
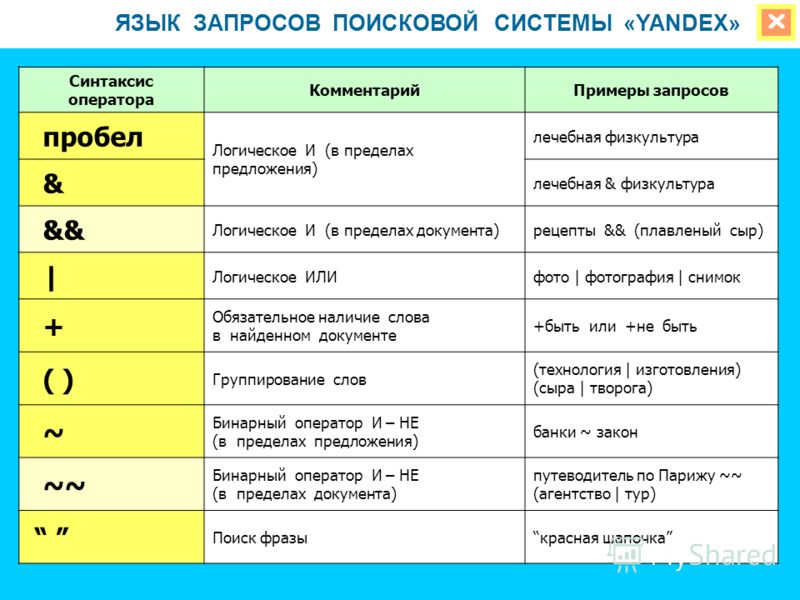
Как искать в яндексе точное соответствие
Как искать в Яндексе точное соответствие?
Часто работаю с документами, и например если надо найти в поиске документ в котором есть точное словосочетание, Яндекс выдает какую-то фигню. Первые страницы 2-3 точно продираюсь через всякие статьи, полные воды (иногда залипаю конечно, но не на все). Помогите, хочу чтобы было все сразу!
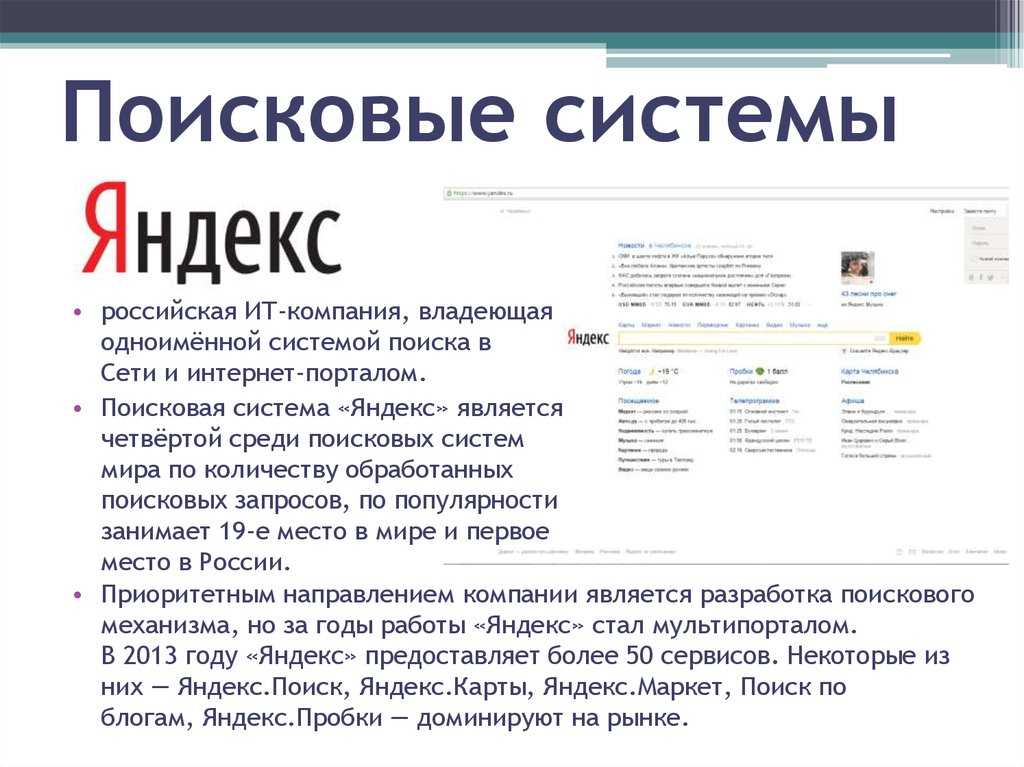
Да, заключаешь в кавычки и все, в выдаче только сайты и страницы с полным соответствием запросу. У Яндекса и другие фишки есть на самом деле, разные операторы, например:
- ! фиксирует форму слова, то есть Яндекс будет искать при запросе !машина именно это слово, и не покажет запросы с «машиной», «машине» и тд;
- mime: (и указываешь расширение, например, pdf) — тогда Яндекс будет искать не страницы на сайтах, а именно сами файлы, которые можно скачать или просмотреть, удобно при поиске документов;
- << — определяет обязательные дополнительные слова, например пишешь «купить автомобиль» и через операторов подержанный в Москве, будет искать только б/у в этом городе;
- () — в скобках через | можно указать разные слова, и Яндекс будет искать страницы, на которых есть все они, это для синонимов, если не уверен в написании.

Полазь по интернету, езе много нового узнаешь про операторы.
По-моему, проще всего если знаешь конкретный сайт, использовать поиск по самому сайту. Если нет его или он не работает, то оператор site:… — вместо троеточия просто домен. То есть вводишь запрос, пишешь оператор и домен после него, и Яндекс ищет строго на этом ресурсе.
Просто поставь словосочетание в кавычки, и все — Яндекс будет искать словосочетание ровно так, как ты его написал, не меняя падежа, склонения и тд, не подставляя других слов. Правда, если это словосочетание встречается не только в документе нужном, то в выдаче все равно увидишь другие сайты, от этого никуда не деться, так работает поисковик.
Смотри, как это работает:
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Продвинутый поиск в Яндекс
Оглавление
Особенности поиска в Яндекс
Предыдущая статья была посвящена тонкостям поиска в Google. Поисковая система Яндекс тоже имеет расширенные возможности поиска и продвинутые операторы. У Яндекс очень хороший охват русскоязычных сайтов, поэтому если целевой сайт на русском языке, то на этапе сбора информации имеет смысл воспользоваться также и Яндексом.
Поисковая система Яндекс тоже имеет расширенные возможности поиска и продвинутые операторы. У Яндекс очень хороший охват русскоязычных сайтов, поэтому если целевой сайт на русском языке, то на этапе сбора информации имеет смысл воспользоваться также и Яндексом.
Синтаксис запросов в Яндекс отличается от Google: операторы называются по-другому и логика их работы отличается, аналоги каких-то гугловских операторов отсутствуют вовсе, а какие-то, напротив, являются уникальными только для Яндекса.
Пожалуй, главным отличием поиска Яндекса является свой собственный индекс, с огромным охватом сайтов на русском языке. А также свои собственные алгоритмы определения релевантности (насколько страница соответствует поисковому запросу) и ранжирования (как высоко в результатах поисковой выдачи должна находиться страница).
И хотя операторы поиска в Яндекс работают иначе чем в Google, они довольно гибкие для составления в том числе и сложных запросов по нескольким критериям. Я покажу несколько примеров Яндекс-дорков, с помощью которых можно найти пароли и другую очень интересную для пентестера информацию.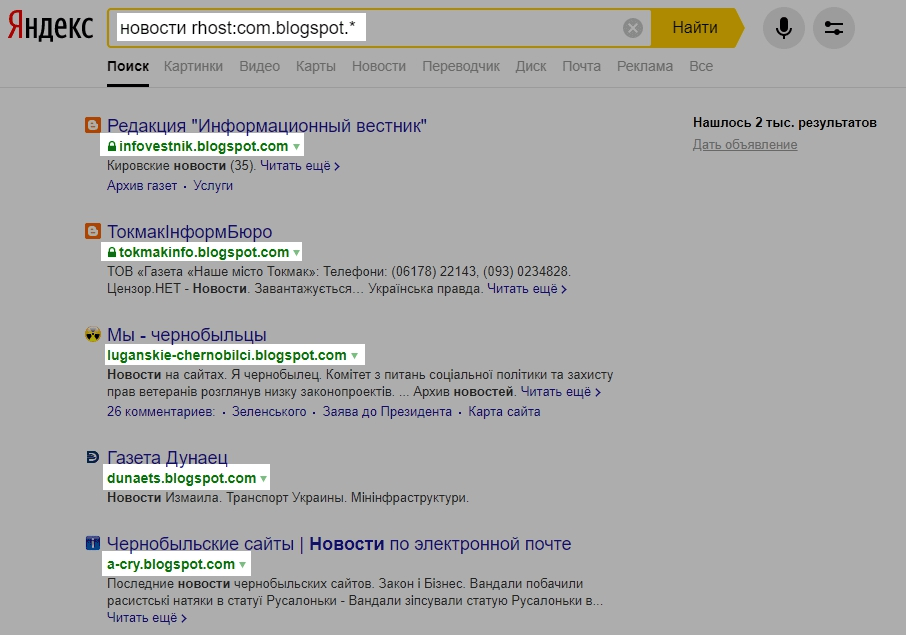
Итак, давайте познакомимся с продвинутыми приёмами поиска Яндекс, которые в любом случае пригодятся всем, кто что-то ищет в Интернете (то есть всем) – даже если вы не занимаетесь расследованиями на основе открытых источников.
Язык запросов Яндекс для расширенного поиска
Поиск по одному слову
Яндекс ищет не только по точной форме слова, но и по различным его формам (единственное-множественное число, различные падежи, различные глагольные формы и другое). В справке это не указано, но очевидно, что поиск производится также по синонимам слова
Поиск по фразе
Ищутся страницы, содержащие все слова из фразы. Как и для отдельных слов, поиск выполняется по различным словоформам, синонимам
Найдёт страницы, содержащие фразы «недорогие авиабилеты», «дешёвые авиабилеты», «поиск дешёвых авиабилетов» и другие.
Поиск слова в заданной форме
Если вы не хотите, чтобы при поиске использовались различные формы слова либо его синонимы, то перед этим словом поставьте восклицательный знак (!):
Допустимо использовать несколько операторов ! в рамках одного запроса.
На самом деле, результаты поиска по-прежнему содержат документы с синонимами – возможно, этот оператор работает не всегда или влияют другие факторы.
Важные слова в поисковом запросе
Необычная концепция – будет выполнен поиск документов, в которых обязательно присутствует выделенное знаком плюс (+) слово. Допустимо использовать несколько операторов + в одном запросе.
Т.е. по приведённому поисковому запросу обязательно будут найдены страницы, содержащие слова «доехать» «суварнабхуми» «сукумвит» и, возможно, слово «дёшево».
Поиск по точной цитате
Точно также как в Гугл, вы можете искать страницы, содержащие точную цитату. Для этого поместите её в кавычки.
Будут найдены страницы (документы) которые содержат все слова поискового запроса, именно в той последовательности и в точной форме, как они идут в самом запросе.
Поиск по цитате с пропущенным словом (словами)
Один оператор * соответствует одному пропущенному слову.
Вы можете использовать это только при поиске по точной цитате – т.е. внутри двойных кавычек.
Правда иногда Яндекс издевается:
В общем, я так и не вспомнил, какое там именно слово…
Поисковый запрос с альтернативами
Вы можете выполнить поиск страниц, в которых присутствует любое слово из запроса – это ещё называют логическим ИЛИ. Для этого используется оператор, обозначенный символом труба (|). Операторы отделяется от слов пробелами.
Допустимо использовать несколько операторов | в одном запросе.
Напомню, что в Google можно использовать оператор OR либо также использовать трубу.
Поиск любой из фраз
Вы можете использовать ИЛИ (|) вместе с поиском по точно совпадающим фразам.
В результате будут найдены страницы, содержащие фразу «большой адронный коллайдер», а также страницы с фразой «смешные кошки».
Использование скобок для группировки
По умолчанию, логическое ИЛИ разбивает поисковый запрос на две части – то, что стоит до этого оператора и то, что стоит после него.
привёл бы к тому, что поисковая система стала бы искать страницы с фразой «обучение java» и страницы с фразой «PHP». Но если нам нужно, чтобы были найдены страницы с фразой «обучение java» и страницы с фразой «обучение PHP», то нам нужно использовать скобки для отделения обязательной части от альтернативной.
Поиск документов, в которых отсутствует заданное слово
При поиске по фразе из нескольких слов, вы можете указать те слова, которые не должны встречаться на найденных страницах. Т.е. в результатах поиска будут те документы, на которых есть искомая раза, но без нежелательного слова.
В качестве оператора отрицания используется знак минус (—). Исключается только слово, перед которым стоит оператор. При этом исключаемое слово должно размещаться в конце поискового запроса.
Допустимо использовать несколько операторов минус (—) в одном запросе.
Видимо, минус работает только со словами для поиска, но не работает с операторами, которые будут рассмотрены далее.
Продвинутые операторы
Уточнить поисковый запрос можно с помощью данных, относящихся к служебной информации о страницах. Например, можно ограничить поиск по:
- типу файла
- хосту
- URL
- языку страницы
- дате
Синтаксис для уточнения поиска по данным параметрам называется «документные операторы».
Документный оператор рекомендуется указывать после текста поискового запроса и отделять от него пробелом. В одном запросе одновременно можно использовать несколько операторов, так же разделяя их пробелом. Например,
При использовании операторов, где в качестве параметра задается имя хоста (url, host и rhost), следует указывать главное зеркало сайта. Например,
Поиск по страницам, размещенным по заданному адресу (URL)
Для поиска по определённому адресу страницы используется оператор url: со следующим синтаксисом:
Регистр букв в адресе не учитывается.
Чтобы найти все документы, адреса которых начинаются с заданного значения, поставьте в конце URL символ *.
URL в запросе следует заключить в кавычки, если он содержит один из следующих символов:
- '
- «
- (
- )
- _
Обратите внимание, что запрос:
Ничего не найдёт! Поскольку поиск будет проводиться именно по домашней странице hackware.ru (а не по всему сайту). Чтобы выполнялся поиск по всему сайту используйте звёздочку:
Параметр url: предназначен в первую очередь для поиска по определённым разделам сайта, например:
Будет выполнен поиск фразы «уязвимость sql инъекция» только по страницам вида hackware.ru/?cat= (категории).
Для поиска по всему целевому хосту используйте один из следующих параметров.
Поиск по всем поддоменам и страницам указанного сайта
Будут найдены документы, содержащие фразу «уязвимость sql инъекция» и размещенные на поддоменах и страницах сайта hackware. ru.
ru.
Поиск по страницам, размещенным на данном хосте
Идентичен оператору url: с заданным именем хоста.
Будут найдены документы, содержащие слово «sqli» и размещенные на хосте tools.kali.org (один из поддоменов сайта kali.org).
Другой вариант поиска страниц на определённому субдомене – это использование оператоора rhost:
Идентичен оператору host:, но имя хоста записывается в обратном порядке: сначала домен верхнего уровня, затем домен второго уровня и т. д.
Для поиска по всем поддоменам заданного домена в конце URL поставьте символ *.
Вариант с подстановочным символом:
Пример, вывод всех страниц поддомена tools.kali.org:
Показать все страницы любых субдоменов kali.org, начинающихся на букву a:
Поиск по доменам
Обратите внимание, что домен может быть любого уровня. То есть можно указать домен верхнего уровня, такой как ru, net, org, name, com и т. д. Можно указать домен второго уровня, например, hackware, zalinux, yandex, google и т. д. Также можно указать домен любого другого уровня.
д. Можно указать домен второго уровня, например, hackware, zalinux, yandex, google и т. д. Также можно указать домен любого другого уровня.
Пример поиска по домену верхнего уровня:
Будет найдена фраза «information security labs» только на сайтах доменной зоны edu.
Поиск по домену других уровней. Этот вариант будет искать любые домены второго и другого уровней с именем hackware на которых встречается слово «уязвимости»:
Будет выполнен поиск по доменом верхнего уровня tools и других уровней с этим же названием:
Поиск по типу файлов
Поиск по документам в заданном типе файла. Поддерживаются следующие типы файлов:
- doc
- docx
- html
- odg
- odp
- ods
- odt
- ppt
- pptx
- rtf
- swf
- xls
- xlsx
Будут найдены документы в формате doc, содержащие слова «анкета» и «загранпаспорт».
Можно указать сразу несколько расширений для поиска, но обязательно объедините их логическим ИЛИ (|):
Поиск по страницам на заданном языке
- русский (ru)
- украинский (uk)
- белорусский (be)
- английский (en)
- французский (fr)
- немецкий (de)
- казахский (kk)
- татарский (tt)
- турецкий (tr)
Будут найдены документы на английском языке, содержащие слово «passport».
Поиск по дате и диапазону дат
А вот в этом поиск Яндекса точно обогнал Google – у Гугла очень невнятный поиск по датам изменения документа, практически, можно сказать что его нет, т.к. результаты странные.
Вы можете выполнять поиск по страницам с ограничением по дате их последнего изменения.
Варианты поиска по дате
Изменение страницы соответствует указанной дате:
Изменение страницы находится в интервале:
Изменение страницы находится до или после указанной даты (<, <=, >, >=):
Дата изменения страницы указана частично:
Примечание. Год изменения указывается обязательно. Месяц и день можно заменить символом *.
Год изменения указывается обязательно. Месяц и день можно заменить символом *.
Примеры, в которых ищется слово «фестиваль» в документах, для которых дата изменения соответствует 10.10.2014:
Дата изменения находится в интервале между 10.10.2014 и 10.11.2014 включительно:
Дата изменения позднее 10.11.2014:
Дата изменения соответствует 2014 году:
Допустим, я хочу узнать, какие страницы сайта hackware.ru изменились в период с 10 июня 2018 года по 10 июля 2018 года:
Я хочу найти любые документы на любом сайте, в которых присутствует точная фраза «алексей милосердов» и которые изменены в период с 5 июля 2018 года по 10 июля 2018 года:
Всего один документ с адресом https://student.knastu.ru/upload/works/__5dDvrTYvFwt9Z5YrqV5PRc0jiZYTcKgZzK.pdf
Кстати, можно посмотреть, какие ещё студенческие работы там есть:
Поиск по заголовку
Вы можете искать по заголовку веб-страниц. Но в Яндекс это реализовано немного необычно – вы можете искать ИЛИ по заголовку ИЛИ по документу, но не одновременно и там и там.
Чтобы выполнить поиск по названию страницы, вы можете воспользоваться формой расширенного поиска: https://yandex.ru/search/advanced. Этот интерфейс расширенного поиска больше не работает, попробуйте альтернативный вариант: https://suip.biz/ru/?act=yandex-search
Либо к адресу страницы с результатами поиска добавьте &zone=title
Возможно имеется специальный оператор, чтобы не нужно было менять URI, но я не нашёл информации об этом. Напрашивается аналогия zone:title, но, на мой взгляд, это не работает.
Если вы об этом что-то знаете – то пишите в комментариях.
Поиск по точной форме слова
Мы уже рассмотрели этот вопрос – если фраза для поиска помещена в кавычки, то на страницах ищется точное соответствие. В противном случае ищутся все формы и синонимы слов.
Если вы хотите искать по точным формам слов, но вам не важен их порядок и слова не обязательно должны составлять одну фразу, то, по идее, каждое слово можно поместить в кавычки. Ещё один вариант – это отредактировать URI. Если там wordforms=all, то выполняется поиск по всем формам, а если wordforms=exact – то ищутся точные совпадения.
Ещё один вариант – это отредактировать URI. Если там wordforms=all, то выполняется поиск по всем формам, а если wordforms=exact – то ищутся точные совпадения.
Яндекс дорки?
Поиск в Яндекс, безусловно, может оказаться полезным для исследователей на основе открытых источников. В том числе, при поиске утечек.
А как насчёт поиска в Яндекс для хакеров и пентестеров? Хотя язык запросов Яндекса менее гибок, всё равно и через Яндекс можно найти разнообразную чувствительную информацию и файлы, не предназначенные для всеобщего доступа.
Брутфорс поддоменов по одной букве
Мы уже рассматривали как с помощью Гугл перечислеть поддомены. Там же я говорил про плюсы и минусы этого способа. В Яндекс тоже есть такая возможность. Причём, для тех сайтов, которые я попробовал, Яндекс знает больше субдоменов чем Google!
Для этого можно использовать оператор rhost: Напомню, при нём домен/поддомен пишется в обратном порядке, т.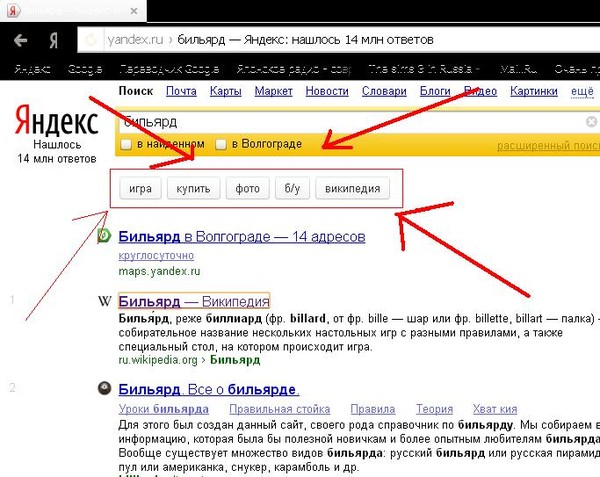 е. начиная с домена верхнего уровня, затем домен второго уровня, затем поддомен третьего уровня и так далее.
е. начиная с домена верхнего уровня, затем домен второго уровня, затем поддомен третьего уровня и так далее.
Самое интересное – используя подстановочный символ * мы можем искать по части поддомена – к слову, Google не воспринимает частично написанные домены вообще.
Допустим, меня интересуют поддомены сайта kali.org. Я делаю запросы вида:
В результате я нашёл несколько новых субдоменов, которые не смог найти с помощью Гугл:
- buildd-amd64.kali.org
- eros.kali.org
- eos.kali.org
- iris.kali.org
- images.kali.org
Можно создать скрипт и при правильно написанном алгоритме можно получить весь список субдоменов за несколько десятков запросов либо сотен запросов (в зависимости от выбранного алгоритма) – это может конкурировать с брут-форсом субдоменов по словарю. Самое важное – кроме Яндекса запросы никуда больше не делаются.
Аналогично для offensive-security.com с помощью Яндекса я нашёл субдомены, о которых не знал Гугл:
- download. offensive-security.com
 offensive-security.com
offensive-security.com- forums.offensive-security.com
- images.offensive-security.com
- support.offensive-security.com
- screenconnect.offensive-security.com:8040
Поиск папок с открытым листингом
В таких папках может быть что угодно – от публичных файлообменников до личных фото архивов.
Иногда там можно найти файлы со списком паролей:
Причём разных пользователей:
Пробуйте разные названия папок. Например, поиск папки admin листингом файлов:
Поиск папки mail (иногда в них лежат электронные письма):
Вариантов много, посмотрите также примеры для Google.
Поиск админок и страниц аутентификации
Пробуйте свои варианты!
Поиск ключей для подключения по SSH
Заключение
У поисковой системы Яндекс большой охват сайтов на русском, а теперь ещё и на некоторых иностранных языках, особенно на английском.
Зная язык запросов Яндекса можно делать очень точные поисковые запросы, чтобы найти именно то, что вам нужно.
Что касается применения поиска Яндекс при пентестинге, то он хорошо подходит для поиска информации и документов на целевом сайте. Но возможности поиска дорков у Яндекса намного беднее.
Как искать в Яндексе
В некоторых случаях требуется найти фразу в той форме, которую вы вбиваете в поисковую строку. Для этого достаточно добавить кавычки перед началом запроса и в конце.
Добавив перед каждым словом восклицательный знак, Яндекс будет искать информацию в том падеже и числе, которое вы ввели.
Это позволит сделать поиск более точным.
Поиск пропущенного слова
Может возникнуть ситуация, когда Вы забыли определенное слово в цитате. Чтобы поисковая система сразу отобразила нужный результат достаточно заключить фразу в кавычки, а на месте пропущенного слова поставить звездочку.
Яндекс сам подставит нужное значение. Хотя если фраза достаточно популярная, то этот оператор не нужен, ответ уже будет отображаться в поиске.
Хотя если фраза достаточно популярная, то этот оператор не нужен, ответ уже будет отображаться в поиске.
Поиск любого слова из списка
Может возникнуть ситуация, когда от поисковой системы требуется выбор того или иного значения для слова. При этом нужно использовать только перечисленные варианты. Например, для поиска квартиры, когда требуется посмотреть только однокомнатные квартиры и студии. Для решения этой проблемы используйте вертикальный слеш.
Это позволит искать только нужные вам ответы.
Поиск слов в одном предложении
Распространенная ситуация, когда требуется найти ответ на запрос, но при этом все слова должны находиться в пределах одного предложения. Решением проблемы является использование амперсанда (&).
Вставляем его после слов, которые должны находиться в пределах одного предложения и запускаем поиск.
Поиск запроса с определенным словом
Когда возникает необходимость получить ответ на вопрос, Яндекс не всегда выдает нужную информацию. В этом случае можно дополнить запрос знаком плюса, тогда он будет искать только те страницы, которые содержат это слово.
В этом случае можно дополнить запрос знаком плюса, тогда он будет искать только те страницы, которые содержат это слово.
Количество слов со знаком плюс не ограничено.
Исключение слова из поиска
С помощью знака минус, можно убрать ненужные слова из поиска. Например, можно использовать данную фишку, чтобы убрать коммерческие запросы из поиска.
В результате данное слово не будет участвовать в поиске.
Поиск на определенном сайте
Это можно сделать с помощью расширенного поиска Яндекса или используя оператор site. Достаточно вбить нужный запрос и добавить после него оператор site:название сайта.
Поиск будет производиться только на указанном ресурсе.
Поиск документов
Иногда требуется найти информацию, которая представлена в виде документов. Проблемой становится тот факт, что существует достаточно много расширений файлов. Чтобы искать только нужный формат, используйте оператор mime.
Поиск сайтов на нужном языке
Вбивая в поисковую строку запрос на английском языке, можно увидеть результаты поиска, которые содержат только англоязычные сайты. Для решения этой проблемы поможет оператор lang.
Для решения этой проблемы поможет оператор lang.
Чтобы отображались только русскоязычные сайты нужно использовать атрибут ru, для остальных языков операторы будут соответствовать их кодам в Яндексе.
Поиск страниц, созданных в конкретную дату
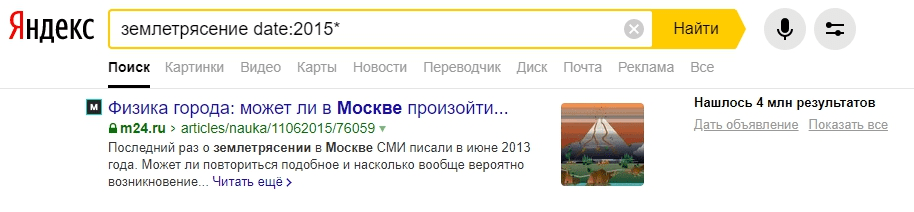
Иногда требуется отобразить данные, которые были опубликованы только сегодня или в конкретную дату. Для решения этой проблемы у Яндекса есть оператор date.
Обратите внимание, что дата должна быть введена в формате год месяц число, без пробелов.
Полезные фишки от Яндекса
Поисковую строку браузера можно использовать не только для поиска информации, но и для других полезных вещей.
Калькулятор
Просто вбейте в поисковую строку нужное алгебраическое выражение, и система выдаст в качестве результата его решение.
Конвертер валют
С помощью Яндекса всегда можно перевести деньги из одной валюты в другую.
Точное время
Поисковик позволяет определить точное время в вашем регионе (зависит от IP) и любой точке земного шара.
Ваш IP адрес
Вбейте в поисковую строку запрос «Мой ip» и он будет отображен в результатах поиска.
Пожалуй, это самые интересные и полезные функции, которые позволят упростить поиск в Яндексе и сделать его более удобным. Если Вы знаете еще какие-то секреты поиска, поделитесь ими в комментариях.
Как правильно искать в «Яндексе» – чтобы и правда нашлось всё.
В поисковике «Яндекса» есть свои любопытные лайфхаки которые помогут тебе найти практически все что угодно.
Поисковый инструментарий
В отличие от конкурента, «Яндекс» дает воспользоваться инструментарием не с главной страницы – yandex.ru, – а уже после того, как была осуществлена попытка поиска:
Инструменты поиска в «Яндексе»Нажми на значок настроек справа от поля запроса, и ты сможешь настроить основные параметры поиска:
- в каком регионе ты хочешь искать информацию;
- выбрать период времени размещения – сутки, 2 недели или месяц;
- задать язык, на котором ты хочешь найти данные.
Также обрати внимание на иконку с микрофоном — в Яндексе ты можешь задавать поисковые запросы голосом.
Ты также можешь искать картинки (здесь инструментарий вообще очень богатый), видео, товары, новости, вопросы, услуги, музыку и т.д. — все эти данные предоставляются различными сервисами того же Яндекса.
Поиск без рекламы
Если тебя раздражает главная страница «Яндекса», переполненная рекламой и отвлекающими блоками, то воспользуйся простой версией ya.ru, которая представляет собой страницу только с одним полем поиска:
Отвлекает реклама? Добро пожаловать на ya.ru!Один минус – после ввода поискового запроса ты попадешь на стандартную главную страницу с рекламой и прочими сервисами.
Уточнение слова
«Яндекс» точнее, чем Google, ищет фразы на русском языке. Но если ты хочешь найти только заданное тобой слово, его лучше уточнить с помощью оператора «!»:
Уточняем запрос с помощью оператораВ этой форме при поиске должны быть найдены все документы с упоминанием слова, которое ты отметил в форме поиска. В этом случае склонение, падеж игнорируется, но учитывается множественное или единственное число.
В этом случае склонение, падеж игнорируется, но учитывается множественное или единственное число.
Тебе предлагается самостоятельно проверить качество работы оператора, потому что даже в приведенном выше примере первая найденная статья не содержит слова, которое мы указали в сниппете (описании). Есть надежда, что он будет присутствовать при переходе на страницу.
Немного изменили запрос с помощью того же восклицательного знакаОператор может быть использован несколько раз для включения всех нужных тебе слов в выдачу.
Поиск по точной фразе
Чтобы найти точную фразу или цитату, заключи ее в любые кавычки:
Ищем точную фразу в «Яндексе» с помощью кавычекЭтот метод должен найти комбинацию слов, указанную тобой в точной форме, в то время как ты можешь оставить за пределами кавычек другие слова, которые могут быть включены в цитату в разных формах или составе.
Метод работает частично, выше ты можешь увидеть, что указанная нами фраза отсутствует во фрагменте второй позиции результатов поиска. Но это присутствует в точном указании в двух других.
Но это присутствует в точном указании в двух других.
Нахождение отсутствующих слов
Если ты знаешь точную фразу, содержание которой хочешь найти, но забыл точное слово или его часть, ты можешь указать ее с помощью оператора «*» :
Ищем информацию помня только часть фразыОператор работает только в сочетании с цитируемой фразой. И сам метод хорошо подходит в том случае, если ты указываешь длинный набор слов, но он означает множество значений, разброс которых в результатах поиска слишком велик.
Уточняем присутствие обязательных слов
Допустим, твой запрос должен содержать несколько слов, относящихся к определенной теме, но информация, найденная в нем, может быть любой. Укажи необходимые слова, используя оператора(ов) «+», а тематику укажите без операторов:
Ищем историю песен Rolling Stones без уточнения конкретного трекаТему ты можешь задать и через кавычки, чтобы гарантированно получить фразы с указанными словами именно по ней.
