
оптимизация — Как запретить индексацию всех страниц с определенным get-параметром в robots.txt?
Вопрос задан
Изменён 1 год 3 месяца назад
Просмотрен 891 раз
Яндекс пожаловался на то, что присутствует некоторое кол-во дубликатов страниц с get-параметром.
Ссылка на подобную страницу выглядит примерно так: site.ru/blog/article?layout=new Параметр всегда одинаков, но его значение меняется. Как запретить индексацию всех ссылок с layout=»»? Насколько правильным будет Disallow: *?*layout=
- оптимизация
- seo
- индексация
- robots.txt
Эта конструкция абсолютно верная:
Disallow: *?*layout=
Однако надо учитывать, что она запретит индексацию всех страниц, которые содержат параметр layout, независимо от его положения в списке параметров и наличия других параметров в адресе.
site.ru/blog/article?layout=new site.ru/blog/article?layout=old site.ru/blog/article?layout=old&author=Example site.ru/blog/article?page=1&layout=fashion site.ru/blog/article?page=2&layout=new&author=Example
1
Я делаю это через Clean-param: в robots.txt по двум причинам:
- Снижается нагрузка на сервер обхода.
- Если закрывать от индекса с помощью Disallow или тега noindex, тогда поисковики так же не будут индексировать и учитывать обратные ссылки на такие страницы. А если закрывать от индекса этим методом, тогда беклинки учтутся сайту.
Эти плюсы относятся только к Yandex!
А в Google получите ошибку в robots.txt, что-то не совмещаются в этом моменте. Но я ее игнорирую и всё нормально.
Для гугла, с моей точки зрения решать проблему таких дублей с помощью этого чудесного инструмента, почитайте, поймете все плюсы. А если не поймете, то лучше не трогайте!
А если не поймете, то лучше не трогайте!
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Файл Robots.
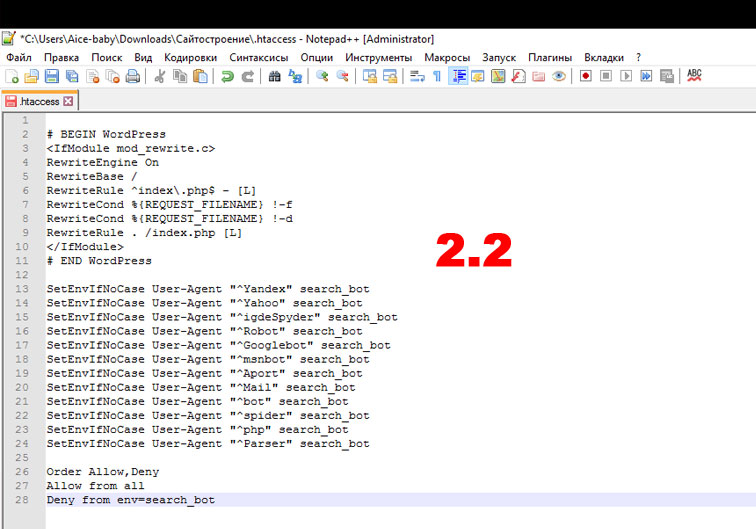 txt. Что это и зачем он нужен?
txt. Что это и зачем он нужен?- Главная страница
- Блог
- Поисковая оптимизация
- Файл Robots.txt. Что это и зачем он нужен?
5 лет назад
- Поисковая оптимизация
Файл robots.txt предназначен для хранения рекомендаций поисковым роботам с описанием адресов страниц и элементов, которые не требуется индексировать. Большинство таких программ следует определенному перечню. Но для полного запрета индексации необходимо использовать дополнительные меры – метатеги «noindex» и специальные атрибуты ссылок «nofollow».
Особенности файла robots.txt:
-
может быть только один;
-
хранится в корневом каталоге;
-
название строго robots.txt;
-
синтаксис рекомендаций соответствует стандартам.
Результатом нарушения этих правил станет игнорирование рекомендаций со стороны поискового робота. Индексация будет осуществляться согласно внутреннему алгоритму программы. Поэтому некоторые важные страницы могут быть отсканированы позже.
Поэтому некоторые важные страницы могут быть отсканированы позже.
