
Как узнать частотность поисковых запросов в Яндекс и Гугл
Зная частотность ключевых слов, что это такое и как ее правильно применять, можно продвигать определенные страницы в выдаче поисковых систем. Такой навык полезен SEO-специалистам, интернет-маркетологам, SMM-специалистам и даже копирайтерам. О методах сбора запросов и классификации их по частотности расскажем далее.
Содержание
- Что такое частотность поискового запроса и зачем ее нужно знать
- Классификация запросов по частотности
- Определение частотностей с помощью сервисов
- Определение частотности по Яндекс.Вордстат
- Определение частотности по Google Ads
- Сбор частотностей программой Key Collector
- Заключение
Что такое частотность поискового запроса и зачем ее нужно знать
Частотностью запроса называют количество ввода конкретной фразы в поиск за определенный временной интервал (чаще всего за месяц). Эти данные фиксируют поисковые системы для оценки трафика и популярности фраз пользователей. Специалисты могут узнать сведения с помощью сервисов Google и Яндекс, а также сторонних программ.
Специалисты могут узнать сведения с помощью сервисов Google и Яндекс, а также сторонних программ.
Для SEO-специалиста знание частотности слов позволяет:
- спрогнозировать потенциальный трафик на сайт;
- составлять качественное семантическое ядро для сайта;
- подобрать фразы для быстрого продвижения конкретной страницы.
Имея данные по популярности фразы, можно с легкостью отфильтровать запросы-пустышки (имеющие нулевую или близкую к ней частотность). Это помогает сконцентрировать бюджет и ресурсы на наиболее важных фразах, заняться вплотную их продвижением.
Простой пример: вряд ли здравомыслящий сеошник будет продвигать страницу по запросу «купить круиз по Ангаре», да еще и зимой. Частотность этой фразы равна нулю.
Фраза «купить круиз по Волге» в этом плане для продвижения более привлекательна: общая частотность равна 301.
Классификация запросов по частотности
Чтобы сконцентрироваться на наиболее важных запросах, их группируют по частотности. Каждая группа называется по-своему:
Каждая группа называется по-своему:
- Низкочастотные фразы (НЧ) — запрашиваемые пользователями менее 150 раз в месяц. Чаще всего НЧ используется для продвижения конкретного товара, услуги, а также в блогах.
- Среднечастотные фразы (СЧ) — запрашиваются в поисковых системах до 1500 раз. Используются на разных страницах сайта, в том числе для продвижения рубрик (категорий).
- Высокочастотные фразы (ВЧ) — запрашиваются более 1500 раз за месяц. Эти фразы используют для продвижения главной страницы сайта.
Лучший результат достигается при комбинировании на одной странице фраз из разных групп. Например, низкочастотные слова помогут более полно раскрыть тему или рассказать о сайте, а потому могут быть и на главной странице.
Классификация условна и меняется в зависимости от ниши или региональности. Например, запрос «торт на заказ», используемый для сайта кондитера из Владимира, будет относиться к числу высокочастотных, хоть и имеет частоту 855 в месяц. Более популярного запроса в этом регионе и в этой нише нет.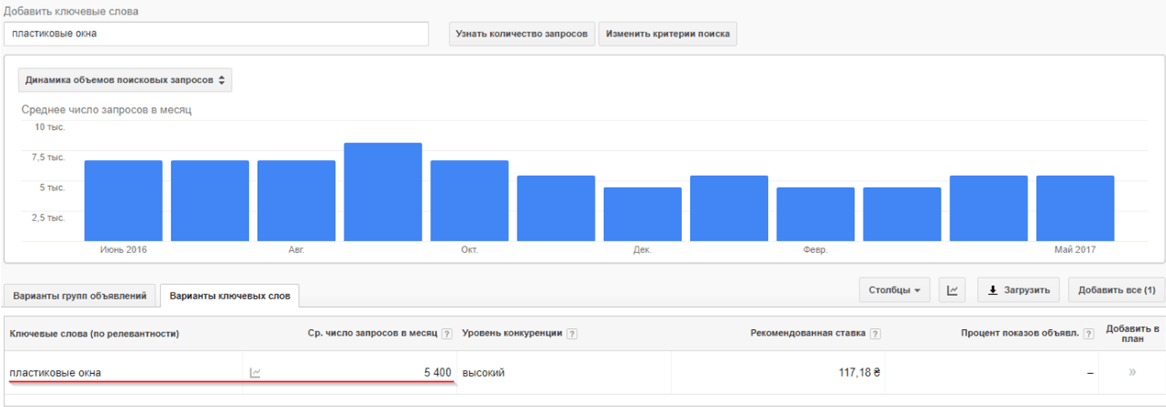
В нишах с высокой конкуренцией даже фразы с частотностью 2000 могут считаться низкочастотными. Точно определить принадлежность к определенной категории можно с помощью сервиса, позволяющего оценить частотность поисковых запросов.
Определение частотностей с помощью сервисов
Популярность фраз анализируют поисковики, логичнее обратиться к ним для получения нужной информации. В России для этой цели используют сервисы Яндекс.Вордстат и Google Ads. Можно воспользоваться сторонними сервисами — Serpstat, Букварикс и другими, но они также будут обращаться к базам поисковых систем, а потому результат будет схожим.
Определение частотности по Яндекс.Вордстат
Сервис Яндекс.Вордстат служит для составления прогнозов количества показа рекламных объявлений по определенным запросам. Его же используют и для сбора поисковых фраз, определения их частотности, сезонности, региональности. Дополнительно тут используются специальные символы.
Перед тем, как узнавать частотность запросов в Яндексе, нужно авторизоваться в системе. После этого можно перейти на страницу Яндекс.Вордстат и начать работу.
После этого можно перейти на страницу Яндекс.Вордстат и начать работу.
Функционал сервиса простой, для описываемых задач понадобятся следующие функции:
- «По словам» — включена по умолчанию, позволяет узнать популярность в Яндекс конкретного слова или фразы.
- «По регионам» — поможет узнать распределение популярности по заданным регионам.
- «Регион» — по умолчанию включены все регионы. Позволяет узнать частоту запросов в Яндексе для конкретного региона или населенного пункта.
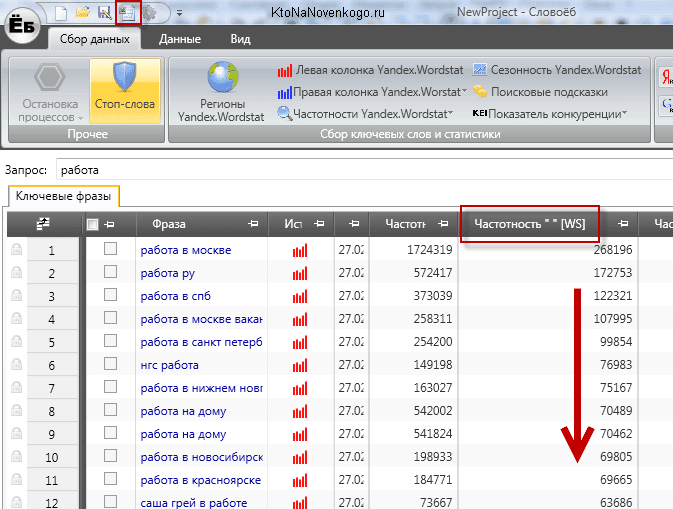
Исследуемый запрос вводится в специальное поле, если нужно — сопровождается спецсимволами. Затем нужно нажать на кнопку «Подобрать» (4). Сервис генерирует результаты автоматически. Пример для запроса «купить экскаватор» на скриншоте.
В результатах в левой колонке можно увидеть общую частоту запроса (127 348). Тут учитываются все варианты фраз, которые вводили пользователи, желающие купить экскаватор. Эта частотность называется базовой, является неточной. На нашем примере она отражает запросы «купить б/у экскаватор», «купить новый экскаватор» и даже «купить игрушечный экскаватор на пульте управления». Использовать базовую частотность для составления стратегии продвижения веб-ресурса нельзя.
Использовать базовую частотность для составления стратегии продвижения веб-ресурса нельзя.
Для уточнения запроса в Яндекс.Вордстат используют специальные операторы. Например, с помощью оператора «»«» (кавычки) можно узнать фразовую частотность. Для этого фразу «купить экскаватор» нужно заключить в кавычки.
Фразовая частотность показывает, сколько раз вводили именно эту фразу, без других слов. На нашем примере базовая (1) и фразовая (2) частотности имеют существенную разницу. Тут уже не учитываются вариации покупки новой, подержанной техники, игрушечных экскаваторов и прочего.
Иногда нужно дать прогноз по частоте набора слов в точном виде, без учета различных окончаний и числа. На нашем примере нужно узнать, сколько раз пользователи вводили запрос «купить экскаватор», без учета «купить экскаваторы» и прочих вариантов. Для этого фразу заключить в кавычки, а перед каждым словом ставим оператор «!».
Мы видим точную частоту для запроса 2070. Она существенно отличается от базового значения и немного ниже фразового. Применяя операторы, можно узнать точные значения в зависимости от заданных целей и более качественно составить прогноз по трафику.
Применяя операторы, можно узнать точные значения в зависимости от заданных целей и более качественно составить прогноз по трафику.
Определение частотности по Google Ads
Сервис Google Ads используется для составления рекламных объявлений в поисковой системе Google и расчета рекламного бюджета, но можно его использовать и для проверки частотности фраз. Для этого нужно войти в систему (необходим аккаунт в Google).
Перейдите в кабинет Google Ads, нажмите на «Инструменты».
В выпадающем списке найдите раздел «Планировщик ключевых слов».
Выберите блок «новые ключевые слова».
Введите исследуемые фразы. В нашем примере используем ту же фразу «купить экскаватор».
Сервис обработает ваши данные, после чего появится результат.
Тут можно узнать примерную частотность фразы «купить экскаватор» (от 100 до 1 тыс.), узнать уровень конкуренции, просмотреть варианты дополнительных ключевых слов (указаны в таблице в соответствующем разделе). В сравнении с Яндекс.Вордстат сервис имеет скудные возможности по изучению частоты запросов. Просматривать базовую, фразовую и точную частотности тут нельзя. В планировщике Google Ads можно получить лишь приблизительное представление о популярности слова или словосочетания.
В сравнении с Яндекс.Вордстат сервис имеет скудные возможности по изучению частоты запросов. Просматривать базовую, фразовую и точную частотности тут нельзя. В планировщике Google Ads можно получить лишь приблизительное представление о популярности слова или словосочетания.
Сбор частотностей программой Key Collector
Сервисы изучения поисковых фраз Google и Яндекс хороши для проверки небольших семантических ядер и отдельных поисковых запросов. Если же нужно собирать частотности к большому семантическому ядру, лучше воспользоваться специальными программами, например, Key Collector.
Кей коллектор — это софт для автоматизированного парсинга ключевых фраз с учетом их частотностей, включая точную. Процесс сбора тут максимально упрощен. Для выяснения фразовой и точной частотностей не нужно использовать специальные символы, из заменяют функции программы. После настройки нужных параметров можно заняться другими делами — программа проанализирует все данные и выдаст результат самостоятельно.
Порядок работы по проверке частотности ключевых слов:
- Укажите исследуемые фразы. Для этого нажмите на иконку «сбор запросов из левой колонки Вордстат» или вызовете контекстное меню правой кнопкой мыши, затем выберете пункт «добавить фразы».
- Нажмите на кнопку «Директ» и задайте нужные параметры — сбор базовой, фразовой или точной частотности.
- Нажмите «Получить результаты».
Кей Коллектор обращается напрямую к Яндекс.Директ, потому результаты по частотностям будут получены быстро. Программа позволяет проверить частоту поисковых запросов в Яндексе, собрать фразы из Google, добавить поисковые подсказки. Результаты будут собраны в удобную таблицу, в дальнейшем можно удалить фразы-пустышки и сгруппировать оставшиеся словосочетания.
Key Collector — это платная программа с мощным функционалом. Для ограниченного числа задач можно установить ее бесплатный аналог «Словоёб» С его помощью также можно парсить ключевые слова и собирать к ним частотность. Процесс более медленный, потому для больших семантических ядер программа не подходит.
Процесс более медленный, потому для больших семантических ядер программа не подходит.
Заключение
Знание частотности ключевых слов поможет точнее прогнозировать трафик на сайт из поисковых систем, поможет в составлении семантического ядра и в продвижении определенных страниц. Чтобы получить нужные данные, можно воспользоваться сервисами Яндекс.Вордстат или Планировщиком ключевых слов Google Ads. Подойдут и программы для парсинга ключей, например Key Collector или Словоёб.
Подбирайте инструмент, исходя из конкретных целей и возможностей, не пренебрегайте сбором частотностей поисковых фраз. Только в этом случае можно быть уверенным в эффективности мероприятий по продвижению конкретной страницы или сайта в поиске.
обзор инструментов для сбора и анализа частотности
Для сбора семантического ядра и подбора ключевых слов для рекламной кампании важно знать частотность ключей. Статистику поисковых запросов в Google можно получить с помощью ряда инструментов, которые позволят определить не только частотность, но и другие важные параметры ключевых фраз. Рассмотрим популярные инструменты для анализа ключевых слов в данной статье.
Рассмотрим популярные инструменты для анализа ключевых слов в данной статье.
Serpstat — многофункциональная SEO-платформа, в которой, помимо анализа частности, доступны десятки других эффективных инструментов. С 15 ноября по 17 декабря 2021 новые пользователи могут подключиться на любой тариф со скидкой 40%. Размер скидки на все тарифы для действующих пользователей — 30%.
Благодаря функционалу Serpstat можно быстро определить наиболее актуальные ключевые слова для семантики и контекстной рекламы, учитывая при этом их уровень конкуренции, сложность и стоимость за клик.
Чтобы проверить частотность, введем нужный ключ в соответствующее поле «Анализа ключевых слов», выберем поисковую систему, а затем нажмем «Проверить».
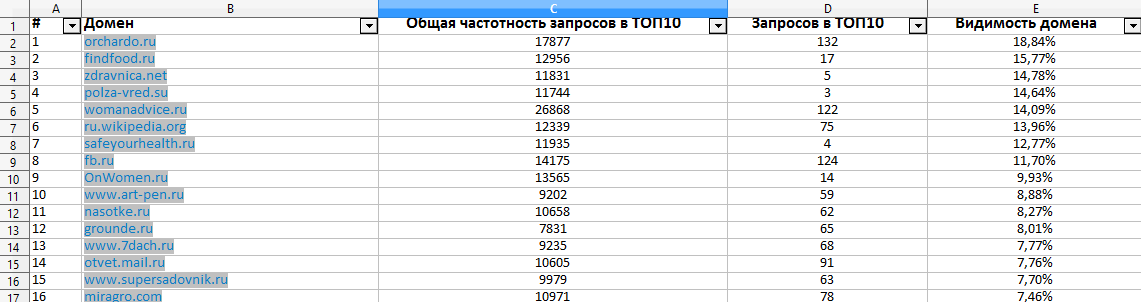
Serpstat также позволяет определить список фраз, по которым ранжируется какой-либо домен. При этом также будет определена их частотность в нужной поисковой системе. Введем интересующий домен в «Анализе домена», укажем поисковик и нажмем «Найти», чтобы получить перечень ключевых слов:
В суммарном отчете также отображаются основные параметры сайта — видимость, примерный трафик из органического поиска, ключевые слова, используемые в контекстной рекламе и пр. Можно получать информацию как про собственный проект, так и про любой конкурентный сайт.
Можно получать информацию как про собственный проект, так и про любой конкурентный сайт.
Дополнительную информацию по ключевым словам можно получить в разделе «Анализ ключевых фраз→ SEO-анализ→ Подбор фраз».
В данном отчете отображается статистика всех ключевых фраз, содержащих определенный запрос. При подборе слов для семантического ядра или рекламной кампании удобно подбирать фразы, анализируя их частотность, сложность, конкуренцию в естественной и платной выдаче.
Для отбора фраз по определенным критериям предназначены фильтры. Нажмите на иконку фильтра в правой верхней панели и выберите подходящие условия отбора, например, запросы с частотностью выше 10000 и без ошибок.
После сбора отфильтрованных поисковых запросов расширим полученный список с помощью отчета «Похожие фразы», позволяющего подобрать дополнительные ключи, связанные по смыслу с исследуемой ключевой фразой. В данный отчет попадают различные фразы, которые используют пользователи при поиске, например, сленговые и разговорные названия. В отчете также будет отображаться частотность фразы и другие метрики.
В отчете также будет отображаться частотность фразы и другие метрики.
Ещё один инструмент для расширения семантики — отчет «Упущенные фразы», который позволяет добавить для страниц проекта ключи, используемые конкурентами, но отсутствующие на вашем сайте.
Если вы собираетесь запустить рекламную кампанию, воспользуйтесь также модулем «PPC-анализ». Этот инструмент определяет все варианты исследуемого ключевого слова с указанием частотности, а также отображает объявления, используемые в контекстной рекламе.
Ускорить процесс определения частотности большого количества ключевых слов можно с помощью API Serpstat, которое позволяет автоматизировать сбор массивов данных.
Также в этом поможет Парсинг частотности — инструмент, позволяющий сделать сбор большого объема данных максимально эффективным, и получить практически неограниченное количество наиболее актуальных поисковых запросов, их частотности и позиций, занимаемых по этим ключам конкурентами в выдаче.
Как определить частотность запросов с помощью инструментов Google
Инструменты Гугл позволяют:
- собрать полную семантику с нуля или расширить уже существующее семантическое ядро;
- исследовать ключевые фразы конкурентов;
- проверить динамику популярности ключевого слова в заданный диапазон времени;
- проанализировать эффективность собранных ключей.
1. Проверка частотности в Google Рекламе
Чтобы начать работу, пройдите регистрацию в Googleser Рекламе.
После регистрации добавьте новую кампанию, указав ее цель, тип, местоположения, ежедневный бюджет и другие параметры.
После сохранения введенных данных Google предложит помощь в подборе ключевых слов:
Затем следует ввести название группы объявлений, указать домен и название продукта или услуги, чтобы подобрать ключевые слова.
Проверить частотность предложенных ключевых слов можно в Планировщике ключевых слов, который позволяет подбирать новые фразы и получать прогнозы по их количеству показов в месяц:
Скопируйте полученные ключевые фразы в Планировщик и нажмите «Начать».
В отчете отображается средняя частотность по каждому запросу, конкурентность и диапазон ставок для показа наверху страницы.
Ключевые слова можно также подобрать, выбрав в Планировщике ключевых слов вариант «Найдите новые ключевые слова». В этом случае можно указать основные ключевые фразы, на основе которых будут подбираться новые ключи и какой-либо домен.
После ввода необходимых данных нажмите «Показать результаты».
В отчете доступен список ключевых фраз и их средняя частотность в месяц, изменения за квартал, конкуренция, ставки. Можно использовать дополнительно уточнения ключевых слов. Для одежды это сезон, материал, бренд, категория и т.д. Полученные ключевые слова можно скачать в виде Google Таблицы или CSV-файла.
Планировщик ключевых слов позволяет приблизительно оценить частотность, уровень конкуренцию, и ставки, на основании анализа которых подбираются ключи для запуска рекламной кампании. Чтобы упростить выбор ключей по заданным критериям, используйте фильтры, например, укажите допустимые уровни конкуренции и нажмите «Применить»:
При подборе ключей обратите внимание на то, что для Гугла имеет значение порядок слов — ставки по фразам с одинаковыми словами, имеющими различный порядок, также будут отличаться.
2. Анализ сезонности запроса в Google Trends
Google Trends — полезный онлайн-сервис, позволяющий оценить динамику спроса на какой-то продукт или услугу в течение года. Это помогает определить, в какой период времени целесообразно запустить рекламу по определенному товару, актуальность которого зависит от сезона.
Например, анализ популярности запроса «пуховик» за пять лет показывает, что этот товар максимально часто ищут в конце ноября, в этот период частотность ключа максимальная.
В марте-августе популярность этого продукта и частотность запроса минимальна, соответственно, в весенне-летний период запускать рекламу пуховиков не имеет смысла.
3. Определение количества показов сайта по используемым запросам в Search ConsoleЗапросы, которые использовали посетители сайта при его поиске в Google, доступны в Search Console. Чтобы просмотреть их список, количество показов, кликов и среднюю позицию по каждому ключевому слову, перейдите в раздел «Эффективность».
Чтобы узнать запросы с наибольшей частотностью, по которым сайт уже успешно ранжируется, отсортируйте данные по количеству показов. Анализ данных позволит понять, на продвижении каких поисковых запросов стоит сконцентрироваться.
После установки связи с Google Analytics эти же данные будут доступны в Аналитике, если перейти в Источники трафика → Search Console → Запросы.
Сервис позволяет просмотреть статистику по 1000 запросам.
Определение частотности в сервисе «Словоеб»
Словоеб — бесплатная программа, которая позволяет определить частотность, конкуренцию и сезонность поисковых запросов в Google с учетом региона. Для использования парсера скачайте архив с дистрибутивом и установите программу на свой компьютер.
Чтобы собрать необходимые ключевые слова, введите исходные запросы во вкладку «Данные» и укажите домен. В сервисе также можно собрать поисковые подсказки Google, чтобы максимально расширить семантическое ядро.
Определение частотности ключевых фраз в Key CollectorKey Collector — платное программное обеспечение, которое предназначено для сбора и анализа статистики по поисковым запросам. Программа позволяет определить не только частотность, но и ряд других важных метрик ключевых слов — позиции сайта, уровень конкурентности, стоимость клика и пр. В Key Collector можно фильтровать, сортировать, маркировать и группировать ключевые слова для более эффективной работы с семантическим ядром.
Программа позволяет определить не только частотность, но и ряд других важных метрик ключевых слов — позиции сайта, уровень конкурентности, стоимость клика и пр. В Key Collector можно фильтровать, сортировать, маркировать и группировать ключевые слова для более эффективной работы с семантическим ядром.
Keyword Tool — онлайн-сервис, позволяющий собрать ключевые фразы и их частотность. Для поиска данных введите исходный поисковый запрос, выберите поисковую систему и укажите региональные настройки.
Бесплатно отображается ограниченное число запросов без указания их частотности, конкуренции, стоимости за клик. Чтобы получить полную информацию, необходимо оплатить Pro версию, минимальная стоимость которой составляет на ноябрь 2021 года $69 в месяц.
Заключение
Чтобы определить частотность поисковых запросов в Google, используют как бесплатные, так и платные инструменты — Планировщик ключевых слов, Key Collector, Keyword Tool.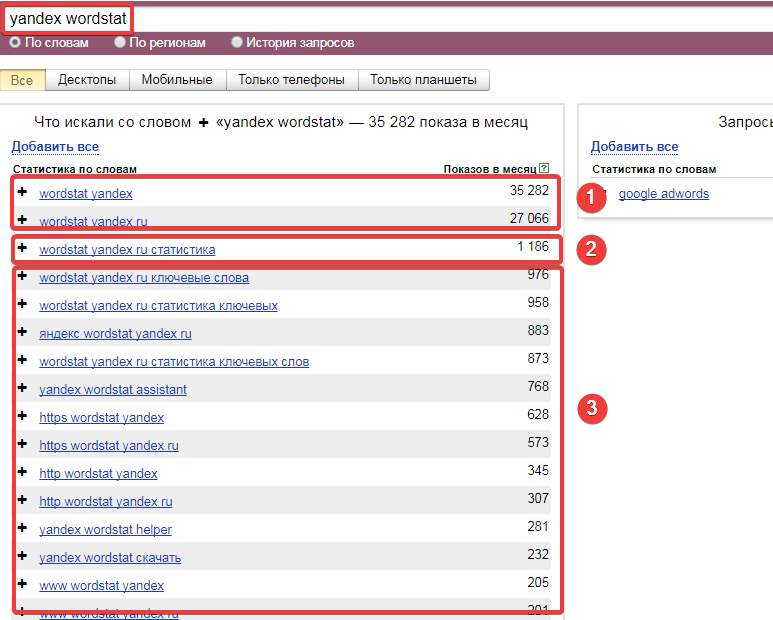 Однако наиболее эффективен в работе с ключевыми словами Serpstat, который позволяет проанализировать важные метрики ключей и собрать наиболее полное семантическое ядро. При этом все рабочие процессы можно автоматизировать при помощи API Serpstat и Парсера частотности.
Однако наиболее эффективен в работе с ключевыми словами Serpstat, который позволяет проанализировать важные метрики ключей и собрать наиболее полное семантическое ядро. При этом все рабочие процессы можно автоматизировать при помощи API Serpstat и Парсера частотности.
Как пользоваться Яндекс Вордстат: операторы, расширения и хитрости
Все самое важное: какими операторами пользоваться в Вордстате, чтобы смотреть нужные запросы, и как облегчить себе работу в сервисе. Обновленный материал для начинающих.
Яндекс Wordstat показывает статистику пользовательских запросов, в которых участвует искомое слово. Сервис нужен не только для SEO, чтобы узнавать частотность ключа и использовать его в текстах и метатегах, но и для настройки рекламных кампаний в Директе.
Какую информацию о запросах потенциальных клиентов можно узнать в Яндекс.Вордстате:
- популярность у пользователей — сколько раз люди вбивали в поисковик запрос, в котором фигурировало это слово ;
- похожие тематические запросы — что еще люди ищут в Яндексе по этой теме;
- географию спроса — в каких регионах чаще используют запросы с этим словом;
- сезонность и тренды — как меняется популярность запроса в разные месяцы.

В сервисе есть три режима: поиск по словам, по регионам и история запросов.
Поиск по словам
Данные о том, что и как часто искали со словом «ваш запрос» и какие есть похожие запросы. Колонку с похожими запросами еще называют «Эхо Вордстат».
Данные по заданному запросу, разбитые по регионам и городам.
История запросов
Динамика интереса пользователей за последние два года, данные группируют по месяцам или неделям.
ПримерНа будущий месяц
Wordstat прогнозирует значения на основе прошлого.
В каждом режиме можно настроить показ результатов в зависимости от региона поиска и устройства: десктопа, мобильного или обоих сразу. Запросы с ноутбуков и настольных компьютеров показаны во вкладке «Десктопы», смартфоны и планшеты отображены во вкладке «Мобильные». Посмотреть данные по мобильным и планшетам отдельно можно только во вкладке «История запросов».
Интересное по теме:
Оригинальные тактики подбора ключевых слов, о которых не все знают
Ограничения сервиса
Из данных, которые дает сервис, можно сделать выводы о популярности темы, эксперта, звезды, бренда, товара или услуги, приблизительно спрогнозировать спрос, спроектировать семантику и найти идеи для нового контента. Но сервис не идеален.
- Вордстат не дает абсолютно точной информации. В нем нет всех запросов, а данные о популярности могут быть искажены, потому что Яндексом пользуются не все пользователи. Часть из них делает запросы через другие поисковые системы, на планшетах и телефонах обычно предустановлен поиск Google.
- Есть оптимизаторы, которые накручивают поведенческие факторы, поэтому в Вордстат попадаются синтетические запросы, то есть накрученные, которые делают боты, а не люди.
- Запросы нужно вводить по одному. Если вам нужна информация о похожих запросах, динамике, сезонности — смотреть данные по одному ключу может и удобнее. Но если нужно только снять частотность, это медленно и неудобно.
- Сервис часто требует капчу перед проверкой запроса даже для авторизованных в Яндексе аккаунтов.
 Но если нужно только снять частотность, это медленно и неудобно.
Но если нужно только снять частотность, это медленно и неудобно.Для просмотра частотности в Яндекс.Вордстате PR-CY сделали бесплатный инструмент. Он забирает у Вордстата данные о частотности по выбранному региону с операторами, но позволяет работать с группой ключей и не требует капчу.
Снять частотность у группы запросов
Для получения информации о сезонности, истории и поиска новых ключей нужно обратиться к исходному Вордстату.
Работа с операторами Яндекс.Вордстата
Можно искать данные, просто вбивая запрос в поиск по сервису, но для конкретизации запросов есть операторы — добавочные символы с уточнениями. Они работают на вкладках поиска по словам и по регионам, на вкладке с историей запросов можно использовать только оператор «+запрос».
Обязательные слова — оператор +
+запрос — оператор делает обязательным слово, перед которым стоит. Обычно его применяют для важных предлогов. Сервис учитывает разные формы слова, иногда из-за этого меняется смысл, а правило для предлога позволяет отсечь лишнее.
Обычно его применяют для важных предлогов. Сервис учитывает разные формы слова, иногда из-за этого меняется смысл, а правило для предлога позволяет отсечь лишнее.
Минус-слова — оператор —
-запрос — позволяет вычеркнуть из результатов запросы со словами, которые не должны в них встречаться. Обычно минусуют слова, размывающие тему, в коммерции убирают запросы с самостоятельным решением проблемы.
Пример применения оператора «-» в ВордстатеТочная словоформа — оператор !
!запрос — оператор фиксирует окончание у слова, перед которым находится. Сервис покажет только запросы, где слово употреблено в заданной вами форме — нужном числе и падеже, с таким же окончанием.
Пример работы с оператором «!»Интересное по теме:
Как собрать брендовые запросы, увеличить трафик и силу бренда
Запрос без дополнений — оператор «…»
«»запрос»» — запрос в кавычках значит, что сервис покажет запросы без дополнений — хвостов, четко с указанным количеством слов.
При этом если какое-то слово или предлог в запросе дублируется, сервис добавит в результаты запросы, где на месте дубля другое слово. Запрос с двумя предлогами «в»:
Пример применения оператора «!» в ВордстатеКомбинируя операторы с кавычками и восклицательным знаком, можно достать более точные значения по нужной фразе без лишних сочетаний.
К примеру, по запросу «купить компьютер» выходят и запросы про очки, блок питания и другие сопутствующие предметы с частью «для компьютера», а с уточняющим словоформу оператором запросы сужаются.
Как искать длинные ключи из глубины Wordstat
С помощью оператора с кавычками и повторения ключа можно достать больше интересных запросов из глубины Вордстат. Вбейте в поиск конструкцию «запрос запрос запрос запрос запрос запрос», то есть одинаковый запрос Х раз в кавычках, тогда сервис выведет запросы длиной в Х слов с употреблением этого ключа.
Способ найти более длинные ключи с помощью оператора «»Обычный парсинг не даст собрать такие запросы. Количеством употреблений нужного слова можно регулировать длину запросов.
Количеством употреблений нужного слова можно регулировать длину запросов.
Точный порядок слов — оператор […]
[запрос запрос] — оператор с квадратными скобками делает строгим порядок слов в запросе. Часто это важно при географических запросах в логистике и туризме.
Пример применения оператора «[ ]» в ВордстатеГруппировка операторов — (…)
(запрос запрос) — этот оператор делает возможным группировку нескольких операторов. Тогда сервис учитывает их одновременно для указанных в скобках слов.
Пример группировки операторов в ВордстатеСинонимы — оператор |
(запрос|запрос) — оператор позволяет указать синонимы для вариативности. Работает вместе со скобками для группировки. С такими операторами сервис будет искать запросы, выбирая слова из предложенных синонимов.
Пример применения оператора «|» в ВордстатеКак читать данные Wordstat
В разделе данных «По словам» есть две колонки: слева информация о запросах за последний месяц, в правой похожие тематические.
К примеру, по фразе «кухонный смеситель» сервис вывел 25 821 результатов — это общее значение, запросы с упоминанием такого словосочетания искал 25 821 человек. Из них 4 536 искали «кухонный смеситель для мойки», 3 627 «кухонный смеситель купить» и так далее.
Посмотреть, какие ключи используют конкуренты, поможет сервис «Анализ сайта». Три сервиса в одном: аудит сайта, поиск ошибок на внутренних страницах и график изменений позиций в ПС.
Фрагмент проверки сервисомПопробовать сервис и проверить свой или конкурентный сайт
SEO-расширения для Яндекс Вордстата
Работать с большими объемами данных удобнее с помощью расширений для сбора и операций ключами. Из самых популярных можно назвать Yandex Wordstat Helper, Yandex Wordstat Assistant, Key Collector, СловоЕб, но есть и другие.
Yandex Wordstat Helper
Бесплатный SEO-плагин для Google Chrome и Opera, ускоряющий сбор слов в Вордстате. Полезно тем, кто работает с небольшой по объему семантикой.
Полезно тем, кто работает с небольшой по объему семантикой.
Результаты можно добавить в список все сразу или по отдельности по клику на плюс, сортировать в виджете по алфавиту. Плагин сам удалит дубли из списка. Дальше нужно скопировать собранные запросы в буфер обмена и вставить в редактор таблиц, которым вам удобно пользоваться.
Yandex Wordstat Assistant
Бесплатное расширение для браузеров Google Chrome, Яндекс.Браузер и Opera. Похоже на предыдущее, позволяет быстро копировать результаты.
Можно добавить все запросы в список или выбрать конкретные с помощью иконки «+», сортировать по алфавиту, частотности или времени добавления. Проверку на дубли плагин делает автоматом. Список фраз в ассистенте сохраняется при закрытии браузера и синхронизируется между вкладками.
Готовый список фраз нужно скопировать в буфер обмена и перенести в удобный редактор таблиц.
Работа с Yandex Wordstat AssistantWordStater
Сочетает в себе основное из Wordstat Helper и Wordstat Assistant, плюс добавляет свои фишки.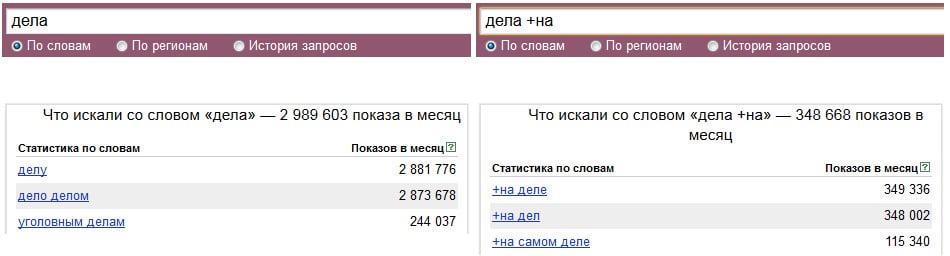
Некоторые функции доступны при регистрации в UTA-manager, это проект тех же создателей.
