
зачем нужен, как пользоваться и сколько стоит
Здравствуйте!
Рассказываем, как собирать статистику запросов Яндекса с помощью парсера Wordstat, для чего эта статистика нужна и что такое «Яндекс.Wordstat». В каких случаях стандартный инструмент Яндекса не подходит и без автоматизации не обойтись. Как использовать парсер Wordstat от Click.ru.
О статистике запросов Яндекса и Вордстате
«Подбор слов» (wordstat.yandex.ru) – бесплатный сервис статистики поисковых запросов в Яндексе. Он показывает, как часто пользователи ищут в поиске то или иное слово или фразу.
С этим инструментом знакомится каждый, кто только начинает изучать продвижение в интернете: поисковую оптимизацию (SEO), контекстную рекламу (в Директе), контент-маркетинг.
Сама статистика поисковых запросов (ключевых слов, фраз или просто ключей) нужна предпринимателям, маркетологам и другим диджитал-специалистам для:
- Поискового продвижения действующего сайта: сервис помогает прогнозировать трафик из поиска Яндекса, оптимизировать имеющиеся страницы, разрабатывать новые разделы.

- Настройки и ведения контекстной рекламы: Вордстат позволяет понять, по каким словам и фразам размещать рекламу в Директе, а какие запросы нет смысла использовать.
- Запуска нового сайта: данные Яндекса стоит учитывать при планировании структуры будущего ресурса, а также закладке бюджета на контент, дизайн, рекламу.
- Анализа рынка перед запуском нового проекта: статистика поисковых запросов отражает интересы и потребности пользователей, спрос на товары и услуги с учетом географии и сезонности.
Статистика поисковых запросов Яндекса в Вордстате
Зачем нужен специальный парсер Wordstat
Стандартный бесплатный инструмент Яндекса не предусматривает автоматизации. Подобрать ключевые слова и узнать статистику запросов в Вордстате можно только вручную. Вручную – значит долго и трудозатратно. И бессмысленно при большом объеме работы.
Конечно, функциональности Wordstat должно хватить, если нужно написать небольшую статью в блог или, например, настроить пару объявлений на один товар.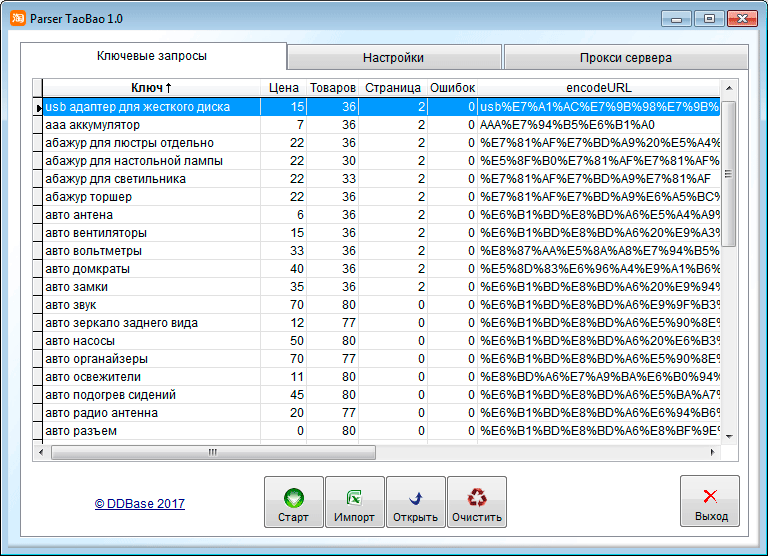 Но что, если:
Но что, если:
- Требуется проверить сотни, тысячи и десятки тысяч запросов? Это нормальная ситуация при работе с интернет-магазинами, сайтами сложных услуг, информационными порталами.
- У бизнеса широкая география, то есть необходимо узнавать частотность ключевых слов по каждому региону?
- Тематика предусматривает множество вложенных, двусмысленных, нерелевантных запросов? Так, например, слово «игрушки» может означать и мягкие, и елочные, и компьютерные игрушки. И игрушки для взрослых.
- Сроки поджимают – нужно запускать, продвигать, дорабатывать сайт в самое ближайшее время, а лучше уже вчера?
В таких случаях единственное решение – парсер Wordstat.
Как пользоваться парсером Wordstat от Click.ru
В числе инструментов Click.ru как раз есть функциональный и недорогой парсер Wordstat. Он быстро выдает частотность даже по большому списку запросов. При этом учитывает типы соответствия и региональность. Еще не требует капчу и прокси-серверы, а отчеты позволяет выгружать в Excel и хранить в «облаке».
Для начала работы зарегистрируйтесь в системе Click.ru. После входа в свой аккаунт на главной странице выберите раздел «Парсер частоты Wordstat» и приступайте к работе.
Для начала парсинга перейдите в соответствующий раздел
Как работать с парсером Wordstat после регистрации в Click.ru:
Есть два способа: скопировать и вставить ключи в специальное поле или же загрузить XLSX-файл с ними.
При копировании списка учитывайте, что каждый ключ должен идти с новой строки. А в эксель-файле смотрите, чтобы не было вспомогательной информации (названий столбцов, лишних цифр и т. д.). Система берет запросы из первого листа .XLSX по принципу «одна ячейка – один ключ».
Этап загрузки запросов
Выберите регионы.
В системе доступны все регионы Яндекса. Можно посчитать общую частотность по нескольким регионам или получить статистику отдельно по каждому.
Разделять регионы в отчете нужно, если вы планируете продвигать бизнес отдельными региональными поддоменами и посадочными страницами, привязанными к географии.
Выбираем регионы
Широкое соответствие – когда фразы пробиваются как есть – часто показывает обманчивую частотность. Все из-за того, что учитываются все вложенные ключи, в том числе нерелевантные (как в примере с игрушками). То есть всегда лучше перепроверять частоту запроса с помощью специальных операторов.
Кавычки позволяют уточнять статистику по конкретной фразе, без учета вложенных ключей.
Пример
Кавычки с восклицательными знаками показывают частотность по заданным словоформам.
Пример
Квадратные скобки – фиксируют порядок слов, что особенно важно в туристическом бизнесе
Пример
Все варианты типов соответствия
Запустите проверку.
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов меньше 1 000, процесс займет 1–2 минуты.
Результат будет доступен в списке задач. Можно открыть отчет в браузере или скачать его в формате XLSX.
Здесь будут появляться отчеты со статистикой
Сколько стоит парсинг Вордстата
Cтоимость парсинга в Click.ru в 3–5 раз ниже, чем у конкурентов. Особенно если нужна проверка большого пула поисковых запросов, например, для e-commerce.
Для тарификации в парсере используется базовая единица – ТЗ. Один ТЗ равен получению статистики одного ключа по одной группе регионов. Так, если разделить частотность по регионам, стоимость парсинга будет расти пропорционально числу регионов.
Первые 50 ТЗ – бесплатные. Далее:
P. S. Помните о сезонности
Вордстат – и, следовательно, парсер тоже – показывает статистику за последние 30 дней. Если запрос сезонный, можно сделать неправильные выводы, если смотреть только один месяц. Сезонные ключи нужно дополнительно проверять на wordstat.yandex.ru в разделе «История запросов»:
Suggester – парсер поисковых запросов. Обзор и полевые испытания
Добрый день, читатели. Сегодня на разделочном столе у нас программа Suggester от компании IndexOne. Программа представляет собой десктопную версию персера уточняющих запросов из поисковых систем Яндекс, Google, Rambler и Mail.ru (GoGo.ru). Не стоит путать, например, в Яндексе уточняющие запросы и wordstat. Конечно, общего у них гораздо больше, чем отличий, но стоит обратить на это внимание. При составлении списка НЧ ключевых запросов стоит ориентироваться именно на подсказки. Давайте посмотрим на картинки, вам сразу станет понятнее, о чем пойдет речь дальше.
Программа представляет собой десктопную версию персера уточняющих запросов из поисковых систем Яндекс, Google, Rambler и Mail.ru (GoGo.ru). Не стоит путать, например, в Яндексе уточняющие запросы и wordstat. Конечно, общего у них гораздо больше, чем отличий, но стоит обратить на это внимание. При составлении списка НЧ ключевых запросов стоит ориентироваться именно на подсказки. Давайте посмотрим на картинки, вам сразу станет понятнее, о чем пойдет речь дальше.
Яндекс
Google
Mail.ru
GoGo.ru (для тех, кто еще не в курсе, что mail использует поисковую базу gogo)
Rambler
Как видите во всех поисковиках примерно одинаковая картина.
Давайте вернемся, собственно, к программе и рассмотрим функционал.
Программа умеет:
- Парсить уточненные запросы и их ответы из Яндекса, Гугла, Рамблера и Mail.Ru
- Получать статистику запросов по этим словам из Яндекса и Гугла.
- Работа как через прокси, так и в живую.
- Выгружать результаты в формате .txt или .csv. Возможность парсить подсказки из поисковых систем: Google, Rambler, Mail.ru
- Из поисковой системы Google можно так же собрать статистику по словам, во время сбора статистики потребуется ввести код с картинки.
- Для поисковой системы Яндекс есть возможность парсить подсказки по выбранному региону, и соответственно получать статистику по тому же региону.
- Есть возможность парсить статистику по слову за последние 30 дней.
- Есть возможность указывать стоп слова для фильтрации ответов.
Формат такой: текстовый файл, по одному слову в строке. Работает следующим образом — После получения ответов нужно подгрузить файл стоп-слов и нажать кнопку «Чистить список». Удаляются все ответы в которых содержатся стоп слова. - Можно копировать результаты из списка ответов. Нажимаем Ctrl — выделяем нужные слова, жмем Enter.

В бесплатной версии доступен весь функционал, кроме парсинга ответов и выбора региона. Программу можно скачать по этой ссылке. На данный момент версия 1.2 fix является последней публичной. Однако, у меня версия 1.4, но ссылку на нее не даю, потому что не уверен, одобрит ли это разработчик, вдруг эта версия только для клиентов, купивших программу. Ссылку на 1.4 я получил вместе с регистрационным кодом.
Программу можно скачать по этой ссылке. На данный момент версия 1.2 fix является последней публичной. Однако, у меня версия 1.4, но ссылку на нее не даю, потому что не уверен, одобрит ли это разработчик, вдруг эта версия только для клиентов, купивших программу. Ссылку на 1.4 я получил вместе с регистрационным кодом.
Кому интересно — в данный момент программа стоит 20$ или 600р. Не много, согласитесь. Но надо определиться с тем, нужна ли программа вам вообще или нет. Этим мы сейчас и займемся.
Если вы еще не скачали программу, то можете попробовать ее упрощенный аналог, без наворотов, но свою функцию выполняет — Suggest. Это он-лайн вариант.
Вам интересно? Тогда продолжаем обзор.
Давайте посмотрим на саму программу.
Как понятно из скриншота, мы можем выбрать интересующую нас поисковую систему.
Ниже можем вбить список интересующих нас запросов для парсинга. Не советую парсить несколько сразу, а то запутаетесь.
Можем выбрать регион. Очень полезная функция для сайтов компаний, работающих в конкретном регионе.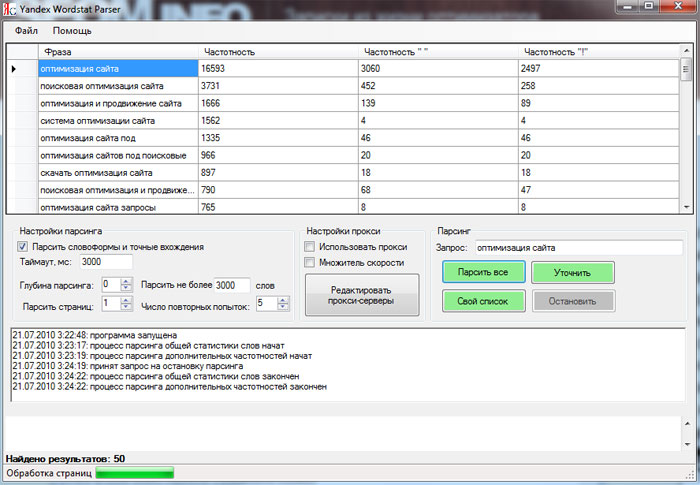 Список регионов внушительный, каждый найдет то, что ищет. Для общерегиональных ресурсов есть пункт «Статистика по всем городам».
