
|
Урок 7.
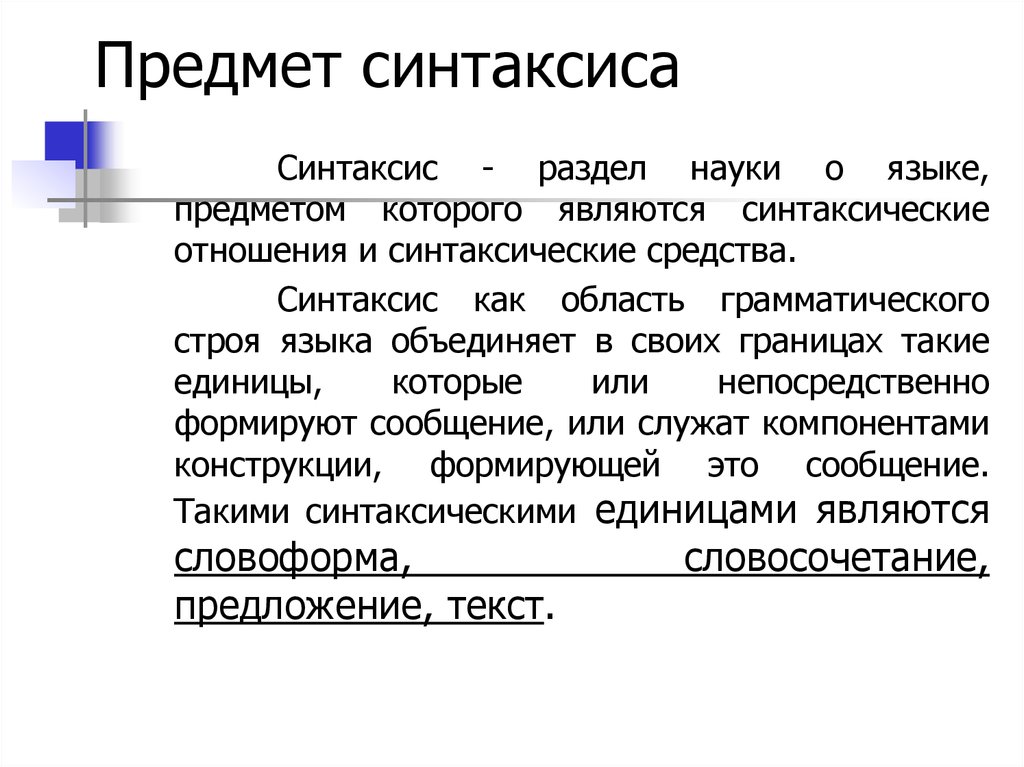
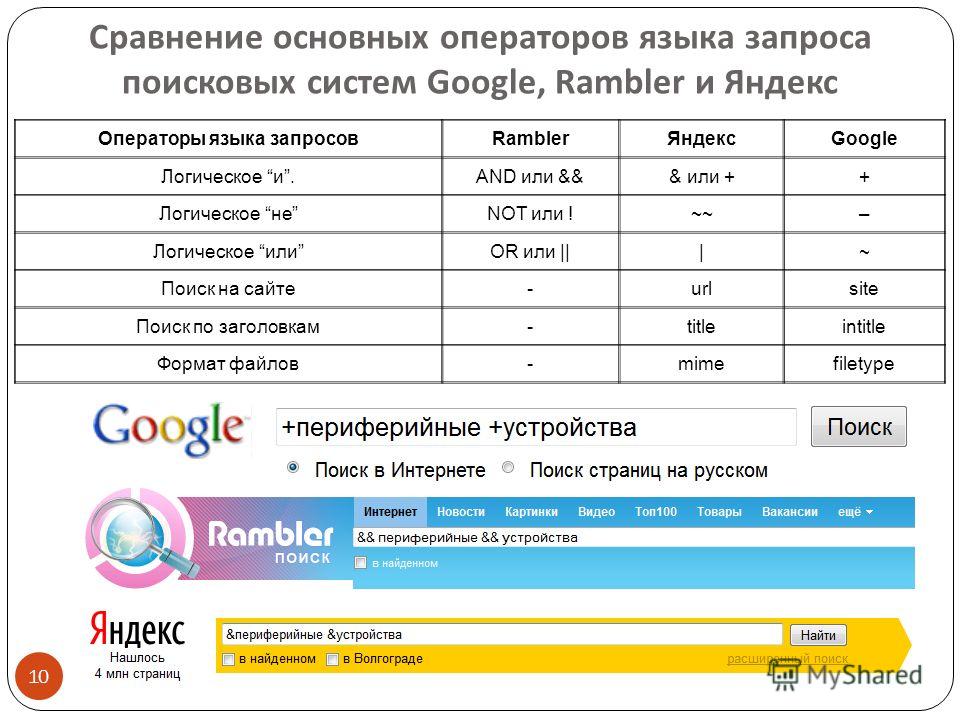
В системе Яндекс существует специальный язык запросов, использовать который более сложно, чем форму расширенного поиска но при его использовании можно получить наилучший результат. Поисковый запрос вводится в поисковое поле, он может содержать ключевые слова и
специальные символы, позволяющие установить
взаимосвязи между этими словами и ввести дополнительные параметры. Синтаксис языка запросов системы Яндекс.
Основные положения языка запросов:
Поиск в зонах и элементах web-страницы. Web-страница состоит из определенных зон и элементов. Соответственно можно осуществлять поиск в зонах и в элементах. Например, для поиска в заголовке страницы (заголовок отображается в заголовке окна обозревателя) указывают: $title (выражение), поиск в тексте ссылок аналогичен (см. следующую таблицу), а общий синтаксис таков: $имя_зоны (выражение) Примечание: выражение может быть представлено как одним ключевым словом, так и несколькими словами, объединенными указанными выше знаками логических операций. Для поиска в элементах используется синтаксис: #имя_элемента=(выражение) Элементы отличаются от зон тем, что в большинстве своем не видны
пользователю, просматривающему страницу. Синтаксис поиска в элементах и зонах.
Сортировка результатов запроса. После
того, как поисковая система выберет страницы, удовлетворяющие запросу, она
сортирует ссылки на эти страницы в порядке убывания их Ревалентность – это степень соответствия содержания документа поисковому
запросу. Релевантность документа зависит от ряда факторов, в том числе от
частотных характеристик искомых слов, веса слова или выражения, близости
искомых слов в тексте документа друг к другу и т. Пользователь может повлиять на порядок сортировки, используя операторы веса и уточнения запроса. Вес указывается для того, чтобы увеличить ревалентность документов, содержащих слово или выражение, вес которого указан. Синтаксис: слово:число или (поисковое_выражение):число Чем больший вес указан у слова (или выражения), тем выше ревалентность документов его содержащих. Например, по запросу родина Путина:5 в результатах поиска наверху списка окажутся документы, где чаще встречается именно слово Путин. Уточняющее слово или выражение применяется для того, чтобы увеличить релеватность документов, их cодержащих. Синтаксис: <- слово или <- (уточняющее_выражение) Например, по запросу телефон <- автоответчик будут найдены все
документы, содержащие слово телефон, но первыми будут выданы
страницы, содержащие слово автоответчик. Примечание: кроме сортировки по ревалентности Вы можете выбрать сортировку по дате документов, щелкнув по соответствующей ссылке. 1 2 3 4 5 Далее > |

 Все слова, написанные через && должны одновременно
находиться в найденных документах, но расстояние между ними не
оговаривается.
Все слова, написанные через && должны одновременно
находиться в найденных документах, но расстояние между ними не
оговаривается. Минус и плюс указывают на
порядок слов: минус – обратный порядок. Если перед символом / указать &&, то
расстояние будет вычисляться в предложениях.
Минус и плюс указывают на
порядок слов: минус – обратный порядок. Если перед символом / указать &&, то
расстояние будет вычисляться в предложениях.
 comptek.ru*»
comptek.ru*»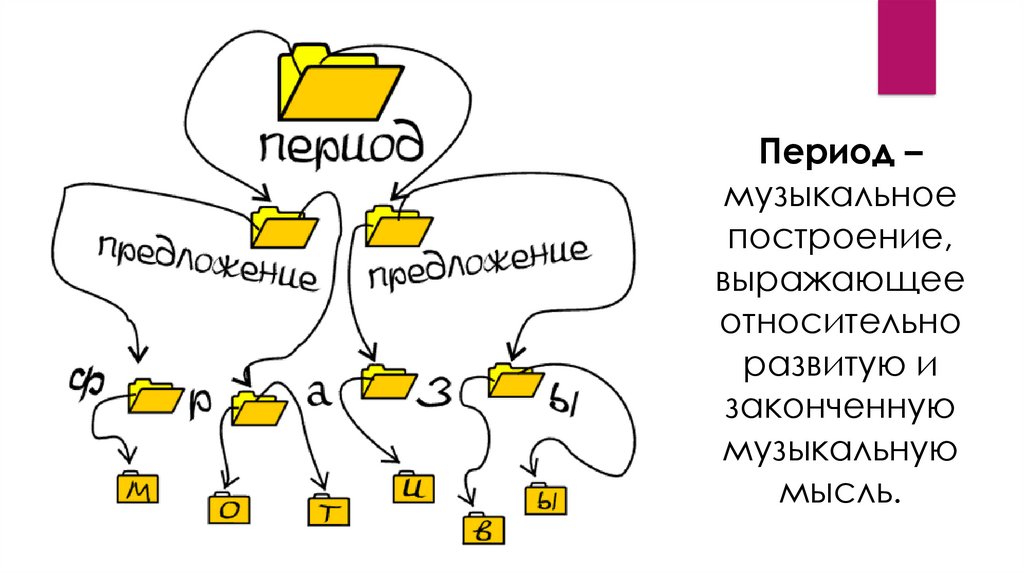 д.
д.
Продвинутые дженерики в TypeScript. Доклад Яндекса / Хабр
Дженерики, или параметризованные типы, позволяют писать более гибкие функции и интерфейсы. Чтобы зайти дальше, чем параметризация одним типом, нужно понять лишь несколько общих принципов составления дженериков — и TypeScript раскроется перед вами, как шкатулка с секретом. AlexandrNikolaichev объяснил, как не бояться вкладывать дженерики друг в друга и использовать автоматический вывод типов в ваших проектах.
— Всем привет, меня зовут Александр Николаичев. Я работаю в Yandex.Cloud фронтенд-разработчиком, занимаюсь внутренней инфраструктурой Яндекса. Сегодня расскажу об очень полезной вещи, без которой сложно представить современное приложение, особенно большого масштаба. Это TypeScript, типизация, более узкая тема — дженерики, и то, почему они нужны.
Сегодня расскажу об очень полезной вещи, без которой сложно представить современное приложение, особенно большого масштаба. Это TypeScript, типизация, более узкая тема — дженерики, и то, почему они нужны.
Сначала ответим на вопрос, почему TypeScript и при чем тут инфраструктура. У нас главное свойство инфраструктуры — ее надежность. Как это можно обеспечить? В первую очередь — можно тестировать.
У нас есть юнит- и интеграционные тесты. Тестирование — нужная стандартная практика.
Еще нужно использовать ревью кода. В довесок — сбор ошибок. Если все-таки ошибка случилась, то специальный механизм ее отсылает, и мы можем оперативно что-то пофиксить.
Как было бы хорошо вообще не совершать ошибок. Для этого есть типизация, которая вообще не позволит нам получить ошибку в рантайме. В Яндексе используется промышленный стандарт TypeScript. И так как приложения большие и сложные, то мы получим вот такую формулу: если у нас фронтенд, типизация, да еще и сложные абстракции, то мы обязательно придем к TypeScript-дженерикам. Без них никак.
Без них никак.
Синтаксис
Чтобы провести базовый ликбез, сначала рассмотрим основы синтаксиса.
Дженерик в TypeScript — это тип, который зависит от другого типа.
У нас есть простой тип, Page. Мы его параметризуем неким параметром <T>, записывается через угловые скобки. И мы видим, что есть какие-то строки, числа, а вот <T> у нас вариативный.
Кроме интерфейсов и типов мы можем тот же синтаксис применять и для функций. То есть тот же параметр <T> пробрасывается в аргумент функции, и в ответе мы переиспользуем тот же самый интерфейс, туда его тоже пробросим.
