
Парсинг постов и их статистики в Instagram при помощи кода на Python
В этом уроке мы разберем с вами код, который позволит скачать контент произвольного аккаунта в инстаграм и сохранить его в формате CSV, пригодном для дальнейшего исследования.
Код использует API инструменты от LevPasha. GitHub
UPDATE 03.09.2020
Внимание! На данный момент страница проекта на GitHub удалена, а инструменты для вытаскивания ID аккаунтов, описанные в статье, не работают. Сама библиотека еще работает, но ее работу нужно изучать.
Небольшие аккаунты в районе 1000-2000 постов собираются быстро, как раньше, и без видимых усилий.
Скачать библиотеку Instagram-API-python вы можете по ссылкам ниже. Соответственно, та часть инструкции, которая касается скачивания библиотеки из GitHub более не актуальна, просто разархивируйте скачанный файл, при помощи CD войдите в получившуюся директорию, установите, и продолжайте инструкцию с этого момента.
UPDATE 06.09.2020 — Как самостоятельно получить ID аккаунта в Instagram
- Открываем страницу нужным аккаунтом в Google Chrome.
- Щелкаем правой кнопкой, просмотреть код страницы. (F12 на Windows; ⌥+⌘+i на Mac OS)
- Там переключаемся в консоль (Console) при помощи кнопки внизу, и вводим в консоли window._sharedData.config.viewerId
- Нажимаем Enter
- Если получили ошибку — перезагружаем страницу.
- На выходе получаем ID аккаунта, можно вставлять в код парсера и парсить!
Для начала — немного об использовании официального API от Instagram. С 15 октября 2019 года регистрация новых клиентов через Instagram Developer прекращена, и не предвидится. Если вы успели зарегистрироваться раньше — доступ еще есть, но вам потребуется получить расширенные права через подтверждение приложения. Без них вы сможете скачать данные только по 20 последним публикациям, не более. Если не зарегистрированы, вам доступен API Instagram Basic Display.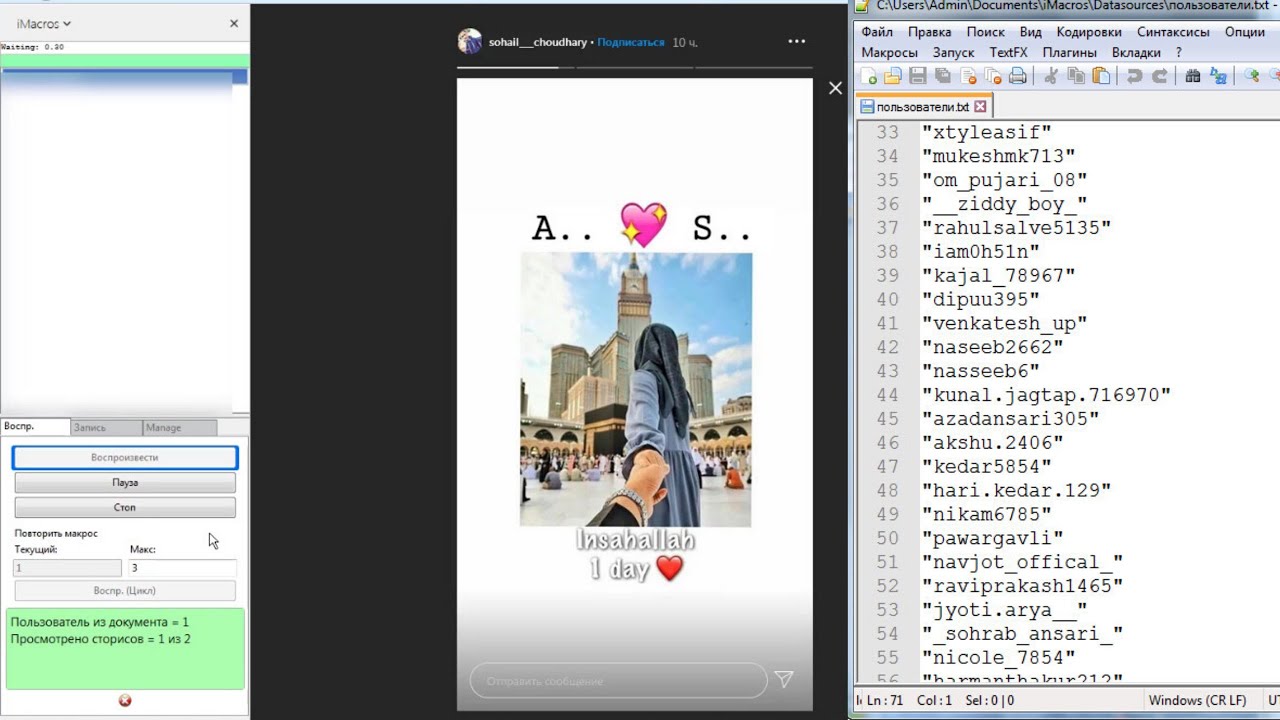 О его возможностях можно почитать по ссылке. Факт в том, что официальный API требует подтверждения вас, как доверенного лица от Instagram.
О его возможностях можно почитать по ссылке. Факт в том, что официальный API требует подтверждения вас, как доверенного лица от Instagram.
Этих проблем позволяет избежать использование неофициальных API. И самый популярный из них — упомянутый выше Instagram-API-python от LevPasha. API написан на Python, так что для взаимодействия с ним мы так же будем использовать Python.
В разделе Examples на GitHub LevPasha можно найти примеры кода для загрузки контента в инсту, для массового удаления своего контента, и еще много полезных фич. Советую ознакомиться.
Покончили с прелюдией, начинаем.
Подготовка
Вам потребуется установленный язык Python на вашей системе. Так как в своей работе я использую язык R и Python для анализа данных, то рекомендую Anaconda — дистрибутив языков программирования Python и R, включающий набор популярных свободных библиотек, объединённых темой науки о данных и машинного обучения. Дистрибутив скачивается единожды, и вся последующая конфигурация, в том числе установка дополнительных модулей, может проводится в офлайне.
Дистрибутив скачивается единожды, и вся последующая конфигурация, в том числе установка дополнительных модулей, может проводится в офлайне.
Последнюю версию дистрибутива можете найти здесь. Скачивайте версию для Python 3.7, устанавливайте и запускайте Jupyter. Процесс создания проекта на сложный, вам всего лишь нужно определиться с рабочей директорией и создать там новую записную книжку Jupyter Notebook.
Никто так же не запрещает вам использовать терминал с Python или любой другой способ взаимодействовать с кодом.
Установка Instagram-API-python
Все инструкции по установке можно найти на странице Instagram-API-python в GitHub LevPasha. Там же вы найдете условия и ограничения по использованию API.
Главное, что нужно знать. Для успешного анализа постов необходимо подтвердить свой номер телефона в учетной записи Instagram, которая будет использоваться в коде.
Новый поддельный аккаунт Instagram с неподтвержденным номером телефона через 1-24 часа будет заблокирован и не сможет выполнять никаких запросов. Все запросы будут перенаправлены на страницу https://instagram.com/challenge.
Все запросы будут перенаправлены на страницу https://instagram.com/challenge.
Кстати, сам проект от LevPasha, по сути, представляет собой Python-порт другого проекта кастомной API, написанного на PHP.
После установки Python (в составе Conda или отдельно), запустите консоль. Сначала копируем содержимое Instagram-API-python в GitHub LevPasha.
git clone https://github.com/LevPasha/Instagram-API-python.git
Переходим в только что скачанный каталог:
cd Instagram-API-python
Устанавливаем зависимые файлы и библиотеки: (необязательно, нужно только если соберетесь закачивать в инсту фотки или видео)
pip install -r requirements.txt
 txt
txtДалее устанавливаем сам InstagramApi через pip. В консоли выполняем:
pip install InstagramApi
Или
py -m install InstagramApi
Готово. После этого вы сможете вызывать API от LevPasha в любом коде на Python через команду
from InstagramAPI import InstagramAPI
Скачиваем контент любого Instagram аккаунта
Далее я привожу различные части одного кода в Python и объясняю его значение. В конце урока я прикреплю файлы, которые можно использовать для старта операции, подавая на них логин и пароль вашего аккаунта, а так же ID любых аккаунтов, как аргументы. В коде ниже логин, пароль от аккаунта для авторизации, а так же ID аккаунтов для скачивания постов будут поданы напрямую через код при выполнении. Учитывайте эту разницу.
