
Правильный Robots.txt для Google и Яндекс


Чистим мусор и делаем хороший роботс.тхт
И снова о Гугле. Что-то он удивляет меня в последнее время… В одной из предыдущих статей я рассказал про интересное «отношение» Google к файлу robots.txt. А вчера заметил ещё кое-что.
Проверял данный сайт на индексацию в Гугле через RDS bar (дело обычное) — оказалось, что только 65% страниц участвуют в выдаче. Меня это удивило, т.к. ранее там было 98%. В общем, решил проверить наличие мусора в индексе и, как оказалось, там много чего есть.
Что может быть в индексе Гугла
Перед проверкой индексации robots.txt у меня был такой:

Нашлось вот что:

Мусор в Гугле 1
и

Мусор в Гугле 2
и много чего из папок wp-content и wp-includes, а также залетел туда и флеш-плеер, хотя уже несколько раз я делал запрос на удаление URL.
Меня удивляет, что Гугл держит в индексе файлы JS-скриптов, например, от плагина Qip Smiles (на первой картинке выше). Какой смысл так делать, ведь это просто код..
В Яндексе такого нет. Это тот редкий случай, когда Яндекс делает что-то лучше Гугла. Хотя зря я так про Яндекс, ну да не о том речь ![]()
![]()
![]()
Что ещё более удивительно — в индексе снова оказался feed сайта (для WordPress обычно это http://site.ru/feed/), который я также много раз удалял в интерфейсе Google Webmaster.
Ну и также:

Мусор в Гугле 3
— очень необычно. Ссылок на такие страницы нет. Гугл мог узнать о них, когда я сам заходил на эти страницы, когда обнаружил, что они существуют. Это, кстати, говорит о том, что браузер Google Chrome действительно отправляет информацию о посещаемых страницах в Гугл.
А это вообще забавно:

Robots.txt в выдаче Гугла
Выводы
Очевидно, Google пытается залезть всюду, в том числе и в те места, которые запрещены в robots.txt. Например, запрещены к индексации файлы .php и .swf — а он их индексирует.
Можно было бы сделать предположение, что он их проиндексировал ранее, когда файл robots.txt ещё не был настроен. Однако я много раз удалял подобные страницы из индекса вручную, но они всё равно залетают в индекс.
Также есть вероятность, что такие страницы, как feed сайта залетают в индекс из-за того, что в некоторых статьях я прописывал (текстом!) /feed/ — например, в тех же статьях про файл robots.txt. Получается, что Гугл переходит даже на те URL, которые прописаны текстом на сайте — запись /feed/ он воспринимает как http://web-ru.net/feed/. Нередко такое замечал, когда анализировал ошибки в интерфейсе Google Webmaster.
Короче, я пришёл к выводу, что robots.txt должен быть максимально «чистым». Теперь о том, что нужно сделать.
Как сделать правильный robots.txt для Google и Яндекс
Надо удалить все запреты (ну или почти все). Однако сперва нужно кое-что настроить на сайте.
Используем мета-тег robots
Подробно про meta name=’robots’ написано здесь. Суть простая:
Это можно сделать разными способами — зависит от движка сайта и/или языка, на котором он написан. Покажу на примере .php (подойдёт для WordPress, Joomla и много-много чего ещё). В шаблон шапки сайта, после head можно вставить такое:

Теперь, когда кто-то зайдёт на URL вида

в шапке сайта появится

что говорит всем роботам о запрете такой страницы к индексации.
Аналогично можно сделать и с другими страницами и файлами с разными расширениями — нужно просто найти закономерность в их URL и задать условие на нужном языке программирования, по которому будет подставляться этот мета-тег.
Однако есть ещё и страницы со скриптами, текстовые документы и прочее (кстати, нередко на многих сайтах в индекс залетают .pdf-документы). Такие файлы не являются стандартными веб-страницами, написанными на HTML, поэтому meta name=’robots’ здесь не пройдёт.
Запрещаем индексацию скриптов и прочих ненужных файлов
Пришлось подумать над этой задачей. Сначала хотел использовать заголовок X-Robots-Tag, но действует он только для Гугла, так что понял, что нужно более универсальное решение.
Предположил, что универсальное решение находится в файле .htaccess. Поискал в Гугле — и кое-что нашлось. Причём на разных сайтах описаны разные методы.
Никогда раньше не использовал такого. В общем, вот, что я поместил в .htaccess:

— собрал это с разных сайтов, так что конкретного ничего не скажу по поводу этого кода. Главное, что тут есть: роботам Google, Yandex и т.д. запрещается индексировать документы с расширениями php, txt, swf, xml.
XML указал для того, чтобы из индекса вывалилась XML-карта сайта. Хотя неизвестно, будет ли она теперь вообще читаться Гуглом.
Через некоторое время я дополню эту статью и сообщу о результатах.
12.6.2015 — на данный момент почти весь мусор вылетел из индекса. Как оказалось, Гугл медленно реагирует на изменения в robots.txt и в выдаче держит всякий мусор с указанием
«A description for this result is not available because of this site’s robots.txt» (хотя в robots.txt уже всё разрешено). XML-карта, тем не менее, осталась…Как найти мусор в индексе?
Используем такой запрос в поиске Гугла: site:http://site.ru/xxx (почему это так, рассказано в статье о дополнительном индексе Google).
Пользователи WordPress’а могут ввести, например, site:http://site.ru/wp-. С помощью этого я нашёл много мусора из папок wp-content и wp-includes. Кстати, я для интереса проверил чужие WP-сайты с помощью этого запроса и обнаружил то же самое. Так что вы обязательно проверьте у себя.
Итоговый вариант robots.txt для Гугла и Яндекса (и для всего остального)
Сейчас для этого сайта у меня такой вариант:

