
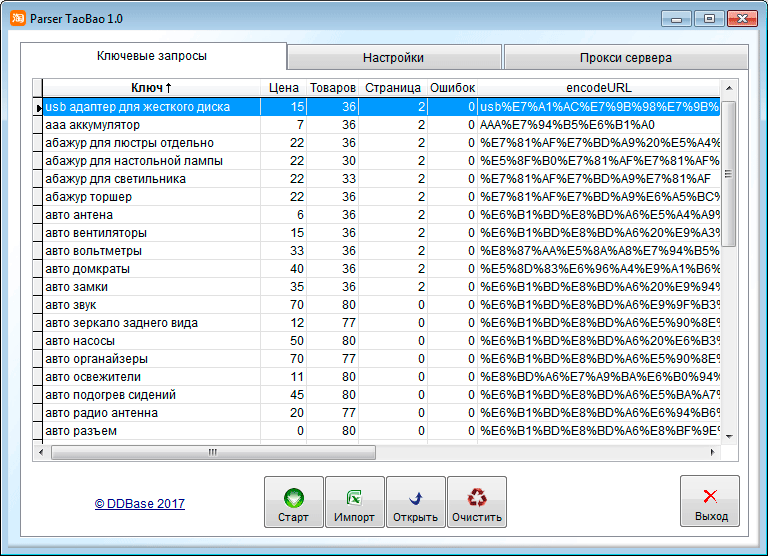
Таргет Культиватор — парсер Инстаграм, ВКонтакте, Тикток. Конкурсы ВКонтакте и Инстаграм
Таргет Культиватор — парсер Инстаграм, ВКонтакте, Тикток. Конкурсы ВКонтакте и Инстаграм{{user.first_name}}
{{#if user.paid_date}}({{user.paid_date}}){{/if}}
{{/if}} {{#if !user.first_name}}Вход / регистрация
{{/if}} Тарифы и оплата Данные по любой ссылке из ВК TOP групп ВК Виджет активности ВК Токен расш.
Таргет Культиватор
— парсер ВКонтакте и Инстаграм
Парсер Инстаграм для настройки таргетированной рекламы.
Определение и анализ целевой аудитории Инстаграм.
Парсер ВКонтакте для настройки таргета.
Определение и анализ целевой аудитории ВКонтакте.
Сервис проведения(подведения итогов и выбора победителей) конкурсов активностей Инстаграм, ВКонтакте.
Сервис проведения(подведения итогов и выбора победителей) конкурсов комментариев, лайков, репостов в Инстаграм и ВКонтакте.
Подведение итогов конкурсов со сложными условиями во ВКонтакте и Инстаграм, автоматический выбор победителей.
Бесплатный парсер ВКонтакте (выдаёт 100 строк, работает один час после регистрации!, без конкурсов, Инстаграма)!
Парсеры Инстаграм
Рейтинг ТОП аккаунтов Инстаграм Парсер постов Инстаграм Парсер постов по хэштегу Парсер комментариев Инстаграм Парсер лайков Инстаграм
Проведение конкурсов Инстаграм (подведение итогов и выбор победителей)
Конкурс активности в Инстаграм Конкурс комментариев в Инстаграм Конкурс лайков в Инстаграм Конкурс в посте с условиями Конкурс по хештегу
Проведение конкурсов ВКонтакте
Конкурс активности в группе Конкурс активности в посте Виджет рейтинга в группе
Поиск парсера / конкурса
- TOP аккаунтов Инстаграм — список аккаунтов со статистикой
- Сбор активности в Инстаграм (сбор лайков и комментариев к постам)
- Парсер постов в Инстаграм
- Парсер постов по хештегу в Инстаграм
- Комментарии к посту в Инстаграм
- Лайки к посту в Инстаграм
- Конкурс активностей в Инстаграм в одном аккаунте
- Конкурс в посте Инстаграм с условиями (лайк + комментарий + указать аккаунты)
- Конкурс комментариев в Инстаграм
- Конкурс лайков в Инстаграм
- Конкурс по хештегу в Инстаграм
- Конкурс активностей вконтакте
- Виджет активности в группу вконтакте/ рейтинг активности
- Конкурс активностей в нескольких группах вконтакте
- Конкурс в посте с условиями вконтакте
- Конкурс активностей в посте вконтакте
- Конкурс случайный репост вконтакте
- Конкурс случайный лайкер вконтакте
- Конкурс последний комментарий по времени вконтакте
- Конкурс случайный проголосовавший вконтакте
- Конкурс лучший комментарий в посте вконтакте
- Данные по любой ссылке из вконтакте (Товары, видео, фото, подписчики, друзья, посты, обсуждения, комментарий)
- TOP групп вконтакте — список групп вконтакте со статистикой
- Пользователи по городу и статусу вконтакте
- Парсер пользователей по интересам вконтакте
- Парсер пользователей по профессии/должности вконтакте
- Пользователи по названию компании в которой они работают
- Пользователи, которые учились(учятся) в определенном университете/ВУЗе
- Сотрудники компании вконтакте
- Сотрудники по списку сообществ вконтакте
- Контакты сообществ вконтакте
- Парсер сообществ, групп по ключевым словам
- Парсер сообщества, групп по названию
- Сообщества по гео (страна, город) вконтакте
- Сообщества по статусу вконтакте, поиск
- Сообщества новые вконтакте
- Сообщества с прометеем вконтакте
- Сообщества вконтакте с открытой предложкой
- Фильтрация сообществ вконтакте по дате последнего поста
- Новости вконтакте
- Целевые сообщества / Похожие сообщества
- Анализ сообществ ER/Вовлеченность
- Анализ и фильтр пользователей — визуальный
- ТОП читателей группы вконтакте
- Лучшие посты сообществ вконтакте
- Рекламные креативы вконтакте в таргетированной рекламе
- Рекламные креативы вконтакте в посевах (посты с пиметкой реклама)
- Рекламные креативы вконтакте в репостах, копирайтах и тексте
- Сбор промопостов сообщества вконтакте
- Парсер подписчиков групп, сообществ вконтакте
- Друзья подписчиков группы вконтакте
- Друзья и подписчики пользователей вконтакте
- Активности в группах вконтакте
- Активности в постах вконтакте
- Сбор активностей по типам под постами пабликов, сообществ, групп и пользователей
- Собрать посты всех друзей пользователя за нужные даты
- Собрать лучшие комментарии в сообществах или у пользователей
- Быстро указать пользователей в посте вконтакте + оформление победителей картинкой
- Сравнение списков — пересечение/вычитание/объединение
- Кто админ сообщества вконтакте — узнать по GIFке в постах
- Скопировать группы из рекламного объявления вконтакте
- Поиск вторых половинок у подписчиков в группах и сообществах
- Получение всех инстаграм и фейсбук аккаунты пользователей группы вконтакте
- Получение постов вконтакте — определенное количество
- Получение постов по датам публикации из вконтакте
- Удаление постов со стены вконтакте с выбором диапазона дат
- Получение комментариев к постам опубликованных в определенные даты
- Получение активных пользователей в постах, опубликованных в определенные даты
- Получение новых подписчиков в своей группе вконтакте
- Получение полной информации об активных пользователях в постах, опубликованных в определенные даты
- Получение списка wiki страниц группы вконтакте
- Удаление всех комментариев к определенному посту вконтакте
- Получение пользователей обращавшихся в сообщения группы
- Получение всех сообщений из личных сообщений группы
- Получить email подписчиков в группах и сообществах из открытых полей
- Получить сайты подписчиков групп и сообществ из открытых полей
- Получить подписчиков групп, которые сейчас в онлайне
- Получение всех ваших личных сообщений
- Получение админов и модераторов группы по gif в посте
- Получение данных пользователей оставивших комментарий к определенному посту вконтакте
- Получить именинников в группах — подписчиков у которых день рождение
- Получить подписчиков групп, аккаунты которых были удалены из вконтакте
- Удаление из сообщества навсегда забаненных подписчиков — собачек
- Выбрать парней у девушек которых скоро день рождение
- Выбрать девушек у парней которых скоро день рождение
- Получить подписчиц групп, у которых статус замужем или указана девичья фамилия
- Удаление из сообщества временно забаненных подписчиков
- Получить подписчиков групп, которые последний раз были онлайн в определенные даты
- Фильтрация подписчиков групп
- Получить все города России — парсер
- Фильтрация пользователей
- Получить телефоны подписчиков в группах и сообществах из открытых полей
- Получение пользователей упомянутых в постах сообществ
- Фильтрация групп и сообществ
- Выбрать подписчиков, которым разрешено посылать рассылку от имени группы
- Получение групп, сообществ, пабликов упомянутых в постах сообществ
- Как узнать номер телефона по вконтакте
- Как узнать номера телефонов подписчиков группы вконтакте
Конкурсы и парсеры Инстаграм
Конкурсы и парсеры ВКонтакте (все парсеры)
Посмотреть некоторые видео работы сервиса вы можете на нашем канале и в группе ВК
Парсинг постов и их статистики в Instagram при помощи кода на Python
В этом уроке мы разберем с вами код, который позволит скачать контент произвольного аккаунта в инстаграм и сохранить его в формате CSV, пригодном для дальнейшего исследования.
Код использует API инструменты от LevPasha. GitHub
UPDATE 03.09.2020
Внимание! На данный момент страница проекта на GitHub удалена, а инструменты для вытаскивания ID аккаунтов, описанные в статье, не работают. Сама библиотека еще работает, но ее работу нужно изучать.
Небольшие аккаунты в районе 1000-2000 постов собираются быстро, как раньше, и без видимых усилий.
Скачать библиотеку Instagram-API-python вы можете по ссылкам ниже. Соответственно, та часть инструкции, которая касается скачивания библиотеки из GitHub более не актуальна, просто разархивируйте скачанный файл, при помощи CD войдите в получившуюся директорию, установите, и продолжайте инструкцию с этого момента.
Скачать библиотеку
Продолжить инструкцию
UPDATE 06.09.2020 — Как самостоятельно получить ID аккаунта в Instagram
- Открываем страницу нужным аккаунтом в Google Chrome.
- Щелкаем правой кнопкой, просмотреть код страницы.
 (F12 на Windows; ⌥+⌘+i на Mac OS)
(F12 на Windows; ⌥+⌘+i на Mac OS) - Там переключаемся в консоль (Console) при помощи кнопки внизу, и вводим в консоли window._sharedData.config.viewerId
- Нажимаем Enter
- Если получили ошибку — перезагружаем страницу.
- На выходе получаем ID аккаунта, можно вставлять в код парсера и парсить!
 (F12 на Windows; ⌥+⌘+i на Mac OS)
(F12 на Windows; ⌥+⌘+i на Mac OS)Для начала — немного об использовании официального API от Instagram. С 15 октября 2019 года регистрация новых клиентов через Instagram Developer прекращена, и не предвидится. Если вы успели зарегистрироваться раньше — доступ еще есть, но вам потребуется получить расширенные права через подтверждение приложения. Без них вы сможете скачать данные только по 20 последним публикациям, не более. Если не зарегистрированы, вам доступен API Instagram Basic Display. О его возможностях можно почитать по ссылке. Факт в том, что официальный API требует подтверждения вас, как доверенного лица от Instagram.
Этих проблем позволяет избежать использование неофициальных API. И самый популярный из них — упомянутый выше Instagram-API-python от LevPasha. API написан на Python, так что для взаимодействия с ним мы так же будем использовать Python.
И самый популярный из них — упомянутый выше Instagram-API-python от LevPasha. API написан на Python, так что для взаимодействия с ним мы так же будем использовать Python.
В разделе Examples на GitHub LevPasha можно найти примеры кода для загрузки контента в инсту, для массового удаления своего контента, и еще много полезных фич. Советую ознакомиться.
Покончили с прелюдией, начинаем.
Подготовка
Вам потребуется установленный язык Python на вашей системе. Так как в своей работе я использую язык R и Python для анализа данных, то рекомендую Anaconda — дистрибутив языков программирования Python и R, включающий набор популярных свободных библиотек, объединённых темой науки о данных и машинного обучения. Дистрибутив скачивается единожды, и вся последующая конфигурация, в том числе установка дополнительных модулей, может проводится в офлайне.
Последнюю версию дистрибутива можете найти здесь. Скачивайте версию для Python 3. 7, устанавливайте и запускайте Jupyter. Процесс создания проекта на сложный, вам всего лишь нужно определиться с рабочей директорией и создать там новую записную книжку Jupyter Notebook.
7, устанавливайте и запускайте Jupyter. Процесс создания проекта на сложный, вам всего лишь нужно определиться с рабочей директорией и создать там новую записную книжку Jupyter Notebook.
Никто так же не запрещает вам использовать терминал с Python или любой другой способ взаимодействовать с кодом.
Установка Instagram-API-python
Все инструкции по установке можно найти на странице Instagram-API-python в GitHub LevPasha. Там же вы найдете условия и ограничения по использованию API.
Главное, что нужно знать. Для успешного анализа постов необходимо подтвердить свой номер телефона в учетной записи Instagram, которая будет использоваться в коде.
Новый поддельный аккаунт Instagram с неподтвержденным номером телефона через 1-24 часа будет заблокирован и не сможет выполнять никаких запросов. Все запросы будут перенаправлены на страницу https://instagram.com/challenge.
Кстати, сам проект от LevPasha, по сути, представляет собой Python-порт другого проекта кастомной API, написанного на PHP.
После установки Python (в составе Conda или отдельно), запустите консоль. Сначала копируем содержимое Instagram-API-python в GitHub LevPasha.
git clone https://github.com/LevPasha/Instagram-API-python.git
Переходим в только что скачанный каталог:
cd Instagram-API-python
Устанавливаем зависимые файлы и библиотеки: (необязательно, нужно только если соберетесь закачивать в инсту фотки или видео)
pip install -r requirements.
 txt
txtДалее устанавливаем сам InstagramApi через pip. В консоли выполняем:
pip install InstagramApi
Или
py -m install InstagramApi
Готово. После этого вы сможете вызывать API от LevPasha в любом коде на Python через команду
from InstagramAPI import InstagramAPI
Скачиваем контент любого Instagram аккаунта
Далее я привожу различные части одного кода в Python и объясняю его значение. В конце урока я прикреплю файлы, которые можно использовать для старта операции, подавая на них логин и пароль вашего аккаунта, а так же ID любых аккаунтов, как аргументы. В коде ниже логин, пароль от аккаунта для авторизации, а так же ID аккаунтов для скачивания постов будут поданы напрямую через код при выполнении. Учитывайте эту разницу.
В конце урока я прикреплю файлы, которые можно использовать для старта операции, подавая на них логин и пароль вашего аккаунта, а так же ID любых аккаунтов, как аргументы. В коде ниже логин, пароль от аккаунта для авторизации, а так же ID аккаунтов для скачивания постов будут поданы напрямую через код при выполнении. Учитывайте эту разницу.
Для начала импортируем необходимые библиотеки. InstagramAPI уже должен быть установлен по инструкции выше.
from InstagramAPI import InstagramAPI import time import sys import traceback import pandas as pd import datetime
Если вы не устанавливали зависимые библиотеки, то после выполнения появится сообщение Fail to import moviepy. Need only for Video upload. Значит, все загрузилось нормально, кроме модуля moviepy который вам не понадобится в данной инструкции.
После этого прогоняем следующую часть кода. Это и есть та часть, которая запускает сбор данных. В ней обращаем внимание на функцию time.sleep(10). Она будет ставить на 10-секундную паузу процесс в случае ошибки.
class MyInstaCrawler(InstagramAPI):
"""
Want to have a direct control over the instaAPI. When the users are loaded from api, the best way is to store
them in the queue, where it would have listeners - parsers that would do next job.
"""
def __init__(self, username, password):
super().__init__(username, password)
def getTotalFollowers(self, usernameId):
import datetime
next_max_id = ''
followers = []
while 1:
try:
if self.getUserFollowers(usernameId, next_max_id):
temp = self. LastJson
for item in temp["users"]:
followers.append(item)
print('Followers: %s ' % len(followers))
temp['collected_date'] = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
if temp.get("big_list") is None:
return followers
elif temp['big_list'] is False:
return followers
next_max_id = temp["next_max_id"]
except:
print(traceback.format_exc())
print("Sleeping 10 secs")
time.sleep(10) LastJson
for item in temp["users"]:
followers.append(item)
print('Followers: %s ' % len(followers))
temp['collected_date'] = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
if temp.get("big_list") is None:
return followers
elif temp['big_list'] is False:
return followers
next_max_id = temp["next_max_id"]
except:
print(traceback.format_exc())
print("Sleeping 10 secs")
time.sleep(10)
LastJson
for item in temp["users"]:
followers.append(item)
print('Followers: %s ' % len(followers))
temp['collected_date'] = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
if temp.get("big_list") is None:
return followers
elif temp['big_list'] is False:
return followers
next_max_id = temp["next_max_id"]
except:
print(traceback.format_exc())
print("Sleeping 10 secs")
time.sleep(10)После этого ваша программа ожидает ввода инструкций. Внимательно посмотрим на следующую часть кода.
В ней нужно вставить ваши значения. В поле usr вставляем имя пользователя аккаунта Instagram, при помощи которого будет осуществляться логин в систему, а в поле pasw, соответственно, пароль от этого аккаунта.
Что это должен быть за аккаунт? Желательно, не ваш основной. Шанс на блокировку в результате действий минимален, но перестраховаться не помешает. К тому же, если вы будете параллельно использовать ваш аккаунт для парсинга в процессе самого парсинга, то код вылетит с ошибкой. Так что создаем новый, чистый аккаунт, заполняем его и подтверждаем телефонный номер. Выкладываем несколько постов, находим друзей и живем с ним несколько дней. После этого его данные можно использовать для парсинга.
