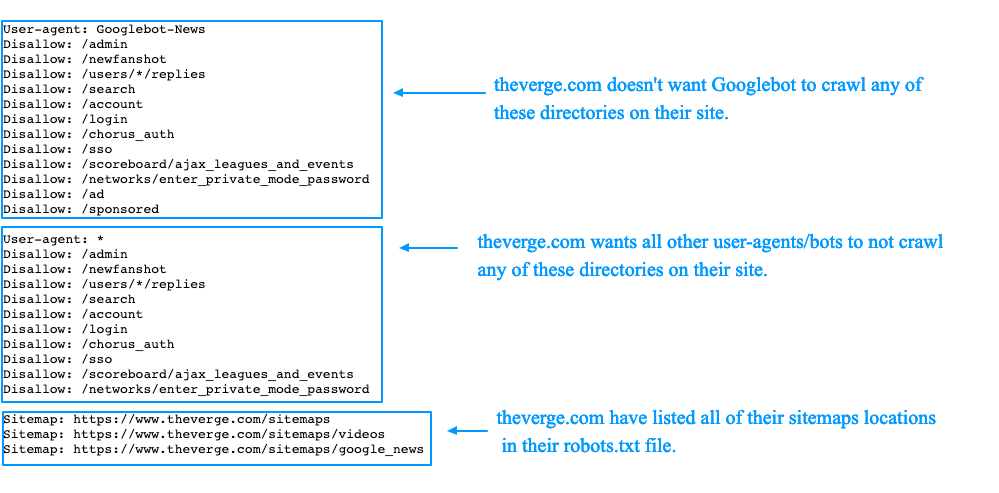
Анализ robots.txt — Вебмастер. Справка
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
Инструмент Анализ robots.txt помогает проверить, правильно ли составлен файл robots.txt или написать содержимое файла и после проверки скопировать его в robots.txt.
Также инструмент поможет отследить изменения в файле и скачать определенную версию.
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
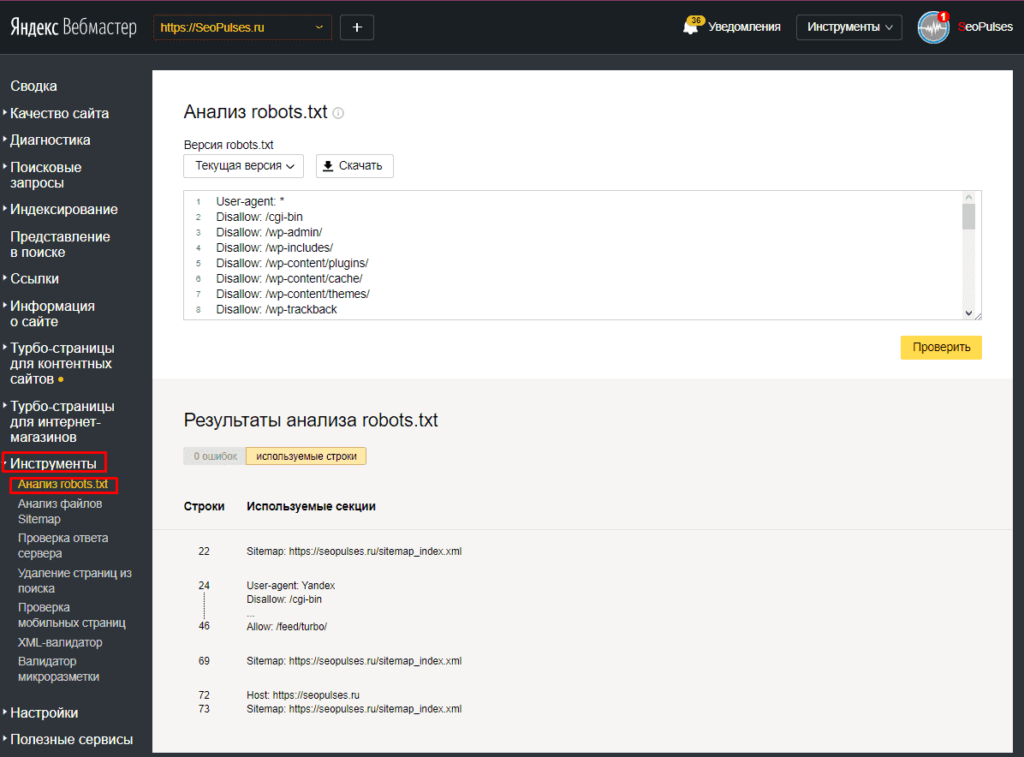
- Если сайт добавлен в Яндекс Вебмастер и права на его управление подтверждены
Содержимое файла появится на странице Инструменты → Анализ robots.txt после подтверждения прав на управление сайтом.
Если содержимое отображается на странице Анализ robots.txt, нажмите кнопку Проверить.
- Если сайт не добавлен в Яндекс Вебмастер
Перейдите на страницу Анализ robots.
 txt.
txt.В поле Проверяемый сайт укажите адрес вашего сайта. Например, https://example.com.
Нажмите значок . Содержимое robots.txt и результаты анализа отобразятся ниже.
 txt.
txt.В предназначенных для робота Яндекса (User-agent: Yandex или User-agent:*) разделах инструмент проверяет директивы, руководствуясь правилами использования robots.txt. Остальные разделы проверяются в соответствии со стандартом.
После проверки могут отобразиться:
Предупреждения. Они сообщают об отклонении от правил, которое инструмент может исправить самостоятельно. Также предупреждения указывают на потенциальную проблему, связанную с опечаткой или неточностью в написании правил.
Ошибки в файле. Это значит, что инструмент не может обработать строку, секцию или весь файл из-за серьезных ошибок в синтаксисе, допущенных при составлении директив.
Подробное описание см. в разделе Справочник по ошибкам анализа robots.txt.
в разделе Справочник по ошибкам анализа robots.txt.
Когда ваш файл robots.txt загружен в Яндекс Вебмастер, на странице Анализ robots.txt отображается блок Разрешены ли URL?.
В поле Список URL укажите адрес страницы, которую хотите проверить. Можно указать полный URL или адрес относительно корневого каталога сайта. Например, https://example.com/page/ или /page/.
Нажмите кнопку Проверить.
Если URL разрешен для индексирования роботами Яндекса, напротив адреса появится значок , если запрещен — отобразится адрес, выделенный красным.
Примечание. Доступна история изменений за шесть месяцев. Максимальное количество сохраненных версий — 100.
Чтобы своевременно узнавать об изменениях файла robots.txt, настройте уведомления.
Яндекс Вебмастер регулярно проверяет обновления файла и сохраняет версии с учетом даты и времени изменения. Чтобы их посмотреть, перейдите на страницу Инструменты → Анализ robots.txt.
