
Поисковые системы
Поиско́вая систе́ма — программно-аппаратный комплекс с веб-интерфейсом, предоставляющий возможность поиска информации в интернете.
Все поисковые системы объединяет то, что они расположены на специально-выделенных мощных серверах и привязаны к эффективным каналам связи. Поисковые системы называют еще информационно-поисковыми системами (ИПС). Количество одновременно обслуживаемых посетителей наиболее популярных систем достигает многих тысяч. Самые известные обслуживают в сутки миллионы клиентов. В случаях, когда поисковая система имеет в своей основе каталог, она называется каталогом. В ее основе лежит работа модераторов. В основе же ИПС с полнотекстовым поиском лежит автоматический сбор информации. Он осуществляется специальными программами. Эти программы периодически исследуют содержимое всех ресурсов Интернета. Для этого они перемещаются, или как говорят, ползают, по разным ресурсам. Соответственно такие программы называются роботы. Есть и другие названия: поскольку WWW – это аббревиатура выражения Всемирная паутина, то такую программу естественно назвать спайдером по англ. – паук. В последнее время используются другие названия: автоматические индексы или директории. Все эти программы исследуют и «скачивают» информацию с разных URL-адресов. Программы указанного типа посещают каждый ресурс через определенное время. Ни одна поисковая система не в состоянии проиндексировать весь Интернет. Поэтому БД, в которых собраны адреса проиндексированных ресурсов, у разных поисковых систем разные. Тем не менее, многие из них стремятся, по возможности, охватывать в своей работе все пространство мировой Сети.
Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос. На основании запроса пользователя поисковая система генерируетстраницу результатов поиска. Такая поисковая выдача может сочетать различные типы файлов, например: веб-страницы, изображения, видеофайлы. Некоторые поисковые системы также извлекают данные из баз данных икаталогов ресурсов в Интернете.
По методам поиска и обслуживания разделяют четыре типа поисковых систем:
1.системы использующие поисковых роботов.
2.системы управляемые человеком
3.гибридные системы
4.мета-системы.
В архитектуру поисковой системы включены: поисковый робот сканирующий сайты сети Интернет, индексатор обеспечивающий быстрый поиск, и поисковик — графический интерфейс для работы пользователя.
Цель поисковой системы заключается в том, чтобы находить документы, содержащие либо ключевые слова, либо слова как-либо связанные с ключевыми словами. Поисковая система тем лучше, чем больше документов релевантных запросу пользователя она будет возвращать.
Примеры поисковых систем
Google— одна из самых полных и популярных зарубежных ИПС. Отличительной особенностью ИПС Google является технология определения степени релевантности документа путем анализа ссылок других источников на данный ресурс. Чем больше ссылок на какую-либо страницу имеется на других страницах, тем выше ее рейтинг в ИПС Google. Google использует алгоритм расчёта авторитетности PageRank. PageRank является одним из вспомогательных факторов приранжированиисайтов в результатах поиска. PageRank не единственный, но очень важный способ определенияположения сайтав результатах поиска Google. Google использует показатель PageRank найденных по запросу страниц, чтобы определить порядок выдачи этих страниц посетителю в результатах поиска.В 2010 году компания запустила голосовой поиск в России. Чтобы осуществить поиск, необходимо нажать в телефоне кнопку рядом со строкой поиска и произнести свой запрос, телефон отправит ваш голос на сервер, и браузер выдаст строку с распознанным вашим запросом и результатами поиска по нему.
Яndex – самая популярная в настоящее время отечественная поисковая система. Начала работу в 1997 г. Она поддерживает собственный каталог Интернет-ресурсов. Также является лучшей поисковой системой для выявления иллюстраций. Англоязычный вариант снабжен справочником ресурсов Интернет. Обладает развернутой системой формирования запроса. В частности, допускается ввод поискового предписания на естественном языке — в этом случае все необходимые расширения производятся автоматически.
Помимо веб-страниц в формате HTML, Яндекс индексирует документы в форматах PDF (Adobe Acrobat), Rich Text Format (RTF), двоичных форматах Word (.doc), Excel (.xls), PowerPoint(.ppt), RSS(блоги и форумы).
Поисковая система компании Mail.ruначала работать в 2007 году. Объем индексного файла весной 2009 г. составлял более 1.5 миллиарда страниц, расположенных на русскоязычных серверах. Помимо разыскания текстов, системой осуществляется поиск иллюстраций и видеофрагментов, размещенных на специализированных «самонаполняемых» российских серверах: Фото@Mail.Ru, Flamber.Ru, 35Photo.ru, PhotoForum.ru, Видео@Mail.Ru, RuTube, Loadup, Rambler Vision и им подобных. Gogo.ru позволяет ограничивать область поиска сайтами коммерческой направленности, информационными сайтами, а также форумами и блогами. Форма «Расширенного поиска» также дает возможность ограничить разыскания определенными типами файлов (PDF, DOC, XLS, PPT), местом положения искомых слов в документе или определенным доменом. В ноябре 2013 в Google Play появилась новая версия поискового приложения от компании Mail.Ru, позволяющего переходить с главного экрана в любые социальные сети и содержащего быстрый доступ к поиску по картинам, видео и новостям. Android-приложение превратилось в мини-браузер, заточенный под эффективный поиск нужной информации. Утилита также научилась распознавать поисковые запросы, заданные не текстом, а голосом. Разработчики также отмечают, что создали специальный виджет, который можно поместить на главный экран смартфона или планшета на базе системы Google Android. Подразумевается, что это позволит еще сильнее сократить время, затрачиваемое на поиск.
AltaVista– одна из старейших поисковых систем занимает одно из первых мест по объему документов – более 350 миллионов. AltaVista позволяет осуществлять простой и расширенный поиск. «Help» позволяет даже неподготовленным пользователям правильно составлять простые и сложные запросы.
Rambler – одна из первых российских ИПС, открыта в 1996 году. В конце 2002 года была произведена коренная модернизация, после которой Rambler вновь вошел в группу лидеров сетевого поиска. В настоящее время объем индекса составляет порядка 150 миллионов документов. Для составления сложных запросов рекомендуется использовать режим «Детальный запрос», который предоставляет широкие возможности для составления поискового предписания с помощью пунктов меню.
АПОРТ. На сегодняшний день объем ее базы составляет более 20 миллионов документов. Система обладает широким спектром поисковых возможностей. АПОРТ обладает функцией встроенного переводчика, это дает пользователю возможность формулировать запросы, как на русском, так и на английском языках. Кроме того, АПОРТ имеет специальные режимы для поиска иллюстраций и аудио файлов.
Поисковые механизмы последнего поколения индексируют все слова на web-странице или в статье из конференции, в то время как ранее область индексирования ограничивалась как правило названием, заголовками, первыми несколькими строками и адресом документа. Это существенно ограничивало возможность выявления материалов по узкой тематике, поскольку результаты поиска не всегда отражали реально существующие данные. Устранив этот недостаток, современные поисковые системы стали намного более надежными, чем их предшественники.
