
Как снизить показатель отказов на сайте
Отказы – это параметр для визитов пользователей на сайт, говорящий о том, сколько времени они провели на странице и совершили ли какие-нибудь действия на ней. Процент отказов косвенно сообщает нам о том, насколько заинтересованная аудитория приходит на сайт и насколько он ей нравится. Условно нормальными считаются отказы до 20-25 % по Яндекс.Метрике. Если они выше, следует искать и исправлять проблемы на сайте и в РК. И сегодня мы расскажем, как это сделать.
Различие в отказах в Яндекс.Метрике и Google Analytics
О чем говорит показатель отказов
10 способов снизить показатель отказов
Способ 1. Проверить адаптивность сайта
Способ 2. Ускорить работу сайта
Способ 3. Отключить/перенастроить всплывающие окна
Способ 4. Проработать юзабилити посадочных страниц
Способ 5. Поработать над контентом
Способ 6. Проверить соответствие объявлений содержанию сайта
Способ 7. Проверить таргетинг объявлений
Способ 8. Проверить соответствие запросов объявлениям
Проверить соответствие запросов объявлениям
Способ 9. Убрать рекламу с первых экранов сайта
Способ 10. Сделать красивую страницу 404 ошибки
Различие в отказах в Яндекс.Метрике и Google Analytics
В Яндекс.Метрике и Google Analytics отказами называются разные вещи. Это важно знать для понимания того, почему счетчики показывают вам не одинаковые цифры.
В Яндекс.Метрике отказом считается визит продолжительностью менее 15 секунд, в процессе которого не совершается никаких действий (кликов по кнопкам, ссылкам и пр.). Например, показатель в 30 % говорит о том, что треть посетителей уходят с сайта сразу же.
В Google Analytics отказом считается посещение только одной страницы сайта без совершения каких-либо дополнительных действий. Здесь нет привязки ко времени визита, поэтому цифры для одного и того же сайта в GA обычно больше, чем в Метрике.
Про отказы также часто говорят в разрезе поведенческих факторов ранжирования. Если пользователь перешел из поисковой выдачи на сайт, а затем вернулся обратно и продолжил изучение выдачи, поисковая система будет расценивать это негативно. Однако такие отказы далеко не всегда пересекаются с отказами в счетчиках, и сегодня мы их рассматривать не будем.
Если пользователь перешел из поисковой выдачи на сайт, а затем вернулся обратно и продолжил изучение выдачи, поисковая система будет расценивать это негативно. Однако такие отказы далеко не всегда пересекаются с отказами в счетчиках, и сегодня мы их рассматривать не будем.
О чем говорит показатель отказов
- О качестве посадочной страницы. Современные пользователи искушены в хорошем дизайне и юзабилити. Поэтому если им что-то не нравится, достаточно всего нескольких секунд для принятия решения об уходе с сайта.
- О качестве рекламы. Объявление может не соответствовать посадочной странице и/или поисковому запросу, содержать ошибочную или заведомо недостоверную информацию. Наконец, в особенно печальных случаях, переход на сайт может происходить случайно, когда пользователя вынуждают кликнуть на объявление. Нередко такое встречается в мобильных приложениях. Все это вызывает рост показателя отказов.
- О заинтересованности аудитории.
 Если с предыдущими двумя пунктами все хорошо, а отказы все равно высокие, есть шанс, что вы приводите незаинтересованную или не готовую к покупке аудиторию. Например, молодые люди могут активно переходить на сайты с дорогостоящими товарами, но быстро покидать их, увидев цены.
Если с предыдущими двумя пунктами все хорошо, а отказы все равно высокие, есть шанс, что вы приводите незаинтересованную или не готовую к покупке аудиторию. Например, молодые люди могут активно переходить на сайты с дорогостоящими товарами, но быстро покидать их, увидев цены.
 Если с предыдущими двумя пунктами все хорошо, а отказы все равно высокие, есть шанс, что вы приводите незаинтересованную или не готовую к покупке аудиторию. Например, молодые люди могут активно переходить на сайты с дорогостоящими товарами, но быстро покидать их, увидев цены.
Если с предыдущими двумя пунктами все хорошо, а отказы все равно высокие, есть шанс, что вы приводите незаинтересованную или не готовую к покупке аудиторию. Например, молодые люди могут активно переходить на сайты с дорогостоящими товарами, но быстро покидать их, увидев цены.К сожалению, нередко отказы говорят сразу о нескольких негативных факторах, поэтому и работать над ними следует комплексно.
10 способов снизить показатель отказов
Способ 1. Проверить адаптивность сайта
У современных сайтов должна быть адаптивная версия. Мы говорим об этом так категорично, потому что посещаемость ресурсов с мобильных устройств растет год от года и доля мобильного трафика на сайты уже крайне редко составляет менее 30 %. Если пользователи, перешедшие по рекламе, видят не адаптированную под экран смартфона верстку, они, скорее всего, уйдут, внеся свой вклад в процент отказов. Юзабилити адаптивной версии сайта имеет несколько иные правила, чем на десктопе, поэтому для создания макета лучше обратиться к профессиональному UX-аналитику или дизайнеру.
Способ 2. Ускорить работу сайта
По статистике, примерно половина современных интернет-пользователей считает, что контент-страницы должны загружаться за 2 секунды. Если сайт грузится дольше, это стремительно увеличивает шансы получить высокие отказы.
Простой и бесплатный сервис для анализа скорости загрузки – PageSpeed Insights от Google. Для проверки достаточно вставить в поисковую строку адрес сайта и нажать «Анализировать».
Через несколько секунд сервис в наглядном виде представит следующие сведения:
- оценку скорости загрузки на смартфонах и компьютерах с расшифровкой;
- рекомендации, которые помогут ускорить загрузку на конкретное количество времени;
- карту эффективности с детальными данными о том, как на скорость влияет каждый из скриптов.
Способ 3. Отключить/перенастроить всплывающие окна
Пользователи уже давно негативно реагируют на модальные окна, появляющиеся без запроса. А в случае первого контакта с сайтом это может оттолкнуть навсегда. Перед запуском рекламы проверьте, есть ли у вас следующие «всплывашки» и через сколько секунд они появляются:
Перед запуском рекламы проверьте, есть ли у вас следующие «всплывашки» и через сколько секунд они появляются:
- акция или подарок новому покупателю;
- оповещение о конкурсе или игре;
- форма сбора данных пользователя для консультации, индивидуального предложения, расчета;
- окно «Не нашли того, что искали?».
Желательно совсем убрать эти окна, настроить их появление через длительное время пребывания на сайте либо запрограммировать их показ после совершения конкретного действия (например, после попытки выхода со страницы).
Способ 4. Проработать юзабилити посадочных страниц
Юзабилити – это удобство использования сайта для поиска информации или совершения покупки. До любых нужных пользователю данных должен быть максимально короткий, понятный и привычный путь. Например, меню сайта всегда ищут сверху в шапке, корзину – там же справа, а в каталогах с товарами обязательно должны быть цены и сортировка по ним. На примере ниже вы видите главную страницу сайта с далеко не очевидным юзабилити.
Способ 5. Поработать над контентом
Здесь мы имеем в виду тексты и дизайн. Напрямую они не влияют на юзабилити, но сильно дополняют впечатление о сайте. Современные молодые люди, пользующиеся топовыми интернет-магазинами, соцсетями, приложениями и стриминговыми сервисами, знают толк в хорошем дизайне и могут уйти со страницы, если посчитают ее оформление старомодным. К цветам тоже стоит подходить внимательно. Сколько бы ни спорили о психологии цвета, ассоциации никто не отменял. Например, красный акцентирует внимание и ассоциируется с силой и энергией. Наиболее спокойными цветами, воплощающими надежность и безопасность, являются синий и зеленый. Неслучайно именно в этих цветах оформляют сайты клиник.
Способ 6. Проверить соответствие объявлений содержанию сайта
Не всегда проблема может заключаться в контенте сайта. Бывает, что для объявления указана не соответствующая товару страница. Такое случается, если семантика для РК подобрана неточно или если посадочная страница по каким-либо причинам изменилась. Например, в объявлении может идти речь про мужские шапки, а на странице находятся только летние головные уборы: кепки и панамы.
Например, в объявлении может идти речь про мужские шапки, а на странице находятся только летние головные уборы: кепки и панамы.
Способ 7. Проверить таргетинг объявлений
Посыл объявления и оформление посадочных страниц должно соответствовать портрету целевой аудитории, которая с наибольшей вероятностью совершит покупку. Если сайт предлагает только молодежную одежду и обувь, есть смысл ограничить таргетинг возрастной аудиторией до 25 лет. Вы можете возразить, что родители часто покупают одежду детям-подросткам. Это так, но и представление о хорошем интернет-магазине у них свое, поэтому суперсовременный дизайн посадочной страницы может вызвать негатив.
Снижать показатель отказов вам помогут автоматизированные инструменты Click.ru: кластеризация запросов, парсер WordStat, парсер объявлений конкурентов и многие другие. А приятным бонусом будет доход до 18 % от оборота ваших клиентов, если переведете ваши рекламные кампании в Click.ru и станете участником нашей партнерской программы.
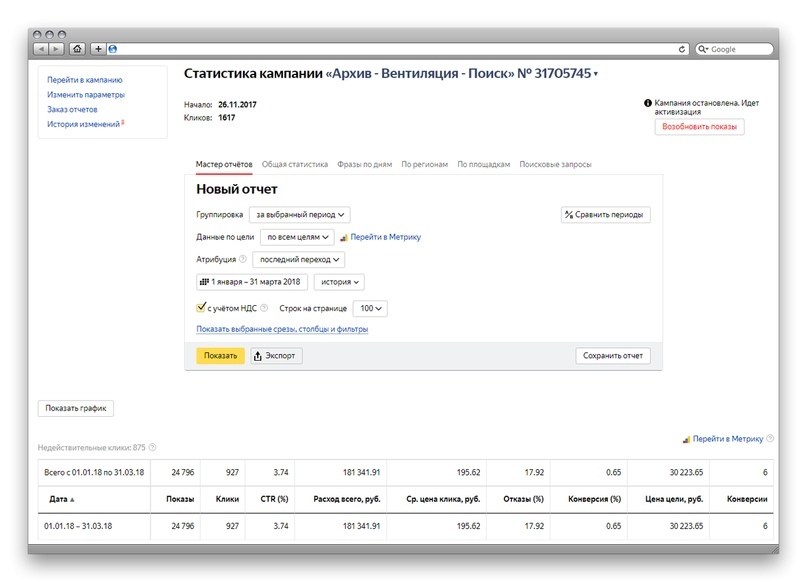
Способ 8. Проверить соответствие запросов объявлениям
Важно, чтобы объявление говорило именно о запрашиваемых услугах и в его тексте были подсвечиваемые ключевые слова. На примере ниже вы видите не соответствующее запросу объявление. В запросе речь идет о юристе для бизнеса, а в объявлении – про патентного поверенного. Конечно, это тоже касается услуг для фирм, но это предложение с очень ограниченной ЦА и в объявлении нет ключевых слов из запроса.
Способ 9. Убрать рекламу с первых экранов сайта
Особенно эта рекомендация касается информационных порталов. Пользователи негативно реагируют на рекламные блоки, так как научились распознавать их, даже если они маскируются под основной контент. Кроме того, поисковые системы могут понижать рейтинг страниц с полноэкранными баннерами.
Способ 10. Сделать красивую страницу 404 ошибки
От поломок никто не застрахован. На случай, если пользователь может попасть на неработающую страницу, советуем создать такую 404-ю, с которой не захочется уходить. Пользователям нравятся заглушки, оформленные с юмором и снабженные полезными ссылками.
