Основные принципы работы поисковых систем в Интернете
Какой бы вопрос не волновал современного человека, ответы он не ищет в книгах. Он ищет их в интернете. Причем не нужно знать адрес сайта, на котором лежит нужная тебе информация. Таких сайтов миллионы, а помогает найти нужный поисковая система.
На просторах нашего отечественного интернета самые популярные две поисковые системы – Google и Яндекс.
Вы хотя бы раз задумывались, как работает поисковая система? Как она понимает, какой сайт показать, на каком из миллионов ресурсов точно есть ответ на ваш запрос?
Если да – читайте дальше.
Что представляет собой поисковая система?
Поисковая система – это огромная база веб-документов, которая постоянно пополняется и расширяется. У каждой поисковой системы есть поисковые пауки, роботы – это специальные боты, которые обходят сайты, индексируют размещенный на них контент, а затем ранжируют по степени его качества и релевантности поисковым запросам пользователей.
Поисковые системы работают для того, чтобы любой человек мог найти любую информацию. Потому они стараются показывать в первую очередь те веб-документы, в которых есть максимально подробный ответ на вопрос человека.
По своей сути поисковая система – это каталог сайтов, справочник, основная функция которого – поиск информации по этому самому каталогу.
Как я уже написал выше, у нас популярные две системы – Google (мировая) и Яндекс (русскоязычный сегмент). Но есть еще такие системы, как Rambler, Yahoo, Bing, Mail.Ru и другие. Принцип работы похож у них у всех, отличаются только алгоритмы ранжирования (и то не сильно существенно).
Как работает поисковая система в Интернете
Принцип работы поисковых систем очень сложный, но я попробую объяснить простыми словами.
Поисковый робот (паук) обходит страницы сайта, скачивает их содержимое и извлекает ссылки. Далее начинает свою работу индексатор – это программа, которая анализирует все скачанные пауками материалы, опираясь на собственные алгоритмы работы.
Таким образом, создается база данных поисковой системы, в которой хранятся все обработанные алгоритмом документы.
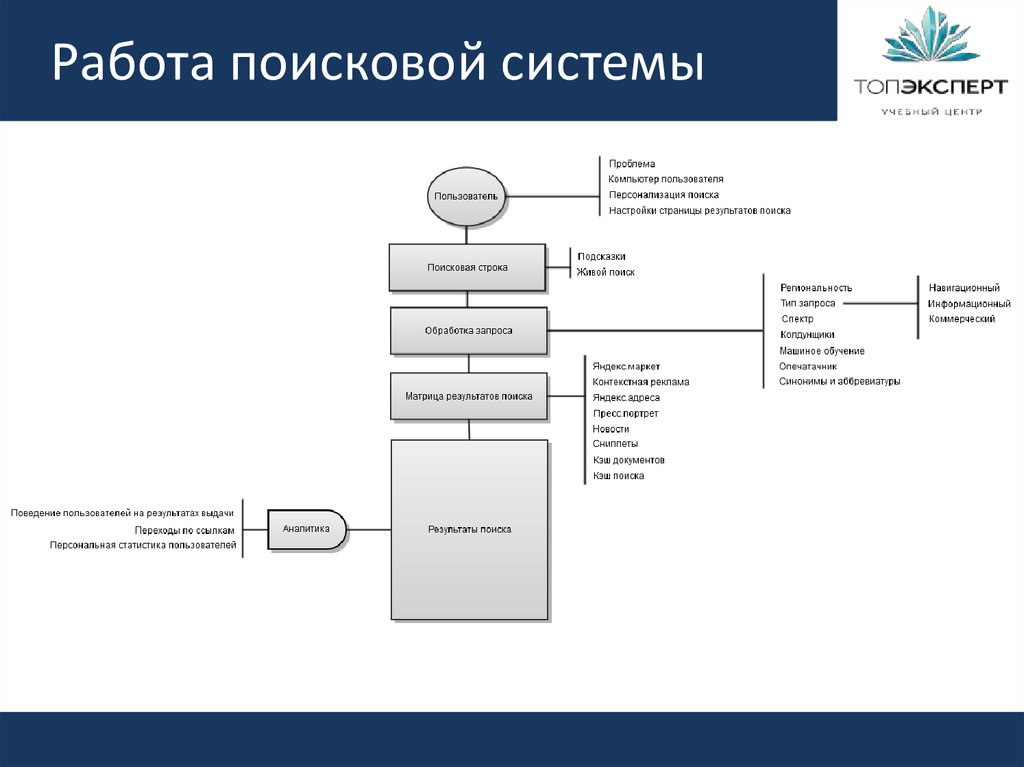
Работа с поисковым запросом проводится следующим образом:
- анализируется введенный пользователем запрос;
- результаты анализы передаются специальному модулю ранжирования;
- обрабатываются данные всех документов, выбираются самые релевантные введенному запросу;
- генерируется сниппет – заголовок, дескрипшн, слова из запроса подсвечиваются полужирным;
- результаты поиска представляются пользователю в виде SERP (страницы выдачи).
Принципы работы поисковых машин
Главная задача любой поисковой системы – предоставить пользователю наиболее полезную и точную информацию по его запросу. Потому поисковый робот обходит сайты постоянно. Сразу после вашего запуска, согласно определенному распорядку, паук заходит к вам в гости, обходит ряд страниц, после чего проходит их индексация.
Принцип работы поисковых машин базируется на двух основных этапах:
- обход страниц, с помощью которого собираются данные;
- присвоение индекса, благодаря которому система сможет быстро проводить поиск по содержимому данной страницы.


Как только страница сайта проиндексирована, она уже появится в результатах поиска по определенному поисковому запросу. Проверить, попала ли новая страница в индекс поисковой системы, можно с помощью инструментов для вебмастеров. Например, в Яндекс.Вебмастере сразу видно, какие страницы проиндексированы и когда, и какие выпали из индекса и по какой причине.
Но вот на какой странице она окажется – зависит от степени индексации и качества ее содержания. Если на вашей странице дается самый точный ответ на запрос – она будет выше всех остальных.
Принципы ранжирования сайтов в поисковых системах
По какому принципу работают поисковые роботы, мы разобрались. Но вот каким образом проходит ранжирование сайтов?
Ранжирование базируется на двух основных «китах» — текстовое содержание страницы и нетекстовые факторы.
Текстовое содержание – это контект страницы. Чем он полнее, чем точнее, чем релевантнее запросу – тем выше будет страница в результатах выдачи. Кроме самого текста, поисковая система обращает внимание на заполнение тегов title (заголовок страницы), description (описание страницы), h2 (заголовок текста).
Кроме самого текста, поисковая система обращает внимание на заполнение тегов title (заголовок страницы), description (описание страницы), h2 (заголовок текста).
Нетекстовые факторы – это внутренняя перелинковка и внешние ссылки. Суть в чем: если сайт интересен, полезен, значит, на него ссылаются другие тематические ресурсы. И чем больше таких ссылок – тем авторитетнее ресурс.
Но это – самые основные принципы, очень кратко. Вникнем чуть глубже.
Основные факторы ранжирования сайта
Есть целый ряд факторов, влияющих на ранжирование сайта. Основные из них – это:
1. Внутренние факторы ранжирования сайта
Это текст на сайте и его оформление – подзаголовки, выделение важных моментов в тексте. Использование внутренней перелинковки тоже сюда относится. Также важны визуальные элементы: использование картинок, фотографий, видео, графиков. Немаловажно также качество самого текста, его содержание.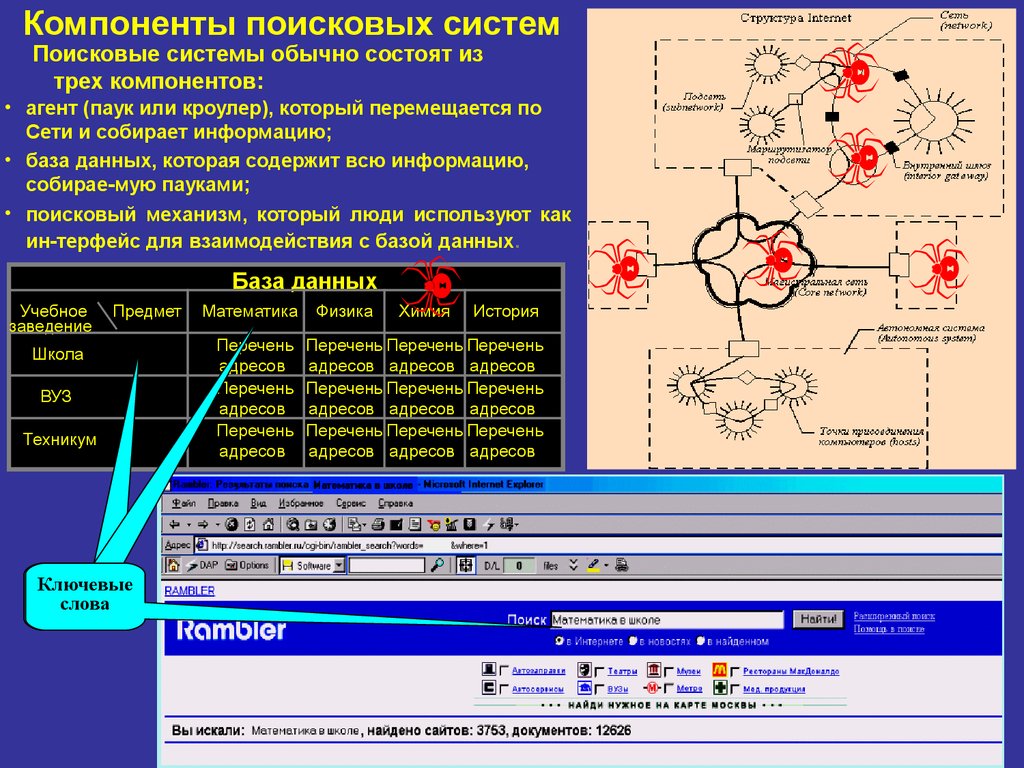
2. Внешние факторы ранжирования сайта, которые определяют его популярность. Это те самые внешние ссылки, которые ведут на ваш сайт с других ресурсов. Определяется не только количество этих сайтов, но их качество (желательно, чтобы сайты были схожей тематики с вашим), а также общее качество ссылочного профиля (насколько быстро появились эти ссылки, естественным путем или с помощью закупки на бирже).
3. Поведенческие факторы ранжирования сайта. Поисковые системы начали отслеживать поведение пользователей на сайте и на основе этого поведения понимать, интересен ли ваш сайт людям, полезен ли он, нравится ли посетителям. Обращают внимание на: показатель отказов (чем он ниже – тем лучше), глубину просмотра, время на сайте. Подробнее об этом здесь https://adtimes.ru/povedencheskie-faktory-ranzhirovaniya-sajta-chto-eto-takoe-i-kak-ix-uluchshit/
4. Коммерческие факторы ранжирования сайта. Они важны в первую очередь для тех, кто ставит на продвижение в Яндексе. Коммерческие факторы определяют, насколько удобен ваш сайт для осуществления заказа или совершения покупки Подробнее можете прочесть здесь https://adtimes.ru/kommercheskie-faktory-ranzhirovaniya-i-chto-k-nim-otnositsya/
Коммерческие факторы определяют, насколько удобен ваш сайт для осуществления заказа или совершения покупки Подробнее можете прочесть здесь https://adtimes.ru/kommercheskie-faktory-ranzhirovaniya-i-chto-k-nim-otnositsya/
Исходя из всего вышесказанного, можно сделать один вывод: поисковые системы стараются работать так, чтобы показывать пользователю те сайты, которые дают максимально полный ответ на его запрос и уже заслужили определенный авторитет. При этом учитываются самые разные факторы: и содержание сайта, и его настройка, и отношение пользователей к нему. Хороший во всех отношениях сайт непременно займет высокое место на выдаче.
Как работают поисковые системы? Руководство для начинающих
Joshua Hardwick
Глава отдела контента в Ahrefs (проще говоря, я отвечаю за то, чтобы каждый пост в блоге был КРУТЫМ).
Показывает, сколько различных веб-сайтов ссылаются на этот контент. Как правило, чем больше сайтов ссылаются на вас, тем выше вы ранжируетесь в Google.
Показывает ежемесячный рассчетный поисковый трафик на эту статью по данным Ahrefs. Фактический поисковый трафик (по данным Google Analytics) обычно в 3–5 раз больше.
Количество ретвитов этой статьи в Twitter.
Поделиться этой статьей
Поисковые системы работают, сканируя Интернет с помощью ботов, называемых краулерами или пауками. Они переходят по ссылкам со страницы на страницу в поисках нового контента для добавления в поисковый индекс. Когда вы используете поисковую систему, релевантные результаты извлекаются из индекса и ранжируются согласно алгоритму.
Если это звучит сложно, это потому, что так и есть. Но если вы хотите ранжироваться выше в поисковых системах, чтобы привлечь больше трафика на свой веб-сайт, вам необходимо базовое понимание того, как поисковые системы находят, индексируют и ранжируют контент.
Вот что вы узнаете из этого руководства:
Contents
Содержание
Прежде чем мы перейдем к техническим вопросам, давайте сначала убедимся, что мы понимаем, что такое поисковые системы на самом деле, почему они существуют и почему это вообще имеет значение.
Что такое поисковые системы?
Поисковые системы — это инструменты, которые находят и ранжируют веб-контент, соответствующий поисковому запросу пользователя.
Каждая поисковая система состоит из двух основных частей.
- Поисковый индекс. Цифровая библиотека информации о веб-страницах.
- Поисковые алгоритмы. Компьютерные программы, которые ранжируют сопоставленные результаты из поискового индекса.
Примеры популярных поисковых систем включают Google, Bing и DuckDuckGo.
В чем состоит цель поисковых систем?
Каждая поисковая система стремится предоставлять пользователям наилучшие и наиболее релевантные результаты. Вот как они получают или удерживают долю рынка — по крайней мере, теоретически.
Как поисковые системы зарабатывают деньги?
Поисковые системы предоставляют два типа результатов поиска.
- Органические результаты из поискового индекса. Вы не можете заплатить, чтобы попасть сюда.
- Платная реклама от рекламодателей. Вы можете заплатить, чтобы попасть сюда.

