Обучение Яндекс Метрике и Google analytics с нуля, записаться на курс по метрике и аналитике в Тюмени
Программа обучения
Введение. Основы веб-аналитики
- Введение. Что такое веб-аналитика?
- Аналитика эффективности работы сайта.
- Для чего нужна аналитика?
- Способы анализа сайта.
- Обзор популярных трекеров.
- Критерии эффективности работы сайта.
- Конверсия и показатели конверсии.
-
Целевые страницы и связь с конверсией.
Практическая работа: Анализ эффективности сайта.
Google Analytics
- Начало работы. Интерфейс.
- Настройки на уровне админ-панели.
- Структура. Настройки представления и ресурса.
- Группа каналов и группа контента.
-
Доступы — типы и возможности.

- Как поставить счетчик на сайт.
- Настройка целей и событий.
- Отчеты.
- Сегменты и фильтры отчетов. Сводки.
- Анализ аудитории.
- Анализ источников трафика.
- Анализ эффективности содержания сайта.
- Знакомство с Google Tag Manager.
- Понятия, принцип работы.
- Обзор интерфейса.
- Администрирование, управление пользователями.
-
События.
Практическая работа: Настройка Google Analytics.

Google Tag Manager
- Уровень данных или dataLayer.
- Переменные — встроенные.
- Переменные — пользовательские.
- Триггеры.
- Теги.
- Отладчик.
-
Настройка целей в Google Analytics.
- Внедрение Google Analytics, фиксация событий.
- Настройки тега Google Analytics.
- Фиксация отправки форм.
- Различные задачи.
- Динамическая подмена контента.
-
Расширенная электронная торговля Google Analytics.
Практическая работа: Настройка основных функций.

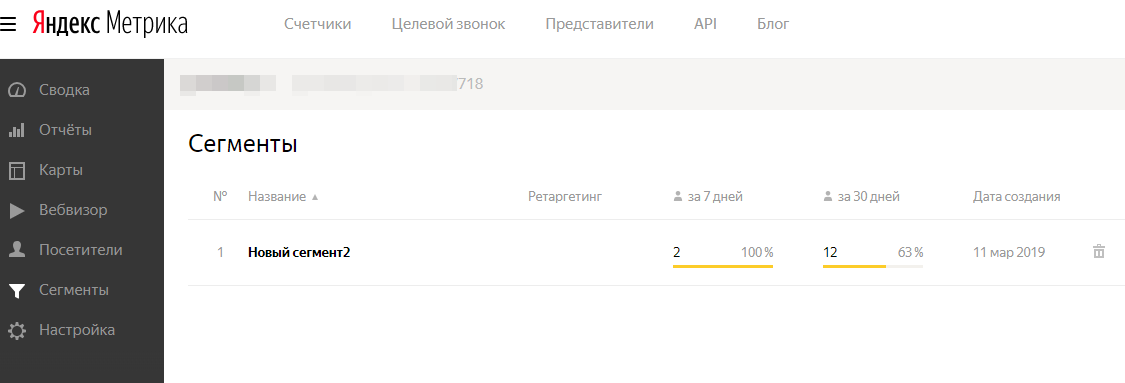
Яндекс.Метрика
- Создание аккаунта в Яндекс.Метрике.
- Управление пользователями. Проверка статуса отслеживания
- Анализ аудитории, качество трафика
- Демографические отчёты, интересы
- Анализ основных источников трафика
- Анализ поисковых систем и ключевых слов, анализ эффективности SEO-продвижения.
- Анализ эффективности содержания сайта и достижения целей.
-
Google Tag Manager. Настройка целей в Яндекс Метрике.
- Внедрение Яндекс Метрики, фиксация событий.
- Дополнительные возможности.
- Использование Google Sheets для анализа данных.
-
Google Data Studio — построение дашбордов.
Защита итогового проекта.

РЕКОМЕНДУЕМ
SEO-оптимизация сайта
32 часа
11 800 р.