Пользователям нравятся заглушки, оформленные с юмором и снабженные полезными ссылками.
Запустить рекламную кампанию
Что такое bounce rate на сайте
Bounce rate, или показатель отказов — это метрика, отражающая количество посетителей сайта, которые уходят вскоре после открытия страницы и не совершают никаких действий. Показатель рассчитывают в процентном соотношении к общему количеству посетителей.
Например, за месяц на сайт зашли 300 человек. 150 из них совершили действия — перешли на другую страницу, заполнили форму, оформили заказ. Другие 150 пользователей сразу закрыли сайт. В итоге процент отказов — 50 %.
Показатель отказов в Google Analytics можно посмотреть как в целом по сайту, так и по каждой отдельной странице
Зачем отслеживать bounce rate
Показатель помогает проанализировать работу сайта, а также поведение и активность посетителей.
Слишком высокий BR указывает на такие проблемы, как:
- несоответствие ресурса запросам пользователей;
- привлечение нецелевой аудитории, в том числе по итогам рекламных кампаний;
- чрезмерное количество рекламы на сайте;
- слишком агрессивные и навязчивые попапы;
- низкая скорость загрузки страниц;
- неудобная навигация по сайту;
- некорректное отображение на мобильных устройствах;
- некачественный или перегруженный дизайн;
- технические проблемы на сайте.

Количество отказов веб-ресурса влияет на его ранжирование в поисковиках. Поисковые системы учитывают BR при расчёте рейтинга. Если bounce rate низкий, значит сайт интересен для посетителей, и его можно размещать выше в поисковой выдаче.
На значение BR нужно обратить особое внимание, если сайт многостраничный. И его основная задача — мотивировать пользователей просмотреть разные разделы, почитать статьи блога, заглянуть в кейсы.
На главной странице новостного сайта есть много ссылок на другие статьи. Низкий Bounce Rate свидетельствует о том, что посетители активно читают и интересуются контентом
Если посещение ресурса не предусматривает переходов или обязательных действий, то показатель отказов не имеет критического значения.
Например, предприниматель запустил одностраничный сайт для салона красоты. Потенциальный клиент зашёл на сайт, посмотрел телефон для записи и ушёл. Ему не нужно читать статьи, искать нужный товар в разных разделах. Он уже решил свою задачу.
Поэтому для лендингов характерен более высокий показатель отказов в сравнении с обычными сайтами, и это не является проблемой.
На первом экране лендинга есть телефон, адрес и режим работы. Пользователь может быстро решить свою задачу и закрыть сайт
Нормы показателя отказов
Не существует строго определенных хороших или плохих значений Bounce Rate. Усредненные нормы выглядят так:
- 70 % и выше — высокое значение. Необходимо срочно проанализировать причины, по которым пользователи быстро покидают сайт. Возможно, что проблема в нерелевантном контенте или технических неполадках.
- 50-70 % — средний результат. Такое значение характерно для большинства новых сайтов и одностраничников.
- 30-50 % — хороший показатель, но можно улучшить параметр.
- 25 % и ниже — отличный результат. Сайт интересный и хорошо оптимизирован.
Ориентироваться при оценке качества сайта только на Bounce Rate не следует.
Как посчитать процент отказов
Показатель отказов рассчитывают по следующей формуле:
Bounce rate = (количество посетителей с просмотром одной страницы / общее количество посетителей) × 100 %
При расчёте параметра для определённого источника учитывают только переходы с конкретной площадки.
Вручную показатель отказов никто не рассчитывает: сервисы аналитики делают это автоматически. Они позволяют посмотреть статистику за отдельные временные периоды, по разным источникам трафика или по отдельным запросам. Но у каждой аналитической системы есть свои особенности.
Как считают bounce rate в Google Analytics
В Google Analytics отказом признают посещение, в процессе которого был сделан лишь один запрос к серверу. То есть пользователь открыл страницу и закрыл её без совершения дополнительных действий.
Продолжительность сеанса с просмотром одной страницы всегда признают равной нулю. При отсутствии дополнительных обращений к серверу система не рассчитывает реальное время пребывания на сайте. По умолчанию сеанс завершается по истечении 30 минут при условии бездействия пользователя. При желании этот период можно изменить.
При отсутствии дополнительных обращений к серверу система не рассчитывает реальное время пребывания на сайте. По умолчанию сеанс завершается по истечении 30 минут при условии бездействия пользователя. При желании этот период можно изменить.
Именно из-за особенностей подсчёта система Google Analytics фиксирует высокий показатель отказов на одностраничниках и лендингах, на которых не предусмотрено никаких действий со стороны пользователей.
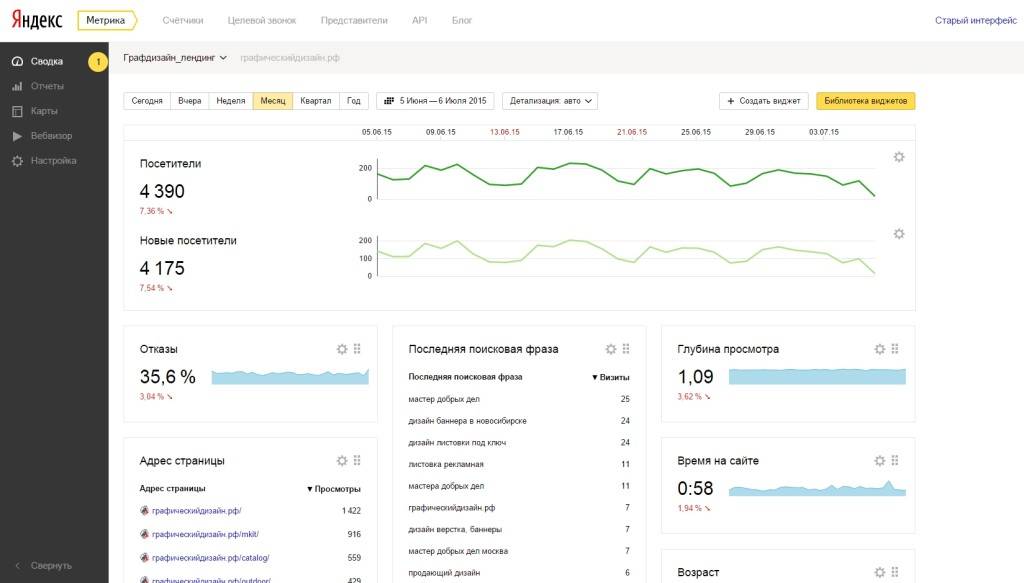
Для просмотра значений bounce rate в системе Google Analytics, нужно войти в нужный аккаунт и перейти во вкладку «Аудитория», раздел «Обзор». Здесь находится сводка по количеству сеансов и пользователей, просмотренным страницам, продолжительности сеансов и показателю отказов.
Показатель отказов можно отслеживать по разным источникам
Как считается в Яндекс.Метрике
В Яндекс.Метрике отказом признаётся посещение длительностью меньше 15 секунд. Этот временной период задаёт система и изменить его нельзя.
При этом должны одновременно соблюдаться ещё два критерия:
- За одно посещение посетитель просмотрел только одну страницу. При этом визит считается завершённым после 30 минут бездействия.
- Не зафиксировано событие «неотказ». То есть система не выявила задержек информации в процессе ее передачи, которые случаются при длительном ответе сервера или ошибках в работе браузера.
 При этом визит считается завершённым после 30 минут бездействия.
При этом визит считается завершённым после 30 минут бездействия. Для просмотра bounce rate в Яндекс.Метрике нужно войти в аккаунт и найти соответствующий показатель во вкладке «Сводка».
При оценке эффективности работы сайта в первую очередь оценивают общий Bounce Rate по всем переходам, а затем анализируют показатели по отдельным источникам
Как снизить показатель отказов
Работу с показателем отказов ведут по принципу «чем ниже значение, тем лучше». Прежде чем приступить к поиску и исправлению ошибок, стоит детально изучить данные аналитики. От этого будут зависеть необходимые действия по снижению bounce rate.
Сначала посмотрите, не зависит ли параметр от какого-то отдельного источника. Проанализируйте показатель по каналам, страницам и запросам.
Отказы по каналам. Иногда высокое значение bounce rate наблюдается только у конкретной группы каналов. Например, быстро уходят посетители из социальных сетей. В этом случае стоит проверить, насколько правильно выбрана аудитория для взаимодействия.
В отчёте видно, что высокий показатель отказов у источника Display, который характеризует медийную и баннерную рекламу. Нужно проверить настройки таргета, офферы и креативы
Отказы по страницам. Большой процент bounce rate могут показывать страницы, на которых пользователю сложно или невозможно выполнить целевые действия. Например, не срабатывает кнопка или форма сбора данных слишком длинная. Нужно выявить момент, когда пользователи уходят, и найти причину. Для этого попробуйте изучить поведение посетителей с помощью Вебвизора в Яндекс.Метрике.
Отслеживание bounce rate помогает выявить непопулярные страницы
Отказы по ключевым запросам. Если высокий показатель соответствует конкретному ключевому слову, то вероятно, он ведёт на нерелевантный материал.
Из отчетов аналитических систем можно понять, по каким ключевым запросам посетители не находят нужной информации
Если общий показатель отказов высокий, то в первую очередь проверьте наличие кода отслеживания на всех нужных страницах. Удостоверьтесь, что в коде нет ошибок. А потом приступайте к оптимизации.
Важно! Любые изменения желательно внедрять в процессе A/B-тестирования. Изменили какой-то элемент, проверили динамику показателя отказов и при положительном результате сохранили изменение.
Чтобы снизить показатель отказов на сайте, попробуйте выполнить следующие действия:
- Повысьте скорость загрузки страниц. Чаще всего сайт долго грузится из-за тяжелых изображений, излишней анимации и видеороликов с автозапуском.
- Оптимизируйте навигацию. Разнесите информацию по разделам и категориям, сделайте понятное меню, добавьте строку поиска с фильтрами.
- Улучшите релевантность и качество контента. Убедитесь, что материалы соответствуют запросам, по которым приходят пользователи.
- Используйте внутреннюю перелинковку. Добавьте ссылки на другие страницы, чтобы повысить вероятность перехода.
- Измените дизайн сайта. Поработайте над шрифтами, цветовой палитрой, визуалом.
- Уберите чрезмерно навязчивую рекламу. Огромные баннеры на половину страницы и часто всплывающие попапы раздражают пользователей. Они побуждают закрыть ресурс даже при его максимальной релевантности и полезности.
- Поработайте над элементами, мотивирующими к действию. Измените дизайн формы заявки, текст кнопки CTA, добавьте онлайн-чат с консультантом.
- Адаптируйте сайт под мобильные устройства. Особенно это важно, когда существенная часть посетителей приходится на мобильный трафик.
 Убедитесь, что материалы соответствуют запросам, по которым приходят пользователи.
Убедитесь, что материалы соответствуют запросам, по которым приходят пользователи. Перечисленные рекомендации помогут снизить bounce rate. Но учтите, что реальную причину не всегда получается найти быстро и сразу.
Главные мысли
Что такое процент показателя отказов в Яндекс Метрике?
Автор Алексей На чтение 5 мин Просмотров 2.1к. Опубликовано Обновлено
Количество отказов – это доля посещений, при которых посетитель не заинтересовался вашим сайтом. В Яндекс Метрике и Google Analytics он считается по-разному, с учетом особенностей каждой системы.
Содержание
- Что такое отказы в Яндекс Метрике?
- Что значат отказы в Яндекс Метрике?
