
Содержание статьи
Вы знаете, насколько важна индексация — это основа основ в продвижении сайтов. Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Индексация сайта — это процесс, в ходе которого страницы вашего сайта попадают в Яндекс, Гугл или другой поисковик. И после этого пользователь может найти страницу вашего сайта по какому-нибудь запросу.
Управляете вы такой важной штукой, как индексация, именно посредством файла robots.txt. Начну с азов.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате .txt, который сможет открыть даже компьютер вашего деда.
Вот видос от Яндекса:
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
User-agent: * Allow: /
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.

Это корневой каталог, и в нем лежит роботс.
Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего нужен этот файл
А вот для чего:
- запрета на индексацию мусора — страниц и разделов, которые не содержат в себе полезный контент;
- разрешение индексации нужных страниц и разделов;
- чтобы давать разные задачи роботам разных поисковиков — то есть, например, Яндексу разрешить индексировать всё, а Рамблеру — ничего;
- можно также задавать роботам разные категории. Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
- чтобы показать через директиву Host Яндексу, какое у сайта главное зеркало;
- еще некоторые вебмастера запрещают всяким нехорошим парсерам сканировать сайт с помощью этого файла;
То есть большую часть проблем по индексации он решает. Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Как работают поисковые роботы и как они обрабатывают данный файл
В большинстве случаев, очень упрощенно, они работают так:
- Обходят Интернет;
- Проверяют, какие документы разрешено индексировать, а какие запрещено;
- Включает разрешенные документы в базу;
- Затем уже другие механизмы решают, какие страницы достаточно полезны для включения в индекс.
Вот ссылка на справку Яндекса о работе поисковых роботов, но там все довольно отдаленно описано.
Справка Google свидетельствует: robots – рекомендация. Файл создается для того, чтобы страница не добавлялась в индекс поисковой системы, а не чтобы она не сканировалась поисковыми системами. Гугл позволяет запрещенной странице попасть в индекс, если на нее направляется ссылка внутри ресурса или с внешнего сайта.
По-разному ли Яндекс и Google воспринимают этот файл
Многие прописывают для роботов разных поисковиков разные директивы. Даже если список этих директив ничем не отличается.
Наверное, это для того, чтобы выразить уважение к Господину Поисковику. Как там раньше делали — «великий князь челом бьет… и просит выдать ярлык на княжение». Других соображений по поводу того, зачем разным юзер-агентам прописывают одни и те же директивы, у меня нет, да и вебмастера, так делающие, дать нормальных объяснений своим действиям не могут.
А те, кто может ответить, аргументируют это так: мол, Google не воспринимает директиву Host и поэтому её нужно указывать только для Яндекса, и вот почему, мол, для яндексовского юзер-агента нужны отдельные директивы. Но я скажу так: если какой-то робот не воспринимает какую-то директиву, то он её просто проигнорирует. Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Чем может грозить неправильно составленный роботс
Некоторые при создании сайта на WordPress ставят галочку, чтобы система закрывала сайт от индексации (и забывают потом убрать её). Тогда Вордпресс автоматом ставит вам такой роботс, чтобы поисковики не включали ваш сайт в индекс, и это — самая страшная ошибка. Те страницы, на которые вы намерены получать трафик, обязательно должны быть открыты для индексации.
Потом, если вы не закрыли ненужные страницы от индексации, в индекс может попасть, как я уже говорил выше, очень много мусора (ненужных страниц), и они могут занять в индексе место нужных страниц.
Вообще, если вкратце, неправильный роботс грозит вам тем, что часть страниц не попадет в поиск и вы лишитесь части посетителей.
Как создать файл robots.txt
В Блокноте или другом редакторе создаем файл с расширением .txt, чтобы он в итоге назывался robots.txt. Заполняем его правильно (дальше расскажу, как) и загружаем в корень сайта. Готово!
Вот тут разработчик сайта Loftblog создает файл с нуля в режиме реального времени и делает настройку роботс:
Пример правильного robots.txt для WordPress
Составить правильный robots.txt для сайта WordPress проще всего. Я сам видел очень много таких роботсов (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Host: znet.ru User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Sitemap: https://znet.ru/sitemap.xml
Этот роботс для WordPress довольно проверенный. Большую часть задач он выполняет — закрывает версию для печати, файлы админки, результаты поиска и так далее.
«Универсальный» роботс
Если вы ищете какое-то решение, которое подойдет для всех сайтов на всех CMS (или для лендинга), «волшебную таблетку» — такой нет. Для всех CMS одинаково хорошо подойдет лишь решение, при котором вы говорите разрешить все для индексации:
User-agent: * Allow: /
В остальном — нужно отталкиваться от системы, на которой написан ваш сайт. Потому что у каждой из них уникальная структура и разные разделы/служебные страницы.
Роботс для Joomla
Joomla — ужасный движок, вы ужасный человек, если до сих пор им пользуетесь. Дублей страниц там просто дофига. В основном нормально работает такой код (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: https://znet.ru/sitemap.xml User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
Но я вам настоятельно советую отказаться от этого жестокого движка и перейти на WordPress (а если у вас интернет-магазин — на Opencart или Bitrix). Потому что Joomla — это жесть.
Robots для Битрикса
Как составить robots.txt для Битрикс (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php Disallow: /e-store/affiliates/ Disallow: /club/$ Disallow: /club/messages/ Disallow: /club/log/ Disallow: /content/board/my/ Disallow: /content/links/my/ Disallow: /*/search/ Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?print= Disallow: /*&print= Disallow: /*register=yes Disallow: /*forgot_password=yes Disallow: /*change_password=yes Disallow: /*login=yes Disallow: /*logout=yes Disallow: /*auth=yes Disallow: /*action=ADD_TO_COMPARE_LIST Disallow: /*action=DELETE_FROM_COMPARE_LIST Disallow: /*action=ADD2BASKET Disallow: /*action=BUY Disallow: /*print_course=Y Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*index.php$ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
Как правильно составить роботс
У каждой поисковой системы есть свой User-Agent. Когда вы прописываете юзер-эйджент, то вы обращаетесь к какой-то определенной поисковой системе. Вот названия ботов поисковых систем:
Google: Googlebot
Яндекс: Yandex
Мэйл.ру: Mail.Ru
Yahoo!: Slurp
MSN: MSNBot
Рамблер: StackRambler
Это основные, которые включают ваш сайт в текстовые индексы поисковиков. А вот их вспомогательные роботы:
Googlebot-Mobile — это юзер-агент для мобильных
Googlebot-Image — это для картинок
Mediapartners-Google — этот робот сканирует содержание обьявлений AdSense
Adsbot-Google — это для качества целевых страниц AdWords
MSNBot-NewsBlogs – это для новостей MSN
Сначала в любом нормальном роботсе идет указание юзер-агента, а потом директивы ему. Юзер-агента мы указываем в первой строке, вот так:
User-agent: Yandex
Это будет обращение к роботу Яндекса. А вот обращение ко всем роботам всех систем сразу:
User-agent: *
После юзер-агента идут указания, относящиеся именно к нему. Пример:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
Сначала мы прописываем директивы для всех интересующих нас юзер-агентов. Затем дополняем их тем, что нас интересует, и заканчиваем обычно ссылкой на XML-карту сайта:
Sitemap: https://znet.ru/sitemap.xml
А вот что прописывать в директивах — это для каждой CMS, как я уже писал выше, по-разному. Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Что нужно закрывать в нем
Всю эту хрень нужно закрыть от индексации:
- Страницы поиска. Обычно поиск генерирует очень много страниц, которые нам не будут нести трафика;
- Корзина и страница оформления заказа. Обычно они не должны попадать в индекс;
- Страницы пагинации. Некоторые мастера знают, как получать с них трафик, но если вы не профессионал, лучше закройте их;
- Фильтры и сравнение товаров могут генерировать мусорные страницы;
- Страницы регистрации и авторизации. На этих страницах вводится только конфиденциальная информация;
- Системные каталоги и файлы. Каждый ресурс включает в себя административную часть, таблицы CSS, скрипты. В индексе нам это все не нужно;
- Языковые версии, если вы не продвигаетесь в других странах и они нужны вам чисто для информации;
- Версии для печати.
