Noindex nofollow – что означают HTML теги, применение в статьях и ссылках
Автор Валентин На чтение 8 мин Просмотров 1.2к. Опубликовано
В оптимизации сайта и SEO огромную роль играют запрещающие директивы noindex nofollow, с помощью которых можно управлять поведением поисковых роботов на странице. Технология немного стала терять свою силу, но в статье разберем как пользоваться ноуиндекс и нофоллов, чтобы вебмастер понимал для чего они нужны и какую пользу несут в себе.
Содержание
- Что такое noindex и nofollow – их разница
- Как пользоваться noindex
- Ноуидекс в атрибуте robots на примере HTML кода для страницы
- Noindex для отдельных кусков кода или текста
- Как пользоваться nofollow
- Значение nofollow в атрибуте content
- Блокировка отдельных ссылок
- Применение noindex и nofollow вместе
- Disallow в robots и noindex – как с ними работать
- Как вставить noindex nofollow на разных CMS
- WordPress
- Opencart
- Bitrix
- Итог
Что такое noindex и nofollow – их разница
Для начала зададим определения, что это такое noindex и nofollow, чтобы понимать весь дальнейший процесс их постановки внутри кода.
Метатег noindex – запрещает к индексации (обходу) страницу целиком поисковыми системами либо отдельный участок. Простыми словами ноуиндекс запрещает брать в индекс участок документа либо всю ее, применяется для внутренней оптимизации.
Метатег nofollow – атрибут работающий только с ссылками, то есть тегом <a>, он запрещает переходить роботам ПС по URL и передавать при этом вес другой внутренней странице или внешнему сайту. В основном применяется для внешней оптимизации.
Разница у них огромная – первый регулирует сам документ, второй урлы и переходы по ним. Многие спрашивают про Noreferre и Noarchive, это тоже значения robos в meta, о них поговорим в других статьях.
Как пользоваться noindex
Сейчас noindex применяют в 3 видах, рассмотрим каждый из них и напишу какой из них самый действенный.
Ноуидекс в атрибуте robots на примере HTML кода для страницы
Стопроцентный метод закрыть что-то от индексации в SEO – это поставить noindex на всю страницу. Да гибкости меньше, потому что закрываем все или ничего. Но для удаления дублей и полностью ненужных документов метод идеален. Ниже показано как это выглядит в HTML общий для всех ботов любой поисковой системы.
Да гибкости меньше, потому что закрываем все или ничего. Но для удаления дублей и полностью ненужных документов метод идеален. Ниже показано как это выглядит в HTML общий для всех ботов любой поисковой системы.
<meta name="robots" content="noindex"/>Исходный HTML
Для разных ботов необходимо указывать его имя, например для Гугла это googlebot, а для Яндекса YandexBot, так выглядит строка. Инструкция должна быть вставлена строго внутри раздела head, чем выше к начал тем лучше.
<meta name="googlebot" content="noindex"/>
Соответственно если хотим наоборот открыть доступ роботам ПС, то меняем команду на index.
Noindex для отдельных кусков кода или текста
Если хотим закрыть от индексирования только часть страницы, чтобы она вырезалась из обхода роботом. То есть тот кусок который будет обернут в ноуиндекс будет невидим для поисковика. Выглядит комбинация так:
<!--noindex-->Кусок кода или текста<!--/noindex--> или <noindex>Раздел сайта для блокировки</noindex>
Но сейчас данные приемы работают 50 на 50, причем с очень не стабильной статистикой. Например, поместили информацию об авторе в noindex в сайдбаре, данный блок может на одной странице вырезан из обхода, а на другой взят в поиск. Поэтому данную технологию применяют для исключения блоков, которые просто желательно убирать.
Например, поместили информацию об авторе в noindex в сайдбаре, данный блок может на одной странице вырезан из обхода, а на другой взят в поиск. Поэтому данную технологию применяют для исключения блоков, которые просто желательно убирать.
Многие помещают блоки контекстной рекламы в noindex – доказано множеством специалистов, что это никак не действует на SEO, а даже усугубляет. Потому что предпринимаются попытки манипуляцией роботов, что идет во вред блогу.
Как пользоваться nofollow
У nofollow в основном другое предназначение – это работа с ссылками, но его команды в robots так же действуют. Рассмотрим все комбинации применения ноуфолов.
Значение nofollow в атрибуте content
Код означает, что переходить по всем ссылкам на странице запрещено по внешним и внутренним одинаково. Методом блокируем переход только роботам, пользователь может перейти беспрепятственно.
<meta name="robots" content="nofollow"/>
Аналогично можно регулировать поведение по видам роботов по ПС, например для Yandex.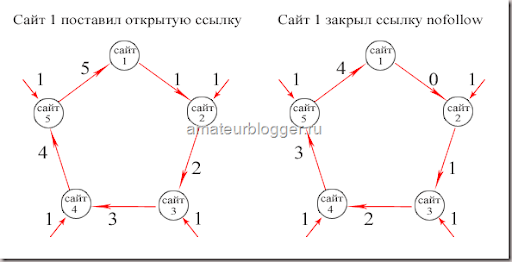 Если подставим follow, то даем разрешение на сканирование, в этом случае можно ничего не прописывать.
Если подставим follow, то даем разрешение на сканирование, в этом случае можно ничего не прописывать.
<meta name="yandexbot" content="nofollow"/>
Блокировка отдельных ссылок
У nofollow нет механизма закрытия кусков страницы, это не логично, поэтому есть механизм блокировки отдельных ссылок.
