
Как бесплатно парсить ключевые слова и объявления конкурентов в «Яндексе» и Google — Маркетинг на vc.ru
20 099 просмотров
Перед запуском рекламной кампании полезно посмотреть, как с контекстной рекламой работают конкуренты: какие ключи используют, на какие регионы таргетируются, как составляют тексты объявлений. Так вы пополните семантику, почерпнете идеи для объявлений и получите представление о масштабах рекламной активности конкурентов.
Для анализа конкурентов в контекстной рекламе есть разные сервисы: Semrush, SpyFu, Serpstat и др. Однако для работы в них потребуется платная подписка. Если хотите провести анализ бесплатно, обратитесь к альтернативе — бесплатному инструменту «Слова и объявления конкурентов» от Click.ru.
Этот инструмент покажет, сколько активных объявлений, в каких регионах и по каким ключевикам запускали конкуренты за последние 3 года. Инструмент работает для Яндекса и Google, в нем есть возможность сужать поиск так, как это вам необходимо.
Для примера возьмем онлайн-магазин подарков и рассмотрим, как парсить ключевые слова и объявления конкурентов для решения различных задач.
Готовимся к анализу конкурентов: собираем домены
Перед началом анализа нужно понять, кто, собственно, наши конкуренты в поисковой выдаче. Для этого открываем поисковик (Яндекс или Google) и вбиваем основной запрос, по которому планируем рекламироваться. Вот результаты выдачи:
Нам нужны домены из платной выдачи, поэтому копируем URL первых четырех объявлений, указанных на скрине выше.
Под органической выдачей тоже можно найти нескольких конкурентов. Забираем из нижнего блока рекламы в Яндексе еще два домена — manbox.ru и planetasharov.ru.
Проделываем те же операции с поисковиком Google. Наш список конкурентов пополняется тремя URL — topbox.ru, dolina-podarkov.ru и giftbaskets.ru.
Если нужно расширить список, указываем еще несколько запросов по нашей тематике и добавляем новые домены. Для привязки к региону нужно уточнить поиск.
Итак, список конкурентов готов. Переходим к парсингу.
Приступаем к парсингу конкурентов
Рассмотрим 5 ситуаций, в которых пригодится парсер. Детально покажем, как и что делать.
1. Выгружаем сразу все ключевики и объявления конкурентов
Переходим на страницу инструмента «Слова и объявления конкурентов».
Также в него можно попасть, если у вас уже создан проект в Click.ru — инструмент находится в левом боковом меню в разделе «Инструменты». Кликаем по кнопке «Объявления» и выбираем инструмент.
Далее в поле «Домены конкурентов списком» вставляем собранный ранее список URL конкурентов.
Второй способ загрузки доменов — через XLSX-файл. Для этого адреса конкурентов нужно оформить в таблице Excel. Каждый URL должен находиться в отдельной ячейке, а весь список — на одном листе.
Под блоком с задачами расположены «Профессиональные настройки». Сейчас они нам не понадобятся, поэтому не обращаем на них внимания.
Также нужно отметить, в каких поисковиках будем парсить данные. Изначально сервис советует собирать их и в Яндексе, и в Google. Поэтому галочки снимать не будем.
Ниже можно выбрать, как будут представлены результаты парсинга. Если не снимать галочку, то они будут на одном листе таблицы. Количество URL на вид отчета не повлияет. А если снять галочку, инструмент вынесет данные на отдельные листы для каждого домена.
Какой вид отчета с результатами парсинга выбрать?
Если вы собираете ключи и объявления для списка, где меньше пяти доменов, лучше получить результаты на одной странице в XLS. Такую выборку проще анализировать, когда она представлена на одном листе.
В ином случае стоит убрать галочку из пункта выше. Большое число URL и данных по ним сложно обрабатывать на едином листе. Удобнее, чтобы сервис представил результаты по каждому URL-адресу на отдельной странице.
У нас второй вариант, поэтому галочку снимаем.
Затем нажимаем на кнопку «Запустить проверку», чтобы начать парсинг.
Чтобы посмотреть статус сбора данных, откройте раздел «Список задач»:
Инструмент работает в облаке. Поэтому можно не ждать завершения парсинга. Закрытие и перезагрузка страницы не остановят сбор данных.
Когда парсинг будет завершен, список задач обновится — здесь будет статус «Выполнен». В столбце «Действия» нажимаем на иконку документа Excel, после чего начнется загрузка результатов.
Для парсинга мы выбрали выгрузку результатов по каждому домену на отдельном листе. Расскажем, как отобразится итог работы инструмента в обоих случаях.
Результаты в виде «Один домен — один лист»
Скачиваем архив с файлом rezyltati.xlsx:
Открываем таблицу. Видим большое количество листов — на каждом из них собраны данные по каждому конкуренту:
В документе также есть три дополнительных листа: на двух представлена информация по всем доменам, а еще один — сервисный лист. Рассмотрим все виды листов:
1. «Rezyltati_obschie». Здесь указана статистика по всем конкурентам: число объявлений и регионы их показа. К примеру, количество объявлений у домена manbox.ru в Яндексе в регионе Москва — 742, а в Google— 65.
К примеру, количество объявлений у домена manbox.ru в Яндексе в регионе Москва — 742, а в Google— 65.
2. «Slova». На этом листе собраны все уникальные ключевики, используемые для рекламы доменов конкурентов. Мы провели парсинг по десяти URL-адресам — в результате инструмент нашел 35 тысяч ключевых слов.
3. «Ish_nastroiki». Перечислены домены конкурентов, а также варианты настроек парсинга.
Каждая из оставшихся страниц в документе посвящена отдельному домену. Откроем лист dolina-podarkov.ru. Здесь такие столбцы:
- Domain — название домена, по которому парсили данные.
- Region — показывает, в каком регионе рекламируется конкурент. Можно отфильтровать информацию по конкретному региону и проанализировать объявления.
- Search engine — поисковик (Яндекс или Google). Настройте фильтр только на Яндекс, если планируете рекламную кампанию в этой системе. Можно оценить рекламу конкурента в Яндексе, а также ключи, заголовки и тексты объявлений.

Важно! При показе объявление может содержать расширение (например, быстрые ссылки). В таком случае при парсинге инструмент соберет их вместе с текстом.
Все домены на одной странице
Загруженный документ в этом случае будет состоять из четырех листов.
Первый лист — «Rezyltati_obschie». В нем указана информация об объявлениях по всем конкурентам (регионы и количество). Ее можно отфильтровать по региону и поисковой системе.
Второй лист — «Slova_i_obyavleniya». Можно посмотреть всю текстовую часть парсинга — заголовки и тексты объявлений, а также ключевые слова.
Важно! Если вы парсили большое количество доменов, то и итоговая таблица по ключевым словам и объявлениям будет огромной. Чтобы с ней было удобно работать, стоит отфильтровать информацию — по домену, региону или поисковику.
Оставшиеся две страницы («Slova» и «Ish-nastroiki») совпадают по содержанию с листами из документа с разбивкой по доменам, который мы разбирали выше.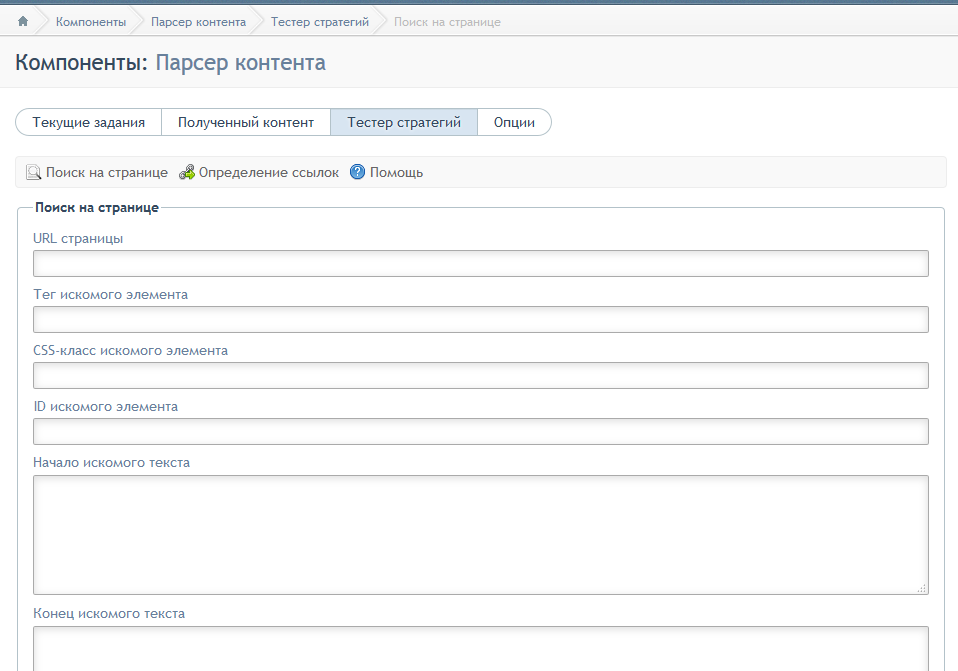
2. Находим упущенные ключевые слова
Для настройки действующей кампании полезно собрать упущенные ключи, чтобы запустить рекламу по ним. Это ключи, которые не используются в нашей рекламной кампании, но по которым рекламируются конкуренты.
Парсим упущенные ключевики
Вначале выгружаем список ключевых слов, по которым вы рекламируетесь в Яндекс.Директе и Google Ads. Списки не смешиваем — будем собирать упущенные слова по каждой рекламной системе отдельно.
Открываем парсер конкурентов Click.ru и указываем домены конкурентов, по которым нужно собрать данные. В блоке «Профессиональные настройки» заполняем поле с минус-словами. Сюда вставляем список наших ключей. Таким образом, система исключит их из парсинга и соберет только те ключевые слова конкурентов, которые мы не используем.
Обратите внимание, что для точности подбора должна стоять галочка напротив пункта «Точное вхождение без учета морфологии».
3. Исключаем из парсинга определенные товары/категории
Нет смысла собирать ключи и тексты объявлений конкурентов по группам товаров, не представленных на вашем сайте.
С этим нам помогут минус-слова. Прописываем в поле товары и услуги, которые хотим исключить. Также есть смысл сразу добавить минус-слова, по которым пойдет нецелевой трафик (вроде «бесплатно» или «бу»). При этом важно снять галочку с пункта «Точное вхождение без учета морфологии».
В примере мы указали четыре минус-слова для исключения групп товаров. Поэтому в документ с результатами парсинга не попадут такие ключевики, как например, «сувенирные подарки» или «подарки идея».
4. Парсим ключи и объявления по отдельным услугам/товарам/категориям
Теперь покажем процесс, обратный исключению товаров из парсинга. Предположим, что нам нужно настроить парсер только на те ключи и объявления, которые подходят для рекламы конкретных товаров.
Для примера возьмем группу товаров «Подарки для мужчин» — посмотрим, какие слова и объявления используют конкуренты для ее рекламы.
В поле «Фиксированный список слов» прописываем несколько слов, похожих по тематике на выбранную группу товаров. Не забываем убрать галочку в строчке «Точное вхождение».
Кликаем «Запустить проверку» и смотрим результаты.
5. Собираем объявления по конкретным ключевикам
Составляем список ключевых фраз, по которым будем парсить объявления конкурентов. Открываем парсер конкурентов Click.ru, прописываем URL конкурентов, по которым будет собирать информацию.
Нам вновь понадобится блок «Фиксированный список слов». Вставляем сюда подобранные фразы. Ставим галочку в пункте «Точное вхождение». Тогда инструмент будет собирать объявления только по точным вхождениям указанных ключей.
Запускаем инструмент, а потом скачиваем документ с результатами. Там будут тексты объявлений конкурентов, запщенные по указанным ключам.
Как использовать результаты парсинга конкурентов
Их нужно проанализировать и выбрать те слова, заголовки и тексты, которые помогут улучшить качество вашей кампании.
Можно расширить семантическое ядро за счет упущенных ключевиков. Это поможет достучаться до большего числа потенциальных клиентов и сэкономить бюджет.
Изучите тексты объявлений. Некоторые формулировки и формы предложений можно использовать в своей кампании.
Посмотрите на структуру объявлений — на чем сделан упор, на каких преимуществах продукта акцентировано внимание и что конкуренты предлагают. Не исключено, что вы можете предложить больше.
Сбор поисковых подсказок Яндекс, Google
Редакция от 21 марта 2022 года
Cбор поисковых подсказок Яндекс и Google не совсем простая операция, как это может показаться с первого раза. Есть множество нюансов и «подводных камней», о которых мы расскажем в этой статье
Как использовать функционал перебора
В Rush Analytics представлен расширенный функционал перебора символов для того, чтобы сборать поисковые подсказки Google и Яндекс.
Функционал выглядит следующим образом:
Для разных случаев и задач стоит использовать разные настройки перебора.
Для получения максимально полного семантического ядра, мы рекомендуем использовать все представленные методы перебора: [a-z], [а-я] и [0-9], а так же глубину парсинга 3!
Когда можно оставить перебор только слова и слова с пробелом?
Использовать только переборы типа «ключевое слово» и «ключевое слово_» следует тогда, когда вам нужно быстро оценить семантику по большому количеству разных ключевых слов.
Если говорить проще – когда вы пытаетесь только прикинуть структуру спроса в тематике и у вас нет ее четкого понимания.
Использование всего двух вышеописанных типов перебора обусловлено тем, что при использовании всех возможных типов перебора вы можете получить слишком много ключевых слов, в том числе не совсем целевых т.к. вы еще не знаете стоп-слова для тематики.
Иными словами — если вы собираете ключевые слова для популярной тематики — стоит сначала «прицелиться» и выявить стоп-слова, спарсив подсказки на первый уровень глубины.
Во всех остальных случаях рекомендуем перебирать как русский, так и английский алфавит + цифры.
В сборщике подсказок реализован мощнейший функционал по работе со стоп словами.
Всего лишь в один клик вы сможете загрузить списки стоп слов в ваша задача по разным тематикам. Так же в данный функционал есть возможность загрузить свои собственные списки стоп слов. Их можно будет использовать в любой вашей задаче.
Как правильно подобрать стоп-слова для своей тематики мы подробно рассказываем в этойстатье. Так же в статье вы найдете готовые списки стоп-слов для большинства тематик.
Используйте словоформы как в единственном, так и в множественном числе
Рекомендуем подавать на вход ключевое слово во множественном и единственном числе, например: «мультиваркА редмонд» и «мультиваркИ редмонд». Это поможет получить больше целевых ключевых слов.
На скриншотах ниже наглядно показана разница между единственным и множественным числом
Глубина парсинга — как использовать?
Нам задают много вопросов насчет глубины парсинга. Так какая же глубина оптимальная? Тут, как и в случае с перебором, все зависит от конкретной задачи:
Так какая же глубина оптимальная? Тут, как и в случае с перебором, все зависит от конкретной задачи:
- Глубина парсинга 1 — даст вам базовые (самые частотные и популярные) ключевые слова.
- Глубина парсинга 2 — даст намного более широкую семантику – добавится много среднечастотных и низкочастотных запросов.
- Глубина парсинга 3 — в этом случае вы получите максимальное количество ключевых слов – высокочастотные, среднечастотные и огромное количество низкочастотных.
Однако, если вы не знаете стоп-слов в своей тематике — придется почистить готовый файл от нецелевых слов.
Во всех задачах рекомендуем использовать такие стоп-слова, как «вк,vk, одноклассники, minecraft, battlefield……» и другие слова очевидные и характерные для вашей тематики.
Готовые списки стоп-слов можно найти в этой статье из нашей базы знаний
Сбор поисковых подсказок для разных типов проектов
В зависимости от того, проект какого типа вы продвигаете – интернет-магазин, сайт услуг или информационный портал, зависят и настройки для сбора поисковых подсказок.
Интернет-магазин
Для интернет-магазинов эффективно добавлять не только название категории, например «мультиварки», а еще и названия подкатегорий и брендов, которые вам заранее известны. Например, «мультиварки встраиваемые «мультиварки Редмонд» (не забудьте указать название бренда как на русском, так и на английском языке – добавьте еще и «мультиварки Redmond»).
Но, в большинстве случаев не рекомендуем добавлять просто название бренда, например «Редмонд», так как, с большой вероятностью, вы получите много информационных нецелевых запросов, а так же вы получите запросы по всем товарным категориям данного бренда, некоторые из которых могут оказаться нецелевыми.