Список регионов внушительный, каждый найдет то, что ищет. Для общерегиональных ресурсов есть пункт «Статистика по всем городам».
Есть возможность использования прокси-серверов. Их список хранится в настройках программы. Разработчик уверяет, что программа умная, и неработающие прокси будут удаляться автоматически.
Если отметим галочкой пункт «Уточнять статистику», то в списке результатов получим цифры, означающие количество запросов за месяц. Для Яндекса данные берутся из wordstat.
Отдельное внимание стоит уделить пункту «Полный парсинг». Довольно спорная функция. В переписке с разработчиками выяснил, что эту опцию лучше не использовать, потому что программа начинает собирать «мусор». И я, пожалуй, соглашусь. Можете сами убедиться в этом. Специально для вас я экспортировал результат полученный программой при парсинге по запросу «хочу жениться». Вот txt-файл — https://alaev.info/wp-content/uploads/2010/03/442.txt.
Это я парсил, выбрав в качестве поисковой системы Яндекс. Google в результате парсинга выдал всего лишь 4 результата: «хочу жениться на иностранке», «хочу жениться на американке», «хочу жениться на немке», «хочу жениться на дочери миллионера». Пункт полный парсинг ситуацию не исправляет.
Google в результате парсинга выдал всего лишь 4 результата: «хочу жениться на иностранке», «хочу жениться на американке», «хочу жениться на немке», «хочу жениться на дочери миллионера». Пункт полный парсинг ситуацию не исправляет.
Rambler и Mail.ru, к сожалению, вообще промолчали. Хотя мы с вами видели на скриншотах в самом начале поста, что подсказки mail.ru выдает. Наверное, «хочу жениться» тут мало кто спрашивает, потому и не выдается результат. Например, по запросу «телевизор» результатов много.
Вот, я вам все подробненько рассказал. Я уверен, пост оказался полезным. Потому что на сайте разработчика нет никаких упоминаний о программе, кроме ссылки с анкором «Suggester», ведущей на пустую страницу. Кстати, пользуясь случаем, хочу сказать разработчикам огромное спасибо за программу и за то, что эта программа была предоставлена мне бесплатно.
В прошлом посте я забыл подвести итоги прошедшего месяца, подведу сегодня.
По итогам февраля:
Самый комментируемый пост Технология изготовления «неубиваемого» сателлита
Самый скандальный пост Как на счет нескольких SEO советов для блога Билла Гейтса?
Самый «неоциненный» пост Image SEO Tool.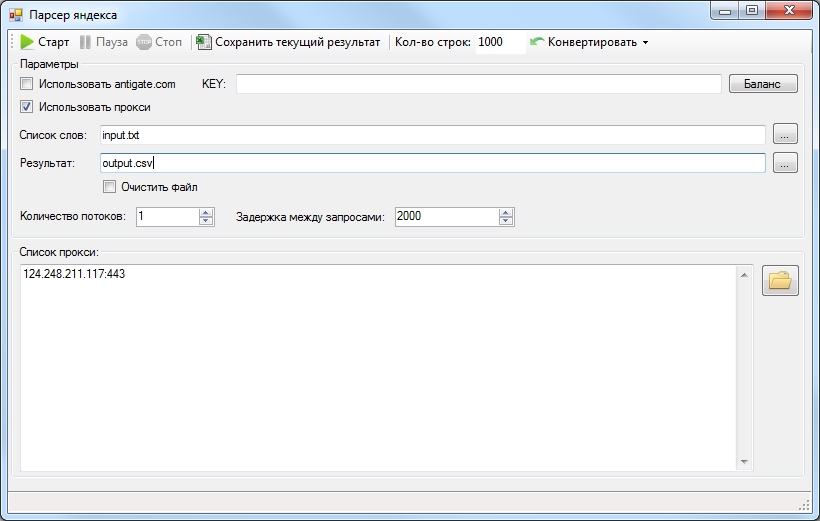 Полюбит ли поисковик ваши картинки?
Полюбит ли поисковик ваши картинки?
Топ-100 для 100 000 запросов за 1 час — Парсинг выдачи от Serpstat
Получайте актуальные данные по массиву ключевых фраз в топе результатов в соответствии с выбранным регионом, типом выдачи, языком и поисковой системой:
Узнать больше
Позиция сайта по ключевому слову
Домен, поддомен и целевой URL
Сниппет (title, description и их длина)
Наличие и тип спецэлемента
Хлебные крошки
Платная выдача по фразе (объявление, позиция, Google shopping)
HTML топа выдачи
Парсинг поисковой выдачи
Узнайте долю конкурентов в выдаче по рынку.
Отслеживайте динамику позиций сайтов в топе выдачи по любому расписанию.
Определите выпавшие из топа и выросшие фразы сайта или конкурентов.
Парсинг выдачи Google и Яндекс дополняет возможности стандартных подписок Serpstat и работает отдельно от них.
 Как можно использовать парсер поисковой выдачи по запросу?
Как можно использовать парсер поисковой выдачи по запросу?Мониторьте региональную выдачу.
Сравнивайте органическую и платную выдачу.
Быстрая выгрузка данных помогает их структурировать и делать выводы.
Парсинг поисковой выдачи Google
Парсер позиций сайта в Google существенно расширяет возможности для анализа ниши. Отследите динамику позиций и трафика по вашему сайту или для конкурентов и скорректируйте свою стратегию продвижения. Например, сравните выдачу в органике и контексте, а также в разных регионах для своей ниши. Так вы определите оптимальные методы продвижения (SEO или PPC), а также сможете выбрать регион с наименьшей конкуренцией. Кроме того, такой анализ топа по запросу помогает точнее определить конкурентов и дополнить информацию об их стратегии.
Парсер запросов Яндекса покажет, какую выдачу видит в этой поисковой системе именно ваша аудитория. Сервис парсинга от Serpstat позволит проанализировать, как меняется топ выдачи по фразе со временем, в разных типах выдачи и в разных регионах. Парсер запросов Яндекса покажет уровень конкуренции, динамику трафиковых и конверсионных фразы, а также наличие спецэлементов в результатх выдачи по вашим фразам.
Сервис парсинга от Serpstat позволит проанализировать, как меняется топ выдачи по фразе со временем, в разных типах выдачи и в разных регионах. Парсер запросов Яндекса покажет уровень конкуренции, динамику трафиковых и конверсионных фразы, а также наличие спецэлементов в результатх выдачи по вашим фразам.
Парсинг выдачи Яндекса
Получайте данные с помощью API в формате JSON.
Настройте удобное расписание сканирования и автоматических отчетов
Сканируйте топ всей выдачи в поисковых системам Яндекс и Google
Выбирайте любые регионы с точностью до города
Изучайте выдачу для Google и Яндекс с помощью отдельного инструмента Serpstat. Используй API и создай свой собственный Serpstat, обрабатывай большие массивы данных и визуализируй их любым удобным форматом.
Подойдите к настройке парсинга гибко. Serpstat соберет результаты выдачи по ключевым запросам в соответствии с рядом параметров:
Анализ топа выдачи поисковых систем, который видит именно ваша целевая аудитория
Поисковые системы Google (топ-100) и Yandex (топ-50).
Локальные настройки: язык, страна, регионы и город.
Органические и платные результаты
Запуск сканирования в любое время
Мобильная или десктопная версия выдачи
Узнать больше
Анализируйте SERP по необходимому количеству ключевых фраз от
$0,001 дo $0,0013 за один запрос, в зависимости от объема:Serpstat — самый рентабельный инструмент для парсинга топа
Узнать больше
Без ограничения по количеству запросов в день и месяц
Минимальный бюджет для заказа — $300 (более 230 тыс. запросов)
Независимо от наличия тарифного плана или доступных лимитов
Лимиты на парсинг топа не сгорают в конце месяца, вы используете их тогда, когда вам удобно.
Как использовать данные парсинга SERPa?
Проанализируйте новую нишу, чтобы определить лидеров в тематике и ваши перспективы
Изучите сниппеты в топе, узнайте слабые стороны конкурентов и оптимизируйте свои страницы
Отследите динамику позиций по фразам и определите, как вы обойдете конкурентов с минимальными усилиями
Сравните мобильную и десктопную выдачу, органические и платные результаты
Проанализируйте региональную выдачу, чтобы оценить перспективы в зависимости от языка, страны, региона и города
Узнайте стратегии ваших конкурентов в контексте (тексты обьявлений, целевые страницы и расписание)
Другие преимущества парсинга топа выдачи
Специальные методы API, которых нет в стандартном тарифе Serpstat
Результаты хранятся 24 часа с момента их готовности
Данные в JSON-формате, которые можно хранить в базе данных (My SQL или Big Query и др. )
Интегрируйте результаты парсинга в свои отчеты или визуализируйте в Data Studio или другой BI системе
Полезные статьи об использовании сервиса парсинга топа
Serpstat
Serpstat
Персональная демонстрация
Оставьте заявку и мы проведем для вас персональную демонстрацию сервиса, предоставим пробный период и предложим комфортные условия для старта использования инструмента.
Запросить демо
Инструмент, который стал нашим помощником в трафиковом отделе, позволяет значительно сократить временные затраты на анализ сайтов конкурентов и получить на основе этого анализа готовую семантику для собственных проектов.
Serpstat — находка для SEO-шника =) Пользуюсь сервисом уже давно, всем доволен, очень удобно. С нетерпением жду новых крутых фишек!)
Отличный сервис анализа и аудита конкурентов. Другие альтернативы стоят дороже, и не всегда есть тот функционал который нужен нам. Очень часто чекаем конкурентов на трафикообразующие страницы, в общем есть все что нужно для взрывного маркетинга и трафика.
Инструмент удобен как для частных SEO-оптимизаторов (при небольших бюджетах), так и для крупных SEO-компаний. После работы с сервисом остаются приятные впечатления. В тоже время большинство предложенных функций упрощают жизнь оптимизатора, к тому же огромным плюсом является структурированная подача информации.
Илья Василенко
Александр Шпион
ART LEMON
Дмитрий Ваврик
OdesSeo
Александр Sli
My-Master
Алексей Бузин
SEO-IMPULSE
С Serpstat работаем с тех времен когда он еще назывался Prodvigator. Must Have инструмент для SEO-специалистов на каждый день 😉
based on 120 reviews
based on 127 reviews
based on 406 reviews
based on 17 reviews
based on 17 reviews
FAQ. Распространенные вопросы о парсинге топа выдачи
Что значить слово парсить?
Парсить — собирать и систематизировать нужные данные с сайтов, выбранных по определенным критериям. Для парсинга используются специальные сервисы и программы, которые позволяют автоматизировать задачу. Парсинг запросов в поисковых системах — один из вариантов использования таких программ.
С помощью Serpstat и его API из топа можно парсить:
- позицию определенного сайта в определенном регионе;
- позиции конкурентов по ключевой фразе;
- домены, которые появляются в выдаче;
- целевые URL в выдаче по запросу;
- title и description страниц;
- платную выдачу;
- наличие и типы спецэлементов;
- количество результатов.
Парсер запросов, что это?
Парсер поисковых запросов — это онлайн сервис и программный продукт, основная функция которого в получении данных по заданному запросу или группе запросов.
Serpstat предлагает парсер запросов Яндекса и Google. С его помощью можно собрать данные по 244 региональным базам поисковых фраз в двух поисковых системах. Результаты будут доступны в формате JSON.
Для чего нужен парсер?
Парсер нужен, чтобы автоматически и быстро собрать из поисковых систем информацию по заданным критериям. Также парсер структурирует данные в максимально удобной для анализа форме. Такие данные легко интегрировать во внутренние системы данных и визуализировать для анализа и интерпретации данных.Парсер от Serpstat помогает SEO и PPC-специалистам, диджитал-маркетологам экономить время на сборе и обработке больших массивов информации.
Какие преимущества парсинга топа выдачи?
С помощью парсера выдачи собирают большие объемы информации из Google и Яндекс. Какие преимущества есть у парсера от Serpstat?
- Любая частота парсинга. Вы можете заказать получение данных по удобному для вас расписанию. Отчеты могут приходить даже каждый час, так вы не упустите ни одно важное изменение ситуации.
