
Правильный файл robots.txt для сайта
Автор Алексей На чтение 15 мин Просмотров 14.6к. Опубликовано Обновлено
Robots.txt – это специальный файл, расположенный в корневом каталоге сайта. Вебмастер указывает в нем, какие страницы и данные закрыть от индексации от поисковых систем. Файл содержит директивы, описывающие доступ к разделам сайта (так называемый стандарт исключений для роботов). Например, с его помощью можно установить различные настройки доступа для поисковых роботов, предназначенных для мобильных устройств и обычных компьютеров. Очень важно настроить его правильно.
Содержание
- Нужен ли robots.txt?
- Где лежит файл Robots.txt?
- Как создать правильный robots.txt
- Директивы Disallow и Allow
- Использование спецсимволов * и $
- Директива Sitemap
- Директива Crawl-delay
- Директива Clean-param
- Синтаксис директивы
- Директива HOST
- Правильный robots.
 txt: настройка
txt: настройка - Правильный Robots.txt пример для WordPress
- Robots.txt пример для Joomla
- Robots.txt пример для Bitrix
- Robots.txt пример для MODx
- Robots.txt пример для Drupal
- Проверить robots.txt
- Проверка robotx.txt для поискового робота Яндекса
- Проверка robotx.txt для поискового робота Google
- Генераторы robots.txt
 txt: настройка
txt: настройкаНужен ли robots.txt?
После того, как вы добавите свой сайт в Google и Яндекс, ПС начнут индексировать все, абсолютно все, что находится в вашей папке с сайтом на сервере. Это не очень хорошо с точки зрения продвижения, ведь в папке содержится очень много лишнего для ПС «мусора», что негативно скажется на позициях в поисковой выдаче.
Именно правильно настроенный файл robots.txt запрещает индексирование документов, папок и ненужных страниц.
С помощью robots.txt можно:
- запретить индексирование похожих и ненужных страниц, чтобы не тратить краулинговый лимит (количество URL, которое может обойти поисковый робот за один обход). Т.е. робот сможет проиндексировать больше важных страниц.
- скрыть изображения из результатов поиска.
- закрыть от индексации неважные скрипты, файлы стилей и другие некритичные ресурсы страниц.
 Т.е. робот сможет проиндексировать больше важных страниц.
Т.е. робот сможет проиндексировать больше важных страниц.Если это помешает сканеру Google или Яндекса анализировать страницы, не блокируйте файлы.
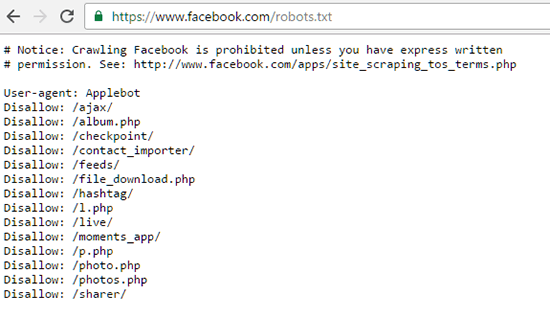
Где лежит файл Robots.txt?
Если вы хотите просто посмотреть, что находится в файле robots.txt, то просто введите в адресной строке браузера: site.ru/robots.txt.
Физически файл robots.txt находится в корневой папке сайта на хостинге. У меня хостинг beget.ru, поэтому покажу расположения файла robots.txt на этом хостинге.
- Заходите на хостинг beget.ru и авторизуетесь (или регистрируетесь, если нет аккаунта).
- После выбираете Файловый менеджер.
- Находите домен вашего сайта. Далее откройте папку public_html.
- В папке должен лежать robots.txt.
Как создать правильный robots.txt
Файл robots.txt состоит из одного или нескольких правил. Каждое правило блокирует или разрешает индексирование пути на сайте.
- В текстовом редакторе создайте файл с именем robots.txt и заполните его в соответствии с представленными ниже правилами.
- Файл robots.txt должен представлять собой текстовый файл в кодировке ASCII или UTF-8. Символы в других кодировках недопустимы.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать индексацию всех страниц сайта
http://www.example.com/, файл robots.txt следует разместить по адресуhttp://www.example.com/robots.txt. Он не должен находиться в подкаталоге (например, по адресуhttp://example.com/pages/robots.txt). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. - Файл robots.txt можно добавлять по адресам с субдоменами (например,
http://website.example.com/robots.txt) или нестандартными портами (например,http://example.com:8181/robots.txt). - Проверьте файл в сервисе Яндекс.Вебмастер и Google Search Console.
- Загрузите файл в корневую директорию вашего сайта.

Вот пример файла robots.txt с двумя правилами. Ниже есть его объяснение.
User-agent: Googlebot Disallow: /nogooglebot/ User-agent: * Allow: / Sitemap: http://www.example.com/sitemap.xml
Объяснение
- Агент пользователя с названием Googlebot не должен индексировать каталог
http://example.com/nogooglebot/и его подкаталоги. - У всех остальных агентов пользователя есть доступ ко всему сайту (можно опустить, результат будет тем же, так как полный доступ предоставляется по умолчанию).
- Файл Sitemap этого сайта находится по адресу http://www.example.com/sitemap.xml.

Директивы Disallow и Allow
Чтобы запретить индексирование и доступ робота к сайту или некоторым его разделам, используйте директиву Disallow.
Примеры:
User-agent: Yandex
Disallow: / # блокирует доступ ко всему сайту
User-agent: Yandex
Disallow: /cgi-bin # блокирует доступ к страницам,
# начинающимся с '/cgi-bin'В соответствии со стандартом перед каждой директивой User-agent рекомендуется вставлять пустой перевод строки.
Символ # предназначен для описания комментариев. Все, что находится после этого символа и до первого перевода строки не учитывается.
Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow
Примеры:
User-agent: Yandex Allow: /cgi-bin Disallow: / # запрещает скачивать все, кроме страниц # начинающихся с '/cgi-bin'
Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow.

Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
# Исходный robots.txt: User-agent: Yandex Allow: /catalog Disallow: / # Сортированный robots.txt: User-agent: Yandex Disallow: / Allow: /catalog # разрешает скачивать только страницы, # начинающиеся с '/catalog'
# Исходный robots.txt: User-agent: Yandex Allow: / Allow: /catalog/auto Disallow: /catalog # Сортированный robots.txt: User-agent: Yandex Allow: / Disallow: /catalog Allow: /catalog/auto # запрещает скачивать страницы, начинающиеся с '/catalog', # но разрешает скачивать страницы, начинающиеся с '/catalog/auto'.
При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.

Использование спецсимволов * и $
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
Примеры:
User-agent: Yandex
Disallow: /cgi-bin/*.aspx # запрещает '/cgi-bin/example.aspx'
# и '/cgi-bin/private/test.aspx'
Disallow: /*private # запрещает не только '/private',
# но и '/cgi-bin/private'Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots. txt, где она указана.
txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Директива работает только с роботом Яндекса.
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots. txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123
Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123.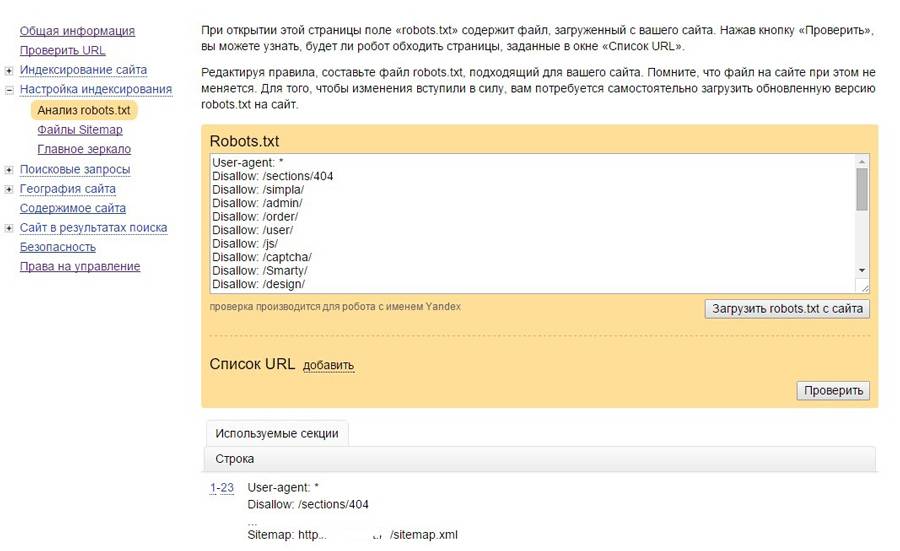 Тогда, если указать директиву следующим образом:
Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123
Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn] [path]
В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.
Clean-param: s /forum/showthread.php
означает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php Clean-param: sid&sort /forum/*.php Clean-param: someTrash&otherTrash
Директива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т. д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично 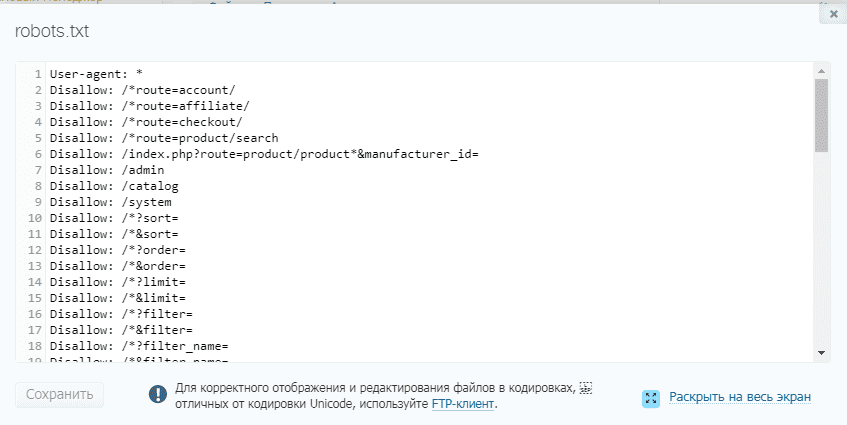
 д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогичноRobots.
 txt пример для Joomla
txt пример для JoomlaUser-agent: *Disallow: /administrator/Disallow: /cache/Disallow: /includes/Disallow: /installation/Disallow: /language/Disallow: /libraries/Disallow: /media/Disallow: /modules/Disallow: /plugins/Disallow: /templates/Disallow: /tmp/Disallow: /xmlrpc/Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для Bitrix
User-agent: *Disallow: /*index.php$Disallow: /bitrix/Disallow: /auth/Disallow: /personal/Disallow: /upload/Disallow: /search/Disallow: /*/search/Disallow: /*/slide_show/Disallow: /*/gallery/*order=*Disallow: /*?print=Disallow: /*&print=Disallow: /*register=Disallow: /*forgot_password=Disallow: /*change_password=Disallow: /*login=Disallow: /*logout=Disallow: /*auth=Disallow: /*?action=Disallow: /*action=ADD_TO_COMPARE_LISTDisallow: /*action=DELETE_FROM_COMPARE_LISTDisallow: /*action=ADD2BASKETDisallow: /*action=BUYDisallow: /*bitrix_*=Disallow: /*backurl=*Disallow: /*BACKURL=*Disallow: /*back_url=*Disallow: /*BACK_URL=*Disallow: /*back_url_admin=*Disallow: /*print_course=YDisallow: /*COURSE_ID=Disallow: /*?COURSE_ID=Disallow: /*?PAGENDisallow: /*PAGEN_1=Disallow: /*PAGEN_2=Disallow: /*PAGEN_3=Disallow: /*PAGEN_4=Disallow: /*PAGEN_5=Disallow: /*PAGEN_6=Disallow: /*PAGEN_7=Disallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*PAGE_NAME=searchDisallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*SHOWALLDisallow: /*show_all=Sitemap: http://путь к вашей карте XML формата
Robots.
