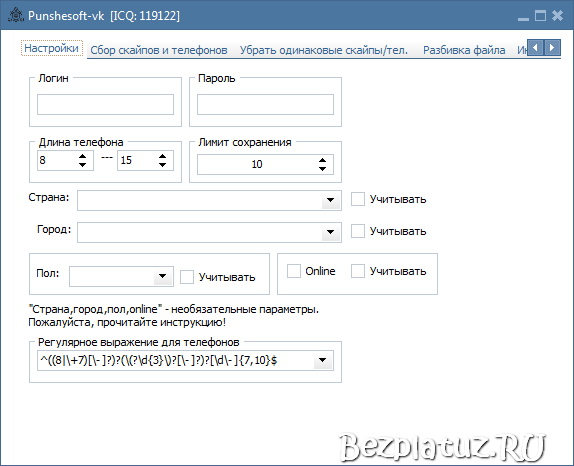
Сбор и парсинг мобильных телефонов с сайтов объявлений для СМС-рассылок » Программа для поиска объявлений на avito.ru, auto.ru, drom.ru, youla.ru, irr.ru, bibika.ru и т.д.
Недокументированные возможности Autodrom Engine (edrom)
Кроме выполнения своей основной задачи — отслеживания и мониторинга объявлений, программа Autodrom Engine может автоматически проводить сбор и извлечение (парсинг) мобильных телефонов из объявлений пользователей, размещенных как на специализированных автомобильных сайтах (auto.ru, avito.ru, irr.ru, drom.ru, bibika.ru, am.ru, mail.ru, cars.ru, dmir.ru и еще более 50 других), так и на сайтах частных объявлений широкой направленности (avito.ru, irr.ru).
Сбор мобильных телефонов, как правило, проводится с целью обзвона потенциальных клиентов, СМС-рассылки и т.д.
Некоторые функции, которые реализованы в программе:
1) Все найденные телефоны приводятся к одиннадцатизначному формату 7XXXAAABBCC (напр. 79171112233, 79161111111 и т.д).
79171112233, 79161111111 и т.д).
2) Поддерживается распознавание телефонов из графических изображений (на защищенных данной функцией сайтах).
3) Преодоление защиты капчей (на защищенных данной функцией сайтах).
4) Эмуляция действий пользователя для доступа к контактным данным (на защищенных данной функцией сайтах).
5) Обход автоматического бана на ip-адрес (на защищенных данной функцией сайтах).
6) Автоматическая фильтрация дублей телефонов, гибкие возможности экспорта списка новых телефонов в вашу базу данных (через определенный интервал времени, по завершению работы программы и т.п.).
7) Возможность настройки программы на сбор и парсинг телефонов с сайтов объявлений для определенных регионов и категорий товаров и услуг (например, продавцы автомобилей, недвижимости, поиск работы и т.п.).
8) О других особенностях работы программы с некоторыми сайтами можно ознакомиться по ссылке Парсер avito, slando, drom, bibika
Полный функционал программы предоставляется только в оплаченной версии. В пробной и тестовой версии функции экспорта и сохранения найденных в объявлениях мобильных телефонов доступны в демо-режиме.
В пробной и тестовой версии функции экспорта и сохранения найденных в объявлениях мобильных телефонов доступны в демо-режиме.
Стоимость программы оплачивается по установленным тарифам.
Если у вас все нет возможности заниматься сбором необходимых данных с использованием программы edrom, всегда есть возможность приобретения собираемых с ее помощью уже готовых баз. Полная база данных edrom в настоящий момент насчитывает более 5 млн. уникальных номеров мобильных телефонов, которые собирались по частным объявлениям городов Москвы, Санкт-Петербурга, Екатеринбурга, Новосибирска, Волгограда, Казани, Уфы, Краснодара, Красноярска, Нижнего Новгорода, Омска, Перми, Ростова-на-Дону, Самары, Челябинска с прилегающими областями, а также некоторыми другими регионами, начиная с 2009г. Доступ к указанным базам мобильных телефонов предоставляется за отдельную плату.
