные и дополнительные операторы;
- научимся определять сезонность спроса;
- дадим полезные советы по использованию софта, облегчающего работу.
Яндекс Вордстат – это бесплатный сервис компании Yandex, призванный помочь оптимизаторам и владельцам сайтов узнать, как люди ищут товары или услуги и собрать ключевые слова для продвижения сайтов.
Помимо этого, сервис позволит:
- узнать частотность;
- определить сезонность по каждому продвигаемому запросу;
- определить спрос по конкретным регионам;
-
определить долю популярности фраз по устройствам (смартфон, десктоп, планшет).


Вы сможете собрать полное семантическое ядро и разработать структуру проекта. Сделать это проще с помощью специализированного софта, но вернемся к этому позже.
Начало работы
Для доступа к статистике сначала необходимо зарегистрироваться в Яндексе.
- заведите почтовый ящик на Яндекс и авторизуйтесь;
- откройте инструмент по ссылке https://wordstat.yandex.ru/.
Готово, можно приступать к работе.
Поиск по словам
Осуществляется поиск запросов, в которых присутствует введенная фраза (в левой колонке), а также всех похожих (в правой колонке). В колонке «Показов в месяц» выводится базовая частотность за последний месяц (суммарная частотность фраз из левой колонки).
Частота по регионам
Отражает частотность запроса в отдельности по регионам, во второй и третьей колонках отражена популярность в числовом и процентном соотношении.
История запросов — сезонность запроса
С помощью этого инструмента можно проанализировать сезонность спроса по товару или услуге. Показывает популярность поискового запроса по месяцам или неделям. По скриншоту ниже видим, что спрос на услугу по «созданию сайтов» имеет значительный рост популярности в период с апреля по июнь.
Регион отображаемой статистики
Выбираем регион, статистика по которому нас интересует. При продвижении, скажем, по Москве – выбираем «Москва и область».
Инструмент позволяет сделать выгрузку по всей России, а также СНГ, Европе, Азии, Африке, Северной и Южной Америке, Австралии и Океании.
Статистика по устройствам
Вкладки «десктоп, мобильные, только телефон, только планшеты» содержат информацию с каких конкретно устройств наиболее часто вводят поисковый запрос.
Операторы Wordstat
Операторы необходимы для уточнения формулировки запроса и точного определения частотности ключевых фраз.
Пример:
Частотность всех ключей со словом «велосипед» – купить велосипед, детский велосипед, трехколесный велосипед и т.д.
Ниже предлагаем рассмотреть основные операторы.
“Кавычки”
Фразы, зафиксированные оператором “кавычки”, например «создание сайтов», отобразят частотность только данного словосочетания без хвостов, во всех возможных формах и в любом порядке.
Сбор статистики запросов определенной длины
С помощью оператора “кавычки” можно вывести на экран статистику запросов, состоящих из заданного количества слов – из 2, 3, 4 и так далее.
Например, чтобы получить список ключей из 2 слов по фразе «велосипед», введите в Wordstat следующую конструкцию – “велосипед велосипед”.
В итоге получаем ключевые слова и базовую частотность по всем запросам из двух слов с заданной фразой. Данная конструкция применима для произвольного количества слов в запросе и любых тематик.
!Восклицательный !знак
Если перед введенными фразами применить оператор «восклицательный знак», то получите частотность по всем фразам с их присутствием именно в том виде и с тем окончанием, как вы ввели.
“!Кавычки !с !восклицательным !знаком”
Если совместить использование операторов Яндекс Вордстат “кавычки” и !восклицательный !знак, сервис покажет частотность четко по заданной фразе слово в слово, без учета порядка.
Дополнительные операторы
Операторы, предназначенные для более сложной сортировки данных при работе со статистикой запросов Wordstat.
[Квадратные скобки]
С помощью данной конструкции фиксируется порядок слов в запросе.
Пример – [стол для обеда]
Абсолютно точная частота запроса с учетом порядка, состава слов и окончаний.

Для получения точной частотности, используйте конструкцию вида – «[!стол !для !обеда]».
(Или|Или)
Вводится с применением вертикального разделителя “|” между словами и заключением их в круглые скобки. Чаще всего применяется, когда необходимо сравнить статистику по двум одинаковым по смыслу запросам, но с разным написанием.
Пример –
(Iphone|айфон), (сайт|вебсайт), (раскрутка|продвижение).
Таким образом, Вордстат показывает все ключи и число их показов сразу по обеим фразам – “iphone” и “айфон”.
Оператор “+”
Если перед любым словом указать символ «плюс», то оно становится обязательным для программы. Также его использование очень полезно для выделения предлогов, так как сам Вордстат их не учитывает.
Пример #1. Вводим поисковый запрос с предлогом
Как мы видим, инструмент проигнорировал наличие предлога и мы не получили статистику в том виде, в каком хотели.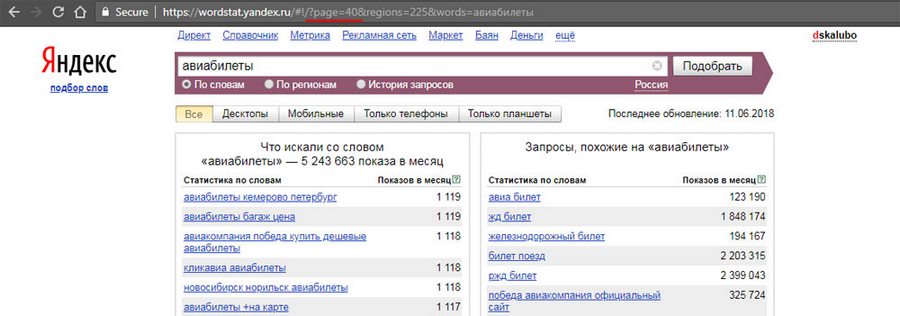
Пример #2. Указываем перед предлогом «+»
Теперь видим, что в левой колонке все запросы содержат нужное нам слово.
С помощью данной конструкции удобно готовить контент-план для публикаций в блоге. Для этого используйте вместе с основным запросом вопросительные плюс-фразы: «как, зачем, почему, своими руками» и так далее.
Оператор “-”
Добавление символа “минус” перед словом поможет исключить все ключи с его участием. Можно добавлять неограниченное количество минус-фраз.
Например, вы хотите создать сайт веб-студии и ваш основной запрос «Создание сайтов». Вам необходимо оценить количество коммерческих запросов и их частотность для понимания целесообразности продвижения в данной тематике.
Для этого соберите список всех минус-фраз, либо найдите в интернете (существует множество готовых списков почти под любую тематику) и введите их все по данной конструкции: создание сайтов -бесплатно -самостоятельно -обучение -курсы и так далее.
Группировка запросов с использованием различных операторов
Пример конструкции:
В данному случае, мы сгруппировали фразы «seo, сео, поисковое, поисковая система, поисковик, яндекс, google» с фразами «продвижение, раскрутка, оптимизация» и убрали ключевые слова с вхождениями «бесплатно, самостоятельно, самому, инструкция».
Как автоматизировать работу со статистикой Вордстат?
Сбор семантического ядра через Вордстат для крупного ресурса или интернет-магазина – очень трудоемкий процесс. Его можно автоматизировать с помощью дополнительного программного обеспечения, сильно сэкономив свое время. Существует большое количество различного ПО для подбора, расширения семантики, анализа видимости конкурентов. Ниже перечислим самые основные и популярные.
1. Yandex Wordstat Helper – бесплатное расширение для браузера Chrome, с помощью которого вы сможете добавлять выбранные запросы в отдельное поле (нажатием на «+»), а потом копировать вместе с частотами одним нажатием кнопки.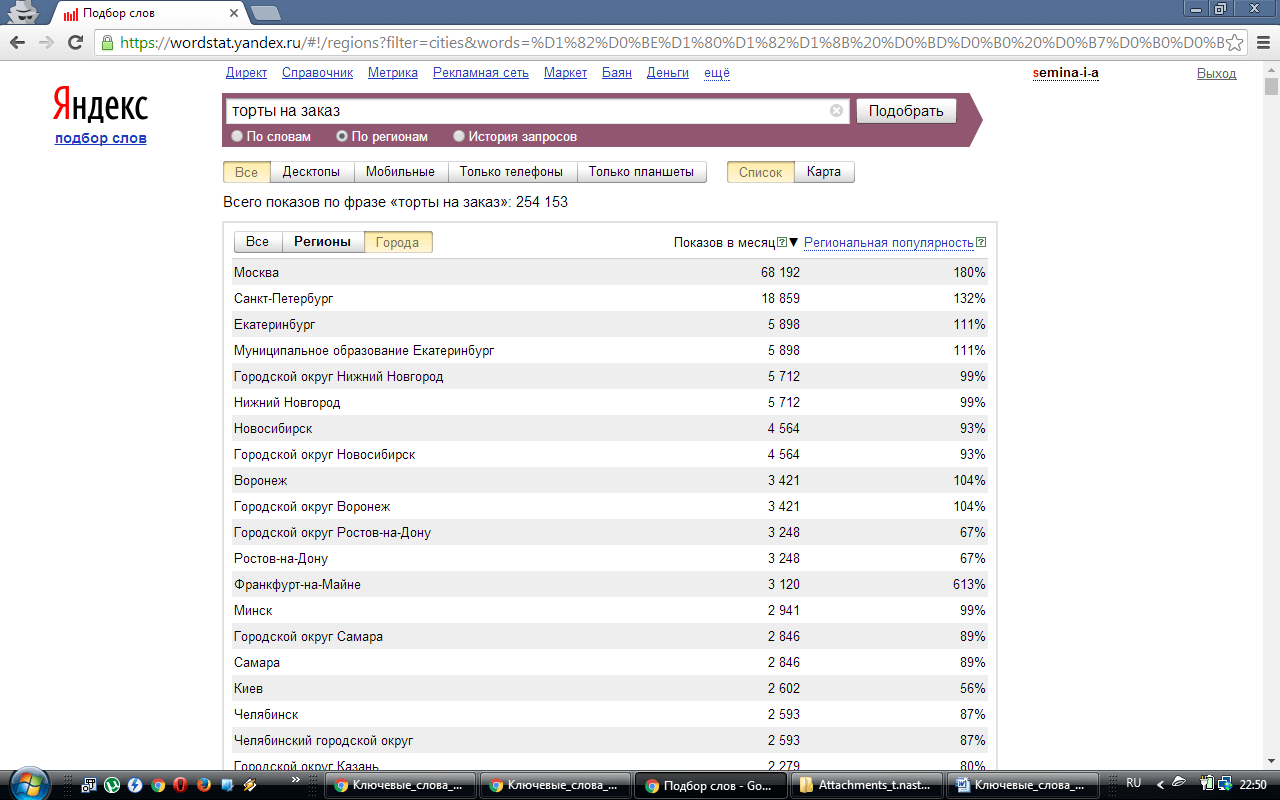
Скачать его можно здесь
2. KeyCollector — инструмент для автоматического парсинга статистики с Wordstat. Использование КейКоллектор исключает необходимость ручного сбора и копирования. Для формирования полного семантического ядра вам понадобится только список базовых запросов:
- вносите их в инструмент;
- выбираете регион сбора статистики;
- запускаете процесс.
Программе понадобится от нескольких часов до нескольких дней, в зависимости от количества ключевых слов в вашей тематике. После окончания сбора ядра необходимо произвести чистку от ненужных фраз и кластеризацию. Но это уже тема для отдельной статьи.
2. Just Magic – содержит модуль парсинга статистики из левой колонки Wordstat с функцией поддержки всех операторов.
3. Букварикс – готовая онлайн база ключевых слов. Для моментальной выгрузки достаточно ввести базовые запросы и инструмент предоставит полный список необходимых вам фраз.
4. SpyWords – позволяет выгрузить видимость сайта конкурента в Яндекс и Google, определив по каким запросам его находят в поиске.
Итог
Надеемся, наша инструкция по Яндекс Вордстат помогла вам разобраться с сервисом. В этой статье мы рассказали о функциях и возможностях программы, а также упомянули инструменты, помогающие упростить и автоматизировать работу.
Еще мы помогаем с продвижением сайтов. Делаем полный анализ тематики вашей деятельности, составляем стратегию, оптимизируем ресурс для выхода в ТОП поисковых систем. Заполните форму ниже, мы вам перезвоним и проконсультируем.
что такое – статистика ключевых слов
«Яндекс.Вордстат» — бесплатный сервис, расположенный по адресу https://wordstat.yandex.ru. Российский аналог Keyword Tool (кейвордс) в Google. Он анализирует частоту показов рекламных объявлений и их зависимость от частоты и качества пользовательских запросов.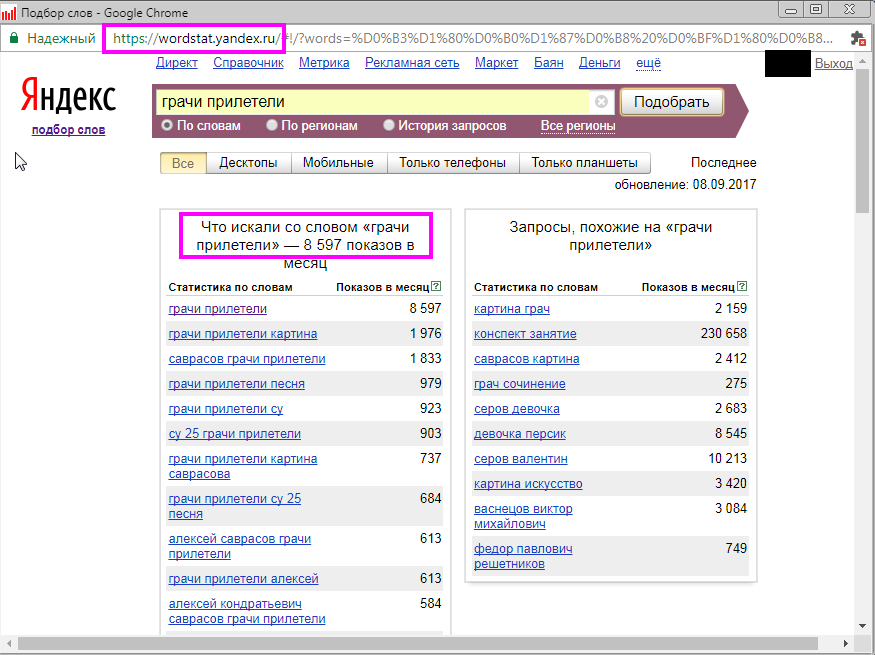 Основной целью сервиса является соотношение зависимости пользователей и тематики сайта и выявление ключевых слов для рекламодателей Direct.Yandex и «Google эдвардс». Статистика ключевых слов отслеживается каждый месяц. Для повышения информативности выдачи поисковых запросов следует не забывать задавать регион продвижения перед поиском. Делается это нажатием на кнопку «Все регионы», расположенную справа. Далее выбирается нужный город/страна.
Основной целью сервиса является соотношение зависимости пользователей и тематики сайта и выявление ключевых слов для рекламодателей Direct.Yandex и «Google эдвардс». Статистика ключевых слов отслеживается каждый месяц. Для повышения информативности выдачи поисковых запросов следует не забывать задавать регион продвижения перед поиском. Делается это нажатием на кнопку «Все регионы», расположенную справа. Далее выбирается нужный город/страна.
Инструкция по использованию «Яндекс.Вордстат»
Для начала работы в поисковую строку вводится запрос. Это может быть продвигаемый продукт, услуга и т. п. Нажимается кнопка «Подобрать». Далее сервис «Вордстарт яндекс» выдает две информативные колонки. В той, что находится слева, отображается ежемесячная статистика поиска по запросам. В правой колонке можно увидеть, что еще дополнительно искали вместе с введенным запросом. Анализ левой колонки позволяет создать прогноз трафика при условии, что в поисковую строку будет вписано ключевое слово. Кроме ежемесячной статистики и выдачи данных по регионам, можно выгрузить еженедельные данные. Также имеется возможность выбрать определенный участок на карте. И информация будет выдаваться только по нему. Отдельно можно получить выгрузку от пользователей десктопом, мобильными, планшетами.
Кроме ежемесячной статистики и выдачи данных по регионам, можно выгрузить еженедельные данные. Также имеется возможность выбрать определенный участок на карте. И информация будет выдаваться только по нему. Отдельно можно получить выгрузку от пользователей десктопом, мобильными, планшетами.
Инструменты
Для повышения точности выдачи в разделах «Статистика на карте, по месяцам и по неделям» можно использовать специальные символы (операторы).
-
Написав запрос в кавычках «»«„, пользователь получит сведения в левом столбце только по заданному слову.
-
Оператор “!», разделяющий каждое слово в поисковой фразе, дает возможность увидеть, сколько раз искали его или определенную фразу именно в таком виде.
-
Символ «+» учитывает служебные части речи, такие как предлоги и союзы.
-
Символ «()» дает возможность сформировать слова в группы.
-
Оператор «_» позволяет не учитывать минус-слова в выдаче.

