
Как проверить файл robots.txt в гугл вебмастер – INFO-EFFECT
 robots.txt
robots.txtНа чтение 2 мин. Опубликовано
Всем привет !
Прочитав данную статью, вы узнаете – как проверить файл robots.txt на наличие ошибок. Проверять данный файл мы будем в сервисе гугл вебмастер. Кстати, чтобы проверить файл robots.txt в сервисе гугл вебмастер, вам необходимо добавить свой сайт в гугл вебмастер, так что если вы ещё не сделали это, то вперёд и с песней. Итак, не будем тянуть и приступим к делу.
Зайдите на главную страницу гугл вебмастер и нажмите на вкладку с адресом вашего сайта, доменным именем – info-effect.ru
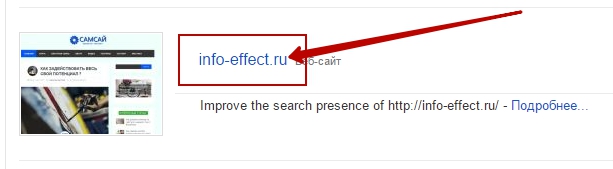
Далее, в панели инструментов, слева в боковой колонке, перейдите по вкладке: Сканирование – Инструмент проверки файла robots.txt.
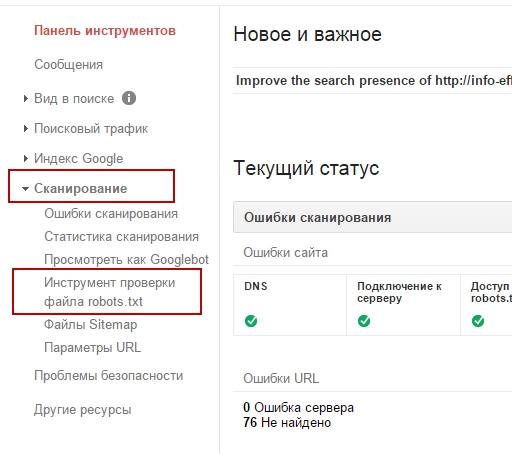
Далее, на странице инструмент проверки файла robots.txt, вам будет показан ваш файл robots.txt, конечно если он есть на вашем сайте. И здесь же, сразу же, будет показано есть ли ошибки или предупреждения в вашем файле robots.txt.
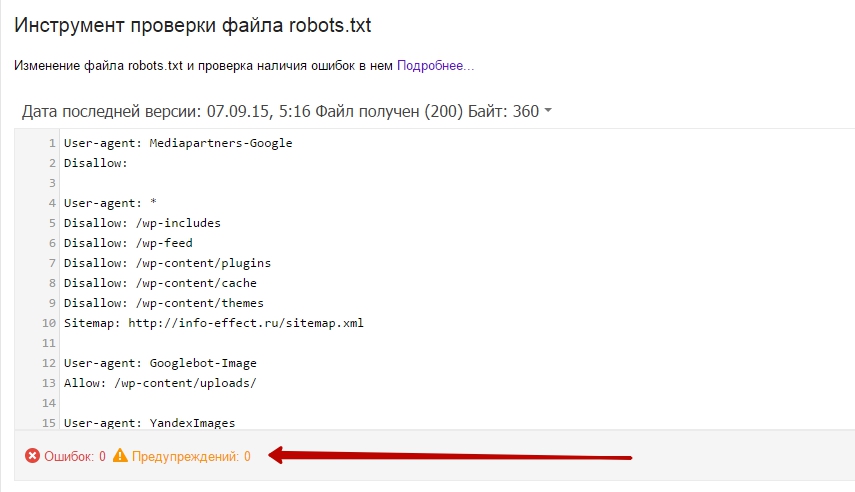
Как видите в моём файле – 0 ошибок и 0 предупреждений, а это значит можно закрывать сервис гугл вебмастер и идти гулять по своим делам. Дело сделано, да кстати, не забудьте так же проверить файл robots.txt в Яндекс вебмастер. Потому что мало ли что, у каждого поисковика свои заморочки. А у меня всё на этом, до новых встреч !