Следующая важнейшая черта — совершенствование внутреннего поискового механизма, выражающееся в увеличении числа операторов и других элементов составления запросов. Несколько лет назад применение находили только два, в лучшем случае, три классических булевых оператора: AND (и), OR (или) и NOT (не). Теперь появились NEAR (рядом, около) в Alta Vista и FOLLOWED BY (следует за) в OpenText — в высшей степени полезные операторы расстояния, которые дают возможность в максимальной степени конкретизировать запрос. Многие системы позволяют усекать окончания терминов, ограничивать поиск по дате создания документа, искать ключевые слова только в обозначенных элементах web-страниц (названии, заголовках, электронном адресе и т.д.), а также вести разыскание на точное словосочетание. Новейшие разработки также позволяют выявлять файлы определенного вида (например графические или аудио) и обладают чувствительностью к строчным и заглавным буквам. Общепринятой становится возможность искать данные на любых языках. Все это дает возможность составлять поисковое предписание с большой степенью точности, что конечно же повышает релевантность получаемых результатов.
На данный момент самые популярные поисковики Google и Яндекс, сравним их:
Количество проиндексированных страниц. У Google 8 миллиардов, а у Яндекса всего 2 миллиарда. То есть, в четыре раза меньше. Победа за Google.
Скорость индексации страниц. Google индексирует новые страницы в течение суток, тогда как Яндексу на это может потребоваться несколько дней. Опять побеждает Google.
Релевантность выдачи. Под релевантностью понимается соответствие результатов, отображенных на странице поисковика, вашему запросу. Сразу скажу, победителя тут сложно определить. Google показал хорошие результаты в зарубежном сегменте интернета, зато в Рунете, Яндекс всегда был немного впереди.
- Дополнительные интернет сервисы. Тут преимущество однозначно за Яндексом. У него есть десятки разнообразных сервисов, которые удобно сгруппированы по категориям, тогда как у Google их поменьше, плюс есть интеграция с социальной сетью Google+, которая многим не нравится.
studfile.net
Поисковые системы мира [14 лучших поисковиков]
Что такое поисковая система
Поисковая система (или «поисковик») – это специальная компьютерная система, которая разработана и предназначена для поиска необходимой информации, соответственно поисковым запросам пользователей.
Ключевой параметр работы поисковых систем – запрос. Именно в соответсвии с поисковыми запросами поисковики мира выдают пользователям нужную информацию посредством генерации поисковой выдачи.
Чтобы точно отвечать на как можно большее количество запросов пользователей, поисковые боты (например, «Googlebot») выполняют 3 обязательных этапа.
- Сканируют страницы. Следят, какие новые страницы / сайты появляются, и как обновляются старые.
- Индексируют страницы. Распознают содержание страницы и добавляют их в свою огромную базу данных.
- Ранжируют страницы. В зависимости от запроса пользователя, поисковая система генерирует выдачу, произведя отбор лучших результатов из своей базы по определенному алгоритму.
Полезный материал: Как работает Google Поиск
Если вы создали сайт, и хотите, чтобы ваша аудитория вас нашла и выбрала среди конкурентов, вам нужно выполнить ряд правил. В разных поисковых системах они могут отличатся в деталях, но основные принципы работы похожие.
Как вывести сайт в ТОП Google?
Запустите бесплатный аудит сайта и узнайте, какие страницы вы закрыли от Google и какие технические ошибки отдаляют вас от ТОПа
Согласно данным Statcounter за май 2019 года, Google занимает 92.04% рынка поисковых систем. Эти данные не включают социальные сети (Facebook, YouTube, Twitter и т.д.).
Google старается дать наилучший ответ на запрос пользователя. Именно с этой целью и происходит регулярная эволюция его алгоритмов. Но этот процесс завел Google к интересному результату.
Часто факторы связанные с авторитетом домена, трастом сайта, количеством обратных ссылок имеют большее значение, чем ценность информации для пользователя. Как результат, сайты, которые лучше отвечают на запрос пользователя, но не обладают большим «авторитетом» в глазах поисковой системы, остаются вне внимания пользователя. Удивительно, но одна из самых инновационных компаний в мире делает свои алгоритмы консервативнее. Продвинутые пользователи (как читатели, так и авторы контента) замечают это и их всё больше раздражает монополия Google среди поисковых систем.
Кроме того, многие знают, что Google детально отслеживает каждый шаг пользователя. Кроме понимания, как улучшать свои продукты, это также дает возможность Google создавать лучшие условия для таргетинга в рекламной системе Google Ads. Кто-то из нас не обращает на это внимания. Но все больше растет количество пользователей, которые хотят использовать поисковые системы без рекламных объявлений, или же искать информацию по другим алгоритмам. К счастью, существует множество альтернатив для Google. Каждая из них имеет определенные преимущества и особые сферы применения.
Важно уточнить, что данная статья создана не для того, чтобы занизить значение гугла в глазах активных пользователей всей сети. Её цель, лишь показать большое количество инструментов и вариантов поиска информации, которые сейчас существуют. Google не был первопроходцем на рынке поисковых систем, но он (а именно Сергей Брин и Ларри Пейдж) создал самый совершенный для своего времени алгоритм ранжирования сайтов. И на протяжении всей истории развития рынка поисковых систем, он определял и определяет правила игры на этом рынке.
Bing
Bing является самой популярной поисковой системой после Google (Yahoo был выкуплен компанией Microsoft в 2009 году). Это единственная поисковая система Microsoft, которая была разработана специально для систем Windows.
У Bing есть отличные возможности поиска видео, которые даже лучше, чем у Google. Здесь больше параметров автозаполнения, при введении запросов пользователя. Он отслеживает больше взаимосвязей между отдельными веб-сайтами, и благодаря этому поиск в интернете похожих вариантов упрощается.
Yandex
Яндекс – одна из наиболее популярных поисковых систем в России. Обычно пользователи называют Яндекс российским аналогом Google, поскольку у него похожий интерфейс и дополнительные сервисы. Этот сервис известен хорошо продуманным логическим алгоритмом, который распределяет результаты с некоторыми дополнительными функциями. Сейчас, известно, что Яндекс лучше понимает смысл текста. Молодой сайт, который продвигается в СНГ, может достигнуть ТОПа в Яндексе значительно быстрее, чем в поисковой выдаче Google. Но только в том случае, если упор сделан на качество контента и удобство сайта, а не на ссылки.
DuckDuckGo
DuckDuckGo – еще один популярный вариант поиска, который предустановлен в некоторых популярных браузерах (например Firefox). Это один из лучших вариантов для тех, кто не хочет, чтобы их данные отслеживались. Обычно DuckDuckGo противопоставляется Google, который похож на «Большого брата» и следит за каждым шагом пользователя.
