
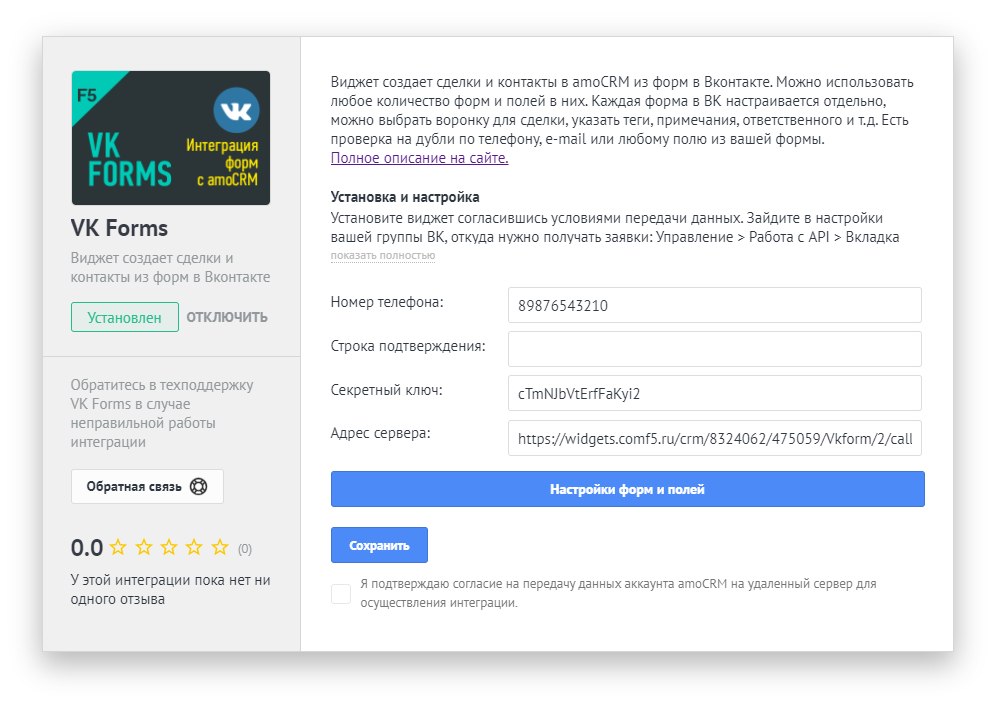
Как найти дубли страниц на сайте
Содержание статьи
- Что такое дубли страниц?
- Могут ли дубли плохо сказаться на продвижении сайта
- Причины возникновения дублей
- Способы поиска дублирующего контента
- XENU
- Screaming Frog
- Comparser
- Поисковая выдача
- Онлайн-сервисы
- Google Webmaster
- Sitereport
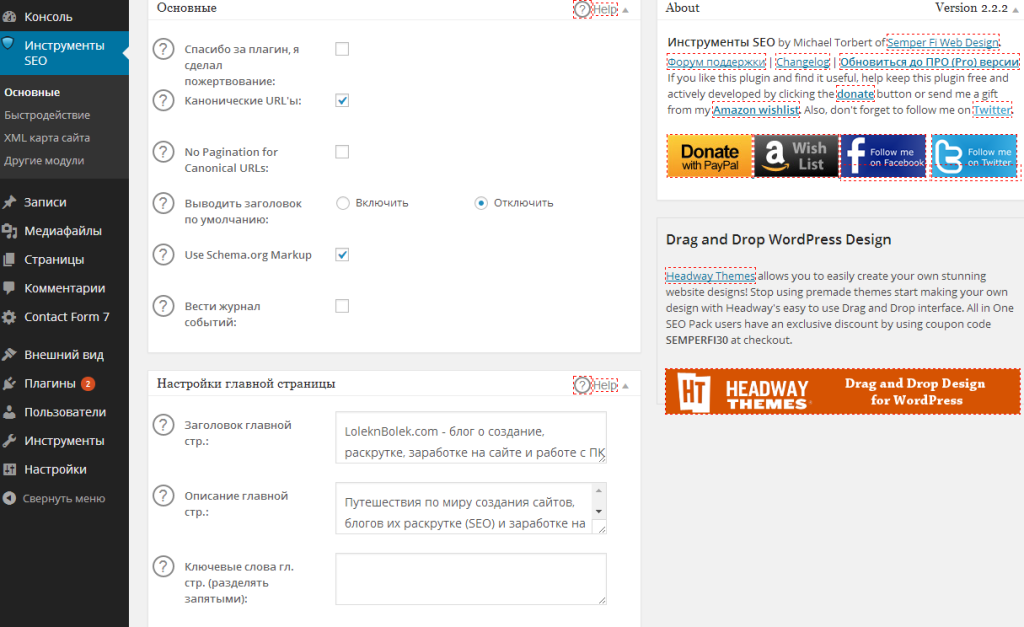
- Решение проблемы
Наличие дублей страниц в индексе — это такая страшная сказка, которой seo-конторы пугают обычно владельцев бизнеса. Мол, смотрите, сколько у вашего сайта дублей в Яндексе! Честно говоря, не могу предоставить примеры, когда из-за дублей сильно падал трафик. Но это лишь потому, что эту проблему я сразу решаю на начальном этапе продвижения. Как говорится, лучше перебдеть, поэтому приступим.
Что такое дубли страниц?
Дубли страниц – это копии каких-либо страниц. Если у вас есть страница site.ru/bratok.html с текстом про братков, и точно такая же страница site. ru/norma-pacany.html с таким же текстом про братков, то вторая страница будет дублем.
ru/norma-pacany.html с таким же текстом про братков, то вторая страница будет дублем.
Могут ли дубли плохо сказаться на продвижении сайта
Могут, если у вашего сайта проблемы с краулинговым бюджетом (если он маленький).
Краулинговый бюджет — это, если выражаться просто, то, сколько максимум страниц вашего сайта может попасть в поиск. У каждого сайта свой КБ. У кого-то это 100 страниц, у кого-то — 25000.
Если в индексе будет то одна страница, то другая, в этом случае они не будут нормально получать возраст, поведенческие и другие «подклеивающиеся» к страницам факторы ранжирования. Кроме того, пользователи могут в таком случае ставить ссылки на разные страницы, и вы упустите естественное ссылочное. Наконец, дубли страниц съедают часть вашего краулингового бюджета. А это грозит тем, что они будут занимать в индексе место других, нужных страниц, и в итоге нужные вам страницы не будут находиться в поиске.
Причины возникновения дублей
Сначала вам нужно разобраться, почему на вашем сайте появляются дубли. Это можно понять по урлу, в принципе.
- Дубли могут создавать ID-сессии. Они используются для контроля за действиями пользователя или анализа информации о вещах, которые были добавлены в корзину;
- Особенности CMS (движка). В WordPress такой херни обычно нету, а вот всякие Джумлы генерируют огромное количество дублей;
- URL с параметрами зачастую приводят к неправильной реализации структуры сайтов;
- Страницы комментариев;
- Страницы для печати;
- Разница в адресе: www – не www. Даже сейчас поисковые роботы продолжают путать домены с www, а также не www. Об этом нужно позаботиться для правильной реализации ресурса.
Способы поиска дублирующего контента
Можно искать дубли программами или онлайн-сервисами. Делается это по такому алгоритму — сначала находите все страницы сайта, а потом смотрите, где совпадают Title.
Делается это по такому алгоритму — сначала находите все страницы сайта, а потом смотрите, где совпадают Title.
XENU
XENU – это очень олдовая программа, которая издавна используется сеошниками для сканирования сайта. Лично мне её старый интерфейс не нравится, хотя задачи свои она в принципе решает. На этом видео парень ищет дубли именно при помощи XENU:
Screaming Frog
Я лично пользуюсь либо Screaming Frog SEO Spider, либо Comparser. «Лягушка» — мощный инструмент, в котором огромное количество функций для анализа сайта.
Comparser
Comparser – это все-таки мой выбор. Он позволяет проводить сканирование не только сайта, но и выдачи. То есть ни один сканер вам не покажет дубли, которые есть в выдаче, но которых уже нет на сайте. Сделать это может только Компарсер.
Поисковая выдача
Можно также и ввести запрос вида site:vashsite. ru в выдачу поисковика и смотреть дубли по нему. Но это довольно геморройно и не дает полной информации. Не советую искать дубли таким способом.
ru в выдачу поисковика и смотреть дубли по нему. Но это довольно геморройно и не дает полной информации. Не советую искать дубли таким способом.
Онлайн-сервисы
Чтобы проверить сайт на дубли, можно использовать и онлайн-сервисы.
Google Webmaster
Обычно в панели вебмастера Google, если зайти в «Вид в поиске — Оптимизация HTML», есть информация о страницах с повторяющимся метаописанием. Так можно найти часть дублей. Вот видеоинструкция:
Sitereport
Аудит сайта от сервиса Sitereport также поможет найти дубли, помимо всего прочего. Хотя дублированные страницы можно найти и более простыми/менее затратными способами.
Решение проблемы
Для нового и старого сайта решения проблемы с дублями — разные. На новом нам нужно скорее предупредить проблему, провести профилактику (и это, я считаю, самое лучшее). А на старом уже нужно лечение.
На новом сайте делаем вот что:
- Сначала нужно правильно настроить ЧПУ для всего ресурса, понимая, что любые ссылки с GET-параметрами нежелательны;
- Настроить редирект сайта с www на без www или наоборот (тут уж на ваш вкус) и выбрать главное зеркало в инструментах вебмастера Яндекс и Google;
- Настраиваем другие редиректы — со страниц без слеша на страницы со слешем или наоборот;
- Завершающий этап – это обновление карты сайта.
Отдельное направление – работа с уже имеющимся, старым сайтом:
- Сканируем сайт и все его страницы в поисковых системах;
- Выявляем дубли;
- Устраняем причину возникновения дублей;
- Проставляем 301 редирект и rel=»canonical» с дублей на основные документы;
- В обязательном порядке 301 редиректы ставятся на страницы со слешем или без него. Обязательная задача – все url должны выглядеть одинаково;
- Правим роботс — закрываем дубли, указываем директиву Host для Yandex с заданием основного зеркала;
- Ждем учета изменений в поисковиках.


Как-то так.
Как найти и исправить ошибки SEO
Внутренняя оптимизация помогает сайту с хорошим контентом занимать высокие позиции в поисковой выдаче. Но когда проект развивается и обрастает новыми страницами, можно допустить ошибки, которые негативно повлияют на рост позиций сайта. Как вовремя найти и исправить эти ошибки, расскажем в статье.
Содержание
Зачем проверять настройки сайта для SEO
Краткий словарь SEO терминов
Какими бывают ошибки оптимизации и как их найти
Чеклист для проверки сайта на ошибки
Проверка сайта на наличие технических ошибок
Зачем проверять настройки сайта для SEO
Чем выше позиции сайта в поисковой выдаче, тем людям проще его найти и тем больше посетителей может на него перейти. На позиции влияют разные факторы: контент, история сайта, количество упоминаний в других источниках и техническая оптимизация. Последняя играет большую роль в общем успехе продвижения в поисковых системах.
Технические настройки включают в себя настройку названий и описаний страниц (метатегов), заголовков, атрибутов у изображений, переадресаций, создание страницы для 404 ошибки и многое другое.
В Тильде все настройки можно сделать в интерфейсе. В справочном центре мы подготовили чек-лист по оптимизации сайта, который поможет проделать основную работу, связанную с SEO.
Когда вы только запускаете сайт, вы можете несколько раз проверить, чтобы все настройки были сделаны идеально. Когда проект развивается, постоянно создаются новые страницы, редактируются и удаляются старые, можно допустить ошибки, которые повлияют на продвижение. Чтобы этого не произошло, нужно периодически проводить проверку.
Пример
Руководитель турагентства открыл новое направление — фитнес-туры в Испанию. За полгода контент-менеджер Иван написал 10 статей для блога, которые нравятся читателям. Но он поставил у всех страниц со статьями одинаковые названия (метатег Title) и описания (метатег Description), а также не добавил заголовкам статьи теги h2 и h3. Статьи плохо ранжировались и не попали на первые страницы поисковой выдачи.
Иван посоветовался с SEO-специалистом и сделал все настройки. Несколько материалов поднялось на первую страницу поисковой выдачи по важным запросам: «как выбрать фитнес-тур», «фитнес-туры на море». За месяц их прочитала 1000 новых посетителей, а 10 из них заказали тур.
Несколько материалов поднялось на первую страницу поисковой выдачи по важным запросам: «как выбрать фитнес-тур», «фитнес-туры на море». За месяц их прочитала 1000 новых посетителей, а 10 из них заказали тур.
Краткий словарь SEO терминов
Чтобы было проще разобраться, что это за настройки и зачем они нужны, мы подготовили краткий словарь SEO терминов
Метатеги Title и Description — заголовок и описание страницы, которые отображаются в поисковой выдаче. На самой странице они не видны, но название отображается на вкладке браузера. Помимо этого, указанные вами Title и Description часто используются поисковыми системами для показа в результатах поиска.
Индексация — передача страниц и другого содержимого сайта (изображений, видео, ссылок и т. д.) роботом-пауком в индекс поисковой системы. Индекс представляет собой своеобразный список страниц, к которым поисковая система обращается во время поиска страниц, соответствующих запросам пользователей.
Код ответа сервера — трехзначное число, которым обозначается определённый статус запрашиваемой страницы. Даёт понять браузеру и поисковому роботу, как сайт отреагировал на запрос к определённой странице.
Даёт понять браузеру и поисковому роботу, как сайт отреагировал на запрос к определённой странице.
h2-H6 — шесть тегов, которые используются при создании HTML-страниц для структурирования и деления информации на блоки. Заголовок, обозначенный тегом h2, имеет наибольшую значимость для поисковых систем.
Альтернативный текст для изображений (тег ALT) — показывается на месте изображения, если само изображение не видно (например, в момент загрузки при медленном соединении). Кроме этого, поисковые системы воспринимают альтернативный текст как ключевые слова и учитывают их при индексации.
Глубина страницы — количество кликов, отделяющих страницу от главной.
Rel=canonical — атрибут, указывающий каноническую, приоритетную для индексации страницу. С его помощью все характеристики (ссылочный вес, поведенческий фактор и т. д.) передаются нужной версии документа, а копии отмечаются поисковым роботом как малозначительные и не попадают в индекс.
Внутренний PageRank — относительный показатель распределения ссылочного веса веса между страницами в пределах одного сайта. Вес передаётся при помощи ссылок с одной страницы на другую, а также атрибута rel=canonical и редиректов.
Вес передаётся при помощи ссылок с одной страницы на другую, а также атрибута rel=canonical и редиректов.
Какими бывают ошибки оптимизации и как их найти
В SEO существуют ошибки разной степени критичности, включая как очень важные, так и незначительные. Например, критическая ошибка — это дубли страниц. Если вы не указали в настройках при помощи атрибута Canonical, какая страница основная, а какую не нужно индексировать, поисковые системы могут понизить позиции обеих страниц.
Основные ошибки
Критические
- Важная страница закрыта от индексации
- Дубли страниц
- Бесконечный редирект
- Максимальная длина URL
- Нет адаптивной версии
- Наличие битых ссылок или битых изображений на сайте
- У страницы нет названия и/или описания (метатеги Tiltle и Description)
- Ссылка на логотипе в верхней части страницы ведет на другой сайт
- Купленный домен находится в черном списке
Важные
- Цепочка переадресаций (редиректов)
- На странице отсутствует тег заголовка h2 Нет страницы 404 ошибки
- Большой размер изображений
- Системный URL вместо понятных слов
- Не прописан альтернативный текст у изображений
- Низкая скорость ответа сервера и загрузки страницы
Незначительные
- Короткий Title и/или Description
- Слишком длинный заголовок h2
- На сайте не настроено безопасное соединение по про протоколу HTTPS
Лучше устранять все виды ошибок, но к критическим нужно относиться особенно внимательно. Допустив их, вы можете упустить шанс оказаться в зоне видимости пользователя или серьёзно понизить уже имеющиеся позиции в выдаче. Вернуть всё назад будет сложно.
Допустив их, вы можете упустить шанс оказаться в зоне видимости пользователя или серьёзно понизить уже имеющиеся позиции в выдаче. Вернуть всё назад будет сложно.
Чеклист для проверки сайта на ошибки
Поиск дубликатов страниц. Проверка настроек переадресации, канонического атрибута страницы
На сайте не должно присутствовать страниц с одинаковым контентом. Если нужно оставить страницы с частично или полностью повторяющимся контентом, у второстепенных страниц должен присутствовать атрибут rel=canonical.
Проверка доступности страниц для индексации. Проверка кодов ответа сервера
Страницы с важным контентом должны быть открыты для индексации и отдавать код ответа сервера 200 OK.
Проверка времени загрузки страниц сайта и скорости ответа сервера
Скорость ответа сервера должна быть меньше 500 мс.
Проверка метатегов Title и Description, тега заголовка h2
У каждой страницы должен быть уникальный Title и Description.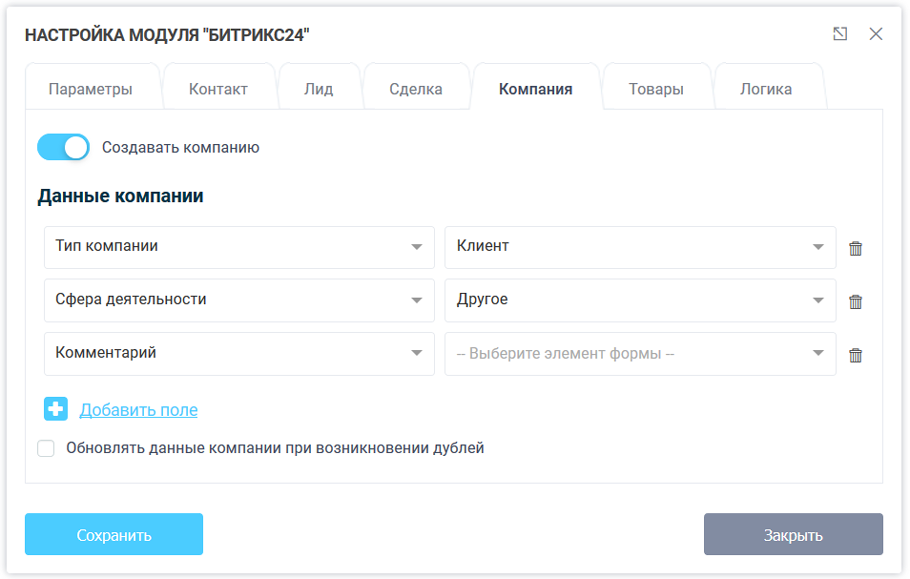 Длина Title должна быть от 10 до 70 символов, Description — от 60 до 260 символов в среднем.
Длина Title должна быть от 10 до 70 символов, Description — от 60 до 260 символов в среднем.
На каждой странице должен быть назначен тег h2 главному заголовку. Не рекомендуется делать его длиннее 65 символов.
Проверка структуры URL-адресов и глубины страниц
URL должны состоять из понятных слов. Глубина страниц — количества кликов, отделяющих страницу от главной. Рекомендуется, чтобы она не превышала 4.
Проверка оптимизации изображений
Оптимальный размер изображений — 100 кб. У изображений должен присутствовать альтернативный текст. Он должен соответствовать содержимому изображения и содержать от 70 до 250 символов.
Анализ внутреннего PageRank
PageRank — внутренний показатель распределения ссылочного веса между страницами в пределах одного сайта. На сайте не должно быть недостижимых страниц и страниц без исходящих ссылок.
Внутри Тильды есть встроенный инструмент для быстрой проверки следующих критических ошибок: наличие Title, Description, тега h2, читаемого URL, неопубликованных или закрытых от индексации страниц.
Чтобы запустить проверку, откройте Настройки сайта > SEO > SEO-рекомендации.
