
Что такое индексация сайта и как проиндексировать свой сайт в поисковых системах?
Что такое индексация и как проходит этот процесс в поисковых системах
Любой сайт — будь то корпоративный блог или магазин в e-commerce — проходит несколько важных этапов «рождения». После создания и первичного наполнения контентом, важно проиндексировать сайт поисковыми системами (далее — ПС). Как это происходит:
-
Роботы ПС «видят», что создан новый сайт (или страница).
-
Планируют его «осмотр».
-
Запрашивают контент сайта и анализирует его по ряду параметров.
-
Если все соответствует требованиям — сайт/страница попадает в индекс (своего рода «реестр» ПС), и включается в поисковую выдачу.
Когда пользователь вводит в поисковике запрос, сервис сверяет его с проиндексированными данными и выдает максимально релевантные страницы. Но если при индексации сайта были обнаружены проблемы (ошибки, низкая уникальность текстов, и др.) — ПС могут наложить
Но если при индексации сайта были обнаружены проблемы (ошибки, низкая уникальность текстов, и др.) — ПС могут наложить
Технологии и алгоритмы индексации сайтов в поисковиках
Технология индексации сайта в Google
Google и Яндекс могут проиндексировать сайты по-разному. У Google действует правило «Mobile-first»: поисковые роботы (краулеры) рассматривают именно мобильную версию сайта и присваивают ей индекс. Поэтому если она проигрывает десктопной, содержит ошибки или не обладает полным функционалом — на нее могут быть наложены ограничения.
На частоту проверки сайта краулерами и на индексацию сайта в Гугл влияет так называемый «краулинговый бюджет»: чем он больше — тем чаще и быстрее проверяют сайт. Считается, что возраст сайта и частота обновления контента положительно влияют на размер «краулингового бюджета».
Технология индексации сайта в Яндекс
Яндекс принимает за основную десктопную версию сайта, проверяет и индексирует именно ее.
Как проверить индексацию сайта?
Существует несколько способов проверить индексацию страниц вашего сайта:
-
С помощью плагинов проверки (SEO Magic, RDS bar и др.). Их преимущество — не нужно заходить каждый раз в ПС и вводить запрос, они работают в автоматическом режиме.
-
Через специальные сайты-сервисы проверок: Netpeak Spider, Screaming Frog Seo Spider, Se Ranking, arsenkin.ru, serphunt.ru, raskruty.ru и др.
Факторы индексирования и их влияние на поисковые системы
На индексирование страниц и контента вашего сайта влияют несколько факторов:
-
Файл robots.
 txt. В нем содержатся «подсказки» для краулеров: какие страницы на сайте можно индексировать, а какие — нет. Влияние на индексацию этого файла зависит от типа ПС, но основные — Google и Яндекс, его все же учитывают.
txt. В нем содержатся «подсказки» для краулеров: какие страницы на сайте можно индексировать, а какие — нет. Влияние на индексацию этого файла зависит от типа ПС, но основные — Google и Яндекс, его все же учитывают.
-
Метатег <meta name=“robots” содержит (и при желании — позволяет настроить) команды для поисковых роботов, указывая им как лучше проиндексировать страницы.
-
В серверном программном обеспечении сайта можно добавить в заголовки X-Robots-Tag HTTP-ответы, содержащие настройки, указанные в файлах .htaccess и httpd.conf. Прописанные в них команды будут выполняться всеми краулерами.
-
Тег <noindex> запрещает индексировать определенный контент — например, текст, при помощи пары тегов <noindex>…</noindex> (работает только для поисковой системы Яндекс).
-
Вывод контента Ajax.
Если версия, отображаемая для пользователей, отличается от того, что находится в сохраненной копии, при этом в текстовой версии или коде сохраненной копии отсутствует контент, то это первый признак, что контент страницы может не индексироваться роботами ПС.
 txt. В нем содержатся «подсказки» для краулеров: какие страницы на сайте можно индексировать, а какие — нет. Влияние на индексацию этого файла зависит от типа ПС, но основные — Google и Яндекс, его все же учитывают.
txt. В нем содержатся «подсказки» для краулеров: какие страницы на сайте можно индексировать, а какие — нет. Влияние на индексацию этого файла зависит от типа ПС, но основные — Google и Яндекс, его все же учитывают.
 Если версия, отображаемая для пользователей, отличается от того, что находится в сохраненной копии, при этом в текстовой версии или коде сохраненной копии отсутствует контент, то это первый признак, что контент страницы может не индексироваться роботами ПС.
Если версия, отображаемая для пользователей, отличается от того, что находится в сохраненной копии, при этом в текстовой версии или коде сохраненной копии отсутствует контент, то это первый признак, что контент страницы может не индексироваться роботами ПС.Что делать, если сайт не индексируется?
Если ваш интернет-сайт не индексируется продолжительное время — возможно, существуют проблемы с оптимизацией и стоит проверить некоторые аспекты:
1) Не закрыт ли сайт для индексации через:
- файл Robots.txt,
- в файлах .htaccess и httpd.conf.,
- X-robots-tag.
2) Если в указанных местах доступ не закрыт — стоит проверить, нет ли ошибок в теге rel canonical.
3) Проблемы могут возникать и на хостинге (например, слишком долгое время ответа сервера, или сервер дает неверный ответ на запрос ПС).
4) На сайте содержится неуникальный или контент низкого качества.
И только после проверки всех этих факторов можно искать причины в неверной работе самих ПС. Редко, но иногда сбои происходят именно на стороне поисковиков, но такая информация, как правило, быстро становится общедоступной.
Как ускорить индексацию сайта
Что можно предпринять для более быстрой индексации сайта поисковыми системами? Способов много, перечислим самые очевидные и действенные.
-
Установите автоматическое обновление карты сайта (sitemap). Особенно, если вам нужно быстро проиндексировать страницу в Google — эта ПС обращается к карте в первую очередь, в отличие от Яндекса, которая вначале «смотрит» на файл robots.txt. Все новые страницы должны тут же заноситься в карту сайта.
-
Тщательно проверьте страницы и размещенный контент. Сайт не должен содержать дубли страниц и контент с низким процентом уникальности.
Эти аспекты «воруют» краулинговый бюджет, в результате чего роботы ПС могут просто не добраться до новых страниц, которым нужно индексироваться.
-
Проверьте, нет ли на сайте битых ссылок и каково количество внутренних редиректов. От первых нужно избавиться вовсе, количество вторых — свести к минимуму. Каждый из них также расходует бюджет поисковых роботов.
-
Еще раз проверьте, не закрыты ли добавленные страницы для индексации через robots.txt. Это важно для их дальнейшего продвижения.
-
Проверьте скорость загрузки страниц сайта при помощи PageSpeed Insight. И время ответа сервера, и скорость загрузки отдельных страниц должны быть минимальными (сервис сам измеряет эти показатели и выдаст вам рекомендации по устранению технических недостатков).
-
Проверьте качество внутренней перелинковки.
Краулеры «путешествуют» по внутренним ссылкам так же, как и посетители, автоматически ускоряя скорость индексации страниц.
- Выводите «превью» свежего контента на главную страницу — будь то текстовый материал или карточка с новым товаром. Так ваш контент окажется «на поверхности» сайта и будет быстрее замечен краулерами.
-
Следите за регулярностью обновления контента на сайте. Это относится не только к вновь публикуемым статьям, но и обновлению/корректировке старых.
 Эти аспекты «воруют» краулинговый бюджет, в результате чего роботы ПС могут просто не добраться до новых страниц, которым нужно индексироваться.
Эти аспекты «воруют» краулинговый бюджет, в результате чего роботы ПС могут просто не добраться до новых страниц, которым нужно индексироваться.
 Краулеры «путешествуют» по внутренним ссылкам так же, как и посетители, автоматически ускоряя скорость индексации страниц.
Краулеры «путешествуют» по внутренним ссылкам так же, как и посетители, автоматически ускоряя скорость индексации страниц.
|
Статью подготовил Сергей Лысенко, ведущий спикер Webcom Academy. |
Поделиться с друзьями:
10 способов заставить Google индексировать сайт
Содержание
- Как проверить, есть ли сайт в индексе Google
- Способы, как ускорить индексацию сайта в Google
- Отправьте сайт на проверку вручную
- Проверьте правила в robots.txt
- Проверьте карту сайта sitemap.xml
- Сделайте грамотную внутреннюю перелинковку сайта
- Получите качественные обратные ссылки
- Проработайте nofollow-ссылки
- Проверьте дубли и корректность использования атрибута rel=«canonical»
 org/ListItem»>
Что такое индексирование сайта
org/ListItem»>
Что такое индексирование сайта
 org/ListItem»>
Проверьте использование тега noindex
org/ListItem»>
Проверьте использование тега noindex
 org/ListItem»>
Проверьте наличие страниц-сирот
org/ListItem»>
Проверьте наличие страниц-сирот
Базовый этап работы по SEO — это настройка индексации сайта, ведь без индексации ресурс не смогут увидеть пользователи. Грамотная индексация в дальнейшем позволит избежать проблемы с продвижением.
Что такое индексирование сайта
Индексация сайта в Google — сбор и внесение информации о контенте ресурса в базу поисковой системы. Ранее Google сначала проверял десктопную версию сайта, но с 2019 года индексация сайта в Гугл начинается с проверки мобильной версии.
к содержанию ↑
Как проверить, есть ли сайт в индексе Google
Если вам надо знать, как проверить индексацию страницы в Google, обратитесь к одному из этих способов:
1. Используйте операторы поиска Google.
2. Откройте инструмент проверки URL-адресов в Google Search Console.
к содержанию ↑
Способы, как ускорить индексацию сайта в Google
Сложно сказать, как долго Гугл индексирует новый сайт. Это зависит от скорости загрузки, количества страниц и краулингового бюджета. Но все же существует ряд способов, которые могут ускорить индексацию сайта в Google.
Это зависит от скорости загрузки, количества страниц и краулингового бюджета. Но все же существует ряд способов, которые могут ускорить индексацию сайта в Google.
Отправьте сайт на проверку вручную
Чтобы отправить сайт на индексацию в Гугл, необходимо:
- зайти в Google Search Console и найти инструмент проверки URL;
- ввести URL-адрес и подождать, пока Google его проверит;
- нажать на «Запросить индексирование».
Подобный способ больше подходит для новых страниц. Если вам необходимо понять, почему Google не индексирует сайт, либо вас интересует, как индексировать сайт в Гугл, когда ему уже несколько лет, присмотритесь к следующим способам.
к содержанию ↑
Проверьте правила в robots.txt
Просканируйте файл robots.txt на наличие блоков и запретов. Проблема может возникнуть из-за наличия правила «disallow». Если найдете подобные правила, значит Googlebot не сканирует и, соответственно, не индексирует страницу.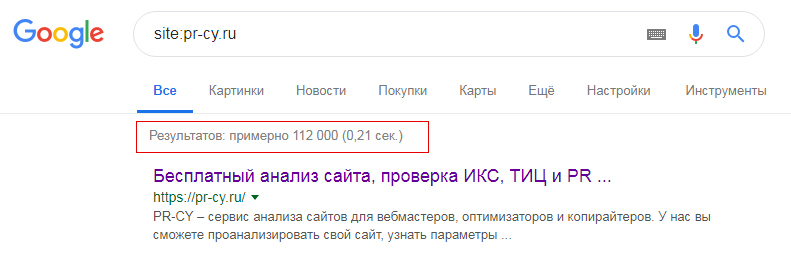
Для проверки откройте Google Search Console, найдите вкладку «Покрытие» и просканируйте robots.txt. Чтобы исправить ситуацию, достаточно удалить правило Disallow: / и снова отправить страницу на индексацию в Гугл.
к содержанию ↑
Проверьте карту сайта sitemap.xml
Sitemap распределяет и отображает важность страниц сайта. Быстро проверить наличие страниц в Sitemap вам поможет инструмент проверки URL в Search Console. Когда на экране появятся такие ошибки, вероятно страницы в карте сайта нет.
После того, как вы добавите необходимые страницы в файл sitemap.xml, не забудьте сообщить Google об обновлении.
к содержанию ↑
Проверьте использование тега noindex
Наличие тега в описании страницы не разрешает Googlebot индексировать ее. Чтобы проверить, если он на сайте, перейдите в контейнер <head>. Если там тег noindex присутствует рядом с тегом googlebot, тогда страница не индексируется в данной поисковой системе. Удалите теги, и страница снова будет доступна для индексации.
Удалите теги, и страница снова будет доступна для индексации.
к содержанию ↑
Сделайте грамотную внутреннюю перелинковку сайта
Она предусматривает проставление ссылок с одной страницы ресурса на другую. Внутренняя структура повышает юзабилити, помогает пользователю быстро ориентироваться. Грамотная внутренняя перелинковка обеспечит значительное увеличение скорости индексации новых материалов и их появление в списке поисковых систем.
к содержанию ↑
Получите качественные обратные ссылки
Наличие этих ссылок показывает Google, что страница, на которую они указывают, имеет вес. Такие ресурсы Google считает более важными, поэтому чаще их сканирует. Но в погоне за обратными ссылками важно размещаться только на качественных и авторитетных ресурсах.
Проработайте nofollow-ссылки
Иногда индексация сайтов в Google невозможна из-за тега rel=«nofollow». Для исправления просканируйте внутренние ссылки и удалите его в случае обнаружения.
к содержанию ↑
Проверьте дубли и корректность использования атрибута rel=«canonical»
Наличие дублированного контента может быть еще одной причиной медленной или нулевой индексации Google. Если страница дублируется или имеет содержание на 99% похожее на другую страницу, Google вряд ли проиндексирует ее.
Итак, убедитесь, что на сайте нет повторяющихся страниц. Если есть, то рекомендуется указать каноническую версию ресурса с помощью тега rel=«canonical» или же удалить такие страницы, поскольку Google будет считать их содержание неуникальным.
к содержанию ↑
Пишите качественный и уникальный контент
Google не обращает внимание на страницы с неуникальным контентом. Поэтому если нет технических проблем, проблема может быть в содержании. Попробуйте взглянуть на контент глазами обычного человека, сделать его более интересным и полезным.
Проверьте наличие страниц-сирот
Страницы-сироты — это страницы, не связанные ни с одной другой страницей ресурса. Если SEO-аудит сайта выявил страницы-сироты, либо полностью уберите их из sitemap, либо добавьте, чтобы Google смог их индексировать.
Если SEO-аудит сайта выявил страницы-сироты, либо полностью уберите их из sitemap, либо добавьте, чтобы Google смог их индексировать.
Индексирование сайта значит, что поисковая система знает о ресурсе, но не факт, что он попадет в ТОП поисковой выдачи. Чтобы сайт получил ключевое место в выдаче, вам нужна SEO-оптимизация.
Специалисты digital-агентства Ланет CLICK осуществят проверку индексации сайта в Гугл, займутся SEO-продвижением, обеспечат грамотный линкбилдинг и качественный копирайтинг. С Ланет CLICK сайт не только будет индексироваться, но и попадет в ТОП поисковой выдачи.
Как проверить индексацию сайта в Google и что делать, если страниц нет в выдаче?
В начале оптимизации сайта важно проверить, какие страницы есть в индексе, а каких нет.
Количество проиндексированных страниц не отвечает фактическому? Давайте разберемся, почему и как это исправить.
Содержание:
Что такое индексация и зачем она нужна
Проверяем индексацию сайта в поисковой системе
Проверяем индексацию сайта с помощью Search Console
Подаем запрос на индексирование страницы в Google Search Console
Как подать на индексирование сразу много ссылок?
Отказ в индексировании: что делать?
Переиндексирование
Закрыть от индексирования
Выводы
Читайте также: Актуальные тренды SEO на 2022 год: 10 важных тенденций для улучшения поисковой оптимизации
Что такое индексация и зачем она нужна
Индексация сайта — это анализ содержимого страницы поисковой системой.
Индексирование страниц необходимо для включения их в результаты поиска.
Можно провести аналогию с картотекой, где хранится информация обо всех книгах в библиотеке. В нашем случае, картотека — это база данных «поисковой индекс», в которой поисковик ищет результаты по запросу пользователя.
Проверяем индексацию сайта в поисковой системе
Введите в Google поиске запрос «site:адрес сайта».
После чего поисковик покажет все проиндексированные страницы сайта. Сразу сравните количество результатов с реальным количеством страниц.
Если цифры совпадают, значит все материалы проиндексированы. Прекрасно!
Если цифры не совпадают, значит поисковые роботы выборочно проиндексировали страницы сайта или еще могут быть проблемы с самими страницами, из-за чего они не попадают в индекс.
Для проверки индексации конкретной страницы используется такой же алгоритм: ввести в поисковике запрос «site:адрес страницы».
Если ваша страница не отобразилась, значит Google не знает о ней.![]() Этому есть несколько причин, о которых расскажем далее.
Этому есть несколько причин, о которых расскажем далее.
Читайте также: SEO букмарклеты: 14 скриптов, которые помогут ускорить оптимизацию сайта
Проверяем индексацию сайта с помощью Search Console
В чем преимущество Google Search Console?
- Помогает быстро найти ошибки и ускорить индексацию;
- Показывает статус каждой страницы.
Как проверить?
- заходим в Search Console;
- переходим в раздел «Проверка URL»;
- вписываем ссылку в поисковую строку;
- видим результат:
Подаем запрос на индексирование страницы в Google Search Console
Но что делать, если страницы нет в индексе?
Либо ждать пока поисковые роботы найдут страницу, либо подать запрос на индексирование – это ускорит процесс.
Нажмите на кнопку «Запросить индексирование».
Как подать на индексирование сразу много ссылок?
Чтоб просканировать сразу много URL:
- создайте sitemap и сделайте его доступным для Google;
- откройте Search Console;
- перейдите в раздел Sitemaps → Сканирование → файлы Sitemap;
- загрузите и отправьте файл.
Отказ в индексировании: что делать?
Почему не индексируется:
- новый сайт, который еще не отсканировался Google
Читайте также: Ошибки, которых следует избегать при создании сайта
- отсутствие sitemap — может быть выборочная индексация страниц сайта
Читайте также: Записки оптимизатора. Дело №2 «О карте сайта»
- ошибки на странице — проверяйте отчеты Google Search Console
- мало контента (текст и медиа-объекты)
Читайте также: Что такое SEO-тексты и как их правильно писать? Научитесь, чтобы оказаться в Топе Google
- ошибки в robots.txt — добавлена директива noindex или доступ к странице только по паролю
- неуникальный контент
Читайте также: Above-the-fold: какой контент хотят видеть люди, а какой — алгоритмы Google?
- дублирование страниц или повторение заголовка страницы
Читайте также: Как быстро найти дубли страниц на сайте? 10 простых способов
- низкая скорость загрузки
Читайте также: Топ-6 ошибок мобильной версии сайта, которые снижают его конверсию
Отказ в индексировании — это не конец света. Исправьте ошибки и подайте запрос на переиндексацию.
Исправьте ошибки и подайте запрос на переиндексацию.
Переиндексирование
Исправили ошибки страницы или внесли изменения — нужна переиндексация.
Как подать запрос на переиндексацию страницы? Также как и запрос на индексирование:
- зайти в Google Search Console;
- вписать ссылку в разделе «Проверка URL»;
- нажать на «Запросить индексирование».
Закрыть от индексирования
Зачем закрывать страницу от индексирования?