Чтобы добавить фразу в семантику, нужно кликнуть на плюс рядом с ней. Если кликнуть на конкретное слово, оно отправится в список минус-слов и будет помечено розовым во всех запросах.
Зафиксировать фразовое соответствие по ключу нужно по клику на кавычки рядом с нужным запросом. Посмотреть вложенность запросов для фраз в кавычках можно по клику на значок с двумя плюсами на панели Вордстата.
О работе с программами и инструментами для сбора ключей:
Как составить семантическое ядро: обзор инструментов
Сервис Вордстат полезен, чтобы парсить ключи, прогнозировать спрос, определять востребованность предложения. Операторы делают работу с сервисом быстрее и полезнее. Если вы знаете другие особенности использования операторов, поделитесь ими в комментариях!
Операторы делают работу с сервисом быстрее и полезнее. Если вы знаете другие особенности использования операторов, поделитесь ими в комментариях!
MPSTATS — Подбор запросов | MPSTATS SEO
Создание успешного списка ключевых слов — базовый этап SEO-оптимизации карточки на маркетплейсах. Он во многом определит успех продвижения и дальнейшие продажи ваших товаров.
В этой статье мы расскажем про инструмент, который поможет вам правильно и полно сформировать список запросов, чтобы вывести карточку в ТОП выдачи, а также сделать SEO-анализ ниши и выбрать новый товар.
Чем поможет Подбор запросов в работе с маркетплейсами:
✅ Сформировать качественное семантическое ядро и вывести карточку в ТОП выдачи
✅ Выставить фильтры для ключевых слов и увидеть популярные запросы покупателей, которые имеют наименьшую конкуренцию.
Как сформировать эффективный список запросов?
Теперь при выборе ключевых слов вы можете учитывать не только частотность, но и параметры, которые подходят под конкретный товар, например, цену.
1️⃣ Заходите на сервисе во вкладку SEO → Подбор запросов.
2️⃣ Перед вами откроется страница с фильтрами ↓
Указывайте необходимые параметры для поиска:
- — какое слово содержит запрос,
- — его частотность,
- — количество продавцов и брендов,
- — ценовой сегмент.
Таким образом, мы отталкиваемся не только от частотности запроса, но и от его коммерческого потенциала.
3️⃣ Нужно больше фильтров для выбора? Жмите на кнопку — Расширенный поиск
4️⃣ После того, как вы примените заданные параметры, перед вами откроется таблица: список запросов. Напротив каждого показаны данные в заданных фильтрах:
Данные рассчитываются за последние 30 суток, обновляются каждый день в 03:00 MSK
- — Частота — то, сколько раз пользователи обращались с конкретным запросом к поисковику на маркетплейсе за месяц.
- — Результаты — количество карточек товаров в выдаче по конкретному запросу.
5️⃣ Чтобы добавить или убрать ненужные параметры, проставьте галочки во вкладке Столбцы:
А также вы можете изменить ранжирование, например, по частоте или продажам, нажав на название столбца.
Как сделать SEO-анализ ниши?
Вы можете отфильтровать запросы таким образом, чтобы получить высокочастотные варианты, но имеющие небольшое количество товаров, брендов и поставщиков.
Сервис покажет товары, которые:
- — чаще всего ищут покупатели на маркетплейсах;
- — имеют небольшую конкуренцию.
Отчет Карточка запроса
Как выбирать только релевантные слова для своих карточек товаров?
Здесь вы научитесь делать подробный анализ динамики ключевиков и их коммерческого потенциала:
1️⃣ Кликайте на любую фразу и переходите в отчет Карточка запроса.
Второй способ попасть в Отчет:
Вкладка SEO → Результаты поиска (SERP).
Введите любой необходимы запрос в поисковую строку, и нажмите Enter.
2️⃣ Перед вами сводные данные по конкретному ключевому слову — сколько товаров, продавцов и брендов сервис нашел по нему на Wildberries, по каким ценам и общая выручка.
Вы можете выбрать любой период для анализа, начиная с июля 2021 года.
3️⃣ Далее идет график с динамикой изменения. По оси X указаны даты, по оси Y — позиция, на которой находится товар только по этому запросу.
Чтобы вывести на график динамику необходимого товара, поставьте галочку в таблице:
Для удобства мы присвоили каждому товару отдельный цвет линии на графике.
В самой таблице с товарами мы указали наши стандартные данные, а также добавили столбики с датами, которые фиксируют изменения позиции товара по выбранному запросу.
4️⃣ Над графиком есть вкладка — Похожие запросы ↓
Кликайте на нее, и откроется список всех смежных запросов:
Как мы составили список?
Мы берем все ключевые слова из выдачи товаров по выбранному запросу и сортируем их по степени похожести.
- — Степень похожести — это процент совпадения выдачи каждого запроса из списка с тем, в чьей карточке мы находимся.
Вы можете ранжировать и фильтровать этот список по любому параметру.
Применяйте инструмент Подбор запросов от MPSTATS в своей работе, чтобы сделать процесс работы на маркетплейсах легким и эффективным!
Сбор семантического ядра — как правильно и быстро собрать СЯ для сайта
В этом руководстве вы найдете пошаговый алгоритм быстрого сбора семантического ядра для сайта
Для старта вам пригодятся следующие инструменты:
Для ручного сбора семантики:
-
Yandex Wordstat Assistant от B1. ru:
https://be1.ru/faq/seo-tools/wordstat-assistent-zachem-on-kak-im-polyzovatysya/
- Yandex Wordstat Assistant от Semantica: https://semantica.in/tools/yandex-wordstat-assistant Можно использовать 1 расширение на выбор или протестировать оба. Рекомендуем первый вариант, он более функциональный.
- Сервис KeysSo: https://www.keys.so/ru/
 ru:
https://be1.ru/faq/seo-tools/wordstat-assistent-zachem-on-kak-im-polyzovatysya/
ru:
https://be1.ru/faq/seo-tools/wordstat-assistent-zachem-on-kak-im-polyzovatysya/
Содержание:
- С чего начать
- Шаг 1. Определение нюансов сбора запросов
- Шаг 2. Сбор первичных ключевых запросов
- Шаг 3. Поиск конкурентов
- Шаг 4. Расширение ключей
- Шаг 5. Чистка от неявных дублей
- Шаг 6. Кластеризация
- Шаг 7. Проверка частотности и коммерциализация
С чего начать
Для сбора семантического ядра нужно:
- Вручную подобрать первичные ключевые запросы: используя Yandex.Wordstat.
- Собрать список конкурентов, находящихся в ТОП-10. Проанализировав их, вы поймете, по каким ключам продвигаются ваши конкуренты и можно ли использовать их семантику. Для сбора используйте сервис выгрузки сайтов по ТОПу.
- Собрать ключи конкурентов. Делается это с помощью сервиса KeysSo. Мы рекомендуем использовать для сбора поисковых фраз не меньше 3-х конкурентов из ТОП-10.
- Собрать ключи конкурентов. Делается это с помощью сервиса KeysSo. Мы рекомендуем использовать для сбора поисковых фраз не меньше 3-х конкурентов из ТОП-10.
- Объединить файлы с ключевыми запросами от разных конкурентов в 1. Также обязательно проведение чистки.
- При необходимости расширить ключи. Если удалось собрать, например, всего 50-100 ключевых запросов вместо нескольких сотен, то ключи следует расширить для увеличения СЯ. После этого вновь дополнительно почистить от дублей и мусора.
- Очистить и кластеризовать. Это можно сделать вручную с помощью Excel или через специальные сервисы.
- Проверить частотность и провести коммерциализацию. Кроме частотности, провести коммерциализацию, распределив запросы на коммерческие и информационные.
- Скачать готовый файл. Провести последнюю чистку.
 Проанализировав их, вы поймете, по каким ключам продвигаются ваши конкуренты и можно ли использовать их семантику. Для сбора используйте сервис выгрузки сайтов по ТОПу.
Проанализировав их, вы поймете, по каким ключам продвигаются ваши конкуренты и можно ли использовать их семантику. Для сбора используйте сервис выгрузки сайтов по ТОПу.
Все действия описанные в шагах ниже вы можете выполнять и сверять полученные результаты скачав наш файл.
Шаг 1. Определение нюансов сбора запросов
Ответьте на следующие вопросы:
Сбор нужен для всего сайта или для его конкретных разделов?
Если семантика понадобится для определенного раздела, а не всего сайта, разбейте сбор на разделы и собирайте семантическое ядро по требуемым разделам. Также делайте то же самое, если планируете собирать больше 1000 запросов для всего сайта.
Например, если планируете собирать семантическое ядро для сайта digital-компании, рекомендуем разбить сайт на разделы. Например, вам понадобится семантика для 3 услуг:
- Разработка сайтов
- Разработка лендинга
- Разработка интернет-магазина
- Разработка корпоративного сайта
- SEO
- SEO-аудит
- Регулярное SEO
- Написание SEO текстов
- SMM
- VK
- Telegram
Какова тематика собираемых запросов?
Они могут быть информационными и содержать вопросы (например, как сделать что-то), или коммерческими. Продающие запросы включают в себя слова «купить», «заказать» и т.д.
Продающие запросы включают в себя слова «купить», «заказать» и т.д.
Геозависимы и сезонны ли запросы?
Некоторые запросы могут быть геозависимыми, т.е. вводиться пользователями в конкретном регионе. Например, если вы продвигаете компанию, которая продает яблоки в Ростове, то запрос «яблоки Ростов» будет геозависимым.
Сезонность — зависимость поискового запроса от конкретного месяца или сезона. Например, на 8 марта, как правило, повышается доля запросов «купить цветы». Если вы делаете ставку на продвижение с помощью сезонных запросов, вам понадобится в первую очередь собирать сезонные ключи.
Шаг 2. Сбор первичных ключевых запросов
К примеру, вам нужно собрать семантическое ядро сайта digital-компании. Можно начать с раздела «разработка сайтов».
Для сбора выполните следующие действия:
- Установите расширение для Yandex.Wordstat (от Semantica или B1.ru). В примере будет рассмотрен способ с расширением от B1.
- Кликните на значок расширения и перейдите на веб-сайт «Яндекс. Вордстат».
- Введите подходящий запрос. Например, «разработка сайтов». Всего нужно ввести 3-4 запроса на каждый раздел — к примеру, кроме разработки сайтов ещё «заказать разработку сайта» и «сайт под ключ».
- Как только вам покажет список поисковых запросов, добавьте подходящие в расширение, нажимая на значок «+». Добавленные запросы выделятся серым цветом.
- В итоге после сбора ключей для digital агентства должно получиться что-то подобное:
 Вордстат».
Вордстат».Расширение Be1
Для начальных запросов мы выбрали 3-4 подходящих, которые могут понадобиться для услуг по разработке сайтов, SEO и SMM продвижению.
При этом не брали нерелевантные запросы — например, во время сбора запросов для разработки сайтов, мы не взяли ключи, связанные с дипломными работами. Поскольку мы продвигаем коммерческую страницу, связанную с разработкой сайтов, а не написанием дипломных работ.
Повторите шаг 2 для других разделов, если решили собирать семантическое ядро по разделам.
Данный этап выполнен в файле (Вкладка «Шаг 1 — Сбор первичных ключей»).
Шаг 3. Поиск конкурентов
Собрав запросы под каждый подраздел, дальше понадобится собрать список конкурентов — мы рекомендуем брать от 3-х из ТОП-10.
Для этого можно воспользоваться сервисом для выгрузки топ-10 сайтов конкурентов — тогда нужно будет указать ключевые запросы конкретного подраздела и нажать кнопку «Начать проверку»:
Ключевые запросы подраздела
В результате получите список конкурентов:
Список конкурентов
В первую очередь нас интересуют сайты веб-студий из вкладки «видимость по Host» — там будут отображаться студии, имеющие позиции в ТОП-10 . Исключите из списка агрегаторы и биржи.
Далее:
- Перейдите по нужным URL конкурентов, для начала выберите от 3-х.
-
Откройте в соседней вкладке сервис KeysSo. На главной странице укажите URL конкурента и нажмите кнопку «Анализировать»:
Сервис анализа конкурентов
-
Дойдите до отчета «Ключевые фразы» из раздела «Органическая выдача», нажмите кнопку «Открыть все»:
Ключевые фразы
Далее вы увидите список ключевых запросов, по которым продвигается компания в конкретном подразделе.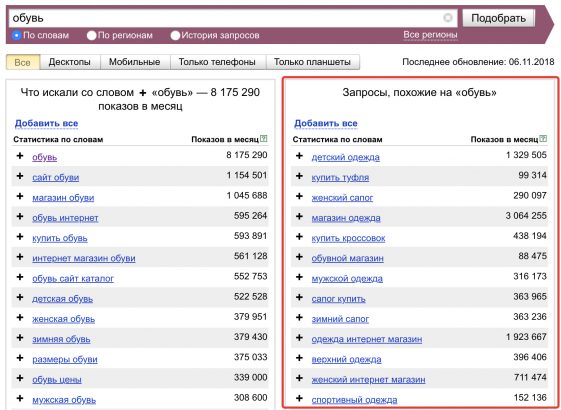
Обратите внимание:
организации могут оказывать комплексные услуги. Проверьте у них наличие дополнительных страниц.
Например, кроме разработки сайтов фирма из примера предлагает услуги по SMM и SEO.
Чтобы в отчет не попали лишние ключи из других подразделов, вы можете использовать настройки фильтров: «Страница» > «Не содержит» и «Запрос» > «Не содержит».
В поле укажите URL-адреса с подразделами дополнительных услуг и лишние запросы. Если вы видите, что примененных фильтров оказалось недостаточно, лучше настройте дополнительные, чтобы полностью исключить лишние элементы.
Также рекомендуем сделать сортировку столбцов по страницам, так вы явно сможете увидеть какие лишние URL попадаются в выдаче:
Сортировка столбцов по страницам
Если у компании нет дополнительных услуг или страниц, использовать этот фильтр не обязательно.
Обратите внимание:
в отчете могут быть нерелевантные ключевые фразы и другой мусор. Чтобы от него избавиться, в фильтре выставьте значение по WordStat «больше или равен» 100. Для того, чтобы добавить дополнительное поле фильтра, кликните на кнопку «и», затем выберите фильтр по WordStat от 100. Если запросов найдено мало, не применяйте данный фильтр.
Для того, чтобы добавить дополнительное поле фильтра, кликните на кнопку «и», затем выберите фильтр по WordStat от 100. Если запросов найдено мало, не применяйте данный фильтр.
В результате вы увидите наиболее релевантные запросы, которые используются в продвижении сайта:
Наиболее релевантные запросы
Если вы собрали запросы и увидели, что некоторых услуг не хватает, то вернитесь к шагу 1 и при поиске конкурентов оставьте только услуги, которые нужно найти:
Поиск конкурентов по услугам
Выберите столбец «Запросы» и скопируйте данные из него, воспользовавшись кнопкой копирования (она расположена слева от кнопки скачивания), и перенесите данные в ваш отдельный файл
Перенос данных в отдельный файл
После этого повторите точно такие же действия для 2 и 3 конкурентов.
В итоге у вас получится основа семантического ядра. Далее ее нужно будет почистить, удалив дубли, расширить (при необходимости, если запросов собралось меньше 100) и кластеризовать.
Чтобы почистить основу, соберите все ключевые запросы из разных файлов в один и в общем файле Excel перейдите во вкладку «Данные», затем нажмите «Удалить дубликаты»:
Удаление дубликатов
Данный этап выполнен в файле (Вкладка «Шаг 2 — Поиск конкурентов»).
Шаг 4. Расширение ключей
Расширение ключей пригодится, если получилось собрать очень мало ключей, например, меньше 150 штук. Для расширения ключей воспользуйтесь сервисом KeysSo. Наведите мышку на вкладку «Запросы» и выберите пункт меню «Расширение ключевых слов»:
Расширение ключевых слов
Затем вставьте список ваших ключевых запросов, как в примере, и нажмите кнопку «Обработать»:
Добавление ключевых запросов
В результате вы получите расширенный список ключевых фраз с дополнениями. Мы рекомендуем устанавливать значение «менее похожие ключи» на уровне 50-60%. Также вы можете использовать фильтр «является вопросом» со значением «нет», чтобы исключить информационные запросы:
Исключение информационных запросов
После того, как отчёт будет готов, скачайте его сразу целым файлом, либо скопировав только ключевые запросы и вставив их в свой общий файл. Для этого выберите столбец «Запросы» и потом нажмите на первую кнопку справа.
Для этого выберите столбец «Запросы» и потом нажмите на первую кнопку справа.
Скачайте отчет файлом
Данный этап выполнен в файле (Вкладка «Шаг 3 — Расширение ключей»).
Шаг 5. Чистка от неявных дублей
Чтобы почистить от неявных дублей, перейдите в инструмент чистки KeysSo, вставьте ключи из семантического ядра и нажмите кнопку «Обработать». Готовый результат из левого нижнего столбца скопируйте в ваш файл с семантическим ядром:
Очистка неявных дублей
Данный этап выполнен в файле (Вкладка «Шаг 4 — Чистка неявных дублей»).
Шаг 6. Кластеризация
Готовый отчет с расширенными ключевыми словами (иногда может быть семантика из шагов 3/4, если расширение ключевых слов не проводилось) нужно будет почистить от ключей, не относящихся напрямую к продвигаемым страницам и тематике сайта. Сделать это можно только вручную после кластеризации.
После ручной чистки приступайте к кластеризации. Для этого воспользуйтесь инструментом «Разбивка» Кулакова, указав ключевые слова, регион и порог кластеризации (стандартно он будет равен 3):
Инструмент «Разбивка» Кулакова
После завершения работы вы получите подробный отчет с группами поисковых запросов, экспортируйте его в Excel:
Экспорт результатов в Excel
В готовом отчете вы увидите разбивку по кластерам и запросам:
Разбивка по кластерам и запросам
Удалите из нее лишние столбцы: «№», «запросов в кластере» и «конкуренты», затем перенесите ключи из столбца «Запросы» в ваш основной файл.
Рекомендуем дополнительно вручную почистить от мусорных запросов, явно не подходящих по теме. Примеры нерелевантных ключей указаны на скриншоте.
Важно: если вы хотите оформить таблицу в удобной цветовой расцветке, скачайте этот макрос. Для его активации используйте комбинацию клавиш Ctrl+D, убедившись, что у вас стоит английская раскладка:
Удаление лишних столбцов
Если вы не планируете продвигаться в конкретном регионе, региональные запросы тоже можно удалить.
Дополнительно удалите ключевые слова со словами «бесплатно».
После кластеризации нужно будет дополнительно проверить частотность запросов и провести их коммерциализацию и локализацию.
Данный этап выполнен в файле (Вкладка «Шаг 5 — Кластеризация»).
Шаг 7. Проверка частотности и коммерциализация
Для проверки частотности используются специальные сервисы, например, ArsenkinTools. На странице инструмента сбора частотности укажите ваши ключевые слова, регион и настройки сбора:
Проверка частотности
Для коммерциализации используется тот же сервис. Перейдите на страницу инструмента Arsenkin, укажите ключевые слова и начните коммерциализацию:
Перейдите на страницу инструмента Arsenkin, укажите ключевые слова и начните коммерциализацию:
Проверка ключевых слов
В итоге программа предоставит подробный отчет, с указанием процента коммерциализации, геозависимости и локализации каждого запроса:
Подробный отчет
Скачайте его и перенесите запросы в ваш Excel файл. Дополнительно можно ещё раз почистить от дублей и прочего мусора.
Данный этап выполнен в файле (Вкладка «Шаг 6 — Частотность и коммерция»).
На этом сбор семантического ядра можно считать завершенным. Объединить полученные файлы можно с помощью функции ВПР.
Для этого:
- Скопируйте полученные данные по частотности, геозависимости и коммерциализации на отдельный лист. Пример можно посмотреть по этой ссылке.
- Перейдите на вкладку с семантикой из шага 6.
- Пропишите названия столбцов для будущих знаний (частота, геозависимость, коммерциализация и локализация). Пример, как должно выглядеть в итоге.
- В ячейку С1 из столбца «Частотность» пропишите формулу:

=ВПР(A:A;’Шаг 7 — ВПР’!A:F;2;0)
где:
- A:A — Искомое значение (запрос для которого будем подставлять значения)
- ‘Шаг 7 — ВПР’!A:F — таблица в которой будут искаться значения (в примере значения будут искаться на листе ‘Шаг 7 — ВПР’ в диапазоне столбцов A:F)
- 2 — номер столбца из которого будут подставляться значения из диапазона ‘Шаг 7 — ВПР’!A:F (в примере второй столбец это частота (столбец B))
- 0 — точное совпадение поиска
Говоря простым языком, каждые значения столбца А (из шага 6) будут сверяться с данными из столбца А (из шага 7), и затем произойдёт заполнение столбца А из шага 6.
Не забудьте применить формулу для остальных таких же значений, повторив такой же алгоритм для других столбцов.
Что показывает частотность в сервисе яндекс подбор слов wordstat
Сервис подбора слов яндекс. Что такое Wordstat Yandex.
 Для чего нужна статистика поисковых запросов
Для чего нужна статистика поисковых запросовЯндекс Вордстат удобный и бесплатный сервис от Яндекса. Он прост в освоении и обладает широким спектром использования.
Для чего используют Яндекс Вордстат:
- Для просмотра заинтересованности в товарах или услугах
- Для просмотра сезонности запросов
- Для составления семантического ядра
- Для прогноза кол-во переходов на сайт
- Подбор минус-слов
Начало использования Яндекса Вордстата
Как и в большинства сервисах перед началом работы нужно создать почту. В данном случае почта подойдет только от Яндекса. Если у вас ее нет, тогда надо перейти по адресу mail.yandex.ru и зарегистрироваться. Процесс не займет у вас больше десяти минут.
Перед нами главная страница Яндекса Вордстата
Мы можем ввести интересующий нас запрос и в правом углу нажать “Подобрать”. Перед нами будет две колонки левая и правая.
С помощью левой колонки мы можем посмотреть, какое количество показов в месяц имеет наше ключевое слово.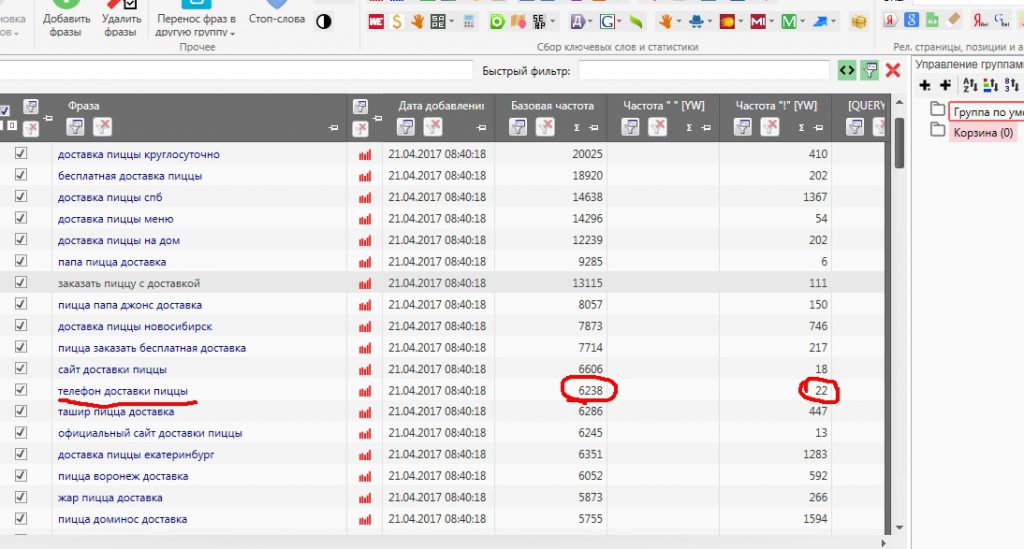
Показывает список слов, которые “входят” в наше ключевое слово.
Количество показов в месяц по ключевым словам, входящих в наш запрос.
- Левую колонку Yandex Wordstat еще называют “Эхо”. Это связанно с тем, что она показывает, чем еще интересовались люди вводившие запросы. В нашем случае это “Купить телефон”
- Показывает список слов, которые искали вместе с нашим запросом.
- Показывает сколько раз пользователи в месяц вводили ключевые слова.
Из рисунка ниже видно, что запрос “купить телефон” в Москве вводили более 200 000 раз в месяц.
Изменив регион поиска мы получим совершенно другие результаты. Как видим, количество людей, интересовавшиеся покупкой телефона в Звенигороде в разы меньше.
Мы можем посмотреть сколько людей вводило запрос используя:
- Десткопы
- Мобильные телефоны
- Только планшеты
- Только телефоны
В разделе “По регионам” нам показан спрос на продукцию среди городов и регионов. Также мы можем посмотреть количество показов объявлений за месяц.
Также мы можем посмотреть количество показов объявлений за месяц.
Для наглядности мы можем переключиться в режим “карты”, в таком случае нам будет предоставлена карта. При наведении мышки на страну будет показан уровень популярности и количество вводимого запроса в месяц.
В разделе “История запросов” можно посмотреть статистику по фразе “купить телефон” за предыдущие года. По графику видно, что пик запроса приходится на середину декабря, а момент спада на Апрель. Используя эти данные можно вносить корректировки в рекламную кампанию. Например, зная, что в Апреле спрос будет гораздо меньше, можно уменьшить бюджет и отдать приоритете на внутреннею оптимизацию, чтобы ближе к июлю РК работала еще более эффективно.
Сбор минус-слов с помощью Яндекса Вордстата
Собрать минус слова с помощью Яндеса Вордстата достаточно просто. Для этого нужно ввести интересующий запрос в поиск. В моем случае я буду использовать “ занятия боксом ”. Мы видим, все запросы, которые вводят вместе с нашим словом.
Видим, что теперь в статистике, по словам отсутствует ненужный запрос. Таким образом, нужно будет собрать, как можно больше “мусорных” слов. Чем лучше вы их проработаете, тем больше сможете сэкономить бюджет. Более подробную информацию о минус словах можете почитать в .
В этой статье речь пойдет о статистике поисковых запросов: как её следует смотреть, где её можно посмотреть, для чего она нужна и т.д. Эта тема будет очень интересна для новичков в SEO . Не будем лить много воды, а перейду ближе к делу.
1. Для чего нужна статистика поисковых запросов
Теперь поговорим о том, как и где её можно посмотреть статистику запросов.
3. Сервисы статистики запросов Яндекс и Google
Я рассмотрю два сервиса в самых популярных поисковых машинах рунета: Яндекса и Google (этого вполне достаточно для анализа запросов). Если сравнить статистики других поисковых систем, то разница в цифрах будет совсем небольшая (естественно, если сравнивать пропорционально частотность и аудитории поисковиков).
3.1. Сервис Яндекс Вордстат
В Яндексе существует специальный сервис: wordstat.yandex.ru (Яндекс Вордстат). Это очень популярный сервис, однако он показывает не частотность поисковых запросов, а частотность запросов в Яндекс Директе . В большинстве случаев этого оказывается достаточно, чтобы понять популярен ли запрос или нет.
Объясню кратко как пользоваться wordstat yandex . Введя в форме запрос, Яндекс предложит все словоформы этого запроса:
Частотность запроса в общей таблице будет указана с учетом всех-всех уточнений и дополнений. Если необходимо узнать частотность конкретного ключевого слова в той же словоформе, то его нужно написать в кавычках и перед каждым словом поставить восклицательный знак:
Стоит также учитывать то, что Яндексу нету разницы во множественным числе писать словосочетания или нет. Яндекс вообще не учитывает словоформы, а также не учитывает все предлоги.
Получив какие-то данные по поисковым запросам в вордстате, нужно помнить, что эти данные далеко не точные. Например, я их учитываю только пропорционально, т.е. если в Яндекс Директе запрос популярен, то логично предположить, что и в выдаче он тоже будет популярен.
Например, я их учитываю только пропорционально, т.е. если в Яндекс Директе запрос популярен, то логично предположить, что и в выдаче он тоже будет популярен.
Чтобы учитывать предлоги (что, как, в, на и т.д.) перед ним нужно ставить знак плюс «+». Например, запрос «+как заработать +в интернете».
3.2. Сервис Google Adwords
Теперь поговорим о Google, который предоставляет даже немного более интересный инструмент, чем Яндекс. Ссылка на сервис: adwords.google.com . Вам нужно авторизоваться, далее нажать на «Инструменты и анализ» далее «Планировщик ключевых слов». Здесь нужно вбивать ключевые слова и вам на выбор предлагается большой выбор ключевых фраз, которые Гугл находит из своей базы контекстной рекламы Adwords. Также очень здорово, что можно посмотреть историю изменения частотности запроса.
Когда у Рамблера был очень хороший сервис, но с недавних пор теперь у него нету своей поисковой базы, т.к. он использует выдачу Яндекса. Вообще в рунете существует только два хороших сервиса, которые я и рассмотрел.
Все системы для анализа ключевых слов, сбора СЯ и т.д. берут данные именно с этих двух сервисов — помните это!
4. Как узнать динамику популярности запроса
Яндекс и Гугл дают бесплатную возможность посмотреть динамику популярности запроса. Это удобно для того, чтобы определить общий тренд и перспективность каких-то запросов. Также с помощью этого можно определять сезонность запросов.
В Яндекс Вордстате нужно выбрать галочку «История запросов» и Вы увидите график изменения.
Подобрать поисковые запросы для продвижения сайта можно через сервисы статистики. В Яндексе для этой задачи используется система Wordstat, доступная по адресу http://wordstat.yandex.ru В нашей статье мы расскажем, как при помощи сервиса Яндекса узнать частоту поисковых запросов.
Инструмент Wordstat создан для людей, желающих разместить контекстную рекламу. Он работает так: вы вводите слово или фразу и получаете список слов и фраз с указанием их частоты. Но это не частота конкретного запроса, а частота всех запросов, в которых встречались указанные слова или фразы.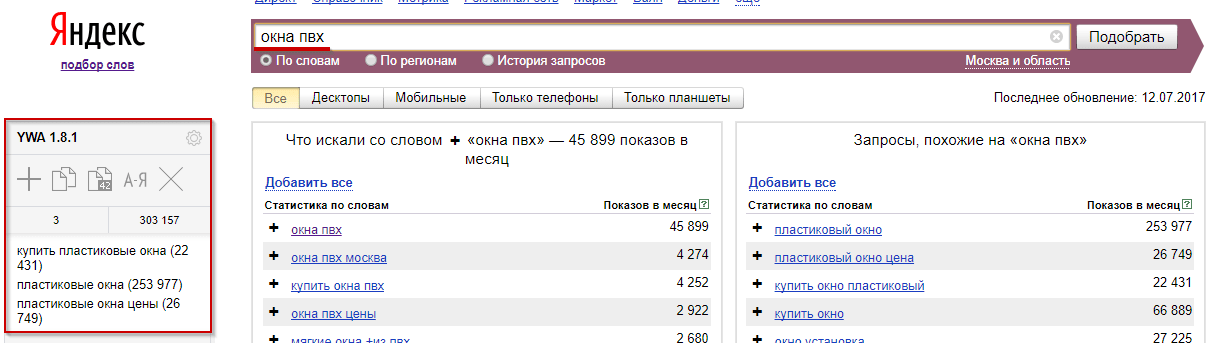
Разберем на примере (см. картинку ниже):
В указанном примере частота по слову «кондиционеры» составляет 1 741 974 – это суммарная частота всех запросов, включающих слово кондиционер. Но это совсем не означает, что запрос из одного слова «кондиционеры» вводят столько раз – на самом деле нет.
Как посмотреть частоту запроса?
Чтобы посмотреть, сколько раз вводят поисковый запрос «кондиционеры», состоящий из одного слова (без учета словоформ), необходимо взять это слово в кавычки. Если вам нужно проверить частоту запроса из нескольких слов – то вы берете в кавычки целую фразу.
См. пример ниже:
Цифра 64 981 означает частоту всех запросов, состоящих из одного слова «кондиционеры».
Как определить наиболее популярную форму запроса?
Как узнать, сколько раз задают запрос «кондиционеры» (мн. число), а сколько раз – запрос «кондиционер» (ед. число)? Задаем запрос в кавычках и перед словоформой ставим знак «!».
См. пример проверки частоты запроса, состоящего из одного слова, во множественном числе:
пример проверки частоты запроса, состоящего из одного слова, во множественном числе:
Число 50 368 означает частоту запроса из одного слова во множественном числе.
Используя аналогичную схему, можно проверить частоту слова в единственном числе и сравнить частоты разных форм запроса. Это позволит выбрать форму с наибольшей частотой.
Чтобы проверить частоту запроса из нескольких слов, внутри которого есть стоп-слова, необходимо взять фразу в кавычки, рядом с каждым словом поставить восклицательный знак, а перед стоп-словом знак «+».
Как узнать порядок слов в запросе?
К сожалению, специальных операторов для этого в системе Wordstat нет, но по умолчанию она выводит, как правило, наиболее популярный порядок слов.
Также, чтобы узнать порядок слов в поисковых запросах, можно купить размещение контекстной рекламы и посмотреть – по каким запросам будут переходить на сайт чаще. Это дорого, но если вы желаете собрать наиболее полное и качественное семантическое ядро – затраты будут оправданны.
Полезные статьи
Есть несколько сервисов, позволяющих спрогнозировать частотность поисковых запросов , но большинство специалистов использует сервис от Яндекса — Яндекс Вордстат.
