
Google прекращает поддержку директивы noindex в robots.txt — SEO на vc.ru
{«id»:13961,»url»:»\/distributions\/13961\/click?bit=1&hash=c44cac1eb31aec60280b707a54de8f9e7765dd2abc1c61ae0e9263d900201087″,»title»:»\u041a\u0430\u043a \u0434\u0438\u0437\u0430\u0439\u043d-\u0441\u0438\u0441\u0442\u0435\u043c\u0430 Consta \u043f\u043e\u043c\u043e\u0433\u0430\u0435\u0442 \u0441\u043e\u0437\u0434\u0430\u0432\u0430\u0442\u044c \u043d\u043e\u0432\u044b\u0435 \u0438\u043d\u0442\u0435\u0440\u0444\u0435\u0439\u0441\u044b»,»buttonText»:»»,»imageUuid»:»»,»isPaidAndBannersEnabled»:false}
После 1.09.2019 года, поисковый гигант прекратит следовать директивам, которые не поддерживаются и не опубликованы в robots exclusion protocol. Изменения были анонсированы в блоге компании (https://webmasters.googleblog.com/2019/07/a-note-on-unsupported-rules-in-robotstxt.html). Это значит, что Google не будет учитывать файлы robots с записанной внутри директивой “noindex”.
1809 просмотров
Что произошло? В течение многих лет файл robots позволял ограничивать доступ к некоторым (или всем) страницам сайта для разного рода роботов, парсеров, пауков или скраулеров.
- Директивы теперь используются для любого протокола: кроме HTTP/HTTPS, они распространяются на FTP и прочие;
- Поисковые пауки обязательно сканируют первые 512Кб файла robots.txt. Если файл большой, то дальше они могут его не сканировать..
- Все записи в файле кешируются сроком до 24 часов. Это сделано, чтобы не загружать сервер запросами, а также, чтобы SEO-специалист мог обновлять файл по мере необходимости и в удобные сроки. Срок кеширования можно задавать, используя директиву Cache-Control.
- Если файл по какой-то причине перестал сканироваться — правила продолжают работать. Согласно новой спецификации, в течение продолжительного времени используется последняя кэшированная копия.


Также, были пересмотрены правила для файла robots.txt. Теперь поисковой машиной Google не учитываются директивы, которые не указаны в стандарте. Первой записью, которая не попала в документ, стала директива noindex.
Каковы же альтернативы? Google такие варианты, которые, вероятно, уже использовались в любом случае:
1) noindex в метатегах. Данная директива, поддерживаемая в HTTP-ответах/HTML-коде — самый эффективный способ, чтобы удалить ссылки из индекса, если парсинг разрешен.
2) 404 и 410 коды ответов. Оба HTTP-ответа означают, что по данному URL отсутствует страница, и приведут к удалению страниц с такой ошибкой из поискового индекса если они будут или были просканированы.
3) Защита паролем. Если разметка не указывает на подписку или платный контент (https://developers.google.com/search/docs/data-types/paywalled-content), то сокрытая за формой авторизации страница со временем удалится из индекса Google.
4) Disallow в robots. txt. Поисковики индексируют известные им страницы. Поэтому, блокирование доступа к странице для краулеров означает, что контент никогда не будет проиндексирован. В то же время, поисковик также может индексировать URL-адрес, основываясь на переходах с других страниц (внутренних или внешних), не видя при этом непосредственно контент. Так что, при использовании директивы disallow рекомендую сделать страницы, закрытые ею, менее видимыми в целом.
txt. Поисковики индексируют известные им страницы. Поэтому, блокирование доступа к странице для краулеров означает, что контент никогда не будет проиндексирован. В то же время, поисковик также может индексировать URL-адрес, основываясь на переходах с других страниц (внутренних или внешних), не видя при этом непосредственно контент. Так что, при использовании директивы disallow рекомендую сделать страницы, закрытые ею, менее видимыми в целом.
5) Инструмент удаления URL в Google Search Console (https://support.google.com/webmasters/answer/1663419). С его помощью можно легко и быстро (но временно) убрать страницы из результатов поиска.
Новый стандарт. За день до этой новости, Google анонсировал, что компания также работает над разработкой стандарта, основанного на robots exclusion protocol, что является первым существенным изменением в данном направлении. Также, компания выложила исходный код парсера robots.txt в открытый доступ одновременно с новостью о разработке стандарта.
