
Парсер Wordstat (вордстат) онлайн, парсинг ключевых слов Яндекс
Парсер Wordstat (вордстат) онлайн, парсинг ключевых слов Яндекс | XMLRiverС помощью инструмента можно отправлять запросы к Yandex вордстат и получать ответы в формате JSON.
Парсер может быть использован для:
- сбора левой колонки Wordstat;
- сбора правой колонки;
- проверки всех видов частотностей по любым регионам;
- проверки сезонности ключевых слов (история запросов).
Начать работу
Экономия времени
Не нужно возиться с прокси и аккаунтами, решением капчей и с другими сопутствующими проблемами. Это мы берём на себя.
Удобный формат
Выдаём данные в том формате, который вы используете для сбора вордстата напрямую в JSON.
Экономия денег
Платите только за то, что использовали. Не нужно арендовать прокси на месяц или оплачивать месячные тарифные планы. Стоимость 1000 запросов от 10р.
В режиме реального времени
Всё происходит в режиме реального времени, вы сразу видите результаты живой выдачи, не используем баз. Парсим Wordstat, а не Яндекс.Директ.
Проверка частотностей запросов в вордстат
Собирайте любые виды частот — 1) базовую; 2) фразовую “”; 3) точную “!”; 4) уточненную []. Поддерживаем настройки сбора: выбор региона или нескольких регионов и устройства).
Сбор ключевых слов с wordstat
Сбор ключевых фраз из левой и правой колонки на любую глубину. Сервис позволяет собирать от 1 до 40 страницы.
История запросов
Поддерживаем выбор регионов и устройств (десктопные, мобильные, планшеты или все). Функционал позволяет отследить, как менялась популярность ключевых фраз. С помощью этих данных Вы можете определить сезонность ключа и общий тренд.
Бесплатная десктопная программа для сбора данных
Предоставляем программу XMLRiver.Parser для сбора фраз, частот всех видов и истории запросов. Выгрузка осуществляется в csv формат.
Выгрузка осуществляется в csv формат.
Павел Горбунов,
SEO-оптимизатор, pavel-gorbunov.ru
Мне понравился сервис. Я парсил выдачу Гугл с его помощью, скорость была хорошая, 1000 запросов сервис собрал очень быстро. В сравнении с другими сервисами получилось чуть быстрее.
Александр Ожгибесов,
SEO-оптимизатор, ozhgibesov.net
XMLRiver — это единственный работоспособный вариант в больших объемах за адекватный чек парсить Google. Я, как специалист по семантике, использую сервис для парсинга выдачи для SEO. Относительно недавно добавили множество вариаций для дополнительного парсинга, который очень полезен для серьёзной аналитики выдачи (0 позиция, доп ссылки и т. д.). Всячески хвалю и рекомендую XMLRiver для работы!
д.). Всячески хвалю и рекомендую XMLRiver для работы!
Тарифы
Basic
- Срок действия: ∞
Предоплата: нет - Цена за 1 тыс. запросов
Google: ₽20
Яндекс: ₽20
Wordstat: ₽20
Pro
- Срок действия: 30 дней
Предоплата: ₽3000 - Цена за 1 тыс. запросов
Google: ₽15
Яндекс: ₽15
Wordstat: ₽15
Mega
- Срок действия: 30 дней
Предоплата: ₽10000 - Цена за 1 тыс. запросов
Google: ₽10
Яндекс: ₽10
Wordstat: ₽10
Если для Вас важны скорость сбора, точность и полнота выдачи, удобный формат, то Вам к нам!
Обеспечим бесперебойность работы, доброжелательный саппорт и высочайшее качество сервиса.
Зарегистрируйтесь   –или–   Войдите
Парсеры вордстата яндекса онлайн бесплатно ключевых слов и фраз
Автор author На чтение 5 мин Просмотров 12.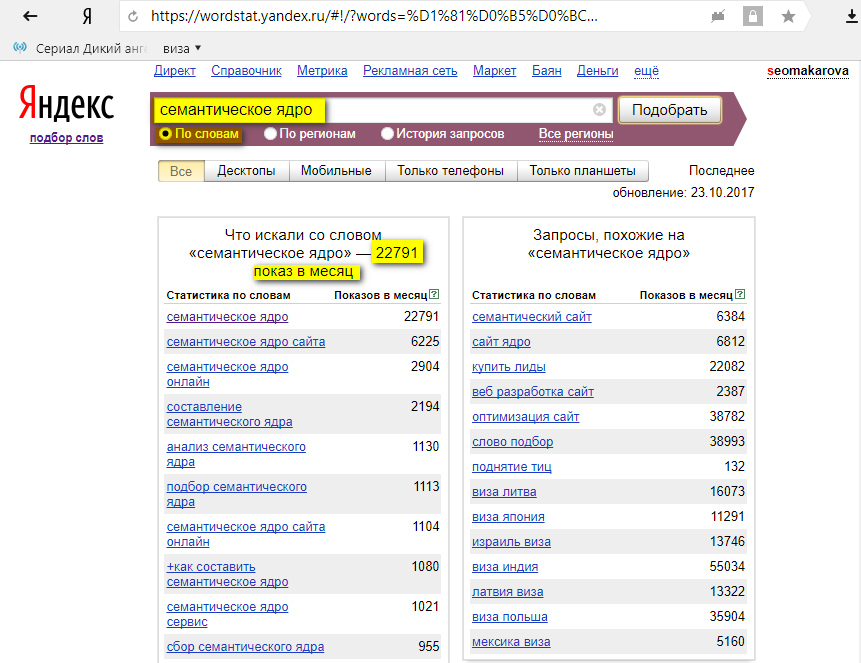 2к. Опубликовано Обновлено
2к. Опубликовано Обновлено
WordStat от Яндекс используется для анализа поисковых запросов, количества просмотров по регионам, сезонности. Но интерфейс и ограниченная функциональность делают сервис неудобным для обработки большого числа ключевых слов. Выход – использование парсеров.
Содержание
- Какие есть парсеры для Вордстата?
