
Плагин отнесен в категорию noindex
Noindex Pages
(6 общий рейтинг)
Ask search engines not to index individual pages by checking an option in the publish…
Radley Sustaire 5 000+ активных установок Протестирован с 4.4.29 Обновлен 7 лет назад
noindex SEO
(1 общий рейтинг)
Allows to add a meta-tag for robots noindex in some parts of your WordPress site.
Javier Casares 2 000+ активных установок Протестирован с 6.1 Обновлен 1 месяц назад
Easy Noindex And Nofollow
(1 общий рейтинг)
Easily add Noindex and Nofollow to post, page, search and category page.
Ivan Kristianto 1 000+ активных установок Протестирован с 3.1.4 Обновлен 11 лет назад
Скрытие ссылок
(13 общий рейтинг)
Скрытие внешних ссылок от индексации поисковыми системами с помощью скрипта.
Alexandra Vovk 1 000+ активных установок Протестирован с 4.9.22 Обновлен 4 года назад
Bulk NoIndex & NoFollow Toolkit
(5 общий рейтинг)
Add the NoIndex and/or Nofollow directives via meta robots tag to multiple pages in less…
Mad Fish Digital 1 000+ активных установок Протестирован с 6.0.3 Обновлен 3 месяца назад
duplicate-content-cure
(0 общий рейтинг)
Duplicate content cure is a simple plugin that improves SEO by preventing search engines from…
Badi Jones 700+ активных установок Протестирован с 4.2.34 Обновлен 7 лет назад
MWS Noindex Attachment Pages
(0 общий рейтинг)
This plugin add meta tag noindex,nofolow to head of any attachment page().
ModernWebStudios 700+ активных установок Протестирован с 4.
 9.22
Обновлен 4 года назад
9.22
Обновлен 4 года назадWPSSO WP Sitemaps XML
(3 общий рейтинг)
Select post types and taxonomies added to the WordPress sitemaps XML, includes localized pages for…
JS Morisset 400+ активных установок Протестирован с 6.1.0 Обновлен 4 дня назад
NoIndex NoFollow All Posts
(1 общий рейтинг)
This plugin lets you Noindex Nofollow All Posts in a category.
DigitalChef.in — Madhu Ramrakhyani 200+ активных установок Протестирован с 4.7.25 Обновлен 6 лет назад
Noindex Links
(1 общий рейтинг)
Плагин заключает любые ссылки в комментариях в теги <noindex></noindex>.
Flector 200+ активных установок Протестирован с 6.0.3 Обновлен 5 месяцев назад
Noindex Password-Protected Posts
(2 общий рейтинг)
Disables search-engine indexing for all password-protected posts.
Kyle Gilman 100+ активных установок Протестирован с 4.7.25 Обновлен 6 лет назад
WordPress Countdown
(2 общий рейтинг)
Add JQuery Countdown easily to your page/post with one shortcode only
Ivan Kristianto 100+ активных установок Протестирован с 3.3.2 Обновлен 7 лет назад
Noindex by Path
(0 общий рейтинг)
Ask search engines not to index individual pages by a relative path — which means…
Marcin Kijak 80+ активных установок Протестирован с 4.7.25 Обновлен 5 лет назад
noindex Past Events for The Events Calendar
(1 общий рейтинг)
Automatically add a «noindex» meta tag to The Events Calendar’s detail pages for past events,…
Room 34 Creative Services, LLC 60+ активных установок Протестирован с 5.
 8.6
Обновлен 10 месяцев назад
8.6
Обновлен 10 месяцев назадNoindex/Nofollow links
(0 общий рейтинг)
This plugin can add rel=»noindex,nofollow» to archive, tag, and category links. You can configure exactly…
John Syrinek 60+ активных установок Протестирован с 2.7.1 Обновлен 14 лет назад
LionScripts: Site Maintenance & Noindex Nofollow Plugin
(1 общий рейтинг)
LionScripts’ Site Maintenance & Noindex Nofollow is a very useful Site Maintenance plugin, which provides…
LionScripts.com 30+ активных установок Протестирован с 4.7.25 Обновлен 5 лет назад
Noindex Duplicate Posts
(2 общий рейтинг)
This plugin will automatically add a ‘Noindex’ meta tag to posts that are a duplicate…
Kane Andrews 30+ активных установок Протестирован с 3.
