
как использовать, примеры, все роботы Яндекса и Google
User-agent – это директива, указывающая, для какой поисковой системы и какого конкретно робота прописываются инструкции в файле robots.txt.
С данного правила начинается любой корректный Robots. Все боты при обращении к файлу проверяют записи, начинающиеся с User-Agent, где учитываются подстроки с названиями ботов поисковиков (Yandex, Google и пр.) либо «*».
На заметку.Если строки User-agent: *, User-agent: Yandex или User-agent: Google не указаны в файле, то по умолчанию робот считает, что никаких ограничений на индексацию у него нет.
Примеры использования директивы User-agent в robots.txt
Пример использования нескольких User-agent в robots.txt
Роботы Яндекс и Google
Примеры использования директивы User-agent в robots.txt
# Указывает инструкции для всех роботов всех поисковиков одновременно User-agent: *
# Указывает директивы для всех роботов Яндекса User-agent: Yandex
# Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot
# Указывает директивы для всех роботов Google User-agent: Googlebot
Если в файле задавать конкретного робота, то он будет следовать инструкциям, которые относятся только к нему.
Пример использования нескольких User-agent в robots.txt
# Правило указано для всех ботов Яндекса User-agent: Yandex Disallow: /*utm_ # Директива обращается ко всем роботам Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Данная инструкция лишь обращается к определенному поисковому роботу или всем роботам, а уже под директивой прописываются непосредственно команды для него/них.
Для корректной настройки файла Robots не стоит допускать пустые строки между директивами User-agent и Disallow, Allow, идущими в пределах одной директивы User-agent, к которой они относятся.
Пример некорректного отображения строк в файле Robots:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример корректного отображения строк в файле Robots:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видите, директории в роботсе делятся на блоки, и в
каждом из них прописываются указания для всех ботов или для определенного.
Роботы Яндекс и Google
У популярнейших поисковых систем присутствует большое количество роботов, и все они выполняют определенные функции. Благодаря robots.txt вы можете контролировать действия каждого из них. Но некоторые роботы держатся в секрете поисковыми системами. Ниже перечислены все публичные роботы Яндекса и Гугла с кратким описанием.
Роботы Яндекс:
- YandexBot. Это основной индексирующий робот Яндекса. Он работает с органической выдачей поисковика.
- YandexDirect. Робот, отвечающий за контекстную рекламу. Посещает сайты и оценивает их на основе того, в каком месте располагается контекстная реклама.
- YandexDirectDyn. Выполняет похожие функции, что и предыдущий бот, но с тем лишь отличием, что оценивает динамические объявления.
- YandexMedia. Индексирует мультимедийные файлы. Сканирует, загружает и оценивает видео, аудио.
- YandexImages.
 Обрабатывает изображения и контролирует раздел поисковика “Картинки”.
Обрабатывает изображения и контролирует раздел поисковика “Картинки”. - YandexNews. Новостной бот, отвечающий за раздел Яндекса “Новости”. Индексирует все, что связано с изданиями новостных сайтов.
- YandexBlogs. Занимается постами, комментариями, ответами и прочим контентом в блогах.
- YandexMetrika. Как понятно из названия, это робот Яндекс Метрики, анализирующей трафик сайтов и их поведенческие факторы.
- YandexPagechecker. Отвечает за распознание микроразметки на сайте и ее индексацию.
- YandexCalendar. Бот, индексирующий все, что связано с Календарем Яндекса.
- YandexMarket. Робот сервиса Яндекс.Маркет, добавляющий в индекс товары, описания к ним, цены и прочую информацию, полезную для Маркета.
 Обрабатывает изображения и контролирует раздел поисковика “Картинки”.
Обрабатывает изображения и контролирует раздел поисковика “Картинки”.Роботы Google:
- Googlebot. Это основной робот поискового гиганта, индексирующий главный текстовый контент страниц и обеспечивающий формирование органической выдачи.
- GoogleBot (Google Smartphone). Главный индексирующий бот Гугла для смартфонов и планшетов.
- Googlebot-News. Робот, индексирующий новостные публикации сайта.
- Googlebot-Video. Включает в поисковую выдачу видеофайлы.