<a href="seodesc.ru/author" rel="nofollow">анкор</a>
Способ не дает 100%, что робот не перейдет по ссылке, потому что сейчас данный атрибут является частичной рекомендацией, но для усиления и намека на то что этот урл служебный – комбинация подойдет.
Будет ли работать nofollow для внутренних ссылок и необходимо ли это делать? Да, для служебных страниц, особенно сквозные адреса (корзина, регистрация, вход), советую проставлять его, чтобы исключить их из режима обхода.
Идет ли передача веса в ссылках с nofollow? Минимальное количество ссылок не даст плохого эффекта и передачи веса страницы не будет.
Но в разрезе всего сайта, если много документов будет ссылаться на один и тот же адрес, то соответственно вес будет утекать.
 Но в разрезе всего сайта, если много документов будет ссылаться на один и тот же адрес, то соответственно вес будет утекать.
Но в разрезе всего сайта, если много документов будет ссылаться на один и тот же адрес, то соответственно вес будет утекать.Для SMM продвижения и продажи dofollow ссылок – nofollow не пользуются, потому что в первом случае трафик идет из соцсетей, а второй направлен на продажу, правилами запрещено ставить нофолоу.
Применение noindex и nofollow вместе
Употреблять их вместе можно только в теге meta, в других местах их комбинировать нельзя, точнее можно, но боты их понимать не будут, пример в таком исполнении, означает, что не индексировать ни переходить по адресам нельзя.
<meta name="yandexbot" content="noindex,nofollow"/>
Их можно менять местами и вариацию без приставки NO, тем самым более точно руководя поведением. Например, моя любимая для блокировки дублей в пагинации. Расшифрую – ходить по странице можно, но в индекс брать нельзя, одновременно с этим можно ходить по ссылкам.
<meta name="yandexbot" content="noindex,follow"/>
Так же есть вариант применения для ссылок точечно обоих команд, но она сработает только для Яндекса, все остальные не будут воспринимать noindex.
<noindex><a href="http://domen.ru/" rel="nofollow">текст ссылки</a></noindex>
Disallow в robots и noindex – как с ними работать
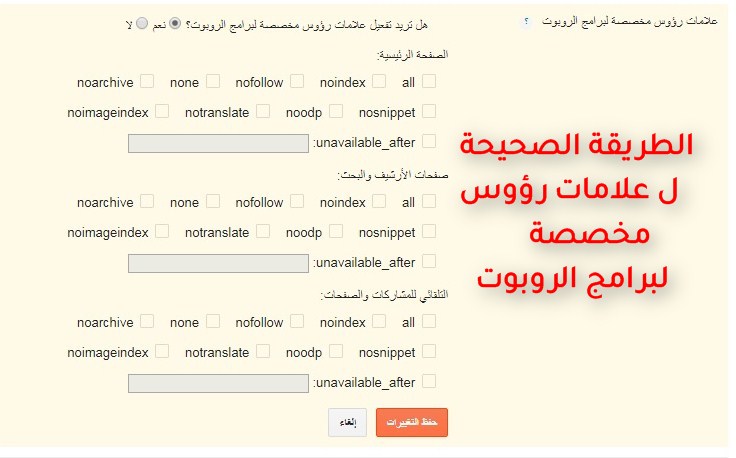
У некоторых пользователей есть вопрос, а нужно ли ставить на страницу noindex если в robots txt уже есть запрет на индексацию и наоборот. Я советую всегда использовать значения ноуиндекс и nofollow, а для усиления добавлять запрещающую строку в robots. Например с пагинацией в WordPress, я ставлю в head строку с meta (показывал на скриншоте ранее) и одновременно есть запрет в роботсе через директиву Disallow.
Robots txtКак вставить noindex nofollow на разных CMS
Для новичков в SEO не всегда понятно как проставлять правильно noindex nofollow в своей CMS системе, потому что задачи разные и требуется максимально точно настроить данный пункт.
WordPress
Советую всем использовать плагин YoastSEO, он умеет проставлять теги автоматически и с помощью точной простановки. Сейчас разберу только базовый принцип, в отдельной рубрике по WordPress опишу подробно весь процесс. В WP есть три вида сущностей – содержимое, таксономии (рубрики и категории товаров) и архивы.
В WP есть три вида сущностей – содержимое, таксономии (рубрики и категории товаров) и архивы.
На каждой вкладке для отдельной сущности можете настроить параметр «Показывать … в результатах поиска?» вместо многоточия будет своя сущность (запись, страница, рубрика, товар). Если переместим в режим «Выкл», то ко всем документам такого типа примениться noindex,follow в теге meta.
Второй вариант ручной, если хотим закрывать только некоторые адреса, то в визуальном редакторе внизу есть блок. Рассмотрим на примере записи.
Индивидуальная панель Йоаст СЕО- Спускаемся вниз страницы.
- Открываем спойлер дополнительно.
- Первое поле – это noindex, если выставляем NO то он применится.
- Радиокнопки – это nofollow, отмечаем NO если необходимо запретить все ссылки.
- Расширенная настройка – тут можно вручную прописать noindex,nofollow. Но могут произойти баги, лучше используйте параметры из списка выше.