- Программы парсеры
- Кей Коллектор
- Словоёб
- Магадан
- Онлайн парсеры
- Букварикс онлайн версия
- Оффлайн парсеры
- Букварикс десктопная версия
- Бесплатные парсеры
Обработка запросов в ВордСтат возможна только в ручном режиме. Это увеличивает время формирования семантического ядра (СЯ) даже для небольшого проекта. Для автоматизации разрабатывают программы и онлайн-сервисы – парсеры. Они собирают данные статистики Яндекс, используя технологию API и другие программные комплексы. В итоге пользователь может обрабатывать большой объем информации.
В итоге пользователь может обрабатывать большой объем информации.
Цель работы парсеров – актуальная статистика ключевых фраз с возможностью углубленного анализа по параметрам. Это реализуется следующими способами:
- Программы. Сбор актуальной статистики WordStat, анализ по критериям пользователя. Условия использования – условно-бесплатное или платное.
- Онлайн-сервисы. По сравнению с программами обладают меньшим функционалом. Преимущества – экономия времени, не нужно устанавливать ПО.
- Специализированные программы. Разрабатываются для решения узконаправленных задач.
Выбор зависит от объема запросов и точности результатов. Онлайн-сервисы скачивают данные из Яндекса, чтобы уменьшить время формирования отчета. Поэтому информация не объективная. На это влияет частота обновления баз конкретного парсера.
Программы парсеры
Для точной обработки ключевых слов рекомендуется использовать программные комплексы. Преимущество – они работают напрямую с базами данных Ворстат. Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Кей Коллектор
Программа «Кей Коллектор» популярна среди разработчиков и СЕО-оптимизаторов. Причины – работа с популярными поисковыми системами, сегментация выборок по параметрам пользователя. Предоставляется только на платной основе, стоимость зависит от количества приобретаемых лицензий.
Особенности «Кей Коллектор»:
- Анализируется только актуальная статистика, сбор информации ведется напрямую из баз данных (БД) Яндекса.
- Ключевые слова подбираются по региону, частоте, сезонности.
- Учитываются стоп-слова.
Возможен многопоточный режим работы. Но есть вероятность получения бана или многократного ввода капчи при формировании нескольких потоков запроса информации с одного IP. Возможен сбор информации через Яндекс.Директ, что уменьшает скорость обработки.
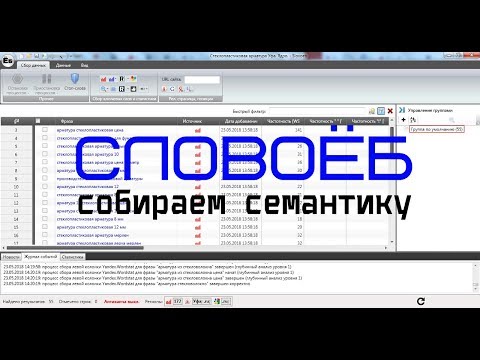
Словоёб
Бесплатная альтернатива Кей Коллектор, но с меньшими функциональными возможностями. Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Особенности программы «Словоёб»:
- меньшие возможности работы с таблицами;
- нет «поисковых подсказок»;
- отсутствует сбор главных страниц выдачи;
- нет позиций по запросам.
Программа подходит для формирования СЯ небольшого проекта. Причина – скорость обработки полученных данных, нет углубленного анализа запросов.
Магадан
Программный комплекс «Магадан» по возможностям схож с Кей Коллектором, в том числе – по цене. Отличия – интерфейс и наличие бесплатной версии. Последняя с ограниченным функционалом, что делает ее аналогичной «Словоёбу». Есть полноценная информационная и техническая поддержка как для версии Lite, так и для Pro.
Технические ограничения в бесплатном варианте программы:
- нельзя выбрать региональность для запросов;
- отключены фильтры по количеству символов, слов;
- нет импорта файлов со стоп-словами;
- нельзя задавать правила к генерируемым ключевым фразам;
- отключен экспорт КС.


Несмотря на такие ограничения «Магадан» можно использовать для формирования СЯ 1-3 проектов. Но по отзывам пользователей по сравнению с ручной обработкой Вордстата теряются низкочастотные запросы.
Онлайн парсеры
Подобные сервисы появились относительно недавно. Их преимущество – не нужно скачивать и устанавливать локально программные комплексы. Это экономит время, но сказывается на точности выборки КС. Причина – онлайн-парсеры не работают напрямую с базами данных Wordstat, а периодически скачивают их. Недостаток – не все запросы попадают в информационное поле сервиса.
Букварикс онлайн версия
Первым онлайн-сервисом с расширенными возможностями для SEO-оптимизаторов стал «Букварикс». До недавнего времени его использование было полностью бесплатным. Но с вводом нового функционала появилась платная подписка. Ее преимущества – фильтрация по частотности, количеству символов и слов. Есть ограничения для незарегистрированных пользователей. Но эта процедура бесплатная, возможна авторизация через социальные сети.
Но эта процедура бесплатная, возможна авторизация через социальные сети.
Особенности работы с «Букварикс»:
- максимальное количество поисковых фраз – 300 для платной версии;
- возможность скачивания отчета в формате .csv;
- группировка словоформ;
- дополнительные инструменты – анализ доменов, нормализатор, дубликатор и комбинатор слов.
Сервис значительно уступает по возможностям аналогичным программам, но прост в использовании. Рекомендован для начинающих оптимизаторов.
Оффлайн парсеры
Возможность парсинга Яндекс Вордстат без доступа к интернету или при его низкой скорости – одно из требований к современным инструментам СЕО анализа. Технически это реализовано просто – на компьютер или аналогичное устройство, скачивается базы Wordstat и затем с помощью программы происходит выборка ключевых слов.
Букварикс десктопная версия
Впервые полноценный десктопный вариант представили разработчики «Букварикс». Однако уже в октябре 2017 года этот проект был «заморожен», ПО и базы данных не обновляются. Компания предлагает все инструменты в онлайн-режиме. Скачать приложение можно на старой версии официального сайта, использование бесплатное.