В конце урока я прикреплю файлы, которые можно использовать для старта операции, подавая на них логин и пароль вашего аккаунта, а так же ID любых аккаунтов, как аргументы. В коде ниже логин, пароль от аккаунта для авторизации, а так же ID аккаунтов для скачивания постов будут поданы напрямую через код при выполнении. Учитывайте эту разницу.
Для начала импортируем необходимые библиотеки. InstagramAPI уже должен быть установлен по инструкции выше.
from InstagramAPI import InstagramAPI import time import sys import traceback import pandas as pd import datetime
Если вы не устанавливали зависимые библиотеки, то после выполнения появится сообщение 
После этого прогоняем следующую часть кода. Это и есть та часть, которая запускает сбор данных. В ней обращаем внимание на функцию time.sleep(10). Она будет ставить на 10-секундную паузу процесс в случае ошибки.
class MyInstaCrawler(InstagramAPI):
"""
Want to have a direct control over the instaAPI. When the users are loaded from api, the best way is to store
them in the queue, where it would have listeners - parsers that would do next job.
"""
def __init__(self, username, password):
super().__init__(username, password)
def getTotalFollowers(self, usernameId):
import datetime
next_max_id = ''
followers = []
while 1:
try:
if self.getUserFollowers(usernameId, next_max_id):
temp = self. LastJson
for item in temp["users"]:
followers.append(item)
print('Followers: %s ' % len(followers))
temp['collected_date'] = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
if temp.get("big_list") is None:
return followers
elif temp['big_list'] is False:
return followers
next_max_id = temp["next_max_id"]
except:
print(traceback.format_exc())
print("Sleeping 10 secs")
time.sleep(10) LastJson
for item in temp["users"]:
followers.append(item)
print('Followers: %s ' % len(followers))
temp['collected_date'] = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
if temp.get("big_list") is None:
return followers
elif temp['big_list'] is False:
return followers
next_max_id = temp["next_max_id"]
except:
print(traceback.format_exc())
print("Sleeping 10 secs")
time.sleep(10)
LastJson
for item in temp["users"]:
followers.append(item)
print('Followers: %s ' % len(followers))
temp['collected_date'] = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
if temp.get("big_list") is None:
return followers
elif temp['big_list'] is False:
return followers
next_max_id = temp["next_max_id"]
except:
print(traceback.format_exc())
print("Sleeping 10 secs")
time.sleep(10)После этого ваша программа ожидает ввода инструкций. Внимательно посмотрим на следующую часть кода.
В ней нужно вставить ваши значения. В поле usr вставляем имя пользователя аккаунта Instagram, при помощи которого будет осуществляться логин в систему, а в поле pasw, соответственно, пароль от этого аккаунта.
Что это должен быть за аккаунт? Желательно, не ваш основной. Шанс на блокировку в результате действий минимален, но перестраховаться не помешает. К тому же, если вы будете параллельно использовать ваш аккаунт для парсинга в процессе самого парсинга, то код вылетит с ошибкой. Так что создаем новый, чистый аккаунт, заполняем его и подтверждаем телефонный номер. Выкладываем несколько постов, находим друзей и живем с ним несколько дней. После этого его данные можно использовать для парсинга.
Шанс на блокировку в результате действий минимален, но перестраховаться не помешает. К тому же, если вы будете параллельно использовать ваш аккаунт для парсинга в процессе самого парсинга, то код вылетит с ошибкой. Так что создаем новый, чистый аккаунт, заполняем его и подтверждаем телефонный номер. Выкладываем несколько постов, находим друзей и живем с ним несколько дней. После этого его данные можно использовать для парсинга.
Далее, в поле args вставляем ID аккаунтов, от которых мы хотим получить контент, стату и мотоцикл. Как узнать ID аккаунта? При помощи специальных сервисов. Вот несколько бесплатных:
- https://codeofaninja.com/tools/find-instagram-user-id
- http://www.otzberg.net/iguserid/index.php
Кстати, советую где нибудь сохранить ID аккаунтов. Определить потом, чей этот ID можно будет только по результату работы кода.
ВАЖНО. Аккаунт, из-под которого осуществляется вход в систему, должен быть подписан на скрытые аккаунты, с которых предполагается скачивание данных. Если вы хотите скачать данные по закрытому аккаунту, а аккаунт для авторизации на него не подписан (и, соответственно, не имеет разрешение на просмотр контента), то код вылетит с ошибкой.
Если вы хотите скачать данные по закрытому аккаунту, а аккаунт для авторизации на него не подписан (и, соответственно, не имеет разрешение на просмотр контента), то код вылетит с ошибкой.
Так происходит, потому что, фактически, Instagram API от LevPasha представляет из себя эмулятор приложения Instagram для Android. Он заходит на каждый аккаунт в каждый пост, читает и записывает то что видит в таблицу. Просто делает это очень быстро. Если вы не можете зайти на этот аккаунт из-за его настроек приватности, получить доступ к его контенту будет нельзя.
Внимательно перепроверяем все настройки. Стоят ли кавычки вокруг каждого ID аккаунта? Запятые? Фигурная скобка в конце?
Если все окей, то запускаем последнюю часть кода.
usr = "Instagram_Login" pasw = "Instagram_Password" ic = MyInstaCrawler(usr, pasw) ic.username'] = username reduced_r['caption.text'] = caption_text reduced_r['likes.count'] = r['like_count'] reduced_r['video_views'] = view_count reduced_r['comments.count'] = r['comment_count'] reduced_r['link'] = 'https://instagram.com/p/' + r['code'] total_results.append(reduced_r) except Exception as e: print(e) print('Finished for %s, id: %s' % (username, arg)) except ValueError: print("Pass ID as an argument. Couldn't transform to int") except: print(traceback.format_exc()) df = pd.DataFrame(total_results) df.to_csv('Database %s.csv' % datetime.datetime.now().strftime("%Y-%m-%d,%H:%M:%S"))
 login()
args = ["отдельные", "айдишки", "каждого", "аккаунта", "для", "парсинга", "в кавычках через запятую"]
total_results = []
for arg in args:
try:
arg = int(arg)
results = ic.getTotalUserFeed(arg)
if results is None:
print('Some problems with id %s. No results.' % arg)
continue
print('Gathered %s media, saving...' % len(results))
if len(results) != 0:
username = results[0]['user']['username']
for r in results:
try:
reduced_r = {}
date = datetime.datetime.fromtimestamp(r['taken_at'])
date = date.strftime("%Y-%m-%d"'T'"%H:%M:%S"'Z')
caption = r['caption']
caption_text = ''
if caption is not None:
caption_text = caption['text']
view_count = 0
if r['media_type'] == 2:
if r.get('view_count'):
view_count = int(r['view_count'])
reduced_r['created_time'] = date
reduced_r['user.
login()
args = ["отдельные", "айдишки", "каждого", "аккаунта", "для", "парсинга", "в кавычках через запятую"]
total_results = []
for arg in args:
try:
arg = int(arg)
results = ic.getTotalUserFeed(arg)
if results is None:
print('Some problems with id %s. No results.' % arg)
continue
print('Gathered %s media, saving...' % len(results))
if len(results) != 0:
username = results[0]['user']['username']
for r in results:
try:
reduced_r = {}
date = datetime.datetime.fromtimestamp(r['taken_at'])
date = date.strftime("%Y-%m-%d"'T'"%H:%M:%S"'Z')
caption = r['caption']
caption_text = ''
if caption is not None:
caption_text = caption['text']
view_count = 0
if r['media_type'] == 2:
if r.get('view_count'):
view_count = int(r['view_count'])
reduced_r['created_time'] = date
reduced_r['user.
