
Почему сайт в поисковых системах не виден
В этой статье мы рассмотрим пять причин почему сайт в поисковых системах не виден.
- Сайт слишком молод, поэтому Google еще не знает о нем
- Вы запретили индексацию сайта или контента
- Google не может сканировать ваш сайт
- Контент не соответствует критериям и намерениям пользователей
- Контенту не хватает качественных обратных ссылок
- Бонус: Вы попали под ручные санкции?
- Есть и другие причины
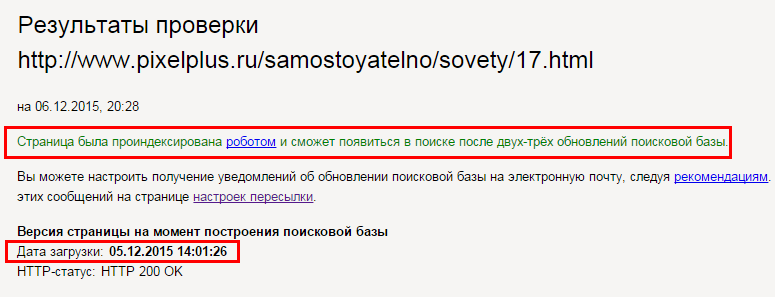
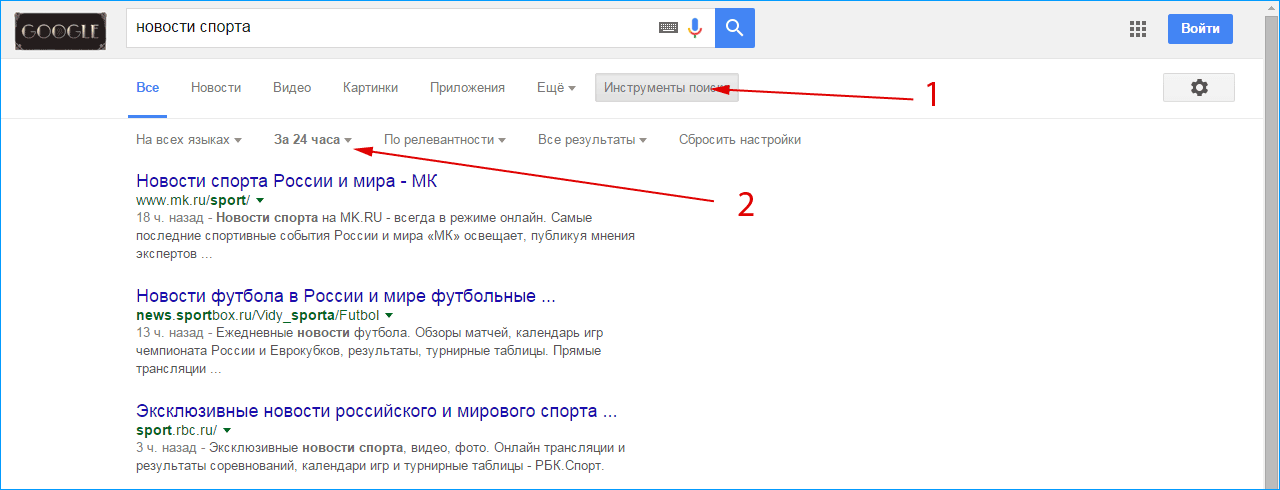
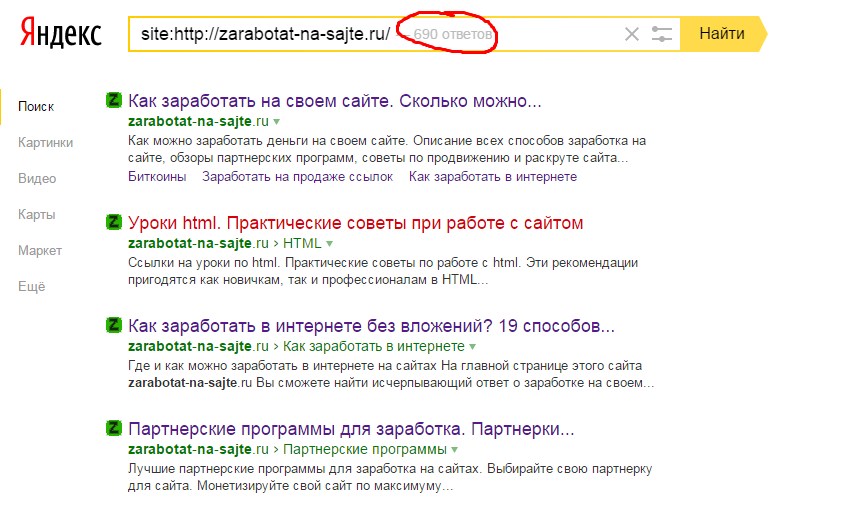
Если ваш сайт новый, то для его обнаружения поисковой системе может потребоваться дни или даже недели. Чтобы проверить его индексацию, воспользуйтесь оператором site:. Введите в Google site:адрес_вашего_сайта, и вы увидите список страниц, найденных на указанном домене. Если вы увидите свои веб-страницы, то это означает, что Google знает о вашем сайте.
Оператор site: поможет найти свой сайт в индексе Google
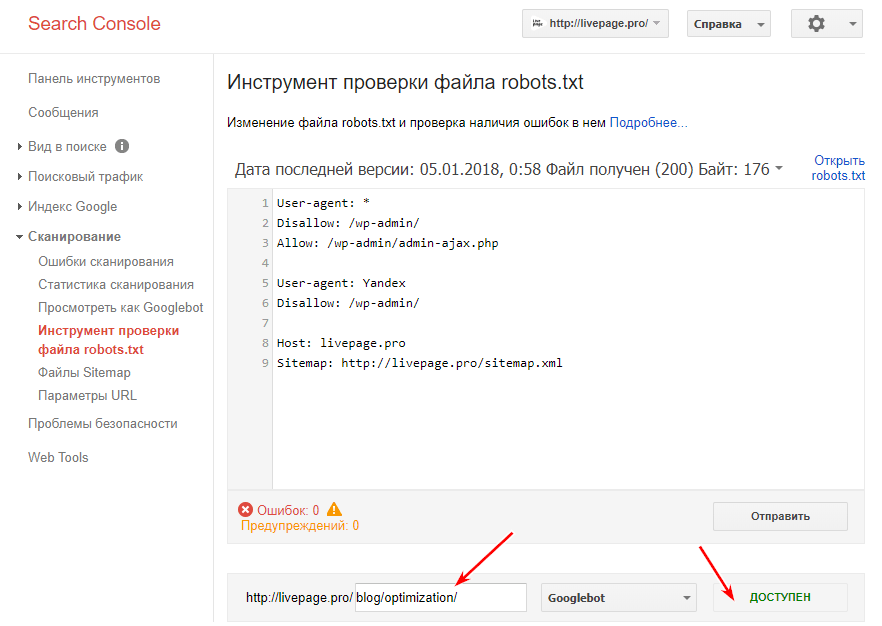
Чтобы ускорить индексацию, установите плагин Yoast SEO и отправьте созданный с его помощью XML-файл сайта в Google Search Console. Также на этой платформе доступен инструмент проверки URL-адресов. Он позволяет понять, как Google сканирует ваш сайт.
