что это и зачем нужны — Блог Lineate
ко всем статьям
< ко всем статьям
<
Автор: Татьяна Сергиенко, Software Engineer
MySQL — это система управления реляционными базами данных с открытым исходным кодом с моделью клиент-сервер. Говоря совсем простым языком, база данных — набор структурированных данных. Чем их больше, тем труднее найти нужные. Для облегчения поиска информации и используются индексы MySQL.
Что такое индексы?
Когда мы работаем с базой данных, нам нужно выполнять запросы, которые позволяют быстро найти нужную информацию. Если этих данных очень много, то базе придется перебирать все строки нашей таблицы, чтобы найти нужный ответ.
Важность индексов увеличивается по мере роста объема данных. Если у вас какая-то небольшая база данных, она может работать без индексов, но производительность ваших запросов может сильно упасть, как только она начнет расти.
Для чего используются индексы?
Индексы помогают:
- быстро находить строки, соответствующие выражению WHERE
- извлекать строки из других таблиц при выполнении объединений
- находить величины MAX() или MIN() для заданного индексированного столбца
- производить сортировку или группирование в таблице, если эти операции делаются на крайнем левом префиксе используемого ключа (например, ORDER BY key_part_1, key_part_2).


Индекс – это специальная структура данных, обычно это B-Tree дерево, которое позволяет повышать скорость извлечения данных за счет дополнительных операций записи и хранения. Здесь стоит отметить, что индексы хранятся отдельно от данных.
Схематично B-Tree можно изобразить так: дерево состоит из корня (верхняя вершинка), дальше у нас идут ветви, ветви заканчиваются листьями, на листьях находится нужная информация.
Мощность Индекса
Мощность индекса относится к уникальности значений, хранящихся в указанном столбце индекса.
MySQL генерирует количество элементов индекса на основе статистики, хранящейся в виде целых чисел, поэтому значение не обязательно может быть точным.
При создании индексов нужно найти золотую середину, не создавая индексы на каждый столбец, в этом поможет оптимизация баз данных. Можно пересмотреть запросы, убрать неэффективные, перестроить индексы, убрать дубликаты. Мощность индекса позволяет проанализировать значения.
Действия с индексами MySQL
Создание индекса
Есть два варианта, которые можно использовать в зависимости от ситуации:
- при создании таблицы мы можем указать, какие поля мы хотим создать и тут же указать, какое из этих полей у нас будет индексом
- или мы можем создать индекс отдельно.
Если вы уже работаете с готовой базой данных, в которой нет индекса, вы можете с помощью ALTER-команды обновить таблицу, добавив в нее нужный вам индекс.
Просмотр индексов
Немаловажная возможность – посмотреть, какие индексы есть у таблицы в целом или, например, выбрать индексы с каким-то определенным параметром.
Удаление индекса
В зависимости от ситуации мы можем руководить процессом удаления индексов или указать, какой алгоритм использовать, как блокировать.
ДРУГИЕ СТАТЬИ
>
ко всем статьям
Wednesday, August 18
Индексы MySQL: что это и зачем нужны — Блог Lineate
MySQL — это система управления реляционными базами данных с открытым исходным кодом с моделью клиент-сервер. Говоря совсем простым языком, база данных — набор структурированных данных. Чем их больше, тем труднее найти нужные. Для облегчения поиска информации и используются индексы MySQL.
Говоря совсем простым языком, база данных — набор структурированных данных. Чем их больше, тем труднее найти нужные. Для облегчения поиска информации и используются индексы MySQL.
Wednesday, August 18
Типы индексов MySQL — Блог Lineate
Кластеризованные — специальные индексы, Primary Key и Unique Index (Key и Index – это синонимы в данном случае). Некластеризованные, или вторичные, индексы — все остальные индексы, которые не попадают под Primary и Unique
Давайте работать вместе
Присоединяйтесь к нашей команде!
Смотреть вакансии
Разбираемся что MySQL пишет на диск и зачем [часть 1] / Хабр
Оглавление
Double Write buffer и Binlogs [эта статья]
Redo logs и общая картина [https://habr.com/ru/post/699342/]
Disclaimer: автор не является разработчиком MySQL, все нижеописанное может не совпадать с реальным положением дел.
Часть 0: Размышления о хранении данных
Разработчики предъявляют высокие требования к базам данных: максимальная надежность (ничего из того, что было записано не должно быть утеряно ни при каких обстоятельствах), и, одновременно, максимальная производительность при различных видах нагрузки (Запись/Чтение или OLTP/OLAP). Достичь этих требований может быть не просто. Давайте попробуем разобраться, как это делает MySQL.
Достичь этих требований может быть не просто. Давайте попробуем разобраться, как это делает MySQL.
Размышляя о базе данных, легко представить таблицу базы данных как HashMap/BinaryTree, отображающие первичный ключ (primary key) в структурированные записи с данными. Такое хранилище может работать in memory. Но, как только мы захотим записать данные на диск, придется использовать какие-то алгоритмы во внешней памяти. Просто положить наш HashMap на диск не получится, потому что память и диски слишком разные: чтение/запись диска производится блоками, latency диска больше чем у RAM, а еще нельзя будет воспользоваться обычными указателями и аллокаторами памяти — все это придется заменить самостоятельно.
