
Как правильно использовать атрибут rel = «canonical» и настраивать пагинацию на сайте — Light Spider на vc.ru
6647 просмотров
Об инструменте rel canonical слышал, пожалуй, каждый SEO специалист, как начинающий, так и опытный. Все дело в том, что настройка каноничности и пагинации — неотъемлемый элемент поисковой оптимизации web-сайта. И осуществляется она за счет правильной простановки тега каноникал.
Поскольку алгоритмы поисковых систем регулярно подвергаются апдейтам, рекомендации по задействованию атрибута rel = «canonical» и настройке пагинации менялись соответственно тому времени. В данной статье мы рассмотрим, что такое каноникал в СЕО, как и когда он используется сейчас, и какие ошибки чаще всего случаются при работе с этим элементом поисковой оптимизации.
Что представляет собой атрибут rel = «canonical» и в каких целях он используется?
Tag canonical в SEO-оптимизации применяется с целью предотвращения дублей контента. Прописывается он на любой веб-странице в хедере онлайн-ресурса, среди тегов head. Благодаря этому поисковые боты воспринимают страницу, где прописан rel = «canonical», как приоритетную, или, как говорят сеошники, каноническую. Именно она отобразится в органической выдаче, и ей будет передан ссылочный вес остальных web-страниц с подобным содержимым. Таким образом, добавив тег canonical, вы укажите каноническую ссылку, что сделает веб-страницу приоритетной для индексирования. В случае, если на сайте имеются онлайн-страницы с идентичным или схожим контентом, доступным по разным URL-адресам, а такое часто встречается в интернет-магазинах, где реализована пагинация товарных страниц, наиболее оптимальным решением станет внедрение rel = «canonical».
Прописывается он на любой веб-странице в хедере онлайн-ресурса, среди тегов head. Благодаря этому поисковые боты воспринимают страницу, где прописан rel = «canonical», как приоритетную, или, как говорят сеошники, каноническую. Именно она отобразится в органической выдаче, и ей будет передан ссылочный вес остальных web-страниц с подобным содержимым. Таким образом, добавив тег canonical, вы укажите каноническую ссылку, что сделает веб-страницу приоритетной для индексирования. В случае, если на сайте имеются онлайн-страницы с идентичным или схожим контентом, доступным по разным URL-адресам, а такое часто встречается в интернет-магазинах, где реализована пагинация товарных страниц, наиболее оптимальным решением станет внедрение rel = «canonical».
Как посредством canonical обозначить каноническую страницу?
Наиболее популярным вариантом использования каноникала является вышеописанный способ. На веб-странице, которую необходимо «запустить» в индекс, между тегами head прописывается полный урл, и таким образом обозначается каноническая ссылка.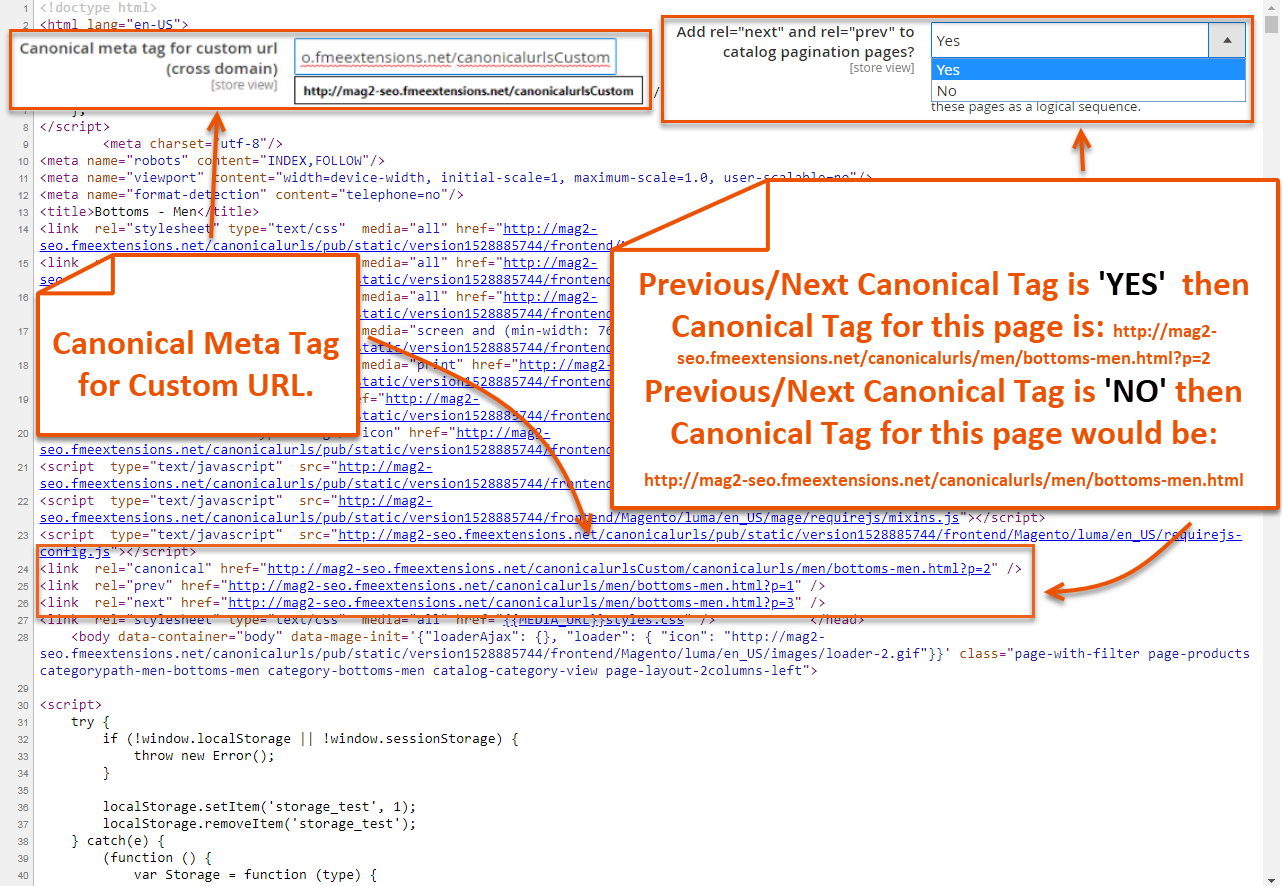
Помимо этого, канонические урлы можно указывать в техническом файле sitemap. Правда, атрибут canonical по факту является для поисковых систем не правилом, а рекомендацией. Поэтому, в случае прописывания в xml-карте веб-сайта, боты-поисковики, скорее всего, проигнорируют его.