Чаще всего сайт в поисковых системах не виден потому, что страницы сайта не были проиндексированы. Добавление на страницу сайта метатега robots noindex указывает роботу Google, что он может сканировать ее контент, но не добавлять в индекс поисковой системы.
Чтобы проверить, не закрыта ли страница сайта от индексации, просмотрите ее HTML-разметку. Приведенный ниже код указывает роботам поисковых систем не добавлять содержимое веб-страницы в индекс. Это и препятствует ее ранжированию.
<meta name="robots" content="noindex">
Возможно, что вы указали Google вообще не сканировать сайт в файле robots.txt.
Осуществить блокировку поисковых роботов очень просто. Например, в WordPress для этого достаточно активировать параметр «Видимость для поисковых систем». Уберите этот флажок, чтобы сайт снова стал доступен для индексации.
Например, в WordPress для этого достаточно активировать параметр «Видимость для поисковых систем». Уберите этот флажок, чтобы сайт снова стал доступен для индексации.
Уберите этот флажок, чтобы WordPress не блокировал индексацию сайта в Google
Начиная с WordPress 5.3, WordPress использует атрибут noindex для отключения индексации сайта с помощью параметра «Видимость для поисковых систем». Это изменение было необходимо, потому что Google иногда все равно индексировал страницы, с которыми сталкивался.
Если сервер сайта выводит в коде ошибки сервера или ошибки JavaScript, то это тоже может быть причиной отсутствия страниц в индексе.
Ваш контент может быть некачественным или недостаточно авторитетным для того, чтобы Google мог выбрать именно его для той или иной ключевой фразы. То есть, он не соответствует ожиданиям пользователя. В этом случае вы должны исследовать ключевые слова и внимательно изучить цели поиска.
Входящие ссылки по-прежнему играют важную роль в обнаружении и ранжировании контента.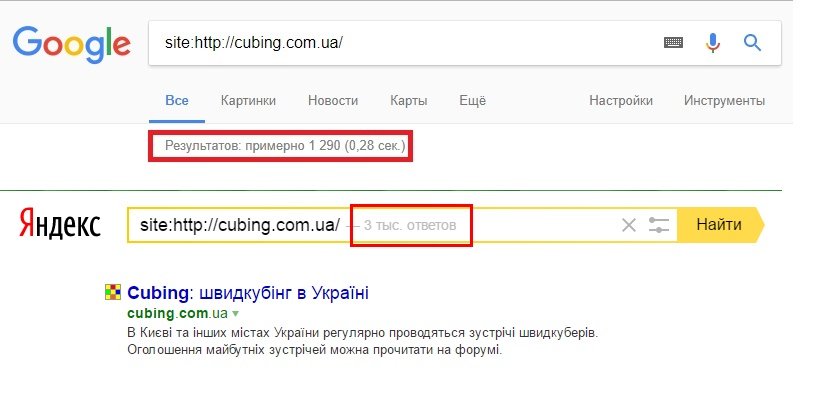 Ваш сайт может ранжироваться без ссылок, но это крайне сложно.
Ваш сайт может ранжироваться без ссылок, но это крайне сложно.
Создание качественного и уникального контента – эффективный способ получить ссылки на страницы своего сайта. Такой контент привлекать клики от читателей, которые могут распространять контент в социальных сетях. Все это помогает получить ссылки.
Отсутствие сайта в выдаче Google также может быть связано с ручными санкциями. Чаще всего они накладываются за нарушение действующих правил поисковой системы Google. Сайты, которые получают ручные санкции, информируются об этом через электронное письмо от Google. Вы также можете проверить страницу ручных санкций в Search Console.
Это далеко не весь перечень причин, из-за которых сайт или его конкретная страница может не отображаться в выдаче Google. Данная статья дает только общее представление о том, где стоит искать причину этого.
Вадим Дворниковавтор-переводчик статьи «5 reasons why your site isn’t showing up on Google»
Блог о программировании — Проверка индексации страниц сайта в Google
Проверив индексацию сайта можно сразу же определить есть ли у Google претензии к страницам вашего ресурса. Проверять руками не очень удобно, сторонни сервисы снова платные. Потому сегодня мы рассмотрим как проверить страницы в индексе с помощью Python.
Проверять руками не очень удобно, сторонни сервисы снова платные. Потому сегодня мы рассмотрим как проверить страницы в индексе с помощью Python.