- Высокая скорость. Отчет по сотням тысяч поисковых запросов можно сформировать примерно за час.
- Точность и детализация. При заказе парсинга можно указать несколько важных параметров: расписание парсинга, город и регион, язык и поисковую систему.
- Цена. Стоимость парсинга не связана с подпиской на стандартные планы сервиса. Вы можете заказать парсинг, даже не если не используете другие возможности платформы Serpstat. Цена проверки одного запроса от $0,001 до $0,0013 (в зависимости от количества запросов, по которым собираются данные). Часто это выгоднее, чем покупка лимитов на мониторинг позиций, который входит в тарифные планы.
- Гибкость. Данные подаются в формате, который позволяет выбрать разные форматы визуализации и, при необходимости, интегрировать их с BI системой.
Страница Serpstat в Facebook
Страница Serpstat в Facebook
Чат любителей серпстатить в Телеграм
YouTube-канал Serpstat
Страница Serpstat в Instagram
Парсер Wordstat для macOS — Трибуна на vc.ru
Реализовал простой и функциональный онлайн-сервис по сбору, группировки и минусации семантики. Идеально подойдет пользователям macOS, так как работает онлайн и имеет весь необходимый функционал как в кей коллекторе для парсинга и сбора семантического ядра. Можно снимать частоту, парсить запросы, собирать семантические карты, группировать, минусовать….
1070 просмотров
Парсинг без заморочек
Первое на чем хочется остановиться — это максимальное упрощение работы с парсерами. Все что нужно, это загрузить ключевые слова, выбрать гео и запустить парсинг. Проще не придумаешь 🙂
Обзор парсера Wordstat на Youtube.
Основная идея такая — с вас только ключевые слова, с нас все остальное.
По такому принципу и реализована логика работа следующих парсеров:
1. Парсеры для проработки ключевых слов «вглубь»: Wordstat, Букварикс
2. Парсеры для расширения ядра «вширь»: Keyword Planner, Подсказки
3. Парсеры для поиска неочевидных ключевых слов: SEO, синонимы, ассоциации
4. Парсеры по доменам конкерентов: Keyword Planner, Букварикс, SEO
Для работы с парсерами вам не потребуется где-то покупать Proxy, регистрировать аккаунты, выполнять какие-то сложные технические настройки.
Основные возможности
- Снятие частоты. Снимать частоту можно из любого ГЕО из Яндекс.Вордстат и Google Keyword Planner.
- Составление семантических карт.
- Перемножение ключевых слов. Тут же можно перемножить слова и получить маски для парсинга.
- Группировка и минусация. Можно минусовать и группировать ключевые слова аналогично как в Key Collektor
- Многопоточный парсинг. Можно парсить сразу в несколько потоков. Скорость 1-го потока около 100 запросов/минуту
- Без сложных настроек. От вас только ключевые слова, от нас все остальное 🙂
- Для Mac OS. Сервис работает онлайн, поэтому он идеально подойдет пользователям с операционной системой Mac OS
Сбор ключевых слов
Если у вас нет готового списка запросов для парсинга, его можно собрать внутри сервиса.
Пословные парсеры
Для сбора ключевых слов реализовано несколько парсеров: Wordstat, Keyword Planner, Букварикс, Подсказки, СЕО.
Возможности парсинга
- По ключевым словам
- По сайтам конкурентов
- Бурж семантики через Keyword Planner
- Расширения семантики через Букварикс и Подсказки
Синонимы и ассоциации
Для поиска неоднозначных запросов, по которым обычно более низкие цены за клик, реализованы парсеры синонимом и ассоциация к словам.
Сбор семантической карты
Для более глубокой проработки семантики, предусмотрен функционал по сбору семантического ядра и перемножения ключевых слов
1. Собираем маски для дальнейшего превращения их в поисковые запросы
2. Перемножаем одну группу масок на другую с получением сотни и тысячи уникальных ключевых слов
3. Сперва снимаем частоту у полученных запросов, отделяем нулевики, а запросы с частотой от 500 запускаем в парсер Wordstat
Обработка ключевых слов
В сервисе реализован бесплатный функционал по минусации и группировке ключевых слов.
Обзорное видео по сбору, минусации и группировки ключевых слов на YouTube.
Минусация
Собранные запросы можно проминусовать: удалить ненужные ключевые слова, собрать список минус-слов.
Для этого есть пофразное и пословное отображение семантики.
Удалять можно так же, по словам или же пофразно
Группировка
После чистки семантики — ее необходимо разбить на смысловые группы.
Логика аналогичная минусации: выделяете фразу или слова, и переносите запросы в новый сегмент.
Папочная структура
Если запросов много, то хранить их удобно в большом количестве сегментов.
Поэтому мы реализовали папочную архитектуру сегментов.
Любой сегмент можно сделать папкой, зайти внутрь него и создавать сегменты уже внутри этой папки.
Выгрузка ключевых слов
Excel файл
Структура файла: Сегмент-Запрос-Частота
Можно легко фильтровать по сегментам с выборкой нужных ключевых слов.
Рекламная кампания
На сервисе можно создавать РК для Директа и Ads.
Поэтому вы можете выгрузить сегменты в рекламную кампанию, написать для них объявления и уже выгрузить готовую РК.
Итог
Сам работаю на сервисе и поэтому стараюсь делать все максимально удобно и функционально.
Думаю из описания функционала по сбору, обработке и выгрузке ключевых слов, вы видите, что сделано все максимально просто и удобно для работы с семантикой.
Кому интересно — можете переходить на сервис. Надеюсь он вам понравится.
Успехов!
Исследование прямого эфира Яндекса : есть ли смысл парсить и что он в себя включает?
Оксана Мамчуева
2082
Прямой эфир Яндекса (https://export. yandex.ru/last/last20x.xml) — отличная штука, чтобы получить новые запросы. По крайней мере, так считает множество оптимизаторов. Специалисты AmazingSoftware решили проверить, так ли это на самом деле.
В целях эксперимента, был написан многопоточный парсер и оставлен на неделю работать в одиночестве. Через неделю было обнаружено 414 Гб информации и 4 460 619 547 на сервере. Радостно потирая ручки, специалисты приступили к удалению дублей из массива фраз. И каково же было их удивление, когда после удаления дублей в массиве осталось всего лишь 15 068 199 уникальных фраз — поистине несущественное количество, по сравнению с исходным объемом.
Таким образом, можно сделать вывод о том, что на практике парсинг прямого эфира не дает статистически значимых результатов — за неделю было получено 8 млн фраз, за год получится в лучшем случае 300-350 млн, что вовсе не является существенным объемом с точки зрения современного рынка баз ключевых запросов.
Давайте подробнее рассмотрим, что же было получено в результате недельного парсинга.
Статистика по парсингу прямого эфира Яндекса за период с 02.02.2015 по 08.02.2015 включительно (7 дней):
- количество потоков парсинга – 10
- скорость получения ключевых слов – около 10 тыс в секунду
- запись велась в 70 текстовых файлов файлов (7 дней по 10 потоков):
- размер файлов от 1.6 гб до 8.8 гб
- количество ключевых фраз, полученных за время парсинга – 4 460 619 547
- количество ключевых фраз после удаления дублей – 15 068 199
Также при помощи лемматизатора, используемого в программе «МегаЛемма» — был составлен частотный словарь полученной выборки, который опубликован здесь.
Самыми частотными словами выборки, за исключением союзов и предлогов стали (указана частота употребления, раз):
купить 382468
фото 290786
скачать 253934
отзывы 172763
видео 170758
ru 153455
онлайн 147839
смотреть 146245
игры 110075
Таким образом, можно сделать вывод, что имеет место быть явное преобладание коммерческих запросов («купить»), запросов, связанных с онлайн кинотеатрами, фильмами, видеороликами и фото. Это делает базу ценной для оптимизаторов, работающих с коммерческой тематикой, Директом, с download-трафиком из поисковых машин.
Сам по себе прямой эфир также выдает показатель found — судя по всему, это количество найденных результатов в поисковой выдаче по данному запросу. Оптимизаторы, заинтересованные в получении данного параметра, могут воспользоваться прямым эфиром — в отличии от обычной выдачи, здесь нет капчи и парсинг получается фактически бесплатным.
Скачать базу бесплатно можно по ссылке — https://www.dropbox.com/s/isd37ddcjkaeod5/onair.7z?dl=0 . Внутри находится в формате .akdb — это специальный формат, используемый в базах ключевых слов AmazingSoftware.
- Новости
- Интернет и медиа
Google тестирует новый пользовательский интерфейс поисковой выдачи на мобильных устройствах
Пользователи заметили, что Google тестирует новый интерфейс для результатов поисковой выдачи мобильного поиска
Джон Мюллер: Panda не наказывает сайты за дублирование метаописаний и тегов title
Во время очередной видеоконференции специалист отдела качества поиска Google по работе с вебмастерами Джон Мюллер (John Mueller) заявил, что наличие дублированных тегов title и. ..
Отчеты Google Webmaster Tools не обновляются с 7 февраля
Пользователи заметили, что отчеты Google Webmaster Tools не обновлялись в течение недели – с субботы, 7 февраля
Как отпраздновать День влюбленных? Спросите у Яндекса!
Специально к 14 февраля Яндекс запустил интерактивный колдунщик, который поможет пользователям не только выбрать подарок для любимого человека, но и определиться с программой…
Google выпустил альфа-версию нового отчёта по поисковым запросам Search Impact в WMT
Google запустил альфа-тестирование нового отчёта по поисковым запросам в Инструментах для вебмастеров (Webmaster Tools
В отчетах Google Analytics отсутствуют данные за 9 февраля
В форумах помощи Google Analytics появились десятки жалоб веб-мастеров на отсутствие в отчетах данных за 9 февраля
Парсер ключевых слов онлайн яндекс.
Парсер ключевых словСамое первое, что потребуется выяснить: что такое парсить. Возможно, Вы знаете это определение, а даже если и нет, понять будет легко. Парсить (Parsing) – значит собирать информацию из какого-либо источника с последующей обработкой данных. Если говорить о частных случаях, парсинг в seo (по-другому парсинг поисковой выдачи) – это сбор и анализ статистики запросов пользователей.
Поисковые системы тоже используют парсинг. Так, поисковые роботы парсят, анализируя веб-страницы и занося информацию о них в базу данных поисковиков.
Яндекс.Вордстат – сервис очень полезный в seo. Но работать с ним возможно только при наличии аккаунта Яндекс. Он позволяет подбирать ключевые слова на основе запросов пользователей, чтобы далее составить из них семантическое ядро.
Первым делом, необходимо определить тематику. Что Вы продаете? Какие услуги Вы предоставляете? Определив свою тематику и что будете запрашивать, можно начинать пользоваться Вордстат.
В строку поиска вводите свой запрос. И расширяете его с помощью выданных результатов.
Результаты формируются в две колонки. Цифра рядом с запросом – прогнозируемое количество показов в месяц, которое можно получить, выбрав понравившийся запрос ключевой фразой. Прогноз идет за последние 30 дней до даты обновления статистики.
Можно настроить, чтобы выдача показывалась по регионам. Если Вы предоставляете услуги только в Москве, выберите вкладку «Все регионы» (она находится чуть ниже поисковой строки) и настройте под себя.
В левой колонке все фразы со словами Вашего запроса, и слова в ней отсортированы по убыванию частоты показов. Вам важно сразу выделить те варианты расширенных ключей, которые будут являться для вашего проекта целевыми. Целевые — это те запросы, по которым пользователь, вводящий запрос в поисковую систему, может найти нужное ему на Вашем сайте. Целевые фразы будут более низкочастотными, и пользователи, пришедшие по ним с выдачи, смогут найти то, что хотели, а значит не покинут Ваш сайт сразу. Вам важны эти посетители, ведь именно они могут совершить целевое действие – купить товар или заказать услугу.
Проверьте выбранные фразы – исключите те, у которых частотность близка к нулю. Для этого используйте оператор “ “ (Кавычки).
После чего переходите к правой колонке.
В правой колонке показываются запросы, похожие на Ваши. Собрав нужное, не забудьте проверить фразы оператором “ “ (Кавычки).
Набрав достаточное количество ключевых фраз, Вы приступаете к следующему этапу: делите фразы по частотности. На этом Ваша работа с Вордстатом завершена.
