
Как скрыть страницы от индексации Google?
Это небольшой, но очень полезный совет, использовать который лучше прямо сейчас для улучшения ваших SEO показателей Joomla.
Это секретный трюк, который Кристофер Вагнер — эсперт по SEO Joomla — основатель www.1aseo.de поделился в одном из своих интервью.
Как вы знаете, наличие большого количество бесполезного контента на вашем сайте , вероятно, будет приносить больше вреда , чем пользы. Потому лучше ограничить индексируемые страницы, чтобы показать Google только качественный контент. Давайте посмотрим, как Кристофер сделал это.
Кристофер Вагнер
Многие страницы сайтов Joomla толкают в 3-4 раза больше страниц в индексацию, потому что Get-параметры компонентов (типа ??option=com_bla_bla) настроены не правильно.
В качестве примера приведу небольшой локальнй проект одного моего клиента (https://www.xn--kln-personaltrainer-q6b.de) – персонального тренера из города Кельн.
Я покажу вам, как я адаптировал в htaccess сайта:
Redirect gone /?option=com_ajax&format=json
Это пример Get-параметров – добавление этих параметров к URL означает создание новых страниц “на лету”. Многие, очень многие компоненты Joomla используют Get-параметры, которые, в конечном счете, добавляют дополнительные страницы в индексацию, что ухудшает SEO.
Google, конечно, разумен в том, что касается страниц, которые должны попасть в индекс и находит нужные страницы. НО: если поисковик вынужден искать нужные страницы среди слишком большого количества бесполезных страниц, то страницы, которые являются важными для вас, могут и не подняться в поисковой выдаче.
Чтобы избавиться от большого количества проблем, я рекомендую вам установить расширение Sh504SEF и адаптировать файл . htaccess, чтобы сказать Google, какие страницы лучше удалить из индекса.
htaccess, чтобы сказать Google, какие страницы лучше удалить из индекса.
Redirect gone /table/news/
Redirect gone /table/news/page-2.html
Redirect gone /table/uncategorised/
Redirect gone /table/uncategorised/page-2.html
Redirect gone /table/uncategorised/page-3.html
Все эти страницы будут доступны при использовании sef-компонента, например Sh504SEF. Для этого перейдите на страницу конфигурации Sh504SEF — вкладка “Расширения» — вкладка «Joomla». Найдите параметр “Insert content table name” и измените его:
Если ввести сейчас: https://www.xn--kln-personaltrainer-q6b.de/table/news/ в вашем браузере, вы увидите, что статус страницы “Gone”, как мы и прописали – эта страница удаляется из индекса через пару дней или недель в Google и тем самым сильно ускоряет поиск наиболее важных страниц, потому что страниц для индексации, о которых Google нужно беспокоиться, стало меньше.
Это действительно просто, верно? Но это может решить огромное количество проблем , связанных с индексированием контента.
Попробуйте и вы этот метод прямо сейчас!
Как скрыть страницу WordPress от Google
Недавно один из наших читателей спросил, возможно ли спрятать страницу WordPress от Google. Иногда вам может понадобиться спрятать страницу от поисковой системы для защиты личных данных или же от нежелательных пользователей. В этой статье мы покажем вам как скрыть страницу WordPress от Google не затрагивая SEO сайта в целом.
Поисковые системы вроде Google позволяют владельцам сайтов исключать контент из результатов поиска. Это можно сделать с помощью файла robots.txt сайта или же используя мета теги HTML.
Способ 1: Скрываем страницу WordPress от поисковиков с помощью Yoast SEO
Этот способ самый простой и рекомендован для новичков.
Сначала устанавливаем и активируем плагин Yoast SEO.
Далее нужно отредактировать запись или страницу, которую нужно скрыть от поисковиков. Прокручиваем до мета блока Yoast SEO под редактором записей и нажимаем на кнопку «advanced settings».
Этот раздел позволяет вам добавлять мета теги robots на страницы сайта. С помощью этих тегов можно сообщить поисковикам о том, что не нужно индексировать текущую страницу.
Сначала выбираем ‘noindex’ из выпадающего меню рядом с опцией ‘Meta robots index’. Затем нажимаем на ‘nofollow’ рядом с опцией ‘Meta robots follow’.