Коммерческие сайты (сайты услуг)
Для сайтов услуг, при сборе подсказок, мы рекомендуем указывать синонимы и альтернативные названия услуг, например:
- «автоюрист» и «автоадвокат»
- «установка стекол» и «остекление»
- «станок для фрезеровки» и «фрезеровальный станок»
- «рабочая одежда» и «спецодежда»
- «выведение насекомых», «уничтожение насекомых» и «дезинсекция» и т. д.
 д.
д.Информационные порталы
Здесь стоит очень серьезно относиться к стоп словам! Можно случайно «зацепить» огромный пласт нецелевых ключевых слов!
Для порталов не стоит выбирать сразу третий уровень глубины парсинга. Рекомендуем сначала оценить спрос, загрузив ваши базовые ключевые слова (названия разделов), выбрав все виды перебора и глубину парсинга 2.
Была ли статья полезной?
2
0
Навигация по статье
- Как использовать функционал перебора
- Глубина парсинга — как использовать?
- Сбор поисковых подсказок для разных типов проектов
Сбор семантического ядра в онлайн-сервисе Shinta
разрабатывается сообществом интренет-маркетологов
Создать аккаунт Вход
парсер Wordstat, Keyword Planner
все из коробки: без капчи, аккаунтов, прокси
подсказки, синонимы, ассоциации
углубленный парсер Wordstat: «маска +слово»
сбор частоты с любого ГЕО
снятие частоты в «»
минусация
группировка
семантическая карта
перемножение слов
папочная структура
. .. … …
подробнее в видео
Загрузили запросы
Сгенерировали объявления
Скачали готовые РК
Работаете с Key Collector?
Преимущества 🚀 онлайн-сервиса перед КК:
не нужны прокси, капчи, акки
работает с MacOS
перемножение ключей
сбор семантической карты
не нагружает компьютер
простота
СБОР КЛЮЧЕВЫХ СЛОВ
Парсинг без заморочек
Не нужно покупать, настраивать прокси, капчи, аккаунты.
Все из коробки: загрузили запросы, выставили ГЕО и все
Yandex Wordstat
любое ГЕО из Wordstat
многопоточный парсер
до 41 страницы вглубь
снятие частоты с учетом кавычек
углубленный парсинг «маска +слово»
парсинга фраз ≈ 600 запросов/час
снятия частоты ≈ 18к запросов/час
Keyword Planner
любое ГЕО
парсер по домену конкурента
парсер по запросам
снятие частоты
скорость ≈ 2 000 запросов/час
Остальные парсеры
Букварикс (по запросам/домену)
SEO (тайтлы/дескрипшены)
Подсказки
Синонимы
Ассоциации
Ну как Вам функционал?
Круто, да? Сутки на тест бесплатно!
Создать аккаунт
ОБРАБОТКА КЛЮЧЕЙ
Минусация и сегментация запросов
Группировка и чистка ключевых слов онлайн совершенно бесплатно
Минусация
удаление по ключу или наличию слова
сохранение списка минус-слов
загрузка своего списка минус-слов
поиск слоформ (для Ads)
удаление лишних слоформ (для Директ)
Сегментация
Перенос по ключу или наличию слова
Сохранение списка слов для переноса
Папочная сегментация
Гибкие фильтры
Копирование фраз
Бесплатная Skype-демонстрация
Все проще, чем кажется! Покажу и объясню как все работает.
Написать в Telegram Написать в WhatsApp
Чащин И.О. ИНН 253716533443 WatsApp/Telegram +79140789009
© 2018-2021 Все права защищены.
Правила предоставляемых услуг
Политика конфиденциальности
Свяжусь с Вами в течение суток
Я получил Ваши данные, проанализирую и свяжусь с Вами в течение суток по следующим данным:
Проверка частотности ключевых фраз — Serpstat
Проверьте частотность ключевых фраз и найдите самые популярные и трендовые запросы для своего бизнеса. Закажите массовую проверку частотности запросов от Serpstat, чтобы оценить спрос по фразе, спрогнозировать продажи и оценить конкуренцию в нише.
Узнать больше
Настройте сканирование частотности в соответствии с потребностями вашего бизнеса
в мобильных и десктопных результатах поисковых систем;
по заданному региону и городу;
на любом языке;
Парсинг частотности Serpstat соберет автоматически миллионы результатов для ваших задач:
в поисковой системе Google;
по нужному графику (задайте время и частоту парсинга).
Проверка частотности запросов онлайн
Товарных агрегаторов и маркетплейсов. В таких сайтах тысячи страниц, которые нужно правильно оптимизировать, а для этого необходимо обработать частотность по десяткам тысяч запросов.
Тематических агрегаторов. Парсер ключевых слов быстро собирает большие массивы информации. С ее помощью можно оценить трафик и конкуренцию в нише, эффективнее продвигать сайты по продаже стройматериалов, билетов, недвижимости и пр.
Бизнесов с ярко выраженной сезонностью. Таким компаниям массовая проверка частоты запросов нужна, чтобы быстро реагировать на изменения на рынке.
Проверка частоты запросов поисковых слов от Serpstat позволяет автоматически собрать данные по тысячам фраз из 244 региональных баз выдачи поисковых систем.
Инструмент будет полезен при продвижении:
Проверка частоты запросов Google
Собирая крупное семантическое ядро, используйте сервис проверки частотности ключевых запросов в Google. Вы получите данные по десяткам и даже сотням тысяч поисковых фраз. Отслеживайте изменения частотности, потенциального трафика и спроса от сезона к сезону.
Вы получите данные по десяткам и даже сотням тысяч поисковых фраз. Отслеживайте изменения частотности, потенциального трафика и спроса от сезона к сезону.
Узнать больше
Преимущества парсинга частотности Serpstat
Кастомизируйте расписание парсинга, чтобы уловить сезонность и колебания конкуренции.
Получайте инсайты по изменению частотности поисковых запросов в нише и реагируйте на тенденции рынка
Анализируйте и сравнивайте результаты разных поисковиков и локаций.
Получайте данные со скоростью парсинга 100.000 ключевых слов в час.
Получайте максимум пользы от сезонных трендов с Serpstat. Настраивайте персонализированный график парсинга частотности ключевых слов в своей нише, чтобы оставить конкурентов позади:
Поставляйте данные своим пользователям
Бесконечные лимиты на парсинг частотности
Специальные методы API, которые не входят в стандартную подписку Serpstat.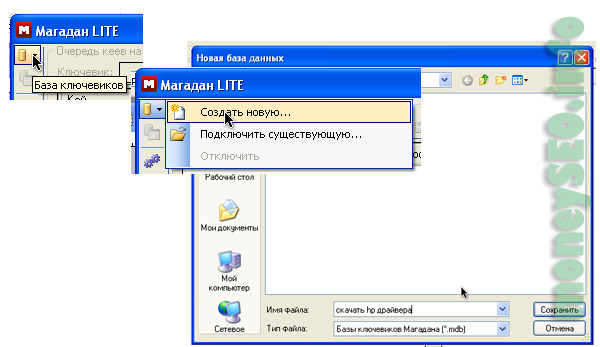
Результаты хранятся 24 часа с момента их готовности
Данные в JSON-формате, которые можно хранить в любой базе данных (My SQL или Big Query и др.).
Быстрая интеграция результатов в ваши дашборды отчеты или визуализация в Data Studio или другой BI-системе.
Узнать больше
Количество запросов в день, месяц — неограниченно!
Инструмент парсинга частоты запросов от Serpstat позволяет вам проверить столько ключевых слов, сколько вам необходимо, независимо от вашего тарифного плана.
Serpstat — самый рентабельный инструмент для парсинга частотности
Без ограничения по количеству запросов в день и месяц.
Минимальный бюджет для заказа сервиса — 300$ (более 100 тыс. запросов).
Независимо от наличия тарифного плана или доступных лимитов.
Дубликаты ключевых слов не учитываются и не влияют на стоимость сканирования.
Анализируйте частотность фраз по необходимому количеству ключевых фраз от 0,005$ дo 0,0010$ за один запрос, в зависимости от объема:
Рассчитать стоимость
Полезные статьи об использовании сервиса парсинга топа
Алексей Данилин
Александр Иванов
Анастасия Сотула
Персональная демонстрация
Оставьте заявку и мы проведем для вас персональную демонстрацию сервиса, предоставим пробный период и предложим комфортные условия для старта использования инструмента.
Запросить демо
Инструмент, который стал нашим помощником в трафиковом отделе, позволяет значительно сократить временные затраты на анализ сайтов конкурентов и получить на основе этого анализа готовую семантику для собственных проектов.
Serpstat — находка для SEO-шника =) Пользуюсь сервисом уже давно, всем доволен, очень удобно. С нетерпением жду новых крутых фишек!)
Отличный сервис анализа и аудита конкурентов. Другие альтернативы стоят дороже, и не всегда есть тот функционал который нужен нам. Очень часто чекаем конкурентов на трафикообразующие страницы, в общем есть все что нужно для взрывного маркетинга и трафика.
Другие альтернативы стоят дороже, и не всегда есть тот функционал который нужен нам. Очень часто чекаем конкурентов на трафикообразующие страницы, в общем есть все что нужно для взрывного маркетинга и трафика.
Инструмент удобен как для частных SEO-оптимизаторов (при небольших бюджетах), так и для крупных SEO-компаний. После работы с сервисом остаются приятные впечатления. В тоже время большинство предложенных функций упрощают жизнь оптимизатора, к тому же огромным плюсом является структурированная подача информации.
Илья Василенко
Александр Шпион
ART LEMON
Дмитрий Ваврик
OdesSeo
Александр Sli
My-Master
Алексей Бузин
SEO-IMPULSE
С Serpstat работаем с тех времен когда он еще назывался Prodvigator. Must Have инструмент для SEO-специалистов на каждый день 😉
based on 120 reviews
based on 127 reviews
based on 406 reviews
based on 17 reviews
based on 17 reviews
FAQ.
 Распространенные вопросы о парсинге частотности фраз
Распространенные вопросы о парсинге частотности фразЧто такое частотность ключевых слов?
Частотность ключевых слов — показывает, сколько раз пользователи вводили поисковую фразу за определенный период времени. В большинстве случаев частотность измеряется за один месяц.
Частотность ключевых слов отличается в зависимости от:
- региона;
- поисковой системы;
- сезона.
Поэтому для комплексного анализа ниши важно учитывать динамику частотности в зависимости от этих критериев.
Как определить частотность запросов?
Определить частотность поисковых запросов в Google с помощью Serpstat можно двумя способами.
- Первый вариант. Инструмент Анализ ключевых словИнструмент Анализ ключевых слов. Просто введите в поисковую строку запрос, выберите поисковую систему и региональную базу, нажмите кнопку Найти. Вы получите список фраз, которые содержат искомую и частотность каждого варианта ключевого слова. Такой способ подходит для предварительной быстрой оценки потенциала фразы и неудобен для анализа большого числа запросов.
- Второй вариант. Парсер ключевых слов. Для этого оставьте заявку на консультацию с менеджером для детального просчета. Укажите, какие данные вам нужны, регион и тип выдачи, а также по какому расписанию вы хотели бы получать аналитику. Цена парсинга зависит от количества запросов, расписания парсинга и других особенностей задачи.
- Третий вариант. API Serpstat. С его помощью можно получать и обрабатывать большие объемы информации. Основная сложность — каждый раз, когда нужна новая сводка, нужно делать делать запрос.
 Такой способ подходит для предварительной быстрой оценки потенциала фразы и неудобен для анализа большого числа запросов.
Такой способ подходит для предварительной быстрой оценки потенциала фразы и неудобен для анализа большого числа запросов.Как узнать количество запросов по слову в Гугле?
Узнать количество запросов в Google можно несколькими способами:
- По статистике из Google Ads. Для этого создайте рекламную кампанию. После этого можно использовать бесплатный планировщик ключевых слов. Затем введите одну или несколько поисковых фраз. Недостаток в том, что этот способ не показывает точную частотность, но он позволяет оценить конкурентность.
- С помощью Google Trends. Этот бесплатный сервис от Google показывает тендеции роста или падения частотности поисковых запросов, но не показывает их точную частотность.
- С помощью данных из Google Analytics и Search Console. С помощью этого источника можно оценить эффективность использования поисковых фраз и решить, нужно ли менять или расширять семантическое ядро.
- С помощью Serpstat. Пользователям Sepstat доступны два варианта: инструмент Анализ ключевых слов и проверка частотности ключевых слов с помощью парсинга.
 Недостаток в том, что этот способ не показывает точную частотность, но он позволяет оценить конкурентность.
Недостаток в том, что этот способ не показывает точную частотность, но он позволяет оценить конкурентность.Где посмотреть количество запросов?
Вы можете увидеть количество запросов с помощью инструмента Анализ поисковых запросов. Данные отобразятся в табличном виде в основном окне Serpstat вместе с показателями:
- сложности фразы;
- конкуренции в PPC;
- спецэлементов в выдаче;
- количества результатов в выдаче и пр.
сбор ключевых слов и составление семантического ядра
Мы уже писали про сервис Вордстат и поиск ключевых фраз с его помощью. Сегодня мы расскажем, как подобрать СЯ из реальных данных Яндекс.Wordstat.
Создание семантического ядра
Профессионалы утверждают, что ручной парсинг пользовательских запросов в Вордстате выдает лишь 30-40% всех словосочетаний. Как для бесплатной платформы — это более чем хорошие результаты. Но поиск ключевых фраз возможен также с использованием поисковых подсказок и иных ресурсов.
Рассмотрим на примере запроса на стеклянные двери.
Алгоритм:
Определение стратегии формирования пользовательского запроса
Переходим на ресурс wordstat.yandex.ru и вводим в поиск нужную фразу. Получаем огромное количество результатов. Чтобы просмотреть все их вручную, придется потратить уйму времени. Среди всех результатов есть много нерелевантных запросов, к примеру «двери в стеклянное здание», «стеклянные полки», «стеклянные двери продажа» и другие.
В этом случае, стоит конкретнее сформулировать свой запрос. Для начала уберем совершенно лишние результаты, используя символ минус и ненужные слова: «-продажа», «-полки», «-здание» и прочие.
Выбираем необходимый регион, например город Киев, и тип устройств, с которых потребители посещают сайт. Например, в поле нашего интереса все юзеры, ибо мы продвигаем рекламную кампанию.
Следом выделите целевой спрос. Чтобы это настроить, нужно выбрать релевантные предложения из поиска и добавить их в таблицу приложения Excel, разбив по разным категориям. Если представить идеальный вариант, то нужно просмотреть все страницы, для вычисления всех особенностей, и собрать полную картину о нуждах и предпочтениях ваших потенциальных клиентов. Для упрощения задачи исключите неподходящие фразы из поиска, как нерелевантные.
Анализируем пересекающиеся словосочетания, так как высока вероятность, что они будут соответствовать потребностям аудитории.
Непременно стоит учесть, что предполагаемые покупатели также заинтересованы в других товарах для ремонта и строительства. Этот анализ покажет более обширную картину, она полезна для составления ключевых слов по результатам и грамотной настройки контекстной рекламы в РСЯ.
Этот анализ покажет более обширную картину, она полезна для составления ключевых слов по результатам и грамотной настройки контекстной рекламы в РСЯ.
Советуем обратить внимание на второй перечень ключевиков, составленный вами ранее, и, возможно, дополнить его.
После проведения этих настроек, в таблице будут выписаны все подходящие ключевые слова.
Простого парсинга в Wordstat не хватит. Воспользуйтесь сложными платными функциями, и, в комбинации с простыми бесплатными, семантическое ядро будет достаточно обширным и эффективным. Помимо этого, преимущество использования платных услуг сервиса — автоматизация работы с Вордстатом в будущем.
Некоторые примеры платных функций
Key Collector
С его помощью проводится сбор СЯ, определяется конкурентность, цена и эффективность ключевиков.
Парсер ключевиков «Магадан»
Его стоимость от 20 долларов, хотя есть пробная бесплатная версия. Плюс этой функции — простой и удобный автоматический сбор, проведение анализа и обработка результатов статистики.
All Submitter
Программа формирует подходящие ключевые слова.
Параметры для использования Яндекс.Wordstat
Слишком много времени тратится на то, чтобы придумать запросы на каждое словосочетание. Но, к сожалению, без этого невозможно обойтись. Несмотря на это, есть несколько удобных приемов, которые помогут сделать использование этого сервиса более удобным, простым для понимания и быстрым.
