
Импорт в Facebook — Облачный парсер
Облачный парсер позволяет наполнить альбом в Facebook* товарами, при этом товары можно бесплатно выгрузить как в альбом группы, так и в альбом страницы.
Если вы хотите загружать товары в Facebook* каталоги, то следуйте инструкции Импорт товаров в Facebook* каталог.
Автоматически выгружать фото в профиль нельзя — ограничение Facebook*.
Для загрузки фото в группу необходимо установить приложение cloudparser.
Настройка группы (новый интерфейс Facebook*)
Перейдите в группу, куда планируется выгрузка
- Далее [Настройки], прокручиваем вниз к [Приложения] -> [Редактировать].
- [Добавить приложения].
- Введите название приложения — «cloudparser«, выберите найденное приложение и далее нажмите [Добавить].
- Далее [Еще] -> [Редактировать настройки группы].

- Рядом с пунктом Приложения нажмите [Добавить приложения].
- Введите название приложения — «cloudparser«, выберите найденное приложение и далее нажмите [Добавить].

На этом настройка группы закончена и вы можете приступать в выгрузке товаров в Facebook*.
Подробная инструкция по установке приложений в Facebook*
Настройка страницыДля выгрузки на страницу никаких специальных действий не требуется, достаточно предоставить необходимые права при входе через Facebook*.
Выгрузка в Facebook*Будем считать, что вы уже загрузили товары с сайта поставщика (как выгружать товары) и произвели необходимые наценки на товары.
Для загрузки товаров в фейсбук выполняем несколько простых шагов:
- Открываем список выгруженных товаров, нажимаем кнопку [FB].
- Выполняем вход через Facebook*, предоставляем необходимые права приложению.
- Выбираем группу или страницу, альбом куда будем выгружать товары.
Важно: Facebook* не позволяет обновлять товары, если они уже есть в альбоме, то будут добавлены еще раз. - Указываем параметры выгрузки и нажимаем [Выгрузить].
- Прогресс выгрузки вы увидите прямо на кнопке, при этом вы можете смело продолжить работу с сервисом, закрыть вкладку, браузер или выключить компьютер — Облачный парсер выгрузит товары автоматически.
- Выгрузка товаров завершена, вы можете перейти в выбранный альбом, кликнув по ссылке с названием альбома.

Важно: рекомендуется делать параллельно не большой одной выгрузки в группу или страницу, иначе Facebook* может заблокировать ваш аккаунт.
Группы или страницы нет в списке
* Meta, а также принадлежащая ей Facebook признана экстремистской организацией, её деятельность в России запрещена
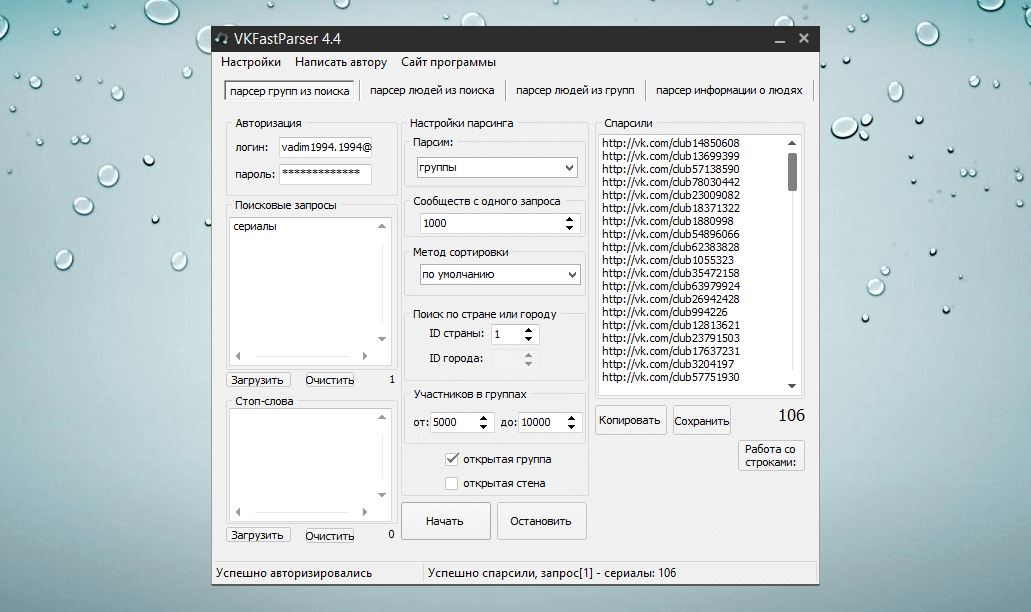
Facebook — Парсер ID
SOC-SOFT. com
com
Реклама:
ZennoBoxBot — Магазин в телеграме
Baza-Akk.ru — Магазин аккаунтов
S-SMM.RU — Раскрутка в соц.сетях
Ваша ссылка (1 месяц = 3500руб)
Инструкции:
Как купить? где скачать?