- Googlebot-Image. Робот, занимающийся графическим контентом веб-ресурсов.
- AdsBot-Google. Проверяет качество целевых страниц – скорость загрузки, релевантность контента, удобство навигации и так далее.
- AdsBot-Google-Mobile-Apps. Оценивает качество мобильных приложений по тому же принципу, что и предыдущий бот.
- Mediapartners-Google. Робот контекстной рекламы, включающий сайт в индекс и оценивающий его для дальнейшего размещения рекламных блоков.
- Mediapartners-Google (Google Mobile AdSense). Аналогичный предыдущему бот, только отвечает за размещение релевантной рекламы для мобильных устройств.

Зачастую в файле Robots прописывают директории сразу для всех роботов поисковиков Google и Яндекс. Но для специфических задач оптимизаторы дают указания роботам разных поисковых систем отдельно.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Описание файла robots.txt с примерами
Яндекс: описание, валидатор
Google: описание, валидатор
1
Указывает для каких ботов будут действовать последующие правила.
User-agent: Googlebot Disallow: /category User-agent: * Disallow: /
TEXT
Недопустимы пустые строки между директивами User-agent
Disallow и Allow.Основные роботы поисковиков
Яндекс
| YandexBot | Основной робот |
| YandexImages | Яндекс. Картинки Картинки |
| YandexMedia | Мультимедийные данные |
| YandexNews | Яндекс.Новости |
| YandexBlogs | Поиск по блогам |
| YandexCalendar | Яндекс.Календарь |
| YandexDirect | Рекламная сеть |
| YandexMarket | Яндекс.Маркет |
| YandexMetrika | Яндекс.Метрика |
| Googlebot | Основной робот |
| Googlebot-Image | Изображения |
| Googlebot-Video | Видео |
| Mediapartners-Google | AdSense |
2
Директива запрещающая индексировать указанные адреса страниц.
Запретить GET параметр view:
Disallow: *view=*$
TEXT
Запретить все GET параметры:
Disallow: /*?
TEXT
Запретить http://example.com/page и все дочерние страницы:
Disallow: /page/
TEXT
Запретить страницу http://example.com/page, но не дочерние:
Disallow: /page/$
TEXT
Disallow: /*.php$
TEXT
Запретить индексирование pdf файлы:
Disallow: /*.pdf$
TEXT
Не индексировать UTM-метки:
Disallow: /*?utm_source*
TEXT
3
Разрешает индексирование страниц сайта, используется в основном в связке Disallow.
Например, следующая запись запрещает индексирование всего сайта кроме раздела http://example.. com/category
com/category
Allow: /category Disallow: /
TEXT
4
Директива задает интервал в секундах между загрузками страниц Яндексом. Эту директиву следует выносить в отдельный блок т.к. файл не пройдет валидацию в Google.
Например, задержка 5 сек:
User-agent: Yandex Crawl-delay: 5.0 User-agent: * ...
TEXT
5
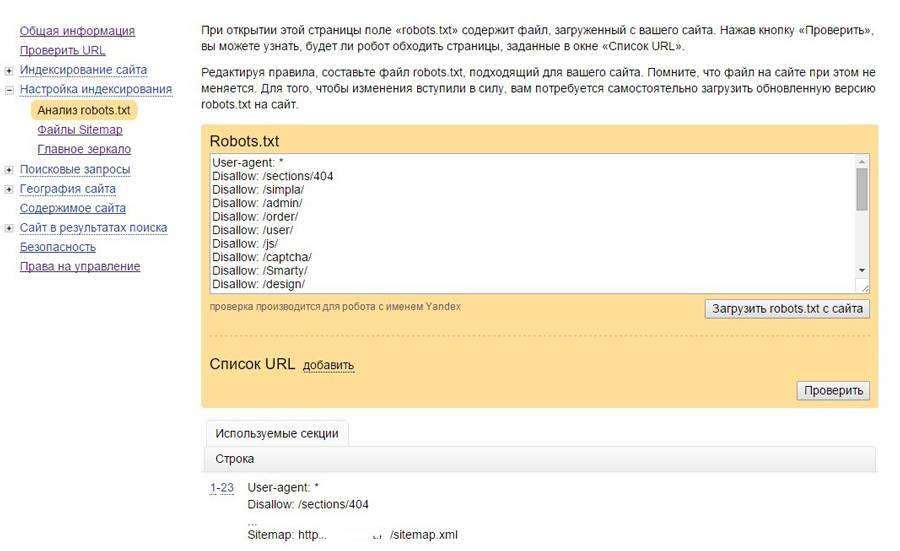
Чтобы не индексировать страницы с динамическими GET параметрами (сортировки, сессии и т.д.) Яндекс ввел директиву Clean-param которая сводит такие адреса к одному. Также директиву следует выносить в отдельный блок.