Yandex Wordstat Helper
Этот сервис создан при поддержке Google Chrome и Mozilla Firefox. Нужен он для упрощения подбора ключевых слов, которые будут использоваться в контекстной рекламе. Это избавит вас от неудобств и сложностей при переключении между разными площадками, такими как Excel и Гугл Документы.
Когда установка будет завершена, вы увидите виджет в Вордстате. К тому же, удаление и добавление нужных фраз, копирование информации производится за одно нажатие клавиши.
Этот ресурс включает такие функции:
- Автоматизация сортировки слов в алфавитном порядке.
- Проведение тестирования на дубли.
- Наличие счетчика для подсчета слов.
- Уведомления.

Yandex Wordstat Assistant
Доступен для использования в Google Chrome, Яндекс.Браузер и Opera. Делает сбор слов в Вордстате более быстрым.
Начать следует с установки расширения для браузера. Затем забейте фразу в Яндекс.Wordstat. Для удаления и добавления подходящих вариантов кликайте на символы минус и плюс соответственно.
Функционал данного ресурса:
- Удаляет ненужные дубли автоматически.
- Производит подсчет суммы показателей частотности.
- При добавлении своих словосочетаний вместо частотности Вордстат выдаст вопросительный знак.
- Удаление символов плюс перед стоп-словами.
- Автоматизация синхронизации вкладок.
- Перечень можно настроить в алфавитном порядке, частотности и порядке включения.
- Составленные вами инфоматериалы по СЯ в буфер обмена можно загрузить одним нажатием кнопки.

К тому же существует сервис Вордстатер, его ассортимент функций намного богаче и разнообразнее Вордстата.
Технические запреты в Яндекс.Wordstat
Если стремительно пролистывать вкладки в Вордстате или пользоваться сервисом на протяжении долгого времени, вскоре появится капча. Таким образом система Яндекс запрашивает подтверждение того, что пользователь человек, а не робот.
В случае, если это сильно нервирует вас либо мешает работать на платформе, можно использовать обходные пути, чтобы избежать капчи:
- Отключение блокировщика рекламных объявлений.
- Переход в Wordstat с Директа: там примените инструмент «Прогноз бюджета» и перейдите по линку. После этого вам будет открыт доступ к старой версии Вордстата, где нет необходимости все время вводить капчу. Такой метод действует вместе с блокировщиком рекламы в поисковой системе. Иногда все же капча высвечивается, но это случается намного реже.
- Смена IP-адреса. Есть вероятность входа с американским IP с помощью прокси-сервиса.
 Есть вероятность входа с американским IP с помощью прокси-сервиса.
Есть вероятность входа с американским IP с помощью прокси-сервиса.Обратите внимание! В случае ввода большого количества запросов, Яндекс может заблокировать ваш аккаунт или наложить вечную капчу. Специалисты компании AdButton предлагают способ избежать этого — установить дополнительные прокси-сервисы. Также может помочь смена IP-адреса, если разорвать подключение к интернету — это работает, когда IP-адрес выдается динамически.
Итоги
Парсинг семантического ядра для контекстной рекламы вручную требует от пользователя затрат времени и вложения максимума аналитических усилий, даже при использовании сервиса Яндекс.Wordstat. Тем не менее, это может гарантировать хорошие результаты, если специалист сумеет корректно составить перечень ключевых запросов.
Желаем успехов в применении Wordstat!
Мы используем файлы cookie. 🍪 Продолжая использовать наш сайт, вы соглашаетесь с нашей Политикой конфиденциальности
Парсинг ключевых слов для формирования СЯ
Парсинг или подбор ключевых слов для формирования Семантики сайта проводят при помощи сервисов или программ, наделенных такими функциями.
Наиболее популярными в Рунете являются сервисы Rash-Analytics и Just-Magic. Есть еще несколько сервисов и программ, которые хорошо справляются с этой задачей.
Можно назвать и программу Кей Коллектор или сервис ТопВизор.
У каждого сео специалиста есть свои рабочие инструменты для сбора поисковых запросов при работе над Семантическим Ядром.
Источники и инструменты сбора поисковых запросов
Для сбора ключевых слов существует много возможностей. У каждой есть свои плюсы и минусы. Ниже я привел наиболее популярные, на мой взгляд, инструменты.
- Поисковые системы
- Яндекс
- …….
- Парсеры
- Кей Коллектор – keycollector.ru
- Datacol
- A-Parser
- …….
- Облачные сервисы
- Rush-Analytics.ru
- Just-Magic.ru
- Topvisor.ru
- SemRush.ru
- ……
- Базы поисковых слов
- Pastuhov. com – базы Пастухова
- MOAB – moab.pro
- …….
- И еще достаточно много других достойных сервисов.
 com – базы Пастухова
com – базы ПастуховаКак собирать ключевые слова
Для Рунета основным источником ключевых слов является сервис Wordstat от ПС Яндекс.
Запросов от Google, как правило, получается гораздо меньше и поэтому они чаще используются на этапе сбора базовых запросов. Как результат, в подавляющем большинстве случаев парсят Вордстат и этого бывает вполне достаточно.
Если же у Вас какая-то узкая ниша и надо обеспечивать максимальную полноту, тогда можно подключать сервисы Google и/или базы запросов.
Процедура парсинга запросов в облачных сервисах проходит довольно просто. Например, для Rush-Analytics необходимо задавать следующие параметры:
- Настроить проект в сервисе.
- Установить региональность.
- Выбрать пункт «Собрать ключевые слова».
- Загрузить список Базовых Запросов.
- Загрузить список минус-слов, если они у Вас уже есть.
- Инициировать работу парсера по сбору ключевых фраз.

Более наглядно этот процесс можно увидеть в этом небольшом видеоролике.
У меня первый прогон обычно используется для формирования списка минус слов. Выгружаю полученный результат и методом пристального взора составляю список таких слов.
Второй прогон, с учетом собранных минусов, уже будет более результативным и список ключей будет содержать гораздо меньше мусорных запросов. Тем не менее мы опять просматриваем полученные ключи, чистим мусор, пополняем список минус-слов и у нас все готово для следующего шага — сбора подсказок.
Плюсы и минусы работы с Кей Коллектором
Еще один вариант – сбор парсером KeyCollector (КК). Эта программа покупается один раз, причем по вполне сходной и доступной цене, а затем используем бесплатно.
При больших объемах КК очень сильно подгружает Ваш ПК, да и скорость сбора данных у него низкая. Поэтому мощность компьютера, на котором Вы хотите парсить большие объемы должна быть соответствующей.
Поэтому мощность компьютера, на котором Вы хотите парсить большие объемы должна быть соответствующей.
Для настройки многих операций сбора КК может потребовать определенных умственных усилий и хлопот при подключение разных аккаунтов, прокси-серверов, работе с капчей и т.п.
Но без этого получить данные без ощутимых материальных затрат не получится.
Я использую KeyCollector при работе над СЯ в основном на этапе чистки собранных ключей от мусора, дублей и т.п..
Дополнительные варианты подбора запросов
Можно собирать запросы и руками, используя для этого тот же Вордстат. Но при профессиональной работе это приведет к большим временным затратам, да и качество будет заметно хромать.
Такой способ подходит для подбора ключей на одну страницу, можно назвать экспресс методом для быстрой оценки ситуации.
Для сайта более целесообразно воспользоваться средствами автоматизации. Вы получите качественный результат гораздо быстрее и за сравнительно небольшие деньги.
Базы ключевых слов Пастухова, MOAB и другие используются реже, поскольку данные в этих базах не успевают обновляться так быстро как в Вордстат. Но в некоторых случаях, когда собранных запросов в облачных сервисах недостаточно, то подключают данные и из этих источников.
P.S. Облачные сервисы, к которым относятся Just-Magic, Rush-Analytics, TopVisor и другие собирают запросы быстро и не загружают Ваш компьютер. Но при больших объемах данных сумма за оказанные услуги будет довольно большой.
Поэтому, с точки зрения финансов и времени, Вам придется определяться самим. Если есть возможность переложить денежные затраты на Заказчика, то облачные сервисы будут гораздо уместнее. Если же Вы хотите заработать эти деньги, то тогда придется вложиться в покупку мощного ПК, программы КейКоллектор и освоить работу с этим парсером.
Полезные Материалы:
Поиск идей для имени пользователя канала
Генератор имен YouTube № 1: Поиск идей для имени пользователя канала Изучите руководство по процессу бренд-нейминга. Получайте предложения по названиям на YouTube. Создайте имя пользователя, используя свое воображение и генератор Kparser
Получайте предложения по названиям на YouTube. Создайте имя пользователя, используя свое воображение и генератор Kparser
Посмотрите на картинку справа. Имена пользователей каналов 10 самых подписанных ютуберов выглядят интересно. Некоторые действительно цепляют. Но некоторые длинные и трудные для произношения и запоминания. Мы предполагаем, проблема в следующем. На первых этапах развития собственного канала ютуберы считают, что качество имени пользователя не имеет значения. Но создание хорошего имени на YouTube похоже на создание названия бренда. Это не случайный выбор. Чем больше у вас просмотров и подписчиков, тем важнее становится качество вашего имени пользователя. Более того, вам всегда нужно искать дальше и оптимизировать свои видео с помощью ключевых слов канала Youtube. Тогда вы получите больше просмотров и больше подписчиков на ваши видео.
Выберите свой путь в генерации идей для имени пользователя{
{
Фактически, я утверждаю, что будущее рекламы, какой бы ни была технология, будет состоять в том, чтобы ассоциировать каждый бренд с одним словом.
}
}
 Это справедливость одним словом. Это современный эквивалент лучшего сайта на главной улице, за исключением того, что местоположение находится в уме. – Морис Саатчи в интервью для www.ft.com
Это справедливость одним словом. Это современный эквивалент лучшего сайта на главной улице, за исключением того, что местоположение находится в уме. – Морис Саатчи в интервью для www.ft.com Ник Коленда создал отличное 5-минутное руководство о пошаговом процессе именования. Мы настоятельно рекомендуем прочитать его с вниманием к деталям. Он пишет о 4 основных вариантах названия бренда, каждый со своими плюсами и минусами:
- Deviant – слово или фраза, описывающие продукт
- Описательный – не слово(а), описывающее продукт
- Неологический – слово или фраза, не имеющие отношения к продукту
- Ассоциативный – не слово(а), не имеющее отношения к продукту
Такое простое разделение всех торговых марок на четыре категории помогает направить ваш мыслительный процесс по понятным путям.
Представьте свой канал на YouTube в будущем. Чем популярнее вы будете, тем больше ваша лояльная аудитория будет делиться с другими вашими видео, каналом, идеями. Чем проще будет объяснить другим, кто вы, тем больше будет расти ваша аудитория. Название вашего бренда должно быть уникальным и расширяемым, легко произносимым, идентифицируемым и запоминающимся.
A7d: Используйте такие инструменты, как @SEMrush или Kparser, чтобы усилить заголовки, заголовки, метаописания и теги с ключевыми словами. #TweetHour
— Лиза Догерти (@BrandLoveLLC) 11 октября 2017 г.
Определите лучшие ключевые слова без Планировщика ключевых слов Google: KParser: https://t.co/tg9Nt8sbw5
— Мишель Сморгон (@maxOz) 22 августа 2017 г.
Kparser — новый бесплатный поисковик по ключевым словам звучит мощно.
— Кевин Доннеллон (@MacaliComm) 19 июня 2017 г.
 https://t.co/QZrkint2SG
https://t.co/QZrkint2SGПросто попробовать Kparser выглядит круто >> 9 инструментов для ведения блога, которые облегчат вашу работу https://t.co/OuXPKXZibU через @cmicontent
— Аманда Уэбб (@Spiderworking) 20 июня 2017 г.
Подписаться на генератор ключевых слов Kparser
Basic
$26.00/м
Неограниченное количество ключевых слов Количество результатов по ключевым словам в месяц.
18 источников парсинга Мы парсим ключевые слова в реальном времени из Google, Bing, Amazon, Youtube, Ebay и т. д.
38 языков Есть ли в других инструментах корейский язык? Вам так повезло, что мы это делаем, как и 37 других языков 😊
248 регионов Выберите нужный язык и регион, просматривайте данные в реальном времени, сделайте поиск ключевых слов прибыльным.
Расширенный поиск по ключевым словам Прежде чем начать поиск по ключевым словам, не забудьте указать свои предпочтения. Это помогает сделать ваше исследование ключевых слов более точным.
Это помогает сделать ваше исследование ключевых слов более точным.
Группировка ключевых словВсе найденные ключевые слова группируются для облегчения дальнейшей кластеризации ключевых слов.
2000 результатов экспорта (.csv) Простой способ экспорта ключевых слов в формате .csv для дальнейшего использования.
2000 результатов скопировать в буфер обмена Просто выберите нужные ключевые слова и нажмите «Копировать в буфер обмена».
Подпишитесь сейчас
Лучшая цена
Аккаунт Pro
$61.00/м
Неограниченное количество ключевых слов Количество результатов ключевых слов в месяц.
18 источников парсинга Мы парсим ключевые слова в реальном времени из Google, Bing, Amazon, Youtube, Ebay и т. д.
38 языков Есть ли в других инструментах корейский язык? Вам так повезло, что мы это делаем, как и 37 других языков 😊
248 регионов Выберите нужный язык и регион, просматривайте данные в реальном времени, сделайте поиск ключевых слов прибыльным.
Расширенный поиск по ключевым словам Прежде чем начать поиск по ключевым словам, не забудьте указать свои предпочтения. Это помогает сделать ваше исследование ключевых слов более точным.
Группировка ключевых словВсе найденные ключевые слова группируются для облегчения дальнейшей кластеризации ключевых слов.
Неограниченное количество результатов экспорта (.csv) Простой способ экспорта ключевых слов в формате .csv для дальнейшего использования.
Неограниченное копирование результатов в буфер обмена Просто выберите нужные ключевые слова и нажмите «Копировать в буфер обмена».
Данные об объеме поиска Количество точных поисков по ключевому слову. Это помогает определить, насколько популярно ключевое слово среди пользователей.
Цена за клик за клик.
Минус-слова Легко исключить ключевые слова или группы ключевых слов из вашего исследования.
Подписаться сейчас
Запуск
$30.00/м
Неограниченное количество ключевых слов Количество результатов по ключевым словам в месяц.
18 источников парсинга Парсим ключевые слова в реальном времени из Google, Bing, Amazon, Youtube, Ebay и т.д.
38 языков Есть ли в других инструментах корейский язык? Вам так повезло, что мы это делаем, как и 37 других языков 😊
248 регионов Выберите нужный язык и регион, просматривайте данные в реальном времени, сделайте поиск ключевых слов прибыльным.
Расширенный поиск по ключевым словам Прежде чем начать поиск по ключевым словам, не забудьте указать свои предпочтения. Это помогает сделать ваше исследование ключевых слов более точным.
Группировка ключевых словВсе найденные ключевые слова группируются для упрощения дальнейшей кластеризации ключевых слов.
Неограниченное количество результатов экспорта (.csv) Простой способ экспорта ключевых слов в формате .csv для дальнейшего использования.
Неограниченное копирование результатов в буфер обмена Просто выберите нужные ключевые слова и нажмите «Копировать в буфер обмена».
Подписаться
10-дневная гарантия возврата денег
Мы предоставляем 10-дневную гарантию возврата денег. Это означает, что вы можете смело подписаться и попробовать Kparser в течение месяца.
Это означает, что вы можете смело подписаться и попробовать Kparser в течение месяца.
Если вы понимаете, что это не для вас, вы можете написать нам в течение 10 дней, чтобы получить полный возврат средств.
Kparser упоминается в самых надежных блогах по SEO и маркетингу
Kparser — это бесплатный инструмент, который бесплатно выполняет полный анализ ключевых слов без регистрации. — «Четыре крутых инструмента для исследования ключевых слов, которые вы можете использовать бесплатно прямо сейчас»
Kparser — это бесплатный инструмент для исследования ключевых слов, который может вам пригодиться. Это займет некоторое время, но вы будете поражены разнообразием ключевых слов, которые он возвращает. — «9Инструменты для ведения блога, которые сделают вашу работу проще»
Инструменты «Расширение ключевых слов» обычно являются первыми инструментами, к которым я обращаюсь для планирования контент-маркетинга. Существует множество отличных инструментов для исследования ключевых слов, в том числе Kparser… — «Ваше полное руководство по планированию продуктивного и информированного контент-маркетинга»
Kparser — бесплатный инструмент для исследования ключевых слов, который бесплатно создает огромные списки ключевых слов, даже не требующий входа в систему. — «Как повысить эффективность маркетинга в социальных сетях с помощью инструментов контент-маркетинга»
— «Как повысить эффективность маркетинга в социальных сетях с помощью инструментов контент-маркетинга»
Инструмент подсказки ключевых слов Amazon | Исследуйте тонны ключевых слов Amazon для SEO
Контент
- Профессиональный инструмент предложения ключевых слов для Amazon
- Почему исследования ключевых слов недостаточно для продуктов Amazon?
