
Как добавить ресурс в Google Search Console: пошаговая инструкция
20567
| How-to | – Читать 9 минут |
Прочитать позже
ЧЕК-ЛИСТ: МОНИТОРИНГ
Инструкцию одобрил SEO Classifieds Specialist в Inweb
Виктор Саркисов
Google Search Console — это инструмент от Google, который показывает технические ошибки ресурса, поисковый трафик, состояние индексирования страниц, позволяет добавить карту сайта и прочее. Умение работать с сервисом обязательно для продвижения в поисковой системе Google и ускорения внутренней оптимизации.
Содержание
Зачем нужно добавлять сайт в Google Search Console?
— Что будет, если не добавлять свой сайт в Google Search Console?
Как добавить сайт в Google Search Console?
— Подтверждение прав на сайт с помощью DNS
— Подтверждение прав на сайт с помощью загрузки файла
— Подтверждение прав на сайт с помощью тега HTML
— Подтверждение с помощью Google Analytics
— Как найти код отслеживания?
— Подтверждение с помощью Менеджера тегов Google
Как предоставить доступ в Google Search Console
Общие ошибки при добавлении сайта в Google Search Console
FAQ
Заключение
Зачем нужно добавлять сайт в Google Search Console?
Search Console — это панель вебмастера Google. Аналог данной консоли для Яндекса — Яндекс.Вебмастер.
Аналог данной консоли для Яндекса — Яндекс.Вебмастер.
Официальная справка Google подробно рассказывает, чем полезен Google Вебмастер:
Почему следует добавить сайт в Google Search Console
Благодаря Google Search Console вы получаете бесплатный функционал для внутреннего мониторинга сайта. Остается только сразу реагировать на ошибки.
Благодаря сервису Serpstat вы можете мониторить позиции сайта в поисковой выдаче.
Что будет, если не добавлять свой сайт в Google Search Console?
Вы потеряете важную информацию об индексации страниц сайта, sitemap.xml, robots.txt и других параметрах. Согласно Google поиск, добавить сайт в консоль — опция, а не требование к вебмастеру. Для попадания в индекс это необязательно. Однако для продвижения нужны следующие инструменты:
Инструменты Google Search Console
Поэтому для внутренней оптимизации сайта и его анализа консоль Google — must have.
Как добавить сайт в Google Search Console?
Чтобы создать аккаунт Search Console, понадобится аккаунт в Google. Создайте для сайта отдельную почту. Техническая поддержка поможет разобраться в тонкостях. Выполните инструкцию пошагово:
Перейдите на страницу Google Search Console по ссылке и нажмите кнопку «Попробовать», которая находится внизу:
Начало работы с Search Console
После авторизации следует нажать кнопку добавить ресурс и вам сразу предложат выбрать один из двух вариантов — доменный ресурс или ресурс с префиксом. Если вы выбрали «Ресурс с префиксом в URL», добавьте полную ссылку из адресной строки вместе со слешем и с корректным протоколом http или https, обратите на это внимание, если подключен ssl сертификат. Например, https://example.com/. При выборе доменного ресурса можно указать домен сайта в любой форме, но при этом понадобится подтверждение с помощью записи dns.
После добавления домена или URL-адреса нажмите «Продолжить»:
Выбор типа ресурса
Возможны такие способы подтверждения прав собственности на сайт:
- скачать html файл и загрузить его в каталог с сайтом;
- с помощью метатега HTML, установленного в коде главной страницы ресурса;
- при помощи кода отслеживания Google Analytics;
- посредством фрагмента-контейнера в Google Tag Manager.


Если выбран доменный ресурс, подтвердить права на сайт можно только с помощью DNS.
#1
Подтверждение прав на сайт с помощью DNS
В Search Console можно открыть инструкцию по подтверждению прав с помощью DNS для нужного хостинг-провайдера.
Для этого понадобится доступ к регистратору домена с правом добавлять записи TXT, CNAME. Воспользуйтесь справкой, если это необходимо. Вы получите подробное описание: кто такие провайдеры доменных имен и как можно подтвердить право на домен, если его нет в предложенном списке. Добавьте текстовую TXT-запись в DNS для подтверждения. Выберите из списка провайдера или регистратора доменного имени. После внесения изменений может потребоваться несколько часов для успешного подтверждения прав на сайт.
#2
Подтверждение прав на сайт с помощью загрузки файла
Вам понадобится доступ к FTP. Загрузите HTML-файл на свой компьютер, щелкнув по нему в пункте 1.
Скачайте файл для подтверждения прав на сайт
Теперь следует добавить файл в корневую папку сайта, как показано на скриншоте на примере корневой папки для платформы WordPress:
Корневая папка сайта WordPress
Распространенная ошибка — загрузка регистрационного файла не в корень, а во внутренние папки корня. Система не примет подтверждение прав в таком случае. Файл должен располагаться в корне сайта, а не в папках.