Шанс на блокировку в результате действий минимален, но перестраховаться не помешает. К тому же, если вы будете параллельно использовать ваш аккаунт для парсинга в процессе самого парсинга, то код вылетит с ошибкой. Так что создаем новый, чистый аккаунт, заполняем его и подтверждаем телефонный номер. Выкладываем несколько постов, находим друзей и живем с ним несколько дней. После этого его данные можно использовать для парсинга.
Далее, в поле args вставляем ID аккаунтов, от которых мы хотим получить контент, стату и мотоцикл. Как узнать ID аккаунта? При помощи специальных сервисов. Вот несколько бесплатных:
- https://codeofaninja.com/tools/find-instagram-user-id
- http://www.otzberg.net/iguserid/index.php
Кстати, советую где нибудь сохранить ID аккаунтов. Определить потом, чей этот ID можно будет только по результату работы кода.
ВАЖНО. Аккаунт, из-под которого осуществляется вход в систему, должен быть подписан на скрытые аккаунты, с которых предполагается скачивание данных. Если вы хотите скачать данные по закрытому аккаунту, а аккаунт для авторизации на него не подписан (и, соответственно, не имеет разрешение на просмотр контента), то код вылетит с ошибкой.
Если вы хотите скачать данные по закрытому аккаунту, а аккаунт для авторизации на него не подписан (и, соответственно, не имеет разрешение на просмотр контента), то код вылетит с ошибкой.
Так происходит, потому что, фактически, Instagram API от LevPasha представляет из себя эмулятор приложения Instagram для Android. Он заходит на каждый аккаунт в каждый пост, читает и записывает то что видит в таблицу. Просто делает это очень быстро. Если вы не можете зайти на этот аккаунт из-за его настроек приватности, получить доступ к его контенту будет нельзя.
Внимательно перепроверяем все настройки. Стоят ли кавычки вокруг каждого ID аккаунта? Запятые? Фигурная скобка в конце?
Если все окей, то запускаем последнюю часть кода.
usr = "Instagram_Login" pasw = "Instagram_Password" ic = MyInstaCrawler(usr, pasw) ic.
 login()
args = ["отдельные", "айдишки", "каждого", "аккаунта", "для", "парсинга", "в кавычках через запятую"]
total_results = []
for arg in args:
try:
arg = int(arg)
results = ic.getTotalUserFeed(arg)
if results is None:
print('Some problems with id %s. No results.' % arg)
continue
print('Gathered %s media, saving...' % len(results))
if len(results) != 0:
username = results[0]['user']['username']
for r in results:
try:
reduced_r = {}
date = datetime.datetime.fromtimestamp(r['taken_at'])
date = date.strftime("%Y-%m-%d"'T'"%H:%M:%S"'Z')
caption = r['caption']
caption_text = ''
if caption is not None:
caption_text = caption['text']
view_count = 0
if r['media_type'] == 2:
if r.get('view_count'):
view_count = int(r['view_count'])
reduced_r['created_time'] = date
reduced_r['user.
login()
args = ["отдельные", "айдишки", "каждого", "аккаунта", "для", "парсинга", "в кавычках через запятую"]
total_results = []
for arg in args:
try:
arg = int(arg)
results = ic.getTotalUserFeed(arg)
if results is None:
print('Some problems with id %s. No results.' % arg)
continue
print('Gathered %s media, saving...' % len(results))
if len(results) != 0:
username = results[0]['user']['username']
for r in results:
try:
reduced_r = {}
date = datetime.datetime.fromtimestamp(r['taken_at'])
date = date.strftime("%Y-%m-%d"'T'"%H:%M:%S"'Z')
caption = r['caption']
caption_text = ''
if caption is not None:
caption_text = caption['text']
view_count = 0
if r['media_type'] == 2:
if r.get('view_count'):
view_count = int(r['view_count'])
reduced_r['created_time'] = date
reduced_r['user. username'] = username
reduced_r['caption.text'] = caption_text
reduced_r['likes.count'] = r['like_count']
reduced_r['video_views'] = view_count
reduced_r['comments.count'] = r['comment_count']
reduced_r['link'] = 'https://instagram.com/p/' + r['code']
total_results.append(reduced_r)
except Exception as e:
print(e)
print('Finished for %s, id: %s' % (username, arg))
except ValueError:
print("Pass ID as an argument. Couldn't transform to int")
except:
print(traceback.format_exc())
df = pd.DataFrame(total_results)
df.to_csv('Database %s.csv' % datetime.datetime.now().strftime("%Y-%m-%d,%H:%M:%S"))
username'] = username
reduced_r['caption.text'] = caption_text
reduced_r['likes.count'] = r['like_count']
reduced_r['video_views'] = view_count
reduced_r['comments.count'] = r['comment_count']
reduced_r['link'] = 'https://instagram.com/p/' + r['code']
total_results.append(reduced_r)
except Exception as e:
print(e)
print('Finished for %s, id: %s' % (username, arg))
except ValueError:
print("Pass ID as an argument. Couldn't transform to int")
except:
print(traceback.format_exc())
df = pd.DataFrame(total_results)
df.to_csv('Database %s.csv' % datetime.datetime.now().strftime("%Y-%m-%d,%H:%M:%S"))Процесс начнется с серии ошибок логина, после чего вы получите надпись об успешном логине. После этого начнется процесс сбора постов. Выглядеть будет как то так:
Request return 405 error!
{'message': '', 'status': 'fail'}
Request return 404 error!
Login success!
Gathered 18 media, saving. ..
Finished for ваш аккаунт, id: айди вашего аккаунта ..
Finished for ваш аккаунт, id: айди вашего аккаунта
..
Finished for ваш аккаунт, id: айди вашего аккаунтаЕсли увидите ошибку Pass ID as an argument. Couldn’t transform to int, перепроверьте, точно ли каждый ID находится в кавычках, и нет ли лишних или отсутствующих запятых.
После окончания процесса, готовая таблица появится в том же каталоге, в котором запускался код, с названием «Database (текущие дата и время).csv».
Готово! По возникающим вопросам, можете писать комментарии под этим постом на Open SMM Asia, или же в мой Facebook.
Если вы хотите использовать этот код в другом приложении, подавая на него аргументы извне, можете скачать специальную версию. Она будет ждать первым аргументом логин, вторым аргументом пароль, и последующими аргументами ID всех аккаунтов через запятую.
insta_api_saver_v3_opensmm_asia.py_Скачать
Тэги урока: api, instagram, levpasha, parsing Назад: Исследование данных в Digital маркетингеПарсинг Инстаграм, точный подбор аудитории для продвижения аккаунта
Что такое парсинг аудитории в социальных сетях, и для чего он нужен, мы рассказывали в обзоре сервисов парсинга ВКонтакте. В этом материале вы познакомитесь с возможностями сервисов парсинга аудитории в Инстаграм и узнаете, как использовать результаты парсинга для «белого» продвижения вашего аккаунта. Рекомендовать вам массфолловинг, масслайкинг и масслукинг мы точно не будем.
Как работать с парсерами?
-
Вы определяете источники поиска — это могут быть аккаунты конкурентов, геолокации, хештеги.
-
Выбираете параметры поиска — количество подписок, подписчиков, публикаций и пр.
-
Сервис выполняет поиск, отбирает данные, анализирует результаты, некоторые парсеры могут самостоятельно исключать ботов и «заброшенные» аккаунты из результатов поиска.
-
Экспортируете результаты или предварительно конвертируете их, например, из ID пользователей в ссылки на аккаунты или номера телефонов.
Сервисы для парсинга
Segmento target
Функционал
-
Поиск аккаунтов/ID Инстаграм из базы пользователей ВКонтакте и наоборот; аккаунтов Инстаграм по геоточкам, параметрам количества подписчиков, подписок, публикаций;
-
Аналитика — информация о поле, возрасте, городе подписчиков;
-
Сбор номеров телефонов и электронных ящиков аудитории;
-
Фильтр аудитории по количеству подписчиков, подписок, публикаций, по наличию аватарки и т.
д.;
-
Конвертер ID пользователей Инстаграм в ссылки на аккаунты Инстаграм и наоборот;
-
Инструмент работы с базами — объединение, пересечение, исключение.
Плюсы
-
Парсинг аудитории в 3 социальных сетях — ВКонтакте, Инстаграм, Одноклассники;
-
Наличие тарифного плана сразу на 3 социальные сети;
-
Наличие практических кейсов из разных ниш в видеоформате;
-
Онлайн-доступ к сервису, для использования не нужно ничего скачивать.
Минусы
-
Отсутствие бесплатного тарифа;
-
Автоматическое продление подписки;
-
Сложный интерфейс сервиса.
Тарифы Segmento target
Сайт сервиса: segmento-target.ru
Pepper.ninja
Функционал
-
Сбор Инстаграм-аккаунтов из базы ВКонтакте по указанным городам;
-
Сбор Инстаграм-аккаунтов родителей и родственников пользователей ВКонтакте;
-
Сбор аудитории в Инстаграм по гео, хештегам, подписчикам и подпискам определенного аккаунта;
-
Сбор Инстаграм-аккаунтов, поставивших лайки на определенные посты;
-
Конвертация ID пользователей Инстаграм в ссылки на аккаунты Инстаграм и наоборот, ссылок на аккаунты Инстаграм — в номера телефонов и наоборот и пр.
Плюсы
-
Парсинг аудитории в 4 социальных сетях — ВКонтакте, Инстаграм, Одноклассники, Facebook;
-
Бесплатный пробный период на 3 дня, за вступление в официальную группу сервиса можно получить бесплатный доступ на месяц;
-
Наличие видеоуроков по работе с сервисом.
Минусы
Тарифы Pepper.ninja
Сайт сервиса: pepper.ninja
Zengram
Сервис для комплексного продвижения в Инстаграм, в функционал которого входят возможности для парсинга аудитории.
-
Сбор контактов аккаунтов — номеров телефонов, электронной почты, ссылок на сайты;
-
Выгрузка описаний собранных профилей;
-
Фильтр собранных аккаунтов по полу, по количеству подписчиков и подписок, по наличию/отсутствию приватности;
-
Исключение коммерческих аккаунтов из результатов сбора;
-
Возможность скачивания собранных списков для настройки рекламы или обзвона.
Плюсы
-
Возможность оплатить отдельно парсер, а не полный функционал сервиса;
-
Скидки при покупке подписки на длительные периоды;
-
Есть подробная инструкция по использованию.
Минусы
Тарифы Zengram
Сайт сервиса: zengram.ru
Tooligram
Сервис для продвижения и раскрутки в Инстаграм, в функционал которого входит получение подписчиков, автопостинг, отслеживание комментариев, рассылки в Direct, а также парсер.
Возможности парсера — поиск Инстаграм-аккаунтов по геоточкам конкурентов, по близлежащим геоточкам, по хештегам.
Плюсы
Минусы
Тарифы Tooligram
Сайт сервиса: https://tooligram.com/clients/
INSTAPLUS.PRO
Сервис для продвижения в Инстаграм, в функционал которого входит парсер.
Возможности парсера — поиск целевой аудитории по конкурентам, хештегам, по гео.
Плюсы
Минусы
Оплачивается полный функционал сервиса, нельзя купить подписку только на использование парсера.
Тарифы INSTAPLUS.PRO
Сайт сервиса: instaplus.pro
WonderLead
Функционал
Плюсы
Минусы
-
Работа с собранной аудиторией осуществляется только из личного кабинета сервиса или с помощью Telegram-бота
-
Отсутствует возможность выгрузить контакты собранной базы для настройки таргетинговой рекламы на них
Стоимость подписки на WonderLead
Сайт сервиса: wonderlead.ru
INSTAPARSER PRO
Программа для парсинга номеров WhatsApp/Viber из Инстаграм и сбора логинов по хештегам и подписчикам.
Плюсы
Минусы
- Бесплатного тарифа и пробного доступа нет
Тарифы InstaParser PRO
Сайт: instaparserpro. com
InstaTurbo
Сервис продвижения в Инстаграм, в функционале которого есть поиск целевой аудитории по хештегам, подписчикам и подпискам.
Плюсы
Минусы
Тарифы InstaTurbo
Сайт сервиса: instaturbo.ru
SMMflow
Облачный сервис для продвижения в Инстаграм, в функционале которого есть парсер. Парсер собирает аккаунты по хештегам, лайкам, геолокациям, подписчикам и подпискам конкурентов.
Плюсы
Минусы
Стоимость подписки на SMMflow
Сайт сервиса: https://smmflow.com/
Ibot Pro
Программа для продвижения в Инстаграм, в которую встроен парсер аккаунтов.
Функционал
-
Сбор аудитории по хештегам, подписчикам, подпискам, активным подписчикам, геолокациям
-
Сбор аудитории из групп и публичных страниц ВКонтакте
Плюсы
Минусы
Стоимость лицензии Ibot Pro
Сайт: http://www. socialnetworkingtools.com.ua/instagram-software/ibot/
Social Kit
Программа для массового продвижения в Инстаграм.
Функционал
-
Поиск по пользователям — автоматический подбор по заданным критериям поиска, выгрузка вашей базы;
-
Поиск по хештегам — автоматический подбор хештегов из Инстаграм по критериям поиска и вставка ваших хештегов, сбор пользователей по одному или нескольким хештегам;
-
Поиск по геолокации — сбор гео-меток и аккаунтов по заданным координатам, адресу;
-
Получение информации о подписчиках, подписках, публикациях по собранной базе и фильтр этой информации;
-
Сохранение списка пользователей в файл.
Плюсы
Минусы
Стоимость SocialKit за месяц и год
Сайт сервиса: http://socialkit. ru/
Как использовать собранную аудиторию для продвижения в Инстаграм?
-
Отправлять пользователям собранной базы персональные сообщения в Direct
-
Подписываться на них, ставить лайки и комментировать их публикации
-
Настраивать таргетинговую рекламу
Важно! Рекламный кабинет Facebook «понимает» только телефоны и электронные ящики аккаунтов — для настройки таргетинговой рекламы их необходимо выгрузить в сервисе парсинга (такой функционал есть, например, у Segmento target), после чего в разделе «Аудитории» загрузить списки с номерами телефонов или email-ов. Далее нужно заполнить необходимые поля на странице рекламной кампании, создать объявление и запустить рекламную кампанию.
Читайте также Как оценить эффективность рекламной кампании в Фейсбуке?
Если у вас остались вопросы по теме парсинга аудитории в Инстаграм, задайте их у нас в Телеграме — мы обязательно ответим. А если вы хотите доверить SMM профессионалам — оставляйте заявку специалистам «Веб-Центра».
Эффективный парсер Инстаграм от Зенграм
При продвижении аккаунтов в социальных сетях иногда возникает острая необходимость получить определенные данные пользователей. Для этого существуют различные инструменты, об одном из которых данная статья.
Содержание статьи:
- Что такое парсинг и зачем он нужен
- Парсинг в Instagram
- Парсер от Зенграм
- Использование парсера для личной страницы
- Сбор данных по местоположению
- Как пользоваться парсером от Zengram
- Поиск по хэштегам
- Сбор по конкурентам
- Сбор личных данных
- Результаты сбора
Что такое парсинг и зачем он нужен
Парсинг в переводе с английского означает «разбор, анализ». Собственно говоря, это и есть анализ информации, содержащейся на каком-либо интернет-сайте. Во время парсинга собирают и оценивают самые разные данные: сведения о пользователях, ассортимент интернет-магазина, услуги, предлагаемые той или иной компанией на ее странице в интернете. Благодаря парсингу можно получить обобщенную информацию со схожих по содержанию и оформлению ресурсов и на основе полученных сведений создавать, улучшать или обновлять собственные сайты.
Проводят парсинг с помощью специально созданных для этого программ-скриптов, которые называют парсерами. Они позволяют быстро обработать большие объемы информации. Пользователю нужно установить только необходимые параметры поиска – все остальное программа сделает самостоятельно в автоматическом режиме.
Анализировать с помощью парсинга можно любой интернет-сайт. Например, при анализе тематического форума можно собрать информацию о его пользователях, а при исследовании онлайн-магазина получить полный каталог товаров, разделенных по категориям.
Парсинг в Instagram
Сегодня, с повышением популярности социальных сетей, парсинг стали применять и там – для продвижения аккаунтов. Instagram – не исключение. При этом парсинг в Инстаграме имеет некоторые особенности.
Прежде всего парсингом пользуются для раскрутки коммерческих страниц, предлагающих те или иные товары и услуги, а также блогов. При этом парсер позволяет решить следующие задачи:
- Найти и привести на свою инстаграм-страницу целевую аудиторию, представители которой являются потенциальными покупателями. Сервис ищет по заданным параметрам аккаунты, принадлежащие живым людям (а не фейки или страницы-боты), которых может заинтересовать ваш товар или услуга. Например, у вас есть интернет-магазин, продающий женскую бижутерию. Парсер с помощью фильтров, настроенных определенным образом, найдет пользователей женского пола, проживающих в необходимом регионе.
- Получение информации от конкурентов. Парсер позволяет анализировать коммерческие профили, которые ведут схожую деятельность. Например, вы нашли коммерческую страничку, ведущую торговлю обувью, как и вы. С помощью парсера можно получить сведения о людях, которые подписаны на этот аккаунт, которые, по сути, представляют собой готовую базу клиентов. Кроме того, можно посмотреть, как конкуренты оформляют посты, какие хэштеги выставляют, а также узнать об их ценовой политике.
Парсер можно использовать не только в коммерческих целях. Рядовым пользователям, не занимающимся бизнесом в Инстаграм, он поможет быстро найти новых знакомых при перемене места жительства или отыскать друзей по интересам.
Парсер от Зенграм
Сегодня для каждой социальной сети существует несколько сервисов-парсеров. Есть такие инструменты и для Инстаграм. Один из них – Zengram. Парсер от Зенграма обладает широкими возможностями и позволяет фильтровать аккаунты по нескольким параметрам:
- геолокации;
- хэштегам;
- конкурентам;
- по подпискам;
- по подписчикам.