- Анализ трафика и сайта на основе показателя отказов
- Анализ каналов трафика
- Выявление страниц с высоким показателем отказа
- Что надо сделать для снижения показателей отказа
- Соответствие заметки и ключевого запроса
- Правильность настроек счетчиков статистики
- Дизайн, юзабилити, количество рекламы
- Повышение скорости загрузки страниц
- Текст неудобно форматирован
- Адаптивность под мобильные устройства
- Показатель отказов в Яндекс Метрике
Что такое отказы в Яндекс Метрике?
В каждой системе аналитики используется свой уникальный алгоритм работы, по этой причине учет различных типов данных происходит по-разному и говорят они совершенно о разных вещах.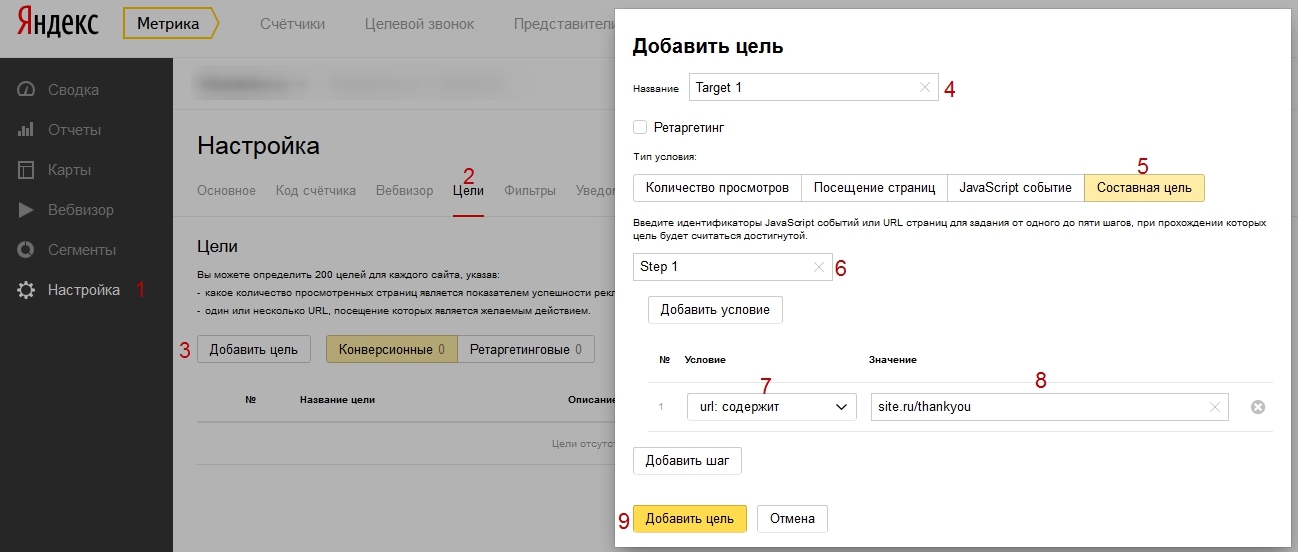 Так, например, в Яндекс Метрике за отказ считается визит, в рамках которого выполнены сразу несколько условий:
Так, например, в Яндекс Метрике за отказ считается визит, в рамках которого выполнены сразу несколько условий:
- За время одного визита просмотрено только одна страница;
- Визит, длительность которого составила менее 15 секунд;
- Не было фиксации служебного события «неотказ».
Только при совокупности всех этих условий будет засчитываться отказ.
Что значат отказы в Яндекс Метрике?
В Яндекс Метрике показатель отказов является процентным соотношением, то есть долей от общего числа визитов. Опытные интернет-маркетологи выявили определенные диапазоны, ориентируясь на которые можно понять насколько качественен трафик:
- 0% — 20% — высокое качество трафика;
- 20% — 35% — нормальное качество;
- 35% — 50% — ниже среднего;
- 50% и выше — плохо.
Кроме этого, процент отказов говорит о таких вещах, как: удобство пользования сайтом, качество контента, привлекательность.
Конечно, в полной мере полагаться на данные диапазоны показателей отказов не стоит, так как для каждой ниши эти цифры сугубо индивидуальные.
Анализ трафика и сайта на основе показателя отказов
Анализ каналов трафика и выявлению некачественных страниц сайта на основе данного показателя. Воспользуемся для этого простыми отчетами в Яндекс Метрике.
Анализ каналов трафика
Довольно часто случается, что при использовании различных каналов привлечения трафика один показывает хорошие результаты, а другой совсем наоборот. Чтобы понять, по какому именно каналу идут не совсем целевые посетители, достаточно воспользоваться отчетом «Источники, сводка» в Яндекс Метрике (Отчеты > Стандартные отчеты > Источники > Источники, сводка):
В этом отчете вы можете видеть насколько целевых посетителей приводит на ваш сайт тот или иной канал.
Обратите внимание, основная доля трафика на сайт приходит с поисковых систем, где процент показателя отказов равен 10,5%. Можно с уверенностью сказать, что трафик идет целевой.
Выявление страниц с высоким показателем отказа
Также необходимо провести анализ страниц, полагаясь на отказы.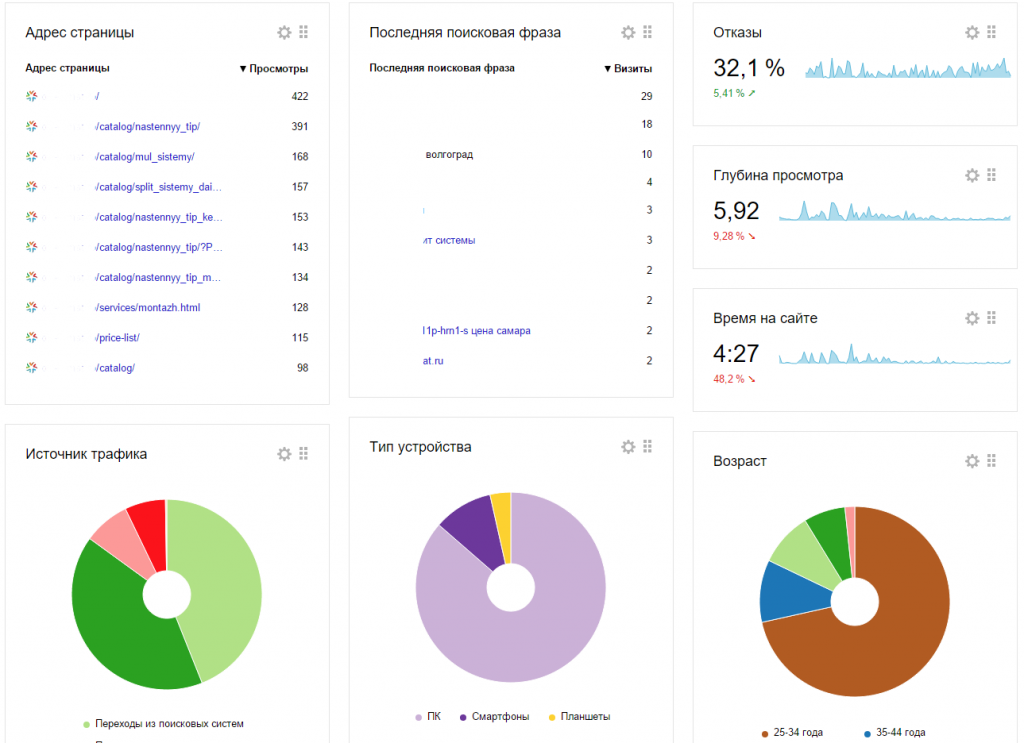 Сделать это можно в Яндекс Метрике с помощью отчета «Страница входа» (Отчеты > Стандартные отчеты > Содержание > Страницы входа):
Сделать это можно в Яндекс Метрике с помощью отчета «Страница входа» (Отчеты > Стандартные отчеты > Содержание > Страницы входа):
В этом отчете вы можете видеть URL-адреса различных страниц со всеми метриками, в том числе показателями отказов.
Что надо сделать для снижения показателей отказа
Соответствие заметки и ключевого запроса
Высокочастотные запросы – это правильно и хорошо. Тем не менее обязательными условиями качественного ресурса являются релевантные запросам материалы. Не гонитесь за высокой посещаемостью, предоставляйте качественный контент, соответствующий ключевым запросам, следите за метриками в Яндекс Метрике.
Выбирая ключевую фразу для заметки, раскройте тему полностью, чтобы у читателей не осталось вопросов.
Также с вниманием отнеситесь к материалам, которые со временем теряют свою актуальность. Если берете какой-либо инфоповод следите, чтобы статья своевременно обновлялась. Чем точнее и релевантнее информация на странице, тем меньше процент показателя отказов.
Правильность настроек счетчиков статистики
Настройки счетчика Яндекс Метрики иногда нужно доработать. Поэтому, прежде, чем паниковать, по поводу высокого показателя отказов посмотрите корректность настроек в счетчиках на сайте. Проанализируйте с каких страниц чаще всего покидают ваш сайт пользователи, и по каким запросам на них попали.
Дизайн, юзабилити, количество рекламы
Большинство пользователей понимает, что реклама кормит хозяина сайта. Но если ее больше, чем контента – это моветон. Это мешает читать и, конечно, бросается в глаза раньше, чем качественные материалы. Отсюда и отказы в Яндекс Метрике.
Визуальное сопровождение и дизайн в целом крайне важны. Сделайте страницу удобной для восприятия информации.
Может, ваш посетитель и не разбирается в тонкостях сайтов, но вот поехавшую верстку обязательно заметит. Еще разозлится, если не найдет нужную кнопку там, где она должна быть. Захочет положить товар в корзину и долго будет искать эту самую корзину по сайту – безуспешно.
Повышение скорости загрузки страниц
Показатель отказов зависит от скорости загрузки страниц. Максимально ускоряйте свой сайт. Помочь в этом могут:
- установка плагина кэширования,
- уменьшение количества плагинов, различных скриптов, виджетов, всевозможных ненужных анимаций на сайте,
- регулярная проверка скорости загрузки страниц.
Старайтесь избегать пусть и хороших, но не оптимизированных заметок со множеством визуальных эффектов. Она не дождется своего звездного часа, но точно замедлит работу сайта. Следите за процентом отказов в Яндекс Метрике.
Текст неудобно форматирован
Проще говоря простыня текст без абзацев и такое конечно же нет желание читать. Видя подобный контент пользователь просто покидает сайт, зафиксировав отказ в Яндекс Метрике.
Адаптивность под мобильные устройства
Как правило, если сайт информативен и на мобильных устройствах он открывается в полном масштабе, пользователям это не нравится и чаще всего такой сайт закрывают, ведь есть более удобные аналоги – это также влияет на показатель отказов у сайта.
Показатель отказов в Яндекс Метрике
Показатель отказов – сложный параметр, который трудно загнать в определенные рамки, но он важен.
Изучайте Яндекс Метрику и улучшайте свои сайты – понижайте процент показателя отказов!
MTTR, MTBF или MTTF? – Наглядное руководство по метрикам отказов
10 августа 2018 г.
Прежде чем углубляться в MTTR, MTBF и MTTF, необходимо провести четкое различие. Показатели обслуживания (такие как MTTR, MTBF и MTTF) не совпадают с KPI обслуживания. Показатели обслуживания поддерживают достижение ключевых показателей эффективности, которые, в свою очередь, поддерживают общую стратегию бизнеса. Имея так много показателей эффективности обслуживания, трудно понять, какой из них выбрать.
В этой статье мы сосредоточимся на трех наиболее распространенных показателях отказов. Мы упростим для вас понимание того, что это такое, как они работают и когда их использовать. Если вы хотите узнать больше об остальном, мы предлагаем посетить эту статью, посвященную метрикам и ключевым показателям эффективности, связанным с обслуживанием.
Знакомство с метриками сбоев
Чтобы понять, как использовать MTTR, MTBF и MTTF в своих интересах, вы должны понимать общую картину метрик сбоев.