Не будем оттягивать и сразу приступим к делу. Импортируем модули:
import requests
import pandas as pd
Присвоим переменной словарь с юзерагентом:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}
Создадим словарь в который сохраним результаты и опции. Опции будем добавлять в URL запроса перед отправкой самого запроса:
d = {}
options = {
'muteHttpExceptions': True,
'followRedirects': False
};
В переменной среде path руками создаем файл и вставим туда все url нашего сайта, каждый с новой строки, у нас он будет называться all-website-url.txt, теперь вернемся к коду и открыв файл прочитаем из него все данные в переменную response_url:
with open('all-website-url. txt', encoding="utf-8") as f:
response_url = [line.strip() for line in f]
txt', encoding="utf-8") as f:
response_url = [line.strip() for line in f]
 txt', encoding="utf-8") as f:
response_url = [line.strip() for line in f]
txt', encoding="utf-8") as f:
response_url = [line.strip() for line in f]
С помощью цикла начнем перебор всех URL нашего сайта из переменной, которую мы создали выше, отправляя запрос Google и проверим ответ с помощью условия, данные сохраним в наш пустой словарь, который мы создали в самом начале:
for i in response_url:
resp = f'https://www.google.ru/search?q=site:{i}'
response = requests.get(resp, options, headers=headers).text
if "не знайдено жодного документа" in response:
print("Не в индексе")
d.setdefault("URL", []).append(i)
d.setdefault("Статус", []).append("Не в индексе")
else:
print("В индексе")
d.setdefault("URL", []).append(i)
d.setdefault("Статус", []).append("В индексе")
Создадим табличку с данными с помощью Pandas и сохраним его в таблицу Excel, запускаем и отдыхаем, когда код завершит работу, у нас будет готовая таблица с данными:
df = pd. DataFrame(data=d)
df.to_excel('./googlecheckindex.xlsx')
 DataFrame(data=d)
df.to_excel('./googlecheckindex.xlsx')
DataFrame(data=d)
df.to_excel('./googlecheckindex.xlsx')
И самое важное, помните, что в Python нужно соблюдать отступы или один таб или 4 пробела, код нужно привести к такому виду как он указан на сайте, если при копировании (такое бывает довольно часто) количество отступов изменилось или они пропали вообще.
Не забудьте подписаться на наш телеграм канал@py4seo, будет еще много интересного
Все бэкслеши в конце строк можно удалить и убрать перенос строки, т.е. грубо говоря бэкслеш говорит питону от том, что тут код очень длинный, делаем перенос строки.
Полная версия кода ниже:
import requests
import pandas as pd
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"}
d = {}
options = {
'muteHttpExceptions': True,
'followRedirects': False
}
with open('all-website-url.txt', encoding="utf-8") as f:
response_url = [line.strip() for line in f]
for i in response_url:
resp = f'https://www. google.ru/search?q=site:{i}'
response = requests.get(resp, options, headers=headers).text
if "не знайдено жодного документа" in response:
print("Не в индексе")
d.setdefault("URL", []).append(i)
d.setdefault("Статус", []).append("Не в индексе")
else:
print("В индексе")
d.setdefault("URL", []).append(i)
d.setdefault("Статус", []).append("В индексе")
df = pd.DataFrame(data=d)
df.to_excel('./googlecheckindex.xlsx')
 google.ru/search?q=site:{i}'
response = requests.get(resp, options, headers=headers).text
if "не знайдено жодного документа" in response:
print("Не в индексе")
d.setdefault("URL", []).append(i)
d.setdefault("Статус", []).append("Не в индексе")
else:
print("В индексе")
d.setdefault("URL", []).append(i)
d.setdefault("Статус", []).append("В индексе")
df = pd.DataFrame(data=d)
df.to_excel('./googlecheckindex.xlsx')
google.ru/search?q=site:{i}'
response = requests.get(resp, options, headers=headers).text
if "не знайдено жодного документа" in response:
print("Не в индексе")
d.setdefault("URL", []).append(i)
d.setdefault("Статус", []).append("Не в индексе")
else:
print("В индексе")
d.setdefault("URL", []).append(i)
d.setdefault("Статус", []).append("В индексе")
df = pd.DataFrame(data=d)
df.to_excel('./googlecheckindex.xlsx')
Какой инструмент вы используете для проверки URL-адресов, которые не проиндексированы? | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
 org/BreadcrumbList»>
org/BreadcrumbList»>Эта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
-
Какой ваш любимый инструмент для получения отчета о URL-адресах, которые не кэшируются/не индексируются в Google и Bing для всего сайта? В основном мне нужен список URL-адресов, не кэшированных в Google, и отдельный список для Bing.
Спасибо,
Марк
Я могу работать над созданием этого инструмента, если будет достаточно интереса.
Обычно я просто использую поисковик гиперссылок Xenu (если у вас тысячи страниц), чтобы перечислить все URL-адреса, которые у вас есть, и затем я мог бы просмотреть их вручную, однако посмотрите на востребованную гитару. Я не сталкивался с автоматическим устройством. еще. Если все люди знают о каких-либо, я хотел бы признать, как должным образом.
Если я что-то не упустил, кажется, нет способа заставить Google показывать более 100 результатов на странице. На нашем сайте около 8000 страниц, и мне не нравится идея вручную экспортировать 80 SERP.
-
Энни Кушинг из Seer Interactive составила потрясающий список всех необходимых инструментов для SEO.
Вы можете получить его по ее ссылке, которая находится на http://bit.ly/tools-galore
В списке есть инструмент под названием scrapebox, который отлично подходит для этого. На самом деле у программного обеспечения много применений, оно также полезно для поиска потенциальных партнеров по ссылкам.
-
Я бы посоветовал использовать Аудитор веб-сайтов из Advanced Web Ranking. Он может анализировать 10 000 страниц и сообщит вам гораздо больше информации, чем просто проиндексирована ли она Google или нет.
хм.
.. Я думал, что есть способ перенести эти URL-адреса SERP в документы Google, используя какую-то функцию?- Я думаю, вам не нужен какой-либо инструмент для этого, вы можете напрямую перейти на google.com и выполнить поиск: Site:www.YourWebsiteNem.com Site:www.YourWebsiteName.com/directory сайт сканируется гугл или нет.
-
Я делаю что-то подобное, но использую Advanced Web Ranking, использую site:www.domain.com в качестве фразы, запускаю его для получения 1000 результатов и генерирую отчет Top Site Report в Excel, чтобы получить проиндексированный список.
Также помните, что вы можете сделать это с подкаталогами (или частичными путями URL), чтобы получить более 1000 страниц с сайта. Обычно я запускаю его один раз с site:www.domain.com, затем определяю наиболее часто встречающиеся подкаталоги, добавляю их в качестве дополнительных фраз в проект и запускаю второй раз, то есть: site:www.domain.com site: www.domain.com/dir1 сайт:www.domain.com/dir2 и т. д.
Еще не окончательный, но думаю, что он указывает, где находится значение.
-
У Дэвида Каузларика, на мой взгляд, лучший ответ. Если Google не проиндексировал его, и вы исследовали свою учетную запись веб-мастера Google, то, насколько я понимаю, нет ничего лучше. Это, безусловно, самый простой, быстрый и легкий способ определить результат поисковой выдачи.
re: Дэвид Каузларик
Мы создали внутренний инструмент, который делает это за нас, но в основном вы можете сделать это вручную.
