Возможные проблемы — Вебмастер. Справка
Раздел содержит решения часто встречающихся проблем категории «Возможные», выявленных при диагностике сайта в Вебмастере. Проблемы этой группы могут влиять на качество и скорость индексирования страниц сайта.
Совет. Настройте уведомления о результатах проверки сайта.
- Не найден файл robots.txt
- Обнаружены ошибки в файле robots.txt
- Нет используемых роботом файлов Sitemap
- Обнаружены ошибки в файлах Sitemap
- Отсутствуют элемент title и метатег description
- На страницах есть одинаковые заголовки и описания
- Файл favicon недоступен для робота
Несколько раз в сутки индексирующий робот запрашивает файл robots.txt и обновляет информацию о нем в своей базе. Если при очередном обращении робот не может загрузить файл, в Вебмастере появляется соответствующее предупреждение.
В сервисе проверьте доступность файла robots.txt. Если файл по-прежнему недоступен, добавьте его.
Проверьте файл robots.txt вашего сайта. Чтобы исправить ошибки, посмотрите описания директив.
Файл Sitemap является вспомогательным инструментом при индексировании сайта, он позволяет регулярно сообщать роботу о появлении новых страниц на сайте. Данное предупреждение появляется, если робот не использует ни одного файла Sitemap для сайта.
Чтобы робот начал использовать созданный файл, добавьте его в Вебмастер и дождитесь обработки файла роботом. Обычно на это требуется до двух недель. После этого предупреждение пропадет.
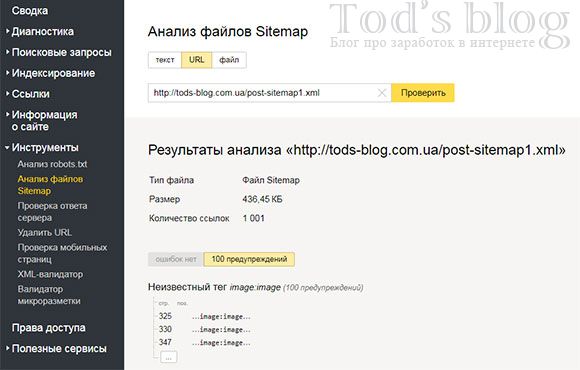
Проверьте файл Sitemap вашего сайта. Проверка может выявить ошибку «Неизвестный тег». Она сообщает, что файл содержит неподдерживаемые Яндексом элементы. Такие элементы игнорируются роботом при обработке Sitemap, но данные из поддерживаемых элементов учитываются.
Элемент title и метатег description помогают сформировать корректное описание сайта в результатах поиска. Подробно см. раздел Отображение заголовка и описания сайта в результатах поиска.
Если элементы или один из них отсутствуют на вашем сайте, добавьте их в HTML-код страниц и сохраните изменения. Если элементы уже размещены, дождитесь, пока робот переобойдет страницы. После этого сообщение об ошибке исчезнет. Подробно
Эта проблема отображается, если заголовок или описание повторяется на значительной доле страниц сайта. Когда title и description отражают контент страницы, информативны и привлекательны, пользователям удобнее находить ответы в поисковой выдаче.
Посмотрите примеры страниц с повторяющимися заголовками или описаниями, которые обнаружил Вебмастер при обходе сайта роботом. Чтобы исправить их, следуйте рекомендациям по:
написанию title;
составлению description.


Проблема перестанет отображаться, когда робот узнает об изменениях на сайте. Чтобы это произошло быстрее, отправьте наиболее важные страницы на переобход или настройте обход страниц со счетчиком Метрики.