В robots.txt указывается имя GET переменной которая будет игнорироваться и через пробел адрес страницы которая будет использована.
Например для следующих адресов:
http://example.com/category
http://example.com/category?sort=asc
http://example. com/category?sort=desc
com/category?sort=desc
Запись будет следующая:
User-agent: Yandex Clean-param: sort /category
TEXT
Можно указать несколько GET переменных через символ &:
User-agent: Yandex Clean-param: sort&session /category
TEXT
6
Указывает основное зеркало сайта.
Host: example.com
TEXT
Основное зеркало с www:
Host: http://www.example.com
TEXT
Если сайт работает на https:
Host: https://example.com
TEXT
С апреля 2018 года Яндекс прекратил поддержку директивы Host, Google эту директиву никогда не поддерживал.
7
Карта сайта – файл sitimap.xml
Sitemap: http://example.com/sitemap.xml
TEXT
- Кодировка файла должна быть в UTF-8.
- Максимальное количество ссылок – 50 000
Можно указать несколько файлов:
Sitemap: http://example.com/sitemap.xml Sitemap: http://example.com/sitemap-2.xml Sitemap: http://example.com/sitemap-3.xml
TEXT
8
User-agent: * Disallow: /search Disallow: /themes Disallow: /plugins Sitemap: http://example.com/sitemap.xml
TEXT
Крошечный файл веб-сайта, который может улучшить или сломать вашу SEO
Когда моя стиральная машина перестала работать около месяца назад, я перепробовал все, чтобы исправить это.
Запустил дополнительную стирку, почистил барабан, повторил.
Но когда я пошел опустошить фильтр с помощью моей тети, нам удалось это сделать только после того, как мы нашли монету в 2 евро.
С его помощью нам удалось открыть дверцу фильтра и навсегда ее опустошить.
Эта монетка спасла меня и мою стиральную машину.
Файл robots.txt влияет на поисковую оптимизацию точно так же, как эта маленькая монета оказала огромное влияние на то, что моя стиральная машина снова заработала.
Robots.txt — это крошечный текстовый файл, расположенный в корневой папке вашего веб-сайта, и он может иметь огромное значение для вашего SEO в целом.
Жаль, что иногда веб-хостинги не создают файл robots.txt по умолчанию.
Но вы все равно можете создать (и оптимизировать) его самостоятельно.
Это руководство предназначено именно для этого — от основ SEO-оптимизации robots.txt до технических деталей, которые легко понять.
Погружаемся!
Знакомство с файлом Robots.txt
Практически файл robots.txt — это то, что вы видите ниже — небольшой текстовый файл, расположенный в корневом каталоге вашего веб-сайта:
В трех строках указано:
- User-agent , с которым вы хотите работать
- a Запретить поле, чтобы указать поисковым роботам и сканерам, что не сканировать
- и Разрешить поле , чтобы они знали, что сканировать вместо
Синтаксис прост:
После каждого имени поля (или директивы) вы добавляете двоеточие, за которым следует значение, которое должны учитывать роботы.
В именах полей регистр не учитывается, а в именах значений — нет. Так, например, если ваша папка называется «/My-Work/», вы не можете указать «/my-work/» в файле robots.txt.
Не работает корректно.
Позвольте мне более подробно объяснить поля и значения файла robots.txt ниже.
Агент пользователяВ этом поле указывается, с каким агентом пользователя мы хотим работать. На языке robots.txt пользовательский агент — это робот-паук или поисковый робот.