Зайдите в Google, введите «site:YOURURLHERE» без кавычек. Вы можете проверить определенную страницу, сайт, поддомен и т. д. Конечно, если у вас есть тысячи URL-адресов, этот метод не идеален, но это можно сделать.
Удачи!
Согласен, Xenu — чрезвычайно ценный инструмент для меня, которым я пользуюсь каждый день. Кроме того, как только вы получите список всех URL-адресов на своем сайте, вы можете сравнить два списка в Excel (два списка — это список страниц Xenu для вашего сайта и список страниц, которые были проиндексированы Google).
-
Отличное решение, Киран!
Я использую тот же метод, чтобы сравнить список URL из выходных данных Screaming Frog со столбцом URL Found из моего инструмента ранжирования ключевых слов — конечно, он не захватывает все страницы, которые могут быть проиндексированы.
На самом деле цель состоит не в том, чтобы получить полный список, а в том, чтобы «начертить» страницы, над которыми нужно поработать.
Я согласен, это не автоматизировано, но пока, насколько нам известно, выглядит как хороший и чистый вариант.
Спасибо.-
Увидел это и попробовал следующее, которое не автоматизировано, но является одним из способов сделать это.
- Сначала установите плагин SEO Quake
- Перейти к Google
- Отключить Живой поиск Google (http://www.google.com/preferences)
- Перейти к расширенному поиску установить количество отображаемых результатов (оцените количество страниц на вашем сайте)
- Затем запустите свой сайт: www.example.com поисковый запрос
- Экспортировать это в CSV
- Импорт в Excel
- Один раз выполните преобразование данных в столбцы с помощью ; в качестве разделителя (это разделитель CSV)
- Это дает вам отформатированный список.
- Затем импортируйте файл sitemap.xml в другую вкладку в Excel
- Запустите vlookup между вкладками URL, чтобы пометить, какие из них находятся на карте сайта, или наоборот.
Не совсем автоматизирован, но работает.
Меня также интересует этот вопрос, было бы очень полезно увидеть основной список всех URL-адресов на нашем сайте, которые не проиндексированы Google, чтобы мы могли принять меры, чтобы увидеть, какие аспекты страницы отсутствуют и что нам нужно для этого. для индексации.
Обычно я просто использую средство поиска ссылок Xenu (если у вас тысячи страниц), чтобы перечислить все имеющиеся у вас URL-адреса, а затем проверить их вручную, но я еще не сталкивался с автоматизированным инструментом.
Если кто-то что-то знает, я бы тоже хотел узнать.Manual не годится для больших сайтов. Если кто-то знает такой инструмент, было бы здорово узнать, какой/где найти. Или ….. Это сделало бы крутой инструмент SEOmoz pro
Плохо — вы правы, он не отображает фактические URL-адреса. Поэтому я думаю, что лучшее, что вы можете сделать, это site:examplesite.com и посмотреть, что получится.
Я бы использовал Инструменты Google для веб-мастеров, так как вы можете видеть, сколько URL-адресов проиндексировано на основе вашей карты сайта. Получив это, вы можете сравнить его со своим общим списком. То же самое можно сделать с Bing.
Да, сейчас я делаю это вручную, поэтому искал что-то более эффективное.

 org/Comment»>
org/Comment»> В этом сообщении от Distilled упоминается, что плагин SEO для Excel имеет «Проверку индексации»:
https://www.distilled.net/blog/seo/awesome-examples-of-how-to-use-seotools-for- excel/
Увы, после загрузки и установки оказалось, что эта функция удалена…
 .. Я думал, что есть способ перенести эти URL-адреса SERP в документы Google, используя какую-то функцию?
.. Я думал, что есть способ перенести эти URL-адреса SERP в документы Google, используя какую-то функцию?
 Спасибо.
Спасибо.
 Если кто-то что-то знает, я бы тоже хотел узнать.
Если кто-то что-то знает, я бы тоже хотел узнать. org/Comment»>
org/Comment»>Это сообщит вам число проиндексированных, но все еще не скажет вам, какие из этих URL-адресов проиндексированы, а какие нет. Я думаю, мы все хотели бы этого!
 org/Comment»>
org/Comment»> Мы создали внутренний инструмент, который делает это за нас, но в основном вы можете сделать это вручную.
Зайдите в Google, введите «site:YOURURLHERE» без кавычек. Вы можете проверить определенную страницу, сайт, поддомен и т. д. Конечно, если у вас есть тысячи URL-адресов, этот метод не идеален, но это можно сделать.
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией All CategoriesAffiliate MarketingAlgorithm UpdatesAPIBrandingCommunityCompetitive ResearchContent DevelopmentConversion Rate OptimizationDigital MarketingFeature RequestsGetting StartedImage & Video OptimizationIndustry EventsIndustry NewsIntermediate & Advanced SEOInternational SEOJobs and OpportunitiesKeyword ExplorerKeyword ResearchLink BuildingLink ExplorerLocal ListingsLocal SEOLocal Website OptimizationMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn-Page OptimizationOther SEO ToolsPaid Search MarketingProduct SupportReporting & AnalyticsResearch & TrendsReviews and RatingsSearch BehaviorSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Связанные вопросы
 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»>Поскольку site:mysite.com *** -sljktf несколько лет назад перестал работать для поиска страниц в дополнительном индексе, кто-нибудь нашел другой способ идентифицировать контент, который был отнесен к дополнительному индексу?