Если эта проблема отображается для вашего сайта, значит Небольшая картинка, которая отображается в сниппете в результатах поиска Яндекса, рядом с адресом сайта в адресной строке браузера, около названия сайта в Избранном или в Закладках браузера.»}}»> не отображается в результатах поиска. В Вебмастере на странице Диагностика → Диагностика сайта (блок Возможные проблемы) посмотрите причину, по которой робот не смог загрузить файл и следуйте указаниям:
| Ошибка | Решение |
|---|---|
| Файл отвечает HTTP-кодом, отличным от 200 OK | Проверьте ответ сервера. Ответ должен соответствовать 200 OK. Другие статусы ответа см. в разделе Проверка ответа сервера. Ответ должен соответствовать 200 OK. Другие статусы ответа см. в разделе Проверка ответа сервера. |
| Файл перенаправляет на другой адрес | |
| Неправильный тип данных | Проверьте значение параметра type в ссылке на файл. Он должен соответствовать формату файла. |
Как установить фавиконку
Чтобы ваш вопрос быстрее попал к нужному специалисту, уточните тему:
Посмотрите рекомендации. Если файл доступен для робота и загружается в Вебмастере, но проблема продолжает отображаться, заполните форму:
Посмотрите рекомендации выше. Если файл добавлен больше 2 недель назад, но сообщение не пропадает, заполните форму:
Посмотрите рекомендации выше. Если ошибок в файле нет, но сообщение продолжает отображаться, заполните форму:
Посмотрите рекомендации выше. Если ответ сервера соответствует 200 ОК и значение параметра type соответствует формату файла, но сообщение продолжает отображаться, заполните форму:
Почему в Я.
 Вебмастер «Нет используемых роботом файлов Sitemap»?
Вебмастер «Нет используемых роботом файлов Sitemap»?warlife
#1
#1
Здравствуйте поменял домен http на https и теперь в вебмастере яндекс выбивает вот такая ошибка
как ее исправить
Alisa
#2
#2
Яндекс получает sitemap из robots., если там есть карта сайта, значит всё хорошо.
Alexdron
#3
#3
warlife написал(а):
Здравствуйте поменял домен http на https и теперь в вебмастере яндекс выбивает вот такая ошибка
Посмотреть вложение 1064
как ее исправить
Нажмите для раскрытия…
После отправки на индексацию , пришел такой же ответ! Нужно что то делать или нет ? где то читал что нужно переименовать на sitemap.xml . Это поможет или же все такие пока ничего не надо делать ?
Alisa
#4
#4
Alexdron написал(а):
После отправки на индексацию , пришел такой же ответ! Нужно что то делать или нет ? где то читал что нужно переименовать на sitemap. xml . Это поможет или же все такие пока ничего не надо делать ?
xml . Это поможет или же все такие пока ничего не надо делать ?
Нажмите для раскрытия…
По умолчанию после создания, на сайте не индексируются фильмы без уникальных описаний,
Если дело не в этом, смотрите какую ошибку пишет Яндекс или напишите им в поддержку.