Почему MMAP не лучший выход: Are You Sure You Want to Use MMAP in Your Database Management System? https://www.cidrdb.org/cidr2022/papers/p13-crotty.pdf
К счастью, давно уже придуманы структуры данных и алгоритмы, такие как B+Tree и LSM Tree, а также бесчисленное количество их вариаций (Подробнее можно прочитать в книге “Database Internals: A Deep Dive into How Distributed Data Systems Work” за авторством Alex Petrov). InnoDB — основной движок хранения MySQL, использует вариацию B+Tree. Данные хранятся в страницах (pages), которые загружаются с диска в buffer pool и при необходимости сохраняются на диск обратно.
InnoDB — основной движок хранения MySQL, использует вариацию B+Tree. Данные хранятся в страницах (pages), которые загружаются с диска в buffer pool и при необходимости сохраняются на диск обратно.
Unix-like операционные системы поддерживают разные гарантии записи файла.
Самым быстрым и заодно ненадежным способом является обычная запись в файл. Операционная система запишет данные в page cache (в память). И уже в фоне запишет данные на диск.
Если при открытии файла указать флаг O_DIRECT — то запись в файл будет идти мимо page cache — сразу во внутренний буфер диска. Но при отключении питания сервера — мы все еще можем потерять данные.
fsync— это отдельный системный вызов для сброса данных на диск. На Linux системахfsyncожидает записи на физический носитель, а не только во внутренний буфер диска. Факт записи на диск дает гарантии сохранности данных.fdatasync— так же сбрасывает данные на диск, но не дожидается надежной записи обновленных метаданных файловой системы. Если метаданные изменились, но из-за отказов не были записаны на диск, то при следующем старте, Linux не узнает об этих изменениях (например, о том, что файл был увеличен в размере и туда были записаны данные) — данные будут поломаны.
 Если метаданные изменились, но из-за отказов не были записаны на диск, то при следующем старте, Linux не узнает об этих изменениях (например, о том, что файл был увеличен в размере и туда были записаны данные) — данные будут поломаны.
Если метаданные изменились, но из-за отказов не были записаны на диск, то при следующем старте, Linux не узнает об этих изменениях (например, о том, что файл был увеличен в размере и туда были записаны данные) — данные будут поломаны.Часть 1: Double Write Buffer
Страницы с данными в InnoDB по умолчанию занимают 16Кб. Размер страницы — это компромисс. С одной стороны, большие страницы с данными улучшают пропорцию полезных данных к служебным, с другой стороны, большие страницы приводят к бОльшему write amplification: Например, UPDATE одного числа (4 байта) в одной строке приводит к перезаписи всей страницы (килобайты). Разные базы данных выбирают различные размеры страниц: PostgreSQL использует страницы по 8Кб, а MySQL по-умолчанию по 16Кб, но администраторы баз данных при большом желании могут выбрать размер от 4Кб до 64Кб (innodb_page_size).
Уже на этом этапе мы сталкиваемся с проблемой атомарности записи данных на диск: современные Linux-based системы не гарантируют атомарность записи блоков размером больше 4Кб.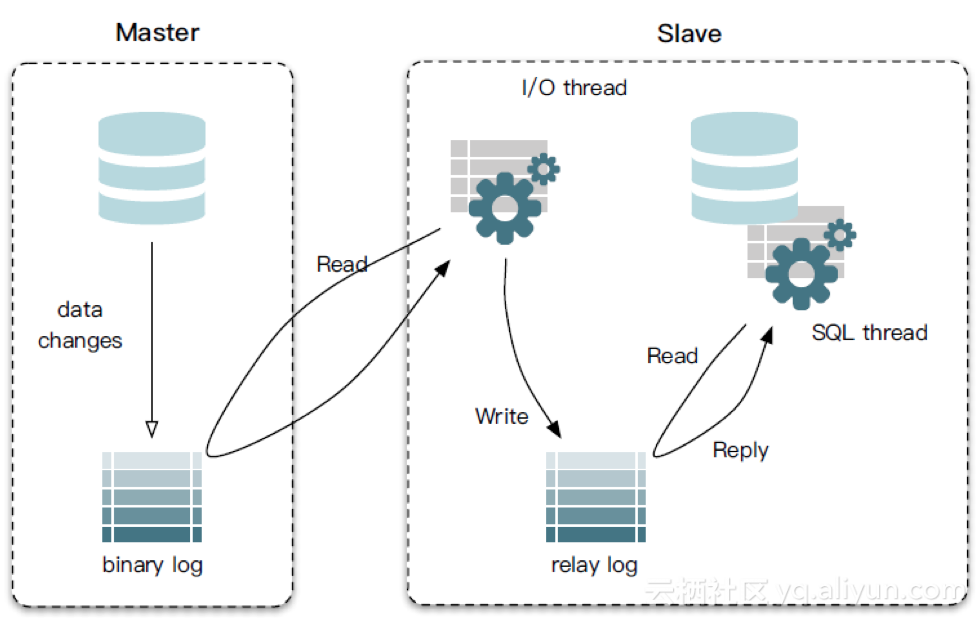
Детальное описание состояние дел с атомарностью записи на диск можно найти на StackOverflow. [ https://stackoverflow.com/a/61832882 ]. Там же героическая история как инженеры Google патчили ядро, драйвера и файловые системы, чтобы атомарно писать блоками по 16Кб.