Наш вызов дженерика также записывается через угловые скобки с нужным типом, как и при его инициализации.
Для классов существует похожий синтаксис. Прокидываем параметр в приватные поля, и у нас есть некий геттер. Но там мы тип не записываем. Почему? Потому что TypeScript умеет выводить тип. Это очень полезная его фишка, и мы ее применим.
Посмотрим, что происходит при использовании этого класса. Мы создаем инстанс, и вместо нашего параметра <T> передаем один из элементов перечисления. Создаем перечисление — русский, английский язык. TypeScript понимает, что мы передали элемент из перечисления, и выводит тип lang.
Но посмотрим, как работает вывод типа. Если мы вместо элементов перечисления передадим константу из этого перечисления, то TypeScript понимает, что это не всё перечисление, не все его элементы. И будет уже конкретное значение типа, то есть lang en, английский язык.
Если мы передаем что-то другое, допустим, строку, то, казалось бы, она имеет то же самое значение, что и у перечисления. Но это уже строка, другой тип в TypeScript, и мы его получим. И если мы передаем строку как константу, то вместо строки и будет константа, строковый литерал, это не все строки. В нашем случае будет конкретная строка en.
Теперь посмотрим, как можно это расширить.
У нас был один параметр. Ничто нам не мешает использовать несколько параметров. Все они записываются через запятую. В тех же угловых скобках, и мы их применяем по порядку — от первого к третьему. Мы подставляем нужные значения при вызове.
Ничто нам не мешает использовать несколько параметров. Все они записываются через запятую. В тех же угловых скобках, и мы их применяем по порядку — от первого к третьему. Мы подставляем нужные значения при вызове.
Допустим, объединение числовых литералов, некий стандартный тип, объединение строковых литералов. Все они просто записываются по порядку.
Посмотрим, как это происходит в функциях. Мы создаем функцию random. Она рандомно дает либо первый аргумент, либо второй.
Первый аргумент типа A, второй — типа B. Соответственно, возвращается их объединение: либо тот, либо этот. В первую очередь мы можем явно типизировать функцию. Мы указываем, что A — это строка, B — число. TypeScript посмотрит, что мы явно указали, и выведет тип.
Но мы также можем воспользоваться и выводом типа. Главное — знать, что выводится не просто тип, а минимально возможный тип для аргумента.
Предположим, мы передаем аргумент, строковый литерал, и он должен соответствовать типу A, а второй аргумент, единичка, типу B. Минимально возможные для строкового литерала и единички — литерал A и та же самая единичка. Нам TypeScript это и выведет. Получается такое сужение типов.
Минимально возможные для строкового литерала и единички — литерал A и та же самая единичка. Нам TypeScript это и выведет. Получается такое сужение типов.
Прежде чем перейти к следующим примерам, мы посмотрим, как типы вообще соотносятся друг с другом, как использовать эти связи, как получить порядок из хаоса всех типов.
Отношение типов
Типы можно условно рассматривать как некие множества. Посмотрим на диаграммку, где показан кусок всего множества типов.
Мы видим, что типы в нем связаны некими отношениями. Но какими? Это отношения частичного порядка — значит, для типа всегда указан его супертип, то есть тип «выше» его, который охватывает все возможные значения.
Если идти в обратную сторону, то у каждого типа может быть подтип, «меньше» его.
Какие супертипы у строки? Любые объединения, которые включают строку. Строка с числом, строка с массивом чисел, с чем угодно. Подтипы — это все строковые литералы: a, b, c, или ac, или ab.
Но важно понимать, что порядок не линейный. То есть не все типы можно сравнить. Это логично, именно это и приводит к ошибкам несоответствия типов. То есть строку нельзя просто сравнить с числом.
И в этом порядке есть тип, как бы самый верхний, — unknown. И самый нижний, аналог пустого множества, — never. Never — подтип любого типа. А unknown — супертип любого типа.
И, конечно, есть исключение — any. Это специальный тип, он вообще игнорирует этот порядок, и используется, если мы мигрируем с JavaScript, чтобы не заботиться о типах. С нуля не рекомендуется использовать any. Это стоит делать, если нам на самом деле не важно положение типа в этом порядке.
Посмотрим, что нам даст знание этого порядка.
Мы можем ограничивать параметры их супертипами. Ключевое слово — extends. Мы определим тип, дженерик, у которого будет всего один параметр. Но мы скажем, что он может быть только подтипом строки либо самой строкой. Числа мы передавать не сможем, это вызовет ошибку типа. Если мы явно типизируем функцию, то в параметрах можем указать только подтипы строки или строку — apple и orange. Обе строки это объединение строковых литералов. Проверка прошла.
Если мы явно типизируем функцию, то в параметрах можем указать только подтипы строки или строку — apple и orange. Обе строки это объединение строковых литералов. Проверка прошла.
Еще мы можем сами автоматически выводить типы, исходя из аргументов. Если мы передали строку литерал, то это тоже строка. Проверка сработала.
Посмотрим, как расширить эти ограничения.
Мы ограничились просто строкой. Но строка — слишком простой тип. Хотелось бы работать с ключами объектов. Чтобы с ними работать, мы сначала поймем, как устроены сами ключи объектов и их типы.
У нас есть некий объектик. У него какие-то поля: строки, числа, булевы значения и ключи по именам. Чтобы получить ключи, используем ключевое слово keyof. Получаем объединение всех имен ключей.
Если мы хотим получить значения, то можем сделать это через синтаксис квадратных скобок. Это похоже на JS-синтаксис. Только он возвращает типы. Если мы передадим все подмножество ключей, то получим объединение вообще всех значений этого объекта.
Если мы хотим получить часть, то мы можем так и указать — не все ключи, а какое-то подмножество. Мы ожидаемо получим лишь те поля, которым соответствуют указанным ключам. Если совсем всё редуцировать до одинарного случая, — это одно поле, и один ключ дает одно значение. Так можно получать соответствующее поле.
Посмотрим, как использовать ключи объекта.
Важно понимать, что после ключевого слова extends может быть любой валидный тип. В том числе и образованный из других дженериков или с применением ключевых слов.
Посмотрим, как это работает с keyof. Мы определили тип CustomPick. На самом деле это почти полная копия библиотечного типа Pick из TypeScript. Что он делает?
У него есть два параметра. Второй — это не просто какой-то параметр. Он должен быть ключами первого. Мы видим, что у нас он расширяет keyof от <T>. Значит, это должно быть какое-то подмножество ключей.
Далее мы для каждого ключа K из этого подмножества бегаем по объекту, кладем то же самое значение и специально убираем синтаксисом опциональность, минус знак вопроса. То есть все поля будут обязательными.
То есть все поля будут обязательными.
Смотрим на применение. У нас есть объект, в нем имена полей. Мы можем брать только их подмножество — a, b или c, либо все сразу. Мы взяли a или c. Выводятся только соответствующие значения, но мы видим, что поле a стало обязательным, потому что мы, условно говоря, убрали знак вопроса. Мы определили такой тип, использовали его. Никто нам не мешает взять этот дженерик и засунуть его в еще один дженерик.
Как это происходит? Мы определили еще один тип Custom. Второй параметр расширяет не keyof, а результат применения дженерика, который мы привели справа. Как это работает, что мы вообще в него передаем?
Мы в этот дженерик передаем любой объект и все его ключи. Значит, на выходе будет копия объекта со всеми обязательными полями. Эту цепочку вкладывания дженерика в другой дженерик и так далее можно продолжать до бесконечности, в зависимости от задач, и структурировать код. Выносить в дженерики переиспользуемые конструкции и так далее.
Указанные аргументы не обязательно должны идти по порядку. Вроде как параметр P расширяет ключи T в дженерике CustomPick. Но никто нам не мешал указать его первым параметром, а T — вторым. TypeScript не идет последовательно по параметрам. Он смотрит все параметры, что мы указали. Потом решает некую систему уравнений, и если он находит решение типов, которые удовлетворяют этой системе, то проверка типов прошла.
Вроде как параметр P расширяет ключи T в дженерике CustomPick. Но никто нам не мешал указать его первым параметром, а T — вторым. TypeScript не идет последовательно по параметрам. Он смотрит все параметры, что мы указали. Потом решает некую систему уравнений, и если он находит решение типов, которые удовлетворяют этой системе, то проверка типов прошла.
В связи с этим можно вывести такой забавный дженерик, у которого параметры расширяют ключи друг друга: a — это ключи b, b — ключи a. Казалось бы, как такое может быть, ключи ключей? Но мы знаем, что строки TypeScript — это на самом деле строки JavaScript, а у JavaScript-строк есть свои методы. Соответственно, подойдет любое имя метода строки. Потому что имя у метода строки — это тоже строка. И у нее оттуда есть свое имя.
Соответственно, мы можем получить такое ограничение, и система уравнений разрешится, если мы укажем нужные типы.
Посмотрим, как это можно использовать в реальности. Используем для API. Есть сайт, на котором деплоятся приложения Яндекса. Мы хотим вывести проект и сервис, который ему соответствует.
Мы хотим вывести проект и сервис, который ему соответствует.
В примере я взял проект для запуска виртуальных машин qyp для разработчиков. Мы знаем, что у нас в бэкенде есть структура этого объекта, берем его из базы. Но помимо проекта есть и другие объекты: черновики, ресурсы. И у всех есть свои структуры.
Более того, мы хотим запрашивать не весь объект, а пару полей — имя и имя сервиса. Такая возможность есть, бэкенд позволяет передавать пути и получить неполную структуру. Здесь описан DeepPartial. Мы его чуть попозже научимся конструировать. Но это значит, что передается не весь объект, а какая-то его часть.
Мы хотим написать некоторую функцию, которая бы запрашивала эти объекты. Напишем на JS. Но если присмотреться, видны опечатки. В типе какой-то «Projeact», в путях тоже опечатка в сервисе. Нехорошо, ошибка будет в рантайме.
Вариант TS, казалось бы, не сильно отличается, кроме путей. Но мы покажем, что на самом деле в поле Type не может быть других значений, кроме тех, что есть у нас на бэкенде.
Поле путей имеет специальный синтаксис, который просто не позволит нам выбрать другие отсутствующие поля. Мы используем такую функцию, где просто перечисляем нужные нам уровни вложенности и получаем объект. На самом деле из этой функции получить пути — забота нашей реализации. Секрета тут нет, она использует прокси. Нам это не столь важно.
Посмотрим, как получить функцию.
У нас есть функция, ее использование. Есть вот эта структура. Сначала мы хотим получить все имена. Мы записываем такой тип, где имя соответствует структуре.
Допустим, для проекта мы где-то описываем его тип. В нашем проекте мы генерируем тайпинги из protobuf-файлов, которые доступны в общем репозитории. Далее мы смотрим, что у нас есть все используемые типы: Project, Draft, Resource.
Посмотрим на реализацию. Разберем по порядку.
Есть функция. Сначала смотрим, чем она параметризуется. Как раз этими уже ранее описанными именами. Посмотрим, что она возвращает. Она возвращает значения. Почему это так? Мы использовали синтаксис квадратных скобок. Но так как мы передаем в тип одну строку, объединение строковых литералов при использовании — это всегда одна строка. Невозможно составить строку, которая одновременно была бы и проектом, и ресурсом. Она всегда одна, и значение тоже одно.
Почему это так? Мы использовали синтаксис квадратных скобок. Но так как мы передаем в тип одну строку, объединение строковых литералов при использовании — это всегда одна строка. Невозможно составить строку, которая одновременно была бы и проектом, и ресурсом. Она всегда одна, и значение тоже одно.
Обернем все в DeepPartial. Необязательный тип, необязательная структура. Самое интересное — это параметры. Задаем их с помощью еще одного дженерика.
Тип, которым параметризуется дженерик параметров, также совпадает с ограничением на функцию. Он может принимать только тип имени — Project, Resource, Draft. ID — это, конечно, строка, она нам не интересна. Вот тип, который мы указали, один из трех. Интересно, как устроена функция для путей. Это еще один дженерик — почему бы нам его не переиспользовать. На самом деле все, что он делает, — просто создает функцию, которая возвращает массив из any, потому что в нашем объекте могут быть поля любых типов, мы не знаем каких. В такой реализации мы получаем контроль над типами.
Если кому-то это показалось простым, перейдем к управляющим конструкциям.