Почему Google вводит эти изменения сейчас? Поисковый гигант искал возможности для этих изменений в течение нескольких лет и со стандартизацией протокола он наконец-то может двигаться вперед. В Google сказали, что «провели анализ по использованию разных директив в файле robots» и теперь сфокусированы на удалении основных неподдерживаемых директив – crawl-delay, nofollow, noindex.
«Поскольку эти правила никогда официально не разъяснялись компанией, их использование может плохо влиять на сканирование Googlebot’а. Также, такие ошибки плохо влияют на присутствие сайтов в поисковой выдаче»
Стоит ли переживать? Самое главное на данный момент – избавиться от директивы noindex в файле robots.txt. Если же без нее никак, то стоит воспользоваться одной из перечисленных выше альтернатив до 1 сентября. Также, обратите внимание на использование nofollow или crawl-delay команд и если они есть, то переделайте также их с использованием поддерживаемых директив. Поисковый гигант дал достаточно времени для того, чтобы все ознакомились с вносимыми изменениями и поменяли свои файлы robots. txt, поэтому нет поводов для беспокойства.
txt, поэтому нет поводов для беспокойства.
Тем не менее, все равно интересно как коллеги решают данную проблему. Со статическими сайтами все понятно, там и в хедере можно написать все нужные метатеги. Но для SPA-сайтов было гораздо удобнее закрывать страницы по определенной маске (например https://ntile.app/some_id/*) или же скрывать целые разделы (например, https://ntile.app/taynaya-komnata-5d2ec134e12fd4000146d3ec-5d2ec134e12fd4000146d3ee, изначально созданный не для индексации, а для тестов по переспаму). С кодами ответов в заголовках много мороки получается. Да и скрывать всё за формой авторизации несколько усложняет разработку.
Подскажите, кто как решает такого рода проблемы?
Основной синтаксис robots.txt и примеры удачного использования
Содержание
Файл robots.txt предоставляет важную информацию для поисковых роботов, которые сканируют интернет. Перед тем как пройтись по страницам вашего сайта, поисковые роботы проверяют данный файл.
Это позволят им с большей эффективностью сканировать сайт, так как вы помогаете роботам сразу приступать к индексации действительно важной информации на вашем сайте (это при условии, что вы правильно настроили robots.txt).