 5.2
Обновлен 10 лет назад
5.2
Обновлен 10 лет назадMetaMax
(0 общий рейтинг)
MetaMax automagically inserts meta tags in your html to make your site more SEO friendly.
Appex 30+ активных установок Протестирован с 4.7.25 Обновлен 6 лет назад
Noindex Login
(0 общий рейтинг)Adds the noindex meta tag to your WordPress Login page. If your WordPress blog has…
Jonathan Kemp 30+ активных установок Протестирован с 2.7.1 Обновлен 14 лет назад
LH SEO Meta Tags
(0 общий рейтинг)
Basic SEO meta tags, decisions not options
Peter Shaw Менее 10 активных установок Протестирован с 5.0.18 Обновлен 4 года назад
как, зачем и для чего используют в SEO
Noindex и Nofollow: как, зачем и для чего используют в SEOStarting a new project?
получить консультациюЧитайте наш Telegram 👈
Заказать
звонок
Оставьте свои контактные данные, наш менеджер перезвонит вам.
Спасибо! Скоро с Вами свяжется наш менеджер.
Получить
консультацию
Спасибо! Скоро с Вами свяжется наш менеджер.
POWER IS IN TRUST
Прокачайте свой сайт!
Подписывайтесь и получайте советы по оптимизации сайта и повышению продаж
Заказать обратный звонок
Подтвердите свой Email для завершения подписки.
Вы уже подписаны на нашу рассылку!
1141
10
Поделиться:
Noindex, nofollow имеют несколько разных понятий, и в зависимости от значений выполняют определенные функции.
- метатег <meta name=»robots» content=»noindex, nofollow» />;
- тег <noindex>;
- атрибут rel=”nofollow”.
Для чего же созданы эти элементы и в каких случаях их стоит применять? Давайте разберемся вместе.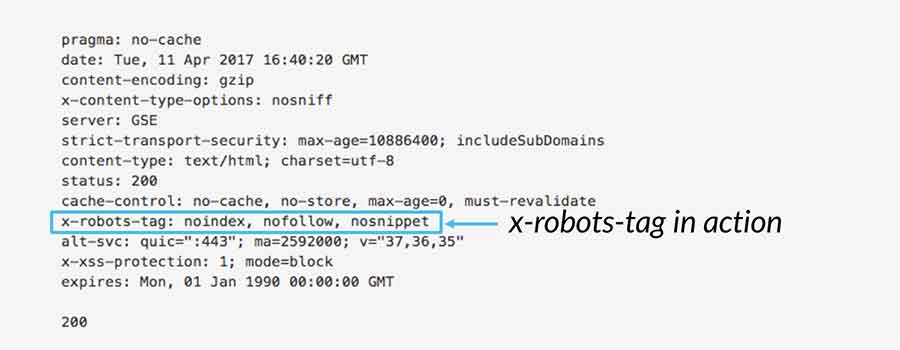
1. Метатег robots
Поисковая выдача формируется из документов, просканированных и проиндексированных поисковым роботом. Но не вся информация должна попадать в индекс. И тогда на помощь приходит метатег robots, благодаря которому можно скрыть страницу от индексации поисковыми роботами.
Тег необходимо установить в секцию <head> для того, чтобы страница не попала в индекс.
Пример:
<head> <meta name = “robots” content = “noindex”/> </head> |
Большинство поисковых роботов понимают этот метатег. А при необходимости можно закрыть страницу только от определенного робота.
Например, от Google
<meta name=«googlebot» content=«noindex»/>
Что же тогда означает комбинация значений «noindex, nofollow»?
Как вы уже поняли, noindex запрещает индексировать страницу, включая весь контент, который на ней находится.
А nofollow запрещает поисковым роботам переходить как по внутренним, так и по внешним ссылкам, размещенным на странице.
Рассмотрим различные варианты значений метатега robots:
| <meta name=“robots” content=“noindex, nofollow”> | Запрещает индексировать страницу и переходить по ссылкам |
| <meta name=“robots” content=“index,follow”> | Разрешает индексировать страницу и переходить по ссылкам на ней. Но в этой комбинации нет необходимости, т. к. по умолчанию поисковые роботы выполняют те же действия |
| <meta name=“robots” content=“index,nofollow”> | Можно индексировать страницу, но нельзя переходить по ссылкам |
| <meta name=“robots” content=“noindex,follow”> | Нельзя индексировать страницу, но можно переходить по URL-адресам. Используется для того, чтобы страница не попала в индекс, но поисковые роботы могли посещать ссылки, размещенные на ней. |

Очень часто для запрета индексирования используют файл robots.txt. Но для поисковых роботов условия, написанные в нем, скорее служат рекомендациями и могут быть проигнорированы. Более надежным способом запрета от индексирования считается метатег <meta name=«robots» content=«noindex»/>.
