
как его создать и правильно настроить
Robots.txt – это текстовый файл, в котором указаны рекомендации для роботов поисковых систем относительно индексации сайта. Расположен данный файл в корневом каталоге сайта и среди его основных функций мы можем выделить следующие:
- Указание главного зеркала сайта;
- Указание пути к карте сайта для роботов;
- Создание необходимых правил обхода страниц поисковым краулером.
Помимо возможности давать рекомендации поисковыми системам по индексации сайта, роботс тхт максимально удобен в редактировании. Для этого через доступ FTP файл можно открыть через любой текстовый редактор, внести необходимые правки и загрузить обновленный файл в корень сайта с заменой старого документа. При этом некоторые CMS обеспечивают возможность редактирования без необходимости скачивать файл.
Важно отметить, что директивы robots txt могут не работать даже при правильном их составлении. Зачастую это связано со следующими синтаксическими ошибками:
- Итоговый размер файла превышает максимально допустимое значение для Яндекса в 500 килобайт и Гугла в 500 кибибайт;
- В процессе создания вы использовали кодировку, которая отличается от UTF-8, что актуально именно для Google;
- Расширение файла не txt или в его названии содержатся недопустимые символы;
- К файлу по определенным причинам нет доступа на сервере.


Исходя из всех вышеперечисленных пунктов можно отметить необходимость регулярно делать анализ robots txt, проверяя его на работоспособность.
Синтаксис и директивы файла Robots.txt для сайта
Настройка robots txt для сайта предполагает создание директив, которые можно разделить на обязательные и необязательные. Размещение данных директив также должно быть в определенном порядке, что позволи краулерам поисковых систем нормально их воспринимать. Стандартно первой директивой должна быть User Agent, после следует запрет на индексацию Disallow, затем разрешение индексации Allow и окончательным этапом указывается основное зеркало сайта через директиву Host. Во избежания ошибок в процессе настройки Robots.txt мы рекомендуем обратить внимание на следующие правила работы с синтаксисом:
- В одной строке прописывается одна директива;
- Любая новая директива прописывается с новой строки;
- В начале строки и между строками не допускаются пробелы;
- Описываемый параметр нельзя переносить в новую строку;
- Перед всеми страницами сайта в директории обязательно нужно ставить слэш (/).

Важно отметить, что все директивы должны быть прописаны только латинскими символами. Правильный robots txt содержит в себе ряд директив, которые стоит рассмотреть более детально.
User-agent
Это обязательная директива файла, которая прописывается в первой строке. Основная цель данной директивы – это обращение к поисковому роботу, соответственно, существуют следующие ее варианты:
- User-agent: *
- User-agent: Yandex
- User-agent: Googlebot
Первый вариант предполагает обращение ко всем поисковым роботам, а остальные к конкретной поисковой системе.
Disallow
Директива указывает поисковому роботу на запрет индексации конкретной части сайта. При сочетании с директивой User-agent можно обеспечить запрет индексации для всех роботов или для конкретного поискового краулера.
Allow
Директива разрешает поисковым роботам индексацию всех страниц сайта или разделов, которые включают в себя данные страницы.
Crawl-Delay
Директива позволяет задать временной период, через который робот будет индексировать страницы. При заданном параметре Crawl-delay: 5 краулер будет индексировать следующую страницу через 5 секунд.
Host
Благодаря данной директиве можно указать главное зеркало сайта с www или без www.
Sitemap
Можно указать путь к карте сайта, а сама директива выглядит следующим образом Sitemap: mysite.com/sitemap.xml.
Как сделать Robots.txt
Правильный файл robots txt можно создать вручную, используя необходимые вам вышеперечисленные директивы в зависимости от особенностей вашего сайта. Если вы не можете самостоятельно создать роботс для сайта или боитесь допустить ошибки, можно использовать один из следующих генераторов онлайн:
- PR-CY;
- Seolib;
- Media Sova.
Любой из вышеперечисленных сервисов обеспечивает автоматическую генерацию файла, поэтому проблем с тем, как как сделать robots txt для сайта у вас не возникнет. Важно отметить, что содержимое файла robots txt отличается не только в зависимости от конкретного сайта, но и в зависимости от CMS.
Важно отметить, что содержимое файла robots txt отличается не только в зависимости от конкретного сайта, но и в зависимости от CMS.
Проверка файла robots.txt
Когда мы уже рассмотрели как создать robots txt и сгенерировали текстовый файл, его необходимо проверить на работоспособность. Для этого мы рекомендуем воспользоваться одним из множества онлайн сервисов.
Google Search Console и Яндекс.Вебмастер
Стандартные сервисы поисковых систем, которые в своем функционале предлагают возможность проверки файла роботс на правильность и отсутствие ошибок.
Website Planet
На главной странице сайта доступны все инструменты сервиса, среди которых есть проверка файла robots. После ввода адреса сайта мы получаем не только наличие ошибок или их отсутствие, но и любые предупреждения по файлу.
Данный сервис можно с уверенностью назвать самым информативным для анализа роботс.
Tools.descript.ru
Проверка осуществляется стандартным методом через инструменты, которые предлагает Tools. descript. В окне для проверки просто вводим URL сайта и получаем детальный отчет.
descript. В окне для проверки просто вводим URL сайта и получаем детальный отчет.
Ключевой особенностью сервиса можно отметить возможность выбора не только целевого краулера определенной поисковой системы, но и выбор конкретной CMS. Это позволяет проверить правильность создания Robots для любого движка сайта.
Возьмем на себя все заботы по продвижению и раскрутке сайта:
> Создание сайта > SEO продвижение > Контекстная реклама в Яндекс и Google
Подпишись на рассылку, чтобы не пропустить ничего интересного!
Бесплатная консультация
Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt
Как настроить robots.txt
Как создать robots.txt
Требования к файлу robots.txt
Как проверить правильность Robots. txt
txt
Читайте наc в Telegram
Разбираемся, что происходит в мире рассылок и digital-маркетинга. Публикуем анонсы статей, обзоры, подборки, мнения экспертов.
Смотреть канал
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.Кому нужен robots.txtЕсли у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т. д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.д.
 д.
д.Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image. Индексирует изображения.
Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт 
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *.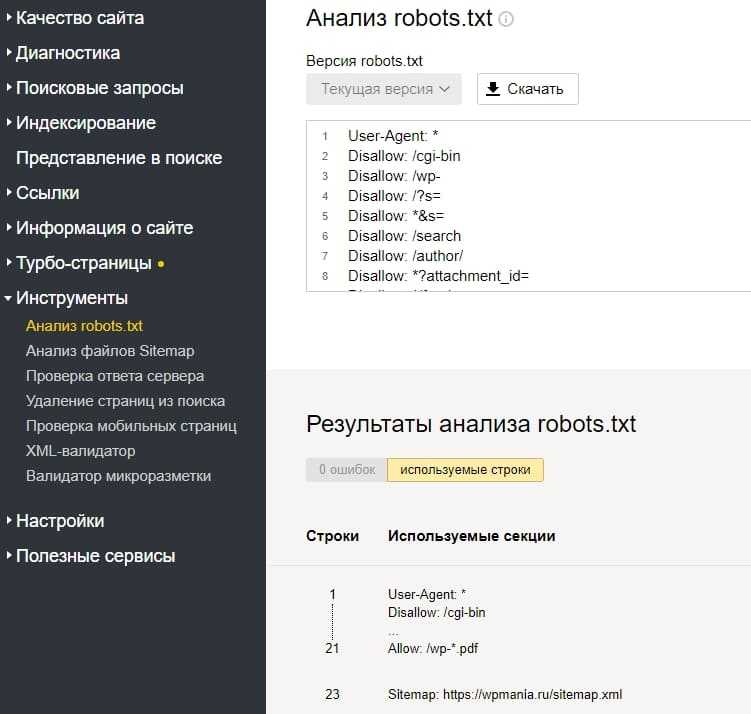 js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.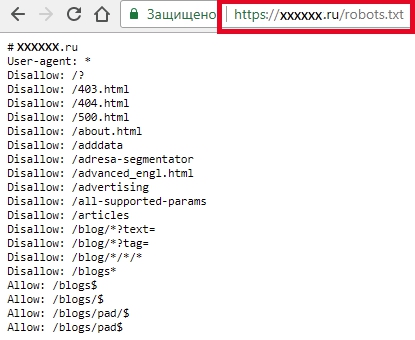
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки описан в видеоинструкции:
;
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся шутить, но получается не всегда
Пытаемся шутить, но получается не всегда
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
как создать, настройка, закрыть, индексация, правильный robots для Яндекса и Google, пример файла
Зачем сайту файл robots. txt и как его создать
txt и как его создать
Запускаете сайт? Поздравляем! Прежде чем устремиться к вершинам топа Яндекс или Google, проверьте, не забыта ли одна маленькая, но значительная деталь — файл robots.txt
Robots.txt — текстовый файл в главной директории веб-ресурса, который инструктирует роботов-поисковиков. В первую очередь, содержание файла подсказывает, какие страницы нужно индексировать, а какие — не стоит.