- чтоб удалить страницу из выдачи Google;
- чтоб не дать новой странице сканироваться;
- и не нарушать оптимизацию, если на сайте технические работы.
Как это сделать?
- в настройках сервера: запросить доступ по паролю;
- добавить директиву noindex в мета-тег;
- изменить заголовок HTTP-ответа на noindex;
- добавить директиву Disallow в robots.txt.
Читайте также: 3 способа проверить, что сайт попал под фильтр поисковика
Выводы
Два самых простых и быстрых способа проверить индексацию сайта:
- Ввести в поисковой выдаче запрос «site:адрес сайта»;
- Проверить URL в Google Search Console.
Долго не индексируется страница? Подайте запрос на индексацию в Google Search Console.
Уже подавали? Тогда проверьте статус по страницам: исправьте ошибки и подайте запрос еще раз.
Затеяли технические работы на сайте? Закройте от индексирования, чтоб оптимизация страницы не была нарушена.
Если на вашем сайте регулярно появляются новые страницы, вы делитесь ими в соцсетях и добавляете новый контент — то поисковые роботы быстро найдут и отсканирут ваш сайт.
К примеру, информационному ресурсу, на котором постоянно публикуются новые объявления, подавать запрос на индексирование не обязательно. Если сайт активный, то Google достаточно быстро его найдет.
Но если ваша цель повысить органический трафик — то запрос на индексирование ускорит процесс. Это важно для коммерческих сайтов, если продавать нужно уже.
Также читайте другие статьи в блоге Webpromo:
- Похожие URL-адреса могут стать причиной исключения страниц из индекса Google;
- 7 рекомендаций по составлению UTM-меток. Виды, способы использования, полезные UTM-генераторы;
- Сайт упал! Что делать, чтобы поддерживать индексацию страниц в Google?
 Виды, способы использования, полезные UTM-генераторы;
Виды, способы использования, полезные UTM-генераторы;И подписывайтесь на наш Telegram-канал про маркетинг.
Индексация сайта и ее основные принципы
12 мин — время чтения
Фев 18, 2020
Поделиться
Когда-нибудь задумывались, как сайты попадают в выдачу поисковых систем? И как поисковикам удается выдавать нам тонны информации за считанные секунды?
Секрет такой молниеносной работы — в поисковом индексе. Его можно сравнить с огромным и идеально упорядоченным каталогом-архивом всех веб-страниц. Попадание в индекс означает, что поисковик вашу страницу увидел, оценил и запомнил. А, значит, он может показывать ее в результатах поиска.
Предлагаю разобраться в процессе индексации с нуля, чтобы понимать, как сайты попадают в выдачу, можно ли управлять этим процессом и что нужно знать про индексирование ресурсов с различными технологиями.
Что такое сканирование и индексация?
Сканирование страниц сайта — это процесс, когда поисковая система отправляет свои специальные программы (мы знаем их как поисковых роботов, краулеров, спайдеров, пауков) для сбора данных с новых и измененных страниц сайтов.
Индексация страниц сайта — это сканирование, считывание данных и добавление их в индекс (каталог) поисковыми роботами. Поисковик использует полученную информацию, чтобы узнать, о чем же ваш сайт и что находится на его страницах. После этого он может определить ключевые слова для каждой просканированной страницы и сохранить их копии в поисковом индексе. Для каждой страницы он хранит URL и информацию о контенте.
В результате, когда пользователи вводят поисковый запрос в интернете, поисковик быстро просматривает свой список просканированных сайтов и показывает только релевантные страницы в выдаче. Как библиотекарь, который ищет нужные вам книги в каталоге — по алфавиту, тематике и точному названию.
Индексация сайтов в разных поисковых системах отличается парой важных нюансов. Давайте разбираться, в чем же разница.
Индексация сайта в GoogleКогда мы гуглим что-то, поиск данных ведется не по сайтам в режиме реального времени, а по индексу Google, в котором хранятся сотни миллиардов страниц. Во время поиска учитываются разные факторы ― ваше местоположение, язык, тип устройства и т. д.
Во время поиска учитываются разные факторы ― ваше местоположение, язык, тип устройства и т. д.
В 2019 году Google изменил свой основной принцип индексирования сайта — вы наверняка слышали о запуске Mobile-first. Основное отличие нового способа в том, что теперь поисковик хранит в индексе мобильную версию страниц. Раньше в первую очередь учитывалась десктопная версия, а теперь первым на ваш сайт приходит робот Googlebot для смартфонов — особенно, если сайт новый. Все остальные сайты постепенно переходят на новый способ индексирования, о чем владельцы узнают в Google Search Console.
Еще несколько основных отличий индексации в Google:
- индекс обновляется постоянно;
- процесс индексирования сайта занимает от нескольких минут до недели;
- некачественные страницы обычно понижаются в рейтинге, но не удаляются из индекса.
В индекс попадают все просканированные страницы, а вот в выдачу по запросу — только самые качественные. Прежде чем показать пользователю какую-то веб-страницу по запросу, поисковик проверяет ее релевантность по более чем 200 критериям (факторам ранжирования) и отбирает самые подходящие.![]()
Что поисковые роботы делают на вашем сайте, мы разобрались, а вот как они попадают туда? Существует несколько вариантов.
Как поисковые роботы узнают о вашем сайте
Если это новый ресурс, который до этого не индексировался, нужно «представить» его поисковикам. Получив приглашение от вашего ресурса, поисковые системы отправят на сайт своих краулеров для сбора данных.
Вы можете пригласить поисковых ботов на сайт, если разместите на него ссылку на стороннем интернет-ресурсе. Но учтите: чтобы поисковики обнаружили ваш сайт, они должны просканировать страницу, на которой размещена эта ссылка. Этот способ работает для обоих поисковиков.
Также можно воспользоваться одним из перечисленных ниже вариантов:
- Создайте файл Sitemap, добавьте на него ссылку в robots.txt и отправьте файл Sitemap в Google.
- Отправьте запрос на индексацию страницы с изменениями в Search Console.
Каждый сеошник мечтает, чтобы его сайт быстрее проиндексировали, охватив как можно больше страниц. Но повлиять на это не в силах никто, даже лучший друг, который работает в Google.
Но повлиять на это не в силах никто, даже лучший друг, который работает в Google.
Скорость сканирования и индексации зависит от многих факторов, включая количество страниц на сайте, скорость работы самого сайта, настройки в веб-мастере и краулинговый бюджет. Если кратко, краулинговый бюджет — это количество URL вашего сайта, которые поисковый робот хочет и может просканировать.
На что же мы все-таки можем повлиять в процессе индексации? На план обхода поисковыми роботами нашего сайта.
Как управлять поисковым роботом
Поисковая система скачивает информацию с сайта, учитывая robots.txt и sitemap. И именно там вы можете порекомендовать поисковику, что и как скачивать или не скачивать на вашем сайте.
Файл robots.txtЭто обычный текстовый файл, в котором указаны основные сведения — например, к каким поисковым роботам мы обращаемся (User-agent) и что запрещаем сканировать (Disallow).
Указания в robots.txt помогают поисковым роботам сориентироваться и не тратить свои ресурсы на сканирование маловажных страниц (например, системных файлов, страниц авторизации, содержимого корзины и т.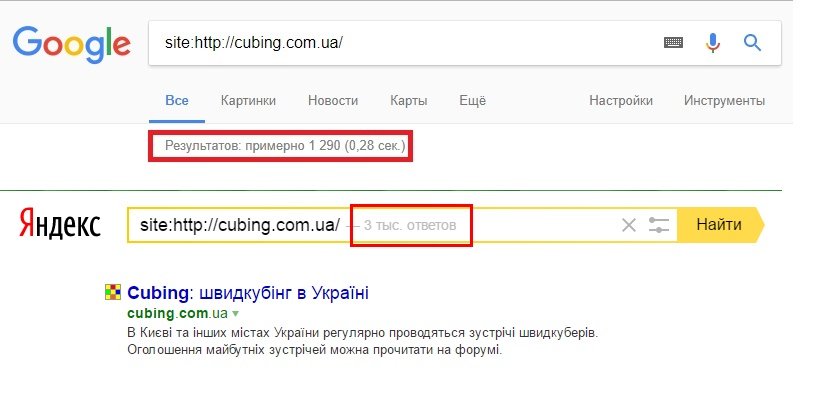 д.). Например, строка Disallow:/admin запретит поисковым роботам просматривать страницы, URL которых начинается со слова admin, а Disallow:/*.pdf$ закроет им доступ к PDF-файлам на сайте.
д.). Например, строка Disallow:/admin запретит поисковым роботам просматривать страницы, URL которых начинается со слова admin, а Disallow:/*.pdf$ закроет им доступ к PDF-файлам на сайте.
Также в robots.txt стоит обязательно указать адрес карты сайта, чтобы указать поисковым роботам ее местоположение.
Чтобы проверить корректность robots.txt, воспользуйтесь отдельным инструментом в Google Search Console.
Файл SitemapЕще один файл, который поможет вам оптимизировать процесс сканирования сайта поисковыми роботами ― это карта сайта (Sitemap). В ней указывают, как организован контент на сайте, какие страницы подлежат индексации и как часто информация на них обновляется.
Если на вашем сайте несколько страниц, поисковик наверняка обнаружит их сам. Но когда у сайта миллионы страниц, ему приходится выбирать, какие из них сканировать и как часто. И тогда карта сайта помогает в их приоритезации среди прочих других факторов.
Также сайты, для которых очень важен мультимедийный или новостной контент, могут улучшить процесс индексации благодаря созданию отдельных карт сайта для каждого типа контента. Отдельные карты для видео также могут сообщить поисковикам о продолжительности видеоряда, типе файла и условиях лицензирования. Карты для изображений ― что изображено, какой тип файла и т. д. Для новостей ― дату публикации. название статьи и издания.
Чтобы ни одна важная страница вашего сайта не осталась без внимания поискового робота, в игру вступают навигация в меню, «хлебные крошки», внутренняя перелинковка. Но если у вас есть страница, на которую не ведут ни внешние, ни внутренние ссылки, то обнаружить ее поможет именно карта сайта.
А еще в Sitemap можно указать:
- частоту обновления конкретной страницы — тегом <changefreq>;
- каноническую версию страницы ― атрибутом rel=canonical;
- версии страниц на других языках ― атрибутом hreflang.
Карта сайта также здорово помогает разобраться, почему возникают сложности при индексации вашего сайта. Например, если сайт очень большой, то там создается много карт сайта с разбивкой по категориям или типам страниц. И тогда в консоли легче понять, какие именно страницы не индексируются и дальше разбираться уже с ними.
Проверить правильность файла Sitemap можно в Google Search Console вашего сайта в разделе «Файлы Sitemap».
Итак, ваш сайт отправлен на индексацию, robots.txt и sitemap проверены, пора узнать, как прошло индексирование сайта и что поисковая система нашла на ресурсе.
Как проверить индексацию сайта
Проверка индексации сайта осуществляется несколькими способами:
1. Через оператор site: в Google. Этот оператор не дает исчерпывающий список страниц, но даст общее понимание о том, какие страницы в индексе. Выдает результаты по основному домену и поддоменам.
2. Через Google Search Console. В консоли вашего сайта есть детальная информация по всем страницам ― какие из них проиндексированы, какие нет и почему.
3. Воспользоваться плагинами для браузера типа RDS Bar или специальными инструментами для проверки индексации. Например, узнать, какие страницы вашего сайта попали в индекс поисковика можно в инструменте «Проверка индексации» SE Ranking.
Для этого достаточно ввести нужную вам поисковую систему (Google, Yahoo, Bing), добавить список урлов сайта и начать проверку. Чтобы протестировать работу инструмента «Проверка индексации», зарегистрируйтесь на платформе SE Ranking и откройте тул в разделе «Инструменты».
В этом месте вы можете поднять руку и спросить «А что, если у меня сайт на AJAX? Он попадет в индекс?». Отвечаем 🙂
Особенности индексирования сайтов с разными технологиями
AjaxСегодня все чаще встречаются JS-сайты с динамическим контентом ― они быстро загружаются и удобны для пользователей. Одно из основных отличий таких сайтов на AJAX — все содержимое подгружается одним сплошным скриптом, без разделения на страницы с URL. Вместо этого ― страницы с хештегом #, которые не индексируются поисковиками. Как следствие — вместо URL типа https://mywebsite.ru/#example поисковый робот обращается к https://mywebsite.ru/. И так для каждого найденного URL с #.
Вместо этого ― страницы с хештегом #, которые не индексируются поисковиками. Как следствие — вместо URL типа https://mywebsite.ru/#example поисковый робот обращается к https://mywebsite.ru/. И так для каждого найденного URL с #.
В этом и кроется сложность для поисковых роботов, потому что они просто не могут «считать» весь контент сайта. Для поисковиков хороший сайт ― это текст, который они могут просканировать, а не интерактивное веб-приложение, которое игнорирует природу привычных нам веб-страниц с URL.
Буквально пять лет назад сеошники могли только мечтать о том, чтобы продвинуть такой сайт в поиске. Но все меняется. Уже сейчас в справочной информации Google есть данные о том, что нужно для индексации AJAX-сайтов и как избежать ошибок в этом процессе.
Сайты на AJAX с 2019 года рендерятся Google напрямую — это значит, что поисковые роботы сканируют и обрабатывают #! URL как есть, имитируя поведение человека. Поэтому вебмастерам больше не нужно прописывать HTML-версию страницы.
Но здесь важно проверить, не закрыты ли скрипты со стилями в вашем robots.txt. Если они закрыты, обязательно откройте их для индексирования поисковыми роботам. Для этого в robots.txt нужно добавить такие команды:
User-agent: Googlebot Allow: /*.js Allow: /*.css Allow: /*.jpg Allow: /*.gif Allow: /*.pngФлеш-контент
С помощью технологии Flash, которая принадлежит компании Adobe, на страницах сайта можно создавать интерактивный контент с анимацией и звуком. За 20 лет своего развития у технологии было выявлено массу недостатков, включая большую нагрузку на процессор, ошибки в работе флеш-плеера и ошибки в индексировании контента поисковиками.
В 2019 году Google перестал индексировать флеш-контент, ознаменовав тем самым конец целой эпохи.
Поэтому не удивительно, что поисковик предлагает не использовать Flash на ваших сайтах. Если же дизайн сайта выполнен с применением этой технологии, сделайте и текстовую версию сайта.![]() Она будет полезна как пользователям, у которых не установлена совсем или установлена устаревшая программа отображения Flash и пользователям мобильных устройств (они не отображают flash-контент).
Она будет полезна как пользователям, у которых не установлена совсем или установлена устаревшая программа отображения Flash и пользователям мобильных устройств (они не отображают flash-контент).
Фрейм это HTML-документ, который не содержит собственного контента, а состоит из разных областей ― каждая с отдельной веб-страницей. Также у него отсутствует элемент BODY.
Как результат, поисковым роботам просто негде искать полезный контент для сканирования. Страницы с фреймами индексируются очень медленно и с ошибками.
Вот что известно от самого поисковика: Google может индексировать контент внутри встроенного фрейма iframe. Именно iframe поддерживается современными технологиями, так как он позволяет встраивать фреймы на страницы без применения тега <iframe>.
А вот теги <frame>, <noframes>, <frameset> устарели и уже не поддерживаются в HTML5, поэтому и не рекомендуется использовать их на сайтах. Ведь даже если страницы с фреймами будут проиндексированы, то трудностей в их продвижении вам все равно не избежать.
Ведь даже если страницы с фреймами будут проиндексированы, то трудностей в их продвижении вам все равно не избежать.
Что в итоге
Поисковые системы готовы проиндексировать столько страниц вашего сайта, сколько нужно. Только подумайте, объем индекса Google значительно превышает 100 млн гигабайт ― это сотни миллиардов проиндексированных страниц, количество которых растет с каждым днем.
Но зачастую именно от вас зависит успех этого мероприятия. Понимая принципы индексации поисковых систем, вы не навредите своему сайту неправильными настройками. Если вы все правильно указали в robots.txt и карте сайта, учли технические требования поисковиков и позаботились о наличии качественного и полезного контента, поисковики не оставят ваш сайт без внимания.
Помните, что индексирование ― это не о том, попадет ваш сайт в выдачу или нет. Намного важнее ― сколько и каких страниц окажутся в индексе, какой контент на них будет просканирован и как он будет ранжироваться в поиске. И здесь ход за вами!
467 views
Как проверить индексацию страницы и сайта в Google
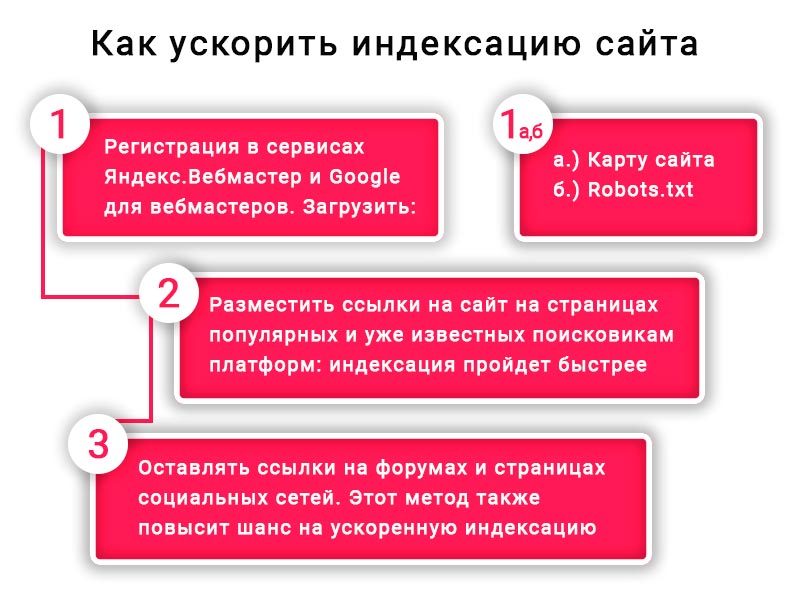
Посмотреть, что попало или не попало в индекс Google — часть работы любого веб-мастера. Но немногие знают, что факт присутствия ссылок на страницы сайта в индексе — очень расплывчатое понятие. Мерилом должны служить показы ссылок в поиске по запросам. Если показов нет, то уже и особой разницы — находится ссылка в индексе или не находится, нет.
Но немногие знают, что факт присутствия ссылок на страницы сайта в индексе — очень расплывчатое понятие. Мерилом должны служить показы ссылок в поиске по запросам. Если показов нет, то уже и особой разницы — находится ссылка в индексе или не находится, нет.
Search Console
Основной инструмент по работе с ссылками сайта — Проверка URLв новой Search Console:
Здесь всё просто: указываете URL страницы, проверяете на наличие её в индексе, и если нет ошибок и противоречий, отправляете на индексацию. Серч коносль работает крайне медленно, поэтому много ссылок отправить быстро не получится.
Обратите внимание на инструменты (там же в новой Серч консоли) Эффективность и Покрытие. Они показывают более масштабную картинку и дают статистику по показам.
См. статью Отчет об эффективности.
Файлы Sitemap
Сайтмап делится на два вида:
- стандартный формат sitemap
- rss фид
В первом случае это файл или группа файлов, куда генерируются вообще все ссылки страниц с сайта. Обрабатывается он редко и долго.