Довольно часто для удаления уже проиндексированной страницы используют директиву Disallow в файле robots.txt. Это ошибка, ведь в таком случае вы запрещаете доступ к странице, и поисковый робот не удалит ее из индекса.
В выдаче поисковой системы вместо описания страницы вы увидите сообщение о том, что доступ к данной странице заблокирован с помощью файла robots.txt.
Чтобы удалить проиндексированную страницу из индекса, необходимо добавить метатег <meta name=“robots” content=“noindex,follow”>.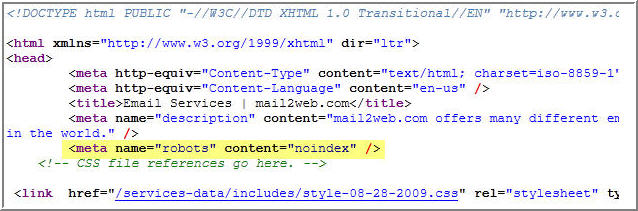 Поисковый робот просканирует страницу, увидит атрибут noindex, и исключит страницу из индекса.
Поисковый робот просканирует страницу, увидит атрибут noindex, и исключит страницу из индекса.
3. Атрибут rel=”nofollow”
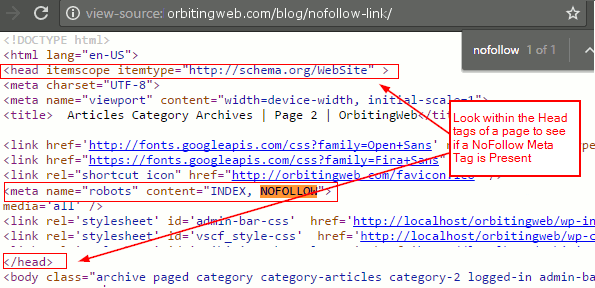
rel=”nofollow” применим к тегу <а> и относится только к гиперссылке, для которой он прописан.
Как он выглядит:
| <a href=»http://site.com/» rel=»nofollow»>текст ссылки</a> |
Вид в коде страницы:
Рис. 1 — nofollow в коде страницы
История атрибута очень интересна. Изначально Google позиционировал nofollow как инструмент для борьбы со спамом в комментариях. Но это было в далеком 2005.
Затем шла борьба с накруткой PageRank. Все пытались манипулировать внутренним весом, чтобы у продаваемых страниц был самый высокий PageRank. Ведь ссылочный вес делился одинаково между всеми гиперссылками на странице, не учитывая rel=«nofollow». И поэтому в 2009 Google внес поправки, согласно которым ссылочный вес не передавался по ссылкам, к которым применим атрибут rel=«nofollow».
Более того, изменились правила передачи ссылочного веса. Например, если на странице Х размещены 3 ссылки (2 dofollow и 1 nofollow), а вес страницы Х равен 6 “баллам”, то до внесения изменений Гуглом каждая ссылка без nofollow получила бы по 3 “балла”. А сейчас такие ссылки получат по 2 “балла”. Это означает, что ссылочный вес разделяется между всеми внутренними ссылками, но передается только по dofollow.
Когда специалисты стали меньше заморачиваться над передачей ссылочного веса, Google заявил, что все купленные ссылки должны иметь атрибут rel=«nofollow», утверждая, что некоторые проплаченные ссылки ничем не отличаются от тех, что были получены естественным путем (когда люди просто делятся тем, что по их мнению может быть интересным и полезным для других). Таким образом Google стимулирует получать естественные ссылки путем создания качественного контента.
В каких случаях сейчас стоит использовать ссылки с атрибутом «nofollow»?
Могу порекомендовать вам использовать nofollow ссылки для того, чтобы:
- сделать ссылочный профиль сайта разнообразным;
- обезопасить себя от санкций, применив атрибут к некачественным ссылкам.


Расширенный сниппет. Как создать?
Как сделать украинскую версию сайта по умолчанию и при этом не потерять имеющийся трафик?
Google May 2022 Core Update
Подпишитесь на наши обновления
Больше полезных статей и мануалов еще впереди. Будьте в курсе!
