
Q-Parser — как появился сервис для парсинга товаров — Трибуна на vc.ru
Как из простенького скрипта «для своих» появился сервис по парсингу и выгрузке товаров.
543 просмотров
Идея
Почти четыре года назад нам с женой захотелось сделать собственный интернет-проект, который был бы полезен людям и, само-собой, приносил бы прибыль. Было время, были возможности и желание «что-нибудь небольшое, но свое».
На тот момент мы развивали сайт совместных покупок СП-Юга (который, увы, ушел на дно из-за самой концепции СП) и основной проблемой было наполнение каталога товаров актуальной информацией.
Оптовые поставщики обычно имеют свой сайт, но не имеют больше ничего. Хорошо, если есть хоть какой-то файл с товарами (иногда нет ничего). Его нужно привести к определенному формату, скачать фото товаров и т.д. и т.п. А если файла нет, то товары переносились вручную. Это занимает просто огромную кучу времени.
Чтобы оптимизировать этот процесс я писал парсеры товаров для популярных сайтов поставщиков.
Именно тогда на участке дороги Краснодар — Ейск родилась идея сделать парсинг услугой в виде отдельного сервиса. И в мае 2017 года мы приступили к реализации, чтобы уже 6 ноября запустить первую версию Q-Parser.
Первая версия самопального дизайна (из веб-архива 2018). Очень цветасто.
6 месяцев разработки
Начали в мае, а закончили уже в ноябре. 6 ноября сайт стал публичным и появились первые пользователи.
Быстро? Медленно? Не знаю. Для одного разработчика и его второй половинки, думаю, вышло неплохо.
Инвестиции в проект составили ужасающие 199 руб за домен и 800 руб за первую VDS в месяц. Это действительно весь список затрат. Реклама появилась чуть позже, но и по сей день она занимает небольшое место в бюджете.
Вся разработка и первое наполнение — своими силами.
Название? Вот у меня буква Q на клавиатуре первая, пусть будет.
Дизайн? Я всю жизнь в вебе, сайтов что-ли не видел. Что-то накидал и пойдет.
И оно пошло. Скоро будет 2 миллиона парсингов.
Так сейчас выглядит страница со списком товаров. Номер парсинга настоящий.
Q-Parser — сервис с душой
Техническая реализация и эволюция сервиса по парсингу и выгрузке товаров — это отдельная история взлетов (в основном нагрузки) и падений. Если вам интересно как развить сервис с одной VDS за 800 руб до kubernetes кластера на десятке машин, обязательно напишите: будет заинтересованность, будут и статьи.
Фишкой Q-Parser изначально было (и остается сейчас) отношение к клиентам и поддержка. Не просто «парсим товары». Сервис решает проблемы.
Оказалось, что чат на сайте подобного сервиса — это кладезь идей. Поначалу использовался Carrotquest, но наплыв в чат был настолько большой, что стоимость «морковки» выросла выше стоимости основных серверов (в итоге сделал собственный чат. Он, кстати, доступен бесплатно всем желающим).
Он, кстати, доступен бесплатно всем желающим).
Сделать универсальный сервис для каждого оказалось противоречащей самой-себе задачей. «Универсально для каждого» — не бывает. На старте брался за реализацию буквально каждой «хотелки» пользователей, что доставляло много технических проблем, но в итоге привело к появлению основных фишек парсера. Например:
- Парсинг по расписанию. Попросили примерно через месяц после запуска. Юлии понадобились постоянные ссылки на файлы для загрузки товаров в Яндекс.Маркет. Теперь у нас есть парсинг по расписанию с постоянными, обновляемыми ссылками на файлы.
- Скачивание фото товаров. Необходимо было скачать фото с одного сайта электроинструментов. В итоге на Q-Parser появилась возможность скачивать фото любых товаров, которые мы парсим.
- Редактирование фото. Кто-то захотел покрутить и обрезать фото товаров. Хотели? Готово. Теперь можно крутить-вертеть, резать и даже накладывать на фото товаров свои вотермарки.

- Фильтры и сортировки. Часто просили не просто спарсить «втупую», но еще и убрать ненужные товары или оставить только товары определенного бренда или с определенной ценой. Сказано — сделано. Фильтрация миллионов товаров в реал-тайме — задачка не из легких.

Спустя все эти года стало ясно, что универсальность для каждого — все же возможна. Q-Parser сейчас работает как
Текущая версия дизайна. Тоже есть «свои» изменения по сравнению с разработанным макетом
Аудитория
Идея парсера родилась из совместных покупок и основная аудитория должна была быть именно оттуда: организаторы совместных покупок.
Но реальность оказалась иной. «Орги» СП — очень своеобразная аудитория (не хочу никого обидеть, честно). Совместные покупки построены на принципе экономии, а платить за сервис, чтобы сэкономить — такое себе.
Совместные покупки построены на принципе экономии, а платить за сервис, чтобы сэкономить — такое себе.
Сейчас аудитория проекта почти полностью состоит из владельцев небольших интернет-магазинов. Работать с такими магазинами через парсер — очень удобно.
Есть и недовольные, без этого никуда. Парсинг — сам по себе не может что-то гарантировать. Сайты меняются, перестают работать или ставят защиту от ботов, которую за адекватные цены не обойти. Редко, но случается. С этим приходится мириться, либо уходить на фриланс разработку парсеров (но и цены там в десятки раз выше, плюс никакой поддержки).
Продвижение
Парсинг — как ни крути, довольно узко-специализорованная штука. Кому-то действительно проще тратить кучу времени на наполнение каталогов, а кто-то просто ничего не обновляет.
Продвигать парсинг на старте было достаточно просто. У нас уже была стартовая аудитория организаторов СП. Из контекстной рекламы потянулись пользователи. Хорошо работает сарафанное радио: люди любят Q-Parser.
В целом парсить сайты за 400 руб в месяц без особых ограничений — это практически бесплатно. Некоторые парсят миллионы товаров в месяц за все ту же цену.
До недавнего времени было много пользователей из стран СНГ и, особенно, из Украины. Кто-то даже остался.
Но с определенного этапа, которого проект уже достиг, сделать рывок по размеру аудитории становится сложно. Контекстная реклама уперлась в размер аудитории (просто некуда тратить деньги в Директе), а другая реклама либо не эффективна, либо слишком уж дорогая.
Во время короно-пандемии люди массово кинулись в онлайн и это было хорошо заметно и в посещаемости и в прибыли.
При этом проект все же постепенно развивается, даже не смотря на события последних лет.
А минусы?
Куда же без минусов. Универсальность сервиса накладывает свои ограничения.
За годы работы реализованы десятки форматов выгрузки товаров: от обычного YML до форматов для Insales или там Storeland (их много разных). И проблема в том, что невозможно «любые» данные о товарах поместить в «любой» формат.
И проблема в том, что невозможно «любые» данные о товарах поместить в «любой» формат.
Как это работает технически. Берем страницу каждого товара и приводим ее к «голым» данным: название, артикул, цена, характеристики и т.п.
В итоге получается, что из какой-то абстрактной массы данных нужно получить довольно стандартизированный файл с данными, что не всегда возможно. Например, на каких-то сайтах есть информация об остатках, а на других ее просто нет и в форматах, где обязательно указание остатков будет просто какое-то число (обычно 999 для товаров в наличии и 0 для отсутствующих)
Тем не менее, в целом идея очень даже работает. Пользователи постоянно пишут благодарности: переносить каталоги из тысяч товаров вручную — очень сложно, а мы делаем это быстро и за пару чашек кофе.
Что дальше?
Q-Parser постоянно развивается и никто не планирует останавливаться. И хоть внешне это может быть не слишком заметно, но обновления выходят практически каждый день: на данный момент в основном репозитории 3659 коммитов (а всего там 11 отдельных репозиториев).
Буду рад новым идеям и комментариям, а для новых пользователей: ловите промокод на подключение тарифов -15% VCRU
P.S. Если кто-то знает адекватный способ приема платежей из СНГ (кроме крипты), поделитесь.
ВЗакупке — парсер для СП
Search Engine Results For vzakupke.com
vzakupke.com — ВЗакупке — парсер для СП
ВЗакупке — сервис для организаторов совместных покупок и выгрузки каталогов товаров в социальные сети. Отправив фотографии на выкладку — НЕ ЖДИТЕ! Вы можете выключить компьютер…
vzWidget — vzakupke.com
vzWidget — vzakupke.com
vzakupke.org
We would like to show you a description here but the site won’t allow us.
vzakupke.net
We would like to show you a description here but the site won’t allow us.
vzakupke.com Competitive Analysis, Marketing Mix and …
vzakupke.com Competitive Analysis, Marketing Mix and Traffic . vs. spparser.ru bestsp.ru xn—-ptbggfebebr8g. xn--p1ai grably-parser.ru. Overview. Find, Reach, and Convert Your…
xn--p1ai grably-parser.ru. Overview. Find, Reach, and Convert Your…
Vzakupke.info — vzakupke.info — Registered at Namecheap …
vzakupke.info is hosted in Los Angeles, California, United States and is owned by Whoisguard Protected (Whoisguard Inc). vzakupke.info was created on 2017-03-15. Website IP is…
ВЗакупке — парсер для СП | ВКонтакте
#реклама Чтение неоспоримо приносит пользу как взрослым, так и детям. Чем больше вы читаете, тем более широкий у вас взгляд на мир, тем менее вы привязаны к мнению окружающих,…
VZakupke | ВКонтакте
VZakupke. Информация СП — не магазин! Организатор — не продавец! Пересорт — возможен. Совместные покупки — удобно и выгодно! Нет необходимости ходить и искать по магазинам.
Платок женский с русским колоритным принтом (100*100 см …
Павлопосадские платки оптом в Москве. Купить Павлопосадские платки по оптовым ценам дешево в интернет магазине palantinsky.ru с доставкой по Москве и …
Дропшиппинг — Markethot
Выгрузить на vzakupke. com. Выгрузить на bestsp.ru. Выгрузить на sliza.ru. X. Акция! Уважаемые клиенты! Получите дополнительный заработок 20-40%, покупая у нас!
com. Выгрузить на bestsp.ru. Выгрузить на sliza.ru. X. Акция! Уважаемые клиенты! Получите дополнительный заработок 20-40%, покупая у нас!
Батарейки оптом от … — 1000opt.ru
1000 мелочей оптом от производителя с доставкой по России
Одежда оптом по низким ценам от производителя — интернет …
Дешевая одежда оптом от производителя в интернет-магазине «modavi.ru». Продажа одежды оптом по низким ценам в Москве и по всей России. ☎+7(495)908-56-96.
Бижутерия оптом от производителя. Купить бижутерию оптом …
Главная; Оплата и доставка; Условия сотрудничества; MadamBROSH
Ремень мужской из натуральной кожи (4 см.) арт. 157726 …
Ремень мужской из натуральной кожи (4 см.) арт. 157726 (Черный Экокожа, металл) купить в интернет-магазине Ремнилэнд, Доставка по России.
Обувь оптом от производителя. Купить обувь оптом дешево по …
Обувь оптом от производителя. Купить обувь оптом по низкой цене с доставкой по Москве и России .