Каждый раз, когда кто-то нажимает на рекламу в поиске, рекламодатель платит поисковой системе. Это называется рекламой с оплатой за клик (от англ. pay-per-click, PPC).
Вот почему доля рынка имеет значение. Больше пользователей означает больше кликов по рекламе и больший доход.
Почему вам должно быть важно, как работают поисковые системы?
Поняв, как поисковые системы находят, индексируют и ранжируют контент, вы сможете ранжировать ваш сайт в органических результатах поиска по релевантным и популярным ключевым словам.
Если вы сможете занять высокие позиции по этим запросам, вы получите больше кликов и органического трафика на ваш контент.
Какая поисковая система самая популярная?
Google. Их доля рынка составляет 92%.
Google — это поисковая система, которая интересует большинство специалистов по SEO и владельцев веб-сайтов, потому что она способна направить больше трафика, чем любая другая.
Большинство известных поисковых систем, таких как Google и Bing, содержат в своих поисковых индексах триллионы страниц. Прежде чем говорить об алгоритмах ранжирования, давайте подробнее рассмотрим механизмы, используемые для создания и поддержания веб-индекса.
Вот основной процесс, любезно предоставленный Google::
Давайте рассмотрим процесс, шаг за шагом:
- URL-адреса
- Сканирование
- Обработка и рендеринг
- Индексирование
Примечание.
Приведенный ниже процесс применяется конкретно в Google, но, вероятно, он очень похож и у других поисковых систем, таких как Bing. Существуют и другие типы поисковых систем, такие как Amazon, YouTube и Wikipedia, которые показывают результаты только со своих веб-сайтов.
Шаг 1. URL-адреса
Все начинается со списка известных URL-адресов. Google обнаруживает URL-адреса с помощью различных процессов, но наиболее распространенными из них являются приведенные ниже.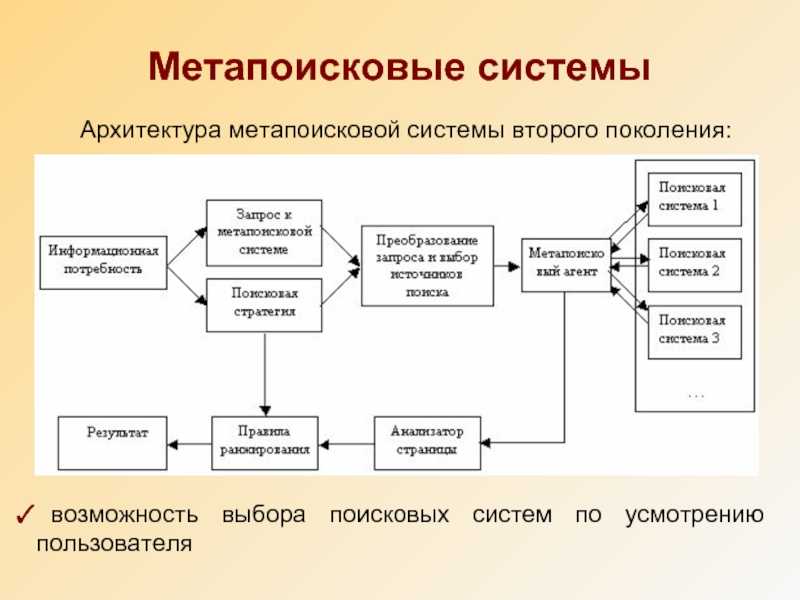
Из обратных ссылок
У Google уже есть индекс, содержащий триллионы веб-страниц. Если кто-то добавит ссылку на одну из ваших страниц, ведущую с одной из них, Google сможет найти ее в этом индексе.
Вы можете бесплатно просматривать обратные ссылки своего веб-сайта с помощью Сайт Эксплорера в Ahrefs Webmaster Tools.
- Зарегистрируйте бесплатную учетную запись Ahrefs Webmaster Tools
- Вставьте свой домен в Сайт Эксплорер
- Перейдите в отчет Бэклинки
Наш краулер является вторым по активности после Google, поэтому этот отчет предоставляет вам достаточно полное представление о ваших обратных ссылках.
Из карт сайта
Карты сайта перечисляют все важные страницы вашего сайта. Если вы добавите карту сайта в Google, это может помочь им быстрее обнаружить ваш сайт.
Из добавлений URL-адресов
Google также позволяет добавлять отдельные URL-адреса через Google Search Console.
Шаг 2. Сканирование
На этом шаге компьютерный бот (краулер), например, Googlebot, посещает и скачивает обнаруженные страницы.
Важно отметить, что Google не всегда сканирует страницы в том порядке, в котором они их обнаруживают.
Google ставит URL-адреса в очередь для сканирования на основе нескольких факторов, в том числе:
- PageRank URL-адреса;
- как часто меняется URL-адрес;
- новый он или нет.
Это важно, потому что это означает, что поисковые системы могут сканировать и индексировать одни из ваших страниц раньше других. Если у вас большой веб-сайт, поисковым системам может потребоваться время, чтобы полностью его просканировать.
Шаг 3. Обработка
Обработка — это этап, на котором Google распознает и извлекает ключевую информацию из просканированных страниц. Никто, кроме Google, не знает всех подробностей этого процесса, но важными частями для нашего понимания являются извлечение ссылок и сохранение контента для индексации.
Google необходимо получить рендеры страниц, чтобы полностью обработать их, и именно здесь Google выполняет код страницы, чтобы понять, как она выглядит для пользователей.
При этом часть обработки происходит как до, так и после рендеринга, как вы можете видеть на диаграмме.
Шаг 4. Индексирование
На этом шаге обработанная информация с просканированных страниц добавляется в большую базу данных, называемую поисковым индексом. По сути, это цифровая библиотека из триллионов веб-страниц, из которой поступают результаты поиска Google.
Это важный момент. Когда вы вводите запрос в поисковую систему, вы не ищете соответствующие результаты напрямую в Интернете. Вы выполняете поиск в индексе веб-страниц поисковой системы. Если веб-страница отсутствует в поисковом индексе, пользователи поисковых систем не найдут ее. Вот почему так важно проиндексировать ваш сайт в основных поисковых системах, таких как Google и Bing.
Обнаружение, сканирование и индексирование контента — это лишь первая часть головоломки. Поисковым системам также необходим способ ранжирования подходящих результатов, когда пользователь выполняет поиск. Это работа для алгоритмов поисковых систем.
Каждая поисковая система использует уникальные алгоритмы для ранжирования веб-страниц. Но поскольку Google является наиболее широко используемой поисковой системой (по крайней мере, в западном мире), именно на ней мы собираемся сосредоточиться в остальной части этого руководства.
У Google более 200 факторов ранжирования.
Никто не знает все эти факторы ранжирования, но мы знаем о ключевых из них.
Давайте кратко обсудим их.
- Обратные ссылки
- Релевантность
- Новизна
- Тематическая авторитетность
- Скорость загрузки страницы
- Оптимизация для мобильных устройств
Обратные ссылки
Обратные ссылки — один из самых важных факторов ранжирования Google.
Андрей Липатцев, старший стратег Google по качеству поиска, подтвердил это во время вебинара в прямом эфире в 2016 году. Когда его спросили о двух наиболее важных факторах ранжирования, он ответил просто: контент и ссылки.
Конечно. Я могу сказать вам, какие они [два главных фактора ранжирования]. Это контент. И это ссылки, указывающие на ваш сайт.
Ссылки являются важным фактором ранжирования в Google с 1997 года, когда они ввели PageRank, формулу для оценки ценности веб-страницы на основе количества и качества обратных ссылок, указывающих на нее.
Когда мы проанализировали более миллиарда страниц, мы обнаружили четкую корреляцию между количеством веб-сайтов, ссылающихся на страницу, и объемом органического трафика, который она получает из Google.
Однако дело не только в количестве, потому что не все обратные ссылки одинаковы. Вполне возможно, что страница с несколькими обратными ссылками высокого качества превзойдет страницу с большим количеством обратных ссылок низкого качества.
У хорошей обратной ссылки есть шесть ключевых атрибутов.
Давайте подробнее рассмотрим, возможно, два самых важных из них: авторитет и релевантность.
Авторитет ссылки
Обратные ссылки с авторитетных страниц и веб-сайтов обычно имеют наибольшее влияние на ранжирование.
Как определить авторитет? В контексте SEO авторитетные страницы и веб-сайты — это те, которые имеют много обратных ссылок или “избирательных голосов”.
В Ahrefs есть две метрики для оценки относительного авторитета веб-сайтов и страниц.
- Рейтинг домена (DR): относительный авторитет веб-сайта по шкале от 0 до 100.
- Рейтинг URL-адреса (UR): относительный авторитет страницы по шкале от 0 до 100.
Вы можете проверить авторитет любого веб-сайта или веб-страницы в Сайт Эксплорере Ahrefs.
Релевантность ссылки
Ссылки с релевантных веб-сайтов и страниц имеют наивысшую ценность.
Google говорит о релевантности в контексте ранжирования полезных страниц на своей странице о том, как работает поиск.
Если другие известные веб-сайты по данной теме ссылаются на эту страницу, это явный признак высокого качества информации.

Если вам интересно, почему важна релевантность, подумайте о том, как все работает в реальном мире. При поиске лучшего итальянского ресторана вы, вероятно, поверите совету вашего друга-повара, а не совету друга-ветеринара. Но если бы вы искали рекомендации по кошачьему корму, было бы наоборот.
Релевантность
У Google есть много способов определения релевантности страницы.
На самом базовом уровне он ищет страницы, содержащие те же ключевые слова, что и поисковый запрос.
Но релевантность выходит далеко за рамки совпадения по ключевым словам.
Google также использует данные о взаимодействии, чтобы оценить, соответствуют ли результаты поиска запросам. Другими словами, находят ли эту страницу полезной пользователи?
Отчасти поэтому все лучшие результаты по запросу “apple” (яблоко) относятся к технологической компании, а не к фрукту. Из данных о взаимодействии Google знает, что большинство пользователей ищут информацию о первом, а не втором.
Однако данные о взаимодействии — далеко не единственное, что Google учитывает.
Google инвестировал во множество технологий, помогающих понимать взаимосвязи между сущностями, такими как люди, места и предметы. Граф знаний — одна из таких технологий, которая, по сути, представляет собой огромную базу знаний об объектах и связях между ними.
И apple (яблоко, фрукт), и Apple (технологическая компания) являются сущностями в графе знаний.
Google использует связи между сущностями, чтобы лучше понять релевантность страницы. Соответствующий результат по слову “apple”, в котором говорится об апельсинах и бананах, явно относится к фруктам. Но тот, в котором говорится об iPhone, iPad и iOS, явно относится к технологической компании.
Отчасти благодаря графу знаний Google может выйти за рамки сопоставления ключевых слов.
Иногда вы даже можете увидеть результаты поиска, в которых не упоминаются, казалось бы, важные ключевые слова из запроса. Возьмем для примера второй результат для “приложение Paper в магазине Apple”, в котором нигде на странице не упоминается слово “apple”.
Google может сказать, что это релевантный результат, отчасти потому, что он упоминает такие сущности, как iPhone и iPad, которые, несомненно, тесно связаны с Apple в графе знаний.
Примечание.
Данные о взаимодействии и граф знаний — не единственные технологии, которые Google использует для определения релевантности страницы поисковому запросу. Большая часть работы выполняется с использованием технологий, таких как BERT и RankBrain, позволяющих понять смысл и интент самого запроса. Google даже иногда незаметно переписывает запросы, чтобы предоставлять более релевантные результаты.
Новизна
Новизна как фактор ранжирования зависит от запроса, т. е. для одних запросов она важнее, чем для других.
Для такого запроса, как “что нового на Amazon Prime”, важна свежесть, потому что пользователи хотят знать о недавно добавленных фильмах и телешоу. Вероятно, поэтому Google ранжирует недавно опубликованные или обновленные результаты поиска выше.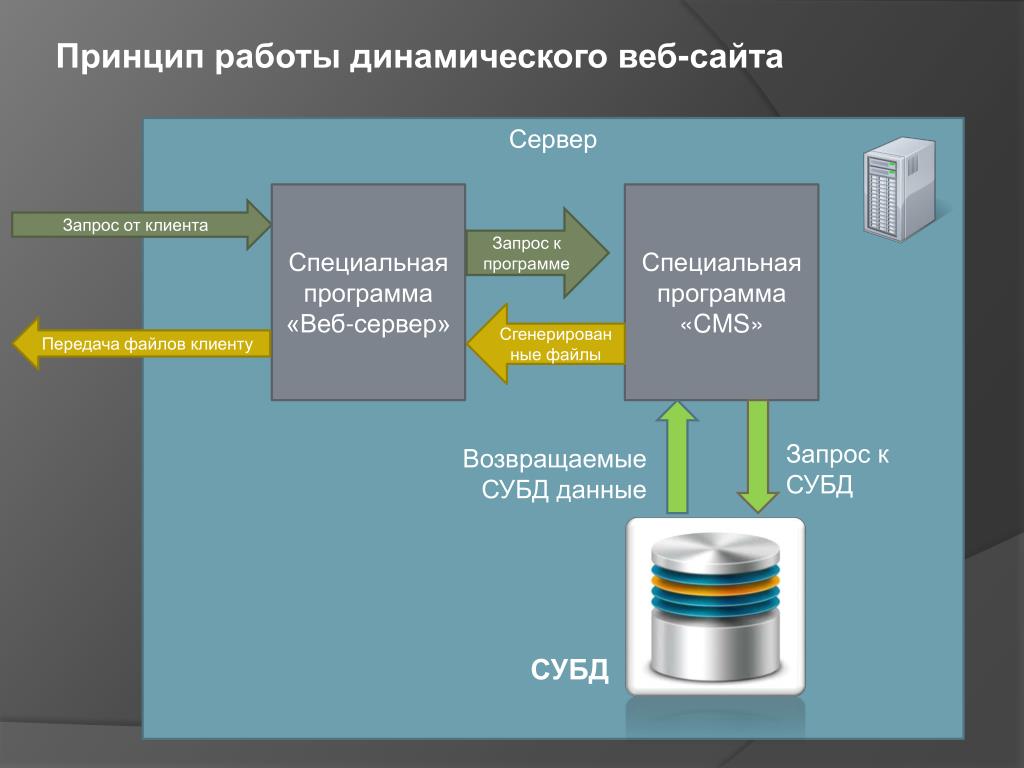
Для таких запросов, как “лучшие наушники”, свежесть важна, но не настолько. Технологии наушников развиваются быстро, поэтому результаты 2015 года вряд ли будут очень полезны, но пост, опубликованный 2—3 месяца назад, вполне может оказаться полезен.