Управляющие конструкции
Мы рассмотрим всего две конструкции, но их хватит, чтобы покрывать практически все задачи, которые нам нужны.
Что такое условные типы? Они очень напоминают тернарки в JavaScript, только для типов. У нас есть условие, что тип a — это подтип b. Если это так, то возврати c. Если это не так — возврати d. То есть это обычный if, только для типов.
Смотрим, как это работает. Мы определим тип CustomExclude, который по сути копирует библиотечный Exclude. Он просто выкидывает нужные нам элементы из объединения типов. Если a — это подтип b, то возврати пустоту, иначе возврати a. Это странно, если посмотреть, почему это работает с объединениями.
Нам пригодится специальный закон, который говорит: если есть объединение и мы проверяем с помощью extends условия, то мы проверяем каждый элемент отдельно и потом снова их объединяем. Это такой транзитивный закон, только для условных типов.
Это такой транзитивный закон, только для условных типов.
Когда мы применяем CustomExclude, то смотрим поочередно на каждый элемент наблюдения. a расширяет a, a — это подтип, но верни пустоту; b это подтип a? Нет — верни b. c — это тоже не подтип a, верни c. Потом мы объединяем то, что осталось, все плюсики, получаем b и c. Мы выкинули a и добились того, что хотели.
Ту же технику можно использовать, чтобы получить все ключи кортежа. Мы знаем, что кортеж — это тот же массив. То есть у него есть JS-методы, но нам это не нужно, а нужны только индексы. Соответственно, мы просто из всех ключей кортежа выкидываем имена всех методов и получаем только индексы.
Как нам определить наш ранее упомянутый тип DeepPartial? Тут впервые используется рекурсия. Мы пробегаемся по всем ключам объекта и смотрим. Значение — это объект? Если да, применяем рекурсивно. Если нет и это строка или число — оставляем и все поля делаем опциональными. Это все-таки Partial-тип.
Этот рекурсивный вызов и условные типы на самом деле делают TypeScript полным по Тьюрингу. Но не спешите этому радоваться. Он надает вам по рукам, если вы попытаетесь провернуть нечто подобное, абстракцию с большой рекурсивностью.
Но не спешите этому радоваться. Он надает вам по рукам, если вы попытаетесь провернуть нечто подобное, абстракцию с большой рекурсивностью.
TypeScript за этим следит и выдаст ошибку еще на уровне своего компилятора. Вы даже не дождетесь, пока там что-то посчитается. А для таких простых кейсов, где у нас всего один вызов, рекурсия вполне подходит.
Посмотрим, как это работает. Мы хотим решить задачу патчинга поля объекта. Для планирования выкатки приложений у нас используется виртуальное облако, и нам нужны ресурсы.
Допустим, мы взяли ресурсы CPU, ядра. Всем нужны ядра. Я упростил пример, и тут всего лишь ресурсы, только ядра, и они представляют собой числа.
Мы хотим сделать функцию, которая их патчит, патчит значения. Добавить ядер или убавить. В том же JavaScript, как вы могли догадаться, возникают опечатки. Здесь же мы складываем число со строкой — не очень хорошо.
В TypeScript почти ничего не изменилось, но на самом деле этот контроль еще на уровне IDE вам подскажет, что вы не можете передать ничего кроме этой строки или конкретного числа.
Посмотрим, как этого добиться. Нам надо получить такую функцию, и мы знаем, что у нас есть вот такого вида объект. Нужно понять, что мы патчим только число и поля. То есть надо получить имя только тех полей, где есть числа. У нас всего одно поле, и оно является числом.
Посмотрим, как это реализовывается в TypeScript.
Мы определили функцию. У нее как раз три аргумента, сам объект, который мы патчим, и имя поля. Но это не просто имя поля. Оно может быть только именем числовых полей. Мы сейчас узнаем, как это делается. И сам патчер, который представляет собой чистую функцию.
Есть некая обезличенная функция, патч. Нам интересна не ее реализация, а то, как получить такой интересный тип, получить ключи не только числовых, а любых полей по условию. Здесь у нас содержатся числа.
Вновь разберем по порядку, как это происходит.
Мы пробегаемся по всем ключам переданного объекта, потом делаем вот такую процедуру. Смотрим, что поле объекта — это подтип нужного, то есть числовое поле. Если да, то важно, что мы записываем не значение поля, а имя поля, а иначе вообще, пустоту, never.
Если да, то важно, что мы записываем не значение поля, а имя поля, а иначе вообще, пустоту, never.
Но потом получился такой странный объект. Все числовые поля стали иметь свои имена в качестве значений, а все не числовые поля — пустоту. Дальше мы берем все значения этого странного объекта.
Но так как все значения содержат пустоту, а пустота при объединении схлопывается, то остаются только те поля, которые соответствуют числовым. То есть мы получили только нужные поля.
В примере показано: есть простой объект, поле — единичка. Это число? Да. Поле — число, это число? Да. Последняя строка — не число. Получаем только нужные, числовые поля.
С этим разобрались. Самый сложный я оставил напоследок. Это вывод типа — Infer. Захват типа в условной конструкции.
Он неотделим от предыдущей темы, потому что работает только с условной конструкцией.
Как это выглядит? Допустим, мы хотим знать элементы массива. Пришел некий тип массива, нам бы хотелось узнать конкретный элемент. Мы смотрим: нам пришел какой-то массив. Это подтип массива из переменной x. Если да — верни этот x, элемент массива. Если нет — верни пустоту.
Мы смотрим: нам пришел какой-то массив. Это подтип массива из переменной x. Если да — верни этот x, элемент массива. Если нет — верни пустоту.
В этом условии вторая ветка никогда не будет выполнена, потому что мы параметризовали тип любым массивом. Конечно, это будет массив чего-то, потому что массив из any не может не иметь элементов.
Если мы передаем массив строк, то нам ожидаемо возвратится строка. И важно понимать, что у нас определяется не просто тип. Из массива строк визуально понятно: там — строки. А вот с кортежем все не так просто. Нам важно знать, что определяется минимально возможный супертип. Понятно, что все массивы как бы являются подтипами массива с any или с unknown. Нам это знание ничего не дает. Нам важно знать минимально возможное.
Предположим, мы передаем кортеж. На самом деле кортежи — это тоже массивы, но как нам сказать, что за элементы у этого массива? Если есть кортеж из строки числа, то на самом деле это массив. Но элемент должен иметь один тип. А если там есть и строка, и число — значит, будет объединение.
А если там есть и строка, и число — значит, будет объединение.
TypeScript это и выведет, и мы получим для такого примера именно объединение строки и числа.
Можно использовать не только захват в одном месте, но и сколько угодно переменных. Допустим, мы определим тип, который просто меняет элементы кортежа местами: первый со вторым. Мы захватываем первый элемент, второй и меняем их местами.
Но на самом деле не рекомендуется слишком с этим заигрываться. Обычно для 90% задач хватает захвата всего лишь одного типа.
Посмотрим пример. Задача: нужно показать в зависимости от состояния запроса либо хороший вариант, либо плохой. Тут представлены скриншоты из нашего сервиса для деплоймента приложений. Некая сущность, ReplicaSet. Если запрос с бэкенда вернул ошибку, надо ее отрисовать. При этом есть API для бэкенда. Посмотрим, при чем тут Infer.
Мы знаем, что используем, во-первых, redux, а, во-вторых, redux thunk. И нам надо преобразовать библиотечный thunk, чтобы получить такую возможность. У нас есть плохой путь и хороший.
У нас есть плохой путь и хороший.
И мы знаем, что хороший путь в extraReducers в redux toolkit выглядит так. Знаем, что есть PayLoad, и хотим вытащить кастомные типы, которые нам пришли с бэкенда, но не только, а плюс еще информация про хороший или плохой запрос: есть там ошибка или нет. Нам нужен дженерик для этого вывода.
Про JavaScript я не привожу сравнение, потому что оно не имеет смысла. В JavaScript в принципе нельзя никак контролировать типы и полагаться только на память. Здесь нет плохого варианта, потому что его просто нет.
Мы знаем, что хотим получить этот тип. Но у нас же не просто так появляется action. Нам нужно вызвать dispatch с этим action. И нам нужен вот такой вид, где по ключу запроса нужно отображать ошибку. То есть нужно поверх redux thunk примешивать такую дополнительную функциональность с помощью метода withRequestKey.
У нас, конечно, есть этот метод, но у нас есть и исходный метод API — getReplicaSet. Он где-то записан и нам надо оверрайдить redux thunk с помощью некоего адаптера. Посмотрим, как это сделать.
Посмотрим, как это сделать.
Надо получить функцию вот такого вида. Это thunk с такой дополнительной функциональностью. Звучит страшно, но не пугайтесь, сейчас разберем по полочкам, чтобы было понятно.
Есть адаптер, который расширяет исходный библиотечный тип. Мы к этому библиотечному типу просто примешиваем дополнительный метод withRequestKey и кастомный вызов. Посмотрим, в чем основная фишка дженерика, какие параметры используются.
Первое — это просто наш API, объектик с методами. Мы можем делать getReplicaSet, получать проекты, ресурсы, неважно. Мы в текущем методе используем конкретный метод, а второй параметр — это просто имя метода. Далее мы используем параметры функции, которую запрашиваем, используем библиотечный тип Parameters, это TypeScript-тип. И аналогично для ответа с бэкенда мы используем библиотечный тип ReturnType. Это для того, что вернула функция.
Дальше мы просто прокидываем свой кастомный вывод в AsyncThunk-тип, который нам предоставила библиотека.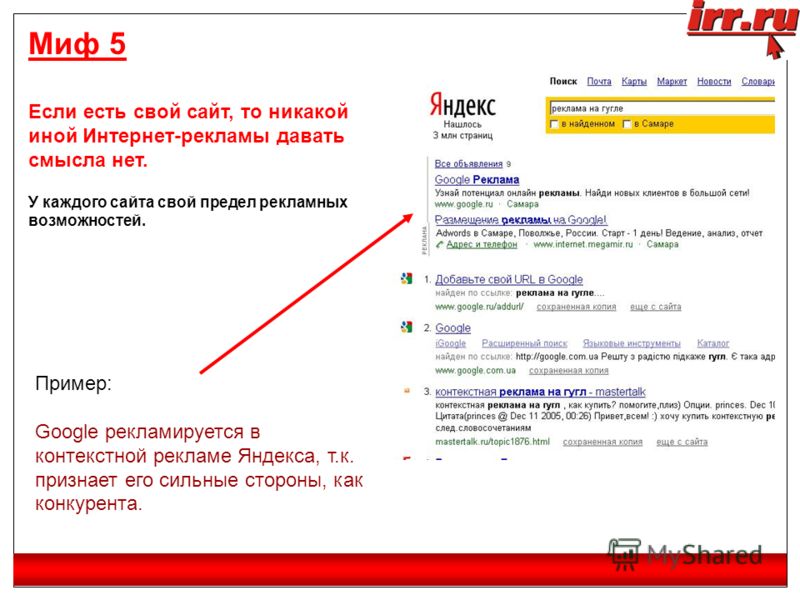 Но что это за вывод? Это еще один дженерик. На самом деле он выглядит просто. Мы сохраняем не только ответ с сервера, но и наши параметры, то, что мы передали. Просто чтобы в Reducer за ними следить. Дальше мы смотрим withRequestKey. Наш метод просто добавляет ключ. Что он возвращает? Тот же адаптер, потому что мы можем его переиспользовать. Мы вообще не обязаны писать withRequestKey. Это просто дополнительная функциональность. Она оборачивает и рекурсивно нам возвращает тот же самый адаптер, и мы прокидываем туда то же самое.
Но что это за вывод? Это еще один дженерик. На самом деле он выглядит просто. Мы сохраняем не только ответ с сервера, но и наши параметры, то, что мы передали. Просто чтобы в Reducer за ними следить. Дальше мы смотрим withRequestKey. Наш метод просто добавляет ключ. Что он возвращает? Тот же адаптер, потому что мы можем его переиспользовать. Мы вообще не обязаны писать withRequestKey. Это просто дополнительная функциональность. Она оборачивает и рекурсивно нам возвращает тот же самый адаптер, и мы прокидываем туда то же самое.
Наконец, посмотрим, как выводить в Reducer то, что нам этот thunk вернул.
У нас есть этот адаптер. Главное — помнить, что там четыре параметра: API, метод API, параметры (вход) и выход. Нам надо получить выход. Но мы помним, что выход у нас кастомный: и ответ сервера, и параметр запроса.