Организатор СП — Главная страница
Сегодня совместные покупки пользуются большой популярностью. Но при всех их огромных преимуществах, могут возникнуть проблемы не только у покупателей, но и у организатора.
Купить Влагопоглощающее яйцо :: Товары для дома …
Выгрузить на vzakupke.com. Выгрузить на bestsp.ru. Выгрузить на sliza.ru. X. Акция! Уважаемые клиенты! Получите дополнительный заработок 20-40%, покупая у нас!
Комплекты и наборы бижутерии оптом от производителя …
Купить комплекты и наборы бижутерии оптом по низкой цене с доставкой по Москве и России. Заказать комплекты и наборы бижутерии в интернет магазине madambrosh.ru и …
Соковыжималка арт. 909629
Товары для кухни оптом по низкой цене с доставкой по Москве и России. Купить товары для кухни оптом в интернет магазине — цена, фото, отзывы. Заказ товара на сайте optomoll.ru и…
Куртка (10200225) купить за — интернет-магазин «MODAVI.RU»
Куртка (10200225) — Цена — продажа в оптовом интернет-магазине «modavi. ru». Доставка по РФ Отзывы. ☎ +7(495)908-56-96.
ru». Доставка по РФ Отзывы. ☎ +7(495)908-56-96.
Купить футболка арт. 923648 — футболки, майки и топы оптом …
Купить футболки, топы и майки оптом по низкой цене с доставкой по Москве и России. Заказать футболки и майки в интернет магазине optomoll.ru и по телефону +7 (495) 790-94-05….
Page Title of vzakupke.com
ВЗакупке — парсер для СП
Meta Description of vzakupke.com
ВЗакупке — сервис для организаторов совместных покупок и выгрузки каталогов товаров в социальные сети. Отправив фотографии на выкладку — НЕ ЖДИТЕ! Вы можете выключить компьютер и заниматься другими делами — мы все сделаем за вас!
Meta Tags of vzakupke.com
сп, парсинг, парсить, спарсить, социальная сеть, вконтакте, vkontakte, сайт скачать, помощник, совместые покупки, организатор, загрузчик, выкладка
Website Inpage Analysis
Mobile Friendly Check
HTTP Header Analysis
Http-Version: 1. 1
1
Status-Code: 200
Status: 200 OK
Server: nginx/1.10.3 (Ubuntu)
Date: Sun, 28 Jul 2019 00:35:11 GMT
Last-Modified: Mon, 22 Jul 2019 07:11:00 GMT
Transfer-Encoding: chunked
Connection: keep-alive
Vary: Accept-Encoding
Expires: Mon, 29 Jul 2019 00:35:11 GMT
Cache-Control: max-age=86400
Content-Encoding: gzip
Domain Information
Domain Nameserver Information
DNS Record Analysis
Full WHOIS Lookup
Domain Name: VZAKUPKE.COM
Registry Domain ID:
1948663868_DOMAIN_COM-VRSN
Registrar WHOIS Server:
whois.danesconames.com
Registrar URL:
http://www.danesconames.com
Updated Date:
2019-07-23T20:21:13Z
Creation Date:
2015-07-23T17:07:45Z
Registry Expiry Date:
2020-07-23T17:07:45Z
Registrar: Danesco Trading Ltd.
Registrar
IANA ID: 1418
Registrar Abuse Contact Email:
abuse@danesconames. com
com
Registrar Abuse Contact Phone:
+357.95713635
Domain Status: ok https://icann.org/epp#ok
Name
Server: DNS1.YANDEX.NET
Name Server: DNS2.YANDEX.NET
DNSSEC:
unsigned
URL of the ICANN Whois Inaccuracy Complaint Form:
https://www.icann.org/wicf/
>>> Last update of whois database:
2019-07-28T00:35:46Z
Similarly Ranked Websites
Что такое облачный парсер
Облачный парсинг – синтаксический анализатор или специализированный сервис, позволяющий оптимизировать загрузку товаров с социальных сетей ВК, ОК и сайтов клиентов. Инструмент помогает увеличить объем продаж в будущем. Программное обеспечение сокращает время на сбор информации. При этом не нужно ничего скачивать. ПО работает в режиме онлайн, потребуется только стабильное соединение с интернетом.
Зачем вообще делать парсинг?
Парсинг широко используется владельцами сайтов и интернет-магазинов. Программа после ввода ключевых слов ищет схожие площадки и собирает информацию, необходимую пользователю, помогает находить сведения, позволяющие оптимизировать бизнес.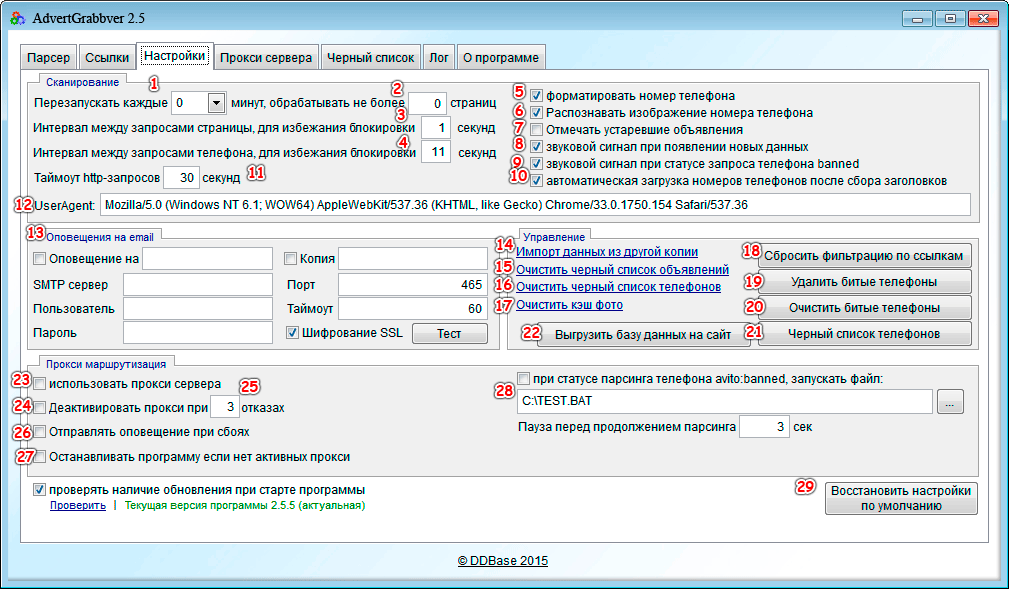 Процесс занимает минимум времени по сравнению с ручным сбором. Благодаря этому удается получить атрибуты товаров, их стоимость и прочие полезные данные.
Процесс занимает минимум времени по сравнению с ручным сбором. Благодаря этому удается получить атрибуты товаров, их стоимость и прочие полезные данные.
Парсинг помогает осуществлять анализ цен конкурентов, эффективность проводимых акций.
Существуют так же разновидности парсера для SEO задач.
Виды парсеров
В сети предлагается более 100 парсеров. Однако их можно разделить на 2 вида – десктопные и облачные. У каждого типа есть определенные характеристики и отличия, о которых следует узнать перед использованием сервиса.
Десктопные
Десктопные парсеры – программы, работающие с ПК. Большинство ПО разработаны для операционных систем Windows и macOS. Необходима установка на компьютер, но некоторые парсеры имеют портативные версии, которые запускаются с флешки или внешнего накопителя.
Большинство программных решений распространяется в интернете платно. Однако некоторые ПО можно протестировать в течение 7-30 дней бесплатно. Правда, некоторые функции могут быть недоступны. Эта опция позволяет протестировать несколько программ и выбрать оптимальный вариант.
Эта опция позволяет протестировать несколько программ и выбрать оптимальный вариант.
Облачные
Облачный парсер не требует установки на ПК. Сервис работает в режиме онлайн, нужен лишь стабильный интернет. От пользователя потребуется ввести ключевые слова, после чего алгоритм проведет поиск по страницам и сайтам, а затем произведет выгрузку данных, которые нужно будет скачать.
Облачные парсеры могут иметь веб-интерфейс и/или API. Эти опции дарят дополнительное преимущество тем, кто проводит парсинг регулярно и анализирует данные. В сети можно найти бесплатные сервисы, но большинство площадок предлагают услугу на платной основе. У каждой свои преимущества и функционал. Стоимость варьируется, зависит от задач, которые предстоит решить алгоритму.
Облачные парсеры становятся популярнее десктопных, поскольку при возникновении вопросов пользователи могут написать в техподдержку. Операторы помогут справиться с затруднениями, либо же вовсе полностью создать шаблон парсинга для определенного сайта.
Обзор функций парсера
Основная функция парсеров – сбор информации в интернете. Вытаскивать со страниц сайтов можно все, что угодно:
- каталоги товаров;
- данные о пользователях социальных сетей;
- объявления на досках объявлений, например недвижимости;
- информацию конкурентов;
- ссылки на документацию;
- ключевые слова в статьях и прочее.
Алгоритм проводит поиск информации в сети среди тысяч сайтов автоматически по заданным пользователем параметрам. В парсере выгрузка данных также занимает минимум времени. После чего они доступны для дальнейшего анализа в таблице. Информацию можно импортировать в различные программы для удобства работы с ней. Также некоторые инструменты поддерживают выгрузку на сайты, в социальные сети и интернете-магазины. Эта опция значительно экономит время пользователей.
Почему десктопные парсеры — это неудобно
Несколько лет назад десктопные парсеры были на пике популярности. Сегодня им на смену пришли облачные аналоги. Их не нужно скачивать и устанавливать, мириться с неточными данными и ошибками, сбоями, а также долго выбирать подходящую программу, тратить деньги на покупку лицензии, мучиться с блокировками, самостоятельно приобретать прокси.
Сегодня им на смену пришли облачные аналоги. Их не нужно скачивать и устанавливать, мириться с неточными данными и ошибками, сбоями, а также долго выбирать подходящую программу, тратить деньги на покупку лицензии, мучиться с блокировками, самостоятельно приобретать прокси.
При использовании десктопного парсинга нужно, чтобы ПК во время всего процесса поиска был включен. Часто программы работают с ошибками. Пользователем приходится находить их и исправлять. Нужно все время находиться около ПК, чтобы процесс не прерывался, и работа была закончена в срок, иначе придется начинать все заново.
Почему стоит выбрать облачный парсер
Большинство СЕО-специалистов и программистов отдают предпочтение именно облачному парсеру. У него больше преимуществ по сравнению с десктопным аналогом.
Повышенная безопасность
Сервис работает на сервере разработчиков, а значит, в случае бана со стороны сайтов – бан будет наложен именно на IP адреса сервиса. Опять же, если вы опасаетесь за легальность ваших действий – облачный парсер лучший вариант.
Опять же, если вы опасаетесь за легальность ваших действий – облачный парсер лучший вариант.