Наличие файла robots.txt на сайте — непременное условие: он полезен для продвижения, кроме того, без него невозможно добиться высоких позиций в выдаче Яндекс, Google и других поисковых систем.
Зачем нужен файл robots.txt
Перед тем, как начать индексировать сайт, дружелюбный робот-поисковик сразу обратит внимание на robots.txt — прочитает инструкции и лишь затем приступит к работе. От того, как составлен файл, напрямую зависит успех или неудача кампании по продвижению, а также сохранность приватных данных на сайте.
Если robots.txt заполнен верно, ресурс получи:
- быструю и правильную индексацию страниц
Без файла robots.txt или при неверном его составлении поисковая машина может добавить в результаты выдачи нерелевантные страницы — например, экран авторизации и регистрации. Такой “мусор” будет конкурировать с целевыми страницами, и в поисковой выдаче окажется совсем не то, что хотелось бы видеть.
К тому же, это негативно повлияет на поведенческие факторы, а значит, сайт “просядет” в выдаче.
- защиту приватной информации и личных данных
Чтобы администраторская панель сайта, а также личные данные и пароли, не оказались доступны всем пользователям интернета — закройте приватные страницы от индексации в файле robots.txt.
Как создать и настроить файл robots.txt
Создать файл robots.txt нетрудно, настроить — немного сложнее, однако это тоже можно сделать без специальных знаний.
Создание
Откройте текстовый редактор — стандартный Блокнот или, например, более продвинутый editor для программистов — Notepad++. Создайте файл в формате .txt, дайте ему имя “robots” и приступайте к заполнению.
Создайте файл в формате .txt, дайте ему имя “robots” и приступайте к заполнению.
Ещё один способ — создать robots.txt онлайн. Генератор предложит заполнить поля, сам пропишет синтаксис и позволит скачать уже готовый robots.txt. В сети множество инструментов для создания такого типа файлов. К примеру, сервис Seolib.
Интерфейс генератора robots.txt
Редактирование
Если файл создан вручную, текст внутри придётся написать самостоятельно. Если скачан из онлайн-генератора — внимательно проверить и отредактировать содержимое.
Пример блока в файле robots.txt
User-agent — поисковый робот, которому даётся инструкция: например, Googlebot, Yandexbot или * (все роботы).
Allow — разрешающая директива, Disallow — запрещающая.
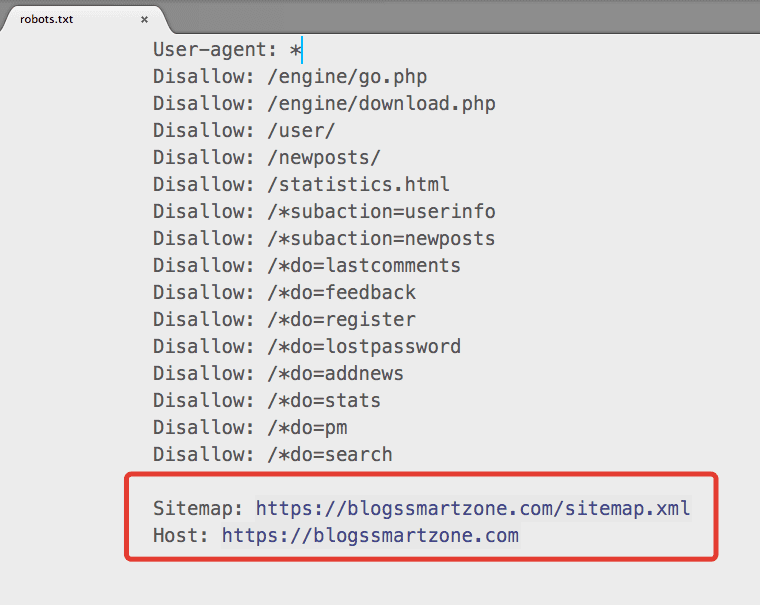
Host и Sitemap — также обязательные директивы для robots.txt. Первая подсказывает, какое из зеркал сайта следует индексировать, вторая — объясняет, “как пройти” к карте сайта.
В примере мы закрыли роботам доступ к панели администратора, разрешили индексировать содержимое страницы content, правда, исключая файл picture.png. Кроме того, указали основное зеркало сайта и путь к карте сайта.
Заполняя файл robots.txt, стремитесь к краткости — не путайте машину слишком подробными указаниями. Старайтесь сделать инструкцию смысловой и конкретной.
Следите за размером файла robots.txt — у бота Google, к примеру, есть ограничение для него в 500 кб.
Загрузка на сайт
Поместите файл robots.txt в корневую директорию сайта. Он должен отображаться по адресу: имя-сайта.ru/robots.txt. Если файл окажется в другом месте, поисковый робот не станет его искать и просто проигнорирует.
Чтобы загрузить файл robots.txt на сайт, как правило, требуется доступ к протоколу FTP. У популярных CMS также есть функция редактирования файла на панели администратора: по умолчанию или после установки специального модуля.
Проверяем robots.
 txt
txtУзнать, на месте ли файл robots.txt, проще простого — перейдите по адресу его расположения: имя-сайта.ru/robots.txt.
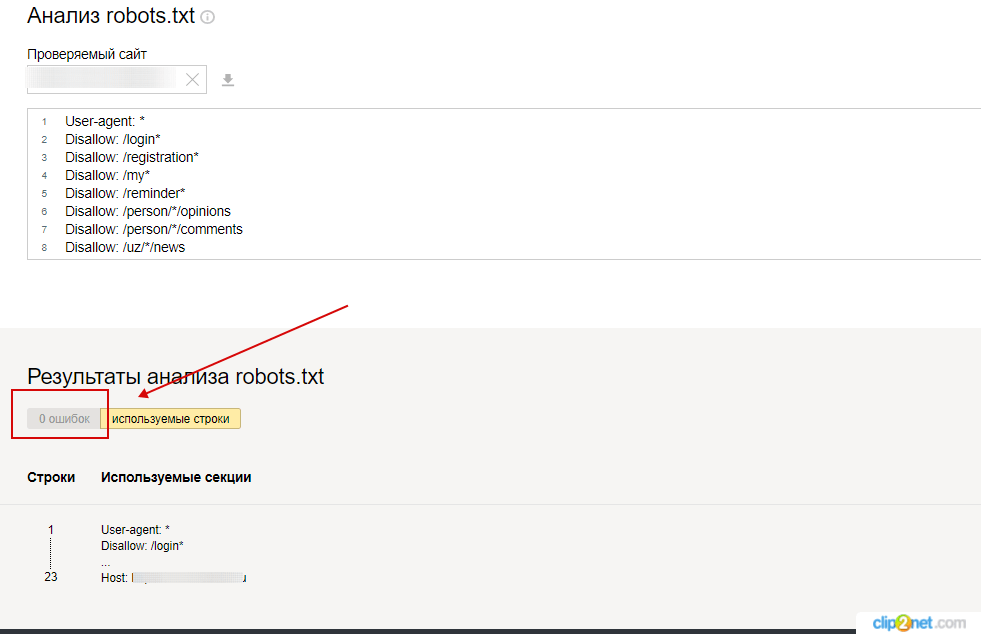
Хотите проверить синтаксис и структуру файла? На помощь придут специальные сервисы поисковых систем для вебмастеров: Яндекс.Вебмастер и Search Console Google.
