
Прогноз бюджета в Яндекс Директе
С тегом «Сам себе маркетолог» на ppc.world выходят обучающие материалы, которые помогут новичкам погрузиться в удивительный и сложный мир контекстной рекламы.
Инструмент Прогноз бюджета в Директе доступен только авторизованным пользователям Яндекс Директа. Он дает ориентировочные данные о расходах на рекламную кампанию на поиске до ее запуска, а также о средних CTR и СРС в тематике. При оценке расходов система опирается на статистику по заданным ключевым фразам за последние 28 дней.
Однако расчеты инструмента приблизительные: после запуска рекламы реальный бюджет может оказаться в несколько раз меньше. Вот причины, по которым данные Прогноза бюджета могут отличаться от реальных:
- Стоимость клика и показатель кликабельности зависят от коэффициента качества объявления. Например, чем больше заголовок и текст соответствуют пользовательскому запросу, тем релевантнее будет реклама, по оценке Яндекса.

- Цена за клик также меняется в зависимости от накопленного CTR: чем выше кликабельность, тем меньше придется платить за клики в будущем.
- Прогноз бюджета не всегда может учесть увеличение сезонного спроса, хотя алгоритм инструмента недавно начал ориентироваться на данные из прошлых аналогичных сезонов.
- Расход также зависит от стратегии, которую рекламодатель использует для управления ставками.
- При внесении изменений в кампанию, в том числе при добавлении ключевых фраз и минус-слов, смены региона, уточнения таргетинга, ставки могут изменяться.
- Инструмент прогнозирует только расход на поиске, не учитывая показы в РСЯ, где клики часто бывают дешевле.

И все же Прогноз бюджета дает примерное представление о будущих расходах. Из инструкции ниже вы узнаете, как использовать этот инструмент.
1. Откройте Прогноз бюджета
К инструменту можно перейти из интерфейса Директа, поэтому сначала зайдите в аккаунт рекламной системы. Прогноз бюджета находится в Инструментах, в левом боковом меню.
Прогноз бюджета находится в Инструментах, в левом боковом меню.
2. Выберите регион показа рекламы
Отметьте галочками регионы, в которых находятся потенциальные клиенты. Если вы занимаетесь продажей товара, то выберите города, в которые осуществляете доставку. Если ваш бюджет сильно ограничен, то начать можно с того населенного пункта, в котором находится ваша компания.
Настройки геотаргетинга3. Выберите параметры
В качестве периода выберите время, расходы на какой период вы хотите получить. Если вам нужен прогноз только для рекламы на смартфонах, в графе Площадки выберите только мобильные. В инструменте доступно несколько валют: у.е., российские и белорусские рубли, украинские гривны, доллары США, евро, турецкие лиры, швейцарские франки и казахские тенге.
Параметры расчета: период, площадки и валюта4. Подберите ключевые фразы и минус-слова
Подумайте, какие запросы могут вводить ваши потенциальные клиенты. Подбирайте ключевые фразы с помощью сервиса Подбор слов, в него можно перейти из интерфейса Прогноза бюджета.
Подбирайте ключевые фразы с помощью сервиса Подбор слов, в него можно перейти из интерфейса Прогноза бюджета.
Здесь также укажите регион, так как статистика запросов отличается в разных городах.
Можно не пытаться собрать все фразы, которые вы будете использовать в кампании: достаточно указать только высокочастотные и среднечастотные (от 50 показов в месяц). Если у вас есть статистика по конверсиям с поискового трафика, то вы можете использовать в прогнозе конверсионные запросы. Используйте операторы для уточнения ключевых фраз.
Нажмите на кнопку Добавить, и ключевые фразы появятся в окне Прогноза бюджета.
Оставьте галочку у пункта автоматическая корректировка фраз минус-словами, чтобы система осуществила кросс-минусацию. Это позволит удалить пересечения между фразами, чтобы в будущем на разные запросы показывать релевантные объявления по актуальной цене. В примере есть общий запрос горный велосипед и несколько более конкретных — складной горный велосипед, купить горный велосипед и т. п. К фразе горный велосипед система добавит минус-слова -складной, -купить, чтобы по запросам с такими словами показывались специально написанные объявления.