У Яндекса существенная доля рынка (большая выборка данных) и удобный инструмент для анализа (Яндекс Вордстат). В инструменте от Mail вы можете получить более расширенные данные по каждому ключевому запросу, но на гораздо меньшей выборке данных. Сервис Яндекс Вордстат создавался в первую очередь для Яндекс Директа, но является очень полезным для seo-специалистов.
3 вида частотности запроса в Яндекс Вордстат
Ежедневно seo специалисты в своей работе используют 3 вида частотности. Вам необходимо уловить разницу и научиться правильно интерпретировать информацию, понять ее ценность.
Общая частость — это прогнозируемое количество показов в месяц введенной фразы с любым другими словами в любом падеже/склонение/числе и т.п. То есть, если вы введете запрос [доставка пиццы], то получите количество показов в месяц таких запросов, как: [доставка пиццы], [доставка пиццы круглосуточно], [недорогая доставка пиццы в Санкт-Петербурге в 3 часа ночи], [пицца ахтынзан доставка в Екатеринбург] и т. п.
п.
Яндекс:
Цифры рядом с каждым запросом в результатах подбора слов дают предварительный прогноз числа показов в месяц, которое вы получите, выбрав этот запрос в качестве ключевого слова. Так, цифра рядом со словом «телефон» обозначает число показов по всем запросам со словом «телефон»: «купить телефон», «сотовый телефон», «купить сотовый телефон», «купить новый сотовый телефон в крапинку» и т.п.
То есть Яндекс говорит нам, что слово «пицца» и любые словосочетания со словом «пицца» наберут 2 242 196 раз в месяц, а фразу «доставка пиццы» и все словосочетания с фразой «доставка пиццы» наберут 240 705 раз в месяц. С помощью этой информации можно найти интересные кластеры запросов, которые набирают пользователи и проанализировать потребности потенциальных клиентов. Например, здесь явно видно, что только 10% пользователей, которые искали что-либо связанное с пиццей, ищут ее доставку.
Часть пользователей хотят получать пиццу круглосуточно, а для другой части пользователей очень важно, чтобы пиццу привезли быстро. Это весьма ценная информация для вашего бизнеса, поэтому экспериментируйте и ищите интересные потребности в запросах.
Это весьма ценная информация для вашего бизнеса, поэтому экспериментируйте и ищите интересные потребности в запросах.
2. Точная частотность запросов
Точная частость — это прогнозируемое количество показов в месяц введенной фразы без каких-либо других слов , но в любом падеже/склонение/числе и т.п. То есть, если вы введете запрос «доставка пиццы», то получите количество показов в месяц таких запросов, как: [доставка пицца], [пицца доставка], [доставка пицц] и т.п.
Чтобы получить точную частотность запроса, весь запрос необходимо взять в кавычки:
Точная частотность поможет найти ключевые запросы, которые реально набирают пользователи. Также обратите внимание, что только 6% пользователей , которые ищут что-либо с доставкой пиццы ограничиваются запросом [доставка пиццы], а 94% пользователей дополняют (конкретизируют) свой запрос.
3. Супер точная частотность запросов
Супер точная частость — это прогнозируемое количество показов в месяц введенной фразы без каких-либо других слов и в указанном падеже/склонение/числе и т. п. То есть, если вы введете запрос «!доставка!пиццы», то получите количество показов в месяц запроса [доставка пиццы].
п. То есть, если вы введете запрос «!доставка!пиццы», то получите количество показов в месяц запроса [доставка пиццы].
Чтобы получить точную частотность запроса, весь запрос необходимо взять в кавычки и перед каждым словом поставить восклицательный знак:
Супер точная частотность позволяет выявить в каком падеже, числе и склонение люди набирают определенные запросы.
Предлоги в Яндексе
В вордстате не учитываются предлоги, когда вы анализируете общую частотность. Если вам нужно посмотреть ключевой запрос с предлогом, то перед предлогом необходимо поставить «+».
Представьте, что вы хотите узнать сколько человек желает купить авиабилеты в Москву. Если вы наберете [авиабилеты в Москву], то получите 716 174 общей частотности, но в эту частотность входят и запросы [авиабилеты из Москвы], [авиабилеты Москва], [москва сочи авиабилеты] и другие.
Но если вы введете запрос [авиабилеты + в Москву], то увидите 66 841 общей частотности. Цифры отличаются в 10 раз, надеюсь, что вы не забудете указать «+»
В сервисе Яндекс Вордстат есть возможность проанализировать частотность запросов по необходимому региону. Иногда это бывает очень полезно.
Иногда это бывает очень полезно.
В некоторых сферах деятельности вы сможете найти для себя подходящие запросы, которые встречаются только в определенных регионах. Например, названия географических объектов.
Также предусмотрен отдельный функционал, где вы сможете посмотреть популярность любого ключевого слова в разных регионах.
Сезонность (история запросов) — очень полезный функционал с помощью которого можно проанализировать частотность по ключевому слову в разные периоды времени. Данные хранятся за 2 года.
Например, вот так выглядит спрос на авиабилеты в Москву в разное время года:
Дополнительные операторы
Есть некоторые операторы, которыми пользуются квалифицированные специалисты. Если вы только начинаете осваивать поисковую оптимизацию, то не стоит фокусировать на них внимание.
Оператор «-»
Оператор «-» позволяет убрать ненужные слова (по аналогии с директом).
Оператор «|» (или)
Оператор «|» (или) позволяет получить результат сразу по нескольким условиям.
Оператор «()» (группировка)
Оператор «()» (группировка) позволяет комбинировать условия.
Мы продолжаем серию статей о Яндекс Директе. На прошлой неделе, напомню, и говорили о том, где она может размещаться. Сегодня Вера Каргина рассказывает, как подбирать слова для Яндекс Директа (хотя точнее их называть запросами), как правильно использовать специальные операторы и как прогнозировать бюджет кампании.
Между прочим, если вы расшарите статью в соцсетях (для этого есть кнопки соцсетей под формой подписки под статьёй), больше людей получат доступ к такой подробной и понятной информации про директ. А то мы пишем, «а мужики-то не знают»
Что такое запрос?
Запрос – это та фраза или слово, которую пользователь вводит в строке поиска. Именно она отражает его интерес, и этим нужно пользоваться в первую очередь.
Все запросы как матрешка: они включены друг в друга от самого широкого до самого узкого. Чем уже запрос, тем больше слов он содержит.
В этом примере широкий запрос «велосипед» включает в себя все остальные более узкие запросы. И, в свою очередь, каждый из этих запросов включает в себя все последующие более узкие фразы.
Также запросы можно представить в виде пирамиды:
В этом примере самый широкий запрос — «холодильник».
Широкие запросы охватывают очень большую аудиторию, которую может интересовать, например, не только покупка холодильника, но и ремонт, и отзывы, и правильное хранение в холодильнике каких-либо продуктов, поскольку этот запрос включает в себя абсолютно все фразы, в которых присутствует слово «холодильник».
Морфология
Яндекс Директ не учитывает морфологию по умолчанию, поэтому запросы в любом числе и падеже воспринимаются системой как равные. Но обратите внимание, что, если это просто однокоренные слова, но разные части речи, для системы это будут разные запросы.
Wordstat.Yandex
Прежде, чем рассказывать о запросах что-либо еще, необходимо познакомиться с самым главным инструментом статистики в Яндексе – Wordstat. Найти его можно по ссылке «Подбор слов» в интерфейсе Яндекс Директа или по прямой ссылке: http://wordstat.yandex.ru
Найти его можно по ссылке «Подбор слов» в интерфейсе Яндекс Директа или по прямой ссылке: http://wordstat.yandex.ru
Сразу стоит отметить, что подбирать слова в Яндекс Директе для дальнейшей загрузки их в кампанию именно здесь не очень удобно, так как копировать фразы придется вручную. Этот инструмент больше предназначен для просмотра статистики.
Чтобы посмотреть статистику по ключевому слову, необходимо сначала выбрать регион показа будущих объявлений.
В строчку добавляем сам запрос (по умолчанию галочка стоит на пункте «по словам», который нам и нужен) и нажимаем «подобрать». Получаем такую табличку.
В левом столбике мы видим все слова, которые включает в себя запрос «новогодние подарки», и статистику по ним (сколько раз пользователи из выбранного региона набирали этот запрос в поиске Яндекса за прошедший месяц).
В правой колонке запросы, которые также набирали пользователи, искавшие пластиковые окна. Они могут служить подсказками, какие бы еще слова выбрать по данной тематике.
В этом же инструменте можно посмотреть, как отличается статистика по запросу в разных регионах. Для этого надо поставить галочку в поле «по регионам».
Многие запросы имеют сезонность. Например, шины или новогодние подарки. Если делать расчет бюджета к зимнему сезону осенью, то можно получить некорректные данные, т.к. статистика берется по предыдущему месяцу. Вряд ли летом или в начале осени эти запросы популярны, но можно посмотреть, как изменялась статистика в течение года и знать, чего ждать от бюджета. Для этого ставится галочка на «истории запросов»:
Из графика видно, что пик для запроса «зимняя резина» приходится на ноябрь-декабрь и разница огромна.
Использование специальных операторов
Представьте, что пользователь вводит в поисковую строку слово аквариум . Что он может иметь в виду? Он хочет купить пустой аквариум? А может быть, ему нужен аквариум вместе с рыбками? Или он хочет сделать аквариум своими руками? Ищет обои для рабочего стола? Или хочет послушать Бориса Гребенщикова?
Предположим, что мы занимаемся продажей аквариумов, и нам не нужно, чтобы наше объявление видели поклонники БГ или мастера на все руки.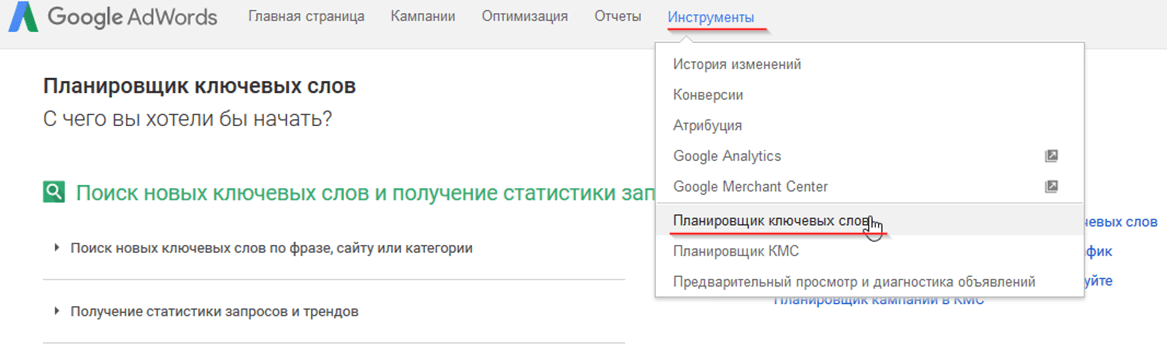
Для уточнения запроса и ограничения целевой аудитории можно использовать специальные операторы.
Оператор «-» (минус-слова). Позволяет исключать из статистики запросы, включающие то или иное слово. Оператор «-» ставится вплотную к исключаемому слову, без пробела. Перед оператором ставится пробел. Например, если указать ремонт -гарантийный , можно получить статистку показов по всем запросам, включающим слово ремонт , кроме тех, в которых есть слово гарантийный . Если необходимо исключить из расчета запросы со словами гарантийный и бесплатный , нужно указать: ремонт -гарантийный -бесплатный .
Для нашего аквариума это будет выглядеть следующим образом:
Рассмотрим еще один пример. Нам нужно продать дом у озера и, конечно, мы будем использовать для нашей рекламы такой запрос. Но по этой фразе пользователи могут искать информацию об одноименном фильме.
Чтобы отсечь ненужную аудиторию, нам необходимо отминусовать все, что связано с фильмом.
Запрос в этом случае будет выглядеть так: дом у озера –фильм –киану –ривз –скачать – dvd –смотреть –онлайн –бесплатно .
Обратите внимание, что пробел после минуса не ставится, а перед минусом ставится.
А теперь представьте, что вы, наоборот, рекламируете онлайн-кинотеатр. В запросе дом у озера есть предлог «у », а Яндекс по умолчанию не учитывает предлоги. То есть запросы дом у озера и дом озеро будут для системы одинаковыми. И, если в случае с недвижимостью пользователи могут набрать запрос в любом виде, например, дома у озера , дом перед озером , дом около озера , то название фильма уж точно никак не изменится, и предлог «у » будет присутствовать во фразе в любом случае. Предлог можно закрепить при помощи специального оператора.
Оператор «+». Позволяет принудительно учитывать в статистике предлоги или союзы, которые игнорируются поисковой системой и, соответственно, статистикой подбора слов. Например, общее количество показов по запросу товары для автомобиля совпадает с количеством показов по запросу товары автомобиля. Если присутствие в запросе предлога «для » принципиально, необходимо набрать в поле ввода: товары +для автомобиля . Предлог будет включен в запрос во всех его формах.
Например, общее количество показов по запросу товары для автомобиля совпадает с количеством показов по запросу товары автомобиля. Если присутствие в запросе предлога «для » принципиально, необходимо набрать в поле ввода: товары +для автомобиля . Предлог будет включен в запрос во всех его формах.
Обычно в статистике запросов оператор «+ » используется по умолчанию во всех фразах, содержащих в себе предлоги или союзы. Для получения количества показов по фразе без учета служебного слова необходимо переформулировать запрос, убрав из него «+ » или само служебное слово.
Но вернемся к фильму «Дом у озера». После фиксации предлога «у » необходимо отминусовать все, что связано с недвижимостью.
Фраза будет выглядеть следующим образом: дом +у озера –подмосковье –большое –маленький –город –метр –квадратный .
Иногда бывает так, что слово необходимо отминусовать полностью, то есть показы объявления должны вестись строго по тому запросу, который вы выбрали, а по всем вложенным в него фразам показов быть не должно.
Такая необходимость возникает, когда запрос очень широкий, а нужных фраз среди вложенных мало и их лучше прописать отдельно. Чтобы не минусовать этот запрос бесконечно, существует оператор кавычки.
Оператор «» (кавычки). Позволяет учитывать в подсчете показы только по этому слову (фразе) и всем его словоформам, и не учитывать показы по запросам, содержащим словосочетание с заданным словом.
Рассмотрим пример. Если ввести в Wordstat слово пледы , то мы увидим, что за прошедший месяц пользователи набирали его в поисковике 199 068 раз. Но здесь фраза пледы включает в себя и все вложенные в нее запросы.
Если же мы введем запрос в кавычках, то увидим, что по одному слову пледы было всего 3 934 показа.
Теперь давайте представим, что нам надо осуществить подбор запросов для сайта фирмы, продающей кии для бильярда.
Как мы уже знаем, Яндекс Директ не учитывает склонения, а если мы поставим слово «кий» в родительный падеж и множественное число, то получим…
Чтобы зафиксировать форму слова, используют восклицательный знак перед ним.
Оператор «!». Позволяет учитывать в подсчете показы только по заданной форме слова. Оператор «!» ставится вплотную к ключевому слову, без пробела. Перед оператором ставится пробел (продажа!кий для бильярда ).
Если мы не будем использовать восклицательный знак перед словом кий в данном примере, то по запросу «продажа киев для бильярда » нас увидят те, кто вводит, например, запрос «продажа столов для бильярда в киеве ».
И еще один пример. Мы продаем товары для дома и используем запрос покрывало. Кроме нужного нам существительного, это слово является глаголом в прошедшем времени. А у глагола покрывать в свою очередь есть форма повелительного наклонения покрой , которая также является существительным (например, покрой платья ). Таким образом, покрывало и покрой для системы будут являться одним и тем же запросом. Поэтому здесь тоже нужно фиксировать форму слова восклицательным знаком.
Иногда для запроса важен порядок слов, который по умолчанию система тоже не учитывает.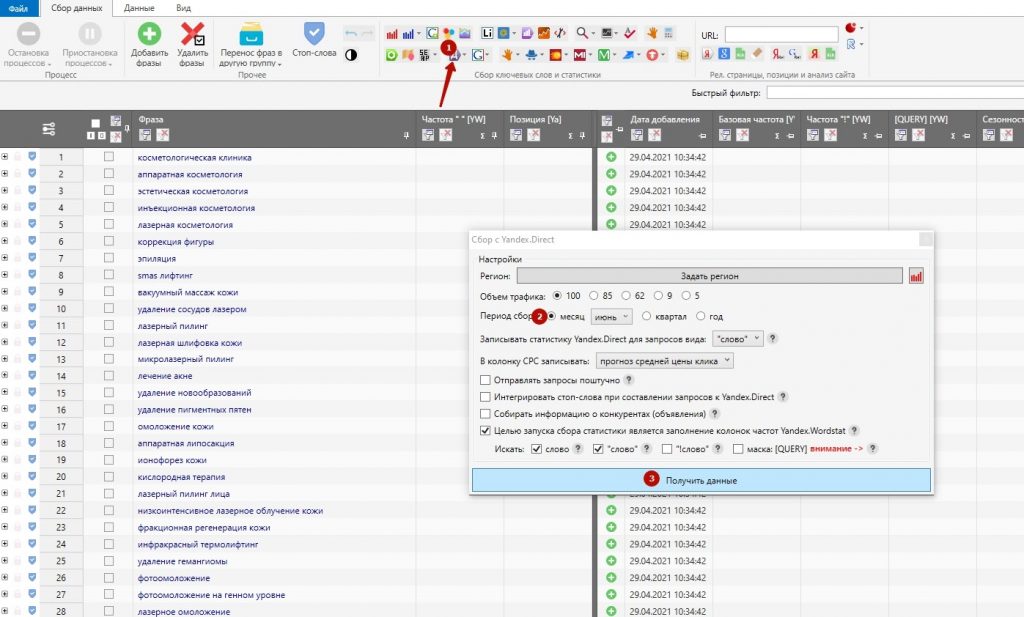 Чаще всего это бывает необходимо при продаже билетов для запросов о направлениях.
Чаще всего это бывает необходимо при продаже билетов для запросов о направлениях.
Оператор «» (порядок) . Позволяет зафиксировать порядок слов в запросе. В квадратные скобки не обязательно брать всю фразу, а только ту ее часть, которую необходимо зафиксировать.
Или, например, вы продаете автозапчасти. Запрос запчасти для автомобиля равен запросу автомобиль на запчасти , поскольку предлоги не учитываются. Конечно, можно зафиксировать предлог «для », но наверняка найдутся пользователи, которые напишут и автомобиль для запчастей . Поэтому в данном случае лучше зафиксировать и предлог, и порядок слов.
Запрос будет выглядеть следующим образом: [запчасти +для автомобиля] .
С их помощью можно составить выражение типа: ремонт (автомобилей | автомашин) (ВАЗ | ГАЗ) -гарантийный -бесплатный . Оно будет равнозначно запросам по следующему набору слов: ремонт автомобилей ВАЗ -гарантийный -бесплатный , ремонт автомобилей ГАЗ -гарантийный -бесплатный , ремонт автомашин ВАЗ -гарантийный -бесплатный , ремонт автомашин ГАЗ -гарантийный -бесплатный .
Операторы – это очень полезный инструмент, которым можно пользоваться не только для уточнения ключевых фраз в Яндекс Директе, но и для поиска Яндекса.
Как подбирать запросы для разных типов площадок?
Поисковые площадки и тематические площадки имеют различную аудиторию, поэтому и подбирать запросы для них нужно по-разному.
Поисковые площадки Директа
Аудитория поиска – это горячая аудитория, она уже готова к покупке вашего товара или услуги, и уже сама ищет их. Поисковые площадки отлично подходят для того, чтобы продать что-то быстро.
Для эффективного подбора слов для объявлений, которые будут показываться в поиске, важно следовать следующим принципам:
На тематических площадках запрос как таковой не используется, ведь здесь нечего искать.
И хоть запросы на самих площадках не видны, в интерфейсе Яндекс.Директа именно при помощи ключевых слов мы выбираем, на сайтах какой тематики будут показываться наши объявления. Поэтому для тематических площадок лучше всего:
Прогноз бюджета рекламной кампании и подбор запросов в инструменте для прогноза
Инструмент «Прогноз бюджета» удобен не только для планирования расходов по рекламной кампании, но и для простого подбора запросов, ведь именно здесь выбранные фразы можно выгрузить в Excel-файл.
Прогноз бюджета находится по одноименной ссылке в интерфейсе Директа. Здесь также сначала необходимо выбрать регионы, в которых будет работать рекламная кампания. Затем можно сразу ввести слова в поле (через запятую или в столбик), если они уже есть.
В этом случае справа появится колонка с подсказками, из которой тоже можно выбрать запросы, просто кликнув на них.
Также можно нажать кнопку «подобрать», тогда откроется Wordstat, но в нем теперь можно будет ставить галочки напротив нужных запросов, тем самым добавляя их к расчету.
После того, как слова выбраны, необходимо нажать кнопку «посчитать». Открывается страница с прогнозом, который в дальнейшем можно выгрузить в один файл.
В полученной таблице можно увидеть прогноз цены клика для каждого слова на разных позициях и примерный прогноз CTR. Ниже есть поле, в котором можно добавить еще запросы.
Теперь можно работать с выбранными словами, уточнять их или подбирать еще слова.
Если напротив запроса нажать кнопку «уточнить», появятся вложенные в эту фразу запросы. Выбирая среди них ненужные, мы добавляем к фразе минус-слова.
Выбирая среди них ненужные, мы добавляем к фразе минус-слова.
Нажав кнопку «подобрать», мы можем добавить к расчету фразы из вложенных в данный запрос.
Здесь же можно выгрузить прогноз бюджета в таблицу, с которой потом удобно будет работать.
Подбор слов внутри кампании
Можно добавлять новые слова к уже готовым объявлениям или создавать новые.
Откроется уже знакомый инструмент подбора:
Теперь вы знаете, как правильно подбирать запросы для рекламной кампании.
Yandex Wordstat: подробная инструкция по использованию сервиса и операторов
Яндекс Вордстат — бесплатный сервис поисковой статистики и подбора слов от компании Яндекс. Преимущественно сервис создавался для оценки ключевых слов рекламодателями Яндекс Директ. Но в дальнейшем, стал инструментом и SEO оптимизатора.
Для чего нужен Яндекс Вордстат?
Если вы работаете с контекстной рекламой или с продвижением сайта под поисковые системы, то сервис подбора слов от Яндекса для вас будет незаменим.
В чем он поможет:
- Подбор эффективных ключевых слов для контекстной рекламной компании или для поискового продвижения сайта (семантическое ядро).
- Прогноз трафика, оценка частотности показов ключевых фраз и ниши в целом.
- Помощь в разработке структуры сайта.
- Выявление трендов по фразам.
Как работать с сервисом?
Для работы с Wordstat необходима регистрация в сервисе по email или через социальные сети. Если у вас уже имеется аккаунт в других сервисах Яндекса, то для работы с подбором слов можно использовать его.
Войти (правый верхний угол) > Регистрация
Инструмент «По словам»
При входе в систему, у вас по умолчанию отображается инструмент «По словам».
- Поле ввода запроса — в эту строчку мы вводим слово или фразу по которой хотим увидеть данные.
- Инструменты сервиса — отображение слов по регионам и истории(тренд) запроса.
- Все регионы — выбор региона по которому будет отображаться статистика.
- Платформа — выбор платформы по которой будет отображаться статистика.
- Последнее обновление — дата последнего обновления данных в сервисе.
- Левая колонка Wordstat — показывается список запросов в которой содержится введенное в пункте(1) слово или фраза.
- Правая колонка Wordstat — показывается список фраз, которые еще могли искать люди вводившие наше слово или фразу.

Разберем подробнее, как работает левая и правая колонка Яндекс Вордстат.
Левая колонка
В левой колонке отображаются все фразы, которые содержат наш введенный запрос.
Например, мы вводим запрос яндекс вордстат. Нам покажутся все фразы, которые содержат наш запрос, при этом порядок слов не будет иметь значения.
Это надо запомнить! Цифра напротив запроса — количество показов этой фразы в месяц, а не количество переходов по этой фразе! Например, если мы зайдем в поисковую систему https://www. yandex.ru/, наберем фразу яндекс вордстат и нажмем найти — это и будет 1 показ по этой фразе.
yandex.ru/, наберем фразу яндекс вордстат и нажмем найти — это и будет 1 показ по этой фразе.
Цифра отображает все входящие в него запросы.
Например: В число показов 60 897 по запросу вордстат яндекс входят все числа запросов ниже, которые содержат фразу яндекс вордстат или вордстат яндекс порядок слов не имеет значения.
А в число показов 2295 по фразе яндекс вордстат ключевые входит число показов по фразе яндекс вордстат ключевые слова.
Если мы нажмем на фразу яндекс вордстат ключевые, то мы в этом убедимся. Нам отобразятся все фразы, которые входят в этот запрос.
Это основной принцип и логика работы инструмента «По словам» и левой колонки Wordstat. Для более расширенного отображения статистики, существуют операторы подбора слов.
Еще показы называют частотностью (частоткой). Прям так и говорят, частотность фразы яндекс вордстат равна 60 897.
Основные операторы Яндекс ВордСтат
Существует два основных оператора:
- Восклицательный знак.
- Кавычки.
Также они могут использоваться вместе друг с другом. Рассмотрим суть применения каждого оператора на примере простейшего запроса.
Восклицательный знак
Прописав перед словом ! вы фиксируете окончание у слов, перед которым стоит знак !.
То есть, написав !купить !телефон, в отображаемые показы уже не будет входить склонения слов, например: телефоны, купил и другие измененные окончания и склонения слов перед которыми стоит !. Но сюда в эти показы входят все фразы которые имею точно написание купить телефон, например в эти показы входят такие запросы: как купить сотовый телефон, где купить телефон и т.д.
Восклицательный знак фиксирует только точное написание этих слов перед которыми он стоит.
Посредством базового оператора «Восклицательный знак» пользователь может посмотреть результаты по конкретному запросу без каких-либо склонений одного либо нескольких слов, содержащихся во фразе.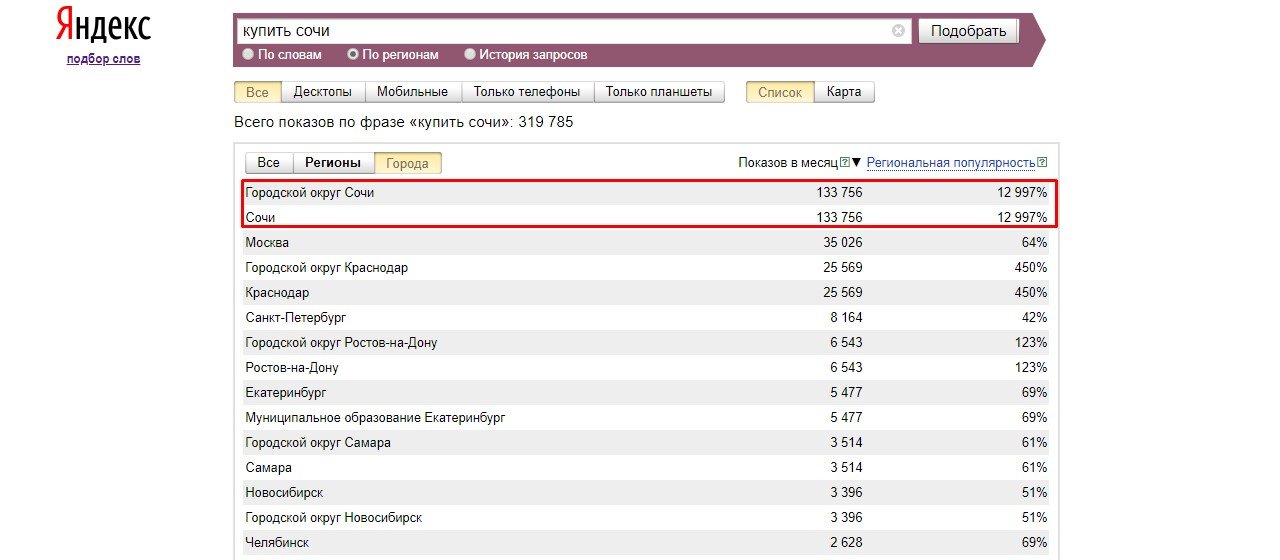
Кавычки
Введя фразу «купить телефон» в кавычках, вы увидите количество показов лишь данного запроса без других каких либо дополнительных слов, то есть в этот запрос могут входить фразы: купить телефоны, телефоны купить, купил телефон и т.д. Сюда уже не входят другие дополнительные слова, например: как купить телефон, где купить сотовый телефон и т.д.
Значение в кавычках называют фразовой частотностью.
Совместное применение операторов кавычки + восклицательный знак
Прописав «!купить !телефон», вы зафиксируете и сам запрос, и окончания у слов. Таким образом, вы узнаете точную частоту по конкретному запросу без дополнительных слов, позволяющую спрогнозировать число переходов по этому запросу. Но помним, число показов — это не число переходов, поэтому это лишь примерные данные, так же надо понимать что количество кликов уменьшается в зависимости от позиции сайта в выдаче поисковой системы по данному запросу.
Значение ковычки+восклицательный знак называют точной частотностью.
Дополнительные операторы
Есть еще 5 основных вспомогательных операторов, открывающих еще больше возможностей в Яндекс Вордстат:
- Оператор «Плюс». Для его использования указывается символ +. Он помогает отыскать поисковые запросы, где есть стоп-слова, такие как союзы, предлоги и т.п.
- Оператор «Квадратные скобки». Применяются символы [ ] с написанием между ними ключевой фразы. С его помощью фиксируется расстановка слов во фразе, то есть, они остаются в таком порядке, как вы их прописали. Оператор актуален тогда, когда нужно проанализировать популярность схожих фраз по различным запросам.
- Оператор «Или». Используется с помощью символа | и важен для оперативного подбора семантики на веб-страницу, а также в процессе сравнения или «смещения» в статистике некоторых фраз.
- Оператор «Минус». Для его применения прописывается символ —. Он убирает при необходимости запросы, содержащие ненужные для изучения статистики слова.
- Оператор «Группировка». Указываются символы ( ), внутри которых прописываются вышеперечисленные операторы, чтобы использовать их вместе.
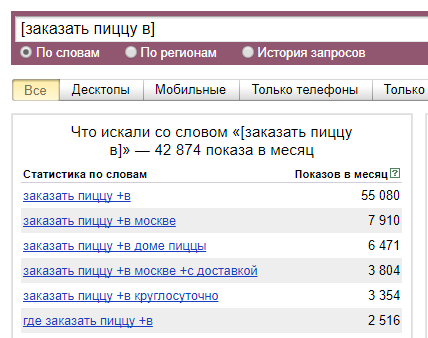 Он убирает при необходимости запросы, содержащие ненужные для изучения статистики слова.
Он убирает при необходимости запросы, содержащие ненужные для изучения статистики слова.Примеры использования операторов
Представляем ниже примеры применения всех указанных выше операторов, как базовых, так и дополнительных.
Нам отображаются все слова где содержится слово работа и предлог на. Оператор +, как бы зафиксировал предлога на.
«Минус»
Нам показываются все запросы где есть слово окна, но нет слова цена.
«Квадратные скобки»
Мы зафиксировали восклицательным знаком точное написание слов, кавычками мы зафиксировали только слова прописанные между ними, а квадратными скобками мы зафиксировали порядок слов.
«Группировка» и усложненный запрос
Сбор запроса по длине
Еще одна удобная функция, предоставляемая сервисом WordStat. Она позволяет задавать длину запросов (2, 5 слов и так дальше) с вхождением ключевиков и производить их парсинг. Такая функция особенно полезна в тех случаях, когда вебмастер работает над сайтом, посвященным очень популярной теме и, собрав максимальное количество страниц, не может получить все поисковые фразы, касающиеся данной ниши.
Она позволяет задавать длину запросов (2, 5 слов и так дальше) с вхождением ключевиков и производить их парсинг. Такая функция особенно полезна в тех случаях, когда вебмастер работает над сайтом, посвященным очень популярной теме и, собрав максимальное количество страниц, не может получить все поисковые фразы, касающиеся данной ниши.
На заметку. Статистика Яндекс Вордстат при анализе одного запроса выдает максимум 41 страницу, но нередко случается так, что фраз для запроса куда больше, и не все вы сможете увидеть.
Чтобы собрать все фразы, длина которых содержит 3 слова, применяется такая конструкция: «Samsung Samsung Samsung»
Задав подобный запрос, вы соберете не максимальное число страниц поисковых фраз разной длины, а 41 страницу только фраз длинной в 3 слова, содержащих ключевик «Samsung». Если поэтапно анализировать запросы, длина которых составляет от 2 до 7 слов, то вы сможете собрать совершенно всю статистику по слову Samsung.
Правая колонка Wordstat
Показывает, что еще искали люди введя данный запрос обувь.
История запроса
Вкладка «История запросов» создана с целью изучения динамики запросов за последние 2 года, а также определения их популярности в зависимости от сезона. Например, узнать, как изменяется интерес потребителей к модели Samsung Galaxy S9. Здесь есть настройки графиков по неделям или месяцам, еще есть возможность фильтровать вид устройства, например отображение только на смартфонах.
Абсолютное значение – это наше фактическое значение показов в определенный периоды времени.
Относительное значение – это отношение абсолютного значения (показов) к общему числу всех показов. Этот показатель показывает популярность заданного запроса среди всех других запросов.