По другим вопросам можно написать разработчику.
Более полное описание особенностей работы с программой и настройки, которые можно использовать при парсинге и сборе телефонов с досок объявлений см. в описании Базы телефонов с досок объявлений avito.ru, slando.ru, auto.ru, drom.ru, irr.ru и других сайтов объявлений
телефонных номеров · PyPI
Это порт Python библиотеки Google libphonenumber Он поддерживает Python 2.5-2.7 и Python 3.x (в той же кодовой базе, без необходимо преобразование 2to3).
Исходный код Java защищен авторскими правами (C) 2009-2015 The Libphonenumber Authors.
ИСТОРИЯ выпусков, получено из примечаний к выпуску основной ветки разработки.
Установка
Установка с использованием pip с помощью:
pip install phonenumbers
Пример использования
Основным объектом, с которым работает библиотека, является Объект PhoneNumber . Вы можете создать это из строки
представляющий номер телефона с помощью функции parse , но также необходимо указать страну
с которого набирается телефонный номер (если только номер не находится в формате E. 164, который
уникальный).
164, который
уникальный).
>>> импортировать номера телефонов
>>> x = phonenumbers.parse("+442083661177", Нет)
> >> напечатать(х)
Код страны: 44 Национальный номер: 2083661177 Ведущий ноль: Ложь
>>> тип(х)
<класс 'phonenumbers.phonenumber.PhoneNumber'>
>>> y = phonenumbers.parse("020 8366 1177", "GB")
>>> напечатать(у)
Код страны: 44 Национальный номер: 2083661177 Ведущий ноль: Ложь
>>> х == у
Истинный
>>> z = phonenumbers.parse("00 1 650 253 2222", "GB") # при наборе из ГБ, а не из ГБ
>>> напечатать (г)
Код страны: 1 Национальный номер: 6502532222 Ведущие нули: Ложь
Объект PhoneNumber , который синтаксический анализ создает, как правило, все еще нуждается в проверке, чтобы проверить,
это возможный номер (например, он имеет правильное количество цифр) или действительный номер (например, это
на назначенной бирже).
>>> z = phonenumbers.parse("+120012301", Нет)
>>> напечатать (г)
Код страны: 1 Национальный номер: 20012301 Ведущий ноль: Ложь
>>> phonenumbers. is_possible_number(z) # слишком мало цифр для США
ЛОЖЬ
>>> phonenumbers.is_valid_number(z)
ЛОЖЬ
>>> z = phonenumbers.parse("+12001230101", Нет)
>>> напечатать (г)
Код страны: 1 Национальный номер: 2001230101 Ведущий ноль: Ложь
>>> номера телефонов.is_possible_number(z)
Истинный
>>> phonenumbers.is_valid_number(z) # NPA 200 не используется
ЛОЖЬ
is_possible_number(z) # слишком мало цифр для США
ЛОЖЬ
>>> phonenumbers.is_valid_number(z)
ЛОЖЬ
>>> z = phonenumbers.parse("+12001230101", Нет)
>>> напечатать (г)
Код страны: 1 Национальный номер: 2001230101 Ведущий ноль: Ложь
>>> номера телефонов.is_possible_number(z)
Истинный
>>> phonenumbers.is_valid_number(z) # NPA 200 не используется
ЛОЖЬ
 is_possible_number(z) # слишком мало цифр для США
ЛОЖЬ
>>> phonenumbers.is_valid_number(z)
ЛОЖЬ
>>> z = phonenumbers.parse("+12001230101", Нет)
>>> напечатать (г)
Код страны: 1 Национальный номер: 2001230101 Ведущий ноль: Ложь
>>> номера телефонов.is_possible_number(z)
Истинный
>>> phonenumbers.is_valid_number(z) # NPA 200 не используется
ЛОЖЬ
is_possible_number(z) # слишком мало цифр для США
ЛОЖЬ
>>> phonenumbers.is_valid_number(z)
ЛОЖЬ
>>> z = phonenumbers.parse("+12001230101", Нет)
>>> напечатать (г)
Код страны: 1 Национальный номер: 2001230101 Ведущий ноль: Ложь
>>> номера телефонов.is_possible_number(z)
Истинный
>>> phonenumbers.is_valid_number(z) # NPA 200 не используется
ЛОЖЬ
Функция parse также полностью завершится ошибкой (с NumberParseException ) на входах, которые не могут быть
быть однозначно проанализированы, или это не могут быть телефонные номера.