Кроме того, фильтры парсера можно настроить более тонко, указав пол владельцев аккаунтов, количество подписчиков на них, а также то, является страница частной или коммерческой.
Скидка 15% на все пакеты продвижения по промокоду exprom_15. Действует весь 2019 год!
Помимо сбора адресов страниц, отвечающих заданным параметрам, Зенграм позволяет получить контактные данные их обладателей, указанные ими в своем профиле (электронная почта, телефон, аккаунты в других соцсетях), которые тоже могут быть использованы для продвижения своего товара или для раскрутки аккаунта в Инстаграм.
Новым клиентам Зенграм бесплатно предоставляет десять баллов, которые используются для работы парсера. Бесплатный период работы парсера позволяет понять, насколько вам подходит эта услуга, и решить, стоит ей пользоваться или нет.
Использование парсера для личной страницы
Несмотря на то что Инстаграм – отличная площадка для коммерческой деятельности по продаже различных товаров и услуг, он остается социальной сетью, важнейшая функция которой – коммуникация между людьми. Инстаграм помогает оставаться на связи с родственниками и друзьями, заводить новые знакомства и просто общаться. Однако продвинуть свою страницу в Инстаграм и сделать ее по-настоящему популярной – дело непростое.
Привлечение подписчиков, являющихся живыми людьми, а не ботами и фейками, которые к тому же будут проявлять активность на вашей странице, долгий и трудоемкий процесс. Впрочем, для его облегчения можно использовать парсер. С помощью этого инструмента можно найти людей, отвечающих определенным критериям. Так, можно искать пользователей Инстаграм по:
- месту проживания;
- полу;
- возрасту;
- кругу интересов.
С помощью Zengram можно найти людей, имеющих те же увлечения, что и вы, или проживающих в том же регионе. Это позволяет сформировать обширную базу подписчиков, с которой потом можно проводить необходимую работу.
Как пользоваться парсером от Zengram
В пользовании Зенграмом нет ничего сложного: сервис имеет простой и понятный интерфейс. Кроме того, на сайте Zengram выложена подробная инструкция.
Вот что потребуется, чтобы работать с парсером от Зенграм:
- Зайти на сайт Zengram и зарегистрироваться на нем. Для этого нужно нажать соответствующую кнопку, которая расположена в правой верхней части страницы, после чего ввести адрес электронной почты и придуманный пароль.
- Добавить аккаунт Инстаграм, с которого будет проводиться парсинг. Страницу, которую вы собираетесь продвигать, добавлять не нужно. Для парсинга лучше использовать другой аккаунт. В этих целях можно создать новый профиль, который будет использоваться исключительно для работы с парсером.
- Выбрать в расположенной в левой части страницы панели сервиса пункт «парсер Зенграм».
Все, теперь можно приступать к парсингу. Собирать данные можно по:
- местоположению;
- хэштегам;
- конкурентам.
Давайте рассмотрим каждый из этих способов подробнее.
Сбор данных по местоположению
Вот что потребуется для сбора сведений о пользователях по геолокации:
- открыть меню сбора данных в левой части страницы и выбрать сбор по геолокации;
- указать населенный пункт, пользователей из которого вы хотите отыскать;
- нажать кнопку «сбор».
Поиск по геолокации затрудняет одно неприятное обстоятельство – весьма немало пользователей не пишут на своих страницах, где они живут. Однако Зенграм решил эту проблему, добавив к поиску по местоположению поиск по ключевым словам. Нередко люди, имеющие страницу в Instagram, но не указавшие, откуда они, в своих постах упоминают город, в котором живут. Кроме того, данные о местоположении пользователя могут содержаться в геотегах. Эти сведения можно использовать при работе с парсером. Для этого в специальной строке поиска парсера нужно ввести название города вручную. Результаты парсинга после этого будут содержать страницы даже тех людей, которые не указали место своего проживания. Также поиск по ключевым словам помогает найти пользователей с привязкой к определенному району города, тем или иным улицам. Это тоже иногда необходимо для коммерческого продвижения страницы.
Поиск по хэштегам
Парсинг данных о пользователях по хэштегам принципиально ничем не отличается от сбора сведений по геолокации. Разница заключается лишь в том, что в меню сбора данных необходимо выбрать пункт «сбор по хэштегам», указать интересующий хэштег и запустить поиск.
При парсинге по хэштегам можно воспользоваться функцией исключения дублей, поставив галочку напротив соответствующего пункта. Это позволит избежать включения в результаты поиска одних и тех же повторяющихся аккаунтов, владельцы которых используют одинаковые хэштеги.
Сбор по конкурентам
Похожим образом проводят и сбор данных по конкурентам. Для этого нужно выбрать в меню сбора пункт «сбор по конкурентам», указать аккаунт, данные о котором необходимо собрать, и начать сбор.
При сборе данных о конкурентах доступны функции сбора подписок и подписчиков. Для того, чтобы воспользоваться этими инструментами, надо поставить галочки напротив них.
Сбор данных в любом из режимов можно остановить, не дожидаясь его завершения. После такой остановки данные, которые успел собрать парсер, не исчезнут, а станут доступны пользователю.
Сбор личных данных
Зенграм – относительно «молодой» сервис, поэтому его создатели регулярно вносят в него различные изменения, упрощающие работу с инструментами Zengram, в том числе с парсером. Одно из последних нововведений – сбор личных и контактных данных, указанных пользователями Instagram на своей странице. Среди них:
- адрес электронной почты;
- мобильный телефон;
- адрес персонального интернет-сайта;
- адреса страниц в других соцсетях;
- данные, содержащиеся в описании странички.
Получение такой информации, несмотря на ее приватный характер, не нарушает закона. Ведь владельцы аккаунтов Instagram сами выкладывают ее на свою страницу, открывая к ней доступ всех остальных пользователей социальной сети.
Сбор этих сведений особенно актуален для коммерческих аккаунтов. Ведь, обладая ими, можно производить рекламную рассылку по e-mail, с помощью СМС или личных сообщений в других социальных сетях.
По сравнению с другими сервисами, которые тоже умеют собирать личные данные пользователей Instagram, Зенграм имеет одно неоспоримое преимущество – он способен обходить алгоритмы Инстаграма, направленные против такого сбора, и, тем самым, избегать блокировки.
Для получения персональных данных владельцев аккаунтов нужно во время любого из режимов сбора сведений поставить галочку напротив пункта «собирать дополнительные сведения».
При сборе личных данных пользователей с баланса парсера списывается в три раза больше баллов, чем при стандартной работе. Это следует помнить при расчете затрат на продвижение.
Результаты сбора
Когда сбор данных завершен и база аккаунтов сформирована, можно отфильтровать пользователей по интересующим параметрам. Доступен отбор по следующим критериям:
- полу;
- числу подписчиков;
- числу подписок;
- характеру страницы (можно оставить только коммерческие или только личные).
Как только необходимые параметры заданы, нужно нажать кнопку «начать фильтрацию». После ее завершения можно выгрузить базу в документ формата .txt для дальнейшей работы. Если вы не хотите фильтровать найденные аккаунты, можно сразу приступить к выгрузке, нажав кнопку «выгрузить в файл».
Парсер от Zengram – удобный инструмент как для продвижения коммерческого аккаунта в Инстаграм, так и для использования в личных целях. Он позволяет в автоматическом режиме обработать большое количество данных о пользователях социальной сети, выбрав из них нужные. Искать людей можно по геолокации, хэштегам или используя страницы конкурентов. По завершении поиска полученную информацию можно отфильтровать по заданным критериям. Благодаря парсеру Zengram продвижение вашей страницы в Instagram будет гораздо быстрее и эффективнее.
Регистрируйтесь по этой ссылке и приступайте к сбору данных!
Напоследок с меня подарок — промокод exprom_15 даст вам скидку 15% на все пакеты продвижения в Зенграм. Действует весь 2019 год! Удачи вам!
Быстрый парсинг instagram / СоХабр
{
«country_code»:«UA»,
«language_code»:«ru»,
«gatekeepers»:{
«rhp»:true
},
«qs»:»{«shift»:10,«header»:«tqZmR8t0opy5WBnx4lR4XoOq0OzzFJWO»,«edges»:100,«blob»:«AQCBu1-tD-iXYs1MVrRHOea1mr1Wcl-Z0XubfRjryfXmaWBxW3CFWaQlSyzUmlg1WRh3iwmmH5xZx3y_Y4Wd-yk1fpDgS9oJY_Yg8JOWS0KWDAj1cQ7VmvUQ6yBtMlaJ_prkbUqIyEHio3N7tKKbe6_VC4E12cYljIz1a8h9ZKfQI9FxAVGjOjAmA-1GYpOC7OK7T-QxoAI68ANuoYfkesHEuXufXh5vYsYq901pCpD0kg»,«iterations»:7,«size»:42}»,
«static_root»:»//instagramstatic-a. akamaihd.net/bluebar/abdffdf»,
«platform»:«web»,
«hostname»:«www.instagram.com»,
«entry_data»:{
«ProfilePage»:[
{
«__query_string»:»?»,
«__path»:»/nagiev.universal/»,
«__get_params»:{
},
«user»:{
«username»:«nagiev.universal»,
«follows»:{
«count»:0
},
«requested_by_viewer»:false,
«followed_by»:{
«count»:1549665
},
«country_block»:null,
«has_requested_viewer»:false,
«followed_by_viewer»:false,
«follows_viewer»:false,
«profile_pic_url»:«scontent.cdninstagram.com/hphotos-xfa1/t51.2885-19/11084701_1664610437093184_1741192215_a.jpg»,
«id»:«2030072568»,
«biography»:«для деловых контактов 8 (903) 618-85-85 Елена»,
«full_name»:«Дмитрий Нагиев»,
«media»:{
«count»:83,
«page_info»:{
«has_previous_page»:false,
«start_cursor»:«1148428813125297990»,
«end_cursor»:«1060985519936644118»,
«has_next_page»:true
},
«nodes»:[
{
«code»:»_wCevAKCdG»,
«date»:1451123404,
«dimensions»:{
«width»:1080,
«height»:1350
},
«comments»:{
«count»:1129
},
«caption»:«Ребята, догоняем по сборам „Звёздные войны“. Медленно, нехотя, но догоняем.»,
«likes»:{
«count»:79650
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xfp1/t51.2885-15/s640x640/sh0.08/e35/c0.135.1080.1080/12338682_666732683429124_1873383133_n.jpg»,
«is_video»:false,
«id»:«1148428813125297990»,
«display_src»:«scontent.cdninstagram.com/hphotos-xfp1/t51.2885-15/e35/12338682_666732683429124_1873383133_n.jpg»
},
{
«code»:»_onXg9KCaI»,
«date»:1450874308,
«dimensions»:{
«width»:640,
«height»:360
},
«comments»:{
«count»:776
},
«caption»:«Поём во всех кинотеатрах с 24 декабря.»,
«likes»:{
«count»:50556
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/e15/c140.0.360.360/12393595_117851415255516_1009376049_n. jpg»,
«is_video»:true,
«id»:«1146339244913469064»,
«display_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/e15/12393595_117851415255516_1009376049_n.jpg»
},
{
«code»:»_Zo3paKCSp»,
«date»:1450371779,
«dimensions»:{
«width»:1080,
«height»:796
},
«comments»:{
«count»:405
},
«caption»:«Премьера „Самый лучший день“. Спасибо всем за тёплые слова. Мы правда старались.»,
«likes»:{
«count»:61469
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xap1/t51.2885-15/s640x640/sh0.08/e35/c142.0.796.796/12383265_421732398017494_1395538556_n.jpg»,
«is_video»:false,
«id»:«1142123726409049257»,
«display_src»:«scontent.cdninstagram.com/hphotos-xap1/t51.2885-15/e35/12383265_421732398017494_1395538556_n.jpg»
},
{
«code»:»_Eah_wqCYL»,
«date»:1449659619,
«dimensions»:{
«width»:640,
«height»:600
},
«comments»:{
«count»:128
},
«caption»:«Друзья мои! Давайте вместе с благотворительным фондом „Анна“ подарим детям счастливое детство и здоровое будущее. Всё просто! Отправьте SMS-сообщение на номер 3434 со словом АННА и через пробел укажите цифрами сумму пожертвования. Например: „Анна 300“. Спасибо, что вы с нами! Вместе мы сможем многое! Подробности на сайте fondanna.org и fond.anna»,
«likes»:{
«count»:22425
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xft1/t51.2885-15/e35/c21.0.640.640/12354042_199129050423634_180735219_n.jpg»,
«is_video»:false,
«id»:«1136149691418289675»,
«display_src»:«scontent.cdninstagram.com/hphotos-xft1/t51.2885-15/s640x640/sh0.08/e35/12354042_199129050423634_180735219_n.jpg»
},
{
«code»:»-6i4_hqCYH»,
«date»:1449328457,
«dimensions»:{
«width»:750,
«height»:655
},
«comments»:{
«count»:676
},
«caption»:«Раньше я только радиво слушал. Сегодня купил небольшой телевизор от LG. Оказывается и телек может быть произведением искусства. Мечты сбываются не только у тех.»,
«likes»:{
«count»:86456
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xtp1/t51.2885-15/s640x640/sh0.08/e35/c67.0.929.929/12356533_931958760173232_1240448449_n.jpg»,
«is_video»:false,
«id»:«1133371706319578631»,
«display_src»:«scontent.cdninstagram.com/hphotos-xtp1/t51.2885-15/s750x750/sh0.08/e35/12356533_931958760173232_1240448449_n.jpg»
},
{
«code»:»-3Xc9NqCZ4″,
«date»:1449221797,
«dimensions»:{
«width»:1080,
«height»:1350
},
«comments»:{
«count»:551
},
«caption»:«Благодарю „собака ru“ за нескромное признание моих скромных заслуг. @sobaka_ru»,
«likes»:{
«count»:86263
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent. cdninstagram.com/hphotos-xtf1/t51.2885-15/s640x640/sh0.08/e35/c0.135.1080.1080/12269792_1196978800315863_367400789_n.jpg»,
«is_video»:false,
«id»:«1132476976249448056»,
«display_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/e35/12269792_1196978800315863_367400789_n.jpg»
},
{
«code»:»-pIaE-qCYx»,
«date»:1448744147,
«dimensions»:{
«width»:1080,
«height»:1130
},
«comments»:{
«count»:865
},
«caption»:«Я офигенный актёр. Возможно, в следующей жизни, реинкарнируюсь в себя же. За 10 минут до спектакля.»,
«likes»:{
«count»:106928
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/s640x640/sh0.08/e35/c0.25.1080.1080/12317576_507540552761342_2017114497_n.jpg»,
«is_video»:false,
«id»:«1128470158057678385»,
«display_src»:«scontent. cdninstagram.com/hphotos-xtf1/t51.2885-15/e35/12317576_507540552761342_2017114497_n.jpg»
},
{
«code»:»-bdP8BqCSF»,
«date»:1448285312,
«dimensions»:{
«width»:1080,
«height»:1117
},
«comments»:{
«count»:386
},
«caption»:«Давно ли ты звонил родителям? Неделю, месяц назад? А сколько времени прошло с твоего последнего поста в Instagram? 5 минут, 30 секунд? Вот тебе мой совет: подари им онлайн-фоторамку @EasyFrame. Коль компьютером они пользоваться не умеют и смартфона у них нет. Себе установишь приложение #EasyFrame и будешь время от времени свои фотки папе тоже отправлять, чтоб знал, что сын живой, здоровый ходит и помнит о своих родителях! #направахрекламы»,
«likes»:{
«count»:78587
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xap1/t51.2885-15/s640x640/sh0.08/e35/c0. 18.1080.1080/12224446_774508552674655_1681650241_n.jpg»,
«is_video»:false,
«id»:«1124621170552349829»,
«display_src»:«scontent.cdninstagram.com/hphotos-xap1/t51.2885-15/e35/12224446_774508552674655_1681650241_n.jpg»
},
{
«code»:»-WddpTKCXD»,
«dimensions»:{
«width»:640,
«height»:799
},
«comments»:{
«count»:315
},
«date»:1448117652,
«likes»:{
«count»:56694
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xta1/t51.2885-15/e15/c0.79.640.640/12276758_1019583288084031_368304059_n.jpg»,
«is_video»:true,
«id»:«1123214737633977795»,
«display_src»:«scontent.cdninstagram.com/hphotos-xta1/t51.2885-15/e15/12276758_1019583288084031_368304059_n.jpg»
},
{
«code»:«91d1TxqCbU»,
«dimensions»:{
«width»:1080,
«height»:1255
},
«comments»:{
«count»:832
},
«date»:1447010550,
«likes»:{
«count»:110877
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent. cdninstagram.com/hphotos-xtf1/t51.2885-15/s640x640/sh0.08/e35/c0.87.1080.1080/11906318_925228030886285_103073514_n.jpg»,
«is_video»:false,
«id»:«1113927689559353044»,
«display_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/e35/11906318_925228030886285_103073514_n.jpg»
},
{
«code»:«9OZtKKKCYV»,
«date»:1445699763,
«dimensions»:{
«width»:750,
«height»:938
},
«comments»:{
«count»:1277
},
«caption»:«Бывает. Всяко-разно — это не заразно.»,
«likes»:{
«count»:84684
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xpa1/t51.2885-15/s640x640/sh0.08/e35/c0.104.831.831/12142487_436103659916025_1237832219_n.jpg»,
«is_video»:false,
«id»:«1102932013199402517»,
«display_src»:«scontent.cdninstagram.com/hphotos-xpa1/t51. 2885-15/sh0.08/e35/p750x750/12142487_436103659916025_1237832219_n.jpg»
},
{
«code»:«859rCNqCcE»,
«date»:1445013977,
«dimensions»:{
