10.1.3. Язык запросов. Яндекс для всех
10.1.3. Язык запросов. Яндекс для всехВикиЧтение
Яндекс для всех
Абрамзон М. Г.
Содержание
10.1.3. Язык запросов
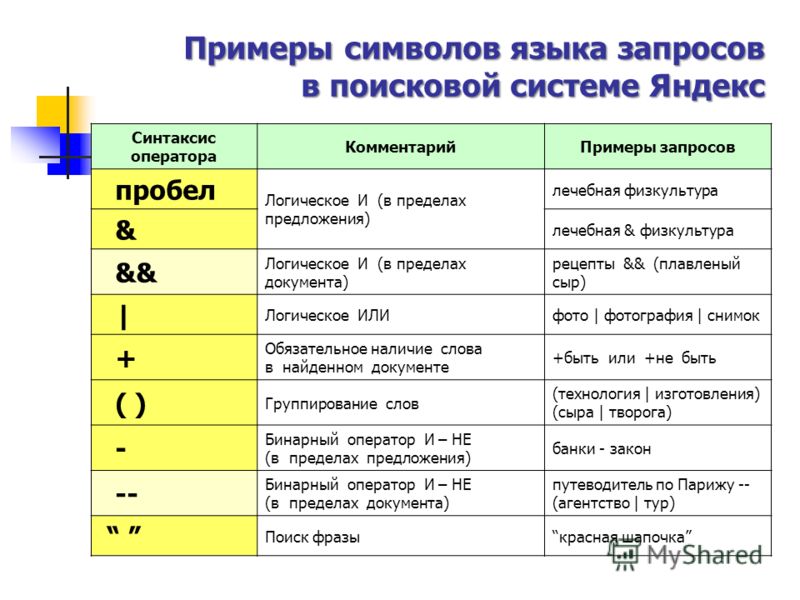
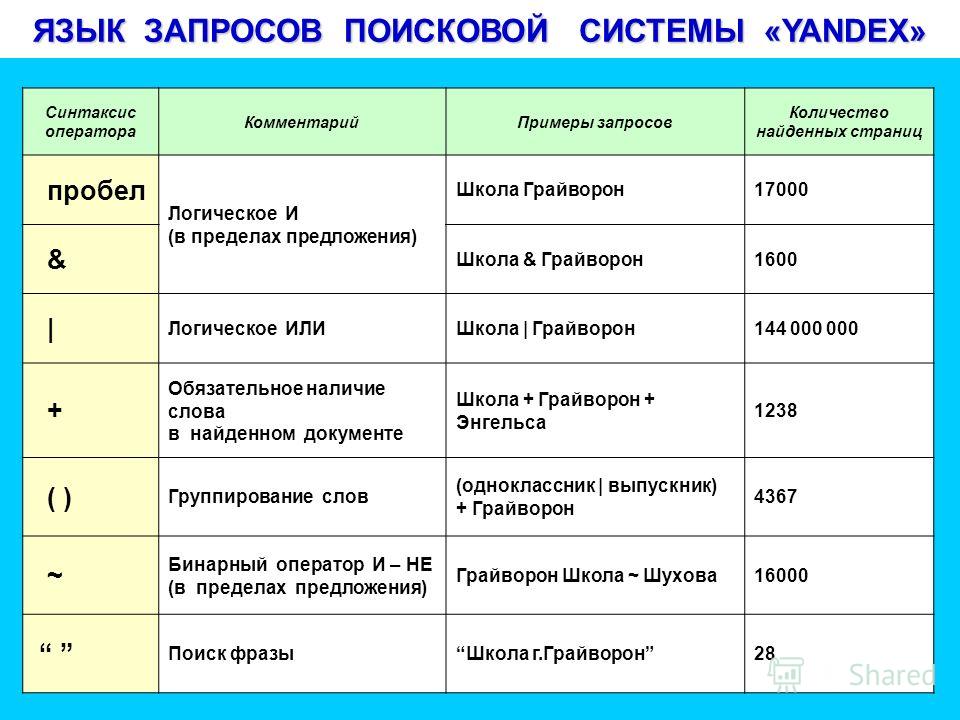
Язык запросов, используемый в Яndex.Server, в полной мере соответствует языку запросов, с которым работает поисковая система Яндекс. Поэтому все, что можно использовать для поиска в Интернете, новостях, среди картинок, поддерживается и в версии программы, предназначенной для установки на сайте. Такой подход удобен для пользователей — если он знаком с возможностями формирования запросов на Яндексе, то без проблем сможет искать информацию и на вашем сайте.
Задавать вопросы можно и на естественном языке, и используя логические операторы (расширенные возможности Яндекса). Часть расширенных возможностей реализована в виде поисковой страницы, на которую можно перейти по ссылке Расширенный поиск

С заданием запросов на естественном языке справится любой, поэтому здесь остановимся кратко на использовании логических операторов, позволяющих в одном запросе задать несколько условий поиска. Такой вариант удобен, когда есть возможность выделить для запроса ключевые слова, определить возможные синонимы, задать слова, которые не должны попадать в результаты.
Языковый модуль, входящий в состав программы, обеспечивает поиск всех форм заданного слова. Но если требуется найти документы, в которые входят лишь точная форма слова в запросе, перед этим словом в запросе нужно поставить восклицательный знак. Два восклицательных знака действуют иначе — ведется поиск всех производных слов от заданного.
Как и в поиске на Яндексе, здесь также поддерживается поиск синонимов, поиск слов, находящихся на определенном расстоянии друг от друга, поиск словосочетаний.
Поиск в зонах документа и их атрибутах будет полезен, на мой взгляд, в первую очередь даже не для посетителей вашего сайта.