Теперь можно сохранить/опубликовать запись или страницу.
Yoast SEO добавит новую строку кода в вашу запись:
<meta name="robots" content="noindex,nofollow"/>
Эта строчка просто сообщает поисковикам о том, что не нужно проходить по ссылкам или индексировать текущую страницу.
Способ 2: Скрываем страницу WordPress от поисковиков с помощью файла robots.txt
Этот способ предполагает редактирование файла robots.txt. Добавление некорректных инструкций в этот файл может сильно повлиять на SEO вашего сайта, именно поэтому способ не рекомендуется для новичков.
Добавление некорректных инструкций в этот файл может сильно повлиять на SEO вашего сайта, именно поэтому способ не рекомендуется для новичков.
Файл robots.txt — это файл конфигурации, который добавляется в корневую директорию вашего WordPress сайта. Он позволяет сайту указывать инструкции для поисковых роботов, и поэтому он называется robots.txt.
Отредактировать файл можно, если подключиться к сайту через FTP или Файловый менеджер в панели управления хостингом.
Вам потребуется добавить вот такую строку в него:
User-agent: *
Disallow: /your-page/
Строка user-agent указывает на определенных ботов. Мы используем звездочку для указания всех поисковых систем.
Следующая строка определяет часть ссылки, которая идет после доменного имени.
Давайте представим, что вам нужно скрыть запись в блоге вот с таким URL:
http://example.com/2016/12/my-blog-post/
Вот так нужно будет добавить этот URL в файл robots. txt:
txt:
User-agent: *
Disallow: /2016/12/my-blog-post/
Не забудьте сохранить изменения и загрузить файл обратно на сервер.
Недостатки использования robots.txt для сокрытия контента
Следует помнить, что файл robots.txt публично доступен. Любой может получить к нему доступ и посмотреть какие страницы вы скрыли в нем.
И хотя большинство поисковиков следуют инструкциям, указанным в файле, многие другие роботы и пауки могут просто игнорировать эти директивы.
Способ 3: Защищаем паролем страницу или запись в WordPress
Этот способ использует другую логику. Вместо того, чтобы просить поисковики не индексировать страницу, вы можете просто защитить ее паролем, чтобы она стала видна только пользователям, знающим пароль.
В WordPress есть встроенная функция защиты паролем страниц и записей. Просто переходим в редактирование материала, который нужно защитить.
Под блоком публикации нажимаем на ссылку ‘Редактировать’ рядом с опцией «Видимость».
Появятся все опции видимости записи, доступные в WordPress. Можно оставить страницу/запись публично доступной, сделать ее личной или же защитить паролем.
Личные записи будут видны только залогиненным пользователям, которым назначена как минимум роль редактора.
Записи, защищенные паролем, смогут увидеть любым посетителем, у которого есть пароль. Нажимаем на опцию «Защитить паролем» и затем указываем надежный пароль.
Теперь публикуем страницу. Все пользователи, которые зайдут на эу страницу вашего сайта, должны будут указать пароль для просмотра контента.
Вот и все, мы надеемся, что эта статья помогла вам научиться скрывать страницы WordPress от Google.
По всем вопросам и отзывам просьба писать в комментарии ниже.
Не забывайте, по возможности, оценивать понравившиеся записи количеством звездочек на ваше усмотрение.
Rating: 3.4/5 (7 votes cast)
Полное руководство по сокрытию страниц сайта от индексации
Индексация страниц сайта — это то, с чего начинается процесс поисковой оптимизации. Предоставление ботам движка доступа к вашему контенту означает, что ваши страницы готовы для посетителей, у них нет технических проблем, и вы хотите, чтобы они отображались в поисковой выдаче, поэтому всеобъемлющая индексация на первый взгляд кажется огромным преимуществом.
Предоставление ботам движка доступа к вашему контенту означает, что ваши страницы готовы для посетителей, у них нет технических проблем, и вы хотите, чтобы они отображались в поисковой выдаче, поэтому всеобъемлющая индексация на первый взгляд кажется огромным преимуществом.
Однако некоторые типы страниц лучше держать подальше от SERP, чтобы обеспечить ваш рейтинг. Это означает, что вам нужно скрыть их от индексации. В этом посте я расскажу вам о типах контента, который нужно скрыть от поисковых систем, и покажу, как это сделать.