Частота запроса в заданном регионе
Нельзя не упомянуть и о такой функции, как получение частоты запроса в конкретном регионе.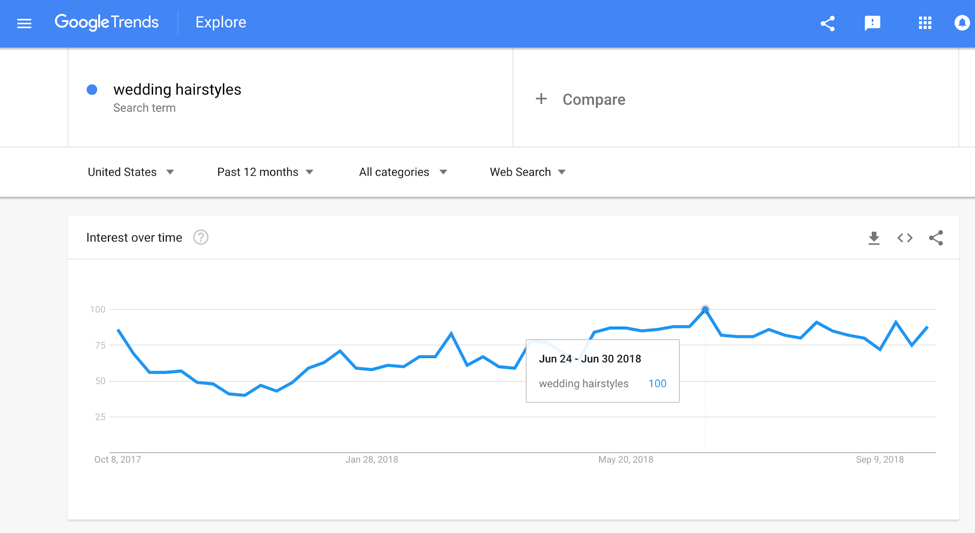 Возможность разделять суммарную частоту запроса по регионам позволяет проанализировать, как часто определенную фразу вводят пользователи конкретного региона, и насколько она популярна здесь.
Возможность разделять суммарную частоту запроса по регионам позволяет проанализировать, как часто определенную фразу вводят пользователи конкретного региона, и насколько она популярна здесь.
Так, запрос, содержащий в себе слова «купить» и «Сочи» чаще всего вводят жители города Сочи, и это логично. Однако, углубившись в возможности данной функции, можно открыть для себя и куда более неожиданные результаты.
Yandex Wordstat Assistant
Для удобного использования Яндекс Вордстат, существуют специальное расширение для браузера, которое называется Yandex Wordstat Assistant.
После его установки у вас в браузере появляется специальное окно, в которое вы можете добавлять ключевые слова из Вордстат. Добавленные слова помечаются серым цветом. Список слов можно копировать, сортировать.
Видеоинструкция как пользоватья Яндекс Вордстат
Заключение
Бесплатный сервис Yandex WordStat – важнейших инструмент для SEO-специалистов и рекламодателей Яндекс Директ. Он позволяет подробно изучить статистику запросов поисковой системы и проанализировать подбор слов, чтобы привлечь на продвигаемый сайт больше целевой аудитории. Сегодня мы изучили все самые важные функции сервиса, успешное применение которых поможет вам сделать свой ресурс более заметным и вывести его на лидирующие позиции выдачи поисковика.
Он позволяет подробно изучить статистику запросов поисковой системы и проанализировать подбор слов, чтобы привлечь на продвигаемый сайт больше целевой аудитории. Сегодня мы изучили все самые важные функции сервиса, успешное применение которых поможет вам сделать свой ресурс более заметным и вывести его на лидирующие позиции выдачи поисковика.
Сервис Wordstat Yandex — как пользоваться. Подбор ключевых слов с помощью Яндекс.Вордстат
Привет, пацаны! Все вы прекрасно знаете, что я уже давно барыжу ключевыми словами. В смысле, давно уже занимаюсь этим на коммерческой основе.
Все те свои услуги, которые я описал , уже давно были мною многократно расширены. Обращаются разные извращенцы, которые придумывают такие задания, что я бы раньше и подумать не мог. Ну и я постепенно матерею за счет того, что они вынуждают меня выполнять их сложные задания
Наверно, все помнят, что я много раз писал про базы пастухова: давным давно я рассказал, что представляет собой этот офигительный софт — , потом рассказал о том, что Максим Пастухова (автор софта) анонсировал выход 180-миллионной русской базы ключевых слов. Это .
Это .
Но вот недавно я делал проект для сайта одного солидного человека. Проект был исключительно под Яндекс. Я отпарсил его сайт, нашел ключи, по которым он уже занимает нормальные позиции в выдаче, оценил эти ключи с помощью вордстата, рамблера, Rookee… все, на этом тормозим.
В итоге получается список хороших ключей. Но! Из них получается много неоднозначных ключей. Вот они
То есть, берем к примеру ключ «радио радио слушать онлайн ». Смотрим частотность по wordstat. Здесь на скриншоте указана точная частотность. То есть, использовался оператор «!слово!слово». И что же видим? Что этот кей имеет частотность 563141 для моего региона, для которого делался анализ.
Меня клиент сразу спрашивает: «Сергей, что за херня? Откуда у несчастного «радио радио слушать онлайн » 563141 показов в месяц?» И прогноз переходов Rookee показывает -1 переход по этому ключику, что означает, что хз, сколько этих переходов будет. То есть, это говорит о том, что их будет 0.
И я потом только допер, что епта, ведь это отличная идея для поста – расписать эту залепу, которая есть в вордстате, тем более, что и Маул недавно про это писал. Только я расскажу про это со своей колокольни, и еще покажу вдобавок, как эта проблема решается.
Только я расскажу про это со своей колокольни, и еще покажу вдобавок, как эта проблема решается.
А что залепа, то залепа. Вот как понять, что это такое на самом деле? Первое, что приходим на ум – пойти в хелп самого Вордстата, да почитать, что они сами об этом пишут. Но нет, единственное, что видим:
И что в итоге? А ничего! Из того что здесь написано, ни фига не понятно, почему мля по запросу «радио радио слушать онлайн » такое большое количество показов.
А на самом деле эта залепа имеет простое объяснение. Открываем свеженькие базы пастухова на 180 млн. кеев, делаем выборку из базы по ключевому слову «радио слушать онлайн»
Думаю, те, кто часто копаются в вордстате, прекрасно понимают, что выдернуть оттуда такие вот ключевые слова — это почти нереально.
Это, кстати, не самые длинные ключевые слова. В базах пастухова я добавил отображение частотности по wordstat.yandex. Смотрите, есть и покруче, вернее, подлиннее ключики
Понятно, 10-ти словник «интернет радио онлайн слушать бесплатно европа плюс mediaplayer classic » не может иметь частотности, а если и может, то она настолько ничтожная, что не отображается в wordstat. Но дело в том, что вот такие вот многословники и создают эту залепу с ключевыми словами. Смотрите сами
Но дело в том, что вот такие вот многословники и создают эту залепу с ключевыми словами. Смотрите сами
Что здесь видим? Видим, что десятисловник » имеет частоту 5967, что само по себе представляется какой-то утопией.
Так почему же так получается?
Есть одна особенность в вордстате – в нем похер порядок ключевых слов, в связи с чем если не понимаешь всего этого механизма, то можно тупо просаживать баблос, двигая в перспективе ключевые слова, не дающие на выходе трафа.
Все это очень хорошо видно, когда в базах пастухова добавляем колонку со статистикой запросов в Рамблер, в котором порядок слов не похер . Тогда картина становится сразу ясна, и мы видим, для каких запросов есть система, а для каких нет. То есть, какие запросы вводят регулярно, какие действительно можно продвигать, а какие просто создают статистику для таких вот залеп, которые я показал выше. Здесь в базах пастухова особенно зашибенно то, что можно сразу прикинуть частотности Яндекса и Рамблера по отдельно взятому ключевику
Я здесь специально сгруппировал запросы, чтобы было понятно. То есть, в идеале, если продвигать, то брать такие ключи, где будет частота и по Рамблеру и по Яндексу. Но это в идеале.
То есть, в идеале, если продвигать, то брать такие ключи, где будет частота и по Рамблеру и по Яндексу. Но это в идеале.
И все же, как так, что 10-ти словный запрос с повторяющимися словами может иметь частоту 5967?
Я хз если честно, почему в хелпе вордстата не расписали, почему же такое вот может быть. Но суть вот в чем.
Как уже писал выше, в Яндексе вводят множество запросов, среди которых много и десятисловных. И даже больше. Из вордстата эту информацию часто не вытянуть, зато хорошо все эти ключи показывают базы пастухова (примечание — теперь уже закрытый проект). А сама разгадка кроется в том, что дублирующиеся слова не учитываются непосредственно в запросе.
То есть, запрос «!радио!радио!радио!радио!радио!радио!радио!радио!слушать!онлайн », имеющий частоту 5967, на самом деле в точно таком же виде не показывается столько, сколько это отображает вордстат. Здесь учитывается только словосочетание «радио слушать онлайн». То есть, последние три слова. А вместо предыдущих 7 слов «радио» могут употребляться абсолютно разные слова. И все это создает статистику для вот этого десятисловника. Я специально в базах пастухова сделал выборку полученных результатов по «радио слушать онлайн». Там можно сортировать и по длине поисковых запросов, и по количеству слов
А вместо предыдущих 7 слов «радио» могут употребляться абсолютно разные слова. И все это создает статистику для вот этого десятисловника. Я специально в базах пастухова сделал выборку полученных результатов по «радио слушать онлайн». Там можно сортировать и по длине поисковых запросов, и по количеству слов
И в итоге мы получаем все (или почти все) ключевые слова-десятисловники, которые и делают статистику для нашего «!радио!радио!радио!радио!радио!радио!радио!радио!слушать!онлайн ». Вот они:
И таких десятисловников более чем предостаточно. То есть, еще раз повторяюсь, что вместо слова «радио» может быть любое другое слово, лишь бы оно входило в десятисловник, который содержит словосочетание «радио слушать онлайн».
Ситуация не была бы настолько неоднозначной, если бы вордстат показывал ключевые слова в точно таком же порядке, как они запрашиваются. Но ведь нет. В нашем десятисловнике вместо слова «радио» могут быть любые другие слова, и все они могут меняться местами внутри этого десятисловника, тем самым накручивая его показатель в вордстате.
Вот поэтому и получается, что запрос «радио радио слушать онлайн » на самом деле в точно такой же последовательности и с точно такими же словами, как здесь указано, не имеет частоту 563141 и никогда не имел. А такая цифра получается, потому что вместо первого слова «радио» может быть любое другое, и может оно стоять на любом месте в рамках этого четырехсловника, что и образует в конечном итоге такую большую цифру в 563141. И таких четырехсловников разной интерпретации превеликое множество
В этой статье речь пойдет о статистике поисковых запросов: как её следует смотреть, где её можно посмотреть, для чего она нужна и т.д. Эта тема будет очень интересна для новичков в SEO . Не будем лить много воды, а перейду ближе к делу.
1. Для чего нужна статистика поисковых запросов
Теперь поговорим о том, как и где её можно посмотреть статистику запросов.
3. Сервисы статистики запросов Яндекс и Google
Я рассмотрю два сервиса в самых популярных поисковых машинах рунета: Яндекса и Google (этого вполне достаточно для анализа запросов). Если сравнить статистики других поисковых систем, то разница в цифрах будет совсем небольшая (естественно, если сравнивать пропорционально частотность и аудитории поисковиков).
Если сравнить статистики других поисковых систем, то разница в цифрах будет совсем небольшая (естественно, если сравнивать пропорционально частотность и аудитории поисковиков).
3.1. Сервис Яндекс Вордстат
В Яндексе существует специальный сервис: wordstat.yandex.ru (Яндекс Вордстат). Это очень популярный сервис, однако он показывает не частотность поисковых запросов, а частотность запросов в Яндекс Директе . В большинстве случаев этого оказывается достаточно, чтобы понять популярен ли запрос или нет.
Объясню кратко как пользоваться wordstat yandex . Введя в форме запрос, Яндекс предложит все словоформы этого запроса:
Частотность запроса в общей таблице будет указана с учетом всех-всех уточнений и дополнений. Если необходимо узнать частотность конкретного ключевого слова в той же словоформе, то его нужно написать в кавычках и перед каждым словом поставить восклицательный знак:
Стоит также учитывать то, что Яндексу нету разницы во множественным числе писать словосочетания или нет. Яндекс вообще не учитывает словоформы, а также не учитывает все предлоги.
Яндекс вообще не учитывает словоформы, а также не учитывает все предлоги.
Получив какие-то данные по поисковым запросам в вордстате, нужно помнить, что эти данные далеко не точные. Например, я их учитываю только пропорционально, т.е. если в Яндекс Директе запрос популярен, то логично предположить, что и в выдаче он тоже будет популярен.
Чтобы учитывать предлоги (что, как, в, на и т.д.) перед ним нужно ставить знак плюс «+». Например, запрос «+как заработать +в интернете».
3.2. Сервис Google Adwords
Теперь поговорим о Google, который предоставляет даже немного более интересный инструмент, чем Яндекс. Ссылка на сервис: adwords.google.com . Вам нужно авторизоваться, далее нажать на «Инструменты и анализ» далее «Планировщик ключевых слов». Здесь нужно вбивать ключевые слова и вам на выбор предлагается большой выбор ключевых фраз, которые Гугл находит из своей базы контекстной рекламы Adwords. Также очень здорово, что можно посмотреть историю изменения частотности запроса.
Когда у Рамблера был очень хороший сервис, но с недавних пор теперь у него нету своей поисковой базы, т.к. он использует выдачу Яндекса. Вообще в рунете существует только два хороших сервиса, которые я и рассмотрел.
Все системы для анализа ключевых слов, сбора СЯ и т.д. берут данные именно с этих двух сервисов — помните это!
4. Как узнать динамику популярности запроса
Яндекс и Гугл дают бесплатную возможность посмотреть динамику популярности запроса. Это удобно для того, чтобы определить общий тренд и перспективность каких-то запросов. Также с помощью этого можно определять сезонность запросов.
В Яндекс Вордстате нужно выбрать галочку «История запросов» и Вы увидите график изменения.
Поводом для написания новой статьи о самом популярном инструменте для подбора слов послужило его недавнее глобальное обновление, которое привело к ряду новшеств и улучшению. Помимо небольшого рассказа на эту тему, я подробно остановлюсь на правильном использовании операторов Вордстата и других фишках сервиса.
Как узнать количество запросов в Яндексе?
Для начала небольшая справка, Яндекс Вордстат (wordstat.yandex.ru) – это инструмент для подбора ключевых слов на основе запросов пользователей, который отображает статистику по частоте использования указанного слова (первый столбец), а также, по словам из схожей тематики (второй столбец). С помощью Вордстата количество запросов в Яндексе узнают, как рекламодатели, так и SEO-специалисты.
Принцип работы заключается в том, что вы указываете слово или фразу по которой интересует статистика. Далее система показывает все ключевые фразы, в которых употребляется указанное вами слово, а рядом располагается его частотность. Каждая из последующих фраз агрегирует информацию. Минимальная частотность составляет 3.
Информация обновляется раз в месяц. Дата обновления указана в правом верхнем углу.
Новый Яндекс Вордстат. Обновление от 07.08.13
Если ранее вы использовали Wordstat для проверки запросов в Яндексе, то наверняка сталкивались с дикими проблемами в скорости работы интерфейса. Думаю, что по этому поводу было написано множество жалоб в службу поддержки. В новой версии изменилось не только это:
Думаю, что по этому поводу было написано множество жалоб в службу поддержки. В новой версии изменилось не только это:
- Увеличена скорость работы сервиса – по моим ощущениям сервис стал быстрее в несколько раз.
- Изменена архитектура сервиса – раньше при использовании сервиса менялся URL и можно было в один клик перейти к 20-й странице, заменив один из параметров. Сейчас такая возможность отсутствует.
- Пересмотрены отдельные части интерфейса – сводная таблица по регионам объединена с данными на карте, а статистика запросов Яндекс по месяцам и неделям сгруппирована на одной вкладке.
Об автоматических программах парсерах Wordstat
Как говорится, в каждой бочке меда есть ложка дегтя. И в этот раз ложкой дегтя стал полный запрет доступа к интерфейсу проверки ключевых фраз сторонними программами, которые очень популярны у специалистов по контексту и SEO. Все мы искренне надеемся, что наши любимые сервисы как можно скорее восстановят свою работу.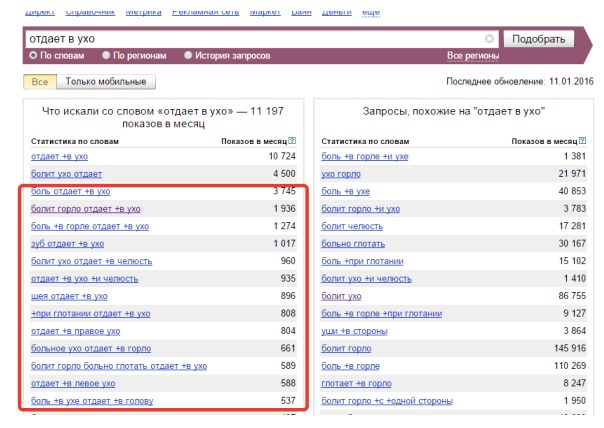 Здесь я привожу сводную таблицу, в которой отражены данные для популярных парсеров Wordstat по состоянию на текущий момент. Информация будет обновляться по мере восстановления работы сервисов.
Здесь я привожу сводную таблицу, в которой отражены данные для популярных парсеров Wordstat по состоянию на текущий момент. Информация будет обновляться по мере восстановления работы сервисов.
| Название сервиса | Статус |
|---|---|
| Словоеб | Работает |
| Магадан | Работает |
| SiteAuditor | Не работает |
| KeyCollector | Работает |
Как пользоваться Вордстатом?
Большинство людей допускают ошибки при использовании сервиса, в следствие чего в статистике фигурируют неверные данные, а дальнейшие действия по или продвижению в поисковых системах полностью бессмыслены. Помимо этого, часто встречается искусственная накрутка количества запросов для ключевых слов. Ниже я собрал основные рекомендации по работе с Вордстатом с подробными комментариями, которые пригодятся как новичкам, так и профи:
Уточняйте фразы, используя операторы
Операторы для Яндекс Вордстата такие же, как и в Яндекс Директе. Подробнее о них — я рассказывал в статье « «. Основные операторы:
Подробнее о них — я рассказывал в статье « «. Основные операторы:
| Оператор | Комментарий | Пример |
|---|---|---|
| Знак минус | Частота запроса без учета | Купить мопед –бу –москва |
| Двойные кавычки | Статистику слова или фразы по фразовому соответствию | «стоимость модем» |
| Восклицательный знак | Частотность по заданной словоформе | !ваза цена |
| Знак плюс | Принудительный учет предлогов | +как работает яндекс директ |
| Круглые скобки и прямой слеш | Группирует статистику по запросам | Кондиционер (авто | машина) |
Если первые четыре оператора популярны, поскольку они очень часто используются в Директе, то пятым практически никто не пользуется. Хотя в умелых руках он приносит пользы больше остальных, а скорость подбора слов с ним возрастает в разы. Приведу пример: для того чтобы собрать статистику для рекламы магазина галстуков-бабочек, можно использовать следующий запрос:
Хотя в умелых руках он приносит пользы больше остальных, а скорость подбора слов с ним возрастает в разы. Приведу пример: для того чтобы собрать статистику для рекламы магазина галстуков-бабочек, можно использовать следующий запрос:
В результате мы получим информацию одновременно о таких запросах, как:
- заказать мужскую бабочку;
- галстук бабочка цена;
- сколько стоит женская бабочка и т.д.
Таким образом с помощью оператора группировки статистика собирается в один клик. Спектр применения достаточно широк, например, в приведенном образце можно проверить частотность для транзакционных ключевых фраз.
Подбирайте ключевые слова правильно
Не забывайте указывать регион для проверки частотности запросов и не заостряйте внимания на частотности слов по широкому соответствию, т.е. без использования операторов. Посмотрите на колоссальную разницу:
- Купить интернет магазин — 811 430
- «Купить!интернет!магазин» – 1 362
Когда вы подбираете ключевые слова для сайта, то каждое слово необходимо дополнительно уточнять, для проверки частотности по точному соответствию, поскольку очень часто встречаются фразы – пустышки.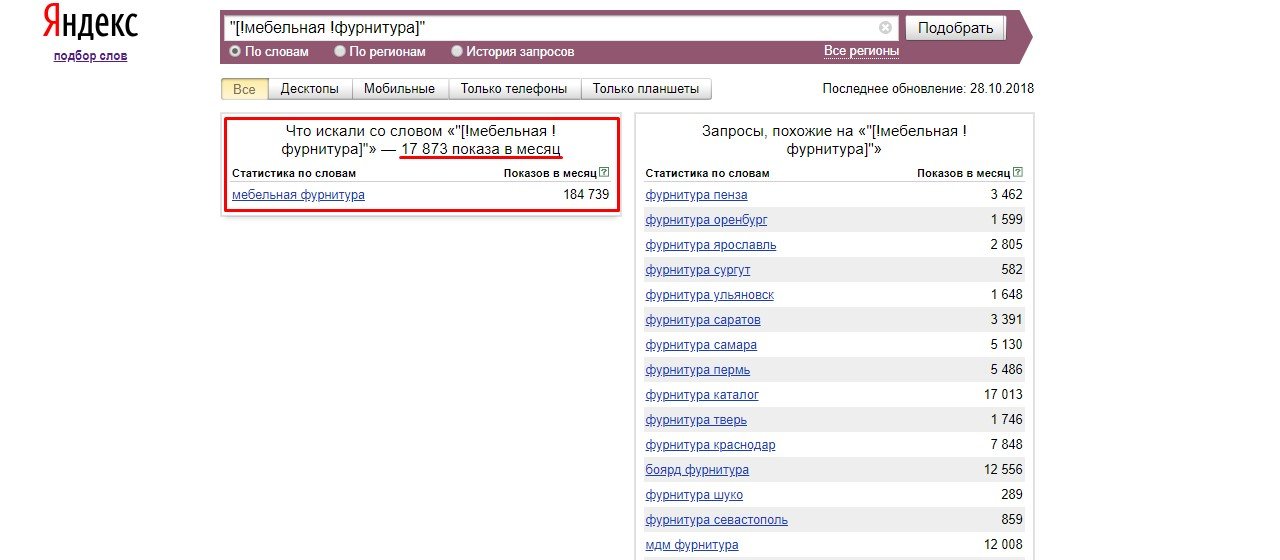
Анализируйте статистику запросов по месяцам
Используя вкладку «История запроса» можно оценить сезонность спроса, а также посмотреть его динамику в зависимости от времени года. Также статистика по месяцам помогает с высокой долей вероятности определить натуральность частотности слова. Не вооруженным взглядом будет заметен резкий скачок графика у слов с искусственной накруткой, количество низкочастотников при этом останется на одинаковом уровне.
Используйте автоматический подбор слов (программы — парсеры)
Автоматические сервисы для подбора ключевых слов я перечислил выше. Их использование позволяет в разы сократить количество монотонной работы и время на проверку частотности с операторами и без. В ближайшее время опубликую статью о своей любимой программе для Wordstat`a – Словоеб. Чтобы не пропустить выход статьи, рекомендую подписать на обновления моего !
С уважением, Александр Golfstream!
Пожалуй, самый посещаемый сервис в России — это wordstat от компании Яндекс. Для подбора достаточно перейти по следующей ссылке http://wordstat.yandex.ru/?cmd=words и в поле «Ключевые слова и словосочетания» ввести интересующий вас запрос. После нажатия на кнопку «Подобрать» перед вами появится таблица, в левом части которой будут отображаться наиболее популярные запросы, а в правой части будут показаны смежные запросы.
Для подбора достаточно перейти по следующей ссылке http://wordstat.yandex.ru/?cmd=words и в поле «Ключевые слова и словосочетания» ввести интересующий вас запрос. После нажатия на кнопку «Подобрать» перед вами появится таблица, в левом части которой будут отображаться наиболее популярные запросы, а в правой части будут показаны смежные запросы.
Не забывайте, что выдача статистики запросов различна для регионов, поэтому, если вас интересует региональное , воспользуйтесь вкладкой «По ». Там же следует конкретизировать свой выбор — регион или город.
Rambler (Рамблер) — не менее известная , чем Яндекс, но явно уступающая по , а совсем недавно и полностью использующая технологии поиска выше обозначенной компании. Для перехода к сервису проверки статистики запросов необходимо нажать на ссылку http://adstat.rambler.ru/wrds/. В пустом прямоугольном окошке введите интересующие слова или словосочетания, после чего нажмите кнопку «Подсчитать».
Данный сервис явно уступает Яндексу, но также есть региональная выдача: поставьте отметку напротив пункта «География запросов» либо нажмите ссылку «Статистика по географии» и нажмите соответствующую кнопку.
У компании Google есть два продукта, которые позволяют создать объективную оценку вводимым запросам: при помощи сервиса для подбора ключевых слов можно подобрать наиболее релевантный запрос, а сервис сравнительной статистики поиска Google дает представление о продвигаемом запросе.
Сервис подбора ключевых слов (AdWords) представляет собой Wordstat от Яндекса, найти его можно по следующей ссылке https://adwords.google.com/select/KeywordToolExternal. Статистику поисковых запросов можно посмотреть на этой странице http://www.google.ru/insights/search/.
Прежде чем приступать к изготовлению сайта, нужно точно знать, кто и зачем его будет искать. И тем более необходимы сведения о статистике запросов , если планируется его продвижение.
- компьютер, интернет
Уточните список параметров, которые вас интересуют в запросах. Кроме набираемых слов может иметь значение и срок анализа данных — неделя, месяц. Поймите, какая вам нужна аудитория. Например, в России наиболее используемый поисковик — «Яндекс». И для работы с отечественными интернет-пользователями ориентируйтесь на его показатели. Если реальное местоположение посетителя сайта не так уж важно, то необходимо провести анализ и по «Гуглу» с «Рамблером».
И для работы с отечественными интернет-пользователями ориентируйтесь на его показатели. Если реальное местоположение посетителя сайта не так уж важно, то необходимо провести анализ и по «Гуглу» с «Рамблером».
Зайдите на http://wordstat.yandex.ru/ и введите нужное слово. Уточните регион, если это имеет значение (в нашем случае, скорее всего, надо выбрать «Россия». Введите слово или словосочетание, обозначающее ваш товар или услугу. Нажмите кнопку «подобрать». Вы получите два столбика: левый с данными по вашему запросу, правый — с данными о том, что еще интересовало этих людей.
Перейдите на вкладку «регионы», чтобы узнать, насколько популярен данный запрос в разных частях России и мира. Здесь тоже две колонки: абсолютное число запросов и региональная популярность в процентах. Эти данные можно визуализировать на карте. Для этого перейдите на соответствующую вкладку. Если для вас важны сезонные колебания, откройте по месяцам и неделям.
Подобрать поисковые запросы для продвижения сайта можно через сервисы статистики.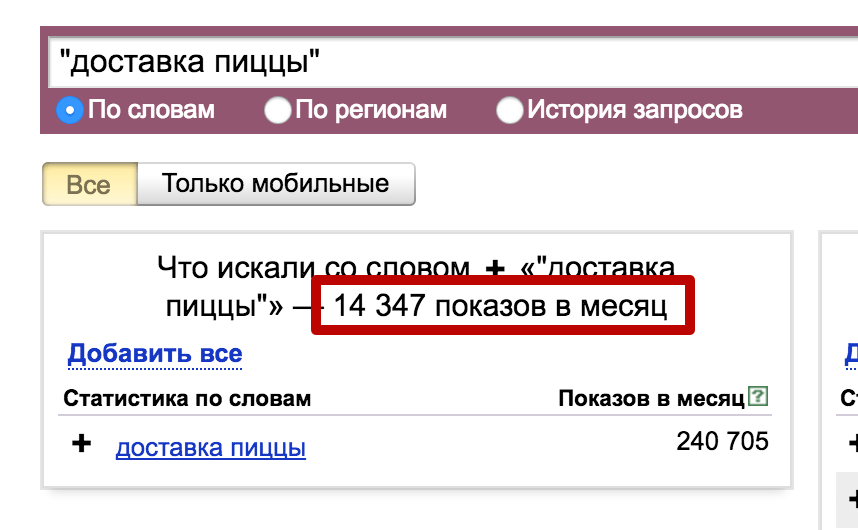 В Яндексе для этой задачи используется система Wordstat, доступная по адресу http://wordstat.yandex.ru В нашей статье мы расскажем, как при помощи сервиса Яндекса узнать частоту поисковых запросов.
В Яндексе для этой задачи используется система Wordstat, доступная по адресу http://wordstat.yandex.ru В нашей статье мы расскажем, как при помощи сервиса Яндекса узнать частоту поисковых запросов.
Инструмент Wordstat создан для людей, желающих разместить контекстную рекламу. Он работает так: вы вводите слово или фразу и получаете список слов и фраз с указанием их частоты. Но это не частота конкретного запроса, а частота всех запросов, в которых встречались указанные слова или фразы.
Разберем на примере (см. картинку ниже):
В указанном примере частота по слову «кондиционеры» составляет 1 741 974 – это суммарная частота всех запросов, включающих слово кондиционер. Но это совсем не означает, что запрос из одного слова «кондиционеры» вводят столько раз – на самом деле нет.
Как посмотреть частоту запроса?
Чтобы посмотреть, сколько раз вводят поисковый запрос «кондиционеры», состоящий из одного слова (без учета словоформ), необходимо взять это слово в кавычки. Если вам нужно проверить частоту запроса из нескольких слов – то вы берете в кавычки целую фразу.
Если вам нужно проверить частоту запроса из нескольких слов – то вы берете в кавычки целую фразу.
См. пример ниже:
Цифра 64 981 означает частоту всех запросов, состоящих из одного слова «кондиционеры».
Как определить наиболее популярную форму запроса?
Как узнать, сколько раз задают запрос «кондиционеры» (мн. число), а сколько раз – запрос «кондиционер» (ед. число)? Задаем запрос в кавычках и перед словоформой ставим знак «!».
См. пример проверки частоты запроса, состоящего из одного слова, во множественном числе:
Число 50 368 означает частоту запроса из одного слова во множественном числе.
Используя аналогичную схему, можно проверить частоту слова в единственном числе и сравнить частоты разных форм запроса. Это позволит выбрать форму с наибольшей частотой.
Чтобы проверить частоту запроса из нескольких слов, внутри которого есть стоп-слова, необходимо взять фразу в кавычки, рядом с каждым словом поставить восклицательный знак, а перед стоп-словом знак «+».
Как узнать порядок слов в запросе?
К сожалению, специальных операторов для этого в системе Wordstat нет, но по умолчанию она выводит, как правило, наиболее популярный порядок слов.
Также, чтобы узнать порядок слов в поисковых запросах, можно купить размещение контекстной рекламы и посмотреть – по каким запросам будут переходить на сайт чаще. Это дорого, но если вы желаете собрать наиболее полное и качественное семантическое ядро – затраты будут оправданны.
Яндекс Wordstat
Яндекс Wordstat — это полезный сервис, позволяющий определить популярность поисковых запросов. Пользование инструментарием бесплатно. Вордстат помогает оценить пользовательский интерес к теме, продукту или услуге. Сервис показывает предварительный прогноз числа показов в месяц для выбранного ключевого слова.
Возможности Вордстат Яндекс
Wordstat многофункциональный инструмент. Статистика запросов в Яндекс позволяет собрать семантическое ядро. Кроме простого подбора ключевых слов, с его помощью можно анализировать запросы по:
Популярности в различных регионах;
Однако у сервиса есть ограничения. Например, объем выдачи по запросу ограничивается 41 страницей по 50 фраз. В популярной тематике за бортом могут остаться важные низкочастотные ключи.
Например, объем выдачи по запросу ограничивается 41 страницей по 50 фраз. В популярной тематике за бортом могут остаться важные низкочастотные ключи.
Особенности работы с сервисом Подбор слов
Чтобы работать с сервисом, необходимо зарегистрировать почту на Яндексе и войти в свой аккаунт. Теперь можно заниматься подбором слов. Введите в строку нужное слово или сочетание слов и нажмите «Подобрать».
В строку достаточно ввести словосочетание в именительном падеже. Сервис покажет ключевые слова в разных грамматических формах: падежах, склонениях, числах.
В первой строке появится искомый запрос и число его показов в месяц. Ниже находятся различные словоформы введенного запроса. Количество показов словоформ уже входит в число в верхней строке.
Операторы Wordstat
Для уточнения запросов удобно использовать специальные символы — операторы:
— исключает фразу из результатов поиска. Используется для отдельного слова. Для словосочетания просто добавьте минус перед всеми словами.
+ учитывает при анализе служебные части речи: союзы и предлоги. Детализированный запрос слева по умолчанию учитывается во всех фразах, которые содержат стоп-слова.
«» удаляет из статистических данных дополнительные фразы.
! нужен для получения точных вхождений ключевого слова: в выбранном падеже и числе.
| нужен для получения результатов по двум и более условиям. Здесь действует правило логического «или».
() группирует фразы, а вместе с «|» создает регулярное выражение. В результате получается поиск фраз по определенным условиям.
[ ] определяет порядок слов, учитывая словоформы, стоп-слова.
Операторы «-»,«+», «!» ставятся перед словами без пробелов.
Выбор региона
Если для продвижения вашего продукта или услуги важна география, необходимо настроить статистику по регионам. По умолчанию Wordstat ориентируется на ваше фактическое местоположение. Чтобы это исправить, нужно выбрать правильный регион под поисковой строкой.
Кроме того, Яндекс Вордстат позволяет делать сортировку по регионам. Для этого нажимаем на «Все регионы» и выбираем подходящие. Там же можно найти опцию «Быстрый выбор», которая позволяет отметить один из четырех наиболее популярных регионов: Москва и область; Санкт-Петербург и область; Украина; Россия, СНГ и Грузия.
Для этого нажимаем на «Все регионы» и выбираем подходящие. Там же можно найти опцию «Быстрый выбор», которая позволяет отметить один из четырех наиболее популярных регионов: Москва и область; Санкт-Петербург и область; Украина; Россия, СНГ и Грузия.
Сезонность
«История запросов» позволяет:
Определить сезонность запросов. Большинство товаров и услуг подвержены сезонности спроса. Так, например, елки покупают перед Новым годом.
