
Причины высокого показателя отказов на сайте и способы его снизить — Маркетинг на vc.ru
Отказы — это метрика, с которой многие сталкивались в Яндекс.Метрике или Google Analytics. Но что это за зверь такой и как с ним работать мало кому известно. И вообще, нужно ли его улучшать и какая норма отказов?
1203 просмотров
Начнем с того, что же такое отказы.
У Яндекс.Метрики и Google Analytics разное представление об отказах.
Google Analytics считает отказом “сеанс с просмотром одной страницы на вашем сайте.” А рассчитывается он путем “деления количества сеансов с просмотром одной страницы на общее число сеансов”.
Т.е. если клиент зашел только на одну страницу и более не выполнил никаких активных действий и никуда не переходил, то Google Analytics посчитает такое посещение нецелевым и запишет его в “отказы”.
В Яндекс.Метрике отказом считает “визит, продолжительность которого меньше 15 секунд”. Но рассчитывается он точно также — отношение доли людей, покинувших сайт, к общему числу посетителей.
Многие люди, увидев высокий процент отказов начинают паниковать. Поэтому важно отметить, что исключением в этом расчете выступают лендинги (одностраничные сайты). Для них отказы скорее правильнее рассчитывать в случае, если посетитель не достиг поставленной в метриках целей.
А вот если у вас многостраничный сайт, то стоит обратить внимание на данный показатель.
Норма процента отказа.
Так как для каждого сайта норма отказов будет своя, то принято считать в среднем нормальным процентом отказа в Яндекс. Метрике < 20%, а в Google Analytics < 60%.
Как работать с отказами.
(Для разбора работы с данной метрикой будут взяты отказы Яндекс.Метрики, так как данный сервис более знаком российскому бизнесу.)
Процент отказов может рассказать о многих проблемах на сайте: от отношения пользователей к скорости загрузки сайта до некорректной настройки рекламных кампаний.
Но даже если вы выполните все пункты, указанные в этой статье, привести отказы к 0 у вас не получится.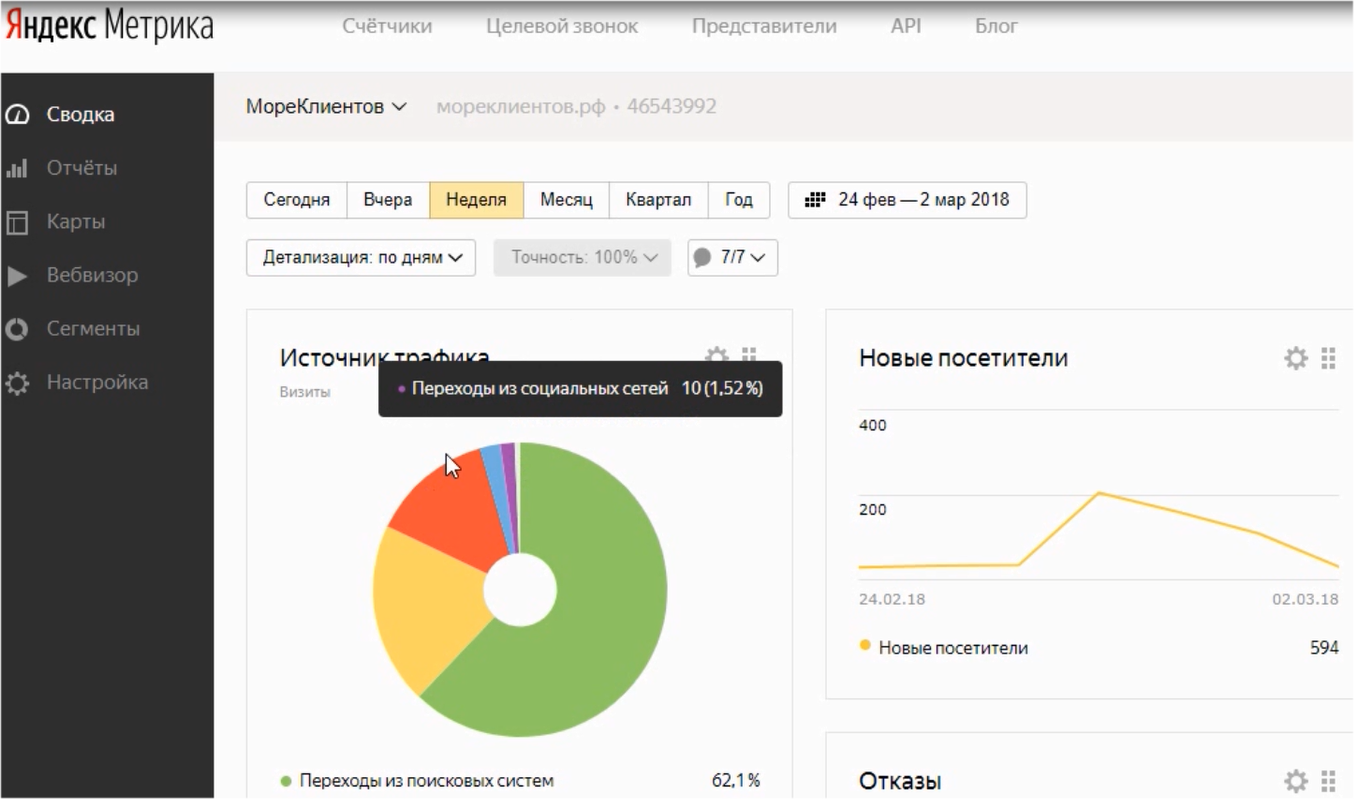
Теперь пройдемся по причинам высоких отказов и по способам работы с ними:
1) Скорость загрузки страницы.