Богатый функционал
Облачный парсер товаров, социальных сетей, каталогов сайтов поддерживает больше опций, чем десктопный. Одновременно разработчики время от времени обновляют функционал, чтобы привлечь большую аудиторию к инструменту и повысить прибыль. Из последних инноваций:
- перевод на русский язык иностранных сайтов;
- фоновое выполнения задач;
- редактор фото с возможностью наложения надписей;
- изменения стоимости товаров и прочее.
Сервисы быстро развиваются, предлагая клиентам новые опции для комфортного решения их задач. Такой подход позволяет облегчить ведение бизнеса и повысить его доходность.
Онлайн поддержка
Облачные сервисы не оставляют пользователей без поддержки. На сайтах работает весьма отзывчивый саппорт. Операторы оказывают помощь на всех этапах парсинга – объясняют функционал, дают инструкции по выгрузке, сбору информации, анализу данных и прочее.
Парсинг без вашего участия
Облачный инструмент упрощает парсинг по максимуму. Все операции по загрузке и выгрузке информации, товаров происходят автоматически, без участия пользователя. Отсутствует нагрузка на ПК, не нужно искать дополнительные каналы, можно выключить компьютер. После чего просмотреть результаты во смартфона или планшета.
Работа в любое время и в любом месте
Облачный парсер не привязан к конкретному ПК. На сервис можно выйти с любого устройства, находясь в любой точке земного шара. Выставив необходимые настройки, удастся оперативно получить информацию и выгрузить ее для последующий действий.
Где использовать облачный парсер
У каждого сервиса есть определенный пакет услуг. Благодаря этому можно выбрать тариф для выполнения определенной задачи:
- осуществить поиск ключевых слов;
- выгрузить товары в нужный формат, интернет-магазин, социальную сеть;
- улучшить оформление каталога сайтов, категорий товаров;
- осуществить совместные покупки;
- совершить ценовую разведку;
- улучшить продажи и прочее.

Обзор парсеров
В сети более сотни облачных парсеров. О каждом можно найти огромное количество отзывов. Чтобы сэкономить время, прочитайте краткие обзоры наиболее популярных онлайн-сервисов и выберите оптимальный вариант, который решит поставленные перед них задачи за максимально короткий срок.
Cloudparser.ru
Один из самых популярных сервисов в рунете. Парсер добавляется в браузер в виде плагина-надстройки, и позволяет собирать данные со страницы интернет-магазина.
У сервиса Cloudparser.ru широкий спектр преимуществ. Наиболее весомые:
- оперативная техподдержка;
- простая регистрация;
- автоматическое формирования конечного файла загрузки без необходимости его дальнейшего переформатирования и преобразования;
- официальный парсер платформы создания сайтов совместных покупок pokupki-prosto.ru;
- выбирает качественное описание товаров, определяет точное название и их стоимость;
- проводит поиск фотографий;
- позволяет парсить в ВКонтакте, ОК;
- отсутствие многочисленных ошибок и прочие.
Минусы
Имеются ограничения по функционалу, так как парсер в основном создан для магазинов совместных покупок. В основном весь парсинг происходит с сайтов, которые заранее добавлены в базу этого сервиса.
Турбо.Парсер
Бесплатный облачный парсер ВКонтакте. Создан талантливыми отечественными разработчиками. Пользователей ждет простой и приятный интерфейс, новые решения, удобство работы.
Инструмент обладает рядом преимуществ, которыми не могут похвастаться большинство конкурентов:
- автоматическая выгрузка товаров в социальные сети ВК, ОК;
- удобный сервис для организации совместных покупок, позволяющий за несколько минут скопировать товары с площадки поставщика;
- возможность скачать товары списком или в таблице XLS (Excel) и CSV для последующей загрузки на форум, сайт;
- возможность протестировать поисковые возможности парсера бесплатно;
- приемлемые тарифы;
- хорошая и оперативная техподдержка пользователей;
- простая регистрация;
- гарантия безопасности.

Сервис постоянно совершенствуется, добавляются новые опции. Это позволяет привлечь новых клиентов и оптимизировать многие процессы.
Минусы
Инструмент Турбо.Парсер станет незаменимым для организации совместных покупок. Также он подойдет для небольшого бизнеса. Однако крупным интернет-магазинам придется искать другие варианты. Также он не подойдет тем, кто хочет парсить Авито.
Парсер— 访问 Python 解析树 — Python 3.9.14 Версия
Модуль синтаксического анализатора предоставляет интерфейс для внутреннего синтаксического анализатора Python и
компилятор байт-кода. Основная цель этого интерфейса — позволить Python
код для редактирования дерева синтаксического анализа выражения Python и создания исполняемого кода
из этого. Это лучше, чем пытаться разобрать и изменить произвольный код Python.
фрагмент кода в виде строки, потому что синтаксический анализ выполняется способом, идентичным
код, формирующий приложение. Это также быстрее.
警告
Парсер 模块 被 被 并 并 将 未来 的 的 Python 版本 移除。 对于 大多数 用 例 都 可以 使用 AST 模块 控制 抽象 语法树 ((的 生成 编译。
Есть несколько вещей, на которые следует обратить внимание в отношении этого модуля, которые важны для создания
использование созданных структур данных. Это не учебник по редактированию синтаксического анализа
деревья для кода Python, но некоторые примеры использования модуля синтаксического анализатора :
представлены.
Самое главное, хорошее понимание грамматики Python, обрабатываемой
требуется внутренний парсер. Полную информацию о синтаксисе языка см.
на Python 语言参考手册. Парсер
сам создается из спецификации грамматики, определенной в файле Grammar/Grammar в стандартном дистрибутиве Python. Деревья синтаксического анализа
хранящиеся в объектах ST, созданных этим модулем, являются фактическими выходными данными из
внутренний синтаксический анализатор при создании функциями expr() или suite() ,
описано ниже. Объекты ST, созданные с помощью
Объекты ST, созданные с помощью sequence2st() точно
имитировать эти структуры. Имейте в виду, что значения последовательностей, которые
считается «правильным», будет варьироваться от одной версии Python к другой, поскольку
формальная грамматика языка пересмотрена. Однако перенос кода из одного
Версия Python на другую в качестве исходного текста всегда будет позволять правильные деревья синтаксического анализа
быть создан в целевой версии, с единственным ограничением, что
переход на более старую версию интерпретатора не будет поддерживать более новую
языковые конструкции. Деревья синтаксического анализа обычно несовместимы из одного
версию на другую, хотя исходный код обычно был совместим с предыдущими версиями в пределах
крупная серия релизов.
Каждый элемент последовательностей, возвращаемых st2list() или st2tuple() имеет простую форму. Последовательности, представляющие нетерминальные элементы в грамматике
всегда имеют длину больше единицы. Первый элемент представляет собой целое число, которое
определяет произведение в грамматике. Этим целым числам даны символические имена
в заголовочном файле C
Первый элемент представляет собой целое число, которое
определяет произведение в грамматике. Этим целым числам даны символические имена
в заголовочном файле C Include/graminit.h и модуль Python символ . Каждый дополнительный элемент последовательности представляет компонент
продукции, распознанной во входной строке: это всегда последовательности
которые имеют ту же форму, что и родитель. Важным аспектом этой структуры
следует отметить, что ключевые слова, используемые для идентификации типа родительского узла,
например ключевое слово если в if_stmt включены в
дерево узлов без какой-либо специальной обработки. Например, ключевое слово , если .
представлен кортежем (1, 'if') , где 1 — числовое значение
связан со всеми токенами NAME , включая имена переменных и функций
определяется пользователем. В альтернативной форме возвращается, когда информация о номере строки
запрашивается, тот же токен может быть представлен как (1, 'if', 12) , где 12 представляет собой номер строки, в которой был найден терминальный символ.
Терминальные элементы представлены почти так же, но без дочерних элементов.
элементы и добавление исходного текста, который был идентифицирован. Пример
из , если приведенное выше ключевое слово является репрезентативным. Различные типы
терминальные символы определены в заголовочном файле C Include/token.h и
токен модуля Python .
Объекты ST не требуются для поддержки функциональности этого модуля, но предоставляются для трех целей: позволить приложению амортизировать стоимость обработки сложных деревьев синтаксического анализа, чтобы обеспечить представление дерева синтаксического анализа который экономит место в памяти по сравнению со списком или кортежем Python представление и облегчить создание дополнительных модулей на C, которые манипулировать деревьями синтаксического анализа. В Python можно создать простой класс-оболочку для скрыть использование объектов ST.
Модуль анализатора определяет функции для нескольких различных целей. наиболее важными целями являются создание объектов ST и преобразование объектов ST в
другие представления, такие как деревья синтаксического анализа и объекты скомпилированного кода, но
также являются функциями, которые служат для запроса типа дерева синтаксического анализа, представленного
СТ объект.
参见
- 模块
символ 代表解析树内部节点的有用常量。
- 模块
жетон 代表解析树叶子节点和测试节点值的函数的有用常量。
创建 ST 对象
Объекты ST могут быть созданы из исходного кода или дерева синтаксического анализа. При создании
объект ST из исходного кода, для создания 'eval' используются разные функции
и 'exec' форм.
-
парсер.выражение( источник ) Функция
expr()анализирует параметр source , как если бы это был вход доcompile(source, 'file.py', 'eval'). Если синтаксический анализ успешен, объект ST создается для хранения внутреннего представления дерева синтаксического анализа, в противном случае возникает соответствующее исключение.
-
парсер.набор( источник ) Функция
suite()анализирует параметр source , как если бы это был вход вкомпиляция (источник, 'file.py', 'exec'). Если синтаксический анализ успешен, объект ST создается для хранения внутреннего представления дерева синтаксического анализа, в противном случае возникает соответствующее исключение.
-
парсер.последовательность 2-я( последовательность ) Эта функция принимает дерево синтаксического анализа, представленное в виде последовательности, и строит внутреннее представительство, если возможно. Если он может подтвердить, что дерево соответствует к грамматике Python, и все узлы являются допустимыми типами узлов в основной версии Python объект ST создается из внутреннего представления и возвращается к вызываемому. Если возникла проблема с созданием внутреннего представления или если дерево не может быть проверено,
Возникает исключение ParserError. Ан
Объект ST, созданный таким образом, не должен считаться корректно компилируемым; обычный
исключения, вызванные компиляцией, все еще могут быть инициированы, когда объект ST
передан в compilest(). Это может указывать на проблемы, не связанные с синтаксисом (например, исключениеMemoryError), но также может быть связано с такими конструкциями, как в результате синтаксического анализаdel f(0), который ускользает от синтаксического анализатора Python, но проверяется компилятором байт-кода.Последовательности, представляющие терминальные токены, могут быть представлены как двухэлементными списки вида
(1, 'имя')или трехэлементные списки вида(1, 'имя') 'имя', 56). Если присутствует третий элемент, он считается допустимым. номер строчки. Номер строки может быть указан для любого подмножества терминала символов во входном дереве.
-
парсер.tuple2st( последовательность ) Это та же функция, что и
последовательность2st(). Эта точка входа
поддерживается для обратной совместимости.
转换 ST 对象
Объекты ST, независимо от исходных данных, использованных для их создания, могут быть преобразованы в деревья синтаксического анализа, представленные в виде деревьев списков или кортежей, или могут быть скомпилированы в объекты исполняемого кода. Деревья синтаксического анализа могут быть извлечены со строкой или без нее. информация о нумерации.