Получить статистику по месяцам и неделям. Инструмент выдает статистику за последние 2 года.
Выявить фразы-«пустышки» (показы накручены искусственно за короткий временной промежуток).
Важно помнить, что история запросов не учитывает операторы Wordstat.
Как правильно подбирать ключевые слова
Основные принципы работы с Yandex Wordstat описаны выше. Поэтому остановимся на ключевых аспектах. Для правильного сбора ключевых слов важно указывать нужный регион и помнить о нюансах работы с частотностью.
В Wordstat существует три вида частотности:
Базовая частота – количество показов в месяц во всех возможных формах. Показатель имеет смысл использовать для определения общей заинтересованности аудитории в тематике.
Показатель имеет смысл использовать для определения общей заинтересованности аудитории в тематике.
Фразовая частота (оператор «») – количество показов в разных словоформах.
Точная частотность (оператор (!)) – количество показов в конкретной словоформе: падеже, числе, склонении и т.д.
Так, может оказаться, что высокочастотный по базовой частотности запрос на деле окажется, средне- или даже низкочастотным. Поэтому важно использовать правильные операторы, чтобы корректно определять частотность запроса и отбраковывать фразы-пустышки.
Если ключей по вашей теме много, это хорошо. Но нужно понимать, что высокочастотный запрос всегда и высококонкурентный. Поэтому не стоит продвигаться только по таким запросам.
Заключение
Яндекс Вордстат – это простой, полезный и бесплатный сервис. С его помощью можно определить интерес аудитории к товару или услуге, определить тренды, собрать семантическое ядро, анализировать география и сезонность поисковых запросов.
Подсчет данных с помощью запроса
В этой статье объясняется, как подсчитывать данные, возвращаемые запросом. Например, в форме или отчете вы можете подсчитать количество элементов в одном или нескольких полях таблицы или элементах управления. Вы также можете рассчитать средние значения и найти самые маленькие, самые большие, самые ранние и самые последние значения. Кроме того, Access предоставляет функцию под названием «Строка итогов», которую можно использовать для подсчета данных в таблице без необходимости изменять структуру запроса.
Например, в форме или отчете вы можете подсчитать количество элементов в одном или нескольких полях таблицы или элементах управления. Вы также можете рассчитать средние значения и найти самые маленькие, самые большие, самые ранние и самые последние значения. Кроме того, Access предоставляет функцию под названием «Строка итогов», которую можно использовать для подсчета данных в таблице без необходимости изменять структуру запроса.
Что ты хочешь сделать?
Понимание способов подсчета данных
Подсчет данных с помощью строки Total
Подсчет данных с помощью итогового запроса
Справочник по агрегатной функции
Понимание способов подсчета данных
Вы можете подсчитать количество элементов в поле (столбце значений) с помощью функции Count . Функция Count принадлежит к набору функций, называемых агрегатными функциями. Вы используете агрегатные функции для выполнения вычислений в столбце данных и возврата одного значения. Access предоставляет ряд агрегатных функций в дополнение к Подсчитать , например:
Функция Count принадлежит к набору функций, называемых агрегатными функциями. Вы используете агрегатные функции для выполнения вычислений в столбце данных и возврата одного значения. Access предоставляет ряд агрегатных функций в дополнение к Подсчитать , например:
Sum , для суммирования столбца чисел.
Average , для усреднения столбца чисел.
Максимум , для нахождения максимального значения в поле.
Минимум для поиска наименьшего значения в поле.
Стандартное отклонение , для измерения того, насколько широко значения разбросаны по сравнению со средним значением (среднее значение).
Дисперсия , для измерения статистической дисперсии всех значений в столбце.

Access предоставляет два способа добавления Count и других агрегатных функций в запрос. Вы можете:
Откройте запрос в режиме таблицы и добавьте строку «Итого». Строка итогов позволяет использовать агрегатную функцию в одном или нескольких столбцах результирующего набора запроса без необходимости изменения структуры запроса.
Создать итоговый запрос. Итоговый запрос вычисляет промежуточные итоги по группам записей. Например, если вы хотите подытожить все продажи по городам или кварталам, вы используете итоговый запрос, чтобы сгруппировать записи по нужной категории, а затем просуммировать данные о продажах. В противоположность этому, строка «Итого» вычисляет общие итоги для одного или нескольких столбцов (полей) данных.
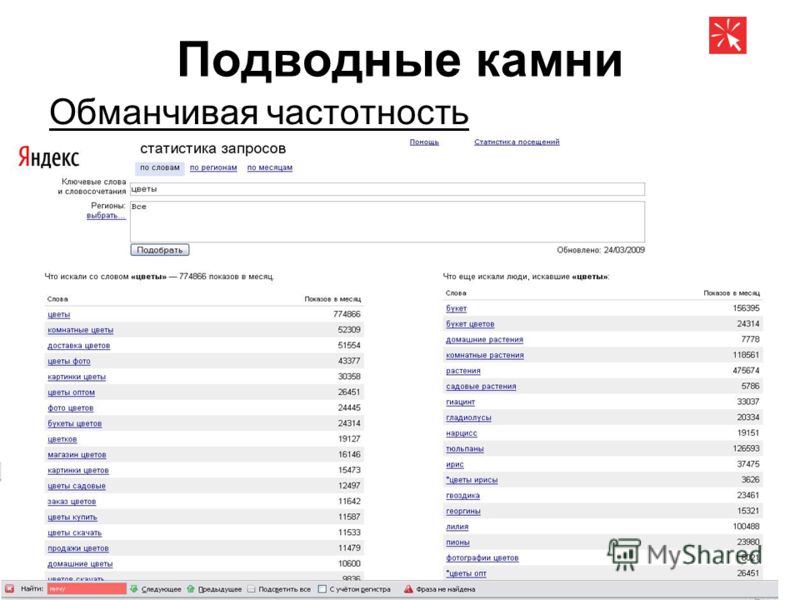
Примечание. В разделах с практическими рекомендациями в этом документе особое внимание уделяется использованию функции Count , но помните, что вы можете использовать другие агрегатные функции в строках и запросах Total. Дополнительные сведения об использовании других агрегатных функций см. в разделе Справочник по агрегатным функциям далее в этой статье.
Дополнительные сведения о способах использования других агрегатных функций см. в статье Отображение итогов столбца в таблице.
в статье Отображение итогов столбца в таблице.
Шаги в следующих разделах объясняют, как добавить строку итогов и как использовать итоговый запрос для подсчета данных. По мере продвижения помните, что функция Count работает с большим числом типов данных, чем другие агрегатные функции. Например, вы можете запустить функцию Count для поля любого типа, кроме поля, содержащего сложные, повторяющиеся скалярные данные, такие как поля многозначных списков.
Напротив, многие агрегатные функции работают только с данными в полях, для которых задан определенный тип данных. Например, функция Сумма работает только с полями, для которых заданы типы данных Числовой, Десятичный или Денежный. Дополнительные сведения о типах данных, которые требуются для каждой функции, см. в разделе Справочник по агрегатным функциям далее в этой статье.
Общие сведения о типах данных см. в статье Изменение или изменение набора типов данных для поля.
Верх страницы
Подсчет данных с использованием строки Total
Вы добавляете итоговую строку в запрос, открыв запрос в режиме таблицы, добавив строку, а затем выбрав функцию Count или другую агрегатную функцию, например Sum , Minimum , Maximum или В среднем . Шаги в этом разделе объясняют, как создать базовый запрос на выборку и добавить строку «Итог».
Создать базовый запрос выбора
На вкладке Создать в группе Другие щелкните Дизайн запроса .
Дважды щелкните поля таблицы, которые вы хотите использовать в своем запросе.
Вы можете включить поля, содержащие описательные данные, такие как имена и описания, но вы должны включить поле, содержащее значения, которые вы хотите подсчитать.
Каждое поле появляется в столбце в сетке макета запроса.
При необходимости вернитесь в представление «Дизайн» и измените свой запрос. Для этого щелкните правой кнопкой мыши вкладку документа для запроса и выберите Представление проекта . Затем вы можете настроить запрос по мере необходимости, добавляя или удаляя поля таблицы. Чтобы удалить поле, выберите столбец в сетке дизайна и нажмите DELETE.
При необходимости сохраните запрос.
 org/ListItem»>
org/ListItem»>Дважды щелкните таблицу или таблицы, которые вы хотите использовать в своем запросе, а затем щелкните Закрыть .
Выбранная таблица или таблицы отображаются в виде окон в верхней части конструктора запросов. На этом рисунке показана типичная таблица в конструкторе запросов:
 org/ListItem»>
org/ListItem»>На вкладке Design в группе Results нажмите Run .
Результаты запроса отображаются в режиме таблицы.
Добавить итоговую строку
 org/ItemList»>
org/ItemList»>Откройте запрос в режиме таблицы. Чтобы сделать это для базы данных в формате файла .accdb, щелкните правой кнопкой мыши вкладку документа для запроса и выберите Просмотр таблицы .
-или-
Для базы данных формата файлов .mdb, созданной в более ранней версии Access, на вкладке Главная в группе Представления щелкните стрелку под Представление и щелкните Представление таблицы .
-или-
В области навигации дважды щелкните запрос. При этом выполняется запрос и загружаются результаты в таблицу данных.
На вкладке Главная в группе Записи щелкните Итоги .
Новая строка Всего появится под последней строкой данных в таблице.
В строке Итого щелкните поле, которое вы хотите суммировать, а затем выберите Отсчитайте из списка.
Скрыть строку итогов
Дополнительные сведения об использовании строки итогов см. в статье Отображение итогов столбца в таблице.
Верх страницы
Подсчет данных с использованием итогового запроса
Вы подсчитываете данные, используя итоговый запрос вместо итоговой строки, когда вам нужно подсчитать некоторые или все записи, возвращаемые запросом. Например, вы можете подсчитать количество сделок купли-продажи или количество сделок в одном городе.
Как правило, вы используете итоговый запрос вместо итоговой строки, когда вам нужно использовать полученное значение в другой части вашей базы данных, например, в отчете.
Подсчитать все записи в запросе
На вкладке Создать в группе Другие щелкните Дизайн запроса .
Дважды щелкните таблицу, которую вы хотите использовать в своем запросе, а затем щелкните Закрыть .
Таблица отображается в окне в верхней части конструктора запросов.
На вкладке Design в группе Показать/скрыть щелкните Итоги .
Строка Total появляется в сетке дизайна, а Group By появляется в строке для каждого поля в запросе.
В строке Всего щелкните поле, которое вы хотите подсчитать, и выберите Отсчитайте из полученного списка.
При необходимости сохраните запрос.
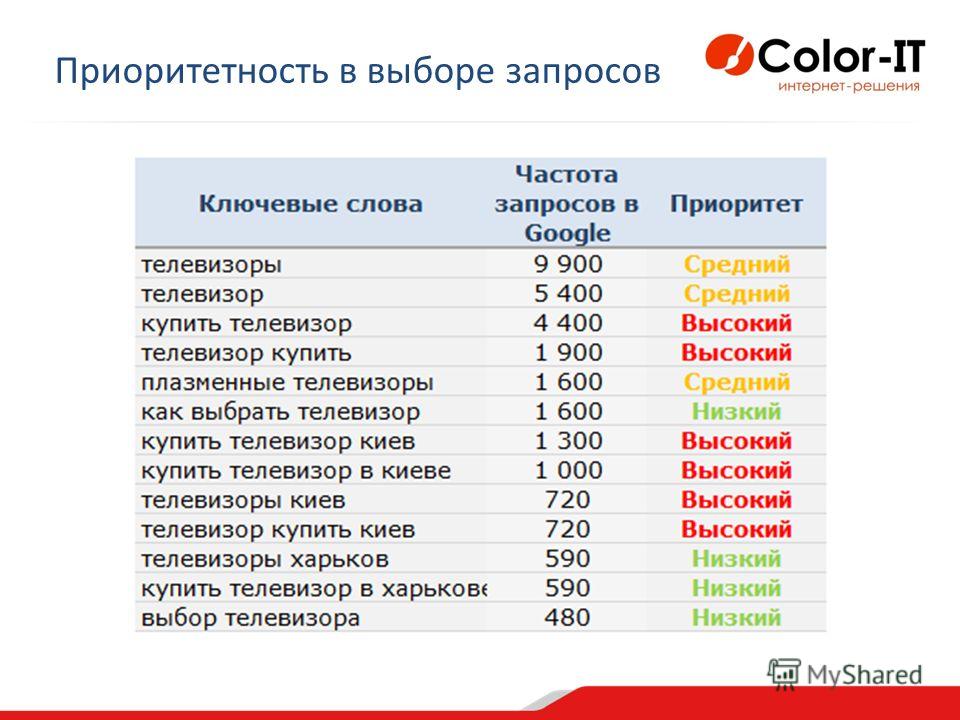 org/ListItem»>
org/ListItem»>Дважды щелкните поля, которые вы хотите использовать в запросе, и убедитесь, что вы включили поле, которое хотите подсчитать. Вы можете подсчитывать поля большинства типов данных, за исключением полей, содержащих сложные повторяющиеся скалярные данные, такие как поля многозначных списков.
 org/ListItem»>
org/ListItem»>На вкладке Design в группе Results нажмите Run .
Результаты запроса отображаются в режиме таблицы.
Количество записей в группе или категории
На вкладке Создать в группе Другие щелкните Дизайн запроса .
Дважды щелкните таблицу или таблицы, которые вы хотите использовать в своем запросе, а затем щелкните Закрыть .
Таблица или таблицы отображаются в окне в верхней части конструктора запросов.
Дважды щелкните поле, содержащее данные вашей категории, а также поле, содержащее значения, которые вы хотите подсчитать. Ваш запрос не может содержать другие описательные поля.
На вкладке Design в группе Показать/скрыть щелкните Итоги .
Строка Total появляется в сетке проекта и Group By появляется в строке для каждого поля в запросе.
В строке Итого щелкните поле, которое вы хотите подсчитать, и выберите Подсчет из полученного списка.
На вкладке Design в группе Results нажмите Run .
Результаты запроса отображаются в режиме таблицы.
При необходимости сохраните запрос.
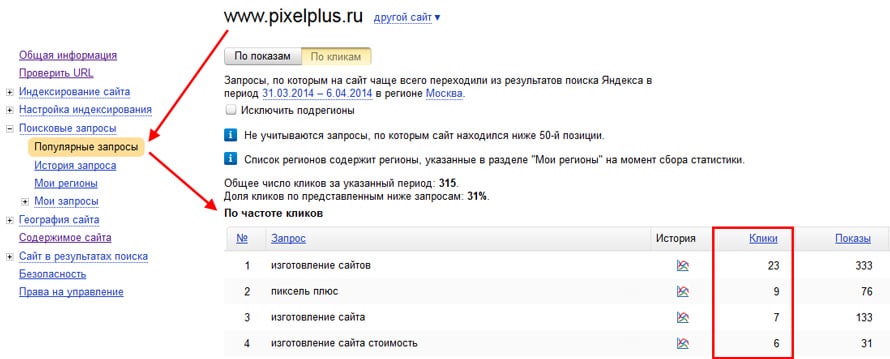

Верх страницы
Ссылка на агрегатную функцию
В следующей таблице перечислены и описаны агрегатные функции, которые Access предоставляет для использования в строке Итого и в запросах. Помните, что Access предоставляет больше агрегатных функций для запросов, чем для строки Итого. Кроме того, если вы работаете с проектом Access (внешний интерфейс Access, подключенный к базе данных Microsoft SQL Server), вы можете использовать более широкий набор агрегатных функций, предоставляемых SQL Server. Дополнительные сведения об этом наборе функций см. в электронной документации по Microsoft SQL Server.
Дополнительные сведения об этом наборе функций см. в электронной документации по Microsoft SQL Server.
Функция | Описание | Используйте с типом(ами) данных |
Сумма | Добавляет элементы в столбец. Работает только с числовыми и денежными данными. | Число, десятичное число, валюта |
Средний | Вычисляет среднее значение для столбца. | Число, десятичное число, валюта, дата/время |
Счет | Подсчитывает количество элементов в столбце. | Все типы данных, кроме тех, которые содержат сложные повторяющиеся скалярные данные, такие как столбец многозначных списков. Дополнительные сведения о списках с несколькими значениями см. в статьях Руководство по полям с несколькими значениями и Создание или удаление поля с несколькими значениями. |
Максимум | Возвращает элемент с наибольшим значением. | Число, десятичное число, валюта, дата/время |
Минимум | Возвращает элемент с наименьшим значением. Для текстовых данных наименьшее значение — это первое буквенное значение, и Access игнорирует регистр. Функция игнорирует нулевые значения. | Число, десятичное число, валюта, дата/время |
Стандартное отклонение | Измеряет, насколько сильно значения отличаются от среднего значения (среднего значения). Дополнительные сведения об использовании этой функции см. в статье Отображение итогов по столбцам в таблице данных. | Число, десятичное число, валюта |
Дисперсия | Измеряет статистическую дисперсию всех значений в столбце. Вы можете использовать эту функцию только для числовых и денежных данных. Если таблица содержит менее двух строк, Access возвращает нулевое значение. Дополнительные сведения о функциях дисперсии см. в статье Отображение итогов по столбцам в таблице. | Число, десятичное число, валюта |
 Столбец должен содержать числовые данные, валюту или дату/время. Функция игнорирует нулевые значения.
Столбец должен содержать числовые данные, валюту или дату/время. Функция игнорирует нулевые значения. Для текстовых данных самым высоким значением является последнее буквенное значение, и Access игнорирует регистр. Функция игнорирует нулевые значения.
Для текстовых данных самым высоким значением является последнее буквенное значение, и Access игнорирует регистр. Функция игнорирует нулевые значения.
Верх страницы
Отслеживание и настройка запросов с использованием индексов SQL Server
В предыдущих статьях этой серии (см. полное оглавление статьи внизу) мы обсуждали внутреннюю структуру таблиц и индексов SQL Server, рекомендации по разработке правильного индекса, группу операций, которые вы можете выполнять с индексы SQL Server, как создавать эффективные кластерные и некластеризованные индексы и, наконец, различные типы индексов SQL Server, помимо классификации кластерных и некластеризованных индексов. В этой статье мы обсудим, как настроить производительность плохих запросов с помощью индексов SQL Server.
полное оглавление статьи внизу) мы обсуждали внутреннюю структуру таблиц и индексов SQL Server, рекомендации по разработке правильного индекса, группу операций, которые вы можете выполнять с индексы SQL Server, как создавать эффективные кластерные и некластеризованные индексы и, наконец, различные типы индексов SQL Server, помимо классификации кластерных и некластеризованных индексов. В этой статье мы обсудим, как настроить производительность плохих запросов с помощью индексов SQL Server.
До этого момента, получив полное представление о концепции, структуре, дизайне и типах индексов SQL Server, мы готовы разработать наиболее эффективный индекс SQL Server, который оптимизатор запросов SQL Server всегда будет использовать для ускорения извлечения данных. обрабатывать наши запросы, что является основной целью создания индекса, с минимальными дисковыми операциями ввода-вывода и наименьшим использованием системных ресурсов.
Прежде чем разрабатывать индекс, который поможет обработчику запросов быстро находить данные и обращаться к базовой таблице как можно меньше раз, вы должны хорошо понимать базовую структуру данных и их использование, тип запросов, считывающих эти данные, и частоту их выполнения. выполняются запросы. Как администратор базы данных, вы можете использовать различные инструменты и сценарии, чтобы предоставить владельцам систем список предлагаемых индексов, которые могут повысить производительность их системных запросов. Но в зависимости от их понимания поведения системы, они должны предоставить окончательное подтверждение создания таких индексов только после изучения производительности запроса в среде разработки до и после создания предложенного индекса.
выполняются запросы. Как администратор базы данных, вы можете использовать различные инструменты и сценарии, чтобы предоставить владельцам систем список предлагаемых индексов, которые могут повысить производительность их системных запросов. Но в зависимости от их понимания поведения системы, они должны предоставить окончательное подтверждение создания таких индексов только после изучения производительности запроса в среде разработки до и после создания предложенного индекса.
Администраторам баз данных приходится балансировать между созданием слишком большого количества индексов и созданием слишком малого количества индексов. Например, нет необходимости индексировать каждый столбец по отдельности или включать столбец во множество перекрывающихся индексов. Они также должны учитывать, что индекс, который повысит производительность запросов SELECT, также замедлит различные операции DML, такие как запросы INSERT, UPDATE и DELETE.
Еще одна вещь, которую следует учитывать, — это настройка самого индекса, поскольку индекс, который хорошо работал с вашими запросами в прошлом, может не соответствовать запросам сейчас из-за частых изменений в схеме таблицы и самих данных.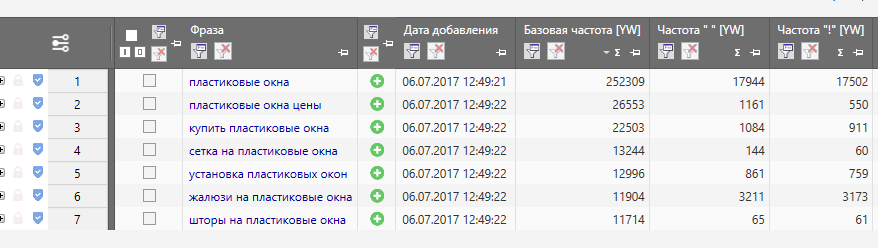 Это может потребовать удаления индекса и создания более эффективного. В следующей статье мы подробно обсудим, как получить информацию об использовании индекса и решить, нужно ли нам сохранить или удалить этот индекс. С другой стороны, индекс может страдать от проблем фрагментации только из-за очень частого изменения данных, которые можно решить с помощью различных задач обслуживания индекса, которые подробно обсуждались в последней статье этой серии.
Это может потребовать удаления индекса и создания более эффективного. В следующей статье мы подробно обсудим, как получить информацию об использовании индекса и решить, нужно ли нам сохранить или удалить этот индекс. С другой стороны, индекс может страдать от проблем фрагментации только из-за очень частого изменения данных, которые можно решить с помощью различных задач обслуживания индекса, которые подробно обсуждались в последней статье этой серии.
Давайте начнем нашу демонстрацию, чтобы понять концепцию настройки производительности на практике. Мы создадим новую базу данных IndexDemoDB, содержащую три таблицы; таблицу STD_Info, содержащую информацию о студентах, таблицу Courses, содержащую список доступных курсов, и, наконец, таблицу STD_Evaluation, содержащую оценки зарегистрированных студентов на доступных курсах. Таблица STD_Evaluation содержит два внешних ключа; идентификатор учащегося, который ссылается на таблицу STD-Info, и идентификатор курса, который ссылается на таблицу «Курсы». Приведенный ниже сценарий T-SQL используется для создания базы данных и таблиц, как описано:
Приведенный ниже сценарий T-SQL используется для создания базы данных и таблиц, как описано:
1 2 3 4 5 6 7 8 10 110003 12 13 14 19990001 9000 214 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 0 3 603 | СОЗДАТЬ БАЗУ ДАННЫХ IndexDemoDB GO Create Table STD_INFO (STD_ID INT IDENITY (1,1) Первичный ключ, STD_NAME VARCHAR (50), STD_BIRTHDATE DATETIME, GOADDRESS VARCH Создание табличных курсов (COURD_ID INT IDEDITY (1,1) Первичный ключ, COUST_NAME VARCHAR (50), COUSE_MAXGRADE INT ) GO CREATE TABLE STD_EVALUATIA0002 ( EV_ID INT IDEDITY (1,1), STD_ID Int, COUSE_ID INT, STD_CURSE_GRADE Int, Constraint FK_STD_EVALUATION_STD_INFO Foreign Key (STD_ID) . ССЫЛКИ Курсы (Course_ID) ) |
 KEY (Course_ID)
KEY (Course_ID) После создания базы данных и таблиц без определения индекса или ключа в таблице STD_Evaluation мы заполним каждую таблицу 100 тыс. записями с помощью ApexSQL Generate, как показано ниже:
Настройка простого запроса
Чтение из таблицы без индекса похоже на поиск слова в книге путем изучения каждой отдельной страницы этой книги. Если вы попытаетесь выполнить приведенный ниже запрос SELECT для извлечения данных из таблицы STD_Evaluation после включения статистики TIME и IO и включения плана выполнения, используя приведенный ниже оператор T-SQL:
УСТАНОВИТЬ ВРЕМЯ СТАТИСТИКИ НАСТРОЙКА СТАТИСТИЧЕСКОГО ВВОДА-ВВОДА НА GO ВЫБЕРИТЕ * ИЗ [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
Из плана выполнения, сгенерированного после выполнения запроса, вы увидите, что SQL Server выполнит операцию Table Scan для этой таблицы, проверив все строки таблицы, чтобы проверить, соответствуют ли эти строки условию WHERE, как показано в плане выполнения ниже.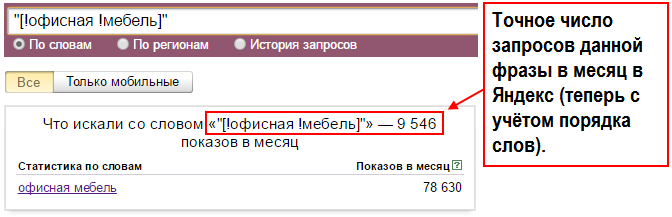 :
:
Вы также можете видеть из статистики TIME и IO, что запрос выполняется в течение 655 мс , потребляя 94 мс из процессорного времени, как показано ниже:
Наличие указателя в начале книги позволит читателю быстрее найти свою цель. То же самое относится и к таблицам SQL Server; наличие индекса в таблице ускорит процесс извлечения данных, предоставляя клиенту запрошенные данные в более короткие сроки, конечно, если индекс разработан правильно.
Если мы взглянем на поверхность предыдущего запроса SELECT и решим добавить индекс в столбец STD_ID, упомянутый в предложении WHERE этого запроса, используя инструкцию CREATE INDEX T-SQL ниже:
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС IX_STD_Evaluation_STD_ID ON [STD_Evaluation] (STD_ID) |
Затем выполните тот же оператор SELECT:
SELECT * FROM [dbo]. |
 [STD_Evaluation] WHERE STD_ID < 1530
[STD_Evaluation] WHERE STD_ID < 1530Из плана выполнения, сгенерированного после выполнения запроса, вы увидите, что SQL Server снова выполняет операцию сканирования таблицы, чтобы получить данные из этой таблицы без учета созданного индекса, как показано в плане выполнения ниже:
Проверив статистику TIME и IO запроса, вы увидите, что требуемое время и время ЦП, затраченное на выполнение запроса, не очень далеко от предыдущего оператора SELECT без индексов, с небольшим улучшением, как показано ниже:
Наличие индекса, созданного для этой таблицы, не означает, что SQL Server обязательно будет его использовать. В некоторых ситуациях SQL Server обнаруживает, что сканирование базовой таблицы выполняется быстрее, чем использование индекса, особенно если таблица небольшая или запрос возвращает большую часть записей таблицы.
Давайте еще раз взглянем на предыдущий план выполнения, вы увидите зеленое сообщение от SQL Server, которое рекомендует индекс для повышения производительности этого запроса на 77,75%. Щелкните правой кнопкой мыши этот план выполнения и выберите параметр Missing Index Details , чтобы отобразить предлагаемый индекс, как показано ниже:
Щелкните правой кнопкой мыши этот план выполнения и выберите параметр Missing Index Details , чтобы отобразить предлагаемый индекс, как показано ниже:
Тот же самый вариант индекса можно найти, запросив динамическое административное представление sys.dm_db_missing_index_details , которое возвращает подробную информацию об отсутствующих индексах, за исключением пространственных индексов, как показано ниже:
ВЫБЕРИТЕ * ИЗ sys.dm_db_missing_index_details |
Предыдущий запрос предложит тот же покрывающий индекс с STD_ID, который используется в предложении WHERE запроса в качестве ключа индекса, а остальные возвращенные столбцы в операторе SELECT, столбцы EV_ID, Course_ID и STD_Course_Grade, как неключевые столбцы. в предложении INCLUDE оператора создания индекса, показанного ниже:
Мы удалим неправильный индекс, созданный ранее, и создадим новый индекс, предложенный SQL Server, с помощью приведенного ниже сценария T-SQL:
1 2 3 4 5 6 7 8 | USE [IndexDemoDB] GO DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation] 9STD_Evaluation_0003 ON [dbo]. ВКЛЮЧИТЬ ([EV_ID],[Course_ID],[STD_Course_Grade]) GO |
 [STD_Evaluation] ([STD_ID])
[STD_Evaluation] ([STD_ID])Если вы попытаетесь выполнить тот же оператор SELECT:
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
Затем проверьте план выполнения, сгенерированный после выполнения запроса, вы увидите, что SQL Server выполнит Операция Index Seek для извлечения данных для пользователя, как показано ниже:
Статистика TIME и IO покажет, что время, необходимое для выполнения запроса, уменьшилось с 655 мс до 554 мс, с увеличением примерно на 15% после добавления индекса, а потребляемое время ЦП сократилось с 94 мс до 31 мс, примерно на 67% улучшение при использовании индекса. Вы можете себе представить улучшение, которое можно получить в случае больших таблиц, как показано ниже:
Предыдущий некластеризованный индекс создается поверх таблицы кучи.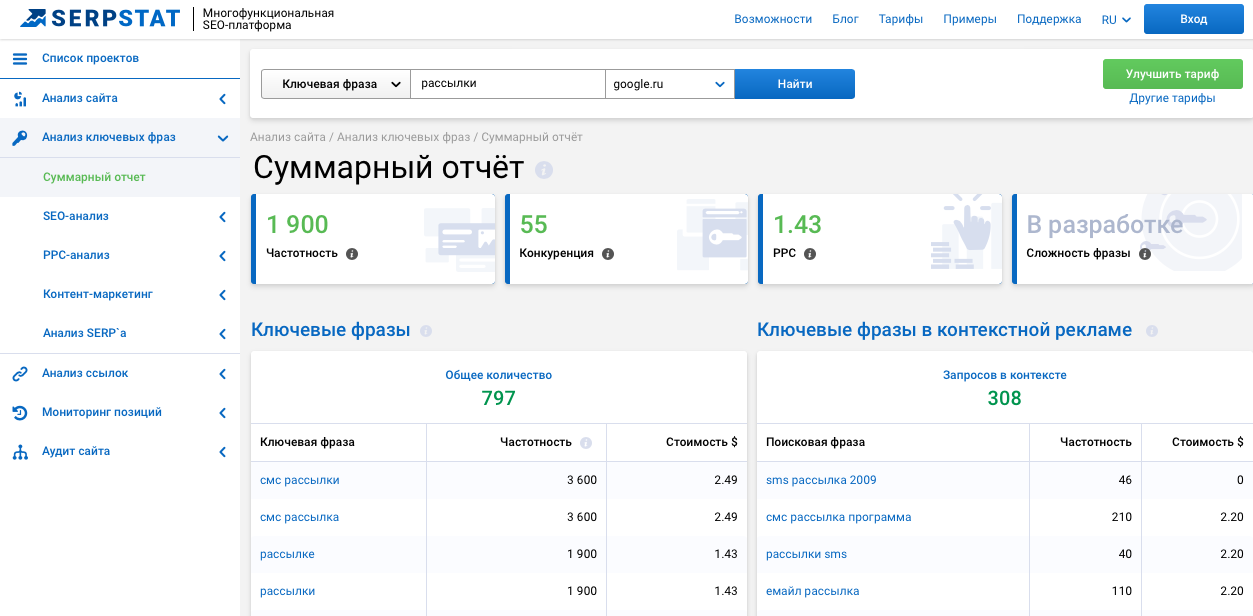 Мы удалим ранее созданный некластеризованный индекс, создадим кластеризованный индекс для столбца EV_ID, затем снова создадим некластеризованный индекс, используя приведенный ниже сценарий T-SQL:
Мы удалим ранее созданный некластеризованный индекс, создадим кластеризованный индекс для столбца EV_ID, затем снова создадим некластеризованный индекс, используя приведенный ниже сценарий T-SQL:
1 2 3 4 5 6 7 | DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO Создание кластерного индекса IX_EVALUATION_EV_ID на [std_evaluation] ([ev_id]) GO Создание некластерированного индекса [ix_std_evaluation_std_id] на [DBO]. ],[Course_ID],[STD_Course_Grade]) |
Напомним, что мы упоминали в предыдущих статьях этой серии, что некластеризованный индекс будет автоматически перестроен при создании кластеризованного индекса для таблицы, чтобы указывать на кластеризованный ключ, а не на базовую таблицу. Если мы снова выполним тот же оператор SELECT:
SELECT * FROM [dbo]. |
 [STD_Evaluation] WHERE STD_ID < 1530
[STD_Evaluation] WHERE STD_ID < 1530Вы увидите, что тот же план выполнения будет создан без каких-либо изменений по сравнению с предыдущим, как показано ниже:
Кроме того, статистика ВРЕМЕНИ и ввода-вывода покажет, что время, необходимое для выполнения запроса, и время ЦП, потребляемое запросом, в чем-то схожи с предыдущим результатом, с небольшим улучшением в сокращении операций ввода-вывода, выполняемых для извлечения данных, из-за для работы с небольшой таблицей, как показано ниже:
Вы также можете подумать о замене некластеризованного индекса кластеризованным индексом в столбце STD_ID, принимая во внимание, что кластеризованный индекс не содержит предложения INCLUDE. Если мы удалим все индексы, доступные в этой таблице, и заменим их только одним кластеризованным индексом, используя приведенный ниже сценарий T-SQL:
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO DROP INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] GO CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([STD_ID]) |
Затем выполните тот же оператор SELECT:
SELECT * FROM [dbo]. |
 [STD_Evaluation] WHERE STD_ID < 1530
[STD_Evaluation] WHERE STD_ID < 1530Из сгенерированного плана выполнения вы увидите, что Clustered Index Seek 9Для получения запрошенных данных будет выполнена операция 0680, как показано ниже:
Без заметного улучшения статистики ВРЕМЕНИ и ввода-вывода, сгенерированной при выполнении запроса, в случае нашей небольшой таблицы, как показано ниже:
Настройка сложного запроса
Давайте теперь попробуем настроить производительность более сложного запроса, который возвращает имя учащегося, название курса, максимальную оценку за курс и, наконец, оценку учащегося в этом классе, объединив три ранее созданных запроса. таблицы вместе на основе общих столбцов между каждыми двумя таблицами, с учетом того, что в таблице STD_Evaluation нет индекса , как показано в операторе SELECT ниже:
1 2 3 4 5 6 7 | ВЫБЕРИТЕ ST. FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID ГДЕ ST.[STD_ID] > 1500 AND C.Course_ID >320 |
 [STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade]
[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade]Если вы проверите план выполнения, сгенерированный после выполнения запроса, вы увидите, что из-за того, что STD_Evaluation не имеет индекса, SQL Server будет сканировать все записи таблицы STD_Evaluation для поиска строк, соответствующих условию WHERE, путем выполнение операции сканирования таблицы. Кроме того, в плане выполнения будет отображаться зеленое сообщение с предлагаемым индексом из SQL Server для повышения производительности запроса, как показано ниже:
Щелкните правой кнопкой мыши этот план выполнения и выберите параметр «Отсутствующие сведения об индексе», чтобы отобразить предлагаемый индекс. Оператор T-SQL, который используется для создания нового индекса, с процентом повышения производительности, который здесь составляет 82%, будет отображаться в появившемся окне, как показано ниже:
Статистика TIME и IO, созданная при выполнении предыдущего запроса, показывает, что SQL Server выполняет 310 логических операций чтения в течение 65 мс и потребляют 16 мс времени ЦП для извлечения данных, как показано ниже:
Тот же самый вариант индекса можно найти, запросив динамическое административное представление sys.![]() dm_db_missing_index_details , которое возвращает подробную информацию об отсутствующих индексах, за исключением пространственных индексов, как показано ниже:
dm_db_missing_index_details , которое возвращает подробную информацию об отсутствующих индексах, за исключением пространственных индексов, как показано ниже:
Производительность запроса также можно настроить с помощью комбинации SQL Server Profiler и средства Database Engine Tuning Advisor . Щелкните правой кнопкой мыши запрос, который вам удалось настроить, и выберите параметр Trace Query в SQL Server Profiler , как показано ниже:
Будет показан новый сеанс SQL Server Profiler. Когда вы выполняете запрос для настройки, статистика запроса будет зафиксирована в открытом сеансе SQL Server Profiler, как показано на снимке ниже:
Сохраните предыдущую трассировку, чтобы использовать ее в качестве рабочей нагрузки для помощника по настройке ядра СУБД. В меню Tools SQL Server Management Studio выберите параметр Database Engine Tuning Advisor , как показано ниже:
В открывшемся окне помощника по настройке ядра СУБД подключитесь к целевому SQL Server, базе данных, из которой запрос будет извлекать данные, и, наконец, выделите файл рабочей нагрузки, содержащий трассировку запроса, затем нажмите как показано ниже:
После успешного завершения операции анализа в сгенерированном отчете будут отображаться рекомендации, включающие индексы и статистику, которые могут повысить производительность запроса, с предполагаемым процентом улучшения. В нашем случае в отчете с рекомендациями будет отображаться тот же ранее предложенный индекс, как показано ниже:
В нашем случае в отчете с рекомендациями будет отображаться тот же ранее предложенный индекс, как показано ниже:
Если мы возьмем инструкцию CREATE INDEX, предоставленную из предыдущего плана выполнения или из отчета помощника по настройке ядра СУБД, и создадим предложенный индекс для повышения производительности запроса, как в приведенной ниже инструкции T-SQL:
1 2 3 4 5 6 | Использование [indexDemodb] GO Создание неклегированного индекса [IX_STD_EVALUATION_COURSE_ID] на [DBO]. [STD_EVALUAUTION] ([STD_ID], [COURE_ID]) Включите (STD_CURSE_GRAGE] . |
Затем выполните тот же оператор SELECT:
1 2 3 4 5 6 7 | ВЫБЕРИТЕ ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV. FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Курсы] C ON C.Course_ID= EV.Course_ID ГДЕ ST.[STD_ID] > 1500 AND C.Course_ID >320 |
 [STD_Course_Grade]
[STD_Course_Grade]Из сгенерированного плана выполнения вы увидите, что предыдущая медленная операция сканирования таблицы сменилась быстрой операцией поиска по индексу, как показано ниже:
Статистика TIME и IO также показывает, что после создания предложенного индекса SQL Server выполняет только 90 679 3 90 680 логических операций rea по сравнению с 310 операциями логического чтения перед созданием индекса, с улучшением около 90 679 91% 90 680 в течение 90 679 40 мс 90 680 по сравнению с с 65 мс, необходимыми для выполнения запроса перед созданием индекса, с примерно 39% Улучшение и потребляют нет процессорного времени по сравнению с 16 мс, потребляемыми до создания индекса, как показано ниже:
Предыдущий некластеризованный индекс создается поверх таблицы кучи. Мы удалим ранее созданный некластеризованный индекс, создадим кластеризованный индекс для столбца EV_ID, затем снова создадим некластеризованный индекс, используя приведенный ниже сценарий T-SQL:
Мы удалим ранее созданный некластеризованный индекс, создадим кластеризованный индекс для столбца EV_ID, затем снова создадим некластеризованный индекс, используя приведенный ниже сценарий T-SQL:
1 2 3 4 5 6 7 8 10 11 12 13 | Использование [indexDemoDB] GO Индекс падения [IX_STD_EVALUATION_CURSE_ID] на [DBO].