«В вашем файле robots.txt нет ссылки на карту сайта»
спросил
Изменено 1 год, 9 месяцев назад
Просмотрено 8к раз
Относительно новое для всего, что не требует здравого смысла в WordPress. Мой предыдущий сайт был сделан плохо и т. д., поэтому, короче говоря, я установил новую тему и снова начал создавать страницы и т.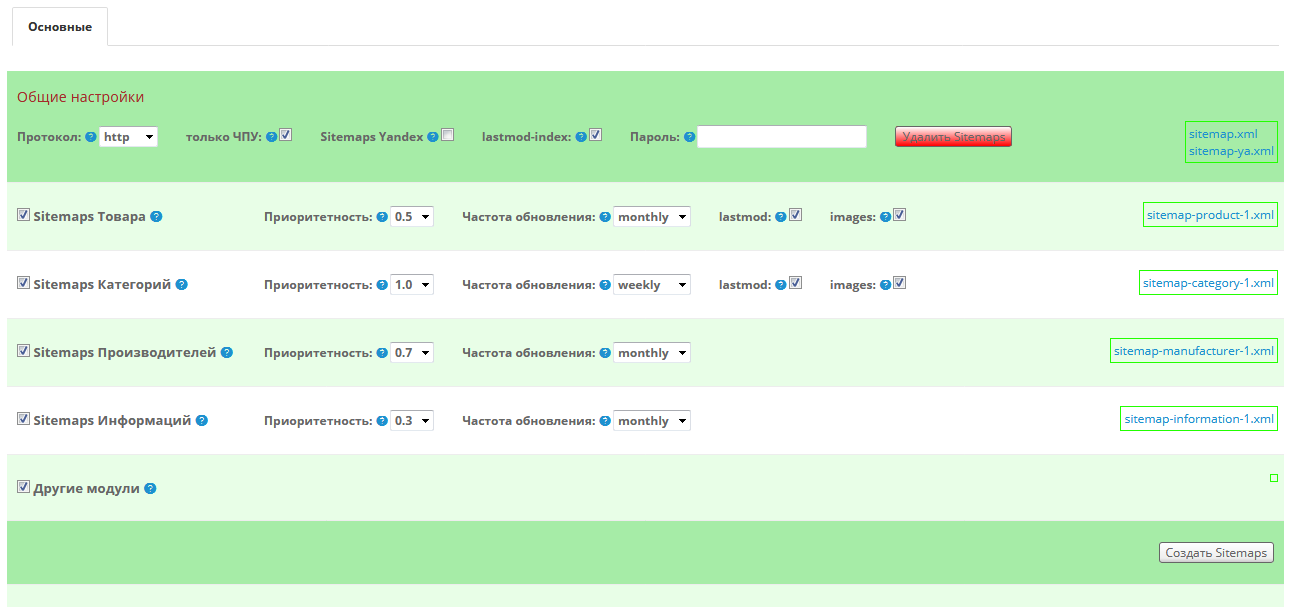 д.
д.
Во время работы я провел различные диагностики SEO и т. д., и у меня возникли проблемы с индексируемостью и картами сайта.
Получение этого сообщения на проверке сайта onpage.org и нечто подобное на другой платформе, где говорится, что есть ресурсы, индексация которых запрещена.
Пожалуйста, помогите как можно скорее, так как у меня хороший рейтинг, и я не хочу, чтобы это повлияло на следующее сканирование.
- карта сайта
- robots.txt
1
Ну, это сообщение говорит само за себя. В вашем файле robots.txt нет ссылки на карту сайта. Итак, вы проверяете, есть ли у вас карта сайта (если нет, то устанавливаете плагин, который сгенерирует ее для вас) и добавляете эту строку в файл robots.txt в корне вашего сайта:
Карта сайта: http://www.example. com/sitemap.xml
Во-первых, я не знаю, есть ли у вас карта сайта. Если нет, я предлагаю вам установить плагин YOAST SEO для управления вашими картами сайта.
С Yoast ваша карта сайта имеет эту ссылку: http://domain.com/sitemap_index.xml
Затем добавьте карту сайта в файл robots.txt, например:
Карта сайта: http://domain.com/sitemap_index.xml
Если у вас уже есть карта сайта без Yoast, выполните те же действия. Просто добавьте URL-адрес карты сайта в файл robots.txt, как показано выше.
О вашем комментарии:
Пожалуйста, помогите как можно скорее, так как у меня хороший рейтинг и я не хочу, чтобы это повлияло на следующее сканирование
Карта сайта — это всего лишь файл, который помогает поисковым роботам находить ваши страницы. Но если ваши новые страницы связаны на других страницах вашего сайта (например, на главной странице), поисковые роботы идентифицируют ваши новые страницы таким же образом.
Тогда не беспокойтесь об этом предупреждении. Есть много других важных вещей, которые следует учитывать, когда мы говорим о SEO, например, хороший контент, удобочитаемость контента, скорость страницы и мобильная навигация (отзывчивая и с усилителем).
Вы должны использовать Yoast Tool, Edit Files для создания и изменения robots.text.
WordPress Robot.txt tutorial
Тогда да, добавьте
Карта сайта: https://domain.com/sitemap_index.xml
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
.
robots.txt Объяснение! Не упускайте из виду важность этого
Информационного файла robots.txt Карта сайта Опубликовано
Последнее обновление 27 июля 2020 г.
В предыдущем блоге мы обсуждали преимущества карты сайта. xml на нашем сайте. В этом блоге мы собираемся обсудить важность файла /robots.txt на нашем сайте.
Что такое /Robots.Txt?