Сюда нужно добавить файл для подтверждения прав на сайт
После добавления файла нажмите кнопку «Подтвердить» в Google Search Console.
#3
Подтверждение прав на сайт с помощью тега HTML
Выберите соответствующее поле, скопируйте ключ подтверждения и добавьте следующий тег <meta> в HTML-код на главную страницу. Пример тега:
Подтверждение прав на сайт через тег HTML
Разместите его в разделе <head> перед первым <body>.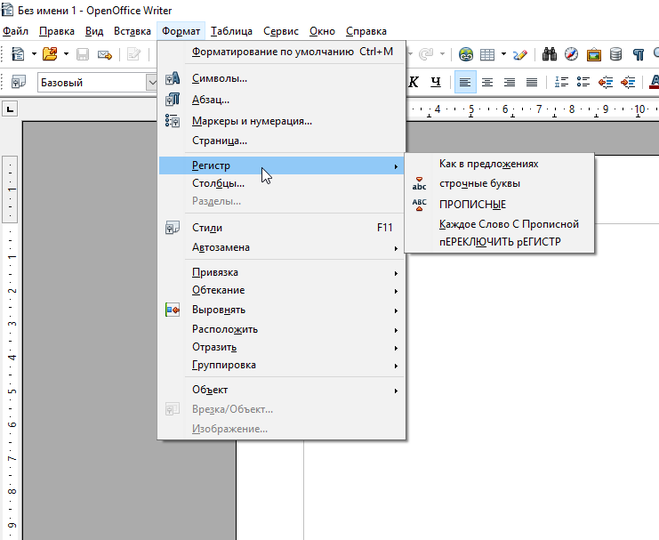 Перечень возможных ошибок доступен по ссылке.
Перечень возможных ошибок доступен по ссылке.
#4
Подтверждение с помощью Google Analytics
Выберите одноименное поле, как на картинке ниже:
Выбор подтверждения прав на сайт через Google Аналитику
Тут нужны права, позволяющие менять настройки сайта в этой системе. Скопируйте код, в котором обязательно должен присутствовать фрагмент analytics.js или gtag.js.
Как найти код отслеживания?
Зайдите в учетную запись Google Analytics и выберите ваш сайт, нажав «Администратор». В раскрывающемся окне нажмите на нужный аккаунт.
В меню ресурса выберите нужный сайт. Потом нажмите на поле «Отслеживание» и выберите «Код отслеживания». Здесь содержится идетификатор отслеживания.
Идентификатор отслеживания в Google Аналитике
Далее добавьте данный код в раздел <head> страницы сайта. При выборе данного способа все администраторы из Google Analytics также получают доступ в Google Search Console.
#5
Подтверждение с помощью Менеджера тегов Google
Выберите способ подтверждения своих прав через Менеджер тегов:
Подтверждение прав через Менеджер тегов
Зарегистрируйтесь или войдите в существующий аккаунт. Создайте контейнер для своего сайта. Следуйте инструкции:
Создание аккаунта и контейнера в Менеджере тегов
После установки контейнера, которая подробнее расписана по ссылке выше, переходите к подтверждению прав в Google Search Console. У вас должно быть разрешение на «Просмотр, изменение и управление» на уровне контейнера в Менеджере тегов Google. Вставьте элемент <noscript> кода Менеджера после открывающего тега <body> страницы.
Как предоставить доступ в Google Search Console
Владелец ресурса может предоставлять право доступа к аккаунту Search Console другим пользователям. Для предоставления доступа следует перейти в раздел «Настройки» → «Пользователи и разрешения». При открытии доступа следует выбрать подходящие права:
Для предоставления доступа следует перейти в раздел «Настройки» → «Пользователи и разрешения». При открытии доступа следует выбрать подходящие права:
- владелец — пользователю будут предоставлены права владения сайтом;
- полный доступ — тогда пользователь сможет получать все статистические данные по веб-сайту, а также осуществлять отдельные действия;
- ограниченный доступ — пользователю будет доступна основная часть аналитических данных.
Предоставление права доступа к аккаунту Search Console
Общие ошибки при добавлении сайта в Google Search Console
В процессе добавления ресурса в Search Console и подтверждения прав часто возникают ошибки:
Ошибки при добавлении сайта в Search Console
Изучите их, прежде чем паниковать, если что-то пошло не так.
Для чего нужна Google Search Console?
Google Search Console нужна для работы над продвижением и анализом эффективности сайта. Инструмент позволяет добавлять XML-карты и отдельные URL для ускорения индексации, проверять адаптацию под мобильные устройства, анализировать поисковые запросы и средние позиции. При возникновении каких-либо ошибок, связанных с работой ресурса, они отобразятся в соответствующих разделах Search Console, а владелец сайта получит уведомление по email.