Opencart
Не работал плотно с opencart, но поискал в интернете решения проблемы, чтобы работало.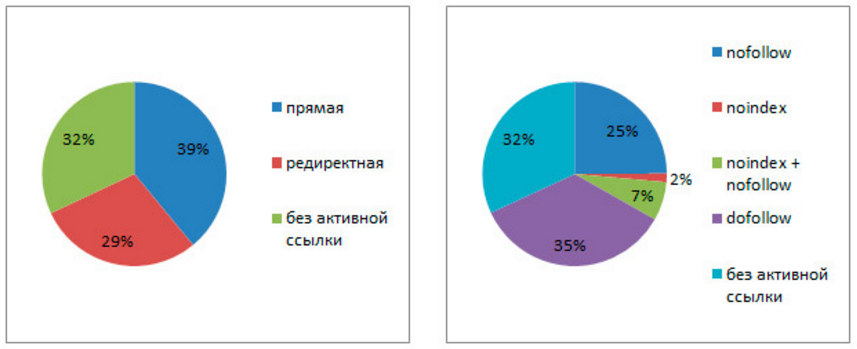 Нашел один модуль, это как плагин на WP, устанавливается стандартно и имеет настройки для достаточного количества видов документов в Opencart для простановки noindex и nofollow. Нажимайте на кнопку и перекинет на репозиторий OC.
Нашел один модуль, это как плагин на WP, устанавливается стандартно и имеет настройки для достаточного количества видов документов в Opencart для простановки noindex и nofollow. Нажимайте на кнопку и перекинет на репозиторий OC.
Скачать модуль
Bitrix
В Bitrix сложнее, он не дает такой гибкости как у других CMS, поэтому приходится прибегать к помощи разработчиков. Нашел один метод, который сможет помочь новичкам, он направлен на создании дополнительных полей в редакторе (типа как в WP произвольные поля). Жмите кнопку и откроется официальная документация. На данном форуме объяснил пользователь «Гуру» наглядно где и что появляется.
Документация
Итог
Единственный стопроцентный метод закрытия страниц это через тег meta с атрибутом robots. Все остальные способы 50 на 50 и могут не работать, потому что не все поисковики воспринимают их, а если берут в обработку то по своим неизвестным алгоритмам.
Noindex или Nofollow? — IPCalc Blog
Ты впадаешь в легкий ступор при виде тегов Noindex и Nofollow? Ты все еще терзаешь себя вопросами, что такое Noindex и что такое и что такое Nofollow? Теперь тебе больше не нужно мучиться! Просто дочитай следующий пост до конца, и ты окончательно определишься в этой странной системе!
Я не буду мучить тебя сложными терминами и заковыристыми html кодами. Я просто расскажу о Noindex и Nofollow так, как вижу их сам. Единственное, что тебе придется вспомнить, так это язык гипертекстовой разметки HTML. Начнем с тега Noindex.
Я просто расскажу о Noindex и Nofollow так, как вижу их сам. Единственное, что тебе придется вспомнить, так это язык гипертекстовой разметки HTML. Начнем с тега Noindex.
Noindex
Вообще тег Noindex был предложен Яндексом. И на фига он был предложен? Ну, Я решил выделиться и придумать нашу незабугорную альтернативу тегу Nofollow. И зачем ему это надо было? Просто специалисты из Я подумали, что раз у них самый популярный поисковик, то значит и теги должны быть свои, а не всякие там заморские.
[bs_notification type=”info” dismissible=”false”]
Кто распознает тег Nofollow:
- Яндекс
- Рамблер
[/bs_notification]
Зачем он нам нужен?
Вообще поисковые системы, при индексировании твоих web-страниц учитывают внешние ссылки, на этих станицах.
Например: чем больше ссылок ведет на твой сайт с других ресурсов, тем больше у тебя рейтинг в поисковиках.
И следовательно, больше ссылок на другие ресурсы ведет с твоего сайта, тем больший вес ты передаешь этим сайтам, а значит меньше и вес твоего сайта.

Хочешь посадить свой сайт на диету? Ставь как можно больше внешних ссылок! – Но мы то здесь говорим, как набрать вес, а не похудеть, поэтому с этим надо поосторожнее. А то ведь так понаставишь кучу левых ссылок и под фильтры залетишь, что не есть хорошо.
Так вот, если тебе все-таки хочется поставить ссылки, но ты не хочешь терять вес, а значит не хочешь, что бы Яндекс индексировал эти ссылки ставь тег Nofollow.
Как это делается. Я хочу оставить ссылки на список новостных социальных сетей, но не хочу чтобы они индексировались. Что я делаю? Открываю визуальный редактор, переключаюсь на HTML и нахожу строчки, где у меня стоят ссылки на эти ресурсы. Нашел! Теперь чтобы запретить индексацию этих ссылок мы ставим тег Noindex

Т.е. вот что мы получили:
<noindex> <li><a href="http://zavoevanie.3dn.ru/news/2008-05-09-174″>Завоевание Америки</a> – неудобный интерфейс, но новости публикуются достаточно быстро</li> <li><a href="http://www.news2.ru/">News.ru</a> – очень строгие требования к статьям</li> <li><a href="http://www.newsgrad.com/">NewsGrad</a> – различные тематики, удобный интерфейс</li> <li><a href="http://livepress.ru/">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li> </noindex>
Вот и все, теперь ссылки есть, но они не индексируются!
Мета тег Noindex
Так же есть мета тег Noindex. Отличие его от тега (контейнера) Noindex заключается в том, что он используется на ВСЮ страницу. И прописывается в <head></head> .
Пример:
<html> <head> <meta content="noindex" /> <title>Интернет заработок и технологии</title> </head>
Вот так вот легко и просто запретить роботам индексировать Всю страницу, поэтому будь осторожен!
С Noindex закончили, переходим к Nofollow.
Nofollow
В принципе Nofollow выполняет те же функции, что и Noindex, но у него есть некоторые отличия. Это забугорный вариант Noindex. Прописывается в HTML код по другому.
Яндекс его не учитывает (также как Google не учитывает Noindex)
Nofollow – прописывается в теге <a></a> атрибутом rel=”Nofollow”.