: Технологии и медиа :: РБК
Графики запросов пользователей о потере обоняния во многом совпадают со статистикой суточного прироста заболевших. В «Яндексе» призвали относиться к такой связи с осторожностью из-за влияния на поисковые запросы разных факторов
Фото: Marko Djurica / Reuters
С 1 ноября «Яндекс» на своей странице статистики, связанной с коронавирусной инфекцией, начал публиковать данные о поисковых запросах пользователей, связанных с потерей обоняния — одним из главных симптомов заражения COVID-19.
Компания приводит график о количестве запросов на фоне заболеваемости COVID-19 в стране. Как следует из статистики, запросы про потерю способности ощущать запахи начали расти в апреле, пик пришелся на май, после чего пошел на спад. Вторая волна таких запросов началась в октябре, пиковые показатели идут в последние дни — примерно 150–180 на 1 млн всех запросов в «Яндексе».
При этом поисковые запросы про обоняние по всей России за вычетом Москвы более умеренны: их было не так много в весеннюю волну эпидемии, однако сейчас идет плавный рост, сообщает компания.
Врачи назвали способ восстановить обоняние после коронавирусаГрафик запросов практически совпадает с графиком новых случаев заболевания. Однако в «Яндексе» связь между этим показателем и числом заражений назвали «очень опосредованной». В компании отметили, что на поисковые запросы может влиять множество внешних факторов: слухи и новости увеличивают их число, а появление у людей знаний о симптомах коронавируса, напротив, снижает.
Однако в «Яндексе» связь между этим показателем и числом заражений назвали «очень опосредованной». В компании отметили, что на поисковые запросы может влиять множество внешних факторов: слухи и новости увеличивают их число, а появление у людей знаний о симптомах коронавируса, напротив, снижает.
Wordstat Yandex — статистика по ключевым словам от Яндекса
Вордстат (Яндекс Wordstat) – инструмент для поиска популярных пользовательских запросов в поисковой системе. Принадлежит компании Яндекс и является абсолютно бесплатным.
Статистика Яндекс WordstatИзначально сервис был придуман для специалистов по контекстной рекламе – чтобы они могли понять, сколько показов объявлений они получат, выбрав тот или иной запрос в качестве ключевого слова. Но наряду со специалистами по контексту Яндекс Вордстат также популярен среди SEO-специалистов, контент-маркетологов и т.д.
Официальный сайт Вордстат Яндекс – https://wordstat.yandex.ru/. Перед тем как начать работу с сервисом, необходимо залогиниться (или создать аккаунт) в Яндексе. Авторизованные пользователи могут сразу начинать вводить в строку поиска ключевое слово и смотреть его популярность.
Перед тем как начать работу с сервисом, необходимо залогиниться (или создать аккаунт) в Яндексе. Авторизованные пользователи могут сразу начинать вводить в строку поиска ключевое слово и смотреть его популярность.
В результатах подбора Яндекс Wordstat отображается следующая информация по ключевому запросу:
- «Что искали со словом «…» –n показов в месяц» – число пользовательских запросов в поиск Яндекса с данным словом. Для расчета система использует данные за последние 30 дней. Причем в этих расчетах используется только статистика из основного поиска Яндекса, запросы пользователей, сделанные на поиске РСЯ, не учитываются.
- В левой колонке также представлена статистика по показам ключевых слов, которые включают в себя запрос, и прогнозируемые показы по ним.
- В правой колонке представлены запросы, похожие на тот, что задал пользователь, и прогнозируемые по ним показы.
По умолчанию в Вордстат-статистике учитываются все города и регионы.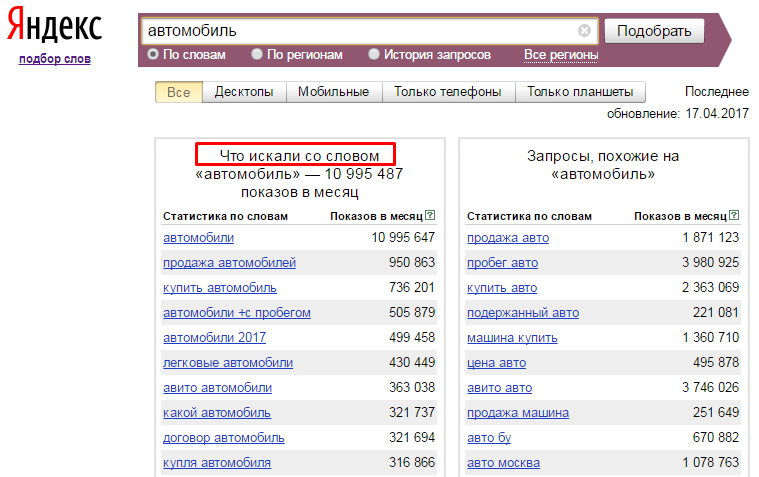 Определенный регион для подбора данных можно выбрать, нажав «Все регионы»:
Определенный регион для подбора данных можно выбрать, нажав «Все регионы»:
Также можно отфильтровать общую статистику по популярности и спросу в разных регионах:
В Яндекс Wordstat доступны срезы по типам устройств пользователей:
- Срез «Десктопы» для запросов, введенных с компьютеров и ноутбуков,
- Срез «Мобильные» для запросов, введенных с планшетов и смартфонов,
- Срез «Только телефоны» – запросы исключительно со смартфонов,
- Срез «Только планшеты» – запросы, введенные только с планшетов.
В Wordstat Yandex для уточнения запроса можно использовать минус-слова, минус-фразы и дополнительные операторы, они поддерживаются во вкладках По словам и По регионам.
История запросовВкладка История запросов пригодится для отслеживания динамики пользовательского интереса к определенной тематике – здесь можно посмотреть помесячный или понедельный срез статистики показов по заданному запросу. Используются данные за последние два года. Интерес пользователей представлен в виде графика.
Используются данные за последние два года. Интерес пользователей представлен в виде графика.
- Статистика доступна в абсолютных и относительных значениях,
- В данном отчете не работают операторы языка запросов.
Статистика поисковых запросов Текст научной статьи по специальности «Компьютерные и информационные науки»
УДК 004.457+ 330.43
UDC 004.457+330.43
СТАТИСТИКА ПОИСКОВЫХ ЗАПРОСОВ SEARCH QUERY STATISTICS
Кириченко Евгений Владимирович магистрант
Kirichenko Evgeniy Vladimirovich undergraduate
Сытников Демид Анатольевич магистрант
Sytnikov Demid Anatolevich undergraduate
Петухов Александр Валерьевич магистрант
Petuhov Aleksandr Valeryevich undergraduate
Кацко Игорь Александрович д.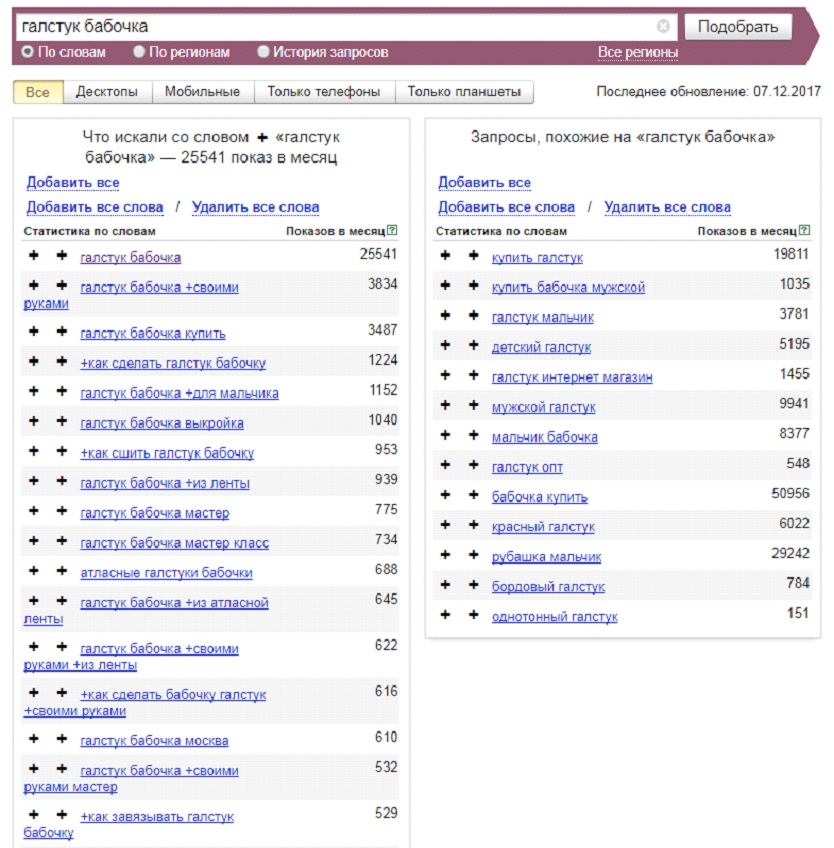 э.н., профессор
э.н., профессор
Кубанский государственный аграрный университет, Краснодар, Россия
Katsko Igor Aleksandrovich Dr.Sci.Econ., professor
Kuban State Agrarian University, Krasnodar, Russia
В статье дан обзор имеющихся статистических сервисов в современных поисковых системах. Обсуждаются статистические результаты на примере вступления России в ВТО
This article surveys the available statistical services in modem search engines. The statistical results are discussed on the example of Russia’s accession to the
WTO
Ключевые слова: ПОИСКОВЫЙ ЗАПРОС, ВТО, Keywords: WTO, SEARCH ENGINES, SERVICE
ПОИСКОВАЯ СИСТЕМА, ФУНКЦИОНАЛЬНЫЙ FUNCTIONALITY
СЕРВИС
В последнее время особую актуальность приобретает изучение интересов населения к тем или иным событиям в жизни общества и государства через интернет. Целью данной статьи является иллюстрация возможностей использования статистического сервиса различных поисковых систем для изучения динамики изменения интересов населения на примере вступления России в ВТО.
Целью данной статьи является иллюстрация возможностей использования статистического сервиса различных поисковых систем для изучения динамики изменения интересов населения на примере вступления России в ВТО.
Согласно теории искусственного интеллекта знания подразделяются на отделимые (<кодифицированные), которые можно представить в одной из естественных или искусственных семиотических (знаковых) систем, и неотделимые, носителем которых является человек. Кодифицированные знания обычно формализованы и достаточно легко могут храниться, копироваться и распространяться. Неотделимые знания накапливаются через личный опыт, обучение в процессе деятельности, социальные взаимоотношения и т.д. Как следствие, они трудно поддаются количественному определению, хранению или передаче. Они выходят далеко за рамки технического прогресса и инноваций,
Классификация знаний
находящих материальное воплощение в продуктах, услугах или процессах.
В свою очередь переносимые (кодифицированные) знания подразделяются на: структурированные, слабоструктурированные, неструктурированные. В первом случае знания имеют определенную последовательность удобных для восприятия форм: уравнения, формулы, графики, схемы, таблицы типа «объект-свойство», а также связи, которые позволяет облегчить их обработку и передачу — теоретической основой изучения таких знаний являются математические и статистические дисциплины, а также современные информационные технологии (например, KDD и Data Mining). Слабоструктурированные знания сегодня являются предметом изучения теории когнитивного моделирования. Неструктурированные же знания являются более сложными для восприятия и обработки, поэтому обычно предлагаются различные подходы к их структуризации.
Одним из примеров неструктурированной формы знаний, которые поддаются обработке, являются всевозможные тексты или же ЖЕЙ-контент. Развитию последнего способствовало появление глобальных каналов связи, в частности сети Интернет.
Развитию последнего способствовало появление глобальных каналов связи, в частности сети Интернет.
Автоматические программные средства поиска и анализа информации
Рост объема доступных через Интернет данных, хранимых в слабо структурированном виде, способствовал появлению автоматических программных средств поиска информации и получения данных об использовании определенных ресурсов. Возник целый ряд интеллектуальных систем, основная задача которых состоит в эффективном извлечении знаний из сети Интернет.
Большинство систем мониторинга сети Интернет предоставляют возможность фильтрации и получения статистической информации о запросах пользователей. Подобные инструменты помогает определять количество обращений к разным файлам и серверам, адресам отдельных ресурсов.
Статистика запросов фактически представляет собой механизм, позволяющий
проводить исследования, которые невозможно провести никаким другим способом. Подобная статистика является наиболее достоверным источником современного языка, в отличие от анализа поисковых результатов, которые являются приблизительными, в силу того, что информация в интернете быстро устаревает. Кроме того, запросы к поисковой системе считаются одним из наиболее репрезентативных источников живого языка [3].
Подобная статистика является наиболее достоверным источником современного языка, в отличие от анализа поисковых результатов, которые являются приблизительными, в силу того, что информация в интернете быстро устаревает. Кроме того, запросы к поисковой системе считаются одним из наиболее репрезентативных источников живого языка [3].
Прежде чем перейти к системам, позволяющим просмотреть статистику запросов пользователей, необходимо раскрыть понятие «статистика запросов».
Поисковый запрос — это информация, с помощью которой осуществляется поиск специальной системой, такой как: Yandex, Google, Rambler и др. Как правило, поисковый запрос задаётся в виде фраз или слов. Бывают и запросы в виде изображений. Формат ключевых запросов зависит от типа информации для поиска и устройства конкретной поисковой системы.
Ключевое слово — это слово, которое в совокупности с другими ключевыми словами, представляет текст сайта. Ключевое слово используется для поиска. Содержание текста, представленное ключевыми словами, анализируется лингвистическими и математическими методами. Например, анализ частоты появления слова в тексте [4].
Ключевое слово используется для поиска. Содержание текста, представленное ключевыми словами, анализируется лингвистическими и математическими методами. Например, анализ частоты появления слова в тексте [4].
Статистика запросов — это информация об обращениях пользователей к поисковой системе по «ключевым словам» [3].
Другими словами статистика запросов — это количество поисковых запросов пользователей по «ключевым словам» за определенный промежуток времени.
В большинстве случаев при работе с сервисом статистики имеется возможность фильтровать результаты по территориальному признаку, языку, а также в хронологической последовательности. При этом обычно, сервис показывает не только данные об искомом запросе, но также и о словосочетаниях, синонимах и близких темах.
В данной статье рассмотрены наиболее интересные и функциональные сервисы, предоставляемые такими поисковыми системами как Yandex, Google,
Rambler и проанализированы полученные с их помощью данные по запросу о вступлении России в ВТО.
Прежде чем приступить к поиску интересующей нас информации, рассмотрим некоторые преимущества и недостатки предоставляемых сервисов каждой из поисковых систем.
Yandex
Яндекс предоставляет доступ к своей статистике всем желающим в рамках системы по продаже рекламы Яндекс.Директ. Кроме стандартной информации о количестве запросов в месяц, а также словосочетаниях и близких темах, поисковик предоставляет возможность отсеивать результаты по регионам, городам в хронологической последовательности.
Учитывая тот факт, что Яндекс является самой популярной в Рунете поисковой системой [5], подобная статистика является наиболее репрезентативной при оценке положения дел в Рунете.
В Яндекс Wordstat статистика запросов представляется в несколько упрощенном виде — объединяются все возможные словоформы (падежи, числа и т. п.), в большинстве случаев не учитываются предлоги, а так же вопросительные формы, например, «что такое» и т. п.
п.), в большинстве случаев не учитываются предлоги, а так же вопросительные формы, например, «что такое» и т. п.
При помощи специальных операторов можно добиться конкретизации статистики Яндекса именно по интересующей словоформе поискового запроса. Обычно для этого достаточно бывает заключить нужный поисковый запрос в кавычки. При этом учитываться будут только эти слова запроса, но в любой допустимой словоформе или же вместе с кавычками можно будет дополнительно поставить восклицательные знаки перед каждым из слов, обязав тем самым статистику Яндекса учитывать только эти слова и только в выбранной вами словоформе.
Следует отметить, что в статистике поисковых запросов Яндекса приводятся не только производные от введенных вами слов (в левой колонке как раз будут
показаны эти самые расширенные варианты запросов с добавлением других слов), но еще дополнительно в правой колонке будут показаны ассоциативные запросы, которые набирали те же самые пользователи в Яндексе вместе с введенными вами словами за одну и ту же сессию поиска.
Rambler
Система статистики имеется и у Рамблера. Она менее репрезентативна в силу меньшей популярности поисковой системы, чем статистика Яндекса, но её преимуществом является более подробная информация. К примеру, сервис выдает информацию о количестве запросов не только с заглавной страницы, но также и со всех остальных. Кроме того, статистика Рамблера позволяет использовать несложный язык запросов для уточнения или, наоборот, расширения результата.
Данный механизм отличается от статистики запросов в Яндексе тем, что в ней не объединяются результаты для разных словоформ. Т.е. можно без дополнительных операторов получить статистику частотности запроса именно по словам в нужном падеже и требуемом числе.
Крупнейшая в мире поисковая система Google также предоставляет открытый доступ к своей статистике запросов. В отличие от двух предыдущих, количественная статистика доступна в формате csv. Визуально статистика представляется лишь относительно — в виде графика. Отчёты выделяются особой подробностью: например, кроме обычной статистики запросов пользователей, можно посмотреть степень конкуренции рекламодателей за конкретный поисковый запрос, просмотреть историю трафика для выбранных ключевых слов; предоставляется подсказка возможно полезных минус-слов.
В особом виде статистику отображают графики Google Trends. Сервис позволяет вводить до 5 разных запросов, изучать и сравнивать изменение интереса к ним в мире в виде графика за прошедшие 2-3 года.