Синтаксис:
Агент пользователя: (значение)
Например, если бы я хотел, чтобы последующие правила (значения) применялись к всем агентам пользователя, я бы ввел следующее:
User-agent: *
А если бы я хотел сказать, что правила применяются к конкретному агенту, то это выглядело бы так (заменив «AgentName» на имя юзер-агента, с которым вы хотите работать) :
User-agent: AgentName
Примеры часто используемых пользовательских агентов для поисковых систем и социальных сетей:
- Googlebot
- Googlebot-Изображения
- Бингбот
- Slurp (сканер Yahoo!)
- УткаУткаБот
- ЯндексБот
- Байдуспайдер
- ЯндексБот
- Facebot (краулер Facebook)
- Twitterbot (краулер Twitter)
- ia_archiver (сканер Alexa)
Здесь вы можете найти полный список пользовательских агентов, используемых Google.
Disallow — это директива черного списка в языке robots.txt.
Основное использование:
Агент пользователя: * Disallow:
Простое написание «Disallow:» без указания значения означает, что вы хотите, чтобы все роботов сканировали ваш сайт.
С другой стороны, если вы не хотите, чтобы роботы вообще сканировали ваш сайт (даже небольшую его часть), введите:
Агент пользователя: * Запретить: /
Вы также можете использовать поле «Запретить», если хотите, чтобы боты сканировали весь ваш веб-сайт минус один или несколько определенных файлов или областей.
Например:
Агент пользователя: Googlebot Разрешить: /public.jpg Disallow: /private.jpg
Allow
Директива robots.txt о внесении в белый список!
Это хороший способ сообщить роботам, что вы хотите, чтобы один или несколько определенных файлов сканировались, когда они расположены в области вашего сайта, которую вы ранее запретили другим правилом.
Например, вам может понадобиться, чтобы робот Googlebot сканировал только одно изображение в частной области вашего сайта, но не сканировал остальную часть частной области.
Чтобы выполнить это намерение, вы можете использовать следующий синтаксис:
Агент пользователя: Googlebot Запретить: /частное/ Разрешить: /private/the-only-image-you-can-see.jpg
Комментарии и длина файла robots.txt
Чтобы добавить комментарий к файлу robots.txt, просто поместите символ решетки (#) перед строкой, которую вы пишете.
Например:
# Это правило запрещает Bingbot сканировать каталог моего блога. Агент пользователя: Bingbot Disallow: /blog/
Файл robots.txt может быть любой длины, максимальный размер не установлен.
Хотите взглянуть на Google?
(Возможно, вам придется немного прокрутить страницу.)
Как robots.txt может помочь вам в SEO-оптимизации
Как я упоминал ранее, файл robots. txt может сильно повлиять на SEO. В частности, это влияет на индексацию страниц и индексацию других типов содержимого (например, мультимедиа и изображений).
txt может сильно повлиять на SEO. В частности, это влияет на индексацию страниц и индексацию других типов содержимого (например, мультимедиа и изображений).
Вот как вы можете использовать файл robots.txt для улучшения результатов SEO.
Использование «User-agent» для SEOКак вы видели, когда вы пишете поле User-agent, у вас есть возможность применить определенные правила ко всем поисковым системам и сканерам (со звездочкой *), или к одиночным роботам.
Или и то, и другое, если вы хотите обрабатывать сочетание различных вариантов поведения.
Взгляните на этот пример с одного из моих веб-сайтов:
Здесь я хотел исключить Google Images из индексации моих изображений после того, как узнал, что некоторые из моих работ с этого и подобного веб-сайта были удалены много лет назад. Я также хотел запретить поисковому роботу Alexa сканировать мой сайт.
Я применил это решение по SEO и управлению репутацией к файлу robots. txt, просто записав пользовательские агенты Google Images и Alexa и применив правило Disallow к ним обоим, по одному на строку.
txt, просто записав пользовательские агенты Google Images и Alexa и применив правило Disallow к ним обоим, по одному на строку.
Как оптимизатор, вы знаете, в каких поисковых системах (или частях поисковых систем) вы хотите появляться по какой-либо причине.