Сначала хотел оставить Disallow: /feed/, т.к., несмотря на то, что он является XML-файлом (в .htaccess я их запретил), внешне этот файл является каталогом — URL заканчивается на «/». Но потом решил убрать для Гугла + удалил вручную в аккаунте вебмастера.
Пока не ясно, как подействуют правила в .htaccess, поэтому на всякий случай оставил одно правило для Яндекса. Если фид снова появится в Гугле — также дополню эту статью.
12.6.2015 — фид не появился. В общем, всё хорошо ![]()
![]()
![]()
Таким образом, если вы можете (а вы можете) запретить индексацию страниц с помощью всяких хитрых способов,
то в robots.txt ничего запрещать не надо! Loading…
Loading…Как настроить robots.txt для Google?
Пришло мне сегодня на почту письмо от Google, в котором он пугал меня понижениям позиций в выдаче, если я не последую его советам:
Мы обнаружили на Вашем сайте проблему, которая может помешать его сканированию. Робот Googlebot не может обработать код JavaScript и/или файлы CSS из-за ограничений в файле robots.txt. Эти данные нужны, чтобы оценить работу сайта. Поэтому если доступ к ресурсам будет заблокирован, то это может ухудшить позиции Вашего сайта в Поиске.
Как настроить robots.txt для Гугла?
Серьезное предупреждение, которое касается всем моих сайтов. Я не стал откладывать это в долгий ящик и сразу постарался решить проблему на всех сайтах. На данный момент в robots.txt для Google у меня были такие правила (для этого сайта):
User-agent: *
Allow: /wp-content/uploads/
Allow: /wp-content/plugins/wpsmart-mobile/themesAllow: /proxy/$
Disallow: /proxy/ — это у меня стоит свой прокси сервер.Disallow: /wp-login.php
Disallow: /login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/languages
Disallow: /wp-content/backups
Disallow: /wp-trackback
Disallow: /wp-feed
Disallow: /wp-comments
Disallow: */trackback
Disallow: */feed
Disallow: */trackback/
Disallow: */feed/
Disallow: /?feed=
Disallow: /?s=
Disallow: /links/
Disallow: /redirect.php*
Disallow: *?attachment_id=
Disallow: /author
Disallow: /75e282 — это относится к плагину для скрытия ссылок.
Disallow: */comments
Disallow: */comments/
Disallow: /comment-subscriptionsDisallow: /*/page/*/ — об этом правиле писал в статье про настройку рубрик.
Что же не понравилось Гуглу? Не понравилось, что у меня закрыта мобильная версия сайта. Вот на что он пожаловался в отношении этого сайта:
 Очень странно, но googlebot в упор не видит мою мобильную версию Mobile Smartphone. Почему? Не понимаю.
Очень странно, но googlebot в упор не видит мою мобильную версию Mobile Smartphone. Почему? Не понимаю.
Очень важно вот это правило : Allow: /wp-content/plugins/wpsmart-mobile/themes, так как у меня стоит мобильная версия сайта через плагин, но все открыто. На других сайтах тоже самое и проблем нет.
Как проверить мобильную версию сайта?
Проверил сайт этим тестом, результат тот же, но не показывает, в чем собственно проблема? Что закрыто конкретно?
 Сделал ход конем, на время открыл ВООБЩЕ все — толку НОЛЬ, все тоже самое. Может собака зарыта в самом шаблоне сайта? Попробую на время его сменить. Нет, не помогло, и на новом шаблоне та же песня. Еще один вариант — это удалить плагин мобильной версии и установить его заново — пробую… Переустановка плагина решила все проблемы! Ура!
Сделал ход конем, на время открыл ВООБЩЕ все — толку НОЛЬ, все тоже самое. Может собака зарыта в самом шаблоне сайта? Попробую на время его сменить. Нет, не помогло, и на новом шаблоне та же песня. Еще один вариант — это удалить плагин мобильной версии и установить его заново — пробую… Переустановка плагина решила все проблемы! Ура!
 Но на этом статья не заканчивается, так как другой мой сайт тоже испытывает трудности с googlebot, но там немного другие проблемы. Googlebot видит мобильную версию сайта, но не видит всего, что хочет. Вот что он выдает:
Но на этом статья не заканчивается, так как другой мой сайт тоже испытывает трудности с googlebot, но там немного другие проблемы. Googlebot видит мобильную версию сайта, но не видит всего, что хочет. Вот что он выдает:
 Примечательно, что и на том и другом сайте стоят одни и те же плагин, но тут все нормально, а там ему подавай доступ к их стилям! Какая подозрительная избирательность?
Примечательно, что и на том и другом сайте стоят одни и те же плагин, но тут все нормально, а там ему подавай доступ к их стилям! Какая подозрительная избирательность?
Открывать для индексации папку с плагинами опасно, так как их создатели на то и рассчитывают, пихая туда тонну ссылок на свои ресурсы. Но можно открыть то, что нас просят. Нужно, в моем случае, добавить такие правила:
Allow: /wp-content/plugins/totop-link/totop-link.css.php
Allow: /wp-content/plugins/totop-link/totop-link.js
Allow: /wp-content/plugins/crayon-syntax-highlighter/css/min/crayon.min.css
Allow: /wp-content/plugins/wp-special-textboxes/css/
Allow: /wp-includes/js/jquery/
Allow: /wp-content/plugins/q2w3-fixed-widget/js/q2w3-fixed-widget.min.js
Allow: /wp-content/plugins/wp-fluid-images//lib/fluidimage.js
Allow: /wp-content/plugins/crayon-syntax-highlighter/js/min/crayon.min.js
Allow: /wp-includes/js/tw-sack.min.js
Allow: /wp-content/plugins/wp-ds-blog-map/wp-ds-blogmap.css
Allow: /wp-content/plugins/top-10/top-10-addcount.js.php
Allow: /wp-includes/js/jquery/ui/jquery.ui.effect.min.js
Allow: /wp-includes/js/jquery/ui/jquery.ui.effect-blind.min.js
Allow: /wp-content/plugins/wp-special-textboxes/js/wstb.min.js
Проверим теперь сайт, что скажет мне противный гугл бот? Теперь он очень рад, что я все ему показал! Нужно нажать кнопочки ИНДЕКСИРОВАТЬ, чтобы он сразу схавал все эти скрипты и стили, лишь бы не пода