Что такое отказ оборудования?
Отказ существует в различной степени (например, частичный или полный отказ). Проще говоря, отказ оборудования просто означает, что система, компонент или устройство больше не могут давать желаемых результатов.
Даже если часть производственного оборудования все еще работает и производит изделия, оно выходит из строя, когда перестает поставлять ожидаемое количество или качество продукции.
БЕСПЛАТНЫЕ РЕСУРСЫ ДЛЯ ПРОФЕССИОНАЛОВ И СТУДЕНТОВ
Внутри вы найдете рекомендации по следующим вопросам:
[1.] Выбор правильной методики анализа отказов
[2.] FMEA и FMECA: как проводить анализ видов и последствий отказов
[3.] MTTR, MTBF и MTTF: простое руководство по показателям отказов
[4.] Что такое разрушающее тестирование и каковы его применения?
[5. ] Что такое неразрушающий контроль (НК) и как он используется?
] Что такое неразрушающий контроль (НК) и как он используется?
Почему я должен это отслеживать?
Даже у самых эффективных ремонтных бригад случаются отказы оборудования. Вот почему так важно планировать их. Правильно справляться со сбоями означает сводить к минимуму их негативное влияние. Чтобы помочь вам эффективно управлять потерями, необходимо отслеживать несколько критических
показателей.Отслеживание и понимание этих показателей избавит от догадок и предоставит менеджерам по техническому обслуживанию достоверные данные, необходимые им для принятия обоснованных решений, что поможет вам свести сбои в работе к минимуму. Это ваше секретное оружие, источник вашей сверхспособности!
На какие ключевые показатели отказов следует обратить внимание? Мы обсудим 3 из них:
- MTTR (среднее время ремонта)
- MTBF (среднее время наработки на отказ)
- MTTF (среднее время до отказа)
Получение надежных данных с самого начала
Данные важны. Статистика отказов высокого уровня требует большого количества значимых данных. Как мы покажем в расчетах ниже, следующие входные данные должны быть собраны как часть вашей истории обслуживания.
Статистика отказов высокого уровня требует большого количества значимых данных. Как мы покажем в расчетах ниже, следующие входные данные должны быть собраны как часть вашей истории обслуживания.
Рабочее время, затраченное на техническое обслуживание
Если вы работаете с современной CMMS, такой как Limble, она будет автоматически отслеживать часы технического обслуживания. Техники сообщают, сколько времени требуется для завершения работы каждый раз, когда они заканчивают НР. Со временем эти данные становятся бесценными. И это не требует дополнительного времени или работы, чтобы получить.
Техникам предлагается ввести «затраченное время» при закрытии ЗНР
Количество поломок и ремонтов
Limble предоставляет вам представление в режиме реального времени обо всех запланированных и завершенных задачах обслуживания, включая те, которые вызывают простои. Это позволяет легко увидеть, что происходит со всеми вашими активами, и определить, где можно повысить эффективность.
Limble помогает отслеживать задачи, вызвавшие простои
Рабочее время
Вы можете рассчитать общее рабочее время, вычитая время простоя актива из ожидаемого количества рабочих часов в неделю. (Чтобы облегчить вам задачу, Limble позволяет вам увидеть, сколько времени потребуется, чтобы снова запустить активы в случае сбоя).
Пример отчета о времени безотказной работы активов в Limble CMMS
Запись данных об обслуживании может быть утомительной. Тем не менее, это важная часть улучшения операций технического обслуживания — выявление элементов с высокой частотой отказов и поиск основной причины этих отказов.
Делать это вручную очень долго. Но с мобильной CMMS, такой как Limble, это стало проще. Limble позволяет быстро и легко регистрировать достоверные данные о рабочем времени и времени простоя на вашем телефоне, пока вы выполняете задачи по техническому обслуживанию. Более того, Limble автоматически выполняет все расчеты MTTR и MTBF.
Отчет о MTTR и MTBF внутри Limble CMMS
Сбор неточных данных может вызвать множество проблем. Если данные отсутствуют или неверны, ваши показатели отказов будут бесполезны для принятия решений по улучшению операций. Что еще хуже, если вы не знаете, что информация ненадежна, вы можете принять оперативные решения, которые могут повредить или замедлить производство.
Теперь, когда мы разобрались с этим, давайте сосредоточимся на вещах, ради которых вы пришли сюда.
БЕСПЛАТНЫЕ РЕСУРСЫ ДЛЯ ПРОФЕССИОНАЛОВ И СТУДЕНТОВ
Вы получите:
- Инструкции и рекомендации
- Электронная таблица трекера MTBF
- Генератор метрик отказов
- Прямая поддержка от нашей команды
Что такое MTTR (среднее время ремонта)?
Среднее время ремонта (MTTR) — это количество времени, необходимое для ремонта системы и восстановления ее полной функциональности. Часы MTTR начинают тикать с момента начала ремонта и продолжают тикать до тех пор, пока работа не будет восстановлена.
Часы MTTR начинают тикать с момента начала ремонта и продолжают тикать до тех пор, пока работа не будет восстановлена.
Включает:
- Время устранения неполадок и диагностики проблемы
- Время ремонта
- Период тестирования
- Время на сборку и запуск актива
MTTR — это мера, но это не магия
MTTR — это метрика, которую вы будете использовать для подтверждения эффективности работы. Однако вы не можете ожидать, что это решит все ваши проблемы. Его необходимо сочетать с другими показателями, чтобы помочь создать сильный и ценный KPI, который будет напрямую влиять на общую стратегию компании.
MTTR могут быть легко искажены выбросами. Если у вас есть один инцидент с разрешением или ремонтом, который сильно отличается от других, ваши данные могут быть искажены.
Например, предположим, что большая часть водонагревателей в вашем здании имеет неисправные термостаты. Для большинства из них это относительно просто и недорого. Но один выделяется среди остальных. Он издает странные звуки, в нем накапливаются минералы, и его необходимо слить, а устройство отремонтировать, прежде чем произойдет дорогостоящая утечка или взрыв. Починка термостата занимает гораздо больше времени. В результате среднее время ремонта термостата покажется вам необычно большим.
Но один выделяется среди остальных. Он издает странные звуки, в нем накапливаются минералы, и его необходимо слить, а устройство отремонтировать, прежде чем произойдет дорогостоящая утечка или взрыв. Починка термостата занимает гораздо больше времени. В результате среднее время ремонта термостата покажется вам необычно большим.
Кроме того, MTTR не ограничен по времени . Он не может рассчитать время использования в пиковые и непиковые часы, а это означает, что он не может точно сообщить о периодах чрезмерного использования или простоя, влияющих на время ремонта.
Поскольку существует множество способов интерпретации MTTR, успех придет только тогда, когда у вас есть четкое определение того, что это означает в вашей организации. Вам нужно будет объединить это с хорошо обученной командой и системами для управления информацией. Найдите правильный набор показателей, которые дадут вам полную картину, которую вы ищете.
Чем полезен показатель MTTR?
Активы в ремонте равны времени простоя. Регулярные системные сбои и длительные периоды простоя оказывают огромное влияние на производительность. Это, в свою очередь, оказывает еще большее влияние на результаты бизнеса. Особенно это касается процессов, которые особенно чувствительны к сбоям.
Регулярные системные сбои и длительные периоды простоя оказывают огромное влияние на производительность. Это, в свою очередь, оказывает еще большее влияние на результаты бизнеса. Особенно это касается процессов, которые особенно чувствительны к сбоям.
В производственной среде длительное время ремонта приводит к нарушению сроков производства, увеличению затрат на рабочую силу, потере дохода и различным операционным проблемам.
Понимание MTTR — важный инструмент для любой организации, поскольку он показывает, насколько хорошо вы реагируете на проблемы с вашими активами. Большинство организаций работает над сокращением MTTR с помощью собственной группы технического обслуживания, поддерживаемой необходимыми ресурсами, инструментами, запасными частями и программным обеспечением CMMS.
Как рассчитать MTTR?
Для расчета MTTR необходимо сложить все время, затраченное на ремонт, и разделить на количество выполненных ремонтов.
Представьте насос, который выходит из строя три раза в течение рабочего дня. Первый ремонт длился 30 минут, а два других ремонта длились всего 15 минут. В этом случае:
Первый ремонт длился 30 минут, а два других ремонта длились всего 15 минут. В этом случае:
MTTR = (30 + 15 +15) / 3
MTTR = 60 / 3
MTTR = 20
Среднее время ремонта этого насоса составляет 20 минут .
Особое примечание о Расчет MTTR —
Каждый сбой будет иметь разный уровень серьезности, поэтому диагностика и устранение некоторых из них потребуют дней, а устранение других может занять несколько минут. MTTR может дать вам среднее значение того, что вы ожидаете.
В Limble можно получить два представления MTTR. Они могут помочь сделать разные выводы:
1.) MTTR для конкретного актива , который рассчитывается на основе количества задач, вызвавших простои только для этого актива.)
2.) Комбинированный MTTR для всех активов , который рассчитывается на основе того, сколько задач вызвало простои для всех активов в течение определенного периода времени.
Если вы работаете только с небольшим количеством устройств, вы можете удалить все выделяющиеся данные. Это может исказить ваши результаты.
Например, кто-то может совершить серьезную ошибку в процессе ремонта, например, случайно перерезать провод или сломать часть устройства при устранении первоначальной проблемы. Это может превратить небольшой ремонт в ремонт, который продлится несколько дней, если у вас не было детали или ноу-хау, чтобы ее починить.
Что может сказать вам MTTR?
Показатель MTTR сам по себе отличный, но требуется гораздо больше анализа данных, чтобы перейти к конкретному действию. MTTR может сказать вам:
- Ремонт или замена . MTTR — это особенно хороший инструмент, который поможет вам решить, когда пора наконец прекратить ремонт актива и заменить его. Когда вы заметите, что ремонт занимает все больше и больше времени, а затраты продолжают расти, вы можете использовать MTTR в качестве одного из отчетов, чтобы обосновать необходимость инвестирования в новое оборудование.
- Дополнительное обучение. Даже самый обученный персонал допускает ошибки. MTTR может выявить пробелы в обучении или навыках определенных сотрудников или команд. Предположим, вы видите необычно высокое MTTR для определенного человека или группы. В этом случае вы можете более внимательно изучить их обучение и подумать о переподготовке.
- Улучшение процессов . Как и в случае с обучением, рабочий процесс и операционные процедуры могут иметь большое влияние на MTTR. Их следует регулярно оценивать, независимо от производительности. Используя отчет MTTR, вы можете легко обнаружить проблемы с активами.
Когда использовать MTTR?
Используйте MTTR, если вы хотите:
- Измерить и улучшить среднее время, которое ваша команда тратит на ремонт активов
- Поймите, сколько времени вы должны запланировать на ремонт, чтобы не слишком давить на команды
- Помогите сократить время простоя на тех участках фабрики или бизнеса, которые, кажется, постоянно приостановлены из-за ремонта
- Выявление аномалий в управлении инцидентами
Тактика для снижения MTTR
Каждая эффективная система технического обслуживания должна искать способы максимально сократить MTTR. Это можно сделать несколькими способами:
Это можно сделать несколькими способами:
- Оптимизация Управление запчастями и Инвентаризация активов управление процессы . Это гарантирует, что ваши техники будут иметь быстрый доступ к инструментам и запасным частям, когда они им понадобятся.
- Используйте датчики контроля состояния для отслеживания состояния и производительности машины. Хотя датчики следует использовать для предотвращения неожиданных сбоев, данные датчиков также могут ускорить процесс диагностики и устранения неполадок. Знание исходного состояния и отслеживание признаков износа может дать вашей команде больше времени для организации всех ресурсов, необходимых для завершения ремонта.