Третий вариант — в HTTP-заголовках. Этот способ подходит только в случаях, когда имеется доступ к серверным настройкам. Внедрять его для HTML-страниц — не лучшее решение. С другой стороны, указывать каноничность PDF-файлов через HTTP-заголовок — вполне рабочий вариант.
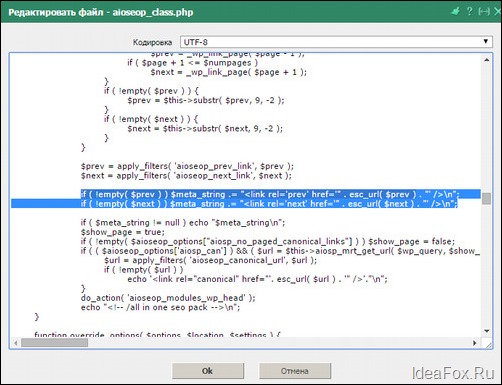
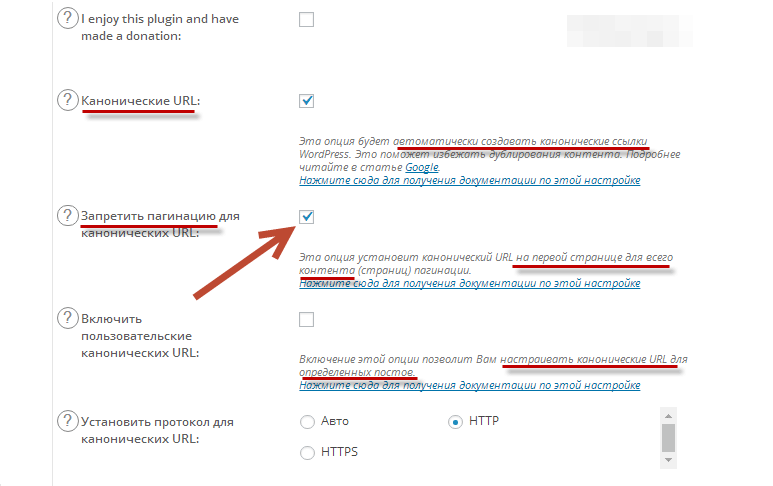
Настройка каноничности плагином. Для самых популярных CMS уже давно разработаны плагины, помогающие сформировать канонические урл любых страниц. Допустим, в WordPress для этого используется Yoast SEO. В Опенкарт каноничность указывается в опциях движка, правда, только для карточек товаров в разделе SEO URL. В Joomla 3-й версии и старше каноникал включается за счет функционала SEF.
Канонические URL — когда их следует настраивать?
1. Если необходимо предупредить возникновение дублей:
- веб-страниц с GET-параметрами в урл,
- UTM-меток,
- страниц фильтрации,
- вызванных спецификой работы движка.
Тег canonical SEO специалистами в таких случаях добавляется на всех статических страницах веб-ресурса.
2. Для устранения дублирования контента. Бывает так, что схожий контент оказывается доступным для индексации по разным урл-адресам. Как правило, этим «страдают» крупные интернет-магазины, которые содержат страницы товаров, размещенных в нескольких меню одновременно либо похожих серийно, но отличающихся цветом, размерами, формой. Для решения проблемы нужно на всех однотипных стр. разместить канонический урл на ключевую, приоритетную для индексации веб-страницу.
3. Когда на сайте есть пагинация. При этом в каталог нужно добавить страницы «Show all», показывающие сразу все товары раздела, блоговые статьи и т. п. Если таковые добавлены на web-сайт, то на каждой стр. пагинации СЕО оптимизаторы размещают канонический URL на «Показать все».
п. Если таковые добавлены на web-сайт, то на каждой стр. пагинации СЕО оптимизаторы размещают канонический URL на «Показать все».
Правила формирования канонических страниц
Задействуя тег canonical, придерживайтесь указанных ниже рекомендаций, и тогда ваши манипуляции пойдут сайту на пользу:
- Избегайте цепочек канонических урлов. Последовательность, когда стр. 1 ссылается на неканоническую стр. 2, а та указывает посредством canonical на третью является ошибочной.
- На веб-странице, вне зависимости от ее назначения, допускается использование только 1 canonical URL.
- Канонический урл должен указывать на веб-страницу, расположенную на том же домене, что и онлайн-ресурс.
- Страница, обозначенная канонической, должна присутствовать на сайте и отдавать код сервера 200.
- При самостоятельном поиске канонических веб-страниц ПС Google предпочитает варианты с https протоколом.


Когда rel = «canonical» не работает?
Данный метод не принесет ожидаемого эффекта, если применять его к страницам, контент на которых явно отличается. В этом случае поисковые системы не последуют рекомендации, прописанной в теге каноникал. Также простановка rel = «canonical» не сработает, когда нужно склеить страницы с www и без, либо http и https версии онлайн-сайта. Для этих случаев используется постраничный 301 редирект.
Проверка канонических ссылок и ошибки, возникающие при работе с rel = «canonical»
Проверить настройку каноникала можно, используя программы для SEO-аудита сайтов, например, Screaming Frog. Интерфейс данного софта содержит отдельный раздел Canonical, где показывается количество страниц с тегом каноникал и без него, а также тех, что имеют канонические урл-адреса.
Какие ошибки чаще всего допускают оптимизаторы при задействовании rel = «canonical»:
- Указание в качестве канонической ссылки, расположенной на поддомене либо имеющей иное доменное имя.
- Использование «canonical» со стр. пагинации на 1-ю страницу каталога вместо «Показать все».
- Обозначение каноническим URL, что не попал в индексацию, поскольку закрыт файлом или метатегом роботс, либо оказался вне индекса ПС по другим причинам.
- Наличие 404 ошибки в канонической ссылке, проще говоря, каноникал ведет на несуществующую интернет-страницу.
- Использование нескольких атрибутов rel = «canonical» в коде одной страницы или указание различных канонических URL.