FAQ — Часто задаваемые вопросы
ZennoBoxBot — Наш telegram магазин
Популярные программы:
Google — Регистратор аккаунтов
Instagram — Регистратор аккаунтов
Mail — Регистратор аккаунтов
Twitter — Регистратор аккаунтов
Новые программы:
Email — Чекер писем по ключевому слову
BlaBlaCar — Регистратор аккаунтов
BlaBlaCar — Чекер аккаунтов
Instagram — Спамер в direct
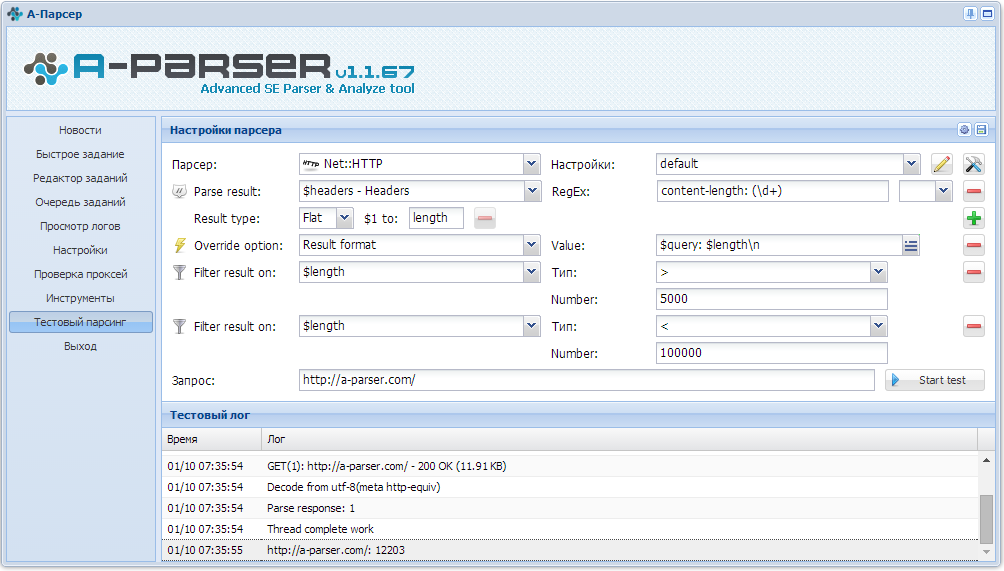
Функционал
Скриншоты
Инструкция
Обновления
Функционал
Скриншоты
Инструкция
Обновления
Функционал
Скриншоты
Инструкция
Обновления
Парсер ID
– Парсер id людей по ключевому слову.
– Парсер id участников группы.
– Парсер id друзей профиля.
– Парсер id лайкнувшие пост на фан-страничке.
встроенный чекер
Аккаунты проверяются на валид, бан, невалид, мусор.
Автоудаление дублей
Автоматически удаляются дубли в файле результата.
Лимит
Возможность задавать лимит парсинга.
Многопоточность
Можно работать одновременно в несколько потоков.
Отчет
Весь результат сохраняется в текстовой файл Результат.txt
Сохранение результата происходит по умолчанию в директорию проекта:
ID результат.txt – Сюда сохраняются спарсенный список ID
Валид.txt – Сюда сохраняются хорошие валидные аккаунты
Невалид.txt – Сюда сохраняются плохие невалидные аккаунты
Бан.txt – Сюда сохраняются заблокированные аккаунты
Proxy
Поддержка прокси IPv6, но можно работать без прокси.
Купить Proxy
капча
Автоматическое распознавание капчи через сервис RuCaptcha.com, Anti-captcha.com или CapMonsterCloud.
О сервисах капчи
Главные настройки
Настройки парсера
1 неделя
Купить
2 недели
Купить
3 недели
Купить
4 недели
Купить
Навсегда
Купить
наш магазин в TELEGRAMе
Купить на @ZennoBoxBot
После того как скачали и установили ZennoBox открываем входящие настройки двойным кликом по шаблону и выполняем пошаговую инструкцию входных параметров для проекта:
Пошаговая инструкция (по скриншоту 1) :
- Загружаем текстовой файл с аккаунтами (аккаунты берутся по порядку с удалением, формат выбираете сами в четвертом пункте)
- Ставим галочку если будем брать акканты из файла с удалением.
- Выбираем режим парсинга.
- Выберите как хотите сохранять результат, в 1 текстовой файл или каждый спарсенный профиль или группу в разный текстовой документ.
- Укажите сколько всего спрасить участников из групп.
- Укажите сколько всего отпрасить из постов.
- Укажите сколько раз скролить страницу вниз при парсинга друзей из профилей. Примерное соотношение 1 выдает 230 друзей. то есть если аккаунт с 5000 друзьями то нужно указать 22, если с 1000 то 5, чем больше значение тем дольше будет идти парсинг.
- Указываем задержку в секундах во время парсинга.
- Ставим галочку “Использовать прокси” если намерены работать через прокси.