Ведение и продвижение в социальных сетях
с 16.01.2023
56 часов
19 000 р.
Создание сайтов на Tilda
с 19.04.2023
36 часов
12 500 р.
онлайн, обучение с нуля, для начинающих и продвинутых — Хабр Карьера
НетологияМенеджер по маркетингу
10 месяцев • 16 января
Раскрутка сайтов • Яндекс.Метрика • Google Analytics • SEO-аудит сайтов
СертификатОнлайн
НетологияТаргетолог
4 месяца • 16 января
Таргетированная реклама • Контекстная реклама • Яндекс. Метрика • Google Analytics
Метрика • Google Analytics
СертификатОнлайн
LoftschoolМенеджер по маркетингу
12 недель • 23 января
Google Analytics • Яндекс.Метрика • Google AdWords • Яндекс директ • SEO-аудит сайтов • Таргетированная реклама • SMM • Копирайтинг • Веб аналитика • Поисковая оптимизация
СертификатТрудоустройствоОнлайн
SkillboxМенеджер по маркетингу
2 года • По факту набора потока
Интернет маркетинг • Яндекс.Метрика • Google Analytics • Jira
СертификатТрудоустройствоОнлайн
SkillFactoryМенеджер по маркетингу
12 месяцев • По факту набора потока
Интернет маркетинг • Поисковая оптимизация • Google Analytics • Яндекс.Метрика • Контекстная реклама • Таргетированная реклама
СертификатТрудоустройствоОнлайн
SkillboxSMM-специалист
24 месяца • По факту набора потока
SMM • Google Analytics • Яндекс.Метрика • Интернет маркетинг • Таргетированная реклама
СертификатТрудоустройствоОнлайн
SkillboxТаргетолог
17 месяцев • По факту набора потока
Яндекс. Метрика • Таргетированная реклама • Google Analytics • Google Tag Manager • Веб аналитика • Интернет маркетинг
Метрика • Таргетированная реклама • Google Analytics • Google Tag Manager • Веб аналитика • Интернет маркетинг
СертификатТрудоустройствоОнлайн
SkillboxВеб-аналитик
5 месяцев • По факту набора потока
Google Analytics • Яндекс.Метрика • Google Tag Manager • Веб аналитика
СертификатОнлайн
SkillboxБизнес-аналитик
12 месяцев • По факту набора потока
Бизнес аналитика • PowerBI • Python • Системный анализ • Яндекс.Метрика • Google Analytics • SQL • Базы данных
СертификатТрудоустройствоОнлайн
SkillboxБизнес-аналитик
12 месяцев • По факту набора потока
Бизнес аналитика • Python • Яндекс.Метрика • Google Analytics • SQL • PowerBI
СертификатТрудоустройствоОнлайн
ProductStarАналитик по данным
6 месяцев • В любой момент
Веб аналитика • Google Analytics • Яндекс.Метрика • SQL • Python • MySQL • ClickHouse
СертификатТрудоустройствоОнлайн
SkillboxАналитик по данным
6 месяцев • По факту набора потока
Microsoft Excel • Python • NumPy • Pandas • SQL • PowerBI • Microsoft PowerPoint • Яндекс. Метрика • Google Analytics
Метрика • Google Analytics
СертификатОнлайн
SkillboxВеб-аналитик
6 месяцев • По факту набора потока
Google Analytics • Google Tag Manager • Яндекс.Метрика • Веб аналитика • SQL
