
Как составить файл robots.txt | SEO-notes
Как составить файл robots.txt
Подробная инструкция по составлению файла robots.txt с готовыми примерами. С помощью инструкции вы сможете создать эффективный robots.txt и улучшить индексацию вашего сайта.
Файл robots.txt позволит улучшить индексацию вашего сайта и исключить из индекса лишние страницы, которые могут негативно сказаться на ранжировании сайта.
Подробнее о том, для чего нужен robots.txt читайте в статье Для чего нужен файл robots.txt.
Чтобы файл robots.txt эффективно решал свою задачу необходимо придерживаться правил составления robots.txt и соблюдать синтаксис файла.
Подробнее познакомиться с правилами вы сможете в статье Синтаксис и правила составления файла robots.txt.
Ниже приведена пошаговая инструкция по составлению файла robots.txt.
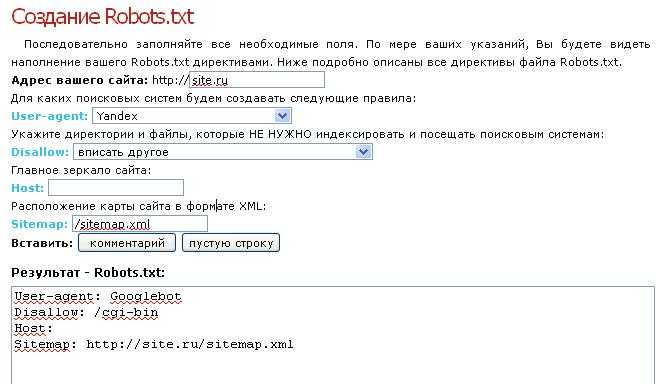
Robots.txt — это текстовый файл в кодировке UTF-8.
Для составления файла robots. txt можно использовать любой текстовый редактор.
txt можно использовать любой текстовый редактор.
Укажите User-Agent
В первой строке файла robots.txt необходимо указать User-Agent, для которого будут прописаны правила. Пропишите User-Agent: и добавьте название поискового робота.
Пример:
User-Agent: Googlebot
Если на правила в файле robots.txt необходимо реагировать всем роботам укажите всех User-Agent с помощью символа *:
User-Agent: *
Подробнее с User-Agent вы можете ознакомиться в статье User-Agent robots.txt.
Добавьте запрещающие директивы Disallow
После указания User-Agent необходимо разместить запрещающие директивы Disallow.
Закройте от индексации страницы, которые не содержат полезной информации для пользователей, например:
- Служебные файлы и папки
- Страницы результатов поиска
- Страницы сортировки
- Страницы фильтров (в некоторых случаях)
- Страницы с результатами поиска по сайту
- Личный кабинет
- Корзину
- Страницы, которые содержат данные о пользователях
- Страницы оформления заказа
Пример:
#сообщаем, что правило в robots. txt действуют для всех роботов
txt действуют для всех роботов
User-agent: *
#закрываем всю папку со служебными файлами
Disallow: /bitrix/
#закрываем сортировку на всех страницах сайта
Disallow: /*sort=
#закрываем страницы результатов поиска с любым значением после =
Disallow: /*search=
#закрываем корзину
Disallow: /basket/
#закрываем страницы оформления заказа
Disallow: /order
#закрываем личный кабинет
Disallow: /lk/
#закрываем страницы фильтров в каталоге
Disallow: /filter/
Подробнее о том, как закрыть страницы сайта для индексации читайте в статье Как запретить индексацию сайта или страницы в robots.txt.
Добавьте разрешающие директивы Allow
Если в ранее закрытых папках находятся страницы или файлы, которые необходимо проиндексировать, например изображения, PDF документы, необходимо добавить разрешающие директивы.
Также необходимо открыть для индексации скрипты и стили.
Пример:
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Важно! Разрешающие директивы должны быть длиннее запрещающих.
User-agent: *
#разрешаем индексировать изображения и PDF документы, которые лежат в закрытой папке /bitrix/upload/
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
#далее идут ранее составленные закрывающие директивы
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Добавьте Clean-param для Яндекса
В правилах Clean-param необходимо указать динамические параметры, которые не влияют на содержание страницы, например рекламные метки.
Пример:
Clean-param: utm_&k50id&cm_id&from&yclid&gclid&_openstat
Правило Clean-param действует только для Яндекса, в связи с этим необходимо указать User-Agent для которого предназначено данное правило:
User-agent: *
Allow: /bitrix/upload/*. png
png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
User-agent: Yandex
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Clean-param: utm_&k50id&cm_id&from&yclid&gclid&_openstat
Подробнее о том, что такое Clean-param и как правильно прописать правило читайте в статье Директива Clean-param в файле robots.txt.
Закройте от индексации страницы с динамическими параметрами в URL для Google
Правило Clean-param действует для поисковой системы Яндекс.
Чтобы страницы с динамическими параметрами не индексировались Google, необходимо закрыть от индексации страницы с метками, указав запрещающие директивы для всех остальных User-Agen.
Пример:
User-agent: *
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Disallow: /*utm_
Disallow: /*k50id
Disallow: /*cm_id
Disallow: /*from
Disallow: /*yclid
Disallow: /*gclid
Disallow: /*_openstat
User-agent: Yandex
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Clean-param: utm_&k50id&cm_id&from&yclid&gclid&_openstat
Добавьте ссылку на файл Sitemap. xml
xml
В файле robots.txt можно указать путь к xml-карте сайта. Это позволит ускорить индексацию новых страниц и страниц, на которые были внесены изменения.
User-agent: *
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Disallow: /*utm_
Disallow: /*k50id
Disallow: /*cm_id
Disallow: /*from
Disallow: /*yclid
Disallow: /*gclid
Disallow: /*_openstat
Sitemap: https://site.ru/sitemap.xml
User-agent: Yandex
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*. css
css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Clean-param: utm_&k50id&cm_id&from&yclid&gclid&_openstat
Sitemap: https://site.ru/sitemap.xml
Пожалуйста, оцените статью
Оставьте комментарий
Нажимая на кнопку, вы даете согласие на обработку персональных данных и соглашаетесь c политикой конфиденциальности.
Читайте далее
09-09-2022
Что такое файл robots.txt
Robots.txt – это стандарт исключений для поисковых роботов. В файле robots.txt приведены инструкции, которые сообщают поисковым роботам, какие URL запрещены или разрешены для индексации.
09-09-2022
Для чего нужен файл robots.txt
Robots.txt – это важный инструмент для улучшения индексации сайта. Файл robots.txt используется для управления трафиком поисковых роботов и указывает, какие страницы запрещены для индексации.
09-09-2022
Синтаксис и правила составления файла robots.txt
Файл robots.txt имеет определенный синтаксис и правила составления. Чтобы обеспечить эффективную работу файла robots.txt, необходимо четко придерживаться правилам составления robots.txt и соблюдать синтаксис.
09-09-2022
User-Agent в файле robots.txt
User-Agent – это идентификационная строка клиентского приложения, которая используется для приложений, поисковых роботов или пауков.
09-09-2022
Как запретить индексацию сайта или страницы в robots.txt
Чтобы удалить из поисковой выдачи Яндекса и Google весь сайт или отдельные разделы и страницы, необходимо закрыть их от индексации. Тогда страницы постепенно будут исключены из индекса и не будут отображаться в поиске. Закрыть страницы от индексации можно с помощью файла robots.txt.
12-09-2022
Как проверить файл robots.txt
С помощью файла robots.txt можно улучшить индексацию сайта. При этом файл robots. txt должен соответствовать требованиям поисковых систем. Для проверки корректности robots.txt используйте нашу инструкцию.
txt должен соответствовать требованиям поисковых систем. Для проверки корректности robots.txt используйте нашу инструкцию.
02-09-2022
Директива Clean-param в файле robots.txt
Clean-param — директива robots.txt, поддерживаемая роботами Яндекса. Clean-param позволяет сообщать о динамических параметрах, которые присутствуют в URL-адресах страниц (например, рекламные метки).
13-09-2022
Ошибки при составлении файла robots.txt
При продвижении сайтов мы часто замечаем ошибки в файле robots.txt, которые негативно влияют на ранжирование сайта. Рассказываем, какие ошибки бывают в robots.txt и как их исправить.
| Показать еще |
Автор статьи
Дмитрий Лашманов
SEO-специалист
Опыт работы в SEO 4 года
60+ реализованных проектов
Дополнительные курсы:
SEO в СНГ — Rush Agency
SEO на запад — Rush Agency
UX/UI-дизайн — Skillbox
Школа экспертов Нетологии
Примеры robots.
 txt WordPress для Яндекса и Google. Как правильно составить robots.txt
txt WordPress для Яндекса и Google. Как правильно составить robots.txtВ сегодняшнем видео уроке по WordPress SEO я расскажу и покажу на примерах особенности создания и использования файла robots.txt для WordPress, этот урок не планировался как исчерпывающее руководство по robots.txt, но он должен дать вам хорошее представление о том что это за файл и что туда добавлять для минимизации попадания ненужных файлов в индекс поисковых систем и как его использовать для управления тем как поисковые роботы Google и Яндекс индексируют ваш сайт. Если у вас возникнут вопросы — пишите в комметариях, ниже привожу текстовый транскрипт видео, на тот случай если у вас возникнут вопросы или будет нужен фрагмент кода в текстовом виде.
Текстовый транскрипт видео:
Оглавление
- 1 Для чего нужен файл robots.txt
- 2 Пример robots.txt для WordPress
- 3 Проверка robots.txt в Google Webmaster Tools
- 4 Проверка robots.txt в Яндекс Вебмастер
- 5 Заключение
Здравствуйте,
Меня зовут Дмитрий, и в этом видео вы узнаете о том, как контролировать индексирование вашего сайта поисковыми системами с помощью файла robots.txt. Плюс в качестве примера мы разберем robots.txt для WordPress, который минимизирует индексирование ненужных файлов поисковыми системами. Итак, приступим.
Для чего нужен файл robots.txt
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции, запрещающие посещение и индексирование отдельных разделов сайта. robots.txt предназначен для использования ботами, в качестве примера ботов можно назвать поисковых роботов Яндекса и Google или ботов архиваторов, как например робот Web Archive.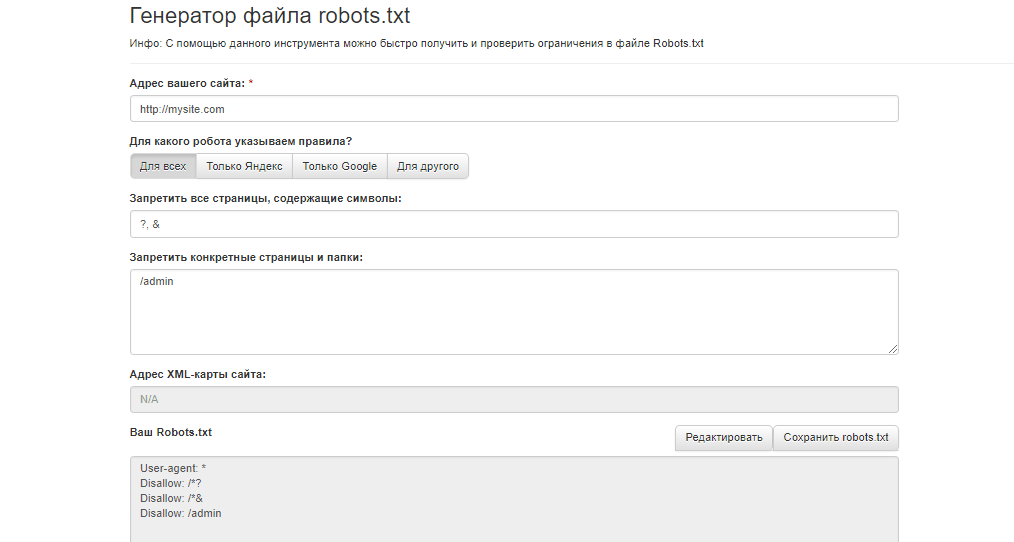
Для создания robots.txt воспользуйтесь любым текстовым редактором, заполните его в соответствии с вашими пожеланиями и примерами в этом видео и сохраните как просто тест без форматирования, расширение файла должно быть .txt. После этого необходимо загрузить файл в корневой каталог вашего сайта.
Используйте файл robots.txt для ограничения поисковых роботов от индексации отдельных разделов вашего сайта. Вы можете указать параметры индексирования своего сайта как для всех роботов сразу, так и для каждой поисковой системы в отдельности, используя директиву User-Agent. Для списка роботов популярных поисковых систем перейдите по ссылке в описании этого видео.
Пример robots.txt для WordPress
В качестве примера robots.txt для WordPress, который минимизирует индексирование ненужных файлов поисковыми системами, вы можете использовать следующий шаблон:
User-Agent: * Disallow: /wp-content/plugins/ Disallow: /wp-content/themes/ Disallow: /wp-admin/ Disallow: /*.swf Disallow: /*.flv Disallow: /*.pdf Disallow: /*.doc Disallow: /*.exe Disallow: /*.htm Disallow: /*.html Disallow: /*.zip Allow: /
 swf
Disallow: /*.flv
Disallow: /*.pdf
Disallow: /*.doc
Disallow: /*.exe
Disallow: /*.htm
Disallow: /*.html
Disallow: /*.zip
Allow: /
swf
Disallow: /*.flv
Disallow: /*.pdf
Disallow: /*.doc
Disallow: /*.exe
Disallow: /*.htm
Disallow: /*.html
Disallow: /*.zip
Allow: /
Давайте разберем по порядку, что здесь написано. Строчка User-Agent: * говорит, что это относится к любым агентам, к любым поисковым системам, к любым ботам, которые посещают сайт. Строчки, начинающиеся с Disallow: — это директивы, запрещающие индексирование какой-либо части сайта. Например, строчка Disallow: /wp-admin/ запрещает индексирование папки /wp-admin/, любых файлов, которые находятся в папке /wp-admin/. Сейчас у нас запрещены к индексированию папки – плагины, темы и wp-admin (/plugins/ /themes/ /wp-admin/). Директива Disallow: /*. и расширение файла запрещает к индексированию определенный тип файлов. В данный момент запрещены к индексированию .swf, *.flv, *.pdf, *.doc, *.exe, *.js, *.htm, *.html, *.zip. Последняя строчка Allow: / разрешает индексирование любых других частей сайта и любых других файлов.
Если вы используете плагин кеширования, который генерирует статичные версии ваших страниц или структуру постоянных ссылок, оканчивающуюся .htm/.html, уберите строчки
Disallow: /*.htm Disallow: /*.html
В общем, если в адресной строке браузера адреса ваших страниц заканчиваются на .htm или .html, то уберите эти две строчки из robots.txt, иначе вы запретите к индексированию большую часть вашего сайта. Если вы хотите открыть все разделы сайта для индексирования всем роботам, то можете использовать следующий фрагмент:
User-agent: * Disallow:
Так как помимо полезных ботов (например, роботы поисковых систем, которые соблюдают директивы указанные в robots.txt) ваш сайт посещается вредными ботами (спам боты, скрейперы контента, боты которые ищут возможности для инъекции вредоносного кода), которые не только не соблюдают правила, указанные в robots.txt, а, наоборот, посещают запрещенные папки и файлы с целью выявления уязвимостей и кражи пользовательских данных. В таком случае если вы не хотите явно указывать адрес папки или файла, запрещенного к индексированию, вы можете воспользоваться директивой частичного совпадения. Например, у вас есть папка /shop-zakaz/, которую вы хотите запретить к индексированию. Для того, чтобы явно не указывать адрес этой папки для скрейперов и ботов шпионов вы можете указать часть адреса:
В таком случае если вы не хотите явно указывать адрес папки или файла, запрещенного к индексированию, вы можете воспользоваться директивой частичного совпадения. Например, у вас есть папка /shop-zakaz/, которую вы хотите запретить к индексированию. Для того, чтобы явно не указывать адрес этой папки для скрейперов и ботов шпионов вы можете указать часть адреса:
Disallow: *op-za*
или
Disallow:*zakaz*
Символ * заменяет произвольное количество символов, тогда любые папки и файлы, содержащие в своем названии эту комбинацию, будут запрещены к индексированию. Старайтесь выбирать часть адреса, который уникален для этой папки, потому что если эта комбинация встретится в других файлах и папках, вы запретите их к индексированию.
Для того, чтобы случайно не запретить к индексированию нужную часть сайта всегда имеет смысл проверить, как поисковые системы воспринимают правила, указанные в вашем robots.txt. Если вы — подтвержденный владелец сайта в инструментах вебмастера Google или Яндекс — вы можете воспользоваться встроенными инструментами для проверки правил robots.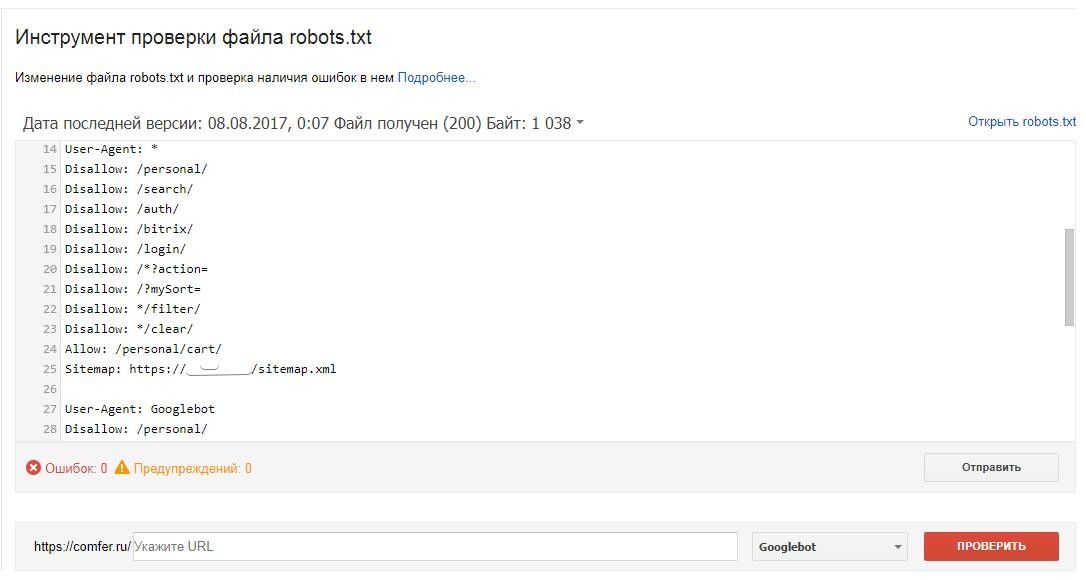
Для того, чтобы проверить robots.txt в Google Webmaster Tools перейдите в секцию «Crawl>Blocked URLs», здесь вы можете воспользоваться текущей версией robots.txt или же отредактировать ее, чтобы протестировать изменения, затем добавьте список URL, которые вы хотите протестировать и нажмите на кнопку «Проверить». Результаты теста покажут, какие из указанных URL разрешены к индексированию, а какие запрещены.