- Рейтинг Kparser
- Том
- Цена за клик
- Чем A9 отличается от Google?
- A9 имеет разные алгоритмы ранжирования
- Как Kparser может помочь вам найти наиболее релевантные ключевые слова Amazon для страниц ваших товаров?
- Каковы основные функции Kparser?
- Почему Kparser лучше, чем другие аналогичные инструменты Amazon для исследования ключевых слов?
- Ограниченные бесплатные планы
- Нет оценки релевантности
- Алгоритмы без оплаты за клик
- Давайте посмотрим, что ищут ваши клиенты
Профессиональный инструмент для подбора ключевых слов для Amazon
Поисковая система Amazon играет ключевую роль в том, как пользователи находят товары. Вот почему владельцы бизнеса, которые стремятся добиться успеха на этой платформе, обращают внимание на свои списки так же, как владельцы веб-сайтов обращают внимание на свои рейтинги в поисковых системах. Процесс поисковой оптимизации начинается с ключевых слов. Чтобы помочь людям найти вашу страницу, важно понимать, что они ищут. Чтобы решить эту проблему, большинство владельцев бизнеса могут использовать наш инструмент подсказки ключевых слов Amazon. Для лучшей оптимизации веб-сайта и бизнеса профессиональные специалисты используют генератор названий компаний, чтобы добавить дополнительные ключевые слова в процесс поиска названия компании.
Вот почему владельцы бизнеса, которые стремятся добиться успеха на этой платформе, обращают внимание на свои списки так же, как владельцы веб-сайтов обращают внимание на свои рейтинги в поисковых системах. Процесс поисковой оптимизации начинается с ключевых слов. Чтобы помочь людям найти вашу страницу, важно понимать, что они ищут. Чтобы решить эту проблему, большинство владельцев бизнеса могут использовать наш инструмент подсказки ключевых слов Amazon. Для лучшей оптимизации веб-сайта и бизнеса профессиональные специалисты используют генератор названий компаний, чтобы добавить дополнительные ключевые слова в процесс поиска названия компании.
Почему исследования ключевых слов недостаточно для продуктов Amazon?
Несмотря на то, что поисковая система Amazon имеет схожие характеристики с Google, у нее есть свои алгоритмы и особенности для ориентации на предпочтения аудитории, потому что люди на Amazon используют другие слова для поиска вещей, чем при поиске в Google.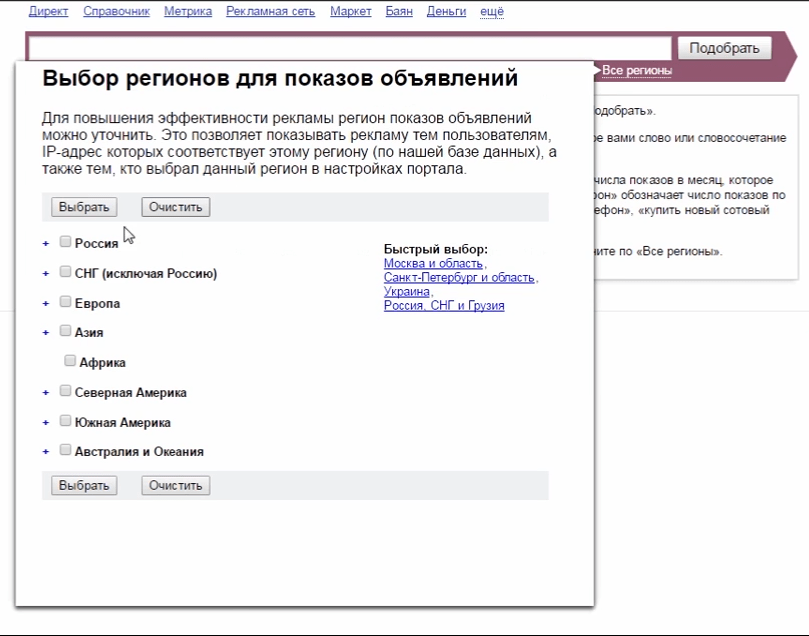 К счастью, есть альтернативный подход: использование специальных алгоритмов, разработанных специально для Amazon и оптимизации его страниц. Вот почему мы разработали бесплатный инструмент Kparser для подбора ключевых слов Amazon, инструмент, специально разработанный и настроенный для сбора ключевых слов для списков и описаний продуктов, включая Merch и Kindle. Krasper анализирует поисковые запросы, которые пользователи выполняют на платформе, и сравнивает результаты с существующим содержимым страницы. По своему дизайну он не просто собирает поисковые запросы, но сочетает процесс с инновационным аналитическим подходом, собирая наиболее релевантные короткие и длинные ключевые слова.
К счастью, есть альтернативный подход: использование специальных алгоритмов, разработанных специально для Amazon и оптимизации его страниц. Вот почему мы разработали бесплатный инструмент Kparser для подбора ключевых слов Amazon, инструмент, специально разработанный и настроенный для сбора ключевых слов для списков и описаний продуктов, включая Merch и Kindle. Krasper анализирует поисковые запросы, которые пользователи выполняют на платформе, и сравнивает результаты с существующим содержимым страницы. По своему дизайну он не просто собирает поисковые запросы, но сочетает процесс с инновационным аналитическим подходом, собирая наиболее релевантные короткие и длинные ключевые слова.
Как использовать инструмент ключевых слов Amazon?
Это просто. Все, что вам нужно сделать, это ввести название вашего продукта, ниши или области, и Kparser просмотрит сотни тысяч популярных поисковых запросов и выберет наиболее релевантные. Вам не нужен опыт в SEO или профессиональная помощь; процесс прост и может быть легко понят любым. После завершения исследования вы можете увидеть результаты, упорядоченные по рейтингу, объему и CPC (цене за клик). Давайте посмотрим, что все это значит.
После завершения исследования вы можете увидеть результаты, упорядоченные по рейтингу, объему и CPC (цене за клик). Давайте посмотрим, что все это значит.
Рейтинг Kparser
Для эффективной оптимизации страницы Amazon количество ключевых слов не так важно, как их качество. Вот почему мы стремимся не только предоставить самый широкий спектр запросов на выбор, но и убедиться, что варианты действительно актуальны. Именно поэтому мы создали алгоритм, который оценивает качество слова продавца и его релевантность искомой теме. Вот как мы определяем качество ключевых слов и их релевантность:
- Наш алгоритм анализирует существующие страницы, оптимизированные под ваши ключевые слова, и оценивает их рентабельность.
- Инструмент анализирует, как часто поиски с этими запросами конвертируются в продажи или, по крайней мере, во взаимодействие на странице (клики, прокрутки и т. д.)
- Мы объединяем популярные и непопулярные ключевые слова, чтобы предоставить вам различные возможности оптимизации вашей страницы как для конкурентных, так и для неконкурентных ключевых слов.
Том
Чтобы рассчитать объем поиска по конкретному запросу, мы создали средство проверки, которое подсчитывает количество ключевых слов, введенных только на Amazon, а не на Google или какой-либо другой платформе. В настоящее время на платформе нет поисковика ключевых слов Amazon, поэтому мы разработали собственные методы максимально точного расчета объема поиска. Наши алгоритмы ежедневно анализируют результаты поиска по сотням тысяч различных категорий и на основе исследований определяют самые популярные и релевантные запросы для конкретной ниши.
Стоимость клика
Одной из основных целей исследования ключевых слов является не только улучшение органического трафика на ваш сайт, но и определение того, какие поисковые запросы повлияют на вашу рекламу. В Kparser мы используем алгоритмы, аналогичные тем, которые использует Google Ads; единственное отличие состоит в том, что Google оценивает поисковые запросы Google, а наш инструмент исследования ключевых слов Amazon ориентирован только на поисковые запросы Amazon.
Что такое алгоритм A9 и как он работает?
A9 — это собственная поисковая система Amazon, а также собственный алгоритм, который они разработали, чтобы помочь индексировать свои страницы, контролировать результаты поиска и ранжировать продукты по определенным ключевым словам и терминам. На A9, чем чаще клиент ищет термин, а затем покупает продукт, связанный с этим словом, тем выше этот продукт будет ранжироваться в поисковой системе Amazon.
Чем A9 отличается от Google?
Одно из основных различий между Google и A9 заключается в том, что A9 использует лучшие и более сложные алгоритмы для своих поисковых систем. Во-вторых, А9имеет меньше рекламы, что дает пользователям возможность получать более высокий органический трафик без необходимости платить за продвижение.
A9 имеет разные алгоритмы ранжирования
Логично, что алгоритмы A9 тесно связаны со спецификой контента на страницах Amazon. Основными факторами ранжирования являются следующие:
Основными факторами ранжирования являются следующие:
- Перечислены и описаны релевантные ключевые слова – чем больше вопросов от клиентов вы ответите, тем выше ваши шансы получить более высокие позиции в рейтинге
- Ваш заголовок и описание должны быть оптимизированы по основным ключевым словам так же, как в Google
- Товарные списки можно оптимизировать с помощью как низкоконкурентных, так и наиболее популярных ключевых слов на Amazon, чтобы охватить более широкую аудиторию
Как вы заметили, все эти критерии включают подбор релевантных ключевых слов и оптимизацию контента под такие запросы. Вот почему использование специальных инструментов для сбора семантического ядра имеет решающее значение для успешной поисковой оптимизации A9.
Как Kparser может помочь вам найти наиболее релевантные ключевые слова Amazon для страниц ваших товаров?
Процесс поиска лучших ключевых слов с Kparser прост.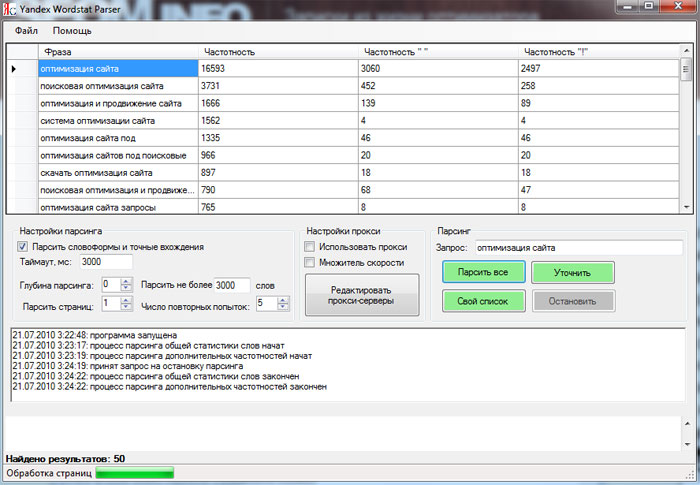 Давайте разберем это в один пошаговый контрольный список: Введите название области, в которой вы работаете. В этом примере мы ввели «разделочные доски» в качестве начального ключевого слова. Чтобы расширить поиск, взгляните на связанные темы, которые можно использовать для других поисков. Попробуйте объединить эти ключевые слова с первым, и вместе они помогут вам получить больше результатов и расширить область оптимизации. После завершения поиска экспортируйте результаты в предпочтительный формат. Это поможет вам на самом деле использовать ваши ключевые слова для прямых рекламных кампаний и аналитики. Чтобы завершить экспорт, подпишитесь на платформу и заранее выберите месячный план. Мы предлагаем вам выбрать одну из наших функций Basic, Pro и Free. Чем продвинутее план, тем больше функций вам доступно.
Давайте разберем это в один пошаговый контрольный список: Введите название области, в которой вы работаете. В этом примере мы ввели «разделочные доски» в качестве начального ключевого слова. Чтобы расширить поиск, взгляните на связанные темы, которые можно использовать для других поисков. Попробуйте объединить эти ключевые слова с первым, и вместе они помогут вам получить больше результатов и расширить область оптимизации. После завершения поиска экспортируйте результаты в предпочтительный формат. Это поможет вам на самом деле использовать ваши ключевые слова для прямых рекламных кампаний и аналитики. Чтобы завершить экспорт, подпишитесь на платформу и заранее выберите месячный план. Мы предлагаем вам выбрать одну из наших функций Basic, Pro и Free. Чем продвинутее план, тем больше функций вам доступно.
Каковы основные функции Kparser?
- У вас есть 15 источников парсинга, включая Amazon.
- Доступно 38 языков для работы с разными странами и выхода на глобальные рынки.
- Экспорт результатов и автоматическая настройка кампаний CPC в расширенной версии.
- Возможность сегментировать поиск с помощью фильтров, таких как местоположение, время, тема и т. д.

Почему Kparser лучше других подобных инструментов Amazon для исследования ключевых слов?
Это правда, что Kparser — не единственный инструмент для работы с ключевыми словами. Мы не были первыми, кто разработал алгоритмы, но мы учились на ошибках тех, кто начинал до нас, и адаптировались к современным тенденциям. Когда мы выясняли, как продвигать наши продукты на страницах Amazon, нам нужно было программное обеспечение, которое позволило бы нам быстро и прозрачно собирать ключевые слова для оптимизации страницы, а также давало нам представление об их релевантности и популярности. Однако у других существующих сервисов было несколько критических недостатков. что мешало полагаться на них каждый день.
Ограниченные бесплатные планы
Первой проблемой, с которой мы столкнулись, была высокая стена ограничений для неоплачиваемых предложений.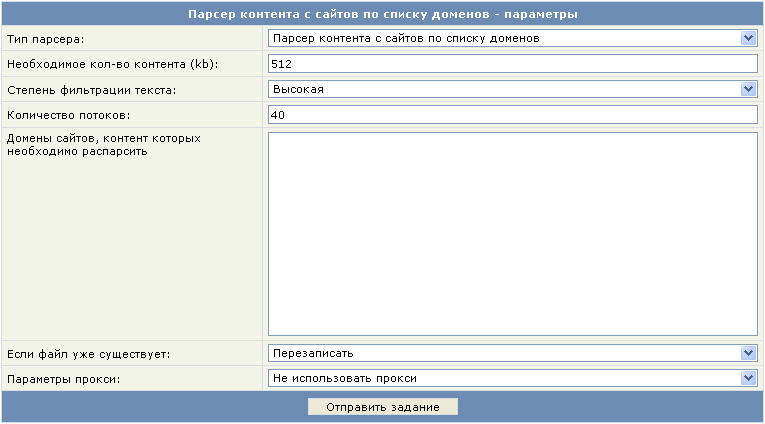 Если вы хотели изучить, отфильтровать и экспортировать результаты, необходимо было заплатить. Бесплатные версии позволяли нам только просматривать результаты, и это, очевидно, не давало нам полной картины возможных поисковых запросов. Вот почему мы решили создать Kparser на основе стратегии Freemium, где бесплатная версия продукта имеет все необходимые функции, чтобы сделать его удобным инструментом для исследований. Да, некоторые функции немного ограничены, но это полностью рабочий инструмент, готовый к использованию от начала до конца процесса.
Если вы хотели изучить, отфильтровать и экспортировать результаты, необходимо было заплатить. Бесплатные версии позволяли нам только просматривать результаты, и это, очевидно, не давало нам полной картины возможных поисковых запросов. Вот почему мы решили создать Kparser на основе стратегии Freemium, где бесплатная версия продукта имеет все необходимые функции, чтобы сделать его удобным инструментом для исследований. Да, некоторые функции немного ограничены, но это полностью рабочий инструмент, готовый к использованию от начала до конца процесса.
Нет оценки релевантности
Допустив собственные ошибки и неудачи, мы обнаружили, что собранные нами ключевые слова на самом деле не релевантны продвигаемому продукту. Это связано с тем, что большинство существующих инструментов ориентированы на количество ключевых слов, а не на их качество. Kparser rank устраняет эту проблему, анализируя возможные последствия использования ключевого слова на странице продукта. Вы используете рекомендуемые поисковые запросы, которые уже были оценены как релевантные для ваших продуктов.