СертификатОнлайн
GBМенеджер по маркетингу
16 месяцев • По факту набора потока
Интернет маркетинг • Контекстная реклама • Таргетированная реклама • Медийная реклама • Яндекс.Метрика • Google Analytics
СертификатОнлайн
GBSMM-специалист
4 месяца • По факту набора потока
SMM • Стратегический маркетинг • Веб аналитика • Яндекс.Метрика • Google Analytics • Интернет маркетинг • Контент маркетинг • Копирайтинг
СертификатОнлайн
SkillboxБизнес-аналитик
12 месяцев • По факту набора потока
Python • SQL • Microsoft Excel • Яндекс.Метрика • Google Analytics • PowerBI • Бизнес аналитика
СертификатТрудоустройствоОнлайн
GBМенеджер по маркетингу
По факту набора потока
Яндекс директ • Google AdWords • Яндекс.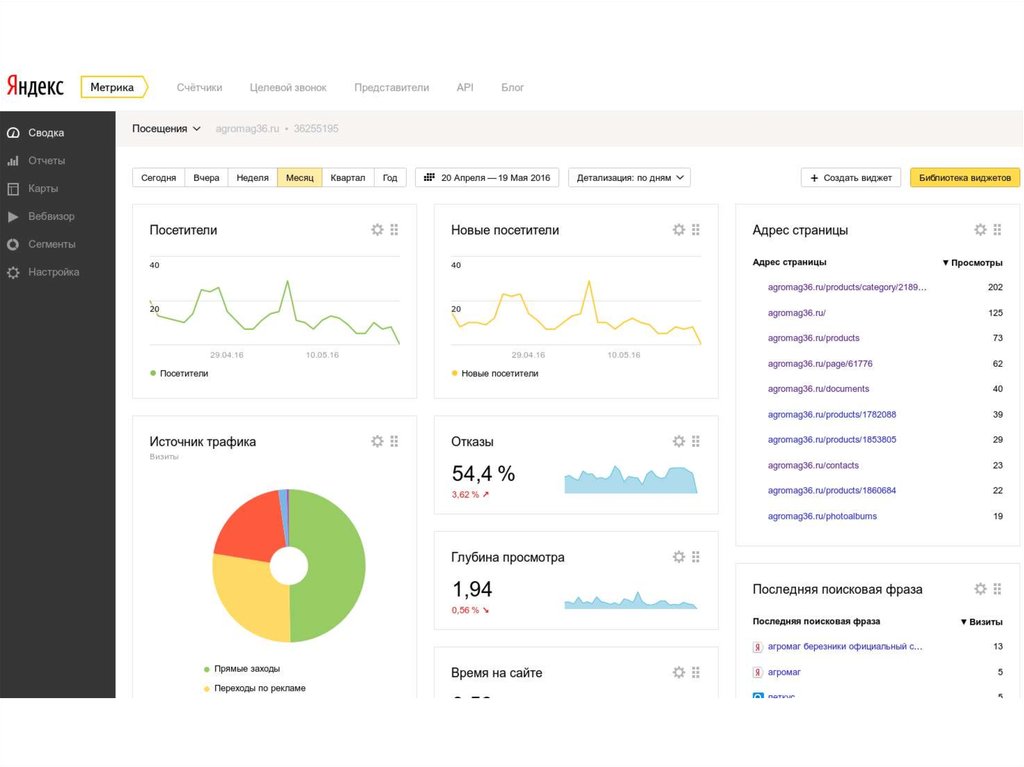 Метрика • Google Analytics • Медиапланирование • Интернет маркетинг
Метрика • Google Analytics • Медиапланирование • Интернет маркетинг
Онлайн
SkillboxМенеджер по маркетингу
4 месяца • По факту набора потока
Раскрутка сайтов • Интернет маркетинг • Google Analytics • Яндекс.Метрика
СертификатТрудоустройствоОнлайн
Яндекс ПрактикумМенеджер по маркетингу
6 месяцев • В любой момент
Контекстная реклама • Интернет маркетинг • Яндекс директ • Google AdWords • Google Analytics • Яндекс.Метрика
СертификатОнлайн
MaedSEO-специалист
По факту набора потока
Google Analytics • Яндекс.Метрика • Интернет маркетинг • Google AdWords • Составление семантического ядра
СертификатОнлайн
SkillboxSEO-специалист
12 месяцев • По факту набора потока
Поисковая оптимизация • SEO-аудит сайтов • Яндекс.Метрика • Google Analytics • Веб аналитика
СертификатТрудоустройствоОнлайн
SkillboxМенеджер по маркетингу
3 месяца • По факту набора потока
Контекстная реклама • Яндекс. Метрика • Google Analytics • Яндекс директ
Метрика • Google Analytics • Яндекс директ
СертификатОнлайн
SkillFactoryМенеджер по маркетингу
По факту набора потока
Интернет маркетинг • Google AdWords • Яндекс директ • Google Analytics • Яндекс.Метрика • Таргетированная реклама • Контекстная реклама • SMM
СертификатОнлайн
БруноямSEO-специалист
4 недели • По факту набора потока
Поисковая оптимизация • Раскрутка сайтов • HTML • SEO-аудит сайтов • Яндекс.Метрика • Google Analytics
СертификатСанкт-Петербург
Как данные улучшают обучение и преподавание
Если вы хотите, чтобы обучение было эффективным, вы должны использовать несколько проверенных и надежных методов, которые исследуются в рамках доказательного образования. В этой статье мы углубимся в эту область вместе с Дмитрием Аббакумовым, руководителем Центра психометрии и образовательной аналитики Яндекс Практикума, и экспертами из ИТМО, которые рассказали о доказательном образовании на «Еще одной конференции Яндекса по образованию».