Проверка robots.txt в Яндекс ВебмастерДля того, чтобы проверить robots.txt в Яндекс Вебмастер перейдите в секцию «Настройка индексирования>Анализ robots.txt», при необходимости внесите изменения в robots.txt, добавьте список URL и нажмите кнопку «Проверить». Результаты теста покажут, какие из указанных URL разрешены к индексированию, а какие запрещены.
Редактируя правила составьте файл robots.txt, подходящий для вашего сайта. Помните, что файл на сайте при этом не меняется. Для того, чтобы изменения вступили в силу, вам потребуется самостоятельно загрузить обновленную версию robots.txt на сайт.
Для того, чтобы изменения вступили в силу, вам потребуется самостоятельно загрузить обновленную версию robots.txt на сайт.
Ну, вот мы и осветили основные моменты работы с robots.txt. Если вам нужны фрагменты и примеры файлов robots.txt, которые я использовал в этом видео, перейдите по ссылке, которая указана в описании этого видео. Спасибо за то, что посмотрели это видео, мне было приятно его для вас делать, буду вам благодарен, если вы поделитесь им в социальных сетях)) Ставьте «палец вверх» и подписывайтесь на новые видео.
Если у вас возникли проблемы с просмотром – вы можете посмотреть видео «Уроки WordPress — правильный файл robots.txt WordPress для Яндекса и Google» на YouTube.
Как составить правильный robots.txt для сайта на wordpress
Автор: Ксана
(Людмила Лунева)
Веб-дизайнер и разработчик сайтов на wordpress
Начало статьи читайте здесь »
Файл robots. txt — это служебный файл, в котором можно указать роботам ПС (поисковых систем), какие разделы сайта индексировать, а какие нет. Сделать это можно с помощью специальных директив. Директивы можно написать для всех роботов одновременно или отдельно для робота каждой ПС.
txt — это служебный файл, в котором можно указать роботам ПС (поисковых систем), какие разделы сайта индексировать, а какие нет. Сделать это можно с помощью специальных директив. Директивы можно написать для всех роботов одновременно или отдельно для робота каждой ПС.
Разделы, закрытые от индексации, не попадут в индекс поисковых систем.
Что такое Индекс?
Это база данных поисковой системы, в которой она хранит набор встречающихся на интернет-страницах слов и словосочетаний. Эта информация соотнесена с адресами тех веб-страниц, на которых она встречаются, и постоянно пополняется новой информацией, собираемой роботом-пауком поисковой системы.
Вообщем, robots.txt – это очень полезный и нужный любому сайту файл.
Общая для всех сайтов часть файла:
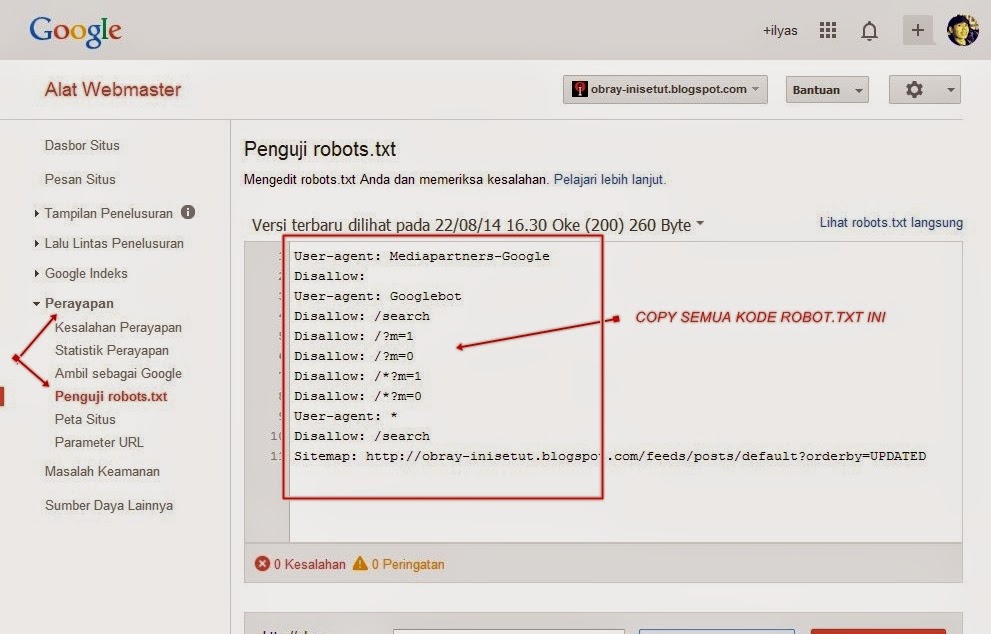
Итак, создаем текстовый документ с названием robots.txt и пишем в него следующее:
User-agent: * Disallow: /cgi-bin/ Disallow: /wp- Disallow: /*trackback Disallow: /feed Disallow: /?s= Disallow: /xmlrpc. |
 php
Allow: /wp-content/uploads/
Host: www.yourdomain.ru
Sitemap: http://yourdomain.ru/sitemap.xml
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
User-agent: ia_archiver
Disallow: /
php
Allow: /wp-content/uploads/
Host: www.yourdomain.ru
Sitemap: http://yourdomain.ru/sitemap.xml
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
User-agent: ia_archiver
Disallow: /Пояснения:
User-agent: * — Директива всем роботам
Если нужно, чтобы эти правила работали только для одного, конкретного робота, то вместо * указываем его имя (User-agent: Yandex, User-agent: Googlebot и т.д.).
Disallow: /cgi-bin/
Здесь мы запрещаем индексировать папку со скриптами.
- Disallow: /wp- — Запрещает индексацию всех папок и файлов движка, начинающихся с wp- (т.е. папок /wp-admin/, /wp-includes/, /wp-content/ и всех файлов, расположенных в корневой папке).
Disallow: /*trackback Disallow: /*comment- Disallow: /feed
Запрещаем индексацию комментариев, трекбеков и фида.
Спецсимвол * означает любую (в том числе пустую) последовательность символов, т.е. все, что находится в адресе до указанной части или после нее.- Disallow: /?s= — Запрещаем индексацию результатов поиска.
Allow: /wp-content/uploads/ — Разрешение индексировать папку uploads (а значит и расположенные в ней картинки).
Правило Яндекса для robots.txt гласит:
«Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то выбирается последняя в порядке появления в сортированном списке.»
Получается, что директиву Аllow можно указать в любом месте.
Яндекс самостоятельно сортирует список директив и располагает их по длине префикса.
Google понимает Allow и вверху и внизу секции.
Касательно директивы Allow: /wp-content/uploads/ — поскольку, далее мы разрешаем индексировать роботам-индексаторам картинок папку с картинками, я не уверена, что эта директива нужна.
Но, наверное, лишней не будет. Так что, это — на ваше усмотрение.Host: www.glavnoye-zerkalo.ru — Директива Host понимается только Яндексом и не понимается Гуглом.
В ней указывается главное зеркало сайта, в случае, если у вашего сайта есть зеркала. В поиске будет участвовать только главное зеркало.
Директиву Host лучше написать сразу после директив Disallow (для тех роботов, которые не полностью следуют стандарту при обработке robots.txt).
Для Яндекса директива Host являются межсекционной, поэтому будет найдена роботом не зависимо от того, где она указана в файле robots.txt.
Важно: Директива Host в файле robots.txt может быть только одна.
В случае указания нескольких директив, использоваться будет первая.Sitemap: http://mysite.ru/sitemaps.xml — Указываем путь к файлу sitemaps.xml
Для Яндекса и Google Sitemap — это межсекционная директива, но лучше написать ее в конце через пустую строку. Так она будет работать для всех роботов сразу.
User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
Разрешает роботам Googlebot и YandexImages индексировать наши картинки.
User-agent: ia_archiver Disallow: /
Полностью запрещаем роботу веб архива индексацию нашего сайта.
Это предупредительная мера, которая защитит сайт от массового парсинга контента через веб архив.

Итак, мы рассмотрели стандартную часть файла robots.txt, которая подойдет для любого сайта на wordpress.
Но, нам нужно спрятать от роботов-индексаторов еще некоторые разделы сайта, в частности, те, которые создают дублированный контент — разного рода архивы.
Индивидуальные настройки:
Если на вашем сайте есть система древовидных комментариев, как на моем блоге, тогда нужно запретить индексацию таких адресов:
*?replytocom=
Их создает кнопка (ссылка) «Ответить на комментарий».
- Страницы архивов на разных сайтах имеют различные адреса, в зависимости от того, как формируются URL на сайте, включены ли ЧПУ или нет.
Как определить адреса архивов вашего сайта?Для этого нужно открыть архив любого месяца и посмотреть, как выглядит адрес страницы архива.
Он может выглядеть, например, так: http://sait.ru/archives/date/post-1.
В этом случае, выделяем общую для всех архивов по дате часть адреса:
/archives/date/.
Соответственно, в файле robots.txt указываем:
Disallow: /archives/date/*
Например, архив года может иметь такой адрес: http://sait.ru/2012
Тогда закрывать нужно эту часть — /2012/
Напоминаю, что спецсимвол * означает любую последовательность символов, т.е. все, что находится в адресе далее. - Точно так же определяем адреса архивов тегов и архивов автора.
И закрываем их в robots.txt.Disallow: /archives/tag/ Disallow: /archives/author/
Рекомендую архивы тегов закрыть примерно на полгода-год, (если у вас молодой сайт) пока он стабильно пропишется в поисковой выдаче.
После этого срока архивы тегов стоит открыть для индексации, так как по наблюдениям, на страницы тегов по поисковым запросам приходит значительно больше посетителей, чем на страницы постов, к которым эти теги созданы.
Но, не добавляйте к постам много тегов, иначе вашему сайту будут грозить санкции за дублированный контент.
Один-два (редко три) тега к одному посту вполне достаточно. - Можно, также, закрыть индексацию всех главных страниц, кроме первой.
Обычно, их адреса выглядят так: http://sait.ru/page/2, http://sait.ru/page/3 и т. д., но лучше проверить.
Перейдите по ссылкам навигации внизу Главной страницы на вторую страницу и посмотрите, как выглядит ее адрес в адресной строке.
Закрываем эти страницы:
Disallow: /page/* Иногда, на сайте требуется закрыть от индексации еще какие то страницы или папки. В этом случае, действуете аналогично — открываете в браузере нужную вам страницу и смотрите ее адрес. А дальше закрываете его в robots.
txt.Учтите, что если вы закрываете, например, папку «book», то автоматически закроются и все файлы, расположенные в этой папке.
Если закрыть страницу, в URL’е которой есть, например, «news» так: */news/,
то закроются и страницы /news/post-1 и /category/news/.

 txt.
txt.robots.txt полностью ↓
Открыть ↓Справка:
Подробности составления robots.txt можно изучить на странице помощи Яндекса — http://help.yandex.ru/webmaster/?id=996567
Проверить правильность составления файла можно в webmaster.yandex — Настройка индексирования — Анализ robots.txt
В Google robots.txt можно проверить по этой ссылке:
https://www.google.com/webmasters/tools/crawl-access?hl=ru&siteUrl=http://site.ru/
Проверяемый сайт должен быть добавлен в панель веб-мастера.
P.S. Для Яндекса и Google правила составления robots.txt немного различаются.
Толкование правил составления robots.txt можно прочитать здесь — http://robotstxt.org.ru
К сожалению, проверить можно только синтаксис.
Правильно ли вы закрыли от индексации разделы сайта, покажет только время :).
Ну вот и все — файл robots.txt готов, осталось только загрузить его в корневой каталог нашего сайта.
Напоминаю, что корневой каталог это папка в которой находится файл config.php.
И последнее — все, сделанные вами изменения в robots.txt, будут заметны на сайте только спустя несколько месяцев.
В тему:
Однажды видела сайт на wordpress, на котором не было файла robots.txt.
Этот сайт некоторое время простоял пустым — т.е. с одной стандартной записью, которая по умолчанию присутствует в wordpress.
Представьте себе, какой шок испытал владелец сайта, когда обнаружил, что Яндекс проиндексировал 2 страницы с контентом и больше тысячи страниц самого движка 🙂
На этой веселой ноте заканчиваю.
1. Оптимизация кода шаблона.
2. Оптимизация контента.
3. Перелинковка.
4. Файл robots.txt.
5. Файл sitemap.xml.
6. Пинг.
- 5
- 4
- 3
- 2
- 1
(8 голосов, в среднем: 3.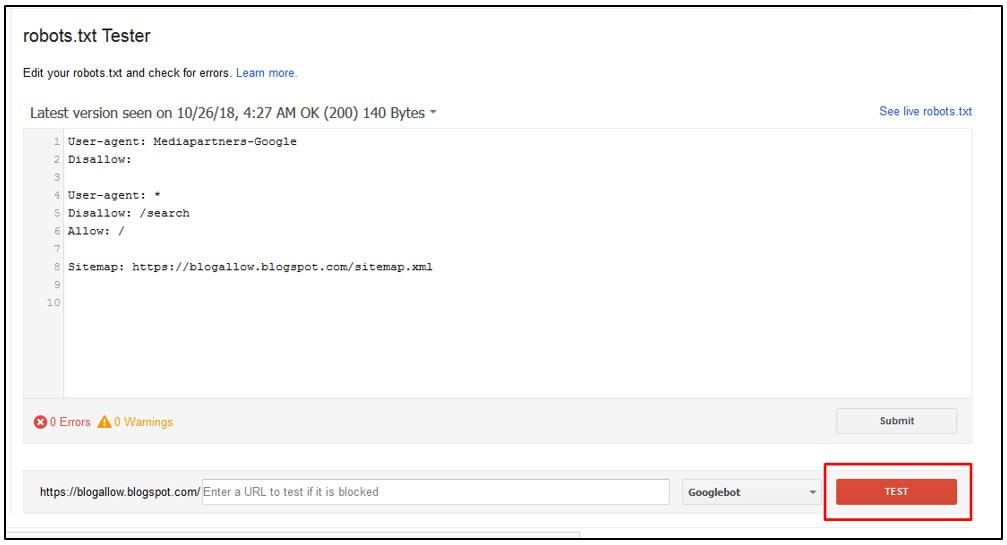 3 из 5)
3 из 5)
Robots.txt для различных CMS | Jeto
В данной статье собраны примеры robots.txt, которые помогут составить корректный настройки файл для различных популярных CMS и фрэймворков: 1C-Битрикс, Joomla, Drupal, WordPress, OpenCart, NetCat, UMI CMS, HostCMS, MODX.
Файл robots.txt – это текстовый файл с технической информаций, размещаемый в корне вашего сайта, он сообщает поисковым системам орядок индексации сайта. Наборы директив (строк) сообщают поисковому роботу, какие разделы сайта запретить или разрешить к индексации. Для ряда поисковых систем, в файле robots.txt могут быть прописаны дополнительные параметры, обрабатываемые только определенной поисковой системой.
Нужно понимать, что приведенные ниже директивы являются лишь примерами и файлы не гарантируют 100% правильную работу, так как в них могуть не предусмотрены специальные разделы, типы файлов, которые должны быть закрыты или открыты на вашей сайте. В некоторых случаях может потребоваться тонкая коррекция настроек под ваш проект, поэтому рекомендуем дополнительно консультироваться по настройке robots. txt с программистом и\или администратором вашего проекта, который знаком с его спецификой и «узкими местами».
txt с программистом и\или администратором вашего проекта, который знаком с его спецификой и «узкими местами».
Обратите внимание: значение site.ru нужна заменить на ваш домен.
Как загрузить файл robots.txt на сайта через ISPmanager?
Авторируйтесь в панели хостина и в ISPmanager перейдите в Менеджер файлов — www — каталог Вашего сайта и на панели нажмите «Закачать».
Перед Вами откроется окно загрузки файла, в котором нужно выбрать robots.txt с локального компьютера и загрузить на сервер.
Проверка robots.txt
Проверить успешную загрузку файла на сайта можно открыв его браузере по адресу http://site.ru/ robots.txt , где site.ru — имя Вашего сайта.
После загрузки robots.txt на сайт проверяем корректность работы файла по инструкциям:
Для Яндекс – через Яндекс.Вебмастер, без регистрации.
Для Google – через Google Вебмастер, с регистрацией.