«width»:1080,
«height»:1080
},
«comments»:{
«count»:224
},
«caption»:«Если это выпускается — значит это кому-нибудь нужно. Ребята, спасибо, тронут. @_dn_store»,
«likes»:{
«count»:50813
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xta1/t51.2885-15/s640x640/sh0.08/e35/12105047_1008085539211870_760465353_n.jpg»,
«is_video»:false,
«id»:«1097179222392710916»,
«display_src»:«scontent.cdninstagram.com/hphotos-xta1/t51.2885-15/e35/12105047_1008085539211870_760465353_n.jpg»
},
{
«code»:«8sYfMmKCfM»,
«date»:1444558274,
«dimensions»:{
«width»:480,
«height»:601
},
«comments»:{
«count»:491
},
«caption»:«Эх, чёс, птица-чёс, кто ж тебя выдумал? спектакль „Кыся“ 9 и 10 ноября — Ростов-на-дону, 19:00 театр им. М.Горького 12 и 13 ноября — Краснодар, 19:00, ЦКЗ Красная,5 В Москве — 23 октября, 19:00 театр Эстрады и в Санкт-Петербурге — 7 ноября, 19:00 ДК Горького»,
«likes»:{
«count»:73335
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xap1/t51.2885-15/e35/c0.63.503.503/11349159_1624396781145618_1870065076_n.jpg»,
«is_video»:false,
«id»:«1093356506489300940»,
«display_src»:«scontent.cdninstagram.com/hphotos-xap1/t51.2885-15/e35/p480x480/11349159_1624396781145618_1870065076_n.jpg»
},
{
«code»:«8fJR6gKCaE»,
«dimensions»:{
«width»:1080,
«height»:1080
},
«comments»:{
«count»:187
},
«date»:1444114093,
«likes»:{
«count»:39914
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram. com/hphotos-xat1/t51.2885-15/s640x640/sh0.08/e35/12106273_831678336953789_244335017_n.jpg»,
«is_video»:false,
«id»:«1089630448313181828»,
«display_src»:«scontent.cdninstagram.com/hphotos-xat1/t51.2885-15/e35/12106273_831678336953789_244335017_n.jpg»
},
{
«code»:«8a1IMBqCaW»,
«date»:1443969310,
«dimensions»:{
«width»:750,
«height»:519
},
«comments»:{
«count»:492
},
«caption»:«Выступаю в ООН. Рассказываю о себе. Путин и Обама слушают внимательно. Плачут.»,
«likes»:{
«count»:74601
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xat1/t51.2885-15/e35/c124.0.560.560/12145160_179459972388920_1669657538_n.jpg»,
«is_video»:false,
«id»:«1088415919096997526»,
«display_src»:«scontent.cdninstagram.com/hphotos-xat1/t51. 2885-15/s750x750/sh0.08/e35/12145160_179459972388920_1669657538_n.jpg»
},
{
«code»:«8VD7mEKCQn»,
«date»:1443775744,
«dimensions»:{
«width»:640,
«height»:640
},
«comments»:{
«count»:391
},
«caption»:«Снималис. Ждёмс.»,
«likes»:{
«count»:39532
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xpt1/t51.2885-15/e15/12139770_448350388699998_358872140_n.jpg»,
«is_video»:true,
«id»:«1086792174540432423»,
«display_src»:«scontent.cdninstagram.com/hphotos-xpt1/t51.2885-15/e15/12139770_448350388699998_358872140_n.jpg»
},
{
«code»:«8No7kGKCdM»,
«dimensions»:{
«width»:640,
«height»:640
},
«comments»:{
«count»:2198
},
«date»:1443526707,
«likes»:{
«count»:58325
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent. cdninstagram.com/hphotos-xtf1/t51.2885-15/s640x640/sh0.08/e35/11950578_1503381619975758_1086947347_n.jpg»,
«is_video»:false,
«id»:«1084703100333729612»,
«display_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/s640x640/sh0.08/e35/11950578_1503381619975758_1086947347_n.jpg»
},
{
«code»:«8FyiWlKCeR»,
«date»:1443263308,
«dimensions»:{
«width»:640,
«height»:640
},
«comments»:{
«count»:1208
},
«caption»:«Уровень карьерного взлёта — Бог.»,
«likes»:{
«count»:75978
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/e15/11917836_1626573190942869_1899434459_n.jpg»,
«is_video»:true,
«id»:«1082493548485945233»,
«display_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/e15/11917836_1626573190942869_1899434459_n. jpg»
},
{
«code»:«7dLTUPKCVj»,
«date»:1441900560,
«dimensions»:{
«width»:1080,
«height»:1319
},
«comments»:{
«count»:545
},
«caption»:«С хорошими людьми сводит жизнь. Меховые салоны „Бродвей“(Невский проспект, 27 и Невский проспект, 91 ) Люблю хозяйку салонов Марину и её сына Витю, безо всякой помощи построили целую меховую империю. Обещали всем пришедшим от Нагиева скидку 10% на всё. Пароль — »Зима близко».»,
«likes»:{
«count»:88030
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xpf1/t51.2885-15/s640x640/sh0.08/e35/c0.119.1080.1080/11910381_1626518630951765_521156034_n.jpg»,
«is_video»:false,
«id»:«1071061992294851939»,
«display_src»:«scontent.cdninstagram.com/hphotos-xpf1/t51.2885-15/e35/11910381_1626518630951765_521156034_n.jpg»
},
{
«code»:«7a459UKCQQ»,
«date»:1441823807,
«dimensions»:{
«width»:750,
«height»:750
},
«comments»:{
«count»:917
},
«caption»:«Ты молод, образован, полон сил и идей, но не знаешь с чего начать? Жаль. »,
«likes»:{
«count»:110511
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/s640x640/sh0.08/e35/11910403_807149036049953_1054755736_n.jpg»,
«is_video»:false,
«id»:«1070418134905136144»,
«display_src»:«scontent.cdninstagram.com/hphotos-xtf1/t51.2885-15/s750x750/sh0.08/e35/11910403_807149036049953_1054755736_n.jpg»
},
{
«code»:«7WAC3SqCfx»,
«date»:1441659777,
«dimensions»:{
«width»:750,
«height»:938
},
«comments»:{
«count»:1078
},
«caption»:«Когда-нибудь и я уйду в закат…»,
«likes»:{
«count»:113125
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xft1/t51.2885-15/s640x640/sh0.08/e35/c0.113.898.898/10611202_437269856457196_1661341871_n. jpg»,
«is_video»:false,
«id»:«1069042158354835441»,
«display_src»:«scontent.cdninstagram.com/hphotos-xft1/t51.2885-15/sh0.08/e35/p750x750/10611202_437269856457196_1661341871_n.jpg»
},
{
«code»:«7NaFIMKCey»,
«date»:1441371438,
«dimensions»:{
«width»:480,
«height»:480
},
«comments»:{
«count»:235
},
«caption»:«Это самый серьёзный фильм, в котором я снимался. Рванёт так рванёт.»,
«likes»:{
«count»:49769
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xft1/t51.2885-15/e35/11849000_542230202594960_1391342715_n.jpg»,
«is_video»:false,
«id»:«1066623388357240754»,
«display_src»:«scontent.cdninstagram.com/hphotos-xft1/t51.2885-15/s480x480/e35/11849000_542230202594960_1391342715_n.jpg»
},
{
«code»:«7Kj7B1KCVS»,
«date»:1441275934,
«dimensions»:{
«width»:750,
«height»:770
},
«comments»:{
«count»:775
},
«caption»:«Красавчик. Всё на месте. Паранойя, апатия, психоз.»,
«likes»:{
«count»:100214
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xpt1/t51.2885-15/s640x640/sh0.08/e35/c0.13.986.986/11910170_892300930857280_1225078669_n.jpg»,
«is_video»:false,
«id»:«1065822249869124946»,
«display_src»:«scontent.cdninstagram.com/hphotos-xpt1/t51.2885-15/sh0.08/e35/p750x750/11910170_892300930857280_1225078669_n.jpg»
},
{
«code»:«65YLWDqCQW»,
«date»:1440699351,
«dimensions»:{
«width»:1080,
«height»:1080
},
«comments»:{
«count»:941
},
«caption»:«Всех с днём кино! Это я. Лучше порно, чем никогда.»,
«likes»:{
«count»:62433
},
«owner»:{
«id»:«2030072568»
},
«thumbnail_src»:«scontent.cdninstagram.com/hphotos-xap1/t51. 2885-15/s640x640/sh0.08/e35/11925754_1687704031451714_1616999181_n.jpg»,
«is_video»:false,
«id»:«1060985519936644118»,
«display_src»:«scontent.cdninstagram.com/hphotos-xap1/t51.2885-15/e35/11925754_1687704031451714_1616999181_n.jpg»
}
]
},
«blocked_by_viewer»:false,
«is_verified»:false,
«has_blocked_viewer»:false,
«is_private»:false,
«external_url»:«m-rnagiev.ru»
}
}
]
},
«qe»:{
«su»:{
«p»:{
«enabled»:«true»
},
«g»:«test»
}
},
«display_properties_server_guess»:{
«viewport_width»:1280,
«pixel_ratio»:1
},
«config»:{
«viewer»:null,
«csrf_token»:«7411d740243ea88936c8a365eb45d6b9»
},
«environment_switcher_visible_server_guess»:true
}
Парсинг аудитории Инстаграм реально поможет в раскрутке
Оглавление:
- 1 Особенности парсинга аудитории Инстаграм
- 2 Основное предназначение парсинга
- 3 Как использовать парсинг подписчиков для продвижения профиля?
- 4 Подборка сервисов для парсинга
- 5 Вопросы наших читателей
Социальные сети уже давно переросли свою первостепенную функцию, общение. Сейчас большая аудитория может быть очень полезна как в плане распространения какой-то информации, так и в плане заработка. Но продвижение как таковое требует знания полезных инструментов и фишек, которые ускорят процесс. Один из таких помощников – парсинг аудитории Инстаграм.
Особенности парсинга аудитории Инстаграм
Instagram – социальная сеть, которая сильно отличается от привычных вариантов. Для примера, сравним со ВКонтакте: в профиле вы можете указать информацию, начиная именем и фамилией и заканчивая воинской частью, где проходила служба. Благодаря этому, в поиске этого сайта есть подробная система фильтров, каждый из которых можно использовать для того, чтобы получить список пользователей, которые заинтересуются контентом.
В Инстаграм же всё, что можно заполнить, это: контакты, веб-сайт, имя пользователя, никнейм и поле «О себе». Конечно, есть ещё некоторые поля, но их используют реже. В общем, информации настолько негусто, по сравнению с ВК, что парсинг потенциальных подписчиков работает иначе – софту приходится определять перспективность аккаунта по косвенным показателям: хэштегам, геометкам и прочему.
Основное предназначение парсинга
Для чего нужен парсинг аудитории Инстаграм? Начнём с того, что это может стать альтернативой поиску людей. У вас есть места, в которых бывает человек, хэштеги, которыми он пользуется, и несколько блогеров, на которых он может быть подписан? Можно использовать парсинг подписчиков Инстаграм и изучить результаты запроса. Однако, это – нечастое применение таких инструментов, потому что даже они не могут сделать процесс поиска по фотосети более удобным. Чаще с его помощью люди организовывают более эффективное продвижение. Согласитесь, нужно знать, для кого вы делаете контент, чтобы уметь привлекать к себе потенциальных читателей и клиентов.
Как использовать парсинг подписчиков для продвижения профиля?
За счёт того, что фотосеть сильно отличается от аналогов, парсинг аккаунтов Инстаграм – основной способ набора аудитории. Как я уже писала выше, важно знать, для кого вы ведёте страницу, чтобы контент обеспечил увеличение количества подписчиков и их активность. Однако, знание ЦА полезно не только для более эффективной работы постов. Люди не смогут вас лайкать и комментировать, если не видят публикации. Поэтому следует заявить о своём существовании тем, кто может заинтересоваться.
Парсинг аудитории Инстаграм чаще всего используется в следующих способах раскрутки:
- Таргетированная реклама. В эту часть социальной сети встроен свой парсер. Равных ему нет – вы можете настроить параметры «жертв» максимально точно. Поэтому таргетинг остаётся самым эффективным способом продвижения. Дело за малым – нужно знать целевых фолловеров.
- Сервисы комплексного продвижения. У таких сайтов есть две основы – массовые действия и отбор аккаунтов. Под массовыми действиями я подразумеваю массфолловинг, масслайкинг, масскомментинг и масслукинг. Сюда же можно отнести и рассылки в директ. Разумеется, если на человека подпишется кто-то, чьи посты ему неинтересны, он не проявит взаимность. Поэтому, опять же, важно точно знать, чем интересуются ваши потенциальные подписчики.
Подборка сервисов для парсинга
Человечество уже давно придумало все за нас, в том числе и парсинг аудитории. Вам не нужно перебирать всех пользователей в Инстаграм, отбирая нужных пользователей. Онлайн-сервисы сделают это за вас:
- Zengram. Этот сайт очень популярен у тех, кто предпочитает пользоваться не совсем «чистыми» способами продвижения. Такой популярностью Зенграм обязан двум характеристикам: невысокая цена и доступ к нескольким полезным инструментам. Один из таких модулей – парсер. Отбирает страницы по хэштегам, геометкам и фолловерам конкурента. К слову, заодно Zengram может собрать контактные данные, ссылки на сайт и Био.
- Instaplus.me. Ещё один сервис комплексного продвижения. В общем-то, в плане парсинга он не очень отличается от предыдущего, поэтому больше мне сказать нечего.
- Tooligram. Реализован он и как онлайн-сервис и как программа, опять же, для раскрутки. Пожалуй, только этим он отличается от предыдущих вариантов. Программа имеет дополнительный плюс – дополнительная безопасность, ведь ваши данные остаются только на компьютере. Поэтому риск того, что их перехватят злоумышленники, меньше.
Аудитория в Instagram – показатель популярности и коммуникабельности. А сейчас популярность может приносить деньги. Но бездумное продвижение будет крайне медленным, по скорости примерно сравнится с обычным сарафанным радио. Поэтому нужно понимать, как раскрутка работает и как следует простроить стратегию набора подписчиков. Один из самых удобных помощников в этом нелёгком деле является парсинг пользователей в Инстаграм.
Вопросы наших читателей
#1. Какие программы помогут собрать целевую аудиторию?
Если говорить именно о программах, то это Socialkit. Помимо сбора ЦА в нем еще куча полезных инструментов. Обязательно попробуйте.
#2. Как правильно определить целевую аудиторию?
Для качественной настройки парсера необходимо знать характеристики целевой аудитории. С тематическими хэштегами, в принципе, ясно – вводите варианты в поиске и смотрите популярные или пользуетесь специальными сервисами. Возраст, пол и местоположение пользователей же определить можно и с помощью встроенной статистики, которая доступна после перехода на бизнес-аккаунт.
#3. Парсер и чекер аккаунтов Инстаграм – одно и то же?
Обычно чекерами называют программы, в которые загружают базу с логинами и паролями для проверки их актуальности. Check – проверка по английски. Но некоторые путают эти понятия и под «чекером» для Инстаграм понимают именно парсер. Я бы на вашем месте использовала именно второй термин, потому что у него есть только одно значения.
Чтобы задать вопрос или оставить мнение – пишите в комментариях. А также смотрите полезное видео по теме.
[Всего: 0 Средний: 0/5]
Понравился материал? Поделись с друзьями!
lifeweb-instagram-parser — пакет npm | Snyk
Все уязвимости безопасности принадлежат производственных зависимостей прямых и косвенных
пакеты.
Риск безопасности и лицензии для важных версий
Все версии
| Версия | Уязвимости | Риск лицензии | |||
|---|---|---|---|---|---|
| 0.0022 | 11/2020 | Популярный |
|
| |
Ваш проект подвержен уязвимостям?
Сканируйте свои проекты на наличие уязвимостей. Быстро исправить с помощью автоматизированного
исправления. Начните работу со Snyk бесплатно.
Начните бесплатно
Еженедельные загрузки (1)
Скачать тренд
- Иждивенцы
- 0
- Звезды GitHub
- 0
- Вилки
- 0
- Авторы
- 1
Популярность прямого использования
Пакет npm lifeweb-instagram-parser получает в общей сложности
1 загрузка в неделю. Таким образом, мы забили
Уровень популярности lifeweb-instagram-parser будет ограничен.
На основе статистики проекта из репозитория GitHub для npm package lifeweb-instagram-parser мы обнаружили, что он снялся? раз, и что 0 других проектов в экосистеме зависят от него.
Загрузки рассчитываются как скользящие средние за период из последних 12 месяцев, за исключением выходных и известных отсутствующих точек данных.
Частота фиксации
Нет последних коммитов
- Открытые вопросы
- 0
- Открытый PR
- 0
- Последняя версия
- 2 года назад
- Последняя фиксация
- 2 года назад
Дальнейший анализ состояния обслуживания lifeweb-instagram-parser на основе
каденция выпущенных версий npm, активность репозитория,
и другие точки данных определили, что его обслуживание
Неактивный.
Важным сигналом обслуживания проекта для lifeweb-instagram-parser является это не видел никаких новых версий, выпущенных для npm в за последние 12 месяцев и может считаться прекращенным проектом или проектом, который получает мало внимания со стороны его сопровождающих.
За последний месяц мы не обнаружили никаких запросов на вытягивание или изменений в статус issue был обнаружен для репозитория GitHub.
- Совместимость с Node.js
- не определено
- Возраст
- 2 года
- Зависимости
- 0 Прямые
- Версии
- 13
- Установочный размер
- 3,94 КБ
- Распределенные теги
- 1
- Количество файлов
- 6
- Обслуживающий персонал
- 2
- Типы TS
- Нет
lifeweb-instagram-parser имеет более одного последнего тега по умолчанию, опубликованного для
пакет нпм. Это означает, что для этого могут быть доступны другие теги.