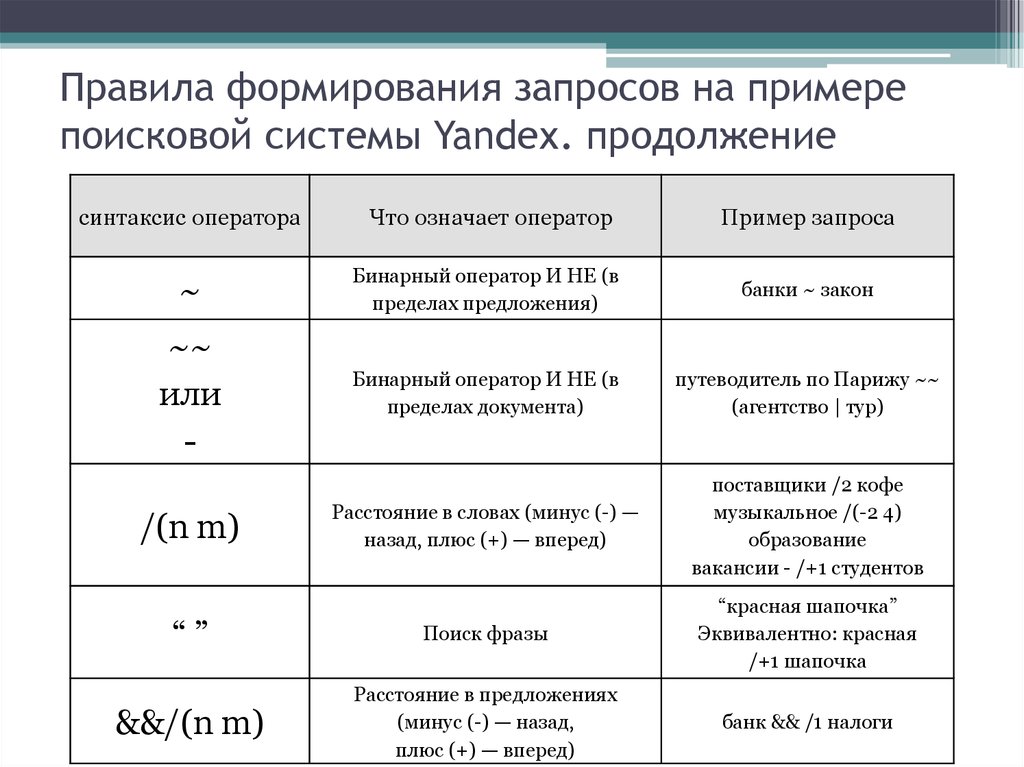
В отличие от других правил формирования запросов, операторы зонноатрибутивного поиска зависят от настроек, примененных при создании индексных файлов. А именно, в них используются имена поисковых зон и атрибутов, заданные в конфигурационных файлах парсеров. Имена документных атрибутов также могут быть заданы в конфигурационном файле источника данных. В табл. 10.3 приведено краткое описание операторов запросов, связанных с поиском по зонам и атрибутам.
И последнее, что связано с языком запросов. Формирование списка результатов выполняется с учетом релевантности найденного документа поисковому запросу. Релевантность определяется по сложным формулам и зависит от множества факторов, в том числе от частотных характеристик слов в поисковом выражении, веса слова или выражения, близости слов в тексте документа.
Вес слова или выражения определяется числом. Это число ставится через двоеточие после слова (или выражения) в строке запроса. Например, если поисковый запрос выглядит так: экспериментальные:4 модели, то? хотя будут найдены те же документы, что и по запросу экспериментальные модели, но вот в начало списка будут выведены те результаты (документы), в которых слово «экспериментальные» встречается чаще.
Аналогично, если в запрос будет добавлено уточняющее слово, то в начало списка результатов будут выведены те документы, которые содержат как основное слово или выражение, так и уточняющее.
Данный текст является ознакомительным фрагментом.
Очереди запросов
Очереди запросов
Для блочных устройств поддерживаются очереди запросов (request queue), в которых хранятся ожидающие запросы на выполнение операций блочного ввода-вывода. Очередь запросов представляется с помощью структуры request_queue, которая определена в файле <linux/blkdev.h>.
Очередь запросов представляется с помощью структуры request_queue, которая определена в файле <linux/blkdev.h>.
Количество DNS-запросов
Количество DNS-запросов Система DNS устанавливает соответствие имен хостов их IP-адресам, точно так же как телефонный справочник позволяет узнать номер человека по его имени. Когда вы набираете «www.yahoo.com» в адресной строке браузера, преобразователь DNS, к которому обратился
Обработка запросов с помощью PHP
Обработка запросов с помощью PHP Основы клиент-серверных технологийВ самом начале курса мы уже говорили о том, что PHP – это скриптовый язык, обрабатываемый сервером. Сейчас мы хотим уточнить, что же такое сервер, какие функции он выполняет и какие вообще бывают серверы.
Предсказывающий регулятор запросов
Предсказывающий регулятор запросов
В большинстве реляционных баз данных присутствует регулятор запросов (query governor) гарантирующий, что единичный запрос не будет выполняться слишком долго.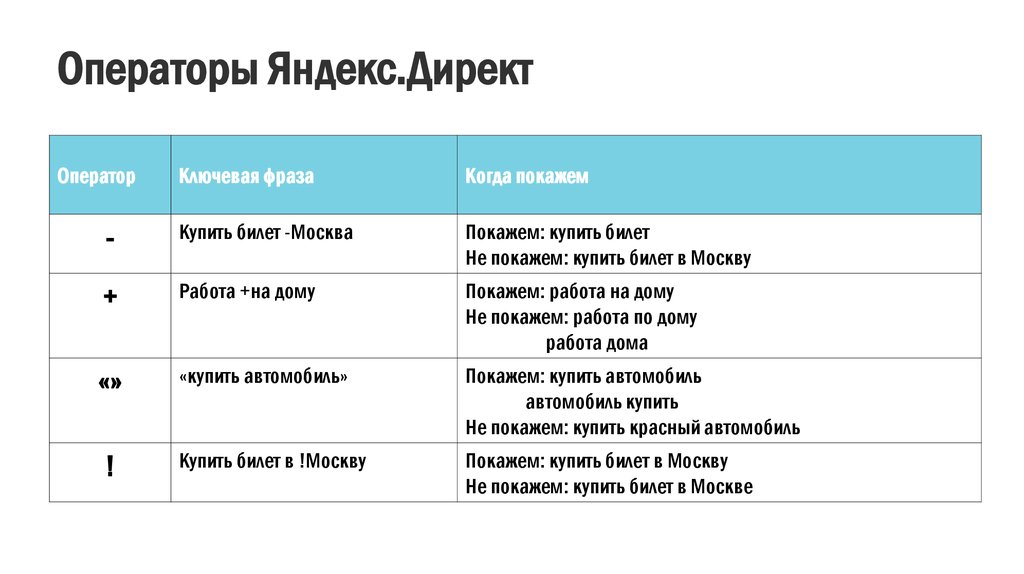 По истечении заданного времени такой регулятор останавливает выполнение
По истечении заданного времени такой регулятор останавливает выполнение
Формирование запросов
Формирование запросов Если вы не хотите углубляться в детали техники поиска, то можете просто задать поисковой машине вопрос так же, как задали бы его человеку, у которого хотите получить совет. Например, «как быстро похудеть», «есть ли жизнь на Марсе», «где раки зимуют»
Приложение № 1 Язык запросов
Приложение № 1 Язык запросов Мощный язык запросов позволяет контролировать малейшие нюансы поведения «Яндекса» при поиске (в том числе при поиске по блогам). Для использования наиболее востребованных команд не обязательно запоминать операторы: можно воспользоваться
7.6 Сообщения запросов ICMP
7.6 Сообщения запросов ICMP
Не все сообщения ICMP сигнализируют об ошибках.