Исключение слов из запроса
В случае, когда тебе нужно найти информацию без упоминания определенных слов или тем, добавь слова в поисковый запрос с оператором «-», который можно использовать столько раз, сколько тебе захочется, прежде чем результаты поиска будут полностью очищены от ненужных:
Циничное исключение сервисов «Яндекса» из выдачи поиска «Яндекса»По данным Яндекса, по общему количеству поисковых запросов всегда лидируют три темы: школа, кино и порно (последние две темы-вечером и ночью). Первым делом утром люди спрашивают о погоде, включают радио и узнают значение своих снов.
Около четверти всех запросов связаны с развлекательным контентом: люди хотят смотреть, слушать и играть.
Выбор из нескольких вариантов в поиске
Когда тебе нужно найти информацию по нескольким направлениям, но не имеет значения, какое из них будет представлено в результатах поиска, раздели их оператором «|». Одно из слов, разделенных оператором, обязательно будет включено в выдачу, но не обязательно вместе с другим:
Одно из слов, разделенных оператором, обязательно будет включено в выдачу, но не обязательно вместе с другим:
Для обязательного включения нескольких слов в запрос используй операторы-кавычки или восклицательный знак.
Поиск по определенному URL
Чтобы найти текст, размещенный на выбранной тобой странице, тебе необходимо сообщить об этом через оператор «url:». Сначала нужно ввести нужное слово или фразу, затем указать страницу через оператор, и лучше заключить ее в кавычки. Следует отметить, что метод не самый удобный и не очень эффективный. Лучше использовать его расширение: используй оператор «*», чтобы отметить все страницы, расположенные в данном разделе сайта, например, так:
Оператор «звездочка» показывает, что нужно искать слово «поиск» на всех страницах в разделе /blog/«Звездочка» заменяет в поиске любые символы или даже фразы.
Поиск на заданном сайте
Чтобы избежать указания конкретных страниц, добавь URL-адрес всего сайта к нужным словам, используя оператор «site:». Таким образом, Яндекс будет искать информацию исключительно на указанном сайте, включая все его страницы.
Ищем слова «контекстная реклама» по всему заданному сайту
Ищем информацию на определенном домене
Чаще всего домен обозначает принадлежность сайта к определенной стране, поэтому ты можешь найти необходимую информацию, указав нужный домен через «domain:»:
Находим японские сайты на тему Олимпиады в Токио
Поиск файлов для скачивания
В случае, когда тебе нужен не сайт, а сразу файл с необходимой информацией, ты можешь выполнить поиск по формату этого файла. Укажи это через оператор «mime:» и добавь нужный текст:
Поиск книги рецептов в виде файла PDFКак и в Google, здесь невозможно указать сразу несколько типов файлов, чтобы искать данные сразу в нескольких типах исполнения.
Совмещай оператор с другими, например, с «site:», чтобы искать нужные файлы на определенном сайте.
Поиск на заданном языке
Если тебе нужно найти контент на определенном языке, то выбери его обозначение в соответствии со стандартом ISO 639-1 и укажи его через оператора «lang:»
Например:
- английский – en;
- испанский – es;
- итальянский – it;
- португальский – pt;
- русский – ru.
Информация по дате изменения страницы
Чтобы найти данные с указанием даты их выкладки или последнего изменения, используй оператор «date:» следующим образом:
- date:ГГГГММДД – для указания точной даты размещения;
- date:<ГГГГММДД (>) – информация раньше или позже указанной даты;
- date:ГГГГММДД..ГГГГММДД – в указанном интервале;
- date:ГГГГММ* – в указанном месяце года;
- date:ГГГГ* – в указанном году.

Поиск только по заголовкам
Если тебе нужно найти слова или фразы исключительно в заголовке страниц сайта, то используй оператор «title:»
Ищем фразу, расположенную исключительно в заголовке страницы
Переводчик в поисковой строке
Чтобы сразу перевести текст (по умолчанию с русского на английский или с определенного системой языка на русский), набери «перевод:слово»:
Переводи текст прямо в поисковой строке
«Яндекс.Калькулятор»
Просто набери в поисковой строке слово «калькулятор»:
Стандартный сервис «Яндекса» решит твои проблемыКроме того, ты можешь написать выражение в поисковую строку, и «Яндекс.Калькулятор» сразу его посчитает:
И даже считать за тебя будет
«Яндекс.Конвертер»
Ты можешь переводить одни единицы в другие, просто начав вводить их название:
Шпаргалка всегда под рукойЕсли тебе нужно рассчитать конкретное значение одних единиц в других, то введи выражение и получи ответ прямо в браузере.
Быстрый прогноз погоды
Чтобы не ходить по сайтам с погодой, ты можешь набрать слово «погода» и указать свой город, после чего увидишь краткую сводку гидрометцентра:
Сводка погодыЕсли ты не укажешь город, то «Яндекс» покажет погоду в месте, определенном по твоим координатам из браузера.
Дополнительные настройки поиска в «Яндексе»
Для персонализации поиска ты можешь воспользоваться настройками, ссылка на которые располагается в нижней части страницы поисковой выдачи:
Меню настроек поиска в «Яндексе» на странице выдачиДо этого ты можешь включить семейный поиск, чтобы избавить выдачу от непристойных результатов и спорного контента.
Содержание самих настроек поиска:
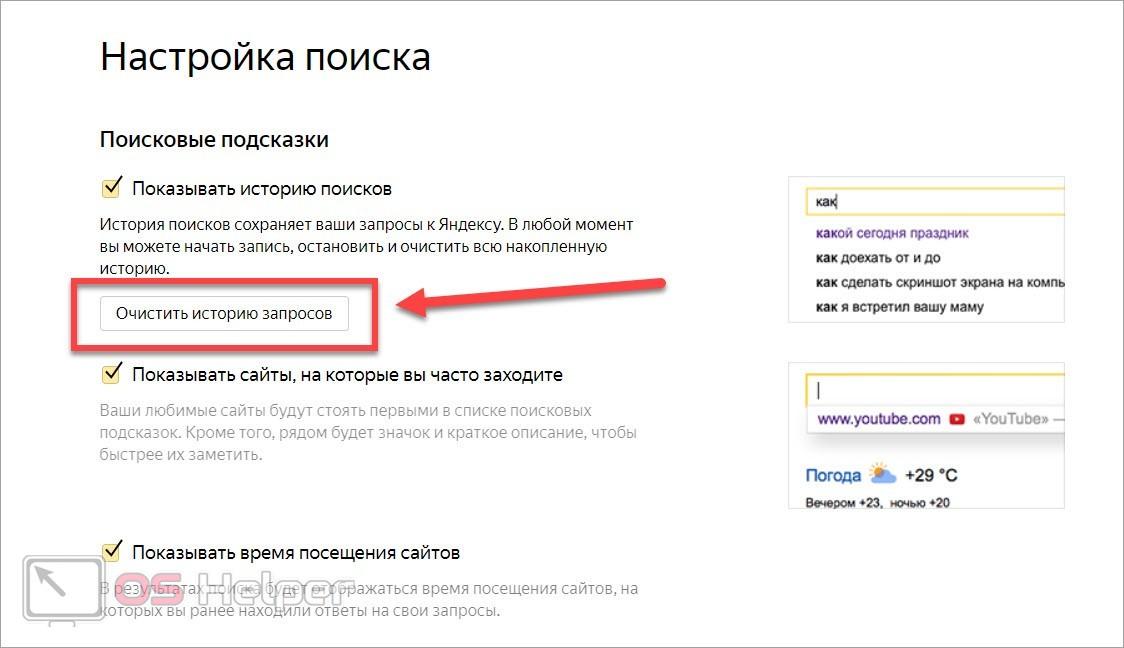
Укажи, насколько сильно ты хочешь персонализации- Чтобы не забыть какие запросы ты вводил, используй историю поиска. Ее ты можешь очистить в настройках или отключить, сняв галочку.
- Часто используемые сайты могут помочь, если ты используешь некоторые ресурсы постоянно – так они всегда будут под рукой. Но и их можно отключить в настройках.
- Время посещения сайтов позволяет тебе легче вспоминать, с чем и когда ты работал. Эта возможность также отключается здесь.
- Выделяй меткой персонализированные результаты в выдаче либо отключи и эту возможность.
- Кроме семейного поиска, можно использовать два типа фильтрации контента – без ограничений и с умеренным фильтром. По умолчанию включен именно он, так что имей в виду.
 Но и их можно отключить в настройках.
Но и их можно отключить в настройках.
Надеемся, что эти лайфхаки помогут тебе быстро находить нужную информацию.
Поиск в интернете – правила и советы
Мы живем в поистине восхитительные времена. Всего за несколько мгновений можем найти практически любую информацию, которая нас интересует. Если раньше приходилось идти в библиотеку или спрашивать у более опытных людей, то сейчас достаточно иметь под рукой смартфон или компьютер. Ведь гора информации лежит в интернете и только и ждет, чтобы кому-нибудь себя показать.
И если раньше поисковик вообще не всегда мог понять, что от него хочет пользователь, то сейчас алгоритмы поисковых систем стали просто безумно умными и могучими: понимают вас с полуслова и находят нужную информацию за доли секунд.
Однако все же иногда случается, что поисковик вас не понимает и выдает на запрос ну совсем уж какую-то несусветную чушь. Предлагаю разобраться, что делать в таком случае и почему так происходит.
Почему не получается найти нужную информацию в интернете
Итак, всего можно выделить две основные причины.
Первая — то, что вы ищете, попросту отсутствует в сети. Например, если вы учитесь в университете и ищете информацию на какую-то узкоспециализированную тему, вполне возможно, что ничего полезного для себя вы не найдете. Либо вам будут предлагаться материалы на похожие или приближенные к вашей темы, либо вы будете находить превью платного контента, за доступ к которому необходимо будет платить.
И вторая причина отсутствия нужной информации при поиске — это неправильная постановка запроса.
В первом случае мы вам помочь, к сожалению, никак не сможем, тут уж ничего не поделаешь, а вот что можно сделать во втором — сейчас расскажем.
Советы по поиску в интернете: как правильно гуглить
Упрощаем запрос
Убираем из запроса лишние слова, делаем его максимально сжатым и четким.
Некоторые пользователи как будто бы обращаются к человеку, а не к безличной системе. Могут писать «подскажите, пожалуйста» и т.д. Но для поисковика это все лишние и ненужные слова. Ему важны лишь ключевые запросы, по которым он осуществляет поиск.
К примеру, вместо того, чтобы напечатать «какая сегодня погода в Москве», можно ввести запрос «погода Москва», вместо «что делать, если болит голова» — «головная боль» (да, уверяю вас, даже без уточнения про то, что вам нужна именно помощь при головной боли, введя просто запрос «головная боль», вы получите нужную вам информацию).
Знаки препинания в запросе можно не использовать, так как поисковые системы их все равно игнорируют.
Также не имеет значения регистр. С большой или маленькой буквы вы напишите запрос — неважно, результат будет один и тот же.-
Уточняем запрос
Если вы производите поиск по какому-то многозначному слову, лучше будет уточнить запрос, чтобы поисковая система поняла, что вам от нее нужно.
Например, если вы ищете информацию о торте «Наполеон», так и пишите: торт Наполеон. Чтобы поисковик не путался и не предлагал вам информацию про французского императора. Если же вам нужна не ознакомительная информация о торте, а рецепт, также указываем это в запросе: рецепт Наполеон. В этом случае даже можно обойтись без слова «торт» — и так понятно, о чем идет речь.Также, например, в случае со словом «Цезарь»: если написать просто это слово, поисковик предлагает смешанную выдачу с рецептами салата и информацией о Гае Юлии Цезаре.
Таких запросов еще много, я привела лишь пару примеров, поэтому лучше все-таки уточнять запрос, чтобы поисковик вас понял и предоставил нужную информацию.
-
Используем наиболее релевантные слова
Для запроса рекомендуем выбирать наиболее подходящие по теме слова. Также стоит думать о том, какие слова наиболее популярны и употребляемы.
Например, если вы ищете современные шутки на какую-то актуальную тему, вы с большей вероятностью найдете то, что нужно, если будете искать по запросу «мемы» или «шутки», нежели чем «анекдоты».
-
Используем синонимы
Если поисковик не может ничего найти по запросу «реферат на тему», можно поискать по запросу «курсовая на тему», «сочинение на тему» и т.д.

 Например, если вы ищете информацию о торте «Наполеон», так и пишите: торт Наполеон. Чтобы поисковик не путался и не предлагал вам информацию про французского императора. Если же вам нужна не ознакомительная информация о торте, а рецепт, также указываем это в запросе: рецепт Наполеон. В этом случае даже можно обойтись без слова «торт» — и так понятно, о чем идет речь.
Например, если вы ищете информацию о торте «Наполеон», так и пишите: торт Наполеон. Чтобы поисковик не путался и не предлагал вам информацию про французского императора. Если же вам нужна не ознакомительная информация о торте, а рецепт, также указываем это в запросе: рецепт Наполеон. В этом случае даже можно обойтись без слова «торт» — и так понятно, о чем идет речь.
Расширенный поиск в интернете
Для более эффективного и точного нахождения результатов поисковые системы предлагают воспользоваться расширенным поиском.
В Google это можно сделать следующим образом: вводим запрос, нажимаем настройки (справа от поисковой строки) и выбираем «Расширенный поиск»:
И здесь уже можно максимально точно настроить поиск: указать нужные слова или исключить ненужные, выбрать язык, на котором будут показываться результаты, страну, дату обновления, указать сайт (если нужно найти информацию на определенном ресурсе, например, на Википедии) и т.д.
В Яндексе расширенный поиск можно включить, нажав сюда:
Поисковые операторы
Яндекс и Google предоставляют возможность пользоваться поисковыми операторами для уточнения поискового запроса — это специальные слова или символы, которые помогут получить более точный результат.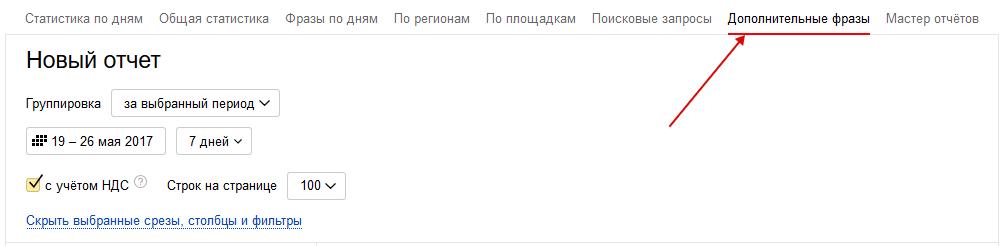
В Google
- Минус — исключение результатов поиска. Пример: цезарь -салат
- Кавычки — поиск точного слова или фразы. Пример: «фентифлюшки»
- OR — поиск по одному либо другому слову одновременно. Пример: стрельба OR тир
- Site: — поиск по определенному сайту или домену. Пример: site:ru.wikipedia.org
- Related: — поиск сайтов с похожим контентом. Пример: related:lifehacker.ru
Операторы Яндекса:
- ! поиск слов в заданной форме. Пример: !цветочек
- + поиск сайтов с определенным словом. Пример: лапенко +роза
- «» поиск по цитате. Пример: «город это злая сила»
- «*» поиск по цитате с пропущенным словом. Пример: «обожаю запах * по утрам»
-
| поиск по нескольким словам сразу. Пример: психолог | шаман
 Пример: психолог | шаман
Пример: психолог | шаман
Поиск в интернете: что лучше — Яндекс или Google?
На этот вопрос, конечно, ответа нет. Каждый пользуется той поисковой системой, которая ему больше нравится. Но в случае с поиском труднонаходимой информации рекомендую пользоваться обоими поисковиками сразу. Выдача у них разная, соответственно, если не нашли искомое в одной поисковой системе, есть шанс найти это в другой.
Предлагаю проверить, как справляются с поиском и чем отличается выдача в Яндексе и Google.
Сравнивать выдачу по обычным запросам не будем. Предлагаю выбрать что-то более интересное.
Вообще, есть такое мнение, что Google более серьезен, политкорректен и чтит правила, в отличие от Яндекса. Например, если вам нужно бесплатно посмотреть фильм, скачать игру или найти книгу — в Яндексе это удастся сделать с большей долей вероятности, чем в Google.
В процессе написания данной статьи наткнулась на пост в Пикабу, который навел меня на мысль сравнить выдачу по таким запросам:
-
Расистские шутки
Нет, ну а вдруг вы собрались писать диссертацию по лингвокриминалистике про расистские шутки и вам нужны примеры.
Google действительно оказался более серьезен в этом плане. При поиске по данному запросу он предлагает ознакомиться со статьями на тему того, что расистский юмор — это плохо, рассказывает про известных людей, которых осудили за такие шутки и т.п.
Яндекс же не сильно беспокоится об этической стороне вопроса и просто предлагает ознакомиться с шутками на тему расизма (даже с картинками):
-
То же самое будет, если искать шутки про геев.
Вот результаты выдачи Google:
Опять-таки разного рода статьи на эту тему и только в конце выдачи один результат с шутками:
А вот такая выдача в Яндексе:
-
Также из злободневного: решила погуглить шутки про вакцинацию.
Что мы видим? В Google шутки на этот раз встречаются, но все-таки перемежаются с информационными статьями на тему вакцинации.
В Яндексе все-таки больший упор именно на развлекательный контент:
-
При этом если искать шутки, например, про женщин, Google превосходно справляется с этой задачей:
Значит, про женщин можно шутить, а про геев и расизм нельзя. Все ясно.
Ну а с Яндексом и так все понятно уже:
-
Также по наводке Пикабу (господи, что бы я без этого сайта делала) продемонстрирую вам такой пример.
Нас интересует вопрос, существует ли на самом деле Дед Мороз. Что по этому поводу скажет Google?
Говорит: «Да, конечно, существует». Даже статью про научные доказательства приводит.
А Яндекс?
Он в самом начале приводит ссылку на сервис Яндекс.Кью, где написано, что Деда Мороза все-таки не существует.
-
А что делать, если вы пытаетесь вспомнить название какого-то фильма, но никак не можете это сделать? С этим оба поисковика уже давно справляются на раз-два: у Яндекса для этого есть алгоритм Палех, а у Google — Колибри.
Например, вот поиск по запросу «фильм в котором на острове стареют» в Google:
Четкий ответ на вопрос, все ок.
То же самое в Яндексе:
-
Похвалю Яндекс еще раз. Если вбить запрос «Джек Воробей», он заботливо исправляет на «Капитан Джек Воробей» (что за прелесть):
Google так, увы, не делает:



Чем отличается поиск информации в Яндексе и Google для бизнеса
Ладно, шутки в сторону, настало время и серьезных примеров. Для владельцев сайтов, думаю, будет полезно узнать, как отличается выдача в этих поисковиках по важным для них запросам.
Над Яндексом в последнее время постоянно шутят на тему монополизации: появляются все новые и новые сервисы, и Яндекс постепенно подминает рынок под себя. Для сферы услуг теперь есть Яндекс.Услуги, для покупки товаров — Яндекс.Маркет, информационным сайтам теперь конкуренцию составит Яндекс.Кью и Яндекс.Дзен. Помимо этого, в выдаче Яндекса вы увидите ссылки на карты и справочник Яндекса, ну и, конечно, рекламу.
Для сферы услуг теперь есть Яндекс.Услуги, для покупки товаров — Яндекс.Маркет, информационным сайтам теперь конкуренцию составит Яндекс.Кью и Яндекс.Дзен. Помимо этого, в выдаче Яндекса вы увидите ссылки на карты и справочник Яндекса, ну и, конечно, рекламу.
У нас была статья, в которой мы уже говорили о нынешней ситуации с выдачей в Яндексе. Что с этим делать и как жить – рассказывали здесь.
Вот, например, выдача по запросу «ремонт авто Москва» в Яндексе:
Куча сервисов Яндекса + реклама.
В Google получше: реклама также есть, но сервисов Яндекса в разы меньше, а значит, и владельцам бизнесов легче пробиться в ТОП.
И подобная ситуация, к сожалению, встречается нередко. Особенно «страдают» такие тематики, как установка натяжных потолков, монтаж пластиковых окон, продажа техники, услуги различных мастеров и т.д.
Поэтому перед продвижением сайта рекомендую сразу проверять выдачу по важным запросам в обеих поисковых системах. Возможно, вам больше подойдет одна из них (только Google или только Яндекс), и вы все силы направите на продвижение сайта именно под нее.
Также Яндекс иногда не может понять, что от него хочет пользователь. Например, вот такая выдача по запросу «заказ такси в Москве без водителя»:
То есть Яндекс увидел слово «такси» и решил, что именно это пользователю и нужно.
В Google другая картина:
Google понял, что от него нужно, в отличие от Яндекса.
Вывод
Как мы поняли, у каждого поисковика есть свои особенности. В чем-то они схожи, а в чем-то кардинально различаются. При продвижении сайта рекомендую обращать внимание на выдачу по важным для вас запросам в обоих поисковиках и отстраивать от этого стратегию продвижения. Кстати о стратегиях: при необходимости подготовим для вас детальный план продвижения сайта на полгода, а также сможем выполнить все работы по предложенной стратегии. Обращайтесь!
А по поводу правильного поиска информации в интернете, надеюсь, советы были полезны, и впредь вам всегда будет удаваться находить все, что нужно, в любой поисковой системе.
Поисковые операторы Яндекс и Google 2021 для решения SEO задач
Привет, друзья. Первая часть заголовка подсказывает, что ниже будет инструкция из разряда — для дилетантов, которым использование кавычек, минуса или восклицательного знака будет казаться взломом поисковой системы или как минимум секретными операторами. Я, и правда, планировал перечислить несколько базовых операторов, известных большинству seo-специалистов, но в процессе обнаружился ряд интересных особенностей, когда операторы работали не так, как предполагалось, либо модификации и сочетание простых операторов выдавали совсем необычные результаты. Так что, работая над данным постом, я получил интересный опыт и открыл несколько вещей, о которых прежде не догадывался.
Даже если кажется, что вам известны все поисковые операторы и их свойства, рекомендую ознакомиться с постом.
Кроме этого, вторая половина поста состоит из рассмотрения ряда прикладных задач, которые доводилось решать мне и моим коллегам в процессе работы над клиентскими сайтами.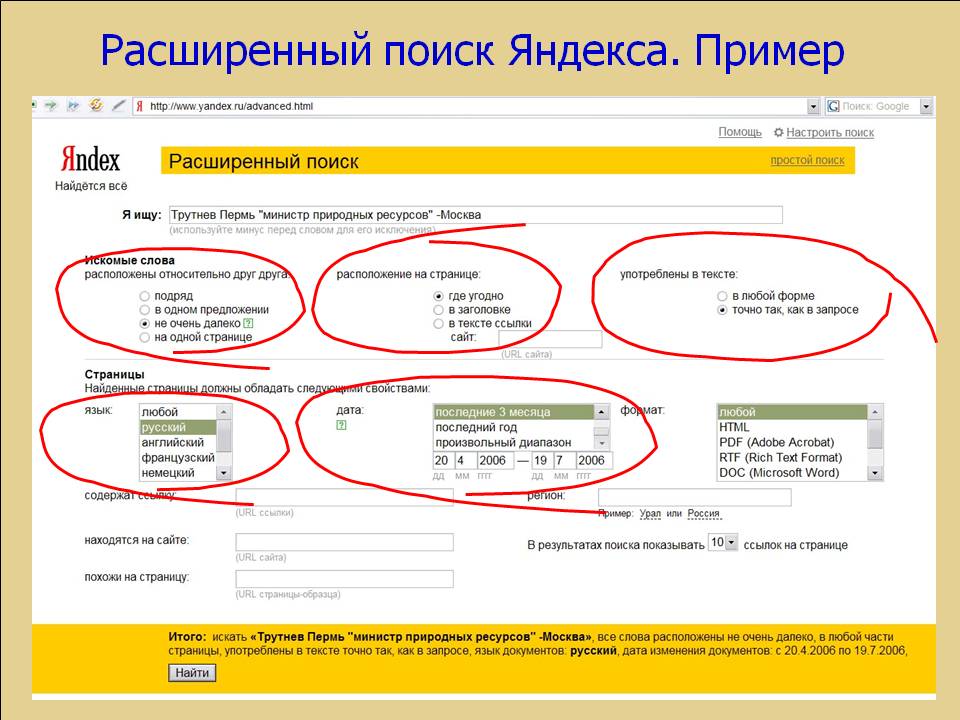 Уверен, вы найдете для себя много полезного.
Уверен, вы найдете для себя много полезного.
В SEO есть список ключевых операторов ПС, которые необходимо знать наизусть, так как они используются постоянно и позволяют мгновенно проверять возникающие гипотезы.
Также есть операторы, которые редко используются, но знать об их существовании важно, чтобы в случае необходимости вспомнить, что вопрос решается элементарно, стоит лишь использовать нужный запрос.
Основная сложность заключается в приобретении навыка умелого сочетания простых элементов между собой с целью решения неочевидных на первый взгляд задач.
Не всегда и не во всех случаях операторы отрабатывают так как ожидается.
Поисковый запрос проходит через сервис исправления опечаток, по результатам которого и формируется выдача. Учитывается статистика по запросу, статистика совместной встречаемости слов, вероятность ошибки – и в итоге имеем то, что имеем.
Общие операторы для Яндекс и Google
Оператор
+ (плюс) и - (минус)С помощью этих операторов происходит поиск документов, которые обязательно содержат (или не содержат) указанное слово (или слова). Однако же на практике есть отличия от теории.
Однако же на практике есть отличия от теории.
Оператор «минус» отрабатывает при любых условиях – «заминусованное» слово никогда не попадет в выдачу.
Что касается оператора «плюс», сегодня у меня сложилось впечатление, что он просто не работает.
С одной стороны логично: если ты указал какое-то слово в поисковом запросе — ты хочешь его найти, и нет нужды что-то дополнительно отмечать плюсом. С другой стороны, если мы отмечаем одно слово в многословном запросе плюсом, можно было бы придавать ему максимальное значение при ранжировании, но мои попытки заметить хоть какую-то закономерность не увенчались успехом.
Например, поисковиками игнорируются союзы и предлоги из запроса, но можно было их «вернуть» как раз плюсом. Это работает в вордстате – сравните результат для вариантов «продвижение» и «продвижение +в». При этом, если во втором варианте вы уберете плюс перед «в», получите результат такой, как будто «в» вообще отсутствует.
Так же это работало и в обычном поиске, но, похоже, что-то изменилось.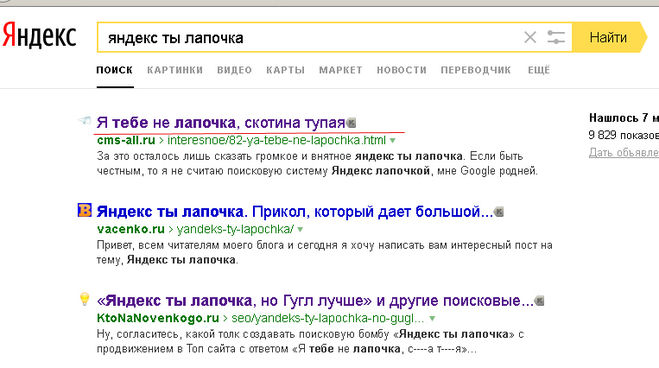
Оператор
" " (кавычки)При использовании кавычек поисковая система будет искать точное совпадение фразы.
Можно использовать кавычки несколько раз в одном запросе и даже добавить «минус» перед одним из запросов.
Этот оператор тоже сложно назвать полезным, так как не понятно, как он работает на практике. Вот вам пример:
Яндекс говорит: «Точного совпадения не нашлось. Показаны результаты по запросу без кавычек.»
Фраза содержится в одном из последних постов на моем блоге, который точно в индексе, что подтверждается поиском по соседнему с искомой фразой предложению:
Обратите внимание, что в сниппете есть та самая фраза, которую мы изначально искали, но не нашли. Как это работает — одному Яндексу известно, так что я бы не стал полагаться на данный оператор.
Зачем я рассказываю о как бы нерабочих операторах? А затем, что знание особенностей (а точнее того, что операторы не всегда работают так, как заявлено) очень важно, чтобы однажды не наделать ложных выводов.
Оператор
* (звёздочка)В Яндексе используется для указания пропущенного слова в цитате.
Одна звездочка – одно слово. Применяется только с оператором " " (кавычки).
В Гугле используется для указания пропущенных слов в запросе. В справке указано, что одного слова, но на практике – любое количество слов.
Оператор
! (восклицательный знак)Осуществляет поиск документов, где слово содержится строго в заданной форме. В Гугле все четко:
В Яндексе это так не работает и, кажется, он считает накопленную статистику о том, как правильно задавать запросы, приоритетной перед поисковыми операторами.
То есть, согласно статистике, человек ошибся, написав «билет в москвА», вместо «билет в москвУ». Чуть лучше это работает с запросами «»купить !айфон»» и «»купить !iphone»», но тоже не так четко, как ожидаешь.
Оператор
site:Осуществляет поиск только по указанному домену и его поддоменам (в отличии от оператора url:, который ограничивает поиск только страницами указанного сайта).
формат: [фраза] site:[example.com]
пример: сайт site:narod.ru
В Гугле все работает по аналогии.
формат: [фраза] site:[example.com]
пример: тлен site:alaev.info
Далее мы рассмотрим некоторые операторы, уникальные для каждой поисковой системы, либо похожие с виду, но работающие по-разному.
Операторы поиска для Яндекса
Большая часть перечисленных ниже операторов не задокументированы в справке Яндекса. Какие-то действительно полезные, а для каких-то найти практическое применение довольно сложно. Так что все на ваше усмотрение, а можете сразу пролистать на 10 страниц вниз до заголовка про решение прикладных задач.
Оператор
& (амперсанд) и && (двойной амперсанд)формат: [слово] & [слово]
Первый оператор & позволяет искать документы, где слова, связанные оператором, находятся в одном предложении. А второй оператор
А второй оператор && позволяет искать слова в пределах одного документа.
Но понять, насколько корректно работают эти операторы, сложно, так как по запросам с операторами и без них результат очень схожий.
Оператор
<< (двойной знак меньше)формат: [слово] << [слово]
Поиск слов в пределах документа, но релевантность (она влияет на положение в результатах поиска) рассчитывается только по первому слову (которое до оператора). Выражение после << ищется, но не участвует в ранжировании.
Оператор
~ (тильда) и ~~ (двойная тильда)формат: [слово] ~ [слово]
пример: сериал ~ метод
Оператор ~ исключает из результатов поиска страницы, содержащие в одной фразе ключевое слово, идущее после тильды. Сравните обычную выдачу:
И выдачу, где есть «сериал», но нет «метод»:
Двойная тильда ~~ исключает из результатов страницы, где встречается ключевое слово до оператора и отсутствует слово, идущее после оператора.
На практике различие между операторами ~ и ~~ сложно заметить. Однако этот оператор используется в одном из методов определения аффилиатов сайтов.
Оператор
host:Исключает из выдачи поддомены указанного сайта (в отличии от оператора site:), то есть поиск будет осуществляться только по указанному домену.
формат: [слово] host:[example.com]
пример: сайт host:narod.ru
Оператор
rhost:Позволяет искать исключительно по поддоменам указанного сайта.
формат: [слово] rhost:[com.example.*]
пример: сайт rhost:ru.narod.*
Обратите внимание на формат указания сайта – в обратном порядке.
Оператор
domain:Позволяет искать по сайтам, расположенным в определенной доменной зоне.