Как закрыть страницы от индексации и использовать Disallow
Вот чтобы закрыть от индексации какой-то тип страниц, нам потребуется она. Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
Disallow: /page.html
А если мне нужно закрыть все страницы, которые начинаются с https://znet.ru/instrumenty/? То есть страницы https://znet.ru/instrumenty/1.html, https://znet.ru/instrumenty/2.html и другие? Тогда я добавляю такую строку в роботс:
Disallow: /instrumenty/
Короче, это самая нужная директива.
Нужно ли использовать директиву Allow?
Крайне редко ей пользуюсь. Вообще, она нужна для того, чтобы разрешать роботу индексировать определенные страницы. Но он индексирует все, что не запрещено. Так что Allow я почти не использую. За исключением редких случаев, например, таких:
Допустим, у меня в роботсе закрыта категория /instrumenty/. Но страницу https://znet.ru/instrumenty/44.html я должен открыть для индексации. Тогда у меня в роботс тхт будет написано так:
Disallow: /instrumenty/ Allow: /instrumenty/44.html
В таком случае проблема будет решена. Как пишет Яндекс, «При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow». Короче, Allow я использую тогда, когда нужно перебить требования какой-то из директив Disallow.
Регулярные выражения
Когда прописываем директивы, мы можем использовать спецсимволы * и $ для создания регулярных выражений. Для чего они нужны? Давайте на практике рассмотрим:
User-agent: Yandex Disallow: /cgi-bin/*.aspx
Такая директива запретит Яндексу индексировать страницы, которые начинаются на /cgi-bin/ и заканчиваются на .aspx, то есть вот эти страницы:
/cgi-bin/loh.aspx
/cgi-bin/pidr.aspx
И подобные им будут закрыты.
А вот спецсимвол $ «фиксирует» запрет какой-то конкретной страницы. То есть такой код:
User-agent: Yandex Disallow: /example$
Запретит индексировать страницу /example, но не запрещает индексировать страницы /example-user, /example.html и другие. Только конкретную страницу /example.
Для чего нужна директива Host
Если сайт доступен сразу по нескольким адресам, директива Host указывает главное зеркало одного ресурса. Эту директиву распознают только роботы Яндекса, остальные поисковики забивают на нее болт. Пример:
User-agent: Yandex Disallow: /page Host: znet.ru
Host используется в robots только один раз. Если же их будет указано несколько, учитываться будет только первая директива.
Что такое Crawl-delay
Директива Crawl-delay устанавливает минимальное время между завершением загрузки роботом страницы 1 и началом загрузки страницы 2. То есть если у вас в роботсе добавлено такое:
User-agent: Yandex Crawl-delay: 2
То таймаут между загрузками двух страниц составит две секунды.
Это нужно, если ваш сервер плохо выдерживает запросы на загрузку страниц. Но я скажу так: если это так и есть, то ваш сервер — говно, и тут не Crawl-delay нужно устанавливать, а менять сервер.
Нужно ли указывать Sitemap в роботсе
В конце роботса нужно указывать ссылку на сайтмап, да. Я вам скажу, что это очень круто помогает индексации.
Был у меня один сайт, который хреново индексировался месяца полтора, когда я еще только начинал в SEO. Я не мог никак понять, в чем причина. Оказалось, я просто не указал путь к сайтмапу. Когда я это сделал — все нужные страницы через 1 апдейт уже попали в индекс.
Указывается путь к сайтмапу так:
Sitemap: https://znet.ru/sitemap.xml
Это если ваша карта сайта открывается по этому адресу. Если она открывается по другому адресу — прописывайте другой.
Прочие рекомендации к составлению
Рекомендую соблюдать:
- В одной строке — одна директива;
- Без пробелов в начале строк;
- Директива будет работать, только если написана целиком и без лишних знаков;
- Как пишет сам Яндекс, «Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке»;
- Правильный код роботс должен содержать как минимум одну директиву Dissallow.
А вот еще видео для продвинутых с вебмастерской Яндекса:
Как запретить индексацию всего сайта
Вот этот код поможет закрыть сайт от индексации:
User-agent: * Disallow: /
Пригодиться это может, если вы делаете новый сайт, но он еще не готов, и поэтому его лучше закрыть, чтобы он во время доработки не попал под какой-нибудь фильтр АГС.
Как проверить, правильно ли составлен файл
В Яндекс Вебмастере и Гугл Вебмастере есть инструмент, который поможет вам понять, правильно ли составлен роботс. Рекомендую обязательно проверять файл в этих сервисах перед размещением. В Яндекс Вебмастере вы также сможете добавить список страниц, чтобы проверить, разрешены ли они к индексации роботом.
Как создать файл robots.txt для WordPress. 4 способа
(Последнее обновление: 29.04.2020)Всем, привет! Сегодня небольшой пост — как автоматически создать файл robots.txt для WordPress? Друзья, вы можете создать правильный robots.txt для WordPress в пару кликов, прочитав данное руководство. Создание правильного файла robots.txt для WordPress очень важно. Благодаря ему поисковые системы будут знать, какие страницы индексировать и показывать в поиске. То есть, результаты поиска будут именно такими, как вам нужно, без дублирования страниц WordPress.
 robots.txt для сайта WordPress
robots.txt для сайта WordPressЧитайте, дамы и господа — WordPress robots.txt: лучшие примеры для SEO.
Файл robots.txt для WordPress
WordPress robots.txt где лежит/находится? По умолчанию WordPress автоматически создает виртуальный файл robots.txt для вашего сайта. Таким образом, даже если вы ни чего не делали, на вашем сайте ВордПресс уже должен быть файл robots.txt. Вы можете проверить, так ли это, добавив /robots.txt в конец вашего доменного имени. Например, так https://ваш сайт/robots.txt
 Виртуальный файл robots.txt в WordPress
Виртуальный файл robots.txt в WordPressПоскольку этот файл является виртуальным, вы не можете его редактировать. Однако, если вы хотите отредактировать свой файл robots.txt WordPress как надо, вам необходимо создать физический файл на вашем хостинге. Создайте свой правильный robots.txt для WordPress, который вы сможете легко редактировать по мере необходимости.
Как создать файл robots.txt для WordPress
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Файл robots.txt сообщает поисковым роботам, какие страницы или файлы на вашем сайте можно или нельзя обрабатывать.
Яндекс и Google
Для начала напомню вам, создать (и редактировать) файл robots.txt для WordPress можно вручную и с помощью плагина Yoast SEO
 Создать файл robots.txt
Создать файл robots.txtДрузья, имейте ввиду, что Yoast SEO устанавливает свои правила по умолчанию, которые перекрывают правила существующего виртуального файла robots.txt ВордПресс:
 Редактирование robots.txt в плагине Yoast SEO
Редактирование robots.txt в плагине Yoast SEOЧто должно быть в правильно составленного robots.txt? Идеального файла не существует. Например, сайт Yoast SEO использует такой robots.txt для WordPress:
User-agent: *И всё. Для большинства сайтов WordPress лучший пример. Вот даже скриншот сделал у Yoast SEO:
 Правильный robots.txt на сайте yoast.com
Правильный robots.txt на сайте yoast.comЧто это значит? Директива говорит что, все поисковые роботы могут свободно сканировать этот сайт без ограничений. Этого хватит для правильной индексации сайта WP. А наша SEO специалисты рекомендуют почти тоже самое. Пример, правильно составленного robots.txt для WordPress сайта:
User-agent: *
Disallow:
Sitemap: https://mysite.ru/sitemap.xmlДанная запись в файле роботс делает доступным для индексирования полностью сайт для роботов всех известных поисковиков. Здесь, также прописан путь к карте сайта XML.
