
Как найти и удалить дубли на сайте – проверка сайта на дубли онлайн-сервисами и программами
Краткое содержание статьи:
- Виды дублей страниц
- Полные дубли
- Частичные дубли
- Виды проверки
- Онлайн-сервисы
- Десктопные программы
При работе над технической оптимизацией сайта крайне важно уделить внимание устранению дублей страниц, т.к. они негативно воспринимаются поисковыми системами, вплоть до наложения санкций. Это происходит из-за того, что дубли снижают уникальность страниц, которые они дублируют, а также всего сайта в целом. Из-за них снижается релевантность сайта, вес страниц, они могут затруднять индексацию. Частая проблема – основная страница в выдаче может замениться дублированной, и из-за этого могут происходить скачки позиций по продвигаемым фразам. Такая ситуация происходит, потому что поисковая система не может определиться с релевантной страницей и постоянно меняет ее с одной на другую.
Плагины, модули и особенности CMS. В зависимости от CMS и установленных на них плагинов и модулей, они могут создавать разные дубли страниц, которые также важно находить и убирать. Например, на CMS WordPress обычное дело встретить автоматические дубли, в url которых есть feed, tag, attacment, trackback, replytocom и пр.
Решение:
Закрыть дубли от индексации в robots.txt, например с помощью правила Disallow: *?replytocom.
Т.к. в адресах дублей часто имеется знак вопроса, самый простой способ избавиться от большей их части – это правило Disallow: /*? (при условии, что на сайте нет актуальных адресов со знаком вопроса).
Еще один вид дублей – когда отсутствует уровень вложенности, и одна и та же страница доступна по разным адресам, например: https://site.ru/katalog/bumaga и https://site.ru/bumaga. Дубль может появляться как из-за установленных модулей, так и из-за особенностей CMS.
Решение:
Поможет только настройка 301-редиректа с дубля на основную страницу. (.*)$ https://site.ru/page/? [R=301,L]
(.*)$ https://site.ru/page/? [R=301,L]
Дублирование товара. Бывает так, что один и тот же товар добавляется на сайт несколько раз (например, это могло произойти случайно) или из-за особенностей CMS специально, чтобы товары могли оказаться в разных разделах (например, когда CMS не умеет привязывать один и тот же товар в разные категории под одним адресом).
Решение:
В случае, если виновата CMS, то рекомендуется настроить для дублей атрибут canonical. Если такие дубли были добавлены вручную и их не много, то можно удалить самостоятельно.
UTM-метки – спецпараметры в url, которые позволяют передавать данные для анализа рекламы и источника переходов. Бывает так, что после их настройки такие url попадают в индекс и создают дубли продвигаемым страницам.
Разные решения:
- На страницах с UTM-метками настроить каноническую ссылку.

- Закрыть индексацию таких страниц с помощью robots.txt – Disallow: /*?utm_* или с помощью директивы Clean-param.
- Можно настроить мета-тег robots, указав в нём noindex на страницах с UTM-метками.

Аналогично можно избавиться от меток yclid, gclid и многих других.
404-ошибка отдает ответ сервера 200. Часто бывает так, что у несуществующей страницы не настроен необходимый ответ сервера, а именно 404. Чтобы проверить это, нужно взять любую страницу и вместо адекватного url, ввести абракадабру: https://site.ru/jshfjdjgkls и далее с помощью любого сервиса для просмотра HTTP-заголовков, например bertal.ru, проверить ответ сервера https://site.ru/jshfjdjgkls. Если он отдает 200-ответ, значит потенциально у сайта может быть гигантское количество дублей. Рекомендуется проверить url разных видов – например, адрес раздела, товара и пр., желательно добавлять символы на разных уровнях адреса страницы, а также пробовать добавлять множественные слеши, заменять черточки на нижние подчеркивания.
Решение:
Для несуществующих страниц настроить 404-ответ сервера путём доработки кода.
Тестовый дубль сайта. Часто после разработки сайта или его доработок на отдельном тестовом домене делается полный дубль сайта для внедрения на него нового функционала, дизайна и пр. Если дубль сайта не закрыть от индексации, он может спокойно индексироваться поисковыми системами.
Решения:
Версия для печати, RSS и PDF. Чем мешают такие страницы? Например, печатная версия полностью дублирует весь контент страницы, аналогично с RSS-лентой и PDF-версией страниц.
Решение:
Проще всего закрыть такие дубли от индексирования поисковыми системами в файле robots.txt, например для версии страницы для печати задать такое правило:
Disallow: */print.
Частичные дубли
Частичные дубли (или нечеткие) – это когда контент страниц совпадает лишь частично. Нечеткие дубли имеют меньше отрицательного влияния на сайт, но они все еще ухудшают его ранжирование, хоть и незначительно.
Когда товары имеют одинаковые характеристики. Такие дубли тоже бывают, и они появляются тогда, когда у товара совпадает название и все описание, иногда даже изображение. Эти дубли заводятся вручную, и они свойственны сайтам, которые продают продукцию, которая отличается друг от друга какой-то деталью, например, цветом или составом.
Решение:
Такие товары рекомендуется уникализировать относительно друг друга, это можно сделать как вручную, там и автоматически – например, найти, какой-то параметр, который их отличает и добавить его в заголовок h2, мета-теги title и description, например это может быть артикул, цвет и др. Для добавления большей уникальности рекомендуется добавить разные описания товарам.
Страницы пагинации – разбивка контента сайта по отдельным страницам с нумерацией. На страницах пагинации может дублируется текст, заголовок и мета-теги, которые размещены на первой странице.
Решения:
- Если на странице с листингом размещен текст – то лучше с помощью доработки кода сайта убрать его со страниц с пагинацией.
- Для добавления уникальности рекомендуется в title и description (можно и в заголовок h2) добавлять приписку с номером страницы. Пример title: «Купить перчатки оптом по цене производителя – страница 2».

Страницы сортировки и фильтров тоже будут частичными дублями, т.к. категории с таким функционалом отображают одни и те же товары, которые просто отсортированы по разным параметрам, например по цене, новинкам и др.
Решение:
Если вы не планируете к продвижению такие страницы, то рекомендуется их закрыть от индексации, например в файле robots.txt (или с помощью мета-тега robots) или с помощью атрибута canonical.
Разные страницы, но одинаковые мета-теги. Такое может произойти, например, если для не важных страниц, например новостей, был задан один шаблон для формирования мета-тегов. Получается, что на сайте есть совершенно разные новости с одинаковыми мета-данными, и они будут считаться неполными дублями.
Решение:
Прописать для каждой страницы отдельно мета-тег, либо настроить шаблон мета-тегов так, чтобы добавить в них уникальность, например включив в него главный заголовок.
Виды проверки
Какие-то простые и распространенные дубли можно быстро и легко найти вручную, например, задать в строке браузера разные версии адреса: с http, с www и без, со слешем на конце и без и т.д. Но, чтобы найти другие виды дублей, могут понадобится дополнительные инструменты, о которых мы сейчас расскажем.
Онлайн-сервисы
Яндекс.Вебмастер. Чтобы посмотреть, какие страницы Яндекс посчитал дублями и исключил их из поиска, необходимо перейти в Яндекс.Вебмастер в раздел «Индексирование», затем «Страницы в поиске» и выбрать вкладку «Исключенные страницы». У дублированных страниц будет стоять статус «Удалено: Дубль».
Но, ограничиваться только Яндекс.Вебмастером в нахождении дублированных страниц не стоит, возможно он их еще не проиндексировал, либо наоборот они находятся в индексе вместе с оригинальным контентом.
Google Search Console. В сервисе Google также можно посмотреть обнаруженные им дубли страниц. Это можно сделать, перейдя в Google Search Console, далее в раздел «Покрытие», вкладка «Исключено» и смотреть сведения по исключенным страницам. Дублированные страницы будут помечены «Страница является копией».
Apollon.guru «Поиск дублей». Чтобы начать искать дублированные страницы с помощью данного сервиса, необходимо выбрать разные типы страниц вашего сайта для их проверки (например, главная страница, страница категории, товар, страница новостей и пр.). Далее эти страницы нужно добавить в поле сервиса и запустить проверку.
На примере выше найден дубль с ответом сервера 200, выделен красным.
Десктопные программы
Xenu. Бесплатная программа, с помощью которой можно найти дубли страниц по одинаковым мета-тегам title, а также по description. Чтобы начать проверять сайт необходимо установить программу на ПК и далее нажать кнопку Check URL, добавив в нее домен сайта.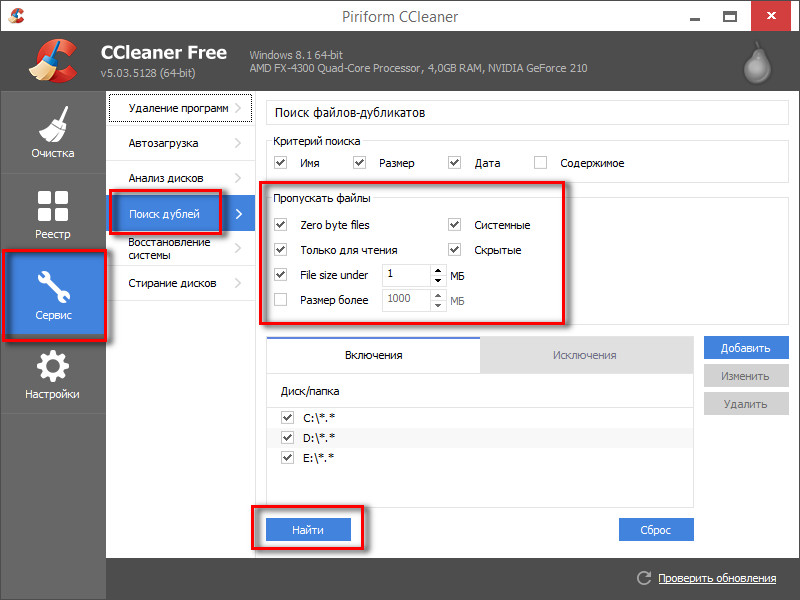 По результатам проверки можно будет искать дубли, нажав на поле title или description – тогда они отсортируются по алфавиту.
По результатам проверки можно будет искать дубли, нажав на поле title или description – тогда они отсортируются по алфавиту.
Screaming Frog Seo Spider. Платная программа, бесплатно можно проверить до 500 адресов. Смысл поиска дублей такой же как у Xenu – поиск по дублированным title, description и h2. Например, выбираем вкладку Page Titles и сортируем результат с заголовками по алфавиту. Также можно посмотреть вкладку URL – если её отсортировать, то отобразятся похожие адресации страниц, которые были найдены на сайте, например: страницы с пагинацией, идентичные или похожие товары.
SiteAnalyzer. Бесплатная десктопная программа, которая покажет дубликаты страниц, текста, title, description, h2-h6. Для начала проверки нужно вставить адрес сайта и нажать кнопку «Старт», а чтобы найти дублированный контент достаточно просто отсортировать по алфавиту.
Netpeak Spider. Платная программа, но есть freemium-тариф благодаря которому можно бесплатно найти на сайте дублированный контент и многие другие критичные ошибки. Перед тем, как запустить проверку, рекомендуем зайти в «Настройки», далее «Продвинутые» отметить весь раздел «Учитывать инструкции по сканированию и индексации» и «Next/Prev», чтобы робот пропустил и так уже ранее обнаруженные и закрытые дубли.
Перед тем, как запустить проверку, рекомендуем зайти в «Настройки», далее «Продвинутые» отметить весь раздел «Учитывать инструкции по сканированию и индексации» и «Next/Prev», чтобы робот пропустил и так уже ранее обнаруженные и закрытые дубли.
Чтобы начать сканирование сайта, введите домен сайта в адресную строку и нажмите «Старт». После того, как сканирование завершится, ошибки, связанные с дублированием контента, можно будет посмотреть справа в разделе «Отчеты»/«Ошибки».
Многие дубли страниц несложно найти и устранить, но их наличие может повлиять на SEO-продвижение сайта. Для некоторых требуется серьезная доработка кода – а значит нужна помочь разработчика. Для поиска рекомендуем использовать разные инструменты – так вы найдете максимально большое количество дублей и избавите сайт от такого вида технических ошибок, влияющих на ранжирование сайта в поисковых системах.
Автор: Мария Саловарова
для чего необходимо устранять дубли страниц и как
723
10 мин.
Одна из главных причин потери трафика и рейтинга — дублированный контент.
Дублированный контент — это две или более страниц, содержащих одинаковый или очень похожий контент. Поисковые системы стремятся предоставить пользователям наилучшие варианты, соответственно, они редко будут показывать повторяющиеся фрагменты контента. Вместо этого они будут вынуждены выбрать, какая версия, по их мнению, лучше всего подходит для этого запроса. Именно поэтому дублированный контент снижает рейтинг страницы в результатах поиска.
Также дубли страниц влияют на внутренний ссылочный вес. Допустим, на веб-сайте есть две идентичные страницы, каждая имеет 10 входящих ссылок. Этот сайт мог бы использовать вес 20 ссылок для повышения рейтинга страницы. Вместо этого на сайте две страницы с 10 ссылками. Ни то, ни другое не будет нормально ранжироваться и оказываться в ТОПе.
Дублированный контент также вредит краулинговому бюджету и приводит к тому, что нужные вам страницы по итогу не индексируются. И напротив, могут проиндексироваться 2 идентичные страницы.
И напротив, могут проиндексироваться 2 идентичные страницы.
- Ошибки в системе управления контентом (CMS).
- После перехода с http на https не настраивается перенаправление (301 редирект). Аналогично, когда нет перенаправления на главное зеркало сайта (если веб-сайт доступен с www и без www, со слешем и без него в конце).
- Добавление в URL-адрес get-параметров и UTM-меток.
- Человеческий фактор. Веб-мастер может по ошибке продублировать страницу.
- Изменения в структуре сайта, когда страницы получают новые адреса, а старые не удаляются.
Полные дубли
Это страницы сайта с одинаковым контентом, доступные по разным URL:
- С www и без www:
https://test.ru и https://www.test.ru. - С http и https:
https://test.ru и http://test.ru. - Прописные и строчные буквы на разных уровнях вложенности в URL:
https://test.ru/sample/ и https://test.ru/saAmpLe/. - Со слешем на конце URL и без слеша:
https://test. ru/sample/ и https://test.ru/sample. - С большим количеством слешей в конце или середине URL:
https://test.ru/////////, https://test.ru/////////sample/. - Дубли главной страницы по адресам: /home, /index.php, /index.html, /index.htm, /main, /default:
https://test.ru/sample/ и https://test.ru/sample/index.html. - С отсутствующими уровнями вложенности:
https://test.ru/category/sample/ и https://test.ru/sample/. - С заменой дефиса на нижнее подчеркивание или наоборот:
https://test.ru/test-url/ и https://test.ru/test_url. - При добавлении случайных символов или цифр либо в качестве нового уровня вложенности (в конце или середине URL), либо в существующие уровни вложенности:
https://test.ru/sample/gefYY7/ и https://test.ru/jerh2EE/sample/, https://test.ru/sample/ и https://test.ru/sample/56436/. - При добавлении * в конце URL:
https://test.ru/sample/ и https://test.ru/sample/*. - С неверными уровнями вложенности:
https://test. ru/category/sample/ и https://test.ru/sample/category/.
 ru/sample/ и https://test.ru/sample.
ru/sample/ и https://test.ru/sample. ru/category/sample/ и https://test.ru/sample/category/.
ru/category/sample/ и https://test.ru/sample/category/.Частичные дубли
Частичные дубли — это когда контент на сайте дублируется не полностью, а только его отдельные элементы, при этом URL, как правило, разный. Частичный дублирующий контент не так просто найти. При этом он также плохо влияет на позиции в выдаче.
Несколько видов частичных дублей:
- Описание товаров. Обычно возникает, когда описание одного товара на сайте дублируется для другого. Чтобы описания не повторялись, рекомендуем их уникализировать для каждого товара.
- Повторяющиеся метаданные (title, description) и h2.
- Дублирующийся контент на фильтрах, сортировке, в поиске и на страницах пагинации с повторяющимся текстом, описаниями и метаданными.
- Дублирующийся контент, который полностью соответствует основной странице для печати или для скачивания: https://test.ru/blog/blog1/ и https://test.ru/blog/blog1/printer.
Сложно объяснить, почему дублированный контент — это плохо, легче рассказать, почему уникальный контент — это хорошо.
Уникальный контент — один из лучших способов выделиться среди других сайтов. Когда контент на вашем веб-сайте принадлежит вам и только вам, вы выделяетесь. У вас есть то, чего нет ни у кого.
С другой стороны, когда вы используете одинаковый контент для описания ваших продуктов или услуг или повторно публикуете его на других сайтах, вы теряете уникальность. А в случае дублирования контента на сайте отдельные страницы теряют свою уникальность.
Это влечет за собой:
- Проблемы с индексацией: робот будет индексировать несколько дублирующихся страниц, что повлечет собой неправильную индексацию, расход краулингового бюджета. И по итогу нужные вам страницы могут не попасть в выдачу.
- Некорректные страницы в выдаче: в этом случае может быть два варианта. Или в выдачу попадет не та страница, которая вам нужна, или из-за конкуренции между собой же не попадет ни одна.
- Ссылочный вес: независимо от того, на сайте или вне его, весь дублирующийся контент конкурирует сам с собой. Каждая версия может привлечь внимание и ссылки, но ни одна из них не получит полной ценности, которую получила бы, если бы была единственной и уникальной версией. А в противном случае еще и потеряет часть своего ссылочного веса, распыляясь на две страницы одновременно.
 Каждая версия может привлечь внимание и ссылки, но ни одна из них не получит полной ценности, которую получила бы, если бы была единственной и уникальной версией. А в противном случае еще и потеряет часть своего ссылочного веса, распыляясь на две страницы одновременно.
Каждая версия может привлечь внимание и ссылки, но ни одна из них не получит полной ценности, которую получила бы, если бы была единственной и уникальной версией. А в противном случае еще и потеряет часть своего ссылочного веса, распыляясь на две страницы одновременно.Оператор site
Начнем с оператора site:. Этот запрос даст вам понимание, сколько страниц находится в индексе Google. А также можно увидеть полностью повторяющиеся страницы, которые и будут означать, что это дубли.
Парсеры и сервисы Netpeak Spider, Xenu, Screaming frog
Вы можете скачать, например, screaming frog и использовать его для сканирования всего сайта. Этот инструмент позволяет собрать дубли на сайте, такие как повторяющиеся метаданные страниц. Для запуска нового сканирования скопируйте и вставьте свое доменное имя в сканер и нажмите «Пуск», после щелкните на Duplicate.