Проверка сайта на наличие технических ошибок
Чтобы наглядно показать, как искать ошибки, мы попросили Александру Метизу провести проверку трех разных проектов, сделанных на Тильде:
Проект малого бизнеса Another Georgia
Интернет-магазин Kitchen Ceremony
Сервис для клиентской поддержки Юздеск
Александра Метиза
Контент-маркетолог Netpeak Software
Для проверки использовали Netpeak Spider — инструмент для комплексного внутреннего SEO-аудита сайта. Фактически программа «обходит» выбранные для сканирования страницы или весь сайт целиком, переходя по внутренним ссылкам.
В процессе Spider анализирует свойства страницы, проверяя метаданные, атрибуты, редиректы, инструкции для поисковых роботов, а также множество других данных, важных для поисковой оптимизации.
Выбор анализируемых параметров зависит от целей сканирования: можно выбрать их вручную, или воспользоваться одним из шаблонов.
1. Мастер-классы грузинской кухни Another Georgia
Сайт: another-georgia.com
Тип компании: малый бизнес
География: Москва
Краткое описание: практические мастер-классы по грузинской кухне
Контент и основные метаданные
Всего в сайте 16 страниц, ни одна из которых не дублируется. Важные проблемы были обнаружены всего на двух страницах: на них отсутствуют заголовки первого порядка h2, а длина Description — меньше рекомендованной.
Как исправить
Добавить тег h2 к заголовкам на страницах.
Инструкция →
Составить более развёрнутый Description (Описание) и указать его в настройках страницы.
Инструкция →
Настройки переадресации и атрибут Canonical
На сайте используются серверные редиректы, которые перенаправляют на зеркала без слеша в конце. Но отсутствует переадресация на единую версию с префиксом www. или без него. Есть вероятность, что это повлечёт за собой появление дублей, которые крайне негативно воспринимаются поисковыми системами. Поисковые роботы воспринимают атрибут rel=»canonical» не как строгую директиву, а как рекомендацию, то есть указанный URL может быть проигнорирован.
Есть вероятность, что это повлечёт за собой появление дублей, которые крайне негативно воспринимаются поисковыми системами. Поисковые роботы воспринимают атрибут rel=»canonical» не как строгую директиву, а как рекомендацию, то есть указанный URL может быть проигнорирован.
Нет переадресации и на HTTP-версию сайта при попытке ввести адрес сайта с https://, хотя имеется ведущий на неё атрибут Canonical.
Как исправить
В настройках сайта настроить переадресацию: Настройки > SEO > Редиректы страниц.
Инструкция →
Проверка кодов ответа сервера. Открытость к индексации
Ни одна из стратегически важных страниц не была закрыта от поисковых роботов: все отдают код ответа 200 OK, а значит, могут быть проиндексированы поисковыми роботами. Исключение составляют несколько служебных страниц.
Время загрузки страниц сайта и скорость ответа сервера
Время ответа сервера в пределах сайта варьируется от 93 до 234 мс, скорость загрузки контента — от 1 до 108 мс. Показатели близки к идеалу.
Показатели близки к идеалу.
Структура URL и глубина страниц
Все URL составлены грамотно: их вид отвечает структуре сайта и смыслу каждой отдельно взятой страницы. Нет проблем ни с кодировкой, ни с излишней глубиной: до любой страницы сайта можно добраться в 2 клика.
Распределение внутреннего PageRank
Внутренний PageRank распределяется между страницами равномерно. Перелинковка сделана грамотно, тупиковых страниц нет. Нет таких проблем, как «Висячий узел», «Отсутствуют связи», «Отсутствуют исходящие ссылки».
Висячий узел. Так определяются страницы, на которые ведут ссылки, но на них самих отсутствуют исходящие ссылки, из-за чего нарушается естественное распределение ссылочного веса по сайту.
Отсутствуют связи. Это страницы, на которые не было найдено ни одной входящей ссылки.
Отсутствуют исходящие ссылки. Показывает URL, у которых не были найдены исходящие ссылки.
Изображения
На сайте не было обнаружено проблем с оптимизацией изображений. Но у 15 из них не прописан атрибут ALT, который мог бы поспособствовать продвижению сайта в поиске по картинках.
Но у 15 из них не прописан атрибут ALT, который мог бы поспособствовать продвижению сайта в поиске по картинках.
Как исправить
Добавить альтернативный текст к изображениям.
Инструкция →
2. Интернет-магазин пряностей Kitchen Ceremony
Сайт: kitchenceremony.com
Тип компании: интернет-магазин
География: международный рынок
Контент и основные метаданные
Первая проблема, которая бросается в глаза по итогу сканирования сайта, — несколько битых ссылок, отдающих 404 код ответа.
Кликнув по одной из обнаруженных ссылок, мы неизменно попадаем на страницу «Пряности», однако битый URL не меняется на http://www.kitchenceremony.com/spices/.
В действительности абсолютно нормальная страница имеет код ответа сервера 404 Not Found, что подтверждает даже консоль разработчика в Chrome. Возможно, всё дело в том, что владельцы сайта не создали выделенную страницу для 404 ошибки и назначили на её роль страницу «Пряности».
Как исправить
Создать отдельную страницу 404 ошибки и указать её в настройках сайта: Настройки > Еще > Страница 404.
Инструкция →
Следующая проблема — обилие дубликатов. Netpeak Spider обнаружил несколько одинаковых Title, Description и заголовков первого порядка, использованных для страниц с несколькими разными рецептами и товарами.
Также, просматривая ссылки с дублями, мы обнаружили, что страницы /decor/05 и /decor/06 фактически дублируют друг друга: программа не определила их как полные дубли только потому, что в тексте есть несущественное различие, которое можно обнаружить лишь целенаправленно.
Как исправить
Создать для всех страниц уникальный Title и Description.
Удалить дубликаты страниц.
Также на некоторых страницах были обнаружены слишком короткие или слишком длинные h2, Description и Title. Эти проблемы имеют низкий уровень критичности, но лучше не оставлять их без внимания.
Эти проблемы имеют низкий уровень критичности, но лучше не оставлять их без внимания.
Как исправить
Привести h2, Title и Description к нужной длине:
- Title — от 10 до 70 символов,
- Description — от 60 до 260 символов в среднем,
- h2 — не более 65 символов.
Настройки переадресации и атрибут Canonical
Не настроены серверные редиректы на одну основную версию сайта, так что внутри сайта смешиваются страницы с префиксом www. и без него.
Страница «Пряности» отдаёт разный код ответа в зависимости от наличия слеша и префикса в адресе. На этом, кстати, проблемы страницы не завершаются: её каноническая версия (http://www.kitchenceremony.com/spices/) закрыта при помощи запрещающей директивы Disallow в robots.txt. Это происходит из-за того, что страница «Пряности» установлена в качестве страницы 404 ошибки.
Как исправить
Настроить редирект с версии сайта без www.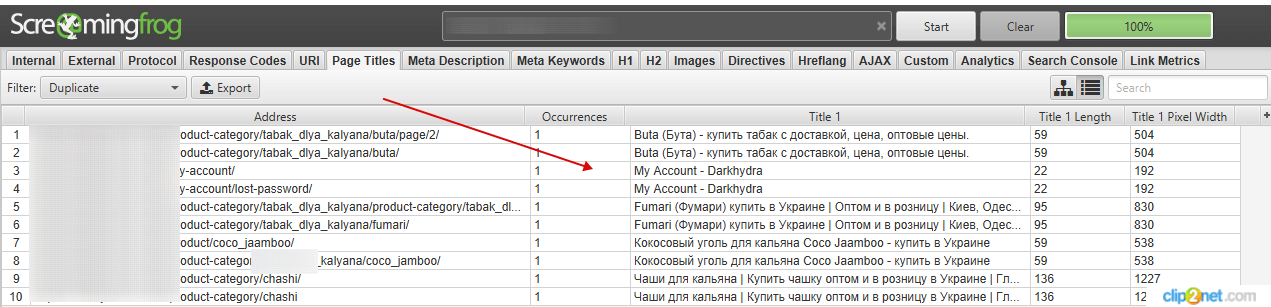 на версию с www., или наоборот.
на версию с www., или наоборот.
Создать отдельную страницу 404 ошибки и указать её в настройках сайта: Настройки > Еще > Страница 404.
Инструкция →
Проверка кодов ответа сервера. Открытость к индексации
Согласно результатам сканирования, 77,3% процента обнаруженных на сайте страниц могут быть проиндексированы. Это те страницы, которые открыты для индексации, отдают код ответа 200 OK и не перенаправляют поисковых роботов на канонические URL-адреса. Большинство стратегически важных страниц попадают в их число, но всё же результат мог бы быть значительно лучше.
Скорость ответа сервера и загрузки контента
Минимальное время ответа сервера составляет 49 мс, максимальное — 578 мс, что незначительно превышает допустимую норму. Время загрузки контента также колеблется в рекомендуемых пределах — от 0 до 540 мс.
Структура URL и глубина страниц
Как и в случае с Another Georgia, URL на сайте формируются согласно иерархии страниц. В большинстве случаев адреса страниц включают в себя краткие версии русскоязычных заголовков, прописанных латиницей. Почти на всех из них можно попасть в 2 клика. Но есть и исключения, которые портят идеальную картину.
В большинстве случаев адреса страниц включают в себя краткие версии русскоязычных заголовков, прописанных латиницей. Почти на всех из них можно попасть в 2 клика. Но есть и исключения, которые портят идеальную картину.
Как исправить
Проставить ссылки на страницы с глубоким уровнем вложенности таким образом, чтобы «сократить» к ним путь от главной.
Распределение внутреннего PageRank
На сайте есть некоторые проблемы с распределением внутреннего PageRank:
Внутри сайта есть недостижимые страницы
Это касается товарных страниц с описаниями кориандра, хмели-сунели и жёлтого цветка. Клик по миниатюрам этих товаров из каталога специй не перенаправляет пользователя на страницу — он просто добавляет артикул в корзину.
Как исправить
Добавить ссылки на недостижимые страницы. Например, можно добавить ссылки на описание специй в статьи с рецептами.
Страницы, отдающие 404 код ответа, создают так называемые «висячие узлы»
«Висячие узлы», на которых не только теряется ссылочный вес, но и «тормозятся» поисковые роботы. И наличие подобных страниц может негативно сказаться на пользовательском опыте.
И наличие подобных страниц может негативно сказаться на пользовательском опыте.
Как исправить
Добавить на тупиковые страницы исходящие ссылки, например, на главную или на другие связанные страницы.
Изображения
Размер имеющихся на сайте изображений не превышает рекомендуемой нормы. Но в то же время у большинства картинок отсутствует атрибут ALT, необходимый для ранжирования в поиске.
Как исправить
Добавить альтернативный текст к изображениям.
Инструкция →
3. Онлайн-сервис Юздеск
Сайт: usedesk.ru
Тип компании: онлайн-сервис
География: международный рынок
Краткое описание: сервис для общения с клиентами во всех цифровых каналах (чат на сайте, электронная почта, мессенджеры, соцсети).
Контент и основные метаданные
На сайте есть несколько битых ссылок. Некоторые размещены на важных лидогенерирующих страницах. Нужно заменить их корректными рабочими ссылками без потери смысловой связи.
Как исправить
Заменить битые ссылки на соответствующие рабочие.
На сайте существует сразу несколько вариантов ссылок с разными GET-параметрами на страницы авторизации и регистрации, которые открыты для индексации. Они могут определяться поисковыми роботами как дубли из-за того, что страницах не настроен атрибут Canonical. К тому же, на этих же страницах отсутствуют метатеги Description.
Как исправить
Настроить атрибут Canonical, указав в качестве канонических страницы авторизации и регистрации без GET-параметров и дополнительных атрибутов в адресе.
Прописать Description.
Инструкция →
Примерно у десятка страниц Description короче, чем рекомендуется.
Как исправить Исправить Description.
Инструкция →
Редиректы и атрибут Canonical
На сайте исправно работают редиректы на основное зеркало сайта (с HTTPS, без слеша и префикса www. ).
).
Директивы по индексации. Индексируемость страниц
В robots. txt от индексации закрыто всего несколько страниц, хотя по большому счёту, нет особенного смысла скрывать их от поисковых роботов.
Все ссылки на страницах, связанных с клиентами компании, и ещё нескольких лендингах закрыты при помощи rel=nofollow, хотя в данный момент в этом нет необходимости. Атрибут nofollow больше не помогает «сохранить» ссылочный вес от передачи другим сайтам.
Скорость ответа сервера и загрузки контента
Время ответа сервера для абсолютного большинства страниц варьируется в рекомендуемых пределах от 47 до 496 мс. Всего 2 страницы составили исключение и превысили планку в 600 мс.
Структура URL и глубина страниц
URL в большинстве случаев отвечают принципу ЧПУ (человеко-понятные URL), а их строение соответствует общей структуре сайта. Средняя глубина страниц составляет от 1 до 4, что не превышает допустимой нормы.
Распределение внутреннего PageRank
Использование вышеупомянутого атрибута rel=nofollow на нескольких десятках страниц привело к неравномерному распределению внутреннего PageRank. Как следствие, 8 страниц сайта были определены краулером как «Висячие узлы», то есть, как страницы без открытых исходящих ссылок.
Как следствие, 8 страниц сайта были определены краулером как «Висячие узлы», то есть, как страницы без открытых исходящих ссылок.
Как исправитьУбрать атрибут rel=nofollow и добавить на тупиковые страницы исходящие ссылки, например, на главную или на другие связанные страницы.
Изображения
Все изображения на сайте имеют размер не более 100 кбайт, но при этом ни у одного из них нет сопутствующего атрибута ALT.
Как исправить
Добавить альтернативный текст к изображениям.
Инструкция →
Результаты проверки
Мы провели базовый аудит трёх работающих сайтов. У двух из них выявили критические ошибки, которые влияют на потенциальную индексацию и ранжирование в поисковой выдаче. Но исправить их можно довольно быстро.
Чтобы избежать проблем с ранжированием сайта, для каждой новой страницы не забывайте делать необходимые настройки по чек-листу и проверяйте весь сайт на критические ошибки не реже раза в месяц.
Текст: Александра Метиза, Роман Яковенко
Верстка, дизайн и иллюстрации: Юля Засс
Если материал вам понравился, поставьте лайк — это помогает другим узнать о нем и других статьях Tilda Education и поддерживает наш проект. Спасибо!
*Компания Meta Platforms Inc., владеющая социальными сетями Facebook и Instagram, по решению суда от 21.03.2022 признана экстремистской организацией, ее деятельность на территории России запрещена.
Читайте также:
Как создать сайт. Пошаговое руководство
SEO продвижение сайта на Тильде самостоятельно — пошаговая инструкция
Аналитика сайта — как повысить конверсию сайта, используя веб-аналитику
Навигация по сайту — примеры как сделать навигацию удобной
SEO-кейс: продвижение онлайн-магазина
Почему любому сайту нужна страница 404
Как сделать интернет-магазин самостоятельно с нуля
Как работает SEO: основные принципы сео продвижения сайтов
Дубли страниц сайта — поиск и удаление
Что такое дубли страниц
В рамках одного доменного имени очень может такое быть, что один и тот же контент доступен по разным адресам.
Вполне вероятно, что на разных страницах сайта опубликован очень похожий или же полностью дублированный контент. Это может быть одинаковые (или очень похожие) описания meta name="description" content="", заголовки h2, title страницы. Если после проверки на наличие дубликатов выяснилось, что они присутствуют в вашем приложении, то необходимо устранить ненужные дубли страниц.
Дубли — это страницы, которые или очень похожи или являются полной копией (дублем) основной (продвигаемой вами) страницы.
Причины появления дублей страниц на сайте
- Не указано главное зеркало сайта. Одна и та же страница доступна по разным URL (с www. и без | с http и с https).
- Версии страниц сайта для печати, не закрытые от индексации.
- Генерация страниц с одними и теми же атрибутами, расположенными в разном порядке. Например,
/?id=1&cat=2и/?cat=2&id=1. - Автоматическая генерация дубликатов движком приложения (CMS). Из-за ошибок в системе управления контентом (CMS), так же могут появляются дубли страниц.
- Ошибки веб-мастера при разработке (настройке) приложения.
- Дублирование страницы (статьи, товара…) веб-мастером или контент-маркетологом.
- Изменение структуры сайта, после которого страницам присваиваются новые адреса, а старые не удаляются.
- На сайте используются «быстрые» мобильные версии страниц, с которых не выставлен
Canonicalна основные версии. - Сознательное или несознательное размещение ссылок третьими лицами на ваши дубли с других ресурсов.

Виды дублей
Дубликаты различают на 3 вида:
- Полные — с полностью одинаковым контентом;
- Частичные — с частично повторяющимся контентом;
- Смысловые, когда несколько страниц несут один смысл, но разными словами.
Полные
Полные дубли ухудшают факторы всего сайта и осложняют его продвижение в ТОП, поэтому от них нужно избавиться сразу после обнаружения.
- Версия с/без
www. Возникает, если пользователь не указал зеркало в панели Яндекса и Google. - Различные варианты главной страницы:
- site.com
- site.com/default/index
- site.com/index
- site.com/index/
- site.com/index.html
- Страницы, появившиеся вследствие неправильной иерархии разделов:
- site.com/products/apple/
- site.com/products/category/apple/
- site.com/category/apple/
- UTM-метки. Метки используются, чтобы передавать данные для анализа рекламы и источника переходов. Обычно они не индексируются поисковиками, но бывают исключения.
- GET-параметры в URL. Иногда при передаче данных GET-параметры попадают в адрес страницы:
- site. com/products/apple/page.php?color=green
- site.
- Страницы, сгенерированные реферальной ссылкой. Обычно они содержат специальный параметр, который добавляется к URL. С такой ссылки должен стоять редирект на обычный URL, однако часто этим пренебрегают.
- Неправильно настроенная страница с ошибкой 404, которая провоцирует бесконечные дубли. Любой случайный набор символов в адресе сайта станет ссылкой и без редиректа отобразится как страница 404.
 com/products/apple/page.php?color=green
com/products/apple/page.php?color=greenИзбавиться от полных дубликатов можно, поставив редирект, убрав ошибку программно или закрыв документы от индексации.
Частичные
Частичные дубликаты не так страшны для на сайта, как полные. Однако, если их много — это ухудшает ранжирование веб-приложения. Кроме того, они могут мешать продвижению и по конкретным ключевым запросам. Разберем в каких случаях они возникают.
Характеристики в карточке товара
Нередко, переключаясь на вкладку в товарной карточке, например, на отзывы, можно увидеть, как это меняет URL-адрес. При этом большая часть контента страницы остаётся прежней, что создает дубль.
При этом большая часть контента страницы остаётся прежней, что создает дубль.
Если CMS неправильно настроена, переход на следующую страницу в категории меняет URL, но не изменяет Title и Description. В итоге получается несколько разных ссылок с одинаковыми мета-тегами:
- site.com/fruits/apple/
- site.com/fruits/apple/?page=2
Такие URL-адреса поисковики индексируют как отдельные страницы. Чтобы избежать дублирования, проверьте техническую реализацию вывода товаров и автогенерации.
Также на каждой странице пагинации необходимо указать каноническую страницу, которая будет считаться главной.
Подстановка контента
Часто для повышения видимости по запросам с указанием города в шапку сайта добавляют выбор региона. При нажатии которого на странице меняется номер телефона. Бывают случаи, когда в адрес добавляется аргумент, например city_by_default=. В результате, у каждой страницы появляется несколько одинаковых версий с разными ссылками. Не допускайте подобной генерации или используйте 301 редирект.
Не допускайте подобной генерации или используйте 301 редирект.
Версия для печати
Версии для печати полностью копируют контент и нужны для преобразования формата содержимого. Пример:
- site.com/fruits/apple
- site.com/fruits/apple/print – версия для печати
Поэтому необходимо закрывать их от индексации в robots.txt.