Компания предлагает все инструменты в онлайн-режиме. Скачать приложение можно на старой версии официального сайта, использование бесплатное.
Что нужно учитывать при использовании десктопной версии:
- скачиваемый объем – около 30 Гбайт;
- скачать можно только с Яндекс.Диска, состоит из 20 частей;
- последняя дата обновления БД – 1 октября 2017 г.
Информация в этой версии устарела, возможно использование как вспомогательного инструмента.
Бесплатные парсеры
В Сети можно найти бесплатные версии парсеров, которые по заверениям разработчиков ничем не уступают вышеописанным программам и сервисам. Однако в большинстве случаев это «сырой» продукт с рядом недостатков – отсутствие обновлений, неудобный интерфейс, ограниченные функции. Низкая точность выборки, часто возникают ошибки. Причина – Яндекс.Вордстат постоянно изменяется, за этим нужно следить и вносить корректировки в ПО.
Если бесплатное использование является обязательным условием, можно скачать актуальные версии «Словоёб» или «Магадан». Альтернатива – воспользоваться возможностями «Букварикса» после регистрации.
Альтернатива – воспользоваться возможностями «Букварикса» после регистрации.
Выбор парсеров зависит от поставленной задачи – объема ключевых фраз, точности выборки и дальнейшей обработки результатов. Для больших проектов рекомендуются платные версии, для ознакомления с возможностями и для составления СЯ для 1-3 сайтов – бесплатные.
Руководство по поиску ключевых слов Яндекса | Rush Analytics
Отредактировано 27 декабря 2022 г.
Этот сервис собирает данные из Яндекс.Вордстата: данные левой и правой колонок по заданному ключевому слову и частоте ключевого слова (база, «», «!»). Полезно при составлении семантического ядра онлайн.
Основное преимущество нашего парсера Wordstat в том, что нет необходимости покупать прокси, и это анти-капча. Никаких специальных настроек не требуется. Все, что вам нужно сделать здесь, это указать свои ключевые слова, и вы моментально получите данные Яндекс.Вордстата.
Пошаговая инструкция по работе с сервисом:
Создание задачи. Чтобы создать задачу, перейдите на вкладку «Яндекс.Исследование ключевых слов» и нажмите «Создать новую задачу».
Чтобы создать задачу, перейдите на вкладку «Яндекс.Исследование ключевых слов» и нажмите «Создать новую задачу».
Шаг первый: Поисковая система и регион.
Здесь необходимо ввести название задачи (обязательное поле). Вы можете ввести любое имя; часто бывает удобно ввести название сайта, чтобы в дальнейшем можно было легко найти нужную задачу.
Шаг второй: Настройки задачи
Здесь есть два флажка, которые будут определять тип задачи:
Результаты исследования ключевых слов Яндекса в левой колонке.
Результаты поиска (сколько раз в месяц запрашивалось ключевое слово)
Результаты исследования ключевых слов Яндекса в левой колонке — в этом разделе вы можете указать количество страниц вывода Wordstat, которое будет проходить робот через.
Количество веб-страниц, которые необходимо разобрать — чем глубже проникнет робот, тем больше ключевых слов вы сможете извлечь.
Вы также можете выбрать «Результаты исследования ключевых слов Яндекса из правой колонки». В этом случае вы будете собирать ключевые слова как из левого, так и из правого столбцов Wordstat.
В этом случае вы будете собирать ключевые слова как из левого, так и из правого столбцов Wordstat.
Результаты по объему поиска (сколько раз в месяц запрашивалось ключевое слово)
Укажите тип объема поиска, который вы хотите парсинг через Яндекс.Директ (парсинг через Яндекс.Директ используется большинством SEO-специалистов при работе в Key Collector).
Шаг третий: Ключевые слова и цена
Загрузка ключевых слов.
Вы можете загрузить список ключевых слов путем копирования-вставки или через файл. Поддерживаемые форматы файлов: xls, xlsx. Вы должны указать столбец, из которого должны быть взяты данные, и следует ли учитывать первую строку.
Функциональность отрицательных слов отфильтрует ваш список и сэкономит ваше время и деньги. Вы можете использовать готовый список минус-слов — выберите минус-слова по теме и нужному региону.
Затем нажмите «Создать новую задачу».
На странице списка задач отображается статус задачи.
В очереди – данные еще не собраны.
Парсинг — счетчик показывает, сколько ключевых слов было обработано.
Готово — рядом можно скачать файл .xlsx.
После завершения обработки файл можно сразу отправить на кластеризацию.
Полученный файл выглядит следующим образом:
Вы также можете создать задачу по исследованию ключевых слов Яндекса через API
– https://rush-analytics.com/api
Содержание
- Шаг первый: поисковая система и регион
- Параметры задачи
- Ключевые слова и цена
- Полученный файл
Яндекс собирает данные Google и других специалистов по SEO из утечки исходного кода
«Фрагменты» кодовой базы Яндекса просочились в сеть на прошлой неделе. Как и Google, Яндекс — это платформа со многими аспектами, такими как электронная почта, карты, служба такси и т. д. Утечка кода содержала фрагменты всего этого.
Как и Google, Яндекс — это платформа со многими аспектами, такими как электронная почта, карты, служба такси и т. д. Утечка кода содержала фрагменты всего этого.
Согласно документации, кодовая база Яндекса была объединена в один большой репозиторий под названием Arcadia в 2013 году. Утекшая кодовая база является подмножеством всех проектов в Arcadia, и мы находим в ней несколько компонентов, связанных с поисковой системой в «Ядре», Архивы «Библиотека», «Робот», «Поиск» и «ExtSearch».
Ход совершенно беспрецедентный. С тех пор, как в данных поисковых запросов AOL за 2006 год не было ничего такого, что могло бы стать достоянием общественности, материалы, относящиеся к поисковой системе.
Хотя нам не хватает данных и многих файлов, на которые есть ссылки, это первый пример реального взгляда на то, как современная поисковая система работает на уровне кода.