>>> z = phonenumbers.parse("02081234567", None) # без региона, без + => невозможно разобрать
Traceback (последний последний вызов):
Файл "phonenumbers/phonenumberutil.py", строка 2350, анализируется
«Отсутствует или недействителен регион по умолчанию».)
phonenumbers.phonenumberutil.NumberParseException: (0) Отсутствует или недействителен регион по умолчанию.
> >> z = phonenumbers.parse("тарабарщина", нет)
Traceback (последний последний вызов):
Файл "phonenumbers/phonenumberutil. py", строка 2344, в разборе
«Введенная строка не является номером телефона».)
phonenumbers.phonenumberutil.NumberParseException: (1) Предоставленная строка не является номером телефона.
 py", строка 2344, в разборе
«Введенная строка не является номером телефона».)
phonenumbers.phonenumberutil.NumberParseException: (1) Предоставленная строка не является номером телефона.
py", строка 2344, в разборе
«Введенная строка не является номером телефона».)
phonenumbers.phonenumberutil.NumberParseException: (1) Предоставленная строка не является номером телефона.
После того, как вы получили номер телефона, обычной задачей является его форматирование в стандартном формате. Есть несколько
доступные форматы (под PhoneNumberFormat ), а функция format_number выполняет форматирование.
>>> phonenumbers.format_number(x, phonenumbers.PhoneNumberFormat.НАЦИОНАЛЬНЫЙ)
'020 8366 1177'
>>> phonenumbers.format_number(x, phonenumbers.PhoneNumberFormat.INTERNATIONAL)
«+44 20 8366 1177»
>>> phonenumbers.format_number(x, phonenumbers.PhoneNumberFormat.E164)
'+442083661177'
Если ваше приложение имеет пользовательский интерфейс, который позволяет пользователю вводить номер телефона, было бы неплохо получить форматирование
применяются как типы пользователей. Это позволяет объект AsYouTypeFormatter .
>>> formatter = phonenumbers.AsYouTypeFormatter("US")
>>> formatter.input_digit("6")
6
>>> formatter.input_digit("5")
'65'
>>> formatter.input_digit("0")
«650»
>>> formatter.input_digit("2")
«650 2»
>>> formatter.input_digit("5")
'650 25'
>>> formatter.input_digit("3")
«650 253»
>>> formatter.input_digit("2")
'650-2532'
>>> formatter.input_digit("2")
«(650) 253-22»
>>> formatter.input_digit("2")
«(650) 253-222»
>>> formatter.input_digit("2")
«(650) 253-2222»
Иногда у вас есть большой блок текста, который может содержать или не содержать телефонные номера внутри него. Для этого,
объект PhoneNumberMatcher обеспечивает соответствующую функциональность; вы можете перебрать его, чтобы получить
последовательность из PhoneNumber вместе.
с информацией о том, где произошло совпадение в исходной строке.
>>> text = "Позвоните мне по телефону 510-748-8230, если это до 9:30 или по телефону 703-4800500 после 10:00».
>>> для совпадения в phonenumbers.PhoneNumberMatcher(text, "US"):
... печать (совпадение)
...
Номер телефонаMatch [11,23) 510-748-8230
Соответствие номеру телефона [51,62) 703-4800500
>>> для совпадения в phonenumbers.PhoneNumberMatcher(text, "US"):
... print (номера телефонов.format_number (совпадение. номер, номера телефонов. PhoneNumberFormat. E164))
...
+15107488230
+17034800500
 >>> для совпадения в phonenumbers.PhoneNumberMatcher(text, "US"):
... печать (совпадение)
...