Немного сумбурный пост, но я заметил, что очень полезно записывать все свои действия, потом ОЙ как пригождается!
Правильная настройка robots.txt для Google и Яндекс
Основные правила настройки robots.txt
Перед тем, как приступить к настройке роботса для вашего сайта, неплохо ознакомиться с официальными рекомендациями Яндекс и Google.
Теперь о том, что должно быть в файле robots.txt. В нем необходимо создавать 3 отдельных набора директив — для Яндекс, для Google, и для остальных роботов-краулеров. Почему отдельно? Да потому что есть директивы, предназначенные только для определенных ПС, а также можете считать это неким проявлением уважения к основным поисковикам рунета
Следовательно, роботс должен состоять из таких секций:
User-agent: * User-agent: Yandex User-agent: Googlebot
Между наборами директив для разных роботов необходимо оставлять пустую строку.
В robots.txt необходимо указать путь к XML карте сайта. Директива является межсекционной, поэтому она может быть размещена в любом месте файла, однако перед ней рекомендуется вставить пустой перевод строки. Запись должна выглядеть так:
Sitemap: http://site.com/sitemap.xml
Адрес сайта и сам путь к карте необходимо заменить на те, которые являются актуальными для вашего сайта. Также следует помнить, что для сайтов с большим количеством страниц (более 50 000) необходимо создать несколько карт и все их прописать в роботсе.
Настройка robots.txt для Яндекс
Для того, чтобы наглядно показать правильную настройку директив для Яши, я возьму в качестве примера стандартный robots.txt для WordPress.
User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: */trackback Disallow: */feed Host: site.com
Обратите внимание на директиву Host. Она указывает пауку-роботу Яндекса, какое из зеркал сайта является главным. Наиболее распространенная группа зеркал — site.com и www.site.com. Тут есть еще один тонкий нюанс, о котором редко упоминают. Дело в том, что директива Host не является прямой командой роботам считать зеркало главным. Сначала Яндекс должен найти и идентифицировать сайты именно как зеркала, и только тогда данная директива сработает. Тем не менее, прописывать Host рекомендую в любом случае.
Проверить корректность настройки robots.txt для Яндекса можно при помощи данного сервиса.
Настройка robots.txt для Google
Для Google настройка роботса мало чем отличается от уже написанного выше. Однако, есть пара моментов, на которые следует обратить внимание.
User-agent: Googlebot Allow: *.css Allow: *.js Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: */trackback Disallow: */feed
Как видно из примера, отсутствует директива Host — она распознается исключительно ботами Яндекса. Кроме этого, появились две директивы, разрешающие индексировать JS скрипты и CSS таблицы. Это связано с рекомендацией Google, в которой говорится, что следует разрешать роботу индексировать
файлы шаблона (темы) сайта. Естественно, скрипты и таблицы в поиск не попадут, однако это позволит роботам корректнее индексировать сайт и отображать его в результатах выдачи.
Ну а корректность настройки директив для Google вы можете проверить инструментом проверки файла robots.txt, который находится в Google Webmaster Tools.
Что еще стоит закрывать в роботсе?
Страницы поиска
Тут кое-кто может поспорить, так как бывают случаи, когда на сайте используют внутренний поиск именно для создания релевантных страниц. Однако, так поступают далеко не всегда и в большинстве случаев открытые результаты поиска могут наплодить невероятное количество дублей. Поэтому вердикт — закрыть.
Корзина и страница оформления/подтверждения заказа
Данная рекомендация актуальна для интернет-магазинов и других коммерческих сайтов, где есть форма заказа. Данные страницы ни в коем случае не должны попадать в индекс ПС.
Страницы пагинации. Обычно для таких страниц автоматически прописываются одинаковые мета-теги плюс на них размещен динамический контент, что приводит к дублям в выдаче. Поэтому пагинацию необходимо закрывать от индексации.
Фильтры и сравнение товаров. Рекомендация относится к интернет-магазинам и сайтам-каталогам.
Страницы регистрации и авторизации. Информация, которая вводится при регистрации или входе на сайт, является конфиденциальной. Поэтому следует избегать индексации подобных страниц, Google это оценит.
Системные каталоги и файлы. Каждый сайт состоит из множества данных — скриптов, таблиц CSS, административной части. Такие файлы следует также ограничить для просмотра роботам.
Замечу, что для выполнения некоторых из вышеописанных пунктов можно использовать и другие инструменты, например, rel=canonical, про который я позже напишу в отдельной статье.
Robots.txt для WordPress и Joomla
robots.txt для WordPress
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */trackback Disallow: */feed Disallow: /*? Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */trackback Disallow: */feed Disallow: /*? Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php Host: site.com User-agent: Googlebot Allow: *.css Allow: *.js Allow: /wp-includes/*.js Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/cache Disallow: */trackback Disallow: */feed Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php Disallow: /*? Sitemap: http://site.com/sitemap.xml
Обратите внимание, что директивы Sitemap и Host в вашем роботсе нужно заменить на необходимые вам.
robots.txt для Joomla
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /media/ Disallow: /system/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /component/ Disallow: /*start Disallow: /*searchword User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /system/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /component/ Disallow: /*start Disallow: /*searchword Host: site.com User-agent: Googlebot Allow: *.css Allow: *.js Disallow: /administrator/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /system/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /tmp/ Disallow: /component/ Disallow: /*start Disallow: /*searchword Sitemap: http://site.com/sitemap.xml
Замечу, что в наборе поисковых правил для Joomla я закрыл пагинацию страниц в разделах, а также страницу поиска по сайту. Если вам необходимы данные страницы в поиске — можете убрать из robots.txt эти две строчки:
Disallow: /*start Disallow: /*searchword
Немного о нестандартном использовании robots.txt
С учетом написанного выше, тему правильной настройки robots.txt можно считать раскрытой, однако есть еще кое-что, о чем я бы хотел рассказать. Роботс можно с пользой применять помимо назначения и без вреда для сайта. Дело в том, что в файле можно использовать такой знак, как «#» — он обозначает комментарии, не учитываемые роботами. Данный знак действителен в пределах одной строки, там, где он используется. Его можно использовать для пометок, чтобы не забыть, что и зачем было закрыто от поисковых систем.
Но есть и другое применение. Например, после знака комментария, вы можете разместить полезную информацию: контакты сайта, вакансию для оптимизатора, ссылку на важную информацию, и даже рекламу. Не буду заниматься плагиатом, так как идея не моя, поэтому предлагаю ознакомиться с различными вариантами на блоге Devaka. Уверен, вы будете удивлены, узнав, насколько разнообразным может быть использование роботса не по назначению.
На этом все, правильная настройка robots.txt описана в полной мере, надеюсь, вы узнали что-то новое. Если же после прочтения статьи у вас остались вопросы — задавайте их в комментариях, и я постараюсь на них ответить.
Файл robots.txt для поисковых систем Яндекса и Google

Что это за файл и зачем он нужен?
Если вы заходили на ftp-сервер, где находится ваш сайт, то наверняка задавались вопросом, какие функции выполняют разные файлы, зачем они нужны и как они работают.
В этой статье мы рассмотрим robots.txt и ответим на эти вопросы о нем.
Прежде всего поисковые роботы проверяют наличие файл robots.txt, который лежит в корневой папке, а затем уже происходит обращение ботов к страницам сайта, блога или форума.
При этом роботы читают инструкции, которые прописаны специально для них в этом файле, в основном там прописано, что из страниц и даже целых разделов сайта разрешено, а что – запрещено индексировать и разглашать всему миру.

Запрет не означает, что на сайте есть секретные материалы, просто мы помогаем поисковым системам делать их работу на «отлично». Хорошему вебмастеру лишние страницы в индексе мешают и он лучше знает, какие из них выполняют вспомогательные функции и не несут полезной нагрузки ни роботам ни людям. Поэтому важно знать, как правильно составить и настроить robots.txt.
Примеры страниц, которые рекомендуется исключить из индекса: версия для печати, страница регистрации, логина, RSS, архивы сайта и тому подобные.
Кроме запретов и разрешений robots.txt может приносить пользу, – например, указывать расположение карты сайта, задавать главное зеркало сайта (домен с www или без), уменьшать нагрузку поисковых ботов на хостинг, задавая интервалы посещения и т.д.
Итак, файл robots.txt нужен для правильной обработки сайта поисковыми ботами.