 txt пример для MODx
txt пример для MODxUser-agent: *Disallow: /assets/cache/Disallow: /assets/docs/Disallow: /assets/export/Disallow: /assets/import/Disallow: /assets/modules/Disallow: /assets/plugins/Disallow: /assets/snippets/Disallow: /install/Disallow: /manager/Sitemap: http://site.ru/sitemap.xml
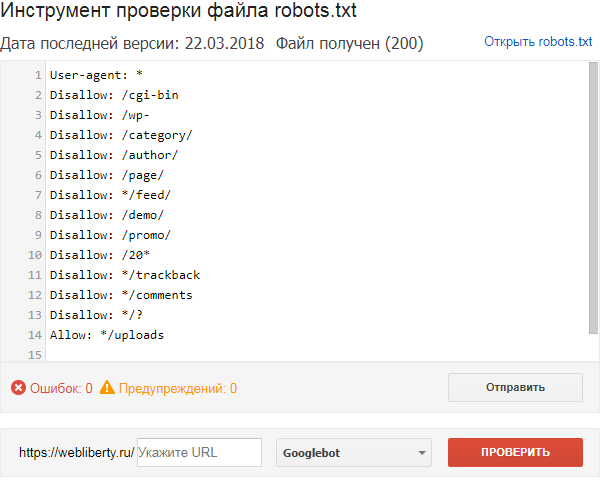
Robots.txt пример для Drupal
User-agent: *Disallow: /database/Disallow: /includes/Disallow: /misc/Disallow: /modules/Disallow: /sites/Disallow: /themes/Disallow: /scripts/Disallow: /updates/Disallow: /profiles/Disallow: /profileDisallow: /profile/*Disallow: /xmlrpc.phpDisallow: /cron. php
phpDisallow: /update.phpDisallow: /install.phpDisallow: /index.phpDisallow: /admin/Disallow: /comment/reply/Disallow: /contact/Disallow: /logout/Disallow: /search/Disallow: /user/register/Disallow: /user/password/Disallow: *register*Disallow: *login*Disallow: /top-rated-Disallow: /messages/Disallow: /book/export/Disallow: /user2userpoints/Disallow: /myuserpoints/Disallow: /tagadelic/Disallow: /referral/Disallow: /aggregator/Disallow: /files/pin/Disallow: /your-votesDisallow: /comments/recentDisallow: /*/edit/Disallow: /*/delete/Disallow: /*/export/html/Disallow: /taxonomy/term/*/0$Disallow: /*/edit$Disallow: /*/outline$Disallow: /*/revisions$Disallow: /*/contact$Disallow: /*downloadpipeDisallow: /node$Disallow: /node/*/track$Disallow: /*&Disallow: /*%Disallow: /*?page=0Disallow: /*sectionDisallow: /*orderDisallow: /*?sort*Disallow: /*&sort*Disallow: /*votesupdownDisallow: /*calendarDisallow: /*index. php
phpAllow: /*?page=Disallow: /*?Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер, еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список – выберите Анализ robots.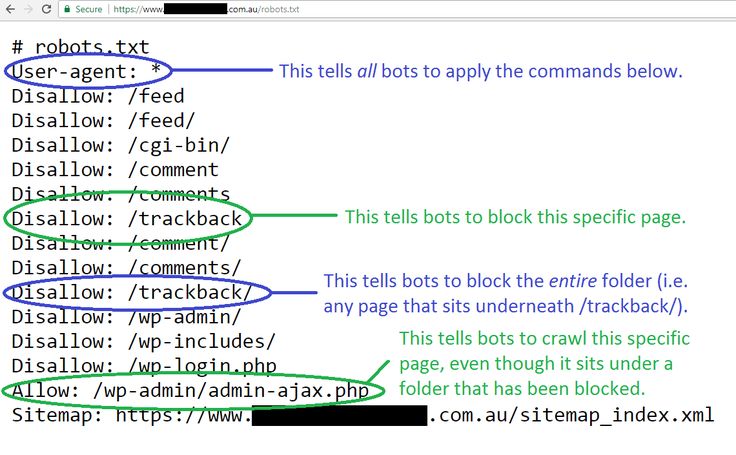 txt или по ссылке http://webmaster.yandex.ru/robots.xml
txt или по ссылке http://webmaster.yandex.ru/robots.xml
Вариант 2:
Этот вариант подразумевает, что ваш сайт добавлен в Яндекс Вебмастер и в корне сайта уже есть robots.txt.
Слева выберите Инструменты — Анализ robots.txt
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.

Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru.С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru.В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots. txt и загрузить в корневой каталог вашего сайта.
 txt и загрузить в корневой каталог вашего сайта.
txt и загрузить в корневой каталог вашего сайта.Robots txt – главный инструмент управления индексацией сайта
- запрет индексации отдельных разделов, страниц или файлов, которые могут затруднить раскрутку сайта,
- рекомендации по соблюдению временного промежутка между скачиванием файлов с сервера,
- информацию о зеркалах домена т.д.
История
Документ «Стандарт исключений для роботов» — это результат соглашения между основными производителями поисковых систем, заключенного 30 июня 1994 года. Данный стандарт не является официальным или корпоративным и не гарантирует его соблюдения будущими поисковыми ботами. Причиной принятия соглашения стал тот факт, что индексация происходит периодически против желания владельцев сайтов, может осуществляться некорректно и затруднять работу посетителей ресурса с сервером.
Создание файла
Для создания robots.txt необходим обычный текстовый файл. Если раскрутка сайта не требует установки запретов по индексации, достаточно сделать пустой документ. На ресурсе может быть только один robots.txt, обязательно в его корне (размещение файла в поддиректориях сделает его незаметным для поисковых роботов без использования специальных мета-тегов robots). Так как URL чувствителен к регистру, название файла пишется строчными латинскими буквами. Если в процессе оптимизации сайта файл robots.txt не был создан, если он пуст или заполнен не по стандарту, поисковые боты работают по своему алгоритму.
На ресурсе может быть только один robots.txt, обязательно в его корне (размещение файла в поддиректориях сделает его незаметным для поисковых роботов без использования специальных мета-тегов robots). Так как URL чувствителен к регистру, название файла пишется строчными латинскими буквами. Если в процессе оптимизации сайта файл robots.txt не был создан, если он пуст или заполнен не по стандарту, поисковые боты работают по своему алгоритму.
