
Robots и теги X-Robots
Существуют две директивы, которым сканеры поисковых систем выполняют команды перед сканированием и индексированием. Это Robots.txt и метатег Robots. В котором robots.txt помогает разрешить или запретить веб-страницы или веб-сайты для каждого поискового робота.
Напротив, метатег robots дает команду сканеру индексировать или исключать из индексации, передавая вес ссылки.
Давайте приступим к изучению полной концепции тега robots и HTTP-заголовка X-Robots-tag.
Что такое метатег роботов?
Тег robots — это код мета-директивы, присутствующий в разделе заголовка (…) HTML-файла любой веб-страницы. Этот HTML-код помогает поисковым роботам либо индексировать, либо не индексировать веб-страницу.
Мета-директивы предоставляют сканерам набор инструкций о том, как и что сканировать и индексировать. Любой веб-сайт или веб-страницы без этих директив, вероятно, будут проиндексированы или закончатся нежелательными страницами индексации.
В нем также есть дополнительные директивы, которыми мы поделимся в другом разделе. И robots.txt, и метатег robots играют роль в управлении работой поисковых роботов, но оба они конфликтуют друг с другом в процессе.
При этом robots.txt – это файл, который должен быть включен в базовый файл веб-сайта, он должен содержать директивы и XML-карту сайта. Напротив, тег robots — это просто фрагмент HTML-кода.
В HTML-файле выглядит следующим образом:
Существует два типа метадиректив Robots. Один из них — метатег robots, а другой — тег X-Robots в HTTP-заголовке веб-сервера.
Почему метатег Robots используется в SEO?
HTML-теги robots используются для включения или исключения веб-страниц из индексации поисковыми системами.
Вот важные роли, которые метатеги роботов помогают предотвратить индексацию веб-страниц
- Исключение веб-сайта из индексации в тестовой среде.

- Тонкие страницы или страницы-дубликаты
- Страницы администратора и входа.
- Добавить в корзину, инициировать оформление заказа и страницу благодарности.
- Целевые страницы, которые используются для кампаний PPC.
- Поиск по страницам сайта.
- Рекламные страницы, страницы конкурса или запуска продукта.
- Внутренние веб-страницы и веб-страницы с конфиденциальными данными.
- Категория, тэг веб-страниц.
- Кэшированные веб-страницы.

Вы должны полностью понимать концепцию атрибутов, директив и фрагментов кода, чтобы давать указания сканерам в соответствии с рекомендациями для веб-мастеров.
Что такое тег X-Robots?
Мета-тег robots позволяет сканерам контролировать индексацию/неиндексацию веб-страницы, но x-robots-tag может препятствовать индексации всего веб-сайта или части веб-страниц, поскольку он присутствует в HTTP-заголовке сервера. файл.
Теги X-robot обычно доступны в файлах сервера, файлах header. php или .htaccess.
php или .htaccess.
Оба тега robots и x-robots-tag используют одни и те же директивы, такие как index, noindex, follow, nofollow, nosnippet, noimageindex, imageindex и т. д. По сравнению с метатегами x-robots имеют более специфические и гибкие функции.
X-роботы могут выполнять директивы обхода файлов, отличных от HTML, поскольку они используют регулярные выражения с глобальными параметрами.
Рассмотрите возможность использования тега x robots в следующих условиях:
- Вы хотите запретить индексирование изображений, видео или PDF-файлов на странице, а не самой веб-страницы.
- Для индексации или исключения из индексации любого файла веб-страницы, отличного от кодов HTML.
- Если у вас нет доступа для редактирования или модерации заголовка HTML-файла, вы можете получить доступ к тегу X-Robots с сервера, чтобы включить директивы.
Набор заголовков X-Robots-Tag "noindex, follow"
Директивы метатегов роботов:
Чтобы лучше понять директивы, давайте еще раз посмотрим на структуру метатега robots.
