
Перекластеризация что это | Что делать если трафик уменьшился
Содержание
- 1 А может это просто сезонность?
- 1.1 Или летняя просадка?
- 2 Грубые нарушения регламента ПС
- 3 Сопоставляем даты наложения санкций
- 4 Сайт низкого качества
- 5 Проблемы хостинга
- 6 Акция на комплексный SEO тариф + настройка Директ и РСЯ
Привет! Сегодня решил написать про одну интересную проблему — падение посещаемости из органической выдачи и что с этим делать. Нередко бывает, что качественный в техническом плане ресурс, который не использует какие-либо запрещенные техники стабильно теряет посещаемость, а сайт у которого множество проблем растет. Встречали такое? И часто причина падения трафика на качественном ресурсе совсем не очевидна.
Причем перекластеризация запросов, покупка качественных ссылок и другие типовые манипуляции тут не помогают. Потери трафика невелики, но общая динамика стабильно отрицательна. Поддержка Яндекс же отвечает, что с сайтом все хорошо, в панели вебмастера Яндекс и Гугл нет никаких аномалий и владелец проекта никак не может выяснить, что же произошло с его детищем. Возможно, данная ситуация вам знакома?!
Возможно, данная ситуация вам знакома?!
Кстати, как написать в службы поддержки Яндекс и Гугл я подробно разбирал в данной статье. Также, чтобы повысить посещаемость необходимо пройти все этапы поисковой оптимизации сайта, которые я описывал ранее.
А бывает и наоборот — в один день сайт может потерять практически все переходы с одной из поисковых систем!
Источников проблем у сайта великое множество, но большинство из них явно себя проявляют и их легко детектировать, например часть страниц попала под Баден или на сайт наложили фильтр за ссылки и так далее. В большинстве случаев провалы трафика заметны невооруженным глазом и далее остается просто детально изучить аналитику под разными срезами. Сегодня мы рассмотрим различные случаи, когда сайт начинает терять посещаемость из поиска.
А может это просто сезонность?
Итак, мы имеем наглядную просадку поисковых переходов на проекте и надо первым делом однозначно убедиться в том, что проблема действительно есть. Бывает так, что посещаемость и позиции просели, но причиной этого послужили не проблемы в оптимизации, а банальная сезонность тематики или основных запросов по которым сайт в ТОП. Быстро проверить сезонность вашей тематике можно в Wordstat во вкладке — «история запросов»:
Бывает так, что посещаемость и позиции просели, но причиной этого послужили не проблемы в оптимизации, а банальная сезонность тематики или основных запросов по которым сайт в ТОП. Быстро проверить сезонность вашей тематике можно в Wordstat во вкладке — «история запросов»:
Динамика популярности запроса про мангалы
Как видно на скриншоте — поисковый запрос «купить мангал» имеет ярко выраженную сезонность и спад трафика в зимнее время обусловлен не проблемами сайта, а уменьшением общего объема трафика, генерируемого данной тематикой.
Или летняя просадка?
Еще одна частая причина того что упал трафик кроется в общей просадке трафика из поисковых систем в летний период. Сам по себе сезон сильно влияет на объем генерируемых поиском переходов! Стоит понимать, что летом общий уровень трафика из поисковиков падает практически в 2 раза, особенно заметно это становится у проектов без сезонности. То есть то, что ваш сайт в летний период может потерять до половины переходов так же не является аномалией, подробнее увидеть общую динамику поискового трафика в Рунете можно на следующем скриншоте:
В живую посмотреть этот и другие интересные графики вы можете по ссылке.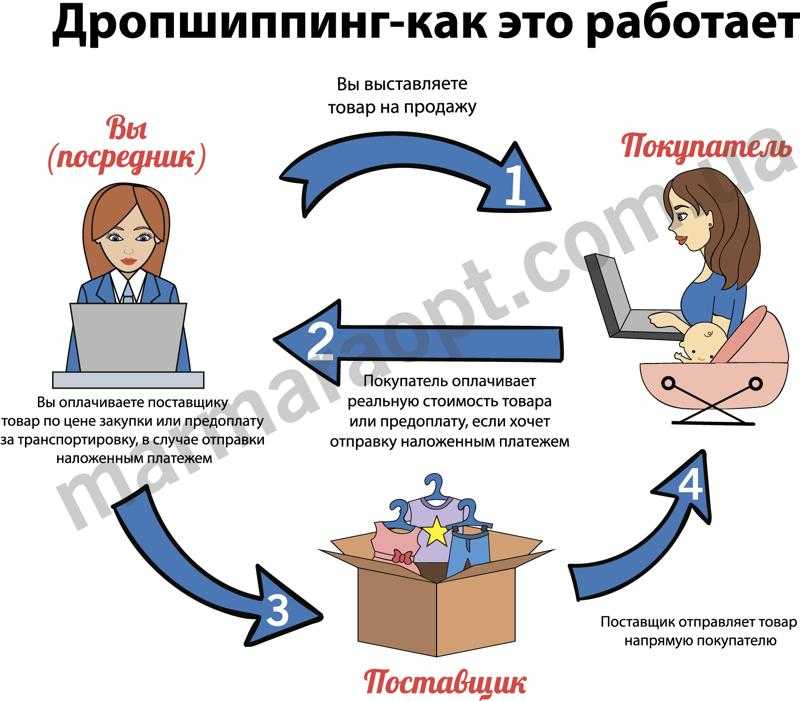
Грубые нарушения регламента ПС
Итак, в прошлой главе мы определились с тем, что падение трафика не вызвано сезонностью и следующим пунктом проверки является проверка сайта на грубые нарушения регламента поисковых систем.