Boardreader
Boardreader понравится тем, кто интересуется необычными поисковыми системами. Он разработан как простая доска объявлений и ищет результаты исключительно на форумах по всему миру, где реальные люди делятся своим опытом по указанной теме.
Dogpile
Dogpile – настоящий комбайн для сбора данных, поскольку он сканирует результаты поиска трех популярных поисковых систем (Google, Yandex и Yahoo), и выбирает лучшие результаты из каждой. Простота интерфейса и отсутствие рекламных объявлений позволяет лучше сосредоточиться на поиске.
Creative Commons Search
Creative Commons Search или в сокращенном варианте CC Search – уникальная анонимная поисковая система. Она дает возможность получать авторские материалы с правами для повторного использования в личных целях. Если вы планируете создать персональную веб-страницу, CC Search станет отличным местом для сбора дизайнерских материалов.
Giphy
Giphy – идеальная поисковая система для тех, кто увлечен анимационными картинками в формате GIF. Она была специально разработана для поиска миниатюрных видеороликов. Здесь можно получить много положительных эмоций, при поиске смешных котят или веселых ситуаций с бесконечным повторением.
Quora
Quora больше похожа на информационный портал, чем на поисковую систему. Здесь можно общаться с людьми на разнообразные темы и получать ответы на важные вопросы от пользователей по всему миру. Более того, на сайте есть специальная категория тематических вопросов, которые задавались раньше. Русскоязычным аналогом такого сервиса является Thequestion. У них разный дизайн и структура, но суть одна – пользователь хочет получить лучший ответ на свой вопрос от реальных людей.
Vimeo
YouTube – это подразделение Google, наполненное множеством рекламных объявлений. Vimeo – популярная альтернатива, которая очень удобна для использования и построена на простой системе обмена видео. Самое лучшее в этом сервисе – полное отсутствие рекламы и большой выбор HD-видео.
WolframAlpha
WolframAlpha вероятнее всего понравится компьютерным гикам. Выделяющийся дизайн, большое количество дополнительных функций, свои нестандартные алгоритмы поиска.
StartPage
StartPage – еще один анонимный сервис для людей, которые помешаны на своей конфиденциальности и негативно воспринимают политику передачи секретных данных Google для коммерческого использования. Он не только позволит провести абсолютно безопасный поиск, но также скроет ваши данные, такие как IP и MAC-адреса. Это позволяет заходить на любые веб-сайты через специальный прокси-сервер и не оставлять следов присутствия пользователя на сайтах.
Ask.com
Ask.com – сервис, который объединяет все популярные поисковые системы и генерирует специальные тематические страницы, где пользователи могут добавлять в закладки наиболее интересные результаты поиска. Кроме того, здесь вы можете попросить людей о дополнительном совете.
SlideShare станет отличным источником для поиска полезных материалов: презентаций, инфографик, документов. У этого сайта есть неограниченная база презентаций, которая доступна для всех зарегистрированных пользователей (и она постоянно обновляется).
sitechecker.pro
Поисковые системы Интернета: Яндекс, Google, Rambler, Yahoo — информация, принципы работы
1. Введение
2. Понятие и функции поисковой системы
3. Основные характеристики поисковой системы
4. Краткая история развития поисковых систем
5. Состав и принципы работы поисковой системы
6. Заключение
1. Введение
Поисковые системы уже давно стали неотъемлемой частью российского Интернета. Поисковые системы сейчас – это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации, но и заманчивые сферы для бизнеса.
Большинство пользователей поисковых систем никогда не задумывались (либо задумывались, но не нашли ответа) о принципе работы поисковых систем, о схеме обрабатки запросов пользователей, о том, из чего эти системы состоят и как функционируют…
Данный мастер-класс призван дать ответ на вопрос о том, как работают поисковые системы. Однако, Вы не найдете здесь факторов, влияющих на ранжирование документов. И тем более не стоит рассчитывать на подробное объяснение алгоритма работы Яндекса. Его, по словам Ильи Сегаловича, — директора по технологиям и разработке поисковой машины «Яндекс», можно узнать, лишь «под пыткой» самого Ильи Сегаловича…
2. Понятие и функции поисковой системы
Поисковая система — это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
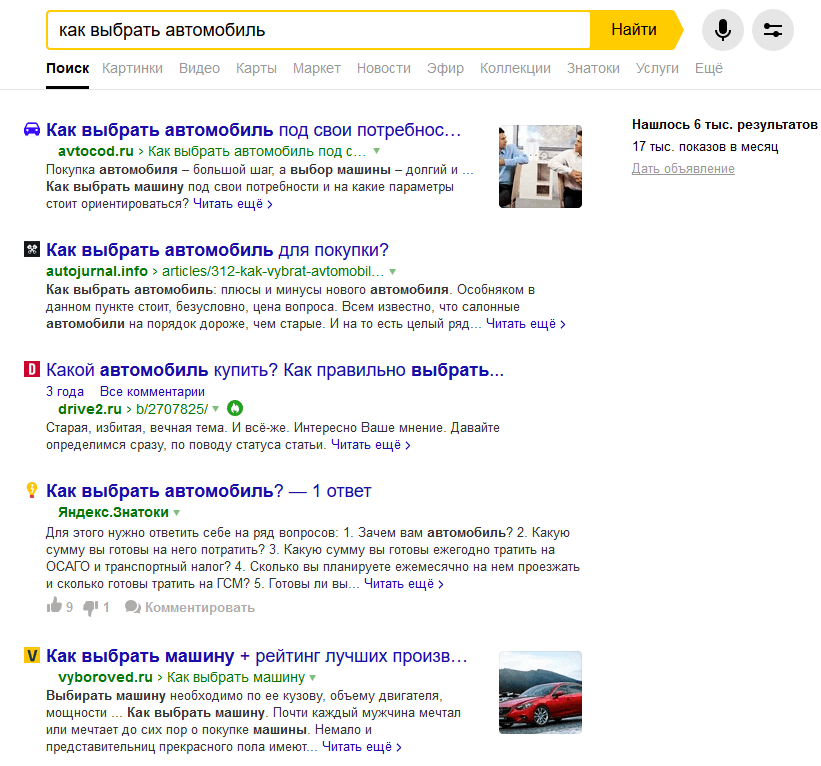
Рассмотрим подробнее понятие поискового запроса на примере поисковой системы «Яндекс». Поисковый запрос должен быть сформулирован пользователем в соответствии с тем, что он хочет найти, максимально кратко и просто. Допустим, мы хотим найти информацию в «Яндексе» о том, как выбрать автомобиль. Для этого, открываем главную страницу «Яндекса», и вводим текст поискового запроса «как выбрать автомобиль». Далее, наша задача сводится к тому, чтобы открыть предоставленные по нашему запросу ссылки на источники информации в Интернет. Однако, вполне можно и не найти нужную нам информацию. Если таковое произошло, то либо нужно перефразировать свой запрос, либо в базе поисковой системе действительно нет никакой актуальной информации по нашему запросу (такое может быть при задании очень «узких» запросов, как, например «как выбрать автомобиль в Архангельске»)
Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. А научить пользователей делать «правильные» запросы к системе, т.е. запросы, соответствующие принципам работы поисковых систем, невозможно. Поэтому разработчики создают такие алгоритмы и принципы работы поисковых систем, которые бы позволяли находить пользователям искомую ими информацию.