п. К фразе горный велосипед система добавит минус-слова -складной, -купить, чтобы по запросам с такими словами показывались специально написанные объявления.
Автоматическая фиксация стоп-слов добавит оператор + (плюс) к служебным частям речи, так как без него система не будет учитывать такие слова.
Для более точной оценки бюджета добавьте Единый набор минус-фраз. Включите в список те слова и фразы, которые используют пользователи, не заинтересованные в покупке продукта. Чаще всего это такие слова, как бесплатно, фото, скачать и другие.
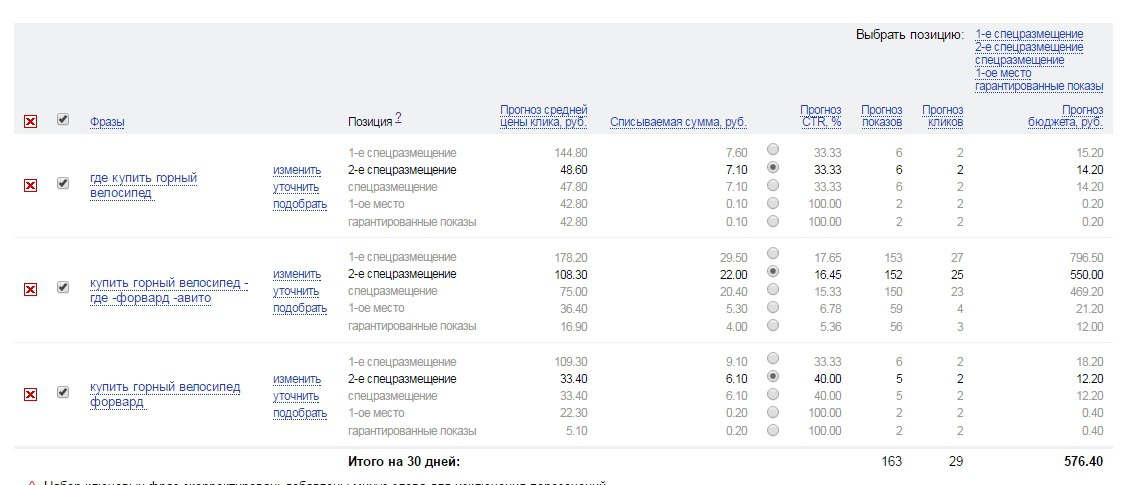
После нажатия на кнопку Посчитать появится таблица с прогнозом для каждой фразы о количестве запросов, ставках для ключа, списываемой сумме (т.е. фактической стоимости клика), прогнозном CTR (средняя кликабельность объявлений), количестве показов и кликов (ожидаемые показатели), объеме бюджета для разных позиций на поиске.
В настройках «Выбрать позицию» можно выбирать целевую позицию в поиске Яндекса, а система будет быстро пересчитывать бюджет на выбранный период. Кроме того, ключевые фразы можно фильтровать по любым показателям.
Кроме того, ключевые фразы можно фильтровать по любым показателям.
Некоторые фразы могут отображаться серым цветом, и по ним не будут доступны показатели. Их нужно скорректировать, сделав менее точными.
Колонка «Ключевые фразы»
Если в таблице нажать на ключевую фразу, Директ покажет объявления конкурентов.
Объявления конкурентов в ДиректеЕсли нажать на ссылку «Уточнить», откроется Подбор слов со вложенными запросами для данной ключевой фразы. Стоит посмотреть список лишний раз и пополнить перечень минус-слов. Если поставить галочку около нерелевантного запроса, то к фразе автоматически добавится минус-слово.
Поиск минус-словЕсли нажать ссылку «Подобрать», то вы попадете в Подбор слов, где с ключом будут все минус-слова, т.е. в списке запросов не будет множества нерелевантных запросов. Можно еще раз просмотреть список и подобрать ключи для своей кампании.
Поиск дополнительных ключевых фразПод таблицей с результатами можно посмотреть весь список фраз, скорректированных при кросс-минусации.
А также выгрузить прогноз в xls, выбрав интересующие рекламные позиции.
После этого можно сопоставить количество прогнозируемых кликов со значением конверсии сайта и узнать примерную стоимость лида.