info-effect.ru
Google обновил инструмент проверки файлов robots.txt
5 мин 4828 просмотров 0
Google сообщил об обновлении инструмента проверки файла robots.txt в сервисе Webmaster Tools. Усовершенствованную версию инструмента можно найти в разделе «Сканирование:
«Файл robots.txt — один из ключевых компонентов поисковой оптимизации сайтов, однако иногда он приносит больше вреда, чем пользы. В частности, этот самый файл может блокировать для роботов поисковых систем обход (сканирование) важных страниц сайта. Кроме того, robots.txt может препятствовать индексированию сайта в целом»,
Целью обновления инструмента Google как раз таки и является упрощение обнаружения и исправления ошибок в файле robots.txt, а также облегчение поиска директив, блокирующих индивидуальные URL-адреса, внутри единого большого файла.
Возможности модернизированного инструмента
Новая версия инструмента тестирования файла robots.txt в Google Webmaster Tools позволяет проверять новые URL-адреса на предмет их запрещённости к сканированию поисковыми роботами. Вебмастерам больше не придётся искать нужную строчку в длинном и сложном списке директив — инструмент сам подсветит указание для робота, нуждающееся в пересмотре и принятии окончательного решения.
Владельцы сайтов могут внести изменения в файл и тут же их протестировать: для этого надо всего-навсего загрузить обновлённую версию robots.txt на сервер.
Кроме того, модернизированная версия инструмента позволяет просматривать предыдущие версии файла robots.txt и проверять, когда и в связи с чем у сканирующих роботов Google возникли проблемы с доступом к определённым страницам сайта. По словам представителя команды Webmaster Tools Асафа Арнона (Asaph Arnon), Googlebot может взять паузу в сканировании сайта, если, к примеру, обнаружит внутреннюю ошибку сервера 500 для файла robots.txt.
Google советует дважды проверять файл robots.txt во избежание пропуска ошибок или важных предупреждений сервиса о нарушениях в сканировании и индексировании ресурса. Вебмастера также могут совмещать использование инструмента проверки файла robots.txt с другим функционалом Webmaster Tools: например, с обновлённым инструментом «Просмотреть как Googlebot», предоставляющим информацию об HTTP-ответе сервера, дате и времени сканирования, проблемах с доступом к картинкам, мобильному контенту, JavaScript и CSS файлам.
Понравилась статья? Поделись ей в социальных сетях:
Возможно, вам понравится:
Наглядное пособие по Paid, Owned и Earned MediaПока компания Netpeak работает над созданием первого SEO-словаря в отечественной истории, английские специалисты из Media Octopus продолжают объяснять смысл профессиональных терминов на общедоступном языке визуальных образов. На днях digital-агентство поделилось с аудиторией маркетологов своей новой инфографикой
13971 просмотров 0
 Google перейдет на новую модель рекламы
Google перейдет на новую модель рекламыТеперь рекламодатели будут платить только за видимые показы объявлений
10552 просмотров 0
 Поисковые системы Yandex vs Google
Поисковые системы Yandex vs Google «Погуглить» или
«пробить по Яндексу»?..
В качестве стартовых страниц при входе в Сеть россияне чаще всего выбирают поисковые порталы. Всего поисковиков в России под сотню. На слуху, если верить опросам общественного мнения, в лучшем случае, шесть-семь. Выясняла, где ищут нужную информацию наши соотечественники, Карина Нараевская.
8692 просмотров 0
 Google поможет привязать Android-приложение к сайту
Google поможет привязать Android-приложение к сайтуЧтобы пользователи планшетов и смартфонов из поисковой выдачи направлялись на мобильную версию контента, необходимо связать страницы веб-сайта с релевантными ими разделами приложения и помочь Google с индексацией глубоких ссылок
8674 просмотров 0

Google обновляет правила для robots.txt. Что изменится и что делать? || Блог Megaindex.com
Поисковые краулеры сканируют любой сайт согласно правилам, которые прописаны в файле robots.txt.Правила прописываются на основе протокола Robots Exclusion Protocol.