Первым делом переходим в Панель «Яндекс.Вебмастер» и изучаем оповещения:
Если подобных сообщений в панели вебмастера не обнаружено идем дальше. Заходим в панель вебмастеров Гугл и выбираем вкладку — «санкции, принятые вручную»:
Следующим этапом проверки на грубые нарушения стоит написать в поддержку Яндекс, где детально рассказать о провале посещаемости и спросить — «Добрый день, уважаемые Платоны. Подскажите, нет ли на моем сайте понижающих фильтров, т.к. Метрика показывает явный тренд спада посещаемости, а запросы … ухудшили свои позиции в serp». Чтобы написать в поддержку Яндекс необходимо нажать на соответствующую кнопку в самом низу интерфейса «Яндекс.Вебмастер» :
В большинстве случаев поддержка напишет вам о проблемах, если они есть, за одним исключением — фильтр Яндекс NoName, хотя я давно его уже не встречал.
Суть данного фильтра переоптимизация элементов ресурса, например меню, картинок, кода. Когда в теги ALT и TITLE картинок добавляют ключевые слова, когда даже у ссылок прописывают тег title с ключевым словом (привет перелинковке времен Снежинска), когда в меню стараются использовать как можно больше ключей, когда ключи используют даже в тех картинках, которые формируют дизайн. В таком случае на сайт накладывается фильтр noname, отличительной особенностью которого является полное молчание поддержки Яндекс, то есть они не признают наличие фильтра и говорят развивать ресурс дальше, хотя пессимизация очевидна. Для выхода из под фильтра приходится пересобрать весь сайт заново.
Если советы выше не помогли найти причину спада посещаемости — начинаем копать глубже.
Сопоставляем даты наложения санкций
Еще один интересный метод обнаружения и фиксации понижающих фильтров —0 четко определить дату начала падения и сопоставить с датами выхода основных фильтров поисковых систем. Для использования данной методики переходим в метрику, во вкладку Отчеты -> Стандартные отчеты -> Источники — > Поисковые системы. Выбираем в Метрике даты начала и конца анализируемого периода. В зависимости от размера среза, детализацию ставим по неделям или месяцам:
Для использования данной методики переходим в метрику, во вкладку Отчеты -> Стандартные отчеты -> Источники — > Поисковые системы. Выбираем в Метрике даты начала и конца анализируемого периода. В зависимости от размера среза, детализацию ставим по неделям или месяцам:
Определив дату наложения фильтра стоит сопоставить ее с известными датами релизов поисковых алгоритмов и ситуация может проясниться!
Сайт низкого качества
Грубое нарушение регламента поисковых роботов приводит к резким и явным провалам трафика, которые легко заметить, но бывает, что сайт никогда и не набирал трафика, т.к. с самого начала находился под понижающими фильтрами за низкое качество. Сайт низкого качества определить достаточно легко, он имеет много битых и внешних ссылок (проверяем через бесплатную программу Xenu) и большие проблемы с индексацией. Про индексацию подробней писал тут. Нередко такой сайт имеет плохую внутреннюю перелинковку, которая концентрирует весь вес на мусорных страницах.
Если вы обнаружили разницу в индексации между Яндекс и Гугл в несколько раз да еще и много внешних ссылок, которые вы сами, вероятно даже и не ставили (сайт мог быть взломан вирусом, который наплодил тысячи страниц) — порядок дальнейших действий становится очевиден. Необходимо вычистить весь мусор и привести индексацию в порядок. Ранее писал про работу над одним из таких сайтов.
Чтобы избежать взлома сайта и размещения спамных ссылок — регулярно обновляйте движок (CMS) своего сайта.
Проблемы хостинга
Сразу несколько причин падения трафика можно связать с хостингом. Наиболее явными из них является периодическая недоступность и низкая скорость загрузки. Причем та скорость, которую вы видите у себя на компьютере совершенно ничего не показывает. И это не абстрактная фраза — даже если ваш проект открывается у вас очень быстро/очень медленно это не является совершенно никаким показателем скорости и это важно! Нередко мне доводилось встречать людей, которые свято верили в то, что если сайт у них быстро открывается, значит и поисковики так же считают, отнюдь. Скорость, как ее видят роботы, складывается из множества параметров, среди которых и пинг до целевой аудитории сайта. Наиболее адекватно оценить скорость поможет тест Google PageSpeed:
Скорость, как ее видят роботы, складывается из множества параметров, среди которых и пинг до целевой аудитории сайта. Наиболее адекватно оценить скорость поможет тест Google PageSpeed:
По этому тесту ваш сайт как минимум должен попадать в оранжевую зону!
Помимо классической скорости работы и тесту Гугл есть очень важный параметр — скорость открытия ресурса у пользователей из целевого региона, например, если вашему сайту присвоен регион Москва — не имеет особого значения то, как быстро он работает в Санкт-Петербурге и уж совсем не важно с какой скоростью он открывается у вас, важна именно скорость в целевом регионе. Нередко сервер на котором расположен сайт, находится за рубежом, что вызывает большие задержки при обмене данными между сервером и пользователем. И именно этот фактор может служить причиной очень интересной и распространенной проблемы — долговременное, медленное, но планомерное уменьшение трафика из поисковиков.
В настоящее время я готовлю очень подробное руководство по подготовке наиболее эффективной SEO статьи и планирую завершить его в течении нескольких недель, так что подписывайтесь на авторские материалы блога.
Акция на комплексный SEO тариф + настройка Директ и РСЯ
Бонусом к этой статье запускаю акцию, в рамках которой возьму один сайт на комплексный тариф по настройке контекстной рекламы и SEO, так что уже сейчас можете оставлять заявки. В тариф войдет:
- сбор семантики
- кластеризация запросов
- семантическое проектирование (построение структуры сайта на основе кластеров семантики). Подробнее в руководстве
- подготовка сео текстов
- настройка рекламы Директ
- настройка РСЯ
- и другое
Результат прошлого проекта на аналогичном тарифе:
В все это с оптовой скидкой, так что >>> оставляйте заявки <<< (не забудьте указать, что это заявка по акции). Возьму только 1 сайт, так что не стоит тянуть
Кластеризация запросов – создание, оформление, использование
Недавно мне задали вопрос – а как оформлять кластеры? В каком виде их хранить, чтобы не запутаться? Ведь семантическое ядро большое, групп много.