пакет, например рядом, чтобы указать будущие выпуски, или стабильный, чтобы указать
стабильные релизы.
Первый шаг анализа данных Instagram: очистка и анализ данных формата JSON с использованием Python | Ирис С
Эпидемия COVID-19 привела к снижению потребительских расходов на товары второстепенной важности. Швейная промышленность является одной из отраслей, которая страдает больше всего, и роскошные дома моды принимают меры, чтобы транслировать «правильное сообщение» потребителям через основные каналы социальных сетей. Мы собираемся исследовать посты модных брендов в Instagram, чтобы изучить «послание», которое они хотят донести в эти особенно трудные дни.
Тем не менее, мы собираем данные о последних публикациях в учетной записи IG модных домов для нашего анализа.
Официальный аккаунт Louis Vuitton в Instagram | @louisvuitton
Мы будем использовать Python для достижения этой цели, учитывая его универсальность и широкий спектр библиотек с открытым исходным кодом, которые мы могли бы легко использовать. Вот шаги, которые мы предпримем:
Выбор пакетов Python:
- Сбор данных: instagram-scraper (неофициальный API с открытым исходным кодом)
- Очистка данных: pandas, json, glob, emoji, nltk
- Анализ данных: Google Sentiment Analysis API, matplotlib
импортировать панды как pd
импортировать glob
импортировать json
импортировать повторно
импортировать дату и время
импортировать смайлики
из wordcloud импортировать WordCloud, STOPWORDS
импортировать matplotlib.pyclot как plt
из google.cloud импортировать язык как 8 lg из lg 90.cloud2. .language import enums
from google.cloud.language import types
from nltk.corpus import стоп-слова
from nltk.tokenize import word_tokenizestop_words = set(stopwords.words('english'))
В первой части мы поговорим о том, как очищать и обрабатывать данные JSON. Мы поработаем над некоторыми простыми текстовыми анализами в Части 2.
Сбор данных
Приложение командной строки: Instagram-scraper
Это API с открытым исходным кодом, который упрощает задачи парсинга с помощью широкого спектра методов (например, получение описания профиля пользователя, загрузка медиафайлов пользователя). Пожалуйста, найдите установку и подробное использование в этом репозитории Github.
После того, как все настроено, запустите команду в терминале (Mac OS) или в командной строке (Windows):
Например, мы могли бы структурировать следующую команду, чтобы предоставить список идентификаторов пользователей, которые мы хотим очистить. (в user.txt). В дополнение к метаданным мультимедиа по умолчанию мы также хотим включить информацию о профиле пользователя; последнее, но не менее важное: мы хотим очистить 50 самых последних сообщений и сохранить их в выходных данных вызова папки.
instagram-scraper -f user.txt — media-metadata — profile-metadata -m 50 -d output
Вывод: файлы JSON, содержащие метаданные сообщений
Некоторые люди могут предпочесть очищать сообщения IG, написав свои собственные script с учетом особых ограничений в рамках этого API. Не проблема! Существуют методы выполнения аналогичной задачи с использованием Selenium и агентов веб-браузера. Вот удивительная статья, которая показывает вам шаги.
Извлечение и очистка данных из дерева JSON
Вернемся к тому, что мы обсуждали до сих пор. К сожалению, результат, который мы получили, выполнив команды, еще не готов к использованию! Обратите внимание, что нужные нам данные вложены в дерево JSON. Поэтому мы начнем писать скрипт на Python, который анализирует и очищает данные и делает их пригодными для анализа.
Всегда первый шаг: исследуйте дерево JSON, и мы находим текст сообщения с ключом «текст».
Помните, что каждый идентификатор пользователя создает один отдельный файл JSON и сохраняется в выходной папке, поэтому мы можем использовать библиотеку glob с сопоставлением подстановочных знаков, чтобы найти все файлы с окончанием файла «JSON» и начать чтение данных внутри каждого из них:
file_list = glob.glob("*.json")file_merge=[] для файла в file_list:
с open(file, 'r') в виде текста:
jdata = json.load(text)
, если jdata:
file_merge. append(jdata) Вывод этого шага: список со всеми файлами JSON
— — —
Мы начнем с создания фрейма данных, который сохраняет проанализированные и очищенные данные:
df=pd.DataFrame( columns=['Id','post','likes','comments','date','sentiment','followers'])
— —
Вот что мы будем делать дальше:
- Перебрать каждую строку JSON. В каждой строке найдите путь к ключам, которые соответствуют каждому значению, которое мы хотим извлечь (например, «заголовок»: «контент публикации»).
- Для захваченного значения примените простые методы обработки текста, такие как удаление стоп-слов, эмодзи и специальных символов:
stop_words = set(stopwords.words('english')) def filter_stop(txt):
txt_tokens=word_tokenize (txt)txt_tokens=[слово в слово в txt_tokens, если слово не в stop_words]
return ' '.join(txt_tokens)def strip_emoji(text):new_text = re.sub(emoji.get_emoji_regexp(), r"", text)return new_text
Начните перебирать список!
Вывод этого шага: у нас есть фрейм данных очищенных данных, который готов к экспорту в любой формат, удобный для Excel:
— —
ВАУ! Я надеюсь, что у нас достаточно на данный момент! Теперь у нас есть как медиа-контент, так и некоторые пользовательские показатели для проведения различных типов анализа! В следующем сообщении блога мы будем изучать WordCloud и использовать API анализа настроений Google, чтобы подробно изучить наш набор данных. До встречи!
Примечания относительно этических и юридических вопросов парсинга без официального API: пожалуйста, имейте в виду, что это всего лишь краткий пример, демонстрирующий один из многих способов сбора медиафайлов IG. Большие масштабы и объемы очистки несут риск возможных правовых последствий. Тщательно думайте и действуйте разумно!
анализ html страницы входа в Instagram с помощью BeautifulSoup на Python 3.9.10
В основном я пытаюсь создать программу, которая может идентифицировать страницы входа по URL-адресу. Моя идея для этого состоит в том, чтобы анализировать страницы в поисках текстовых полей (и затем идентифицировать их по имени и типу). вот код:
запросы на импорт
из bs4 импортировать BeautifulSoup
\\парсить html страницы (суп)
деф синтаксический анализ (суп):
найдено = []
для супа.find_all('input'):
if(a['type'] in ['text','password','email']):
found.append(a['имя'])
возвращение найдено
\\получить html сайта
определение get_site_content (url):
html = запросы. get(url)
суп = BeautifulSoup(html.text, 'html5lib')
textBoxes = анализ (суп)
print("Найдено в: " +url)
печать (текстовые поля)
если __name__ == '__main__':
get_site_content('https://login.facebook.com')
get_site_content('https://www.instagram.com/accounts/login/')
get_site_content('https://instagram.com')
get_site_content('https://instagram.com/login')
get_site_content('https://login.yahoo.com')
Кажется, все работает нормально, но по какой-то причине у меня возникли проблемы со страницей входа в Instagram. вот вывод:
Найдено в: https://login.facebook.com ['электронная почта', 'проход'] Найдено в: https://www.instagram.com/accounts/login/ [] Найдено на: https://instagram.com [] Найдено в: https://instagram.com/login [] Найдено на: https://login.yahoo.com ['имя пользователя', 'пароль'] Процесс завершен с кодом выхода 0
После использования разных библиотек для получения html и разных парсеров я понял, что проблема с html = request. строка. он просто не получает полный html.
Любые идеи о том, как это исправить?
Заранее спасибо! get(url)
кстати, если у вас есть лучшее представление о том, что я пытаюсь сделать, я бы хотел услышать это 🙂
Контент предоставляется динамически JavaScript , который не будет отображаться запросами . Чтобы получить обработанный page_source , используйте selenium .
Вы также можете выбрать более конкретные элементы:
для супа.
Пример
время импорта
из bs4 импортировать BeautifulSoup
из веб-драйвера импорта селена
из webdriver_manager.chrome импортировать ChromeDriverManager
драйвер = webdriver.Chrome(ChromeDriverManager().install())
деф синтаксический анализ (суп):
найдено = []
для супа.select('input[name]'):
if(a['type'] in ['text','password','email']):
found.append(a['имя'])
возвращение найдено
определение get_site_content (url):
driver. get(url)
время сна(2)
суп = BeautifulSoup(driver.page_source, 'html5lib')
textBoxes = анализ (суп)
print("Найдено в: " +url)
печать (текстовые поля)
если __name__ == '__main__':
get_site_content('https://login.facebook.com')
get_site_content('https://www.instagram.com/accounts/login/')
get_site_content('https://instagram.com')
get_site_content('https://instagram.com/login')
get_site_content('https://login.yahoo.com')
Выход
Найдено на: https://login.facebook.com ['электронная почта', 'проход'] Найдено в: https://www.instagram.com/accounts/login/ ['имя пользователя Пароль'] Найдено на: https://instagram.com ['имя пользователя Пароль'] Найдено в: https://instagram.com/login ['имя пользователя Пароль'] Найдено на: https://login.yahoo.com ['имя пользователя', 'пароль']
1
Итак, благодаря @user:14460824 (HedgHog) я понял, что проблема заключалась в необходимости рендеринга страницы, поскольку она рендерится динамически из Javascript. Лично мне селен не понравился, и вместо него я использовал запросы-html. он работает так же, как селен, но просто кажется более простым в использовании, и в будущем, когда я пойму, как определить, отображается ли веб-страница динамически из Javascript или нет, эту библиотеку будет намного проще использовать, поэтому я не буду тратить ресурсы впустую.
вот код:
из request_html импортировать HTMLSession
запросы на импорт
#парсить html страницы
деф синтаксический анализ (html):
найдено = []
для в html.find('input'):
if(a.attrs['type'] в ['text','password','email'] и 'name' в a.attrs):
found.append(a.attrs['имя'])
возвращение найдено
#получить html сайта
определение get_site_content (url):
пытаться:
сеанс = HTMLSession()
ответ = session.get(url)
#if(JAVASCRIPT): #здесь мне нужно найти способ узнать погоду
#Визуализация страницы #страница визуализируется динамически из Javascript
#response.html.render(время ожидания=20)
response. html.render(timeout=20) #пока отображаем все страницы
вернуть ответ.html
кроме request.exceptions.RequestException как e:
печать (е)
определение find_textboxes (url):
текстовые поля = анализ (get_site_content (url))
print("Найдено в: " +url)
печать (текстовые поля)
если __name__ == '__main__':
find_textboxes('https://login.facebook.com')
find_textboxes('https://www.instagram.com/accounts/login/')
find_textboxes('https://instagram.com')
find_textboxes('https://login.yahoo.com')
Твой ответ
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
How to Scrape Instagram
В этом руководстве по парсингу веб-страниц на Python мы изучим Instagram — одну из крупнейших социальных сетей. Мы рассмотрим, как парсить результаты поиска в Instagram и изучить конечные точки, чтобы найти данные профиля пользователя и опубликовать информацию.
Мы также сосредоточимся на некоторых советах и рекомендациях по эффективному доступу к этим конечным точкам и тому, как избежать блокировки парсером веб-страниц и получить доступ ко всей этой информации без входа в Instagram. Итак, давайте погрузимся!
Настройка
В этом учебном пособии по веб-скрапингу в Instagram мы будем использовать Python с клиентской библиотекой HTTP httpx, которая обеспечит все наши взаимодействия с сервером Instagram. Мы можем установить его с помощью команды pip :
$ pip install httpx
Это все, что нам нужно для этого урока. В основном мы будем работать с объектами JSON, которые мы можем анализировать в родном Python без каких-либо дополнительных пакетов.
Поиск сообщений и пользователей
По хэштегу
Чтобы найти пользователей, мы можем обратиться ко многим страницам исследования Instagram. Например, наиболее распространенный подход — использовать конечную точку /explore/tags для поиска сообщений по хэштегу . Вместо очистки конечной точки HTML мы можем использовать службу Instagram GraphQl:
def scrape_hashtag (хэштег: str, сеанс: httpx.AsyncClient, page_size = 12, page_limit: необязательно [int] = None):
"""удалить данные поста пользователя"""
base_url = "https://www.instagram.com/graphql/query/?query_hash=174a5243287c5f3a7de741089750ab3b&variables="
переменные = {
"tag_name": хэштег,
"первый": page_size,
"после": нет,
}
страница = 1
пока верно:
результат = session.get(base_url + цитата(json.dumps(переменные)))
сообщения = json.loads(result.content)["данные"]["хэштег"]["edge_hashtag_to_media"]
для сообщения в сообщениях ['края']:
выходной пост["узел"]
page_info = сообщения["page_info"]
если не page_info["has_next_page"]:
ломать
переменные["после"] = page_info["конечный_курсор"]
страница += 1
если страница > page_limit:
ломать
Код выполнения и пример вывода # Пример использования:
если __name__ == "__main__":
с httpx. Client(
время ожидания = httpx.Timeout (20.0),
) как сеанс:
для пользователя в scrape_hashtag("кошки", сеанс):
печать (пользователь)
[
{
"comments_disabled": ложь,
"__typename": "Изображение графика",
"id": "2891447792099336443",
"edge_media_to_caption": {
"края": [
{
"узел": {
"text": "🥰\n.\sofinstagram #cats #beautyfullcat #beautifulcatsofttheworld #mycat #prettycat #cats #catsofinstagram #beautifulcatsofinstagram #catoftheday #catstagram #catlife #catlovers #bestmeow #katzen #ilovemycats #ilovemycat #katzenliebe #katzenleben #katzenaufinstagram # katzenfotografie #instacat #katze #katzenwelt #catlove #catfluencer#rescuecat #adoptedcat #adoptedcatsofinstagram #adoptedcatsarethebest"
}
}
]
},
"короткий код": "CggfHKGqyD7",
"edge_media_to_comment": { "количество": 0},
"взято_в_временной метке": 16588, г.
"размеры": { "высота": 1350, "ширина": 1080},
"display_url": "https://scontent-vie1-1.
cdninstagram.com/v/t51.2885-15/295609100_475025094450455_8311596005796267513_n.webp?stp=dst-jpg_e35_p1080x1080&_nc_ht=scontent-vie1-1.cdninstagram.com&_nc_cat=111&_nc_ohc=Y -hZeZUhkzYAX_mIOop&edm=AA0rjkIBAAAA&ccb=7-5&oh=00_AT-EeW536WMuxlQ3iG6S-LzW2HoLtmSI0Ss_VIxzZJ4Y-A&oe=62E87315&_nc_sid=d997c6",
"edge_liked_by": {"количество": 0},
"edge_media_preview_like": {"количество": 0},
"владелец": {"id": "51742215330"},
"thumbnail_src": "https://scontent-vie1-1.cdninstagram.com/v/t51.2885-15/295609100_475025094450455_8311596005796267513_n.webp?stp=c0.180.1440.1440a_dst-jpg_e35_s640x640_sh0.08&_nc_ht=scontent-vie1-1.cdninstagram.com&_nc_cat=111&_nc_ohc=Y-hZeZUhkzYAX_mIOop&edm=AA0rjkIBAAAA&ccb=7-5&oh=00_AT8rtjj_08vk70Qk4AOEgatMsuAVOOJuk8-FFyKHH0uEKQ&oe=62E87315&_nc_sid=d997c6",
"thumbnail_resources": [
{
"src": "https://scontent-vie1-1.cdninstagram.com/v/t51.2885-15/295609100_475025094450455_8311596005796267513_n.webp?stp=c0.180.1440.1440a_dst-jpg_e35_s640x640_sh0. 08&_nc_ht=scontent-vie1-1.cdninstagram .com&_nc_cat=111&_nc_ohc=Y-hZeZUhkzYAX_mIOop&edm=AA0rjkIBAAAA&ccb=7-5&oh=00_AT8rtjj_08vk70Qk4AOEgatMsuAVOOJuk8-FFyKHH0uEKQ&oe=62E87315&_nc_sid=d997с6",
"config_width": 640,
"config_height": 640
},
"..."
],
"is_video": ложь,
"accessibility_caption": ноль
},
]
Выше мы используем конечную точку GraphQl, которая принимает несколько переменных: имя тега, размер страницы и смещение. Используя эти несколько параметров, мы можем разбивать посты, отмеченные хэштегом в Instagram, и находить пользователей (см. поле owner.id ) или просто собирать сами посты!
По местонахождению
В качестве альтернативы мы также можем найти сообщения по местоположению , используя конечную точку /explore/locations REST. Например, мы могли бы найти все посты, помеченные местоположением Лондона, путем очистки explore/locations/213385402/london-united-kingdom/?__a=1
. Хотя для этого нам нужно знать числовой идентификатор местоположения. Для Лондона это 213385402 , но как найти его для любого другого места?
Для этого нам нужна еще одна конечная точка — /web/search/topsearch/ , которая позволяет нам искать лучшие результаты по заданному запросу. Чтобы найти идентификатор Лондона, мы будем использовать URL-адрес web/search/topsearch/?query=london, который вернет нам результаты основного пользователя, хэштега и местоположения, соответствующие этому запросу:
"мест": [
{
"место": {
"расположение": {
"пк": "213385402",
"short_name": "Лондон",
"facebook_places_id": 106078429431815,
"внешний_источник": "facebook_places",
"name": "Лондон, Великобритания",
"адрес": "",
"город": "",
"has_viewer_saved": ложь,
"лнг": -0,1094,
«широта»: 51,5141
},
"title": "Лондон, Великобритания",
"подзаголовок": "",
"медиа_связки": [],
"слаг": "лондон-соединенное королевство"
},
"позиция": 51
}
],
Мы видим, что идентификатор местоположения находится в полях pk или facebook_places_id (которые взаимозаменяемы в этом сценарии).