Пример возьмем все тот же. Нам нужно прописать Nofollow в каждый тег <a>, где хотим запретить индексирование ссылки:
<li><a href=http://zavoevanie.3dn.ru/news/2008-05-09-174 rel="nofollow">Завоевание Америки</a> – неудобный интерфейс, но новости публикуются достаточно быстро</li> <li><a href=http://www.news2.ru/ rel="nofollow">News.ru</a> – очень строгие требования к статьям</li> <li><a href=http://www.newsgrad.com/ rel="nofollow">NewsGrad</a> – различные тематики, удобный интерфейс</li> <li><a href=http://livepress.
 ru/ rel="nofollow">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li>
ru/ rel="nofollow">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li>Вот и все!
Мета тег Nofollow
Также как и с Noindex есть мета тег Nofollow. Предназначение у него такое же, НО область действия опять же на ВСЮ страницу
, поэтому с мета тегом Nofollow будь поаккуратнее.Как он используется:
<html> <head> <meta content="Nofollow" /> <title>Интернет заработок и технологии</title> </head>
Вот мы и разобрались с Noindex и Nofollow. Да, чуть не забыл…
[bs_notification type=”info” dismissible=”false”]Эти теги Noindex и Nofollow можно использовать вместе! [/bs_notification]
Вот пример:
<noindex> <li><a href=http://zavoevanie.3dn.ru/news/2008-05-09-174 rel="nofollow">Завоевание Америки</a> – неудобный интерфейс, но новости публикуются достаточно быстро</li> <li><a href=http://www.
 news2.ru/ rel="nofollow">News.ru</a> – очень строгие требования к статьям</li>
<li><a href=http://www.newsgrad.com/ rel="nofollow">NewsGrad</a> – различные тематики, удобный интерфейс</li>
<li><a href=http://livepress.ru/ rel="nofollow">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li>
</noindex>
news2.ru/ rel="nofollow">News.ru</a> – очень строгие требования к статьям</li>
<li><a href=http://www.newsgrad.com/ rel="nofollow">NewsGrad</a> – различные тематики, удобный интерфейс</li>
<li><a href=http://livepress.ru/ rel="nofollow">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li>
</noindex>Noindex Nofollow и Disallow: Директивы поискового робота
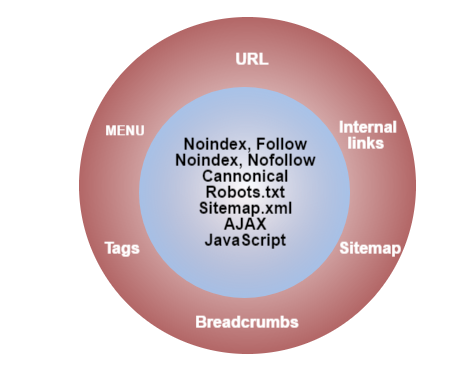
Существуют три директивы (команды), которые можно использовать для определения того, как поисковые системы обнаруживают, сохраняют и предоставляют информацию с вашего сайта в качестве результатов поиска:
- NoIndex: Don не добавлять мою страницу в результаты поиска.
- NoFollow: Не смотрите ссылки на этой странице.
- Запретить: Вообще не смотреть на эту страницу.
Эти директивы позволяют вам контролировать, какие страницы вашего сайта могут сканироваться поисковыми системами и отображаться в результатах поиска.
Что означает «Нет индекса»?
Директива noindex указывает поисковым роботам, таким как googlebot, не включать веб-страницу в результаты поиска.
Индексирование — это процесс, с помощью которого Google сканирует или «сканирует» Интернет в поисках нового контента, который затем добавляется в библиотеку контента, доступного для поиска.
Как пометить страницу как неиндексированную?
Существует два способа выпуска директивы noindex :
- Добавить метатег noindex в HTML-код страницы
- Возвращает заголовок noindex в HTTP-запросе
Используя метатег «no index» для страницы или заголовок ответа HTTP, вы фактически скрываете страницу от поиска.
Директива noindex также может использоваться для блокировки только определенных поисковых систем. Например, вы можете запретить Google индексировать страницу, но разрешить Bing:
Пример: блокировка большинства поисковых систем*
Пример: блокировка только Google
Обратите внимание: с сентября 2019 года Google больше не соблюдает директивы noindex в файле robots. txt . Noindex теперь ДОЛЖЕН быть выдан через метатег HTML или заголовок ответа HTTP. Для более продвинутых пользователей disallow все еще работает, хотя и не для всех случаев использования.
txt . Noindex теперь ДОЛЖЕН быть выдан через метатег HTML или заголовок ответа HTTP. Для более продвинутых пользователей disallow все еще работает, хотя и не для всех случаев использования.
В чем разница между noindex и nofollow?
Есть разница между хранением контента и обнаружением контента:
noindex применяется на уровне страницы и указывает сканеру поисковой системы не индексировать и не отображать страницу в результатах поиска.
nofollow применяется на уровне страницы или ссылки и сообщает сканеру поисковой системы не переходить (обнаруживать) ссылки.
По сути, тег noindex удаляет страницу из поискового индекса, а атрибут nofollow удаляет ссылку из графа ссылок поисковой системы.
NoFollow как атрибут страницы
Использование nofollow на уровне страницы означает, что сканеры не будут переходить ни по одной из ссылок на этой странице для обнаружения дополнительного контента, и сканеры не будут использовать ссылки в качестве сигналов ранжирования для целевых сайтов.
NoFollow как атрибут ссылки
Использование nofollow на уровне ссылки не позволяет поисковым роботам исследовать ссылку на конкретное объявление и не позволяет использовать эту ссылку в качестве сигнала ранжирования.