Google знает об этом и показывает результаты, которые были обновлены или опубликованы в последние несколько месяцев.
Есть также вопросы, по которым новизна результатов не имеет значения, например, “как завязать галстук”. В этом процессе ничего не изменилось за десятилетия, поэтому не имеет значения, были ли результаты поиска написаны вчера или в 1998 году. Google знает это и не стесняется ранжировать посты, опубликованные много лет назад.
Тематическая авторитетность
Google хочет ранжировать контент с веб-сайтов, авторитетных в данной теме. Это означает, что Google может рассматривать веб-сайт как хороший источник результатов для запросов по одной теме, но не по другой.
Google говорит об этом в одном из своих патентов:
Считает ли поисковая система сайт авторитетным, обычно зависит от запроса.
 […] поисковая система может рассматривать сайт Центра по контролю за заболеваниями, “cdc.gov”, как авторитетный сайт для запроса “CDC об укусах комаров”, но не может считать тот же сайт авторитетным для запроса “рекомендации ресторанов”.
[…] поисковая система может рассматривать сайт Центра по контролю за заболеваниями, “cdc.gov”, как авторитетный сайт для запроса “CDC об укусах комаров”, но не может считать тот же сайт авторитетным для запроса “рекомендации ресторанов”.Хотя это лишь один из многих патентов, поданных Google, мы видим доказательства того, что “тематический авторитет” играет роль для результатов поиска по многим запросам.
Достаточно взглянуть на результаты поиска по запросу “вакууматор для готовки sous vide”.
Здесь мы видим два небольших нишевых сайта о готовке в вакууме, превосходящих The New York Times.
Хотя здесь, несомненно, играют роль и другие факторы, вполне вероятно, что “тематическая авторитетность” является одной из причин, по которым эти сайты ранжируются на своих позициях.
Вероятно поэтому в руководстве Google по поисковой оптимизации для начинающих сказано следующее:
Старайтесь заслужить репутацию в своей области.
Скорость загрузки страницы
Никто не любит ждать, пока загрузится страница, и Google это знает. Вот почему они сделали скорость страницы фактором ранжирования для поиска на компьютерах в 2010 году и на мобильных устройствах в 2018 году.
Вот почему они сделали скорость страницы фактором ранжирования для поиска на компьютерах в 2010 году и на мобильных устройствах в 2018 году.
Многие люди зацикливаются на скорости загрузки страниц, поэтому стоит отметить, что ваши страницы не должны загружаться молниеносно, чтобы ранжироваться. Google заявляет, что скорость загрузки страниц считается проблемой только для страниц, которые “загружаются у пользователей медленнее всего”.
Другими словами, сокращение на несколько миллисекунд и без того быстрого сайта вряд ли поможет ему ранжироваться выше. Просто он должен быть достаточно быстрым, чтобы не влиять негативно на восприятие пользователей.
Вы можете проверить скорость любой веб-страницы в инструменте PageSpeed Insights, который также генерирует предложения по ускорению загрузки страниц.
PageSpeed Insights также показывает производительность вашей страницы, по метрикам Core Web Vitals.
Core Web Vitals или основные интернет-показатели состоят из трех метрик, которые оценивают загрузку, интерактивность и визуальную стабильность ваших веб-страниц. Google подтвердил, что Core Web Vitals станут сигналом ранжирования в июне 2021 года.
Google подтвердил, что Core Web Vitals станут сигналом ранжирования в июне 2021 года.
Вы можете проверить производительность всех страниц своего веб-сайта с помощью отчета “Основные интернет-показатели” в Google Search Console.
Если окажется, что многие URL-адреса работают плохо или нуждаются в улучшении, обратитесь к разработчику.
Оптимизация для мобильных устройств
В Google 65% поисковых запросов выполняются на мобильных устройствах. Вот почему удобство для мобильных устройств с 2015 года является важным для мобильных устройств.
С 2019 года удобство для мобильных устройств также является фактором ранжирования для поиска на компьютерах благодаря переходу Google на индексацию, ориентированную на мобильные устройства. Это означает, что “для индексирования и ранжирования Google отдают преимущество мобильной версии контента” на всех устройствах.
Другими словами, отсутствие поддержки мобильных устройств может повлиять на ранжирование по запросам с любых устройств.
Вы можете проверить удобство использования любой веб-страницы на мобильных устройствах с помощью инструмента Google Проверка оптимизации для мобильных или в отчете Удобство для мобильных в Google Search Console.
Поисковые системы понимают, что разным людям нравятся разные результаты. Поэтому они адаптируют свои результаты для каждого пользователя.
Если вы когда-либо искали одно и то же на нескольких устройствах или в разных браузерах, вы, вероятно, могли заметить эффект такой персонализации. Результаты часто отображаются на разных позициях в зависимости от различных факторов.
Именно из-за этой персонализации, если вы занимаетесь SEO, для отслеживания позиций ранжирования вам лучше использовать специальный инструмент, такой как Ранк Трекер от Ahrefs. Заявленные позиции в этих инструментах, вероятно, будут ближе к истине, потому что они просматривают Интернет так, чтобы поисковые системы получали минимум информации для персонализации.
Как поисковые системы персонализируют результаты?
Google заявляет: “Чтобы предоставлять пользователям наиболее подходящую и актуальную информацию, мы учитываем сведения об их местоположении, предыдущих запросах, настройках Google Поиска и т. д.”.
д.”.
Давайте подробнее рассмотрим эти три пункта.
1. Местоположение
Если вы введете что-то вроде “итальянский ресторан”, все результаты на картах будут местными ресторанами.
Google делает это, потому что вы вряд ли проедете полмира ради обеда.
Но Google также использует ваше местонахождение для персонализации результатов поиска не только на картах. Если мы пролистаем поисковую выдачу по запросу “итальянский ресторан”, даже результаты TripAdvisor будут персонализированными, и мы увидим, что многие из лучших результатов — это веб-сайты местных ресторанов.
Схожая ситуация с запросом “купить дом”. Google показывает страницы с местными объявлениями вместо международных, потому что вы, вероятно, не хотите переезжать в другую страну.
Ваше местонахождение настолько сильно влияет на результаты локальных запросов, что при поиске одного и того же запроса из двух разных мест, поисковые выдачи почти полностью отличаются.
2. Язык
Google знает, что нет смысла показывать результаты на английском пользователям в Испании. Поэтому Google ранжирует английскую версию нашего руководства по SEO для YouTube для поиска на английском языке, а испанскую версию для поиска на испанском языке.
Поэтому Google ранжирует английскую версию нашего руководства по SEO для YouTube для поиска на английском языке, а испанскую версию для поиска на испанском языке.
Однако в этом Google в некоторой степени полагается на владельцев веб-сайтов. Если у вас есть страницы на нескольких языках, Google может не понять этого, пока вы им на это не укажете.
Вы можете сделать это с помощью HTML-атрибута под названием hreflang.
Hreflang немного сложен и выходит далеко за рамки этого руководства, но, если коротко, это небольшой фрагмент кода, указывающий на взаимосвязь между несколькими версиями одной и той же страницы на разных языках.
3. Журнал поиска
Возможно, наиболее очевидный пример использования Google истории поиска для персонализации результатов — это когда он “ставит” результат, по которому вы ранее кликали, выше при следующем выполнении того же поиска.
Это случается не всегда, но кажется довольно часто, особенно если вы нажимаете или посещаете страницу несколько раз за короткий промежуток времени.
Подведем итоги
Понимание того, как работают поисковые системы, — это первый шаг к более высокому ранжированию в Google и увеличению трафика. Если поисковые системы не могут найти, просканировать и проиндексировать ваши страницы, то они будут неконкурентоспособными еще до того, как вы начнете их оптимизировать.
Если вы хотите знать, как это сделать и как начать оптимизацию своего сайта для SEO, прочитайте наше руководство по основам SEO.
Есть вопросы? Дайте знать в комментариях или Твиттере.
Что такое поисковая система — определение, принцип работы алгоритмов Яндекс и Google
В статье разберем особенности процесса: как работает поисковая система, на каких принципах работы держатся алгоритмы ранжирования поисковика, как устроена выдача Яндекс и Google и для чего нужны все эти возможности в интернете.
- Общие принципы обработки информации
- Spider
- Crawler
- Indexer
- Database
- Search Engine Results Engine
- Web server
- Принципы работы поисковой системы
- Сбор данных
- Индексация
- Обработка информации
- Ранжирование
- Основные характеристики поисковых систем
- Полнота
- Точность
- Актуальность
- Скорость поиска
- Наглядность
- Принцип работы поисковых систем
- Яндекс
- Заключение
Общие принципы обработки информации
Несмотря на кажущуюся простоту – «запрос-ответ», для формирования топа и его релевантности любой сервис производит сложный процесс взаимодействия различных составляющих.
Spider
Он же «паук», который просматривает домены и дублирует содержимое на выделенные сервера, то есть «обходит паутину» для дальнейшего анализа вспомогательными программами. Он работает только с исходным кодом ресурса и документами формата html.
Crawler
Проверяет все ссылки на сайте, что дает возможность составить древо, и находит точные адреса, которые будут отображаться в поисковой выдаче. Важно учитывать, что битые ссылки сильно осложняют работу программы и впустую расходуют краулинговый бюджет.
Indexer
Алгоритм, который суммирует информацию от двух предыдущих и делит проиндексированные страницы по html-тегам, тем самым создавая список данных.
Database
На основе индексации разделяет полученные данные на две самостоятельные базы:
- Сведения, благодаря которым формируется рейтинг и определяется лист ключевиков, на которые поисковик будет выдавать ссылки.
- Древо со всей метаинформацией. Оно будет применяться для последующих индексаций. Для того чтобы заново не проходить предыдущие этапы выполняется только сверка структуры, что дает возможность понять, происходили ли какие-либо правки на ресурсе.
 Для того чтобы заново не проходить предыдущие этапы выполняется только сверка структуры, что дает возможность понять, происходили ли какие-либо правки на ресурсе.
Для того чтобы заново не проходить предыдущие этапы выполняется только сверка структуры, что дает возможность понять, происходили ли какие-либо правки на ресурсе.Search Engine Results Engine
Программа, определяющая финальное ранжирование и релевантность выдачи при получении определенного запроса. Она определяет, какие из них будут показаны и в топ-10, и в топ-100.
Web server
Сервер, на котором располагается сайт поисковика. Непосредственно с ним взаимодействует пользователь, вводя свой вопрос и получая информацию.
Коммерческий трафик
от 35 600 ₽ Страница услуги
Продвижение по коммерческому трафику от студии SEMANTICA – привлечение целевых пользователей из систем Яндекс и Google. Мы работаем над внутренними и внешними факторами ранжирования и видимостью сайта в поисковиках. Вы получаете рост посещаемости и высокий охват среди своих потенциальных клиентов.
Принципы работы поисковой системы
Основными этапами формирования базы данных являются индексация и ранжирование. Чтобы человек получал максимально точный ответ на свой вопрос, алгоритмы Яндекса и Гугла сегодня активно используют методы машинного обучения. Благодаря способам противопоставления двух различных результатов и настройке схемы обработки, робот понимает, какая страница будет наиболее полезной. Это делает возможным вывод релевантности или рейтинга, который есть у каждого сайта после обхода поисковиком. Чем этот показатель выше, тем выше позиция ресурса в выдаче. Этот процесс также делится на несколько подпроцессов.
Чтобы человек получал максимально точный ответ на свой вопрос, алгоритмы Яндекса и Гугла сегодня активно используют методы машинного обучения. Благодаря способам противопоставления двух различных результатов и настройке схемы обработки, робот понимает, какая страница будет наиболее полезной. Это делает возможным вывод релевантности или рейтинга, который есть у каждого сайта после обхода поисковиком. Чем этот показатель выше, тем выше позиция ресурса в выдаче. Этот процесс также делится на несколько подпроцессов.
Сбор данных
Как только появляется необходимость обхода, начинается автоматический анализ с использованием программ Spider и Crawler, которые собирают сведения и систематизируют их.
Индексация
Производится регулярно с определенными интервалами. После нее ресурс попадает в базу поисковика. По окончании этого действия формируется файл индекса, который в дальнейшем применяется для оперативного нахождения конкретного материала на странице.
Обработка информации
При поступлении запроса от пользователя производится его анализ и выделение ключевых слов, поиск которых проходит по файлам индекса. На основе этого определяются все результаты, похожие на изначальный.
На основе этого определяются все результаты, похожие на изначальный.
Ранжирование
Из полученных результатов формируется список от наибольшего к наименьшему совпадению. Также на этом этапе происходит вычисление релевантности для отображения.
В зависимости от используемой ПС, принцип отбора может варьироваться, но основные факторы таковы:
- соответствие текста интенту;
- оптимизация;
- авторитетность домена;
- цитируемость;
- похожий контент.
Что такое DDoS атака и как от нее защититься?
Что называется DDoS-атакой ДДоС атака — это вид киберпреступления, при котором на сайт поступает колоссальное количество трафика, нарушающее его работу и ограничивающее доступ к нему обычным пользователям. О них впервые заговорили в 1999 году, когда сайты крупных западных компаний подверглись массовым нападениям. Одна из самых известных и масштабных произошла в 2020 году и нацелена была на Amazon Web Services (AWS). Пиковый объем трафика составил 2,3 Тбит/с, несмотря на то, что DDoS атака на сайт была смягчена AWS Shield — сервисом…
Пиковый объем трафика составил 2,3 Тбит/с, несмотря на то, что DDoS атака на сайт была смягчена AWS Shield — сервисом…
Основные характеристики поисковых систем
С точки зрения рядового пользователя самая важная функция – получить ответ на вопрос. Но на самом деле у поисковика есть и другие важные критерии оценки контента.