Создать и редактировать файл также можно при помощи All in One SEO Pack прямо из интерфейса SEO плагина. Модуль robots.txt в SEO-пакете Все в одном позволяет вам настроить файл robots.txt для вашего сайта, который переопределит файл robots.txt по умолчанию, который создает WordPress:
 Применение плагина All in One SEO Pack
Применение плагина All in One SEO PackВы сможете управлять своим файлом Robots.txt, в разделе All in One SEO Pack — Robots.txt. Сам официальный сайт плагина использует вот такой роботс:
 Пример файла Robots
Пример файла RobotsПравила по умолчанию, которые отображаются в поле Создать файл Robots.txt (показано на снимке экрана выше), требуют, чтобы роботы не сканировали ваши основные файлы WordPress. Для поисковых систем нет необходимости обращаться к этим файлам напрямую, потому что они не содержат какого-либо релевантного контента сайта.
А если вы не используете данные SEO модули, то предлагаю вам воспользоваться специальным плагином — Robots.txt Editor.
Плагин Robots.txt Editor
Плагин Robots.txt для WordPress — создание и редактирование файла robots.txt для сайта ВордПресс. Очень простой, лёгкий и эффективный плагин.
 WordPress плагин Robots.txt Editor
WordPress плагин Robots.txt EditorПлагин Robots.txt Editor (редактор) позволяет создать и редактировать файл robots.txt на вашем сайте WordPress.
Плагин Robots.txt возможности
- Работает в сети сайтов Multisite на поддоменах;
- Пример правильного файла robots.txt для WordPress;
- Не требует дополнительных настроек;
- Абсолютно бесплатный.
Как использовать? Установите плагин robots.txt стандартным способом. То есть, из админки. Плагины — Добавить новый. Введите в окно поиска его название — Robots.txt Editor:
 Добавить плагин Robots.txt Editor
Добавить плагин Robots.txt EditorУстановили и сразу активировали. Всё, готово. Теперь смотрим, что получилось. Заходим, Настройки — Чтение и видим результат. Автоматически созданный правильный файл robots.txt для WordPress со ссылкой на ваш файл Sitemap. Пример, правильный robots.txt для сайта ВордПресс:
 Созданный файл robots.txt WordPress
Созданный файл robots.txt WordPressЕстественно, вы можете его легко отредактировать под свои нужды. А также просмотреть, нажав соответствующею ссылку — Просмотр robots.txt.
Как создать robots.txt вручную
Если вы не захотите использовать плагины, которые предлагают функцию robots.txt, вы все равно можете создать и управлять своим файлом robots.txt на своём хостинге. Как создать файл robots.txt самостоятельно?
В текстовом редакторе создайте файл с именем robots в формате txt и заполните его:
 Создать файл с именем robots.txt
Создать файл с именем robots.txtФайл должен иметь имя robots.txt и никакое другое больше. Сохраните данный файл локально на компьютере. А затем, загрузите созданный файл в корневую директорию вашего сайта.
Корневая папка (корневая директория/корневой каталог/корень документа) — это основная папка, в которой хранятся все файлы сайта. Обычно, это папка public_html (там где находятся файлы — .htaccess, wp-config.php и другие). Именно в эту папку загружается файл robots.txt:
 Загрузите файл в корневую папку вашего сайта
Загрузите файл в корневую папку вашего сайта Чтобы проверить, получилось ли у вас положить файл в нужное место, перейдите по адресу: https://ваш_сайт.ru/robots.txt
Теперь, когда ваш файл robots.txt создан и загружен на сайт, вы можете проверить его на ошибки.
Проверка вашего файла robots.txt
Вы можете проверить файл robots.txt WordPress в Google Search Console и Яндекс.Вебмастер, чтобы убедиться, что он правильно составлен.
Например, проверка файла robots.txt WordPress в Яндекса.Вебмастер. В блоке Результаты анализа robots.txt перечислены директивы, которые будет учитывать робот при индексировании сайта.
 Анализ robots.txt в Яндекс.Вебмастер
Анализ robots.txt в Яндекс.ВебмастерЕсли будет найдена ошибка, информация об этом будет показана вам.
В заключение
Для некоторых сайтов WordPress нет необходимости срочно изменять стандартный виртуальный файл robots.txt (по умолчанию). Но, если вам нужен физический файл robots.txt, то используйте плагины Robots.txt Editor, All in One SEO Pack или Yoast SEO. С ними можно легко редактировать файл прямо из панели инструментов WordPress, чтобы добавить свои собственные правила.
До новых встреч, друзья и я надеюсь, что вам понравилось это маленькое руководство. И не стесняйтесь, обязательно оставьте комментарий, если у вас возникнут дополнительные вопросы по использованию файла robots.txt на сайте WordPress.
Как создать robots txt для всех поисковиков
Автор Анна Апрельская На чтение 3 мин. Опубликовано
 Файл robots.txt создается специально для поисковых ботов, чтобы они знали куда идти и индексировать, а куда вход запрещен. Если неправильно его настроить, вы можете вообще не попасть в поиск или попасть только у некоторых.
Файл robots.txt создается специально для поисковых ботов, чтобы они знали куда идти и индексировать, а куда вход запрещен. Если неправильно его настроить, вы можете вообще не попасть в поиск или попасть только у некоторых.
Чтобы не было проблем с продвижением и индексацией статей, вам нужно знать, как создать robots txt для всех поисковиков. Это занимает мало времени, но после этого вы будете спокойны.
Как создать robots txt
Некоторые вебмастера и вовсе обходятся без него (в основном, конечно, по незнанию). С одной стороны это разумно для новичков – так вы точно не закроете от поисковых роботов нужную информацию. Но с другой стороны, этот небольшой файл защищает личные данные и не дает спам-ботам просматривать информацию на сайте.
Начинающим блоггерам я рекомендую использовать шаблоны. К примеру, шаблон robots txt для WordPress Скачать. Скачайте и исправьте «ваш_сайт.ru» на название вашего сайта (к примеру, яработаюдома.рф).
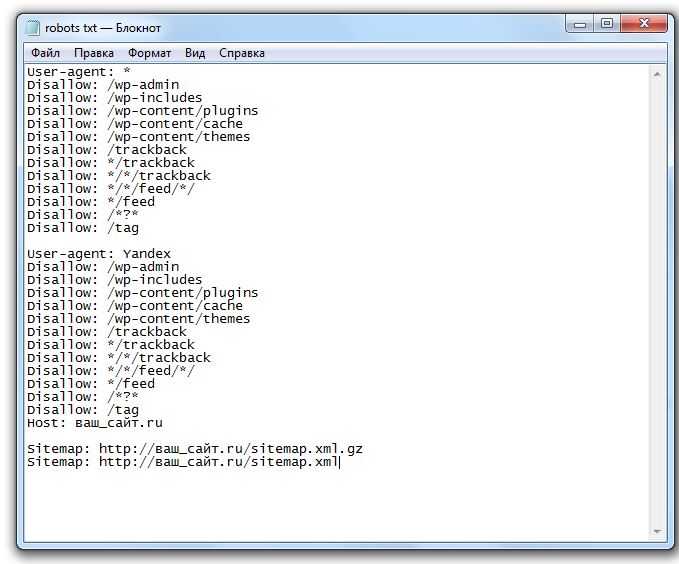
Расшифровка значений:
- User-agent: * — вы обращаетесь сразу ко всем поисковым системам, Yandex — только к Яндексу.
- Disallow: перечислены папки и файлы, которые запрещены для индексации
- Host – пропишите название вашего сайта без www.
- Sitemap: ссылка на XML-карту сайта.
Файл поместите в корневую директорию сайта с помощью Filezilla или через сайт хостера. Скидывайте в главную директорию, чтобы он был доступен по ссылке: ваш_сайт.ру/robots.txt
Он подойдет только для тех, у кого стоят ЧПУ (ссылки прописаны словами, а не в виде p=333). Достаточно зайти в Настройки – Постоянные ссылки, выбрать нижний вариант и в поле прописать /%postname%
Robots txt для всех поисковиков
Некоторые предпочитают создавать этот файл самостоятельно:
Для начала создайте блокнот на компьютере и назовите его robots (не используйте верхний регистр). В конце настроек его размер не должен быть больше 500 кб.