Техническое SEO | | SEMСтрасть
0
 org/ListItem»> Структура URL-адреса
org/ListItem»> Структура URL-адреса Я занимаюсь редизайном нашего веб-сайта, и структура URL-адреса была поднята. В настоящее время наши URL-адреса структурированы как domain.com/keyword. Кажется, некоторые люди считают, что настройка URL-адресов в следующем виде: domain.com/directory/keyword имеет больше смысла с точки зрения пользователя и с точки зрения поисковой системы. С нашими каталогами, помеченными как услуги, решения, клиенты — я не вижу смысла в добавлении каталогов, поскольку это разбавляет ключевое слово и отдаляет ключевое слово от домена. Есть ли ситуации, когда имеет смысл добавить каталог перед страницей в URL-адресе? Если у кого-то есть данные, показывающие разницу между ними, это было бы здорово! Спасибо, Брайан
Техническое SEO | | ПрасунГоэль
0
 org/ListItem»> Удаление проиндексированного веб-сайта
org/ListItem»> Удаление проиндексированного веб-сайта У меня была версия моего веб-сайта .com с доменом верхнего уровня .in в течение примерно 15 дней, которая была дубликатом веб-сайта .com. Я не хотел использовать домен .in в дальнейшем из соображений SEO-дублирования и позволил домену .in истечь 26 апреля. Но все же теперь, когда я ищу на своем веб-сайте, версия .in также отображается в результатах, и даже в веб-мастере Google он показывает веб-сайт с максимальным (190) количество ссылок на мой сайт .com. Я уверен, что это вредит рейтингу моего веб-сайта .com. Как можно удалить веб-сайт .in из индексации и результатов поиска Google. Учитывая, что срок его действия также истек. спасибо
Техническое SEO | | гиквик
0
 org/ListItem»> Должен ли я использовать канонический?
org/ListItem»> Должен ли я использовать канонический? Я работаю над сайтом, который продает звуковые дорожки, сайт представляет собой сборку WordPress. У меня есть Yoast и XML Sitemaps для SEO.
Сайт был разработан (не мной) для использования аудиоплеера на основе флэш-памяти. Теперь этот плеер предлагает возможность делиться, продавать товары и т. д. Плеер был размещен на главной странице и на главной странице музыкального каталога.
Для главной страницы каталога был создан собственный тип страницы. Эта страница была создана таким образом, что если вы перейдете на фактическую страницу из панели управления > Страницы и добавите контент, то на странице не будет отображаться никакого контента. Даже заголовок страницы
вытягивается из PHP.
Насколько мне известно, поисковая система не видит на странице никакого реального контента.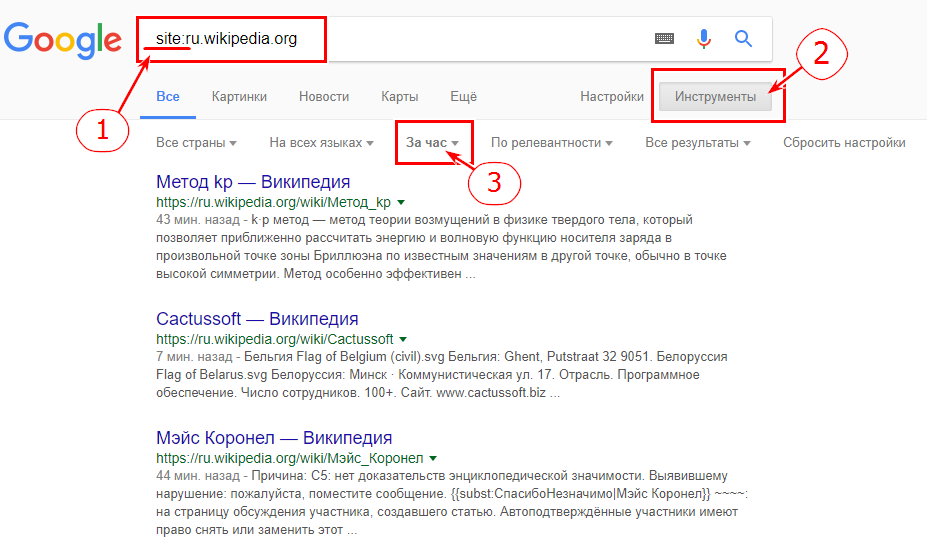 За исключением контента на боковых панелях (у него есть 2 боковые панели по обеим сторонам страницы).
На главной странице есть вводный абзац и заголовок, которые можно редактировать обычным способом в WordPress.
Пользовательский тип записи был создан специально для музыкальных объектов. Когда музыкальный элемент загружается, он добавляется в ленту музыкальных элементов на домашней странице и страницах музыкального каталога. Он также создает отдельный пост для самого элемента. Эти элементы на данный момент также не имеют содержания, поскольку представляют собой только боковые панели с музыкальным флеш-плеером. Я начал добавлять к ним короткие абзацы и заголовки, чтобы в постах с музыкальными элементами был контент. Однако я не могу, учитывая временные рамки/бюджет, начать вводить подробное описание каждого элемента. (Я подумал о том, чтобы добавить вступительный абзац с главной страницы и использовать канонический тег на главной странице для каждого музыкального элемента).
Вот мой вопрос.
За исключением контента на боковых панелях (у него есть 2 боковые панели по обеим сторонам страницы).
На главной странице есть вводный абзац и заголовок, которые можно редактировать обычным способом в WordPress.
Пользовательский тип записи был создан специально для музыкальных объектов. Когда музыкальный элемент загружается, он добавляется в ленту музыкальных элементов на домашней странице и страницах музыкального каталога. Он также создает отдельный пост для самого элемента. Эти элементы на данный момент также не имеют содержания, поскольку представляют собой только боковые панели с музыкальным флеш-плеером. Я начал добавлять к ним короткие абзацы и заголовки, чтобы в постах с музыкальными элементами был контент. Однако я не могу, учитывая временные рамки/бюджет, начать вводить подробное описание каждого элемента. (Я подумал о том, чтобы добавить вступительный абзац с главной страницы и использовать канонический тег на главной странице для каждого музыкального элемента).