Стандарт
Robots.txt может содержать одну или несколько записей (каждая обязательно с новой строки) в форме <поле:> <пробел> <значение> <пробел>. Поле от регистра не зависит. В файл могут быть включены комментарии в стандартном для UNIX виде (# — начало комментария, конец строки — его окончание). Запись начинается со строки User-Agent (одной или нескольких), затем Disallow. Нераспознанные поля игнорируются.
Простейший robots.txt выглядит следующим образом:
User-agent: *Disallow: /название 1-го раздела/Disallow: /название 2-го раздела/Disallow: /название 3-го раздела/
В данном случае запрещена индексация трех разделов.
- User-Agent. Значением для этого поля является имя поискового бота, для которого устанавливаются права доступа. Если указаны несколько имен, то права доступа распространяются на всех перечисленных. Символ «*» вместо имени значит, что запись содержит инструкции для всех поисковых роботов.
- Disallow. Значением для этого поля является полный или частичный URL, который нельзя индексировать. Если оно не указано, анализируется все дерево страниц на сервере.
В robots.txt не прописывается путь к панелям управления на сайте или консолям администратора, так как файл доступен для чтения посетителям ресурса. Поисковики в любом случае не индексируют страницы, запрашивающие логин или пароль, или те, на которые нет ссылок.
Другие термины на букву «R»
ROI (ROMI)RookeeRotapostRSS
Все термины SEO-Википедии
Теги термина
Продвижение сайтовТехническая оптимизацияВеб-разработка
Какие услуги тебе подходят
Продвижение сайтов в Москве
SEO-оптимизация сайта
Оптимизация сайта под Google
Продвижение сайта в Яндексе
Продвижение интернет-магазина
SEO-продвижение лендинга в поисковых системах
Продвижение медицинских сайтов
Продвижение молодого сайта
SEO-продвижение с гарантией
Продвижение по ключевым словам
Продвижение сайта в ТОП 10 Яндекса и Google
Продвижение туристических сайтов
Продвижение сайтов в ТОП 3 Яндекса и Google
Оптимизация сайта под Яндекс
Раскрутка сайтов за рубежом
Продвижение сайта в Google
Продвижение сайта по позициям
Продвижение сайта по трафику
Оптимизация сайта в мобильной выдаче
SEO аудит
Поисковый аудит сайта
Заказать продвижение сайта
Продвижение сайтов в Москве: проверенные решения от профессионалов
Продвижение стоматологической клиники
Продвижение сайтов медицинских клиник
Продвижение салона красоты
Продвижение автомобильных сайтов
Продвижение магазина автозапчастей
Продвижение и раскрутка автосервиса
Продвижение отелей и гостиниц
SEO-продвижение сайта в Новосибирске
SEO-продвижение сайта в Екатеринбурге
SEO-продвижение сайта в Самаре
SEO-продвижение сайта в Омске
SEO-продвижение сайта в Нижнем Новгороде
SEO-продвижение сайта в Казани
SEO-продвижение сайта в Челябинске
SEO-продвижение сайта в Красноярске
Поисковое продвижение сайтов в Перми: эффективно, профессионально, прозрачно
Поисковое продвижение сайтов в Ростове-на-Дону
Поисковое продвижение сайтов в Уфе
SEO-продвижение сайта в Воронеже
SEO-продвижение сайта в Волгограде
SEO-продвижение сайта в Краснодаре
Продвижение интернет-магазина бытовой техники
Продвижение интернет-магазина одежды
Продвижение интернет-магазина зоотоваров
Продвижение интернет-магазина книг
Продвижение интернет-магазина мебели
Продвижение интернет-магазина обуви
Продвижение интернет-магазина сантехники
Продвижение интернет-магазина спортивных товаров
Продвижение интернет-магазина стройматериалов
Продвижение интернет-магазина часов
Маркетинговый аудит сайта
Продвижение автосалона
Поисковое продвижение сайтов в Тольятти
Как оптимизировать файл WordPress Robots.
 txt для улучшения SEO
txt для улучшения SEOКонтент Themeisle бесплатный. Когда вы покупаете по реферальным ссылкам на нашем сайте, мы получаем комиссию. Узнать больше
Если вам интересно, как оптимизировать файл WordPress robots.txt для улучшения SEO, вы пришли в нужное место.
В этом кратком руководстве я объясню, что такое файл robots.txt, почему он важен для улучшения вашего поискового рейтинга и как вносить в него изменения и отправлять в Google.
Давайте погрузимся!
Что такое файл robots.txt WordPress и нужно ли мне беспокоиться об этом?
Файл robots.txt — это файл на вашем сайте, который позволяет запретить поисковым системам доступ к определенным файлам и папкам. Вы можете использовать его, чтобы заблокировать роботов Google (и других поисковых систем) от сканирования определенных страниц вашего сайта. Вот пример файла:
Так как же отказ в доступе к поисковым системам на самом деле улучшает вашу поисковую оптимизацию? Кажется нелогичным…
Это работает следующим образом: чем больше страниц на вашем сайте, тем больше страниц должен просканировать Google.
Например, если в вашем блоге много страниц категорий и тегов, эти страницы некачественные и не нуждаются в сканировании поисковыми системами; они просто потребляют краулинговый бюджет вашего сайта (количество страниц, которые Google будет сканировать на вашем сайте в любой момент времени).
Бюджет сканирования важен, потому что он определяет, насколько быстро Google улавливает изменения на вашем сайте и, следовательно, как быстро ваш рейтинг. Это может особенно помочь с SEO электронной коммерции!
Просто будьте осторожны, чтобы сделать это правильно, так как это может повредить вашему SEO, если все сделано плохо. Для получения дополнительной информации о том, как правильно не индексировать нужные страницы, ознакомьтесь с этим руководством от DeepCrawl.
Итак, вам нужно возиться с файлом robots.txt WordPress?
Возможно, если вы находитесь в высококонкурентной нише с большим сайтом. Однако, если вы только начинаете свой первый блог, создание ссылок на ваш контент и создание большого количества высококачественных статей являются более важными приоритетами.
Как оптимизировать файл WordPress robots.txt для улучшения SEO
Теперь давайте обсудим, как на самом деле получить (или создать) и оптимизировать файл WordPress robots.txt.