-
парсер.st2list( st , line_info=False , col_info = Ложь ) Эта функция принимает объект ST от вызывающего объекта в st и возвращает Список Python, представляющий эквивалентное дерево синтаксического анализа. Полученный список представление можно использовать для проверки или создания нового дерева синтаксического анализа в форма списка. Эта функция не дает сбоев, пока доступна память для сборки представление списка. Если дерево синтаксического анализа будет использоваться только для проверки,
Вместо этого следует использовать st2tuple(), чтобы уменьшить потребление памяти и фрагментация. Когда требуется представление списка, эта функция
значительно быстрее, чем извлечение представления кортежа и преобразование этого
во вложенные списки.Если line_info истинно, информация о номере строки будет включена для всех токены терминала в качестве третьего элемента списка, представляющего токен. Примечание что предоставленный номер строки указывает строку, на которой маркер заканчивается . Эта информация опускается, если флаг ложный или опущен.
-
парсер.st2tuple( st , line_info=False , col_info=False ) Эта функция принимает объект ST от вызывающей программы в st и возвращает Кортеж Python, представляющий эквивалентное дерево синтаксического анализа. Кроме возврата кортеж вместо списка, эта функция идентична
st2list().Если line_info истинно, информация о номере строки будет включена для всех токены терминала в качестве третьего элемента списка, представляющего токен.
Этот
информация опускается, если флаг ложен или опущен.
-
парсер.компилятор( st , имя_файла='<синтаксическое дерево>' ) Компилятор байтов Python может быть вызван для объекта ST для создания объектов кода который можно использовать как часть вызова встроенной функции
exec()илиeval()функции. Эта функция предоставляет интерфейс компилятору, передавая внутреннее дерево синтаксического анализа от st до синтаксического анализатора, используя имя исходного файла указывается параметром имя файла . Значение по умолчанию для имя файла указывает, что источником был объект ST.Компиляция объекта ST может привести к исключениям, связанным с компиляцией; ан примером может быть
SyntaxError, вызванная деревом синтаксического анализа дляdel f(0): это утверждение считается допустимым в рамках формальной грамматики Python, но не юридическая языковая конструкция. SyntaxErrorподнят для этого условие обычно генерируется байтовым компилятором Python, что почему он может быть поднят в этот момент на 9Модуль парсера 0004 . Большинство причин Ошибка компиляции может быть диагностирована программно путем проверки синтаксического анализа. дерево.
Запросы к объектам ST
Предусмотрены две функции, которые позволяют приложению определить, было ли
созданный как выражение или набор. Ни одна из этих функций не может быть использована для
определить, было ли ЗП создано из исходного кода с помощью expr() или suite() или из дерева синтаксического анализа через sequence2st() .
-
парсер.исэкспр( ст ) Когда st представляет форму
'eval', эта функция возвращаетTrue, в противном случае он возвращаетFalse. Это полезно, поскольку объекты кода обычно не могут быть запрошены. для получения этой информации с помощью существующих встроенных функций. Обратите внимание, что код
объекты, созданные compilest(), также не могут быть запрошены таким образом, и идентичны созданным встроеннымифункция compile().
-
парсер.issuite( ст ) Эта функция повторяет
isexpr()в том, что она сообщает, является ли объект ST представляет собой форму'exec', широко известную как «набор». Это не безопасно предположим, что эта функция эквивалентна, а не isexpr(st), как дополнительная синтаксические фрагменты могут поддерживаться в будущем.
异常和错误处理
Модуль синтаксического анализатора определяет одно исключение, но может также передать другие встроенные
исключения из других частей среды выполнения Python. Посмотреть каждый
функцию для получения информации об исключениях, которые она может вызвать.
- исключение
парсер.Ошибка синтаксического анализа Исключение возникает при сбое в модуле анализатора. Это обычно производится для ошибок проверки, а не для встроенного
SyntaxErrorвозникает во время обычного синтаксического анализа. Аргумент исключения либо строка, описывающая причину сбоя, либо кортеж, содержащий последовательность, вызывающая сбой из дерева синтаксического анализа, переданного впоследовательность2st()и поясняющая строка. Вызовыsequence2st()должны иметь возможность обрабатывать любой тип исключения, в то время как вызовы других функций в модуле нужно будет знать только простые строковые значения.
Обратите внимание, что функции compilest() , expr() и suite() могут
вызывать исключения, которые обычно возникают при разборе и компиляции
процесс. К ним относятся встроенные исключения MemoryError 9. 0005 , OverflowError , SyntaxError и SystemError . В этих
случаях эти исключения имеют все значения, обычно связанные с ними.
Подробную информацию см. в описаниях каждой функции.
ST 对象
Упорядоченные сравнения и сравнения на равенство поддерживаются между объектами ST. Маринование
Также поддерживаются объекты ST (с использованием модуля pickle ).
-
парсер.STТип Тип объектов, возвращаемых
expr(),suite()ипоследовательность2st().
ST 对象具有以下方法:
-
СТ.компиляция( имя файла = '<синтаксическое дерево>' ) 和
компилятор(st, имя файла)相同.
-
СТ.isexpr() 和
isexpr(st)相同。
-
СТ.issuite() 和
issuite(st)相同。
-
СТ. tolist( line_info=False , col_info=False ) 和
st2list(st, line_info, col_info)相同。
-
СТ.всего( line_info = False , col_info = False ) 和
st2tuple(st, line_info, col_info)相同。
Хотя между синтаксическим анализом и байт-кодом может выполняться множество полезных операций.
генерации, самая простая операция — ничего не делать. С этой целью с помощью
модуль парсера для создания промежуточной структуры данных эквивалентен
на код
>>> code = compile('a + 5', 'file.py', 'eval')
>>> а = 5
>>> оценка(код)
10
Эквивалентная операция с использованием модуля анализатора несколько длиннее, и
позволяет сохранить промежуточное внутреннее дерево синтаксического анализа как объект ST:
>>> парсер импорта
>>> st = parser.expr('a + 5')
>>> code = st. compile('file.py')
>>> а = 5
>>> оценка(код)
10
Приложение, которое нуждается как в объектах ST, так и в коде, может упаковать этот код в легкодоступные функции:
парсер импорта
защита load_suite (исходная_строка):
ул = parser.suite (исходная_строка)
вернуть st, st.compile()
def load_expression (исходная_строка):
st = parser.expr(исходная_строка)
вернуть st, st.compile()
Промежуточное ПО Express Body-Pser - Express 中文文档
Примечание: Эта страница создана на основе README анализатора тела.
Промежуточное ПО для анализа тела Node.js.
Анализ тела входящего запроса в промежуточном программном обеспечении до ваших обработчиков, доступных
по рек.тел им.
Примечание Так как форма req.body основана на пользовательском вводе, все
свойства и значения в этом объекте ненадежны и должны быть проверены
прежде чем доверять. Например, req. может дать сбой в нескольких
способами, например, свойство body.foo.toString() foo может отсутствовать или может не быть строкой,
и toString может быть не функцией, а строкой или другим вводом пользователя.
Узнайте об анатомии транзакции HTTP в Node.js.
Это не относится к составным телам из-за их сложного и типичного большая природа. Для составных тел вас может заинтересовать следующее модули:
- официант и коннект-официант
- многопартийный и подключение-многопартийный
- грозный
- мультер
Этот модуль предоставляет следующие анализаторы:
- Анализатор тела JSON
- Парсер исходного тела
- Анализатор текста
- Анализатор тела формы с URL-кодированием
Другие парсеры тела, которые могут вас заинтересовать:
- тело
- совместное тело
Установка
$ npm установить парсер тела
API
var bodyParser = require('body-parser')
Объект bodyParser предоставляет различные фабрики для создания ПО промежуточного слоя. Все
ПО промежуточного слоя заполнит свойство req.body проанализированным телом, когда
заголовок запроса Content-Type соответствует опции type или пустой
объект ( {} ), если не было тела для анализа, Content-Type не совпадал,
или произошла ошибка.
Различные ошибки, возвращаемые этим модулем, описаны в раздел ошибок.
bodyParser.json([options])
Возвращает ПО промежуточного слоя, которое анализирует только json и просматривает только те запросы, где
заголовок Content-Type соответствует опции type . Этот парсер принимает любые
Кодировка Unicode тела и поддерживает автоматическое наполнение gzip и дефляции кодировок.
Новый объект body , содержащий проанализированные данные, заполняется запрос объект после промежуточного программного обеспечения (например, req.body ).
Options
Функция json принимает необязательный объект options , который может содержать любой из
следующие ключи:
inflate
При установке true , то сдутые (сжатые) тела будут надуты; когда false , сдутые тела отбраковываются. По умолчанию true .
limit
Управляет максимальным размером тела запроса. Если это число, то значение
указывает количество байтов; если это строка, значение передается в
байтовая библиотека для разбора. По умолчанию
до '100 КБ' .
Reviver
Параметр Reviver передается непосредственно в JSON.parse в качестве второго
аргумент. Вы можете найти больше информации об этом аргументе
в документации MDN о JSON.parse.
strict
При значении true будут приниматься только массивы и объекты; когда ложно будет
принять что-либо JSON.parse принимает. По умолчанию true .
тип
тип 9Параметр 0005 используется для определения типа носителя, который будет использоваться промежуточным программным обеспечением.
разобрать. Эта опция может быть строкой, массивом строк или функцией. Если не
функция, тип параметр передается непосредственно в
type-is библиотека, и это может
быть именем расширения (например, json ), типом mime (например, application/json ) или
тип mime с подстановочным знаком (например, */* или */json ). Если функция, то типа option вызывается как fn(req) , и запрос анализируется, если он возвращает правдивый
ценность. По умолчанию приложение/json .
Verify
Опция Verify , если она предоставлена, называется Verify(req, res, buf, encoding) ,
где buf — это буфер необработанного тела запроса, а кодировка — это
кодировка запроса. Парсинг можно прервать, выдав ошибку.
bodyParser.raw([options])
Возвращает промежуточное ПО, которое анализирует все тела как буфер и просматривает только
запросы, где Заголовок Content-Type соответствует опции type . Этот
Парсер поддерживает автоматическое расширение кодировок gzip и deflate .
Новый объект body , содержащий проанализированные данные, заполняется по запросу объект после промежуточного программного обеспечения (например, req.body ). Это будет объект Buffer .
тела.
Options
Функция raw принимает необязательный объект options , который может содержать любой из
следующие клавиши:
inflate
Если установлено значение true , то сдутые (сжатые) тела будут надуты; когда false , сдутые тела отбраковываются. По умолчанию true .
limit
Управляет максимальным размером тела запроса. Если это число, то значение
указывает количество байтов; если это строка, значение передается в
байтовая библиотека для разбора. По умолчанию
до '100kb' .
type
Параметр type используется для определения типа носителя, который будет использоваться промежуточным ПО.
разобрать. Эта опция может быть строкой, массивом строк или функцией.