Google внес изменения в данный протокол. Например, теперь не поддерживается директива noindex.
Что еще изменяется и что делать?
Разберемся с вопросами далее.
Что произошло?
Поисковые оптимизаторы создают директивы для поисковых краулеров согласно правилам протокола Robots Exclusion Protocol. Такие директивы прописываются в файле robots.txt.
На протяжении 25 лет протокол REP являлся важным инструментом для поисковых оптимизаторов, так как позволял запрещать различным роботам доступ к некоторым страницам сайта.
Итак, используя директивы в файле robots.txt можно отсечь часть различных роботов, что приводит к снижению нагрузки на сайт. Как результат, у пользователей сайт открывается быстрее. Еще уменьшаются расходы на поддержку пропускного канала.
Поисковые системы такие как Yandex, Bing и Google следовали правилам из robots.txt.
Но протокол не был закреплен на официальном уровне.
Утверждает такие протоколы на официальном уровне организация под названием Internet Engineering Task Force (Инженерный совет интернета).
Ссылка на сайт — IETF.
Так как стандарт не был закреплен, то и правила обработки были не всегда понятными для всех.
Google решил задокументировать протокол REP и направил стандарт в соответствующую организацию на рассмотрение и регистрацию.
Такие действия призваны решить ряд целей:
- Расширить базу функциональных возможностей, чтобы можно было задавать более точные правила;
- Определить четкие стандарты, чтобы избежать различных спорных сценариев по использованию. В результате все причинно-следственные связи по использованию файла robots должны стать ясными для всех.
Что изменяется?
Список из наиболее существенных изменений:
- Теперь директивы можно использовать для любого URI. Например, теперь помимо HTTP/HTTPS правила можно применять к FTP или CoAP;
- Поисковые краулеры должны сканировать первые 512 килобайт файла. Роботы могут, но не обязаны сканировать весь файл если файл большой. Также роботы не обязаны сканировать весь файл, если соединение не стабильное;
- Размещенные в файле директивы подлежат кешированию. Делается так, чтобы не нагружать сервер запросами. По умолчанию кеширование проводится на срок не более чем 24 часа, чтобы дать возможность поисковому оптимизатору в приемлемые сроки обновлять файл. Значение по кешированию можно задавать самостоятельно используя директиву кеширования посредством заголовка Cache-Control;
- Если файл не доступен, то директивы продолжают работать. Спецификация предусматривает, что если файл robots.txt стал не доступен для поискового краулера, то правила описанные ранее будут продолжать действовать еще на протяжении длительного времени.
Далее были пересмотрены директивы, которые допускаются к использованию в файле robots.txt.
Правила, которые не опубликованы в стандарте, не будут поддерживаться Google.
В результате правило noindex больше не будет поддерживаться Google.
Поддержка отключается с 1 сентября 2019 года.
Еще был открыт исходный код парсера robots.txt. Данный парсер используется краулером Google для парсинга данных из robots.txt.
Ссылка на код — Google Robots.txt Parser and Matcher Library.

Если покопаться в коде, то можно найти информацию о том, что директива disallow будет работать, даже если ключевая фраза написана с опечаткой. Значит, указывать на такие ошибки в аудите сайта является бессмысленной затеей 🙂

Что делать?
Теперь для реализации noindex на практике следует использовать такие способы:
- Задавать noindex в мета-теге robots;
- Задавать noindex в HTTP заголовках.
Директива noindex является наиболее эффективным способом для удаления страниц из индекса.
Как задать директиву через HTTP заголовок? Требуется использовать заголовок X-Robots-Tag.
К примеру, если требуется запретить индексацию страницы indexoid, следует указать так:
X-Robots-Tag: noindex
Если есть только доступ к шаблону сайта, следует использовать мета-тег robots. Например, если для сайта 2yachts.com требуется запретить индексацию страниц, следует использовать такой код:
<meta name="googlebot" content="noindex">
Данный код указывает на запрет индексации для Google.