/robots.txt — это текстовый файл, расположенный в корневом каталоге веб-сервера нашего веб-сайта. Это важный файл, поскольку он используется для предоставления веб-роботам инструкций о веб-контенте нашего сайта. Веб-роботы, сканеры или пауки — это программы, используемые поисковыми системами для индексации веб-контента веб-сайта. Эти данные инструкции называются протоколом исключения роботов.
Файл /robots.txt — это общедоступный файл, доступ к которому можно получить, введя URL-адрес, например http://wwwmysite. com/robots.txt. Любой может увидеть содержимое файла и места, к которым вы не хотите, чтобы веб-роботы имели доступ. Это означает, что файл /robots.txt не должен использоваться для сокрытия важной информации на вашем сайте.
com/robots.txt. Любой может увидеть содержимое файла и места, к которым вы не хотите, чтобы веб-роботы имели доступ. Это означает, что файл /robots.txt не должен использоваться для сокрытия важной информации на вашем сайте.
Файл /robots.txt — это первое, что ищут роботы поисковых систем при посещении веб-сайта… Нажмите, чтобы твитнуть
Синтаксис и содержимое файла Robot.txt
Инструкции, данные в файле /robots.txt, включают расположение карты сайта нашего сайта, к какому каталогу мы хотим и не хотим, чтобы веб-роботы имели доступ, и к каким страницам мы хотим и не хотим, чтобы веб-робот имел доступ. Простая синтаксическая инструкция файла /robots.txt:
User-agent: *
Disallow: /
Строка «User-agent: *» означает, что инструкции в файле распространяются на всех роботов. «Запретить: /» указывает роботу не сканировать страницы сайта.
Другими стандартными инструкциями в /robots.txt могут быть:
- Разрешить полный доступ к содержимому веб-сайта, но заблокировать папку или страницу:
User-agent: *
Disallow: /folder/
Disallow: /page. html
html
- Разрешить полный доступ к содержимому веб-сайта, но заблокировать файл:
User-agent: *
Disallow: /file-name.pdf
- Разрешить полный доступ к содержимому веб-сайта, но заблокировать сканирование определенного веб-робота:
User-agent: *
Disallow:
User-agent: Googlebot
Disallow: /
посещение сайта robots. .org/db.html
Узнайте о нашем White Label SEO — запланируйте встречу
Нам нужно отделить строку «Запретить» для каждого префикса URL, который мы хотим исключить. Подстановка и регулярное выражение не поддерживаются ни в User-agent, ни в строках Disallow. «*» в поле User-agent — это специальное значение, означающее «любой робот».
Правильно:
User-agent: *
Disallow: /file-name.pdf
Disallow: /folder1/
DISLAING: /FOLDER2 /
ОШИБКА:
Пользовательский агент: *
DISLAIN /*
Почему файл robots.
 txt важен?
txt важен?Мы должны знать о важности файла /robots.txt, потому что неправильное использование файла может повредить рейтингу веб-сайта . Это первый файл, который ищет робот поисковой системы при посещении веб-сайта.
Файл /robots.txt содержит инструкции, управляющие тем, как роботы поисковых систем видят веб-страницы сайта и взаимодействуют с ними. Этот файл, а также боты, с которыми он взаимодействует, являются фундаментальными элементами работы поисковой системы.
Файл /robots.txt — это первое, что ищут роботы поисковых систем при посещении веб-сайта, поскольку они хотят знать, есть ли у них разрешение на доступ к содержимому сайта и какие папки, страницы и файлы могут сканироваться.
Некоторые из причин наличия файла /robots.txt на нашем веб-сайте могут включать:
- У нас есть контент, который мы хотим заблокировать от поисковых систем.
- Существуют платные ссылки или рекламные объявления, требующие специальных инструкций для различных веб-роботов.
- Мы хотим ограничить доступ к нашему сайту авторитетных роботов.
- Мы разрабатываем работающий сайт, но вы пока не хотите, чтобы поисковые системы его индексировали.
- Часть или все вышеперечисленное верно, но у нас нет полного доступа к нашему веб-серверу и его настройке.

Другие методы могут контролировать вышеуказанные причины, однако файл /robots.txt является правильным и простым центральным местом для их устранения. Если на нашем веб-сайте нет файла /robots.txt, поисковая система робота будут иметь полный доступ к нашему сайту.