Лично я не могу смириться с тем, какое фантастическое время для того, чтобы увидеть код, когда я заканчиваю свою книгу «Наука SEO», где я рассказываю о поиске информации, о том, как на самом деле работают современные поисковые системы, и как самому построить простую.
В любом случае, я разбирал код с прошлого четверга, и любой инженер скажет вам, что времени недостаточно, чтобы понять, как все работает. Итак, я подозреваю, что будет еще несколько постов, пока я продолжаю возиться.
Прежде чем мы начнем, я хочу поблагодарить Бена Уиллса из Онтоло за то, что он поделился со мной кодом, указал мне начальное направление, где находится хороший материал, и ходил со мной туда и обратно, пока мы расшифровывали вещи. Не стесняйтесь взять электронную таблицу со всеми данными, которые мы собрали о факторах ранжирования, здесь.
Кроме того, спасибо Райану Джонсу за то, что он покопался и поделился со мной некоторыми ключевыми выводами через мгновенные сообщения.
Ладно, приступим!
Это не код Google, так какая нам разница?
Некоторые считают, что просмотр этой кодовой базы отвлекает и что ничто не повлияет на то, как они принимают бизнес-решения. Я нахожу это любопытным, учитывая, что это люди из того же SEO-сообщества, которое использовало модель CTR из данных AOL за 2006 год в качестве отраслевого стандарта для моделирования в любой поисковой системе в течение многих последующих лет.
Тем не менее, Яндекс — это не Google. Тем не менее, эти две современные поисковые системы продолжают оставаться на переднем крае технологий.
Программисты обеих компаний участвуют в одних и тех же конференциях (SIGIR, ECIR и т. д.) и делятся результатами и инновациями в области поиска информации, обработки/понимания естественного языка и машинного обучения. Яндекс также присутствует в Пало-Альто, а Google ранее был в Москве.
Быстрый поиск в LinkedIn выявляет несколько сотен инженеров, которые работали в обеих компаниях, хотя мы не знаем, сколько из них на самом деле работали над поиском в обеих компаниях.
При более прямом совпадении Яндекс также использует технологии Google с открытым исходным кодом, которые были критически важны для инноваций в поиске, таких как TensorFlow, BERT, MapReduce и, в гораздо меньшей степени, Protocol Buffers.
Итак, хотя Яндекс — это, конечно, не Google, но и не какой-то случайный исследовательский проект, о котором мы здесь говорим. Изучив эту кодовую базу, мы можем многое узнать о том, как устроена современная поисковая система.
Изучив эту кодовую базу, мы можем многое узнать о том, как устроена современная поисковая система.
По крайней мере, мы можем избавиться от некоторых устаревших представлений, которые все еще пронизывают инструменты SEO, таких как соотношение текста и кода и соответствие W3C, или общее мнение, что 200 сигналов Google — это просто 200 отдельных функций на странице и за ее пределами, а не классы составных факторов, которые потенциально могут использовать тысячи отдельных показателей.
Некоторый контекст архитектуры Яндекса
Без контекста или возможности успешно скомпилировать, запустить и выполнить пошагово исходный код очень сложно понять.
Как правило, новые инженеры получают документацию, обзоры и занимаются парным программированием, чтобы освоиться с существующей кодовой базой. Кроме того, в архиве документов есть некоторая ограниченная документация по адаптации, связанная с настройкой процесса сборки. Тем не менее, код Яндекса также везде ссылается на внутренние вики, но они не просочились, а комментарии в коде также довольно скудны.
К счастью, Яндекс дает некоторое представление о своей архитектуре в общедоступной документации. Есть также пара патентов, опубликованных в США, которые помогают пролить свет. А именно:
- Реализованный компьютером способ и система для поиска в инвертированном индексе, имеющем множество списков рассылки
- Ранжирование результатов поиска
Когда я исследовал Google для своей книги, я получил гораздо более глубокое понимание структуры его систем ранжирования благодаря различным документам, патентам и выступлениям инженеров, основанным на моем опыте SEO. Я также потратил много времени, оттачивая свое понимание общих рекомендаций по поиску информации для поисковых систем. Неудивительно, что у Яндекса действительно есть некоторые передовые практики и сходства.
В документации Яндекса обсуждается двухраспределенная система краулеров. Один для сканирования в реальном времени под названием «Оранжевый краулер», а другой — для обычного сканирования.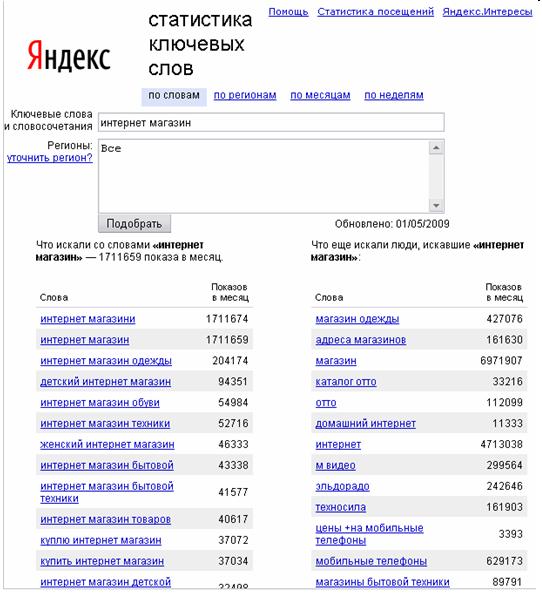
Исторически у Google был индекс, разделенный на три сегмента: один для сканирования в реальном времени, один для регулярного сканирования и один для редко сканируемого. Этот подход считается лучшей практикой в IR.
Яндекс и Google различаются в этом отношении, но общая идея сегментированного сканирования, основанная на понимании частоты обновления, сохраняется.
Стоит отметить, что у Яндекса нет отдельной системы рендеринга для JavaScript. Они говорят об этом в своей документации и, хотя у них есть система визуального регрессионного тестирования на основе Webdriver под названием Gemini, они ограничиваются текстовым сканированием.
В документации также обсуждается сегментированная структура базы данных, которая разбивает страницы на инвертированный индекс и сервер документов.