Как правильно настроить robots.txt?
В одних системах управления контентом файл robots.txt может генерироваться автоматически, в других – его нужно создавать вручную. Но этот файл всегда нужно проверять, а в большинстве случаев и редактировать.
Следует учесть, что нет универсального файла robots.txt даже для одинаковых систем управления контентом, ведь у каждого проекта есть свои особенности, которые отражаются на реализации всех технических деталей. Даже по мере развития вашего проекта придется менять многое, в том числе и файл роботс.
Итак, когда мы знаем, зачем нам нужен этот файл, мы можем углубиться в технические подробности.
Поскольку это обычный текстовый файл с названием robots.txt, то его можно создать в любом блокноте (системном, Notepad++, AkelPad или другом) и загрузить в корневую папку сайта на сервер.
После загрузки можно просмотреть все содержимое этого файла по адресу: http://<имя сайта>/robots.txt. Это работает для всех сайтов, у которых есть этот файл. А вот роботс самого Яндекса http://yandex.ru/robots.txt

и Google http://www.google.com/robots.txt
Изучим основы синтаксиса robots.txt и самые распространенные директивы
Прежде всего нужно знать, что использование кириллицы запрещено в файлах robots.txt, файлах sitemap и http-заголовках сервера. То есть никакой кириллицы в этом файл быть не должно, а вместо нее нужно использовать специальный Punycode.
Поисковые агенты (User-agent)
В первой строке, которая не закомментирована знаком #, обычно указывается поисковый агент (робот конкретной поисковой системы или группа ботов), которому предназначены последующие правила. Будьте внимательны – User-agent не должен быть пустым! То есть вот такая строка и последующие не сработают:
User–agent:
Последующие директивы не обрабатываются, так как задан пустой поисковый агент.
А вот так правильно:
#robots.txtcomment
User-agent: *
# со знака решетки начинается комментарий, который игнорируется поисковыми ботами. Для улучшения читаемости и соблюдения хорошего стиля комментарий лучше писать с новой строки, а не продолжать ту, в которой уже прописаны директивы.
* звездочка означает последовательность любых символов, то есть любой агент должен выполнять дальнейшие указания.
User-agent: Yandex
– означает, что следущие правила написаны для ботов Яндекса.
User–agent: Googlebot
– соответственно для ботов Гугла.
В старых версиях robots.txt можно встретить устаревшие инструкции:
User–agent: StackRambler
– устарел, так как Рамблер перешел к использованию поисковых технологий Яндекса.
User–agent: Slurp
– поисковый робот Yahoo!, имел смачное имя Slurp. Больше не используется, так как компания Yahoo! вместо своей поисковой машины SearchMonkey перешла на использование поисковика Bing от Майкрософт.
Пустые строки после User-agent означают конец директив (инструкций текущему поисковому агенту), поэтому нужно следить, чтобы пустые строки ошибочно не оборвали работу агента.
Директивы robots.txt
Сразу после указания поискового агента должны идти директивы, относящиеся к нему.
Disallow
Обязательная инструкция, даже если мы хотим открыть сайт полностью и ничего не запрещать его просто нужно оставить пустым:
User-agent: *
Disallow:
Такой роботс ничего не запрещает, но наличие строки Disallow ожидается поисковым ботом, без нее он может некорректно обработать директивы.
Вот так закрываются определенные папки, каждая папка – отдельной строкой.
Disallow: /css/
Disallow: /cgi–bin/
Disallow: /images/
Запись одной строкой не только нарушает стандарты robots.txt, но и может повлечь непредсказуемую работу разных ботов.
Disallow: /css/ /cgi-bin/ /images/
Директива распространяется только для текущего поискового агента, то есть такой роботс закроет каталог для всех роботов кроме Яндекса:
User-agent: *
Disallow: /css/
User-agent: Yandex
Disallow:
Вот так выглядит роботс, полностью закрывающий весь сайт от индексации:
User-agent: *
Disallow: /
Allow
Эта директива появилась сравнительно недавно, по логическому смыслу является противоположной команде Disallow, но ее понимает только Яндекс.
User-agent: Yandex
Allow: /
Такой роботс запрещает доступ к всему сайту для ботов Яндекса, строка
Allow:
аналогично
Disallow: /
Иногда для ботов Яндекса (но не для других ботов) удобней разрешить несколько каталогов, чем прописывать множество запрещающих строк.
Sitemap
Если сайт достаточно большой и содержит тысячи страниц, то ему для лучшей индексации потребуется карта сайта.
Чтобы подсказать поисковому боту, где находится эта карта, нужно добавить в robots.txt строку, указывающую на эту карту. Кириллица недопустима (см ниже).
Sitemap: http://<имя_сайта>/sitemap.xml
Host
Директива host сообщает поисковому боту, какое зеркало домена главное – с www или без. Поддерживается только Яндексом. Обратите внимание, он указывается без http:// и без слеша в конце строки /.
Указание хоста не гарантирует, что главным зеркалом сайта будет установлен именно этот хост, однако Яндекс будет его учитывать при определении главного зеркала.
Для счастливых обладателей кириллических доменов нужно учитывать то, что необходимо использовать специальный Punycode, а не кириллицу. Так, если нам нужно указать домен.рф главным зеркалом, то это будет выглядеть так:
Host: xn--d1acufc.xn--p1ai
Узнать Punycode для своего домена можно с помощью специального сервиса – Punycode-конвертера.
Особенности robots.txt для разных поисковых систем
Разные поисковые системы имеют свои особенности и поэтому в robots.txt, как уже упоминалось в этой статье, существуют разные директивы для различных поисковых агентов.
Директивы Allow и Host обрабатывают только боты Yandex, для остальных юзерагентов они не сработают.
GoogleBot – поддерживает в директивах регулярные выражения. Если нам нужно запретить индексацию файлов по расширениям, то можно написать так:
User-agent: googlebot
Disallow: *.cgi
Нужно учитывать, что Гугл может игнорировать правила, так как для него это не догма, а рекомендация. Если на страницу есть ссылка, то она может попасть в индекс Гугла. Поэтому нежелательно закрывать от индексации страницу, на которую есть ссылки. У таких страниц плохой сниппет:
В таких случаях для закрытия дублей страниц лучше воспользоваться средствами, предоставляемыми самой CMS, а уже потом использовать robots.txt.