Буду делиться своим опытом.
Что такое кластеризация
Кластеризация – это разбивка ключевых фраз на группы. Каждая группа включает запросы, по которым можно продвинуть одну страницу. То есть выбираются синонимичные и близкие по смыслу фразы. Проверить это можно вручную. Введите запросы в поисковую систему. Если вам показали одни и те же страницы, значит они могут принадлежать одному и тому же кластеру. На основании этой информации используют две методики объединения запросов:
- Hard. Группа состоит из ключей, по которым в ТОП присутствует общий набор URL-ов.
- Soft. Строится вокруг центрального запроса. Все остальные ключи выбираются по принципу общих с ним адресов в ТОП.
Soft проще, но часто ошибается, выделяя в отдельные разделы несовместимые для продвижения на одной странице запросы.
Как сделать кластеризацию
Обычно это делают за нас сервисы. Но я в любом случае все перепроверяю и иногда провожу «перекластеризацию» — разбиваю так, как мне удобно или логично.
Для примера возьмем запрос «Криптовалюта». Я пользуюсь ассистентом «Wordstater» чтобы быстро собрать ключи (напишу у нем следующую статью, удобный инструмент).
Расширение Wordstater
Для начала было собрано 250 ключей, в учебных целях этого хватит. Но в реальности количество запросов на сайт в разы больше.
С помощью Wordstater все фразы были скопированы и вставлены в Excel. Лист назвала «Общие ключи».
Полный перечень ключей без кластеров
Теперь нам нужно кластеризовать полученные данные.
Сервисы кластеризации
Самый удобный – KeyCollector, но он платный. Для моих учебных целей не подходит, но если вы всерьез занимаетесь СЕО, то без него никуда. У меня есть лицензия, но чаще приходится пользоваться бесплатными.
Я нашла несколько удобных и на первом месте стоит Coolakov. Позволяет задать 1000 запросов, а для начала это очень неплохо.
Копируем из Excel наши запросы и вставляем. Можно указать регион, если ваши услуги привязаны в определенной области.
Кластеризация Coolakov
Теперь разберемся с порогом кластеризации. Это ключевой параметр, который определяет минимальное количество общих адресов для образования кластера. Чем выше это число, тем точнее и меньше полученные группы. Обычно достаточно указать 3 для «soft» и 4 для «hard». Выбираю число 5, так как в этом сервисе напрямую не указано, какой метод кластеризации используется.
Нажимаем большую синюю кнопку и ждем.
В результате было сформировано 129 кластеров.
Результат кластеризации Coolakov
Сразу же можно экспортировать в Excel. В результате мы получаем частоты (WS) запроса и кластера, а также общие URL конкурентов.
Для обработки этого списка я использую фильтры. Удобный инструмент Excel, который позволяет просматривать данные так, как удобно.
Где искать фильтры в Excel
Можно просмотреть отдельно все кластера по номерам, или выбрать по запросу.
Использование фильтра по названию кластера
Самые важные кластера копирую на отдельный лист, чтобы еще раз перепроверить, удалить лишние и использовать запросы для продвижения.
Когда кластер для определенной страницы выбран, переношу его на отдельный лист, которому даю релевантное имя. Так я не запутаюсь. Для большого сайта листов получается очень много, поэтому создаю отдельные книги Excel для разных разделов.
Выбор кластера для страницы и размещение его на отдельном листе
Другие сервисы
Еще одна возможность провести кластеризацию – Majento
В бесплатной версии доступно всего 250 запросов, зато можно выбрать метод.
Кластеризация Majento
Результат этой кластеризации – 98 групп. Страницы конкурентов не подобраны.
Результат кластеризации Majento
Также можно скачать в csv формат и проанализировать.
Иногда я пользуюсь Megaindex, но в нем кластеризация работает только вместе с подбором. Нужно ввести домен (укажите главного конкурента) и сервис выполнит всю работу. Учтите, что даже если введен домен со страницей (часто бывает, что конкурент – страница портала), то ключи будут собираться для ВСЕГО домена.
На втором шаге конкурентов можно отфильтровать.
Подбор семантики на Megaindex
На следующем шаге получаю список из 6000 запросов, из которых вручную можно удалить лишние.
Просмотр ключей
Довольно трудозатратная работа, но минус-слова в Мегаиндексе мы указать не можем.
Следующим шагом можно перейти к кластеризации. Увы, бесплатная версия позволяет кластеризовать только 1000 запросов из предложенных. Так что вам придется вручную отбирать нужные, чтобы получить нормальный результат.
Укажем порог кластеризации и попросим добавить связанные запросы.
Настройки кластеризации
Ждать придется довольно долго, но результат впечатляет.
Результат от Мегаиндекс
Но если вы поленились отфильтровать ключи, то полезности будет ноль. Если же предварительная работа была проведена тщательно, то вы получите хорошие кластеры.
Экспорт в Excel
Вид не такой удобный, как у Coolakov, фильтровать практически невозможно, только ручная обработка.
Что делать с кластерами
Следующим этапом нужно распределить кластера по страницам. Если сайт уже готов и требует полного наполнения, составьте список разделов, а в нем список страниц. Для каждого раздела удобно завести отдельную книгу Excel. В ней каждый лист – отдельная страница. Скопируйте на нее выбранный кластер и выберите главный ключ – тот, что пойдет в Title, Description и в заголовок. Остальные запросы можно вставлять в текст «как есть», но это грозит переспамом, а значит фильтром Баден-Баден. Поэтому составьте из них LSI – латентное семантическое индексирование. Это слова, задающие смысл страницы.
Если сайт уже готов и требует полного наполнения, составьте список разделов, а в нем список страниц. Для каждого раздела удобно завести отдельную книгу Excel. В ней каждый лист – отдельная страница. Скопируйте на нее выбранный кластер и выберите главный ключ – тот, что пойдет в Title, Description и в заголовок. Остальные запросы можно вставлять в текст «как есть», но это грозит переспамом, а значит фильтром Баден-Баден. Поэтому составьте из них LSI – латентное семантическое индексирование. Это слова, задающие смысл страницы.