По некоторым ключевым словам Вордстат выдает неправильную информацию. Как же ее проверить? Перейдите на вкладку «История запросов» и обратите внимание на статистику.
Показания статистики представлены в 2-х графиках: абсолютное и относительное.
Абсолютный показатель – это фактическое значение показов в разные периоды времени. А относительный показатель – это отношение показов по интересующему запросу к общему числу показов в сети. Он демонстрирует популярность запроса среди всех других.
Если график относительного значения выше абсолютного, то, может быть, идет автоматическая накрутка запроса, или интерес к запросу выше нормы. Возможно, это связано с сезоном. Так спрос на лыжи выше зимой.
Процесс парсинга можно автоматизировать. В этом случае возможно использование не только платных и бесплатных программ, но и расширений для браузера.
1. Расширение для браузера Yandex Wordstat Assistant. Устанавливаете его в браузер, и при работе с Яндекс.Вордстат слева появится панель, в которую вы сможете собрать понравившиеся ключевые слова.
2. Key Collector – программа платная, но высокофункциональная.
- В настройках есть вкладка «Yandex.Wordstat». Перейдя на нее, Вы сможете установить глубину парсинга. Так можно собрать большее число ключей. Но рекомендуется ставить 0, чтобы не увеличивать время. А ключи можно расширить и другим способом, а времени на их собирание уйдет меньше. Максимальное количество страниц для парсинга в Yandex.Wordstat равно 40. На каждой странице при этом находится до 50 фраз. Таким образом, максимальное количество результатов по одной фразе в Вордстат – 2000. И если Вы хотите собрать больше данных, Вам нужно расширить входной список слов, добавив уточняющие слова. Например, не просто «капуста», а «цветная капуста», «производство капусты» и т.д.;
Простой и бесплатный пример PHP парсера (parser) статистики ключевых слов с wordstat Яндекс.
Понятно, что перед тем как продвигать сайт, нужно определиться с ключевиками. это не сложный, но кропотливый труд. Для того же чтоб найти что-то стоящее, нужно перелопатить кучу данных. Поэтому здесь не обойтись без средств автоматизации процесса. В данной заметке я хочу остановиться на создании PHP парсера данных с wordstat Яндекс.
И так. Основная проблема при парсинге данных с сервиса статистики ключевых слов wordstat Яндекс заключается в наличии капчи. Обойти ее не так уж и сложно. Достаточно передать в запросе куку fuid01, генерируемую при обработки капчи. Другими словами, вам понадобится зайти на сервис, сделать запрос, указав символы с картинки и получить содержание требуемой куки.
Как получить содержание куки fuid01 в браузере Firefox?
Т.к. я не собираюсь замахиваться на эпосы и прочие великие труды человечества, то опишу лишь процесс получения содержания куки fuid01 в браузере Firefox (использую версию 8.0). В общем, запускаем Firefox. Считаем, что запрос в wordstat уже сделан и кука создана. Жмем кнопку «Firefox» в левом верхнем углу окна браузера. В меню выбираем: Настройки > Настройки (я ничего не путаю).
В открывшемся окне «Настройки», переходим на вкладку «Приватность». Здесь нас интересует блок «История». Выбираем в списке Firefox «будет использовать ваши настройки хранения истории» и жмем появившуюся кнопку «Показать куки…».
В окне «Куки», в поле «Поиск» введите имя интересующей нас куки, т.е. «fuid01». В списке должно отобразиться найденное. Выберите одну из предложенных кук и в поле информации, выделите и скопируйте ее «Содержимое».
Как работать с PHP парсером wordstat Яндекс
Бесплатно скачать PHP парсер wordstat Яндекс можно здесь . Сразу скажу, что это лишь пример, работа которого заключается в парсинге ключевых слов и выводе их на экран, но все по порядку.
Первое, что вам надо понять – все данные представлены в кодировке UTF-8. Так что если что не забудьте сконвертировать данные. Более того, на некоторых серверах с этим может возникнуть проблема, подробней . Следующий нюанс заключается в том, что для работы скрипта понадобится поддержка . В остальном все достаточно просто.
Содержание куки fuid01 мы присваиваем переменной $fuid01 . По сути, это значение задается в curl_setopt() через CURLOPT_COOKIE , но для удобства я вывел его отдельно. Далее нас интересует массив $params — это переменные, передаваемые в запросе к wordstat Яндекс. В качестве примера я ограничился простейшим вариантом, так что обошлось без динамики. В частности, парсится только первая страница выдачи: «page» => 1 , значение text получается через GET, ну а для региона выбрана Москва : «geo» => 1 .
Понятно, что идентификатор региона, в случае если нужен другой, придется уточнять. Для этого заходим на wordstat Яндекс, кликаем ссылку «Уточнить регион…» и выбираем требуемое.
Сделав запрос, в URL надо посмотреть значение требуемого параметра. Следует отметить, что если выбрано более одного региона, их идентификаторы будут перечислены через запятую.
Дальше идет запрос к сервису статистики и парсинг данных wordstat Яндекс. Последнее имеет один небольшой нюанс. Дело в том, что wordstat Яндекс выводит статистику в виде двух таблиц: «что искали со словом…» и «что еще искали люди, искавшие…» — я же использовал только первую. Впрочем, там нет ничего сложного. Регулярные выражения достаточно простые. Думаю, разберетесь. Удачи!
)
Для работы парсера SE::Yandex::WordStat необходимы аккаунты Яндекс. Аккаунты можно зарегистрировать с помощью парсера или просто добавить существующие аккаунты в файл files/SE-Yandex/accounts. txt в формате:
[email protected];password
[email protected];password2
…Нажмите, чтобы раскрыть…
Собираемые данные(top)
- Количество показов по указанному запросу
- Дату обновления статистики
- Список всех кейвордов связанных с указанным и число их показов в месяц
- Список всех дополнительных кейвордов которые искали пользователи и число их показов в месяц
Возможности(top)
- Парсит максимальное отдаваемое вордстатом число результатов — 40 страниц по 50 элементов выдачи
- Поддерживает выбор региона поиска(с подгруппами)
- Может автоматически подставлять найденные кейворды заново в запросы(опция Parse to level)
- Возможность выбора сразу нескольких регионов для оценки
- Возможность обхода каптчи с помощью сервиса AntiCaptcha или любого другого поддерживающего их API
Варианты использования(top)
- Оценка количества трафика по кейворду(частота)
- Поиск новых ключевых слов схожей тематики
- Сбор больших баз ключевых слов разной тематики
- Любые другие варианты подразумевающие парсинг Яндекс. WordStat в том или ином виде
Запросы(top)
- В качестве запросов необходимо указывать ключевые слова, точно так же как если бы их вводили прямо в форму поиска Вордстата, например:
окна москва
«окна москва»
!окна!москваНажмите, чтобы раскрыть…
Результаты(top)
- В результате отображен исходный запрос, число его показов, дата обновления статистики, список связанных кейвордов и их показы в месяц, список дополнительных кейвордов и их показы в месяц
Окна!москва — 10368, updated: 16/05/2013
keywords:
окна москва: 32367
пластиковые окна москва: 8994
окна пвх москва: 4813
купить окна москва: 2561
окна цены москва: 1706
москва работа окна: 1547
вакансии окна москва: 1187
деревянные окна москва: 1087
служба +одного окна москва: 1021
…
additional keywords:
производство окон пвх: 8512
окна rehau: 15686
окна salamander: 1576
окна kbe: 3798
окна кбе: 6089
окна кве: 3227
остекление балконов: 83216
беседки: 471213
остекление лоджий: 26366
офисные перегородки: 18740
монтаж окон: 26223
.Нажмите, чтобы раскрыть…
Возможные настройки(top)
| Параметр | Значение по умолчанию | Описание |
|---|---|---|
| Pages count | 10 | Количество страниц для парсинга |
| Region | All | Регион поиска |
| Remove + from keywords | ☐ | Удалять символ плюса (+) из найденных запросов |
| Use AntiGate | ☐ | Определяет использовать ли AntiGate для обхода каптч |
| AntiGate preset | default | Необходимо предварительно настроить парсер Util::AntiGate — указать свой ключ доступа и другие параметры, после чего выбрать созданный пресет здесь |
| AntiGate preset for Login | default | Пресет AntiGate для логина. Необходимо предварительно настроить парсер Util::AntiGate с параметрами, после чего выбрать созданный пресет здесь |
| Use Accounts | ☑ | |
| First sleep | 50 | Задержка после первого запроса при использовании AntiGate для экономии каптч |
| Use session | ☑ | Сохраняет хорошие сессии для дальнейшего использования |
| Mobile only | ☐ | Получать статистику только для мобильного трафика |
| Remove bad accounts | ☑ | Автоматическое удаление аккаунтов с неверным логин/паролем или требующих подтверждения по телефону |
Яндекс Вордстат – это сервис компании Яндекс, используемый для подбора ключевых слов путем анализа поисковых запросов пользователей.
Зачем нужен Вордстат
В основном он применяется для составления семантического ядра. Wordstat бесплатен, он является многофункциональным инструментом, но настолько простым, что разобраться сможет даже новичок. С помощью Вордстата возможно узнать подробную статистику запросов в системе Яндекс за последний месяц, и составить не только структуру целого сайта, но и отдельных его страниц. В практике сервис применяется для решения следующих проблем:
- Сбор наиболее полной семантики за счет расширений запросов;
- Проверка частотности запросов, в том числе и региональной;
- Проверка сезонности запросов.
Это самое основное, но есть конечно и более мелкие задачи, которые помогает решить Wordstat.
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис , вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
Также важно, чтобы в вашем профиле в Яндексе был указан ваш регион, по которому вы и собираетесь смотреть статистику запроса.
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:
Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
В основном с Вордстатом работают через специальные сервисы и программы. Тысячи их! Самая известная — Кей Коллектор. Все эти программы повышают удобство работы с этим инструментом в разы.
Напрямую с вордстатом работают очень редко, однако я слышал офигенные истории, что в студии Ашманова, одной из самых крутых SEO-студий, сидят мартышки, которые каждый запрос вводят в Вордстат руками и копируют выдачу в.txt-файл. Я сразу представил сотню рабов, которые за день работы выполняют такой же объем, как один сеошник с Кей Коллектором.
Давайте теперь смотреть остальные функции интерфейса:
В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.
В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.
В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.
В блоке 4 — выбираем регион/регионы.
По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:
А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:
История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:
Но самое профессиональное начинается, когда вы работаете с операторами.
Какие операторы полезны при работе с Wordstat
Надо знать, как пользоваться операторами Яндекс Вордстата, чтобы наиболее эффективно работать в интерфейсе.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.
А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:
Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
Он кстати позволяет провести сравнение двух запросов, для этого я его в основном и использую.
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
Круглые скобки «()» — группирует использование нескольких операторов.
Квадратные скобки «» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:
Как видим, с неправильным порядком фразу почти никто не вводит:
Плагины
Работать с голым Яндекс Wordstat в целом неудобно. Чтобы облегчить свой труд, можно установить себе в браузер специальный плагин, предназначенный для работы в Wordstat. Плагины для браузеров Хромиума (Яндекса, Мейла, Амиго, Оперы и Гугл Хрома) одинаковые, а вот для Мозилы идет отдельный плагин, все являются бесплатными и доступными для скачивания, устанавливать их можно сразу из браузера. Наиболее популярные — плагины Wordstat Assistant и Yandex Wordstat Helper.
Yandex Wordstat Assistant
Пожалуй, самый лучший плагин для wordstat.yandex.ru. Я сам им пользуюсь. Он удобен в использовании, практичен и не мешает, когда вы работаете на других сайтах. Установленный wordstat assistant запускается только в случае перехода на страницу Вордстата. Путем нажатия на плюсики, требуемое ключевое слово можно добавить в список (он находится слева). В ассистант есть возможность отсортировать выбранные ключевики, а ненужные удалить. Получившийся список просто скопируйте в буфер обмена, и перенесите в Excel для последующей обработки. Кстати, удобность использования плагина еще и в том, что когда вы добавляете в список уже находящиеся там фразы, дубли автоматически удаляются, что существенно сокращает работу.
