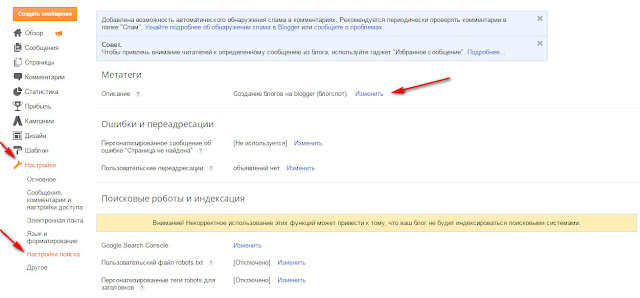
▷ Какие страницы закрыть от индексации: запрет индексации страниц
27355
| How-to | – Читать 15 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ИСПРАВЛЕНИЕ
Инструкцию одобрил
Tech Head of SEO в TRINET.Group
Рамазан Миндубаев
Контент сайта должен быть информативным и полезным для пользователя, а соответствующие страницы — открытыми для сканирования поисковым роботом. Однако есть случаи, когда нужно закрыть страницу от индексации. Разберемся в каких случаях это уместно.
Содержание:
- Причины запретить индексацию страницы
- Какие страницы не индекстровать
- Как закрыть страницы от индексации
4.1. Как закрыть сайт от индексации Яндексом
4.2. Как закрыть сайт от индексации Google - Как проверить, сколько страниц закрыто от индексации
- Заключение
FAQ
Причины запретить индексацию страниц
Владелец сайта заинтересован, чтобы потенциальный клиент находил его веб-ресурс в выдаче, а поисковая система — в том, чтобы предоставить пользователю ценную и релевантную информацию. Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Рассмотрим причины, по которым следует запретить индексацию сайта или отдельных страниц:
Контент не несет в себе смысловой нагрузки для поисковой системы и пользователей или же вводит их в заблуждение.
К такому контенту можно отнести технические и административные страницы сайта (корзина, страница оплаты, результатов поиска, авторизация и т.д.), данные с персональной информацией, наборы фильтров каталога товара в электронной коммерции (множественный выбор фильтров по цене, цвету, фактуре и другое).
Нерациональное использование краулингового бюджета.
Краулинговый бюджет — это определенное количество страниц сайта, которое периодически сканирует поисковая система. Для всех сайтов это значение количества страниц разное и не постоянное и в том числе зависит от типа сайта и частоты его обновления. В наших интересах тратить ресурсы краулеров на те страницы, которые представляют ценность и пользу как для клиента так и для нас (бизнеса). Чтобы краулер чаще посещал и обновлял контент в индексе нужных нам страниц, необходимо закрыть от сканирования те, которые вытягивают краулинговый бюджет и не приносят собственно пользы.
В наших интересах тратить ресурсы краулеров на те страницы, которые представляют ценность и пользу как для клиента так и для нас (бизнеса). Чтобы краулер чаще посещал и обновлял контент в индексе нужных нам страниц, необходимо закрыть от сканирования те, которые вытягивают краулинговый бюджет и не приносят собственно пользы.
Схема сканирования, индексирования и ранжирования сайта
Хотите прямо сейчас проверить, какие страницы вашего сайта индексируются и находятся в топе поисковой выдачи? А по каким фразам ранжируется ваш конкурент? Попробуйте Serpstat (нужно зарегистрироваться и после вы получите доступ к бесплатным инструментам). Если хотите доминировать на своем рынке — используйте Serpstat и достигайте большей эффективности в онлайн.
Какие закрыть страницы от индексации
Страницы сайта в процессе разработки
Если проект только в процессе создания, лучше закрыть сайт от поисковых систем. Рекомендуется открыть доступ к сканированию наполненных и оптимизированных страниц, отображение которых в результатах поиска целесообразно. При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, мета тега noindex или пароля, однако приоритетный вариант — это именно присвоение метатега <meta name=»robots» content=»noindex, nofollow» /> ко всем страницам разрабатываемого ресурса, так как в таком случае индексация страницы невозможна, в отличие от robots.txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, мета тега noindex или пароля, однако приоритетный вариант — это именно присвоение метатега <meta name=»robots» content=»noindex, nofollow» /> ко всем страницам разрабатываемого ресурса, так как в таком случае индексация страницы невозможна, в отличие от robots.txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
Закрыть сайт от индексации в robots.txt можно следующим содержимым (первая директива — означает обращение ко всем краулерам, вторая директива — запрещает сканировать все URL сайта):
User-agent: *
Disallow: /
Эти две строчки запретят доступ к сайту всем роботам поисковых систем.
Если нужно при этом разрешить сканировать конкретные URL, нужно добавить директиву Allow: /namepage$ где /namepage URL страницы разрешенной к сканированию. Директива разрешения сканирования доминирует над запретом (для конкретного URL), а значек $ отменяет применение по умолчанию не выводимывого символа «*». То есть если не поставить $ — мы разрешим сканировать вложенные URL относительно родителя, такие как /namepage/indexpage.html и т.д.
Запрет индексации для сайта на сервере NGINX осуществляется с помощью добавления кода add_header X-Robots-Tag «noindex, nofollow»; в файл .conf.
Копии сайта
Настраивая копию сайта, важно правильно указать зеркало с помощью 301 редиректов, либо атрибута rel= «canonical», чтобы сохранить рейтинг существующего ресурса и проинформировать поисковую систему: где сайт-первоисточник, а где его аналог. Закрывать от индексации работающий ресурс крайне нежелательно. Тем самым можно обнулить возраст сайта и наработанную репутацию.
Страницы печати
Страницы печати могут быть полезны посетителю. Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
По сути страница печати является копией её основной версии. Если эта страница открыта для индексации, поисковый робот может выбрать ее приоритетной и более релевантной. Для правильной оптимизации сайта с большим числом страниц следует установить запрет индексации страниц для печати.
Чтобы закрыть ссылку на документ, можно использовать вывод контента с помощью AJAX, закрыть страницы с помощью метатега <meta name=»robots» content=»noindex, follow»/>, либо в роботс закрыть от индексации все страницы печати.
Ненужные документы
На сайте, кроме страниц с основным контентом, могут присутствовать документы PDF, DOC, XLS, доступные для чтения и загрузки. В результатах поиска на ряду со страницами сайта можно увидеть заголовки pdf-файлов.
Возможно, содержимое этих файлов не отвечает запросам целевой аудитории сайта. Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.
Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.
Пример индексации pdf-файла на сайте
Пользовательские формы и элементы
Сюда относят все страницы, которые полезны для клиентов, но не несут информационной ценности для других пользователей и, как следствие, поисковых систем. Это могут быть формы регистрации и оформления заявок, корзина, личный кабинет. Доступ к таким страницам следует ограничить.
Технические данные сайта
Технические страницы нужны исключительно для служебного использования администратором. Например, форма авторизации для входа в панель управления.
Форма авторизации в админку OpenCart
Персональная информация о клиентах
Эти данные могут содержать не только только имя и фамилию зарегистрированного пользователя, но и контактные и платежные данные, оставленные при оформлении заказа. Эта информация должна быть надежно защищена от просмотра.
Страницы сортировки
Особенности структуры таких страниц делают их похожими друг на друга. Чтобы снизить риск санкций от поисковых систем за дублированный контент, рекомендуем закрывать к ним доступ.
Страницы пагинации
Данные страницы хоть частично и дублируют содержание основной страницы, закрывать от индексации их не рекомендуется, для них необходимо настроить атрибут rel=»canonical», атрибуты rel=»prev» и rel=»next», указать в Google Search Console в разделе «Параметры URL», какие параметры разбивают страницы, либо целенаправленно их оптимизировать.