Подобно доказательной медицине, которая отдает предпочтение экспериментально проверенным методам лечения, основанное на доказательствах образование полностью опирается на исследования при разработке образовательных программ или новых методов обучения. Дмитрий Аббакумов считает, что такой подход к обучению гарантирует использование педагогами тех приемов и инструментов, которые помогут их ученикам достичь желаемых результатов. Согласно исследованию, описанному в Teaching Today. В практическом руководстве Джеффа Петти и «Видимое обучение» Джона Хэтти подход, основанный на фактических данных, по сравнению с более традиционным подходом коррелирует с более высокими оценками и лучшими способностями к обучению.
Хотя может показаться, что обучение, основанное на фактических данных, является недавним изобретением, на самом деле его основа была заложена более 100 лет назад американским психологом Луи Терстоном , который придумал уравнение кривой обучения. Придуманная в 1919 году кривая обучения описывает, как навыки человека в определенной задаче меняются со временем или в зависимости от его опыта. Эта концепция все еще используется сегодня, например, в системах адаптивного обучения, где образовательный контент подбирается вручную для каждого отдельного учащегося.
Придуманная в 1919 году кривая обучения описывает, как навыки человека в определенной задаче меняются со временем или в зависимости от его опыта. Эта концепция все еще используется сегодня, например, в системах адаптивного обучения, где образовательный контент подбирается вручную для каждого отдельного учащегося.
Впервые в России это направление было введено психологом Александром Нечаевым , основателем экспериментальной педагогики в 1910-1930-х годах. Его интересовало, как учатся школьники с разными способностями, каких результатов они достигают, как их можно эффективно обучать.
Обучение на основе фактических данных состоит из трех ключевых компонентов: качественные данные, надежные статистические модели (со значениями, максимально приближенными к реальной жизни) и прозрачность предлагаемых данных и моделей для учителей и учащихся.
В процессе обучения всем нам приходится сталкиваться с трудностями, которые могут быть случайными или систематическими. Первые больше связаны с каждым отдельным случаем и могут быть исправлены обратной связью со студентами, но в случае систематических проблем нам необходимо рассмотреть вопрос об изменении всего подхода к обучению.
Первые больше связаны с каждым отдельным случаем и могут быть исправлены обратной связью со студентами, но в случае систематических проблем нам необходимо рассмотреть вопрос об изменении всего подхода к обучению.