Как и в большинстве других поисковых систем, процесс индексации создает словарь, кэширует страницы, а затем помещает данные в инвертированный индекс таким образом, чтобы были представлены биграммы и тригамы и их размещение в документе.
Это отличается от Google тем, что они давно перешли на индексацию на основе фраз, что означает, что n-граммы могут быть намного длиннее триграмм.
Однако система Яндекса также использует BERT в своем пайплайне, поэтому в какой-то момент документы и запросы конвертируются во вложения, а для ранжирования используются методы поиска ближайших соседей.
Процесс ранжирования становится более интересным.
В Яндексе есть слой под названием Метапоиск , где кешированные результаты популярных поисков обслуживаются после обработки запроса. Если результаты там не найдены, то поисковый запрос отправляется на серию из тысяч разных машин в
Судя по видеороликам, в которых инженеры Google рассказывают об инфраструктуре поиска, этот процесс ранжирования очень похож на поиск Google. Они говорят о том, что технология Google находится в общих средах, где различные приложения находятся на каждой машине, а задания распределяются между этими машинами в зависимости от наличия вычислительной мощности.
Они говорят о том, что технология Google находится в общих средах, где различные приложения находятся на каждой машине, а задания распределяются между этими машинами в зависимости от наличия вычислительной мощности.
Одним из вариантов использования является именно это, распределение запросов по набору машин для быстрой обработки соответствующих осколков индекса. Вычисление списков публикации — это первое место, которое нам нужно учитывать для факторов ранжирования.
В кодовой базе 17 854 фактора ранжирования
В пятницу после утечки неподражаемый Мартин Макдональд охотно поделился файлом из кодовой базы под названием web_factors_info/factors_gen.in. Файл взят из архива «Kernel» в утечке кодовой базы и содержит 1,922 фактора ранжирования.
Естественно, SEO-сообщество использовало этот номер и этот файл, чтобы охотно распространять новости о содержащихся в нем сведениях. Многие люди перевели описания и создали инструменты или Google Sheets и ChatGPT, чтобы разобраться в данных. Все они являются прекрасными примерами силы сообщества. Однако число 1922 представляет собой лишь один из многих наборов факторов ранжирования в кодовой базе.
Все они являются прекрасными примерами силы сообщества. Однако число 1922 представляет собой лишь один из многих наборов факторов ранжирования в кодовой базе.
Более глубокое погружение в кодовую базу показывает, что существует множество файлов факторов ранжирования для различных подмножеств систем обработки запросов и ранжирования Яндекса.
Прочесывая их, мы обнаруживаем, что всего существует 17 854 фактора ранжирования. В эти факторы ранжирования входят различные показатели, связанные с:
- Кликами.
- Время ожидания.
- Использование аналога Google Analytics от Яндекса, Метрики.
Существует также серия ноутбуков Jupyter, которые имеют дополнительные 2000 факторов помимо тех, что указаны в основном коде. Предположительно, эти блокноты Jupyter представляют собой тесты, в ходе которых инженеры рассматривают дополнительные факторы для добавления в кодовую базу. Опять же, вы можете просмотреть все эти функции с метаданными, которые мы собрали по всей кодовой базе, по этой ссылке.
Документация Яндекса также поясняет, что у них есть три класса факторов ранжирования: статические, динамические и те, которые связаны конкретно с поиском пользователя и тем, как он был выполнен. По их собственным словам:
В кодовой базе они указаны в файлах ранговых факторов с тегами TG_STATIC и TG_DYNAMIC. Факторы, связанные с поиском, имеют несколько тегов, таких как TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH и TG_USER_SEARCH_ONLY.
Несмотря на то, что мы выявили 18 000 потенциальных факторов ранжирования на выбор, документация, относящаяся к MatrixNet, указывает, что оценка строится на основе десятков тысяч факторов и настраивается на основе поискового запроса.
Это указывает на то, что среда ранжирования очень динамична, подобно среде Google. Согласно патенту Google «Структура для оценки функций оценки», у них уже давно есть что-то похожее, когда запускаются несколько функций и возвращается лучший набор результатов.
Наконец, учитывая, что в документации упоминаются десятки тысяч факторов ранжирования, мы также должны помнить, что в коде есть много других файлов, которые отсутствуют в архиве. Так что, вероятно, происходит что-то еще, чего мы не можем видеть. Это дополнительно иллюстрируется просмотром изображений в документации по подключению, на которых показаны другие каталоги, которых нет в архиве.
Так что, вероятно, происходит что-то еще, чего мы не можем видеть. Это дополнительно иллюстрируется просмотром изображений в документации по подключению, на которых показаны другие каталоги, которых нет в архиве.
Например, я подозреваю, что в каталоге /semantic-search/ есть еще что-то связанное с DSSM.
Первоначальное взвешивание факторов ранжирования
Сначала я действовал, исходя из предположения, что кодовая база не имеет весов для факторов ранжирования. Затем я был потрясен, увидев, что файл nav_linear.h в каталоге /search/relevance/ содержит начальные коэффициенты (или веса), связанные с факторами ранжирования, в полном отображении.
Этот раздел кода выделяет 257 из 17 000+ факторов ранжирования, которые мы выявили. ( Скидка Райану Джонсу за то, что он вытащил их и сопоставил с описаниями факторов ранжирования.) страница оценивается на основе ряда факторов. Хотя это упрощение, следующий снимок экрана является выдержкой из такого уравнения. Коэффициенты показывают, насколько важен каждый фактор, а результирующая вычисленная оценка будет использоваться для оценки релевантности страниц выбора.
Жестко закодированные значения позволяют предположить, что это не единственное место, где происходит ранжирование. Вместо этого эта функция, скорее всего, используется там, где первоначальная оценка релевантности выполняется для создания серии списков публикации для каждого сегмента, рассматриваемого для ранжирования. В первом патенте, упомянутом выше, они говорят об этом как о концепции независимой от запроса релевантности (QIR), которая затем ограничивает документы до их просмотра на предмет релевантности запроса (QSR).