Инструмент позволяет добавлять XML-карты и отдельные URL для ускорения индексации, проверять адаптацию под мобильные устройства, анализировать поисковые запросы и средние позиции. При возникновении каких-либо ошибок, связанных с работой ресурса, они отобразятся в соответствующих разделах Search Console, а владелец сайта получит уведомление по email.
Что такое доменный ресурс?
При добавлении сайта в Search Console доступно 2 варианта: использование домена с учетом всех поддоменов и вариантов протоколов http/https или ресурса с определенным протоколом http/https. При выборе доменного ресурса необходимо подтвердить права на него только с помощью DNS-записи.
Заключение
Добавление сайта в Google Search Console — де-факто обязательное условие на старте продвижения проекта.
Настройка Search Console происходит через панель, где сначала нужно подтвердить права на веб-ресурс одним из способов:
- разместить HTML-файл на сервере;
- добавить тег HTML;
- указать провайдера доменных имен;
- подключить Google Analytics;
- с помощью Менеджера тегов Google.
Для первого способа подтверждения нужен доступ к FTP. Здесь загрузите готовый документ в корень.
Во втором способе скопируйте код и разместите его в соответствующем поле Главной страницы.
Чтобы подтвердить принадлежность к сайту через провайдеров — получите доступ на внесение записи.
Если у вас настроен Google Analytics, то воспользуйтесь кодом для подтверждения права.
Google Tag Manager потребует от вас ряд манипуляций с контейнерами и размещением тега.
«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
| Начать работу со «Списком задач» |
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Получить бесплатный доступ на 7 дней
Оцените статью по 5-бальной шкале
3.79 из 5 на основе 13 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Анастасия Сотула
Какими должны быть шрифты, кнопки и цвета в мобильной версии сайта
How-to
Анастасия Сотула
Что такое CDN и как его настроить
How-to
Анастасия Сотула
Как провести юзабилити-аудит сайта
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Регистр имени сайта настройка | WordPress Mania
|
Просмотров: 856
Сегодня я покажу вам, как можно изменить написание регистра имени сайта для поисковой выдачи Яндекс, а так же, как сообщить Yandex о скором появлении оригинального текста на вашем сайте. Читайте небольшой пост — Регистр имени сайта настройка для Yandex. Вы можете изменить способ записи URL-адреса сайта в результатах поиска для Яндекс. Это сделает его более понятным и информативным для пользователей. Это изменение не влияет на ранжирование в результатах поиска.
Это изменение не влияет на ранжирование в результатах поиска.
Что это такое Регистр имени сайта
Инструмент Яндекс.Вебмастер позволяет изменить написание адреса (url) сайта в поиске, чтобы сделать его более понятным и информативным для пользователей. Изменение регистра имени блога касаются только отображения сайта на странице результатов поиска, поэтому на ранжирование не влияют.
Кому не понятно поясню о чем идет речь. На странице результатов поиска Яндекс, ваш адрес блога выглядит например так — wpmania.ru или wordpressmania.ru, а после изменения написание адреса (url) сайта будет смотреться вот — WPMania.ru и соответственно WordPressMania.ru. Заметили разницу?
Сразу заметно, что доменное имя состоит из двух слов и смотрится более красиво. После небольшой манипуляции, мои адреса блогов на странице выдачи Yndex, теперь выглядят так:
Регистр имени сайта WPMania.ruи вот мой блог для новичков о WordPress:
Регистр имени сайта в ЯндексЕсли вас эта фишка заинтересовала тогда вперед, будем менять регистр имени сайта.
Настройка регистра имени сайта. Как изменить написание адреса (url) сайта для поисковой выдачи Yandex
Изменения в регистр должны вноситься исключительно с целью улучшения читабельности доменного имени. Допускается не более пяти прописных букв подряд. Заглавные буквы в известных аббревиатурах или аббревиатурах, которые поддерживаются контентом сайта, допускаются в соответствии с правилами русского языка. Например, NASA.com, RusPromAuto.ru или как у меня. WPMania.ru состоит из двух слов WP — аббревиатура WordPress и слово Mania.
Зайдите на Яндекс. Вебмастер — Мои сайты. Выберите из списка блог который вам нужен. Далее, «Информация о сайте» — «Регистр имени сайта»:
Настройка регистра имени сайтаВы можете определить способ написания регистр имени сайта / блога (Регистр букв URL-адреса) в результатах поиска Яндекс. Введите желаемый способ написания, причину изменения и нажмите «Изменить». Если все правильно указали то, появится информация например такая: Вы оставили заявку на изменение имени хоста на JaPovarenok. ru.
ru.
Изменения вступают в силу после их проверки и обновления поисковой базы. Яндекс оставляет за собой право не применять те изменения в имени сайта, которые предназначены только для искусственного выделения сайта в выдаче, а не для улучшения понимания пользователем имени сайта.
Я подал заявку для блога WordPress Mаnia раньше и все прошло успешно. Мой Регистр имени сайта изменён без проблем. Результаты Вы уже видели на скриншотах выше. Идем дальше.