15.5 Работа с дубликатами запросов RPC
15.5 Работа с дубликатами запросов RPC Если служба основана на протоколе TCP, запросы и ответы будут доставляться надежно. TCP берет на себя обеспечение целостности доставляемых данных.Если RPC базируется на UDP, то, в зависимости от требований конкретного приложения, клиент и
1.3.3. Язык запросов
1.3.3. Язык запросов Для того чтобы Яндекс корректно понимал запросы, состоящие из нескольких слов, был разработан специальный язык запросов. Отдельные его элементы мы уже рассмотрели — это и специальные символы, используемые в обычном поиске, и дополнительные параметры,
10.
 1.3. Язык запросов
1.3. Язык запросов10.1.3. Язык запросов Язык запросов, используемый в Яndex.Server, в полной мере соответствует языку запросов, с которым работает поисковая система Яндекс. Поэтому все, что можно использовать для поиска в Интернете, новостях, среди картинок, поддерживается и в версии программы,
Создание запросов TOP PERCENT
Создание запросов TOP PERCENT Можно писать запросы, возвращающие записи, количество которых определяется заданным процентом от общего количества записей в таблице. Например, если у вас есть таблица с 1000 записей и необходимо возвратить один процент первых записей, то, как
6.2. Оптимизация запросов
6.2. Оптимизация запросов Основным способом повышения производительности запросов являются индексы. Определить, действительно ли созданные вами индексы используются запросом, позволяет командаEXPLAIN <Текст запроса>; Набор данных, выводимый командой EXPLAIN, содержит
Планы запросов
Планы запросов
Перед выполнением запроса комплект программ подготовки — известный как оптимизатор- начинает анализировать столбцы и операции запроса для вычислен? самого быстрого способа выполнения. Подготовка начинается с просмотра индексов таблицы и используемых
Подготовка начинается с просмотра индексов таблицы и используемых
Типы запросов
Типы запросов Запрос SQL – это запрос, создаваемый при помощи инструкций SQL [15] .Запросы являются основным средством просмотра, изменения и анализа информации, которая содержится в одной или в нескольких таблицах базы данных. В этой главе, а также в главах 10 и 12,
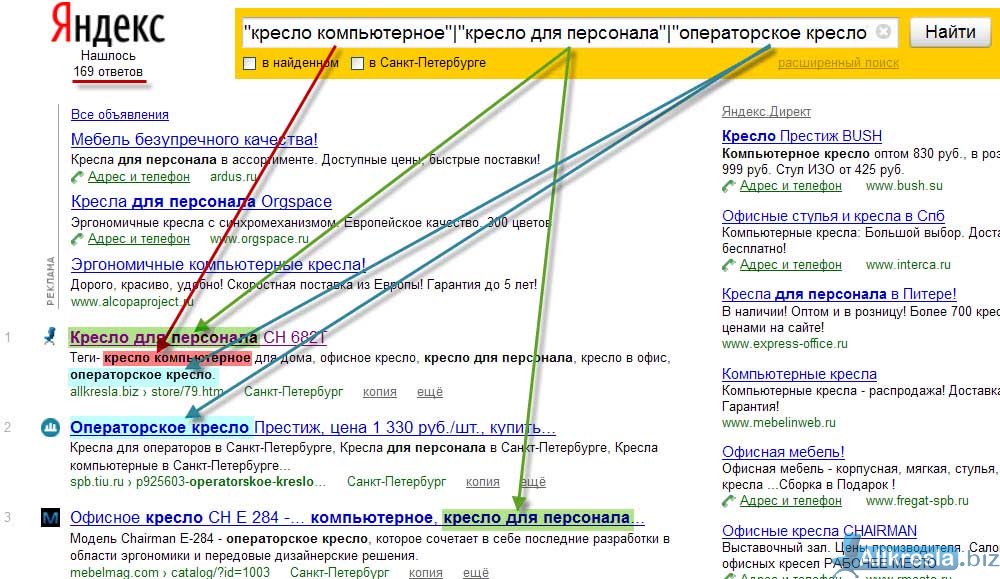
Язык запросов Яндекс — языки запросов различных браузеров
Поисковая система
Яндекс. Укажем в ней необходимые слова и нажмем на клавиатуре
клавишу <Enter> или же щелкнем мышью на кнопке «Найти», размещенной возле строки
поиска. На Web-странице с результатами сразу под поисковой строкой будет расположена статистика по нашему запросу. Здесь будет указано, сколько по нему найдено Web-страниц и Web-сайтов. Внизу страницы Вы также можете узнать, насколько часто пользователи Яндекса ищут то же, что искали мы. После статистических данных размещаются ссылки на Web-сайты, найденные по нашему запросу. По умолчанию на одной Web-странице Яндекс отображает только 10 таких ссылок, поэтому для ознакомления с полными результатами поиска необходимо будет листать Web-страницы с помощью цифр-ссылок. Каждый обнаруженный ресурс в результатах поиска
представлен названием Web-страницы и текстом ссылки. Кроме того, в большинстве
случаев поисковая система демонстрирует небольшой фрагмент текста,
содержащегося на той или иной найденной Web-странице, в котором обнаружено совпадение
с текстом вашего запроса. Внизу Web-страницы, на которой отображена итоговая сводка по обработанному запросу, находится дополнительный блок ссылок, где среди множества предложений наибольший интерес представляет строка «в других поисковых системах». Рядом с этими словами имеются ссылки на несколько других популярных поисковых систем. Поиск информации в Яндексе можно осуществлять в простом и расширенном поисковом режиме. О том, что представляют собой эти виды, речь пойдет ниже. Простой поиск Перед тем как начинать вводить в строку поиска
поисковой системы запрос, тщательно его сформулируйте. Чем более расплывчатой
и нечеткой будет выбранная формулировка, тем больше ненужных Вам Web-сайтов предложит в результатах
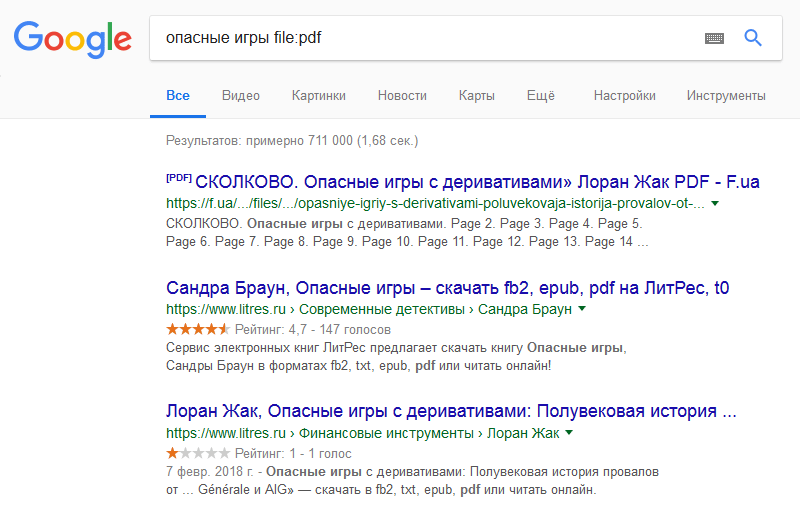
поиска поисковая система. Предположим, мы хотим найти обзор футбольного матча между командами Ювентус и Реал. (Работаем в Интернете). В этом случае не стоит вводить в строку поиска слова вроде «футбол» или «матч» — в Интернет эти слова встречаются чересчур часто, и маловероятно, что поисковая система предложит нам подходящие ссылки. Лучше всего подойдет следующий вариант: Ювентус Реал. Все очень просто. Если поисковая система найдет на одной Web-странице рядом или на расстоянии нескольких слов упоминание введенных нами слов, с большой долей вероятности можно утверждать, что это будет именно та информация, которая нам нужна. Расширенный поиск Все популярные поисковые системы располагают