Заключение
Полученный прогноз бюджета поможет составить примерные представления о расходах на поисковую кампанию, а также даст информацию об уровне спроса, конкуренции в Директе, а также средних CTR и стоимости клика в тематике.
Как провести и улучшить расчет бюджета в Яндекс Директ
Любой рекламодатель перед стартом рекламной кампании хочет понимать, сколько денег будет потрачено. В случае с контекстной рекламой быстрый прогноз бюджета можно сделать в интерфейсе Директа с помощью специального инструмента.
На конечную стоимость рекламной кампании влияет огромное количество факторов: от качества объявлений до активности конкурентов. Система не может учитывать их все, поэтому выдаёт приблизительные цифры. Однако, общее понимание сколько денег будет потрачено с помощью инструмента получить можно.
Как рассчитать бюджет в Яндекс.Директ?
Здесь важно выбрать правильные настройки.
- Регион размещения;
- Параметры расчёта;
- Список ключевых фраз.
Если вы оказываете услуги на ограниченной территории, например, рекламируете доставку еды в черте одного города, то нет смысла транслировать рекламу на всю область. Важно правильно выбрать местонахождение своей целевой аудитории.
Ваши задачи |
Решения Marilyn |
|---|---|
| Сложности своевременного старта/остановки кампаний | Планирование и букирование рекламных размещений |
| Много времени тратится на управление кампаниями | Автоматизация рекламы в поиске и социальных сетях |
| Долго формировать отчётность по размещениям клиенту | Автоматизация статистической отчётности по рекламным кампаниям |
Сверка и подведение финансовых итогов размещения для бухгалтерии, перекруты/недокруты. |
Автоматизация финансовой отчётности и бухгалтерской документации |
Изменение параметров расчёта обычно не требуется, кроме тех случаев, когда речь идёт о продукте с ярко выраженной сезонностью. Например, по умолчанию система делает прогноз на основе данных за предыдущие 30 дней, но если это искусственные ёлки, то в октябре спроса на них ещё нет, нужно поднимать статистику за декабрь прошлого года.
В списке ключевых фраз важно использовать переминусовку, чтобы устранить пересечение фраз друг с другом и избежать подсчёта показов по вложенным запросам. Например, запрос «купить белый стол» будет являться вложенным по отношению к запросу «купить стол».
То же самое касается автоматической фиксации стоп-слов, то есть частей речи, не несущих смысловой нагрузки: местоимений, союзов, междометий и др. Для Яндекса запросы «купить стол в Москве» и «купить стол москва» — одинаковы.
+25% коэффициент конверсии в звонки
Как доминировать в высококонкурентной тематике, автоматизировав рекламу
Перейти
+57% освобожденного времени
Способ работать в два раза меньше, автоматизировав performance-кампании
Перейти
-30% стоимости рекламы
Для чего нужна многоканальная аналитика агентству
Перейти
Как Marilyn улучшает работу с бюджетами?
Прогнозирование и контроль бюджетов — задача сложная, но необходимая.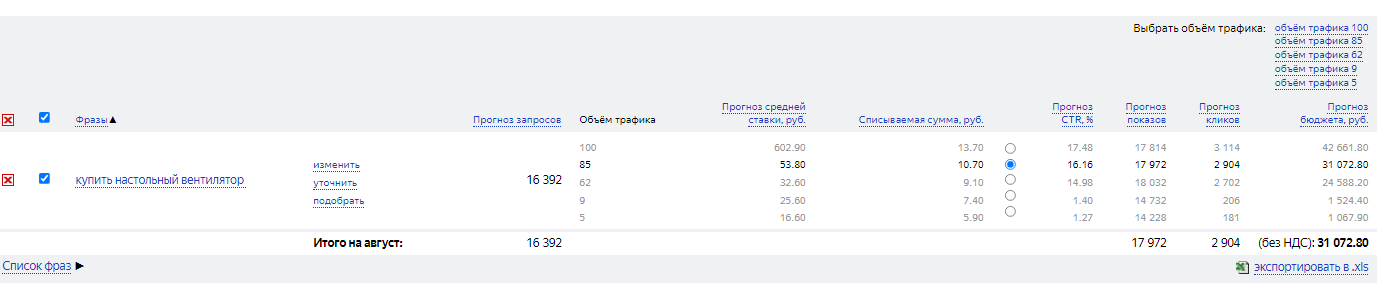 Поэтому для облегчения работы и экономии времени специалистов по контекстной рекламе на платформе Marilyn был создан специальный инструмент, автоматизирующий процесс контроля за ходом рекламной кампании — «Балансировка дневных бюджетов».