формат: [слово] domain:[доменная зона]
пример: сайт domain:co
Как видите, указанная доменная зона не обязательно одиночная (.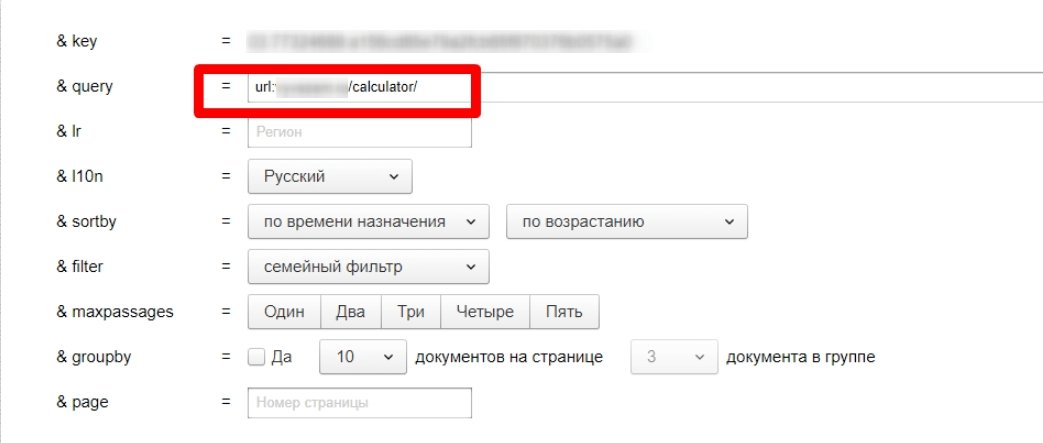 co), но может быть и такой: .co.ua. Чего только не обнаружишь, тестируя различные варианты ?
co), но может быть и такой: .co.ua. Чего только не обнаружишь, тестируя различные варианты ?
Оператор
url:Позволяет искать слово или фразу только на странице с указанным адресом.
формат: [фраза] url:[адрес страницы]
пример: полпути url:https://alaev.info
Поиск нашел нужное мне ключевое слово на обозначенной странице.
Еще вы можете использовать звездочку, чтобы найти все документы, адреса которых начинаются с указанного.
пример: полпути url:https://alaev.info/blog*
Оператор
inurl:Поиск ограничивается группой страниц, адреса которых содержат заданный фрагмент.
формат: [слово] inurl:[фрагмент адреса]
пример: сайт inurl:web
Обратите внимание, что часть адреса может содержаться как в названии домена, так и в адресе страницы.
Оператор
title:Позволяет искать только по заголовкам страниц (по тегу title).
формат: title:[фраза]
пример: title:жирный таракан
К сожалению, практика показывает, что не «только», так как сразу же встречаются результаты, не содержащие часть фразы не только в title, но и в тексте:
Странно, что Яндекс учитывает операторы таким образом – не как строгое правило, а, скорее, как рекомендацию, которую чаще всего игнорирует. В отличии от Гугла, где все четко и предсказуемо.
Оператор
mime:Позволяет искать по документам и файлам, указанного расширения и типа.
формат: [слово] mime:[тип файла]
пример: коммерческое mime:doc*
В справке Яндекса заявлены следующие типы файлов: pdf, xls, ods, rtf, ppt, odp, swf, odt, odg, doc.
Посмотрев на этот список, я сразу подумал, что тут явно чего-то не хватает, например docx, ныне более распространенного, чем doc.
И я подумал, что можно искать одновременно и .doc и .docx, используя звездочку, как показано на скриншоте.
А потом пошел дальше. Захотелось мне .txt файлы поискать, ведь если они не заявлены в списке, то это не значит, что их нельзя искать. Но оказалось и правда нельзя. Зато помня про звездочку…
Вбил запрос 1 mime:t* и нашел txt, m3u, trf и еще всяких интересных вещей. Работает непредсказуемо и ищет не только файлы с расширением, начинающимся с буквы t. Таким образом можно перехитрить поиск!
Сочетая различные операторы между собой, можно найти много интересного, только я вам об этом, конечно же, ничего не говорил 🙂
Оператор
date:Ограничивает поиск документами по дате их последнего изменения.
Год указывается обязательно, а месяц и день можно заменить символом *.
формат: [фраза] date:[yyyymmdd]
пример: продвижение сайтов date:202001*
В данном случае показаны страницы и сайты про продвижение сайтов, созданные (а точнее — проиндексированные) в январе 2020 года.
И вот тут есть нюанс и некоторое несоответствие с описанием, предоставленным Яндексом. В справке говорится «по дате последнего изменения», но что такое изменение? Дата переиндексации или дата, когда при посещении роботом было замечено, что контент изменился относительно его прошлой копии?
Не то, и не другое. Я сначала было решил, что оператор date: делает выборку дате первой индексации страницы. Например, потому что я завел блог в конце 2009 года:
С тех пор контент много раз менялся на всех страницах, я три раза менял дизайн глобально. Вряд ли поисковик не заметил каких-либо изменений. Я был уверен, что это работает именно так. Тогда почему нет еще нескольких страниц, появившихся в 2009 году?
Я начал копать дальше и обнаружил в апреле 2019 года большое количество результатов:
А как раз в апреле я переезжал с http на https. Соответственно, старые страницы как бы пропали, а новые появились и проиндексировались. В каком-то смысле их дата первой индексации сбросилась. Но тогда почему же главная страница блога, которая тоже переехала на https до сих пор болтается в 2009 году?
В каком-то смысле их дата первой индексации сбросилась. Но тогда почему же главная страница блога, которая тоже переехала на https до сих пор болтается в 2009 году?
По определенным запросам я подтверждаю теорию о том, что оператор выбирает дату индексации, а не изменения – например: нашествие фестиваль date:2008*. А потом по схожему запросу нашествие фестиваль date:2018* убеждаюсь, что выдаются страницы, которые были созданы задолго до 2018 года.
Даже если посмотреть на примеры, которые приводит сам Яндекс:
- соответствует 10.10.2018: [фестиваль date:20201010];
- позднее 10.10.2018: [фестиваль date:>20181010];
- находится в интервале между 10.10.2018 и 10.11.2018 включительно: [фестиваль date:20181010..20181110];
- соответствует октябрю 2018 года: [фестиваль date:201810*];
- соответствует 2018 году: [фестиваль date:2018*].
Можно найти там недостоверные данные:
Короче, мы просто не знаем, что считает изменением сам Яндекс и в этом заключается недостоверность описанного метода.
Вообще в справке Яндекса есть целый раздел о том, как искать в Яндексе и как уточнить поиск, однако там приведены не все операторы, которые мы рассмотрели. По всей видимости, Яндекс не считает их столь уж необходимыми простым людям, но мы же сеошники ?
Кстати, основные операторы используются не только непосредственно в поиске, но и в других сервисах, например, в Яндекс Вордстате – у меня есть подробный обзор операторов и сочетаемости друг с другом. Хотя бы там операторы работают так, как ожидается и без всяких приколов.
Операторы поиска для Google
Оператор
cache:Возвращает последнюю кэшированную версию веб-страницы (при условии, что страница проиндексирована, конечно) вместе с датой и точным временем, когда снимок был сделан.
формат: cache:[example.com]
пример: cache:microsoft.com
Оператор
filetype:Ограничивает результаты поиска файлами определённого формата, например: pdf, docx, txt, ppt и т. д.
д.
формат: [фраза] filetype:[тип файла]
пример: seo filetype:txt
У данного оператора есть аналог ext: — работает аналогично, включая особенности.
Конечно, я сразу захотел проверить будет ли работать поиск по файлам txt, которые не ищет Яндекс.
Но вместо этого я обнаружил другую особенность работы данного оператора: он ищет не конкретно файлы, а url-адреса, которые оканчиваются на указанное расширение, в моем случае это .txt. То есть это могут быть и обычные страницы сайта, которые имеют искомое окончание. По этой причине на четвертом месте нашелся вот такой url: https://help.megagroup.ru/upravlenie-robots.txt. Неожиданно ?
Стоит добавить, что filetype: или ext: сочетаются, например, с операторами inurl: и intext:, что расширяет наши возможности по поиску «нужных» файлов!
Оператор
inurl:Осуществляет поиск фразы по страницам сайтов, содержащих в своем адресе одно или несколько слов, идущих после оператора.
формат: [фраза] inurl:[фрагмент url]
пример: протест inurl:в москве
При этом вы не обязаны указывать искомую фразу, можно указывать только часть адреса.
формат: inurl:[фрагмент url]
пример: inurl:в москве
В этом случае в выдачу попали абсолютно все известные поиску страницы, содержащие в своем адресе «в» или «москве».
Обратите внимание, что я использовал исключительно кириллические слова в качестве части url, и поиск меня понял.
Оператор
allinurl:Думаю, вы уже догадались на примере предыдущих описаний, что оператор allinurl: должен возвратить нам все страницы, адрес которых в обязательном порядке содержит все слова из фразы в указанной словоформе.
формат: allinurl:[фрагмент url]
пример: allinurl:seo bomzh
По моему запросу я и не ожидал найти много результатов, и это показывает нам, что оператор работает четко и не позволяет себе вольностей, как это бывает в Яндексе.
И есть одно важное отличие оператора allinurl: от inurl: — он не сочетается с каким-нибудь поисковым запросом. При попытке искать слово «alaev» по страницам, содержащим в адресе «seo» при помощи оператора: alaev allinurl:seo мы получаем результаты аналогичные поиску по трехсловной фразе «alaev allinurl seo».
Оператор
intitle:Ищет слова только по содержимому заголовков title страниц.
формат: intitle:[фраза]
пример: intitle:seo бомж
Оператор
allintitle:Работает по аналогии с вышеописанным intitle:, но обязательно в title должны содержаться все слова из искомой фразы и, как я в очередной раз убедился, обязательно в указанной словоформе.
формат: allintitle:[фраза]
пример: allintitle:seo бомж
Для примера я взял для обоих операторов один и тот же запрос «seo бомж». Но отличия для этих запросов не столь радикальное, как если вы введете поочередно: allintitle: в москву, allintitle:в москве, allintitle:в москва или даже allintitle:в москвой. Вот при этих запросах видно, как Гугл бескомпромиссно следует своим же правилам (операторам).
Вот при этих запросах видно, как Гугл бескомпромиссно следует своим же правилам (операторам).
Если вы хотите еще ужесточить запрос, чтобы слова фразы шли в определённом порядке, берем фразу в кавычки.
формат: allintitle:"[фраза]"
пример: allintitle:"в москвей"
Оператор
intext:Позволяет искать страницы, содержащие обязательно в тексте искомое слово или слова. Ну и что тут такого и зачем вообще нам нужен такой оператор, когда поисковик и так всегда ранжирует по вхождениям в текст (сайты, которые содержат фразу только в title и не содержат в тексте обычно ранжируются ниже и до них надо долго пролистывать, так что условно их можно игнорировать).
Но я придумал интересный вариант использования:
формат: intext:[фраза]
пример: intext:кондибобир
Вы можете использовать данный оператор для поиска какой-нибудь дичи, целенаправленно неверно написанных слов или чего-то другого, что вам в голову придет.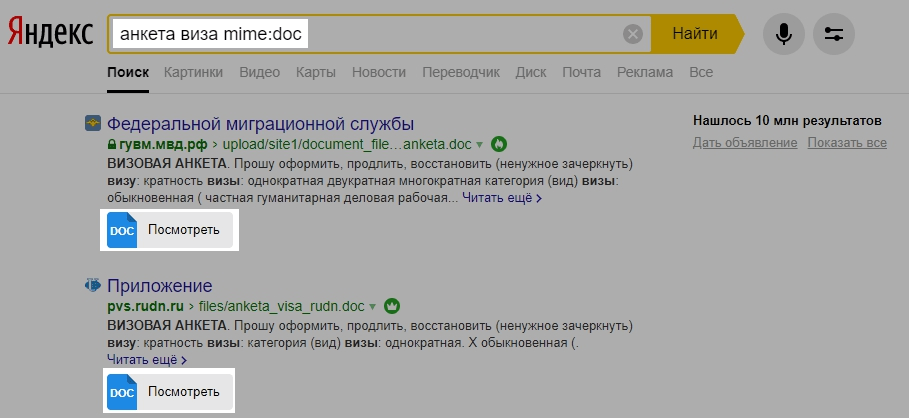 При этом поисковик не будет говорить вам: «Возможно, вы имели в виду: …» и показывать результаты, где искомое слово встречается в транслите. Используя данный оператор, вы всегда найдете именно то и в том виде, в котором ищете.
При этом поисковик не будет говорить вам: «Возможно, вы имели в виду: …» и показывать результаты, где искомое слово встречается в транслите. Используя данный оператор, вы всегда найдете именно то и в том виде, в котором ищете.
Оператор
allintext:Будет искать обязательно все слова, указанные в запросе.
формат: allintext:[фраза]
пример: allintext:алаичъ плащ
Для оператора allintext: также можно использовать кавычки в запросе, чтобы искать нужные слова в определенной последовательности.
И еще я обнаружил интересную особенность, что allintext: ищет не только в тексте, но в том числе и в заголовке title (я встречал в выдаче документы, которые содержат искомую фразу только в title, а в тексте – нет).
Оператор
related:Согласно теории, данный оператор предназначен для поиска сайтов с похожим контентом.
формат: related:[example.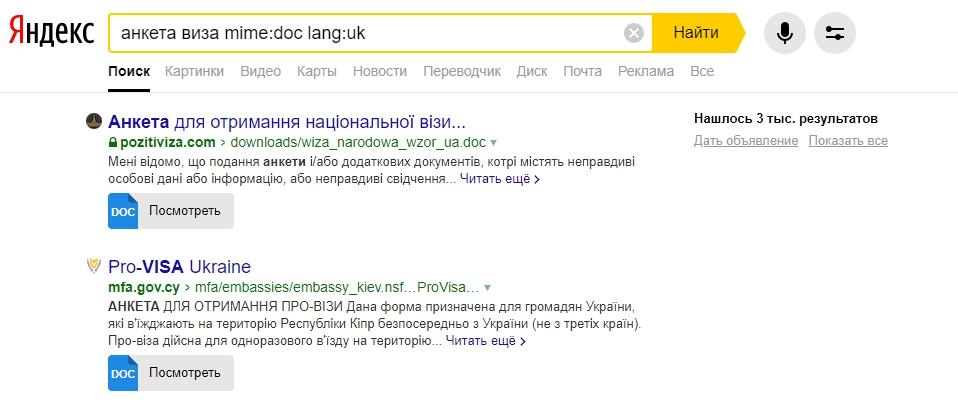 com]
com]
пример: related:ya.ru
Забавно, что если я запрошу related:yandex.ru, то получу ответ «По запросу related:yandex.ru ничего не найдено.» И при запросе related:google.ru в выдаче будет показываться именно ya.ru, а не yandex.ru.
Также меня смутило, что нет никаких результатов для alaev.info и alaev.co, а по запросу related:maxitop.ru (это сайт одной из веб-студий Краснодара) показываются не веб-студии, а автомобильные сайты, техцентры, СТО и магазины автозапчастей.
Так что у меня большой вопрос к Гуглу, друг, а что учитывается при определении похожести сайтов?
На этом я закончу теорию и перейду к разбору прикладных задач, с которыми вы можете столкнуться в процессе продвижения сайтов.
И не забывайте, что у Гугла тоже есть справка о том, как уточнять поисковые запросы, но, как и в Яндексе, она содержит мало полезных нам, сеошникам, операторов.
Решение прикладных задач в SEO
Как быстро поменять регион поисковой выдачи в Яндексе:
&lr=Я считаю, это первое, что должен изучить seo-специалист, ежедневно работающий с поисковыми системами, — быстрое переключение региона.
Вот медленный способ переключения региона:
- Первый шаг – нажать на иконку, открывающую настройки.
- Второй шаг – нажать на кнопку редактирования названия региона.
- Третий шаг – ввести текстом название города (благо, там есть подсказки), выбрать его из списка и нажать «Найти» в поисковой строке.
Представьте, сколько действий надо совершить! Достичь аналогичных результатов можно всего в несколько кликов. Я привел тут этот алгоритм отнюдь не ради того, чтобы проиллюстрировать сложность, а чтобы мы могли узнать числовой код региона, который нам нужен.
Когда вы что-то ищете без всяких настроек, Яндекс будет подставлять вам тот регион (город), в котором вы находитесь (если он смог верно определить вашу геолокацию и, если она не заблокирована браузером). Я поищу «продвижение сайтов»:
Я выделил на скриншоте стрелкой параметр &lr=35, значение 35 которого показывает мой регион – Краснодар. У вас будет свой собственный код, например, 213 – Москва, 54 – Екатеринбург, 2 – СПб.
У Яндекса есть список основных городов — https://yandex.ru/dev/xml/doc/dg/reference/regions.html — но есть вероятность, что вы не найдете там город, выдачу в котором необходимо посмотреть.
Вариант первый – следуя пошаговому «сложному алгоритму», описанному выше, зайти в настройки и указать нужный вам город. Я решил выбрать Верхнюю Пышму – город-спутник Екатеринбурга, где живет 70 тысяч человек. В реальности, конечно, жители предпочтут найти исполнителя в самом ЕКБ, но моя задача показать, как это работает:
Я отметил на скриншоте два параметра &lr=35 и &rstr=-20720 – первый показывает, что я по-прежнему нахожусь в Краснодаре, а второй показывает, что я изменил регион, и значит код Верхней Пышмы – 20720.
Второй вариант – при условии, что мы знаем код нужного нам региона, то для поиска по этому региону надо будет в адресной строке просто изменить &lr= на 20720.
Так как сеошники в регионах, изучая коммерческие характеристики сайтов, смотрят не только на региональных конкурентов, но и часто на московских, имеет смысл в первую очередь запомнить параметр &lr= и код Москвы 213, это поможет вам сэкономить кучу времени!
Также существует полный список всех имеющихся регионов Яндекса отдельным файлом, который раньше лежал у Яндекса, но был удален, когда они решили закрыть свой Каталог, но добрые люди сохранили это наследство, так что я тоже залил файл к себе, чтобы он был всегда доступен, пока существует мой блог. Скачать список регионов Яндекса в .pdf
Как узнать количество страниц в индексе Яндекса для домена
Используем оператор host: с указанием домена.
формат: host:[example.com]
пример: host:alaev.info
Как видите, количество проиндексированных страниц моего блога – 340.
Как узнать количество страниц в индексе Яндекса для сайта и всех его поддоменов
Используем оператор site: с указанием домена.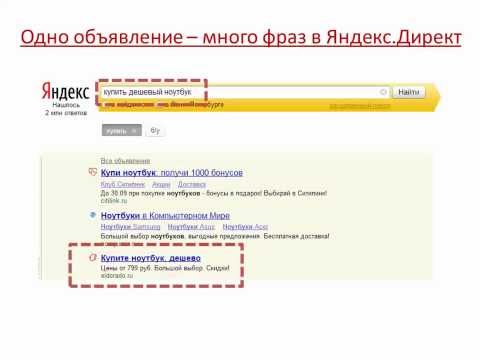
формат: site:[example.com]
пример: site:alaev.info
Количество страниц вместе с поддоменами составляет около двух тысяч. К сожалению, Яндекс округляет результат, потому это лишь ориентировочное число.
Чтобы вы понимали, вот реальное количество страниц в индексе на тот же самый момент времени:
Как узнать проиндексирована ли страница в Яндексе
Используем оператор url: с указанием конкретного адреса страницы.
формат: url:[url страницы]
пример: url:https://alaev.info/blog/post/8742
Если выдача не пустая, значит страница проиндексирована. А если увидите «По вашему запросу ничего не нашлось» — значит страница не в индексе.
Как узнать сколько страниц (и каких) опубликовано на сайте за определенную дату
Используем следующие операторы:
site: – если хотим искать по основному домену и всем его поддоменам,host: – если нужно искать только по основному домену,date: – указываем дату появления в индексе (не забывайте, что я писал про данный оператор выше в разделе операторов Яндекса).
И еще есть замечательный оператор – * (звездочка) – с помощью которого мы можем указывать не только конкретный день, но и весь месяц или целый год.
формат: site:[example.com] date:[yyyymmdd]
пример: site:alaev.info date:2020*
На моем блоге за 2020 год появилось 5 новых постов, их появление повлекло за собой появление одной дополнительной страницы пагинации, и одна новая тема на форуме. Итого 7 штук!
А, например, в феврале 2021 года на блоге появились 2 новых поста и в одном из них я выкладывал чек-лист в форматах pdf и xlsx – они тоже проиндексировались и посчитались:
Напоминаю, что оператор date: работает не всегда так, как ожидаешь. Иногда результат совпадает, иногда нет. Чем дальше в историю (просмотр результатов за давнишние даты), тем выше вероятность получить неверный результат.
Как найти сайты, у которых в Title страницы имеется вхождение искомой фразы в Google
Например, у нас есть ключевой запрос «утюг недорого цена», и необходимо посмотреть, как реализовано вхождение этого запроса у конкурентов.
формат: allintitle:[ключевые слова]
пример: allintitle:утюг недорого цена
Пусть вас не смущает то, что в заголовке на выдаче не везде встречаются все три слова из нашего запроса. Во-первых, Гугл на свое усмотрение сокращает заголовки (в конце заголовка может поставить троеточие) и часть содержимого тега title с сайта не видна, во-вторых, Гугл на свое усмотрение может менять заголовок на более подходящий (по его мнению, разумеется). Во-вторых, если вы перейдете на сайты из выдачи, вы увидите, что в title каждого из них содержатся слова, которые мы указывали в запросе.
Как узнать, когда проиндексированы страницы в Яндексе
Чтобы отсортировать результаты поиска, необходимо в конец поисковой строки добавить &how=tm, и тогда напротив каждой страницы в выдаче появится отметка о времени индексации:
Жаль, что это не сочетается с другими операторами, например, site: или host:, а раньше это работало и можно было узнать, когда конкретно проиндексировались страницы сайта или конкретный url.
Как найти мусорные страницы по URL в Яндекс и Google
К мусорным страницам относятся, например: корзина (cart), регистрация (register, login), страницы пользователей (users), файлы (files), страницы сортировки (sort), страницы фильтров и поиска (filter, search).
Для того чтобы найти данные страницы, будем использовать оператор site: совместно с оператором inurl:, с помощью которого можно осуществлять поиск по страницам в URL которых есть заданный фрагмент.
формат: site:[example.com] inurl:[часть url]
пример: site:tatarcha.net inurl:auth
Смотрите, сколько дублирующихся ненужных страниц! Все это вредит продвижению, сами знаете.
В Google поиск осуществляется аналогичным способом. Только он предпочитает не показывать кучу одинаковых результатов.
Если в url запроса добавить &filter=0, то Гугл сразу будет показывать в выдаче все скрытые результаты (вдруг пригодится).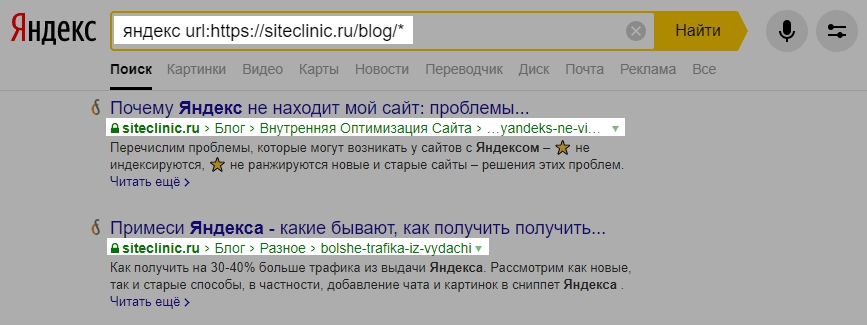
Не забывайте, что для поиска фразы, а не одного слова, стоит использовать оператор allinurl:.
Кроме поиска мусорных страниц сочетание site: и inurl: / allinurl: можно, например, применять для поиска всех страниц конкретного раздела и определения их числа в индексе.
формат: site:[example.com] inurl:[/раздел/]
пример: site:robinzonada.ru inurl:/camps/
И тут надо сделать оговорку. Мы видим на скриншоте число 37. Но, если досмотрим до самого низа, увидим, что Гугл скрыл часть результатов.
Окей, значит раз вверху было 37, а скрыто еще 40, значит страниц итого 77?
Жмем на «Показать скрытые результаты.»
Хм… уже 152! И как это работает вообще?
Осталось только спуститься в самый низ и перейти на следующую страницу, число снова изменится.
Реальное же (во всяком случае наиболее приближенное к реальному) число отобразится тогда, когда вы дойдете до последней страницы выдачи.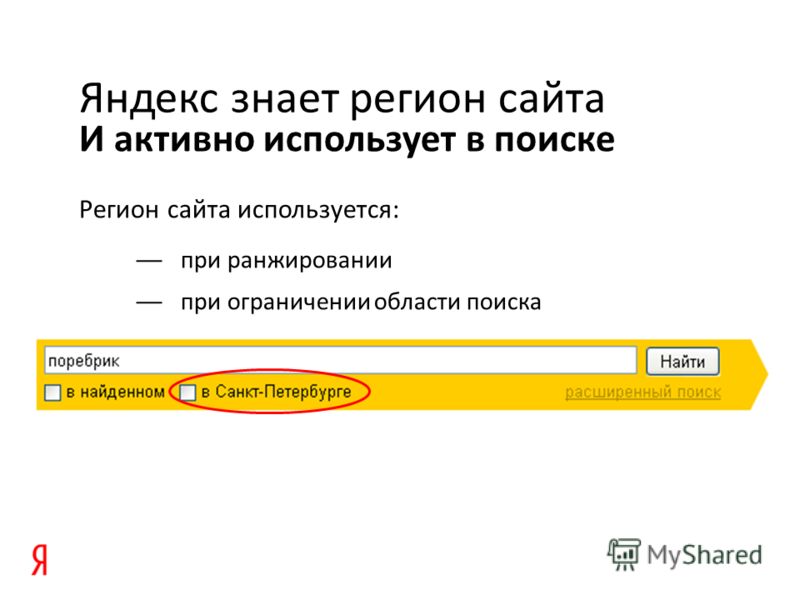 В нашем случае наиболее точным числом оказалось 46.
В нашем случае наиболее точным числом оказалось 46.
Также я отметил один из результатов в сниппете которого написано «Информация об этой странице недоступна.» Это означает, что сайт не позволяет Google создать описание страницы, хотя она доступна посетителям. Проще говоря, страница закрыта в robots.txt, но ее адрес все равно индексирует робот Гугла, но саму страницу не сканирует.
В Яндексе такого не бывает, но в Гугле всегда происходит именно так, поэтому если вы хотите, чтобы страница не индексировалась, стоит использовать запрещающий meta robots, а не robots.txt.
Поиск одинаковых товаров по фрагменту URL + их число в выдаче
Частный случай из предыдущего пункта – нужно узнать в каких категориях лежит один и тот же товар. В некоторых интернет-магазинах бывает такая ситуация, если положить один товар в несколько разных категорий и при этом ЧПУ формируется согласно иерархии, страница товара будет дублироваться столько раз, скольким категориям или подкатегориям товар принадлежит.
формат: site:[example.com] inurl:[фрагмент URL товара]
пример: site:gikom.ru inurl:metallicheskie-stellazhi-skladskie-mkf-1570
Это работает и в Гугле, и в Яндексе, только если вы хотите искать в Яндексе по указанному домену, надо использовать вместо site: оператор host:, иначе будут показываться результаты и с поддоменов:
Проверка релевантности и каннибализации страниц
Если мы введем интересующий нас поисковый запрос и ограничим выдачу только страницами определенного сайта с помощью оператора site:, то поисковик выдаст нам страницы указанного сайта в порядке убывания релевантности запросу.
формат: [фраза] site:[example.com]
пример: перелинковка site:alaev.info
Что это нам даёт:
- Проверка страницы на фильтр переспама. Если на первом месте выдается не продвигаемая страница, а любая другая – есть вероятность, что мы имеем переспам по текстам. Необходимо проанализировать, почему наша целевая страница не является самой релевантной запросу.
- Если в топ-20 есть несколько страниц, заточенных под одинаковый ключ (мета-теги, h2, текст), – значит, есть риск получения каннибализации. Тогда велика вероятность, что поисковик будет считать релевантными разные страницы сайта, и в выдачу они будут попадать по переменке. Актуально для молодых сайтов, пока нет ссылочного профиля.
- Если на первом месте ранжируется нужная нам целевая страница, то все нижестоящие можно использовать для прокачки основной страницы за счет внутренней перелинковки, используя нужные ключевые слова. Это называется контекстная перелинковка страниц и, на мой взгляд, это самый эффективный вид перелинковки. Рекомендую ознакомиться с моим руководством по ссылке.
 Необходимо проанализировать, почему наша целевая страница не является самой релевантной запросу.
Необходимо проанализировать, почему наша целевая страница не является самой релевантной запросу.Поиск страниц с http в индексе Google
Наверняка вы уже перевели все свои или клиентские сайты на защищенный https протокол (если нет, читайте как перевести сайт с HTTP на HTTPS без потерь). И все же в Гугле переклейка страниц происходит довольно долго, а иногда и годы спустя в выдаче зачем-то остаются адреса страниц с http. Используя операторы
И все же в Гугле переклейка страниц происходит довольно долго, а иногда и годы спустя в выдаче зачем-то остаются адреса страниц с http. Используя операторы site: и inurl:, мы вычитаем из поиска по домену результаты с https и получаем в остатке только http.
формат: site:[домен] -inurl:https
пример: site:www.yandex.ru -inurl:https
Задумка хороша, только вот реализация страдает. Гугл предпочитает в памяти хранить древние ископаемые. Начиная с того, что я уже больше двух лет назад переехал на https, а в индексе до сих пор болтается несколько http версий страниц форума. И заканчивая тем, что Гугл помнит, как в 2014 году случайно проиндексировалось зеркало моего диетного сайта на поддомене mail.alaev.info, который случайно появился при переезде на новый сервер. Я сразу же сделал 301-редирект, как только заметил это, но в индексе вот уже 7 лет болтаются эти результаты.
Так что когда будете проверять свой сайт, сначала проверьте, действительно ли проблема есть, либо это только кажется, как в моем случае.
Проверка поддоменов и числа их страниц в индексе Google
Мы можем посмотреть, какие поддомены есть в индексе Гугла, и сколько проиндексировано страниц в рамках этих поддоменов.
формат: site:*[example.com] -www
пример: site:*gikom.ru -www
В данном случае мы исключили из выдачи поддомен www, как зеркало основного сайта. Кроме того, что нам зачем-то понадобилось посмотреть количество страниц поддоменов в индексе (это актуально, когда мы только запускаем региональные поддомены и нам важно знать, как они индексируются), мы ведь можем найти то, чего не ожидаем, например, поддомены, которые мы не создавали, либо технические поддомены, на которых проиндексировалось зеркало сайта, как в предыдущем пункте про диетный сайт.
Как и говорил в самом начале, я открыл для себя несколько необычных свойств совершенно обычных операторов. А сколько интересного я не открыл?
Если вы знаете какие-то операторы, не упомянутые в посте, либо в своей работе используете определённые сочетания, о которых я не знаю, и я и все читатели блога будут вам благодарны, если вы поделитесь в комментариях.
Так что, возможно, будет продолжение 🙂
Спасибо за внимание, друзья! До связи!
Операторы поисковых систем Google и Яндекс [инструкция с примерами]
Умение быстро и безошибочно использовать информацию, предоставленную в интернете, — полезный навык для обычного человека, а уж тем более для вебмастера или интернет-маркетолога. Желаете повысить эффективность работы с поисковыми системами?
В этом вам смогут помочь операторы поисковых систем, которые представляют собой специальные символы, команды для Яндекса и Google. Они уточняют запрос, позволяя получить нужные вам материалы.
Это своего рода джинны из восточных сказок: в ответ на правильно составленную фразу они исполняют желания. Попробуйте — вам точно понравится!
Все операторы поисковых запросов Google
Настало время познакомиться с основными и второстепенными операторами поисковых запросов.
- Поиск по сайту (site:)
Это популярная и любимая многими вебмастерами команда для поиска запроса на конкретном ресурсе.
Must have для забывчивых читателей и поклонников быстрой перелинковки!
Формула успеха проста: введите запрос, затем синтаксис (site:) и url.
Пример: «seo site:livepage.ua/ru». В результате вы получите все тексты о SEO на сайте livepage.ua/ru.
Важно! Пробел между двоеточием (:) и ссылкой ставить не нужно.
- Точное соответствие (» «)
Оператор показывает страницы, которые содержат точное соответствие вашему ключу — взятые в кавычки (» «) слова находятся в том же порядке.