Во всех сомнительных ситуациях лучше обращаться к документации, которую предоставляют поисковые системы для вебмастеров. Тем более, что рассмотренные правила могут обновиться.
Советы по работе с robots.txt
При разработке сайта нужно закрыть его полностью, чтобы не засорять индекс ненужными страницами
- Закрыть приватные данные, которые не должны попасть в индекс
- Запретить определенным поисковым системам индексировать сайт. Например, если на русскоязычном сайте не нужен трафик с Yahoo! Или наоборот – на англоязычном нам не нужны посетители с Yandex.
- Снятие нагрузки на сервер: если сайт часто обновляется, содержит множество страниц и боты некоторых поисковых систем чрезмерно нагружают его, то можно умерить их пыл директивой
Crawl-delay: 20
Выставили таймаут, чтобы текущий юзерагент сканировал сайт не чаще, чем раз в 20 секунд. При этом нужно убедиться, что этот бот поддерживает директиву.
Чего следует избегать при использовании robots.txt
Закрывать дубли страниц с помощью роботс нужно только в том случае, если исчерпаны средства самой CMS. В остальных случаях лучше воспользоваться 301 редиректом через соответствующую команду в файле .htaccess, тегами robots noindex, rel=canonical, страницей 404.
- Удалить существующие в индексе страницы с помощью robots.txt не получится
- Закрытие админ панели помогает злоумышленнику узнать путь к админке сайта, так как robots.txt доступен всем желающим.
Если закрываете страницы, четко представляйте, что при этом происходит. Например, если мы закроем в WordPress всю папку /wp-content/, то /wp-content/uploads/ также закроется. А если у нас сайт с большими фотографиями или уникальными изображениями, то будет обидно, что они не индексируются и по ним мы не получим трафика.
Что можно еще почитать по robots.txt
У Яндекса и Google есть соответствующие разделы для вебмастеров о robots.txt. У Яндекса есть анализатор robots.txt
По файлу robots.txt есть полезный сайт robotstxt.org.ru, на котором можно найти множество подробной информации.
Читайте также:
Google открывает исходный код парсера robots.txt / Хабр
Сегодня компания Google анонсировала черновик RFC стандарта Robots Exclusion Protocol (REP), попутно сделав доступным свой парсер файла robots.txt под лицензией Apache License 2.0. До сегодняшнего дня какого-либо официального стандарта для Robots Exclusion Protocol (REP) и robots.txt не существовало (ближайшим к нему было вот это), что позволяло разработчикам и пользователям интерпретировать его по-своему. Инициатива компании направлена на то, чтобы уменьшить различия между реализациями.
Черновик нового стандарта можно просмотреть на сайте IETF, а репозиторий доступен на Github по ссылке https://github.com/google/robotstxt.
Парсер представляет собой исходный код, который Google используют в составе своих продакшн-систем (за исключением мелких правок — вроде убранных заголовочных файлов, используемых только внутри компании) — парсинг файлов robots.txt осуществляется именно так, как это делает Googlebot (в том числе то, как он обращается с Юникод-символами в паттернах). Парсер написан на С++ и по сути состоит из двух файлов — вам потребуется компилятор, совместимый с C++11, хотя код библиотеки восходит к 90-ым, и вы встретите в ней «сырые» указатели и strbrk. Для того, чтобы его собрать, рекомендуется использовать Bazel (поддержка CMake планируется в ближайшем будущем).
Сама идея robots.txt и стандарта принадлежит Мартейну Костеру, который создал его в 1994 году — по легенде, причиной тому стал поисковый паук Чарльза Стросса, который «уронил» сервер Костера при помощи DoS-атаки. Его идея была подхвачена другими и быстро стала стандартом де-факто для тех, кто занимался разработкой поисковых систем. Тем же, кто хотел заниматься его парсингом, иногда приходилось заниматься реверс-инженирингом работы Googlebot — в их числе компания Blekko, написавшая для своей поисковой системы собственный парсер на Perl.
В парсере не обошлось и без забавных моментов: взгляните к примеру на то, сколько труда пошло на обработку «disallow».
Что такое robots.txt и зачем он вообще нужен
Каждый блог дает свой ответ на этот счет. Поэтому новички в поисковом продвижении часто путаются, вот так:
Что за роботс ти экс ти?
Файл robots.txt или индексный файл — обычный текстовый документ в кодировке UTF-8, действует для протоколов http, https, а также FTP. Файл дает поисковым роботам рекомендации: какие страницы/файлы стоит сканировать. Если файл будет содержать символы не в UTF-8, а в другой кодировке, поисковые роботы могут неправильно их обработать. Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, протокола и номера порта, где размещен файл.
Файл должен располагаться в корневом каталоге в виде обычного текстового документа и быть доступен по адресу: https://site.com.ua/robots.txt.
В других файлах принято ставить отметку ВОМ (Byte Order Mark). Это Юникод-символ, который используется для определения последовательности в байтах при считывании информации. Его кодовый символ — U+FEFF. В начале файла robots.txt отметка последовательности байтов игнорируется.
Google установил ограничение по размеру файла robots.txt — он не должен весить больше 500 Кб.
Ладно, если вам интересны сугубо технические подробности, файл robots.txt представляет собой описание в форме Бэкуса-Наура (BNF). При этом используются правила RFC 822.
При обработке правил в файле robots.txt поисковые роботы получают одну из трех инструкций:
- частичный доступ: доступно сканирование отдельных элементов сайта;
- полный доступ: сканировать можно все;
- полный запрет: робот ничего не может сканировать.
При сканировании файла robots.txt роботы получают такие ответы:
- 2xx — сканирование прошло удачно;
- 3xx — поисковый робот следует по переадресации до тех пор, пока не получит другой ответ. Чаще всего есть пять попыток, чтобы робот получил ответ, отличный от ответа 3xx, затем регистрируется ошибка 404;
- 4xx — поисковый робот считает, что можно сканировать все содержимое сайта;
- 5xx — оцениваются как временные ошибки сервера, сканирование полностью запрещается. Робот будет обращаться к файлу до тех пор, пока не получит другой ответ.Поисковый робот Google может определить, корректно или некорректно настроена отдача ответов отсутствующих страниц сайта, то есть, если вместо 404 ошибки страница отдает ответ 5xx, в этом случае страница будет обрабатываться с кодом ответа 404.