Но, как директивы в robots.txt, так и инструкция noindex в мета-теге robots являются лишь рекомендацией для роботов, поэтому они не гарантируют что закрытые страницы не будут проиндексированы и не будут добавлены в индекс.
Если вам нужно действительно закрыть часть сайта от индексации, то, например, можно дополнительно воспользоваться закрытие директорий паролем.
Основной синтаксисUser-Agent: робот для которого будут применяться следующие правила (например, «Googlebot»)
Disallow: страницы, к которым вы хотите закрыть доступ (можно указать большой список таких директив с каждой новой строки)
Каждая группа User-Agent / Disallow должны быть разделены пустой строкой.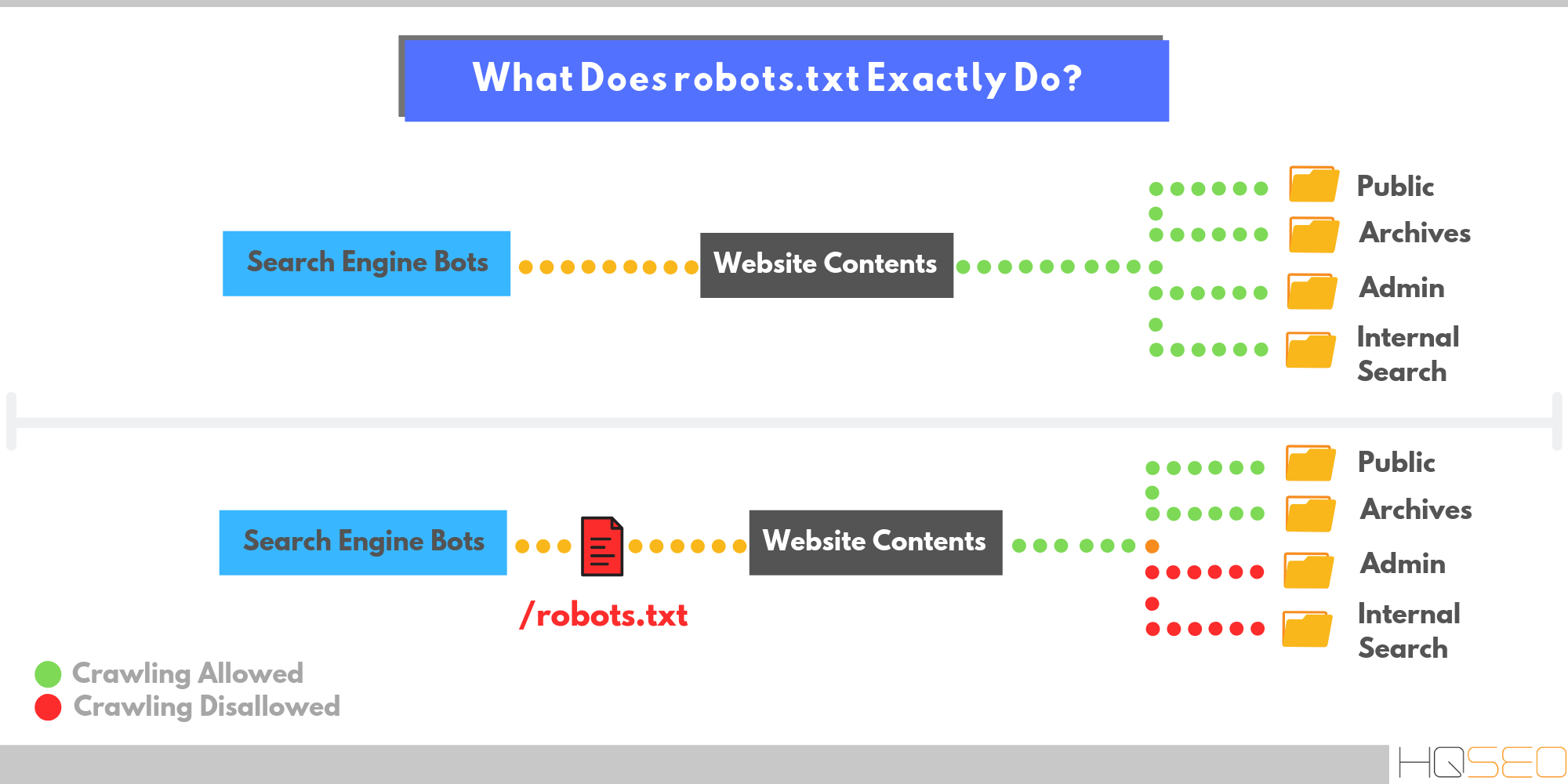
Символ хэш (#) может быть использован для комментариев в файле robots.txt: для текущей строки всё что после # будет игнорироваться. Данные комментарий может быть использован как для всей строки, так в конце строки после директив.
Каталоги и имена файлов чувствительны к регистру: «catalog», «Catalog» и «CATALOG» – это всё разные директории для поисковых систем.
Host: применяется для указание Яндексу основного зеркала сайта. Поэтому, если вы хотите склеить 2 сайта и делаете постраничный 301 редирект, то для файла robots.txt (на дублирующем сайте) НЕ надо делать редирект, чтобы Яндекс мог видеть данную директиву именно на сайте, который необходимо склеить.
Crawl-delay: можно ограничить скорость обхода вашего сайта, так как если у вашего сайта очень большая посещаемость, то, нагрузка на сервер от различных поисковых роботов может приводить к дополнительным проблемам.
Регулярные выражения: для более гибкой настройки своих директив вы можете использовать 2 символа
- * (звездочка) – означает любую последовательность символов
- $ (знак доллара) – обозначает конец строки
Запрет на индексацию всего сайта
User-agent: *
Disallow: /
Эту инструкцию важно использовать, когда вы разрабатываете новый сайт и выкладываете доступ к нему, например, через поддомен.
Очень часто разработчики забывают таким образом закрыть от индексации сайт и получаем сразу полную копию сайта в индексе поисковых систем. Если это всё-таки произошло, то надо сделать постраничный 301 редирект на ваш основной домен.