Вот мой вопрос.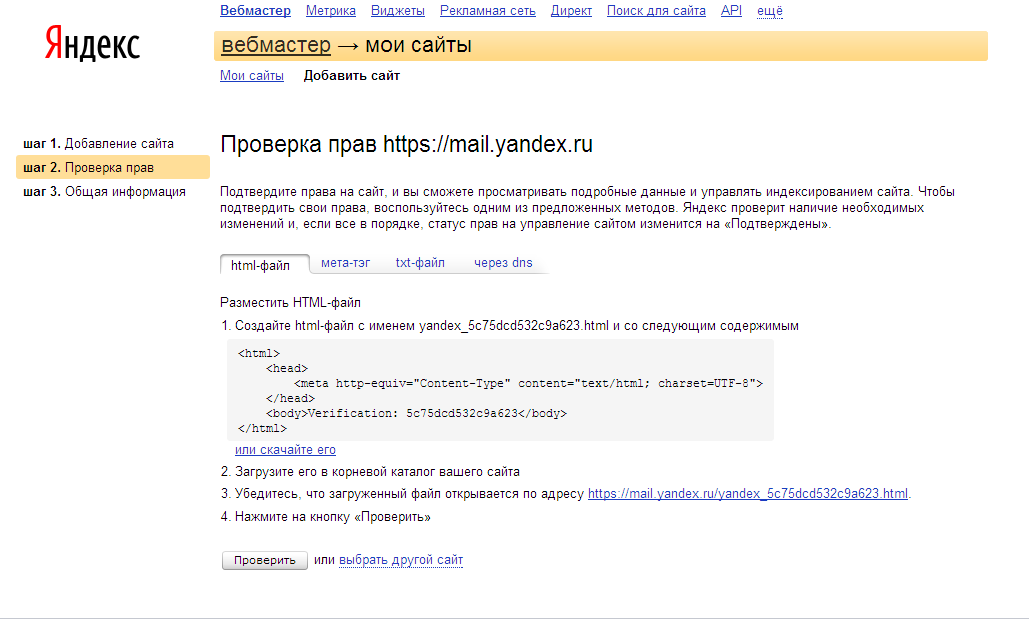 Что мне делать с этими музыкальными объектами? Использую ли я canonical и указываю ли им музыкальный каталог или домашнюю страницу? Если да, то какой? Я хочу, чтобы домашняя страница или страница музыкального каталога имели хороший рейтинг, и я обеспокоен тем, что поисковые системы не увидят эти наиболее важные части сайта. Я не думаю, что ранжирование отдельных предметов полезно, так что мне делать?!?! Домашняя страница и страницы каталога являются двумя основными страницами сайта. Я собираюсь посоветовать использовать новый проигрыватель, тип страницы и т. д., но на данный момент мне нужно быстрое решение.
Любая помощь будет высоко ценится.
Что мне делать с этими музыкальными объектами? Использую ли я canonical и указываю ли им музыкальный каталог или домашнюю страницу? Если да, то какой? Я хочу, чтобы домашняя страница или страница музыкального каталога имели хороший рейтинг, и я обеспокоен тем, что поисковые системы не увидят эти наиболее важные части сайта. Я не думаю, что ранжирование отдельных предметов полезно, так что мне делать?!?! Домашняя страница и страницы каталога являются двумя основными страницами сайта. Я собираюсь посоветовать использовать новый проигрыватель, тип страницы и т. д., но на данный момент мне нужно быстрое решение.
Любая помощь будет высоко ценится.
Техническое SEO | | Беньямин
0
Сегодня я читал последнюю запись в блоге SEOmoz о. Uncrawled 301s — быстрое решение, когда перезапуски идут слишком хорошо
Это очень интересное исследование о 301 и о том, как это полезно для поддержания трафика. Я работаю над веб-сайтом электронной коммерции, и я сделал нечто подобное на своем веб-сайте. У меня есть большая путаница, чтобы управлять переадресацией 301.
Мой веб-сайт генерирует новые URL-адреса из-за следующих действий.
Перепишите динамические URL-адреса.
Перезапустите весь веб-сайт на другой платформе электронной коммерции. [из osCommerce в Magento Commerce]
Переименовать категорию.
Перенесите один товар из одной категории в другую.
Я управляю своим перенаправлением 301 по старой практике. Данные листа Excel из инструментов Google для веб-мастеров и установите новые URL-адреса для перенаправления. Уууу… Сейчас у меня в htaccess редирект 8,5К… И я думаю, что это слишком много.
Можем ли мы удалить старый 301 редирект из htaccess или нет? Это большой вопрос для меня. Потому что не все страницы являются гиперссылками на внешний сайт.
Uncrawled 301s — быстрое решение, когда перезапуски идут слишком хорошо
Это очень интересное исследование о 301 и о том, как это полезно для поддержания трафика. Я работаю над веб-сайтом электронной коммерции, и я сделал нечто подобное на своем веб-сайте. У меня есть большая путаница, чтобы управлять переадресацией 301.
Мой веб-сайт генерирует новые URL-адреса из-за следующих действий.
Перепишите динамические URL-адреса.
Перезапустите весь веб-сайт на другой платформе электронной коммерции. [из osCommerce в Magento Commerce]
Переименовать категорию.
Перенесите один товар из одной категории в другую.
Я управляю своим перенаправлением 301 по старой практике. Данные листа Excel из инструментов Google для веб-мастеров и установите новые URL-адреса для перенаправления. Уууу… Сейчас у меня в htaccess редирект 8,5К… И я думаю, что это слишком много.
Можем ли мы удалить старый 301 редирект из htaccess или нет? Это большой вопрос для меня. Потому что не все страницы являются гиперссылками на внешний сайт. Google только что деиндексировал старые URL-адреса и проиндексировал новые URL-адреса. Итак, требуется ли поддерживать перенаправление 301 после процесса Google?
Google только что деиндексировал старые URL-адреса и проиндексировал новые URL-адреса. Итак, требуется ли поддерживать перенаправление 301 после процесса Google?
Техническое SEO | | Коммерческий эксперт
0
Рассматриваемая страница получает много качественного трафика, но имеет отношение только к небольшому проценту моих пользователей. Я хочу сохранить ссылочный вес, полученный с этой страницы, но не хочу, чтобы он отображался в поисковой выдаче.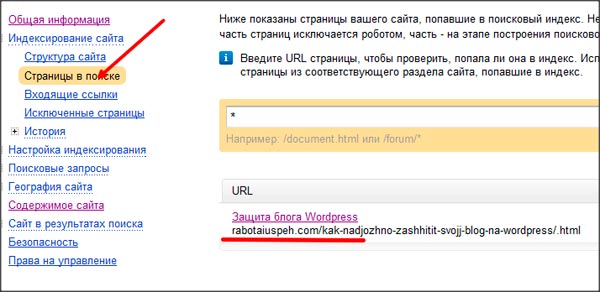
Техническое SEO | | съемочная штуковина
0
Сегодняшний веб-семинар по картам сайта заставил меня задуматься о функции запрета, которая кажется противоположной картам сайта, но также кажется, что обе они по-разному игнорируются движками.
Мне не нужна помощь семантически, я получил эту часть. Я просто не могу найти современный ответ о том, что должно быть заблокировано с помощью файла robots.txt.
Например, у меня есть папки, содержащие сайты для клиентов, которые я действительно не хочу показывать в поисковой выдаче. Лучше вообще не иметь этих папок в домене?