Search Console
Иногда дублированный контент можно обнаружить в Инструментах Google — Search Console. Вы можете посмотреть их в разделе “Покрытие” в подразделе “Исключено”.
Вы можете посмотреть их в разделе “Покрытие” в подразделе “Исключено”.
Вручную на сайте
Чаще всего дубли возникают на таких страницах, как:
- пагинация;
- сортировка;
- фильтры.
Чтобы избежать этого, необходимо научиться правильно удалять дубли страниц. Как это сделать, смотрите ниже в статье.
Дублированный контент — это проблема, которая может повлиять на ваш обычный трафик, ссылочный вес, позиции в выдаче. Плюсы в том, что это легко можно исправить. Три самых быстрых способа решения проблем с дублированием контента:
301 редирект
Идеальный вариант. 301 редирект перенаправляет пользователя на нужную страницу, объединяет вес ссылок. Важно: используйте 301 редирект только когда была выявлена и устранена причина появления дублей.
Canonical
В поисковой оптимизации канонические теги определяют, какую страницу следует проиндексировать, и назначают ссылки на них. Теги — это предложение для поисковой системы, а не команды вроде 301 редиректа. Канонический тег подходит, когда вы хотите, чтобы пользователям было доступно несколько версий страницы, например, страницы сортировки, фильтры, пагинация.
Канонический тег подходит, когда вы хотите, чтобы пользователям было доступно несколько версий страницы, например, страницы сортировки, фильтры, пагинация.
Вариант с каноническими тегами подходит, когда 301 редирект непрактичен или дублирующая страница должна оставаться доступной. Например, если у вас есть две страницы товаров, одна отсортирована по убыванию, а другая — по возрастанию. В таком случае подойдет именно Canonical, чтобы не перенаправлять с одной страницы на другую.
Каноникал можно проверить в инструменте SEO META in 1 click, а также в коде сайта, который будет иметь такой вид:
<link rel="canonical" href="https://..." />
Метатеги
Вы можете использовать метатеги, чтобы запретить поисковым системам индексировать определенную страницу.
Этот тег сообщает Google не индексировать ссылки на определенной странице, но позволяет сканировать их. Другими словами, вы говорите Google не принимать во внимание эти ссылки для ранжирования.
<html> <head> <title> .
 .. </title>
<meta name = "robots" content = "noindex, nofollow">
</head>
.. </title>
<meta name = "robots" content = "noindex, nofollow">
</head>Метатеги работают лучше всего, когда вы хотите, чтобы эта страница была доступна пользователю, но не индексировалась ботом.
Файл robots.txt
Благодаря файлу robots.txt мы даем роботу рекомендацию, какие страницы сайта не нужно сканить. В отличии от метатега, robots.txt имеет рекомендательный характер, а не указательный. Поэтому в любом случае есть риск, что страница проиндексируется.
В robots.txt нужно прописать директиву “Disallow” — именно она запрещает роботам посещать страницы, которые нам не нужны.
User-agent: * Disallow: / contact
Выявление дублей — это очень важный этап внутренней оптимизации сайта.
Небольшое количество повторяющегося или шаблонного контента не принесет вреда вашему сайту. Но нужно внимательно следить за техническими ошибками SEO, которые приводят к созданию сотен или тысяч страниц дублей, что может нанести серьезный ущерб вашему краулинговому бюджету.
Если вам нужен надежный метод удаления дублей, лучшие варианты — 301 редирект, настройка Canonical, файл robots.txt и метатегов Noindex, Nofollow.
Как видите, нет ничего сложного в поиске и устранение дублей. Используйте эти рекомендации, и тогда ваш сайт определенно выйдет в ТОП.
12 апреля 2021
Рык Екатерина
SEO Specialist
Работаю в Brander с 2020 года. Я сеошник простой, когда вижу рост трафика — говорю “Это моя работа”.
Многоуровневые редиректы
Быстрая индексация страниц через Google Indexing API
Кейсы из digital-маркетинга, дизайна, разработки интернет-магазинов, вебсайтов и мобильных приложений
Как найти дубли страниц на сайте. Проблема дублирования страниц.
Продвижение
Одинаковый контент на страницах – это опасность для любого сайта и серьезная проблема для SEO. Казалось бы, что в этом страшного? Одинаковый контент может привести попасть под санкции систем Яндекс и Google, понизив позиции. Дубли необходимо быстро находить, удалять и не допускать повторных появлений.
Дубли необходимо быстро находить, удалять и не допускать повторных появлений.
Содержание
Виды дублей
Существует два вида дублей: полные и неполные
Полные дубли
Полные дубли – страницы, полностью повторяющие контент. Они ухудшают ранжирование и к ним плохо относятся поисковые системы.
Фактически, полные дубли – самая частая и серьезная проблема. Обычно, это страница, доступная по нескольким адресам: техническому адресу, через другую категорию, с параметрами в URL. То есть она получилась в результате неправильной настройки CMS.
Пример полного дублирования:
- https://sobaka.com/index.php?page=catalog
- https://sobaka.com/catalog
Неполные дубли
Неполные дубли – страницы, выборочно дублирующие фрагменты контента. Их тяжелее обнаружить, особенно если у вас интернет-магазин, где много схожих по описанию товаров. К тому же URL у неполных дублей разный.
В чем опасность дублей?
Скриншот из Яндекс.Вебмастера сайта с серьезными проблемами и дублированием контента.
Наложение санкций
В худшем случае поисковые системы исключают ваш сайт, в лучшем – снизят ранжирование страниц на поиске. Это происходит из-за того, что робот не понимает, что вы ведете технические работы или у вас серьезные проблемы, поэтому плодиться несколько одинаковых страниц. Чем больше таких страниц, тем больше поисковые боты думают, что сайт не достоин быть в выдаче.
Увеличение времени на обход страниц
При множестве дублей робот может так и не добраться до основного контента. Особенно опасно на сайтах, где сотни/тысячи страниц. В поисковике не будет отображаться желаемая страница. Вы вкладываете силы и время на продвижение одной страницы, но это не будет давать должного результата.
Проблема с индексацией
В Яндекс Вебмастере можно увидеть проблему с индексацией. Когда ваши страницы добавляются/удаляются, то в поисковой выдаче нет постоянства. Дубли сменяют друг друга и не успевают набрать достаточного веса, чтобы показываться по поисковым запросам.
Низкие позиции в поисковых системах
Страницы с одинаковым контентом отвечают на одинаковые запросы. Поисковая система не может определиться, что важней, а в худшем случае, вообще не покажет никакую. Ведь есть сайты конкурентов с конкретными страницами, отвечающими на данный запрос.
Причины возникновения дублей
- CMS “плодит” дубли – самая распространенная проблема. Например, материал был написан для нескольких рубрик, но их домены входят в адрес сайта. Возникает следующая ошибка:
- sobaka.site.com/number1/info
- sobaka.site.com/number2/info
- Невнимательность так же может привести к дублям. Например, если вы просто скопировали страницу и забыли запретить индексирование на вторую.
- Технические разделы могут возникнуть из-за CMS. Например, когда на сайте есть разделы, фильтры, каталоги и подкаталоги. На Bitrix или Joomla могут сгенерироваться сайты с одной и той же информацией.
- В интернет-магазинах товар часто находится в нескольких категория и доступен по разным URL:
- magazin.com/category1/product1
- magazin.com/category1/subcategory1/product1
- magazin.com/product1/
- magazin.com/category2/product1
- Технические ошибки возникают при ошибочной генерации ссылок и настройках в разных CMS случаются ошибки, которые приводят к дублированию страниц. Может произойти зацикливание: sobaka.com/tools/tools/tools/…/…/…

Ошибка:
- sobaka.com/rubric.php
- sobaka.com/rubric.php?ajax=Y
Поиск дублей страниц
Ручной поиск- Первое, что можно сделать для быстрого обнаружения – сделать поиск по запросу «site:ваш сайт» в Яндекс/Google и посмотреть количество найденных страниц. Такой запрос выводит все страницы с вашего сайта, попавшие в индекс поисковика.
- Конкретно для систем Google можно воспользоваться расширенным поиском. Необходимо ввести сайт с конкретной страницей – гугл выдаст дубли страниц. Так проходим по каждой странице на сайте.
- Еще один надежный способ обнаружения – ручной ввод возможных адресов сайта.
 Так проходим по каждой странице на сайте.
Так проходим по каждой странице на сайте.Популярные варианты дублирования страниц
Заходим на какую-нибудь страницу своего сайта и начинаем экспериментировать:
http://site.ru/category/post1- исходный адрес, на который мы перешли в процессе навигации по сайту. Все остальные варианты должны либо исправиться автоматически на этот адрес, либо выдать, что страница не существует.
http://www.site.ru/category/post1
http://site.ru/category/post1.html
http://site.ru/category/post1.php
http://site.ru/category/post1/index.php
http://site.ru/category/post1/index.html
http://site.ru/post1/ — часто страница доступна в нескольких категориях и без категории
http://site.ru/category/post1?param=234234
http://site.ru/category/post1/index.php
http://site.ru/category/post1/ — (добавляем и убираем косую черту в конце, это тоже считается разный адрес)
Обычно, если проблема есть, то этих проверок достаточно.
Простой способ найти дубли через Яндекс Вебмастер
- Переходим в Вебмастер и нажимаем СТРАНИЦЫ В ПОИСКЕ
- Выбираем ПОСЛЕДНИЕ ИЗМЕНЕНИЯ
- Выгружаем архив – смотрим на статус страниц. Если обнаружен дубль, тогда вы увидите DUPLICATE.
Можно не выгружать, а воспользоваться фильтром прямо в Яндекс.Вебмастер и просматривать существующие дубли прямо в браузере онлайн.
Выбираем фильтр по статусу «Дубль»Google Search ConsoleЧерез Google Search Console дубликаты можно увидеть еще быстрее.
- Заходим на вкладку ПОКРЫТИЕ
- Выбираем ИСКЛЮЧЕННЫЕ и смотрим на сведения
- В списке будут указаны страницы, которые являются копией.
Как избавиться от дублей
Естественно, все зависит от движка, который вы используете. В большинстве случаев следует применять следующие действия.
- Скрыть дубли от поисковых роботов (одна страница = одна ссылка), и исключить все остальные варианты страниц.
- Настройка Redirect 301 всех вариантов на одну существующую страницу.
- Запретить индексацию адресам с GET-параметрами в robot.txt
- Поставить re=canonical для страниц фильтров, каталогов, пагинцаций и т.п
Программы и сервисы для нахождения дублей
Рассмотрим популярные программы и сервисы для проверки дублей онлайн или на своем компьютере.
Парсер проиндексированных страниц от PromoPult
https://promopult.ru/tools/indexing_analysis.html
Интерфейс сервиса проверки проиндексированных страницСервис позволяет быстро сопоставлять проиндексированные страницы Яндекса и Google.
Сервис Apollon
https://apollon.guru/
Проверяем предыдущий сервис на варианты дублей. Оказалось много!Сервис позволяет быстро находить дубли с помощью перебора распространенных вариантов дублирования и показывает, на какую страницу происходит редирект.
Сервис Siteliner
https://www.siteliner.com/
Проверка в сервисе SitelinerСервис проверяет сайт на дубли онлайн и показывает количество оригинального контента и дублированного. Так же можно скачать полный список проиндексированных страниц.
Бесплатная тариф дает проверить 250 самых важных страниц вашего веб-сайта на основе внутренней структуры ссылок. Этого достаточно для большинства сайтов малого бизнеса и самостоятельной проверки.
Программа XENU
http://home.snafu.de/tilman/xenulink.html
Скриншот сканирования в программе XenuЧерез XENU можно провести проверку сайта и найти дубликаты страниц. Достаточно просто ввести URL. XENU найдет полные и частичные дубли сайта. Программа очень старая и не обновляется, но со своей работой справляется. Полностью бесплатна, легко сканирует большие сайты.
Программа Screaming Frog SEO Spider
www.screamingfrog.co.uk/seo-spider/
Найдены полные и частичные дубли страниц.«Лягушка» — мощный инструмент для SEO-оптимизаторов . Сканирование 500 страниц происходит бесплатно, остальное – требует платной подписки. Находит полные и частичные дубли, но это всего лишь маленькая доля полезных вещий, которые позволяет делать программа.
Сканирование 500 страниц происходит бесплатно, остальное – требует платной подписки. Находит полные и частичные дубли, но это всего лишь маленькая доля полезных вещий, которые позволяет делать программа.
Выводы
Дублирование страниц — серьезная проблема, особенно если сайт находится на SEO-продвижении. Это не надуманная проблема и в кабинетах вебмастеров Яндекс и Гугл есть предупреждения о дублировании контента.
Дубли можно легко найти с помощью программ. Если это технические страницы, то их желательно удалить. Если страницы важны для пользователя, то можно просто закрыть от индексации.
Самые простой способ перестраховаться от дублирования страниц — это использование метатега Canonical для указания основного адреса.
← Как узнать какой используется блок на ТильдеВозможности поиска Google для профессионалов →
специалист по SEO продвижению
Дублирование страниц — Вебмастер. Справка
Если страницы сайта доступны по разным адресам, но имеют одинаковое содержимое, робот Яндекса может посчитать их дублями и объединить в группу дублей.
Примечание. Дублями признаются страницы в рамках одного сайта. Например, страницы на региональных поддоменах с одинаковым содержимым не считаются дублями.
Если на сайте есть страницы-дубли:
Из результатов поиска может пропасть нужная вам страница, так как робот выбрал другую страницу из группы дублей.
Также в некоторых случаях страницы могут не объединяться в группу и участвовать в поиске как разные документы. Таким образом конкурировать между собой. Это может оказать влияние на сайт в поиске.
В зависимости от того, какая страница останется в поиске, адрес документа может измениться. Это может вызвать трудности при просмотре статистики в сервисах веб-аналитики.
Индексирующий робот дольше обходит страницы сайта, а значит данные о важных для вас страницах медленнее передаются в поисковую базу. Кроме этого, робот может создать дополнительную нагрузку на сайт.
- Как определить, есть ли страницы-дубли на сайте
- Как избавиться от страниц-дублей
Страницы-дубли появляются по разным причинам:
Естественным.
Например, если страница с описанием товара интернет-магазина присутствует в нескольких категориях сайта.Связанным с особенностями работы сайта или его CMS (например, версией для печати, UTM-метки для отслеживания рекламы и т. д.)
 Например, если страница с описанием товара интернет-магазина присутствует в нескольких категориях сайта.
Например, если страница с описанием товара интернет-магазина присутствует в нескольких категориях сайта.Чтобы узнать, какие страницы исключены из поиска из-за дублирования:
Перейдите в Вебмастер на страницу Страницы в поиске и выберите Исключённые страницы.
Нажмите значок и выберите статус «Удалено: Дубль».
Также вы можете выгрузить архив — внизу страницы выберите формат файла. В файле дублирующая страница имеет статус DUPLICATE. Подробно о статусах
Если дубли появились из-за добавления GET-параметров в URL, об этом появится уведомление в Вебмастере на странице Диагностика.
Примечание. Страницей-дублем может быть как обычная страница сайта, так и ее быстрая версия, например AMP-страница.
Чтобы оставить в поисковой выдаче нужную страницу, укажите роботу Яндекса на нее . Это можно сделать несколькими способами в зависимости от вида адреса страницы.
Это можно сделать несколькими способами в зависимости от вида адреса страницы.
Контент дублируется на разных URLКонтент главной страницы дублируется на других URLВ URL есть или отсутствует / (слеш) в конце адресаВ URL есть несколько / (слешей)URL различаются значениями GET-параметров, при этом контент одинаковВ URL есть параметры AMP-страницы
Пример для обычного сайта:
http://example.com/page1/ и http://example.com/page2/
Пример для сайта с AMP-страницами:
http://example.com/page/ и http://example.com/AMP/page/
В этом случае:
Установите редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа.
Укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске.
Добавьте в файл robots.txt директиву Disallow, чтобы запретить индексирование страницы-дубля.
Если вы не можете ограничить такие ссылки в robots.txt, запретите их индексирование при помощи мета-тега noindex. Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода.
Также вы можете ограничить AMP-страницы, которые дублируют контент страниц другого типа.

Чтобы определить, какая страница должна остаться в поиске, ориентируйтесь на удобство посетителей вашего сайта. Например, если речь идет о разделе с похожими товарами, вы можете выбрать в качестве страницы для поиска корневую или страницу этого каталога — откуда посетитель сможет просмотреть остальные страницы. В случае дублирования обычных HTML и AMP-страниц, рекомендуем оставлять в поиске обычные HTML.
https://example.com и https://example.com/index.php
В этом случае:
Рекомендуем устанавливать перенаправление с внутренних страниц на главную. Если вы настроите редирект со страницы https://example.com/ на https://example.com/index.php, контент страницы https://example.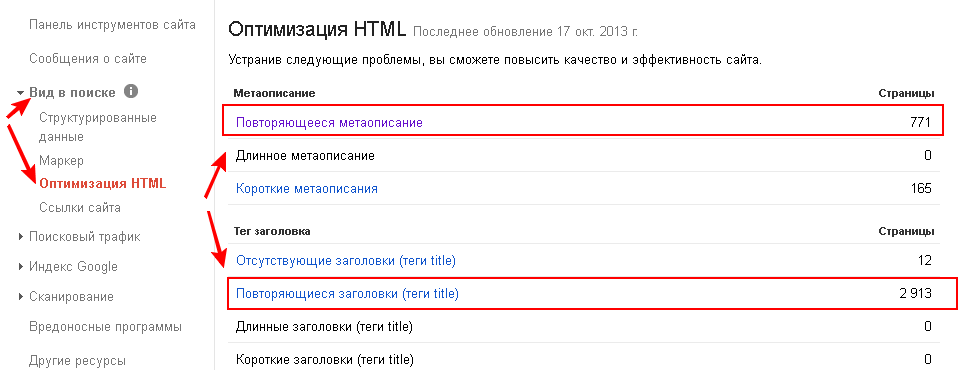 com/index.php будет отображаться по адресу https://example.com/ — согласно правилам обработки редиректов.
com/index.php будет отображаться по адресу https://example.com/ — согласно правилам обработки редиректов.
http://example.com/page/ и http://example.com/page
В этом случае установите редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. Тогда в поиске будет участвовать цель установленного редиректа.
Не рекомендуем в этом случае использовать атрибут rel=canonical, так как он может игнорироваться. При редиректе пользователи будут попадать сразу на нужный URL страницы.
Если проблема на главной странице, настраивать на ней ничего не нужно. Поисковая система распознает страницы http://example.com и http://example.com/ как одинаковые.