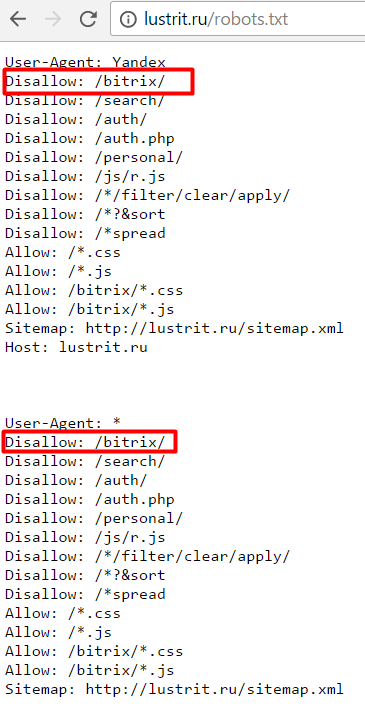
Анализ robots.txt в Яндекс.Вебмастер
Robots.txt — необходимый “винтик” в механизме веб-ресурса. Возможно, не потребуется он только сайтам-одностраничникам, которые почти не участвуют в seo. Но подстраховаться всё равно можно, тем более что создание файла для сайта с простейшей структурой займёт всего несколько минут.
Подписывайтесь на наш канал в Яндекс.Дзен!
Нажмите «Подписаться на канал», чтобы читать DigitalNews в ленте «Яндекса» .
Есть вопрос по теме «
«?
Аэрофлот vs кот Виктор: epic fail или иначе не могло быть?Подводя итоги года, мы решили написать про самое яркое событие в мире соцсетей: конфликте «Аэрофлота.
 ..
..Просмотров: 15,038
Бесплатные инструменты от Click.ruВ 2019 году еще есть люди, которые платят за связь и ЖКУ с комиссией, покупают товары и услуги тольк…
Просмотров: 23,707
Скликивание бюджета в Яндекс.ДиректДаже среди опытных пользователей Директа нет единого мнения о том, можно ли свернуть рекламную кампа…
Просмотров: 10,508
Яндекс для бизнеса: подключение диалоговЯндекс.Диалоги — новый сервис для разработчиков сайтов, при помощи которого можно наладить общение с…
Просмотров: 10,013
Free Robots.txt Validator — Инструмент тестирования txt для роботов
Полезный технический SEO-инструмент для проверки любого веб-сайта Разрешать а также Disallow Directives
ETTVI’s Robots.txt Validator
Найдите исключения для роботов, которые запрещают поисковой системе сканировать или индексация ваш веб-сайт в режиме реального времени
Убедитесь, что все второстепенные веб-страницы, мультимедийные файлы и файлы ресурсов
заблокирован
от сканирования — проверьте, как работают сканеры поисковых систем (пользовательские агенты).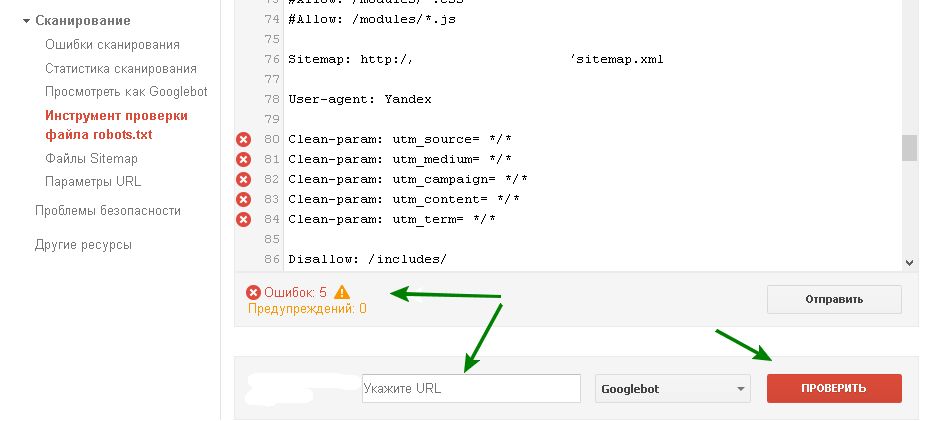 проинструктирован
для сканирования веб-сайта с помощью ETTVI Robots.txt Validator. Введите URL-адрес веб-сайта;
Выбрать
в
пользовательский агент и проверьте, разрешает или запрещает он соответствующий пользовательский агент.
такие действия, как сканирование и индексирование
сеть
страница.
проинструктирован
для сканирования веб-сайта с помощью ETTVI Robots.txt Validator. Введите URL-адрес веб-сайта;
Выбрать
в
пользовательский агент и проверьте, разрешает или запрещает он соответствующий пользовательский агент.
такие действия, как сканирование и индексирование
сеть
страница.
ETTVI’s Robots.txt Validator упростил определение того, все ли поисковые роботы находятся запрещено сканировать определенную страницу/файл или существует какой-либо конкретный робот что Можно не ползать по нему.
Используйте этот полезный SEO-инструмент для мониторинга поведения поисковых роботов.
а также
бесплатно регулируйте краулинговый бюджет вашего веб-сайта.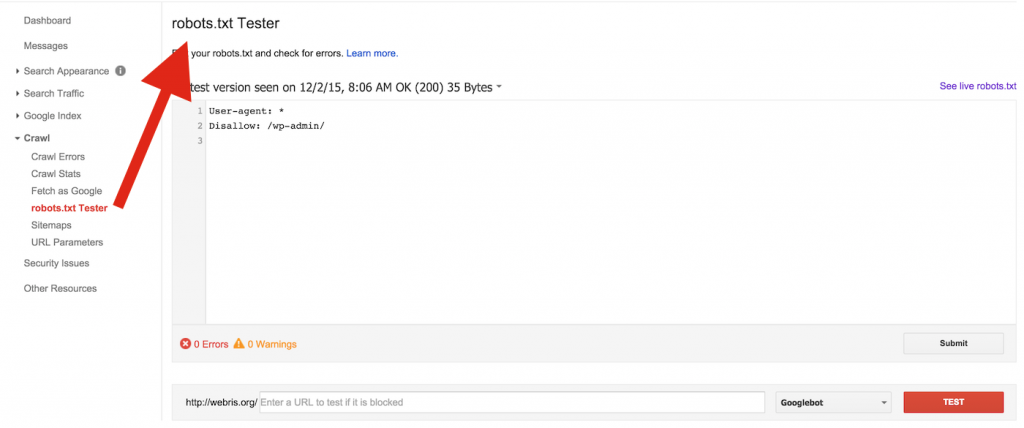
Как использовать ETTVI’s Robots.txt Validator?
Выполните следующие простые действия, чтобы протестировать файл robots.txt веб-сайта с ETTVI. передовой инструмент:
ШАГ 1. Введите URL-адрес
Введите URL-адрес веб-сайта следующим образом:
Примечание: Не забудьте добавить «robots.txt» после косой черты.
ШАГ 2. Выберите User-Agent
Укажите сканер, с которым вы хотите проверить файл robots.txt
Вы можете выбрать любой из следующих пользовательских агентов:
Google-бот
Новости ботов Google
Адсенс
AdsBot
БингБот
MSNBot-Media
Yahoo!