Поэтому для облегчения работы и экономии времени специалистов по контекстной рекламе на платформе Marilyn был создан специальный инструмент, автоматизирующий процесс контроля за ходом рекламной кампании — «Балансировка дневных бюджетов».
По умолчанию система учитывает расход за предыдущий день и на основе этих данных делает прогноз на следующий день. Но можно использовать и другие варианты настройки, например, по KPI, в качестве которого могут выступать:
- статистические данные по показам, кликам, досмотрам видео и т.д.
- данные из сервисов веб-аналитики (посетители, просмотры, время на странице и т.д.)
- данные по целям из веб-аналитики.
Ценность инструмента «Балансировка дневных бюджетов» в том, что благодаря ему можно плавно вести рекламную кампанию, не допуская перекрутов или недокрутов бюджета. Marilyn избавляет менеджера от необходимости вручную контролировать ход кампании. Достаточно один раз задать правила, и система сама будет распределять бюджет между размещениями, чтобы наилучшим образом достичь заданные KPI.
Решайтесь, используйте тестовый период!
Прямой прогноз X Рекурсивный прогноз
[Эта статья была впервые опубликована на R — инсайте R и любезно предоставлена R-блогерами]. (Вы можете сообщить о проблеме с содержанием на этой странице здесь)
Габриэль Васконселос
При работе с моделями прогнозирования возникает много путаницы, а именно разница между прямым и рекурсивным прогнозами. Я считаю, что большинство людей больше привыкли к рекурсивным прогнозам, потому что они первыми изучаются при изучении моделей ARIMA.
Предположим, вы хотите спрогнозировать переменную
на несколько шагов вперед, используя только прошлую информацию, и рассмотрите два приведенных ниже уравнения:
Первое уравнение представляет собой AR(1), а второе уравнение представляет собой более общую версию, в которой мы оцениваем модель непосредственно до желаемого горизонта прогнозирования.
, а во втором уравнении мы должны сделать, чтобы получить тот же результат.
На два шага вперед все начинает меняться. В первом уравнении мы имеем:
, а во втором:
Обратите внимание, что в коэффициентах уравнения выше есть дополнительный индекс 2. Он указывает, что и
, ибудут зависеть от выбора . Теперь мы можем обобщить оба случая на любой, чтобы иметь:
Первый случай называется рекурсивным прогнозом, а второй — прямым прогнозом. В рекурсивном прогнозе нам нужно только оценить одну модель и использовать ее коэффициенты для итерации по горизонту прогнозирования, пока мы не получим желаемый горизонт. В прямом прогнозе нам нужно оценить одну другую модель для каждого горизонта прогнозирования, но нам не нужно повторять прогноз.
Многомерные задачи
Теперь предположим, что мы хотим спрогнозировать
, используя прошлую информацию и . Рекурсивная модель будет:
Прогноз на один шаг вперед:
Прогноз на два шага вперед:
Теперь у нас есть проблема. В прогнозе на два шага вперед мы можем просто заменить
уравнением на один шаг вперед, как мы это делали в одномерном случае. Однако у нас нет способа получить . Фактически, если мы используем другие переменные в рекурсивных прогнозах, мы также должны прогнозировать эти переменные, например, в рамках векторной авторегрессии (VAR). В прямом случае ничего не меняется: можно было просто оценить уравнение для on и .