Содержание
- Страницы, которые нужно скрыть от поиска
- Как скрыть страницу из поиска
- Ограничение сканирования с помощью файлов robots.txt
- Ограничить индексирование с помощью метатега robots и тега X-Robots
- Роботы noindex метатег
- X-Robots-тег
- Особые случаи
Страницы, которые нужно скрыть от поиска
Давайте без лишних слов приступим к делу. Вот список страниц, которые вам лучше скрыть от поисковых систем, чтобы они не появлялись в поисковой выдаче.
Вот список страниц, которые вам лучше скрыть от поисковых систем, чтобы они не появлялись в поисковой выдаче.
Страницы с личными данными
Защита контента от прямого поискового трафика обязательна, если страница содержит личную информацию. Это страницы с конфиденциальной информацией о компании, информацией об альфа-продуктах, информацией о профилях пользователей, личной перепиской, платежными данными и т. д. Поскольку частный контент должен быть скрыт от кого-либо, кроме владельца данных, Google (или любая поисковая система) не должен t сделать эти страницы видимыми для более широкой аудитории.
Страницы входа
Если форма входа размещена не на главной, а на отдельной странице, нет необходимости показывать эту страницу в поисковой выдаче. Такие страницы не несут никакой дополнительной ценности для пользователей, которую можно считать малосодержательным контентом.
Страницы благодарности
Это страницы, которые пользователи видят после успешного действия на веб-сайте, будь то покупка, регистрация или что-то еще. Эти страницы также, вероятно, будут иметь мало контента и практически не несут никакой дополнительной ценности для пользователей.
Эти страницы также, вероятно, будут иметь мало контента и практически не несут никакой дополнительной ценности для пользователей.
Версии страниц для печати или чтения
Содержимое страниц этого типа дублирует содержание основных страниц вашего веб-сайта, то есть эти страницы будут рассматриваться как дубликаты содержимого при сканировании и индексировании.
Страницы с похожими товарами
Это распространенная проблема для крупных интернет-магазинов, на которых много товаров, отличающихся только размером или цветом. Google может не определить разницу между ними и рассматривать их как дубликаты контента.
Внутренние результаты поиска
Когда пользователи приходят на ваш сайт из поисковой выдачи, они ожидают, что щелкнут вашу ссылку и найдут ответ на свой запрос. Не очередная внутренняя поисковая выдача с кучей ссылок. Поэтому, если ваши внутренние результаты поисковой выдачи попадут в индекс, они, скорее всего, не принесут ничего, кроме низкого времени пребывания на странице и высокого показателя отказов.
Страницы с биографией автора в блогах с одним автором
Если в вашем блоге все сообщения написаны одним автором, то страница биографии автора является чистой копией главной страницы блога.
Страницы форм подписки
Подобно страницам входа в систему, формы подписки обычно не содержат ничего, кроме формы для ввода ваших данных для подписки. Таким образом, страница а) пуста, б) не представляет ценности для пользователей. Вот почему вы должны запретить поисковым системам вытягивать их в поисковую выдачу.
Страниц в разработке
Эмпирическое правило: страницы, которые находятся в процессе разработки, должны быть недоступны для роботов поисковых систем, пока они не будут полностью готовы для посетителей.
Зеркальные страницы
Зеркальные страницы — это идентичные копии ваших страниц на отдельном сервере/в другом месте. Они будут считаться техническими дубликатами, если будут просканированы и проиндексированы.
Специальные предложения и рекламные целевые страницы
Специальные предложения и рекламные страницы предназначены для просмотра пользователями только после выполнения ими каких-либо специальных действий или в течение определенного периода времени (специальные предложения, события и т. д.). После завершения мероприятия эти страницы не должны быть видны никому, в том числе поисковым системам.
д.). После завершения мероприятия эти страницы не должны быть видны никому, в том числе поисковым системам.
Хотите быстро научиться SEO?
Присоединяйтесь к нашему 30-дневному курсу SEO и ежедневно получайте по одному очень простому уроку SEO на свой почтовый ящик.