- Загружаем файл с IPv4 проксями (продробнее о проксях и формате загрузки проксей)
прокси берутся по порядку и с удалением, их не должно быть меньше количества аккаунтов - Переходим во вкладку “Откуда парсить”

Пошаговая инструкция (по скриншоту 2) :
- От куда брать – Выберите от куда будем брать ключевые слова, ссылки, ID для парсинга.
- Ключ.слово/ID/Ссылка – На скриншоте расписано, что и в каком формате сюда следует указать.
- Загружаем текстовой файл с текстами для рассылок (каждый текст с новой строки, берутся с удалением)
- Файл – Загружаем списки ссылок на посты от куда следует спарсить людей, каждая ссылка с новой строки, ссылки берутся с удалением. В Файле указываем все тоже самое что в “Поле” только больше и каждое значение с новой строки, будут объекты браться с удалением.
- Сохраняем настройки нажатием на кнопку “ОК”

Запускаем процесс работы (любым способом):
- В поле “Сколько делать” указываем количество 1 (если нужно спарсить с 1 объекта)
- Указываем количество потоков – 1 если работаем с 1 объектом.
- Тут ничего не меняем, оставляем по умолчанию “Не использовать”, даже когда вы работаете через прокси.
- Во вкладке “Лог” можно смотреть статус работы.
Часто задаваемые вопросы
Сколько аккаунтов я могу загрузить в программу?
Нет ограничений в количестве загруженных аккаунтов в программу, можете хоть миллион аккаунтов загрузить и спамить 24/7.
Можно использовать прокси IPv6?
Да, можно.
Какие прокси рекомендуете использовать?
Рекомендуем использовать прокси IPv6, динамические, 32 подсети. Купить можно их тут https://soc-soft.com/proxy#IPv6_din_32
Можете доработать программу и добавить нужный мне функционал?
Да, можем. Мы уже давно пишем программы на заказ и может допилить уже существующие программы под ваши задачи. Свяжитесь с нами, скидывайте техническое задание, обсудим цену и добавим необходимый функционал.
Не получается настроить программу, могли бы вы мне помочь?
Да, мы можем помочь Вам и все сами настроить за вас с помощью программы TeamViewer или AnyDesk.
Если я куплю программу навсегда, то буду ли я получать обновления и поддержку?
Да, купив программу навсегда Вы так же будете автоматически получать новые версии программы и поддержку без ограничения по времени.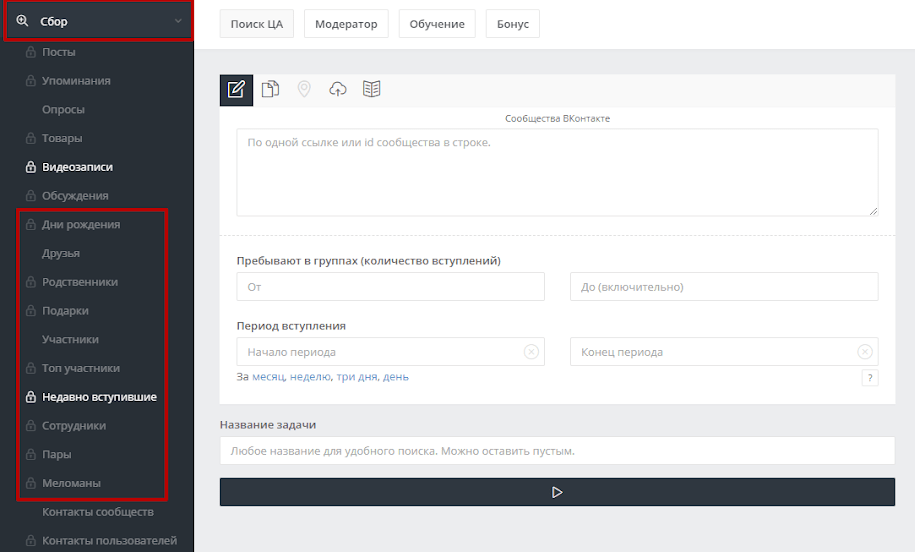
Где находится директория проекта?
1. Кликаем правой кнопкой мыши по шаблону.
2. Выбираем пункт “Директория проекта”.
Как и где указать API ключи от сервисов распознавание капчи?
- Заходим в настройки ZennoBox.
- Переходим во вкладку “Капчи”.
- Вводим API ключи всех ваших сервисов.
Подробнее о сервисах капчи
Взял программу на неделю, все понравилось, могу я доплатить и купить ее навсегда?
Да, если в течение суток (24 часа) после аренды Вы надумали купить программу навсегда, то можете просто доплатить разницу. Например взяли аренду за 750р, доплатить нужно будет не 4500р, а всего 3750р, но это предложение действует только в течение суток.
Как связаться с поддержкой?
В разделе КОНТАКТЫ указаны все контакты поддержки, рекомендуем писать в телеграм или через чат на сайте (онлайн-консультанту).
31.07.2017
Релиз программы.
26.02.2022
Создан новостной телеграм канал https://t.me/+DmsEIH84655jMGYy Теперь все новости будут выходить только там.
Новостной Telegram канал
парсер фейсбука · PyPI
Очистка общедоступных страниц Facebook без ключа API. Вдохновлен твиттер-скребком.