Вы используете рекомендуемые поисковые запросы, которые уже были оценены как релевантные для ваших продуктов.
Алгоритмы без оплаты за клик
Имея большой опыт использования Google Ads в качестве основного инструмента исследования, мы знаем, насколько удобно, когда инструмент исследования ключевых слов Amazon может автоматически настроить рекламную кампанию. Существующие инструменты либо вообще не имели таких функций, либо были недостаточно развиты. Когда мы создавали Кпарсер, мы сосредоточились на решении этих задач и дали возможность создать прямую рекламную кампанию, а также спрогнозировать ее стоимость и результат. Планирование, управление и исполнение — все в одном пакете.
Давайте посмотрим, что ищут ваши клиенты
Теперь, когда вы знакомы с продуктом, пришло время увидеть Kparser в действии. Просто введите название ниши вашего продукта, и пусть инструмент сделает всю работу за вас. Это займет всего несколько секунд, и вы узнаете интересы своих клиентов и получите информацию для оптимизации и вашей рекламной кампании.
Пришло время начать исследование ключевых слов для продуктов Amazon или eBay с помощью Kparser!
Это займет всего несколько секунд, и вы узнаете интересы своих клиентов и получите информацию для оптимизации и вашей рекламной кампании.
Пришло время начать исследование ключевых слов для продуктов Amazon или eBay с помощью Kparser!
Подписаться на генератор ключевых слов Kparser
Базовый
26,00 $/м
Неограниченное количество ключевых слов Количество результатов по ключевым словам в месяц.
18 источников парсинга Парсим ключевые слова в реальном времени из Google, Bing, Amazon, Youtube, Ebay и т.д.
38 языков Есть ли в других инструментах корейский язык? Вам так повезло, что мы это делаем, как и 37 других языков 😊
248 регионов Выберите нужный язык и регион, просматривайте данные в реальном времени, сделайте поиск ключевых слов прибыльным.
Расширенный поиск по ключевым словам Прежде чем начать поиск по ключевым словам, не забудьте указать свои предпочтения. Это помогает сделать ваше исследование ключевых слов более точным.
Группировка ключевых словВсе найденные ключевые слова группируются для упрощения дальнейшей кластеризации ключевых слов.
2000 результатов экспорта (.csv) Простой способ экспорта ключевых слов в формате .csv для дальнейшего использования.
2000 результатов скопировать в буфер обмена Просто выберите нужные ключевые слова и нажмите «Копировать в буфер обмена».
Подпишитесь сейчас
Лучшая цена
Аккаунт Pro
$61.00/м
Неограниченное количество ключевых слов Количество результатов ключевых слов в месяц.
18 источников парсинга Мы парсим ключевые слова в реальном времени из Google, Bing, Amazon, Youtube, Ebay и т. д.
38 языков Есть ли в других инструментах корейский язык? Вам так повезло, что мы это делаем, как и 37 других языков 😊
248 регионов Выберите нужный язык и регион, просматривайте данные в реальном времени, сделайте поиск ключевых слов прибыльным.
Расширенный поиск по ключевым словам Прежде чем начать поиск по ключевым словам, не забудьте указать свои предпочтения. Это помогает сделать ваше исследование ключевых слов более точным.
Группировка ключевых словВсе найденные ключевые слова группируются для облегчения дальнейшей кластеризации ключевых слов.
Неограниченное количество результатов экспорта (.csv) Простой способ экспорта ключевых слов в формате .csv для дальнейшего использования.
Неограниченное копирование результатов в буфер обмена Просто выберите нужные ключевые слова и нажмите «Копировать в буфер обмена».
Данные об объеме поиска Количество точных поисков по ключевому слову. Это помогает определить, насколько популярно ключевое слово среди пользователей.
Цена за клик за клик.
Минус-слова Легко исключить ключевые слова или группы ключевых слов из вашего исследования.
Подписаться сейчас
Запуск
$30.00/м
Неограниченное количество ключевых слов Количество результатов по ключевым словам в месяц.
18 источников парсинга Парсим ключевые слова в реальном времени из Google, Bing, Amazon, Youtube, Ebay и т. д.
38 языков Есть ли в других инструментах корейский язык? Вам так повезло, что мы это делаем, как и 37 других языков 😊
248 регионов Выберите нужный язык и регион, просматривайте данные в реальном времени, сделайте поиск ключевых слов прибыльным.
Расширенный поиск по ключевым словам Прежде чем начать поиск по ключевым словам, не забудьте указать свои предпочтения. Это помогает сделать ваше исследование ключевых слов более точным.
Группировка ключевых словВсе найденные ключевые слова группируются для упрощения дальнейшей кластеризации ключевых слов.
Неограниченное количество результатов экспорта (.csv) Простой способ экспорта ключевых слов в формате .csv для дальнейшего использования.
Неограниченное копирование результатов в буфер обмена Просто выберите нужные ключевые слова и нажмите «Копировать в буфер обмена».
Подписаться
10-дневная гарантия возврата денег
Мы предоставляем 10-дневную гарантию возврата денег. Это означает, что вы можете смело подписаться и попробовать Kparser в течение месяца.
Если вы понимаете, что это не для вас, вы можете написать нам в течение 10 дней, чтобы получить полный возврат средств.
Kparser упоминается в самых надежных блогах по SEO и маркетингу
Kparser — это бесплатный инструмент, который бесплатно выполняет полный анализ ключевых слов без регистрации. — «Четыре крутых инструмента для исследования ключевых слов, которые вы можете использовать бесплатно прямо сейчас»
Kparser — это бесплатный инструмент для исследования ключевых слов, который может вам пригодиться. Это займет некоторое время, но вы будете поражены разнообразием ключевых слов, которые он возвращает. — «9Инструменты для ведения блога, которые сделают вашу работу проще»
Инструменты «Расширение ключевых слов» обычно являются первыми инструментами, к которым я обращаюсь для планирования контент-маркетинга. Существует множество отличных инструментов для исследования ключевых слов, в том числе Kparser… — «Ваше полное руководство по планированию продуктивного и информированного контент-маркетинга»
Kparser — бесплатный инструмент для исследования ключевых слов, который бесплатно создает огромные списки ключевых слов, даже не требующий входа в систему. — «Как повысить эффективность маркетинга в социальных сетях с помощью инструментов контент-маркетинга»
Анализ на
Выбор метода анализа
В этом разделе рассказывается, как выбрать подходящий метод анализа при определении анализатора.
▪Ключевое слово
▪Абзац
▪Таблица
▪Фильтр
▪Скрипт
Ключевое слово
Пример. Используйте метод Keyword для анализа номера версии.
1.Введите команду show version и получите образцы данных на странице редактора парсера.
2.Выделите номер версии точно в образце данных и щелкните Определить ключевое слово в плавающем меню.
3. В диалоговом окне синтаксического анализатора ключевых слов будут автоматически определены как шаблон синтаксического анализатора, так и тип переменной. Переименуйте переменную с var1 на Version.
4.Нажмите Сохранить переменную. Эта переменная будет отображаться в дереве переменных.
Paragraph
Метод Paragraph используется для анализа данных с несколькими экземплярами, таких как коллизии и ошибки CRC для каждого интерфейса в возвращаемых выходных данных команды show interface.
Пример. Используйте метод Paragraph для анализа MTU интерфейса.
1.Введите команду show interface и получите образцы данных на странице редактора анализатора. Пример вывода выглядит следующим образом:
Bos-Core1-Tr>show interface
Vlan1 включен, линейный протокол включен
Аппаратное обеспечение — EtherSVI, адрес — 0024.1358.1540 (bia 0024.1358.1540)
КБбит 0 байт 1500 , DLY 10 мкс,
………….
Vlan10 включен, протокол линии включен
Оборудование — EtherSVI, адрес — 0024.1358.1542 (bia 0024.1358.1542)
Интернет-адрес: 10.83.10.254/24
MTU 1500 байт, BW 1000000 Кбит, DLY 10 мкс,
…………
2.Выделите значение MTU 1500 в образце данных и нажмите Определите ключевое слово в плавающем меню. Появится диалоговое окно анализатора ключевых слов.
3. Нажмите «Определить переменную» в разделе «Абзацы» во всплывающем диалоговом окне, чтобы перейти в диалоговое окно «Синтаксический анализ абзацев».
Совет. Анализатор абзацев используется, когда выходные данные команды соответствуют ключевому слову несколько раз, и каждое ключевое слово имеет одинаковое форматирование абзаца, например, начиная с …is…, line protocol is.
4. Укажите идентификатор абзаца, чтобы определить начало нового абзаца для каждой переменной.
1)Выделите Vlan 1 включен, протокол линии и щелкните Set Paragraph Identifier в плавающем меню.
2) Идентификатор абзаца включает в себя ключевые слова, которые всегда одинаковы, и выборочные значения, которые изменяются. Замените его на $intf is $status, протокол линии.
3) Нажмите клавишу Enter на клавиатуре, чтобы применить идентификатор абзаца.
5. Переименуйте переменную с var1 на MTU.
6. Дополнительно: Настройте дополнительные параметры.
Нажмите «Дополнительно», чтобы настроить дополнительные параметры: 1) Чтобы дополнительно разделить абзац вручную, используйте один из следующих двух способов: ▪Введите конечное ключевое слово абзаца и выберите, следует ли исключить конечную строку в абзаце. ▪Установите флажок Задать _ строк как абзац и введите количество строк, которые вы хотите включить после строки переменной. 2)Чтобы заполнить пустую переменную, скопировав значение последней переменной, вы можете включить последний флажок и выбрать применяемую переменную из выпадающего меню. 3)Нажмите OK. |
|---|
7.Нажмите Сохранить переменную.
Эта переменная MTU будет отображаться под синтаксическим анализатором абзаца в дереве переменных.
Таблица
Метод таблицы используется для анализа данных в табличном формате, таких как таблица NDP.
Пример. Используйте метод Table для анализа соседей OSPF устройства.
1.Введите команду show ip ospf Neighbour и получите образцы данных на странице редактора синтаксического анализатора. Выбор вывода выглядит следующим образом:
BST, POP1> Показать IP OSPF Nogence
Соседний ID PRI Wation Dead Time Adder Interface
172.24.255.9 1 Full/-00:00:32 172. 24.33.140 Serial0
172.24.255.10 1 Full/ DR 00:00:32 172.24.32.6 Ethernet1
172.24.31.2 1 FULL/ — 00:00:39 172.24.32.1 Serial1
2.Выделите таблицу в образце данных и щелкните Определить таблицу в плавающем меню. Диалоговое окно Table Parser предлагает заголовки таблиц, идентифицированные как переменные.
3.Необязательно: Настройте дополнительные параметры.
Нажмите «Дополнительно», чтобы настроить дополнительные параметры: 1)Выберите способ выравнивания данных таблицы или способ разделения столбца, если он не отформатирован в виде таблицы: ▪Выравнивание по левому краю — выравнивание данных таблицы по левому краю. 9$.3) Чтобы игнорировать несколько первых строк данных таблицы, вы можете установить флажок Пропустить _ строки из заголовка и ввести количество строк. 4)Чтобы заполнить пустое значение переменной, скопировав значение последней переменной, вы можете включить последний флажок и выбрать применяемую переменную из выпадающего меню. |
|---|
4.Нажмите Сохранить переменную. Переменные будут отображаться под синтаксическим анализатором таблицы в дереве переменных.
Фильтр
Метод Фильтр используется для фильтрации данных на основе условий.
Пример. Используйте метод Filter для анализа пассивных интерфейсов протокола маршрутизации.
1.Введите команду show ip protocols и получите образцы данных на странице редактора парсера.
2. Определите начальную и конечную строки содержимого, которое необходимо отфильтровать, выделите интересующее вас содержимое (информация о начальной и конечной строках должна быть включена) и нажмите «Определить фильтр» в плавающем меню.
3. В диалоговом окне Filter Parser автоматически определяются и заполняются начальная и конечная строки. Переименуйте переменную с filter1 на eigrp_passive.
4.Необязательно: Настройте дополнительные параметры.
Нажмите Дополнительно, чтобы настроить условия для фильтра: 1) Выберите «Содержит» или «Не содержит» в раскрывающемся меню и введите ниже ключевое слово. 2)Выберите метод фильтрации: ▪Отфильтровать все совпадающие строки — адресовать все совпадения в пределах области фильтра; если флажок не установлен, фильтр остановится, как только будет найдено первое совпадение. ▪Исключить начальную строку — убрать начальную строку из области фильтра. ▪Исключить конечную строку — убрать конечную строку из области действия фильтра. 3)Нажмите OK. |
|---|
5.Нажмите Сохранить переменную.
Этот синтаксический анализатор фильтров будет отображаться под деревом переменных.
6.Добавьте синтаксический анализатор вложенных таблиц под синтаксический анализатор фильтров:
1) Выберите узел Фильтр($eigrp_passive) в дереве синтаксических анализаторов и выберите Таблица.
2)Введите пассивные_интерфейсы в поле Имя.
3)Введите заголовок таблицы Пассив в поле Заголовок.
4) Нажмите «Применить», и таблица узла ($passive_interfaces) будет добавлена под узлом «Фильтр» ($eigrp_passive).
Сценарий
Метод сценария гораздо более гибкий и обычно используется для сложных случаев конфигурации. Следующий пример — определение простого синтаксического анализатора сценариев.
1. Получить образец данных файла конфигурации.
2.Выберите «Сценарий» и введите сценарий Python.
3.Нажмите Добавить парсер. Парсер скрипта отобразится в дереве переменных.
Библиотека sXML — Анализ — Документация по ключевым словам ABAP
SAP NetWeaver AS ABAP, выпуск 750, © Copyright 2016 SAP AG. Все права защищены.
ABAP — Документация по ключевым словам → ABAP – Справочник → Интерфейсы данных и коммуникационные интерфейсы → ABAP и XML → Библиотеки классов для XML → библиотека sXML →
Библиотека sXML — разбор
XML-данные можно прочитать с помощью библиотеки sXML или просто проверить их синтаксис, связав их со средством чтения XML и его методами. Читатель, подобный этому, является «проверочным», что означает, что недопустимые данные XML вызывают
исключение. Он интерпретирует XML-данные как иерархическую древовидную структуру, в которой каждый токен представлен узлом, однозначно назначенным подузлу (см.
Информационный набор W3C). Например, элемент с литеральным значением интерпретируется следующим образом:
- |
|—CO_NT_ELEMENT_OPEN
| |
| |—CO_NT_VALUE
|
|—CO_NT_ELEMENT_CLOSE
Значение является подузлом узла, представляющего открытый элемент. Имена узлов здесь то же, что и константы интерфейса IF_SXML_READER, описывающие тип узла. Атрибуты элемента имеют особую задачу. Они назначаются в виде списка узел с типом CO_NT_ELEMENT_OPEN и может быть достигнут с помощью специальных методов, когда синтаксический анализатор останавливается на открытом элементе.
Доступные классы и интерфейсы в библиотеке sXML
для синтаксического анализа XML-данные организованы таким образом, что существуют отдельные классы чтения XML для различных требований. Эти классы наследуются от абстрактного суперкласса CL_SXML_READER.
абстрактный суперкласс содержит реализации функций, необходимых всем читателям, и включает в себя интерфейс
IF_SXML_READER, который содержит компоненты, общие для всех читателей. Этот
Интерфейс обеспечивает одинаковый доступ ко всем считывателям. Если необходимо получить доступ к специальным компонентам, которые не объявлены в интерфейсе, для рассматриваемого класса необходимо использовать приведение вниз.
Специализированные классы читателей:
- CL_SXML_STRING_READER
- Читатели в этом классе анализируют XML-данные в байтовой строке.
- CL_SXML_TABLE_READER
- Читатели в этом классе анализируют XML-данные во внутренней таблице с плоским байтовым типом строки.
- CL_SXML_DATASET_READER
- Читатели этого класса анализируют XML-данные в файле на сервере приложений.
- CL_SXML_HTTP_READER
- Читатели этого класса анализируют XML-данные из службы HTTP в ICF.
- CL_SXML_XOP_READER
- Читатели этого класса анализируют XML-данные, сохраненные в формате XOP.
XML-данные, ожидающие анализа, передаются фабричному методу CREATE каждого модуля чтения. Читатели обнаруживают формат и формат символов самих данных. За исключением считывателя XOP, считыватели поддерживают все форматы, кроме XOP. Считыватель XOP поддерживает только формат XOP. Инструкции по стандартизации и обработке пустого пространства могут быть переданы фабричному методу, если это разрешено форматом.