User-agent – название поисковой системы (Yandex, Googlebot, StackRambler). Если вы хотите обратиться сразу ко всем, поставьте звездочку *
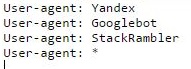
А затем укажите страницы или папки, которые нельзя индексировать этому роботу с помощью Disallow:

Сначала перечислены три директории, а потом конкретный файл.
Чтобы разрешить индексировать все и всем, нужно прописать:
User-agent: *
Disallow:
Настройка robots.txt для Яндекс и Google
Для Яндекса обязательно нужно добавить директиву host, чтобы не появлялось дублей страниц. Это слово понимает только бот от Яндекса, так что прописывайте указания для него отдельно.
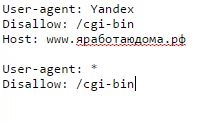
Для Google нет никаких дополнений. Единственное, нужно знать, как к нему обращаться. В разделе User-agent нужно писать:
- Googlebot;
- Googlebot-Image – если ограничиваете индексацию изображений;
- Googlebot-Mobile — для мобильной версии сайта.
Как проверить работоспособность файла robots.txt
Это можно сделать в разделе «Инструменты для веб-мастеров» от поисковика Google или на сайте Яндекс.Вебмастер в разделе Проверить robots.txt.
Укажите ссылку на ваш сайт и посмотрите, нет ли ошибок. Обычно никаких проблем не возникает.
Если будут ошибки, исправьте их и проверьте еще раз. Добейтесь хорошего результата, затем не забудьте скопировать правильный код в robots.txt и залить его на сайт.
Теперь вы имеете представление, как создать robots.txt для всех поисковиков. Новичкам рекомендую использовать готовый файл, подставив название своего сайта.
В данном разделе мы постарались описать все термины, относящиеся к созданию сайтов в нашей системе. Если Вы заметили, что какого-то понятия не хватает — пишите нам на [email protected]
Robot.txt
Robot.txt — текстовый файл, интерпретируемый большинством поисковых систем как протокол (стандарт) исключений для роботов (Robots Exclusion Protocol, or Robots Exclusion Standard). Информация, содержащаяся в robot.txt, влияет на поведение поисковых пауков и кроулеров, указывая порядок обработки данных, а также запрещая индексацию каких-либо файлов, страниц и директорий сайта.
Данный стандарт был разработан Мартином Костером (Martijn Koster) во время его работы над WebCrawler в 1994 году и получил распространение благодаря внедрению AltaVista и других популярных поисковых систем в последующие годы.
Создание файла robot.txt
Чтобы поисковые системы «видели» этот файл и следовали его инструкциям, он должен, во-первых, называться именно robot.txt, а во-вторых — размещаться в корневом каталоге сайта (пример: http://www.site.org но не http://www.site.org/articles). При несоблюдении этих двух условий robot.txt будет рассматриваться как обыкновенный текстовый файл.
Описание работы robot.txt
Поисковый робот при проведении индексации сайта заходит на ресурс, обращается к robot.txt и анализирует находящуюся там информацию. Рассмотрим образец кода:
- User-agent: *
- Allow: /customer
- Disallow: /
В разделе «User-agent» перечисляются кроулеры, к которым будут применяться описанные ниже правила.
«Disallow» указывает недоступные для индексирования элементы сайта.
«Allow», наоборот, дает доступ к определенным страницам и разделам.
На приведенном выше примере «User-agent: *» говорит, что правила будут применяться ко всем поисковым роботам. «Disallow: /» и «Allow: /customer» сообщают, что ни один элемент сайта, кроме тех, что начинаются с «/customer», не должен подвергаться индексированию.
Недостатки данного стандарта
- Robots Exclusion Protocol носит рекомендательный характер, из-за чего поисковые роботы и другие программы могут игнорировать файл robot.txt. Это относится в первую очередь к вредоносным программам, которые ищут «дыры» в системе безопасности сайта, и к спам-ботам, собирающим электронные адреса.
- Robot.txt находится в общем доступе, так что любой желающий может увидеть список разделов сайта, к которым не имеют доступа поисковые роботы. Поэтому не следует использовать файл для хранения конфиденциальной информации.
Правильный robots.txt для WordPress — 2020
Robots.txt – текстовой файл, который сообщает поисковым роботам, какие файлы и папки следует сканировать (индексировать), а какие сканировать не нужно.
Поисковые системы, такие как Яндекс и Google сначала проверяют файл robots.txt, после этого начинают обход с помощью веб-роботов, которые занимаются архивированием и категоризацией веб сайтов.
Файл robots.txt содержит набор инструкций, которые просят бота игнорировать определенные файлы или каталоги. Это может быть сделано в целях конфиденциальности или потому что владелец сайта считает, что содержимое этих файлов и каталогов не должны появляться в выдаче поисковых систем.

Если веб-сайт имеет более одного субдомена, каждый субдомен должен иметь свой собственный файл robots.txt. Важно отметить, что не все боты будут использовать файл robots.txt. Некоторые злонамеренные боты даже читают файл robots.txt, чтобы найти, какие файлы и каталоги Вы хотели скрыть. Кроме того, даже если файл robots.txt указывает игнорировать определенные страницы на сайте, эти страницы могут по-прежнему появляться в результатах поиска, если на них ссылаются другие просканированные страницы. Стандартный роботс тхт для вордпресс открывает весь сайт для интдекса, поэтому нам нужно закрыть не нужные разделы WordPress от индексации.
Оптимальный robots.txt
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # системная папка на хостинге, закрывается всегда
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # запрос поиска
Disallow: *&s= # запрос поиска
Disallow: /search/ # запрос поиска
Disallow: /author/ # архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть
# архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.Расширенный вариант (разделенные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Host прописывать больше не нужно.Оптимальный Robots.txt для WooCommerce
Владельцы интернет-магазинов на WordPress – WooCommerce также должны позаботиться о правильном robots.txt. Мы закроем от индексации корзину, страницу оформления заказа и ссылки на добавление товара в корзину.
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Sitemap: https://site.ru/sitemap_index.xmlГде находится файл robots.txt в WordPress
Обычно robots.txt располагается в корне сайта. Если его нет, то потребуется создать текстовой файл и загрузить его на сайт по FTP или панель управления на хостинге. Если Вы не смогли найти robots.txt в корне сайта, но при переходе по ссылке вашсайт.ру/robots.txt он открывается, значит какой то из SEO плагинов сам генерирует его.
К примеру плагин Yoast SEO создает виртуальный файл, которого нет в корне сайта.
Как редактировать robots.txt с помощью Yoast SEO
- Зайдите в админ панель сайта
Админа панель находится по следующему адресу вашсайт.ру/wp-admin/
- Слева в консоли наведите на кнопку SEO и в выпадающем окне выберите “Инструменты”. Перейдите в раздел, как указано на картинке.

- Зайдите в редактор файлов
Этот инструмент позволит быстро отредактировать такие важные для вашего SEO файлы, как robots.txt и .htaccess (при его наличии).
- Если файла robots.txt нет, нажмите на кнопку создать, либо вставьте нужное содержимое.
Содержимое файла для WordPress и WooCommerce можно взять из примеров выше.
- Сохраните изменения в robots.txt
После сохранения файла вы можете проверить правильность через сервисы проверки.



Чтобы установить плагин Yoast SEO воспользуйтесь данной статьей – ссылка.
Часто задаваемые вопросы
Закрывать ли feed в robots.txt?По умолчанию мы рекомендуем закрывать feed от индексации в robots.txt. Открытие feed может потребоваться, если вы например настраиваете Турбо-страницы от Яндекса или выгружаете свою ленту в другой сервис.
Добавьте директиву: Allow: /feed/turbo/, тогда Яндекс сможет проверять ваши турбо-страницы и обновлять их.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Robots.txt Генератор
SEO Инструменты
Инструменты, которые помогут вам создать и продать свой веб-сайт.
Firefox ExtensionsВеб Инструменты Если вам нужна обратная связь или у вас есть острые вопросы, пожалуйста, задавайте их на форуме сообщества, чтобы мы могли разобраться с ними.
