
Что значит noindex и nofollow
В статье разберем, что значит noindex и nofollow, в каких случаях использовать.
Страницы не «автоматически» появляются в индексе поисковой системы. Для этого они должны быть проиндексированы роботами Google или Яндекса, также известными как поисковые роботы, которые просматривают интернет и индексируют найденные страницы.
Содержание
- Как работают поисковые роботы Google и Яндекс
- Что такое атрибуты noindex и nofollow
- Когда используют атрибуты noindex и nofollow
- Nofollow-ссылки
- Рекомендации
Как работают поисковые роботы Google и Яндекс
Цель роботов — перемещаться между веб-страницами и добавлять их в индекс Google или Яндекса. Они перемещаются с одного URL на другой, используя ссылки на них.
Однако у каждого сайта есть краулинговый бюджет, определяющий количество URL-адресов, которые боты могут сканировать за одно посещение. Как только сканер оказывается на сайте, он остается там до тех пор, пока все страницы не будут проиндексированы или не будет исчерпан краулинговый бюджет.
Что такое атрибуты noindex и nofollow
Однако бывают ситуации, когда не нужно, чтобы роботы индексировали подстраницу или переходили по ссылке. В таких ситуациях используются атрибуты noindex и nofollow.
Это кодовые теги, содержащие информацию, предназначенную для роботов. Используя их, можно влиять на поведение ботов, когда они попадут на сайт. В то время как rel noindex указывает поисковым роботам не индексировать определенную страницу, nofollow говорит им не переходить по ссылке.
Когда используют атрибуты noindex и nofollow
Не в каждой ситуации нужно, чтобы подстраница веб-сайта находилась в индексе Google (Яндекс) или чтобы ее посещали и оценивали боты.
Некоторые подстраницы могут негативно повлиять на оценку всего веб-сайта или должны отображаться только в определенном контексте. Использование метатегов также может быть целесообразным в ситуации, когда веб-сайт очень большой и содержит некоторые адреса, которые не следует включать в индекс.
Noindex — когда и как использовать
Когда поисковый робот, индексирующий сайт, достигает noindex, он не добавит указанный URL. В результате подстраница никогда не появится в результатах поиска Google (Яндекс).
В результате подстраница никогда не появится в результатах поиска Google (Яндекс).
Метатег можно разместить в коде сайта одним из двух способов:
- В HTML-коде.
- Заголовок HTTP в виде метатегов X-Robots-Tag.
Независимо от того, как вы это реализуете, тег будет вести себя одинаково.
Кроме того, можно использовать файл robots.txt, чтобы сообщить роботам, что вы не хотите, чтобы они индексировали данную подстраницу.
Nofollow-ссылки
Может показаться, что атрибут nofollow поисковика менее важен, чем noindex — что может быть более решительным действием, чем запретить роботам индексировать конкретную подстраницу? Однако недооценивать второй атрибут не стоит. Nofollow информирует поисковых роботов не вводить конкретную ссылку или набор ссылок на странице.
Причина, по которой nofollow играет очень важную роль при создании веб-сайта, заключается в важности создания ссылок для SEO. Ссылки используются поисковыми роботами для навигации и перемещения по веб-сайту и влияют на его оценку.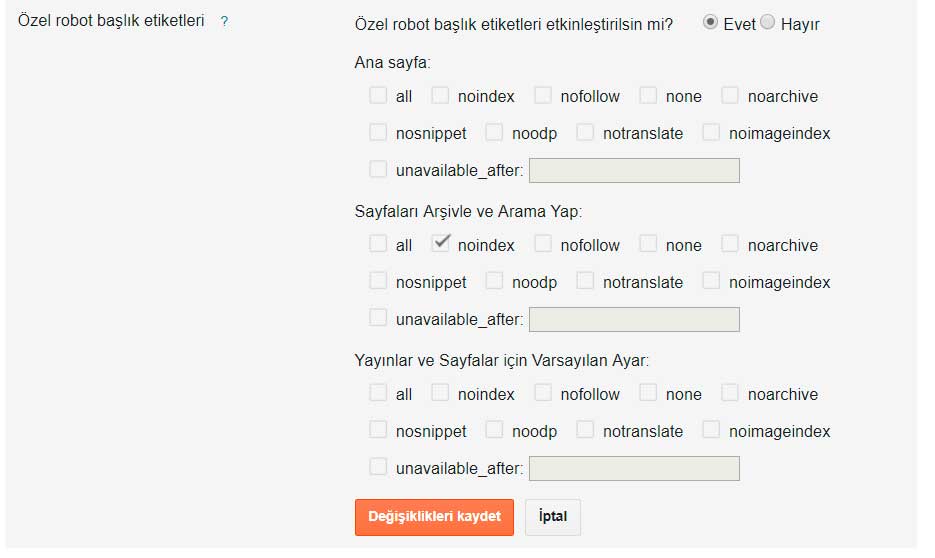 Если вы поместите команду в содержимое страницы, что боты не должны переходить по данной ссылке, они не будут оценивать подстраницу за ней.