Яндекс индексирует ссылки со слешем на конце и без одинаково. При выборе URL, который останется в поиске, нужно учесть, по какому адресу сейчас индексируются страницы, если редирект еще не был установлен. Например, если в поиске уже участвуют страницы без слеша, стоит настроить перенаправление со страниц со слешем на ссылки без слеша. Это позволит избежать дополнительной смены адреса страниц в поиске.
Это позволит избежать дополнительной смены адреса страниц в поиске.
http://example.com/page////something/
В этом случае поисковая система убирает дублирующиеся символы. Страница будет индексироваться по адресу http://example.com/page/something/.
Если в URL есть \ (например, http://example.com/page/something/\\\\), поисковая система воспринимает такую страницу как отдельную. Она будет индексироваться по адресу http://example.com/page/something/\\\\.
В этом случае:
Установите редирект с HTTP-кодом 301 с одной страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа.
Укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске.
Добавьте в файл robots.txt директиву Disallow, чтобы запретить индексирование страницы.
Если вы не можете ограничить такие ссылки в robots.txt, запретите их индексирование при помощи мета-тега noindex.
Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода.
 Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода.
Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода.Используйте рекомендации, если различия есть в тех параметрах, которые не влияют на контент. Например, такими параметрами могут быть UTM-метки:
https://example.com/page?utm_source=instagram&utm_medium=cpc
В этом случае добавьте в файл robots.txt директиву Clean-param, чтобы робот не учитывал параметры в URL. Если в Вебмастере отображается уведомление о дублировании страниц из-за GET-параметров, этот способ исправит ошибку. Уведомление пропадет, когда робот узнает об изменениях.
Совет. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла. Если вы указываете другие директивы именно для робота Яндекса, перечислите все предназначенные для него правила в одной секции. При этом строка User-agent: * будет проигнорирована.
- Пример директивы Clean-param
#для адресов вида: example.com/page?utm_source=instagram&utm_medium=cpc example.com/page?utm_source=link&utm_medium=cpc&utm_campaign=new #robots.txt будет содержать: User-agent: Yandex Clean-param: utm /page #таким образом указываем роботу, что нужно оставить в поиске адрес https://example.com/page #чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес: User-agent: Yandex Clean-param: utm
Если у вас нет возможности изменить robots.txt, укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске.
http://example.com/page/ и http://example.com/page?AMP
В этом случае добавьте директиву Clean-param в файл robots.txt, чтобы робот не учитывал параметры в URL.
Если AMP-страницы формируются не GET-параметром, а при помощи директории формата /AMP/, их можно рассматривать как обычные контентные дубли.
Робот узнает об изменениях, когда посетит ваш сайт. После посещения страница, которая не должна участвовать в поиске, будет исключена из него в течение трех недель. Если на сайте много страниц, этот процесс может занять больше времени.
Проверить, что изменения вступили в силу, можно в Яндекс Вебмастере на странице Страницы в поиске.
Если вы следовали рекомендациям выше, но через три недели изменения не отобразились в результатах поиска, заполните форму ниже. В форме укажите примеры страниц.
Страницы с разным содержанием могут считаться дублями, если отвечали роботу сообщением об ошибке (например, на сайте была установлена заглушка). Проверьте, как отвечают страницы сейчас. Если страницы отдают разное содержимое, отправьте их на переобход — так они смогут быстрее вернуться в результаты поиска.
Чтобы избежать исключения страниц из поиска в случае кратковременной недоступности сайта, настройте HTTP-код ответа 503.
Как найти и удалить дубли страниц на сайте
Если Ваш сайт очень медленно растёт в поисковых системах, делает один шаг вперёд, а затем два назад, при постоянном изменении позиций, то одной из причин такой нестабильности могут быть дубли страниц на сайте. Это когда, страницы имеют разные адреса (url), но при этом содержат один и тот же контент, полностью или частично.
Это когда, страницы имеют разные адреса (url), но при этом содержат один и тот же контент, полностью или частично.
Чтобы вернуть сайту стабильность и поднять в ТОП, необходимо найти и удалить дубли страниц. О том, как это сделать, мы расскажем в сегодняшней публикации.
Начните размещать официальную рекламу в Telegram Ads. Опередите конкурентов!
Зарегистрируйтесь и продавайте товары или услуги в Telegram Ads с помощью готового решения от Click.ru.
- Бюджет от 3000 евро – это гораздо дешевле, чем работать напрямую.
- Для юрлиц и физлиц – юрлица могут получить закрывающие документы, возместить НДС. Физлица могут запустить рекламу без общения с менеджерами.
- 3 способа оплаты – оплачивайте рекламу картой физического лица, с расчетного счета организации, электронными деньгами.
Подробнее >> Реклама
Чем опасны дубли страниц на сайте?
Но для лучшего понимания, зачем находить и удалять дубли страниц, мы расскажем о том, как вред может нанести сайту дублированный контент из-за которого и так снижается доверие поисковых систем к сайту.
- Некорректная индексации. Допустим, у Вас большой новостной портал, на котором ежедневно публикуются по 10 новостей и статей. Если для каждой страницы будет существовать хотя бы один дубль, то объём сайта вырасти вдвое, а значит и поисковикам придётся больше времени тратить на обход ресурса. А если таких дублей 4-5? Поисковая система будет удалять дубли страниц из поиска и занижать позиции сайта.
- Неправильное определение веса страниц. С помощью внутренней оптимизации сайта, без применения внешней, можно добиться значительных результатов, в том числе за счёт правильно поставленных внутренних ссылок, которые передают вес нужной странице, с товаром или услугой, или продвигаемой по ВЧ-запросам. Соответственно при наличии дублей страниц, передаваемый рейтинг будет распыляться, а значимость страницы для ПС будет падать.
- Показ в результатах поиска нерелевантной страницы. Так же одной из проблем, которой грозят дубли страниц является показ в результатах поиска нерелевантной страницы (например, вместо страницы услуги, показывается прайс, где эта услуга упоминается).
Таким образом, все усилия приложенные на продвижение определённой страницы (сюда относятся, как внешние, так и внутренние ссылки), пойдут к коту под хвост. Кроме того, в последствии поисковая система может ещё больше занизить рейтинг страницы, так как она нерелевантна запросу. - Потеря естественных ссылок. Пользователь, который был на Вашем сайте и захотел поделиться ссылкой на его страницу, может как раз поделиться ссылкой на дубль, а не на ту, которую нужно. В итоге, такие ценные для SEO-продвижения естественные ссылки будут вести на дубликаты, которые не индексируются.
Дубли могут быть полными (одна и та же страница, доступ по разным адресам) и частичными (фрагмент контента одной страницы дублируется на других).
Проверка сайта на дубли страниц
Ну, что? Убедились во вредности дубликатов страниц? Значит пора проверить свой сайт на дубли страниц! Есть несколько стандартных процедур, которые помогут выявить дубли страниц.
1. Search Console.
Или Google Webmaster. Это один из самых лёгких способов, для поиска дублей страниц. Заходим в сервис, далее идём в раздел «Вид в поиске» и выбираем вкладку «Оптимизация HTML».
Здесь нам необходимо обратить внимание на следующие строчки:
- «Повторяющееся метаописание» — страницы с одинаковыми описаниями Description;
- «Повторяющиеся заголовки (теги title)» — список страниц с одинаковыми Title.
Данный подход выявления дублей основывается на том, что страницах может совпадать не только содержание, но и мета-данные. Просмотрев страницы, которые показываются в данном отчёте, мы довольно-таки просто обнаружим страницы, которые являются дубликатами.
2. Яндекс Вебмастер.
Периодически Яндекс индексирует новые страницы сайта или какие-то удаляет. Эта информация отражается, как на главной странице сервиса, так и в разделе «Индексирование» — «Страницы в поиске». Зайдите туда прямо сейчас.
Зайдите туда прямо сейчас.
Рядом с удалёнными из поисковой выдачи страницами (они выделены синим), есть комментарий, говорящий о причине исключения. Одним из возможных вариантов является «Дубль».
В данном случае это страница категории, которая содержит часть контента из постов в виде анонсов. Поэтому поисковая система считает её дублем.
3. Просмотр поисковой выдачи.
Промониторьте выдачу, используя специальный оператор «site:».
Довольно часто причиной возникновения дублей страниц становятся несовершенства систем управлений сайтом (CMS). Например, WordPress грешен тем, что может автоматически генерировать дубли страниц или в рубриках публиковать анонсы с частичным содержанием текста из самой статьи.
Также причины дубликатов могут быть в присутствующих на сайте версиях для печати или ускоренных страниц (AMP), пагинация, страницы с utm-метками, динамические урлы, страницы тегов, не добавленные описания товаров в интернет-магазине, не прописанные мета-теги.
Как удалить дубли страниц на сайте?
- Если на сайте, есть две страницы, у которых совпадают мета-теги, но при этом разное содержание — нужно просто изменить мета-описание.
- Закрыть от индексации рубрики, категории и страницы тегов, с помощью параметра Disallow в robots.txt. Либо, если не хотите терять возможный трафик, который могут принести эти разделы сайта, придумайте способ их уникализировать. Например, сделать так, чтобы вместо анонса отображался только заголовок, который является ссылкой на статью.
- Для ускоренных страниц, страниц с utm-метками и версий для печати задайте в настройках канонический URL.
- Действительно есть две одинаковые страницы — удалите одну из них (ту, что не ранжируется поисковыми системами например).
- Настройте 301-редирект для удалённых страниц, чтобы заходя по старому адресу на сайт, пользователь не попал на 404-ую страницу.
Не пропусти обновление!
Будь в курсе новых функций соцсетей и рекламных платформ — подпишись на наш Телеграм-канал.
С нас самые актуальные новости, с тебя — подписка:
Посмотреть, что за канал
Реклама
Больше статей по теме:
РЕКОМЕНДУЕМ:
Реклама
НОВОСТИ
ОБЗОРЫ
СТАТЬИ
Реклама
проверка онлайн, как проверить и определить одинаковый контент, найти и убрать дубликат
С точки зрения SEO дубли страниц негативно влияют на ранжирование. Присутствие их на сайте может грозить фильтрами от поисковых систем и потерей позиций. В этой статье мы разберем, как находить внутренние страницы-дубли и как с ними бороться.
- Дубли страниц что это
- Почему возникают дубли страниц
- Какие виды дублей существуют
- Дублирующийся контент
- URL с параметрами
- Дубли карточек товаров
- Региональные версии сайта
- Несколько категорий для одного товара
- Технические дубли
- Поиск дублей страниц
- Поиск «вручную»
- Яндекс. Вебмастер
- Google Search Console
- Apollon
- Как убрать дубли страниц
- 301 редирект
- Тег canonical
- Disallow в robots.txt
- Clean-param
- Заключение
Дубли страниц что это
Это страницы с одинаковым наполнением (контент, товары, мета-теги). Они возникают из-за неправильной структуры домена или генерируются CMS автоматически.
К чему это приводит?
- Фильтры поисковых систем. Чем больше повторов, тем выше риск попасть под АГС или Панду.
- Низкая релевантность ресурса. Страницы с одинаковым контентом теряют позиции и трафик в выдаче.
- Долгая индексация. Чем больше страниц, тем больше времени требуется поисковым ботам для индексации.
Почему возникают дубли страниц
Выделяют 4 причины возникновения:
- Проблемы CMS. Автоматически создаются админкой при неправильной настройке генерации URL.
https://semantica.ru/
https://semantica.ru/index.php
- Ошибки в технических разделах. Характерны для Bitrix и Joomla, они возникают вследствие того, что панель управления создает отдельные страницы для функций сайта, таких как поиск, фильтрация или регистрация.
https://semantica.ru/rarticles.php
https://semantica.ru/rarticles.php?ajax=Y
- Человеческий фактор. Невнимательность при размещении контента или добавлении карточек в интернет-магазине может привести к возникновению повторов.
- Технические ошибки. Некорректная настройка CMS и генерации ссылок может приводить к сбою и образованию цикличности.
https://semantica.
Какие виды дублей существуют
Их можно разделить на две группы — полные и частичные.
Полные:
- Версия страницы http/https, c www и без, index.php/html, home.php/html, бесконечное число слэшей, доступность страницы в разных регистрах URL или с несуществующими в нем символами.
- UTM-метками и GET-параметрами (?, *).
- Одинаковое наполнение на страницах с разными URL-адресами.
- Неправильно настроенная страница 404.
Частичные:
- Пагинация и фильтры.
https://semantica.ru/catalog/
https://semantica.ru/catalog/?page=2
- Отзывы. При открытии вкладки на карточке товара внешний вид сохраняется, а к URL добавляется GET-параметр.
- Страницы для скачивания.
https://semantica.ru/stranica/
https://semantica.ru/stranica/print/
Дублирующийся контент
Такие дубли возникают при одинаковом описании товара на листинге в каталоге и в карточке, а также при размещении одинаковой информации, которая будет доступна по разным URL-адресам.
Еще одна причина появления — это одинаковый текст на основной странице и всех разделах сайта. Лучше размещать такую информацию кратко или ссылкой на страницу с полным описанием.
Елизавета Чекалина
Вебмастер
Также не следует копировать информацию с других источников, даже если это описание товара или услуги, которые вы тоже продаете, так как это тоже приводит к появлению дублей, но не только на ресурсе, а в рамках всего интернета.
URL с параметрами
Сюда относятся страницы пагинации, фильтры и UTM-метки, например, from, utm_content, utm_term. GET-параметры формируются после основного адреса и начинаются со знака вопроса.
Такие метки как, например, /?page=1 и /?sort=, автоматически генерируются CMS при переходе по страницам пагинации или при применении фильтров в каталоге.
UTM-метки добавляются на сайте при подключении рекламной кампании или сервисов для аналитики и отслеживания трафика.
7 ошибок в SEO, которые допускают даже профессионалы
1. Неудачная структура внутренних ссылок Сайт развивается продолжительный период, и все это время вам придется встречаться с различными ошибками внутренних ссылок: от создания массового дублирования контента до возникновения 404 Errors. Я замечаю, что веб-мастера часто не берут во внимание внутренние структуры ссылок, а они представляют весомую ценность для стратегии UX и SEO. Внутренние ссылки дают 5 преимуществ вашему веб-ресурсу: Предоставляют посетителям дополнительную информацию для ознакомления или интерактивные материалы на сайте. Категорическая организация страниц по якорному тексту, оптимизированному для ключей. Обеспечивают…
Дубли с параметрами необходимо отслеживать и закрывать от индексации. Для этого используется директива Disallow или Clean-param в robots.txt. Также для устранения подойдет тег canonical, где канонической будет страница без GET-параметра.
Также для страниц пагинации можно прописать уникальные мета-теги.
Продвижение блога
от 46 200 ₽ Страница услуги
Продвижение блога от студии SEMANTICA — увеличение потока пользователей на сайт и повышение экспертности бренда в глазах целевой аудитории. Мы создаем востребованный контент, отвечающий на запросы потенциальных клиентов, оптимизируем статьи и настраиваем коммерческие триггеры. Вы получаете ощутимый прирост переходов в каталог товаров и услуг из блогового раздела.
Дубли карточек товаров
Это один и тот же товар из каталога, доступный по разным URL-адресам.
Эти страницы дублируют друг друга, что негативно сказывается на их ранжировании. Для решения этой проблемы необходимо настроить 301 редирект со всех дублирующих страниц на основную.
Также дублями могут считаться карточки, имеющие незначительные отличия, например, некоторые характеристики. Поисковики могут выбрать одну из них и посчитать ее основной, а остальные признать неоригинальными. Чтобы этого избежать, не следует создавать страницы для каждого типа товара (разный цвет или размер), а объединить их в один с возможностью выбора необходимой характеристики.
Региональные версии сайта
При использовании подпапок для поддоменов, контент с основного домена полностью дублируется для регионов. Чтобы избежать такого дублирования, следует создавать поддомены и наполнять их оригинальным контентом.
Несколько категорий для одного товара
Часто в интернет-магазинах разные позиции добавляются сразу в несколько разделов, например, https://semantica.ru/catalog/obuv/tufli/model1234 и https://semantica.ru/catalog/obuv/tufli-letnie/model1234.
Чтобы такого не происходило, необходимо настроить корректную генерацию URL. Правильно будет так: все товары, которые добавлены в разные категории, имеют один адрес и открываются по нему.
Технические дубли
Наиболее распространенные из всех. Возникают из-за автогенерации самой CMS.
К ним относятся:
- Дубли главного зеркала
https://semantica.ru/
https://www.semantica.ru/
или
https://semantica.ru/
http://semantica.ru/
- Cо слешем и без него в конце URL.
https://semantica.ru/
https://semantica.
- Index.php, home.php, index.html, home.html.
https://semantica.ru/index.php
- C любым количеством слэшей между частями URL и рандомными символами.
https://semantica.ru/////////
https://semantica.ru/catalog/aksfhskdf
Для решения таких проблем подойдет настройка 301 редиректа на основную страницу.
Поиск дублей страниц
Чтобы устранить проблему, ее сначала необходимо найти. Для этого можно воспользоваться следующими методами.
Поиск «вручную»
Этот способ подходит для поиска пагинации и фильтров. Зайдите в каталог и, воспользовавшись функцией сортировки или поиска по страницам, посмотрите добившиеся к URL параметры.
Также вы можете воспользоваться поисковой строкой и найти дублирующиеся страницы через него. Для этого необходимо ввести site:(доменное имя) inurl:(часть URL).
Яндекс.Вебмастер
Если сайт подключен к этой системе аналитики, вы можете отслеживать появляющиеся на нем дубли через нее.
Чтобы проверить, есть ли они, заходим в раздел “Индексирование” → “Страницы в поиске”.
Далее выбираем “Исключенные” → “Исключенные страницы” и сортируем все страницы по статусу “Дубль”.
Что такое Яндекс Вебмастер
Любой человек, кто занимается продвижением сайтов, должен знать, для чего нужен Яндекс Вебмастер. Со временем в интернет-магазине или в блоге могут появляться ошибки. Чаще всего они связаны с техническими сбоями или новыми требованиями к качеству контента. Яндекс проверяет ваш проект и указывает на недочеты, дает рекомендации по их устранению и принимает только исправленную работу. Словно учитель в школе. Вы исправляете ошибки. И сайт начинает лучше ранжироваться в поисковой системе. Его позиции растут, к вам приходит больше посетителей. Повышается конверсия, растет…
Сюда будут вынесены все повторы, встречающиеся на сайте — карточек товаров, страницы пагинации, GET-параметры и UTM-метки, страницы с дублирующимся контентом.
Для удобства Вебмастер указывает, какая страница признана поисковой системой основной, а на какой странице контент дублируется.
ГЕТ-параметры выделяются сервисом в критичные ошибки и выводятся на главной странице.
Google Search Console
Чтобы проверить наличие дублей через GSC заходим в раздел “Покрытие” → ”Полный отчет”.