Есть также проблемы с безопасностью, о которых я слышал, которые имеют смысл, просто посмотрите на файл robots сайта, чтобы увидеть, что они скрывают. Это облегчает поиск файлов, когда они знают каталог, в котором находятся файлы. Меня это волнует?
Другим примером является папка для моего генератора карт сайта xml. Я предполагаю, что Google не будет пытаться индексировать это или считать его контентом, поэтому мне нужно добавлять такие папки в список запрещенных?
Лучше вообще не иметь этих папок в домене?
Есть также проблемы с безопасностью, о которых я слышал, которые имеют смысл, просто посмотрите на файл robots сайта, чтобы увидеть, что они скрывают. Это облегчает поиск файлов, когда они знают каталог, в котором находятся файлы. Меня это волнует?
Другим примером является папка для моего генератора карт сайта xml. Я предполагаю, что Google не будет пытаться индексировать это или считать его контентом, поэтому мне нужно добавлять такие папки в список запрещенных?
Техническое SEO | | ВеснаГора
0
Использование файла . htaccess как переписать URL из
www.exampleurl.com/index.php?page=example
к
www.exampleurl.com/example
удаление index.php?page= Любая помощь приветствуется
htaccess как переписать URL из
www.exampleurl.com/index.php?page=example
к
www.exampleurl.com/example
удаление index.php?page= Любая помощь приветствуется
Техническое SEO | | КрейгАддиман
0
Масштабирование проверок индексации Google с помощью Node.js
Почему важно знать статус индексации вашего веб-сайта
Как специалист по SEO или владелец веб-сайта, вы хотите привлечь потенциальных пользователей/клиентов на свой сайт через поиск Google. Если ваш веб-сайт (или часть вашего веб-сайта) не проиндексирован, вы не будете отображаться в результатах поиска и потеряете любой потенциальный органический трафик, конверсии и доход.
У вас может быть и противоположная проблема. Если ваш веб-сайт экспоненциально создает URL-адреса (распространенная проблема на сайтах электронной коммерции) или допускает неконтролируемый пользовательский контент, возможно, Google сканирует и индексирует больше, чем следует. Это может быстро привести к огромной неэффективности, которая нанесет ущерб вашей базовой архитектуре.
Это может быстро привести к огромной неэффективности, которая нанесет ущерб вашей базовой архитектуре.
Распространенные проблемы при сборе данных индексации Google
Прямо сейчас вы можете использовать Google Search Console или несколько сторонних решений для сбора данных индексации. Однако оба варианта имеют свои собственные недостатки, когда речь идет о проверке данных индексации в масштабе. Обычно они делятся на две группы: доступность данных и точность результатов.
Ограничения Google Search Console
Google Search Console (GSC) — невероятно точный источник данных о статусе индексации. В конце концов, у него есть преимущество подключения к системе индексации Google (Caffeine). В новой версии GSC представлены три очень полезных отчета, предоставляющих данные о статусе индексации: Инструмент проверки URL, Отчет о покрытии и Отчет о файлах Sitemap.
Однако ни один из этих отчетов не подходит для крупных веб-сайтов, поскольку GSC ограничивает количество URL-адресов, которые вы можете проверять в день.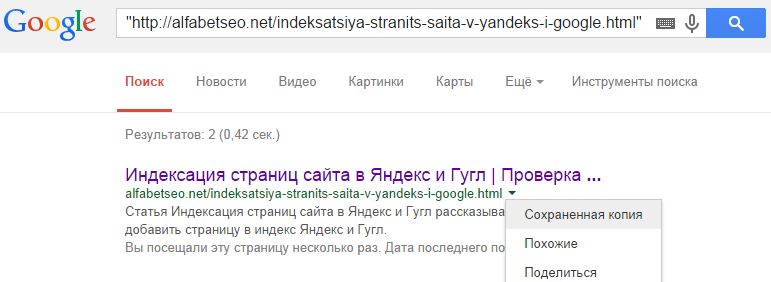 Я знаю это, потому что Гамлет Батиста создал удивительный инструмент для автоматизации Инспектора URL, и я узнал об этом на собственном горьком опыте!
Я знаю это, потому что Гамлет Батиста создал удивительный инструмент для автоматизации Инспектора URL, и я узнал об этом на собственном горьком опыте!
Ограничение квоты для Инспектора URL-адресов GSC составляет около 100 URL-адресов в день. Доступ к API для извлечения большего.
GSC ограничивает экспорт до 1000 URL-адресов, но у меня 25 миллионов страниц…
Единственный способ обойти это — разделить всю вашу архитектуру на XML-карты сайта с 1000 URL-адресов максимум. Таким образом, если у вас есть 100 000 (известных/важных) URL-адресов, вам потребуется создать 100 XML-карт сайта. С этим будет очень сложно справиться, и поэтому это не вариант.
Кроме того, это не даст вам необходимых данных индексации о неконтролируемых URL-адресах, созданных с помощью фасетной навигации или пользовательского контента.
Ограничения профилировщика URL
Как упоминалось в сообщении Ричарда, в некоторых случаях профилировщик URL был допустимым вариантом для сбора данных индексации. Хотя нам нравится этот инструмент для других задач, мы поняли, что у него было много проблем с получением точных данных для «нечистых» URL-адресов.
Хотя нам нравится этот инструмент для других задач, мы поняли, что у него было много проблем с получением точных данных для «нечистых» URL-адресов.
Некоторые примеры включают параметризованные URL-адреса, URL-адреса с закодированными символами (т. е. символами, отличными от ASCII) и символами, URL-адреса с различным регистром букв и URL-адреса с небезопасными символами.
Неверные результаты с использованием site: operator — результаты, не отображающие запрошенный URL-адрес.
Мне еще предстоит найти инструмент, решающий все эти проблемы, поэтому мы создали свой собственный.
Решение: Средство проверки индексации Builtvisible
Средство проверки индексации Builtvisible – это скрипт, разработанный нашим старшим веб-разработчиком Альваро Фернандесом. Он был создан специально для устранения ограничений, с которыми, я уверен, сталкиваемся не только мы.