Полнота
Условное соотношение числа ресурсов с прямым ответом на изначальный запрос от общего их количества в выдаче. Чем выше этот показатель, тем полнее анализ сервисом своих баз данных.
Точность
Более конкретный показатель, который дает возможность показывать в топе не просто ресурсы с прямым вхождением ключа, но и понимание, что именно хочет увидеть пользователь. Так, например, вводя «купить машину», человек не хочет увидеть сайты, где автолюбители делятся впечатлениями от совершенных сделок. Ему интересны страницы салонов, который занимаются продажей авто.
Актуальность
Как видно из названия, определяется тем, насколько актуальными будут полученные сведения, то есть сколько времени прошло с их размещения. Для большинства ПС этот период может составлять до трех месяцев, а для релевантных доменов два-три дня.
Для большинства ПС этот период может составлять до трех месяцев, а для релевантных доменов два-три дня.
Скорость поиска
Формируется из временного показателя, который требуется сервису для формирования списка поисковой выдачи, после получения запроса. Он напрямую зависит от вычислительных мощностей оборудования, которое используется для обработки данных, но также может меняться исходя из общего объема получаемой информации. Из-за чего его часто называют «стрессоустойчивость» или «готовность к нагрузкам». Для больших поисковиков скорость обработки может достигать ста миллионов в секунду.
Наглядность
Клиентская оценка, которая формируется на основании того, насколько точные сведения попадают в топ 10. Так как не увидев прямого ответа на первой странице, как правило, принимается решение воспользоваться другим сервисом.
Продвижение блога
от 46 200 ₽ Страница услуги
Продвижение блога от студии SEMANTICA — увеличение потока пользователей на сайт и повышение экспертности бренда в глазах целевой аудитории. Мы создаем востребованный контент, отвечающий на запросы потенциальных клиентов, оптимизируем статьи и настраиваем коммерческие триггеры. Вы получаете ощутимый прирост переходов в каталог товаров и услуг из блогового раздела.
Мы создаем востребованный контент, отвечающий на запросы потенциальных клиентов, оптимизируем статьи и настраиваем коммерческие триггеры. Вы получаете ощутимый прирост переходов в каталог товаров и услуг из блогового раздела.
Принцип работы поисковых систем
Самыми популярными для продвижения в Российском сегменте являются Гугл и Yandex. Далее разберемся, что учитывается при ранжировании в этих ПС.
Данные получаются из различных типов контента, например, тексты статей, музыка, видео, карты и справочники.
В этом процессе можно выделить три основных этапа:
- Сканирование. Роботы производят сбор сведений со страниц и файлов. За каждый тип информации отвечает отдельный бот. Для сканирования применяется Googlebot, для ранжирования PageRank, мобильная версия проверяется Mobile, а Image предназначен для поиска изображений. Также в процессе определяются дубли. Для упрощения работы краулерам, необходимо, чтобы у ресурса была карта-сайта (Sitemap).
- Индексирование. После сбора происходит обработка полученных данных.
- Показ результатов в ответ на запрос.

Помимо перечисленного, на место домена в SERP влияет еще и следующие факторы:
- E-A-T;
Введен, дабы избежать распространения фейков из источников, на первый взгляд, кажущихся авторитетными. Применяется к статьям на медицинские и научные тематики, которые могут напрямую повлиять на жизнь и здоровье людей. Теперь весь контент, претендующий на звание экспертного, обязан соответствовать трем основным требованиям: компетентность, авторитет, достоверность. Это значит, что такого рода информация должна быть написана от лица специалистов в области, имеющих официальное подтверждение в виде дипломов и сертификатов.
- опыт пользователя;
Результат взаимодействия человека с сайтом. Складывается из удобного дизайна, времени ожидания, адаптивности под различные виды устройств.
- Mobile-Friendly;
Сюда относятся такие показатели как: ширина контента на экране смартфона, размер шрифта и расположение интерактивных элементов.
- ПФ;
Поведенческие факторы – это взаимосвязь действий пользователя с характеристиками сайта. Сюда относятся взаимодействия со страницей, отказы, глубина просмотра.
- скорость загрузки.
Сейчас один из главных показателей у Гугла, определяющий качество ресурса. Оптимальное время должно составлять не более 2-х секунд, вне зависимости от устройства. Недавно сюда добавился такой пункт как Core Web Vitals. CWV демонстрирует, насколько в целом домен оптимизирован для взаимодействия, а не только как быстро он открывается.
Яндекс
За релевантную выдачу здесь отвечает алгоритм YATI. Он достаточно молодой, так как был запущен только в 2020 году. Принцип его работы базируется на машинном обучении, а основной его задачей было улучшение ответов и голосового поиска.
С ним пришли и новые требования к ресурсам, желающих занять свое место в SERP:
- Больше внимания рекомендуется удалить «длиннохвостым» и низкочастотным запросам, а также использованию синонимов. Это поможет давать более точные ответы на поставленные вопросы.
- Высокое качество контента. Малоинформативные и мусорные страницы будут удаляться.
- Представление материалов в формате лонгридов.
- Естественность ПФ. Yandex блокирует домены, замеченные в накрутке поведенческих факторов. Чтобы в этому не прибегать, найдите, чем заинтересовать свою целевую аудиторию.
 Это поможет давать более точные ответы на поставленные вопросы.
Это поможет давать более точные ответы на поставленные вопросы.Доступность сайта: что такое и как проверить
В этой статье расскажем, как проверить доступность сайта и на что обратить внимание. Почему важно отслеживать изменения и доступность сайтов Отслеживание работы сайта — такой же важный аспект в продвижении, как и его оптимизация. Если ваш сайт долго загружается, при подключении возникает ошибка безопасности или домен сайта становится недоступен, онлайн-продаж и заявок с сайта ждать не стоит. Когда сайт недоступен для пользователей, он недоступен и для поисковых ботов. Боты не проиндексируют сайт, если сервер недоступен или срок действия домена или…
Заключение
Сегодня мы получили определение, что такое алгоритмы поисковых систем, какое они имеют значение и зачем нужно применяться различные способы оптимизации для попадания в ТОП.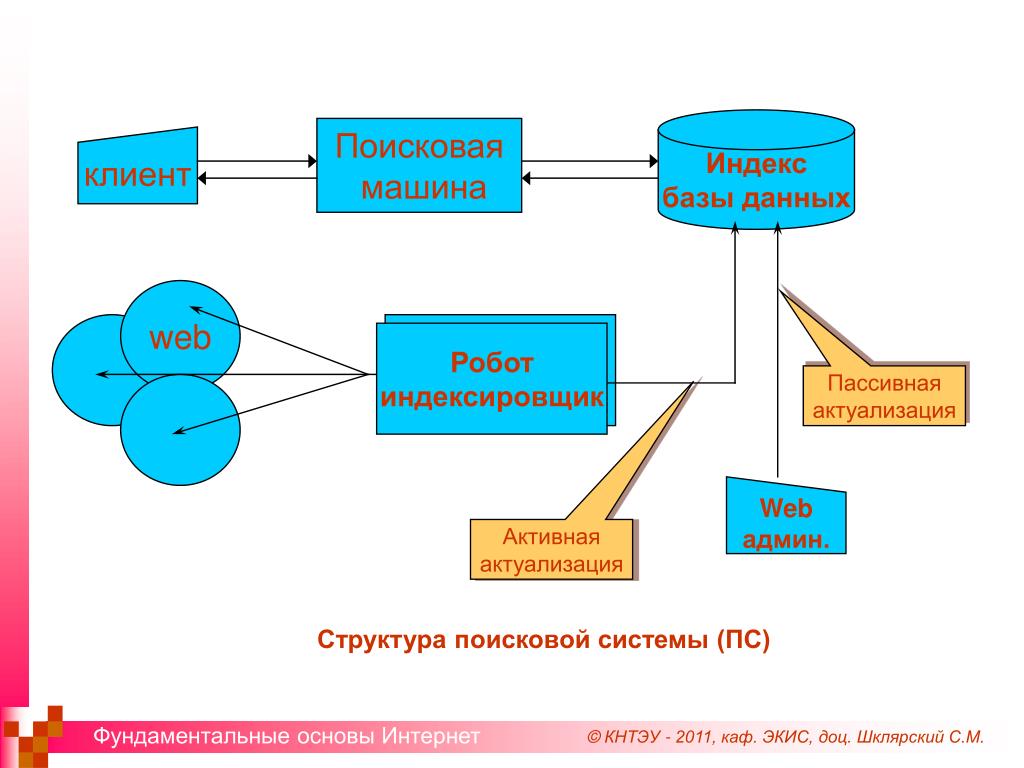
Подробное руководство по работе поиска Google | Центр поиска Google | Документация
Поиск Google – это полностью автоматизированная поисковая система, использующая программное обеспечение, известное как поисковые роботы. регулярно исследуйте Интернет, чтобы найти страницы для добавления в наш индекс. На самом деле, подавляющее большинство страницы, перечисленные в наших результатах, не отправляются вручную для включения, а обнаруживаются и добавляются автоматически, когда наши поисковые роботы исследуют Интернет. Этот документ объясняет этапы того, как Поиск работает в контексте вашего сайта. Наличие этих базовых знаний может помочь вам исправить проблем со сканированием, проиндексируйте свои страницы и узнайте, как оптимизировать внешний вид вашего сайта в Поиск Гугл.

Несколько замечаний, прежде чем мы начнем
Прежде чем мы углубимся в детали работы Поиска, важно отметить, что Google не принимать оплату, чтобы чаще сканировать сайт или повышать его рейтинг. Если кто-нибудь скажет вам в противном случае они ошибаются.
Google не гарантирует, что он будет сканировать, индексировать или обслуживать вашу страницу, даже если она следует за Google Search Essentials.
Знакомство с тремя этапами поиска Google
Поиск Google работает в три этапа, и не все страницы проходят каждый этап:
- Сканирование: Google загружает текст, изображения и видео со страниц, найденных в Интернете с помощью автоматических программ, называемых поисковыми роботами.
- Индексирование: Google анализирует текст, изображения и
видеофайлы на странице и сохраняет информацию в индексе Google, который является большим
база данных.
- Обработка результатов поиска: Когда пользователь выполняет поиск на Google, Google возвращает информацию, относящуюся к запросу пользователя.

Ползание
Первый этап — выяснить, какие страницы существуют в Интернете. Нет центрального реестра все веб-страницы, поэтому Google должен постоянно искать новые и обновленные страницы и добавлять их в свои список известных страниц. Этот процесс называется «обнаружение URL». Некоторые страницы известны, потому что Гугл их уже посещал. Другие страницы обнаруживаются, когда Google переходит по ссылке из известной страницы на новую страницу: например, центральная страница, такая как страница категории, ссылается на новую Сообщение блога. Другие страницы обнаруживаются, когда вы отправляете список страниц ( карта сайта) для сканирования Google.
Как только Google обнаружит URL-адрес страницы, он может посетить (или «просканировать») страницу, чтобы узнать, что находится на ней. Это. Мы используем огромное количество компьютеров для сканирования миллиардов страниц в Интернете. Программа, которая
выборка называется Googlebot
(также известный как робот, бот или паук). Googlebot использует алгоритмический процесс для определения
какие сайты сканировать, как часто и сколько страниц получать с каждого сайта.
Поисковые роботы Google
также запрограммированы таким образом, что стараются не сканировать сайт слишком быстро, чтобы не перегружать его.
Этот механизм основан на ответах сайта (например,
Ошибки HTTP 500 означают «медленнее»)
а также
настройки в Search Console.
Это. Мы используем огромное количество компьютеров для сканирования миллиардов страниц в Интернете. Программа, которая
выборка называется Googlebot
(также известный как робот, бот или паук). Googlebot использует алгоритмический процесс для определения
какие сайты сканировать, как часто и сколько страниц получать с каждого сайта.
Поисковые роботы Google
также запрограммированы таким образом, что стараются не сканировать сайт слишком быстро, чтобы не перегружать его.
Этот механизм основан на ответах сайта (например,
Ошибки HTTP 500 означают «медленнее»)
а также
настройки в Search Console.
Однако робот Googlebot не сканирует все обнаруженные страницы. Некоторые страницы могут быть
запрещен для сканирования
владельца сайта, другие страницы могут быть недоступны без авторизации на сайте, и другие
страницы могут быть дубликатами ранее просканированных страниц.
Например, многие сайты доступны через www ( www. ) и
версия доменного имени без www (  example.com
example.com example.com ), даже если содержимое
идентичен для обеих версий.
Во время сканирования Google отображает страницу и запускает любой найденный JavaScript используя последнюю версию Chrome, аналогично тому, как ваш браузер отображает страницы, которые вы посещаете. Рендеринг важен, потому что веб-сайты часто полагаются на JavaScript для отображения контента на странице. и без рендеринга Google может не увидеть этот контент.
Сканирование зависит от того, могут ли поисковые роботы Google получить доступ к сайту. Некоторые распространенные проблемы с Доступ к сайтам робота Googlebot включает:
- Проблемы с сервером, обрабатывающим сайт
- Проблемы с сетью
- директивы robots.txt, запрещающие роботу Googlebot доступ к странице
Индексация
После сканирования страницы Google пытается понять, о чем эта страница.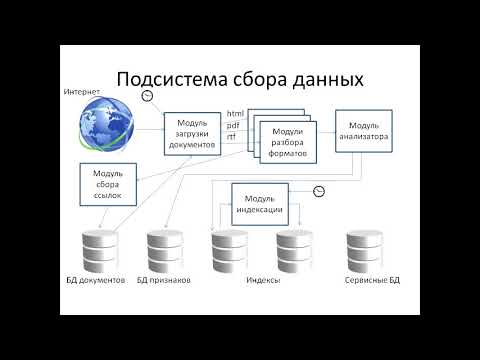 Этот этап
называется индексированием и включает в себя обработку и анализ текстового контента и ключевого контента
теги и атрибуты, такие как
Этот этап
называется индексированием и включает в себя обработку и анализ текстового контента и ключевого контента
теги и атрибуты, такие как <название> элементов
и атрибуты alt,
картинки,
видео и
более.