- Как провести анализ индексации сайта
- SEO-аудит сайта с помощью Serpstat: обзор инструмента
- Как автоматизировать поиск ошибок на сайте: Аудит сайта теперь доступен в API Serpstat
Как закрыть страницы от индексации
Метатег robots со значением noindex в html-файле
Чтобы закрыть страницу от индексации, используйте атрибут noindex в html-коде страницы — это сигнал поисковой системе о том, что ее следует исключить из результатов поиска. Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
Это позволяет полностью закрыть страницу, оставив роботам возможность переходить по размещенным на странице ссылкам. Если это не нужно, замените follow на nofollow:
<meta name=»robots» content=»noindex, nofollow»/>
При использовании данных методов страница будет закрыта для сканирования даже при наличии внешних ссылок на нее.
Чтобы закрыть текст от индексации (или отдельный фрагмент текста), а не всю страницу, воспользуйтесь html-тегом: <noindex>текст</noindex>. Помните, что данный тег «понимает» только Яндекс: бот Google его проигнорирует.
Как закрыть сайт от индексации Яндексом
Если необходимо закрыть сайт от индексации только роботами Яндекса, достаточно прописать в файле robots данный код:
User-agent: Yandex
Disallow: /
Аналогично можно запретить доступ ботам Яндекса к сайту с помощью метатега:
<meta name=»yandex» content=»none»/>
При желании можно закрыть Яндексу доступ к конкретному файлу или директории через robots. txt:
txt:
User-agent: Yandex
Disallow: /folder/file.php
Как закрыть сайт от индексации Google
Вы можете также закрыть доступ к сайту только ботам Google. Добавьте для этой цели данный метатег внутри <head> </head> всех страниц ресурса:
<meta name=»googlebot» content=»noindex, nofollow»/>
Через robots доступ к сайту ботам Google закрывается так:
User-agent: googlebot
Disallow: /
Еще можно запретить доступ к каким-либо статьям сайта роботам Google Новостей, тогда они не появятся в Google News:
<meta name=»Googlebot-News» content=»noindex, nofollow»>.
Файл robots.txt
В этом документе можно заблокировать доступ ко всем выбранным страницам или указать поисковикам не индексировать сайт.
Ограничить индексацию страниц через файл robots.txt можно так:
User-agent: * #название поисковой системы Disallow: /catalog/ #частичный или полный URL закрываемой страницы
Чтобы использование этого метода было эффективным, следует проверить, нет ли внешних ссылок на раздел сайта, который нужно скрыть, а также изменить все внутренние ссылки, ведущие на него.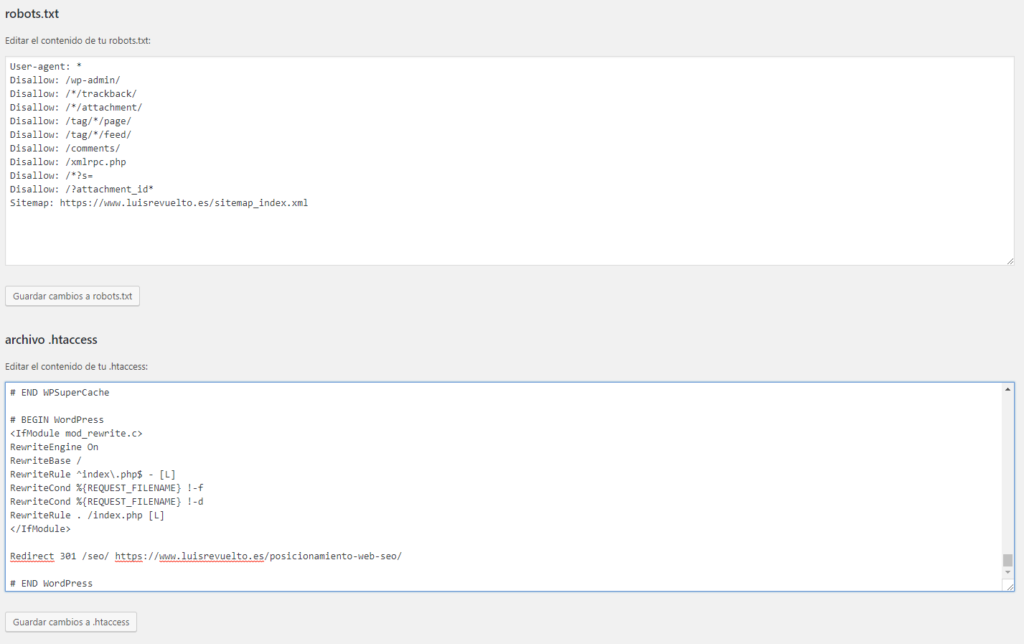
Файл конфигурации .htaccess
Используя этот документ можно ограничить доступ к сайту с помощью пароля. Необходимо указать Username пользователей, которые смогут попасть к нужным страницам и документам, в файле паролей .htpasswd. Затем указать путь к этому файлу с помощью специального кода в файле .htaccess.
AuthType Basic AuthName "Password Protected Area" AuthUserFile путь к файлу с паролем Require valid-user
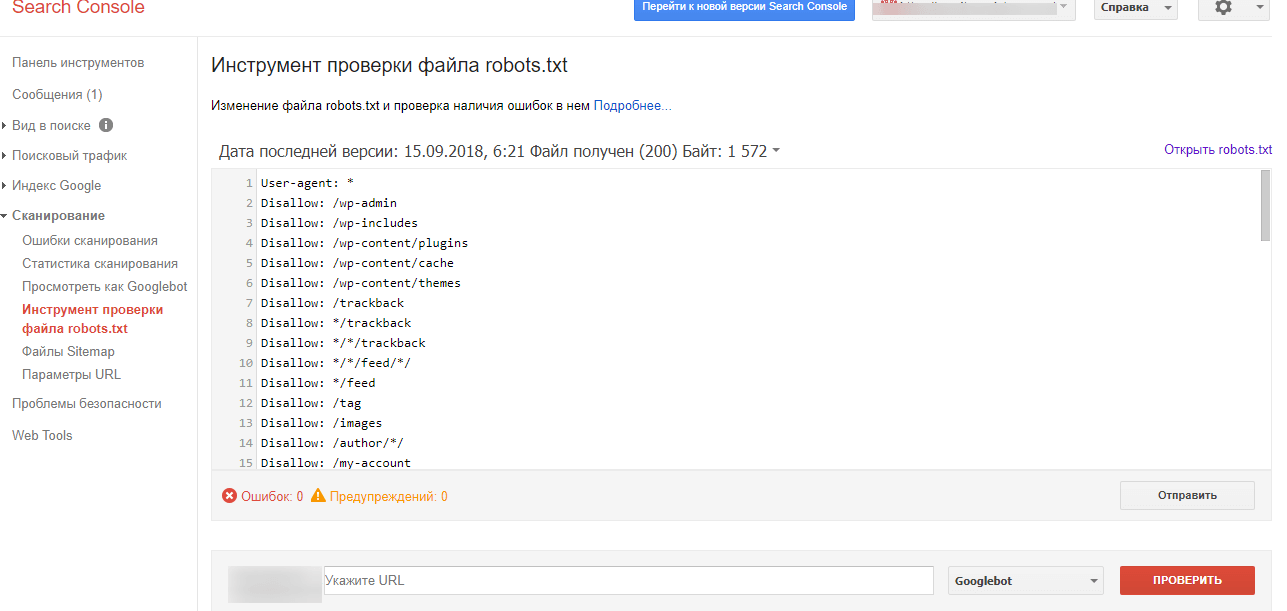
Удаление URL через сервисы веб-мастеров
В Google Search Console можно убрать страницу из результатов поиска, указав URL в специальной форме и обозначив причину ее удаления. Функция удаления страниц доступна в разделе «Индекс Google». Обработка запроса может занять некоторое время.