Один из наиболее распространенных методов решения систематических проблем в наши дни основан на обзорах образовательного курса или программы. Например, если методисты замечают, что учащиеся продолжают делать ошибки при решении той или иной задачи, ответ может состоять в том, чтобы упростить задачу или добавить примечания, подсказки и примеры. Однако этот метод работает только после того, как проблемы разрослись до такой степени, что их нельзя игнорировать, в то время как более эффективным способом было бы выявление потенциальных проблем на ранних этапах реализации курса или программы.
Что произойдет, если мы рассмотрим содержание курса как связанные элементы и предположим, что учащиеся сталкиваются с трудностями при выполнении одного задания, потому что они не получили то, что изучали ранее? Чтобы ответить на этот вопрос, психолог Саша Эпскамп придумал психометрическую сеть, которая помогает исследователям анализировать связи между процессами в академических и психологических системах.
вводная лекция по сетевой психометрии Саши Эпскамп
В психометрии два типа задач называются «связанными»: те, которые проверяют ключевой навык, и те, которые проверяют основную концепцию. Задания на ключевые навыки довольно сложны для большинства учащихся, и ошибки в этих заданиях вызывают ошибки у других. И наоборот, базовые концептуальные задания даются большинству учащихся легко, но тем, кто допускает в них ошибки, скорее всего, будет трудно выполнять и другие задания. Эти два типа заданий являются основой обучения, и, обращая на них внимание, мы можем предотвратить дальнейшие трудности в учебном процессе.
В настоящее время специалисты Яндекса работают над новым инструментом для онлайн-симуляторов программирования на основе модели Epskamp. Таким образом, они могут анализировать комбинацию попыток одного учащегося, а также количество времени, затраченное на одно решение, эффективность этого решения и многое другое. С помощью модели эксперты планируют улучшить образовательный контент, обратную связь и поддержку, оказываемую студентам, а также системы рекомендаций по доработке.
В Университете ИТМО специалисты по учебной аналитике собирают данные, на основе которых принимаются различные управленческие решения в так называемом data-driven подходе к образованию: опираясь на фактические данные и аналитику в управлении образовательными программами и оценивая эффективность и статистическую достоверность задействованных решения.
Святослав Орешин , руководитель Центра учебной аналитики Университета ИТМО, говорит:
«Алгоритм принятия решения у нас такой: допустим, к нам поступил запрос об отчислении студентов с какой-то программы.
 Во-первых, нам придется подтвердить или опровергнуть эту гипотезу, используя имеющиеся у нас данные, потому что, если мы этого не сделаем, это будет сродни принятию решений с завязанными глазами. Наша главная цель — сохранить фокус на исходной проблеме и глобальных задачах Университета ИТМО с учетом фактов. Для этого нам необходимо установить систему метрик и OKR (цели и ключевые результаты), связанные с нашей задачей — если мы будем анализировать каждый бит данных, с которыми сталкиваемся, мы можем получить практически любые результаты. Вот почему нам нужно сохранять объективность и не только выявлять факторы проблемы, но и оценивать существующие решения и их вклад в цели университета. В противном случае, как говорится, «без данных вы просто еще один человек со своим мнением».
Во-первых, нам придется подтвердить или опровергнуть эту гипотезу, используя имеющиеся у нас данные, потому что, если мы этого не сделаем, это будет сродни принятию решений с завязанными глазами. Наша главная цель — сохранить фокус на исходной проблеме и глобальных задачах Университета ИТМО с учетом фактов. Для этого нам необходимо установить систему метрик и OKR (цели и ключевые результаты), связанные с нашей задачей — если мы будем анализировать каждый бит данных, с которыми сталкиваемся, мы можем получить практически любые результаты. Вот почему нам нужно сохранять объективность и не только выявлять факторы проблемы, но и оценивать существующие решения и их вклад в цели университета. В противном случае, как говорится, «без данных вы просто еще один человек со своим мнением». Среди проектов центра — ИТМО.ОБЪЕКТИВ, предоставляющий решения компьютерного зрения для умного кампуса и реализующий концепцию университета, управляемого данными. Еще одна выдающаяся инициатива — ITMO. TRACK, которая дает каждому студенту возможность построить свою индивидуальную траекторию обучения, сочетая фундаментальный подход университетского образования и edtech-подход, используемый коммерческими компаниями (Skillbox, Яндекс Практикум и др.).