Для robots. txt рекомендуется устанавливать права 444.
txt рекомендуется устанавливать права 444.
robots.txt для 1С-Битрикс
User-agent: *
Allow: /map/
Allow: /search/map.php
Allow: /bitrix/templates/
Disallow: */index.php
Disallow: /*action=
Disallow: /*print=
Disallow: /*/gallery/*order=
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*?utm_source=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*arrFilter=
Disallow: /*auth=
Disallow: /*back_url_admin=
Disallow: /*BACK_URL=
Disallow: /*back_url=
Disallow: /*backurl=
Disallow: /*bitrix_*=
Disallow: /*bitrix_include_areas=
Disallow: /*building_directory=
Disallow: /*bxajaxid=
Disallow: /*change_password=
Disallow: /*clear_cache_session=
Disallow: /*clear_cache=
Disallow: /*count=
Disallow: /*COURSE_ID=
Disallow: /*forgot_password=
Disallow: /*ID=
Disallow: /*index.php$
Disallow: /*login=
Disallow: /*logout=
Disallow: /*modern-repair/$
Disallow: /*MUL_MODE=
Disallow: /*ORDER_BY
Disallow: /*PAGE_NAME=
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGEN_
Disallow: /*print_course=
Disallow: /*print=
Disallow: /*q=
Disallow: /*register=
Disallow: /*register=yes
Disallow: /*set_filter=
Disallow: /*show_all=
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*SHOWALL_
Disallow: /*sort=
Disallow: /*sphrase_id=
Disallow: /*tags=
Disallow: /access. log
log
Disallow: /admin
Disallow: /api
Disallow: /auth
Disallow: /auth.php
Disallow: /auto
Disallow: /bitrix
Disallow: /bitrix/
Disallow: /cgi-bin
Disallow: /club/$
Disallow: /club/forum/search/
Disallow: /club/gallery/tags/
Disallow: /club/group/search/
Disallow: /club/log/
Disallow: /club/messages/
Disallow: /club/search/
Disallow: /communication/blog/search.php
Disallow: /communication/forum/search/
Disallow: /communication/forum/user/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /error
Disallow: /e-store/affiliates/
Disallow: /e-store/paid/detail.php
Disallow: /examples/download/download_private/
Disallow: /examples/my-components/
Disallow: /include
Disallow: /personal
Disallow: /search
Disallow: /temp
Disallow: /tmp
Disallow: /upload
Disallow: /*/*ELEMENT_CODE=
Disallow: /*/*SECTION_CODE=
Disallow: /*/*IBLOCK_CODE
Disallow: /*/*ELEMENT_ID=
Disallow: /*/*SECTION_ID=
Disallow: /*/*IBLOCK_ID=
Disallow: /*/*CODE=
Disallow: /*/*ID=
Disallow: /*/*IBLOCK_EXTERNAL_ID=
Disallow: /*/*SECTION_CODE_PATH=
Disallow: /*/*EXTERNAL_ID=
Disallow: /*/*IBLOCK_TYPE_ID=
Disallow: /*/*SITE_DIR=
Disallow: /*/*SERVER_NAME=
Sitemap: http://site. ru/sitemap_index.xml
ru/sitemap_index.xml
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для WordPress
User-agent: *
Allow: /wp-content/uploads
Disallow: */comment-page-*
Disallow: */comments
Disallow: */feed
Disallow: */trackback
Disallow: /*?
Disallow: /?feed=
Disallow: /?s=
Disallow: /author
Disallow: /cgi-bin
Disallow: /comments
Disallow: /page
Disallow: /search
Disallow: /tag
Disallow: /trackback
Disallow: /webstat
Disallow: /wp-admin
Disallow: /wp-comments
Disallow: /wp-content/cache
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-feed
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-trackback
Disallow: /xmlrpc.php
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для Joomla
User-agent: *
Allow: /images
Allow: /index. php?option=com_xmap&sitemap=1&view=xml
php?option=com_xmap&sitemap=1&view=xml
Disallow: /*?action=print
Disallow: /*?sl*
Disallow: /*atom.html
Disallow: /*rss.html
Disallow: /administrator
Disallow: /bin
Disallow: /cache
Disallow: /cli
Disallow: /component
Disallow: /components
Disallow: /includes
Disallow: /index*
Disallow: /index2.php?option=com_content&task=emailform
Disallow: /installation
Disallow: /language
Disallow: /layouts
Disallow: /libraries
Disallow: /logs
Disallow: /media
Disallow: /modules
Disallow: /plugins
Disallow: /templates
Disallow: /tmp
Disallow: /trackback
Disallow: /xmlrpc
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для OpenCart
User-agent: *
Disallow: /*filter_description=
Disallow: /*filter_name=
Disallow: /*filter_sub_category=
Disallow: /*keyword
Disallow: /*limit=
Disallow: /*manufacturer
Disallow: /*order=
Disallow: /*page=
Disallow: /*route=account
Disallow: /*route=account/login
Disallow: /*route=affiliate
Disallow: /*route=checkout
Disallow: /*route=checkout/cart
Disallow: /*route=product/search
Disallow: /*sort=
Disallow: /*tracking=
Disallow: /admin
Disallow: /cache
Disallow: /cart
Disallow: /catalog
Disallow: /change-password
Disallow: /checkout
Disallow: /download
Disallow: /export
Disallow: /index. php?route=account
php?route=account
Disallow: /index.php?route=account/account
Disallow: /index.php?route=account/login
Disallow: /index.php?route=checkout/cart
Disallow: /index.php?route=checkout/shipping
Disallow: /index.php?route=common/home
Disallow: /index.php?route=product/category
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /index.php?route=product/search
Disallow: /login
Disallow: /my-account
Disallow: /order-history
Disallow: /request-return
Disallow: /search
Disallow: /search?filter_name=
Disallow: /search?tag=
Disallow: /system
Disallow: /vouchers
Disallow: /vqmod
Disallow: /wishlist
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для MODX
User-agent: *
Disallow: /*?
Disallow: /*?id=
Disallow: /assets
Disallow: /assets/cache
Disallow: /assets/components
Disallow: /assets/docs
Disallow: /assets/export
Disallow: /assets/import
Disallow: /assets/modules
Disallow: /assets/plugins
Disallow: /assets/snippets
Disallow: /connectors
Disallow: /core
Disallow: /index. php
php
Disallow: /install
Disallow: /manager
Disallow: /profile
Disallow: /search
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для Drupal
User-agent: *
Disallow: *comment*
Disallow: *login*
Disallow: *register*
Disallow: /*&sort*
Disallow: /*/delete
Disallow: /*/edit
Disallow: /*?sort*
Disallow: /*calendar
Disallow: /*index.php
Disallow: /*order
Disallow: /*section
Disallow: /*votesupdown
Disallow: /?q=admin
Disallow: /?q=admin/
Disallow: /?q=comment/reply
Disallow: /?q=contact
Disallow: /?q=filter/tips
Disallow: /?q=logout
Disallow: /?q=node/add
Disallow: /?q=search
Disallow: /?q=user/login
Disallow: /?q=user/logout
Disallow: /?q=user/password
Disallow: /?q=user/register
Disallow: /admin
Disallow: /admin/
Disallow: /archive/
Disallow: /book/export/html
Disallow: /CHANGELOG.txt
Disallow: /comment
Disallow: /comment/reply
Disallow: /comments/recent
Disallow: /contact
Disallow: /cron.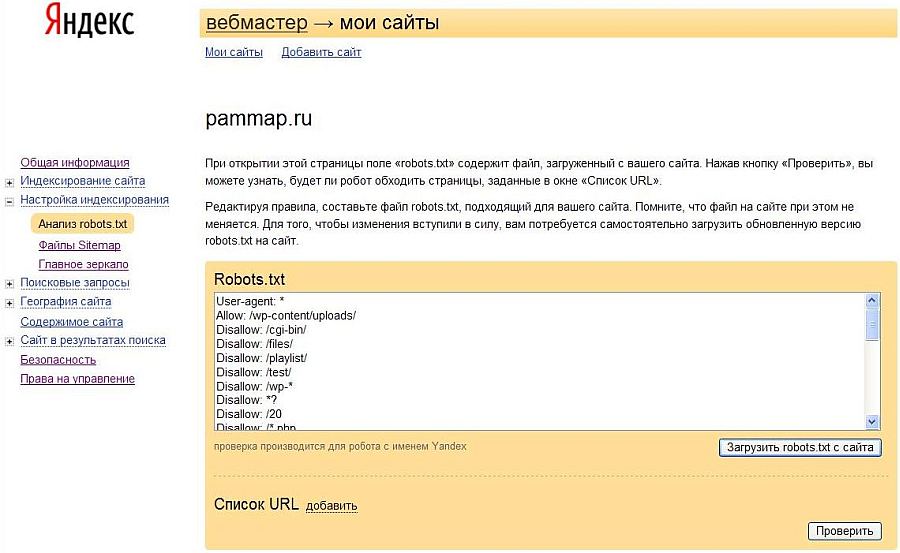 php
php
Disallow: /filter/tips
Disallow: /forum
Disallow: /forum/active
Disallow: /forum/unanswered
Disallow: /includes
Disallow: /INSTALL.mysql.txt
Disallow: /INSTALL.pgsql.txt
Disallow: /install.php
Disallow: /INSTALL.sqlite.txt
Disallow: /INSTALL.txt
Disallow: /LICENSE.txt
Disallow: /logout
Disallow: /logout/
Disallow: /MAINTAINERS.txt
Disallow: /messages
Disallow: /misc
Disallow: /modules
Disallow: /node
Disallow: /node/add
Disallow: /print/node
Disallow: /profile
Disallow: /profiles
Disallow: /scripts
Disallow: /search
Disallow: /taxonomy
Disallow: /taxonomy/term*/feed
Disallow: /themes
Disallow: /update.php
Disallow: /UPGRADE.txt
Disallow: /user
Disallow: /user/
Disallow: /user/login
Disallow: /user/logout
Disallow: /user/password
Disallow: /user/register
Disallow: /xmlrpc.php
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots. txt для NetCat
txt для NetCat
User-agent: *
Disallow: /*.swf
Disallow: /*?
Disallow: /eng
Disallow: /install
Disallow: /js
Disallow: /links
Disallow: /netcat
Disallow: /netcat_cache
Disallow: /netcat_dump
Disallow: /netcat_files
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для UMI.CMS
User-agent: *
Disallow: /*?
Disallow: /?
Disallow: /admin
Disallow: /emarket/addToCompare
Disallow: /emarket/basket
Disallow: /files
Disallow: /go_out.php
Disallow: /images
Disallow: /images/lizing
Disallow: /images/ntc
Disallow: /index.php
Disallow: /install-libs
Disallow: /install-static
Disallow: /install-temp
Disallow: /search
Disallow: /users
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
robots.txt для HostCMS
User-agent: *
Disallow: /403
Disallow: /404
Disallow: /admin
Disallow: /articles/tag
Disallow: /captcha.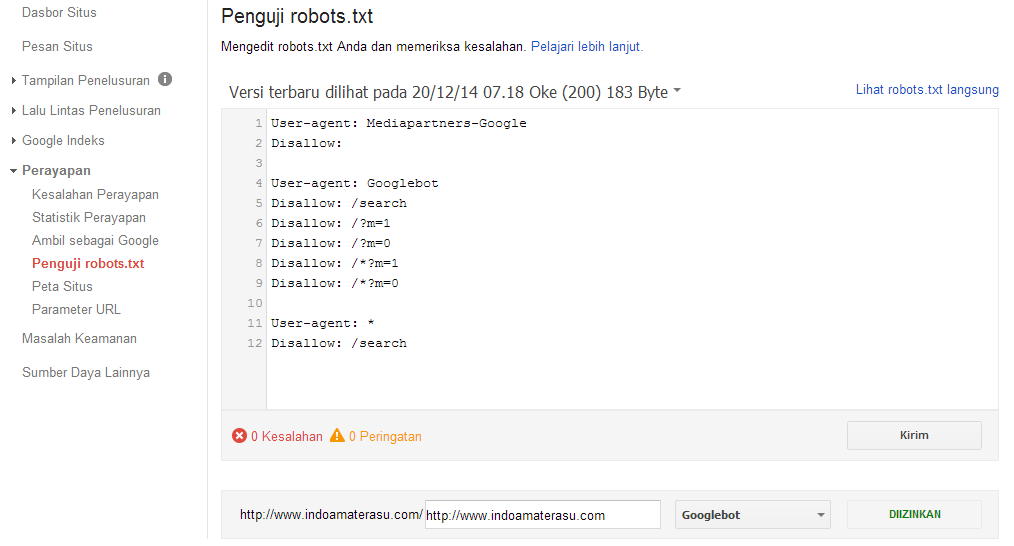.png) php
php
Disallow: /chmod.sh
Disallow: /config.php
Disallow: /config_db.php
Disallow: /data_templates
Disallow: /documents
Disallow: /download_file.php
Disallow: /glossary/tag
Disallow: /hostcmsfiles
Disallow: /lib
Disallow: /logs
Disallow: /main_classes.php
Disallow: /modules
Disallow: /news/tag
Disallow: /search
Disallow: /structure
Disallow: /templates
Disallow: /tmp
Disallow: /upload
Disallow: /xsl
Disallow: captcha.php
Disallow: download_file.php
Sitemap: http://site.ru/sitemap.xml
Host: site.ru
Правильный пример robots txt | Как создать файл robots txt для wordpress?
Сегодня я расскажу, как создать файл robots txt для wordpress. Этот пост, будет очень важным для тех, у кого до сих пор нет файла robots txt.
Я постараюсь рассказать вам основные команды, которые используются в этом файле, чтобы вы могли составить самостоятельно robots txt а также покажу пример, каким должен быть правильный robots. txt для wordpress :smile:.
txt для wordpress :smile:.
Дублированный контент является одной из причин всех санкций поисковых систем. Это, то же самое, что пойти на другой сайт, скопипастить оттуда статью и опубликовать на своем ресурсе. Таким образом, у вас появиться неуникальная информация, которую поисковики очень сильно не любят.
Но, самое страшное то, что многие новички даже не подозревают, что у них на блоге может быть дублированный контент. После создания блога, они просто начинают писать себе статьи. Пишут, пишут, а тут раз, и страницы вылетают из индексации :smile:. Потом они думают, почему мой сайт попал под АГС? Я же писал интересные, уникальные статьи для людей. Мой блог несет пользу людям. Да, возможно это правда, и я это понимаю, но поисковый робот, к сожалению, нет :smile:.
Перед тем, как я вам покажу, как создать файл robots txt для wordpress, давайте подумаем, откуда вообще могут взяться дубли на сайте.
1. Доступность ресурса по адресу c www и без www.
Наберите сейчас в адресной строке www. (.*)$ http://vachevskiy.ru/$1 [R=301,L]
(.*)$ http://vachevskiy.ru/$1 [R=301,L]
Этот код будет перенаправлять сайт с www. vachevskiy.ru на vachevskiy.ru. Только не забудьте вместо vachevskiy.ru указать адрес своего сайта.
2. Лишние переменные.
Это когда страница открыта для индексации по такому адресу
Как легко узнать и проверить тиц сайта?
и по такому
Как легко узнать и проверить тиц сайта?
Это две разные страницы для поискового робота, и последнюю, нужно закрывать от индексации. Как правильно это сделать, я объясню немножко позже.
3. Анонс новостей.
Возможно, вы замечали на многих блогах, что идет анонс статьи, картинка, а потом, кнопка читать далее. Так вот, этот анонс будет как раз таки дублированным контентом. Я, например, вообще не делаю анонсов. У меня идет заголовок, картинка и кнопка читать далее. Если вы решили делать анонсы, но старайтесь чтобы они были небольшие, поскольку запретить их индексацию в файле robots. txt невозможно.
txt невозможно.
Ну а вообще, сейчас я вам покажу правильный robots.txt для wordpress, который стоит на моем сайте. Вот пример robots txt:
User-agent: Yandex
Disallow: /wp-register.php
Disallow: /wp-content/themes
Disallow: /*?
Disallow: /webstat/
Disallow: */comments
Disallow: /trackback
Disallow: */trackback
Disallow: */feed
Disallow: /*?*
Disallow: /comments
Disallow: /wp-content/plugins
Disallow: /wp-admin/
Disallow: /feed/
Disallow: /wp-login.php
Disallow: /category/*/*
Disallow: /wp-includes/
Host: vachevskiy.ruUser-agent: *
Disallow: /wp-login.php
Disallow: /webstat/
Disallow: /feed/
Disallow: */trackback
Disallow: /wp-register.php
Disallow: */feed
Disallow: */comments
Disallow: /*?*
Disallow: /*?
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /category/*/*
Disallow: /wp-admin/
Disallow: /trackback
Disallow: /wp-includes/
Disallow: /commentsSitemap: http://vachevskiy.
Sitemap: http://vachevskiy.ru/sitemap.xml.gz
 ru/sitemap.xml
ru/sitemap.xmlЕсли у вас сайт на движке wordpress, и настроены ЧПУ, то можете смело ставить этот пример robots txt и не париться. Что значит, настроены ЧПУ? Если ссылка вод такая:
Как легко узнать и проверить тиц сайта?
то этот robots.txt подойдет. А если, например, такая (вот статья о том, как сделать ссылку):
http://www.mycharm.ru/articles/text/?id=2766
то нужно просто убрать из файла robots.txt вот эту строчку
Disallow: /*?*, поскольку она заблокирует индексацию всех страниц, где встречается знак вопроса «?». Ее нужно убрать в двоих местах.
Как составить правильный robots.txt самому?
Если у вас другая система управления сайтом, то я вам сейчас кратко расскажу основные команды для того, чтобы вы могли составить robots.txt для своего сайта самостоятельно. Итак, поехали.
Директива «User-agent» отвечает за то, к какому поисковому роботу вы обращаетесь.
- User-agent: * — ко всем поисковикам;
- User-agent: Yandex – только к Яндексу;
- User-agent: Googlebot – только к Гуглу;
Директива «Disallow» закрывает страницы, категории или сайт от индексации.
Например, у меня есть на сайте вод такая страница http://vachevskiy.ru/search/ и я хочу закрыть ее от индексации всех поисковиков. В таком случаи нужно прописать следующее.
User-agent: *
Disallow: /search/
Если вы хотите закрыть весь сайт от индексации гуглом, то нужно прописать так:
User-agent: Googlebot
Disallow: /
А если, наоборот, хотите, чтобы весь сайт индексировался гуглом, то нужно прописать в файле robots.txt вод так:
User-agent: Googlebot
Disallow:
Таким образом, мы можем запретить индексировать сайт или страницу, яндексу и гулу отдельно, или всем поисковикам сразу.
Директива «Allow» разрешает индексировать сайт, категории или страницы.
Например, вы хотите запретить индексировать папку wp-includes всем поисковикам, но в этой папке хотите разрешить индексировать файл compat.php, тогда нужно прописать следующее:
User-agent: *
Disallow: /wp-includes/
Allow: /wp-includes/compat.php
Директива «Sitemap» позволяет указать карту сайта поисковым роботам:
User-agent: *
Sitemap: http://vachevskiy.ru/sitemap.xml
Есть еще несколько директив, которые понимает только Яндекс.