Если требуется запретить индексацию для разных ботов, а не только для Google, то в name следует использовать значение robots вместо googlebot.
Пример:
<meta name="robots" content="noindex">
Какой способ для удаления страниц из индекса поисковой системы является наиболее эффективным? Наиболее эффективным является манипуляция с кодом ответа. Если для страницы задать код ответа 404 или 410, то страница будет удалена из индекса поисковой системы.
Как задать время на которое файл robots.txt будет кешироваться? Следует использовать заголовок Cache-Control.
Например:
Cache-Control: max-age=[секунды]
Директива задает период времени, в течение которого скачанный ответ может быть повторно использован.
Отсчет начинается с момента запроса.
max-age=[n секунд] означает, что ответ может быть закеширован и использован в течение n секунд.
Применив на практике вариант с кешированием процесс обработки файла будет выглядеть так:

Вопросы и ответы
Как проверить правильность настройки robots.txt?
Проверить директивы из файла robots.txt на валидность можно используя инструментарий для тестирования от Google.
Инструмент бесплатный.
Тест позволяет выявить проблемы в синтаксисе и сигнализирует на тему предупреждений, если такие есть.
Ссылка на инструмент — Google Robots.txt Tester.
И обратите внимание, что ссылки в файле robots.txt чувствительны к регистру.
Например такие ссылки считаются разными:
- ru.megaindex.com/SEO
- ru.megaindex.com/seo
Тест делает проверку как валидатор, поэтому на подобные нюансы не указывает.
Поддерживают ли другие поисковые системы noindex?
Yandex и Bing не поддерживают директиву в robots.txt.
Yandex рекомендует использовать noindex в метатеге robots или X-Robots-Tag.
Нужно ли закрывать файлы CSS и JavaScript в robots?
Файлы стилей и скрипты закрывать не рекомендуется.
В поисковой системе используется рендеринг сайта. Рендеринг происходит перед ранжированием. Если запретить доступ к стилям и скриптам, поисковая система все равно проведет рендеринг сайта, но результат будет не корректным, что скажется на позициях в поисковой выдаче.
Весь процесс до старта алгоритма ранжирования выглядит так:

Рекомендованные материалы в блоге MegaIndex по теме краулинга страниц сайта поисковыми системами по ссылкам далее:
Влияет ли запрет robots.txt на краулинговый бюджет?
На краулинговый бюджет влияют два главных фактора:
- Авторитетность доменного имени;
- Пропускная способность сервера сайта.
Авторитетность сайта зависит от качества внешней ссылочной массы.
Выгрузить и проанализировать список всех внешних ссылок по любому сайту можно используя сервис MegaIndex.
Ссылка на сервис — Внешние ссылки.

Еще в MegaIndex есть методы API, позволяющие обращаться к базе для выгрузки данных. Пример запроса к базе MegaIndex через API для сайта wixfy.com:
api.megaindex.com/backlinks?key=[ключ]&domain=wixfy.com&link_per_domain=1&offset=0&count=100&sort=link_rank&desc=1
Директивы в robots.txt не меняют значение по краулинговому бюджету.
Если посредством директивы Disallow в robots.txt исключается часть ненужных страниц, то краулинговый бюджет расходуется более рационально, что качественно влияет на индексацию сайта.
Как прописывать правила в robots.txt для поддоменов?
Директивы robots.txt распространяются только на верхний уровень хоста.
Например, если файл размещен на хосте smmnews.com, то все директивы будут применимы лишь для smmnews.com. Директивы не будут применены для www.smmnews.com и подобных хостов.
Указывать в файле robots.txt не имеет смысла.
Для указания директив на поддоменах файл robots.txt следует размещать на поддомене.
Выводы
25 лет директивы robots.txt использовались де-факто, но не были зафиксированы как стандарт. Теперь стандарт будет создан, а значит появится официальная документация и будет снята неопределенность по нюансам.
Например, теперь определен оптимальный размер файла — до 512 килобайт.
Если размер файла превышает пороговое значение, то директивы после 512 килобайт не учитываются.