Как скрыть страницу из поиска
А теперь вопрос: как скрыть все вышеперечисленные страницы от надоедливых пауков и сохранить остальную часть вашего сайта видимой, как и должно быть?
При настройке инструкций для поисковых систем у вас есть два варианта. Вы можете ограничить сканирование или ограничить индексирование страницы.
Ограничение сканирования с помощью файлов robots.txt
Возможно, самый простой и прямой способ ограничить доступ сканеров поисковых систем к вашим страницам — это создать файл robots.txt. Файлы robots.txt позволяют заблаговременно исключить нежелательный контент из результатов поиска. С помощью этого файла вы можете ограничить доступ к одной странице, целому каталогу или даже одному изображению или файлу.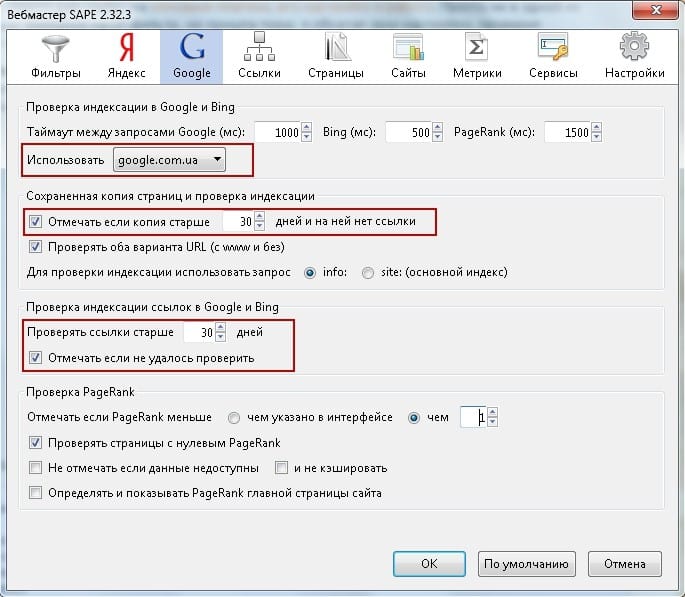
Как это работает
Создание файла robots.txt
Процедура довольно проста. Вы просто создаете файл .txt со следующими полями:
- User-agent: – в этой строке вы идентифицируете рассматриваемого поискового робота;
- Disallow: – две или более строк, которые предписывают указанным поисковым роботам не получать доступ к определенным частям сайта.
Обратите внимание, что некоторые поисковые роботы (например, Google) также поддерживают дополнительное поле с именем Разрешить: . Как следует из названия, Разрешить: позволяет явно перечислить файлы/папки, которые можно сканировать.
Вот некоторые основные примеры файлов robots.txt.
* в строке User-agent означает, что всем ботам поисковых систем предписывается не сканировать ни одну из страниц вашего сайта, что обозначается 
В приведенном выше примере вы запрещаете роботу изображений Google сканировать ваши изображения в выбранном каталоге.
Дополнительные инструкции о том, как писать такие файлы вручную, можно найти в руководстве разработчика Google.
Но процесс создания robots.txt можно полностью автоматизировать — существует множество инструментов, способных создавать такие файлы. Например, WebSite Auditor может легко скомпилировать файл robots.txt для вашего сайта.
Когда вы запустите инструмент и создадите проект для своего веб-сайта, перейдите к Структура сайта > Страницы , щелкните значок гаечного ключа и выберите Robots.txt .
Загрузите WebSite AuditorЗатем нажмите Добавить правило и указать инструкции. Выберите поискового робота и каталог или страницу, для которых вы хотите ограничить сканирование.
Загрузить WebSite Auditor Когда вы закончите со всеми настройками, нажмите Далее , чтобы инструмент сгенерировал файл robots. txt, который вы затем можете загрузить на свой веб-сайт.
txt, который вы затем можете загрузить на свой веб-сайт.
Чтобы просмотреть ресурсы, заблокированные для сканирования, и убедиться, что вы не запретили сканирование ничего, перейдите к Структура сайта > Аудит сайта и проверьте раздел Ресурсы, заблокированные от индексации :
Загрузить WebSite AuditorПримечание: Хотя robots.txt запрещает поисковым системам сканировать определенные страницы, URL-адреса этих страниц все же могут быть проиндексированы, если другие страницы указывают на них с описательным текстом. URL-адрес с ограниченным доступом может отображаться в результатах поиска без описания, поскольку контент не будет сканироваться и индексироваться.