 Это означает, поисковая система должна «думать» так же, как думает пользователь при поиске информации. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Это означает, поисковая система должна «думать» так же, как думает пользователь при поиске информации. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?Для того, чтобы удовлетворить ответами все эти вопросы, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции и возможности, всячески пытаются ускорить работу системы.
3. Основные характеристики поисковой системы
Опишем основные характеристики поисковых систем:
- Полнота
Полнота — одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
- Точность
Точность — еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
- Актуальность
Актуальность — не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
- Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
- Наглядность
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска. Подробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http://help.yandex.ru/search/?id=481937.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google — самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные поисковые системы (международные) – Google, Yahoo и MSN, имеющие собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее — Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
- URL страницы
- дата, когда страница была скачана
- http-заголовок ответа сервера
- тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) — программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
- Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
- Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
- В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
- Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
- Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
По информации ООО «Рамблер Интернет Холдинг» обработка поискового запроса в системе «Рамблер» происходит, так, как это изображено на рисунке.

Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня — frontend (1.1 — 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2.1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
На текущий момент в поиск включено 77 backend’ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend’ах первой группы (5.1.1 — 5.1.11 на рис), оранжевый сектор — на backend’ах второй группы (5.2.1 — 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend’ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин «быстрой базы». Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend’ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим — с 6.1, четвертым — с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
При написании мастер-класса были использованы материалы и данные ООО «Рамблер Интернет Холдинг», RuSeo.info
6. Заключение
Теперь подытожим все вышесказанное.
- Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут.
- Основные характеристики поисковых систем:
- Полнота
- Точность
- Актуальность
- Скорость поиска
- Наглядность
- Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
- В состав поисковой системы входят компоненты:
- Модуль индексирования
- База данных
- Поисковый сервер
Надеемся, наш мастер-класс позволит Вам поближе ознакомиться с понятием ПС, лучше узнать основные функции, характеристики и принцип работы поисковых систем.
www.seonews.ru
Поисковые системы Интернета, список Топ 14 лучших поисковиков
Мы рассмотрим поисковые системы Интернета, список лучших поисковиков в этой статье. Возможно Вы ещё новичок и не определились, какую именно поисковую систему использовать для поиска информации и работы в Интернете. С помощью этого обзора, Вы точно будете знать, какой поисковик лучше.
Что такое поисковая система в Интернете
 Здравствуйте друзья! Существуют огромное количество поисковых систем в Интернете. Они исполняют только одну цель – поиск той или иной информации в Сети. В основном новички ещё не знают, что такое поисковая система в Интернете. Поэтому, подробно об этом расскажу.
Здравствуйте друзья! Существуют огромное количество поисковых систем в Интернете. Они исполняют только одну цель – поиск той или иной информации в Сети. В основном новички ещё не знают, что такое поисковая система в Интернете. Поэтому, подробно об этом расскажу.
Поисковая система – это программно-аппаратный комплекс для поиска различной информации (текст, видео, музыка, картинки, книги). Функции этой системы предназначены для поиска нужной информации, для любого пользователя Интернета.
Например, человек хочет найти какую-нибудь книгу. И вводит поисковый запрос в поисковой строке – «Скачать книги бесплатно». Так же можно написать её название. После этого, мы как обычно нажимаем «Enter» или на значок поиска «Найти» (Скрин 1).

Результат поиска нам выдал 12 000 000 результатов. Выбирать можно любой из них. Вот именно так и работает поисковая система. Дальше, мы будем рассматривать поисковые системы Интернета, список по рейтингу всех основных поисковых систем. Для безопасной работы в Сети, вероятно Вас могут заинтересовать несколько поисковиков, которые будут служить Вам для удобной и комфортной работы в Интернете.
к оглавлению ↑Поисковые системы Интернета, список 2019 года
Перед тем, как пополнить поисковые систем списком, сделаем для начала небольшой обзор на топ 14 лучших поисковых систем 2019 года.
- Поисковая система Google. Она является самой популярной и известной во всём мире в том числе США и Европе.
- Поиск Яндекс. Эта российская поисковая система. В основном она имеет популярность в русскоязычном Интернете.
- Bing. Данный поиск в Интернете был разработан компанией Майкрософт. Его часто используют в США, Германии, и в Китае.
- Поисковик Yahoo. Данная поисковая «машина» Интернета не так популярна в России, как например в странах Индии, США, Индонезии и так далее.
- Китайская поисковая система Baidu. Этим поисковиком пользуются только китайцы. Поскольку у него полностью отсутствует перевод на русский язык.
Низкие по рейтингу поисковые системы
- AOL. Название данного поисковика Америка Онлайн. Это американский поисковик.
- ASK.COM. Такая поисковая система, немного похожа на ресурс Ответы Мейл ру. Только в виде ответов выдаёт полноценные статьи.
- EXCITE. Эта поисковая система, включает в себя не только поиск, но и различные сервисы. Например, Новости, погода, с помощью него можно узнать в какие страны ездят отдыхать и так далее.
- DuckDuckGo. Такая поисковая система позволяет пользователям «сидеть в Интернете» в приватной зоне.
- WOLFRAM ALPHA. Данный поисковик очень хорошо подойдёт студентам. Поскольку он выдаёт информацию на основе различных знаний и поможет Вам написать студенческие работы.
- Спутник. Поисковая система в основном предназначена для поиска в Рунете. Она потеряла свою популярность, поскольку ею никто не пользуется. Но со временем, на неё должны перейти государственные служащие.
- TUT BY. Поисковик относится к белорусской поисковой системе.
- Рамблер. Это встроенный поисковик в систему поиска Яндекса.
- MIL.RU. Русскоязычная поисковая система. Она популярна и её посещают не более чем 54 000 000 пользователей Рунета.
Итак, мы рассмотрели лучшие поисковые системы Интернета, список, которых Вы можете посмотреть здесь (Скрин 2).

Далее, мы эти поисковые системы разберём ещё подробнее.