Google рекомендует на каждую стр. пагинации размещать каноникал сам на себя, в противном случае, если указать каноничной 1-ю веб-страницу категории или блога, индексация последующих становится невозможной. При размещении в коде страницы нескольких канонических урлов, будет учитываться только первый. Что касается внедрения атрибута различными методами, например, в XML-карте и непосредственно на веб-странице, необходимо указывать один и тот же canonical URL.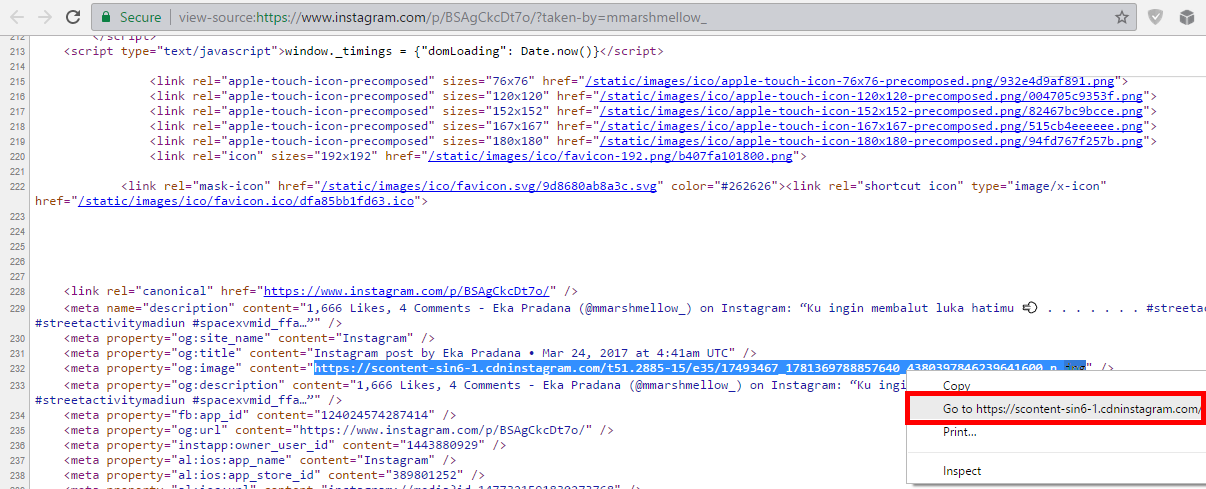
Каноникал и «Смотреть все»
Как мы уже писали выше, одним из популярных и доступных вариантов, как настроить пагинацию в интернет-магазине, является генерация страницы «Show all». Она создается и после указывается в качестве канонической для остальных стр. каталога. С точки зрения SEO пагинация, настроенная таким образом, считается эффективной, поскольку данный метод рекомендует Гугл, а значит, он демонстрирует лучший результат для продвижения в этой поисковой системе. Также считается, что посетителям удобно смотреть все товары на одной странице, правда, это работает не всегда. Для комфортного взаимодействия пользователей с сайтом необходима высокая скорость загрузки web-страницы «Show all», не более 3 секунд. Поэтому для онлайн-платформ с тысячами товаров данный метод может не подойти. Также, с некоторыми движками сайтов web-страница «Показать все» может выдавать ошибки, поэтому необходимо заранее определить возможность создания в рамках используемой вами CMS подобных страниц.
Подводим итоги
Как показывает практика и опыт SEO-оптимизаторов, атрибут rel = «canonical» зарекомендовал себя в качестве полезного и эффективного инструмента продвижения web-платформ в поисковой сети. При корректном использовании он способен улучшить качество работы специалистов и ускорить индексацию сайта, что окажет положительное воздействие на ранжирование продвигаемого онлайн-ресурса.
Как правильно использовать rel=”canonical“ в SEO продвижении
Когда использовать атрибут rel=»canonical», некоторые распространенные сложности с реализациейСодержание
- Как rel=»canonical» может помочь продвижению?
- Где прописать атрибут rel=canonical
- Мой атрибут canonical не работает
- Взаимодействие атрибута canonical с другими
- Другие способы применения canonical
В идеале должна быть одна версия для каждой страницы. Но на деле часто бывает, что одинаковый контент присутствует в нескольких местах одного сайта, а также на других ресурсах. Чтобы решить проблему дублирующего контента было разработано решение под названием «элемент канонической ссылки», больше известное как атрибут rel=»canonical» .
Чтобы решить проблему дублирующего контента было разработано решение под названием «элемент канонической ссылки», больше известное как атрибут rel=»canonical» .
Этот атрибут устраняет проблемы, связанные с дублирующимся контентом. Устанавливает предпочтительную версию страницы и передает сигналы, такие как ссылки, на эту версию страницы. Объединяет дубликаты контента, которые могут появляться по следующим причинам:
- HTTP и HTTPS
- одни и те же материалы в субдомене www и по обычным адресам http
- параметры и многоаспектная навигация
- идентификаторы сессий
- завершающий слэш
- индекс/страницы по умолчанию
- версии альтернативной страницы, такие как m. или AMP-страницы или версии для печати
Большинству веб-мастеров известно, что атрибут добавляется в тег head:
<link rel=»canonical» href=»https://example.
 com/» />
com/» />Но не все знают, что canonical может также отправляться в заголовок HTTP:
HTTP/1.1 200 OK Link: <https://example.com/>; rel=»canonical»
Атрибут canonical в заголовке может использоваться применительно к любой странице, но самый распространенный случай — для выбора предпочтительной версии PDF.
Мой атрибут canonical не работаетrel=»canonical» — это не директива. Его можно проигнорировать. Каноническая версия — это версия страницы, которая должна присутствовать в файле sitemap, к примеру. На присутствие несовместимых URL в sitemap или внешних ссылках могут указывать разные сигналы. Атрибут canonical может также игнорироваться, если между страницами нет близкого соответствия.
Случаются и другие ошибки, например, когда страницы копируются, а атрибут canonical не изменяется, или остается указатель места заполнения. Также следует использовать абсолютные — не относительные — пути URL, чтобы было меньше ошибок. Поскольку из-за этого, а также из-за автореферентных атрибутов canonical, несколько страниц будут сообщать поисковым системам о том, что данные страницы являются каноническими; в этом нет смысла. Если на странице есть несколько отличающихся атрибутов canonical, Google их проигнорирует. Что делает Google, когда получает противоречивые сигналы? Поисковая система будет пытаться определить лучший URL по разным сигналам: предложенные canonical, внешние ссылки и ссылки в sitemap, но существуют и другие факторы. К примеру, Google может предпочесть короткий URL длинному, выбрать HTTPS, а не HTTP.