Также имейте в виду, что протокол robots.txt носит исключительно рекомендательный характер. Это не блокировка страниц вашего сайта, а больше похоже на «Личное — не входить». Robots.txt может предотвратить доступ «законопослушных» ботов (например, ботов Google, Yahoo! и Bing) к вашему контенту. Однако вредоносные боты просто игнорируют его и все равно просматривают ваш контент. Таким образом, существует риск того, что ваши личные данные могут быть удалены, скомпилированы и повторно использованы под видом добросовестного использования. Если вы хотите, чтобы ваш контент был на 100% безопасным, вам следует ввести более безопасные меры (например, добавить регистрацию на сайте, скрыть контент под паролем и т. д.).
Однако вредоносные боты просто игнорируют его и все равно просматривают ваш контент. Таким образом, существует риск того, что ваши личные данные могут быть удалены, скомпилированы и повторно использованы под видом добросовестного использования. Если вы хотите, чтобы ваш контент был на 100% безопасным, вам следует ввести более безопасные меры (например, добавить регистрацию на сайте, скрыть контент под паролем и т. д.).
Распространенные ошибки
Вот наиболее распространенные ошибки, которые допускают люди при создании файлов robots.txt. Внимательно прочитайте эту часть.
1) Использование прописных букв в имени файла. Имя файла — robots.txt. Период. Не Robots.txt и не ROBOTS.txt
2) Не помещать файл robots.txt в основной каталог
3) Заблокировать весь ваш веб-сайт (если вы этого не хотите), оставив инструкцию запрета следующим образом
4) Неверное указание user-agent
5) Упоминание нескольких каталогов в одной строке запрета. Для каждой страницы или каталога нужна отдельная строка
Для каждой страницы или каталога нужна отдельная строка
6) Оставить строку агента пользователя пустой
7) Список всех файлов в каталоге. Если вы скрываете весь каталог, вам не нужно заморачиваться перечислением каждого отдельного файла
9) Не указана карта сайта внизу файла robots.txt
10) Добавление инструкций noindex в файл
Ограничить индексирование с помощью метатега robots и тега X-Robots
Использование метатега robots noindex или тега X-Robots страницу, но предотвратить попадание страницы в индекс, т.е. от появления в результатах поиска.
Теперь давайте рассмотрим каждый вариант поближе.
Метатег robots noindex
Метатег noindex роботов помещается в исходный код HTML вашей страницы (раздел
). Процесс создания этих тегов требует совсем немного технических знаний и может быть легко выполнен даже младшим SEO-специалистом.
Как это работает
Когда бот Google получает страницу, он видит метатег noindex и не включает эту страницу в веб-индекс. Страница по-прежнему сканируется и существует по указанному URL-адресу, но не будет отображаться в результатах поиска независимо от того, как часто на нее ссылаются с любой другой страницы.
Примеры метатегов robots
Добавление этого метатега в HTML-код вашей страницы указывает роботу поисковой системы проиндексировать эту страницу и все ссылки переход с этой страницы.
Изменяя «follow» на «nofollow», вы влияете на поведение бота поисковой системы. Вышеупомянутая конфигурация тега указывает поисковой системе индексировать страницу, но не переходить ни по каким ссылкам, размещенным на ней.
Этот метатег указывает роботу поисковой системы игнорировать страницу, на которой он размещен, но переходить по всем размещенным на нем ссылкам.
Этот тег, размещенный на странице, означает, что ни страница, ни содержащиеся на ней ссылки не будут отслеживаться или индексироваться.
Примечание: Упомянутые выше атрибуты nofollow и follow не имеют ничего общего с rel=nofollow. Это две разные вещи. Rel=nofollow применяется к ссылкам, чтобы предотвратить передачу ссылочного веса. Упомянутый выше атрибут nofollow применяется ко всей странице и не позволяет сканерам переходить по ссылкам.
X-Robots-tag
Помимо метатега robots noindex, вы можете скрыть страницу, настроив ответ HTTP-заголовка с X-Robots-Tag со значением noindex или none .