Процесс начнется с серии ошибок логина, после чего вы получите надпись об успешном логине. После этого начнется процесс сбора постов. Выглядеть будет как то так:
Request return 405 error!
{'message': '', 'status': 'fail'}
Request return 404 error!
Login success!
Gathered 18 media, saving. ..
Finished for ваш аккаунт, id: айди вашего аккаунта ..
Finished for ваш аккаунт, id: айди вашего аккаунта
..
Finished for ваш аккаунт, id: айди вашего аккаунтаЕсли увидите ошибку Pass ID as an argument. Couldn’t transform to int, перепроверьте, точно ли каждый ID находится в кавычках, и нет ли лишних или отсутствующих запятых.
После окончания процесса, готовая таблица появится в том же каталоге, в котором запускался код, с названием
Готово! По возникающим вопросам, можете писать комментарии под этим постом на Open SMM Asia, или же в мой Facebook.
Если вы хотите использовать этот код в другом приложении, подавая на него аргументы извне, можете скачать специальную версию. Она будет ждать первым аргументом логин, вторым аргументом пароль, и последующими аргументами ID всех аккаунтов через запятую.
insta_api_saver_v3_opensmm_asia.py_Скачать
Тэги урока: api, instagram, levpasha, parsing Назад: Исследование данных в Digital маркетингеКак парсить инстаграм? Ваш окончательный путеводитель 2023
Предприятия могут использовать парсинг в социальных сетях для сбора полезной информации из социальных сетей для ряда целей, таких как исследование рынка, мониторинг бренда и привлечение потенциальных клиентов.
Один из лучших способов для бизнеса увеличить свое присутствие в Интернете, потенциальных клиентов и продажи через Instagram.
Недавние исследования также показали, что:
- 90% пользователей Instagram следят за корпоративным аккаунтом, что делает его четвертой по популярности социальной сетью в мире.
- В 2022 году маркетологи со всего мира оценили Instagram как вторую по популярности социальную сеть в мире.
- Instagram использовали 79% маркетологов для рекламы своих брендов.
Вы должны очистить большое количество общедоступных данных Instagram, чтобы использовать их данные. Извлечение данных вручную занимает много времени; для ускорения и управления данными вам необходимо использовать веб-приложение для парсинга.
В этой статье дается определение парсинга Instagram, исследуется его легитимность, перечисляются шесть лучших парсеров Instagram и обсуждаются, какие данные Instagram следует извлекать.
Содержание
Как работает парсинг Instagram?Парсинг Instagram — это компьютеризированное извлечение открыто существующих фактов, таких как ключевые слова и хэштеги, сообщения и профили, из учетных записей социальных сетей.
Один из лучших способов для бизнеса повысить свою видимость в Интернете, потенциальных клиентов и доходов через Instagram. Предприятия могут собирать полезную информацию из Instagram для различных целей, включая исследования рынка, мониторинг бренда и создание лидов.
Разрешен ли парсинг Instagram?Извлечение общедоступных данных Instagram является законным, если ваши операции по очистке не наносят вреда очищаемому веб-сайту, например, путем дублирования или ухудшения обслуживания и работы веб-сайта.
Вы не собираете личную информацию (PII). Вы можете собирать информацию с веб-сайтов приличным образом, соблюдая определенные передовые технологические методы веб-скрейпинга, такие как:
- Использование прокси-сайтов вместе со скребком Instagram.
- Выбор надежного парсера Instagram, способного управлять мерами защиты от парсинга, такими как CAPTCHA.
- Если возможно, используйте API веб-сайта вместо парсера Instagram.
- Использование безголового браузера.
- Соблюдение правил онлайн парсинга, описанных в файле robot.txt для сайта

Данные Instagram настолько широко доступны для широкой публики, что мы можем разделить их на три группы, например:
- Ключевые слова или хэштеги: Вы можете получить URL-адреса сообщений и URL-адреса мультимедиа, которые содержат определенное ключевое слово или хэштег.
- Сообщений: Вы можете получить информацию о публикациях в Instagram, такую как URL-адрес, постоянная ссылка, дата, количество лайков и комментариев, а также идентификатор автора публикации.
- Профили: Введя определенное имя пользователя или URL-адрес, вы можете получить доступ ко всей общедоступной информации в профиле Instagram, включая публикации, URL-адреса изображений, отметки «Нравится», комментарии и общее количество подписчиков и подписчиков.
Вы также можете прочитать
- 13 лучших панелей подписчиков в Instagram
- Как идеально оптимизировать Instagram Bio
- Почтовый обзор
- 3 причины, почему маркетинг в социальных сетях настолько силен
 API парсинга веб-страниц для парсинга Instagram
API парсинга веб-страниц для парсинга InstagramПосредством запросов и ответов API-интерфейсы парсинга веб-страниц позволяют пользователям получать доступ и собирать данные из веб-источников. Например, API парсинга веб-страниц использует протокол передачи гипертекста для доставки запроса пользователя на подключение к целевому веб-сайту (HTTP).
Затем он получает запрошенные данные в формате XML или JSON с целевого веб-сайта.
Пункт назначения веб-сервер должен поддерживать API технология для использования API; в противном случае нельзя использовать API для сбора данных с веб-сервера. Данные Instagram можно получить любым способом:
- Используйте API-интерфейс Instagram Graph.
- Создайте свой Instagram API, используя веб-фреймворк, такой как FastAPI, и язык программирования, такой как Python.
- Используйте сторонние API парсинга.
Компании и создатели могут получать доступ к общедоступным данным из Instagram и получать их через API Instagram Graph. Вам не нужно беспокоиться о том, что вас заблокируют или признают злоумышленником, потому что он разрешает одобренный доступ к Instagram.
Вам не нужно беспокоиться о том, что вас заблокируют или признают злоумышленником, потому что он разрешает одобренный доступ к Instagram.
Если учетная запись Instagram, к которой вы стремитесь, бизнес счета, только тогда вы сможете использовать Instagram Graph API.
2. Парсинг-боты для инстаграма2.1 Парсеры с низким кодом и без кода
Как программисты, так и непрограммисты могут очищать данные Instagram, используя парсеры без кода или без кода, используя готовые шаблоны для сбора данных. Не написав ни строчки кода, вы можете собирать данные из Instagram с помощью парсера Instagram.
Стоимость аутсорсинга создания инфраструктуры для парсинга может быть выше, чем стоимость разработки внутреннего парсера Instagram.
Вы можете использовать сервис веб-скрейпинга для очистки Instagram, если у вас ограниченный бюджет и вы не хотите тратить время на обслуживание программного обеспечения для веб-скрейпинга.
2.2 Облачные парсеры
Пользователи могут использовать облачные парсеры для очистки Instagram. Собранные данные Instagram хранятся не локально на устройстве пользователя, а в облаке. Если вам нужно получить много данных из Instagram, гораздо дешевле запустить парсер Instagram в облаке.
Собранные данные Instagram хранятся не локально на устройстве пользователя, а в облаке. Если вам нужно получить много данных из Instagram, гораздо дешевле запустить парсер Instagram в облаке.
2.3 Парсеры с открытым исходным кодом
Пользователи могут собирать информацию с сети социальных сетей и веб-источники без оплаты лицензии благодаря поисковым роботам с открытым исходным кодом. В соответствии со своими потребностями в очистке Instagram пользователи могут изменять программы очистки Instagram с открытым исходным кодом.
3. Собственные парсеры для парсинга InstagramСоздание собственного парсера — еще один способ очистить Instagram. Чтобы создать среду кода, вы можете использовать библиотеки очистки, написанные на таких языках, как javascript, python и ruby. Пользователи могут настраивать и изменять внутренние парсеры Instagram в соответствии с потребностями своего бизнеса.
Если вам не хватает базовых навыков программирования или у вас меньше опыта в качестве разработчика, некоторые языки программирования, такие как Javascript, могут быть трудны для понимания. Вы должны изучить интернет-сообщество и ресурсы, доступные для языка программирования, прежде чем выбрать его.