Список версий отображается, если одновременно выполнены следующие условия:
вы добавили сайт в Яндекс Вебмастер и подтвердили права на управление сайтом;
в Яндекс Вебмастере есть информация об изменениях robots.
txt.
 txt.
txt.Вы можете:
- Просмотреть текущую и предыдущие версии файла
Выберите из списка Версия robots.txt версию файла. В поле ниже отобразится содержимое robots.txt, а также результаты анализа.
- Скачать выбранную версию файла
Выберите из списка Версия robots.txt версию файла.
Нажмите кнопку Скачать. Файл сохранится на вашем устройстве в формате TXT.
Ошибка «Этот URL не принадлежит вашему домену»
Скорее всего, в списке URL вы указали адрес одного из зеркал вашего сайта, например http://example.com вместо http://www.example.com. Формально это два различных URL. Проверяемые URL должны принадлежать сайту, для которого производится анализ robots.txt.
Укажите инструмент, в работе которого вы нашли ошибку, опишите ситуацию как можно подробнее, а при необходимости приложите скриншот, иллюстрирующий ситуацию.
Синтаксис и правила составления файла robots.txt
User-Agent: указывает имя робота, для которого будут применяться следующие правила (например, Googlebot, Yandex).
После User-Agent необходимо поставить двоеточие, пробел и указать имя User-Agent.
Пример:
User-Agent: Googlebot
Disallow: закрывающая директива, которая указывает, какие страницы необходимо закрыть от индексации.
После Disallow необходимо поставить двоеточие, пробел и указать раздел или путь к странице, которую необходимо закрыть от индексации.
Пример:
Disallow: /bitrix/
Подробнее о том, как закрыть страницы от индексации читайте в статье Как запретить индексацию сайта или страницы в robots.txt.
Allow: разрешающая директива, которая указывает страницы, которые необходимо проиндексировать.
Allow необходимо размещать для тех страниц, которые находятся в закрытой от индексации папке.
После Allow необходимо поставить двоеточие, пробел и указать раздел или путь к странице, которую необходимо открыть для индексации.
Директива Allow для конкретного файла или страницы должна быть длиннее, чем закрывающая директива Disallow, которая закрывает раздел, где находится документ или страница.
Например, в robots.txt указана закрывающая директива Disallow: /bitrix/. При этом в папке /bitrix/upload/ лежат png изображения, которые необходимо открыть для индексации.
Для того, чтобы открыть png изображения для индексации необходимо разместить следующие директивы:
Disallow: /bitrix/
Allow: /bitrix/upload/*.png
В примере мы видим, что содержание открывающей директивы Allow длиннее, чем закрывающей директивы Disallow.
*: означает любую последовательность символов в пути страницы или любо обозначает всех User Agent. Символ * по умолчанию используется в конце строки, если не указывается иной символ.
Например:
User-Agent: * — директивы будут применяться для всех User-Agent.
Disallow: /*bitrix – закрывает все страницы, в URL которых содержится bitrix, вне зависимости от расположения.
Disallow: /bitrix* и Disallow: /bitrix – являются одинаковыми.
$: обозначает конец строки и по умолчанию отменяет символ * в конце строки.
Например:
Disallow: /bitrix$
#: правило для размещения комментария. Данные правила игнорируются поисковыми роботами и служат в качестве подсказки для вебмастеров.
/: указывает, что папка закрыта для сканирования.
Пример:
Disallow: /bitrix/ — закрыта вся папка /bitrix/. Соответственно все страницы, сложенные в эту папку, например /bitrix/upload/, будут закрыты от индексации
Disallow: / — закрывает весь сайт от индексации, так как / указывает на корневую папку сайта.
Sitemap: правило для указания ссылки на xml-карту сайта sitemap.xml.
Пример:
Sitemap: https://site.ru/sitemap.xml
Clean-param: директива для поисковых роботов Яндекса, которая сообщает о динамических параметрах в URL страницы, которые не меняют содержания страницы. Данная директива позволяет разрешить для индексации только основную страницу без дополнительных параметров в URL.
Данная директива позволяет разрешить для индексации только основную страницу без дополнительных параметров в URL.
С помощью Clean-param можно закрыть страницы с рекламными метками (например, URL с utm-метками).
Пример:
Clean-param: utm_
Если необходимо закрыть несколько страницы с разными метками, необходимо перечислить метки через символ &.
Пример:
Clean-param: utm_& yclid_
Подробнее о Clea-param вы можете узнать в статье Директива Clean-param в файле robots.txt.
Robots.txt — все, что нужно знать SEO-специалистам
Рэйчел Костелло
SEO и контент-менеджер
Давайте делиться
| 17 минут чтения
В этом разделе нашего руководства по директивам robots. txt мы более подробно рассмотрим 9Текстовый файл 0013 robots.txt и как его можно использовать для инструктирования поисковых роботов. Этот файл особенно полезен для управления краулинговым бюджетом и обеспечения того, чтобы поисковые системы эффективно проводили время на вашем сайте и сканировали только важные страницы.
txt мы более подробно рассмотрим 9Текстовый файл 0013 robots.txt и как его можно использовать для инструктирования поисковых роботов. Этот файл особенно полезен для управления краулинговым бюджетом и обеспечения того, чтобы поисковые системы эффективно проводили время на вашем сайте и сканировали только важные страницы.
Для чего используется текстовый файл robots?
Файл robots.txt указывает сканерам и роботам, какие URL-адреса на вашем веб-сайте им не следует посещать. Это важно, чтобы помочь им избежать сканирования некачественных страниц или застревания в ловушках сканирования, где потенциально может быть создано бесконечное количество URL-адресов, например, раздел календаря, который создает новый URL-адрес на каждый день.
Как объясняет Google в своем руководстве по спецификациям robots.txt , формат файла должен быть обычным текстом, закодированным в UTF-8. Записи файла (или строки) должны быть разделены символами CR, CR/LF или LF.
Записи файла (или строки) должны быть разделены символами CR, CR/LF или LF.
Следует помнить о размере файла robots.txt, так как у поисковых систем есть собственные ограничения на максимальный размер файла. Максимальный размер для Google составляет 500 КБ.
Где должен находиться файл robots.txt?
Файл robots.txt всегда должен находиться в корне домена, например:
Этот файл относится к протоколу и полному домену, поэтому robots.txt на https://www.example.com не влияет на сканирование https://www.example.com или https ://subdomain.example.com ; у них должны быть свои собственные файлы robots.txt.
Когда следует использовать правила robots.txt?
В общем, веб-сайты должны стараться как можно меньше использовать файл robots.txt для контроля сканирования. Гораздо лучшее решение — улучшить архитектуру вашего веб-сайта и сделать его чистым и доступным для поисковых роботов. Однако рекомендуется использовать robots.txt там, где это необходимо для предотвращения доступа сканеров к некачественным разделам сайта, если эти проблемы не могут быть устранены в краткосрочной перспективе.