Директива «Host» позволяет указать основной адрес сайта. С www или без www. Я указал без www.
User-agent: Yandex
Host: vachevskiy.ru
Директива «Crawl-delay» позволяет указать задержку, с которой поисковый робот будет отправлять вам команду. Если у вас большой сайт, то поисковик постоянным его штудированием может создать большую нагрузку на сервер. И чтобы этого не случилось, вы можете воспользоваться директивой «Crawl-delay»
Вод пример:
User-agent: Yandex
Crawl-delay: 3
Это значит, что интервал между посылками команды будет 3 секунды. Но опять же, это актуально только для яндекса.
Но опять же, это актуально только для яндекса.
Для того, чтобы без проблем самому составить файл robots.txt, очень важно научиться понимать некоторые спецсимволы. Адрес начинается с третьего слеша.
- Символ * — любая, последовательность символов.
- Символ $ — конец строки.
Я сейчас объясню, что это значит, и как эти символы использовать при составлении файла robots.txt
Сначала разберем, как использовать «*». Например, у меня есть дублирована страница
http://vachevskiy.ru/page?replytocom=29#respond
Для того, чтобы убрать ее с индекса нужно прописать следующее:
User-agent: *
Disallow: /*?*
Таким образом, я говорю поисковому роботу: «Если в URL страницы встретишь знак вопроса «?» то не индексируй ее. И неважно, какие символы стоят до знака вопроса и после него».
Потому что перед знаком вопроса и после него мы поставили звездочку «*». А она, в свою очередь, означает любую последовательность символов.
Ну а теперь разберем, как использовать символ $. Например, у нас есть вод такая страница
http://vachevskiy.ru/index.php
и мы хотим запретить поисковому роботу ее индексировать.
Для этого нужно прописать следующее
User-agent: *
Disallow: /*index.php$
Я говорю поисковикам: «Если index.php конец строки и неважно какие символы до index.php – не индексируй». Пояснил, как мог, если что-то не понятно, то спрашивайте в комментариях ;-).
Таким образом, зная всего лишь эти два спецсимволы, можно запрещать от индексации любую страницу или раздел сайта.
Как убедиться в том, что мы составили правильный robots.txt?
Для этого, прежде всего, нужно добавить сайт в яндекс вебмастер. Потом, нужно зайти в раздел: «Настройка индексирования» — «Анализ robots.txt».
После этого нужно загрузить файл robots.txt и нажать на кнопку проверить. Если вы увидите примерно такое сообщения, как на картинке, без ошибок, значит у вас правильный robots. txt для wordpress или другой системы управления.
txt для wordpress или другой системы управления.
Но мы еще можем проверить конкретную страницу. Например, я копирую url статьи, которая должна быть открыта для индексации, и проверяю, так ли это на самом деле.
Ну вод и все, наверное, что касается вопроса, как создать файл robots txt для wordpress. Да и не только для wordpress. Теперь вы должны уметь составить правильный robots.txt для любой системы управления :smile:.
Правильный Robots.txt для Joomla | PRIME
Перейти к содержанию
Содержание
- Что собой представляет robots.txt?
- Как правильно составить файл роботс
- Шаблон правильного robots.txt для Joomla
Сегодня мы поговорим о том, как верно написать «robots.txt», что бы боты поисковых систем быстро и верно проиндексировали Ваш интернет-ресурс.
Любой администратор интернет ресурса или web-мастер знает, что это за файл и особенности его написания. Что бы было понятнее, предположим, что сайт – это музей, а боты поисковых систем, например, яндекса и гугла – это люди пришедшие на экскурсию. В там случае файл robots – это гид, который четко знает, куда нужно вести людей, что им показывать, а куда никого пускать не стоит. Что бы все работало верно, нужно правильно написать robots с внесением нужных команд.
Что бы было понятнее, предположим, что сайт – это музей, а боты поисковых систем, например, яндекса и гугла – это люди пришедшие на экскурсию. В там случае файл robots – это гид, который четко знает, куда нужно вести людей, что им показывать, а куда никого пускать не стоит. Что бы все работало верно, нужно правильно написать robots с внесением нужных команд.
Уже по названию “robots.txt ” видно, что это текстовый файл. В нем прописывают правила по индексации для поисковых роботов, располагается в корневой папке веб-сайта- http://имясайта/robots.txt. В случае если он еще не создан, то вы можете при помощи блокнота создать его самостоятельно.
Правила содержащиеся в robots, указывают поисковикам:
- Папки, отдельные страницы, разделы вашего интернет ресурса, которые запрещены к индексированию.
- Основное зеркало сайта (к примеру, “вашсайт.ru “ или “вашсайт. ru”).
- Время между загрузкой поисковым роботом документов и файлов с сервера (используется для снижения нагрузки на сервер, где находится ваш сайт)
 ru”).
ru”).Для примера возьмем Joomla 3.3. После того как устанавливается дистрибутив, файл роботс имеет такой вид:
Теперь подробно разберем, какое значение у всех этих команд, для чего они нужны и как их использовать для настройки своего сайта.
Следующие директивы лучше прописывать отдельно для каждого сайта:
<User-agent: * > — эта строка значит, что правила по индексированию веб- сайта для всех поисковиков будут одинаковыми.
Можно так же прописать отдельно правила для каждой поисковой системы.
Например:
<User-agent: Yandex> — запись будет говорит о том, что эти команды только для поискового бота Яндекса. После нее должны перечислятся основные каталоги сайта, которые будут индексироваться.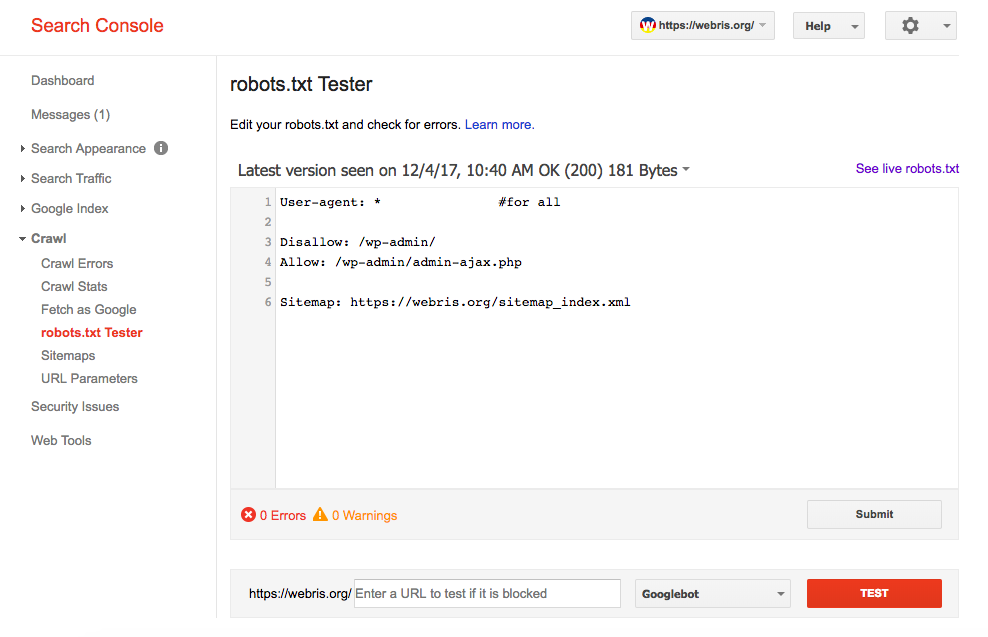
Все инструкции записанные в robots.txt для Yandex , будут являться “правилом”, а вот для других ботов, например, Google – лишь “рекомендацией”.
<User-agent: Googlebot > — для поискового бота Гугл.
<Disallow > — запрещает поисковикам проводить индексацию указанных URL или папок/разделов интернет-ресурса.
Директива <Allow > напротив “разрешает” доступ для индексирования указанных страниц, папок, файлов. К примеру:
Такая запись значит, что всем поисковым поисковикам доступ к веб-сайту, исключая те страницы, которые начинаются с ”/spitit”.
Если случится так, что одна и та же страница попадет под правила и одновременно, то поисковик Yandex учтет лишь ту директиву у которой длиннее запись «хвостика» URL. Например:
Запись значит, что страницы начинающиеся с «/razdel»-нельзя индексировать, а те что начинаются с «/razdel/statya» можно индексировать.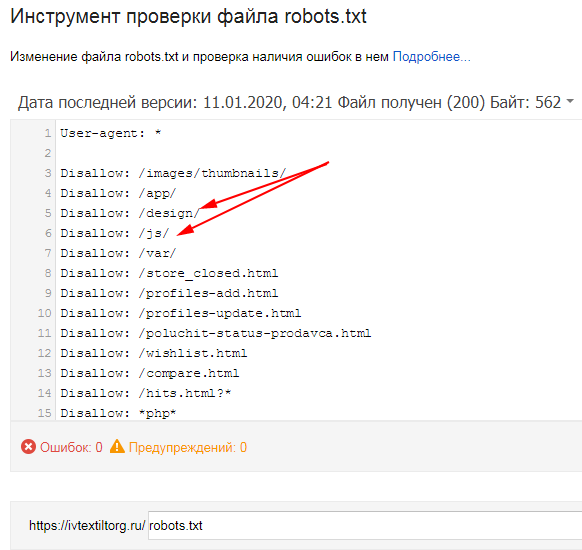
Директива <Crawl-delay > обычно используется, для сайтов со слабым хостингом, или очень больших сайтов. С ее помощью указывают время между закачками страниц поисковым ботом, для снижения нагрузки на сервер.
На примере выглядит так:
Для ботов яндекса можно прописывать не только целые числовые значения, например Crawl-delay: 4.5.
Для западных поисковых систем можно так же применять директиву Request-rate : 1/15, что будет означать время между загрузками 15 сек.
Команду< Clean-param > применяют если сайт содержит страницы с часто меняющейся информацией (к примеру, результаты поиска, идентификаторы пользователей и т.д.). Эти параметры складываются из меняющихся цифр, которые дописываются к адресу страницы.
Пример:
Чтобы поисковой бот яндекса не перегружал сервер индексированием подобных страниц, используют вышеупомянутую директиву.
Это пример для результатов поиска:
Директивой < Sitemap > указывается местоположение карты сайта “sitemaps.xml”. Это файл только для поисковиков, для обеспечения быстрой индексации, и для посетителей сайта полезным не является. Нужно указать все карты сайта, если их несколько, начиная с новой строки каждую.
Например:
Используя директиву < Host > мы указываем основное зеркало сайта, которое и будет индексироваться. В основном она пишется для ботов Yandex .
Примечание! Прописывать это правило нужно в поле «User-agent», чуть ниже команд «Disallow«(«Allow«). А вот директиву «Sitemap» можно прописывать, просто пропустив строку вниз.
Особые символы
«#»— значит что все что написано после него до конца данной строки- комментарий.![]()
«*» – это цепочка символов, в т.ч. нулевая.
К примеру:
В конце каждой директивы по умолчанию автоматически дописывается «*» в конце:
Что бы убрать этот символ, используем знак “$”. Представим, что раздел «car» нужно закрыть от индексации, а статьи содержащиеся в нем разрешить индексировать.
Шаблон правильного robots.txt для Joomla
#К какому роботу обращаемся (по умолчанию ко всем)
User-agent: *
#разрешаем доступ к карте сайта
Allow: /index.php?option=com_xmap&sitemap=1&view=xml
#Запрет доступа к админ панели
Disallow: /administrator/
#Запрет доступа к кешу
Disallow: /cache/
#Запрет доступа к компонентам joomla
Disallow: /components/
#Запрещает доступ к папке includes
Disallow: /includes/
#Запрет доступа к языковым пакетам
Disallow: /language/
#Запрет доступа к библиотекам
Disallow: /libraries/
#Запрет доступа к логам
Disallow: /logs/
#Запрет доступа к папке медиа
Disallow: /media/
#Запрет доступа к модулям
Disallow: /modules/
#Запрет индексации плагинов
Disallow: /plugins/
#Папка с вашими шаблонами
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
#Запрет на индексацию формы отправки писем
Disallow: /*com_mailto
#Запрет на индексацию всплывающих окон
Disallow: /*pop=
#Запрет на индексацию дополнительных языков сайта
Disallow: /*lang=ru
#Запрет индексации ссылки вывода на печать
Disallow: /*format=
Disallow: /*print=
#Голосования
Disallow: /*task=vote
#Водяные знаки
Disallow: /*=watermark
#Ссылки на скачивание
Disallow: /*=download
#Профили пользователей
Disallow: /*user/
#Запрет индексации 404 ошибки
Disallow: /404
#Запрет индексации ? и переменных
Disallow: /index. php?
php?
Disallow: /*?
#ссылки содержащие данный знак индексироваться не будут
Disallow: /*%
#ссылки содержащие данный знак индексироваться не будут
Disallow: /*&
#Запрет дублей
Disallow: /index2.php
#Запрет индексации облаков тегов
Disallow: /*tag
#Запрет pdf файлов (на ваше усмотрение)
Disallow: /*.pdf
#Если есть на сайте swf файлы — flash (на ваше усмотрение)
Disallow: /*.swf
#Запрет индексации ссылки на печать
Disallow: /*print=1
#Запрет параметра
Disallow: /*=atom
#Запрещаем RSS
Disallow: /*=rss
#Указываем главное зеркало вашего сайта
Host: domen.ru
# Ваш URL адрес карты сайта в формате .xml
Sitemap: http://domen.ru/sitemap.xml
Go to Top
Как редактировать файл Shopify Robots.txt (2022)
Если вы работаете с сайтом электронной коммерции, файл robots.txt является одним из важнейших элементов SEO вашего сайта. Сайты электронной коммерции, как правило, намного больше, чем большинство сайтов в Интернете, а также содержат такие функции, как фасетная навигация, которые могут экспоненциально увеличивать размер сайта. Это означает, что эти сайты должны иметь возможность более жестко контролировать, как Google сканирует их сайт. Это помогает этим сайтам управлять бюджетом сканирования и предотвращать сканирование низкокачественных страниц роботом Googlebot.
Это означает, что эти сайты должны иметь возможность более жестко контролировать, как Google сканирует их сайт. Это помогает этим сайтам управлять бюджетом сканирования и предотвращать сканирование низкокачественных страниц роботом Googlebot.
Однако, когда дело доходит до Shopify, файл robots.txt уже давно вызывает недовольство сообщества SEO. В течение многих лет одним из самых больших разочарований для Shopify SEO было отсутствие контроля над файлом robots.txt. Это усложнило работу с платформой по сравнению с другими, такими как SEO для Magento, где пользователи всегда могли легко редактировать robots.txt. Хотя файл robots.txt по умолчанию отлично справляется с блокировкой поисковых роботов, некоторые сайты требуют внесения изменений в этот файл. По мере того, как все больше сайтов начинают использовать платформу, мы видим, что сайты, использующие Shopify, становятся больше и надежнее, требуя большего вмешательства сканирования с помощью файла robots.txt.
К счастью, Shopify проделал большую работу по улучшению своей платформы.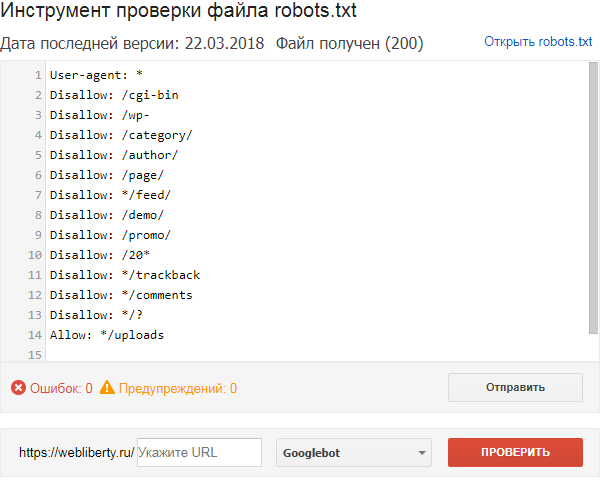 В июне 2021 года Shopify объявил, что теперь вы сможете настроить файл robots.txt для своего сайта:
В июне 2021 года Shopify объявил, что теперь вы сможете настроить файл robots.txt для своего сайта:
.User-agent: все
Разрешить: /
С сегодняшнего дня у вас есть полный контроль над тем, как роботы поисковых систем видят ваш магазин. #shopifyseohttps://t.co/Hz9Ijj5h2y— Тоби Лютке (@tobi) 18 июня 2021 г.
Это отличная новость для SEO-специалистов и владельцев магазинов Shopify, которые годами умоляли изменить файл. Это также показывает, что Shopify прислушивается к отзывам, которые им дают SEO-специалисты, и предпринимает шаги для улучшения платформы с точки зрения поиска.
Итак, теперь, когда мы знаем, что вы можете редактировать файл, давайте поговорим о том, как сделать эти настройки и о ситуациях, в которых вы можете это сделать.
Что такое Shopify Robots.txt?
Shopify robots.txt — это файл, который указывает поисковым системам, какие URL-адреса они могут сканировать на вашем сайте. Чаще всего файл robots.txt может блокировать поисковые системы от поиска страниц низкого качества, которые не следует сканировать. Shopify robots.txt создается с использованием файла robots.txt.liquid.
Чаще всего файл robots.txt может блокировать поисковые системы от поиска страниц низкого качества, которые не следует сканировать. Shopify robots.txt создается с использованием файла robots.txt.liquid.
Что блокирует файл robots.txt Shopify по умолчанию?
Глядя на готовый сайт Shopify, вы можете заметить, что файл robots.txt уже настроен. Вы можете найти этот файл, перейдя по адресу:
domain.com/robots.txt
В этом файле robots.txt вы увидите, что уже имеется большое количество предварительно настроенных правил.