Если вы поместите команду в содержимое страницы, что боты не должны переходить по данной ссылке, они не будут оценивать подстраницу за ней.
В результате nofollow может иметь тот же эффект, что и метатег noindex. Если вы запретите роботам переходить по всем ссылкам, ведущим на вашем сайте, на определенную подстраницу, у них не будет способа туда попасть, а, следовательно, и ее проиндексировать.
Если вы хотите понять, как это работает, следует знать о существовании такого явления, как ссылочный вес. Это ценность, которую дает качественная ссылка на ваш веб-сайт, положительно влияющая на оценку Google и Яндекс. Если ссылки ведут на ваш портал, вы получаете ссылочный вес. Когда вы ссылаетесь на другую страницу, эта страница получает его.
Внутри страницы этот тег используется, потому что он говорит сканерам не заходить на подстраницы, которые не имеют отношения к процессу позиционирования веб-сайта.
Рекомендации
Рекомендуется тщательно подумать об использовании метатегов.

Хотя во многих случаях использование noindex и nofollow может быть выгодным, стоит тщательно обдумать действия. Следует помнить, что их использование лишит подстраницу возможности отображения в рейтинге Google (Яндекс), а значит — не позволит войти на ваш сайт. Любое использование атрибутов должно быть преднамеренным и тщательно продуманным.
Когда поисковые роботы Google (Яндекс) обнаруживают один из описанных атрибутов, они рассматривают URL-адрес так же, как ошибку 404, и перестают регулярно его посещать.
Правильное использование noindex rel позволит избежать штрафов за использование дублированного контента или размещение ненужной подстраницы в результатах.
Использование HTML-метатега nofollow — это способ предложить ботам не проходить по ссылке или оценивать ее. Таким образом, вы можете повлиять на то, как сканеры перемещаются по сайту, и исключать вход на ненужные подстраницы.
проверка индексации, noindex, nofollow, seohide, ошибки robots.
 txt и sitemap.xml
txt и sitemap.xml*Публикация написана в рамках цикла статей про “Идеальный аудит сайта”.
Как только вы наладили сайт, чтобы он корректно собирал хостовые факторы, следует проверить индексацию.
Индексация сайта — это добавление информации о нём в базу поисковых систем. Данный процесс напоминает внесение информации в каталог библиотеки. Информация вносится специалистами, а за её проверку и обработку отвечают поисковые роботы — алгоритмы.
1. Проверка индексации
Проверка индексации сайта происходит на всех страницах. Для больших проектов с сотнями страниц — это один из щепетильных шагов, поскольку нужно промониторить весь сайт вдоль и поперёк. На прицеле такого розыска — дубликаты страниц, пустые страницы и страницы с ошибками. Пока они не устранены, у продвигаемых страниц уменьшается статический вес, а сайт не получает нормальный трафик.
Что нужно для проверки:
- Составить список самых важных страниц сайта и всех страниц сайта.
- Проверить все ссылки с помощью запросов через автоматический парсер ПС.

- Составить 4 списка:
- все проиндексированные важные страницы;
- все проиндексированные мусорные страницы;
- все непроиндексированные важные страницы;
- все непроиндексированные мусорные страницы.

2. Создание списка непроиндексированных страниц, которые посещал поисковый алгоритм
Иногда страницы не попадают в индекс даже после посещения робота. Такие страницы нужно отличать от страниц, не отображённых в индексе и не посещённых роботом. Архитектура таких страниц обладает значительными различиями.
Этапы работы
- Сделать анализ логов и составить список страниц, где был робот.
- Сделать список важных непроиндексированных страниц, где не было робота.