Смысловые
Смысловые дубли — контент страниц, написанный под запросы из одного кластера. Чтобы их обнаружить (смысловые дубли страниц), нужно воспользоваться результатом парсинга сайта, выполненного, например, программой Screaming Frog. Затем скопировать заголовки всех статей и добавить их в любой Hard-кластеризатор с порогом группировки 3,4. Если несколько статей попали в один кластер – оставьте наиболее качественную, а с остальных поставьте 301 редирект.
Чем опасны дубли страниц на сайте
Наличие дубликатов на сайте — один ключевых факторов внутренней оптимизации (или её отсутствия), который крайне негативно сказывается на позициях сайта в органической поисковой выдаче.
- Индексация сайта. При большом количестве дублей поисковые роботы в силу ограниченного краулингового бюджета могут не проиндексировать нужные страницы. Также есть риск того, что сайт будет пессимизирован, а его краулинговый бюджет — урезан.
- Проблемы с выдачей приоритетной страницы в органическом поиске. За счет дублей в поисковую выдачу может попасть не та страница, продвижение которой планировалось, а её копия. Есть и другой вариант: обе страницы будут конкурировать между собой, и ни одна не окажется в выдаче.
- «Распыление» ссылочного веса. Вес страницы сайта — это своеобразный рейтинг, выраженный в количестве и качестве ссылок на неё с других сайтов или других страниц внутри этого же сайта. При наличии дублей ссылочный вес может переходить не на единственную версию страницы, а делиться между ее дубликатами. Таким образом, все усилия по внешней оптимизации и линкбилдингу оказываются напрасными.

Инструменты для поиска
Как найти дублирующиеся страницы? Это можно сделать с помощью специальных программ и онлайн сервисов. Часть из них платные, другие – бесплатные, некоторые – условно-бесплатные (с пробной версией или ограниченным функционалом).
Яндекс Вебмастер
Чтобы посмотреть наличие дубликатов в панели Яндекса, необходимо зайти: Индексирование -> Страницы в поиске -> Исключённые.
Страницы исключаются из индекса по разным причинам, в том числе из-за повторяющегося контента (дублирования). Обычно конкретная причина прописана под ссылкой.
Google Search Console
Посмотреть наличие дублей страниц в панели Google Search Console можно так: Покрытие -> Исключено.
Netpeak Spider
Netpeak Spider – платная программа с 14-дневной пробной версией. Если провести поиск по заданному сайту, программа покажет все найденные ошибки и дубликаты.![]()
Xenu
Xenu — бесплатная программа, в которой можно проанализировать даже не проиндексированный сайт. При сканировании программа найдет повторяющиеся заголовки и мета-описания.
Сайт Репорт
Сайт Репорт — это неплохой сервис, предоставляющий пользователю инструмент диагностики внутренних и внешних факторов с целью оптимизации сайта. Поиск дубликатов — это один из множества инструментов сервиса по оптимизации сайта или другого приложения. Сервис предоставляет бесплатный анализ до 25 страниц. Если у вас на сайте большее количество страниц, то (при необходимости) придётся немного потратиться. Но оно того стоит.
Screaming Frog Seo Spider
Screaming Frog Seo Spider является условно-бесплатной программой. До 500 ссылок можно проверить бесплатно, после чего понадобится платная версия. Наличие дублей программа определяет так же, как и Xenu, но быстрее и эффективнее.
Как начать пользоваться бесплатно:
- Скачать программу Screaming Frog Seo Spider и установить её на свой ПК. Скачать ключ-активатор для программы. Пароль к архиву:
prowebmastering.ru - Запустить
keygen.exe, задать имя пользователя и ключ (ключ можно сгенерировать) - В самой программе Screaming Frog Seo Spider выбрать вкладку «Licence» -> «Enter Licence»
- В появившемся окне указать то, что указали (или сгенерировали) при запуске
keygen.exe, жмём «OK», перезапускаем программу.
 Скачать ключ-активатор для программы. Пароль к архиву:
Скачать ключ-активатор для программы. Пароль к архиву: Документация по работе с программой Screaming Frog Seo Spider здесь.
Поисковая выдача
Результаты поиска могут отразить не только нужный нам сайт, но и некое отношение поисковой системы к нему. Для поиска дублей в Google можно воспользоваться специальным запросом.
site:mysite.ru -site:mysite.ru/&
site:mysite.ru — показывает страницы сайта mysite.ru, находящиеся в индексе Google (общий индекс).
site:mysite.ru/& — показывает страницы сайта mysite.
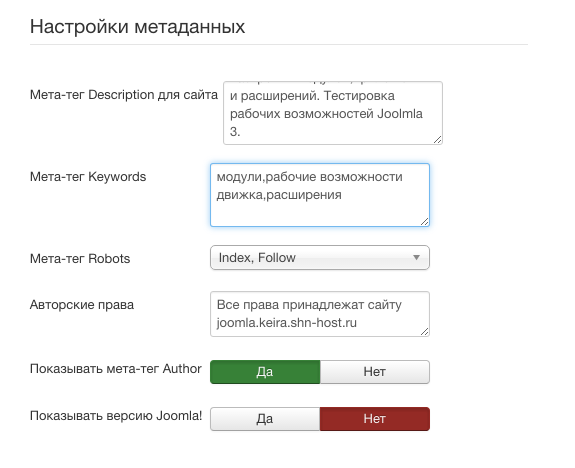 ru, участвующие в поиске (основной индекс).
ru, участвующие в поиске (основной индекс).
Таким образом, можно определить малоинформативные страницы и частичные дубли, которые не участвуют в поиске и могут мешать страницам из основного индекса ранжироваться выше. При поиске обязательно кликните по ссылке «повторить поиск, включив упущенные результаты», если результатов было мало, чтобы видеть более объективную картину.
Варианты устранения дубликатов
При дублировании важно не только избавиться от копий, но и предотвратить появление новых.
Физическое удаление
Самым простым способом было бы удалить повторяющиеся страницы вручную. Однако перед удалением нужно учитывать несколько важных моментов:
- Источник возникновения. Зачастую физическое удаление не решает проблему, поэтому ищите причину
- Страницы можно удалять, только если вы уверены, что на них не ссылаются другие ресурсы
Настройка 301 редиректа
Если дублей не много или на них есть ссылки, настройте редирект на главную или продвигаемую страницу. Настройка осуществляется через редактирование файла
Настройка осуществляется через редактирование файла .htaccess либо с помощью плагинов (в случае с готовыми CMS). Старый документ со временем выпадет из индекса, а весь ссылочный вес перейдет новой странице.
Создание канонической страницы
Указав каноническую страницу, вы показываете поисковым системам, какой документ считать основным. Этот способ используется для того, чтобы показать, какую страницу нужно индексировать при пагинации, сортировке, попадании в URL GET-параметров и UTM-меток. Для этого на всех дублях в теге прописывается следующая строчка со ссылкой на оригинальную страницу:
<link rel="canonical" href="http://site.com/original.html">
Например, на странице пагинации главной должна считаться только одна страница: первая или «Показать все». На остальных необходимо прописать атрибут rel="canonical", также можно использовать теги rel=prev/next:
// Для 1-ой страницы: <link rel="next" href="http://site.
 com/page/2">
<link rel="canonical" href="http://site.com">
// Для второй и последующей:
<link rel="prev" href="http://site.com">
<link rel="next" href="http://site.com/page/3">
<link rel="canonical" href="http://site.com">
com/page/2">
<link rel="canonical" href="http://site.com">
// Для второй и последующей:
<link rel="prev" href="http://site.com">
<link rel="next" href="http://site.com/page/3">
<link rel="canonical" href="http://site.com">
Запрет индексации в файле Robots.txt
Файл robots.txt — это своеобразная инструкция по индексации для поисковиков. Она подойдёт, чтобы запретить индексацию служебных страниц и дублей.
Для этого нужно воспользоваться директивой Disallow, которая запрещает поисковому роботу индексацию.
Disallow: /dir/ – директория dir запрещена для индексации Disallow: /dir – директория dir и все вложенные документы запрещены для индексации Disallow: *XXX – все страницы, в URL которых встречается набор символов XXX, запрещены для индексации.
Внимательно следите за тем какие директивы вы прописываете в robots.txt. При некорректном написании можно заблокировать не те разделы либо вовсе закрыть сайт от поисковых систем.
При некорректном написании можно заблокировать не те разделы либо вовсе закрыть сайт от поисковых систем.
Запрет индексировать страницы действует для всех роботов. Но каждый из них реагирует на директиву Disallow по-разному: Яндекс со временем удалит из индекса запрещенные страницы, а Google может проигнорировать правило, если на данный документ ведут ссылки..
Вывод
Дублирующиеся h2, title, description, а также некоторые части контента вроде отзывов и комментариев очень нежелательны и осложняют продвижение сайта. Поэтому обязательно проверяйте ресурс на дубликаты, как сгенерированные, так и смысловые и применяйте описанные в статье методы для их устранения.
что такое, как найти и удалить с сайта
Всем, привет! Дубли страниц на сайтах – одна из серьезных и к сожалению, весьма распространенных проблем. Из-за появления в интернете повторяющихся страниц и одинакового контента, возрастает нагрузка на сервера поисковых машин.
Содержание
- Как удалить дубли страниц и что это такое
- Причины возникновения дублей веб-страниц
- Способы обнаружения дублей и удаления на сайта
- Онлайн-сервис поиска дублей, битых ссылок и прочего
- Trash Duplicate and 301 Redirect для WordPress
- Поиск и удаление дублей в Яндекс.Вебмастере
- Заключение
Как удалить дубли страниц и что это такое
Естественно, поисковые компании не хотят платить лишних денег за обработку одной и той же информации два, а то и несколько раз. Поэтому сайты, имеющие дубли страниц и дублированный контент, в случае их обнаружения поисковыми системами (что часто и бывает) подвергаются различным санкциям.
В общем плане считается, что сайты с дублями, с точки зрения поисковых систем, являются менее информационно ценными и полезными для людей. Соответственно, снижаются перспективы успешного продвижения в ТОП10 и привлечения хорошего трафика.
Кроме того, поисковые алгоритмы все еще не абсолютно совершенны. Зачастую в результате канонической (основной) посадочной страницы поисковые роботы выбирают дубль, случайно оказавшийся первым в поле внимания.
Зачастую в результате канонической (основной) посадочной страницы поисковые роботы выбирают дубль, случайно оказавшийся первым в поле внимания.
В результате ошибочного назначения канонической страницы ресурс требует ссылочную массу, ухудшается поисковое продвижение. Потенциальные клиенты попадают из поиска не на сервисную или продающую страницу, а на дубль и это приводит к снижению качества продаж.
Большое число одинаковых страниц увеличивает потребление программно-аппаратного ресурса на сервере хостинг-провайдера, из-за чего нормальная работа сайта оказывается затруднена. В этом случае дубли могут привести к необходимости переходить на более дорогой тариф хостинговых услуг.
Неопрятности, возникающие из-за появления дублей на сайте, можно еще долго перечислять. Важно разобраться с вопросом – как найти и удалить дубли страниц практически?
Причины возникновения дублей веб-страниц
Приводит к появлению одинаковых или очень похожих веб-страниц могут как ошибки человеческого фактора, так и технические проблемы.
- Баги систем управления контентом.
- Недоработки плагинов.
- Ошибки в работе систем автоматизации SEO-оптимизации динамических сайтов.
Больше всего нареканий со стороны веб-мастеров в отношении дублирования к самой популярной в мире CMS WordPress. В частности, при использовании функции пагинации на сайтах, движок Вордпресс оформляет страниц так, что с точки зрения поисковых алгоритмов они выглядят как дубли.
Опытные блогеры и веб-разработчики время от времени публикуют статьи, в которых рассказывается, как устранить проблему создания дублирующих страниц и контента в том или ином плагине.
Однако решить проблему дублирования для абсолютно всех плагинов Вордпресс нереально – слишком много и часто создаются расширения и дополнения для этой самой распространенной системы управления сайтами. Зачастую плагины разрабатываются независимыми программистами, а исходный код дополнения не публикуется в открытом доступе.
В итоге, задачу найти и удалить дубли на сайте приходится решать вручную либо при помощи различных SEO-приложений и онлайн-сервисов.
Способы обнаружения дублей и удаления на сайта
Для масштабных интернет-ресурсов с тысячами страниц основная задача – максимально автоматизировать процесс и избавиться от ручного просмотра всех разделов ресурса в поисках повторений.
Следует учитывать и то, что для поисковых роботов-индексаторов дублями будут являться не полные клоны (реплики) веб-страниц, но повторяющиеся мета-теги Title, Description, совпадающие фрагменты текста (низкая уникальность), похожие URL-адреса. Как вы понимаете, если все эти параметры проверять вручную – на это уйдет слишком много времени, которого веб-мастерам и администраторам сайтов и так всегда не хватает.
Поэтому чтобы найти дублированные элементы используется специальное программное обеспечение.
- Онлайн-анализаторы, иногда отдельные инструменты в составе комплексных SEO-сервисов.
- Устанавливаемое на компьютер программное обеспечение. Возможны варианты поиска дублей в онлайн-режиме, с запросом данных непосредственно на сервере хостинг-провайдера либо офлайн-приложения, для которых файлы сайта необходимо предварительно скопировать на локальный диск компьютера.
 Возможны варианты поиска дублей в онлайн-режиме, с запросом данных непосредственно на сервере хостинг-провайдера либо офлайн-приложения, для которых файлы сайта необходимо предварительно скопировать на локальный диск компьютера.
Возможны варианты поиска дублей в онлайн-режиме, с запросом данных непосредственно на сервере хостинг-провайдера либо офлайн-приложения, для которых файлы сайта необходимо предварительно скопировать на локальный диск компьютера.Здесь можно упомянуть качественный софт от авторитетного американского SEO-блогера и цифрового антрепренера Нила Пателя (Neil Patel) приложение для анализа сайтов «Screaming Frog SEO Spider».
- Плагины для систем управления контентом. В частности, для CMS WordPress разработан плагин «Trash Duplicate».
- Профессиональные конструкторы сайтов обычно имеют встроенный SEO-модуль, с помощью которого можно провести комплексное тестирование (аудит) сайта на предмет поиска различного рода ошибок. В том числе найти и удалить дубли. Например, такой модуль для комплексного тестирования и автоматизации процесса исправления ошибок имеется в конструкторе сайтов Serif WebPlus.
- Инструменты для веб-мастеров, предоставляемый поисковыми компаниями – Яндекс. Вебмастер или Google Console (ранее сервис назывался Google Webmaster Tools).
- SEO-расширения и дополнения, плагины, устанавливаемые в веб-браузерах.
 Вебмастер или Google Console (ранее сервис назывался Google Webmaster Tools).
Вебмастер или Google Console (ранее сервис назывался Google Webmaster Tools).Сторонние SEO-сервисы и приложения могут только находить дублирования на сайте, но не имеют возможностей их удалять, поскольку для редактирования сайта требуются права администратора. После составления списка адресов дублей администратору предстоит вручную заняться редактированием сайта и удалением дублированный.
В этом смысле более удобны в работе устанавливаемые в CMS плагины и SEO-модули в составе инструментов конструкторов сайтов. В этих случаях поиск и уничтожение дублей может происходить «одним кликом».
Чтобы наглядно разобраться, как осуществляется проверка сайта на наличие дублей, можно рассмотреть некоторые из упомянутых в списке инструментов отдельно.
Онлайн-сервис поиска дублей, битых ссылок и прочего
Интерфейс сервиса www.siteliner.com (сайт закрыт) на английском, поэтому для удобства воспользуемся Google-переводчиком.![]() Все очень просто:
Все очень просто:
- Вставляем тестируемый домен в поле поиска и нажимаем кнопку «Go».
- Ждем пока закончится процесс сканирования и анализа.
- Получаем результат теста.
Результаты исследования оформлены в виде таблицы.
В таблице указано количество сходных страниц, процент сходства, URL-адреса дублей. Полученные данные можно импортировать в различные форматы документов и скачать на компьютер для дальнейшего подробного рассмотрения.
Дается вывод относительно текущего состояния ресурса:
Состояние неплохое – если в среднем по всемирной сети сайты имеют около 14% дублирования, то наш испытуемый ресурс – всего 5%.
Кликнув по ссылке на станицу можно изучить подробности, что именно и где повторяется.
Сервис условно-бесплатный, без подписки доступно для анализа 250 веб-страниц. Для расширения возможностей необходимо зарегистрироваться и оплатить тариф Siteliner Premium.

Дополнительно сервис находит битые (неработающие, ведущие на несуществующие страницы) гиперссылки. Веб-страницы и контент, запрещенные к индексации при помощи тега Noindex и указанные в файле Robots.txt при сканировании пропускаются.
Trash Duplicate and 301 Redirect для WordPress
SEO-дополнение для движка WordPress, с помощью которого можно автоматизировать следующие задачи:
- Поиск дублей страниц и контента.
- Пакетное удаление дублирований одним кликом.
- Автоматическая расстановка редиректов 301. Удаление нежелательных переадресаций.
Для установки этого плагина требуется подписка на Бизнес-тариф сервисов Вордпресс. В реальности, пресловутая «бесплатность» здесь очень ограничена и создаваемые за 5 минут сайты на WordPress годятся разве что для персонального блога с нулевой посещаемостью.
Если вы хотите по-настоящему заниматься цифровым бизнесом на сайте Powered by WordPress, в любом случае придется инвестировать в профессиональные темы[/mask_link], плагины, и прочие возможности.

Чтобы установить плагин Trash Duplicate нужно перейти в раздел «Plagins Manage».
Ввести в строку поиска название расширения и кликнуть по значку для запуска процесса инсталляции.
После установки запускается сканирование и по результатам формируется список.
Теперь можно отметить галочками нежелательные или ошибочные публикации и сразу все удалить.
Поиск и удаление дублей в Яндекс.Вебмастере
В раздел «Статистика индексации» можно посмотреть отчет о страницах, которые были по каким-то причинам исключены из поиска. В одном из столбцов таблицы указана причина отказа от включения веб-страницы в базу поисковой системы.
Часть страниц обозначена как «неканонические», а часть прямо отмечена как «дубли».
Теперь дублированные посты можно либо удалить, либо установить на них редиректы. В разделе «Инструменты» имеется возможность указать URL нежелательных публикаций и пакетом их удалить из поиска. Следует понимать, что на сайте эти страницы останутся, просто перестанут индексироваться и участвовать в поиске по запросам.
Следует понимать, что на сайте эти страницы останутся, просто перестанут индексироваться и участвовать в поиске по запросам.
Альтернативно можно указать для поисковых роботов канонические страницы при помощи атрибута rel=»canonical». Вот как эта процедура описана в Помощи к Яндекс.Вебмастеру:
Исследуемый сайт у нас как раз на WordPress и выше мы рассмотрели, как найти и удалить дубли страниц онлайн при помощи инструментов, предоставленных поисковой системой.
Заключение
Как видите, возможностей и способов найти и удалить дубли страниц онлайн на сайте в WordPress существует много. Конкретный выбор инструментов зависит от особенностей интернет-ресурса и предпочтений веб-мастера.
Наиболее удобные возможности для выявления и удаления дублей страниц, имеются в функционале профессиональных конструкторов сайтов, где действительно можно решить проблему дублей «одним кликом».
А на этом я буду закруглятся. А вы как ищите и удаляете дубли страниц у себя на сайте? Напишите своё решение проблемы в комментариях. И конечно, если хотите быть профессиональным веб-мастером, обязательно подпишитесь на обновление моего блога. До встречи, друзья.
И конечно, если хотите быть профессиональным веб-мастером, обязательно подпишитесь на обновление моего блога. До встречи, друзья.
Бала ли вам статья полезной? |
Дубли страниц на сайте — как их найти и удалить? Онлайн поиск без помощи Яндекс Вебмастер
Январь 29, 2018
Основы SEO Инструкции к Labrika Негативные факторы
Что такое дубли страниц?