Подавляющее большинство этих правил полезно для предотвращения сканирования ненужных страниц поисковыми системами. Ниже приведены некоторые из наиболее важных правил в файле Shopify robots.txt по умолчанию:
- Запретить: /search – Блокирует внутренний поиск по сайту
- Запретить: /cart – Блокирует страницу корзины
- Запретить: /checkout — Блокирует страницу оформления заказа
- Запретить: /account — Блокирует страницу учетной записи
- Запретить: /collections/*+* — Блокирует дубликаты страниц категорий, созданные фасетной навигацией
- Карта сайта: [Ссылки на карту сайта] — ссылается на ссылку sitemap. xml
 xml
xmlВ целом, правила Shopify по умолчанию довольно хорошо блокируют сканирование веб-страниц низкого качества для большинства сайтов. На самом деле, вполне вероятно, что большинству владельцев магазинов Shopify не нужно вносить какие-либо изменения в свой файл robots.txt. Конфигурации по умолчанию должно быть достаточно для обработки большинства случаев. Большинство сайтов Shopify, как правило, имеют меньший размер, и контроль сканирования не является большой проблемой для многих из них.
Конечно, поскольку все больше и больше сайтов переходят на платформу Shopify, это означает, что сайты становятся все больше и больше. Кроме того, мы видим больше сайтов с пользовательскими конфигурациями, где правил robots.txt по умолчанию недостаточно.
Хотя существующие правила Shopify в большинстве случаев хорошо справляются с учетом, иногда владельцам магазинов может потребоваться создать дополнительные правила, чтобы адаптировать файл robots.txt к своему сайту. Это можно сделать, создав и отредактировав файл robots. txt.liquid.
txt.liquid.
Как создать Shopify Robots.txt.liquid?
Вы можете создать файл Shopify robots.txt.liquid, выполнив следующие шаги в своем магазине:
- На левой боковой панели страницы администрирования Shopify перейдите в Интернет-магазин > Темы
- Выберите Действия > Изменить код
- В разделе «Шаблоны» щелкните ссылку «Добавить новый шаблон»
- Щелкните крайний левый раскрывающийся список и выберите «robots.txt»
- Выберите «Создать шаблон»
После этого в редакторе должен открыться файл Shopify robots.txt.liquid:
Как редактировать файл Shopify Robots.txt?
Добавление правила
Если вы хотите добавить правило в файл robots.txt Shopify, вы можете сделать это, добавив дополнительные блоки кода в файл robots.txt.liquid.
{%- if group.user_agent.value == ‘*’ -%}
{{ ‘Disallow: [URLPath] ‘ }}
{%- endif -%}
Например, если ваш сайт Shopify использует /search-results/ для функции внутреннего поиска и вы хотите заблокировать его с помощью файла robots. txt, вы можете добавить следующую команду:
txt, вы можете добавить следующую команду:
{%- if group.user_agent .value == ‘*’ -%}
{{ ‘Disallow: /search-results/.*’ }}
{%-endif -%}
Если вы хотите заблокировать кратные каталоги (/search-results/ & /private/) вы должны добавить в файл следующие два блока:
{%- if group.user_agent.value == ‘*’ -%}
{{ ‘Запретить: /search-results/.*’ }}
{%- endif -%}
{%- if group.user_agent.value == ‘*’ -%}
{{ ‘Disallow: /private/.*’ }}
{%- endif -%}
Это должно позволить заполнить следующие строки в вашем файле Shopify robots.txt:
Потенциальные варианты использования
Итак, зная, что стандартного файла robots.txt обычно достаточно для большинства сайтов, в каких ситуациях ваш сайт будет полезен от редактирования файла robots.txt.liquid Shopify? Ниже приведены некоторые из наиболее распространенных ситуаций, когда вы, возможно, захотите рассмотреть возможность корректировки своей:
Внутренний поиск по сайту
Общепринятым правилом для поисковой оптимизации является блокировка внутреннего поиска по сайту через файл robots. txt. Это связано с тем, что существует бесконечное количество запросов, которые пользователи могут вводить в строку поиска. Если Google сможет начать сканирование этих страниц, это может привести к тому, что в индексе появится много низкокачественных страниц с результатами поиска.
txt. Это связано с тем, что существует бесконечное количество запросов, которые пользователи могут вводить в строку поиска. Если Google сможет начать сканирование этих страниц, это может привести к тому, что в индексе появится много низкокачественных страниц с результатами поиска.
К счастью, файл robots.txt Shopify по умолчанию блокирует стандартный внутренний поиск с помощью следующей команды:
Запретить: /search
Однако многие сайты Shopify не используют внутренний поиск Shopify по умолчанию. Мы обнаружили, что многие сайты Shopify в конечном итоге используют приложения или другие технологии внутреннего поиска. Это часто изменяет URL-адрес внутреннего поиска. Когда это происходит, ваш сайт больше не защищен правилами Shopify по умолчанию.
Например, на этом сайте результаты внутреннего поиска отображаются по URL-адресам с /pages/search в пути:
Это означает, что эти внутренние поисковые URL разрешены для сканирования Google:
Этот веб-сайт может захотеть рассмотреть возможность изменения правил Shopify robots. txt, чтобы добавить пользовательские команды, которые блокируют Google от сканирования каталога /pages/search.
txt, чтобы добавить пользовательские команды, которые блокируют Google от сканирования каталога /pages/search.
Многогранная навигация
Если на вашем сайте есть многогранная навигация, возможно, вы захотите изменить файл Shopify robots.txt. Многогранная навигация — это параметры фильтрации, которые вы можете применять на страницах категорий. Обычно они находятся в левой части страницы. Например, этот сайт Shopify позволяет пользователям фильтровать товары по цвету, размеру, типу продукта и т. д.:
Когда мы выбираем цветовые фильтры «Черный» и «Желтый», мы видим, что загружается URL-адрес с параметром «?color»: хорошо блокирует пути к страницам, которые может создать фасетная навигация, но, к сожалению, не может учитывать каждый вариант использования. В этом случае «цвет» не блокируется, что позволяет Google сканировать страницу.
Это может быть еще один случай, когда мы можем захотеть заблокировать страницы с помощью файла robots. txt в Shopify. Поскольку большое количество этих фасетных навигационных URL-адресов может быть просканировано, мы можем захотеть заблокировать многие из них, чтобы уменьшить сканирование менее качественных/похожих страниц. Этот сайт может определить все параметры многогранной навигации, которые они хотели бы заблокировать (размер, цвет), а затем создать правила в файле robots.txt, чтобы заблокировать сканирование.
txt в Shopify. Поскольку большое количество этих фасетных навигационных URL-адресов может быть просканировано, мы можем захотеть заблокировать многие из них, чтобы уменьшить сканирование менее качественных/похожих страниц. Этот сайт может определить все параметры многогранной навигации, которые они хотели бы заблокировать (размер, цвет), а затем создать правила в файле robots.txt, чтобы заблокировать сканирование.
Навигация по сортировке
Подобно функциям многогранной навигации, многие сайты электронной коммерции включают сортировку на страницах своих категорий. На этих страницах пользователи могут видеть продукты, предлагаемые на страницах категорий, в другом порядке (цена: от низкой к высокой, наиболее релевантные, в алфавитном порядке и т. д.).
Проблема заключается в том, что эти страницы содержат дублированный/похожий контент, поскольку они являются просто вариантами исходной страницы категории, но с продуктами в другом порядке. Ниже вы можете увидеть, как при выборе «По алфавиту, от А до Я» создается параметризованный URL-адрес, который сортирует товары по алфавиту. Этот URL-адрес использует параметр «?q», добавленный в конце:
Этот URL-адрес использует параметр «?q», добавленный в конце:
Конечно, это не уникальный URL-адрес, который следует сканировать и индексировать, поскольку это просто те же продукты, что и на исходной странице категории, отсортированные в другом порядке. Этот сайт Shopify может захотеть добавить правило robots.txt, которое блокирует сканирование всех URL-адресов «?q».
Заключение
Файл robots.txt.liquid от Shopify позволяет SEO-специалистам гораздо лучше контролировать сканирование своего сайта, чем раньше. Хотя для большинства сайтов файла robots.txt Shopify по умолчанию должно быть достаточно, чтобы поисковые системы не попадали в нежелательные области, вы можете рассмотреть возможность его корректировки, если заметите, что к вам относится пограничный случай. Как правило, чем больше ваш магазин и чем больше вы его настроили, тем больше вероятность того, что вы захотите внести изменения в файл robots.txt. Если у вас есть какие-либо вопросы об услугах SEO-агентства robots. txt или Shopify, не стесняйтесь обращаться к нам!
txt или Shopify, не стесняйтесь обращаться к нам!
Другие SEO-ресурсы Shopify
- Оптимизация скорости Shopify
- Улучшение Shopify Дублированный контент
- Руководство по Shopify Sitemap.xml
- Shopify Структурированные данные
- Shopify Инструменты SEO
- Shopify Плюс SEO
- Все SEO-статьи Shopify
Поиск новостей прямо в папку «Входящие»
*Обязательно
О Крисе Лонге
Крис Лонг — вице-президент по маркетингу в Go Fish Digital. С 9+ многолетний опыт, Крис работает с уникальными проблемами и сложными поисковыми ситуациями, чтобы помочь клиентам улучшить органический трафик благодаря глубокому пониманию алгоритма Google и веб-технологий. Крис консультировал по стратегиям поиска таких клиентов, как GEICO, Adobe и The New York Times. Он является сотрудником Moz, Search Engine Land и Search Engine Journal. Он также выступает на отраслевых конференциях, таких как SMX East и BrightonSEO.
WordPress Robots.txt — Как создать и оптимизировать для SEO
Что такое robots.txt? Как создать файл robots.txt? Зачем нужно создавать файл robots.txt? Помогает ли оптимизация файла robots.txt улучшить ваш поисковый рейтинг?
Мы расскажем обо всем этом и многом другом в этой подробной статье о robots.txt!
Вы когда-нибудь хотели запретить поисковым системам сканировать определенный файл? Хотели, чтобы поисковые системы не сканировали определенную папку на вашем сайте?
Здесь на помощь приходит файл robots.txt. Это простой текстовый файл, который сообщает поисковым системам, где и где не сканировать ваш сайт при индексировании.
Хорошей новостью является то, что вам не нужно иметь никакого технического опыта, чтобы раскрыть всю мощь файла robots.txt.
Robots.txt — это простой текстовый файл, создание которого занимает несколько секунд. Это также один из самых простых файлов, который можно испортить. Всего один неуместный символ, и вы испортите SEO всего своего сайта и запретите поисковым системам доступ к вашему сайту.
При работе над SEO сайта важную роль играет файл robots.txt. Хотя он позволяет запретить поисковым системам доступ к различным файлам и папкам, часто это не лучший способ оптимизировать ваш сайт.
В этой статье мы объясним, как использовать файл robots.txt для оптимизации вашего веб-сайта. Мы также покажем вам, как его создать, и поделимся некоторыми плагинами, которые нам нравятся, которые могут сделать тяжелую работу за вас.
Содержание
- Что такое robots.txt?
- Как выглядит файл robots.txt?
- Что такое бюджет сканирования?
- Как создать файл robots.txt в WordPress?
- Способ 1. Создайте файл robots.txt с помощью плагина Yoast SEO
- Метод 2. Создание файла Robots.txt вручную с помощью FTP Файл robots.txt для вашего сайта WordPress?
- Заключительные мысли
Что такое robots.txt?
Robots.txt — это простой текстовый файл, который сообщает роботам поисковых систем, какие страницы вашего сайта сканировать.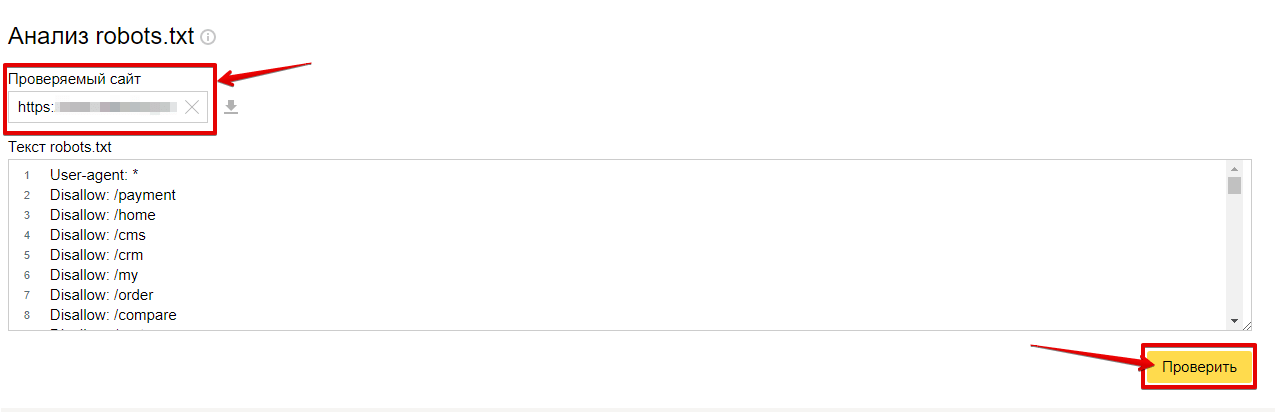 Он также сообщает роботам, какие страницы не сканировать.
Он также сообщает роботам, какие страницы не сканировать.
Прежде чем мы углубимся в эту статью, важно понять, как работает поисковая система.
Поисковые системы выполняют три основные функции: сканирование, индексирование и ранжирование.
(Источник: Moz.com)
Поисковые системы начинают с того, что рассылают по сети своих поисковых роботов, также называемых пауками или ботами. Эти боты представляют собой часть интеллектуального программного обеспечения, которое перемещается по всей сети в поисках новых ссылок, страниц и веб-сайтов. Этот процесс поиска в сети называется сканирует .
Как только боты обнаружат ваш веб-сайт, ваши страницы будут организованы в удобную структуру данных. Этот процесс называется индексированием .
И, наконец, все сводится к рейтингу . Где поисковая система предоставляет своим пользователям лучшую и наиболее актуальную информацию на основе их поисковых запросов.
Как выглядит robots.txt?
Допустим, поисковая система собирается посетить ваш сайт. Прежде чем он просканирует сайт, он сначала проверит robots.txt на наличие инструкций.
Например, предположим, что робот поисковой системы собирается просканировать наш сайт WPAstra и получить доступ к нашему файлу robots.txt, доступ к которому осуществляется с https://wpastra.com/robots.txt.
Пока мы обсуждаем эту тему, вы можете получить доступ к файлу robots.txt для любого веб-сайта, введя «/robots.txt» после имени домена.
ОК. Возвращение на правильный путь.
Выше приведен типичный формат файла robots.txt.
И прежде чем вы подумаете, что все это слишком технично, хорошая новость заключается в том, что это все, что есть в файле robots.txt. Ну, почти.
Давайте разберем каждый элемент, упомянутый в файле.
Первый User-agent: * .
Звездочка после User-agent указывает, что файл применяется ко всем роботам поисковых систем, которые посещают сайт.
У каждой поисковой системы есть собственный пользовательский агент, который сканирует Интернет. Например, Google использует Googlebot для индексации контента вашего сайта для поисковой системы Google.
Некоторые другие пользовательские агенты, используемые популярными поисковыми системами,
- Google: Googlebot
- Googlebot News: Googlebot-News
- Googlebot Images: Googlebot-Image
- Googlebot Video: Googlebot-Video
- Bing: Bingbot
- Yahoo: Slurp Bot
- DuckDuckGo: DuckDuckBot
- Baidu: Baiduspider
- Яндекс: YandexBot
- Exalead: ExaBot
- Amazon Alexa: ia_archiver
Таких юзер-агентов сотни.
Вы можете установить пользовательские инструкции для каждого пользовательского агента. Например, если вы хотите указать конкретные инструкции для робота Googlebot, первая строка вашего файла robots.txt будет такой:
Агент пользователя: Googlebot
Вы назначаете директивы всем агентам пользователя, используя звездочку (*) рядом с Агентом пользователя.
Допустим, вы хотите запретить всем ботам, кроме робота Google, сканировать ваш сайт. Ваш файл robots.txt будет иметь следующий вид:
User-agent: * Запретить: / Агент пользователя: Googlebot Разрешить: /
Косая черта ( / ) после Запретить указывает боту не индексировать какие-либо страницы на сайте. И хотя вы назначили директиву, которая будет применяться ко всем ботам поисковых систем, вы также явно разрешили роботу Google проиндексировать ваш веб-сайт, добавив ‘ Разрешить: / .’
Точно так же вы можете добавить директивы для любого количества пользовательских агентов.
Подводя итоги, давайте вернемся к нашему примеру Astra robots.txt, т. е.
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
Для всех ботов поисковых систем задана директива не сканировать что-либо в папке « /wp-admin/», но следовать « admin-ajax». php ‘ в той же папке.
Просто, правда?
Здравствуйте! Меня зовут Суджей, и я генеральный директор Astra.
Наша миссия — помочь малым предприятиям расти в Интернете с помощью доступных программных продуктов и образования, необходимого для достижения успеха.
Оставьте комментарий ниже, если хотите присоединиться к беседе, или нажмите здесь, если хотите получить личную помощь или пообщаться с нашей командой в частном порядке.
Что такое краулинговый бюджет?
Добавляя косую черту после Disallow , вы запрещаете роботу посещать какие-либо страницы сайта.
Итак, ваш следующий очевидный вопрос: зачем кому-то мешать роботам сканировать и индексировать ваш сайт? В конце концов, когда вы работаете над SEO веб-сайта, вы хотите, чтобы поисковые системы сканировали ваш сайт, чтобы помочь вам в рейтинге.
Именно поэтому вам следует подумать об оптимизации файла robots.txt.
Вы представляете, сколько страниц у вас на сайте? От реальных страниц до тестовых страниц, страниц дублированного контента, страниц благодарности и других. Много, полагаем.
Много, полагаем.
Когда бот сканирует ваш сайт, он будет сканировать каждую страницу. А если у вас несколько страниц, поисковому роботу потребуется некоторое время, чтобы просканировать их все.
(Источник: Seo Hacker)
Знаете ли вы, что это может негативно повлиять на рейтинг вашего сайта?
И это из-за краулингового бюджета поисковой системы .
ОК. Что такое краулинговый бюджет?
Бюджет обхода — это количество URL-адресов, которое поисковый робот может просканировать за сеанс. Для каждого сайта будет выделен определенный краулинговый бюджет. И вам нужно убедиться, что краулинговый бюджет расходуется наилучшим образом для вашего сайта.