Здесь у вас есть два атрибута, и все используемые директивы должны быть указаны под этими двумя атрибутами.
- Имя.
- Содержание.
Атрибуты имени:
Команда общего доступа к атрибутам имени, для которого или какого поискового робота применяются следующие HTML-коды тега robots. Он действует так же, как пользовательский агент в файле robots.txt.
name=»robots» -Эта команда предназначена для всех поисковых роботов, обращающихся к веб-странице.
name = «Googlebot» — Команда предназначена только для робота Googlebot.
Большинство экспертов по поисковой оптимизации обычно используют директиву robots в атрибутах Name, которые применяются метатегом и контролируют все поисковые роботы.
Код может состоять из нескольких строк, если атрибуты имени используются для определенных поисковых роботов или пользовательских агентов.
Вот наиболее распространенные атрибуты имени или пользовательские агенты, используемые во всем мире.
Роботы -> Все поисковые роботы
Googlebot -> Поисковые роботы Google для настольных компьютеров
Новый робот Google -> Поисковые роботы Google News
Googlebot-images
901 25 смартфон Googlebot-mobile -> Google-бот для мобильных устройств
Adsbot-Google -> Google Ads Bot for Desktop
Adsbot-Google-mobile -> Google Ads Bot for mobile
Mediapartners-Google -> Adsense Bot
Googlebot-Video -> Google Bot for videos
BingBot -> Поисковые роботы Bing для компьютеров и мобильных устройств
MSNBot-Media -> Бот Bing для сканирования изображений и видео.
Baiduspider -> Поисковые роботы Baidu для компьютеров и мобильных устройств.
Slurp -> Yahoo Crawlers
DuckDuckBot -> DuckDuckGo Crawlers
Атрибуты содержимого:
Атрибуты содержимого — это команда, дающая указание программе-обходчику, упомянутой в атрибутах имени.
Было бы полезно, если бы вы плохо понимали различные директивы тегов роботов, чтобы следовать идеальной стратегии SEO. Значение по умолчанию в соответствии с метатегом robots — «индексировать, следовать».
Вот наиболее часто используемые директивы в атрибутах содержимого.
все -> Это то же самое, что и настройка по умолчанию для команды index, follow (можно использовать как ярлык)
нет -> Ярлык для noindex, nofollow
index -> Команды для указатель веб-страница
noindex -> Дайте указание имени (пользовательскому агенту) исключить веб-страницу из сканирования.
следовать -> Помогает поисковым роботам обнаруживать новые веб-страницы, на которые есть ссылки, и передавать ссылочный вес.
nofollow -> Блокирует поиск новых веб-страниц и ссылочного веса поисковых роботов.
nosnippet -> Эта команда исключает метаописание и другие расширенные результаты, видимые в поисковой выдаче.
noimageindex -> Указывает поисковым роботам не индексировать изображения на веб-странице.
noarchive -> Не показывать кешированную версию страницы в поисковой выдаче
nocache -> то же, что и noarchive, но используется только для MSN.
notranslate -> Указывает сканерам не отображать переведенную версию веб-страницы в SERP (странице результатов поисковой системы).
nositelinkssearchbox -> Эта команда не позволяет отображать окно поиска сайта в поисковой выдаче.
nopagereadaloud -> Исключает сканеры, которые не читают веб-страницу во время голосового поиска.
unavailable_after
Noodyp/noydir -> С помощью этого тега поисковые системы не могут использовать описание DMOZ в качестве фрагмента SERP
Вы можете просмотреть полный список всех директив, поддерживаемых Google и Bing.
Мета-роботы Примеры тегов:
Вот примеры метатегов robots, которые могут улучшить методы поисковой оптимизации.