Исследование предметной области
Нами анализировались данные в интернет ресурсах на тему вступления России во Всемирную Торговую Организацию. Анализировалось не наполнение 1¥ЕВ-ресурсов информацией, а частота и тип запросов, вводимых россиянами и связанными с вступлением России в ВТО.
Такой подход позволил проанализировать не мнение отдельно взятых лиц, а общую тенденцию интересов населения относительно вступления России в ВТО. Это позволило отразить наиболее реальную тематику вопросов, волнующих население страны.
О том, как применять подобные инструменты на практике и какую информацию мы можем получить, будет рассказано ниже.
Прежде всего, для проведения исследования по поисковым запросам нам необходимо составить список интересующих нас запросов — семантический словарь.
Для того что бы в различных сервисах мы получали наиболее актуальную информацию конкретизируем условия нашего поиска. Поиск будем производить по всем регионам России (Центр, Северо-Запад, Поволжье, Юг, Сибирь, Дальний Восток, Северный Кавказ, Урал) в период с 01 марта 2011 по 01 марта 2013 года.
В таблице 1 представлен используемый нами семантический словарь. Он составлен на основе «рейтингов запросов» за март 2013 г. со словом «ВТО».
Таблица 1 — Семантический словарь
Слово Количество запросов в месяц
ВТО 42226
Вступление + ВТО 9953
ВТО плюсы + минусы 935
ВТО + влияние 1099
ВТО + пошлины 707
Яндекс статистика
262144
1633а 409Ь 1024
64 16 4
гп- о 3 ип о 3 Ё Щ © О гН « см* ч—1 о гч о т О О 4Л О 3 ц 3 © -ч И ГЧ н О гч О
■!—с 1-4 чН ■I—с тН 1—1 р-н ^1 гч гч гч гЧ ГЧ ГЧ гч гч ¡¡»4 ГЧ ГЧ гч т гл
pH! Г-1 ч—( ■pH! ■pH *Н гН 1—1 П рН1 ■«—1 г1 Г11 ч—1 г1 ■гН 1—1 г*Н •pH’ и г! ■pH г-1 pH
О О О О О о О о О О О О о О О О о о О о ■с О О О
гч гЧ гч ГЧ гч о# ГЧ гч ГЧ! -«Ч гч г* ГЧ гч ГЧ1 гч гч гч гч гч гч гч гч
0-гй Д птсмаоуплонпс ■ — 0Ю илнЗСЬ! ^минусы нгО ШвЯНиб —-ню и пошлины
Рисунок 1 — Количество поисковых запросов в системе Яндекс Проанализируем результаты, полученные от поисковых системам при вводе слов из семантического словаря. На рисунке 1 и в таблице 2 представлены результаты работы поисковой системы Яндекс.
На рисунке 1 и в таблице 2 представлены результаты работы поисковой системы Яндекс.
Таблица 2 — Количество поисковых запросов в системе Яндекс
Месяц ВТО ВТО + вступление ВТО плюсы + минусы ВТО + влияние ВТО + пошлины
2011.03 82508 18697 3485 299 853
2011.04 82523 18326 3181 368 769
2011.05 69606 13090 2212 453 426
2011.06 56350 10429 1804 238 643
2011.07 19309 3287 579 60 320
2011.08 20479 3645 495 44 373
2011.09 37534 6705 1262 191 249
2011.10 93905 24176 4909 299 1726
2011. 11 249031 90306 19942 706 12694
11 249031 90306 19942 706 12694
2011.12 235793 82589 18740 936 11322
2012.01 105774 34032 6768 623 5564
2012.02 84969 25856 4064 558 3221
2012.03 128316 41040 5072 924 5334
2012.04 129286 40327 4499 1241 4362
2012.05 122649 35902 3573 1268 3253
2012.06 119297 37315 3363 776 3570
2012.07 257671 95112 11175 217 12009
2012.08 219650 89573 11935 575 23636
2012.09 129119 48705 7412 1535 8940
2012. 10 125561 36757 5377 2316 3420
10 125561 36757 5377 2316 3420
2012.11 124178 34512 4219 1659 2558
2012.12 122652 34225 4257 1909 2145
2013.01 89905 22958 2124 997 1972
2013.02 88834 22677 2469 1422 1572
По полученным результатам следует отметить, что поведение всех графиков практически одинаково и в определенные промежутки времени наблюдается как возрастание интересов, так и затухание. А именно, в период с марта 2011 до июля наблюдается спад интереса, а с июля до конца года по всем запросам активность пользователей возросла и достигла своего максимума в ноябре 2011 года. Далее по всем запросам пошел спад и пользователи практически с постоянной частотой интересовались исследуемыми запросами. Следующий скачок активности россиян приходится на июль — август 2012 года.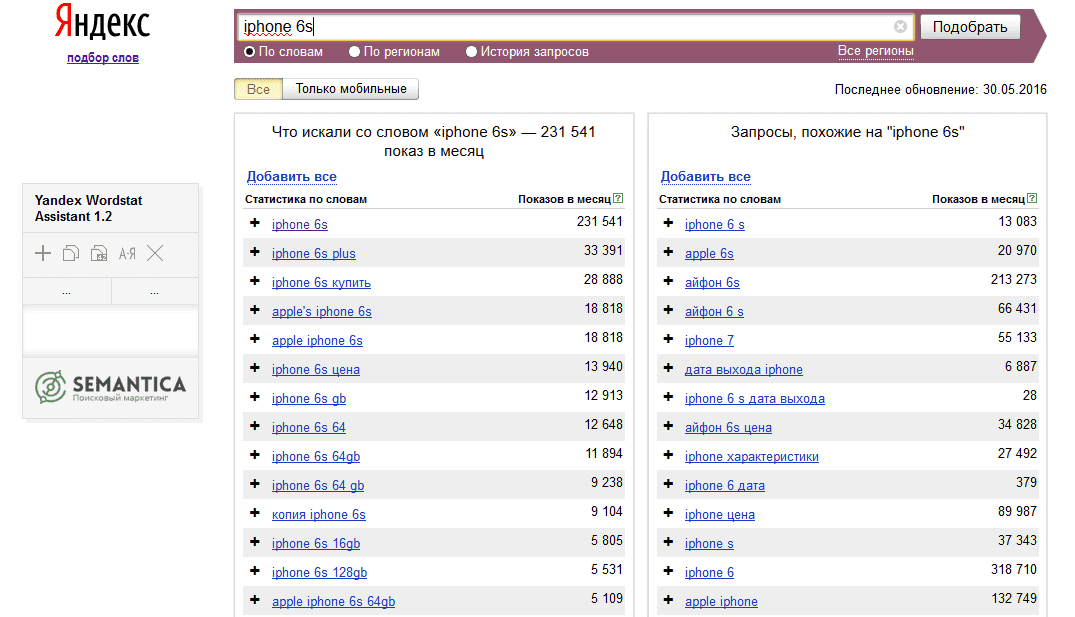
Стоит отметить, что представленный рисунок 1 был построен средствами MS Excel, так как сервис от Яндекс позволяет строить графики только по отдельно взятому запросу, что не всегда является удобным при анализе нескольких запросов.
Рассмотрим данные полученные с помощью сервисов от компании Google на рисунке 2.
Тренды Динамика популярности ■?
Популярные запросы Отметка 100 соответствует наибольшей заинтересованности пользователей. Поиск по новостям
Вступление +В1
плюсы ВТО
ПЛЮСЫ ВТО +МИ1
влияние ВТО
‘ Что сравнивать
3 средй&у зпр. 2. .. июля 2011 окт 2011 янв 2012 апр. 2012 июля 2012 ост. 2012 яьв 2013
2. .. июля 2011 окт 2011 янв 2012 апр. 2012 июля 2012 ост. 2012 яьв 2013
Слово «влияние вто» использовалось слишком редко. Выберите более продолжительный отрезок времени.
Код для сайта
Рисунок 2 — Количество поисковых запросов в системе Google
Поисковые запросы
Сервис от компании Google представляет данные в относительной частоте. Числа на графике показывают долю запросов по ключевым словам в общем числе запросов, выполненных в Google за определенное время. Они являются не абсолютным выражением объема поисковых запросов, а относительным, в масштабе от 0 до 100. Каждая точка на графике соотносится с максимальным значением. При отсутствии достаточного количества данных отображается значение равное нулю.
Период пиковых величин представлен в таблице 3.
Запросов «ВТО +пошлины» практически не было, поэтому мы не включали данные результаты в таблицу пиковых значений.
Таблица 3 — Периоды наибольшей активности пользователей, %
Даты ВТО ВТО + вступление ВТО плюсы ВТО плюсы + минусы
6-12 ноября 2011 79 88 6 41
11-17 декабря 2011 87 100 6 47
8-14 июля 2012 68 73 5 34
19-25 августа 2012 79 86 5 36
В отличие от сервиса «Яндекс статистика», «Google Тренды» не http://ej.kubagro.ru/2013/09/pdf/75.pdf
предоставляет данные в табличном виде.
Одной из интересных возможностей Google Тренды является функция поиска по новостям.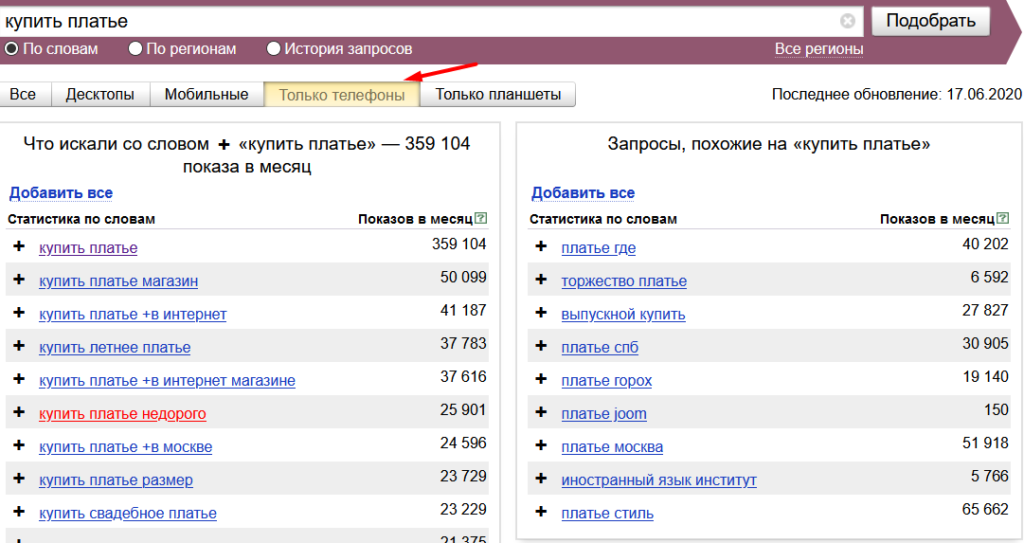 Данная возможность позволяет отобразить на графике в его пиковых точках наиболее популярную ссылку.
Данная возможность позволяет отобразить на графике в его пиковых точках наиболее популярную ссылку.
Популярность по регионам Щ
Калининградская область 100 1 >
Тюменская область
Томская область
Москва
Ульяновская область
Удмуртия республика
Приморский край
Марий Зл республика
Татарстан, республика
Санкт-Петербург 72
Рггиснь. | Гсрсда
Рисунок 4 — Популярность запроса «ВТО» по регионам России
Еще одной интересной особенностью, отличающей «Google Тренды» от других сервисов, является возможность рассмотрения популярности запроса по регионам.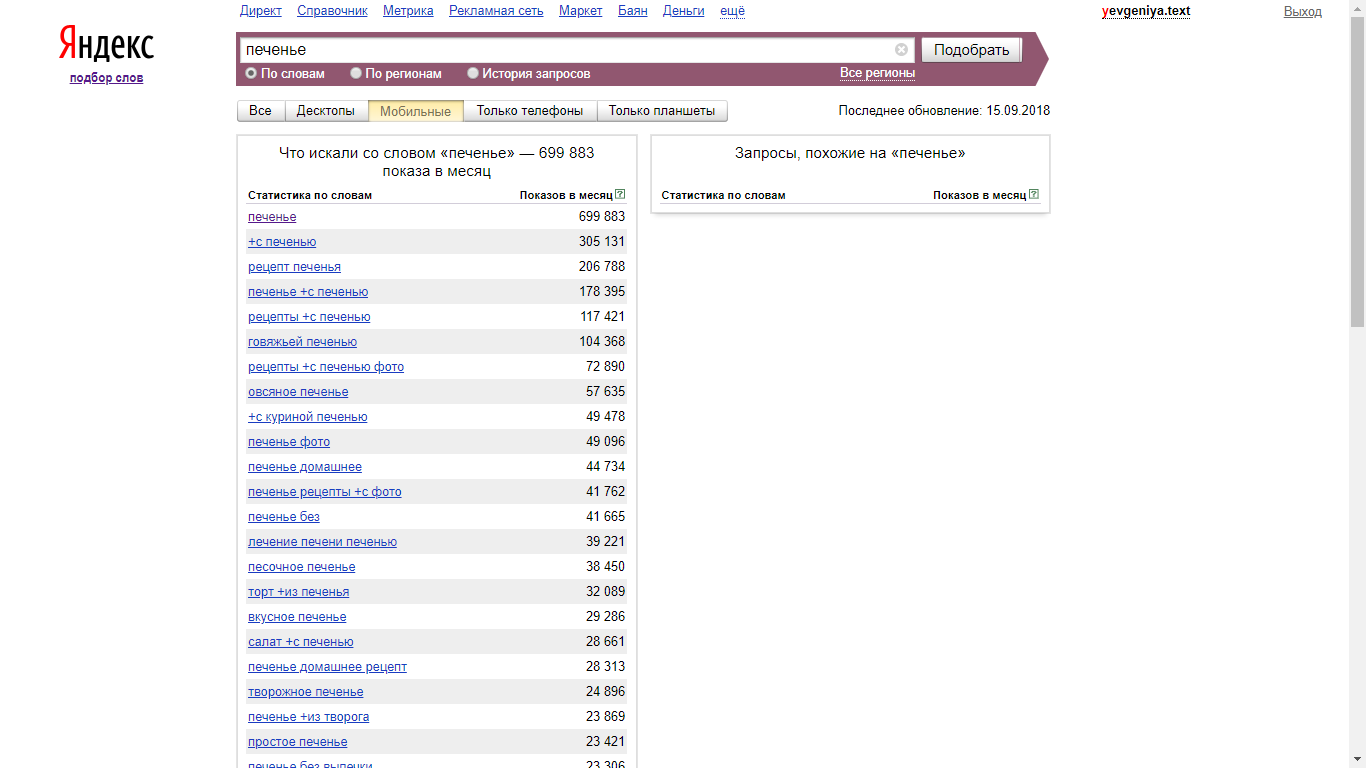 Данные представлены в относительном виде. Данный интерфейс показывает, какой регион из общей массы был наиболее заинтересован исследуемым поисковым запросом (рисунок 4).
Данные представлены в относительном виде. Данный интерфейс показывает, какой регион из общей массы был наиболее заинтересован исследуемым поисковым запросом (рисунок 4).
Для изучения активности пользователей конкретного региона по месяцам можно перейти по ссылке, представленной в списке (рисунок 5).
Научный журнал КубГАУ, №93(09), 2013 года Динамика популярности
Отметка 100 соответствует наибольшей заинтересованности пользователей.
Поиск по новостям
В среднее апр…. коля 2011 ост. 2011 я*в. 2012 апр 2012 «оля 2012 окт. 2012 якв. 2013
Рисунок 5 — Популярность запроса «ВТО» в Калининградской области
Данные, полученные с помощью сервисов поисковой системы Рамблер изображены на рисунке 6 и представлены в таблице 4.
■его
*ЄСтуп/іЄннС0 ВТО ВТО ллкмьр минусы ■ ВТО пошлины
Рисунок 6 — количества поисковых запросов в системе Рамблер
Сервис «Рамблер статистка» смог предоставить данные только в период с февраля 2012 по февраль 2013.
По полученным данным, так же как и в других системах, наблюдается одновременный рост и спад активности пользователей по всем запросам. Следует
отметить, что пользователи поисковой системы Рамблер проявляли больше интереса к вопросу о пошлинах после вступления России в ВТО, чем к положительным или отрицательным сторонам вступления России в ВТО.
Таблица 4 — Количество поисковых запросов в системе Рамблер
Месяц ВТО ВТО + вступление ВТО плюсы + минусы ВТО + пошлины
2012.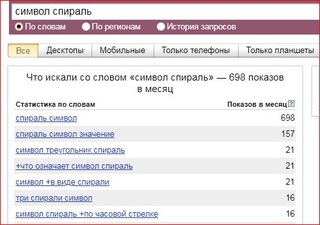 02 3892 343 68 71
02 3892 343 68 71
2012.03 8387 863 102 145
2012.04 5560 449 58 108
2012.05 5541 340 41 62
2012.06 4607 456 45 66
2012.07 6837 909 118 185
2012.08 6639 862 119 324
2012.09 3204 341 68 103
2012.10 4000 274 68 81
2012.11 4345 268 84 41
2012.12 6664 317 73 60
2013.01 4483 230 55 36
2013.02 5280 250 43 59
Сервис «Рамблер статистика» не отображает полученные результаты в
графическом виде, поэтому для построения графика мы обратились к
возможностям MS Excel.