Yandex Wordstat Helper
Этот плагин попроще, чем предыдущий, но не менее популярен, его также можно устанавливать прямо с браузера. Хелпер сделан в виде виджета, который добавляется на страницу вордстата сразу после установки, нужно просто обновить страницу и можно начинать работу. Его функции:
- Возможность автоматической сортировки в алфавитном порядке;
- Проверяет наличие дублей, удаляя последние;
- Есть возможность обработки разных запросов в нескольких вкладках браузера. Нужные слова добавляются в один и тот же список;
- Есть счетчик слов;
- Возможность копирования уже готового списка в Excel, собрав всё воедино по начальным фразам.
Прежде чем решить, какой плагин использовать, попробуйте в действии и тот и другой, это позволит вам сделать правильный выбор.
Парсеры Вордстата
Для экономии времени при подборе ключевых слов часто пользуются специально предназначенными для этого автоматическими программами – парсерами, которые могут быть как платными, так и бесплатными.
Некоторые пацаны заказывают парсеры и чисто под свои нужды.
Лучший платный парсер Wordstat – KeyCollector. Используют его в основном те, кто профессионально занимается составлением семантики. Бесплатным аналогом КейКоллектора является программа Словоеб. Функции его урезаны, но составлять небольшие ядра с его помощью вполне реально.
Магадан тоже достаточно популярный парсер Вордстат, который тоже можно бесплатно скачать. Подбирает и анализирует запросы, есть поддержка регионов, предназначен для парсинга фраз Яндекс Директа.
Под конец хочу отметить, что Вордстат дает только те данные, которыми располагает Яндекс. Поэтому например частотность в Гугле и других поисковиках может быть совсем другая.
Парсер ключевых слов — это настройка Datacol, которая автоматически собирает запросы из статистики сервиса Wordstat по заданным пользователем ключевым словам. Таким образом, вам необходимо всего лишь задать базовые ключевые слова, после чего Datacol самостоятельно соберет информацию по производным запросам. Наряду с запросами сохраняется частота показов каждого запроса в месяц. При парсинге Datacol проходит по всем страницам выдачи Wordstat.
- С помощью парсера Wordstat Вы сможете собрать запросы и частоту показа из статистики;
- Вам нужно указать только список ключевых слов, данные по которым Вам необходимо собрать;
- Сохраняйте собранную информацию в любом удобном формате (Excel, TXT, WordPress, MySQL и т. д.).
Парсинг Wordstat подразумевает обработку Javascript, а также необходимость авторизации для сбора данных. Такую возможность мы получаем благодаря плагину . При запуске кампании Datacol откроет один или более экземпляров браузера Chrome для загрузки через них вебстраниц. Количество работающих экземпляров Chrome равно количеству потоков кампании. Обратите внимание, что инициализация экземпляров браузеров может занять некоторое время.
Кем и для чего используется парсер ключевых слов яндекса
Парсер ключевых слов чаще всего используется специалистами по поисковому продвижению сайтов. В частности, это касается реализации задачи составления семантического ядра сайта. Оговоримся, что ниже речь пойдет о продвижении сайтов в рунете. В данном контексте более актуален парсер ключевых слов яндекс директа.
Парсер поисковых запросов директа
Для начала опишем стандартную схему работы парсера директа.
1. Пользователь задает поисковые запросы, производные которых необходимо собрать.
2. Парсер авторизуется на яндексе и начинает парсить яндекс вордстат поочередно для каждого запроса.
3. Для каждого запроса получаются производные ключевые слова не только с первой страницы выдачи директа, но и со всех последующих.
В результате на выходе мы имеем достаточно большое количество вариантов ключевых слов, которые в дальнейшем используются для формирования семантического ядра сайта.
Парсер ключевиков и количества показов — “скользкий момент”
Отметим, что помимо ключевых слов мы получаем так называемое “прогнозируемое количество показов” — показатель к которому стоит относиться очень осторожно. Для начала разберемся, что об этом значении пишет сам Яндекс:
В результатах выводится статистика запросов поисковой системы Яндекс, содержащих заданное слово или словосочетание, и других запросов, которые осуществляли искавшие его люди (справа).
Цифры рядом с каждым запросом в результатах выдачи вордстат дают предварительный прогноз числа показов в месяц, которое вы будете иметь, выбрав данный запрос в качестве ключевого слова.
Ошибкой многих оптимизаторов является то, что они читают только первую часть описания, и при этом — читают не совсем внимательно. Идем дальше:
Цифра рядом со словом «телевизор» обозначает число показов по абсолютно всем запросам, включающим слово «телевизор»: «купить телевизор» , «плазменный телевизор», «купить плазменный телевизор», «купить новый плазменный телевизор» и т.п.
Вы уже наверное догадались, на что мы намекаем? Итак, вы должны понять главное — при парсинге производных запросов по Wordstat не стоит обращать внимание на показатель их частотности, поскольку данное значение суммируется из частотностей всех производных запросов.
Но как в таком случае определить какие ключевики более “жирные” а какие менее? Сразу развенчаем ошибочное мнение, что производные ключевики всегда имеют меньше реальных показов, что основные. Это откровенная чушь! Найти реальные количества показов ключевиков (с вычетом количества показов производных) нам позволит операторы кавычки. Таким образом, для поиска запросов и определения самых “жирных” необходимо применять следующую схему:
1. Запустить парсер ключей для поиска производных.
2. Взять все производные запросы и отпарсить количество показов каждого, задавая запрос в кавычках.
Мы согласны, что это несколько более длинный и сложный путь. Однако представьте ситуацию. У вас есть около 500 запросов, по которым вы хотите продвинуть основной сайт. 30 из них являются (по вашему первоначальному мнению, то есть по изначально спарсенной статистике Wordstat) наиболее высокочастотными. Далее вы тратите 3 месяца времени и несколько тысяч убитых енотов (да ребята — качественное продвижение это дорогостоящее и длительное мероприятие) и в итоге оказывается, что поискового трафика в несколько раз меньше чем ожидалось. Вы сильно расстраиваетесь, ищите профессионального специалиста по продвижению и он вам открывает глаза на то, что вы продвигали совсем не те запросы, которые приводят трафик (в частности, он показывает вам реальную статистику по запросам в кавычках).
Тестирование парсера запросов
На нашем сайте вы можете бесплатно скачать парсер ключевых слов яндекса и протестировать его. Мы также можем обсудить настройку парсера кеев, которая будет проверять значения собранных запросов в кавычках.
Тестирование парсера Wordstat
Чтобы протестировать работу парсера Wordstat :
Шаг 1. Установите . Демо-версия программы имеет все возможности платной, но сохраняет только первые 25 результатов парсинга.
Шаг 2. В дереве кампаний присутствует кампания seo-parsers/wordstat-keywords-parser.par . Выберите ее и нажмите кнопку Запуск (Play) . Перед запуском можно отредактировать Входные данные , чтобы изменить набор базовых запросов , по которым будет собираться статистика.
кликните на изображении для увеличения
После запуска кампании открывается окно браузера, в которое необходимо ввести авторизационные данные для доступа к статистике Wordstat.
Яндекс : Уязвимости безопасности
Копировать результаты Скачать результаты
Нажмите ESC, чтобы закрыть
| # | CVE-идентификатор | Идентификатор CWE | # эксплойтов | Тип(ы) уязвимости | Дата публикации | Дата обновления | Счет | Получен уровень доступа | Доступ | Сложность | Аутентификация | конф. | Интегр. | Доступно. | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | CVE-2021-43305 | 787 | Переполнение | 14.03.2022 | 22.03.2022 | 6,5 | Нет | Удаленный | Низкий | ??? | Частично | Частично | Частично | ||||||
| Переполнение буфера кучи в кодеке сжатия LZ4 от Clickhouse при анализе вредоносного запроса. Нет проверки того, что операции копирования в цикле LZ4::decompressImpl и особенно операция произвольного копирования wildCopy | |||||||||||||||||||
| 2 | CVE-2021-43304 | 787 | Переполнение | 14.03.2022 | 22.03.2022 | 6,5 | Нет | Удаленный | Низкий | ??? | Частично | Частично | Часть | ||||||
| Переполнение буфера кучи в кодеке сжатия LZ4 от Clickhouse при анализе вредоносного запроса. Нет проверки того, что операции копирования в цикле LZ4::decompressImpl и особенно операция произвольного копирования wildCopy | |||||||||||||||||||
| 3 | CVE-2021-42391 | 369 | 14.03.2022 | 22.03.2022 | 5,0 | Нет | Удаленный | Низкий | Не требуется | Нет | Нет | Частично | |||||||
| Деление на ноль в кодеке сжатия Clickhouse Gorilla при анализе вредоносного запроса. Первый байт сжатого буфера используется в операции по модулю без проверки на 0, | |||||||||||||||||||
| 4 | CVE-2021-42390 | 369 | 14.03.2022 | 22.03.2022 | 4,0 | Нет | Удаленный | Низкий | ??? | Нет | Нет | Частично | |||||||
| Деление на ноль в кодеке сжатия DeltaDouble от Clickhouse при разборе вредоносного запроса. Первый байт сжатого буфера используется в операции по модулю без проверки на 0. | |||||||||||||||||||
| 5 | CVE-2021-42389 | 369 | 14.03.2022 | 22.03.2022 | 4,0 | Нет | Удаленный | Низкий | ??? | Нет | Нет | Частично | |||||||
| Деление на ноль в кодеке сжатия Delta от Clickhouse при анализе вредоносного запроса. Первый байт сжатого буфера используется в операции по модулю без проверки на 0. | |||||||||||||||||||
| 6 | CVE-2021-42388 | 125 | 14.03.2022 | 22.03.2022 | 5,5 | Нет | Удаленный | Низкий | ??? | Частично | Нет | Частично | |||||||
| Heap out-of-bounds считывается кодеком сжатия Clickhouse LZ4 при анализе вредоносного запроса. В рамках цикла LZ4::decompressImpl() из сжатых данных считывается 16-битное введенное пользователем значение без знака («смещение»). Смещение позже используется в длине операции копирования без проверки нижних границ источника операции копирования. | |||||||||||||||||||
| 7 | CVE-2021-42387 | 125 | 14.03.2022 | 22.03.2022 | 5,5 | Нет | Удаленный | Низкий | ??? | Частично | Нет | Частично | |||||||
| Heap out-of-bounds считывается кодеком сжатия Clickhouse LZ4 при анализе вредоносного запроса. В рамках цикла LZ4::decompressImpl() из сжатых данных считывается 16-битное введенное пользователем значение без знака («смещение»). Смещение позже используется в длине операции копирования без проверки верхних границ источника операции копирования. | |||||||||||||||||||
| 8 | CVE-2021-25263 | Исполнительный код | 17.08.2021 | 15.06.2022 | 4,0 | Нет | Удаленный | Низкий | ??? | Частично | Нет | Нет | |||||||
| Уязвимость локальных привилегий в Яндекс.Браузере для Windows до версии 21.9.0.390 позволяет локальному злоумышленнику с низкими привилегиями выполнять произвольный код с привилегиями SYSTEM, манипулируя файлами в каталоге с небезопасными разрешениями в процессе обновления Яндекс.Браузера. | |||||||||||||||||||
| 9 | CVE-2021-24428 | 79 | XSS | 2021-08-02 | 09.08.2021 | 3,5 | Нет | Удаленный | Средний | ??? | Нет | Частично | Нет | ||||||