Как это сделать с помощью Infer? Мы смотрим, что на вход подается этот адаптер, но он вообще любой: any, any, any, any. Мы должны вернуть этот тип, выглядит он вот так, ответ сервера и параметры запроса. И мы смотрим, на каком месте должен быть вход. На третьем. На это место мы и помещаем наш захват типа. Получаем вход. Аналогично, на четвертом месте стоит выход.
И мы смотрим, на каком месте должен быть вход. На третьем. На это место мы и помещаем наш захват типа. Получаем вход. Аналогично, на четвертом месте стоит выход.
TypeScript основывается на структурной типизации. Он эту структуру разбирает и понимает, что вход находится здесь, на третьем месте, а выход на четвертом. И мы возвращаем нужные типы.
Так мы добились вывода типов, у нас есть доступ к ним уже в самом Reducer. В JavaScript сделать такое в принципе невозможно.
синтаксис и инструкция по работе
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
- Инструкция;
- Синтаксис;
- Директивы;
- Проверка работы;
Директивы и инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.
 Картинок.
Картинок.
 Картинок.
Картинок.Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.
Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.

Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat. com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Поисковые операторы Google и Яндекс: синтаксис поиска
Операторы можно использовать как самостоятельно, так в сочетании друг с другом — создать сложные запросы в поисковых системах. Комбинаций команд поиска в Google может быть много — всё зависимости от задачи. Вот некоторые из них.
Комбинаций команд поиска в Google может быть много — всё зависимости от задачи. Вот некоторые из них.
intext: название конкурента или его продукта –site: адрес сайта конкурента
Результатом выдачи будут все страницы, на которых есть название конкурента или его продукта (если вы его указали).
2. Найти незащищенные страницы — без расширения протокола https.Для этого можно использовать оператор «site:».
Пример: site: адрес страницы –inurl.https
Результатом выдачи будет количество страниц на сайте без https.
3. Найти повторяющийся контент: можно проверить, кто из конкурентов пользуется вашим контентом, а не создает свой.-site: адрес страницы «Искомый текст»
Искомый текст – текст с вашего сайта.
Поисковая система выдаст ресурсы, где еще размещен этот текст.
Например, на сайте размещены каталоги или прайс-листы. Чтобы предоставлять клиентам достоверную информацию — актуальный прайс, катало и проч. — необходимо его периодически обновлять.
Для того, чтобы проверить какие документы размещены на сайте, можно использовать filetype.
site: адрес страницы filetype:pdf
Поисковая система выдаст все страницы, где есть загруженные pdf –документы.
Ту же операцию можно повторить с другими расширениями.
5. Как найти профиль человека или компании в социальных сетях.Имя Фамилия (@facebook | @Instagram)
Если в этих социальных сетях есть человек зарегистрированный под указанными именем и фамилией, поисковая система выдаст ссылки на эти профили. Лучше начинать поиск с латиницы.
6. Поиск статей на своем сайте, где можно разместить внутреннюю ссылку.Алгоритм:
1) обозначаем сайт, на котором будем искать статьи:
site:адрес
2) исключаем ту страницу, на которую хотим сделать ссылку:
-site:URL страницы
3) ищем слово или словосочетание по теме страницы:
Intext:«слово или словосочетание»
Формат такого поискового запроса:
site:адрес сайта -site:URL страницы intext:«слово или словосочетание»
 Проверить, как часто конкуренты размещают контент в своем блоге.
Проверить, как часто конкуренты размещают контент в своем блоге.site:URL сайта конкурентов/blog
Гугл выдаст страницы блога. Затем необходимо нажать на «Инструменты» и указать за какой период: час, день, неделя и проч.
8. Посмотреть, что конкуренты выкладывает у себя на сайте: прайс-листы, каталоги, коммерческие предложения и т.п.site: адрес сайта конкурента filetype:pdf
Можно указать несколько форматов одновременно, но это может усложнить анализ полученных данных.
9. Анализ конкурентов.Чтобы быть всегда начеку, время от времени необходимо мониторить рынок. Это можно сделать по основным тематикам отрасли или типовым запросам (совпадающим или близким с предполагаемым названием страниц).
intitle :«типовый запрос» –site:адрес своего сайта
Выдача — список страниц с указанным названием. Запросу нужно варьировать, можно заменить некоторые слова на *.
site: адрес сайта intext: «типовый запрос»
В выдаче будут все страницы, на которых будет информация по «типовому запросу» или близкая к ней.
Если необходимо сделать более точный поиск:
site: адрес конкурента allintext: «типовый запрос»
intext: название продукта –site: адрес сайта1 –site: адрес сайта2 и т.д.
Этот вид анализа дает возможность быстро отреагировать на внезапно появившихся конкурентов.
12. Проверка цен:"Артикул" -$ХХХХ
С помощью этой комбинации можно проверить, кто не соблюдает рекомендованные розничные цены. Для этого в кавычках пишем артикул изделия, а с помощью -$ исключаем рекомендованную цену из поиска.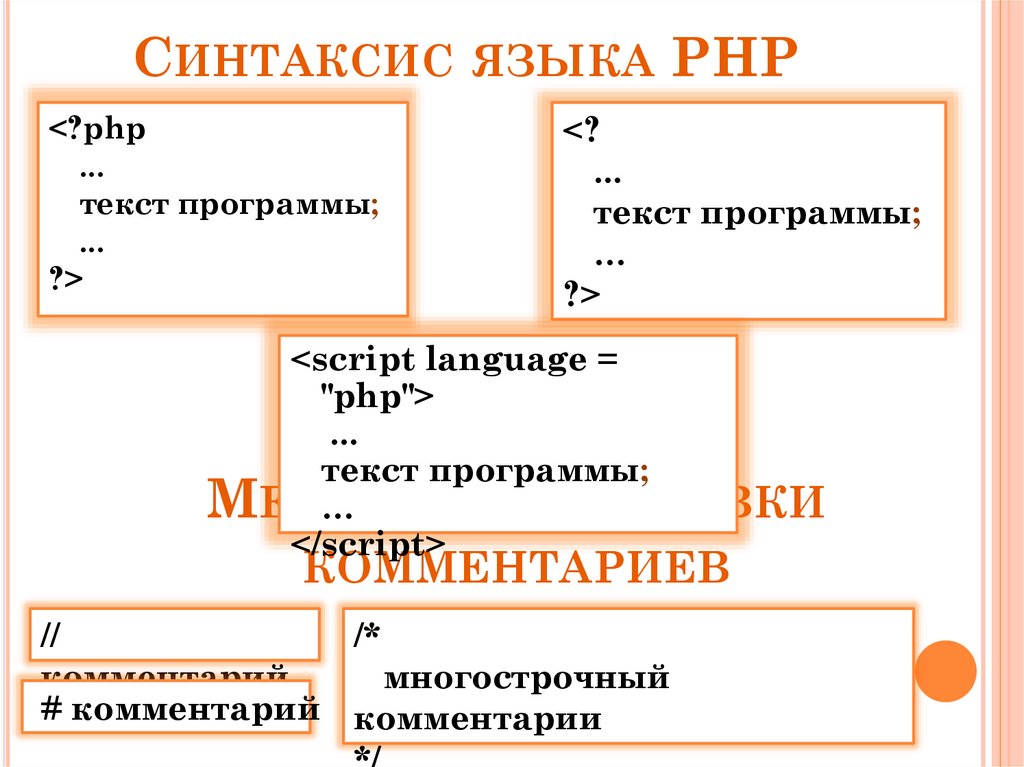
link:URL сайта -site:URL сайта
Ключевое слово loc: placename -site:URL сайта1 -site: URL сайта2
Вместо placename указать интересующий вас город.
15. Находим все страницы, в которых есть интересующее нас слово, исключив заведомо известные сайты:inurl: Запрос -site: URL сайта1 -site: URL сайта2
Синтаксис и операторы поисковых запросов Яндекс
Синтаксис | Значение | Пример |
» « | кавычки используются для поиска точного вхождения искомого выражения | «сео
курсы» – найдет все страницы,
содержащие искомое выражение, причем
слова и их порядок будут неизменны. |
* | звездочка служит заменой неизвестного слова в искомом выражении | наша маша * плачет – найдет «наша маша громко плачет», «наша маша горько плачет» и т.п. |
& | логическое И. Слова, «связанные» этим символом, должны встречаться одновременно в одном предложении. | учебный & запрос – каждый из результатов поиска будет содержать предложение, в котором одновременно будет слово учебный и запрос. |
&& | логическое И. Слова, «связанные» этим символом, должны встречаться одновременно в одном документе. | учебный
&& запрос – найдет все страницы,
в которых слова учебный и запрос
присутствуют одновременно. |
<< | неранжирующее И. Похож на &&, но ранжирование найденных страниц происходит только по первому слову. | белка << стрелка – будут найдены страницы по запросу белка стрелка, но ранжирование осуществится по слову белка. |
~~ | логическое НЕ. Исключение из результатов поиска страниц, в которых в любом месте присутствует слово после этого символа. | волга ~~ река – в данном случае будут найдены все страницы со словом волга, но из их числа будут исключены все страницы, в которых содержится слово река. |
~ | логическое
НЕ. Исключение из результатов поиска
страниц, которые содержат предложение
с искомым словом и словом после этого
символа. | волга ~~ река – найдет страницы со словом волга, но исключит те страницы, которые содержат в одном предложении слова волга и река. |
/n | задает расстояние между ключевыми словами. Расстояние между ключевыми словами – это разница между численными значениями их позиций в тексте. n может быть как положительным (прямой порядок слов) так и отрицательным (обратный порядок слов) значением. | гадкий /2 утенок – найдет страницы, содержащие такие выражения, как гадкий желтый утенок, гадкий надоедливый утенок и т.п. Но не найдет гадкий желтый надоедливый утенок и т.п., потому что расстояние в этом случае уже будет равно 3. |
&&/n | аналогично
предыдущему, только расстояние между
ключевыми словами задается в
предложениях. | |
/(n m) | помогает задать не только нужный порядок слов, но и количество «лишних» слов между искомыми. | александр /(-1 +2) пушкин – найдет страницы с такими выражениями, как александр пушкин, александр сергеевич пушкин, пушкин александр сергеевич и т.п. |
| | логическое ИЛИ. Обычно используется, когда нужны результаты как с искомым словом так и с его синонимами. | фильм|кино|видео – найдет страницы, содержащие любое из этих слов. |
( ) | скобки служат для комбинирования различных операций | |
! | отменяет
морфологию. | !день – найдет страницы только со словом день; не найдет страницы со словами дню, дни и т.п. |
!! | указывает нормальную форму слова. | !!день – найдет страницы со словами день, дню, дни и т.п. Но уберет из результатов поиска страницы со словом деть (от слова девать). |
Операторы | ||
Оператор | Значение | Пример |
title: | поиск в заголовке страниц (в HTML тэге <title>) | title:
кролик – найдет все страницы, в
заголовке которых присутствует слово
«кролик». |
url: | Поиск на страницах с заданным адресом. | url:mysoundtrack.ru/* «k filmam» – найдет все страницы на сайте mysoundtrack.ru, в адресе которых есть «k filmam». Звездочка (*) помогает задействовать страницы, адреса которых начинаются с указанного адреса. |
inurl: | ищет по страницам, адрес которых содержит заданный фрагмент. | inurl:masha – в адресе каждой найденной страницы будет содержаться слово masha. |
host: | поиск по указанному хосту (сайту). | host:mysoundtrack.ru «k filmam» тоже самое, что и url:mysoundtrack.ru/* «k filmam». |
site: | показывает
полное количество проиндексированных
страниц сайта. | site:www.relax.ru – покажет полное количество страниц, известное Яндексу на сайте www.relax.ru. |
mime: | поиск по определенному типу файлов. Поддерживаются следующие типы файлов: pdf, doc, ppt, xls, rtf, swf | резюме mime:doc – найдет файлы с различными резюме, причем все файлы будут Microsoft Word |
lang: | поиск по страницам на заданном языке. Поддерживаются языки: ru, uk, be, en, fr, de | «news hockey» lang:en – поиск хоккейных новостей на англ. языке |
domain: | поиск по страницам, которые расположены в заданном домене | «купить велосипед» domain:ru – найдет сайты в зоне .ru, которые продают велосипеды |
date: | поиск
по страницам, дата создания (или
изменения) которых соответствует
заданной дате. | кризис date:20100516 – сайты, которые писали про кризис 16 мая 2010г. |





 Можно задавать интервалы
и сравнивать дату знаками неравенства:
<, >, <=, >=
Можно задавать интервалы
и сравнивать дату знаками неравенства:
<, >, <=, >=Rambler (http://www.rambler.ru) — система имеет дружественный интерфейс, предлагающий воспользоваться простой или детальной формами запроса («Расширенный поиск»). Лучше сразу обратиться к последней, так как при использовании основного интерфейса возможности детализации запроса невелики.