Что делает InnoDB, чтобы страницы с данными не побились во время записи? InnoDB пишет их дважды: сначала в doublewrite buffer, и только потом страницы записываются в положенное им место.
Несмотря на название, сам doublewrite buffer не удваивает количество IO операций — страницы в doublewrite buffer пишутся большими блоками и выполняется всего один fsync() (да и то, если не используется IO_DIRECT). Если в процессе crash-recovery InnoDB найдет “битую” страницу — он сможет достать ее целый вариант из doublewrite buffer.
В старых версиях MySQL, doublewrite buffer занимал фиксированные 128 страниц в начале system tablespace (файл ibdata1). Запись велась:
Страницы копировались в doublewrite buffer в памяти.
Большим блоком записывались в system tablespace. Если не использовался IO_DIRECT — вызывался
fsync().Страницы пишутся в нужные места, если не используется IO_DIRECT — вызывается
fsync().По завершению всех операций, doublewrite buffer считается пустым и готовым к следующей итерации.
Начиная с версии MySQL 8.0.20, алгоритм был изменен — теперь doublewrite buffer пишется в разные файлы (например, в файл #ib_16384_0.dblwr ). Новый подход должен лучше работать на SSD.
Часть 2: Binlogs
MySQL была спроектирована как база данных, которая может работать с различными движками (storage engines), поэтому MySQL можно разделить на два крупных “слоя” — непосредственно MySQL и различные Storage Engine (на практике это почти всегда InnoDB, реже Memory Engine, но изредка еще встречается MyISAM и MyRocksDB). Из-за этой “двухслойности” у нас есть и явное разделение обязанностей — MySQL занимается обработкой SQL запросов, репликацией (пишет binlogs), а InnoDB отвечает за надежное хранением данных на диске.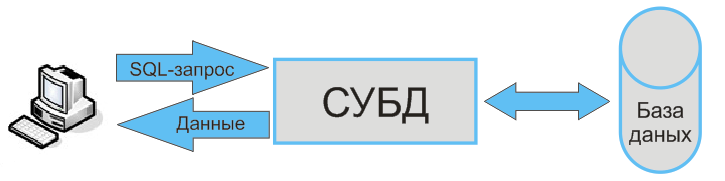
Для распространения изменений, записанных на мастере, MySQL использует подход Replicated State Machine (RSM)- все изменения записываются в binlog, и доставляются на реплики. Реплики применяют транзакции к своему текущему состоянию. Если транзакции полностью детерминированы — то в результате на мастере и на репликах получается одинаковое состояние (чего, собственно, мы и ожидаем от базы данных). Как побочный эффект детерминизма — к развернутой из бекапа базе данных можно проигрывать бинлоги и тем самым восстановить базу на любой момент времени (aka Point-in-Time Recovery).
MySQL может писать в binlog как SQL Statements (Statement-based replication), так и просто измененные данные (row-based replication). Для Statment-based replication сложнее гарантировать детерминированность транзакций и совпадение данных, хранящихся на разных хостах.
Binary Log в широком смысле слова — хранилище Binary Log Events (далее “события”). Эти события хранятся в binlog-файлах. Каждый файл начинается с заголовка, содержащего служебную информацию, потом идут события, и в конце пишется rotate event.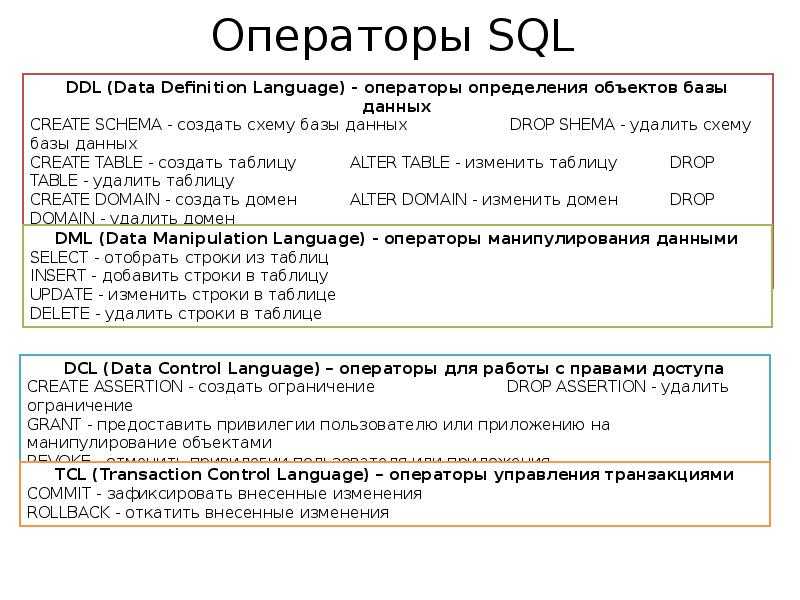 Кроме этого, MySQL поддерживает Binlog Index, где хранится список всех имеющихся бинлогов.