к оглавлению ↑Обзор поисковых систем Интернета
Выше мы сделали небольшое описание поисковых систем. А здесь, хотелось бы Вам рассказать о них немного подробно. Когда их создали, и какие у них плюсы и минусы:
- Google. Эта поисковая система была создана в США в 1998 году. Её создали программисты Сергей Брин и Ларри Пейдж. Сейчас она включает в себя более 25 миллиардов веб-сайтов и её используют 200 миллионов пользователей из разных стран мира. Плюсы этой поисковой системы в том, что можно найти качественную информацию быстрее, чем не качественную. Минусы – нагрузка на компьютер, так как частое обновление Гугла нагружает оперативную память компьютера.
- ЯНДЕКС. Её создали в 1997 году. Создатели этой поисковой системы – Аркадий Волож и Илья Сегалович. Занимает второе место по популярности в России. Плюсов у этой системы много и из них – использование электронной почты, кошелька Яндекс деньги, и быстрый доступ к любой информации. Компания установила фильтры поиска, но это не спасает пользователей посещать сомнительные сайты в Интернете. Это один главный минус и недостаток этого поисковика.
- YAHOO. Поисковик является более старым из всех поисковых систем, которые мы рассматриваем. Его создание принято считать в 1995 году, предпринимателями Джерри Янгом и Дэвидом Филом. Он является достаточно крупным Интернет порталом и у него есть только один минус – не устанавливается на компьютер, а используется через браузер.
- MAIL.RU. Эту поисковую систему организовали в 1998 году. Её авторы и создатели – Евгений Голанд и Владимир Шутов. Этот портал принадлежит крупной компании – Мейл Ру Групп. Так же включает в себя популярные проекты: Одноклассники, Вконтакте, Мой мир. Пользоваться этим поисковиком удобно. Но минусы в том, что электронная почта от Мейл не имеет хорошей защиты от взлома и нередко браузеры заражаются вирусной рекламой от этой системы.
- BING. Она была создана в 2009 году. Эта поисковая система работает, как на компьютерах, так и на Смартфонах. В большинстве случаев, ей выгодно пользоваться на телефонах, это считается её главным преимуществом.
Менее популярные поисковые системы
- DUCKDUCK.GO. Наличие поисковика на компьютере, позволит Вам использовать его в полной мере и вместе с этим сохранить свои конфиденциальные данные. Её создал предприниматель Гэбриель Вайнберг в 2006 году. Эта система не сохраняет во время поиска кэш и историю браузера.
- СПУТНИК. Как было уже сказано выше, это поисковая система пока ещё не всеми используется. Её создали в 2014 году, и создателем считают компанию Ростелеком. Эту поисковую систему, планирует использовать государство.
- РАМБЛЕР. Самый известный в Рунете поисковый портал. Создатель портала Дмитрий Крюков – 1996 год. Он существовал до 2011 года, и сейчас по-прежнему работает в полной мере, как поисковая система.
- BAIDU. Данную китайскую поисковую систему основали в 2000 году, предприниматели – Робин Ли и Эрик Сю. Этим поисковиком пользуется только китайское население. К нему очень негативное отношение во многих странах из-за рекламного вируса и нет возможности перевода языка.
- TUT BY. Данная поисковая система была создана в Белоруссии в 2000 году. Его основал журналист Сергей Дмитриев. Посещаемость поисковика уже превышает более 2 000 000 пользователей в этой стране.
Известные поисковики за рубежом
- AOL (Американская поисковая система). Была разработана в США в 90-е годы. У неё довольно слабая популярность среди пользователей. Работают с поисковиком, в основном, жители Америки.
- ASK.COM. Создание поисковой системы принято считать в 1995 году. Чтобы пользоваться этой системой, достаточно лишь внести в поисковую строку какой-либо вопрос, и она выдаст результаты. Её поиск распределяет результаты по порядку, и всегда можно найти необходимую информацию и качественную.
- ECITE. Данная поисковая машина, особо ничем от других не отличается. Сайт был запущен в 1994 году и в данный момент принадлежит компании IAC Search Media. Этот сервис может предлагать пользователям различную информацию в виде обмена быстрыми сообщениями, отправка писем по электронной почте, и имеет полную настройку домашней страницы в браузере.
- Wolfram Alpha. Он был запущен в Интернет – 15 мая 2009 года. Имеет огромную базу знаний, и мощные вычислительные алгоритмы для нахождения этой информации в поиске.
Итак, эти поисковые системы на сегодняшний день самые лучшие. Думаю, Вы сможете выбрать для себя подходящий вариант. Часто приходиться использовать несколько поисковиков для эффективного поиска нужной информации.
к оглавлению ↑Заключение
В статье мы рассмотрели вопрос, какие есть поисковые системы Интернета, список этих поисковых систем в том числе. Возможно Вы заинтересуетесь одной из них, или будете использовать несколько. Выбирайте только те, которые имеют защиту и приватные настройки. Ведь работа и поиск в Интернете должны быть максимально безопасны. Спасибо и удачи!
С уважением, Иван Кунпан.
Просмотров: 6073
Получайте новые статьи блога прямо себе на почту. Заполните форму, нажмите кнопку «Подписаться»
Вы можете почитать:
biz-iskun.ru
Поисковые машины | Поисковые системы
Одним из основных способов найти информацию в Internet являются поисковые машины. Поисковые машины каждый день «ползают» по Сети: они посещают веб-страницы и заносят их в гигантские базы данных. Это позволяет пользователю набрать некоторые ключевые слова, нажать «submit» и увидеть, какие страницы удовлетворяют его запросу.
Понимание того как работают поисковые машины просто необходимо вебмастерам. Для них жизненно важна правильная с точки зрения поисковых машин структура документов и всего сервера или сайта. Без этого документы будут недостаточно часто появляться в ответ на запросы пользователей к поисковой машине или даже вовсе могут быть не проиндексированы.
Вебмастера желают повысить рейтинг своих страниц и это понятно: ведь на любой запрос к поисковой машине могут быть выданы сотни и тысячи отвечающих ему ссылок на документы. В большинстве случаев только 10 первых ссылок обладают достаточной релевантностью к запросу.
Естественно, хочется, чтобы документ оказался в первой десятке, поскольку большинство пользователей редко просматривает следующие за первой десяткой ссылки. Иными словами, если ссылка на документ будет одиннадцатой, то это также плохо, как если бы ее не было вовсе.
Какие из сотен поисковых машин действительно важны для вебмастера? Ну, разумеется, широко известные и часто используемые. Но при этом следует учесть ту аудиторию, на которую рассчитан Ваш сервер. Например, если Ваш сервер содержит узкоспециальную информацию о новейших методах доения коров, то вряд ли Вам стоит уповать на поисковые системы общего назначения. В этом случае я посоветовал бы обменяться ссылками с Вашими коллегами, которые занимаются сходными вопросами 🙂 Итак, для начала определимся с терминологией.
Существует два вида информационных баз данных о веб-страницах: поисковые машины и каталоги.