Дубли страниц на сайте — это грубая SEO-ошибка, которая характеризуется тем, что контент одной страницы полностью идентичен содержанию другой. Таким образом, они в точности копируют друг друга, но при этом доступны по разным URL-адресам. Это затрудняет индексирование страниц.
Самые частые причины возникновения дублей:
Не сделан редирект flhtcjd страниц, имеющих адреса с www и без www. В этом случае каждая страница сайта будет дублироваться, так как остается доступной по двум адресам, например:
http://www. site.ru/page и http://site.ru/page - полные дублиСтраницы сайта доступны по адресу со слэшем и без слэша:
http://site.ru/page/ и http://site.ru/pageТакже URL страницы может быть с .php и .html на конце либо без расширения. Как правило, это связано с особенностями cms (административной панели сайта):
http://site.ru/page.html и http://site.ru/page; http://site.ru/page.php и http://site.ru/page- Отдельно стоит выделить неполные дубли страниц. В этом случае контент на двух разных страницах не будет идентичным на 100%. Сходство и дублирование может появляться по причине того, что некоторые блоки на сайте являются сквозными — например, это может быть блок о доставке, который отображается на страницах всех товаров.
- Некоторые карточки интернет магазина со схожими товарами содержат идентичное описание, что также может рассматриваться как грубая ошибка.
- Постраничная пагинация каталога с товарами. В этом случае текст и МЕТА-теги на всех страницах одной категории могут быть одинаковыми.
 site.ru/page и http://site.ru/page - полные дубли
site.ru/page и http://site.ru/page - полные дубли В этом случае текст и МЕТА-теги на всех страницах одной категории могут быть одинаковыми.
В этом случае текст и МЕТА-теги на всех страницах одной категории могут быть одинаковыми.Как дубли влияют на ранжирование?
Дубли негативно влияют на ранжирование вашего сайта в выдаче — за наличие полных дубликатов страниц интернет-ресурс может с большой степенью вероятности подвергнуться пессимизации со стороны поисковых систем.
- Яндекс и Google очень трепетно относятся к уникальности контента на web-ресурсах. В случае, если данные на страницах дублируются, они признаются неуникальными. За это на сайт могут быть наложены санкции.
- Наличие большого количества дублей страниц сильно усложняет процесс индексации сайта и запутывает поисковых роботов.
- Затрудняется продвижение посадочных страниц, так как поисковая система не может выбрать релевантную страницу из двух одинаковых.
- Теряется «вес» страниц, поскольку распределяется между двумя одинаковыми документами.
Подробно описывается негативное влияние дублей и методы борьбы с ними в статье Google «Консолидация повторяющихся URL»
Яндекс, в свою очередь, предлагает на эту тему видеоурок «Поисковая оптимизация сайта: ищем дубли страниц», где разъясняется терминология и способы решения проблемы.
Как обнаружить дубли у себя на сайте?
С поиском дублей могут возникнуть трудности не только у обладателей больших web-ресурсов, но и у владельцев совсем небольших сайтов, так как некоторые дубли, возникающие из-за особенностей и ошибок CMS, очень сложно обнаружить. Быстро и без лишних трудозатрат найти дубли страниц можно с помощью онлайн сервиса Labrika. Для этого нужно просто провести анализ вашего проекта и получить отчет с результатами проверки. соответствующий отчет. Находится он в подразделе «Похожие страницы» раздела «SEO-аудит» в левом боковом меню:
В отчете вы можете увидеть следующую информацию:
- Страница сайта, которая имеет дубль.
- Дубль этой страницы
- Процент схожести страниц. Благодаря этому проценту вы сможете определить, является ли дубль страницы полным.
Получив данные из отчета, вы сможете сэкономить время и сразу начать устранять эти ошибки.
Как устранить дубли на сайте?
Важно в первую очередь установить характер дубля и уже после этого выбирать способ его устранения.
- Если копий на сайте небольшое количество и их происхождение связано с ошибками CMS (допустим, страница доступна по адресам
http://site.ru/category/tovarиhttp://site.ru/tovar, то самым простым методом решения проблемы будет следующий. Дубль необходимо запретить для индексации поисковых систем вручную в файле robots.txt помощью директивы Disallow, или указать информацию о каноничных страницах с помощью rel canonical (также см. информацию о robots.txt от Google). Затем воспользоваться формой удаления URL из индекса в Яндекс.Вебмастер — https://webmaster.yandex.ru/tools/del-url/ и инструментом аналогичного назначения в Google Search Console — https://www.google.com/webmasters/tools/url-removal. Подробнее про использование инструмента от Google вы можете прочитать здесь. - Если появление дубликатов носит системный характер и связано с такими ошибками, как, например, несклеенный домен (страница доступна по адресу с www и без www), то в таком случае необходимо выбрать главное зеркало (например, адрес сайта без www), воспользоваться командой 301 redirect (перенаправление со страниц с www на страницы без них), которая прописывается в специальном файле htaccess.
- В случае, если вы имеете дело с постраничной пагинацией товаров одной категории, Яндекс советует использовать атрибут rel=»canonical». Более подробно о применении этого атрибута на страницах с пагинацией вы можете прочитать в статье Блога Яндекс «Несколько советов интернет-магазинам по настройкам индексирования».

Читать дальше подобные статьи
- Канонические URL. Руководство по использованию атрибута rel = Canonical
- Как правильно использовать атрибут rel=»canonical»? Канонические страницы на сайте
- Настроить редирект
- Как настроить страницу с ошибкой 404?
- Релевантность. Карта релевантных страниц
Online SEO-инструменты для продвижения сайтов
Проверьте свой сайт и сайты конкурентов на 205 факторов поисковых систем.

Как проверить дубли страниц на сайте
Дубли страниц на сайте могут возникать автоматически, а могут появляться из-за человеческого фактора. В любом случае дубль негативно сказывается на ранжировании сайта. Поэтому важно на моменте разработки убедиться, что дублей нет, или настроить имеющиеся так, чтобы они не индексировались как отдельные страницы с таким же контентом. В статье рассказываем, как это сделать.
Что такое дубли страниц и какие они могут быть
Дубли страниц — это любые страницы сайта, которые по содержанию копируют другую. Например, если вы заходите на страницу товара в интернет-магазине, но выбираете иной цвет одежды, и вас перенаправляют на другую страницу. Сами урлы изменяются незначительно — у них меняется набор символов. Также изображения разные, хоть товар один и тот же, но разного цвета. Текст к товару идентичен, но он скрыт от пользователя, пока он его не откроет.
Вот так выглядит это в реальности — товар магазина Sela разных цветов:
По сути, страницы одинаковые, и они дублирующиеся.![]() Если бы вебмастер не позаботился о сокрытии текста, изменении картинок, то тогда эти страницы были бы неявными дублями. То есть это дубли, но их отредактировали так, чтобы для роботов они выглядели уникально.
Если бы вебмастер не позаботился о сокрытии текста, изменении картинок, то тогда эти страницы были бы неявными дублями. То есть это дубли, но их отредактировали так, чтобы для роботов они выглядели уникально.
И подобных примеров много — давайте разберем самые частые из них:
- страница доступна под разными протоколами — есть страница для https:/ и для http:/;
- страница для www и без www — то есть пользователь попадает по этим адресам на одну страницу, но их всего две;
- со слешем и без слеша — если к урлу добавить слеш, откроется та же самая страница, но это будет дубль;
- один товар доступен по разным адресам — например, в одном урле есть название товара, в другом к нему добавили и название категории, но при этом открывается один и тот же товар;
- страницы с GET-параметрами — это когда есть один вариант урла страницы, а также такая же страница по адресу типа www.что-то.ru/news?hfkznsm;
- страницы версии для печати тоже копируют контент и доступны по тому же адресу, что и оригинал.

Это основные виды явных дублей, но они могут быть и неявными. Например, если в разделе статей вы открываете доступ к комментариям. И каждый новый комментарий или ответ на него доступен почти по такому же адресу, что и страницы со статьей, но с добавлением номера или GET-параметров.
Типичный пример — это dtf, где часто можно увидеть древовидные комментарии. Также дублями могут быть страницы одного товара, которые доступны по разным адресам. Под это подходит наш пример с одеждой в Sela — если бы не настройка вебмастера, то страницы с разными цветами товаров дублировали бы оригинал. Другой вариант — это страницы пагинации, когда перечисляют пул товаров. И каждая последующая страница немного меняет свой урл — появляется дополнение в виде порядкового номера или категории товара. Но их контент остается неизменным.
Причины появления дублей — это ошибка вебмастера, автоматическое появление в зависимости от движка, ошибки в директивах robot. txt или при настройке редиректов. Поэтому пока вы находитесь на этапе разработки сайта, важно проверить все эти причины.
txt или при настройке редиректов. Поэтому пока вы находитесь на этапе разработки сайта, важно проверить все эти причины.
Почему нужно работать с дублями страниц
Хоть и стало понятней, почему эти дубли появляются, до сих неясно, зачем от них избавляться. Давайте рассмотрим, почему дубли негативно влияют на сайт.
- Поисковик индексирует страницу-оригинал неправильно — предположим, что у вас два урла, которые приводят пользователя на одну страницу. Вы продвигаете один из них, и все вроде хорошо. Но потом поисковик находит дубль и индексирует его, но этот урл не продвигается, поэтому и охватов получает меньше.
- Индексация длится слишком долго — как правило, поисковый робот индексирует страницы сайта не так долго. Но если дублей много, индексация идет дольше — поисковик просто не успевает за определенное время добраться до вашего контента.
- Ограничения со стороны поисковой системы — хоть дубли не нарушают никаких правил, поисковый робот может подумать, что вы специально их создаете. Тогда органическое продвижение сайта замедляется. Это происходит, если у вас есть дубли, и вы с ними ничего не делаете.
- Сложности в устранении — когда с дублями не работают, со временем их число может расти. Тогда-то и придется на их устранение потратить огромное время и ресурсы.
 Тогда органическое продвижение сайта замедляется. Это происходит, если у вас есть дубли, и вы с ними ничего не делаете.
Тогда органическое продвижение сайта замедляется. Это происходит, если у вас есть дубли, и вы с ними ничего не делаете.То есть основная причина в том, что дубли проблемны, — это плохое ранжирование сайта поисковой системой.
Как выявить дубли страниц сайта
Чтобы выявить дубль страницы, необязательно вручную сидеть и искать их — это довольно энергозатратно и долго. Но такой вариант все равно присутствует, если вы знаете, как искать и не можете использовать другие способы. Если не знаете, мы на всякий случай подскажем — достаточно в поисковую строку ввести команду «site: {домен} inurl1: {часть урла}». Вместо части урла нужно указать тот, по которому, вероятно, есть дубль. Например, если это GET-параметры, то можно попробовать ввести знак вопроса — именно по такой логике создаются урлы GET-параметров. Или введите слово page и номер — подойдет для поиска страниц пагинации.
Или введите слово page и номер — подойдет для поиска страниц пагинации.
Есть вероятность, что вы просто не введете нужную часть урла. То есть дубль создается нетипичный — это будет просто набор рандомных цифр или слов. В этих ситуациях можно использовать другие способы поиска дублей — всего их три.
Через Яндекс.Вебмастер. Обычно в первую очередь дубли находит именно поисковый робот, и он может об этом сообщить. Достаточно зайти в Яндекс.Вебмастер и пройти в раздел диагностики сайта. Всю информацию по ошибкам система загрузит в раздел Индексирования, «Страницы в поиске» — чтобы вся информация была перед глазами во время работы, можно загрузить таблицу с урлами в формате XLS или CSV.
Google Search Console. В вебмастере Google тоже можно искать дубли — это необходимо, ведь та информация, что вы нашли в Яндекс. Вебмастере касается только поисковика Яндекса. Чтобы узнать о дублях, которые отображаются в Google, нужна Google Search Console — просто зайдите в раздел «Вид в поиске» и потом «Оптимизация HTML». Там и покажут все дубли страниц по заголовкам и мета-описаниям, а также битые ссылки.
Вебмастере касается только поисковика Яндекса. Чтобы узнать о дублях, которые отображаются в Google, нужна Google Search Console — просто зайдите в раздел «Вид в поиске» и потом «Оптимизация HTML». Там и покажут все дубли страниц по заголовкам и мета-описаниям, а также битые ссылки.
Бесплатный митап для арбитражников в Москве! Регистрируйся и успевай забрать билет!
Использовать парсеры или программы. Можно автоматизировать процесс поиска — даже если вы загружаете таблицу через Вебмастер, искать-то придется все равно вручную, хоть и в списке. Поэтому можно использовать различные парсеры и программы, которые полностью автоматизируют процесс.
PromoPult — позволяет анализировать все данные урлов из Вебмастера. Мы уже сказали, что придется самостоятельно идти по списку таблицы и проверять дубли. Чтобы этого не делать, можно загрузить готовую таблицу в PromoPult и начать поиск дублей. Также сервис позволяет проанализировать данные не только из Яндекса, но из Google — это поможет понять, какие урлы дублируются и в каких поисковых системах. Так легче и подобрать сам способ настройки этих страниц. Кроме того, на сервисе можно и заказать услугу по аудиту сайта от специалистов — они сами подобьют информацию по дублям и в целом по оптимизации.
Так легче и подобрать сам способ настройки этих страниц. Кроме того, на сервисе можно и заказать услугу по аудиту сайта от специалистов — они сами подобьют информацию по дублям и в целом по оптимизации.
Овнеры магазинов ФБ акков про свой бизнес и тренды в арбитраже. ФБ аккаунты для арбитража трафика
Apollon — это полноценный онлайн-парсер, который быстро и бесплатно найдет все дублированные страницы. Можно выгрузить таблицу с Вебмастера, скопировать до пяти ссылок оттуда и вставить в поле на сайте. После обработки запроса перед вами откроется таблица со страницами и адресами. Если адрес один и тот же, то вы нашли дубль — осталось решить, что с ним делать.
Seoto — сервис находит все ошибки, которые мешают продвижению сайта. В их числе не только дубли страниц, но и поиск всех битых ссылок, анализ структуры на всех страницах сайта, расчет веса страниц, а также анализ данных из Вебмастера. То есть платформа дает пул инструментов, которые смогут решить ваши проблемы с оптимизацией и улучшить сайт визуально и технически.
То есть платформа дает пул инструментов, которые смогут решить ваши проблемы с оптимизацией и улучшить сайт визуально и технически.
Siteliner — бесплатный онлайн-сервис, который помогает найти быстро все битые ссылки и дублированные страницы. Но есть ограничение — бесплатно только до 250 страниц.
ScreamingFrog — это программа для компьютера, которая является частично бесплатно. Некоторые про-функции нужно оплачивать. Принцип работы программы простой — достаточно вбить нужный сайт и начать его анализ. Если ваш сайт действительно большой или у вас несколько сайтов, то понадобится про-версия — утилита может сканировать бесплатно только до 500 ссылок.
Xenu — это полностью бесплатная программа, причем она анализирует сайты, которые Яндекс еще не проиндексировал. Даже если создать сайт и сразу же проверить его через программу, она все равно соберет все ошибки и дубли страниц — то есть не нужны данные из инструментов вебмастеров. Весь поиск дублей происходит через мета-описания и заголовки страниц.
Весь поиск дублей происходит через мета-описания и заголовки страниц.
Как избавиться от неявных и явных дублей
Мы выяснили, как можно обнаружить все дубли страниц. Теперь давайте разбираться, что с ними делать. Скажем сразу — это зависит от вида вашего дубля.
Если проблема возникла из-за наличия или отсутствия слешей в урле. В этом случае можно настроить редирект 301 — он будет перенаправлять юзеров с дубля на целевую страницу. Стандартную команду нужно добавить в файл .htaccess — в ней будет такое содержание:
Redirect 301 /урл, с которого идет перенаправление
http://доменное имя/новый урл, на который нужно перенаправить
Если нужно сделать редирект с домена без WWW на домен с WWW. Для этого также используют редирект 301 — только нужно ввести следующую команду для протокола http:
Успей зарегистрироваться на бесплатный митап в Москве от Партнеркина! Тебя ждут нетворкинг, крутейшие спикеры и подарки от спонсоров 🔥
RewriteCond %{HTTP_HOST} ^домен\. (.*)$ http://домен.ru/$1
(.*)$ http://домен.ru/$1
[R=301, L]
Запрет на индексацию дублей в файле robot.txt. Способ самый простой — нужно просто запретить индексирование страницы-дубля для поискового робота, чтобы он игнорировал адрес. Для этого в файл нужно добавить следующее содержание:
User-agent: __
Disallow: /ваш урл, который не нужно индексировать
Если у вас несколько страниц с товарами, то есть страницы пагинации. В таком случае можно в коде обозначить каноническую страницу — то есть «материнскую». Для этого в коде канонической страницы вбиваем в теге & It;link& + rel=canonical href=href=”адрес канонической страницы”>адрес канонической страницы/>. Теперь все дочерние страницы будут ссылаться на каноническую — они не будут считаться дублями.
Чтобы не индексировать страницу и не переходить/переходить по ссылкам. Для этой команды можно ввести специальный мета-тег на страницу-дубль. Если ввести мета-тег & It;meta name=robots content=noindex, nofollow& qt, тогда робот не будет индексировать страницу и допускать переход по ссылкам на нее. Если ввести мета-тег & It;meta name=robots content=noindex, follow& qt, то страница не будет индексироваться, однако перейти на нее будет возможность.
Для этой команды можно ввести специальный мета-тег на страницу-дубль. Если ввести мета-тег & It;meta name=robots content=noindex, nofollow& qt, тогда робот не будет индексировать страницу и допускать переход по ссылкам на нее. Если ввести мета-тег & It;meta name=robots content=noindex, follow& qt, то страница не будет индексироваться, однако перейти на нее будет возможность.
О чем важно помнить после всех настроек и проверок
Если вы исправили проблему с дублями, и кажется, что все хорошо — все равно убедитесь в этом. Хорошо, если вы специалист и можете самостоятельно выявлять проблемы с оптимизацией. Тогда достаточно сделать повторную проверку сайта.
Но если вы еще новичок или просто делали сайт по заказу, и сейчас вам необходима профессиональная помощь, то проще всего прогнать сайт через сервисы и программы проверок и анализа. В других случаях — можно заказать аудит от специалиста. В этом больше преимуществ, ведь вебмастер сможет полностью и точно проанализировать настройки и оптимизацию, а также исправить проблемы.
В этом больше преимуществ, ведь вебмастер сможет полностью и точно проанализировать настройки и оптимизацию, а также исправить проблемы.
Главное правило — проверять эти данные регулярно, ведь может быть так, что движок сам будет создавать дубли страниц, а вы о них даже не узнаете. Зато пропадет органический трафик.
Какие еще могут быть проблемы с технической оптимизацией сайта
Дубли влияют на ранжирование сайта, но они — не единственная возможная проблема. Мы разберем еще несколько ошибок, которые могут влиять на продвижение в поисковике:
- Отсутствие файла robot.txt — это частая проблема среди новичков. Если у сайта нет этого файла, то возникают проблемы с индексацией — поисковый робот просто не видит этого файла и проверяет все страницы подряд, в том числе и служебные. Поэтому важно проверить наличие этого файла — просто введите в поисковую строку домен/robot.txt. Если страница открылась, то файл в наличии.
- Нет страницы 404 — это страница, которая всплывает у пользователя при проблемах с вводом домена. Смысл этой страницы в том, что она перенаправляет пользователя на каноническую. Так трафик теряется меньше. Если страницы ошибки нет, то пользователь может просто покинуть ресурс.
Знаешь, кто делает лучшие митапы для арбитражников? Партнеркин! Успей забрать свой бесплатный билет!
- Отсутствие микроразметки — эта деталь необязательна, но она вызывает больше доверия у робота. Кроме того, это позволяет делать прикольные сниппеты в соцсетях, а также органично смотреться в поиске. Например, для многих рецептов делают микроразметки — при их поиске робот выбивает микроразметку с началом рецепта в отдельный блок, что привлекает внимание пользователей лучше.