А такая конструкция ПОЗВОЛЯЕТ индексировать весь сайт:
User-agent: *
Disallow:
Запрет на индексацию определённой папки
User-agent: Googlebot
Disallow: /no-index/
Запрет на посещение страницы для определенного робота
User-agent: Googlebot
Disallow: /no-index/this-page. html
html
Запрет на индексацию файлов определенного типа
User-agent: *
Disallow: /*.pdf$
Разрешить определенному поисковому роботу посещать определенную страницу
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Ссылка на Sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Нюансы с использованием данной директивы: если у вас на сайте постоянно добавляется уникальный контент, то
- лучше НЕ добавлять в robots.txt ссылку на вашу карту сайта,
- саму карту сайта сделать с НЕСТАНДАРТНЫМ названием sitemap.xml (например, my-new-sitemap.xml и после этого добавить эту ссылку через «вебмастерсы» поисковых систем),
так как, очень много недобросовестных вебмастеров парсят с чужих сайтов контент и используют для своих проектов.
Что лучше использовать robots. txt или noindex?
txt или noindex?Если вы хотите, чтобы страница не попала в индекс, то лучше использовать noindex в мета-теге robots. Для этого на странице в секции <head> необходимо добавить следующий метатег:
<meta name=”robots” content=”noindex, follow”>.
Это позволит вам
- убрать из индекса страницу при следующем посещение поискового робота (и не надо будет делать в ручном режиме удаление данной страницы, через вебмастерс)
- позволит вам передать ссылочный вес страницы
Через robots.txt лучше всего закрывать от индексации:
- админку сайта
- результаты поиска по сайту
- страницы регистрации/авторизации/восстановление пароля
После того, как вы окончательно сформировали файл robots.txt необходимо проверить его на ошибки. Для этого можно воспользоваться инструментами проверки от поисковых систем:
Google Вебмастерс: войти в аккаунт с подтверждённым в нём текущим сайтом, перейти на Сканирование -> Инструмент проверки файла robots.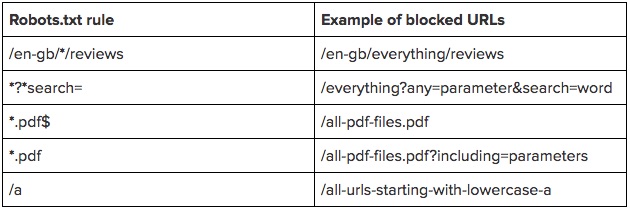 txt.
txt.
В данном инструменте вы можете:
- сразу увидеть все свои ошибки и возможные проблемы,
- прямо в этом инструменте провести все правки и сразу проверить на ошибки, чтобы потом уже перенести готовый файл себе на сайт,
- проверить правильно ли вы закрыли все не нужные для индексации страницы и открыты ли все нужные страницы.
Яндекс Вебмастер: чтобы воспользоваться данным инструментом просто перейдите по этой ссылке http://webmaster.yandex.ru/robots.xml.
Этот инструмент почти аналогичный предыдущему с тем небольшим отличием, что:
- тут можно не авторизоваться и нет необходимости в подтверждении прав на сайт, а поэтому, можно сразу приступать к проверке вашего файла robots.txt,
- для проверки сразу можно задать список страниц, а не вбивать их по одному,
- точно убедиться, что Яндекс правильно понял ваши инструкции.
Создание и настройка robots. txt является в списке первых пунктов по внутренней оптимизации сайта и началом поискового продвижения.
txt является в списке первых пунктов по внутренней оптимизации сайта и началом поискового продвижения.
Важно его настроить грамотно, чтобы нужные страницы и разделы были доступны к индексации поисковых систем. А не нужные были закрыты.
Но главное помнить, что robots.txt не гарантирует того, что страницы не будут проиндексированы. Как когда-то сказала наша коллега Анастасия Пареха:
Robots.txt — как презерватив, вроде защищает, но вероятность всегда есть)
SEO — Метатег vs robots.txt
спросил
Изменено 3 года, 9 месяцев назад
Просмотрено 20 тысяч раз
Что лучше использовать метатеги* или файл robots.txt для информирования поисковых роботов о включении или исключении страницы?