Давайте соберем это на Python:
import httpx
def find_location_id (запрос: str, сеанс: httpx.Client):
"""находит наиболее вероятный идентификатор местоположения по заданному названию местоположения"""
resp = session.get(f"https://www.instagram.com/web/search/topsearch/?query={query}")
данные = соотв.json()
пытаться:
first_result = отсортировано (данные ["места"], ключ = лямбда-место: место ["позиция"]) [0]
вернуть first_result["место"]["местоположение"]["пк"]
кроме IndexError:
print(f'не найдено местоположений, соответствующих запросу "{query}"')
возвращаться
def scrape_users_by_location (location_id: str, session: httpx.Client, page_limit = None):
url = f"https://www.instagram.com/explore/locations/{location_id}/?__a=1"
страница = 1
следующий_id = ""
пока верно:
resp = session.get(url + (f"&max_id={next_id}", если next_id еще ""))
данные = resp.json () ["native_location_data"]
print(f"удаленная страница {location_id} {page}")
для раздела в данных ["последние"]["разделы"]:
для медиа в разделе["layout_content"]["medias"]:
yield media["media"]["user"]["username"]
next_id = данные["последние"]["next_max_id"]
если не следующий_id:
print(f"больше нет результатов после страницы {page}")
ломать
если page_limit и page_limit < страница:
print(f"достигнут лимит страниц {страница}")
ломать
страница += 1
Код запуска и пример вывода, если __name__ == "__main__":
с httpx. Client(
время ожидания = httpx.Timeout (20.0)
) как сеанс:
location_name = "Лондон"
location_id = find_location_id(location_name, session=session)
print(f'разрешенный идентификатор местоположения от {location_name} до {location_id}')
для имени пользователя в scrape_users_by_location(location_id, session=session):
печать (имя пользователя)
[ "имя пользователя1", "имя пользователя2", "имя пользователя3", "..." ]
В приведенном выше примере мы создали две функции, определяющие логику, описанную ранее: одну для получения идентификатора местоположения из строки местоположения, а другую для получения всех имен пользователей последних сообщений, помеченных этим местоположением.
примечание: в данных о последних сообщениях гораздо больше информации, чем просто имена пользователей, мы просто сделали их краткими для примера, но там можно найти изображения сообщений, подписи и даже информацию о комментариях.
Сканирование пользовательских данных
Страница Google в Instagram
Чтобы получить данные страницы профиля пользователя Instagram, мы можем использовать внутреннюю конечную точку API:
def scrape_user (имя пользователя: str, сеанс: ScrapflyClient):
"""удалить данные пользователя"""
результат = session.scrape(ScrapeConfig(
url=f"https://i.instagram.com/api/v1/users/web_profile_info/?username={имя пользователя}",
заголовки={"x-ig-app-id": "936619743392459"},
asp=Истина
))
данные = json.loads (результат. содержимое)
вернуть данные['данные']['пользователь']
Рабочий код и пример вывода если __name__ == "__main__":
с httpx.Client(
время ожидания = httpx.Timeout (20.0),
) как сеанс:
пользователь = scrape_user("google", сессия)
Этот подход вернет пользовательские данные Instagram, такие как биография, количество подписчиков, изображения профиля и т. д.:
{
"biography": "Google без фильтров — иногда с фильтрами. ",
"external_url": "https://linkin.bio/google",
"external_url_linkshimmed": "https://l.instagram.com/?u=https%3A%2F%2Flinkin.bio%2Fgoogle&e=ATOah2Vrx_TkkMUhpCCh2_PM-C1k5t35gAtJ0eBjTPE84RItj-cCFdqRoRHwlbiCSrB5G_v6MgjePl1SQN4vTw&s=1",
"edge_followed_by": {
"количество": 13015078
},
"fbid": "17841401778116675",
"edge_follow": {
"количество": 33
},
"full_name": "Гугл",
"highlight_reel_count": 5,
"идентификатор": "1067259270",
"is_business_account": правда,
"is_professional_account": правда,
"is_supervision_enabled": ложь,
"is_guardian_of_viewer": ложь,
"is_supervised_by_viewer": ложь,
"is_embeds_disabled": ложь,
"is_joined_recently": ложь,
"guardian_id": ноль,
"is_verified": правда,
"profile_pic_url": "https://instagram.furt1-1.fna.fbcdn.net/v/t51.2885-19/126151620_3420222801423283_6498777152086077438_n.jpg?stp=dst-jpg_s150x150&_nc_nc.fnat.fnat1-1instagram.furt1 =1&_nc_ohc=bmDCZ2Q8wTkAX-Ilbqq&edm=ABfd0MgBAAAA&ccb=7-4&oh=00_AT9pRKzLtnysPjhclN6TprCd9FBWo2ABbn9cRICPhbQZcA&oe=62882D44&_nc_sid=7bff83",
"имя пользователя": "гугл",
. ..
}
Хотя этот подход также включает сведения о первых 12 сообщениях, мы не сможем получить больше. Чтобы очистить все сообщения пользователей Instagram, нам придется воспользоваться другой конечной точкой.
Извлечение пользовательских сообщений
Для извлечения пользовательских сообщений мы будем использовать еще одну конечную точку GraphQl, для которой требуются три переменные: пользовательский идентификатор , который мы получили при очистке профиля пользователя ранее, размер страницы и курсор смещения страницы:
{
"id": "ЧИСЛОВОЙ ID ПОЛЬЗОВАТЕЛЯ",
"первый": 12,
"after": "ИД КУРСОРА ДЛЯ ПЕЙДИНГА"
}
Например, если мы хотим получить сообщения Instagram, созданные Google, нам сначала нужно получить идентификатор этого пользователя, а затем скомпилировать наш запрос graphql.
Страница Google в Instagram — мы можем получить доступ ко всем этим данным публикации в формате JSON
В примере Google URL-адрес graphql будет следующим:
https://www. instagram.com/graphql/query/?query_hash=e769aa130647d2354c40ea6a439bfc08&variables={id:1067259270,first: 12}
Что мы можем попробовать в нашем браузере, и мы должны увидеть JSON, возвращенный с данными самых последних 12 сообщений.
Однако, чтобы получить все сообщения, нам нужно реализовать небольшую логику синтаксического анализа:
import json
цитата импорта из urllib.parse
def scrape_user_posts (user_id: str, сеанс: httpx.Client, page_size = 12):
base_url = "https://www.instagram.com/graphql/query/?query_hash=e769aa130647d2354c40ea6a439bfc08&variables="
переменные = {
"идентификатор": user_id,
"первый": page_size,
"после": нет,
}
пока верно:
resp = session.get(base_url + quote(json.dumps(переменные)))
сообщения = resp.json () ["данные"] ["пользователь"] ["edge_owner_to_timeline_media"]
для публикации в сообщениях["края"]:
выходной пост["узел"]
page_info = сообщения["page_info"]
если не page_info["has_next_page"]:
ломать
переменные["после"] = page_info["конечный_курсор"]
Выполнить код и пример вывода import json
импортировать httpx
если __name__ == "__main__":
с httpx. Client(timeout=httpx.Timeout(20.0)) в качестве сеанса:
сообщения = список (scrape_user_posts («1067259270», сеанс, page_limit = 3))
печать (json.dumps (сообщения, отступ = 2, обеспечить_ascii = False))
[
{
"__typename": "Изображение графика",
"id": "28001563912589",
"Габаритные размеры": {
"высота": 1080,
"ширина": 1080
},
"display_url": "https://scontent-atl3-2.cdninstagram.com/v/t51.2885-15/295343605_719605135806241_7849792612912420873_n.webp?stp=dst-jpg_e35&_nc_ht=scontent-atl3-2.cdninstagram.com&_nc_cat=101&_nc_ohc=cbVYU-YGD04AX9-DGya&edm=APU89FABAAAA&ccb=7-5&oh=00_AT-C93CjLzMapgPHOinoltBXypU_wi7s6zzLj1th-s9p-Q&oe=62E80627&_nc_sid=86f79a",
"отображаемые_ресурсы": [
{
"src": "https://scontent-atl3-2.cdninstagram.com/v/t51.2885-15/295343605_719605135806241_7849792612912420873_n.webp?stp=dst-jpg_e35_s640x640_sh0.08&_nc_ht=scontent-atl3-2.cdninstagram.com&_nc_cat=101&_nc_ohc =cbVYU-YGD04AX9-DGya&edm=APU89FABAAAA&ccb=7-5&oh=00_AT8aF_4X2Ix9neTg1obSzOBgZW83oMFSNb-i5uqZqRqLLg&oe=62E80627&_nc_sid=86f79a",
"config_width": 640,
"config_height": 640
},
". .."
],
"is_video": ложь,
"tracking_token": "eyJ2ZXJzaW9uIjo1LCJwYXlsb2FkIjp7ImlzX2FuYWx5dGljc190cmFja2VkIjp0cnVlLCJ1dWlkIjoiOWJiNzUyMjljMjU2NDExMTliOGI4NzM5MTE2Mjk4MTYyODkwMjUzMDAxNTYzOTEyNTg5In0sInNpZ25hdHVyZSI6IiJ9",
"edge_media_to_tagged_user": {
"края": [
{
"узел": {
"пользователь": {
"full_name": "Джамар Гейл | Аналитик данных",
"id": "51661809026",
"is_verified": ложь,
"profile_pic_url": "https://scontent-atl3-2.cdninstagram.com/v/t51.2885-19/284007837_5070066053047326_6283083692098566083_n.jpg?stp=dst-jpg_s150x150&_nc_ht=scontent-atl3-2.cdninstagram.com&_nc_cat=106&_nc_ohc=KXI8oOdZRb4AX8w28nr&edm =APU89FABAAAA&ccb=7-5&oh=00_AT-4iYsawdTCHI5a2zD_PF9F-WCyKnTIPuvYwVAQo82l_w&oe=62E7609B&_nc_sid=86f79a",
"имя пользователя": "datajayintech"
},
«х»: 0,68611115,
"у": 0,32222223
}
},
"..."
]
},
"accessibility_caption": "Скриншот твита от @DataJayInTech, в котором говорится: \"Мне только что позвонил рекрутер и сказал, что сертификат Google Data Analytics хорош. Этот пост призван побудить ВАС закончить курс. \" Фон изображения красный с белыми, желтыми и синими геометрическими фигурами.",
"edge_media_to_caption": {
"края": [
{
"узел": {
"text": "Звоните, звоните — возможность зовет📱\nНачните свое путешествие по карьерному сертификату Google по ссылке в био. #Расти вместе с Google"
}
},
"..."
]
},
"короткий код": "CgcPcqtOTmN",
"edge_media_to_comment": {
"количество": 139,
"страница_информация": {
"has_next_page": правда,
"end_cursor": "QVFCaU1FNGZiNktBOWFiTERJdU80dDVwMlNjTE5DWTkwZ0E5NENLU2xLZnFLemw3eTJtcU54ZkVVS2dzYTBKVEppeVpZbkd4dWhQdktubW1QVzJrZXNHbg=="
},
"края": [
{
"узел": {
"id": "18209382946080093",
"text": "@google ваша компания - мусор из-за вмешательства в предположительно честные выборы... вас разоблачили",
"создано_в": 1658867672,
"did_report_as_spam": ложь,
"владелец": {
"идентификатор": "39246725285",
"is_verified": ложь,
"profile_pic_url": "https://scontent-atl3-2. cdninstagram.com/v/t51.2885-19/115823005_750712482350308_4191423925707982372_n.jpg?stp=dst-jpg_s150x150&_nc_ht=scontent-atl3-2.cdninstagram.com&_nc_cat=104&_nc_ohc=4iOCWDHJLFAAX -JFPh7&edm=APU89FABAAAA&ccb=7-5&oh=00_AT9sH7npBTmHN01BndUhYVreHOk63OqZ5ISJlzNou3QD8A&oe=62E87360&_nc_sid=86f79a",
"имя пользователя": "bud_mcgrowin"
},
"viewer_has_liked": ложь
}
},
"..."
]
},
"edge_media_to_sponsor_user": {
"края": []
},
"comments_disabled": ложь,
"взято_в_временной метке": 1658765028,
"edge_media_preview_like": {
"количество": 9251,
"края": []
},
"gating_info": ноль,
"fact_check_overall_rating": ноль,
"fact_check_information": ноль,
"media_preview": "ACoqbj8KkijDnBOfpU1tAkis8mcL2H0zU8EMEqh2Dc56H0/KublclpoejKoo3WtylMgQ4HeohW0LKJ+u7PueaX+z4v8Aa/OmoNJJ6kqtG3UxT0pta9xZRxxswzkDjJrIoatuawkpq6NXTvuN9f6VdDFeAMAdsf8A16oWDKFYMQMnuR6e9Xd8f94fmtax2OGqnzsk3n/I/wDsqN7f5H/2VR74/wC8PzWlEkY7g/iv+NVcys+wy5JML59P89zWDW3dSx+UwGMnjjH9KxKynud1BWi79wpQM+g+tJRUHQO2+4pCuO4pKKAFFHP+RSUUgP/Z",
"владелец": {
"id": "1067259270",
"имя пользователя": "гугл"
},
"местоположение": ноль,
"viewer_has_liked": ложь,
"viewer_has_saved": ложь,
"viewer_has_saved_to_collection": ложь,
"зритель_на_фото_вас": ложь,
"viewer_can_reshare": правда,
"thumbnail_src": "https://scontent-atl3-2. cdninstagram.com/v/t51.2885-15/295343605_719605135806241_7849792612912420873_n.webp?stp=dst-jpg_e35_s640x640_sh0.08&_nc_ht=scontent-atl3-2.cdninstagram.com&_nc_cat=101&_nc_ohc=cbVYU-YGD04AX9-DGya&edm=APU89FABAAAA&ccb=7-5&oh=00_AT8aF_4X2Ix9neTg1obSzOBgZW83oMFSNb-i5uqZqRqLLg&oe=62E80627&_nc_sid=86f79a",
"thumbnail_resources": [
{
"src": "https://scontent-atl3-2.cdninstagram.com/v/t51.2885-15/295343605_719605135806241_7849792612912420873_n.webp?stp=dst-jpg_e35_s150x150&_nc_ht=scontent-atl3-2.cdninstagram.com&_nc_cat=101&_nc_ohc=cbVYU -YGD04AX9-DGya&edm=APU89FABAAAA&ccb=7-5&oh=00_AT9nmASHsbmNWUQnwOdkGE4PvE8b27MqK-gbj5z0YLu8qg&oe=62E80627&_nc_sid=86f79a",
"config_width": 150,
"config_height": 150
},
"..."
]
},
...
]
С помощью этого последнего фрагмента кода мы можем находить пользователей по местоположению или использованию хэштегов и очищать данные их профилей, а также все их сообщения. Чтобы масштабировать этот парсер, давайте посмотрим, как избежать блокировки с помощью ScrapFLy.
Блокировка / Требование входа
Парсинг Instagram кажется простым, но, к сожалению, Instagram начал ограничивать публичный доступ к своим общедоступным данным. Часто разрешая пользователям несколько запросов в час, а для чего-то большего требуется вход в систему.
Instagram перенаправляет на страницу входа, если обнаружен парсинг
Чтобы обойти это, давайте воспользуемся преимуществами ScrapFly API , который поможет нам избежать всех этих блоков!