Обрабатывается он редко и долго.
Во втором случае фид имеет смысл указывать короткий, на 20-50 страниц с сортировкой в порядке обновления. Фид Google сканирует чаще, поэтому быстрее будет забирать обновлённые страницы.
Индексация Sitemap — это не индексация всего сайта. И Google не обязан проиндексировать всё. Очень часто встречающееся заблуждение, что в индексе должны быть все страницы. Вообще, нет смысла на крупных сайтах держать группы sitemap с миллионами страниц. Достаточно в sitemap указывать категории, далее Гугл построит скелет сайта и сам найдёт все ссылки.
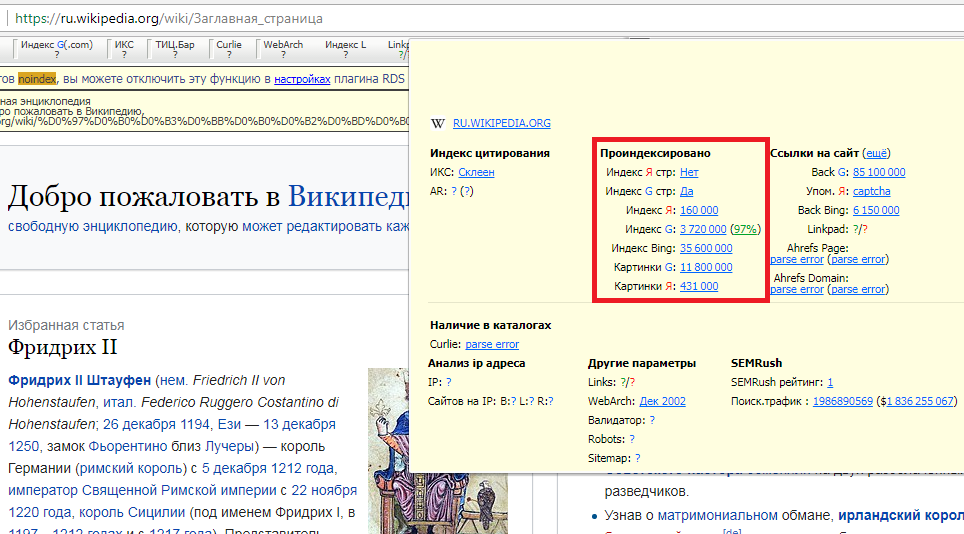
На скрине видим здоровую ситуацию, sitemap читается, ошибок нет, практически всё проиндексировано. В итоге у нас цифры (кол-во страниц) 279 со Статуса индексирования и 161 с Sitemap.
Оператор Site
Поисковый оператор site изначально служил для оценки деятельности сайта в поиске, но со временем утратил свою актуальность и не рекомендуется гуглерами для проверки индексации сайта.
С официального форума для веб-мастеров Google:
Ни актуальных заголовков (изменяются по запросам), ни точных данных site уже не показывает. В нём можете встретить остаточный мусор, страницы, закрытые в robots, страницы, по которым нет показов и т.п., не участвующее в поиске.
С возрастом сайта уменьшается точность данных, выводимых оператором. На данный момент оператор site годится лишь для мониторинга ошибок в индексе и получения общего представления о сайте, например, с его помощью можно проверить микроразметку или увидеть, есть ли ручные меры за спам или нет. При дальнейшем щёлканье по страницам выдачи с оператора можно увидеть, как цифра страниц в поиске изменяется:
Всё равно, полученная цифра 130 записывается в блокнотик, а ссылки изучаются на предмет поросятины в сниппетах (паразитных кусков кода, опечаток и т.п.), заодно можно оценить кол-во отсортированных страниц, ушедших в дополнительные, т.![]() е, в скрытые, результаты выдачи Мы скрыли некоторые результаты, которые очень похожи на уже представленные выше:
е, в скрытые, результаты выдачи Мы скрыли некоторые результаты, которые очень похожи на уже представленные выше:
Сервисы проверки индексации страниц
Проверить индексацию сайта в Google и Яндексе можно с помощью сервиса Serphunt https://serphunt.ru/indexing/.
Данный сервис позволяет производить пакетную (списком, возможность загрузки до 50 адресов) проверку ссылок на наличие индексации в обоих поисковиках.
Так же Серпхант умеет проверять позиции, имеет инструменты для оценки эффективности и мониторинга сайтов, а так же есть функция анализа страниц конкурентов.
Инструменты статистики
Основной инструмент для изучения ссылок в индексе — Метрика или Аналитика. Они позволяют разом оценить важность страниц для обеих поисковых систем (Яндекс и Google) и произвести сравнительный анализ.
В данном примере в Метрике можно увидеть главные Страницы входа.
Но это популярные страницы со входящим трафиком отовсюду. Списки страниц на скриншоте обрезаны.
Сегментируем страницы по поисковой системе, в частности, Google (еще можно смотреть содержимое поискового трафика Google):
Тут можно увидеть, что одна страница (кстати, из мобильного поиска) круче остальных, а список остальных страниц входа с Google представлен в Метрике ниже (не попал на скриншот). Эта цифра ~100. Но реальную пользу можно извлечь где-то из 50 страниц, что в не согласуется с цифрами, полученными выше. Далее можно отслеживать конверсии и прийти к выводу, что действительно первостепенно для сайта, и в каком русле надо продолжить работу.
По урлам и запросам (Последняя поисковая фраза в Метрике, к примеру) можно определить, какие страницы приводят посетителей, какие нет и на что вообще надо тратить время. Если ожидаемых результатов нет, тогда страница переделывается (дописывается, переписыватся, перевёрстывается — нужное подчеркнуть) и отправляется через Инструмент проверки URL в Search Console. Дополнительное средство для анализа — Отчет об эффективности.
Дополнительное средство для анализа — Отчет об эффективности.
Резюмируя выше описанное:
- В связи с технологическим совершенствованием поиска Googleна первый план вышла актуальность страниц, имеющих показы в поиске (мобильный, планшетный, декстоп).
- Страницы в индексе, как таковые, не играют роли, если не приводят посетителей, и мониторить их обязательное включение в индекс, без соответствующей качественной обработки, не имеет смысла.
- Популярные жалобы «сайт не индексируется» нужно рассматривать не только в техническом плане, но и в контентном. Если страница не отвечает на запрос пользователя, то очевидно, ей в поиске делать нечего.
- Проверка индексации сайта в Гугле — это процесс не двух нажатий, а следствие тщательного анализа различных источников, главные из которых — Search Console, Яндекс Вебмастер (для сравнительного анализа), Метрика или Аналитика.
- Первостепенную важность имеют запросы, а не наполнение поиска Google страницами вашего сайта.

настройка, статусы, ошибки индексации и способы их исправления — Топвизор
 txt
txtПодробный SEO-гайд по Отчёту об индексировании Google Search Console. Разберёмся, как проверить индексацию сайта с его помощью, как «читать» статусы URL, какие ошибки можно обнаружить и как их исправить.
Разберёмся, как проверить индексацию сайта с его помощью, как «читать» статусы URL, какие ошибки можно обнаружить и как их исправить.
Перевод с сайта onely.com.
В Отчёте вы можете получить данные о сканировании и индексации всех URL-адресов, которые Google смог обнаружить на вашем сайте. Он поможет отследить, добавлен ли сайт в индекс, и проинформирует о технических проблемах со сканированием и индексацией.
Но перед тем, как говорить об Отчёте, вспомним все этапы индексации страницы в Google.
Как проходит индексация в Google
Чтобы страница ранжировалась в поиске и показывалась пользователям, она должна быть обнаружена, просканирована и проиндексирована.
Обнаружение
Перед тем, как просканировать страницу, Google должен её обнаружить. Он может сделать это несколькими способами.
Наиболее распространённые — с помощью внутренних или внешних ссылок или через карту сайта (файл Sitemap.xml).
Сканирование
Суть сканирования состоит и том, что поисковые системы изучают страницу и анализируют её содержимое.
Главный аспект в этом вопросе — краулинговый бюджет, который представляет собой лимит времени и ресурсов, который поисковая система готова «потратить» на сканирование вашего сайта.
Что такое «краулинговый бюджет, как его проверить и оптимизировать
Индексация
В процессе индексации Google оценивает качество страницы и добавляет её в индекс — базу данных, где собраны все страницы, о которых «знает» Google.
В этот этап включается и рендеринг, который помогает Google видеть макет и содержимое страницы. Собранная информация даёт поисковой системе понимание, как показывать страницу в результатах поиска.
Некоторые страницы могут содержать контент низкого качества или быть дублями. Если поисковые системы их увидят, это может негативно отразится на всём сайте.
Поэтому важно в процессе создания стратегии индексации решить, какие страницы должны и не должны быть проиндексированы.
Ранжирование
Только проиндексированные страницы могут появиться в результатах поиска и ранжироваться.
Google определяет, как ранжировать страницу, основываясь на множестве факторов, таких как количество и качество ссылок, скорость страницы, удобство мобильной версии, релевантность контента и др.
Теперь перейдём к Отчёту.
Как пользоваться Отчётом об индексировании в Google Search Console
Чтобы просмотреть Отчёт, авторизуйтесь в своём аккаунте Google Search Console. Затем в меню слева выберите «Покрытие» в секции «Индекс»:
Как найти Отчёт об индексировании в Google Search ConsoleПеред вами Отчёт. Отметив галочками любой из статусов или все сразу, вы сможете выбрать то, что хотите визуализировать на графике:
Статусы URL на странице ОтчётаВы увидите четыре статуса URL-адресов:
- Ошибка — критическая проблема сканирования или индексации.
- Без ошибок, есть предупреждения — URL-адреса проиндексированы, но содержат некоторые некритичные ошибки.
- Страница без ошибок — страницы проиндексированы корректно.
- Исключено — страницы, которые не были проиндексированы из-за проблем (это самый важный раздел, на котором нужно сфокусироваться).

Фильтры «Все обработанные страницы» vs «Все отправленные страницы»
В верхнем углу вы можете отфильтровать, какие страницы хотите видеть:
Фильтр отображаемых страниц«Все обработанные страницы» показываются по умолчанию. В этот фильтр включены все URL-адреса, которые Google смог обнаружить любым способом.
Фильтр «Все отправленные страницы» включает только URL-адреса, добавленные с помощью файла Sitemap.
Так что когда открываете Отчёт, убедитесь, что смотрите нужные данные.
Проверка статусов URL
Чтобы увидеть подробную информацию о проблемах, обнаруженных для каждого статуса, посмотрите «Сведения» под графиком:
Раздел «Сведения»Тут показан статус, тип проблемы и количество затронутых страниц. Обратите внимание на столбец «Проверка» — после исправления ошибки, вы можете попросить Google проверить URL повторно.
Например, если кликнуть на первую строку со статусом «Предупреждение», то вверху появится кнопка «Проверить исправление»:
Проверка исправленийВы также можете увидеть динамику каждого статуса: увеличилось, уменьшилось или осталось на том же уровне количество URL-адресов в этом статусе.
Если в «Сведениях» кликнуть на любой статус, вы увидите количество адресов, связанных с ним. Кроме того, вы сможете посмотреть, когда каждая страница была просканирована (но помните, что эта информация может быть неактуальна из-за задержек в обновлении отчётов).
Подробная информация о сканировании в СведенияхЧто учесть при использовании отчёта
- Всегда проверяйте, смотрите ли вы отчёт по всем обработанным или по всем отправленным страницам. Разница может быть очень существенной.
- Отчёт может показывать изменения с задержкой. После публикации контента подождите несколько дней, пока страницы просканируются и проиндексируются.
- Google пришлёт уведомления на электронную почту, если увидит какие-то критичные проблемы с сайтом.
- Стремитесь к индексации канонической версии страницы, которую вы хотите показывать пользователям и поисковым ботам.
- В процессе развития сайта, на нём будет появляться больше контента, так что ожидайте увеличения количества проиндексированных страниц в Отчёте.

Как часто смотреть Отчёт
Обычно достаточно делать это раз в месяц.
Но если вы внесли значимые изменения на сайте, например, изменили макет страницы, структуру URL или сделали перенос сайта, мониторьте Отчёт чаще, чтобы вовремя поймать негативное влияние изменений.
Рекомендую делать это хотя бы раз в неделю и обращать особое внимание на статус «Исключено».
Дополнительно: инструмент проверки URL
В Search Console есть ещё один инструмент, который даст ценную информацию о сканировании и индексации страниц вашего сайта — Инструмент проверки URL.
Он находится в самом верху страницы в GSC:
Инструмент проверки URLПросто вставьте URL, который вы хотите проверить, в эту строку и увидите данные по нему. Например:
Например:
Инструментом можно пользоваться для того, чтобы:
- проверить статус индексирования URL, и обнаружить возможные проблемы;
- узнать, индексируется ли URL;
- просмотреть проиндексированную версию URL;
- запросить индексацию, например, если страница изменилась;
- посмотреть загруженные ресурсы, например, такие как JavaScript;
- посмотреть, какие улучшения доступны для URL, например, реализация структурированных данных или удобство для мобильных.
Если в Отчёте об индексировании обнаружены какие-то проблемы со страницами, используйте Инструмент, чтобы тщательнее проверить их и понять, что именно нужно исправить.
Статус «Ошибка»
Под этим статусом собраны URL, которые не были проиндексированы из-за ошибок.
Если вы видите проблему с пометкой «Отправлено», то это может касаться только URL, которые были отправлены через карту сайту. Убедитесь, что в карте сайте содержатся только те страницы, которые вы действительно хотите проиндексировать.
Убедитесь, что в карте сайте содержатся только те страницы, которые вы действительно хотите проиндексировать.
Ошибка сервера (5xx)
Эта проблема говорит об ошибке сервера со статусом 5xx, например, 502 Bad Gateway или 503 Service Unavailable.
Советую регулярно проверять этот раздел и следить, нет ли у Googlebot проблем с индексацией страниц из-за ошибки сервера.
Что делать. Нужно связаться с вашим хостинг-провайдером, чтобы исправить эту проблему или проверить, не вызваны ли эти ошибки недавними обновлениями и изменениями на сайте.
Как исправить ошибки сервера — рекомендации Google
Ошибка переадресации
Редиректы перенаправляют поисковых ботов и пользователей со старого URL на новый. Обычно они применяются, если старый адрес изменился или страницы больше не существует.
Ошибки переадресации могут указывать на такие проблемы:
- цепочка редиректов слишком длинная;
- обнаружен циклический редирект — страницы переадресуют друг на друга;
- редирект настроен на страницу, URL которой превышает максимальную длину;
- в цепочке редиректов найден пустой или ошибочный URL.

Что делать. Проверьте и исправьте редиректы каждой затронутой страницы.
Доступ к отправленному URL заблокирован в файле robots.txt
Эти страницы есть в файле Sitemap, но заблокированы в файле robots.txt.
Robots.txt — это файл, который содержит инструкции для поисковых роботов о том, как сканировать ваш сайт. Чтобы URL был проиндексирован, Google нужно для начала его просканировать.
Что делать. Если вы видите такую ошибку, перейдите в файл robots.txt и проверьте настройку директив. Убедитесь, что страницы не закрыты через noindex.
Страница, связанная с отправленным URL, содержит тег noindex
По аналогии с предыдущей ошибкой, эта страница была отправлена на индексацию, но она содержит директиву noindex в метатеге или в заголовке ответа HTTP.
Что делать. Если страница должна быть проиндексирована, уберите noindex.
Отправленный URL возвращает ложную ошибку 404
Ложная ошибка 404 означает, что страница возвращает статус 200 OK, но её содержимое может указывать на ошибку. Например, страница пустая или содержит слишком мало контента.
Например, страница пустая или содержит слишком мало контента.
Что делать. Проверьте страницы с ошибками и посмотрите, есть ли возможность изменить контент или настроить редирект.
Отправленный URL возвращает ошибку 401 (неавторизованный запрос)
Ошибка 401 Unauthorized означает, что запрос не может быть обработан, потому что необходимо залогиниться под правильными user ID и паролем.
Что делать. Googlebot не может индексировать страницы, скрытые за логинами. Или уберите необходимость авторизации или подтвердите авторизацию Googlebot, чтобы он мог получить доступ к странице.
Отправленный URL не найден (ошибка 404)
Ошибка 404 говорит о том, что запрашиваемая страница не найдена, потому что была изменена или удалена. Такие страницы есть на каждом сайте и наличие их в малом количестве обычно ни на что не влияет. Но если пользователи будут находить такие страницы, это может отразиться негативно.
Что делать. Если вы увидели эту проблему в отчёте, перейдите на затронутые страницы и проверьте, можете ли вы исправить ошибку. Например, настроить 301-й редирект на рабочую страницу.
Например, настроить 301-й редирект на рабочую страницу.
Дополнительно убедитесь, что файл Sitemap не содержит URL, которые возвращают какой-либо другой код состояния HTTP кроме 200 OK.
При отправке URL произошла ошибка 403
Код состояния 403 Forbidden означает, что сервер понимает запрос, но отказывается авторизовывать его.
Что делать. Можно либо предоставить доступ анонимным пользователям, чтобы робот Googlebot мог получить доступ к URL, либо, если это невозможно, удалить URL из карты сайта.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Страница может быть непроиндексирована из-за других ошибок 4xx, которые не описаны выше.
Что делать. Чтобы понять, о какой именно ошибке речь, используйте Инструмент проверки URL. Если устранить ошибку невозможно, уберите URL из карты сайта.
Статус «Без ошибок, есть предупреждения»
URL без ошибок, но с предупреждениями, были проиндексированы, но могут требовать вашего внимания. Тут обычно случается две проблемы.
Тут обычно случается две проблемы.
Проиндексировано, несмотря на блокировку в файле robots.txt
Обычно эти страницы не должны быть проиндексированы, но скорее всего Google нашёл ссылки, указывающие на них, и посчитал их важными.
Что делать. Проверьте эти страницы. Если они всё же должны быть проиндексированы, то обновите файл robots.txt, чтобы Google получил к ним доступ. Если не должны — поищите ссылки, которые на них указывают. Если вы хотите, чтобы URL были просканированы, но не проиндексированы, добавьте директиву noindex.
Страница проиндексирована без контента
URL проиндексированы, но Google не смог прочитать их контент. Это может быть из-за таких проблем:
- Клоакинг — маскировка контента, когда Googlebot и пользователи видят разный контент.
- Страница пустая.
- Google не может отобразить страницу.
- Страница в формате, который Google не может проиндексировать.
Зайдите на эти страницы сами и проверьте, виден ли на них контент. Также проверьте их через Инструмент проверки URL и посмотрите, как их видит Googlebot. После того, как устраните ошибки, или если не обнаружите каких-либо проблем, вы можете запросить у Google повторное индексирование.
Статус «Страница без ошибок»
Здесь показываются страницы, которые корректно проиндексированы. Но на эту часть Отчёта всё равно нужно обращать внимание, чтобы сюда не попали страницы, которые не должны были оказаться в индексе. Тут тоже есть два статуса.
Страница была отправлена в Google и проиндексирована
Это значит, что страницы отправлена через Sitemap и Google её проиндексировал.
Страница проиндексирована, но её нет в файле Sitemap
Это значит, что страница проиндексирована даже несмотря на то, что её нет в Sitemap. Посмотрите, как Google нашёл эту страницу, через Инструмент проверки URL.