Вы открываете сайт и вот уже 2 секунды вместо оформленной страницы на экране ничего нет кроме белого полотна. Какая мысль у вас возникает? Готовы ли вы ждать ещё, чтобы найти ответ на свой вопрос именно на этом сайте или же легче поискать что-то другое?
Ответ прост:
Многие пользователи уже через 3 секунды загрузки белого экрана решат, что сайт нерабочий и смело закроют страницу в поисках сайта ваших конкурентов. И вроде заход на сайт был, но продлился он не более 15 секунд, отсюда и высокий уровень отказов.
Что в этом случае делать:
Первым делом полезно будет прогнать свой сайт через сервисы по замеру скорости, чтобы после обновления сайта вы могли сравнивать данные и делать выводы, улучшилась ли скорость или нет.
Также через некоторые сервисы вы сможете понять, какой формат сайта вас подводит: десктоп версия или мобильная.
Сервисов для замера скорости загрузки страниц много. Вот некоторые из них:
— PageSpeed Insights
— be First
— Rusonyx site speed
После определения слабой стороны сайта, необходимо её проработать.
В этом помогут всевозможные оптимизации:
1. Оптимизируйте изображения, используя специальные программы.
2. Проверьте скорость загрузки через инструменты браузера, чтобы выявить неоптимальные части кода.
Для этого зайдите в панель разработчика браузера, откройте вкладку Network и перезагрузите страницу. (удобно зайти в панель разработчика браузера (Cmd+Alt+I для Mac или Ctrl+Shift+I)
После чего с помощью сортировки по времени можно будет легко выявить те элементы, которые грузятся очень долго, и оптимизировать их.
3. Сторонние сервисы (как Яндекс Метрика или Google аналитика) увеличивают скорость загрузки страницы — откажитесь от ненужных сервисов.
4. Используйте прелоадер для сайта, чтобы у пользователя не возникало мысли, что сайт завис или не работает.
Итак, вы выполнили все рекомендации из 1 пункта, время идёт, но процент отказов стоит на месте.
Теперь ответьте на вопрос: “А запущена ли у Вас реклама?”Если да, то этот пункт для Вас.
2) Нерелевантные рекламные объявления
Вот вы давно уже прочесываете весь интернет в поисках корма своему любимому котику.
И, о чудо! Вы видите рекламное объявление, где обещают нужный Вам корм по самой низкой цене, так ещё и бесплатная доставка.
Пытаясь не упустить выгодное предложение, вы кликаете по злосчастному объявлению и попадаете на страницу, где и в помине нет никакого кошачьего корма, а только игрушки для кошек и одежда.
Что же первым делом вы сделаете?
Ответ прост:
Конечно закроете страницу, ругая этот сайт и объявления в поисковиках.
Чем это грозит клиенту — потерянным временем и подрывом доверия к рекламным объявлениям.
А вам, как владельцу сайта, это грозит увеличением процента отказов и сливом бюджета.
Что в этом случае делать:
При настройке рекламных кампаний нужно быть весьма аккуратным. Важно помнить, что страница должна соответствовать тому, о чем вы заявляете в рекламе.
Вот кстати ссылка на удобный инструмент — конструктор UTM-меток.
Перепроверьте соответствие объявлений целевой странице, пропишите UTM-метки, если вы все ещё этого не сделали.
3) Некорректное отображение сайта на мобильных устройствах
Количество пользователей мобильных устройств с каждым годом растет и растет. Поэтому важно обращать внимание не только на десктоп версию сайта, но и на мобильную.
Вообще именно мобильная версия сайта должна стать чуть ли не основной версией, так как именно через неё проходит основной поток пользователей (в этом вы можете убедиться, изучив отчет в яндекс метрике)
Если же с адаптивной версией сайта возникают проблемы, процент отказов на сайте ( а именно на мобильной версии) будет зашкаливать.
Проверить этот показатель можно через Яндекс Метрику.
Что же делать, если процент отказов на мобильной версии сайта высокий?
Ответ прост:
Нужно привести в порядок адаптивную версию сайта.
Что в этом случае делать:
Обратитесь к специалистам, которые помогут Вам протестировать сервис с разных устройств, составят подробный план работ и помогут привести сайт в порядок.
4) Некорректное отображение сайта через некоторые браузеры
С помощью Яндекс Метрики можно узнать, из какого браузера пользователи чаще всего заходят на ваш сайт и какой при этом процент отказов.
Если вы видите, что у определенного браузера высокий процент отказов, то стоит убедиться, что сайт корректно отображается через него: возможно не будут поддерживаться шрифты или стилистические решения.
Что в этом случае делать:
Не стоит паниковать и переверстывать весь сайт. Достаточно будет небольшой косметики и процент отказов должен стремительно упасть вниз.
Причин, по которым процент отказов может быть высоким, намного больше. Выше описаны лишь самые основные.
При этом, если Ваш сайт хорошо отрабатывает, а процент отказов высокий, это не значит, что необходимо искать причину и впопыхах уменьшать отказы. Важно помнить, что для каждой сферы бизнеса норма процента отказа будет своей.
Поэтому, прежде чем вносить изменения на сайт, всегда думайте наперед — что вы хотите получить от них.
Но если вы все же решились исправить картину с отказами, то вот ещё раз шаги по уменьшению показателя:
1. Проверьте скорость загрузки страниц и оптимизируйте изображения.
2. Если у Вас запущена реклама, убедитесь в соответствии целевой страницы объявлению.
3. Проверьте адаптивную верстку сайта.
4. Протестируйте сайт на корректность отображения через разные браузеры.
Высоких вам конверсий!