Robots.txt позволяет указать веб-службам, что вы разрешаете, а что нет, де-факто определяя, как ваш сайт отображается (или не отображается) на каждой платформе.
Другое распространенное применение этого поля — когда вы не хотите, чтобы Wayback Machine (Archive.org) сохраняла снимки вашего веб-сайта.
Добавив эти две строки в файл robots.txt:
Агент пользователя: archive.org_bot Запретить: /
Вы можете запретить интернет-архиву сканирование и создание снимков вашего веб-сайта.
Использование директив «Запретить» и «Разрешить» для SEO Директивы «Запретить» и «Разрешить» — это мощные инструменты, указывающие поисковым системам и инструментам веб-майнинга, что именно следует сканировать и индексировать.
До сих пор вы видели, как использовать их для исключения (или включения) файлов и папок из сканирования и индексирования. Если вы используете эти директивы правильно, вы можете оптимизировать свой краулинговый бюджет, чтобы исключить дубликаты страниц и служебных страниц, которые вы не хотите ранжировать в поисковой выдаче (например, страницы благодарности и страницы транзакций).
Вот как я сделал бы это для страницы благодарности:
Агент пользователя: Googlebot Disallow: /thank-you-for-buying-heres-your-guide/
(Черт возьми, представляете, сколько продаж вы можете потерять, если такая страница будет проиндексирована?)
Опасности невнимательности of Your Robots.txt
В тематическом исследовании для Search Engine Land Гленн Гейб сообщает, как плохо написанный файл robots.txt компании привел к утечке URL-адресов и выпадению индекса.
Плохие вещи, которых точно не хочется!
Рассматриваемая компания столкнулась с проблемой чувствительности к регистру при запрете папок категорий («/CATEGORY/» вместо «/Category/») и запретила весь свой веб-сайт, используя «Disallow: /» вместо «Disallow: ” (без косой черты в конце).
Поскольку заблокированные URL-адреса не исчезают полностью, а из-за медленной утечки, компания стала свидетелем снижения их рейтинга в течение определенного периода времени.
Гейб также написал длинную статью о том, что произошло, когда другая компания по ошибке запретила весь свой сайт.
Легко понять, что регулярный аудит (и надлежащее обслуживание) вашего файла robots.txt для SEO имеет решающее значение для предотвращения таких катастрофических проблем.
Хитрости Robots.txt для SEO и безопасности файлов
В дополнение к основному использованию robots.txt вы можете реализовать еще несколько хаков, которые помогут поддержать и улучшить вашу SEO-стратегию.
Добавление правила Sitemap в файл robots.txtВы можете добавить карту сайта в файл robots.txt — даже больше одной!
На снимке экрана ниже показано, как я сделал это для своего бизнес-сайта:
Я добавил три карты сайта, одну для моего основного сайта и две для дочерних сайтов (блогов), которые я хочу учитывать как часть основного сайта.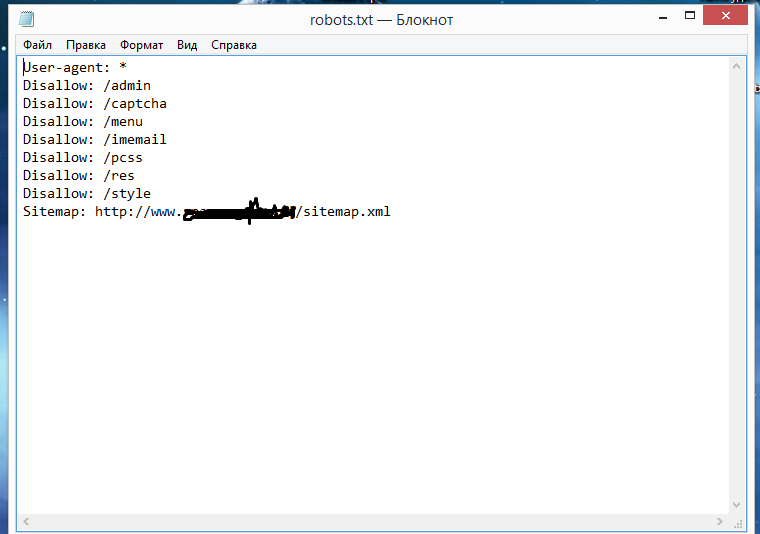
Хотя добавление карты сайта в файл robots.txt не гарантирует улучшения индексации сайта, это сработало для некоторых веб-мастеров, так что стоит попробовать!