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] ([STD_ID],[Course_ID]) ВКЛЮЧИТЬ ([STD_Course_Grade]) GO |
Если вы снова выполните тот же оператор SELECT:
1 2 3 4 5 6 7 | ВЫБЕРИТЕ ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo]. ПРИСОЕДИНЯЙТЕСЬ [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] ПРИСОЕДИНЯЙТЕСЬ [dbo].[Курсы] C ON C.Course_ID= EV.Course_ID ГДЕ STD_ID STD_ID] > 1500 И C.Course_ID >320 |
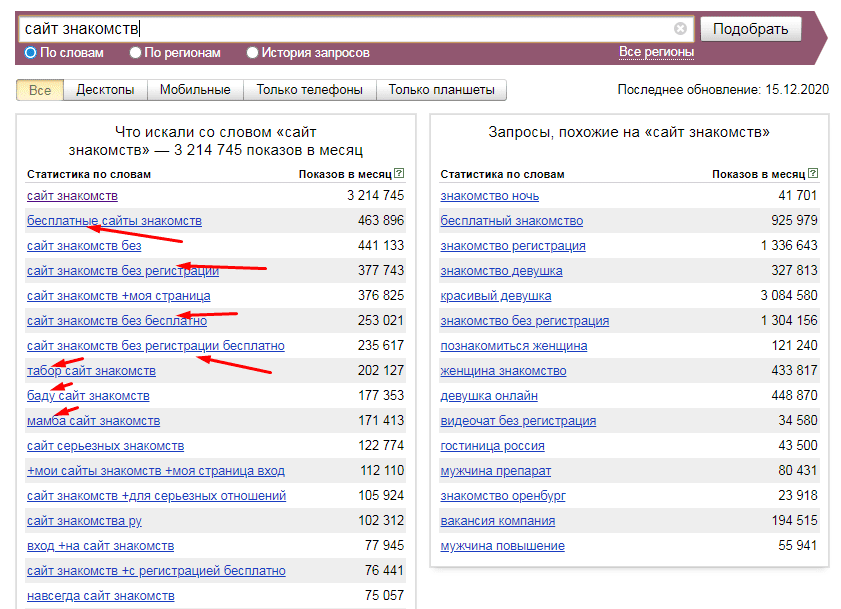 [STD_Info] ST
[STD_Info] STТот же план выполнения будет сгенерирован, как показано ниже:
Кроме того, статистика TIME и IO покажет небольшое увеличение числа логических операций чтения и времени, необходимого для выполнения запроса, поскольку мы работаем с небольшой таблицей, как показано ниже:
В предыдущих статьях этой серии мы упоминали, что порядок сортировки столбцов в ключе индекса должен соответствовать тому же порядку столбцов в запросе, который будет охватывать индекс. Чтобы понять причину с практической точки зрения, давайте рассмотрим два приведенных ниже примера.
В ранее созданном индексе порядок сортировки столбцов STD_ID и Course_ID является порядком сортировки по умолчанию ASC . Если мы изменим запрос SELECT для сортировки возвращаемых строк на основе столбцов STD_ID и Course_ID DESC , что полностью противоположно порядку столбцов в индексе, как показано в запросе T-SQL ниже:
Если мы изменим запрос SELECT для сортировки возвращаемых строк на основе столбцов STD_ID и Course_ID DESC , что полностью противоположно порядку столбцов в индексе, как показано в запросе T-SQL ниже:
1 2 3 4 5 6 7 8 | ВЫБЕРИТЕ ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID ГДЕ ST.[STD_ID] > 1500 AND C.Course_ID >320 ПОРЯДОК ПО ST.[STD_ID] DESC,C. [Курс_ID] DESC |
Из сгенерированного плана выполнения вы увидите, что ничего не изменится, за исключением Scan Direction некластеризованного индекса, который будет Backward , который можно просмотреть в окне свойств узла Index Seek.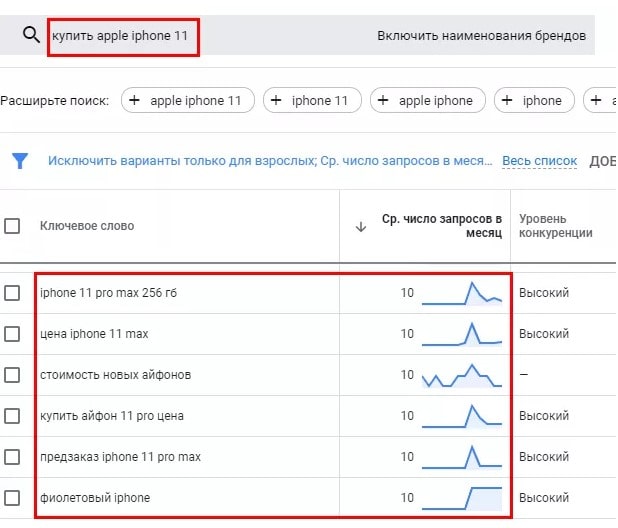 Это означает, что вместо того, чтобы читать индекс сверху вниз, SQL Server будет читать данные из этого индекса снизу вверх без необходимости повторной сортировки данных, как ясно показано ниже:
Это означает, что вместо того, чтобы читать индекс сверху вниз, SQL Server будет читать данные из этого индекса снизу вверх без необходимости повторной сортировки данных, как ясно показано ниже:
С минимальными издержками обратного чтения статистика показана ниже:
Все будет по-другому при изменении запроса для извлечения строк в порядке, очень далеком от порядка сортировки в ключе индекса. Например, если мы изменим запрос SELECT, чтобы получить данные, отсортированные на основе столбца STD_ID в порядке ASC и на основе столбца Course_ID в порядке DESC, как показано в операторе T-SQL ниже:
1 2 3 4 5 6 7 8 | ВЫБЕРИТЕ ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo]. ON C.Course_ID= EV.Course_ID ГДЕ ST.[STD_ID] > 1500 И C.Course_ID >320 ЗАКАЗ ПО СТ.[STD_ID] ASC,C.[Course_ID] DESC |
 [Курсы] C
[Курсы] CSQL Server не может извлечь выгоду из порядка сортировки столбцов в индексе, поскольку он очень далек от запрошенного порядка в запросе, но все же может извлечь выгоду из индекса для извлечения данных с помощью операции поиска по индексу, тогда он должен отсортируйте строки, возвращенные из индекса, с помощью дорогостоящей операции Sort , как показано в сгенерированном плане выполнения ниже:
Из статистики TIME видно, что дорогостоящая операция Sort заметно замедлит выполнение запроса. Вот почему мы продолжаем говорить, что очень важно сопоставить порядок сортировки столбцов в индексе и запрос, который получит преимущества от этого индекса. Дополнительные затраты времени на операцию Sort ясно показаны ниже:
Здесь важно отметить, что индексирование столбцов по отдельности может быть не оптимальным решением для повышения производительности запроса. Предположим, что мы планируем индексировать оба столбца STD_ID и Course_ID, которые используются в условиях WHERE и JOIN в предыдущем запросе, принимая во внимание, что таблица STD_Evaluation содержит 9 столбцов.0679 на нем не создан индекс с использованием приведенного ниже сценария T-SQL:
Предположим, что мы планируем индексировать оба столбца STD_ID и Course_ID, которые используются в условиях WHERE и JOIN в предыдущем запросе, принимая во внимание, что таблица STD_Evaluation содержит 9 столбцов.0679 на нем не создан индекс с использованием приведенного ниже сценария T-SQL:
1 2 3 4 5 6 | Создание неклегированного индекса [IX_STD_EVALUATION_STD_ID] на [DBO]. |
Если вы выполните тот же оператор SELECT:
1 2 3 4 5 6 7 | ВЫБЕРИТЕ ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID ГДЕ ST. |
 [STD_ID] > 1500 И C.Course_ID >320
[STD_ID] > 1500 И C.Course_ID >320Из плана выполнения, сгенерированного после выполнения запроса, вы увидите, что созданные индексы не покрывают предыдущий запрос, который требует от SQL Server выполнения дополнительной операции Key Lookup для извлечения остальных столбцов, которые не включены в созданные индексы из базовой таблицы, как показано ниже:
И высокая стоимость операции поиска ключа будет переведена в дополнительные затраты ВРЕМЕНИ, как показано в статистике ниже:
В этой статье мы перевели советы и рекомендации по дизайну индексов, упомянутые в предыдущих статьях этой серии, в практические термины. Готовьтесь к следующей статье, в которой мы проверим информацию об индексах, чтобы сохранить полезные индексы и удалить плохие.
Содержание
| Индексы SQL Server — введение в серию |
| Обзор структуры таблицы SQL Server |
| Структура и концепции индекса SQL Server |
| Основы и рекомендации по проектированию индексов SQL Server |
| Операции с индексами SQL Server |
| Разработка эффективных кластерных индексов SQL Server |
| Разработка эффективных некластеризованных индексов SQL Server |
| Работа с разными типами индексов SQL Server |
| Отслеживание и настройка запросов с использованием индексов SQL Server |
| Сбор статистики индекса SQL Server и информации об использовании |
| Поддержка индексов SQL Server |
| 25 самых популярных вопросов и ответов на собеседованиях об индексах SQL Server |
- Автор
- Последние сообщения
Ахмад Ясин
Ахмад Ясин — инженер Microsoft по работе с большими данными, обладающий глубокими знаниями и опытом в области SQL BI, администрирования и разработки баз данных SQL Server.
Он является сертифицированным экспертом Microsoft по решениям в области управления данными и аналитики, сертифицированным специалистом по решениям Microsoft в области администрирования и разработки баз данных SQL, специалистом по разработке Azure и сертифицированным тренером Microsoft.
Кроме того, он публикует свои советы по SQL во многих блогах.
Просмотреть все сообщения Ахмада Ясина
Последние сообщения Ахмада Ясина (посмотреть все)
Расчет частотного распределения в PostgreSQL
Я всегда любил статистику. Работа инженером-программистом открыла мне много возможностей решать сложные статистические задачи на языке SQL. При программировании мы хотим учитывать текущее состояние данных, которые означает выполнение расчетов по требованию. Недавно мне представилась возможность рассчитать распределения частоты в SQL и хотел поделиться с вами тем, что я узнал.
Пример
Итак, прежде чем мы углубимся, сначала нам нужен пример.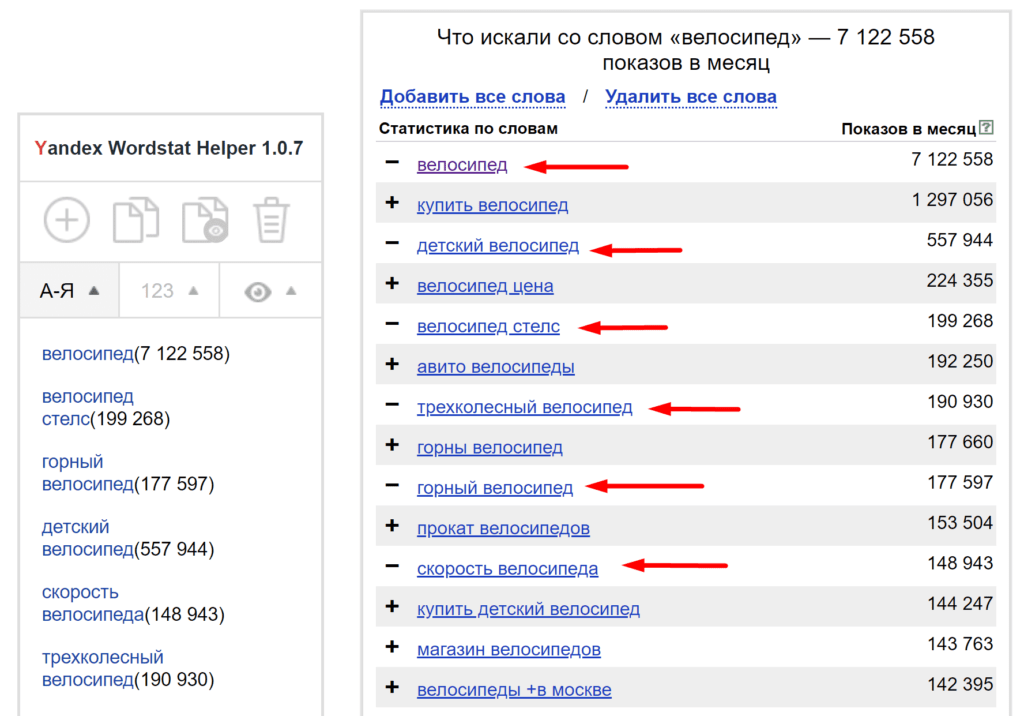 Хороший пример…
Хороший пример…
Когда вы идете по грязной дорожке, легкий ветерок касается вашей шеи. Внезапно, из ниоткуда седой старый смотритель моста преграждает вам путь. «Останавливаться!» — восклицает он.
Его дыхание пахнет бузиной, и он слегка пахнет хомяком. как он смотрит на тебя с молочно-белыми глазами он говорит следующее:
«Тот, кто перейдет Мост Смерти, должен ответить мне на эти три вопроса, прежде чем он увидит другую сторону».
На что вы, конечно же, отвечаете: «Задавай мне вопросы, смотритель моста. Я не боюсь.». Так что спроси он делает:
- Ваш любимый цвет?
- Каков твой квест?
- Какова скорость полета порожней ласточки?
Пока вы смотрите на него озадаченно, он (услужливо) предлагает вам несколько вариантов ответа на каждый вопрос. Каждый вопрос теперь имеет набор вариантов: a, b, c и d. Учитывая ваши варианты вы отвечаете что ваш любимый цвет действительно B) фуксия, ваш квест A) не докучать жутким мостиков, а вы отвечаете за скорость полета порожней ласточки A) An Африканская или европейская ласточка?
Конечно, это тревожный опыт, но теперь вам действительно любопытно, как другие
путешественников, прежде чем вы ответили на вопросы. Так любопытно на самом деле, что вы думаете
выяснить, каково было частотное распределение ответов на каждый вопрос.
Так любопытно на самом деле, что вы думаете
выяснить, каково было частотное распределение ответов на каждый вопрос.
Хорошо, хорошо, хорошо. Так что это была не реальная ситуация, с которой я столкнулся на работе, а работа со мной здесь.
Базовое распределение частот
Что такое частотное распределение?
Распределение частоты вычисляет частоту (также известную как скорость или возникновение) какой вариант вопроса был выбран
Вспомните вопросы хранителя моста, есть определенное количество вариантов: a, b, c и d. за каждый вопрос и заданное количество путешественников, которым ответили. Частота распределение измеряет общее количество раз, когда был выбран каждый вариант множественного выбора. Вы можете думать о каждом варианте (a, b, c, d) как о отдельной категории, которую мы хотели бы группировать путешественников в зависимости от их ответа.
Теперь, когда мы заинтересованы в анализе ответов предыдущих путешественников, нам нужно
узнать, насколько хорошо они ответили.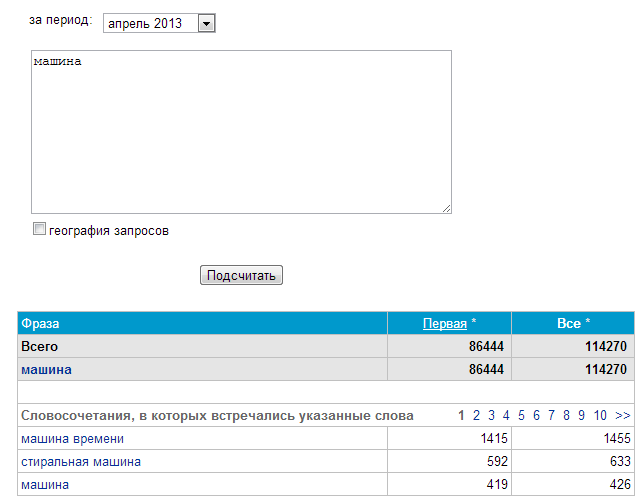 Глядя на частотное распределение, мы
также мог предположить, был ли вопрос слишком сложным или слишком простым.
Глядя на частотное распределение, мы
также мог предположить, был ли вопрос слишком сложным или слишком простым.
Сначала давайте напишем SQL для сбора ответов путешественников по всем трем вопросы.
ВЫБЕРИТЕ traveler_answers.choice, COUNT(traveler_answers.choice) как total_answers ОТ traveler_answers СГРУППИРОВАТЬ ПО traveller_answers.choice ORDER BY traveler_answers.choice -- Чтобы убедиться, что порядок a, b, c, d
Приведенный выше запрос возвращает вариант (a, b, c или d) вместе с количеством
сколько раз путешественник выбрал его. Мы группируем вышеперечисленное по traveler_answers.choice так как это гарантирует, что агрегатная функция COUNT() возвращает результат для каждого типа
выбора. Приведенный выше запрос дает нам базовое частотное распределение
который вы можете увидеть ниже:
| выбор | всего_ответов |
|---|---|
| и | 25 |
| б | 50 |
| с | 25 |
| д | 75 |
Так как это самое простое распределение частот, оно довольно простое. написать поддерживающий SQL. Тем не менее, он не очень полезен в его нынешнем виде. какая
действительно ли говорят нам 25 полных ответов на вариант А? Ну, по всем пяти вопросам… Я имею в виду
три вопроса, 25 путешественников выбирают вариант А. Не очень убедительный материал.
написать поддерживающий SQL. Тем не менее, он не очень полезен в его нынешнем виде. какая
действительно ли говорят нам 25 полных ответов на вариант А? Ну, по всем пяти вопросам… Я имею в виду
три вопроса, 25 путешественников выбирают вариант А. Не очень убедительный материал.
«Ну, поехали! Пойдем, Пэтси»
Распределение частот для двух категорий
Что может быть полезнее распределения частот по всем вопросам? Как о частотном распределении на основе одного вопроса? Конкретно посчитаем, сколько путешественников выбрал с заданным выбором на заданный вопрос . Вы могли бы также подумать об этом как сравнение двух категорий в частотном распределении.
Для этого мы следуем нашему примеру выше, добавляя новый GROUP BY пункт, чтобы гарантировать, что мы группируем категории по выбору путешественника
( traveler_answers.choice )
и вопрос хранителя моста ( bridgekeeper_questions.question_text ).
ВЫБЕРИТЕ bridgekeeper_questions.question_text, traveler_answers.choice, COUNT(traveler_answers.choice) как total_answers ОТ traveler_answers ВНУТРЕННЕЕ СОЕДИНЕНИЕ bridgekeeper_questions ON bridgekeeper_questions.id = traveler_answers.exam_question_id ГРУППА ПО traveler_answers.choice, bridgekeeper_questions.question_text ЗАКАЗАТЬ traveler_answers.choice
Так как мы группируем результаты по traveler_answers.choice и bridgekeeper_questions.question_text , мы заканчиваем
с несколькими результатами на текст вопроса (1 на пару вариантов/вопросов). Ты можешь видеть
что результирующий запрос вернет ниже.
| Текст вопроса | выбор | всего_ответов |
|---|---|---|
| «Какой твой любимый цвет?» | и | 12 |
| «Какой твой любимый цвет?» | б | 20 |
| «Какой твой любимый цвет?» | в | 10 |
| «Какой твой любимый цвет?» | д | 5 |
| «Какое у тебя задание?» | и | 12 |
| «Какое у тебя задание?» | б | 5 |
| «Какое у тебя задание?» | в | 15 |
| «Какое у тебя задание?» | д | 40 |
| «Какова скорость полета порожней ласточки?» | и | 1 |
| «Какова скорость полета порожней ласточки?» | б | 25 |
| «Какова воздушная скорость порожней ласточки?» | в | 5 |
| «Какова скорость полета порожней ласточки?» | д | 25 |
Теперь у нас есть частотное распределение для каждого вопроса. Это начинает выглядеть как полезные данные.
Это начинает выглядеть как полезные данные.
Что такое описательная статистика?
«Описательная статистика (в смысле исчисляемого существительного) — это сводная статистика, которая количественно описывает или обобщает особенности набора информации» — Википедия
Тут мы кое-что забыли. Кого волнует ответ предыдущего путешественника если мы не знаем, был ли их выбор правильным или нет. «Кто ты, кто так мудр в путях науки?». Совершенно нормально, если вы так думаете. Ну… наверное, нет, но не разрушай мои заблуждения.
Вот наши новые цели анализа:
- Каково общее количество правильных ответов на вопрос?
- Каков процент правильных ответов на вопрос?
Теперь это не будет иметь большого смысла, если для каждой строки в приведенной выше таблице мы вернемся общее количество и процент от общего числа правильных. На самом деле мы хотим их в формате:
Текст вопроса | выбор | Всего ответов | всего правильных ответов | процент правильных ответов
Таким образом, вы можете сказать, что ш руб бери здесь заключается в том, что нам нужно сжать многострочный формат выше
в одну строку на вопрос.
ВЫБЕРИТЕ
внутренний_запрос.текст_вопроса,
SUM(inner_query.total_answers) как total_answers,
SUM(inner_query.total_correct_answers) как total_correct_answers,
(СУММ(inner_query.total_correct_answers) / SUM(inner_query.total_answers)) * 100 как процент_правильного_ответа
ИЗ (
ВЫБРАТЬ
bridgekeeper_questions.question_text,
traveler_answers.choice,
COUNT(traveler_answers.choice) как total_answers
COUNT(traveler_answers.choice) FILTER (ГДЕ bridgekeeper_questions.correct_choice = traveler_answers.choice) как total_correct_answers
ОТ traveler_answers
ВНУТРЕННЕЕ СОЕДИНЕНИЕ bridgekeeper_questions ON bridgekeeper_questions.id = traveler_answers.exam_question_id
ГРУППА ПО
traveler_answers.choice,
bridgekeeper_questions.question_text
ЗАКАЗАТЬ ПО traveler_answers.choice
) внутренний_запрос
СГРУППИРОВАТЬ ПО inner_query.question_text В чем разница между суммой и количеством?COUNT — возвращает общее количество строк в текущей группе
SUM — возвращает общее значение из столбца в текущей группе
Вы заметите, что в приведенном выше запросе мы использовали синтаксис ВЫБЕРИТЕ столбцы FROM (inner_query) , чтобы выбрать и агрегировать уже существующие
совокупные значения. Думайте об этом как о запросе запроса. Это необходимо для нас
для вычисления агрегата на основе группы нескольких агрегатов. Это также позволяет
нам снова возвращать одну строку на вопрос.
Думайте об этом как о запросе запроса. Это необходимо для нас
для вычисления агрегата на основе группы нескольких агрегатов. Это также позволяет
нам снова возвращать одну строку на вопрос.
Чтобы понять, как мы вернулись к возврату одной строки, давайте посмотрим, что происходит за кулисами, рассчитав процент правильных ответов. Формула расчета процента правильных ответов:
( всего_правильных_ответов / всего_ответов ) * 100
Сначала внутренний запрос вычисляет индивидуальное количество ответов
за вопрос. COUNT(traveler_answers.choice) возвращает:
| Текст вопроса | выбор | всего_ответов |
|---|---|---|
| «Какой твой любимый цвет?» | и | 12 |
| «Какой твой любимый цвет?» | б | 20 |
| «Какой твой любимый цвет?» | в | 10 |
| «Какой твой любимый цвет?» | д | 5 |
Кроме того, мы подсчитываем правильные ответы по выбору с помощью предложения FILTER: COUNT(traveler_answers. .
результаты внутреннего запроса здесь немного странные, но станут полезными, как только мы агрегируем его
приводит к внешнему запросу. choice) ФИЛЬТР (ГДЕ bridgekeeper_questions.correct_choice = traveler_answers.choice)
choice) ФИЛЬТР (ГДЕ bridgekeeper_questions.correct_choice = traveler_answers.choice)
| Текст вопроса | выбор | всего_ответов | total_correct_answers |
|---|---|---|---|
| «Какой твой любимый цвет?» | и | 12 | 0 |
| «Какой твой любимый цвет?» | б | 20 | 20 |
| «Какой твой любимый цвет?» | в | 10 | 0 |
| «Какой твой любимый цвет?» | д | 5 | 0 |
Думайте об этом как о построении необработанных данных, которые мы хотим выполнять в расчетах.
внешний запрос. Именно это мы и сделаем, опираясь на функцию SUM() . со следующим:
со следующим: (SUM(inner_query.total_correct_answers) / SUM(inner_query.total_answers)) * 100 .
Предложение PostgreSQL FILTERЕще вы могли заметить синтаксис `FILTER`. Это отличный способ расширения агрегатной функции дополнительным предложением `WHERE`. – Modern-sql.com
Мы используем SUM() вместо COUNT() , потому что COUNT() даст нам только количество возвращенных строк.
в то время как мы хотим знать, какая промежуточная сумма основана на значении столбца.
Оглядываясь назад, мы можем видим, что мы находимся прямо на этапе использования нашей формулы для расчета процент.
Вот выписано полностью:
total_correct_answers: 0 + 20 + 0 + 0 = 20 total_answers: 12 + 20 + 10 + 5 = 47 (всего_правильных_ответов/всего_ответов): (20/47) = 0,425532 (0,425532) * 100 = 42,5532%
Учитывая наши последние изменения SQL выше, вот конечный результат:
| Текст вопроса | total_correct_answers | процент_правильного_ответа |
|---|---|---|
| «Какой твой любимый цвет?» | 20 | 42,5532 |
| «Какое у тебя задание?» | 40 | 55,5555 |
| «Какова скорость полета порожней ласточки?» | 1 | 1. 78571 78571 |
К сожалению, при запуске агрегата для общее количество правильных ответов и процент правильных ответов, мы потеряли частотное распределение для каждый вопрос. Немного сложно вернуть это, но есть способ…
«Чёрные рыцари всегда побеждают!»
Кхм, извините. Прости за это.
JSONB-методы PostgreSQLjsonb_agg — агрегирует значения в виде массива JSON
jsonb_build_object — строит объект JSON из вариативного списка аргументов. По соглашению список аргументов состоит из чередующихся ключей и значений. — Postgresql.org
Поскольку мы по-прежнему хотим возвращать одну строку на вопрос, нам нужен способ форматирования
распределение в единое значение. JSONB — идеальное решение этой проблемы.
поскольку это позволяет нам использовать пары ключ-значение для описания значения в одном столбце.
Мы будем использовать jsonb_agg() и методы jsonb_build_object() PostgreSQL для достижения этой цели.
Точно так же, как мы сделали выше при вычислении total_correct_answers и Interest_correct_answer , агрегат внутреннего запроса используется как агрегат внешнего запроса.
ВЫБЕРИТЕ
внутренний_запрос.текст_вопроса,
SUM(inner_query.total_answers) как total_answers,
SUM(inner_query.total_correct_answers) как total_correct_answers,
(СУММ(inner_query.total_correct_answers) / SUM(inner_query.total_answers)) * 100 как процент_правильного_ответа,
jsonb_agg(inner_query.frequency_distribution) как Frequency_distribution_json
ИЗ (
ВЫБРАТЬ
bridgekeeper_questions.question_text,
traveler_answers.choice,
COUNT(traveler_answers.choice) как total_answers,
COUNT(traveler_answers.choice) FILTER (ГДЕ bridgekeeper_questions.correct_choice = traveler_answers.choice) как total_correct_answers,
jsonb_build_object('выбор', traveler_answers.choice, 'частота', COUNT(traveler_answers.choice)) как Frequency_distribution
ОТ traveler_answers
ВНУТРЕННЕЕ СОЕДИНЕНИЕ bridgekeeper_questions ON bridgekeeper_questions. id = traveler_answers.exam_question_id
ГРУППА ПО
traveler_answers.choice,
bridgekeeper_questions.question_text
ЗАКАЗАТЬ ПО traveler_answers.choice
) внутренний_запрос
СГРУППИРОВАТЬ ПО inner_query.question_text  id = traveler_answers.exam_question_id
ГРУППА ПО
traveler_answers.choice,
bridgekeeper_questions.question_text
ЗАКАЗАТЬ ПО traveler_answers.choice
) внутренний_запрос
СГРУППИРОВАТЬ ПО inner_query.question_text
id = traveler_answers.exam_question_id
ГРУППА ПО
traveler_answers.choice,
bridgekeeper_questions.question_text
ЗАКАЗАТЬ ПО traveler_answers.choice
) внутренний_запрос
СГРУППИРОВАТЬ ПО inner_query.question_text «О, смотрите. Здесь прекрасная грязь.