Зачем скрывать отдельные страницы от поисковой индексации:
-
административные и вспомогательные файлы. Не несут смысловой нагрузки, загружают сервер;
-
страницы с идентичным контентом. Несколько страниц, содержащих одинаковые тексты, могут восприниматься поисковой системой, как спам. Это влечет бан;
-
Содержимое User-agent
Строка «User-agent» в robots.txt указывает название поискового робота, для которого запрещена индексация. Если необходимо сделать запрет для всех программ, пишется следующая строка:
User-agent: *
где «*» означает все поисковые роботы.
Строка «User-agent» – мощный инструмент. Если на сайте присутствует отдельная мобильная версия, можно запретить индексацию страниц, предназначенных для десктопа и содержащих аналогичный контент для мобильного поисковика. То же самое действует в обратном случае.
Строка «User-agent» начинает инструкции для каждого поисковика. Можно написать отдельные рекомендации для каждой поисковой системы, если это необходимо.
Содержимое «Disallow»
«Disallow» – команда, после которой отображается адрес страницы или запрещенного к индексации каталога. Правильное использование этого инструмента предоставит возможность оптимально направить поискового робота.
Хорошей практикой использования «Disallow» для большого количества хранящихся в одном каталоге файлов будет перемещение в другую папку вместо запрета каждого элемента отдельно. В данной инструкции можно указать конкретные адреса и специальные символы, предоставляющие возможность запрещать целые блоки линков с конкретными элементами в написании.
Противоположная по действию команда «Allow». Она показывает адрес, который необходимо проиндексировать. Практика использования этой инструкции ограничена, так как все незапрещенные для сканирования поисковым роботом страницы подпадают под индексацию.
Частный случай применения «Allow» – возможность указания отдельного файла для индексации, находящегося в закрытом каталоге (который указан в «Disallow»). Прибегать к подобному подходу рекомендуется, когда не получается перенести страничку за пределы запрещенной папки без потери структуры.
«Host» и «Sitemap»
Инструкция «Host» применяется исключительно для поисковой машины Яндекс. Она позволяет указывать основное зеркало ресурса с «www» или без него.
Команда «Sitemap» содержит правильный адрес файла с картой сайта. Это позволяет ускорить индексирование.
Поисковый робот первым проверяет файл robots.txt. Если он правильно составлен, сайт будет лучше сканироваться. Правильность его составления проверяется SEO-специалистами в ходе проведения поискового аудита сайта , технического и комплексного.
Правильность его составления проверяется SEO-специалистами в ходе проведения поискового аудита сайта , технического и комплексного.
Получить бесплатную консультацию
Давайте обсудим проект и мы бесплатно рассчитаем стоимость
Как исправить ошибку «Индексировано, хотя и заблокировано robots.txt» (2 метода)
Может быть обескураживающе видеть снижение рейтинга вашего сайта в поиске. Когда ваши страницы больше не сканируются Google, эти более низкие рейтинги могут привести к меньшему количеству посетителей и конверсий.
Ошибка «Проиндексировано, но заблокировано robots.txt» может означать проблему со сканированием вашего сайта поисковыми системами. Когда это происходит, Google проиндексировал страницу, которую не может просканировать. К счастью, вы можете редактировать свои robots.txt файл, указывающий, какие страницы следует или не следует индексировать.
В этом посте мы расскажем об ошибке «Проиндексировано, но заблокировано robots. txt» и как проверить ваш сайт на наличие этой проблемы. Затем мы покажем вам два разных метода исправления. Давайте начнем!
txt» и как проверить ваш сайт на наличие этой проблемы. Затем мы покажем вам два разных метода исправления. Давайте начнем!
Что такое ошибка «Проиндексировано, но заблокировано robots.txt»?
Как владелец веб-сайта, Google Search Console может помочь вам проанализировать эффективность вашего сайта во многих важных областях. Этот инструмент может отслеживать скорость страницы, безопасность и «сканируемость», чтобы вы могли оптимизировать свое присутствие в Интернете:
Google Search ConsoleНапример, отчет об индексировании Search Console может помочь вам улучшить поисковую оптимизацию вашего сайта (SEO). Он проанализирует, как Google индексирует ваш онлайн-контент, и вернет информацию о распространенных ошибках, таких как предупреждение «Проиндексировано, но заблокировано robots.txt»:
Отчет Google Search Console об индексе Чтобы понять эту ошибку, давайте сначала обсудим robots. txt файл. По сути, он информирует сканеры поисковых систем, какие файлы вашего веб-сайта должны или не должны быть проиндексированы. С хорошо структурированной robots.txt , вы можете убедиться, что сканируются только важные веб-страницы.