УткаДакГоу
Байду
Яндекс
Фейсбук
Твиттербот
Ботифай
ШАГ 3.
 Проверка файла Robots.txt
Проверка файла Robots.txtКогда вы нажимаете «Проверить», запускается программа ETTVI Free Robots.txt Validator для идентификации и осмотреть мета-директивы роботов данного веб-сайта. Он выделяет URL-адреса, которые в выбранный бот может или не может сканировать.
Когда вы нажимаете «Проверить», запускается ETTVI Free Robots.txt Validator для идентификации и осмотреть мета-директивы роботов данного веб-сайта. Он выделяет URL-адреса, которые в выбранный бот может или не может сканировать.
User-agent: * указывает, что все сканеры поисковых систем разрешено/запрещено к сканировать сайт
Разрешить: указывает, что URL-адрес может быть просканирован соответствующей поисковой системой. сканер(ы)
сканер(ы)
Disallow: указывает Disallow: указывает, что URL-адрес не может быть просканирован поисковые роботы соответствующей поисковой системы
Зачем использовать ETTVI’s Robots.txt Validator?
Дружественный интерфейс
Все, что вам нужно сделать, это просто ввести URL вашего веб-сайта, а затем запустить инструмент.
Это
быстро обрабатывает файл robots.txt данного веб-сайта, чтобы отслеживать все
заблокирован
URL-адреса
и мета-директивы robots. Являетесь ли вы новичком или экспертом, вы можете
без труда
найдите URL-адреса с разрешающими/запрещающими директивами для выбранного пользовательского агента
(гусеничный трактор).
Эффективный инструмент SEO
ETTVI’s Robots.txt Validator — обязательный инструмент для SEO-специалистов. Требуется всего несколько секунд, чтобы проверить файл robot.txt веб-сайта на соответствие всем пользовательским агентам, чтобы отслеживать логические и синтаксические ошибки, которые могут повредить SEO сайта. это самый простой путь к сэкономьте краулинговый бюджет и убедитесь, что роботы поисковых систем не сканируют ненужные страницы.
Свободный доступ
Тестер Robots.txt от ETTVI позволяет проверить файлы robots.txt любого веб-сайта, чтобы убедиться,
что
ваш
веб-сайт правильно сканируется и индексируется без взимания абонентской платы.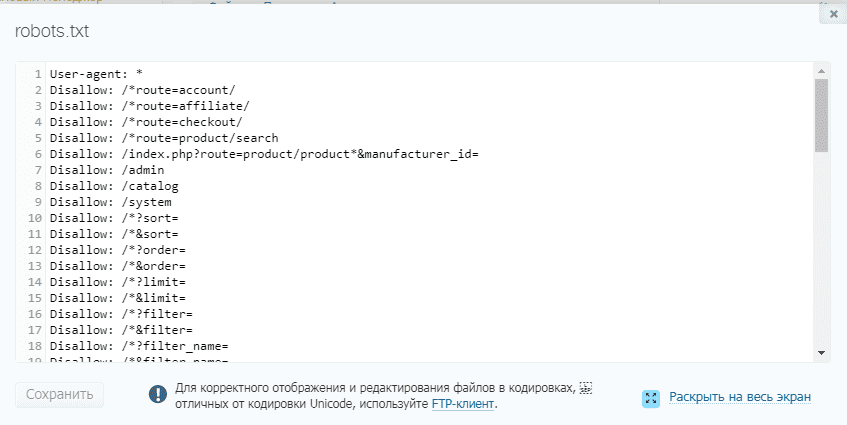
Неограниченное использование
доступ Это и использовать его независимо от каких-либо ограничений. Люди со всего мира могут принять преимущество этот продвинутый инструмент SEO для проверки стандарта исключения роботов любого веб-сайта Однако а также всякий раз, когда они хотят.
Понимание файлов Robots.txt
Файл Robots.txt представляет собой сущность технического SEO, в основном используется для управления
поведение
из
сканеры поисковых систем. Поэтому прочитайте это окончательное руководство, чтобы узнать, как
Роботы.txt
файл работает и как создать его хорошо оптимизированным способом.
Что такое файл robots.txt?
Файл robots.txt разрешает или запрещает поисковым роботам доступ и сканирование сеть страницы. Думайте о файле Robots.txt как о инструкции для поисковой системы. гусеницы. Он предоставляет набор инструкций, чтобы указать, какие части веб-сайта доступный а какие нет.
Точнее, файл robots.txt позволяет веб-мастерам управлять поисковыми роботами.
—
какие
получить доступ и как. Вы должны знать, что поисковый робот никогда не попадает на сайт напрямую.
структуру, а обращается к файлу robots.txt соответствующего веб-сайта для
знать
который
URL-адреса разрешены для сканирования, а какие URL-адреса запрещены.
Использование файла Robots.txt
Файл Robots.txt помогает веб-мастерам, чтобы веб-страницы, мультимедийные файлы и файлы ресурсов не достигать всех поисковых роботов. Проще говоря, он используется для хранения URL-адресов. или же изображения, видео, аудио, сценарии и файлы стилей вне поисковой выдачи.
Большинство специалистов по поисковой оптимизации склонны использовать файл Robots.txt как средство блокировки сеть страницы от появления в результатах поисковой системы. Однако его не следует использовать для это цель, поскольку есть и другие способы сделать это, такие как применение мета-роботов директивы и шифрование паролей.
Имейте в виду, что файл Robots. txt следует использовать только для предотвращения
из
перегрузка сайта запросами на сканирование. Более того, если требуется, то
Роботы.txt
файл можно использовать для экономии краулингового бюджета, блокируя веб-страницы, которые
либо
неважно или недоразвито.
txt следует использовать только для предотвращения
из
перегрузка сайта запросами на сканирование. Более того, если требуется, то
Роботы.txt
файл можно использовать для экономии краулингового бюджета, блокируя веб-страницы, которые
либо
неважно или недоразвито.
Преимущества использования файла robots.txt
Файл Robots.txt может быть как козырем в рукаве, так и опасным для SEO вашего сайта. Кроме за рискованную возможность того, что вы непреднамеренно запретите роботам поисковых систем из сканируя весь ваш сайт, файл Robots.txt всегда пригодится.
Используя файл Robots.txt, веб-мастера могут:
Укажите расположение карты сайта
Запретить сканирование дублированного контента
Предотвратить появление определенных URL-адресов и файлов в поисковой выдаче
Установить задержку сканирования
Сохранить краулинговый бюджет
Все эти методы считаются лучшими для SEO сайта и только
Роботы. txt
Можно
помочь вам применить
txt
Можно
помочь вам применить
Ограничения на использование файла Robots.txt
Все веб-мастера должны знать, что в некоторых случаях стандарт исключения роботов вероятно терпит неудачу для предотвращения сканирования веб-страниц. Существуют определенные ограничения на использование Файл robots.txt, например:
Не все сканеры поисковых систем следуют директивам robots.txt
Каждый сканер по-своему понимает синтаксис robots.txt
Существует вероятность того, что робот Google может просканировать запрещенный URL-адрес
Определенные методы SEO могут быть выполнены, чтобы убедиться, что заблокированные URL-адреса
останки
скрыт от всех поисковых роботов.
Создание файла Robots.txt
Взгляните на эти примеры форматов, чтобы узнать, как создавать и изменять Роботы.txt file:
User-agent: * Disallow: / указывает, что каждый поисковый робот запрещено сканировать все веб-страницы
User-agent: * Disallow: указывает, что каждый поисковый робот допустимый к просканировать весь веб-сайт
User-agent: Googlebot Disallow: / указывает, что только сканер Google является запрещено сканировать все страницы сайта
User-agent: * Disallow: /subfolder/ указывает на отсутствие поисковой системы гусеничный трактор Можно получить доступ к любой веб-странице этой конкретной подпапки или категории
Таким же образом вы можете создать и изменить файл Robots. txt. Просто будь осторожен
о
в
синтаксис и отформатируйте файл Robots.txt в соответствии с установленными правилами.
txt. Просто будь осторожен
о
в
синтаксис и отформатируйте файл Robots.txt в соответствии с установленными правилами.