| Плагин RSS для Yandex Turbo WordPress до версии 1. 30 не очищает и не экранирует некоторые из своих настроек перед сохранением и выводом их на панели администратора, что приводит к проблеме аутентификации сохраненных межсайтовых сценариев, даже если возможность unfiltered_html запрещена. | |||||||||||||||||||
| 10 | CVE-2020-27970 | 290 | 13.09.2021 | 22.09.2021 | 5,0 | Нет | Удаленный | Низкий | Не требуется | Нет | Частично | Нет | |||||||
| Яндекс.Браузер до 20.10.0 позволял удаленным злоумышленникам подделывать адресную строку | |||||||||||||||||||
| 11 | CVE-2020-27969 | 346 | Обход | 13.09.2021 | 22.09.2021 | 7,5 | Нет | Удаленный | Низкий | Не требуется | Частично | Частично | Частично | ||||||
| Яндекс. Браузер для Android 20.8.4 позволяет удаленным злоумышленникам выполнять обход SOP и подмену адресной строки | |||||||||||||||||||
| 12 | CVE-2020-7369 | 306 | 20.10.2020 | 21.10.2020 | 4,3 | Нет | Удаленный | Средний | Не требуется | Частично | Нет | Нет | |||||||
| Пользовательский интерфейс (UI) Уязвимость «Искажение критической информации» в адресной строке Яндекс.Браузера позволяет злоумышленнику скрыть истинный источник данных, представленный в браузере. Эта проблема затрагивает Яндекс.Браузер версии 20.8.3 и более ранних версий и была исправлена в версии 20.8.4, выпущенной 1 октября 2020 года. | |||||||||||||||||||
| 13 | CVE-2019-18657 | 74 | 31. 10.2019 | 06.11.2019 | 5,0 | Нет | Удаленный | Низкий | Не требуется | Нет | Частично | Нет | |||||||
| ClickHouse до 19.13.5.44 разрешал внедрение заголовков HTTP через функцию таблицы URL-адресов. | |||||||||||||||||||
| 14 | CVE-2019-16535 | 125 | 2019-12-30 | 03.01.2020 | 7,5 | Нет | Удаленный | Низкий | Не требуется | Частично | Частично | Часть | |||||||
| Во всех версиях ClickHouse до 19.14 чтение OOB, запись OOB и потеря значимости целочисленного значения в алгоритмах распаковки могут использоваться для достижения RCE или DoS через собственный протокол. | |||||||||||||||||||
| 15 | CVE-2019-15024 | 2019-12-30 | 24.08.2020 | 4,0 | Нет | Удаленный | Низкий | ??? | Нет | Частично | Нет | ||||||||
| Во всех версиях ClickHouse до 19.14.3 злоумышленник, имеющий доступ на запись к ZooKeeper и способный запустить собственный сервер, доступный в сети, где работает ClickHouse, может создать собственный вредоносный сервер, который будет действовать как реплика ClickHouse и зарегистрируйте его в ZooKeeper. Когда другая реплика будет извлекать часть данных из вредоносной реплики, она может заставить clickhouse-server выполнить запись по произвольному пути в файловой системе. | |||||||||||||||||||
| 16 | CVE-2018-14672 | 22 | Реж. Трав. | 15.08.2019 | 27.08.2019 | 5,0 | Нет | Удаленный | Низкий | Не требуется | Частично | Нет | Нет | ||||||
| В ClickHouse до 18.12.13 функции загрузки моделей CatBoost позволяли обход пути и чтение произвольных файлов через сообщения об ошибках. | |||||||||||||||||||
| 17 | CVE-2018-14671 | 20 | Исполнительный код | 15.08.2019 | 29.08.2019 | 7,5 | Нет | Удаленный | Низкий | Не требуется | Частично | Частично | Частично | ||||||
| В ClickHouse до версии 18.10.3 unixODBC позволял загружать произвольные общие объекты из файловой системы, что приводило к уязвимости Remote Code Execution. | |||||||||||||||||||
| 18 | CVE-2018-14670 | 285 | 15.08.2019 | 28.08.2019 | 7,5 | Нет | Удаленный | Низкий | Не требуется | Частично | Частично | Частично | |||||||
| Неправильная настройка deb-пакета в ClickHouse до версии 1.1.54131 могла привести к несанкционированному использованию базы данных. | |||||||||||||||||||
| 19 | CVE-2018-14669 | 200 | +Инфо | 15.08.2019 | 28.08.2019 | 5,0 | Нет | Удаленный | Низкий | Не требуется | Частично | Нет | Нет | ||||||
| Клиент ClickHouse MySQL до версий 1. 1.54390 имел включенную функцию «LOAD DATA LOCAL INFILE», которая позволяла вредоносной базе данных MySQL считывать произвольные файлы с подключенного сервера ClickHouse. | |||||||||||||||||||
| 20 | CVE-2018-14668 | 352 | 15.08.2019 | 29.08.2019 | 6,8 | Нет | Удаленный | Средний | Не требуется | Частично | Частично | Частично | |||||||
| В ClickHouse до версии 1.1.54388 «удаленная» табличная функция допускала произвольные символы в полях «пользователь», «пароль» и «база данных по умолчанию», что приводило к атакам с подделкой межпротокольных запросов. | |||||||||||||||||||
| 21 | CVE-2017-7327 | 426 | 2018-01-19 | 01.02. 2018 | 6,8 | Нет | Удаленный | Средний | Не требуется | Частично | Частично | Частично | |||||||
| Установщик Яндекс.Браузера для ПК до версии 17.4.1 имеет уязвимость, связанную с перехватом DLL, поскольку для dnsapi.dll, winmm.dll, ntmarta.dll, cryptbase.dll или profapi.dll используется ненадежный путь поиска. | |||||||||||||||||||
| 22 | CVE-2017-7326 | 362 | Мем. Корр. | 2018-01-19 | 01.02.2018 | 5.1 | Нет | Удаленный | Высокий | Не требуется | Частично | Частично | Частично | ||||||
| Проблема состояния гонки в Яндекс. Браузере для Android до версии 17.4.0.16 позволяла удаленному злоумышленнику потенциально использовать повреждение памяти через созданную HTML-страницу | .|||||||||||||||||||
| 23 | CVE-2017-7325 | 20 | 2018-01-19 | 05.02.2018 | 5,0 | Нет | Удаленный | Низкий | Не требуется | Нет | Частично | Нет | |||||||
| Яндекс.Браузер до версии 16.9.0 позволял удаленным злоумышленникам подделывать адресную строку через window.open. | |||||||||||||||||||
| 24 | CVE-2016-10666 | 310 | Исполнительный код | 2018-05-29 | 09.10.2019 | 9,3 | Нет | Удаленный | Средний | Не требуется | Полный | Полный | Полный | ||||||
| tomita-parser — это Node-оболочка для Яндекса Tomita Parser tomita-parser загружает бинарные ресурсы по HTTP, что делает его уязвимым для MITM-атак. Можно вызвать удаленное выполнение кода (RCE), заменив запрошенные ресурсы копией, контролируемой злоумышленником, если злоумышленник находится в сети или находится между пользователем и удаленным сервером. | |||||||||||||||||||
| 25 | CVE-2016-8508 | 254 | 01.03.2017 | 10.07.2020 | 4,3 | Нет | Удаленный | Средний | Не требуется | Нет | Частично | Нет | |||||||
| Яндекс.Браузер для ПК до версии 17.1.1.227 не отображает предупреждения Защиты (по аналогии с Safebrowsing в Chromium) на веб-сайтах с особым типом контента, которые могут быть использованы удаленным злоумышленником для предотвращения предупреждения Защиты на собственном вредоносном веб-сайте. | |||||||||||||||||||
| 26 | CVE-2016-8507 | 200 | +Информация | 01. 03.2017 | 09.07.2020 | 4,3 | Нет | Удаленный | Средний | Не требуется | Частично | Нет | Нет | ||||||
| Яндекс.Браузер для iOS до версии 16.10.0.2357 не ограничивает должным образом обработку URL-адресов facetime://, что позволяет удаленным злоумышленникам инициировать вызов лицом к лицу без согласия пользователя и получать видео- и аудиоданные с устройства через специально созданный веб-сайт. | |||||||||||||||||||
| 27 | CVE-2016-8506 | 79 | XSS | 26.10.2016 | 2016-12-02 | 4,3 | Нет | Удаленный | Средний | Не требуется | Нет | Частично | Нет | ||||||
| XSS в Яндекс. Браузере Переводчик в Яндекс.Браузере для компьютеров версий с 15.12 по 16.2 может использоваться удаленным злоумышленником для оценки произвольного кода JavaScript. | |||||||||||||||||||
| 28 | CVE-2016-8505 | 79 | XSS | 26.10.2016 | 2016-12-02 | 4.3 | Нет | Удаленный | Средний | Не требуется | Нет | Частично | Нет | ||||||
| XSS в Яндекс Браузере BookReader в Яндекс браузере для десктопа для версий до 16.6. может быть использован удаленным злоумышленником для оценки произвольного кода javascript. | |||||||||||||||||||
| 29 | CVE-2016-8504 | 352 | CSRF | 26.10.2016 | 2016-12-02 | 4,3 | Нет | Удаленный | Средний | Не требуется | Частично | Нет | Нет | ||||||
| CSRF формы синхронизации в десктопном Яндекс. Браузере до версии 16.6 может быть использован удаленным злоумышленником для кражи сохраненных данных в профиле браузера. | |||||||||||||||||||
| 30 | CVE-2016-8503 | 254 | 26.10.2016 | 2016-12-02 | 5,0 | Нет | Удаленный | Низкий | Не требуется | Частично | Нет | Нет | |||||||
| Предупреждение Яндекс Защиты от фишинга в десктопном Яндекс Браузере версий с 16.7 по 16.9 может быть использовано удаленным злоумышленником для подбора паролей от важных веб-ресурсов с помощью специального JavaScript. | |||||||||||||||||||
| 31 | CVE-2016-8502 | 254 | 26.10.2016 | 2016-12-02 | 5,0 | Нет | Удаленный | Низкий | Не требуется | Частично | Нет | Нет | |||||||
| Предупреждение Яндекс Защиты от фишинга в десктопном Яндекс Браузере версий с 15. 12.0 по 16.2 может быть использовано удаленным злоумышленником для подбора паролей от важных веб-ресурсов с помощью специального JavaScript. | |||||||||||||||||||
| 32 | CVE-2016-8501 | 264 | Обход | 26.10.2016 | 2016-12-02 | 5,0 | Нет | Удаленный | Низкий | Не требуется | Частично | Нет | Нет | ||||||
| Обход безопасности WiFi в Яндекс Браузере с версии 15.10 по 15.12 позволяет удаленному злоумышленнику прослушивать трафик в открытых или защищенных WEP сетях wi-fi, несмотря на включенный специальный механизм безопасности. | |||||||||||||||||||
| 33 | CVE-2012-2941 | 79 | 1 | XSS | 27.05.2012 | 2017-08-29 | 4,3 | Нет | Удаленный | Средний | Не требуется | Нет | Частично | Нет | |||||
| Уязвимость межсайтового скриптинга (XSS) в поиске/ в Яндекс. Сервер 2010 9.0 Enterprise позволяет удаленным злоумышленникам внедрить произвольный веб-скрипт или HTML через текстовый параметр. | |||||||||||||||||||
| 34 | CVE-2007-3485 | XSS | 28.06.2007 | 15.11.2008 | 4,3 | Нет | Удаленный | Средний | Не требуется | Нет | Частично | Нет | |||||||
| Множественные уязвимости межсайтового скриптинга (XSS) в Яндекс.Сервере позволяют удаленным злоумышленникам внедрить произвольный веб-скрипт или HTML через (1) запрос или (2) параметр в пределах URI по умолчанию. | |||||||||||||||||||
Общее количество уязвимостей: 34 Страница : 1 (Эта страница)
Журнал изменений безопасности | ClickHouse Docs
Исправлено в ClickHouse 21.10.2.15, 18.10.2021
CVE-2021-43304
Переполнение буфера кучи в кодеке сжатия ClickHouse LZ4 при анализе вредоносного запроса. Нет проверки того, что операции копирования в цикле LZ4::decompressImpl и особенно операция произвольного копирования wildCopy
Авторы: JFrog Security Research Team
CVE-2021-43305
Переполнение буфера кучи в кодеке сжатия ClickHouse LZ4 при анализе вредоносного запроса. Нет проверки того, что операции копирования в цикле LZ4::decompressImpl и особенно операция произвольного копирования wildCopy
Авторы: JFrog Security Research Team
CVE-2021-42387
Куча за пределами границ, прочитанная в кодеке сжатия LZ4 ClickHouse при анализе вредоносного запроса. В рамках цикла LZ4::decompressImpl() из сжатых данных считывается 16-битное введенное пользователем значение без знака («смещение»). Смещение позже используется в длине операции копирования без проверки верхних границ источника операции копирования.
Кредиты: исследовательская группа безопасности JFrog
CVE-2021-42388
Heap out-of-bounds считан в кодеке сжатия ClickHouse LZ4 при разборе вредоносного запроса. В рамках цикла LZ4::decompressImpl() из сжатых данных считывается 16-битное введенное пользователем значение без знака («смещение»). Смещение позже используется в длине операции копирования без проверки нижних границ источника операции копирования.