Поскольку из-за этого, а также из-за автореферентных атрибутов canonical, несколько страниц будут сообщать поисковым системам о том, что данные страницы являются каноническими; в этом нет смысла. Если на странице есть несколько отличающихся атрибутов canonical, Google их проигнорирует. Что делает Google, когда получает противоречивые сигналы? Поисковая система будет пытаться определить лучший URL по разным сигналам: предложенные canonical, внешние ссылки и ссылки в sitemap, но существуют и другие факторы. К примеру, Google может предпочесть короткий URL длинному, выбрать HTTPS, а не HTTP.
Известно, что Google отдает предпочтение HTTPS-страницам в качестве канонических, а не их аналогам HTTP; исключение — случаи, когда присутствуют противоречивые сигналы, согласно справке Search Console:
- Страница HTTPS имеет недействительный сертификат SSL.
- Страница HTTPS содержит небезопасные зависимости.
- Доступ к странице HTTPS запрещен в файле robots.txt, а к странице HTTP – нет.
- Страница HTTPS выполняет переадресацию на страницу HTTP.
- Страница HTTPS указывает на страницу HTTP с помощью атрибута rel=»canonical».
- Страница HTTPS содержит метатег noindex для роботов.

Редкий случай, но все же возможный, когда из-за ошибок в коде раздел заголовка заканчивается прежде, чем это должно быть. При этом canonical может быть в теле контента, где поисковая система его никак не ожидает найти. Еще хуже, когда большинство инструментов (таких как Screaming Frog или Deep Crawl) эту ошибку не фиксируют. Проблему можно установить только с помощью программного интерфейса DOM (объектная модель документа) — например, когда используется Inspect для Chrome Dev Tools
Рассмотрим канонический атрибут в Home Depot на скриншоте ниже. Можно видеть, что раздел заголовка закончился, и часть контента, которая при рассмотрении источника находится в заголовке, попадает в тело, когда рассматривается DOM.
Взаимодействие атрибута canonical с другимиС атрибутом canonical можно легко ошибиться. Допустить, например, грамматическую ошибку, поставить завершающий слэш, в особенности когда есть еще нумерация страниц и hreflang. Если индексируется страница отличная от той, что значится в теге, страницы не будут объединены должным образом. Например, канонический элемент устанавливается на второй странице нумерованного списка для URL первой страницы. Атрибут canonical не следует использовать вместе с noindex.
Допустить, например, грамматическую ошибку, поставить завершающий слэш, в особенности когда есть еще нумерация страниц и hreflang. Если индексируется страница отличная от той, что значится в теге, страницы не будут объединены должным образом. Например, канонический элемент устанавливается на второй странице нумерованного списка для URL первой страницы. Атрибут canonical не следует использовать вместе с noindex.
Атрибут canonical можно использовать для альтернативных версий сайта (мобильная и AMP-версия). Для индексации mobile-first не нужно специально менять эти атрибуты.
Полное руководство по Rel Canonical — Как делать и почему (не)
Взгляды авторов являются полностью их собственными (за исключением маловероятного случая гипноза) и могут не всегда отражать взгляды Моза.
См. также:
• Канонические теги — передовой опыт
• Передовой опыт поисковой оптимизации для канонических URL + тег Rel=Canonical
Существует множество замечательных публикаций и ресурсов о теге rel canonical, но их может быть трудно идентифицировать с помощью простого поиска. Даже если вы прорветесь сквозь беспорядок и найдете что-то действительно полезное, актуальную информацию будет сложно отличить от старой. В сети отсутствует текущий ресурс сверху вниз по тегу rel canonical. В этом посте я сделаю все возможное, чтобы осветить все это и сообщить вам о
Даже если вы прорветесь сквозь беспорядок и найдете что-то действительно полезное, актуальную информацию будет сложно отличить от старой. В сети отсутствует текущий ресурс сверху вниз по тегу rel canonical. В этом посте я сделаю все возможное, чтобы осветить все это и сообщить вам о
последний.
Узнайте, почему и как использовать тег rel canonical, когда его не использовать, различные мнения опытных SEO-специалистов и другие сведения, которые вам необходимо знать, чтобы правильно его использовать.
Давайте начнем с основ, а затем перейдем к более сложным идеям и проблемам.
Что такое канонический тег?
Во-первых, мы не можем договориться, как это назвать. Будьте уверены, что «rel canonical», «rel=canonical», «rel canonical tag», «canonical URL tag», «link canonical tag» и просто «canonical tag» относятся к одному и тому же.
Канонический тег — это метатег уровня страницы, который помещается в заголовок HTML веб-страницы. Он сообщает поисковым системам, какой URL-адрес является канонической версией отображаемой страницы. Его цель состоит в том, чтобы не допустить дублирования контента в индекс поисковой системы, объединяя силу вашей страницы в одну «каноническую» страницу.
Его цель состоит в том, чтобы не допустить дублирования контента в индекс поисковой системы, объединяя силу вашей страницы в одну «каноническую» страницу.
Как используется канонический тег?
Канонический тег — это относительно быстрое решение для устранения дублированного контента. Если ваш веб-сайт генерирует и отображает одинаковый (или очень похожий) контент на нескольких URL-адресах, тег canonical можно использовать для их объединения и назначения одной основной (канонической) версии. Давайте посмотрим на список часто повторяющихся URL-адресов контента.
- http://example.com/quality-wrenches.htm (главная страница)
- http://www.example.com/quality-wrenches.htm (к сожалению, все страницы также разрешаются с поддоменом www)
- http://example.com/quality-wrenches.htm?ref=crazy-… (это похоже на способ отслеживания источников перехода)
- http://example.com/quality-wrenches.htm?sort=price (как пользователи просматривают товары по самой низкой цене)
- http://example. com/quality-wrenches.htm/print (версия для облегченной печати без рекламы и графики)
 com/quality-wrenches.htm/print (версия для облегченной печати без рекламы и графики)
com/quality-wrenches.htm/print (версия для облегченной печати без рекламы и графики)Канонический тег, ссылающийся на главную страницу, http://example.com/quality-wrenches.htm, можно разместить в заголовке всех вышеперечисленных страниц.
Как это реализовано?
Канонический тег является частью заголовка HTML на веб-странице. Это то же самое место, где мы помещаем другие забавные вещи SEO, такие как тег заголовка, тег мета-описания и тег robots. Код, как в моем примере выше, будет выглядеть так.