TRACK, которая дает каждому студенту возможность построить свою индивидуальную траекторию обучения, сочетая фундаментальный подход университетского образования и edtech-подход, используемый коммерческими компаниями (Skillbox, Яндекс Практикум и др.).
«ITMO.TRACK состоит из ряда моделей машинного обучения и алгоритмов искусственного интеллекта, которые помогают нам переводить интересы и карьерные устремления студентов на язык курсов и образовательных программ. Таким образом, мы можем построить учебные траектории на основе максимальной совместимости между курсами и навыками, желаемыми студентом. Помимо разработки сопутствующих алгоритмов и пользовательского интерфейса, мы систематизировали данные об учебном процессе и разметили доступные курсы», — добавляет Святослав Орешин.
В Университете ИТМО данные собираются на разных уровнях: от всего университета до факультета, программы, курса или даже отдельного класса. Среди всей собираемой информации есть субъективные данные, полученные в результате опросов выпускников, и ее субъективность и невоспроизводимость являются ее основными недостатками. Поэтому специалисты Центра образовательной аналитики предпочитают опираться на более объективные данные, полученные через университетскую информационную систему ИСУ, которая содержит сведения о студентах, преподавателях, переводах, реадмиссиях, академических отпусках, отчислениях и других процедурах. Благодаря этим данным специалисты могут строить цифровые представления участников учебного процесса, которые по сути являются динамическими векторами, описываемыми сотнями различных признаков. Этот метод облегчает проверку гипотез, а также процесс обучения и внедрения моделей машинного обучения.
Среди всей собираемой информации есть субъективные данные, полученные в результате опросов выпускников, и ее субъективность и невоспроизводимость являются ее основными недостатками. Поэтому специалисты Центра образовательной аналитики предпочитают опираться на более объективные данные, полученные через университетскую информационную систему ИСУ, которая содержит сведения о студентах, преподавателях, переводах, реадмиссиях, академических отпусках, отчислениях и других процедурах. Благодаря этим данным специалисты могут строить цифровые представления участников учебного процесса, которые по сути являются динамическими векторами, описываемыми сотнями различных признаков. Этот метод облегчает проверку гипотез, а также процесс обучения и внедрения моделей машинного обучения.
Наверх
Регрессия CatBoost за 6 минут. Краткое практическое введение в… | Саймон Тизен
Краткое практическое введение в регрессионный анализ CatBoost в Python
Фото Маркуса Списке на Unsplash -Kit Узнать библиотеку.
- Введение в CatBoost
- Приложение
- Заключительные замечания
CatBoost — это относительно новый алгоритм машинного обучения с открытым исходным кодом, разработанный в 2017 году компанией Яндекс. Яндекс — российский аналог Google, работающий в рамках поисковых и информационных сервисов [1].
Одним из основных преимуществ CatBoost является его способность интегрировать различные типы данных, такие как изображения, аудио или текстовые функции, в одну структуру. Но CatBoost также предлагает своеобразный способ обработки категориальных данных, требующий минимального преобразования категориальных признаков, в отличие от большинства других алгоритмов машинного обучения, которые не могут обрабатывать нечисловые значения. С точки зрения разработки функций преобразование нечислового состояния в числовые значения может быть очень нетривиальной и утомительной задачей, и CatBoost делает этот шаг устаревшим.
CatBoost основан на теории деревьев решений и повышения градиента. Основная идея бустинга состоит в том, чтобы последовательно объединить множество слабых моделей (модель работает немного лучше, чем случайный случай) и, таким образом, с помощью жадного поиска создать сильную конкурентную прогностическую модель. Поскольку повышение градиента соответствует деревьям решений последовательно, подобранные деревья будут учиться на ошибках прежних деревьев и, следовательно, уменьшать ошибки. Этот процесс добавления новой функции к существующим продолжается до тех пор, пока выбранная функция потерь не перестанет быть минимизированной.