Что означают КЛЮЧЕВЫЕ слова инструкции?
«User-agent:» -> Укажите, какие инструкции применять к конкретному роботу. Утверждение типа «User-agent: *» означает, что директивы применяются ко всем роботам. Утверждение вроде «Агент пользователя: Googlebot» означает, что инструкции применимы только к Googlebot.
«Запретить:» -> Сообщите веб-роботам, какие папки им не следует просматривать.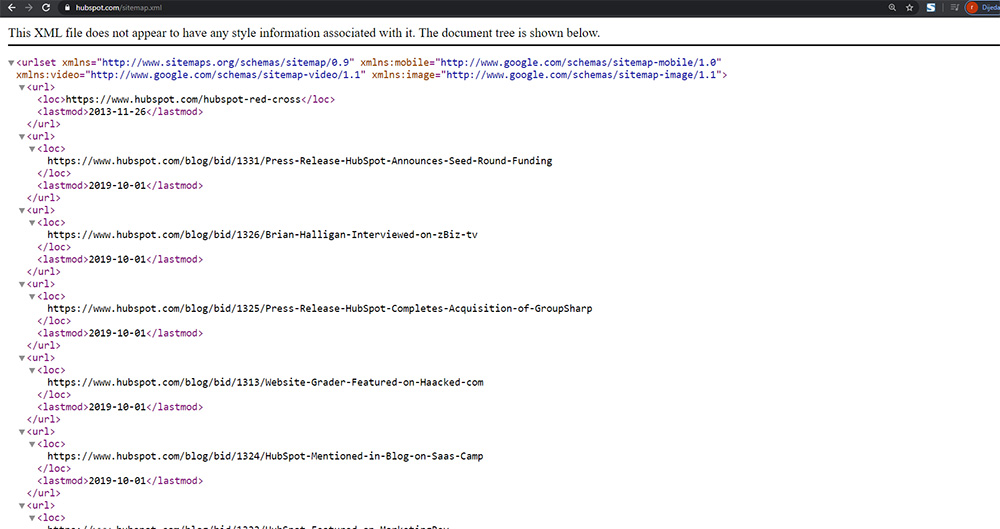 Это означает, что если, например, вы не хотите, чтобы поисковые системы индексировали изображения на вашем сайте, вы можете поместить эти изображения в одну папку и исключить ее, например «Запретить: /images/».
Это означает, что если, например, вы не хотите, чтобы поисковые системы индексировали изображения на вашем сайте, вы можете поместить эти изображения в одну папку и исключить ее, например «Запретить: /images/».
«Разрешить:» -> Сообщите роботу, что он может видеть файл в папке, которая была «Запрещена» другими инструкциями. Например:
Агент пользователя: *
Запретить: /images/
Разрешить: /images/myphoto.jpg
«Карта сайта:» -> Сообщить роботу местоположение карты сайта. файл. Например:
Агент пользователя: *
Карта сайта: https://www.mysite.com/sitemap.xml
Запретить: /images/
Разрешить: /images/myphoto.jpg
Роботы Метатег, это важно?
Мы обсудили важность и использование файла /robots.txt на нашем веб-сайте, но есть и другой способ контролировать посещение веб-роботами наших сайтов. Другой способ — через метатег Robots.
Как и любой тег, он должен быть помещен в раздел
HTML-страницы. Кроме того, лучше всего размещать его на каждой странице вашего сайта, потому что робот может столкнуться с глубокой ссылкой на любую страницу вашего сайта.Атрибут «имя» должен быть «РОБОТЫ».
Допустимые значения атрибута «content»: «INDEX», «NOINDEX», «FOLLOW», «NOFOLLOW». Допускается несколько значений, разделенных запятыми, но, очевидно, только некоторые комбинации имеют смысл. Если тег robots отсутствует, по умолчанию используется «INDEX, FOLLOW», поэтому нет необходимости указывать это. Другие возможные варианты использования тега robots:
Использование метатега больше связано с конкретными страницами, которые мы не хотим сканировать веб-роботами.