Команда Pocket Rocket Science
Отказы в Яндекс.Метрике — как улучшить показатель?
Отказ в Яндекс.Метрике — это показатель, когда пользователь за 1 визит проводит на сайте меньше 15 секунд, не идет дальше одной страницы и не совершает никаких действий. Эти параметры нельзя изменить, так как они установлены самой системой.
Эти параметры нельзя изменить, так как они установлены самой системой.
Вся контекстная реклама в eLama
Один кабинет и кошелек для рекламы в Яндекс.Директе и Google Ads, инструменты для повышения эффективности, бесплатное обучение и помощь на всех этапах работы.
Зарегистрироваться
Что еще нужно знать о показателе отказов в Яндекс.Метрике
Если пользователь совершит событие «неотказ» в течение 15 и меньше секунд, то это будет зафиксировано как действие.
Конкретного показателя отказов не существует. Однако можно ориентироваться на проценты отказов в вашей нише, которые можно найти в поиске по интересующему запросу. В целом старайтесь опираться на актуальные показатели сайта по отказам в Яндекс.Метрике.
Как узнать количество отказов
Прежде всего установите счетчик на сайт по инструкции. Подождите, пока накопится достаточно статистики по всем каналам.
Если счетчик установлен и собрана статистика, то перейдите в отчеты:
Под графиком будет таблица с источниками трафика, где есть столбец «Отказы» для каждого канала:
Эту информацию можно визуализировать в виде графиков, чтобы видеть пики активности и падения:
Если вы видите высокий процент отказов по одному или нескольким каналам, то постарайтесь это исправить, следуя нашим советам ниже.
Как уменьшить процент отказов в Яндекс.Метрике
1. Обратите внимание на содержание сайта:
- насколько современен дизайн;
- как оформлена страница, которая может выдавать ошибку;
- релевантен ли контент страниц, которые посещает пользователь, его запросу;
- понятно ли пользователю куда нажимать, например, для звонка с сайта.
2. Проверьте скорость загрузки сайта, наличие ошибок в верстке страниц и SSL-сертификата.
3. Посмотрите на адаптивность сайта для мобильных устройств на различных моделях. Если сейчас вы ограничены бюджетом, то попробуйте сделать турбо-страницу. Яндекс самостоятельно определит, с какого устройства заходит пользователь на сайт и покажет ему релевантный контент:
4. Соберите фокус-группу, которая протестирует сайт на удобство использования. Если вы пока не можете этого сделать, то используйте Вебвизор, Карту кликов для понимания действий пользователя на сайте:
Улучшение показателя отказов для рекламных кампаний
Отказы в Яндекс. Метрике помогают определить нерелевантные ключевые фразы в поисковых кампаниях, по которым приходит нецелевой трафик. Однако это не относится к ключевым фразам, где меньше 5 переходов и высокий процент отказов.
Метрике помогают определить нерелевантные ключевые фразы в поисковых кампаниях, по которым приходит нецелевой трафик. Однако это не относится к ключевым фразам, где меньше 5 переходов и высокий процент отказов.
В кампаниях для рекламы в партнерской сети Яндекса (РСЯ) смотрите на площадки, которые не приносят конверсий или приносят нецелевой трафик:
В этом же отчете проверьте, показывается ли реклама в приложениях. Если да, то отключите их.
Заключение
Яндекс.Метрика предоставляет возможность улучшить ваш сайт и рекламные кампании благодаря анализу процента отказов. Чем быстрее будут проведены тесты и устранены ошибки, тем раньше на сайт пойдет целевой трафик, а показатель отказов в Яндекс.Метрике станет ниже.
Хотите быть в курсе всех акций eLama?Кликайте на изображение и подписывайтесь на рассылку!
MTTR против MTBF против MTTF
Показатели являются краеугольным камнем в оценке успеха или неудачи любого проекта. Поскольку успех — это конечная цель каждого проекта, мы часто забываем смотреть на показатели неудач. Большинство компаний не анализируют неудачи и, следовательно, не учитывают их в большинстве проектов. Чтобы понять метрики отказов, нам нужно начать с понимания самих отказов или, скорее, того, как мы должны их определять.
Поскольку успех — это конечная цель каждого проекта, мы часто забываем смотреть на показатели неудач. Большинство компаний не анализируют неудачи и, следовательно, не учитывают их в большинстве проектов. Чтобы понять метрики отказов, нам нужно начать с понимания самих отказов или, скорее, того, как мы должны их определять.
Может быть, вы думаете, что неудача очевидна, и мы не должны тратить время на обсуждение такой базовой концепции. Когда что-то не работает, это означает, что это не удалось. Верно? Согласно Википедии, отказ определяется как:
Состояние или условие не достижения желаемой или намеченной цели.
Хотя это простое определение, его можно интерпретировать. Возьмем, к примеру, хип-хоп-сингл известного исполнителя, получивший множество наград и одобренный критиками, но не проданный тиражом более 100 000 копий. Был ли это успех или провал?
Это можно распространить на мир программного обеспечения. Представьте себе аналитическое приложение, которое всегда дает правильные результаты. Но из-за сложного интерфейса его очень сложно использовать большинству пользователей, не являющихся экспертами в области данных. Это делает так, что уровень принятия приложения в любой организации ниже 25%. Будет ли это приложение считаться успешным или неудачным?
Но из-за сложного интерфейса его очень сложно использовать большинству пользователей, не являющихся экспертами в области данных. Это делает так, что уровень принятия приложения в любой организации ниже 25%. Будет ли это приложение считаться успешным или неудачным?