Robots.txt обычно находится в корневой папке вашего сайта. Вам нужно будет подключиться к своему сайту с помощью FTP-клиента или с помощью файлового менеджера cPanel, чтобы просмотреть его. Это обычный текстовый файл, который затем можно открыть в блокноте.
Если у вас нет файла robots.txt в корневом каталоге вашего сайта, вы можете создать его. Все, что вам нужно сделать, это создать новый текстовый файл на вашем компьютере и сохранить его как robots.txt. Затем просто загрузите его в корневую папку вашего сайта.
Как выглядит идеальный файл robots.txt?
Формат файла robots.txt очень прост. Первая строка обычно называет пользовательский агент. Пользовательский агент — это имя поискового бота, с которым вы пытаетесь связаться. Например, Googlebot или Bingbot . Вы можете использовать звездочку
Вы можете использовать звездочку * , чтобы проинструктировать всех ботов.
Следующая строка содержит инструкции Разрешить или Запретить для поисковых систем, чтобы они знали, какие части вы хотите, чтобы они индексировали, а какие — нет.
Вот пример:
Агент пользователя: * Разрешить: /?display=широкий Разрешить: /wp-content/uploads/ Запретить: /readme.html Запретить: /см./ Карта сайта: http://www.codeinwp.com/post-sitemap.xml Карта сайта: http://www.codeinwp.com/page-sitemap.xml Карта сайта: http://www.codeinwp.com/deals-sitemap.xml Карта сайта: http://www.codeinwp.com/hosting-sitemap.xml
Обратите внимание: если вы используете такой плагин, как Yoast или All in One SEO, вам может не понадобиться добавлять раздел карты сайта, поскольку они пытаются сделать это автоматически. Если это не удается, вы можете добавить его вручную, как в примере выше.
Что я должен запретить или noindex?
В руководстве Google для веб-мастеров веб-мастерам рекомендуется не использовать файл robots. txt для сокрытия некачественного контента. Таким образом, использование файла robots.txt для запрета Google индексировать вашу категорию, дату и другие страницы архива может быть неразумным выбором.
txt для сокрытия некачественного контента. Таким образом, использование файла robots.txt для запрета Google индексировать вашу категорию, дату и другие страницы архива может быть неразумным выбором.
Помните, что файл robots.txt предназначен для указания ботам, что делать с контентом, который они сканируют на вашем сайте. Это не мешает им сканировать ваш сайт.
Кроме того, вам не нужно добавлять страницу входа в WordPress, каталог администратора или страницу регистрации в файл robots.txt, поскольку страницы входа и регистрации имеют тег noindex, автоматически добавленный WordPress.
Однако я рекомендую вам запретить файл readme.html в файле robots.txt. Этот файл readme может быть использован кем-то, кто пытается выяснить, какую версию WordPress вы используете. Если это человек, он может легко получить доступ к файлу, просто просмотрев его. Кроме того, размещение тега Disallow может блокировать вредоносные атаки.
Как отправить файл WordPress robots.
 txt в Google?
txt в Google?После того как вы обновили или создали файл robots.txt, вы можете отправить его в Google с помощью Google Search Console.
Тем не менее, я рекомендую сначала протестировать его с помощью инструмента тестирования robots.txt от Google.
Если вы не видите созданную вами версию здесь, вам придется повторно загрузить файл robots.txt, который вы создали, на свой сайт WordPress. Вы можете сделать это с помощью Yoast SEO.
Вывод
Теперь вы знаете, как оптимизировать файл WordPress robots.txt для улучшения SEO.
Будьте осторожны при внесении каких-либо серьезных изменений на свой сайт с помощью файла robots.txt. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы не будете осторожны.
А если вам не терпится узнать больше, ознакомьтесь с нашим последним обзором руководств по WordPress!
Дайте нам знать в комментариях; У вас есть вопросы о том, как оптимизировать файл robots. txt WordPress? Какое влияние оказала забота об этом на ваш поисковый рейтинг?
txt WordPress? Какое влияние оказала забота об этом на ваш поисковый рейтинг?
Бесплатная направляющая
5 основных советов по ускорению
вашего сайта WordPress
Сократите время загрузки даже на 50-80%
просто следуя простым советам.
Была ли эта статья полезной?
НетСпасибо за отзыв!
WordPress Robots.txt — Как создать и оптимизировать для SEO
Что такое robots.txt? Как создать файл robots.txt? Зачем нужно создавать файл robots.txt? Помогает ли оптимизация файла robots.txt улучшить ваш поисковый рейтинг?
Мы расскажем обо всем этом и многом другом в этой подробной статье о robots.txt!
Вы когда-нибудь хотели запретить поисковым системам сканировать определенный файл? Хотели, чтобы поисковые системы не сканировали определенную папку на вашем сайте?
Здесь на помощь приходит файл robots.txt. Это простой текстовый файл, который сообщает поисковым системам, где и где не сканировать ваш сайт при индексировании.
Хорошей новостью является то, что вам не нужно иметь никакого технического опыта, чтобы раскрыть всю мощь файла robots.txt.
Robots.txt — это простой текстовый файл, создание которого занимает несколько секунд. Это также один из самых простых файлов, который можно испортить. Всего один неуместный символ, и вы испортите SEO всего своего сайта и запретите поисковым системам доступ к вашему сайту.
При работе над SEO сайта важную роль играет файл robots.txt. Хотя он позволяет запретить поисковым системам доступ к различным файлам и папкам, часто это не лучший способ оптимизировать ваш сайт.
В этой статье мы объясним, как использовать файл robots.txt для оптимизации вашего веб-сайта. Мы также покажем вам, как его создать, и поделимся некоторыми плагинами, которые нам нравятся, которые могут сделать тяжелую работу за вас.
Содержание
- Что такое robots.txt?
- Как выглядит robots.txt?
- Что такое краулинговый бюджет?
- Как создать файл robots. txt в WordPress?
- Способ 1. Создание файла Robots.txt с помощью плагина Yoast SEO
- Способ 2. Создание файла Robots.txt вручную с помощью FTP
- Плюсы и минусы файла Robots.txt
- Как проверить файл robots.txt
- Вам нужен файл robots.txt для вашего сайта WordPress?