Пример
В этом примере мы собираемся спрогнозировать инфляцию в Бразилии, используя прошлую информацию об инфляции, промышленном производстве и уровне безработицы.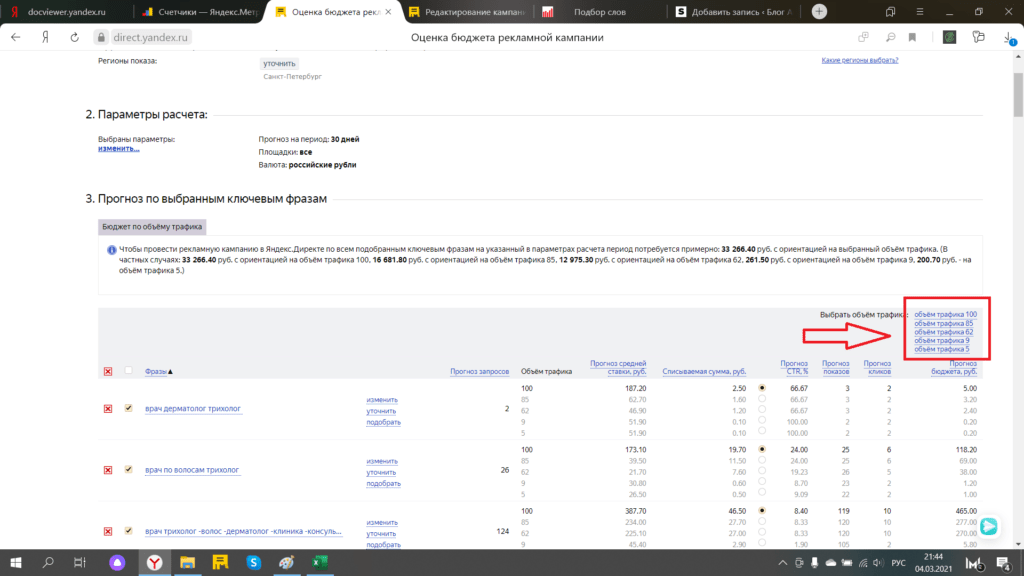 Рекурсивная модель будет VAR(3), а прямая модель будет простой регрессией с тремя лагами для каждой переменной.
Рекурсивная модель будет VAR(3), а прямая модель будет простой регрессией с тремя лагами для каждой переменной.
#инструменты для разработки библиотеки
#install_github(gabrielrvsc/HDeconometrics)
библиотека (HDEconometrics)
библиотека (изменить форму2)
библиотека (ggplot2)
# = Загрузить данные = #
данные("BRinf")
данные = BRinf[ c(1, 12, 14)]
имена столбцов (данные) = c ("INF", "IP", "U")
Рекурсивный прогноз
Сначала мы собираемся оценить рекурсивный прогноз на 1-24 шага (месяца) вперед. VAR будет прогнозировать все переменные, но нас интересует только инфляция. График ниже показывает, что прогноз очень быстро сходится к желтой линии, которая является безусловным средним значением инфляции в обучающей выборке. Рекурсивные прогнозы с использованием AR или VAR на стационарных и стабильных данных всегда будут сходиться к безусловному среднему, если мы не включим в модель больше функций, таких как экзогенные переменные.
# = 24 вневыборочных (тестовых) наблюдения = # поезд = данные[1:132, ] тест = данные[-c(1:132),] # = Оценка модели и вычисление прогнозов = # VAR = HDvar(поезд, p = 3) рекурсивный = предсказать(VAR, 24) df = data.
 frame(date = as.Date(имена строк(данные)),
ИНФ = данные["ИНФ"],
приспособлено = c (реп (NA, 3), приспособлено (VAR) [ 1], rep (NA, 24)),
прогноз = c(rep(NA,132), рекурсивный[ 1]))
# = Сюжет = #
dfm = расплав (df, id.vars = «дата»)
ggplot (данные = dfm) + geom_line (aes (x = дата, y = значение, цвет = переменная)) +
geom_hline (yintercept = среднее (поезд [ 1]), тип линии = 2, цвет = «желтый»)
frame(date = as.Date(имена строк(данные)),
ИНФ = данные["ИНФ"],
приспособлено = c (реп (NA, 3), приспособлено (VAR) [ 1], rep (NA, 24)),
прогноз = c(rep(NA,132), рекурсивный[ 1]))
# = Сюжет = #
dfm = расплав (df, id.vars = «дата»)