Директива nofollow применяется на уровне ссылки с использованием атрибута rel в теге href:
Специально для Google: использование атрибута ссылки nofollow не позволит вашему сайту передать PageRank целевым URL-адресам.
Однако Google недавно объявил, что с 1 марта 2020 года поисковая система начнет рассматривать ссылки NoFollow как «подсказки», которые способствуют общему поиску сайта.
Почему вы должны пометить страницу как NoFollow?
Для большинства случаев использования вы должны , а не пометить всю страницу как nofollow — пометки отдельных ссылок как nofollow будет достаточно.
Вы бы пометили всю страницу как nofollow , если вы не хотели, чтобы Google просматривал ссылки на странице, или если вы думали, что ссылки на странице могут повредить вашему сайту.
В большинстве случаев общие директивы уровня страницы nofollow используются, когда вы не имеете контроля над контентом, размещаемым на странице (например, контент, созданный пользователем, может быть размещен на странице).
Некоторые высококлассные издатели также полностью применяют директиву nofollow к своим страницам, чтобы отговорить своих авторов от размещения рекламных ссылок в своем контенте.
Как использовать страницы без индекса?
Отметить страницы как неиндексированные, которые вряд ли будут представлять ценность для пользователей и не должны отображаться в результатах поиска. Например, маловероятно, что страницы, которые существуют для разбиения на страницы, со временем будут отображать одно и то же содержимое.
Domain. com/category/resultspage=2
com/category/resultspage=2
Вот типы страниц, которые следует исключить из индексации:
- Страницы, используемые для разбиения на страницы
- Страницы внутреннего поиска
- целевых страниц, оптимизированных для рекламы
- Пример: Отображает только форму презентации и регистрации, без основной навигации
- Пример: повторяющиеся варианты одного и того же контента, используемые только для рекламы
- Авторские страницы в архиве
- Страниц в потоках оформления заказа
- страниц подтверждения
- Пример: страницы благодарности
- Пример: Заказ полных страниц
- Пример: Успех! Страницы
- Некоторые страницы, сгенерированные подключаемым модулем, которые не имеют отношения к вашему сайту (например, если вы используете коммерческий подключаемый модуль, но не используете их обычные страницы продуктов)
- Страницы администратора и страницы входа администратора
Пометка страницы как Noindex и Nofollow
Страница, помеченная как noindex, так и nofollow, заблокирует индексирование этой страницы поисковым роботом и просмотр ссылок на странице.
Изображение ниже демонстрирует, что поисковая система увидит на веб-странице в зависимости от того, как вы использовали директивы noindex и nofollow:
Узнайте, как занять первое место в рейтинге Google и победить в конкурентной борьбе
Забронировать Звонок
Пометка уже проиндексированной страницы как NoIndex
Если поисковая система уже проиндексировала страницу, и вы помечаете ее как noindex , то при следующем сканировании страницы она будет удалена из результатов поиска .
Чтобы этот метод удаления страницы из индекса работал, вы не должны блокировать (запрещать) поисковый робот своим файлом robots.txt.
Если вы укажете сканеру не читать страницу, он никогда не увидит маркер noindex и страница останется проиндексированной, хотя ее содержимое не будет обновляться.
Как запретить поисковым системам индексировать мой сайт?
Если вы хотите удалить страницу из поискового индекса, после того как она уже была проиндексирована, вы можете выполнить следующие шаги:
- Применить директиву noindex Добавить атрибут noindex в метатег или заголовок ответа HTTP
- Запросите поисковую систему просканировать страницу Для Google вы можете сделать это в консоли поиска, запросив переиндексацию страницы Google. Это приведет к тому, что робот Googlebot просканирует страницу, где робот Googlebot обнаружит директиву noindex. Вам нужно будет сделать это для каждой поисковой системы, для которой вы хотите удалить страницу.
- Подтверждение удаления страницы из поиска После того, как вы запросили сканер повторно посетить вашу веб-страницу, подождите некоторое время, а затем подтвердите, что ваша страница была удалена из результатов поиска. Вы можете сделать это, зайдя в любую поисковую систему и введя целевой URL-адрес сайта, как на изображении ниже.
Если ваш поиск не дал результатов, ваша страница была удалена из этого поискового индекса. - Если страница не была удалена Убедитесь, что в вашем файле robots.txt нет директивы «запретить». Google и другие поисковые системы не могут прочитать директиву noindex, если им не разрешено сканировать страницу. Если вы это сделаете, удалите директиву disallow для целевой страницы, а затем снова запросите сканирование.
- Установить директиву запрета для целевой страницы в файле robots.txt Запретить: /page$
Вам нужно поставить знак доллара в конце URL-адреса в файле robots.txt, иначе вы можете случайно запретить любые страницы под этой страницей, а также любые страницы, начинающиеся с той же строки. Пример: Disallow: /sweater также запретит /sweater-weather и /sweater/green, но Disallow: /sweater$ запретит только конкретную страницу /sweater.
 Это приведет к тому, что робот Googlebot просканирует страницу, где робот Googlebot обнаружит директиву noindex. Вам нужно будет сделать это для каждой поисковой системы, для которой вы хотите удалить страницу.
Это приведет к тому, что робот Googlebot просканирует страницу, где робот Googlebot обнаружит директиву noindex. Вам нужно будет сделать это для каждой поисковой системы, для которой вы хотите удалить страницу.
Как удалить страницу из поиска Google
Если страница, которую вы хотите удалить из поиска, находится на сайте, которым вы владеете или управляете, большинство сайтов могут использовать инструмент удаления URL для веб-мастеров.