Механизм
составления детального запроса реализован
через меню. Пользователю предлагается
ввести один или несколько терминов и
определить параметры для разыскания.
К основным параметрам относятся: область
поиска (во всем документе или в заглавии),
условия поиска (выдавать ссылки на
документ, в котором обязательно
встречаются все термины или любой из
них) употребление словоформ (искать ли
все производные корня данного слова,
ограничиться точно введенной формулировкой
или усекать все встречающиеся окончания).
Очень полезными и, кстати, практически дублирующими друг друга параметрами являются требование минимального расстояния между искомыми словами и поиск на полное соответствие запросу. Можно также уточнить поисковое предписание по языку документа, дате его последнего обновления и указать термины, появление которых в источнике должно быть исключено.
Google (http://www.google.com). При составлении поискового запроса в режиме расширенного поиска следует указать поисковой системе множество дополнительных параметров. Различные пункты в анкете, расположенной на Web-странице расширенного поиска, предоставляют пользователю следующие возможности: найти результаты со всеми словами; найти результаты с точной фразой; найти результаты с любым из слов; найти результаты без слов; язык; формат файла; дата; упоминание; домен.
Для
составления запроса можно сочетать все
возможности практически в любой
комбинации. Составив подходящий запрос,
можно выбрать количество WEB-сайтов из
списка, которое Google выведет на каждую
Web-страницу.
Составив подходящий запрос,
можно выбрать количество WEB-сайтов из
списка, которое Google выведет на каждую
Web-страницу.
Синтаксис. Пользовательский интерфейс
Илья Бирман
🔍 Начните печатать, чтобы искать по книге или перейти к нужной странице по номеру
Удобно листать не только прокруткой, но и клавишами‑стрелками:
между важными местами
между
разворотами
Илья Бирман
Илья Бирман
Издательство Бюро Горбунова
2017
Илья Бирман
Издательство Бюро Горбунова
2017
удк 655.262
ббк 85.15
Б64
Бирман И. Б.
Б64
Пользовательский интерфейс. —
М.: Изд‑во Бюро Горбунова, 2017
ISBN 978‑5‑9907024‑1‑7
Представляем книгу Издательства Дизайн‑бюро Артёма Горбунова — практическое руководство по пользовательскому интерфейсу. Учебник предназначен для дизайнеров, редакторов, руководителей, разработчиков и всех, кто причастен к созданию продуктов.
УДК 655.262
ББК 85.15
Принципы 4
Взаимодействие 86
Язык 213
Экраны 311
удк 655.262
ббк 85.15
Б64
Б64
Бирман И. Б.
Пользовательский интерфейс. —
М.: Изд‑во Бюро Горбунова, 2017
ISBN 978‑5‑9907024‑1‑7
Представляем книгу Издательства Дизайн‑бюро Артёма Горбунова — практическое руководство по пользовательскому интерфейсу. Учебник предназначен для дизайнеров, редакторов, руководителей, разработчиков и всех, кто причастен к созданию продуктов.
УДК 655.262
ББК 85.15
Принципы 4
Взаимодействие 86
Язык 213
Экраны 311
Скрыто 215 разворотов
Настройка фильтров в почте «Яндекса» — пример сложной формы. Синтаксически точно было бы в заголовке написать «Фильтр», а на кнопке — «Сохранить».
Но здесь форма слишком длинная, заголовок и кнопка не попадут одновременно в поле зрения на большинстве экранов. Поэтому заголовок и кнопку сделали более информативными.
Поэтому заголовок и кнопку сделали более информативными.
Избыточно
Достаточно
В обычных случаях стоит избегать повторений, оставляя в заголовке подлежащее, а в кнопке — сказуемое. Обилие слов часто маскирует проблемы с информативностью.
Если убрать лишние слова, проявляется бестолковый заголовок «Товар». Осталось заменить его названием этого товара.
Избыточно
В обычных случаях стоит избегать повторений, оставляя в заголовке подлежащее, а в кнопке — сказуемое. Обилие слов часто маскирует проблемы с информативностью.
Достаточно
Если убрать лишние слова, проявляется бестолковый заголовок «Товар». Осталось заменить его названием этого товара.
Нарушение синтаксиса мешает однозначному пониманию интерфейса.
На сайте «Аэрофлота» был оранжевый элемент с призывом «Вернитесь к началу регистрации». Но как вернуться, да и зачем?
На кнопке должен быть глагол совершенного вида в начальной форме: «Вернуться» (а лучше — «Сохранить место»).
Выбор места в салоне при регистрации на рейс «Аэрофлота»
Выбор места в салоне при регистрации на рейс «Аэрофлота»
Нарушение синтаксиса мешает однозначному пониманию интерфейса.
На сайте «Аэрофлота» был оранжевый элемент с призывом «Вернитесь к началу регистрации». Но как вернуться, да и зачем?
На кнопке должен быть глагол совершенного вида в начальной форме: «Вернуться» (а лучше — «Сохранить место»).
В Ай‑ОСе, наоборот, глагол совершенного вида в начальной форме стоит в заголовке экрана и в подписях тумблеров. Как это понять? Когда я включу тумблер, сохранятся настройки?
На самом деле не сохранятся, а будут сохраняться, в другой программе и в другое время.
Раз это настройка поведения, а не однократное действие, следует использовать глагол несовершенного вида: «Помнить настройки».
См. также о режимах камеры:
Модальность 54
В Ай‑ОСе, наоборот, глагол совершенного вида в начальной форме стоит в заголовке экрана и в подписях тумблеров. Как это понять? Когда я включу тумблер, сохранятся настройки?
Как это понять? Когда я включу тумблер, сохранятся настройки?
На самом деле не сохранятся, а будут сохраняться, в другой программе и в другое время.
Раз это настройка поведения, а не однократное действие, следует использовать глагол несовершенного вида: «Помнить настройки».
См. также о режимах камеры:
Модальность 54
Скрыто 196 разворотов
Бирман Илья Борисович
Пользовательский интерфейс
Арт‑директор и издатель Артём Горбунов
Дизайнер обложки и фотограф
Владимир КолпаковИллюстратор Андрей Кокорин
Разработчики Рустам Кулматов
и Василий ПоловнёвМетранпаж и тестировщик Сергей Фролов
Помощники Юрий Мазурский
и Александра Шабалдина
Книга набрана шрифтами
«Бюросериф» и «Бюросанс»Дизайн‑бюро Артёма Горбунова
Большая Новодмитровская улица,
дом 36, строение 2
Москва, Россия, 127015bureau.
ru
 ru
ruБирман Илья Борисович
Пользовательский интерфейс
Арт‑директор и издатель Артём Горбунов
Дизайнер обложки и фотограф
Владимир КолпаковИллюстратор Андрей Кокорин
Разработчики Рустам Кулматов
и Василий ПоловнёвМетранпаж и тестировщик Сергей Фролов
Помощники Юрий Мазурский
и Александра Шабалдина
Книга набрана шрифтами
«Бюросериф» и «Бюросанс»Дизайн‑бюро Артёма Горбунова
Большая Новодмитровская улица,
дом 36, строение 2
Москва, Россия, 127015bureau.ru
Визуальные интерфейсы от сторонних разработчиков
Open-Source
Tabix
Веб-интерфейс для ClickHouse в проекте Tabix.
Особенности:
- Работает с ClickHouse прямо из браузера, без необходимости установки дополнительного ПО.
- Редактор запросов с подсветкой синтаксиса.
- Автодополнение команд.
- Средства графического анализа выполнения запросов.
- Варианты цветовой схемы.

Документация Tabix.
HouseOps
HouseOps — это UI/IDE для OSX, Linux и Windows.
Особенности:
- Построитель запросов с подсветкой синтаксиса. Просмотрите ответ в виде таблицы или JSON.
- Экспорт результатов запроса в формате CSV или JSON.
- Список процессов с описаниями. Режим записи. Возможность остановить (
KILL) процесс. - График базы данных. Показывает все таблицы и их столбцы с дополнительной информацией.
- Быстрый просмотр размера столбца.
- Конфигурация сервера.
Планируется разработка следующих функций:
- Управление базой данных.
- Управление пользователями.
- Анализ данных в реальном времени.
- Мониторинг кластера.
- Управление кластером.
- Мониторинг реплицированных таблиц и таблиц Kafka.

LightHouse
LightHouse — это легкий веб-интерфейс для ClickHouse.
Особенности:
- Список таблиц с фильтрацией и метаданными.
- Предварительный просмотр таблицы с фильтрацией и сортировкой.
- Выполнение запросов только для чтения.
Redash
Redash — платформа для визуализации данных.
Поддерживает несколько источников данных, включая ClickHouse, Redash может объединять результаты запросов из разных источников данных в один окончательный набор данных.
Особенности:
- Мощный редактор запросов.
- Обозреватель баз данных.
- Средства визуализации, позволяющие представлять данные в различных формах.
Grafana
Grafana — платформа для мониторинга и визуализации.
«Grafana позволяет вам запрашивать, визуализировать, предупреждать и понимать ваши показатели независимо от того, где они хранятся. Создавайте, исследуйте и делитесь информационными панелями с вашей командой и развивайте культуру, основанную на данных. Пользуйтесь доверием и любовью сообщества» — grafana .ком.
Пользуйтесь доверием и любовью сообщества» — grafana .ком.
Плагин источника данных ClickHouse обеспечивает поддержку ClickHouse в качестве серверной базы данных.
qryn (#qryn)
qryn — это многоязычный, высокопроизводительный стек наблюдения для ClickHouse (ранее cLoki) с собственной интеграцией Grafana, позволяющий пользователям получать и анализировать журналы, метрики и трассировки телеметрии от любого агента, поддерживающего Loki/ LogQL, Prometheus/PromQL, OTLP/Tempo, Elastic, InfluxDB и многие другие.
Особенности:
- Встроенный пользовательский интерфейс Explore и интерфейс командной строки LogQL для запроса, извлечения и визуализации данных
- Встроенные API-интерфейсы Grafana для запросов, обработки, приема, отслеживания и оповещения без подключаемых модулей
- Мощный конвейер для динамического поиска, фильтрации и извлечения данных из журналов, событий, трассировок и т. д. Grafana-Agent, Vector, Logstash, Telegraf и многие другие
DBeaver
DBeaver — универсальный настольный клиент БД с поддержкой ClickHouse.
Особенности:
- Разработка запросов с подсветкой синтаксиса и автодополнением.
- Список таблиц с фильтрами и поиском по метаданным.
- Предварительный просмотр данных таблицы.
- Полнотекстовый поиск.
По умолчанию DBeaver не подключается с использованием сеанса (например, CLI). Если вам требуется поддержка сеанса (например, чтобы установить настройки для вашего сеанса), отредактируйте свойства подключения драйвера и установите session_id в случайную строку (под капотом используется http-соединение). Затем вы можете использовать любую настройку из окна запроса.
clickhouse-кли
clickhouse-cli — это альтернативный клиент командной строки для ClickHouse, написанный на Python 3.
Особенности:
- Автодополнение.
- Подсветка синтаксиса для запросов и вывода данных.
- Поддержка пейджера для вывода данных.
- Пользовательские команды, подобные PostgreSQL.

clickhouse-flamegraph
clickhouse-flamegraph — это специализированный инструмент для визуализации system.trace_log в виде flamegraph.
clickhouse-plantuml
cickhouse-plantuml — это скрипт для создания диаграммы PlantUML схем таблиц.
xeus-clickhouse
xeus-clickhouse — это ядро Jupyter для ClickHouse, которое поддерживает запросы данных CH с использованием SQL в Jupyter.