Оригинальные тексты в Яндекс
Если Вы публикуете на своем сайте оригинальные тексты, а их перепечатывают другие интернет-ресурсы, предупредите Яндекс о скором выходе нового контента. Поисковик будет знать, что оригинальный текст впервые появился именно на вашем блоге, и попробует использовать это в настройке поисковых алгоритмов.
Яндекс отключил инструмент Оригинальные тексты
Многие вебмастера пользовались инструментом Оригинальные тексты, чтобы рассказывать роботу Яндекса о появляющихся на их сайтах текстах. Эти данные могли применяться, чтобы обучить алгоритмы отличать оригинальные тексты от заимствований. С сегодняшнего дня Оригинальные тексты прекращают свою работу.
Эти данные могли применяться, чтобы обучить алгоритмы отличать оригинальные тексты от заимствований. С сегодняшнего дня Оригинальные тексты прекращают свою работу.
C 15 сентября мы отключаем инструмент «Оригинальные тексты». Поисковые роботы оценят качество, ценность и оригинальность вашего контента. Задача вебмастеров — оперативно донести обновления сайта до робота. Это можно сделать двумя способами: через обход по счетчикам Метрики или в разделе Переобход страниц в Вебмастере.
Яндекс.Вебмастер
Чтобы сообщить Яндексу о новом контенте сайта, используйте «Переобход страниц» или через Обход по счётчикам Метрики.
В 2015 году SEO-специалист Игорь Бакалов попытался на практике проверить эффективность использования инструмента – дает ли он какие-то преимущества оригинальным текстам в ранжировании Яндекса или нет. Эксперимент показал, что инструмент «Оригинальные тексты» не выполняет свою функцию — даже сайты, находящиеся под фильтром АГС, ищутся в поиске выше оригинала.
Надеюсь было для вас полезно. До новых встреч.
Почему URL-адреса чувствительны к регистру? — Webmasters Stack Exchange
Почему URL-адрес не чувствителен к регистру?
Я понимаю, что это может выглядеть как провокационный (и «адвокат дьявола») тип риторического вопроса, но я думаю, что это полезно рассмотреть. Конструкция HTTP заключается в том, что «клиент», который мы обычно называем «веб-браузером», запрашивает данные у «веб-сервера».
Выпущено очень много различных веб-серверов. Microsoft выпустила IIS с операционными системами Windows Server (и другими, включая Windows XP Professional). У Unix есть тяжеловесы, такие как nginx и Apache, не говоря уже о более мелких предложениях, таких как внутренний httpd OpenBSD, или thttpd, или lighttpd. Кроме того, многие сетевые устройства имеют встроенные веб-серверы, которые можно использовать для настройки устройства, включая устройства, предназначенные для конкретных сетей, такие как маршрутизаторы (включая множество точек доступа Wi-Fi и модемы DSL) и другие устройства, такие как принтеры или ИБП (блоки бесперебойного питания с батарейным питанием), которые могут иметь возможность подключения к сети.
Таким образом, вопрос «Почему URL-адреса чувствительны к регистру?» спрашивается: «Почему веб-серверы обрабатывают URL-адреса как чувствительные к регистру?» И фактический ответ таков: они не все делают это. По крайней мере, один довольно популярный веб-сервер обычно НЕ чувствителен к регистру. (Веб-сервером является IIS.)
Ключевая причина различий в поведении разных веб-серверов, вероятно, сводится к простоте. Простой способ создать веб-сервер — это делать все так же, как операционная система компьютера/устройства находит файлы. Во многих случаях веб-серверы находят файл, чтобы предоставить ответ. Unix был разработан для компьютеров более высокого уровня, и поэтому Unix обеспечивал желаемую функциональность, разрешая использование прописных и строчных букв. Unix решил рассматривать прописные и строчные буквы как разные, потому что они разные. Это простое, естественное дело. Windows имеет историю нечувствительности к регистру из-за желания поддерживать уже созданное программное обеспечение, и эта история восходит к DOS, которая просто не поддерживала строчные буквы, возможно, в попытке упростить работу с менее мощными компьютерами, которые использовали меньше памяти.
Теперь, со всей этой предысторией, вот несколько конкретных ответов на конкретные вопросы:
Когда URL-адреса только разрабатывались, почему регистрозависимость стала функцией?
Почему бы и нет? Если бы все стандартные веб-серверы были нечувствительны к регистру, это означало бы, что веб-серверы следуют набору правил, установленных стандартом. Просто не было правила, говорящего о том, что регистр нужно игнорировать. Причина отсутствия правила заключается просто в том, что не было причин для существования такого правила. Зачем придумывать ненужные правила?
Я спрашиваю об этом, потому что мне (т. е. непрофессионалу) кажется, что нечувствительность к регистру предпочтительнее, чтобы предотвратить ненужные ошибки и упростить и без того сложную строку текста.