Если у вас есть несколько страниц на вашем веб-сайте, вам определенно нужно, чтобы бот сначала сканировал наиболее ценные страницы. Таким образом, необходимо явно указать это в файле robots.txt.
Ознакомьтесь с ресурсами, доступными в Google, чтобы узнать, что означает краулинговый бюджет для робота Googlebot.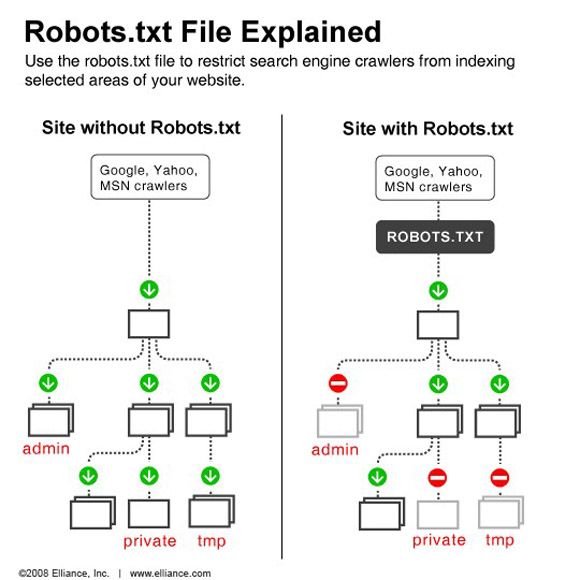
Как создать файл robots.txt в WordPress?
Теперь, когда мы рассмотрели, что такое файл robots.txt и насколько он важен, давайте создадим его в WordPress.
У вас есть два способа создать файл robots.txt в WordPress. Один использует плагин WordPress, а другой вручную загружает файл в корневую папку вашего сайта.
Способ 1. Создайте файл Robots.txt с помощью плагина Yoast SEO
Чтобы оптимизировать свой веб-сайт WordPress, вы можете использовать плагины SEO. Большинство этих плагинов поставляются с собственным генератором файлов robots.txt.
В этом разделе мы создадим его с помощью плагина Yoast SEO. С помощью плагина вы можете легко создать файл robots.txt на панели управления WordPress.
Шаг 1. Установите плагин
Перейдите к Плагины > Добавить новый . Затем найдите, установите и активируйте плагин Yoast SEO, если у вас его еще нет.
Шаг 2. Создайте файл robots.txt
После активации плагина перейдите Yoast SEO > Инструменты и нажмите Редактор файлов .
Поскольку мы создаем файл впервые, нажмите Создать файл robots.txt .
Вы заметите файл, созданный с некоторыми директивами по умолчанию.
По умолчанию генератор файла robots.txt Yoast SEO добавит следующие директивы:
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
При желании вы можете добавить дополнительные директивы в robots.txt. Когда вы закончите, нажмите Сохранить изменения в robots.txt .
Продолжайте и введите свое доменное имя, а затем « /robots.txt ». Если вы обнаружите, что в браузере отображаются директивы по умолчанию, как показано на изображении ниже, вы успешно создали файл robots.txt.
Мы также рекомендуем добавить URL-адрес карты сайта в файл robots.txt.
Например, если URL-адрес карты сайта вашего веб-сайта https://yourdomain.com/sitemap.xml, рассмотрите возможность включения Карта сайта: https://yourdomain.com/sitemap. xml в файле robots.txt.
xml в файле robots.txt.
Другой пример: если вы хотите создать директиву, запрещающую боту сканировать все изображения на вашем веб-сайте. И допустим, мы хотели бы ограничить это только GoogleBot.
В этом случае наш robots.txt будет выглядеть следующим образом:
User-agent: Googlebot Запретить: /загрузки/ Пользовательский агент: * Разрешить: /загрузки/
И на всякий случай, если вам интересно, как узнать имя папки с изображениями, просто щелкните правой кнопкой мыши любое изображение на вашем веб-сайте, выберите «Открыть в новой вкладке» и запишите URL-адрес в браузере. Вуаля!
Способ 2. Создание файла robots.txt вручную с помощью FTP
Следующий способ — создать файл robots.txt на локальном компьютере и загрузить его в корневую папку веб-сайта WordPress.
Вам также потребуется доступ к вашему хостингу WordPress с помощью FTP-клиента, такого как Filezilla. Учетные данные, необходимые для входа, будут доступны в панели управления хостингом, если у вас их еще нет.
Помните, что файл robots.txt должен быть загружен в корневую папку вашего сайта. То есть он не должен находиться ни в одном подкаталоге.
Итак, как только вы войдете в систему с помощью FTP-клиента, вы сможете увидеть, существует ли файл robots.txt в корневой папке вашего веб-сайта.
Если файл существует, просто щелкните его правой кнопкой мыши и выберите параметр редактирования.
Внесите изменения и нажмите «Сохранить».
Если файл не существует, вам необходимо его создать. Вы можете создать его с помощью простого текстового редактора, такого как Блокнот, и добавить директивы в файл.
Например, включите следующие директивы,
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
… и сохранить файл как robots.txt.
Теперь, используя FTP-клиент, нажмите « File Upload » и загрузите файл в корневую папку веб-сайта.
Чтобы убедиться, что ваш файл был успешно загружен, введите имя своего домена, а затем «/robots. txt».
Плюсы и минусы Robots.txt
Плюсы файла robots.txt
- Он помогает оптимизировать краулинговые бюджеты поисковых систем, говоря им не тратить время на страницы, которые вы не хотите индексировать. Это помогает поисковым системам сканировать наиболее важные для вас страницы.
- Помогает оптимизировать ваш веб-сервер, блокируя ботов, которые тратят ресурсы впустую.
- Помогает скрыть страницы благодарности, целевые страницы, страницы входа и многое другое, что не нужно индексировать поисковыми системами.
Минусы файла robots.txt
- Теперь вы знаете, как получить доступ к файлу robots.txt для любого веб-сайта. Это довольно просто. Просто введите доменное имя, а затем «/ robots.txt». Это, однако, также сопряжено с определенным риском. Файл robots.txt может содержать URL-адреса некоторых ваших внутренних страниц, которые вы не хотели бы индексировать поисковыми системами.
Например, может существовать страница входа, которую вы не хотели бы индексировать. Однако его упоминание в файле robots.txt позволяет злоумышленникам получить доступ к странице. То же самое происходит, если вы пытаетесь скрыть некоторые личные данные. - Хотя создать файл robots.txt довольно просто, если вы ошибетесь хотя бы в одном символе, это испортит все ваши усилия по SEO.
Куда поместить файл robots.txt
Мы полагаем, что теперь вы хорошо знаете, куда следует добавить файл robots.txt.
Файл robots.txt всегда должен находиться в корне вашего сайта. Если ваш домен — yourdomain.com, то URL-адрес вашего файла robots.txt будет https://yourdomain.com/robots.txt.
В дополнение к включению файла robots.txt в корневой каталог, необходимо следовать некоторым рекомендациям. Так что сделайте это правильно, иначе это не будет работать
txt, начав строку с решётки (#)Как протестировать файл robots.txt
Теперь, когда вы создали файл robots.txt, пришло время протестировать его с помощью инструмента для проверки robots.txt.
Мы рекомендуем инструмент внутри Google Search Console.
Чтобы получить доступ к этому инструменту, щелкните Открыть тестер robots.txt.
Мы предполагаем, что ваш веб-сайт добавлен в Google Search Console. Если это не так, нажмите « Добавить свойство сейчас » и выполните простые шаги, чтобы добавить свой веб-сайт в Google Search Console.
После этого ваш веб-сайт появится в раскрывающемся списке под « Пожалуйста, выберите свойство ».
Нужен ли вам файл robots.txt для вашего сайта WordPress?
Да, вам нужен файл robots.txt на вашем сайте WordPress. Независимо от того, есть у вас файл robots.txt или нет, поисковые системы все равно будут сканировать и индексировать ваш сайт. Но после того, как вы узнали, что такое robots. txt, как он работает и какой у него краулинговый бюджет, почему бы вам не включить его?
Файл robots.txt сообщает поисковым системам, что сканировать и, что более важно, что не сканировать.
Основной причиной для включения файла robots.txt является рассмотрение неблагоприятных последствий краулингового бюджета.
Как указывалось ранее, каждый веб-сайт имеет определенный краулинговый бюджет. Это сводится к количеству страниц, которые бот просматривает за сеанс. Если бот не завершит сканирование всех страниц вашего сайта во время сеанса, он вернется и возобновит сканирование в следующем сеансе.
И это замедляет индексацию вашего сайта.
Чтобы быстро исправить это, запретите поисковым ботам сканировать ненужные страницы, медиафайлы, плагины, папки тем и т. д., тем самым сэкономив квоту сканирования.
Заключительные мысли
При работе над SEO вашего веб-сайта мы придаем большое значение оптимизации контента, поиску правильных ключевых слов, работе с обратными ссылками, созданию файла sitemap. xml и другим факторам. Элементом SEO, на который некоторые веб-мастера обращают меньше внимания, является файл robots.txt.
Файл robots.txt может не иметь большого значения при запуске веб-сайта. Но по мере роста вашего веб-сайта и увеличения количества страниц он принесет богатые дивиденды, если мы начнем следовать передовым методам в отношении файла robots.txt.
Мы надеемся, что эта статья помогла вам получить полезную информацию о том, что такое robots.txt и как создать его на своем веб-сайте. Итак, какие директивы вы установили в файле robots.txt?
Что такое Robots.txt и как его использовать
Поддержка > Продвижение вашего сайта > Поисковая оптимизация
Как использовать Robots.txt
Перейти к разделу
- Что такое robots.txt?
- Как работает файл robots.txt?
- Как настроить файл robots.txt на моем веб-сайте?
- Где находится файл robots. txt?
- Как настроить файл robots.txt (примеры)
- Как загрузить собственный файл robots.txt
Что такое robots.txt?
Файл Robots.txt — это текстовый файл, связанный с вашим веб-сайтом, который используется поисковыми системами для определения того, какие страницы вашего веб-сайта вы хотите, чтобы они посещали, а какие нет.
Как работает файл robots.txt?
Структура файла robots.txt очень проста. По сути, это заметка, которая сообщает поисковым системам, как вы хотите, чтобы они индексировали ваши страницы. Самый простой файл robots.txt выглядит так, как показано в примере ниже, что позволяет любой поисковой системе индексировать все, что она может найти:
User-agent: *
Disallow:
Это направление разбито на две части, первой является User-agent. Это (по большей части) поисковые системы, которые сканируют ваш сайт. Вы можете структурировать файл robots.txt, чтобы применять правила к определенным поисковым системам. Например, вы можете использовать следующее правило для ссылки на роботов Bing:
User-agent: bingbot
Disallow:
В большинстве случаев после User-agent стоит *, который означает, что правила применяются ко всем роботам.
Вторая часть — это функция Disallow:, которая указывает страницу или каталог, которые поисковые системы не должны индексировать. Таким образом, приведенный выше пример сообщает Bing, что они могут получить доступ ко всему, поскольку команда не указана.
Как настроить файл robots.txt на моем веб-сайте?
Мы автоматически настроили ваш файл robots.txt следующим образом:
пользовательский агент: *
Карта сайта: http://yourdomain.co.uk/sitemap.xml
disallow: /include/
/904basket 3. newshop0_3.basket0_3.basket33.xml: /include/
DISLAING: /SHOP/CHECKOUT_PROCESS.PHP
DISLAIN Файл? Чтобы получить доступ к файлу robots.txt, как это сделают поисковые системы, введите свое полное доменное имя в адресную строку браузера и добавьте «/robots.txt» в конце адреса вашего веб-сайта. Например: https://www.yourdomain.co.uk/robots.txt Вы можете полностью настроить файл robots.txt, следуя приведенным ниже инструкциям: На компьютере откройте Блокнот (или TextEdit на Mac) Используйте эту программу для записи нового файла robots в виде обычного текста без стилей и форматирования Сохраните файл под именем: robots.txt Ниже приведены несколько сценариев, которые могут потребоваться для вашего веб-сайта, и способы настройки файла robots. 1. Разрешить всем поисковым системам доступ к изображениям Чтобы указать все поисковые системы вам нужно будет добавить символ * в качестве вашего агента пользователя, поскольку он представляет все поисковые системы: Агент пользователя: * Разрешить: /siteimages/ 2. Запретить всем поисковым системам доступ к изображения Агент пользователя: * Запретить: /siteimages/ 3. Разрешить только некоторые поисковые системы Если вы хотите разрешить только определенные поисковые системы, Как показано ниже: Пользовательский агент: * DISLAING: / SiteFiles / DINLOWALE: / SiteImages / DISER-AGENT: Googlebot Агент пользователя: bingbot Disallow: В приведенном выше примере все поисковые системы не могут сканировать ваши файлы и изображения, кроме Bing (bingbot) и Google (googlebot). 4. Разрешить доступ к изображениям только некоторым поисковым системам Если вы хотите, чтобы только определенные поисковые системы сканировали ваши изображения, вам необходимо указать их, как показано ниже: Запретить: /siteimages/ Как настроить файл robots.txt
Примеры
txt для разрешения этого: 0003
Агент пользователя: googlebot-image
Запретить:
но для того, чтобы они не отображались в Google Images, вам нужно указать это, указав робота Google Image в файле robots.txt, как показано ниже:
User-agent: *
Disallow: /sitefiles/
User-agent: googlebot-image
Disallow: /siteimages/
Указав конкретно этого робота Google Image, вы не позволяете своим изображениям появляться в поиске Google Image, однако разрешаете Google продолжать сканирование это означает, что они все еще могут появляться в веб-поиске Google.
6. Запретите некоторые поисковые системы, чтобы они ничего не сканировали
Если вы хотите, чтобы конкретная поисковая система вообще не сканировала ваш сайт, вам нужно будет добавить символ /, так как он представляет весь ваш контент:
Пользовательский агент: *
DISLAING: / SiteFiles /
DISLANGE: / SITEIMAGES /
DISER-AGENT: Bingbot
Дис. ваши роботы не позволяют Bing получить доступ к вашему веб-сайту, но все другие сайты, такие как Google, могут!
7. Разрешить всем поисковым системам доступ ко всем страницам сайта
Если вы хотите разрешить всем поисковым системам доступ ко всему, вам необходимо добавить в файл robots.txt следующее:
User-agent: *
Disallow:
8. Запретить поисковым системам доступ к некоторым страницам сайта
Если вы хотите, чтобы все поисковые системы не имели доступа к определенным страницам необходимо добавить имя файла страницы в ваш файл, как показано ниже:
User-agent: *
Disallow: /guestbook/
Disallow: /onlineshop/
Эти страницы могут быть защищены паролем. сканируется вашими роботами, но посетитель сайта не может получить к нему доступ без имени пользователя и пароля. Из-за этого, а также из-за того, что страница, вероятно, будет иметь очень мало преимуществ для SEO, если вы вообще не хотите, чтобы эта страница индексировалась, вы можете добавить это в свой файл robots.txt, но это не обязательно, так как он не может быть доступен все посетители.
9. Запретить поисковым системам доступ к личным документам любые страницы или личные документы, проиндексированные на вашем веб-сайте с помощью robots. txt, чтобы люди могли найти их через ваш файл robots.txt, если они искали его. Если вы хотите ограничить доступ к этим ресурсам на своем веб-сайте, мы рекомендуем защитить вашу страницу паролем.
Как загрузить собственный файл robots.txt
Чтобы загрузить свой файл robots.txt и заменить созданный, выполните следующие действия:
Войти в свою учетную запись Создать
Нажмите «Содержимое» в верхнем меню
Нажмите «Файлы» в меню слева
Нажмите зеленую кнопку «Добавить файл» в правом верхнем углу
Нажмите кнопку «Загрузить» и выберите файл.
Нажмите зеленую кнопку Загрузить файл
Опубликуйте свой веб-сайт, чтобы изменения вступили в силу
Теперь файл robots. txt будет изменен.
Еще вопросы?
Если у вас есть дополнительные вопросы, свяжитесь с нами, и мы будем рады помочь.
Свяжитесь с нами
Передовой опыт для SEO-оптимизации robots.txt
НАЧАЛО
- 1 Почему SEO-оптимизация robots.txt важна для вашего сайта?
- 1.1 Индексированные страницы неполностей или низкого качества
- 1,2 Бюджетный лимит максимизированного
- 1,3 индексированных ресурсов с безвозвратом
- 2 Работа роботов.txt Директивы
- 2.1 Агент
- 2.2 DISTILLINGLE
- 2.1 Агент
- 2.2 DISTILLIPLAIN
- 2.1.
- 2.3 Разрешить
- 2.4 Задержка сканирования
- 2.5 Sitemap
- 3 7 Лучшие практики для роботов.txt SEO
- 3.1 Содержание должно быть полным
- 3.2. Использование DINALOW Термины с учетом регистра
- 3.5 Укажите User-Agent
- 3.6 Размещение файла robots. txt в корневой папке
- 3.7 Мониторинг содержимого вашего файла
- 4 Как создать файл robots.txt
- 4.1 Создайте файл с именем Robots.txt
- 4.2 Добавьте правила в файл Robots.txt
- 4.3 Загрузите файл Robots.txt на свой сайт
- 4.4 Протестируйте файл Robots.txt
2 Заключение Бот поисковой системы индексирует и ранжирует ваш сайт, но у вас больше власти над роботами, чем вы можете себе представить.
Эта возможность предоставляется вам текстовым файлом robots.txt, который представляет собой протокол исключения роботов (REP) с такими директивами, как метатеги и поддирективы, такие как ссылки «follow» и «no-follow».
В инструментах для веб-мастеров карта сайта robots.txt предоставляет расположение веб-страниц на вашем веб-сайте, которые необходимо просканировать и проиндексировать.
По словам Google,
«Robots.txt — это обычный текстовый файл, соответствующий стандарту исключения роботов ».