На мой взгляд, аналитическое приложение провалилось. Несмотря на то, что результаты всегда точны, если они не могут донести информацию до команды, это не более чем «забавный факт», о котором знают несколько пользователей в организации. Теперь, когда мы поняли, что считается провалом, давайте перейдем к сути этого поста — метрикам. Мы должны найти способ отложить в сторону субъективность и дать измеримое определение неудачи. Когда дело доходит до мира технологий — и это особенно верно, когда речь идет об аппаратном обеспечении, инфраструктуре и операционных аспектах, — самый популярный способ измерения сбоя — это сбои или простои системы.
Наиболее важными показателями отказов, которые следует учитывать в каждом проекте, являются MTTR, MTBF и MTTF. MTTR означает «среднее время ремонта». MTBF — это аббревиатура от «среднее время наработки на отказ», и, наконец, MTTF означает «среднее время до исправления». Все три из них указывают на определенный отрезок времени.
MTTR означает «среднее время ремонта». MTBF — это аббревиатура от «среднее время наработки на отказ», и, наконец, MTTF означает «среднее время до исправления». Все три из них указывают на определенный отрезок времени.
Итак, насколько эти показатели отличаются друг от друга или нет? Есть ли разница между «ремонтировать» и «фиксировать»? Что квалифицируется как провал? Вот на такие вопросы мы и ответим сегодня. Давайте копать.
MTTR против MTBF против MTTF
Чтобы улучшить любой проект, над которым вы сейчас работаете, вам нужны объективные показатели, которые вы можете отслеживать и улучшать. Во всем мире организации вкладывают значительные средства в свои технологические инфраструктуры. Таким образом, если вы не используете метрики для их мониторинга и улучшения, вы буквально не заботитесь о рентабельности инвестиций.
После разговора о важности объективного определения сбоя и объяснения того, почему отслеживание метрик так важно для организаций, пришло время рассказать о метриках и о том, как их рассчитать.
MTTR (среднее время ремонта)
Среднее время ремонта (MTTR) является основным показателем ремонтопригодности ремонтопригодных элементов. Он представляет собой среднее время, необходимое для восстановления неисправного компонента, устройства, кода или решения.
MTTR показывает время, необходимое для реагирования на незапланированные инциденты и возобновления работы оборудования или устройств. Эта метрика рассчитывает время, прошедшее с начала инцидента до момента его решения.
Почему вам следует заботиться о MTTR?
Отслеживая его, вы можете узнать, насколько быстро ваша организация реагирует на возникающие проблемы. Чем меньше число, тем лучше. Знание этого числа позволит вам сбалансировать ожидания клиентов и сотрудников при возникновении проблем.
MTTR часто включает время, необходимое для выполнения следующих действий:
- Уведомить соответствующих ремонтников.
- Диагностируйте проблему.

- Устраните проблему.
- В случае кода исправить ошибки.
- В случае проверки кода, чтобы убедиться, что ремонт не затронул другие части программы.
- В случае физического оборудования дайте оборудованию/устройствам остыть.
- В случае физического оборудования соберите устройство и снова подготовьте его к использованию.
- Наконец, настройте и протестируйте устройство.

Как рассчитать MTTR
Рассчитать среднее время ремонта очень просто. Во-первых, вы узнаете общее время, затраченное на внеплановое обслуживание данного актива (например, конкретного устройства). Затем вы делите это число на количество отказов, произошедших с этим оборудованием за указанный период времени.
Представьте, что ваша организация потратила 30 часов на исправление созданной вами неработающей аналитики. Такие баги возникали 5 раз в течение года. Это означает, что ваш MTTR равен 6.
Это означает, что ваш MTTR равен 6.
Какова желаемая цель для вашего MTTR? Это сильно различается, особенно в зависимости от типа и размера организации. Значение MTTR 5 часов или менее считается хорошей целью.
MTBF (среднее время наработки на отказ)
MTBF зависит от самих устройств. В то время как MTTR показывает, насколько быстро организация может реагировать на непредвиденные проблемы, MTBF указывает на уровень качества и надежности активов.
Почему вас должна волновать наработка на отказ?
Во-первых, вы отслеживаете среднее время безотказной работы, чтобы его можно было улучшить. Улучшение MTBF означает увеличение времени наработки на отказ. Это может означать, что происходит меньше инцидентов или что они решаются быстрее. Среднее время безотказной работы измеряет надежность. Таким образом, внимательно отслеживая этот показатель, вы сможете узнать ожидаемую продолжительность жизни данного актива.
Получив эти знания, ваша организация сможет использовать их для принятия взвешенных решений по таким вопросам, как планирование технического обслуживания, управление запасами и т. д.
д.
Среднее время безотказной работы, наряду с другими ключевыми показателями эффективности, также может помочь вашей организации оценить собственные возможности мониторинга. Если ваша организация уже использует инструменты и механизмы мониторинга, поддерживать высокий показатель MTBF не должно быть так сложно.
Как рассчитать среднее время безотказной работы
Расчет среднего времени безотказной работы также прост. Во-первых, вы находите общее количество часов работы (онлайн) для данного актива за определенный период. Затем вы делите это число на количество отказов, которые произошли за то же время.
Итак, представьте, что оборудование полностью работает в течение 3000 часов в течение 12 месяцев. За тот же период этот актив ломался 3 раза. Таким образом, среднее время безотказной работы для этого оборудования составляет 1000 часов.