специальными возможностями для расширенного поиска ресурсов. Чтобы попасть на Web-страницу, предоставляющую такие
возможности, необходимо воспользоваться ссылкой с названием вроде «Расширенный
поиск». А теперь подробнее о логическом языке запросов, который позволяет в режиме обычного поиска вводить в строку поиска дополнительные служебные команды, уточняющие ваши требования. Для каждой поисковой системы существуют свои языки
запросов. Мы познакомимся с языком запросов для Яндекса (Для тех, кто желает
более подробно познакомиться с логическим языком запросов, можно
порекомендовать: Открыв «расширенный поиск» в любой поисковой системе, щелкнув
на «Памятку по использованию языка запросов», Вы найдете для себя не только эту
памятку, но и раздел «Как пользоваться поиском?» (Поиск – помощь)). Памятка по использованию языка запросов
|
 Получив такую команду, Яндекс просмотрит всю свою базу данных и
попытается найти в ней Web-страницы, где встречается введенное нами слово или
словосочетание. При этом нужно заранее учитывать, что чем обширнее наш запрос,
тем меньшее количество Web-страниц будет ему
соответствовать.
Получив такую команду, Яндекс просмотрит всю свою базу данных и
попытается найти в ней Web-страницы, где встречается введенное нами слово или
словосочетание. При этом нужно заранее учитывать, что чем обширнее наш запрос,
тем меньшее количество Web-страниц будет ему
соответствовать. При этом слова, которые мы ввели для поиска, в этих
фрагментах будут выделены полужирным начертанием. Чтобы открыть в новом окне Web-обозревателя один из найденных Web-сайтов, щелкнем на Web-странице с результатами поиска
на его ссылке.
При этом слова, которые мы ввели для поиска, в этих
фрагментах будут выделены полужирным начертанием. Чтобы открыть в новом окне Web-обозревателя один из найденных Web-сайтов, щелкнем на Web-странице с результатами поиска
на его ссылке.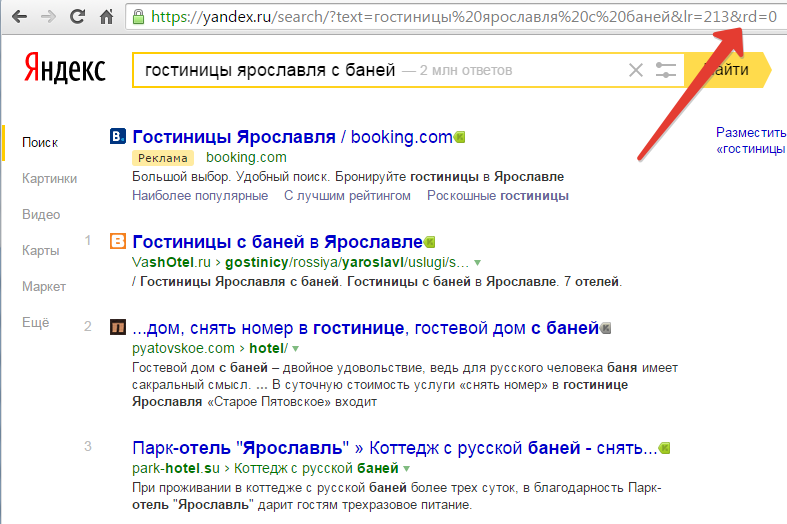 Поэтому очень важно четко себе представить, какой
именно текст может находиться на требуемых нам Web-сайтах, и ввести в строку поиска
именно его.
Поэтому очень важно четко себе представить, какой
именно текст может находиться на требуемых нам Web-сайтах, и ввести в строку поиска
именно его. (Работаем в Интернете).
Перейдя по этой ссылке, мы увидим большую поисковую форму, в которой можно
указать множество параметров. Известная поисковая система Яндекс позволяет настраивать
параметры поиска слов на Web-странице в зависимости от их
расположения (рядом, в одном предложении, на одной странице) и формы. Кроме
того, она может искать Web-страницы по их языку (русский, украинский,
белорусский и т.д.), по дате последнего изменения и даже по формату файла Web-страницы. Наконец, с помощью
Яндекса информацию можно искать на каком-то конкретном Web-сайте. Это бывает полезно в том
случае, если на нужном вам Web-сайте нет встроенной поисковой
системы или если она есть, но функционирует некорректно.
(Работаем в Интернете).
Перейдя по этой ссылке, мы увидим большую поисковую форму, в которой можно
указать множество параметров. Известная поисковая система Яндекс позволяет настраивать
параметры поиска слов на Web-странице в зависимости от их
расположения (рядом, в одном предложении, на одной странице) и формы. Кроме
того, она может искать Web-страницы по их языку (русский, украинский,
белорусский и т.д.), по дате последнего изменения и даже по формату файла Web-страницы. Наконец, с помощью
Яндекса информацию можно искать на каком-то конкретном Web-сайте. Это бывает полезно в том
случае, если на нужном вам Web-сайте нет встроенной поисковой
системы или если она есть, но функционирует некорректно. .
. 


docs/connect.md на мастере · yandex-cloud/docs · GitHub
Вы можете подключиться к {{ mch-short-name }} узлам кластера:
{% включает примечание о подключении к кластеру %}
Подключиться к кластеру можно как с помощью шифрования через порты {{ port-mch-cli }} для [clickhouse-client]({{ ch.docs }}/interfaces/cli/), так и {{ port-mch -http }} для [интерфейса HTTP]({{ ch.docs }}/interfaces/http/) и без шифрования через порты 9000 и 8123 соответственно.
Настройка групп безопасности {#configuring-security-groups}
{% включает группы безопасности %}
{% включают SG-правила%}
Настройки правил зависят от выбранного вами метода подключения:
{% вкладок списка %}
Через Интернет
Настройте все группы безопасности в кластере, чтобы разрешить входящий трафик через порты 8443 и 9440 с любого IP-адреса.