Я выбираю главный ключ по семантическому принципу, например, тема статьи. Дополнительные по частотности (средние) и по дополнительному смыслу. Из них хорошо составлять подзаголовки статьи. Остальные слова идут в LSI.
Формирование семантики для страницы на отдельном листе
Для проверки вбиваю ключи в поисковик и проверяю ТОП – страницы должны совпадать. Не сайты – страницы!
Результат проверки
На том же Мегаиндексе по ключам можно сформировать ТЗ, но для меня, как для копирайтера, оно не совсем адекватно, хотя включает множество LSI, так что отсюда я беру дополнительные слова.
Фрагмент ТЗ на копирайт от Мегаиндекс
Что в итоге
Выполнив всю эту работу, вы получите одну или несколько книг Excel со множеством листов, где будут четко и ясно обозначены ключи и LSI. Каждая группа обозначает семантику одной страницы сайта – это очень удобно при формировании и выдаче ТЗ на тексты.
P.S. А если вам нужно вставить эту информацию в диплом или курсовую, добавьте в таблицу просто список кластеров, а их содержимое в виде таблиц приведите в приложениях.
Рабочий процесс фильтрации и рекластеризации — Программное обеспечение — Экспрессия гена одной клетки — Официальная поддержка 10x Genomics
Cell Ranger 6.4 (последняя версия), напечатано 25.04.2023
По умолчанию набор данных экспрессии генов . включает все штрих-коды, называемые ячейками
Звонивший сотовому рейнджеру.
Кластеры и проекции по умолчанию в файле  cloupe
cloupe .cloupe получены из этого набора ячеек.
Однако может быть полезнее анализировать только подмножество этих ячеек. Например, может быть желательно более точно отсеивать возможные мультиплеты ячеек, мертвые клетки или клетки с низким разнообразием. В качестве альтернативы может быть предпочтительнее сосредоточиться на конкретном типе клеток или даже исключить конкретный тип клеток из анализа.
По этим причинам в Loupe Browser 5.0 и более поздних версиях предусмотрена интерактивная фильтрация. и рабочий процесс рекластеризации. За несколько коротких шагов можно идентифицировать интересующие клетки, а затем вычислить кластеризацию Лувена и проекцию t-SNE по этим ячейкам. Loupe Browser 5.1 и более поздние версии дополнительно поддерживают создание проекций UMAP.
Loupe Browser 6.2 поддерживает повторную кластеризацию данных GEX (Gene Expression) в наборах данных GEX + Antibody Capture, GEX + CRISPR Guide Capture и GEX + ATAC. |
Вход в рабочий процесс рекластеризации
Чтобы войти в рабочий процесс рекластеризации, выберите режим «Категории» и выберите любую категорию. A Рекластер кнопка появится над именами кластеров, и нажатие на нее запустит отдельное окно для рабочего процесса:
Для всех шагов рабочего процесса есть три столбца. Крайний левый столбец показывает текущий пройти этапы рабочего процесса. Можно продвинуться вперед или вернуться к любому этапу рабочего процесса. в любое время. Средний столбец содержит инструменты для активного шага. Крайний правый столбец показывает статистика о том, какие штрих-коды были удалены. В нижней части окна Recluster есть кнопки для перехода к следующему шагу или перехода к последнему шагу. Каждый шаг рабочего процесса описан в следующих разделах.
Просмотр штрих-кодов
Первый шаг, просмотр штрих-кодов, позволяет выполнить первоначальную фильтрацию либо по целым кластерам, либо по списку штрих-кодов. Подключено к главному окну; изменение категории в главном окне изменит активную категорию в рабочем процессе рекластеризации. Выбирая или отменяя выбор кластеров в главном окне, можно включать или исключать целые кластеры штрих-кодов из последующего анализа. На изображении ниже показан встроенный набор данных AML Tutorial. С выбранной категорией «AMLStatus» и отключенным кластером «Нормальный», как показано ниже:
Подключено к главному окну; изменение категории в главном окне изменит активную категорию в рабочем процессе рекластеризации. Выбирая или отменяя выбор кластеров в главном окне, можно включать или исключать целые кластеры штрих-кодов из последующего анализа. На изображении ниже показан встроенный набор данных AML Tutorial. С выбранной категорией «AMLStatus» и отключенным кластером «Нормальный», как показано ниже:
Рабочий процесс повторной кластеризации отреагирует тем же, удалив «обычные» штрих-коды:
Также можно фильтровать по пользовательским категориям, например, созданным с помощью инструментов лассо, количественные фильтры, логические фильтры или импорт CSV. Рекомендуется, чтобы эти категории должны быть созданы до запуска рабочего процесса рекластеризации.
Наконец, для более точного управления или для фильтрации по спискам, определенным внешними алгоритмами,
можно явно добавить или удалить набор штрих-кодов, щелкнув значок Загрузить CSV-файл ссылка под сюжетом.
Пороговое значение по UMI
Следующим шагом является пороговое значение по количеству UMI. На этом шаге показан скрипичный график подсчетов UMI для выбранные в данный момент штрих-коды. Перемещение ползунков вверху и внизу раздачи приведет к удалить штрих-коды за пределами диапазона. Также можно явно ввести числовые значения, или посмотрите распределение на логарифмическом графике. Для целей этого руководства верхний счетчик UMI будет использоваться ограничение в 20 000 UMI на штрих-код на линейной шкале, как показано ниже:
Порог по функциям
Следующим шагом является определение порога по определенному количеству обнаруженных функций. Для экспрессии генов наборы данных (даже с помощью Feature Barcoding), это будет количество найденных различных генов для каждого штрих-кода. В зависимости от эксперимента штрих-коды с аномально низким или высоким количество отдельных признаков может быть нежелательным. Для целей этого руководства Будет использоваться граница количества элементов, равная 50 элементам на штрих-код в линейной шкале (эквивалент 5,6439 в логарифмической шкале), как показано ниже:
Митохондриальные UMI
Следующим шагом является фильтрация клеток по митохондриальной фракции — процент UMI на
штрих-код, связанный с митохондриальными генами.