Установить
Чтобы установить последнюю версию PyPI:
pip install facebook-scraper
Или, чтобы установить последнюю основную ветку:
pip install git+https://github.com/kevinzg/facebook-scraper.git
Использование
Отправить уникальное имя страницы , имя профиля или идентификатор в качестве первого параметра и все готово:
>>> from facebook_scraper import get_posts
>>> для сообщения в get_posts('nintendo', pages=1):
. .. печать (сообщение ['текст'] [: 50])
...
Последний шаг на пути к Super Smash Bros.
Мы отправляемся на PAX East 28–31 марта с новыми играми.
 .. печать (сообщение ['текст'] [: 50])
...
Последний шаг на пути к Super Smash Bros.
Мы отправляемся на PAX East 28–31 марта с новыми играми.
.. печать (сообщение ['текст'] [: 50])
...
Последний шаг на пути к Super Smash Bros.
Мы отправляемся на PAX East 28–31 марта с новыми играми.
Дополнительные параметры
(Для функции get_posts ) .
- группа : идентификатор группы, чтобы очищать группы вместо страниц. По умолчанию
Нет. - страницы : сколько страниц сообщений запрашивать, первые 2 страницы могут не дать результатов, поэтому попробуйте с числом больше 2. По умолчанию 10.
- timeout : сколько секунд ждать до истечения времени ожидания. По умолчанию 30.
- учетные данные : кортеж пользователя и пароль для входа в систему перед запросом сообщений. По умолчанию
Нет. - extra_info : bool, если true, функция попытается сделать дополнительный запрос, чтобы получить реакцию на публикацию. По умолчанию — Ложь.
- youtube_dl : bool, используйте Youtube-DL для извлечения (высококачественного) видео. В вашей среде должен быть установлен youtube-dl. По умолчанию — Ложь.
- post_urls : список, URL-адреса или идентификаторы сообщений для извлечения сообщений. Альтернатива выборке по имени пользователя.
- печенья : Одно из:
- Путь к файлу, содержащему файлы cookie в формате Netscape или JSON. Вы можете извлечь файлы cookie из своего браузера после входа в Facebook с помощью расширения, такого как Get Cookies.txt (Chrome) или Cookie Quick Manager (Firefox). Убедитесь, что вы включили как файл cookie c_user, так и файл cookie xs, иначе вы получите исключение InvalidCookies.
- CookieJar
- Словарь, который можно преобразовать в CookieJar с помощью cookiejar_from_dict
- Строка
"from_browser", чтобы попытаться извлечь файлы cookie Facebook из вашего браузера
- опции : Словарь опций. Установите
options={"comments": True}, чтобы извлечь комментарии, установитеoptions={"reactors": True}, чтобы извлечь людей, реагирующих на сообщение. Оба комментария options={"progress": True}, чтобы получить индикатор выполненияtqdmпри извлечении комментариев и ответов. Установитеoptions={"allow_extra_requests": False}, чтобы отключить дополнительные запросы при извлечении данных сообщения (требуется для некоторых вещей, таких как полные текстовые ссылки и ссылки на изображения). Установитеoptions={"posts_per_page": 200}, чтобы запросить 200 сообщений на страницу. По умолчанию 4.
 В вашей среде должен быть установлен youtube-dl. По умолчанию — Ложь.
В вашей среде должен быть установлен youtube-dl. По умолчанию — Ложь. Оба комментария
Оба комментария Использование CLI
$ facebook-scraper --filename nintendo_page_posts.csv --pages 10 nintendo
Запустите facebook-scraper --help для получения более подробной информации об использовании CLI.
Примечание: Если вы получаете UnicodeEncodeError , попробуйте добавить --encoding utf-8 .