Если не функция, 9Опция 0004 типа передается непосредственно в
type-is библиотека и это
может быть именем расширения (например, bin ), типом mime (например, application/octet-stream ) или MIME-тип с подстановочным знаком (например, */* или заявка/* ). Если функция, то опция type вызывается как fn(req) и запрос анализируется, если он возвращает истинное значение. По умолчанию приложение/октет-поток .
проверка
Проверка 9Опция 0005, если она указана, вызывается как verify(req, res, buf, encoding) ,
где buf — это буфер необработанного тела запроса, а кодировка — это
кодировка запроса. Парсинг можно прервать, выдав ошибку.
bodyParser.text([options])
Возвращает ПО промежуточного слоя, которое анализирует все тела как строку и просматривает только
запросы, в которых заголовок Content-Type соответствует опции type . Этот
парсер поддерживает автоматическую инфляцию gzip и дефлятируют кодировки .
Новая строка body , содержащая проанализированные данные, заполняется по запросу объект после промежуточного программного обеспечения (например, req.body ). Это будет строка
тело.
Options
Функция text принимает необязательный объект options , который может содержать любой из
следующие ключи:
defaultCharset
Укажите набор символов по умолчанию для текстового содержимого, если набор символов не
указано в Content-Type заголовок запроса. По умолчанию utf-8 .
inflate
Если установлено значение true , то сдутые (сжатые) тела будут надуты; когда false , сдутые тела отбраковываются. По умолчанию true .
limit
Управляет максимальным размером тела запроса. Если это число, то значение
указывает количество байтов; если это строка, значение передается в
байтовая библиотека для разбора. По умолчанию
до '100 КБ' .
type
Параметр type используется для определения типа носителя, который будет использоваться промежуточным ПО.
разобрать. Эта опция может быть строкой, массивом строк или функцией. Если не
функция, тип параметр передается непосредственно в
type-is библиотека, и это может
быть именем расширения (например, txt ), типом mime (например, text/plain ) или mime
введите с подстановочным знаком (например, */* или text/* ). Если функция, то тип option вызывается как fn(req) , и запрос анализируется, если он возвращает
истинное значение. По умолчанию текст/обычный .
Verify
Опция Verify , если она предоставлена, называется Verify(req, res, buf, encoding) ,
где buf — это буфер необработанного тела запроса, а кодировка — это
кодировка запроса. Парсинг можно прервать, выдав ошибку.
bodyParser.urlencoded([параметры])
Возвращает промежуточное ПО, которое анализирует только urlencoded тел и просматривает только
запросы, в которых заголовок Content-Type соответствует опции type . Этот
парсер принимает только кодировку UTF-8 тела и поддерживает автоматический
инфляция gzip и дефляция кодировок.
Новый объект body , содержащий проанализированные данные, заполняется по запросу объект после промежуточного программного обеспечения (например, req.body ). Этот объект будет содержать
пары ключ-значение, где значение может быть строкой или массивом (когда расширенный есть false ) или любого типа (когда расширенный равен true ).
Options
Функция urlencoded принимает необязательный объект options , который может содержать
любой из следующих ключей:
расширенный
Параметр расширенный позволяет выбирать между анализом данных в кодировке URL
с библиотекой querystring (когда false ) или библиотекой qs (когда верно ). «Расширенный» синтаксис позволяет использовать расширенные объекты и массивы.
закодирован в формате URL-кодирования, что позволяет использовать JSON-подобный опыт
с URL-кодированием. Для получения дополнительной информации, пожалуйста
см. библиотеку qs.
По умолчанию true , но использование значения по умолчанию устарело. Пожалуйста
исследуйте разницу между qs и querystring и выберите
соответствующую настройку.
inflate
Если установлено значение true , то сдутые (сжатые) тела будут надуты; когда false , сдутые тела отбраковываются. По умолчанию true .
limit
Управляет максимальным размером тела запроса. Если это число, то значение
указывает количество байтов; если это строка, значение передается в
байтовая библиотека для разбора. По умолчанию
до '100kb' .
Ограничение параметра
Опция Ограничение параметра управляет максимальным количеством параметров, которые
разрешены в URL-кодированных данных. Если запрос содержит больше параметров
чем это значение, клиенту будет возвращена ошибка 413. По умолчанию 1000 .
type
Параметр type используется для определения типа носителя, который будет использоваться промежуточным ПО.
разобрать. Эта опция может быть строкой, массивом строк или функцией. Если не
функция, тип параметр передается непосредственно в
type-is библиотека, и это может
быть именем расширения (например, urlencoded ), типом mime (например, application/x-www-form-urlencoded ) или MIME-тип с подстановочным знаком (например, */x-www-form-urlencoded ). Если функция, то тип вариант называется как fn(req) и запрос анализируется, если он возвращает истинное значение. По умолчанию
на application/x-www-form-urlencoded .
Verify
Опция Verify , если она предоставлена, называется Verify(req, res, buf, encoding) ,
где buf — это буфер необработанного тела запроса, а кодировка — это
кодировка запроса. Парсинг можно прервать, выдав ошибку.
Ошибки
Промежуточное программное обеспечение, предоставляемое этим модулем, создает ошибки, используя http-ошибки модуль. Ошибки
обычно имеет свойство status / statusCode , которое содержит предлагаемый
Код ответа HTTP, раскрывает свойство , чтобы определить, является ли свойство сообщения должно быть показано клиенту, свойство типа для определения типа
ошибка без сопоставления с сообщением и телом свойство, содержащее
прочитанное тело, если оно доступно.
Ниже приведены распространенные ошибки, хотя может возникнуть любая ошибка. по разным причинам.
кодировка содержимого не поддерживается
Эта ошибка возникает, если запрос имеет заголовок Content-Encoding , который
содержал кодировку, но для параметра «инфляция» было установлено значение false . свойство status установлено на 415 , свойство type установлено на 'encoding. , а для свойства unsupported' charset будет установлено значение
кодировка, которая не поддерживается.
Ошибка синтаксического анализа объекта
Эта ошибка возникает, когда запрос содержит объект, который не может быть
анализируется промежуточным программным обеспечением. Свойство status имеет значение 400 , тип свойство имеет значение 'entity.parse.failed' , а для свойства body установлено значение
значение сущности, которое не удалось проанализировать.
проверка объекта не удалась
Эта ошибка возникает, когда запрос содержит объект, который не может быть
не удалось выполнить проверку с помощью определенной опции Verify . Свойство статуса :
установлен на 403 , свойство type установлено на 'entity.verify.failed' , а
Свойство body установлено на значение сущности, которая не прошла проверку.
запрос прерван
Эта ошибка возникает, когда запрос прерывается клиентом перед чтением
тело закончилось. получено свойство будет установлено на количество
байтов, полученных до того, как запрос был прерван, и свойство ожидаемое равно
установить количество ожидаемых байтов. Для свойства status установлено значение 400 .
и свойство type установлено на 'request.aborted' .
объект запроса слишком велик
Эта ошибка возникает, когда размер тела запроса превышает «предел»
вариант. Свойство limit будет установлено на ограничение в байтах, а значение длина свойство будет установлено на длину тела запроса. Свойство статуса :
установлено значение 413 , а для свойства type установлено значение 'entity.too.large' .
размер запроса не соответствует длине содержимого
Эта ошибка возникает, когда длина запроса не соответствует длине от
заголовок Content-Length . Обычно это происходит, когда запрос неправильно сформирован,
обычно, когда заголовок Content-Length был рассчитан на основе символов
вместо байтов. свойство статуса имеет значение 400 и свойство типа установлено значение 'request.size.invalid' .
кодирование потока не должно быть установлено к этому промежуточному программному обеспечению. Этот модуль работает непосредственно только с байтами, и вы не можете вызовите
req.setEncoding при использовании этого модуля. Для свойства status установлено значение 500 и 9Свойство 0004 type имеет значение 'stream.encoding.set' .слишком много параметров
Эта ошибка возникает, когда содержание запроса превышает настроенное параметрLimit для парсера urlencoded . Для свойства status установлено значение 413 и свойство type установлено на 'parameters. . too.many'
неподдерживаемый набор символов «BOGUS»
Эта ошибка возникает, когда запрос содержит параметр набора символов в Заголовок Content-Type , но модуль iconv-lite не поддерживает его ИЛИ
парсер не поддерживает. Кодировка также содержится в сообщении
как в свойстве charset . Для свойства status установлено значение 415 , свойство типа имеет значение 'charset.unsupported' , а свойство charset установлена кодировка, которая не поддерживается.
неподдерживаемое кодирование содержимого «подделка»
Эта ошибка возникает, если запрос имеет Content-Encoding заголовок, который
содержал неподдерживаемую кодировку. Кодировка содержится в сообщении
а также в свойстве кодировка . Для свойства status установлено значение 415 ,
свойство type имеет значение 'encoding. , а свойство unsupported' encoding для свойства задана неподдерживаемая кодировка.
Примеры
Экспресс/Подключение универсального верхнего уровня
В этом примере показано добавление универсального синтаксического анализатора JSON и URL-кодированного промежуточное ПО верхнего уровня, которое будет анализировать тела всех входящих запросов. Это самая простая установка.
переменная экспресс = требуется('экспресс')
var bodyParser = требуется ('тело-парсер')
вар приложение = экспресс()
// разбираем приложение/x-www-form-urlencoded
app.use (bodyParser.urlencoded ({расширенный: ложь}))
// разбираем приложение/json
app.use(bodyParser.json())
app.use (функция (req, res) {
res.setHeader('Тип содержимого', 'текст/обычный')
res.write('вы опубликовали:\n')
res.end(JSON.stringify(req.body, null, 2))
})
Express для конкретных маршрутов
В этом примере показано добавление парсеров тела специально для маршрутов, которые
нужно их. В общем, это наиболее рекомендуемый способ использования body-parser с
Выражать.
переменная экспресс = требуется('экспресс')
var bodyParser = требуется ('тело-парсер')
вар приложение = экспресс()
// создаем парсер приложения/json
вар jsonParser = bodyParser.json()
// создаем парсер application/x-www-form-urlencoded
var urlencodedParser = bodyParser.urlencoded({extended: false})
// POST /login получает тела в кодировке urlencode
app.post('/login', urlencodedParser, function (req, res) {
res.send('добро пожаловать,' + req.body.username)
})
// POST /api/users получает тела JSON
app.post('/api/users', jsonParser, function (req, res) {
// создаем пользователя в req.body
})
Изменить допустимый тип для синтаксических анализаторов
Все синтаксические анализаторы принимают опцию типа , которая позволяет изменить Content-Type , который будет анализировать ПО промежуточного слоя.
переменная экспресс = требуется('экспресс')
var bodyParser = требуется ('тело-парсер')
вар приложение = экспресс()
// анализировать различные пользовательские типы JSON как JSON
app. use(bodyParser.json({ тип: 'application/*+json' }))
// парсить что-то нестандартное в буфер
app.use (bodyParser.raw ({ тип: 'application/vnd.custom-type' }))
// разбираем тело HTML в строку
app.use(bodyParser.text({тип: 'текст/html'}))
Лицензия
MIT
Анализ многострочных строк - Вопрос
sathish
#1
У меня есть многострочная строка (электронная почта), которую мне нужно проанализировать. Я хотел бы получить приведенную ниже информацию из строки, используя Scala. Иногда может отсутствовать несколько строк, например, строка «Кому:» в электронном письме, и код должен быть в состоянии справиться с этим.