- Сделать список важных непроиндексированных страниц, где был робот.
- Изучить список непроиндексированных страниц, которые где не было робота. Алгоритм должен просмотреть эти страницы, чтобы они попали в индекс.
- Изучить список непроиндексированных страниц, где был робот. Это страницы с дублями или статическим весом.
 Это страницы с дублями или статическим весом.
Это страницы с дублями или статическим весом.3. Проверка возможности индексации важных областей на flash и ajax сайтах
Если при создании сайта вы использовали технологии Flash или Ajax, с индексацией могут возникнуть проблемы.
Какие страницы нужно индексировать, а какие не нужно:
Что делать?
Открыть текстовую сохранённую копию всех типов страниц и найти там тексты, при выкладке которых использовались Flash или Ajax. Если вы нашли текст, значит блок индексируется.
Исключение
Иногда у сайта бывает такая некачественная вёрстка, что даже при отсутствии Flash или Ajax, текст не попадёт в текстовый индекс.
4. Проверка возможности индексации всех страниц сайта при текущих инструкциях robots.txt
Как только вы скорректировали robots.txt, следует проверить доступны ли все важные страницы для индексации.
5. Проверка целесообразности использования <noindex>, nofollow, meta noindex, meta nofollow, SEOHide
Если допускаются ошибки в инструкциях индексации, важные страницы начинают выпадать из индекса, снижая трафик.
Этапы проверки:
- Проверка по матрице с использованиям сервисов RDS-bar и «СайтРепорт».
- Поиск незакрытых <noindex>.
- Изучение внутренних и внешних ссылок, которые закрыты в nofollow.
- Изучение страниц, закрытых в meta noindex и в meta nofollow.
- Проверка на наличие SEOHide и его корректной работы.
6. Проверка корректности использования <noindex>, nofollow, SEOHide
Как только вы составили список страниц, где используются инструкции по скрытию индексации, можно приступать поиску в них ошибок.
Контрольные точки:
- Не закрытый <noindex>
- Индексируемый SEOHide
- Проверка корректности SEOHide с помощью плагина WebDeveloper
- Важные страницы с meta nofollow, meta noindex
- Nofollow на внутренних ссылках
7. Поиск ошибок при сравнении индексов по категориям и типам страниц
Нужно сравнить списки проиндексированных страниц в разных поисковых системах по тем разделам и типам страниц, где их количество в индексе различается.
Процесс поиска:
- Изучить области сайта, где в одной ПС страниц меньше, чем в другой:
- Открыть страницы из списка проиндексированных и изучить страницы, которых нет в индексе одной из поисковых систем, но есть в другой поисковой системе.
- Изучить страницы в Google, помеченные как supplimental.
8. Анализ динамики индексации сайта
Динамика индексации сайта укажет на слабые места и проблемы проекта. Сведение статистики по списку проиндексированных страниц, собранных с параметром &how=tm показывают возраст страниц и помогают изучить динамику индексации сайта.
9. Проверка robots.txt на ошибки
Если есть ошибка в robots.txt, весь сайт может быть исключен из индекса.
Что делать?
- Открываем сервис http://webmaster.yandex.ru/robots.xml и проверяем закрывает ли robots все ненужные страницы и не находит ли валидатор ошибок.
- Проверяем, что robots.txt соответствует правилам http://help.yandex. ru/webmaster/?id=996567.
 ru/webmaster/?id=996567.
ru/webmaster/?id=996567.10. Проверка robots.txt на наличие директив для всех поисковых систем
Яндекс и Google используют различные директивы в robots.txt, инструкции для них следует писать отдельно: User-Agent: Yandex + User-Agent: * обязательно, опционально User-Agent: Google
11. Проверка sitemap.xml на ошибки
С помощью sitemap.xml можно управлять индексацией своего сайта.
В каких случаях все будет работать корректно:
- Ссылка на sitemap.xml есть в robots.txt
- Атрибуты дат страниц расставлены верно
- Приоритеты расставлены верно
- Исключены уже проиндексированные страницы
- Нет страниц, закрытых от индексации в robots.txt
- Нет нарушений валидности составления sitemap.xml
Почему сайт не индексируется в Google? Ёмкий ответ одного из SEO-специалистов:
Подведём итог и сконцентрируем все рассмотренные выше этапы, которые включает в себя индексация сайта:
- Проверка индексации каждой страницы сайта
- Составление списка непроиндексированных страниц, посещённых роботом.