Полученные списки сообщений затем передаются в MatrixNet с функциями запроса для сравнения. Таким образом, хотя мы не знаем специфики последующих операций (пока), эти веса по-прежнему ценны для понимания, потому что они говорят вам о требованиях, предъявляемых к странице, чтобы иметь право на набор вознаграждений.
Однако возникает следующий вопрос: что мы знаем о MatrixNet?
В архиве ядра есть код нейронного ранжирования, и в кодовой базе есть многочисленные ссылки на MatrixNet и «mxnet», а также множество ссылок на глубоко структурированные семантические модели (DSSM).
В описании одного из факторов ранжирования FI_MATRIXNET указано, что MatrixNet применяется ко всем факторам.
Коэффициент {
Индекс: 160
CPPName: «fi_matrixnet»
Имя: «Matrixnet»
Теги: [TG_DOC, TG_DYNAMIC, TG_TRANS, TG_NOT_01, TG_REARR_USE, TG_L3_MODEL_VALUE, TG_FRESHER_POOL_ILIX_BLIX_BLIX_POOL_LIX_LILIX_BLIX_BLIX_FILIX_FILIF_ILIX. }
Также есть куча бинарных файлов, которые сами могут быть предварительно обученными моделями, но мне потребуется больше времени, чтобы разобраться в этих аспектах кода.
Сразу становится ясно, что существует несколько уровней ранжирования (L1, L2, L3) и набор моделей ранжирования, которые можно выбрать на каждом уровне.
В файле selection_rankings_model.cpp указано, что на каждом уровне процесса можно рассматривать разные модели ранжирования. Примерно так работают нейронные сети. Каждый уровень — это аспект, который завершает операции, и их комбинированные вычисления дают переупорядоченный список документов, который в конечном итоге отображается в виде SERP. Я продолжу более глубокое погружение в MatrixNet, когда у меня будет больше времени. Для тех, кому нужен краткий обзор, ознакомьтесь с патентом ранжирования результатов поиска.
Я продолжу более глубокое погружение в MatrixNet, когда у меня будет больше времени. Для тех, кому нужен краткий обзор, ознакомьтесь с патентом ранжирования результатов поиска.
А пока давайте рассмотрим некоторые интересные факторы ранжирования.
Топ-5 факторов начального ранжирования с отрицательным весом
Ниже приводится список факторов начального ранжирования с наибольшим отрицательным весом с их весами и кратким пояснением, основанным на их описаниях, переведенных с русского языка.
- FI_ADV: -0,2509284637 -Этот фактор определяет, есть ли на странице реклама любого рода, и назначает самый высокий взвешенный штраф за один фактор ранжирования.
- FI_DATER_AGE: -0,2074373667 — этот коэффициент представляет собой разницу между текущей датой и датой документа, определенной функцией датирования. Значение равно 1, если дата документа совпадает с сегодняшней, 0, если документ старше 10 лет или если дата не определена. Это говорит о том, что Яндекс отдает предпочтение более старому контенту.
- FI_QURL_STAT_POWER: -0,1943768768 — этот коэффициент представляет собой количество показов URL-адреса по отношению к запросу. Похоже, они хотят понизить URL-адрес, который появляется во многих поисковых запросах, чтобы повысить разнообразие результатов.
- FI_COMM_LINKS_SEO_HOSTS: -0,1809636391 — этот коэффициент представляет собой процент входящих ссылок с «коммерческим» якорным текстом. Коэффициент возвращается к 0,1, если доля таких ссылок превышает 50%, в противном случае устанавливается в 0,
- FI_GEO_CITY_URL_REGION_COUNTRY: -0,168645758 — Этот фактор — географическое совпадение документа и страны, из которой пользователь выполнял поиск. Это не совсем понятно, если 1 означает, что документ и страна совпадают.
 Это говорит о том, что Яндекс отдает предпочтение более старому контенту.
Это говорит о том, что Яндекс отдает предпочтение более старому контенту.Таким образом, эти факторы показывают, что для наилучшего результата вам следует:
- Избегать рекламы.
- Обновляйте старый контент, а не создавайте новые страницы.
- Убедитесь, что большинство ваших ссылок имеют фирменный анкорный текст.

Все остальное в этом списке находится вне вашего контроля.
Топ-5 положительно взвешенных факторов начального ранжирования
В дополнение, вот список положительных факторов ранжирования с наибольшим весом.
- FI_URL_DOMAIN_FRACTION: +0,5640952971 — этот фактор представляет собой странное маскирующее перекрытие запроса по сравнению с доменом URL-адреса. В качестве примера приведена Челябинская лотерея, сокращенно chelloto. Чтобы вычислить это значение, Яндекс находит перекрытые трехбуквенные слова (че, хел, лот, оло), смотрит, какая доля всех трехбуквенных сочетаний приходится на доменное имя.
- FI_QUERY_DOWNER_CLICKS_COMBO: +0,3690780393 — Описание этого фактора таково: «умное сочетание FRC и псевдо-CTR». Непосредственных указаний на то, что такое FRC, нет.
- FI_MAX_WORD_HOST_CLICKS: +0.3451158835 — этот фактор кликабельность самого важного слова в домене. Например, для всех запросов, в которых есть слово «википедия», нажмите на страницы википедии.
- FI_MAX_WORD_HOST_YABAR: +0.3154394573 — В описании фактора указано «наиболее характерное слово запроса, соответствующее сайту, согласно бару». Я предполагаю, что это означает ключевое слово, которое чаще всего ищут в панели инструментов Яндекса, связанную с сайтом.
- FI_IS_COM: +0.2762504972 — Дело в том, что домен .COM.
Другими словами:
- Играйте в словесные игры со своим доменом.
- Убедитесь, что это точка-ком.
- Поощряйте людей искать ваши целевые ключевые слова в Яндекс Баре.
- Продолжайте получать клики.
Существует множество неожиданных начальных факторов ранжирования
Что более интересно в начальных взвешенных факторах ранжирования, так это неожиданные факторы. Ниже приводится список из семнадцати выделяющихся факторов.