Поисковые машины: (spiders, crawlers) постоянно исследуют Сеть с целью пополнения своих баз данных документов. Обычно это не требует никаких усилий со стороны человека. Примером может быть поисковая система Altavista.
Для поисковых систем довольно важна конструкция каждого документа. Большое значение имеют title, meta-таги и содержимое страницы.
Каталоги: в отличие от поисковых машин в каталог информация заносится по инициативе человека. Добавляемая страница должна быть жестко привязана к принятым в каталоге категориям. Примером каталога может служить Yahoo. Конструкция страниц значения не имеет. Далее речь пойдет в основном о поисковых машинах.
Altavista
Система открыта в декабре 1995. Принадлежит компании DEC. С 1996 года сотрудничает с Yahoo.
Excite Search
Запущенная в конце 1995 года, система быстро развивалась. В июле 1996 куплена Magellan, в сентябре 1996 — приобретена WebCrawler. Однако, оба используют ее отдельно друг от друга. Возможно в будущем они будут работать вместе.
Существует в этой системе и каталог — Excite Reviews. Попасть в этот каталог — удача, поскольку далеко не все сайты туда заносятся. Однако информация из этого каталога не используется поисковой машиной по умолчанию, зато есть возможность проверить ее после просмотра результатов поиска.
HotBot
Запущена в мае 1996. Принадлежит компании Wired. Базируется на технологии поисковой машины Berkeley Inktomi.
InfoSeek
Запущена чуть раньше 1995 года, широко известна, прекрасно ищет и легко доступна. В настоящее время «Ultrasmart/Ultraseek» содержит порядка 50 миллионов URL.
Опция для поиска по умолчанию Ultrasmart. В этом случае поиск производится по обоим каталогам. При опции Ultraseek результаты запроса выдаются без дополнительной информации. Поистине новая поисковая технология также позволяет облегчить поиски и множество других особенностей, которые Вы можете прочитать об InfoSeek. Существует отдельный от поисковой машины каталог InfoSeek Select.
Lycos
Примерно с мая 1994 года работает одна из старейших поисковых систем Lycos. Широко известная и часто используемая. В ее состав входит поисковая машина Point (работает с 1995 года) и каталог A2Z (работает с февраля 1996 года).
OpenText
Система OpenText появилась чуть раньше 1995 года. С июня 1996 года стала партнерствовать с Yahoo. Постепенно теряет свои позиции и вскоре перестанет входить в число основных поисковых систем.
WebCrawler
Открыта 20 апреля 1994 года как исследовательский проект Вашингтонского Университета. В марте 1995 года была приобретена компанией America Online Существует каталог WebCrawler Select.
Yahoo
Старейший каталог Yahoo был запущен в начале 1994 года. Широко известен, часто используем и наиболее уважаем. В марте 1996 запущен еще один каталог Yahoo — Yahooligans для детей. Появляются все новые и новые региональные и top-каталоги Yahoo.
Поскольку Yahoo основан на подписке пользователей, в нем может не быть некоторых сайтов. Если поиск по Yahoo не дал подходящих результатов, пользователи могут воспользоваться поисковой машиной. Это делается очень просто. Когда делается запрос к Yahoo, каталог переправляет его к любой из основных поисковых машин. Первыми ссылками в списке удовлетворяющих запросу адресов идут адреса из каталога, а затем идут адреса, полученные от поисковых машин, в частности от Altavista.
Каждая поисковая машина обладает рядом особенностей. Эти особенности следует учитывать при изготовлении своих страниц.
Тип поисковой машины
«Полнотекстовые» поисковые машины индексируют каждое слово на веб-странице, исключая лишь некоторые стоп-слова. «Абстрактные» поисковые машины создают некий экстракт каждой страницы.
Для вебмастеров полнотекстовые машины полезней, поскольку любое слово, встречающееся на веб-странице, подвергается анализу при определении его релевантности к запросам пользователей. Однако для абстрактных поисковых машин может случиться, что страницы проиндексированы лучше, чем для полнотекстовых. Это может исходить от алгоритма экстрагирования, например по частоте употребления в странице одних и тех же слов.
Размер
Размер поисковой машины определяется количеством проиндексированных страниц. Например, в поисковой машине с большим размером могут быть проиндексированы почти все ваши страницы, при среднем объеме ваш сервер может быть частично проиндексирован, а при малом объеме ваши страницы могут вообще не попасть в каталоги поисковой машины.
Период обновления
- некоторые поисковые машины сразу индексируют страницу по запросу пользователя, а затем продолжают индексировать еще не проиндексированные страницы
- другие чаще могут «ползать» по наиболее популярным страницам сети, чем по другим
Дата индексирования документа
Некоторые поисковые машины показывают дату, когда был проиндексирован тот или иной документ. Это помогает пользователю понять, какой «свежести» ссылку выдает поисковая система. Другие оставляют пользователям только догадываться об этом.
Указанные (submitted) страницы
В идеале поисковые машины должны найти любые страницы любого сервера в результате прохода по ссылкам. Реальная картина выглядит по-другому. Станицы серверов гораздо раньше появляются в индексах поисковых систем, если их прямо указать (Add URL).
Не указанные (non-submitted) страницы
Если хотя бы одна страница сервера указана, то поисковые машины обязательно найдут следующие страницы по ссылкам из указанной. Однако на это требуется больше времени. Некоторые машины сразу индексируют весь сервер, но большинство все-таки, записав указанную страницу в индекс, оставляют индексирование сервера на будущее.
Глубина индексирования
Этот параметр относится только к не указанным страницам. Он показывает сколько страниц после указанной будет индексировать поисковая система.
Большинство крупных машин не имеют ограничений по глубине индексирования. На практике же это не совсем так. Вот несколько причин, по которым могут быть проиндексированы не все страницы:
- не слишком аккуратное использование фреймовых структур (без дублирования ссылок в управляющем (frameset) файле)
- использование imagemap без дублирования их обычными ссылками
Поддержка фреймов
Если поисковый робот не умеет работать с фреймовыми структурами, то многие структуры с фреймами будут упущены при индексировании.
Поддержка ImageMap
Тут примерно та же проблема, что и с фреймовыми структурами серверов.
Защищенные паролями директории и сервера
Некоторые поисковые машины могут индексировать такие сервера, если им указать Username и Password. Зачем это нужно? Чтобы пользователи видели, что есть на Вашем сервере. Это позволяет как минимум узнать, что такая информация есть, и, быть может, они тогда подпишутся на Вашу информацию.
Частота появления ссылок
Основные поисковые машины могут определить популярность документа по тому, как часто на него ссылаются из других мест Сети. Некоторые машины на основании таких данных «делают вывод» стоит или не стоит тратить время на индексирование такого документа.
Способность к обучению
Если сервер обновляется часто, то поисковая машина чаще будет его реиндексировать, если редко — реже.