Приведенный ниже набор данных довольно уродлив, но содержит правильные пары ключ-значение. нам нужно для того, чтобы показать частотное распределение.
| Текст вопроса | total_correct_answers | процент_правильного_ответа | частота_распределения_json |
|---|---|---|---|
| «Какой твой любимый цвет?» | 20 | 42.5532 | [{ "выбор": "а", "частота": 12}, { "выбор": "б", "частота": 20}, { "выбор": "с", "частота": 10} , { "выбор": "d", "частота": 5 }] |
| «Какое у тебя задание?» | 40 | 55,5555 | [{ "выбор": "а", "частота": 12}, { "выбор": "б", "частота": 5}, { "выбор": "с", "частота": 15} , { "выбор": "d", "частота": 40 }] |
| «Какова воздушная скорость порожней ласточки?» | 1 | 1. 78571 78571 | [{ "выбор": "а", "частота": 1}, { "выбор": "б", "частота": 25}, { "выбор": "с", "частота": 5} , { "выбор": "d", "частота": 25 }] |
Это последнее изменение запроса, и теперь у нас есть таблица, содержащая:
Альтернативный метод PostgreSQL`width_bucket()` позволяет указать столбец с минимальным и максимальным диапазоном, а затем разделить его на ведра (категории). Ознакомьтесь со следующей документацией
- Всего правильных ответов на вопрос
- Процент правильных ответов на вопрос
- Частотное распределение на вопрос
Так как же выглядит внутренний запрос с новым методом jsonb_build_object() ?
Если бы мы вернулись к таблице, которая содержала результат по каждому вопросу выбор и посмотрите, что возвращает следующий SQL, это будет выглядеть так:
jsonb_build_object('выбор', traveler_answers. choice, 'частота', COUNT(traveler_answers.choice)) as Frequency_distribution  choice, 'частота', COUNT(traveler_answers.choice)) as Frequency_distribution
choice, 'частота', COUNT(traveler_answers.choice)) as Frequency_distribution | Текст вопроса | выбор | всего_ответов | частота_распределение |
|---|---|---|---|
| «Какой твой любимый цвет?» | и | 12 | { "выбор": "а", "частота": 12} |
| «Какой твой любимый цвет?» | б | 20 | { "выбор": "б", "частота": 20 } |
| «Какой твой любимый цвет?» | в | 10 | { "выбор": "с", "частота": 10} |
| «Какой твой любимый цвет?» | д | 5 | { "выбор": "d", "частота": 5} |
| «Какое у тебя задание?» | и | 12 | { "выбор": "а", "частота": 12 } |
| «Какое у тебя задание?» | б | 5 | { "выбор": "б", "частота": 5} |
| «Какое у тебя задание?» | в | 15 | { "выбор": "с", "частота": 15} |
| «Какое у тебя задание?» | д | 40 | { "выбор": "д", "частота": 40 } |
| «Какова скорость полета порожней ласточки?» | и | 1 | { "выбор": "а", "частота": 1} |
| «Какова скорость полета порожней ласточки?» | б | 25 | { "выбор": "б", "частота": 25} |
| «Какова скорость полета порожней ласточки?» | с | 5 | { "выбор": "с", "частота": 5} |
| «Какова скорость полета порожней ласточки?» | д | 25 | { "выбор": "d", "частота": 25} |
Магия… «Я не ведьма, я не ведьма»… это происходит во внешнем запросе с jsonb_agg() который
объединяет все столбцы внутреннего частотного распределения в массив
пар ключ-значение jsonb, как мы видим в последнем запросе выше.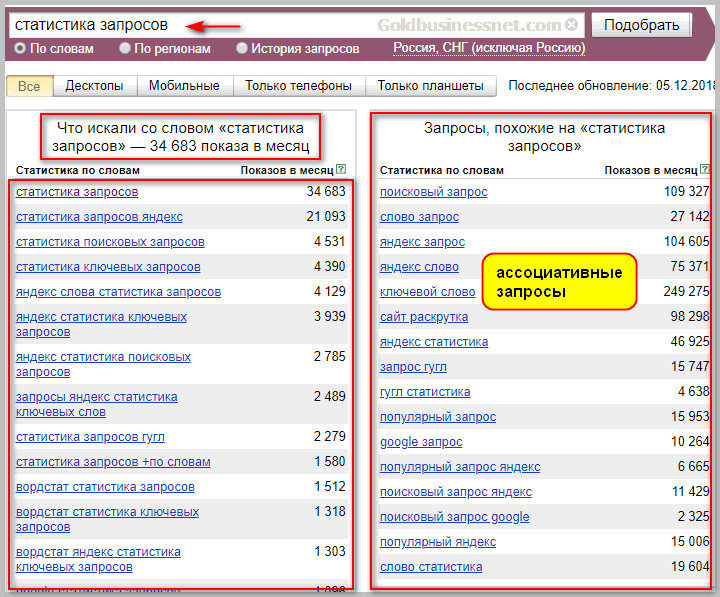 Это позволяет
как для описательной статистики по всему набору данных, так и для предоставления частотного распределения
на один вопрос.
Это позволяет
как для описательной статистики по всему набору данных, так и для предоставления частотного распределения
на один вопрос.
«Что, если вы неправильно ответите на вопрос?»
«Тогда вы будете брошены в Ущелье Вечной Опасности».
Есть другой трюк со статистикой SQL? Как насчет улучшенного подхода к вышеизложенному? Просто любите Монти Пайтон? Я хотел бы услышать об этом в комментариях.
« Предыдущая записьФорматирование столбцов Enum в удобочитаемый формат с помощью SQL
Следующая запись »Fix Selenium::WebDriver::Error::UnknownError для Capybara chromedriver-helper
Включите JavaScript, чтобы просматривать комментарии с помощью Disqus. комментарии от DisqusАнатомия запросов
Запросы — это мост между вашими данными и вашими приложениями Retool. Вот обзор в наших документах, в котором рассматривается чтение и запись данных. В этом модуле мы собираемся глубоко погрузиться в анатомию запроса, чтобы узнать обо всех запросах, которые может предложить Retool.
ПРИМЕЧАНИЕ. Это руководство не включает запросы JS. У них другая анатомия и функциональность, чем у всех других запросов Retool, поэтому продолжайте читать раздел Reschool, посвященный запросам JS.
Это 3 вкладки в запросе, давайте узнаем о них!
Здесь вы будете проводить большую часть своего времени. Вы можете выбрать свой ресурс, написать тело запроса и указать, что делать, если он не сработает. Давайте рассмотрим каждый раздел вкладки «Общие»!
Выберите ресурс, который вы хотите запросить. Ресурсы настраиваются с домашней страницы вашей организации Retool и являются первым шагом в подключении Retool к вашим данным.
Запросы могут выполняться либо автоматически при изменении входных данных, либо при ручном запуске.
При изменении или пересчете входных данных запускается автоматически выполняемый запрос. «Ввод» — это значение внутри тега {{ }} в любом месте внутри панели запросов, например, новое значение переключателя, новый selectedRow таблицы или любое значение Retool, которое использует запрос.
Запрос, инициируемый вручную, будет выполняться при ручном запуске с помощью нажатия кнопки, действия переключения или чего-то подобного, что не зависит от изменения наблюдаемого значения.
| Automatically when inputs change | Manually triggered | |
|---|---|---|
| Automatically runs on page load | ✅ | 🚫 |
| Can be triggered from a button | ✅ | ✅ |
| Can be set to показать модальное подтверждение перед запуском (вкладка «Дополнительно») | 🚫 | ✅ |
| Можно настроить запуск при загрузке страницы** (вкладка «Дополнительно») | 🚫 (поведение по умолчанию) | ✅ |
| Can fire confetti on finish (Advanced Tab) | 🚫 | ✅ |
** 💡 As a general rule of thumb, limit queries that run on page load. Retool позволяет запускать запросы при загрузке страницы и добавлять необязательную задержку. Хотя это может быть полезно для обеспечения того, чтобы ваши информационные панели всегда содержали свежие данные, это может привести к перегрузке вашего приложения при запуске. Ограничьте количество и размер запросов, которые вы запускаете при загрузке страницы, и рассмотрите возможность их запуска вручную или при изменении указанных входных данных.
Хотя это может быть полезно для обеспечения того, чтобы ваши информационные панели всегда содержали свежие данные, это может привести к перегрузке вашего приложения при запуске. Ограничьте количество и размер запросов, которые вы запускаете при загрузке страницы, и рассмотрите возможность их запуска вручную или при изменении указанных входных данных.
В зависимости от типа ресурса и действия (чтение из Postgres или запись в Google Sheets) поля, которые вы видите здесь, будут различаться, как и способы взаимодействия с вашими данными. Документ, указанный здесь и во введении, является хорошей отправной точкой, но в целом ваш тип запроса будет относиться к двум основным режимам запроса:
- Режим SQL. Режим SQL позволяет вам писать операторы SQL и в основном используется для чтения данных. Подробнее о чтении из SQL здесь.
- Режим графического интерфейса. Режим графического интерфейса предоставляет пользовательский интерфейс, похожий на форму, с раскрывающимся списком доступных действий и полей ввода для данных, которые будут переданы обратно в базу данных. Некоторые типы ресурсов (например, Google Sheets или Rest API) используют этот пользовательский интерфейс для всех запросов, поскольку они не являются реляционными базами данных, которые можно запрашивать с помощью SQL. Подробнее о написании на SQL здесь.
 Некоторые типы ресурсов (например, Google Sheets или Rest API) используют этот пользовательский интерфейс для всех запросов, поскольку они не являются реляционными базами данных, которые можно запрашивать с помощью SQL. Подробнее о написании на SQL здесь.
Некоторые типы ресурсов (например, Google Sheets или Rest API) используют этот пользовательский интерфейс для всех запросов, поскольку они не являются реляционными базами данных, которые можно запрашивать с помощью SQL. Подробнее о написании на SQL здесь. Часто преобразователи используются для преобразования результатов запроса в другой формат. Если вы обнаружите, что делаете это, вы можете прикрепить преобразователь непосредственно к запросу. Это изменяет значение запроса везде, так что при использовании query1.data вы получите результаты запроса после применения преобразователя.
Документы по преобразователям запросов здесь и несколько примеров ниже.
Часто бывает необходимо инициировать дополнительные запросы, когда запрос завершен/успешен.
Например, после того, как вы что-то изменили в таблице базы данных, вы, вероятно, захотите обновить запрос getUsers , который извлекает всех ваших пользователей. Таким образом,
Таким образом, updateUsername должен привести к обновлению запроса пользователей .
💡 Остерегайтесь длинных запутанных цепочек запросов! Если getUsers запускается при изменении ввода/при загрузке страницы, то запросы, которые запускаются при успешном выполнении getUsers , также будут выполняться.
Вы также можете инициировать запрос в случае сбоя запроса.
Нажатие кнопки «Предварительный просмотр» фактически не запускает запрос и не обновляет значение query.data . Он просто отображается на панели предварительного просмотра как пример того, какие значения он вернет, за одним небольшим исключением!
Предварительный просмотр запроса REST API запустит запрос и попадет в вашу конечную точку API, поэтому между предварительным просмотром и выполнением нет никакой разницы.
Вы можете включить обозреватель схем для просмотра таблиц, столбцов и типов столбцов выбранного вами ресурса! Вы также можете свернуть его, чтобы было больше места для ввода запроса.
Вы можете использовать «условия отказа» в запросах, чтобы пометить ваши запросы как неудачные. Документы по условиям сбоя здесь.
Ключи (первое поле ввода) — это условия. Если какое-либо из этих условий оценивается как истинное значение, Retool помечает запрос как ошибочный и отображает сообщение об ошибке, указанное в значении.
Условия отказа особенно полезно устанавливать, когда ваш ресурс всегда возвращает успех. Например, большинство API-интерфейсов GraphQL всегда возвращают код успеха 200, даже если в ответе содержатся ошибки.
Давайте рассмотрим конкретный вариант использования. Если вы хотите выдать ошибку, если ваш API возвращает меньше результатов, чем вы хотите, вы можете установить условие отказа, указав {{ data.results.length < количество идеальных результатов }} .
Параметры, доступные на вкладке «Дополнительно», будут различаться в зависимости от того, как вы выполняете запрос: автоматически или вручную.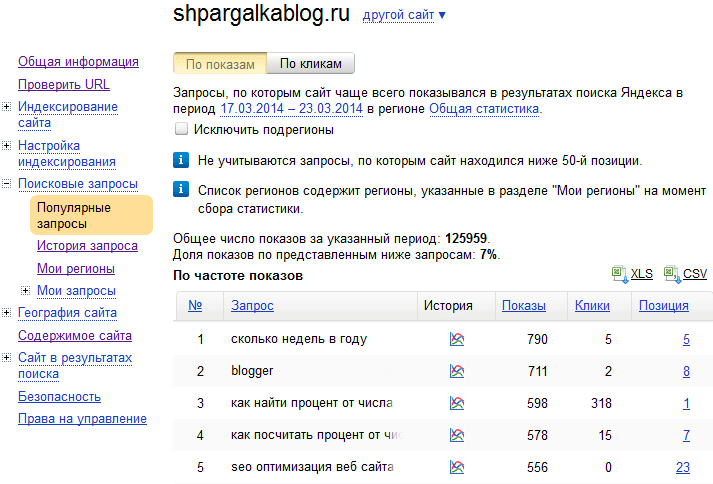
Укажите время ожидания в миллисекундах перед истечением времени запроса. Запросы, которые занимают более 120 секунд, автоматически блокируются по тайм-ауту.
Укажите время ожидания в миллисекундах перед запуском запроса после запуска.
Укажите количество миллисекунд ожидания между запусками запроса.
Укажите время ожидания в миллисекундах перед запуском при загрузке страницы.
Если да, вы можете указать частоту обновления этого запроса в миллисекундах.
Укажите параметры для удаления из журналов аудита.
Отключить запрос при передаче выражения (между {{ }} ) оценивается как true . Если вы используете динамическое значение, которое меняется с true на false , запрос выполняется немедленно.
Например, вы можете использовать компонент Switch для отключения запроса, установив Disable query на {{ !switch2. . Это оценивается как 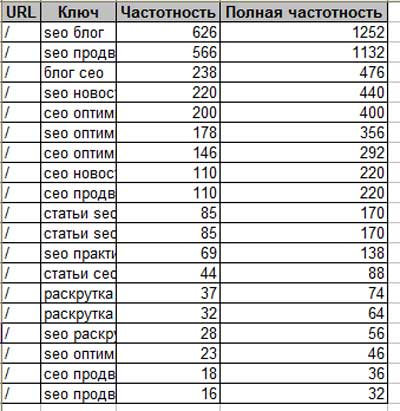 value }}
value }} true , когда переключатель выключен. Когда переключатель включен, {{ !switch2.value }} оценивается как false , что разрешает запрос и запускает его.
Выберите, какие параметры должны отслеживаться запросом и обновляться в ответ на него. Для запросов, инициируемых вручную, вы можете указать входные данные для отслеживания и запуска на их основе. Это позволяет вам «выборочно-автоматически» запускать запросы.
Установите этот флажок и укажите количество секунд, в течение которых результаты этого запроса должны кэшироваться.
Чтобы аннулировать или удалить кеш, просто щелкните текст Invalidate cache, показанный выше. В настоящее время нет способа программно аннулировать кеш.
💡 Используйте кеширование запросов в своих интересах. Retool позволяет кэшировать результаты запросов. Просто нажмите на вкладку «Дополнительно» в редакторе запросов для данного запроса и установите флажок. Вы также можете кэшировать запросы между пользователями на странице дополнительных настроек вашей организации (
Вы также можете кэшировать запросы между пользователями на странице дополнительных настроек вашей организации ( /settings/advanced ). Если вы выполняете большие аналитические запросы или вообще не нуждаетесь в постоянно обновляемых данных, рассмотрите возможность использования кэширования для повышения производительности.
Дополнительную информацию см. на странице Кэширование в Retool.
R — Запустить конфетти после завершения запроса 🎉 [Только вручную]
Обновлено 2 месяца назад
Ого! Вы официально завершили 3-й раздел и собираетесь приступить к строительству. У вас остался 1 последний, очень важный раздел. Вернитесь на главную страницу, чтобы узнать больше.
- Reschool
Помогла ли вам эта страница?
Настройка сканирования кода — GitHub Docs
О настройке сканирования кода
Вы можете запустить сканирование кода на GitHub, с помощью GitHub Actions или из вашей системы непрерывной интеграции (CI). Дополнительные сведения см. в разделах «О действиях GitHub» или «О сканировании кода CodeQL в вашей системе CI».
Дополнительные сведения см. в разделах «О действиях GitHub» или «О сканировании кода CodeQL в вашей системе CI».
Эта статья посвящена запуску сканирования кода на GitHub с помощью действий.
Прежде чем вы сможете настроить сканирование кода для репозитория, вы должны настроить сканирование кода, добавив в репозиторий рабочий процесс GitHub Actions. Дополнительные сведения см. в разделе «Настройка сканирования кода для репозитория».
Как правило, вам не нужно редактировать рабочий процесс по умолчанию для сканирования кода. Однако при необходимости вы можете отредактировать рабочий процесс, чтобы настроить некоторые параметры. Например, вы можете отредактировать рабочий процесс анализа кода CodeQL GitHub, чтобы указать частоту сканирования, языки или каталоги для сканирования, а также то, что сканирование кода CodeQL ищет в вашем коде. Вам также может понадобиться отредактировать рабочий процесс анализа CodeQL, если вы используете определенный набор команд для компиляции кода.
Анализ CodeQL — это всего лишь один из видов сканирования кода, который вы можете выполнять в GitHub. GitHub Marketplace содержит другие рабочие процессы сканирования кода, которые вы можете использовать. Их можно найти на странице «Начало работы со сканированием кода», доступ к которой можно получить с Безопасность вкладка. Конкретные примеры, приведенные в этой статье, относятся к файлу рабочего процесса анализа CodeQL.
Редактирование рабочего процесса сканирования кода
GitHub сохраняет файлы рабочего процесса в каталоге .github/workflows вашего репозитория. Вы можете найти рабочий процесс, который вы добавили, выполнив поиск по имени файла. Например, по умолчанию файл рабочего процесса для сканирования кода CodeQL называется codeql-analysis.yml .
- В репозитории перейдите к файлу рабочего процесса, который вы хотите отредактировать.
- В правом верхнем углу представления файла, чтобы открыть редактор рабочего процесса, щелкните .
- После редактирования файла нажмите Начать фиксацию и заполните форму «Зафиксировать изменения». Вы можете выбрать фиксацию непосредственно в текущей ветке или создать новую ветку и запустить запрос на извлечение.

Дополнительные сведения о редактировании файлов рабочих процессов см. в разделе «Изучение действий GitHub».
Настройка частоты
Вы можете настроить рабочий процесс анализа CodeQL для сканирования кода по расписанию или при возникновении определенных событий в репозитории.
Сканирование кода, когда кто-то вносит изменения и когда создается запрос на вытягивание, не позволяет разработчикам вносить в код новые уязвимости и ошибки. Сканирование кода по расписанию информирует вас о последних уязвимостях и ошибках, которые обнаруживают GitHub, исследователи безопасности и сообщество, даже если разработчики не занимаются активным обслуживанием репозитория.
Сканирование при отправке
По умолчанию рабочий процесс анализа CodeQL использует событие on. для запуска сканирования кода при каждой отправке в ветку репозитория по умолчанию и любые защищенные ветки. Чтобы сканирование кода запускалось в указанной ветке, рабочий процесс должен существовать в этой ветке. Дополнительные сведения см. в разделе «Синтаксис рабочего процесса для действий GitHub». push
push
При сканировании по запросу результаты отображаются на вкладке Безопасность для вашего репозитория. Дополнительные сведения см. в разделе «Управление оповещениями о сканировании кода для вашего репозитория».
Кроме того, когда сканирование on:push возвращает результаты, которые можно сопоставить с открытым запросом на вытягивание, эти оповещения автоматически появляются в запросе на вытягивание в тех же местах, что и другие предупреждения запроса на вытягивание. Оповещения идентифицируются путем сравнения существующего анализа главы филиала с анализом для целевого филиала. Дополнительные сведения об оповещениях о сканировании кода в запросах на вытягивание см. в разделе «Сортировка предупреждений о сканировании кода в запросах на вытягивание».
в разделе «Сортировка предупреждений о сканировании кода в запросах на вытягивание».
Сканирование запросов на вытягивание
Рабочий процесс анализа CodeQL по умолчанию использует событие pull_request для запуска сканирования кода в запросах на вытягивание, нацеленных на ветвь по умолчанию. Если запрос на вытягивание исходит из частного форка, событие pull_request будет запущено только в том случае, если вы выбрали параметр «Запускать рабочие процессы из запросов на вилку» в настройках репозитория. Дополнительные сведения см. в разделе «Управление настройками GitHub Actions для репозитория».
Для получения дополнительной информации о 9Событие 1534 pull_request , см. «События, запускающие рабочие процессы».
При сканировании запросов на вытягивание результаты отображаются в виде предупреждений при проверке запросов на вытягивание. Дополнительные сведения см. в разделе «Сортировка предупреждений о сканировании кода в запросах на вытягивание».
Использование триггера pull_request , настроенного на сканирование коммита слияния запроса на вытягивание, а не коммита головы, даст более эффективные и точные результаты, чем сканирование головы ветки при каждом нажатии. Однако если вы используете систему CI/CD, которую нельзя настроить для запуска запросов на вытягивание, вы все равно можете использовать on:push триггер и сканирование кода сопоставят результаты с открытыми запросами на вытягивание в ветке и добавят оповещения в качестве аннотаций к запросу на вытягивание. Дополнительные сведения см. в разделе «Сканирование при отправке».
Определение уровней серьезности, вызывающих сбой проверки запроса на вытягивание
По умолчанию, только предупреждения с уровнем серьезности Ошибка или уровнем серьезности безопасности Критический или Высокий приведут к сбою проверки запроса на вытягивание, и проверка все равно будет добиться успеха с предупреждениями более низкой серьезности. Вы можете изменить уровни серьезности предупреждений и серьезности безопасности, которые приведут к сбою проверки запроса на вытягивание, в настройках репозитория. Дополнительные сведения об уровнях серьезности см. в разделе «О предупреждениях сканирования кода».
Вы можете изменить уровни серьезности предупреждений и серьезности безопасности, которые приведут к сбою проверки запроса на вытягивание, в настройках репозитория. Дополнительные сведения об уровнях серьезности см. в разделе «О предупреждениях сканирования кода».
На GitHub.com перейдите на главную страницу репозитория.
Под именем репозитория щелкните Настройки .
В разделе «Безопасность» боковой панели нажмите Безопасность и анализ кода .
В разделе «Сканирование кода» справа от «Проверить сбой» используйте раскрывающееся меню, чтобы выбрать уровень серьезности, который должен привести к сбою проверки запроса на вытягивание.
Предотвращение ненужного сканирования запросов на вытягивание
Возможно, вы захотите избежать запуска сканирования кода для конкретных запросов на вытягивание, нацеленных на ветвь по умолчанию, независимо от того, какие файлы были изменены. Вы можете настроить это, указав on:pull_request:paths-ignore или on:pull_request:paths в рабочем процессе сканирования кода. Например, если единственными изменениями в запросе на вытягивание являются файлы с расширениями .md или .txt вы можете использовать следующие пути — игнорировать массив .
по:
толкать:
ветки: [основная, защищенная]
pull_request:
ветки: [основная]
пути-игнорировать:
- '**/*.мд'
- '**/*.текст'
Примечания
-
on:pull_request:paths-ignoreиon:pull_request:pathsзадают условия, определяющие, будут ли выполняться действия в рабочем процессе по запросу на вытягивание. Они не определяют, какие файлы будут проанализированы при выполнении действий это пробега. Когда запрос на вытягивание содержит какие-либо файлы, которые не соответствуютon:pull_request:paths-ignoreилиon:pull_request:paths, рабочий процесс запускает действия и сканирует все файлы, измененные в запросе на вытягивание, включая совпавшие поon:pull_request:paths-ignoreилиon:pull_request:paths, если файлы не были исключены. Информацию о том, как исключить файлы из анализа, см. в разделе «Указание каталогов для сканирования». - Для файлов рабочего процесса сканирования кода CodeQL не используйте пути
— игнорируйте путиилипутис событиемon:push, так как это может привести к отсутствию анализа. Для получения точных результатов сканирование кода CodeQL должно иметь возможность сравнивать новые изменения с анализом предыдущего коммита.
Дополнительные сведения об использовании on:pull_request:paths-ignore и on:pull_request:paths для определения времени выполнения рабочего процесса для запроса на вытягивание см. в разделе «Синтаксис рабочего процесса для действий GitHub».
Сканирование по расписанию
Если вы используете рабочий процесс анализа CodeQL по умолчанию, рабочий процесс будет сканировать код в вашем репозитории раз в неделю в дополнение к сканированиям, запускаемым событиями. Чтобы настроить это расписание, отредактируйте значение cron в рабочем процессе. Дополнительные сведения см. в разделе «Синтаксис рабочего процесса для действий GitHub».
Примечание : GitHub запускает только запланированные задания, которые находятся в рабочих процессах в ветке по умолчанию. Изменение расписания рабочего процесса в любой другой ветке не повлияет, пока вы не объедините ветку с веткой по умолчанию.
Пример
В следующем примере показан рабочий процесс анализа CodeQL для определенного репозитория, который имеет ветвь по умолчанию с именем main и одну защищенную ветвь с именем protected .
по:
толкать:
ветки: [основная, защищенная]
pull_request:
ветки: [основная]
расписание:
- cron: '20 14 * * 1'
Этот рабочий процесс сканирует:
- Каждое нажатие на ветку по умолчанию и защищенную ветку
- Каждый запрос на включение в ветку по умолчанию
- Ветка по умолчанию каждый понедельник в 14:20 UTC
Указание операционной системы
Если для компиляции вашего кода требуется определенная операционная система, вы можете настроить операционную систему в рабочем процессе анализа CodeQL. Измените значение jobs.analyze.runs-on , чтобы указать операционную систему для компьютера, на котором выполняются действия по сканированию кода.
рабочих мест:
анализировать:
Название: Анализ
запуски: [ubuntu-последняя]
Если вы решите использовать локальный runner для сканирования кода, вы можете указать операционную систему, используя соответствующую метку в качестве второго элемента в двухэлементном массиве после самостоятельных .
рабочих мест:
анализировать:
Название: Анализ
запуски: [собственный хостинг, ubuntu-последняя]
Сканирование кода CodeQL поддерживает последние версии Ubuntu, Windows и macOS. Таким образом, типичные значения для этого параметра: ubuntu-latest , windows-latest и macos-latest . Дополнительные сведения см. в разделах «Выбор исполнителя для задания» и «Использование ярлыков с самостоятельными исполнителями».
Если вы используете автономный runner, вы должны убедиться, что Git находится в переменной PATH. Дополнительные сведения см. в разделах «О самостоятельных исполнителях» и «Добавление самостоятельных исполнителей».
Рекомендуемые характеристики (ОЗУ, ядра ЦП и диск) для выполнения анализа CodeQL на собственных компьютерах см. в разделе «Рекомендуемые аппаратные ресурсы для запуска CodeQL».
Указание местоположения для баз данных CodeQL
В общем, вам не нужно беспокоиться о том, где рабочий процесс анализа CodeQL размещает базы данных CodeQL, поскольку последующие шаги автоматически найдут базы данных, созданные на предыдущих шагах. Однако если вы пишете настраиваемый шаг рабочего процесса, для которого требуется, чтобы база данных CodeQL находилась в определенном месте на диске, например, для загрузки базы данных в качестве артефакта рабочего процесса, вы можете указать это место с помощью параметра 9.1534 параметр db-location под действием init .
— использует: github/codeql-action/init@v2
с:
db-location: '${{ github. workspace }}/codeql_dbs'
Рабочий процесс анализа CodeQL предполагает, что путь, указанный в db-location , доступен для записи и либо не существует, либо является пустым каталогом. При использовании этого параметра в задании, работающем на локальном исполнителе или с использованием контейнера Docker, пользователь должен убедиться, что выбранный каталог очищается между запусками или что базы данных удаляются после того, как они больше не нужны. В этом нет необходимости для заданий, выполняемых на исполнителях, размещенных на GitHub, которые каждый раз получают новый экземпляр и чистую файловую систему. Дополнительные сведения см. в разделе «О бегунах, размещенных на GitHub».
Если этот параметр не используется, рабочий процесс анализа CodeQL создаст базы данных во временном расположении по своему выбору.
Изменение анализируемых языков
Сканирование кода CodeQL автоматически обнаруживает код, написанный на поддерживаемых языках.
- С/С++
- С#
- Перейти
- Ява
- JavaScript/TypeScript
- Питон
- Рубин
Примечание : анализ CodeQL для Ruby в настоящее время находится в стадии бета-тестирования. Во время бета-тестирования анализ Ruby будет менее полным, чем анализ CodeQL других языков.
Дополнительные сведения см. в документации на веб-сайте CodeQL: «Поддерживаемые языки и платформы».
Файл рабочего процесса анализа CodeQL по умолчанию содержит матрицу с именем язык , в которой перечислены анализируемые языки в вашем репозитории. CodeQL автоматически заполняет эту матрицу, когда вы добавляете сканирование кода в репозиторий. Использование матрицы языка оптимизирует CodeQL для параллельного выполнения каждого анализа. Мы рекомендуем использовать эту конфигурацию для всех рабочих процессов, поскольку распараллеливание сборок повышает производительность. Дополнительные сведения о матрицах см. в разделе «Использование матрицы для ваших заданий».
Если ваш репозиторий содержит код более чем на одном из поддерживаемых языков, вы можете выбрать языки для анализа. Есть несколько причин, по которым вы можете захотеть предотвратить анализ языка. Например, у проекта могут быть зависимости на языке, отличном от основной части вашего кода, и вы можете предпочесть не видеть предупреждения для этих зависимостей.
Если в вашем рабочем процессе используется матрица языка , тогда CodeQL жестко закодирован для анализа только языков в матрице. Чтобы изменить языки, которые вы хотите анализировать, отредактируйте значение матричной переменной. Вы можете удалить язык, чтобы предотвратить его анализ, или добавить язык, которого не было в репозитории при настройке сканирования кода. Например, если репозиторий изначально содержал только JavaScript, когда было настроено сканирование кода, а позже вы добавили код Python, вам нужно будет добавить питон на матрицу.
рабочих мест:
анализировать:
Название: Анализ
...
стратегия:
отказоустойчивость: ложь
матрица:
язык: ['javascript', 'python']
Если ваш рабочий процесс не содержит матрицы с именем language , CodeQL настроен на последовательное выполнение анализа. Если вы не укажете языки в рабочем процессе, CodeQL автоматически обнаружит и попытается проанализировать все поддерживаемые языки в репозитории. Если вы хотите выбрать, какие языки анализировать, не используя матрицу, вы можете использовать 9Параметр 1534 языка под действием init .
— использует: github/codeql-action/init@v2
с:
языки: cpp, csharp, python
Анализ зависимостей Python
Для исполнителей, размещенных на GitHub и использующих только Linux, рабочий процесс анализа CodeQL попытается автоматически установить зависимости Python, чтобы получить больше результатов для анализа CodeQL. Вы можете управлять этим поведением, указав параметр setup-python-dependencies для действия, вызываемого шагом «Инициализация CodeQL». По умолчанию этот параметр установлен на правда :
Если репозиторий содержит код, написанный на Python, шаг «Инициализация CodeQL» устанавливает необходимые зависимости от исполнителя, размещенного на GitHub.
Если автоматическая установка прошла успешно, это действие также задает для переменной среды CODEQL_PYTHONисполняемый файл Python, который включает зависимости.Если в репозитории нет зависимостей Python или зависимости указаны неожиданным образом, вы получите предупреждение, и действие будет продолжено с оставшимися заданиями. Действие может успешно выполняться даже при наличии проблем с интерпретацией зависимостей, но результаты могут быть неполными.
Кроме того, вы можете установить зависимости Python вручную в любой операционной системе. Вам нужно будет добавить setup-python-dependencies и установить для него значение false , а также установить CODEQL_PYTHON для исполняемого файла Python, который включает зависимости, как показано в этом фрагменте рабочего процесса:
заданий:
CodeQL-сборка:
запуски: ubuntu-последняя
разрешения:
безопасность-события: написать
действия: читать
шаги:
- имя: Репозиторий Checkout
использует: action/checkout@v3
- название: Настроить Python
использует: действия/настройка-python@v4
с:
Python-версия: «3. x»
- имя: Установить зависимости
запустить: |
python -m pip install --upgrade pip
если [ -f требования.txt ];
затем pip install -r requirements.txt;
фи
# Установите переменную среды `CODEQL-PYTHON` в исполняемый файл Python
# который включает зависимости
echo "CODEQL_PYTHON=$(какой питон)" >> $GITHUB_ENV
- имя: Инициализировать CodeQL
использует: github/codeql-action/init@v2
с:
языки: питон
# Переопределить поведение по умолчанию, чтобы действие не пыталось
# для автоматической установки зависимостей Python
установка-python-зависимости: ложь
Настройка категории для анализа
Используйте категорию , чтобы различать несколько анализов для одного и того же инструмента и фиксации, но выполненных на разных языках или в разных частях кода. Категория, указанная вами в рабочем процессе, будет включена в файл результатов SARIF.
Этот параметр особенно полезен, если вы работаете с монорепозиториями и имеете несколько файлов SARIF для разных компонентов монорепозитория.