- Проверка возможности индексации важных областей на flash и ajax сайтах.
- Проверка возможности индексации всех страниц сайта при текущих инструкциях robots.txt.
- Проверка целесообразности использования <noindex>, nofollow, SEOHide.
- Проверка корректности использования <noindex>, nofollow, SEOHide.
- Сравнение индексов по категориям и типам страниц.
- Поиск в индексе технических страниц.
- Анализ динамики индексации сайта.
- Проверка robots.txt на ошибки.
- Проверка robots.txt на полноту данных.
- Проверка robots.txt на наличие директив для всех поисковых систем.
- Проверка актуальности robots.txt.
- Проверка sitemap.xml на ошибки.
- Анализ расстановки дат индексации и приоритетов в sitemap.xml.
- Проверка актуальности sitemap.xml.
- Поиск запрещённых к индексации страниц в sitemap.xml.

Теги публикации: nofollow, noindex, robots.txt, seo, seo-аналитика, seohide, sitemap. xml, анализ проекта, аудит сайта, идеальный аудит сайта, лайфхак, полезные советы
xml, анализ проекта, аудит сайта, идеальный аудит сайта, лайфхак, полезные советы
Bulk NoIndex & NoFollow Toolkit — Плагин WordPress
- Детали
- отзывов
- Развитие
Опора
Этот плагин, разработанный Mad Fish Digital, экономит время веб-мастеров при поиске и удалении тонких страниц вашего сайта из индексов поисковых систем.
Этот плагин имеет интерфейс, который позволяет вам сортировать сообщения по количеству слов, количеству символов, а затем массовый noindex или массовый nofollow для сообщений или страниц, чтобы они перестали появляться в индексах поисковых систем.
В настоящее время этот плагин анализирует только страницы и сообщения. Пользовательские типы сообщений пока не поддерживаются.
Имейте в виду
После того, как страница не проиндексирована, в некоторых случаях поисковым системам может потребоваться до нескольких недель, прежде чем страница перестанет отображаться в поисковом индексе. Количество времени будет зависеть от того, как часто поисковая система сканирует ваш сайт и страницы. Мы рекомендуем использовать Google Search Console для дальнейшего анализа и понимания того, как ваши страницы потенциально будут отображаться в поисковом индексе.
Количество времени будет зависеть от того, как часто поисковая система сканирует ваш сайт и страницы. Мы рекомендуем использовать Google Search Console для дальнейшего анализа и понимания того, как ваши страницы потенциально будут отображаться в поисковом индексе.
Преимущества
1) Сокращение времени, необходимого для Noindex/Nofollow для каждой страницы или публикации вручную через простой в использовании интерфейс
2) Сортировка сообщений и страниц по количеству слов и символов для быстрого определения страниц с недостаточным содержанием
3 ) Ускорение времени восстановления штрафных санкций поисковой системы веб-сайта за счет выявления и массового запрета на индексацию большого количества сообщений и страниц
4) Быстрое неиндексирование контента, идентифицированного поисковыми роботами, такими как DeepCrawl
5) Простое управление директивами метатегов robots на большом количестве страниц
6) Визуализация всех сообщений и страниц со статусами «noindex» и «nofollow»
7) Синхронизация с плагинами Yoast и All in One SEO Pack (AIOSEO) для поддержки и управления существующими сообщениями noindex и nofollow и страницы
Поддержка
По вопросам, связанным с поддержкой, посетите страницу поддержки плагина Mad Fish Digital, чтобы написать нам или задать вопрос.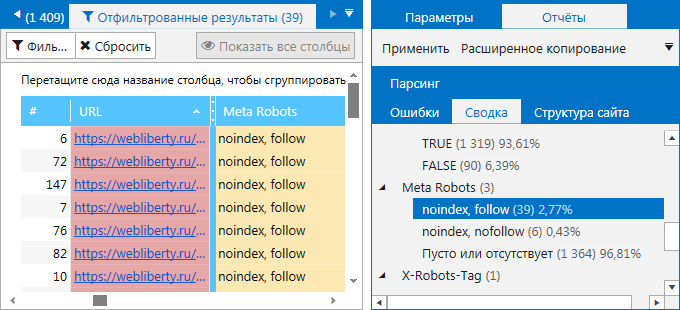 Обратите внимание, что ответы на конкретные запросы могут занять до 24 часов.