1. Индексируйте и переходите по ссылкам на другие страницы:
или
2. Проиндексируйте, но не разрешайте переходить по ссылке:
3. Не индексировать и не разрешать переходить по ссылке:
или
4. Не индексировать, но разрешить переход по ссылке на другие страницы:
Роль сниппетов и директив в метатеге Robots:
Тег robots предназначен не только для управления индексацией и позволяет поисковым роботам переходить по ссылке. Это также помогает поддерживать видимость сниппетов в поисковой выдаче.
Это также помогает поддерживать видимость сниппетов в поисковой выдаче.
Вот наиболее распространенные директивы сниппета, используемые в метатеге robots.
nosnippet -> Указывает на исключение отображения фрагментов или метаописаний в поисковой выдаче.
max-snippet:[number] -> Этот фрагмент помогает контролировать максимальное количество символов, которое может содержать фрагмент.
max-video-preview:[число]
max-image-preview[setting] -> Фрагмент кода указывает указать максимальный размер предварительного просмотра изображения: «нет», «стандартный» или «большой».
Как использовать директивы сниппета в метатеге robots?1. Не показывать фрагменты веб-страницы в поисковой выдаче:
2.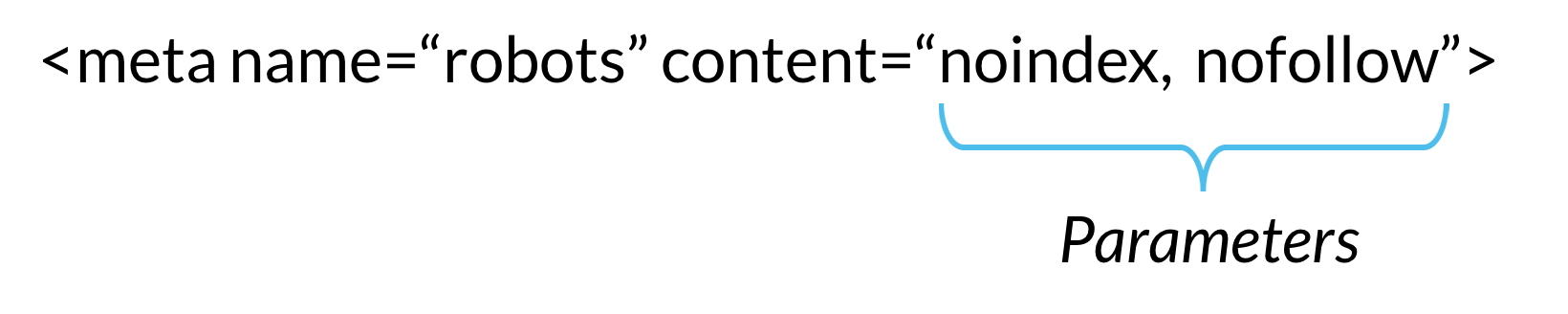 Установить максимальное количество символов в описании веб-страница:
Установить максимальное количество символов в описании веб-страница:
3. Установите размер изображения и просмотрите его в поисковой выдаче:
Размер изображения может быть нулевым, стандартным или большим
4. Установите продолжительность в секундах и видимость видео в поисковой выдаче.
5. Использование всех фрагментов в одном коде:
Используйте запятые для разделения каждого фрагмента при объединении каждого фрагмента в один код.
Передовые методы оптимизации роботов Метатег:
Сканирование и индексирование играют огромную роль в том, чтобы сделать ваш контент видимым в поисковой выдаче, это цель каждого эксперта по SEO. При работе с огромным веб-сайтом краулинговый бюджет играет роль в индексации потенциальных веб-страниц.
При работе с огромным веб-сайтом краулинговый бюджет играет роль в индексации потенциальных веб-страниц.
Тег robots играет огромную роль в управлении сканированием, и вот несколько советов, которые вам понадобятся для оптимизации метатега robots, который не повредит сканированию и индексированию.
Никогда не добавляйте директивы тегов Robots на веб-страницы, заблокированные файлом Robots.txt
Если какая-либо страница запрещена в файле robots.txt, поисковые системы обычно исключают веб-страницы из сканирования. Одновременно сканеры также читают директивы веб-страниц, указанные в метатеге robots и теге X-robots.