Скройте файлы, которые вы не хотите, чтобы поисковые системы или пользователи виделиЭто может быть электронная книга в формате .PDF, которую вы продаете в своем блоге только для самых преданных читателей.
Или это может быть страница только для подписчиков, которую вы не хотите, чтобы простые смертные получили в свои руки.
Или устаревшая версия файла, которую вы больше не хотите находить, кроме как через частный обмен.
Какой бы ни была причина нежелания публиковать файл, вы должны помнить это правило здравого смысла:
Хотя поисковые системы будут игнорировать страницу или файл, указанные в файле robots.txt, пользователи-люди этого не сделают.
Пока они могут загрузить файл robots.txt в свой браузер, они могут читать ваши заблокированные URL-адреса, копировать и вставлять их в свой браузер и получать к ним полный доступ.
Итак, когда дело доходит до robots.txt, SEO и обычного использования недостаточно. Вы также должны следить за тем, чтобы пользователи-люди держали руки подальше от конфиденциальных материалов, которые вы доверили файлу robots.txt для защиты от поисковых систем!
Теперь вопрос: Как вы это делаете?
Я рад сообщить вам, что для этого нужно всего три шага:
1. Создайте специальную папку для ваших секретных файлов
2. Добавьте защиту индекса в эту папку (чтобы никто не мог просматривать ее содержимое)
3 Добавьте правило Disallow в эту папку (не в файлы в ней, потому что они наследуют это правило)
Приступим к практическому применению.
Шаг 1. Создайте папку для секретных файлов
Сначала войдите в панель администрирования вашего веб-сайта и откройте файловый менеджер, который поставляется вместе с ним (например, файловый менеджер в Cpanel). В качестве альтернативы вы можете использовать настольный FTP-клиент, такой как FileZilla.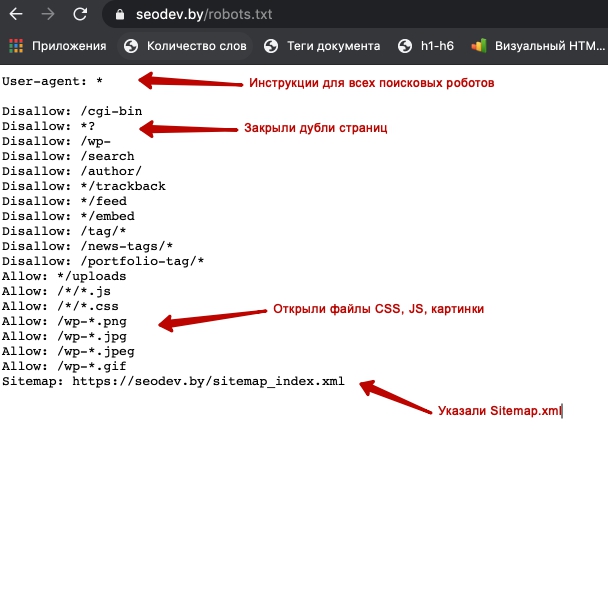
Вот как я создал папку «/secret-folder/» на своем веб-сайте с помощью файлового менеджера cPanel:
Шаг 2. Добавьте защиту индекса к папке
Во-вторых, вам необходимо добавить защиту индекса этой папки.
Если вы используете WordPress, вы можете защитить все папки по умолчанию, загрузив и активировав бесплатный плагин Protect Uploads из репозитория.
Во всех остальных случаях, в том числе если вы хотите защитить только эту папку, вы можете использовать два метода (следуя моему примеру выше):
A. .htaccess 403 Error Method
Создать новый .htaccess файл в папке «/secret-folder/» и добавьте в него эту строку:
Options -Indexes
Эта строка указывает браузерам запретить просмотр файлов каталогов.
Если это не работает на вашем веб-сервере, используйте:
Запретить все
вместо этого.
B. Метод файла index.html
Создайте index.html (или default.html) в папке «/secret-folder/».