Однако рекомендуется использовать robots.txt там, где это необходимо для предотвращения доступа сканеров к некачественным разделам сайта, если эти проблемы не могут быть устранены в краткосрочной перспективе.
Google рекомендует использовать robots.txt только в случае возникновения проблем с сервером или проблем с эффективностью сканирования, например, когда робот Googlebot тратит много времени на сканирование неиндексируемого раздела сайта.
Некоторые примеры страниц, сканирование которых нежелательно:
- Страницы категорий с нестандартной сортировкой , так как это обычно создает дублирование со страницей основной категории
- Пользовательский контент , который не может модерироваться
- Страницы с конфиденциальной информацией
- Страницы внутреннего поиска , так как может быть бесконечное количество этих страниц результатов, которые создают плохой пользовательский опыт и тратят впустую краулинговый бюджет
Когда не следует использовать robots.
 txt ?
txt ?Файл robots.txt — полезный инструмент при правильном использовании, однако бывают случаи, когда это не лучшее решение. Вот несколько примеров, когда не следует использовать файл robots.txt для управления сканированием:
1. Блокировка Javascript/CSS
Поисковые системы должны иметь доступ ко всем ресурсам на вашем сайте для правильного отображения страниц, что является необходимой частью поддержания хорошего рейтинга. Файлы JavaScript, которые резко изменяют взаимодействие с пользователем, но не могут быть просканированы поисковыми системами, могут привести к ручным или алгоритмическим штрафам.
Например, если вы показываете межстраничное объявление или перенаправляете пользователей с помощью JavaScript, к которому поисковая система не имеет доступа, это может рассматриваться как маскировка, и рейтинг вашего контента может быть скорректирован соответствующим образом.
2. Блокировка параметров URL
Вы можете использовать robots.txt для блокировки URL-адресов, содержащих определенные параметры, но это не всегда лучший способ действий. Лучше обрабатывать их в консоли поиска Google, так как там есть больше параметров для конкретных параметров, чтобы сообщить Google о предпочтительных методах сканирования.
Лучше обрабатывать их в консоли поиска Google, так как там есть больше параметров для конкретных параметров, чтобы сообщить Google о предпочтительных методах сканирования.
Вы также можете поместить информацию во фрагмент URL-адреса ( /page#sort=price ), так как поисковые системы его не сканируют. Кроме того, если необходимо использовать параметр URL, ссылки на него могут содержать атрибут rel=nofollow, чтобы сканеры не пытались получить к нему доступ.
3. Блокировка URL-адресов с обратными ссылками
Запрет URL-адресов в файле robots.txt предотвращает передачу ссылочного капитала на веб-сайт. Это означает, что если поисковые системы не могут переходить по ссылкам с других веб-сайтов, поскольку целевой URL-адрес запрещен, ваш веб-сайт не получит авторитета, который проходят эти ссылки, и, как следствие, ваш общий рейтинг может ухудшиться.
4. Деиндексация проиндексированных страниц
Использование Disallow не приводит к деиндексации страниц, и даже если URL-адрес заблокирован и поисковые системы никогда не сканировали страницу, запрещенные страницы все равно могут быть проиндексированы. Это связано с тем, что процессы сканирования и индексации в значительной степени разделены.
Это связано с тем, что процессы сканирования и индексации в значительной степени разделены.
Даже если вы не хотите, чтобы поисковые системы сканировали и индексировали страницы, вы можете захотеть, чтобы социальные сети могли получить доступ к этим страницам, чтобы можно было создать фрагмент страницы. Например, Facebook попытается посетить каждую страницу, которая публикуется в сети, чтобы предоставить соответствующий фрагмент. Учитывайте это при настройке правил robots.txt.
6. Блокировка доступа с промежуточных сайтов или сайтов разработки
Использование файла robots.txt для блокировки всего промежуточного сайта — не лучшая практика. Гугл рекомендует не индексирует страницы, но позволяет их сканировать, но в целом лучше сделать сайт недоступным из внешнего мира.
7. Когда вам нечего блокировать
Некоторые веб-сайты с очень чистой архитектурой не нуждаются в блокировке поисковых роботов на любых страницах. В этой ситуации вполне допустимо не иметь файла robots. txt и возвращать статус 404 по запросу.
txt и возвращать статус 404 по запросу.
Синтаксис и форматирование robots.txt
Теперь, когда мы узнали, что такое robots.txt и когда его следует и не следует использовать, давайте рассмотрим стандартизированный синтаксис и правила форматирования, которых следует придерживаться. при написании файла robots.txt.
Комментарии – это строки, полностью игнорируемые поисковыми системами и начинающиеся с # . Они существуют для того, чтобы вы могли писать заметки о том, что делает каждая строка вашего файла robots.txt, почему она существует и когда она была добавлена. В общем, рекомендуется документировать назначение каждой строки вашего файла robots.txt, чтобы его можно было удалить, когда он больше не нужен, и не изменять, пока он все еще необходим.
Указание агента пользователя
Блок правил может быть применен к определенным агентам пользователя с помощью « User-agent ” директива. Например, если вы хотите, чтобы определенные правила применялись к Google, Bing и Яндексу; но не Facebook и рекламные сети, этого можно добиться, указав токен пользовательского агента, к которому применяется набор правил.
У каждого сканера есть собственный токен пользовательского агента, который используется для выбора совпадающих блоков.
Сканеры будут следовать наиболее конкретным правилам пользовательского агента, установленным для них, с именами, разделенными дефисами, а затем вернутся к более общим правилам, если точное совпадение не будет найдено. Например, Googlebot News будет искать совпадение « googlebot-news ’, затем ‘ googlebot ’, затем ‘*’.
Вот некоторые из наиболее распространенных токенов агента пользователя, с которыми вы столкнетесь:
- * — Правила применяются к каждому боту, если нет более конкретного набора правил
- Googlebot — Все поисковые роботы Google
- Googlebot-News – Поисковый робот для новостей Google
- Googlebot-Image – Поисковый робот для Google Images
- Mediapartners-Google – Google Adsense crawler
- Bingbot – Bing’s crawler
- Yandex – Yandex’s crawler
- Baiduspider – Baidu’s crawler
- Facebot – Facebook’s crawler
- Twitterbot – Twitter’s crawler
This list токенов пользовательского агента, ни в коем случае не является исчерпывающим, поэтому, чтобы узнать больше о некоторых сканерах, взгляните на документацию, опубликованную Google , Bing , Yandex , Baidu , Facebook и Twitter .
При сопоставлении токена пользовательского агента с блоком robots.txt регистр не учитывается. Например. «googlebot» будет соответствовать токену пользовательского агента Google «Googlebot».
URL-адреса, соответствующие шаблону
Возможно, у вас есть определенная строка URL-адреса, которую вы хотите заблокировать от сканирования, так как это намного эффективнее, чем включение полного списка полных URL-адресов, которые необходимо исключить в файле robots.txt.