Несмотря на то, что поведение кривой графика во всех рассматриваемых сервисах, практически одинаково, существуют и различия. А именно:
1. Сервис от Яндекс и Рамблер показывает нам довольно большую
заинтересованность россиян вопросами пошлин после вступления России в ВТО, в то время как сервис от Google показал практически нулевую активность
пользователей данного сервиса.
2. График, полученный с использованием сервиса от Google, показал нам
резкие скачки, в периоды, представленные в таблице 3, в то время как Яндекс и Рамблер показал нам одноразовое возрастание и затухание кривой.
З.Что касается запроса «ВТО плюсы +минусы», то сервис от Google показывает стабильную заинтересованность россиян этим вопросом, без резких скачков, в то время как в Яндекс и Рамблер практически идентично с остальными кривыми рассматриваемых запросов.
Проанализируем результаты, полученные с помощью всех рассматриваемых сервисов, и сопоставим их с событиями, связанными со вступлением России в ВТО.
Наиболее важные события, связанные со вступлением в ВТО
1.В течение осени 2011 г. были согласованы остававшиеся вопросы на переговорах с США.
2. Одновременно в течение осени 2011 г. в результате многомесячных неформальных российско-грузинских консультаций при посредничестве Швейцарии удалось выработать приемлемое для обеих сторон решение по контролю за передвижением гражданских грузов по территории Абхазии и Южной Осетии. В результате со стороны Грузии были сняты возражения по созыву формального заседания Рабочей группы.
3. 10 ноября 2011 г. переговоры о присоединении России к ВТО были завершены. Рабочая группа одобрила пакет документов о присоединении РФ к ВТО для внесения на рассмотрение Восьмой министерской конференции ВТО. Таким образом, мандат Рабочей группы по присоединению России к ВТО был исчерпан, после чего она была распущена.
Рабочая группа одобрила пакет документов о присоединении РФ к ВТО для внесения на рассмотрение Восьмой министерской конференции ВТО. Таким образом, мандат Рабочей группы по присоединению России к ВТО был исчерпан, после чего она была распущена.
4. 16 декабря 2011 г. в ходе на 8-й Министерской конференции стран-членов ВТО в Женеве был одобрен пакет документов по присоединению России к ВТО. Пакет включал в себя: протокол о присоединении России к ВТО, содержащий Перечень тарифных уступок и перечень специфических обязательств по услугам; доклад Рабочей группы по присоединению РФ к ВТО.
5. В соответствии с правилами ВТО, России был предоставлен срок в 220 дней
для ратификации пакета документов о присоединении к ВТО национальным парламентом.
6. 10 июля 2012 г. Государственная дума РФ 238 голосами против 208 и 1 воздержавшемся одобрила Протокол о присоединении России к Всемирной торговой организации.
7. 18 июля 2012г. Совет Федерации РФ ратифицировал Протокол о присоединении России к Всемирной торговой организации.
8. 21 июля 2012 г. Президент России В. Путин подписал федеральный закон «О ратификации Протокола о присоединении РФ к Марракешскому соглашению об учреждении Всемирной торговой организации от 15 апреля 1994 г.»
9. 22 августа 2012 г. Российская Федерация официально стала 156-м членом Всемирной торговой организации.
Пики в интересах Россиян практически совпадают с перечисленными событиями, что говорит о политической активности и заинтересованности граждан в событиях, происходящих в стране.
Выводы
1. В результате проведенных исследований была выявлена прямая взаимосвязь роста активности пользователей в наиболее важные периоды государственной деятельности, связанной со вступлением России в ВТО.
Таким образом, анализ результатов, полученных из рассмотренных в работе сервисов, позволяет отразить наиболее точные интересы россиян, касающиеся вступления России во Всемирную Торговую Организацию. Следует отметить, что только совместное использование нескольких сервисов позволяет отразить наиболее верную картину.
Полученные результаты можно использовать для дальнейшего анализа ЖЕв-контента. Например, можно более точно указывать период появления статей касающихся рассматриваемых вопросов или анализировать только те результаты запросов, которые наиболее сильно волновали пользователей в определенный период времени. Потенциально существует возможность привлечение средств
Web-Mining, Text-Mining для более глубокого изучения не только запросов, но и текстовой информации по интересующему нас направлению.
2. Сегодня ни для кого не секрет, что тенденции изменений в обществе всегда начинаются «снизу» (да, конечно их можно инициировать с помощью СМИ и т.д.). Именно этот факт и является одной из причин по которой проводятся всевозможные социологические и эконометрические обследования. Из настоящей статьи, очевидно, что уже сегодня существует альтернатива всевозможным «выборочным» обследованиям, проводимым службами государственной статистики, социологами и политологами. Нужно понимать, что изучение социально-экономических процессов и тенденций в обществе требует комплексного подхода, опирающегося на системную методологию и адекватный инструментарий. Использование средств и инструментов, имеющихся на сегодня статистических сервисов, в современных поисковых системах позволяют поднять возможности изучения социально-экономических систем на новый качественный уровень.
Литература
1. Байков В. Интернет. Поиск информации. Продвижение сайтов / В. Байков — Санкт -Петербург, 2000. — 288 с.
2. Щербаков А. Ю. Интернет-аналитика. Поиск и оценка информации в web- ресурсах. Практическое пособие / А. Ю. Щербаков — Книжный мир, 2012. — 80 с.
3. Информационные ресурсы и услуги. Многоязычный проект по созданию полноценной и точной энциклопедии со свободно распространяемым содержимым: [сайт]. — Режим доступа: http://rn.wikipedia.org/
4. Информационные ресурсы и услуги. Блог Яремчук Романа по созданию сайтов и все что с этим связано: [сайт]. — Режим доступа: http : http://www.delaydengi.com/
5. Информационные ресурсы и услуги, крупный сервис дневников и сообществ, авторитетный сервис статистики для сайтов: [сайт]. — Режим доступа: http:// www.liveintemet.ru/
References
1. Bajkov V. Internet. Poisk informacii. Prodvizhenie sajtov / V. Bajkov — Sankt — Peterburg,
2000. — 288 s.
2. Shherbakov A. Ju. Internet-analitika. Poisk i ocenka informacii v web- resursah. Prakticheskoe posobie / A. Ju. Shherbakov — Knizhnyj mir, 2012. — 80 s.
3. Informacionnye resursy i uslugi. Mnogojazychnyj proekt po sozdaniju polnocennoj i tochnoj jenciklopedii so svobodno rasprostranjaemym soderzhimym: [sajt], -Rezhim dostupa: http://ru.wikipedia.org/
4. Informacionnye resursy i uslugi. Blog Jaremchuk Romana po sozdaniju saj-tov i vse chto s jetim svjazano: [sajt], — Rezhim dostupa: http : http://www.delaydengi.com/
5. Informacionnye resursy i uslugi. krupnyj servis dnevnikov i soob-shhestv, avtoritetnyj statistiki dlja sajtov: [sajt], — Rezhim dostupa: http:// www.liveinternet.ru/
Статистика запросов Яндекс, Гугл. Что за кадром?
Статистика запросов — информация об обращении пользователей к поисковым системам, включает в себя количество запросов, по словам и словосочетаниям, набираемым посетителями, отбор её по географическому признаку, а также любые другие сведения, которые поисковики считают возможным предоставлять в открытом доступе.
Иными словами, правильный анализ статистики запросов пользователей интернета является необходимой составляющей комплексного интернет маркетинга и основой для развития интернет ресурса.
Кому нужна статистика ключевых слов?
Статистика ключевых слов, а точнее статистика частоты запросов пользователей в поисковых системах нужна специалистам продвигающим сайты. Статистика запросов Яндекс, Гугл, Рамблер является самым простым способом подбора семантического ядра для сайта. Статистика необходима специалистам по контекстной рекламе для создания компаний.
Вместе с тем, Заказчикам продвижения также необходимо понимать, как узнать частоту поиска той или иной услуги (товара). При заказе раскрутки сайта также важно проверить правильность подбора ключевых слов оптимизатором с учетом определенных нюансов.
Статистика запросов Яндекс
Яндекс предоставляет свою статистику по адресу http://wordstat.yandex.ru/ Давайте попробуем вместе набрать какое-нибудь запрос и посмотрим на примере результаты и их трактовку.
1. Наберем — Статистика Яндекс — увидим цифру 24927.
Иногда, заказчики seo услуг полагают, что число в колонке отображает общее количество наборов того или иного сочетания в поисковике. Однако, вынужден разочаровать — это не так.
2. Для исключения добавления всех «хвостов» воспользуемся языком запросов Яндекс и возьмем слово в кавычки — «Статистика Яндекс». Чуть выше основной цифры появится количество наборов данного словосочетания 4585.
Данная цифра теперь не включает дополнительные слова, такие как «статистика слов Яндекс», «сайт статистики Яндекс», «статистика посещений Яндекс»
3. Однако в полученном результате присутствуют различные словоформы ключевых слов. Чтобы их исключить надо к каждому из слов добавить восклицательный знак «!статистика !яндекс». И теперь мы видим цифру 4416.
Вы думаете, мы получили конечный результат? Давайте разберемся, что собой представляет итоговая цифра статистики по запросу «Статистика Яндекс» или «Статистика Яндекса» — кстати, одно и то же, так как поисковик объединил эти слова как идентичные.
4416 различных пользователей набрали одно из данных словосочетаний? Ничего подобного!
Поскольку статистика Яндекса является статистикой Яндекс Директа — она показывает количество просмотров рекламных объявлений на разных страницах. То есть, посетители, просмотревшие две страницы на Яндексе с показом Директа, приносят в копилку статистики цифру 2. Можно предположить, что итоговое значение количества людей набравших этот запрос лежит между 3000-4000.
На что еще стоит обратить внимание при подборе статистики ключевых слов ?
1. Отбор запросов именно для Вашего региона. Сделать его можно во вкладке «Все регионы». Это важно для определения статистики запроса в том регионе, где продвигается Ваш сайт.
2. Отбор статистики по мобильным устройствам. Данная информация может быть для понимания насколько важно в данной тематике иметь адаптированный сайт под мобильные устройства.
3. Для понимания сезонности запроса, естественных всплесков и падения посещаемости, можно просматривать статистику по месяцам.
Статистика запросов Гугл
Гугл не представляет, как таковую полную статистику запросов посетителей в конкретных цифрах. Однако при помощи сервиса https://adwords.google.com/KeywordPlanner можно подобрать запросы для дальнейшей оптимизации сайта и, что интересно, узнать цену за клик при размещении рекламы к контекстной рекламе Google Adwords.
Статистика запросов Рамблера
Располагается по адресу http://wordstat.rambler.ru/wrds/
Полная статистика поисковых запросов, предоставляемая пользователям. Есть также отбор по географическим признакам. Рамблер даёт точную информацию конкретно по тем словам, которые набирает пользователь в запросе, включая словоформы и предлоги. Сервис требует обязательную регистрацию при поиске по географической принадлежности или поиске большого кол-ва информации.
ключевых слов — Яндекс.Директ. Справка
Ключевые слова — это отдельные слова или фразы, которые определяют, кому будет показано ваше объявление.
В поиске Яндекса объявления показываются по поисковым запросам, содержащим целые указанные вами ключевые слова. При показе объявлений в других рекламных сетях система автоматически выбирает объявления с ключевыми словами, соответствующими тематике сайта или интересам пользователя.
Ключевые слова по-разному работают в результатах поиска и в рекламных сетях.
Ключевое слово определяет, какие поисковые запросы в поиске Яндекса и на поисковых сайтах в Рекламной сети Яндекса будут вызывать показ объявлений из группы.
Например, если вы установите для ключевого слова туры на марс , мы будем показывать ваши объявления по поисковым запросам туры на марс , туры со скидкой на марс , туры на марс предложения , зарезервировать туры на марс и так далее, но мы не будем их показывать для туров на Луну. или есть ли жизнь на Марсе .
Используйте отчет «Поисковый запрос», чтобы узнать, какие запросы или типы соответствия привели к показу вашей рекламы. Проанализируйте статистику и добавьте запросы с высоким CTR к ключевым словам.Исключите нерелевантные запросы, добавив их к минус-словам.
Ключевые слова определяют контент сайта и интересы аудитории, для которой будет отображаться реклама в рекламных сетях. Например, реклама туров на Марс может отображаться на странице о путешествиях или показываться пользователю, который интересуется полетами на Марс.
Вы можете использовать боковое меню для добавления ключевых слов: нажмите, выберите кампанию и группу объявлений и нажмите Добавить ключевые слова. Используйте Генератор ключевых слов или перейдите на вкладку Ввод вручную, чтобы вводить запросы вручную.Узнайте больше о планировщике ключевых слов.
Дополнения или изменения ключевых слов выполняются в течение 3 часов. Чтобы добавить ключевые слова для отдельного объявления, создайте новую группу для объявления.
- Требования и ограничения
В ключевых словах разрешены только буквы, цифры, «
-» и другие операторы Яндекс.Директа. В десятичных числах разрешены десятичные точки. Регистр букв и порядок слов не важны.Максимальная длина ключевого слова — 4096 символов (включая минус-слова, пробелы и Яндекс.Прямые операторы). Количество ключевых слов в группе не может превышать 200. Каждое ключевое слово может содержать максимум 7 слов.
- Перекрывающиеся и повторяющиеся ключевые слова
Если ключевые слова перекрываются (ключевое слово содержит одно из других ключевых слов), минус-слова добавляются автоматически. Это предотвращает конкуренцию ключевых слов между собой при выборе объявления для показа.
Любые повторяющиеся слова в ключевом слове сокращаются до одного экземпляра. Например, ключевое слово Baden-Baden будет сокращено до Baden .Объявления будут отображаться как по запросу Baden-Baden , так и по запросу Baden .
- Стоп-слова
Вспомогательные части речи, местоимения и любые слова, не имеющие собственного значения (стоп-слова), автоматически исключаются из поискового запроса пользователя при выборе рекламы для показа. Например, если пользователь ищет , как и когда отправиться на марс , будут показаны объявления с ключевым словом travel mars . Как , и , , когда , и с по являются стоп-словами в этом случае.
Помните, что стоп-слова учитываются во всех языках. Например, если вы установите ИТ-услуги в качестве ключевого слова, реклама будет отображаться, когда пользователь вводит нецелевые запросы стилист услуг или юридические услуги , поскольку это местоимение. Чтобы включить в запрос стоп-слово, необходимо добавить его с помощью оператора +.
Как оценить востребованность вашего товара в Яндексе? • Runetology.com
Перед тем, как начать рекламную кампанию, следующим естественным шагом будет оценка спроса на товары или услуги на выбранном рынке.В этой статье я покажу вам, как провести первичный анализ спроса в России, но вы можете использовать это руководство также для Беларуси или Украины.
Лучшим способом, на мой взгляд, является оценка спроса в поисковых системах. Google предоставляет Планировщик ключевых слов и Google Trends. Инструмент поиска ключевых слов Яндекса называется Wordstat (https://wordstat.yandex.com). Он доступен на английском языке.
Таким образом, Wordstat — это инструмент, позволяющий выбирать ключевые фразы для кампании в Яндекс.Прямой. Он показывает данные о показах объявлений для введенных вами ключевых слов. Просто как тот.
Как подбирать ключевые слова без знания русского языка
Все, что вам нужно на этом этапе, — это выбрать правильные ключевые слова. Если вы не знаете русский язык, воспользуйтесь Яндекс.Переводчиком или Google Translate (по моему опыту Яндекс справляется с переводом на русский язык лучше, чем Google):
Чтобы убедиться, что переведенное выражение имеет смысл, попробуйте скопировать и вставить его в поиске Яндекса и проверьте несколько сайтов на первых позициях.Это позволит свести к минимуму вероятность ошибки. Не забудьте сменить локацию, например, на Москву. Щелкните значок справа от поля поиска. Можно ввести слово «Москва» латиницей:
Важно понимать, что ключевое слово и запрос — это не одно и то же. Запрос — это просто текст, который пользователи вводят в поле поиска. Однако понятие ключевого слова относится к настройкам кампании в Яндекс.Директе. Используя ключевые слова (или ключевые фразы), мы можем определить, по каким запросам пользователь увидит нашу рекламу.
Теперь давайте определим, что такое показов и чем оно отличается от статистики объема поиска .
Возьмем, к примеру, ключевое слово «купить квартиру» , которое имеет 15000 показов в статистике Wordstat. Это не значит, что пользователи вводят такой запрос 15 000 раз в месяц. Это число означает, что на странице результатов поиска с рекламой Яндекса за последний месяц было просмотрено 15 000 страниц. Если пользователь ввел запрос и просмотрел три страницы результатов поиска, он генерирует 3 просмотра страниц из этих 15 000.
Однако ни Wordstat, ни Google Keyword Planner не показывают нам статистику реальных объемов поиска. Цифры, которые мы видим в этих инструментах, — это впечатления.