Методы интерфейса IF_SXML_READER позволяют последовательно анализировать передаваемые XML-данные. Есть два основных способа сделать это:
- Разбор на основе токенов
- Анализ на основе объектов
Средство чтения нельзя использовать более одного раза для одних и тех же данных XML или для других данных. Положение для чтения
читателя контролируется при разборе с использованием его методов. Действия, разрешенные считывателем, указаны
по его текущей позиции чтения. Например, программа чтения, расположенная в конце проанализированных XML-данных, может
больше нельзя использовать в качестве XML-источника оператора CALL TRANSFORMATION. Не существует метода, который может восстановить считыватель в исходное состояние. Вместо этого создается новый считыватель.
Заметки
- Анализатор в библиотеке sXML является более строгим средством проверки, чем анализатор в iXML-библиотека. Префикс пространства имен должен быть объявлен в том же элементе или в суперэлементе. Предшествующие объявления в параллельном элементе интерпретируются как ошибки.
- Средство чтения XML в библиотеке sXML может быть указано как источник XML оператора
ПРЕОБРАЗОВАНИЕ ЗВОНКА. Это позволяет выполнять преобразования для всех источников, поддерживаемых считывателями SXML, во всех поддерживаемых форматах.
форматы. В частности, это позволяет
Данные JSON также будут напрямую использоваться объектами данных ABAP.
- Метод SKIP_NODE, который можно использовать как в токенизированном, так и в объектно-ориентированном анализе, предлагает различные простые способы проверки правильности поддерева или дерева или копирования дерева в устройство записи (которое изменяет его формат).
- Если содержимое элементов или атрибутов содержит обозначения <, >, &, " или ', они автоматически преобразуются в соответствующие символов при разборе.
Пример
Преобразование из XML Reader.
Продолжить
Библиотека sXML, анализ на основе токенов
Библиотека sXML — объектно-ориентированный анализ
PARSER (CCP4: Library) — документация CCP4Docs
ИМЯ
синтаксический анализатор — библиотека подпрограмм синтаксического анализатора CCP4
ОПИСАНИЕ
Начиная с CCP4 5.0, основная обработка входных данных выполняется набором C
функции. Отдельная документация
описывает используемые структуры и функции, а также API для C/C++
программы.
Для программ на Фортране исходный набор подпрограмм (хранящийся в parser.f ) в основном заменен
интерфейс к библиотеке C. От
с точки зрения разработчика приложений, этот интерфейс должен быть
идентичен исходному набору подпрограмм. Этот документ исходит
из исходной библиотеки Fortran, но должен быть применим к новой
библиотека.
Модуль PARSER библиотеки CCP4 содержит подпрограммы, которые в основном используется для «свободного» «ключевого» ввода управляющих данных для программ. Большинство программ имеют цикл по входным записям, которые изначально подпрограмма PARSER для их токенизации и извлечения начальное ключевое слово. PARSER может справиться с продолжением, комментированием входные строки и включенные файлы. Он вызывает PARSE для токенизации отдельные записи, и PARSE иногда полезен сам по себе. компенсировать отсутствие внутренних операций чтения в свободном формате в Fortran 77 стандарт. Подробности смотрите в записях ниже.
См. также библиотеку keyparse, которая является оболочкой
подпрограммы для подпрограмм синтаксического анализатора, предназначенные для облегчения чтения
ввод с ключевыми словами.
Содержимое
Общие ключевые слова
Команды выбора атома
Список подпрограмм
Описание подпрограмм
Общие ключевые слова
Библиотека содержит подпрограммы для декодирования параметров, следующих за «стандартные» ключевые слова программы:
-
СИММЕТРИЯ< номер > | < имя > | < операторов > Задает симметрию с точки зрения либо < номер > номер пробела например.
19; < имя > имя пространственной группы например.P212121; < операторов > явных операторов симметрии например. « X,Y,Z * 1/2-X,-Y,1/2+Z * 1/2+X,1/2-Y,-Z * -X,1/2+Y,1/2 -Z« (См. RDSYMM)-
РЕЗОЛЮЦИЯ< limit > [ < limit > ] Задает пределы разрешения. Если указан только один предел, верхний предел, в противном случае верхний и нижний пределы могут быть в любой порядок.
Они находятся в Å , если только они оба < 1,0, в которых
случае они указаны в единицах 4sin 2 (тета)/(лямбда): sup: 2 .
(См. RDRESL и RDRESO)-
ЯЧЕЙКАа б в [ альфа бета гамма ] Задает размеры ячейки (в Å) и, при необходимости, углы в градусах (по умолчанию 90 или ). (См. RCELL)
-
ЗАГОЛОВОК НЕТ | КРАТКИЙ ОБЗОР | ИСТОР | ПОЛНЫЙ Управляет печатью информации МТЗ как: НЕТ без вывода заголовка BRIEF вывод краткого заголовка HIST бриф, с историей МТЗ FULL Полный вывод заголовка из чтения MTZ. (См. RDHEAD)
- «МАСШТАБ… «
См. RDSCAL.
Существуют также подпрограммы для извлечения действительных и целых чисел из полей.
Команды выбора атома
В настоящее время PARSER поддерживает только один синтаксис команды выбора атома, с
подпрограмма RDATOMSELECT. Это будет декодировать строки
со следующим типом команд выбора атома:
Ключевые слова... ATOM
Это основано на синтаксисе, используемом при выборе атома в DISTANG. Для В целях декодирования команд выбора предшествующие ключевые слова не имеющий отношения.
На практике описанный выше синтаксис предназначен для например:
... АТОМ 1 ДО 1000 ... АТОМ 7 9 ... АТОМ 10 ... ОСТАТОК 11 ДО 22 ... ОСТАТОК 10 ЦЕПЬ А ... ОСТАТОЧНАЯ ЦЕПЬ S CA 12 19
Выбор будет указывать диапазон номеров атомов или номера остатков. В последнем случае его также можно опционально использовать для укажите идентификатор цепочки (один символ) и/или «тип атома» ключевое слово выбора:
ВСЕ все типы атомов в выбранном диапазоне ONS только кислород и азот в выбранном диапазоне CA только атомы углерода в выбранном диапазоне
(Обратите внимание, что RDATOMSELECT также может обрабатывать ALL/ONS/CA как недопустимый
ввода, что может быть уместно в некоторых приложениях. )
Порядок подаргументов RESIDUE является гибким, так что ОСТАТОК 1-9 CA CHAIN B такой же, как ОСТАТОК CA CHAIN B 1 TO 9 и так далее.
Для примеров см. DISTANG и КОНТАКТ.
Список подпрограмм
Библиотека parser.f содержит следующие подпрограммы:
Подпрограмма (список аргументов) | Комментарии |
|---|---|
ПАРСЕР считывать и интерпретировать данные из входной поток | |
РАЗБОР подпрограмма чтения в свободном формате | |
ПАРСДЛ изменить разделители | |
КЕЙНУМ проверить количество числовых полей | |
[КЕЙЕРР] — внутренняя подпрограмма (KEYNUM) | |
[CHKNUM] — не используется (сентябрь 1993 г.) | |
[ ЧКТОК ] — внутренний (ЧКНУМ) | |
[ ГЕТРЕА ]
— не используется (сентябрь 1993 г. | |
[ ПОЛУЧИТЬ ] — не используется (сентябрь 1993 г.) | |
ГТНРЕА извлечь вещественные числа из ввода | |
GTNINT извлечь целые числа из ввода | |
ГПРЕА извлечь единственное реальное число | |
GTPINT извлечь одно целое число | |
[ ГЕТСТР ] — не используется (сентябрь 1993 г.) | |
ПУСТО пустые символы в массиве | |
[GCFLD] — не используется (сентябрь 1993 г.) | |
[ КПИКПЧ ] — не используется (сентябрь 1993 г.) | |
[ ПЕРЕМЕЩЕНИЕ ] — не используется (сентябрь 1993 г.) | |
КЛЮЧ проверить ключевое слово по списку | |
ПУТЛИН фиктивная рутина? | |
ПУСТОЙ поставить пустые строки для вывода | |
ЛЕРРОР общая процедура сообщения об ошибках | |
RDSYMM прочитать ключевое слово «симметрия» | |
RDHEAD прочитать ключевое слово «заголовок» | |
РДЦЕЛЛ прочитать ключевое слово «ячейка» | |
РДРЕСО прочитать ключевое слово «разрешение» | |
РДСКАЛ читать ключевое слово «масштаб» | |
РДРЕСЛ чтение и декодирование пределов «разрешения» | |
RDATOMSELECT читать и декодировать выбор атома ключевые слова | |
ГТТРЭА извлечь реальное число | |
ГТТИНТ извлечь целое число | |
СМАТЧ сравнить символы в строке |
Описание подпрограмм
ПАРСЕР
ПОДПРОГРАММА PARSER (KEY, LINE, IBEG, IEND, ITYP, FVALUE, CVALUE, IDEC, NTOK, LEND, PRINT)
Нормальным поведением является чтение данных с ключевыми словами из входного потока,
и интерпретировать его. Это тот случай, когда строка LINE изначально пуста. Поток 5
является стандартным входным потоком, но строка, начинающаяся с @
Каждая логическая «карта» может быть продолжена на следующей строке продолжением символы `&’, `-’ или `\’ в конце строки: этот символ исключено из списка и возвращено в вызывающую процедуру.
Могут присутствовать завершающие комментарии после символа «#» или «!»: любой символ продолжения (`&’, `-‘ или `\’) должен ПРЕДШЕСТВОВАТЬ символ комментария – комментарии не могут быть продолжены. Полный (продолжение) строка без комментариев возвращается в LINE. Линии содержащие ТОЛЬКО комментарии (или пустые), не будут возвращены из этого рутина – чтение продолжится.
Строки могут быть заключены в кавычки или не заключены в кавычки. См. также PARSE для получения подробной информации о токене. разделители и т. д.
В качестве альтернативы, если строка LINE не пуста, она будет интерпретирована до
возможно чтение дополнительных данных на стандартном вводе, если LINE заканчивается символом
характер продолжения.
Аргументы
KEY (O) CHARACTER*4 Ключевое слово в начале строки (если присутствует),
в верхнем регистре перед возвратом.
LINE (I/O) CHARACTER*(*) Проанализируйте эту входную строку. Если пусто читать
строки из блока 5. LINE будет обновлена до
содержать всю прочитанную строку, включая
продолжения.
IBEG (O) INTEGER(*) Массив размером не менее NTOK.
1-й столбец количество жетонов в поле
IEND (O) INTEGER(*) Массив размером не менее NTOK.
Количество токенов в последнем столбце поля
ITYP (O) INTEGER(*) Массив размером не менее NTOK.
=0 нулевое поле
=1 символьная строка
=2 число
FVALUE (O) REAL(*) Массив размером не менее NTOK.
Значение числа.
CVALUE (O) CHARACTER(*)*4 Массив размером не менее NTOK.
Строка символов (первые 4 символа),
как для чисел, так и для строк.
Элементы в FVALUE и CVALUE остаются без изменений для нулевых полей.
IDEC (O) INTEGER(*) Массив размером не менее NTOK.
Количество «цифр»:
для строки, количество символов (=4, если.gt.4)
для целого числа, количество цифр
для реального числа,
(количество цифр до точки+1)*100
+количество цифр после точки
NTOK (I/O) INTEGER При вводе задает максимальное количество полей
для анализа (если <20, то по умолчанию 20)
На выходе возвращает количество проанализированных полей.
ЛЕНД (О) ЛОГИЧЕСКИЙ .ЛОЖЬ. для контрольной карты
.ПРАВДА. для конца файла
ПЕЧАТЬ (I) ЛОГИЧЕСКИЙ .ИСТИНА. эхо-линия на блок 6 через PUTLIN
. ЛОЖНЫЙ. не повторяй
РАЗБОР
ПОДПРОГРАММА РАЗБОР (СТРОКА, IBEG, IEND, ITYP, FVALUE, CVALUE, IDEC, N)
Процедура чтения в произвольном формате. Это действительно сканер, а не парсер. Это сканирует LINE на N токенов, которые разделены разделителями и обновляет информационные массивы для каждого, как показано ниже. По умолчанию разделители – пробел, табуляция, запятая и знак равенства; их можно изменить с помощью ПАРСДЛ. Смежные запятые ограничивают пустые поля (то же, что и пустые поля). струны). Строки могут быть не заключены в кавычки или заключены в одинарные или двойные кавычки, если они не содержат разделителей, но должны быть окружены разделителями, чтобы признанный. Это позволяет читать буквальные кавычки, например. «аб» в» будет распознается как токен ‘ab’c’. Без кавычек `!’ или `#’ в LINE вводит завершающий комментарий, который игнорируется.
Аргументы:
LINE (I) CHARACTER*(*) Строка для анализа
N (I/O) INTEGER Обычно <0, когда abs(N) является максимальным
количество полей для интерпретации и должны
be <= размеры массива. Если N>0 это
количество токенов, прочитанных на данный момент,
предназначен для строк продолжения с PARSER.
Возвращает количество просканированных полей или 0, если
строка пуста или содержит только комментарий
Для I=1,N:
IBEG(I) (O) INTEGER(*) Номер 1-го столбца в поле
IEND(I) (O) INTEGER(*) номер последнего столбца в поле
ITYP(I) (O) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
FVALUE(I) (O) REAL(*) Значение числа. Используйте NINT(FVALUE(I)) для
извлечь целое число.
CVALUE(I) (O) CHARACTER(*)*4 Строка символов (первые 4 символа)
как для чисел, так и для строк
Элементы в FVALUE и CVALUE остаются без изменений для нулевых полей.
IDEC(I) (O) INTEGER(*) Количество «цифр»
для строки, количество символов (=4, если. gt.4)
для целого числа, количество цифр
для реального числа,
(количество цифр до точки+1)*100
+количество цифр после точки
ПАРСДЛ
ПОДПРОГРАММА PARSDL(NEWDLM,NNEWDL,NSPECD)
Вызов для изменения разделителей, используемых PARSE(R)
NEWDLM (I) CHARACTER*(*) Массив, содержащий новые разделители NNEWDL
NNEWDL (I) INTEGER Количество новых разделителей.
Если .ле. 0, сбросить разделители на стандартные
установлен по умолчанию (в DDELIM).
NSPECD (I) INTEGER Количество специальных разделителей,
не может разграничивать нулевое поле. Это
в начале массива разделителей.
(по умолчанию в NDSDLM)
КЕЙНУМ
ПОДПРОГРАММА KEYNUM(N,NSTART,LINE,IBEG,IEND,ITYP,NTOK)
Проверить наличие правильного количества цифр (числовых полей)
Аргументы:
N (I) INTEGER Ожидаемое количество последовательных числовых полей
NSTART (I) INTEGER Номер первого поля для проверки
LINE (I) CHARACTER*(*) Массив, содержащий поля
IBEG (I) INTEGER(*) Количество полей в первом столбце (из PARSER)
IEND (I) INTEGER(*) Число полей в последнем столбце (из PARSER)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
(из ПАРСЕРА)
NTOK (I) INTEGER Количество полей (из PARSER)
ГТНРЕА
ПОДПРОГРАММА GTNREA(N,M,X,NTOK,ITYP,FVALUE)
Извлечь M действительных чисел X, начиная с N-го значения массива Parser
FVALUE, если возможно. Если нет значения, X = 0.0 . Если незаконно, напишите сообщение.