Синтаксис Robots.txt
Синтаксис Robots.txt относится к языку, который мы используем для форматирования и структурирования robots.txt файлы. Позвольте нам предоставить вам информацию об основных терминах, которые составляют Синтаксис robots.txt.
User-agent — это сканер поисковой системы, которому вы предоставляете сканирование инструкции включая URL-адреса, которые следует сканировать, а какие нет.
Запретить — метадиректива robots, предписывающая агентам пользователя не ползти соответствующий URL-адрес
Разрешить — это метадиректива robots, применимая только к роботу Googlebot. Это
указывает поисковому роботу Google, что он может получить доступ, просканировать и затем проиндексировать веб-страницу.
страница или
подпапка.
Это
указывает поисковому роботу Google, что он может получить доступ, просканировать и затем проиндексировать веб-страницу.
страница или
подпапка.
Crawl-delay определяет период времени в секундах, который сканер должен ждать перед сканированием веб-контента. Для справки, поисковый робот Google не следует этому команда. В любом случае, при необходимости вы можете установить скорость сканирования через поиск Google. Приставка.
Карта сайта указывает расположение XML-карт сайта данного веб-сайта. Только Google, Ask, Bing и Yahoo подтверждают эту команду.
Специальные символы, включая * , / и $ облегчают
сканеры к
понять директивы.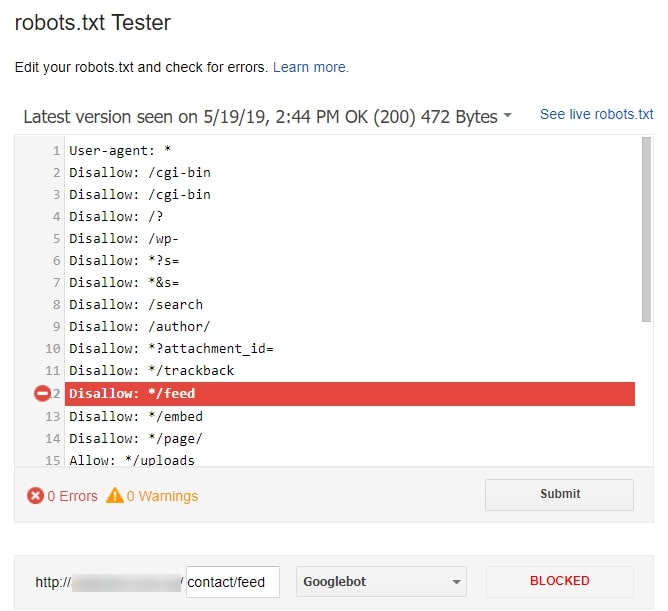 Как следует из названия, каждый из этих персонажей имеет
специальный
значение:
Как следует из названия, каждый из этих персонажей имеет
специальный
значение:
* означает, что всем сканерам разрешено/запрещено сканировать соответствующий Веб-сайт . / означает, что директива allow/disallow предназначена для всех веб-страниц
Краткие сведения о Robots.txt
- ➔ Файл Robots.txt поддомена создается отдельно
- ➔ Имя файла Robots.txt должно быть сохранено строчной буквой случаи как « robots.txt », потому что он чувствителен к регистру.
- ➔ Файл Robots.txt должен быть помещен в каталог верхнего уровня из в сайт
- ➔ Не все поисковые роботы (пользовательские агенты) поддерживают файл robots. txt
- ➔ Поисковый робот Google может найти заблокированные URL-адреса из связанных сайты
- ➔ Файл Robots.txt каждого веб-сайта общедоступен который означает, что любой может получить к нему доступ
 txt
txtСовет PRO: В случае крайней необходимости используйте другие методы блокировки URL-адресов, такие как пароль шифрование и метатеги robots, а не файл robots.txt для предотвращения сканирования из определенные веб-страницы.
Файл Robots.txt: доступ, проверка и создание с нуля
Последнее обновление этой статьи: 17.05.210008
Если у вас есть веб-сайт или вы занимаетесь интернет-маркетингом, вы, вероятно, слышали о файле robots. txt. При неправильной реализации этот файл может иметь очень негативные и непредвиденные последствия, такие как блокировка страниц и ресурсов. Представьте, что вы пытаетесь ранжироваться по ключевому слову на странице, к которой у Google нет доступа. В этой статье мы подробно рассмотрим, в том числе почему файл robots.txt важен, как получить доступ к файлу robots.txt и многое другое!
txt. При неправильной реализации этот файл может иметь очень негативные и непредвиденные последствия, такие как блокировка страниц и ресурсов. Представьте, что вы пытаетесь ранжироваться по ключевому слову на странице, к которой у Google нет доступа. В этой статье мы подробно рассмотрим, в том числе почему файл robots.txt важен, как получить доступ к файлу robots.txt и многое другое!
Содержание
- Что такое файл robots.txt и почему он важен?
- Как получить доступ к файлу robots.txt?
- Как должен выглядеть файл robots.txt?
- Агент пользователя
- Запретить
- Карта сайта
- Как проверить, работает ли ваш файл Robots.txt
- Как создать файл robots.txt, который будет простым и оптимизированным для SEO
- Использовать обычный текстовый редактор
- Назначить пользовательский агент
- Укажите правила запрета
- Добавьте карту сайта
- (Необязательно) Страницы Noindex в файле robots. txt
- Отправить в корневой каталог
 txt
txtЧто такое файл robots.txt и почему он важен?
Файл robots.txt позволяет роботам поисковых систем лучше понять, какие части вашего веб-сайта вы сканируете, а какие не хотите, чтобы они сканировали. Это самое первое место вашего сайта, которое посетит поисковая система.
Почему это важно?
- Предотвращает дублирование контента в поисковой выдаче.
- У вас больше контроля над тем, что вы хотите, чтобы поисковая система видела или не видела.
- Карта сайта может быть добавлена непосредственно в файл robots.txt, что поможет поисковым системам лучше читать и понимать структуру вашего веб-сайта.
- Помогает предотвратить индексирование определенных страниц, изображений, файлов и т. д. и их использование в краулинговом бюджете.
- Если у вас есть несколько фрагментов контента, которые загружаются одновременно, установка задержки сканирования в файле поможет избежать перегрузки серверов.

Как получить доступ к файлу robots.txt
Если вы не уверены, есть ли на вашем сайте файл robots.txt, это легко проверить! Получите доступ к файлу robots.txt, добавив /robots.txt в конце своего домена. Вот наш пример на Boostability: https://www.boostability.com/robots.txt
.Если вы ничего не видите, когда пробуете это для своего веб-сайта или попадаете на страницу с ошибкой 404, у вас ее нет. Следующим шагом будет создание файла robots.txt для вашего сайта!
Как должен выглядеть файл robots.txt?
Как минимум, файл robots.txt должен содержать три основные части и концепцию, которые вам необходимо понять.
Агент пользователя
Эта команда определяет, каким поисковым роботам разрешено сканировать ваш веб-сайт. Веб-сайты чаще всего используют * для пользовательского агента, потому что это означает «все пользовательские агенты».
С появлением на рынке новых поисковых систем и в зависимости от вашего местоположения список пользовательских агентов поисковых систем может стать длинным. Ниже приведен список некоторых основных пользовательских агентов поисковых систем:
Ниже приведен список некоторых основных пользовательских агентов поисковых систем:
- «Googlebot» для Google
- «Бингбот» для Bing
- «Яху! Slurp» для Yahoo
- «Яндекс» для Яндекс
- «Baidu» для Baidu
- «Duckduckgo» для DuckDuck Go
- «Aolbuild» для AOL
Если вы хотите дать команду для определенного поискового робота, вы должны поместить идентификатор пользовательского агента в расположение пользовательского агента. Каждый раз, когда вы обращаетесь к сканеру, вам потребуется отдельный набор команд запрета.