URL-адреса были созданы для машинной обработки. Хотя человек может ввести полный URL-адрес в адресную строку, это не было основной частью задуманного дизайна. Предполагаемый дизайн заключается в том, что люди будут следовать («нажимать») гиперссылкам. Если это делают обычные неспециалисты, то им все равно, простой или сложный невидимый URL-адрес.
Хотя человек может ввести полный URL-адрес в адресную строку, это не было основной частью задуманного дизайна. Предполагаемый дизайн заключается в том, что люди будут следовать («нажимать») гиперссылкам. Если это делают обычные неспециалисты, то им все равно, простой или сложный невидимый URL-адрес.
Кроме того, есть ли реальная цель/преимущество в использовании URL-адреса с учетом регистра (в отличие от подавляющего большинства URL-адресов, которые указывают на одну и ту же страницу независимо от заглавных букв)?
Пятый пронумерованный пункт ответа Уильяма Хэя упоминает одно техническое преимущество: URL-адреса могут быть эффективным способом для веб-браузера отправить немного информации на веб-сервер, и больше информации может быть включено, если есть меньше ограничений, поэтому ограничение чувствительности к регистру уменьшит количество информации, которую можно включить.
Однако во многих случаях чувствительность к регистру не дает супер убедительного преимущества, о чем свидетельствует тот факт, что IIS обычно не беспокоится об этом.
Подводя итог, можно сказать, что наиболее убедительной причиной является простота для тех, кто разработал программное обеспечение веб-сервера, особенно на такой чувствительной к регистру платформе, как Unix. (HTTP не повлиял на первоначальный дизайн Unix, поскольку Unix значительно старше HTTP.)
Должен ли URL учитывать регистр?
В соответствии с «HTML и URL-адресами» W3 они должны:
Могут быть URL-адреса или части URL-адресов, где регистр не имеет значения, но определить их может быть непросто. Пользователи всегда должны учитывать, что URL-адреса чувствительны к регистру.
8
Все « нечувствительные » выделены жирным шрифтом для удобства чтения.
Доменные имена нечувствительны к регистру в соответствии с RFC 4343. Остальная часть URL-адреса отправляется на сервер с помощью метода GET. Это может быть чувствительным к регистру или нет.
Возьмем, к примеру, эту страницу: stackoverflow.com получает строку GET /questions/7996919/should-url-be-case-sensitive, отправляя HTML-документ в ваш браузер. Stackoverflow.com нечувствителен к регистру , потому что он дает тот же результат для /QUEStions/7996919/Should-url-be-case-sensitive.
С другой стороны, Википедия чувствительна к регистру, за исключением первого символа названия. URL-адреса https://en.wikipedia.org/wiki/Case_sensitivity и https://en.wikipedia.org/wiki/case_sensitivity ведут к одной и той же статье, но https://en.wikipedia.org/wiki/CASE_SENSITIVITY возвращает 404.
3
Зависит от хостинга. Сайты, размещенные в Windows, как правило, нечувствительны к регистру, поскольку базовая файловая система нечувствительна к регистру. Сайты, размещенные в системах типа Unix, как правило, чувствительны к регистру, поскольку их базовые файловые системы обычно чувствительны к регистру.
2
Часть доменного имени URL-адреса не чувствительна к регистру, поскольку DNS игнорирует регистр: http://en.example.org/ и HTTP://EN.EXAMPLE.ORG/ открывают одну и ту же страницу.
Путь используется для указания и, возможно, поиска запрошенного ресурса. Он чувствителен к регистру, хотя некоторые серверы, особенно основанные на Microsoft Windows, могут считать его нечувствительным к регистру.
Если сервер чувствителен к регистру и http://en.example.org/wiki/URL правильный, то http://en.example.org/WIKI/URL или http://en.example.org/wiki/url отобразит страницу ошибки HTTP 404, если эти URL-адреса сами не указывают на допустимые ресурсы.
4
Я не любитель копаться в старых статьях, но, поскольку это был один из первых ответов на эту конкретную проблему, я почувствовал необходимость кое-что прояснить.
В ответе @Bhavin Shah говорится, что доменная часть URL-адреса нечувствительна к регистру, поэтому
http://google.com
и
http://GOOGLE.COM
и
http://GoOgLe.CoM
все одинаковы, но все, что следует за доменным именем, считается чувствительным к регистру.
так…
http://GOOGLE.COM/ABOUT
и
http://GOOGLE.COM/about
разные.
Примечание. Во многих случаях я говорю «технически», а не «буквально», в большинстве случаев серверы настроены для одинаковой обработки этих элементов, но их можно настроить так, чтобы они НЕ обрабатывались одинаково. .