- Внедрить программное обеспечение CMMS. Решения Mobile CMMS, такие как Limble, позволяют техническим специалистам получить быстрый доступ к истории обслуживания (журналы, отчеты, заметки о предыдущих ремонтах…), что может ускорить процесс ремонта и сократить как запланированные, так и незапланированные простои.
- Оптимизация процесса ремонта . Создайте четкие стандартные рабочие процедуры и контрольные списки обслуживания для регулярно выполняемого ремонта. Разместите их в Limble, чтобы технические специалисты могли получить к ним доступ во время работы.
- Правильная подготовка. Если вы хотите, чтобы работа была выполнена должным образом и в кратчайшие сроки, ваши специалисты должны иметь квалификацию и знать, что они делают. Limble позволяет отслеживать производительность каждого техника. Если вы обнаружите, что есть недостатки, вы можете налететь и обучить членов команды, которые в этом нуждаются, гарантируя, что вы будете предоставлять услуги самого высокого качества каждый день.

Среднее время восстановления по сравнению со средним временем восстановления
MTTR имеет МНОГО разных значений. Двумя наиболее важными для нашего обсуждения являются «среднее время восстановления» и «среднее время восстановления».
Среднее время восстановления измеряет время между первым обнаружением отказа и возвратом оборудования в работу. Таким образом, помимо времени ремонта, периода тестирования и возврата в нормальное рабочее состояние, фиксирует время отказа уведомления .
Таким образом, помимо времени ремонта, периода тестирования и возврата в нормальное рабочее состояние, фиксирует время отказа уведомления .
Хотя эти термины часто используются взаимозаменяемо, они должны быть более четко определены, когда речь идет о соглашениях об уровне обслуживания (SLA) и контрактах на техническое обслуживание, чтобы все стороны точно договорились о том, что они означают и что они измеряют.
БЕСПЛАТНЫЕ РЕСУРСЫ ДЛЯ ПРОФЕССИОНАЛОВ И СТУДЕНТОВ
Загрузите эту статью в формате PDF
Приступайте к работе, когда расписание прояснится (может быть, немного почитать перед сном? ?)
Что такое MTBF (среднее время наработки на отказ)?
Среднее время наработки на отказ измеряет время, которое проходит от одного отказа оборудования до следующего отказа. Это дает вам лучшее представление о том, как долго оборудование может оставаться в рабочем состоянии в течение заданного периода времени между незапланированными поломками. Это способ спланировать неожиданное.
Это способ спланировать неожиданное.
Итак, в то время как MTTR влияет на доступность, MTBF измеряет доступность и надежность . Чем выше показатель MTBF, тем дольше система может работать до отказа.
Чем полезна наработка на отказ?
Поскольку отказ оборудования может дорого стоить и нанести ущерб организации, вам необходимо быть в курсе непредвиденных поломок, насколько это возможно. Среднее время безотказной работы — важный показатель ожидаемой производительности. Если значение MTBF низкое, это означает, что вы испытываете значительное число сбоев , что, вероятно, означает, что есть более глубокая проблема, которую нужно раскрыть.
Производители могут использовать среднее время наработки на отказ в качестве измеримого показателя надежности на многих этапах проектирования и производства продукции. В настоящее время он широко используется при проектировании механических и электронных систем, безопасной эксплуатации предприятия, закупке продукции и т. д.
д.
Среднее время безотказной работы не учитывает плановое техническое обслуживание, но его все же можно использовать для расчета частоты проверок для профилактических замен.
Если известно, что актив, вероятно, будет работать в течение определенного количества часов до следующего сбоя, введение профилактических мер, таких как смазка или повторная калибровка, может помочь предотвратить этот сбой.
По сути, это помогает сэкономить деньги, сократить время простоя и сделать вашу работу лучше (а кто этого не хочет?).
Как рассчитать среднее время безотказной работы?
Уравнение для MTBF простое. Это сумма наработок, разделенная на количество отказов .
Основываясь на примере насоса, который мы упоминали в разделе MTTR, из ожидаемого времени работы в десять часов он проработал девять часов. Это не удалось в течение одного часа, распределенного по трем случаям. Так:
Среднее время безотказной работы = 9 часов / 3 ремонта
Среднее время безотказной работы = 3 часа
Насос выходит из строя в среднем каждые 3 часа .
Имейте в виду, что это очень упрощенный пример. Как правило, вам понадобится гораздо большая выборка информации для работы, чтобы получить более точный прогноз. Как видно из приведенного выше примера, мы не учитывали время ремонта в расчете MTBF.
Другие распространенные факторы могут влиять на среднее время безотказной работы систем в полевых условиях. Большим из них является тот факт, что у нас есть люди, которые делают работу. Например, низкая наработка на отказ может указывать либо на плохое обращение с активом его операторами, либо на плохо выполненный ремонт в прошлом.
При расчете среднего времени наработки на отказ вы не будете принимать во внимание профилактическое или профилактическое обслуживание или плановую замену деталей. Хотя профилактическое и профилактическое обслуживание иногда может вызывать кратковременные отключения, это не поломки. Вы просто посчитаете время от окончания последней поломки, когда машина снова была в эксплуатации, до следующей поломки.
Вы должны прийти с ожиданием того, что в какой-то момент произойдет сбой.
Что может сказать вам среднее время безотказной работы?
Из-за того, что MTBF падает в процессе, его часто сочетают с другими стратегиями обслуживания. MTBF может помочь в принятии решений, сообщив вам:
- Стоимость поломок . Сочетание MTBF с MTTR и кодами отказов может помочь вам избежать дорогостоящих поломок за счет заблаговременного планирования на основе имеющихся данных. Это может иметь большое влияние на итоговый результат.
- Частота отказов . Среднее время безотказной работы измеряет, как часто вы можете ожидать сбоя. Чем выше показатель MTBF, тем дольше система может работать до отказа.
Когда использовать среднее время безотказной работы?
Используйте его, чтобы начать завоевание простоя . Это, безусловно, самое важное применение MTBF. Используя MTBF, вы также сможете прогнозировать, предотвращать и преодолевать большую часть незапланированных поломок.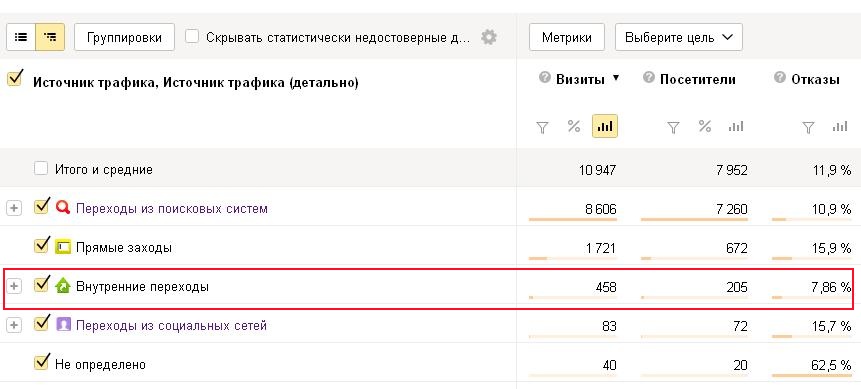 Вы сможете использовать его для:
Вы сможете использовать его для:
- Планирование запасов
- Бюджетирование капитальных затрат
- Планирование графика обслуживания.
- Индикатор производительности PM
- Качество информации в вашей системе и то, как она используется
Тактика увеличения среднего времени безотказной работы
Есть небольшие вещи, которые вы можете сделать, чтобы увеличить время наработки на отказ. Вот некоторые из них:
- Больше Упреждающее обслуживание Работа . Активы, которые хорошо обслуживаются, с меньшей вероятностью будут иметь критические сбои. Используя Limble в качестве CMMS, вы можете создавать ежемесячные графики обслуживания за считанные минуты.
- Используйте качественные запасные части . Самая дешевая часть не всегда является лучшей в долгосрочной перспективе. Убедитесь, что вы используете качественные, проверенные детали в своей работе. Это сэкономит вам тонну в долгосрочной перспективе.
- Используйте рекомендуемый исходный материал . Будь то размер цыпленка в системе переработки птицы или толщина фольги, используемой для упаковки продукта, каждая машина рассчитана на работу с определенными параметрами. Соблюдайте эти параметры.
- Обеспечить надлежащие условия труда. Не выставляйте машины за пределы их возможностей, чтобы ваши показатели производительности выглядели хорошо. Неправильное использование машин — верный способ сократить срок их службы и среднее время безотказной работы.
- Иметь надежную программу адаптации для операторов станков. Активы следует использовать в соответствии с тем, как они спроектированы. Неправильное обращение обязательно сократит среднее время безотказной работы. Limble позволяет пользователю регистрировать рабочие задания и добавлять сведения о том, как устройство использовалось во время сбоя, чтобы вы могли отслеживать использование активов.
- Понять особенности старого оборудования и устаревающих активов. Когда это возможно, специалисты по техническому обслуживанию должны давать операторам машин советы о том, каких действий им следует избегать со старыми активами, чтобы избежать повторяющихся проблем. Limble хранит полную историю обслуживания, журнал активов и примечания по обслуживанию. Это позволяет любому члену вашей команды легко вмешаться и спасти ситуацию, даже если предыдущий технический специалист больше не работает в вашей организации.

 Когда это возможно, специалисты по техническому обслуживанию должны давать операторам машин советы о том, каких действий им следует избегать со старыми активами, чтобы избежать повторяющихся проблем. Limble хранит полную историю обслуживания, журнал активов и примечания по обслуживанию. Это позволяет любому члену вашей команды легко вмешаться и спасти ситуацию, даже если предыдущий технический специалист больше не работает в вашей организации.
Когда это возможно, специалисты по техническому обслуживанию должны давать операторам машин советы о том, каких действий им следует избегать со старыми активами, чтобы избежать повторяющихся проблем. Limble хранит полную историю обслуживания, журнал активов и примечания по обслуживанию. Это позволяет любому члену вашей команды легко вмешаться и спасти ситуацию, даже если предыдущий технический специалист больше не работает в вашей организации.Что такое MTTF (среднее время до отказа)?
Среднее время до отказа — базовый показатель надежности , используемый для неремонтопригодных систем . Он представляет собой период времени, в течение которого ожидается, что элемент будет работать до тех пор, пока его не потребуется заменить.
MTTF может использоваться для представления срока службы продукта или устройства. Его стоимость рассчитывается путем просмотра большого количества однотипных предметов в течение длительного периода и отслеживания того, как долго они служат.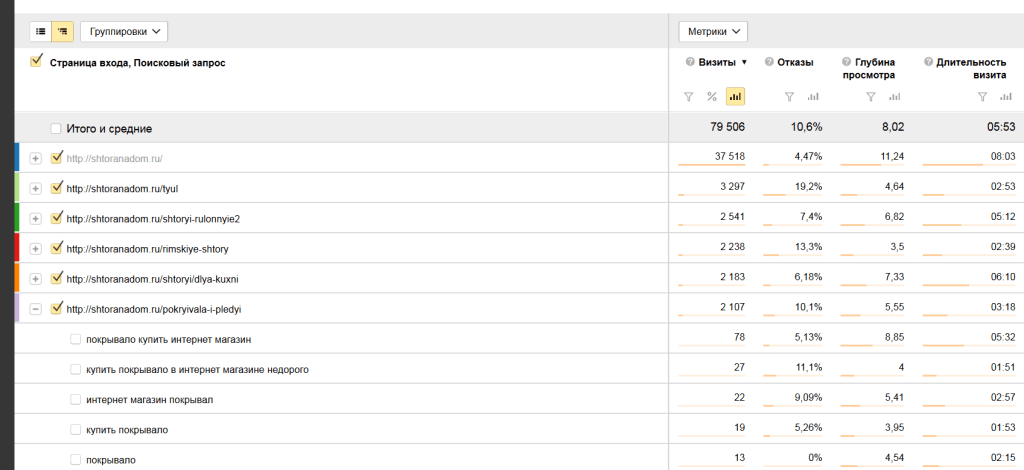
В обрабатывающей промышленности MTTF является одним из многих показателей, обычно используемых для оценки надежности выпускаемой продукции. Однако по-прежнему существует много путаницы в разграничении MTTF и MTBF, потому что они оба несколько похожи по определению. Это решается, если вспомнить, что Среднее время безотказной работы используется для обозначения ремонтопригодных элементов, а среднее время безотказной работы используется для неремонтопригодных элементов .