Обзор
Обзор содержимого сайта.Включает в себя карту сайта, глоссарий и список быстрого запуска.
SEO
Содержит информацию о ключевых словах, SEO страницы, создании ссылок и социальном взаимодействии.
КПП
Советы о том, как купить трафик с поисковых систем.
ОтслеживаниеУзнайте, как отслеживать свой успех с помощью обычной рекламы SEO и PPC. Включает информацию о веб-аналитике.
Достоверность
Создание надежного веб-сайта является ключевым фактором для того, чтобы быть доступным для ссылок и продавать клиентам.
монетизация
Узнайте, как заработать на своих сайтах.
Аудио и видео
Ссылки на полезную аудио и видео информацию. Мы будем создавать новые SEO видео каждый месяц.
Интервью
Эксклюзивный член только интервью.
Скидки
Купоны и предложения, которые помогут вам сэкономить деньги на продвижении ваших сайтов.
Карта сайта
Посмотреть все наши учебные модули, ссылки на которые есть на одной странице.
Хотите проверить свой файл robots.txt?
Получите конкурентное преимущество сегодня
Ваши главные конкуренты инвестировали в свою маркетинговую стратегию в течение многих лет.
Теперь вы можете точно знать, где они находятся, выбрать лучшие ключевые слова и отслеживать новые возможности по мере их появления.
Изучите профиль рейтинга ваших конкурентов в Google и Bing сегодня, используя SEMrush.
Введите конкурирующий URL-адрес ниже, чтобы быстро получить доступ к своей истории платных и эффективных результатов поиска — бесплатно.
Посмотрите, где они ранги и победить их!
- Всесторонние конкурентные данные: результатов исследований в области обычного поиска, AdWords, рекламы Bing, видео, медийной рекламы и многого другого.
- Сравните по разным каналам: используют чью-то стратегию AdWords, чтобы стимулировать ваш рост SEO, или используют свою стратегию SEO для инвестирования в платный поиск.
- Глобальный охват: Отслеживает результаты Google по 120+ миллионам ключевых слов на многих языках на 28 рынках
- Исторические данные о производительности: , начиная с прошлого десятилетия, до появления Panda и Penguin, так что вы можете искать исторические штрафы и другие потенциальные проблемы ранжирования.
- Без риска: Бесплатная пробная версия и низкая месячная цена.
Ваши конкуренты, исследуют ваш сайт
найти новые возможности сегодня
,Знаете ли вы, что у вас есть полный контроль над тем, кто сканирует и индексирует ваш сайт, вплоть до отдельных страниц?
Это делается с помощью файла Robots.txt.
Robots.txt — это простой текстовый файл, который размещается в корневом каталоге вашего сайта. Он сообщает «роботам» (таким как пауки поисковых систем), какие страницы сканировать на вашем сайте, какие страницы игнорировать.
Пока не обязательно, роботы.TXT-файл дает вам большой контроль над тем, как Google и другие поисковые системы видят ваш сайт.
При правильном использовании это может улучшить сканирование и даже повлиять на SEO.
Но как именно вы создаете эффективный файл Robots.txt? После создания, как вы используете это? И каких ошибок следует избегать при его использовании?
В этом посте я поделюсь всем, что вам нужно знать о файле Robots.txt и о том, как его использовать, в своем блоге.
Давайте окунемся в:
Что такое роботы.текстовый файл?
Еще в первые дни Интернета программисты и инженеры создавали «роботов» или «пауков» для сканирования и индексации страниц в Интернете. Эти роботы также известны как «пользовательские агенты».
Иногда эти роботы попадают на страницы, которые владельцы сайтов не хотят индексировать. Например, строящийся сайт или частный сайт.
Чтобы решить эту проблему, Мартейн Костер, голландский инженер, который создал первую в мире поисковую систему (Aliweb), предложил набор стандартов, которых должен будет придерживаться каждый робот.Эти стандарты были впервые предложены в феврале 1994 года.
30 июня 1994 года ряд авторов роботов и первых веб-пионеров достигли консенсуса по стандартам.
Эти стандарты были приняты как «Протокол исключения роботов» (REP).
Файл Robots.txt является реализацией этого протокола.
REP определяет набор правил, которым должен следовать каждый законный сканер или паук. Если Robots.txt указывает роботам не индексировать веб-страницу, то каждый законный робот — от робота Google до робота MSN — должен следовать инструкциям.
Примечание: Список легальных сканеров можно найти здесь.
Имейте в виду, что некоторые мошеннические роботы — вредоносные программы, шпионское ПО, сборщики электронной почты и т. Д. — могут не следовать этим протоколам. Вот почему вы можете видеть трафик ботов на страницах, заблокированных вами через Robots.txt.
Существуют также роботы, которые не соответствуют стандартам REP, которые не используются ни для чего сомнительного.
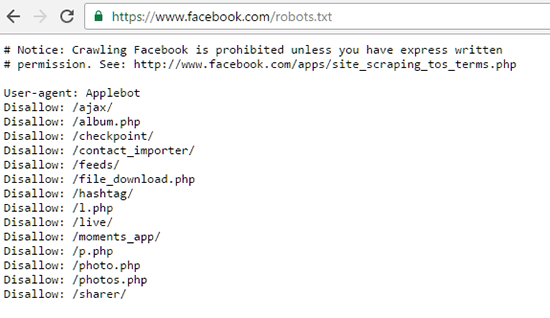
Вы можете увидеть robots.txt любого веб-сайта, перейдя по этому адресу:
http: // [website_domain] / robots.txt
Например, вот файл Robots.txt Facebook:
А вот файл Robots.txt Google:
Использование Robots.txt
Robots.txt не является обязательным документом для веб-сайта. Ваш сайт может очень хорошо расти и расти без этого файла.
Тем не менее, использование Robots.txt дает некоторые преимущества:
- Отказ от ботов при сканировании личных папок — Хотя это и не идеально, запрет ботов из обхода личных папок сделает их более трудными для индексации — по крайней мере, законными ботами ( такие как пауки поисковой системы).
- Контроль использования ресурсов — Каждый раз, когда бот сканирует ваш сайт, он истощает вашу пропускную способность и ресурсы сервера — ресурсы, которые лучше потратить на реальных посетителей. Для сайтов с большим количеством контента это может привести к увеличению расходов и плохому опыту реальных посетителей. Вы можете использовать Robots.txt, чтобы заблокировать доступ к сценариям, неважным изображениям и т. Д. Для экономии ресурсов.
- Приоритезация важных страниц — Вы хотите, чтобы пауки поисковых систем сканировали важные страницы на вашем сайте (например, страницы с контентом), а не тратили ресурсы на копирование бесполезных страниц (например, результатов поисковых запросов).Блокируя такие бесполезные страницы, вы можете определить приоритетность страниц, на которых сосредоточены боты.
Как найти файл Robots.txt
Как следует из названия, Robots.txt представляет собой простой текстовый файл.
Этот файл хранится в корневом каталоге вашего сайта. Чтобы найти его, просто откройте инструмент FTP и перейдите в каталог вашего сайта в public_html.

Это крошечный текстовый файл — у меня чуть более 100 байтов.
Чтобы открыть его, используйте любой текстовый редактор, например Блокнот.Вы можете увидеть что-то вроде этого:
Существует вероятность того, что вы не увидите файл Robots.txt в корневом каталоге вашего сайта. В этом случае вам придется самостоятельно создать файл Robots.txt.
Вот как:
Как создать файл Robot.txt
Поскольку Robots.txt — это основной текстовый файл, его ОЧЕНЬ просто: просто откройте текстовый редактор и сохраните пустой файл как robots.txt .
Чтобы загрузить этот файл на свой сервер, используйте ваш любимый инструмент FTP (я рекомендую использовать WinSCP) для входа на ваш веб-сервер.Затем откройте папку public_html и откройте корневой каталог вашего сайта.
В зависимости от того, как настроен ваш веб-хост, корневой каталог вашего сайта может находиться непосредственно в папке public_html. Или это может быть папка в этом.