Теперь протокол Robots Exclusion Protocol станет стандартом для интернета.
Вариант в виде черновика — Robots Exclusion Protocol.
Google больше не станет поддерживать директиву noindex, если ее использовать в файле robots.txt.
Для запрета индексации используйте заголовок или специальный мета-тег.
Новые сайты до запуска следует закрывать от индексации на уровне сервера.
Если сайт переведен на HTTPS, следует провести проверку на предмет доступности файла robots.txt по протоколу HTTPS. Если сайт переведен на HTTPS, но файл robots.txt доступен только по HTTP, то директивы для HTTPS страниц сайта действовать не будут.
Рекомендованный материал в блоге MegaIndex по теме перевода сайта на HTTPS по ссылке далее — Зачем и как перевести сайт на HTTPS бесплатно и без ошибок?.
Если говорить о практике, то в сухом остатке список действий следующий:
- Удалить из файла robots.txt директивы noindex;
- Разместить noindex в заголовке X-Robots-Tag или мета-теге с значением content=»noindex»;
- Если файл превышает 512 килобайт, то уменьшить размер файла за счет использование масок;
- Удалить из файла директивы на запрет индексации CSS и JavaScript файлов;
- Если требуется убрать страницу из индекса и запретить индексацию, следует использовать 404 или 410 код ответа;
- Задать время кеширования файла через Cache-Control.
Остались ли у вас вопросы, замечания или комментарии по теме robots.txt?
Интересно ли вам было бы узнать подробную информацию про краулинговый бюджет?
ru.megaindex.com
Правильный файл Robots.txt для WordPress (Яндекс, Google)
Содержание статьи:
Здравствуйте! После того как мы разобрались с правильной структурой сайта настало время поговорить о robots.txt, что это такое и с чем его едят. Кроме того, из данной статьи вы узнаете, каков он, идеально правильный robots.txt для WordPress, как с его помощью запретить индексацию сайта или разрешить всё.
Robots.txt – что это такое?

Файл robots.txt – это файл, с помощью которого можно выставить запрет на индексацию каких-либо частей сайта или блога поисковым роботом.
Создается единый стандартный robots txt для Яндекса и для Google, просто вначале прописываются запреты для одной поисковой сети, а затем для другой. В принципе в нём можно прописать параметры для всех поисковых систем, однако, зачастую не имеет смысла это делать, т.к. конкретно для России основными считают Яндекс и Гугл, с остальных поисковых систем трафик настолько мал, что ради них нет необходимости прописывать отдельные запреты и разрешения.
Зачем он нужен?
Если вы сомневаетесь нужен ли robots txt вообще, то ответ однозначный – ДА. Данный файл показывает поисковым системам куда им ходить нужно, а куда нет. Таким образом, с помощью «Роботса» можно манипулировать поисковыми системами и не давать индексировать те документы, которые вы бы хотели оставить в тайне.
Важно! К файлу robots txt Яндекс относится, так сказать, с уважением, он всегда учитывает все нововведения и поступает так, как указано в файле. С Google ситуация сложнее, чаще всего поисковый гигант игнорирует запреты от «Роботса», но тем не менее лично я рекомендую всё равно прописывать все необходимые данные в этот файлик.
Зачем не пускать поисковики к каким-то файлам или директориям?
- Во-первых, некоторые директории (например теги в WordPress или страницы пагинации) оставляют много “мусора” в выдаче, что негативно сказывается на самом сайте.
- Во-вторых, быть может вы разместили неуникальный контент, но очень нужно, чтобы он был на сайте, с помощью robots.txt можно не дать поисковому роботу добраться до такого документа.
Где находится?
Файл robots.txt располагается в корне сайта, т.е. он всегда доступен по адресу site.ru/robots.txt. Так что если вы раньше не знали, как найти robots txt на сайте, то теперь вы с лёгкостью сможете посмотреть и возможно отредактировать его.
Зная, где находится данный файл, вы теперь без труда сможете заменить старый и добавить новый robots.txt на сайт, если в этом есть необходимость.