Такая команда пригодится тем, кто ищет информацию о редких товарах с длинными артикулами. Кроме того, она поможет быстро отыскать воров ваших новостей и другого контента.
Чтобы увеличить область целенаправленного поиска, добавьте кавычки в одну часть запроса, а другую оставьте в широком соответствии.
- Файлы (file:)
Спецсимвол ищет в Сети документы обозначенного формата, экономя пользователю время и нервы.
Например, если вы хотите изучить легендарный труд основоположника маркетинга Филипа Котлера в «пдф», надо ввести в поисковик следующий запрос: «котлер маркетинг filetype:pdf».
Скачивание книги начнётся сразу после нажатия на адрес сайта.
- Плюс слова (+)
Эти операторы соответствия AdWords находят полный набор перечисленных слов в рамках одного предложения. Главное — поставить между ними плюс (+).
- Минус слова (-)
Они полезны в случаях, когда требуется исключить нежелательные слова из запроса.
Необходимо лишь поставить перед ненужным фрагментом минус (-) без пробела.
Если вы введете в Гугл «как интернет-магазин -оптимизация», то сможете посмотреть сайты со всеми сведениями об интернет-магазине (открытии, нишевании, выборе дизайна) за исключением его оптимизации.
- Или (OR)
Показывает ресурсы, где встречается хотя бы одно из указанных слов и словосочетаний.
- Оператор *
Это универсальная команда в Windows, предназначенная для поиска точного соответствия, где * заменяет любое количество слов. Напечатав «заказать *недорого», вы получите информацию обо всем, что можно недорого заказать на той или иной онлайн-площадке: сайт, реферат, платье.
- Спецсимвол ..
Идеальное решение, если нужны данные с цифровым диапазоном (как 1.15).
- @ и #
Такие поисковые операторы Google готовы показать пользователю информацию, найденную по тегам и хештегам Instagram, «ВКонтакте», Facebook, Twitter и «Одноклассников».
- Дополнительный синтаксис loc:
Он уточняет запрос с учетом определенной локации. Например, при вводе ресторан loc:москва, вы получите список заведений, расположенных в столице России.
- Оператор define:
Позволяет мгновенно найти определение термина из авторитетного источника, допустим, из «Википедии».
- Символ date:
Ищет информацию, появившуюся в индексе за определенный период. Так, человек, напечатавший в поисковой строке «продвижение в соцсетях date:6», получит данные, которые были добавлены в течение последних шести месяцев.
- Уточнение запроса source:
Эта возможность предназначена для Google News, она призвана сузить круг поиска в соответствии с выбранным источником. К примеру, с новостным журналом.
- Синтаксис related:
Помогает за считанные минут обнаружить сайты конкурентов с похожими материалами.
- Оператор соответствия allinurl:
Крайне полезная функция, демонстрирующая сайты, в url которых имеются упомянутые после самой команды слова. Для расширения области поиска лучше использовать латиницу или транслитерацию. Например, «allinurl:marketing».
- Специальный символ inurl:
В данном случае система ограничит результаты отбором одного слова. Желаете найти ответ на запрос «советы», адрес которых содержит «seo»? Тогда смело набирайте в поиске «советы inurl:seo».
Желаете найти ответ на запрос «советы», адрес которых содержит «seo»? Тогда смело набирайте в поиске «советы inurl:seo».
- Команда allintext:
Пригодится, когда требуется полное вхождение запроса исключительно по контенту страницы.
- Дополнительный синтаксис intext:
Если вы укажете в поиске «seo intext:юмор», он выдаст вам данные по слову «юмор», которые содержат материалы с включением «seo».
- Оператор allintitle:
Ищет в заголовке страниц полное вхождение указанного запроса.
- Функция intitle:
Напоминает по своему действию предыдущий спецсимвол, но только с той разницей, что его поиск ограничивается лишь первым словом, указанным в запросе.
- Кэш (cache:)
После ввода «cache:livepage.ua/ru» вам откроется последняя копия страницы кэша Гугла анализируемого сайта. Подобную манипуляцию можно сделать с любым порталом в интернете.
- Информация (info:)
Отображает всю информацию об указанной странице. Этим методом можно проверить проиндексирована ли страница в поисковой системе.
- Команда allinanchor:
Она служит для поиска проектов, в описании ссылок на которые присутствуют ключевые слова.
- Символ inanchor:
Аналог allinanchor: работающий только с одним ключом.
Удобные комбинации операторов
Полумеры не для вас, вы хотите узнавать информацию быстро и сверхточно? Тогда смело комбинируйте символы.
Ниже представлено несколько таких вариантов.
- Точный запрос и функция date:
К примеру, сочетание «»новости от google» date:2» покажет все новости от поисковика, очутившиеся в индексе в последние два месяца.
- Запрос и оператор соответствия inurl
Так, результатом запроса «отзывы inurl:Livepage» станет список страниц по запросу «отзывы», в адресе которых упоминается наша компания.
- Запрос с точным запросом и site:
Хотите отыскать на нашем сайте все статьи от Алексея Андрусенко — просто введите «»Алексей Андрусенко» site:livepage.ua/ru».
Собственно, вы можете комбинировать любые команды. Однако старайтесь не перебарщивать с их количеством, чтобы не упустить какие-нибудь важные сведения.
Операторы поиска Яндекс
- Кавычки (» «)
Представленная функция предназначена для поиска страниц с точным соответствием. На запрос «FAQ по SEO» ответом станет перечень материалов с идентичным совпадением фразы.
- Символ *
Пригодится для поиска пропущенных слов в точном соответствии, синтаксис служит их заменой. Напечатав в поисковой строке «купить * недорого», вы получите в выдаче «купить купальник недорого», «купить мебель недорого» и т. п.
- Восклицательный знак (!)
Он фиксирует форму слова: время, число и падеж.
- Функция & и &&
Одинарный символ (&) ищет страницы с объединенными в одном предложении словами запроса, а двойной (&&) — в пределах всего документа.
- Команда ~
Дает возможность быстро отыскать предложение со словом, расположенным слева от знака, в котором нет слова, указанного справа. Например, запрос «результат ~ конкурса» предоставит информацию о результате, который однако не связан с конкурсом.
- Плюс (+)
Указав этот элемент между элементами запроса, на выходе вы получите предложения с полным набором введенных слов, в том числе и местоимений, союзов, предлогов.
- Минус (-)
Данный синтаксис очищает запрос от мусорных добавок.
- Квадратные скобки [ ]
Запоминает порядок элементов в запросе, берет во внимание стоп-слова и разные словоформы.
- Круглые скобки ()
Они удобно комбинируют элементы в сложных запросах.
- Вертикальная черта (|)
Выполняет поиск любого из перечисленных слов. Допустим, вам нужна обновка от любого из двух брендов. Просто введите «брюки korpo | orsa» — и вы получите нужный результат.
- Тайтл (title:)
Эта команда осуществляет поиск по заголовкам страниц.
- Оператор site:
Безупречный помощник, когда требуется найти данные по сайту и всем его страницам, а также поддоменам.
- Функция url:
Весьма полезная лексика, если нужно отыскать страницу, размещенные по конкретному адресу. Например, запрос «url:livepage.ua/ru/blog» покажет проиндексирована ли данная страница в Яндексе.
- Команда host:
Проводит поиск запросов по указанному хосту.
Операторы поиска для настройки контекстной рекламы
Дополнительный синтаксис сэкономит не только ваше время, но и деньги. При помощи нескольких простых спецсимволов пользователь существенно сузит поиск и найдет желаемое за считаные минуты.
При помощи нескольких простых спецсимволов пользователь существенно сузит поиск и найдет желаемое за считаные минуты.
Операторы Яндекс.Директ и Google AdWords способны оптимизировать контекстную рекламу. Неопытные владельцы сайтов часто сталкиваются с тем, что запуск кампании дает большое количество просмотров и даже переходов по объявлению, однако минимум заказов. Кстати, тут может помочь бесплатный анализ вашей контекстной рекламы.
Использование специальных знаков для поисковых систем — лучший способ решить данную проблему. Они отсеют нецелевые запросы, благодаря чему ваш рекламный контент увидит только заинтересованная аудитория. Результат от этого будет такой же, как при увеличении бюджета на Директ, но вы обойдетесь без дополнительных затрат.
Хотите знать, какие уточняющие символы стоит выбирать в том или ином случае, как именно они помогут вашему бизнесу? Тогда читайте дальше!
Как функционируют операторы Google AdWords?
Сервис дает возможность работать с широким, фразовым и точным соответствием, а также использовать минус-слова и модификатор широкого соответствия.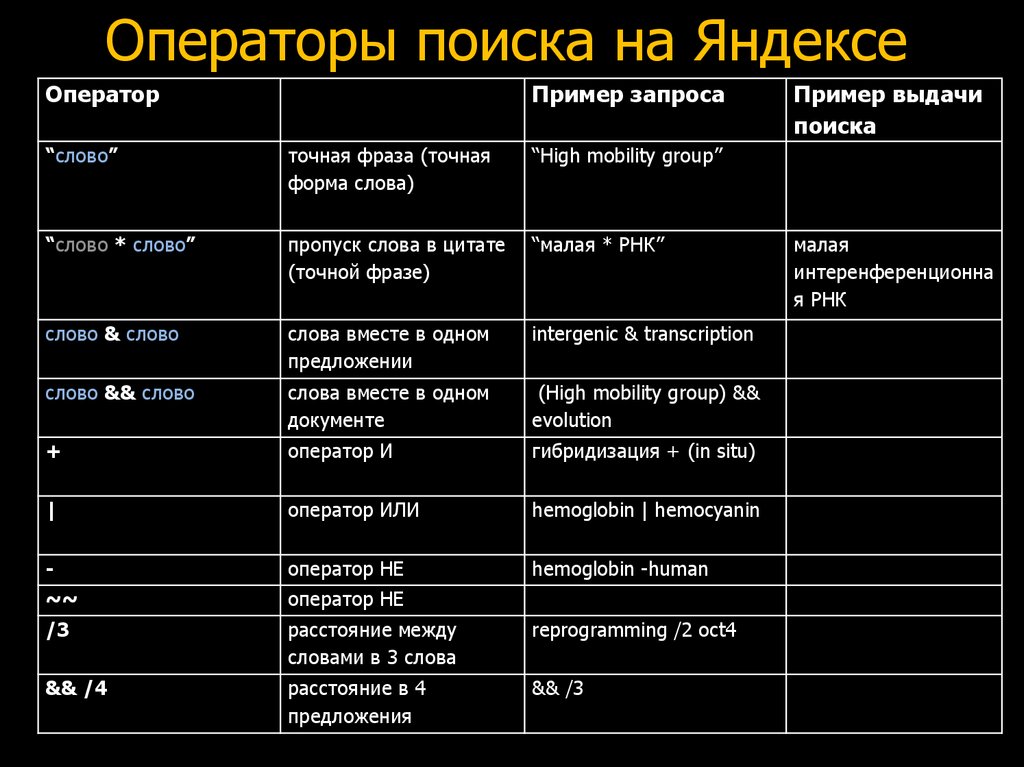
Все ключевые слова, указанные без спецсимволов, воспринимаются поисковиком в широком соответствии. В таком случае объявление демонстрируется в ответ на запросы с релевантными фразами и словоформами ключа. Среди них:
- синонимы;
- близкие по тематике варианты;
- похожие по смыслу слова.
Стоит лишь запустить рекламу с одиночным существительным, например, с ключом «кран», как пойдут показы по фразам «кран в кухне», «как заменить кран», «заказ вышки с краном в Москве»… Список может быть весьма обширным.
Учтите! Если соответствующие поисковые операторы Google отсутствуют, порядок слов в ключевой фразе не учитывается.
Гугл Адвордс по умолчанию поддерживает неотключаемую функцию «Близкие варианты». Значит, что он будет показывать аналоги в единственном и множественном числе, с разными падежами, формами слов, склонениями и опечатками.
Для широкого соответствия предусмотрен модификатор, предназначенный для отображения фраз с обязательным присутствием указанного ключа. Это знак плюс (+).
Это знак плюс (+).
Так, запрос «+купить путевку +Таити» увидит каждый пользователь, который ищет путевки и туры на Таити и хочет их купить. Слова «Таити» и «купить» непременно должны встречаться в запросе, а вот вместо «путевки» может быть «отпуск», «тур» или «отдых».
Точное и фразовое соответствие
Чтобы получить только введенные слова с любым падежом, склонением и числом, а также их синонимы без каких-либо дополнений, необходимо использовать синтаксис в виде квадратных скобок ([ ]).
Что касается фразового соответствия, оно предназначено находить пассажи с указанным словом или словосочетанием (его надо заключить в кавычки » «). При этом до и после такого ключа, как правило, присутствуют дополнительные слова.
Существуют еще и минус-слова, которые исключают нерелевантные фразы — для этого придуман символ минус (-). Кстати, используйте генератор минус слов для ускорения процесса.
Поисковые операторы Яндекс Директ и их секреты
В Директе предусмотрено широкое, фразовое, точное соответствие, а также принудительное вхождение слов, соответствие с фиксированным порядком запроса и минус-слова.
Яндекс, как и Google, всегда использует широкое соответствие введенного ключа, что по аналогии приводит к отображению неточных результатов и высокой вероятности слива бюджета. Кроме того, в рекламной кампании накапливается отрицательная статистика. Избежать этого вам помогут операторы Яндекс Вордстат: круглые и квадратные скобки, кавычки и другой синтаксис.
Внимание! Поисковая система по умолчанию не учитывает служебные слова, союзы и предлоги. Так, ответами на запрос «билеты по Киеву» станут «билет в Киев» и «билет Киев».
Чтобы исключить большой пласт нецелевых запросов и выйти на высокую конверсию, возьмите на вооружение спецсимвол кавычки (» «). В этом случае объявление будет демонстрироваться лишь на запрос с конкретным ключом и его словоформами.
Хотите принудительно задать фиксированный порядок слов? Используйте квадратные скобки [ ]. Данная команда особенно актуальна при продаже билетов. Например, размещенное в Директе объявление «[билет Самара-Калининград]», отобразится именно для тех пользователей Сети, которым надо отправиться из Самары в Калининград. Желающие заказать билет из Калининграда в Самару его вообще не увидят. А всем известно: чем конкретнее предложение, тем более оно эффективно.
Желающие заказать билет из Калининграда в Самару его вообще не увидят. А всем известно: чем конкретнее предложение, тем более оно эффективно.
Минус и плюс-слова
Знак минус (-) исключает из запроса нецелевые, лишние слова. Чаще всего к ним относятся «скачать», «реферат», «бесплатно» и «форум». Счет паразитных запросов исчисляется сотнями, они могут составлять до 80% от общего количества. По этой причине многие рекламодатели нередко используют целую портянку — список из десятков минус-слов.
Оператор соответствия плюс (+) служит для обязательного учета союзов и предлогов, которые, как уже говорилось, игнорируются поисковиком. Благодаря ему вы создадите более релевантный заголовок и, соответственно, повысите продажи. Фраза «+как купить готовый интернет-магазин» подойдет для пользователей, которым нужна дополнительная информация о приобретении, а «+где купить готовый интернет-магазин» — для тех, кто интересуется местом покупки.
Если вам необходимо «заморозить» текущее число и падеж слова, воспользуйтесь спецсимволом восклицательный знак «!». К примеру, «!ищу инвестора» или «!поиск инвесторов». Для максимального эффекта можно группировать команду с точным соответствием, то есть с кавычками.
К примеру, «!ищу инвестора» или «!поиск инвесторов». Для максимального эффекта можно группировать команду с точным соответствием, то есть с кавычками.
Подведем итоги
Как вы убедились, операторы поисковых систем Яндекс и Google существенно облегчают и ускоряют поиск информации.
Кроме того, с их помощью можно составить семантическое ядро, проверить внешние ссылки и проанализировать веб-проекты конкурентов.
Еще одним важным моментом является оптимизация рекламных объявлений путем отсечения нецелевых кликов и пустых показов.
В умелых руках это мощный, к тому же бесплатный инструмент с широким функционалом. Главное — подобрать оптимальные для себя команды, использовать их в подходящих случаях.
Пробуйте, экспериментируйте, и у вас все получится!
Основы работы с инструментами Яндекс
Главная / Офисные технологии / Основы работы с инструментами Яндекс / Тест 1
Упражнение 1:
Номер 1
Вы хотите купить ноутбук HP, для чего набрали два запроса: продажа ноутбуков "hp" продажа "ноутбуков hp" Какой из них вернет меньшее количество ссылок? А какой из них будет точнее, то есть выделять только ноутбуки HP?
Ответ:
 (1) первый вернет меньшее количество ссылок, он будет точнее 
 (2) между запросами нет никакой разницы 
 (3) первый вернет большее количество ссылок, поэтому он будет точнее 
 (4) второй вернет меньшее количество ссылок, он будет точнее 
 (5) второй вернет большее количество ссылок, поэтому он будет точнее 
Номер 2
Вы хотите найти карманный нетбук, для чего набрали следующий запрос (вместе с кавычками): "карманный нетбук" Какими будут результаты на двадцатой странице поиска?
Ответ:
 (1) как со словом «карманный», так и со словом «нетбук». Слова будут находиться в пределах одной страницы, необязательно рядом 
Слова будут находиться в пределах одной страницы, необязательно рядом 
 (2) как со словом «карманный», так и со словом «нетбук». Слова будут находиться в пределах одного предложения, необязательно рядом 
 (3) содержащими это словосочетание полностью 
 (4) запрос не даст результатов, поскольку словосочетание должно быть указано без кавычек 
 (5) на двадцатой странице не будет результатов, поскольку поиск в кавычках возвращает только первые пять результатов 
Номер 3
Все знают крылатое выражение "книга - лучший подарок". А как проверить с помощью запроса, что еще может быть вместо слова "лучший"?
Ответ:
 (1) книга лучший подарок? 
 (2) книга подарок открытки магазины 
 (3) книга ~~подарок 
 (4) книга /2 подарок 
 (5) книга ~~лучший ~~подарок 
Упражнение 2:
Номер 1
Вы набрали запрос вида "электронные книги ~~скачать" (без кавычек).
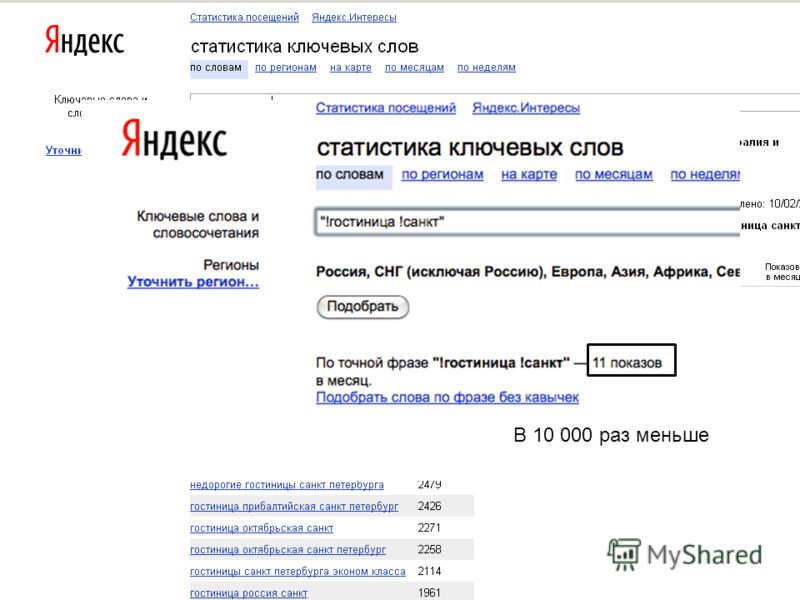 Каких слов (или слова) не будет в результатах?
Каких слов (или слова) не будет в результатах?Ответ:
 (1) книги, скачать 
 (2) электронные, скачать 
 (3) электронные книги 
 (4) скачать 
 (5) книги 
Номер 2
Вы хотите найти предложения по продаже мебели из Молдавии, для чего набираете следующие запрос: Мебель domain="md" Будут ли результаты включать в себя документы, которые являются доменами второго уровня, например, www.md.name.somename.ru?
Ответ:
 (1) нет, не будут 
 (2) поиск вообще не даст результатов, поскольку заданы неверные условия 
 (3) да, будут 
 (4) будут, но только для доменных имен вида www. md.name.somename.net 
md.name.somename.net 
 (5) будут, но только для доменных имен вида www.md.name.somename.com 
Номер 3
Вы хотите найти на сайте www.osp.ru все публикации, связанные с программой Photoshop. Выберите правильный запрос для этого:Ответ:
 (1) Photoshop << url="*www.osp.ru*" 
 (2) Photoshop << host="*www.osp.ru*" 
 (3) Фотошоп << host="*www.osp.ru*" 
 (4) Photoshop << url=www.  osp.ru*
osp.ru*
Упражнение 3:
Номер 1
Выберите запрос, который вернет страницы, которые обязательно содержат в заголовке слова "доска объявлений" и необязательно "Волгоград":
Ответ:
 (1) title[доска объявлений Волгоград] domain="ru" 
 (2) title["доска объявлений Волгоград"] domain="ru" 
 (3) доска объявлений волгоград 
 (4) title[доска объявлений] Волгоград 
 (5) title[доска объявлений Волгоград] 
Номер 2
Можно ли с помощью языка запросов Яндекса сформулировать поиск точной фразы в заголовке страницы?
Ответ:
 (1) нет, поскольку это различные конструкции 
 (2) да, но только если область поиска ограничена доменом ru 
 (3) да, можно 
 (4) да, но только если область поиска ограничена доменом com 
 (5) да, но только если область поиска ограничена доменами ru и com 
Номер 3
Выберите языковый запрос Яндекса, которые отобразит все сервисы портала Mail.
 Ru:
Ru:Ответ:
 (1) rhost="*mail.ru" 
 (2) rhost="*.mail.ru" 
 (3) rhost="*.mail.ru*" 
 (4) rhost="mail.ru" 
 (5) rhost="ru.mail.*" 
Упражнение 4:
Номер 1
Выберите запрос, который вернет все разделы сайта www.
 osp.ru:
osp.ru:Ответ:
 (1) host="www.osp.ru" 
 (2) site=www.osp.ru 
 (3) domain="www.osp.ru" 
 (4) rhost="www.osp.ru" 
 (5) www*ospru* 
Номер 2
Выберите запрос, который позволяет найти все сайты, которые имеют схожее доменное имя с Яндексом:
Ответ:
 (1) host="ru.  yandex*"
yandex*"
 (2) host="ru.yandex.*" 
 (3) rhost="ru.yandex*" 
 (4) domain="ru.yandex.*" 
 (5) domain="Яндекс*" 
Номер 3
Вы хотите найти примеры документов Microsoft Excel, для чего набираете в Яндексе следующий запрос:mime="xls". Чем он будет отличаться от запроса"*.xls"(без кавычек)?
Ответ:
 (1) в первом случае ссылки будут представлять собой документы Microsoft Excel, а во втором случае будет обычный поиск по значению 
 (2) ничем не будет отличаться, это два эквивалентных запроса 
 (3) первая форма некорректна, результаты будут только по запросу *.  xls
xls
 (4) запрос mime="xls" некорректен, так как не указано название файла. Запрос *.xls вернет все документы Microsoft Excel 
 (5) оба запроса некорректны, так как не задано название документа 
Упражнение 5:
Номер 1
Что такое Дзен-поиск Яндекса?
Ответ:
 (1) поиск без строки ввода, который возвращает результаты на основании одного из текущих запросов, вводимых другими пользователями 
 (2) локализованная версия поиска Яндекса 
 (3) программа для поиска на локальном компьютере 
 (4) система подсказок, которая заканчивает запрос при вводе первых нескольких букв 
 (5) версия поисковой системы, оформленная в минималистичном дизайне, однако позволяющем вводить собственные запросы 
Номер 2
В чем заключается задача поискового колдунщика Яндекса?
Ответ:
 (1) помогать пользователю вводить поисковый запрос, предлагая в выпадающем списке готовые словосочетания 
 (2) выдавать точные и краткие ответы прямо на страницу результатов 
 (3) подстраивать выдачу результатов в соответствии с текущим профилем пользователя 
 (4) запоминать поисковые запросы данного пользователя 
 (5) сортировать результаты с учетом их релевантности 
Номер 3
Вы настраиваете отображение 30 результатов поиска на одной странице в Яндексе без авторизации, после чего закрываете браузер и выключаете компьютер.
 Будут ли сохранены созданные настройки после включения?
Будут ли сохранены созданные настройки после включения?Ответ:
 (1) да, но только если в браузере не были удалены Cookie 
 (2) нет, не будут 
 (3) будут, причем на всех компьютерах — домашнем, рабочем, переносном 
 (4) будут, но только в расширенной версии поиска 
 (5) не будут, потому что компьютер был выключен 
Упражнение 6:
Номер 1
Для поиска дистанционного обучения вы набираете соответствующий запрос: дистанционное & обучение Будут ли результаты поиска содержать такие слова, как "дистанционно" и "дистанционная" (без кавычек)?
Ответ:
 (1) нет, поскольку это поиск по точной фразе 
 (2) да, поскольку производится поиск с учетом всех форм слов 
 (3) нет, поскольку слово «дистанционная» употреблено с неверным окончанием по отношению к слову «обучение» 
 (4) нет, поскольку поисковый запрос содержит недопустимые символы 
 (5) да, но только если исходный запрос заключить в кавычки 
Номер 2
Выберите символ, который объединяет поисковые слова с возможностью их сочетания в пределах документа:
Ответ:
 (1) && 
 (2) ~~ 
 (3) rhost 
 (4) host 
 (5) domain 
Номер 3
Вы набираете запрос следующего вида: загадочные /3 явления Будет ли в результаты попадать словосочетание "необъяснимые и загадочные явления"?
Ответ:
 (1) да, будет 
 (2) «загадочные явления» будут попадать, а «необъяснимые» — нет 
 (3) нет, не будет 
 (4) поиск вообще не даст результатов, поскольку в исходном запросе допущена ошибка 
 (5) будет, но только без предлога «и» 
Главная / Офисные технологии / Основы работы с инструментами Яндекс / Тест 1
Поисковый оператор Google Around(X) не работает.
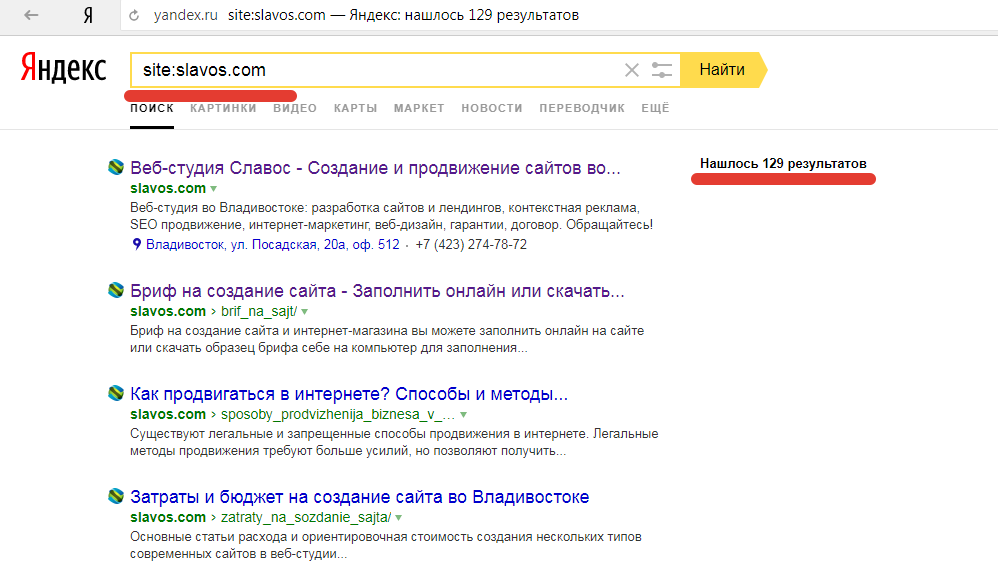 Или это так? – SourceCon
Или это так? – SourceConНедавно я видел в Интернете несколько презентаций, в которых упоминались операторы поиска Google AROUND(X) и Bing NEAR:X, что напомнило мне о недавнем обмене мнениями, который у меня был с подключением к LinkedIn. Кто-то обратился ко мне, чтобы спросить о поиске по близости и посмотреть на один из поисков, которые они выполняли.
Вот чем они поделились: (Komodo ИЛИ KMD ИЛИ «Agama Wallet» ИЛИ JL777) ВОКРУГ(10) (кошелек ИЛИ merkle ИЛИ ICO ИЛИ блокчейн ИЛИ децентрализованный ИЛИ децентрализованный ИЛИ dICO ИЛИ крипто ИЛИ криптовалюта ИЛИ атомный ИЛИ etomic ИЛИ DEX ИЛИ обмен ИЛИ CEX ИЛИ dPOW ИЛИ «отложенное доказательство работы» ИЛИ ERC20 ИЛИ контракты ИЛИ bitcointalk ИЛИ финтех ИЛИ «альтернативы» ИЛИ инвестиции* ИЛИ «обратите внимание»)
Учитывая большие операторы ИЛИ по обе стороны от оператора AROUND(10), я не мог легко сказать, работает ли оператор приближения или нет, но я сказал им, что в некоторых из моих предыдущих тестов за эти годы он оказалось, что AROUND(X) не работает.
Во-первых, поиск по близости — это то, чем я пользуюсь почти 20 лет и о чем пишу со времен AROUND (2009). Возможность контролировать, насколько близки термины друг к другу в результатах поиска, может дать вам возможность ориентироваться на предложения, в которых люди описывают ответственность, которая обычно представляет собой глагол (например, разработка, проектирование, внедрение и т. д.) в сочетании с существительным. (Node.js, Hadoop, SAP и т. д.). Это невероятно мощная форма семантического поиска. Возможность таргетировать предложения и находить людей на основе того, что они конкретно сделали, гораздо лучше предсказывает совпадение, чем поиск по ключевым словам независимо от местоположения или отношения друг к другу. Некоторые ATS (например, iCIMS), доски объявлений (например, Monster) и решения для поиска и сопоставления (например, Sovren, Textkernel) надежно поддерживают поиск по близости.
Во-вторых, почти все, что вы видите и читаете о поиске источников, касается поиска, а не просмотра и обработки результатов.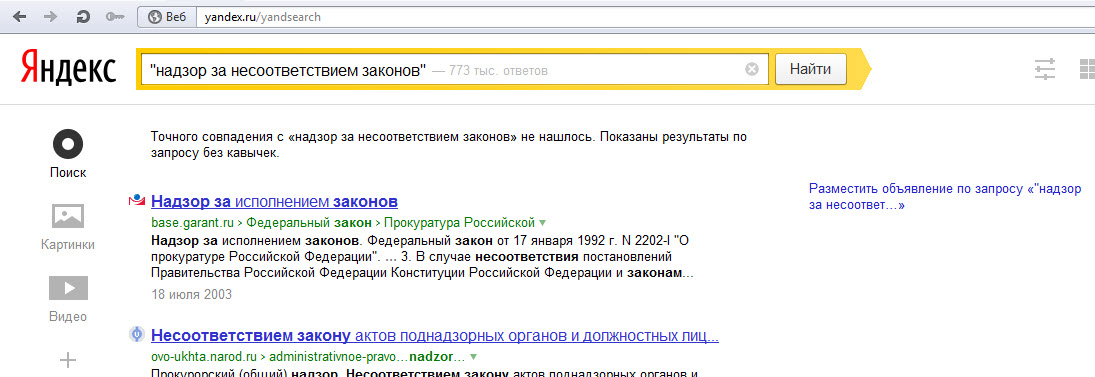 Я обнаружил, что многие люди не уделяют должного внимания своим результатам поиска, поэтому я хотел бы уделить время, чтобы сказать кое-что о важности изучения результатов не только на предмет терминов, которые вы искали, но и на то, чтобы увидеть, действительно ли ваш поиск « работающий.» Как я люблю говорить, (почти) все поиски работают. Однако это не обязательно означает, что поисковая система действительно придерживалась вашего синтаксиса поиска или, другими словами, работала так, как вы предполагали.