Этот файл должен быть пустым или содержать небольшую строку текста, чтобы напомнить пользователям, которые просматривают, что этот каталог недоступен (например, «Прочь. Здесь личные вещи!»).
Шаг 3. Добавьте правило запрета в папку
В качестве третьего и последнего действия вернитесь к файлу robots.txt в корневом каталоге веб-сайта и запретите всю папку.
Например:
Агент пользователя: * Disallow: /secret-folder/
И готово!
Как видите, оптимизация robots.txt не тратит ваше время на второстепенный SEO-фактор.
Ваш файл robots.txt может показаться таким же маленьким и незначительным, как монета, которую я использовал, чтобы «починить» свою стиральную машину, но он может быть таким же мощным и важным для хорошей репутации вашего сайта в поисковых системах.
Так что береги его!
robots.
 txt недействителен — Разработчики Chrome
txt недействителен — Разработчики Chrome Файл robots.txt сообщает поисковым системам, какие страницы вашего сайта они могут сканировать. Недопустимая конфигурация robots.txt может вызвать два типа проблем:
- Она может помешать поисковым системам сканировать общедоступные страницы, в результате чего ваш контент будет реже отображаться в результатах поиска.
- Поисковые системы могут сканировать страницы, которые вы не хотите показывать в результатах поиска.
# Как не проходит аудит Lighthouse
robots.txt Lighthouse помечает недействительные файлы robots.txt :
Большинство аудитов Lighthouse применяются только к той странице, на которой вы сейчас находитесь. Однако, поскольку robots.txt определяется на уровне имени хоста, этот аудит применяется ко всему вашему домену (или поддомену).
Разверните robots.txt недопустимый аудит в своем отчете, чтобы узнать, что не так с вашим robots. . txt
txt
Common errors include:
-
No user-agent specified -
Pattern should either be empty, start with "/" or "*" -
Unknown directive -
Invalid sitemap URL -
$ следует использовать только в конце шаблона
Lighthouse не проверяет правильность расположения файла robots.txt . Для корректной работы файл должен находиться в корневом каталоге вашего домена или поддомена.
Каждый SEO-аудит имеет одинаковый вес в рейтинге Lighthouse SEO Score, за исключением , проведенного вручную. Структурированные данные действительны. аудит. Узнайте больше в Руководстве по подсчету очков Lighthouse.
# Как исправить проблемы с
robots.txt # Убедитесь, что
robots.txt не возвращает код состояния HTTP 5XX Если ваш сервер возвращает ошибку сервера (код состояния HTTP в 500-х) для robots. поисковые системы не будут знать, какие страницы следует сканировать. Они могут перестать сканировать весь ваш сайт, что предотвратит индексацию нового контента. txt
txt
Чтобы проверить код состояния HTTP, откройте robots.txt в Chrome и проверьте запрос в Chrome DevTools.
# Сохранить файл
robots.txt меньше 500 КиБ Поисковые системы могут прекратить обработку robots.txt на полпути, если файл больше 500 КиБ. Это может сбить с толку поисковую систему, что приведет к некорректному сканированию вашего сайта.
Чтобы файл robots.txt был небольшим, уделяйте меньше внимания отдельно исключенным страницам и больше — более широким шаблонам. Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf с помощью disallow: /*.pdf .
# Исправление любых ошибок формата
- В
robots.разрешены только пустые строки, комментарии и директивы, соответствующие формату «имя:значение». txt - Убедитесь, что значения
разрешитьизапретитьлибо пусты, либо начинаются с/или*. - Не используйте
$в середине значения (например,allow: /file$html).
 txt
txt # Убедитесь, что для
user-agent имен агентов пользователя задано значение, чтобы сообщать сканерам поисковых систем, каким директивам следовать. Вы должны указать значение для каждого экземпляра агента пользователя , чтобы поисковые системы знали, следует ли следовать соответствующему набору директив.
Чтобы указать конкретный поисковый робот, используйте имя пользовательского агента из его опубликованного списка. (Например, вот список пользовательских агентов Google, используемых для сканирования.)