Различные серверы обрабатывают это по-разному, и в некоторых случаях они должны быть чувствительны к регистру. Во многих случаях значения строки запроса закодированы (например, идентификаторы сеанса или данные в кодировке Base64, которые передаются как значение строки запроса). Эти элементы по своей природе чувствительны к регистру, поэтому сервер должен учитывать регистр при их обработке.
Таким образом, чтобы ответить на вопрос, «должны ли» серверы учитывать регистр при захвате этих данных, ответ будет «да, определенно».
Конечно, не все должно быть чувствительно к регистру, но сервер должен знать, что это такое и как обрабатывать такие случаи.
Комментарий @Hart Simha в основном говорит то же самое. Я пропустил это, прежде чем опубликовать, поэтому я хочу отдать должное там, где это необходимо.
См. спецификацию здесь: раздел 2.7.3 https://datatracker.ietf.org/doc/html/draft-ietf-httpbis-p1-messaging-25#page-19
Схема и хост нечувствительны к регистру и обычно указываются строчными буквами; все остальные компоненты сравниваются с учетом регистра способ.
Раздел 6.2.2.1 RFC 3986 говорится, что «схема и хост нечувствительны к регистру и поэтому должны быть приведены к нижнему регистру. Например, URI HTTP://www.EXAMPLE.com/ эквивалентен http://www.. Другие компоненты общего синтаксиса считаются чувствительными к регистру , если иное не указано в схеме специально». example. com/
example. com/
Сервер может внутренне нормализовать переданный URI и обслуживать один и тот же ресурс для URI в другом регистре ( /about/ и /ABOUT/ ), что делает URI нечувствительным к регистру для пользователя.
2
Рассмотрим следующее:
https://www.example.com/createuser.php?name=Paul%20McCartney
В этом гипотетическом примере HTML-форма с использованием метода GET отправляет параметр «имя» в PHP-скрипт, создающий новую учетную запись пользователя.
В этом примере я хочу подчеркнуть, что этот параметр GET должен быть чувствительным к регистру, чтобы сохранить заглавную букву «Маккартни» (или, как другой пример, сохранить «Вальтер д’Исней», поскольку есть другие способы для имен нарушить обычные правила использования заглавных букв).
Это случаи, подобные этим, которые определяют рекомендацию W3C о том, что схема и хост нечувствительны к регистру, но все, что после этого, потенциально чувствительно к регистру — и оставлено на усмотрение сервера. Принудительная нечувствительность к регистру по стандарту сделает приведенный выше пример неспособным сохранить регистр пользовательского ввода, переданного в качестве параметра запроса GET.
Но я бы сказал, что, хотя это и есть буква закона, обязательно учитывающая такие случаи, дух закона таков, что там, где дело не имеет значения, следует вести себя без учета регистра. Стандарты, однако, не могут сказать вам, где регистр не имеет значения, потому что, как и в примерах, которые я привел, это зависит от контекста.
(например, имя пользователя учетной записи, вероятно, лучше сделать нечувствительным к регистру — поскольку «User123» и «user123», являющиеся разными учетными записями, могут привести к путанице — даже если их настоящее имя, как указано выше, лучше оставить чувствительным к регистру. )
)
Иногда это актуально, в большинстве случаев это не так. Но это должно быть оставлено на усмотрение сервера/веб-разработчика, чтобы решить эти вещи — и не может быть предписано стандартом — поскольку только на этом уровне может быть известен контекст.
Схема и хост нечувствительны к регистру (что показывает предпочтение стандарта нечувствительности к регистру, где это может быть предписано повсеместно). Остальное решать вам, поскольку вы лучше понимаете контекст. Но, как уже обсуждалось, вы, вероятно, должны, в духе закона, по умолчанию не учитывать регистр, если у вас нет веской причины не делать этого.
2
URL-адреса должны быть нечувствительны к регистру, если только нет веских причин, по которым они не должны быть чувствительными.
Это не является обязательным (это не часть RFC), но делает связь и хранение URL гораздо более надежными.
Если у меня есть две страницы на веб-сайте:
http://stackoverflow.
 com/ABOUT.html
com/ABOUT.html
и
http://stackoverflow.com/about.html
Чем они должны отличаться? Может быть, один из них написан «кричащим стилем» (заглавными буквами), но с точки зрения IA различие никогда не должно проводиться путем изменения URL-адреса.
Более того, это легко реализовать в Apache — просто используйте CheckSpelling On из mod_Speling.
0
Старый вопрос, но я наткнулся на него, так почему бы не попробовать его, так как вопрос ищет разные точки зрения, а не окончательный ответ.
У w3c могут быть свои рекомендации, которые меня очень волнуют, но я хочу переосмыслить, так как вопрос здесь.
Почему w3c считает доменные имена нечувствительными к регистру и оставляет все после этого нечувствительным к регистру?
Я думаю, причина в том, что доменная часть URL-адреса вводится пользователем вручную.
Все, что после гипертекста, будет разрешено машиной (браузером и сервером сзади).