Основная идея бустинга состоит в том, чтобы последовательно объединить множество слабых моделей (модель работает немного лучше, чем случайный случай) и, таким образом, с помощью жадного поиска создать сильную конкурентную прогностическую модель. Поскольку повышение градиента соответствует деревьям решений последовательно, подобранные деревья будут учиться на ошибках прежних деревьев и, следовательно, уменьшать ошибки. Этот процесс добавления новой функции к существующим продолжается до тех пор, пока выбранная функция потерь не перестанет быть минимизированной.
В процедуре выращивания деревьев решений CatBoost не следует аналогичным моделям повышения градиента. Вместо этого CatBoost выращивает забывчивые деревья, что означает, что деревья выращиваются путем наложения правила, согласно которому все узлы на одном уровне проверяют один и тот же предиктор с одним и тем же условием, и, следовательно, индекс листа можно вычислить с помощью побитовых операций. Процедура забывчивого дерева позволяет использовать простую схему подгонки и эффективность на ЦП, в то время как древовидная структура работает как регуляризация, чтобы найти оптимальное решение и избежать переобучения.
Скорость обучения, Яндекс [2]Сравнительная вычислительная эффективность:
Google Trends (2021) [3]Согласно тенденциям Google, CatBoost все еще остается относительно неизвестным с точки зрения поисковой популярности по сравнению с гораздо более популярным алгоритмом XGBoost.
CatBoost до сих пор остается довольно неизвестным, но алгоритм предлагает огромную гибкость благодаря своему подходу к обработке разнородных, разреженных и категориальных данных, при этом поддерживая быстрое время обучения и уже оптимизированные гиперпараметры.
Цель этого руководства — предоставить практический опыт регрессии CatBoost в Python. В этом простом упражнении мы будем использовать набор данных Boston Housing для прогнозирования цен на жилье в Бостоне. Но прикладная логика к этим данным применима и к более сложным наборам данных.
Итак, приступим.
Во-первых, нам нужно импортировать необходимые библиотеки вместе с набором данных:
импортировать catboost как cb
импортировать numpy как np
импортировать pandas как pd
импортировать seaborn как sns
Import Shap
Import Load_boston
из Matplotlib Import Pyplot как pltfrom sklearn.
от Sklearn.model_selection import_test_split
от Sklearn.metrics import_squared_error
от Sklearn.metrics r2.sment.mpormon r2.smormon r2.smormon r2.sporemon raister.mportemon raister.mportemon raister.mportemon. pd.DataFrame(boston.data, columns=boston.feature_names)
 datasets
datasets Исследование данных
Всегда считается хорошей практикой проверять любые значения Na в вашем наборе данных, так как это может запутать или, в худшем случае, снизить производительность алгоритма. .
boston.isnull().sum()
Однако этот набор данных не содержит Na.
Этап исследования данных и разработки функций является одним из наиболее важных (и трудоемких) этапов при создании проектов по науке о данных. Но в данном контексте основной упор делается на внедрение алгоритма CatBoost. Следовательно, если вы хотите глубже погрузиться в описательный анализ, посетите EDA и прогноз стоимости дома в Бостоне [4].
Обучение
Далее нам нужно разделить наши данные на 80% обучающих и 20% тестовых наборов.
Целевой переменной является «MEDV» — медианная стоимость домов, занимаемых владельцами, в 1000 долларов.