Я обнаружил, что многие люди не уделяют должного внимания своим результатам поиска, поэтому я хотел бы уделить время, чтобы сказать кое-что о важности изучения результатов не только на предмет терминов, которые вы искали, но и на то, чтобы увидеть, действительно ли ваш поиск « работающий.» Как я люблю говорить, (почти) все поиски работают. Однако это не обязательно означает, что поисковая система действительно придерживалась вашего синтаксиса поиска или, другими словами, работала так, как вы предполагали.
Я считаю, что многие статьи и презентации о поиске источников посвящены «ответам», а не процессу получения «ответов». Я также знаю, что многие люди просто хотят получить «ответы» — например, определенные логические строки поиска, строки темы электронной почты и т. д. Однако я обнаружил, что некоторые из наиболее эффективных способов обучения — это совершение ошибок, вдумчивое экспериментирование и подвергая сомнению статус-кво. В процессе написания этой статьи я (пере)извлек некоторые уроки, которые, я думаю, будут полезны каждому.
Возможно, вам будет интересно отметить, что я начал этот пост как статью о том, что поисковый оператор Google AROUND(X) не работает, но когда я начал прокручивать множество поисковых запросов, чтобы проверить свое утверждение (я перепробовал более 20 ), я столкнулся с проблемами, чтобы найти четкие доказательства того, что это не работает.
Однако в конце концов я остановился на паре терминов, которые не очень часто встречались вместе, поэтому мне не пришлось продираться через массу результатов, чтобы найти примеры неработающего AROUND(X).
расшифровать AROUND(3) hadoop
На первый взгляд кажется, что поиск явно работает, особенно если вы допускаете автоматическое определение корней (например, расшифровку).
Я начал копаться в результатах, чтобы найти некоторые, в которых decrypt и Hadoop не упоминались в течение трех терминов.
На первой странице я нашел результат без упоминания о Hadoop. Мне это показалось странным, но я не принял на первый взгляд тот факт, что поиск в Google не работает должным образом.
Просматривая результат, я заметил, что хотя Hadoop нигде не упоминается, я видел, что Hive упоминался много раз, и один раз прямо рядом с decrypt . Обратите особое внимание на нижнюю часть изображения ниже.
Я думаю, что мы видим здесь то, что Google фактически выполняет мой поисковый запрос, чтобы увидеть Hadoop в пределах трех слов , расшифровать , используя термины, синонимичные Hadoop, такие как Hive в этом случае и HDFS по крайней мере в одном другом.
Это довольно круто, но затрудняет определение того, действительно ли работает оператор Google AROUND(X), потому что вам нужно искать синонимы (или, по крайней мере, то, что Google может считать синонимами).
Поэтому я решил удалить эту переменную из уравнения и поискал точные термины: «расшифровать» ВОКРУГ(3) «Hadoop»
Помните, я намеренно выбрал относительно необычную комбинацию терминов, чтобы найти рядом, чтобы было легко найти проверить результаты, чтобы увидеть, работает ли оператор Google AROUND. Если вы используете очень распространенные термины и/или большое расстояние между терминами, вас легко обмануть, думая, что Google подчиняется правилам оператора AROUND(X), хотя на самом деле ваши поисковые термины в любом случае близки друг к другу, а не потому, что вы «заставили» их быть с помощью AROUND(X). Это важно понимать.
Если вы используете очень распространенные термины и/или большое расстояние между терминами, вас легко обмануть, думая, что Google подчиняется правилам оператора AROUND(X), хотя на самом деле ваши поисковые термины в любом случае близки друг к другу, а не потому, что вы «заставили» их быть с помощью AROUND(X). Это важно понимать.
Вернемся к моему поиску. Если вы просмотрите примерно 31 результат поиска (без рекламы), во всех из них есть упоминание о Hadoop в трех словах после расшифровки. Тем не менее, это проливает некоторый свет на то, что означает «в пределах X терминов», поскольку в 2 случаях между дешифрованием и Hadoop было три термина.
На самом деле я никогда не задумывался слишком глубоко о том, что именно имел в виду внутри(X) – думаю об этом сейчас; Обычно я интерпретирую «в пределах трех терминов» как максимум 2 термина, разделяющих термины, поэтому один из них должен быть 3 9.0049 рд срок по порядку, вперед или назад. Многие результаты Google из этого поиска соответствуют этому критерию. Однако в некоторых случаях оказывается, что AROUND(X) Google может интерпретировать X как максимальное количество условий, которые могут разделять условия поиска. Или, возможно, в приведенном выше примере Google просто игнорирует обычное слово «the» и не считает его третьим словом между decrypt и Hadoop . Любой способ работает для меня. ????
Однако в некоторых случаях оказывается, что AROUND(X) Google может интерпретировать X как максимальное количество условий, которые могут разделять условия поиска. Или, возможно, в приведенном выше примере Google просто игнорирует обычное слово «the» и не считает его третьим словом между decrypt и Hadoop . Любой способ работает для меня. ????
Я решил провести еще один поиск, чтобы убедиться, что то, что я нашел с помощью «decrypt» AROUND(3) «Hadoop», не было какой-то случайностью.
Вот второй тестовый поиск, на котором я остановился:
(разработчик | программист | инженер) migrate AROUND(4) Резюме JavaScript — образец
Имейте в виду, что я не пытался запустить окончательный поиск резюме – просто протестируйте Google. AROUND(X) функциональность с другим поиском.
Я не просматривал более 100 результатов (помните, игнорируйте «Около 1060 результатов» — продолжайте нажимать на последнюю страницу, которую сможете, и вы часто быстро обнаружите, что фактическое количество результатов составляет часть первоначальной оценки ), но я проверил много случайных результатов на многих страницах. Хотя большинство результатов, которые я проверил, строго придерживались термина «мигрировать» в рамках четырех терминов JavaScript, мне удалось найти пару подозрительных результатов, в которых я не был уверен, что Google не пытается заменить термин «мигрировать» другими терминами. ».
Хотя большинство результатов, которые я проверил, строго придерживались термина «мигрировать» в рамках четырех терминов JavaScript, мне удалось найти пару подозрительных результатов, в которых я не был уверен, что Google не пытается заменить термин «мигрировать» другими терминами. ».
Итак, как и в предыдущем примере (я должен был научиться!), я использовал кавычки, чтобы исключить эту переменную. Хотя, если честно, я был доволен тем, как Google находил термины, связанные с JavaScript, которые соответствовали моим критериям.
(разработчик | программист | инженер) «мигрировать» ВОКРУГ(4) Резюме «JavaScript» — образец
Я проверил более 20 результатов на многих страницах и смог найти пару результатов, которые я не мог понять, почему Google вернул их, так как они вообще не упоминали о миграции.
Как этот.
В замешательстве (сочетание недоверия и замешательства) я продолжал нажимать CTRL-F и использовать расширение Multi-Highlight Chrome (которое не всегда работает должным образом — гррр).
Нет — нигде не упоминается о переносе .
Я собирался списать это на то, что Google AROUND (X) не работает, но один результат меня действительно обеспокоил. Непонятно, почему Google вернул его, если во всех других результатах упоминалась миграция.
Тогда из любопытства я решил просмотреть исходный код страницы и поковыряться.
Угадайте, что я нашел?
Это напомнило мне, почему я люблю писать о подобных вещах.
Я сделал то же самое, чтобы проверить несколько других подозрительных результатов, проверил пару других подозрительных результатов и обнаружил то же самое.
Хотя мне потребовалось бы значительно больше тестов, чтобы со 100% уверенностью сказать, что оператор AROUND(X) работает во всех возможных условиях поиска, мои тестовые поиски ясно показывают, что AROUND(X) Google работает так, как задумано.
В случае с Bing я могу сказать довольно просто: NEAR:X определенно не работает.
Вот документация. Проверьте этот поиск: расшифровать около: 3 Hadoop.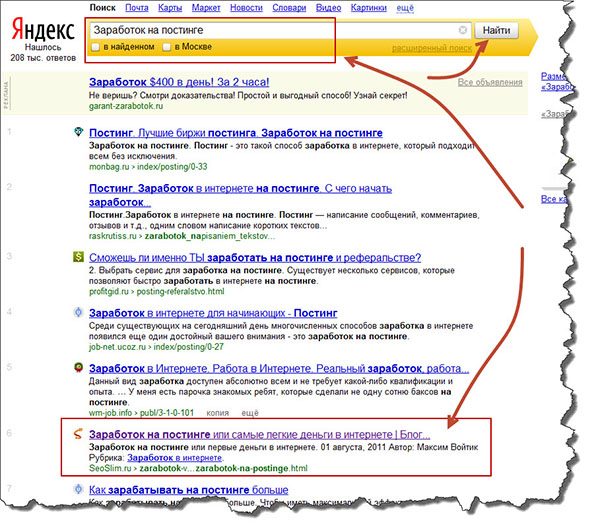 Не работает, если использовать NEAR с большой буквы: decrypt NEAR:3 Hadoop
Не работает, если использовать NEAR с большой буквы: decrypt NEAR:3 Hadoop
Для Яндекса это не так просто сказать.
В качестве первого теста я запустил «decrypt» /3 «hadoop».
Судя по результатам поиска, вроде работает. Однако я понял, что предположил, что кавычки будут правильными операторами. После проверки поисковых операторов Яндекса кавычки предназначены для «поиска точного порядка слов», поэтому я не могу быть уверен, что кавычки работают с отдельными терминами.
Интересно, что в другом руководстве оператора поиска Яндекса кавычки описываются как соответствующие «точному количеству слов», но приведенный пример показывает, что он может давать результаты, изменяя порядок терминов.
Что за противоречие‽
В любом случае ! — оператор Яндекса для поиска слов в их точной форме.
Несмотря на то, что изначально я использовал не тот оператор поиска для поиска точных терминов, вы можете видеть, что поиск выполнялся и возвращал результаты, которые на первый взгляд выглядели «правильными», поэтому я покопался в результатах, и это не заняло много времени. попытаться найти примеры, где decrypt и Hadoop не упоминались в пределах 3 слов друг от друга.
попытаться найти примеры, где decrypt и Hadoop не упоминались в пределах 3 слов друг от друга.
Итак, я предпринял вторую попытку, используя ! оператор: !decrypt /3 !hadoop
Результаты изменились по сравнению с первым поиском, но опять же, на первый взгляд, все выглядит довольно хорошо.
Однако, после изучения и тестирования случайных результатов, многие из результатов поиска соответствуют требованию близости, но многие не соответствуют. Некоторые результаты в нижней части страницы 1 даже не упоминают поисковый запрос 9.0023 расшифровать , в том числе при проверке через исходный код страницы. На странице 2 ситуация не улучшается. Не стесняйтесь проверить сами.
Я решил попробовать свой другой поиск с проверкой близости, но упростил его, чтобы сосредоточиться исключительно на аспекте близости: !migrate /4 !JavaScript
На первый взгляд все выглядит великолепно, правда? (вы уже видите закономерность?)
Однако не думайте, что только потому, что вы видите кучу упоминаний , мигрируйте близко к JavaScript , что Яндекс фактически соблюдает условие близости.
Все, что вам нужно сделать, это случайным образом открыть результаты и найти migrate и JavaScript и проверить, действительно ли они находятся в пределах четырех слов друг от друга хотя бы один раз в каждом результате. Из моей случайной выборки, есть много результатов, которые не упоминают migrate в пределах четырех слов JavaScript, , хотя вам нужно перейти на страницу 5, чтобы добраться до более очевидных примеров. Это действительно потому, что упоминания о migrate и JavaScript нередко упоминаются вместе на страницах/документах (и почему моя расшифровка /Hadoop была лучшим тестом).
Другой вариант поиска по близости в Яндексе — это &, о котором я видел на SourceCon — он должен «искать термины, которые появляются в одном предложении». Поскольку /X не работал, по крайней мере, для моих тестовых поисков, я решил попробовать &.
!расшифровать и !Hadoop
Да, еще раз, страница 1 выглядит хорошо на первый взгляд. На самом деле это выглядело довольно хорошо, когда я также погрузился в индивидуальные результаты.
На самом деле это выглядело довольно хорошо, когда я также погрузился в индивидуальные результаты.
Однако мне нужно было только перейти на страницу 2, чтобы найти результаты, в которых даже нигде не упоминается , расшифровывающий .
Помните, я начал эту статью как «Оператор Google AROUND(X) не работает». Когда я углубился в тестирование, мне пришлось вернуться и изменить заголовок и всю статью, что, как мне кажется, делает этот пост намного лучше, чем он должен был быть.
Видите ли, когда я начал искать, чтобы подтвердить свое мнение о том, что оператор Google AROUND(X) не работает должным образом, я нашел доказательства обратного и изменил свою точку зрения.
Я всегда люблю, когда мне доказывают неправоту, даже если я делаю это против себя. Пожалуй, это лучший способ.
Вот что, я надеюсь, вы сможете почерпнуть из моего опыта и из этой статьи:
- Не верьте слепо всему, что видите и слышите
- Проверьте себя, прежде чем верить тому, что говорят или пишут другие люди
- При экспериментировании не ищите подтверждающих доказательств
- При проверке гипотез старайтесь удалить как можно больше переменных
- Почти все поисковые запросы «работают» — даже те, которые содержат синтаксические ошибки, часто дают результаты!
- Пусть вас не вводит в заблуждение внешний вид результатов
- При просмотре результатов поиска ищите не только то, что вы ожидаете, но и то, чего вы не ожидаете
- При изменении результатов поиска обратите внимание на изменения количества результатов и характера самих результатов
- Если что-то не имеет смысла, не сдавайтесь — проявите творческий подход и продолжайте в том же духе! Что вам не хватает? Есть ли другой способ, о котором вы не подумали?
- Оставайтесь любознательными и открытыми: задавайте вопросы и бросайте вызов другим и себе
Заключительные мысли о AROUND(X) Google:
- Если вы используете AROUND(X) Google для поиска 8, 9, 10 или более слов между двумя поисковыми запросами, вам может быть невероятно сложно проверить, каждый ли результат на самом деле придерживается максимального расстояния X, так как термины обязательно будут присутствовать во всех документах. Однако, если они находятся в отдельных предложениях, семантический аспект поиска, скорее всего, будет нарушен. Помните, что реальная сила поиска по близости, когда речь идет о поиске людей, которые выполняли определенные обязанности, заключается в возможности нацеливания терминов в одном и том же предложении – обычно, когда вы ищете людей с определенным опытом/обязанностями (глагол/существительное). комбинации).
- Если вы попытаетесь найти операторы ИЛИ по обе стороны от оператора AROUND(X), я не могу точно сказать, работает ли это на самом деле — это потребует дополнительного тестирования. Комбинация операторов OR с оператором AROUND(X) может затруднить определение того, соответствуют ли возвращаемые результаты пределу поиска близости.
 Однако, если они находятся в отдельных предложениях, семантический аспект поиска, скорее всего, будет нарушен. Помните, что реальная сила поиска по близости, когда речь идет о поиске людей, которые выполняли определенные обязанности, заключается в возможности нацеливания терминов в одном и том же предложении – обычно, когда вы ищете людей с определенным опытом/обязанностями (глагол/существительное). комбинации).
Однако, если они находятся в отдельных предложениях, семантический аспект поиска, скорее всего, будет нарушен. Помните, что реальная сила поиска по близости, когда речь идет о поиске людей, которые выполняли определенные обязанности, заключается в возможности нацеливания терминов в одном и том же предложении – обычно, когда вы ищете людей с определенным опытом/обязанностями (глагол/существительное). комбинации).Советы по поиску от Xapien
Заблудились?
Как убедиться, что вы экономите время, а не тратите его впустую при использовании поисковых систем для фоновых исследований?
Подпишитесь на наши руководства
Мы ежедневно пользуемся поисковыми системами. Но действительно ли они возвращают нам то, что нам нужно? Или в конечном итоге мы тратим больше времени на их поиск, чем на поиск нужных результатов?
Но действительно ли они возвращают нам то, что нам нужно? Или в конечном итоге мы тратим больше времени на их поиск, чем на поиск нужных результатов?
Вот несколько советов о том, какие поисковые системы использовать, когда и как их эффективно использовать для фоновых исследований и должной осмотрительности.
Лучшие поисковые системы
Посмотрим правде в глаза, Google великолепен. Но его коммерческие функции страницы результатов поисковой системы (SERP), такие как реклама, график знаний, фрагменты и пакет карт, могут вытеснять релевантные результаты, что затрудняет поиск нужной информации.
Он также ориентирован на Запад и может быть не лучшей платформой для работы с международными темами.
Вот некоторые из других поисковых систем, о которых вам нужно знать:
Запросить демонстрацию
Яндекс
Лучшее покрытие для России и СНГ. Google по-прежнему используется в России, но Яндекс вполне может найти для вас ту важную часть информации, которой вам не хватает.
Baidu
Лучшее покрытие для Китая. Baidu лучше других поисковых систем понимает китайский язык и культуру. Он учитывает контекст, в котором слова используются для получения наиболее релевантных результатов. Другие поисковые системы боролись с этим в Китае.
Поисковая система Baidu выдает результаты на упрощенном китайском языке.
Bing
Лучше всего подходит для поиска изображений. Bing может понять, относится ли поиск к человеку или предмету, а затем показать соответствующие изображения. Это полезно для проверки информации и лучшего понимания предмета.
Яндекс (выше) тоже имеет хорошую функцию обратного поиска картинок. Обязательно стоит проверить, могло ли ваше изображение быть снято в России.
Duckduckgo
Лучший вариант для уединения и чистого обзора.
Google предоставляет персонализированный поиск на основе собранных данных. DuckDuckGo не собирает ваши данные, поэтому результаты поиска будут одинаковыми для всех, кто ищет. Это может помочь, когда вы пытаетесь понять, что может увидеть кто-то другой, если решит покопаться в вас или в вашей теме.
Это может помочь, когда вы пытаетесь понять, что может увидеть кто-то другой, если решит покопаться в вас или в вашей теме.
Претенденты
Ландшафт меняется независимо от того, где вы находитесь. Новые прорывные поисковые системы, такие как Ecosia, Neeva и Mojeek, бросают вызов первенству Google. Ecosia предлагает экологичный поиск, обещая направить все доходы на посадку деревьев. Neeva на основе подписки обещает меньше рекламы и большую конфиденциальность. В то время как Neeva, DuckDuckGo и Ecosia лицензируют свой веб-индекс у Microsoft Bing, Mojeek хочет создать свой собственный индекс, чтобы стать по-настоящему независимым.
Главный совет
Когда люди беспокоятся о своей репутации, они, скорее всего, посоветуются с Google, чтобы удалить определенные страницы. Но вряд ли они думают о других. Рассмотрите возможность использования различных движков, чтобы получить полную картину.
Takeaway
Разные поисковые системы содержат разную информацию. Магазин вокруг и попробовать ассортимент, чтобы получить то, что вы хотите найти.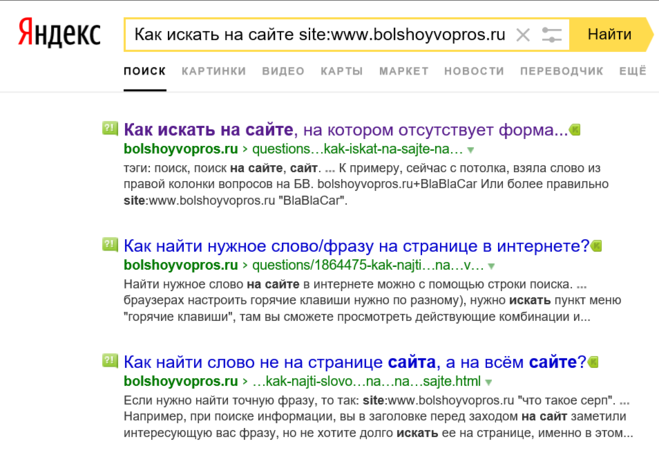 Не то, что они хотят показать вам.
Не то, что они хотят показать вам.
Подпишитесь на наши руководства
Информация, а не информация
Самая большая проблема с поисковыми системами — это просмотреть миллионы результатов, чтобы найти нужную информацию. Чтобы помочь, организации часто устанавливают ограничения на количество посещенных страниц при проведении комплексной проверки и фоновых исследований. Но что, если эта важная часть информации была на странице 15, а не на странице 10?
Кто-то еще может найти этот самородок, и он вернется, чтобы укусить вас.
Извлечение информации из информации — это не просто упорство. Речь идет об умном поиске.
Ключевым моментом является уточнение набора результатов, чтобы получить управляемое число, не пропуская при этом то, что вам нужно. На разных этапах вашего исследования вам может понадобиться сузить или расширить область поиска. Когда вы начинаете, вы хотите изучить свои варианты и посмотреть, что может или не может иметь отношение к вашей теме, чтобы лучше понять. Но затем, когда вы научитесь, вы захотите сузить круг до конкретных областей.
Но затем, когда вы научитесь, вы захотите сузить круг до конкретных областей.
Составьте список идей для первоначального поиска. Проведите мозговой штурм с коллегами, чтобы создать разнообразный и всесторонний поиск.
По мере нахождения новой информации расширяйте ее, используя «или» и альтернативные условия поиска
Уменьшить с помощью:
– Фильтр диапазона дат
– Поиск по фразе
– Операторы поиска
Главный совет
Будьте культурными. Терминология, которую вы используете при поиске, определяет то, что вы найдете, поэтому старайтесь использовать язык человека, который, вероятно, написал часть информации, которую вы ищете. Например, официальные отчеты будут записываться как таковые и могут даже содержать такое слово, как «официальный».
Подпишитесь на наши руководства
Интеллектуальный поиск
Хотя Google является основным сторонником логического поиска, ряд других платформ используют аналогичные структуры. Это включает в себя социальные сети.
Это включает в себя социальные сети.
Все мы знаем о:
И/+ (раскрыть)
или (расширить)
Нет/- (исключить)
Вот еще несколько важных инструментов для исследователей:
Кавычки и знак минус
Кавычки («») и знак минус (-) являются двумя наиболее важными операторами для выполнения запросов.
Поместите что-нибудь в кавычки, и результаты будут содержать именно то, что вы написали. Например: «Гомер Симпсон» не вернет греческого поэта Гомера.
Поставьте что-то со знаком минус перед ним, чтобы исключить это из поиска. Например: Гомер -Греция -Греческий -Поэт -Илиада -Одиссея.
Подстановочный знак
Подстановочный знак, представляющий собой звездочку (* или shift + 8), заменяет неизвестную переменную для вашего поиска.
Этот оператор может представлять один символ, слово или целую фразу. Его можно использовать, если вы не знаете отчество, имя или фамилию субъекта, но у вас есть другая информация, которая поможет вам найти его. Его также можно использовать для частичных дат рождения, если вы поэкспериментируете с правильным форматом даты.
Его также можно использовать для частичных дат рождения, если вы поэкспериментируете с правильным форматом даты.
Подпишитесь на наши руководства
Главный совет
Комбинируйте несколько логических операторов в одном поиске, чтобы получить наиболее точные и релевантные результаты.
Тип файла
Функция Тип файла: вернет результаты, относящиеся именно к этому типу файла, а также поисковый запрос или указанный сайт, например тип файла: pdf, XLS, XLSX, Doc и т. д. Это может помочь вам найти официальные списки и записи на других запутанных сайтах.
Сайт
Сайт: найдет информацию только с определенного сайта. Это может быть очень полезно для сайтов, которые не имеют собственной функции поиска. Например, если я хочу узнать о риске на сайте Xapien, я могу указать site:www.xapien.com «риск» и сразу перейти к интересующим меня страницам.
Вывод
Меньше, а чаще больше, когда речь идет о результатах поиска. Избавьтесь от шума с помощью интеллектуального поиска.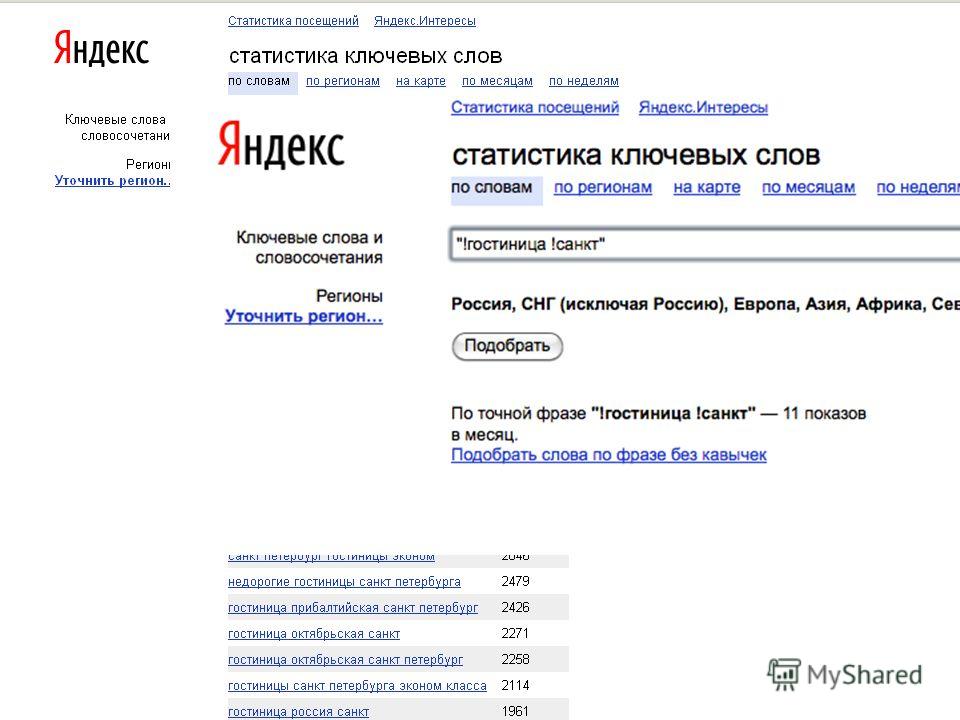
Проверка
Поиск «золотых самородков» информации — это хорошо, но непроверенная информация может легко ввести вас в заблуждение. Это кажется очевидным, но критическое мышление необходимо. Даже самые логичные и умные мыслители могут быть убеждены в заговорах и слухах, которыми изобилует Интернет. Лучший способ защититься от этого — применить процесс к вашей проверке.
Как узнать, верны ли утверждения, сделанные в блогах, статьях и на других сайтах?
Триангуляция: используйте более одного источника, когда другие доступны, чтобы получить разные точки зрения.
Перекрестная проверка: подтвердите основные информационные пункты из других авторитетных источников.
Используйте оригинальные источники: когда они доступны, используйте оригинальные источники, не полагайтесь на вторичные источники. Если в статье СМИ говорится о банкротстве компании, можете ли вы проверить это в исходной записи?
Владельцы, мотивы, ограничения: Определите, кто стоит за источником и является ли их отчет каким-либо образом ограниченным или предвзятым.
Поймите историю, которую представляет источник, и пытается ли он убедить или повлиять. Это может исказить результаты. Попытайтесь определить любые признаки предвзятости, явные или неявные, в том, как источник представляет свою информацию.
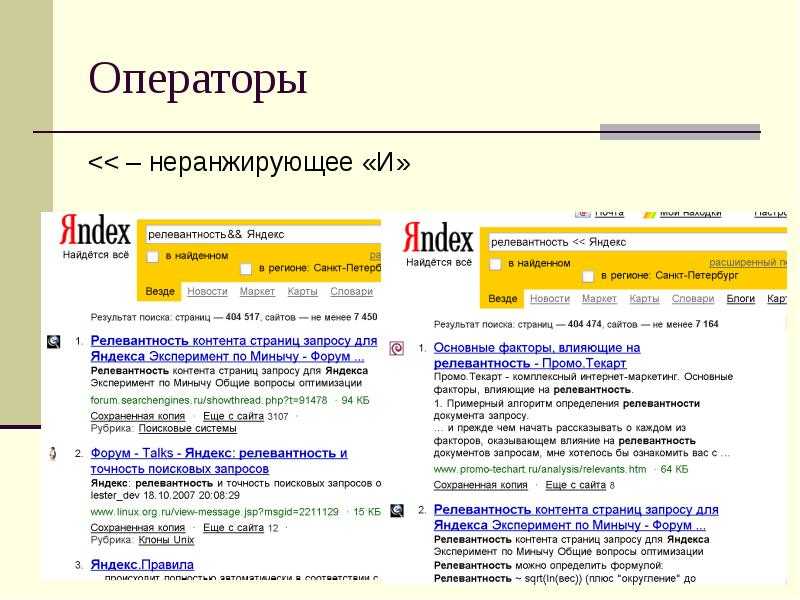 Поймите историю, которую представляет источник, и пытается ли он убедить или повлиять. Это может исказить результаты. Попытайтесь определить любые признаки предвзятости, явные или неявные, в том, как источник представляет свою информацию.
Поймите историю, которую представляет источник, и пытается ли он убедить или повлиять. Это может исказить результаты. Попытайтесь определить любые признаки предвзятости, явные или неявные, в том, как источник представляет свою информацию.Еда на вынос
Интернет — опасное место. Заговоры, ложная и дезинформация изощренны и широко распространены. Особенно, когда речь идет об онлайн-данных.
Практический результат
Сеть — это огромный банк ресурсов, но переизбыток информации может скрыть критическое понимание. Поисковые системы помогают обрабатывать и упорядочивать онлайн-данные, но этим дело не ограничивается.
Широкий спектр источников, умный поиск и проверка на основе процесса могут помочь в любом фоновом исследовании. Но упорство и время остаются важными.
Автоматизированные решения, такие как Xapien, могут помочь. Мощные механизмы обработки естественного языка и устранения неоднозначности Xapien могут триангулировать информацию из тысяч источников за несколько минут.
Заставьте онлайн-данные работать на вас.
Заказать демонстрацию
Подпишитесь на наши руководства…
Десять важных советов по поиску в Интернете
Чтобы найти нужную страницу среди миллиардов в Интернете, требуется не только поисковая система, но и некоторые знания. -как. Вот подборка моих любимых советов по поиску в Интернете.
1. Поиск фразы
Для поиска точной, полной фразы, а не только слов, входящих в ее состав, заключите ее в кавычки. Например, вместо ввода на рассвете в день моего рождения введите «на рассвете в день моего рождения» . Количество просмотров резко сократится, так как вы увидите только те страницы, которые содержат именно эту фразу.
2. Уточните
Если вы хотите найти статьи об управлении закладками в Safari на iPhone под управлением iOS 7, не ищите только управление закладками . Добавьте все эти термины в: управление закладками сафари iphone ios 7 .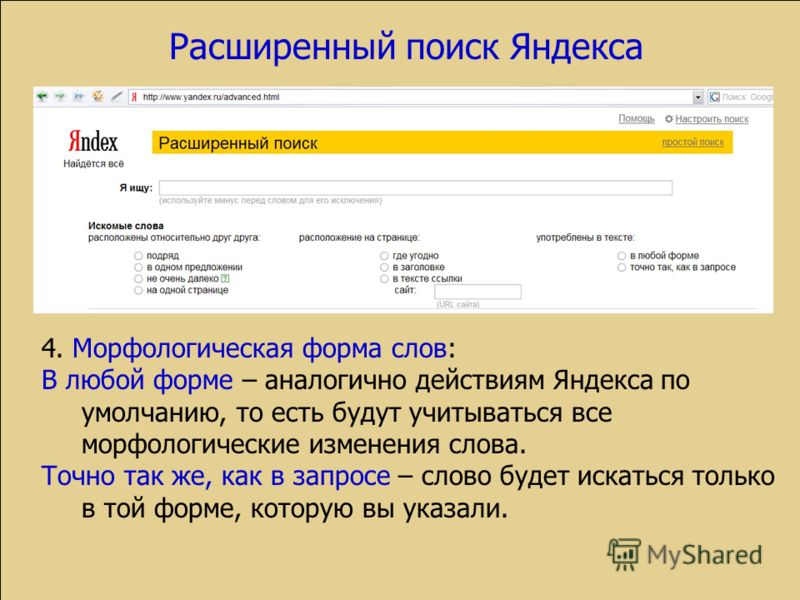 Чем больше информации вы предоставите, тем полезнее будут ваши результаты.