Чтобы уточнить URL-адреса, вы можете использовать символы * и $. Вот как они работают:
- * — это подстановочный знак, представляющий любое количество любых символов. Он может быть в начале или в середине URL-адреса, но не обязателен в конце. Вы можете использовать несколько подстановочных знаков в строке URL, например, « Disallow: */products?*sort= ». Правила с полными путями не должны начинаться с подстановочного знака.
- $ — этот символ означает конец строки URL, поэтому « Disallow: */dress$ » будет соответствовать только URL-адресам, оканчивающимся на « / dress », а не на « / dress?parameter ».
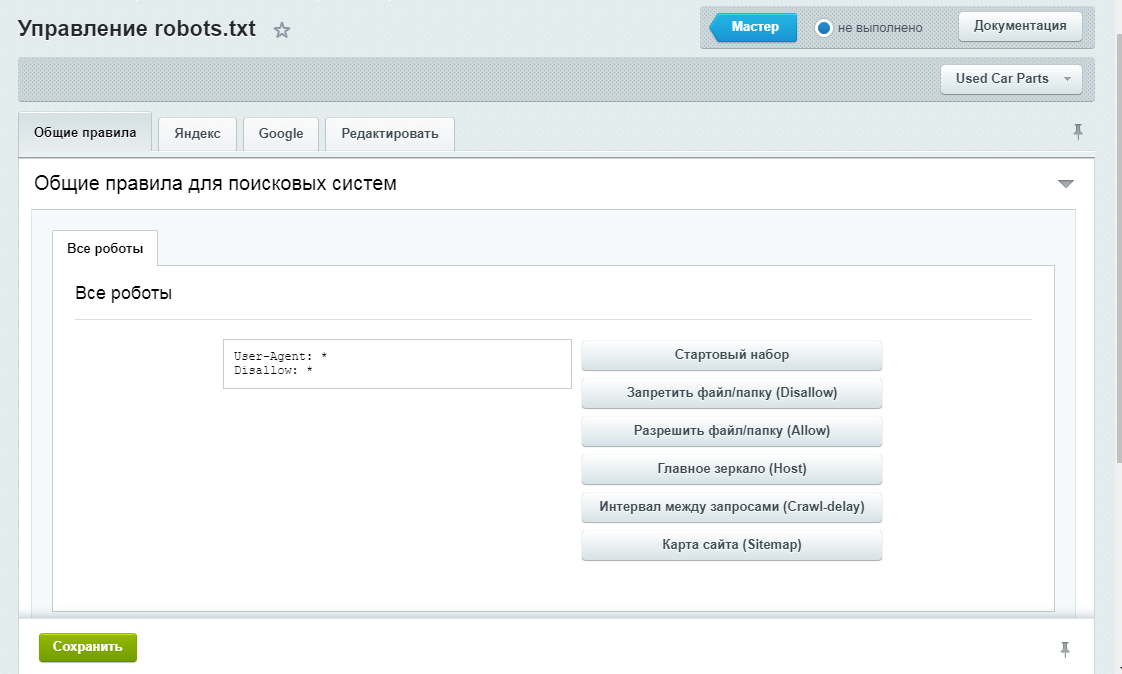
Стоит отметить, что правила robots.txt чувствительны к регистру, а это означает, что если вы запретите URL-адреса с параметром « search » (например, « Disallow: *?search= »), роботы все равно могут сканировать URL-адреса с другими заглавными буквами, например « ?Search=anything ».
Правила директивы соответствуют только путям URL и не могут включать протокол или имя хоста. Косая черта в начале директивы соответствует началу пути URL. Например. Disallow: /starts ” будет соответствовать www.example.com/starts .
Если вы не добавите директиву start a, соответствующую / или *, она не будет соответствовать чему-либо. Например. « Disallow: запускает » никогда не будет соответствовать чему-либо.
Чтобы наглядно представить, как работают различные правила URL-адресов, мы собрали для вас несколько примеров:
Robots.txt Ссылка на карту сайта
Директива карты сайта в файле robots. txt сообщает поисковым системам, где найти XML-карту сайта, что помогает им обнаружить все URL-адреса на веб-сайте. Чтобы узнать больше о картах сайта, ознакомьтесь с нашими руководство по аудиту карты сайта и расширенной настройке .
txt сообщает поисковым системам, где найти XML-карту сайта, что помогает им обнаружить все URL-адреса на веб-сайте. Чтобы узнать больше о картах сайта, ознакомьтесь с нашими руководство по аудиту карты сайта и расширенной настройке .
При включении карт сайта в файл robots.txt следует использовать абсолютные URL-адреса (например, https://www.example.com/sitemap.xml ) вместо относительных URL-адресов (например, /sitemap.xml .) Это также стоит отметить, что карты сайта не обязательно должны находиться в одном корневом домене, они также могут размещаться на внешнем домене.
Поисковые системы обнаружат и могут сканировать карты сайта, указанные в файле robots.txt, однако эти карты сайта не будут отображаться в Google Search Console или Bing Webmaster Tools без отправки вручную.
Robots.txt блокирует
Правило «запретить» в файле robots.txt можно использовать несколькими способами для разных пользовательских агентов. В этом разделе мы рассмотрим несколько различных способов форматирования комбинаций блоков.
В этом разделе мы рассмотрим несколько различных способов форматирования комбинаций блоков.
Важно помнить, что директивы в файле robots.txt — это только инструкции. Вредоносные сканеры будут игнорировать ваш файл robots.txt и сканировать любую общедоступную часть вашего сайта, поэтому не следует использовать запрет вместо надежных мер безопасности.
Несколько блоков пользовательских агентов
Вы можете сопоставить блок правил с несколькими пользовательскими агентами, перечислив их перед набором правил, например, следующие правила запрета будут применяться как к Googlebot, так и к Bing в следующем блоке правил:
Агент пользователя: googlebot
Агент пользователя: bing
Запретить: /a
Интервал между блоками директив
Google будет игнорировать пробелы между директивами и блоками. В этом первом примере будет выбрано второе правило, даже если есть пробел, разделяющий две части правила:
[код]
User-agent: *
Disallow: /disallowed/
Disallow: /test1/robots_excluded_blank_line
[/code]
Во втором примере Googlebot-mobile унаследует те же правила, что и Bingbot3:
[код]
Агент пользователя: googlebot-mobile
Агент пользователя: bing
Запретить: /test1/deepcrawl_excluded
[/код]
Объединены отдельные блоки
Объединены несколько блоков с одним и тем же агентом пользователя. Таким образом, в приведенном ниже примере верхний и нижний блоки будут объединены, и роботу Googlebot будет запрещено сканировать « /б » и «/а ».
Таким образом, в приведенном ниже примере верхний и нижний блоки будут объединены, и роботу Googlebot будет запрещено сканировать « /б » и «/а ».