Пока что неизвестно, как обрабатывается файл robots.txt, который недоступен из-за проблем сервера с выходом в интернет.
Зачем нужен файл robots.txt
Например, иногда роботам не стоит посещать:
- страницы с личной информацией пользователей на сайте;
- страницы с разнообразными формами отправки информации;
- сайты-зеркала;
- страницы с результатами поиска.
Важно: даже если страница находится в файле robots.txt, существует вероятность, что она появится в выдаче, если на неё была найдена ссылка внутри сайта или где-то на внешнем ресурсе.
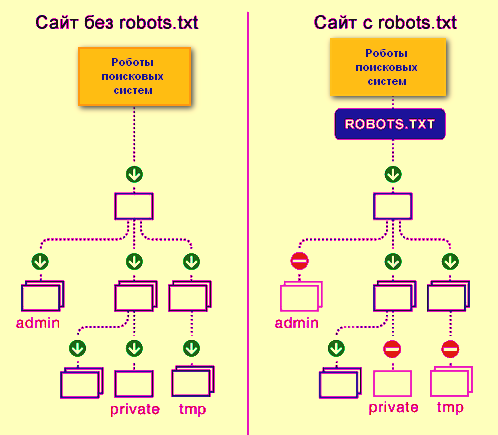
Так роботы поисковых систем видят сайт с файлом robots.txt и без него:
Без robots.txt та информация, которая должна быть скрыта от посторонних глаз, может попасть в выдачу, а из-за этого пострадаете и вы, и сайт.
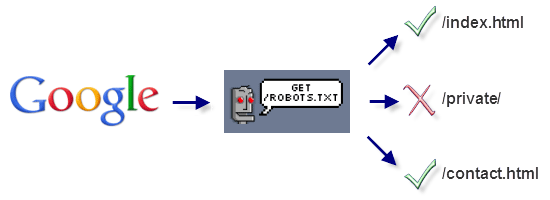
Так робот поисковых систем видит файл robots.txt:
Google обнаружил файл robots.txt на сайте и нашел правила, по которым следует сканировать страницы сайта
Как создать файл robots.txt
С помощью блокнота, Notepad, Sublime, либо любого другого текстового редактора.
В содержании файла должны быть прописаны инструкция User-agent и правило Disallow, к тому же есть еще несколько второстепенных правил.
User-agent — визитка для роботов
User-agent — правило о том, каким роботам необходимо просмотреть инструкции, описанные в файле robots.txt. На данный момент известно 302 поисковых робота. Чтобы не прописывать всех по отдельности, стоит использовать запись:
Она говорит о том, что мы указываем правила в robots.txt для всех поисковых роботов.
Для Google главным роботом является Googlebot. Если мы хотим учесть только его, запись в файле будет такой:
В этом случае все остальные роботы будут сканировать контент на основании своих директив по обработке пустого файла robots.txt.
Для Yandex главным роботом является… Yandex:
Другие специальные роботы:
- Mediapartners-Google — для сервиса AdSense;
- AdsBot-Google — для проверки качества целевой страницы;
- YandexImages — индексатор Яндекс.Картинок;
- Googlebot-Image — для картинок;
- YandexMetrika — робот Яндекс.Метрики;
- YandexMedia — робот, индексирующий мультимедийные данные;
- YaDirectFetcher — робот Яндекс.Директа;
- Googlebot-Video — для видео;
- Googlebot-Mobile — для мобильной версии;
- YandexDirectDyn — робот генерации динамических баннеров;
- YandexBlogs — робот поиск по блогам, индексирующий посты и комментарии;
- YandexMarket— робот Яндекс.Маркета;
- YandexNews — робот Яндекс.Новостей;
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы;
- YandexPagechecker — валидатор микроразметки;
- YandexCalendar — робот Яндекс.Календаря.
Disallow — расставляем «кирпичи»
Disallow дает рекомендацию, какую именно информацию не стоит сканировать.
Такая запись открывает для сканирования весь сайт:
А эта запись говорит о том, что абсолютно весь контент на сайте запрещен для сканирования:
Ее стоит использовать, если сайт находится в процессе доработок, и вы не хотите, чтобы он в нынешнем состоянии засветился в выдаче.
Важно снять это правило, как только сайт будет готов к тому, чтобы его увидели пользователи. К сожалению, об этом забывают многие вебмастера.
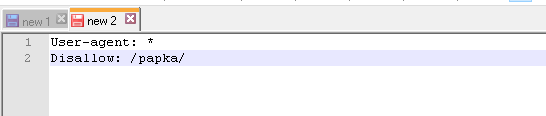
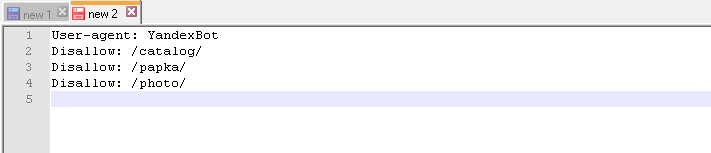
Пример. Как прописать правило Disallow, чтобы дать рекомендации роботам не просматривать содержимое папки /papka/:
Чтобы роботы не сканировали конкретный URL:
Чтобы роботы не сканировали конкретный файл:
Чтобы роботы не сканировали все файлы определенного разрешения на сайте:
Данная строка запрещает индексировать все файлы с расширением .gif
Allow — направляем роботов
Allow разрешает сканировать какой-либо файл/директиву/страницу. Допустим, необходимо, чтобы роботы могли посмотреть только страницы, которые начинались бы с /catalog, а весь остальной контент закрыть. В этом случае прописывается следующая комбинация:
Правила Allow и Disallow сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для страницы подходит несколько правил, робот выбирает последнее правило в отсортированном списке.
Host — выбираем зеркало сайта
Host — одно из обязательных для robots.txt правил, оно сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
Зеркало сайта — точная или почти точная копия сайта, доступная по разным адресам.
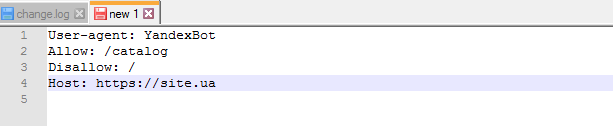
Робот не будет путаться при нахождении зеркал сайта и поймет, что главное зеркало указано в файле robots.txt. Адрес сайта указывается без приставки «http://», но если сайт работает на HTTPS, приставку «https://» указать нужно.
Как необходимо прописать это правило:
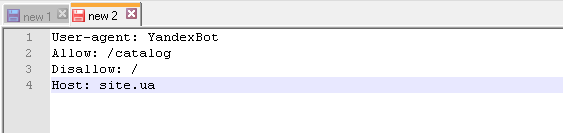
Пример файла robots.txt, если сайт работает на протоколе HTTPS:
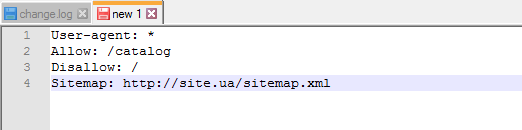
Sitemap — медицинская карта сайта
Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу http://site.ua/sitemap.xml. При каждом обходе робот будет смотреть, какие изменения вносились в этот файл, и быстро освежать информацию о сайте в базах данных поисковой системы.
Инструкция должна быть грамотно вписана в файл:
Crawl-delay — секундомер для слабых серверов
Crawl-delay — параметр, с помощью которого можно задать период, через который будут загружаться страницы сайта. Данное правило актуально, если у вас слабый сервер. В таком случае возможны большие задержки при обращении поисковых роботов к страницам сайта. Этот параметр измеряется в секундах.
Clean-param — охотник за дублирующимся контентом
Clean-param помогает бороться с get-параметрами для избежания дублирования контента, который может быть доступен по разным динамическим адресам (со знаками вопроса). Такие адреса появляются, если на сайте есть различные сортировки, id сессии и так далее.
Допустим, страница доступна по адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
В таком случае файл robots.txt будет выглядеть так:
Здесь ref указывает, откуда идет ссылка, поэтому она записывается в самом начале, а уже потом указывается остальная часть адреса.
Но прежде чем перейти к эталонному файлу, необходимо еще узнать о некоторых знаках, которые применяются при написании файла robots.txt.
Символы в robots.txt