Правильно выбирайте ключевые слова
Но это еще не все. В Wordstat есть специальные операторы для ключевых слов (в Google AdWords это называется параметрами соответствия ключевых слов), которые помогают определить, какие формы ключевых слов (существительные, числа и т. Д.) Вы хотите настроить, какие слова исключить и т. Д.
Есть несколько операторов, но в данном случае нам понадобится только один из них — цитата ( «ваше ключевое слово» ), потому что наша задача сейчас просто оценить спрос.
Итак, зачем нужны операторные «кавычки»? Если ввести ключевое слово без кавычек ( мужские кроссовки ), вы увидите количество показов всех фраз, содержащих фразу «мужские кроссовки» (например, «купи мужские кроссовки» , «купи лето» мужские кроссовки » и др.)
Но если вы вводите фразу в кавычках, вы даете сигнал, что вас интересует статистика только для этой конкретной фразы, заключенной в кавычки, без лишних слов, как в примере выше.Например, фраза «продается дом» в кавычках означает, что вы получите статистику по фразам: продается дом , продается дом (Яндекс не рассматривает предлоги как слова), продажа дома, продажа домов. Wordstat подсчитает все показы и покажет общее число рядом с вашим ключевым словом:
Как определить спрос в конкретном регионе России
Однако количество показов теперь дает нам небольшое представление о спросе.Откройте вкладку «Регион», чтобы узнать, в каких регионах наиболее востребована данная ключевая фраза.
Сначала вы увидите список с тремя вкладками: Все, Регионы, Города. Если региональная популярность больше 100%, это означает, что в данном регионе интерес к данной ключевой фразе выше среднего. Если меньше 100%, меньше среднего.
Теперь нажмите «Карты», а затем выберите любую страну, которая вас интересует. В моем примере я выбрал Россия:
Наведите курсор на интересующую вас область.Здесь, как и в списке городов, вы видите количество показов в конкретном районе, а также его популярность в регионе. Таким образом, можно провести анализ спроса в зависимости от региона страны.
Давайте проверим сезонность спроса
Может быть, в случае с вашим продуктом необходимо оценить сезонность спроса. Нажмите «История запросов» (вы найдете кнопку под текстовым полем). Помните, что в этом отчете вы должны ввести ключевое слово без кавычек !
Чтобы уточнить, на какой товар мы хотим оценить спрос (мужские кроссовки — очень общая категория товаров), укажите, например, мужские кроссовки nike air .
Пик спроса приходится на ноябрь. В этот период проходит Черная пятница (также в России) и ежегодная акция AliExpress ’11.11. Выбор за вами — работать с большим спросом в этот период или искать менее конкурентоспособный сезон.
Таким образом, с помощью этих простых шагов вы можете предварительно оценить востребованность ваших товаров в Яндексе.
Помните, что Wordstat дает нам лишь небольшую часть статистики, которая может служить основой для оценки интереса к вашему продукту или услуге.По многим ключевым фразам (неконкурентоспособным, непопулярным) Яндекс, как и Google, не предоставляет статистику показов. Чтобы оценить количество клиентов, заинтересованных в вашем предложении, вам необходимо запустить тестовую кампанию в Яндекс.Директе. Минимальный бюджет такой кампании составляет 10 евро.
Бонус
И напоследок порекомендую вам плагин для комфортной работы с описываемым сервисом — « Яндекс Wordstat Assistant ». Нажав на значок «плюс» рядом с фразой, вы добавите ее в список слева.Затем вы можете скопировать его в буфер обмена и легко вставить в свою кампанию в Яндекс.Директе или любой другой документ для дальнейшей работы.
Плагинработает в Chrome, Firefox, Opera и Яндекс.Браузере.
Инструмент подсказки ключевых слов Яндекса: советы по использованию его возможностей
Поскольку Яндекс по-прежнему занимает самую большую долю рынка среди поисковых систем в России, 62% по данным LiveInternet.ru, важно знать, как его инструменты могут помочь вам в продвижении вашей интернет-маркетинговой кампании в России.
Эта статья призвана дать вам несколько полезных советов о том, как использовать инструмент подсказки ключевых слов Яндекса, и о том, о чем следует помнить при выборе ключевых слов для своей кампании в России.
Во-первых, чтобы получить доступ к инструменту, перейдите на wordstat.yandex.ru или wordstat.yandex.com в зависимости от того, какой интерфейс вы предпочитаете: русский или английский (см. Скриншоты двух ниже) .
Чтобы начать получать статистику по предпочтительным ключевым словам, введите слово в поле «Ключевые слова и фразы» и нажмите «Соответствие».
Лучше всего использовать для начала более широкие запросы, чтобы не только собрать больше предложений по ключевым словам, но и потому, что алгоритмы поиска Яндекс и Google отличаются тем, что русскоязычные интернет-пользователи обычно ищут более широкие запросы, а не более конкретные запросы с длинным хвостом. что некоторые англоговорящие пользователи могут предпочесть.
Помня об этом, а также усложнив русский язык, Яндекс разработал множество дополнительных методов поиска, чтобы сделать результаты поиска более эффективными и релевантными.Например, учитывается морфология слова, что означает, что различные формы плюрализации, склонения, спряжения и времени рассматриваются как часть одного слова.
Что касается интерпретации результатов, столбец слева отображает ключевые слова и ежемесячный объем поиска, включая только слова, указанные в поле поиска, следовательно, список, содержащий слово «футбол» в каждом ключевом слове, тогда как столбец справа отображает дополнительные предложения. относящиеся к слову, которое вы искали, e.грамм. футбол, спорт и др.
Чтобы получить статистику по количеству локального поиска, вы можете изменить регион, нажав «Указать регион» и выбрав Россию. Если вы предпочитаете получать статистику глобально, оставьте поле настроек по умолчанию без изменений.
Яндекс.СловоСтат фильтры
Как видно, статистику, которую вы получаете от инструмента, можно фильтровать по словам , регионам , местоположению на карте , месяцам и неделям. Чтобы сделать исследование ключевых слов более релевантным и ориентированным на определенный регион, возможно, стоит рассмотреть возможность применения следующих фильтров при анализе статистики:
1. Статистика по ключевым словам — это фильтр по умолчанию, применяемый к ключевым словам, которые вы искали. Как следует из названия, он отображает ежемесячный объем поиска по ключевым словам, найденным в указанном вами регионе (ах).
2. Статистика по регионам. Выбор этого фильтра позволит вам увидеть статистику по регионам и городам.Вы можете не только увидеть ежемесячный объем поиска для указанных вами городов и регионов, но и выбрать этот вариант, если вы хотите собрать данные о региональной популярности выбранного вами ключевого слова.
Процент региональной популярности можно интерпретировать следующим образом:
- 100% — нет значительной популярности
- Более 100% — ключевое слово значительно популярно
- Менее 100% — непопулярность
- 0% — ключевое слово не используется в указанном регионе (существенно непопулярно)
3.Статистика на карте. Аналогично фильтру выше, но статистика по ключевым словам представлена в формате карты мира. Когда курсор мыши находится над определенным регионом, вы можете увидеть данные об объеме локального поиска вместе с процентом региональной популярности.
4. Статистика по месяцам отображает ежемесячную статистику для указанных ключевых слов и регионов. Статистика отображается в виде графика с возможностью выбора абсолютного или относительного масштаба.График с прерывистой линией состоит из координатных точек, представленных объемом поиска, отображаемым на оси Y, и месяцами, отображаемыми на оси X. Данные об объеме поиска по месяцам отображаются в таблице под графиком.
Типы соответствий Яндекс.Статистика
При проведении исследования ключевых слов в Яндекс.Слове может оказаться полезным знать о различных типах соответствия, чтобы сузить круг и сделать выбор ключевых слов более релевантным.
Яндекс, в отличие от Google, называет типы соответствия «операторами».Итак, давайте посмотрим, какие операторы можно применять к ключевым словам.
- — (оператор «минус»). Этот оператор используется для исключения определенных слов из предложений ключевых слов. При нанесении перед оператором следует поставить пробел. Например, если вы введете computer –repair в поле ключевого слова, результаты, которые вы получите, будут включать только все ключевые слова, содержащие слово «компьютер», и исключить любое появление слова «ремонт»
- «» (оператор «речевые знаки»).Это очень полезный оператор, если вы хотите искать только словоформы определенного слова или фразы. Например, если вы примените оператор к слову «стул» , результаты, которые вы получите, будут включать склонения и формы множественного числа этого слова, например «Стулья», «кресло» и т. Д., Но они будут исключать любые ключевые слова, состоящие из дополнительных слов в сочетании с целевым словом, например «офисное кресло», «кожаное кресло» и т. Д.
- + (оператор «плюс»). Этот оператор используется для принудительного включения предлогов в ключевые слова.По умолчанию все входящие в ключевые слова предлоги исключаются Яндекс.Словом. Например, в ключевом слове праздники + в России предлог «в» будет учтен Яндекс.Словом при формировании статистики.
- ! (оператор «восклицательный знак»). Этот оператор применяется перед каждым словом в ключевом слове, чтобы исключить любую из его словоформ, появляющихся в результатах. При его применении Яндекс.Статистика будет отображать статистику только по ключевому слову с точным соответствием.Например, если вы примените оператор к ключевому слову ! Компьютер! Игра , вы получите статистику только по ключевому слову «компьютерная игра», исключая такие ключевые слова, как «компьютерные игры», «компьютерные игры» и т. Д.
По сравнению с Google тип соответствия по умолчанию в Яндекс.Статике слов эквивалентен фразовому соответствию Google, поскольку он отображает объем поиска для всех ключевых слов, содержащих указанные вами слова или фразу (помните тот левый столбец, который я упоминал в начале?). Тип широкого соответствия в терминах Google представлен дополнительными ключевыми словами или столбцом «Люди, которые искали ключевое слово , также искали» справа от результатов, содержащих указанное вами ключевое слово.
Советы по проведению исследования ключевых слов с помощью Яндекс.Слова
- Учитывайте поисковые предпочтения русскоязычных пользователей Интернета: используйте более широкие запросы, а не длинные. Возможно, будет полезно попросить носителей языка провести для вас исследование ключевых слов, поскольку они могут лучше понимать особенности и сложности русского языка.
- Сделайте выбор ключевых слов более релевантным, применив соответствующие типы соответствия или операторы.
- Примените фильтры, предлагаемые инструментом, чтобы собрать дополнительную и релевантную статистику по вашим ключевым словам.
Если вы последуете этим советам и поэкспериментируете с этим инструментом, вы лучше подготовитесь к выходу на растущий российский онлайн-рынок.
Следующие две вкладки изменяют содержимое ниже.Анастасия Скромане работает в сфере поискового маркетинга последние 4 года. В настоящее время она помогает команде семантики WebSecurity, работая над рядом русскоязычных и английских проектов SEO, PPC и Link Building.Сфера ее интересов — создание международных ссылок и контекстная реклама, в том числе создание кампаний в Яндекс.Директе и Google AdWords.
Статистика запросов по дням. Поиск по ключевым словам в Яндекс. Статистика по ключевым словам. «Яндекс.Директ»
Проверка запросов в Яндексе необходима для составления посевного ядра, настройки контекстной рекламы, а также других способов продвижения сайта. Служба статистики обращается после определения тематики проекта.В русскоязычном сегменте Интернета самые популярные поисковые системы — Яндекс и Google. Следовательно, выбор фраз должен производиться со статистическими данными этих двух поисковых систем.
Но статистика поисковых запросов Google несколько сложнее аналогичного сервиса от Яндекс. Кроме того, ядра обычно достаточно для анализа выдачи с любой из этих поисковых систем. Разница в частоте запросов к Яндексу и Гуглу невелика и для большинства проектов несущественна.И поэтому большинство веб-мастеров ограничиваются более простым и понятным вариантом.
Справки и «ключи»: в чем разница?
Когда говорят о подготовке или настройке рекламы, используют два разных термина — поисковые запросы Яндекс или Google и ключевые слова («ключевые слова»). Более того, эти термины часто путают или используют как синонимы.
Запросы — Отдельные слова или целые фразы, которые вводятся в строке поиска, для получения конкретной информации.Рейтинг поисковых запросов позволяет определить, какие из них используются чаще всего.
Ключевые слова (сокращенно «ключи») — Они выбираются из статистики Google, Яндекс или других поисковых систем, которые веб-мастер или SEO-специалист будет использовать для продвижения страниц ресурсов в поисковых системах.
Как пользоваться правой колонкой?
Для большинства выбранных вами «ключевых слов» список запросов Яндекс отображает две колонки, о которых мы говорили выше. Справа отображаются результаты анализа запросов в Яндексе и активности пользователей.Обычно они не содержат ключевую фразу, которую вы указали для проверки, но очень близки по тематике.
Дело в том, что счетчик запросов Яндекс, as, анализирует последовательность слов и уточнений, которые в процессе одной сессии вводит пользователь в поисковике. Кроме того, боты поисковых систем «учатся понимать» не только последовательность символов, но и тематику, для чего обе поисковые системы используют словари синонимов, таблицы фраз, относящиеся к определенной теме, и многое другое.И эти алгоритмы работают не только при «умном поиске», но и при выдаче статистики Яндекс.
Слова из правого столбца могут быть полезными подсказками и содержать те ключевые слова для семантического ядра, о существовании которых вы не подозревали. Добавьте их в свой список и проверьте периодичность, аналогичную основному списку.
Сервисные символы: для опытных пользователей
Каждая поисковая система позволяет для уточнения использовать специальные символы (операторы), они дополняют основную фразу.Этот метод работает и при обычном поиске, и при работе с анализом поисковых запросов в Яндекс.
Основные операторы:
В большинстве случаев эти символы не нужны. Иногда они имеют преимущества при анализе имеющихся ключевых фраз. Опытные пользователи пользуются ими, чтобы сэкономить время (совмещая две или более проверки в одной). Но чаще всего для того, чтобы получить результат как можно быстрее, используются специализированные программы.
Подсчет слов и возможностей Google
Этот сервис даже опытные СЕО специалисты чаще всего используют как вспомогательный после того, как Вордстат собрал полноценное ядро.Используйте статистику Google, чтобы расширить список ключевых слов в процессе продвижения проекта. В отличие от Яндекса, для определения количества запросов по ключевым словам регион и язык сайта уточнять не надо.
Сервис также самостоятельно определит эти параметры, после чего предложит свой список списков. Также есть гибкие настройки и множество возможностей, но чтобы ими воспользоваться, вам нужно будет потратить время на чтение разделов помощи и внимательное изучение услуг для веб-мастера.
Надеемся, что удалось максимально подробно рассказать, как обнаруживать запросы в Яндексе, и поговорили о главном конкуренте этой поисковой системы — о Google. Для небольшого проекта возьмите в руки клавиатуру и составьте на их основе Seo-ядро, которое вы, скорее всего, сможете уметь сами. Но если вам нужна оптимизация интернет-магазина или коммерческого ресурса, отдайте эту работу профессионалам. Они выполнят это в рамках полной оптимизации и продвижения. В коммерческой сфере ошибка в оптимизации приводит к потере прибыли.Помните об этом и грамотно планируйте свое время и рекламный бюджет.
Бесплатная статистика поиска и подбор слов от Яндекс. В основном сервис создавался для оценки рекламодателей Яндекс Директ. Но позже стал инструментом и оптимизатором SEO.
Чем поможет:
- Подбор эффективных ключевых слов для контекстной рекламы компании или для поискового продвижения сайта (семантическое ядро).
- Прогноз посещаемости, оценка повторяемости ключевых фраз и ниши в целом.
- Помощь в разработке структуры сайта.
- Обнаружение трендов во фразах.
Как работать с сервисом?
Для работы с Wordstat необходима регистрация в сервисе По электронной почте или через социальные сети. Если у вас уже есть аккаунт в других сервисах Яндекса, вы можете использовать его для работы с выделением слов.
Вход (правый верхний угол)> Регистрация
Инструмент «По»
При входе в систему у вас есть инструмент по умолчанию «согласно».
- Поле ввода запроса — В этой строке мы вводим слово или фразу, согласно которой мы хотим видеть данные.
- Сервисные инструменты — Отображение слов по регионам и запрос истории (тренда).
- Все регионы — Выбор региона для отображения статистики.
- Платформа — Выбор платформы, для которой будет отображаться статистика.
- Последнее обновление — Дата последнего обновления данных в сервисе.
- Левый столбец WordStat. — Список запросов, в которых содержится слово или фраза, введенные в абзаце (1).
- Правый столбец Wordstat. — Показывает список фраз, по которым все еще могут искать люди, которые представили наше слово или фразу.
Опишем подробнее, как работает левый и правый столбцы Яндекс Wordstat.
Левая колонка
В левом столбце отображаются все фразы, содержащие наш введенный запрос.
Для примера вводим запрос яндекс Wordstat . Нам будут показаны все фразы, содержащие наш запрос, при этом порядок слов значения не имеет.
Это нужно помнить! Цифра напротив запроса — это количество вкладов данной фразы в месяц, а не количество переходов по этой фразе! Например, если мы зайдем в поисковую систему https://www.yandex.ru/, наберем фразу yandex Wordstat и нажмем «Найти» — по этой фразе будет отображаться 1.
Цифра отображает все запросы, включенные в нее.
Например: по количеству обращений 60 897 по запросу wordstat Яндекс. Включите все указанные ниже номера запросов, которые содержат фразу yandex Wordstat или wordstat Yandex. Порядок слов не имеет значения.