Убедитесь, что директивы тегов robots не указывают индексировать веб-страницу. Поскольку он отключает директивы, указанные в robots.txt.
Поэтому мы рекомендуем никогда не добавлять на веб-страницу какие-либо директивы метатегов robots, которые заблокированы файлом robots.txt
Никогда не используйте директивы тегов Meta Robots в Robots.
 txt:
txt:В 2019 году Google официально объявил, что никогда не поддерживает директивы тегов роботов, такие как index, noindex, follow и nofollow в robots.txt.
Поэтому не включайте эти директивы в файл robots.txt.
Никогда не блокировать весь сайт от блокировки:
Когда сайт перемещается на действующий сервер, директивы robots могут быть случайно оставлены на месте при использовании в промежуточной среде.
Прежде чем перемещать сайт из промежуточной среды в реальную среду, убедитесь, что все директивы для роботов верны.
Аналогичным образом можно случайно исключить весь сайт из индексации с помощью директив noindex в теге x-robots или метатеге robots.
Никогда не удалять страницы с директивой Noindex из файлов Sitemap:
@nishanthstephen обычно все, что вы добавляете в карту сайта, будет получено раньше
— Гэри 鯨理/경리 Illyes (@methode) 13 октября 2015 г.
Когда веб-страница помечена как директива noindex , никогда не удаляйте ее сразу из карты сайта.
Поскольку веб-страницы в карте сайта XML будут иметь высокий приоритет при сканировании и выполнении инструкций тега robots.
Таким образом, удаление веб-страницы из XML-карты сайта до ее деиндексации может продлить процесс.
Заключение:
МетатегRobots играет огромную роль в указании любой веб-странице индексировать, не индексировать, следовать или nofollow относительно ссылочного веса между веб-страницами.
Как SEO-эксперт или SEO-компания, вы должны четко понимать плюсы и минусы метатега robots.