MindsDB Studio
MindsDB — это уровень искусственного интеллекта с открытым исходным кодом для баз данных, включая ClickHouse, который позволяет без особых усилий разрабатывать, обучать и развертывать современные модели машинного обучения. MindsDB Studio (GUI) позволяет обучать новые модели из базы данных, интерпретировать прогнозы, сделанные моделью, выявлять потенциальные смещения данных, а также оценивать и визуализировать точность модели с помощью функции объяснимого ИИ для более быстрой адаптации и настройки моделей машинного обучения.
DBM
DBM DBM — это визуальный инструмент управления для ClickHouse!
Особенности:
- Поддержка истории запросов (разбивка на страницы, очистка всего и т. д.)
- Поддержка выбранных запросов sql
- Поддержка завершающего запроса
- Поддержка управления таблицами (метаданные, удаление, предварительный просмотр)
- Поддержка управления базой данных (удаление , создать)
- Поддержка пользовательского запроса
- Поддержка управления несколькими источниками данных (проверка соединения, мониторинг)
- Монитор поддержки (процессор, соединение, запрос)
- Поддержка переноса данных
Bytebase
Bytebase — это веб-инструмент для изменения схемы и контроля версий с открытым исходным кодом для команд. Он поддерживает различные базы данных, включая ClickHouse.
Функции:
- Проверка схемы между разработчиками и администраторами баз данных.
- База данных как код, управление версиями схемы в VCS, например GitLab, и запускает развертывание после фиксации кода.
- Упрощенное развертывание с политикой для каждой среды.
- Полная история миграции.
- Обнаружение дрейфа схемы.
- Резервное копирование и восстановление.
- RBAC.

Zeppelin-Interpreter-for-ClickHouse
Zeppelin-Interpreter-for-ClickHouse — интерпретатор Zeppelin для ClickHouse. По сравнению с интерпретатором JDBC он может обеспечить лучший контроль времени ожидания для длительных запросов.
ClickCat
ClickCat — это удобный пользовательский интерфейс, который позволяет вам искать, исследовать и визуализировать данные ClickHouse.
Особенности:
- Онлайн-редактор SQL, который может запускать ваш код SQL без какой-либо установки.
- Вы можете наблюдать за всеми процессами и мутациями. Для этих незавершенных процессов вы можете убить их в пользовательском интерфейсе.
- Метрики содержат кластерный анализ, анализ данных, анализ запросов.
ClickVisual
ClickVisual ClickVisual — это облегченная платформа для запросов к журналам с открытым исходным кодом, анализа и визуализации сигналов тревоги.
Особенности:
- Поддерживает создание библиотек журналов анализа одним щелчком мыши
- Поддерживает управление конфигурацией коллекции журналов
- Поддерживает пользовательскую настройку индекса
- Поддерживает настройку сигналов тревоги
- Поддержка детализации разрешений для библиотек и настроек разрешений для таблиц
ClickHouse-Mate
5
6 ClickHouse-Mate — это угловой веб-клиент + пользовательский интерфейс для поиска и изучения данных в ClickHouse.
Возможности:
- Автозаполнение SQL-запросов ClickHouse
- Быстрая навигация по базе данных и дереву таблиц
- Расширенная фильтрация и сортировка результатов
- Встроенная документация ClickHouse SQL
- Предустановки и история запросов
- 100 % на основе браузера, без сервера/бэкенда
Клиент-концентратор доступен для мгновенного использования через git-концентратор страницы: https://metrico. github.io/clickhouse-mate/
github.io/clickhouse-mate/
Uptrace
Uptrace — это инструмент APM, который обеспечивает распределенную трассировку и метрики на основе OpenTelemetry и ClickHouse.
Функции:
- Трассировка, метрики и журналы OpenTelemetry.
- Уведомления по электронной почте/Slack/PagerDuty с использованием AlertManager.
- SQL-подобный язык запросов для объединения интервалов.
- Язык, похожий на Promql, для запроса метрик.
- Готовые панели показателей.
- Несколько пользователей/проектов через конфигурацию YAML.
Коммерческий
DataGrip
DataGrip — это интегрированная среда разработки баз данных от JetBrains со специальной поддержкой ClickHouse. Он также встроен в другие инструменты на базе IntelliJ: PyCharm, IntelliJ IDEA, GoLand, PhpStorm и другие.
Особенности:
- Очень быстрое завершение кода.
- Подсветка синтаксиса ClickHouse.
- Поддержка специфичных для ClickHouse функций, например, вложенных столбцов, табличных движков.
- Редактор данных.
- Рефакторинг.
- Поиск и навигация.

Yandex DataLens
Yandex DataLens — сервис визуализации и аналитики данных.
Особенности:
- Широкий спектр доступных визуализаций, от простых гистограмм до сложных информационных панелей.
- Информационные панели могут быть общедоступными.
- Поддержка нескольких источников данных, включая ClickHouse.
- Хранилище материализованных данных на базе ClickHouse.
DataLens доступен бесплатно для проектов с низкой нагрузкой, даже для коммерческого использования.
- Документация DataLens.
- Учебник по визуализации данных из базы данных ClickHouse.
Программное обеспечение Holistics
Holistics — это полнофункциональная платформа данных и инструмент бизнес-аналитики.
Особенности:
- Автоматизированная электронная почта, Slack и Google Sheet расписания отчетов.
- Редактор SQL с визуализацией, контролем версий, автозавершением, многократно используемыми компонентами запросов и динамическими фильтрами.
- Встроенная аналитика отчетов и дашбордов через iframe.
- Возможности подготовки данных и ETL.
- Поддержка моделирования данных SQL для реляционного отображения данных.

Looker
Looker — это платформа данных и инструмент бизнес-аналитики с поддержкой более 50 диалектов баз данных, включая ClickHouse. Looker доступен как на платформе SaaS, так и на собственном хостинге. Пользователи могут использовать Looker через браузер для изучения данных, создания визуализаций и информационных панелей, планирования отчетов и обмена своими знаниями с коллегами. Looker предоставляет богатый набор инструментов для внедрения этих функций в другие приложения, а также API интегрировать данные с другими приложениями.
Особенности:
- Простая и гибкая разработка с использованием LookML, языка, который поддерживает Моделирование данных для поддержки составителей отчетов и конечных пользователей.
- Мощная интеграция рабочего процесса с помощью Looker’s Data Actions.

Как настроить ClickHouse в Looker.
SeekTable
SeekTable — это инструмент самообслуживания BI для исследования данных и оперативной отчетности. Он доступен как в виде облачного сервиса, так и в виде собственной версии. Отчеты из SeekTable можно встраивать в любое веб-приложение.
Особенности:
- Удобный конструктор отчетов для бизнес-пользователей.
- Мощные параметры отчета для фильтрации SQL и настройки запросов для конкретных отчетов.
- Может подключаться к ClickHouse как с собственной конечной точкой TCP/IP, так и с интерфейсом HTTP(S) (2 разных драйвера).
- Можно использовать всю мощь диалекта ClickHouse SQL в определениях измерений/мер.
- Веб-API для автоматического создания отчетов.
- Поддерживает поток разработки отчетов с резервным копированием/восстановлением данных учетной записи; Конфигурация моделей данных (кубов)/отчетов представляет собой удобочитаемый XML и может храниться в системе контроля версий.

SeekTable бесплатен для личного/индивидуального использования.
Как настроить подключение ClickHouse в SeekTable.
Chadmin
Chadmin — это простой пользовательский интерфейс, в котором вы можете визуализировать ваши текущие запросы в вашем кластере ClickHouse и информацию о них, а также убивать их, если хотите.
TABLUM.IO
TABLUM.IO — онлайн-инструмент запросов и аналитики для ETL и визуализации. Он позволяет подключаться к ClickHouse, запрашивать данные через универсальную консоль SQL, а также загружать данные из статических файлов и сторонних сервисов. TABLUM.IO может визуализировать результаты данных в виде диаграмм и таблиц.
Возможности:
- ETL: загрузка данных из популярных баз данных, локальных и удаленных файлов, вызовы API.
- Универсальная консоль SQL с подсветкой синтаксиса и визуальным конструктором запросов.
- Визуализация данных в виде диаграмм и таблиц.
- Материализация данных и подзапросы.
- Отправка данных в Slack, Telegram или по электронной почте.
- Конвейерная передача данных через проприетарный API.
- Экспорт данных в форматы JSON, CSV, SQL, HTML.
- Веб-интерфейс.
TABLUM.IO можно запускать как локальное решение (как образ докера) или в облаке. Лицензия: коммерческий продукт с 3-месячным бесплатным периодом.
Попробуйте бесплатно в облаке. Узнайте больше о продукте на TABLUM.IO
Оригинал статьи
Добавление почтового ящика — API. Yandex.Mail for Domain API
Üzgünüz, bu belge Türkçe diline henüz çevrilmedi.
Sayfada belgenin varsayılan dili gösterilmektedir: Английский .
Этот запрос используется для добавления почтового ящика для домена.
- Синтаксис запроса
- Пример запроса
- Структура ответа
Запрос должен быть отправлен по протоколу HTTPS методом POST.
POST /api2/admin/email/добавить Хост: pddimp.Токен PDD.
"}}">: <токен PDD> ... ТипСтрока
Значение
Имя домена.
"}}">=<имя домена> & 9", "&", "*", "(", ")", "_", "-", "+", ":", ";", ", "."
 yandex.ru
Описание
yandex.ru
Описание отличаться от имени пользователя.
Headers:
| Name | Description |
|---|---|
| PddToken | PDD token. |
Параметры:
| Параметр | Тип | Значение |
|---|---|---|
| Обязательный | ||
| домен | ||
| логин | String | Электронный адрес почтового ящика в формате «username@domain. |
| пароль | Строка | Пароль пользователя. 9″, «&», «*», «(«, «)», «_», «-«, «+», «:», «;», «, «.» отличаться от имени пользователя. |
 ru» или «username».
ru» или «username».POST /api2/registrar/email/добавить Хост: pddimp.yandex.ru ОписаниеТокен PDD.
"}}">: <токен PDD> ОписаниеМаркер доступа OAuth.
"}}">: OAuth <токен OAuth> ... ТипСтрока
Значение
Имя домена.
"}}">=<имя домена> & ТипСтрока
Значение
Электронный адрес почтового ящика в формате «[email protected]» или «username».
"}}">=<имя пользователя почтового ящика> & ТипСтрока
Значение
Пароль пользователя.
 », « &», «*», «(», «)», «_», «-», «+», «:», «;», «, «.»
», « &», «*», «(», «)», «_», «-», «+», «:», «;», «, «.» отличаться от имени пользователя.
Заголовки:
| Имя | Описание |
|---|---|
| Авторизация | Маркер доступа OAuth. |
Параметры:
| Parameter | Type | Value |
|---|---|---|
| Mandatory | ||
| domain | String | Name of the domain. |
| логин | String | Электронный адрес почтового ящика в формате «[email protected]» или «username». |
| пароль | строка | 9″, «&», «*», «(«, «)», «_», «-«, «+», «:», «;», «, «.» отличаться от имени пользователя. |

POST /api2/admin/email/добавить HTTP/1.1 Хост: pddimp.yandex.ru PddToken: 123456789ABCDEF00000000000000000000000000000000000000 ... domain=domain.com&login=newlogin&password=1234567890
cURL
curl -H 'PddToken: 123456789ABCDEF0000000000000000000000000000000000000' -d 'domain=domain.com&login=newlogin&password=1234567890' 'https://pddimp.
 yandex.ru/api2/admin/email/add'
yandex.ru/api2/admin/email/add' POST /api2/admin/email/add HTTP/1.1 Хост: pddimp.yandex.ru PddToken: 123456789ABCDEF00000000000000000000000000000000000000 Авторизация: OAuth 00123456789ABCDEF000000000000000000000000000000000000 ... domain=domain.com&login=newlogin&password=1234567890
cURL
curl -H 'PddToken: 123456789ABCDEF0000000000000000000000000000000000000' -H 'Authorization: OAuth 00123456789ABCDEF00000000000000000000000000000000000' -d 'domain=domain.com&login=newlogin&password=1234567890' 'https://pddimp.yandex.ru/api2/admin/email/add'
{
" Тип значения Строка
Описание
Имя домена.
"}}">": "{имя домена}",
" Тип значения String
Описание
Адрес электронной почты почтового ящика.