А в количество просмотров 2295 по фразе яндекс Wordstat Key Включено количество просмотров по фразе яндекс Wordstat Ключевые слова .
Если мы нажмем на фразу яндекс Wordstat Key , мы в этом убедимся. Мы отобразим все фразы, которые входят в этот запрос.
Это основной принцип и логика работы инструмента «по» и левому столбцу WordStat. Для более продвинутого отображения статистики существуют операторы выбора состояния.
Базовые операторы Яндекс Wordstat
Есть два основных оператора:
- Восклицательный знак.
- Цитаты.
Их также можно использовать вместе друг с другом. Рассмотрим суть применения каждого оператора на примере простейшего запроса.
Восклицательный знак
Говоря раньше слова! закрепите конец слов перед знаком ! .
То есть писать ! Купить! phone На дисплее больше не будут вводиться слова с отклонением, например: телефоны, купленные и другие измененные окончания и слова с отклонением перед !.Но вот в эти шоу включены все фразы, которые у меня точно есть, пишу купи телефон Например, в эти шоу включены такие запросы: как купить сотовый телефон, где купить телефон и т. Д.
Восклицательный знак фиксирует только точное написание тех слов, перед которыми он стоит.
Через базовый оператор «восклицательный знак» пользователь может видеть результаты по конкретному запросу без отклонения одного или нескольких слов, содержащихся во фразе.
Цитаты
Ввод фразы «Купить телефон» В кавычках вы увидите количество вариантов только для этого запроса без каких-либо дополнительных слов, то есть этот запрос может включать фразы: купить телефоны, купить телефоны, купить телефон, и т.п.Это больше не включается с другими дополнительными словами, например: как купить телефон, где купить сотовый телефон и т. Д.
Операторы общего улова + восклицательный знак
Рецепт «! Купить! Телефон» Вы исправите сам запрос и конец слов. Таким образом, вы узнаете точную частоту по конкретному запросу без дополнительных слов, что позволит спрогнозировать количество переходов по этому запросу. Но помните, количество совпадений — это не количество переходов, поэтому это только приблизительные данные, также необходимо понимать, что количество кликов уменьшается в зависимости от позиции сайта в выдаче поисковой системы по этому запросу.
Дополнительные операторы
Еще 5 основных вспомогательных операторов открывают еще больше возможностей в Яндекс Wordstat:
- Оператор Плюс. Для использования обозначает символ + . Это помогает находить поисковые запросы, в которых есть стоп-слова, такие как союзы, предлоги и т. Д.
- Оператор «Квадратные скобки» . Используются символы с написанием ключевой фразы между ними. С его помощью записывается выравнивание слов во фразе, то есть они остаются в таком виде, как вы их прописали.Оператор актуален, когда необходимо проанализировать популярность похожих фраз по разным запросам.
- Оператор «Или» . Используется символ | и важен для семантики операционной сессии на веб-странице, а также в процессе сравнения или «смещения» в статистике некоторых фраз.
- Оператор «Минус» . Его назначают для его применения. — . Удаляет ненужные запросы для изучения статистики слов.
- Менеджер «Группировки» . Обозначены символы () Внутри которого указанным выше операторам предписано использовать их вместе.
Примеры использования операторов
Ниже представлены примеры применения всех перечисленных выше операторов, как основных, так и дополнительных.
«А плюс»
У нас отображаются все слова, в которых содержится слово. работа и предлог на . Оператор +, как бы зафиксировал предлог на .
«Минус»
Нам показаны все запросы, где есть слово окно , но нет слова цена .
«Квадратные скобки»
Записываем восклицательный знак аккуратное написание слов, с кавычками, записываем только слова, прописанные между ними, а порядок слов записываем в квадратных скобках.
«Группировка» и сложный запрос
Еще одна удобная функция, предоставляемая сервисом Wordstat.Он позволяет задавать длину запросов (2, 5 слов и т. Д.) С вводом ключевых слов и производить их синтаксический анализ. Эта функция особенно полезна в случаях, когда веб-мастер работает над сайтом, посвященным очень популярной теме, и, собрав максимальное количество страниц, не может получить все поисковые фразы, относящиеся к этой нише.
На заметку. Статистика Яндекс Wordstat При анализе одного запроса выдает максимум 41 страницу, но часто бывает, что фраз для запроса намного больше, и не все могут увидеть.
Для сбора всех фраз, длина которых содержит 3 слова, используется такой дизайн: «SAMSUNG SAMSUNG SAMSUNG»
Указав такой запрос, вы соберете не максимальное количество страниц поисковой фразы разной длины, а 41 Только страницы фразы состоят из 3 слов, содержащих ключевое слово SAMSUNG. Если он постепенно анализирует запросы, длина которых от 2 до 7 слов, то вы можете полностью собрать всю статистику по слову SAMSUNG.
Правый столбец Wordstat.
Показывает, что они все еще искали людей, введя этот запрос обувь .
История запросов
Вкладка «История запросов» создана для изучения динамики запросов за последние 2 года, а также определения их популярности в зависимости от сезона. Например, чтобы узнать, как меняется интерес потребителей к модели Samsung Galaxy S9. Есть настройки расписаний на недели или месяцы, еще есть возможность отфильтровать тип устройства, например отображение только на смартфонах.
Абсолютное значение — это наша фактическая стоимость шоу в определенные периоды времени.
Относительное значение — это отношение абсолютного значения (совпадений) к общему количеству всех показов. Этот индикатор показывает популярность указанного запроса среди всех остальных запросов.
Нельзя не упомянуть эту функцию как получение частоты запроса в конкретном регионе. Возможность разделить общую частоту запроса по регионам позволяет анализировать, как часто определенная фраза вводится пользователями из определенного региона и насколько она здесь популярна.
Итак, запрос, содержащий слова «купить» и Сочи Чаще всего жители города Сочи, и это логично. Однако, углубившись в возможности этой функции, вы можете открыть для себя и гораздо более неожиданные результаты.
Заключение
Бесплатный сервис Яндекс Wordstat — важнейший инструмент для SEO-специалистов и рекламодателей Яндекс Директ. Он позволяет детально изучить статистику запросов поисковых систем и проанализировать подбор слов для привлечения на программу большей целевой аудитории.Сегодня мы изучили все важнейшие функции сервиса, успешное применение которых поможет вам сделать свой ресурс более заметным и вывести его на лидирующие позиции поисковой системы.
Прежде чем приступить к созданию нового онлайн-проекта, опытные веб-мастера оценивают его перспективы — есть ли смысл вкладывать время и средства? Может случиться так, что масштабное начинание закончится провалом из-за того, что Ниша абсолютно востребована.
Знание самых популярных запросов в Яндексе или других поисковых системах, которые вы продвигаете, поможет вам выбрать нишу с большой целевой аудиторией.
- популярность темы в сети;
- платежеспособность аудитории.
В первую очередь посмотрите на популярность, ведь хороший трафик можно монетизировать в любом случае, например, добавив сайт в рекламную сеть Яндекса (ОК) или Google AdSense.
Темы популярности = Много запросов в поиске = Высокочастотные ключевые слова
Итак, необходимо выучить частоту интересующих нас слов и словосочетаний.
Как узнать частоту конкретных запросов
Если у вас уже есть определенные наценки на будущие темы сайта, достаточно составить предварительный список самых популярных в данной теме запросов и «пробить» их частоту через сервис — WordStat.yandex.ru.
Например, у меня возникла идея сделать сайт по разведению оленей, можно посмотреть, сколько людей ищут «как разводить оленей».
Популярность запроса в поисковике Яндекс будет выражаться конкретными цифрами, и тогда вы уже оцените, насколько он впишется в ваш бизнес-план.
Мы видим, что тема про оленей не особо востребована, возможно, сайту нужно выбрать какие-то более популярные запросы и вложиться в них.
Максимум, что мы можем узнать из этого сервиса, — это увидеть популярность сложных ключевых запросов (состоящих из 2 и более слов) с обязательным вводом одного из них.
Например, мы ищем, кого чаще всего хотят купить люди. Их просьбы должны выглядеть так — «купи …» (вместо форелевого слова). В поле Wordstat вводим «купить» и в списке предложенных вариантов мы увидим все самые популярные запросы на покупку в Яндекс. Подбор ключей для магазина автомобильных шин можно начать с общей просьбы «купить шины»:
В списке уже видно, что и сколько ищут.Из общего запроса вы можете выбрать несколько групп более узкой специализации. Каждую из этих групп затем можно рассматривать индивидуально по той же схеме и изложить запросы из 4-5 слов. Для интернет-магазина все закончится на самых узких запросах — карточках товаров.
Точно так же вы можете искать слова «смотреть», «скачать» и т. Д. Если у нужного вам предмета есть похожие объединяющие слова, то вам повезло. Сложнее, когда все запросы в теме не похожи друг на друга.Как их выявить, я расскажу дальше.
Откуда брать все поисковые запросы
Вы уже поняли, что сервис Wordstat не покажет нам всю статистику в Интернете и не будет «засыпать» самые востребованные запросы, он скажет мне только частоту каких мы спросили.
Некоторые веб-мастера рекомендуют использовать Google Trends, чтобы найти сервис Trends, который показывает популярные на данный момент темы на данный момент, но это неэффективно, так как есть солидные новости шоу-бизнеса, фильмов и прочей ерунды — никаких реальных чаевых для многообещающего сайта не будет.
Есть реальный способ получить полную выборку всех ключевых запросов, которые обрабатываются поисковиками, но это удовольствие не бесплатное — называется база Пастухова (сайт pastukhov.com).
Для удовлетворения любопытства по самым популярным клавишам в Пастухове прямо на сайте есть несколько десятков ключей от Топа в таком виде,
но на работу он не катается (солидно скачать, смотреть, игры, фильмы, песни), а за полную версию просят от 200 до 600 долларов в зависимости от разных акций.
Если вы занимаетесь постоянно и много сайтов, база может быть полезна, но есть вариант узнать популярные ключевые слова дешевле, точнее бесплатно.
LiveInternet — самые популярные запросы бесплатно
Для этого мы используем сервис статистики LiveInternet. К сожалению, использование данных сервиса не даст 100% совпадения с данными поисковых систем Яндекс или Google, так как не все интернет-сайты используют счетчики посещаемости от Liventernet и не все, кто пользуется их статистикой, открыты, но выборка очень большой там поэтому для реальной работы более чем достаточно.В конце концов, нам понадобится список, а точные цифры позже в пробной версии Wordstat.
Полезная штука в LiveInternet — можно сразу делать сортировку по категориям — копать поисковые запросы не по всему Интернету, а по определенной теме (впрочем, можно и по всему Интернету).
Открытый сайт — LiveInternet.ru
Если нам нужны данные по распространенным в сети поисковым запросам, то сразу переходим в рейтинг сайтов, если нужны ключевые фразы по определенной тематике, то выбираем одну из колонок.
Например, я выбрал группу компьютеров. Теперь нам нужна групповая статистика — это такая ссылка с графическим значком сверху списка сайтов в рейтинге. Обращаем ваше внимание, что мы можем уточнить страну и регион — для сайтов, имеющих привязку к территории, нужны запросы, популярные в данной области.
В статистике мы увидим общие цифры посещаемости и многое другое, но интересует левый столбец меню и, в частности, пункт «по поисковым фразам».
Существенная часть запросов здесь скрыта под кодовым названием «Другое», но пусть это не так, самый популярный открытый.
Чтобы сделать выборку максимально удобной, в настройках итоговой таблицы выберите «По месяцам» и «Всего». Снизу вы можете настроить определенное количество строк, одновременно отображаемых на странице (от 10 до 100).
Таким образом, мы получаем список самых популярных запросов в указанной категории.Не стоит удивляться, если среди запросов не будет проскальзывать тематика — это связано с тем, что выборка идет не по актуальным категориям запросов, а по сайтам, которые находятся в рейтинге LiveInternet. И часто бывает, что сайт неправильно помещен в категорию и его запросы учитываются. Также бывает, что сайт тематический, но на нем есть страница с текстом другой тематики, что дает ощутимый поисковый трафик, не относящийся к указанной категории.
Итак, самые популярные слова и фразы нужно выделить своими руками.
Теперь мы можем расширить нашу выборку, чтобы выбрать конкретные ключевые фразы для написания статей для вашего сайта. Для этого нужно взять выписанный из liventher список слов и вернуться в любимый Яндекс Wordstat. Поочередно вводя слова, мы будем получать более узкие значения популярных запросов, но, главное, в правом столбце мы найдем похожие по тематике запросы, расширяющие нашу исходную выборку.
Метод бесплатного получения самых популярных поисковых систем без покупки каких-либо Пастуховских баз и других списков.
Полезные статьи:
Частота запроса — это количество раз, когда пользователи вводили этот запрос в поисковой системе за последний месяц.
Какая частота запросов в Яндексе и Гугле?
Этот термин используется для обозначения количественного показателя, который определяется количеством поисковых запросов (ключевых слов / фраз), поступающих в поисковую систему за фиксированный период.Чаще всего через 30 дней. Этот показатель используется в нескольких сферах: реклама, интернет-маркетинг, продвижение сайтов.
В зависимости от объема использования запросы делятся на:
- Высокочастотный (HF). Состоит из 1 или 2 слов. Запрос попадает в эту категорию, если по данным статистических служб в месяц набирается более 10 000 человек. Удаление сайта из топа по данному типу запросов — сложный процесс из-за высокого уровня конкуренции.
- Среднечастотный (сч). Общее количество обращений в поисковик по таким запросам лежит в пределах от 1000 до 10000. Уровень конкуренции ниже, чем в РФ, но посещаемость хорошая. Значения показателя конверсии SC варьируются от среднего до высокого.
- Низкочастотный (НЧ). Запрашивается от 100 до 1000 раз в месяц. Служат для продвижения ресурсов и увеличения целевого трафика.
- Micronzcuprem (мкм) — до 100 запросов в месяц.
Как проверить частоту запроса?
Поисковые системы разрабатывают собственные сервисы для определения частоты запросов. Для того, чтобы их использовать, вам необходимо:
- Регистр.
- Авторизовать
- Введите интересующий вас поисковый запрос.
Анализ частоты поисковых запросов в Яндекс.
Продукт яндекса называется Яндекс Wordstat. Он работает со всеми словоформами поисковых запросов, исключает формы вопросов и предлоги.Чтобы проверить запрос с поводом — нужно поставить перед ним «+». Пример:
Результат простого поиска будет представлен в виде общего количества запросов для предполагаемого ключа и фраз, в которых он содержится. Если вам нужно получить результат в Wordstat по определенной словоформе, вам придется позировать с использованием специальных операторов: кавычки, восклицательный знак, плюс, минус. Принцип использования аналогичен тому, что используется в Яндекс Директ.
Виртуальный хостинг сайтов для популярных CMS:
Просто запрос:
Всего запросов, содержащих это слово, почти 4.5 миллионов. Эти 4,5 миллиона включают другие запросы, так называемые «хвосты»:
Теперь пользуемся оператором «». Запрос, заключенный в кавычки, будет показан без «хвостов»:
Почти 35000. Но цитаты не фиксируют словоформы. Те. Эти 40 000 также включают «портативные компьютеры», «портативные компьютеры» и «портативные компьютеры». Для фиксации словоформы используется восклицательный знак:
Допустим, нас интересуют только информационные запросы. Затем с помощью оператора «-» можно отсечь коммерческие запросы:
Как узнать частоту поискового слова в гугле?
Статистическая служба Google называется Google AdWords (в целом она создана для ведения контекстной рекламы, но запросы на запросы можно просматривать и не разбивать баланс).С его помощью они получают данные о поисковых запросах, сделанных в системе. Сервис позволяет выбрать регион и язык, показывает частоту и конкурентоспособность ключевых слов . Google AdWords подходит для сравнения популярности поисковых запросов, позволяет отслеживать динамику их популярности по расписанию.
Также как и в VORDSTAD — можно указать желаемый регион, минус-слова и (в vordstate история нужно искать для каждого запроса отдельно) — период статистики.
Чем полезна такая статистика?
На основе этих объективных данных, отражающих потребности и предпочтения пользователей, оптимизатор может соответствовать семантическому ядру сайта. Подобная стратегия помогает избежать лишнего времени и денег при попытке создать ресурс по бесперспективной тематике или конкурировать с гигантами, занимающими первые позиции в топе поисковых систем.
Кроме того, эта информация в руках siene становится полезным инструментом в повышении эффективности продвижения ресурсов.В зависимости от целей и задач он может регулировать преобладание запросов HF, SC или LF. Продвижение сайта в поисковых системах по высокочастотным запросам увеличивает количество уникальных пользователей.
Но этот вид оптимизации самый затратный во временном и финансовом отношении. Яндекс использует политики принудительного запрета продвижения ресурсов по RF запросам. Во-первых, сайт обязан заработать репутацию и продемонстрировать положительную динамику развития. Только после выполнения этих условий ресурс может претендовать на право соревноваться в топе.
запросов SC и LF имеют высокую конверсию, но низкую конкуренцию, что снижает стоимость продвижения. В то же время они помогают улучшить качество аудитории и добиться роста посещаемости.