Ниже приводится список из семнадцати выделяющихся факторов.
- FI_PAGE_RANK: +0,1828678331 — PageRank — 17-й по значимости фактор в Яндексе. Ранее они полностью удалили ссылки из своей системы ранжирования, поэтому неудивительно, насколько низко она находится в списке.
- FI_SPAM_KARMA: +0,00842682963 — Спам-карма названа в честь «антиспамеров» и представляет собой вероятность того, что хост является спамом; на основе информации Whois
- FI_SUBQUERY_THEME_MATCH_A: +0,1786465163 — Насколько тесно тематически совпадают запрос и документ. это 19й наивысший взвешенный фактор.
- FI_REG_HOST_RANK: +0,1567124399 — у Яндекса есть фактор ранжирования хоста (или домена).
- FI_URL_LINK_PERCENT: +0,08940421124 — Отношение ссылок, анкорный текст которых является URL-адресом (а не текстом), к общему количеству ссылок.
- FI_PAGE_RANK_UKR: +0. 08712279101 — Есть конкретный украинский PageRank
- FI_IS_NOT_RU: +0.08128946612 – Хорошо, если домен не .RU. Судя по всему, русский поисковик не доверяет русским сайтам.
- FI_YABAR_HOST_AVG_TIME2: +0,07417219313 — это среднее время пребывания по данным YandexBar
- FI_LERF_LR_LOG_RELEV: +0,06059448504 — это релевантность ссылки на основе качества каждой ссылки
- FI_NUM_SLASHES: +0,05057609417 — количество косых черт в URL является фактором ранжирования.
- FI_ADV_PRONOUNS_PORTION: -0,001250755075 — Доля местоимений на странице.
- FI_TEXT_HEAD_SYN: -0.01291908335 — Наличие [запросных] слов в заголовке с учетом синонимов
- FI_PERCENT_FREQ_WORDS: -0.02021022114 – Процент количества слов, которые являются 200 наиболее часто встречающимися словами языка, от количества всех слов текста.
- FI_YANDEX_ADV: -0,09426121965 – Уточняя неприязнь к рекламе, Яндекс наказывает страницы с рекламой Яндекса.
- FI_AURA_DOC_LOG_SHARED: -0,09768630485 — логарифм количества черепиц (областей текста) в документе, которые не уникальны.
- FI_AURA_DOC_LOG_AUTHOR: -0.09727752961 – Логарифм количества гонтов, на которых данный владелец документа признан автором.
- FI_CLASSIF_IS_SHOP: -0.1339319854 — Судя по всему, Яндекс будет меньше любить вас, если ваша страница — магазин.
 08712279101 — Есть конкретный украинский PageRank
08712279101 — Есть конкретный украинский PageRank
Главный вывод из рассмотрения этих странных факторов ранжирования и множества факторов, доступных в кодовой базе Яндекса, заключается в том, что есть много вещей, которые могут быть факторами ранжирования.
Я подозреваю, что заявленные Google «200 сигналов» на самом деле представляют собой 200 классов сигналов, где каждый сигнал является составным, состоящим из многих других компонентов. Во многом так же, как Google Analytics имеет параметры со многими связанными показателями, Google Search, вероятно, имеет классы сигналов ранжирования, состоящие из многих функций.
Яндекс очищает Google, Bing, YouTube и TikTok
Кодовая база также показывает, что у Яндекса есть много парсеров для других веб-сайтов и их соответствующих сервисов. Для жителей Запада наиболее заметными из них являются те, которые я перечислил в заголовке выше. Кроме того, у Яндекса есть парсеры для множества незнакомых мне сервисов, а также парсеры для его собственных сервисов.
Что сразу бросается в глаза, так это то, что синтаксические анализаторы полностью укомплектованы. Извлекается каждый значимый компонент поисковой выдачи Google. На самом деле, любой, кто рассматривает возможность парсинга любого из этих сервисов, может сделать все возможное, чтобы просмотреть этот код.
Существует другой код, который указывает, что Яндекс использует некоторые данные Google как часть расчетов DSSM, но сами по себе 83 названных Google фактора ранжирования ясно показывают, что Яндекс довольно сильно опирался на результаты Google.
Очевидно, что Google никогда не станет копировать результаты Bing из другой поисковой системы и не будет полагаться на нее для расчетов основного рейтинга.
Яндекс имеет анти-SEO верхние границы для некоторых факторов ранжирования
315 факторов ранжирования имеют пороговые значения, при которых любое вычисленное значение, превышающее это, указывает системе, что эта функция страницы переоптимизирована. 39 из этих факторов ранжирования являются частью первоначально взвешенных факторов, которые могут препятствовать включению страницы в первоначальный список публикаций. Вы можете найти их в электронной таблице, на которую я дал ссылку выше, отфильтровав по столбцу «Коэффициент ранжирования» и «Анти-SEO».
С концептуальной точки зрения не будет надуманным ожидать, что все современные поисковые системы устанавливают пороговые значения для определенных факторов, которыми оптимизаторы исторически злоупотребляли, таких как анкорный текст, CTR или наполнение ключевыми словами. Например, говорят, что Bing использует злоупотребление мета-ключевыми словами как негативный фактор.
Яндекс продвигает «Vital Hosts»
В кодовой базе Яндекса есть ряд механизмов повышения. Это искусственные улучшения определенных документов, чтобы обеспечить более высокие оценки при рассмотрении для ранжирования.
Это искусственные улучшения определенных документов, чтобы обеспечить более высокие оценки при рассмотрении для ранжирования.
Ниже приведен комментарий «мастера повышения», в котором говорится, что более мелкие файлы лучше всего выигрывают от алгоритма повышения.
Есть несколько типов бустов; Я видел один буст, связанный со ссылками, и я также видел серию «HandJobBoosts», которые, я могу только предположить, являются странным переводом «ручных» изменений.
Один из этих бонусов, который показался мне особенно интересным, связан с «Жизненно важными хостами». Где важным хостом может быть любой указанный сайт. В переменных конкретно упоминается NEWS_AGENCY_RATING, что наводит меня на мысль, что Яндекс дает повышение, которое искажает его результаты в пользу определенных новостных организаций.