Чтобы выбрать из списка предварительно распознанных ссылок, нажмите кнопку Выберите эталонный геном в раскрывающемся меню. Параметры покажут процент митохондриальных генов в эталоне, которые присутствуют в наборе данных. Набор данных AML Tutorial представляет собой набор данных человека, в котором присутствует большинство митохондриальных генов. Обратите внимание, что справочный список митохондриальных генов человека начинается с «MT-» (например, «MT-ATP6», «MT-CO1» и т. д.), что может не совпадать со всеми именами генов, используемыми в пользовательских ссылках.
Пользовательский список митохондриальных генов
Чтобы задать собственный список митохондриальных генов, создайте текстовый файл с расширением «.
Например, используя файл GTF из примера пользовательского справочника макаки-резуса на компьютере с Linux, мы посмотрим на содержимое файла GTF (флаг -S облегчает просмотр столбцов):
zcat Macaca_mulatta.Mmul_10.105.gtf.gz | меньше -S
Выходной файл должен выглядеть примерно так (используйте клавиши со стрелками для прокрутки вправо, вверх и вниз):
#!genome-build Mmul_10 #!геном-версия Mmul_10 #!дата генома 2019-02 #!Genome-build-accession GCA_003339765,3 #!genebuild-последнее обновление 2019-12 1 ген ансамбля 8231 26653 . - . ген_ид "ENSMMUG00000023296"; версия_гена "4"; ген_источник "ансамбль"; ген_биотип "кодирование_белка"; 1 транскрипт ансамбля 8231 26653 . - . ген_ид "ENSMMUG00000023296"; версия_гена "4"; транскрипт_id "ENSMMUT00000032773"; версия_транскрипта "4"; ген_источник "ансамбль"; ген_биотип "кодирование_белка"; исходник_транскрипта "ансамбль"; расшифровка_биотипа "белковое_кодирование"; 1 экзон ансамбля 26570 26653 .- . ген_ид "ENSMMUG00000023296"; версия_гена "4"; идентификатор_транскрипта "ENSMMUT00000032773"; версия_транскрипта "4"; номер_экзона "1"; источник_гена "ансамбл"; биотип_гена "кодирование_белка"; источник_транскрипта "ансамбль"; биотип_транскрипта "кодирование_белка"; идентификатор_экзона "ENSMMUE00000287659"; версия_экзона " 3"; ... Ген MT RefSeq 3259 4213 . + . ген_ид "ENSMMUG00000065372"; версия_гена "1"; имя_гена "ND1"; ген_источник "RefSeq"; ген_биотип "кодирование_белка"; ...

Далее мы будем искать митохондриальные гены в файле GTF. Вы можете посмотреть на .fai индекс файла генома FASTA, чтобы перечислить имена контигов. Для этого примера макаки митохондриальные контиги называются «МТ». Эта команда ищет записи, в которых контиг «MT» находится в 1-м столбце, а тип записи «ген» — в 3-м столбце, и сохраняет результаты в текстовом файле. Обратите внимание, что точное использование одинарных (‘) и двойных («) кавычек в этих командах важно для успешного анализа файла!
zcat Macaca_mulatta.Mmul_10.105.gtf.gz | ) && ($3 == "ген")' > macaque-mito-genes.txt
 Mmul_10.105.gtf.gz | ) && ($3 == "ген")' > macaque-mito-genes.txt
Mmul_10.105.gtf.gz | ) && ($3 == "ген")' > macaque-mito-genes.txt
Наконец, мы анализируем текстовый файл, чтобы сохранить только список имен митохондриальных генов, и сохраняем результаты в файле CSV. Первая команда awk печатает только столбец с именами генов. Остальные команд cut , sort
кошачья макака-mito-genes.txt | awk 'FS="; " {print $3}' | вырезать -d" " -f2 | cut -d'"' -f2 | sort | uniq > macaque-mito-intermediate.txt
Этот конкретный пример по-прежнему содержит строки с «RefSeq» и «gene» — их можно удалить в текстовом редакторе, таком как nano , или с помощью команд awk :
cat macaque-mito-intermediate.txt | awk '!/RefSeq/' | awk '!/gene/' > macaque-mito-genenames.csv
Вывод выглядит следующим образом:
ATP6 АТФ8 ЦОГ1 ЦОГ2 ЦОГ3 ЦИТБ НД1 НД2 НД3 ND4 ND4L ND5 НД6
Теперь файл CSV можно использовать в Recluster, нажав кнопку Upload csv .
После выбора эталона или загрузки списка генов появится другой график скрипки и ползунок. быть видимым. В этом руководстве мы устанавливаем верхнюю границу митохондриальной фракции 5%. Этот порог зависит от вашего эксперимента.
Повторный кластер
После выполнения шагов фильтрации следующим шагом будет определение типа создаваемого графика. Можно создать проекцию t-SNE или UMAP. Обратите внимание, что выбор обоих вариантов удвоит время обработки.
Под Настроить параметры повторного анализа (для опытных пользователей) Выпадающее меню, можно ввести пользовательские параметры для уменьшения размерности, используемого для кластеризации, или параметры для генерации
Графики t-SNE и UMAP соответственно. Для каждого параметра есть подробные инструкции, если вы выберете Подробнее . Рекомендуются значения по умолчанию, и никаких действий не требуется, если значения по умолчанию приемлемы. В этом руководстве была выбрана проекция UMAP с параметрами повторного анализа по умолчанию.
Наконец, последним шагом является присвоение имени рекластерному набору данных. имя будет использоваться в главном окне как категория проекции и кластеризации, поэтому он должен быть узнаваем. В этом руководстве мы используем имя «Только для пациентов», поскольку фильтрация ограничивает штрих-коды подмножеством «Пациент», а также удаляет некоторые митохондриальные штрих-коды с высоким UMI, малой функциональностью и высоким процентом.