- Проблемы с прогрузкой сайта — не секрет, что сайты иногда получаются очень тяжелыми. Из-за габаритности они дольше грузятся и могут погружаться некорректно. Лучше заранее это проверить через сервисы вроде Google Pagespeed Insights и увеличить скорость.
- Отсутствие протокола HTTPS — большинство пользователей уверены, что этот протокол равно безопасный сайт. Поэтому можно потерять часть трафика, если его не добавить — в браузерной строке просто не будет пометки безопасности, и пользователи могут отсеяться.
 Лучше заранее это проверить через сервисы вроде Google Pagespeed Insights и увеличить скорость.
Лучше заранее это проверить через сервисы вроде Google Pagespeed Insights и увеличить скорость.Вывод
Дубли страниц — не критично, но важно о них позаботиться, чтобы с ранжированием не было проблем. Для поиска дублей можно использовать различные сервисы и программы — о них рассказали в статье. Способы решения проблемы зависят от того, что это за дубль, — иногда достаточно настроить редирект, но в других случаях лучше просто запретить роботу считывать и индексировать страницу. После решения проблемы с дублями страниц проверяйте их появление регулярно, а также заботьтесь в целом о качестве оптимизации.
А вам приходилось работать с дублями?
0 голосов
Нет Да, надоело уже
Как проверить большое количество веб-страниц на наличие дублирующегося контента
Проверка веб-страниц на дублированный контент — один из важнейших этапов технического аудита веб-сайта. Чем больше у вас дубликатов страниц, тем хуже SEO-показатели вашего веб-ресурса. Вы должны избавиться от повторяющегося контента, чтобы оптимизировать краулинговый бюджет и улучшить рейтинг в поисковых системах. Если вы хотите, чтобы ваш сайт процветал, вы должны свести к минимуму количество дубликатов страниц.
Чем больше у вас дубликатов страниц, тем хуже SEO-показатели вашего веб-ресурса. Вы должны избавиться от повторяющегося контента, чтобы оптимизировать краулинговый бюджет и улучшить рейтинг в поисковых системах. Если вы хотите, чтобы ваш сайт процветал, вы должны свести к минимуму количество дубликатов страниц.
Множество онлайн-проверок на плагиат позволяют проверить уникальность текста в пределах одной веб-страницы. Однако существует не так много инструментов для одновременной проверки нескольких URL-адресов на наличие дублирующегося контента. Однако это не означает, что проблема менее важна. Из-за этого рейтинг вашего сайта может сильно пострадать!
Распространенные проблемы, связанные с дублированием контента
1. Один и тот же контент появляется более чем на одном веб-адресе.
Обычно это страница с параметрами и SEF URL (удобный для поисковых систем URL) той же страницы.
- Пример:
- https://some-site.com/index. php?page=contacts
- https://some-site.com/contacts/
- https://some-site.com/index.
 php?page=contacts
php?page=contactsЭто довольно распространенная проблема. Бывает, что вебмастера забывают настроить 301 редиректы со страниц с параметрами на SEF URL.
Эту проблему можно легко решить с помощью любого поискового робота. Он может сравнивать все страницы сайта и определять два URL-адреса с одинаковыми хеш-кодами (MD5). Как только это произойдет, вам нужно будет только настроить правильное перенаправление 301 на URL-адрес SEF.
Однако иногда дублированный контент может вызвать гораздо больше проблем.
2. Почти дублированный контент.
Страницы с большим количеством перекрывающихся данных называются «почти дублирующимся содержимым» или «общим содержимым».
Пример 1
Год назад копирайтер разместил в новостном разделе интернет-магазина поздравление с Международным женским днем. Он написал 500-символьный пост о скидке 15%.
В этом году контент-менеджер просто повторно использовал этот пост вместо того, чтобы писать новый с нуля. Он лишь изменил скидку с 15% на 12% и добавил в поздравление дополнительные 50 символов.
Он лишь изменил скидку с 15% на 12% и добавил в поздравление дополнительные 50 символов.
В итоге на сайте есть две почти дублирующиеся страницы, которые идентичны на 90%. Оба они должны быть переписаны для улучшения SEO.
Несмотря на то, что эти страницы на 90% идентичны, инструменты технического аудита сочтут их разными, поскольку их URL-адреса SEF будут иметь разные контрольные суммы.
В результате трудно сказать, какая из двух веб-страниц будет ранжироваться лучше.
Однако новости очень быстро устаревают. Давайте рассмотрим куда более интересный пример.
Пример 2
Допустим, у вас есть веб-сайт или блог о еде (или любом другом увлечении, которое вас интересует).
Рано или поздно в вашем блоге появится более 100 сообщений. Однажды вы напишете статью только для того, чтобы узнать, что уже освещали эту тему три года назад. Это может произойти, даже если вы просмотрите список существующих сообщений в блоге.
Некоторые из старых страниц вашего блога могут иметь очень похожее содержание. Если некоторые из ваших сообщений идентичны на 70%, это определенно негативно повлияет на рейтинг вашего сайта.
Очевидно, что каждый копирайтер должен использовать программы проверки на плагиат для анализа своих статей. При этом каждый веб-мастер также обязан проверять уникальность нового контента перед его размещением на сайте.
Но что делать, когда нужно раскрутить сайт и быстро проверить все его веб-страницы на наличие дублирующегося контента? Возможно, в вашем блоге есть куча очень похожих статей. Даже если они были опубликованы много лет назад, они все еще могут повредить SEO-эффективности вашего сайта. Очевидно, что вы потратите массу времени, проверяя множество страниц вручную одну за другой.
BatchUniqueChecker
Именно поэтому мы создали BatchUniqueChecker — инструмент, предназначенный для массовой проверки множества страниц на уникальность.
Вот как работает BatchUniqueChecker: инструмент загружает содержимое предварительно выбранного списка URL-адресов, получает PlainText каждой страницы (ничего, кроме текста в абзацах HTML), а затем использует алгоритм Shingle для сравнения их друг с другом.
Таким образом, с помощью черепицы текстов инструмент определяет уникальность каждой страницы. С его помощью можно найти дубликаты страниц с уникальностью текстового контента 0%, а также частичные дубликаты с разной степенью уникальности текстового контента.
В настройках программы можно вручную задать размер черепицы. Опоясывающий лишай — это перекрывающиеся предложения текста, состоящие из слов фиксированной длины. Они накладываются друг на друга. Мы рекомендуем установить значение 4. Если вы проверяете большие объемы текста, установите значение 5 и выше. Установите размер черепицы 3 или 4 для анализа небольших объемов текста.
Осмысленные тексты
Помимо полнотекстового сравнения контента, в программе есть интеллектуальный алгоритм, используемый для обнаружения так называемых «осмысленных» текстов.
Другими словами, он берет определенные части содержимого из HTML-кода страницы, в частности, текст внутри тегов h2-H6, P, PRE и LI. Это позволяет отбрасывать «незначительный» контент, такой как текст из меню навигации сайта, текст из нижнего колонтитула или бокового меню.
Это позволяет отбрасывать «незначительный» контент, такой как текст из меню навигации сайта, текст из нижнего колонтитула или бокового меню.
В результате этих манипуляций вы получите только «содержательный» контент страницы, который при сравнении покажет более точные результаты уникальности с другими страницами.
Список URL для анализа можно добавить несколькими способами: вставить из буфера обмена, загрузить из текстового файла или импортировать из Sitemap.xml с диска вашего компьютера.
Программа является многопоточной, поэтому вы можете проверить сотни URL-адресов или даже больше в течение нескольких минут. Вам пришлось бы потратить целый день на проверку веб-страниц на наличие дублирующегося контента!
Таким образом, вы получаете простой инструмент для быстрой проверки уникальности контента нескольких URL-адресов, который можно активировать даже со съемного носителя.
BatchUniqueChecker предоставляется бесплатно. Он занимает всего 4 Мб и не требует установки.
Все, что вам нужно сделать, чтобы использовать его, это загрузить дистрибутив и проверить список URL-адресов, которые можно импортировать из SiteAnalyzer, бесплатного инструмента для технического аудита.
Проверка дублирующегося контента — 5 лучших онлайн-инструментов для проверки на плагиат
22 января 2020 г. Сарвеш Багла 0
Вы, как владелец/менеджер веб-сайта, знаете, что веб-сайты должны содержать оригинальный контент. Поэтому вы всегда должны стремиться к тому, чтобы страницы вашего веб-сайта не содержали плагиат. Google и другие поисковые системы могут оштрафовать ваш сайт за плагиат, а этого вы не хотите. Это наказание сведет на нет цель создания вами веб-сайта.
Есть и другая возможность: другой сайт публикует ваш контент без вашего разрешения. Да, так поступают недобросовестные интернет-маркетологи. Они видят, что ваш сайт хорошо ранжируется и получает хороший трафик. Они попытаются обогнать вас, используя ваш контент против вас. Они могут даже опередить вас в поисковых системах.
Они видят, что ваш сайт хорошо ранжируется и получает хороший трафик. Они попытаются обогнать вас, используя ваш контент против вас. Они могут даже опередить вас в поисковых системах.
1 Что такое дублированный контент?
2 5 лучших инструментов, которые помогут вам найти дублирующийся контент на веб-сайтах
Что такое дублированный контент?
Справочный центр Google Search Console сообщает: «Повторяющийся контент — это существенные блоки контента внутри или между доменами. Они либо полностью соответствуют другому контенту, либо заметно похожи».
Следует ожидать дублирования контента (как указано выше) из другого источника или сайтов электронной коммерции, которые предоставляют общие описания продуктов от поставщиков.
Когда несколько страниц веб-сайтов содержат похожий контент, это вызывает беспокойство. Это влияет на рейтинг сайта и может привести к его исчезновению из поисковой выдачи.
Поисковые системы не отображают несколько страниц с одинаковым содержанием; они отображают веб-сайт, страницы которого лучше всего соответствуют запросу зрителя. Во-вторых, если входящие ссылки ведут на несколько страниц с дублирующимся контентом на нескольких сайтах, сила входящей ссылки ослабевает.
Существует множество вариантов поиска онлайн-проверки на плагиат . Вы можете попробовать их, так как некоторые из них бесплатны, а другие предлагают бесплатную пробную версию.
5 лучших инструментов, которые помогут вам найти повторяющийся контент на веб-сайтах
Самый простой способ найти повторяющийся контент — использовать онлайн-проверку на плагиат. В Интернете есть несколько бесплатных приложений для проверки на плагиат, и вы должны выбрать лучшее из них.
Лучшая бесплатная программа проверки на плагиат, которую вы найдете при проверке дублирующегося контента или контента на плагиат в Интернете:
Duplichecker
Самая популярная онлайн-проверка на плагиат, указанная по запросу Google, — это duplichecker. com. Он прост в использовании и бесплатен. Он предоставляет три варианта проверки на плагиат; вы можете скопировать/вставить текст или загрузить файл и, в-третьих, ввести URL-адрес веб-страницы для проверки.
com. Он прост в использовании и бесплатен. Он предоставляет три варианта проверки на плагиат; вы можете скопировать/вставить текст или загрузить файл и, в-третьих, ввести URL-адрес веб-страницы для проверки.
Выполняет глубокий поиск и предоставляет полный отчет о плагиате. Если обнаружен процент плагиата, отображается уникальный процент и соответствующий процент значения. Содержимое для проверки отображается в левой колонке, а сайты с похожим содержанием — в правой колонке. Вы также можете распечатать отчет о результатах.
Smallseotools (Проверка на плагиат)
Следующим лучшим средством проверки на плагиат является smallseotools.com/plagiarism-checker. Причина, по которой его считают вторым лучшим средством проверки на плагиат после duplichecker.com, заключается в том, что он предлагает два варианта проверки контента: копирование/вставка контента или ввод URL-адреса веб-страницы для проверки. У него есть третий вариант, который является исключенным URL-адресом. Если вы хотите, чтобы он пропускал URL-адрес при поиске плагиата, вы можете это сделать.
Если вы хотите, чтобы он пропускал URL-адрес при поиске плагиата, вы можете это сделать.
В отчете о результатах отображается плагиат и уникальный процент, а также результат в виде предложения. Предложения, признанные плагиатом, отмечены красными флажками, и есть кнопка сравнения. Нажмите на него, и он отобразит сайт, содержащий такое же предложение. Вы также можете распечатать отчет.
Детектор плагиата
Третья лучшая бесплатная онлайн-программа проверки на плагиат — plagiarismdetector.net. Это также дает вам возможность копировать/вставлять текст, исключать URL и проверять по URL. Представленные результаты имеют процентные показатели уникальности и плагиата. Введенный текст отображается в левом столбце, а предложения с плагиатом выделяются красным цветом. В правом столбце отображаются плагиатные источники. Вы можете скачать отчет.
CopyScape
Четвертое бесплатное приложение для проверки на плагиат — copyscape.com. Он выполняет поиск только путем ввода URL-адреса. Он не предлагает копировать/вставлять текст или исключать параметры URL. Это очень удобно для менеджеров веб-сайтов, которые хотят проверить, имеет ли их URL-адрес контент, похожий на контент на других веб-сайтах. В отчете о результатах отображается контент и веб-сайты с похожим контентом. Нажмите на любой из URL-адресов, и подробный отчет с выделенными красным цветом предложениями скопированного контента отобразится на другой вкладке вашего браузера.
Он не предлагает копировать/вставлять текст или исключать параметры URL. Это очень удобно для менеджеров веб-сайтов, которые хотят проверить, имеет ли их URL-адрес контент, похожий на контент на других веб-сайтах. В отчете о результатах отображается контент и веб-сайты с похожим контентом. Нажмите на любой из URL-адресов, и подробный отчет с выделенными красным цветом предложениями скопированного контента отобразится на другой вкладке вашего браузера.
Siteliner
Последней бесплатной онлайн-проверкой на плагиат в этом списке является siteliner.com. Как и Copyscape, он предлагает проверку на плагиат только по URL-адресу. Вы вводите URL-адрес, который хотите проверить, и он сканирует все страницы URL-адреса и проверяет их на плагиат.
В отчете отображаются результаты «Ваши главные проблемы» и «Ваши страницы». Под вашими страницами отображается дублированный контент, сравнение с другими результатами сайта. Нажмите на повторяющийся контент, и на новой вкладке отобразятся сайты, содержащие дублированный контент, и процентное соотношение.
Заключение
Если вы хотите быть уверены, что содержимое не украдено, не удалено и не дублировано, вам следует выполнить обычную проверку на наличие дублирующегося контента.
Большинство проблем с дублированием на веб-сайте можно устранить. По вопросам внешнего дублирования вы можете связаться с сайтом/сайтами, которые используют ваш контент без вашего разрешения. Вы также можете зарегистрироваться и получить значок DMCA. Они будут взимать плату за каждый удаленный сайт, скопировавший ваш контент. Отображение этого значка на вашем веб-сайте отпугнет парсеров и копировщиков контента.
Что делать с повторяющимся контентом (и как его обнаружить)
Амин Рахал, предприниматель и писатель. Амин является генеральным директором IronMonk , агентства цифрового маркетинга, специализирующегося на SEO и маркетинге в Regal Assets, компании IRA.
getty
Штраф за дублирование контента может разрушить ваш рейтинг SEO. Как владелец двух агентств цифрового маркетинга, одни только слова «дублированный контент» вселяли в меня страх Божий. Если вы отмечены алгоритмом Google PageRank за дублированный контент, вы можете распрощаться со своими шансами на ранжирование, пока они не будут исправлены.
Как владелец двух агентств цифрового маркетинга, одни только слова «дублированный контент» вселяли в меня страх Божий. Если вы отмечены алгоритмом Google PageRank за дублированный контент, вы можете распрощаться со своими шансами на ранжирование, пока они не будут исправлены.
Излишне говорить, что крайне важно избегать дублирования контента, если вы хотите преуспеть в своей контент-стратегии. Но иногда, даже не подозревая об этом, мы можем случайно опубликовать неоригинальный контент на наших сайтах. К счастью, если у вас есть дублированный контент, есть относительно простые решения для решения этой проблемы.
В этой статье я расскажу о своих проверенных и верных стратегиях по исправлению дублированного контента и улучшению вашего PageRank после создания неоригинального контента.
Как обнаружить дублированный контент
Во-первых, важно отметить, что не весь дублированный контент публикуется со злым умыслом. Хотя сейчас это немного устарело, бывший глава группы Google по борьбе со спамом Мэтт Каттс заметил, что в 2013 году не менее 25% интернет-контента было дублировано.![]() Очевидно, что не все это является преднамеренным плагиатом, а скорее случайным или созданным по ошибке. .
Очевидно, что не все это является преднамеренным плагиатом, а скорее случайным или созданным по ошибке. .
ДОПОЛНИТЕЛЬНО ДЛЯ ВАС
Ваш первый шаг — провести SEO-аудит с помощью инструмента исследования ключевых слов, такого как SEMrush, Moz или Ahrefs. Эти программные решения фактически делают одно и то же, и все они предлагают бесплатные пробные версии, поэтому не имеет значения, какое из них вы выберете. Запуск «Аудита сайта» с использованием этих инструментов создаст отчет, который включает URL-адреса всех ваших сильно дублированных страниц (т. е. > 5%).
Некоторые оптимизаторы с ограниченным бюджетом просто любят копировать и вставлять первое предложение своей статьи в поиск Google. Если всплывает что-то, кроме их URL, у вас, вероятно, есть дублированный материал. Однако этот метод иногда бывает неточным и может давать много ложноотрицательных результатов. Вот почему я рекомендую специальное программное обеспечение для борьбы с плагиатом, такое как:
• Duplichecker
• Plagspotter
• Smallseotools
• Plagium
• Plagiarismcheck. org
org
В начале своей карьеры я использовал службу под названием Copyscape (или Siteliner) для сканирования Интернета на предмет плагиата или дублированного контента. Как правило, мне нравится следить за тем, чтобы не более 4% материалов веб-сайта существовало где-либо еще в Интернете. Если мои результаты Copyscape превышают это, я редактирую контент, пока он не станет ниже отметки 4%.
Примечание о коротком содержании и дублированном содержании
Более короткое содержимое, содержащее меньше слов, с большей вероятностью будет иметь высокие результаты дублирования. Это особенно верно для «списков» или обзорных статей, в которых продукты упоминаются по названиям. Часто простое написание длинной формы названия продукта (например, «Сверхздоровый суперкорм для собак Джо Смита для крупных взрослых собак») раз может быть достаточно, чтобы вызвать дублирование 5% или более в статьях, состоящих всего из нескольких сотен слов.
Если вы можете обойти эту проблему, сократив названия заголовков, сделайте это. Однако часто нет способа избежать этих проблем при создании коротких статей. Если это так, не паникуйте. Я ранжировал бесчисленное количество коротких списков с относительно большим количеством дублированного контента из-за этой неизбежности, и я считаю, что алгоритм PageRank делает исключение в этих случаях.
Однако часто нет способа избежать этих проблем при создании коротких статей. Если это так, не паникуйте. Я ранжировал бесчисленное количество коротких списков с относительно большим количеством дублированного контента из-за этой неизбежности, и я считаю, что алгоритм PageRank делает исключение в этих случаях.
Очистка вашего контента
После того, как вы составили список всех URL-адресов вашего домена с содержанием, дублированным на 5% или более, вы можете начать процесс редактирования. Если у вас есть большой веб-сайт (т. е. сотни страниц), изобилующий дублированным контентом, вы можете подумать о найме агентства по написанию SEO-контента для аутсорсинга вашего редактирования. Если нет, вам придется переписать содержимое самостоятельно.
Средства проверки на плагиат выдают отчет для каждой страницы, в котором выделяется дублированный контент. Просто держите эту вкладку открытой в параллельном представлении в текстовом редакторе, вручную просматривайте каждую статью и по существу переписывайте каждый выделенный текстовый сегмент. Нет «легкого» выхода из проблемы — это должен быть тщательный рерайт.