Далее выбиваем “Исключено”.
Если они есть, увидеть их можно в категории “Страница является копией. Канонический вариант не выбран пользователем”.
Минус проверки через GSC в том, что нет возможности увидеть основную страницу.
Apollon
Сервис подойдет для поиска ошибок, генерируемых CMS. Для проверки нужно в поле ввода URL добавить основной урл страницы и начать проверку.
Красным будут отмечены найденные на сайте проблемы.
Как убрать дубли страниц
После того, как они были найдены, нужно выбрать способ, как с ними бороться. Дальше расскажем о нескольких из них.
301 редирект
Самый надежный способ устранения. (.*)$ http://site.ru/ [L,R=301]
- С дублирующих страниц прописываем правило:
Redirect 301 /was.php https://semantica.ru/new.php
Адрес страницы перенаправления необходимо указывать полностью.
Тег canonical
Такой способ подойдет для пагинации, фильтров и меток. Чтобы настроить каноникал, прописываем для дубликатов правило:
<link rel= “canonical” href= «https://semantica.ru/osnovnaya-stranica.html”>.
Эти действия можно проделать вручную для каждой страницы, но чем их больше, тем это трудозатратней. Чтобы упростить и ускорить этот процесс, можно воспользоваться одним из следующих плагинов, например: SEO Link Canonical, Yoast SEO (для WordPress), Aimy Canonical PRO (для Joomla).
Disallow в robots.txt
В файле роботс содержится информация о том, как правильно индексировать сайт. Предназначается она поисковым ботам. Здесь вы можете указать, на какие куда ботам заходить не нужно. Такой способ подойдет для некоторых GET-параметров, например, /?from=, /?calltouch_tm=, /?mc_cid=.
Чтобы запретить индексацию дублей через robots.txt, необходимо прописать в нем запрещающую директиву Disallow c указанием URL или его часть.
Clean-param
Директива для Яндекс, используемая для закрытия от индексации страниц рекламных кампаний. Без настройки Clean-param такие страницы будут массово проверяться ботами и признаваться дублями.
Чтобы настроить Clean-param в файле robots.txt в User-agent: Yandex, прописываем, например:
Clean-param: utm_source=yandex&utm_medium=cpc&utm_campaign=audit
Это правило закрывает все страницы с параметром utm_source=yandex&utm_medium=cpc&utm_campaign=audit.
Заключение
Дубли страниц, попавшие в поисковую выдачу, негативно влияют на ранжирование сайта. Они могут нанести урон не только в рамках конкретного URL, но и всего домена. Поэтому стоит отслеживать и вовремя устранять такие страницы, ведь способов их обнаружения и устранения достаточно много.
15 Средства проверки дублирующегося контента для веб-сайтов
Дублированный контент может нанести серьезный вред вашему сайту, поэтому мы собрали для вас наши любимые бесплатные средства проверки дублированного контента или инструменты проверки на плагиат.
Плагиат контента — рискованная стратегия. Наряду с потерей уважения своих коллег, плагиаторы лишались ученых степеней, были уволены с работы, покончили с политической карьерой, не говоря уже о юридических последствиях.
Итак, если плагиат считается отвратительной практикой в офлайн-мире, почему люди считают, что дублирование контента в онлайн-мире допустимо? На самом деле, дублирование контента в Интернете — это ОГРОМНАЯ ошибка!
Почему вы должны использовать средства проверки дублирующегося контента
Поисковые системы хотят предоставлять ценный, оригинальный контент, поэтому они рассматривают плагиат как угрозу для своих пользователей. Когда поисковая система индексирует веб-страницу, она сканирует содержимое страницы, а затем сравнивает содержимое с другими проиндексированными веб-сайтами.
Если на странице обнаруживается дублированный контент, поисковые системы часто наказывают страницу, снижая ее рейтинг или полностью удаляя ее из результатов поиска, что оказывает серьезное влияние на ваши усилия по поисковой оптимизации.
Принимая во внимание серьезные штрафы, которые могут быть наложены на ваш сайт, если он содержит плагиат, настоятельно рекомендуется проверить существующий веб-контент и любой контент, который вы планируете опубликовать, на предмет дублирования.
Лучшие бесплатные инструменты для проверки вашего веб-контента на плагиат
Даже если вы уверены, что содержимое вашего веб-сайта не было плагиатом, рекомендуется проверить, чтобы ничего не было непреднамеренно дублировано. Чтобы помочь вам выполнить эту задачу (и убедиться, что рейтинг вашего сайта остается здоровым и не подвергается штрафным санкциям), вот наши любимые 4 бесплатных инструмента для проверки дублированного контента:
1. Duplichecker
Этот бесплатный инструмент для проверки на плагиат позволяет выполнять поиск по тексту, DocX или текстовому файлу, а также поиск по URL. Это бесплатно с неограниченным количеством поисков при регистрации (вам разрешен 1 бесплатный поиск перед регистрацией).
Сканирование на наличие дубликатов было завершено всего за несколько секунд (конечно, это будет зависеть от длины сканируемого текста, страницы или файла). Это просто, бесплатно и эффективно!
2. Siteliner
Для проверки целых веб-сайтов на наличие дублирующегося контента существует Siteliner. Просто вставьте URL-адрес вашего сайта в поле, и он просканирует дублированный контент, время загрузки страницы, количество слов на странице, внутренние и внешние ссылки и многое другое. В зависимости от размера вашего сайта сканирование может занять несколько минут, но результаты того стоят. После завершения сканирования вы можете щелкнуть результаты, чтобы получить более подробную информацию, и даже загрузить отчет о сканировании в формате PDF.
Примечание: Бесплатная служба Siteliner ограничена одним сканированием на сайт в месяц, но премиальная услуга Siteliner очень доступна (каждая отсканированная страница стоит всего 1 цент, и вы можете сканировать столько раз, сколько пожелаете) .
3. PlagSpotter
Поиск по URL PlagSpotter бесплатный, быстрый и тщательный. Сканирование веб-страницы на наличие дублирующегося контента заняло чуть меньше минуты с перечислением 49 источников, включая ссылки на эти источники для дальнейшего изучения. Существует также функция «Оригинальность», которая позволяет сравнивать текст, помеченный как дублированный.
Хотя поиск по URL PlagSpotter является бесплатным, вы можете подписаться на их бесплатную 7-дневную пробную версию, чтобы пользоваться множеством полезных функций, включая мониторинг плагиата, неограниченный поиск, пакетный поиск, полное сканирование сайта и многое другое. Если вы хотите продолжить использовать PlagSpotter после бесплатной пробной версии, платная версия очень доступна.
4. Copyscape
Copyscape предлагает бесплатный поиск по URL-адресам, результаты которого приходят всего за несколько секунд. Хотя бесплатная версия не выполняет глубокий поиск (разбивая текст для поиска частичного дублирования), она выполняет тщательную работу по поиску точных совпадений.
Если вы нашли два похожих URL-адреса или текстовых блока, у Copyscape есть бесплатный инструмент сравнения, который выделяет повторяющийся контент в тексте. В то время как существует ограниченное количество поисков на сайте с их бесплатной услугой, Премиум-аккаунт Copyscape (платный) позволяет вам иметь неограниченные поиски, глубокие поиски, поисковые текстовые выдержки, поиск полных сайтов и ежемесячный мониторинг дублированного контента.
Упоминания о проверке заметного дублированного контента
Обновление! Когда мы впервые написали это в 2014 году, на рынке было очень мало инструментов для проверки на плагиат или дублирование контента. Список значительно расширился и теперь включает множество новых опций для проверки оригинальности вашего контента, в том числе следующие почетные упоминания:
- Copyleaks.com
- Plagtracker.com
- Viper / Scanmyessay.com
- Paperrater.com
- Plagiarisma. net
- Plagiarismchecker.com
- Smallseotools.com
Премиум (платные) средства проверки дубликатов контента
Хотя большинство упомянутых выше средств проверки дубликатов контента предлагают бесплатную версию наряду с премиальной (платной) версией, следующие веб-сайты предоставляют только платные варианты.
- Grammarly.com — нам также нравится их средство проверки грамматики!
- Plagiarismcheck.org
- Plagscan.com
- Plagium.com предлагает бесплатный «быстрый поиск», поэтому, если вы не используете его так часто, вам сойдет с рук бесплатная версия.
Теперь, когда вы знаете наши рекомендации по инструменту дублирования контента, у вас есть свои собственные?
Мы надеемся, что перечисленные выше ресурсы помогут вам создавать качественный веб-контент, не беспокоясь о том, что ваш веб-сайт или блог будут наказаны за дублирование контента. Если вы уже использовали средство проверки дублированного контента для своего веб-сайта или блога, мы будем рады, если вы поделитесь своими собственными рекомендациями или опытом в комментариях ниже.
Если вы хотите узнать больше о написании контента и о том, какую пользу он может принести вашему сайту, свяжитесь с нами, и мы поможем вам разработать эффективную стратегию для вашего сайта.
Как найти и исправить повторяющийся контент
14 апреля 2021 г.Что такое дублированный контент?
Согласно стандартному определению, дублированный контент означает, что на вашем веб-сайте есть две или более страниц с идентичным или почти идентичным контентом. Я бы расширил это определение за пределы контента, включив в него две или более страниц вашего веб-сайта, которые служат идентичным или почти идентичным целям. Причина расширения этого определения, включающего намерение, заключается в том, что основная проблема с дублированным контентом заключается в том, что он сбивает с толку посетителей. Посетители будут сбиты с толку страницами, которые возвращают идентичный контент, и будут в равной степени сбиты с толку (если не еще больше) двумя страницами, которые возвращают разный контент, который в основном служит одной и той же цели.
Например, на веб-сайте Elementive у нас может быть две страницы, посвященные нашим техническим SEO-услугам. Эти страницы могут использовать очень разные слова для описания одних и тех же услуг и, следовательно, не иметь идентичного или даже почти идентичного контента. Однако эти страницы описывают одну и ту же концепцию, а это означает, что обе страницы в основном служат одной и той же цели. Посетители, которые попадают на обе эти страницы, по понятным причинам будут сбиты с толку веб-сайтом.
Мы хотим исправить повторяющийся контент, чтобы избежать путаницы. Когда посетители сбиты с толку, они не взаимодействуют с веб-сайтом и не конвертируются. Когда посетители-роботы запутываются, у вас возникают проблемы с ранжированием дублированного контента — контент либо не ранжируется, либо конкурирует с другими версиями контента для ранжирования. Проще говоря: нам не нужен дублированный контент, будь то дублирование точных слов на странице или дублирование намерения страницы.
Теперь, когда мы поняли, что означает дублированный контент, давайте рассмотрим, как мы справляемся с дублированным контентом:
- Распространенные причины дублирования контента
- Пример дублирующегося контента
- Поиск дублирующегося контента
- Как исправить дублирующийся контент
- Общие Причины дублирования контента на веб-сайте
Дублирование контента может происходить по разным причинам. Одной из наиболее распространенных причин дублирования контента является побочный эффект программного выбора. Это может быть ситуация, когда базовая платформа веб-сайта позволяет возвращать одну и ту же страницу по нескольким URL-адресам. Например, платформа может разрешить доступ к страницам продуктов по адресу site.com/view/product-name.html, а также по адресу site.com/product-name.html. Это также происходит со страницами, автоматически создаваемыми системами управления контентом. Например, в блоге автоматически создаются страницы категорий для перечисления сообщений в блоге, но, в зависимости от категоризации сообщений в блоге, на трех разных страницах категорий в блоге могут быть перечислены почти одни и те же сообщения в блоге, что приведет к созданию трех страниц, которые дублируются (или почти дублируется).
Однако это не просто технические неполадки. Дублирование контента также может быть вызвано плохой или беспорядочной информационной архитектурой, когда один и тот же контент дублируется в нескольких местах на веб-сайте. Например, компания может разместить один и тот же контент часто задаваемых вопросов в нескольких разных разделах веб-сайта, потому что не существует более простого и менее повторяющегося способа представления этого контента посетителям. В качестве другого примера, дублирование также может произойти, когда вы пытаетесь написать одну и ту же страницу несколько раз, чтобы удовлетворить несколько аудиторий, но различия между аудиториями и, следовательно, страницами для этих аудиторий слишком тонкие.
В связи с этим дублирование контента может произойти из-за неправильного управления веб-сайтом. Например, два разных человека по незнанию создали одну и ту же страницу. В качестве другого примера, даже один автор может написать новый контент по теме и забыть о существовании старой страницы (это происходит со мной на этом сайте постоянно).
Первый шаг к устранению дублирующегося контента — понять причину; техническая проблема будет решена иначе, чем проблема информационной архитектуры или управления.
Пример дублированного контента
Дублированный контент может принимать различные формы и формы, но давайте подробнее рассмотрим один распространенный пример. Допустим, вы управляете сайтом электронной коммерции. На сайтах электронной коммерции обычно используется фильтрация и сортировка. Предположим, что эти три URL-адреса существуют и перечисляют одни и те же продукты, хотя и в немного другом порядке.
https://www.domain.com/product-list.html
https://www.domain.com/product-list.html?sort=color
https://www.domain.com/ product-list.html?sort=priceЭти три страницы дублируются. Эти три страницы могут быть не совсем одинаковыми, учитывая разные способы сортировки товаров, но страницы служат очень похожей цели. URL-адреса второго и третьего примеров содержат параметр сортировки («?sort=color» или «?sort=price»), что создает лишь небольшую разницу между этими страницами (в способе сортировки перечисленных товаров).
На этих страницах по-прежнему будут те же продукты, те же изображения, тот же текст и, вероятно, те же теги заголовка и описания.При таком сходстве эти три URL будут считаться дубликатами одной и той же страницы. Скорее всего, посетители-люди поймут эту разницу, при условии, что сортировка хорошо объяснена в дизайне и содержании. Однако такой тип дублирования может сбить с толку Google, поскольку их роботы пытаются решить, какие страницы показывать в результатах поиска. Они показывают отсортированную страницу или нет? Если они показывают отсортированную страницу, какой тип сортировки следует ранжировать в результатах поиска? Во многих случаях страница, которую Google выбирает для отображения в результатах поиска, может отличаться от той страницы, которую вы бы хотели, чтобы люди находили. В этом примере вы можете предпочесть, чтобы люди находили первый несортированный URL-адрес, а не отсортированные версии страницы. В некоторых случаях Google может также оштрафовать ваш сайт за дублированный контент.
Поиск повторяющегося контента
Прежде чем вы сможете исправить повторяющийся контент, вы должны найти его на своем веб-сайте. Прежде чем мы сможем обсудить, как устранить дублированный контент, давайте рассмотрим шаги, которые вы можете предпринять, чтобы найти и оценить дублированный контент на вашем веб-сайте.
Шаг 1. Найдите повторяющийся контент
Первый шаг — поиск дублирующегося контента на вашем веб-сайте. В отличие от обнаружения других типов проблем, нет способа получить единый отчет о каждой существующей проблеме. Вместо этого на этом первом шаге мы хотим найти страницы, которые может быть дублированным контентом , и затем мы проверим, является ли страница дублированной на следующем шаге.
Метод № 1: Инструмент сканирования
Siteliner — это бесплатный инструмент, позволяющий просканировать ваш веб-сайт до определенного количества страниц и, среди прочего, найти дублирующийся контент. После загрузки сайта введите URL-адрес вашего сайта.
Введите URL-адрес в Siteliner и нажмите «Перейти».Затем вы увидите отчет о различных аспектах вашего контента. Все они интересны и важны, но мы хотим сосредоточиться на дублированном контенте. Siteliner сообщит вам в навигации, какой процент контента, по мнению их инструмента, дублируется на вашем сайте. В случае с моим сайтом на момент сканирования это 5%.
Вы можете щелкнуть ссылку «Дублированное содержимое» в навигации, чтобы просмотреть полный отчет. На что мы хотим обратить внимание в полном отчете, так это на «Процент совпадений» и «Страницы совпадений». В моем случае страница курсов аналитики на 43 % совпадает с двумя другими страницами. Вы можете щелкнуть URL-адрес, чтобы получить более подробную информацию и посмотреть, какие страницы совпадают. Все, что соответствует совпадению выше 50%, заслуживает проверки, и, независимо от процента совпадения, все, что соответствует более чем двум или более страницам, также заслуживает проверки.
Метод № 2: Заголовки страниц Google Analytics
Альтернативный способ проверки на наличие дублирующегося контента – использование параметра заголовка страницы в Google Analytics.
Чтобы найти это, перейдите к отчету по всем страницам, который находится в разделе «Поведение» -> «Контент сайта» -> «Все страницы». Оказавшись здесь, измените основной параметр, используя ссылки над таблицей, на «Заголовок страницы» или добавьте дополнительный параметр «Заголовок страницы». Затем вы можете отсортировать по столбцу «Заголовок страницы», чтобы увидеть, содержат ли какие-либо страницы одинаковый или почти идентичный заголовок.Это не всегда идеальное средство обнаружения дубликатов, но может дать вам некоторые идеи, если страницы относятся к одной и той же теме. Кроме того, вы можете искать общие фразы в заголовках страниц — например, в моем случае я могу искать другие заголовки страниц, которые могут ссылаться на SEO, плагины или коды статуса ответа. Все, что кажется похожим или идентичным тегам заголовков, стоит проверить на предмет возможных проблем с дублированием контента.
Метод № 3: Google Search Console
Существует множество других методов, которые вы можете использовать для поиска дублирующегося контента, но последний метод, который мы здесь обсудим, основан на отчете по ключевым словам Google Search Console.
Это лучший метод для выявления повторяющихся намерений и того, как дублированный контент влияет на эффективность поиска. В Google Search Console перейдите в «Производительность» и просмотрите таблицу запросов. В таблице выберите различные запросы, по которым ранжируется ваш сайт. Как только вы нажмете на конкретный запрос, отчет перезагрузится, и вы перейдете к данным исключительно по этому запросу. Оттуда вы можете щелкнуть вкладку «Страницы» в таблице под графиком, чтобы увидеть все страницы, которые ранжируются по этому запросу.Как вы можете видеть на снимке экрана ниже, на веб-сайте Elementive есть несколько случаев, когда несколько страниц ранжируются по одному и тому же термину. Это не обязательно означает, что эти страницы дублируются. Но это означает, что эти страницы конкурируют за ранжирование по одному и тому же термину и, по крайней мере, по оценке Google, что страницы могут служить схожим целям. Было бы полезно просмотреть эти страницы и посмотреть, что следует сделать, чтобы устранить это дублирование.
Шаг 2. Просмотр дублированного содержимого
Следующим шагом будет проверка того, что, как вы подозреваете, может быть дублированным содержимым, найденным на основе ваших выводов на первом этапе. Помните, что то, что мы обнаружили на первом шаге, не дублируется окончательно, а лишь потенциально дублируется. Когда вы просматриваете потенциально дублированные страницы, вы хотите задать себе несколько разных вопросов.