X, y = load_boston(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=5)
Чтобы обучить и оптимизировать нашу модель, нам нужно использовать CatBoost интегрированный в библиотеку инструмент для объединения функций и целевых переменных в набор данных для обучения и тестирования. Это объединение позволяет вам точно определить целевые переменные, предикторы и список категориальных признаков, в то время как конструктор пула объединит эти входные данные и передаст их в модель.
train_dataset = cb.Pool(X_train, y_train)
test_dataset = cb.Pool(X_test, y_test)
Далее мы представим нашу модель.
model = cb.CatBoostRegressor(loss_function='RMSE')
Мы будем использовать показатель RMSE в качестве нашей функции потерь, потому что это задача регрессии.
В ситуациях, когда алгоритмы адаптированы к конкретным задачам, может помочь настройка параметров. Библиотека CatBoost предлагает гибкий интерфейс для встроенных методов поиска по сетке, и если вы уже знакомы с функцией поиска по сетке Sci-Kit, вы также будете знакомы с этой процедурой.
Библиотека CatBoost предлагает гибкий интерфейс для встроенных методов поиска по сетке, и если вы уже знакомы с функцией поиска по сетке Sci-Kit, вы также будете знакомы с этой процедурой.
В этом руководстве будут включены только наиболее распространенные параметры. Эти параметры включают количество итераций, скорость обучения, регуляризацию листьев L2 и глубину дерева. Если вы хотите узнать больше о возможностях настройки гиперпараметров, ознакомьтесь с документацией CatBoost здесь.
сетка = {'итерации': [100, 150, 200],
'learning_rate': [0,03, 0,1],
'глубина': [2, 4, 6, 8],
'l2_leaf_reg': [0,2 , 0.5, 1, 3]}model.grid_search(grid, train_dataset) Оценка производительности
Теперь мы выполнили обучение нашей модели и, наконец, можем перейти к оценке тестовых данных.
Посмотрим, как работает модель.
pred = model.predict(X_test)Производительность теста
rmse = (np.sqrt(mean_squared_error(y_test, pred)))
r2 = r2_score(y_test, pred)print("Производительность тестирования")
print('RMSE: {: .
print('R2: {:.2f}'.format(r2))
 2f}'.format(rmse))
2f}'.format(rmse)) Как показано выше, мы получаем R-квадрат 90% на нашем тестовом наборе, который неплохо, учитывая минимальную разработку функций.
С точки зрения логических выводов, CatBoost также предлагает возможность извлекать графики переменной важности. Следовательно, график важности переменных может выявить основные структуры данных, которые могут быть невидимы человеческому глазу.
В этом примере мы сортируем массив в порядке возрастания и строим горизонтальную гистограмму функций с наименее важными функциями внизу и наиболее важными функциями вверху графика.
sorted_feature_importance = model.feature_importances_.argsort()
plt.barh(boston.feature_names[sorted_feature_importance],
model.feature_importances_[sorted_feature_importance],
color='turquoise')
plt.xost90 Feature1")3 plt.xost90 Import1") График переменной важностиСогласно иллюстрации, перечисленные выше признаки содержат ценную информацию для прогнозирования цен на жилье в Бостоне.
Графики SHAPLEY Additive ExPlanations (SHAP) также являются удобным инструментом для объяснения результатов нашей модели машинного обучения путем присвоения значения важности каждой функции для данного прогноза. Значения SHAP позволяют интерпретировать, какие функции определяют прогноз нашей целевой переменной.
объяснитель = shap.TreeExplainer(модель)График SHAP
shap_values = объяснение.shap_values(X_test)shap.summary_plot(shap_values, X_test, feature_names = boston.feature_names[sorted_feature_importance])На графике SHAP объекты ранжируются на основе их среднего абсолютного значения SHAP, а цвета представляют значение объекта (красный высокий, синий низкий). Чем выше значение SHAP, тем выше атрибуция предиктора. Другими словами, значения SHAP отражают ответственность предсказателя за изменение выходных данных модели, т.
 Наиболее влиятельными переменными являются среднее количество комнат в жилище (RM) и процент населения с более низким статусом (LSTAT).
Наиболее влиятельными переменными являются среднее количество комнат в жилище (RM) и процент населения с более низким статусом (LSTAT).