Пример сообщения
{'доступно': True,
«комментарии»: 459,
'comments_full': нет,
«проверка фактов»: нет,
'fetched_time': datetime.datetime (2021, 4, 20, 13, 39, 53, 651417),
'изображение': 'https://scontent.fhlz2-1.fna.fbcdn.net/v/t1.6435-9/fr/cp0/e15/q65/58745049_2257182057699568_1761478225390731264_n.jpg?_nc_cat=111&ccb=1-3&_nc_sid=8024bb&_nc_ohc=ygh3fPmfQpAAX92ABYY&_nc_ht=scontent.fhlz2-1.fna&tp=14&oh=7a8a7b4904deb55ec696ae275fff97dd&oe1=60
'изображения': ['https://scontent.fhlz2-1.fna.fbcdn.net/v/t1.6435-9/fr/cp0/e15/q65/58745049_2257182057699568_1761478225390731264_n.jpg?_nc_cat=111&ccb=1_sid&_nc 8024bb&_nc_ohc=ygh3fPmfQpAAX92ABYY&_nc_ht=scontent.fhlz2-1.fna&tp=14&oh=7a8a7b4904deb55ec696ae255fff97dd&oe=60A36717'],
'is_live': Ложь,
лайков: 3509,
'ссылка': 'https://www.nintendo.com/amiibo/line-up/',
'post_id': '2257188721032235',
'post_text': 'Не позволяйте этой миниатюрной версии Героя Времени обмануть вас,'
«Молодой Линк такой же героический, как и его взрослая версия! Молодой '
'Линк присоединяется к серии фигурок amiibo Super Smash Bros. !\n'
'\n'
'https://www.nintendo.com/amiibo/line-up/',
'post_url': 'https://facebook.com/story.php?story_fbid=2257188721032235&id=119240841493711',
'reactions': {'haha': 22, 'like': 2657, 'love': 706, 'sorry': 1, 'wow': 123}, # если была установлена `extra_info`
«реакторы»: нет,
'shared_post_id': нет,
'shared_post_url': нет,
'общий_текст': '',
'shared_time': нет,
'shared_user_id': нет,
'shared_username': Нет,
«акции»: 441,
'text': 'Не позволяйте этой уменьшенной версии Героя Времени обмануть вас,'
«Молодой Линк такой же героический, как и его взрослая версия! Молодой Линк '
'присоединяется к серии фигурок amiibo Super Smash Bros.!\n'
'\n'
'https://www.nintendo.com/amiibo/line-up/',
'время': datetime.datetime (2019, 4, 30, 5, 0, 1),
'user_id': '119240841493711',
«имя пользователя»: «Нинтендо»,
'видео': нет,
'video_id': нет,
'video_thumbnail': нет,
'w3_fb_url': 'https://www.facebook.com/Nintendo/posts/2257188721032235'}
 !\n'
'\n'
'https://www.nintendo.com/amiibo/line-up/',
'post_url': 'https://facebook.com/story.php?story_fbid=2257188721032235&id=119240841493711',
'reactions': {'haha': 22, 'like': 2657, 'love': 706, 'sorry': 1, 'wow': 123}, # если была установлена `extra_info`
«реакторы»: нет,
'shared_post_id': нет,
'shared_post_url': нет,
'общий_текст': '',
'shared_time': нет,
'shared_user_id': нет,
'shared_username': Нет,
«акции»: 441,
'text': 'Не позволяйте этой уменьшенной версии Героя Времени обмануть вас,'
«Молодой Линк такой же героический, как и его взрослая версия! Молодой Линк '
'присоединяется к серии фигурок amiibo Super Smash Bros.!\n'
'\n'
'https://www.nintendo.com/amiibo/line-up/',
'время': datetime.datetime (2019, 4, 30, 5, 0, 1),
'user_id': '119240841493711',
«имя пользователя»: «Нинтендо»,
'видео': нет,
'video_id': нет,
'video_thumbnail': нет,
'w3_fb_url': 'https://www.facebook.com/Nintendo/posts/2257188721032235'}
!\n'
'\n'
'https://www.nintendo.com/amiibo/line-up/',
'post_url': 'https://facebook.com/story.php?story_fbid=2257188721032235&id=119240841493711',
'reactions': {'haha': 22, 'like': 2657, 'love': 706, 'sorry': 1, 'wow': 123}, # если была установлена `extra_info`
«реакторы»: нет,
'shared_post_id': нет,
'shared_post_url': нет,
'общий_текст': '',
'shared_time': нет,
'shared_user_id': нет,
'shared_username': Нет,
«акции»: 441,
'text': 'Не позволяйте этой уменьшенной версии Героя Времени обмануть вас,'
«Молодой Линк такой же героический, как и его взрослая версия! Молодой Линк '
'присоединяется к серии фигурок amiibo Super Smash Bros.!\n'
'\n'
'https://www.nintendo.com/amiibo/line-up/',
'время': datetime.datetime (2019, 4, 30, 5, 0, 1),
'user_id': '119240841493711',
«имя пользователя»: «Нинтендо»,
'видео': нет,
'video_id': нет,
'video_thumbnail': нет,
'w3_fb_url': 'https://www.facebook.com/Nintendo/posts/2257188721032235'}
Примечания
- Нет гарантии, что каждое поле будет извлечено (они могут быть
None). - В групповых сообщениях могут отсутствовать некоторые поля, такие как
времяиpost_url. - Очистка группы может возвращать только одну страницу и не работать с частными группами.
- Если вы слишком много парсите, Facebook может временно заблокировать ваш IP-адрес.
- Подавляющее большинство уникальных идентификаторов на Facebook (идентификаторы сообщений, идентификаторы видео, идентификаторы фотографий, идентификаторы комментариев, идентификаторы профилей и т. д.) могут быть добавлены к https://www.facebook.com/, чтобы привести к перенаправлению на соответствующий объект .
- Некоторые функции (например, извлечение реакций) требуют, чтобы вы вошли в Facebook (передавали файлы cookie). Если что-то не работает должным образом, попробуйте передать файлы cookie и посмотрите, исправит ли это проблему.
Профили
Функция get_profile может извлекать информацию из раздела about профиля. Передайте имя или идентификатор учетной записи в качестве первого параметра.
Передайте имя или идентификатор учетной записи в качестве первого параметра.