Наш скрипт может проверять неограниченное количество URL-адресов с любыми проблемными символами: параметры, кодировка, зарезервированные символы, небезопасные символы, разные алфавиты — если Google проиндексировал их, наш скрипт найдет их.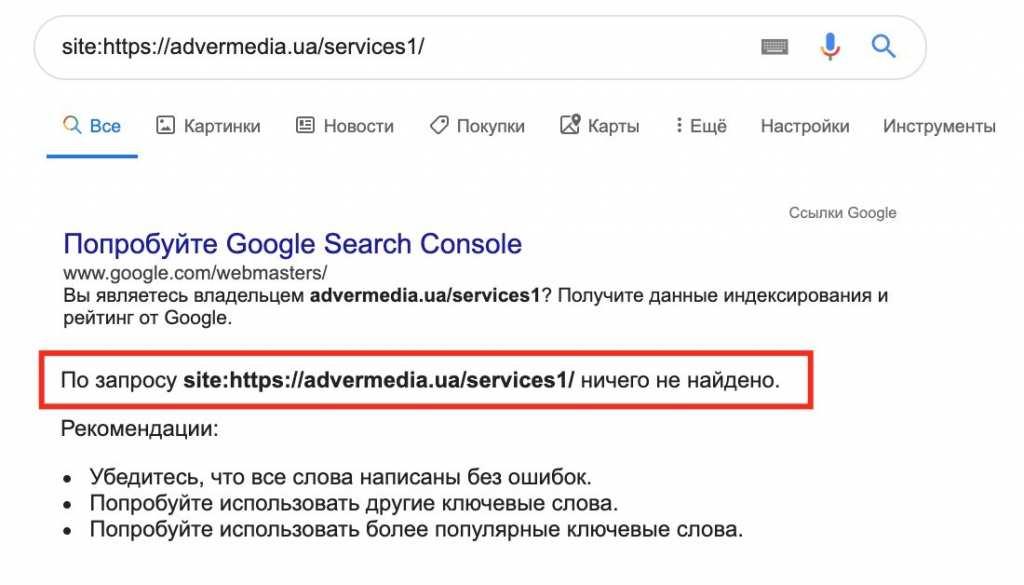
Вот его сравнение с другими решениями:
Как настроить скрипт
Вам нужно быть уверенным в среде командной строки на вашем компьютере.
Сначала установите на свой компьютер последнюю версию Node.js.
Затем загрузите или клонируйте наш репозиторий с Github.
git clone https://github.com/alvaro-escalante/google-index-checker.git
Перейдите в только что загруженную папку. Откройте терминал и установите необходимые модули с помощью следующей команды:
npm install
Раньше, если вы собирали результаты поисковой выдачи Google, вам понадобилось бы много прокси-серверов, но благодаря ребятам из ScraperAPI это больше не проблема. У них есть тысячи прокси-серверов по всему миру, поэтому все, что вам нужно сделать, это запросить желаемый URL-адрес, используя тот же формат вызова API, и они будут выполнять настройку прокси-сервера в фоновом режиме.
Перейдите в ScraperAPI и создайте бесплатную учетную запись. Не волнуйтесь, нет необходимости добавлять кредитную карту, так как у них очень щедрый бесплатный уровень. Первые 1000 запросов в месяц совершенно бесплатны, этого более чем достаточно для тестирования нашего скрипта.
Первые 1000 запросов в месяц совершенно бесплатны, этого более чем достаточно для тестирования нашего скрипта.
Перейдите на панель инструментов и получите ключ API.
Добавьте ключ API вашего скраппера в файл APIKEY.js
Время запуска скрипта
Получите список URL-адресов, которые вы хотите проверить, и сохраните его без заголовков в формате CSV с именем urls.csv. Обязательно используйте полные URL-адреса, включая протокол. Поместите файл в папку google-index.
Если у вас нет списка, вы можете использовать мой Полный список URL-адресов. Я подготовил это, когда мы разрабатывали сценарий, и он включает в себя почти все проблемные типы URL-адресов, а также несколько поддельных URL-адресов, чтобы убедиться, что у нас нет ложных срабатываний.
Перейдите к своему терминалу и запустите скрипт с помощью следующей команды Node.
npm start
Вот и все!
Теперь вы сможете увидеть URL-адреса из вашего CSV, всплывающие в вашем терминале с кодом состояния HTTP из вызова API.
Поскольку мы используем прокси-сервер, вы, скорее всего, получите код состояния 500, сценарий переработает эти ошибки и повторно запустит список, пока не будут проверены все URL-адреса. ScraperAPI не будет взимать кредиты с вашей учетной записи за эти ошибки.
После завершения сценария вы получите сообщение об успешном завершении и новый файл с именем «results.csv». Внутри вы найдете список URL-адресов с проверенным статусом индексации.
Успех! Пришло время проверить результаты
Мы обнаружили, что в среднем проверка 2500 URL-адресов занимает около часа, поэтому, если вы планируете использовать этот скрипт для тысяч URL-адресов, имейте это в виду.
Заключительные мысли
Интернет заполнен странными URL-адресами, и, если вы читаете это, скорее всего, вы имеете дело с гигантским веб-сайтом, который имеет свою долю. Знание того, какие из них были проиндексированы Google, может быть огромной проблемой.
С помощью нашего скрипта вы сможете проверить статус индексации для любого типа URL, и размер списка больше не будет проблемой — мы надеемся, что он вам понравится так же, как и нам!
Несколько дополнительных концепций
Прежде чем я уйду, я хотел бы прояснить несколько вещей, которые я считаю необходимыми.
Во-первых, важно различать индексирование и обслуживание. Мы, как пользователи, не имеем прямого доступа к фактическому индексу Google (кроме данных, которые мы получаем от GSC). Поэтому второй лучший вариант — понять, что Google обслуживает через Google Search.
Это означает, что мы можем быть уверены, что URL-адрес находится в индексе Google, если мы видим его в поиске Google, но мы не можем быть на 100% уверены, что URL-адрес не находится в индексе, если Google не обслуживает его через Google. Поиск.
Однако на практике, если URL-адрес не отображается в поисковой выдаче, пользователи не могут его увидеть. Поэтому для нас это было бы так, как будто этого нет в Индексе, и мы могли бы захотеть выяснить, почему это так.
Во-вторых, проиндексированный URL-адрес не означает, что контент на вашей странице проиндексирован. Например, если на вашем сайте используется платформа JavaScript, которая выполняет рендеринг на стороне клиента (CSR), возможно, Google проиндексировал пустую страницу.