В метатегах роботов обнаружен Noindex — решение проблемы
Вы когда-нибудь сталкивались с термином «noindex» в метатегах роботов и задавались вопросом, что он означает? Если это так, вы находитесь в правильном месте! Правильная индексация вашего веб-сайта необходима для поисковой оптимизации (SEO), поскольку она помогает поисковым системам понимать и ранжировать ваш контент.
В этом подробном руководстве мы углубимся в мир метатегов noindex и robots, чтобы помочь вам понять и исправить любые проблемы, которые могут повлиять на видимость вашего веб-сайта в поисковых системах.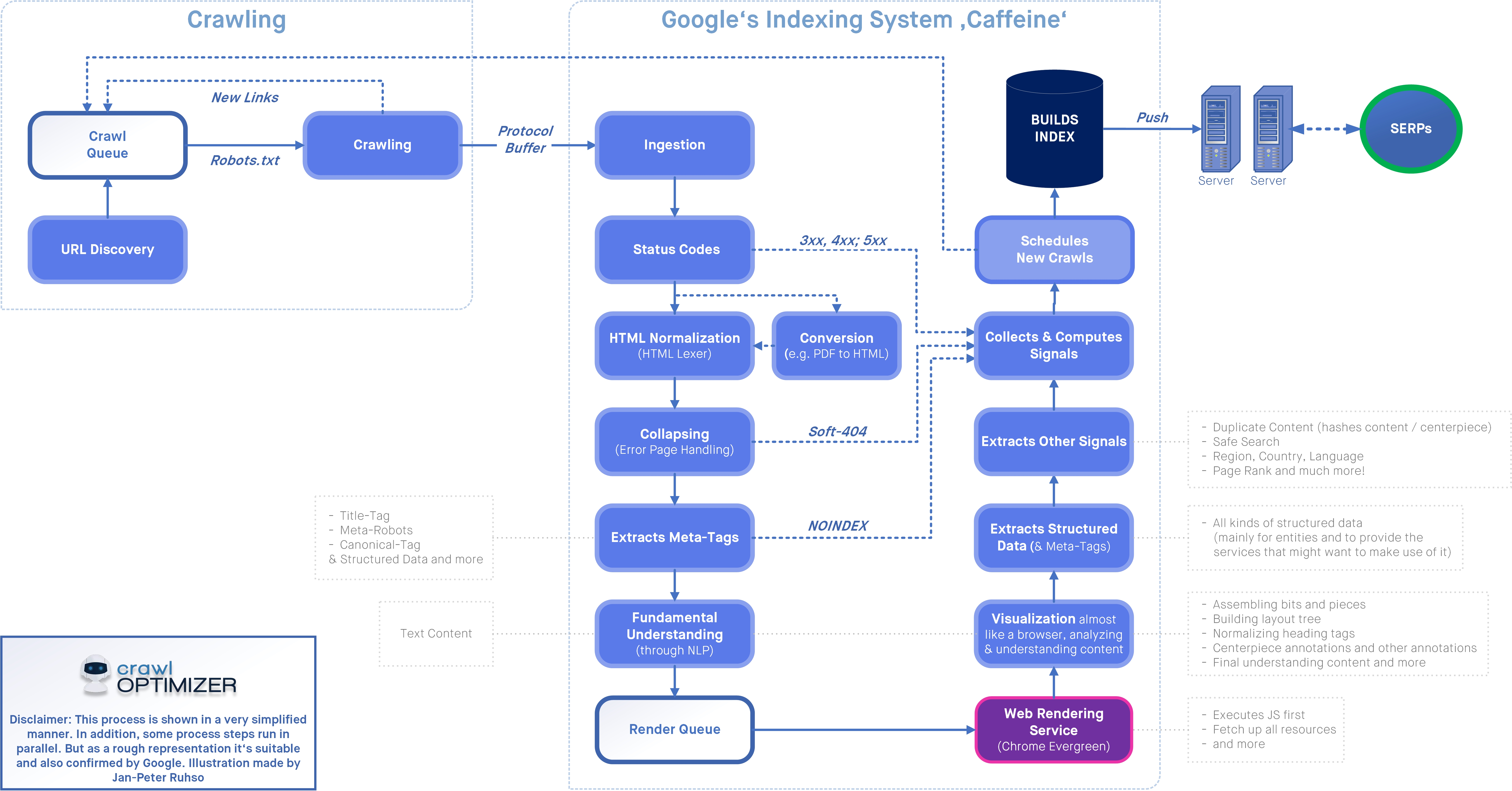
Понимание метатегов Noindex и Robots
Noindex — это директива, используемая в метатегах robots, чтобы запретить поисковым роботам индексировать определенные страницы на вашем веб-сайте. Это может быть полезно, если вы хотите скрыть определенный контент от результатов поиска. Метатеги robots — это фрагменты кода, размещенные в разделе заголовка веб-страницы, которые предоставляют поисковым роботам инструкции о том, как обрабатывать контент.
Сканеры поисковых систем, такие как Googlebot, переходят по ссылкам в Интернете для обнаружения и индексации веб-страниц. Когда они сталкиваются со страницей с тегом noindex, они пропускают ее индексацию, эффективно предотвращая ее появление в результатах поиска. Обнаружение проблем с отсутствием индекса и их частых причин
[图片]
Теги Noindex могут быть обнаружены на вашем сайте по разным причинам. Иногда они размещаются намеренно, чтобы определенные страницы, такие как области администрирования, экраны входа в систему или дублированный контент, были скрыты от результатов поиска. Однако они также могут быть добавлены непреднамеренно во время разработки или обновления веб-сайта.
Однако они также могут быть добавлены непреднамеренно во время разработки или обновления веб-сайта.