Robots txt для WordPress

Правильный robots.txt для WordPress вы можете скачать с моего блога, он располагается по адресу //vysokoff.ru/robots.txt . Это идеальный и правильно оформленный «Роботс», вы можете добавить его к себе на сайт.
После того как вы скачали мой robots.txt для WordPress, в нём необходимо будет исправить домен на свой, после этого смело заливайте файлик к себе на сервер и радуйтесь тому, как из поисковой выдачи выпадают ненужные «хвосты».
Кстати, не пугайтесь, если после 1-2 АПов Яндекса у вас вдруг резко сократится количество страниц в поисковой выдаче. Это нормально, даже наоборот – это отлично, значит ваш robots.txt начал работать и в скором времени вы избавитесь от не нужного хлама, который раньше висел в SERP’e.
Так что если вы не знаете, как создать robots txt для WordPress самостоятельно, то рекомендую просто скачать готовый вариант с моего блога, лучше вы вряд ли составите.
Теперь давайте поговорим о том, как полностью закрыть от индексации весь сайт с помощью данного чудо-файлика или наоборот, как разрешить всё, используя robots.txt.
Пример Robots.txt: disallow и allow, host и sitemap

Как было сказано выше, с помощью robots txt можно как запретить индексацию сайта, так и разрешить всё.
Disallow
Данной командой вы закроете весь сайт от индексации поисковых систем. Выглядеть это будет так:
User-agent: *
Disallow: /
Таким образом, вы полностью закроете сайт от индексации. Для чего это делать? Ну, например, как я рассказывал ранее, в статье про стратегию наполнения нового сайта. Изначально вы добавляете файл robots.txt в корень сайта и прописываете код, который указан выше.

Артём Высоков
Автор блога о SEO и заработке на сайтах — Vysokoff.ru. Продвигаю информационные и коммерческие сайты с 2013 года.
Задать вопрос Загрузка …
Загрузка …Добавляете необходимое количество статей, а затем, скачав мой идеальный robots txt, открываете от индексации только необходимые разделы на сайте или блоге.
Чтобы в robots txt разрешить всё, вам необходимо написать в файле следующее:
User-agent: *
Disallow:
Т.е. убрав слэш, мы показываем поисковым системам, что можно индексировать абсолютно всё.
Кроме того, если вам необходимо закрыть какую-то конкретную директорию или статью от индексации, необходимо просто дописывать после слэша путь до них:
Disallow: /page.htm
Disallow: /dir/page2.htm
Allow
Данный параметр наоборот открывает для индексации какую-то конкретную страницу из закрытой Disallow директории. Пример:
Disallow: /dir/
Allow: /dir/ page2.htm
Прописываем Host и карту сайта
В конце файла robots txt вам необходимо прописать два параметра host и sitemap, делается это так:
Host: www.site.ru
Sitemap: www.site.ru/sitemap.xml
Host указывается для определения правильного зеркала сайта, а второе помогает роботу узнать, где находится карта сайта.
Проверка Robots.txt Яндексом и Google
После того как вы сделали правильный robots.txt и разместили его на сайте, вам необходимо добавить и проверить его в вебмастере Яндекса и Гугла, кстати, о том, как добавить сайт в вебмастеры этих поисковых систем я уже писал.
Чтобы проверить Robots.txt Яндексом необходимо зайти в https://webmaster.yandex.ru/ —> Настройка индексирования —> Анализ robots.txt.
В Google заходим http://google.ru/webmasters —> Сканирование —> Инструмент проверки файла robots.txt
Таким образом вы сможете проверить свой robots.txt на ошибки и внести необходимые коррективы, если они есть.
Резюме
Ну вот, думаю, мне удалось объяснить вам, что такое robots.txt, для чего он нужен. Кроме того, напоминаю, скачать файл robots txt вы можете здесь.