Например, вы указываете Googlebot в качестве пользовательского агента, а затем уведомляете поисковый робот, какие страницы следует запретить.
Большинство авторитетных поисковых роботов, таких как Google, Bing и Yahoo, будут следовать указаниям файла robots.txt. Сканеры спама (которые обычно отображаются как трафик на ваш сайт) с меньшей вероятностью будут следовать командам. В большинстве случаев лучше всего использовать * и давать одну и ту же команду всем поисковым роботам.
В большинстве случаев лучше всего использовать * и давать одну и ту же команду всем поисковым роботам.
Запретить
Эта команда сообщает поисковым роботам, какие файлы или страницы на вашем веб-сайте вы не хотите сканировать. Как правило, запрещенные файлы — это страницы, конфиденциальные для клиентов (например, страницы оформления заказа), или страницы бэкэнд-офиса с конфиденциальной информацией.
Большинство проблем в файле robots.txt возникает в разделе запрета. Проблемы возникают, когда вы блокируете слишком много информации в файле. В приведенном выше примере показан соответствующий файл для запрета. Любые файлы, начинающиеся с /wp-admin/, не будут сканироваться.
В приведенном ниже примере показано, что вы не хотите включать в раздел запрета.
Что команда disallow сообщает поисковым роботам на картинке выше? В этой ситуации поисковым роботам предлагается не индексировать ни одну из страниц вашего веб-сайта. Если вы хотите, чтобы ваш веб-сайт был виден в поисковых системах, включение одного / в раздел запрета наносит ущерб вашей поисковой видимости. Если вы заметили внезапное падение трафика, сначала проверьте файл robots.txt, чтобы увидеть, присутствует ли эта проблема.
Если вы хотите, чтобы ваш веб-сайт был виден в поисковых системах, включение одного / в раздел запрета наносит ущерб вашей поисковой видимости. Если вы заметили внезапное падение трафика, сначала проверьте файл robots.txt, чтобы увидеть, присутствует ли эта проблема.
Google даже отправляет сообщения Search Console, сообщая веб-сайтам, блокирует ли файл robots.txt информацию, необходимую для сканирования, например файлы CSS и Javascript.
Если вы хотите перестраховаться, разрешите всем поисковым роботам сканировать каждую страницу вашего веб-сайта. Вы можете сделать это, ничего не запрещая.
Как видите, после команды disallow следует пробел. Когда поисковый робот увидит это, он просканирует все страницы, которые найдет на вашем сайте.
Карта сайта
Файл robots.txt также может содержать расположение карты сайта вашего веб-сайта, что настоятельно рекомендуется. Карта сайта — это второе место, которое сканер посетит после вашего файла robots.txt. Это помогает поисковым системам лучше понять структуру и иерархию вашего сайта. Убедитесь, что в карте сайта перечислены ваши веб-страницы, особенно те, которые вы пытаетесь продать, или ваши самые ценные страницы.
Карта сайта — это второе место, которое сканер посетит после вашего файла robots.txt. Это помогает поисковым системам лучше понять структуру и иерархию вашего сайта. Убедитесь, что в карте сайта перечислены ваши веб-страницы, особенно те, которые вы пытаетесь продать, или ваши самые ценные страницы.
Примечание. Если у вас есть несколько файлов Sitemap для вашего веб-сайта, добавьте их все в файл robots.txt — вы можете указать несколько.
Как проверить, работает ли ваш файл robots.txt
Рекомендуется проверить, работает ли файл robots.txt для вашего веб-сайта, используя вашу учетную запись Search Console. Используйте этот инструмент, чтобы проверить файл robots.txt или отдельные URL-адреса, если у вас есть сомнения.
Ниже приведен скриншот того, как это выглядит. Вам просто нужно ввести файл robots.txt или конкретный URL-адрес, который вы хотите протестировать, и он сообщит вам, принят он или заблокирован.
Если в файле robots. txt вашего веб-сайта возникнут проблемы или ошибки, Search Console сообщит вам об этом. Помните, что роль поисковой системы состоит в том, чтобы а) сканировать, б) индексировать и в) предоставлять результаты.
txt вашего веб-сайта возникнут проблемы или ошибки, Search Console сообщит вам об этом. Помните, что роль поисковой системы состоит в том, чтобы а) сканировать, б) индексировать и в) предоставлять результаты.
Файл robots.txt может блокировать страницы и разделы, которые поисковая система должна сканировать, но не обязательно индексировать. Например, если вы создаете ссылку и указываете ее на веб-страницу, Google может просканировать эту ссылку и проиндексировать страницу, на которую указывает ссылка. Каждый раз, когда Google индексирует страницу, она может отображаться в результатах поиска.
Если вы не хотите, чтобы веб-страница отображалась в результатах поиска, включите эту информацию на самой странице. Включите код в теги
на конкретной странице, которую поисковые системы не должны индексировать. Или вы можете добавить список страниц, которые не будут индексироваться, непосредственно в файле robots.txt. Продолжайте читать, чтобы узнать, как это сделать.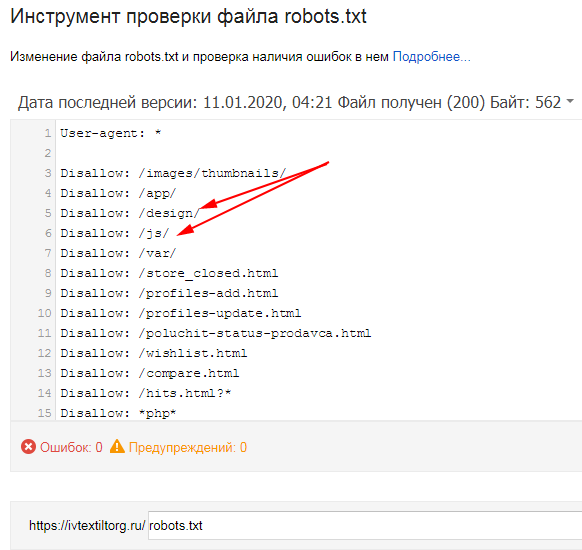
Как создать файл robots.txt, который будет простым и оптимизированным для SEO
Если у вас нет файла robots.txt для вашего сайта, не беспокойтесь, вы можете его создать! Для этого мы покажем вам, как создать файл robots.txt, оптимизированный для SEO, за несколько простых шагов.
Мы рекомендуем обратиться за помощью к надежному веб-разработчику, если вам это нужно, потому что это требует работы с исходным кодом веб-сайта.
1. Используйте обычный текстовый редактор
Для Windows используйте Блокнот; для Mac используйте TextEdit. Избегайте использования Google Docs или Microsoft Word, поскольку они могут вставлять в файл код, который вам не нужен.