ggplot (данные = dfm) + geom_line (aes (x = дата, y = значение, цвет = переменная)) +
geom_hline (yintercept = среднее (поезд [ 1]), тип линии = 2, цвет = «желтый»)
Прямой прогноз
В прямых прогнозах нам потребуется оценить 24 модели инфляции, чтобы получить 24 прогноза. Мы должны правильно расположить данные, чтобы модель могла оценить регрессию на правильных лагах. Здесь большинство людей путаются. Давайте рассмотрим одномерный пример, используя функцию , встраивающую , чтобы упорядочить данные (нажмите здесь, чтобы узнать больше о функции). Я создал переменную
, это просто последовательность от 1 до 10. Функция встраивания использовалась для генерации матрицы с первыми тремя лагами (мы потеряли три наблюдения из-за лагов).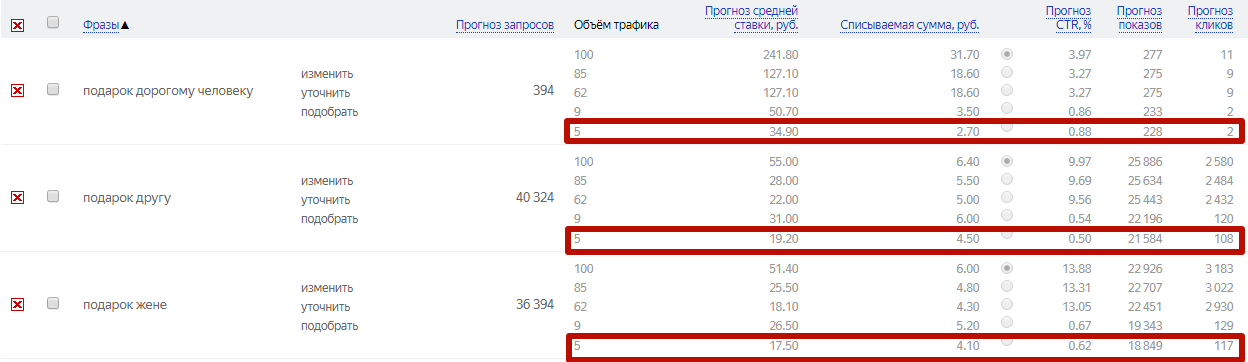 Модель для представляет собой регрессию столбца по остальным столбцам.
Модель для представляет собой регрессию столбца по остальным столбцам.
г=1:10
лаги = встроить (у, 4)
имена столбцов (лаги) = c ("yt", "yt-1", "yt-2", "yt-3")
отстает
## yt yt-1 yt-2 yt-3
## [1,] 4 3 2 1
## [2,] 5 4 3 2
## [3,] 6 5 4 3
## [4,] 7 6 5 4
## [5,] 8 7 6 5
## [6,] 9 8 7 6
## [7,] 10 9 8 7
Если мы хотим запустить модель на два шага вперед, мы должны удалить первое наблюдение в столбце
и последнее наблюдение в отстающих столбцах:
лаги = cbind(лаги[-1, 1], лаги[-nrow(лаги),-1])
colnames(lags) = c("yt", "yt-2", "yt-3", "yt-4")
отстает
## yt yt-2 yt-3 yt-4
## [1,] 5 3 2 1
## [2,] 6 4 3 2
## [3,] 7 5 4 3
## [4,] 8 6 5 4
## [5,] 97 6 5
## [6,] 10 8 7 6
Теперь мы просто запускаем регрессию
столбцов по другим столбцам. Ибо мы должны проделать ту же процедуру еще раз, и для общего мы должны удалить первые наблюдения первого столбца и последние наблюдения остальных столбцов.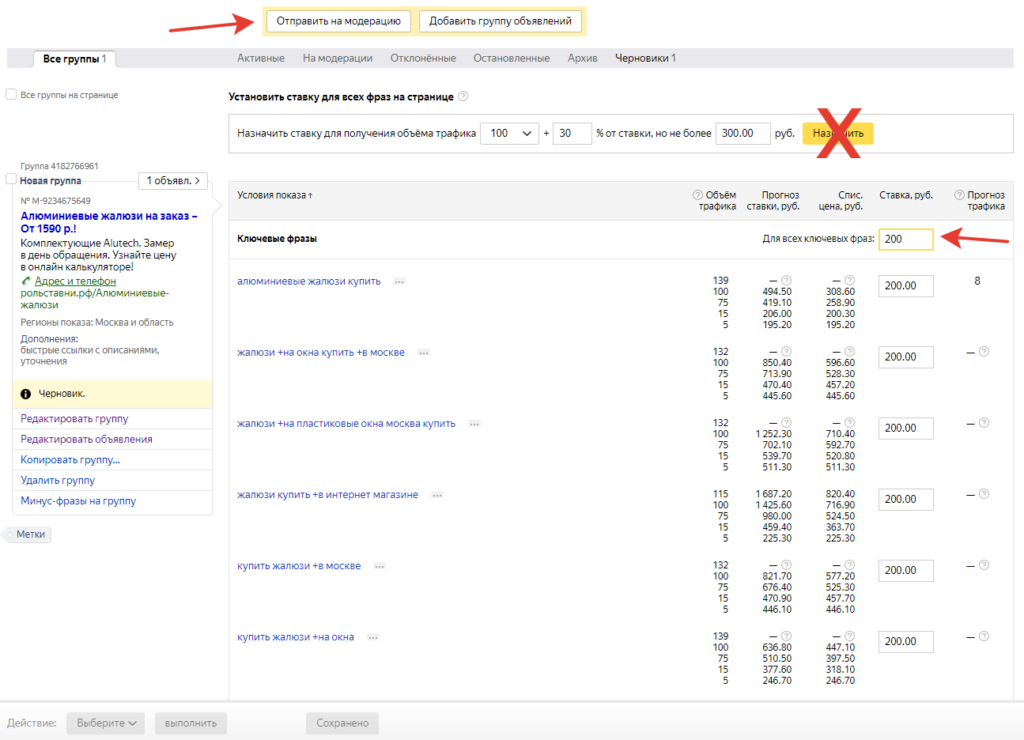
Функция внедрения также работает для матриц с несколькими столбцами. Я буду использовать его для данных, чтобы подготовить их для модели. В приведенном ниже коде выполняется прямой прогноз для горизонтов прогнозирования с 1 по 24. На графике нет подобранной линии, поскольку для каждого горизонта имеется одна подобранная модель. Вы можете видеть, что прямое прогнозирование значительно отличается от рекурсивного случая. Не сходится к безусловному среднему.