Чем больше информации вы предоставите, тем полезнее будут ваши результаты.
3. Исключите слово
Чтобы убедиться, что ваш поиск информации о разъеме, который использует ваш iPhone, не дает совпадений с атмосферным явлением или вымышленным гоночным автомобилем, поставьте дефис (-) перед терминами, которые должны дисквалифицировать страница не появляется в результатах Google — например, молния -гром -буря -Маккуин .
4. Говорите своими словами
Если вы посещаете Google.com в Google Chrome, вы можете щелкнуть значок микрофона справа от поля поиска и произнести вслух условия поиска. Как только вы закончите говорить, Google отобразит совпадающие результаты, а иногда и подведет итоги вслух.
В Google Chrome перейдите на главную страницу Google, щелкните значок микрофона (вверху) и начните говорить. Все, что вы скажете, появится на экране (внизу), а вскоре после этого появятся соответствующие результаты поиска.
5. Воспользуйтесь расширенным поиском
Если вы хотите гораздо больше контролировать свои поисковые запросы, например, указать, в каких географических регионах выполнять поиск, как давно должна быть создана страница или какой уровень чтения страницы, перейдите на сайт Google. Расширенный поиск или, выполнив базовый поиск, щелкните значок шестеренки в правом верхнем углу страницы результатов и выберите 9.0023 Расширенный поиск из всплывающего меню.
Страница расширенного поиска Google позволяет вам заполнить форму с параметрами для подробного, конкретного поиска.6. Преобразование, вычисление и многое другое
Вы также можете использовать Google для поиска любой информации помимо списков веб-страниц. Google может обрабатывать вычисления (попробуйте 104 * 36,8 ), конвертацию валют ( 185 долларов в евро ), конвертацию часовых поясов ( время в Париже ), прогнозы погоды ( погода Сан-Диего ), определения слов ( определяют: педантичный ) и многое другое.
7. Учитесь у первоисточников
Отличное место, где можно узнать десятки дополнительных советов по использованию Google, — это сам Google. Например, Google « Основная помощь в поиске» и « На страницах «Советы и хитрости» есть множество хитростей и ярлыков, которые вы можете использовать.
8. Упростите URL-адреса Google
Одна вещь, которая мне не нравится в Google, заключается в том, что все ссылки на его странице результатов являются URL-адресами Google, которые перенаправляют вас на исходную страницу. Например, если вы ищете macworld , первое обращение к www.macworld.com. Однако, если вы попытаетесь скопировать URL-адрес, он будет выглядеть примерно так:
https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&ved=0CCwQFjAA&url= http%3A%2F%2Fwww.macworld.com%2F&ei=YL48UrOEPYb yQGA3ICIBg&usg=AFQjCNF8KJ4binisdLIm41H5qMrvHdQ gw
И, в зависимости от вашего браузера, такой URL-адрес также может сбрасывать историю посещенных страниц, из-за чего будет трудно увидеть, какие сайты вы используете. был в.
был в.
К счастью, вы можете решить эту проблему с помощью расширения для браузера. Мой выбор для Safari от Apple — бесплатный Шон Инман. Детокс. (Изначально он был разработан для Twitter, но отлично работает и для Google.) Для Google Chrome сначала установите бесплатную Tampermonkey, а затем добавить скрипт Очистите ссылки перенаправления Google. Для Mozilla Firefox попробуйте бесплатную версию Владимира Паланта. Исправлена ссылка поиска Google/Яндекс.
9. Используйте другую поисковую систему
Даже самый лучший поиск Google не поможет вам найти страницы, которые Google не проиндексировал, или элементы, которые находятся на странице 5987 из 28 001. Если Google не сокращает его, у вас есть альтернативы. Конкуренты, в том числе
Бинг,
Яху,
Ask.com и
DuckDuckGo может указать вам на сайты, которые не отображаются в Google. А поскольку каждая поисковая система расставляет приоритеты в результатах поиска по-разному, страница, которую вы ищете, может быть более заметной в одной из них, чем в другой. Если вы застряли, попробуйте выполнить тот же поиск в другом движке.
Если вы застряли, попробуйте выполнить тот же поиск в другом движке.
10. Попробуйте метапоиск
Если вам часто приходится выполнять поиск в нескольких системах (и, возможно, в узкоспециализированных базах данных, в которых хранится информация, не проиндексированная в общедоступных поисковых системах), вы можете быть хорошим кандидатом на DevonAgent Pro (рейтинг 4 из 5), который может одновременно запрашивать множество сайтов и служб и обобщать результаты поиска таким образом, чтобы выявить связи между связанными понятиями.
Стратегии поиска | Блог Карен Блейкман
Google, стратегии поиска
Карен Блейкман
Google уже несколько лет не выводит поисковые запросы. Для меня этот вопрос достиг апогея еще в ноябре 2011 года (см. Уважаемый Google, перестаньте возиться с моим поиском). Многие заметили, что это происходит в течение некоторого времени, но что внезапно сделало это еще более разочаровывающим, так это то, что больше нельзя было ставить перед термином знак плюс, чтобы принудительно включить его в поиск. Кроме того, термины и фразы, заключенные в двойные кавычки, также не всегда работали.
Кроме того, термины и фразы, заключенные в двойные кавычки, также не всегда работали.
Дэн Рассел из Google объяснил, почему в комментарии к моему сообщению в блоге:
«Когда вы выполняете многотерминальный запрос в Google (даже с терминами в кавычках), алгоритм иногда отказывается от жесткого И, объединяя все термины вместе. . Это своего рода «мягкий» откат. Почему? Потому что понятно, что люди часто будут писать длинные запросы (где-то от 5 до 10 терминов), по которым нет результатов. Затем Google выборочно удалит термины с наименьшей частотой, чтобы дать вам некоторые результаты (а не ничего). Имейте в виду, что 99% искателей понятия не имеют, зачем им нужно жесткое И, и просто расстраиваются, когда не получают результатов. Мягкое И — это способ уменьшить общее разочарование и дать искателю что-то для изучения (и, если повезет, шанс переформулировать свой запрос)».
Он добавил:
«Но я понимаю, что вы имеете в виду, говоря о том, что вы хотите знать, нет ли НЕТ совпадений по заданному запросу.
 Я передам эту информацию команде дизайнеров Google и посмотрим, сможем ли мы что-нибудь с этим сделать».
Я передам эту информацию команде дизайнеров Google и посмотрим, сможем ли мы что-нибудь с этим сделать».Ну, Google сделал что-то с этим, а несколько недель спустя Verbatim, который можно было применить ко всему вашему поиску и заставить Google выполнять его без пропусков или изменений, был добавлен в качестве инструмента. Другой вариант, который существовал тогда и существует до сих пор, — ставить перед отдельными терминами или фразами префикс «intext:».
Если вы не использовали Verbatim, вам все еще оставалось гадать, все ли ваши термины или их синонимы присутствуют в том или ином документе, пока вы не щелкнете по нему и не просмотрите его целиком. Примерно пару лет назад Google начал включать информацию об пропущенных терминах в фрагменты результатов, добавляя под записью заявление «Отсутствует:». По крайней мере, теперь нам было с чем работать. Google теперь добавил к нему опцию поиска. Она начала появляться 2-3 месяца назад, исчезла на какое-то время, но теперь кажется постоянной чертой. Это позволяет вам сообщить Google, что он должен включать отсутствующий термин. Давайте рассмотрим пример, который первым натолкнул меня на это: поиск бобов под названием Элеонора, поставляемых Tamar Organics.
Это позволяет вам сообщить Google, что он должен включать отсутствующий термин. Давайте рассмотрим пример, который первым натолкнул меня на это: поиск бобов под названием Элеонора, поставляемых Tamar Organics.
Прежде чем вы спросите, причина, по которой я не зашел непосредственно на веб-сайт Tamar Organics, заключалась в том, что было быстрее зайти через Google, чем через систему поиска и навигации по сайту поставщика семян. Кроме того, обратите внимание, что если вы попробуете этот поиск самостоятельно, вы, вероятно, получите совсем другие результаты. Когда мы попробовали это на семинаре из 20 человек, у нас получилось 11 вариаций на тему!
Во-первых, быстрый и простой подход, заключающийся в добавлении нескольких терминов:
бобы элеонора тамар органические
Первые два результата были релевантными и именно тем, что я искал, но 8 результатов показались мне немного низкими, особенно поскольку Google указал на следующие два в списке, что термин «элеонора» отсутствует. (Мы вернемся к «Обязательно включать:» через мгновение.) В нижней части страницы результатов было обычное сообщение о том, что похожие записи не отображались.
(Мы вернемся к «Обязательно включать:» через мгновение.) В нижней части страницы результатов было обычное сообщение о том, что похожие записи не отображались.
Эээ… но, Google, вы отобразили 8, а не 15, как утверждаете. В любом случае, давайте подыграем и повторим поиск, нажав на ссылку, которую дает нам Google. На этот раз мне дали 11 результатов. Мы знаем, что Google часто ошибается при подсчете при использовании опции повторного поиска, но я все еще думал, что количество результатов было довольно низким, если он пропускал термины. Что произойдет, если я решу воспользоваться предложением Google «Обязательно включать: Элеонора»? Два, три или, может быть, всего четыре результата? Я нажал на ссылку Элеоноры и …. 20 700 результатов!
В строке поиска над результатами мы видим, что Google поместил элеонору в двойные кавычки, чтобы принудительно включить ее.
Первые три результата были в порядке, но когда я подробно рассмотрел четвертый документ, в нем отсутствовали как тамар, так и органика, и во фрагментах, предоставленных Google, не было никаких указаний на то, что эти или какие-либо другие термины были опущены.
Возвращаясь к моему первому набору результатов и просматривая список дальше, я увидел, что помимо одного, в котором не была указана Элеонара, был еще один, в котором не были указаны и Элеонора, и Тамар, а в третьем отсутствовала только Тамар.
Если параметр «Обязательно включать:» содержит более одного термина, вы можете выбрать только один из них. Вы не можете иметь их все. Выбор Тамар дал мне 43 500 результатов, но на этот раз Google сообщил мне, когда Элеоноры не было в документах. Большинство результатов были совершенно неуместны.
Как я обычно поступаю с отсутствующими терминами? Обычно я начинаю с быстрого и грязного поиска, и, если я не ищу документ определенного типа, такой как презентация или отраслевой отчет, я не всегда использую расширенные команды. Я просто вводил отдельные слова, и в этом случае я получил то, что хотел, в верхней части страницы. Но что, если бы я этого не сделал?
Меня интересовал сорт бобов под названием Элеонора, но Google не включил его в некоторые результаты. Я мог бы сделать то, что сделал Google, и использовать кавычки вокруг eleonora, но мой опыт показывает, что Google иногда игнорирует их, если количество результатов невелико. Моя обычная стратегия состоит в том, чтобы использовать «intext:» перед пропущенным словом, например:
Я мог бы сделать то, что сделал Google, и использовать кавычки вокруг eleonora, но мой опыт показывает, что Google иногда игнорирует их, если количество результатов невелико. Моя обычная стратегия состоит в том, чтобы использовать «intext:» перед пропущенным словом, например:
фасоль intext:eleonora tamar Organics
Это дало мне 18 400 результатов, опять же, в большинстве из них отсутствует один или несколько терминов.
Решив довериться Google , а не , чтобы игнорировать двойные кавычки, я изменил свой поиск на:
«широкие бобы» «элеонора» «тамар органикс»
На этот раз было всего 3 результата, и когда я повторил поиск поиск, чтобы включить пропущенные результаты, я видел 5, но ничего на самом веб-сайте Tamar Organics. Причиной этого стало наличие в поисковой строке словосочетания «бобы». Глядя на результаты моего самого первого поиска, я увидел, что Google подбирает фразы «бобы» и «бобы (широкие)», поэтому теперь я упускаю самые важные и релевантные результаты. Напоминание о том, что нужно очень тщательно подумать о том, как и в каком порядке поисковые термины могут появляться в документах, прежде чем применять поиск по фразе.
Напоминание о том, что нужно очень тщательно подумать о том, как и в каком порядке поисковые термины могут появляться в документах, прежде чем применять поиск по фразе.
Для сравнения я применил Verbatim к исходному быстрому и грязному поиску и получил 411 результатов. Основная проблема с этим набором заключалась в том, что Тамар и Органикс появлялись в документах разделенными несколькими словами или даже предложениями. Когда я применил Verbatim к строке поиска:
бобы элеонора «Тамар Органикс»
, я получил респектабельный список из 18 релевантных результатов.
Итак, стоит ли использовать вариант «Обязательно включать:»? Его легко и быстро применить, особенно на мобильном устройстве, и я подозреваю, что именно поэтому он был представлен. Однако все это становится очень запутанным и сложным, если вы пытаетесь использовать его для последующих наборов результатов. Когда я ищу на своем ноутбуке или на настольном компьютере, я иногда пробую ссылку, но если этот набор результатов разочаровывает и Google отбрасывает другой набор терминов, я возвращаюсь к своей практике использования intext и/или Verbatim. Я также пытаюсь использовать двойные кавычки вокруг терминов и фраз, но, по моему опыту, Google иногда их игнорирует. Это полностью зависит от вас, какой подход вы используете. Насколько хорошо каждый из них работает, зависит от одного поиска к другому, а также от того, разрешаете ли вы Google корректировать результаты в соответствии с вашей историей поиска и поведением. Важно знать о доступных вам вариантах и быть готовым к экспериментам.
Я также пытаюсь использовать двойные кавычки вокруг терминов и фраз, но, по моему опыту, Google иногда их игнорирует. Это полностью зависит от вас, какой подход вы используете. Насколько хорошо каждый из них работает, зависит от одного поиска к другому, а также от того, разрешаете ли вы Google корректировать результаты в соответствии с вашей историей поиска и поведением. Важно знать о доступных вам вариантах и быть готовым к экспериментам.
Презентации, Поисковые системы, Стратегии поиска
Карен Блейкман
Теперь доступны отредактированные основные моменты моего недавнего семинара по инструментам поиска исследовательской информации. Обратите внимание, что в эту версию включены не все сервисы, инструменты поиска, примеры или вопросы, рассмотренные на семинаре.
Слайды можно просматривать на Slideshare или на authorSTREAM.
открытый доступсерверы препринтовисследовательская информацияинструменты поискаGoogle, стратегии поиска
Карен Блейкман 5 комментариев
Google внес серьезные изменения в поиск, и это не сулит ничего хорошего. Результаты теперь основаны на вашем текущем местоположении. Так что нового? Google всегда смотрел на ваше местоположение, даже на уровне города/населенного пункта, и соответствующим образом изменял результаты. Это нормально, если вы путешествуете и хотите найти ближайший ресторан тайской кухни, например, с помощью мобильного телефона. Представлять список закусочных в моем родном городе Рединге бесполезно, если я нахожусь в Манчестере и очень голоден!
Проблемы начинаются, если вы ищете человека, компанию или отрасль, расположенную не в вашей стране — возьмем в качестве примера Норвегию — или просто хотите узнать последние новости из этой страны. Раньше хитрость заключалась в том, чтобы перейти к версии Google для соответствующей страны, в данном случае www.google.no, запустить поиск, и Google отдал бы предпочтение норвежскому контенту. Это отличный способ получить альтернативные точки зрения на тему и более актуальную «местную» информацию по теме. Теперь, независимо от того, какую версию Google вы используете, вы увидите одни и те же результаты, адаптированные для вашего домашнего местоположения.
Теперь, независимо от того, какую версию Google вы используете, вы увидите одни и те же результаты, адаптированные для вашего домашнего местоположения.
В сообщении блога Чтобы результаты поиска были более локальными и релевантными, Google сообщает:
Сегодня мы обновили способ маркировки национальных сервисов в мобильном Интернете, приложении Google для iOS, а также в Поиске и Картах для ПК. Теперь выбор страны обслуживания больше не будет указываться доменом. Вместо этого по умолчанию вы будете обслуживаться в той стране, которая соответствует вашему местоположению. Таким образом, если вы живете в Австралии, вы автоматически получите обслуживание страны для Австралии, но когда вы отправитесь в Новую Зеландию, ваши результаты автоматически переключатся на обслуживание страны для Новой Зеландии. По возвращении в Австралию вы без проблем вернетесь к австралийской службе страны.
Это подтверждает, что мобильный поиск — это то, на чем Google концентрируется. В конце концов, можно предположить, что Google зарабатывает большую часть своих денег, но не помогает профессиональным исследователям.
В конце концов, можно предположить, что Google зарабатывает большую часть своих денег, но не помогает профессиональным исследователям.
Есть способ обойти это, но он довольно многословен. Вам нужно перейти в «Настройки» — воспользуйтесь ссылкой в правом нижнем углу главной страницы Google или ссылкой в верхней части страницы результатов поиска — и нажмите «Расширенный поиск» .
На экране расширенного поиска прокрутите вниз до «Затем сузьте результаты поиска по…» и используйте раскрывающееся меню в поле региона, чтобы выбрать страну.
Я провел поиск по Brexit в google.co.uk, google.no и некоторых других национальных версиях Google. Все дали мне практически одинаковые результаты.
Используя фильтр региона и выбрав Норвегию в качестве страны, я получил от Google следующее:
Обратите внимание, однако, что Google дает мне английские статьи или их английские версии. Google решил, что я предпочитаю статьи на английском языке, и мне нужно прокрутить страницу до номера 10 и выше, чтобы увидеть страницы на норвежском языке. Чтобы получить более широкое представление о том, что говорят в Норвегии о Brexit, мне нужно вернуться в настройки, нажать «Языки» и выбрать «Норвежский/норвежский».
Чтобы получить более широкое представление о том, что говорят в Норвегии о Brexit, мне нужно вернуться в настройки, нажать «Языки» и выбрать «Норвежский/норвежский».
Да, и вы получите немного другие результаты, если вы воспользуетесь VPN и установите Норвегию в качестве страны.
Что меня еще больше беспокоит, так это то, что Google может покончить с экраном расширенного поиска и фильтром по региону вместе с ним.
Google говорит:
Мы уверены, что это изменение улучшит ваш поиск, автоматически предоставляя вам наиболее полезную информацию на основе вашего поискового запроса и другого контекста, включая местоположение.
Нет, Гугл. Вы только что усложнили жизнь тем из нас, кто проводит серьезные, глубокие исследования. В данный момент я отношусь к этому изменению так: если бы вы были человеком, я бы ударил вас бейсбольной битой по голове! ОБНОВЛЕНИЕ
: в ответ на комментарий и напоминание Дэвида Пирсона ниже.
Включая команду сайта, например. site:no в поиске работает относительно хорошо для этого конкретного примера (Норвегия) и дает хорошие, но немного разные результаты. Конечно, норвежские сайты, зарегистрированные как .com или другие международные домены, будут пропущены. Количество совпадений (или их отсутствие) зависит от страны. Это еще один пункт, который нужно добавить к списку стратегий, который, я уверен, станет длиннее для решения этой проблемы.
Стратегии поиска, 10 лучших советов по поиску
Карен Блейкман 2 комментария
Это список лучших советов, которые участники семинара UKeiG 7 сентября 2016 года в Лондоне придумали в конце учебного дня. Некоторые из обычных подозреваемых, такие как команда «site:», Carrot Search и Offstats присутствуют, но приятно видеть, что Яндекс впервые включен в список.
- Carrotsearch http://search. carrotsearch.com/carrot2-webapp/search или http://carrotsearch.com/ и нажмите ссылку «Живое демо» в левой части страницы.
Это было рекомендовано для кластеризации результатов, а также визуализации терминов и понятий с помощью кругов и «пенного дерева». Веб-поиск использует eTools.ch для общего поиска, а также есть опция PubMed.Пена для поиска моркови PubMed Foam Tree
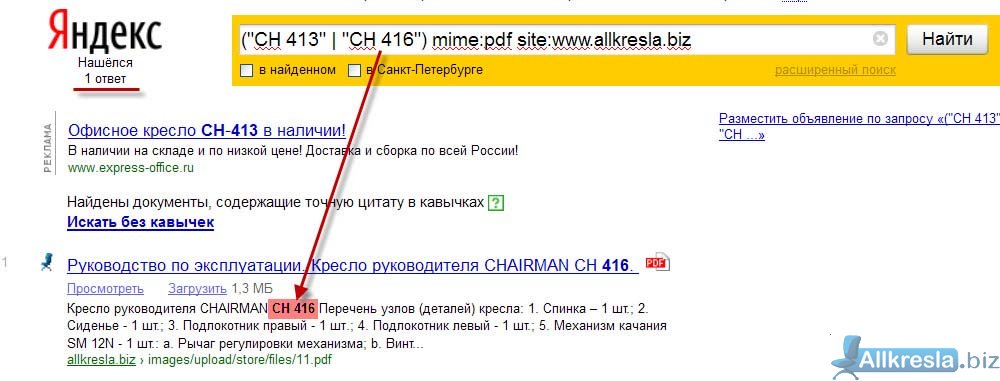 carrotsearch.com/carrot2-webapp/search или http://carrotsearch.com/ и нажмите ссылку «Живое демо» в левой части страницы.
carrotsearch.com/carrot2-webapp/search или http://carrotsearch.com/ и нажмите ссылку «Живое демо» в левой части страницы. - Расширенный поиск в Твиттере http://twitter.com/search-advanced
Лучший способ поиска в Твиттере! Используйте расширенный поиск http://twitter.com/search-advanced или нажмите «Дополнительные параметры» на странице результатов. Подробное описание команд и способов их использования можно найти по адресу https://blog.bufferapp.com/twitter-advanced-search .
- Яндекс http://www.yandex.com/
Международная версия российской поисковой системы с набором расширенных команд, включая оператор близости, что делает ее достойным конкурентом Google. Запустите поиск и на странице результатов нажмите на две строки рядом с полем поиска.
Расширенный поиск ЯндексаВ качестве альтернативы используйте операторы поиска. Большинство из них перечислены на странице https://yandex.com/support/search/how-to-search/search-operators.xml. Существует также оператор /n, который позволяет указать, что слова/фразы должны находиться на определенном расстоянии друг от друга, например:
.«Университет Бирмингема» нанотехнологии /2 2020Есть страновые версии Яндекса для России, Украины, Белоруссии, Казахстана и Турции. Однако вам нужно знать языки, чтобы извлечь из них максимальную пользу, и, кроме Турции, они используют другой алфавит.
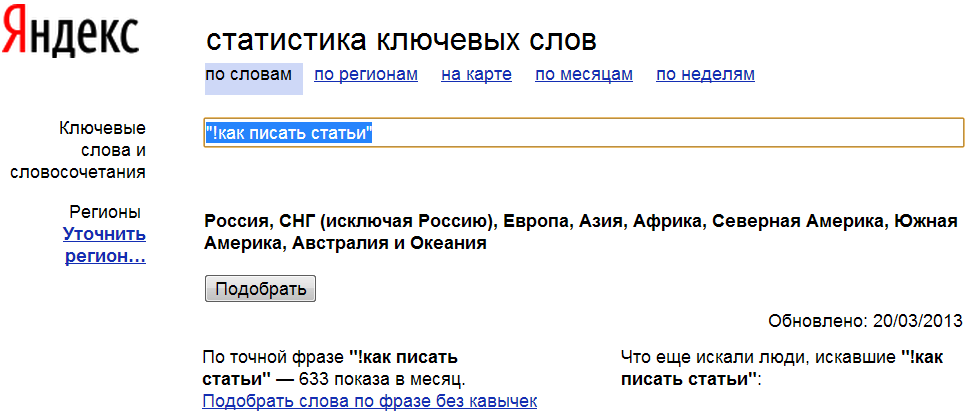 Запустите поиск и на странице результатов нажмите на две строки рядом с полем поиска.
Расширенный поиск Яндекса
Запустите поиск и на странице результатов нажмите на две строки рядом с полем поиска.
Расширенный поиск Яндекса- Millionshort http://millionshort.com/
Если вам надоело снова и снова видеть одни и те же результаты от Google, попробуйте MillionShort. MillionShort позволяет удалить из результатов самые популярные веб-сайты. Страница, которая лучше всего отвечает на ваш вопрос, может быть плохо оптимизирована для поисковых систем или может охватывать тему, которая настолько специализирована, что никогда не попадает в топ результатов в Google или Bing. Первоначально, как следует из названия, она удалила топ-1. миллион, но вы можете изменить число, которое хотите опустить. Слева от результатов есть фильтры, позволяющие удалить или ограничить результаты сайтами электронной коммерции, сайтами с рекламой или без нее, сайтами чата и местоположением. Исключенные сайты перечислены справа от результатов.
 Первоначально, как следует из названия, она удалила топ-1. миллион, но вы можете изменить число, которое хотите опустить. Слева от результатов есть фильтры, позволяющие удалить или ограничить результаты сайтами электронной коммерции, сайтами с рекламой или без нее, сайтами чата и местоположением. Исключенные сайты перечислены справа от результатов.
Первоначально, как следует из названия, она удалила топ-1. миллион, но вы можете изменить число, которое хотите опустить. Слева от результатов есть фильтры, позволяющие удалить или ограничить результаты сайтами электронной коммерции, сайтами с рекламой или без нее, сайтами чата и местоположением. Исключенные сайты перечислены справа от результатов.- site: command
Используйте команду site:, чтобы сосредоточить поиск на определенных типах сайтов, например, включите site:ac.uk в поиск академических веб-сайтов Великобритании. Или используйте его для поиска внутри больших бессвязных сайтов с бесполезной навигацией, например site:www.gov.uk. Вы также можете использовать -site:, чтобы исключить отдельные сайты или тип сайта из поиска. Все основные поисковые системы поддерживают эту команду.
- Microsoft Academic Search http://academic.research.microsoft.com/
Альтернатива Google Scholar. «Семантический поиск предоставляет вам высокорелевантные результаты поиска из постоянно обновляемого и обширного академического контента из более чем 80 миллионов публикаций». Недавно он был переработан, и хотя теперь он загружается и выполняет поиск быстрее, чем раньше, в новой версии были утеряны карты цитирования и соавторства, которые были так полезны. Это может быть полезным способом идентификации исследователей, публикаций и цитат, но не слишком полагайтесь на информацию. Это действительно может сделать что-то очень неправильно. Например, я обнаружил, что почему-то принадлежность нескольких авторов из Словацкого технического университета в Братиславе указана как Технический университет Кении!
 «Семантический поиск предоставляет вам высокорелевантные результаты поиска из постоянно обновляемого и обширного академического контента из более чем 80 миллионов публикаций». Недавно он был переработан, и хотя теперь он загружается и выполняет поиск быстрее, чем раньше, в новой версии были утеряны карты цитирования и соавторства, которые были так полезны. Это может быть полезным способом идентификации исследователей, публикаций и цитат, но не слишком полагайтесь на информацию. Это действительно может сделать что-то очень неправильно. Например, я обнаружил, что почему-то принадлежность нескольких авторов из Словацкого технического университета в Братиславе указана как Технический университет Кении!
«Семантический поиск предоставляет вам высокорелевантные результаты поиска из постоянно обновляемого и обширного академического контента из более чем 80 миллионов публикаций». Недавно он был переработан, и хотя теперь он загружается и выполняет поиск быстрее, чем раньше, в новой версии были утеряны карты цитирования и соавторства, которые были так полезны. Это может быть полезным способом идентификации исследователей, публикаций и цитат, но не слишком полагайтесь на информацию. Это действительно может сделать что-то очень неправильно. Например, я обнаружил, что почему-то принадлежность нескольких авторов из Словацкого технического университета в Братиславе указана как Технический университет Кении!- Wolfram Alpha https://www.wolframalpha.com/
Это сильно отличается от типичной поисковой системы тем, что использует собственные данные. Получит ли вы от него ответ, зависит от типа вопроса и от того, как вы его зададите. Информация извлекается из собственных баз данных, и для многих результатов практически невозможно определить первоисточник, хотя он предоставляет возможный список ресурсов. Если вы хотите увидеть, что может сделать WolframAlpha, попробуйте примеры и категории, перечисленные на его домашней странице.
 Если вы хотите увидеть, что может сделать WolframAlpha, попробуйте примеры и категории, перечисленные на его домашней странице.
Если вы хотите увидеть, что может сделать WolframAlpha, попробуйте примеры и категории, перечисленные на его домашней странице.- OFFSTATS – Библиотека Оклендского университета http://www.offstats.auckland.ac.nz/
Это отличная отправная точка для поиска официальных статистических источников по странам, регионам или предметам. Весь контент в базе данных оценивается людьми на предмет качества и авторитетности и находится в свободном доступе.
- Meltwater IceRocket http://www.icerocket.com/
IceRocket специализируется на поиске в реальном времени и была рекомендована для включения в Top Tips за поиск по блогам и расширенные возможности поиска. Существует также инструмент «Тенденции», который показывает частоту упоминаний терминов в блогах с течением времени и позволяет сравнивать несколько терминов на одном графике. Тенденции IceRocketОчень полезно для сравнения, например, упоминаний продуктов, компаний, людей в блогах.

- Behind the Headlines NHS Choices http://www.nhs.uk/news/Pages/NewsIndex.aspx
Behind the headlines предоставляет беспристрастный и основанный на фактических данных анализ историй о здоровье, которые попадают в новости. Это хороший источник информации для подтверждения или опровержения заявлений о здоровье/медицинских показаниях, сделанных общими новостными службами, включая BBC. Для каждого «заголовка» на простом английском языке кратко излагается история, откуда она взялась и кто проводил исследование, что это было за исследование, результаты, интерпретация исследователя, выводы и обоснованы ли утверждения заголовка.
Поисковые системы, Стратегии поиска
Карен Блейкман 2 комментария
Два сервиса, которые я рассматриваю на своем семинаре для исследователей альтернатив Google, — это Carrot Search и eTools. ch, и недавно один из людей, присутствовавших на сессии в апреле, попросил меня подтвердить, что Carrot Search использовал для получения своих основных результатов. . Строго говоря, ни Carrot Search, ни eTools не являются бесплатными для Google: eTools — это инструмент метапоиска, одним из источников которого является Google, а Carrot Search использует eTools для своего веб-поиска. В начале года Carrot Search предлагал 7 вариантов поиска на вкладках в верхней части экрана поиска, включая Web, «wiki», Bing, News, Images, PubMed и Jobs. Веб-поиск использовал eTools.ch для предоставления результатов.
ch, и недавно один из людей, присутствовавших на сессии в апреле, попросил меня подтвердить, что Carrot Search использовал для получения своих основных результатов. . Строго говоря, ни Carrot Search, ни eTools не являются бесплатными для Google: eTools — это инструмент метапоиска, одним из источников которого является Google, а Carrot Search использует eTools для своего веб-поиска. В начале года Carrot Search предлагал 7 вариантов поиска на вкладках в верхней части экрана поиска, включая Web, «wiki», Bing, News, Images, PubMed и Jobs. Веб-поиск использовал eTools.ch для предоставления результатов.
Набор опций сократился до трех: более понятные веб-поиск eTools, PubMed и Jobs.
Carrot Параметры поиска, июль 2016 г.
Это имеет смысл, так как количество доступов к Bing через API всегда было ограничено, и мне никогда не удавалось заставить работать параметры новостей или изображений. eTools в любом случае представляет собой метапоисковик, охватывающий 17 инструментов, включая Google, Bing и Wikipedia, поэтому дополнительные вкладки Carrot Search кажутся ненужными. Полный список можно увидеть на домашней странице eTools.
Вот тут-то и начинается самое интересное. Оказывается, Carrot Search не просто копирует результаты поиска в eTools. Я провел поиск по Brexit в Carrot Search и сравнил результаты eTools Worldwide и eTools United Kingdom. Все наборы были разными, поэтому Carrot Search должен выполнять дополнительный анализ и обработку.