Помимо страниц и элементов HTML, X-Robots-Tag позволяет не индексировать отдельные файлы PDF, видео, изображения или любые другие файлы, отличные от HTML, где использование метатегов robots невозможно.
Как это работает
Механизм очень похож на механизм тега noindex. Как только поисковый бот заходит на страницу, ответ HTTP возвращает заголовок X-Robots-Tag с инструкциями noindex. Страница или файл все еще сканируются, но не отображаются в результатах поиска.
Как только поисковый бот заходит на страницу, ответ HTTP возвращает заголовок X-Robots-Tag с инструкциями noindex. Страница или файл все еще сканируются, но не отображаются в результатах поиска.
Примеры тегов X-Robots
Это наиболее распространенный пример HTTP-ответа с указанием не индексировать страницу.
HTTP/1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Вы можете указать тип поискового бота, если вам нужно скрыть свою страницу от определенных ботов. В приведенном ниже примере показано, как скрыть страницу от любой другой поисковой системы, кроме Google, и запретить всем ботам переходить по ссылкам на этой странице:
X-Robots-Tag: googlebot: nofollow
X-Robots-Tag: otherbot: noindex, nofollow
Если вы не укажете тип робота, инструкции будут действительны для всех типов сканеров.
Чтобы ограничить индексирование определенных типов файлов на всем веб-сайте, вы можете добавить инструкции ответа X-Robots-Tag в файлы конфигурации программного обеспечения веб-сервера вашего сайта.
Вот как вы ограничиваете все файлы PDF на сервере на базе Apache:
Набор заголовков X-Robots-Tag «noindex, nofollow»
И те же инструкции для NGINX:
location ~* \.pdf$ {
add_header X-Robots -Тэг » noindex, nofollow»;
}
Чтобы ограничить индексацию одного элемента, для Apache используется следующий шаблон:
# файл htaccess должен быть помещен в каталог соответствующего файла.
Набор заголовков X-Robots-Tag «noindex, nofollow»
А вот как вы ограничиваете индексацию одного элемента для NGINX:
location = /secrets/unicorn.pdf {
add_header X-Robots-Tag «noindex, nofollow»;
}
Тег robots noindex против X-Robots-Tag
Хотя тег robots noindex кажется более простым решением для ограничения индексации ваших страниц, в некоторых случаях использование X-Robots-Tag для страниц является лучший вариант :
- Не индексировать весь поддомен или категорию.
 X-Robots-Tag позволяет вам делать это массово, избегая необходимости помечать каждую страницу одну за другой;
X-Robots-Tag позволяет вам делать это массово, избегая необходимости помечать каждую страницу одну за другой; - Нет индексирования файла, отличного от HTML. В этом случае X-Robots-Tag — не лучший, а единственный вариант, который у вас есть.
 X-Robots-Tag позволяет вам делать это массово, избегая необходимости помечать каждую страницу одну за другой;
X-Robots-Tag позволяет вам делать это массово, избегая необходимости помечать каждую страницу одну за другой;Тем не менее, помните, что только Google точно следует инструкциям X-Robots-Tag. Что касается остальных поисковых систем, то нет гарантии, что они правильно интерпретируют тег. Например, Seznam вообще не поддерживает теги x-robots. Поэтому, если вы планируете, чтобы ваш веб-сайт отображался в различных поисковых системах, вам необходимо использовать тег robots noindex 9.0161 во фрагментах HTML.
Распространенные ошибки
Наиболее распространенные ошибки пользователей при работе с тегами noindex:
1) Добавление неиндексируемой страницы или элемента в файл robots.txt. Robots.txt ограничивает сканирование, поэтому поисковые боты не будут заходить на страницу и видеть директивы noindex. Это означает, что ваша страница может быть проиндексирована без содержания и по-прежнему отображаться в результатах поиска.
Это означает, что ваша страница может быть проиндексирована без содержания и по-прежнему отображаться в результатах поиска.
Чтобы проверить, попала ли какая-либо из ваших папок с тегом noindex в файл robots.txt, проверьте Инструкции для роботов в разделе
Примечание. Не забудьте включить экспертные параметры и снять флажок «Следовать инструкциям robots.txt» при сборке проекта, чтобы инструмент видел инструкции, но не следовал им.