MTTF (среднее время до отказа)
MTTF означает «среднее время до отказа». Короче говоря, этот показатель относится к средней продолжительности жизни данного актива.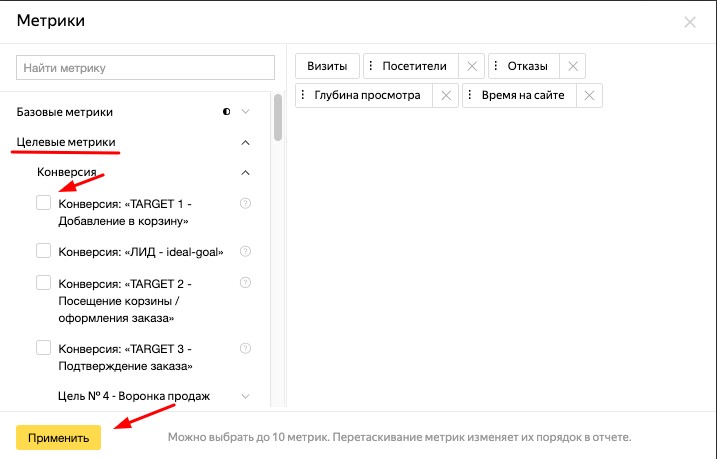
Единственная существенная разница между MTBF и MTTF заключается в том, что MTBF обычно зарезервирован для ремонтопригодных элементов. MTTF, с другой стороны, используется в сценариях, когда исправление элемента невозможно.
Можно сказать, что MTTF представляет собой ожидание. Он устанавливает количество времени, в течение которого вы можете ожидать, что данный актив будет надежно работать до тех пор, пока он не выйдет из строя.
Зачем вам беспокоиться о MTTF?
Как и среднее время безотказной работы, среднее время безотказной работы указывает на надежность. Отслеживая этот показатель, вы сможете получить точную оценку того, как долго данный элемент работает, пока он не сломается и не подлежит ремонту. MTTF помогает организациям принимать обоснованные решения об управлении запасами, включая решения о том, какие бренды покупать, и многое другое.
MTTF зависит от еще одной очень важной метрики, которую мы сегодня не будем обсуждать: MTTD.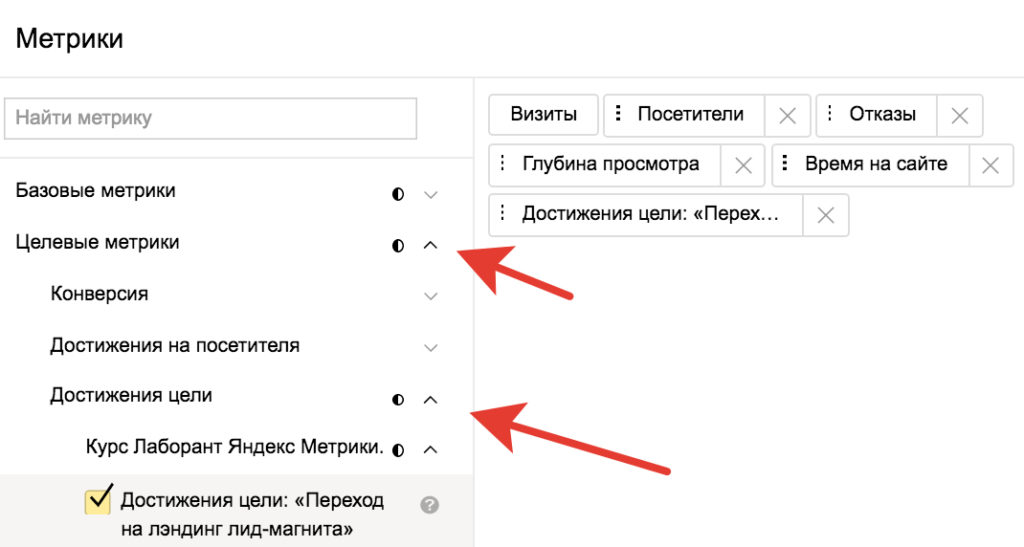 MTTD означает «среднее время обнаружения» и относится к среднему времени, которое требуется вашей организации, чтобы узнать об инцидентах, когда они происходят. Поддержание низкого значения MTTD является ключом к управлению всеми остальными показателями.
MTTD означает «среднее время обнаружения» и относится к среднему времени, которое требуется вашей организации, чтобы узнать об инцидентах, когда они происходят. Поддержание низкого значения MTTD является ключом к управлению всеми остальными показателями.
Как рассчитать MTTF
Среднее время безотказной работы рассчитывается путем деления общего количества часов работы на количество отслеживаемых активов.
Допустим, у нас есть 8 единиц оборудования, которые мы тестируем. Первый вышел из строя через 32 часа, а второй — через 12 часов. Третий вышел из строя через 80 часов, и, наконец, последний вышел из строя через восемь часов. Таким образом, у нас есть общее время безотказной работы 36 часов, которое делится на 8 равно 20 часам. Этот результат предполагает, что этот конкретный актив необходимо будет заменять в среднем каждые 20 часов.
MTTR, MTBF и MTTF: что важнее
Короче говоря, DevOps — это действие. Это не измерение ради измерения. Для DevOps метрики полезны только тогда, когда они действенны, то есть когда они помогают вашей организации принимать решения и устранять проблемы.
Для DevOps метрики полезны только тогда, когда они действенны, то есть когда они помогают вашей организации принимать решения и устранять проблемы.
MTTR — гораздо более привлекательная метрика. MTBF и MTTF, как вы видели, больше ориентированы на определение ожидаемого срока службы активов. Можно сказать, что они более пассивны. С другой стороны, MTTR — это действие. Это стимул для вашей организации пойти туда и исправить все, что не так. Это именно то отношение, которое вы ожидаете от организации, которая занимается DevOps.