Чаще всего страницы в этом статусе — это страницы пагинации, что нормально, учитывая, что их и не должно быть в Sitemap. Посмотрите список этих URL, вдруг какие-то из них стоит добавить в карту сайта.
Посмотрите список этих URL, вдруг какие-то из них стоит добавить в карту сайта.
Статус «Исключено»
В этом статусе находятся страницы, которые не были проиндексированы. В большинстве случаев это вызвано теми же проблемами, которые мы обсуждали выше. Единственное различие в том, что Google не считает, что исключение этих страниц вызвано какой-либо ошибкой.
Вы можете обнаружить, что многие URL здесь исключены по разумным причинам. Но регулярный просмотр Отчёта поможет убедиться, что не исключены важные страницы.
Индексирование страницы запрещено тегом noindex
Что делать. Тут то же самое — если страница и не должна быть проиндексирована, то всё в порядке. Если должна — удалите noindex.
Индексирование страницы запрещено с помощью инструмента удаления страниц
У Google есть Инструмент удаления страниц. Как правило с его помощью Google удаляет страницы из индекса не навсегда. Через 90 дней они снова могут быть проиндексированы.
Что делать. Если вы хотите заблокировать страницу насовсем, вы можете удалить её, настроит редирект, внедрить авторизацию или закрыть от индексации с помощью тега noindex.
Если вы хотите заблокировать страницу насовсем, вы можете удалить её, настроит редирект, внедрить авторизацию или закрыть от индексации с помощью тега noindex.
Заблокировано в файле robots.txt
У Google есть Инструмент проверки файла robots.txt, где вы можете в этом убедиться.
Что делать. Если эти страницы и не должны быть в индексе, то всё в порядке. Если должны — обновите файл robots.txt.
Помните, что блокировка в robots.txt — не стопроцентный вариант закрыть страницу от индексации. Google может проиндексировать её, например, если найдёт ссылку на другой странице. Чтобы страница точно не была проиндексирована, используйте директиву noindex.
Подробнее о блокировке индексирования при помощи директивы noindex
Страница не проиндексирована вследствие ошибки 401 (неавторизованный запрос)
Обычно это происходит на страницах, защищённых паролем.
Что делать. Если они и не должны быть проиндексированы, то ничего делать не нужно. Если вы не хотите, чтобы Google обнаруживал эти страницы, уберите существующие внутренние и внешние ссылки на них.
Если вы не хотите, чтобы Google обнаруживал эти страницы, уберите существующие внутренние и внешние ссылки на них.
Страница просканирована, но пока не проиндексирована
Это значит, что страница «ждёт» решения. Для этого может быть несколько причин. Например, с URL нет проблем и вскоре он будет проиндексирован.
Но чаще всего Google не будет торопиться с индексацией, если контент недостаточно качественный или выглядит похожим на остальные страницы сайта.
В этом случае он поставит её в очередь с низким приоритетом и сфокусируется на индексации более важных страниц. Google говорит, что отправлять такие страницы на переиндексацию не нужно.
Что делать. Для начала убедитесь, что это не ошибка. Проверьте, действительно ли URL не проиндексирован, в Инструменте проверки URL или через инструмент «Индексация» в Анализе сайта в Топвизоре. Они показывают более свежие данные, чем Отчёт.
Как исправить ошибку, когда страница просканирована, но не проиндексирована (на английском)
Обнаружена, не проиндексирована
Это значит, что Google увидел страницу, например, в карте сайта, но ещё не просканировал её. В скором времени страница может быть просканирована.
В скором времени страница может быть просканирована.
Иногда эта проблема возникает из-за проблем с краулинговым бюджетом. Google может посчитать сайт некачественным, потому что ему не хватает производительности или на нём слишком мало контента.
Что такое краулинговый бюджет и как его оптимизировать
Возможно, Google не нашёл каких-либо ссылок на эту страницу или нашёл страницы с большим ссылочным весом и посчитал их более приоритетными для сканирования.
Если на сайте есть более качественные и важные страницы, Google может игнорировать менее важные страницы месяцами или даже никогда их не просканировать.
Вариант страницы с тегом canonical
Эти URL — дубли канонической страницы, отмеченные правильным тегом, который указывает на основную страницу.
Что делать. Ничего, вы всё сделали правильно.
Страница является копией, канонический вариант не выбран пользователем
Это значит, что Google не считает эти страницы каноническими. Посмотрите через Инструмент проверки URL какую страницу он считает канонической.
Посмотрите через Инструмент проверки URL какую страницу он считает канонической.
Что делать. Выберите страницу, которая по вашему мнению является канонической, и разметьте дубли с помощью rel=”canonical”.
Страница является копией, канонические версии страницы, выбранные Google и пользователем, не совпадают
Вы выбрали каноническую страницу, но Google решил по-другому. Возможно, страница, которую вы выбрали, не имеет столько внутреннего ссылочного веса, как неканоническая.
Что делать. В этом случае может помочь объединение URL повторяющихся страниц.
Как правильно настроить внутренние ссылки на сайте
Не найдено (404)
URL нет в Sitemap, но Google всё равно его обнаружил. Возможно, это произошло с помощью ссылки на другом сайте или ранее страница существовала и была удалена.
Что делать. Если вы и не хотели, чтобы Google индексировал страницу, то ничего делать не нужно. Другой вариант — поставить 301-й редирект на работающую страницу.
Страница с переадресацией
Эта страница редиректит на другую страницу, поэтому не была проиндексирована. Обычно, такие страницы не требуют внимания.
Что делать. Эти страницы и не должны быть проиндексированы, так что делать ничего не нужно.
Ложная ошибка 404
Обычно это страницы, на которых пользователь видит сообщение «не найдено», но которые не сопровождаются кодом ошибки 404.
Что делать. Для исправления проблемы вы можете:
- Добавить или улучшить контент таких страниц.
- Настроить 301-й редирект на ближайшую альтернативную страницу.
- Настроить сервер, чтобы он возвращал правильный код ошибки 404 или 410.
Страница является копией, отправленный URL не выбран в качестве канонического
Эти страницы есть в Sitemap, но для них не выбрана каноническая страница. Google считает их дублями и канонизировал их другими страницами, которые определил самостоятельно.
Что делать. Выберите и добавьте канонические страницы для этих URL.
Страница заблокирована из-за ошибки 403 (доступ запрещён)
Что делать. Если Google не может получить доступ к URL, лучше закрыть их от индексации с помощью метатега noindex или файла robots.txt.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Сервер столкнулся с ошибкой 4xx, которая не описана выше.
Гайд по ошибкам 4xx и способы их устранения (на английском)
Попробуйте исправить ошибки или оставьте страницы как есть.
Ключевые выводы
- Проверяя данные в Отчёте помните, что не все страницы сайта должны быть просканированы и проиндексированы.
- Закрыть от индексации некоторые страницы может быть так же важно, как и следить за тем, чтобы нужные страницы сайта индексировались корректно.
- Отчёт об индексировании показывает как критичные ошибки, так и неважные, которые не обязательно требуют действий с вашей стороны.
- Регулярно проверяйте Отчёт, но только для того, чтобы убедиться, что всё идёт по плану. Исправляйте только те ошибки, которые не соответствуют вашей стратегии индексации.
Как проверить, проиндексированы ли веб-страницы в Google
Вы можете проверить, индексируются ли URL-адреса вашего веб-сайта в Google, воспользовавшись API проверки URL-адресов Search Console, который вы можете подключить к Sitebulb через интеграцию Google Search Console.
Это может позволить вам увидеть данные высокого уровня о том, индексируется ли URL-адрес или нет, а также «причины», по которым URL-адреса не индексируются, что позволяет вам исследовать дальше.
Для ясности: возвращаемые данные — это данные, которые Google Search Console хранит для заданного URL-адреса. API будет возвращать информацию об индексации, которая в настоящее время доступна в инструменте проверки URL-адресов. Что делает Sitebulb, так это позволяет вам собирать эти данные в большом количестве.
Подключение Sitebulb к API проверки URL-адресов
Чтобы подключить Sitebulb к API проверки URL-адресов, добавьте Google Search Console в настройки аудита при настройке проекта и установите флажок в разделе Конфигурация Опции для Извлечь данные URL из Search Console Inspection API .
На этом этапе важно убедиться, что вы выбрали правильное свойство. Sitebulb поможет вам сделать это, предварительно выбрав свойство путем сопоставления с начальным URL-адресом, но у вас может быть несколько свойств для одной и той же учетной записи (например, свойства домена и свойства на уровне URL).
Ограничение дневной квоты
Основное предостережение этой функции заключается в том, что Google ограничивает количество запросов до 2000 URL-адресов в день для каждого свойства веб-сайта Search Console (т. е. вызовов, запрашивающих один и тот же сайт).
Это означает, что если у вас есть веб-сайт с более чем 2000 URL-адресов, Sitebulb не сможет одновременно собирать информацию об индексировании всех URL-адресов. В этом случае Sitebulb будет запрашивать 2000 лучших URL-адресов HTML, упорядоченных по рейтингу URL-адресов.
В этом случае Sitebulb будет запрашивать 2000 лучших URL-адресов HTML, упорядоченных по рейтингу URL-адресов.
Таким образом, по умолчанию Sitebulb всегда выбирает наиболее важные страницы для проверки индексации на основе популярности внутренних ссылок.
Важное замечание, которое не стоит игнорировать
Эта квота распространяется на каждый веб-сайт, а не на инструмент. Если вы собираете данные API с помощью нескольких разных инструментов, все они берутся из одного и того же пула квот. Если вы израсходовали лимит в 2000 деней с помощью других инструментов, вы не сможете собирать больше данных с помощью Sitebulb в тот же день.
Точно так же существует ограничение на количество запросов в API, равное 600 URL-адресам в минуту. Sitebulb настроен на безопасный запрос в пределах этого ограничения, но если вы одновременно нажмете на API двумя разными инструментами, вы можете случайно превысить его для любых сообщений об ошибках.
Дополнительную информацию о превышении ограничений API см.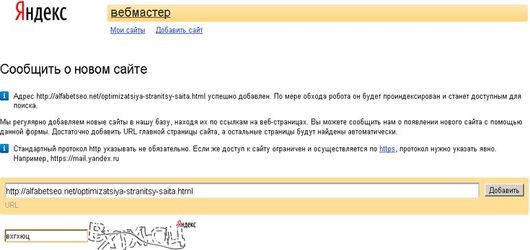 в разделе «Если данные URL не возвращаются».
в разделе «Если данные URL не возвращаются».
Просмотр данных проверки URL-адресов в Sitebulb
Чтобы получить доступ к данным, собранным Sitebulb, перейдите к отчету Проверка URL-адресов с помощью навигации слева.
В обзоре показаны многочисленные диаграммы и таблицы, и если вы нажмете на вкладку URL-адреса , вы увидите все данные в формате таблицы:
Как и во всех списках URL-адресов в Sitebulb, данные могут быть дополнены и точны. -настраивается путем добавления дополнительных столбцов, сортировки или применения расширенных фильтров.
Изучение данных проверки URL
Данные, возвращаемые API, могут быть весьма обширными и детализированными, поэтому для того, чтобы действительно понять, на что вы смотрите, требуется некоторое знакомство с отчетом о покрытии индекса и инструментом проверки URL в Google Search Console.
Тем не менее, Sitebulb предоставляет вам простой и интуитивно понятный доступ к важным элементам данных, таким как «URL-адреса не индексируются в Google», с простым рабочим процессом для более глубокого изучения данных.
На любой из диаграмм щелкните область сегмента, чтобы просмотреть отфильтрованный URL-адрес Список данных:
Это приведет вас к следующим URL-данным:
Кроме того, на любой диаграмме вы можете щелкнуть переключатель «Просмотр таблицы данных», который отображает данные диаграммы в формате таблицы:
Затем данные диаграммы будут отображаться в таблице, и нажатие на любое из этих значений также приведет вас к соответствующему списку URL-адресов:
В самих списках URL-адресов вы можете анализировать проблемы в пакетном режиме, прокручивая вправо, чтобы просмотреть наиболее значимые столбцы:
В качестве альтернативы, чтобы погрузиться в определенный URL-адрес и посмотреть, что говорит инструмент проверки в Google Search Console, просто нажмите оранжевую кнопку, чтобы Открыть проверку URL-адреса :
Это откроет консоль поиска Google в в вашем браузере с уже открытым инструментом проверки URL и предварительно загруженным выбранным URL:
Что показывают различные диаграммы
В отчете о проверке URL есть несколько круговых диаграмм и столбчатых диаграмм, поэтому мы пройдемся по ним что показывает каждый:
Покрытие
На этой диаграмме каждый URL-адрес разбит на разные сегменты в зависимости от того, сможет ли Google найти и проиндексировать страницу. Каждый вариант включает краткую описательную причину статуса URL-адреса, объясняющую, почему URL-адрес находится или не находится в Google.
Каждый вариант включает краткую описательную причину статуса URL-адреса, объясняющую, почему URL-адрес находится или не находится в Google.
Сводка
Эта круговая диаграмма дает сводную оценку того, могут ли URL отображаться в результатах поиска Google.
Важно отметить, что «URL находится в Google» не обязательно означает, что страница появляется в результатах поиска, а просто означает, что она проиндексирована.
Индексирование разрешено
На этой диаграмме показано, разрешают ли URL-адреса явно запрещать индексирование (например, тег noindex). Если индексация запрещена, в легенде указывается причина — эти страницы не будут отображаться в результатах поиска Google.
Обратите внимание: если страница заблокирована файлом robots.txt, для параметра «Индексирование разрешено» всегда будет установлено значение «Да», поскольку Google не может видеть и соблюдать директивы noindex.
URL-адреса карты сайта
На этой диаграмме URL-адреса, отправленные в Inspection API, разделены на основе их статуса карты сайта. Либо они не были найдены на картах сайта в Google Search Console (в этом случае они отображаются как «Не отправлено»), они были отправлены и проиндексированы, либо отправлены, но не проиндексированы.
Либо они не были найдены на картах сайта в Google Search Console (в этом случае они отображаются как «Не отправлено»), они были отправлены и проиндексированы, либо отправлены, но не проиндексированы.
Просканировано как
На этой диаграмме показано распределение между URL-адресами, просканированными с помощью Google Mobile Crawler и их Desktop Crawler.
Результаты на этой диаграмме относятся только к проиндексированным URL-адресам.
Сканирование разрешено
На этой диаграмме показано, разрешено ли Google сканирование URL-адресов в соответствии с правилами сайта robots.txt. Обратите внимание, что это значение отличается от разрешения индексирования, которое задается значением «Индексирование разрешено».
Результаты на этой диаграмме относятся только к проиндексированным URL-адресам.
Пользователь против Google Canonical
На этой диаграмме показано, согласен ли Google с объявленным пользователем каноническим URL-адресом. Если они согласны, это будет отображаться как «Совпадение», а если они не согласны, это будет отображаться как «Несоответствие». Если канонических нет и Google выбрал один, это будет отображаться как «Выбрано Google».
Если они согласны, это будет отображаться как «Совпадение», а если они не согласны, это будет отображаться как «Несоответствие». Если канонических нет и Google выбрал один, это будет отображаться как «Выбрано Google».
Дней с момента последнего сканирования
На этой диаграмме показано распределение URL-адресов на основе даты их последнего сканирования Google. Дни, обозначенные как «0», означают, что URL-адрес был просканирован в течение последнего дня. Диапазоны дат позволяют копать глубже и исследовать URL-адреса, которые недавно сканировались или вообще не сканировались.
Расширенные результаты
На этой диаграмме показано, подходят ли URL-адреса для расширенных результатов и вызывают ли URL-адреса ошибки или предупреждения.
Результаты на этой диаграмме относятся только к URL-адресам, которые содержат структурированные данные, которые могут привести к расширенным результатам.
Подходит для мобильных устройств
На этой диаграмме показано, считает ли Google URL-адреса удобными для мобильных устройств и вызывают ли URL-адреса ошибки или предупреждения.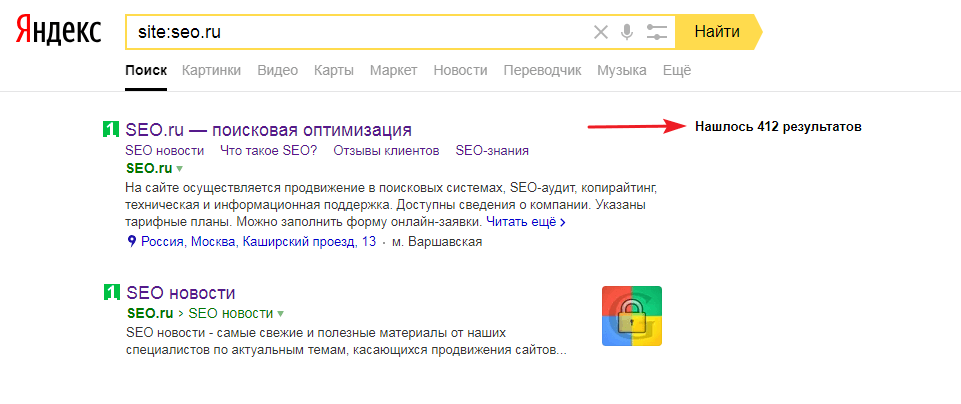
Результаты на этой диаграмме относятся только к проиндексированным URL-адресам.
Когда данные URL не возвращаются
Иногда вы обнаружите, что данные URL не возвращаются, и это может быть по ряду причин:
#1 Превышена квота: вы исчерпали дневную квоту URL
Если вы превысите дневную квоту (см. выше), вам нужно будет подождать 24 часа, прежде чем пытаться снова. Также имейте в виду, что ограничение в 2000 URL-адресов относится к ресурсу в день, что может означать, что вы превысили ограничение из-за инструментов, отличных от Sitebulb.
Как только Sitebulb превысит дневную квоту, он перестанет отправлять запросы API.
#2 Превышена квота: Вы превысили лимит скорости
В API существует ограничение на количество запросов в 600 URL-адресов в минуту. Sitebulb настроен на безопасный запрос в рамках этого ограничения, но если вы одновременно нажмете на API двумя разными инструментами, вы можете случайно превысить его для любых сообщений об ошибках.
#3 Запрещено: запрошенный URL-адрес недействителен для этого ресурса
Это означает, что Sitebulb запросил данные индексации для URL-адреса, который «не является частью выбранного ресурса».
Например, https://example.com для свойства префикса URL https://www.example.com . Если вы хотите проверить URL-адреса из нескольких субдоменов, выберите свойство на уровне домена.
#4 Сбой: вышла ошибка API
Это означает, что сам API Google не работает. Если это произойдет, вернитесь и повторите попытку позже.
Как узнать, что Google индексирует на моем сайте?
Николас Лонгтин | Сентябрь 2021
Мы часто получаем вопросы от клиентов о том, как Google будет сканировать их сайт и какой контент Google сможет «увидеть» и, следовательно, добавить в поисковый индекс Google. В идеальном мире каждая страница на вашем сайте, каждый загруженный и связанный документ, а также каждое изображение будут появляться в релевантных результатах поиска Google, но это не всегда так. Продолжайте читать, чтобы узнать, как вы можете просмотреть свой веб-сайт и определить, какой контент Google будет сканировать и делать доступным в результатах поиска.