2) Использование прописных букв в директивах тегов. Согласно Google, все директивы чувствительны к регистру, поэтому будьте осторожны.
Особые случаи
Теперь, когда с основными проблемами индексации контента все более-менее понятно, перейдем к нескольким нестандартным случаям, заслуживающим отдельного упоминания.
1) Убедитесь, что страниц, которые вы не хотите индексировать, не включены в вашу карту сайта . На самом деле карта сайта — это способ сообщить поисковым системам, куда идти в первую очередь при сканировании вашего сайта. И нет причин просить поисковых ботов посещать страницы, которые вы не хотите, чтобы они видели.
На самом деле карта сайта — это способ сообщить поисковым системам, куда идти в первую очередь при сканировании вашего сайта. И нет причин просить поисковых ботов посещать страницы, которые вы не хотите, чтобы они видели.
2) Тем не менее, если вам нужно деиндексировать страницу, которая уже присутствует в карте сайта, не удаляйте страницу из карты сайта, пока она не будет повторно просканирована и деиндексирована поисковыми роботами. В противном случае деиндексация может занять больше времени, чем ожидалось.
3) Защитите паролем страницы, содержащие личные данные. Защита паролем — самый надежный способ скрыть конфиденциальный контент даже от тех ботов, которые не следуют инструкциям robots.txt. Поисковые системы не знают ваших паролей, поэтому они не попадут на страницу, не увидят конфиденциальный контент и не выведут страницу в поисковую выдачу.
4) Чтобы поисковые роботы не индексировали саму страницу, но переходили по всем ссылкам на странице и индексировали контент по этим URL-адресам , настройте следующую директиву
Это обычная практика для внутренних страниц результатов поиска, которые содержат много полезных ссылок, но сами по себе не несут никакой ценности.
5) Для конкретного робота могут быть указаны ограничения индексации. Например, вы можете заблокировать свою страницу от новостных ботов, ботов с изображениями и т. д. Имена ботов могут быть указаны для любого типа инструкций, будь то файл robots.txt, метатег robots или X-Robots-Tag.
6) Не используйте тег noindex в A/B-тестах , когда часть ваших пользователей перенаправляется со страницы A на страницу B. Так как если noindex сочетается с 301 (постоянной) переадресацией, то поисковые системы получат следующие сигналы:
- Страница A больше не существует, так как она навсегда перемещена на страницу B;
- Страница B не должна быть проиндексирована, так как она имеет тег noindex.
В результате обе страницы A и B исчезают из индекса.
Чтобы правильно настроить A/B-тест, используйте переадресацию 302 (временную) вместо 301. Это позволит поисковым системам сохранить старую страницу в индексе и вернуть ее, когда вы закончите тест. Если вы тестируете несколько версий страницы (A/B/C/D и т. д.), используйте тег rel=canonical, чтобы отметить каноническую версию страницы, которая должна попасть в поисковую выдачу.
Если вы тестируете несколько версий страницы (A/B/C/D и т. д.), используйте тег rel=canonical, чтобы отметить каноническую версию страницы, которая должна попасть в поисковую выдачу.
7) Используйте тег noindex, чтобы скрыть временные целевые страницы. Если вы скрываете страницы со специальными предложениями, рекламными страницами, скидками или любой тип контента, который не должен утекать, то запрещать этот контент с помощью файла robots.txt — не лучшая идея. Поскольку сверхлюбопытные пользователи все еще могут просматривать эти страницы в вашем файле robots.txt. В этом случае лучше использовать noindex , чтобы случайно не скомпрометировать «секретный» URL публично.
Подводя итог
Теперь вы знаете основы того, как найти и скрыть определенные страницы вашего сайта от внимания поисковых роботов. И, как видите, процесс на самом деле несложный. Только не смешивайте несколько типов инструкций на одной странице и будьте внимательны, чтобы не скрыть страницы, которые должны отображаться в поиске.
Я что-то пропустил? Делитесь своими вопросами в комментариях.
Как скрыть страницу от индексации Google
Это краткое руководство о том, как скрыть или удалить страницу из Google.