Обратите внимание, что ответы на конкретные запросы могут занять до 24 часов.
Почему вы хотите удалить большое количество страниц из поисковых индексов?
В Mad Fish Digital мы используем такие инструменты, как DeepCrawl, LinkResearch Tools, Ahrefs и SEM Rush, для сканирования и анализа веб-страниц. Иногда вы хотите удалить несколько веб-страниц из индекса поисковой системы, которые больше не содержат актуального контента, старых продуктов и услуг или устаревших руководств/правил. Во многих из этих случаев вам нужно, чтобы страницы были временно удалены из индекса Google сегодня, но вы можете захотеть обновить содержание позже. Не индексируя сообщение или страницу, вы можете избежать установки кода состояния этих страниц на 404 (или 410).
Вот где может пригодиться инструмент для массового noindex/nofollow этих страниц. Вы можете легко удалить страницы из поискового индекса, а затем удалить директиву noindex после обновления содержимого этих сообщений или страниц.
Этот плагин будет синхронизироваться с вашими существующими настройками Yoast и All In One SEO Pack (AIOSEO) и позволит вам выполнять массовую неиндексацию с помощью Yoast.
Оставаясь синхронизированным с настройками noindex/nofollow от Yoast и AIOSEO, если вы не индексируете/nofollow пост или страницу напрямую, этот плагин распознает изменение и остается в синхронизации.
Fallback Protection
Если вы не используете Yoast или AIOSEO, этот плагин может продолжать обслуживать соответствующий метатег robots на основе noindex/nofollow в соответствии с настройками через интерфейс.
Если вы отключили плагин Yoast или AIOSEO на своем сайте, обязательно дважды проверьте интерфейс «Массовое NoIndex/NoFollow» (из меню инструментов), чтобы убедиться, что ваши сообщения и страницы по-прежнему не просматриваются и не индексируются соответственно. Директивы роботов, которые устанавливаются непосредственно через интерфейс редактирования WP Post, могут не всегда отслеживаться этим плагином, и эти настройки могут больше не отображаться для этого плагина, если плагины Yoast и AIOSEO ранее были включены, но позже отключены.
Установка и использование
1) Войдите в свою учетную запись администратора WordPress как администратор. Используя пункт меню «Добавить новый» в разделе «Плагины» навигации, вы можете либо выполнить поиск: «Массовый инструмент NoIndex & NoFollow», либо, если вы уже загрузили плагин, нажмите ссылку «Загрузить», найдите ZIP-файл, который вы загружаете, а затем нажмите «Установить сейчас». Или вы можете разархивировать и загрузить плагин по FTP в каталог плагинов.
2) Перейдите в Инструменты -> Массовый NoIndex/NoFollow
3) Начало страницы noindex/nofollowing
- Это скриншот интерфейса для массового noindexing и nofollowing постов и страниц
Будет ли этот плагин хорошо работать, если я уже использую Yoast для неиндексируемых и нефолловинговых страниц?
Да, этот плагин будет синхронизироваться с собственными функциями noidexing Yoast
Я попробовал этот плагин на 2 моих сайтах, и он хорошо работает с WordPress 6. 0.1, у меня есть плагин Yoast, а на втором сайте у меня есть плагин AIO SEO.
У них потрясающее обслуживание клиентов!!!
Спасибо за прекрасную работу
0.1, у меня есть плагин Yoast, а на втором сайте у меня есть плагин AIO SEO.
У них потрясающее обслуживание клиентов!!!
Спасибо за прекрасную работу
Мне нравятся легкие плагины, которые сразу начинают работать! Делает не больше, чем нужно, но действительно хорош в том, что делает. Идеальный.