Кроме того, часто упускаемый из виду txt-файл robots следует протоколу для роботов, и Google объясняет:
» Файл robots.txt сообщает поисковым роботам, к каким URL-адресам на вашем сайте может получить доступ сканер. Это используется в основном для того, чтобы не перегружать ваш сайт запросами; это не механизм для защиты веб-страницы от Google .“
Этот файл robots.txt SEO используется и признается всеми основными игроками поисковых систем – Google, Bing и Yahoo!.
Дело в том, что robots.txt разрешает определенным пользовательским агентам (известным как программное обеспечение для сканирования веб-страниц) на вашем веб-сайте, которые могут или не могут сканировать его в соответствии с данной инструкцией.
Теперь базовый формат файла robots.txt предназначен для указания роботам-паукам поисковой системы определенных сайтов, использующих пользовательские агенты с директивами «Разрешить» и «Запретить».
Итак, в этом блоге вы найдете рекомендации по использованию файла robots.
txt для улучшения вашей игры SEO (поисковая оптимизация).Давайте начнем с «Как роботы txt SEO важны для бизнеса?»
Почему файл robots.txt SEO важен для вашего сайта?
Вашему бизнесу требуются все типы файлов и функций, которые могут продвигать ваш контент, продукты и услуги, чтобы вы могли привлечь целевую аудиторию на свой веб-сайт.
Чтобы охватить целевую аудиторию, первым шагом является ранжирование на первой странице поисковой выдачи, и роботы Google сканируют ваш веб-сайт для оценки индекса и рейтинга.
По словам Google, боты поисковых систем являются «добропорядочными гражданами» Интернета, поскольку у них есть единственная обязанность — сканировать веб-сайты в Интернете без ухудшения их качества для ваших целевых пользователей.
Но если, даже после нескольких месяцев применения методов SEO и работы над своим сайтом, вы все еще задаетесь вопросом,
«Почему ваш сайт не ранжируется?»
Ну, может быть три конкретных причины, по которым ваш сайт не ранжируется, что обсуждается ниже, а также причина, по которой вашему сайту нужен robots.
Проиндексированные неавторитетные или некачественные страницы txt SEO.Ваши неавторитетные или некачественные страницы могут испортить общий анализ вашего бизнеса и снизить ваш рейтинг в поисковой выдаче в Интернете.
К таким некачественным страницам относятся: внутренние страницы результатов поиска, промежуточная версия страницы для проверки определенных функций и элементов или страница входа для пользователей.
Эти страницы необходимы для выполнения определенных задач на вашем веб-сайте, но их не нужно открывать каждому случайному целевому пользователю, направляющемуся на ваш веб-сайт.
Таким образом, индексирование этих страниц в файле robots.txt может обеспечить ожидаемую общую производительность, создав их как секретные каталоги на вашей веб-странице, которые могут посещать пользователи, но не сканировать поисковые системы.
Создание файла robots.txt, а затем включение URL-адресов страниц, не имеющих авторитета создания, поможет вам управлять страницами на вашем веб-сайте, которые необходимо просканировать, проиндексировать и получить рейтинг за их лучший авторитет метрики.
Максимальный предел бюджета сканированияОграничение краулингового бюджета — это когда боты поисковых систем не могут проиндексировать все ваши веб-страницы из-за переполненности страниц, дублирования и любых подобных ошибок.
Согласно блогу Google «Что означает бюджет сканирования для робота Googlebot»
«Ограничение скорости сканирования» ограничивает максимальную скорость выборки для данного сайта.
Таким образом, чтобы преодолеть такие ограничения, вы можете заблокировать неважные веб-страницы, такие как страницы благодарности, корзины покупок и некоторые коды, включив их URL-адреса в каталоги robots.txt, что ограничит доступ к этим страницам для сканирования.
На приведенном ниже снимке экрана показана проверка URL-адреса, сканирование которого запрещено, и поэтому отображается сообщение «URL-адрес недоступен для Google».
Указанный выше URL-адрес недоступен для сканирования Google, поскольку он robots.
txt»И важные, номинальные страницы будут индексироваться намного лучше и обеспечат ожидаемый авторитет вашего сайта в поисковой выдаче.
Индексированные ресурсы без полномочийНеважные файлы изображений, скриптов или стилей — это файлы ресурсов, которые могут быть полезны для структуры вашего веб-сайта, но не функционируют как ресурсы, которые необходимо сканировать, поскольку они не влияют на страницу функции.
Таким образом, вы можете использовать директиву robots.txt или метафайлы, чтобы предотвратить их индексацию. Для мультимедийных ресурсов, таких как PDF-файлы и изображения, лучше всего использовать файлы robots.txt, так как мета-директивы для них не работают.
Примечание: Если отсутствие таких ресурсов затрудняет понимание поисковым роботом Google какой-либо из ваших веб-страниц, не блокируйте их
Это может привести к тому, что Google не сможет хорошо анализировать страницы, которые зависят от этих ресурсов и нарушит вашу индексацию.
Ваш веб-сайт по-прежнему может работать без директив robots.txt, разрешающих или запрещающих директивы, и получает рейтинг в поисковой выдаче, но по-прежнему обновляйте файл robots.txt SEO, чтобы улучшить авторитет вашего веб-сайта и рейтинг в Интернете.
Файл robots.txt является частью протокола исключения роботов (REP), его основная функция заключается в том, чтобы не допускать этих поисковых роботов к личным папкам, не анализировать ресурсы, не влияющие на веб-сайты, и изменять роботов, перемещающихся по содержимому вашего веб-сайта.
Рабочие директивы robots.txt
Robots.txt является неотъемлемой частью сканирования и индексирования, поэтому для веб-мастеров становится важным предоставить роботам поисковых систем четкие инструкции, чтобы все страницы на ваших веб-сайтах были обнаружены.
Расположение файла robots.txt всегда должно быть в корне домена, то есть в каталоге верхнего уровня сайта, который должен быть на защитном протоколе.
Поддерживаемые протоколы: FTP и HTTP/HTTPS
Теперь для этого инструкции даны файлами robots.
txt со следующими директивами, приведенными ниже:i. Агент пользователя
ii. Запретить
iii. Разрешить
iv. Crawl Delay
v. Карта сайта
Эти директивы являются общими терминами, используемыми в файлах robots.txt для инструктирования сканеров поисковых систем.
Давайте разберемся с этими техническими терминами на примерах.
User-AgentНа цифровых платформах существует множество поисковых систем, которые используются в качестве User-agent для доступа к содержимому вашего сайта для его индексации. User-Agent — это агент, один из роботов Googlebot в SEO, управляющий их способностью сканирования.
Таким образом, вы можете предоставить строгие инструкции о том, какие поисковые системы могут сканировать ваш веб-сайт и отображать его содержимое в Интернете.
Некоторыми полезными агентами пользователя являются Google bot, Google bot-Image, Bing bot, Slurp и паук Baidu.
Теперь о том, как создать файл robots.
txt для вашего веб-сайта, чтобы разрешить/запретить одну поисковую систему на вашем веб-сайте.Здесь
Агент пользователя: *
Запретить: /
Здесь агент пользователя * называется подстановочным знаком и используется для запрета всем другим поисковым роботам анализировать ваш сайт.
Агент пользователя: Googlebot
Разрешить: /
На этом этапе вы разрешаете только роботу Google сканировать ваш веб-сайт, индексировать его содержимое и ранжировать его соответствующим образом.
ЗапретитьЭта команда второй строки в файле robots.txt позволяет поисковой системе сканировать ваш веб-сайт, но не позволяет сканировать контент или разрешать доступ к файлам и страницам. Все пути указаны в разделе «Запретить». директивы.
Например,
User-agent: *
Disallow: /testimonials
Здесь путь к странице для ‘ testimonials ‘ недоступен для ботов, поэтому ни одна поисковая система неавторитетная страница не индексируется в GSC, что не приводит к ошибкам в ранжировании.
РазрешитьЭта директива позволяет роботам Google получать доступ к определенным страницам или каталогам, к которым вы хотите, чтобы они обращались и сканировали.
При выполнении этой команды боты могут получить доступ к странице или вложенной папке, даже если основная папка или страница, в которой они находятся, запрещены.
Например:
Пользовательский агент: GoogleBot
DISLANGE: /STEDIMONIALS
. в то время как разрешение позволило роботу Google получить доступ к URL-адресу файла в портфолио.
Задержка сканированияБольшинство директив просто приказывает сканерам поисковых систем разрешить или остановить доступ к определенным путям страницы или каталога. При задержке сканирования основная функция заключается в задержке сканирования определенного веб-сайта.
Crawl Rate — это параметр, который останавливает доступ к вашему сайту на несколько или много секунд, указанный в настройках GSC, как показано на рисунке ниже.
Примечание . Эта директива или термин не поддерживается ботами Google, но чтобы установить временную задержку при доступе, сканировании и индексировании страницы, вы можете изменить «скорость сканирования» в настройках Google Search Console.
Карта сайтаКарта сайта — это еще одна команда, установленная в файлах SEO robots.txt для указания путей на вашем веб-сайте, которые сканеры могут сканировать и индексировать.
Карта сайта — это XML-файл, который отправляется непосредственно в файлы robots.txt, записывая их в текстовом виде для понимания поисковыми роботами.
Например:
Агент пользователя: *
Запретить: /blog/
Разрешить: /blog/post-title/
Карта сайта: http://www.example.com/sitemap.xml
Вы можете предоставить все карты сайта в файлах robots.txt или напрямую отправить карту сайта в инструменты каждой поисковой системы для веб-мастеров и вам не нужно делать это в файлах robots.
txt, хотя вам придется делать это отдельно для каждого инструмента для веб-мастеров каждой поисковой системы.Итак, уступите место некоторым из лучших практик для robots.txt SEO, поскольку они дадут вам больше контроля над веб-менеджером ваших веб-сайтов и создадут успешные пути для ботов Google.
7 рекомендаций по поисковой оптимизации Robots.txt
Содержимое должно быть доступным для сканированияСодержимое вашего веб-сайта должно быть релевантным, доступным для сканирования и важным.
Неважный контент включает в себя комментарии в кодировке вашего веб-сайта, ошибочно скопированные коды или дублированный контент, из-за чего ботам Google очень сложно сканировать, индексировать и ранжировать ваши веб-страницы.
Чтобы преодолеть это, постоянно проверяйте содержимое вашей страницы и директивы, используемые для некоторых ненадежных и неважных URL-адресов, которые использовались в SEO Robot.txt.
Это делается для того, чтобы убедиться, что все важные страницы доступны для сканирования, а их содержимое будет иметь реальную ценность при ранжировании в поисковой выдаче.
Использование запрета на дублирование контентаДублирование контента — это очень распространенное явление, возникающее в Интернете из-за местоположения и языка, а также URL-адреса страницы вашего веб-сайта.
Имейте в виду, что это может случиться с любой из ваших страниц!!
Итак, чтобы не сделать их доступными для сканирования в Robot.txt, вы можете использовать директиву Disallow: для указания Google, что те дублированные версии ваших веб-страниц не должны сканироваться, что блокирует этот тип контента.
Но дело в том, что если Google не сможет его просканировать, он также не будет доступен пользователям из-за изменений URL-адресов разных мест, ведущих на ваш сайт.
Итак, чтобы избежать такой потери трафика, вы можете использовать другой тег или вариант канонизации, как показано в данных ниже.
Таким образом, вместо robots.txt вы можете использовать канонические теги, которые являются лучшим вариантом для блокировки сканирования этих дубликатов веб-страниц, но при этом передают их полномочия основному URL-адресу или странице, помогая вашему веб-сайту ранжироваться.
Не используйте файл robots.txt для конфиденциальной информацииКонфиденциальная информация или данные включают информацию о ваших клиентах, вашей компании, вашем веб-сайте и даже ваших сотрудниках, которая может быть использована для причинения им финансового или иного вреда.
Проще говоря, использование файла robots.txt для сокрытия частной информации о пользователе и других данных не будет работать, и данные все равно будут видны.
Вот почему обеспечение их безопасности является приоритетом любого веб-сайта.
Это произошло потому, что другие веб-страницы могут быть связаны с такими личными файлами, сканирование которых разрешено. Это дало ботам новые пути для обхода.
И страницы с такой личной информацией индексируются.
Проблема в том, что если эти типы файлов проиндексированы, ваша информация и информация ваших клиентов будут доступны в Интернете, и ваш сайт станет небезопасным для ваших пользователей.
Проблема была создана из-за общих директив robot.
txt, которые были улучшены с помощью метадирективы «Noindex, follow» для роботов, как показано на рисунке ниже.Вы также можете использовать защиту паролем. Мета-директива Noindex, используемая в метатегах robots, предписывает сканеру не сканировать определенные веб-страницы или файлы, и безопасность вашего веб-сайта сохраняется.
Используйте абсолютные URL-адреса с терминами, чувствительными к региструURL-адреса — это элементы веб-сайта, чувствительные к регистру, и в файле robots.txt вы используете такие URL-адреса для определения путей, по которым поисковые роботы могут сканировать, которые даются после директивы, такие как разрешить или запретить.
Содержимое файла robot.txt содержит директивы, которые являются инструкциями для робота Google по доступу или прекращению сканирования пути URL-адреса, указанного на рисунке ниже.
Дело в том, что директивы будут выполняться поисковыми роботами только в том случае, если путь, указанный в файле robots.
txt, действителен.Поскольку, когда веб-сайт работает со слишком большим количеством подкаталогов, абсолютные URL-адреса необходимы для обеспечения правильного направления сканирования в Google, иначе он запутается.
Также имейте в виду, что имя файла каталога должно быть «robots.txt», иначе сканер не распознает его и не будет соответствовать вашим требованиям.
Таким образом, проверка каждого URL-адреса, даже автоматически заданного, может сэкономить вам деньги на пробных запусках.
Укажите User-AgentGoogle bot, Google bot-Image и Bing bot — некоторые пользовательские агенты, которые могут игнорировать этот файл robots.txt как команду правил для обработки вашего веб-сайта из-за повреждения файла имя или неправильные URL-адреса.
Именно поэтому при использовании файла robots.txt необходимо указывать пользовательский агент, чтобы ваш веб-сайт понимал, что вы должны использовать одни и те же файлы для каждой веб-страницы, будь то в стране или за рубежом.
Размещение robots.txt в корневой папкеСамая распространенная ошибка сайта, когда файл robots.txt не помещается в корневую папку сайта.
Это похоже на полное отсутствие вашего файла для загрузки на ваш веб-сайт, из-за чего бот Google сначала не имеет доступа к командам, поэтому они выбирают свой путь сканирования вашего веб-сайта.
И ты не хочешь этого делать.
Итак, лучше всего поместить файл robots.txt на домашнюю страницу или в корневую папку.
Мониторинг содержимого вашего файлаМониторинг уже существующего файла robots.txt на вашем веб-сайте, который отправляется в Google в качестве командной версии, поможет Google или любой другой поисковой системе лучше работать с кэшированием содержимого robots.txt файл раз в день.
Вы должны следить за содержанием файла robots.txt SEO, чтобы,
и. Ваши команды для веб-страниц обновлены.
ii. Вы можете убедиться, что контент, который вы хотите просканировать, не заблокирован.
iii. Легко предоставляйте обновленный URL-адрес карты сайта в содержимом файлов robots.txt.
iv. Изменение имен файлов и использование каталогов и подкаталогов для инструктирования поискового робота.
Как создать файл robots.txt
Создание файла robots.txt и обеспечение его общедоступности и полезности для ваших веб-сайтов обычно включает четыре шага:
Создать файл с именем Robots.txtПрактически в любом текстовом редакторе (Блокноте) можно создать только один файл robots.txt с таким именем, как показано на рисунке ниже.
Теперь сохраните эти файлы в том же формате в корне используемого хоста веб-сайта, чтобы сканер в первую очередь обращался к ним и не сканировал неавторизованные файлы сканерам.
Добавить правила в файл robots.txtПравила — это команды, которые начинаются с User-agent:, а затем доставляют директивы по одной на строку в текстовых файлах (как показано в файле блокнота robots.
txt выше).В первой строке вы указываете информацию о поисковых ботах, во второй строке какие страницы или файлы запрещены, а затем в третьей строке предоставляете доступ к странице сайта.
Загрузите файл robots.txt на свой сайтКогда вы указали каталоги в файлах robots.txt и сохранили их на своем компьютере. Теперь вам нужно загрузить этот файл на свой сайт, что зависит от сайта и сервера вашего сайта.
Проверка файла robots.txtПоследним этапом создания файла robots.txt является проверка того, является ли файл общедоступным и может ли Google анализировать его в Интернете, как показано на рисунке.
После того, как вы загрузили и протестировали файл robots.txt SEO для своего веб-сайта, теперь вы можете контролировать сканирование своего веб-сайта, поскольку поисковые роботы Google автоматически найдут ваш файл robots.txt и сразу же начнут его использовать.
Заключение
SEO robots.
txt может оказаться очень удобным, но эффективным способом контроля анализа страниц вашего веб-сайта, когда поисковые системы сканируют их для оценки, индексации и ранжирования вашего веб-сайта, потому что только те сайты, которые вы хотите, чтобы ваш веб-сайт был ранжируется по просканированным.Итак, я надеюсь, вы понимаете, как правильно создать файл robots.txt, который, таким образом, предназначен для творчества с вашим SEO и обеспечения лучшего опыта для ботов Google, а также для вашей целевой аудитории.
Это означает, что вы позволяете ботам исследовать ваш веб-сайт через соответствующие страницы и каталоги, позволяя организовать ваши материалы в поисковой выдаче так, как вы этого хотите.
Чтобы получить дополнительные советы и услуги по маркетингу, вы можете записаться на бесплатную 30-минутную сессию по стратегии с нашими экспертами. Во время этого звонка наши эксперты обсудят ваш бизнес и предоставят вам бесплатные стратегии, которые вы можете использовать для увеличения продаж и доходов.
Что такое файл robots.txt и как его создать?
Поделиться
Содержание
- 1 Что такое robots.txt?
- 2 Как работает файл robots.txt
- 3 Какие инструкции используются в файле robots.txt?
- 4 Какую роль robots.txt играет в поисковой оптимизации?
- 5 Ссылки по теме
- 6 Аналогичные изделия
Что такое robots.txt?