В конце концов, для надежного отслеживания любой метрики вам нужна надежная аналитическая платформа, которая может не только вычислять данные, но и отображать их таким образом, чтобы все в организации могли их понять. Здесь на помощь приходит Toucan с управляемой аналитикой и рассказыванием историй. Таким образом, ваши показатели могут быть видны и поняты пользователями, на которых они оказывают наибольшее влияние, и легко сообщаются всем в организации.
MTBF, MTTR, MTTF, MTTA: Понимание показателей инцидентов
Понимание некоторых наиболее распространенных показателей инцидентов
В современном постоянном мире перебои в работе и технические инциденты имеют большее значение, чем когда-либо прежде. Сбои и простои влекут за собой реальные последствия. Пропущенные сроки. Просроченные платежи. Задержки проекта.
Вот почему компаниям важно измерять и отслеживать показатели времени безотказной работы и простоев, а также того, насколько быстро и эффективно команды решают проблемы.
Некоторые из наиболее часто отслеживаемых показателей в отрасли: MTBF (среднее время до отказа), MTTR (среднее время восстановления, ремонта, ответа или разрешения), MTTF (среднее время до отказа) и MTTA (среднее время подтверждения). — ряд показателей, призванных помочь техническим командам понять, как часто происходят инциденты и как быстро команда восстанавливается после этих инцидентов.
Многие эксперты утверждают, что эти метрики на самом деле не так уж полезны сами по себе, потому что они не задают более сложных вопросов о том, как разрешаются инциденты, что работает, а что нет, как, когда и почему возникают проблемы. эскалация или деэскалация.
эскалация или деэскалация.
С другой стороны, MTTR, MTBF и MTTF могут быть хорошей отправной точкой или эталоном, с которого начинаются обсуждения, ведущие к более глубоким и важным вопросам.
Как профессионалы реагируют на серьезные инциденты
Получите наш бесплатный справочник по управлению инцидентами. Изучите все инструменты и методы, которые Atlassian использует для управления крупными инцидентами.
Отказ от ответственности в отношении MTTR
Когда мы говорим о MTTR, легко предположить, что это одна метрика с одним значением. Но правда в том, что он потенциально представляет четыре разных измерения . R может означать ремонт, восстановление, реагирование или разрешение, и хотя четыре показателя действительно перекрываются, каждый из них имеет свое значение и нюанс.
Итак, если ваша команда говорит об отслеживании MTTR, полезно уточнить, какое MTTR они имеют в виду и как они его определяют. Прежде чем вы начнете отслеживать успехи и неудачи, ваша команда должна быть в курсе того, что именно вы отслеживаете, и убедиться, что все знают, что они говорят об одном и том же.
Среднее время наработки на отказ: среднее время наработки на отказ
Что такое среднее время наработки на отказ?
Среднее время наработки на отказ (среднее время наработки на отказ) — это среднее время наработки на отказ технологического продукта, который может быть устранен. Метрика используется для отслеживания доступности и надежности продукта. Чем больше время наработки на отказ, тем надежнее система.
Цель большинства компаний — максимально увеличить среднее время безотказной работы — между выпусками проблем проходят сотни тысяч (или даже миллионы) часов.
Как рассчитать среднее время наработки на отказ
Среднее время безотказной работы рассчитывается с использованием среднего арифметического. По сути, это означает получение данных за период, который вы хотите рассчитать (возможно, шесть месяцев, возможно, год, возможно, пять лет) и деление общего времени работы за этот период на количество отказов.
Итак, предположим, что мы оцениваем 24-часовой период, и было два часа простоя в двух отдельных инцидентах. Наше общее время безотказной работы составляет 22 часа. Делим на два, получается 11 часов. Таким образом, наша наработка на отказ составляет 11 часов.
Наше общее время безотказной работы составляет 22 часа. Делим на два, получается 11 часов. Таким образом, наша наработка на отказ составляет 11 часов.
Поскольку метрика используется для отслеживания надежности, среднее время безотказной работы не учитывает ожидаемое время простоя во время планового обслуживания. Вместо этого он фокусируется на неожиданных сбоях и проблемах.
Происхождение средней наработки на отказ
Среднее время безотказной работы пришло к нам из авиационной промышленности, где системные отказы влекут особенно серьезные последствия не только с точки зрения затрат, но и человеческих жизней. С тех пор инициализм проник в различные технические и механические отрасли и особенно часто используется в производстве.
Как и когда использовать среднее время наработки на отказ
Среднее время безотказной работы полезно для покупателей, которые хотят быть уверенными, что получают самый надежный продукт, летают на самом надежном самолете или выбирают самое безопасное производственное оборудование для своего предприятия.
Для внутренних команд это показатель, который помогает выявлять проблемы и отслеживать успехи и неудачи. Это также может помочь компаниям разработать обоснованные рекомендации о том, когда клиентам следует заменить деталь, обновить систему или принести продукт для обслуживания.
Среднее время безотказной работы — это показатель сбоев в ремонтопригодных системах . Для сбоев, требующих замены системы, обычно используют термин MTTF (среднее время до отказа).
Например, представьте автомобильный двигатель. При расчете времени между внеплановым обслуживанием двигателя вы должны использовать MTBF — среднее время наработки на отказ. При расчете времени между заменой всего двигателя вы должны использовать MTTF (среднее время до отказа).
MTTR: среднее время ремонта
Какое среднее время ремонта?
MTTR (среднее время ремонта) — это среднее время, необходимое для ремонта системы (обычно технического или механического) . Он включает в себя как время ремонта, так и любое время тестирования. Часы не останавливаются на этом показателе, пока система снова не станет полностью функциональной.