Удаление URL-адресов из индекса в Search Console
Как проверить, сколько страниц закрыто от индексации
С помощью Аудита сайта Serpstat можно быстро проверить сайт на наличие технических ошибок и узнать, сколько страниц не проиндексировано.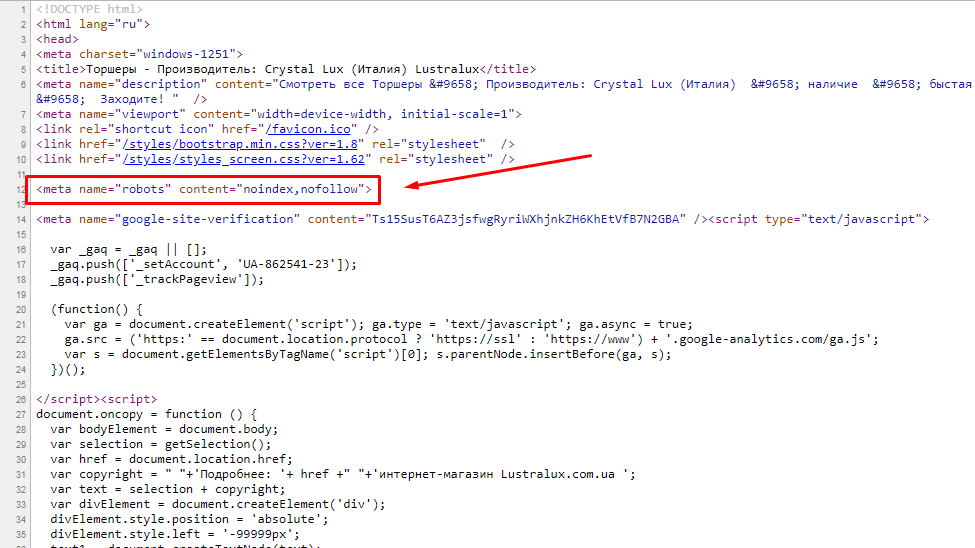
Для того, чтобы это сделать нужно всего лишь нажать на кнопку ниже, и у вас будет возможность создать проект для сайта ↓
В появившихся настройках можно указать имя домена и количество страниц, которые нужно просканировать краулеру:
Запуск аудита в Serpstat
Выбор типа сканирования и указание лимита страниц
Когда сканирование будет закончено, на графике в Суммарном отчете можно проверить, какое количество страниц из указанных не проиндексировано:
Проверка индексации страниц в Аудите Serpstat
Хотите узнать, как с помощью Serpstat найти и исправить технические ошибки на сайте?
Оставьте заявку и наши специалисты проконсультируют вас по продвижению вашего проекта, поделятся учебными материалами и инсайтами рынка!
| Заказать бесплатную консультацию |
Error get alias
Заключение
Управление индексацией — важный этап SEO. Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Ограничение доступа к ряду страниц и документов сэкономит ресурсы поисковой системы и ускорит индексацию сайта в целом.
Как запретить индексацию сайта?
Запретить доступ ботов поисковых систем к сайту можно с помощью нескольких способов: добавления метатега robots со значением noindex в html-код; указания директивы Disallow в файле robots.txt; установки пароля для доступа к сайту в конфигурационном файле .htaccess. Также можно блокировать доступ к отдельным каталогам и документам.
Как временно закрыть сайт от индексации
Чтобы закрыть сайт от индексации, добавьте метатег name=»robots» content=»noindex, nofollow» в раздел всех веб-страниц или добавьте директиву User-agent: * Disallow: / в файл robots.txt.
Как закрыть сайт от индексации WordPress
Чтобы закрыть сайт WordPress от индексации, зайдите в админку CMS, выберите раздел «Настройки» → «Чтение». Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Задавайте вопросы в комментариях или пишите в техподдержку.:) А также вступайте в чат любителей Серпстатить и подписывайтесь на наш канал в Telegram.
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
4.11 из 5 на основе 45 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Анастасия Сотула
Как включить HTTP/2 для сайта
How-to
Анастасия Сотула
Как проверить посещаемость сайта в системах аналитики и без счетчика
How-to
Анастасия Сотула
Что такое SEO продвижение сайтов: SEO оптимизация сайта пошагово
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Как запретить индексацию нужных страниц
Как запретить индексацию определенных страниц?
Разрешения и запрещения на индексацию берутся всеми поисковыми системами из файла robots.txt, находящегося в корневом каталоге сервера. Запрет на индексацию ряда страниц может появиться, например, из соображений секретности или из желания не индексировать одинаковые документы в разных кодировках. Чем меньше ваш сервер, тем быстрее робот его обойдет. Поэтому запретите в файле robots.txt все документы, которые не имеет смысла индексировать (например, файлы статистики или списки файлов в директориях). Обратите особое внимание на CGI или ISAPI скрипты — наш робот индексирует их наравне с другими документами.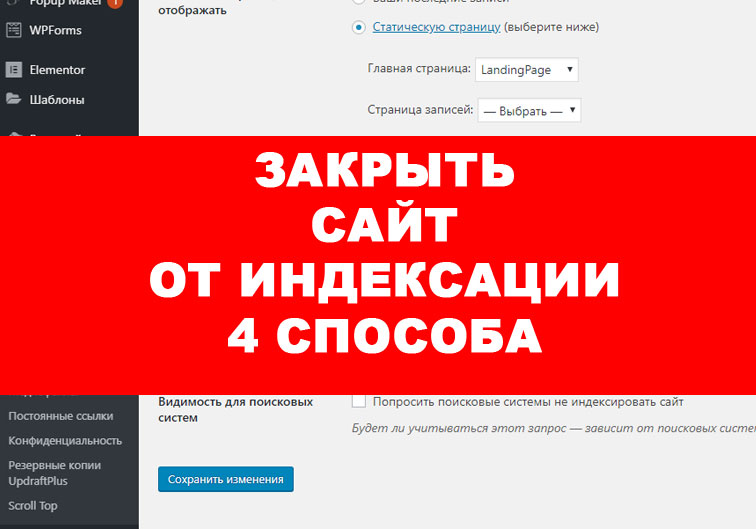
В простейшем виде (разрешено все, кроме директории скриптов) файл robots.txt выглядит следующим образом:
User-Agent: *
Disallow: /cgi-bin/
Детальное описание спецификации файла можно прочитать на странице: «Стандарт исключений для роботов».
При написании robots.txt обратите внимание на следующие часто встречающиеся ошибки:
1. Строка с полем User-Agent является обязательной и должна предшествовать строкам с полем Disallow. Так, приведенный ниже файл robots.txt не запрещает ничего:
Disallow: /cgi-bin
Disallow: /forum
2. Пустые строки в файле robots.txt являются значимыми, они разделяют записи, относящиеся к разным роботам. Например, в следующем фрагменте файла robots.txt строка Disallow: /forum игнорируется, поскольку перед ней нет строки с полем User-Agent.
User-Agent: *
Disallow: /cgi-bin
Disallow: /forum
3. Строка с полем Disallow может запретить индексирование документов только с одним префиксом. Для запрета нескольких префиксов нужно написать несколько строк. Например, нижеприведенный файл запрещает индексирование документов, начинающихся с “/cgi-bin /forum”, которых, скорее всего, не существует (а не документов с префиксами /cgi-bin и /forum).