 Для этого создайте следующие правила для входящего трафика:
Для этого создайте следующие правила для входящего трафика:- Диапазон портов:
8443,9440. - Протокол:
TCP. - Источник:
CIDR. - блоков CIDR:
0.0.0.0/0.
Для каждого порта создается отдельное правило.
- Диапазон портов:
С ВМ в {{ yandex-cloud }}
Настройте все группы безопасности вашего кластера, чтобы разрешить входящий трафик через порты 8123, 8443, 9000 и 9440 из группы безопасности, в которой находится ваша виртуальная машина. Для этого создайте следующие правила для входящего трафика в этих группах безопасности:
- Диапазон портов:
8123(или любой другой из перечисленных портов). - Протокол:
TCP. - Источник:
Группа безопасности. Группа безопасности - : если кластер и виртуальная машина находятся в одной группе безопасности, выберите в качестве значения
Self(Self). В противном случае укажите группу безопасности ВМ.
Для каждого порта создается отдельное правило.
- Диапазон портов:
Настройте группу безопасности, в которой находится виртуальная машина, чтобы разрешить подключения к виртуальной машине и трафик между виртуальной машиной и узлами кластера.
Пример правил для ВМ:
Для входящего трафика:
- Диапазон портов:
22. - Протокол:
TCP. - Источник:
CIDR. - блоков CIDR:
0.0.0.0/0.
Это правило позволяет подключаться к виртуальной машине через SSH.
- Диапазон портов:
Для исходящего трафика:
- Диапазон портов:
{{ порт-любой }}. - Протокол:
Любой. - Тип источника:
CIDR. - блоков CIDR:
0.. 0.0.0/0
Это правило разрешает весь исходящий трафик, что позволяет вам подключаться к кластеру и устанавливать сертификаты и утилиты, необходимые виртуальным машинам для подключения к кластеру.
- Диапазон портов:
 Для этого создайте следующие правила для входящего трафика:
Для этого создайте следующие правила для входящего трафика: В противном случае укажите группу безопасности ВМ.
В противном случае укажите группу безопасности ВМ. 0.0.0/0
0.0.0/0 {% конец списка%}
{% информация о примечании%}
Вы можете установить более подробные правила для групп безопасности, например разрешить трафик только в определенных подсетях.
Группы безопасности должны быть правильно настроены для всех подсетей, которые будут включать узлы кластера. Если параметры группы безопасности неполны или неверны, вы можете потерять доступ к кластеру.
{% примечание%}
Дополнительные сведения о группах безопасности см. в разделе Сеть и кластеры БД.
Получение сертификата SSL {#get-ssl-cert}
Чтобы использовать зашифрованное соединение, получите сертификат SSL.
{% вкладок списка %}
Linux (Баш)
Выполните следующие команды:
{% включает сертификат установки%}
Windows (PowerShell)
Загрузите и импортируйте сертификат:
mkdir -Force $HOME\.clickhouse; ` (Invoke-WebRequest {{ crt-web-path }}).RawContent.Split([Environment]::NewLine)[-31..-1] ` | Out-File -Кодировка ASCII $HOME\.clickhouse\{{ crt-local-file }}; ` Сертификат на импорт ` -FilePath $HOME\.clickhouse\{{ crt-local-file }} ` -CertStoreLocation сертификат:\CurrentUser\RootПодтвердите свое согласие на установку сертификата в хранилище «Доверенные корневые центры сертификации».
Сертификат сохраняется в файле
$HOME\.clickhouse\{{ crt-local-file }}.
{% конец списка%}
{% включает ide-ssl-сертификат%}
Подключение к узлам кластера из графических IDE {#connection-ide}
{% включают среды ide %}
Вы можете использовать только графические IDE для подключения к общедоступным узлам кластера с использованием SSL-сертификатов.
{% включает примечание-подключение-иде%}
{% вкладок списка %}
DataGrip
- Создайте источник данных:
- Выбрать Файл → Новый → Источник данных → {{ CH }} .
- На вкладке Общие :
- Укажите параметры подключения:
- Хост : любое {{ CH }} полное доменное имя хоста или специальное полное доменное имя.
- Порт :
{{порт-mch-http}}. - Пользователь , Пароль : Имя пользователя БД и пароль.
- База данных : Имя БД для подключения.
- Щелкните Загрузить , чтобы загрузить драйвер подключения.
- Укажите параметры подключения:
- На вкладке SSH/SSL :
- Включите параметр Использовать SSL .
- Укажите путь к каталогу, в котором находится файл со скачанным SSL-сертификатом для подключения.
- Включите параметр Использовать SSL .
- Щелкните Test Connection , чтобы проверить соединение. В случае успешного подключения вы увидите статус подключения и информацию о СУБД и драйвере.
- Щелкните OK , чтобы сохранить источник данных.
- Создайте источник данных:
DБивер
- Создайте новое соединение с БД:
- В меню База данных выберите Новое соединение .
- Выберите {{ CH }} из списка БД.
- Щелкните Далее .
- Укажите параметры подключения на вкладке Main :
- Хост : Полное доменное имя любого {{ CH }} хоста или специальное полное доменное имя.
- Порт :
{{ порт-mch-http }}. - БД/Схема : Имя БД для подключения.
- В разделе Аутентификация укажите имя пользователя БД и пароль.
- На вкладке Свойства драйвера :
- Нажмите Загрузить в новом окне с приглашением скачать файлы драйвера.
- Укажите параметры SSL-соединения в списке свойств драйвера:
-
ssl:правда. -
sslrootcert:<путь к сохраненному файлу сертификата SSL>.
-
- Нажмите Проверить соединение… , чтобы проверить соединение. В случае успешного подключения вы увидите статус подключения и информацию о СУБД и драйвере.
- Щелкните Готово , чтобы сохранить настройки подключения к базе данных.
- Создайте новое соединение с БД:

{% конец списка%}
Подключение к кластеру из браузера {#browser-connection}
Существует два способа запуска SQL-запросов из браузера:
Консоль управления.
Встроенный редактор SQL.

При подключении из браузера запросы SQL выполняются отдельно, без создания сеанса, общего с сервером {{ CH }}. Поэтому запросы, выполняемые в рамках сеанса, не влияют. Например, это справедливо для таких запросов, как ИСПОЛЬЗОВАТЬ или НАБОР .
Консоль управления {#console}
{% включает веб-sql-предупреждение%}
Для подключения к кластеру {{ mch-name }} войдите в [консоль управления]({{ link-console-main }}), откройте нужную вам страницу кластера и перейдите на вкладку SQL .
Чтобы разрешить подключения, активируйте опцию Доступ из консоли управления при создании кластера или изменении его настроек.
Для получения дополнительной информации см. {#T}.