Контроль индексации
Показывает, какими средствами можно управлять той или иной поисковой машиной. Все крупные поисковые машины руководствуются предписаниями файла robots.txt. Некоторые также поддерживают контроль с помощью META-тагов из самих индексируемых документов.
Перенаправление (redirect)
Некоторые сайты перенаправляют посетителей с одного сервера на другой, и этот параметр показывает какой URL будет связан с вашими документами. Это важно, поскольку, если поисковая машина не отрабатывает перенаправление, то могут возникнуть проблемы с несуществующими файлами.
Стоп-слова
Некоторые поисковые машины не включают определенные слова в свои индексы или могут не включать эти слова в запросы пользователей. Такими словами обычно считаются предлоги или просто очень часто использующиеся слова. А не включают их ради экономии места на носителях. Например, Altavista игнорирует слово web и для запросов типа web developer будут выданы ссылки только по второму слову. Существуют способы избежать подобного.
Влияние на алгоритм определения релевантности
Поисковые машины обязательно используют расположение и частоту повторения ключевых слов в документе. Однако, дополнительные механизмы увеличения степени релевантности для каждой машины различны. Этот параметр показывает, какие именно механизмы существуют для той или иной машины.
Spam-штрафы
Все крупные поисковые системы «не любят», когда какой-либо сайт пытается повысить свой рейтинг путем, например, многократного указания себя через Add URL или многократного упоминания одного и того же ключевого слова и т. д. В большинстве случаев подобные действия (spamming, stacking) караются, и рейтинг сайта наоборот падает.
Поддержка META-тагов
По идее, все поисковые машины должны учитывать метаданные при индексации страниц, однако на практике не все это делают.
Title
Этот параметр показывает как поисковые машины генерируют заголовки ссылок для пользователя в ответ на его запрос.
Description
Этот параметр показывает как поисковые машины генерируют описания ссылок для пользователя в ответ на его запрос.
Проверка статуса URL
Очень полезная для вебмастера черта поисковой машины — можно ли проверить насколько глубоко проиндексирован его сервер и есть ли он вообще в индексе поисковой машины.
Удаление старых данных
Параметр, определяющий действия вебмастера при закрытии сервера или перемещении его на другой адрес. Возможны два действия: просто удалить старое содержание и переписать файл robots.txt.
- удаление содержимого: когда поисковая машина попытается реиндексировать документы и не найдет их, старые ссылки в индексе будут удалены. В этом случае все зависит от периода обновления данных для поисковой машины.
- robots.txt: когда поисковая машина запросит этот файл и «увидит», что сервер весь закрыт от индексации, то все ссылки на файлы этого сервера будут удалены из индекса.
www.internet-technologies.ru
Поисковые системы: состав, функции, принципы работы.
Поисковая система — это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Опишем основные характеристики поисковых систем:
Полнота — одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
Точность — еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
Актуальность — не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.одробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http://help.yandex.ru/search/?id=481937.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google — самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные международные поисковые системы – Google, Yahoo и MSN, имеющих собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее — Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
URL страницы
дата, когда страница была скачана
http-заголовок ответа сервера
тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) — программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
Ни одна поисковая система не охватывает все ресурсы Интернет.
Каждая поисковая система собирает сведения о ресурсах Интернет, применяя свои уникальные методы, и формирует собственную периодически обновляемую базу данных. Доступ к этой базе предоставляется пользователю.
Поисковые системы реализуют два способа поиска ресурса:
Поиск по тематическим каталогам — информация представляется в виде иерархической структуры. На верхнем уровне — общие категории (“Интернет”, “Бизнес”, “Искусство”, “Образование” и т.д.), на следующем уровне категории делятся на разделы и т.д. Самый нижний уровень — ссылки на конкретные веб-страницы или другие информационные ресурсы.
Поиск по ключевым словам (индексный поиск или детальный) — пользователь отправляет поисковой системе запрос, состоящий из ключевых слов. Система возвращает пользователю перечень найденных по запросу ресурсов.
Большинство поисковых систем сочетают оба способа поиска.
Поисковые системы могут быть локальными, глобальными, региональными и специализированными.
В русской части Интернет (Рунет) наиболее популярны сейчас поисковые системы общего назначения Rambler (www.rambler.ru), Яндекс (www.yandex.ru), Апорт (www.aport.ru), Гугл (www.google.ru).
Большинство поисковых систем реализовано в виде порталов.
Портал (от англ. portal — главный вход, ворота) -это веб-сайт, который интегрирует различные сервисы Интернет: средства поиска, почту, новости, словари и т.д.
Порталы могут быть специализированными (как, www.museum.ru) и общими (например, www.km.ru).
Поиск по ключевым словам
Набор ключевых слов, по которым ведется поиск, называют также критерием поиска или темой поиска.
Запрос может состоять как из одного слова, так и из сочетания слов, объединенных операторами — символами, по которым система определяет, какое действие ей нужно произвести. Например: запрос “Москва Питер” содержит оператор И (так воспринимается пробел), который указывает, что надо искать документы, в которых есть оба слова — и Москва, и Питер.
Для того, чтобы поиск был релевантным (от англ. relevant -уместный, относящийся к делу), следует учитывать несколько общих правил:
Независимо от того, в какой форме употреблено слово в запросе, поиск учитывает все его словоформы по правилам русского языка. Например, по запросу “билет” будут найдены и слова “билетом”, “билету” и т.д.
Заглавные буквы следует использовать только в именах собственных, чтобы не просматривать лишние ссылки. По запросу “кузнецов”, например, будут найдены документы, где говорится и о кузнецах, и о Кузнецовых.
Желательно сужать круг поиска, используя несколько ключевых слов.
Если нужного адреса нет среди первой двадцатки найденных адресов, следует изменить запрос.
Если по запросу не найдено ни одной ссылки, прежде чем менять запрос, надо проверить орфографию.
Каждая поисковая система использует свой язык запросов. Для знакомства с ним, пользуйтесь встроенной справкой поисковой системы
Крупные сайты могут иметь встроенные системы поиска информации в пределах своих веб-страниц.
Запросы в подобных системах поиска, как правило, строятся по тем же правилам, что и в глобальных поисковых системах, однако знакомство со справкой и здесь не будет лишним.
Расширенный поиск
Поисковые системы могут предоставлять в распоряжение пользователя механизм, позволяющий формировать сложный запрос. Переход по ссылке Расширенный поиск дает возможность редактировать параметры поиска, указывать дополнительные параметры и выбирать наиболее удобную форму показа результатов поиска. Ниже описаны параметры, которые могут быть заданы при расширенном поиске в системах Япс1ех и Rambler.