Номер телефонаMatch [11,23) 510-748-8230
Соответствие номеру телефона [51,62) 703-4800500
>>> для совпадения в phonenumbers.PhoneNumberMatcher(text, "US"):
... print (номера телефонов.format_number (совпадение. номер, номера телефонов. PhoneNumberFormat. E164))
...
+15107488230
+17034800500
>>> для совпадения в phonenumbers.PhoneNumberMatcher(text, "US"):
... печать (совпадение)
...
Номер телефонаMatch [11,23) 510-748-8230
Соответствие номеру телефона [51,62) 703-4800500
>>> для совпадения в phonenumbers.PhoneNumberMatcher(text, "US"):
... print (номера телефонов.format_number (совпадение. номер, номера телефонов. PhoneNumberFormat. E164))
...
+15107488230
+17034800500
Возможно, вы захотите получить некоторую информацию о местоположении, которое соответствует номеру телефона. geocoder.area_description_for_number делает это, когда это возможно.
>>> из телефонных номеров импортировать геокодер
>>> ch_number = phonenumbers.parse("0431234567", "CH")
>>> geocoder.description_for_number(ch_number, "de")
'Цюрих'
>>> geocoder.description_for_number(ch_number, "en")
'Цюрих'
>>> geocoder.description_for_number(ch_number, "fr")
'Цюрих'
>>> geocoder.description_for_number(ch_number, "it")
'Суриго'
Для мобильных номеров в некоторых странах также можно узнать информацию о том, какой оператор
изначально владел телефонным номером.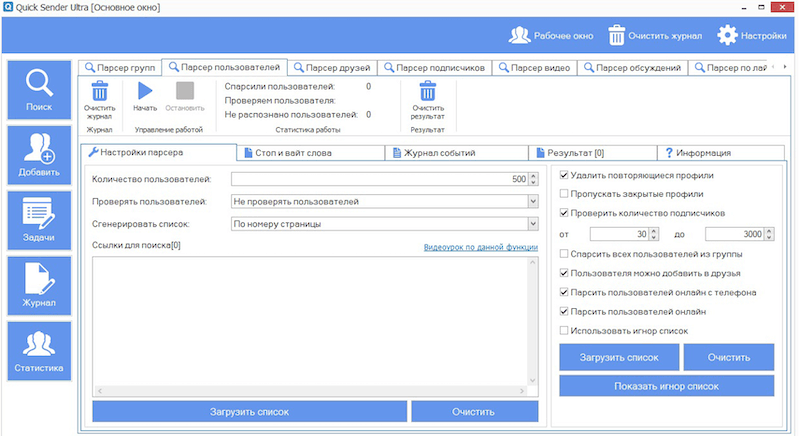
>>> с телефонных номеров импортного перевозчика
>>> ro_number = phonenumbers.parse("+40721234567", "RO")
>>> Carrier.name_for_number(ro_number, "en")
Водафон
Вы также можете получить список названий часовых поясов, которые потенциально могут принадлежит.
>>> из телефонных номеров импортировать часовой пояс
>>> gb_number = phonenumbers.parse("+447986123456", "GB")
>>> timezone.time_zones_for_number(gb_number)
(«Атлантика/Рейкьявик», «Европа/Лондон»)
Дополнительные сведения о других функциях, доступных в библиотеке, см. в модульных тестах или в исходном проект libphonenumber.
Использование памяти
Библиотека содержит большое количество метаданных, что может привести к значительным затратам памяти. Есть два механизма для борьбы с этим.
- Загружены обычные метаданные (чуть более 2 МБ сгенерированного кода Python) для основных функций библиотеки.
по требованию, для каждого региона отдельно (т. е. метаданные для региона загружаются только при первой необходимости).
- Метаданные для расширенной функциональности хранятся в отдельных пакетах, поэтому их необходимо явно
загружается отдельно. Это влияет на:
- Метаданные геокодирования (~19 МБ), которые хранятся в
phonenumbers.geocoderи используются функциями геокодирования. (geocoder.description_for_number,geocoder.description_for_valid_numberилиgeocoder.country_name_for_number). - Метаданные оператора связи (~1 МБ), которые хранятся в
phonenumbers.carrierи используется функциями сопоставления (перевозчик.имя_для_номераилиперевозчик.имя_для_действительного_номера). - Метаданные часового пояса (~100 КиБ), которые хранятся в
phonenumbers.timezoneи используются функциями часового пояса. (time_zones_for_numberилиtime_zones_for_geographical_number).