С хорошо структурированной robots.txt , вы можете убедиться, что сканируются только важные веб-страницы.
Если вы получили предупреждение «Проиндексировано, но заблокировано robots.txt», сканеры Google нашли страницу, но заметили, что она заблокирована в вашем файле robots.txt . Когда это происходит, Google не уверен, хотите ли вы проиндексировать эту страницу.
В результате эта страница может появиться в результатах поиска, но не будет отображать описание. Он также исключит изображения, видео, PDF-файлы и файлы, отличные от HTML. Поэтому вам необходимо обновить robots.txt файл, если вы хотите отобразить эту информацию.
Снижение рейтинга вашего веб-сайта в поисковых системах может обескураживать. 📉 Этот пост поможет 💪Нажмите, чтобы твитнутьПотенциальные проблемы при индексировании страниц
Вы можете намеренно добавить в файл robots.txt директивы, которые блокируют страницы от сканеров. Однако эти директивы не могут полностью удалить страницы из Google. Если внешний веб-сайт ссылается на страницу, это может вызвать ошибку «Проиндексировано, но заблокировано robots.txt».
Однако эти директивы не могут полностью удалить страницы из Google. Если внешний веб-сайт ссылается на страницу, это может вызвать ошибку «Проиндексировано, но заблокировано robots.txt».
Google (и другие поисковые системы) должны проиндексировать ваши страницы, прежде чем они смогут точно ранжировать их. Чтобы в результатах поиска отображался только релевантный контент, важно понимать, как работает этот процесс.
Хотя некоторые страницы должны быть проиндексированы, они могут быть не проиндексированы. Это может быть вызвано несколькими причинами:
- Директива в файле robots.txt , запрещающая индексирование
- Неработающие ссылки или цепочки переадресации
- Канонические теги в заголовке HTML
С другой стороны, некоторые веб-страницы не должны индексироваться. Они могут быть случайно проиндексированы из-за следующих факторов:
- Неправильные директивы noindex
- Внешние ссылки с других сайтов
- Старые URL в индексе Google
- Нет robots.
 txt файл
txt файл
 txt файл
txt файлЕсли проиндексировано слишком много ваших страниц, ваш сервер может быть перегружен поисковым роботом Google. Кроме того, Google может тратить время на индексацию нерелевантных страниц вашего сайта. Поэтому вам нужно будет создать и отредактировать robots.txt Файл правильный.
Поиск источника ошибки «Проиндексировано, но заблокировано robots.txt»
Одним из эффективных способов выявления проблем с индексированием страниц является вход в Google Search Console. После того, как вы подтвердите право собственности на сайт, вы сможете получить доступ к отчетам о его эффективности.
В разделе Index перейдите на вкладку Valid with warnings . Это откроет список ваших ошибок индексации, включая любые предупреждения «Проиндексировано, но заблокировано robots.txt». Если вы ничего не видите, скорее всего, на вашем сайте нет этой проблемы.
Кроме того, вы можете использовать тестер Google robots. txt. С помощью этого инструмента вы можете сканировать файл robots.txt на наличие синтаксических предупреждений и других ошибок:
txt. С помощью этого инструмента вы можете сканировать файл robots.txt на наличие синтаксических предупреждений и других ошибок:
Внизу страницы введите определенный URL-адрес, чтобы проверить, не заблокирован ли он. Вам нужно будет выбрать пользовательский агент из выпадающего меню и выбрать Тест :
Проверить заблокированный URL-адрес Вы также можете перейти к
Затем найдите операторы disallow. Администраторы сайтов могут добавлять эти утверждения, чтобы указать поисковым роботам, как получить доступ к определенным файлам или страницам.