Есть ли проблемы с использованием метатегов и файла robots.
txt?
 txt?
txt? *Например: <#META name="robots" content="index, follow">
- SEO
- robots.txt
- метатеги
2
Есть одно существенное отличие. По словам Google, они все равно будут индексировать страницу за robots.txt DENY, если на страницу ссылаются через другой сайт.
Однако они не увидят метатег:
Хотя Google не будет сканировать или индексировать контент, заблокированный файлом robots.txt, мы все равно можем найти и проиндексировать запрещенный URL-адрес из других мест в Интернете. В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на сайт, по-прежнему могут отображаться в результатах поиска Google. Вы можете полностью запретить отображение своего URL-адреса в результатах поиска Google, используя другие методы блокировки URL-адресов, такие как защита паролем файлов на вашем сервере или , используя метатег noindex или заголовок ответа .

5
Оба поддерживаются всеми поисковыми роботами, которые уважают пожелания веб-мастеров. Не все делают, но против них ни одна техника не является достаточной.
Вы можете использовать правила robots.txt для общих целей, например запретить целые разделы вашего сайта. Если вы скажете Disallow: /family , то все ссылки, начинающиеся с /family , не будут проиндексированы сканером.
Метатег может использоваться для запрета отдельной страницы. Страницы, запрещенные метатегами, не влияют на подстраницы в иерархии страниц. Если у вас есть метатег disallow на /work , он не мешает сканеру получить доступ к /work/my-publications , если на разрешенной странице есть ссылка на него.
Robots.txt ИМХО.
Параметр «Метатег» указывает ботам не индексировать отдельные файлы, тогда как файл robots.txt можно использовать для ограничения доступа ко всем каталогам.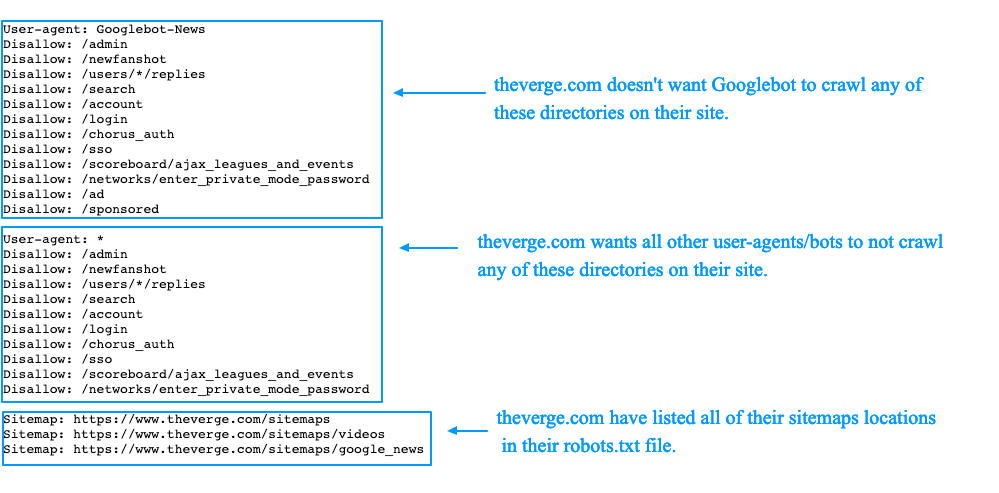
Конечно, используйте метатег, если у вас есть нечетная страница в проиндексированных папках, которую вы хотите пропустить, но в целом я бы рекомендовал вам размещать большую часть неиндексированного контента в одной или нескольких папках и использовать robots.txt, чтобы пропустить большую часть .
Нет, нет проблем с использованием обоих — если есть коллизия, в общих чертах, запрет имеет приоритет над разрешение .
3
мета лучше.
Чтобы исключить отдельные страницы из индексов поисковых систем, метатег noindex лучше, чем robots.txt.
Существует огромная разница между мета-роботом и robots.txt.
В robots.txt мы спрашиваем сканеры, какую страницу вы должны сканировать, а какую исключить, но не просим сканер не индексировать эти исключенные страницы из сканирования.
Но если мы используем метатег robots, мы можем попросить сканеры поисковых систем не индексировать эту страницу. Тег, который будет использоваться для этого:
Тег, который будет использоваться для этого:
<#meta name = "имя робота", content = "noindex"> ( удалить #)
ИЛИ
<#meta name = "имя робота", content = "follow, noindex"> (удалить #)
Во втором метатеге я попросил робота перейти по этому URL-адресу, но не индексировать его в поисковой системе.