Как только вы откроете корневой каталог своего сайта, просто перетащите в него файл Robots.txt.
Кроме того, вы можете создать файл Robots.txt прямо из редактора FTP.
Для этого откройте корневой каталог вашего сайта и щелкните правой кнопкой мыши -> Создать новый файл.
В диалоговом окне введите «robots.txt» (без кавычек) и нажмите «ОК».
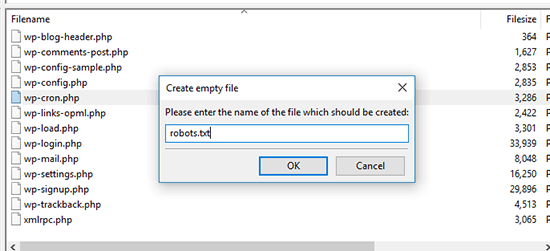
Вы должны увидеть новый файл robots.txt внутри:

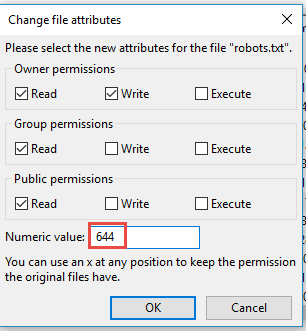
Наконец, убедитесь, что вы установили правильное разрешение для файла Robots.txt. Вы хотите, чтобы владелец — сам — читал и писал файл, но не для других или публики.
В файле Robots.txt должен отображаться код «0644».
Если этого не произойдет, щелкните правой кнопкой мыши свой файл Robots.txt и выберите «Права доступа к файлу…».
Вот оно, полнофункциональные роботы.текстовый файл!
Но что вы можете сделать с этим файлом?
Далее я покажу вам некоторые общие инструкции, которые вы можете использовать для управления доступом к вашему сайту.
Как использовать Robots.txt
Помните, что Robots.txt по сути контролирует взаимодействие роботов с вашим сайтом.
Хотите заблокировать доступ поисковых систем ко всему сайту? Просто измените разрешения в Robots.txt.
Хотите заблокировать Bing от индексации вашей страницы контактов? Вы тоже можете это сделать.
Сам по себе файл Robots.txt не улучшит вашу SEO, но вы можете использовать его для управления поведением сканера на вашем сайте.
Чтобы добавить или изменить файл, просто откройте его в редакторе FTP и добавьте текст напрямую. Как только вы сохраните файл, изменения будут отражены немедленно.
Вот некоторые команды, которые вы можете использовать в файле Robots.txt:
1. Заблокировать всех ботов на вашем сайте
Хотите заблокировать все роботы при сканировании вашего сайта?
Добавьте этот код к своим роботам.TXT-файл:
Пользовательский агент: *
Disallow: /
Вот как это будет выглядеть в реальном файле:
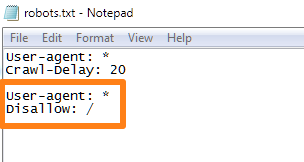
Проще говоря, эта команда сообщает каждому пользовательскому агенту (*) не получить доступ к файлам или папкам на вашем сайте.
Вот полное объяснение того, что именно здесь происходит:
- User-agent: * — Звездочка (*) — это символ подстановки, который применяется к каждому объекту (например, имени файла или в это дело, бот).Если вы ищете «* .txt» на вашем компьютере, он будет отображать каждый файл с расширением .txt. Здесь звездочка означает, что ваша команда применяется к каждому пользовательскому агенту.
- Disallow: / — «Disallow» — это команда robots.txt, запрещающая боту сканировать папку. Одна косая черта (/) означает, что вы применяете эту команду к корневому каталогу.
Примечание: Это идеально, если вы используете какой-либо частный веб-сайт, например, сайт членства.Но имейте в виду, что это не позволит всем законным ботам, таким как Google, сканировать ваш сайт. Используйте с осторожностью.
2. Заблокировать доступ всех ботов к определенной папке
Что если вы хотите запретить боту сканировать и индексировать определенную папку?
Например, папка / images?
Используйте эту команду:
User-agent: *
Disallow: / [имя_папки] /
Если вы хотите остановить доступ ботов к папке / images, вот как будет выглядеть команда:
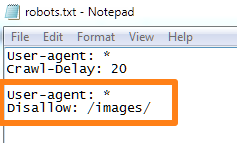
Это Команда полезна, если у вас есть папка ресурса, которую вы не хотите перегружать запросами робота-робота.Это может быть папка с неважными сценариями, устаревшими изображениями и т. Д.
Примечание: Папка / images является лишь примером. Я не говорю, что вы должны запретить ботам сканировать эту папку. Это зависит от того, чего вы пытаетесь достичь.
Поисковые системы обычно недовольны веб-мастерами, блокирующими их ботов от сканирования папок без изображений, поэтому будьте осторожны при использовании этой команды. Ниже я перечислил несколько альтернатив Robots.txt, которые мешают поисковым системам индексировать определенные страницы.
3. Блокировка определенных ботов с вашего сайта
Что, если вы хотите заблокировать доступ определенного сайта определенному роботу — например, Googlebot?
Вот команда для этого:
Пользовательский агент: [имя робота]
Disallow: /
Например, если вы хотите заблокировать робота Googlebot со своего сайта, это то, что вы будете использовать:
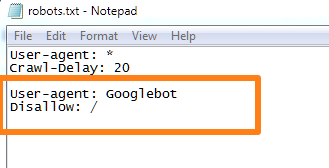
Каждый законный бот или пользовательский агент имеет определенное имя. Например, паук Google просто называется «Googlebot». Microsoft запускает «msnbot» и «bingbot».Бот Yahoo называется «Yahoo! Slurp».
Чтобы найти точные имена различных пользовательских агентов (таких как Googlebot, bingbot и т. Д.), Используйте эту страницу.
Примечание: Приведенная выше команда заблокирует конкретного бота со всего вашего сайта. Googlebot используется исключительно в качестве примера. В большинстве случаев вы никогда не захотите запретить Google сканировать ваш сайт. Один конкретный вариант использования для блокировки определенных ботов — это сохранение ботов, которые приносят вам пользу при переходе на ваш сайт, и остановка тех, которые не приносят пользы вашему сайту.
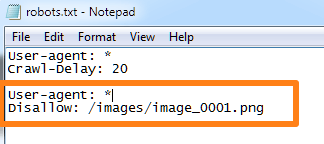
4. Заблокируйте определенный файл от сканирования
Протокол исключения роботов дает вам точный контроль над тем, к каким файлам и папкам вы хотите заблокировать доступ робота.
Вот команда, которую вы можете использовать, чтобы остановить сканирование файла любым роботом:
User-agent: *
Disallow: /[folder_name]/[file_name.extension]
Итак, если вы хотите заблокировать файл с именем «img_0001.png» из папки «images», вы будете использовать эту команду:
5.Заблокировать доступ к папке, но разрешить индексацию файла
Команда «Запретить» блокирует доступ ботов к папке или файлу.
Команда «Разрешить» делает обратное.
Команда «Разрешить» заменяет команду «Запретить», если первая предназначена для отдельного файла.
Это означает, что вы можете заблокировать доступ к папке, но позволить пользовательским агентам по-прежнему иметь доступ к отдельному файлу в папке.
Вот формат для использования:
Пользовательский агент: *
Запретить: / [имя_папки] /
Разрешить: / [имя_папки] / [имя_файла.расширение] /
Например, если вы хотите запретить Google сканировать папку «images», но по-прежнему хотите предоставить ей доступ к файлу «img_0001.png», хранящемуся в ней, вот формат, который вы будете использовать:
Для приведенного выше примера это будет выглядеть так:

Это остановит индексацию всех страниц в каталоге / search /.
Что если вы хотите, чтобы все страницы, которые соответствуют определенному расширению (например, «.php» или «.png»), не индексировались?
Используйте это:
User-agent: *
Disallow: / *.расширение $
Знак ($) здесь обозначает конец URL, то есть расширение является последней строкой в URL.