О, смотри, вот он в действии!
Источник: CNN
Легко, правда?! Компаниям с дорогостоящими циклами разработки нравится решение с каноническими тегами, потому что его относительно легко внедрить. Часто это один простой проект разработки вместо десятков более сложных.
Все это очень интересно, я знаю, но есть некоторые вещи, которые вам нужно знать.
Обычно есть лучшее решение
Тег canonical не является заменой надежной архитектуры сайта, которая изначально не создает дублированный контент. Почти всегда есть лучшее решение для канонического тега с точки зрения передовой практики SEO.
Почти всегда есть лучшее решение для канонического тега с точки зрения передовой практики SEO.
Давайте рассмотрим некоторые из приведенных выше примеров URL, на этот раз мы поговорим о том, как исправить их без канонического тега.
Пример 1: http://www.example.com/quality-wrenches.htm
Это повторяющаяся версия, поскольку наш пример веб-сайта разрешается как с версией с www, так и с версией без www. Если тег canonical использовался для извлечения версии с www из индекса (сохраняя версию без www как каноническую), обе версии по-прежнему разрешались бы в браузере. Поскольку обе версии все еще разрешаются, обе версии могут продолжать генерировать ссылки.
Канонический тег, как и редирект 301, не передает все значение ссылки с одной страницы на другую. Проходит большую часть, но не все. По нашим оценкам, потеря ценности ссылки при использовании любого из этих решений составляет 1-10%. Таким образом, перенаправление 301 и канонический тег — это одно и то же.
Я бы рекомендовал 301 редирект вместо канонического тега.
Почему, спросите вы? Перенаправление 301 принимает потерю значения ссылки один раз. После того, как 301 будет на месте, пользователь никогда не попадет на дублирующую версию URL. Они перенаправлены на каноническую версию. Если они решат дать ссылку на страницу, они предоставят эту ссылку на каноническую версию. Ни одна ссылка любовь не потеряна. Сравните это с решением канонического тега, которое поддерживает разрешение обоих URL-адресов и увековечивает потерю ценности ссылки.
Пример 2: http://example.com/quality-wrenches.htm?ref=crazy-…
Понятно. Вы хотите знать, стоило ли посылать образец гаечного ключа сумасшедшей блоггерше для ознакомления. Что происходит, когда другой блоггер щелкает по своей ссылке, а затем делает собственный пост о ваших продуктах, ИСПОЛЬЗУЯ ТАКОЙ же URL? Ваш причудливый трюк с отслеживанием уже не так эффективен, не так ли?
Было бы гораздо лучше записать этот переход, а затем выполнить перенаправление 301 на каноническую версию URL. Другие веб-серферы будут ссылаться на соответствующий URL-адрес и делиться им, и вы не будете терять эти 1-10% вашей с трудом заработанной любви к ссылкам на постоянной основе.
Другие веб-серферы будут ссылаться на соответствующий URL-адрес и делиться им, и вы не будете терять эти 1-10% вашей с трудом заработанной любви к ссылкам на постоянной основе.
Пример 3: http://example.com/quality-wrenches.htm?sort=price
Подобные URL-адреса появляются, когда веб-страница позволяет пользователю сортировать результаты поиска на основе различных элементов, таких как цена. Для целей этого примера я собираюсь предположить, что эта страница результатов поиска больше похожа на высококачественную целевую страницу с некоторыми встроенными результатами поиска. Таким образом, мне не нужно вникать во всю проблему «результаты поиска в результатах поиска». 🙂
Вместо того, чтобы использовать здесь канонический тег, я бы использовал мета-тег robots ‘noindex’ (что на самом деле означает ‘noindex,follow’, потому что по умолчанию подразумевается следование). Это позволяет поисковым системам получать приоритетный доступ к некоторым из наиболее важных страниц, связанных с этой. При использовании метатега robots «noindex» страница останется вне поискового индекса, но любое значение ссылки будет передано страницам, на которые есть ссылки с этой страницы.
При использовании метатега robots «noindex» страница останется вне поискового индекса, но любое значение ссылки будет передано страницам, на которые есть ссылки с этой страницы.
Пример 4: http://example.com/quality-wrenches.htm/print
Если печатные страницы вашего веб-сайта содержат ссылку на исходную страницу, вы также можете использовать метатег robots ‘noindex’. Страница остается вне индекса, и любое значение ссылки будет передано обратно в исходную каноническую веб-версию страницы.
Видишь, как это работает? Я призываю вас передать мне любой сценарий дублирования контента, и я смогу найти вам решение, которое лучше для вашей программы SEO, по крайней мере, с точки зрения лучших практик SEO, чем канонический тег.
Я просто знаю, что кто-то собирается использовать файл robots.txt в качестве решения для дублирования содержимого. Прежде чем вы это сделаете, помните, что файл robots.txt предназначен для блокировки определенных страниц или каталогов от индексации поисковыми системами. Это не консолидирует ссылочный вес, в основном создает тупик. Прежде чем вы даже подумаете об использовании файла robots.txt для чего-либо, кроме ссылки на вашу XML-карту сайта, вам следует ознакомиться с моей недавней публикацией на тему «Серьезное неправильное использование Robots.txt и высокоэффективные решения».
Это не консолидирует ссылочный вес, в основном создает тупик. Прежде чем вы даже подумаете об использовании файла robots.txt для чего-либо, кроме ссылки на вашу XML-карту сайта, вам следует ознакомиться с моей недавней публикацией на тему «Серьезное неправильное использование Robots.txt и высокоэффективные решения».
Все еще хотите использовать канонический тег по причинам, отличным от SEO? Возможно, ваш ИТ-отдел не сидит сложа руки в ожидании вашего следующего масштабного SEO-проекта?
Несколько слов предостережения
1. Поддержка поисковых систем в лучшем случае неравномерна
Уровень поддержки поисковыми системами канонического тега сильно различается. Google поддерживает его как для отдельных доменов, так и для нескольких доменов. Bing считает канонический тег «подсказкой», и я не слышал о каких-либо реализациях канонического тега, которые повлияли бы на индекс Bing. У вас есть? Наверняка должен быть один…
2. Существуют лучшие средства исправления дублирующегося содержимого
Исправление систем, которые в первую очередь генерируют дублированное содержимое, является лучшим решением. Если это невозможно, обратите внимание на другие решения, такие как переадресация 301 и мета-тег noindex.