Если оператор disallow блокирует все поисковые системы, это может выглядеть так:
Disallow: /
Также может блокироваться определенный пользовательский агент:
Пользовательский агент: * Disallow: /
С помощью любого из этих инструментов вы сможете выявить любые проблемы с индексацией вашей страницы.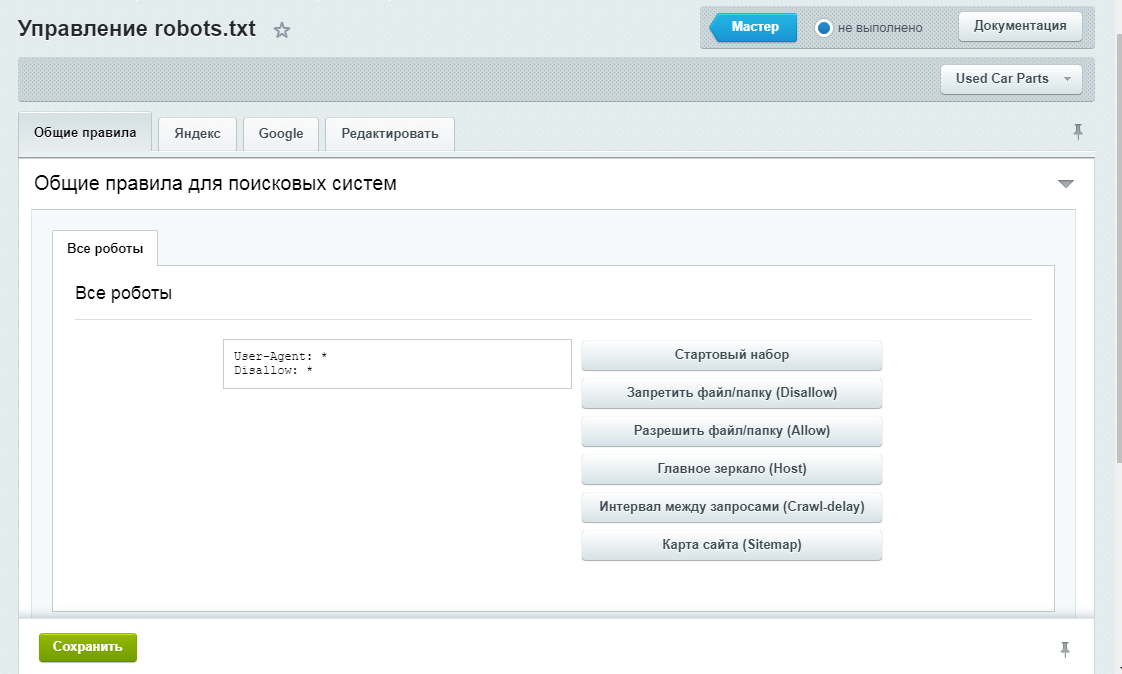 Затем вам нужно будет принять меры, чтобы обновить robots.txt файл.
Затем вам нужно будет принять меры, чтобы обновить robots.txt файл.
Как исправить ошибку «Проиндексировано, но заблокировано robots.txt»
Теперь, когда вы знаете больше о файле robots.txt и о том, как он может предотвратить индексирование страниц, пришло время исправить ошибку «Проиндексировано, хотя и заблокировано». по ошибке robots.txt». Однако перед использованием этих решений обязательно оцените, нужно ли индексировать заблокированную страницу.
Способ 1: отредактируйте robots.txt напрямую
Если у вас есть веб-сайт WordPress, у вас, вероятно, будет виртуальный0005 robots.txt файл. Вы можете посетить его, выполнив поиск domain.com/robots.txt в веб-браузере (заменив domain.com на ваше доменное имя). Однако этот виртуальный файл не позволит вам вносить изменения.
Разверните свое приложение в Kinsta. Начните с
кредита в размере 20 долларов США прямо сейчас.
Запустите свои приложения Node.js, Python, Go, PHP, Ruby, Java и Scala (или почти что угодно, если вы используете свои собственные Dockerfiles) за три простых шага!