# = Создать матрицу с лагами = #
X = встроить (данные, 4)
поезд = X[1:129, ]
тест = X[-c(1:129),]
ytrain = поезд[ ,1]
# = Xtest одинаков для всех горизонтов = #
# = Последние три наблюдения (запаздывания) поезда для каждой переменной = #
Xtest = поезд[nряд(поезд), 1:9]
# = Удалить первые три столбца поезда = #
# = Это три переменные в t = #
Xtrain = поезд[ ,-c(1:3)]
yтест = тест [ 1]
# = запустить 24 модели и прогнозы = #
прямой = с()
для (я в 1:24) {
model = lm(ytrain ~ Xtrain) # = Выполнить регрессию = #
direct[i] = c(1, Xtest) %*% coef(model) # = Расчет прогноза = #
ytrain = ytrain[-1] # = Удалить первое наблюдение yt = #
Xtrain = Xtrain[-nrow(Xtrain), ] # = Удалить последнее наблюдение других переменных = #
}
# = сюжет = #
df = data. frame(data=as.Date(имена строк(данные)),
INF = данные["INF"],
прогноз = c (rep (NA, 132), прямой))
dfm = расплав (df, id.vars = «данные»)
ggplot (данные = dfm) +
geom_line (aes (x = данные, y = значение, цвет = переменная)) +
geom_hline (yintercept = среднее (поезд [ 1]), тип линии = 2, цвет = "желтый")
 frame(data=as.Date(имена строк(данные)),
INF = данные["INF"],
прогноз = c (rep (NA, 132), прямой))
dfm = расплав (df, id.vars = «данные»)
ggplot (данные = dfm) +
geom_line (aes (x = данные, y = значение, цвет = переменная)) +
geom_hline (yintercept = среднее (поезд [ 1]), тип линии = 2, цвет = "желтый")
frame(data=as.Date(имена строк(данные)),
INF = данные["INF"],
прогноз = c (rep (NA, 132), прямой))
dfm = расплав (df, id.vars = «данные»)
ggplot (данные = dfm) +
geom_line (aes (x = данные, y = значение, цвет = переменная)) +
geom_hline (yintercept = среднее (поезд [ 1]), тип линии = 2, цвет = "желтый")
Как упоминалось ранее, прогноз на один шаг вперед одинаков в обоих случаях:
print(direct[1]) ## [1] 0,7843985 печать (рекурсивная [1]) ## [1] 0,7843985
Заключение
- Рекурсивный прогноз:
- Одинарная модель для всех горизонтов,
- должен повторять прогноз, используя коэффициенты для горизонтов, отличных от единицы,
- Прогнозы сходятся к безусловному среднему для длинных горизонтов.