Обратите внимание, что Facebook предоставляет разную информацию в зависимости от того, вошли ли вы в систему (параметр cookie), например, дату рождения и пол. Использование:
из facebook_scraper import get_profile
get_profile("zuck") # Или get_profile("zuck", cookies="cookies.txt")
Выводы:
{'О программе': "Я пытаюсь сделать мир более открытым",
«Образование»: «Гарвардский университет\n».
«Информатика и психология\n»
'30 августа 2002 г. - 30 апреля 2004 г.\n'
'Академия Филлипса в Эксетере\n'
'Классика\n'
'Учебный год 2002\n'
'Средняя школа Ардсли\n'
'Средняя школа\n'
19 сентября98 - июнь 2000',
'Любимые цитаты': '"Удача сопутствует смелым".\n'
'- Вергилий, Энеида X.284\n'
'\n'
«Все дети художники. Проблема в том, как остаться»
'художник, когда вырастешь."\n'
'- Пабло Пикассо\n'
'\n'
'"Сделайте все как можно проще, но не проще."\n'
'- Альберт Эйнштейн',
«Имя»: «Марк Цукерберг»,
'Места проживания': [{'ссылка': '/profile.php?id=104022926303756&refid=17',
'текст': 'Пало-Альто, Калифорния',
'type': 'Текущий город/город'},
{'ссылка': '/profile.php?id=105506396148790&refid=17',
'текст': 'Доббс Ферри, Нью-Йорк',
'тип': 'Родной город'}],
«Работа»: «Инициатива Чана Цукерберга\n»
'1 декабря 2015 г. – настоящее время\n'
'Фейсбук\n'
'Основатель и генеральный директор\n'
'4 февраля 2004 г. - настоящее время\n'
'Пало-Альто, Калифорния\n'
«Сближаем мир».}
 Проблема в том, как остаться»
'художник, когда вырастешь."\n'
'- Пабло Пикассо\n'
'\n'
'"Сделайте все как можно проще, но не проще."\n'
'- Альберт Эйнштейн',
«Имя»: «Марк Цукерберг»,
'Места проживания': [{'ссылка': '/profile.php?id=104022926303756&refid=17',
'текст': 'Пало-Альто, Калифорния',
'type': 'Текущий город/город'},
{'ссылка': '/profile.php?id=105506396148790&refid=17',
'текст': 'Доббс Ферри, Нью-Йорк',
'тип': 'Родной город'}],
«Работа»: «Инициатива Чана Цукерберга\n»
'1 декабря 2015 г. – настоящее время\n'
'Фейсбук\n'
'Основатель и генеральный директор\n'
'4 февраля 2004 г. - настоящее время\n'
'Пало-Альто, Калифорния\n'
«Сближаем мир».}
Проблема в том, как остаться»
'художник, когда вырастешь."\n'
'- Пабло Пикассо\n'
'\n'
'"Сделайте все как можно проще, но не проще."\n'
'- Альберт Эйнштейн',
«Имя»: «Марк Цукерберг»,
'Места проживания': [{'ссылка': '/profile.php?id=104022926303756&refid=17',
'текст': 'Пало-Альто, Калифорния',
'type': 'Текущий город/город'},
{'ссылка': '/profile.php?id=105506396148790&refid=17',
'текст': 'Доббс Ферри, Нью-Йорк',
'тип': 'Родной город'}],
«Работа»: «Инициатива Чана Цукерберга\n»
'1 декабря 2015 г. – настоящее время\n'
'Фейсбук\n'
'Основатель и генеральный директор\n'
'4 февраля 2004 г. - настоящее время\n'
'Пало-Альто, Калифорния\n'
«Сближаем мир».}
Чтобы извлечь друзей, передайте аргумент friends=True или, чтобы ограничить количество получаемых друзей, установите друзей на желаемое число.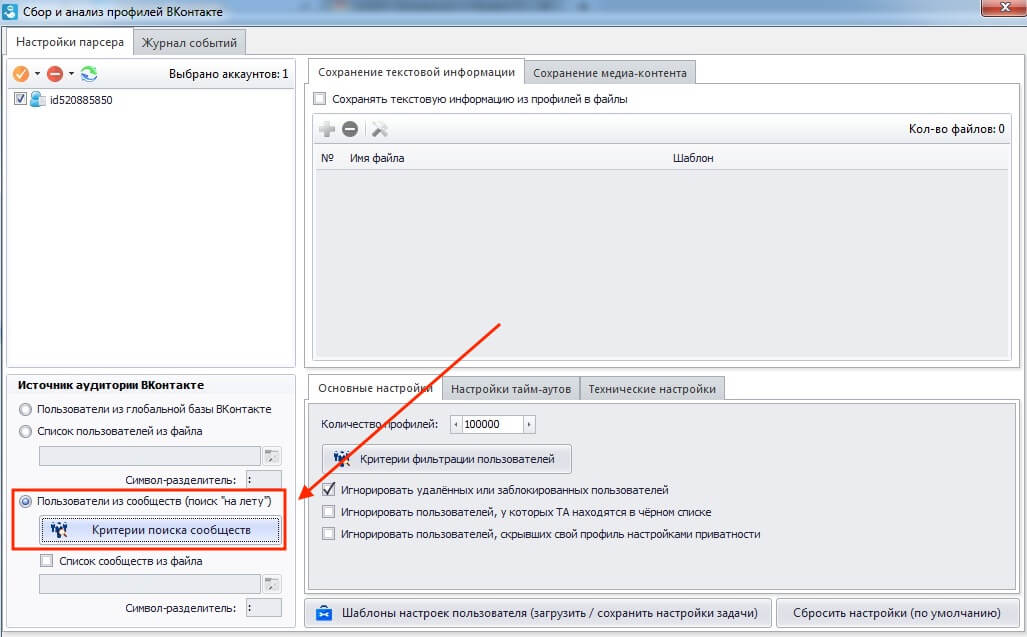
Информация о группе
Функция get_group_info может извлекать информацию о группе. Передайте имя или идентификатор группы в качестве первого параметра.