Пользовательский агент: Googlebot
Diswallow: /BПользовательский агент: Bing
Dislower: /AПользовательский агент: Googlebot
Diswalling: /A
Robots.txt Alling
4
.TXT. Talling
4
.TXT. Talling
4
9
.TXT.Txt. Правило .txt «разрешить» явно разрешает сканирование определенных URL-адресов. Хотя это значение по умолчанию для всех URL-адресов, это правило можно использовать для перезаписи правила запрета. Например, если «
/locations » запрещено, вы можете разрешить сканирование « /locations/london », имея специальное правило « Разрешить: /locations/london ».
Приоритезация файла robots.txt
Если к URL-адресу применяется несколько разрешающих и запрещающих правил, применяется правило с самым длинным соответствием. Давайте посмотрим, что произойдет для URL « /home/search/shirts » со следующими правилами:
Запретить: /home
Разрешить: *search/*
Запретить: *shirts
В этом случае, URL-адрес разрешен для обхода, поскольку правило разрешения имеет 9символов, в то время как правило запрета имеет только 7. Если вам нужно разрешить или запретить конкретный URL-адрес, вы можете использовать *, чтобы сделать строку длиннее. Например:
Disallow: *******************/shirts
одинаковой длины, последует запрет. Например, URL « /search/shirts » будет запрещен в следующем сценарии:
Запретить: /search
Разрешить: *shirts
Директивы robots.
 txt
txtДирективы уровня страницы (которые мы рассмотрим позже в этом руководстве) — отличные инструменты, но проблема с ними заключается в том, что поисковые системы должны просканировать страницу, прежде чем будут в состоянии прочитать эти инструкции, которые могут расходовать краулинговый бюджет.
Директивы robots.txt могут помочь уменьшить нагрузку на бюджет сканирования, поскольку вы можете добавлять директивы непосредственно в файл robots.txt, а не ждать, пока поисковые системы просканируют страницы, прежде чем предпринимать какие-либо действия. Это решение намного быстрее и проще в управлении.
Следующие директивы robots.txt работают так же, как директивы allow и disallow, в том смысле, что вы можете указать подстановочные знаки ( * ) и использовать символ $ для обозначения конца строки URL.
Robots.txt noIndex
Robots.txt noindex — это полезный инструмент для управления индексацией поисковыми системами без расходования краулингового бюджета. Запрет страницы в robots.txt не означает ее удаление из индекса, поэтому директиву noindex гораздо эффективнее использовать для этой цели.
Запрет страницы в robots.txt не означает ее удаление из индекса, поэтому директиву noindex гораздо эффективнее использовать для этой цели.
Google официально не поддерживает robots.txt noindex, и вам не следует полагаться на него, потому что, хотя он работает сегодня, он может не работать завтра. Этот инструмент может быть полезен, и его следует использовать в качестве краткосрочного исправления в сочетании с другими долгосрочными элементами управления индексами, но не в качестве критически важной директивы. Взгляните на тесты, проведенные ohgm и Stone Temple , которые доказывают, что функция работает эффективно.
Вот пример использования файла robots.txt noindex:
[код]
Агент пользователя: *
NoIndex: /directory
NoIndex: /*?*sort=
[/code]
Помимо noindex, Google в настоящее время неофициально подчиняется нескольким другим директивам индексации, когда они помещается в файл robots.txt. Важно отметить, что не все поисковые системы и краулеры поддерживают эти директивы, а те, которые поддерживают, могут перестать их поддерживать в любое время — не стоит полагаться на их постоянную работу.
Важно отметить, что не все поисковые системы и краулеры поддерживают эти директивы, а те, которые поддерживают, могут перестать их поддерживать в любое время — не стоит полагаться на их постоянную работу.
Распространенные проблемы с файлом robots.txt
Существует ряд ключевых проблем и соображений относительно файла robots.txt и его влияния на производительность сайта. Мы нашли время, чтобы перечислить некоторые ключевые моменты, которые следует учитывать при работе с robots.txt, а также некоторые из наиболее распространенных проблем, которых вы, надеюсь, сможете избежать.
- Иметь резервный блок правил для всех ботов — Использование блоков правил для определенных строк пользовательского агента без резервного блока правил для всех остальных ботов означает, что ваш веб-сайт в конечном итоге столкнется с ботом, у которого нет наборов правил. следовать.
- I Важно, чтобы файл robots. txt обновлялся . Относительно распространенная проблема возникает, когда файл robots.txt устанавливается на начальном этапе разработки веб-сайта, но не обновляется по мере роста веб-сайта. потенциально полезные страницы запрещены.
- Помните о перенаправлении поисковых систем через запрещенные URL-адреса — например, /product > /disallowed > /category
- Чувствительность к регистру может вызвать много проблем — Веб-мастера могут ожидать, что часть веб-сайта не будет просканирована, но эти страницы могут быть просканированы из-за альтернативных регистров, т. е. «Disallow: /admin» существует, но поисковые системы сканируют « /ADMIN ».
- Не запрещать URL-адреса с обратными ссылками — Это предотвращает попадание PageRank на ваш сайт от других, которые ссылаются на вас.
- Задержка сканирования может вызвать проблемы с поиском — Директива « Crawl-delay » заставляет сканеры посещать ваш веб-сайт медленнее, чем им хотелось бы, а это означает, что ваши важные страницы могут сканироваться реже, чем оптимально. Этой директиве не следуют ни Google, ни Baidu, но поддерживают Bing и Яндекс.
- Убедитесь, что robots.txt возвращает код состояния 5xx только в том случае, если весь сайт недоступен. — Возврат кода состояния 5xx для /robots.txt указывает поисковым системам, что веб-сайт закрыт на техническое обслуживание. Обычно это означает, что позже они снова попытаются просканировать веб-сайт.
- Запрет Robots.txt переопределяет инструмент удаления параметров . Помните, что ваши правила robots.txt могут переопределять обработку параметров и любые другие подсказки индексации, которые вы могли дать поисковым системам.
- Разметка окна поиска дополнительных ссылок будет работать с заблокированными страницами внутреннего поиска. — страницы внутреннего поиска на сайте не должны быть доступными для сканирования, чтобы разметка поля поиска дополнительных ссылок работала.
- Запрет переноса домена повлияет на успех переноса — Если вы запретите перенос домена, поисковые системы не смогут отслеживать какие-либо перенаправления со старого сайта на новый, поэтому миграция маловероятна. быть успешным.
 txt обновлялся . Относительно распространенная проблема возникает, когда файл robots.txt устанавливается на начальном этапе разработки веб-сайта, но не обновляется по мере роста веб-сайта. потенциально полезные страницы запрещены.
txt обновлялся . Относительно распространенная проблема возникает, когда файл robots.txt устанавливается на начальном этапе разработки веб-сайта, но не обновляется по мере роста веб-сайта. потенциально полезные страницы запрещены. Этой директиве не следуют ни Google, ни Baidu, но поддерживают Bing и Яндекс.