Рисунок: Robots.txt — Автор: Seobility — Лицензия: CC BY-SA 4.0
Robots.txt — это текстовый файл с инструкциями для сканеров поисковых систем. Он определяет, какие области веб-сайта сканерам разрешено искать. Однако они не указаны явно в файле robots.txt. Скорее, некоторые области не разрешены для обыска. Используя этот простой текстовый файл, вы можете легко исключить целые домены, целые каталоги, один или несколько подкаталогов или отдельные файлы из сканирования поисковыми системами. Однако этот файл не защищает от несанкционированного доступа.
Robots.txt хранится в корневом каталоге домена. Таким образом, это первый документ, который сканеры открывают при посещении вашего сайта. Однако файл не только контролирует сканирование. Вы также можете интегрировать ссылку в свою карту сайта, которая дает поисковым роботам обзор всех существующих URL-адресов вашего домена.
Robots.txt Checker
Проверьте файл robots.txt на вашем веб-сайте
Как работает robots.txt
В 1994 году был опубликован протокол под названием REP (стандартный протокол исключения роботов). Этот протокол предусматривает, что все сканеры поисковых систем (пользовательские агенты) должны сначала найти файл robots.txt в корневом каталоге вашего сайта и прочитать содержащиеся в нем инструкции. Только после этого роботы смогут начать индексировать вашу веб-страницу. Файл должен находиться непосредственно в корневом каталоге вашего домена и должен быть написан строчными буквами, поскольку роботы читают файл robots.txt и его инструкции с учетом регистра.
К сожалению, не все роботы поисковых систем следуют этим правилам. По крайней мере, файл работает с наиболее важными поисковыми системами, такими как Bing, Yahoo и Google. Их поисковые роботы строго следуют инструкциям REP и robots.txt.На практике robots.txt можно использовать для разных типов файлов. Если вы используете его для файлов изображений, он предотвращает появление этих файлов в результатах поиска Google. Неважные файлы ресурсов, такие как файлы сценариев, стилей и изображений, также можно легко заблокировать с помощью файла robots.txt. Кроме того, вы можете исключить из сканирования динамически сгенерированные веб-страницы с помощью соответствующих команд. Например, могут быть заблокированы страницы результатов внутренней функции поиска, страницы с идентификаторами сеанса или действия пользователя, такие как корзины покупок. Вы также можете контролировать доступ сканера к другим файлам, не являющимся изображениями (веб-страницам), с помощью текстового файла. Таким образом, вы можете избежать следующих сценариев:
- поисковые роботы сканируют множество похожих или неважных веб-страниц
- ваш краулинговый бюджет бесполезно тратится
- ваш сервер перегружен поисковыми роботами
В этом контексте, однако, обратите внимание, что файл robots.
txt не гарантирует, что ваш сайт или отдельные подстраницы не будут проиндексированы. Он контролирует только сканирование вашего сайта, но не индексацию. Если веб-страницы не должны индексироваться поисковыми системами, вам необходимо установить следующий метатег в заголовке вашей веб-страницы:Однако не следует блокировать файлы, имеющие высокую релевантность для поисковых роботов. Обратите внимание, что файлы CSS и JavaScript также должны быть разблокированы, так как они используются для сканирования, особенно мобильными роботами.
Какие инструкции используются в файле robots.txt?
Ваш robots.txt должен быть сохранен как текстовый файл UTF-8 или ASCII в корневом каталоге вашей веб-страницы. Должен быть только один файл с таким именем. Он содержит один или несколько наборов правил, структурированных в удобном для чтения формате. Правила (инструкции) обрабатываются сверху вниз, при этом различаются прописные и строчные буквы.
В файле robots.txt используются следующие термины:
- user-agent: обозначает имя сканера (имена можно найти в базе данных роботов)
- disallow: предотвращает сканирование определенных файлов, каталогов или веб-страниц
- разрешить: перезаписывает запрет и разрешает сканирование файлов, веб-страниц и каталогов Карта сайта
- (необязательно): показывает расположение карты сайта .
- *: означает любое количество символов
- $: означает конец строки
Инструкции (записи) в robots.txt всегда состоят из двух частей. В первой части вы определяете, для каких роботов (пользовательских агентов) применяется следующая инструкция. Вторая часть содержит инструкцию (запретить или разрешить). «user-agent: Google-Bot» и инструкция «disallow: /clients/» означают, что боту Google не разрешен поиск в каталоге /clients/. Если поисковый бот не должен сканировать весь сайт, запись: «user-agent: *» с инструкцией «disallow: /». Вы можете использовать знак доллара «$», чтобы заблокировать веб-страницы с определенным расширением.
Оператор «disallow: /* .doc$» блокирует все URL-адреса с расширением .doc. Точно так же вы можете заблокировать определенные форматы файлов robots.txt: «disallow: /*.jpg$».Например, файл robots.txt для веб-сайта https://www.example.com/ может выглядеть так:
Агент пользователя: * Запретить: /логин/ Запретить: /карта/ Запретить: /фото/ Запретить: /temp/ Запретить: /поиск/ Запретить: /*.pdf$ Карта сайта: https://www.example.com/sitemap.xml
Какую роль robots.txt играет в поисковой оптимизации?
Инструкции в файле robots.txt оказывают сильное влияние на SEO (поисковую оптимизацию), поскольку файл позволяет управлять поисковыми роботами. Однако, если пользовательские агенты слишком сильно ограничены инструкциями запрета, это отрицательно скажется на рейтинге вашего сайта. Вы также должны учитывать, что вы не будете ранжироваться с веб-страницами, которые вы исключили, запретив в robots.txt. Если, с другой стороны, нет или почти нет запрещающих ограничений, может случиться так, что страницы с дублирующимся контентом будут проиндексированы, что также негативно скажется на рейтинге этих страниц.
Перед тем, как сохранить файл в корневом каталоге вашего веб-сайта, вы должны проверить синтаксис. Даже незначительные ошибки могут привести к тому, что поисковые роботы будут игнорировать правила запрета и сканировать сайты, которые не должны быть проиндексированы. Такие ошибки также могут привести к тому, что страницы больше не будут доступны для поисковых роботов, а целые URL-адреса не будут проиндексированы из-за запрета. Вы можете проверить правильность файла robots.txt с помощью Google Search Console. В разделе «Текущее состояние» и «Ошибки сканирования» вы найдете все страницы, заблокированные инструкциями по запрету.
Правильно используя robots.txt, вы можете гарантировать, что поисковые роботы просканируют все важные части вашего веб-сайта. Следовательно, весь контент вашей страницы индексируется Google и другими поисковыми системами.
Ссылки по теме
- https://support.google.com/webmasters/answer/6062608?hl=ru
- https://support. google.com/webmasters/answer/6062596?hl=ru
Похожие статьи
- Тег Canonical
- hreflang
Как создать файл robots.txt
В ЭТОЙ СТАТЬЕ:
Объяснение SEO для людей может быть трудным, потому что есть много маленьких шагов, которые могут показаться не очень важными на первый взгляд, но они в сумме приносят большие выгоды в поисковые рейтинги, когда все сделано правильно.
Один важный шаг, который легко упустить из виду, — это дать роботам поисковых систем знать, какие страницы индексировать, а какие нет. Это можно сделать с помощью файла robots.txt.
В сегодняшней статье я собираюсь объяснить, как именно создать файл robots.txt, чтобы вы могли привести в порядок эту фундаментальную часть своего сайта и убедиться, что поисковые роботы взаимодействуют с вашим сайтом так, как вы хотите.
Что такое файл robots.txt?
Файл robots.txt представляет собой простую директиву, сообщающую поисковым роботам, какие страницы вашего сайта следует сканировать и индексировать.
Это часть протокола исключения роботов (REP), семейства стандартных процедур, которые определяют, как роботы поисковых систем сканируют Интернет, оценивают и индексируют контент сайта, а затем предоставляют этот контент пользователям. В этом файле указывается, где сканерам разрешено сканировать, а где нет. Он также может содержать информацию, которая может помочь поисковым роботам более эффективно сканировать веб-сайт.
REP также включает «мета-теги роботов», которые представляют собой директивы, включенные в HTML-код страницы и содержащие конкретные инструкции о том, как поисковые роботы должны сканировать и индексировать определенные веб-страницы и изображения или файлы, которые они содержат.
В чем разница между Robots.txt и тегом Meta Robots?
Как я уже упоминал, протокол исключения роботов также включает «мета-теги роботов», которые представляют собой фрагменты кода, включенные в HTML-код страницы. Они отличаются от файлов robots.txt тем, что указывают направление поисковым роботам на определенные веб-страницы , запрещающие доступ либо ко всей странице, либо к определенным файлам, содержащимся на странице, таким как фотографии и видео.
Файлы robots.txt, напротив, предназначены для предотвращения индексации целых сегментов веб-сайта, например подкаталогов, предназначенных только для внутреннего использования. Файл robots.txt находится в корневом домене вашего сайта, а не на конкретной странице, а директивы структурированы таким образом, что они влияют на все страницы, содержащиеся в каталогах или подкаталогах, на которые они ссылаются.
Зачем мне нужен файл robots.txt?
Файл robots.txt — обманчиво простой текстовый файл, имеющий большое значение. Без него поисковые роботы будут просто индексировать каждую найденную страницу.
Почему это важно?
Во-первых, сканирование всего сайта требует времени и ресурсов. Все это стоит денег, поэтому Google ограничивает объем сканирования сайта, особенно если этот сайт очень большой. Это известно как «краулинговый бюджет». Бюджет сканирования ограничен несколькими техническими факторами, включая время отклика, малоценные URL-адреса и количество обнаруженных ошибок.
Кроме того, если вы разрешите поисковым системам беспрепятственный доступ ко всем вашим страницам и позволите их поисковым роботам индексировать их, вы можете столкнуться с раздуванием индекса. Это означает, что Google может ранжировать неважные страницы, которые вы не хотите показывать в результатах поиска. Эти результаты могут вызвать у посетителей плохой опыт, и они могут даже конкурировать со страницами, для которых вы хотите ранжироваться.
Когда вы добавляете файл robots.txt на свой сайт или обновляете существующий файл, вы можете уменьшить траты краулингового бюджета и ограничить раздувание индекса.
Где найти файл robots.txt?
Есть простой способ узнать, есть ли на вашем сайте файл robots.txt: найдите его в Интернете.
Просто введите URL-адрес любого сайта и добавьте в конец «/robots.txt». Например: victoriousseo.com/robots.txt показывает вам наш.
Попробуйте сами, введя URL своего сайта и добавив в конце «/robots.
txt». Вы должны увидеть одну из трех вещей:- Несколько строк текста, указывающих на действительный файл robots.txt
- Совершенно пустая страница, указывающая на отсутствие фактического файла robots.txt
- Ошибка 404
Если вы проверяете свой сайт и получаете один из двух вторых результатов, вам нужно создать файл robots.txt чтобы помочь поисковым системам лучше понять, на чем они должны сосредоточить свои усилия.
Как создать файл robots.txt
Файл robots.txt содержит определенные команды, которые роботы поисковых систем могут читать и выполнять. Вот некоторые из терминов, которые вы будете использовать при создании файла robots.txt.
Общие термины Robots.txt, которые необходимо знать
User-Agent : User-agent — это любая часть программного обеспечения, предназначенная для извлечения и представления веб-контента конечным пользователям. В то время как веб-браузеры, медиаплееры и подключаемые модули могут считаться примерами пользовательских агентов, в контексте файлов robot.
txt пользовательский агент — это поисковый робот или паук (например, Googlebot), который сканирует и индексирует Ваш сайт.Разрешить: Если эта команда содержится в файле robots.txt, она позволяет агентам пользователя сканировать любые страницы, следующие за ней. Например, если команда гласит «Разрешить: /», это означает, что любой поисковый робот может получить доступ к любой странице, которая следует за косой чертой в «http://www.example.com/». Вам не нужно добавлять это для всего, что вы хотите сканировать, поскольку все, что не запрещено в robots.txt, неявно разрешено. Вместо этого используйте его, чтобы разрешить доступ к подкаталогу, находящемуся на запрещенном пути. Например, на сайтах WordPress часто есть директива disallow для папки /wp-admin/, что, в свою очередь, требует от них добавления директивы allow, позволяющей поисковым роботам получать доступ к /wp-admin/admin-ajax.php, не обращаясь ни к чему другому в папке. основная папка.
Disallow: Эта команда запрещает определенным пользовательским агентам просматривать страницы, следующие за указанной папкой.
Например, если команда гласит «Запретить: /blog/», это означает, что пользовательский агент не может сканировать любые URL-адреса, содержащие подкаталог /blog/, что исключит весь блог из поиска. Вы, вероятно, никогда не хотели бы этого делать, но вы могли бы. Вот почему очень важно учитывать последствия использования директивы disallow каждый раз, когда вы думаете о внесении изменений в файл robots.txt.Crawl-delay: Хотя эта команда считается неофициальной, она предназначена для защиты серверов от потенциально перегруженных запросов поисковых роботов. Обычно это реализуется на веб-сайтах, где слишком много запросов могут вызвать проблемы с сервером. Некоторые поисковые системы поддерживают его, но Google — нет. Вы можете настроить скорость сканирования для Google, открыв Google Search Console, перейдя на страницу настроек скорости сканирования вашего ресурса и отрегулировав там ползунок. Это работает только в том случае, если Google считает, что это не оптимально.
Если вы считаете, что это неоптимально, и Google с этим не согласен, вам может потребоваться отправить специальный запрос на его корректировку. Это потому, что Google предпочитает, чтобы вы позволяли им оптимизировать скорость сканирования вашего сайта.XML Sitemap: Эта директива делает именно то, что вы и предполагали: сообщает поисковым роботам, где находится ваша XML-карта сайта. Он должен выглядеть примерно так: «Карта сайта: http://www.example.com/sitemap.xml». Вы можете узнать больше о лучших методах работы с картами сайта здесь.
Пошаговые инструкции по созданию файла robots.txt
Чтобы создать собственный файл robots.txt, вам потребуется доступ к простому текстовому редактору, например Блокноту или TextEdit. Важно не использовать текстовый процессор, так как он обычно сохраняет файлы в проприетарных формах и может добавлять в файл специальные символы.
Для простоты мы будем использовать «www.example.com».
Начнем с настройки параметров пользовательского агента.
В первой строке введите: Агент пользователя: *
Звездочка означает, что всем поисковым роботам разрешено посещать ваш сайт.
Некоторые веб-сайты используют разрешающую директиву, указывающую, что ботам разрешено сканирование, но в этом нет необходимости. Любые части сайта, которые вы не запретили, неявно разрешены.
Далее мы введем параметр запрета. Дважды нажмите «возврат», чтобы вставить разрыв после строки пользовательского агента, затем введите:
Disallow: /
Поскольку после него мы не вводим никаких команд, это означает, что поисковые роботы могут посещать каждую страницу вашего сайта.
Если вы хотите заблокировать доступ к определенному контенту, вы можете добавить каталог после команды disallow. В нашем файле robots.txt есть две следующие команды запрета:
Запретить: /wp/wp-admin/
Запретить: /*?*
Первая обеспечивает доступ к страницам администратора WordPress (где мы редактируем такие вещи, как эту статью) не сканируются.
Это страницы, которые мы не хотели бы ранжировать в поиске, и Google также будет пустой тратой времени, пытаясь их просканировать, потому что они защищены паролем. Второй предотвращает сканирование URL-адресов, содержащих вопросительный знак, таких как страницы результатов поиска по блогам.После того, как вы выполнили свои команды, создайте ссылку на карту сайта. Хотя этот шаг не является обязательным с технической точки зрения, это рекомендуемая передовая практика, поскольку она указывает веб-паукам на наиболее важные страницы вашего сайта и делает архитектуру вашего сайта понятной. Вставив еще один разрыв строки, введите:
Карта сайта: http://www.example.com/sitemap.xml
Теперь ваш веб-разработчик может загрузить ваш файл на ваш веб-сайт.
Создание файла Robots.txt в WordPress
Если у вас есть доступ администратора к вашему WordPress, вы можете изменить файл robots.txt с помощью плагина Yoast SEO или AIOSEO. Кроме того, ваш веб-разработчик может использовать клиент FTP или SFTP для подключения к вашему сайту WordPress и доступа к корневому каталогу.
Не перемещайте файл robots.txt куда-либо, кроме корневого каталога. Хотя некоторые источники предлагают разместить его в подкаталоге или поддомене, в идеале он должен находиться в корневом домене: www.example.com/robots.txt.
Как протестировать файл robots.txt
Теперь, когда вы создали файл robots.txt, пришло время протестировать его. К счастью, Google упрощает это, предоставляя тестер robots.txt как часть Google Search Console.
После того, как вы откроете тестер для своего сайта, вы увидите все синтаксические предупреждения и выделенные логические ошибки.
Чтобы проверить, как конкретный робот Google «видит» вашу страницу, введите URL-адрес вашего сайта в текстовое поле внизу страницы, а затем выберите один из различных роботов Google в раскрывающемся списке справа. Нажатие «TEST» имитирует поведение выбранного вами бота и показывает, не запрещают ли роботу Googlebot доступ к странице какие-либо директивы.
Недостатки Robots.
txtФайлы robots.txt очень полезны, но у них есть свои ограничения.
Файлы robots.txt не должны использоваться для защиты или сокрытия частей вашего веб-сайта (это может привести к нарушению Закона о защите данных). Помните, я предлагал вам найти собственный файл robots.txt? Это означает, что любой может получить к нему доступ, а не только вы. Если есть информация, которую необходимо защитить, лучше всего защитить паролем определенные страницы или документы.
Кроме того, директивы файла robots.txt являются просто запросами. Вы можете ожидать, что Googlebot и другие законные поисковые роботы будут подчиняться вашим указаниям, но другие боты могут просто их игнорировать.
Наконец, даже если вы попросите сканеры не индексировать определенные URL-адреса, они не будут невидимыми. Другие веб-сайты могут ссылаться на них. Если вы не хотите, чтобы определенная информация на вашем веб-сайте была доступна для всеобщего обозрения, вам следует защитить ее паролем. Если вы хотите убедиться, что он не будет проиндексирован, рассмотрите возможность добавления на страницу тега noindex.