Продолжайте читать, чтобы узнать, как вы можете просмотреть свой веб-сайт и определить, какой контент Google будет сканировать и делать доступным в результатах поиска.
Создание индекса Google
Конечной целью Google является «организация мировой информации». То, как они делают это для онлайн-контента, состоит в том, чтобы создать всеобъемлющий индекс всего контента веб-сайта и сделать его доступным для быстрого поиска с помощью различных сервисов. Google создал невероятно продвинутую систему «сканирования» веб-сайтов для загрузки контента, однако у сканера есть технические ограничения и другие причины, по которым некоторый контент никогда не попадает в результаты поиска Google.
Чтобы понять, что нельзя просканировать и добавить в этот индекс, полезно понять, как работают роботы-сканеры Google. Google обнаруживает новые URL-адреса различными способами, когда обнаруживается новая страница, Google «сканирует» страницу, визуализируя ее и загружая весь код, из которого состоит страница. Google найдет все ссылки на другие URL-адреса и файлы на этой странице и продолжит сканировать и анализировать этот контент.
Google найдет все ссылки на другие URL-адреса и файлы на этой странице и продолжит сканировать и анализировать этот контент.
В большинстве случаев Google будет продолжать переходить по ссылкам на протяжении всего процесса сканирования и продолжать добавлять контент в свой индекс. Однако есть некоторые причины, по которым связанный URL-адрес или файл не будут сканироваться.
Преднамеренная блокировка сканера
Существует множество причин, по которым Google не может сканировать определенный URL-адрес. Большинство этих причин связаны с техническими проблемами, которые непреднамеренно присутствуют на веб-страницах. Однако есть некоторые преднамеренные способы, которыми люди намеренно блокируют Google от сканирования URL-адреса, и мы рассмотрим их в первую очередь.
Блокировка контента с помощью Robots.txt
На вашем веб-сайте может быть специальный текстовый файл, называемый файлом robots. В этом файле вы можете сообщить поисковым системам, что вы не хотите, чтобы они сканировали. Google уважает информацию в этом файле, но имейте в виду, что другие поисковые системы могут этого не делать. Кроме того, простое включение URL-адреса в файл robots может не защитить контент от Google, существуют и другие способы обнаружения URL-адреса Google.
Google уважает информацию в этом файле, но имейте в виду, что другие поисковые системы могут этого не делать. Кроме того, простое включение URL-адреса в файл robots может не защитить контент от Google, существуют и другие способы обнаружения URL-адреса Google.
Использование страницы тестера роботов Google для чтения и тестирования файла robot.txt ArcStone.
Причины, по которым люди блокируют некоторые ULR от сканеров, могут быть разными и могут включать:
- Скрытие содержимого, например экрана входа или других скрытых областей
- Запрещение Google индексировать новый контент, который все еще находится в черновой форме
- Не позволять Google индексировать плохой контент, который может быть полезен для некоторых пользователей, но может негативно повлиять на SEO
- Предотвращение Google от индексации отдельных файлов мультимедиа
Вы также можете использовать файл robots, чтобы сообщить Google, что он должен ограничить скорость сканирования, чтобы не перегружать ваш сайт. Однако это редкий случай использования, и любой хорошо построенный современный веб-сайт не должен подвергаться негативному влиянию сканера Google.
Однако это редкий случай использования, и любой хорошо построенный современный веб-сайт не должен подвергаться негативному влиянию сканера Google.
Блокировка содержимого с помощью тега NOINDEX
Еще один способ намеренно запретить Google индексировать URL-адрес с помощью тега NOINDEX. Это специальный фрагмент кода, называемый «МЕТА-ТЕГ». Эти теги не видны пользователям, но используются для управления поведением поисковых систем и браузеров. Использование тега NOINDEX — гораздо более надежный способ предотвратить сканирование контента Google. Google не будет включать страницы с тегом NOINDEX в результаты поиска.
ССЫЛКИ NOFOLLOW
Еще одна причина, по которой Google может не продолжить сканирование содержимого, заключается в том, что сканер встречает атрибут NOFOLLOW в ссылке. Это специальная часть HTML-кода ссылки, которая сообщает поисковым роботам, что по ссылке не следует «следовать», а ссылающаяся страница не должна индексироваться.
Хотя YouTube разрешает ссылки в описаниях видео, вы можете видеть из исходного кода, это ссылка «nofollow», что означает, что поисковый робот Google не будет переходить по ней.
Имейте в виду, что большинство URL-адресов содержат много ссылок, указывающих на них, и атрибут NOFOLLOW не предназначен для защиты контента от поисковой системы Google. Атрибут NOFOLLOW обычно используется для управления SEO-преимуществом ссылки. Когда веб-сайт A ссылается на веб-сайт B, Google интерпретирует это как веб-сайт A, «ручающийся» за содержание веб-сайта B. Часто веб-сайты хотят ссылаться на другой сайт, но не ассоциироваться с ним или рассматриваться как ручающиеся за качество связанного сайта. .
Имейте в виду, что, несмотря на то, что независимые эксперименты подтвердили, что Google соблюдает атрибут NOFOLLOW, который может быть изменен в любое время без предварительного уведомления. Кроме того, даже если Google может не предоставить вашему веб-сайту значительных SEO преимуществ от NOFOLLOW-ссылок, это все равно здорово, когда на ваш сайт ссылаются с других высококачественных веб-сайтов с высоким трафиком.
Регистрация или платный доступ
Имейте в виду, что Google может сканировать только то, что общедоступно на вашем веб-сайте, и не будет индексировать контент, защищенный платным доступом, входом в систему или системами регистрации. В большинстве случаев контент, заблокированный за формой входа или регистрации, намеренно скрыт от Google, но бывают редкие случаи, когда вы хотите ранжировать этот контент. Например, у вас может быть большая библиотека ресурсов на вашем сайте, но вы хотите, чтобы пользователи регистрировались перед доступом к ней. В этом случае возможный обходной путь — предоставить выдержки из контента, которые Google может сканировать, но сохранить паролем полный контент.
В большинстве случаев контент, заблокированный за формой входа или регистрации, намеренно скрыт от Google, но бывают редкие случаи, когда вы хотите ранжировать этот контент. Например, у вас может быть большая библиотека ресурсов на вашем сайте, но вы хотите, чтобы пользователи регистрировались перед доступом к ней. В этом случае возможный обходной путь — предоставить выдержки из контента, которые Google может сканировать, но сохранить паролем полный контент.
Непреднамеренные проблемы со сканированием
Ошибки и другие специфические проблемы с загрузкой страниц — еще одна причина, по которой Google может не индексировать содержимое веб-сайта. Даже если веб-страница выглядит безупречно для пользователей, поисковый робот Google может столкнуться с основными проблемами, препятствующими индексации контента.
Ошибки загрузки
Самая распространенная ошибка и наиболее знакомая людям ошибка 404. Эта ошибка просто означает, что URL-адрес, на который делается ссылка, не может быть найден.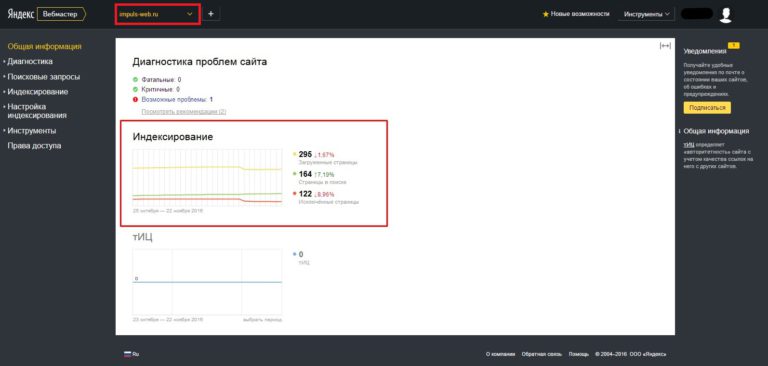 Это может быть URL-адрес, который был удален, перемещен или URL-адрес все еще существует, но веб-сервер возвращает 404 «код состояния». Каждый раз, когда ресурс запрашивается с веб-сервера, возвращается код состояния для запроса, а в некоторых редких случаях, даже если контент загружается, возвращается код 404. Это предотвратит индексацию контента Google. Это редкая ситуация, которая иногда возникает, когда системы CMS веб-сайта содержат основные ошибки или другие проблемы,
Это может быть URL-адрес, который был удален, перемещен или URL-адрес все еще существует, но веб-сервер возвращает 404 «код состояния». Каждый раз, когда ресурс запрашивается с веб-сервера, возвращается код состояния для запроса, а в некоторых редких случаях, даже если контент загружается, возвращается код 404. Это предотвратит индексацию контента Google. Это редкая ситуация, которая иногда возникает, когда системы CMS веб-сайта содержат основные ошибки или другие проблемы,
Другие проблемы с загрузкой, препятствующие сканированию, могут включать:
- 500 ошибок, которые возникают из-за проблем с кодированием и не позволяют веб-серверу возвращать какой-либо контент
- Циклы перенаправления, которые генерируются, когда страница перенаправляется на другую страницу, которая, в свою очередь, пытается выполнить другое перенаправление
- Проблемы с тайм-аутом, которые возникают, когда URL-адрес слишком долго возвращает код состояния или содержимое, Google будет ждать только столько времени, пока страница загрузится
Динамически загружаемый контент
Другая менее очевидная ситуация, которая может помешать Google проиндексировать полное содержимое URL-адреса, — это если компоненты страницы загружаются динамически. Под динамически загружаемым контентом мы подразумеваем то, что иногда JavaScript или другой язык сценариев загружает контент на веб-страницу после первоначальной загрузки. Этот контент не будет виден сканерам и, следовательно, не может быть проиндексирован.
Под динамически загружаемым контентом мы подразумеваем то, что иногда JavaScript или другой язык сценариев загружает контент на веб-страницу после первоначальной загрузки. Этот контент не будет виден сканерам и, следовательно, не может быть проиндексирован.
Это чаще встречается в «одностраничных» веб-приложениях или сайтах с одной длинной страницей, которая продолжает загружаться частями, когда люди прокручивают страницу вниз. В худшем случае навигация вашего сайта загружается динамически. В этих редких случаях Google может вообще не сканировать ваш сайт, за исключением главной страницы.
Скорость сайта и бюджет сканирования
Сейчас большинство людей осознают, что скорость сайта является критической проблемой. Для реальных пользователей на вашем сайте быстрая загрузка страниц означает счастливых посетителей и, как правило, больше просмотров страниц за сеанс, что отлично подходит для SEO. Поисковые системы также заботятся о скорости сайта. Google дает каждому сайту «бюджет сканирования», что означает, что он будет сканировать столько страниц, сколько сможет за определенный период времени. Это означает, что если ваш сайт работает очень медленно, Google не сможет добраться до многих ваших страниц, и этот контент не будет проиндексирован.
Это означает, что если ваш сайт работает очень медленно, Google не сможет добраться до многих ваших страниц, и этот контент не будет проиндексирован.
Для очень крупных веб-сайтов нередко индексируется только определенный процент их сайта. Популярность сайта, возможность сканирования, скорость и структура — все это влияет на то, какая часть вашего сайта сканируется Google. Высококачественные веб-сайты, соответствующие передовым методам SEO, будут гораздо чаще сканироваться Google и иметь больше шансов появиться в результатах поиска.
Связанные файлы, которые поисковые роботы не могут прочитать, и БОЛЬШИЕ ФАЙЛЫ
Google не только сканирует веб-страницы, но и может сканировать и понимать широкий спектр внешних типов файлов, на которые может ссылаться содержимое вашей страницы. Наиболее распространенными типами файлов, на которые ссылаются веб-страницы, являются файлы PDF. В зависимости от структуры этих файлов Google может сканировать и анализировать их содержимое.
Однако файлы PDF «только изображения» и некоторые другие типы файлов не могут быть просканированы Google. Кроме того, если ваш файл может быть понят Google, но он очень большой, это может повлиять на краулинговый бюджет, о котором мы только что говорили, и в конечном итоге означает, что ваш сайт будет проиндексирован меньше. Если возможно, избегайте внешних файлов и сохраняйте все содержимое вашего веб-сайта на реальных веб-страницах HTML.
Как определить, что Google может сканировать
Теперь, когда мы рассмотрели множество деталей о том, как Google сканирует Интернет и что может пойти не так, давайте углубимся в способы тестирования вашего веб-сайта, чтобы убедиться, что Google может просканировать максимальное количество контента.
Использование вашего браузера
Веб-браузер, который вы используете каждый день для работы в Интернете, также имеет несколько простых инструментов, которые вы можете использовать, чтобы определить, что Google может сканировать на вашем сайте. Во всех следующих примерах мы будем использовать браузер Google Chrome, хотя большинство других браузеров имеют аналогичные возможности.
Во всех следующих примерах мы будем использовать браузер Google Chrome, хотя большинство других браузеров имеют аналогичные возможности.
Просмотр исходного кода страницы
«Исходный код» веб-страницы — это базовый код, который интерпретируется вашим веб-браузером для создания визуального отображения страницы. В большинстве браузеров вы можете щелкнуть правой кнопкой мыши или через меню получить доступ к опции для просмотра этого исходного кода. Код будет содержать весь обычный текстовый контент, который вы обычно читаете на веб-странице, в окружении HTML, CSS, JavaScript и другого кода. Все, что вы можете увидеть, просмотрев исходный код, индексируется Google.
Например, если у вас есть текст в слайд-шоу, компонент аккордеона или другой визуальный механизм, который не показывает контент, пока пользователь не взаимодействует с ним, вы можете просмотреть исходный код, чтобы определить, будет ли Google индексировать этот контент. Просто откройте исходный код и найдите текст. Если вы можете найти текст в исходном коде, то и Google сможет.
Если вы можете найти текст в исходном коде, то и Google сможет.
Хотя на этой странице есть область с двумя вкладками контента, все они индексируются Google, поскольку мы можем видеть контент в исходном коде страницы.
Просмотр информации о загрузке страницы
Ранее мы рассмотрели коды состояния, и, хотя веб-сайт редко возвращает неверный код для загрузки страницы, такое иногда случается. В вашем браузере должен быть простой способ проверки кода состояния веб-страницы.
Есть плагины для браузера, которые немного облегчают эту задачу, но они не обязательны. Если щелкнуть правой кнопкой мыши в Chrome на любой веб-странице, появится опция «проверить». При нажатии на нее откроются инструменты разработчика Chrome. Щелкните вкладку «Сеть», затем перезагрузите страницу. После загрузки страницы появится большой список информации. Этот список содержит все отдельные сетевые запросы, необходимые для построения страницы. В этом списке будет основной URL страницы. Нажав на нее, вы увидите подробную информацию о запросе, включая код состояния. Этот код должен быть «200». Если это не Google, возможно, он не сможет проиндексировать эту страницу.
Нажав на нее, вы увидите подробную информацию о запросе, включая код состояния. Этот код должен быть «200». Если это не Google, возможно, он не сможет проиндексировать эту страницу.
Используя вкладку сети в инструментах разработчика Chrome, мы можем увидеть информацию о загрузке страницы.
Использование инструментов Google
Бесплатный инструмент, предлагаемый Google, лучше, чем веб-браузер, для исследования возможности сканирования вашего сайта. Хотя Google Analytics — это отличный инструмент для анализа трафика и использования вашего веб-сайта и составления отчетов, он не является инструментом для просмотра информации о поисковых роботах. Существует три основных инструмента Google, которые помогут вам глубже понять, как Google сканирует ваш сайт.
Консоль поиска Google и инструмент проверки URL
Консоль поиска Google — это бесплатный инструмент, как и Google Analytics, однако его не нужно «устанавливать», как Google Analytics, поэтому не нужно беспокоиться о том, что он еще не настроен. Консоль поиска требует, чтобы вы подтвердили право собственности на свой веб-сайт, после чего у вас будет доступ к индексу Google и доступ к некоторым очень полезным инструментам.
Консоль поиска требует, чтобы вы подтвердили право собственности на свой веб-сайт, после чего у вас будет доступ к индексу Google и доступ к некоторым очень полезным инструментам.
В области «индекс» поисковой консоли вы найдете отчеты о том, как индексируется ваш сайт, и инструменты для управления картой сайта. Отчеты «Покрытие» в этой области покажут вам, какая часть вашего сайта находится в индексе Google, какие ошибки сканирования возникли в Google, а также другую важную информацию. Вы можете щелкнуть любой URL-адрес в зоне охвата и просмотреть важные сведения, например, когда он последний раз сканировался и находится ли он в настоящее время в индексе Google.
Область отчета о покрытии в поисковой консоли Google, которая предоставляет полезную информацию о том, что Google обнаружил при попытке сканирования вашего веб-сайта.
В разделе «Карта сайта» вы можете отправлять XML-файлы карты сайта и управлять ими. Файлы Sitemap не предназначены для чтения человеком, а представляют собой специально отформатированные XML-файлы, которые предоставляют Google информацию об URL-адресах вашего веб-сайта.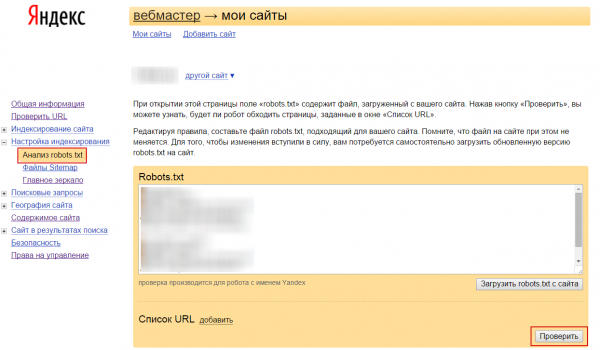 Настоятельно рекомендуется отправить файл карты сайта в Google. Это повысит вероятность того, что Google проиндексирует больше ваших URL-адресов, и позволит вам сообщить Google, какие страницы являются более важными и как часто ожидается обновление определенных страниц. Большинство современных систем CMS для веб-сайтов, таких как WordPress, автоматически генерируют XML-файлы карты сайта. Если вы не знаете, как найти эти URL-адреса карты сайта, поговорите с разработчиком вашего сайта.
Настоятельно рекомендуется отправить файл карты сайта в Google. Это повысит вероятность того, что Google проиндексирует больше ваших URL-адресов, и позволит вам сообщить Google, какие страницы являются более важными и как часто ожидается обновление определенных страниц. Большинство современных систем CMS для веб-сайтов, таких как WordPress, автоматически генерируют XML-файлы карты сайта. Если вы не знаете, как найти эти URL-адреса карты сайта, поговорите с разработчиком вашего сайта.
В верхней части веб-сайта поисковой консоли Google находится «Инструмент проверки URL». Вы можете ввести в это поле любой URL-адрес вашего веб-сайта и открыть отчет с информацией из индекса Google. Это окончательный способ проверить, появится ли страница в поисковой системе Google и какой контент из URL-адреса доступен для Google.
Чтобы «увидеть, что видит Google» при сканировании этого URL-адреса, вы можете щелкнуть ссылку «Просмотреть просканированную страницу» и отобразить содержимое и код страницы точно так же, как они будут представлены Google, когда краулер найдет тот же URL-адрес.
Используя инструмент проверки URL-адресов в консоли поиска Google, мы можем проверить, правильно ли Google сканирует и индексирует определенный контент.