Это работает очень хорошо для меня и действительно сэкономило мне много возни и времени… Очень просто и легко.. Так счастлив, что я наткнулся на это…
Действительно очень приятный бонус в том, что он очень хорошо синхронизирован с Yoast SEO… Он подхватил некоторые noindex и nofollow, уже установленные через Yoast, позволил мне сбросить некоторые из них, а затем увидел, что новые, которые я установил с помощью этого плагина, были подхватывается в настройках Yoast на отдельных страницах…
И самое главное, когда этот плагин деактивирован, настройки в Yoast остаются… Не знаю, что может случиться, если я удалю этот плагин, но, возможно, я останусь(?), и в любом случае это хорошо, просто если я хочу держать его деактивированным до тех пор, пока это необходимо.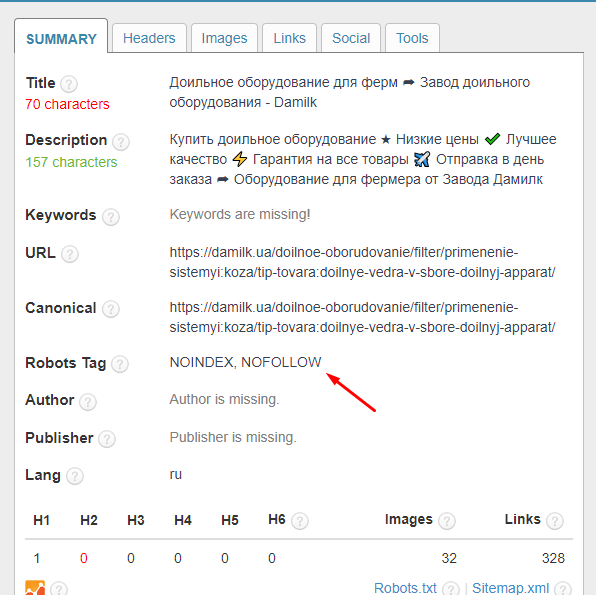
Кажется, это хобби-проект. Мой сайт разбился, надеюсь, вы удалите свой плагин из WordPress!
Именно то, что я искал. Список страниц и сообщений, позволяющий не индексировать, не следовать им массово.
«Bulk NoIndex & NoFollow Toolkit» — это программное обеспечение с открытым исходным кодом. Следующие люди внесли свой вклад в этот плагин.
Авторы- madfishцифровой
1.41
Дата выпуска: 28 июля 2022 г.
- Небольшой патч, устраняющий незначительное предупреждение в PHP 7.4
1.4
Дата выпуска: 27 июля 2022 г.
- Обновлены запросы для интерфейса, чтобы использовать меньше ресурсов
1.3
Дата выпуска: 26 июля 2022 г.
- В этом выпуске добавлена поддержка плагина All in One SEO Pack
1.2
Дата выпуска: 26 января 2021 г.
- В этом выпуске исправлены некоторые небольшие предупреждения PHP, которые появлялись в некоторых экземплярах php 7. 4.
 4.
4.1.1
Дата выпуска: 11 января 2021 г.
- В этом выпуске улучшен отлов ошибок, если функция wordpress is_plugin_active() не была загружена до загрузки этого плагина. В некоторых случаях из-за недоступности функции is_plugin_active возникала ошибка PHP.
Мета
- Версия: 1.41
- Последнее обновление: 7 месяцев назад
- Активные установки: 1000+
- Версия WordPress: 4.1 или выше
- Протестировано до: 6.1.3
- Версия PHP: 5.6 или выше
- Теги:
nofollownoindexseo
- Расширенный вид
Служба поддержки
Проблемы, решенные за последние два месяца:
0 из 1
Посмотреть форум поддержки
Пожертвовать
Хотите поддержать продвижение этого плагина?
Пожертвовать этому плагину
Какой правильный фрагмент кода nofollow/noindex? — Пользовательский код — Forum
myonke (Майкл Йонке) 1
Привет всем,
У меня есть два вопроса относительно noindex/nofollow для поисковых систем.
- Каков правильный фрагмент кода, чтобы запретить поисковым системам сканировать страницу? Я видел 3 разных варианта на форумах, которые были отмечены как правильный ответ. Вот два разных примера, которые я видел:
Один включает «/» в конце, а имена заключены в кавычки разных типов («против»). на самом деле не знаю, как проверить, что nofollow/noindex распознается, поэтому я не могу проверить каждый из них.Может ли кто-нибудь сообщить мне, что правильно?