Аргументы:
N (I) INTEGER Номер 1-го элемента FVALUE для извлечения
M (I) INTEGER Количество извлекаемых элементов
X (O) REAL(M) Поместить извлеченные элементы в этот массив
NTOK (I) INTEGER Общее количество полей (из PARSER)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
FVALUE (I) REAL(*) Массив чисел для извлечения (из PARSER)
GTINTINT
ПОДПРОГРАММА GTNINT(N,M,J,NTOK,ITYP,FVALUE)
Извлечь M целых чисел J, начиная с N-го значения массива парсера FVALUE, если возможный. Если нет значения, J = 0 . Если незаконно, напишите сообщение
Аргументы:
N (I) INTEGER Номер 1-го элемента FVALUE для извлечения
M (I) INTEGER Количество извлекаемых элементов
J (O) INTEGER(M) Поместить извлеченные элементы в этот массив
NTOK (I) INTEGER Общее количество полей (из PARSER)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
FVALUE (I) REAL(*) Массив чисел для извлечения (из PARSER)
ГПРЕА
ПОДПРОГРАММА GTPREA(N,X,NTOK,ITYP,FVALUE)
Извлечь вещественное число X из N-го значения Массив парсера FVALUE, если это возможно. Если нет значения, оставьте X без изменений. Если незаконно, напишите сообщение
Аргументы:
N (I) INTEGER Номер 1-го элемента FVALUE для извлечения
X (O) REAL Извлеченное число помещается сюда
NTOK (I) INTEGER Общее количество полей (из PARSER)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
FVALUE (I) REAL(*) Массив чисел для извлечения (из PARSER)
GTPINT
ПОДПРОГРАММА GTPINT(N,I,NTOK,ITYP,FVALUE)
Извлечь целое число I из N-го значения Массив парсера FVALUE, если возможно Если нет значение, оставьте I без изменений. Если незаконно, напишите сообщение
Аргументы:
N (I) INTEGER Номер 1-го элемента FVALUE для извлечения
I (O) INTEGER Извлеченное число помещаем сюда
NTOK (I) INTEGER Общее количество полей (из PARSER)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
FVALUE (I) REAL(*) Массив чисел для извлечения (из PARSER)
ПУСТО
ПОДПРОГРАММА SBLANK (МАССИВ, N1, N2)
Пустые символы с N1 по N2 в МАССИВЕ
Аргументы:
МАССИВ (ВВОД-ВЫВОД) СИМВОЛОВ(*) N1 (I) ЦЕЛОЕ ЧИСЛО N2 (I) ЦЕЛОЕ ЧИСЛО
СМАТЧ
ЛОГИЧЕСКАЯ ФУНКЦИЯ CMATCH(STRING1,STRING2,NCHAR)
Сравните символ nchar в строках string1 и string2, верните cmatch . true. если
все совпадают, иначе .false.
Аргументы:
STRING1 (I) CHARACTER*(*) 1-я строка для сравнения STRING2 (I) CHARACTER*(*) 2-я строка для сравнения NCHAR (I) INTEGER количество символов для сравнения
КЛЮЧ
ПОДПРОГРАММА CHKKEY(KEY,WORDS,NWORDS,IKEY)
Проверить ключевое слово KEY по списку NWORDS возможных ключевых слов в WORDS. Разрешает использование сокращенных или расширенных ключей при условии, что они не являются двусмысленными.
Аргументы:
KEY (I) CHARACTER*(*) Ключевое слово для проверки
WORDS (I) CHARACTER(NWORDS)*(*) Список возможных ключевых слов
NWORDS (I) INTEGER Количество ключевых слов в WORDS
IKEY (I/O) INTEGER = '?', список всех слов
Возвращает:
= номер найденного ключевого слова (.gt.0)
= 0, если не найдено или null
= -1, если неоднозначно
ПУТЛИН
ПОДПРОГРАММА PUTLIN(STROUT,OUTWIN)
Это муляж ПУТЛИН для связи с подпрограммами МТЗ марк 1 — все это
нужно записать строку в STROUT в лунку 6. Позже подпрограммы будут
связан с Compose-Parser и т. д. от Кима, где PUTLIN делает несколько
больше вещей !
Аргументы:
STROUT (I) CHARACTER*(*) Строка ввода OUTWIN (O) CHARACTER*(*) Не используется
ПУСТОЙ
ПОДПРОГРАММА ПУСТАЯ (OUTWIN, NLINES)
Эта подпрограмма вызывает PUTLIN для вывода NLINES пустых строк в окно АУТВИН
Аргументы:
OUTWIN (I) CHARACTER*6 окно вывода NLINES (I) INTEGER количество пустых строк для вывода
ЛЕРРОР
ПОДПРОГРАММА LERROR(ERRFLG,IFAIL,ERRMSG)
Подпрограмма сообщения об общих ошибках, для процедур MTZ и т. д.
Аргументы:
ERRFLG (I) INTEGER =1 выходное сообщение как предупреждение
=2 выходное сообщение как фатальное
IFAIL (I) INTEGER =0 возвращает после фатальной ошибки
=-1 СТОП после сообщения о фатальной ошибке
ERRMSG (I) CHARACTER*(*) строка символов, содержащая ошибку
сообщение для вывода
РДСИМММ
ПОДПРОГРАММА RDSYMM(JTOK,LINE,IBEG,IEND,ITYP,FVALUE,NTOK,
. SPGNAM,NUMSGP,PGNAME,NSYM,NSYMP,RSYM)
Чтение и декодирование спецификации симметрии
Аргументы:
JTOK (I) INTEGER Номер первого поля для интерпретации
LINE (I) CHARACTER*(*) Входная строка (из PARSER)
IBEG (I) INTEGER(*) 1-й столбец количество токенов в поле
(из ПАРСЕРА)
IEND (I) INTEGER(*) Номер последнего столбца маркеров в поле
(из ПАРСЕРА)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
(из ПАРСЕРА)
FVALUE (I) REAL(*) Массив чисел. (из ПАРСЕРА)
NTOK (I) INTEGER Количество проанализированных полей. (из ПАРСЕРА)
NSYM (I/O) INTEGER Количество уже прочитанных операций симметрии,
в том числе не примитивные.
(должен быть очищен до 0 в начале)
SPGNAM (O) CHARACTER*(*) Имя пространственной группы
NUMSGP (O) INTEGER Номер пространственной группы
PGNAME (O) CHARACTER*(*) Имя группы точек
NSYMP (O) INTEGER Количество операций примитивной симметрии
RSYM (O) REAL(4,4,*) Матрицы симметрии. * должно быть не меньше =NSYM
РДГОЛОВКА
ПОДПРОГРАММА RDHEAD(JTOK,LINE,IBEG,IEND,ITYP,FVALUE,NTOK,
. МТЗПРТ,МТЗБПР)
Чтение и декодирование команды HEADER для установки флагов печати для заголовков MTZ
Аргументы:
JTOK (I) INTEGER Номер первого поля для интерпретации
LINE (I) CHARACTER*(*) Входная строка (из PARSER)
IBEG (I) INTEGER(*) 1-й столбец количество токенов в поле
(из ПАРСЕРА)
IEND (I) INTEGER(*) Номер последнего столбца маркеров в поле
(из ПАРСЕРА)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
(из ПАРСЕРА)
FVALUE (I) REAL(*) Массив чисел. (из ПАРСЕРА)
NTOK (I) INTEGER Количество проанализированных полей. (из ПАРСЕРА)
MTZPRT (O) INTEGER Флаг управления распечаткой из заголовка файла MTZ
NONE устанавливает MTZPRT = 0
нет заголовка о/п
BRIEF устанавливает MTZPRT = 1 (по умолчанию)
краткий заголовок о/п
ИСТОРИЯ устанавливает МТЗПРТ = 2
краткая история + мтз
ВСЕ комплекты МТЗПРТ=3
полный заголовок o/p из mtz читает
MTZBPR (O) INTEGER Управляет распечаткой из ЗАГОЛОВКОВ ПАРТИИ
NOBATCH устанавливает MTZBPR = 0
нет заголовка пакета o/p
BATCH устанавливает MTZBPR = 1 (по умолчанию)
заголовки партий о/п
ОРИЕНТАЦИЯ устанавливает МТЗБПР=2
ориентация партии также
РДЦЭЛЛ
ПОДПРОГРАММА RDCELL(ITOK,TYPE,FVALUE,NTOK,CELL)
Чтение и декодирование параметров ячейки
Аргументы:
ITOK (I) INTEGER Номер первого поля для интерпретации
ITYPE (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
(из ПАРСЕРА)
FVALUE (I) REAL(*) Массив чисел. (из ПАРСЕРА)
NTOK (I) INTEGER Количество проанализированных полей. (из ПАРСЕРА)
CELL (O) REAL(6) Параметры ячейки a, b, c, альфа, бета, гамма.
РДРЕСО
ПОДПРОГРАММА RDRESO(ITOK,ITYPE,FVALUE,NTOK,RESMIN,
+ РЕСМАКС, СМИН, СМакс)
Пределы разрешения чтения и декодирования.
Аргументы:
ITOK (I) INTEGER Номер первого поля для интерпретации
ITYPE (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
(из ПАРСЕРА)
FVALUE (I) REAL(*) Массив чисел. (из ПАРСЕРА)
NTOK (I) INTEGER Количество проанализированных полей. (из ПАРСЕРА)
RESMIN (O) REAL Минимальное разрешение (в As)
RESMAX (O) REAL Максимальное разрешение (в As)
SMIN (O) REAL Минимальное разрешение ( 4sin**2 тета/лямбда**2)
SMAX (O) REAL Максимальное разрешение ( 4sin**2 тета/лямбда**2)
RDSCAL
ПОДПРОГРАММА RDSCAL(ITOK,LINE,IBEG,IEND,ITYP,FVALUE,NTOK,
. NLPRGI,LSPRGI,ILPRGI,SCAL,BB)
Чтение и декодирование SCALE.
Аргументы:
ITOK (I/O) INTEGER Ввод: номер первого поля для интерпретации
Вывод: номер следующего токена для интерпретации (.gt. 0)
= 0, если линия исчерпана (SCAL и BB в порядке)
= -1, если масштаб не указан
= -2 нераспознанный ярлык
LINE (I) CHARACTER*(*) Входная строка (из PARSER)
IBEG (I) INTEGER(*) 1-й столбец количество токенов в поле
(из ПАРСЕРА)
IEND (I) INTEGER(*) Номер последнего столбца маркеров в поле
(из ПАРСЕРА)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
(из ПАРСЕРА)
FVALUE (I) REAL(*) Массив чисел. (из ПАРСЕРА)
NTOK (I) INTEGER Количество проанализированных полей. (из ПАРСЕРА)
LSPRGI (I) CHARACTER(*)*30 Строки меток программы.
L(abel) S(tring) PRG(ram) I(input)
NLPRGI (I) INTEGER Количество строк меток в LSPRGI
ILPRGI (O) INTEGER Номер в массиве LSPRGI, масштаб которого был изменен
SCAL (O) REAL Масштабный коэффициент, по умолчанию нет
BB (O) REAL Температурный коэффициент, по умолчанию = 0,0
РДРЕСЛ
ПОДПРОГРАММА RDRESL(ITOK,ITYPE,FVALUE,CVALUE,NTOK,RESMIN,
+ РЕСМАКС, СМИН, СМАКС, ИСТАТ)
Пределы разрешения чтения и декодирования.
Подключевых слов в CVALUE распознано:
LOW читать следующее число как нижний предел разрешения HIGH читать следующее число как предел высокого разрешения
Если одновременно присутствуют LOW и HIGH, пределы все равно будут заменены на правильный заказ
Если указано только LOW или HIGH, неустановленный предел (т. е. либо RESMAX, SMAX или RESMIN, SMIN) будет установлено на -1.0. Если указано только одно число, рассматривается как предел высокого разрешения
Если оба ограничения заданы без ключевых слов и оба являются . lt. 1.0, это
предполагается, что пределы равны 4(sin theta/lambda)**2, а не A
Аргументы:
ITOK (I) INTEGER Номер первого поля для интерпретации
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
(из ПАРСЕРА)
FVALUE (I) REAL(*) Массив чисел. (из ПАРСЕРА)
NTOK (I) INTEGER Количество проанализированных полей. (из ПАРСЕРА)
CVALUE (I) CHARACTER(*)*4 Проанализированные токены из ввода программы. (из ПАРСЕРА)
RESMIN (O) REAL Минимальное разрешение (в As) (т.е. низкое разрешение)
RESMAX (O) REAL Максимальное разрешение (в As) (т.е. высокое разрешение)
SMIN (O) REAL Минимальное разрешение ( 4sin**2 тета/лямбда**2)
(т.е. низкое разрешение)
SMAX (O) REAL Максимальное разрешение ( 4sin**2 тета/лямбда**2)
(т.е. высокое разрешение)
ISTAT (O) INTEGER =0 OK
=-1 недопустимое подключевое слово
=+1 ограничения не установлены
=+2 недопустимое число (вероятно, этого не может быть)
ГТРЕА
ПОДПРОГРАММА GTTREA(N,X,LFLAG,NTOK,ITYP,FVALUE)
Извлечь действительное число X из N-го значения массива парсера FVALUE, если
возможный.
Если нет значения, оставьте X без изменений. Если незаконно, напишите сообщение
Аргументы:
N (I) INTEGER Номер 1-го элемента FVALUE для извлечения
X (O) REAL Поместите сюда извлеченное число
LFLAG (O) INTEGER = 0 OK (допустимое число или нулевое поле)
= -1 после конца строки
= +1 недопустимый номер
NTOK (I) INTEGER Общее количество полей (из PARSER)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
(из ПАРСЕРА)
FVALUE (I) REAL(*) Массив чисел для извлечения (из PARSER)
ГТТИНТ
ПОДПРОГРАММА GTTINT(N,I,LFLAG,NTOK,ITYP,FVALUE)
Извлечь целое число I из N-го значения массива парсера FVALUE, если возможно.
Если нет значения, оставьте I без изменений. Если незаконно, напишите сообщение.
Аргументы:
N (I) INTEGER Номер 1-го элемента FVALUE для извлечения
I (O) INTEGER Поместите сюда извлеченное число
LFLAG (O) INTEGER = 0 OK (допустимое число или нулевое поле)
= -1 после конца строки
= +1 недопустимый номер
NTOK (I) INTEGER Общее количество полей (из PARSER)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число
(из ПАРСЕРА)
FVALUE (I) REAL(*) Массив чисел для извлечения (из PARSER)
РДАТОМВЫБОР
ПОДПРОГРАММА RDATOMSELECT(JTOK,INAT0,INAT1,IRES0,IRES1,CHNAM,
+ IMODE, NTOK, LINE, IBEG, IEND, ITYP, IDEC,
+ FЗНАЧ, ЕСЛИ НЕ ПРОШЕЛ)
Подпрограмма для обработки ключевого слова выбора атома со следующим общим синтаксис:
<Ключевые слова.[ [TO] ] | ОСТАТОК [ВСЕ | ОНС | CA] [ ЦЕПЬ ] [ [КОМУ] ] например kywd атом от 1 до 100 kywd остаток цепи A от 20 до 30 kywd остаток все 11 32 и т.д...
Для совместимости с DISTANG, CONTACT и т. д. заказ ОСТАТОКА подаргументы являются гибкими, например, RESIDUE 1 TO 9 CA CHAIN B такой же, как ОСТАТОК CA ЦЕПЬ B 1 ДО 9…
Подпрограмма возвращает выбор, введенный пользователем, и ожидает вызывающая программа для обработки результатов. Предыдущие ключевые слова актуально для этой подпрограммы
АРГУМЕНТЫ
JTOK (I) INTEGER Номер первого поля для интерпретации
NTOK (I) INTEGER Количество проанализированных полей из PARSER
LINE (I) CHARACTER*(*) Входная строка из PARSER
IBEG (I) INTEGER(*) 1-й столбец количество токенов в поле
(из ПАРСЕРА)
IEND (I) INTEGER(*) Номер последнего столбца маркеров в поле
(из ПАРСЕРА)
ITYP (I) INTEGER(*) =0 нулевое поле
=1 символьная строка
=2 число (из ПАРСЕРА)
IDEC (I) INTEGER(*) Количество символов/цифр в каждом токене
(из ПАРСЕРА)
FVALUE (I) REAL(*) Массив чисел. (из ПАРСЕРА)
INAT0 (O) INTEGER Нижний предел диапазона атомов (-99, если не установлено)
INAT1 (O) INTEGER Верхний предел диапазона атомов (-99, если не установлен)
IRES0 (O) INTEGER Нижний предел диапазона остатка (-99, если не задано)
IRES1 (O) INTEGER Верхний предел диапазона остатка (-99, если не установлен)
CHNAM (O) CHARACTER*1 Идентификатор цепочки (' ', если не задан)
IMODE (I/O) INTEGER При вводе: -1 = не разрешать MODE
любое другое значение = разрешить РЕЖИМ
На выходе: Тип атомов, которые нужно включить:
1=ВСЕ 2=ONS 3=CA (см., например, КОНТАКТ)
IFAIL (I/O) INTEGER При вводе: 0 = подавление предупреждений
-1 = печатать предупреждения
При выходе: 0 = ЛИНИЯ проанализирована нормально
>0 = ошибка разбора строки
(значение IFAIL - это номер плохого токена)
ВОЗВРАЩАЕМЫЕ ЗНАЧЕНИЯ
Подпрограмма возвращает либо:
первые/последние номера атомов, определяющие диапазон атомов, или
номера первых/последних остатков, определяющие диапазон остатков, плюс
(необязательно) идентификатор цепи
(необязательно) РЕЖИМ, который указывает, какой тип атомов включать:
all = (по умолчанию) все атомы в диапазоне остатков ons = только атомы кислорода и азота ca = только атомы CA(см.