Кроме этого, MySQL поддерживает Binlog Index, где хранится список всех имеющихся бинлогов.
Binlog cache
binlog — это файл, который пишется последовательно, целыми транзакциями. Пока одна транзакция не будет записана полностью, нельзя начинать писать вторую транзакцию. Для того, чтобы одни транзакции не блокировали запись других транзакций, все binlog events пишутся сначала в binlog cache (специальный буффер в памяти каждого потока, выполняющего транзакции) и только в момент коммита записываются уже на диск. В случае отката транзакции — binlog cache очищается, как будто ничего и не было записано в него.
Fun Fact: Если binlog_cache_size было недостаточно, MySQL начнет сбрасывать кэш на диск (в новый файл, который сразу после создания будет удален (
unlink) с файловой системы — т.е. будет “невидим”). Максимальный размер binlog cache на диске настраивается с помощью max_binlog_cache_size (по-умолчанию 18 эксабайт!).
 Хотя, документация говорит, что MySQL не может работать с бинлогами больше 4 Гб: при достижении этого порога будет выброшена ошибка.
Хотя, документация говорит, что MySQL не может работать с бинлогами больше 4 Гб: при достижении этого порога будет выброшена ошибка.Group Commit
Вооружившись знанием о том, что такое binlog, для crash-safe recovery необходимо делать fsync() на каждую запись в бинлоге (настройка sync_binlog = 1). Ведь, с одной стороны, binlog-и не участвуют в непосредственной записи наших данных на диск, используются в репликации (не очень связанной с хранением ваших данных на диске!) и вообще, бинлоги можно отключить, и база продолжит работать!
Если не скидывать бинлоги на диск — велик шанс что упавший MySQL после восстановления будет неконсистентен с другими репликами (и вам повезет, если вы это заметите сразу). В целом жить с sync_binlog отличном от 1 можно, при условии отказа от crash-recovery и переналивкой упавших хостов. Вы же не ожидаете крэша всех хостов MySQL одной транзакцией или retry-ем одной транзакции по всем хостам 🙂
Допустим, мы все-таки хотим надежной записи на диск с помощью fsync. Как мы уже знаем, вызов fsync()-а это довольно медленная операция, где мы очень легко можем упереться в IOPS (особенно на HDD дисках). Очевидным решением бутылочного горлышка IOPS-ов является батчинг — на каждый
Как мы уже знаем, вызов fsync()-а это довольно медленная операция, где мы очень легко можем упереться в IOPS (особенно на HDD дисках). Очевидным решением бутылочного горлышка IOPS-ов является батчинг — на каждый fsync() писать не одну транзакцию, а сразу целую группу транзакций. В MySQL такой батчинг называется Group Commit.
Интересно, что MySQL 5.0 не делал Group Commit, и транзакции ожидали своей очереди для сохранения бинлога на диск. Ни о какой высокой производительности здесь речи идти не может.
В Percona Server 5.5.18-23 добавили одну из первых версий group commit:
Когда поток, выполняющий транзакцию, решит закоммитить транзакцию — он добавляет себя в group commit queue.
После чего поток пытается понять — является ли он первым в group commit queue. Если он первый — то он становится “group commit leader”.
Лидер берет лок на весь бинлог целиком (Этот лок может быть занят предыдущим лидером, который все еще пишет на диск).
Именно в это время другие потоки могут добавлять транзакции в group commit queue — тем самым собираясь в новую группу.Заполучив лок на весь бинлог, лидер забирает себе всю group commit queue (следующий лидер создаст себе новую queue)
Лидер записывает содержимое binlog cache каждого из потоков и делает fsync() (если надо). После чего он “будит” пользовательские потоки, которые заблокировались на записи в бинлог.
 Именно в это время другие потоки могут добавлять транзакции в group commit queue — тем самым собираясь в новую группу.
Именно в это время другие потоки могут добавлять транзакции в group commit queue — тем самым собираясь в новую группу.Чуть позже, помимо группировки транзакций может быть настроен на небольшое ожидание перед записью в бинлог, пытаясь собрать побольше транзакций в group commit queue. По бенчмаркам ребят из Percona — количество транзакций в секунду увеличивается на 30%.