Поиск моркови не просто перечисляет результаты, но также упорядочивает их по темам или папкам, которые отображаются в левой части экрана. Это может быть полезным способом сузить область поиска.
Поиск моркови предлагает два других способа отображения результатов: Круги и Пенное дерево.
Carrot Search CirclesCarrot Search Foam Tree — 13 июля 2016 г.
Оба варианта показывают плотность терминов в 100 лучших результатах и позволяют щелкнуть область, чтобы добавить термин или фразу в поиск. Кроме того, я считаю, что Foam Tree — это интересный способ отслеживания изменений в освещении новостей и дискуссий в социальных сетях по теме, продукту или компании. Вчера, когда я провел поиск по Брекситу, там была область, представляющая Терезу Мэй. Сегодня его заменили на Дэвида Кэмерона. Я предполагаю, что это связано с тем, что освещение в новостях было сосредоточено на последнем дне Дэвида Кэмерона на посту премьер-министра и его последних вопросах премьер-министра (PMQ) в парламенте. Позже он идет к королеве, чтобы официально уйти с поста премьер-министра. Завтра, когда Тереза Мэй станет нашим новым премьер-министром и новым кабинетом министров, пенное дерево может иметь совсем другую структуру, поэтому я буду периодически просматривать его, чтобы увидеть, отражает ли оно изменения в событиях и каким образом.
Как я упоминал ранее eTools.ch, который стоит за основным веб-поиском Carrot Search, представляет собой метапоисковую систему, охватывающую 17 инструментов. Также есть возможность выбрать страну из раскрывающегося списка (весь мир, Швейцария, Лихтенштейн, Германия, Австрия, Франция, Италия, Испания, Великобритания) и язык (все, английский, немецкий, французский, итальянский, испанский). Один или оба из них дают вам совершенно разные взгляды и мнения по предмету.
eTools — Швейцария, французский
eTools — Испания, все языки
Это удобный способ сбора разнообразной информации на иностранных языках, особенно о европейских мероприятиях, и это проще, чем поиск версий Google или Bing для отдельных стран. . Недостатки в том, что диапазон стран и языков ограничен, и многие статьи не будут на английском языке. Тем не менее, я часто нахожу это полезным в начале исследования, поскольку я получаю общее представление о типе и диапазоне доступной информации.
Carrot Search и eTools.ch — это лишь два из инструментов, которые я рассматриваю на своем семинаре по альтернативам Google. Если вы хотите узнать больше, следующая сессия организована UKeiG и пройдет в Лондоне в среду, 7 сентября 2016 г. Более подробная информация доступна на веб-сайте UKeiG.
Carrot SearcheИнструментыПоисковые системыСтратегии поискаBing, Google, Стратегии поиска
Карен Блейкман
Если вы посещали один из моих недавних семинаров по поиску или просматривали слайды, то заметили, что у меня есть новый тестовый запрос: высота Бен-Невиса. Это началось не как тестовый поиск, а как настоящий запрос от меня. Простой поиск, подумал я, даже для Google.
Я ввел запрос «высота Бен-Невиса», и в верхней части экрана Google вывел ответ: 1345 метров. Это прозвучало как звонок и звучало правильно, но, как и в случае со многими быстрыми ответами Google, у меня не было источника, и мне нравится дважды или даже трижды проверять все, что предлагает Google.
Справа от экрана был Google Knowledge Graph с выдержкой из Википедии, в которой говорилось, что Бен-Невис находится на высоте не 1345, а 1346 метров над уровнем моря. Дополнительная информация ниже говорит о том, что гора имеет высоту 1 345 метров и высоту 1 344 метра (источники не указаны). Я знаю, что у меня три разных роста — и что такое «известность»?
Проведя небольшое исследование, я обнаружил, что известность — это не то же самое, что возвышение, но я оставлю вас исследовать это самостоятельно, если вам интересно. Главной проблемой для меня было то, что Google дал мне по крайней мере три немного разных ответа на вопрос о высоте Бен-Невиса, поэтому пришло время прочитать некоторые результаты полностью.
Прежде чем я успел щелкнуть первую из двух статей в верхней части результатов, зазвенел тревожный звонок. Одно из преобразований метров в футы в фрагментах кода выглядело неправильно.
Итак, я провел свои собственные преобразования для обоих наборов метров в футы и в другом направлении (футы в метры):
1344 м = 4409,499 футов, округленное до 4409 футов
4406 футов = 1342,949 м, округленное до 1343 м.
1346 м = 4416,01 футов, округляя до 4416 футов
4414 футов = 1345,387 м, округляя до 1345 м
простое преобразование фут/м, но я подозреваю, что округление цифр в большую и меньшую сторону до проведения расчетов является причиной расхождений.
Приведенные выше результаты получены в результате поиска на Google.co.uk. Google.com дал мне аналогичные результаты, но с быстрым ответом в футах, а не в метрах.
У нас до сих пор нет надежного ответа относительно высоты Бен-Невис.
Три статьи под двумя верхними результатами были взяты из BBC News, The Guardian и Ordnance Survey – наиболее актуальных и авторитетных для этого запроса – и касались высоты Бен-Невиса, которая была повторно измерена ранее в этом году с помощью GPS. Высота на существующих картах Ordnance Survey была указана как 1344 м, но более точные измерения GPS составили 1344,527 м или 4411 футов 2 дюйма. В оригинальной статье Ordnance Survey объясняется, что это всего на несколько сантиметров отличается от более ранних 19 см.49, но это означает, что окончательное число должно быть округлено в большую, а не в меньшую сторону. Поэтому официальная высота на картах ОС была увеличена с 1344 м до 1 345 м. Таким образом, быстрый ответ Google в верхней части страницы результатов был действительно правильным.
Зачем поднимать шум из-за того, что, в конце концов, это относительно небольшие отклонения в цифрах? Потому что у горы есть одна официальная высота, и одна из трех цифр, которые дал мне Google (1346 м), не была ни текущей, ни предыдущей высотой. Глядя на комментарий к статье в Википедии, в котором указано 1346 м, кажется, что авторы пытались согласовать высоту в метрах с высотой в футах, но выполняли преобразование, используя округленные в большую или меньшую сторону цифры. Как давным-давно научил меня один из моих учителей естественных наук, вы всегда должны переносить на следующую стадию своих вычислений как можно больше цифр после запятой. Только когда вы дойдете до конца, вы округлите вверх или вниз, если это уместно. А представьте, если бы ваша команда Pub Quiz проиграла местный чемпионат из-за того, что вы правильно ответили на 1345 м на этот вопрос, но у ведущего было 1 346 м, как правильное число? Будет бунт, если не война!
Вот что дал нам Google. Как поживает Bing?
Версии Bing для США и Великобритании дали результаты, очень похожие на результаты Google, но с двумя разными быстрыми ответами в футах, и ни одна из них не предоставила источники: не утомит вас всеми другими поисковыми инструментами, которые я пробовал, за исключением Wolfram Alpha. Это дало мне 1343 метра или 4406 футов. По крайней мере, преобразование правильное, но нет прямой информации о том, откуда были взяты данные.
Ссылка на источники никоим образом не помогла и направила меня на главные страницы сайтов, а не на конкретные данные Бен-Невиса. На некоторых сайтах, когда я нашел страницы Бен-Невиса, цифры отличались от показанных Wolfram Alpha, поэтому я понятия не имею, как Вольфрам получил 1343 метра.
Итак, ответ на мой вопрос «Как высоко находится Бен-Невис?» составляет 1 344,527 м, округленное на картах ОС до 1 345 м.
Основные выводы из этого упражнения:
- Никогда не доверяйте быстрым ответам или графикам знаний любой из поисковых систем, особенно если источник не указан. Но ты и так знал это, не так ли?
- Если вы видите даже небольшие отклонения в цифрах, и есть расчеты или преобразования, перепроверьте их самостоятельно.
- Не бегло читайте результаты и используйте информацию, выделенную во фрагментах — читайте полные статьи и из более чем одного источника.
- Убедитесь, что статьи, которые вы используете, не просто копируют сказанное другими.
- Попробуйте найти наиболее релевантный и авторитетный источник для вашего запроса, а в идеале — первоисточник. В данном случае это была служба артиллерийского вооружения. Великобритания официально выше – Бен-Невис https://www.ordnancesurvey.co.uk/about/news/2016/gb-officially-taller-ben-nevis.html
Bing, Стратегии поиска
Карен Блейкман
Наконец-то Bing расширил возможности поиска по дате. До недавнего времени можно было ограничить результаты только прошлыми 24 часами, прошлой неделей или прошлым месяцем, и то только в Bing US. Bing теперь добавил настраиваемый диапазон наравне с Google.
В британской версии Bing до сих пор не было опции даты, но странным образом был добавлен старый, ограниченный выбор для США.
Кажется очень странным, что они не реализовали полный список США. Можно только надеяться, что это произойдет в ближайшее время, а не через несколько лет, а именно столько времени потребовалось, чтобы эта версия появилась в Bing UK.
Bingdate searchСтратегии поискаGoogle, Стратегии поиска, 10 лучших советов по поиску, семинары
Карен Блейкман 1 Комментарий
Этот сборник лучших советов представляет собой объединенный список, составленный участниками семинара UKeiG на тему «Новый Google, новые вызовы». Следующий семинар UKeiG Google состоится 8 сентября 2016 года.
1. Не доверяйте фактам и ответам Google
Google старается предоставить факты и быстрые ответы на ваши вопросы вверху и справа от ваших результатов. Это сгенерированные компьютером выдержки из страниц, и для получения «ответа» можно использовать несколько различных источников. Иногда они вводят в заблуждение или совершенно неверны. На момент написания, ответ, предоставленный для поиска на плодоядном, является отличным примером. (Это объясняет, почему ваша кошка так суетится с едой — очевидно, она жаждет 5 раз в день!) Всегда обращайтесь к первоисточнику, чтобы перепроверить информацию, но это не всегда предоставляется Google.
2. Версии Google для разных стран и /ncr
Версии Google для разных стран отдают приоритет локальному контенту. Это полезная стратегия при поиске исследовательских групп, компаний и людей, которые активны или работают в определенной стране. Используйте стандартный двухбуквенный код страны ISO, например http://www.google.fr/ для Google France, http://www.google.it/ для Google Italy.
Также стоит попробовать выполнить поиск на Google.com. Ваши результаты, вероятно, будут больше ориентированы на международный рынок или США, но вы можете увидеть новые функции поиска или макеты на Google.com, которых еще нет в других местах. Если Google настаивает на перенаправлении вас на версию для вашей страны, перейдите в правый нижний угол главной страницы Google, и вы должны увидеть ссылку на Google. com. Если ссылки нет, добавьте ‘/ncr’ к URL-адресу Google, например http://www.google.com/ncr .
Недостатком использования национальных версий любого инструмента поиска является то, что приоритетная информация, скорее всего, будет на местном языке.
3. История поиска
Ваша история поиска, которая записывается и доступна для просмотра, если вы вошли в свою учетную запись Google, используется Google для персонализации ваших результатов, но она также может быть полезна в качестве записи прошлых поисков. Если пользователь возвращается к вам, забыв или потеряв поиск и документы, которые вы ему предоставили, ваша история поиска должна помочь вам найти и то, и другое. На любой странице результатов поиска нажмите на шестеренку в правом верхнем углу экрана и выберите «История». Затем вы можете просмотреть свою историю или выбрать дату из календаря (вверху справа и в области экрана истории).
4. Verbatim
Это важный инструмент, позволяющий Google выполнять поиск так, как вы хотите. Google автоматически ищет варианты ваших условий и иногда исключает их из вашего поиска, что не всегда полезно. Чтобы использовать Verbatim, сначала запустите поиск. Затем нажмите «Инструменты поиска» в меню, расположенном в верхней части страницы результатов. Должен появиться второй ряд опций. Нажмите «Все результаты» и в раскрывающемся меню выберите Verbatim. Затем Google будет искать ваши условия без каких-либо изменений или упущений. Обратите внимание, что Google будет искать документы и страницы, в которых слова встречаются в любом порядке. Если вы ищете по названию статьи, поместите заголовок в двойные кавычки, чтобы добиться точного совпадения фразы. Если Google по-прежнему изменяет ваш поиск, запустите Verbatim.
Если вы проводите углубленное исследование, стоит попробовать Verbatim, даже если «обычные» результаты Google кажутся удовлетворительными. Вы можете увидеть совершенно другой и, возможно, более актуальный контент.
5. тип файла: команда .
Важная команда расширенного поиска, доступная не только в Google, но и во многих альтернативных инструментах поиска. Используйте команду filetype:, чтобы ограничить свои исследования PowerPoint для презентаций, электронными таблицами для данных и статистики или PDF для исследовательских работ и отраслевых/государственных отчетов.
Например:
плазмонные наночастицы тип файла:ppt
Команда должна быть все строчные буквы и не должно быть пробелов между двоеточием и командой или расширением файла, иначе Google обработает команду как слово для поиска. Кроме того, вы должны искать расширения файлов до и после Office 2007 отдельно, так как Google не подбирает оба расширения автоматически.
Например,
плазмонные наночастицы тип файла:ppt ИЛИ тип файла:pptx
Обратите внимание, что раскрывающееся меню расширенного поиска Google для типа файла: поиск только для расширений до Office 2007.
6. Знак «минус» для исключения информации
Используйте знак «минус» непосредственно перед термином, чтобы исключить документы, содержащие этот термин, но используйте его с осторожностью, так как вы можете потерять ценную информацию. Его также можно использовать с командами для исключения форматов файлов или веб-сайтов из поиска.
Например:
профессиональная астма UK site:gov.uk -site:hse.gov.uk
-site:nationalarchives.gov.uk
7. Объедините команды поиска
Объедините несколько команд, таких как тип файла: и сайт:, чтобы сфокусировать поиск. Используйте команду ИЛИ для поиска альтернатив, например:
профессиональная астма UK site:ac.uk тип файла:ppt ИЛИ тип файла:pptx
8. Персонализируйте Новости Google
Персонализируйте Новости Google (http://news .google.co.uk) при входе в свою учетную запись и измените содержание, которое автоматически отображается, или добавьте собственные поисковые запросы. Нажмите кнопку «Персонализация» в верхней части правого столбца.
9. Функция цитирования Google Scholar
Щелкните ссылку Цитировать под ссылкой в Академии Google, и Google предложит вам варианты импорта цитирования в стиле MLA, APA, Чикаго, Гарварда или Ванкувера в BibTex, EndNote, Рефман или рефворкс. Обратите внимание, что если статья доступна только в Интернете, вам может потребоваться добавить doi или URL-адрес, а также дату доступа.
10. Используйте сайт Google: поиск в Google Scholar
Это тот вариант, о котором я не подумал, но один из делегатов рекомендовал его как способ использования команд расширенного поиска Google в Google Scholar вместо собственных Scholar. (У меня не было времени проверить это на себе).
Google, Search Strategies
Карен Блейкман 4 комментария
При проведении семинаров по расширенному поиску и особенно сеансов Google я предпочитаю не останавливаться на командах и параметрах поиска, которые больше не поддерживаются. Они ушли, вот и все, и гораздо лучше сосредоточиться на том, как извлечь максимальную пользу из того, что осталось. Конечно, это неизбежно, когда ваши слайды были подготовлены за несколько дней до мероприятия, и Google решает отключить одну из ваших любимых поисковых функций прямо перед тем, как вы начнете! Точно так же я стараюсь не показывать «вот как НЕЛЬЗЯ использовать…». команда или неверный синтаксис. Часто запоминается неправильный формат. Однако недавно я добавил к своим презентациям слайды, которые охватывают как несуществующие команды, так и ошибки в синтаксисе и формате.
Проблема заключается не только в том, что многие люди не знают, что некоторые параметры поиска больше не доступны, но и в том, что некоторые информационные бюллетени и статьи, посвященные расширенному поиску, понимают это неправильно. В недавней статье Guardian о лучших советах по поиску для Google это почти правильно, но упоминается тильда, которая была исключена в 2013 году, и на самом деле не понимается, как Google автоматически ищет синонимы и варианты термина (см. советы по поиску в гугле не совсем типтоп). Я также видел пару недавно выпущенных информационных бюллетеней Google, полных ошибок.
Замечательная особенность Google заключается в том, что он может принять самую запутанную и полную ошибок строку поиска и все же выдать что-то разумное – в большинстве случаев. Недостатком этого является то, что предполагается, что поисковый запрос работает так, как предполагалось, когда на самом деле Google полностью переписал поиск для вас. Однако в какой-то момент Google перепишет поиск таким образом, что он будет выдавать мусор. Поэтому важно знать, какие команды доступны и как их следует использовать.
Начнем.
Знак плюс (+) перед словом, чтобы обеспечить точное совпадение.
Эта функция была прекращена в октябре 2011 года, поскольку Google намеревался использовать ее для поиска на страницах Google+. От него отказались, и теперь он доступен для поиска. Если вы хотите принудительно выполнить поиск по термину с точным соответствием, перед термином введите intext: например, intext:agriculture.
Я также видел примеры, утверждающие, что знак плюс между словами действует как логическое И. Нет, это не так. Если вы получаете разные результаты при использовании +, это потому, что Google ищет это, а также ваши условия.
Тильда (~) для синонимов
Этот номер был отозван в июне 2013 года, поскольку им пользовались немногие, и в нем больше не было необходимости. Google теперь ищет синонимы по умолчанию.
тезаурус: для альтернативных терминов
«тезаурус:» работает, потому что Google рассматривает «тезаурус», игнорируя двоеточие, как поисковый запрос. Таким образом, «тезаурус: эклектика» даст вам ссылки на страницы и веб-сайты со словарями и определениями, которые дают синонимы для эклектики. Он не дает вам прямого списка альтернатив, как это делает «определение». Если вы используете тезаурус , вам нужно по очереди посещать веб-сайты, чтобы просмотреть синонимы.
Звездочка *
Звездочка (*) является заполнителем для терминов между двумя словами, например. солнечные * панели находит солнечные фотоэлектрические панели, солнечные фотоэлектрические панели, солнечные тепловые панели. Это НЕ символ усечения. Опять же, вы можете подумать, что это связано с тем, что Google игнорирует звездочку и автоматически ищет слова, начинающиеся с введенных вами букв. Я ожидал, что Google найдет ссылки на фенобарбитал. Он получил 76 000 результатов, включая фенобарбитал, но в первых 100 не было упоминания о фенобарбитале. Фенобарб без звездочки дал точно такие же результаты. Поиск по фенобарбитану со звездочкой и без нее дал 241 000 результатов. Я понятия не имею, как и когда Google решит прекратить поиск вариантов вашей строки, но из приведенного выше примера очевидно, что звездочка не является символом усечения.
НЕ используйте заглавную букву в первой букве команд и БЕЗ пробелов
Такие команды, как intitle:, intext:, filetype: и site: должны быть все в нижнем регистре и БЕЗ пробелов между двоеточием и условием поиска. Сделайте первую букву заглавной или добавьте пробел после двоеточия или и того, и другого, и Google будет рассматривать команду как обычное слово, доступное для поиска.
Правильный формат для intitle: поиск, например, intitle:caversham и находит следующее:
Используйте заглавную первую букву команды или вставьте пробел или и то, и другое, и вы найдете:
Я понимаю, почему так много информационных бюллетеней и презентаций показывают команды с заглавной буквы. Вы тратите целую вечность на подготовку своей информации, и когда вы отправляете свои слайды на печать или конвертируете свой документ в PDF, вы обнаруживаете, что Microsoft Office изменил формат команды. Поскольку ваш пример поиска находится в отдельной строке с командой при запуске Office, благослови его, решает автоматически исправить и сделать первую букву заглавной. Я знаю, это случилось со мной! Поэтому, пожалуйста, проверяйте и перепроверяйте свои вспомогательные материалы.
Google выполняет поиск по всем вашим терминам по умолчанию
Не всегда. Если ваш поиск в нынешнем виде не находит результатов или дает небольшое количество результатов, Google отбрасывает одно или несколько условий, которые обычно отображаются зачеркнутыми. На приведенном выше снимке экрана вы можете видеть, что третья запись в результатах имеет «Отсутствует: кавершам » в конце фрагмента.
Если Google отбрасывает термин, важный для вашего поиска, добавьте к нему префикс intext:, например, intext:caversham. Если вы хотите, чтобы все ваши термины были включены без каких-либо вариантов, используйте параметр поиска Verbatim. Если вы используете настольный компьютер или ноутбук, запустите поиск, а затем нажмите кнопку «Инструменты поиска» в верхней части результатов. Появится вторая строка параметров. Щелкните Все результаты и выберите Verbatim. Внешний вид и расположение Verbatim на мобильных устройствах обычно отличаются.
Двойные кавычки вокруг фраз
Двойные кавычки вокруг фраз, названий статей, названий песен, известных высказываний и т. д. работают в большинстве случаев. Но опять же, если Google найдет ноль или всего несколько результатов, он проигнорирует отметки. Google также может изменить написание одного или нескольких слов в двойных кавычках. Используйте Verbatim, если вы уверены, что фраза верна, и вы хотите заставить Google подчиниться.
Полный вложенный логический поиск
Google НИКОГДА не поддерживал полный вложенный логический поиск. Я все еще встречаю людей, которые непреклонны в том, что Google делает, но когда их подталкивают, они признают, что часто получают неожиданные результаты. Однако вы можете использовать ИЛИ для альтернативных терминов и знак минус перед термином, чтобы исключить документы, содержащие этот термин.
Вот как Google интерпретирует поиск (кондитерские изделия ИЛИ шоколад) И (производство ИЛИ производство) И (Франция ИЛИ Германия ИЛИ ВЕЛИКОБРИТАНИЯ ИЛИ Швейцария) НЕ бельгия
Обратите внимание, что страницы, содержащие Бельгию, включаются , а не исключаются.
Удалите «НЕ Бельгия», и вот что мы увидим:
Добавьте «-бельгию» в конец поиска вместо «НЕ бельгия», и мы получим:
Запуск Verbatim на нашем исходном логическом значении поиск показывает, что Google обрабатывает И и НЕ как строчные слова, доступные для поиска:
Если вы действительно хотите использовать полное логическое значение, то отправляйтесь в Bing.
Если вы хотите узнать больше о поиске Google Дэн Рассел, работающий в Google, в настоящее время проводит онлайн-курс Power Searching with Google. В качестве альтернативы, если вы хотите больше деловых или академических исследований и семинара, ориентированного на Великобританию / Европу, о том, что может сделать Google, я проведу расширенный семинар Google с UKeiG 13 апреля 2016 года.
расширенный поискGoogleGoogle, стратегии поиска
Карен Блейкман 4 комментария
Я только что получил сообщение от коллеги-эксперта по поиску Элисон Макнаб о статье Сэмюэля Гиббса (@SamuelGibbs) в Guardian о лучших советах по поиску в Google. Мне пришлось перепроверить дату статьи, потому что, хотя по большей части все в порядке, в ней есть несколько неправильных вещей, одна из команд была отозвана некоторое время назад и в ней пропущено то, что я считаю одной из самых важные параметры поиска Google.
Итак, давайте рассмотрим советы один за другим.
- Точная фраза.
Да, двойные кавычки вокруг слов обычно заставляют Google искать точную фразу. Однако Google иногда игнорирует кавычки.
2. Исключить термины
Да, если поставить перед термином знак минус, будут исключены документы, содержащие этот термин время. Убедитесь, что ИЛИ написано заглавными буквами.
4. Поиск синонимов
Символ тильды (~) для поиска синонимов? Нет! Google отозвал его более двух лет назад, потому что им пользовались немногие. Google теперь ищет синонимы по умолчанию. Если перед термином стоит тильда, Google игнорирует его и продолжает работу в обычном режиме. Я только что попробовал несколько поисков с тильдой и без нее и получил точно такие же результаты.
5. Поиск по сайту
Да. Команда site: — одна из самых мощных команд расширенного поиска, позволяющая выполнять поиск на одном сайте, например site:www,gov.uk, или на сайте определенного типа, например site:ac. uk для академических сайтов Великобритании. .
6. Сила звездочки
Да, звездочка может заменять один или несколько терминов между двумя словами, например солнечные * панели. Нет, это не символ усечения.
Пример, приведенный The Guardian – это поиск по запросу архитектор*, который находит « архитектор», а также «архитектурный», «архитектурный», «архитекторный», «архитектурный» и любое другое слово, начинающееся с «архитектор». » Как и в случае с синонимами, Google по умолчанию ищет варианты слова.
Я провел поиск по фенобарбу*, ожидая, что Google найдет ссылки на фенобарбитон. Он собрал 76 000 результатов, включая фенобарбитал, но в первых 100 документах о фенобарбитале не упоминалось. Фенобарб без звездочки показал точно такие же результаты. Исключение фенобарбитала с использованием знака минус дало мне 70 000 результатов. Поиск по фенобарбитану со звездочкой и без нее дал 241 000 результатов.
7. Поиск между двумя значениями
Да. Поиск по диапазону номеров действительно работает и отлично подходит для поиска в диапазоне значений или лет. Например:
прогнозы потребления шоколада на 2016..2020
топ 10..100 страховых компаний Великобритании
toblerone 1..5 кг
8. Поиск по слову в теле, заголовке или URL страницы
Сюда входят команды intext:, intitle: и inurl:. Все правильно, но intext: особенно полезен тем, что заставляет Google включать этот термин в поиск. Это бесценно, если вы обнаружите, что Google пропускает ключевые термины из вашей стратегии, что он и делает, если вы, вероятно, получите нулевые результаты или считает, что количество результатов слишком мало.
9. Поиск связанных сайтов
Команда related: ищет похожие сайты, например, related:theguardian.com находит другие новостные организации. Он работает, но показывает только 20-30 сайтов. Тем не менее, стоит использовать, если вы хотите расширить свой поиск на другие, но похожие организации и иметь только одну или две для начала.
10. Объедините их
Полностью с этим согласен. После того, как вы освоите несколько продвинутых команд, вы действительно сможете сфокусировать свой поиск и получить более релевантные результаты.
Чего не хватает?
Я удивлен, что тип файла: не был включен. Это почти всегда входит в список лучших советов, которые участники моего семинара по расширенному поиску предлагают в конце дня. Это быстрый и простой способ поиска презентаций (тип файла: ppt, тип файла pptx), государственных документов и научных работ (тип файла: pdf) и наборов данных (тип файла: xls, тип файла: xlsx, тип файла: csv).
Однако самым большим упущением для меня является Verbatim. Он отличается от остальных тем, что это не команда, которую вы можете ввести. Сначала вам нужно запустить поиск. В меню в верхней части результатов выберите «Инструменты поиска», затем «Все результаты», а затем «Verbatim». Используйте это, когда Google сеет хаос в вашем поиске, опуская термины и используя странные и замечательные термины, которые не имеют ничего общего с вашей темой. Verbatim выполнит поиск по всем вашим терминам, не пропуская ни одного и не ища вариантов и синонимов.
Если вам интересно узнать больше о расширенном поиске в Google и других инструментах поиска, некоторые из моих прошлых презентаций и информационных бюллетеней доступны по адресу http://rba.co.uk/as/. Если вы заинтересованы в посещении семинара, мой общедоступный график обучения на 2016 год находится по адресу http://www.rba.co.uk/training/ (в ближайшее время будут добавлены дополнительные мероприятия).
Ищи:Обратите внимание, что этот раздел сайта РБА представляет собой новостной блог, в котором публикуются новости и мои собственные комментарии о развитии поисковых и электронных ресурсов. После публикации статьи не обновляются. Старые публикации могут содержать устаревшие или неработающие ссылки.
- Аарон Тэй – Размышления о библиотечном деле
- Логический черный пояс — поиск/рекрутинг
- Подрывной поисковик
- Энергетический баланс
- Организация хаоса
- OUseful. info, блог
- Out-Law.com
- Часы с ретракцией
- Блог Родди Маклеода
- Поисковая система Land
- Часы поисковой системы
- ПоискПоиск
- Техкранч
- Великобритания Web Focus
Что такое поисковые системы и как они работают?
Что такое поисковая система?
Поисковая система — это онлайн-инструмент, предназначенный для поиска веб-сайтов в Интернете на основе поискового запроса пользователя.
Он ищет результаты в собственной базе данных, сортирует их и составляет упорядоченный список этих результатов, используя уникальные алгоритмы поиска. Этот список называется страницей результатов поисковой системы (SERP).
Хотя в мире существуют различные поисковые системы (например, Google, Bing, Yahoo и т. д.), общие принципы поиска и предоставления ответов во всех них одинаковы.
Как работают поисковые системы
Поисковые системы могут отличаться друг от друга по способам предоставления ответов пользователю, но все они построены на трех фундаментальных принципах:
- Сканирование
- Индексация
- Рейтинг
1.
СканированиеФактическое обнаружение новых веб-страниц в Интернете начинается с процесса, называемого сканированием.
Поисковые системы используют небольшие программы, называемые поисковыми роботами (иногда называемые ботами или роботами-пауками), которые переходят по ссылкам с уже известных страниц на новые, которые необходимо открыть.
Каждый раз, когда поисковый робот находит новую веб-страницу по ссылке, он сканирует и передает ее содержимое для дальнейшей обработки (так называемой индексации) и продолжает обнаружение новых веб-страниц.
2. Индексирование
После того, как боты просканируют данные, наступает время индексации — процесса проверки и сохранения содержимого веб-страниц в базе данных поисковой системы, которая называется «индекс». Это в основном большая библиотека всех веб-сайтов.
Ваш сайт должен быть проиндексирован, чтобы он отображался на странице результатов поисковой системы. Имейте в виду, что и сканирование, и индексирование — это непрерывные процессы, которые выполняются снова и снова, чтобы поддерживать базу данных в актуальном состоянии.
После того, как веб-страница проанализирована и сохранена в индексе, ее можно использовать в качестве результата поиска для потенциального поискового запроса.
3. Ранжирование
Последний шаг включает в себя выбор лучших результатов и создание списка страниц, которые будут отображаться на странице результатов.
Каждая поисковая система использует десятки сигналов ранжирования, и большинство из них держится в секрете, недоступном для общественности.
Как сказал Мартин Сплитт, аналитик тенденций для веб-мастеров:
«У нас есть более 200 сигналов для этого. Поэтому мы смотрим на такие вещи, как заголовок, мета-описание, фактический контент, который есть на вашей странице, изображения, ссылки и многое другое». (Мартин Сплитт, аналитик тенденций для веб-мастеров)
Что такое алгоритм поисковой системы?
Алгоритм поисковой системы — это термин, используемый для определения сложной системы из нескольких алгоритмов, которая оценивает все проиндексированные страницы и определяет, какие из них должны отображаться в результатах поиска по заданному запросу.
Например, алгоритм Google использует десятки факторов (многие из них хорошо известны, а некоторые держат в секрете) в нескольких областях, таких как:
- Значение запроса (понимание того, что пользователь означает использование точных слов, которые они использовали, какова цель поиска и т. д.)
- Релевантность страницы (поисковику необходимо узнать, отвечает ли страница на поисковый запрос)
- Качество контента (алгоритмы определяют, являются ли веб-страницы отличным источником информации на основе внутренних и внешних факторов; здесь важны количество и качество обратных ссылок)
- Удобство использования страницы (учитывает качество веб-страницы с технической точки зрения – отзывчивость, скорость страницы, безопасность и т. д.)
Поисковая оптимизация
Поисковые системы не только предоставляют пользователям полезную информацию, но и помогают брендам продвигать свои веб-сайты.
Оптимизация вашего веб-сайта для релевантных поисковых запросов является важной частью любой стратегии онлайн-маркетинга, поскольку она может привлечь больше трафика на ваши веб-страницы.
Сумма всех практик и методов, которые владельцы веб-сайтов используют для улучшения своего поискового рейтинга, называется поисковой оптимизацией (SEO).
Если бы мы хотели упростить SEO, мы могли бы сказать, что все вращается вокруг трех наиболее важных факторов:
- Техническая оптимизация
- Отличный контент
- Качественные обратные ссылки
Какие поисковые системы самые популярные?