"}}">":"{адрес электронной почты почтового ящика}",
" Тип значения Целое число
Описание
Идентификатор почтового ящика.
"}}">": "{ID почтового ящика}",
" Тип значения Строка
Описание
Статус выполнения запроса.
Возможные значения:
"}}">": "{статус выполнения запроса}"
} 
{
" Тип значения Строка
Описание
Имя домена.
"}}">": "{имя домена}",
" Тип значения Строка
Описание
Статус выполнения запроса.
Возможные значения:
"}}">": "{статус выполнения запроса}",
" Тип значения Строка
Описание
Код ошибки. произошла ошибка (повторите запрос позже). 0859 no_ip ) — пропущен обязательный параметр.
 0859 no_ip ) — пропущен обязательный параметр.
0859 no_ip ) — пропущен обязательный параметр. bad_domain — доменное имя не указано или не соответствует RFC.
запрещено — Запрещенное доменное имя.
bad_token ( bad_login , bad_passwd ) — был передан недопустимый токен PDD (или имя пользователя/пароль).
no_auth — заголовок PddToken был опущен.
not_allowed — Эта операция не разрешена для данного пользователя (пользователь не является администратором домена).
заблокирован — Заблокированный домен (например, из-за спама и т.п.).
-
занято— доменное имя используется другим пользователем. -
domain_limit_reached— Превышено допустимое количество подключенных доменов (50). -
no_reply— Яндекс.Почта для домена не может подключиться к серверу-источнику для импорта.

Была ли статья полезной?
aioymaps · PyPI
Асинхронный клиент для Яндекс Карт
Описание проекта
aioymaps — это асинхронная библиотека, предоставляющая API для получения информации json. об остановках транспорта с Яндекс Карт
Требования
Для aioymapsтребуется Python 3.5 или выше из-за синтаксиса async/await и aiohttp библиотека
Установка
Используйте pip для установки библиотеки:
pip установить aioymaps
Или установить вручную.
sudo python ./setup.py установить
Использование
из aioymaps импортировать YandexMapsRequester
requester = YandexMapsRequester()
данные = ожидание requester.get_stop_info('stop__10067199')
печать (данные) Или вы можете использовать его в своей оболочке:
python -maioymaps -s group__219
Детали проекта
Эта версия
1.2.3
1.2.2
1.2.1
1.2.0
1.1.0
1.0.1
1.0.0
Загрузить файлы
Загрузить файл для вашей платформы. Если вы не уверены, что выбрать, узнайте больше об установке пакетов.
Исходный дистрибутив
aioymaps-1. 2.3.tar.gz
(4,4 КБ
посмотреть хеши)
2.3.tar.gz
(4,4 КБ
посмотреть хеши)
Загружено источник
Встроенный дистрибутив
aioymaps-1.2.3-py3-none-any.whl (4,6 КБ посмотреть хеши)
Загружено ру3
Закрывать
Хэши для aioymaps-1.2.3.tar.gz
| Алгоритм | Дайджест хэша | |
|---|---|---|
| ША256 | а56ф05а0к740ф177506662д1к24е5204180585886010к24ф03дф9бфбк6а272е1 | |
| MD5 | cff112b996d8183778a7fca704b3d6d6 | |
| БЛЕЙК2-256 | 04984e337778584d9a751e6b23a4c9b461b55e13d5452c442966bace5814c06e |
 2.3.tar.gz
2.3.tar.gzЗакрывать
Хэши для aioymaps-1.2.3-py3-none-any.whl
| Алгоритм | Дайджест хэша | |
|---|---|---|
| ША256 | 72b72f06729985399a699f183c10655f8dc2d1c4e8ab2c71bebb2d674bf | |
| МД5 | 02cd0c5044034341e76d39a4350ab0ce | |
| БЛЕЙК2-256 | ф58973829e77c17883cda7d270474cbf0f07ef6e3e02509d2de410aa89c6afd0 |
 whl
whl| Редакционная информация предоставлена DB-Engines | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Имя | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Описание | TiDB — это распределенная база данных гибридной транзакционной/аналитической обработки (HTAP) с открытым исходным кодом, которая поддерживает синтаксис MySQL и Spark SQL. | Служба распределенной отказоустойчивой базы данных с высокой доступностью, масштабируемостью, немедленным согласованием и транзакциями ACID, а также с API, совместимым с Amazon DynamoDB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Первичная модель базы данных | Relational DBMS | Document store Relational DBMS | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Secondary database models | Document store | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Website | pingcap.com | cloud.yandex.com/en/services/ ydb github.com/ydb-platform/ydb ydb.tech | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Техническая документация | docs.pingcap.com/tidb/stable | cloud.yandex.com/en/docs/managed-ydb ydb.tech/en/docs | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Developer | PingCAP, Inc. | Yandex | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Initial release | 2016 | 2019 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Current release | 5.4.2, June 2022 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Коммерческая лицензия или лицензия с открытым исходным кодом | Apache с открытым исходным кодом 2. 0 0 | Apache с открытым исходным кодом 2.0; доступна коммерческая лицензия | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Только облачная версия Доступна только как облачная служба | № | № | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Предложения DBaaS (рекламные ссылки) База данных как услуга Поставщики предложений DBaaS, пожалуйста, свяжитесь с нами, чтобы получить список. | Облако TiDB: полностью управляемая служба TiDB. Перенесите все лучшее, что есть в TiDB, в облако. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Язык реализации | Go, Rust | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Серверные операционные системы | Linux | Linux | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| да | Гибкая схема (определенная схема, частичная схема, свободная схема) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ввод предопределенных типов данных, таких как float или date , например поддержка структур данных XML и/или поддержка XPath, XQuery или XSLT. | нет | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Вторичные индексы | да | да | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SQL Поддержка SQL | yes | SQL-like query language (YQL) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| APIs and other access methods | JDBC ODBC Proprietary protocol | RESTful HTTP API (DynamoDB compatible) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Supported programming languages | Ada C C# C++ D Delphi Eiffel Erlang Haskell Java JavaScript (Node.  js) js) Objective-C OCaml Perl PHP Python 0441 Scheme Tcl | Go Java JavaScript (Node.js) PHP Python | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Server-side scripts Stored procedures | no | no | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Triggers | no | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Partitioning методы Методы хранения разных данных на разных узлах | горизонтальное разбиение (по диапазону ключей) | Шардинг | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Методы репликации Методы избыточного хранения данных на нескольких узлах | Использование алгоритма консенсуса Raft для обеспечения строгой согласованности репликации данных между несколькими репликами. | Активно-пассивная репликация сегментов | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MapReduce Предлагает API для пользовательских методов Map/Reduce | да с TiSpark Connector | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Нет | Немедленная консистенция | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Внешние ключи Ссылочная целостность | нет в настоящее время поддерживается только в синтаксисе | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Концепции транзакций Поддержка обеспечения целостности данных после неатомарных манипуляций с данными | ACID | ACID | да | да | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Долговечность Поддержка сохранения данных | да | да | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Возможности в памяти Есть ли возможность определить некоторые или все структуры, которые будут храниться только в памяти. | нет | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Концепции пользователей Контроль доступа | Пользователи с детализированной концепцией авторизации. Нет групп пользователей или ролей. | Определены права доступа для пользователей Yandex Cloud | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Дополнительная информация предоставлена поставщиком системы | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Особенности | TiDB — это база данных NewSQL с открытым исходным кодом, созданная с помощью PingCAP. TiDB поддерживает гибридные транзакционные… » подробнее | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Конкурентные преимущества | В существующей среде баз данных инженерам по инфраструктуре часто приходится использовать одну… » подробнее | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Типичные сценарии приложений | TiDBAP поддерживает как OLAP, так и OLTP. сценарии. Вы можете использовать TiDB,… » подробнее | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ключевые клиенты | Shopee (Электронная коммерция) BookMyShow. com (Электронная коммерция) Yiguo.com (Электронная коммерция) JD Cloud &… com (Электронная коммерция) Yiguo.com (Электронная коммерция) JD Cloud &… »More | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Метрики рынка | 25K+ звезды GitHub для TIDB и 8K+ Github Stars для TIKV 1,6K+ члены TIDB … » More | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ». 2.0 либо с коммерческой лицензией, либо с полностью размещенной БД как услуга… » подробнее | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Мы приглашаем представителей поставщиков систем связаться с нами для обновления и расширения информации о системе, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Мы приглашаем представителей поставщиков сопутствующих товаров связаться с нами для предоставления информации о своих предложениях здесь. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Дополнительные ресурсы | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Последние цитаты в новостях | PingCAP запускает TiDB Cloud на Google Cloud Marketplace для глобального охвата разработчиков PingCAP представляет новый уровень разработчика для ускорения инноваций приложений с помощью TiDB Cloud PingCAP объявляет о публичной предварительной версии TiDB Cloud USA — English — USA — English Raft Engine: встроенный механизм хранения с логической структурой для журналов Multi-Raft в TiKV Инженеры Uber, Lyft, Square, ScyllaDB и Google о программе P99 CONF предоставлено Google News | Узнать, что думают россияне, не спрашивая их Утечка из службы доставки еды Яндекса раскрыла личную информацию российской тайной полиции1 202 апреля 3 , Tech Timesпредоставлено Google News | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Вакансии | Главный менеджер по продукту — TiDB Cloud Главный инженер-программист — TiDB Cloud Compute Менеджер по продажам — удаленный Главный инженер-программист, хранилище Старший Представитель по развитию продаж вакансий от | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Rclone синхронизирует ваши файлы с облачным хранилищем
- О rclone
- Что может сделать для вас rclone?
- Какие функции есть у rclone?
- Каких провайдеров поддерживает rclone?
- Скачать
- Установить
О rclone
Rclone — это программа командной строки для управления файлами в облачном хранилище. Это
это многофункциональная альтернатива веб-хранилищу облачных поставщиков
интерфейсы. Поддержка более 40 облачных хранилищ
rclone, включая хранилища объектов S3, хранилище файлов для бизнеса и потребителей
услуги, а также стандартные протоколы передачи.
Это
это многофункциональная альтернатива веб-хранилищу облачных поставщиков
интерфейсы. Поддержка более 40 облачных хранилищ
rclone, включая хранилища объектов S3, хранилище файлов для бизнеса и потребителей
услуги, а также стандартные протоколы передачи.
Rclone имеет мощные облачные эквиваленты команд unix rsync, cp,
mv, mount, ls, ncdu, tree, rm и cat. Знакомый синтаксис Rclone
включает поддержку конвейера оболочки и защиту --dry-run . это
используется в командной строке, в сценариях или через его API.
Пользователи называют rclone «швейцарским армейским ножом облачного хранилища» , и «Технология, неотличимая от магии» .
Rclone действительно заботится о ваших данных. Он сохраняет временные метки и
постоянно проверяет контрольные суммы. Переводы по ограниченной пропускной способности;
прерывистые соединения или в соответствии с квотами могут быть перезапущены из
последний хороший файл передан. Вы можете
проверьте целостность ваших файлов. Где
возможно, rclone использует передачу на стороне сервера, чтобы свести к минимуму локальные
использование полосы пропускания и переводы от одного провайдера к другому без
используя локальный диск.
Виртуальные серверные части обертывают локальные и облачные файловые системы для применения шифрование, сжатие, разбивка, хеширование и присоединение.
Rclone монтирует любые локальные, облачные или виртуальная файловая система в виде диска в Windows, macOS, linux и FreeBSD, а также обслуживает их через SFTP, HTTP, WebDAV, FTP и DLNA.
Rclone — это зрелое программное обеспечение с открытым исходным кодом, изначально вдохновленное rsync и написан на Go. Дружеская поддержка сообщество знакомо с различными вариантами использования. Официальная Ubuntu, Debian, Репозитории Fedora, Brew и Chocolatey. включить рклон. Для последних рекомендуется загрузка версии с rclone.org.
Rclone широко используется в Linux, Windows и Mac. Третье лицо
разработчики создают инновационное резервное копирование, восстановление, графический интерфейс и бизнес
обрабатывать решения с помощью командной строки rclone или API.
Rclone выполняет тяжелую работу по обмену данными с облачным хранилищем.
Что может сделать для вас rclone?