- Метаданные геокодирования (~19 МБ), которые хранятся в
 е. метаданные для региона загружаются только при первой необходимости).
е. метаданные для региона загружаются только при первой необходимости).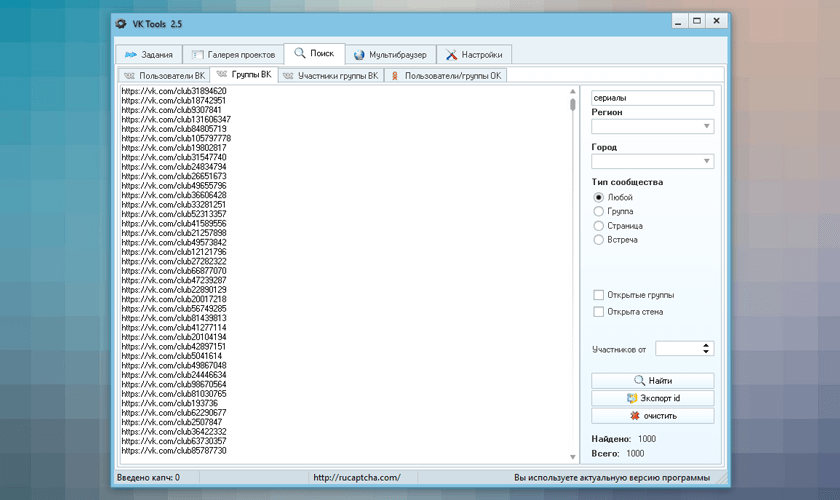
Версия библиотеки phonenumberslite
phonenumbers библиотека из-за ограничений места/памяти.Если вам необходимо убедиться, что использование памяти метаданных учитывается в начале дня (т. загрузка метаданных не вызовет паузы или исчерпания памяти):
- Принудительно загрузите обычные метаданные, вызвав
phonenumbers.PhoneMetadata.load_all(). - Принудительно загрузить расширенные метаданные путем
импортасоответствующих пакетов (phonenumbers.geocoder,phonenumbers.carrier,phonenumbers.timezone).
Версия пакета phonenumberslite не включает метаданные геокодирования, оператора связи и часового пояса,
Это может быть полезно, если у вас возникли проблемы с установкой основного пакета phonenumbers из-за ограничений пространства/памяти.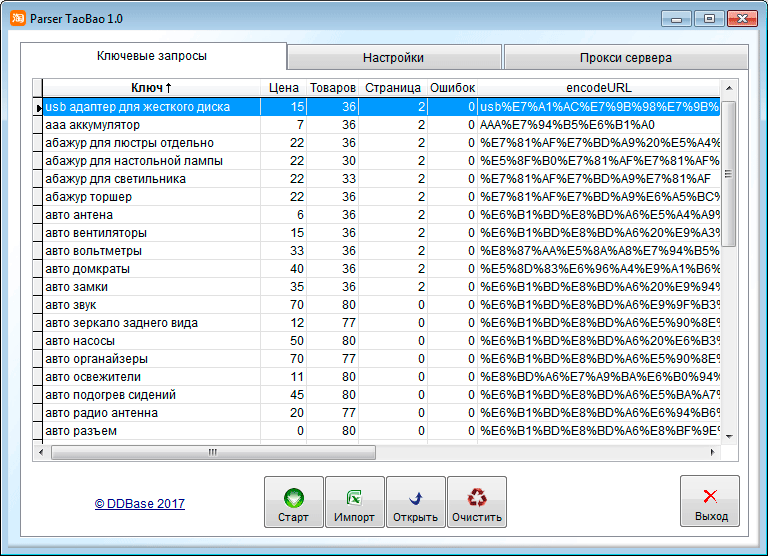
Статическая типизация
Библиотека включает набор файлов-заглушек типов для поддержки статического проверка типов пользователями библиотеки. Эти файлы-заглушки сигнализируют о типах, которые следует использовать, а также могут быть полезны в IDE. которые имеют встроенные функции проверки типов.