Описание параметра | Название в Яндекс | Название в Rambler |
Где искать ключевые слова (заголовок документа, основной текст и т.д.) | Словарный фильтр | Поиск по тексту … |
Какие слова должны или не должны присутствовать в документе и насколько точным должно быть совпадение | Словарный фильтр | Искать слова запроса… Исключить документы, содержащие следующие слова… |
На каком расстоянии друг от друга должны располагаться ключевые слова | Словарный фильтр | Расстояние между словами запроса… |
Ограничение на дату документа | Дата | Дата документа… |
Ограничение поиска пределами одного или нескольких сайтов | Сайт/Вершина | Искать документы только на следующих сайтах… |
Поиск страниц со ссылками на определенный сайт и исключение из поиска страниц со ссылками на определенный сайт | Ссылка | |
Ограничение поиска по языку документа | Язык | Язык документа… |
Поиск документов, содержащих картинку с определенным именем или подписью | Изображение | |
Поиск страниц, содержащих объекты | Специальные объекты | |
Форма представления результатов поиска | Формат выдачи | Вывод результатов поиска |
Некоторые поисковые системы (например, Яндекс) позволяют вводить запросы на естественном языке. Вы пишите, что нужно найти (например: заказ билетов на поезд из Москвы в Питер). Система анализирует запрос и выдает результат. Если он Вас не устраивает, переходите на язык запросов.
studfile.net
Поисковые системы: состав, функции, принципы работы.
Поисковая система — это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт».
Опишем основные характеристики поисковых систем:
Полнота — одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
Точность — еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5). Чем точнее поиск, тем быстрее пользователь найдет нужные ему документы, тем меньше различного рода «мусора» среди них будет встречаться, тем реже найденные документы не будут соответствовать запросу.
Актуальность — не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
Скорость поиска тесно связана с его устойчивостью к нагрузкам. Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.одробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http://help.yandex.ru/search/?id=481937.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google — самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные международные поисковые системы – Google, Yahoo и MSN, имеющих собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее — Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
URL страницы
дата, когда страница была скачана
http-заголовок ответа сервера
тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) — программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).
Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
Ни одна поисковая система не охватывает все ресурсы Интернет.
Каждая поисковая система собирает сведения о ресурсах Интернет, применяя свои уникальные методы, и формирует собственную периодически обновляемую базу данных. Доступ к этой базе предоставляется пользователю.
Поисковые системы реализуют два способа поиска ресурса:
Поиск по тематическим каталогам — информация представляется в виде иерархической структуры. На верхнем уровне — общие категории (“Интернет”, “Бизнес”, “Искусство”, “Образование” и т.д.), на следующем уровне категории делятся на разделы и т.д. Самый нижний уровень — ссылки на конкретные веб-страницы или другие информационные ресурсы.
Поиск по ключевым словам (индексный поиск или детальный) — пользователь отправляет поисковой системе запрос, состоящий из ключевых слов. Система возвращает пользователю перечень найденных по запросу ресурсов.
Большинство поисковых систем сочетают оба способа поиска.
Поисковые системы могут быть локальными, глобальными, региональными и специализированными.
В русской части Интернет (Рунет) наиболее популярны сейчас поисковые системы общего назначения Rambler (www.rambler.ru), Яндекс (www.yandex.ru), Апорт (www.aport.ru), Гугл (www.google.ru).
Большинство поисковых систем реализовано в виде порталов.
Портал (от англ. portal — главный вход, ворота) -это веб-сайт, который интегрирует различные сервисы Интернет: средства поиска, почту, новости, словари и т.д.
Порталы могут быть специализированными (как, www.museum.ru) и общими (например, www.km.ru).
Поиск по ключевым словам
Набор ключевых слов, по которым ведется поиск, называют также критерием поиска или темой поиска.
Запрос может состоять как из одного слова, так и из сочетания слов, объединенных операторами — символами, по которым система определяет, какое действие ей нужно произвести. Например: запрос “Москва Питер” содержит оператор И (так воспринимается пробел), который указывает, что надо искать документы, в которых есть оба слова — и Москва, и Питер.
Для того, чтобы поиск был релевантным (от англ. relevant -уместный, относящийся к делу), следует учитывать несколько общих правил:
Независимо от того, в какой форме употреблено слово в запросе, поиск учитывает все его словоформы по правилам русского языка. Например, по запросу “билет” будут найдены и слова “билетом”, “билету” и т.д.
Заглавные буквы следует использовать только в именах собственных, чтобы не просматривать лишние ссылки. По запросу “кузнецов”, например, будут найдены документы, где говорится и о кузнецах, и о Кузнецовых.
Желательно сужать круг поиска, используя несколько ключевых слов.
Если нужного адреса нет среди первой двадцатки найденных адресов, следует изменить запрос.
Если по запросу не найдено ни одной ссылки, прежде чем менять запрос, надо проверить орфографию.
Каждая поисковая система использует свой язык запросов. Для знакомства с ним, пользуйтесь встроенной справкой поисковой системы
Крупные сайты могут иметь встроенные системы поиска информации в пределах своих веб-страниц.
Запросы в подобных системах поиска, как правило, строятся по тем же правилам, что и в глобальных поисковых системах, однако знакомство со справкой и здесь не будет лишним.
Расширенный поиск
Поисковые системы могут предоставлять в распоряжение пользователя механизм, позволяющий формировать сложный запрос. Переход по ссылке Расширенный поиск дает возможность редактировать параметры поиска, указывать дополнительные параметры и выбирать наиболее удобную форму показа результатов поиска. Ниже описаны параметры, которые могут быть заданы при расширенном поиске в системах Япс1ех и Rambler.
Описание параметра | Название в Яндекс | Название в Rambler |
Где искать ключевые слова (заголовок документа, основной текст и т.д.) | Словарный фильтр | Поиск по тексту … |
Какие слова должны или не должны присутствовать в документе и насколько точным должно быть совпадение | Словарный фильтр | Искать слова запроса… Исключить документы, содержащие следующие слова… |
На каком расстоянии друг от друга должны располагаться ключевые слова | Словарный фильтр | Расстояние между словами запроса… |
Ограничение на дату документа | Дата | Дата документа… |
Ограничение поиска пределами одного или нескольких сайтов | Сайт/Вершина | Искать документы только на следующих сайтах… |
Поиск страниц со ссылками на определенный сайт и исключение из поиска страниц со ссылками на определенный сайт | Ссылка | |
Ограничение поиска по языку документа | Язык | Язык документа… |
Поиск документов, содержащих картинку с определенным именем или подписью | Изображение | |
Поиск страниц, содержащих объекты | Специальные объекты | |
Форма представления результатов поиска | Формат выдачи | Вывод результатов поиска |
Некоторые поисковые системы (например, Яндекс) позволяют вводить запросы на естественном языке. Вы пишите, что нужно найти (например: заказ билетов на поезд из Москвы в Питер). Система анализирует запрос и выдает результат. Если он Вас не устраивает, переходите на язык запросов.
studfile.net