Встроенный редактор SQL {#inline-editor}
Чтобы подключиться к узлу кластера из встроенного редактора SQL, укажите в адресной строке браузера следующее:
https://:8443/play
Вы можете подключаться только к общедоступным узлам кластера.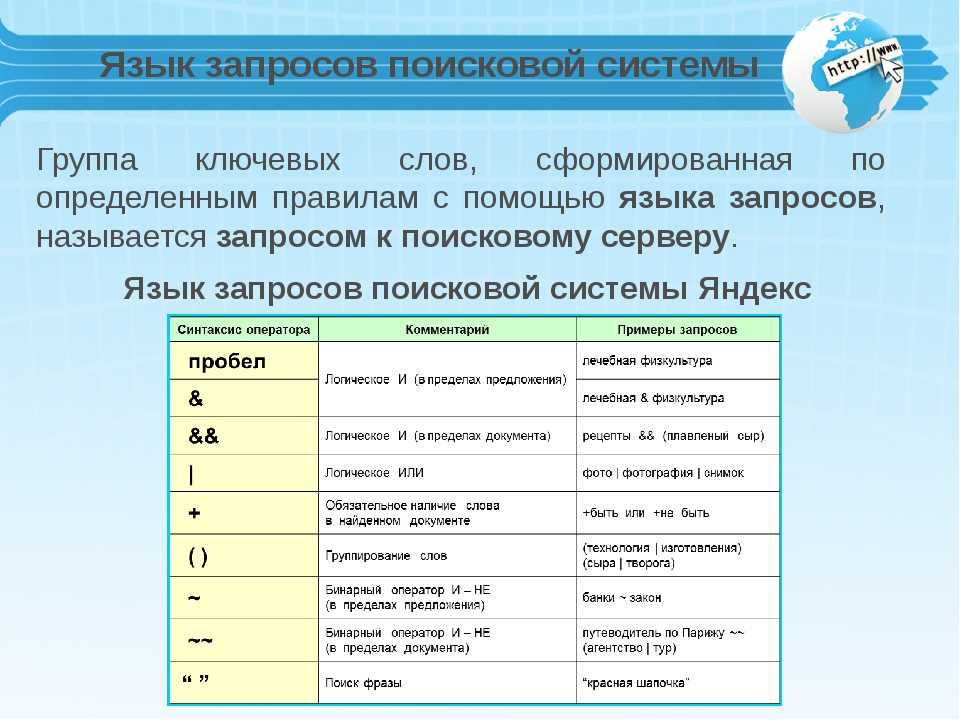
Чтобы подключиться к кластеру путем автоматического выбора доступного хоста, используйте следующий URL-адрес:
-
https://c-<идентификатор кластера>.rw.{{ dns-zone }}:8443/playдля подключения к доступному узлу кластера. -
https://<имя сегмента>.c-<идентификатор кластера>.rw.{{ dns-zone }}:8443/playдля подключения к доступному хосту сегмента.
Чтобы сделать запрос к базе данных, укажите логин и пароль в правом верхнем углу.
Примеры строк подключения {#connection-string}
{% включает среду соединения %}
Вы можете подключаться к общедоступным узлам кластера {{ CH }}, только если используете сертификат SSL. Перед подключением подготовьте сертификат.
В приведенных ниже примерах предполагается, что сертификат {{ crt-local-file }} :
- Находится в папке
{{ crt-local-dir }}(для Ubuntu). - Импортируется в хранилище доверенных корневых сертификатов (для Windows).
Подключение без SSL-сертификата поддерживается только для узлов, которые не являются общедоступными. Для подключений к базе данных трафик внутри виртуальной сети в этом случае не шифруется.
{% включает см. fqdn-в-консоли%}
{% включают строки mch-соединения %}
Если подключение к кластеру и тестовый запрос выполнены успешно, выводится версия {{ CH }}.
Автоматический выбор доступного хоста {#auto}
Если вы не хотите вручную подключаться к другому хосту в случае, если текущий станет недоступен, используйте такой адрес:
Если хост, на который указывает этот адрес, становится недоступным, может возникнуть небольшая задержка, прежде чем адрес начнет указывать на другой доступный хост.
{% примечание предупреждение %}
Если при обслуживании кластера специальное полное доменное имя указывает на узел без общего доступа, к кластеру невозможно подключиться из Интернета.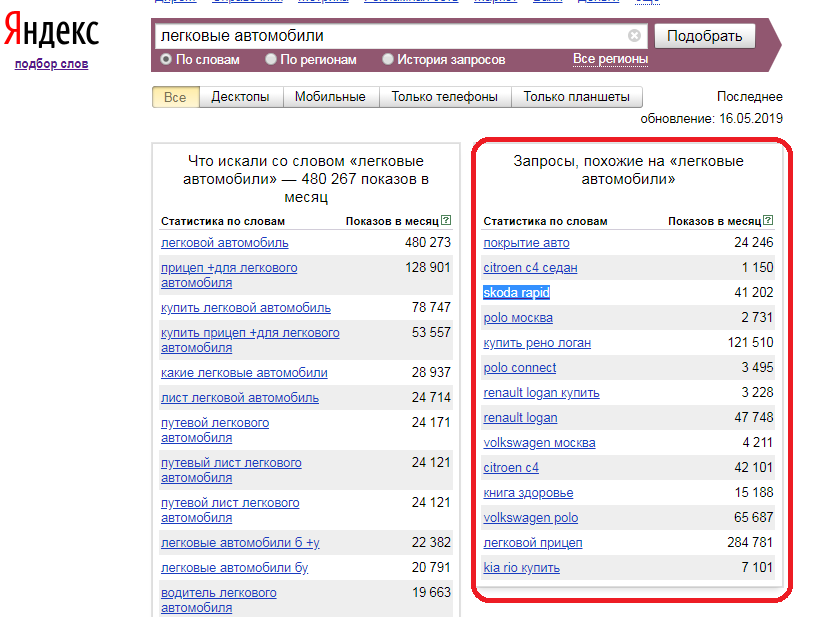 Чтобы этого избежать, включите публичный доступ для всех хостов кластера.
Чтобы этого избежать, включите публичный доступ для всех хостов кластера.