Rclone поможет вам:
- Резервное копирование (и шифрование) файлов в облачное хранилище
- Восстановление (и расшифровка) файлов из облачного хранилища
- Зеркалирование облачных данных в другие облачные службы или локально
- Перенос данных в облако или между поставщиками облачных хранилищ
- Подключить несколько зашифрованных, кэшированных или разнообразных облачных хранилищ в виде диска
- Анализ и учет данных, хранящихся в облачном хранилище, с использованием lsf, ljson, size, ncdu
- Объедините файловые системы вместе, чтобы представить несколько локальных и/или облачных файловых систем как одну
Особенности
- Трансферы
- Хэши MD5, SHA1 постоянно проверяются на целостность файлов
- Временные метки сохраняются в файлах
- Операции могут быть перезапущены в любое время
- Может быть в сеть и из сети, например. два разных облачных провайдера
- Можно использовать многопоточные загрузки на локальный диск
- Копировать новые или измененные файлы в облачное хранилище
- Синхронизировать (в одну сторону), чтобы сделать каталог идентичным
- Переместить файлы в облачное хранилище с удалением локального после проверки
- Проверить хэши и наличие отсутствующих/лишних файлов
- Смонтируйте облачное хранилище как сетевой диск
- Обслуживать локальные или удаленные файлы через HTTP/WebDav/FTP/SFTP/DLNA
- Экспериментальный графический веб-интерфейс
Поддерживаемые провайдеры
(Есть много других, построенных на стандартных протоколах, таких как WebDAV или S3, которые работают сразу после установки.)
- 1Фишье Главная Конфигурация
- Сетевое хранилище Akamai Главная Конфигурация
- Облачная система хранения объектов (OSS) Alibaba Cloud (Aliyun) Главная Конфигурация
- Amazon Drive (см. примечание) Главная Конфигурация
- Амазонка S3 Главная Конфигурация
- Бэкблейз B2 Главная Конфигурация
- Коробка Главная Конфигурация
- Цеф Главная Конфигурация
- China Mobile Ecloud Elastic Object Storage (EOS) Главная Конфигурация
- Облачное хранилище объектов Arvan (AOS) Главная Конфигурация
- Citrix ShareFile Главная Конфигурация
- С14 Главная Конфигурация
- Облачная вспышка R2 Главная Конфигурация
- DigitalOcean Spaces Главная Конфигурация
- Цифровое хранилище Главная Конфигурация
- Хозяин мечты Главная Конфигурация
- Дропбокс Главная Конфигурация
- Корпоративная файловая фабрика Главная Конфигурация
- FTP Главная Конфигурация
- Облачное хранилище Google Главная Конфигурация
- Гугл Диск Главная Конфигурация
- Google Фото Главная Конфигурация
- HDFS Главная Конфигурация
- Ящик для хранения Hetzner Главная Конфигурация
- ХайДрайв Главная Конфигурация
- HTTP Главная Конфигурация
- Хубик Главная Конфигурация
- Интернет-архив Главная Конфигурация
- Джоттаклауд Главная Конфигурация
- IBM COS S3 Главная Конфигурация
- IDrive e2 Главная Конфигурация
- Куфр Главная Конфигурация
- Облако Mail. ru Главная Конфигурация
- Memset Главная Конфигурация
- Мега Главная Конфигурация
- Память Главная Конфигурация
- Хранилище BLOB-объектов Microsoft Azure Главная Конфигурация
- Майкрософт OneDrive Главная Конфигурация
- Минио Главная Конфигурация
- Nextcloud Главная Конфигурация
- ОВХ Главная Конфигурация
- Опендрайв Главная Конфигурация
- OpenStack Swift Главная Конфигурация
- Облачное хранилище Oracle Главная Конфигурация
- ownCloud Главная Конфигурация
- pCloud Главная Конфигурация
- премиум. я Главная Конфигурация
- пут.ио Главная Конфигурация
- Цинстор Главная Конфигурация
- Облачные файлы Rackspace Главная Конфигурация
- rsync.net Главная Конфигурация
- Скейлуэй Главная Конфигурация
- Морской файл Главная Конфигурация
- Облако Seagate Lyve Главная Конфигурация
- ВодорослиFS Главная Конфигурация
- SFTP Главная Конфигурация
- Сиа Главная Конфигурация
- StackPath Главная Конфигурация
- Сторж Главная Конфигурация
- СахарСинк Главная Конфигурация
- Облачное хранилище объектов Tencent (COS) Главная Конфигурация
- Аптобокс Главная Конфигурация
- Васаби Главная Конфигурация
- WebDAV Главная Конфигурация
- Яндекс Диск Главная Конфигурация
- Зохо РабочийДрайв Главная Конфигурация
- Локальная файловая система Главная Конфигурация
Виртуальные провайдеры
Эти серверные части адаптируют или модифицируют других провайдеров хранения:
Главная Конфигурация- Домашняя страница
- Страница проекта GitHub для исходного кода и средства отслеживания ошибок
- Форум Rclone
- Скачано
Файлы конфигурации сервера | База знаний Altinity
Как управлять файлами конфигурации сервера в Clickhouse
Конфигурация сервера Clickhouse состоит из двух частей: настроек сервера (config. xml) и настроек пользователей (users.xml).
По умолчанию они хранятся в папке /etc/clickhouse-server/ в двух файлах config.xml и users.xml.
Мы рекомендуем никогда не изменять файлы конфигурации поставщика и помещать ваши изменения в отдельные файлы .xml в подпапках. Этот способ проще в обслуживании и упрощает обновление Clickhouse.
/etc/clickhouse-server/users.d — подпапка для пользовательских настроек.
/etc/clickhouse-server/config.d — подпапка для настроек сервера.
/etc/clickhouse-server/conf.d — подпапка для любых (обоих) настроек.
Имена ваших файлов xml могут быть произвольными, но они применяются в алфавитном порядке.
Примеры:
$ cat /etc/clickhouse-server/config.d/listen_host.xml <яндекс>:: $ cat /etc/clickhouse-server/config.d/macros.xml <яндекс> <макросы> <кластер>тест <реплика>хост22 <осколок>0 <идентификатор_сервера>41295host22. кошка /etc/clickhouse-server/config.d/zoo.xml <яндекс> <смотритель зоопарка> <узел> <хост>локальный <порт>2181 <распределенный_ddl>/clickhouse/test/task_queue/ddl кошка /etc/clickhouse-server/users.d/enable_access_management_for_user_default.xml <яндекс> <пользователи> <по умолчанию>1 кот /etc/clickhouse-server/users.d/memory_usage.xml <яндекс> <профили> <по умолчанию>252568 50580443136
Кстати, вы можете определить любой макрос в своей конфигурации и использовать его в путях Zookeeper
ReplicatedMergeTree('/clickhouse/{cluster}/tables/my_table','{replica}')
или в вашем коде с помощью функции getMacro:
СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ВИД srv_server_info
SELECT (SELECT getMacro('shard')) AS shard_num,
(ВЫБЕРИТЕ getMacro('имя_сервера')) КАК имя_сервера,
(ВЫБЕРИТЕ getMacro('server_id')) КАК server_key
Параметры могут быть добавлены в XML-дерево (поведение по умолчанию), заменены или удалены.
Пример удаления tcp_port и http_port , определенных на более высоком уровне в основном файле config.xml (отключает открытые порты tcp и http, если вы настроили безопасный ssl):
cat /etc/clickhouse-server/config. д/disable_open_network.xml <яндекс>
Пример замены раздела remote_servers , определенного на более высоком уровне в основном файле config.xml (это позволяет удалить тестовые кластеры по умолчанию.
<яндекс>
<удаленные_серверы заменить="1">
<мойкластер>
....
Настройки и перезагрузка
Общее «эмпирическое правило»:
- настройки сервера (
config.xmlиconfig.d) изменения требуют перезагрузки ; - настройки пользователя (
users.и xml users.d) изменения не требуют перезагрузки .
Но есть исключений из этих правил (см. ниже).
Разделы конфигурации сервера (config.xml), не требующие перезагрузки
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- 11111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111 (с 21. 11)
Те разделы (живут отдельными файлами):
-
<словари> -
<функции> -
<Модели>
См. Также https://github.com/clickhouse/clickhouse/blob/445b0ba7cc6b82e69fef28296981fbddc64cd634/programs/servervelvelvelvelvelvelvelvelvlestrevler.
Большинство изменений пользовательских настроек не требуют перезагрузки, но они применяются во время подключения, поэтому существующее подключение может по-прежнему использовать старые настройки на уровне пользователя. Это означает, что этот новый параметр будет применяться к новым сеансам / после повторного подключения.
The list of user setting which require server restart:
See also select * from system. settings where description ilike '%start%'
Также есть несколько «долгоиграющих» пользовательских сессий, которые практически никогда не перезапускаются и могут сохранять настройки от старта сервера (это DDLWorker, Kafka и некоторые другие сервисные штучки).
Словари
Мы предлагаем хранить описание каждого словаря в отдельном (собственном) файле в подпапке /etc/clickhouse-server/dict .
$ cat /etc/clickhouse-server/dict/country.xml
<словари>
<словарь>
страна
<источник>
...
и добавить в конфигурацию
$ cat /etc/clickhouse-server/config.d/dictionaries.xml <яндекс>dict/*.xml истина
dict/*.xml — относительный путь, серверы ищут файлы в папке /etc/clickhouse-server/dict . Больше информации в нескольких экземплярах Clickhouse.
вкл. атрибут и metrica.xml
вкл.
По умолчанию включает файл /etc/metrika.xml . Вы можете использовать множество включаемых файлов для каждого раздела XML.
Например, чтобы избежать повторения пользователя/пароля для каждого словаря, вы можете создать файл XML:
$ cat /etc/clickhouse-server/dict_sources.xml <яндекс><порт>3306 <пользователь>пользователь <пароль>123 <реплика> <хост>mysql_host <приоритет>1 моя_база данных
Включите этот файл:
$ cat /etc/clickhouse-server/config.d/dictionaries.xml <яндекс> .../etc/clickhouse-server/dict_sources.xml
И использовать в описаниях словарей ( incl=»mysql_config» ):
$ cat /etc/clickhouse-server/dict/country.страна <источник>... моя_таблица
выберите максимальное значение (id) из my_table
Несколько экземпляров Clickhouse на одном хосте
По умолчанию конфигурации сервера Clickhouse находятся в /etc/clickhouse-server/ , поскольку clickhouse-server запускается с параметром –config-file /etc/clickhouse-server/config.xml
конфигурационный файл определяется в сценариях запуска:
- /etc/init.d/clickhouse-server — init-V
- /etc/systemd/system/clickhouse-server.service — systemd
Clickhouse использует путь от параметр config-file как базовую папку и ищет другие конфиги по относительному пути. Все подпапки users.d/config.d относительные.
Вы можете запустить несколько clickhouse-server каждый со своим —config-file.
Например:
/usr/bin/clickhouse-server --config-file /etc/clickhouse-server-node1/config.xml /etc/clickhouse-server-node1/ config.xml ... users.xml /etc/clickhouse-server-node1/config.d/disable_open_network.xml /etc/clickhouse-server-node1/users.d/.... /usr/bin/clickhouse-server --config-file /etc/clickhouse-server-node2/config.xml /etc/clickhouse-server-node2/ config.xml ... users.xml /etc/clickhouse-server-node2/config.d/disable_open_network.xml /etc/clickhouse-server-node2/users.d/....
Если вам нужно запустить несколько серверов для целей CI, вы можете объединить все настройки в один толстый XML-файл и запустить ClickHouse без папок/подпапок конфигурации.
/usr/bin/clickhouse-server --config-file /tmp/ch2.xml /usr/bin/clickhouse-server --config-file /tmp/ch3.
Каждый экземпляр ClickHouse должен работать со своей папкой данных и tmp-папкой .
По умолчанию ClickHouse использует /var/lib/clickhouse/ . Его можно переопределить в настройках пути
/data/clickhouse-ch2/ /data/clickhouse-ch2/tmp/ /data/clickhouse-ch2/user_files/ <локальный_каталог>/data/clickhouse-ch2/access/ /data/clickhouse-ch2/format_schemas/
предварительно обработанные_конфигурации
Сервер Clickhouse следит за конфигурационными файлами и папками. Когда вы изменяете, добавляете или удаляете XML-файлы, Clickhouse немедленно собирает XML-файлы в комбинированный файл. Эти объединенные файлы хранятся в папках /var/lib/clickhouse/preprocessed_configs/.