Содержимое страниц идентично или почти идентично?
Вы хотите начать проверку с изучения страниц с дублированным или почти дублированным содержимым. При первом просмотре вы хотите отличить идентичные страницы от почти идентичных, потому что это меняет способ решения проблемы. Если содержимое точно совпадает, то его решение более важно и, вероятно, представляет большую проблему для производительности вашего веб-сайта. Отметьте эти точные совпадения для точного исправления.
В случае почти повторяющихся совпадений вам необходимо более тщательно просмотреть содержимое, чтобы увидеть, в чем заключаются различия и имеют ли они значение.
Некоторые различия в ближайших совпадениях достаточно легко обнаружить без каких-либо вспомогательных инструментов. Тем не менее, такой инструмент, как Diffchecker, может помочь там, где трудно определить, насколько большим может быть дублирование. Вы можете добавить два набора контента в Diffchecker и посмотреть, насколько близко контент совпадает между страницами. Diffchecker также подчеркнет, что является одинаковым или разным на разных страницах, что полезно для выявления ключевых различий между страницами.Зачем возиться с этой оценкой? Что ж, иногда вы можете получить ложные срабатывания, когда автоматизированный инструмент, такой как Siteliner, говорит, что страницы дублируются, но человек поймет различия. Например, у вас может быть две категории продуктов, которые имеют много общих продуктов. Такой инструмент, как Siteliner, сообщает вам, что эти две категории продуктов совпадают на 80%, поэтому вы отмечаете его для оценки. Когда вы оцениваете, вы не можете точно сказать, чем отличаются страницы, но с помощью Diffchecker вы можете легко определить 20% различий в содержании.
Возможно, эти 20% различий действительно имеют значение, и человек, скорее всего, поймет, что эти страницы разные и не дублируются. Скорее всего, боты тоже поймут эту разницу, поскольку они откалиброваны для просмотра контента, как люди. Конечно, если разница в 20% не имеет большого значения для людей (и, соответственно, не будет иметь большого значения для ботов), то у вас действительно есть дублирующая проблема, которую необходимо решить.Служат ли страницы аналогичному назначению?
Страницы, преследующие аналогичные цели, обычно легче всего обнаружить в Google Search Console, где у вас может быть две или более страниц, ранжируемых по одному и тому же поисковому запросу. Однако и здесь вы хотите просмотреть потенциальное дублирование, чтобы определить, является ли оно ложным срабатыванием или действительно чем-то, что вам нужно решить.
При просмотре потенциально дублирующихся страниц необходимо определить, служат ли страницы аналогичному назначению. Самостоятельно найти такой дубликат может быть сложно.
Как только вы приблизитесь к теме, вы сможете заметить нюансы, которые делают каждую страницу уникальной. Чтобы избежать этой предвзятости, не полагайтесь исключительно на собственную оценку страницы. Попросите своих клиентов и посетителей описать различия в опросе или кратком интервью. Если они могут сказать вам, почему эти страницы разные, то у вас нет проблем. Но если люди не могут описать разницу или, кажется, изо всех сил пытаются найти разницу, у вас есть страницы с повторяющимися намерениями, которые необходимо исправить.Как посетители взаимодействуют с продублированными страницами?
Вы также можете определить, насколько серьезной проблемой является дублированный контент, и действительно ли у вас есть проблема с дублированным контентом, проверив производительность на этих потенциально дублированных страницах. Например, вы можете найти дублированные страницы, где одна копия страницы работает невероятно хорошо — много трафика, высокий коэффициент конверсии, высокий уровень вовлеченности — а другие версии страницы работают ужасно.
В таких случаях особых проблем не возникает, и вы можете легко удалить страницы с низкой производительностью (или перенаправить их на страницу с высокой производительностью), чтобы устранить любые проблемы в будущем.Конечно, когда вы просматриваете производительность, вы можете обнаружить, что дублированные страницы в основном работают одинаково с аналогичными уровнями трафика, аналогичными рейтингами, аналогичными уровнями вовлеченности и аналогичными коэффициентами конверсии. Это говорит о том, что посетители, вероятно, не понимают, что на вашем сайте есть несколько страниц. Я бы по-прежнему утверждал, что это проблема, но пока это не проблема, которая вам чего-то стоит. Лучше устранять дублирование до того, как это заметят посетители или поисковые роботы, или до того, как вы начнете обновлять страницу и забудете обновить одну из дублированных версий, создав при этом устаревшую или противоречивую информацию.
В этих случаях вы также хотите проверить, сколько людей перемещается между этими страницами — вы можете сделать это с помощью сегмента, чтобы увидеть, сколько людей посещают обе версии дублированной страницы.
Если есть много людей, посещающих обе версии дублированной страницы, то это говорит о проблеме. Насколько велика проблема, зависит от показателей конверсии и вовлеченности людей, которые посещают обе версии дублированной страницы. В некоторых случаях я видел, что коэффициент конверсии падает более чем наполовину, когда посетители сталкиваются с дублированным контентом, и это указывает на то, что посетители сбиты с толку дублированием и что существует серьезная проблема.Как исправить повторяющийся контент
Теперь, когда мы обнаружили, оценили и подтвердили наличие дублированного контента, что вы с этим делаете? Решения зависят от характера дублированного контента и серьезности проблемы дублированного контента. Чем больше проблема, тем сложнее решение. В этом разделе мы рассмотрим четыре способа устранения дублирующегося контента:
- Изменения тегов заголовков
- Внедрение канонических URL-адресов
- Объединение или удаление контента и перенаправлений
- Устранение технических или структурных проблем
1.
Изменения тега заголовкаЕсли две страницы имеют одинаковый тег заголовка или заголовок страницы, но страницы принципиально отличаются друг от друга и служат разным целям, вам не нужно делать большой изменение масштаба страницы. Вместо этого вы можете настроить тег заголовка или заголовок страницы, чтобы было понятнее, для какой цели служит каждая страница. Это также может остановить ранжирование нескольких страниц по одним и тем же терминам и тем самым помочь вам ранжироваться по новым терминам.
2. Реализация канонических URL-адресов
Другим решением для дублирования контента является использование элемента канонической ссылки для определения того, какая версия страницы должна рассматриваться для ранжирования. Это не помогает пользователям, но помогает ботам понять ваш сайт (что косвенно помогает пользователям, потому что влияет на ранжирование страниц).
В приведенном выше примере вы можете считать первый URL-адрес (/product-list.html без параметров сортировки) официальной или предпочтительной версией этой страницы.
Как добавить канонический тег Этот URL-адрес не имеет параметра сортировки, что делает URL-адрес более привлекательным, и эта страница может перечислять продукты в том порядке, в котором вы предпочитаете видеть большинство людей. Однако, если сортировка по цвету является наиболее популярным выбором для ваших посетителей, вы можете вместо этого предпочесть канонический URL-адрес /product-list.html?sort=color. В качестве альтернативы вы можете обнаружить, что третий URL-адрес (отсортированный по цене) привлекает наибольшее внимание на других веб-сайтах или в социальных сетях, и поэтому третья версия может иметь больше смысла в качестве предпочтительной версии URL-адреса. Независимо от того, какой URL-адрес вы выберете в качестве официальной версии, вы объявляете эту официальную версию, внедряя канонический тег.После того, как вы выберете официальную или каноническую версию URL-адреса, на каждую потенциально дублирующуюся страницу необходимо добавить элемент канонической ссылки, указывающий предпочтительную версию URL-адреса.
В приведенном выше примере любые повторяющиеся URL-адреса будут содержать канонический тег, ссылающийся на выбранный вами канонический URL-адрес.Канонический URL-адрес можно определить двумя способами. Чаще всего используется элемент с атрибутом rel со значением canonical и атрибутом href с URL-адресом канонической версии страницы. Этот элемент размещается в любом месте раздела
вашего сайта. Вот пример канонического кода, где предпочтительным URL является /product-list.html. Этот тег будет размещен на всех версиях страницы. Таким образом, в этом примере этот канонический тег будет отображаться на странице /product-list.html, а также в отсортированных версиях.Другой вариант — добавить ссылку в заголовки HTTP. Это полезно для файлов, отличных от HTML (но обычно требуется техническая поддержка для добавления на ваш сайт). Здесь снова это будет добавлено ко всем дублированным версиям.
Ссылка:Поддержка Canonical в другом месте
Вы не должны полагаться на канонический тег как на единственное средство передачи ваших предпочтений URL поисковым системам. Ссылки на остальной части вашего веб-сайта также должны указывать на каноническую версию страницы. Это позволяет избежать отправки смешанных сигналов поисковым системам. Кроме того, это снижает вероятность того, что посетители-люди могут попасть на эти дублированные страницы.
Например, в приведенном выше примере, если вы определяете https://www.domain.com/product-list.html как канонический URL-адрес, но большинство ссылок на вашем веб-сайте ссылаются на https://www.domain .com/product-list.html?sort=color, это приведет к противоречивым сигналам о том, какая версия URL-адреса действительно является окончательной, достоверной и канонической версией. Вместо этого вы бы хотели, чтобы большинство ссылок ссылались на каноническую версию, /product-list.
html. Если Google игнорирует ваши канонические теги, это наиболее вероятная причина.Наряду с внутренними ссылками убедитесь, что в вашей XML-карте сайта также указана каноническая версия каждого URL-адреса и только эта версия. В XML-карте сайта не должно быть ни одной дублирующейся версии страницы. В нашем примере это будет означать, что в XML-карте сайта должен быть указан /product-list.html, но ни одна из версий URL с параметром сортировки.
3. Объединение или удаление контента и перенаправлений
Если у вас есть более серьезная проблема с дублированием контента, изменение тега заголовка или добавление канонического будет недостаточным решением. В этих случаях решение требует удаления или объединения страниц, а затем перенаправления удаленных URL-адресов на сохраненный URL-адрес. Например, если страница A и страница B идентичны, вы можете удалить страницу A и оставить страницу B, чтобы устранить дублирование. Конечно, люди могут по-прежнему приходить в поисках страницы А, и вы не хотите, чтобы эти посетители были потеряны.
Таким образом, после удаления страницы А с веб-сайта вы можете перенаправить страницу А на страницу Б. Сделав это, вы удалили дубликаты страниц со своего веб-сайта, но при этом обеспечили людям и ботам, посещающим сайт, возможность найти нужный контент. .Это усложняется, если страницы почти идентичны или дублируются только намерения. Для таких сценариев часто требуется объединить содержимое нескольких дублированных страниц в одну страницу и сохранить часть содержимого обеих версий страницы. Например, предположим, что у вас есть четыре страницы, на которых обсуждаются ваши виджеты для продажи, и каждая из этих страниц имеет отдельный контент и изображения. Вы можете объединить все эти страницы в одну страницу о виджетах, сохранив часть контента и изображений с каждой страницы. Как только контент будет объединен, вы захотите перенаправить дублированные версии на одну страницу.
Как выбрать, какую страницу оставить, а какие удалить, а затем перенаправить? Это зависит от того, как работают страницы.
Как и в случае с каноническим, вы хотите просмотреть, какие страницы предпочитают посетители, и оставить версию страницы с наибольшим трафиком или взаимодействием.4. Устранение основных технических или структурных проблем
Наконец, дублирование содержимого может быть вызвано основной технической проблемой. В некоторых случаях это старая среда разработки, отражающая работающий сайт, который каким-то образом стал доступен посетителям. Это также может произойти с динамическими страницами, которые создают идентичный контент по нескольким URL-адресам (подумайте о сложных системах фильтрации контента). Иногда проблема возникает из-за контента, созданного пользователями, и отсутствия контроля за людьми, публикующими один и тот же контент в разных местах (подумайте о форуме, где люди могут публиковать один и тот же вопрос в трех разных категориях форума).
Это также может быть структурной проблемой. Например, на веб-сайте есть три раздела, в которых может размещаться страница, поэтому веб-мастер, чтобы быть максимально полезным, помещает страницу в каждый из этих разделов.
В некотором смысле это имеет смысл и позволяет посетителям находить страницу в разных местах, каждое из которых может быть релевантным местом для жизни этой страницы. Но лучшим ответом будет реорганизация веб-сайта таким образом, чтобы один раздел мог ссылаться на другой или без необходимости в нескольких копиях страницы в разных местах веб-сайта (или, возможно, сайту нужны более четкие различия между каждым разделом).Подведение итогов
Дублирование может происходить по разным причинам. Дублирование редко происходит намеренно. Но часто дублирование ухудшает эффективность поиска, снижает вовлеченность посетителей и, в конечном итоге, снижает конверсию. Требуется время и усилия, чтобы найти, оценить и исправить дублированный контент. Часто требуется изменить архитектуру сайта или устранить технические неполадки. Но эти усилия того стоят и приведут к повышению производительности для SEO, UX и CRO. Если у вас есть какие-либо вопросы о дублированном контенте или обнаружении проблем, которые могут существовать на вашем веб-сайте, свяжитесь со мной.
Как определить и устранить проблемы с дублированием контента на вашем веб-сайте
Легко обмануться, думая, что SEO — это просто построение ссылок. Существует так много постов, посвященных последним событиям в отношении того, какие ссылки являются хорошими или плохими, что мы иногда забываем об огромной выгоде, которую мы можем получить, просто исправив проблемы с нашим собственным сайтом.
Одной из главных причин потери трафика и рейтинга является дублированный контент. К счастью, вы контролируете свой собственный сайт, поэтому у вас есть возможность его исправить.
Что такое дублированный контент?Дублированный контент существует, когда поисковые системы индексируют более одной версии страницы. Там, где есть несколько проиндексированных версий страницы, поисковым системам сложно решить, какую страницу показывать по релевантному поисковому запросу.
Поисковые системы стремятся предоставить пользователям наилучшие возможности, а это означает, что они редко будут показывать повторяющиеся фрагменты контента.
Причины дублирования контента Вместо этого они будут вынуждены выбирать, какая версия, по их мнению, лучше всего подходит для этого запроса.Тремя основными причинами дублирования контента являются:
1) Параметры URL идентификаторы), или CMS, которую использует веб-сайт, добавляет свои собственные настраиваемые параметры.Например, все следующие URL-адреса могут вести на одну и ту же страницу:
http://www.example.com/page1
http://www.example.com/page1?source=organic
http://www.example.com/page1?campaignid=3532
2) Страницы для печатиЧасто веб-страница имеет возможность создать версию этой страницы для печати. Это часто может приводить к проблемам с дублированием контента. Например, следующие URL-адреса ведут на одну и ту же страницу.
http://www.example.com/page1
http://www.example.com/printer/page1
3) Идентификаторы сеансовСайты часто хотят отслеживать сеанс пользователя на своем веб-сайте.
Например, сайты могут предлагать персонализированные функции в зависимости от того, кто этот пользователь и его прошлые взаимодействия с сайтом, или интернет-магазин может помнить, что этот человек добавил в свою корзину покупок во время своего последнего посещения.Идентификаторы сеансов добавляются к URL-адресу, что приводит к возникновению повторяющихся версий страницы. Например, следующие URL-адреса ведут на одну и ту же страницу.
http://www.example.com/page1
http://www.example.com/page1?sessionid=12455
Проблемы с дублирующимся содержимымСамые большие проблемы, вызванные дублирующимся содержимым:
- Поисковые системы не знают, какую версию страницы они используют. должен индексировать
- Поисковые системы не знают, какой странице следует присвоить авторитет ссылки или следует ли разделить ее на несколько версий.
- Поисковые системы не знают, какую версию страницы ранжировать по релевантному поисковому запросу.
Это может привести к тому, что веб-страницы потеряют позиции и органический трафик.
Поиск дублирующегося контентаЕсть два инструмента, которые можно использовать для поиска дублирующегося контента на вашем сайте: Инструменты Google для веб-мастеров и Screaming Frog.
1) Инструменты Google для веб-мастеровИспользуя Инструменты Google для веб-мастеров, вы можете легко найти страницы с повторяющимися заголовками и мета-описаниями. Вы просто нажимаете «Улучшения HTML» в разделе «Вид в поиске».
Нажав на одну из этих ссылок, вы увидите, какие страницы имеют повторяющиеся метаописания и заголовки страниц.
2) Screaming FrogВы можете скачать поисковый робот Screaming Frog и использовать его для сканирования 500 страниц бесплатно. Это приложение позволяет вам делать множество разных вещей, в том числе находить проблемы с дублированным содержимым.
Заголовки страниц/мета-описания
Вы можете найти повторяющиеся заголовки страниц, просто щелкнув вкладку «Заголовки страниц» или «Мета-описание» и отфильтровав «Повторяющиеся».
URL-адреса
Вы также можете найти страницы с несколькими версиями URL-адресов, просто щелкнув вкладку «URL-адреса» и отсортировав их по «Дублировать».
Исправление дублированного контентаДублированный контент — это проблема, которая может повлиять как на ваш органический трафик, так и на ранжирование в Интернете, но это то, что вы можете легко исправить Три самых быстрых способа для решения проблем с дублированием контента:
1) Тег CanonicalС помощью тега canonical вы можете сообщить поисковым системам, какую версию страницы вы хотите вернуть для релевантных поисковых запросов. Канонический тег находится в заголовке веб-страницы.
Тег canonical — лучший подход, если вы хотите, чтобы пользователям было доступно несколько версий страницы.
2) 301 Перенаправление Если вы используете COS HubSpot, об этом позаботятся автоматически, поэтому ручной труд не потребуется.Перенаправление 301 перенаправит все устаревшие страницы на новый URL-адрес. Он говорит Google передать все полномочия ссылок с этих страниц на новый URL-адрес и ранжировать этот URL-адрес для релевантных поисковых запросов.
Редирект 301 — лучший вариант, когда вам не нужно иметь несколько версий страницы.
3) МетатегиВы можете использовать метатеги, чтобы запретить поисковым системам индексировать определенную страницу.
… и https://www.website.com/blogs/blog1 . Другие варианты URL-адресов, такие как косая черта в конце или URL-адреса с заглавными буквами, могут вызвать ту же проблему.Дублирующийся контент — это реальная проблема для сайтов, но ее можно легко решить с помощью приведенных выше советов. Если вы хотите узнать больше о дублирующемся контенте, посмотрите серию видеороликов от SEO-экспертов Dejan SEO о том, как исправить это на своем сайте.
Первоначально опубликовано 10 марта 2014 г., 4:00:00, обновлено 27 августа 2017 г.
Дублированный контент SEO: как найти и устранить проблемы
Дублированный контент может повлиять на то, какие из ваших страниц отображаются в результатах поиска, и растратить ваш краулинговый бюджет. К счастью, есть способы определить повторяющийся контент и либо удалить его с вашего веб-сайта, либо из индекса Google, чтобы он не повлиял негативно на вашу способность ранжироваться.