Нет «легкого» выхода из проблемы — это должен быть тщательный рерайт.
Недостаточно просто поменять местами несколько ключевых слов синонимами. Вместо этого я всегда сразу удаляю повторяющийся текст и начинаю заново с нуля. Я стараюсь найти совершенно другую мысль, чтобы выразить ее на месте, или хотя бы переписать текст так, чтобы каждое слово было оригинальным и, следовательно, содержательно отличалось от своего предыдущего варианта. Помните, что PageRank умен и может видеть сквозь ленивые попытки переписать.
Когда вы закончите, снова запустите статью через Copyscape или проведите полный аудит сайта, используя свой инструмент исследования SEO. Если страница не отображается или возвращается с пометкой менее 4% ее содержимого, вы можете перейти к следующему фрагменту.
Защита от веб-скрейперов
Боты-скрейперы предназначены для кражи высококачественного контента с веб-сайтов и его повторной публикации. Это неэтично и обычно является нарушением закона об авторском праве.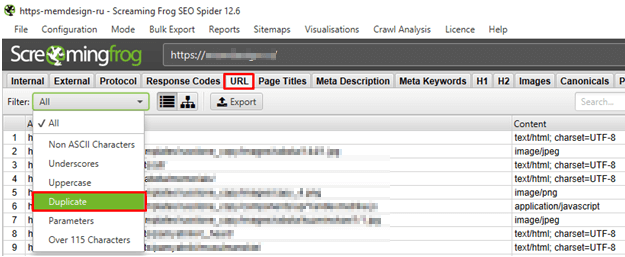 К сожалению, это также может привести к дублированию флажка на вашем собственном веб-сайте.
К сожалению, это также может привести к дублированию флажка на вашем собственном веб-сайте.
Выполнение запроса Site Audit или Copyscape может помочь определить, когда ваш веб-сайт был очищен. Тем не менее, я также рекомендую настроить оповещение Google для каждого из заголовков ваших сообщений в блоге. Таким образом, если бот очистит ваш контент и опубликует его повторно, вы получите уведомление на свой почтовый ящик. Оттуда вы можете связаться с веб-хостингом и попросить удалить контент, поскольку он представляет собой нарушение авторских прав.
Следите за своим контентом
Все мы знаем, что плагиат — это плохо, но мало кто знает, что вы можете непреднамеренно заниматься плагиатом или переиздавать контент, даже если он принадлежит вам, и получить за это наказание.
Чтобы сохранить высокую производительность SEO, убедитесь, что вы регулярно проводите аудит сайта и всегда запускаете свои статьи через Copyscape перед их публикацией. Чтобы защититься от парсеров, я также советую настроить Google Alert для каждого заголовка статьи. Если вы будете следовать этим правилам, вы избежите штрафов за дублирование, и это отразится на ваших результатах SEO.
Если вы будете следовать этим правилам, вы избежите штрафов за дублирование, и это отразится на ваших результатах SEO.
Как найти дублирующийся контент на вашем сайте и улучшить SEO
Знаете ли вы, как найти дублированный контент и исправить его?
Если нет, то следует.
Дублированный контент может вызвать головную боль SEO.
На самом деле, это может сбить с толку сканеры Google и снизить ваш рейтинг без вашего ведома.
Возможно, вы сейчас находитесь там и задаетесь вопросом, почему некоторые из ваших страниц ранжируются не так высоко, как могли бы быть. Возможно, вы целыми днями смотрели на экран компьютера налитыми кровью глазами, пытаясь понять, что происходит не так. 😣
Это может быть дублированный контент, особенно если вы никогда не проверяли его раньше (не говоря уже о слышал об этом).
Забавный факт: согласно последнему исследованию, проведенному в 2015 году, на долю дублированного контента приходится 29 % всей сети. .
.
Итак, давайте остановим эту проблему до того, как она сорвет ваш сайт с обрыва. Пришло время научиться находить повторяющийся контент и исправлять его. 🔧
Именно об этом мы и поговорим в этом руководстве.
Что такое дублированный контент (и почему он должен вас волновать)?
Дублированный контент — это то, на что он похож: точные копии или похожие версии контента, которые появляются либо на разных веб-сайтах, либо на одном и том же веб-сайте.
Рассмотрим каждый сценарий:
- Дублирование контента на отдельных сайтах — Это, друзья мои, плагиат. Если какая-то организация, кроме вас, захватит точную копию вашего контента и опубликует ее на своем веб-сайте, она украдет вашу работу и идеи.
- То же самое происходит, даже если этот человек/бренд/организация использовал вашу страницу в качестве ссылки и не перефразировал должным образом или не переписал контент своими словами. Чтобы узнать больше о плагиате (и его серьезности), ознакомьтесь с этой статьей Оксфордского университета.
- То же самое, если ситуация обратная: если вы копируете или неадекватно перефразируете чужой контент (преднамеренно или нет), вы являетесь плагиатором и создали дублированный контент.
- То же самое происходит, даже если этот человек/бренд/организация использовал вашу страницу в качестве ссылки и не перефразировал должным образом или не переписал контент своими словами. Чтобы узнать больше о плагиате (и его серьезности), ознакомьтесь с этой статьей Оксфордского университета.
- Дублированный контент на одном и том же веб-сайте — это когда очень похожий или полностью совпадающий контент появляется на нескольких страницах вашего сайта. Этот сценарий встречается гораздо чаще, особенно если ваш веб-сайт большой и содержит сотни или даже тысячи страниц контента. Однако это может случиться и с небольшими веб-сайтами, и обычно это совершенно непреднамеренно.

Почему дублирование контента является проблемой?
Когда дублированный контент является плагиатом, проблема очевидна. ❌ И наоборот, проблема с дублированием контента на вашем собственном сайте сводится к рейтингу Google.
Когда у вас есть две (или более) части контента, которые выглядят почти одинаково, Google не будет знать, какую из них ранжировать. В конце концов, эти снижают ваш рейтинг на для всех задействованных страниц, даже если их содержание просто фантастическое.
В конце концов, эти снижают ваш рейтинг на для всех задействованных страниц, даже если их содержание просто фантастическое.
А ранжирование — это то, что приносит трафик и потенциальных клиентов. Чтобы SEO-блоги работали, ваши страницы должны иметь высокий рейтинг и появляться в верхней части Google по вашим ключевым словам. Это потому что:
- Немногие пользователи выполняют поиск в Google дальше первой страницы. В среднем клики сверх этого ужасны — только 78% пользователей нажимают что-то на второй странице.
- Сравните это с позицией № 1 в Google, которая дает вам рейтинг кликов (CTR) 6%, что составляет в среднем более 5 МИЛЛИОНОВ кликов.
Чтобы SEO работало, вам нужно попасть на первую страницу. И вы не будете делать это с дублированным контентом.
Итак, давайте поговорим о том, как найти дублированный контент и исправить его с помощью двух замечательных инструментов: Copyscape (бесплатная и премиум-версии) и Siteliner.
(Кстати, каннибализация ключевых слов — это проблема SEO, связанная с дублированием контента. Узнайте об этом в моем видео ниже [старое, но полезное].)
Siteliner — это инструмент, который сканирует весь ваш веб-сайт, чтобы найти повторяющийся контент.
Для небольших веб-сайтов бесплатная версия предоставит вам много данных для работы, поскольку она будет сканировать до 250 страниц один раз в месяц. (Если у вас сайт большего размера или вы хотите получить полный доступ ко всем данным и функциям, вам нужно перейти на премиум-версию.)
Чтобы выполнить сканирование сайта, просто введите свой URL-адрес в поле поиска.
Когда ваш отчет будет готов, вы увидите много полезной информации, например, сколько страниц было проверено, какой процент вашего контента дублируется, а также статистику о том, как ваш сайт выглядит на фоне других.
Нажмите «Дублированное содержимое» в верхнем левом меню, чтобы увидеть подробную разбивку.
Когда вы просматриваете свой отчет, не беспокойтесь, если вы увидите высокие проценты совпадений вверху, особенно если это основные страницы вашего веб-сайта (страницы продуктов, страница «о нас», целевые страницы и т. д.).
Это потому, что этот инструмент покажет вам КАЖДЫЙ экземпляр дублированного контента на странице, включая меню, выдержки, нижние колонтитулы и содержимое боковой панели.
Вам следует беспокоиться о том, что большие фрагменты контента появляются на нескольких страницах.
Например, первая страница, которая не является главной страницей сайта в моем списке дублированного контента, — это блог. В нем 467 слов, соответствующих другой странице.
Чтобы проверить, является ли этот совпадающий контент частью обычного текста, повторяющегося на моем сайте, или чем-то более серьезным, я могу щелкнуть эту запись в списке, чтобы увидеть, откуда именно берется дублированный контент.![]()
Как видите, есть три разных источника:
- Контент, соответствующий другой странице моего сайта (выделено розовым цветом)
- Навигационное содержимое (выделено зеленым цветом)
- Общий контент, который обычно появляется на моем сайте (выделен серым цветом)
В этом случае я бы исследовал выделенный розовым цветом текст и определил, нужно ли мне внести какие-либо изменения на любую страницу.
Видишь, как это работает? Это довольно просто, и выполнение этого ежемесячно или ежеквартально может гарантировать, что дублированный контент никогда не понизит ваш рейтинг Google.
Кроме проблем SEO, таких как дублированный контент, что еще мешает росту вашего онлайн-бизнеса? Вы изо всех сил пытаетесь нанять, делегировать, масштабировать или управлять всеми мелкими деталями? Узнайте, где вы ошибаетесь, и получите путь к успеху на моем бесплатном обучении.
Как найти дублированный контент в Интернете с помощью Copyscape
Помимо поиска дублирующегося контента на вашем сайте, перед публикацией какой-либо части контента лучше всего проверить его через средство проверки, такое как Copyscape, особенно если вы привлекаете авторов на аутсорсинге. . Вот как ты:
. Вот как ты:
- Узнайте, на 100% ли ваш контент уникален и оригинален
- Обнаружение любых проблем с плагиатом, требующих исправления
Есть два способа сделать это с двумя версиями Copyscape — бесплатной и платной.
Кстати, Copyscape управляется теми же людьми, что и Siteliner. Это еще один надежный инструмент, который используют многие SEO-специалисты. Это также очень доступно, что делает мою главную рекомендацию проверять на плагиат и дублированный контент в Интернете.
Copyscape (бесплатная версия): проверьте опубликованный контент, чтобы найти повторяющийся контент
Бесплатная версия Copyscape позволит вам ввести только URL-адрес (т. е. уже опубликованного контента), чтобы сравнить его с тем, что есть в Интернете. Поиски ограничены.
Вот как это использовать:
Перейдите на домашнюю страницу Copyscape, введите URL-адрес контента, который вы хотите проверить, в поле поиска и нажмите «Перейти». Например, я просматриваю недавний блог Content Hacker.
На первой всплывающей странице будет список результатов, соответствующих проверяемому содержимому. Это означает, что по крайней мере часть текста дублируется.
В этом примере все результаты взяты из моего контента в Интернете, включая мою авторскую страницу на Amazon. Это совершенно нормально, поскольку я использую аналогичные формулировки в своих биографиях и профилях, чтобы рассказать свою историю.
Чтобы рассмотреть результат поближе, нажмите на синий текст. Это покажет вам, какой именно текст дублируется и где он появляется на странице.
Чтобы увидеть дублирующийся текст в действии на исходной странице, нажмите «Просмотреть соответствующий контент на исходной странице».
Это покажет вам, где именно соответствующий текст появляется на исходной странице.
Как видите, этот экземпляр дублирующегося текста не является проблемой. Это просто моя биография, которая остается неизменной на всех платформах, на которых я публикуюсь.
Если вы видите другие сайты, перечисленные в результатах, которые не связаны с вами, копните глубже и проверьте процент дублирующегося текста. Например, о совпадении 1-4% не стоит беспокоиться.
НО, если вы видите большие куски текста — 7% и выше — это красный флаг — скопированные с вашей страницы на их или наоборот, вам нужно перезаписать, STAT.
Copyscape Premium: проверка неопубликованного контента для поиска дубликатов
Я предпочитаю Copyscape Premium бесплатной версии в основном из-за того, насколько она проста и доступна.
В Премиум вы также получаете гораздо больше функций, таких как пакетный поиск, загрузка файлов и отслеживание плагиата.
Вот как его использовать для проверки содержимого до вы публикуете и убедитесь, что это оригинально ✅:
Сначала подпишитесь на Премиум, выбрав имя пользователя и пароль.
Теперь, вот где Copyscape Premium немного отличается от онлайн-инструментов, к которым вы, возможно, привыкли.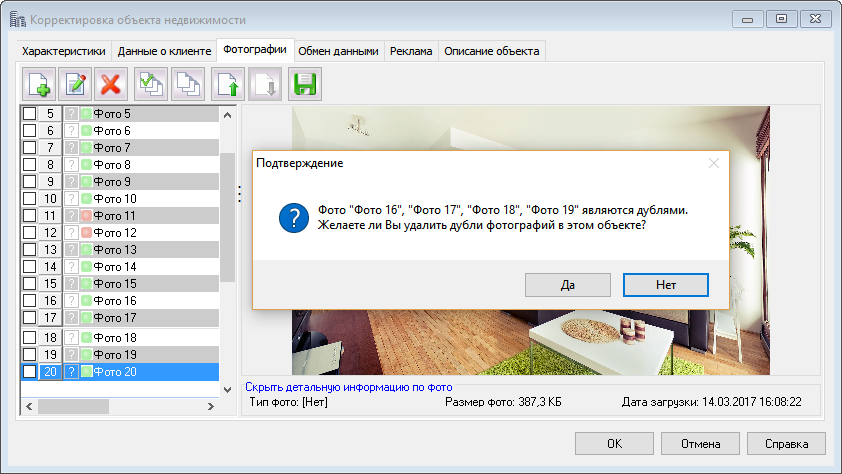 Во-первых, на этот инструмент нет подписки — вместо этого вы покупаете большую сумму кредитов, которые затем тратите на поиски.
Во-первых, на этот инструмент нет подписки — вместо этого вы покупаете большую сумму кредитов, которые затем тратите на поиски.
Цена:
- 0,03 $ за каждый поиск до 200 слов
- Дополнительные 0,01 доллара США за каждые 100 слов сверх первых 200
- + Вы можете использовать кредиты в любое время в течение 12 месяцев с момента покупки
Таким образом, если вы хотите опубликовать сообщение в блоге объемом 2000 слов через Copyscape Premium, общая стоимость составит 0,18 доллара США. (Как я уже сказал, доступным!)
Итак, покупайте столько кредитов, сколько захотите.
Затем вернитесь в Премиум-поиск.
Теперь мы можем загрузить наш неопубликованный файл контента, чтобы проверить его в Интернете. Под текстовым полем (где вы можете вставить часть текста для проверки) найдите кнопку «Выбрать файл» и нажмите ее.
Найдите место сохранения файла содержимого и откройте его. Затем нажмите кнопку «Премиум-поиск».
В этом примере я проверяю блог, который все еще находится на стадии черновика.
Страница результатов покажет вам все совпадения в Интернете с дублирующимся содержимым.
В черновик своего блога я включил фрагмент кода для встраивания видео, и это единственный текст, который отображается как совпадение в моих результатах. Это означает, что эта часть на 100% оригинальна! 💯
Однако, если вы видите какие-либо совпадения в своем контенте, которые привлекают ваше внимание, вы можете щелкнуть каждый результат, чтобы просмотреть более подробную информацию и найти процент совпадения — точно так же, как в бесплатной версии Copyscape.
И, само собой разумеется, если вы обнаружите, что случайно скопировали кого-то другого, отредактируйте свой контент, чтобы он был уникальным на 100%.
Избавьтесь от забот SEO, таких как дублированный контент: вот как
Поиск дублирующегося контента на вашем сайте и его исправление очень важны.
Но большинство владельцев бизнеса даже не осознают, что совершают эту SEO-ошибку, не говоря уже о потере рентабельности инвестиций в контент.
Я дал вам несколько инструментов и советов о том, как найти дублированный контент, но что, если вам вообще не нужно об этом беспокоиться?
Более того, что, если бы вам не нужно было беспокоиться о содержании — точка ?
Что, если вместо этого ваш контент был создан для вас с нуля, включая…
- Преданный писатель, обученный написанию текстов в Интернете и SEO
- Руководство по фирменному стилю
- Темы контента сопоставлены с календарем контента (и проверены на оригинальность)
- Управление контентом
Никаких «что, если». Это существует:
Это наша новая услуга в Content Hacker, наш механизм создания контента Done-For-You, который теперь принимает клиентов. 🚂
Если вы готовы передать контент людям, которые знают, как это сделать правильно, свяжитесь с нами сегодня, чтобы начать.
Лучшие инструменты для поиска дублирующегося контента в Интернете в 2022 году
ПРЕДУПРЕЖДЕНИЕ: Дублированный контент не приводит к наказанию вашего сайта!!
- Сотрудники Google знают, что пользователи хотят разнообразия в результатах поиска, а не одной и той же статьи снова и снова, поэтому они предпочитают объединять и показывать только одну версию.
- Компания Google фактически разработала алгоритмы, предотвращающие влияние дублированного контента на веб-мастеров. Эти алгоритмы группируют различные версии в кластер, отображается «лучший» URL-адрес в кластере, и они фактически объединяют различные сигналы (например, ссылки) со страниц в этом кластере на отображаемую. Они даже дошли до того, что сказали: «Если вы не хотите беспокоиться о сортировке дубликатов на своем сайте, вы можете вместо этого позволить нам позаботиться об этом».
- Дублирующийся контент не является основанием для принятия мер, если его целью не является манипулирование результатами поиска.
- Худшее, что может случиться из-за этой фильтрации, это то, что в результатах поиска будет показана менее желательная версия страницы.
- Google пытается определить исходный источник контента и отобразить его.
- Если кто-то без разрешения копирует ваш контент, вы можете запросить его удаление, подав запрос в соответствии с Законом об авторском праве в цифровую эпоху.
- Не блокировать доступ к дублирующемуся содержимому. Если они не смогут просканировать все версии, они не смогут консолидировать сигналы. (эти пули позаимствованы у Searchengineland).
Если контент появляется в каком-либо месте в Интернете более одного раза, он классифицируется как дублированный контент .
Если контент дублируется на одном веб-сайте или на нескольких URL-адресах, он классифицируется как дублированный контент. Даже на одном веб-сайте может быть дублированный контент, что приводит к снижению позиций SERP для важного контента.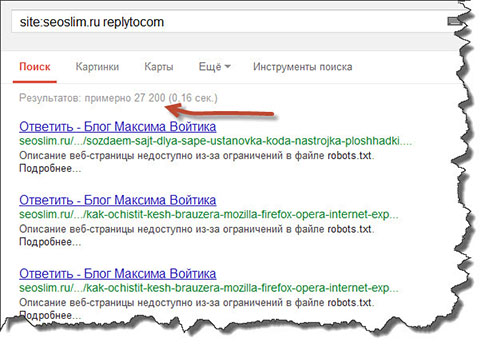
Мы не хотим использовать слово «штраф», но на самом деле, если вы дублируете свой собственный контент на нескольких страницах, это в конечном итоге заставит Google разместить определенные страницы в поисковой выдаче и исключить другие. Пенальти? Не совсем так, но похоже на это.
Простое решение состоит в том, чтобы изменить содержимое на последующих страницах, чтобы оно соответствовало конкретной странице и помечалось как исходное. Существует множество мифов о дублирующемся контенте, убедитесь, что вы знаете, что говорит об этом AHREFS и что Moz говорит о дублирующемся контенте.
Помните, что дублированный контент — это не только копия, извлеченная с другого веб-сайта, но и копия, расположенная на вашем собственном веб-сайте по нескольким URL-адресам.
Оба типа дублированного контента могут негативно повлиять на SEO веб-сайта, и хотя это относительно легко исправить, многие люди не знают о влиянии дублированного контента.