В процессе индексации Google определяет, является ли страница дубликат другой страницы в Интернете или канонической. Каноническая — это страница, которая может отображаться в результатах поиска. Для выбора канонического мы сначала сгруппируем найденные в Интернете страницы с похожим содержанием, а затем выберите тот, который наиболее репрезентативен для группы. Остальные страницы в группе альтернативные версии, которые могут подаваться в разных контекстах, например, если пользователь ищет с мобильного устройства или они ищут очень конкретную страницу из этого кластера.
Google также собирает сигналы о канонической странице и ее содержании, которые могут использоваться в
следующий этап, где мы обслуживаем страницу в результатах поиска. Некоторые сигналы включают язык
страницы, страны, в которой находится контент, удобство использования страницы и т. д.
Некоторые сигналы включают язык
страницы, страны, в которой находится контент, удобство использования страницы и т. д.
Собранная информация о канонической странице и ее кластере может храниться в Google index, большая база данных, размещенная на тысячах компьютеров. Индексация не гарантируется; не каждый страница, которую обрабатывает Google, будет проиндексирована.
Индексация также зависит от содержания страницы и ее метаданных. Некоторые распространенные проблемы с индексацией может включать:
- Качество контента на странице низкое
- Метадирективы robots запрещают индексацию
- Дизайн сайта может затруднить индексацию
Обслуживание результатов поиска
Google не принимает плату за повышение ранжирования страниц, а ранжирование выполняется программно. Когда пользователь вводит запрос, наши машины ищут в индексе соответствующие страницы и возвращают
результаты, которые мы считаем, являются самыми качественными и наиболее релевантными для пользователя. Релевантность
определяется сотнями факторов, которые могут включать в себя такую информацию, как
местоположение, язык и устройство (рабочий стол или телефон). Например, при поиске «ремонт велосипедов
магазины» покажет пользователю в Париже разные результаты, чем пользователю в Гонконге.
Релевантность
определяется сотнями факторов, которые могут включать в себя такую информацию, как
местоположение, язык и устройство (рабочий стол или телефон). Например, при поиске «ремонт велосипедов
магазины» покажет пользователю в Париже разные результаты, чем пользователю в Гонконге.
Search Console может сказать вам, что страница проиндексирована, но вы не видите ее в результатах поиска. Это может быть потому, что:
- Содержание контента на странице не имеет отношения к пользователям
- Качество контента низкое
- Мета-директивы robots предотвращают обслуживание
Хотя в этом руководстве объясняется, как работает Поиск, мы постоянно работаем над улучшением наших алгоритмов. Вы можете отслеживать эти изменения, следуя Блог Google Search Central.
Руководство по алгоритмам Google и Bing
Поисковые системы — ваш портал в Интернет. Они берут массу информации на веб-сайте, разбивают ее и принимают решения о том, насколько хорошо она отвечает на конкретный запрос. Но как на самом деле работают поисковые системы, когда нужно просеять столько данных?
Они берут массу информации на веб-сайте, разбивают ее и принимают решения о том, насколько хорошо она отвечает на конкретный запрос. Но как на самом деле работают поисковые системы, когда нужно просеять столько данных?
Чтобы обнаружить, классифицировать и ранжировать миллиарды веб-сайтов, составляющих Интернет, поисковые системы используют сложные алгоритмы, которые принимают решения о качестве и релевантности любой страницы. Это сложный процесс, в котором задействованы значительные объемы данных, и все они должны быть представлены таким образом, чтобы конечные пользователи могли их легко воспринять.
Поисковые системы анализируют всю эту информацию, просматривая множество различных факторов ранжирования на основе запроса пользователя. Это включает в себя релевантность введенному пользователем вопросу, качество контента, скорость сайта, метаданные и многое другое. Каждая точка данных объединяется, чтобы помочь поисковым системам рассчитать общее качество любой страницы. Затем веб-сайт ранжируется на основе их расчетов и представляется пользователю.
Затем веб-сайт ранжируется на основе их расчетов и представляется пользователю.
Понимание закулисных процессов, которые имеют место для поисковых систем, чтобы принять эти решения, не только поможет вам понять, почему определенные части контента хорошо ранжируются, но также поможет вам создать новый контент с потенциалом для более высокого ранжирования.
Давайте рассмотрим общие процедуры, на которых построен алгоритм каждой поисковой системы, а затем разберем четыре основные платформы, чтобы увидеть, как они это делают.
Как работают поисковые системы?
Чтобы быть эффективными, поисковые системы должны точно понимать, какая информация доступна, и логически представлять ее пользователям. Для этого они выполняют три основных действия: сканирование, индексирование и ранжирование.
Схема процесса поисковой системы
Благодаря этим действиям они обнаруживают недавно опубликованный контент, сохраняют информацию на своих серверах и организуют ее для вашего потребления.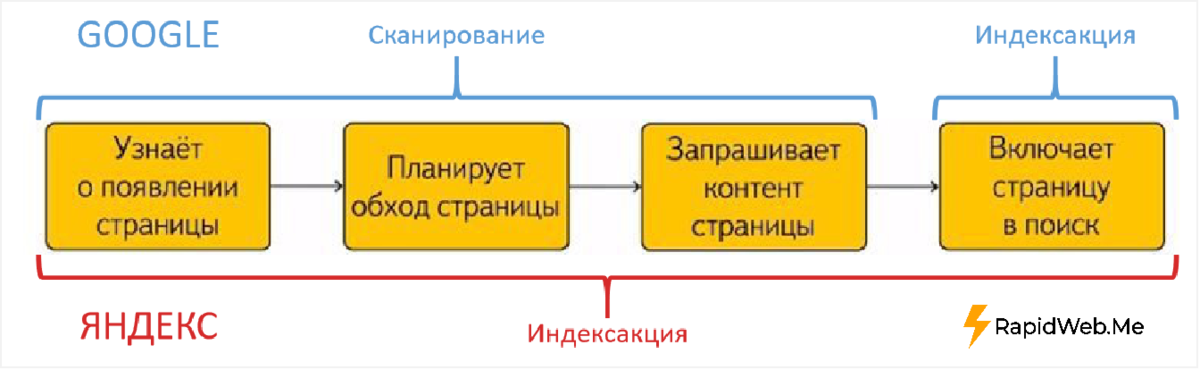 Давайте разберем, что происходит во время каждого из этих действий:
Давайте разберем, что происходит во время каждого из этих действий:
- Сканирование: Поисковые системы отправляют поисковые роботы, также известные как боты или пауки, для просмотра содержимого веб-сайта. Уделяя пристальное внимание новым веб-сайтам и существующему контенту, который недавно был изменен, поисковые роботы просматривают такие данные, как URL-адреса, карты сайта и код, чтобы определить типы отображаемого контента.
- Индекс: После сканирования веб-сайта поисковым системам необходимо решить, как организовать информацию. Процесс индексации заключается в том, что они просматривают данные веб-сайта на наличие положительных или отрицательных сигналов ранжирования и сохраняют их в правильном месте на своих серверах.
- Ранг: В процессе индексации поисковые системы начинают принимать решения о том, где отображать определенный контент на странице результатов поисковой системы (SERP). Ранжирование осуществляется путем оценки ряда различных факторов на основе запроса конечного пользователя о качестве и релевантности.

В ходе этого процесса принимаются решения, определяющие ценность, которую любой веб-сайт потенциально может предоставить конечному пользователю. Эти решения руководствуются алгоритмом. Понимание того, как работает алгоритм, поможет вам создавать контент, который лучше ранжируется для каждой платформы.
Будь то RankBrain для Google и YouTube, Space Partition Tree And Graph (SPTAG) для Bing или проприетарная кодовая база для DuckDuckGo, каждая платформа использует уникальную серию факторов ранжирования, чтобы определить, какое место веб-сайты занимают в результатах поиска. Если вы будете помнить об этих факторах при создании контента для своего веб-сайта, вам будет проще адаптировать определенные страницы для получения хорошего рейтинга.
Анализ алгоритмов поисковых систем по платформам
Каждая поисковая система по-своему обрабатывает результаты поиска. Мы рассмотрим четыре ведущие платформы на современном рынке и разберем, как они принимают решения о качестве и релевантности контента.
Алгоритм поиска Google
Google — самая популярная поисковая система на планете. Их поисковая система обычно владеет более 90% рынка, что приводит к примерно 3,5 миллиардам индивидуальных поисковых запросов на их платформе каждый день. Хотя Google, как известно, молчат о том, как работает их алгоритм, они предоставляют некоторый высокоуровневый контекст о том, как они определяют приоритеты веб-сайтов на странице результатов.
Каждый день создаются новые сайты. Google может найти эти страницы, перейдя по ссылкам из существующего контента, который они просканировали ранее, или когда владелец веб-сайта напрямую отправляет свою карту сайта. Любые обновления существующего контента также можно отправить в Google, попросив их повторно просканировать определенный URL-адрес. Это делается через консоль поиска Google.
Хотя Google не указывает, как часто сканируются сайты, любой новый контент, связанный с существующим контентом, в конечном итоге также будет найден.
Как только поисковые роботы соберут достаточно информации, они вернут ее в Google для индексации.
Индексирование начинается с анализа данных веб-сайта, включая письменный контент, изображения, видео и техническую структуру сайта. Google ищет положительные и отрицательные сигналы ранжирования, такие как ключевые слова и свежесть веб-сайта, чтобы попытаться понять, о чем идет речь на любой просканированной странице.
Индекс веб-сайтов Google содержит миллиарды страниц и 100 000 000 гигабайт данных. Для систематизации этой информации Google использует алгоритм машинного обучения под названием RankBrain и базу знаний под названием Knowledge Graph. Все это работает вместе, чтобы помочь Google предоставить пользователям максимально релевантный контент. После завершения индексации они переходят к ранжированию.
Все, что происходит до этого момента, выполняется в фоновом режиме, еще до того, как пользователь начнет взаимодействие с функцией поиска Google. Ранжирование — это действие, которое происходит в зависимости от того, что ищет пользователь. Google рассматривает пять основных факторов, когда кто-то выполняет поиск:
Google рассматривает пять основных факторов, когда кто-то выполняет поиск:
- Значение запроса: Это определяет цель любого вопроса конечного пользователя. Google использует это, чтобы точно определить, что кто-то ищет, когда выполняет поиск. Они анализируют каждый запрос, используя сложные языковые модели, основанные на прошлых поисках и поведении пользователей.
- Релевантность веб-страницы: После того, как Google определил цель поискового запроса пользователя, он просматривает содержимое рейтинговых веб-страниц, чтобы выяснить, какая из них является наиболее релевантной. Основным драйвером для этого является анализ ключевых слов. Ключевые слова на веб-сайте должны соответствовать тому, как Google понимает вопрос, заданный пользователем.
- Качество контента: При совпадении ключевых слов Google делает еще один шаг вперед и проверяет качество контента на необходимых веб-страницах. Это помогает им расставить приоритеты, какие результаты будут первыми, глядя на авторитет данного веб-сайта, а также на его рейтинг страницы и свежесть.
- Удобство использования веб-страницы: Google отдает приоритет ранжированию веб-сайтам, которые просты в использовании. Юзабилити охватывает все, от скорости сайта до отзывчивости.
- Дополнительный контекст и настройки: Этот шаг адаптирует поиск к прошлому взаимодействию пользователей и конкретным настройкам на платформе Google.

После того, как вся эта информация будет обработана, Google предоставит результаты, которые выглядят примерно так:
Поиск Google по запросу «лучшие беспроводные наушники» Избранный фрагмент из поиска Google «как подключить беспроводные наушники»Давайте разберем эти результаты:
- Пользовательский запрос: Вопрос, который пользователь задал Google.
- Покупки в Google: Google считает, что целью этого запроса является поиск товаров для покупки. В результате они извлекают из своего индекса продукты, соответствующие этому намерению, и отображают их первыми в результатах.
- Фрагмент функции: Результат Knowledge Graph. Google представляет конкретную информацию из результатов поисковой выдачи, чтобы пользователям было проще просматривать ее, не покидая страницы результатов.
- Самые популярные результаты: Первый сайт в результатах — тот, который, по мнению Google, лучше всего соответствует цели запроса пользователя. Результат с наивысшим рейтингом — это тот, который работает лучше всего на основе пяти факторов ранжирования, которые мы обсуждали ранее.
- Люди также спрашивают: Это поле — еще один результат Сети знаний. Это дает пользователям быстрый способ перейти к другому поиску, который может еще лучше соответствовать их намерениям.
Эти результаты возможны только потому, что Google хранит информацию о каждой из этих страниц в своем индексе. Прежде чем пользователь выполнит поиск, Google просматривает веб-сайты, чтобы выяснить, каким ключевым словам и намерениям они соответствуют.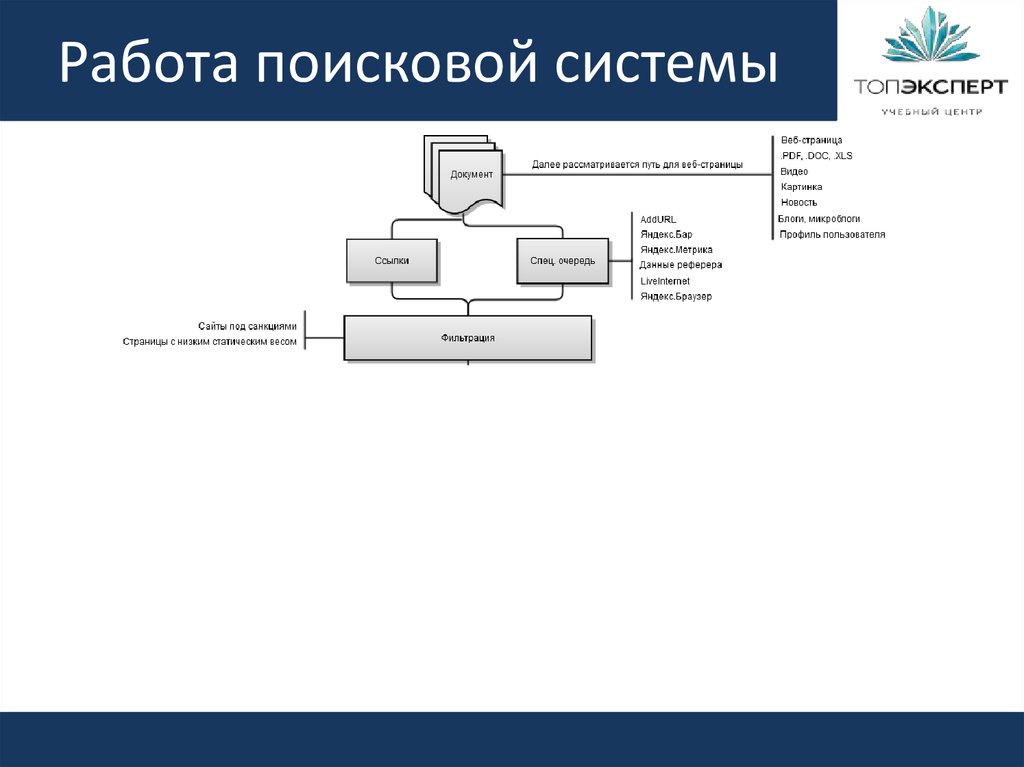 Этот процесс упрощает быстрое заполнение страницы результатов при выполнении поиска и помогает Google предоставлять максимально релевантный контент.