Что такое дублированный контент?
Дублирование содержимого происходит, когда одно и то же содержимое появляется более чем в одном месте с уникальным URL-адресом.
Контент не обязательно должен быть точным совпадением, чтобы его можно было зарегистрировать как дубликат — он также может быть тем, что Google называет «заметно похожим». Этот контент по существу «достаточно близок», чтобы считаться дублирующимся контентом, даже если некоторый текст может отличаться.
Большинство владельцев сайтов усердно работают над тем, чтобы их контент был свежим и оригинальным, и тем не менее в Интернете все еще много дублированного контента. Иногда владельцы сайтов даже не подозревают об этом. Так как же это происходит?
Почему дублируется контент?
Большая часть дублированного контента в Интернете возникает из-за индексации таких вещей, как версии страниц для печати, продукты, которые находятся или связаны с несколькими разными URL-адресами, а также дискуссионные форумы, которые генерируют настольные и урезанные мобильные версии та же страница.
Но это не единственные способы дублирования контента на вашем сайте. Вот еще несколько примеров того, как дублированный контент может возникать внутри вашего сайта и снаружи на других сайтах.
Внутренне Созданные дубликаты Заметно похожие страницы продуктовИногда имеет смысл намеренно создавать заметно похожие страницы, особенно в электронной коммерции.
Например, предположим, что вы продаете один и тот же продукт в двух разных странах. В этом случае вы можете выбрать две почти идентичные страницы, за исключением того, что одна может отображать цену в долларах США, а другая — в канадских долларах.Другим примером являются страницы продуктов, которые кажутся заметно похожими, потому что они содержат одну и ту же копию, с единственными реальными отличиями, заключающимися в другом изображении продукта, названии продукта и цене продукта.
Системы управления контентомИногда системы управления контентом создают дублированный контент, о котором вы даже не подозреваете. Некоторые системы автоматически добавляют теги и параметры URL для поиска, что приводит к нескольким путям к одному и тому же контенту.
Варианты URLВы также можете получить дублированный контент, если у вас есть разные варианты URL с одинаковым содержанием. Как упоминалось ранее, системы управления контентом могут делать это самостоятельно, и в итоге вы можете получить два варианта URL, например 9.
0082 https://www.website.com/blog1 Когда это происходит, Google может не знать, какую страницу ранжировать, и некоторые внешние источники могут ссылаться на одну из этих страниц, в то время как другие ссылаются на дубликат, нарушая при этом ссылочный вес вашей страницы.
HTTP против HTTPS и www против без wwwБольшинство веб-сайтов доступны с www или без него, а также по URL-адресам HTTP или HTTPS. Однако, если вы неправильно настроили свой сайт, Google может индексировать страницы более чем одного из них, что приведет к дублированию контента.
URL-адреса, удобные для печати и мобильных устройствСтраницы, удобные для печати или мобильных устройств, размещенные по URL-адресам, отличным от исходной страницы, приведут к дублированию контента, если они не проиндексированы должным образом.
Идентификаторы сеансаИдентификаторы сеанса могут быть ценными инструментами для отслеживания посетителей, посещающих ваш сайт. Обычно это делается путем добавления длинной строки идентификатора сеанса к URL-адресу. Поскольку каждый идентификатор сеанса уникален, создается новый URL-адрес и дублируется ваш контент.
Параметры UTMПараметры могут отслеживать входящих посетителей из различных источников. Как и идентификаторы сеансов, они генерируют уникальные URL-адреса, несмотря на то, что содержимое страницы одинаково, что создает дублированный контент при индексировании.
Извне Созданные дубликаты Синдицированный контентРаспространение вашего контента на другие сайты в Интернете может стать отличным способом привлечь больше трафика на ваш сайт и сделать ваше имя известным. Однако этот контент может по-прежнему отображаться как дублированный контент, если он не отформатирован с использованием соответствующих тегов канонического заголовка.
Плагиат Например, использование канонических тегов в статьях на Medium может защитить исходный контент от регистрации в качестве дубликата.Хотя большая часть дублированного контента не является злонамеренной по своей природе, некоторые веб-мастера намеренно копируют контент, стремясь извлечь выгоду из контента, который они не создавали сами.
Дублированный контент SEO: почему это важно?
Если дублирование контента происходит так часто, почему это имеет значение? Вот пять способов, которыми это может повлиять на вашу способность занимать высокие позиции в результатах поиска.
1. Штраф Google за дублирование контентаВ большинстве случаев Google напрямую не наказывает дублирующийся контент. Если Google считает, что дублированный контент на вашем сайте является «обманчивым» и «предназначенным для манипулирования результатами поисковых систем», он может принять меры, наложив штраф за дублированный контент.
Таким образом, даже если это случается не часто, в соответствии с рекомендациями Google по дублированию контента, вы все равно можете столкнуться с прямым штрафом, если ваш дублированный контент достаточно вопиющий и считается, что он был создан со злым умыслом.Google наказывает за дублированный контент редко, поэтому более насущной проблемой является взаимосвязь между дублирующимся контентом и SEO.
2. Раздувание индексаРаздувание индекса происходит, когда сканеры поисковых систем получают доступ и индексируют неважный или низкокачественный контент — например, страницы для печати, о которых я упоминал. Это влияет на вашу способность ранжировать важные страницы, поскольку поисковые системы не будут знать, какую версию вашего контента предлагать пользователям, и могут ранжировать другую версию, чем вы бы предпочли. Это также влияет на краулинговый бюджет.
3. Бюджет сканированияGoogle ограничивает время, затрачиваемое на сканирование сайтов.
4. Каннибализация ключевых слов Количество ресурсов, которые Google предоставляет для сканирования и индексации вашего сайта, является вашим краулинговым бюджетом. Когда у вас много дублированного контента, вы рискуете потратить краулинговый бюджет на страницы, которые не так важны. (Узнайте, как оптимизировать краулинговый бюджет здесь.)Если в рейтинге ранжируется более одной копии страницы, то ваши страницы будут конкурировать друг с другом за одни и те же ключевые слова и видимость. Соперничать со всеми достаточно сложно, зачем усложнять задачу еще и с самим собой?
В конечном счете, вы не можете просто игнорировать проблемы дублирования контента SEO. По возможности старайтесь объединять или удалять повторяющийся контент. (Узнайте, как найти и устранить каннибализацию ключевых слов.)
5. Уменьшение ссылочного весаДопустим, Google решает ранжировать две из ваших заметно похожих страниц. Как они узнают, следует ли приписывать всю ценность контента одной странице или вместо этого следует разделить авторитет, ссылочный вес и доверие между обеими страницами? Эта ситуация может снизить ценность SEO вашего контента, что приведет к его низкой эффективности.
Ссылочный вес ваших обратных ссылок также будет разделен между двумя страницами в зависимости от того, будут ли другие сайты ссылаться на них.
Как проверить дублирующийся контент на вашем собственном сайте
Найти дублированный контент на вашем сайте легко и бесплатно. Используйте бесплатные версии Screaming Frog и Siteliner для методичного сканирования вашего сайта и выявления любых точных или почти дублирующих страниц.
Как использовать Screaming Frog для обнаружения повторяющегося контента
Screaming Frog — это сканер веб-сайтов и инструмент SEO-аудита, который может помочь вам выявить проблемы с дублированием контента на вашем веб-сайте. Вот как можно использовать Screaming Frog для бесплатного сканирования до 500 URL-адресов.
1. Просканируйте свой сайт с помощью SEO SpiderСначала загрузите и откройте Screaming Frog. Введите URL-адрес веб-сайта, который вы хотите просканировать, в поле «Введите URL-адрес для Spider» и нажмите «Пуск».
3. Проверка наличия дубликатов для проверки точных дубликатов и близких дубликатов. Вы сможете увидеть точные дубликаты в режиме реального времени, но вам нужно выполнить «Анализ сканирования», чтобы увидеть список близких дубликатов.Щелкните вкладку «Анализ сканирования» в строке меню и выберите «Пуск» в раскрывающемся меню.
Когда анализ сканирования завершится, вы увидите заполненные почти повторяющиеся столбцы. Вы узнаете, что он завершен, потому что индикатор выполнения «анализа» будет показывать 100%, а почти повторяющийся фильтр больше не будет отображать сообщение «требуется анализ сканирования».
4. Просмотр дубликатов на вкладке «Содержание»Рядом с дубликатами» и «Адрес» будут заполнены после завершения анализа сканирования.
Фильтр «Точные дубликаты» будет отображать страницы, идентичные друг другу на основе сканирования HTML-кода. Установленный порог подобия определяет, что квалифицируется как «Близкие дубликаты».
Чтобы изменить порог, перейдите в «Конфигурация → Паук → Контент». По умолчанию этот порог установлен на 90%, но вы можете изменить его на любое другое.Теперь, когда сканирование завершено, вручную просмотрите любую страницу, которая появляется как точная или почти точная копия.
Как использовать Siteliner для обнаружения повторяющегося контента
Siteliner — еще один бесплатный инструмент, который вы можете использовать для сканирования вашего веб-сайта (или любого другого веб-сайта) на наличие дублирующегося контента. Однако бесплатная версия ограничит вас одним использованием каждые 30 дней и ограничит количество результатов до 250 страниц. Если вам нужно выполнить несколько поисков или вы хотите увидеть больше результатов, подпишитесь на премиум-версию.
Чтобы проверить дублированный контент с помощью Siteliner, просто введите URL-адрес, который вы хотите найти, в поле поиска на их домашней странице.
Затем Siteliner проведет сканирование сайта и сообщит вам, сколько дублированного контента было найдено, и выделит то, что, по его мнению, является вашей главной проблемой.
Он также будет отображать еще несколько показателей, включая те, которые могут быть полезны для SEO, например, среднее время загрузки страницы, внутренние и внешние ссылки и входящие ссылки.В главном меню нажмите «Дублированный контент», чтобы увидеть, какие страницы Siteline идентифицирует как имеющие дублирующийся контент.
Нажмите на каждую отдельную строку, чтобы увидеть, какой текст помечен как дублированный.
Примечание. Siteline будет идентифицировать верхние и нижние колонтитулы, которые отображаются на нескольких страницах, как дублированный контент, поэтому вы можете получить много страниц с низким процентом совпадения, поскольку каждая из них имеет одно и то же меню или содержимое нижнего колонтитула.
Как проверить, не скопировал ли кто-то другой ваш контент
Существуют также инструменты поиска дубликатов контента, которые можно использовать для проверки того, не скопировал ли кто-то другой в Интернете ваш контент.
Copyscape — это бесплатный инструмент для проверки контента веб-сайта, который эффективен и прост в использовании.Просто введите URL-адрес в поле поиска и нажмите кнопку «Перейти» рядом с ним. Затем Copyscape выполнит поиск по всей сети, чтобы увидеть, существует ли где-либо еще подобный текстовый контент.
Если он что-нибудь найдет, Copyscape вернет результаты и упорядочит их в списке, похожем на результаты поиска Google. Это позволяет вам легко прокручивать их и видеть, сколько вашего контента было скопировано. Вы можете думать об этом как о средстве проверки дубликатов контента Google.
Что вы можете сделать, если обнаружите, что кто-то заимствовал ваш контент?
Сначала обратитесь к владельцу веб-сайта и попросите его либо удалить контент, либо добавить каноническую ссылку на исходный контент вашего веб-сайта. Если это не сработает, отправьте запрос на удаление DMCA в Google.
Примечание: Если вы намеренно синдицировали свой контент и разрешили другим веб-сайтам его публиковать, он все равно будет отображаться как дубликат.
Вот почему важно требовать, чтобы сайт публикации включал каноническую ссылку или тег noindex на страницу, чтобы она не конкурировала с вашей собственной страницей в рейтинге поисковых систем.Как исправить повторяющийся контент
Чтобы устранить проблемы с дублирующимся контентом, укажите, какую копию вы хотите, чтобы Google распознавал как исходную версию. Вам также нужно будет решить, хотите ли вы полностью удалить дубликаты страниц или просто хотите запретить Google их индексировать. В зависимости от того, что вы решите, существует несколько различных способов очистки дублирующегося контента.
Noindex с тегами Meta Robots и файлом robots.txt
Один из способов свести к минимуму влияние дублирующегося контента на вашу поисковую оптимизацию — вручную деиндексировать все повторяющиеся страницы, изменив метатеги robots. Для этого используйте метатег robots и установите для него значение «noindex, follow». Примените этот тег к заголовку HTML каждой страницы, которую вы хотите исключить из результатов поиска.
Метатег robots позволяет поисковым системам сканировать ссылки на странице, к которой он применяется, но не позволяет поисковым роботам включать их в свои индексы.
Зачем вообще разрешать Google сканировать страницу, если вы не хотите, чтобы она индексировалась? Потому что Google прямо предостерег от ограничения доступа сканирования к любому дублирующемуся контенту на вашем сайте. Они хотят знать, что это там, даже если вы не хотите, чтобы они индексировали это.
Тег noindex должен выглядеть следующим образом при применении к вашему HTML-коду:
[код] [другой код, если необходимо]
Метатег robots — это простой и эффективный способ деиндексации дубликатов контента и избежать возможных проблем с SEO из-за значительного сходства или точных дубликатов страниц на вашем веб-сайте.
Если у вас есть целые каталоги, которые вы хотите запретить Google и другим поисковым системам индексировать, отредактируйте файл robots.
txt.301 Перенаправление
Еще один способ решения проблемы дублирования контента — перенаправление 301. 301 — это постоянные перенаправления, которые перенаправляют трафик с дублирующей страницы на другой URL-адрес. 301 редиректы оптимизированы для SEO и помогают объединить несколько страниц в один URL-адрес, чтобы они консолидировали свой ссылочный вес.
Когда вы используете перенаправление 301, дубликат или во многом похожая страница больше не будет принимать трафик, поэтому используйте его только тогда, когда вы согласны с тем, что дубликат страницы больше не доступен, например, при обрезке контента. Если вы все еще хотите, чтобы страница была доступна, используйте метатег robots, чтобы не индексировать ее.
Rel Canonical
Еще один способ управления дублирующимся контентом — использовать атрибут rel=canonical для определения приоритета страниц. Поместите атрибут rel=canonical внутри HTML-тега
, чтобы сообщить поисковым системам, что конкретная страница существует как копия другой страницы и что все ссылки и ранжирование, принадлежащие этой странице, на самом деле должны быть отнесены к каноническим. страница.Тег rel=canonical выглядит примерно так при применении к вашему HTML-коду:
[код]
Вы также можете использовать канонический тег, ссылающийся на себя, чтобы указать, что вам нужна конкретная страница рассматривается как первоначальная версия.
Удалить URL-адреса из вашей XML-карты сайта
Ваша XML-карта сайта должна включать только те URL-адреса, которые вы хотите проиндексировать. Если вы не используете динамический URL-адрес, который автоматически обновляет карту сайта, вам потребуется вручную отредактировать карту сайта и удалить все URL-адреса, которые вы не индексируете или не перенаправляете.
Удалить URL-адрес в Google Search Console
Если вы решите перенаправить страницу или ограничить индексирование, попросите Google удалить этот URL-адрес из своего индекса.
Войдите в консоль поиска Google и выберите «Удаление» в меню слева.
Появится всплывающее окно, сообщающее, что отправка URL-адреса удалит его из индекса Google всего на шесть месяцев. По истечении этого времени, если Google просканирует ваш сайт и обнаружит URL-адрес, он будет повторно проиндексирован, если только он не был перенаправлен или заблокирован тегом robots. Если у вас есть несколько URL-адресов с общим префиксом, вы также можете отправить префикс, чтобы временно удалить все URL-адреса из индекса Google.
Через шесть месяцев Google снова попытается просканировать ваши URL-адреса. Если вы правильно перенаправили или не проиндексировали их, они больше не будут отображаться на странице результатов поисковой системы (SERP).
Нужна помощь в выявлении технических проблем SEO?
Хотите повысить рейтинг своего сайта? Сотрудничайте с SEO-агентством, работающим с данными, которое будет работать с вами, чтобы выявить технические проблемы SEO на вашем веб-сайте и разработать выигрышную SEO-стратегию, которая поможет вам подняться в поисковой выдаче.
Закажите бесплатную SEO-консультацию сегодня и узнайте, что мы можем сделать для вас!Дублированный контент и SEO: полное руководство
Что такое дублированный контент?
Дублированный контент — это контент, который похож или является точной копией контента на других веб-сайтах или на разных страницах того же веб-сайта. Наличие большого количества дублированного контента на веб-сайте может негативно повлиять на рейтинг Google.
Другими словами:
Дублированный контент — это контент, который дословно совпадает с контентом, который появляется на другой странице.
Но «Дублированный контент» также относится к контенту, который похож на другой контент… даже если он немного переписан.
Как повторяющийся контент влияет на SEO?
Как правило, Google не хочет ранжировать страницы с дублирующимся контентом.
На самом деле Google утверждает, что:
«Google изо всех сил старается индексировать и показывать страницы с четкой информацией».
Таким образом, если на вашем сайте есть страницы БЕЗ отдельной информации, это может повредить вашему рейтингу в поисковых системах.
В частности, вот три основные проблемы, с которыми сталкиваются сайты с большим количеством дублированного контента.
Меньше органического трафика: это довольно просто. Google не хочет ранжировать страницы, которые используют контент, скопированный с других страниц, в индексе Google.
(Включая страницы вашего собственного веб-сайта)
Например, предположим, что на вашем сайте есть три страницы с похожим содержанием.
Google не уверен, какая страница является «оригинальной». Таким образом, все три страницы будут бороться за ранжирование.
Штраф (чрезвычайно редко): Google заявил, что дублирование контента может привести к штрафу или полной деиндексации веб-сайта.
Однако это очень редкое явление. И это делается только в тех случаях, когда сайт намеренно очищает или копирует контент с других сайтов.
Так что, если на вашем сайте есть множество дубликатов страниц, вам, вероятно, не нужно беспокоиться о «штрафе за дублирование контента».
Меньше проиндексированных страниц. Это особенно важно для сайтов с большим количеством страниц (например, сайтов электронной коммерции).
Иногда Google не просто понижает рейтинг дублированного контента. Он фактически отказывается индексировать его.
Таким образом, если на вашем сайте есть страницы, которые не индексируются, это может быть связано с тем, что ваш краулинговый бюджет тратится на дублирование контента.
Передовой опыт
Отслеживание одного и того же контента по разным URL-адресам
Это наиболее распространенная причина всплывающих сообщений о проблемах с дублированием контента.
Допустим, вы управляете сайтом электронной коммерции.