2. Назначить пользовательский агент
Как мы упоминали выше, большинство сайтов, как правило, разрешают доступ к своим веб-сайтам всем поисковым системам. Если вы решите сделать это, просто введите:
Агент пользователя: *
Если вы хотите указать правила для разных пользовательских агентов, вам потребуется разделить правила на несколько пользовательских агентов.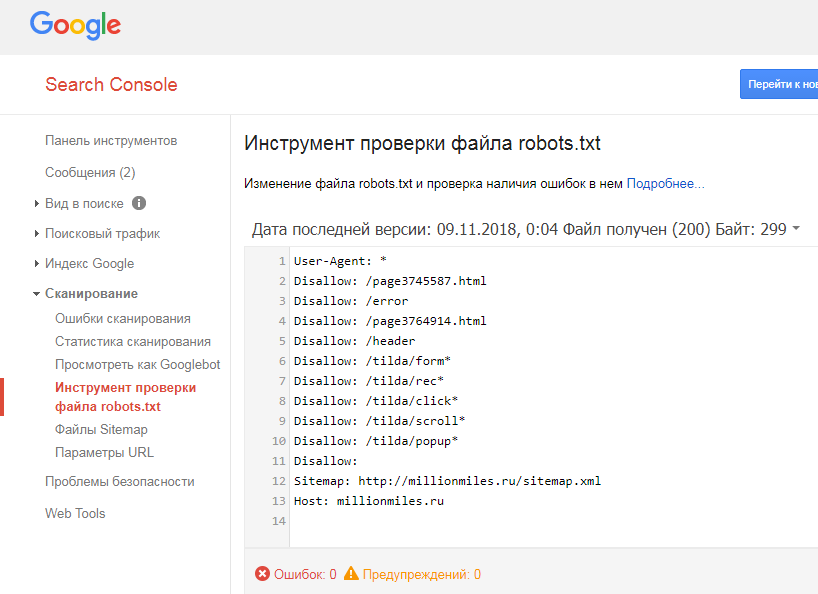 Например, давайте взглянем на файл robots.txt SEMrush ниже:
Например, давайте взглянем на файл robots.txt SEMrush ниже:
Они перечислили особые правила для разных пользовательских агентов. SEMrush имеет специальное правило для пользовательского агента Google по сравнению со страницами, которые он не хочет сканировать с помощью пользовательского агента Bing. Если вы оказались в похожей ситуации, следуйте приведенной выше структуре и разделите правила на отдельные строки в текстовом редакторе.
3. Укажите правила запрета
Чтобы максимально упростить этот сценарий, мы не будем ничего добавлять в disallow. Или вы можете не включать раздел запрета и просто оставить его в правиле пользовательского агента. Это означает, что поисковые системы будут сканировать все на сайте.
Чтобы сделать файл robots.txt еще более оптимизированным для SEO, рекомендуется добавить страницы, с которыми посетители сайта обычно не взаимодействуют, в раздел запрещенных, поскольку это может помочь очистить бюджет сканирования.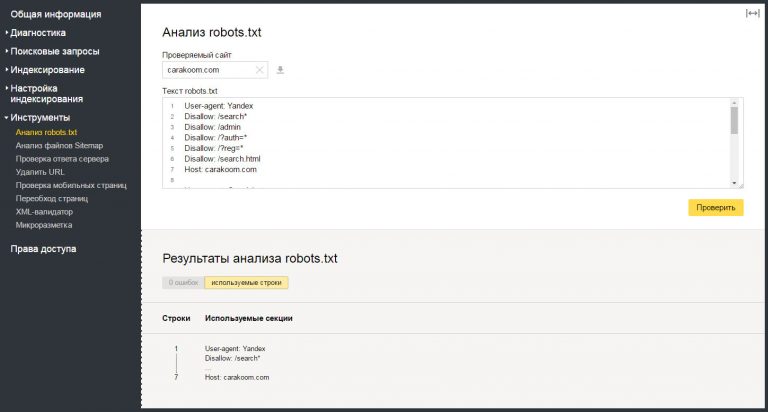 Пример для сайта WordPress:
Пример для сайта WordPress:
На приведенном выше рисунке показано, что страницы администрирования WordPress (или внутренние страницы) не должны сканироваться никаким пользовательским агентом, кроме страницы «Спасибо» (это гарантирует, что будут учитываться только квалифицированные лиды, а не случайные посетители, которые могут получить доступ к странице). страницу через поисковую выдачу). Отфильтровав эти типы страниц из краулингового бюджета, вы можете уделить больше внимания ценным страницам, которые поисковые системы должны сканировать и которые посещают люди.
4. Добавьте карту сайта
И последнее, но не менее важное: не забудьте добавить карты сайта, когда закончите создание файла robots.txt. Перечислите его внизу после раздела «Запретить».
5. (Необязательно) Страницы Noindex в файле robots.txt
Это необязательный шаг, но может быть полезно добавить раздел noindex в файл robots.txt. Как упоминалось ранее, robots. txt автоматически не индексирует страницы. Он просто сообщает поисковым системам, какие из них не сканировать. Если у вас есть определенные страницы, которые вы не хотите индексировать (например, страницы с благодарностью или подтверждения), вы можете обновить метатег непосредственно на странице или добавить его в файл robots.txt, как показано в примере ниже:
txt автоматически не индексирует страницы. Он просто сообщает поисковым системам, какие из них не сканировать. Если у вас есть определенные страницы, которые вы не хотите индексировать (например, страницы с благодарностью или подтверждения), вы можете обновить метатег непосредственно на странице или добавить его в файл robots.txt, как показано в примере ниже:
6. Отправьте его в корневой каталог
Когда вы закончите создание файла robots.txt, последним шагом будет загрузка его в корневой каталог вашего веб-сайта. После загрузки перейдите к файлу robots.txt и посмотрите, загружается ли страница в поисковой системе. Затем проверьте свой файл robots.txt с помощью инструмента тестирования robots.txt от Google.
Сделайте файл robots.txt оптимизированным для SEO
Файл robots.txt, безусловно, является более техническим аспектом SEO, и он может запутать. Хотя этот файл может быть сложным, простое понимание того, как работает файл robots.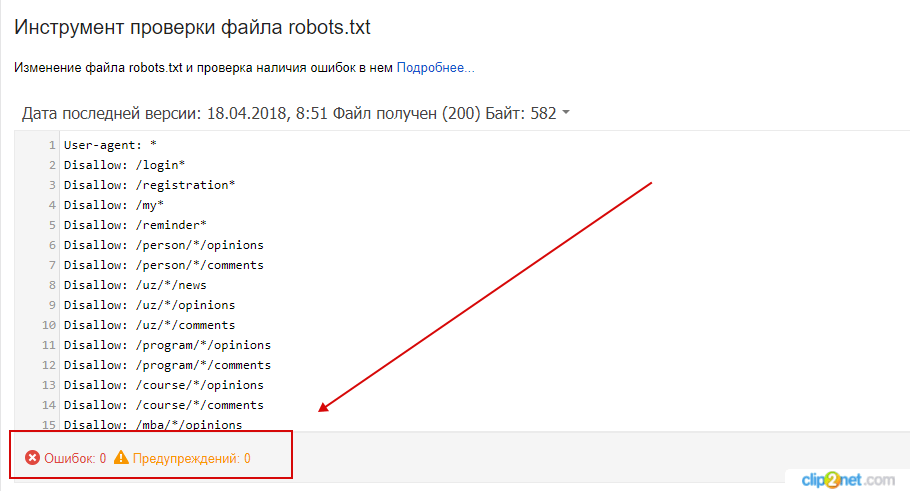 txt и как его создать, поможет вам убедиться, что ваш сайт максимально заметен. Это мощный инструмент, который можно использовать для дальнейшего развития вашей стратегии SEO.
txt и как его создать, поможет вам убедиться, что ваш сайт максимально заметен. Это мощный инструмент, который можно использовать для дальнейшего развития вашей стратегии SEO.
Но если вам нужна помощь с файлом robots.txt или любой другой частью SEO-кампании, мы здесь, чтобы помочь! Boostability помогает малым предприятиям активизировать свои SEO-кампании, увеличить видимость в Интернете и оставаться на высоте по сравнению с другими конкурентами. Позвольте нам помочь вам вывести вашу SEO-стратегию на новый уровень!
Веб-парсер robots.txt с использованием кода Google с открытым исходным кодом
Изюминка: недавно я играл с игрушечным проектом и развернул его как бесплатный веб-инструмент для проверки того, как Google будет анализировать ваших роботов. .txt, поскольку их собственный онлайн-инструмент не воспроизводит реальное поведение робота Googlebot. Проверьте это на realrobotstxt.com.