В актуальных версиях MySQL group commit сделан чуть по-другому: запись в бинлог разбита на этапы, которые управляются с помощью Commit_stage_manager. MySQL гарантирует, что порядок записи событий в бинлоге совпадает с порядком записи изменений в Storage Engines (Это значительно упрощает работу backup-тулам, таким как xtrabackup или MySQL Clone Plugin).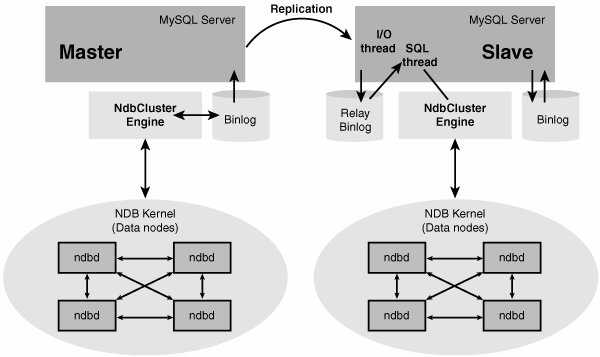
Все этапы (stages) образуют pipeline, в котором события берутся из очереди, обрабатываются и складываются в следующую очередь. Каждая очередь защищена своим мьютексом.
Всего используется 4 очереди:
Binlog flush queue — очередь на запись на диск.
Sync queue — очередь из транзакций, для которых надо вызвать
fsync().Commit queue — очередь транзакций, которая используется для упорядочивания коммитов транзакций в пределах group commit. (необходима при
binlog_order_commit=1).Commit order flush queue — очередь из транзакций, которые не пишут в бинлог, но участвуют в group commit — используется для обновления gtid_executed в экзотических ситуациях.
Все stage работают по похожему алгоритму:
Когда поток, выполняющий транзакцию, решит закоммитить транзакцию — он добавляет себя во flush queue.
После чего поток пытается понять — является ли он первым в очереди или нет.
Если он первый — то он становится stage leader.Stage Leader (после небольшого ожидания в
binlog_max_flush_queue_timems) забирает все транзакции из очереди и выполняет свою операциюbinlog flush stage — производит запись в бинлог: данные из binlog cache (
binlog_cache_mngr) пишутся в файлsync stage — вызывает
fsync()commit stage — транзакция коммитится в storage engine
По завершению операции, Stage Leader добавляет транзакции, которыми он владел, в следующую очередь. Может так оказаться, что очередь, куда пишет stage leader не пуста — это означает что он “нагнал” другого лидера (который ожидает чего-то: блокировки или таймаута). В этот момент наш stage leader теряет свое лидерство. Его события будет обрабатывать “нагнанный” лидер. Такое поведение адаптирует размер group commit-а к самой медленной операции (обычно это
fsync()) — долгие операции работают с бОльшим количеством event-ов за раз.
 Если он первый — то он становится stage leader.
Если он первый — то он становится stage leader.
Параллельная репликация
Дополнительным преимуществом group commit является параллельная репликация — в пределах group-commit-а репликам позволено параллельно выполнять транзакции используя replica_parallel_workers потоков, после чего они делают commit в том же порядке что и на мастере (replica_preserve_commit_order), чтобы гарантировать что на реплике не будет состояния, которого никогда не было на мастере (Полезное свойство, если Вы читаете с реплик!).
Продолжение следует…
В следующей части мы рассмотрим, как InnoDB пишет Redo Log, выполняет Checkpointing и попытаемся разобраться как все части базы данных работают вместе.
UPD: продолжение https://habr.com/ru/post/699342/
Главные причины использовать MySQL
1. Масштабируемость и гибкость
Сервер базы данных MySQL обеспечивает максимальную масштабируемость, способную работать с глубоко встроенными приложениями размером всего 1 МБ для запуска огромных хранилищ данных, содержащих терабайты информации. . Гибкость платформы — это неотъемлемая часть MySQL, которая поддерживает все разновидности Linux, UNIX и Windows. И, конечно же, природа MySQL с открытым исходным кодом позволяет выполнять полную настройку для тех, кто хочет добавить уникальные требования к серверу базы данных.
. Гибкость платформы — это неотъемлемая часть MySQL, которая поддерживает все разновидности Linux, UNIX и Windows. И, конечно же, природа MySQL с открытым исходным кодом позволяет выполнять полную настройку для тех, кто хочет добавить уникальные требования к серверу базы данных.
2. Высокая производительность
Уникальная архитектура механизма хранения данных позволяет специалистам по базам данных настраивать сервер базы данных MySQL специально для конкретных приложений, в результате чего достигается потрясающая производительность. Независимо от того, является ли предполагаемое приложение высокоскоростной системой обработки транзакций или веб-сайтом с большим объемом операций, который обслуживает миллиарды запросов в день, MySQL может удовлетворить самые высокие требования к производительности любой системы. Благодаря высокоскоростным утилитам загрузки, уникальным кэшам памяти, полнотекстовым индексам и другим механизмам повышения производительности MySQL предлагает все необходимое для современных критически важных бизнес-систем.