Для запрета нескольких префиксов нужно написать несколько строк. Например, нижеприведенный файл запрещает индексирование документов, начинающихся с “/cgi-bin /forum”, которых, скорее всего, не существует (а не документов с префиксами /cgi-bin и /forum).
User-Agent: *
Disallow: /cgi-bin /forum
4. В строках с полем Disallowзаписываются не абсолютные, а относительные префиксы. То есть файл
User-Agent: *
Disallow: www.myhost.ru/cgi-bin
запрещает, например, индексирование документа http://www.myhost.ru/www.myhost.ru/cgi-bin/counter.cgi, но НЕ запрещает индексирование документа http://www.myhost.ru/cgi-bin/counter.cgi.
5. В строках с полем Disallowуказываются именно префиксы, а не что-нибудь еще. Так, файл:
User-Agent: *
Disallow: *
запрещает индексирование документов, начинающихся с символа «*» (которых в природе не существует), и сильно отличается от файла:
User-Agent: *
Disallow: /
который запрещает индексирование всего сайта.
Если вы не можете создать/изменить файл robots.txt, то еще не все потеряно — достаточно добавить дополнительный тег <META> в HTML-код вашей страницы (внутри тега <HEAD>):
<META NAME="ROBOTS" CONTENT="NOINDEX">
Тогда данный документ также не будет проиндексирован.
Вы также можете использовать тэг
<META NAME="ROBOTS" CONTENT="NOFOLLOW">
Он означает, что робот поисковой машины не должен идти по ссылкам с данной страницы.
Для одновременного запрета индексирования страницы и обхода ссылок с нее используется тэг
<META NAME="ROBOTS" CONTENT="NOINDEX,NOFOLLOW">
Как запретить индексацию определенных частей текста?
Чтобы запретить индексирование определенных фрагментов текста в документе, пометьте их тегами
<NOINDEX></NOINDEX>
Внимание! Тег NOINDEX не должен нарушать вложенность других тегов. Если указать следующую ошибочную конструкцию:
Если указать следующую ошибочную конструкцию:
<NOINDEX>
…код1…
<TABLE><TR><TD>
…код2…
</NOINDEX>
…код3…
</TD></TR></TABLE>
запрет на индексирование будет включать не только «код1» и «код2», но и «код3».
Как выбрать главный виртуальный хост из нескольких зеркал?
Если ваш сайт находится на одном сервере (одном IP), но виден во внешнем мире под разными именами (зеркала, разные виртуальные хосты), Яндекс рекомендует вам выбрать то имя, под которым вы хотите быть проиндексированы. В противном случае Яндекс выберет главное зеркало самостоятельно, а остальные имена будут запрещены к индексации.
Для того, чтобы индексировалось выбранное вами зеркало, достаточно запретить индексацию всех остальных зеркал при помощи robots.txt. Это можно сделать, используя нестандартное расширение robots.txt — директиву Host, в качестве ее параметра указав имя основного зеркала.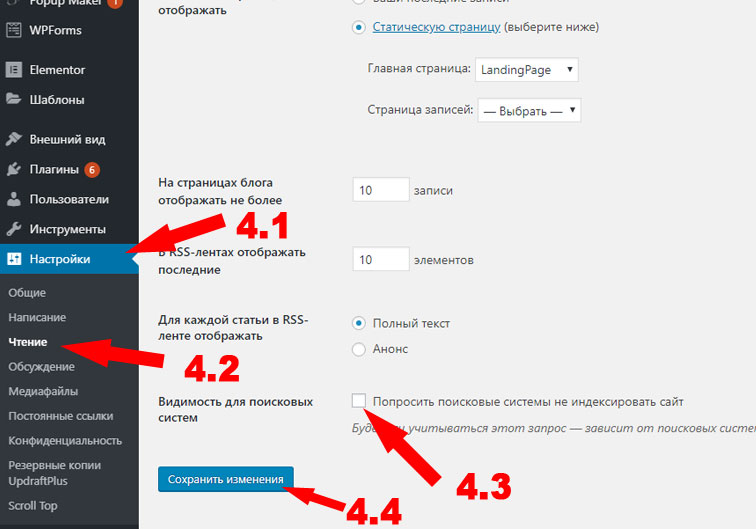 Если www.glavnoye-zerkalo.ru — основное зеркало, то robots.txt должен выглядеть примерно так:
Если www.glavnoye-zerkalo.ru — основное зеркало, то robots.txt должен выглядеть примерно так:
User-Agent: *
Disallow: /forum
Disallow: /cgi-bin
Host: www.glavnoye-zerkalo.ru
В целях совместимости с роботами, которые не полностью следуют стандарту при обработке robots.txt, директиву Host необходимо добавлять в группе, начинающейся с записи User-Agent, непосредственно после записей Disallow.
Аргументом директивы Host является доменное имя с номером порта (80 по умолчанию), отделенным двоеточием. Если какой-либо сайт не указан в качестве аргумента для Host, для него подразумевается наличие директивы Disallow: /, т.е. полный запрет индексации (при наличии в группе хотя бы одной корректной директивы Host). Таким образом, файлы robots.txt вида
User-Agent: *
Host: www.myhost.ru
и
User-Agent: *
Host: www.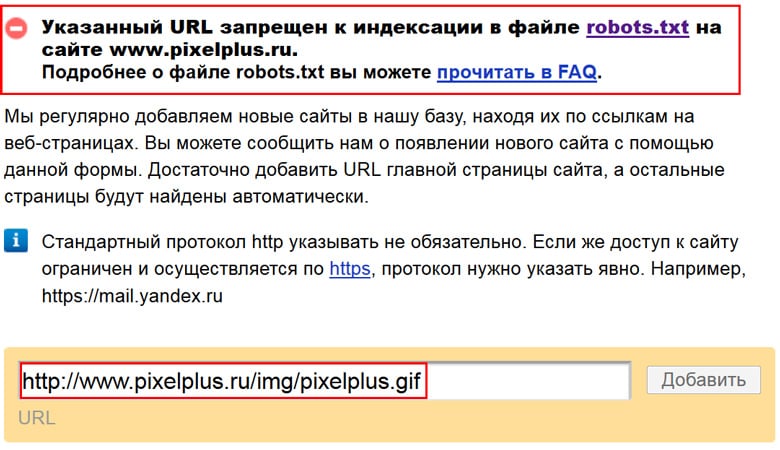 myhost.ru:80
myhost.ru:80
эквивалентны и запрещают индексирование как www.otherhost.ru, так и www.myhost.ru:8080.
Параметр директивы Host обязан состоять из одного корректного имени хоста (т.е. соответствующего RFC 952 и не являющегося IP-адресом) и допустимого номера порта. Некорректно составленные строчки Host игнорируются.
# Примеры игнорируемых директив Host
Host: www.myhost-.ru
Host: www.-myhost.ru
Host: www.myhost.ru:0
Host: www.my_host.ru
Host: .my-host.ru:8000
Host: my-host.ru.
Host: my..host.ru
Host: www.myhost.ru/
Host: www.myhost.ru:8080/
Host: http://www.myhost.ru
Host: www.mysi.te
Host: 213.180.194.129
Host: www.firsthost.ru,www.secondhost.ru
Host: www.firsthost.ru www.secondhost.ru
Если у вас сервер Apache, то можно вместо использования директивы Host задать robots.txt с использованием директив SSI:
<!--#if expr=" "${HTTP_HOST}" != "www. главное_имя.ru" " -->
главное_имя.ru" " -->
User-Agent: *
Disallow: /
<!--#endif -->
В этом файле роботу запрещен обход всех хостов, кроме www.главное_имя.ru
Как включать SSI, можно прочесть в документации по вашему серверу или обратиться к вашему системному администратору. Проверить результат можно, просто запросив страницы:
http://www.главное_имя.ru/robots.txtи т.д. Результаты должны быть разные.
http://www.другое_имя.ru/robots.txt
Рекомендации для веб-сервера Русский Apache
В robots.txt на сайтах с русским апачем должны быть запрещены для роботов все кодировки, кроме основной.