В следующий раз я расскажу вам о супер-плагине WordPress SEO by Yoast, без которого, я считаю, нельзя начинать успешное продвижение сайта.
vysokoff.ru
Robots.txt для Google и его особенности


Особая обработка роботс.тхт Гуглом
Чуть менее года назад обнаружил интересное отличие в обработке Robots.txt Гуглом по сравнению с обработкой этого файла Яндексом. По моим наблюдениям, об этом вообще почти никто не знает, хотя вещь важная.
Как известно, лишние страницы сайта в индексе всё портят (дубли, например). Если кое-что знать и подкорректировать данный файл, то можно выкинуть «мусор» из индекса Гугла и немного улучшить ранжирование сайта.
Интересная особенность обработки Robots.txt в Google и отличие от Яндекса
Суть в том, что если Гугл проиндексировал страницу сайта, а потом она была запрещена к индексации в Robots.txt, то она так и будет болтаться в индексе.
В Яндексе — всё не так. Если проиндексированную ранее страницу запретить к индексации в Robots.txt, то со временем Яндекс выкинет её из индекса.
Я заметил это, когда увидел, что для одного моего WordPress-сайта в индексе Гугла висят страницы-теги, т.е. http://site.ru/tag/xxx/, которые я традиционно запрещаю к индексации в Robots.txt.
Как оказалось, в официальной справке есть об этом информация, правда, написано всё не очень явно:
Googlebot не будет напрямую индексировать содержимое, указанное в файле robots.txt, однако сможет найти эти страницы по ссылкам с других сайтов. Из-за этого в результатах поиска Google могут появиться URL и другие общедоступные сведения – например, текст ссылок на сайт
— т.е. даже если страница запрещена к индексации в файле Robots.txt, но на неё есть внешняя ссылка, то Гугл может её проиндексировать.
Таким образом, если вы, например, создаёте новый сайт, что-то там тестируете, делаете пробные страницы и т.п., а Гугл уже успел всё это проиндексировать, то это так и будет находиться в индексе, даже если в будущем вы это запретите в Robots.txt.
Как проверить наличие запрещённых страниц в индексе?
Тут всё просто, 3 варианта:
- Заходим на запрещённую страницу и проверяем её индексацию с помощью всяких плагинов для браузера, например, RDS bar.
- Вводим соответствующий поисковый запрос в Гугле для проверки индексации: site:http://site.ru/page.html (подробнее об этом в статье про дополнительный индекс Гугла).
- Аналогично предыдущему пункту, но проверяем индексацию всего сайта, и в результатах выдачи отыскиваем запрещённые страницы: site:site.ru/
Так что проверьте. Скорей всего, часть страниц вашего сайта будет находиться в Supplemental Index из-за того, что Гугл не хочет выкинуть их из индекса.
Как исправить?
На мой взгляд, есть 2 варианта.
Удаление ненужных страниц из индекса вручную, оставляя «запреты» в Robots.txt
Пользуемся стандартным инструментом удаления URL — подробно рассказано в статье про удаление страниц из поиска. Тут можно удалять страницы поодиночке, а можно сразу весь раздел (например, указать http://site.ru/tag/ — и все страницы-теги будут удалены).
Убираем все «запреты» в Robots.txt и применяем meta name=robots
Суть здесь такая: запрещаем индексацию страниц с помощью мета-тега robots. Например, делаем так, чтобы на всех страницах-тегах выводилось бы

Важно! В этом случае следует убрать запрещающее правило в Robots.txt (оно могло быть, например, таким Disallow: /tag/). Иначе робот Гугла не пойдёт по этому адресу, а значит и не узнает, что его не нужно индексировать. Такая вот тут особенность.
Из официальной справки:
Поисковый робот не обнаружит атрибут noindex, если страница заблокирована в файле robots.txt. Такая страница будет отображаться в результатах поиска.
Как сделать правильный Robots.txt для Google?
Собственно, всё как обычно, но только с учётом вышесказанного. См. подробное руководство:
Если сайт создаёте новый, то лучше прописывать запрещающие мета-теги вместо запретов в Robots.txt. Ну а для старого сайта возможно придётся повозиться с удалением страниц вручную.
 Loading…
Loading… 
web-ru.net