Усредненная разметка поисковых запросов выглядит так:
- РФ — от 10 до 15%;
- Sch — 20-40%;
- NC, мкм — от 45 до 70%.
Что еще нужно знать о запросах?
Есть категория ключевых слов, частота запросов которой напрямую зависит от времени года или конкретного месяца.Посещаемость сайтов, смысловое ядро которых состоит из такого ключа, колеблется по аналогии с высоким и низким сезоном в туристическом бизнесе. Изучение сезонности помогает подготовить ресурс и обойтись без потерь трафика . Вы можете получить эту статистику через Яндекс Wordstat (вкладка истории запросов) или с помощью программы Key Collector.
Конкурсные запросы совпадают с частотой не всегда. На величину этого показателя влияют особенности целевой аудитории, тематика запросов, количество оптимизируемых ресурсов и степень оптимизации.Чем больше факторов участвует в продвижении запроса, тем выше конкурентоспособность.
Анализ поисковых запросов использует каждый грамотный оптимизатор. Статистика показывает, что чаще всего люди ищут людей в Интернете с помощью поисковых систем.
Его основная цель — компилировать. Если у вас их нет (чаще всего речь идет о блогах), статистика поисковых запросов обрабатывается при написании статьи, «перетаскивая» ее под определенное ключевое слово.
Основным инструментом подбора ключевых слов большинство веб-мастеров считают статистических запросов Яндекс .
WordStat.yandex.ru (Vordstat) — Статистика запросов Яндекса
Яндекс Wordstat (WordStat.yandex.ru) Объединяет всевозможные словарные работы, при этом чаще всего не даются предлоги и анкеты. Если вы просто напишите в Яндекс интересующие вас слова в Яндекс, то сервис покажет вам общее количество показов этого слова, словоформ и словосочетаний, в которых оно было найдено.
Например, напишите:
статистика запросов
(просмотров: 31535.Слова включают: Статистика запросов Яндекс , Статистика поисковых запросов и т. Д.).
Для того, чтобы конкретизировать конкретную словоформу в Яндекс Wordstat, необходимо использовать специальные операторы.
Самым распространенным является заключение искомого поискового запроса в кавычки («»). В этом случае конкретное ключевое слово будет учтено в любой словоформе.
Пример:
«Статистика запросов»
(Показывает уже 4764. Включено: статистика запросов , статистика запросов и т. Д.).
Оператор восклицательный знак! Позволяет учитывать только точные значения ключевых слов.
Пример:
«! Статистика! Запросы»
(Показывает уже 4707. Теперь мы узнали точное количество интересующих нас запросов. Обратите внимание на оператора! Оно стоит перед каждым словом).
С помощью оператора — (минус) есть возможность исключить из показа определенные слова.
С помощью оператора плюс + можно заставить статистику Яндекса учитывать альянсы и предлоги.Вы получите данные о словоформах с этими частями речи.
Операторы скобок () — группировка и | — или же. Эти операторы используются для компиляции в рамках одного запроса как группы ключей.
Стоит отметить, что операторы можно комбинировать различными способами, чтобы значительно сократить время сбора статистического анализа.
Статистика поисковых запросов Яндекса приводит не только производные от введенных слов, но и ассоциативные запросы, которые пользователи использовали с вашими запросами.Такая возможность способствует существенному расширению смыслового ядра (вкладка справа — «что еще искали искали …»).
Первая вкладка WordStat.yandex.ru «По данным» содержит общее количество вариантов для конкретных поисковых запросов. На вкладке «Регион» вы сможете определить конкретное ключевое слово в той или иной области поиска.
Вкладка «На карте» отражает частоту использования запросов на карте мира. Чтобы отслеживать частоту этого запроса за определенный период, вы можете использовать вкладки «По месяцам», «По неделям».Особенно это актуально для сезонных запросов.
- Во-первых, статистика Яндекса не дает данных о количестве людей, выполнивших поиск по конкретным запросам, а только выдает количество результатов пополнения результатов поиска, содержащих этот запрос.
- Во-вторых, Яндекс Wordstat по умолчанию показывает данные за последний месяц. При этом следует учитывать, что некоторые запросы могут носить сезонный характер, а также есть запросы, так называемые «взлеты интересов».
- В-третьих, цифра, стоящая над запросом, включает все ключевые слова, содержащие сам запрос и его словоформу.Следует использовать специальные операторы.
При учете всех возможностей, которые предоставляет WordStat.yandex.ru, и грамотном использовании всех инструментов, этот сервис становится важнейшей составляющей, которую большинство веб-мастеров используют при продвижении современных ресурсов.
Статистика запросов Google
Google имеет столько же двух сервисов, которые могут применяться в качестве ключевых статистических запросов. Статистика Google по подбору ключевых слов часто используется как дополнительный инструмент для расширения семантического ядра.Этот сервис обычно определяет язык и регион для поиска, задача оптимизатора — подготовка стартового набора слов. В результате система предложит вам похожие запросы с указанием частоты их показов и конкурентоспособности.
Статистика поиска Google больше предназначена для сравнения популярности нескольких поисковых запросов. Кроме того, предлагается наглядное представление изменений динамики популярности запроса в виде графиков.
Статистика запросов Рамблера
Статистика запросов Рамблеране так популярна, так как поисковик Рамблер не так активно «использует» интернет-пользователей. Основное отличие от статистики Яндекса в том, что здесь нет комбинации результатов для разных слов. Другими словами, вы можете получить точную статистику по частоте запросов в нужном количестве и регистре без использования дополнительных операторов.
Статистика поисковых запросов Рамблера была бы удобным дополнением к Яндексу, если бы эта поисковая машина была более авторитетной в Рунете.Стоит отметить, что статистика рамблера позволяет определить количество просмотров как первой, так и любых других страниц относительно определенного набора слов.
Поисковые запросы — частота и конкурентоспособность
Что еще нужно знать начинающему оптимизатору о целевых запросах? Обычно принято разделять все поисковые запросы на высокочастотные (RF), средние (ые) и низкочастотные (LF). А также высококонкурентный (VC), средний (SC) и низкоконкурентный (NK).
Конечно, лучшим вариантом будет высокочастотный и одновременно низкий или средний запрос кондиционера. Но такие редко встречаются. Бывает, что низкочастотный запрос весьма конкурентоспособен. Обычно высокочастотные — это высококонкурентные запросы, среднечастотные — это средне-условные и т. Д.
Следует иметь в виду, что эти термины не несут под собой каких-либо конкретных количественных значений, так как для каждой темы эти цифры будут различаться. Стоит понимать, что продвижение того или иного сайта будет определять не только его тематику, но и конкретную ситуацию на рынке.
Необходимо учитывать, что грамотное использование статистики поисковых запросов является одной из составляющих процесса оптимизации. Посетители, которые будут следовать определенным поисковым запросам, должны получать информацию, на которую рассчитывали, только в этом случае они захотят вернуться на ваш ресурс.
Как пользоваться Планировщиком ключевых слов Яндекса
Яндекс — ведущая поисковая система в России и, следовательно, идеальный канал для успешной рекламной кампании в Интернете на этом целевом рынке.Исследование ключевых слов незаменимо, если вы планируете заниматься поисковым маркетингом с Яндексом. Для этого Яндекс предлагает инструмент для планирования ключевых слов Wordstat.
Далее мы покажем вам, как использовать этот инструмент. Для доступа к планировщику ключевых слов вам потребуется аккаунт Яндекс.Директ.
Как работает Планировщик ключевых слов Яндекса
Wordstat — простой инструмент с минималистичным интерфейсом. Для начала введите ключевое слово в поле поиска. Вы можете ввести только одно ключевое слово за один поиск.В нашем примере показан поиск по русскому слову «женская обувь». После того, как вы ввели свой поиск, вы можете выбрать один из нескольких вариантов результатов. Ниже вы найдете список возможностей.
Ежемесячный объем поиска по запрошенному ключевому слову (1).
Ежемесячный объем поиска по предложенным ключевым словам, содержащим запрошенное слово (1). Если введенное ключевое слово состоит из двух или более слов, каждое предлагаемое ключевое слово будет содержать все эти слова.
Ежемесячный объем поиска по похожим ключевым словам (2). Wordstat предоставляет предложения по другим семантически связанным поисковым запросам.
Ежемесячный объем поиска по регионам (3). Как видно из примера, общий объем запросов «женская обувь» в Яндексе составляет 45209. 31’413 из этих поисковых запросов были обработаны в России и 9’850 — в Москве.
Ежемесячный объем поиска по странам на карте. Эта карта отображает популярность запрашиваемого ключевого слова во всем мире на основе цветовой схемы. Шкала варьируется от желтого (нет популярности) до красного (высокая популярность). Таким образом, чем темнее цвет, тем популярнее запрашиваемое ключевое слово в конкретной стране.
Исторический объем поиска по запрошенному ключевому слову за месяц и за неделю (4). Вы можете увидеть количество поисковых запросов в прошлом году за месяц или за неделю на графике и в абсолютных числах.
Наш совет для успешного исследования ключевых слов
Чтобы собрать все ключевые слова, найденные в ходе вашего исследования, мы рекомендуем установить плагин «Яндекс Wordstat Assistant».С помощью этого плагина вы можете добавить выбранные ключевые слова в список в Яндекс Wordstat Assistant, просто одним щелчком по значку плюса. Затем вы можете легко скопировать ключевые слова прямо из списка в Яндекс Wordstat Assistant и вставить их, например, в свою кампанию на Яндексе или в лист Excel.
У вас есть вопросы о Планировщике ключевых слов Яндекса? Я рад ответить на ваше письмо.
Эволюция структур данных в Яндекс.Метрике
Яндекс.Метрика — вторая по величине система веб-аналитики в мире. Метрика принимает поток данных, представляющих события, которые произошли на сайтах или в приложениях. Наша задача — обработать эти данные и представить их в анализируемой форме.
Обработка данных сама по себе не проблема. Настоящая трудность заключается в попытке определить, в какой форме следует сохранять обработанные результаты, чтобы с ними было легко работать. В процессе разработки нам несколько раз приходилось полностью менять подход к организации хранения данных.Мы начали с таблиц MyISAM, затем использовали LSM-деревья и в итоге пришли к базе данных, ориентированной на столбцы, ClickHouse. В этой статье я объясню, что заставило нас остановиться на последнем варианте.
Яндекс.Метрика была запущена в 2008 году и работает уже более девяти лет. Каждый раз, когда мы меняли подход к хранению данных в прошлом, это происходило из-за того, что конкретное решение оказалось неэффективным: либо был недостаточный резерв производительности, либо решение было ненадежным, либо оно использовало слишком много вычислительных ресурсов, либо просто не позволяло нам реализовать то, что нам нужно.
Старая Яндекс.Метрика для веб-сайтов имеет более 40 «фиксированных» типов отчетов (например, отчет по географии посетителей), несколько инструментов внутристраничной аналитики (например, карты кликов), Webvisor (который позволяет изучать действия отдельных пользователей в большая деталь), а также отдельный конструктор отчетов.
С новыми Metrica и Appmetrica вы можете настраивать каждый отчет вместо того, чтобы иметь дело с «фиксированными» типами. Вы можете добавлять новые параметры (например, в отчете по поисковым запросам вы можете разбить данные по целевым страницам), сегментировать и сравнивать (скажем, между источниками трафика для всех посетителей ипосетителей из Сан-Франциско), измените свой набор показателей и т. д. Новая система, таким образом, требует совершенно другого подхода к хранению данных, чем тот, который мы использовали ранее.
MyISAM
Изначально компания Metrica создавалась как ответвление службы поисковой рекламы Яндекс.Директ. Таблицы MySQL с движком MyISAM использовались в Direct для хранения статистики, и именно с этого мы начали в Метрике. Мы использовали MyISAM для хранения «фиксированных» отчетов с 2008 по 2011 годы.
Позвольте мне немного пояснить, какую структуру следует использовать в таблицах отчетов, например, при работе с географией.Отчет составляется по конкретному сайту (точнее, конкретному идентификатору счетчика Метрики). Это означает, что первичный ключ должен содержать CounterID. Пользователь может выбрать произвольный отчетный период. Хранить данные для каждой пары дат не имеет смысла, поэтому данные сохраняются для каждой даты, а затем накапливаются по запросу для выбранного интервала. Следовательно, первичный ключ содержит дату.
Данные в отчете отображаются для регионов либо в виде списка, либо в виде дерева, состоящего из стран, регионов и городов.Таким образом, имеет смысл поместить RegionID в первичный ключ таблицы и собрать данные в дерево на стороне кода приложения, а не на стороне базы данных.
Допустим, мы также хотим учитывать среднюю продолжительность сеанса. Это означает, что столбцы таблицы должны содержать количество сеансов и общую продолжительность сеанса.
Итак, итоговая таблица будет иметь следующую структуру: CounterID, Date, RegionID -> Visits, SumVisitTime,… Теперь посмотрим, что происходит, когда мы запрашиваем отчет.Запрос SELECT выполняется с условиями WHERE CounterID = AND Date BETWEEN min_date AND max_date. Другими словами, считывается диапазон первичного ключа.
Как данные на самом деле хранятся на диске?
Таблица MyISAM состоит из файла данных и индексного файла. Если ничего не было удалено из таблицы и строки не изменились по длине во время обновления, файл данных будет состоять из сериализованных строк, расположенных последовательно в том порядке, в котором они были вставлены. Индекс (включая первичный ключ) представляет собой B-дерево, где листья содержат смещения в файле данных.Когда мы читаем данные диапазона индекса, набор смещений в файле данных извлекается из индекса. Затем файл данных считывается этим набором смещений.
Давайте посмотрим на реальную ситуацию, когда индекс находится в ОЗУ (ключевой кеш в MySQL или системный кеш страниц), но данные в нем не кэшируются. Предположим, что мы используем жесткие диски. Время, необходимое для чтения данных, зависит от объема данных, которые необходимо прочитать, и от количества операций поиска, которые необходимо выполнить. Количество поисков определяется местонахождением данных на диске.
События Метрики принимаются почти в том же порядке, в котором они действительно имели место. В этом входящем потоке данные с разных счетчиков разбросаны совершенно случайным образом. Другими словами, входящие данные являются локальными по времени, но не локальными по номеру счетчика. При записи в таблицу MyISAM данные с разных счетчиков также размещаются довольно случайно. Это означает, что для чтения отчета с данными вам нужно будет выполнить примерно столько произвольных чтений, сколько строк в таблице нам нужно.
Стандартный жесткий диск со скоростью 7200 об / мин может выполнять от 100 до 200 произвольных операций чтения в секунду. RAID-массив при правильном использовании может пропорционально выполнять гораздо больше. Один SSD-накопитель семилетней давности может выполнять 30 000 произвольных операций чтения в секунду, но мы не можем позволить себе хранить наши данные на SSD. В этой системе, если бы нам нужно было прочитать 10 000 строк для отчета, это заняло бы более 10 секунд, что было бы совершенно неприемлемо.
InnoDB намного лучше подходит для чтения диапазонов первичных ключей, поскольку он использует кластеризованный первичный ключ (т.е. данные хранятся упорядоченным образом на первичном ключе). Но InnoDB было невозможно использовать из-за его низкой скорости записи. Если это напоминает вам TokuDB, читайте дальше.
Мы применили несколько приемов, чтобы MyISAM работал быстрее при выборе диапазона первичного ключа.
Стол сортировочный. Поскольку данные должны обновляться постепенно, недостаточно один раз отсортировать таблицу, но сортировать ее каждый раз невозможно. Тем не менее, это можно делать периодически для старых данных.
Разбиение на разделы.Таблица разделена на несколько меньших диапазонов первичных ключей. Это делается в надежде, что данные из одного раздела будут храниться более или менее локально, а запросы для диапазона первичных ключей будут обрабатываться быстрее. Этот метод можно отнести к ручной реализации кластеризованного первичного ключа. Это немного замедляет вставку данных. Однако при выборе количества разделов обычно достигается компромисс между скоростью вставки и скоростью чтения.
Разделение данных по поколениям.При одной схеме разбиения выборки могут сильно замедляться, при другой — скорость вставки. И оба тормозят при использовании промежуточного варианта. Решение этой проблемы — разделить данные на несколько отдельных поколений. Например, первое поколение мы назовем оперативными данными; здесь разбиение либо происходит по мере вставки данных (по времени), либо не происходит вообще. Мы будем называть данные архива второго поколения; здесь происходит разбиение по мере считывания данных (по номеру счетчика).Данные передаются из поколения в поколение с помощью скрипта, но не слишком часто (например, один раз в день) и сразу же считываются из всех поколений. Это помогает, но также создает массу трудностей.
Эти (и другие) уловки какое-то время использовались в Яндекс.Метрике, чтобы все заработало.