Машины справляются с нечувствительностью к регистру лучше, чем люди (не технические:)).
Но вопрос только в том, что машины МОГУТ обрабатывать, что должно быть сделано таким образом?
Я имею в виду, каковы преимущества именования и доступа к ресурсу, расположенному по адресу hereIsTheResource против вот ресурс ?
Боковая сторона очень нечитаема, чем верблюжья, которая более читабельна. Доступно для чтения людьми (включая технический вид).
Итак, вот мои пункты: —
Путь к ресурсу находится где-то в середине структуры программирования и иногда находится рядом с конечным пользователем за браузером.
Ваш URL-адрес (за исключением доменного имени) должен быть нечувствительным к регистру, если ожидается, что ваши пользователи коснутся его или напечатают его и т. д. Вы должны разработать свое приложение таким образом, чтобы ИЗБЕГАТЬ, чтобы пользователи как можно чаще вводили путь.
Ваш URL-адрес (за исключением имени домена) должен быть чувствителен к регистру, если ваши пользователи никогда не будут вводить его вручную.
Заключение
Путь должен быть чувствителен к регистру. Мои очки склоняются к чувствительным к регистру путям.
Символы URL-адресов преобразуются в шестнадцатеричный код (если вы когда-либо замечали, что пробелы в URL-адресах отображаются как %20 и т. д.), а поскольку строчные и прописные буквы имеют разные шестнадцатеричные значения, вполне логично, что URL-адреса, безусловно, имеют регистр чувствительный. Однако дух вопроса, кажется, ДОЛЖЕН ли это быть стандартом, и я говорю «нет», но это так. Разработчик/поставщик должен учитывать это в своем коде, если они хотят, чтобы он работал независимо от конечного пользователя.
1
Я думаю, что это и многие ответы на то, что спецификация говорит или не говорит, упускают суть вопроса. Должны ли учитывать регистр? Это нагруженный вопрос на самом деле. С точки зрения пользователя, чувствительность к регистру — это проблема, и не все знают, что это имеет значение. Вопрос о том, должны или не должны быть URI, зависит от контекста вопроса. Для технической гибкости да, они должны быть. Для удобства использования их быть не должно.
Вопрос о том, должны или не должны быть URI, зависит от контекста вопроса. Для технической гибкости да, они должны быть. Для удобства использования их быть не должно.
2
Сохранение регистра
URL-адреса сохраняют регистр между клиентом и сервером. Но части URL-адресов могут быть или не быть чувствительными к регистру , в зависимости от сервера, по нескольким причинам.
Чувствительность к регистру
Следующие жирные части URL могут быть чувствительны к регистру, в зависимости от сайта и/или конфигурации сервера.
http:// www. example.com /abc/def.ghi?jkl=mno#pqr
пользователь @ example.com
Обоснование
Чувствительность к регистру в URL-адресах может иметь несколько применений. В основном:
- Встроенная совместимость с файловыми системами, чувствительными к регистру.
- Более компактное кодирование данных в URL-адресах, например для сериализации, хеширования, идентификаторов, постоянных ссылок и сокращений URL-адресов.

Как разработчик, я считаю, что вышеперечисленное часто можно решить лучше, но я также понимаю, что бывают случаи, когда ситуация не позволяет этого сделать.
Например, представьте себе существующий продукт, который требует большого количества данных, помещаемых в URL-адрес «GET», но при этом он должен быть совместим с максимальной длиной URL-адреса всех основных серверов, браузеров и механизмов кэширования/прокси. Чтобы соответствовать даже командной строке средней длины (менее 1024 символов для некоторых старых браузеров), вам нужно использовать каждый уникальный URL-безопасный символ, который вы можете (что в основном и является кодировкой base64url).
В идеальном мире
Должны ли URL-адреса быть чувствительным к регистру является спорным. Я лично считаю, что это не должно быть для простоты (хотя это может создавать более длинные URL-адреса, у нас есть процентные экраны, чтобы легко обрабатывать случаи, когда мы должны обеспечить сохранение точных символов, и есть способы передачи данных, отличные от прямо в URL-адресе) .
Многие, кажется, согласны с тем фактом, что URL-адреса без учета регистра явно включены для многих популярных сайтов и служб, чтобы повысить удобство использования. Наиболее ярким примером является часть имени пользователя в адресах электронной почты. Большинство провайдеров электронной почты игнорируют регистр, а иногда даже точки и другие символы (например, «[email protected]» совпадает с «[email protected]»). Несмотря на то, что имена пользователей электронной почты по умолчанию чувствительны к регистру, согласно спецификации.
Однако дело в том, что несмотря на то, что я или другие могли бы хотеть, это состояние того, как все работает в настоящее время. И хотя в конечном итоге всемирный переход к стандарту URL-адресов без учета регистра, безусловно, возможен, это, вероятно, займет довольно много времени, поскольку в настоящее время чувствительность к регистру широко используется в Интернете для различных целей.