Обратите внимание, что для просмотра списка админов вам необходимо войти в систему (параметр cookie).
Использование:
из facebook_scraper import get_group_info
get_group_info("makeupartistsgroup") # или get_group_info("makeupartistsgroup", cookies="cookies.txt")
Вывод:
{'админы': [{'ссылка': '/africanstylemagazinecom/?refid=18',
'name': 'Журнал африканского стиля'},
{'ссылка': '/connectfluencer/?refid=18',
'имя': 'Все яркое и красивое'},
{'link': '/Kaakakigroup/?refid=18', 'name': 'Kaakaki Group'},
{'link': '/opentohelp/?refid=18', 'name': 'Open to Help'}],
«идентификатор»: «579169815767106»,
«члены»: 6814229,
'имя': 'ПРИЧЕСКИ',
'type': 'Общедоступная группа'}
Задача
- Асинхронная поддержка
-
Галереи изображений(изображениязапись) -
Профили или авторы сообщений(get_profile()) -
Комментарии(сoptions={'comments': True})
Альтернативы и сопутствующие проекты
- facebook-post-scraper. Имеет комментарии. Использует селен.
- фейсбук-скребок-селен. «Извлекайте сообщения любой группы или пользователя в файл .csv без необходимости регистрироваться для доступа к API».
- Абсолютный скребок Facebook. «Собирает почти все в профиле пользователя Facebook». Использует селен.
- Неофициальные API. Список неофициальных API для различных сервисов, пока нет для Facebook, но, возможно, стоит проверить в будущем.
- крупных пауков-скребков. Имеет профильный паук для Scrapy.
- страница-пост-скрейпер на фейсбуке. Кажется заброшенным.
- ФБЛИЗ. Вилка (?).
- РСШуб. Генерирует RSS-канал из страниц Facebook.
- RSS-мост. Также генерирует RSS-каналы со страниц Facebook.
 Имеет комментарии. Использует селен.
Имеет комментарии. Использует селен.анализ | Инструмент для разбора и анализа больших групповых чатов Facebook.
Я начал собирать это, когда мои друзья интересовались, кто самый активный в нашем групповом чате на Facebook. В рассматриваемом чате 14 участников с более чем 80 000 сообщений за более чем 4 года.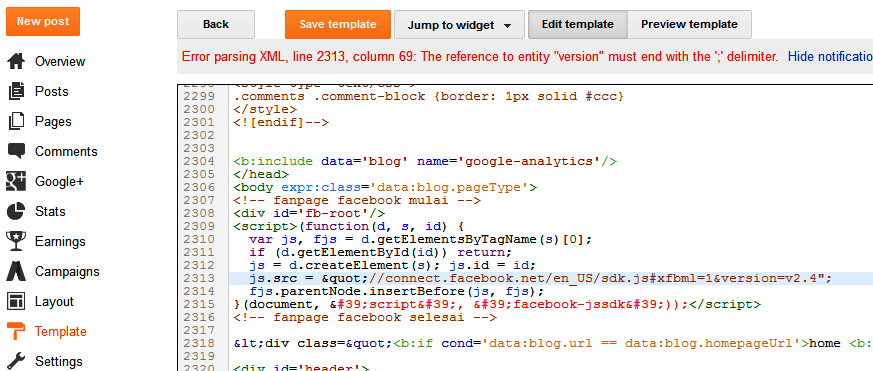 Как только я ответил на очевидные вопросы, вскоре это превратилось в более крупный проект.
Как только я ответил на очевидные вопросы, вскоре это превратилось в более крупный проект.
Если у вас есть вопросы/предложения по проекту или вы нашли что-то интересное в своих групповых чатах, пишите!
Кому начните работу прямо сейчас с анализа собственного группового чата, просмотрите начальную страницу и проверьте страницу документации, если вы застряли. В противном случае, есть несколько примеров простых вещей, которые вы можете сделать ниже.
Чтобы продемонстрировать различные возможности проекта, я просмотрел собственный групповой чат и нашел пару интересных вещей. Имена, очевидно, были изменены повсюду.