Инструмент удаления URL для веб-мастеров удаляет контент из поиска примерно на 90 дней. Если вам нужно более постоянное решение, вам потребуется использовать директиву noindex, запретить сканирование из файла robots.txt или удалить страницу с вашего сайта. Google предоставляет дополнительные инструкции по постоянному удалению URL здесь.
Google предоставляет дополнительные инструкции по постоянному удалению URL здесь.
Если вы пытаетесь удалить страницу из поиска на сайте, который вам не принадлежит, вы можете запросить Google удалить страницу из поиска, если она соответствует следующим критериям:
- Отображает личную информацию, такую как ваша кредитная карта или номер социального страхования
- Страница является частью вредоносного ПО или схемы фишинга
- Страница нарушает закон
- Страница нарушает авторские права
Если страница не соответствует ни одному из вышеперечисленных критериев, вы можете обратиться в SEO-фирму или PR-компанию за помощью в управлении онлайн-репутацией.
Следует ли не индексировать страницы категорий?
Обычно не рекомендуется не индексировать страницы категорий, если только вы не являетесь организацией корпоративного уровня, раскручивающей страницы категорий программно на основе пользовательских поисковых запросов или тегов, и дублированный контент становится громоздким.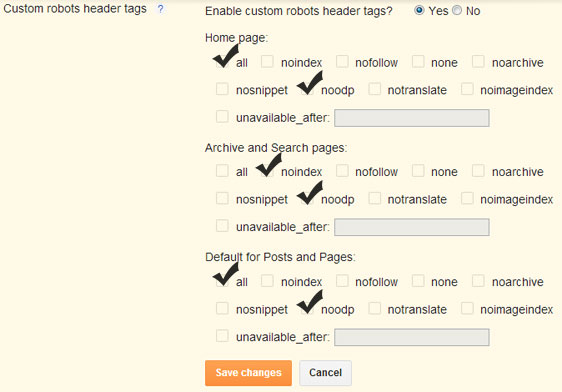
По большей части, если вы разумно помечаете свой контент, чтобы помочь пользователям лучше ориентироваться на вашем сайте и находить то, что им нужно, тогда все будет в порядке.
На самом деле, страницы категорий могут быть золотыми жилами для SEO, поскольку они обычно показывают глубину контента в темах категорий.
Взгляните на этот анализ, который мы провели в декабре 2018 года, чтобы количественно оценить ценность страниц категорий для нескольких онлайн-публикаций.
*Анализ выполнен с использованием данных AHREFS.
Мы обнаружили, что целевые страницы категорий ранжируются по сотням ключевых слов страницы 1 и ежемесячно привлекают тысячи обычных посетителей.
Самые ценные страницы категорий для каждого сайта часто привлекали тысячи органических посетителей каждая.
Взгляните на EW.com ниже, мы измерили трафик на каждую страницу (обозначается размером кружка) и значение трафика на каждую страницу (обозначается цветом кружка).
Ежемесячный органический трафик на страницу = размер
Ежемесячная органическая ценность страницы = глубина цвета
Теперь представьте те же диаграммы, но для сайтов, основанных на продуктах, где посетители могут совершать активные покупки.
При этом, если ваши категории достаточно похожи, чтобы сбивать пользователей с толку или конкурировать друг с другом в поиске, вам может потребоваться внести изменения:
- Если вы устанавливаете категории самостоятельно, мы рекомендуем перенести контент из одной категории в другую и уменьшить общее количество категорий, которые у вас есть.
- Если вы разрешаете пользователям разворачивать категории, вы можете не индексировать созданные пользователями страницы категорий, по крайней мере, до тех пор, пока новые категории не пройдут процесс проверки.
Как запретить Google индексировать поддомены?
Есть несколько способов запретить Google индексировать поддомены:
- Вы можете добавить пароль с помощью файла . htpasswd
- Вы можете запретить поисковые роботы с помощью файла robots.txt
- Вы можете добавить директиву noindex на каждую страницу субдомена
- Вы можете 404 все страницы поддоменов
 htpasswd
htpasswdЕсли ваши поддомены предназначены для целей разработки, то идеальным вариантом будет добавление файла .htpasswd в корневой каталог вашего поддомена. Стена входа не позволит поисковым роботам индексировать контент на субдомене, и предотвратит несанкционированный доступ пользователей.
Примеры использования:
- Dev.domain.com
- Staging.domain.com
- Testing.domain.com
- QA.domain.com
- UAT.domain.com
Использование robots.txt для блокировки индексации
Если ваши субдомены служат другим целям, вы можете добавить файл robots.txt в корневой каталог вашего субдомена. Затем он должен быть доступен следующим образом:
https://subdomain. domain.com/robots.txt
domain.com/robots.txt
Вам нужно будет добавить файл robots.txt к каждому поддомену, который вы пытаетесь заблокировать от поиска. Пример:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
В каждом случае файл robots.txt должен запрещать поисковые роботы, чтобы заблокировать большинство сканеров одной командой, используйте следующий код:
User-agent: *
Disallow: /
Звезда * после user-agent: называется подстановочным знаком, он будет соответствовать любой последовательности символов. Использование подстановочного знака отправит следующую директиву disallow всем пользовательским агентам, независимо от их имени, от googlebot до yandex.
Обратная косая черта сообщает сканеру, что все страницы вне поддомена включены в директиву disallow.