В чем полезность MTTF?
Среднее время безотказной работы важно, поскольку оно помогает оценить срок службы продуктов, не подлежащих ремонту . Некоторые распространенные примеры этих продуктов варьируются от таких предметов, как ремни вентилятора в автомобилях до лампочек в наших домах и офисах.
Среднее время безотказной работы особенно полезно в качестве показателя надежности. Инженеры могут использовать его для оценки того, как долго компонент будет служить частью более крупного оборудования. Это особенно верно, когда весь бизнес-процесс чувствителен к отказу рассматриваемого оборудования. Более короткое время наработки на отказ означает более частые простои, так как неисправные элементы необходимо заменить.
Это особенно верно, когда весь бизнес-процесс чувствителен к отказу рассматриваемого оборудования. Более короткое время наработки на отказ означает более частые простои, так как неисправные элементы необходимо заменить.
Как рассчитать MTTF?
MTTF рассчитывается как общее время работы, деленное на общее количество отслеживаемых объектов.
Предположим, мы протестировали 3 жестких диска для настольных ПК. Первый вышел из строя через 500 000 часов, второй вышел из строя через 600 000 часов, а третий жесткий диск вышел из строя после 700 000 часов использования. MTTF в этом случае будет:
MTTF = (500 000 + 600 000 + 700 000) / 3 единицы
MTTF = 1 800 000 / 3
MTTF = 600 000 часов
Теперь мы можем предположить, что этот конкретный тип и модель жесткого диска, вероятно, выйдет из строя после 600 000 часов использования.
Что может сказать вам MTTF?
Среднее время до отказа можно использовать для:
- Время выполнения запасов . Понимание вашего MTTF может помочь вам спланировать замену оборудования, гарантируя, что вы никогда не застрянете в ожидании прибытия нового оборудования
- Контроль качества. MTTF, который становится все короче и короче, может указывать на проблемы с качеством у ваших поставщиков. Используйте эту информацию, чтобы вести беседы или знать, когда искать новых поставщиков.
- Неправильное использование оборудования . Как и в случае с контролем качества, изменение MTTF может свидетельствовать о том, что пользователи неправильно используют оборудование, а это означает, что необходимо улучшить обучение. Это также может указывать на увеличение общего использования или проблему восходящего потока, которая негативно влияет на эту конкретную часть. В любом случае, это важная информация, на которую стоит обратить внимание.
 Понимание вашего MTTF может помочь вам спланировать замену оборудования, гарантируя, что вы никогда не застрянете в ожидании прибытия нового оборудования
Понимание вашего MTTF может помочь вам спланировать замену оборудования, гарантируя, что вы никогда не застрянете в ожидании прибытия нового оборудованияКогда использовать MTTF?
Предположим, вы планируете инвестировать в новое оборудование, которое заменит ваше текущее оборудование. Важно знать, как долго они продлятся. Это будет основным компонентом, когда вы составляете свой бюджет.
Важно знать, как долго они продлятся. Это будет основным компонентом, когда вы составляете свой бюджет.
MTTF сообщит вам о большом количестве расходов по вашим бюджетам капиталовложений и операционных расходов . Как часто вы будете менять вещи и по какой цене?
Иногда информацию о MTTF можно найти у OEM-производителя. Хотя мы всегда оптимистично относимся к их правильности, иногда они могут вводить в заблуждение. Свяжитесь с другими менеджерами по техническому обслуживанию, чтобы получить их мнение, если можете. Всегда запускайте собственные отчеты по MTTF, чтобы отслеживать срок службы ваших активов.
Тактика для увеличения MTTF
- Используйте предметы самого высокого качества, которые вы можете найти — те, которые сделаны из более прочных материалов и прошли тщательный процесс контроля качества. Limble позволяет вам отслеживать предпочтительные детали и поставщиков в каждой записи актива, чтобы вы всегда могли найти нужные детали и услуги.
- Примите меры для увеличения срока службы актива . Убедитесь, что устройства используются по назначению и в тех условиях (влажность, тепло, давление, напряжение и т. д.), на которые они рассчитаны. Вы можете хранить руководство по эксплуатации и обслуживанию оборудования в Limble, чтобы перепроверить, правильно ли было установлено/модернизировано устройство перед его использованием.
- Разумно используйте свое время, бюджет и ресурсы. Поскольку вы не планируете ничего исправлять, планировать техническое обслуживание здесь нельзя. Возможно, вы можете стереть пыль или запустить диагностику высокого уровня, чтобы оценить оставшийся срок службы. Тем не менее, вы не будете проводить профилактику жесткого диска компьютера или лампочки. Вы просто собираетесь заменить их, когда они перестанут работать должным образом.

Другие заслуживающие внимания показатели технического обслуживания, связанные с отказом
Существует по крайней мере 10 различных метрик, если не больше, многие из них пересекаются.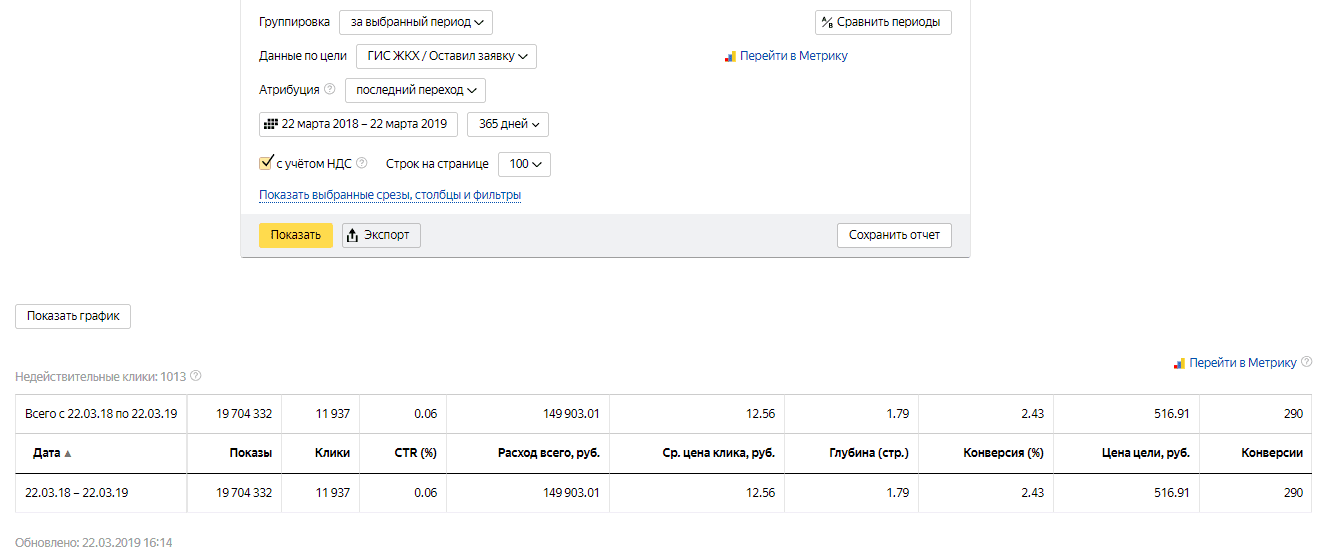 В этой статье мы рассмотрели три самых популярных. Тем не менее, есть несколько других, с которыми мы хотели бы вас познакомить, чтобы вы могли принять обоснованное решение о наборе показателей, который подходит именно вам:
В этой статье мы рассмотрели три самых популярных. Тем не менее, есть несколько других, с которыми мы хотели бы вас познакомить, чтобы вы могли принять обоснованное решение о наборе показателей, который подходит именно вам:
- MDT (среднее подумает сначала. Как долго что-то не работает? Это то, о чем они заботятся.
- MTTD (среднее время обнаружения) полезно при отслеживании времени, необходимого для обнаружения проблемы и сообщения о ней. Это может быть полезно, когда у вас есть ситуация, когда несколько активов зависят от функциональности друг друга. Используя устройства слежения, вы можете в кратчайшие сроки подготовить отчетность и обеспечить бесперебойную работу системы.
- MTTI (среднее время для выявления) — это показатель, направленный на сокращение времени, которое требуется вашей команде для выявления проблемы, чтобы они могли ее исправить.
- MTTA (среднее время до подтверждения) — отличный ключевой индикатор производительности. Это поможет вам отслеживать время реагирования вашей команды на инциденты и видеть, как они реагируют на рабочую нагрузку в течение определенного периода времени. Если ваша команда перегружена, их время подтверждения будет намного медленнее.
 Это поможет вам отслеживать время реагирования вашей команды на инциденты и видеть, как они реагируют на рабочую нагрузку в течение определенного периода времени. Если ваша команда перегружена, их время подтверждения будет намного медленнее.
Это поможет вам отслеживать время реагирования вашей команды на инциденты и видеть, как они реагируют на рабочую нагрузку в течение определенного периода времени. Если ваша команда перегружена, их время подтверждения будет намного медленнее.К счастью, Limble позволяет людям, ответственным за распределение работы, видеть это в режиме реального времени. Они могут быстро и легко перетасовывать назначения заказов на работу, чтобы уменьшить перегрузку и поддерживать максимальную производительность вашей команды.
Отслеживание показателей обслуживания с помощью Limble CMMS
Отслеживание показателей обслуживания кажется большой работой, и это может быть так, если оно не автоматизировано.
Наша система управляет этим как на глобальном уровне для всех активов, так и в отчетах по каждому отдельному активу.
Пока клиент обновляет каждую задачу со всеми данными, эти показатели обслуживания будут отслеживаться автоматически (пример на изображении ниже):
Когда дело доходит до показателей обслуживания и ваших KPI, Limble позволяет вам создавать информационные панели для каждого отчета, который вам нужен.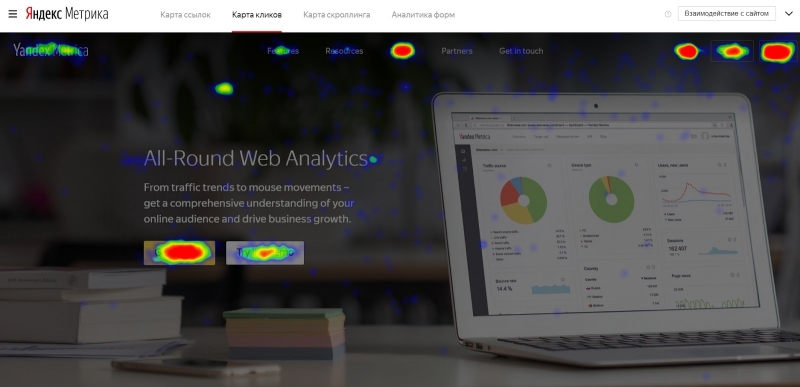 Ваша команда делает работу; Лимбл сделает все остальное.
Ваша команда делает работу; Лимбл сделает все остальное.