С помощью инструмента проверки URL вы можете:
- Проверить, есть ли URL в Google
- Просмотреть полный отчет о сканировании и индексировании, включая дату последнего сканирования URL-адреса
- Проверьте активный URL-адрес и посмотрите, какой контент может быть проиндексирован сканером Google
- Проверить, подходит ли URL для мобильных устройств
- Проверьте, обнаружил ли Google какую-либо разметку SCHEMA в вашем контенте и проиндексировал ее
- Запрос повторного сканирования URL-адреса после внесения исправлений или обновлений
Инструмент тестирования расширенных результатов Google
Google также предоставляет отдельный инструмент для тестирования реализации SCHEMA на ваших веб-страницах. SCHEMA — это специальный код, который помогает поисковым системам понимать содержимое вашего веб-сайта, основанное на данных. Код SCHEMA обычно рекомендуется для событий, статей, объявлений о вакансиях, продуктов и другого контента, для которого Google предоставляет специальные результаты поиска в поисковой системе Google.
Код SCHEMA обычно рекомендуется для событий, статей, объявлений о вакансиях, продуктов и другого контента, для которого Google предоставляет специальные результаты поиска в поисковой системе Google.
Инструмент расширенных результатов извлечет URL-адрес, который вы вводите в качестве поискового робота Google, и отобразит информацию о найденной им разметке SCHEMA. Если у вас есть ошибки или другие проблемы в разметке, это удобный инструмент для обнаружения и исправления проблем.
Google Page Speed Insights
Еще один очень полезный бесплатный инструмент от Google — анализ скорости страницы. Это не инструмент, напрямую связанный с поисковым индексом и сканированием вашего сайта, но он может быть очень полезен для улучшения возможностей сканирования вашего веб-сайта путем обнаружения проблем с производительностью страницы.
Вы можете ввести любой URL-адрес в статистику скорости загрузки страницы, и Google выберет страницу с помощью поисковых роботов как для мобильных устройств, так и для настольных компьютеров.![]() Сайт предоставляет отчеты о производительности страниц как для мобильных устройств, так и для настольных компьютеров, и вы можете подробно изучить любые обнаруженные проблемы и просмотреть рекомендуемые Google шаги для повышения скорости вашего сайта.
Сайт предоставляет отчеты о производительности страниц как для мобильных устройств, так и для настольных компьютеров, и вы можете подробно изучить любые обнаруженные проблемы и просмотреть рекомендуемые Google шаги для повышения скорости вашего сайта.
Если вы обнаружите, что Google не индексирует большую часть вашего сайта или сканирует новый контент слишком долго, проведите небольшое тестирование в анализе скорости загрузки страниц, чтобы узнать, испытывает ли поисковый робот Google чрезвычайно низкую скорость при доступе к вашим URL-адресам.
Сканирование развивается
Я надеюсь, что эти советы помогут вам понять, как Google сканирует ваш сайт, и дадут вам некоторые инструменты для повышения индексируемости вашего сайта. Кроме того, имейте в виду, что поисковый робот Google постоянно обновляется. Google ежегодно вносит около 300 изменений в поисковую систему, и некоторые из этих обновлений могут существенно изменить отображение вашего сайта в результатах поиска.
Google не будет прямо сообщать, как и что они изменяют в своих системах, но было бы неплохо следить за областью документации Google Search Central, чтобы получать последние советы по оптимизации вашего сайта для Google.
Темы: Цифровой маркетинг
Как проверить, какие URL-адреса были проиндексированы, не расстраивая Google: продолжение
Еще в октябре 2016 года я писал о том, как вы можете использовать скрипт Python, чтобы определить, была ли страница проиндексирована Google в поисковой выдаче. . Как оказалось, аналитик тенденций Google для веб-мастеров Гэри Иллиес был не слишком доволен техникой, которую использовал скрипт, поэтому я не могу одобрить этот метод:
Я просто оставлю это здесь: https://t.
— Гэри Иллиес ᕕ( ᐛ )ᕗ (@methode) 5 октября 2016 г.
Вскоре после этого Шон Малсид и его команда из Greenlane SEO создали аналогичный инструмент на основе Google Sheets (среди других замечательных инструментов, таких как InfiniteSuggest) и Googler. Джон Мюллер выразил сомнения:
@greenlaneseo Это черный инструмент или он соответствует рекомендациям для веб-мастеров и файлу robots.txt? (просто интересно)
— Джон ☆.o(≧▽≦)o.☆ (@JohnMu) 14 декабря 2016 г.
Как узнать, какие страницы не были проиндексированы Google, и сделать это так, чтобы не нарушить правила? Google не указывает, была ли страница проиндексирована в Google Search Console, не позволяет нам очищать результаты поиска, чтобы получить ответ, и не заинтересован в косвенном получении ответа из недокументированного API. (Это было умное решение и обходной путь от Шона Малсида. ) Давайте рассмотрим некоторые решения.
Аналитическое решение
Марк Эдмондсон предоставил решение сценария R, которое работает следующим образом:
- Он выполняет аутентификацию с помощью ваших учетных записей Google Analytics.
- Проверяет, есть ли страницы, найденные в XML-карте сайта вашего сайта, но не найденные в Google Analytics для обычных результатов Google за последние 30 (или более) дней.
Методология предполагает, что если URL-адрес не найден в аналитике для результатов обычного поиска Google, то он, вероятно, не был проиндексирован Google.
Интерлюдия: как это сделать без R
Хотя мне лично нравятся скриптовые решения, я знаю, что многим это не нравится. Вам не нужно вычислять R, чтобы сделать этот анализ. Вы можете легко перейти в Google Analytics и выполнить аналогичный анализ или, что еще проще, перейти в Google Analytics Query Explorer и запустить его с этими настройками. Загрузите таблицу в виде файла TSV:
. Затем вы сможете локально загрузить XML-карту сайта и открыть ее в Excel. Затем перетащите его в окно Excel, и вы получите диалоговое окно «Импорт XML». Если вас попросят «Открыть файл без применения таблицы стилей», выберите 9.0011 OK :
Затем выберите открытие файла «Как таблицу XML»:
Вы можете удалить лишние столбцы, оставив только столбец «ns1:loc» (или «loc»):
Затем вам просто нужно выполнить ВПР или другую форму сопоставления Excel и найти URL-адреса в карте сайта, которых нет в данных аналитики.
Я подумал, что это простое, но умное решение, и, хотя это хорошая отправная точка, я боялся, что оно не будет точно показывать, какие страницы были проиндексированы Google. Нередко страницы получают мало или вообще не получают трафика, даже если они проиндексированы. Это может указывать на то, что страница не проиндексирована, но также может просто указывать на то, что на странице есть проблема с тегами, она стала неактуальной, нуждается в некоторой оптимизации для улучшения видимости или просто отсутствует в XML-карте сайта. . (В качестве альтернативы вы можете использовать сканирование, а не карту сайта XML, чтобы сделать эти сравнения.)
Решение для файла журнала
Файлы журнала сервера являются отличным источником данных о вашем веб-сайте, который часто недоступен другими способами. Одна из многих частей информации, которую можно получить из этих файлов журналов, — это доступ определенного бота к вашему веб-сайту. В нашем случае нас интересует бот Googlebot.
Анализ файлов журнала нашего сервера позволяет нам установить, посещал ли робот Google когда-либо определенную страницу на нашем веб-сайте. Если робот Googlebot никогда не посещал определенную страницу, она не может быть проиндексирована Google. Я лично склонен использовать для этой цели KNIME со встроенным узлом Web Log Reader, но не стесняйтесь использовать свое любимое решение.
Пример использования KNIME для обработки лог-файлов сервера
Обязательно проверьте Googlebot, а не просто полагайтесь на сообщенный пользовательский агент. Многие боты будут подделывать пользовательский агент Googlebot, что может сделать ваши выводы недействительными. Чтобы избежать этого, я использую простой фрагмент кода Python в KNIME:
'] = "ошибка"
Чтобы получить достойное руководство по анализу файла журнала, ознакомьтесь с этим руководством от Builtvisible.
Если все это слишком, я рекомендую проверить The Screaming Frog SEO Log File Analyzer — или, для корпоративного решения, Botify.
Анализатор файлов журналов Screaming Frog предоставляет более простое решение для анализа файлов журналов.
Как и решение Google Analytics, анализ файла журнала не является надежным. Робот Googlebot может посетить страницу, но фактически не включить ее в свой индекс (), но это поможет нам сузить наш список, возможно, не проиндексированных интернет страницы.
Объединение ваших данных
Чтобы сузить наш список страниц, которые не могут быть проиндексированы Google, я рекомендую объединить данные, полученные с помощью метода Google Analytics, с методами анализа файла журнала, описанными выше.
Получив список, мы можем провести выборочную проверку, вручную выполнив поиск в Google «info:», что не расстроит Google. Намного проще проверять вручную, потому что мы смогли значительно сузить наш список.
Вывод
Поскольку Google не предоставляет инструмент или данные о том, была ли веб-страница проиндексирована или нет, и нам не разрешено использовать автоматизированное решение, подобное тому, о котором я писал ранее, мы должны полагаться на сужение нашего списка URL-адреса, которые могут быть не проиндексированы.
Мы можем сделать это, изучив данные Google Analytics для страниц, которые находятся на нашем веб-сайте, но не получают органического трафика Google, а также просмотрев файлы журналов сервера. Оттуда мы можем вручную выборочно проверить наш сокращенный список URL-адресов.
Это не идеальное решение, но оно выполняет свою работу. Я надеюсь, что в будущем Google предоставит лучшие средства для оценки того, какие страницы были проиндексированы, а какие нет.
Мнения, высказанные в этой статье, принадлежат приглашенному автору и не обязательно принадлежат Search Engine Land. Штатные авторы перечислены здесь.
Похожие статьи
Новинки на сайте Search Engine Land
Об авторе
Индекс Google: как проверить общее количество проиндексированных страниц и получить мгновенное индексирование поисковыми роботами Google
Если вы хотите, чтобы ваш сайт отображался в результатах поиска Google, он должен быть частью поискового индекса Google.
Вы можете думать об этом индексе как о гигантской библиотеке веб-сайтов и отдельных страниц, которые Google хранит для ускорения поиска.
Если все пойдет правильно, ваш сайт будет проиндексирован автоматически, а если нет? Или что, если проиндексированы только некоторые из ваших веб-страниц?
Это руководство расскажет вам все об индексе Google и о том, как убедиться, что весь ваш контент проиндексирован должным образом, что имеет основополагающее значение для SEO.
Содержание
Что такое проиндексированные страницы веб-сайта?
Google ведет регулярно самообновляемый «индекс» страниц в Интернете, чтобы быстрее генерировать страницы результатов поисковой системы (SERP). Опять же, лучше всего думать об этом индексе как о своего рода библиотеке, которую Google может легко отсортировать, когда это необходимо; если ваших страниц нет в индексе, они не будут в поисковой выдаче.
Google использует автоматических ботов (известных как пауки, или Googlebot, конкретное название веб-паука Google) для постоянного поиска в Интернете нового контента и недавно запущенных веб-сайтов для добавления в индекс.
Любые новые страницы или значительные объемы информации, добавленные на веб-страницу , отмечаются Google. Каждая страница веб-сайта индексируется поисковым роботом на предмет ценности контента и будущих поисковых запросов потребителей.
Будущий клиент Интернета может осуществлять поиск, используя определенные ключевые слова, а ключевые слова могут найти веб-страницу с определенным содержанием или изображением.
Поисковые системы Google и поисковые роботы узнают о каждой новой части информации, напечатанной или размещенной на веб-странице, по мере ее публикации.
Почему страницы сайта индексируются?
Каждая новая страница веб-сайта в Интернете индексируется по определенным категориям и другим инструментам маркировки.
Страницы индексируются, потому что содержание и сами веб-сайты должны быть перечислены среди множества других веб-сайтов, которые могут быть похожими.
Сначала необходимо проиндексировать страницу.
Боты Google сканируют веб-сайт и создают кешированную копию каждой страницы. Добавляются уже заполненные индексы, и, например, может быть создана новая иерархия ценных страниц веб-сайта.
В конечном счете, процесс индексации позволяет Google выполнять поиск в Интернете более тщательно, точнее и быстрее.
Как быть проиндексированным Google
Так как же убедиться, что ваш сайт проиндексирован Google?
Вот хорошие новости. Google делает большую часть работы за вас.
Если вы не спешите индексировать свои страницы и на вашем сайте нет ничего необычного, все, что вам нужно сделать, это подождать, пока поисковые роботы Google в конечном итоге обнаружат ваш сайт и соответствующим образом обновят индекс. В зависимости от нескольких переменных этот процесс может занять от нескольких часов до нескольких недель. И даже когда ваша страница в конечном итоге будет проиндексирована, она, вероятно, испытает волатильность рейтинга из-за явления, ласково называемого Google Dance.
Если вы заинтересованы в ускорении процесса или просто хотите убедиться, что у Google есть точная информация, вы можете отправить карту сайта и/или запросить индексацию через Google Search Console — бесплатный инструмент, предоставляемый Google веб-мастерам. Если вы еще этого не сделали, вам необходимо зарегистрировать учетную запись и подтвердить свое право собственности на веб-домен.
После этого перейдите к «инструменту проверки URL» и вставьте URL-адрес, который Google должен проиндексировать.
Если вы хотите просканировать весь сайт, просто вставьте свой домен высокого уровня и нажмите «Запросить индексирование». Имейте в виду, что этот процесс может занять несколько дней или дольше.
Если вы хотите поработать над созданием XML-файла карты сайта, вы также можете загрузить его непосредственно в Google через Google Search Console. В разделе «Индекс» нажмите «Карты сайта», и у вас будет возможность напрямую загрузить карту сайта.
Как узнать, сколько страниц вашего сайта проиндексировано Google
Как узнать, проиндексирован ли ваш сайт и все его страницы?
Для быстрого и грязного метода просто выполните простой поиск по сайту в строке поиска Google с помощью «site:yourdomain.com»
Ниже приведен результат поиска по сайту SEO.co:
Если ваш сайт не отображается, значит, он может быть не проиндексирован, и может быть что-то не так.
Как использовать средство проверки проиндексированных страниц Google?
Вы также можете использовать средство проверки проиндексированных страниц Google, чтобы определить, проиндексированы ли ваши страницы. Средство проверки проиндексированных страниц Google можно использовать следующим образом:
- Введите свой URL-адрес в средство проверки проиндексированных страниц Google.
- URL-адрес — это веб-сайт, который вы хотите проверить на предмет его рейтинга или ценности содержимого веб-страницы.
- Нажмите «Продолжить», чтобы получить результаты сканирования.
Получение подробной информации о страницах, проиндексированных Google, в Google Search Console
Как узнать, сколько страниц в настоящее время проиндексировано Google для моего бизнеса?
Если вы хотите копнуть глубже и точно узнать, какие из ваших страниц были проиндексированы, лучше всего использовать Google Search Console.
Войдите в систему, перейдите в область «Индекс» и щелкните вкладку «Покрытие». Там вы сможете создать список «Все известные страницы».
Здесь вы получите информацию о том, сколько ваших страниц действительны в настоящее время, сколько «Действительно с предупреждениями» и сколько у вас «Ошибок».
Если вы видите здесь нули по всем направлениям, это означает наличие серьезной проблемы; Google вообще не индексирует ваш сайт.
Если вы видите количество страниц в столбце «Действительные», равное количеству страниц на вашем сайте, все готово. Если у вас есть какие-либо страницы в разделах «Действительно с предупреждениями» или «Ошибка», вы можете изучить их; Google точно скажет вам, что не так и что нужно исправить, чтобы решить проблему.
Пока вы это делаете, вы можете проверить, проиндексирована ли конкретная страница, используя инструмент проверки URL (уже обсуждался выше). Просто скопируйте/вставьте URL-адрес в инструмент, и Google сообщит вам, присутствует ли страница в индексе Google или нет.
Это прекрасно подходит для проверки того, что ваши усилия увенчались успехом, если вам нужно устранить неполадки с конкретной неиндексированной страницей. Это также то, как вы можете мгновенно проиндексироваться.
Почему Google не индексирует ваш сайт
Это случается нечасто, но когда это происходит, это ужасно.
Если вы собираетесь получать органический трафик от онлайн-поиска, вам нужно убедиться, что ваш сайт виден. Другими словами, если вы хотите показываться на страницах результатов поиска Google, Google должен знать, что ваш сайт существует. .
И если ваш сайт не индексируется Google, он может и не существовать.
Но есть большая разница между индексацией Google и ранжированием в Google.
Если ваш сайт вообще не отображается в органическом поиске, боритесь с искушением начать паниковать. В большинстве случаев это просто указание на какую-то ошибку или блокировку, которая не позволяет Google проиндексировать ваш сайт, и эти проблемы легко исправить.
Взгляните на эти 10 причин, по которым Google может не индексировать ваш сайт. Если вас не удается найти в Google, скорее всего, виновата одна из них. Если ваш сайт не ранжируется, это совсем другая история.
1. У вас нет домена с www и без www.
Для обычного посетителя веб-сайта нет реальной разницы между URL-адресом, начинающимся с https:// или https://www. Оба они в конечном итоге приводят вас к одному и тому же месту, поэтому большинство пользователей и веб-мастеров не задумываются об этом. Но вариант с www на самом деле является поддоменом более широкой версии без www. Чтобы правильно проиндексировать ваш веб-сайт, вам необходимо подтвердить свое право собственности на оба в Google Webmaster Tools. Вы также можете указать предпочтительный домен, чтобы сообщить Google, какую версию вы хотите использовать в первую очередь.
2. Google все еще ищет ваш сайт.
Если вы только что запустили сайт и взволнованно искали его в Google, расслабьтесь. Обычно Google требуется не менее нескольких дней, чтобы проиндексировать новый сайт. Если прошло уже несколько дней, а вы все еще не видите никаких результатов, это может означать, что у Google возникли проблемы с индексацией вашего сайта, и обычно это означает, что у вас проблема с картой сайта. Если вы еще не создали или не загрузили правильно отформатированную карту сайта, это может быть вашей проблемой. После исправления вы можете «заставить» Google сканировать ваш сайт через Google Search Console.
Это, безусловно, самый распространенный виновник, поэтому, если ваши страницы не проиндексированы, это, вероятно, причина.
3. У вас есть устаревший файл robots.txt.
Файлы robots.txt — это файлы инструкций, которые могут указывать поисковым роботам, как работать.
Иногда разработчики или контент-менеджеры используют файл robots.txt, чтобы запретить поисковой системе намеренно индексировать данную страницу (например, если страница не готова для публичного просмотра).
По сути, файл связывается со сканерами Google и сообщает им не индексировать сайт или определенную страницу на этом сайте , поэтому, если вы обновите или удалите файл, у вас больше не будет проблем с индексированием.
Надлежащий аудит веб-сайта проведет тщательное сканирование кода вашего веб-сайта и обновит все экземпляры файлов robots.txt, которые отсутствуют по определенной причине.
Вам все равно нужно будет дать Google несколько дней, чтобы проиндексировать ваш сайт после исправления ошибочного файла.
4. Google испытывает ошибки при сканировании.
Это случается не часто, , но есть вероятность, что у Google возникают проблемы со сканированием некоторых ваших веб-страниц.