Разверните сейчас и получите скидку 20 долларов на
Чтобы начать редактирование robots.txt , вам необходимо создать файл на своем сервере. Сначала выберите текстовый редактор и создайте новый файл. Обязательно назовите его «robots.txt»:
Создайте новый файл robots.txtЗатем вам нужно будет подключиться к SFTP-клиенту. Если вы используете учетную запись хостинга Kinsta, войдите в MyKinsta и перейдите на сайты > Информация :
Учетные данные для входа в MyKinsta SFTPЗдесь вы найдете свое имя пользователя, пароль, хост и номер порта. Затем вы можете загрузить SFTP-клиент, например FileZilla. Введите свои учетные данные для входа в SFTP и нажмите Quickconnect :
Подключитесь к FileZilla Наконец, загрузите файл robots. txt в корневой каталог (для сайтов WordPress он должен называться public_html ). Затем вы можете открыть файл и внести необходимые изменения.
txt в корневой каталог (для сайтов WordPress он должен называться public_html ). Затем вы можете открыть файл и внести необходимые изменения.
Вы можете использовать операторы allow и disallow для настройки индексации вашего сайта WordPress. Например, вы можете захотеть, чтобы определенный файл сканировался без индексирования всей папки. В этом случае вы можете добавить этот код:
Пользователь-агент: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
Не забудьте настроить таргетинг на страницу, вызывающую ошибку «Проиндексировано, но заблокировано robots.txt» во время этого процесса. В зависимости от вашей цели вы можете указать, должен ли Google сканировать страницу или нет.
Когда закончите, сохраните изменения. Затем вернитесь в Google Search Console, чтобы узнать, устранил ли этот метод ошибку.
Способ 2. Использование плагина SEO
Если у вас активирован плагин SEO, вам не нужно создавать совершенно новый файл robots. txt . Во многих случаях инструмент SEO создаст его для вас. Кроме того, он также может предоставлять способы редактирования файла, не выходя из панели управления WordPress.
txt . Во многих случаях инструмент SEO создаст его для вас. Кроме того, он также может предоставлять способы редактирования файла, не выходя из панели управления WordPress.
Yoast SEO
Одним из самых популярных SEO-плагинов является Yoast SEO. Он может предоставить подробный SEO-анализ на странице, а также дополнительные инструменты для настройки индексации вашей поисковой системой.
Чтобы начать редактирование файла robots.txt , перейдите в раздел Yoast SEO > Инструменты на панели управления WordPress. Из списка встроенных инструментов выберите Редактор файлов :
Выберите редактор файлов Yoast SEOYoast SEO не будет автоматически создавать файл robots.txt . Если у вас его еще нет, нажмите Создать файл robots.txt :
Создайте файл robots.txt с помощью Yoast SEO Откроется текстовый редактор с содержимым вашего нового файла robots.txt . Как и в первом методе, вы можете добавить операторы allow на страницы, которые хотите проиндексировать. В качестве альтернативы используйте операторы запрета для URL-адресов, чтобы избежать индексации:
Как и в первом методе, вы можете добавить операторы allow на страницы, которые хотите проиндексировать. В качестве альтернативы используйте операторы запрета для URL-адресов, чтобы избежать индексации:
После внесения изменений сохраните файл. Yoast SEO предупредит вас, когда вы обновите файл robots.txt .
Rank Math
Rank Math — еще один бесплатный плагин, который включает редактор robots.txt . После активации инструмента на вашем сайте WordPress перейдите к Rank Math > General Settings > Edit robots.txt :
Rank Math редактор robots.txtВ редакторе кода вы увидите некоторые правила по умолчанию, включая вашу карту сайта. Чтобы обновить его настройки, вы можете вставить или удалить код по мере необходимости.
В процессе редактирования необходимо соблюдать несколько правил:
- Используйте одну или несколько групп, каждая из которых содержит несколько правил.
- Начните каждую группу с пользовательского агента, а затем с определенными каталогами или файлами.
- Предположим, что любая веб-страница разрешает индексирование, если на ней нет запрещающего правила.

Имейте в виду, что этот метод возможен только в том случае, если у вас еще нет файла robots.txt в корневом каталоге. Если вы это сделаете, вам придется отредактировать robot.txt файл напрямую с помощью SFTP-клиента. Кроме того, вы можете удалить этот уже существующий файл и использовать вместо него редактор Rank Math.
После того, как вы запретите страницу в robots.txt , вы также должны добавить директиву noindex. Это защитит страницу от поиска Google. Для этого перейдите к Rank Math > Titles & Meta > Posts :
Настройки публикации Open Rank MathПрокрутите вниз до Post Robots Meta и включите его. Затем выберите Нет индекса :
Включить неиндексирование сообщений Наконец, сохраните изменения. В Google Search Console найдите предупреждение «Проиндексировано, но заблокировано robots.txt» и нажмите Проверить исправление . Это позволит Google повторно просканировать указанные URL-адреса и устранить ошибку.