3. Высокая доступность
Непревзойденная надежность и постоянная доступность являются отличительными чертами MySQL, и клиенты полагаются на MySQL, чтобы гарантировать круглосуточную работоспособность. MySQL предлагает различные варианты обеспечения высокой доступности: от высокоскоростной конфигурации репликации master/slave до специализированных кластерных серверов, обеспечивающих мгновенное восстановление после отказа, до сторонних поставщиков, предлагающих уникальные решения высокой доступности для сервера базы данных MySQL.
4. Надежная поддержка транзакций
MySQL предлагает одну из самых мощных транзакционных баз данных на рынке. Функции включают в себя полную поддержку транзакций ACID (атомарных, согласованных, изолированных, надежных), неограниченную блокировку на уровне строк, возможность распределенных транзакций и поддержку многоверсионных транзакций, когда считыватели никогда не блокируют писатели и наоборот. Полная целостность данных также обеспечивается за счет принудительной ссылочной целостности сервера, специальных уровней изоляции транзакций и мгновенного обнаружения взаимоблокировок.
Полная целостность данных также обеспечивается за счет принудительной ссылочной целостности сервера, специальных уровней изоляции транзакций и мгновенного обнаружения взаимоблокировок.
5. Сильные стороны веб-сайтов и хранилищ данных
MySQL является стандартом де-факто для веб-сайтов с высокой посещаемостью благодаря своему высокопроизводительному механизму запросов, чрезвычайно быстрой возможности вставки данных и надежной поддержке специализированных веб-функций, таких как быстрая полнотекстовый поиск. Те же сильные стороны также применимы к средам хранения данных, где MySQL масштабируется до терабайтного диапазона либо для отдельных серверов, либо для масштабируемых архитектур. Другие функции, такие как таблицы основной памяти, B-tree и хэш-индексы, а также сжатые архивные таблицы, которые снижают требования к хранилищу до восьмидесяти процентов, делают MySQL отличным выбором как для веб-приложений, так и для приложений бизнес-аналитики.
6. Надежная защита данных
Надежная защита данных
Поскольку защита информационных активов корпораций является задачей номер один для специалистов по базам данных, MySQL предлагает исключительные функции безопасности, обеспечивающие абсолютную защиту данных. Что касается аутентификации базы данных, MySQL предоставляет мощные механизмы, гарантирующие, что только авторизованные пользователи имеют доступ к серверу базы данных, с возможностью блокировки пользователей вплоть до уровня клиентской машины. Также предоставляется поддержка SSH и SSL для обеспечения безопасных и надежных соединений. Присутствует детальная структура объектных привилегий, поэтому пользователи видят только те данные, которые им нужны, а мощные функции шифрования и дешифрования данных обеспечивают защиту конфиденциальных данных от несанкционированного просмотра. Наконец, утилиты резервного копирования и восстановления, предоставляемые MySQL и сторонними поставщиками программного обеспечения, позволяют выполнять полное логическое и физическое резервное копирование, а также полное восстановление на определенный момент времени.
7. Комплексная разработка приложений
Одна из причин, по которой MySQL является самой популярной в мире базой данных с открытым исходным кодом, заключается в том, что она обеспечивает всестороннюю поддержку всех потребностей разработки приложений. В базе данных можно найти поддержку для хранимых процедур, триггеров, функций, представлений, курсоров, SQL-стандарта ANSI и многого другого. Для встраиваемых приложений доступны подключаемые библиотеки, позволяющие встроить поддержку базы данных MySQL практически в любое приложение. MySQL также предоставляет соединители и драйверы (ODBC, JDBC и т. д.), которые позволяют всем формам приложений использовать MySQL в качестве предпочтительного сервера управления данными. Независимо от того, PHP это, Perl, Java, Visual Basic или .NET, MySQL предлагает разработчикам приложений все необходимое для успешного создания информационных систем на базе баз данных.
8. Простота управления
MySQL предлагает исключительную возможность быстрого запуска, при этом среднее время от загрузки программного обеспечения до завершения установки составляет менее пятнадцати минут. Это правило остается верным независимо от того, является ли платформа Microsoft Windows, Linux, Macintosh или UNIX. После установки функции самостоятельного управления, такие как автоматическое расширение пространства, автоматический перезапуск и динамические изменения конфигурации, снимают большую часть нагрузки с уже перегруженных работой администраторов баз данных. MySQL также предоставляет полный набор инструментов графического управления и миграции, которые позволяют администратору базы данных управлять, устранять неполадки и контролировать работу многих серверов MySQL с одной рабочей станции. Для MySQL также доступны инструменты многих сторонних поставщиков программного обеспечения, которые решают задачи, начиная от проектирования данных и ETL и заканчивая полным администрированием баз данных, управлением заданиями и мониторингом производительности.
Это правило остается верным независимо от того, является ли платформа Microsoft Windows, Linux, Macintosh или UNIX. После установки функции самостоятельного управления, такие как автоматическое расширение пространства, автоматический перезапуск и динамические изменения конфигурации, снимают большую часть нагрузки с уже перегруженных работой администраторов баз данных. MySQL также предоставляет полный набор инструментов графического управления и миграции, которые позволяют администратору базы данных управлять, устранять неполадки и контролировать работу многих серверов MySQL с одной рабочей станции. Для MySQL также доступны инструменты многих сторонних поставщиков программного обеспечения, которые решают задачи, начиная от проектирования данных и ETL и заканчивая полным администрированием баз данных, управлением заданиями и мониторингом производительности.