КОНТАКТ / РАССТОЯНИЕ)
Количество неустановленных атомов/остатков будет возвращено < 0 (т. е. -99)
Идентификатор неустановленной цепочки будет возвращен как пустое значение, т. е. ‘ ‘
Режим по умолчанию равен 1 = включает все типы атомов.
Авторы
Первоначальный автор: На основе одноименной программы Майка Левитта.
Изменено: Питер Брик, Фил Эванс, Элеонора Додсон, Дэйв Лав, Питер Бриггс
Стандартный синтаксический анализатор запросов | Справочное руководство по Apache Solr 6.6
Парсер запросов Solr по умолчанию также известен как парсер « lucene ».
Основным преимуществом стандартного анализатора запросов является то, что он поддерживает надежный и довольно интуитивно понятный синтаксис, позволяющий создавать разнообразные структурированные запросы. Самым большим недостатком является то, что он очень нетерпим к синтаксическим ошибкам по сравнению с чем-то вроде парсера запросов DisMax, который разработан так, чтобы выдавать как можно меньше ошибок.
Параметры стандартного анализатора запросов
В дополнение к общим параметрам запроса, параметрам фасетирования, параметрам выделения и параметрам MoreLikeThis стандартный анализатор запросов поддерживает параметры, описанные в таблице ниже.
| Параметр | Описание |
|---|---|
q | Определяет запрос, используя стандартный синтаксис запроса. Этот параметр является обязательным. |
q.op | Указывает оператор по умолчанию для выражений запросов, переопределяя оператор по умолчанию, указанный в схеме. Возможные значения: «И» или «ИЛИ». |
дф | Указывает поле по умолчанию, переопределяя определение поля по умолчанию в схеме. |
свиноматки | Разделить по пробелам: если установлено значение |
Значения параметров по умолчанию указаны в solrconfig.xml или переопределены значениями времени запроса в запросе.
Ответ стандартного анализатора запросов
По умолчанию ответ стандартного анализатора запросов содержит один безымянный блок . Если используется параметр debug , то дополнительно будет возвращен блок с именем «debug». Он будет содержать полезную информацию для отладки, включая исходную строку запроса, проанализированную строку запроса и информацию объяснения для каждого документа в блоке объяснения другого , то для всех документов, соответствующих этому запросу, будет предоставлена дополнительная информация объяснения.
Примеры ответов
В этом разделе представлены примеры ответов стандартного анализатора запросов.
Приведенный ниже URL-адрес отправляет простой запрос и запрашивает модуль записи ответов XML для использования отступов, чтобы сделать ответ XML более читаемым.
http://localhost:8983/solr/techproducts/select?q=id:SP2514N
Результаты:
<ответ><результат numFound="1" start="0"> <док> 0 1 электроника жесткий диск 7200 об/мин, 8 МБ кэш-памяти, IDE Ultra ATA-133 NoiseGuard, технология SilentSeek, двигатель с гидродинамическим подшипником (FDB) SP2514N true Samsung Electronics Co. Ltd. Samsung SpinPoint P120 SP2514N — жесткий диск — 250 ГБ — ATA-133 6 <плавающее имя="цена">92.0SP2514N
Вот пример запроса с ограниченным списком полей.
http://localhost:8983/solr/techproducts/select?q=id:SP2514N&fl=id+name
Результаты:
<ответ><результат numFound="1" start="0"> <док> 0 2 SP2514N Samsung SpinPoint P120 SP2514N — жесткий диск — 250 ГБ — ATA-133
Указание терминов для стандартного анализатора запросов
Запрос к стандартному анализатору запросов разбит на термины и операторы. Есть два типа терминов: отдельные термины и словосочетания.
Несколько терминов можно комбинировать с логическими операторами для формирования более сложных запросов (как описано ниже).
Важно, чтобы анализатор, используемый для запросов, разбирал термины и фразы таким же образом, как и анализатор, используемый для индексации, разбирает термины и фразы; в противном случае поиск может дать неожиданные результаты. |
Модификаторы терминов
Solr поддерживает множество модификаторов терминов, которые при необходимости повышают гибкость или точность поиска. Эти модификаторы включают подстановочные знаки, символы для «нечеткого» или более общего поиска и так далее. Разделы ниже подробно описывают эти модификаторы.
Поиск с подстановочными знаками
Стандартный синтаксический анализатор запросов Solr поддерживает односимвольный и многосимвольный поиск с подстановочными знаками в пределах одного термина. Подстановочные знаки можно применять к отдельным терминам, но не к поисковым фразам.
| Тип поиска с подстановочными знаками | Специальный символ | Пример |
|---|---|---|
Один символ (соответствует одному символу) | ? | Строка поиска |
Несколько символов (соответствует нулю или более последовательным символам) | * | Поиск с подстановочными знаками: |
Нечеткий поиск
Стандартный анализатор запросов Solr поддерживает нечеткий поиск на основе алгоритма расстояния Дамерау-Левенштейна или алгоритма редактирования расстояния. Нечеткий поиск обнаруживает термины, похожие на указанный термин, но не обязательно являющиеся точным совпадением. Чтобы выполнить нечеткий поиск, используйте символ тильды ~ в конце термина, состоящего из одного слова. Например, чтобы найти термин, похожий по написанию на «бродить», используйте нечеткий поиск:
блуждать~
Этот поиск будет соответствовать таким словам, как блуждающий, пенный и пенный. Оно также будет соответствовать самому слову «бродить».
Необязательный параметр расстояния определяет максимально допустимое количество правок от 0 до 2, по умолчанию 2. Например:
бродить~1
расстояние редактирования «2».
Во многих случаях поиск по основам (приведение терминов к общей основе) может привести к эффектам, подобным нечеткому поиску и поиску с подстановочными знаками. |
Поиск по близости
Поиск по близости ищет термины, находящиеся на определенном расстоянии друг от друга.
Чтобы выполнить поиск по близости, добавьте символ тильды ~ и числовое значение в конце поисковой фразы. Например, чтобы найти в документе слова «апаш» и «джакарта» в пределах 10 слов друг от друга, используйте поиск:
«апач-джакарта»~10
Расстояние, указанное здесь, — это номер термина. движения, необходимые для соответствия заданной фразе. В приведенном выше примере, если «apache» и «jakarta» находятся на расстоянии 10 пробелов друг от друга в поле, но «apache» стоит перед «jakarta», потребуется более 10 перемещений терминов, чтобы переместить термины вместе и расположить «apache» на справа от «джакарты» с пробелом между ними.
Поиск в диапазоне
Поиск в диапазоне задает диапазон значений для поля (диапазон с верхней и нижней границей). Запрос сопоставляет документы, значения которых для указанного поля или полей попадают в диапазон. Запросы диапазона могут включать или исключать верхнюю и нижнюю границы. Сортировка выполняется лексикографически, за исключением числовых полей. Например, приведенный ниже запрос диапазона соответствует всем документам, в которых поле популярности имеет значение от 52 до 10 000 включительно.
популярность:[52 TO 10000]
Запросы диапазона не ограничиваются полями даты или даже числовыми полями. Вы также можете использовать диапазонные запросы с полями без даты:
title:{Aida TO Carmen}
Это найдет все документы, заголовки которых находятся между Aida и Carmen, но не включая Aida и Carmen.
Скобки вокруг запроса определяют его включенность.
Квадратные скобки
[и]обозначают включающий запрос диапазона, который соответствует значениям, включая верхнюю и нижнюю границу.Фигурные скобки
{и}обозначают запрос исключительного диапазона, который сопоставляет значения между верхней и нижней границами, но исключает сами верхнюю и нижнюю границы.Вы можете смешивать эти типы, чтобы один конец диапазона был включающим, а другой — исключающим. Вот пример:
count:{1 TO 10] 9=1.0 text:shoes
Указание полей в запросе к стандартному синтаксическому анализатору запросов
Данные, проиндексированные в Solr, организованы в поля, которые определены в схеме Solr. Поиск может использовать преимущества полей для повышения точности запросов. Например, вы можете искать термин только в определенном поле, например в поле заголовка.
Схема определяет одно поле как поле по умолчанию. Если вы не укажете поле в запросе, Solr ищет только поле по умолчанию. Кроме того, вы можете указать другое поле или комбинацию полей в запросе.
Чтобы указать поле, введите имя поля, затем двоеточие «:», а затем искомый термин в поле.
Например, предположим, что индекс содержит два поля, заголовок и текст, и этот текст является полем по умолчанию. Если вы хотите найти документ под названием «Правильный путь», который содержит текст «не идите этим путем», вы можете включить в поисковый запрос любой из следующих терминов:
заголовок: «Правильный путь» И text:go
title:"Делай правильно" AND go
Поскольку текстовое поле является полем по умолчанию, индикатор поля не требуется; следовательно, второй запрос выше пропускает его.
Поле допустимо только для термина, которому оно непосредственно предшествует, поэтому запрос title:Do it right найдет только «Do» в поле заголовка. Он найдет «это» и «правильно» в поле по умолчанию (в данном случае в текстовом поле).
Логические операторы позволяют применять логическую логику к запросам, требующим наличия или отсутствия определенных терминов или условий в полях для сопоставления документов. В таблице ниже приведены логические операторы, поддерживаемые стандартным анализатором запросов.
| Логический оператор | Альтернативный символ | Описание |
|---|---|---|
И | | Для совпадения требуется присутствие обоих терминов по обе стороны от логического оператора. |
НЕ | | Требует отсутствия следующего термина. |
ИЛИ | | Требуется, чтобы для совпадения присутствовал один термин (или оба термина). |
| Требуется наличие следующего термина. | |
| Запрещает следующий термин (то есть совпадения в полях или документах, не содержащих этот термин). 9Оператор 0702 — функционально подобен логическому оператору |
Логические операторы позволяют комбинировать термины с помощью логических операторов. Lucene поддерживает И, «+», ИЛИ, НЕ и «-» в качестве логических операторов.
При указании логических операторов с такими ключевыми словами, как И или НЕ, ключевые слова должны быть указаны в верхнем регистре. |
Стандартный анализатор запросов поддерживает все логические операторы, перечисленные в таблице выше. |
Оператор ИЛИ является оператором соединения по умолчанию. Это означает, что если между двумя терминами нет логического оператора, используется оператор ИЛИ. Оператор ИЛИ связывает два термина и находит совпадающий документ, если какой-либо из терминов существует в документе. Это эквивалентно объединению с использованием множеств. Символ || можно использовать вместо слова ИЛИ.
Для поиска документов, содержащих «jakarta apache» или просто «jakarta», используйте запрос:
«jakarta apache» jakarta
или
«jakarta apache» ИЛИ jakarta 03 03 +
Символ + (также известный как «обязательный» оператор) требует, чтобы термин после символа + существовал где-то в поле хотя бы в одном документе, чтобы запрос вернул совпадение.
Например, для поиска документов, которые должны содержать слово «jakarta» и могут содержать или не содержать слово «lucene», используйте следующий запрос:
+jakarta lucene
Этот оператор поддерживается как стандартным парсером запросов, так и парсером запросов DisMax. |
Логический оператор И (
&& )Оператор И сопоставляет документы, в которых оба термина присутствуют в любом месте в тексте одного документа. Это эквивалентно пересечению с использованием множеств. Символ 9Вместо слова AND можно использовать 0702 && .
Для поиска документов, содержащих «jakarta apache» и «Apache Lucene», используйте один из следующих запросов:
«jakarta apache» И «Apache Lucene»
«jakarta apache» && «Apache Lucene»
Булев оператор НЕ (
! ) Оператор НЕ исключает документы, содержащие термин после НЕ. Это эквивалентно различию с использованием наборов. Символ ! можно использовать вместо слова НЕ.
Следующие запросы выполняют поиск документов, содержащих фразу «jakarta apache», но не содержащих фразу «Apache Lucene»:
"jakarta apache" НЕ "Apache Lucene"
"jakarta apache" ! "Apache Lucene"
Логический оператор
- Символ - или оператор «запретить» исключает документы, содержащие термин после символа - .
Например, для поиска документов, содержащих «jakarta apache», но не «Apache Lucene», используйте следующий запрос:
«jakarta apache» - «Apache Lucene»
Экранирование специальных символов
Solr дает особое значение следующих символов при их появлении в запросе:
+ - && || ! ( ) { } [ 9 " ~ * ? : /
. , чтобы найти (1+1):2, не заставляя Solr интерпретировать знак плюс и круглые скобки как специальные символы для формулировки подзапроса с двумя терминами, экранируйте символы, ставя перед каждым из них обратную косую черту:
\(1\+1\)\:2
Группировка условий для формирования подзапросов
Lucene/Solr поддерживает использование круглых скобок для группирования предложений для формирования подзапросов. Это может быть очень полезно, если вы хотите управлять булевой логикой запроса.
Приведенный ниже запрос ищет либо «jakarta», либо «apache» и «веб-сайт»:
(jakarta ИЛИ apache) И веб-сайт
. Это повышает точность запроса, требуя, чтобы термин «веб-сайт» существовал, наряду с любым термином «джакарта» и «апач».
Группировка предложений внутри поля
Чтобы применить два или более логических оператора к одному полю при поиске, сгруппируйте логические предложения в круглых скобках. Например, приведенный ниже запрос ищет поле заголовка, содержащее слово «возврат» и фразу «розовая пантера»:
title:(+return +»pink panther»)
Поддерживаются комментарии C-Style. в строках запроса.
Пример:
"jakarta apache" /* это комментарий в середине обычной строки запроса */ ИЛИ jakarta
Комментарии могут быть вложенными.
Различия между синтаксическим анализатором запросов Lucene и стандартным синтаксическим анализатором запросов Solr
Стандартный синтаксический анализатор запросов Solr отличается от синтаксического анализатора запросов Lucene следующим образом:
A * может использоваться для одной или обеих конечных точек, чтобы указать открытый запрос диапазона
field:[* TO 100]находит все значения поля меньше или равные 100поле: [100 К *]находит все значения полей больше или равные 100field:[* TO *]соответствует всем документам с полем
Чисто отрицательные запросы (все предложения запрещены) разрешены (только как предложение верхнего уровня)
Перехват синтаксиса FunctionQuery.
Вам нужно будет использовать кавычки для инкапсуляции функции, если она включает круглые скобки, как показано во втором примере ниже:Поддержка использования анализатора запросов любого типа в качестве вложенного предложения.
Поддержка специального синтаксиса
filter(…)для указания того, что некоторые предложения запроса должны кэшироваться в кэше фильтра (как логический запрос с постоянной оценкой). Это позволяет кэшировать подзапросы и повторно использовать их в других запросах. Например,inStock:trueбудет кэшировано и повторно использовано во всех трех следующих запросах:q=функции:песни ИЛИ фильтр(на складе:true)q=+manu:Apple +фильтр(на складе:true)q=+manu:Apple & fq=inStock:trueЭто можно использовать даже для кэширования отдельных предложений сложных запросов с фильтрацией. В приведенном ниже первом запросе в кеш фильтра будут добавлены 3 элемента (верхний уровень
fqи оба предложенияfilter(…)), а во втором запросе будет 2 попадания в кеш и один новый кеш. вставка (для нового верхнего уровня fq):q=features:songs & fq=+filter(inStock:true) +filter(price:[* TO 100])q=manu:Apple & fq=-filter(inStock:true) -filter(price:[* TO 100])
Запросы диапазона («[a TO z]»), префиксные запросы («a*») и запросы с подстановочными знаками («a*b») имеют постоянную оценку (все соответствующие документы получают одинаковую оценку). Факторы оценки TF, IDF, повышение индекса и «координация» не используются. Количество совпадающих терминов не ограничено (как это было в прошлых версиях Lucene).
- 9=
, который устанавливает для всего предложения указанную оценку для любых документов, соответствующих этому предложению:
Указание даты и времени
Запросы к полям с использованием типа TrieDateField (обычно запросы диапазона) должны использовать соответствующий синтаксис даты:
метка времени: [* ДО СЕГОДНЯ]создано:[1976-03-06T23:59:59.