Этот процесс упрощает быстрое заполнение страницы результатов при выполнении поиска и помогает Google предоставлять максимально релевантный контент.
Как самая популярная поисковая система, Google в той или иной степени создал основу для того, как поисковые системы смотрят на контент. Большинство маркетологов адаптируют свой контент специально для ранжирования в Google, а это означает, что они потенциально упускают возможности других платформ.
Алгоритм поиска Bing
Bing, собственная поисковая система Microsoft, использует алгоритм векторного поиска с открытым исходным кодом под названием Space Partition Tree And Graph (SPTAG) для отображения результатов. Это означает, что они идут в совершенно другом направлении, чем поиск Google по ключевым словам.
Открытость исходного кода означает, что любой может посмотреть на основные моменты того, что составляет результаты поиска Bing, и оставить комментарии. Эта открытая модель противоречит жесткому контролю Google над своими алгоритмами.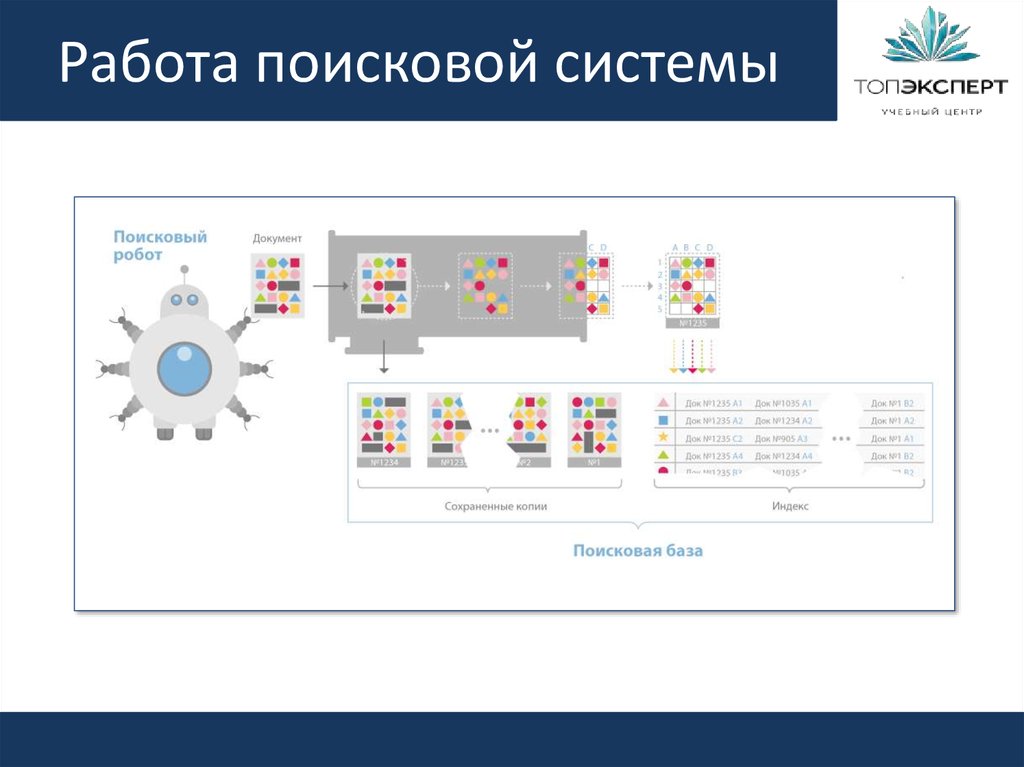 Сам код разделен на два отдельных модуля — построитель индекса и поисковик:
Сам код разделен на два отдельных модуля — построитель индекса и поисковик:
- Построитель индекса: Код, который работает для классификации информации веб-сайта по векторам
- Поисковик: Способ, которым Bing устанавливает связи между поисковыми запросами и векторами в их индексе
Второе большое различие между Bing и Google заключается в том, как информация хранится и индексируется. Вместо модели, основанной на ключевых словах, как в Google, Bing разбивает информацию на отдельные точки данных, называемые векторами. Вектор — это числовое представление понятия; эта концепция лежит в основе структуры поиска Bing.
Поисковые запросы для Bing основаны на алгоритмическом принципе под названием «Приблизительный ближайший сосед», в котором используются модели глубокого обучения и естественного языка для получения более быстрых результатов на основе близости определенных векторов друг к другу.
Графическое представление алгоритма Bing Approximate Nearest Neighbor SPTAG
Если мы посмотрим на желтую точку как на пользовательский запрос, зеленые точки — это первые близкие соседи, за которыми следуют синие точки. Отслеживая оранжевую стрелку, мы видим, как алгоритм Bing решает, какая информация наиболее актуальна для поиска пользователя.
Отслеживая оранжевую стрелку, мы видим, как алгоритм Bing решает, какая информация наиболее актуальна для поиска пользователя.
Хотя основные принципы, лежащие в основе структуры поиска Bing, принципиально отличаются, процесс создания их базы данных по-прежнему следует действиям сканирования, индексирования и ранжирования.
Bing сканирует веб-сайты, чтобы найти новое содержимое или обновления существующего содержимого. Затем они создают векторы для хранения этой информации в своем индексе. Оттуда они смотрят на конкретные факторы ранжирования. Самая большая разница по сравнению с Google заключается в том, что Bing не включает страницы без авторитета ранжирования, а это означает, что новым страницам труднее ранжироваться, если у них нет обратных ссылок на существующую страницу с большим авторитетом.
Для получения дополнительной информации о том, как происходит сканирование и индексирование, ознакомьтесь с Руководством Bing для веб-мастеров. На этой странице представлено описание типа информации, которая наиболее важна, если вы хотите получить рейтинг на их платформе.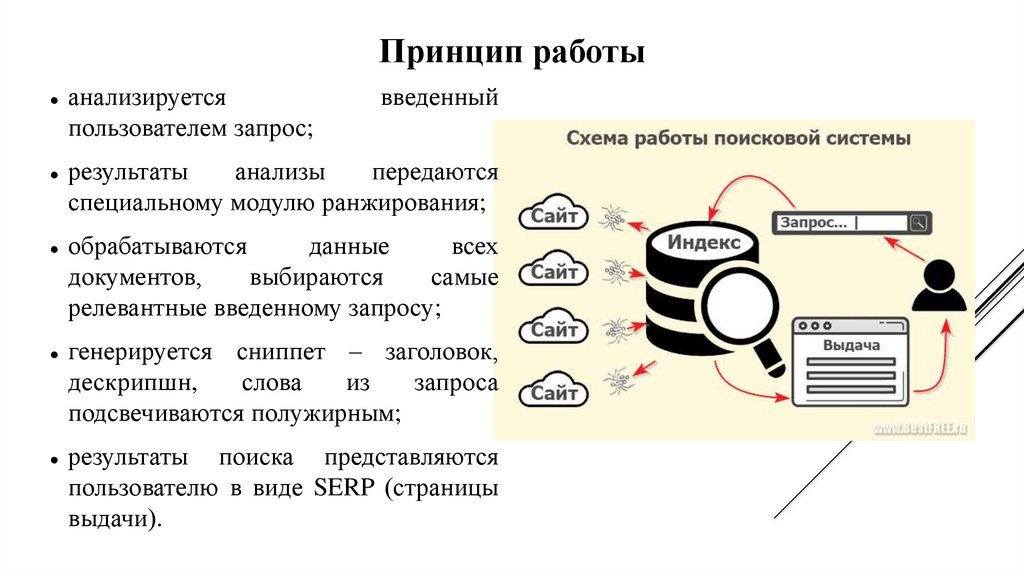
Если мы посмотрим на тот же поиск, выполненный в Bing, результаты будут другими:
Результаты поиска Bing для «лучших беспроводных наушников»Хотя результаты выглядят одинаково по своей структуре, Bing извлекает данные с разных веб-сайтов как для своих покупок, так и для своих выбор фрагментов функций. Результат с самым высоким рейтингом также отличается от нашего поиска в Google, хотя оба они вполне соответствуют нашим намерениям.
Если вы думаете об адаптации контента для Bing, вам следует начать с изучения различий между сайтами с самым высоким рейтингом и фрагментами функций. Их платформа отдает приоритет контенту не так, как Google, и эти различия помогут вам понять, почему.
Алгоритм поиска DuckDuckGo
DuckDuckGo немного индивидуалистична на рынке поисковых систем, но набирает популярность как поисковая система для всех, кто заботится о конфиденциальности своих данных. Хотя у них есть проприетарный веб-сканер под названием DuckDuckBot для просмотра содержимого веб-страницы, большая часть информации, которую DuckDuckGo показывает на своей странице результатов, собрана из более чем 400 дополнительных сторонних источников, включая Bing, Yahoo и Wikipedia.
В отличие от Google и Bing, DuckDuckGo не собирает личную информацию о своих пользователях, включая прошлую историю поиска и IP-адрес. Эта приверженность конфиденциальности в некотором роде усложняет работу их алгоритма для предоставления персонализированных результатов.
Для еще большей конфиденциальности DuckDuckGo также можно использовать для полностью анонимного просмотра с использованием сети Tor или onion-сервиса.
В результате такого внимания к конфиденциальности DuckDuckGo имеет самую оптимизированную страницу результатов.
Результаты DuckDuckGo для «лучших беспроводных наушников»И Bing, и DuckDuckGo имеют одинаковые первый и второй результаты, что имеет смысл, учитывая, что Bing включен в алгоритмы поиска DuckDuckGo.
400 дополнительных источников DuckDuckGo также включают вычислительные базы данных, такие как WolframAlpha, платформа, созданная в первую очередь для решения сложных математических уравнений и предоставления инструментов для анализа данных.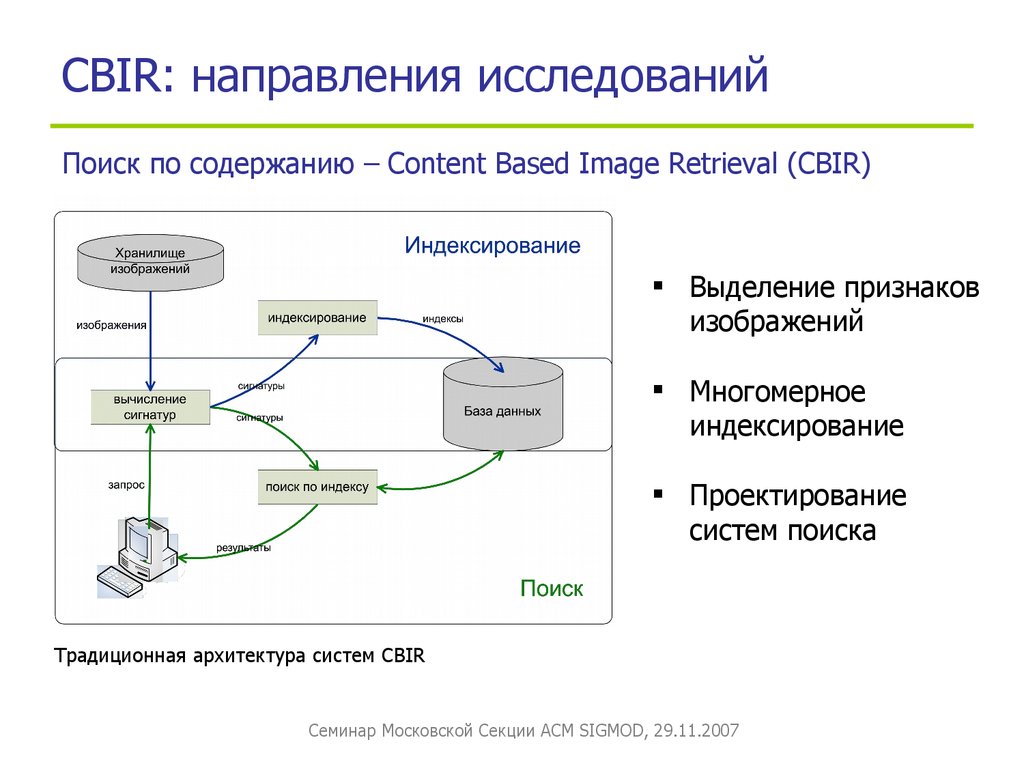 Другие источники представлены в виде мгновенных ответов, которые извлекают контент с соответствующих веб-сайтов, чтобы предоставить ответы на странице, такие как фрагменты функций, которые мы видели в Google и Bing.
Другие источники представлены в виде мгновенных ответов, которые извлекают контент с соответствующих веб-сайтов, чтобы предоставить ответы на странице, такие как фрагменты функций, которые мы видели в Google и Bing.
Информация в нашем примере взята непосредственно из Википедии.
DuckDuckGo не предоставляет конкретной информации о различных видах факторов ранжирования, которые учитываются на этих страницах результатов, но намекает на тот факт, что следует учитывать ссылки на сайты с высоким авторитетом.
Еще один интересный аспект платформы DuckDuckGo заключается в том, что они позволяют пользователям использовать настраиваемые параметры, называемые челками, чтобы полностью обойти страницу результатов поиска. Функция извлечения из нескольких источников для отображения результатов, DuckDuckGo затем выступает в качестве поискового портала для таких платформ, как Википедия, Amazon и Twitter.