- имя: Выполнение анализа CodeQL
использует: github/codeql-action/analyze@v2
с:
# По желанию. Укажите категорию, чтобы различать несколько анализов
# для того же инструмента и арт. Если вы не используете категорию в своем рабочем процессе,
# GitHub сгенерирует для вас название категории по умолчанию
категория: "моя_категория"
Если вы не укажете параметр категории в своем рабочем процессе, GitHub создаст для вас имя категории на основе имени файла рабочего процесса, запускающего действие, имени действия и любых переменных матрицы. Например:
- Рабочий процесс
.github/workflows/codeql-analysis.ymlи действиеanalysisсоздадут категорию.github/workflows/codeql.yml:analyze. -
.github/workflows/codeql-analysis. yml 9Рабочий процесс 1535, действие анализаи матричные переменные{language: javascript, os: linux}создадут категорию.github/workflows/codeql-analysis.yml:analyze/language:javascript/os:linux.
Значение категории будет отображаться как свойство в SARIF v2.1.0. Дополнительные сведения см. в разделе «Поддержка SARIF для сканирования кода».
Указанная вами категория не перезапишет детали объект runAutomationDetails в файле SARIF, если он включен.
Выполнение дополнительных запросов
Когда вы используете CodeQL для сканирования кода, механизм анализа CodeQL создает базу данных из кода и выполняет запросы к ней. Анализ CodeQL использует набор запросов по умолчанию, но вы можете указать дополнительные запросы для выполнения в дополнение к запросам по умолчанию.
Вы также можете указать запросы, которые хотите исключить из анализа или включить в анализ. Это требует использования пользовательского файла конфигурации. Дополнительные сведения см. в разделах «Использование пользовательского файла конфигурации» и «Исключение определенных запросов из анализа» ниже.
Вы можете выполнять дополнительные запросы, если они являются частью пакета CodeQL (бета), опубликованного в реестре контейнеров GitHub, или пакета QL, хранящегося в репозитории. Дополнительные сведения см. в разделе «О сканировании кода с помощью CodeQL».
Для указания дополнительных запросов, которые вы хотите выполнить, доступны следующие параметры:
-
пакетыдля установки одного или нескольких пакетов запросов CodeQL (бета-версия) и запуска набора запросов по умолчанию или запросов для этих пакетов. -
запросыдля указания одного .ql , каталог, содержащий несколько файлов .ql , файл определения набора запросов .qls или любое их сочетание. Дополнительные сведения об определениях наборов запросов см. в разделе «Создание наборов запросов CodeQL».
Вы можете использовать как пакеты , так и запросы в одном рабочем процессе.
Мы не рекомендуем ссылаться на наборы запросов напрямую из репозитория github/codeql , например, github/codeql/cpp/ql/src@main . Такие запросы должны быть перекомпилированы и могут быть несовместимы с версией CodeQL, которая в настоящее время активна в GitHub Actions, что может привести к ошибкам во время анализа.
Использование пакетов запросов CodeQL
Примечание. Функция управления пакетами CodeQL, включая пакеты CodeQL, в настоящее время находится в стадии бета-тестирования и может быть изменена.
Чтобы добавить один или несколько пакетов запросов CodeQL (бета), добавьте с: packs: запись в uses: github/codeql-action/init@v2 раздел рабочего процесса. В пакетах вы указываете один или несколько пакетов для использования и, при желании, версию для загрузки. Если вы не укажете версию, будет загружена последняя версия. Если вы хотите использовать пакеты, которые не являются общедоступными, вам необходимо установить переменную среды GITHUB_TOKEN на секрет, который имеет доступ к пакетам. Дополнительные сведения см. в разделах «Аутентификация в рабочем процессе» и «Зашифрованные секреты».
Примечание: Для рабочих процессов, создающих базы данных CodeQL для нескольких языков, вместо этого необходимо указать пакеты запросов CodeQL в файле конфигурации. Дополнительные сведения см. в разделе «Указание пакетов запросов CodeQL» ниже.
В приведенном ниже примере область действия — это организация или личная учетная запись, опубликовавшая пакет. При запуске рабочего процесса четыре пакета запросов CodeQL загружаются из GitHub и запускаются запросы по умолчанию или набор запросов для каждого пакета:
- Загружается последняя версия
pack1и выполняются все запросы по умолчанию. - Версия 1.2.3 пакета
pack2загружается и выполняются все запросы по умолчанию. - Последняя версия 9Скачивается 1534 pack3 , совместимый с версией 3.2.1, и выполняются все запросы.
- Версия 4.5.6 пакета
pack4загружена, и выполняются только запросы, найденные впути/к/запросам.
— использует: github/codeql-action/init@v2
с:
# Разделенный запятыми список пакетов для скачивания
пакеты: scope/pack1,scope/[email protected],scope/pack3@~3.2.1,scope/[email protected]:path/to/queries
Загрузка пакетов CodeQL с GitHub Enterprise Server
Если в вашем рабочем процессе используются пакеты, опубликованные в установке GitHub Enterprise Server, вам необходимо указать рабочему процессу, где их найти. Вы можете сделать это, используя вход registries действия github/codeql-action/init@v2. Этот ввод принимает список url , пакетов и токенов свойств, как показано ниже.
— использует: github/codeql-action/init@v2
с:
реестры: |
# URL-адрес реестра контейнеров, обычно в этом формате
- URL-адрес: https://containers.GHEHOSTNAME1/v2/
# Список шаблонов пакетов, которые можно найти в этом реестре
пакеты:
- моя компания/*
- моя-компания2/*
# Токен, который следует хранить как секрет
токен: ${{ secrets.GHEHOSTNAME1_TOKEN }}
# URL-адрес реестра контейнеров по умолчанию
- адрес: https://ghcr.io/v2/
# Пакеты также могут быть строкой
пакеты: "*/*"
токен: ${{ secrets.GHCR_TOKEN }}
Шаблоны пакетов в списке реестров проверяются по порядку, поэтому сначала следует размещать наиболее специфические шаблоны пакетов. Значения токена должны быть токеном личного доступа, сгенерированным экземпляром GitHub, из которого вы скачиваете, с разрешением read:packages .
Обратите внимание на | после имени свойства реестров . Это важно, поскольку входные данные GitHub Actions могут принимать только строки. Использование | преобразует последующий текст в строку, которая позже анализируется действием github/codeql-action/init@v2.
Использование запросов в пакетах QL
Чтобы добавить один или несколько запросов, добавьте запись с: запросы: в разделе uses: github/codeql-action/init@v2 рабочего процесса. Если запросы находятся в частном репозитории, используйте параметр external-repository-token , чтобы указать токен, который имеет доступ для извлечения частного репозитория.
— использует: github/codeql-action/init@v2
с:
запросы: СПИСОК ПУТЕЙ, РАЗДЕЛЕННЫХ ЗАПЯТЫМИ
# По желанию. Предоставьте токен для доступа к запросам, хранящимся в частных репозиториях.
токен внешнего репозитория: ${{ secrets.ACCESS_TOKEN }}
Вы также можете указать наборы запросов в значении запросов . Наборы запросов — это наборы запросов, обычно сгруппированные по назначению или языку.
Следующие наборы запросов встроены в сканирование кода CodeQL и доступны для использования.
| Query suite | Description |
|---|---|
security-extended | Queries from the default suite, plus lower severity and precision queries |
security-and-quality | Queries from расширенная безопасность , а также запросы на ремонтопригодность и надежность |
При указании набора запросов механизм анализа CodeQL будет запускать набор запросов по умолчанию и любые дополнительные запросы, определенные в дополнительном наборе запросов. 9Наборы запросов с расширенной безопасностью 1534 и с расширенной безопасностью и качеством для JavaScript содержат экспериментальные запросы. Дополнительные сведения см. в разделе «О предупреждениях о сканировании кода».
Работа с пользовательскими файлами конфигурации
Если вы также используете файл конфигурации для пользовательских настроек, любые дополнительные пакеты или запросы, указанные в вашем рабочем процессе, используются вместо указанных в файле конфигурации. Если вы хотите запустить комбинированный набор дополнительных пакетов или запросов, добавьте префикс значения упаковывает или запросов в рабочем процессе с символом + . Дополнительные сведения см. в разделе «Использование пользовательского файла конфигурации».
В следующем примере символ + гарантирует, что указанные дополнительные пакеты и запросы используются вместе со всеми указанными в указанном файле конфигурации.
— использует: github/codeql-action/init@v2
с:
файл конфигурации: ./.github/codeql/codeql-config.yml
запросы: + безопасность-и-качество, octo-org/python-qlpack/show_ifs.ql@main
пакеты: +scope/pack1,scope/[email protected],scope/pack3@4. 5.6:path/to/queries
Использование пользовательского файла конфигурации
Пользовательский файл конфигурации — это альтернативный способ указания дополнительных пакетов и запросов для выполнения. Вы также можете использовать файл, чтобы отключить запросы по умолчанию, исключить или включить определенные запросы, а также указать, какие каталоги сканировать во время анализа.
В файле рабочего процесса используйте параметр config-file действия init , чтобы указать путь к файлу конфигурации, который вы хотите использовать. В этом примере загружается файл конфигурации ./.github/codeql/codeql-config.yml .
— использует: github/codeql-action/init@v2
с:
файл конфигурации: ./.github/codeql/codeql-config.yml
Файл конфигурации может находиться в репозитории, который вы анализируете, или во внешнем репозитории. Использование внешнего репозитория позволяет указать параметры конфигурации для нескольких репозиториев в одном месте. Когда вы ссылаетесь на файл конфигурации, расположенный во внешнем репозитории, вы можете использовать OWNER/REPOSITORY/FILENAME@BRANCH 9Синтаксис 2473. Например, octo-org/shared/codeql-config.yml@main .
Если файл конфигурации находится во внешнем частном репозитории, используйте параметр external-repository-token действия init , чтобы указать токен, который имеет доступ к частному репозиторию.
— использует: github/codeql-action/init@v2
с:
токен внешнего репозитория: ${{ secrets.ACCESS_TOKEN }}
Параметры в файле конфигурации записываются в формате YAML.
Указание пакетов запросов CodeQL
Примечание. Функция управления пакетами CodeQL, включая пакеты CodeQL, в настоящее время находится в стадии бета-тестирования и может быть изменена.
Вы указываете пакеты запросов CodeQL в массиве. Обратите внимание, что формат отличается от формата, используемого файлом рабочего процесса.
упаковок: # Используйте последнюю версию 'pack1', опубликованную 'scope' - объем/упаковка1 # Используйте версию 1.2.3 'pack2' - объем/упаковка[email protected] # Используйте последнюю версию 'pack3', совместимую с 3.2.1 - объем/pack3@~3.2.1 # Используйте пакет pack4 и ограничьте его запросами, найденными в каталоге 'path/to/queries' - scope/pack4:путь/к/запросам # Используйте пакет pack5 и ограничьте его запросом 'path/to/single/query.ql' - область/пакет5:путь/к/один/запрос.ql # Используйте пакет pack6 и ограничьте его набором запросов 'path/to/suite.qls' - объем/pack6:путь/к/suite.qls
Полный формат для указания пакета запроса: область/имя[@версия][:путь] . И версия , и путь являются необязательными. Версия — это несколько версий. Если он отсутствует, используется последняя версия. Дополнительные сведения о диапазонах semver см. в документации по semver в npm.
Если у вас есть рабочий процесс, который создает более одной базы данных CodeQL, вы можете указать любые пакеты запросов CodeQL для запуска в пользовательском файле конфигурации, используя вложенную карту пакетов.
упаковок:
# Используйте эти пакеты для анализа JavaScript
JavaScript:
- объем/js-pack1
- объем/js-pack2
# Используйте эти пакеты для анализа Java
Ява:
- объем/java-pack1
- объем/[email protected]
Указание дополнительных запросов
Вы указываете дополнительные запросы в массиве запросов . Каждый элемент массива содержит параметр use со значением, которое идентифицирует один файл запроса, каталог, содержащий файлы запроса, или файл определения набора запросов.
запросов: - использует: ./my-basic-queries/example-query.ql - использует: ./my-advanced-queries - использует: ./query-suites/my-security-queries.qls
При желании вы можете дать каждому элементу массива имя, как показано в примерах файлов конфигурации ниже. Дополнительные сведения о дополнительных запросах см. в разделе «Выполнение дополнительных запросов» выше.
Отключение запросов по умолчанию
Если вы хотите выполнять только пользовательские запросы, вы можете отключить запросы безопасности по умолчанию, используя отключить запросы по умолчанию: правда .
Исключение определенных запросов из анализа
Вы можете добавить фильтры исключить и включить в пользовательский файл конфигурации, чтобы указать запросы, которые вы хотите исключить или включить в анализ.
Это полезно, если вы хотите исключить, например:
- Определенные запросы из наборов по умолчанию (
безопасность,расширенная безопасностьибезопасность и качество). - Конкретные запросы, результаты которых вас не интересуют.
- Все запросы, генерирующие предупреждения и рекомендации.
Вы можете использовать фильтры exclude , аналогичные фильтрам в файле конфигурации ниже, чтобы исключить запросы, которые вы хотите удалить из анализа по умолчанию. В приведенном ниже примере файла конфигурации оба запроса js/redundant-assignment и js/useless-assignment-to-local исключены из анализа.
фильтры запросов:
- исключать:
id: js/избыточное назначение
- исключать:
id: js/бесполезное-назначение-местному
Чтобы узнать идентификатор запроса, щелкните предупреждение в списке предупреждений на вкладке «Безопасность». Откроется страница сведений об оповещении. Поле Rule ID содержит идентификатор запроса. Дополнительные сведения о странице сведений об оповещениях см. в разделе «Об оповещениях о сканировании кода».
Советы:
- Порядок фильтров важен. Первая инструкция фильтра, которая появляется после инструкций о запросах и пакетах запросов, определяет, будут ли запросы включены или исключены по умолчанию.
- Последующие инструкции выполняются по порядку, и инструкции, которые появляются позже в файле, имеют приоритет над более ранними инструкциями.
Другой пример, иллюстрирующий использование этих фильтров, вы можете найти в разделе «Примеры файлов конфигурации».
Дополнительные сведения об использовании фильтров исключить и включить в пользовательском файле конфигурации см. в разделе «Создание наборов запросов CodeQL». Сведения о метаданных запросов, по которым можно фильтровать, см. в разделе «Метаданные для запросов CodeQL».
Указание каталогов для сканирования
Для интерпретируемых языков, поддерживаемых CodeQL (Python, Ruby и JavaScript/TypeScript), вы можете ограничить сканирование кода файлами в определенных каталогах, добавив массив путей в файл конфигурации. Вы можете исключить файлы в определенных каталогах из анализа, добавив массив путей — игнорировать .
путей: - источник пути-игнорировать: - источник/node_modules - '**/*.test.js'
Примечание :
- Пути
пути-игнорировать ключевые слова, используемые в контексте файла конфигурации сканирования кода, не следует путать с теми же ключевыми словами при использовании дляon.в рабочий процесс. Когда они используются для измененияна.в рабочем процессе, они определяют, будут ли выполняться действия, когда кто-то изменяет код в указанных каталогах. Дополнительные сведения см. в разделе «Синтаксис рабочего процесса для действий GitHub». - Символы шаблона фильтра
?,+,[,]и!не поддерживаются и будут сопоставляться буквально. -
**символы могут быть только в начале или в конце строки или окружены косой чертой, и вы не можете смешивать**и другие символы. Например,foo/**,**/fooиfoo/**/barявляются допустимым синтаксисом, а**foo— нет. Однако вы можете использовать одиночные звезды вместе с другими символами, как показано в примере. Вам нужно будет процитировать все, что содержит*символов.
Для скомпилированных языков: если вы хотите ограничить сканирование кода определенными каталогами в вашем проекте, вы должны указать соответствующие шаги сборки в рабочем процессе. Команды, которые вам нужно использовать для исключения каталога из сборки, будут зависеть от вашей системы сборки. Дополнительные сведения см. в разделе «Настройка рабочего процесса CodeQL для скомпилированных языков».
Вы можете быстро анализировать небольшие части монорепозитория при изменении кода в определенных каталогах. Вам нужно будет исключить каталоги на этапах сборки и использовать 9Пути 1534 — игнорируйте пути и , ключевые слова для on. в вашем рабочем процессе.
Примеры файлов конфигурации
Этот файл конфигурации добавляет набор запросов по безопасности и качеству в список запросов, выполняемых CodeQL при сканировании кода. Дополнительные сведения о наборах запросов, доступных для использования, см. в разделе «Выполнение дополнительных запросов».
имя: «Моя конфигурация CodeQL» запросы: - использование: безопасность и качество
Следующий файл конфигурации отключает запросы по умолчанию и задает набор настраиваемых запросов для выполнения вместо них. Он также настраивает CodeQL для сканирования файлов в каталоге src (относительно корня), за исключением каталога src/node_modules и файлов, имя которых заканчивается на . test.js . Поэтому файлы в src/node_modules и файлы с именами, заканчивающимися на .test.js , исключаются из анализа.
имя: «Моя конфигурация CodeQL»
отключить запросы по умолчанию: правда
запросы:
- имя: использовать пакет QL в репозитории (выполнять запросы в каталоге my-queries)
использует: ./мои-запросы
- имя: Использовать внешний пакет QL JavaScript (запускать запросы из внешнего репо)
использует: octo-org/javascript-qlpack@main
- имя: Использовать внешний запрос (запустить один запрос из внешнего пакета QL)
использует: octo-org/python-qlpack/show_ifs.ql@main
- имя: Использовать файл набора запросов (выполнять запросы из набора запросов в этом репозитории)
использует: ./codeql-qlpacks/complex-python-qlpack/rootAndBar.qls
пути:
- источник
пути-игнорировать:
- источник/node_modules
- '**/*.test.js'
Следующий файл конфигурации запускает только запросы, которые генерируют предупреждения о серьезных ошибках. Конфигурация сначала выбирает все запросы по умолчанию, все запросы в . и набор по умолчанию в /my-queries codeql/java-queries , а затем исключает все запросы, которые генерируют предупреждения или рекомендации.
запросов:
- имя: использовать пакет QL в репозитории (выполнять запросы в каталоге my-queries)
использует: ./мои-запросы
пакеты:
- codeql/java-запросы
фильтры запросов:
- исключать:
проблема.серьезность:
- предупреждение
- рекомендация
Настройка сканирования кода для компилируемых языков
Для поддерживаемых компилируемых языков можно использовать действие autobuild в рабочем процессе анализа CodeQL для сборки кода. Это избавляет вас от необходимости указывать явные команды сборки для C/C++, C# и Java. CodeQL также запускает сборку для проектов Go, чтобы настроить проект. Однако, в отличие от других скомпилированных языков, все файлы Go в репозитории извлекаются, а не только те, которые созданы. Вы можете использовать пользовательские команды сборки, чтобы пропустить извлечение файлов Go, которые не затронуты сборкой.
Если код C/C++, C# или Java в вашем репозитории имеет нестандартный процесс сборки, автоматическая сборка может завершиться ошибкой. Вам нужно будет удалить шаг autobuild из рабочего процесса и вручную добавить шаги сборки. Если вы хотите указать, какие файлы Go в вашем репозитории нужно извлечь, вам нужно будет добавить шаги сборки. Дополнительные сведения о настройке сканирования кода CodeQL для скомпилированных языков см. в разделе «Настройка рабочего процесса CodeQL для скомпилированных языков».
Загрузка данных сканирования кода на GitHub
GitHub может отображать данные анализа кода, сгенерированные извне сторонним инструментом. Вы можете загрузить данные анализа кода с помощью действия upload-sarif . Дополнительные сведения см. в разделе «Отправка файла SARIF на GitHub».
Полнотекстовые запросы — документация OpenSearch
На этой странице перечислены все типы полнотекстовых запросов и общие параметры. Учитывая огромное количество вариантов и тонкое поведение, лучший способ обеспечить полезные результаты поиска — протестировать различные запросы по репрезентативным индексам и проверить результат.
СОДЕРЖАНИЕ
- СОДЕРЖАНИЕ
- MATCH
- MATCH BOOLEAN PREFIX
- СОТЧИТЕЛЬНАЯ ФРАЗА
- СОТЧА с анализаторами
- Дополнительные поля запроса
- Использование подстановочных знаков
- Использование встроенных анализаторов
- Выполнение нечетких запросов
- Использование синонимов с запросом
- Другие необязательные поля запроса
Запросы общих терминов и необязательное поле запроса cutoff_frequency теперь устарели.
Match
Создает логический запрос, который возвращает результаты, если условие поиска присутствует в поле.
Самая простая форма запроса предоставляет только поле ( название ) и термин ( ветер ):
GET _search
{
"запрос": {
"соответствие": {
"название": "ветер"
}
}
}
Для примера, использующего curl, попробуйте:
curl --insecure -XGET -u 'admin:admin' https://: / /_search \ -H "тип содержимого: приложение/json" \ -д '{ "запрос": { "соответствие": { "название": "ветер" } } }'
Запрос принимает следующие параметры. 4″, «сюжет»]
}
}
}
94″, «описание»],
«тип»: «большинство_полей»,
«оператор»: «и»,
«минимальное_должно_соответствовать»: 3,
«тай-брейк»: 0.0,
«анализатор»: «стандартный»,
«буст»: 1,
«нечеткость»: «АВТО»,
«fuzzy_transpositions»: правда,
«снисходительный»: ложный,
«длина_префикса»: 0,
«max_expansions»: 50,
«auto_generate_synonyms_phrase_query»: правда,
«zero_terms_query»: «нет»
}
}
}
Сопоставление логического префикса
Аналогично сопоставлению, но создает префиксный запрос из последнего термина в строке запроса.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"match_bool_prefix": {
"title": "поднимается с"
}
}
}
Запрос принимает следующие параметры. Описание каждого из них см. в разделе Необязательные поля запроса.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"match_bool_prefix": {
"заглавие": {
"запрос": "поднимается с",
"нечеткость": "АВТО",
"fuzzy_transpositions": правда,
"max_expansions": 50,
"длина_префикса": 0,
"оператор": "или",
"минимальное_должно_соответствовать": 2,
"анализатор": "стандартный"
}
}
}
}
Сопоставление фразы
Создает фразовый запрос, соответствующий последовательности терминов.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"match_phrase": {
"title": "ветер усиливается"
}
}
}
Запрос принимает следующие параметры. Описание каждого из них см. в разделе Необязательные поля запроса.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"match_phrase": {
"заглавие": {
"запрос": "ветер поднимает",
"отстой": 3,
"анализатор": "стандартный",
"zero_terms_query": "нет"
}
}
}
}
Префикс фразы совпадения
Аналогичен фразе совпадения, но создает запрос префикса из последнего термина в строке запроса.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"match_phrase_prefix": {
"title": "ветер ри"
}
}
}
Запрос принимает следующие параметры. Описание каждого из них см. в разделе Необязательные поля запроса.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"match_phrase_prefix": {
"заглавие": {
"запрос": "ветер ри",
"анализатор": "стандартный",
"max_expansions": 50,
"отстой": 3
}
}
}
}
Строка запроса
Строка запроса query разбивает текст на основе операторов и анализирует каждый по отдельности.
Если вы выполняете поиск с использованием параметров HTTP-запроса (например, _search?q=wind ), OpenSearch создает строку запроса query.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"Строка запроса": {
"query": "ветер И (поднимается ИЛИ поднимается)"
}
}
}
Запрос принимает следующие параметры. Описание каждого из них см. в разделе Необязательные поля запроса.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"Строка запроса": {
"query": "ветер И (поднимается ИЛИ поднимается)",
"default_field": "название",
"тип": "best_fields",
"нечеткость": "АВТО",
"fuzzy_transpositions": правда,
"fuzzy_max_expansions": 50,
"нечеткая_префиксная_длина": 0,
"минимальное_должно_соответствовать": 1,
"default_operator": "или",
"анализатор": "стандартный",
«снисходительный»: ложный,
"буст": 1,
"allow_leading_wildcard": правда,
"enable_position_increments": правда,
"фраза_slop": 3,
"max_determinized_states": 10000,
"time_zone": "-08:00",
"quote_field_suffix": "",
"quote_analyzer": "стандартный",
"analyze_wildcard": ложь,
"auto_generate_synonyms_phrase_query": правда
}
}
}
Простая строка запроса
Простой запрос строки запроса похож на запрос строки запроса, но позволяет опытным пользователям указывать множество аргументов непосредственно в строке запроса. Запрос отбрасывает любые недопустимые части строки запроса.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"простая_запрос_строка": {
"query": "\"поднимается ветер\"~4 | *ising~2",
"поля": ["название"]
}
}
}
| Специальный символ | Поведение |
|---|---|
+ | Действует как оператор и . |
| | Действует как оператор или . |
* | Действует как подстановочный знак. |
"" | Объединение нескольких терминов во фразу. |
() | Обертывает предложение для приоритета. |
~n | При использовании после термина (например, wnid~3 ) устанавливает нечеткость . При использовании после фразы устанавливает slop . См. Дополнительные поля запроса. |
- | Отменяет термин. |
Запрос принимает следующие параметры. Описание каждого из них см. в разделе Необязательные поля запроса.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"простая_запрос_строка": {
"query": "\"поднимается ветер\"~4 | *ising~2",
"поля": ["название"],
"флаги": "ВСЕ",
"fuzzy_transpositions": правда,
"fuzzy_max_expansions": 50,
"нечеткая_префиксная_длина": 0,
"минимальное_должно_соответствовать": 1,
"default_operator": "или",
"анализатор": "стандартный",
«снисходительный»: ложный,
"quote_field_suffix": "",
"analyze_wildcard": ложь,
"auto_generate_synonyms_phrase_query": правда
}
}
}
Соответствует всем
Соответствует всем документам. Может быть полезно для тестирования.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"match_all": {}
}
}
Нет совпадений
Нет документов. Редко полезно.
ПОЛУЧИТЬ _поиск
{
"запрос": {
"match_none": {}
}
}
Преобразование текста с помощью анализаторов
OpenSearch предоставляет функцию анализатора для преобразования структурированного текста в формат, который лучше всего подходит для вашего поиска. Вы можете использовать следующие параметры с полем анализатора: стандартный, простой, пробел, стоп, ключевое слово, шаблон, отпечаток пальца и язык. Разные анализаторы имеют разные фильтры символов, токенизаторы и фильтры токенов. Анализатор остановки, например, удаляет стоп-слова (например, «а», «но», «это») из строки запроса.
OpenSearch поддерживает следующие языковые значения с опцией анализатора : арабский, армянский, баскский, бенгальский, бразильский, болгарский, каталанский, чешский, датский, голландский, английский, эстонский, финский, французский, галисийский, немецкий, греческий, хинди , венгерский, индонезийский, ирландский, итальянский, латышский, литовский, норвежский, персидский, португальский, румынский, русский, сорани, испанский, шведский, турецкий и тайский.
Чтобы использовать анализатор при сопоставлении индекса, укажите значение в запросе. Например, чтобы сопоставить ваш индекс с анализатором французского языка, укажите французский значение для поля анализатора:
"анализатор": "французский"
Образец запроса
Следующий запрос сопоставляет индекс с языковым анализатором, установленным на французский :
PUT my-index-000001
{
"сопоставления": {
"характеристики": {
"текст": {
"тип": "текст",
"поля": {
"французский язык": {
"тип": "текст",
"анализатор": "французский"
}
}
}
}
}
}
Дополнительные поля запроса
Вы можете отфильтровать результаты запроса, используя некоторые необязательные поля запроса, такие как подстановочные знаки, анализаторы, нечеткие поля запроса и синонимы.
Use wildcards
| Option | Valid values | Description |
|---|---|---|
allow_leading_wildcard | Boolean | Whether * and ? допускаются в качестве первого символа поискового запроса. По умолчанию верно . |
analysis_wildcard | Boolean | Должен ли OpenSearch пытаться анализировать термины с подстановочными знаками. Некоторые анализаторы плохо справляются с этой задачей, поэтому по умолчанию стоит false. |
Use built-in analyzers
| Option | Valid values | Description |
|---|---|---|
analyzer | standard, simple, whitespace, stop, keyword, pattern, language, fingerprint | Анализатор, который вы хотите использовать для запроса. Разные анализаторы имеют разные фильтры символов, токенизаторы и фильтры токенов. Например, анализатор stop удаляет стоп-слова (например, «ан», «но», «это») из строки запроса. Полный список допустимых языковых значений см. в разделе Преобразование текста с помощью анализаторов на этой странице. |
quote_analyzer | Строка | Эта опция позволяет использовать стандартный анализатор без каких-либо опций, например язык или другие анализаторы. Использование "quote_analyzer": "стандарт" . |
Run fuzzy queries
| Option | Valid values | Description |
|---|---|---|
fuzziness | AUTO , 0 , or a positive integer | The number of character правки (вставка, удаление, замена), необходимые для замены одного слова на другое при определении того, соответствует ли термин значению. Например, расстояние между wined и wind равно 1. Значение по умолчанию, AUTO , выбирает значение на основе длины каждого термина и является хорошим выбором для большинства случаев использования. |
fuzzy_transpositions | Boolean | Установка для fuzzy_transpositions значения true (по умолчанию) добавляет замены соседних символов к операциям вставки, удаления и замены опции fuzziness. |
fuzzy_max_expansions | Положительное целое число | Нечеткие запросы «расширяются до» ряда совпадающих терминов, которые находятся в пределах расстояния, указанного в нечеткости . Затем OpenSearch пытается сопоставить эти термины со своими индексами. |
Использование синонимов с запросом
Вы также можете запускать запросы с несколькими терминами, которые позволяют генерировать синонимы. Используйте логическое поле auto_generate_synonyms_phrase_query . По умолчанию установлено значение true . Он автоматически генерирует фразовые запросы для синонимов, состоящих из нескольких терминов. Например, если у вас есть синоним "ba, batting medium" и поиск "ba", OpenSearch ищет ba ИЛИ "batting medium" (если эта опция истинна) или ba ИЛИ (batting AND medium) (если эта опция неверна) .
Другие необязательные поля запроса
Вы также можете использовать следующие необязательные поля запроса для фильтрации результатов запроса.
| Опция | Допустимые значения | Описание |
|---|---|---|
Boost | С плавающей запятой | Увеличивает предложение на указанный множитель. Полезно для взвешивания предложений в составных запросах. По умолчанию 1.0. |
enable_position_increments | Boolean | При значении true результирующие запросы учитывают приращения позиции. Этот параметр полезен, когда удаление стоп-слов оставляет нежелательный «пробел» между терминами. Значение по умолчанию верно. |
поля | Строковый массив 94", "description"] ). Если не указано, по умолчанию используется параметр index.query.default_field , который по умолчанию равен ["*"] . | |
flags | 3 0 String5 | — строка флагов с разделителями для включения (например, ||
снисходительный | Логический | Установка для снисходительного значения true позволяет игнорировать несоответствия типов данных между запросом и полем документа. Например, строка запроса «8. 2» может соответствовать полю типа с плавающей запятой . Значение по умолчанию — ложь. |
low_freq_operator | и, или | Оператор низкочастотных терминов. По умолчанию или . См. также оператор в этой таблице. |
max_determinized_states | Положительное целое число | Максимальное количество «состояний» (показатель сложности), которое Lucene может создать для строк запроса, содержащих регулярные выражения (например, «query»: «/wind.+? /" ). Большие числа позволяют выполнять запросы, использующие больше памяти. По умолчанию 10 000. |
max_expansions | Положительное целое | max_expansions указывает максимальное количество терминов, до которых может расширяться запрос. Значение по умолчанию — 50. |
Minimum_should_match | Положительное или отрицательное целое число, положительный или отрицательный процент, комбинация | для совпадения, чтобы документ считался совпадением. Например, если Minimum_should_match — 2, «ветер часто поднимается» не соответствует «Ветер поднимается». Если Minimum_should_match равно 1, это соответствует. |
оператор | или, и | Если строка запроса содержит несколько поисковых терминов, должны ли совпадать все термины ( и ) или должен совпадать только один термин ( или 915 ) для a документ, который считается совпадающим. |
фраза_slop | 0 (по умолчанию) или положительное целое число | См. отстой . |
prefix_length | 0 (по умолчанию) или положительное целое число | Количество начальных символов, которые не учитываются при нечеткости. |
quote_field_suffix | String | Этот параметр позволяет выполнять поиск по различным полям в зависимости от того, заключены ли термины в кавычки. Например, если quote_field_suffix равно ".exact" и вы ищете "слегка" (в кавычках) в поле title , OpenSearch выполняет поиск в поле title.exact . Это второе поле может использовать другой тип (например, ключевое слово вместо текст ) или другой анализатор. Значение по умолчанию равно нулю. |
переписать | const_score, scoring_boolean, Constant_score_boolean, top_terms_N, top_terms_boost_N, top_terms_blended_freqs_N По умолчанию константа_счет . | |
slop | 0 (по умолчанию) или положительное целое число | Управляет степенью, в которой слова в запросе могут быть неправильно упорядочены, но при этом считаться совпадением. Из документации Lucene: «Количество других слов, разрешенных между словами в фразе запроса. Например, чтобы изменить порядок двух слов, требуется два хода (первый ход помещает слова друг на друга), поэтому, чтобы разрешить изменение порядка фраз, наклон должен быть не менее двух. Нулевое значение требует точного совпадения». |
tie_breaker | 0,0 (по умолчанию) на 1,0 | Изменяет способ оценки поиска OpenSearch. Например, тип из best_fields обычно использует наивысший балл из любого одного поля. Если вы укажете значение tie_breaker от 0,0 до 1,0, оценка изменится на наивысший балл + tie_breaker * оценка для всех других совпадающих полей. Если вы укажете значение 1,0, OpenSearch суммирует баллы для всех совпадающих полей (фактически нарушая цель 9).1534 лучших_поля ). |
time_zone | Смещение часов UTC | Указывает количество часов для смещения желаемого часового пояса от UTC . Вам необходимо указать номер смещения часового пояса, если строка запроса содержит диапазон дат. Например, установите time_zone": "-08:00" для запроса с диапазоном дат, например "query": "ветр поднимается выпуск_дата[2012-01-01 TO 2014-01-01]" ). |