Если это невозможно, обратите внимание на другие решения, такие как переадресация 301 и мета-тег noindex.
3. Неправильная реализация может привести к катастрофе
Если вы собираетесь реализовать тег rel canonical, пожалуйста, убедитесь, что он корректен перед запуском. Взгляните на недавний пост доктора Пита «Катастрофическая канонизация», чтобы прочитать о его тесте. Не каждому веб-сайту так же повезло, как доктору Питу, в их восстановлении после неудачной реализации канонического тега. Мы постоянно видим примеры этого в вопросах и ответах.
Вот несколько сообщений в пользу того, чтобы держаться подальше.
- Иэн Лори, почему я до сих пор ненавижу Rel Canonical
- Канонический тег Стефана Спенсера еще не надежен
- Каноническая ссылка Адама Одетт взламывает сайты
Что теперь?
Тег rel canonical имеет свое место. Это большая экономия времени для разработки. Решение не такое надежное, как некоторые другие ваши варианты, но если оно означает, что вы можете принять меры для борьбы с дублирующимся контентом сейчас, а не ждать до 2014 года, вы должны пойти на это. В других случаях ваше решение для хостинга может вообще не позволить вам реализовать 301 редиректы, и ваши руки будут связаны.
Если вы пойдете по пути канонического реля, будьте с ним осторожны! Тест, тест, тест. Если у вас есть выбор и ресурсы для поиска более эффективного решения, возможно, вам стоит пойти по этому пути.
Подробнее
Если вам не хватило тега rel canonical на один день, ознакомьтесь с этими полезными ссылками. Как всегда, следите за датами на них!
- Канонический URL-тег — самое важное достижение в SEO-оптимизации со времен Sitemap, Рэнд Фишкин.
- Совет по SEO — URL Canonical, Matt Cutts
- Укажите свой Canonical, центральный блог для веб-мастеров
- О rel=»canonical», Мэтт Каттс [видео]
- Google, Yahoo и Microsoft объединяются для «канонического тега», чтобы уменьшить дублирование контента, Ванесса Фокс
- Узнайте об элементе Canonical Link за 5 минут, Мэтт Каттс
Удачной оптимизации!
П. С. Keyphraseology, мой консалтинговый бизнес по SEO, ищет отличный повод помочь с бесплатным аудитом сайта и несколькими часами консультаций. Если вы представляете некоммерческую организацию, которой может понадобиться помощь в повышении видимости в поисковых системах, подайте заявку здесь.
С. Keyphraseology, мой консалтинговый бизнес по SEO, ищет отличный повод помочь с бесплатным аудитом сайта и несколькими часами консультаций. Если вы представляете некоммерческую организацию, которой может понадобиться помощь в повышении видимости в поисковых системах, подайте заявку здесь.
изображение человека со знаком вопроса предоставлено Shutterstock
Руководство для начинающих по ссылке rel canonical Тег
Канонические URL-адреса могут показаться пугающими. Узнайте, как правильно использовать этот тег, чтобы предотвратить или решить технические и внешние SEO-проблемы (дублированный контент).
Сегодня я расскажу о канонических URL-адресах (или легендарном теге link rel canonical). На этом мы идем глубоко в лес ботаников, ребята, так что пристегнитесь.
На этом мы идем глубоко в лес ботаников, ребята, так что пристегнитесь.
Я собираюсь рассказать о том, как выглядит хорошая канонизация и как она может испортить ваш сайт, если вы ошибетесь. Если вы сделаете это правильно, вы сможете устранить множество действительно серьезных проблем с дублированным контентом и исправить массу технических проблем, оставшихся за кадром.
Начнем.
Небольшое напоминание, прежде чем мы углубимся в технические сложности канонических URL-адресов. Это часть SEO, а SEO — всего лишь часть или один из каналов цифрового маркетинга.
Подходя к теме канонических тегов, мы приближаемся к одному конкретному каналу того, что должно быть гораздо более крупной и всеобъемлющей стратегией цифрового маркетинга.
Даже в рамках SEO канонические URL-адреса или тег link rel canonical являются лишь крошечным компонентом гораздо большей части всей этой головоломки.
10-кратное увеличение трафика от Google.
Получите контрольный список SEO, отправленный на ваш почтовый ящик.
[Бесплатный мини-курс] Изучите стратегию SEO, которую мы использовали в PayPal и Airbnb.
Получите ТОЧНУЮ структуру, которую вам нужно внедрить, чтобы ваша SEO-стратегия была надежной до конца года.
Узнайте точную стратегию ключевых слов SEO, которую мы использовали в PayPal и Airbnb.
Забронируйте место на специальном бесплатном мастер-классе по SEO!
Обучение SEO, чтобы в 10 раз увеличить трафик из Google.
ClickMinded — это место, где 8 702 стартапа, агентства, предпринимателя и студента изучают SEO, получают более высокие рейтинги и больше трафика.
Значительно развивайте любой бизнес с помощью СОП по цифровому маркетингу.
Библиотека ClickMinded SOP представляет собой набор шаблонов стратегии цифрового маркетинга с пошаговыми инструкциями, которые можно использовать для развития любого веб-сайта.
Спасибо за то, что являетесь частью семьи ClickMinded!
Что такое канонические URL-адреса?
«Канонические URL-адреса» — это просто причудливое, чрезмерно техническое слово, обозначающее «Вот как мы поступаем с дублирующимся или похожим контентом».
Канонический тег link rel, который мы используем на наших веб-страницах, сообщает поисковым системам, где находится исходная версия страницы. Фактически это похоже на указание на «мастер-копию» страницы.
Современные веб-приложения создают эту серьезную проблему, когда у нас есть много и лота и множество разных версий одного и того же. Если бы мы не решали эту проблему, добавляя канонические теги, создание карты сайта для вашего сайта было бы серьезной проблемой для Интернета и поисковых систем.
Канонический тег на веб-странице сообщает поисковым системам, какую версию похожих страниц вы хотите ранжировать. Вот почему это очень, очень важно для сайтов электронной коммерции или WordPress, а также для любого современного веб-приложения, в котором есть проблема с сортировкой.
Например, я занимался оптимизацией поисковой системы в Airbnb, и это было для нас серьезной проблемой.
Если у вас есть список из тысячи домов в конкретном городе и множество различных фильтров, существует множество различных способов упорядочить эту страницу.