И у вас есть страница продукта, на которой продаются футболки.
Если все настроено правильно, каждый размер и цвет этой футболки по-прежнему будет находиться на одном и том же URL-адресе.
Но иногда вы обнаружите, что ваш сайт создает новый URL-адрес для каждой новой версии вашего продукта… что приводит к ТЫСЯЧАМ дублирующихся страниц контента.
Другой пример:
Если на вашем сайте есть функция поиска, эти страницы результатов поиска также могут быть проиндексированы. Опять же, это может легко добавить на ваш сайт более 1000 страниц. Все они содержат дублированный контент.
Проверка проиндексированных страниц
Один из самых простых способов найти повторяющийся контент — посмотреть на количество страниц вашего сайта, проиндексированных в Google.
Вы можете сделать это, выполнив поиск site:example.com в Google.
Или проверьте проиндексированные страницы в Google Search Console.
В любом случае это число должно совпадать с количеством страниц, созданных вами вручную.
Например, в Backlinko проиндексировано 112 страниц:
Это количество страниц, которые мы создали.
Если бы это число было 16 000 или 160 000, мы бы знали, что многие страницы добавляются автоматически.
И эти страницы, вероятно, будут содержать значительное количество дублированного контента.Убедитесь, что ваш сайт правильно перенаправляет
Иногда у вас есть не просто несколько версий одной и той же страницы… но одного и того же САЙТА.
Хотя это редкость, я много раз видел это в дикой природе.
Эта проблема возникает, когда «WWW»-версия вашего веб-сайта не перенаправляет на «не-WWW-версию».
(Или наоборот)
Это также может произойти, если вы переключили свой сайт на HTTPS… и не перенаправляли сайт HTTP.
Короче говоря, все разные версии вашего сайта должны оказаться на одном месте.
Используйте переадресацию 301
Переадресация 301 — это самый простой способ исправить проблемы с дублированием контента на вашем сайте.
(Помимо полного удаления страниц)
Так что, если вы обнаружили на своем сайте множество страниц с повторяющимся контентом, перенаправьте их обратно на оригинал.
Как только робот Googlebot зайдет, он обработает перенаправление и проиндексирует ТОЛЬКО исходный контент.
(Что может помочь исходной странице начать ранжироваться)
Следите за похожим контентом
Дублированный контент не ТОЛЬКО означает контент, который дословно скопирован откуда-то еще.
На самом деле Google определяет дублированный контент как:
Таким образом, даже если ваш контент технически отличается от того, что там есть, вы все равно можете столкнуться с проблемами дублирования контента.
Для большинства сайтов это не проблема. Большинство сайтов имеют несколько десятков страниц. И они пишут уникальный материал для каждой страницы.
Но бывают случаи, когда может появиться «похожий» дублированный контент.
Допустим, вы управляете веб-сайтом, который учит людей говорить по-французски.
И вы обслуживаете большую часть Бостона.
Возможно, вы оптимизировали одну страницу услуг по ключевому слову: «Учите французский в Бостоне».
И еще одна страница, которая пытается ранжироваться в категории «Изучайте французский в Кембридже».
Иногда содержимое технически может отличаться. Например, на одной странице указано местоположение в Бостоне. А на другой странице есть адрес в Кембридже.
Но по большей части содержание очень похоже.
Технически это дублированный контент.
Сложно ли писать 100% уникальный контент для каждой страницы вашего сайта? Ага. Но если вы серьезно относитесь к ранжированию каждой страницы на своем сайте, это необходимо.
Используйте тег Canonical
Тег rel=canonical сообщает поисковым системам:
«Да, у нас есть куча страниц с дублирующимся контентом. Но ЭТА страница является оригиналом. На остальное можете не обращать внимания».
Google заявил, что канонический тег лучше, чем блокировка страниц с дублирующимся контентом.
(Например, блокировка робота Googlebot с помощью файла robots.txt или тега noindex в HTML-коде вашей веб-страницы)
Итак, если вы обнаружите на своем сайте несколько страниц с дублирующимся содержимым, вам нужно:
- Удалить их
- Перенаправить их
- Использовать канонический тег
Используйте инструмент
Существует несколько инструментов SEO, которые имеют функции, предназначенные для обнаружения дублированного контента.
Например, Siteliner сканирует ваш веб-сайт на наличие страниц с большим количеством повторяющегося контента.
Объединение страниц
Как я уже упоминал, если у вас много страниц с дублирующимся контентом, вы, вероятно, захотите перенаправить их на одну страницу.
(Или используйте тег canonical)
Но что, если у вас есть страницы с похожим содержанием?
Ну, вы можете создать уникальный контент для каждой страницы… ИЛИ объединить их в одну мега-страницу.
Например, предположим, что на вашем сайте есть 3 сообщения в блоге, которые технически различаются… но содержание в значительной степени одинаково.
Вы можете объединить эти 3 сообщения в один удивительный пост в блоге, который будет уникальным на 100%.
Поскольку вы удалили часть повторяющегося контента со своего сайта, эта страница должна ранжироваться выше, чем остальные 3 страницы вместе взятые.
Noindex Страницы тегов или категорий WordPress
Если вы используете WordPress, вы могли заметить, что он автоматически генерирует страницы тегов и категорий.
Эти страницы являются ОГРОМНЫМИ источниками дублированного контента.
Чтобы они были полезны пользователям, рекомендую добавить на эти страницы тег «noindex». Таким образом, они могут существовать без индексации поисковыми системами.
Вы также можете настроить WordPress так, чтобы эти страницы вообще не генерировались.
Подробнее
Как Google обрабатывает дублированный контент?: Видео от Мэтта Каттса из Google о том, как Google рассматривает дублированный контент.
Миф о штрафе за дублированный контент: в этом посте рассказывается, почему большинству людей не нужно беспокоиться о «штрафе за дублированный контент».
Как найти и исправить это для SEO
Если и есть что-то, что не дает спать по ночам владельцам веб-сайтов, так это то, как бороться с дублирующимся контентом. Существует множество причин дублирования контента — некоторых можно избежать, а некоторых нет.
Но ни для кого не секрет, что дублированный контент влияет на SEO: Google это не нравится.
И когда Google что-то не нравится, это вредит вашему поисковому рейтингу.
Реальность такова, что существует много дублированного контента. По словам Мэтта Каттса, от 25 до 30 % контента в сети дублируется.
Чтобы подтвердить это, недавнее исследование, проведенное Raven Tools, показало, что 29 % страниц, использующих инструмент аудита сайта, содержат дублированный контент.
Другими словами, весьма вероятно, что на вашем сайте есть дублированный контент, который влияет на эффективность вашего поиска.
Но как узнать, где находится дублированный контент? И самое главное, какие шаги вы можете предпринять, чтобы это исправить?
Эта статья поможет вам понять многие причины дублирования контента, найти дублирующийся контент на вашем веб-сайте или на внешних веб-сайтах и принять меры.
Что такое дублированный контент?
Дублированный контент — это контент, который точно такой же или очень похож на контент на других веб-сайтах или на разных страницах того же веб-сайта.
Иногда содержимое дословно совпадает и может быть скопировано и вставлено с одной страницы на другую. Это точно такой же текст.
В других случаях дублированный контент очень похож на контент на другой странице. Это может быть контент, который был немного переписан и переформулирован — думайте об этом как о почти дублирующемся контенте.
Почему дублированный контент вреден для SEO?
Дублированный контент — это плохо по нескольким важным причинам — в основном потому, что Google его не любит.
Google ранжирует страницы с дублирующимся контентом.Целью Google является предоставление пользователям уникального и ценного контента. На самом деле Google заявляет, что:
«Google изо всех сил старается индексировать и показывать страницы с четкой информацией».
Естественно, он не хочет ранжировать страницы с дублирующимся содержимым. Это не обеспечит пользователям Google лучший пользовательский опыт.
Кроме того, когда доступно несколько версий одного и того же контента, поисковым системам сложно определить, какую версию они должны индексировать и отображать в результатах поиска.
Это снижает производительность для всех версий этого контента, поскольку каждая повторяющаяся версия контента конкурирует со следующей.
Это означает, что ваш органический трафик падает для каждой страницы, что может быть чрезвычайно пагубным для вашего коэффициента конверсии для тех страниц, для которых вы хотите получить высокий рейтинг.
У вас будет меньше проиндексированных страницЭто особенно важно для веб-сайтов с большим количеством страниц, таких как сайты крупных брендов или сайты электронной коммерции.
Иногда Google не просто ранжирует повторяющийся контент — поисковые системы не ранжируют его, и точка.
У Google и других поисковых систем есть сканеры, которые просматривают веб-сайты и собирают данные для построения индекса.
Сканирование и индексация — это все, что нужно для поисковой оптимизации. Если поисковые роботы не могут просканировать ваш веб-сайт, они не смогут его проиндексировать или ранжировать, а это значит, что он не будет показан пользователям, выполняющим поиск.Вот в чем дело:
Google выделяет только определенный объем сканирования для каждого веб-сайта, также известный как краулинговый бюджет .
Таким образом, если на вашем сайте есть дубликаты страниц и вы тратите ценный краулинговый бюджет на сканирование и индексацию дублирующегося контента, это означает, что другие важные веб-страницы не будут сканироваться, индексироваться и ранжироваться.
Ваш ссылочный вес разбавленДопустим, у вас есть две версии одного и того же контента. Внешние веб-сайты ссылаются на этот контент, предоставляя вам все важные полномочия по обратной ссылке. Но поскольку у вас есть две версии одной и той же страницы, некоторые веб-сайты ссылаются на одну страницу, а другие ссылаются на дублирующую страницу.
Авторитет, который обратные ссылки придают вашему контенту, поэтому разбавлен на нескольких страницах. Поисковые системы не будут знать, какая страница имеет наивысший авторитет и, следовательно, какую страницу ранжировать.
Взгляните на этот пример от Ahrefs. Он показывает два местоположения одного и того же контента на Buffer.com и разницу в обратных ссылках.
В одной статье больше обратных ссылок, чем в другой, но если бы это была только одна версия, сок ссылок не был бы разбавлен вообще: что дублированный контент может привести к штрафу или, что еще хуже, к полной деиндексации всего сайта.
На самом деле, говорят, что это случается редко и Google делает это только тогда, когда веб-сайт копирует контент с другого сайта.
Несмотря на то, что дублированный контент может отрицательно сказаться на эффективности SEO, иногда значительно, Google не накажет вас за это, если это не было преднамеренным.
Google признает, что веб-сайты часто представляют собой сложных зверей, и владельцам веб-сайтов может быть сложно справиться с техническими проблемами веб-сайта.
Вот что Google говорит об этом:
«Дублирующийся контент на сайте не является основанием для действий на этом сайте, если только не кажется, что цель дублированного контента состоит в том, чтобы ввести в заблуждение и манипулировать результатами поисковой системы. Если на вашем сайте есть проблемы с дублирующимся контентом, а вы не Следуйте советам, перечисленным в этом документе, мы хорошо поработали над выбором версии контента для отображения в наших результатах поиска».
Какое наиболее распространенное решение проблемы дублирования контента?
Существует множество способов исправить повторяющийся контент, которые мы рассмотрим позже, но если вы просто хотите попробовать самое распространенное исправление, вот оно:
Выберите предпочтительную версию и внедрите переадресацию 301 с непредпочтительных версий URL-адресов на предпочтительные версии.
Следующим наиболее распространенным решением является использование канонических тегов.
Элемент rel=canonical — это фрагмент HTML-кода, который сообщает Google, что контент принадлежит вам и является основной версией страницы, даже если контент можно найти в другом месте или на вашем сайте есть несколько версий.
Канонический тег можно использовать для:
Печатные и веб-версии контента
Мобильные и настольные версии страниц
Страницы с таргетингом на несколько местоположений
И еще…
Существует два типа канонических тегов: теги, указывающие на страницу, и теги, указывающие в сторону от страницы — они сообщают поисковым системам, что другая версия страницы является основной версией.
Вот как это выглядит:
Источник: Moz
В конечном счете, чтобы получить наилучшие результаты, вам необходимо включить несколько проактивных шагов в свою цифровую стратегию контента.
Лучший способ решить, как исправить повторяющийся контент, — это сначала понять наиболее распространенные причины.
Распространенные причины дублирования контента
Дублирование контента по техническим причинам
Посмотрим правде в глаза, веб-сайты сложны. Чем больше ваш сайт и чем больше у вас страниц, тем сложнее он становится и тем больше вероятность того, что вы сделаете ошибки.
Вот почему часто дублированный контент возникает просто из-за неправильно настроенного веб-сервера или веб-сайта. Возможно, вы недавно перенесли свой веб-сайт, изменили структуру или обновили оптимизацию на странице. Бывает.
Хорошей новостью является то, что эти причины носят технический характер, а это означает, что они, скорее всего, никогда не приведут к штрафным санкциям Google за дублирование контента.
Плохие новости?
Тем не менее, они могут серьезно повредить вашему рейтингу, поэтому важно быстро их исправить.
Non-WWW vs WWW и HTTP vs HTTPs
Если вы используете HTTPs и поддомен WWW, ваш предпочтительный способ доставки контента – https://www.
mysite.com.Это ваш канонический домен.
Однако, если ваш веб-сервер был плохо настроен, ваш контент также может быть доступен через:
Это одна из старейших проблем в книге, которая означает, что обе версии вашего сайта доступны.
Как это исправить :Выберите способ подачи контента. Затем внедрите переадресацию 301, чтобы перенаправлять нежелательные страницы в предпочтительную версию.
Структура URL-адреса
Это может вас удивить, но URL-адреса чувствительны к регистру для Google.
Это означает, что эти две версии отображаются как разные URL-адреса:
https://mysite.com/blue-dress
https://mysite.com/blue-DRESS и строчные версии домена вашего сайта, вы можете затруднить индексацию вашего сайта поисковыми системами и снизить производительность вашего сайта.
Эта тема рассматривается Джоном Мюллером из Google в разделе Ask Googlebot на канале Google Search Central YouTube.
Чтобы еще больше запутать ситуацию, URL-адреса не чувствительны к регистру для Bing.
Еще одна проблема, вызывающая проблемы, — косая черта в конце.
Здесь у вас есть косая черта (/) в конце URL-адреса (думайте об этом как о конце).
https://mysite.com/blue-dress/
https://mysite.com/blue-dress
Как говорит Мюллер:
» По определению, URL-адреса чувствительны к регистру, а также такие вещи, как косая черта в конце концов, имеют значение. Так что, технически, да — эти вещи имеют значение. Они делают URL-адреса разными».
Google распознает несколько версий одного и того же URL-адреса и попытается просканировать их все и выяснить, какую из них показывать в результатах поиска.
Как это исправить:Опять же, выберите предпочтительную структуру для ваших URL-адресов, а для непредпочтительных версий используйте перенаправление 301. Однако, если у вас есть несколько страниц, которые необходимо перенаправить, вам, вероятно, будет намного проще внедрить исправление для всего сайта.
Например, вы можете принудительно ввести URI нижнего регистра с помощью перезаписи. Используйте файлы конфигурации сервера в своем HTML-коде. Если у вас нет доступа к файлам httpd.conf, ваша хостинговая компания может включить эту функцию для вас.
Возможен доступ через различные индексные страницы
Если ваш веб-сервер неправильно настроен, есть вероятность, что ваша домашняя страница может быть доступна через несколько URL-адресов.
Например, вместе с https://www.mysite.com ваша домашняя страница может быть доступна через:
https://www.mysite.com/index.html
https://www.mysite.com/index.php
https://www.mysite.com/index.asp
https://www.mysite.com/index.aspx
Выберите предпочтительный способ обслуживания вашей домашней страницы и используйте переадресацию 301.
Параметры для фильтрации
Используются ли на вашем сайте параметры URL для вариантов страниц?
Веб-сайты часто используют параметры в URL-адресах, чтобы предлагать функции фильтрации.
Возьмите этот URL, например:https://www.mysite.com/clothing/shoes?colour=red
На этой странице будут показаны все красные туфли.
Это очень удобно для ваших пользователей, так как они могут быстро и легко найти нужные продукты.
НО это может вызвать серьезные проблемы для поисковых систем.
Проблема с параметрами фильтра заключается в том, что они могут генерировать бесконечное количество комбинаций, особенно когда доступно более одного параметра фильтра. Что касается одежды, вы можете отфильтровать ее по типу, стилю, размеру, цене, цвету, бренду, новому выпуску, распродаже — варианты безграничны.
Параметры также можно переупорядочить, поэтому даже если приведенные ниже URL-адреса отличаются, они будут отображать одно и то же содержимое:
Вот еще один пример URL-адресов, которые ведут к дублирующемуся контенту, отличающемуся только разными параметрами:
Источник: Google
Как исправить:Вы можете запретить Google сканировать URL-адреса, которые содержат определенные параметры или параметры с определенными значениями, чтобы он не сканировал дубликаты страниц.
Если на вашем сайте много параметров URL-адресов, стоит использовать инструмент «Параметры URL-адресов», чтобы сократить сканирование повторяющихся URL-адресов.
Google рекомендует использовать инструмент параметров URL только в том случае, если ваш сайт соответствует ВСЕМ следующим требованиям:
На вашем сайте более 1000 страниц
В ваших журналах вы видите значительное количество повторяющихся страниц, индексируемых роботом Googlebot, и все повторяющиеся страницы различаются только параметрами URL
Вы опытный оптимизатор.
Если вы ошибетесь, Google может в конечном итоге проигнорировать важные страницы вашего сайта, что означает, что они не будут ранжироваться.
Еще одна вещь, которую вы можете сделать, это ввести канонические URL-адреса, чтобы предотвратить дублирование контента. Вам нужно будет сделать это для каждой основной нефильтрованной страницы.
Тем не менее, это не предотвращает проблемы с бюджетом сканирования.
Таксономии
В системах управления контентом ваши сообщения могут быть доступны более чем в одной категории. Это связано с таксономиями.
Таксономия — это механизм группировки для классификации содержимого. Вы видите их в своей системе управления контентом (например, WordPress) для поддержки категорий и тегов.
Однако, если вы не назначите основного, все будут считаться дубликатами.
Объясним —
Представьте, что у вас есть запись в блоге об электромобилях — она разделена на три категории и доступна во всех трех:
https://www.mysite.com/cars/topic/
https://www.mysite.com/travel/topic/
https://www.mysite.com/technology/topic/
Итак, поисковая система увидит это как несколько версий одного и того же контента — т.е. дублированный контент.
Как исправить:Выберите одну из этих категорий в качестве основной и используйте тег canonical, чтобы указать поисковым системам, что это основная версия.
Страницы комментариев
Если на вашем веб-сайте включены комментарии, после определенного количества комментариев они могут автоматически переходить на другие страницы. Это в случае с WordPress.