Предлагает несколько мощных функций, которые помогут нам обойти блокировку Instagram:
- Обход защиты от царапин
- Рендеринг Javascript
- 190M пул резидентных или мобильных прокси-серверов
Для этого мы будем использовать пакет python scrapfly-sdk и функцию обхода защиты от скрейпинга ScrapFly. Во-первых, давайте установим scrapfly-sdk , используя pip:
$ pip install scrapfly-sdk
Чтобы воспользоваться преимуществами API ScrapFly в нашем парсере Instagram, все, что нам нужно сделать, это заменить запроса httpx на scrapfly-sdk запросов. Давайте посмотрим на полный код парсера с интеграцией ScrapFly
Полный код парсера
Полный код парсера с ScrapFly import json
от ввода импорта Необязательно
цитата импорта из urllib.parse
из scrapfly импортировать ScrapeConfig, ScrapflyClient, ScrapeApiResponse
def find_location_id (запрос: str, сеанс: ScrapflyClient):
"""находит наиболее вероятный идентификатор местоположения по заданному названию местоположения"""
результат = session.scrape(
ОчиститьКонфиг(
f"https://www.instagram.com/web/search/topsearch/?query={запрос}",
asp=Верно,
proxy_pool="общественный_жилой_пул",
страна = "США",
)
)
данные = json.loads (результат. содержимое)
пытаться:
first_result = отсортировано (данные ["места"], ключ = лямбда-место: место ["позиция"]) [0]
вернуть first_result["место"]["местоположение"]["пк"]
кроме IndexError:
print(f'не найдено местоположений, соответствующих запросу "{query}"')
возвращаться
def scrape_users_by_location (location_id: str, session: ScrapflyClient, page_limit: Optional[int] = None):
url = f"https://www. instagram.com/explore/locations/{location_id}/?__a=1"
страница = 1
следующий_id = ""
пока верно:
соответственно = session.scrape(
ScrapeConfig(url + (f"&max_id={next_id}", если next_id еще ""), asp=True)
).upstream_result_into_response()
данные = resp.json () ["native_location_data"]
print(f"удаленная страница {location_id} {page}")
для раздела в данных ["последние"]["разделы"]:
для медиа в разделе["layout_content"]["medias"]:
yield media["media"]["user"]["username"]
next_id = данные["последние"]["next_max_id"]
если не следующий_id:
print(f"больше нет результатов после страницы {page}")
ломать
если page_limit и page_limit < страница:
print(f"достигнут лимит страниц {страница}")
ломать
страница += 1
def scrape_user (имя пользователя: str, сеанс: ScrapflyClient):
"""удалить данные пользователя"""
результат = session. scrape(
ОчиститьКонфиг(
url=f"https://i.instagram.com/api/v1/users/web_profile_info/?username={имя пользователя}",
заголовки={"x-ig-app-id": "936619743392459"},
asp=Верно,
)
)
данные = json.loads (результат. содержимое)
вернуть данные["данные"]["пользователь"]
def scrape_user_posts (user_id: str, сеанс: ScrapflyClient, page_size = 12, page_limit: необязательно [int] = нет):
"""удалить данные поста пользователя"""
base_url = "https://www.instagram.com/graphql/query/?query_hash=e769aa130647d2354c40ea6a439bfc08&variables="
переменные = {
"идентификатор": user_id,
"первый": page_size,
"после": нет,
}
страница = 1
пока верно:
результат = session.scrape (ScrapeConfig (base_url + цитата (json.dumps (переменные)), asp = True))
сообщения = json.loads(result.content)["data"]["user"]["edge_owner_to_timeline_media"]
для публикации в сообщениях["края"]:
выходной пост["узел"]
page_info = сообщения["page_info"]
если не page_info["has_next_page"]:
ломать
переменные["после"] = page_info["конечный_курсор"]
страница += 1
если страница > page_limit:
ломать
def scrape_hashtag (хэштег: str, сеанс: ScrapflyClient, page_size = 12, page_limit: необязательно [int] = None):
"""удалить данные поста пользователя"""
base_url = "https://www. instagram.com/graphql/query/?query_hash=174a5243287c5f3a7de741089750ab3b&переменные="
переменные = {
"tag_name": хэштег,
"первый": page_size,
"после": нет,
}
страница = 1
пока верно:
результат = session.scrape (ScrapeConfig (base_url + цитата (json.dumps (переменные)), asp = True))
сообщения = json.loads(result.content)["данные"]["хэштег"]["edge_hashtag_to_media"]
для публикации в сообщениях["края"]:
выходной пост["узел"]
page_info = сообщения["page_info"]
если не page_info["has_next_page"]:
ломать
переменные["после"] = page_info["конечный_курсор"]
страница += 1
если страница > page_limit:
ломать
если __name__ == "__main__":
с ScrapflyClient(key="YOUR_SCRAPFLY_KEY", max_concurrency=20) в качестве сеанса:
result_location = find_location_id("Лондон, Великобритания", сессия)
result_location_users = list(scrape_users_by_location(result_location, session, page_limit=3))
result_hashtag_users = список (scrape_hashtag («веб-скрейп», сеанс, page_limit = 3))
result_user = scrape_user("google", сессия)
result_user_posts = list(scrape_user_posts(result_user["id"], сеанс, page_limit=3))
распечатать("сделано")
В приведенном выше примере мы используем функцию обхода защиты от ботов ScrapFly, чтобы обойти требование входа в Instagram. Чтобы включить это, все, что нам нужно было сделать, это заменить несколько строк кода, и к каждой странице Instagram можно было получить доступ без входа в систему!
Часто задаваемые вопросы
В завершение этого руководства давайте рассмотрим некоторые часто задаваемые вопросы о парсинге веб-страниц instagram.com:
Является ли парсинг веб-страниц instagram.com законным?Да. Данные Instagram общедоступны, поэтому очистка instagram.com медленными и уважительными темпами подпадает под определение этического очистки. Однако при работе с персональными данными нам необходимо знать о местных законах об авторских правах и данных о пользователях, таких как GDPR. Подробнее см. в разделе Законен ли веб-скрейпинг? статья.
Как получить идентификатор пользователя Instagram из имени пользователя? Чтобы получить частный идентификатор пользователя из общедоступного имени пользователя, мы можем воспользоваться параметром URL-адреса ?__a=1 и очистить URL-адрес https://www., в котором будет идентификатор пользователя. это содержание. Обратите внимание, что для этой конечной точки может потребоваться вход в систему, но с помощью ScrapFly API мы можем очистить ее без входа в систему. instagram.com/
Чтобы получить общедоступное имя пользователя из личного идентификатора пользователя Instagram, мы можем воспользоваться общедоступным iPhone API 9.0354 https://i.instagram.com/api/v1/users/
импортировать httpx
iphone_api = "https://i.instagram.com/api/v1/users/{}/info/"
iphone_user_agent = "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3, например Mac OS X) AppleWebKit/603.3.8 (KHTML, например Gecko) Mobile/14G60 Instagram 12.0.0.16.90 (iPhone9,4; iOS 10_3_3; en_US; en- США; масштаб = 2,61; гамма = широкая; 1080 x 1920 дюймов.
resp = httpx.get(iphone_api.format("1067259270"), headers={"User-Agent": iphone_user_agent})
печать (соответственно. json() ['пользователь']['имя пользователя'])
Волшебный параметр `__a=1` больше не работает Instagram внедряет новые изменения и постепенно отказывается от этой функции. Однако в этой статье мы рассмотрели две альтернативы функциям ?__a=1 : конечные точки API /v1/ и конечные точки GraphQl, которые работают еще лучше!
Резюме
В этом учебном пособии по парсингу в Instagram мы рассмотрели, как находить посты и пользователей в Instagram с помощью поиска по хэштегу или местоположению, как парсить профиль пользователя и данные постов. Для этого мы использовали несколько общедоступных API и конечных точек GraphQl, которые генерируют даже больше данных, чем мы можем видеть на самой странице!
Наконец, чтобы начать масштабирование парсера, мы рассмотрели, как парсить Instagram без входа в систему, используя преимущества интеллектуальных систем обхода блокировки парсера ScrapFly. Чтобы узнать больше о ScrapFly, ознакомьтесь с нашей документацией и попробуйте бесплатно!
Как извлечь данные из Instagram
Лучшие парсеры веб-страниц
№1 с самым высоким рейтингом
НОВАЯ ЭРА ДАННЫХ
парсер №1 2022 года
РАЗБЛОКИРОВАТЬ БЕСПЛАТНУЮ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ
№1 с самым высоким рейтингом
НОВАЯ ЭРА ДАННЫХ
парсер №1 2022 года
сэкономьте 16%!
РАЗБЛОКИРОВАТЬ БЕСПЛАТНУЮ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ
#3 с самым высоким рейтингом
данные очистки в масштабе
ЗАРЕГИСТРИРОВАТЬСЯ БЕСПЛАТНО
Спешите?
Лучшим парсером Instagram в 2022 году, согласно результатам нашего независимого тестирования , является Phantombuster.
Нужны лиды для целевой аудитории для вашего бизнеса?
Хотите узнать о последних социально-экономических тенденциях и получить данные из социальных сетей, таких как Instagram?
Ну, тогда вам придется сделать очистку. Вы можете получить очень полезную информацию, связанную с анализом цен, мониторингом цен и исследованиями рынка, среди многих других.
В этом руководстве мы покажем вам, как можно извлечь данные из Instagram.
В 2022 году на рынке появятся различные парсеры Instagram, но не все из них будут работать на высоком уровне.
Лучшие парсеры Instagram 2022
- Phantombuster — 🏆 Победитель!
- ScraperAPI
- Bright Data
- Apify's Instagram Scraper
- ScrapingBee
- Octoparse
- WebScraper Chrome Extension
- ScrapeStorm
- InstaScrape
- Jarvee Scraper
- ZenRows
1. Best Instagram Scraper by Phantombuster
Phantombuster боты предназначены для извлечения данных и выполнения действий на платформе для вас.
Итак, если вы хотите получить доступ к данным из Instagram, это правильный парсер Instagram для вас, и самое приятное то, что вы можете выбрать данные для других платформ социальных сетей.
Более того, вы также можете использовать их бесплатную пробную версию. Вы можете использовать этот фантом бесплатно навсегда, но эта пробная версия доступна только в течение 10 минут.
Эти самые маленькие пакеты будут стоить вам 30 долларов в месяц, и вы можете использовать пять фантомов по часу в день.
Phantombuster — отличный сервис, к тому же по довольно разумной цене.
Итак, если вы действительно ищете соотношение цены и качества, это лучший парсер Instagram, который вы найдете.
Если вы считаете, что это довольно тяжелая работа, и вам нечего программировать, не волнуйтесь; есть готовые к использованию скребки Instagram, которые вы можете использовать.
Однако помните, что для этой цели вам нужно выбрать лучший инструмент и настроить его для правильного использования.
Если вы не сделаете это правильно, то система защиты от ботов платформы сразу обнаружит и заблокирует вас. Чтобы помочь вам в этом, мы перечисляем некоторые из лучших парсеров Instagram, доступных в Интернете.
2. ScraperAPI
ScraperAPI — действительно мощный инструмент для очистки Instagram, который может помочь вам извлечь из Instagram все, что вам нужно, и что действительно интересно, так это то, что они предлагают своим клиентам бесплатный план с ограничениями.
Если вы только начинаете заниматься парсингом Instagram и хотите познакомиться с инструментом, прежде чем подписаться на что-то более долгосрочное, это будет отличный вариант.
Их бесплатный план предлагает 1000 запросов в месяц, и он не будет взимать плату за неудачный запрос.
Вы также можете повторять запросы снова и снова, пока они не будут выполнены, и это время истечет каждые 60 секунд.
3. Bright Data
Этот парсер Instagram от Bright Data обойдется вам в 500 долларов США за загрузку 151 000 страниц, и вы также можете попробовать сервис, воспользовавшись бесплатной пробной версией.
Дата, которая будет предоставлена вам после очистки, будет доступна в MS Excel. Поддерживаемой платформой для этого сборщика данных для Instagram является веб-платформа.
Если вы заинтересованы в извлечении общедоступных данных с платформы Instagram, этот парсер Instagram — один из лучших вариантов для вас.
Bright Data — ведущее имя в мире прокси. Этот инструмент имеет большое количество коллекционеров Instagram, включая профили, посты и хэштеги.
Этот инструмент имеет предопределенные наборы данных для пользователей. Вам нужно будет только зарегистрироваться на этом сервисе и добавить средства.
Оттуда вы можете начать пользоваться сервисом и забыть о страхе быть заблокированным.
Но есть загвоздка!
Эта услуга идеально подходит для фирм и организаций.
Для частных лиц платить 500 долларов в месяц — это довольно много.
Однако, если вы представляете фирму, вам нужно использовать этот инструмент для очистки Instagram для получения высококачественных результатов.
4. Instagram Scraper от Apify
Вы можете попробовать их бесплатную пробную версию, прежде чем подписаться на платный план, начиная с 49 долларов в месяц. Платный план предназначен для 100 участников для вычисления единиц, а бесплатная пробная версия — для 10 участников для добавления единиц.
Собранные данные, которые вы получите, будут только в формате JSON. Сервис полностью облачный, и доступ к нему осуществляется через API.
Это платформа, на которой будут размещаться различные инструменты веб-автоматизации, называемые актерами, и инструмент парсинга Instagram является одним из таких акторов.
Этот парсер Instagram позволит вам удалять общедоступные данные, такие как комментарии, сообщения, профили, хэштеги и места.
Этот инструмент также обеспечивает поддержку поисковых запросов, и вы даже можете дать ему свой список URL-адресов, если хотите.
Инструменты автоматизации, доступные здесь, в Apify, доступны в API, и вы можете удобно интегрировать их в пользовательские программы. Вы даже можете сохранить полученные данные в файлах CSV или Excel.
5. ScrapingBee
ScrapingBee — ваш ответ, если вы пытаетесь максимально использовать парсер Instagram, который может помочь вам обойти блоки, с которыми вы, скорее всего, столкнетесь.
Они могут помочь вам сменить ваши прокси-серверы, а также могут помочь вам справиться с безголовыми браузерами. Вы можете попробовать их бесплатно, и они имеют рейтинг 4,9 звезды, основанный на более чем 30 отзывах в Интернете.
Самое приятное то, что они совместимы с последней версией Chrome и работают очень быстро, а это значит, что вы можете легко очистить все необходимые данные Instagram, и это не займет у вас много времени. так.
Они также могут помочь вам с чередованием прокси-серверов, что означает, что если вы собираете много данных из Instagram и вам нужно время от времени переключать прокси-соединение, это возможно.
6. Octoparse
Этот инструмент для парсинга Instagram будет стоить вам около 75 долларов в месяц, и вы также можете воспользоваться 14-дневной бесплатной пробной версией с некоторыми ограничениями.
Вы можете извлекать данные в различных форматах, включая SQLServer, MySQL, JSON, Excel и CSV. Поддерживаемые платформы — настольные и облачные.
Это сервис, который идеально подходит для тех, кто ищет универсальный парсер для Instagram.
Это надежный, проверенный и проверенный парсер, в котором есть шаблоны парсинга, и эти шаблоны позволят вам выполнять парсинг гораздо быстрее.
Это визуальный инструмент для парсинга, и вам не нужно быть программистом, чтобы с ним работать. Вы можете использовать его как облачный инструмент или программное обеспечение для настольных компьютеров.
Он также поставляется с бесплатной пробной версией, и вы можете попробовать его перед покупкой и убедиться, что эта услуга соответствует вашим потребностям или нет.
7. Расширение WebScraper для Chrome
Это бесплатное расширение для Chrome, и вы можете удобно использовать его столько, сколько вам нужно. Он предоставляет вам данные в формате CSV, а поддерживаемая платформа — это только расширение Chrome.
Это расширение зарекомендовало себя как один из лучших парсеров, доступных в Интернете, для парсинга Instagram. И речь идет не только об Instagram, потому что вы можете парсить любой другой сайт.
Разработан под современный веб; поэтому вы можете удобно очищать новые и старые веб-сайты. Это расширение является полезным инструментом для очистки Instagram, поскольку оно может отображать
JavaScript, и он также может позаботиться о бесконечной прокрутке Instagram, с которой приходится иметь дело. Таким образом, это бесплатный инструмент, когда вы используете его в качестве веб-расширения.
Но есть и некоторые ограничения. Облачный парсинг избавляет от этих ограничений, но вам придется платить за облачный сервис.
8. ScrapeStorm
ScrapeStorm — это услуга премиум-класса, когда речь идет о сборе данных из Instagram. И это будет стоить вам 49,99 долларов в месяц. Однако есть и бесплатные пробные версии, и они имеют определенные ограничения.
Вы можете извлекать данные из различных платформ, включая CSV, TXT, JSON, Excel, Google Sheets, MySQL, а также поддерживать формат рабочего стола.
ScrapeStorm — еще один инструмент, который вы можете использовать для очистки Instagram, особенно общедоступных данных.
Вы также можете использовать этот сервис парсинга на других веб-сайтах. Он может очищать веб-сайты и не может быть обнаружен никакими системами защиты от ботов.
Обучение работе с инструментом не требуется. А парсер Instagram разумно использует различные точки данных с помощью ИИ.
Этот инструмент доступен в различных операционных системах, и вы также можете использовать его как облачный инструмент.
9. InstaScrape
Этот инструмент для извлечения данных из Instagram использует Python для простого извлечения данных. Он разработан и адаптирован для извлечения данных из Instagram.
Он позволяет легко загружать контент на ваш компьютер, а тот факт, что он легкий, означает, что он экономит место. Это также полезно для получения встроенных кодов HTML для сообщений.
Если вы хотите извлечь изображения, видео или текст, обязательно используйте этот инструмент для парсинга Instagram по максимуму для следующего сеанса парсинга.
10. Jarvee Scraper
Их планы начинаются с 29,95 долларов в месяц, и доступна бесплатная пробная версия, которая продлится до 5 дней.
После очистки с помощью этого инструмента данные, которые вы получите, доступны в трех форматах: Excel, CSV и JSON, а поддерживаемые платформы — MS Windows.
Если вы занимаетесь автоматизацией Instagram, то поймете, что она может сделать для вас.
Jarvee — один из самых мощных инструментов, доступных в Интернете для парсинга Instagram, и он пережил все обновления платформы, которые были сделаны в рамках схемы защиты от ботов.
Просто выберите лучшие настройки и убедитесь, что вы знаете, что делаете, потому что этот инструмент даст вам полный доступ к элементам управления, и если вы не видите, что делаете, вас могут поймать.
Это инструмент не только для Instagram, но и для других социальных сетей. Платный веб-инструмент довольно уникален и очень быстро дает результаты.
11. ZenRows
Возможность парсинга Instagram определенно изменит ваш бренд в Интернете, особенно если там находится большая часть вашей целевой аудитории.
ZenRows — действительно хороший вариант для очистки Instagram, потому что они могут помочь вам не только очистить Instagram, но и с прокси-серверами, чтобы вы могли легко очищать Instagram, не беспокоясь о том, что ваш IP-адрес будет раскрыт. .
Они говорят, что предлагают бесплатную пробную версию, что является отличным способом заранее познакомиться с такой компанией, и вам не придется разглашать данные кредитной карты.
Они говорят, что с их прокси-серверами и функциями веб-скрейпера еще никогда не было так легко получить нужную вам работу из профилей Instagram, которые вы просматриваете.
Таким образом, вы можете сосредоточиться на данных и не беспокоиться о том, что ваше местоположение будет раскрыто. Вы также можете воспользоваться тем, что у них неограниченная пропускная способность.
Обзор Instagram Scraping
Instagram имеет строгие правила использования парсеров, поисковых роботов и других подобных автоматических ботов на этой платформе.
Но люди используют поисковые роботы и скребки здесь, в Instagram, несмотря на согласие с этими условиями.
Они не виноваты, так как API платформы не позволяет это делать. Instagram также имеет надежную систему защиты от ботов для предотвращения автоматического доступа и трафика на этой платформе.
Эта система защиты от ботов также успешно отключила некоторые высококачественные сервисы парсинга.
Но с правильной системой вы сможете собирать данные с платформы в соответствии с вашими потребностями, и вас не заблокируют или даже не обнаружат.
Прокси — это самый важный инструмент, о котором вам нужно позаботиться, потому что Instagram может отслеживать IP-адреса и обнаруживать прокси.
Но использование резидентных прокси — лучший вариант для вас, если вы можете себе это позволить, потому что это высококачественные прокси от оригинальных пользователей.