Использовать * , чтобы соответствовать всем другим поисковым роботам, которым нет равных.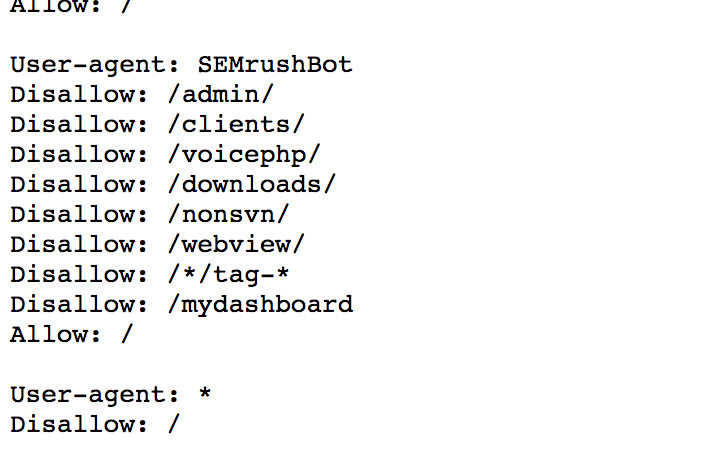
Не делать
пользовательский агент:
запретить: /downloads/
Пользовательский агент не определен.
Do
пользовательский агент: *
disallow: /downloads/пользовательский агент: magicsearchbot
disallow: /uploads/
Определены обычный пользовательский агент и magicsearchbot пользовательский агент.
# Убедитесь, что нет директив
allow или disallow до user-agent Имена агентов пользователя определяют разделы вашего файла robots.txt . Сканеры поисковых систем используют эти разделы, чтобы определить, каким директивам следовать. Размещение директивы перед именем первого пользовательского агента означает, что никакие поисковые роботы не будут ей следовать.
Не
# начало файла
disallow: /downloads/user-agent: magicsearchbot
allow: /
Поисковый робот не прочитает директиву disallow: /downloads .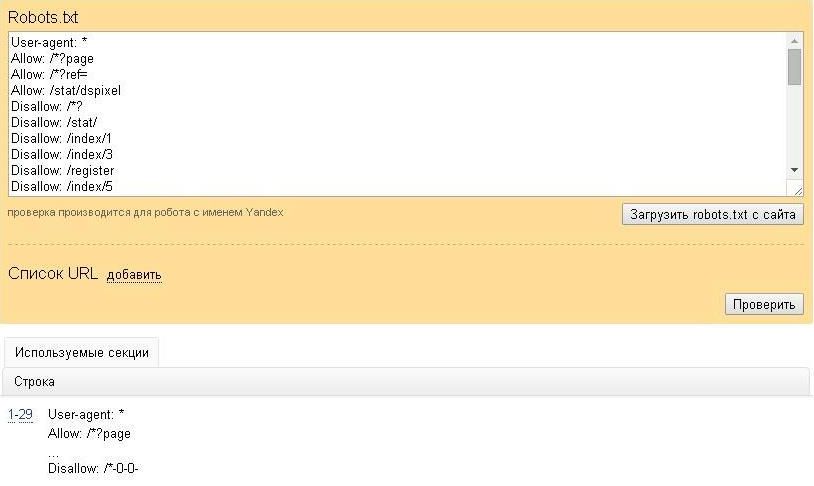
Do
# начало файла
user-agent: *
disallow: /downloads/
Всем поисковым системам запрещено сканировать папку /downloads .
Сканеры поисковых систем следуют директивам только в разделе с наиболее конкретным именем пользовательского агента. Например, если у вас есть директивы для user-agent: * и user-agent: Googlebot-Image , Googlebot Images будет следовать только директивам в user-agent: Googlebot-Image 9раздел 0410.
# Укажите абсолютный URL-адрес для
карты сайта Файлы карты сайта — отличный способ сообщить поисковым системам о страницах вашего сайта. Файл карты сайта обычно включает в себя список URL-адресов на вашем веб-сайте вместе с информацией о том, когда они были в последний раз изменены.
Если вы решите отправить файл карты сайта в robots.txt , обязательно используйте абсолютный URL-адрес.
Не делать
Карта сайта: /sitemap-file.