Если ваша домашняя страница индексируется, но не все ваши внутренние страницы, это может быть признаком простой ошибки сканирования. Войдите в консоль поиска Google и нажмите «Сканирование», затем «Ошибки сканирования».
Это приведет вас к списку всех страниц вашего сайта, на которых в настоящее время возникают ошибки сканирования. Эти ошибки иногда связаны с файлами robots.txt, подробно описанными выше, но также могут быть результатом ошибок DNS или ошибок сервера, которые в большинстве случаев легко исправить.
5. Дублированный контент мешает поисковым роботам.
Если вы следуете передовым методам контент-маркетинга, это не должно быть проблемой, но в некоторых случаях на вашем сайте может существовать дублированный контент, например варианты слов на «главной странице», предназначенные для несколько иной аудитории.
Если Google обнаружит несколько экземпляров дублированного контента, роботы поисковых систем могут запутаться и вообще отказаться от индексации вашего сайта.
Самый простой способ исправить это — избавиться от дублирующегося контента.
Если полное удаление повторяющегося контента невозможно, вы можете использовать переадресацию 301 или выборочные файлы robots.txt, чтобы Google сканировал только один экземпляр каждой страницы.
6. Проблемы с загрузкой вашего сайта.
Если Google собирается проиндексировать ваш сайт, он должен быть запущен.
Это означает, что если у вас возникли проблемы с загрузкой, когда Google пытается проиндексировать ваш сайт, вы можете упустить возможность быть проиндексированным.
Иногда проблема заключается в смехотворно долгом времени загрузки; в этом случае вы можете уменьшить время загрузки, настроив достойную систему кэширования, уменьшив размер изображений и установив несколько приложений, чтобы сайт загружался быстрее. Также возможно, что ваш хостинг ненадежен, что приводит к периодическим простоям, которые прерывают попытки индексации Google.
7. Вы используете плохо оптимизированные языки программирования.
У Google есть определенные предпочтения в отношении типа кода на вашем сайте. HTML — один из самых легко индексируемых языков, но не все варианты так удачны.
JavaScript и AJAX, например, поддерживаются Google, но их не так легко индексировать, как HTML.
Если ваш сайт построен на AJAX или JavaScript, а ваша структура не совсем правильная, у Google могут возникнуть проблемы с индексацией ваших страниц.
8. Вы заблокированы .htaccess или настройками конфиденциальности.
Если вы запускаете сайт WordPress, возможно, вы случайно включили настройки конфиденциальности — вы можете отключить их, проверив «Конфиденциальность» на вкладке «Настройки».
Также возможно, что вы используете файл .htaccess для своего веб-сайта на сервере.
Хотя файлы . htaccess в большинстве случаев полезны, иногда они могут мешать индексации сайта.
9. Где-то в метатеге есть индикация Noindex или Nofollow.
Как и файл robots.txt, это дополнение может скрыть страницы вашего сайта от обнаружения поисковыми роботами. Проверьте код своего сайта и найдите тег «noindex» где-нибудь в мета-заголовке. Если вы обнаружите это где-то, вы сразу же диагностируете проблему с индексацией. Просто удалите тег и замените его, если это необходимо, и вы должны вернуться на быстрый путь к индексации поисковыми системами.
10. Вы получили крупный штраф.
Когда Google наказывает сайты, он обычно делает это, снижая рейтинг и, следовательно, видимость и трафик. Однако бывают редкие и крайние случаи, когда Google наказывает сайт, полностью удаляя его из индексов.
Это тип ручного наказания, зарезервированного за серьезные нарушения, поэтому вам не нужно беспокоиться об этом, если только вы не сделали что-то очень неправильное в глазах Google.
Если вас деиндексировали таким образом, вы, вероятно, уже были уведомлены Google, поэтому, если это не так, вам не нужно беспокоиться о том, что вас не индексируют в качестве наказания.
Как только ваш сайт будет проиндексирован, дайте Google несколько дней, чтобы наверстать упущенное. Вскоре вы должны увидеть свой сайт в результатах поиска.
Если у вас все еще возникают проблемы, возможно, ваша проблема с индексацией может быть более сложной, чем обычно.
Если вы появляетесь, но имеете очень низкий рейтинг, это может быть признаком того, что ваш сайт все еще новый и не имеет большого авторитета, или это может быть признаком штрафа.
В любом случае, сохранение приверженности лучшим практикам в течение длительного периода времени — лучший способ повысить свою узнаваемость.
Как исправить проблему, если страницы моего веб-сайта не отображаются в списке?
Если ваш сайт не полностью проиндексирован в Google, вы можете упустить серьезный трафик (и доход). Если страниц нет в поисковой выдаче Google, их невозможно обнаружить.
Если вы обнаружите, что некоторые (или все) ваши страницы не индексируются, выполните следующие действия:
1. Используйте Google Search Console, чтобы проверить, какие страницы не индексируются. Ваш сайт не индексируется целиком или только несколько страниц? Как вы могли догадаться, чем больше страниц отсутствует, тем больше проблема.
2. Определите основную причину проблемы. Даже если вы не являетесь техническим экспертом, вы сможете выяснить основную причину вашей проблемы. Просмотрите предыдущий раздел, чтобы узнать о возможных причинах, по которым Google может не проиндексировать ваш сайт. Если ваш сайт новый и ни одна из ваших страниц не проиндексирована, это может быть естественной задержкой. Если это не так, возможно, у вас есть файл robots.txt, блокировщик конфиденциальности или другой фрагмент кода, который препятствует индексации ваших страниц.
3. Устраните проблему и отправьте обновленную карту сайта. Какой бы ни была проблема, работайте над ее устранением. Когда вы закончите, вы можете отправить обновленную карту сайта в Google. В Google Search Console выберите «Добавить свойство» и загрузите обновленную карту сайта. Когда вы закончите, вы можете использовать инструмент «Просмотреть как Google», чтобы специально запросить бота для сканирования указанной вами страницы. Просто введите URL-адрес, выберите «Настольный» или «Мобильный» и нажмите «Получить». Этот процесс займет некоторое время, но после его завершения Google оценит ваши страницы на предмет индексации.
Если вы застряли с непроиндексированными страницами и не знаете, что не так, выполните следующие основные действия по устранению неполадок:
- Удалите все блокираторы сканирования в файле robots.txt. Проверьте файл robots.txt, перейдя по адресу yourdomainhere.com/robots.txt. Там вы можете использовать CTRL + F для поиска «Googlebot» и «*». Если у вас есть какие-либо строки, в которых указано User-agent: Googlebot или User-agent: * (что относится ко всем ботам), запрещенные ими страницы не будут проиндексированы в Google. В некоторых случаях это может быть выгодно, но чаще это просто препятствие для индексации. Обновите файл robots.txt на сервере, чтобы решить эту проблему.
- Удаление ненужных тегов noindex. Точно так же, если в ваших метатегах есть теги content=»noindex», поисковые роботы Google не будут индексировать ваш контент. Эту проблему легко найти и исправить, даже если у вас нет навыков кодирования.
- Удалите неточные канонические теги. Канонические теги — это необязательные теги страниц, которые сообщают Google, какая версия вашей страницы является предпочтительной, «канонической» страницей. На некоторых страницах есть канонический тег, который указывает Google, что это единственная версия. Однако при неправильной реализации канонический тег может заставить Google искать другую каноническую страницу, которой не существует. Если это произойдет, это может помешать процессу индексации Google. Если это ваша проблема, она должна отображаться как ошибка сканирования в консоли поиска Google.
- Обновите карту сайта. Робот Google должен иметь возможность органически обнаруживать весь ваш контент, но вы можете создать и обновить свою XML-карту сайта, чтобы быть уверенным. Загрузите это через Google Search Console, чтобы помочь Google «увидеть» весь спектр вашего сайта.
И помните, большинство людей, обеспокоенных тем, что их сайты не индексируются, просто не ждали достаточно долго.
Если с момента запуска вашего веб-сайта прошло всего несколько часов или несколько дней, постарайтесь набраться терпения.
Пауки Google хороши в том, что они делают, но им нужно время, чтобы работать.
Как оцениваются и ранжируются страницы веб-сайта?
Тот факт, что страницы вашего веб-сайта проиндексированы, не означает, что они будут хорошо видны в результатах поиска Google. Это потому, что Google хочет, чтобы пользователи поиска Google находили наилучший возможный контент при выполнении поиска.
Google классифицирует страницы на основе их релевантности и ранжирует их в соответствии с их надежностью (или «авторитетом»), поэтому, даже если ваши страницы проиндексированы, они могут не отображаться в результатах поиска вашей целевой аудитории.
Поисковая оптимизация (SEO) — это процесс внесения внутренних и внешних изменений для повышения вероятности ранжирования ваших страниц.
Это чрезвычайно глубокая тема, которая не может быть достаточно раскрыта в одной статье, но если вы новичок в мире поисковой оптимизации, обратите внимание на следующие факторы ранжирования:
- Актуальность содержания. Google необходимо убедиться, что ваш контент соответствует намерениям пользователей поиска. В старые времена SEO это означало размещение определенных ключевых слов и фраз на вашем сайте. В наши дни Google слишком изощрен, чтобы попасться на эту уловку; вместо этого лучше отвечать на конкретные вопросы, которые могут возникнуть у пользователя, или естественно и подробно освещать конкретную тему.
- Актуальность содержания. Google необходимо убедиться, что ваш контент соответствует намерениям пользователей поиска. В старые времена SEO это означало размещение определенных ключевых слов и фраз на вашем сайте. В наши дни Google слишком изощрен, чтобы попасться на эту уловку; вместо этого лучше отвечать на конкретные вопросы, которые могут возникнуть у пользователя, или естественно и подробно освещать конкретную тему.
- Качество контента. Google хочет, чтобы только лучший контент имел достаточно высокий рейтинг, чтобы пользователь мог щелкнуть его. Ваш контент должен быть глубоким, кратким и хорошо написанным. Он должен ссылаться на несколько источников, полностью освещать тему и не содержать ошибок.
- Заголовки и теги. Также имеет значение внутренний код ваших страниц. Включение кратких, стратегически загруженных ключевых слов тегов заголовков, метаописаний и заголовков может повысить ваш потенциал ранжирования.
- Внешние ссылки. С точки зрения Google, одним из лучших показателей надежности является ссылка, указывающая на вашу страницу с внешнего сайта. Чем больше у вас внешних ссылок и чем авторитетнее эти ссылки (т. е. они исходят из надежного источника), тем лучше.
- Внутренние ссылки. Также полезно, чтобы ваши страницы были тесно связаны друг с другом, чтобы пользователи могли легко переходить со страницы на страницу на вашем сайте. Кроме того, роботу Googlebot будет легче сканировать ваш сайт.
- Внутренние ссылки. Также полезно, чтобы ваши страницы были тесно связаны друг с другом, чтобы пользователи могли легко переходить со страницы на страницу на вашем сайте.
- Скорость загрузки и технические факторы. Google также учитывает множество технических факторов, влияющих на эффективность вашей страницы. Например, страницы, которые оптимизированы для мобильных устройств и быстро загружаются, имеют более высокий рейтинг, чем те, которые не оптимизированы и не могут.
Как мне увеличить трафик и конверсии для моего интернет-бизнеса?
Даже если у вас есть привлекательный продукт и фантастическая бизнес-модель, это не будет иметь значения, если люди не узнают о вашем бизнесе.
И лучший способ сделать ваш бизнес узнаваемым в современную эпоху — это использовать поисковую систему Google.
Индексация — это первый шаг. Прочитав это руководство, вы сможете правильно проиндексировать свой веб-сайт в Google, даже если для этого вам придется выполнить некоторые шаги по устранению неполадок.
После этого вам нужно будет посвятить свое внимание повышению вашего рейтинга в поисковой выдаче Google с помощью построения ссылок для SEO, создания контента и других тактик SEO. Если вы хотите узнать больше или готовы начать SEO-стратегию с нуля, свяжитесь с нами сегодня для бесплатной консультации!
Резюме
Индекс Google — это архив веб-контента, который он использует для более быстрой обработки пользовательского поиска, и индексирование вашего сайта жизненно важно.
К счастью, получить индекс обычно несложно, даже если вы столкнетесь с несколькими препятствиями на этом пути.
После индексации единственный способ убедиться, что ваш сайт виден новым пользователям, — это повысить рейтинг в поисковой выдаче, и единственный способ сделать это — с помощью SEO.
- Автор
- Последние сообщения
Сэм Эдвардс
Директор по маркетингу SEO.co
За более чем 9 лет работы цифровым маркетологом Сэм работал с бесчисленным множеством компаний и организаций из списка Fortune 500, включая NASDAQ OMX, eBay, Duncan Hines, Drew Бэрримор, Вашингтон, округ Колумбия, юридическая фирма Price Benowitz LLP и правозащитная организация Amnesty International.
Он постоянно выступает на конференциях Search Marketing Expo и выступает на TEDx Talker. Сегодня он работает напрямую с высококлассными клиентами по всем вертикалям, чтобы максимизировать рентабельность инвестиций в поисковую оптимизацию на сайте и за его пределами с помощью контент-маркетинга и построения ссылок. Свяжитесь с Сэмом на Linkedin.
Последние сообщения Сэма Эдвардса (посмотреть все)
Итак, вы думаете, что все ваши страницы проиндексированы Google? Подумай еще раз
Опубликовано: 12 марта 2015 г. Патрик Хэтэуэй in Experiments, SEO
SEO-специалисты нередко расходятся во мнениях относительно ключевых показателей эффективности, которые вы должны отслеживать для измерения своих усилий по SEO.
Одна метрика, с которой трудно поспорить, это индексация. Если страница не проиндексирована, у нее нет шансов привлечь трафик из поиска.
Недавно мы обнаружили, что классический метод проверки индексации (с помощью команды info:) дает ложные срабатывания, что, в свою очередь, может привести к неточным выводам об индексации и работоспособности сайта.
Что мы подразумеваем под индексацией?
Когда Google сканирует Интернет, они создают репозиторий найденных веб-страниц и из этого репозитория создают свой «индекс».
Для каждой просканированной веб-страницы Google анализирует документ, разбивая его на набор вхождений слов (вместе с дополнительной информацией).
В то же время они анализируют все ссылки и сохраняют информацию о них, такую как анкорный текст и место, куда ведет ссылка.
Google берет проанализированные данные и создает инвертированный индекс, сопоставляя документ веб-страницы с каждым словом на странице; это то, что позволяет им так быстро искать в своем индексе.
Если это звучит знакомо, значит, так оно и есть.
Данные о ссылках также индексируются, что позволяет им вычислять PageRank и другие показатели качества. Когда Google обрабатывает запрос пользователя, он просматривает свой индекс, чтобы найти документы, содержащие искомые слова, а затем упорядочивает результаты с точки зрения релевантности запросу.
Короче говоря, если веб-страница была проиндексирована, она «доступна для поиска» (то есть является жизнеспособным результатом поиска по релевантному запросу).
Проверка индекса
Google уже много лет говорит нам, что для проверки статуса индекса любого URL-адреса используется оператор info:.
Мэтт Каттс всегда говорил нам делать это таким образом (вот пример почти 10-летней давности), и Джон Мюллер сказал то же самое всего несколько недель назад:
Средство проверки индекса URL Profiler использует эту информацию: команда, как и Scrapebox, поэтому оба позволяют вам массово проверять состояние индекса.
Таким образом, если веб-страница открывается с помощью команды info:, она индексируется и, следовательно, может быть найдена.
По крайней мере, мы так думали…
Тестирование теории
При создании нашего последнего выпуска URL Profiler мы тестировали функцию проверки индекса Google, чтобы убедиться, что она все еще работает должным образом. Мы обнаружили некоторые ложные результаты, поэтому решили копнуть немного глубже. Далее следует краткий анализ уровней индексации этого сайта urlprofiler.com.
Проверка уровней индексации
Мы хотели узнать, сколько именно наших URL-адресов находится в индексе Google.
Во-первых, мы посмотрим на поиск по сайту в Google (команда -inurl:support просто удаляет наш субдомен поддержки, который нам не интересен):
Это звучит примерно так. Мы также можем сравнить статус индекса Google Webmaster Tools:
. Учитывая, что команда site: search не очень надежна, это хороший признак того, что эти цифры примерно совпадают.
Однако мы получаем другую картину, когда смотрим на данные карты сайта в Google Webmaster Tools:
Это кажется странным, тем более что число 63 точно совпадает с тем, что мы видели в поиске по сайту. Это ставит два важных вопроса:
- Есть ли в индексе Google URL-адреса, которых нет в карте сайта?
- Данные карты сайта в GWT совершенно неточны?
Пытаясь ответить на эти вопросы, мы мало что можем узнать, глядя на общие уровни индексации, вместо этого нам нужно смотреть на отдельные URL-адреса.
Массовая проверка индексации
Конечно, мы могли бы проверять каждый отдельный URL вручную, один за другим. Но кто хочет это сделать?
Как я упоминал выше, мы можем массово проверять статус индекса с помощью профилировщика URL (который для этого использует оператор info: )
Итак, в Google» в разделе «Данные уровня URL».
Программное обеспечение предупредит вас об использовании прокси-серверов по очень веской причине — вы либо заблокируете свой IP-адрес Google, либо получите очень странные и совершенно ненадежные результаты.
Необработанные данные выглядят следующим образом:
Каждый URL в моем списке получил ответ «Да». Это означает, что каждый отдельный URL-адрес из нашей карты сайта проиндексирован , а данные карты сайта в GWT просто неверны.
Мы еще вернемся к проблеме с картой сайта, а вместо этого попробуем разобраться с нашим первым вопросом…
- Есть ли в индексе Google URL-адреса, которых нет в карте сайта?
Давайте просканируем Google и узнаем
Если вы еще не видели, у нас есть небольшая область бесплатных инструментов, которая включает инструмент для очистки результатов Google, который называется Simple SERP Scraper.
Мы можем загрузить наш исходный поисковый запрос по сайту и отправить его для очистки поисковой выдачи:
Опять же, вам понадобятся прокси, если вы собираете множество результатов, но мы можем обойтись без прокси и ‘ Функция случайной задержки, так как нам не нужно слишком много результатов.
Результаты выглядят так, и наши перемещаются с позиции 1 на 63, как и ожидалось:
Чтобы сравнить эти результаты с нашей картой сайта, нам просто нужно скопировать результаты очистки и вставить их на другой лист вместе с результатами нашего профилировщика URL, а затем просто использовать вложенную функцию ВПР:
=ЕСЛИОШИБКА(ВПР(A2, ‘Результаты профилирования URL’!A:A,1,FALSE), «Нет в карте сайта»)
Кстати, если вам нужна помощь с функцией ВПР, ознакомьтесь с этим прекрасным руководством.
Это показывает нам, что 59 совпадают идеально, но есть 4 мошеннических «лишних» страницы. URL-адреса слишком длинные для отображения, поэтому для ясности я добавил столбец примечаний:
Ничего особенного здесь нет, просто кое-что по хозяйству, с которым нам нужно разобраться. Однако это помогает нам ответить на наш первый вопрос:
- Есть ли в индексе Google URL-адреса, которых нет в карте сайта?
Не совсем, нет. Всего их 4, половина из которых, вероятно, в какой-то момент выпадет. Конечно, ничем нельзя объяснить 50%-ную неравномерность карты сайта.