Вы должны изучить интернет-сообщество и ресурсы, доступные для языка программирования, прежде чем выбрать его.
При сборе данных вы можете помочь парсеру Instagram, используя прокси-сервис. Парсеры Instagram, интегрированные с прокси-сервером, позволяют собирать обширные данные и получать доступ к материалам, адаптированным к региону.
Вы можете создать внутренний прокси-сервер вместо того, чтобы заключать договор на создание и обслуживание прокси-решения.
Если у вас нет денег на аутсорсинг вашего прокси-сервиса и вам требуется только небольшой объем данных Instagram, имеет смысл использовать аутсорсинговое прокси-решение. Однако создание и поддержание деятельность через доверенных лиц требуется квалифицированная техническая команда для внутренних прокси-сервисов.
Быстрые ссылки
- Как использовать социальные сети
- 25+ лучших SEO-инструментов
- Полное руководство по инструментам Bing для веб-мастеров для SEO
Вы должны очистить значительный объем общедоступных данных Instagram, если хотите использовать его данные. Извлечение данных вручную, оптимизация и ускорение процесса сбора данных и использование инструмента веб-скрейпинга занимает много времени.
Извлечение данных вручную, оптимизация и ускорение процесса сбора данных и использование инструмента веб-скрейпинга занимает много времени.
Мы проанализировали для вас 5 лучших инструментов для парсинга Instagram. К ним относятся веб-скрейперы без кода и API-интерфейсы веб-скрейпинга.
Скребки Instagram без кода1. Bright DataВедущая веб-платформа данных в мире называется Bright Data. Самые последние данные легко доступны для предприятий, которые могут использовать их для принятия более эффективных решений. Более того, Bright Data предоставляет эффективные инструменты для компаний любого размера.
Его также можно использовать для правильного, быстрого и быстрого извлечения данных из Интернета. Он имеет такие функции, как логический поиск и просмотр веб-страниц. Другими словами, вы должны проверить Bright Data если вы ищете лучшие парсеры Instagram.
Он также известен производством первоклассных решений, упрощающих анализ и извлечение полезных данных из социальных сетей. Кроме того, он прост в использовании и может быстро данные урожая из ваших любимых профилей Instagram.
Кроме того, он прост в использовании и может быстро данные урожая из ваших любимых профилей Instagram.
🔥 Проверить Bright Data Ссылка на
2. SmartproxyРазнообразие прокси от SmartProxy доступны и необходимы для эффективного парсинга данных.
Вы получите автоматическую ротацию, как только присоединитесь, чтобы обезопасить себя. Доступ к SmartProxy Также будет доступен парсер Instagram. Он предназначен для сбора всех данных Instagram, которые вы можете себе представить.
Разработчики могут легко очистить любую веб-страницу и визуализировать javascript используя SmartProxy Scraper API, который поддерживает сотни прокси-серверов и безголовых браузеров. Даже не зная, как кодировать, Smartproxy Парсер Instagram действительно имеет успех 100%.
🔥 Проверить Smartproxy Ссылка на
API парсинга веб-страниц3. OxylabsРаботы С Нами Oxylabs, вы можете легко собирать данные из различных источников и искать тенденции в ваших данных. Следовательно, он стал популярным вариантом для предприятий, желающих собирать огромные объемы данных.
Следовательно, он стал популярным вариантом для предприятий, желающих собирать огромные объемы данных.
Тем не менее, Oxylabs хорошо известен своим инструментом для сбора данных Instagram и Scraper API в реальном времени. Это позволяет вам загружать все текущие открытые данные из Instagram без остановки. Для быстрого извлечения профилей, постов, хэштегов, подписчиков и заголовков Instagram.
🔥 Проверить Oxylabs Ссылка на
4. апифайапифай — это бесплатная платформа для веб-скрапинга, извлечения данных и автоматизации, которая быстро собирает информацию с любого веб-сайта. Сбор данных с любого веб-сайта с помощью Apify упрощается благодаря удобному пользовательскому интерфейсу.
Также легко автоматизировать процедуру сбора благодаря встроенным сценариям.
Кроме того, Apify предлагает ряд отчетов, которые могут помочь вам лучше понять ваши данные, а его персонал службы поддержки доступен круглосуточно, чтобы помочь вам максимально эффективно использовать Apify.
Поэтому вы используете этот замечательный инструмент для очистки Instagram. С их настраиваемыми прокси-серверами и возможностью адаптации к браузеру боты Apify также могут быть почти неотличимы от людей.
🔥 Проверьте Apify здесь
5. СоскобScrapingbee, лучший онлайн-API парсинга, позволяет разработчикам быстро и эффективно извлекать данные с веб-сайтов. Любой веб-сайт, будь то общедоступный или частный, может быть очищен для получения данных. Он также предлагает массу возможностей, упрощающих извлечение данных с веб-страниц.
Для пользователей, которые хотят быстро собрать все последние сообщения определенной учетной записи, Scrapingbee — лучший парсер Instagram.
Программное обеспечение простое и имеет опции для фильтрации сообщений по дате, местоположению и другим факторам. Кроме того, он предлагает безопасный парсинг и разрешает массовые загрузки постов. Таким образом, вы можете легко собрать все самые последние публикации с разных аккаунтов одновременно.
🔥 Проверьте ScrapingBee здесь
Вывод: как очистить Instagram?Удалив базовый HTML-код и данные из базы данных, соответствующий инструмент очистки сможет извлекать структурированные данные и контент из Instagram. Мы надеемся, что эта статья будет вам полезна при выборе парсера данных Instagram.
- Лучшие прокси-серверы Tripadvisor
- Лучшие прокси Etsy
- IPRoyal код купона
- Лучшие прокси TikTok
- Лучшие общие прокси
Первый шаг анализа данных Instagram: очистка и анализ данных формата JSON с использованием Python | by Iris S
Чтение через 5 мин.·
15 апреля 2020 г. Эпидемия COVID-19 привела к снижению потребительских расходов на товары второстепенной важности. Швейная промышленность является одной из отраслей, которая страдает больше всего, и роскошные дома моды принимают меры, чтобы транслировать «правильное сообщение» потребителям через основные каналы социальных сетей. Мы собираемся исследовать посты модных брендов в Instagram, чтобы изучить «послание», которое они хотят донести в эти особенно трудные дни.
Мы собираемся исследовать посты модных брендов в Instagram, чтобы изучить «послание», которое они хотят донести в эти особенно трудные дни.
Тем не менее, мы собираем данные о последних публикациях в IG-аккаунте модных домов для нашего анализа.
Официальный аккаунт Louis Vuitton в Instagram | @louisvuitton
Мы будем использовать Python для достижения этой цели, учитывая его универсальность и широкий спектр библиотек с открытым исходным кодом, которые мы могли бы легко использовать. Вот шаги, которые мы будем предпринимать:
Выбор пакетов Python:
- Сбор данных: instagram-scraper (неофициальный API с открытым исходным кодом)
- Очистка данных: pandas, json, glob, emoji, nltk
- Анализ данных: Google Sentiment Analysis API, matplotlib
import pandas as pd
import glob
import json
import re
import datetime 900 31 импортировать эмодзи
из wordcloud импортировать WordCloud, STOPWORDS
импортировать matplotlib.
из google.cloud импортировать язык как lg
из google.cloud.language импортировать перечисления
из google.cloud.language импортировать типы
из nltk.corpus импортировать стоп-слова
из nltk.tokenize import word_tokenizestop_words = set(stopwords.words('english'))
 pyplot как plt
pyplot как plt В части 1 мы поговорим о том, как очищать и обрабатывать данные JSON. Мы поработаем над некоторыми простыми текстовыми анализами во второй части.
Сбор данных
Приложение командной строки: Instagram-scraper
получение описания профиля пользователя, загрузка медиафайлов пользователя). Пожалуйста, найдите установку и подробное использование в этом репозитории Github.