идентификатор сообщения = 26025617,60263913.JavaMail.gia@basi
MessageDate = Mon, 20 Aug 2012 06:02:09 -0800 (PST)
MessageFrom = matt. [email protected]
MessageTo = [email protected]
MessageSubject = Различные предложения
val strMail = «»»Message-ID: 26025617.60263913.JavaMail.gia@basi
Дата: Пн, 20 августа 2012 г. 06:02:09 -0800 (PST)
От: [email protected]
Кому: [email protected]
Тема: Различные предложения
Mime-Version: 1.0
Content-Type: text/plain; charset=us-ascii
Content-Transfer-Encoding: 7bit
X-From: Matt, Spartz
X-To: Dave, Edgar
X-cc:
X-bcc:
X-Folder: \Dedgar (Non-Privileged)\Edgar, Dave\Inbox
X-Origin: Edgar-D
X-FileName : DEDGAR (Non-Privileged).pst
Dave:
Как вы думаете, у вас будет возможность сегодня поработать над различными предложениями? Если нет, не могли бы вы подсказать, когда на этой неделе, по вашему мнению, у вас будет свободное время.
Спасибо, Мэтт»»»
Любая помощь? Спасибо.
martijnhoekstra
#2
Вы можете использовать библиотеку синтаксического анализа, такую как atto или fastparse, или вы можете сделать это специально.
Информацию о библиотеках см. в соответствующей документации. Для специального подхода разделите строку на первой пустой строке (\n\n). Вторая часть – тело. Первая часть представляет собой заголовок на строку. Для каждой строки в linesIterator разделите первые : , часть до — это ключ, а после — значение, а Боб — ваш пресловутый дядя.
1 Нравится
23 января 2020 г., 21:28
#3
Здесь где-то есть шутка про отсутствие типов в разбиении строк, и что твой дядя Боб не возражал бы, потому что тесты надо писать в любом случае, но я не могу найти живицу, чтобы заставить это работать.
tpolecat
#4
Как бы я ни был поклонником комбинаторов синтаксических анализаторов, я думаю, что мог бы использовать для этого JavaMail.
дсб
#5
На самом деле, это не (всегда) одно поле заголовка на строку — не забывайте
, что поле заголовка может быть объединено в несколько строк.
Дэниел
1 Нравится
29 января 2020 г., 13:01
#6
Я этого не понимал. Тогда как-то менее привлекательно.
val headerBlock = strMail.linesIterator.takeWhile(строка => !line.isEmpty)
заголовки val = headerBlock.foldLeft(List.empty[(String, String)]) {
case ((k, v) :: rest, line) if line.startsWith(" ") || line.startsWith("\t") => (k -> (v + строка)) :: остальные
case (l, s"$key:$value") => (ключ -> значение) :: l
}
заголовки.toMap
по-прежнему будет достаточно, чтобы сделать трюк для конкретного (по крайней мере, на 2.13), но использование javamail действительно, вероятно, будет лучше.
сатиш
#7
Я получаю следующую ошибку, когда запускаю код в блокноте.
command-1082574194325029: 5: ошибка: метод s не является классом case и не имеет члена unapply/unapplySeq
case (l, s»$key:$value») => (key -> value): : л
Спасибо
SethTisue
#8
поддержка использования интерполятора s для сопоставления с образцом, подобного этому, не была добавлена в стандартную библиотеку Scala до версии Scala 2.13. (и у Spark пока нет поддержки 2.13, только 2.11 и 2.12)
1 Нравится
Расширенные выражения политики: анализ SSL
6 сентября 2022 г.
Предоставлено:
С S
Существуют расширенные выражения политики для анализа сертификатов SSL и приветственных сообщений клиентов SSL.
Анализ SSL-сертификатов
Вы можете использовать расширенные выражения политики для оценки клиентских сертификатов X.509 Secure Sockets Layer (SSL). Сертификат клиента — это электронный документ, который может использоваться для аутентификации личности пользователя. Сертификат клиента содержит (как минимум) информацию о версии, серийный номер, идентификатор алгоритма подписи, имя издателя, срок действия, имя субъекта (пользователя), открытый ключ и подписи.
Вы можете проверять как соединения SSL, так и данные в сертификатах клиентов. Например, вы можете захотеть отправить SSL-запросы, использующие шифры низкой стойкости, на определенную ферму виртуальных серверов с балансировкой нагрузки. Следующая команда является примером политики переключения содержимого, которая анализирует стойкость шифра в запросе и сопоставляет стойкость шифра, меньшую или равную 40:
добавить политику cs p1 -rule "client.ssl.cipher_bits.le(40)"
В качестве другого примера можно настроить политику, определяющую, содержит ли запрос сертификат клиента:
добавить политику cs p2 -rule "client.
Или можно настроить политику, которая проверяет определенную информацию в сертификате клиента. Например, следующая политика проверяет, что сертификат имеет один или несколько дней до истечения срока действия:
добавить политику cs p2 -rule «client.ssl.client_cert существует && client.ssl.client_cert.days_to_expire.ge(1)»
Пример использования отпечатка пальца JA3:
добавить политику ssl ja3_pol -rule "CLIENT.SSL.JA3_FINGERPRINT.EQ(bb4c15a90e93a25ddc16274395bce4c6)" -сброс действия
Или, пример использования отпечатка пальца JA3 с patset:
добавить политику patset pat1 политика привязки patset pat1 bb4c15a90e93a25ddc16274395bce4c6 -index 1 связать политику patset pat1 cd3c15a90e93a25ddc16274395bce6b4 -индекс 2 добавить политику SSL ssl_ja3_pol -правило CLIENT.SSL.JA3_FINGERPRINT.contains_any(\"pat1\") -сброс действия
Примечание
Сведения об анализе даты и времени в сертификате см.
Префиксы для текстовых данных SSL и сертификатов
В следующей таблице описаны префиксы выражений, идентифицирующие текстовые элементы в транзакциях SSL и клиентских сертификатах.
Таблица 1. Префиксы, которые возвращают текстовые или логические значения для SSL и данных сертификата клиента
| Префикс | Описание |
|---|---|
| CLIENT.SSL.CLIENT_CERT | Возвращает сертификат клиента SSL в текущей транзакции SSL. |
| КЛИЕНТ.SSL.CLIENT_CERT.TO_PEM | Возвращает сертификат клиента SSL в двоичном формате. |
| КЛИЕНТ.SSL.CIPHER_EXPORTABLE | Возвращает логическое значение TRUE, если криптографический шифр SSL можно экспортировать. |
| КЛИЕНТ.SSL.ИМЯ_ШИФРА | Возвращает имя шифра SSL, если он вызывается из SSL-соединения, и строку NULL, если он вызывается из не-SSL-соединения. |
| КЛИЕНТ.SSL.IS_SSL | Возвращает логическое значение TRUE, если текущее соединение основано на SSL. |
| КЛИЕНТ.SSL.JA3_FINGERPRINT | Возвращает логическое значение TRUE, если настроенный отпечаток JA3 совпадает с отпечатком JA3 в приветственном сообщении клиента. Примечание: Это выражение доступно в версии 13.1 сборки 12.x и более поздних версиях. |
Префиксы для числовых данных в сертификатах SSL
В следующей таблице описаны префиксы, которые оценивают числовые данные, отличные от дат, в сертификатах SSL. Эти префиксы можно использовать с операциями, описанными в разделе Основные операции с префиксами выражений и составные операции для чисел.
Таблица 2. Префиксы, которые оценивают числовые данные, отличные от дат, в SSL-сертификатах
| Префикс | Описание |
|---|---|
| CLIENT. SSL.CLIENT_CERT.DAYS_TO_EXPIRE | Возвращает количество дней, в течение которых сертификат действителен, или возвращает -1 для сертификатов с истекшим сроком действия. |
| КЛИЕНТ.SSL.CLIENT_CERT.PK_SIZE | Возвращает размер открытого ключа, используемого в сертификате. |
| КЛИЕНТ.SSL.CLIENT_CERT.ВЕРСИЯ | Возвращает номер версии сертификата. Если соединение не основано на SSL, возвращает ноль (0). |
| КЛИЕНТ.SSL.CIPHER_BITS | Возвращает количество битов в криптографическом ключе. Возвращает 0, если соединение не основано на SSL. |
| КЛИЕНТ.SSL.ВЕРСИЯ | Возвращает число, представляющее версию протокола SSL, следующим образом: 0. Транзакция не основана на SSL: 0x002. Транзакция SSLv2: 0x300. Транзакция SSLv3: 0x301. Транзакция TLSv1: 0x302. Транзакция TLS 1.1: 0x303. Транзакция TLS 1.2: 0x304. Транзакция — TLS 1.3. |
Примечание
Выражения, связанные с датами истечения срока действия сертификата, см.
Выражения для сертификатов SSL
Вы можете анализировать сертификаты SSL, настроив выражения, использующие следующий префикс:
CLIENT.SSL.CLIENT_CERT
В этом разделе обсуждаются выражения, которые можно настроить для сертификатов, за исключением выражений, проверяющих срок действия сертификата. Операции, основанные на времени, описаны в расширенных выражениях политики: работа с датами, временем и числами.
В следующей таблице описаны операции, которые можно указать для префикса CLIENT.SSL.CLIENT_CERT.