Основные символы файла — «/, *, $, #».
С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами. Например, если стоит один слеш в правиле Disallow, мы запрещаем сканировать весь сайт. С помощью двух знаков слэш можно запретить сканирование какой-либо отдельной директории, например: /catalog/.
Такая запись говорит, что мы запрещаем сканировать все содержимое папки catalog, но если мы напишем /catalog, запретим все ссылки на сайте, которые будут начинаться на /catalog.
Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
Эта запись говорит, что все роботы не должны индексировать любые файлы с расширением .gif в папке /catalog/
Знак доллара «$» ограничивает действия знака звездочки. Если необходимо запретить все содержимое папки catalog, но при этом нельзя запретить урлы, которые содержат /catalog, запись в индексном файле будет такой:
Решетка «#» используется для комментариев, которые вебмастер оставляет для себя или других вебмастеров. Робот не будет их учитывать при сканировании сайта.
Например:
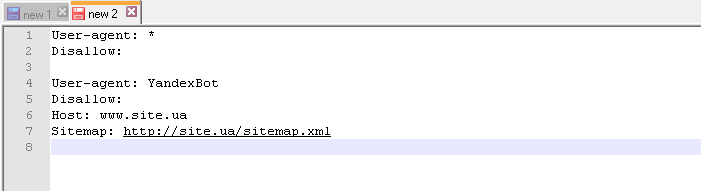
Как выглядит идеальный robots.txt
Такой файл robots.txt можно разместить почти на любом сайте:
Файл открывает содержимое сайта для индексирования, прописан хост и указана карта сайта, которая позволит поисковым системам всегда видеть адреса, которые должны быть проиндексированы. Отдельно прописаны правила для Яндекса, так как не все роботы понимают инструкцию Host.
Но не спешите копировать содержимое файл к себе — для каждого сайта должны быть прописаны уникальные правила, которые зависит от типа сайта и CMS. поэтому тут стоит вспомнить все правила при заполнении файла robots.txt.
Как проверить файл robots.txt
Если хотите узнать, правильно ли заполнили файл robots.txt, проверьте его в инструментах вебмастеров Google и Яндекс. Просто введите исходный код файла robots.txt в форму по ссылке и укажите проверяемый сайт.
Как не нужно заполнять файл robots.txt
Часто при заполнении индексного файла допускаются досадные ошибки, причем они связаны с обычной невнимательностью или спешкой. Чуть ниже — чарт ошибок, которые я встречала на практике.
1. Перепутанные инструкции:
Правильный вариант:
2. Запись нескольких папок/директорий в одной инструкции Disallow:
Такая запись может запутать поисковых роботов, они могут не понять, что именно им не следует индексировать: то ли первую папку, то ли последнюю, — поэтому нужно писать каждое правило отдельно.
3. Сам файл должен называться только robots.txt, а не Robots.txt, ROBOTS.TXT или как-то иначе.
4. Нельзя оставлять пустым правило User-agent — нужно сказать, какой робот должен учитывать прописанные в файле правила.
5. Лишние знаки в файле (слэши, звездочки).
6. Добавление в файл страниц, которых не должно быть в индексе.
Нестандартное применение robots.txt
Кроме прямых функций индексный файл может стать площадкой для творчества и способом найти новых сотрудников.
Вот сайт, в котором robots.txt сам является маленьким сайтом с рабочими элементами и даже рекламным блоком.
Хотите что-то поинтереснее? Ловите ссылку на robots.txt со встроенной игрой и музыкальным сопровождением.
Многие бренды используют robots.txt, чтобы еще раз заявить о себе:
В качестве площадки для поиска специалистов файл используют в основном SEO-агентства. А кто же еще может узнать о его существовании? 🙂
А у Google есть специальный файл humans.txt, чтобы вы не допускали мысли о дискриминации специалистов из кожи и мяса.
Когда у вебмастера появляется достаточно свободного времени, он часто тратит его на модернизацию robots.txt:
Хотите, чтобы все страницы вашего сайта заходили в индекс быстро? Мы выберем для вас оптимальную стратегию SEO-продвижения:
{«0»:{«lid»:»1531306243545″,»ls»:»10″,»loff»:»»,»li_type»:»nm»,»li_name»:»name»,»li_ph»:»Имя»,»li_req»:»y»,»li_nm»:»name»},»1″:{«lid»:»1573230091466″,»ls»:»20″,»loff»:»»,»li_type»:»ph»,»li_name»:»phone»,»li_req»:»y»,»li_masktype»:»a»,»li_nm»:»phone»},»2″:{«lid»:»1573567927671″,»ls»:»30″,»loff»:»y»,»li_type»:»in»,»li_name»:»surname»,»li_ph»:»Фамилия»,»li_req»:»y»,»li_nm»:»surname»},»3″:{«lid»:»1531306540094″,»ls»:»40″,»loff»:»»,»li_type»:»in»,»li_name»:»domains»,»li_ph»:»Адрес сайта»,»li_rule»:»url»,»li_req»:»y»,»li_nm»:»domains»},»4″:{«lid»:»1573230077755″,»ls»:»50″,»loff»:»»,»li_type»:»em»,»li_name»:»email»,»li_ph»:»Email»,»li_req»:»y»,»li_nm»:»email»},»5″:{«lid»:»1575903646714″,»ls»:»60″,»loff»:»»,»li_type»:»hd»,»li_name»:»comment»,»li_value»:»Автоматический коммент: заявка из блога, без пользовательского комментария»,»li_nm»:»comment»},»6″:{«lid»:»1575903664523″,»ls»:»70″,»loff»:»»,»li_type»:»hd»,»li_name»:»lead_channel_id»,»li_value»:»24″,»li_nm»:»lead_channel_id»},»7″:{«lid»:»1584374224865″,»ls»:»80″,»loff»:»»,»li_type»:»hd»,»li_name»:»ip»,»li_nm»:»ip»}}
Поможем обогнать конкурентов
Выводы
С помощью Robots.txt вы сможете задавать инструкции поисковым роботам, рекламировать себя, свой бренд, искать специалистов. Это большое поле для экспериментов. Главное, помните о грамотном заполнении файла и типичных ошибках.
Правила, они же директивы, они же инструкции файла robots.txt:
- User-agent — правило о том, каким роботам необходимо просмотреть инструкции, описанные в robots.txt.
- Disallow дает рекомендацию, какую именно информацию не стоит сканировать.
- Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу http://site.ua/sitemap.xml.
- Crawl-delay — параметр, с помощью которого можно задать период, через который будут загружаться страницы сайта.
- Host сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
- Allow разрешает сканировать какой-либо файл/директиву/страницу.
- Clean-param помогает бороться с get-параметрами для избежания дублирования контента.
Знаки при составлении robots.txt:
- Знак доллара «$» ограничивает действия знака звездочки.
- С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами.
- Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
- Решетка «#» используется, чтобы обозначить комментарии, которые пишет вебмастер для себя или других вебмастеров.
Используйте индексный файл с умом — и сайт всегда будет в выдаче.
И снова про robots.txt для WordPress (шпаргалка начинающим) / Хабр
Перед каждым блогером (продвинутым, да) рано или поздно встает вопрос: «Чего бы такого написать в robots.txt, чтобы было все в шоколаде?»