После того, как все настроено, запустите команду в терминале (Mac OS) или в командной строке (Windows):
Например, мы могли бы структурировать следующую команду, чтобы предоставить список идентификаторов пользователей, которые мы хотим очистить. (в user.txt). В дополнение к метаданным мультимедиа по умолчанию мы также хотим включить информацию о профиле пользователя; последнее, но не менее важное: мы хотим очистить 50 самых последних сообщений и сохранить их в выходных данных вызова папки.
В дополнение к метаданным мультимедиа по умолчанию мы также хотим включить информацию о профиле пользователя; последнее, но не менее важное: мы хотим очистить 50 самых последних сообщений и сохранить их в выходных данных вызова папки.
instagram-scraper -f user.txt — медиа-метаданные — профиль-метаданные -m 50 -d вывод
Вывод: файлы JSON, содержащие метаданные сообщений
Некоторые люди могут предпочесть очищать сообщения IG, написав свой собственный скрипт, учитывая определенные ограничения в этом API. Не проблема! Существуют методы выполнения аналогичной задачи с использованием агентов Selenium и веб-браузера. Вот удивительная статья, которая показывает вам шаги.
Извлечение и очистка данных из дерева JSON
Вернемся к тому, что мы обсуждали до сих пор. К сожалению, результат, который мы получили, выполнив команды, еще не готов к использованию! Обратите внимание, что нужные нам данные вложены в дерево JSON. Поэтому мы начнем писать скрипт на Python, который анализирует и очищает данные и делает их пригодными для анализа.
Всегда первый шаг: изучите дерево JSON и найдите текст сообщения с ключом «текст».
Помните, что каждый идентификатор пользователя создает один отдельный файл JSON и сохраняется в выходной папке, поэтому мы можем использовать библиотеку glob с сопоставлением подстановочных знаков, чтобы найти все файлы с окончанием файла «JSON» и начать чтение данных внутри каждого из них:
file_list = glob.glob("*.json")file_merge=[]для файла в file_list:
с open(file, 'r') в виде текста:
jdata = json.load(text)
if jdata:
file_merge.append(jdata) Выведите этот шаг: список со всеми файлами JSON
— — —
Мы начнем с создания фрейма данных, который сохраняет проанализированные и очищенные данные:
df=pd.DataFrame(columns=['Id','post','likes','comments','date','sentiment','followers'])
— —
Вот что мы будем делать дальше:
- Перебрать каждую строку JSON. В каждой строке найдите путь к ключам, которые соответствуют каждому значению, которое мы хотим извлечь (например, «заголовок»: «контент публикации»).
- Для захваченного значения примените простые методы обработки текста, такие как удаление стоп-слов, эмодзи и специальных символов:

stop_words = set(stopwords.words('english')) def filter_stop(txt):
txt_tokens=word_tokenize (txt)txt_tokens=[слово в слово в txt_tokens, если слово не в stop_words]
return ' '.join(txt_tokens)def strip_emoji(text):new_text = re.sub(emoji.get_emoji_regexp(), r"", text) return new_text
Как очистить Instagram: пошаговое руководство с использованием Python
Парсинг в социальных сетях — отличный способ собрать ценные данные, будь то для исследовательских или коммерческих целей. И Instagram, пожалуй, самая прибыльная платформа на сегодняшний день. Тем не менее, его также сложно очистить как из-за технических, так и из-за юридических проблем.
В этом руководстве вы узнаете, какие данные Instagram можно очистить без проблем и какие инструменты следует выбрать, чтобы избежать блокировки IP-адреса. Кроме того, вы найдете два пошаговых руководства по созданию базового парсера Instagram с помощью Python — одно с использованием Requests, а другое — с Selenium. Если вы предпочитаете видео, у нас тоже есть:
Кроме того, вы найдете два пошаговых руководства по созданию базового парсера Instagram с помощью Python — одно с использованием Requests, а другое — с Selenium. Если вы предпочитаете видео, у нас тоже есть:
Содержание
- Что такое парсинг Instagram
- Как очистить Instagram на законных основаниях
- Выбор инструментов для парсинга Instagram
- Создание простого парсера Instagram на Python
- с помощью Selenium
- With Requests
Что такое парсинг Instagram — определение
Парсинг Instagram — это процесс автоматического сбора общедоступных данных с платформы социальных сетей. В зависимости от ваших знаний в области программирования, это делается с помощью готовых инструментов парсинга или специально созданных парсеров.
Мошенники в социальных сетях знают, что сбор данных может привести к совершенно новой сделке. Просто собирая информацию, такую как хэштеги или сообщения, вы можете проводить анализ рынка и настроений, отслеживать брендинг в Интернете или находить влиятельных лиц для своего бизнеса.
Просто собирая информацию, такую как хэштеги или сообщения, вы можете проводить анализ рынка и настроений, отслеживать брендинг в Интернете или находить влиятельных лиц для своего бизнеса.
Как очистить Instagram легально
Веб-скраппинг остается серой зоной с точки зрения закона, вдвойне, когда речь идет о социальных сетях. Мы не юристы, но общепризнано, что парсинг веб-сайта допустим (несмотря на то, что веб-мастера хотят, чтобы вы думали), если: а) данные общедоступны, б) они не защищены авторским правом или в) личная информация .
Instagram не исключение. Пока вы действуете осторожно, царапать платформу разрешено. Однако есть одна вещь, которую вы не должны делать, так это сбор данных для входа в систему. Это верный способ подать на себя в суд, если Мета узнает о ваших действиях.
Наконец, законодательство устанавливает различные стандарты в зависимости от варианта использования. Например, вы получите больше свободы действий, если будете собирать информацию для исследований, а не для коммерческих целей. Рекомендуется обратиться к юристу, если вы не уверены в своих обстоятельствах.
Рекомендуется обратиться к юристу, если вы не уверены в своих обстоятельствах.
Итак, какие данные можно очистить без входа в систему?
Существует три основных категории общедоступных данных:
- Хэштеги: URL-адрес публикации, URL-адрес СМИ, идентификатор автора публикации.
- Профили: последних сообщений, внешних URL-адресов, лайков, изображений, комментариев, количества лайков на пост и подписчиков.
- Сообщения: последних сообщений, дата, URL, комментарии, лайки, идентификатор автора.
Но имейте в виду, что Instagram часто меняет правила, поэтому всегда полезно проверить, что вы можете очистить, прежде чем делать это.
Выбор инструментов для парсинга Instagram
Обычно существует три типа инструментов, которые вы можете использовать для парсинга Instagram: 1) специально созданный парсер, 2) API парсинга веб-страниц или 3) готовый парсер.
Если у вас есть знания в области программирования, вы можете попытаться создать собственный веб-скрейпер с помощью таких фреймворков, как Selenium или Playwright. Он может обрабатывать сложную автоматизацию, и, поскольку вы сами присматриваете за своим парсинг-ботом, вы можете адаптировать его ко всем структурным изменениям, которые Instagram предлагает вам.
Он может обрабатывать сложную автоматизацию, и, поскольку вы сами присматриваете за своим парсинг-ботом, вы можете адаптировать его ко всем структурным изменениям, которые Instagram предлагает вам.
У Instagram больше нет собственного официального API (не то чтобы он был бесполезен). Но есть много надежных провайдеров, которые предлагают веб- API для парсинга . Например, Apify предоставляет различные API для сбора различных точек данных Instagram, таких как Instagram Profile Scraper и Post Scraper. Или вы можете использовать веб-скрейперы общего назначения на основе больших пулов прокси-серверов, таких как Smartproxy Web Scraping API или Zyte Smart Proxy Manager.
Если у вас нет навыков программирования, вы можете купить готовые парсеры , такие как Parsehub, Octoparse или сборщик данных Bright Data. Эти инструменты позволяют извлекать данные, визуально щелкая элементы или используя удобные шаблоны.
Как очистить данные Instagram: пошаговое руководство с использованием Python
Предположим, вы хотите попробовать очистить данные Instagram самостоятельно. Как вы это делаете?
Как вы это делаете?