- Мой второй вопрос: правильно ли я использую noindex/nofollow . У меня есть несколько пустых страниц коллекции. Я планировал добавить код noindex/nofollow в тег заголовка этих страниц, так как не хочу, чтобы Google думал, что у меня есть страницы без содержания. Должен ли я добавлять этот код на эти страницы? Должен ли я также включать этот код на мою страницу 404 (я видел это краткое упоминание на другом форуме) 9.0004
 Должен ли я добавлять этот код на эти страницы? Должен ли я также включать этот код на мою страницу 404 (я видел это краткое упоминание на другом форуме) 9.0004
Должен ли я добавлять этот код на эти страницы? Должен ли я также включать этот код на мою страницу 404 (я видел это краткое упоминание на другом форуме) 9.0004Спасибо за любую помощь, которую вы все можете предложить. Я действительно ценю это!
Вот моя ссылка для общего доступа и промежуточная ссылка, если она нужна для этого вопроса.
- Майкл
мёнке (Майкл Йонке)
Просто поднимите этот вопрос, если у кого-то есть окончательный ответ
Редактировать: @samliew @vincent есть шанс, что вы, ребята, могли бы помочь мне здесь, когда у вас будет шанс? Я был бы очень признателен!
бгарант (Брайан Гаррант) 3
Привет, Майкл,
Вместо этого используйте файл robots.txt. Это то, что я рекомендую для ваших настроек robots.txt и sitemap.xml для Webflow. Это позволит поисковым системам проиндексировать все страницы вашего сайта. Поскольку Webflow является динамическим, и вы, вероятно, используете CMS для динамических страниц, я не рекомендую выводить список всех ваших страниц вручную. Однако вы можете использовать этот подход, если хотите.
изображение 2324×1012 153 КБ
Если вы хотите исключить страницу или папку, вы можете использовать этот синтаксис:
изображение 1534×340 9,41 КБ
Надеюсь, это поможет!
Брайан
1 Нравится
мёнке (Майкл Йонке) 4
@bgarrant Большое спасибо за ответ, мне очень приятно. Просто чтобы убедиться, что я не ошибаюсь и не скрываю кучу вещей от Google, не могли бы вы пояснить мою настройку:
Просто чтобы убедиться, что я не ошибаюсь и не скрываю кучу вещей от Google, не могли бы вы пояснить мою настройку:
- У меня есть группа страниц коллекции. Страницы «Команды», «Местоположения», «Отзывы» и «Галереи героев» пусты. Однако я отображаю данные CMS из этих коллекций на страницах, отличных от их отдельной страницы коллекции CMS.
изображение480×510 12,6 КБ
Итак, я хочу скрыть указанные выше 4 страницы от Google, потому что я не хочу, чтобы поисковая система думала, что у меня пустой контент. Однако я определенно хочу, чтобы Google сканировал все остальные мои страницы .
Рекомендуется также запрещать юридические страницы, такие как Политика конфиденциальности?
Мой сайт settings/robots.txt выглядит следующим образом:
User-agent: *
Disallow: /team/
Disallow: /location/
Disallow: /testimonial/
Disallow: /hero-gallery/
Disallow: /terms-and-conditions/
Disallow: /privacy-policy/
image1510×1278 88,8 КБ
Все это кажется вам правильным для целей моего конкретного проекта?
Еще раз спасибо, я очень, очень благодарен за помощь.
бгарант (Брайан Гаррант) 5
Мне нравится, Майкл. Итак, чтобы было ясно, если вы добавите эти записи для блокировки папок, любые страницы в этих папках также должны быть заблокированы от индексации.
1 Нравится
мёнке (Майкл Йонке) 6
Еще раз спасибо, @bgarrant. Да, я это понимаю. Поэтому, если я запретлю «/location», то «Hoss Homes» также не будет сканироваться.
Последний вопрос, лучше ли добавлять эти запреты для ваших легальных страниц, например /privacy-policy?
Спасибо!
бгарант (Брайан Гаррант) 7
Я их обычно блокирую. Я не могу придумать причин для их индексации.
Я не могу придумать причин для их индексации.
1 Нравится
мёнке (Майкл Йонке) 8
@bgarrant Спасибо за помощь!
Очистка_Детейлинг (Мэтт Джи) 9
Короткий вопрос: если бы я хотел заблокировать динамические страницы CMS, но при этом индексировать корневую страницу, как бы я это сделал?
Пример: я хочу, чтобы страница mysite.com/reviews была проиндексирована, но я не хочу, чтобы каждый элемент коллекции (например, mysite.com/reviews/item-1 и т. д.) индексировался.
gtddesigns (Габриэла)