Сама идея robots.txt и стандарта принадлежит Мартейну Костеру, который создал его в 1994 году — по легенде, причиной тому стал поисковый паук Чарльза Стросса, который «уронил» сервер Костера при помощи DoS-атаки. Его идея была подхвачена другими и быстро стала стандартом де-факто для тех, кто занимался разработкой поисковых систем. Тем же, кто хотел заниматься его парсингом, иногда приходилось заниматься реверс-инженирингом работы Googlebot — в их числе компания Blekko, написавшая для своей поисковой системы собственный парсер на Perl.





















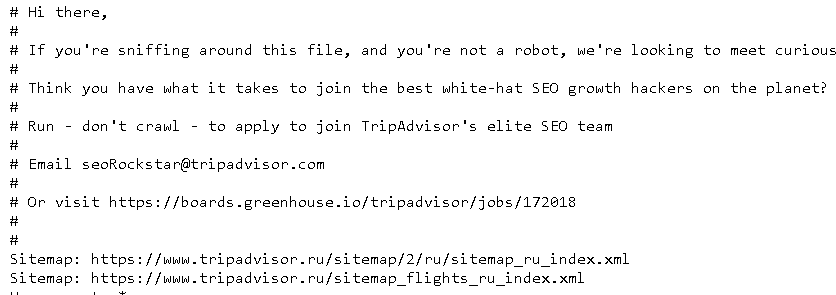

Совершенно естественно встал данный вопрос и передо мной, а написать хотелось грамотно и с пользой. Полез гуглить и все что нашел, были неуклюжие примеры robots.txt стянутые с официального сайта, которые некоторыми авторами выдавались за собственные поделки, продиктованные редкой музой веб-строительства.
Думаю не стоит и говорить, что такие примеры слабо подходили под наши с вами реалии (читай ПС Яндекс — прим. автора).
Поэтому собрав воедино всю информацию найденную в сети, а также собственные мысли и понимание того «как должно быть» написал следующий вариант.
Что имеем?
Во-первых что важно — разные конструкции для Гугла (и остальных) и для Яндекса.
Обусловлено следующим: Для Гугла в дубликатах прописывается мета-тег canonical (в шаблоне вручную, или при помощи многочисленных сео-плагинов), который должен решать проблему дублирующегося контента, а Яндекс пока этого не понимает, там другие штучки…
Во-вторых у Яндекса прописан Host — что в любом случае не помешает.
В-третьих задача разрешить как можно больше страниц для сапы не стояла, поэтому все лишнее закрыто.
В-четвертых используются более-менее принятые настройки ЧПУ и ссылок. Если у вас иерархия ЧПУ и ссылок другая (например изменены каким-либо плагином) — корректируйте исходя их своих настроек.
Основные ошибки виденные мной:
— зачастую для Яндекса прописывают только директива Host, оставляя Dissalow пустым, но такая конструкция дает право Яндексу опять индексировать все что угодно, несмотря на запреты в первой секции, что, впрочем, логично.
— закрывая категории не закрывают архивы по дате и архив автора.
— не закрывают системные адреса (трекбэки, вход и регистрацию)
Остальное я как мог вынес в комментарии, которые можно смело удалить, если вы со всем разобрались.
Не думаю что он универсален и идеален, но думаю послужит многим хорошей отправной точкой. robots.txt:
User-agent: *
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбеков, rss-ленты
Disallow: /trackback
Disallow: /feed
Disallow: /rss
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /xmlrpc.php
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного "мусора"
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploads
User-agent: Yandex
Disallow: /cgi-bin
# запрещаем индексацию системных папок
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
# запрещаем индексацию категорий
Disallow: /category*
# запрещаем индексацию архивов по датам. Прописываем вручную актуальные года
Disallow: /2008*
Disallow: /2009*
# запрещаем индексацию архива автора
Disallow: /author*
# запрещаем индексацию страницы входа и регистрации
Disallow: /wp-login.php
Disallow: /wp-register.php
# запрещаем индексацию трекбеков, rss-ленты
Disallow: /trackback
Disallow: /feed
Disallow: /rss
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /xmlrpc.php
# запрещаем индексацию постраничных комментариев
Disallow: */comments
Disallow: */comment-page*
# запрещаем индексацию результатов поиска и другого возможного «мусора»
Disallow: /*?*
Disallow: /*?
# разрешаем индексацию вложений, особо мнительным можно запретить папку wp-content целиком
Allow: /wp-content/uploads
# прописываем директиву Host
Host: mysite.ru
User-agent: Googlebot-Image
Disallow:
Allow: /*
# разрешаем индексировать изображения
User-agent: YandexBlog
Disallow:
Allow: /*
# разрешаем индексировать rss-ленту
PS. Данный файл использую на своих блогах, валидность и правильность проверял в панели веб-мастера, добиваясь нужного мне результата. Поэтому если что-то не устраивает — проверяйте и дописывайте свое.
PPS. Я еще не матерый сеошник, посему где-то могу ошибаться. С robots.txt не ошибается тот, у кого такого файла вообще нет)