Попробуем построить два простых парсера. Один использует Requests, популярную библиотеку веб-скрейпинга Python. Второй подход использует Selenium для запуска безголового экземпляра Chrome. Вот чем они отличаются.
Selenium имитирует браузер — он открывается и переходит на веб-страницу. Парсинг с помощью Selenium принесет вам больше успешных запросов. Библиотека запросов, с другой стороны, только отправляет ваш HTTP-запрос в браузер. У этого метода меньше шансов на успех, но вы можете парсить Instagram гораздо быстрее.
Другие инструменты, необходимые для начала парсинга Instagram
Если вы хотите безопасно начать парсинг Instagram, вы также должны рассмотреть возможность сокрытия своего IP-адреса, поскольку платформа ограничивает объем информации, к которой можно получить доступ без входа в систему.
Лучший способ сделать это — использовать чередующийся прокси-сервер. В зависимости от вашего прокси-провайдера, он будет давать вам разные IP-адреса каждые пять, 10 минут или каждый запрос на подключение. Если вам не нужно, где взять прокси, взгляните на наш список отличных поставщиков прокси для Instagram.
Если вам не нужно, где взять прокси, взгляните на наш список отличных поставщиков прокси для Instagram.
Управление ожиданиями
Парсинг платформ социальных сетей — трудный и сложный процесс. Вам придется запастись терпением, чтобы увеличить шансы на успешный сбор данных в Instagram.
Некоторые из ваших запросов неизбежно завершатся ошибкой — 20%, 30% или даже больше, пока вы не освоитесь. Неудачный запрос вызовет ошибку прокси, которая остановит парсер. Вы можете добавить функцию повторной попытки, чтобы повторить попытку. Однако для этого вам нужно будет менять свой IP-адрес при каждом неудачном запросе.
В настоящее время большинство онлайн-СМИ, включая Instagram, просят пользователей предоставить личную информацию для доступа к веб-сайту или определенному контенту. Они размещают данные за формами захвата лидов, такими как номер телефона, адрес электронной почты или некоторые вопросы. Скорее всего, скоро будет меньше данных для очистки, потому что Instagram будет блокировать еще больше контента.
Как очистить общедоступные профили Instagram с помощью Selenium
Это реальный пример использования прокси. Мы будем парсить имена пользователей Instagram с параметром __a=1 , который может преобразовать любую страницу в формат JSON. В этом руководстве параметр будет возвращать контент со страницы профиля.
Шаг 1. Начните с установки Selenium, Chromedriver и Selenium-Stealth.
1) Сначала импортируйте веб-драйвер из модуля Selenium.
из веб-драйвера импорта селена
2) Затем импортируйте веб-драйвер, используя модуль выбора By из Selenium, чтобы упростить выбор.
from selenium.webdriver.common.by import By
3) Распечатайте результаты для форматирования вывода консоли.
from pprint import pprint
3) Поскольку мы будем использовать модуль JSON, вам также потребуется импортировать его.
import json
4) Затем импортируйте Selenium-Stealth для более реалистичного браузера.
из selenium_stealth импортировать скрытность
Шаг 2. Настройте имена пользователей профилей Instagram, которые вы хотите очистить.
usernames = ["jlo", "shakira", "beyonce", "katyperry"]
Создайте переменную для ваших прокси. Они помогут вам достичь более высокого уровня успеха.
proxy = "server:port"
Вы можете создать новую переменную словаря для хранения очищенных результатов.
output = {} Шаг 3. Затем напишите начало кода, вызвав main() и добавив еще одну строку для вывода результатов очистки после ее завершения.
если __name__ == '__main__': основной() pprint(output)
Напишите код для перебора имен пользователей, которые вы собираетесь очистить. Функция main() будет перебирать список имен пользователей Instagram и отправлять его другой функции scrape() , которую мы собираемся написать позже.
по умолчанию main(): для имени пользователя в именах пользователей: очистить (имя пользователя)
Шаг 4. Далее вам нужно определить функцию, выполнив следующие шаги:
Далее вам нужно определить функцию, выполнив следующие шаги:
1) Создайте новую функцию. Это позволит вам вносить изменения в настройки браузера перед каждой очисткой, например, менять пользовательский агент или менять прокси.
def prepare_browser():
2) Инициализировать параметры Chrome.
chrome_options = webdriver.ChromeOptions()
3) Добавьте прокси в параметры браузера.
chrome_options.add_argument(f'--proxy-server={proxy}') 4) Теперь укажем параметры, необходимые для работы Selenium-Stealth
chrome_options.add_argument("start-maximized")
chrome_options.add_experimental_option ("excludeSwitches", ["включить автоматизацию"])
chrome_options.add_experimental_option('useAutomationExtension', False) 5) Создайте браузер Chrome с параметрами, которые вы установили ранее.
driver = webdriver.Chrome(options= chrome_options)
6) Примените дополнительные настройки Selenium-Stealth. Для дополнительной анонимности вы можете повернуть свой цифровой отпечаток пальца или пользовательский агент.
Для дополнительной анонимности вы можете повернуть свой цифровой отпечаток пальца или пользовательский агент.
стелс (водитель, user_agent= 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/83.0.4103.53 Safari/537.36', языки = ["en-US", "en"], поставщик = "Google Inc.", платформа = "Win32", webgl_vendor= "Intel Inc.", renderer= "Подсистема Intel Iris OpenGL", fix_hairline = Ложь, run_on_insecure_origins = Ложь, )
6) Верните драйвер Chrome со всеми параметрами и настройками, которые вы настроили до сих пор.
вернуть драйвер
Шаг 5. Теперь давайте перейдем к парсингу.
1) Создайте новую функцию. Функция scrape() требует только одного аргумента — имени пользователя, которое вы передали из цикла в функции main() .
def scrape(имя пользователя):
2) Создайте URL. Добавление ?__a=1&__d=dis в конец позволяет получать ответ от серверной части Instagram напрямую, без анализа содержимого HTML.
url = f'https://instagram.com/{username}/?__a=1&__d=dis' 3) Затем вызовите функцию prepare_browser() и назначьте драйвер переменной.
chrome = prepare_browser()
4) Откройте браузер и сделайте запрос.
chrome.get(url)
5) Чтобы узнать, не прошел ли запрос, вам нужно проверить, не были ли вы перенаправлены на логин. Вы можете сделать это, просмотрев строку login — если она присутствует в URL-адресе, запрос не был успешным. Здесь можно добавить дополнительные функции повтора, чтобы позже попытаться очистить имя пользователя.
print (f"Попытка: {chrome.current_url}")
если "логин" в chrome.current_url:
print("Ошибка/ перенаправление для входа в систему")
chrome.quit() 6) В противном случае запрос выполнен успешно. Это означает, что мы можем извлечь основной текст из ответа и проанализировать его как JSON. Затем результат может быть передан функции parse_data() вместе с именем пользователя Instagram, которое вы очистили.
иначе:
печать ("Успех")
resp_body = chrome.find_element(By.TAG_NAME, "body").text
data_json = json.loads(resp_body)
user_data = data_json['graphql']['пользователь']
parse_data (имя пользователя, user_data)
хром.выход() Шаг 6. Перейдем к разбору наших данных. Создайте упомянутую функцию parse_data() , чтобы получить нужные данные из ответа JSON.
def parse_data(username, user_data):
Например, вы можете получить подписи к некоторым сообщениям из общедоступных сообщений.
подписи = []
если len(user_data['edge_owner_to_timeline_media']['edges']) > 0:
для узла в user_data['edge_owner_to_timeline_media']['edges']:
если len(узел['узел']['edge_media_to_caption']['края']) > 0:
если node['node']['edge_media_to_caption']['edges'][0]['node']['text']:
подписи.добавить(
узел ['узел']['edge_media_to_caption']['края'][0]['узел']['текст']
) Помимо подписей к сообщениям, вы можете получить полные имена пользователей, категорию, к которой они принадлежат, и количество их подписчиков. Вся эта информация, наконец, может быть записана в выходной словарь.