Определение дублированного контента Google довольно ясное, и для многих, ищущих способы улучшить SEO своего веб-сайта, это идеальное место для использования в качестве ориентира. Часто исправление повторяющихся заголовков, h3, копий и метаданных может привести к быстрому увеличению SEO.
Часто исправление повторяющихся заголовков, h3, копий и метаданных может привести к быстрому увеличению SEO.
Определение повторяющегося контента — это существенные области контента, которые заметно похожи или прямо совпадают с другим контентом, содержащимся в одном домене или опубликованным в нескольких доменах. Ничего страшного, если вы являетесь автором и, во-вторых, что более важно, у вас самый сильный веб-сайт! Ситуация усложняется, если кто-то опережает вас по ВАШЕМУ контенту или наоборот.
Есть способы сообщить об этом в Google. Примечание: нужно ли искать термины интернет-маркетинга, которые мы используем в этой статье?
Повторяющиеся примеры контента?Все это примеры дублированного контента, который не считается вредоносным.
- Версии страниц веб-сайта только для печати
- Страницы, которые не индексируются поисковыми системами
- Форумы для обсуждения, на которых создаются страницы, оптимизированные для Интернета и мобильных устройств
- Товары в магазине, представленные с множеством отличительных URL-адресов (при условии, что rel canonicals настроены правильно)
- Страницы, канонические по отношению к исходному контенту
- Меню, разделы нижнего колонтитула, некоторые боковые панели и другие области контента, не входящие в основную область «уникального контента» веб-сайта
- Контент с достаточным количеством геомодификаторов, модифицированных h2s, h3s и копий — даже если он извлечен из одного набора файлов
- HTTP и HTTPS
- с www и без www
- Параметры и фасетная навигация
- Идентификаторы сеанса
- Косая черта в конце
- Альтернативные версии страниц, такие как m. или страницы AMP или распечатать
- Пагинация
- Версии для страны/языка
 или страницы AMP или распечатать
или страницы AMP или распечататьЕсли на вашем веб-сайте есть разные страницы с в основном одинаковым содержанием, существует множество способов сообщить Google предпочтительный URL-адрес. Это также обычно называют канонизацией .
Контент, скопированный у автора и размещенный на веб-сайте или в блоге, также может считаться плагиатом. В этой ситуации человек, копирующий контент, делает его своим исходным контентом. Вычищенный блог или блок контента редко попадает в эту категорию.
Обычно Google может выяснить, кто автор, парсер обычно не пытается быть самозванцем, обычно он просто пытается предложить информацию своим пользователям. Опять же, проблема возникает, когда очищенный материал превосходит исходный материал.
На всякий случай просто добавьте ссылку на оригинал или, если это полный отрывок из чужого материала, просто отнесите канонический пост к первоисточнику. Как правило, привилегии очень легко получить, если только контент не дает одному веб-сайту конкурентное преимущество перед другим. Тем не менее, эту информацию чаще всего можно использовать с кредитом.
Тем не менее, эту информацию чаще всего можно использовать с кредитом.
Когда веб-разработчик копирует контент и размещает его на другом домене, чтобы украсть работы другой компании, это может в крайних случаях привести к штрафам и полному удалению из поисковых систем.
Подобная практика может разрушить пользовательский опыт и является злонамеренной, именно по этой причине Google вводит санкции, чтобы защитить пользовательский опыт и наказать любого, кто пытается использовать нечестную практику для получения трафика или повышения их SEO сайтов.
При заимствовании информации из других онлайн-источников необходимо указывать авторство. Как правило, в ситуации, когда кто-то занимается плагиатом с вашего веб-сайта и выдает себя за вас, авторство не указывается, поскольку автор совершает нарушение, которое, если его поймают, повлечет за собой наказание.
Оператор расширенного поиска Google для поиска повторяющегося контента Если вы хотите проверить, была ли информация извлечена с вашего сайта без указания авторства, просто используйте простой оператор Google, такой как intext: и включите фрагмент интересующего вас контента. о.
о.
Дополнительные операторы поиска Google, которые могут помочь вам найти дублированный контент с вашего сайта, включают: intitle:, allintitle:, inurl:, allinurl:, allintext:. Но, честно говоря, большинство людей не беспокоятся об этом — большинство огромных блогов постоянно копируются.
Хитрость в том, чтобы получить что-то от этой тактики, заключается в том, чтобы включить прочную структуру входящих ссылок, чтобы вы могли получить некоторый трафик или авторитет в таких ситуациях.
Плохо ли повторяющееся содержимое?Да? Нет? Может быть. Это действительно зависит от ситуации. Google довольно открыто говорит о том, что за дублированный контент не будет никаких реальных штрафов, поскольку в Интернете дублируется около 30%.
Что бы они сделали, просто удалили 30% контента со своих серверов? Как бы они выбрали?
Почти 30% онлайн-контента дублируется. В злонамеренных случаях это может вызвать путаницу у поисковых систем, поскольку они не знают, какая версия контента должна быть ранжирована (в зависимости от полномочий).
Если быть честными, дублирование контента на нескольких сайтах обычно связано с кражей данных, когда кто-то, даже если это было сделано невинно, украл или скопировал контент с другого веб-сайта или источника.
Существует множество законов об авторском праве и инструментов, которые можно использовать для обнаружения плагиата. Помните, что плагиат намного хуже, чем простой захват или даже перепрофилирование контента на другом веб-сайте.
Нарушение прав распространяется не только на письменное слово, но и на другие формы мультимедиа, такие как изображения и видеоконтент. Есть много мест, где можно получить бесплатный контент для использования, но большинство из них платные и/или требуют указания авторства.
Если вы скопировали или дублировали контент на своем веб-сайте, это может привести к ряду серьезных проблем.
Мало того, что это считается ленивым в современных интернет-сетях, но в некоторых случаях может создать непрофессиональный или неэтичный образ вашей компании или компании вашего клиента! Еще хуже.
Вы бы купили продукцию компании, которая сознательно ворует и копирует работу других?
Я знаю, что да, верно? Телефонные компании, кажется, грабят друг друга каждый день. Но на секунду подумайте об этом в отношении онлайн-контента.
Если вы надеетесь стать следующим авторитетом в области контента, дублировать контент не стоит. Мы не призываем избегать синдицирования чужого оригинального контента на вашем веб-сайте, мы говорим, что при этом используйте надлежащую атрибуцию. Будьте честны, когда дело доходит до размещения других материалов на вашем URL-адресе.
Где грань с гуглом? В крайнем случае скрейпинг/плагиат Google и другие поисковые системы могут вручную наложить штраф на ваш URL-адрес, что нанесет ущерб прибыльности вашей компании от органического поискового трафика.
Целью любого сайта является привлечение и информирование. Когда на вашем веб-сайте есть дублированный контент, вы теряете огромную возможность привлечь трафик на свой веб-сайт, особенно когда поисковая система не отображает ваш / URL-адрес с контентом. Это действительно риск с небольшой пользой.
Это действительно риск с небольшой пользой.
Таким образом, повторяющийся контент может быть вредным для вашего веб-сайта и вашей деятельности в Интернете.
Если вы хотите улучшить SEO, вы можете начать с обновления контента вашего веб-сайта и убедиться, что любой дублированный контент удален и заменен оригинальным и привлекательным текстом, который актуален для вашей аудитории и уникален для вашего бизнеса.
Что такое тонкий контент?Хотя цель этой статьи — рассказать о способах обнаружения дублированного контента, представляется уместным быстро осветить другую категорию контента, которая считается вредной для SEO.
Поскольку некачественный контент может быть вызван наличием дублированного контента. Узнайте больше о хороших блогах от Yoast и о том, как избежать некачественного контента.
С момента первоначального появления Google Panda и последующих обновлений того, как Google ранжирует веб-сайт; существовала одновременная тема наказания веб-сайтов с некачественным контентом.
Тонкий контент — это контент, который не представляет большой ценности для посетителя. В дальнейшем его можно определить как некачественные страницы на веб-сайте или в магазине электронной коммерции.
Примеры тонкого контента включают автоматически сгенерированный контент, дубликаты страниц и дорвеи.
Если на вашем веб-сайте есть страница, на которой пользователи не задерживаются слишком долго, или страница, которая явно отталкивает людей от вашего сайта, иногда для поисковых роботов это является индикатором того, что страница содержит малосодержательный контент.
Проще говоря, если страница не представляет никакой ценности для посетителя и отталкивает людей от вашего сайта, это значит, что в вашем содержании есть проблемы, которые вы хотите быстро решить.
Как Google измеряет малосодержание? Многое из того, что измеряет Google, автоматизировано. Когда дело доходит до измерения тонкого контента, Google использует одну конкретную метрику.
«Время до долгого клика» означает, что человек нажимает на результат на странице поиска Google, а затем некоторое время остается на целевом сайте.
Скажем, например; если вы нашли статью, которая вам понравилась, возможно, вы захотите просмотреть сайт для получения дополнительной полезной информации.
Затем, допустим, вы нажимаете на бесполезную ссылку, то есть вы возвращаетесь в Google намного быстрее, чтобы найти другой сайт, который предоставляет либо более полные, либо более полезные данные. Последний называется коротким щелчком.
Чтобы вас не оштрафовали за некачественный контент, используйте следующие указатели:
- Старайтесь избегать дублирования контента на вашем сайте
- Постарайтесь убедиться, что вы предоставляете информацию, которая имеет отношение к вашим клиентам или потенциальным клиентам
- Убедитесь, что заголовки и описания ваших страниц соответствуют тому, что на самом деле присутствует на веб-странице
- Постарайтесь, чтобы у вас было не менее 350 слов на странице
- Убедитесь, что ваш контент отвечает на любые вопросы, которые могут возникнуть у посетителя
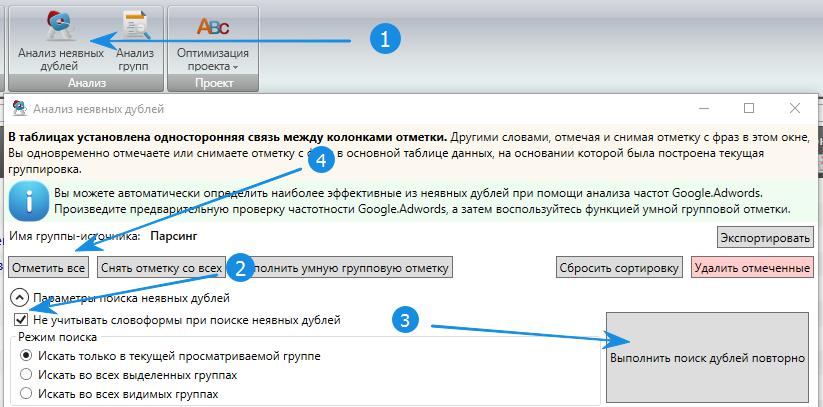 Siteliner
Siteliner Siteliner занимает первое место в нашем списке, потому что он проверяет наличие дублированного контента на сайте и точно сообщает, какой текст воспроизводится на какой странице.
Он также проверяет веб-контент на наличие плагиата и многое другое. Он очень прост в использовании; вы просто вставляете URL-адрес сайта, который хотите просмотреть, и нажимаете поиск.
Помимо этого, он также сообщает вам другую информацию, такую как время загрузки каждой страницы, количество слов на каждой странице, неработающие ссылки, перенаправления и многое другое.
Скорость сканирования зависит от размера сайта, который вы ищете, а результаты выдаются максимум через несколько минут.
Siteliner позволяет проверять области, которые могут содержать малосодержательный контент или контент, найденный по нескольким URL-адресам на вашем веб-сайте, а также позволяет просматривать самые сильные страницы.
Он имеет алгоритм, который сравнивает все страницы сайта с учетом IBL и показывает, какие страницы являются самыми сильными.
После создания отчета вы можете отправить его по электронной почте или загрузить копию полного отчета бесплатно. Бесплатная версия Siteliner ограничена одним сканированием отдельного сайта в месяц.
Однако, если вам нужно больше, цены на премиум-услуги очень разумны. Вам нужно добавить как минимум 10 долларов на баланс, а затем взимается минимальная плата за отсканированную страницу, всего 1 цент за страницу.
Siteliner предоставляется вам той же компанией, которая управляла веб-сайтом Copyscape.
2. Screaming FrogScreaming Frog сканирует сайт так же, как Google. Это позволяет пользователям обнаруживать различные проблемы с дублирующимся контентом, а также ряд других полезных функций, таких как проблемы с параметрами URL-адресов и многое другое.
Мы используем Screaming Frog Premium для проверки следующих технических проблем SEO:
- Проблемы протокола: http/https
- Коды ответов: 4xxs, 5xxs
- URI: Мы проверяем стандартизацию нашего стиля
- Заголовки страниц: отсутствуют, повторяются, длина, кратны
- Мета-описания: отсутствует, повторяется, длина, кратно
- Мета-ключевые слова: устарели
- h2s: отсутствует, повторяется, длина, кратно
- h3s: отсутствует, повторяется, длина, кратно
- Изображения: размер, замещающий текст, длина замещающего текста
- Canonicals: убедитесь, что наши канонические символы установлены
В каждый из этих разделов встроено множество функций, а также многие другие функции, которые мы не используем регулярно.
Хотя они предлагают платную услугу, также можно использовать бесплатную версию их продукта, которая будет сканировать до 500 URI.
Как только вы определитесь, какая версия вам нужна, загрузите программное обеспечение на свой компьютер. Примечание: бесплатная версия предоставляет достаточно «кредитов» для сканирования подавляющего большинства сайтов.
3. PlagspotterPlagspotter, признанный одним из крупнейших конкурентов популярного средства проверки на плагиат Copyscape, становится все популярнее, и на то есть веские причины.
Это инструмент обнаружения контента, разработанный компанией Devellar. Пользоваться Plagspotter просто, и, как и многие другие в том же пространстве, они предлагают как платные, так и бесплатные версии.
Вы просто вводите URL-адрес веб-сайта, который необходимо проверить, и содержимое анализируется. За однократный поиск не взимается плата и нет ограничений по объему возвращаемых результатов.
Copyscape, которые являются ближайшими конкурентами, ограничивают бесплатные результаты только десятью, поэтому в этом аспекте Plagspotter превосходит с большим отрывом. С точки зрения скорости результатов, он уступает многим другим доступным средствам проверки на плагиат.
Если вам нужно просканировать большой сайт, это может быть не лучший инструмент для использования прямо сейчас. При этом его пользовательский интерфейс яркий, а дизайн удобен и прост в навигации. Определенно, есть многообещающее будущее, поскольку это довольно новый продукт для рынка, и в процессе разработки обещано много новых функций.
Единственный существенный момент, на который следует обратить внимание при использовании Plagspotter, заключается в том, что он не будет проверять дублированный контент на сайте. Он будет проверять только скопированный контент на других веб-сайтах, и это в основном только проверка на плагиат.
4. iThenticate iThenticate — известный поставщик профессиональных инструментов для борьбы с плагиатом, которые известны как в академическом мире, так и в Интернете.
Их основная цель — помочь авторам, редакторам и исследователям обеспечить уникальность их работы перед публикацией. Он был разработан компанией Turnitin, которая является уважаемой компанией по проверке на плагиат для ученых, академиков и учебных заведений по всему миру.
Помимо проверки опубликованных веб-страниц, он также проверяет базу данных, содержащую более 50 миллионов документов и журналов. Он предлагает простой в использовании сервис, основанный на облаке и быстро предоставляющий результаты.
Единственным недостатком службы по сравнению с другими средствами проверки дублирующегося контента является ее стоимость. Хотя любые кредиты, которые вы покупаете, действительны в течение 12 месяцев, минимальный кредит, который вы можете добавить, составляет 100 долларов США, что покрывает только 1 документ до 25 000.
Если вы хотите проверить веб-сайт на наличие дублирующегося контента, это не лучший сервис. Однако, если у вас есть большой текстовый файл для проверки, который вы хотите опубликовать, они предлагают исключительно тщательное обслуживание, которому нет равных.
Copyscape — это имя, с которым рано или поздно сталкивается большинство людей. Их функция плагиата — это то, чем они наиболее известны, и они предлагают услугу, которая проста в использовании и предлагает ценность.
Особенно удобен для проверки контента на внешнее дублирование. Одной из лучших функций сервиса Copyscape является возможность экспорта информации в файл CSV.
У них есть дополнительная услуга под названием Copy Sentry. Это ежедневно сканирует Интернет, чтобы убедиться, что ваш контент не был скопирован или опубликован в Интернете. Если он будет найден, вы получите мгновенное уведомление с любой соответствующей информацией.
Несмотря на то, что Copyscape имеет солидную репутацию средства проверки на плагиат, он также может помочь вам найти внутренне дублированный контент на вашем собственном сайте.
Создав закрытый индекс контента, вы сможете легко узнать, есть ли репликация на сайте.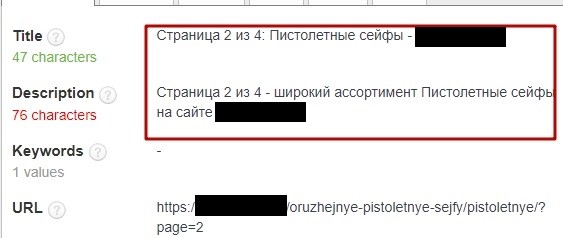 Хотя они предлагают эту услугу, их дочерняя компания Siteliner предлагает гораздо более простой способ сделать это.
Хотя они предлагают эту услугу, их дочерняя компания Siteliner предлагает гораздо более простой способ сделать это.
Copyscape взимает 3 цента за поиск до 200 слов, с дополнительной платой 1 цент за каждые 100 слов за их премиум-сервис, и вам необходимо добавить минимум 10 долларов США, чтобы начать работу.
Они предлагают бесплатную услугу, платную услугу и службу ежедневного обновления (Copysentry). Если вы хотите узнать больше о законах об авторском праве в вашей стране или о том, как бороться с кражей авторских прав, у них также есть огромный банк информации, который вы также можете просмотреть бесплатно.
Оно признано лучшим программным обеспечением для борьбы с плагиатом в мире и является частью группы Indigo Stream Technologies.
6. Moz С точки зрения поиска инструментов, которые могут помочь обнаружить внутреннее дублирование контента, Moz хорошо известен этим и многим другим. Moz в первую очередь рассматривается как SEO-инструмент с оплатой за функциональность. Тем не менее, у них есть ряд инструментов SEO и инструментов местного маркетинга, которые они предлагают на своем веб-сайте бесплатно.
Тем не менее, у них есть ряд инструментов SEO и инструментов местного маркетинга, которые они предлагают на своем веб-сайте бесплатно.
Вам нужно использовать один из платных сервисов MOZ, чтобы воспользоваться их внутренней функцией проверки дублированного контента; это можно легко найти и использовать с помощью функции MOZ Crawler.
Если вы воспользуетесь этой службой, вы обнаружите, что она не только проверяет внутренний дублированный контент, но также ищет метаданные.
Любой повторяющийся контент будет помечен как приоритетный, и с помощью этого инструмента легко найти местоположение дублирующегося контента на вашем сайте.
Это также дает вам возможность экспортировать отчет, что нравится многим людям, так как это немного упрощает решение проблем.
7. Google Search ConsoleКак и следовало ожидать, в этом списке не должно быть никого, кроме короля всех поисковых систем.
Помимо поиска проблем с дублирующимся контентом, вы также можете использовать Google Search Console для выявления проблем, которые могут быть вызваны «неполным контентом»*.
*Еще один способ, которым люди обычно называют неполноценный контент, — это страницы низкого качества, которые не приносят никакой пользы читателю. Это могут быть дорвеи, автоматизированный контент и дублированные страницы.
Есть четыре ключевых области, на которых следует сосредоточиться, если вы используете консоль поиска Google для помощи с недостаточным или дублирующимся контентом.
Параметры URL — Здесь Google сообщит вам, если у него возникнут какие-либо проблемы с индексированием или сканированием вашего веб-сайта.