Как платформа, заботящаяся о безопасности, мы можем предположить, что DuckDuckGo не включает прошлые поиски как часть своего алгоритма ранжирования. Это, в сочетании с информационными аспектами их дополнительных источников, делает платформу менее персонализированной, чем Bing или Google, но все же способной предоставлять качественный и актуальный контент для своих пользователей. Адаптация контента для Bing подойдет и для этой платформы.
Это, в сочетании с информационными аспектами их дополнительных источников, делает платформу менее персонализированной, чем Bing или Google, но все же способной предоставлять качественный и актуальный контент для своих пользователей. Адаптация контента для Bing подойдет и для этой платформы.
Алгоритм поиска YouTube
YouTube — самый популярный видеохостинг. Их поисковая система эффективно работает по правилам, аналогичным правилам Google, которому принадлежит платформа, и фокусируется на ключевых словах и релевантности. Алгоритм разбит на две отдельные функции: ранжирование видео в поиске и отображение релевантных рекомендаций.
Конкретные причины, по которым одни видео ранжируются выше других, как и все свойства Google, не определены внешне. Тем не менее, большинство интерпретаций склоняются к тому, что новизна видео и частота загрузки канала являются наиболее важными факторами.
Что касается рекомендаций, то в этом исследовательском документе от 2016 года перечислены основные приоритеты YouTube, такие как масштаб, свежесть и уровень шума:
- Масштаб: Каждую минуту на YouTube загружается 300 часов видео, а платформа 1,3 миллиарда пользователей. Это значительно усложняет синтаксический анализ информации, поэтому основное внимание алгоритма уделяется поиску способов просеивания этого объема данных для каждого пользователя.
- Свежесть: YouTube уравновешивает то, как они рекомендуют видео, основываясь на том, как давно видео было загружено, а также на прошлом поведении отдельных пользователей.
- Шум: Из-за разного количества контента, который большинство пользователей просматривают на YouTube, любому ИИ сложно анализировать, что является наиболее актуальным в любое время.
 Это значительно усложняет синтаксический анализ информации, поэтому основное внимание алгоритма уделяется поиску способов просеивания этого объема данных для каждого пользователя.
Это значительно усложняет синтаксический анализ информации, поэтому основное внимание алгоритма уделяется поиску способов просеивания этого объема данных для каждого пользователя.Эти факторы приводят к созданию страницы рекомендаций, адаптированной для каждой отдельной учетной записи пользователя.
Рекомендации YouTube на главной странице
Это также показывает, как подписки влияют на то, как YouTube представляет результаты. Когда пользователь подписывается на определенный канал, это повышает его рейтинг в результатах поиска, рекомендациях и том, что смотреть дальше.
Другие факторы ранжирования включают то, что пользователь смотрит, как долго он просматривает разные видео и какова общая популярность видео на YouTube.
Взгляните на страницу результатов поиска «лучшие беспроводные наушники».
Страница результатов поиска YouTube по запросу «лучшие беспроводные наушники»Лучший результат — это самое просматриваемое видео группы.
YouTube показал, вероятно, наибольшее колебание результатов в зависимости от того, что я искал: лучшие беспроводные наушники, лучшие беспроводные наушники 2021 года, лучшие беспроводные наушники 2020 года. титулы. (В одном случае он вернул один с 2018 в названии.)
Из этих результатов мы понимаем, что популярность, вероятно, является одним из самых важных факторов ранжирования для YouTube, ставя его даже выше более нового видео с точным соответствием ключевому слову.
Чтобы занять высокие позиции на YouTube, вам понадобится солидный профиль и постоянная частота загрузки.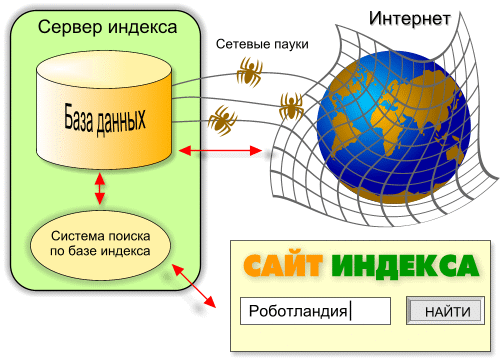 Их ориентация на популярность и силу профиля требует больше инвестиций от маркетологов, но окупается для брендов, которые сосредотачивают свои усилия на платформе.
Их ориентация на популярность и силу профиля требует больше инвестиций от маркетологов, но окупается для брендов, которые сосредотачивают свои усилия на платформе.
Понимание того, как работают поисковые системы, поможет вам создавать более качественный контент
Когда вы знаете, как разные платформы отображают свои результаты, вам будет легче создавать контент, который может иметь высокий рейтинг. Это понимание также поможет вам определить, почему другие типы контента ранжируются лучше или хуже, чем ваш собственный.
На основе этой информации мы составили пять советов, которые помогут вам создавать более качественный контент на любой платформе:
- Важно понимать намерения пользователя. Каждая платформа, которую мы рассматривали сегодня, отдает приоритет контенту в зависимости от того, насколько он релевантен поисковому запросу пользователя.
- Подходящие ключевые слова помогут вам только на этом этапе. Включение релевантных ключевых слов в ваш контент поможет поисковым системам легче обнаруживать и индексировать ваш контент, но хорошее ранжирование в большей степени связано с обеспечением ценности для пользователей.
- Знайте, как ищет ваш целевой клиент. Соответствие как ключевым словам, так и намерениям требует глубокого понимания ваших клиентов и того, что они думают о вашем продукте и вашем рынке.
- Новый контент помогает повысить рейтинг. Создание нового контента или обновление существующего контента помогает ему занять более высокое место в рейтинге и повышает доверие к вашему бренду.
- Получение авторитетных ссылок полезно. Чем больше людей ссылаются на вашу страницу, тем лучше она будет отображаться в поисковых системах. Это сигнализирует о том, что он ценен и актуален для содержания каждой страницы, на которую он ссылается.
В конце концов, все сводится к пониманию вашего клиента. Вы не сможете создать контент с хорошим рейтингом, если не знаете, что ищут люди, когда ищут ваш продукт.
Для получения дополнительной информации о создании контента для поиска ознакомьтесь с нашим Руководством по поисковой оптимизации, чтобы узнать больше!
Подпишитесь на нашу рассылку, чтобы получать больше новостей о поисковом маркетинге и отраслевых тенденциях
Как поисковые системы работают и влияют на ваш сайт
Изучив, как работают поисковые системы, вы сможете сформировать лучшую SEO-стратегию для своего бизнеса, чтобы привлечь трафик на свой сайт.
Чтобы понять поисковую оптимизацию (SEO), полезно узнать, как работают поисковые системы. Поисковые системы существуют, чтобы помочь вам найти то, что вы ищете в Интернете. Для этого они оценивают бесчисленные сайты и веб-элементы, составляющие всемирную паутину, и определяют, какие сайты лучше всего соответствуют тому или иному запросу.
Сеть сама по себе представляет собой набор взаимосвязанных страниц и ресурсов, к которым пользователи получают доступ через глобальную сеть, которой является Интернет. Конечно, вы можете получить доступ к этим документам напрямую, посетив URL-адрес веб-страницы — ее веб-адрес — с помощью веб-браузера. Но чаще люди попадают на сайты через поисковик. Для владельцев бизнеса это открывает бесценную возможность.
Что заставляет сеть работать?
Веб-страницы — это документы, отформатированные с использованием HTML, языка веб-программирования, который позволяет использовать встроенные гиперссылки, соединяющие одну страницу с другой.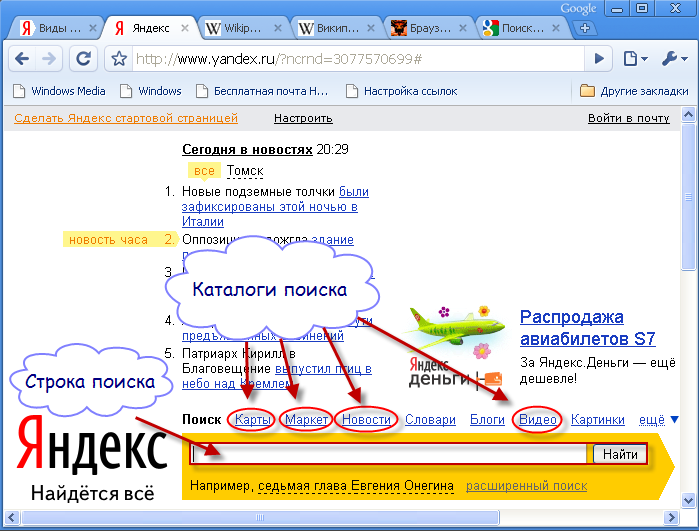 Это самая важная концепция для понимания того, как работает Интернет.
Это самая важная концепция для понимания того, как работает Интернет.
Веб-страницы содержат такое содержимое, как текст, изображения, формы, видео, гиперссылки и многое другое. Этот контент — то, что нужно пользователям. Вы заходите на веб-страницу, чтобы читать, смотреть, слушать или выполнять такие задачи, как покупка продукта или подписка на информационный бюллетень. Вы перемещаетесь, используя ссылки между страницами.
Эти действия возможны из-за содержимого, запрограммированного на веб-странице. Природа Интернета позволяет легко перемещаться по страницам от одной к другой в зависимости от того, что вы собираетесь делать.
Что такое веб-сайт?
Веб-сайт — это набор веб-страниц, которые все находятся в одном домене и обычно принадлежат и управляются одной и той же организацией. Например, домашняя страница Mailchimp доступна по URL-адресу https://mailchimp.com/.
В этом URL-адресе «mailchimp.com» является доменом. Когда вы посмотрите на другие URL-адреса на этом веб-сайте, вы заметите, что они используют один и тот же домен, хотя полный URL-адрес отличается. Например:
Например:
- https://mailchimp.com/resources/
- https://mailchimp.com/why-mailchimp/
Mailchimp также использует ссылки для направления посетителей в другие разделы веб-сайта. Например, из области навигации в верхней части каждой страницы вы можете легко перейти на другую страницу сайта. Это возможно с помощью внутренних ссылок, которые представляют собой ссылки между страницами в одном домене.
Разница между внутренними и внешними ссылками
Ссылки на другой домен являются внешними ссылками. (Вы заметите внешнюю ссылку в подписи автора внизу этой статьи.)
Внизу каждой страницы Mailchimp включает раздел нижнего колонтитула. Это помогает посетителям переходить на определенные страницы, используя как внутренние, так и внешние ссылки. В этом случае внешние ссылки ведут на страницы профилей в социальных сетях.
Большинство веб-сайтов используют больше внутренних, чем внешних ссылок. Обычно все страницы веб-сайта ссылаются на другие страницы того же веб-сайта, создавая собственную миниатюрную сеть взаимосвязанных документов.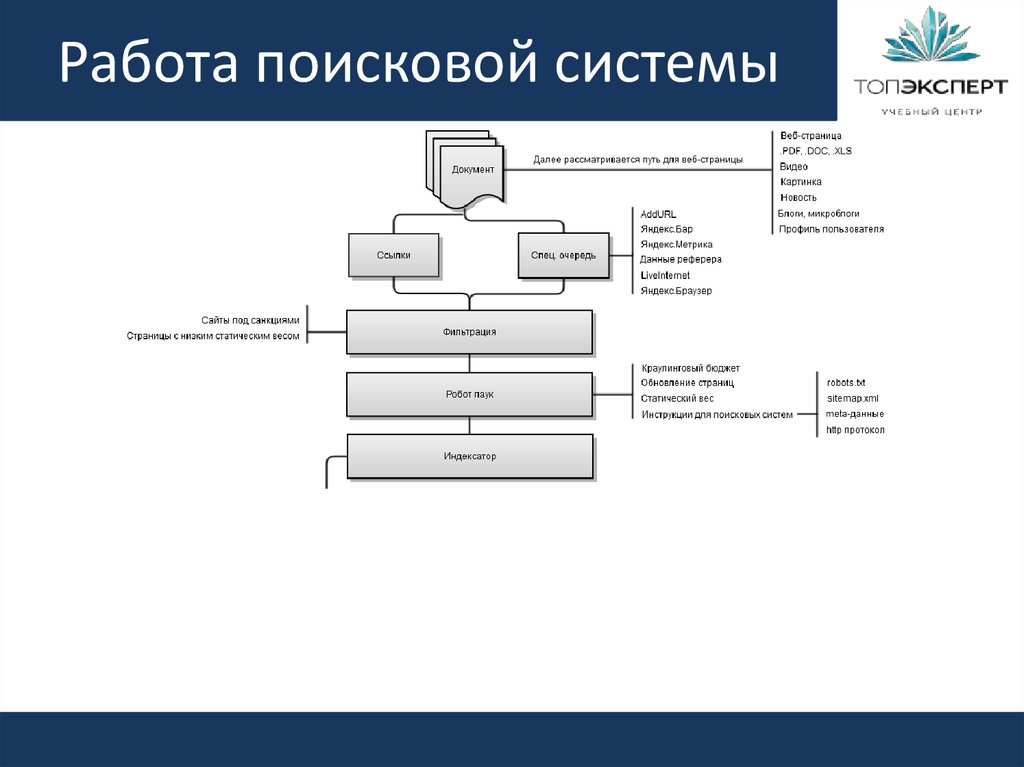
Внутренние ссылки соединяют страницы, которые связаны друг с другом и существуют в одном и том же домене, но сила Интернета больше связана с внешними ссылками. Внешние ссылки создают соединения с веб-страницами, которые существуют и работают за пределами одной организации. Они помогают стать частью сети из миллиардов страниц, существующих в Интернете.
Причины использования внешней ссылки могут быть разными. Возможно, вы включаете статистику в статью и хотите указать ссылку на источник данных на другом веб-сайте. Это не только повышает доверие к тому, что вы публикуете, но также способствует расширению сети Интернета.
Что делает поисковая система
Поисковые системы выполняют 3 основные задачи:
- Сканирование
- Индексация
- Доставка результатов поиска
Проще говоря, сканирование — это доступ к веб-страницам в Интернете. Индексация — это извлечение смысла из содержимого веб-страниц и построение между ними реляционной базы данных. Предоставление результатов поиска означает интерпретацию поискового запроса пользователя, а затем предоставление результатов из индекса, которые лучше всего отвечают на этот запрос.