Если кодировки разложены по портам (или серверам), то надо выдавать на разных портах (серверах) РАЗНЫЙ robots.txt. А именно, во всех файлах robots.txt для всех портов/серверов, кроме «основного», должно быть написано:
User-Agent: *
Disallow: /
Для этого можно использовать механизм SSI, описанный выше.
Если кодировки в вашем Apache выделяются по именам «виртуальных» директорий, то надо написать один robots.txt, в котором должны быть примерно такие строчки (в зависимости от названий директорий):
User-Agent: *
Disallow: /dos
Disallow: /mac
Disallow: /koi
Удачки.
09.07.2007 17:56
Как правильно закрыть сайт от индексирования в Google
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Заказывайте честное и прозрачное продвижение
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
До сих пор есть люди, которые используют файл robots.txt, чтобы закрыть сайт от индексации в поисковых системах и убрать его из результатов поиска. Объясним, почему файла robots.txt для этих целей недостаточно и что нужно сделать, чтобы страница или домен не появлялись в выдаче
.
- Разница между индексированием и показом в результатах поиска Google
- Как запретить отображение страницы в результатах поиска
- С помощью добавления метатега robots
- Использовать X-Robots-Tag HTTP header
- Выжимка
Самый очевидный способ скрыть нежелательные страницы из поисковой выдачи – закрыть их от индексации с помощью файла robots.txt. Но результат отличается от того, который ждешь: сайты все равно отображаются в поиске. В этой статье Йост де Валк из Yoast объясняет, почему так происходит, и рассказывает, что нужно сделать, чтобы страница или сайт исчезли из выдачи.
Разница между индексированием и показом в результатах поиска Google
Прежде чем объяснить, почему запрет на индексирование сайта не мешает поисковику выводить его в выдаче, вспомним несколько терминов:
- Индексирование – процесс скачивания сайта или страницы контента на сервер поисковой системы, вследствие которого сайт или страница добавляется в индекс.

- Ранжирование/ отображение в поиске – отображение сайта среди результатов поиска.

Наиболее распространенное представление о попадании сайта/страницы в результаты поиска выглядит как двухэтапный процесс: индексирование => ранжирование. Но чтобы отображаться в поиске, сайт не обязательно должен индексироваться. Если есть внешняя ссылка на страницу или домен (линк с другого сайта или с индексируемых внутренних страниц), Google перейдет по этой ссылке. Если robots.txt на этом домене препятствует индексированию страницы поисковой системой, Гугл все равно будет выводить URL в выдаче. Он ориентируется на внешние источники, которые содержат ссылку и ее описание. Раньше источником мог быть DMOZ или директория Yahoo. Сегодня я вполне могу представить, что Google использует, например, ваш профиль в My Business или данные из других сайтов.
Если написанное выше кажется вам бессмысленным, посмотрите видео с объяснением Мэтта Каттса.
 youtube.com/embed/KBdEwpRQRD0″ frameborder=»0″ allowfullscreen=»allowfullscreen»>
youtube.com/embed/KBdEwpRQRD0″ frameborder=»0″ allowfullscreen=»allowfullscreen»> Адаптация видео:
Пользователи часто жалуются на то, что Google игнорирует запрет на индексирование страницы в robots.txt и все равно показывает ее в результатах выдачи. Чаще всего происходит следующее: когда некто отправляет роботу сигнал на запрет индексирования страницы, она появляется в поиске с необычным сниппетом – без текстового описания. Причина: краулеры не сканировали страницу. Они видели только упоминание URL. Именно потому что роботы видели ссылку, а не саму страницу, в выдаче пользователям предлагается сниппет без дескрипшна. Обратимся к примеру.
В какой-то момент California Department of Motor Vehicles, домен www.dmv.ca.gov, заблокировала все поисковые системы с помощью robots.txt. Но если пользователь ищет информацию по запросу California DMV, есть только один релевантный ответ, который поисковик должен предложить пользователю. Несмотря на robots.txt, который говорит роботу, что он не должен сканировать страницу, краулер видит, что многие сайты ссылаются на определенную страницу, используя анкоры с текстом California DMV.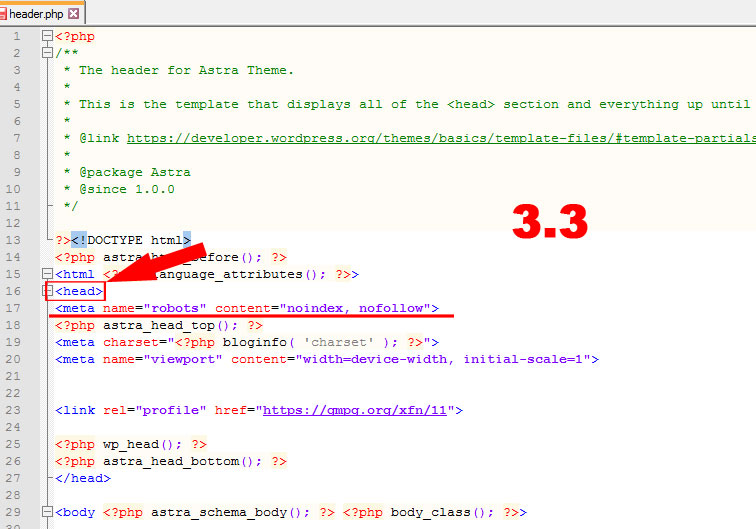 Роботы понимают, что эта страница – результат, наиболее релевантный запросу пользователя. Поэтому они показывают результат в выдаче даже без сканирования страницы. Желание предоставить пользователю результат, наиболее релевантный запросу, может быть единственной причиной, по который Google выводит в результатах поиска страницы, не сканированные краулерами.
Роботы понимают, что эта страница – результат, наиболее релевантный запросу пользователя. Поэтому они показывают результат в выдаче даже без сканирования страницы. Желание предоставить пользователю результат, наиболее релевантный запросу, может быть единственной причиной, по который Google выводит в результатах поиска страницы, не сканированные краулерами.
Еще один пример – сайт Nissan. Долгое время Nissan использовал robots.txt для запрета индексирования всех страниц. Но мы обнаружили сайт и его описание в открытом каталоге DMOZ. Поэтому когда пользователи получали ссылку на сайт среди результатов, они видели такой же сниппет, как и у обычных страниц, которые были просканированы краулерами. Но этот сниппет был составлен не на основе результатов сканирования. Он был создан из информации DMOZ.
В итоге: Google может показать что-то, что считает полезным пользователю, без нарушения запрета на сканирование в robots.txt.
Если вы не хотите, чтобы страница отображалась в поиске, позвольте роботам просканировать страницу, а затем используйте атрибут noindex. Когда робот видит тег «noindex», он выбрасывает страницу изо всех поисковых результатов. Страница не появляется в поиске, даже если на нее ссылаются другие сайты.
Когда робот видит тег «noindex», он выбрасывает страницу изо всех поисковых результатов. Страница не появляется в поиске, даже если на нее ссылаются другие сайты.
Другой вариант – использовать инструмент удаления URL. Блокируйте сайт полностью в robots.txt, а после используйте инструмент удаления URL.
Что получается: закрывая сайт от сканирования, вы лишаете краулеров возможности узнать, что запретили отображение сайта в поисковой системе.
Поэтому:
Чтобы запретить появление сайта в результатах поиска, вам нужно позволить краулерам Google просканировать страницу.