Проблема в том, что на следующей странице будет отображаться тот же контент, только комментарии внизу будут другими.
Это означает, что для каждой страницы новых комментариев у вас есть дубликат страницы контента.
Как это исправить:Используйте отношения ссылок на страницы, которые будут сигнализировать поисковой системе, что это серия разбитых на страницы страниц, а не дублированный контент.
Локализация
Если вы пытаетесь настроить таргетинг на людей из разных регионов, говорящих на одном языке, например, из разных штатов США или Австралии и Канады, вы можете получить дублированный контент.
Ведь бренд один и тот же, поэтому естественно, что контент будет пересекаться на обоих сайтах.
К счастью, Google обычно решает эту проблему, и это не повлияет на ваши результаты.
Однако на всякий случай можно предпринять упреждающие действия.
Как это исправить:
Используйте атрибут hreflang, чтобы предотвратить дублирование контента.
Атрибут hreflang используется для указания поисковым роботам, на каком языке находится ваш контент и для какого географического региона он предназначен.
Индексируемые страницы результатов поиска
Если вы предлагаете посетителям функцию поиска контента на вашем сайте, это может быть еще одной причиной дублирования контента.
Часто страницы результатов поиска на вашем сайте очень похожи.
В то же время они не представляют большой ценности для поисковых систем, и вы не хотите, чтобы они ранжировались. На самом деле они просто созданы для того, чтобы предоставить вашим посетителям лучший пользовательский интерфейс.
Как это исправить:Используйте атрибут noindex, чтобы запретить поисковой системе индексировать страницы результатов поиска.
Вы также можете запретить поисковым системам доступ к ним с помощью файла robots.txt. Это рекомендуется, если у вас много страниц с результатами.Индексируемая промежуточная или тестовая среда
Если вы или ваши веб-разработчики собираетесь запустить некоторые новые функции, например новую платформу электронной коммерции, на вашем сайте, рекомендуется использовать промежуточные среды. Таким образом, вы не тестируете новые функции на действующем веб-сайте.
Однако иногда их можно оставить индексируемыми для поисковых систем, и это означает, что поисковые системы находят идентичный контент в двух местах.
Это может привести к проблемам с дублированием контента, которые повлияют на ранжирование работающего сайта, а также означает, что общественность потенциально может получить доступ к тестовому сайту, а не к рабочему сайту.
Как это исправить:Используйте HTTP-аутентификацию, чтобы запретить поисковым системам (и общедоступным) доступ к промежуточным и тестовым средам.
Вы включаете HTTP-аутентификацию в тестовом домене, поэтому он блокируется для поисковых систем, а работающий сайт остается индексируемым.Если вы обнаружили, что было проиндексировано что-то, чего не должно было быть, вы можете использовать инструмент удаления URL-адресов, чтобы удалить проиндексированный URL-адрес из поисковой системы и из кеша. Это можно сделать через Google Search Console.
Параметры для отслеживания
Параметры также могут использоваться для отслеживания. Параметр отслеживания — это фрагмент кода, который добавляется в конец URL. Затем он может быть проанализирован системой для обмена информацией, содержащейся в этом URL-адресе.
Например, когда пользователь делится URL-адресом на Facebook, источник добавляется к URL-адресу.
Однако на самом деле это еще одна причина дублирования контента.
Как это исправить:Используйте на страницах самоссылающиеся канонические URL-адреса. Самоссылающиеся канонические теги сообщают поисковым системам, какая версия является основной.
Таким образом, любые URL-адреса с этими параметрами отслеживания канонизируются до версии без параметров. Задача решена.Идентификаторы сеанса
Идентификаторы сеанса добавляются к URL-адресам для управления или обработки пользовательских сеансов.
Как тогда происходит дублирование контента?
Проблема дублирования содержимого возникает, когда эти идентификаторы сеансов используются во внутренних ссылках, таких как карты сайта, или публикуются в социальных сетях.
Другими словами, если к каждому URL-адресу, запрашиваемому посетителем, добавляется идентификатор сеанса, это создает много дублированного контента!
Как это исправить:Лучше всего использовать самоссылающиеся канонические URL-адреса. Таким образом, все URL-адреса с этими параметрами отслеживания канонизируются до версии без параметров.
Версия для печати
Иногда веб-страница настраивается для предоставления версии для печати содержимого по отдельному URL-адресу.
Это означает, что существует две версии одного и того же контента с разными URL-адресами, одна из которых более удобна для печати, чем другая!
Как это исправить:Избегайте проблем с дублированием контента, используя канонический URL-адрес, ведущий с версии для печати на основную версию страницы.
Специальные страницы для изображений
Еще одна проблема с некоторыми системами управления контентом заключается в том, что они создают отдельную выделенную страницу для каждого изображения.
На этой отдельной странице просто отображается изображение на пустой странице. Он похож на все остальные страницы изображений и может рассматриваться как дублирующийся контент.
Как это исправить:
Просто отключите функцию, которая дает изображения выделенных страниц. Вам это не нужно! Если вы не можете сделать это на своей CMS, добавьте на страницу мета-атрибут robots noindex.
Дублирование контента из-за скопированного контента
Другая причина дублирования контента — это когда люди копируют и публикуют контент в нескольких местах.
Это так просто.Иногда это злонамеренно и может повлечь за собой штрафы. Но в других случаях есть очень веская причина для дублирования контента.
Взгляните на причины ниже:
Целевые страницы для платного поиска
Любой опытный интернет-маркетолог скажет вам, что для лучших платных поисковых кампаний требуются специально разработанные целевые страницы, нацеленные на определенные ключевые слова и повышающие конверсию.
Вот в чем проблема:
Чтобы сэкономить время и бюджет, иногда маркетологи используют копии оригинальной страницы и вносят небольшие изменения в ключевые слова, основанные на их исследовании.
Если у вас много платных поисковых кампаний, это приводит к множеству страниц с практически одинаковым содержанием. И вы знаете, что это значит — дублировать контент.
Как это исправить:Один из способов исправить это — запретить поисковым системам индексировать целевые страницы с помощью атрибута noindex.
Более того, создавайте совершенно уникальные целевые страницы для платных поисковых кампаний — это также гарантирует, что вы предоставите более релевантный контент, ориентированный на конверсию, для вашей аудитории.
Распространение контента в синдикатыРаспространение — это когда вы берете контент, который уже опубликован на вашем собственном сайте, и даете другим издателям разрешение размещать такой же контент на их сайте.
Иногда синдицированный контент может быть точной копией контента на вашем сайте или может быть только его частью.
Для маркетологов синдикатный контент — отличный способ увидеть ваш контент и отправить его на ваш сайт. Это может привлечь больше вашей целевой аудитории и помочь вам завоевать авторитет в определенной нише.
Короче говоря, синдицированный контент — это хорошо.
Мы знаем, о чем вы думаете — не дублируется ли контент?
К сожалению, синдицированный контент создает дублированный контент.
Как это исправить НО есть способы убедиться, что ваш исходный контент не повлияет на рейтинг поисковых систем.Вот четыре лучших способа решения проблемы дублирования контента:
отн = канонический. Лучшее решение — попросить владельцев веб-сайтов, распространяющих ваш контент, разместить тег rel=canonical на странице с вашей статьей. Этот тег должен указывать на исходную статью на вашем сайте, чтобы сообщить поисковым системам, что синдицированный контент является копией и что вы являетесь настоящим издателем.
Без индекса. Вы можете попросить владельцев веб-сайтов не индексировать копии своих статей. Это говорит поисковым системам не индексировать синдицированную копию. Преимущество этого в том, что ссылки из синдицированной статьи на ваш сайт будут передаваться в PageRank.
Прямая ссылка с указанием авторства : если вы не можете заставить веб-владельца выполнить варианты 1 или 2, убедитесь, что вы получаете прямую ссылку из синдицированного контента на исходную статью, а , а не , на вашу домашнюю страницу.
Этого должно быть достаточно, чтобы сообщить поисковой системе, что ваша версия является оригинальной.
Источник изображения: Fast Company
Другие веб-сайты копируют ваш контент
Мы все видели это — иногда веб-сайты нагло копируют и вставляют контент и размещают его на своем сайте. Часто очень немногие слова (если они вообще есть) изменяются.
Это большая проблема и основная причина дублирования контента.
Настоящая проблема возникает, когда ваш сайт имеет более низкий авторитет домена, чем тот, который копирует ваш контент (да, такое бывает!). Веб-сайты с более высоким авторитетом домена, как правило, сканируются чаще, чем веб-сайты с более низким авторитетом домена, а это означает, что дублированный контент (не ваш оригинальный) будет сначала проиндексирован на неправильный сайт.
Это может означать, что они ранжируются выше вас по вашему собственному контенту.
Как это исправить:Вы можете попытаться сделать так, чтобы другие веб-сайты отдавали вам должное за ваш контент, как в случае с синдицированным контентом выше.
Однако, если они взяли ваш контент с разрешения, скорее всего, это будет трудно обеспечить.Вы можете потребовать, чтобы Google удалил «неправильную» страницу из результатов поиска, подав запрос в соответствии с авторскими правами Digital Millennium, и/или рассмотреть возможность обращения в суд (в зависимости от серьезности нарушения).
Вы копируете контент с других веб-сайтов
Если вы копируете контент с других веб-сайтов так же, как когда другие делают это с вами, это тоже форма дублированного контента.
Это не означает, что вы действуете злонамеренно. Возможно, вы просто копируете описание поставщика нового ассортимента продуктов, чтобы сэкономить время при публикации их на своем сайте электронной коммерции.
Но все это считается дублирующимся контентом.
Как это исправить:Компания Google предложила сделать ссылку на первоисточник, используя либо канонический URL, либо тег robots noindex, чтобы показать, какой контент является исходным.
Но лучшим решением будет всегда создавать свой собственный уникальный контент. Даже если вы имеете дело с тысячами продуктов, стоит создать уникальную версию описания продукта на вашем сайте. Ваши покупатели будут вам за это благодарны, а ваш рейтинг в поисковых системах вознаградит вас за это.
Поиск повторяющегося контента
Поиск дублирующегося контента на вашем веб-сайте
Наиболее распространенный способ найти дублированный контент на вашем собственном веб-сайте — использовать Google Search Console.
Перейдите в консоль поиска Google и перейдите к отчету о покрытии индексом.
Отчет об охвате индекса Google Search Console — бесценный инструмент для понимания того, какие URL-адреса были просканированы и проиндексированы Google, а какие — нет. Он также сообщает вам , почему поисковая система сделала такой выбор в отношении URL — и это действительно важная часть.
Ваша цель — получить каноническую версию каждой важной страницы, проиндексированной Google, и для любых дублировать или альтернативные страницы, которые будут помечены как «Исключенные» в отчете об индексировании.
Вот несколько вещей, на которые следует обратить внимание:
Дублирование, Google выбрал другой канонический URL, чем пользовательский: Это означает, что страница помечена как каноническая для набора страниц, но Google решил проигнорировать ваш запрос, поскольку считает, что другой URL-адрес является лучшим каноническим. Чтобы исправить это, проверьте URL-адрес, чтобы увидеть, какой Google выбрал в качестве канонического URL-адреса. Если вы согласны, измените ссылку rel=canonical. В противном случае поработайте над архитектурой своего веб-сайта, чтобы уменьшить дублированный контент и отправить более сильные сигналы ранжирования на страницу, которую вы предпочитаете в качестве канонической, чтобы Google передумал.
Дублирование без выбранной пользователем канонической версии: Google обнаружил несколько URL-адресов, которые не канонизированы до предпочтительной версии. Google определил страницу с дубликатами, но ни одна из них не отмечена как каноническая.
И поисковик не считает эту страницу канонической версией. Чтобы исправить это, вы должны явным образом пометить эту страницу как каноническую, используя ссылки rel=canonical для каждого доступного для сканирования URL-адреса на вашем веб-сайте.Дубликат отправленного URL-адреса не выбран как канонический: Вы просили проиндексировать этот URL-адрес, но, поскольку это повторяющийся контент, и Google считает, что другой URL-адрес является лучшим кандидатом на канонический, Google не проиндексировал его, а вместо этого проиндексировал выбранный им канонический.
Еще один отличный инструмент для поиска проблем с дублированием контента на вашем сайте — SiteLiner.
SiteLiner предназначен для выявления внутреннего дублированного контента. Выполните поиск по выбранному вами URL, и вы увидите обзорную страницу.
Это дает вам процент внутреннего дублированного контента, затем вы также можете щелкнуть результаты, чтобы увидеть более подробную информацию о дублирующемся контенте.
Бесплатная версия великолепна, но она ограничена 250 страницами и раз в 30 дней.
Поиск дублирующегося контента за пределами вашего собственного веб-сайта
Лучший инструмент для поиска дублирующегося контента на внешних веб-сайтах — CopyScape.
CopyScape — это, по сути, средство проверки дубликатов содержимого, которое можно использовать бесплатно.
Этот инструмент прост в использовании: просто вставьте ссылку в поле на главной странице, и CopyScape просканирует Интернет в поисках более одной страницы с похожим или одинаковым содержанием.
Затем вы увидите ряд результатов с похожим или повторяющимся контентом.
Затем вы можете нажать на каждый из результатов, чтобы увидеть, какие именно части вашего текста являются дублирующимся контентом.
Имейте в виду, что в бесплатной версии вы не получите неограниченное количество сканирований одного веб-сайта. Если вы действительно хотите решить проблемы с дублирующимся контентом, CopyScape предлагает премиум-версию для получения дополнительной информации.
Еще один способ определить дублирующийся контент — это прямой поиск заголовка вашей страницы или заголовка блога в поисковых системах.
Если у вас есть определенная страница, которую вы хотите проверить, вы также можете перейти на эту страницу, скопировать и вставить фрагмент текста в поиск Google.
Вот что сделал Ahrefs в своей собственной статье в блоге:
Источник: Ahrefs не дублировать контент. Но мы уже показали выше, что иногда Google ошибается. Итак, если вы хотите, чтобы ваши страницы занимали высокие позиции, лучше предпринять некоторые активные шаги.
Выше мы описали несколько способов исправить дублирующийся контент — вот полный список шагов, которые вы можете предпринять для управления дублирующимся контентом:
Используйте 301s : используйте переадресацию 301 в файле .htaccess для интеллектуальной переадресации пользователей, робота Googlebot и других поисковых роботов. Это помогает предотвратить большинство проблем с дублированием страниц, предотвращая отображение альтернативных версий.
Сообщите Google, как обрабатывать параметры URL: Сообщите Google, что делают параметры, вместо того, чтобы позволять поисковой системе пытаться это выяснить.
Будьте последовательны : Сохраняйте согласованность внутренних ссылок.
Использовать домены верхнего уровня : это помогает Google предоставлять наиболее подходящую версию документа для содержания в конкретной стране. Например, http://www.example.de будет определяться как содержащий контент, ориентированный на Германию, тогда как http://www.example.com/de или http://de.example.com менее очевидны для поиска. двигатель.
Управление синдицированным контентом : Google может выбрать или не выбрать правильную версию контента для индексации. Поэтому сообщите Google, какая версия является предпочтительной, используя ссылку на исходную статью и тег noindex .
Отн = «альтернативный».
Объединить альтернативные версии страницы, например страницы для мобильных устройств или страны/языка. Используйте атрибут hreflang, чтобы в результатах поиска отображалась страница с нужной страной/языком.Свести к минимуму шаблонное повторение : Лучше всего включить очень краткое изложение текста и ссылку на страницу с более подробным содержанием. Кроме того, используйте инструмент обработки параметров, чтобы сообщить Google об обработке параметров URL.
Минимизируйте похожий контент : Везде, где это возможно, старайтесь не создавать дублированный контент. Если у вас много похожих страниц, рассмотрите возможность их объединения в одну. Создавайте свой собственный уникальный контент для продуктов и услуг, а не полагайтесь на контент поставщиков.
Избегайте блокировки доступа поисковых роботов: Google не рекомендует блокировать доступ поисковых роботов к страницам с повторяющимся содержанием.
Вместо того, чтобы блокировать поисковым роботам Google доступ к дублирующемуся контенту на вашем веб-сайте, например, к файлу robots.txt, лучше разрешить поисковым системам сканировать эти URL-адреса, но идентифицировать их как дубликаты с помощью rel canonical link, инструмента обработки параметров URL, или 301 редиректы. Если дублированный контент означает, что Google слишком много сканирует ваш сайт и расходует бюджет сканирования, вы можете настроить скорость сканирования в Google Search Console, а не блокировать страницы.
Часто задаваемые вопросы о дублированном контенте
Могу ли я получить штраф от поисковых систем за дублирование контента?
Очень маловероятно, что вы получите штраф от Google за дублирование контента, если вы не копировали контент со злым умыслом.
Однако, если у вас есть большое количество копий, идентичных или очень похожих на другой сайт, возможно, что Google сочтет этот дублированный контент преднамеренным и злонамеренным, а это означает, что вам грозит наказание.
Вот что Google говорит о штрафах за дублирование контента:
Дублирование контента на сайте не является основанием для принятия мер на этом сайте, если только не выясняется, что целью дублирования контента является ввод в заблуждение и манипулирование результатами поисковых систем. Если на вашем сайте возникают проблемы с дублированием контента, а вы не следуете приведенным выше советам, мы хорошо поработали, выбрав версию контента для отображения в результатах поиска.
Если я устраню проблемы с дублированием контента, повысится ли мой рейтинг?
Абсолютно.
Когда вы устраняете проблемы с дублированием контента, это означает, что правильный контент, то есть контент, который вы предпочитаете ранжировать, будет сканироваться и индексироваться Google и поисковыми системами.
Принимая активные меры по исправлению повторяющегося контента, вы предотвратите трату Google краулингового бюджета на сканирование и индексирование дубликатов страниц, которые вы не съели, чтобы отобразиться в поиске.
Вместо этого сканеры тратят время на индексацию ваших предпочтительных страниц, и вашей целевой аудитории показываются более релевантные страницы в результатах поиска.Сколько исходного текста требуется для того, чтобы страница считалась «уникальной»?
Это вопрос на миллион долларов!
В конце концов, если вы хотите, чтобы страница занимала высокие позиции, лучше всего сосредоточиться на создании оригинальной страницы, которая будет ценна для ваших посетителей и будет иметь уникальный и актуальный контент. Не существует «правильного процента» уникального контента, который должен быть на странице или в записи блога. Но если вы в первую очередь сосредоточитесь на создании уникального контента, поисковые системы распознают, что это оригинальная страница, и вознаградят ее в рейтинге.
Исправьте повторяющийся контент прямо сейчасМы многое рассмотрели в этой статье, и может быть трудно понять, с чего начать. Вот где мы можем помочь.