Вы уже подписаны на нашу рассылку!
Подтвердите свой Email для завершения подписки.
Заказать
продвижение
Больше полезных статей и мануалов еще впереди. Будьте в курсе!
Спасибо! Скоро с Вами свяжется наш менеджер.
×
Что это такое и как их использовать?
Главная / Блог Lumar / Передовой опыт / Noindex, Nofollow и Disallow
Узнайте, как использовать директивы сканирования и индексации для улучшения поисковой оптимизации. Покрытие директив nofollow, noindex и disallow.
Покрытие директив nofollow, noindex и disallow.
Сэм Марсден
SEO и контент-менеджер
| 9 минут чтения
Три приведенных выше слова могут звучать как SEO-тарабарщина, но их определенно стоит знать, поскольку понимание того, как их использовать, означает, что вы можете командовать роботом Googlebot. Что весело.
Итак, давайте начнем с основ: есть три способа сообщить, какие части вашего сайта поисковые системы должны сканировать и индексировать:
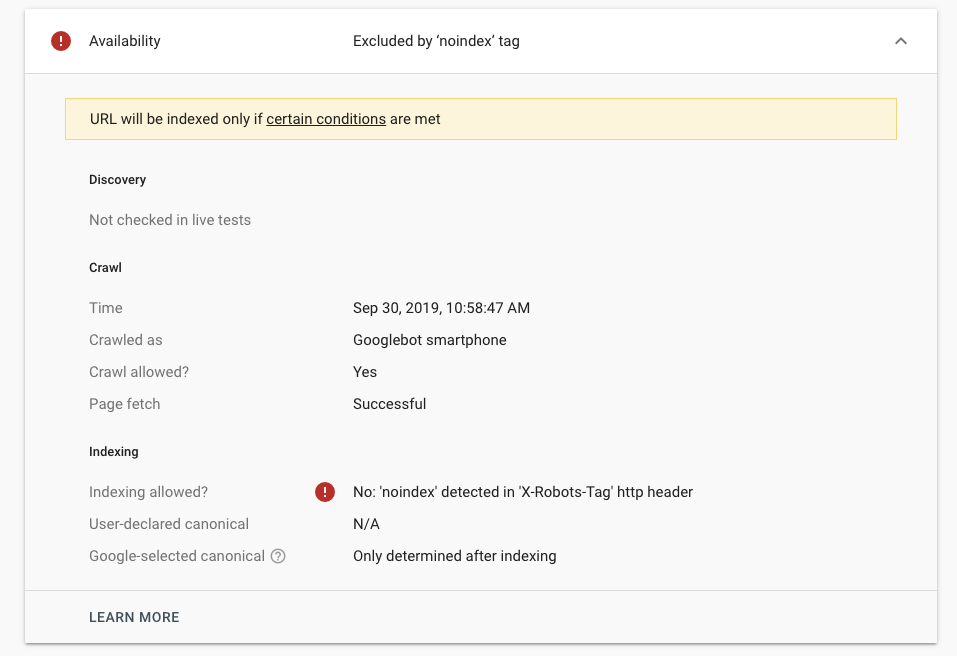
- Noindex : сообщает поисковым системам, чтобы они не включали ваши страницы в результаты поиска. Чтобы боты увидели этот сигнал, страница должна быть доступна для сканирования.
- Disallow : указывает поисковым системам не сканировать ваши страницы. Это не гарантирует, что страница не будет проиндексирована.
- Nofollow : указывает поисковым системам не переходить по ссылкам на вашей странице.
 Это не гарантирует, что страница не будет проиндексирована.
Это не гарантирует, что страница не будет проиндексирована.
Что такое метатег
noindex ?Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный способ неиндексирования страницы — это добавление тега в раздел заголовка HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница еще не должна быть заблокирована (запрещена) в файле robots.txt. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы запретить поисковым системам индексировать вашу страницу, просто добавьте в раздел
следующее:
Вторая часть содержимого тег здесь указывает, что все ссылки на этой странице должны быть пройдены, что мы обсудим ниже.
Кроме того, тег noindex можно использовать в X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Для получения дополнительной информации см. сообщение разработчиков Google о метатеге robots и x -robots-tag спецификация HTTP-заголовка.