Если вы хотите заблокировать все страницы с расширением «.js» (для Javascript), вот что вы бы использовали:
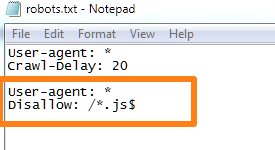
Эта команда особенно эффективна, если вы хотите, чтобы боты не могли сканировать скрипты.
6. Остановите ботов от слишком частого сканирования вашего сайта.
В приведенных выше примерах вы могли видеть эту команду:
User-agent: *
Задержка сканирования: 20
Эта команда инструктирует всех ботов ждать минимум 20 секунд между запросами на сканирование.
Команда Crawl-Delay часто используется на больших сайтах с часто обновляемым контентом (например, Twitter). Эта команда говорит ботам ждать минимальное количество времени между последующими запросами.
Это гарантирует, что сервер не будет перегружен слишком большим количеством запросов одновременно от разных ботов.
Например, это файл Twitter Robots.txt, который инструктирует ботов ждать не менее 1 секунды между запросами:

Вы даже можете контролировать задержку сканирования для отдельных ботов.Это гарантирует, что слишком много ботов не будут сканировать ваш сайт одновременно.
Например, у вас может быть такой набор команд:
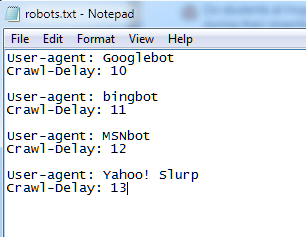
Примечание: На самом деле вам не нужно использовать эту команду, если вы не запускаете огромный сайт с тысячами новых страниц, создаваемых каждую минуту (например, Twitter) ).
Распространенные ошибки, которых следует избегать при использовании Robots.txt
Файл Robots.txt — это мощный инструмент для контроля поведения ботов на вашем сайте.
Однако, это может также привести к катастрофе SEO, если не используется правильно.Не поможет, что существует множество заблуждений о Robots.txt, распространяющихся в Интернете.
Вот некоторые ошибки, которых следует избегать при использовании Robots.txt:
Ошибка № 1 — Использование Robots.txt для предотвращения индексации содержимого
Если вы «запретите» папку в файле Robots.txt, законные боты победили не ползти.
Но это по-прежнему означает две вещи:
- Боты будут сканировать содержимое папки, связанной из внешних источников. Скажем, если другой сайт ссылается на файл в вашей заблокированной папке, боты проследят его индекс.
- Мошеннические боты — спамеры, шпионские программы, вредоносные программы и т. Д. — обычно игнорируют инструкции Robots.txt и индексируют ваш контент независимо от того, что именно.
Это делает Robots.txt плохим инструментом для предотвращения индексации содержимого.
Вот что вы должны использовать вместо этого: используйте тег «meta noindex».
Добавьте следующий тег на страницах, которые вы не хотите индексировать:
Это рекомендуемый, оптимизированный для SEO метод, чтобы остановить страницу от индексируется (хотя он по-прежнему не блокирует спамеров).
Примечание: Если вы используете плагин WordPress, такой как Yoast SEO или All in One SEO; Вы можете сделать это без редактирования какого-либо кода. Например, в плагине Yoast SEO вы можете добавить тег noindex для каждого поста / страницы следующим образом:
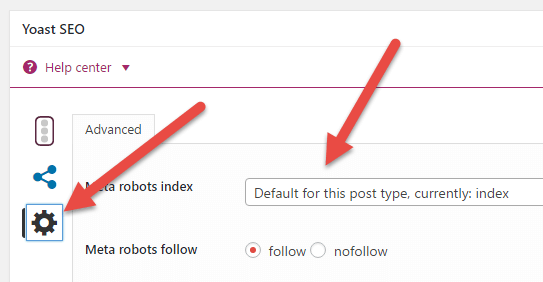
Просто откройте страницу и пост / страницу и нажмите на шестеренку внутри окна Yoast SEO. Затем щелкните раскрывающийся список рядом с «Индекс мета-роботов».
Кроме того, с 1 сентября Google перестанет поддерживать использование «noindex» в файлах robots.txt.Эта статья от SearchEngineLand имеет больше информации.
Ошибка № 2 — Использование Robots.txt для защиты личного контента
Если у вас есть личный контент, например PDF-файлы для курса электронной почты, блокировка каталога с помощью файла Robots.txt поможет, но этого недостаточно.
И вот почему:
Ваш контент может по-прежнему индексироваться, если он связан с внешними источниками. Плюс, бродячие боты все равно будут сканировать его.
Лучший способ — сохранить весь личный контент за логином.Это гарантирует, что никто — законные или мошеннические боты — не получат доступ к вашему контенту.
Недостатком является то, что у ваших посетителей есть дополнительный обруч для прыжка. Но ваш контент будет более безопасным.
Ошибка № 3 — Использование Robots.txt для предотвращения индексации дублированного контента
Дублированный контент — это большая проблема, когда речь заходит о SEO.
Однако использование Robots.txt для предотвращения индексации этого содержимого не является решением. Еще раз, нет никакой гарантии, что пауки поисковых систем не найдут этот контент через внешние источники.
Вот 3 других способа передать дублированный контент:
- Удалить дублированный контент — Это полностью избавит от контента. Однако это означает, что вы ведете поисковые системы на 404 страницы — не идеально. Из-за этого удаление не рекомендуется .
- Использовать перенаправление 301 — Перенаправление 301 сообщает поисковым системам (и посетителям) о том, что страница перемещена в новое место. Просто добавьте перенаправление 301 на дублированный контент, чтобы посетители могли перейти к исходному контенту.
- Добавить rel = «канонический» тег — Этот тег является «мета» версией перенаправления 301. Тег «rel = canonical» сообщает Google, какой является исходным URL для конкретной страницы. Например, этот код:
http://example.com/original-page.html ” rel = ”canonical” />
Сообщает Google, что страница — original-page.html — это «оригинальная» версия дубликата страницы. Если вы используете WordPress, этот тег легко добавить с помощью Yoast SEO или All in One SEO.
Если вы хотите, чтобы посетители могли получить доступ к дублированному контенту, используйте тег rel = ”canonical” . Если вы не хотите, чтобы посетители или боты получали доступ к контенту — используйте перенаправление 301.
Будьте осторожны при реализации любого из них, потому что они повлияют на ваш SEO.
Вам
Файл Robots.txt является полезным союзником в формировании взаимодействия поисковых роботов и других ботов с вашим сайтом. При правильном использовании они могут оказать положительное влияние на ваш рейтинг и упростить сканирование вашего сайта.
Используйте это руководство, чтобы понять, как работает Robots.txt, как он установлен и как его можно использовать. И избегайте любых ошибок, которые мы обсуждали выше.
См. Также:
 .
.Как создать файл Robots.txt
Вы можете использовать файл robots.txt, чтобы управлять тем, какие каталоги и файлы на вашем веб-сервере не соответствуют поисковому роботу поисковой системы, совместимому с протоколом исключения роботов (REP), или , то есть разделам , то есть разделам это не должно быть просканировано. Важно понимать, что это не по определению означает, что страница, которая не сканируется, также не будет проиндексирована . Чтобы узнать, как предотвратить индексацию страницы, см. Эта тема.
шагов
- Определите, какие каталоги и файлы на вашем веб-сервере вы хотите заблокировать для обхода сканером
- Определите, нужно ли указывать дополнительные инструкции для конкретного бота поисковой системы, помимо общего набора директив сканирования
- Используйте текстовый редактор для создания файла robots.txt и директивы для блокировки содержимого
- Необязательно: Добавьте ссылку на ваш файл карты сайта (если есть)
- Проверьте наличие ошибок, проверив своих роботов.TXT-файл
- Загрузите файл robots.txt в корневой каталог вашего сайта
Деталь шага
Определите, какие каталоги и файлы на вашем веб-сервере вы хотите заблокировать от искателя
- Проверьте ваш веб-сервер на предмет опубликованного контента, который вы не хотите посещать поисковыми системами.