- Заключительные мысли
 txt в WordPress?
txt в WordPress?Что такое robots.txt?
Robots.txt — это простой текстовый файл, который сообщает роботам поисковых систем, какие страницы вашего сайта сканировать. Он также сообщает роботам, какие страницы не сканировать.
Прежде чем мы углубимся в эту статью, важно понять, как работает поисковая система.
Поисковые системы выполняют три основные функции: сканирование, индексирование и ранжирование.
(Источник: Moz.com)
Поисковые системы начинают с того, что рассылают по сети своих поисковых роботов, также называемых пауками или ботами. Эти боты представляют собой часть интеллектуального программного обеспечения, которое перемещается по всей сети в поисках новых ссылок, страниц и веб-сайтов. Этот процесс поиска в сети называется сканированием .
Этот процесс поиска в сети называется сканированием .
Как только боты обнаружат ваш веб-сайт, ваши страницы будут организованы в удобную структуру данных. Этот процесс называется индексированием .
И, наконец, все сводится к рейтинг . Где поисковая система предоставляет своим пользователям лучшую и наиболее актуальную информацию на основе их поисковых запросов.
Как выглядит файл robots.txt?
Допустим, поисковая система собирается посетить ваш сайт. Прежде чем он просканирует сайт, он сначала проверит robots.txt на наличие инструкций.
Например, предположим, что робот поисковой системы собирается просканировать наш сайт WPAstra и получить доступ к нашему файлу robots.txt, доступ к которому осуществляется с https://wpastra.com/robots.txt.
Пока мы обсуждаем эту тему, вы можете получить доступ к файлу robots.txt для любого веб-сайта, введя «/ robots.txt» после имени домена.
ОК. Возвращение на правильный путь.
Возвращение на правильный путь.
Выше приведен типичный формат файла robots.txt.
И прежде чем вы подумаете, что все это слишком технично, хорошая новость заключается в том, что это все, что есть в файле robots.txt. Ну, почти.
Давайте разберем каждый элемент, упомянутый в файле.
Первый User-agent: * .
Звездочка после User-agent означает, что файл применяется ко всем роботам поисковых систем, которые посещают сайт.
У каждой поисковой системы есть собственный пользовательский агент, который сканирует Интернет. Например, Google использует Googlebot для индексации контента вашего сайта для поисковой системы Google.
Некоторые другие пользовательские агенты, используемые популярными поисковыми системами:
- Google: Googlebot
- Новости Googlebot: Новости Googlebot
- Googlebot Изображения: Googlebot-Изображение
- Видео робота Googlebot: видео робота Googlebot
- Бинг: Бингбот
- Yahoo: Slurp Bot
- DuckDuckGo: DuckDuckBot
- Baidu: Baiduspider
- Яндекс: ЯндексБот
- Exalead: ExaBot
- Amazon Alexa: ia_archiver
Таких пользовательских агентов сотни.
Вы можете установить пользовательские инструкции для каждого пользовательского агента. Например, если вы хотите указать конкретные инструкции для робота Googlebot, первая строка вашего файла robots.txt будет такой:
Агент пользователя: Googlebot
Вы назначаете директивы всем агентам пользователя, используя звездочку (*) рядом с Агентом пользователя.
Допустим, вы хотите запретить всем ботам, кроме робота Google, сканировать ваш сайт. Ваш файл robots.txt будет иметь следующий вид:
User-agent: * Запретить: / Агент пользователя: Googlebot Разрешить: /
Косая черта ( / ) после Запретить указывает боту не индексировать какие-либо страницы на сайте. И хотя вы назначили директиву, которая будет применяться ко всем ботам поисковых систем, вы также явно разрешили роботу Google проиндексировать ваш веб-сайт, добавив ‘ Разрешить: / .’
Точно так же вы можете добавить директивы для любого количества пользовательских агентов.
Подводя итоги, давайте вернемся к нашему примеру Astra robots.txt, т. е.
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
Для всех ботов поисковых систем задана директива не сканировать что-либо в папке « /wp-admin/», но следовать « admin-ajax». php ‘ в той же папке.
Просто, правда?
Здравствуйте! Меня зовут Суджей, и я генеральный директор Astra.
Наша миссия — помочь малым предприятиям расти в Интернете с помощью доступных программных продуктов и образования, необходимого для достижения успеха.
Оставьте комментарий ниже, если хотите присоединиться к беседе, или нажмите здесь, если хотите получить личную помощь или пообщаться с нашей командой в частном порядке.
Что такое бюджет сканирования?
Добавляя косую черту после Disallow , вы указываете роботу не посещать какие-либо страницы сайта.
Итак, ваш следующий очевидный вопрос: зачем кому-то мешать роботам сканировать и индексировать ваш сайт? В конце концов, когда вы работаете над SEO веб-сайта, вы хотите, чтобы поисковые системы сканировали ваш сайт, чтобы помочь вам в рейтинге.
Именно поэтому вам следует подумать об оптимизации файла robots.txt.
Вы представляете, сколько страниц у вас на сайте? От реальных страниц до тестовых страниц, страниц дублированного контента, страниц благодарности и других. Много, полагаем.
Когда бот сканирует ваш сайт, он будет сканировать каждую страницу. А если у вас несколько страниц, поисковому роботу потребуется некоторое время, чтобы просканировать их все.
(Источник: Seo Hacker)
Знаете ли вы, что это может негативно повлиять на рейтинг вашего сайта?
И это из-за краулингового бюджета поисковой системы .
ОК. Что такое краулинговый бюджет?
Бюджет обхода — это количество URL-адресов, которое поисковый робот может просканировать за сеанс. Для каждого сайта будет выделен определенный краулинговый бюджет. И вам нужно убедиться, что краулинговый бюджет расходуется наилучшим образом для вашего сайта.