{% примечание%}
airflow.providers.yandex.operators.yandexcloud_dataproc — apache-airflow-providers-yandex Documentation
- class
airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateClusterOperator( * , ID_папки: Необязательный [str] = Нет , имя_кластера: Необязательный [str] = Нет , Описание_кластера: Необязательный [str] = » , 904 60 cluster_image_version: необязательно[str] = Нет , ssh_public_keys: Необязательный [Union[str, Iterable[str]]] = Нет , subnet_id: Необязательный [str] = Нет , сервисы: Iterable[str] = (‘HDFS’, ‘YARN’ , ‘MAPREDUCE’, ‘HIVE’, ‘SPARK’) , s3_bucket: Необязательно[str] = Нет , zone: str = ‘ru-central1-b’ , service_account_id: Optional[str] = None , masternode_resource_preset: Optional[str] = None , masternode_disk_size: Optional[int] = None , masternode_disk_type: Необязательный [str] = Нет , datanode_resource_preset: Необязательный [str] = Нет , datanode_disk_size: Необязательный [int] = Нет , datanode_disk_type: Необязательный [str] = Нет , datanode_count : интервал = 1 , Computenode_resource_preset: Optional[str] = None , Computenode_disk_size: Optional[int] = None , Computenode_disk_type: Optional[str] = None , Computenode_count: int = 0 , Computenode_ max_hosts_count: необязательно [int] = нет , Computenode_measurement_duration: Optional[int] = None , Computenode_warmup_duration: Optional[int] = None , Computenode_стабилизация_duration: Optional[int] = None , calculatenode_preemptible: bool = False , Computenode_cpu_utilization_target: Optional[int] = None , Computenode_decommission_timeout: Optional[int] = None , connection_id: Optional[str] = None , **kwargs )[source] 9052 8 Основания:
airflow. models.BaseOperator Создает кластер Yandex.Cloud Data Proc.
- Параметры
folder_id ( Дополнительно [ стр ] ) — ID папки, в которой должен быть создан кластер.
имя_кластера ( Дополнительно [ str ] ) — Имя кластера. Должен быть уникальным внутри папки.
cluster_description ( str ) — Описание кластера.
cluster_image_version ( str ) — версия образа кластера. Использовать по умолчанию.
ssh_public_keys ( Дополнительно [ Union [ str , Итеративный [ str ] ] ] ) — Список открытых ключей SSH, которые будут развернуты на созданных вычислительных экземплярах.
subnet_id ( str ) — идентификатор подсети. Все узлы кластера Data Proc будут использовать одну подсеть.
услуги ( Iterable [ str ] ) — список служб, которые будут установлены в кластере. Возможные варианты: HDFS, ПРЯЖА, MAPREDUCE, HIVE, TEZ, ZOOKEEPER, HBASE, SQOOP, FLUME, SPARK, SPARK, ZEPPELIN, OOZIE
s3_bucket ( Опционально [ str ] ) — корзина Yandex.Cloud S3 для хранения логов кластера. Задания не будут работать, если ведро не указано.
zone ( str ) — Зона доступности для создания кластера. В настоящее время существуют ru-central1-a, ru-central1-b и ru-central1-c.
service_account_id ( Дополнительно [ str ] ) — идентификатор учетной записи службы для кластера.
Учетная запись службы может быть создана внутри папки.masternode_resource_preset ( str ) — Предустановка ресурсов (конфигурация CPU+RAM) для основного узла кластера.
masternode_disk_size ( int ) — Размер хранилища Мастерноды в ГиБ.
masternode_disk_type ( str ) — Тип хранилища Мастерноды. Возможные варианты: сеть-ssd, сеть-hdd.
datanode_resource_preset ( str ) — Предустановка ресурсов (конфигурация CPU+RAM) для узлов данных кластера.
datanode_disk_size ( int ) — Размер хранилища узлов данных в ГиБ.
datanode_disk_type ( str ) — Тип хранилища узлов данных. Возможные варианты: сеть-ssd, сеть-hdd.
calculatenode_resource_preset ( str ) — Предустановка ресурсов (конфигурация CPU+RAM) для вычислительных узлов кластера.
Computenode_disk_size ( int ) — Размер хранилища вычислительных узлов в ГиБ.
Computenode_disk_type ( str ) — Тип хранилища вычислительных узлов. Возможные варианты: сеть-ssd, сеть-hdd.
connection_id ( Опционально [ str ] ) — идентификатор подключения к Yandex.Cloud Airflow.
Computenode_max_count ( int ) — максимальное количество узлов подкластера автоматического масштабирования вычислений.
Computenode_warmup_duration ( int ) — Время прогрева экземпляра в секундах. В течение этого времени, трафик отправляется на инстанс, но метрики экземпляра не собираются. В секундах.
Computenode_стабилизация_duration ( int ) — Минимальное количество времени в секундах для мониторинга до Группы экземпляров могут уменьшить количество экземпляров в группе.
За это время размер группы не уменьшается,
даже если новые значения метрик указывают на то, что это необходимо. В секундах.calculatenode_preemptible ( bool ) — Выгружаемые экземпляры останавливаются не реже одного раза в 24 часа, и могут быть остановлены в любое время, если их ресурсы потребуются вычислительным ресурсам.
Computenode_cpu_utilization_target ( int ) — определяет правило автомасштабирования. на основе средней загрузки ЦП группы экземпляров. в процентах. 10-100. По умолчанию не задано и используется стратегия автомасштабирования по умолчанию.
Computenode_decommission_timeout ( int ) — Тайм-аут для корректного вывода узлов из эксплуатации во время уменьшения масштаба. В секундах.
-
выполнить( self , контекст )[источник]
 models.BaseOperator
models.BaseOperator 
 Учетная запись службы может быть создана внутри папки.
Учетная запись службы может быть создана внутри папки.
 За это время размер группы не уменьшается,
даже если новые значения метрик указывают на то, что это необходимо. В секундах.
За это время размер группы не уменьшается,
даже если новые значения метрик указывают на то, что это необходимо. В секундах.- class
airflow. providers.yandex.operators.yandexcloud_dataproc. DataprocDeleteClusterOperator( * , connection_id: Необязательный [str] = Нет , cluster_id: Необязательный [str] = None , **kwargs ) [источник] Основания:
airflow.models.BaseOperatorУдаляет кластер Yandex.Cloud Data Proc.
- Параметры
-
template_fields= [‘cluster_id’] [источник]
-
выполнить( self , контекст )[источник]
 providers.yandex.operators.yandexcloud_dataproc.
providers.yandex.operators.yandexcloud_dataproc. - class
airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateHiveJobOperator( * , запрос: необязательный [str] = нет , query_file_uri: необязательный [str] = нет , script_variables: необязательный [Dict [str, str]] = нет 904 61, continue_on_failure: bool = False , свойства: Необязательный [Dict[str, str]] = None , name: str = ‘Hive job’ , cluster_id: Optional[str] = None , connection_id: Необязательный [str] = None , **kwargs ) [источник] Основания:
airflow. models.BaseOperator Запускает задание Hive в кластере Data Proc.
- Параметры
запрос ( Необязательный [ str ] ) — запрос куста.
query_file_uri ( Дополнительно [ ул ] ) — URI скрипта, содержащего запросы Hive. Можно разместить в HDFS или S3.
свойства ( Дополнительно [ Расст. [ стр , стр 90 460 ] ] ) — сопоставление имен свойств со значениями, используемое для настройки Hive.
script_variables ( Дополнительно [ Расст. [ ул , str ] ] ) — Сопоставление имен переменных запроса со значениями.
continue_on_failure ( bool ) — следует ли продолжать выполнение запросов в случае сбоя запроса.