Это может выглядеть противоречиво. Но только так вы сможете скрыть сайт в результатах поиска.
Как запретить отображение страницы в результатах поиска
С помощью добавления метатега robots
Первый вариант запрета показа страницы в Google – использование метатега robots. Вам нужно добавить этот тэг на свою страницу:
Проблема с тэгом в том, что его нужно будет добавить на каждую страницу.
Ирина Винниченко
Контент-маркетолог SEMANTICA
Есть еще одна проблема – с помощью метатега robots можно скрывать только html-документы. Это значит, что метатег нельзя применить для документов в формате pdf, doc, xml, а также для аудио и видео контента. Чтобы скрыть документы не в html, нужно использовать файл robots.txt. Что замыкает круг. Потому что эти документы могут появиться в выдаче.
Использовать X-Robots-Tag HTTP header
Добавлять метатег robots к каждой странице сайта сложно. Упрощает задачу X-Robots-Tag HTTP header. С его помощью можно управлять индексированием сайта и его показом в результатах поиска. Так, вы можете установить директиву noindex и nofollow. Noindex – запрет на отображение страницы и сохраненной копии в результатах поиска, nofollow – запрет на переход по ссылкам на этой странице.
Почему X-Robots-Tag HTTP header крут:
- Закрывает от попадания в поиск все файлы – как html, так и pdf, doc, xml.
- Не нужно обрабатывать каждую страницу, можно сразу скрыть из результатов поиска весь сайт.

Если ваш сайт на базе Apache, и mod_headers недоступны, в корневой файл .htaccess добавьте фрагмент кода:
Таким образом ваш сайт будет индексироваться. Но не появятся в результатах поиска.
Чтобы убрать сайт из поиска, не используйте robots.txt. Вместо этого используйте X-Robots-Tag или метатег robots.
Выжимка
- robots.txt закрывает сайт от индексирования, но сайт все равно может появиться в результатах поиска.
- Чтобы скрыть страницы или сайт из поиска, используйте метатег robots или X-Robots-Tag HTTP header.
- Метатег robots нужно добавлять на каждую страницу, которую хотите скрыть, по отдельности. Его можно использовать только для html-документов.
- X-Robots-Tag HTTP header позволяет скрыть из результатов поиска сразу весь сайт. Его можно использовать как для скрытия html-документов, так и файлов других форматов – pdf, doc, xml.
- Не нужно запрещать сканирование страницы файлом robots.txt. Если сканирование будет запрещено, краулеры не увидят директивы относительно индексирования и отображения в поиске. Значит, они не выполнят директивы, и сайт появится в выдаче.
 Значит, они не выполнят директивы, и сайт появится в выдаче.
Значит, они не выполнят директивы, и сайт появится в выдаче.Оригинал статьи.
Отключить индексацию поисковыми системами | Webflow University
Вы можете указать поисковым системам, какие страницы сканировать, написав файл robots.txt. Вы также можете запретить поисковым системам сканировать и индексировать определенные страницы, папки, весь ваш сайт или субдомен webflow.io. Это полезно для того, чтобы скрыть такие страницы, как страница 404 вашего сайта, от индексации и отображения в результатах поиска.
В этом уроке:
- Как отключить индексацию поддомена Webflow
- Как создать файл robots.txt
- Рекомендации по обеспечению конфиденциальности
- Часто задаваемые вопросы и советы по устранению неполадок
Как отключить индексирование поддомена Webflow
Вы можете запретить Google и другим поисковым системам индексировать поддомен webflow.io вашего сайта отключив индексирование в настройках сайта .
- Перейти к Настройки сайта > SEO вкладка > Индексирование раздел
- Установить Отключить индексирование поддоменов Webflow – «Да»
- Нажмите Сохранить изменения и опубликовать свой сайт
Уникальный файл robots.txt будет опубликован только на субдомене, что позволит поисковым системам игнорировать этот домен.
Как создать файл robots.txt
Файл robots.txt обычно используется для перечисления URL-адресов сайта, которые вы не хотите сканировать поисковыми системами. Вы также можете включить карту сайта своего сайта в файл robots.txt, чтобы указать роботам поисковых систем, какой контент им следует сканировать.
Как и карта сайта, файл robots.txt находится в каталоге верхнего уровня вашего домена. Webflow сгенерирует файл /robots.txt для вашего сайта после того, как вы создадите его в настройках сайта .
Чтобы создать файл robots.txt:
- Перейдите к Настройки сайта > SEO вкладка > Индексирование раздел
- Добавьте нужные изменения в robots.txt 90 Нажмите Сохранить и опубликовать свой сайт
Важно: Контент с вашего сайта может быть проиндексирован, даже если он не просканирован. Это происходит, когда поисковая система знает о вашем контенте либо потому, что он был опубликован ранее, либо есть ссылка на этот контент из другого контента в Интернете. Чтобы убедиться, что ранее проиндексированная страница не проиндексирована, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex, чтобы удалить этот контент из индекса Google.
Правила robots.txt
Любое из этих правил можно использовать для заполнения файла robots.txt.
- Агент пользователя: * означает, что этот раздел относится ко всем роботам.
- Запретить: предписывает роботу не посещать сайт, страницу или папку.

Чтобы скрыть весь сайт
User-agent: *
Disallow: /
Чтобы скрыть отдельные страницы
User-agent: *
Disallow: /page-name
Чтобы скрыть всю папку страниц
Агент пользователя: *
Запретить: /имя-папки/
Включить карту сайта
Карта сайта: https://your-site.com/sitemap.xml
Полезные ресурсы
Ознакомьтесь с другими полезными правилами robots.txt.
Примечание: Любой может получить доступ к файлу robots.txt вашего сайта, поэтому он может идентифицировать и получить доступ к вашему личному контенту.Рекомендации по обеспечению конфиденциальности
Если вы хотите предотвратить обнаружение определенной страницы или URL-адреса на вашем сайте, не используйте файл robots.txt, чтобы запретить сканирование URL-адреса. Вместо этого используйте любой из следующих вариантов:
- Используйте метакод noindex, чтобы запретить поисковым системам индексировать ваш контент и удалить контент из индекса поисковых систем.
- Сохраняйте страницы с конфиденциальным содержимым как черновики и не публикуйте их. Защитите паролем страницы, которые вам нужно опубликовать.
Часто задаваемые вопросы и советы по устранению неполадок
Можно ли использовать файл robots.txt, чтобы предотвратить индексацию ресурсов сайта Webflow?
Невозможно использовать файл robots.txt для предотвращения индексации ресурсов сайта Webflow, поскольку файл robots.txt должен находиться в том же домене, что и контент, к которому он применяется (в данном случае там, где обслуживаются ресурсы) . Webflow обслуживает ресурсы из нашей глобальной CDN, а не из пользовательского домена, в котором находится файл robots.txt.
Я удалил файл robots.txt из настроек своего сайта, но он по-прежнему отображается на моем опубликованном сайте. Как я могу это исправить?
Созданный файл robots.txt нельзя удалить полностью. Однако вы можете заменить его новыми правилами, чтобы разрешить сканирование сайта, например:
User-agent: *
Disallow:
Обязательно сохраните изменения и повторно опубликуйте свой сайт. Если проблема не устранена и вы по-прежнему видите старые правила robots.txt на своем опубликованном сайте, обратитесь в службу поддержки.
Если проблема не устранена и вы по-прежнему видите старые правила robots.txt на своем опубликованном сайте, обратитесь в службу поддержки.
Попробуйте Webflow — это бесплатно
Был ли этот урок полезен? Дайте нам знать!Спасибо за отзыв! Это поможет нам улучшить наш контент.