Пользовательский рейтинг
При загрузке чата мы можем сразу посмотреть, кто пишет больше всего:
>>> groupchat.message_rank() Линвуд Зук 21610 26,00% Митчелл Эшворт 17929 21,57% Диедра Девейн 13538 16,29% Хенаро Эгглстон 10650 12,81% Эрна Клейпул 6162 7,41% Гарольд Каллиган 3914 4,71% Лестер Снид 3739 4,50% Мелиссия Дубиэль 2478 2,98% Уилберн Малбон 1213 1,46% Марианн Пегуэро 942 1,13% Ашанти Санки 486 0,58% Эвелин Боден 420 0,51% Хай Крузан 24 0,03% Ирвин Альм 8 0,01%
Это не станет большим сюрпризом для всех в групповом чате. .. почти половина активности в чате приходится на двух пользователей. За исключением двух нижних пользователей, сообщения всех остальных хорошо разбросаны по данным за три года, поэтому я подумал, что стоит включить всех, когда я буду двигаться дальше.
.. почти половина активности в чате приходится на двух пользователей. За исключением двух нижних пользователей, сообщения всех остальных хорошо разбросаны по данным за три года, поэтому я подумал, что стоит включить всех, когда я буду двигаться дальше.
Использование с течением времени
Сначала посмотрим на активность всей группы…
>>> групповой чат.time_plot()
Очевидно, что активность за эти годы сильно изменилась. Периодические скачки активности происходят в декабре/январе, когда люди остаются дома на праздники. На пике активности в июне 16 года групповой чат в течение короткого периода времени в среднем обрабатывал 300 сообщений в день. Это на самом деле совпадает с референдумом ЕС здесь, в Великобритании. Мы можем проверить, так ли это, нанеся на график использование конкретных слов…
>>> groupchat.word_plot([['брексит', 'референдум', 'ЕС', 'голосование']])
Индивидуальная деятельность
Мы также можем сделать то же самое для конкретных пользователей, чтобы увидеть, как они по-разному использовали чат на протяжении многих лет. Берем пятерку лучших пользователей из рейтинга…
Берем пятерку лучших пользователей из рейтинга…
>>> groupchat.time_plot_user(['Линвуд Зук', 'Митчелл Эшворт',
«Диедра Девейн», «Хенаро Эгглстон», «Эрна Клейпул»])
Мы можем видеть длительные периоды времени, когда разные пользователи, кажется, не следят друг за другом так близко, хотя все они растут и падают в соответствии с общей тенденцией группы. Какая-то корреляция/свертка активности каждого пользователя с активностью группы могла бы показать это лучше.
Ежедневная активность
Если мы просто сопоставим время всех сообщений и проигнорируем даты, мы сможем получить картину того, как группа ведет себя в течение обычного дня…
>>> групповой чат.daily_plot()
Мы можем видеть довольно гладкую синусоиду, охватывающую все 24 часа, прерываемую только временем приема пищи; скачок активности во время обеда и снижение активности во время ужина. Ночью также наблюдается небольшое увеличение активности около 2:00–3:00 ночи, в чем я не слишком уверен.
Точно так же, как и активность за всю жизнь, мы можем разбить дневную активность по пользователям…
>>> groupchat.daily_plot(names=['Линвуд Зук', 'Митчелл Эшворт',
«Диедра Девейн», «Хенаро Эгглстон», «Эрна Клейпул»])
Это показывает нам довольно большие различия в среднем дне каждого пользователя. Например, Митчелл Эшворт почти не отправляет сообщений, пока он на работе, а затем значительно активизируется по вечерам.
Еженедельная активность
То же самое можно сделать для каждого дня недели отдельно, а затем собрать вместе, чтобы увидеть, как группа ведет себя в среднем за неделю…
групповой чат.weekly_plot()
Здесь мы получаем своего рода тепловую карту активности за неделю. Что сразу бросается в глаза, так это то, что ранние вечера пятницы и субботы самые активные. Между будними днями разница в активности незначительна, хотя в среду (по какой-то причине) активность намного выше, чем в другие будние дни в то же время.
Матрица разговоров
Вот тот, который может потребовать дополнительной настройки для отдельных групп. Сначала мы определяем разговор как хронологический набор сообщений, ограниченный некоторым промежутком во времени, скажем, 30 минутами. Каждые 30 минут без сообщения определяется новый разговор.
Теперь возьмем матрицу со строкой и столбцом для каждого участника группового чата. Затем для каждого найденного разговора мы добавляем точку в запись матрицы между участниками этого разговора. В конце мы делим по строкам на общее количество сообщений каждого участника и нормализуем так, чтобы сумма строк равнялась 1,0. Диагональные элементы обнуляются.
Приведенное ниже дает нам представление о том, кто с кем наиболее активно общается в групповом чате.
>>> групповой чат.matrix_plot()
Число в каждом квадрате представляет процент разговоров Y, в которых участвует X. Чтобы заявить это как фактический процент, я думаю, что необходимо проделать некоторую работу по нормализации, но я думаю, что значения имеют смысл для сравнения.