Как выборочно заблокировать индексирование страниц поддоменов
Если вы хотите, чтобы некоторые страницы из поддомена отображались в поиске, но не отображались другие, у вас есть два варианта:
- Использовать директивы noindex на уровне страницы
- Использовать директивы запрета на уровне папки или каталога
Директивы noindex уровня страницы будут более громоздкими для реализации, поскольку директиву необходимо добавлять в HTML или заголовок каждой страницы. Однако директивы noindex не позволят Google индексировать поддомен независимо от того, был ли он уже проиндексирован или нет.
Однако директивы noindex не позволят Google индексировать поддомен независимо от того, был ли он уже проиндексирован или нет.
Директивы запрета на уровне каталога реализовать проще, но они будут работать только в том случае, если страницы поддоменов еще не включены в поисковый индекс. Просто обновите файл robots.txt поддомена, чтобы запретить сканирование соответствующих каталогов или подпапок.
Бесплатное предложение SEO при планировании с помощью LinkGraph
Заказать звонок
Как узнать, не проиндексированы ли мои страницы?
Случайное добавление страниц без индекса на ваш сайт может иметь серьезные последствия для вашего поискового рейтинга и видимости в поиске.
Если вы обнаружите, что страница не получает органического трафика, несмотря на хороший контент и обратные ссылки, сначала проверьте, не запретили ли вы случайно сканерам доступ к файлу robots.txt. Если это не решит вашу проблему, вам нужно проверить отдельные страницы на наличие директив noindex.
Проверка NoIndex на страницах WordPress
WordPress упрощает добавление или удаление этого тега на ваших страницах. Первым шагом в проверке наличия nofollow на ваших страницах является простое переключение параметра Search Engine Visibility на вкладке «Чтение» в меню «Настройки».
Это, вероятно, решит проблему, однако этот параметр работает как «предложение», а не как правило, и часть вашего контента все равно может быть проиндексирована.
Чтобы обеспечить абсолютную конфиденциальность ваших файлов и контента, вам нужно будет сделать последний шаг: либо защитить свой сайт паролем с помощью инструментов управления cPanel, если они доступны, либо с помощью простого плагина.
Точно так же удалить этот тег из вашего контента можно, удалив защиту паролем и сняв флажок в настройках видимости.
Проверка наличия NoIndex в Squarespace
Страницы Squarespace также легко обрабатываются NoIndex с помощью платформы Code Injection. Как и WordPress, Squarespace можно легко заблокировать от рутинных поисков с помощью защиты паролем, однако платформа также рекомендует не делать этого шага, чтобы защитить целостность вашего контента.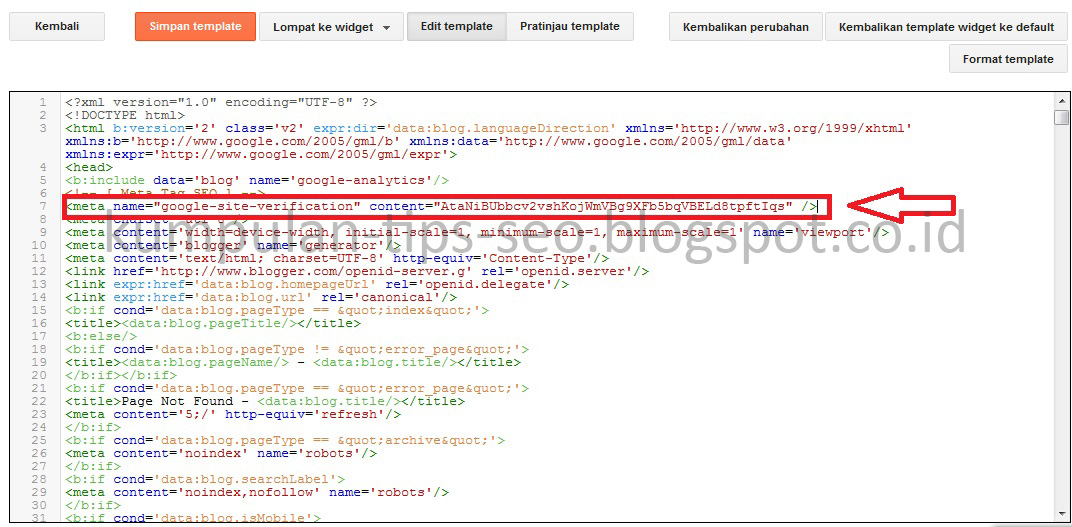
Добавляя строку кода NoIndex на каждую страницу, которую вы хотите скрыть от поисковых систем в Интернете, и на каждую подстраницу под ней, вы можете обеспечить безопасность защищенного контента, доступ к которому должен быть закрыт. Как и на других платформах, удаление этого тега также довольно просто: просто используйте функцию «Внедрение кода», чтобы вернуть код, — это все, что вам нужно сделать.
Squarespace уникален тем, что его конкуренты предлагают эту опцию в первую очередь как часть набора настроек в инструментах управления страницами. Squarespace уходит отсюда, позволяя лично манипулировать кодом. Это интересно, потому что вы можете видеть изменения, которые вы вносите в контент своей страницы, в отличие от других в этом пространстве.
Проверка наличия NoIndex на Wix
Wix также позволяет быстро и просто решить проблемы NoIndexing. В настройках «Меню и страницы» вы можете просто деактивировать опцию «показывать эту страницу в результатах поиска», если вы хотите не индексировать одну страницу на вашем сайте.
Как и его конкуренты, Wix также предлагает пароль для защиты ваших страниц или всего сайта для дополнительной конфиденциальности. Однако Wix отличается от других тем, что служба поддержки не предписывает параллельные действия на обоих фронтах, чтобы обезопасить контент от сканера. Wix особо отмечает разницу между скрытием страницы в вашем меню и ее скрытием в критериях поиска.