В Google Search Console найдите предупреждение «Проиндексировано, но заблокировано robots.txt» и нажмите Проверить исправление . Это позволит Google повторно просканировать указанные URL-адреса и устранить ошибку.
Squirrly SEO
С помощью плагина Squirrly SEO вы можете аналогичным образом отредактировать robots.txt . Чтобы начать, нажмите Squirrly SEO > SEO Configuration . Это откроет Твики и карта сайта настройки:
Настройки карты сайта Squirrly SEOС левой стороны выберите вкладку Файл роботов . Затем вы увидите редактор файла robots.txt , похожий на другие плагины SEO:
Squirrly SEO файл robots.txt С помощью текстового редактора вы можете добавить операторы разрешения или запрета для настройки robots.txt файл. Продолжайте добавлять столько правил, сколько вам нужно. Когда вы будете довольны тем, как выглядит этот файл, выберите Сохранить настройки 9. 0006 .
0006 .
Кроме того, вы можете добавить правила noindex для определенных типов сообщений. Для этого вам просто нужно отключить параметр Разрешить индексировать Google на вкладке Автоматизация . По умолчанию SEO Squirrly оставит это включенным.
Не позволяйте этой надоедливой ошибке повлиять на ваш с трудом завоеванный поисковый рейтинг. 🙅♀️ Начните исправлять это с помощью этого руководства ✅Нажмите, чтобы твитнуть
Сводка
Как правило, Google находит ваши веб-страницы и индексирует их в результатах поиска. Однако плохо настроенный robots.txt может ввести поисковые системы в заблуждение относительно того, следует ли игнорировать эту страницу при сканировании. В этом случае вам нужно будет уточнить инструкции по сканированию, чтобы продолжить максимизировать SEO на вашем веб-сайте.
Вы можете редактировать robots.txt напрямую с помощью SFTP-клиента, такого как FileZilla. Кроме того, многие SEO-плагины, в том числе Yoast, Rank Math и Squirrly SEO, включают редакторы robots.txt в свои интерфейсы. Используя любой из этих инструментов, вы сможете добавлять разрешающие и запрещающие операторы, чтобы помочь поисковым системам правильно индексировать ваш контент.
Кроме того, многие SEO-плагины, в том числе Yoast, Rank Math и Squirrly SEO, включают редакторы robots.txt в свои интерфейсы. Используя любой из этих инструментов, вы сможете добавлять разрешающие и запрещающие операторы, чтобы помочь поисковым системам правильно индексировать ваш контент.
Чтобы помочь вашему веб-сайту подняться на вершину результатов поиска, мы рекомендуем выбрать веб-хостинг, оптимизированный для SEO. В Kinsta наши планы управляемого хостинга WordPress включают инструменты SEO, такие как мониторинг времени безотказной работы, SSL-сертификаты и управление перенаправлением. Ознакомьтесь с нашими планами на сегодня!
Получите все свои приложения, базы данных и сайты WordPress онлайн и под одной крышей. Наша многофункциональная высокопроизводительная облачная платформа включает в себя:
- Простая настройка и управление на панели инструментов MyKinsta
- Экспертная поддержка 24/7
- Лучшее оборудование и сеть Google Cloud Platform на базе Kubernetes для максимальной масштабируемости
- Интеграция Cloudflare корпоративного уровня для скорости и безопасности
- Глобальный охват аудитории за счет 35 центров обработки данных и более 275 точек присутствия по всему миру
Протестируйте сами со скидкой 20 долларов на первый месяц размещения приложений или баз данных. Ознакомьтесь с нашими планами или поговорите с отделом продаж, чтобы найти наиболее подходящий вариант.
Ознакомьтесь с нашими планами или поговорите с отделом продаж, чтобы найти наиболее подходящий вариант.
seo — Google: отключить определенную строку запроса в robots.txt
спросил
Изменено 9 лет, 3 месяца назад
Просмотрено 15 тысяч раз
http://www.site.com/shop/maxi-dress?colourId=94&optId=694 http://www.site.com/shop/maxi-dress?colourId=94&optId=694&product_type=sale
У меня есть тысячи URL-адресов, подобных приведенным выше. Различные комбинации и имена.