Вся эта информация, наконец, может быть записана в выходной словарь.
выход[имя пользователя] = {
'имя': user_data['полное_имя'],
'категория': user_data['имя_категории'],
'подписчики': user_data['edge_followed_by']['count'],
«сообщения»: подписи,
} Это вывод скрипта:
из веб-драйвера импорта селена
из selenium.webdriver.common.by импорт
из pprint импортировать pprint
импортировать json
из selenium_stealth импортировать скрытность
имена пользователей = ["jlo", "shakira", "beyonce", "katyperry"]
вывод = {}
защита prepare_browser():
chrome_options = веб-драйвер.ChromeOptions()
прокси = "сервер:порт"
chrome_options.add_argument(f'--прокси-сервер={прокси}')
chrome_options.add_argument ("начало максимизировано")
chrome_options.add_experimental_option ("excludeSwitches", ["включить автоматизацию"])
chrome_options.add_experimental_option('useAutomationExtension', False)
драйвер = webdriver.Chrome (параметры = chrome_options)
стелс (водитель,
user_agent= 'Mozilla/5. 0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/83.0.4103.53 Safari/537.36',
языки = ["en-US", "en"],
поставщик = "Google Inc.",
платформа = "Win32",
webgl_vendor = "Intel Inc.",
renderer= "Подсистема Intel Iris OpenGL",
fix_hairline = Ложь,
run_on_insecure_origins = Ложь,
)
обратный водитель
def parse_data (имя пользователя, user_data):
подписи = []
если len(user_data['edge_owner_to_timeline_media']['edges']) > 0:
для узла в user_data['edge_owner_to_timeline_media']['edges']:
если len(узел['узел']['edge_media_to_caption']['края']) > 0:
если node['node']['edge_media_to_caption']['edges'][0]['node']['text']:
подписи.добавить(
узел ['узел']['edge_media_to_caption']['края'][0]['узел']['текст']
)
вывод [имя пользователя] = {
'имя': user_data['полное_имя'],
'категория': user_data['имя_категории'],
'подписчики': user_data['edge_followed_by']['count'],
«сообщения»: подписи,
}
деф скребок (имя пользователя):
url = f'https://instagram. com/{имя пользователя}/?__a=1&__d=dis'
хром = prepare_browser()
chrome.получить(url)
print (f"Попытка: {chrome.current_url}")
если "логин" в chrome.current_url:
print("Ошибка/ перенаправление для входа в систему")
хром.выход()
еще:
печать ("Успех")
resp_body = chrome.find_element(By.TAG_NAME, "body").text
data_json = json.loads(resp_body)
user_data = data_json['graphql']['пользователь']
parse_data (имя пользователя, user_data)
хром.выход()
деф основной():
для имени пользователя в именах пользователей:
очистить (имя пользователя)
если __name__ == '__main__':
основной()
печать (выход)  0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/83.0.4103.53 Safari/537.36',
языки = ["en-US", "en"],
поставщик = "Google Inc.",
платформа = "Win32",
webgl_vendor = "Intel Inc.",
renderer= "Подсистема Intel Iris OpenGL",
fix_hairline = Ложь,
run_on_insecure_origins = Ложь,
)
обратный водитель
def parse_data (имя пользователя, user_data):
подписи = []
если len(user_data['edge_owner_to_timeline_media']['edges']) > 0:
для узла в user_data['edge_owner_to_timeline_media']['edges']:
если len(узел['узел']['edge_media_to_caption']['края']) > 0:
если node['node']['edge_media_to_caption']['edges'][0]['node']['text']:
подписи.добавить(
узел ['узел']['edge_media_to_caption']['края'][0]['узел']['текст']
)
вывод [имя пользователя] = {
'имя': user_data['полное_имя'],
'категория': user_data['имя_категории'],
'подписчики': user_data['edge_followed_by']['count'],
«сообщения»: подписи,
}
деф скребок (имя пользователя):
url = f'https://instagram.
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/83.0.4103.53 Safari/537.36',
языки = ["en-US", "en"],
поставщик = "Google Inc.",
платформа = "Win32",
webgl_vendor = "Intel Inc.",
renderer= "Подсистема Intel Iris OpenGL",
fix_hairline = Ложь,
run_on_insecure_origins = Ложь,
)
обратный водитель
def parse_data (имя пользователя, user_data):
подписи = []
если len(user_data['edge_owner_to_timeline_media']['edges']) > 0:
для узла в user_data['edge_owner_to_timeline_media']['edges']:
если len(узел['узел']['edge_media_to_caption']['края']) > 0:
если node['node']['edge_media_to_caption']['edges'][0]['node']['text']:
подписи.добавить(
узел ['узел']['edge_media_to_caption']['края'][0]['узел']['текст']
)
вывод [имя пользователя] = {
'имя': user_data['полное_имя'],
'категория': user_data['имя_категории'],
'подписчики': user_data['edge_followed_by']['count'],
«сообщения»: подписи,
}
деф скребок (имя пользователя):
url = f'https://instagram. com/{имя пользователя}/?__a=1&__d=dis'
хром = prepare_browser()
chrome.получить(url)
print (f"Попытка: {chrome.current_url}")
если "логин" в chrome.current_url:
print("Ошибка/ перенаправление для входа в систему")
хром.выход()
еще:
печать ("Успех")
resp_body = chrome.find_element(By.TAG_NAME, "body").text
data_json = json.loads(resp_body)
user_data = data_json['graphql']['пользователь']
parse_data (имя пользователя, user_data)
хром.выход()
деф основной():
для имени пользователя в именах пользователей:
очистить (имя пользователя)
если __name__ == '__main__':
основной()
печать (выход)
com/{имя пользователя}/?__a=1&__d=dis'
хром = prepare_browser()
chrome.получить(url)
print (f"Попытка: {chrome.current_url}")
если "логин" в chrome.current_url:
print("Ошибка/ перенаправление для входа в систему")
хром.выход()
еще:
печать ("Успех")
resp_body = chrome.find_element(By.TAG_NAME, "body").text
data_json = json.loads(resp_body)
user_data = data_json['graphql']['пользователь']
parse_data (имя пользователя, user_data)
хром.выход()
деф основной():
для имени пользователя в именах пользователей:
очистить (имя пользователя)
если __name__ == '__main__':
основной()
печать (выход) Как очистить общедоступные профили Instagram с помощью библиотеки запросов
Это еще один пошаговый пример использования библиотеки на основе Python — Requests. Этот метод значительно быстрее и легче, так как вам не нужно имитировать веб-браузер. Однако, это также терпит неудачу намного больше. Но даже при низком уровне успеха вы можете очистить довольно много данных, просто повторив попытку с новыми прокси.
Но даже при низком уровне успеха вы можете очистить довольно много данных, просто повторив попытку с новыми прокси.
Шаг 1. Начните с импорта запросов, JSON и Random.
импортные запросы, json, random
Затем мы распечатаем результаты, чтобы отформатировать вывод консоли.
from pprint import pprint
Шаг 2. Теперь давайте создадим список имен пользователей , который будет содержать всех пользователей Instagram, которых мы собираемся очистить.
usernames = ["jlo", "shakira", "beyonce", "katyperry"]
После этого настройте прокси.
proxy = "http://username:[email protected]:port"
Вы можете создать новую переменную словаря для хранения результатов очистки.
output = {} Шаг 3. Затем напишите начало кода, вызвав функцию main() .
если __name__ == '__main__': основной() pprint(output)
Теперь подготовьте заголовки и маску, которую вы отправляете через парсер. Заголовки также будут чередовать пару пользовательских агентов.
Заголовки также будут чередовать пару пользовательских агентов.