Готовясь к своей недавней презентации на SearchLove London, я был слегка одержим тем, что чем глубже я копался в том, как работают файлы robots. txt, тем больше удивительных вещей я находил и тем больше мест, где противоречивая информация из разных источников. Парсер Google robots.txt с открытым исходным кодом должен был все упростить, не только соответствуя их недавно опубликованному черновому варианту спецификации, но и, по-видимому, являясь реальным производственным кодом Google.
txt, тем больше удивительных вещей я находил и тем больше мест, где противоречивая информация из разных источников. Парсер Google robots.txt с открытым исходным кодом должен был все упростить, не только соответствуя их недавно опубликованному черновому варианту спецификации, но и, по-видимому, являясь реальным производственным кодом Google.
Две проблемы завели меня дальше в кроличью нору, что в конечном итоге привело к созданию веб-инструмента:
- Это проект C++, поэтому его необходимо скомпилировать, что требует хотя бы некоторых навыков программирования/администрирования кода, поэтому я не чувствовал, что это было особенно доступно для более широкого поискового сообщества
- Когда я скомпилировал его и поэкспериментировал с ним, я обнаружил, что в нем отсутствуют важные специфические для Google функции, позволяющие нам увидеть, как поисковые роботы Google, такие как изображения и видео, будут интерпретировать файлы robots.txt
Чем этот инструмент отличается от других ресурсов
Помимо того, что он представляет собой веб-инструмент, а не требует компиляции для локального запуска, мой инструмент realrobotstxt. com должен на 100 % соответствовать черновой спецификации, опубликованной Google, поскольку он полностью основан на их инструменте с открытым исходным кодом, за исключением двух конкретных изменений, которые я внес, чтобы привести его в соответствие с моим пониманием того, как работают настоящие поисковые роботы Google:
com должен на 100 % соответствовать черновой спецификации, опубликованной Google, поскольку он полностью основан на их инструменте с открытым исходным кодом, за исключением двух конкретных изменений, которые я внес, чтобы привести его в соответствие с моим пониманием того, как работают настоящие поисковые роботы Google:
- Googlebot-image, Googlebot-video и Googlebot-news(*) все должны вернуться к подчинению Директивы Googlebot , если нет наборов правил , в частности , нацеленных на их собственных индивидуальных пользовательских агентов — мы убедились, что это, по крайней мере, то, как бот изображений ведет себя в реальном мире
- У Google есть ряд ботов (AdsBot-Google, AdsBot-Google-Mobile и бот AdSense, Mediapartners-Google), которые, по-видимому, игнорируют директивы User-agent: * и только соблюдают наборы правил, специально предназначенные для их отдельных пользователей. агенты
[(*) Примечание: не имеет отношения к настройкам, которые я сделал, но имеет значение, потому что я упомянул Googlebot-news, очень мало известно, что Googlebot-news не является поисковым роботом и не был им с 2011 года, по всей видимости. Если вы этого не знали, не переживайте — вы не одиноки. Я узнал об этом только недавно, и довольно сложно отличить его от документации, которая регулярно называет его поисковым роботом. Единственная реальная официальная ссылка, которую я могу найти, — это сообщение в блоге, объявляющее о его выходе из эксплуатации. Я имею в виду, что для меня это имеет смысл, потому что наличие разных сканеров для веб-поиска и поиска новостей открывает опасные возможности маскировки, но почему тогда в документации он упоминается как пользовательский агент сканера? Это кажется , хотя я не смог проверить это в реальной жизни, как будто правила, непосредственно нацеленные на Googlebot-news, функционируют как noindex для Google News. Это очень сбивает с толку, потому что обычная блокировка Googlebot , а не удерживает URL-адреса вне веб-индекса, но вот так.]
Если вы этого не знали, не переживайте — вы не одиноки. Я узнал об этом только недавно, и довольно сложно отличить его от документации, которая регулярно называет его поисковым роботом. Единственная реальная официальная ссылка, которую я могу найти, — это сообщение в блоге, объявляющее о его выходе из эксплуатации. Я имею в виду, что для меня это имеет смысл, потому что наличие разных сканеров для веб-поиска и поиска новостей открывает опасные возможности маскировки, но почему тогда в документации он упоминается как пользовательский агент сканера? Это кажется , хотя я не смог проверить это в реальной жизни, как будто правила, непосредственно нацеленные на Googlebot-news, функционируют как noindex для Google News. Это очень сбивает с толку, потому что обычная блокировка Googlebot , а не удерживает URL-адреса вне веб-индекса, но вот так.]
Я ожидаю, что средство проверки robots.txt в Search Console скоро будет удалено
Мы наблюдаем постепенный переход чтобы отключить старые функции Search Console, и я ожидаю, что программа проверки robots.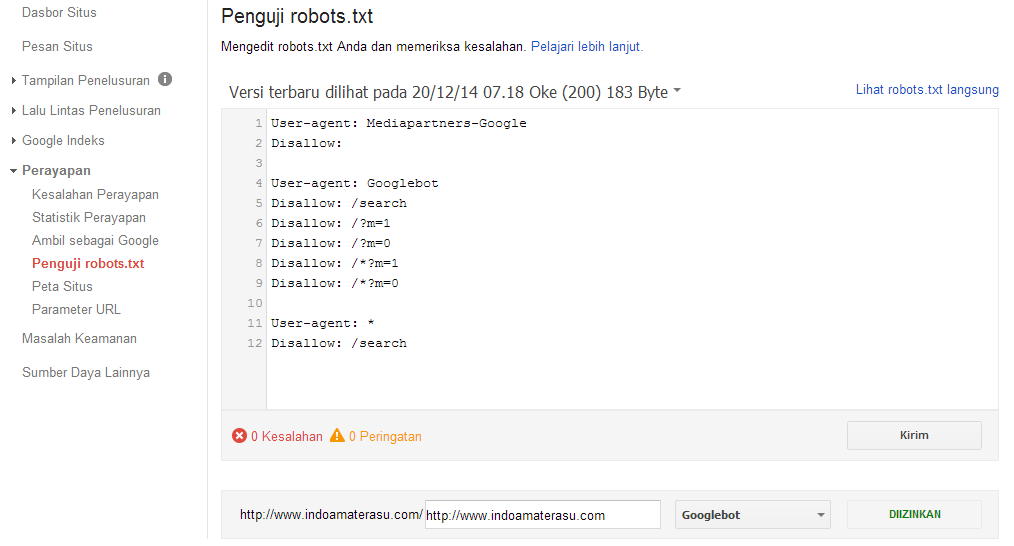.png) txt скоро будет удалена. Сотрудники Google недавно говорили о том, что они не соответствуют тому, как работают их настоящие сканеры, и мы можем увидеть различия в нашем собственном тестировании:
txt скоро будет удалена. Сотрудники Google недавно говорили о том, что они не соответствуют тому, как работают их настоящие сканеры, и мы можем увидеть различия в нашем собственном тестировании:
Эти случаи, кажется, правильно обрабатываются синтаксическим анализатором с открытым исходным кодом — вот мой веб-инструмент по точно такому же сценарию:
Это показалось мне еще одной причиной для выпуска моей веб-версии, поскольку единственный официальный веб-инструмент, который у нас есть, устарел и, вероятно, исчезнет. Кто знает, выпустит ли Google обновленную версию на основе своего парсера с открытым исходным кодом, но пока этого не произойдет, мой инструмент может оказаться полезным для некоторых людей.
Я хочу, чтобы документация обновлялась
К сожалению, хотя я могу сделать запрос на включение открытого исходного кода, я не могу сделать то же самое с документацией Google. Несмотря на заявления Google о том, что старая программа проверки Search Console не синхронизирована с реальным роботом Googlebot, и, следовательно, ей не следует доверять как авторитетному ответу о том, как Google будет анализировать файл robots.