Еще одна причина, по которой вы можете обнаружить теги noindex на своем сайте, связана со сторонними плагинами и темами, которые могут автоматически добавлять их на определенные страницы. Системы управления контентом, такие как WordPress, также могут вводить теги noindex во время обновлений или в результате определенных настроек. Наконец, неправильные директивы в вашем файле robots.txt также могут вызвать проблемы с отсутствием индекса.
Выявление проблем с отсутствием индекса на вашем сайте
Чтобы выявить проблемы с отсутствием индекса, вы можете использовать несколько методов. Google Search Console — отличный инструмент, предоставляющий отчеты об индексации, позволяющие увидеть, какие страницы были исключены из-за тегов noindex. Другой способ определить проблемы с отсутствием индекса — вручную проверить исходный код страницы. Это позволит вам найти метатег robots и проверить директивы noindex. Кроме того, инструменты SEO, такие как SEMrush, Ahrefs или SEO-GO, могут помочь в обнаружении проблем с отсутствием индекса на вашем веб-сайте.
Кроме того, инструменты SEO, такие как SEMrush, Ahrefs или SEO-GO, могут помочь в обнаружении проблем с отсутствием индекса на вашем веб-сайте.
Решение проблем с Noindex
[图片]
После того, как вы точно определили проблемы с Noindex, вы можете предпринять следующие шаги для их устранения:
- Отредактируйте HTML-код своего веб-сайта, чтобы удалить директиву noindex из метатега robots.
- Убедитесь, что ваш файл robots.txt не блокирует непреднамеренно индексацию ваших страниц поисковыми роботами.
- Проверьте настройки CMS на наличие параметров, которые могут вызвать проблемы с отсутствием индекса, и исправьте их.
- Определите и устраните любые конфликты, вызванные плагинами или темами, которые могут добавлять теги noindex.
Обеспечение правильной индексации
После устранения проблем с отсутствием индексации крайне важно убедиться, что ваш веб-сайт правильно индексируется. Вы можете сделать это, повторно отправив карту сайта вашего веб-сайта в Google Search Console, используя инструмент «Просмотреть как Google» или «Проверка URL», чтобы запросить повторное сканирование ваших страниц, и отслеживая статус индексации в Google Search Console.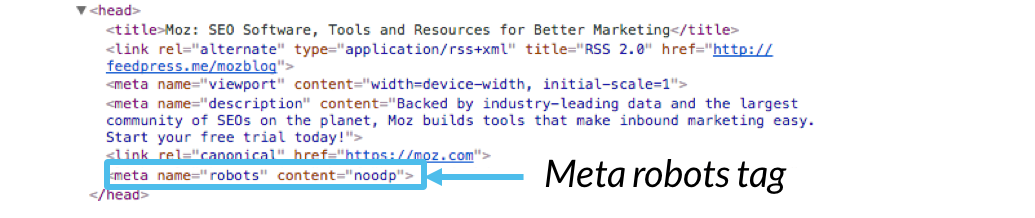
Внедрение рекомендаций по индексированию веб-сайтов
[图片]
Чтобы оптимизировать индексацию веб-сайта, следуйте приведенным ниже рекомендациям.0003
- Используйте теги noindex только для страниц, которые вы хотите исключить из результатов поиска, и теги index для страниц, которые поисковые системы должны сканировать и индексировать.
- Регулярно обновляйте карту сайта новыми и измененными страницами, чтобы помочь поисковым системам быстрее находить и индексировать ваш контент.
- Оптимизируйте свой краулинговый бюджет, уменьшив количество некачественных или нерелевантных страниц на своем веб-сайте, обеспечив эффективное использование ресурсов сканерами поисковых систем.
- Упростите для поисковых систем и пользователей навигацию по вашему веб-сайту, используя четкие структуры URL-адресов, логические внутренние ссылки и удобные меню навигации.
Заключительные мысли
Понимание важности метатегов noindex и robots имеет решающее значение для успеха SEO вашего сайта.