Он включает в себя как время ремонта, так и любое время тестирования. Часы не останавливаются на этом показателе, пока система снова не станет полностью функциональной.
Как рассчитать среднее время ремонта
Вы можете рассчитать MTTR, сложив общее время, затраченное на ремонт в течение любого заданного периода, а затем разделив это время на количество ремонтов.
Допустим, нам нужен ремонт в течение недели. За это время произошло 10 отключений, а системы активно ремонтировались в течение четырех часов. Четыре часа — это 240 минут. 240 разделить на 10 равно 24. Это означает, что среднее время ремонта в этом случае будет 24 минуты.
Ограничения среднего времени ремонта
Среднее время ремонта не всегда равно времени простоя самой системы. В некоторых случаях ремонт начинается в течение нескольких минут после отказа продукта или выхода из строя системы. В других случаях существует задержка между возникновением проблемы, ее обнаружением и началом ремонта.
Этот показатель наиболее полезен при отслеживании того, насколько быстро обслуживающий персонал может устранить проблему. Он не предназначен для выявления проблем с вашими системными предупреждениями или задержками перед ремонтом — оба эти фактора также являются важными факторами при оценке успехов и неудач ваших программ управления инцидентами.
Как и когда использовать среднее время ремонта
MTTR — это метрика, которую команды поддержки и технического обслуживания используют для отслеживания сроков ремонта. Цель состоит в том, чтобы максимально снизить это число за счет повышения эффективности ремонтных процессов и бригад.
MTTR: Среднее время восстановления
Что такое среднее время восстановления?
MTTR (среднее время восстановления или среднее время восстановления) — это среднее время восстановления после сбоя продукта или системы. Сюда входит полное время простоя — с момента сбоя системы или продукта до момента, когда он снова становится полностью работоспособным.
Это ключевой показатель DevOps, который можно использовать для измерения стабильности команды DevOps, как отмечает DevOps Research and Assessment (DORA).
Как рассчитать среднее время до восстановления
Среднее время до восстановления рассчитывается путем сложения всего времени простоя за определенный период и деления его на количество инцидентов. Итак, предположим, что наши системы были отключены в течение 30 минут в результате двух отдельных инцидентов в течение 24 часов. 30 разделить на два равно 15, поэтому наше среднее время восстановления равно 15 минутам.
Ограничения среднего времени восстановления
Этот показатель MTTR является мерой скорости вашего полного процесса восстановления. Это так быстро, как вы хотите, чтобы это было? Каково это по сравнению с вашими конкурентами?
Это метрика высокого уровня, которая помогает определить наличие проблемы. Однако, если вы хотите диагностировать , где , проблема заключается в вашем процессе (это проблема с вашей системой оповещений? Не слишком ли долго команда занимается исправлениями? Слишком долго кто-то отвечает на запрос об исправлении ?), вам понадобятся дополнительные данные . Потому что между неудачей и восстановлением происходит не одно и то же.
Потому что между неудачей и восстановлением происходит не одно и то же.
Проблема может быть связана с вашей системой оповещения. Есть ли задержка между сбоем и предупреждением? Предупреждения занимают больше времени, чем должны, чтобы добраться до нужного человека?
Проблема может быть связана с диагностикой. Вы можете быстро понять, в чем проблема? Существуют ли процессы, которые можно было бы улучшить?
Или проблема может быть в ремонте. Насколько эффективны ваши ремонтные бригады? Если они занимают большую часть времени, что их сбивает с толку?
Чтобы ответить на эти вопросы, вам потребуется изучить больше, чем MTTR, но среднее время восстановления может стать отправной точкой для диагностики того, есть ли проблема с вашим процессом восстановления, требующая более глубокого изучения.
Как и когда использовать среднее время восстановления
MTTR — хороший показатель для оценки скорости всего процесса восстановления.
MTTR: Среднее время решения
Что такое среднее время решения?
MTTR (среднее время устранения) — это среднее время, необходимое для полного устранения сбоя . Сюда входит не только время, затраченное на обнаружение сбоя, диагностику проблемы и ее устранение, но и время, затраченное на то, чтобы сбой не повторился.
Сюда входит не только время, затраченное на обнаружение сбоя, диагностику проблемы и ее устранение, но и время, затраченное на то, чтобы сбой не повторился.
Этот показатель расширяет ответственность команды, работающей над исправлением, за повышение производительности в долгосрочной перспективе. В этом разница между тушением пожара и тушением пожара, а затем противопожарной защитой вашего дома.
Существует сильная корреляция между этим MTTR и удовлетворенностью клиентов, так что на это стоит обратить внимание.
Как рассчитать среднее время разрешения
Чтобы рассчитать это MTTR, сложите время полного разрешения за период, который вы хотите отслеживать, и разделите на количество инцидентов.
Таким образом, если ваши системы были отключены в общей сложности два часа в течение 24-часового периода в одном инциденте, и команды потратили дополнительные два часа на исправление ошибок, чтобы гарантировать, что сбой системы не повторится, это четыре часа. Всего потрачено на решение проблемы. Это означает, что ваш MTTR составляет четыре часа.
Всего потрачено на решение проблемы. Это означает, что ваш MTTR составляет четыре часа.
Примечание об отслеживании среднего времени решения
Имейте в виду, что MTTR чаще всего рассчитывается с использованием рабочих часов (так, если вы устраняете проблему в момент закрытия в один день и тратите время на исправление основной проблемы первым делом на следующее утро , ваш MTTR не будет включать 16 часов, которые вы провели вне офиса). Если у вас есть команды в нескольких местах, работающие круглосуточно, или если у вас есть дежурные сотрудники, работающие в нерабочее время, важно определить, как вы будете отслеживать время для этой метрики.