Хотя в мире существуют сотни поисковых систем, лишь немногие из них доминируют на общем рынке поисковых систем и остаются популярными благодаря своему качеству, полезности и т. д. годы. Это список 5 самых популярных поисковых систем:
1. Google
Google — крупнейшая и самая популярная поисковая система в мире.
Компания Google, принадлежащая материнской компании Alphabet, доминирует на рынке поисковых систем, занимая более 90 процентов мирового рынка.
Благодаря всем своим функциям, включая сложные алгоритмы, эффективное сканирование, индексирование и ранжирование, Google обеспечивает отличные результаты поиска не только в своей собственной поисковой системе, но и в некоторых других поисковых системах (например, ask.com).
2. Microsoft Bing
Bing — вторая по величине поисковая система. Он был запущен в 2009 году и принадлежит Microsoft.
Хотя невозможно сравнивать Bing как реального соперника Google, занимающего всего 2–3 процента от общей доли рынка поисковых систем, это все же отличная альтернатива для тех, кто хотел бы попробовать что-то другое.
Microsoft Bing во многом похож на Google, предоставляя такие типы результатов поиска, как изображения, видео, места, карты или новости.
Хотя Bing использует основные принципы поисковых систем (сканирование, индексирование, ранжирование), он также использует специальный алгоритм под названием «Дерево разделов пространства и график», основанный на векторах для категоризации информации и ответов на поисковые запросы.
3. Yahoo!
Yahoo — популярный веб-сайт, поставщик электронной почты и третья по величине поисковая система в мире, на долю которой приходится почти 2% общей доли рынка поисковых систем.
Некогда очень популярная и доминирующая поисковая система Yahoo с годами падала в цене и стала несколько затмеваться Google.
В настоящее время Yahoo конкурирует с более мелкими поисковыми системами, такими как Bing или DuckDuckGo.
4. Яндекс
Яндекс (от термина « Y et Another i NDEX er») — поисковая система, популярная в основном в восточных странах.
Хотя на нее приходится менее 1 процента общей доли рынка поисковых систем, она является одной из самых популярных поисковых систем в таких странах, как Россия (более 60 процентов всех поисковых запросов в стране), Турция, Украина или Беларусь.
Подобно Google, Яндекс предоставляет различные виды услуг, включая Карты, Переводчик, Яндекс Деньги и даже Яндекс Музыку.
5. Baidu
Baidu является самой доминирующей поисковой системой в Китае. Несмотря на то, что его общая доля на мировом рынке составляет едва 1 процент, на него приходится более 80 процентов доли рынка в Китае с миллиардами поисковых запросов каждый день.
Baidu во многом похож на Google. Он предоставляет классические синие ссылки с зелеными URL-адресами и показывает расширенные результаты так же, как это делает Google.
Часто задаваемые вопросы
Ответим на несколько часто задаваемых вопросов о поисковых системах.
Почему Google является самой популярной поисковой системой?
Google, как поисковая система, уже много лет является лидером в своей отрасли и до сих пор доминирует на рынке поисковых систем. Есть несколько причин, по которым Google является наиболее широко используемой поисковой системой.
- Одна из первых поисковых систем
- Предлагает релевантные результаты
- Быстро
- Постоянно совершенствуется
- Подключен к нескольким бесплатным сервисам
Как поисковые системы зарабатывают деньги?
Основным источником дохода поисковых систем, таких как Google, являются различные косвенные источники. Поисковые системы могут монетизировать свои услуги с помощью:
- Реклама – Google использует собственный рекламный сервис под названием Google Ads, благодаря которому он может помогать брендам отображать свои продукты в результатах поиска, а взамен берет небольшую комиссию каждый раз, когда пользователь кликает по объявлению.
- Интернет-магазины – поисковые системы могут продвигать различные продукты в расширенных результатах поиска. Если пользователь нажимает или покупает один из продуктов, поисковая система взамен берет небольшой процент от покупки.
- Службы — Google объединяет свои службы (например, Play Store, Google Cloud, Google Apps и т. д.) с собственной поисковой системой и, таким образом, получает доход от клиентов, которые их используют.
Какой была первая поисковая система?
Archie (от названия «Архив») — первая поисковая система, созданная в 1990 году студентом Аланом Эмтаджем.
Хотя и раньше существовало несколько программ индексирования (таких как «X.500» или «Whois»), Archie была первой настоящей поисковой системой, способной находить определенные файлы в Интернете.
Archie работал довольно просто — он просматривал доступные в Интернете сайты и индексировал их как загружаемые файлы. Однако он не мог индексировать содержимое сайтов и поэтому страницы результатов имели вид простого списка.
В чем разница между браузером и поисковой системой?
Веб-браузер (например, Chrome, Firefox, Microsoft Edge и т. д.) — это программное приложение, устанавливаемое на компьютер или смартфон. Целью браузера является предоставление удобного интерфейса для отображения веб-страниц.
Поисковая система (например, Google, Bing, Yahoo! и т. д.) — это онлайн-инструмент, доступный на веб-сайте, доступ к которому можно получить через веб-браузер. Цель поисковой системы — предоставлять ответы на запросы пользователей в виде соответствующих веб-страниц.
Как поисковые системы распространяют информацию о COVID-19 и почему они должны работать лучше
Как поисковые системы распространяют информацию о COVID-19 и почему они должны работать лучше | Обзор дезинформации HKS Перейти к основному содержаниюСпециальный выпуск: COVID-19
Это эссе было опубликовано в рамках специального выпуска о дезинформации и COVID-19 под гостевой редакцией доктора Меган МакГинти (директор по управлению в чрезвычайных ситуациях, NYC Health + Hospitals) и Нэт Гинес (директор , Meedan Digital Health Lab).
Подробнее из этого выпуска
Поделиться
Скачать PDF
Экспертная оценка
Доступ к точной и актуальной информации необходим для индивидуального и коллективного принятия решений, особенно в чрезвычайных ситуациях. 26 февраля 2020 года, за две недели до того, как Всемирная организация здравоохранения (ВОЗ) официально объявила чрезвычайную ситуацию, связанную с COVID-19, «пандемией», мы систематически собирали и анализировали результаты поиска по термину «коронавирус» на трех языках из шести поисковых систем. Мы обнаружили, что разные поисковые системы отдают приоритет определенным категориям источников информации, таким как веб-сайты, связанные с правительством, или альтернативные СМИ. Мы также заметили, что ранжирование источников в одной и той же поисковой системе подвергается рандомизации, что может привести к неравному доступу к информации среди пользователей.
By
Николай Махортых
Институт коммуникаций и медиа исследований, Бернский университет, Швейцария
Александра Урман
Институт коммуникаций и медиа исследований Бернского университета, Швейцария
Роберто Уллоа
Департамент вычислительных социальных наук, Институт социальных наук GESIS-Leibniz, Германия
Резюме эссе
- Используя несколько (N=200) виртуальных агентов (т. е. программ), мы изучили, как информация о коронавирусе распространяется в шести поисковых системах: Baidu, Bing, DuckDuckGo, Google, Yandex и Yahoo. . Мы составили сценарий последовательности действий при просмотре для каждого агента, а затем отследили эти действия в контролируемых условиях, включая время, местоположение агента и историю браузера.
- 26 февраля 2020 года агенты одновременно ввели поисковые запросы на основе наиболее распространенного термина, используемого для обозначения пандемии COVID-19 (т. е. «коронавирус» на английском, русском и китайском языках) в шесть поисковых систем.
- Анализ результатов поиска, полученных агентами, выявил тревожные различия в типах источников информации, приоритет которых определяется разными поисковыми системами. Мы также выявили значительное влияние рандомизации на ранжирование источников в одной и той же поисковой системе.
- Такие несоответствия в результатах поиска могут дезинформировать общественность и ограничивать права граждан принимать решения на основе достоверной и непротиворечивой информации, что вызывает особую озабоченность во время чрезвычайной ситуации, такой как пандемия COVID-19.
Последствия
Мы выявили большие расхождения в том, как разные поисковые системы распространяют информацию о пандемии COVID-19. Некоторые различия в результатах ожидаемы, учитывая, что поисковые системы персонализируют свои услуги (Hannak et al., 2013), но наше исследование подчеркивает, что даже неперсонализированные результаты поиска существенно различаются. Например, мы обнаружили, что некоторые алгоритмы поиска потенциально отдают предпочтение вводящим в заблуждение источникам информации, таким как альтернативные СМИ и контент социальных сетей в случае Яндекса, в то время как другие отдают приоритет авторитетным источникам (например, страницам, связанным с правительством), например, в случае Google.
Особую озабоченность вызывает рандомизация результатов поиска среди пользователей одной и той же поисковой системы. Мы обнаружили, что степень рандомизации различается между поисковыми системами: для некоторых, таких как Google и Bing, она в основном влияет на состав «длинного хвоста» результатов поиска, например, тех, которые находятся ниже 10 лучших результатов, в то время как для других, таких как DuckDuckGo и Яндекс также рандомизируют 10 лучших результатов. Рандомизация гарантирует, что то, что видит пользователь, не обязательно совпадает с тем, что он хочет видеть, и что разные пользователи получают разную информацию. С помощью рандомизации пользователь видит то, что поисковая система случайным образом решила, что этому конкретному пользователю разрешено видеть. Тогда в этом сценарии доступ к надежной информации — это просто вопрос удачи.
Хотя рандомизация может стимулировать открытие знаний за счет диверсификации информации, получаемой отдельными лицами (Helberger, 2011), она может нанести ущерб, когда обществу срочно требуется доступ к последовательной и точной информации, например, во время кризиса в области общественного здравоохранения. Если предположить, что основной движущей силой рандомизации является максимальное вовлечение пользователей путем тестирования различных способов ранжирования результатов поиска и выбора оптимальной иерархии информационных ресурсов по конкретной теме (например, так называемого «Google Dance» (Battelle, 2005). )) то мы оказались бы в ситуации, когда частные интересы компаний прямо нарушают права людей на доступ к достоверной и проверяемой информации.
Точное функционирование и обоснование рандомизации и различных приоритетов источников в настоящее время неизвестны. Критика алгоритмической непрозрачности в распространении информации не нова (Pasquale, 2015; Kemper & Kolkman, 2019; Noble, 2018). Однако отсутствие прозрачности особенно неприятно во время чрезвычайных ситуаций, когда предвзятость механизмов фильтрации и ранжирования становится вопросом общественного здравоохранения и национальной безопасности. Наши наблюдения показывают, что поисковые системы получают противоречивые и иногда вводящие в заблуждение результаты в отношении COVID-19., но остается неясным, какие факторы способствуют этим расхождениям в информации и какие принципы использует каждая машина для построения иерархии знаний. Эти проблемы вызывают множество вопросов, в том числе, что такое «хорошая» информация, кто должен принимать решения о ее качестве и могут ли эти решения применяться однозначно. Самое главное: должны ли поисковые системы приостанавливать рандомизацию во время чрезвычайных ситуаций?
Ответы на эти вопросы найти непросто, это потребует времени и соответствующих усилий. Одной из отправных точек для повышения прозрачности поиска может быть предоставление ресурсов для проведения «алгоритмического аудита» (то есть анализа эффективности алгоритмов, аналогичного тому, который реализован в данном исследовании) более доступными для академического сообщества и широкой общественности (Миттельштадт, 2016). В настоящее время не существует общедоступной и масштабируемой инфраструктуры, которую можно было бы использовать для сравнения производительности различных алгоритмов поисковых систем, а также их особенностей (например, рандомизации). Предоставляя такую инфраструктуру и делая данные о влиянии алгоритмов на распространение информации более доступными, компании, занимающиеся поисковыми системами, могут решить проблему отсутствия прозрачности в своих алгоритмических системах и повысить доверие к тому, что информационные технологии играют в нашем обществе (Foroohar, 2019). ).
Еще один момент, который следует учитывать, — это возможность реализации «механизмов контроля пользователей», которые могут гарантировать, что пользователи поисковых систем смогут решать алгоритмические функции (например, рандомизацию), мешающие их способности получать информацию (He, Parra, & Verbert, 2016; Harambam и др., 2019). Подходы, ориентированные на пользователя, могут варьироваться от четкой политики в отношении приоритизации источников (например, решение Google отдавать приоритет правительственным источникам информации о COVID-19, но последовательно применяться к другим темам поиска) до возможности отказаться не только от персонализации поиска, но и его рандомизация.
Выводы
Вывод 1: Ваша поисковая система определяет, что вы видите .
Мы обнаружили большие расхождения в результатах поиска (N=~50) между идентичными агентами, использующими разные поисковые системы (рис. 1). Несмотря на использование одних и тех же поисковых запросов, все метрики показали сходство результатов поиска между поисковыми системами менее чем на 25%, за исключением DuckDuckGo и Yahoo, у которых почти 50% результатов совпадают. Во многих случаях мы почти не наблюдали совпадений в результатах поиска (например, между Google и DuckDuckGo), что указывает на то, что пользователи получают совершенно разные наборы источников информации. Хотя различия в выборе источника не обязательно являются негативным аспектом, полное отсутствие общих ресурсов между поисковыми системами может привести к существенным расхождениям в информации среди их пользователей, что вызывает беспокойство во время чрезвычайной ситуации. Кроме того, как показывает вывод 3, поисковые системы отдают предпочтение не только разным источникам одного типа (например, различные устаревшие СМИ), но и разным типам источников, что напрямую влияет на качество информации, которую предоставляют поисковые системы.
Индекс Жаккара (JI), метрика, которая измеряет долю общих результатов между различными агентами, показал, что для большинства механизмов перекрытие источников происходило в длинном хвосте результатов, то есть за пределами первых 10 результатов. В топ-10 результатов перекрытие было выше только для пары Yahoo-Baidu; остальные результаты получены в основном из разных источников. Эти наблюдения были подтверждены ранжированным предвзятым перекрытием (RBO), метрикой, которая учитывает ранжирование результатов поиска. Параметр p определяет, насколько важны лучшие результаты: p 0,8 придает больший вес нескольким лучшим результатам, тогда как p = 0,9.5 более равномерно распределяет вес между 30 лучшими результатами. Наши значения RBO показали, что ранжирование результатов с длинным хвостом обычно было более согласованным между поисковыми системами, чем ранжирование лучших результатов поиска.
Вывод 2: Результаты поиска, которые вы получаете, рандомизированы .
Мы наблюдали существенные различия в результатах поиска, полученных одинаковыми агентами с использованием одной и той же поисковой системы и браузера (рис. 2). Для некоторых поисковых систем, таких как Yahoo и Baidu, мы обнаружили существенную согласованность в составе общих и первых 10 результатов (на что указывают значения JI). Однако, как показывают их значения RBO, ранжирование этих результатов было непоследовательным. Напротив, в Google и, в некоторой степени, в Bing первые 10 результатов были последовательными, тогда как остальные результаты были менее совпадающими. Наконец, в случае агентов, использующих DuckDuckGo в Chrome, общий выбор результатов был последовательным, но их рейтинги существенно различались.
Одно из возможных объяснений такой рандомизации состоит в том, что алгоритмы поиска привносят определенную степень «прозорливости» в способ выбора результатов, чтобы дать возможность увидеть различные источники (Cornett, 2017). Более прагматичной причиной рандомизации может быть то, что поисковые системы постоянно экспериментируют с результатами, чтобы определить, какие из них максимизируют удовлетворенность пользователей и потенциально увеличивают прибыль от поисковой рекламы. Такие эксперименты кажутся особенно интенсивными в случае разворачивающихся и быстро меняющихся тем, для которых не существует ранее существовавших иерархий знаний.
Чтобы проверить последнее предположение, мы выполнили серию запросов, которые не были связаны с пандемией COVID-19, а были связаны с более устоявшимися новостными темами. Когда мы сравнили результаты поиска «коронавирус» с другими поисковыми запросами, выполненными ботами (например, «выборы в США»; см. Приложение), мы обнаружили более высокую волатильность результатов поиска коронавируса, что может быть связано с его новизной и отсутствием исторической информации о пользователе. предпочтения.
Наконец, мы рассмотрели, влияет ли тип браузера на степень рандомизации. Для большинства поисковых систем (кроме DuckDuckGo, где ранжирование результатов в Chrome сильно рандомизировано) мы не наблюдали существенных различий между браузерами. Эти наблюдения могут указывать на то, что выбор браузера не оказывает существенного влияния на выбор результатов. В то же время отсутствие такого влияния также может быть связано с недавним случаем коронавируса, что приводит к отсутствию исторических данных, на основе которых алгоритмы предлагают более специфичный для браузера выбор результатов.
Вывод 3. Поисковые системы отдают приоритет разным типам источников .
Мы обнаружили, что поисковые системы присваивают разный приоритет отдельным категориям источников информации в отношении коронавируса. Наше изучение 20 наиболее часто встречающихся результатов поиска на английском языке (рис. 3) показало, что большинство поисковых систем отдавали приоритет источникам, связанным с традиционными СМИ (например, CNN) и организациями здравоохранения (включая организации общественного здравоохранения, такие как ВОЗ). Однако соотношение этих источников существенно различается: например, для Bing источники, связанные со здравоохранением, составили почти половину первых 20 результатов, тогда как для Google, Yandex и Yahoo они составили менее четверти лучших результатов. Напротив, Yahoo отдавала приоритет последним обновлениям информации о коронавирусе из устаревших СМИ, в то время как Google отдавал предпочтение веб-сайтам, связанным с правительством, таким как сайты городских советов.
Учитывая их способность распространять непроверенную информацию, эти различия в иерархии знаний, построенной поисковыми системами, вызывают беспокойство. Для некоторых поисковых систем самые популярные результаты поиска о пандемии включали социальные сети (например, Reddit) или информационно-развлекательные программы (например, HowStuffWorks). Такие источники, как правило, менее надежны, чем официальные информационные агентства или качественные СМИ. Более того, в случае с Яндексом в топ поисковой выдачи попали альтернативные СМИ (например, https://coronavirusleaks. com/), достоверность информации в которых вызывает сомнения.
Вывод 4. Выбор языка влияет на различия между двигателями .
Наконец, мы обнаружили, что степень расхождений между результатами поиска варьировалась в зависимости от языка, на котором выполнялись запросы. Различия между агентами, использующими одну и ту же поисковую систему, были относительно низкими, что позволяет предположить, что выбор языка не оказал существенного влияния на рандомизацию (за исключением Google, где результаты на китайском/русском языках были более рандомизированы, чем на английском).
РИСУНОК 4. СРЕДНЕЕ СХОДСТВО (%) ДЛЯ ПАРНЫХ АГЕНТОВ СОГЛАСНО ПОИСКОВЫМ СИСТЕМАМ НА РАЗНЫХ ЯЗЫКАХ. JI ОБОЗНАЧАЕТ ИНДЕКС ЖАККАРДА, а RBO ОБОЗНАЧАЕТ РЕЙТИНГОВОЕ СМЕЩЕННОЕ ПЕРЕКРЫТИЕ. НА ОСИ X ПОКАЗАН СРЕДНИЙ ПРОЦЕНТ ПО КАЖДОМУ ПОКАЗАТЕЛЮ СХОДСТВА, А НА ОСИ Y ПОКАЗАНЫ СРАВНЕННЫЕ ПАРЫ ПОИСКОВЫХ СИСТЕМ. Мы заметили, что выбор языка приводит к более существенным различиям между парами поисковых систем (рис. 4). Для нескольких пар, таких как Bing и DuckDuckGo, мы обнаружили, что результаты поиска были более похожими для русского и китайского языков, чем для английского. Однако эта закономерность не была универсальной, о чем свидетельствуют результаты запроса «выборы в США» (рис. A1 в приложении). Эти наблюдения можно объяснить разным объемом информации на соответствующих языках, обрабатываемой поисковыми системами. Меньший объем данных на русском и китайском языках может увеличить вероятность дублирования источников. Тем не менее, эти языковые расхождения подтверждают наше общее утверждение об отсутствии единообразия среди поисковых систем.
МетодыСбор данных
Мы разработали распределенную облачную исследовательскую инфраструктуру для эмуляции и отслеживания поведения нескольких виртуальных агентов в Интернете. Используя Amazon Elastic Compute Cloud (Amazon EC2), мы создали 100 виртуальных машин CentosOS с двумя установленными браузерами (Firefox и Chrome) на каждой машине. В каждый браузер («агент») мы установили два браузерных расширения: бота и трекер. Бот эмулирует поведение при просмотре, ища термины из предварительно определенного списка, а затем перемещается по результатам поиска. Трекер собирает HTML-код с каждой страницы, которую посещает бот, и отправляет его на центральный сервер — другую машину, на которой хранятся все данные.
Мы рассмотрели шесть поисковых систем — Baidu, Bing, Google, Yahoo, Yandex и DuckDuckGo — и запросили у них термин «коронавирус» на английском, русском и китайском языках. Выбор первых пяти поисковых систем объясняется тем, что они наиболее часто используются во всем мире (см. Statista 2020), тогда как DuckDuckGo был выбран из-за его акцента на конфиденциальность (Schofield 2019), что означает, что он не использует личные данные пользователей для персонализации. результаты поиска (Вайнберг, 2012). Мы выбрали слово «коронавирус» как наиболее распространенный термин, используемый в отношении продолжающейся пандемии на момент сбора данных (см. Google Trends (2020)) и обозначающий обширное семейство вирусов, включающее COVID-19.. Во всех случаях мы использовали фиксированное написание термина (то есть «коронавирус», а не «коронавирус»), чтобы расхождения в запросах не влияли на результаты поиска.
Мы разделили всех агентов на шесть групп (n=32/33; поровну распределены между Chrome и Firefox), каждая из которых была закреплена за определенной поисковой системой. 26 февраля 2020 г., за две недели до того, как ВОЗ объявила коронавирус пандемией, каждый агент выполнял аналогичную процедуру просмотра, состоящую из действий, типичных для навигации в веб-поиске, таких как набор текста, нажатие и прокрутка. Продолжительность подпрограммы не превышала трех минут, чтобы можно было собрать сопоставимый объем данных (~50 лучших результатов поиска). Все агенты были синхронизированы, чтобы запускать каждый запрос точно в одно и то же время (т. е. каждые семь минут). В случае сбоя сети инициировалось обновление страницы, чтобы включить повторную синхронизацию агента для следующего раунда запросов.
Мы также очищали данные браузера в начале каждого раунда запросов, чтобы уменьшить влияние предыдущих поисков на последующие. Во-первых, мы удалили данные, к которым может получить доступ поисковая система JavaScript, включая локальное хранилище, хранилище сеансов и файлы cookie. Во-вторых, мы удалили данные, доступ к которым может получить только браузер или расширения с расширенными привилегиями (полный список см. в таблице A1 в приложении), в том числе историю браузера и кеш.
Анализ данных
После сбора данных мы использовали BeautifulSoup (Python) и rvest (R) для извлечения URL-адресов результатов поиска из HTML для заданного запроса и для фильтрации нерелевантных URL-адресов (например, цифровых объявлений). Хотя мы признаем, что нерелевантные URL-адреса также могут влиять на то, как пользователи воспринимают информацию о коронавирусе, мы решили удалить их из-за нашего интереса к механизмам фильтрации и ранжирования поиска по умолчанию.
Затем мы провели поиск между каждой парой двух агентов (200*199/2 = 19900 пар) с использованием двух показателей подобия: JI и RBO. JI измеряет перекрытие между двумя наборами результатов и может быть определен как доля идентичных результатов в обоих наборах среди всех уникальных результатов. Он часто используется для проверки алгоритмов поиска (Hannak et al., 2013; Kliman-Silver et al., 2015; Pushmann, 2019). Значение JI варьируется от 0 до 1, где 1 указывает, что сравниваемые наборы на 100% идентичны, а 0 — что они совершенно разные. Мы рассчитали два JI для каждой пары агентов: один измеряет перекрытие между полными наборами результатов поиска от каждого агента, а другой измеряет перекрытие для первых 10 результатов.
JI полезно оценить, сколько URL-адресов повторяется в результатах поиска, полученных агентами, но не учитывает порядок этих URL-адресов. Однако ранжирование источников имеет решающее значение для проверки алгоритмов поиска: состав двух наборов результатов может быть идентичным (следовательно, JI = 1), но порядок этих результатов может быть разным, что приводит к несовместимому пользовательскому опыту. Расхождения в ранжировании особенно важны, поскольку пользователи редко прокручивают страницу ниже нескольких первых результатов (Cutrell & Guan, 2007; González-Caro & Marcos, 2011).
Чтобы учесть различия в ранжировании результатов поиска, мы использовали показатель RBO, специально разработанный для изучения сходства результатов поисковых систем (Webber et al., 2010; Cardoso & Magalhães, 2011; Robertson et al., 2018). В отличие от JI, RBO взвешивает верхние результаты поиска больше, чем нижние, чтобы учесть, что ранжирование источника влияет на вероятность того, что пользователь его увидит (Cutrell & Guan, 2007). Подобно JI, значение RBO, равное 1, указывает на то, что состав результатов и их ранжирование на 100 % идентичны, тогда как значение RBO, равное 0, указывает на то, что и результаты, и их ранжирование совершенно разные.
Для RBO точный вес позиционирования результатов определяется параметром p. Значение параметра определяется исследователем и может быть любым числом в диапазоне 0 < p < 1. Чем ниже значение p, тем больший вес придается лучшим результатам. Мы провели наш анализ с двумя разными значениями p: 0,95 и 0,8. Первое значение позволяет более систематически анализировать различия в ранжировании между двумя агентами, тогда как второе фокусируется на различиях между лучшими результатами (Webber et al., 2010, стр. 24).
После расчета показателей сходства мы изучили типы источников информации, которым поисковые системы отдают предпочтение. Используя метод индуктивного кодирования, мы изучили 20 наиболее распространенных URL-адресов среди результатов поиска на английском языке для каждой из шести систем и закодировали каждый URL-адрес в соответствии с категорией источника информации, к которой он принадлежал. Мы определили 10 типов источников информации: 1) альтернативных СМИ : неосновные и нишевые источники, такие как анонимные блоги; 2) торговля : коммерческие источники и интернет-магазины; 3) правительство : источники, связанные с местными и национальными государственными органами; 4) здравоохранение : источники, связанные с организациями здравоохранения, такими как медицинские клиники и учреждения общественного здравоохранения; 5) информационно-развлекательные ресурсы : источники новостей и развлечений, такие как HowStuffWorks; 6) унаследованные СМИ : источники, связанные с основными медиа-организациями, такими как CNN; 7) неправительственная организация (НПО) : источники, относящиеся к основным неправительственным организациям; 8) справочная работа : справочные онлайн-источники, такие как Википедия; 9) социальные сети : платформы социальных сетей, такие как Reddit; 10) аналитический центр : источники, связанные с исследовательскими институтами. Кодирование проводилось двумя авторами, которые кодировали разногласия между собой на основе консенсуса.
Методическое приложение доступно в PDF-версии этой статьи.
Поделиться
Скачать PDF
Процитировать это эссе
Махортых М., Урман А. и Уллоа Р. (2020). Как поисковые системы распространяют информацию о COVID-19 и почему они должны работать лучше. Обзор дезинформации Гарвардской школы Кеннеди (HKS) . https://doi.org/10.37016/mr-2020-017
Библиография
Battelle, J. (2005). Поиск: как Google и его конкуренты переписали правила ведения бизнеса и изменили нашу культуру. Портфолио.
Кардосо, Б., и Магальяйнс, Дж. (2011). Google, Bing и новый взгляд на схожесть ранжирования. В материалах 20-й международной конференции ACM по управлению информацией и знаниями (стр. 1933–1936). АКМ Пресс.
Корнетт, Л. (2007, 17 августа). Поиск и интуиция: находите больше, когда знаете меньше. Страна поисковых систем. https://searchengineland.com/search-serendipity-finding-more-when-you-know-less-11971
Катрелл, Э., и Гуан, З. (2007). Что Вы ищете? Исследование использования информации в веб-поиске с помощью отслеживания взгляда. В материалах конференции SIGCHI по человеческому фактору в вычислительных системах — CHI ’07 (стр. 407–416). АКМ Пресс.
Форухар, Р. (2019). Не будь злым: Дело против больших технологий. Пингвин Великобритания.
Гонсалес-Каро, К., и Маркос, М.К. (2011). Разные пользователи и намерения: анализ веб-поиска с помощью отслеживания взгляда. В материалах WSDM 11 (стр. 9–12). АКМ Пресс.
Google Тренды. (2020, 21 апреля). ковид-19, коронавирус. Google. https://trends.google.com/trends/explore?q=covid-19,coronavirus
Ханнак А., Сапезинский П., Молави Кахки А., Кришнамурти Б., Лазер Д., Мислов , А., и Уилсон, К. (2013). Измерение персонализации веб-поиска. В материалах 22-й международной конференции по всемирной паутине (стр. 527–538). АКМ Пресс.
Харамбам Дж., Бунтуридис Д., Махортых М. и Ван Хобокен Дж. (2019). Проектирование к лучшему с учетом пользователей: качественная оценка механизмов пользовательского контроля в (новостных) рекомендательных системах. В материалах 13-й конференции ACM по рекомендательным системам (стр. 69–77). АКМ Пресс.
Хе, К., Парра, Д., и Верберт, К. (2016). Интерактивные рекомендательные системы: обзор современного состояния и будущих исследовательских задач и возможностей. Экспертные системы с приложениями , 56 , 9-27.
Хелбергер, Н. (2011). Разнообразие по дизайну. Журнал информационной политики, 1, 441–469.
Джи, К. (2020, 20 апреля). WhatsApp ограничивает пересылку сообщений для борьбы с дезинформацией о коронавирусе. Обзор технологий Массачусетского технологического института. https://www.technologyreview.com/2020/04/07/998517/whatsapp-limits-message-forwarding-combat-coronavirus-misinformation/
Кемпер, Дж., и Колкман, Д. (2019). Прозрачный для кого? Никакой алгоритмической подотчетности без критической аудитории. Информация, коммуникации и общество, 22 (14), 2081–209.6.
Климан-Сильвер, К., Ханнак, А., Лазер, Д., Уилсон, К., и Мислов, А. (2015). Местоположение, местоположение, местоположение: влияние геолокации на персонализацию веб-поиска. В материалах конференции по интернет-измерениям 2015 г. (стр. 121–127). АКМ Пресс.
Миттельштадт, Б. (2016). Автоматизация, алгоритмы и политика: аудит прозрачности систем персонализации контента. Международный журнал связи, 10: 4991–5002. Паскуале, Ф. (2015). Общество черного ящика. Издательство Гарвардского университета.
Ноубл, США (2018). Алгоритмы угнетения: как поисковые системы усиливают расизм. Нью-Йорк Пресс.
Пушманн, К. (2019). За пределами пузыря: оценка разнообразия результатов политического поиска. Цифровая журналистика, 7(6), 824–843.
Робертсон, Р. Э., Цзян, С., Джозеф, К., Фридланд, Л., Лазер, Д., и Уилсон, К. (2018). Аудит необъективной аудитории в поиске Google. Труды ACM по взаимодействию человека с компьютером, 2 (CSCW): 1–22.
Шофилд, Дж. (2019 г., 12 декабря). Может ли DuckDuckGo заменить поиск Google, предлагая лучшую конфиденциальность? Хранитель. Получено с https://www.theguardian.com/technology/askjack/2019/dec/12/duckduckgo-google-search-engine-privacy
Statista. (2020). Доля ведущих поисковых систем на мировом рынке настольных компьютеров с января 2010 г. по январь 2020 г. А. и Зобель Дж. (2010). Мера сходства для неопределенного ранжирования. Транзакции ACM в информационных системах, 28 (4), 1–38.
Вайнберг, Г. (2012). Конфиденциальность. DuckDuckGo https://duckduckgo.com/privacy
Финансирование
Исследование проведено в рамках исследовательского проекта «Взаимные отношения между популистскими радикально-правыми установками и политическим информационным поведением: лонгитюдное исследование развития установок в условиях выбора информации среды», финансируемой Deutsche Forschungsgemeinschaft (номер проекта 4131
) и Швейцарским национальным научным фондом (номер проекта 182630).