- Прямой прогноз:
- Одна модель для каждого горизонта,
- Повторение не требуется,
- Прогнозы не сходятся к безусловному среднему,
- Необходимо быть внимательным при размещении данных.
К оставьте комментарий для автора, пройдите по ссылке и прокомментируйте в их блоге: R – озарение R.
R-bloggers.com предлагает ежедневных обновления по электронной почте о новостях R и руководствах по изучению R и многим другим темам. Нажмите здесь, если вы хотите опубликовать или найти работу R/data-science.
Хотите поделиться своим контентом с R-блогерами? нажмите здесь, если у вас есть блог, или здесь, если у вас его нет.
Прямое прогнозирование параметров глобальной и пространственной модели по динамическим данным
- Парк, Джихун ;
- Каерс, Джеф
Аннотация
Прямое прогнозирование недавно было предложено в качестве метода количественной оценки неопределенности в нелинейных обратных задачах. Метод напрямую прогнозирует желаемый будущий отклик без необходимости полной инверсии модели. Этот метод был успешно применен к целому ряду случаев подземных месторождений, таких как прогнозы подземных вод, неглубоких и глубоких геотермальных и нефтегазовых месторождений. В этой статье мы расширяем рамки прямого прогнозирования, чтобы сделать то, чего раньше избегали: инверсию модели. Идея проста: заменить переменные предсказания переменными модели. Теперь возникают две проблемы: размеры модели, по крайней мере, в подземной области, намного выше, чем переменные данных. Именно так обстоит дело в статье, где мы рассматриваем динамические данные и многомерные пространственные модели геологической структуры и свойств. Во-вторых, регрессия, примененная в исходном методе, представляющая собой линейную регрессию переменных прогноза на преобразованных данных, вряд ли приведет к моделям, которые соответствуют полевым наблюдениям. Сначала мы решаем эти проблемы, добавляя метод выбора переменных (через глобальный анализ чувствительности) для пространства модели.
Метод напрямую прогнозирует желаемый будущий отклик без необходимости полной инверсии модели. Этот метод был успешно применен к целому ряду случаев подземных месторождений, таких как прогнозы подземных вод, неглубоких и глубоких геотермальных и нефтегазовых месторождений. В этой статье мы расширяем рамки прямого прогнозирования, чтобы сделать то, чего раньше избегали: инверсию модели. Идея проста: заменить переменные предсказания переменными модели. Теперь возникают две проблемы: размеры модели, по крайней мере, в подземной области, намного выше, чем переменные данных. Именно так обстоит дело в статье, где мы рассматриваем динамические данные и многомерные пространственные модели геологической структуры и свойств. Во-вторых, регрессия, примененная в исходном методе, представляющая собой линейную регрессию переменных прогноза на преобразованных данных, вряд ли приведет к моделям, которые соответствуют полевым наблюдениям. Сначала мы решаем эти проблемы, добавляя метод выбора переменных (через глобальный анализ чувствительности) для пространства модели. В частности, мы выбираем те компоненты модели, которые наиболее чувствительны только к переменным данным. Линейное предположение смягчается последовательным обновлением чувствительных переменных модели. Мы иллюстрируем наш метод на ливийском нефтяном пласте со сложной геологической неопределенностью, включающей структурные, петрофизические параметры и параметры флюидной модели.
В частности, мы выбираем те компоненты модели, которые наиболее чувствительны только к переменным данным. Линейное предположение смягчается последовательным обновлением чувствительных переменных модели. Мы иллюстрируем наш метод на ливийском нефтяном пласте со сложной геологической неопределенностью, включающей структурные, петрофизические параметры и параметры флюидной модели.
- Публикация:
Компьютеры и науки о Земле
- Дата публикации:
- Октябрь 2020
- DOI:
- 10.1016/j.cageo.2020.104567
- Биб-код:
- 2020CG.