Нажмите кнопку Повторная кластеризация , чтобы запустить алгоритмы повторной кластеризации. В фоновом режиме Loupe будет запускать практически те же основные компоненты, кластеры Louvain, и алгоритмы t-SNE в качестве конвейера Cell Ranger.
Время выполнения будет зависеть от скорости вашего локального компьютера, но больше всего зависит от количества штрих-кодов, поступающих в повторную кластеризацию, и от того, используете ли вы проекцию t-SNE, проекцию UMAP или обе. При создании только одной проекции ожидайте, что большинство наборов данных менее 10 000 ячеек будут повторно обработаны менее чем за две минуты. Для больших наборов данных, содержащих более 30 000 ячеек, может потребоваться более 10 минут, и существует жесткое ограничение в 100 000 ячеек. Обработка наборов данных, близких к этому пределу в 100 000 ячеек, может занять около часа. Создание как t-SNE, так и UMAP-проекции удвоит время обработки. Чтобы сократить время выполнения, рассмотрите возможность создания только проекции UMAP, которая будет завершена примерно вдвое быстрее по сравнению с проекцией t-SNE для наборов данных из 20 000 ячеек и выше.
Для больших наборов данных, содержащих более 30 000 ячеек, может потребоваться более 10 минут, и существует жесткое ограничение в 100 000 ячеек. Обработка наборов данных, близких к этому пределу в 100 000 ячеек, может занять около часа. Создание как t-SNE, так и UMAP-проекции удвоит время обработки. Чтобы сократить время выполнения, рассмотрите возможность создания только проекции UMAP, которая будет завершена примерно вдвое быстрее по сравнению с проекцией t-SNE для наборов данных из 20 000 ячеек и выше.
Экспорт прогнозов
После завершения рекластеризации вы должны увидеть следующее:
На этом этапе в браузере Loupe 6.0 и более поздних версиях вы можете экспортировать файл CSV с координатами проекции для проекций t-SNE и/или UMAP, которые были созданы из этого окна, нажав Экспорт проекций. .
Когда рекластеризация завершится, нажмите кнопку Готово , которая закроет окно рабочего процесса,
и вызовите новую проекцию и категорию в главном окне. Теперь вы можете найти его в отдельной категории «Анализ» в меню «Выбор вида». Вы также можете экспортировать CSV-файл проекции, щелкнув три вертикальные точки в селекторе видов для каждого типа графика. Набор данных PatientOnly Tutorial AML показан ниже:
Теперь вы можете найти его в отдельной категории «Анализ» в меню «Выбор вида». Вы также можете экспортировать CSV-файл проекции, щелкнув три вертикальные точки в селекторе видов для каждого типа графика. Набор данных PatientOnly Tutorial AML показан ниже:
Анализ рекластеризованных данных
Все операции в Лупе, выполненные, когда проекция, полученная в результате рекластеризации, видна, будут
ограничиваться штрих-кодами в этой проекции. можно
искать значимые гены, ограниченные рекластеризованными штрих-кодами, см. экспрессию генов
проекции с этим подмножеством клеток, а также просматривать списки клонотипов, ограниченные
активный набор штрих-кодов. Кроме того, выбор категории, полученной в результате повторной кластеризации,
автоматически загружать проекцию, связанную с этой рекластеризацией. Тем не менее, это
все еще возможно изменить прогнозы, пока активна категория, полученная из рекластеризации,
чтобы увидеть, как пересчитанные кластеры сопоставляются с большими данными.
Сохранение .cloupe в это время сохранит рекластеризованные прогнозы и категории
только (но не какие-либо вычисленные данные дифференциального выражения). Наконец, можно
либо настроить повторную кластеризацию, либо вызвать ее параметры, щелкнув значок Кнопка «Редактировать параметры повторной кластеризации» , расположенная под любой категорией повторной кластеризации.
Часто задаваемые вопросы о рекластеризации
Информация и характеристики
Какие продукты 10x Genomics можно фильтровать и повторно кластеризовать?
- Повторная кластеризация доступна для наборов данных Single Cell Gene Expression, Single Cell Multiome ATAC + Gene Expression и Visium Spatial Gene Expression. Если вы анализируете набор данных Single Cell Gene Expression с данными Feature Barcode, повторная кластеризация возможна, но алгоритм повторной кластеризации будет учитывать только гены в повторном анализе, а не создавать новые проекции на основе анализируемых признаков Feature Barcode.
- Повторная кластеризация доступна для наборов данных Single Cell Gene Expression, Single Cell Multiome ATAC + Gene Expression и Visium Spatial Gene Expression. Если вы анализируете набор данных Single Cell Gene Expression с данными Feature Barcode, повторная кластеризация возможна, но алгоритм повторной кластеризации будет учитывать только гены в повторном анализе, а не создавать новые проекции на основе анализируемых признаков Feature Barcode.
Сколько ячеек можно повторно кластеризовать? Есть ли ограничения?
- Вы можете повторно кластеризовать минимум десять ячеек и максимум 100 000 ячеек. Если ваш набор данных превышает 100 000 ячеек, вы можете использовать конвейер повторного анализа cellranger.
Повторно вычисляет PCA при повторной кластеризации?
- Да, повторная кластеризация повторно вычисляет PCA. Вы также можете указать точное количество основных компонентов, введя определенное число в поле «Количество основных компонентов» на шаге «Рекластеризация» в разделе 9.0047 Настройка параметров повторного анализа (для опытных пользователей) раскрывающийся список.
Какой тип прогноза генерирует рекластеризация (например, t-SNE, UMAP)?
- В браузере Loupe 5.1 и более поздних версиях рекластеризация позволяет создать проекцию t-SNE, проекцию UMAP или и то, и другое.
- В браузере Loupe 5.1 и более поздних версиях рекластеризация позволяет создать проекцию t-SNE, проекцию UMAP или и то, и другое.
Почему повторная кластеризация занимает так много времени?