Свяжитесь с нашим сообществом
Свяжитесь со службой поддержки
Что-то пошло не так при отправке формы.
Связаться со службой поддержки
У вас есть предложение по уроку? Дайте нам знать
Спасибо! Ваша заявка принята!
Ой! Что-то пошло не так при отправке формы.
Запретить отображение контента в результатах поиска
Вы можете запретить появление нового контента в результатах, добавив URL-слаг в файл robots.txt. Поисковые системы используют эти файлы, чтобы понять, как индексировать содержимое веб-сайта.
Если поисковые системы уже проиндексировали ваш контент, вы можете добавить метатег «noindex» в заголовок HTML контента. Это сообщит поисковым системам, чтобы они перестали отображать его в результатах поиска.
Это сообщит поисковым системам, чтобы они перестали отображать его в результатах поиска.
Обратите внимание: в файле robots.txt может быть заблокирован только контент, размещенный в домене, подключенном к HubSpot. Узнайте больше о настройке URL-адресов файлов в инструменте работы с файлами.
Использовать файлы robot.txt
Вы можете добавить содержимое, которое еще не проиндексировано поисковыми системами, в файл robots.txt, чтобы предотвратить его отображение в результатах поиска.
Чтобы отредактировать файл robots.txt в HubSpot:
настройки значок настроек на главной панели навигации.»}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4″:[null,2,16777215],»14″:[null,2,0],»15″:»Arial»,»16″:10, «26»:400}» data-sheets-formula=»=»»»>В своей учетной записи HubSpot щелкните значок настроек настроек на главной панели навигации.
настройки значок настроек на главной панели навигации.
«}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4″:[null,2,16777215] ,»14″:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>На левой боковой панели меню, перейдите к Веб-сайт > Страниц .- настройки значок настроек на главной панели навигации.»}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4″:[null,2,16777215] ,»14″:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>Выберите домен, чей файл robots.txt, который вы хотите отредактировать:
- Чтобы отредактировать файл robots.txt для всех подключенных доменов, щелкните раскрывающееся меню Выберите домен для редактирования его настроек и выберите Настройки по умолчанию для всех доменов . настройки значок настроек на главной панели навигации.»}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4»:[null,2,16777215], «14»:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>
- настройки значок настроек на главной панели навигации. «}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4″:[null,2,16777215] ,»14″:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>Для редактирования роботов .txt для определенного домена, щелкните значок Выберите домен, чтобы изменить его настройки в раскрывающемся меню и выберите домен . При необходимости нажмите Переопределить настройки по умолчанию . Это переопределит все настройки файла robots.txt по умолчанию для этого домена.
 «}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4″:[null,2,16777215] ,»14″:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>На левой боковой панели меню, перейдите к Веб-сайт > Страниц .
«}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4″:[null,2,16777215] ,»14″:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>На левой боковой панели меню, перейдите к Веб-сайт > Страниц . «}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4″:[null,2,16777215] ,»14″:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>Для редактирования роботов .txt для определенного домена, щелкните значок Выберите домен, чтобы изменить его настройки в раскрывающемся меню и выберите домен . При необходимости нажмите Переопределить настройки по умолчанию . Это переопределит все настройки файла robots.txt по умолчанию для этого домена.
«}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4″:[null,2,16777215] ,»14″:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>Для редактирования роботов .txt для определенного домена, щелкните значок Выберите домен, чтобы изменить его настройки в раскрывающемся меню и выберите домен . При необходимости нажмите Переопределить настройки по умолчанию . Это переопределит все настройки файла robots.txt по умолчанию для этого домена.- настройки значок настроек на главной панели навигации.»}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4″:[null,2, 16777215],»14″:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>Нажмите SEO и поисковые роботы вкладка. настройки значок настроек на главной панели навигации.»}» data-sheets-userformat=»{«2″:8402947,»3″:[null,0],»4»:[null,2,16777215], «14»:[null,2,0],»15″:»Arial»,»16″:10,»26″:400}» data-sheets-formula=»=»»»>
- В разделе Robots. txt отредактируйте содержимое файла. Файл robots.txt состоит из двух частей:
- Агент пользователя: определяет поисковую систему или веб-бот, к которому применяется правило. По умолчанию будут включены все поисковые системы, которые отмечены звездочкой (*), но вы можете указать здесь конкретные поисковые системы. Если вы используете модуль поиска по сайту HubSpot, вам нужно будет включить HubSpotContentSearchBot в качестве отдельного агента пользователя. Это позволит функции поиска сканировать ваши страницы.
 txt отредактируйте содержимое файла. Файл robots.txt состоит из двух частей:
txt отредактируйте содержимое файла. Файл robots.txt состоит из двух частей: - Запретить: указывает поисковой системе не сканировать и не индексировать файлы или страницы, используя определенный URL-слаг. Для каждой страницы, которую вы хотите добавить в файл robots.txt, введите Disallow: /url-slug (например, www.hubspot.com/welcome будет отображаться как Disallow: /welcome).
- В левом нижнем углу нажмите Сохранить .

Узнайте больше о форматировании файла robots.txt в документации для разработчиков Google.
Используйте метатеги «noindex»
Если контент уже проиндексирован поисковыми системами, вы можете добавить метатег «noindex», чтобы запретить поисковым системам индексировать его в будущем.
Обратите внимание: этот метод не следует сочетать с методом robots.txt, так как это не позволит поисковым системам увидеть тег «noindex» и недоступен для страниц, использующих начальные шаблоны.
Чтобы добавить к контенту метатег noindex:
- Наведите курсор на контент и нажмите Изменить .
- В редакторе контента перейдите на вкладку Настройки , затем нажмите Дополнительные параметры .
- В разделе Дополнительные фрагменты кода добавьте следующий код в поле Head HTML :
- В правом верхнем углу нажмите Обновите , чтобы применить это изменение.

Если у вас есть учетная запись Google Search Console , вы можете ускорить этот процесс для результатов поиска Google с помощью инструмента удаления Google.
Уважает ли Google файл robots.txt NoIndex и следует ли его использовать?
Наличие директивы NoIndex в Robots.txt малоизвестно среди веб-мастеров во многом потому, что о ней мало кто говорит. Мэтт Каттс обсуждал поддержку этой директивы Google еще в 2008 году. Совсем недавно Джон Мюллер из Google обсуждал ее в этой видеовстрече Google для веб-мастеров. Кроме того, Deepcrawl написали об этом в своем блоге.
Учитывая уникальные возможности этой директивы, команда IMEC решила провести тест. Мы набрали 13 веб-сайтов, которые хотели бы взять страницы своего сайта и попытаться удалить их из индекса Google с помощью файла robots.txt NoIndex. Восемь из них создали новые страницы, а пять из них предложили существующие страницы. Мы подождали, пока все 13 страниц не будут проверены на наличие в индексе Google, а затем мы попросили веб-мастеров добавить директиву NoIndex для этой страницы в свой файл Robots. txt.
txt.
Этот пост расскажет вам, работает ли он, расскажет, как он реализован в Google, и поможет вам решить, стоит ли вам его использовать.
Разница между метатегом Robots и Robots.txt NoIndex
Этот момент смущает многих, поэтому я воспользуюсь моментом, чтобы изложить его для вас. Когда мы говорим о метатеге роботов, мы говорим о чем-то, что существует на определенной веб-странице. Например, если вы не хотите, чтобы ваша страница www.yourdomain.com/contact-us находилась в индексе Google, вы можете поместить следующий код в раздел заголовка этой веб-страницы:
Для каждой страницы вашего веб-сайта, которую вы не не хотите индексироваться, вы можете использовать эту директиву. Как только Google повторно просканирует страницу и увидит эту директиву, он должен удалить страницу из своего индекса. Однако выполнение этой директивы и удаление Google (или Bing) из своего индекса не запрещает повторное сканирование страницы. Фактически, они будут продолжать сканировать страницу на постоянной основе, хотя поисковые системы могут со временем сканировать эту страницу несколько реже.