Таблица 3. Операции, которые можно указать с помощью префикса CLIENT.SSL.CLIENT_CERT
| Операция SSL-сертификата | Описание |
|---|---|
<сертификат>.EXISTS | Возвращает логическое значение TRUE, если у клиента есть сертификат SSL. |
<сертификат>. | Возвращает отличительное имя (DN) издателя в сертификате в виде списка значений имени. Знак равенства («=») является разделителем имени и значения, а косая черта («/») — разделителем, разделяющим пары «имя-значение». Ниже приведен пример возвращаемого DN: /C=US/O=myCompany/OU=www.mycompany.com/CN=www.mycompany.com/[email protected] |
<сертификат>.ЭМИТЕНТ. IGNORE_EMPTY_ELEMENTS | Возвращает эмитента и игнорирует пустые элементы в списке «имя-значение». Например, рассмотрим следующее: Издатель сертификата: /c=in/st=kar//l=bangelore //o=mycompany/ou=sales/ /[email protected] . Следующее действие перезаписи возвращает число 6 на основе предыдущего определения издателя: действие перезаписи sh insert_ssl_header Имя: insert_ssl Операция: insert_http_header Цель: Cert-Issuer Значение: CLIENT. . Однако, если вы измените значение на следующее, возвращенное количество будет равно 9: CLIENT.SSL.CLIENT_CERT.ISSUER.IGNORE_EMPTY_ELEMENTS.COUNT |
Анализ приветствия клиента SSL
Вы можете проанализировать сообщение приветствия клиента SSL, настроив выражения, использующие следующий префикс:
| Префикс | Описание |
|---|---|
| CLIENT.SSL.CLIENT_HELLO.CIPHERS.HAS_HEXCODE | Сопоставляет шестнадцатеричный код, указанный в выражении, с шестнадцатеричными кодами наборов шифров, полученных в приветственном сообщении клиента. |
| КЛИЕНТ.SSL.CLIENT_HELLO.CLIENT_VERSION | Версия получена в заголовке приветственного сообщения клиента. |
| КЛИЕНТ.SSL.CLIENT_HELLO.IS_RENEGOTIATE | Возвращает значение true, если клиент или сервер инициируют повторное согласование сеанса. |
| КЛИЕНТ.SSL.CLIENT_HELLO.IS_REUSE | Возвращает значение true, если устройство повторно использует сеанс SSL на основе ненулевого идентификатора сеанса, полученного в сообщении client-hello. |
| КЛИЕНТ.SSL.CLIENT_HELLO.IS_SCSV | Возвращает значение true, если в приветственном сообщении клиента объявлена возможность Signaling Cipher Suite Value (SCSV). Шестнадцатеричный код резервного SCSV — 0x5600. |
| КЛИЕНТ.SSL.CLIENT_HELLO.IS_SESSION_TICKET | Возвращает значение true, если в сообщении client-hello объявлено расширение билета сеанса с ненулевой длиной. |
| КЛИЕНТ.SSL.CLIENT_HELLO.LENGTH | Длина, полученная в заголовке приветственного сообщения клиента. |
| КЛИЕНТ.SSL.CLIENT_HELLO.SNI | Возвращает имя сервера, полученное в расширении имени сервера приветственного сообщения клиента. |
| КЛИЕНТ. SSL.CLIENT_HELLO.ALPN.HAS_NEXTPROTOCOL | Возвращает значение true, если протокол приложения в расширении ALPN, полученном в приветственном сообщении клиента, соответствует протоколу, указанному в выражении. |
Эти выражения можно использовать в точке привязки CLIENTHELLO_REQ. Дополнительные сведения см. в разделе Привязка политики SSL.
Написание простого синтаксического анализатора рекурсивного спуска
30 июля 2015 г. — Простая реализация строки запроса на основе полей с бинарными операциями с использованием синтаксического анализатора рекурсивного спуска. — 5-минутное чтение
Недавно кто-то задал вопрос по местному рубиновому списку. Они искали реализацию синтаксического анализатора, который бы обрабатывал ключевые слова и спецификации полей, например:
страна:(ru ИЛИ cn ИЛИ "Южная Корея") штат: (техас ИЛИ ок) компания: "АКМЭ Продактс" last:smith AND first:john
Теперь вы должны понимать, что курс компиляции, который я посещал в колледже (почти 20 лет назад?!), был одним из моих любимых. Это полностью взорвало мой разум. У меня до сих пор есть (и мне нравится) «Книга дракона» Ахо и др. al., и время от времени — по старой памяти — беру его с полки, листаю и испытываю ностальгию. Десять с лишним лет назад я даже изобрел и реализовал несколько простых языков программирования… но в целом моя карьера была на удивление лишена возможностей для реализации парсеров.
Итак, когда появился этот запрос, я оживился. Парсер? Хммм!
Есть много разных способов реализовать это, но я решил использовать парсер с рекурсивным спуском. Они всегда были моими любимыми, и, честно говоря, я не мог сразу вспомнить, как делать какие-либо другие.
Итак, во-первых, я взял неофициальную спецификацию, предоставленную OP, и преобразовал ее в форму Бэкуса-Наура (BNF). (Технически, я думаю, я использовал EBNF — расширенную форму Бэкуса-Наура — но это все равно было только для моего собственного использования.)
выражение := термин
| термин И выражение
| термин ИЛИ выражение
термин := значение
| атом ':' значение
атом := слово+
| quoted_строка
значение := атом
| '(' expr ')' Предостережение : я намеренно избегал приоритета оператора, поэтому в этой реализации И и ИЛИ имеют эквивалентный приоритет. Кроме того, синтаксический анализ строк очень наивен для простоты (и демонстрации).
Честно говоря, преобразование описания в BNF обычно является самой сложной частью, но как только вы это сделаете, остальная часть синтаксического анализатора будет работать очень естественно. Каждая из левых частей этих определений БНФ становится методом, который рекурсивно вызывает соответствующие методы, соответствующие элементам в правой части. (Таким образом, «рекурсивный» в «рекурсивном спуске».)
Идея состоит в том, что процесс синтаксического анализа возвращает AST — абстрактное синтаксическое дерево, — которое представляет входные данные. Для поддержки этого дерева я определил две простые структуры: одну для выражения с оператором и одну для спецификации поля:
class Expression < Struct.new(:op, :left, :right) конец поле класса < Struct.new (: имя,: значение) end
Затем я прыгнул прямо вверх и написал метод #parse . Он принимает один аргумент, ввод для анализа (в виде строки). Я использовал Ruby’s StringScanner для выполнения лексического анализа (сканирования), потому что на самом деле редко бывают причины не делать этого. StringScanner великолепен!
анализ по определению (строка) сканер = StringScanner.new(строка) parse_expr (сканер) end
Вызов БНФ из предыдущего. Элемент expr является элементом верхнего уровня, поэтому мой метод #parse вызывает его. Реализация для #parse_expr хороша и проста:
def parse_expr(scanner)
слева = parse_term (сканер)
scan.skip(/\s+/)
op = scan.scan(/И|ИЛИ/i)
если оп
Expression.new (op.downcase.to_sym, слева, parse_expr (сканер))
еще
оставил
конец
конец Наш элемент expr (в БНФ) может быть термином или термином , за которым следует оператор. Поскольку он всегда начинается с термина , мы сначала вызываем соответствующий метод #parse_term . Затем мы пропускаем все пробелы и ищем оператор. Если мы находим его, мы создаем новый Expression , даем ему оператор, левый операнд, и анализируем правый операнд (как expr — обратите внимание на рекурсию!). В противном случае мы просто возвращаем операнд, который мы проанализировали в начале.
Легко!
Далее, давайте посмотрим, как определяется #parse_term :
def parse_term(scanner)
scan.skip(/\s+/)
значение = parse_value (сканер)
возвращаемое значение, если value.is_a?(Выражение)
если scan.skip(/:/)
Field.new (значение, parse_value (сканер))
еще
ценность
конец
end Мы начинаем с того, что пропускаем (или, как это называется, «съедаем») все пробелы. Затем ищем значение. Посмотрите еще раз на БНФ: посмотрите, как -значение может быть либо -атомом или заключенное в скобки expr ? Сравнивая это с определением термина , мы видим, что термин может начинаться либо с атома , либо с выражения . Это означает, что мы можем вызвать parse_value , и если результатом будет Expression , то мы закончим и просто вернем его. В противном случае нам нужно рассмотреть случай, когда у нас есть спецификация поля.
Для этого проверяем следующий символ. Если это двоеточие, мы создаем новый экземпляр Поле и возвращаем его, анализируя новое значение в процессе. В противном случае мы просто возвращаем уже проанализированное значение.
Итак, что насчет parse_value ? Это точно будет зверюга? Я имею в виду, что все не могут быть такими простыми, верно?
Ха-ха! Ты веселый. Проверь это.
определение parse_value (сканер)
start = сканер.pos
если сканер.пропустить(/\(/)
parse_expr(сканер).нажмите сделать
scan.scan(/\)/) или
поднять "выражение не завершено (начать с # {начало})"
конец
еще
parse_atom (сканер)
конец
конец Здесь у нас есть первый пример обработки ошибок. Сохраняем текущую позицию в сканере, а затем ищем открывающую скобку. Если мы находим его, мы анализируем (и возвращаем) expr , а затем съедаем закрывающую скобку. Однако, если закрывающая скобка не найдена, это ошибка! Мы вызываем исключение, говорящее, где в строке началось выражение.
Если, с другой стороны, с самого начала не было открывающей скобки, значение должно быть атомом , и вместо этого мы разбираем его.
Осталось еще два способа! Парсер atom очень прост:
def parse_atom(scanner)
scan.scan(/\w+/) ||
parse_quoted_string(сканер) ||
поднять("ожидается атом в #{scanner.pos}")
end Атом является либо словом ( /\w+/ ), либо строкой в кавычках. Если это не так, мы создаем исключение и показываем, где произошла ошибка.
Последний метод: разбор строк в кавычках. 9#{delim}]*/).нажмите сделать scan.scan(/#{delim}/) или поднять "строка в кавычках не завершена (начинается с #{start})" конец конец end
Сохраняем позицию (для сообщения об ошибках), а затем смотрим, с какими кавычками мы имеем дело. Затем мы сканируем все символы до (но не включая) следующего экземпляра этой кавычки и возвращаем их, убедившись, что в процессе есть закрывающая кавычка. Если закрывающей кавычки не было, мы сообщаем об этой ошибке.
Вот и все! Серьезно. Теперь мы можем анализировать такие запросы:
# простые слова
разобрать "компиляторы"
#-> "компиляторы"
# спецификация поля
разобрать "тема: компиляторы"
#-> Field.new("тема", "компиляторы")
# логические операции
parse "тема: компиляторы или автор: Ахо"
#-> Expression.new(:or,
# Field.new("тема", "компиляторы"),
# Field.new("автор", "Ахо"))
# булевы операции в спецификациях полей
parse "subject:(компиляторы ИЛИ парсеры)"
#-> Field.new("тема",
# Expression.new(:или, "компиляторы", "парсеры") Парсеры с рекурсивным спуском такие элегантные! Есть что-то в том, как естественно они имитируют грамматику… и как четко рекурсия описывает отношения между различными элементами синтаксиса… Это не идеально для каждой грамматики, но для таких простых случаев, как этот, я очень, очень врубаюсь.
Если синтаксические анализаторы пугали вас в прошлом, надеюсь, это показало вам, насколько простыми они могут быть. На самом деле, они могут быть довольно забавными!
Вот суть моей полной реализации, даже с несколькими спецификациями (предназначенными скорее как примеры, чем как реальные тесты). Наслаждаться!
Включите JavaScript для просмотра комментариев с помощью Disqus.
Один синтаксический анализатор для управления всеми уведомлениями об обслуживании цепи
Несколько месяцев назад Network to Code выпустила два проекта с открытым исходным кодом (дополнительная информация), чтобы внести свой вклад в решение общей проблемы в современных сетях: понять, когда цепь проходит через плановое техническое обслуживание . С одной стороны, -схемный анализатор для разбора уведомлений в общую структуру данных, а с другой стороны, 9Плагин 0004 nautobot-circuit-maintenance , который использует библиотеку парсера для автоматического заполнения данных в Nautobot. После нескольких месяцев разработки мы рады объявить о выпуске версии 2.0.0 парсера, которая содержит множество улучшений, основанных на существующих клиентских развертываниях, и теперь охватывает 19 различных интернет-провайдеров!