Если не вдаваться в геополитику, это очень отличается от Google тем, что они были непреклонны в отношении того, чтобы не вводить подобные предубеждения в свои системы ранжирования.
Структура сервера документов
Кодовая база показывает, как документы хранятся на сервере документов Яндекса. Это полезно для понимания того, что поисковая система не просто делает копию страницы и сохраняет ее в своем кеше, она фиксирует различные функции в качестве метаданных, которые затем используются в последующем процессе ранжирования.
На приведенном ниже снимке экрана выделено подмножество тех функций, которые особенно интересны. Другие файлы с SQL-запросами предполагают, что сервер документов имеет около 200 столбцов, включая дерево DOM, длину предложений, время выборки, ряд дат и оценку защиты от спама, цепочку перенаправления и информацию о том, переведен ли документ. Самый полный список, который мне встречался, находится в файле /robot/rthub/yql/protos/web_page_item.proto.
Что самое интересное в подмножестве здесь, так это количество используемых симхэшей. Симхэши — это числовые представления контента, и поисковые системы используют их для молниеносного сравнения для определения дублирующегося контента. В архиве роботов есть различные экземпляры, указывающие на то, что дублированный контент явно понижен.
В архиве роботов есть различные экземпляры, указывающие на то, что дублированный контент явно понижен.
Кроме того, в рамках процесса индексации кодовая база включает TF-IDF, BM25 и BERT в конвейере обработки текста. Непонятно, почему все эти механизмы существуют в коде, потому что в их использовании есть некоторая избыточность.
Кодовая база также содержит много информации о факторах ссылок и о том, как ссылки расставляются по приоритетам.
Калькулятор ссылочного спама Яндекса учитывает 89 факторов. Все, что помечено как SF_RESERVED, устарело. Там, где это предусмотрено, вы можете найти описания этих факторов в таблице Google, указанной выше.
Примечательно, что у Яндекса есть рейтинг хоста и некоторые баллы, которые, по-видимому, сохраняются в течение длительного времени после того, как сайт или страница заработали репутацию спама.
Еще одна вещь, которую делает Яндекс, — это просмотр копии на домене и определение наличия дублированного контента с этими ссылками. Это могут быть размещения ссылок по всему сайту, ссылки на дубликаты страниц или просто ссылки с одинаковым анкорным текстом с одного и того же сайта.
Это могут быть размещения ссылок по всему сайту, ссылки на дубликаты страниц или просто ссылки с одинаковым анкорным текстом с одного и того же сайта.
Это показывает, насколько тривиально не учитывать несколько ссылок из одного и того же источника, и разъясняет, насколько важно нацеливаться на большее количество уникальных ссылок из более разнообразных источников.
Что мы можем применить от Яндекса к тому, что мы знаем о Google?
Естественно, этот вопрос до сих пор у всех на уме. Хотя, безусловно, между Яндексом и Google есть много аналогов, по правде говоря, только инженер-программист Google, работающий над поиском, может окончательно ответить на этот вопрос.
Но это неправильный вопрос.
Действительно, этот код должен помочь нам расширить наши представления о современном поиске. Коллективное понимание поиска во многом основано на том, что SEO-сообщество узнало в начале 2000-х посредством тестирования и из уст поисковых инженеров, когда поиск был гораздо менее непрозрачным.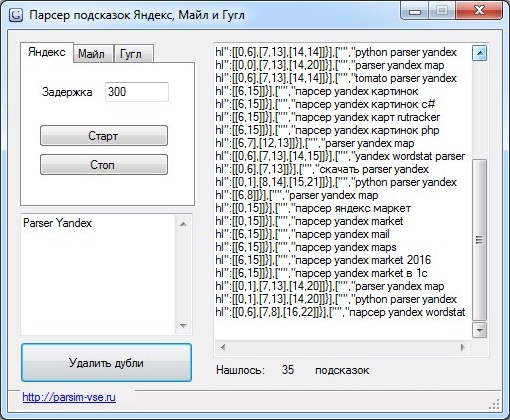 Это, к сожалению, не поспевает за быстрым темпом инноваций.
Это, к сожалению, не поспевает за быстрым темпом инноваций.
Понимание многих особенностей и факторов утечки Яндекса должно дать больше гипотез о вещах, которые нужно проверить и рассмотреть для ранжирования в Google. Они также должны ввести больше вещей, которые можно анализировать и измерять с помощью SEO-сканирования, анализа ссылок и инструментов ранжирования.
Например, мера косинусного сходства между запросами и документами, использующими встраивание BERT, может быть полезна для понимания по сравнению со страницами конкурентов, поскольку это то, что делают сами современные поисковые системы.
Во многом так же, как журналы поиска AOL уводят нас от угадывания распределения кликов в поисковой выдаче, кодовая база Яндекса уводит нас от абстрактного к конкретному, и наши утверждения «это зависит» могут быть лучше квалифицированы.
С этой целью эта кодовая база является подарком, который будет продолжаться. Прошли только выходные, а мы уже почерпнули очень убедительные выводы из этого кода.
Я предполагаю, что некоторые амбициозные SEO-инженеры, располагающие гораздо большим количеством свободного времени, будут продолжать копаться и, возможно, даже дополнять недостающее, чтобы скомпилировать эту штуку и заставить ее работать. Я также считаю, что инженеры различных поисковых систем также изучают и анализируют инновации, на которых они могут учиться и добавлять в свои системы.
Одновременно юристы Google, вероятно, готовят агрессивные письма о прекращении и воздержании, связанные со всей очисткой данных.
Мне не терпится увидеть эволюцию нашего пространства, которой руководят любознательные люди, которые максимально используют эту возможность.
Но, эй, если получение информации из фактического кода не имеет для вас ценности, вы можете вернуться к чему-то более важному, например, спорить о поддоменах и подкаталогах.
Мнения, высказанные в этой статье, принадлежат приглашенному автору и не обязательно принадлежат Search Engine Land.