Этой директиве не следуют ни Google, ни Baidu, но поддерживают Bing и Яндекс. быть успешным.
быть успешным.
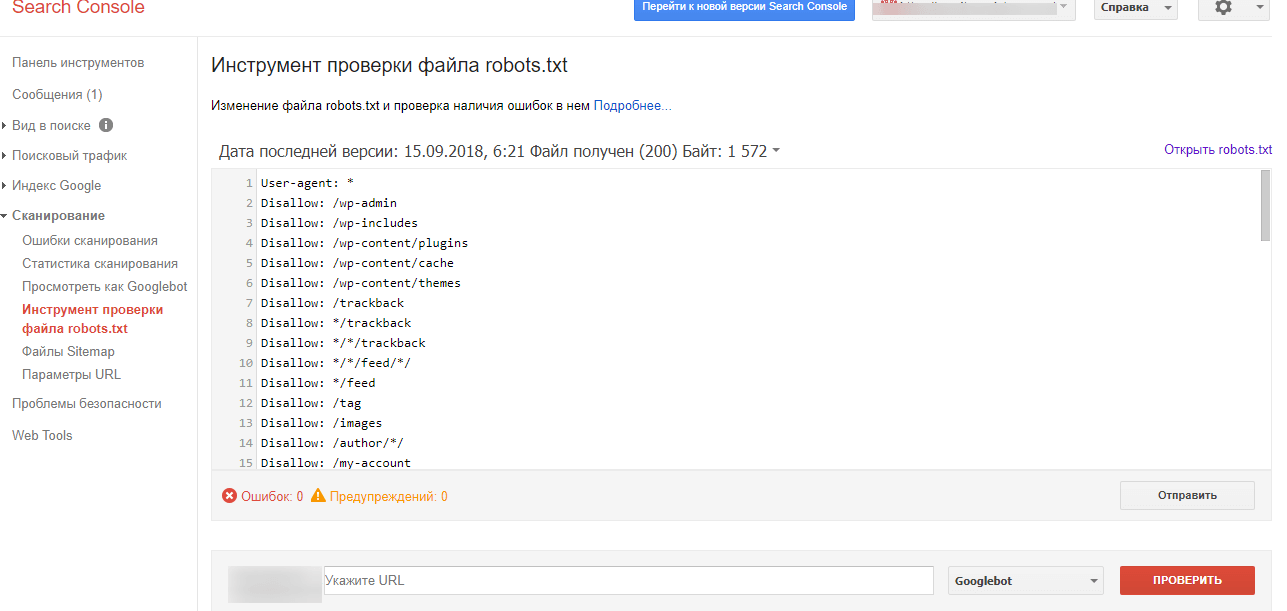
Testing & Auditing Robots.txt
Учитывая, насколько опасным может быть файл robots.txt, если содержащиеся в нем директивы обрабатываются неправильно, существует несколько способов проверить его, чтобы убедиться, что он настроен правильно. . Взгляните на это руководство о том, как проверять URL-адреса, заблокированные robots.txt , а также на следующие примеры: показать вам, какие страницы заблокированы от поисковых систем вашим файлом robots.txt.
Мониторинг изменений robots.txt
Когда над сайтом работает много людей, и с проблемами, которые могут возникнуть, если хотя бы один символ не на месте в файле robots.txt, постоянно отслеживание ваших robots.txt имеет решающее значение. Вот несколько способов проверить наличие проблем:
- Проверьте Google Search Console, чтобы увидеть текущий файл robots.txt, который использует Google. Иногда robots.txt может быть доставлен условно на основе пользовательских агентов, так что это единственный способ увидеть именно то, что видит Google.
- Проверьте размер файла robots.txt, если вы заметили значительные изменения, чтобы убедиться, что он не превышает установленного Google ограничения размера в 500 КБ.
- Перейдите к отчету о статусе индекса Google Search Console в расширенном режиме, чтобы сверить изменения robots.txt с количеством запрещенных и разрешенных URL-адресов на вашем сайте.
- Запланируйте регулярное сканирование с помощью Lumar, чтобы постоянно видеть количество запрещенных страниц на вашем сайте и отслеживать изменения.

Далее: Директивы о роботах на уровне URL
Полное руководство по работе поисковых систем:
Как поисковые системы сканируют веб-сайты
Как работает индексирование в поисковых системах?
Каковы различия между поисковыми системами?
Что такое краулинговый бюджет?
Что такое Robots.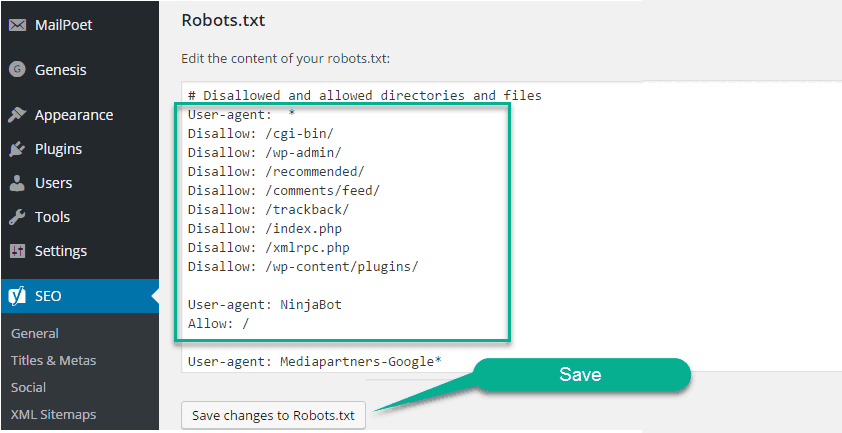 txt? Как robots.txt используется поисковыми системами?
txt? Как robots.txt используется поисковыми системами?
Руководство по директивам Robots.txt
Дополнительные учебные ресурсы:
Noindex, Nofollow и Disallow
Узнайте, как использовать директивы сканирования и индексации для улучшения SEO. Покрытие директив nofollow, noindex и disallow.
Как сделать свой сайт мультипликатором производительности для формирования спроса
Узнайте, как использовать состояние веб-сайта и поисковую оптимизацию в качестве мультипликаторов эффективности для усилий маркетинговых групп по формированию спроса.
Рэйчел Костелло
SEO и контент-менеджер
Рэйчел Костелло — бывший технический SEO-менеджер и менеджер по контенту в Lumar. Вы чаще всего найдете, что она пишет и говорит обо всем, что связано с SEO.
Вы чаще всего найдете, что она пишет и говорит обо всем, что связано с SEO.
Каковы лучшие правила файла robots.txt для мультисайтов? » Rank Math
Одна из самых важных вещей, которые вы можете сделать для обеспечения успеха своего веб-сайта, — это создать и поддерживать хорошо оптимизированный файл robots.txt.