Это быстрый и простой способ определить параметры URL-адреса, которые приводят к дублированию URL-адресов, которые были созданы технически.
Улучшения в HTML — Здесь Google обнаружит дублированные URL-адреса с тегами заголовков и метаописаниями.
Статус индекса — Здесь Google отобразит график трафика, охватывающий страницы в его историческом индексе. Это особенно полезно для проверки скачков вверх.
Если вы не публиковали новый контент на своем сайте, эти всплески указывают на некачественные URL-адреса и повторяющиеся URL-адреса, которые могли попасть в индекс Google.
Консоль поиска Google немного более техническая, чем другие средства проверки дублирующегося контента.
Тем не менее, для тех, кто знает, как им пользоваться, он может оказаться очень информативным и поможет вам найти источник проблем с дублированным содержимым.
8. Small SEO ToolsЭто чисто проверка на плагиат. Он быстрый и простой в использовании. Основным недостатком этого сервиса является надоедливая реклама, разбросанная по всему сайту. Если вы можете обойти это и вам нужен сайт без излишеств, который проверяет скопированный контент, небольшие инструменты SEO предлагают именно это.
Вы можете загружать файлы из облака, выбирать файл с Google Диска или Dropbox и загружать либо Docx, либо текстовый файл. Помимо этих параметров, вы можете быстро копировать и вставлять текст в поле поиска.
Это инструмент, специально проверяющий на плагиат и позволяющий выполнять поиск DocX, Text, URL и текстовых файлов.
Он предоставляет неограниченное количество бесплатных поисков после регистрации и один бесплатный поиск, если вы не хотите регистрироваться. Он не будет искать на сайте дублированный контент, но поможет вам узнать, есть ли на вашем сайте какой-либо контент, который присутствует где-либо еще в Интернете.
Как устранить проблемы с дублированным содержимымТеперь, когда вы знаете лучшие инструменты для обнаружения дублированного и скопированного содержимого на веб-сайте, вы можете приступить к исправлению ситуации.
На этом этапе важно напомнить вам, что плагиат большого количества контента, очистка/дублирование контента и некачественный контент — это разные вещи.
Скопированный или плагиатный контент Единственный способ справиться с контентом, скопированным из других мест в Интернете, — это переписать и обновить этот контент, чтобы он стал полностью уникальным.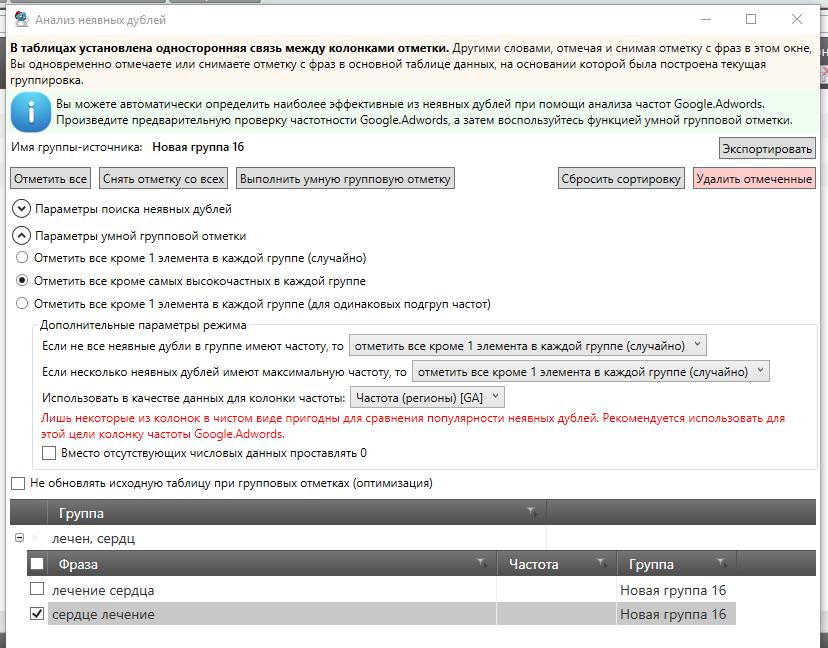 Для многих людей, которые, возможно, написали контент для своего веб-сайта несколько лет назад, регулярное обновление контента на веб-сайте всегда полезно.
Для многих людей, которые, возможно, написали контент для своего веб-сайта несколько лет назад, регулярное обновление контента на веб-сайте всегда полезно.
Однако, если содержание не является оригинальным, то первая задача, которую вам нужно сделать, это нанять профессионального копирайтера, который сделает для вас SEO-оптимизированный текст; или переписать содержание самостоятельно. Это исправление сейчас, исправьте быстро проблему.
Владельцы контента и копирайтера могут получить доступ к инструментам, которые будут автоматически искать и обнаруживать плагиат.
Таким образом, независимо от того, копируются ли изображения, видео или слова, вам необходимо убедиться, что любые их экземпляры полностью удалены с вашего веб-сайта.
Как удалить экземпляры дублированного контента на веб-сайте Если вы скопировали сообщение с другого веб-сайта, скорее всего, это не так уж и важно. Лучшей практикой является канонизация контента или добавление авторства. Если вы сделаете это в больших масштабах, это может привести к проблемам с SEO.
Если вы сделаете это в больших масштабах, это может привести к проблемам с SEO.
Создание уникального контента на собственном веб-сайте — это самый быстрый способ завоевать популярность в поисковой выдаче, при условии, что вы не пишете о контенте, не имеющем отношения к теме вашего сайта, или даже о релевантном контенте, который требует гораздо более сильного веб-сайта для ранжирования для этого контента. .
Минимальный контентМинимальный контент заставляет поисковых роботов выяснять, какую страницу ранжировать для материала. Повторяющийся контент, извлеченный с других сайтов, может вызвать это, и даже информация, которая хранится на нескольких URL-адресах в одном и том же домене. И то, и другое приводит к низкому содержанию, высокому показателю отказов и, в конечном итоге, к потере позиции в поисковой выдаче.
Ключевым моментом является сохранение контента в «областях контента» страницы высокого качества, полной формы, оригинального, уникального и всегда актуального.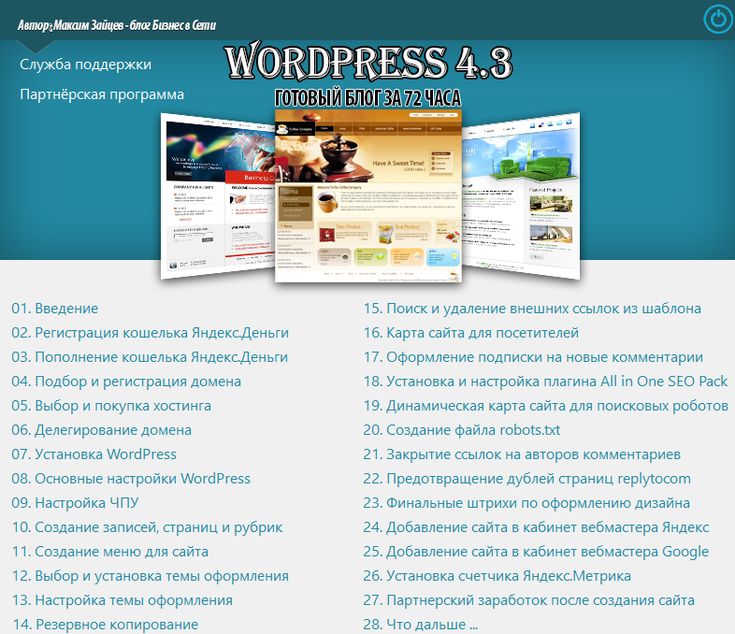 Чем больше вы сможете изменить повторяющийся контент, который находится на других сайтах и в других местах на вашем собственном сайте, тем лучше будет оптимизация вашего сайта и больше шансов, что ваш сайт будет ранжироваться в дополнительных поисковых запросах.
Чем больше вы сможете изменить повторяющийся контент, который находится на других сайтах и в других местах на вашем собственном сайте, тем лучше будет оптимизация вашего сайта и больше шансов, что ваш сайт будет ранжироваться в дополнительных поисковых запросах.
Если вы задаетесь вопросом, почему у вас есть 50-страничный веб-сайт, а поисковая консоль Google индексирует лишь некоторые из них, часто причина в этом.
Перенаправление 301Действительно эффективным способом решения проблем с дублированием контента на веб-сайте является использование перенаправления 301. Избавьтесь от этих страниц вместе и 301 перенаправьте этот старый URL-адрес на имя и улучшенный URL-адрес.
Это полностью постоянное перенаправление, которое передает сок ссылок на другую страницу. Когда вы перенаправляете с помощью 301, это не окажет негативного влияния на вашу поисковую оптимизацию, и вы не должны потерять трафик, который пришел бы по старому URL-адресу.
Иногда страница с повторяющимся содержимым является лучшим ярлыком. В этом случае переработайте эту страницу и перенаправьте URL более оригинального поста на этот, конечно же, исправьте контент на лучшем слаге.
Meta No IndexЭтот метод удаления повторяющегося контента наиболее полезен, когда вам нужно решить проблемы со страницами, индексируемыми поисковой системой. Вводится точный термин «без индекса, nofollow», и это позволяет роботам узнать, что конкретная страница не должна индексироваться поисковой системой.
Это можно сделать на отдельных страницах или в файле /robots.txt.
Canonical LinkingЭто лучший способ сообщить поисковым системам, что конкретная страница должна рассматриваться как копия указанного URL-адреса страницы, которую вы хотите оставить на своем сайте. При извлечении чужого материала используйте эту стратегию.
Если вам нужна помощь в поиске и исправлении дублирующегося контента на вашем веб-сайте или вы хотите найти лучший способ улучшить SEO, наша профессиональная команда может помочь вам быстро исправить ситуацию.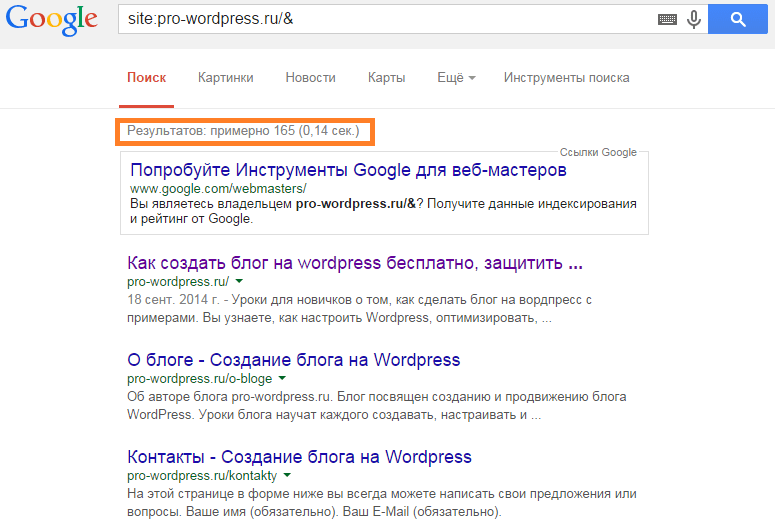 Так как многие наши предприятия зависят от эффективной поисковой оптимизации, ключевым моментом является написание вашего контента с намерением ранжироваться.
Так как многие наши предприятия зависят от эффективной поисковой оптимизации, ключевым моментом является написание вашего контента с намерением ранжироваться.
Влияет ли дублирование контента на SEO?
Именно поэтому мы составили эту статью. Продолжайте читать, чтобы узнать больше о дублирующемся контенте, о том, вредит ли дублированный контент вашему SEO, и что вы можете сделать, чтобы это исправить.
Если вы хотите поговорить со специалистом о дублирующемся содержании и поисковой оптимизации или подозреваете, что на вашем веб-сайте есть дублированный контент, вы можете связаться с нами через Интернет или связаться с нами по телефону 888-601-5359 .
Лучшее в отрасли 9Служба поддержки клиентов 1008.Net Promoter Score (NPS) — основной показатель удовлетворенности клиентов.
Клиенты WebFX набрали баллов, что на 394 % выше, чем в среднем по отрасли.
Что такое дублированный контент?
Дублированный контент — это существенные блоки идентичного или похожего контента, которые появляются в одном домене (например, на вашем веб-сайте) или в разных доменах. В большинстве случаев дублированный контент не является преднамеренным или вводящим в заблуждение, поэтому Google не наказывает за дублирование контента.
В большинстве случаев дублированный контент не является преднамеренным или вводящим в заблуждение, поэтому Google не наказывает за дублирование контента.
Как происходит дублирование контента на веб-сайте?
Дублировать контент на веб-сайте очень легко. Вот несколько наиболее распространенных причин:
| Дублирующийся контент | Пример |
| Несколько URL-адресов для одной и той же страницы | https://www.shop.com/shoes.html https://www.shop.com/shoes.html?color=blue |
| Версии страниц HTTP и HTTPS | http://www.shop.com https://www.shop.com |
| www. и без www. версии страницы | www.shop.com shop.com |
| Скопированный контент | Описание переработанного продукта от производителя Повторная публикация содержимого сайта путем парсинга |
Для перспективы подумайте о следующих примерах.
Рассмотрим веб-сайт с несколькими целевыми страницами, географически ориентированными на разные местоположения.
Создатель контента может подумать, что достаточно использовать все ту же копию и просто изменить название штата или города, на который они нацелены. И хотя это, безусловно, было бы удобно, это загромождает ваш сайт страницами, которые в основном одинаковы.
Дубликат также может существовать, если у компании несколько веб-сайтов.
Если ваша компания сочла хорошей идеей приобрести два URL-адреса и разместить идентичные сайты с целью привлечения большего трафика, у меня для вас плохие новости: если контент одинаков для обоих сайтов, это дублированный контент. Даже если компания ТАКАЯ ЖЕ компания, это не имеет значения.
Независимо от причин наличия страниц с одной и той же копией, это дублированный контент.
Почему дублированный контент на вашем веб-сайте (или даже вне его) имеет значение?
WebFX — это трастовый бизнес-партнер.

Послушайте, что сообщает HydroWorx, 236% увеличение числа органических сеансов с услугами WebFX.
Посмотрите видео-отзыв
Почему дублированный контент является проблемой SEO?
Некоторые компании задаются вопросом, почему дублированный контент вообще является проблемой, особенно если дублированный контент находится на их собственном сайте. Проблема связана с тем, что люди крадут контент из других источников и используют его как свой собственный.
Посмотрите на это так: вы тратите много времени и сил на создание своего контента. Как бы вы себя чувствовали, если бы ваши конкуренты могли безнаказанно украсть этот контент? Вас это не рассердит? Конечно!
Другая проблема с дублирующимся контентом заключается в том, что поисковая система не знает, какую страницу ранжировать. Если на вашем сайте есть две страницы с одинаковым содержанием, какую из них Google должен показывать пользователям, выполняющим поиск? Какой из них более актуален?
Не говоря уже о том, что с точки зрения Google сайт с большим количеством дублированного контента не кажется таким уж ценным. Ваш сайт выглядит тонким, что может повредить вашему рейтингу в результатах поиска. Для вашего бизнеса это означает меньше трафика, а значит, меньше лидов и продаж для вашей компании.
Ваш сайт выглядит тонким, что может повредить вашему рейтингу в результатах поиска. Для вашего бизнеса это означает меньше трафика, а значит, меньше лидов и продаж для вашей компании.
Хотя Google не наказывает дублирующийся контент, он использует дублированный контент в качестве фактора ранжирования. Вот почему ответ на вопрос «Вредит ли дублированный контент SEO?» да, и почему вам нужно исправлять дублированный контент на вашем сайте, если он у вас есть.
Есть ли штраф за дублирование контента?
Нет, Google не штрафует за дублирование контента. По крайней мере, не напрямую.
Если на вашем веб-сайте есть дублированный контент, Google использует это как сигнал. Он рассматривает этот идентичный (или почти идентичный) контент как признак того, что вашему сайту нечего предложить пользователям, когда речь идет об оригинальном и полезном контенте.
Для вашего веб-сайта это приводит к более низкому рейтингу, что влияет на трафик и доход вашего сайта.
Что может произойти, если у вас есть дублированный контент?
Если на вашем веб-сайте много дублированного контента, может произойти несколько вещей, в том числе:
- Низкий рейтинг в результатах поиска
- Недовольные пользователи, желающие узнать больше о теме, например, о продукте и его функциях
- Снижение посещаемости веб-сайта, продаж и потенциальных клиентов
Вы хотите избежать этого сценария, поэтому очень важно применять упреждающий подход к дублированию контента. Хотя на вашем сайте может быть идентичный или почти идентичный контент, вы хотите создать веб-сайт практически со всем оригинальным контентом.
Как исправить дублированный контент на вашем веб-сайте
Многие владельцы сайтов в прошлом спрашивали нас: «Как SEO влияет на дублированный контент?», так что если это то, что вам интересно, вы не одиноки. Но правда в том, что лучший способ исключить любую возможность наказания — это удалить контент.
Вот как это сделать:
Проверить все содержимое и теги
Хотя повторять некоторые слова и фразы нормально, иметь одинаковые целые блоки текста — это плохо. Потратьте время на изучение страниц вашего сайта и поиск любых экземпляров дублированного контента, а также составьте список страниц, над которыми вам нужно поработать.
Настройте переадресацию 301
Существуют определенные сигналы, которые вы можете отправить в Google, чтобы помочь ботам эффективно сканировать ваш сайт. Например, вы можете указать переадресацию 301 на страницу с таким же содержанием, как и на другой странице.
Используйте rel=»canonical»
Тег rel=»canonical» — это еще один способ исправить дублированный контент на вашем сайте.
Этот тег сообщает Google, а также другим поисковым системам, какая страница является дубликатом, а какая оригиналом. Например, если вы используете параметры UTM для отслеживания некоторых маркетинговых инициатив в Интернете, вам следует использовать этот HTML-тег.
Применить noindex
Вы также можете использовать дублированный контент и SEO с помощью тега noindex.
С помощью этого HTML-тега вы разрешаете Google и его поисковым роботам сканировать дублирующийся контент. Однако вы указываете ему не индексировать эту страницу. Это означает, что ваш дублированный контент не будет отображаться в результатах поиска Google — только ваши исходные страницы.
Убедитесь, что любой синдицированный контент размещен на соответствующих сайтах.
У вас есть синдицированный контент, например, статья, опубликованная на многих веб-сайтах, или пресс-релиз, опубликованный в нескольких новостных онлайн-изданиях? Вы не должны подвергаться наказанию за этот контент, если сайт, на котором он расположен, является законным.
Убедитесь, что весь ваш контент актуален в будущем
Теперь, когда вы знаете, почему дублирование контента является такой проблемой (и насколько болезненным может быть устранение его постфактум), обязательно избегайте его в будущее. Вы даже можете запустить весь контент с помощью такой программы, как CopyScape или Duplichecker, чтобы избежать проблем с непреднамеренным плагиатом.
Вы даже можете запустить весь контент с помощью такой программы, как CopyScape или Duplichecker, чтобы избежать проблем с непреднамеренным плагиатом.
А еще лучше создайте блог для своего веб-сайта, чтобы всегда создавать свежий контент. Любой новый контент отлично подходит для вашего сайта, и хотя он не избавит вас от дублированного контента и не уменьшит его последствия, это отличная практика для вашего сайта.
Убедитесь, что ваш контент не дублируется на другом сайте
Если вы обнаружите, что другой веб-сайт удалил ваш контент, немедленно примите меры. Сообщите Google и сделайте так, чтобы ваш голос был услышан.
Вы должны быть в состоянии доказать, что контент был у вас изначально, что уменьшит ваши шансы быть наказанными и повысит их. Вы можете подумать, что о достаточно маленьких сайтах не стоит беспокоиться, но штраф не стоит риска.
Хорошие агентства имеют более 50 отзывов.
Лучшие агентства имеют более 100 отзывов.
WebFX имеет
более 1020+ блестящих отзывов клиентов.