Конечно, у вас есть тысяча домов, но:
- Некоторые из них занимают целый дом.
- Некоторые из них являются общими.
- Некоторые из них с двумя спальнями, четырьмя спальнями и восемью спальнями.
- В некоторых из них есть бассейн.
- Некоторые из них подходят для семейного отдыха.
- В некоторых из них есть сауна.
- В некоторых из них доступно мгновенное бронирование.
Каждый раз, когда вы добавляете уровень фильтрации, вы, по сути, отображаете новый тип страницы в том же наборе данных, в той же тысяче списков, но с немного другим содержанием и, возможно, с некоторыми дополнительными параметрами в URL.
Если вы сделаете это до отвращения к как можно большему количеству возможных фильтров, вы, по сути, получите бесконечные страницы с разными URL-адресами, и это станет огромным беспорядком для любой поисковой системы.
Основная идея здесь в том, что мы говорим: «Хорошо, мы все еще хотим, чтобы наши пользователи могли фильтровать. Мы по-прежнему хотим, чтобы наши пользователи могли отображать страницу по-разному, но мы хотим сообщить поисковой системе: «Привет, Google. Я знаю, кажется, что у нас тысяча страниц, но на самом деле у нас только одна».
Вот для чего нужна каноническая страница. Поисковым системам очень конкретно предлагается сказать: «Это основная копия URL. Поместите только это в результаты поиска и игнорируйте остальные ».
Еще один способ взглянуть на канонические URL-адреса — с точки зрения дублирующегося фрагмента контента.
Дублированный контент — это проблема, возникающая, когда поисковые системы находят несколько копий одного и того же контента, что создает проблему при попытке ранжировать их.
- Это может повредить вашему краулинговому бюджету. По сути, Google.com и другие поисковые системы, такие как Yahoo, выделяют определенное количество запросов в день, неделю или месяц, и если они тратят все это время на сканирование страниц, которые вы не хотите сканировать, это вредит вам, поскольку веб-мастер.
- Может понизить рейтинг. Если робот Googlebot снова и снова видит на вашем сайте шаблон дублирования, он может понизить ваш рейтинг. Очевидно, это нехорошо.
- Может отправлять пользователей на некачественные страницы. Допустим, вас не волнует краулинговый бюджет. Допустим, дублированный контент еще не вредит вашему рейтингу. Если пользователи находят ваш ненужный мусор в результатах поиска, это совсем не хорошо.
Когда и как использовать канонизацию
Давайте рассмотрим здесь несколько примеров.
Допустим, я отвечаю за Nike.com, и на нашем веб-сайте есть страница продукта, посвященная мужской обуви, и я хочу, чтобы она заняла первое место в Google по запросу «мужская обувь».
Если я нахожусь на «nike.com/mens-shoes» (исходная версия страницы) и хочу добавить здесь канонический тег, я бы использовал тег ссылки с атрибутом HTTP-заголовка rel=»canonical» и атрибут href «nike.com/mens-shoes».
Это называется самоссылающимся каноническим тегом. Исходная мастер-копия страницы указывает сама на себя, и это нормально. Я могу это сделать. вообще никаких проблем. Я канонизирую себя здесь, и это прекрасное предложение для Google.0005
Давайте посмотрим на ту же страницу с фильтром.
Допустим, я захожу на «nike.com/mens-shoes» и хочу отсортировать эту страницу по всему размеру 10, поэтому я добавляю фильтр. Возможно, к URL-адресу добавляется параметр URL (что-то вроде «?size=10»).
Теперь у меня есть новая страница с новым фильтром, но я не хочу, чтобы эта страница отображалась в результатах поиска Google, поэтому элемент канонической ссылки остается прежним.
Страница существует для пользователей, но если Google когда-либо найдет ее, он увидит этот канонический тег в заголовке, и это будет похоже на то, что мы говорим:
«Вы находитесь на этой странице, но фактически не индексируете ее. Пожалуйста, проиндексируйте этот другой, который является моим предпочтительным URL-адресом, мастер-копией и любыми ссылками, которые получает эта страница, вы можете продолжить и передать это в мастер-копию ».
Это был бы пример, когда для этого конкретного типа фразы (например, «Обувь Nike, размер 10») нет никакого намерения поисковика, поэтому я не хотел, чтобы эта страница ранжировалась.
Давайте сделаем еще один сценарий:
Допустим, у меня есть еще один фильтр для красных туфель, поэтому URL-адрес будет «nike.com/mens-shoes?size=10& 9».0007 цвет=красный ”.
Теперь мы рассмотрим всю мужскую обувь Nike 10-го размера и красного цвета. Это то же самое. Это другая страница. Это другой набор фильтров. Это более конкретно, но я не хочу, чтобы эта страница была в индексе.
Мы собираемся оставить канонический тег обратно в мастер-копии, так как этот URL получает все больше и больше параметров, мы по-прежнему указываем обратно на мастер-копию.
В каждой из этих ситуаций у меня по существу было слишком много повторяющихся URL-адресов, которые были бесполезны для пользователей, приходящих из поисковых систем, поэтому я удалил все эти страницы и добавил каноническую версию каждой из них обратно в основную копию.
Однако давайте рассмотрим здесь другую ситуацию.
Допустим, у меня есть тот же URL, однако есть определенный тип фильтрации, который действительно важен для нас. В данном случае это Jordans: обувь Nike Jordan.
Допустим, я рекламирую на главной странице, 25 000 человек в месяц ищут мужскую обувь Nike Jordan, и я хочу, чтобы эта страница была в индексе.
В этом случае я бы сам канонизировал URL-адрес с фильтром для Jordans: nike.com/mens-shoes?type=jordans.
Это был бы один из способов захватить кучу объема поиска, который может быть не захвачен, если вы канонизируете резервную копию основной страницы, потому что вы не можете поместить ее в индекс.
В этой ситуации, когда Google переходит по этому URL-адресу, я бы сказал Google: «Эй, на самом деле эта страница является мастер-копией. Пожалуйста, поместите его в свой индекс».
Мы делаем это, потому что страница важна для нас. Это уникальный и хороший опыт для пользователей, и за ним стоит объем поиска. Поэтому мы решили оставить его в индексе.
Поэтому мы решили оставить его в индексе.
Когда вы делаете это, вы должны следить и убедиться, что содержимое этой страницы не является точной копией оригинальной страницы мужской обуви . Убедитесь, что там есть какая-то дифференциация.