В файле robots.txt указано, какие страницы вашего веб-сайта поисковые системы, такие как Google, должны сканировать, а какие страницы следует игнорировать. Это важно, потому что вы не хотите, чтобы каждая страница на вашем сайте была проиндексирована, особенно если некоторые из этих страниц имеют низкое качество или дублируют контент.
Если у вас мультисайт WordPress, вам нужно быть особенно осторожным с файлом robots.txt. Это связано с тем, что мультисайт WordPress может иметь сотни или даже тысячи веб-сайтов, каждый со своими индивидуальными настройками.
Хорошей новостью является то, что Rank Math упрощает управление файлом robots.txt на мультисайте WordPress. В этой статье базы знаний мы поможем вам создать лучшие правила файла robots.txt для мультисайтов с помощью Rank Math SEO.
В этой статье базы знаний мы поможем вам создать лучшие правила файла robots.txt для мультисайтов с помощью Rank Math SEO.
1 Технические данные Robots.txt Синтаксис
Во-первых, давайте посмотрим, что вам нужно включить в файл robots.txt.
- Агент пользователя: Каждая поисковая система идентифицирует себя строкой агента пользователя, которая обычно скрыта от пользователя, но может быть видна в журналах веб-сервера. Пользовательские агенты используются для определения того, какой поисковый робот обращается к странице, и могут использоваться для идентификации поисковой системы. Например, роботы Google идентифицируются как Googlebot, роботы Yahoo — как Slurp, а роботы Bing — как BingBot.
- Disallow: Вы можете запретить поисковым системам открывать или сканировать определенные файлы, страницы или разделы вашего веб-сайта с помощью директивы Disallow. Директива Disallow используется для предотвращения прямого доступа к файлу, папке или ресурсу на веб-сервере.
- Allow: Директива Allow разрешает запрос, если на сервере есть указанный файл, каталог или URL-адрес. Другими словами, он переопределяет директиву Disallow. Он поддерживается как Google, так и Bing. Директивы Allow и Disallow вместе позволяют вам контролировать, какие поисковые роботы, такие как Googlebot, могут видеть и получать доступ к вашему веб-сайту. Вы даже можете установить правила для определенных страниц, чтобы сканер видел только набор страниц в определенной папке и ничего больше.
- Карта сайта: Вы можете использовать эту команду, чтобы вызвать местоположение любой карты сайта XML, связанной с этим URL-адресом. Это полезно при отправке сайта для целей SEO. Google и Bing — основные поисковые системы, поддерживающие карты сайта.
- Crawl-Delay: Печальная правда веб-хостинга заключается в том, что, хотя большую часть времени ваш сайт работает нормально, вы неизбежно столкнетесь с ситуацией, когда возникает проблема с вашим сервером, и ему может потребоваться некоторое работать над тем, чтобы вернуть все как было. Директива Crawl-delay — это неофициальный метод, позволяющий избежать перегрузки веб-сервера слишком большим количеством запросов.
 Директива Crawl-delay — это неофициальный метод, позволяющий избежать перегрузки веб-сервера слишком большим количеством запросов.
Директива Crawl-delay — это неофициальный метод, позволяющий избежать перегрузки веб-сервера слишком большим количеством запросов.Теперь, когда вы знаете, что включить в файл robots.txt, давайте посмотрим, как создать лучшие правила для мультисайта WordPress с помощью Rank Math. Прежде чем мы начнем, вам необходимо убедиться, что на вашем сайте WordPress установлена и активирована последняя версия Rank Math.
Примечание: Если вы хотите узнать, как добавить robots.txt для одного сайта, в этой базе знаний есть статья, в которой объясняется, как настроить robots.txt для одного сайта.
2 Как установить файл robots.txt для мультисайта?
Когда вы устанавливаете Rank Math на мультисайт или несколько доменов, вы должны установить его в сети и использовать только на отдельных веб-сайтах.
Но учтите, что файл robots.txt можно изменить только на основном сайте сети, а все остальные наследуют настройки от основного сайта.
Это связано с тем, что сайты в сети не имеют фактической файловой структуры, которая могла бы поддерживать эти типы файлов, и это ограничение функциональности мультисайта.
Обычно файл robots.txt должен находиться в верхнем каталоге вашего веб-сервера. Даже если это установка из подкаталога, файл robots.txt должен быть доступен по основному URL-адресу.
Но Rank Math использует фильтр robots_txt для добавления содержимого. Если файл robots.txt существует на сервере, Rank Math автоматически отключает возможность редактировать или изменять файл robots.txt. Это делается для того, чтобы пользователь не перезаписал файл.
3 Как обработать файл robots.txt на мультисайте с помощью Rank Math?
Если вы используете мультисайт WordPress, файл robots.txt немного сложнее, и вам нужно быть осторожным при его редактировании. Лучший способ отредактировать файл robots.txt на мультисайте WordPress — использовать сетевые настройки, чтобы определить, какие правила применяются к тем или иным сайтам в вашей сети.
Примечание: Мы предполагаем, что вы уже установили Rank Math на мультисайт WordPress, в противном случае мы рекомендуем прочитать эту статью Установка Rank Math в мультисайтовой среде.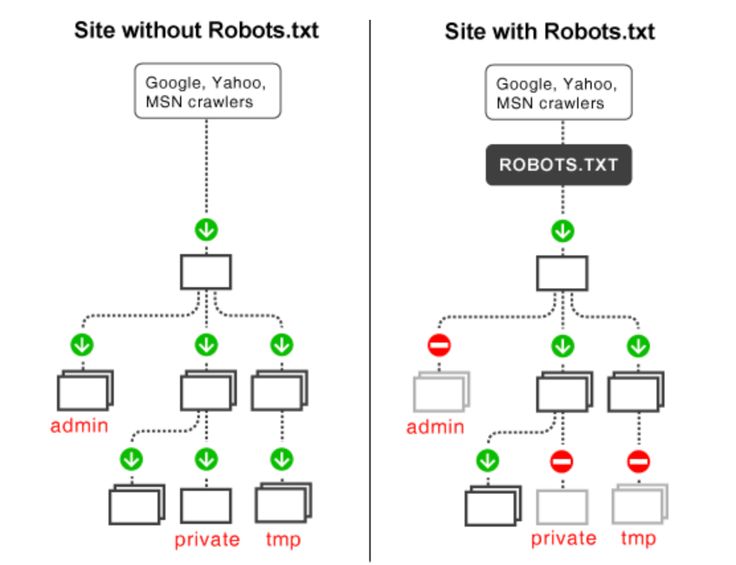
Для этого перейдите в раздел Network Admin > Sites .
Затем щелкните вкладку Dashboard для сайта, для которого вы хотите добавить правила robots.txt.
Когда вы окажетесь на панели инструментов сайта, перейдите Rank Math > General Settings . Здесь вы сможете отредактировать файл robots.txt и добавить необходимые правила.