- Не беспокойтесь, если повторная кластеризация займет некоторое время. Скорость рекластеризации зависит от вашей вычислительной мощности, размера набора данных и от того, выбираете ли вы одну или обе проекции t-SNE и UMAP. Набор данных из 30 000 ячеек с одной проекцией может занять около десяти минут или более. Если повторная кластеризация занимает намного больше времени, чем ожидалось, попробуйте перезапустить браузер Loupe.
Как указать митохондриальные гены для этапа фильтра UMI митохондрий?
- См. приведенный выше пример анализа пользовательского эталонного файла GTF макаки-резуса.
Как я могу отправить отзыв или запрос на добавление функций, связанных с рекластеризацией?
- Поделитесь отзывом с командой здесь или отправьте электронное письмо в нашу службу поддержки по адресу [email protected].
- Поделитесь отзывом с командой здесь или отправьте электронное письмо в нашу службу поддержки по адресу [email protected].



Автоматическая кластеризация | Снежинка Документация
Автоматическая кластеризация — это служба Snowflake, которая беспрепятственно и непрерывно управляет всей рекластеризацией кластеризованных таблиц по мере необходимости.
Обратите внимание, что после определения кластеризованной таблицы рекластеризация не обязательно начинается немедленно. Snowflake выполняет повторную кластеризацию кластеризованной таблицы только в том случае, если она выиграет от операция.
Примечание
Если в вашей учетной записи все еще доступна ручная повторная кластеризация, возможно, автоматическая кластеризация еще не включена для вашей учетной записи. Дополнительные сведения см. в разделе Рекластеризация вручную — устарело.
Преимущества автоматической кластеризации
Простота обслуживания
Автоматическая кластеризация устраняет необходимость выполнения любой из следующих задач:
Мониторинг состояния кластеризованных таблиц.
Вместо этого, когда для этих таблиц выполняется DML, Snowflake отслеживает и оценивает таблицы, чтобы определить, выиграют ли они от повторной кластеризации, и автоматически перегруппирует их по мере необходимости.
Назначение складов в вашей учетной записи для повторной кластеризации.
Snowflake выполняет автоматическую повторную кластеризацию в фоновом режиме, и вам не нужно указывать используемый склад.

Все, что вам нужно сделать, это определить ключ кластеризации для каждой таблицы (если это необходимо), и Snowflake будет управлять всем будущим обслуживанием.
Полный доступ
Вы можете приостановить и возобновить автоматическую кластеризацию для кластеризованной таблицы в любое время с помощью ALTER TABLE … SUSPEND / RESUME RECLUSTER. Пока автоматическая кластеризация приостановлена
для таблицы таблица никогда не подвергается автоматической повторной кластеризации, независимо от ее состояния кластеризации, и, следовательно, не влечет за собой никаких связанных кредитных расходов.
Вы также можете в любое время удалить ключ кластеризации для кластеризованной таблицы, что предотвратит повторную кластеризацию таблицы в будущем.
Неблокирующий DML
Автоматическая кластеризация прозрачна и не блокирует операторы DML, выдаваемые таблицам во время их повторной кластеризации.
Оптимальная эффективность
Благодаря автоматической кластеризации Snowflake внутренне управляет состоянием кластеризованных таблиц, а также ресурсами (серверами, памятью и т. д.), используемыми для всех автоматических кластеризаций. операции. Это позволяет Snowflake динамически распределять ресурсы по мере необходимости, что приводит к наиболее эффективной и действенной повторной кластеризации.
Кроме того, автоматическая кластеризация не выполняет ненужной повторной кластеризации. Повторная кластеризация запускается, только если/когда таблица получит выгоду от операции.
Использование кредитов и склады для автоматической кластеризации
Автоматическая кластеризация потребляет кредиты Snowflake, но не требует предоставления виртуального склада. Вместо этого Snowflake внутренне управляет и обеспечивает эффективное использование ресурсов.
Использование для повторной кластеризации таблиц.
Вместо этого Snowflake внутренне управляет и обеспечивает эффективное использование ресурсов.
Использование для повторной кластеризации таблиц.
С вашей учетной записи выставляется счет только за фактические кредиты, потребленные автоматическими операциями кластеризации в ваших кластеризованных таблицах.
Важно
После включения или возобновления автоматической кластеризации для кластеризованной таблицы, если с момента повторной кластеризации таблицы прошло некоторое время, вы можете столкнуться с активностью повторной кластеризации (и соответствующие кредитные расходы), поскольку Snowflake приводит таблицу в состояние оптимальной кластеризации. Как только таблица будет оптимально кластеризована, активность рекластеризации прекратится.
Аналогично, определение ключа кластеризации в существующей таблице или изменение ключа кластеризации в кластеризованной таблице может инициировать повторную кластеризацию и начисление кредита.
Чтобы предотвратить любые непредвиденные кредитные расходы, мы рекомендуем начать с одной или двух выбранных таблиц и следить за кредитными расходами, связанными с поддержанием правильной кластеризации таблиц. по мере выполнения DML. Это поможет вам установить базовый уровень количества кредитов, израсходованных на операцию рекластеризации.
по мере выполнения DML. Это поможет вам установить базовый уровень количества кредитов, израсходованных на операцию рекластеризации.
Включение автоматической кластеризации для таблицы
В большинстве случаев для включения автоматической кластеризации для таблицы не требуется никаких задач. Вы просто определяете ключ кластеризации для таблицы.
Однако правило не применяется к таблицам, созданным путем клонирования (CREATE TABLE … CLONE …)
из исходной таблицы, имеющей ключи кластеризации. Новая таблица начинается с приостановленной автоматической кластеризации, даже если автоматическая
Кластеризация для исходной таблицы не приостанавливается. (Это верно, если команда CLONE клонировала таблицу, схема
Подсказка
Перед определением ключа кластеризации для таблицы рассмотрите следующие условия, которые могут привести к повторной кластеризации (и соответствующей оплате кредита):
Таблица не имеет оптимальной кластеризации.