Предоставление результатов поиска означает интерпретацию поискового запроса пользователя, а затем предоставление результатов из индекса, которые лучше всего отвечают на этот запрос.
Как работает сканирование
Сканирование URL-адресов — это задача, выполняемая компьютерной программой, известной как сканер или паук. Работа сканера заключается в посещении веб-страниц и извлечении найденного HTML-контента. Одна из основных вещей, которую ищет сканер, — это ссылки.
Каждая веб-страница имеет единственный уникальный идентификатор — URL-адрес. Введите URL-адрес в адресную строку браузера, и вы перейдете на веб-страницу. Сами веб-страницы состоят из контента, размеченного в HTML.
HTML является машиночитаемым языком, поэтому внешняя программа, такая как поисковый робот, может посетить URL-адрес, извлечь HTML-код и получить доступ к содержимому в структурированном виде. Важно отметить, что он может различать текст и гиперссылки.
Когда поисковые роботы проверяют HTML-код такой страницы, которая содержит статью, которую вы читаете, они обнаружат, что каждый абзац смещен фрагментом кода, называемым элементом абзаца или тегом p, в начале и в конце.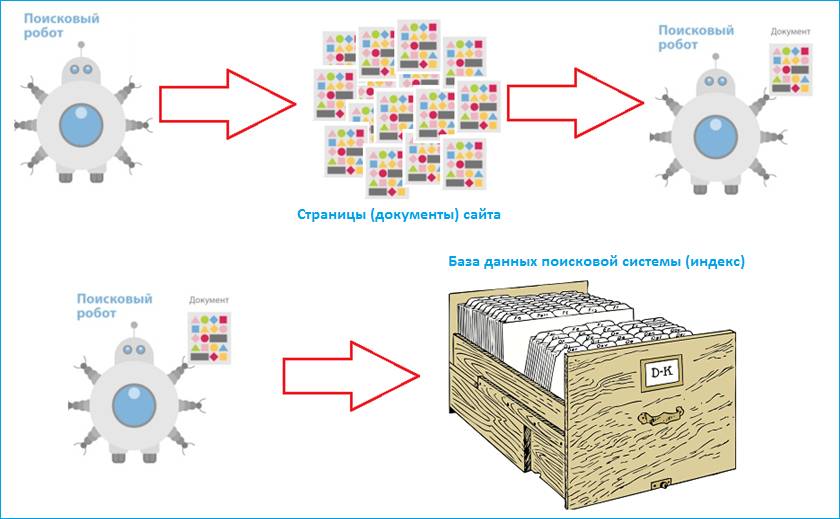 . Идентифицирует блок текста абзаца — тег p в начале открывает элемент абзаца, а тег p в конце закрывает его. Хотя вы не видите этот код, если не просматриваете страницу, сканер видит его и понимает, что эта страница содержит текстовый контент, предназначенный для чтения посетителями.
. Идентифицирует блок текста абзаца — тег p в начале открывает элемент абзаца, а тег p в конце закрывает его. Хотя вы не видите этот код, если не просматриваете страницу, сканер видит его и понимает, что эта страница содержит текстовый контент, предназначенный для чтения посетителями.
Ссылки также видны и интерпретируются поисковыми роботами из-за их HTML-кода. Программисты кодируют ссылки с элементом привязки в начале и в конце. Ссылки также включают «атрибут», указывающий место назначения гиперссылки, и «якорный текст». Якорный текст — это связанный текст, видимый читателям, часто отображаемый в браузерах синим цветом с подчеркиванием.
Поисковый робот может легко обработать этот блок HTML и отделить текст от ссылки. Однако на одной веб-странице есть гораздо больше, чем абзац и ссылка. Чтобы увидеть такие данные самостоятельно, посетите любую веб-страницу в своем браузере, щелкните правой кнопкой мыши в любом месте экрана, затем нажмите «Просмотреть исходный код» или «Просмотреть исходный код страницы». На большинстве страниц вы найдете сотни строк кода.
На большинстве страниц вы найдете сотни строк кода.
Для каждой веб-страницы, которую обнаруживает сканер, он анализирует HTML, что означает, что он разбивает HTML на составные части для дальнейшей обработки. Сканер извлекает все ссылки, которые он находит на данной странице, а затем планирует их сканирование. По сути, он создает небольшую петлю обратной связи:
Сканировать URL → Найти ссылки на URL → Запланировать URL для сканирования → Сканировать URL продолжайте, пока он не перестанет находить новые URL-адреса для сканирования — это могут быть тысячи или даже миллионы URL-адресов позже.
Короче говоря, сканирование — это метод обнаружения. Поисковые системы определяют, что там есть, отправляя поисковые роботы для поиска веб-страниц, используя ссылки в качестве указателей для следующего места для поиска.
Вот почему так важны внутренние ссылки на вашем веб-сайте, поскольку они позволяют поисковым роботам обнаруживать все страницы вашего сайта. По внешним ссылкам они откроют для себя другие веб-сайты, изучая сеть взаимосвязанных страниц, составляющих Интернет.
Как работает индексация
Когда поисковые системы сканируют Интернет, они создают репозиторий найденных веб-страниц, которые затем используют для создания своего индекса.
Подумайте об указателе, который вы могли найти в конце учебника, когда учились в школе. Если вы хотите узнать о клеточной структуре, вы можете заглянуть в указатель книги по биологии и найти страницы по этой теме. Индексация веб-страниц работает аналогичным образом.
Индекс полезен, поскольку он позволяет выполнять быстрый поиск. Поисковым системам, таким как Google, также нужен быстрый способ получения информации и предоставления результатов поиска, поэтому индексирование имеет решающее значение.
Поисковые системы берут каждую просматриваемую веб-страницу и анализируют HTML-документ, чтобы отделить все ссылки. Они делают это, чтобы хранить целевой URL-адрес, на который указывает каждая ссылка, вместе с используемым якорным текстом. Точно так же они берут все найденное текстовое содержимое и разбивают его на набор вхождений слов.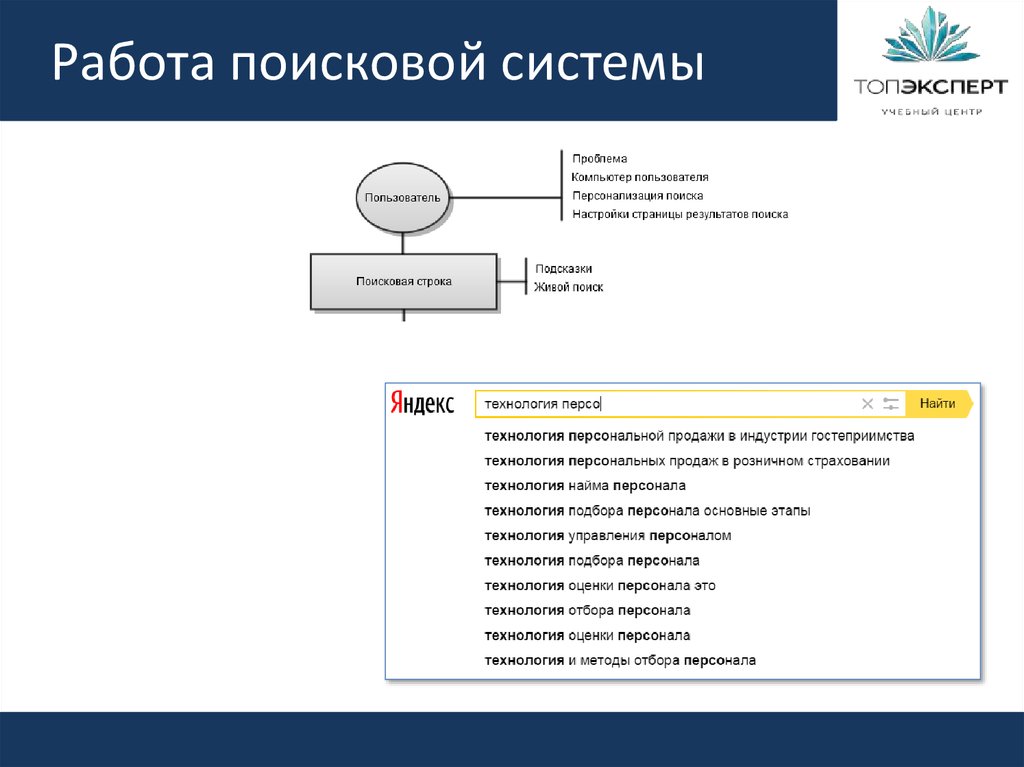
Используя эти проанализированные данные, они создают инвертированный индекс, назначая URL-адрес веб-страницы каждому слову на странице. Как только они сохраняют URL-адрес таким образом, он индексируется. Это означает, что он потенциально может быть в наборе результатов поиска.
Для каждого проиндексированного URL-адреса поисковые системы сохраняют столько взаимосвязей между словом и URL-адресом, сколько они считают релевантным, вместе с другими связанными метаданными, которые они собрали о странице. Это данные, которые они используют при определении того, какие URL-адреса отображаются в результатах поиска.
Как доставляются результаты поиска
Сканирование и индексирование происходят автоматически и постоянно. Индекс обновляется в режиме реального времени. Этот сбор и хранение данных выполняются сами по себе, в фоновом режиме, и на них не влияют пользователи, вводящие запросы.
Однако предоставление результатов поиска полностью зависит от пользовательского ввода через его поисковые запросы. Если кто-то ищет «лучший сервис потокового телевидения», поисковая система сопоставляет каждое слово с документами в своем индексе.
Если кто-то ищет «лучший сервис потокового телевидения», поисковая система сопоставляет каждое слово с документами в своем индексе.
Но простое сопоставление слов с проиндексированными страницами приводит к миллиардам документов, поэтому им нужно определить, как сначала показать вам лучшие совпадения. Вот где все становится сложно — и вот почему SEO так важно. Как поисковые системы решают из миллиардов потенциальных результатов, какие показывать? Они используют алгоритм ранжирования.
Алгоритмы — это набор правил, которым следуют компьютерные программы для выполнения определенного процесса. Алгоритм ранжирования — это большое количество алгоритмов и процессов, работающих в унисон.
Алгоритм ранжирования ищет следующие факторы:
- Все ли слова в поисковом запросе появляются на странице?
- Появляются ли на странице определенные сочетания слов (например, «лучший» и «потоковое»)?
- Отображаются ли слова в заголовке страницы?
- Присутствуют ли слова в URL-адресе страницы?
Это основные примеры, и есть сотни других факторов, которые алгоритм ранжирования учитывает при определении того, какие результаты показывать.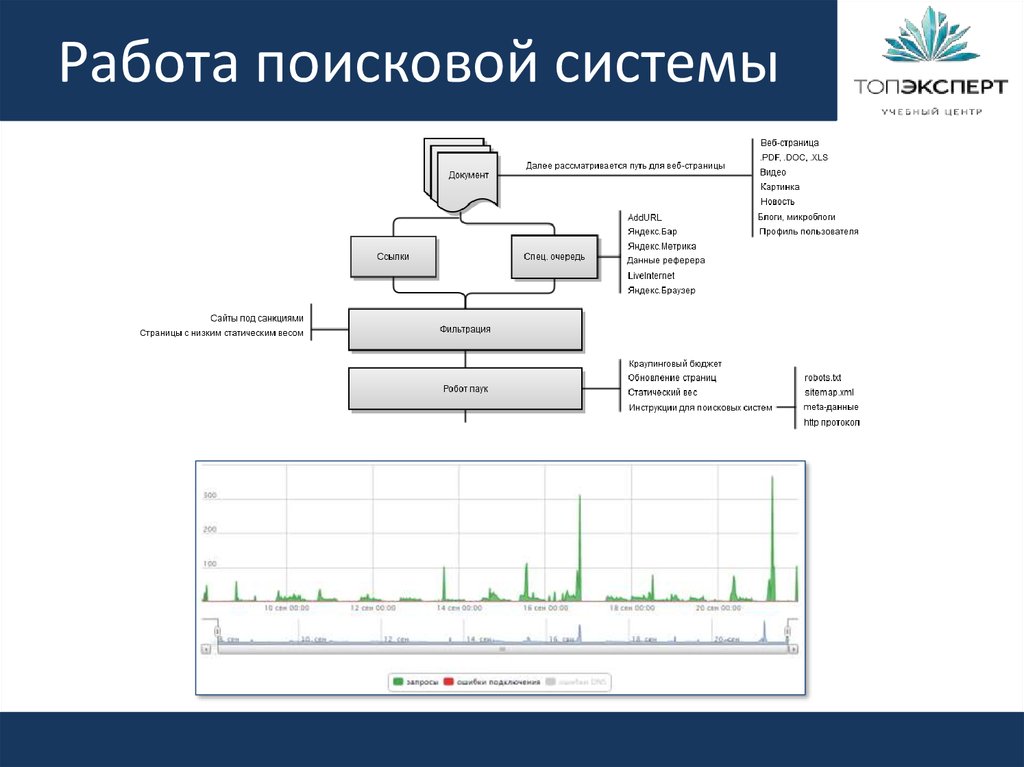 Это факторы ранжирования.
Это факторы ранжирования.
Причина, по которой Google стал доминирующей поисковой системой в мире, проста: его алгоритм ранжирования был лучше, чем алгоритмы ранжирования его конкурентов.
Разбираемся в сложности
Поисковые системы — чрезвычайно сложные структуры, которые ежедневно обрабатывают невообразимые объемы данных. Они применяют сложные алгоритмы, чтобы разобраться в этих данных и удовлетворить запросы пользователей.
Тысячи лучших в мире инженеров-программистов работают над еще более детальными уточнениями и улучшениями, что возлагает на такие компании, как Google, ответственность за продвижение одних из самых сложных технологий на планете.
Такие технологии, как машинное обучение, искусственный интеллект и обработка естественного языка, будут по-прежнему оказывать большее влияние на предоставление результатов поиска. Вам не нужно понимать всю сложность, но, применяя ряд основных передовых методов, вы можете сделать свой веб-сайт доступным для поиска по словам и фразам, которые ищут ваши клиенты.