Можем ли мы использовать прокси для этой цели?
Вы можете подумать, что прокси — хороший вариант для очистки данных из Instagram. Но не все прокси работают, когда речь идет о сборе данных из Instagram.
Некоторые могут работать, но они не будут получать все общедоступные данные, включая сообщения, комментарии, места и профили.
В Instagram установлена качественная система защиты от ботов. Эта система также может отслеживать прокси, независимо от того, насколько качественные прокси вы используете.
Следовательно, вам нужно получить парсер Instagram, чтобы получить данные с платформы.
Если вы умеете программировать, то вы можете разработать программу очистки. Вы можете проектировать именно так, как хотите, и он будет работать как инструмент автоматизации и извлекать все необходимые данные из платформы.
Если вам не нравится разрабатывать программу, вы можете воспользоваться различными онлайн-инструментами и услугами парсинга.
Эти программы имеют простой интерфейс, и вам не нужно много учиться, чтобы их использовать.
Конечно, некоторые из них нуждаются в небольшом обучении, но с практикой вы очень хорошо их узнаете. Вам придется пойти на платные инструменты для лучших услуг, и некоторые из них довольно дороги.
У вас также будет возможность внести некоторые изменения в эту программу, если что-то не получится. Но если вы думаете, что можете собирать данные из Instagram, используя прокси, чтобы сэкономить деньги, этого не произойдет.
Однако вы можете сделать это с помощью резидентных прокси-серверов, и они довольно дороги, особенно если вы собираетесь использовать их для парсинга веб-страниц.
Итак, лучший вариант — выбрать резидентный прокси-сервер Instagram или использовать инструмент для очистки Instagram, который имеет это встроенное.
Как работает парсинг Instagram
Когда дело доходит до парсинга веб-данных из Instagram, определение цели — это первый шаг.
Вы должны четко понимать, чего именно вы хотите достичь с помощью данных, которые вы можете извлечь из Instagram.
Вам нужно подумать о таких вещах, как, например, из какого профиля вы хотите иметь возможность собирать данные, какие ключевые слова вы ищете, используете ли вы парсинг на основе определенного хэштега, включен ли парсинг в профили этих кто прокомментировал конкретный пост и многое другое.
После того, как вы определили свою цель, вы можете выполнить эвакуацию. Во-первых, вам нужно будет установить API, потому что фактический API Instagram не будет поддерживать очистку ваших данных.
Вам нужно найти API, который не требует входа в Instagram, потому что любой вход может привести к блокировке IP-адреса, а ваша учетная запись в конечном итоге будет помечена.
Еще одна полезная вещь, когда речь заходит об инструментах очистки Instagram, о которых мы говорили в этом списке, заключается в том, что вы можете настроить их для очистки изображений, сообщений или видео с определенного URL-адреса.
Вы также можете установить другие параметры, включая даты постов, подписи к постам и количество лайков и комментариев.
Инструментам очистки Instagram также необходимо установить ограничения и параметры, такие как менее 1000 запросов, потому что Instagram устанавливает ограничения очистки и собирается заблокировать прокрутку более 1000 комментариев или сообщений.
После того, как вы все это сделаете, вы можете сесть, расслабиться и смотреть, как ваш веб-парсер Instagram позаботится обо всем остальном за вас.
После того, как вы успешно извлекли данные из Instagram, вы можете сохранить эту информацию в виде локального файла, чтобы иметь к ней доступ позже.
Пользователи Instagram Scrapers
Инвесторы
Когда инвесторы могут извлекать данные из Instagram, они могут получить представление о ценности бренда на основе этой информации.
Они могут легко отслеживать новости о продукте, получать информацию об общественных настроениях или даже угадывать финансовую информацию компании, а также комментарии руководства.
Владельцы брендов
Когда компания или бренд извлекает информацию из Instagram, это может помочь им принять действительно важные бизнес-решения.
Полученные данные предлагают информацию о минимальной цене, рекламируемой их конкурентами, чтобы они могли определить, как оценивать свои будущие продукты.
Влиятельные лица
Влиятельные лица должны иметь возможность оценивать свою ценность на основе аудитории, которую они привлекают, и иногда извлечение данных из Instagram может быть ключом к получению этой важной информации.
Преимущества скрейперов
Лидогенерация
Одной из наиболее распространенных стратегий, используемых компаниями для достижения высоких коэффициентов конверсии, является генерация лидов. Парсеры данных Instagram могут упростить процесс создания новых лидов для вашего бизнеса.
Он позволяет вам получить доступ к контактам влиятельных лиц из Instagram и может извлекать такие данные, как возраст и род занятий, а также другие важные детали.
Парсер будет получать эту информацию из учетных записей с помощью инструмента или опции поиска.
Затем вы можете использовать эту информацию, чтобы связаться с потенциальными посетителями и в конечном итоге превратить их в платных клиентов.
Идти в ногу с конкуренцией
В наши дни бренды активно используют социальные сети, когда речь идет о маркетинге и продажах.
Instagram — одна из таких платформ, которая используется как компаниями, так и брендами для привлечения новых клиентов, особенно когда речь идет о молодом поколении.
Чтобы не отставать от рыночных тенденций, владельцы бизнеса должны быть в курсе того, что касается деятельности их конкурентов.
Извлечение важной веб-информации позволит вам выяснить, что делают ваши конкуренты, чтобы вы могли не отставать от них и нацеливаться на нужных людей на основе вашего продукта.
Когда вы очищаете данные из Instagram, вы можете загрузить список подписчиков Instagram, с которыми вы могли бы взаимодействовать, и, возможно, снизить остроту своих конкурентов.
Миграция сайта
Вполне естественно, что когда дело доходит до размещения сайта в сети, время от времени можно ожидать изменений.
Для тех, кто использует сайты социальных сетей, вероятно, в какой-то момент будет важно объединить или удалить контент.
Этот процесс приведет к некоторой потере данных. Если вы не сделали резервную копию своих данных, они также могут быть повреждены.
Поврежденные данные становятся непригодными для использования. Веб-скрапинг считается неофициальным резервным копированием, поэтому вы можете быть уверены, что сохраните важную информацию Instagram во время миграции.
Анализ комментариев
Как влиятельный человек или бренд в Instagram, вы должны понимать, что хочет видеть ваша аудитория, а что нет.
Извлечение комментариев и размещение их в удобной для чтения электронной таблице позволит вам провести подробный анализ, чтобы вы могли разработать важные рыночные стратегии для своих будущих продуктов.
Парсер комментариев в Instagram позволит вам просмотреть раздел комментариев, найти лучших комментаторов в их профилях и определить, например, как часто они комментируют.
Часто предприятия используют подобную систему для выбора победителей, когда они проводят онлайн-рекламу.
С помощью подобного анализа вы также можете составить список комментариев и немного больше узнать о своей аудитории в их сообщениях.
В бизнесе эти шаблоны помогут вам решить, какие посты создавать и какие стратегии принесут пользу вашей бизнес-модели.
Кампании по развитию рынка
Как бренду или бизнесу, понимание вашей целевой аудитории поможет вам принимать обоснованные решения и запускать эффективную бизнес-стратегию.
Одной из конкретных стратегий является маркетинговая кампания, которую вы разработали на основе количества потенциальных клиентов или пользователей продукта в определенной области.
Проблема в том, что сбор данных, которые вы можете использовать для создания маркетинговых кампаний, может занять много времени, а в отрасли, где время — деньги, это может в конечном итоге помешать развитию вашего бренда, а не помочь ему.
С помощью парсера Instagram вы можете легко собирать информацию о географическом местоположении пользователей из сообщений, что поможет вам провести правильную маркетинговую кампанию на основе вашей аудитории.
Итак, зачем собирать данные из Instagram?
Instagram — популярное фото- и видеоприложение и платформа для социальных сетей, которыми теперь владеет Facebook. Эта платформа является огромным источником информации.
Возможно, у него не так много информации, как у Facebook, но все же есть важные данные о различных пользователях платформы. Более того, все эти данные несут в себе подавляющее количество личного прикосновения.
Эти данные включают фотографии, видео и связанные с ними комментарии из кругов. Эти данные нужны предприятиям и социальным исследователям для оценки и анализа.
Это сделано для того, чтобы упростить их рабочий процесс и лучше понять их целевую аудиторию. Это позволит им создавать более качественный контент и проводить исследования.
Но официальный API Instagram разрешает доступ только к данным, непосредственно связанным с вами. Кроме того, существует множество ограничений, основанных на данных API и лимитах вызовов.
Если вы хотите получить доступ к общедоступным данным и не привязаны напрямую к своей учетной записи, вы должны обойти обычный путь, заданный API.
Другими словами, вы будете создавать автоматизированные инструменты, которые называются парсерами Instagram.
Эти парсеры представляют собой компьютерные программы, которые могут автоматизировать весь процесс извлечения данных из платформы социальных сетей.
Эта программа делает это, отправляя HTTP-запросы на интересующие страницы для скачивания. После этого он будет анализировать данные со страницы и сохранять их в базе данных в соответствии с требованиями.
Парсинг Instagram с помощью Selenium и Python
Если вы можете выполнить реверс-инжиниринг на платформе Instagram или в мобильном приложении, тогда хорошо, но все ваше внимание должно быть сосредоточено на его веб-приложении, потому что это то, что вы можете воспроизвести с точки зрения его запросов.
Веб-приложение этой платформы в значительной степени разработано с использованием JavaScript. Это сделано для того, чтобы предоставить вам почти родной и очень отзывчивый интерфейс.
Вам также придется иметь дело с большим количеством запросов AJAX и XHR. Таким образом, дуэт Beautifulsoup и Requests не делает парсинг Instagram идеальным вариантом.
Чтобы выполнить его лучше, вам нужно будет отобразить и выполнить JavaScrip, и для этого вы можете использовать безголовые браузеры.
Самым мощным и популярным инструментом автоматизации браузера для Python-разработчика является Selenium, и вы также можете использовать эти управляющие браузеры в автономном режиме.
Конечно, в социальных сетях есть общедоступные данные, и вы можете получить к ним доступ, даже не входя в Instagram. Эти данные включают хэштеги, сообщения, профили, места и комментарии.
Это удобный способ начать работу, поскольку доступ к этой платформе социальных сетей осуществляется с помощью автоматизированного инструмента. Тем не менее, если вы вошли в систему, активируется система защиты от ботов платформы.
Таким образом, ваш IP-адрес может быть забанен. Кроме того, вы также можете заблокировать свой аккаунт.
Вы можете подумать, почему бы не создать отдельные учетные записи для парсинга. Но для этого вам нужно уметь проектировать своего бота и избегать проверки активированных учетных записей, вошедших в систему.
Вот небольшой парсер Instagram, который вы можете использовать для очистки комментариев под разными постами, чтобы начать.
Из Selenium Import Webdriver
Класс InstagramScraper:
def __init__(я, post_url):
self.post_url = сообщение_url
самокомментарии = []
chrome_options = веб-драйвер.ChromeOptions()
chrome_options.add_argument («– без головы»)
self.chrome = webdriver.Chrome(chrome_options=chrome_options)
def scrape_comments (я):
браузер = self.chrome.get(self.post_url)
контент = self.chrome.page_source
комментарии =
self.chrome.find_element_by_class_name("XQXOT").find_elements_by_class_name("Mr508")
для комментариев в комментариях:
д =
comment.find_element_by_class_name("ZyFrc").find_element_by_tag_name("li").find_elemen
t_by_class_name("P9YgZ").find_element_by_tag_name("div")
d = d.find_element_by_class_name("C4VMK")
постер = d.find_element_by_tag_name("h4"). text
сообщение = d.find_element_by_tag_name («диапазон»).текст
self.comments.append({
«плакат»: плакат,
«пост»: пост
})
вернуть собственные комментарии
post_url = «https://www.instagram.com/p/CAbDmzDnSvn/»
x = InstagramScraper (post_url)
x.scrape_comments() Заключение
Instagram — один из самых сложных веб-сайтов для парсинга в Интернете. Эта платформа имеет систему защиты от ботов, и она может очень хорошо обнаруживать прокси.
Но если вы опытный разработчик, вы можете довольно удобно избавиться от него.
Если вы не являетесь опытным программистом, вы можете использовать различные парсеры Instagram, упомянутые выше. Эти инструменты отлично подходят для сбора данных из Instagram.
Эти парсеры Instagram позволят вам очищать и загружать данные с платформы социальных сетей в различных форматах.
Доступны как платные, так и бесплатные парсеры для Instagram. Вы можете выбрать один в зависимости от ваших требований.
Instagram-Ad-Kampagnen mit deiner Mailchimp-Kontaktliste erstellen
Präsentiere deine Marke und finde neue Fans
Deine Zielgruppe tummelt sich da draussen. Füge Instagram‑Ads zu deinen Mailchimp‑Kampagnen hinzu, um neue Zielgruppen zu erreichen, deine Markenbekanntheit zu stärken und mehr zu verkaufen.
Einen Tarif auswählen
Nutze deine Mailchimp-Daten, um Instagram-Kampagnen zu erstellen, von denen deine Interessenten begeistert sein werden.
Mehr als nur eine Möglichkeit, eine Zielgruppe anzusprechen
Finde neue Fans mit ähnlichen Interessen ausgehend von deinen besten Kontakten.
Sprich Kontakte an, die bereits von dir und deinem Angebot begeistert sind.
Baue deine Zielgruppe andhand von Interessen und demografischen Merkmalen auf.
Sprich deine Website-Besucher auch in sozialen Netzwerken erneut an.
Wir machen es dir einfach, Anzeigen für deine Kampagnen zu erstellen. Все das beetet Mailchimp und du kannst über eine vertraute Plattform deine Anzeigen erstellen, kaufen und nachverfolgen.
Du kannst deine Mailchimp Kontaktliste verwenden, um gezielt Personen anzusprechen, die deinen Top-Kunden ähneln und deine Produkte wahrscheinlich mögen.
Wenn du deinen Shop verbindest, dann kannst du sehen, wie deine Anzeigen deinen Umsatz erhöhen, neue Kunden gewinnen und deinen ROI steigern. Alles funktioniert zusammen, um dir dabei zu helfen, Intelligere Entscheidungen zu treffen.
Интересующие вас продукты с другими ретаргетинговыми кампаниями в Instagram, если вы пользуетесь веб-сайтом. Deine Besucher sehen deine Anzeigen während sie auf Facebook и Instagram просмотрены. So haben sie einen direkten Weg zurück zu deiner Website, wenn sie zum Kauf bereit sind.
Es ist wirklich unglaublich leicht, eine Zielgruppe auszuwählen. Soll deine Zielgruppe deinen E-Mail-Abonnenten ähneln? Dann nutze einfach diese Liste, um eine maximale Kosteneffizienz zu erzielen.
Ihre Geschichte lesen
Du kannst Instagram-Ads в Mailchimp erstellen und schalten, indem du ein paar einfache Schritte befolgst. Bevor du mit der Erstellung von Instagram-Ads beginnst, musst du sicherstellen, dass die Facebook- und Instagram-Accounts deines Unternehmens miteinander verbunden sind. Wenn das der Fall ist, verbinde die Facebook-Seite deines Unternehmens mit Mailchimp.
Sobald die Facebook-Seite deines Unternehmens verbunden ist, kannst du deine Zielgruppe auswählen. Mit gezielten Ads auf Instagram kannst du bestimmte Zielgruppen ansprechen, die auf Faktoren wie Verhalten, Interessen, Websitebesuche usw. базьер.
Im nächsten Schritt legst du dein Budget fest. Je nach gewählter Kampagnenart bestimmen sich die Kosten für deine Ads durch ein Gebotsmodell, die Anzahl der Klicks oder die Anzahl der genericerten Impressions.
Durch Festlegen определяет бюджеты, которые распределяются между максимальными значениями Betrag и в Mailchimp для Instagram-Ads, которые могут быть проверены.Der Letzte Schritt beim Erstellen eines Instagram-Ads in Mailchimp ist die Gestaltung des Ads. Je nachdem, был du den Leuten zeigen willst, kannst du ein einzelnes Bild, mehrere Bilder, Grafiken oder GIFs einfügen. Der Creative Assistant Mailchimp beetet dir Zugriff auf eine Vielzahl из Instagram-Kampagnenvorlagen, mit denen du ganz uncompliziert markkonforme digitale Assets erstellen kannst.
Nachdem du ein Instagram-Ad in Mailchimp erstellt hast, musst du es Facebook zur Überprüfung vorlegen. Wir benachrichtigen dich, sobald dein Ad genehmigt wurde, damit du deine Instagram-Werbekampagne starten kannst.
С Ad-Builder добавлен в Mailchimp schnell und einfach ein Instagram-Ad erstellen.
Der Ad-Builder фон Mailchimp бьёт через Wahl, das Ad von Grund auf neu zu erstellen, eine unserer Instagram-Kampagnenvorlagen zu verwenden oder unseren Creative Assistant zu nutzen. Der Creative Assistant ist ein KI-gestütztes Designtool, mit dem du markenkonforme digitale Assets erstellen kannst, die anschließend auf verschiedenen Kanälen eingesetzt werden können.Du kannst Instagram-Ads als Vielseitiges Marketingtool für dein Unternehmen einsetzen. Auf Instagram können Ads im Hauptfeed der Nutzer*innen, auf der Erkundungsseite oder in Instagram-Stories erscheinen. Außerdem kannst du bestimmte Zielgruppen ansprechen, indem du gezielte Ads в Instagram schaltest, um etwa Personen zu erreichen, die ein bestimmtes Alter haben oder an einem bestimmten Ort leben. Sobald du ein Instagram-Ad в Mailchimp erstellt und eine Kampagne gestartet hast, kannst du anhand von Analysen erkennen, wie gut die Kampagne läuft und wie die Leute mit deinen Ads interagieren.