Вот мои знания о них. Я говорю об их рабочей области. Оба мы можем использовать для блокировки контента.
Разница между ними следующая:
- Meta Robot может заблокировать одну страницу с помощью фрагмента кода, вставленного в заголовок веб-сайта. Используя метатег робота, мы сообщаем поисковой системе, для какой функции мы используем метатег.
- В файле robots.txt можно заблокировать весь сайт.
Вот пример мета-робота:
Вот пример файла Robots.
 txt:
txt:Разрешение сканерам сканировать весь веб-сайт
агент пользователя: * Позволять: Запретить:
Запрет сканерам сканировать весь веб-сайт
user-agent: * Позволять: Запретить:/
Я бы, вероятно, использовал robots.txt поверх метатега . Robots.txt существует дольше и может иметь более широкую поддержку (но я не уверен в этом на 100%).
Что касается второй части, я думаю, что большинство поисковых роботов примут самые ограничительные настройки для страницы, если есть несоответствие между robots.txt и метатегом.
Robots.txt подходит для страниц, которые потребляют большую часть бюджета сканирования, таких как внутренний поиск или фильтры с бесконечными комбинациями. Если вы разрешите Google индексировать yoursite.com/search=lalalala , это приведет к трате вашего краулингового бюджета.
2
Вы хотите использовать ‘noindex,follow’ в метатеге robots, а не robots. , потому что это позволит пройти ссылочному соку. Это лучше с точки зрения SEO.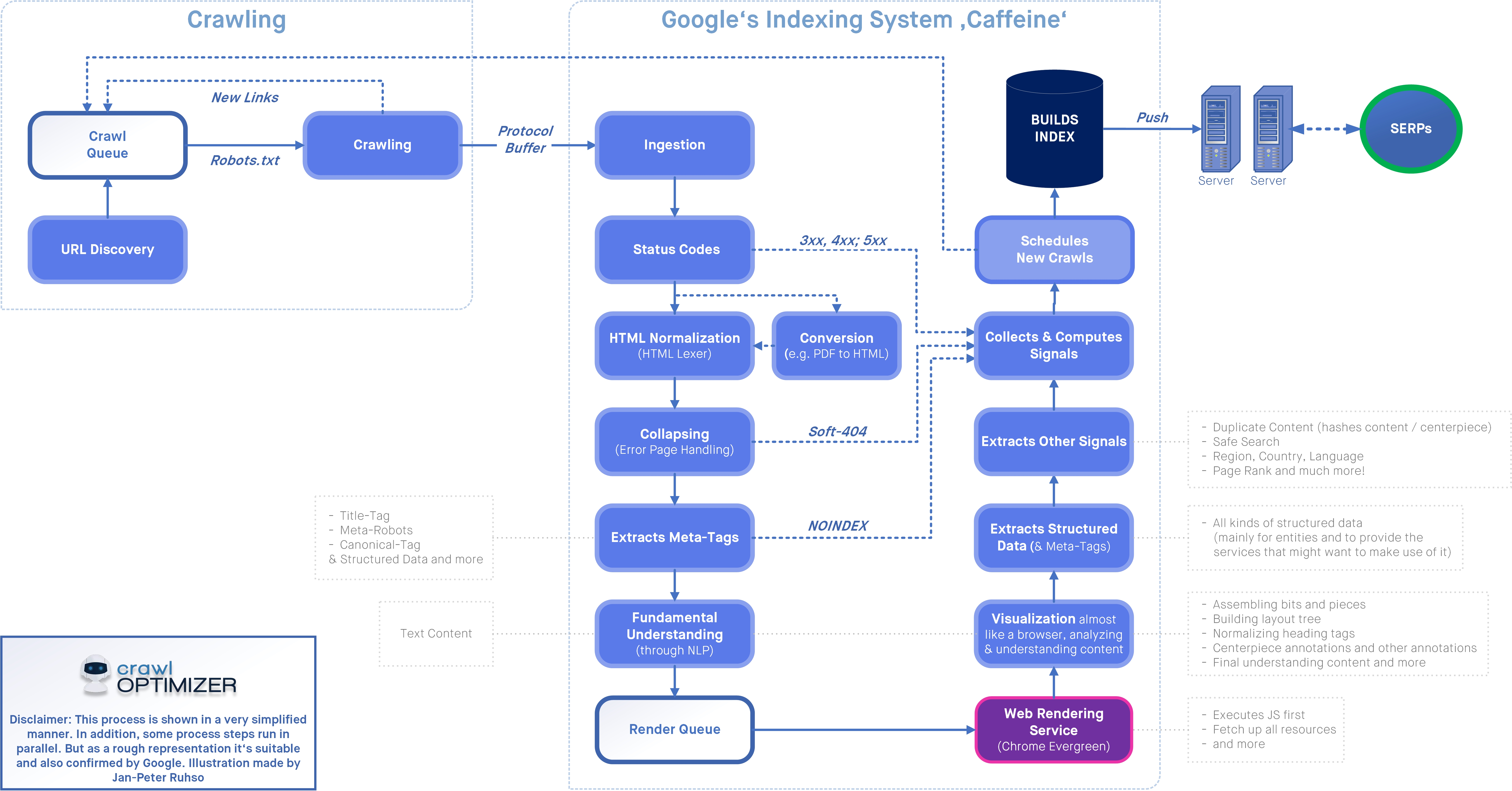 txt
txt
Что лучше использовать метатеги* или файл robots.txt для информирования поисковых роботов о включении или исключении страницы?
Ответ: Оба важны для использования, они используются для разных целей. Файл robots используется для включения или исключения страниц или корневых файлов из индекса паука. В то время как метатеги используются для анализа страницы веб-сайта, которая определяет ее нишу и контент на странице.
Есть ли проблемы с использованием метатегов и файла robots.txt?
Ответ: И то, и другое должно быть реализовано на сайтах, чтобы поисковые роботы могли индексировать или деиндексировать URL-адреса сайта.
Подробнее о работе поисковых роботов здесь >>https://www.playbuzz.com/alexhuber10/how-search-and-spider-engines-work