Авторы: JFrog Security Research Team
CVE-2021-42389
Деление на ноль в кодеке сжатия Delta ClickHouse при разборе вредоносного запроса. Первый байт сжатого буфера используется в операции по модулю без проверки на 0,
Авторы: JFrog Security Research Team
CVE-2021-42390
Деление на ноль в кодеке сжатия ClickHouse DeltaDouble при разборе вредоносного запроса. Первый байт сжатого буфера используется в операции по модулю без проверки на 0.
Авторы и права: JFrog Security Research Team
CVE-2021-42391 вредоносный запрос.
Первый байт сжатого буфера используется в операции по модулю без проверки на 0,Авторы: JFrog Security Research Team
Исправлено в ClickHouse 21.4.3.21, 12 апреля 2021 г.
CVE-2021-25263
Злоумышленник с привилегией CREATE DICTIONARY может читать произвольный файл за пределами разрешенного каталога.
Исправление перенесено на версии 20.8.18.32-lts, 21.1.9.41-stable, 21.2.9.41-stable, 21.3.6.55-lts, 21.4.3.21-stable и более поздние версии.
Авторы: Вячеслав Егошин
Исправлено в ClickHouse Release 19.14.3.3, 10.09.2019
CVE-2019-15024
Злоумышленник, имеющий доступ на запись к ZooKeeper и который может запустить собственный сервер, доступный из сети, где работает ClickHouse, может создать собственный вредоносный сервер, который будет действовать как реплика ClickHouse, и зарегистрировать его в Зоокипере. Когда другая реплика будет извлекать часть данных из вредоносной реплики, она может заставить clickhouse-server выполнить запись по произвольному пути в файловой системе.
Авторы и права: Эльдар Заитов из группы информационной безопасности Яндекса
CVE-2019-16535
Чтение OOB, запись OOB и потеря значимости целого числа в алгоритмах декомпрессии могут использоваться для достижения RCE или DoS через собственный протокол.
Авторы: Эльдар Заитов из группы информационной безопасности Яндекса
CVE-2019-16536
Переполнение стека, ведущее к DoS, может быть вызвано вредоносным аутентифицированным клиентом.
Авторы и права: Эльдар Заитов из группы информационной безопасности Яндекса
Исправлено в ClickHouse Release 19.13.6.1, 20 сентября 2019 г.-18657
Табличная функция url содержала уязвимость, позволяющую злоумышленнику внедрить в запрос произвольные HTTP-заголовки.
Авторы: Никита Тихомиров
Исправлено в ClickHouse Release 18.12.13, 10.09.2018
CVE-2018-14672
Функции загрузки моделей CatBoost позволяли обход пути и чтение произвольных файлов через сообщения об ошибках.
Авторы и права: Андрей Красичков из группы информационной безопасности Яндекса
Исправлено в ClickHouse Release 18.10.3, 13 августа 2018 г.
CVE-2018-14671
unixODBC позволял загружать произвольные общие объекты из файловой системы, что приводило к уязвимости удаленного выполнения кода.
Авторы: Андрей Красичков и Евгений Сидоров из группы информационной безопасности Яндекса
Исправлено в ClickHouse Release 1.1.54388, 28-06-2018 user», «password» и «default_database», которые привели к атакам с подделкой межпротокольных запросов.
Авторы: Андрей Красичков из группы информационной безопасности Яндекса
Исправлено в ClickHouse Release 1.1.54390, 06 июля 2018 г. позволил вредоносной базе данных MySQL читать произвольные файлы с подключенного сервера ClickHouse.
Авторы: Андрей Красичков и Евгений Сидоров из группы информационной безопасности Яндекса
Исправлено в ClickHouse Release 1.1.54131, 10 января 2017 г.
CVE-2018-14670
Неправильная конфигурация в пакете deb может привести к несанкционированному использованию базы данных.
Кредиты: Национальный центр кибербезопасности Великобритании (NCSC)
ClickHouse — База данных баз данных
CilckHouse — это столбцовая СУБД OLAP с открытым исходным кодом. Он предназначен для обеспечения линейной масштабируемости запросов.
История
ClickHouse разработан российской компанией Яндекс. Он предназначен для нескольких проектов в рамках Яндекс. Яндексу нужна была СУБД для анализа больших объемов данных, поэтому они начали разрабатывать собственную СУБД, ориентированную на столбцы. Прототип ClickHouse появился в 2009 году, а в 2016 году он был выпущен в открытый доступ.
wikipedia.org/wiki/ClickHouse
Сжатие
Кодировка словаря Дельта-кодирование Наивный (уровень страницы)
Помимо кодирования общего назначения с помощью LZ4 (по умолчанию) или Zstd, ClickHouse поддерживает кодирование по словарю с использованием типа данных LowCardinality, а также кодирование дельта, двойная дельта и Gorilla с помощью кодеков столбцов.
Параллельный контроль
Не поддерживается
ClickHouse не поддерживает транзакции с несколькими операторами.
Модель данных
Относительный
ClickHouse использует модель реляционной базы данных.
Внешние ключи
Не поддерживается
ClickHouse не поддерживает внешние ключи.
Индексы
Лог-структурированное дерево слияния
ClickHouse поддерживает индексы первичных ключей. Механизм индексации называется разреженным индексом. В MergeTree данные сортируются по первичному ключу лексикографически в каждой части. Затем ClickHouse выбирает несколько меток для каждой N-й строки, где N по умолчанию выбирается адаптивно. Вместе эти метки служат разреженным индексом, который позволяет выполнять эффективные запросы диапазона.
Присоединяется
Хэш-соединение
ClickHouse по умолчанию использует хэш-соединение, которое выполняется путем помещения нужной части данных в хеш-таблицу в памяти. Если для хеш-соединения недостаточно памяти, оно возвращается к объединению.
Параллельное выполнение
Внутриоператорный (горизонтальный) Межоператорский (вертикальный)
ClickHouse по умолчанию использует половину ядер для одноузловых запросов и одну реплику каждого сегмента для распределенных запросов. Его можно настроить на использование только одного ядра, всех ядер всего кластера или чего-то промежуточного.
Компиляция запросов
Генерация кода
ClickHouse поддерживает генерацию кода во время выполнения. Код генерируется для каждого типа запроса на лету, удаляя всю косвенность и динамическую диспетчеризацию. Генерация кода во время выполнения может быть лучше, если она объединяет множество операций и полностью использует исполнительные блоки ЦП.
Выполнение запроса
Векторизованная модель
Интерфейс запросов
Пользовательский API SQL HTTP/ОТДЫХ Командная строка/оболочка
ClickHouses предоставляет два типа синтаксических анализаторов: полный синтаксический анализатор SQL и синтаксический анализатор формата данных. Он использует синтаксический анализатор SQL для всех типов запросов и синтаксический анализатор формата данных только для запросов INSERT. Помимо языка запросов, он предоставляет несколько пользовательских интерфейсов, включая интерфейс HTTP, драйвер JDBC, интерфейс TCP, клиент командной строки и т. д.
Архитектура хранения
Дискоориентированный В памяти Гибридный
ClickHouse имеет несколько типов движков таблиц. Тип механизма таблиц определяет, где хранятся данные, параллельный уровень, поддерживаются ли индексы и некоторые другие свойства. Ключевым семейством движков таблиц для производственного использования является MergeTree, которое обеспечивает отказоустойчивое хранение больших объемов данных и поддерживает репликацию. Существует также семейство журналов для легкого хранения временных данных и распределенный механизм для запросов к кластеру.
Модель хранения
Модель хранения декомпозиции (столбцовая)
ClickHouse — это СУБД, ориентированная на столбцы, и она хранит данные по столбцам.
Организация хранения
Метод индексированного последовательного доступа (ISAM) Отсортированные файлы
Хранимые процедуры
Не поддерживается
В настоящее время хранимые процедуры и UDF числятся открытыми проблемами в ClickHouse.
Архитектура системы
Общий-Ничего
Система ClickHouse в распределенной установке представляет собой кластер шардов. Он использует асинхронную репликацию с несколькими мастерами, и в системе нет единой точки состязания.
com/yandex/ClickHouse/blob/master/doc/developers/architecture.md
Просмотры
Виртуальные виды Материализованные представления
ClickHouse поддерживает как виртуальные представления, так и материализованные представления. Материализованные представления хранят данные, преобразованные соответствующим запросом SELECT. Запрос SELECT может содержать DISTINCT, GROUP BY, ORDER BY, LIMIT и т. д.
Редакция №14 |
Веб-сайт
https://clickhouse.com/
Исходный код
https://github.com/ClickHouse/ClickHouse
Техническая документация
https://clickhouse.tech/docs/en/
@ClickHouseDB
Разработчик
Яндекс
Страна происхождения
RU
Год начала
2016
Тип проекта
Коммерческий, с открытым исходным кодом
Написано на
С++
Поддерживаемые языки
С, С#, С++, Go, Java, Котлин, Скала
Совместим с
MySQL
Операционные системы
линукс
Лицензии
Апач v2
Википедия
https://en. wikipedia.org/wiki/ClickHouse
Редакция №14 |
поисковая система-парсер · PyPI
«Если это поисковая система, то ее можно разобрать» — какой-то случайный парень
search-engine-parser — это пакет, который позволяет запрашивать популярные поисковые системы и получать заголовки результатов, ссылки, описания и многое другое. Он нацелен на то, чтобы очистить самый широкий спектр поисковых систем. Посмотреть все поддерживаемые движки здесь.
- Анализатор поисковых систем
- Популярные поддерживаемые двигатели
- Установка
- Разработка
- Кодовая документация
- Запуск тестов
- Использование
- Код
- Командная строка
- Часто задаваемые вопросы
- Кодекс поведения
- Вклад
- Лицензия (MIT)
Популярные поддерживаемые системы
Популярные поддерживаемые поисковые системы включают:
- DuckDuckGo
- Гитхаб
- Переполнение стека
- Байду
- Ютуб
Посмотреть все поддерживаемые двигатели здесь.
Установка
Установка из PyPi:
# установить только зависимости пакетов
pip установить поисковую систему-парсер
# Устанавливает инструмент `pysearch` cli
pip install "поисковая система-парсер[cli]"
или от мастера:
pip install git+https://github.com/bisoncorps/search-engine-parser
Разработка
Клонировать репозиторий:
91 918 git clone [email protected]:bisoncorps/search-engine-parser.gitЗатем создайте виртуальную среду и установите необходимые пакеты:
mkvirtualenv search_engine_parser
pip install -r требования/dev.txt
Документация по коду
Документацию по коду можно найти в Read the Docs.
Запуск тестов
pytest
Использование
Код
Результаты запроса можно извлечь из популярных поисковых систем, как показано в примере ниже.