Если у вас есть несколько страниц на вашем веб-сайте, вам определенно нужно, чтобы бот сначала сканировал наиболее ценные страницы.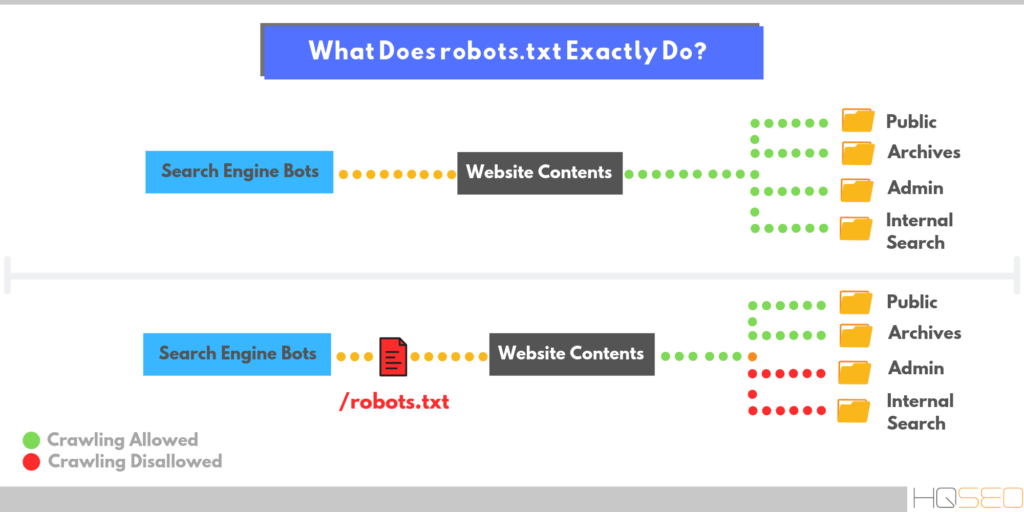 Таким образом, необходимо явно указать это в файле robots.txt.
Таким образом, необходимо явно указать это в файле robots.txt.
Ознакомьтесь с ресурсами, доступными в Google, чтобы узнать, что означает краулинговый бюджет для робота Googlebot.
Как создать файл robots.txt в WordPress?
Теперь, когда мы рассмотрели, что такое файл robots.txt и насколько он важен, давайте создадим его в WordPress.
У вас есть два способа создать файл robots.txt в WordPress. Один использует плагин WordPress, а другой вручную загружает файл в корневую папку вашего сайта.
Способ 1. Создайте файл Robots.txt с помощью плагина Yoast SEO
Чтобы оптимизировать свой веб-сайт WordPress, вы можете использовать плагины SEO. Большинство этих плагинов поставляются с собственным генератором файлов robots.txt.
В этом разделе мы создадим его с помощью плагина Yoast SEO. С помощью плагина вы можете легко создать файл robots.txt на панели управления WordPress.
Шаг 1. Установите плагин
Перейдите к Плагины > Добавить новый . Затем найдите, установите и активируйте плагин Yoast SEO, если у вас его еще нет.
Затем найдите, установите и активируйте плагин Yoast SEO, если у вас его еще нет.
Шаг 2. Создайте файл robots.txt
После активации плагина перейдите Yoast SEO > Инструменты и нажмите Редактор файлов .
Поскольку мы создаем файл впервые, нажмите Создать файл robots.txt .
Вы заметите файл, созданный с некоторыми директивами по умолчанию.
По умолчанию генератор файла robots.txt Yoast SEO добавит следующие директивы:
User-agent: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
При желании вы можете добавить дополнительные директивы в robots.txt. Когда вы закончите, нажмите Сохранить изменения в robots.txt .
Продолжайте и введите свое доменное имя, а затем « /robots.txt ». Если вы обнаружите директивы по умолчанию, отображаемые в браузере, как показано на изображении ниже, вы успешно создали файл robots.txt.
Мы также рекомендуем добавить URL-адрес карты сайта в файл robots. txt.
txt.
Например, если URL-адрес карты сайта вашего веб-сайта https://yourdomain.com/sitemap.xml, рассмотрите возможность включения Карта сайта: https://yourdomain.com/sitemap.xml в файле robots.txt.
Другой пример: если вы хотите создать директиву, запрещающую боту сканировать все изображения на вашем веб-сайте. И допустим, мы хотели бы ограничить это только GoogleBot.
В этом случае наш robots.txt будет выглядеть следующим образом:
User-agent: Googlebot Запретить: /загрузки/ Пользовательский агент: * Разрешить: /загрузки/
И на всякий случай, если вам интересно, как узнать имя папки с изображениями, просто щелкните правой кнопкой мыши любое изображение на вашем веб-сайте, выберите «Открыть в новой вкладке» и запишите URL-адрес в браузере. Вуаля!
Способ 2. Создайте файл robots.txt вручную с помощью FTP
Следующий способ — создать файл robots.txt на локальном компьютере и загрузить его в корневую папку веб-сайта WordPress.
Вам также потребуется доступ к вашему хостингу WordPress с помощью FTP-клиента, такого как Filezilla. Учетные данные, необходимые для входа, будут доступны в панели управления хостингом, если у вас их еще нет.
Помните, что файл robots.txt должен быть загружен в корневую папку вашего сайта. То есть он не должен находиться ни в одном подкаталоге.
Итак, как только вы войдете в систему с помощью FTP-клиента, вы сможете увидеть, существует ли файл robots.txt в корневой папке вашего веб-сайта.
Если файл существует, просто щелкните его правой кнопкой мыши и выберите параметр редактирования.
Внесите изменения и нажмите «Сохранить».
Если файл не существует, вам необходимо его создать. Вы можете создать его с помощью простого текстового редактора, такого как Блокнот, и добавить директивы в файл.
Например, включите следующие директивы,
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php
… и сохранить файл как robots. txt.
txt.
Теперь, используя FTP-клиент, нажмите « File Upload » и загрузите файл в корневую папку веб-сайта.
Чтобы убедиться, что ваш файл был успешно загружен, введите имя своего домена, а затем «/robots.txt».
Вот как вы вручную загружаете файл robots.txt на свой сайт WordPress!
Плюсы и минусы Robots.txt
Плюсы файла robots.txt
- Он помогает оптимизировать краулинговые бюджеты поисковых систем, говоря им не тратить время на страницы, которые вы не хотите индексировать. Это помогает поисковым системам сканировать наиболее важные для вас страницы.