9. Свобода открытого исходного кода и круглосуточная поддержка 7 дней в неделю
Многие корпорации не решаются полностью перейти на программное обеспечение с открытым исходным кодом, потому что они считают, что не могут получить тот тип поддержки или профессиональных услуг, на которые они в настоящее время полагаются, с проприетарным ПО. программного обеспечения для обеспечения общего успеха их ключевых приложений. Нередко возникают и вопросы возмещения убытков. Эти заботы могут быть сняты с помощью MySQL, поскольку через MySQL Enterprise доступна полная круглосуточная поддержка, а также возмещение убытков. MySQL не является типичным проектом с открытым исходным кодом, поскольку все программное обеспечение принадлежит и поддерживается Oracle, и поэтому доступна уникальная модель стоимости и поддержки, которая обеспечивает уникальное сочетание свободы открытого исходного кода и надежного программного обеспечения с поддержкой.
программного обеспечения для обеспечения общего успеха их ключевых приложений. Нередко возникают и вопросы возмещения убытков. Эти заботы могут быть сняты с помощью MySQL, поскольку через MySQL Enterprise доступна полная круглосуточная поддержка, а также возмещение убытков. MySQL не является типичным проектом с открытым исходным кодом, поскольку все программное обеспечение принадлежит и поддерживается Oracle, и поэтому доступна уникальная модель стоимости и поддержки, которая обеспечивает уникальное сочетание свободы открытого исходного кода и надежного программного обеспечения с поддержкой.
10. Самая низкая совокупная стоимость владения
Мигрируя существующие приложения для работы с базами данных на MySQL или используя MySQL для новых проектов разработки, корпорации получают экономию средств, выражающуюся в семизначных числах. Благодаря использованию сервера баз данных MySQL и масштабируемых архитектур, использующих недорогое стандартное оборудование, корпорации обнаруживают, что они могут достичь удивительных уровней масштабируемости и производительности, и все это по цене, которая намного меньше, чем та, которую предлагают проприетарные и поставщиков программного обеспечения для масштабирования. Кроме того, надежность и простота сопровождения MySQL означают, что администраторы баз данных не тратят время на устранение проблем с производительностью или простоями, а вместо этого могут сосредоточиться на положительном влиянии на задачи более высокого уровня, связанные с деловой стороной данных.
Кроме того, надежность и простота сопровождения MySQL означают, что администраторы баз данных не тратят время на устранение проблем с производительностью или простоями, а вместо этого могут сосредоточиться на положительном влиянии на задачи более высокого уровня, связанные с деловой стороной данных.
5 главных причин выбрать MySQL и 5 основных проблем
Последняя версия MySQL — одна из самых популярных баз данных в мире. Он с открытым исходным кодом, надежен, совместим со всеми основными хостинг-провайдерами, экономичен и прост в управлении. Многие организации используют безопасность данных и надежную поддержку транзакций, предлагаемые MySQL, для защиты онлайн-транзакций и улучшения взаимодействия с клиентами. Однако предприятия, использующие MySQL, сталкиваются с рядом проблем, когда их приложения испытывают экспоненциальный рост и нуждаются в дополнительном масштабировании.
Наряду с пониманием того, почему MySQL является идеальным решением для быстрорастущих сред, не менее важно понимать проблемы, которые могут нанести ущерб вашим бизнес-операциям. Вот 5 основных причин использования MySQL, а также наиболее распространенные проблемы:
Вот 5 основных причин использования MySQL, а также наиболее распространенные проблемы:
Безопасные денежные транзакции
успешно завершена, транзакция не очищена. Таким образом, если операция завершается сбоем на каком-либо этапе, вся транзакция, происходящая в этой группе, завершается сбоем. MySQL гарантирует целостность данных финансовых транзакций, поэтому клиенты могут без проблем совершать транзакции в Интернете. Деньги не списываются до завершения всего процесса, а в случае неудачи каждый процесс возвращается к предыдущему этапу.
Масштабируемость по требованию
Преимущество MySQL заключается в непревзойденной гибкости, которая облегчает эффективное управление глубоко встроенными приложениями даже в гигантских центрах обработки данных, хранящих огромные объемы критически важной информации. Он обеспечивает полную настройку для удовлетворения уникальных требований предприятий электронной коммерции с гораздо меньшей площадью. MySQL обеспечивает максимальную гибкость платформы для предприятий, которым нужны дополнительные функции и функции для их серверов баз данных.
MySQL обеспечивает максимальную гибкость платформы для предприятий, которым нужны дополнительные функции и функции для их серверов баз данных.