Распространенной ошибкой, которую совершают многие люди, является добавление метатега Robots на страницу и одновременное блокирование сканирования этой страницы в файле robots.txt. Проблема с этим подходом заключается в том, что поисковые системы не могут прочитать метатег робота, если им говорят не сканировать страницу.
Напротив, реализация директивы NoIndex в файле Robots.txt работает несколько иначе. Если Google на самом деле поддерживает этот тип директивы, это позволит вам объединить концепцию блокировки сканирования страницы и одновременного запрета ее индексирования. Вы бы сделали это, реализовав строки директив в Robots.txt, подобные этим двум:
Disallow: /page1/
Noindex: /page1/
Так как чтение инструкции NoIndex не требует загрузки страницы, поисковая система сможет не только не включать ее в индекс, но и не сканировать ее. Это мощное сочетание! Тем не менее, остается один существенный недостаток: страница по-прежнему может накапливать PageRank, который она не сможет передать другим страницам на вашем сайте (поскольку сканирование заблокировано, Google не может видеть ссылки на странице для передачи PageRank).
Предварительные результаты
Выбор глобального партнера по разработке программного обеспечения для ускорения вашей цифровой стратегии
Чтобы добиться успеха и опередить конкурентов, вам нужен партнер по разработке программного обеспечения, который преуспевает именно в тех цифровых проектах, с которыми вы сейчас сталкиваетесь, и наиболее экономичным и оптимизированным способом.
Получить руководство
22 сентября 2015 г. мы попросили 13 сайтов добавить директиву NoIndex в файл Robots.txt. Все они выполнили этот запрос, хотя у одного из них возникла проблема: выполнение директивы привело к зависанию их веб-сервера. Поскольку этот сбой сервера был неожиданным, я проверил это на PerficientDigital.com для данной страницы, и это также вызвало проблему для нашего сервера, что привело к следующему сообщению:
Позже я проверил это еще раз, и проблема меня осенила. Я внедрил директиву NoIndex в свой файл .htaccess вместо robots. txt. Очевидно, это приведет к зависанию вашего сервера (или, по крайней мере, некоторых серверов). Но это была «Ошибка оператора»! С тех пор я без проблем протестировал его реализацию в Robots.txt. Однако я обнаружил это только после того, как тестирование было завершено, а значит, у нас было 12 сайтов в тесте.
txt. Очевидно, это приведет к зависанию вашего сервера (или, по крайней мере, некоторых серверов). Но это была «Ошибка оператора»! С тех пор я без проблем протестировал его реализацию в Robots.txt. Однако я обнаружил это только после того, как тестирование было завершено, а значит, у нас было 12 сайтов в тесте.
Наш мониторинг длился 31 день. В течение этого времени мы каждый день тестировали каждую страницу, чтобы увидеть, осталась ли она в индексе. Вот результаты, которые мы увидели:
Вот это интересно! 11 из 12 протестированных страниц действительно выпали из индекса, а последние две выбыли из индекса только через 26 дней. Это явно не тот процесс, который происходит в тот момент, когда Google загружает Robots.txt. Так что же здесь работает? Чтобы выяснить это, я еще немного покопался.
[Tweet «Исследование показывает, что Google может занять до 3 недель для деиндексации после добавления robots.txt NoIndex на страницу. Подробнее в»]
Предположение о том, что делает Google
Мое непосредственное предположение заключалось в том, что похоже, что Google выполняет директиву Robots. txt NoIndex только во время повторного сканирования страницы. Чтобы выяснить это, я решил покопаться в лог-файлах некоторых протестированных сайтов. Первое, что вы заметите, это то, что робот Googlebot загружает файлы Robots.txt для этих сайтов много раз в день. Затем я просмотрел файлы журналов для двух сайтов, начиная с того дня, когда сайт внедрил NoIndex в Robots.txt, и заканчивая днем, когда Google окончательно исключил страницу из индекса.
txt NoIndex только во время повторного сканирования страницы. Чтобы выяснить это, я решил покопаться в лог-файлах некоторых протестированных сайтов. Первое, что вы заметите, это то, что робот Googlebot загружает файлы Robots.txt для этих сайтов много раз в день. Затем я просмотрел файлы журналов для двух сайтов, начиная с того дня, когда сайт внедрил NoIndex в Robots.txt, и заканчивая днем, когда Google окончательно исключил страницу из индекса.
Цель состояла в том, чтобы проверить мою теорию, но то, что я увидел, меня удивило. Первым был сайт, который так и не вышел из индекса за время нашего теста. Для этого я смог получить файлы журналов с 30 сентября по 26 октября. Вот что показали мне файлы журналов:
Помните, что для этого сайта целевая страница никогда не удалялась из индекса. Далее давайте посмотрим на данные одного из сайтов, где целевая страница была удалена из индекса. Вот что мы увидели для этой страницы:
Вот это интересно. Robots.txt используется регулярно, как и другой сайт, но целевая страница никогда не сканировалась Google, и тем не менее она была удалена из индекса. Вот вам и моя теория!
Вот вам и моя теория!
Так что же здесь происходит? Честно говоря, непонятно. Google не отвечает на директиву NoIndex каждый раз, когда они читают файл Robots.txt как директиву. Они также не обязаны это делать. Вот что привело к моему предположению, что они могут подождать, пока они просканируют страницу в следующий раз, и тогда рассмотрят вариант NoIndex для страницы, но очевидно, что это не так.
В конце концов, два набора файлов журналов, которые я просмотрел, противоречили этой теории. На сайте, на котором целевая страница никогда не удалялась из индекса, во время теста страница сканировалась пять раз. Для другого сайта, где страница была удалена из индекса, целевая страница никогда не сканировалась.
Что мы знаем, так это то, что задействована некоторая условная логика, но мы просто не знаем, что это за условия.
[Tweet «Исследование показывает, что использование метатега NoIndex в robots.txt не гарантирует, что Google деиндексирует страницу. Подробнее в»]
Резюме
В конечном счете, директива NoIndex в Robots. txt довольно эффективна. Это сработало в 11 из 12 протестированных нами случаев. Это может сработать для вашего сайта, и из-за того, как он реализован, он дает вам возможность предотвратить сканирование страницы, а также удалить ее из индекса. Это довольно полезно в концепции. Однако наши тесты не показали 100-процентного успеха, поэтому это не всегда работает.
txt довольно эффективна. Это сработало в 11 из 12 протестированных нами случаев. Это может сработать для вашего сайта, и из-за того, как он реализован, он дает вам возможность предотвратить сканирование страницы, а также удалить ее из индекса. Это довольно полезно в концепции. Однако наши тесты не показали 100-процентного успеха, поэтому это не всегда работает.
Кроме того, имейте в виду, что даже если вы заблокируете страницу от сканирования И используете файл robots.txt для NoIndex, эта страница все равно может накапливать PageRank (или ссылочный вес, если вы предпочитаете этот термин). И PageRank по-прежнему имеет значение. Последние результаты факторов ранжирования Moz для получения дополнительной информации о том, что различные аспекты ссылок по-прежнему оцениваются как два наиболее важных фактора ранжирования.
Кроме того, не забывайте, что сказал Джон Мюллер, что вы не должны полагаться на этот подход. Google может удалить эту функцию в какой-то момент в будущем, и официальный статус этой функции — «не поддерживается».