- Создайте список доступных файлов и каталогов на вашем веб-сервере, который вы хотите запретить. Пример Возможно, вы захотите, чтобы боты игнорировали сканирование таких каталогов сайтов, как / cgi-bin, / scripts и / tmp (или их эквиваленты, если они существуют в вашей серверной архитектуре).
Укажите, нужно ли указывать дополнительные инструкции для конкретного робота поисковой системы, помимо общего набора директив сканирования .
- Изучите журналы реферера вашего веб-сервера, чтобы увидеть, есть ли роботы, просматривающие ваш сайт, которые вы хотите заблокировать, кроме общих директив, которые применяются ко всем ботам.
| Примечание |
|---|
| Bingbot, найдя для себя определенный набор инструкций, будет игнорировать директивы, перечисленные в общем разделе, поэтому вам нужно будет повторить все общие директивы в дополнение к конкретным директивам, которые вы для них создали, в их собственном разделе файла. , |
С помощью текстового редактора создайте файл robots.txt и добавьте директивы REP, чтобы заблокировать доступ ботов к содержимому. Текстовый файл должен быть сохранен в кодировке ASCII или UTF-8 .
- Боты упоминаются как пользовательские агенты в файле robots.txt. В начале файла запустите первый раздел директив, применимых ко всем ботам, добавив следующую строку: User-agent: *
- Создайте список директив Disallow со списком контента, который вы хотите заблокировать. Пример Учитывая наши ранее используемые примеры каталогов, такой набор директив будет выглядеть так:
- Пользователь-агент: *
- Disallow: / cgi-bin /
- Disallow: / scripts /
- Disallow: / tmp /
Примечание - Вы не можете перечислить несколько ссылок на контент в одну строку, поэтому вам нужно будет создать новую директиву Disallow: для каждого шаблона, который нужно заблокировать.Однако вы можете использовать символы подстановки. Обратите внимание, что каждый шаблон URL начинается с косой черты, представляющей корень текущего сайта.
- Вы также можете использовать директиву Allow: для файлов, хранящихся в каталоге, содержимое которого в противном случае будет заблокировано.
- Дополнительную информацию об использовании подстановочных знаков и создании директив Disallow и Allow см. В статье блога Центра веб-мастеров. Предотвратите «потерю бота в космосе».
- Если вы хотите добавить настраиваемые директивы для определенных ботов, которые не подходят для всех ботов, например, crawl-delay:, добавьте их в пользовательский раздел после первого общего раздела, изменив ссылку User-agent на конкретного бота.Список применимых имен ботов см. В базе данных роботов.
Примечание Добавление наборов директив, настроенных для отдельных ботов, не является рекомендуемой стратегией. Типичная необходимость повторения директив из общего раздела усложняет задачи обслуживания файлов. Кроме того, упущения в правильном обслуживании этих настраиваемых разделов часто являются источником проблем с роботами поисковых систем.
Дополнительно: добавьте ссылку на ваш файл карты сайта (если есть)
- Если вы создали файл Sitemap со списком наиболее важных страниц вашего сайта, вы можете указать боту на него, сославшись на его собственную строку в конце файла.
- Пример Файл Sitemap обычно сохраняется в корневом каталоге сайта. Такая директива Sitemap будет выглядеть так:
- Карта сайта: http://www.your-url.com/sitemap.xml
Проверьте наличие ошибок, проверив файл robots.txt
Загрузите файл robots.txt в корневой каталог вашего сайта
| Примечание |
|---|
|
Веб-страницы роботов
О файле /robots.txt
В двух словах
Владельцы веб-сайтов используют файл /robots.txt, чтобы дать инструкции о их сайт для веб-роботов; это называется Исключение роботов Протокол .
Это работает так: робот хочет просмотреть URL-адрес веб-сайта, скажем, http://www.example.com/welcome.html. Прежде чем он это делает, он первый проверяет http://www.example.com/robots.txt и находит:
Пользователь-агент: * Disallow: /
«User-agent: *» означает, что этот раздел применяется ко всем роботам.«Disallow: /» говорит роботу, что он не должен посещать страницы на сайте.
При использовании /robots.txt необходимо учитывать два важных момента:
- роботы могут игнорировать ваш /robots.txt. Особенно вредоносные роботы, которые сканируют Интернет для уязвимостей безопасности и сборщики адресов электронной почты, используемые спамерами не будет обращать внимания.
- файл /robots.txt является общедоступным файлом. Любой может увидеть, какие разделы вашего сервера вы не хотите использовать роботов.
Поэтому не пытайтесь использовать /robots.txt, чтобы скрыть информацию.
Смотрите также:
Подробности
/Robots.txt является стандартом де-факто и не принадлежит никому орган по стандартизации. Есть два исторических описания:
Кроме того есть внешние ресурсы:
Стандарт /robots.txt активно не разрабатывается. Смотрите Как насчет дальнейшего развития /robots.txt? для дальнейшего обсуждения.
Остальная часть этой страницы дает обзор того, как использовать / роботы.текст на ваш сервер, с некоторыми простыми рецептами. Чтобы узнать больше, смотрите также FAQ.
Как создать файл /robots.txt
Где это поставить
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Чем дольше ответ:
Когда робот ищет файл «/robots.txt» для URL, он удаляет Компонент пути из URL (все, начиная с первой косой черты), и помещает «/robots.txt» на его место.
Например, для «http: // www.example.com/shop/index.html, это будет удалите «/shop/index.html» и замените его «/robots.txt», и в конечном итоге «Http://www.example.com/robots.txt».
Таким образом, как владелец веб-сайта, вы должны поместить его в нужном месте на вашем веб-сервер для этого результирующего URL для работы. Обычно это то же самое место, где вы размещаете главное приветствие index.html вашего сайта стр. Где именно это находится, и как поместить туда файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать все строчные буквы для имени файла: «роботы.txt «, а не» Robots.TXT.
Смотрите также:
Что положить в него
Файл /robots.txt представляет собой текстовый файл с одной или несколькими записями. Обычно содержит одну запись, похожую на эту:Пользователь-агент: * Disallow: / cgi-bin / Disallow: / tmp / Disallow: / ~ Джо /
В этом примере три каталога исключены.
Обратите внимание, что вам нужна отдельная строка «Disallow» для каждого префикса URL, который вы хотите исключить — вы не можете сказать «Disallow: / cgi-bin / / tmp /» на одна линия.Кроме того, вы можете не иметь пустых строк в записи, так как они используются для разделения нескольких записей.
Обратите внимание, что глобализация и регулярное выражение не поддерживается в User-agent или Disallow линий. ‘*’ В поле User-agent является специальным значением, означающим «любой робот «. В частности, вы не можете иметь такие строки, как» User-agent: * bot * «, «Disallow: / tmp / *» или «Disallow: * .gif».
То, что вы хотите исключить, зависит от вашего сервера. Все, что явно не запрещено, считается справедливым игра для извлечения.Вот несколько примеров:
Чтобы исключить всех роботов из всего сервера
Пользователь-агент: * Disallow: /
Чтобы разрешить всем роботам полный доступ
Пользователь-агент: * Disallow:
(или просто создайте пустой файл «/robots.txt», или не используйте его вообще)
Чтобы исключить всех роботов из части сервера
Пользователь-агент: * Disallow: / cgi-bin / Disallow: / tmp / Disallow: / мусор /
Чтобы исключить одного робота
Пользователь-агент: BadBot Disallow: /
Разрешить одного робота
Пользователь-агент: Google Disallow: Пользователь-агент: * Disallow: /
Исключить все файлы, кроме одного
В настоящее время это немного неудобно, так как нет поля «Разрешить». Самый простой способ — поместить все файлы, которые нужно запретить, в отдельный каталог, скажите «вещи», и оставьте один файл на уровне выше этот каталог:Пользователь-агент: * Disallow: / ~ Джо / вещи /В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользователь-агент: * Disallow: /~joe/junk.html Disallow: /~joe/foo.html Disallow: /~joe/bar.html,