- Это помогает оптимизировать ваш веб-сервер, блокируя ботов, которые тратят ресурсы впустую.
- Это помогает скрыть страницы благодарности, целевые страницы, страницы входа и многое другое, что не нужно индексировать поисковыми системами.
Минусы файла robots.txt
- Теперь вы знаете, как получить доступ к файлу robots. txt для любого веб-сайта. Это довольно просто. Просто введите доменное имя, а затем «/ robots.txt». Это, однако, также сопряжено с определенным риском. Файл robots.txt может содержать URL-адреса некоторых ваших внутренних страниц, которые вы не хотели бы индексировать поисковыми системами.
Например, может быть страница входа, которую вы не хотели бы индексировать. Однако его упоминание в файле robots.txt позволяет злоумышленникам получить доступ к странице. То же самое происходит, если вы пытаетесь скрыть некоторые личные данные. - Несмотря на то, что создать файл robots.txt довольно просто, если вы ошибетесь хотя бы в одном символе, это сведет на нет все ваши усилия по поисковой оптимизации.
 txt для любого веб-сайта. Это довольно просто. Просто введите доменное имя, а затем «/ robots.txt». Это, однако, также сопряжено с определенным риском. Файл robots.txt может содержать URL-адреса некоторых ваших внутренних страниц, которые вы не хотели бы индексировать поисковыми системами.
txt для любого веб-сайта. Это довольно просто. Просто введите доменное имя, а затем «/ robots.txt». Это, однако, также сопряжено с определенным риском. Файл robots.txt может содержать URL-адреса некоторых ваших внутренних страниц, которые вы не хотели бы индексировать поисковыми системами. Куда поместить файл robots.txt
Мы полагаем, что теперь вы хорошо знаете, куда следует добавить файл robots.txt.
Файл robots.txt всегда должен находиться в корне вашего сайта. Если ваш домен — yourdomain.com, то URL-адрес вашего файла robots.txt будет https://yourdomain. com/robots.txt.
com/robots.txt.
В дополнение к включению вашего robots.txt в корневой каталог, вот некоторые рекомендации, которым необходимо следовать:
- Важно назвать ваш файл robots.txt
- Имя чувствительно к регистру. Так что делайте это правильно, или это не сработает
- Каждая директива должна быть на новой строке
- Включите символ «$», чтобы отметить конец URL-адреса
- Использовать отдельные пользовательские агенты только один раз
- Используйте комментарии, чтобы объяснить людям свой файл robots.txt, начав строку с решётки (#)
Как протестировать файл robots.txt
Теперь, когда вы создали файл robots.txt, пришло время протестировать его с помощью инструмента для тестирования robots.txt.
Мы рекомендуем инструмент внутри Google Search Console.
Чтобы получить доступ к этому инструменту, щелкните Открыть тестер robots.txt.
Мы предполагаем, что ваш веб-сайт добавлен в Google Search Console.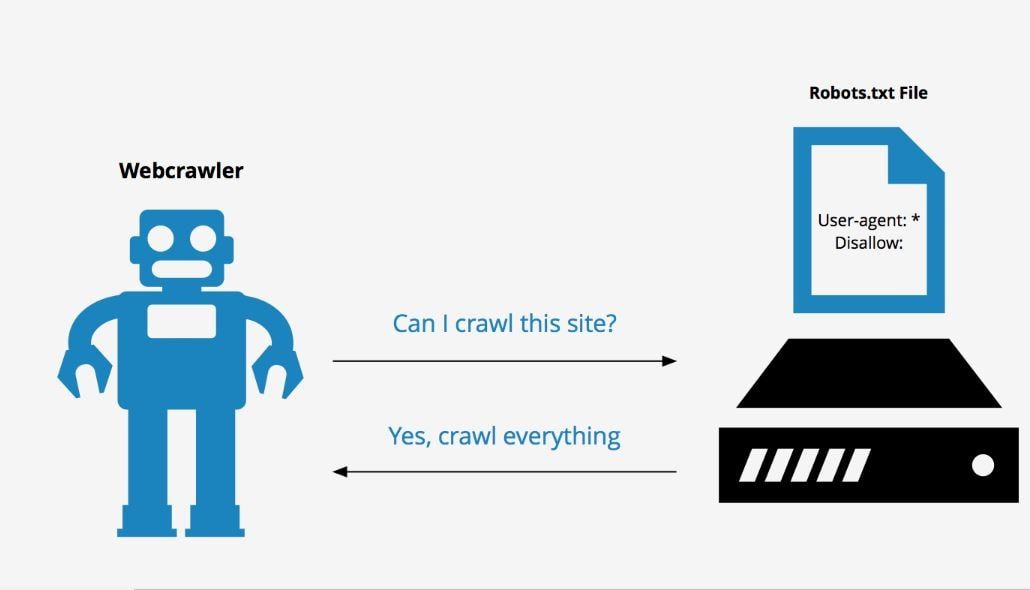 Если это не так, нажмите « Добавить свойство сейчас » и выполните простые шаги, чтобы добавить свой веб-сайт в Google Search Console.
Если это не так, нажмите « Добавить свойство сейчас » и выполните простые шаги, чтобы добавить свой веб-сайт в Google Search Console.
После этого ваш веб-сайт появится в раскрывающемся списке под « Пожалуйста, выберите свойство ».
Нужен ли вам файл robots.txt для вашего сайта WordPress?
Да, вам нужен файл robots.txt на вашем сайте WordPress. Независимо от того, есть у вас файл robots.txt или нет, поисковые системы все равно будут сканировать и индексировать ваш сайт. Но после того, как вы узнали, что такое robots.txt, как он работает и какой у него краулинговый бюджет, почему бы вам не включить его?
Файл robots.txt сообщает поисковым системам, что сканировать и, что более важно, что не сканировать.
Основной причиной для включения файла robots.txt является рассмотрение неблагоприятных последствий краулингового бюджета.
Как указывалось ранее, каждый веб-сайт имеет определенный краулинговый бюджет. Это сводится к количеству страниц, которые бот просматривает за сеанс.