Высокая доступность
Постоянная доступность — важная особенность MySQL. Предприятия, которые ее развертывают, могут наслаждаться круглосуточной безотказной работой. MySQL поставляется с широким спектром кластерных серверов и конфигураций репликации master-slave, которые обеспечивают мгновенное переключение при сбое для бесперебойного доступа. Независимо от того, используете ли вы веб-сайт электронной коммерции или высокоскоростную систему обработки, MySQL предназначен для обработки миллионов запросов и тысяч транзакций, обеспечивая при этом уникальные кэши памяти, полнотекстовые индексы и оптимальную скорость.
Присоединяйтесь к блокчейн-хакатону Partisia, проектируйте будущее, приобретайте новые навыки и побеждайте!
Непревзойденная надежность
Защита важной деловой информации является первостепенной задачей каждого предприятия. MySQL обеспечивает безопасность данных с исключительными функциями защиты данных. Мощное шифрование данных предотвращает несанкционированный просмотр данных, а поддержка SSH и SSL обеспечивает более безопасные соединения. Он также имеет мощный механизм, который ограничивает доступ к серверу для авторизованных пользователей и имеет возможность блокировать пользователей даже на человеко-машинном уровне. Наконец, функция резервного копирования данных облегчает восстановление на определенный момент времени.
MySQL обеспечивает безопасность данных с исключительными функциями защиты данных. Мощное шифрование данных предотвращает несанкционированный просмотр данных, а поддержка SSH и SSL обеспечивает более безопасные соединения. Он также имеет мощный механизм, который ограничивает доступ к серверу для авторизованных пользователей и имеет возможность блокировать пользователей даже на человеко-машинном уровне. Наконец, функция резервного копирования данных облегчает восстановление на определенный момент времени.
Возможность быстрого запуска
Вы можете перейти от загрузки программного обеспечения к полной установке всего за 15 минут. MySQL исключительно быстр, независимо от базовой платформы. Он имеет возможности самоуправления, такие как автоматический перезапуск, расширение пространства и автоматическое изменение конфигурации для простоты управления. Он также поставляется с полным набором инструментов миграции и полностью загруженным графическим пакетом управления. MySQL обеспечивает мониторинг производительности в режиме реального времени для своевременного устранения неполадок в работе с одной рабочей станции.
MySQL обеспечивает мониторинг производительности в режиме реального времени для своевременного устранения неполадок в работе с одной рабочей станции.
По всем этим причинам организации используют MySQL для мгновенной разработки и запуска приложений. От розничной торговли и финансов до здравоохранения и производства — многие отрасли извлекают выгоду из рентабельности, эффективности и надежности MySQL для предоставления бесперебойных услуг и увеличения доходов. Но когда дело доходит до оптимизации развертываний MySQL для обеспечения производительности и доступности, предприятия сталкиваются со следующими проблемами, поскольку для масштабирования MySQL требуется гораздо больше, чем просто база данных:
5 Проблемы масштабирования MySQL Длительное время разработки
Масштабирование фреймворков, которые не могут быть оптимизированы с помощью настроек master/slave, требует длительного времени разработки. Задержка репликации еще больше усложняет логику приложения, поскольку нарушает согласованность данных между ведомым и ведущим. Наконец, модификации сервера MySQL требуют постоянной координации между группами баз данных и приложениями.
Наконец, модификации сервера MySQL требуют постоянной координации между группами баз данных и приложениями.
Репликация
Серверы MySQL часто сталкиваются с конфликтами репликации во время ручного аварийного переключения, когда используются настройки с несколькими мастерами.
Затраты на ведение журнала базы данных
Ведение журнала базы данных стоит дорого, поэтому в большинстве случаев оно остается отключенным. В результате организациям не хватает информации о медленных журналах в режиме реального времени, что задерживает устранение неполадок.
Кэши запросов
Кэш запросов сервера MySQL мало помогает при обработке больших объемов рабочей нагрузки, поскольку невозможно контролировать аннулирование кэша.
Высокий отток подключений
Если ваши приложения используют стек LAMP, они, как правило, имеют большой объем пользовательских сеансов, выполняемых одновременно, и, следовательно, они испытывают высокий отток подключений. Таким образом, большая часть ваших ценных ресурсов сервера расходуется на управление соединениями.
Таким образом, большая часть ваших ценных ресурсов сервера расходуется на управление соединениями.
Некоторые компании рассматривают сегментирование как вариант масштабирования, но сегментирование добавляет значительную сложность, стоимость и создает собственный набор дополнительных проблем. Самый простой способ использовать мощные функции MySQL без внесения каких-либо изменений на уровне приложения или написания единой строки кода — использовать программное обеспечение для балансировки нагрузки базы данных.
Решение? Программное обеспечение для балансировки нагрузки базы данных для MySQL
Программное обеспечение для балансировки нагрузки базы данных решает проблемы, возникающие при масштабировании базы данных MySQL. Он обеспечивает автоматическое разделение чтения/записи, чтобы вы могли использовать реплики, доступные для чтения, без изменения кода, дополняет отработку отказа, делая ее невидимой на уровне пользователя или приложения, обеспечивает непревзойденную видимость аналитики и упрощает прозрачное кэширование одним щелчком мыши.