Лучшие практики
Что касается лучших практик, как пользователь, вы можете разумно придерживаться строчных букв в большинстве ситуаций и ожидать, что все будет работать. Основными исключениями будут URL-адреса, которые используют кодировку на основе регистра или пути к документам с прямыми эквивалентами файловой системы. Однако такие сложные URL-адреса обычно копируются (или просто щелкаются), а не вводятся вручную.
Основными исключениями будут URL-адреса, которые используют кодировку на основе регистра или пути к документам с прямыми эквивалентами файловой системы. Однако такие сложные URL-адреса обычно копируются (или просто щелкаются), а не вводятся вручную.
Как веб-разработчик, вы должны учитывать регистр URL-адресов, насколько это возможно. Хотя, как отмечалось выше, в зависимости от контекста явно бывают ситуации, которых трудно избежать.
Чувствительность URL-адресов к регистру в целом (наряду с тем, совпадают ли они или нет, если они в разных регистрах) необходимо рассматривать со следующих точек зрения:
- Эквивалентность ресурсов
- Сравнение URL-адресов
С точки зрения эквивалентности ресурсов, как правило, невозможно сказать, что два URL-адреса, различающиеся каким-либо регистром (нижний регистр, верхний регистр, регистр предложения, регистр верблюда… любое сочетание регистров), отличаются друг от друга, если только ресурс не извлекаются из обоих URL-адресов, что во многих случаях нецелесообразно (RFC 3986, раздел 6. 1, пункт 1). Поэтому там, где ресурс не может быть извлечен, используется перспектива сравнения.
1, пункт 1). Поэтому там, где ресурс не может быть извлечен, используется перспектива сравнения.
Однако в случае, когда есть возможность получить ресурс, дело усложняется (как и ожидалось). В соответствии с положениями RFC 3986, раздел 3.3, параграф 5, как указано ниже
Помимо точечных сегментов в иерархических путях, сегмент пути считается непрозрачным по общему синтаксису
может показаться, что для остальной части URI/URL нельзя делать никаких предположений, кроме его схемы и авторитета общего синтаксиса (включая вопрос конфиденциальности).
Однако для схемы и хост-части органа спецификация (из сострадания) утверждает, что они нечувствительны к регистру. См. RFC 3986, раздел 3.1, параграф 1, и RFC 3986, раздел 6.2.2.1, параграф 2.
Исчерпав эту строку запроса, следует взглянуть на перспективу сравнения, чтобы определить, должны ли URI/URL учитывать регистр или нет.
Первый намек на это направление появляется при прочтении раздела 6. 2.2.1 (выше)
2.2.1 (выше)
Другой общий синтаксис предполагается, что компоненты чувствительны к регистру, если специально иначе определяется по схеме
Что дополнительно подкрепляется рассмотрением RFC 2616, раздел 3.2.3
При сравнении двух URI, чтобы решить, совпадают они или нет, клиент СЛЕДУЕТ использовать пооктетное сравнение всей строки с учетом регистра. URI
Затем, наконец, вопрос решен, и URL-адреса чувствительны к регистру… (хе-хе!), не совсем, рабочие слова «непрозрачный», «клиент» и «сравнение».
Помимо синтаксиса, в приведенном выше RFC ничего не упоминается о фактической интерпретации пути и запроса, за исключением того, что он «непрозрачный» и только указывает, как (с ДОЛЖЕН, а не ДОЛЖЕН) «клиент» может ‘ сравнить URL. В нем ничего не говорится о том, как сервер (ДОЛЖЕН, не говоря уже об ДОЛЖЕН) интерпретировать остальную часть URL-адреса за рамками схемы/авторитета.
Таким образом, сервер имеет полную свободу интерпретировать URL-адрес по своему усмотрению, что они и делают, как было указано в более ранних сообщениях других.
Имея упоминание официальных рекомендаций, есть интересный случай, когда следует рассмотреть возможность использования всего URL-адреса ЗАГЛАВНЫМИ БУКВАМИ: QR-коды.
Например, https://example.com/ не впишется в QR-код версии 1 (21×21) и потребует более крупного QR-кода версии 2 (25×25).
При использовании буквенно-цифрового режима позволяет набить HTTPS://EXAMPLE.COM/12345 в уменьшенную версию 1!
вопрос в том, должен ли URL быть чувствительным к регистру?
Я не вижу никакой пользы или хорошей практики в URL-адресах, чувствительных к регистру. Это глупо, это отстой, и его следует избегать всегда.
Просто чтобы подтвердить мое мнение, когда кто-то спрашивает, какой URL-адрес, как бы вы объяснили, какие символы URL-адреса в верхнем или нижнем регистре? Это ерунда, и никто никогда не должен говорить вам обратное.
5
Для веб-сайтов, размещенных на сервере Linux, URL-адрес чувствителен к регистру.