по определению get_headers (имя пользователя):
заголовки = {
"авторитет": "www.instagram.com",
"метод": "ПОЛУЧИТЬ",
"путь": "/{0}/".format(имя пользователя),
"схема": "https",
"принять": "текст/html, приложение/xhtml+xml, приложение/xml; q=0.9,изображение/webp,изображение/apng,*/*;q=0,8,приложение/подписанный обмен;v=b3;q=0,9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
"небезопасные запросы на обновление": "1",
«Соединение»: «закрыть»,
"пользовательский агент": random.choice([
«Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/75.0.3770.80 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/75.0.3770.100 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.169 Сафари / 537,36 дюйма
«Mozilla/5.0 (Windows NT 6. 1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.131 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/74.0.3729.131 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Сафари / 537,36 дюйма
])
}
возвращать заголовки  1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.131 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/74.0.3729.131 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Сафари / 537,36 дюйма
])
}
возвращать заголовки
1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.131 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/74.0.3729.131 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Сафари / 537,36 дюйма
])
}
возвращать заголовки Шаг 4. Напишите код для итерации имен пользователей, которые вы собираетесь очистить. Функция main() будет перебирать список имен пользователей Instagram.
по умолчанию main():
для имени пользователя в именах пользователей:
url = f"https://instagram.com/{username}/?__a=1&__d=dis" Шаг 5. Теперь напишем строку, которая будет отправлять запрос и применять заголовки и прокси к этому.
response = request.get(url, headers=get_headers(username), proxies = {'http': proxy, 'https': proxy}) Чтобы узнать, не удалось выполнить запрос, вам нужно проверить если вас не перенаправили на логин. Вы можете сделать это, проверив, является ли ответ JSON . Также эта строка позволит вам проанализировать текст ответа.
Вы можете сделать это, проверив, является ли ответ JSON . Также эта строка позволит вам проанализировать текст ответа.
если response.status_code == 200: пытаться: resp_json = json.loads(response.text)
Если вы не получили свои результаты в JSON, это означает, что вы были перенаправлены на вход; сценарий переходит к следующему имени пользователя.
за исключением:
print ("Ошибка. Ответ не в формате JSON")
продолжить Здесь можно добавить дополнительные функции повтора, чтобы позже попытаться очистить имя пользователя.
else:
Если вы получили результаты в формате JSON, вы можете очистить (разобрать) свои данные.
user_data = resp_json['graphql']['user'] parse_data(username, user_data)
На этом пути могут быть ошибки. Попробуем их поймать. В случае неудачи используйте логику повторной попытки.
elif response.status_code == 301 или response.
 status_code == 302:
print("Ошибка. Перенаправлено на вход")
status_code == 302:
print("Ошибка. Перенаправлено на вход") иначе:
print("Запрос не выполнен. Статус: " + str(response.status_code)) Шаг 6. Создайте функцию parse_data() для получения нужных данных из ответа JSON.
def parse_data(username, user_data):
Например, вы можете получить подписи некоторых сообщений из общедоступных сообщений и назначить их список переменной.
подписи = []
если len(user_data['edge_owner_to_timeline_media']['edges']) > 0:
для узла в user_data['edge_owner_to_timeline_media']['edges']:
если node['node']['edge_media_to_caption']['edges'][0]['node']['text']:
подписи.добавить(
узел ['узел']['edge_media_to_caption']['края'][0]['узел']['текст']
)
вывод [имя пользователя] = {
'имя': user_data['полное_имя'],
'категория': user_data['имя_категории'],
'подписчики': user_data['edge_followed_by']['count'],
«сообщения»: подписи,
} Это вывод скрипта .
запросов на импорт, json, случайный
из pprint импортировать pprint
имена пользователей = ["jlo", "shakira", "beyonce", "katyperry"]
прокси = "http://имя пользователя:[электронная почта защищена]:порт"
вывод = {}
деф get_headers (имя пользователя):
заголовки = {
"авторитет": "www. instagram.com",
"метод": "ПОЛУЧИТЬ",
"путь": "/{0}/".format(имя пользователя),
"схема": "https",
"accept": "текст/html,приложение/xhtml+xml,приложение/xml;q=0.9,изображение/webp,изображение/apng,*/*;q=0.8,application/signed-exchange;v=b3;q =0,9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
"небезопасные запросы на обновление": "1",
«Соединение»: «закрыть»,
"пользовательский агент": random.choice([
«Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/75.0.3770.80 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/75.0.3770.100 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.169 Сафари / 537,36 дюйма
«Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74. 0.3729.131 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/74.0.3729.131 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Сафари / 537,36 дюйма
])
}
возвращать заголовки
def parse_data (имя пользователя, user_data):
подписи = []
если len(user_data['edge_owner_to_timeline_media']['edges']) > 0:
для узла в user_data['edge_owner_to_timeline_media']['edges']:
если len(узел['узел']['edge_media_to_caption']['края']) > 0:
если node['node']['edge_media_to_caption']['edges'][0]['node']['text']:
подписи.добавить(
узел ['узел']['edge_media_to_caption']['края'][0]['узел']['текст']
)
вывод [имя пользователя] = {
'имя': user_data['полное_имя'],
'категория': user_data['имя_категории'],
'подписчики': user_data['edge_followed_by']['count'],
«сообщения»: подписи,
}
деф основной():
для имени пользователя в именах пользователей:
url = f"https://instagram. instagram.com",
"метод": "ПОЛУЧИТЬ",
"путь": "/{0}/".format(имя пользователя),
"схема": "https",
"accept": "текст/html,приложение/xhtml+xml,приложение/xml;q=0.9,изображение/webp,изображение/apng,*/*;q=0.8,application/signed-exchange;v=b3;q =0,9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
"небезопасные запросы на обновление": "1",
«Соединение»: «закрыть»,
"пользовательский агент": random.choice([
«Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/75.0.3770.80 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/75.0.3770.100 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.169 Сафари / 537,36 дюйма
«Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.
instagram.com",
"метод": "ПОЛУЧИТЬ",
"путь": "/{0}/".format(имя пользователя),
"схема": "https",
"accept": "текст/html,приложение/xhtml+xml,приложение/xml;q=0.9,изображение/webp,изображение/apng,*/*;q=0.8,application/signed-exchange;v=b3;q =0,9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
"небезопасные запросы на обновление": "1",
«Соединение»: «закрыть»,
"пользовательский агент": random.choice([
«Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/75.0.3770.80 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/75.0.3770.100 Safari/537.36", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.169 Сафари / 537,36 дюйма
«Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74. 0.3729.131 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/74.0.3729.131 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Сафари / 537,36 дюйма
])
}
возвращать заголовки
def parse_data (имя пользователя, user_data):
подписи = []
если len(user_data['edge_owner_to_timeline_media']['edges']) > 0:
для узла в user_data['edge_owner_to_timeline_media']['edges']:
если len(узел['узел']['edge_media_to_caption']['края']) > 0:
если node['node']['edge_media_to_caption']['edges'][0]['node']['text']:
подписи.добавить(
узел ['узел']['edge_media_to_caption']['края'][0]['узел']['текст']
)
вывод [имя пользователя] = {
'имя': user_data['полное_имя'],
'категория': user_data['имя_категории'],
'подписчики': user_data['edge_followed_by']['count'],
«сообщения»: подписи,
}
деф основной():
для имени пользователя в именах пользователей:
url = f"https://instagram.
0.3729.131 Safari/537.36», «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML , например Gecko) Chrome/74.0.3729.131 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, например Gecko) Chrome/74.0.3729.157 Сафари / 537,36 дюйма
])
}
возвращать заголовки
def parse_data (имя пользователя, user_data):
подписи = []
если len(user_data['edge_owner_to_timeline_media']['edges']) > 0:
для узла в user_data['edge_owner_to_timeline_media']['edges']:
если len(узел['узел']['edge_media_to_caption']['края']) > 0:
если node['node']['edge_media_to_caption']['edges'][0]['node']['text']:
подписи.добавить(
узел ['узел']['edge_media_to_caption']['края'][0]['узел']['текст']
)
вывод [имя пользователя] = {
'имя': user_data['полное_имя'],
'категория': user_data['имя_категории'],
'подписчики': user_data['edge_followed_by']['count'],
«сообщения»: подписи,
}
деф основной():
для имени пользователя в именах пользователей:
url = f"https://instagram.