Убедитесь, что вы сохранили изменения, прежде чем покинуть страницу. Повторите эти шаги для каждого сайта в вашей сети, на который вы хотите добавить правила robots.txt.
4 Примеры правила robots.txt
В robots.txt разрешено лишь несколько правил, и их следует использовать немедленно. Если вы совершите небольшую ошибку, вы можете потерять весь с трудом заработанный трафик и потерять позицию в рейтинге. Вот несколько примеров правил robots.txt:
4.1 Разрешить весь домен и заблокировать определенный подкаталог
Это позволит ботам поисковых систем получить доступ ко всем страницам вашего сайта, за исключением страниц, расположенных в папке /subdirectory/ .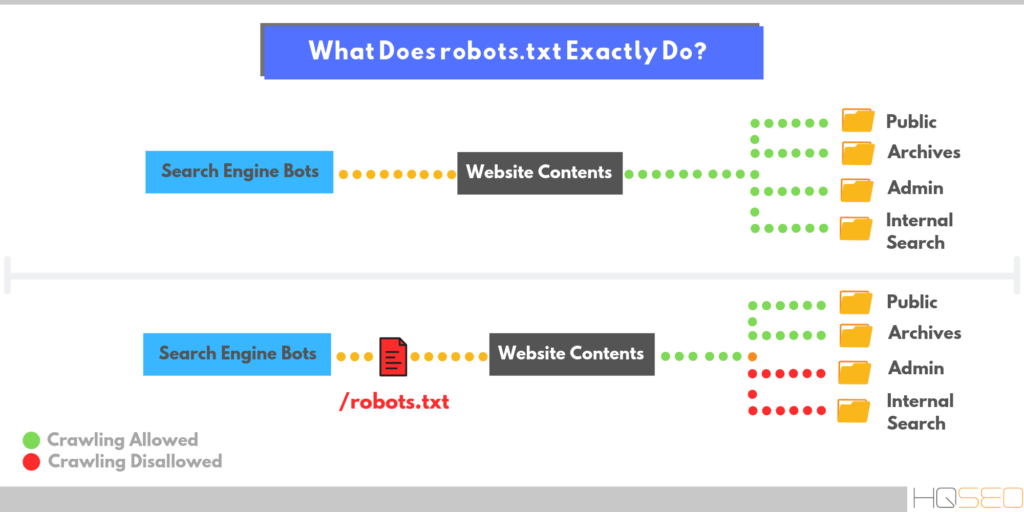 Если у вас многосайтовая сеть и вы хотите заблокировать доступ к определенному дочернему сайту, вы можете использовать этот код:
Если у вас многосайтовая сеть и вы хотите заблокировать доступ к определенному дочернему сайту, вы можете использовать этот код:
Агент пользователя: * Запретить: /подсайт/ Карта сайта: https://www.example.com/sitemap.xml
В приведенном выше примере символ * является подстановочным знаком, который позволяет всем ботам получить доступ к веб-сайту. Disallow говорит ботам не сканировать какие-либо страницы в каталоге дочернего сайта. Карта сайта сообщает ботам, где найти вашу карту сайта, чтобы они могли более эффективно сканировать ваш сайт.
Обязательно замените /subsite/ на нужный каталог.
4.2 Запрет сканирования всего веб-сайта
Это правило запрещает роботам поисковых систем сканировать весь ваш сайт. / в правиле представляет корень каталога веб-сайта и включает все веб-страницы.
Это правило не рекомендуется для действующих веб-сайтов, поскольку оно блокирует поисковые роботы от сканирования и индексации вашего веб-сайта.
Вы можете использовать это правило, когда ваш веб-сайт находится в стадии разработки, когда вы не хотите, чтобы поисковые роботы получали доступ и индексировали содержимое, которое еще не показано.
Агент пользователя: * Запретить: /
4.3 Запретить сканирование всего веб-сайта для определенного бота
Если вы хотите защитить доступ к вашему веб-сайту только от определенных поисковых роботов, вы можете заменить подстановочный знак в агенте пользователя на имя поисковых роботов, например как Рекламный робот Google .
Агент пользователя: AdsBot-Google Disallow: /
Теперь, блокируя вышеупомянутый краулер, если вы хотите, чтобы другие боты поисковых систем сканировали ваш сайт, используйте следующее.
Агент пользователя: AdsBot-Google Запретить: / Пользовательский агент: * Разрешить: /
4.4 Default Robots.txt в Rank Math
По умолчанию вы сможете увидеть следующие правила в поле редактора файла robots.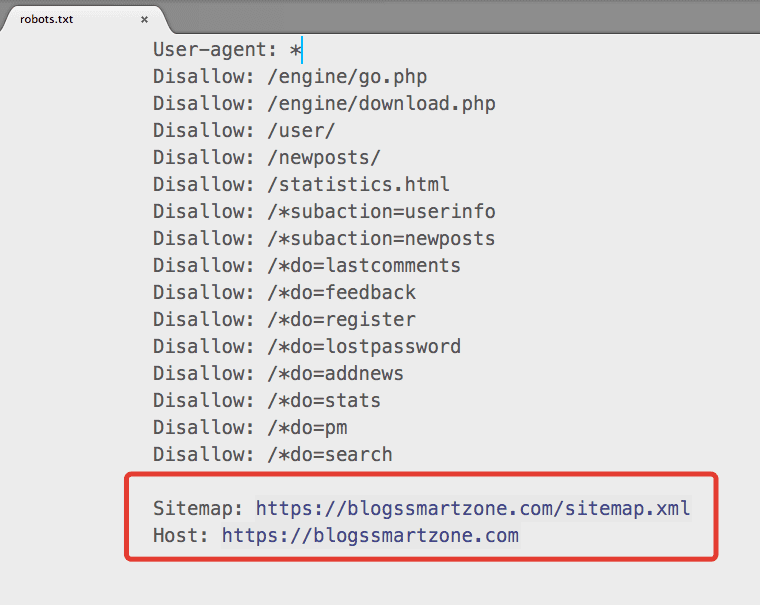
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php Карта сайта: yoursite.com/sitemap_index.xml
Вы можете изменить или настроить это правило в соответствии со своими потребностями. Но мы рекомендуем вам сохранить копию этого правила, прежде чем вносить какие-либо изменения.
4.5 Запретить доступ к определенному каталогу
Если вы хотите заблокировать доступ к определенным каталогам на своем веб-сайте, вы можете включить относительный путь каталога в правило запрета. Следующее правило показывает вам один пример, когда вы можете заблокировать доступ к страницам каналов на своем веб-сайте.
Агент пользователя: * Запретить: */feed/
4.6 Запретить сканирование файлов определенного типа
Вы также можете рассмотреть возможность использования следующего правила, чтобы запретить сканерам поисковых систем доступ к определенным типам файлов или их сканирование.
Агент пользователя: * Disallow: /*.