Как и когда использовать среднее время для разрешения
MTTR обычно используется, когда речь идет о незапланированных инцидентах, а не о запросах на обслуживание (которые обычно планируются).
MTTR: Среднее время ответа
Что такое среднее время ответа?
MTTR (среднее время ответа) — это среднее время восстановления после сбоя продукта или системы с момента, когда вы впервые получили предупреждение об этом сбое. Это не включает время задержки в вашей системе предупреждений.
Это не включает время задержки в вашей системе предупреждений.
Как рассчитать среднее время ответа
Чтобы рассчитать этот показатель MTTR, сложите полное время ответа от предупреждения до момента, когда продукт или услуга снова станет полностью функциональной. Затем разделите на количество инцидентов.
Например: если у вас было четыре инцидента за 40-часовую рабочую неделю, и вы потратили на них один час (от оповещения до исправления), ваше MTTR за эту неделю составит 15 минут.
Как и когда использовать среднее время ответа
Этот показатель MTTR часто используется в кибербезопасности для измерения успеха команды в нейтрализации системных атак.
MTTA: Среднее время подтверждения
Что такое среднее время между подтверждением?
MTTA (среднее время до подтверждения) — это среднее время, которое проходит с момента срабатывания предупреждения до начала работы над проблемой. Этот показатель полезен для отслеживания скорости реагирования вашей команды и эффективности вашей системы оповещения.
Как рассчитать среднее время до подтверждения
Чтобы рассчитать MTTA, сложите время между предупреждением и подтверждением, а затем разделите на количество инцидентов.
Например: если у вас было 10 инцидентов и между оповещением и подтверждением для всех 10 прошло 40 минут, вы делите 40 на 10 и получаете в среднем четыре минуты.
Как и когда использовать среднее время подтверждения
MTTA полезен для отслеживания отклика. Ваша команда страдает от бдительности и слишком долго реагирует? Этот показатель поможет вам отметить проблему.
MTTF: Среднее время до отказа
Что такое среднее время до отказа?
MTTF (среднее время до отказа) — это среднее время между неустранимыми отказами технологического продукта. Например, если двигатели автомобилей марки X в среднем нарабатывают 500 000 часов, прежде чем они полностью выйдут из строя и должны быть заменены, 500 000 будет MTTF двигателей.
Расчет используется, чтобы понять, как долго система обычно работает, определить, превосходит ли новая версия системы старую, и предоставить клиентам информацию об ожидаемом сроке службы и о том, когда запланировать проверки их системы.
Как рассчитать среднее время наработки на отказ
Среднее время наработки на отказ — это среднее арифметическое, поэтому его можно рассчитать, сложив общее время работы оцениваемых продуктов и разделив полученную сумму на количество устройств.
Например: допустим, вы вычисляете среднее время безотказной работы лампочек. Как долго в среднем работают лампочки марки Y, прежде чем они перегорают? Предположим также, что у вас есть образец из четырех лампочек для тестирования (если вам нужны статистически значимые данные, вам понадобится гораздо больше, но для целей простой математики давайте оставим это небольшим).
Лампочка А горит 20 часов. Лампа B горит 18 часов. Лампа C горит 21 час. А лампочка D горит 21 час. Это в общей сложности 80 ламповых часов. Разделенное на четыре, среднее время безотказной работы равно 20 часам.
Проблема средней наработки на отказ
В примере с лампочкой MTTF — показатель, который имеет большой смысл. Мы можем запускать лампочки до тех пор, пока не выйдет из строя последняя, и использовать эту информацию, чтобы делать выводы об отказоустойчивости наших лампочек.
Но что происходит, когда мы измеряем вещи, которые выходят из строя не так быстро? Вещи, предназначенные для последних лет и лет? В этих случаях, хотя MTTF часто используется, это не такой хороший показатель. Потому что вместо того, чтобы запускать продукт до тех пор, пока он не выйдет из строя, большую часть времени мы запускаем продукт в течение определенного периода времени и измеряем количество отказов.
Например: Допустим, мы пытаемся получить статистику MTTF на планшетах Brand Z. Планшеты, надеюсь, рассчитаны на долгие годы. Но у Brand Z может быть всего шесть месяцев на сбор данных. И так тестируют 100 таблеток полгода. Допустим, одна таблетка выходит из строя ровно на шестимесячной отметке.
Итак, умножаем общее время работы (полгода умножаем на 100 таблеток) и получаем 600 месяцев. Вышел из строя только один планшет, поэтому мы разделим это на единицу, и наш MTTR будет равен 600 месяцам, то есть 50 годам.
Планшеты бренда Z прослужат в среднем 50 лет каждый? Это маловероятно. И поэтому метрика ломается в таких случаях.
И поэтому метрика ломается в таких случаях.
Как и когда использовать среднее время наработки на отказ
MTTF хорошо работает, когда вы пытаетесь оценить средний срок службы продуктов и систем с коротким сроком службы (например, лампочек). Это также предназначено только для случаев, когда вы оцениваете полный отказ продукта. Если вы рассчитываете время между инцидентами, требующими ремонта, предпочтительным исходным значением является MTBF (среднее время между сбоями).
MTBF, MTTR, MTTF, MTTA
Итак, какое измерение лучше, когда речь идет об отслеживании и улучшении управления инцидентами?
Ответ: все.
Хотя иногда они взаимозаменяемы, каждая метрика дает разное понимание. При совместном использовании они могут рассказать более полную историю о том, насколько успешно ваша команда справляется с управлением инцидентами и что можно улучшить.
Среднее время восстановления показывает, насколько быстро вы можете восстановить работоспособность своих систем.