Вы можете иметь любой, но если на вашем сайте их много веб-страниц, то файл robots. txt упрощается и сокращает время
txt упрощается и сокращает время
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
МетатегRobots и robots.
 txt: в чем основные отличия?
txt: в чем основные отличия?Редактор: Steve Paine
Изменено: 22.03.2021
Если вы хотите повлиять на содержание вашего сайта, которое поисковые системы сканируют и индексируют, у вас есть несколько вариантов. Два из этих вариантов предполагают использование метатегов robots и robots.txt . Несмотря на то, что они могут звучать одинаково, они существенно различаются.
Contents
Contents
Конечно, вы можете просто ничего не делать и полностью доверить сканирование и индексирование вашего веб-сайта Google. Однако у этого есть потенциальные недостатки, особенно на больших сайтах.
Сканирование может занять больше времени, чем необходимо, и в результатах поиска может появиться контент, который не должен там отображаться. К счастью, обе эти вещи можно предотвратить. Важно то, что вы предпринимаете соответствующие действия. Это подводит нас к теме выбора метатегов robots или robots.txt.
Что такое метатеги robots?
Метатеги Robots — это фрагменты, которые вы размещаете в разделе заголовка страницы. Выглядят они так:
Выглядят они так:
Атрибутом name вы отмечаете, к какой поисковой системе вы хотите обратиться, а атрибутом content указывается желаемое действие. В этом примере тег предотвращает индексацию контента всеми поисковыми системами.
Что такое robots.txt?
Файл robots.txt (стандартный протокол исключения роботов) — это текстовый файл, который сообщает сканерам поисковых систем, какие файлы или страницы они могут сканировать. Для этого его необходимо загрузить в корневой каталог сайта.
Поисковая система или ее сканер идентифицируется в файле robots.txt с помощью пользовательского агента. С помощью команд disallow и allow можно указать, какие каталоги следует и не следует сканировать. Вы также можете указать расположение карты сайта в файле robots.txt.
Результат выглядит так, например:
# Группа 1 Агент пользователя: Googlebot Запретить: /nogooglebot/ # Группа 2 Пользовательский агент: * Позволять: / Карта сайта: http://www.