Почему важна канонизация
Тег rel canonical и канонизация в целом могут выглядеть так: «Как бы выглядели результаты поиска, если бы у Google не было возможности удалять повторяющийся контент?»
В следующий раз, когда вы будете на сайте электронной коммерции, каждый раз, когда вы нажимаете что-либо, следите за строкой URL. Это огромная, масштабная, масштабная проблема.
Подумайте об этом: у меня есть куча URL-адресов, которые по сути являются одним и тем же (мужская обувь, мужская обувь? размер=10 и т. д.). Подумайте о каждой возможной перестановке этого.
Это может стать очень грязным, очень быстро.
Интернет был бы отстойным без этого.
Очень хорошо, что Google разработала технический способ решения подобных проблем.
Советы по каноническим URL-адресам
Помимо описанных выше основ, есть еще несколько советов, которые вы, возможно, захотите иметь в виду:
Самореферентные канонические теги — это нормально
Существует много споров на действительно высоком техническом уровне, связанных с массивными веб-приложениями.
Некоторым людям нравится не ссылаться на канонические теги. Я видел доказательства за и против этого. Это действительно зависит от вашей ситуации. Например, TripAdvisor делает очень интересные вещи по этому поводу. Взгляните на их исходный код и проверьте, что они делают.
Если вы только начинаете, канонические теги, ссылающиеся на самих себя, вполне подойдут.
Канонизировать вашу домашнюю страницу
Лично я считаю, что домашние страницы наиболее странно связаны с вещами.
Существует множество различных способов отображения домашних страниц, например http://www.website.com, https://website.com, www.website.com/index. php, www.website.com/index. html и так далее.
php, www.website.com/index. html и так далее.
Люди постоянно что-то портят.
Выберите основную версию для отображения домашней страницы и канонизируйте каждую возможную версию до основной.
Канонические теги равны
предложение , не директиваФайлы robots.txt являются директивой. 301 переадресация является директивной. Используя эти вещи, вы говорите поисковой системе: «Эй, у тебя есть для этого».
Канонические теги, однако, являются предложением.
Google считает, что веб-мастера часто путают это, поэтому Google активно признает, что им разрешено игнорировать вас, если они думают, что вы стреляете себе в ногу.
Канонические теги — это еще одно предложение, которое мы даем поисковым системам, чтобы посоветовать им, как справляться с проблемами нумерации страниц и дублированием контента.
Итак, если вы поставили канонический тег, он не работает, и если вам интересно, что произошло, копните немного глубже в то, что вы делаете, потому что Google может получать от вас смешанные сигналы.
Google говорит, что они не будут полностью применять канонические теги, но чаще всего, я вижу, что они это делают.
Междоменная канонизация в порядке.
Допустим, вы управляете сайтом публикации, и у вас есть 20 разных сайтов, и каждый раз, когда вы пишете новую запись в блоге, она распространяется на все ваши разные домены.
Совершенно нормально написать сообщение в блоге для веб-сайта 1.com, а затем опубликовать его на веб-сайте 2.com, веб-сайте 3.com и веб-сайте 4.com, а затем выполнить междоменную канонизацию до исходного состояния.
Все, что делает кросс-канонизируется, не будет отображаться в индексе, поэтому, делая это, вы фактически говорите Google: «Эй, не индексируйте эту страницу, поскольку исходная версия здесь».
Однако имейте в виду, что любые ссылки, которые вы получаете на любой из этих страниц, должны быть связаны с исходной мастер-копией.
Не отправляйте смешанные сигналы
Есть много способов все испортить.
Например, вы можете взять две страницы и канонизировать их друг с другом. Или вы можете взять две страницы и канонизировать одну на другую и перенаправить 301 одну на другую.
Не отправлять смешанные сообщения. Выясните, каков ваш план, выясните, какой должна быть ваша мастер-копия, и воплотите этот план в жизнь.
Убедитесь, что все четко в каждом элементе.
Имейте в виду, что перенаправления 301 и канонизация имеют разные эффекты.
Многие люди спрашивают «Хорошо, по сути, я хочу удалить кучу дубликатов страниц и объединить их все в одну страницу. Должен ли я использовать канонический тег или код состояния 301?» .
Прежде всего, помните, что перенаправление 301 посылает более сильный сигнал с точки зрения ссылочного капитала. Например, если у вас есть две устаревшие страницы, вы хотите их удалить и передать все эти ссылки на другую страницу, перенаправление 301 будет более полезным.
В то же время имейте в виду, что 301 редиректы и канонизация предлагают разные возможности для пользователя.
- При переадресации 301 пользователь перемещает на новую конечную страницу.
- С канонической ссылкой — нет. По сути, вы говорите Google: «Привет. Страница, на которой вы находитесь, является копией. Игнорируйте это и отправляйте любые ссылки на эту другую страницу». Однако пользователь по-прежнему останется там, так что имейте это в виду.
Вы не можете использовать канонические теги для манипулирования ссылками
Некоторые люди говорят «Хорошо, тогда все, что мне нужно сделать, это получить кучу ссылок на страницу, а затем канонизировать ее до совершенно не связанной страницы. Тогда я смогу занять супервысокое место и выиграть Интернет».
Это так не работает .
На самом деле похоже, что Google использует релевантность документа, чтобы справиться с этим. Они хотят убедиться, что то, что вы отправляете, является реальной копией.
Если страница, которую вы канонизируете, сильно отличается от той, на которой вы сейчас находитесь, она будет проигнорирована.
Например, если у вас есть страница о синих виджетах, и вы канонизируете ее до страницы о гориллах, это не сработает.
Вот и все, это действительно все, что нужно знать о канонических URL-адресах и теге rel canonical. Используя информацию в этом посте, вы сможете правильно канонизировать свой дублированный контент, что является очень важным элементом всего процесса поисковой оптимизации.
Еще больше ресурсов
Если вы новичок в SEO и онлайн-маркетинге, обязательно загрузите наше руководство по стратегии цифрового маркетинга и наше руководство по стратегии SEO, чтобы получить общий обзор того, как все это работает.
Увеличьте свой трафик из Google в 10 раз.
Получите контрольный список SEO, отправленный на ваш почтовый ящик.
[Бесплатный мини-курс] Изучите стратегию SEO, которую мы использовали в PayPal и Airbnb.
Получите ТОЧНУЮ структуру, которую вам нужно внедрить, чтобы ваша SEO-стратегия была надежной до конца года.