парсер схемы обслуживания Библиотека В упомянутом блоге мы признали, что мы не первые, кто пытается решить эту проблему. Мы решили принять предложенный здесь формат (используя iCalendar ) в качестве нашего золотого стандарта.
Теперь вы можете задаться вопросом: зачем нам библиотека парсера, когда есть четко определенный формат? Ответ хорошо известен… будучи просто рекомендацией, он не полностью принят всеми поставщиками сетевых услуг (NSP). Таким образом, по-прежнему необходимо анализировать произвольные форматы данных, чтобы получить нечто, соответствующее стандарту Maintenance , содержащему следующие атрибуты:
- поставщик : идентифицирует поставщика услуги, которая является предметом уведомления о техническом обслуживании.
- учетная запись : идентифицирует учетную запись, связанную со службой, которая является предметом уведомления об обслуживании.
- Maintenance_id : содержит текст, который однозначно идентифицирует обслуживание, являющееся предметом уведомления.
- цепи : список цепей, затронутых уведомлением о техническом обслуживании, и их конкретное воздействие.
- статус : определяет общий статус или подтверждение обслуживания.
- start : метка времени, определяющая дату начала технического обслуживания по Гринвичу.
- end : метка времени, определяющая дату окончания технического обслуживания по Гринвичу.
- штамп : штамп времени, определяющий дату обновления технического обслуживания по Гринвичу.
- организатор : определяет контактную информацию, включенную в исходное уведомление.
Дополнительные сведения об этих атрибутах см. в BCOP.
Эта библиотека предназначена для заполнения существующего разрыва между идеальным представлением уведомления о техническом обслуживании канала и форматами текущих поставщиков, что позволяет строить автоматизацию вокруг этих уведомлений.
В первой версии анализатора схемы был простой рабочий процесс, который в конечном итоге стал блокировщиком для решения более сложных вариантов использования.
и для этого требовалось новое промежуточное программное обеспечение, которое могло бы объединять несколько данных, используя пользовательскую логику для обработки составных уведомлений, и иметь возможность приспосабливаться к будущим новым вариантам использования. Дополнительные сведения о рабочем процессе логики доступны в файле Readme библиотеки.
Поддерживаемые провайдеры
Очевидно, что одним из ключевых показателей успеха библиотеки является количество поддерживаемых провайдеров , и благодаря многочисленным примерам, полученным от первых пользователей, список поддерживаемых провайдеров увеличился до 19 провайдеров, и он быстро растет.
- АкваКоммс
- АВС
- Когент
- Кольт
- EuNetworks
- ГТТ
- HGC
- Люмен
- Мегапорт
- Импульс
- НТТ
- PacketFabric
- Сиборн
- Блеск
- Телия
- Телстра
- Туркселл
- Веризон
- Зайо
Кроме того, золотой формат поддерживается по умолчанию с
GenericProvider, поэтому любой NSP, который отправляет уведомление в форматеiCalendar, поддерживается по умолчанию.
Как им пользоваться?
Библиотеке Circuit_maintenance_parser требуются две вещи:
- Данные уведомления
- Идентификатор
провайдера: используется для выбора требуемогопровайдера. КаждаяПоставщиксодержит логику для обработкиданных уведомленияс использованием связанных синтаксических анализаторов.
Библиотека Python
Первым шагом является определение поставщика , который мы будем использовать для анализа уведомлений. По умолчанию GenericProvider (используется, когда не определен другой тип поставщика) будет поддерживать синтаксический анализ уведомлений iCalendar с использованием рекомендуемого формата.
из Circuit_maintenance_parser импортировать init_provider универсальный_провайдер = init_provider() тип (общий_провайдер) <класс 'circuit_maintenance_parser.provider.GenericProvider'>
Однако обычно некоторые провайдеры не полностью реализуют стандарт. Или, возможно, отсутствует какая-то информация, например электронная почта органайзера . Мы также поддерживаем определяемые пользователем поставщики , которые можно использовать для настройки извлечения данных на основе уведомлений, получаемых вашей организацией:
ntt_provider = init_provider("ntt")
тип (ntt_provider)
<класс 'circuit_maintenance_parser.provider.NTT'>
Как только у нас появится провайдер готово, нам нужно инициализировать данные для обработки. Мы называем его NotificationData , и его можно инициализировать из простого содержимого и типа или из более сложных структур, таких как электронная почта.
из Circuit_maintenance_parser импорта NotificationData raw_data = b"""НАЧАЛО:КАЛЕНДАРЬ VC ВЕРСИЯ: 2.0 PRODID:-//Основное примечание//https://github.com/maint-notification// НАЧАЛО:ВЕВЕНТ РЕЗЮМЕ:Пример основной ноты DTSTART;ЗНАЧЕНИЕ=ДАТА-ВРЕМЯ:20151010T080000Z DTEND; ЗНАЧЕНИЕ = ДАТА-ВРЕМЯ: 20151010T100000Z DTSTAMP;ЗНАЧЕНИЕ=ДАТА-ВРЕМЯ:20151010T001000Z UID: 42 ПОСЛЕДОВАТЕЛЬНОСТЬ:1 X-MAINTNOTE-PROVIDER:example.
Наконец, мы извлекаем техническое обслуживание (это список , поскольку уведомление может содержать несколько техобслуживаний) из данных, вызывающих метод get_maintenances из экземпляра Provider :
Maintenances = generic_provider.get_maintenances(data_to_process)
печать (обслуживание [0].to_json())
{
"счет": "137.035999173",
"схемы": [
{
"circuit_id": "acme-виджеты как услуга",
"воздействие": "БЕЗ ВОЗДЕЙСТВИЯ"
},
{
"circuit_id": "acme-виджеты-как-сервис-2",
"влияние": "ОТКЛЮЧЕНИЕ"
}
],
"конец": 1444471200,
"maintenance_id": "WorkOrder-31415",
"organizer": "mailto:noone@example. com",
"провайдер": "example.com",
"последовательность": 1,
"штамп": 1444435800,
"старт": 1444464000,
"статус": "ПРЕДВАРИТЕЛЬНЫЙ",
"summary": "Пример основной ноты",
"ИД": "42"
}
Обратите внимание, что с поставщиком GenericProvider или NTT мы получаем одинаковый результат из одних и тех же проанализированных данных, потому что они используют точно такой же процессор и Parser . Единственное отличие состоит в том, что NTT Provider предоставит некоторые пользовательские значения по умолчанию для NTT, если уведомление не содержит этих данных. В этом случае уведомление содержит всю информацию, поэтому пользовательские значения по умолчанию для Provider не используются.
ntt_maintenances = ntt_provider.get_maintenances(data_to_process) утверждать ntt_maintenances == обслуживание
CLI
Существует также точка входа cli парсер схемы , который предлагает легкий доступ к библиотеке с использованием нескольких аргументов:
-
файл данных: файл, хранящий уведомление. -
тип данных:ical,htmlилиэлектронная почта, в зависимости от типа данных. -
тип провайдера: выбрать правильный провайдерGenericProvider.
Circuit-Maintenance-Parser --data-file "/tmp/___ZAYO TTN-00000000 УВЕДОМЛЕНИЕ О ОБСЛУЖИВАНИИ___.eml" --data-type email --provider-type zayo
Уведомление о техническом обслуживании цепи № 0
{
"аккаунт": "мой_аккаунт",
"схемы": [
{
"circuit_id": "/OGYX/000000/ /ZYO/",
"влияние": "ОТКЛЮЧЕНИЕ"
}
],
"конец": 1601035200,
"maintenance_id": "TTN-00000000",
"организатор": "[email protected]",
"провайдер": "zayo",
"последовательность": 1,
"штамп": 1599436800,
"старт": 1601017200,
"статус": "ПОДТВЕРЖДЕНО",
"summary": "Zayo проведет плановое техническое обслуживание для устранения неполадок и восстановления изношенного диапазона",
"ИД": "0"
}
Как расширить библиотеку?
Несмотря на то, что библиотека нацелена на поддержку как можно большего количества поставщиков, вполне вероятно, что поддерживаются не все тысячи NSP, и вам может потребоваться добавить поддержку для какого-то нового. Добавление нового провайдера довольно просто, и в следующем примере мы добавляем поддержку воображаемого провайдера, ABCDE, который использует уведомления HTML.
Первый шаг — создание нового файла: Circuit_maintenance_parser/parsers/abcde.py . Этот файл будет содержать все пользовательские парсеры, необходимые для провайдера, и он будет импортировать базовые классы для каждого типа парсера из Circuit_maintenance_parser.parser . В примере нам нужно только импортировать Html , а в дочернем классе реализовать методы, требуемые классом, в данном случае parse_html() , который вернет dict со всеми данными, которые этот Парсер может извлекать. В этом случае нам нужны вспомогательные методы _parse_bs и _parse_tables , которые реализуют логику навигации по данным уведомления.
от ввода импорта Dict import bs4 # тип: ignore from bs4.element import ResultSet # type: ignore из Circuit_maintenance_parser.
Следующим шагом является создание нового Provider путем определения нового класса в Circuit_maintenance_parser/provider.py . Этот класс, который наследуется от GenericProvider , должен определить только два атрибута:
-
_processors: списокProcessor, который использует несколько данныхParsers. В этом примере нам не нужно создавать новый пользовательский процессорHtmlParserABCDE1, а также общийEmailDateParser, который извлекает дату электронной почты. Также обратите внимание, что в этом списке может быть несколько процессоров -
_default_organizer: это помощник по умолчанию для заполнения атрибута органайзераОбслуживание, если информация не является частью исходного уведомления. -
_include_filter: сопоставлениеdata_typesсо списком выражений регулярных выражений, которые, если они предоставлены, должны соответствовать для анализа уведомления. Эта функция удаляет шум из уведомлений, полученных от одного и того же поставщика, но не связанных с уведомлениями об обслуживании канала. -
_exclude_filter: сопоставление антагонистов для определения через регулярное выражение уведомлений, которые не должны анализироваться.
класс ABCDE (GenericProvider):
_processors: Список[GenericProcessor] = [
Комбинированный процессор (data_parsers = [EmailDateParser, HtmlParserABCDE1]),
]
_default_organizer = "noc@abcde. com"
_include_filter = {EMAIL_HEADER_SUBJECT: ["Плановое обслуживание"]}
И выставить новый Provider в Circuit_maintenance_parser/__init__.py :
из импорта .provider (
универсальный провайдер,
АВСДЕ,
...
)
ПОДДЕРЖИВАЕМЫЕ_ПРОВИДЕРЫ = (
универсальный провайдер,
АВСДЕ,
...
)
И последнее, но не менее важное: вы должны обновить тесты!
- Протестировать новый
Parserвtests/unit/test_parsers.py - Протестируйте новую логику
Providerвtests/unit/test_e2e.py
… добавление необходимых выборок данных в tests/unit/data/abcde/ .
Что дальше?
Попробуйте! , так как сообщество растет все больше и больше провайдеров будут добавлены, и вы можете извлечь выгоду из них всех. Кроме того, разработать новый Provider или Parser несложно, и вы можете внести свой вклад в библиотеку через Pull Requests или Issues , предоставив образцы уведомлений для разработки.