У меня также есть дубликаты этих URL-адресов, которые имеют строку запроса product_type=sale
I want to disable Google from indexing anything with product_type=sale
Is this possible in robots. txt
txt
- seo
- query-string
- google-search
- robot
1
Google поддерживает подстановочные знаки в файле robots.txt. Следующая директива в файле robots.txt запрещает роботу Googlebot сканировать любую страницу с любыми параметрами:
Запретить: /*?
Это не помешает многим другим поисковым роботам сканировать эти URL-адреса, поскольку подстановочные знаки не являются частью стандартного файла robots.txt.
Google может не сразу удалить заблокированные вами URL-адреса из поискового индекса. Дополнительные URL-адреса могут индексироваться в течение нескольких месяцев. Вы можете ускорить процесс, используя функцию «Удалить URL-адреса» в инструментах для веб-мастеров после того, как они были заблокированы. Но это ручной процесс, когда вам нужно вставить каждый отдельный URL-адрес, который вы хотите удалить.
Использование этого правила robots. txt также может повредить рейтингу вашего сайта в Google, если Googlbot не найдет версию URL без параметров. Если вы часто ссылаетесь на версии с параметрами, вы, вероятно, не хотите блокировать их в robots.txt. Было бы лучше использовать один из других вариантов ниже.
txt также может повредить рейтингу вашего сайта в Google, если Googlbot не найдет версию URL без параметров. Если вы часто ссылаетесь на версии с параметрами, вы, вероятно, не хотите блокировать их в robots.txt. Было бы лучше использовать один из других вариантов ниже.
Лучшим вариантом является использование метатега rel canonical на каждой из ваших страниц.
Таким образом, оба ваших примера URL-адресов будут иметь следующее в разделе заголовка:
Это указывает роботу Googlebot не индексировать так много вариантов страницы, а индексировать только «каноническую» версию выбранного вами URL-адреса. В отличие от файла robots.txt, робот Googlebot по-прежнему сможет сканировать все ваши страницы и присваивать им ценность, даже если они используют различные параметры URL.
Другой вариант — войти в Инструменты Google для веб-мастеров и использовать функцию «Параметры URL», которая находится в разделе «Сканирование».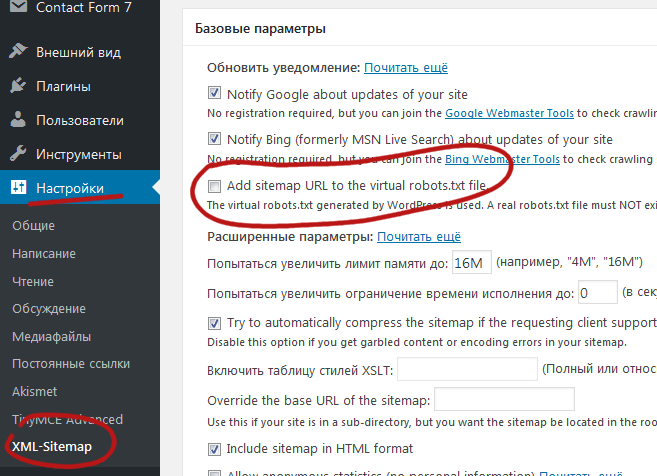
Оказавшись там, нажмите «Добавить параметр». Вы можете установить для product_type значение «Не влияет на содержимое страницы», чтобы Google не сканировал и не индексировал страницы с этим параметром.
Сделайте то же самое для каждого используемого параметра, который не изменяет страницу.
2
Да, это довольно просто сделать. Добавьте в файл robots.txt следующую строку:
.Запретить: /*product_type=sale
Предыдущий подстановочный знак (*) означает, что любые URL-адреса, содержащие product_type=sale , больше не будут сканироваться Google.
Хотя они могут по-прежнему оставаться в индексе Google, если они были там ранее, но Google больше не будет их сканировать, и при просмотре в поиске Google будет указано: Описание этого результата недоступно из-за файла robots.txt этого сайта. — учить больше.
Дальнейшее чтение здесь: Технические характеристики Robots.