Дополнительные сведения см. в разделе Микроразделы и кластеризация данных.Ключ кластеризации в таблице изменился.
 Дополнительные сведения см. в разделе Микроразделы и кластеризация данных.
Дополнительные сведения см. в разделе Микроразделы и кластеризация данных.Поэтому мы рекомендуем начать с одной или двух выбранных таблиц и оценить влияние автоматической кластеризации на эти таблицы. Как только вы освоитесь/познакомитесь с тем, как Автоматическая кластеризация выполняет повторную кластеризацию, после чего вы можете определить ключи кластеризации для других ваших таблиц.
Сведения о выборе оптимальных ключей кластеризации см. в разделе Стратегии выбора ключей кластеризации.
Чтобы добавить кластеризацию к таблице, вы также должны иметь привилегии USAGE или OWNERSHIP для схемы и базы данных, которые содержать таблицу.
Приостановка автоматической кластеризации для таблицы
Чтобы приостановить автоматическую кластеризацию для таблицы, используйте команду ALTER TABLE с предложением SUSPEND RECLUSTER . Например:
ИЗМЕНИТЬ ТАБЛИЦУ t1 ПРИОСТАНОВИТЬ РЕКЛАСТЕР; ПОКАЗАТЬ ТАБЛИЦЫ, КАК 't1'; +---------------------------------+------+-------- -------+-------------+-------+---------+---------- --+------+-------+-----------+----------------+---- ------------------+ | создан_на | имя | имя_базы_данных | имя_схемы | вид | комментарий | кластер_по | строки | байты | владелец | удерживание_время | автоматическая_кластеризация | +---------------------------------+------+-------- -------+-------------+-------+---------+---------- --+------+-------+-----------+----------------+---- ------------------+ | Чт, 12 апр 2018 13:29:01 -0700 | Т1 | ТЕСТДБ | МОЯ_СХЕМА | ТАБЛИЦА | | ЛИНЕЙНЫЙ(C1) | 0 | 0 | СИСАДМИН | 1 | ВЫКЛ | +---------------------------------+------+-------- -------+-------------+-------+---------+---------- --+------+-------+-----------+----------------+---- ------------------+
Возобновление автоматической кластеризации для таблицы
Чтобы возобновить автоматическую кластеризацию для кластеризованной таблицы, используйте команду ALTER TABLE с RESUME RECLUSTER 9Пункт 0028. Например:
Например:
ALTER TABLE t1 RESUME RECLUSTER; ПОКАЗАТЬ ТАБЛИЦЫ, КАК 't1'; +---------------------------------+------+-------- -------+-------------+-------+---------+---------- --+------+-------+-----------+----------------+---- ------------------+ | создан_на | имя | имя_базы_данных | имя_схемы | вид | комментарий | кластер_по | строки | байты | владелец | удерживание_время | автоматическая_кластеризация | +---------------------------------+------+-------- -------+-------------+-------+---------+---------- --+------+-------+-----------+----------------+---- ------------------+ | Чт, 12 апр 2018 13:29:01 -0700 | Т1 | ТЕСТДБ | МОЯ_СХЕМА | ТАБЛИЦА | | ЛИНЕЙНЫЙ(C1) | 0 | 0 | СИСАДМИН | 1 | НА | +---------------------------------+------+-------- -------+-------------+-------+---------+---------- --+------+-------+-----------+----------------+---- ------------------+
Совет
Прежде чем возобновить автоматическую кластеризацию для кластеризованной таблицы, примите во внимание следующие условия, которые могут вызвать повторную кластеризацию (и соответствующие расходы по кредиту):
Дополнительные сведения см. в разделах Микроразделы и кластеризация данных и Ключи кластеризации и кластеризованные таблицы.
в разделах Микроразделы и кластеризация данных и Ключи кластеризации и кластеризованные таблицы.
Просмотр стоимости автоматической кластеризации
Автоматическая кластеризация потребляет кредиты, поскольку использует бессерверные вычислительные ресурсы для автоматизированное фоновое обслуживание каждой кластеризованной таблицы, включая первоначальную кластеризацию и повторную кластеризацию по мере необходимости. Чтобы узнать, сколько кредитов на час вычислений потребляются автоматической кластеризацией, см. «Таблица кредитов бессерверных функций» в Таблица потребления услуг Snowflake.
Пользователи с соответствующими правами могут просматривать стоимость автоматической кластеризации с помощью Snowsight, Классическая консоль или SQL:
- Снежный прицел
Выберите Администратор » Использование.
- Классическая консоль
Нажмите «Учетная запись» » Оплата и использование
Затраты на автоматическую кластеризацию отображаются как отдельный склад Snowflake с именем AUTOMATIC_CLUSTERING.
- SQL
Запрос любого из следующих:
Табличная функция AUTOMATIC_CLUSTERING_HISTORY (в информационной схеме Snowflake).
AUTOMATIC_CLUSTERING_HISTORY Просмотр (в разделе Использование учетной записи).
Следующие запросы могут быть выполнены для представления AUTOMATIC_CLUSTERING_HISTORY:
Запрос: Автоматическая кластеризация истории затрат (по дням, по объектам)
Этот запрос предоставляет список таблиц с автоматической кластеризацией и объем кредитов, потребленных через службу за последние 30 дней, разбито по дням. Любые нарушения в потреблении кредита или постоянно высокое потребление являются сигналами для дополнительного расследования.
SELECT TO_DATE(start_time) КАК дата, имя_базы_данных, имя_схемы, имя_таблицы, СУММ(использованные кредиты) КАК кредиты_использованные ОТ snowflake.account_usage.automatic_clustering_history ГДЕ start_time >= DATEADD(месяц,-1,CURRENT_TIMESTAMP()) СГРУППИРОВАТЬ ПО 1,2,3,4 ЗАКАЗАТЬ ПО 5 DESC;Запрос: история автоматической кластеризации и среднее значение m-day
Этот запрос показывает среднее ежедневное потребление кредитов автоматической кластеризацией, сгруппированное по неделям за последний год.