Пример пользовательской информационной панели Limle
При использовании пользовательских информационных панелей Limbles вы сможете:
- Создавать свои собственные ключевые показатели эффективности.
- Просматривайте критически важные показатели обслуживания, такие как MTTR, MTBF, MTTF и другие.
- Просматривайте настраиваемую информационную панель в реальном времени, которую могут видеть ваша команда и остальная часть компании.
- Будьте в состоянии видеть, сколько актив стоит вам в любое время и почему.
- Всегда точно знайте, на что расходуется ваш бюджет. (Представьте, как это могло бы поддержать ваши отношения с финансовым отделом, особенно когда вам нужно обсудить замену активов!)
Используя Limble, ваша команда технического обслуживания может получить доступ ко всей информации об истории актива и прошлых ремонтах, чтобы быстро найти основную причину проблемы и сократить количество операций по устранению неполадок, необходимых для поиска решения.
Limble удобен для мобильных устройств, что упрощает доступ к важной информации на вашем мобильном устройстве в любое время. Больше не нужно бегать между рабочим столом и рабочим местом, чтобы получить необходимую информацию, что сделает выполнение ваших заданий менее утомительным и ускорит вашу реакцию.
Что дальше?
Мы в Limble знаем, что вы должны убедиться, что оборудование доступно и находится в идеальном рабочем состоянии. Вы герой безотказной работы, а также эксплуатации и безопасности завода.
Если у вас есть представление о метриках сбоев и расчетах для их получения, вы можете разрабатывать лучшие стратегии управления активами и улучшать общие процессы технического обслуживания.
Рассчитывая показатели сбоев и планируя техническое обслуживание на основе результатов, вы также можете уменьшить зависимость своей организации от оперативного обслуживания в пользу упреждающих методов, которые в первую очередь предотвратят неожиданные сбои.
Позвольте Limble CMMS избавиться от догадок при измерении метрик и автоматизировать процесс для вас. Свяжитесь с нами по электронной почте, и мы свяжемся с вами, чтобы узнать, как мы можем облегчить вашу жизнь, поставив управление техническим обслуживанием на вашу ладонь.
Свяжитесь с нами по электронной почте, и мы свяжемся с вами, чтобы узнать, как мы можем облегчить вашу жизнь, поставив управление техническим обслуживанием на вашу ладонь.
Используйте метрики Four Keys, такие как частота сбоев изменений, для измерения производительности DevOps0003
Отчет Accelerate State of DevOps
Получите полное представление об отрасли DevOps, предоставляя практические рекомендации для организаций любого размера.
Скачать Примечание редактора : Многое изменилось с тех пор, как этот пост был впервые опубликован в 2020 году. В 2021 году команда DORA добавила пятый показатель — надежность — в список факторов, которые могут повлиять на эффективность организации. А в отчете о состоянии DevOps за 2022 год кластерный анализ выявил только три кластера: высокий, средний и низкий. Это означает, что больше никаких «элитных» исполнителей! Несмотря на это, «Четыре ключа» остаются ценным инструментом, помогающим вам оценить эффективность DevOps вашей команды, и мы надеемся, что вы расскажете нам о том, как DevOps помог вашей организации, подав заявку на участие в конкурсе DevOps Awards 2022.
За шесть лет исследований команда DevOps Research and Assessment (DORA) определила четыре ключевых показателя, отражающих производительность команды разработчиков программного обеспечения:
Частота развертывания в производство
Время выполнения изменений — количество времени, которое требуется для перехода в производство
Частота отказов изменений — Процент развертываний, вызвавших сбой в работе
Время восстановления службы — Сколько времени требуется организации для восстановления после сбоя в работе
На высоком уровне частота развертывания и время выполнения для Изменения измеряют скорость, в то время как изменение частоты отказов и время восстановления обслуживания измеряют стабильность. И, измеряя эти значения и постоянно совершенствуя их, команда может добиться значительно лучших бизнес-результатов. DORA, например, использует эти показатели для определения элитных, высоко-, средне- и низкоэффективных команд и обнаруживает, что элитные команды в два раза чаще достигают или превышают свои организационные цели.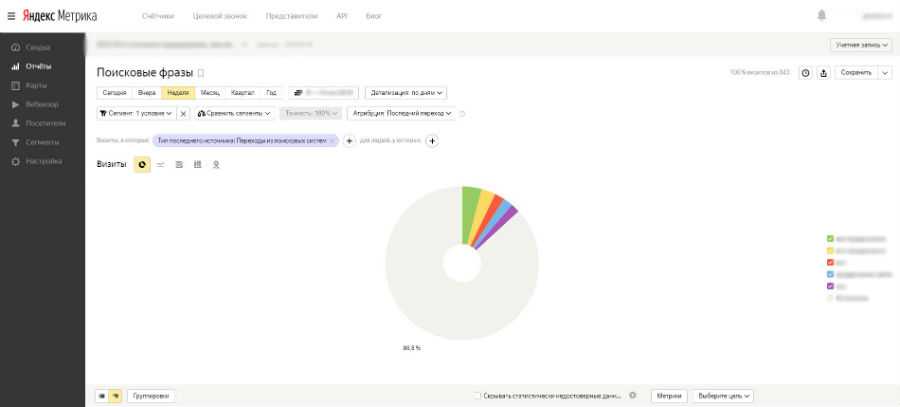 1
1
Оценка производительности вашей организации на основе этих показателей — отличный способ повысить эффективность и результативность вашей собственной деятельности. Но как начать? Путешествие начинается со сбора данных. Чтобы помочь вам создать эти показатели для вашей команды, мы создали проект с открытым исходным кодом Four Keys, который автоматически настраивает конвейер приема данных из ваших репозиториев Github или Gitlab через сервисы Google Cloud и в Google DataStudio. Затем он собирает ваши данные и компилирует их в панель мониторинга с этими ключевыми показателями, которые вы можете использовать для отслеживания своего прогресса с течением времени.
Для использования проекта Four Keys мы включили в репозиторий сценарий установки, чтобы упростить сбор данных из источников по умолчанию и просмотр показателей DORA. Для всех, кто заинтересован в том, чтобы внести свой вклад в проект или адаптировать его к сценариям использования своей команды, мы выделили три ключевых компонента ниже: конвейер, метрики и панель инструментов.
Конвейер Four Keys
Конвейер Four Keys — это конвейер ETL, который собирает данные DevOps и преобразует их в показатели DORA.
Одна из проблем сбора этих показателей DORA, однако, заключается в том, что для любой отдельной команды (не говоря уже обо всех командах в организации) данные о развертывании, изменениях и инцидентах обычно находятся в разных несопоставимых системах. Как нам разработать инструмент с открытым исходным кодом, который может собирать данные из этих различных источников, а также из источников, которые вы, возможно, захотите использовать в будущем?
Решение Four Keys заключалось в создании универсального конвейера, который можно расширить для обработки входных данных из самых разных источников. Любой инструмент или систему, которые могут выводить HTTP-запрос, можно интегрировать в конвейер Four Keys, который получает события через веб-перехватчики и загружает их в BigQuery.
Нажмите, чтобы увеличить В конвейере Four Keys известные источники данных должным образом разбиваются на изменения, инциденты и развертывания. Например, коммиты GitHub подхватываются сценарием изменений, развертывания Cloud Build подпадают под развертывания, а проблемы GitHub с меткой «инцидент» классифицируются как инциденты. Если добавляется новый источник данных, а существующие запросы не классифицируют его должным образом, разработчик может переклассифицировать его, отредактировав сценарий SQL.
Например, коммиты GitHub подхватываются сценарием изменений, развертывания Cloud Build подпадают под развертывания, а проблемы GitHub с меткой «инцидент» классифицируются как инциденты. Если добавляется новый источник данных, а существующие запросы не классифицируют его должным образом, разработчик может переклассифицировать его, отредактировав сценарий SQL.
Извлечение и преобразование данных
Когда необработанные данные находятся в хранилище данных, возникают две проблемы: извлечение и преобразование. Для оптимизации бизнес-гибкости оба этих процесса обрабатываются с помощью SQL. Four Keys использует запланированные запросы BigQuery для создания нижестоящих таблиц из таблицы необработанных событий.
Four Keys распределяет события по категориям «Изменения», «Развертывание» и «Инциденты» с помощью операторов «WHERE», а также нормализует и преобразует данные с помощью оператора «SELECT». Точное определение изменения, развертывания или инцидента зависит от бизнес-требований команды, поэтому еще более важно иметь гибкий способ включения или исключения дополнительных событий.
Хотя определение может отличаться от команды к команде, сценарии предоставляют значения по умолчанию, чтобы вы могли начать работу. В качестве примера, вот скрипт Deployments:
SELECT...СЛУЧАЙ, КОГДА источник = "cloud_build", затем JSON_EXTRACT_SCALAR (метаданные, '$.substitutions.COMMIT_SHA')КОГДА источник типа "github%", затем JSON_EXTRACT_SCALAR(метаданные, '$.deployment.sha')КОГДА источник типа "gitlab%", тогда JSON_EXTRACT_SCALAR(метаданные, '$.commit.id') заканчивается как main_commitОТ four_keys.events_rawГДЕ ((источник = "cloud_build"И JSON_EXTRACT_SCALAR(метаданные, '$.status') = "УСПЕХ")ИЛИ (источник LIKE "github%" и event_type = "deployment")ИЛИ (источник LIKE "gitlab%" и event_type = "конвейер" и JSON_EXTRACT_SCALAR(метаданные, '$.
 object_attributes.status') = "успех")
object_attributes.status') = "успех") Four Keys использует фильтр WHERE, чтобы извлекать только соответствующие строки из events_raw и оператор SELECT для сопоставления соответствующих полей в JSON с идентификатором фиксации. Одно из преимуществ преобразования данных в BigQuery заключается в том, что вам не нужно повторно запускать конвейер для редактирования или изменения категории данных. Функция JSON_EXTRACT_SCALAR позволяет анализировать данные JSON и управлять ими в самом SQL. BigQuery даже позволяет вам писать собственные функции JavaScript в SQL!
Расчет показателей
В этом разделе обсуждается, как преобразовать показатели DORA в расчеты на системном уровне. В первоначальном исследовании, проведенном командой DORA, были опрошены реальные люди, а не сбор системных данных и группировка метрик по уровням производительности, как показано ниже:
Нажмите, чтобы увеличить это спросить компьютер! Когда менеджера DevOps спрашивают, развертывают ли они его ежедневно, еженедельно, ежемесячно и т. д., он обычно интуитивно чувствует, в какую категорию попадает его организация. Однако, когда вы требуете от компьютера ту же информацию, вы должны быть очень точными в своих определениях и делать оценочные суждения.
д., он обычно интуитивно чувствует, в какую категорию попадает его организация. Однако, когда вы требуете от компьютера ту же информацию, вы должны быть очень точными в своих определениях и делать оценочные суждения.
Давайте рассмотрим некоторые нюансы в определениях и расчетах метрик.
Частота развертывания
`Как часто организация успешно выпускает производство .`
Частота развертывания — это самый простой показатель для сбора, поскольку для него требуется только одна таблица. Однако группировка по частоте также является одним из самых сложных элементов для расчета. Было бы просто и понятно показать ежедневный объем развертывания или получить среднее количество развертываний в неделю, но метрика — это частота развертывания, а не объем.
В сценариях «Четыре ключа» частота развертывания попадает в корзину «Ежедневно», если среднее количество дней в неделю, в течение которых хотя бы одно успешное развертывание, равно трем или превышает его. Проще говоря, чтобы претендовать на «ежедневное развертывание», вы должны выполнять развертывание в большинстве рабочих дней. Точно так же, если вы развертываете большинство недель, это будет еженедельно, затем ежемесячно и так далее.