Это особенно полезный совет для менее опытных создателей веб-сайтов, которые могут изначально не понимать разницы, учитывая, что удаление из меню вашего сайта делает страницу недоступной с сайта, но не из благоразумного поискового запроса Google.
Изолированный URL-адрес — можно найти только через noindex, следуйте
Высокий Этот совет очень важен и определенно заслуживает внимания. Проблема Эта подсказка представляет собой ошибку или проблему, которую необходимо исправить.
Это означает, что рассматриваемый URL изолирован, так как его можно найти только по ссылке noindex,follow.
Почему это важно?
Это ситуация, когда URL-адрес существует в сети и доступен для поисковых роботов, но только в соответствии с директивой robots с noindex,follow:
Это любопытный случай, потому что Страница B фактически говорит поисковым системам: ‘не индексируйте эту страницу, но, пожалуйста, перейдите по всем ссылкам на ней’.
В видеовстрече Google для веб-мастеров в 2017 году Джон Мюллер разъяснил, как Google обрабатывает noindex. случае, когда мы видим noindex. На первом этапе мы говорим: «Хорошо, вы не хотите, чтобы эта страница отображалась в результатах поиска, мы все равно оставим ее в нашем индексе, мы просто не будем ее показывать, а затем мы можем следуйте этим ссылкам».
Если мы видим noindex там дольше, то мы думаем, что эта страница ДЕЙСТВИТЕЛЬНО не хочет использоваться в поиске, поэтому мы полностью ее удалим. И тогда мы все равно не будем ходить по ссылкам. Таким образом, noindex и follow — это, по сути, то же самое, что и noindex, nofollow. В долгосрочной перспективе нет большой разницы».
В долгосрочной перспективе нет большой разницы».
Это означает, что в долгосрочной перспективе страница B считается noindex, nofollow, поэтому Google перестанет переходить по ссылкам. Поскольку страница C не имеет входящих ссылок с других страниц, он оказывается изолированным от графа ссылок:
Это означает, что в конечном итоге , Google посчитает, что этот URL не имеет входящих внутренних ссылок для перехода. И если URL-адрес не имеет входящих внутренних ссылок, это означает, что он не является частью общей структуры веб-сайта.
Со временем эта страница потеряет способность ранжироваться по релевантным поисковым запросам и может оказаться исключенной из индекса.
Что проверяет подсказка?
Эта подсказка будет срабатывать для любого внутреннего URL-адреса, который не имеет входящих внутренних ссылок, за исключением страниц с noindex,follow.
Примеры, вызывающие эту подсказку:
Рассмотрим URL-адрес: https://example.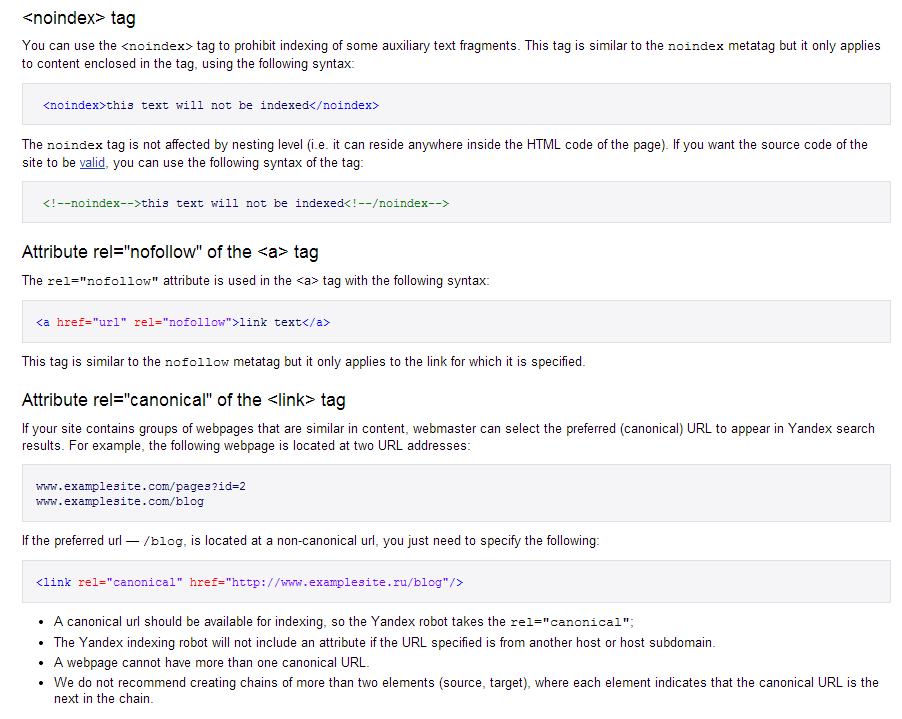 com/page-c
com/page-c
Этот URL-адрес получает только входящие внутренние ссылки со страниц, которые имеют либо;
noindex,следуйте в
:ИЛИ в заголовке HTTP:
example
...
...
HTTP/... 200 OK
...
X-Robots-Tag: noindex,follow
Подсказка сработает для этого URL: https ://example/com/page-c
Как решить эту проблему?
Страницы, изолированные таким образом, в долгосрочной перспективе пострадают, даже если в настоящее время вы не видите никаких негативных последствий. Это самая важная часть цитаты Джона Мюллера:
«…Если мы видим noindex там дольше, то мы думаем, что эта страница ДЕЙСТВИТЕЛЬНО не хочет использоваться в поиске, поэтому мы удалим ее полностью. И тогда мы все равно не будем переходить по ссылкам.