импорт ппринт
из search_engine_parser. core.engines.bing импортировать Поиск как BingSearch
из search_engine_parser.core.engines.google импортировать Поиск как GoogleSearch
из search_engine_parser.core.engines.yahoo импортировать Поиск как YahooSearch
search_args = ('проповедь хору', 1)
gsearch = GoogleПоиск()
yпоиск = YahooSearch()
bsearch = BingSearch()
gresults = gsearch.search(*search_args)
yresults = ysearch.search(*search_args)
bresults = bsearch.search(*search_args)
а = {
«Гугл»: результаты,
"Yahoo": результаты,
«Бинг»: итоги
}
# красиво вывести результат каждого движка
для k, v в a.items():
print(f"-------------{k}------------")
для результата в v:
pprint.pprint(результат)
# вывести первый заголовок из поиска Google
печать (результаты ["названия"] [0])
# вывести 10-ю ссылку из поиска yahoo
print(yresults["ссылки"][9])
# вывести 6-е описание из поиска bing
print(результаты["описания"][5])
# вывести первый результат, содержащий ссылки, описания и заголовок
печать (результаты [0])
Для локализации можно передать ключевое слово url и локализованный URL. Это запрашивает и анализирует локализованный URL-адрес с помощью анализатора того же движка:
# Используйте google.de вместо google.com.
результаты = gsearch.search(*search_args, url="google.de")
Если вам нужны результаты на определенном языке, вы можете передать ключевое слово «hl» и двухбуквенное сокращение страны (вот удобный список):
# Используйте 'it' для получения результатов на итальянском языке
результаты = gsearch.search(*search_args, hl="it")
Кэш
Результаты автоматически кэшируются для поисковых систем. Вы можете либо обойти кеш, добавив cache=False в метод search или async_search , либо очистить кеш движка
из search_engine_parser.core.engines.github import Search as GitHub
гитхаб = гитхаб()
# обход кэша
github.search («поисковая система-парсер», кеш = ложь)
#ИЛИ ЖЕ
# очистить кеш перед поиском
github. clear_cache()
github.search («поисковая система-парсер»)
Прокси
Добавление прокси влечет за собой отправку сведений в функцию поиска
из search_engine_parser.core.engines.github import Искать как GitHub
гитхаб = гитхаб()
github.search("поисковая система-парсер",
# поддерживаются только http-прокси
прокси='http://123.12.1.0',
proxy_auth=('имя пользователя', 'пароль'))
Async
search-engine-parser поддерживает async :
results = await gsearch.async_search(*search_args)
Результаты
The SearchResults после поиска:
>>> results = gsearch.search("проповедь хору", 1)
>>> результаты
6a280>
# объект поддерживает получение отдельных результатов итерацией только по типу (ссылки, описания, заголовки)
>>> results[0] # возвращает первый
>>> results[0]["description"] # получает описание первого элемента
>>> results[0]["link"] # получает ссылку первого элемента
>>> results["descriptions"] # возвращает список всех описаний из всех результатов
Его можно повторить как обычный список, чтобы вернуть отдельные SearchItem s.
Командная строка
search-engine-parser поставляется с инструментом CLI, известным как pysearch . Вы можете использовать его как таковой:
pysearch --engine bing --type descriptions "Проповедь хору"
Результат:
«Проповедь хору» зародилась в США в 1970-х годах. Это вариант более ранней «проповеди обращенным», которая восходит к Англии конца 1800-х годов и имеет то же значение. Происхождение - полный рассказ «Проповедь хору» (также иногда пишется как quire) имеет американское происхождение.
использование: pysearch [-h] [-V] [-e ENGINE] [--show-summary] [-u URL] [-p PAGE]
[-t ТИП] [-cc] [-r РАНГ] [--proxy ПРОКСИ]
[--прокси-пользователь PROXY_USER] [--прокси-пароль PROXY_PASSWORD]
запрос
SearchEngineParser
позиционные аргументы:
query Строка запроса к поисковой системе для
необязательные аргументы:
-h, --help показать это справочное сообщение и выйти
-V, --version показать номер версии программы и выйти
-e ДВИГАТЕЛЬ, --engine ДВИГАТЕЛЬ
Движок, используемый для разбора запроса, например, google, yahoo,
bing,duckduckgo (по умолчанию: Google)
--show-summary Показывает сводку по движку
-u URL-адрес, --url URL-адрес Пользовательская ссылка для использования в качестве базового URL-адреса для поиска, например
google. de
-p СТРАНИЦА, --page СТРАНИЦА Страница результата, для которой возвращаются сведения (по умолчанию: 1)
-t ТИП, --type ТИП Тип возвращаемых сведений, т. е. полное, ссылки, описания
или заголовки (по умолчанию: полные)
-cc, --clear-cache Очистить кэш движка перед поиском
-r RANK, --rank RANK Идентификатор детали для возврата, например, 5 (по умолчанию: 0)
--proxy PROXY Адрес прокси для использования
--proxy-пользователь PROXY_USER
Прокси-пользователь для использования
--proxy-пароль PROXY_PASSWORD
Прокси-пароль для использования
Кодекс поведения
Всегда соблюдайте кодекс поведения.
Пожертвование
Прежде чем делать какие-либо пожертвования, прочтите руководство по пожертвованиям.
Лицензия (MIT)
Этот проект находится под лицензией MIT 2.0 License, которая позволяет очень широкое использование как в академических, так и в коммерческих целях.
Авторы ✨
Спасибо этим замечательным людям (клавиша эмодзи):
| Эд Лафф 💻 | Диретнан Домнан 🚇 ⚠️ 🔧 💻 | MeNsaaH 🚇 ⚠️ 🔧 💻 | Адитья Пал ⚠️ 💻 📖 | Авинаш Редди 🐛 | Давид Онух 💻 ⚠️ | Панайотис Симакис 💻 ⚠️ |
| Рейартур 💻 | Ашоккумар Т. А. 💻 | Андреас Тойбер 💻 | mi096684 🐛 | деваджитвы 💻 | Гег Закарян 💻 🐛 | Хакан Боган 🐛 |
| Ник Кёлер 🐛 💻 | КрисЛин 🐛 💻 | Пьетро 💻 🐛 |
Этот проект соответствует спецификации всех участников. Пожертвования любого рода приветствуются!
testsuite.databases.pgsql.pytest_plugin — документация yandex-taxi-testsuite 0.1.5.1
импорт коллекций импорт коллекций.abc импортировать повторно импорт импортировать pytest из . импортное соединение из .\w+)(/?\w*)\.sql$') [документы] класс ServiceLocalConfig (коллекции.abc.Mapping): деф __инит__( себя, базы данных: typing.List[discover.PgShardedDatabase], pgsql_control: управление.PgControl, cleanup_exclude_tables: набрав.FrozenSet[str], ): self._initialized = Ложь self._pgsql_control = pgsql_control self._databases = базы данных self._shard_connections = { осколок.pretty_name: pgsql_control.get_connection_cached( шард.dbname, ) для БД в self._databases для шарда в db.shards } self._cleanup_exclude_tables = cleanup_exclude_tables def __len__(self) -> int: вернуть len(self._shard_connections) def __iter__(self) -> typing.
[документы] def __getitem__(self, dbname: str) -> connection.PgConnectionInfo: """ Получить :py:класс:`testsuite.databases.pgsql.connection.PgConnectionInfo` экземпляр по имени базы данных """ вернуть self._shard_connections[dbname].conninfo
def initialize(self) -> typing.Dict[str, control.ConnectionWrapper]: если self._initialized: вернуть self._shard_connections для базы данных в self._databases: self._pgsql_control.initialize_sharded_db (база данных) для шарда в database.shards: self._shard_connections[shard.pretty_name].initialize( self._cleanup_exclude_tables, ) self._initialized = Истина вернуть self._shard_connections
защита pytest_addoption (парсер): """ :param parser: парсер аргументов pytest """ группа = parser.[документы] @pytest.fixture(scope='session') защита pgsql_cleanup_exclude_tables(): вернуть замороженный набор ()
[документы]@pytest.fixture def pgsql(_pgsql, pgsql_apply) -> typing.
[документы] @pytest.fixture(scope='session') защита pgsql_local_create( pgsql_control, pgsql_cleanup_exclude_tables, ) -> набрав.Callable[ [ввод.Список[обнаружить.PgShardedDatabase]], ServiceLocalConfig, ]: """Создает конфигурацию pgsql. :param databases: список баз данных. :returns: :py:class:`ServiceLocalConfig` экземпляр. """ def _pgsql_local_create (базы данных): вернуть ServiceLocalConfig( базы данных, pgsql_control, pgsql_cleanup_exclude_tables, ) вернуть _pgsql_local_create
@pytest.[документы]@pytest.fixture def pgsql_local(pgsql_local_create) -> ServiceLocalConfig: """Настраивает локальный экземпляр pgsql. :returns: :py:class:`ServiceLocalConfig` экземпляр. Чтобы использовать приспособление pgsql, вы должны переопределить pgsql_local() в вашем локальном файле conftest.py, например: .. блок кода:: python @pytest.fixture(scope='сеанс') определение pgsql_local (pgsql_local_create): базы данных = Discover.find_schemas ( 'service_name', [PG_SCHEMAS_PATH]) вернуть pgsql_local_create (список (базы данных. значения ())) Иногда желательно иметь базу данных только для тестов, возможно, используемую в одном конкретный тест или группу тестов. Это может быть достигнуто путем переопределения ``pgsql_local`` в вашем тестовом файле: .. блок кода:: python @pytest.
@pytest.fixture защита _pgsql( _pgsql_service, pgsql_local, pgsql_control, pgsql_disabled: логическое значение, ) -> typing.Dict[str, control.ConnectionWrapper]: если pgsql_disabled: pgsql_local = ServiceLocalConfig( [], pgsql_control, pgsql_cleanup_exclude_tables, ) вернуть pgsql_local.initialize() @pytest.fixture определение pgsql_apply( запрос, _pgsql: ServiceLocalConfig, нагрузка, получить_файл_путь, получить_каталог_путь, mockserver_info, ) -> Нет: """Инициализировать базу данных PostgreSQL с данными.
| Редакционная информация предоставлена DB-Engines | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Имя | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Описание | Служба крупномасштабного хранилища данных с таблицами только для добавления и ACID, а также предоставление совместимого с Amazon DynamoDB API 9.0041 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Модель первичной базы данных | Реляционные DBMS | Магазин документов Реляционные DBMS | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Веб -сайт | . github.com/ydb-platform/ydb ydb.tech | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Техническая документация | cloud.google.com/bigquery/docs | cloud.yandex.com/en/docs/managed-ydb ydb.tech /ru/документы | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Разработчик | YANDEX | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Первоначальный выпуск | 2010 | 2019 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Лицензия. доступна коммерческая лицензия | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Только облачная версия Доступна только как облачная служба | да | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Предложения DBaaS (рекламные ссылки) База данных как услуга Поставщики предложений DBaaS, пожалуйста, свяжитесь с нами, чтобы получить список. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Серверные операционные системы | размещенные | Linux | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Схема данных | Да | Гибкая схема (Defined Schema, Partial Schema, Schema Free). или дата | да | да | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Поддержка XML Некоторая форма обработки данных в формате XML, напр. поддержка структур данных XML и/или поддержка XPath, XQuery или XSLT. | NO | NO | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Вторичные индексы | NO | Да | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SQL-поддержка SQL | SQL-Lik RESTful HTTP/JSON API | RESTful HTTP API (совместимый с DynamoDB) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Поддерживаемые языки программирования | .Net Java JavaScript Objective-C PHP Python Ruby | Go Java JavaScript (Node.js) PHP Python | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Server-side scripts Stored procedures | user defined functions in JavaScript | no | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Triggers | no | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Методы секционирования Методы хранения различных данных на разных узлах | нет | Разделение | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Методы репликации Методы избыточного хранения данных на нескольких узлах | Активно-пассивная репликация осколка | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MapReduce предлагает API для пользовательских методов/снижения методов | NO | NO | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Консинговое Немедленная согласованность | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Внешние ключи Ссылочная целостность | нет | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Концепции транзакций Поддержка обеспечения целостности данных после неатомарных манипуляций с данными | Нет, так как BigQuery разработан для запросов данных | Acid | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| . Поддержка параллелистики для одновременных манипуляций с данными | Да, | Да | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DURULITION. Возможности в памяти Есть ли возможность определить некоторые или все структуры, которые будут храниться только в памяти. | нет | нет | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Концепции пользователя Контроль доступа | Права доступа (владелец, писатель, читатель) на уровне набора данных, таблицы или представления Google Cloud Identity & Access Management (IAM) | Права доступа, определенные для пользователей Yandex Cloud | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Приглашаем представителей поставщиков систем связаться с нами для обновления и расширения системной информации, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Сопутствующие товары и услуги | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| третьи лица | CData: подключение к большим данным и NoSQL через стандартные драйверы. » далее SQLFlow: Обеспечивает визуальное представление общего потока данных. Автоматизированный анализ происхождения данных SQL в базах данных, ETL, бизнес-аналитике, облачных средах и средах Hadoop путем анализа сценария SQL и хранимой процедуры. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Мы приглашаем представителей поставщиков сопутствующих товаров связаться с нами для предоставления информации о своих предложениях здесь. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Подробнее ресурсы | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| DB-инженерные посты в блоге | Облачная популярность DBMS. за четыре года Рост популярности использования СУБД вне облака показать все | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Последние цитаты в новостях | Язык Google Logica устраняет недостатки SQL Новости Google | Утечка из службы доставки еды Яндекса раскрыла личную информацию секретной полиции России | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||