Проще говоря, чтобы претендовать на «ежедневное развертывание», вы должны выполнять развертывание в большинстве рабочих дней. Точно так же, если вы развертываете большинство недель, это будет еженедельно, затем ежемесячно и так далее.
Далее вы должны рассмотреть, что представляет собой успешное развертывание в рабочей среде. Включаете ли вы развертывания, трафик которых составляет всего 5 %? 80%? В конечном счете, это зависит от индивидуальных бизнес-требований вашей команды. По умолчанию панель мониторинга включает любое успешное развертывание для любого уровня трафика, но этот порог можно настроить, отредактировав сценарии SQL в проекте.
Время подготовки к изменениям
`Количество времени требуется фиксация для перехода к рабочей среде произошло развертывание. Это означает, что для каждого развертывания вам необходимо вести список всех изменений, включенных в развертывание. Это легко сделать с помощью триггеров с SHA-сопоставлением коммитов. Имея список изменений в таблице развертывания, вы можете присоединиться к таблице изменений, чтобы получить метки времени, а затем рассчитать среднее время выполнения заказа.
Имея список изменений в таблице развертывания, вы можете присоединиться к таблице изменений, чтобы получить метки времени, а затем рассчитать среднее время выполнения заказа.
Коэффициент отказов при изменении
` процент из развертываний , вызвавших отказ в производственной среде`
Частота отказов при изменении зависит от двух факторов: сколько попыток развертывания было предпринято и сколько из них привело к сбоям в производственной среде? Чтобы получить это число, Four Keys требуется общее количество развертываний, которое легко получить из таблицы развертываний, а затем связывает его с инцидентами. Инцидент может быть связан с ошибками или метками в инцидентах github, формой для конвейера электронных таблиц, системой управления проблемами и т. д. Единственное требование состоит в том, чтобы он содержал идентификатор развертывания, чтобы мы могли объединить две таблицы вместе.
Время восстановления служб
`Сколько времени требуется организации для восстановления после сбоя в производстве`
Чтобы измерить время восстановления служб, необходимо знать, когда был создан инцидент и когда это было решено. Вам также необходимо знать, когда был создан инцидент и когда развертывание разрешило этот инцидент. Как и в случае с последней метрикой, эти данные могут поступать из любой системы управления инцидентами.
Вам также необходимо знать, когда был создан инцидент и когда развертывание разрешило этот инцидент. Как и в случае с последней метрикой, эти данные могут поступать из любой системы управления инцидентами.
Приборная панель
Нажмите, чтобы увеличитьТеперь, когда все данные собраны и обработаны в BigQuery, вы можете визуализировать их на панели управления Four Keys. Сценарий настройки Four Keys использует коннектор DataStudio, который позволяет подключать данные к шаблону панели мониторинга Four Keys. Панель инструментов предназначена для предоставления вам высокоуровневой категоризации на основе исследования DORA по четырем ключевым показателям, а также для отображения текущего журнала вашей недавней производительности. Это позволяет командам разработчиков заранее почувствовать падение производительности, чтобы смягчить его. С другой стороны, если производительность низкая, команды увидят ранние признаки прогресса до того, как сегменты будут обновлены.
Готовы начать?
Пожалуйста, зайдите на проект «Четыре ключа», чтобы попробовать. Сценарии установки помогут вам начать настройку архитектуры и интеграцию с вашими проектами. Мы приветствуем отзывы и дополнения!
Сценарии установки помогут вам начать настройку архитектуры и интеграцию с вашими проектами. Мы приветствуем отзывы и дополнения!
Чтобы узнать больше о том, как применять методы DevOps для повышения производительности доставки программного обеспечения, посетите сайт cloud.google.com/devops. И следите за дальнейшим сообщением о сборе показателей DORA для приложений, полностью размещенных в Google Cloud.
1. Accelerate State of DevOps в 2019 году: первоклассная производительность, производительность и масштабирование
Связанная статья
Вы являетесь элитным исполнителем DevOps? Узнайте с помощью проекта Four Keys Project
Узнайте, как проект с открытым исходным кодом Four Keys позволяет оценить производительность DevOps в соответствии с показателями DORA.
Прочитать статью
Опубликовано в:
Действительные метрики и условия сбоя
Действенные метрики и условия сбоя:
На прошлой неделе я писал о разнице между предположением и гипотезой, и Стивен Диболд написал отличный ответ. Стив обучил меня нескольким темам и указал на отсутствие у меня ясности в некоторых областях. Одна вещь, которую он поднял, заслуживает большего обсуждения: Успех/действующие метрики.
Стив обучил меня нескольким темам и указал на отсутствие у меня ясности в некоторых областях. Одна вещь, которую он поднял, заслуживает большего обсуждения: Успех/действующие метрики.
Я отвергаю идею показателя успеха. Нажмите, чтобы твитнуть
Бонус: Я пишу более полную версию о том, как разрабатывать великие эксперименты, в виде «Настоящей книги» с открытым исходным кодом, вы можете получить список загрузки здесь:
Скачать
Объявляем Победу!
Метрика успеха — это идея о том, что для любой гипотезы существует метрика, которая будет указывать на то, что на жаргоне бережливого стартапа и планирования экспериментов гипотеза подтверждена. Проще говоря, это хорошая идея.
Установка показателей успеха/эффективности кажется простой. Например, наша гипотеза может быть такой:
Ценностное предложение «Более высокая скорость загрузки для вашего BitTorrent-клиента» (версия A) создаст больше регистраций, чем ценностное предложение «Скрывайте свой IP-адрес при загрузке Game of Thrones с помощью BitTorrent».
 (Версия Б)
(Версия Б)(Не лучшая гипотеза, но пока давайте рассмотрим ее.)
Показателем для измерения этой гипотезы будет процент уникальных посетителей, зарегистрировавшихся в версии A, по сравнению с версией B. Если коэффициент конверсии для B составляет 5%, то если коэффициент конверсии для A составляет 25%, гипотеза считается подтвержденной. Победа!
Теперь давайте рассмотрим некоторые ситуации, когда объявить чистую победу немного сложнее.
Летающие пингвины
Если наша гипотеза состоит в том, что «некоторые пингвины умеют летать», мы можем очень легко установить показатель успешности, подтверждающий эту гипотезу. Если мы увидим хотя бы одного летающего пингвина (за пределами кинотеатра), то явно некоторые пингвины умеют летать.
Итак, мы идем смотреть на 10 пингвинов в зоопарке и… они не умеют летать.
Но, может быть, это не те пингвины. Мы можем поехать в другой город, пойти в другой зоопарк и посмотреть еще на 20 пингвинов.
Они все равно летать не умеют.
Может быть, только пингвины в зоопарках не умеют летать. Итак, мы берем лодку, отправляемся в Антарктиду и смотрим на 1000 пингвинов в дикой природе.
Они все равно летать не умеют.
Но может они просто не любят летать на глазах у людей! Очевидно, что у них не было бы крыльев, если бы они не могли летать, поэтому мы, вероятно, просто не нашли летающих… еще.
Скользкий путь неудачи
Это довольно распространенная проблема со стартапами:
Возможно, эти клиенты не хотели покупать наш продукт, но я уверен, что если мы будем продолжать искать, мы найдем тех, кто будут.
Если мы определим наши действенные показатели на уровне 20%, когда конверсия составит 19%… это достаточно близко.
Когда конверсия составляет 15 %… есть возможности для улучшения.
Когда это 10%… очевидно, нам нужно потратить больше времени на оптимизацию.
Когда 5%…ну…. некоторые человека все еще заинтересованы!
Когда это 1%… возможно, мы недостаточно хорошо это объясняем.
Когда 0%…мы забыли установить аналитику?
Почти невозможно смириться с неудачей. Всегда есть потенциальная рационализация. Ведь… у нас просто не получилось… еще .
Совсем как пингвины.
Показатели успеха — плохая наука. Нажмите, чтобы твитнуть
Научный метод!
Эта общая проблема хорошо известна науке…
Мы никогда не сможем доказать гипотезу. Мы можем только не опровергнуть это. Нажмите, чтобы твитнуть
Мы можем снова и снова пытаться опровергнуть нашу гипотезу, пока не сдадимся и не примем истину.
Вот почему у нас есть общая теория относительности вместо факта общей теории относительности. Хотя общая теория относительности позволяет нам запускать ракеты в космос и позволяет нашим телефонам определять наше местоположение, это всего лишь теория. В конце концов, мы можем столкнуться с ситуацией, когда теория не работает и не может объяснить все факты (например, квантовая физика). Тогда нам придется придумать новую теорию.
В конце концов, мы можем столкнуться с ситуацией, когда теория не работает и не может объяснить все факты (например, квантовая физика). Тогда нам придется придумать новую теорию.
Таким образом, вместо того, чтобы пытаться доказать гипотезу с помощью действенных показателей, мы должны попытаться опровергнуть гипотезу с условием несостоятельности.
Установка условия отказа
Сколько пингвинов нужно понаблюдать, прежде чем мы убедимся, что пингвины не умеют летать?
10? 50? 1000? Чем больше пингвинов вы смотрите, тем выше уровень вашей уверенности в том, что пингвины могут или не могут летать.
У науки есть четкие критерии приемлемого уровня уверенности (шесть сигм), но у нас нет такой роскоши в предпринимательстве или бережливом стартапе.
К счастью, нам это не нужно. Нам не нужно доказывать всем , что пингвины не умеют летать. Нам просто нужно доказать это самим себе. Потому что в конечном счете наша цель — построить бизнес.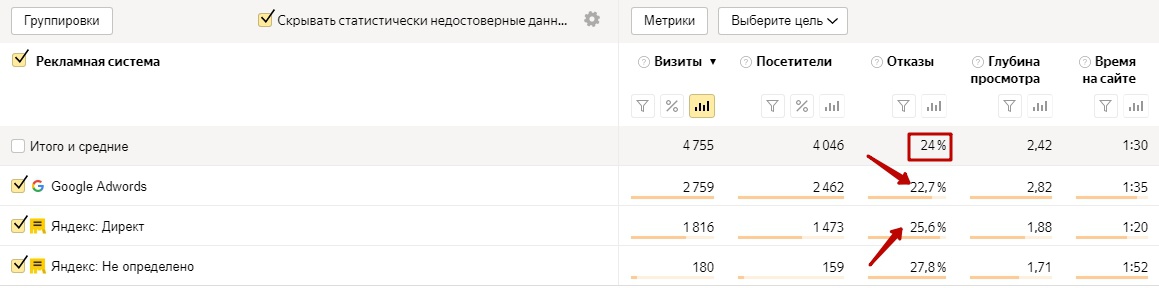
Если бы мы занимались продажей пингвинам крутых летных очков, нам нужно было бы знать, что высокая скорость ветра во время полета является серьезной проблемой для большинства пингвинов. Если большинство пингвинов не умеют летать, это, вероятно, не очень хороший бизнес.
Итак, какой процент пингвинов должен уметь летать, чтобы этот бизнес стоил того, чтобы в него вкладывать наше время? 50%? 30%? 1%?
Сосредоточив внимание только на пингвинах Адели, если нам нужен рынок из 2 миллионов пингвинов, чтобы сделать это прибыльным бизнесом, и существует около 3,75 миллиона пингвинов Адели, то нам нужно почти 50% всех пингвинов, которых мы обследуем, чтобы иметь возможность летать, чтобы заставить этот бизнес работать. Итак, сколько нам нужно посмотреть?
Если мы посмотрим на 10 и НИ ОДИН не может летать, то даже с погрешностью ~7% из-за небольшого размера выборки… это плохой бизнес.
Семантика
Это больше, чем просто семантика.
Конечно, очень умный и опытный человек может установить показатель успеха и быть очень строгим при его применении.