Эти файлы написаны для Python 3, поэтому проверка типа библиотеки с этими заглушками на Python 2.5-2.7 является обязательной. не поддерживается.
Макет проекта
- Каталог
python/содержит код Python. - Каталог ресурсов
/является копией каталога ресурсов/. каталог из номер телефона библиотеки. Это не требуется для запуска кода Python, но необходимо при восходящем потоке. необходимо внести изменения в основные метаданные. - Каталог
tools/содержит инструменты, которые используются для обработки восходящего потока. изменения основных метаданных.
libphonenumber — исключение синтаксического анализа в библиотеке номеров телефонов в python
спросил
Изменено 1 год, 4 месяца назад
Просмотрено 926 раз
У меня есть мобильные номера в формате ниже без знака «+» перед мобильными номерами. Как получить страну из этого формата чисел.
Я проверил документацию, знак «+» обязателен.
Любой способ добавить знак «+» вручную перед проверкой номера, чтобы избежать исключения при синтаксическом анализе.
Как получить страну из этого формата чисел.
Я проверил документацию, знак «+» обязателен.
Любой способ добавить знак «+» вручную перед проверкой номера, чтобы избежать исключения при синтаксическом анализе.
Мобильный_Номер: 9687655xxxx Мобильный_Номер: 6142499xxxx Mobile_Number: 20109811xxxx
py script-
импортировать телефонные номера
из телефонных номеров импортировать геокодер
запрос = номера телефонов.parse("96650072xxxx", нет)
print (geocoder.description_for_number(запрос, "en"))
печать (запрос.код_страны)
Ошибка-
<>@ubuntu:~/elk$ python3 a.py
Traceback (последний последний вызов):
Файл "a.py", строка 4, в
запрос = phonenumbers.parse ("96650072xxxx", нет)
Файл "/home/<>/.local/lib/python3.6/site-packages/phonenumbers/phonenumberutil.py", строка 2855, анализируется
«Отсутствует или недействителен регион по умолчанию».)
phonenumbers.phonenumberutil.NumberParseException: (0) Отсутствует или недействителен регион по умолчанию.
Выход после добавления знака «+»
<>@ubuntu:~/<. .>$ python3 a.py
Саудовская Аравия
966 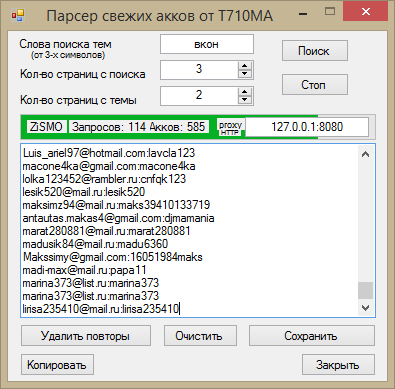 .>$ python3 a.py
Саудовская Аравия
966
.>$ python3 a.py
Саудовская Аравия
966 Исх ссылка- https://pypi.org/project/phonenumbers/
- python
- libphonenumber
- python-phonenumber
5
Вы можете определить функцию для проверки того, начинается ли строка с «+», и если нет, то добавить ее в строку перед синтаксическим анализом.
def parse_phone_number (номер_телефона: ул) -> ул:
"""При необходимости добавьте знак '+', затем проанализируйте номер телефона"""
если не phone_number.startswith('+'):
номер_телефона = '+' + номер_телефона
вернуть phonenumbers.parse (номер_телефона, нет)
Затем вы просто измените эту строку:
query = phonenumbers.parse("96650072xxxx", None)
в:
запрос = parse_phone_number("96650072xxxx")
0
Если в исходном наборе данных просто отсутствуют начальные + , вы можете просто добавить их в вызове синтаксического анализа.