Сравнение с картой сайта
Выше мы сравнили результаты поиска с данными карты сайта. Чтобы проверить точность данных карты сайта, нам нужно будет сделать обратную ВПР:
=ЕСЛИОШИБКА(ВПР(B2,’Результаты очистки’!A:A,1,ЛОЖЬ)»,Нет в результатах поиска»)
Сравнивает данные карты сайта с результатами поиска.
Как я и ожидал, большинство результатов совпали с картой сайта. Тем не менее, было 2, которые не соответствовали:
. Но было 61, которые совпали, а это означает, что заявление Google о том, что только 33 были проиндексированы из 63, которые мы отправили, является полной чушью.
2. Являются ли данные карты сайта в GWT полностью неточными?
Да. По крайней мере, для этого конкретного теста.
Разница между индексируемым и доступным для поиска
Посмотрите на последнюю таблицу выше. У нас была массовая проверка индексации на каждой странице (используя URL Profiler), и все они, по-видимому, были проиндексированы.
Однако топ 2 не появился в результатах поиска по сайту: оператор.
Нам лучше изучить 2 рассматриваемых URL-адреса, как показано ниже (вы увидите дерьмо, которое может быть проиндексировано, если вы не будете осторожны):
Страница 1: https://urlprofiler.com/update/
Это страница, необходимая для наших ссылок на обновления, но не для просмотра пользователями. На нем вообще ничего нет.
На самом деле он даже заблокирован в нашем файле robots.txt. Тогда почему это в нашей карте сайта…
Страница 2: https://urlprofiler.com/documentation/getting-started/installing/
Я даже не знаю, почему эти страницы существуют. На нем ничего нет. Вообще.
Эти страницы просто… дерьмо.
Они проиндексированы или нет?
Я могу полностью понять, почему Google не хочет, чтобы эти страницы были в их индексе. Ни на одном из них практически нет контента — не говоря уже об уникальном контенте.
Но когда мы проверили URL Profiler, мы обнаружили, что они были проиндексированы . Как упоминалось ранее, проверки, которые выполняет URL Profiler, основаны на операторе info:, который мы также можем использовать для подтверждения вручную:
Но мы также можем попробовать другие методы, чтобы проверить, проиндексирован ли URL-адрес. Рассматривая сначала страницу обновления, мы можем протестировать site: operator;
Это показывает, что, хотя страница не была указана в общем списке site: search, Google отобразит ее при прямом запросе, подобном этому. Также нам предлагают «повторить поиск с включением пропущенных результатов», что дает следующее:
Это еще 2 результата, ни одного из которых не было ни в общем сайте: ни в поиске, ни в карте сайта, но явно по-прежнему проиндексированы и доступны при прямом запросе.
Таким образом, мы также можем попробовать тот же поиск по другому нашему мошенническому URL-адресу, первому из документации:
Это показывает похожие URL-адреса — с тем же путем — , но не фактический URL-адрес, который мы искали . Даже при прямом запросе Google не будет отображать URL-адрес.
Если, конечно, вы не сделаете инфо: запрос.
Эти страницы явно в какой-то степени проиндексированы , но если вы действительно не заставите Google показать их вам, они этого не сделают.
Недоступно для поиска
Хотя эти веб-страницы проиндексированы, их невозможно найти — по крайней мере, для любого обычного поисковика. И это то, что мы на самом деле имеем в виду, когда проверяем статус индекса: « могут ли поисковики найти мои вещи?» ‘
Сама по себе команда info: не является достаточной проверкой.
Если веб-страница возвращается по команде info:, это не обязательно означает, что ее можно найти.
Пример за пределами нашего крошечного веб-сайта
Возможно, этот пост следовало бы начать с предостережения, что мы сделали это только на нашем сайте, который очень мал. НО только с помощью такого маленького сайта мы смогли получить исчерпывающие ответы на некоторые из заданных нами вопросов.
Если у вас есть сайт с несколькими тысячами страниц или более, вы никак не сможете выполнить парсинг Google, чтобы проверить, что было проиндексировано. Приведенный выше тест показывает доказательство концепции и демонстрирует, что наша первоначальная теория (на которую мы годами полагались как на точную) изначально ошибочна.
Вот пример с более крупного сайта — dundee.com. Команда Hit Reach и я публично провели аудит этого сайта в прошлом году, указав на множество проблем с Panda (сюрприз-сюрприз, они не были исправлены).
Вот одна из страниц, с которой мы обнаружили проблему:
Угадайте почему?
Google «проиндексировал» его с помощью команды info: command:
Однако мы хотим знать, можно ли его «найти» — можно ли его найти при поиске по URL-адресу или поиске по сайту по конкретному URL-адресу?
Нет.
Информация: командование фактически продало нам отвлекающий маневр. Эта проверка заставила бы нас думать, что URL-адрес «правильно проиндексирован» (то есть доступен для поиска).
Просто быть в индексе ни хрена не значит, если никто не может тебя найти.
Это просто старый дополнительный указатель?
Нет, ничего подобного. Дополнительный индекс был просто вторым уровнем индекса, который сканировался и запрашивался с более низким приоритетом по сравнению с основным индексом.
Компания Google публично заявила, что поддерживает несколько уровней индекса, которые работают таким образом. То, что мы видим здесь, совершенно другое — это индексный уровень, полный абсолютного дерьма.
Пока мы видели, что это может включать:
- Пропущенные страницы результатов
- Страницы заблокированы robots.txt
- Тонкие страницы
- Потерянные страницы
- Неуникальные страницы
Возможно, Google просто очищает индекс, чтобы владельцам сайтов не приходилось этого делать. Судя по этому ответу Джона Мюллера в Google Webmaster Hangout в прошлом году (смотрите примерно до 38:30), это действительно так:
Примечание: Чтобы уточнить, владелец сайта, о котором идет речь, сказал, что 90% его сайта теперь отображаются в разделе «пропущенные результаты» (которые он назвал дополнительным индексом).
Джон ясно заявляет, что Google решил отфильтровать этот материал по той или иной причине.
По сути это означает, что хотя Google и знает об этих страницах, они никогда не предоставят вам поисковый трафик.
Не знаю, как вы, но я совершенно точно не хотел бы, чтобы значительное количество моих страниц попало в этот репозиторий дерьма.
Какое место занимает кэширование?
Еще одна точка данных, которую мы можем получить от Google, — это последняя дата кэширования, которую в большинстве случаев можно использовать в качестве прокси для даты последнего обхода (последняя дата кэширования Google показывает, когда они последний раз запрашивали страницу, даже если им была предоставлена 304 (не изменен) ответ сервера).
Маленькая зеленая стрелка рядом с URL-адресом позволяет получить доступ к кешированной версии страницы.
URL Profiler также имеет возможность массовой проверки даты кеша. Когда мы делаем это на карте сайта URL Profiler, мы на самом деле видим еще больше хитрых URL-адресов, которые нам нужно исправить:
Есть 7 URL-адресов, которые Google решил не кэшировать. Некоторые из них мы видели ранее, и 1 запрещен в robots.txt, но ни для одного из них не задано значение noarchive.
Для краткости я не буду делать для вас скриншоты каждого из них (*кхм* URL Profiler имеет функцию массового скриншота…) – поверьте мне, они также очень плохие, тонкие страницы с небольшим количеством уникального контента или вообще без него. на любой из них.
Кэш Google — это прежде всего пользовательская функция, позволяющая пользователям получать доступ к содержимому, когда сам веб-сайт может быть недоступен. Вполне логично, что Google не хотел бы кэшировать результаты, которые, по их мнению, не представляют для пользователя никакой ценности.
Это также согласуется с пояснением Джона Мюллера в видео выше — страницы с «пропущенными результатами» всегда не кэшируются — если вы считаете, что страница не представляет никакой дополнительной ценности для ищущего, зачем хранить ее копию?
Подобно тому, что мы видели при проверке индекса, страницы, не кэшированные, похоже, являются индикатором низкого качества.
Нам нужно сделать лучше, чем это
Мы уже видели, насколько неточными могут быть данные Google Webmaster Tools — и даже если они точны, одна только цифра говорит вам только о сколько URL-адресов было проиндексировано, а не какие именно.
Массовая проверка индексации может помочь пролить свет на реальную ситуацию, но мы делаем это неправильно .
Представьте, что вы проводите аудит сайта и хотите знать, какие из его 20 000 URL-адресов были проиндексированы. Вы можете проверить все это с помощью команды info:, и, насколько вам известно, каждый из них может быть в репозитории дерьма.
Использование чего-то вроде URL Profiler или Scrapebox для массовой проверки состояния индекса даст вам неточные результаты, которые могут привести к ложным выводам о состоянии веб-сайта.
Нам нужно что-то получше.
Итак, мы создали это
Последний выпуск URL Profiler версии 1.50 включает улучшенную проверку индекса Google, реализующую все, что мы узнали выше. Вы можете прочитать больше об обновлении здесь (а также прочитать о нашей другой интересной новой функции — проверке дубликатов контента).
Наша новая проверка индексации предлагает больше, чем просто Да/Нет, это пример вывода:
Вот что мы сейчас вам покажем:
- Проиндексировано Google: Можем ли мы найти URL-адрес в базовом индексе? Например, отображается ли он для поиска по URL-адресу? В некоторых случаях вместо этого присутствует альтернативный URL, поэтому в качестве результата мы возвращаем «Альтернативный URL». Все остальные результаты — «Да» или «Нет».
- Информация Google: проиндексировано : мы проверяем это только в том случае, если в базовом индексе указан URL-адрес , а не (т. е. не получил «Да» в первом столбце). В противном случае будет отображаться Да/Нет/Альтернативный URL, как указано выше.
- Google Index : На основе проверок мы определяем, находится ли URL в базовом индексе, находится ли он в «глубоком» индексе («дерьмохранилище») или вообще не индексируется. Обратите внимание: если мы обнаружим альтернативный URL-адрес в обеих проверках, конкретный запрошенный вами URL-адрес будет указан как , а не проиндексирован.
- Альтернативный URL, проиндексированный Google: Если мы нашли альтернативный проиндексированный URL вместо того, который мы искали, мы показываем это здесь.
- Кэш Google Дата: Просто отображает дату последнего кеша для каждого URL. Если дата кэширования отсутствует, результат отображается как «Не кэшировано». Иногда мы не можем проверить дату кеша, и в этом случае вместо этого отображается сообщение «Проверить не удалось».
Мы обнаружили, что альтернативные URL-адреса обычно встречаются в канонической ситуации. Например, вы запрашиваете URL-адрес example.com/product1/product1-red, но этот URL-адрес не индексируется, вместо этого индексируется канонический URL-адрес example.com/product1.
Примечание: Если вы еще не поняли, да, эта функция зависит от прокси. Больше информации о них можно найти в нашем руководстве по проверке дубликатов контента.
Как использовать эти данные
Если вас вообще беспокоит индексация URL-адресов вашего сайта, единственный способ узнать , проиндексированы ли все ваши URL-адреса, — это проверить их все.
Вот простой рабочий процесс, который вы можете использовать:
- Просканируйте свой сайт с помощью Screaming Frog
- Используйте функцию «Импорт из Screaming Frog», чтобы импортировать ваши URL-адреса в URL Profiler 9. 0232
- Запустите проверку индексации для всех URL-адресов, а также при необходимости извлеките данные GA и метрики ссылок
Это даст вам гораздо более полный документ аудита, чтобы дать рекомендации и исправления SEO (кстати, у нас также есть полное руководство по проверке индексации).
Если вы не беспокоитесь об индексации URL-адресов, не думаете ли вы, что вам следует это сделать?
Патрик Хэтэуэй
Кажется, я тот, кто пишет все сообщения в блоге, поэтому я собираюсь неофициально называть себя «редактором». На самом деле, я думаю, что предпочитаю главного редактора. Вы можете подписаться на меня в Твиттере или «обвести меня» в Google+.
Если вам нравится звук URL Profiler,
Загрузите бесплатную пробную версию сегодня
(Вы будете поражены, сколько времени она экономит вам каждый день!)
- Бесплатная 14-дневная пробная версия (полная функция)
- Кредитная карта не требуется
- Лицензия всего от 12,95 фунтов стерлингов в месяц
Предыдущий пост:Обновление 1. 50 — Массовая индексация и проверка дубликатов контента
Следующий пост: Создание SEO-профилей конкурентов
Ваш сайт проиндексирован Google? Что, почему и как
Индексирование — очень важная тема, в которой все владельцы веб-сайтов должны иметь хотя бы базовое представление. Без индексации вашего веб-сайта поисковыми системами органический трафик веб-сайта, как правило, будет минимальным. Это делает чрезвычайно важным, чтобы ваш сайт был проиндексирован Google и другими поисковыми системами. В этом сообщении блога мы объясним, что такое индексирование, почему оно важно и как это сделать.
Каждый веб-сайт, указанный в результатах поиска, проиндексирован. Веб-сайты, которые индексируются, распознаются поисковыми системами и появляются в результатах поиска. Поисковые системы, такие как Google, индексируют и включают веб-сайты в свою базу данных. После того, как веб-сайт проиндексирован, он может появиться в результатах поиска. Вы также должны знать, что веб-сайты индексируются более одного раза. Индексы обновляются по мере того, как веб-сайты регулярно сканируются (переиндексируются). Причина, по которой они часто сканируются, заключается в том, что поисковые системы хотят быть в курсе любых изменений, которые могли быть внесены на ваш сайт. Если вы вносите изменения в свой веб-сайт, это может положительно или отрицательно повлиять на то, как ваш сайт должен позиционироваться в поисковых системах.
В первую очередь важно проверить и убедиться, что ваш сайт проиндексирован Google. Если ваш сайт уже проиндексирован Google, то молодцы! Вы все равно должны продолжать читать этот пост в блоге, потому что мы упоминаем некоторые очень важные факторы, которые следует учитывать, чтобы избежать удаления вашего сайта из поисковых систем. Ниже приведены несколько методов, которые вы можете использовать, чтобы узнать, был ли ваш веб-сайт проиндексирован:
1. Проверить результаты поиска Google
Очень просто проверить, включен ли ваш веб-сайт в результаты поиска Google. Все, что вам нужно сделать, это зайти на веб-сайт Google и ввести «сайт: [ваш домен и домен верхнего уровня]». Например, мы можем ввести «site:jjlyonsmarketing.com» в Google. Этот подход будет извлекать результаты поиска только с вашего сайта. Если вы получили нулевой результат, ваш сайт не указан в Google.
2. Используйте сторонний веб-сайт
Существует множество сторонних веб-сайтов, на которых можно проверить кэш Google. Если Google «кэшировал» ваш сайт, значит, он проиндексирован. Использование стороннего веб-сайта может быть проще, чем проверка Google, потому что все, что вам нужно сделать, это скопировать и вставить URL-адрес вашего веб-сайта. Эти веб-сайты делают примерно то же самое, что и вы в Google, поэтому какой бы метод вы ни использовали, это просто вопрос предпочтений.
Если вы проверите, проиндексирован ли ваш веб-сайт, используя один из перечисленных выше методов, вы можете обнаружить, что ваш веб-сайт не проиндексирован. Это определенно проблема, если вы хотите получить постоянный поток трафика на сайт. Вот основные причины, по которым это может быть.
1. Google еще не нашел ваш сайт
Google в значительной степени полагается на технологии и роботов. Все мы знаем, что иногда роботы ошибаются и что-то упускают. Вероятно, проблема связана с вашим веб-сайтом, и Google просто еще не нашел ее. Проблема неотображения обычно возникает с новыми веб-сайтами, потому что Google требуется некоторое время, чтобы обнаружить новые веб-сайты. В конце концов, в Интернете почти два миллиарда веб-сайтов. Это может занять время, чтобы добраться до вашего. Продолжайте читать, чтобы узнать, как сделать так, чтобы Google заметил вас.
Вам нравится эта запись в блоге? Если это так, не забудьте подписаться на периодические обновления по электронной почте от нашей команды!
2. Вы были удалены из Google
Есть много черных тактик SEO, на которые Google не одобряет. Google наказывает веб-сайты, полностью удаляя их из результатов поиска, если они нарушают определенные правила или законы. Это удаление называется «деиндексацией». Если есть какой-либо спам, наполнение ключевыми словами, невидимый текст и т. д., вы можете быть подвергнуты риску деиндексации в Google. Помимо удаления, очень сложно снова попасть в результаты поиска. Не совершайте ошибку, наказывая руководство Google и удаляясь из результатов поиска. У нас есть целая запись в блоге, посвященная этой теме, если вы хотите узнать о ней больше: Покупка ссылок и другие тактики черного SEO, которые доставят вам неприятности Если ваш веб-сайт был переиндексирован, вполне вероятно, что вы намеренно или случайно применили тактику черного SEO. Вот почему важно нанять квалифицированную SEO-компанию, чтобы помочь вам.
Компания Google услышала жалобы владельцев веб-сайтов на то, сколько времени потребовалось для сканирования их веб-сайтов роботом Googlebot. Чтобы решить эту проблему, Google создал для владельцев веб-сайтов способ вручную запрашивать индексацию своего веб-сайта. Для этого вам нужно будет настроить бесплатную учетную запись в Google Search Console. После того, как ваша учетная запись настроена, вы можете либо отправить карту сайта в Google, чтобы они видели все страницы вашего веб-сайта, либо вручную отправить отдельный URL-адрес для просмотра Google. Отдельные URL-адреса отправляются с помощью инструмента под названием «Проверка URL-адресов», который также доступен на панели инструментов Google Search Console.
Если вы уже заполнили форму, убедитесь, что ваш веб-сайт не нарушает рекомендации Google для веб-мастеров. Эти рекомендации показывают владельцам веб-сайтов, чего Google ожидает от них и какие тактики SEO являются этичными. Кроме того, убедитесь, что вы не применяете какие-либо методы черной шляпы, о которых мы упоминали ранее в этом посте. Никогда не бойтесь обращаться в Google и спрашивать их, почему ваш сайт не был проиндексирован, если вы не можете найти ответ самостоятельно.
На этот вопрос нет однозначного ответа. По данным Google, это может занять от четырех дней до четырех недель. Есть много различных факторов, таких как содержание и количество обратных ссылок, которые влияют на это количество времени. Другими словами, количество времени, необходимое роботу Googlebot для сканирования, зависит от веб-сайта. Мы рекомендуем отправить карту сайта, как только ваш сайт заработает. И если на ваш веб-сайт добавлена важная новая страница или запись в блоге, и вы хотите, чтобы она была быстро проиндексирована, попробуйте использовать инструмент проверки URL-адресов, чтобы ускорить ее. Когда мы делаем это, мы обычно видим, что новая страница проиндексирована в течение дня или двух.
Если вы видите, что ваш веб-сайт был проиндексирован, это не означает, что все ваши веб-страницы были проиндексированы. Опять же, это может быть связано с тем, что Google просто не закончил сканирование всех страниц вашего сайта. Это особенно актуально, если страница, которая не проиндексирована, была недавно добавлена на ваш сайт. Другая причина, по которой некоторые страницы не индексируются, заключается в том, что они содержат метатеги noidex. Это конкретно указывает Google НЕ индексировать страницу.
Дважды проверьте и убедитесь, что все ваши веб-страницы проиндексированы, чтобы все они могли получать больше веб-трафика, если только вы не хотите, чтобы некоторые из них были проиндексированы по какой-либо причине.