На самом деле, мы ничего не «скрываем» от Google, мы просто говорим Google не индексировать определенные страницы на нашем сайте, чтобы они не отображались в поисковых системах.
Зачем тебе это?
В некоторых случаях вы действительно не хотите, чтобы содержимое вашего сайта отображалось в поисковых системах. Скажем, например, у вас есть информационный бюллетень, и он поставляется с бесплатной электронной книгой или отчетом. Если вы создадите специальную страницу со ссылками для загрузки вашей электронной книги, она будет подхвачена роботами поисковых систем, появится на странице результатов по определенным ключевым словам, и люди потенциально могут обойти вашу форму подписки, чтобы получить электронную книгу, которую вы раздаем.
Откуда мне это знать?
Потому что это случилось со мной.
Две недели назад я ввел имя своего гида, Электронные книги Smart Way , и первым результатом была начальная страница с формой подписки.
Это хорошо.
Однако вторая результирующая ссылка была реальной страницей, на которой были ссылки для загрузки моей электронной книги!
Это плохо.
Хотя я не уверен, сколько людей загрузили мою электронную книгу, перейдя прямо на страницу загрузки, даже если число было равно нулю, просто не рекомендуется иметь возможность обойти вводную страницу и получить доступ к такая раздача. Это определенно был акт небрежности с моей стороны, и я должен был знать лучше.
Вот почему я пишу этот пост для вас, чтобы вы не совершили ту же ошибку, что и я.
Как скрыть страницу (или публикацию) от Google
Перед публикацией
Лучше всего не включать страницу, которую вы не хотите включать в поисковые системы, с самого начала начало.
Чтобы сделать это, вам нужно сказать роботам поисковых систем «пропускать» эту страницу при просмотре вашего сайта. Самый простой способ сделать это — использовать плагин WordPress под названием 9.0160 Роботы Мета .
Этот плагин имеет множество опций, касающихся метаданных и бэкенда вашего блога, но что приятно, так это то, что на каждой новой странице и в каждом посте, который вы создаете, вы увидите маленькую рамку сбоку, которая выглядит вот так:
Если вы выберете «noindex», страница не будет обнаружена поисковыми системами. Элементы «follow» и «nofollow» относятся к ссылкам на странице, что является темой для другого поста в блоге.
Если у вас нет WordPress, вы можете следовать дополнительным техническим инструкциям в Online Tech Tips.
После публикации
В моем случае я уже опубликовал страницу, которую хотел убрать из поисковых систем. Если вы находитесь в похожем затруднительном положении, не волнуйтесь — вот что вам нужно сделать.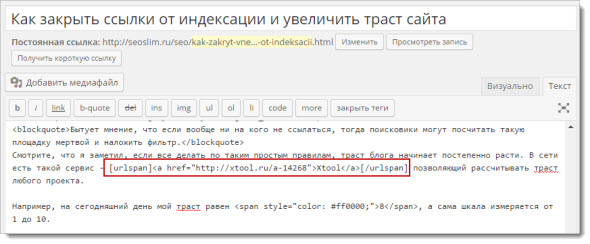
Обратите внимание, для этого вам не нужен WordPress.
Шаг 1: Выполните шаги для Перед публикацией Сначала
Чтобы удалить URL-адрес из индекса Google, вы должны сначала «заблокировать» эту страницу, используя технику, описанную выше. Если вы используете WordPress, используйте плагин Robots Meta и обязательно измените настройку на «noindex» и обновите страницу.
Одно это ничего не изменит сразу, поэтому вам придется выполнить следующие шаги.
Шаг 2. Зарегистрируйтесь в Инструментах Google для веб-мастеров и подтвердите свой веб-сайт
Перейдите в Инструменты Google для веб-мастеров и зарегистрируйте учетную запись, если вы еще этого не сделали. Если вы новичок, вам нужно будет вставить короткий фрагмент кода в раздел вашего сайта перед , чтобы убедиться, что это действительно ваш сайт.
Шаг 3: Перейдите в «Доступ для сканера»
Откройте меню «Конфигурация сайта» и нажмите «Доступ для сканера»:
Шаг 4: Нажмите «Удалить URL», а затем «Новый запрос на удаление»
901 60
Шаг 5: Вставьте URL-адрес (с учетом регистра), который вы хотите удалить.