имя ( ул ) — Название работы. Используется для маркировки.
cluster_id ( Необязательный [ str ] ) — ID кластера для запуска задания. Попытается получить идентификатор из объекта Dataproc Hook, если он не указан. (шаблон)
connection_id ( Опционально [ str ] ) — идентификатор подключения к Yandex.Cloud Airflow.
-
template_fields= [‘cluster_id’] [источник]
-
выполнить( self , контекст )[источник]
 models.BaseOperator
models.BaseOperator 
- class
airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateMapReduceJobOperator( * , main_class: Необязательный [str] = Нет , main_jar_file_uri: Необязательный [str] = Нет , jar_file_uris: Необязательный [Iterable [str]] = Нет , archive_uris: необязательно[ Iterable[str]] = None , file_uris: Optional[Iterable[str]] = None , args: Optional[Iterable[str]] = None , свойства: Optional[Dict[str, str]] = Нет , name: str = ‘Mapreduce job’ , cluster_id: Необязательный [str] = Нет , connection_id: Необязательный [str] = Нет , **kwargs ) [источник] Основания:
airflow. models.BaseOperator Запускает задание Mapreduce в кластере Data Proc.
- Параметры
main_jar_file_uri ( Необязательный [ str ] ) — URI jar-файла с заданием. Можно разместить в HDFS или S3. Можно указать вместо main_class.
main_class ( Необязательный [ str ] ) — Имя основного класса задания. Можно указать вместо main_jar_file_uri.
file_uris ( Необязательный [ Итерируемый [ str ] ] 904 61 ) — URI файлов, используемых в задании. Можно разместить в HDFS или S3.
archive_uris ( Необязательный [ Iterable [ str ] ] ) — URI архивных файлов, используемых в задании. Можно разместить в HDFS или S3.
jar_file_uris ( Необязательный [ Итерируемый [ str ] ] 9 0461 ) — URI файлов JAR, используемых в задании. Можно разместить в HDFS или S3.
свойства ( Дополнительно [ Расст [ ул , ул ] ] ) — Свойства для задания.
args ( Необязательный [ Итерируемый [ str ] ] 9046 1 ) — Аргументы для передачи в задание.
имя ( ул ) — Название работы. Используется для маркировки.
cluster_id ( Необязательный [ str ] ) — идентификатор кластера, в котором выполняется задание. Попытается получить идентификатор из объекта Dataproc Hook, если он не указан.
(шаблон)connection_id ( Опционально [ str ] ) — идентификатор подключения к Yandex.Cloud Airflow.
-
template_fields= [‘cluster_id’] [источник]
-
выполнить( self , контекст )[источник]
 models.BaseOperator
models.BaseOperator 
 (шаблон)
(шаблон)- class
airflow.providers.yandex.operators.yandexcloud_dataproc.DataprocCreateSparkJobOperator( * , main_class: необязательный [str] = нет , main_jar_file_uri: необязательный [str] = нет , jar_file_uris: необязательный [Iterable [str]] = Нет , archive_uris: необязательно[ Iterable[str]] = Нет , file_uris: Необязательный[Iterable[str]] = Нет , аргументы: Необязательный[Iterable[str]] = Нет , свойства: Необязательный[Dict[str, str]] = Нет , name: str = ‘Spark job’ , cluster_id: Optional[str] = None , connection_id: Optional[str] = None , **kwargs )[source] Основания:
airflow. models.BaseOperator Запускает задание Spark в кластере Data Proc.
- Параметры
main_jar_file_uri ( Дополнительно [ str ] ) — URI файла jar с заданием. Можно разместить в HDFS или S3.
main_class ( Необязательный [ str ] ) — Имя основного класса задания.
file_uris ( Необязательный [ Итерируемый [ str ] ] ) — URI файлов, используемых в задании. Можно разместить в HDFS или S3.
archive_uris ( Необязательный [ Итерируемый [ str ] ] 904 61 ) — URI архивных файлов, используемых в задании. Можно разместить в HDFS или S3.
JAR_FILE_URIS ( Опционально [ итерабильный [ STR ] ] ) — URI файлов JAR, используемых в задании.
Можно разместить в HDFS или S3.свойства ( Дополнительно [ Расст. [ стр , стр 90 460 ] ] ) — Свойства задания.
args ( Необязательный [ Итерируемый [ str ] ] 9046 1 ) — Аргументы для передачи в задание.
имя ( ул ) — Название работы. Используется для маркировки.
cluster_id ( Необязательный [ str ] ) — ID кластера для запуска задания. Попытается получить идентификатор из объекта Dataproc Hook, если он не указан. (шаблон)
connection_id ( Опционально [ str ] ) — идентификатор подключения к Yandex.Cloud Airflow.
-
template_fields= [‘cluster_id’] [источник]
-
выполнить( self , контекст )[источник]
 models.BaseOperator
models.BaseOperator  Можно разместить в HDFS или S3.
Можно разместить в HDFS или S3.- class
airflow. providers.yandex.operators.yandexcloud_dataproc. DataprocCreatePysparkJobOperator( * , main_python_file_uri: необязательно [str] = нет , python_file_uris: необязательно [Iterable [str]] = нет , jar_file_uris: Необязательный[Iterable[str]] = Нет , archive_uris: Необязательный[Iterable[str]] = Нет , file_uris: Необязательный[Iterable[str]] = Нет , аргументы: Необязательный[Iterable [str]] = None , свойства : Необязательный [Dict[str, str]] = None , имя: str = ‘Pyspark job’ , cluster_id: Необязательный [str] = Нет , connection_id: Необязательный [str] = Нет , **kwargs )[источник] Основания:
airflow.models.BaseOperatorЗапускает задание Pyspark в кластере Data Proc.
- Параметры
main_python_file_uri ( Необязательный [ str ] ) — URI файла Python с заданием.
Можно разместить в HDFS или S3.python_file_uris ( Необязательный [ Итерируемый [ str ] ] ) — URI файлов Python, используемых в задании. Можно разместить в HDFS или S3.
file_uris ( Необязательный [ Итерируемый [ str ] ] 904 61 ) — URI файлов, используемых в задании. Можно разместить в HDFS или S3.
archive_uris ( Необязательный [ Итерируемый [ str ] ] 904 61 ) — URI архивных файлов, используемых в задании. Можно разместить в HDFS или S3.
jar_file_uris ( Необязательный [ Итерируемый [ str ] ] 90 461 ) — URI файлов JAR, используемых в задании.
 providers.yandex.operators.yandexcloud_dataproc.
providers.yandex.operators.yandexcloud_dataproc.  Можно разместить в HDFS или S3.
Можно разместить в HDFS или S3.