Подведем итог недостаткам предыдущей системы:
- локальность данных на диске очень сложно поддерживать
- таблиц заблокированы во время INSERT
- репликация медленная; реплики часто лагают
- согласованность данных после аппаратного сбоя не гарантируется
- агрегатов, таких как количество уникальных пользователей, очень сложно подсчитать и сохранить
- сжатие данных сложно использовать и работает неэффективно Индексы
- занимают много места и не помещаются в ОЗУ полностью
- данные должны быть сегментированы вручную
- многие вычисления должны выполняться на стороне кода приложения после SELECT
- сложные в обслуживании и эксплуатации
Изображение: расположение данных на диске (художественная визуализация)
В общем, MyISAM было крайне неудобно использовать.Днем серверы работали со 100% загрузкой дисковых массивов (постоянное движение головы). В этих условиях диски выходят из строя чаще, чем обычно. Мы использовали дисковые полки на серверах. Другими словами, восстанавливать RAID-массивы приходилось довольно часто. Иногда реплики отставали настолько, что нам приходилось отбрасывать и воссоздавать их. Переключение мастера репликации действительно неудобно.
Несмотря на его недостатки, по состоянию на 2011 год мы хранили более 580 миллиардов строк в таблицах MyISAM. Затем все было переконвертировано в Metrage, удалено, и в конце концов освободилось много серверов.
Metrage и OLAPServer
Мы используем Metrage для хранения фиксированных отчетов с 2010 года. Предположим, у вас есть следующий сценарий:
- данные постоянно записываются в базу данных небольшими партиями
- поток записи относительно велик (не менее нескольких сотен тысяч строк в секунду)
- сравнительно мало запросов на чтение (несколько тысяч запросов в секунду)
- все чтения диапазона первичного ключа (до миллионов строк на запрос)
- строк довольно короткие (около 100 байт без сжатия)
Для этого хорошо подходит довольно распространенная структура данных LSM Tree.Эта структура состоит из сравнительно небольшой группы «блоков» данных на диске, каждый из которых содержит данные, отсортированные по первичному ключу. Новые данные изначально помещаются в какую-либо структуру данных RAM (MemTable), а затем записываются на диск в новом отсортированном фрагменте. Периодически несколько отсортированных кусков в фоновом режиме сжимаются в один более крупный. Таким образом сохраняется относительно небольшой набор фрагментов.
Такие структуры данных используются в HBase и Cassandra. Среди встроенных структур данных LSM-Tree реализованы LevelDB и RocksDB.Впоследствии RocksDB используется в MyRocks, MongoRocks, TiDB, CockroachDB и многих других.
Metrage также является LSM-деревом. Произвольные структуры данных (фиксированные во время компиляции) могут использоваться в нем как «строки». Каждая строка — это пара ключ-значение. Ключ — это структура с операциями сравнения на равенство и неравенство. Значение представляет собой произвольную структуру с операциями по обновлению (добавлению чего-либо) и слиянию (агрегированию или объединению с другим значением). Короче говоря, это CRDT.
В качестве значений могут использоваться как простые структуры (целочисленные кортежи), так и более сложные (например, хеш-таблицы для расчета количества уникальных посетителей или структуры карты кликов).Используя операции обновления и слияния, инкрементное агрегирование данных постоянно выполняется в следующих точках:
- при вставке данных при формировании новых пакетов в RAM
- во время фонового слияния
- во время запросов на чтение
Metrage также содержит нужную нам предметную логику, которая выполняется во время запросов. Например, для отчетов по регионам ключ в таблице будет содержать идентификатор самого низкого региона (города, деревни), и, если нам нужен отчет по стране, данные страны завершат агрегирование на стороне сервера базы данных.
Вот основные преимущества этой структуры данных:
- Данные расположены довольно локально на жестком диске; чтение диапазона первичного ключа происходит быстро.
- Данные сжимаются блоками. Поскольку данные хранятся упорядоченно, сжатие очень хорошо работает при использовании алгоритмов быстрого сжатия (в 2010 году мы использовали QuickLZ, с 2011 года — LZ4).
- Хранение данных, отсортированных по первичному ключу, позволяет нам использовать разреженный индекс. Разреженный индекс — это массив значений первичного ключа для каждой N-й строки (порядка N тысяч).Этот индекс максимально компактен и всегда умещается в оперативной памяти.
Поскольку чтение выполняется не очень часто (даже если при этом читается много строк), увеличение задержки из-за наличия большого количества фрагментов и распаковки блоков данных не имеет значения. Чтение дополнительных строк из-за разреженности индекса также не имеет значения.
Записанные блоки данных не изменяются. Это позволяет читать и писать без блокировки — для чтения берется моментальный снимок данных.Используется простой и единообразный код, но мы можем легко реализовать всю необходимую логику для конкретной предметной области.
Нам пришлось написать Metrage вместо изменения существующего решения, потому что его действительно не было. LevelDB не существовал в 2010 году, и TokuDB в то время был проприетарным.
Все системы, реализующие LSM-Tree, подходили для хранения неструктурированных данных и преобразования BLOB в BLOB с небольшими вариациями. Но адаптация этого типа системы для работы с произвольным CRDT заняла бы гораздо больше времени, чем разработка Metrage.
Преобразование данных из MySQL в Metrage было довольно трудоемким: программа преобразования работала всего за неделю, а основная часть работала около двух месяцев.
После передачи отчетов в Metrage мы сразу увидели увеличение скорости интерфейса Metrica. Мы используем Metrage пять лет, и это оказалось надежным решением. За это время было всего несколько мелких сбоев. Его преимущества заключаются в простоте и эффективности, что сделало его гораздо лучшим выбором для хранения данных, чем MyISAM.
По состоянию на 2015 год мы хранили 3,37 триллиона строк в Metrage и использовали для этого 39 * 2 серверов. Затем мы отошли от хранения данных в Metrage и удалили большую часть таблиц. У системы есть свои недостатки; он действительно эффективно работает только с фиксированными отчетами. Metrage агрегирует данные и сохраняет агрегированные данные. Но для этого вы должны заранее перечислить все способы агрегирования данных. Так что если мы сделаем это 40 различными способами, это означает, что Метрика будет содержать 40 типов отчетов и не более того.
Чтобы смягчить это, нам пришлось на время сохранить отдельное хранилище для мастера настраиваемых отчетов под названием OLAPServer. Это простая и очень ограниченная реализация базы данных, ориентированной на столбцы. Он поддерживает только одну таблицу, установленную во время компиляции — сеансовую таблицу. В отличие от Metrage, данные обновляются не в реальном времени, а несколько раз в день. Единственный поддерживаемый тип данных — числа фиксированной длины от 1 до 8 байтов, поэтому он не подходил для отчетов с другими типами данных, например URL-адресами.
ClickHouse
Используя OLAPServer, мы разработали понимание того, насколько хорошо ориентированные на столбцы СУБД справляются с задачами специальной аналитики с неагрегированными данными.Если вы можете получить какой-либо отчет из неагрегированных данных, тогда возникает вопрос, нужно ли вообще агрегировать данные заранее, как мы это сделали с Metrage.
Изображение: обработка запросов в базе данных, ориентированной на столбцы
С одной стороны, предварительная агрегация данных может уменьшить объем данных, которые используются в момент загрузки страницы отчета. С другой стороны, агрегированные данные не решают всего. Вот причины, почему:
- вам необходимо иметь список отчетов, которые потребуются вашим пользователям заранее
- другими словами, пользователь не может составить собственный отчет
- при агрегировании большого количества ключей объем данных не уменьшается и агрегирование бесполезно
- при большом количестве отчетов слишком много вариантов агрегирования (комбинаторное разнесение)
- при агрегировании ключей с высокой мощностью (например, URL-адресов) объем данных не уменьшается намного (менее чем наполовину)
- из-за этого объем данных может не уменьшаться, а фактически увеличиваться при агрегации
- пользователей не будут просматривать все отчеты, которые мы рассчитываем для них (другими словами, многие вычисления оказываются бесполезными)
- трудно поддерживать логическую последовательность при хранении большого количества различных агрегатов
Как видите, если ничего не агрегируется и мы работаем с неагрегированными данными, то возможно даже сокращение объема вычислений.Но только работа с неагрегированными данными предъявляет очень высокие требования к эффективности системы, выполняющей запросы.
Итак, если мы агрегируем данные заранее, мы должны делать это постоянно (в реальном времени), но асинхронно по отношению к запросам пользователей. Нам действительно нужно просто агрегировать данные в реальном времени; большая часть получаемого отчета должна состоять из подготовленных данных.
Если данные не агрегированы заранее, вся работа должна выполняться в тот момент, когда пользователь запрашивает их (т.е. пока они ждут загрузки страницы отчета). Это означает, что в ответ на запрос пользователя необходимо обработать многие миллиарды строк; чем быстрее это можно будет сделать, тем лучше.
Для этого нужна хорошая колоночная СУБД. На рынке не было СУБД, ориентированных на столбцы, которая бы достаточно хорошо справлялась с задачами интернет-аналитики в масштабе Рунета (российского Интернета) и не была бы слишком дорогой для лицензирования.
В последнее время в качестве альтернативы коммерческим СУБД, ориентированной на столбцы, начали появляться решения для эффективной специальной аналитики данных в распределенных вычислительных системах: Cloudera Impala, Spark SQL, Presto и Apache Drill.Хотя такие системы могут эффективно работать с запросами для внутренних аналитических задач, их сложно представить в качестве серверной части веб-интерфейса аналитической системы, доступной для внешних пользователей.
В Яндексе мы разработали, а затем открыли исходный код собственной колоночной СУБД — ClickHouse. Давайте рассмотрим основные требования, которые мы имели в виду, прежде чем приступить к разработке.
Умение работать с большими наборами данных. В нынешней Яндекс.Метрике для веб-сайтов ClickHouse используется для хранения всех данных для отчетов.По состоянию на сентябрь 2017 года база данных состоит из 25,1 трлн строк. Он состоит из неагрегированных данных, которые используются для получения отчетов в режиме реального времени. Каждая строка в самой большой таблице содержит более 500 столбцов.
Система должна масштабироваться линейно. ClickHouse позволяет увеличивать размер кластера, добавляя новые серверы по мере необходимости. Например, основной кластер Яндекс.Метрики за три года увеличился с 60 до 426 серверов. В целях отказоустойчивости наши серверы распределены по разным центрам обработки данных.ClickHouse может использовать все аппаратные ресурсы для обработки одного запроса. Таким образом можно обрабатывать более 2 терабайт в секунду.
Высокая эффективность. Мы действительно делаем упор на высокую производительность нашей базы данных. По результатам внутренних тестов ClickHouse обрабатывает запросы быстрее, чем любая другая система, которую мы могли бы приобрести. Например, ClickHouse обрабатывает запросы веб-аналитики в среднем в 2,8–3,4 раза быстрее, чем одна из самых эффективных коммерческих СУБД, ориентированных на столбцы (назовем ее DBMS-V).
Функциональности должно хватить для инструментов веб-аналитики.База данных поддерживает диалект языка SQL, подзапросы и СОЕДИНЕНИЯ (локальные и распределенные). Существует множество расширений SQL: функции для веб-аналитики, массивы и вложенные структуры данных, функции высшего порядка, агрегатные функции для приближенных вычислений с использованием эскизов и т. Д.
ClickHouse изначально был разработан командой Яндекс.Метрики. Кроме того, нам удалось сделать систему достаточно гибкой и расширяемой, чтобы ее можно было успешно использовать для решения различных задач. Хотя база данных может работать на больших кластерах, ее можно установить на одном сервере или даже на виртуальной машине.
ClickHouse хорошо оборудован для создания всевозможных аналитических инструментов. Только подумайте: если система справится с задачами Яндекс.Метрики, вы можете быть уверены, что ClickHouse справится с другими задачами с большим запасом производительности.
ClickHouse хорошо работает как база данных временных рядов; в Яндексе он обычно используется как бэкэнд для Graphite вместо Ceres / Whisper. Это позволяет нам работать с более чем триллионом метрик на одном сервере.
ClickHouse используется аналитикой для внутренних задач.Исходя из нашего опыта в Яндексе, ClickHouse работает примерно на три порядка выше, чем древние методы обработки данных (скрипты на MapReduce). Но это не простая количественная разница. Дело в том, что обладая такой высокой скоростью вычислений, вы можете позволить себе использовать радикально другие методы решения задач.
Если аналитик должен составить отчет, и он компетентен в своей работе, он не будет просто строить один отчет. Вместо этого они начнут с поиска десятков других отчетов, чтобы лучше понять природу данных и проверить различные гипотезы.Часто бывает полезно взглянуть на данные с разных сторон, чтобы сформулировать и проверить новые гипотезы, даже если у вас нет четкой цели.
Это возможно только в том случае, если скорость анализа данных позволяет проводить мгновенное исследование. Чем быстрее выполняются запросы, тем больше гипотез вы сможете проверить. Работая с ClickHouse, даже возникает ощущение, что они могут думать быстрее.
В традиционных системах данные, образно говоря, подобны мертвому грузу. Вы можете манипулировать им, но это занимает много времени и неудобно.Однако, если ваши данные находятся в ClickHouse, они гораздо более податливы: вы можете изучать их в разных сечениях и переходить к отдельным строкам данных.
После года использования открытого исходного кода ClickHouse теперь используется сотнями компаний по всему миру. Например, CloudFlare использует ClickHouse для анализа трафика DNS, обрабатывая около 75 миллиардов событий каждый день. Другой пример — Vertamedia (платформа SSP для видео), которая ежедневно обрабатывает 200 миллиардов событий в ClickHouse со скоростью загрузки около 3 миллионов строк в секунду.
Выводы
Яндекс.Метрика стала второй по величине системой веб-аналитики в мире. Объем данных, которые принимает Метрика, вырос с 200 миллионов событий в день в 2009 году до более чем 25 миллиардов в 2017 году. Чтобы предоставить пользователям широкий спектр возможностей, при этом не отставая от растущей рабочей нагрузки, нам пришлось постоянно меняем наш подход к хранению данных.
Для нас очень важно эффективное использование оборудования. По нашему опыту, когда у вас большой объем данных, лучше не беспокоиться о том, насколько хорошо масштабируется система, и вместо этого сосредоточиться на том, насколько эффективно используется каждая единица оборудования: каждое ядро процессора, диск и SSD, RAM и сеть.В конце концов, если ваша система уже использует сотни серверов и вам нужно работать в десять раз эффективнее, маловероятно, что вы сможете просто приступить к установке тысяч серверов, независимо от того, насколько масштабируема ваша система.
Чтобы добиться максимальной эффективности, важно настроить решение в соответствии с потребностями конкретного типа рабочей нагрузки. Нет такой структуры данных, которая бы хорошо справлялась с совершенно разными сценариями. Например, очевидно, что базы данных «ключ-значение» не работают для аналитических запросов.Чем больше нагрузка на систему, тем уже требуется специализация. Не нужно бояться использовать совершенно разные структуры данных для разных задач.
Нам удалось наладить работу так, что оборудование Яндекс.Метрики было относительно недорогим. Это позволило нам предлагать услугу бесплатно даже очень крупным сайтам и мобильным приложениям, даже больше, чем у Яндекса, в то время как конкуренты обычно начинают запрашивать платную подписку.
Яндекс. Персонализированный поиск в Интернете.
Мы рады объявить о запуске конкурса Yandex Personalized Web Search Challenge , который является частью семинара WSDM 2014 Web Search Click Data (WSCD).Конкурс проводится на Kaggle и предоставляет уникальную возможность консолидировать и тщательно изучить работу промышленных лабораторий по персонализации веб-поиска с использованием контекста поведения пользователей при поиске. Он также предоставляет полностью анонимный набор данных, используемый Яндексом, который содержит анонимные идентификаторы пользователей, запросы, условия запроса, URL-адреса, домены URL-адресов и клики. Эта задача и общий набор данных позволят совершенно новому набору исследователей изучить проблему персонализации поиска в Интернете.
Задача задумана как логическое продолжение двух предыдущих задач.Мы просим участников повторно ранжировать URL-адреса каждой выдачи, возвращаемой поисковой системой, в соответствии с личными предпочтениями пользователей. Другими словами, участникам необходимо персонализировать поиск, используя долгосрочный (на основе истории пользователя) и краткосрочный (на основе сеанса) контекст пользователя.
Оценка основана на варианте модели персональной релевантности, основанной на времени задержки, и основана на данных, как это принято в настоящее время в современных исследованиях персонализированного поиска.
The Challenge является частью семинара Web Search Click Data (WSCD 2014), и отчеты лучших команд могут быть представлены на этом семинаре, который состоится на конференции WSDM 2014 28 февраля 2013 года, Нью-Йорк, США.Организаторы семинара — Павел Сердюков (Яндекс), Жорж Дюпре (Yahoo!) и Ник Красвелл (Microsoft Research / Bing).
Участники могут участвовать как индивидуально, так и в составе команд. Подробное описание задачи, наборов данных и методологии оценки результатов вы найдете по адресу:
https://www.kaggle.com/c/yandex-personalized-web-search-challenge
Важные даты:
- 11 октября 2013 г. — конкурс открыт
- 20 декабря 2013 г. — Регистрация новых участников прекращается
- 10 января 2014 г. — Конец испытания (23:59 UTC)
- 14 января 2014 — объявлены предварительные победители
- 30 января 2014 г. — крайний срок подачи отчетов
- 28 февраля 2014 г. — семинар WSCD на WSDM 2014 и объявление победителей
Три лучших участника получат следующие денежные призы:
- 1 место: 5000 долларов
- 2 место: 3000 $
- 3 место: 1000 долларов
Challenge Организаторы:
Павел Сердюков, Евгений Харитонов (Яндекс)