Что такое директива
disallow ?Запрет страницы означает, что вы говорите поисковым системам не сканировать ее, что должно быть сделано в файле robots.txt вашего сайта. Это полезно, если у вас есть много страниц или файлов, которые бесполезны для пользователей, так как это означает, что поисковые системы не будут тратить время на сканирование этих страниц. Часто это может быть полезно для максимизации краулингового бюджета.
Чтобы добавить директиву disallow, просто объедините ее с относительным путем URL и добавьте в файл robots.txt:
Disallow: /your-page-url
Целые каталоги вашего сайта также могут быть запрещены. Чтобы это правило вступило в силу, завершите правило знаком /:
Disallow: /directory/
Над этой строкой должен быть указан пользовательский агент.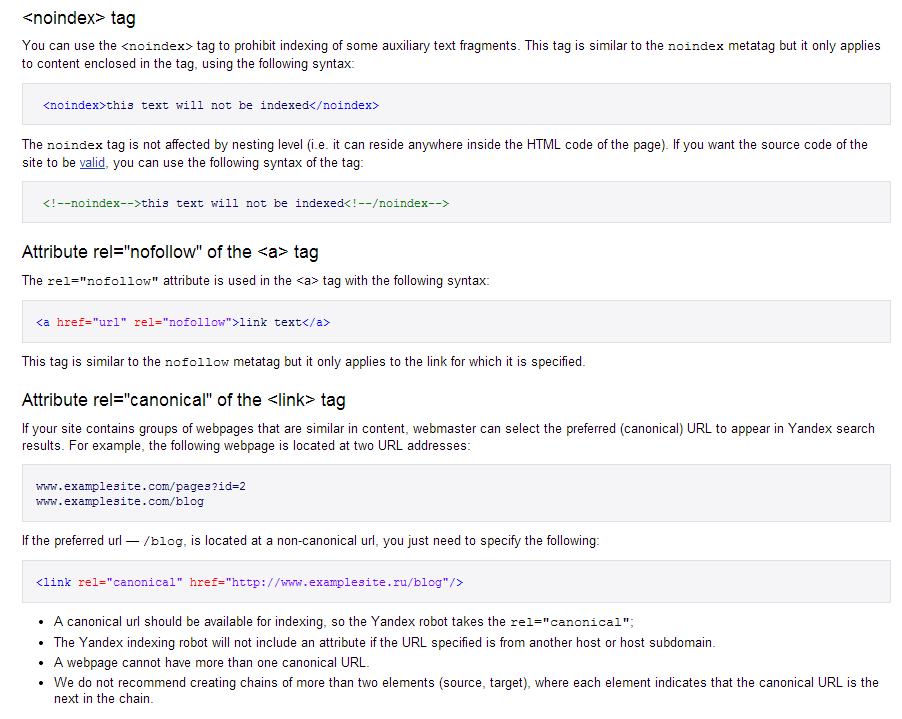 Используйте звездочку в этом поле, чтобы сопоставить все поисковые роботы (кроме Adsbot, имя которого необходимо указать явно). Например:
Используйте звездочку в этом поле, чтобы сопоставить все поисковые роботы (кроме Adsbot, имя которого необходимо указать явно). Например:
User-agent: *
Директива disallow просто запрещает ботам сканировать содержимое этих URL-адресов. Запрещенная страница все еще может появиться в индексе, например, если поисковые системы могут найти ее по входящим внешним ссылкам. Поскольку страница остается недоступной для сканирования, эти страницы обычно отображают сообщение «нет доступной информации для этой страницы», когда они появляются в поисковой выдаче.
Можно ли сочетать noindex и disallow?
Директивы Disallow не следует сочетать с тегами noindex. Это связано с тем, что предотвращение сканирования страницы поисковыми системами также не позволяет им видеть тег noindex. Страница не будет просканирована, но есть шанс, что она будет проиндексирована, если она будет найдена из других источников.
Если вы действительно не хотите, чтобы страница появлялась в поисковой выдаче, вам подойдет тег noindex.
Что такое тег nofollow?
А Тег nofollow на ссылке указывает поисковым системам не передавать ссылочный вес с исходной страницы на целевой сайт. Они также предназначены для предотвращения перехода поисковых систем по ссылке и обнаружения по ней большего количества контента.
Обычно nofollow используется для ссылок в комментариях и сообщениях на форумах, а также в любом другом контенте, который вы не контролируете. Их также можно найти во многих платных ссылках, встраиваниях, таких как виджеты или инфографика, ссылки в гостевых постах или что-то не по теме, на что вы все еще хотите связать людей, но не обязательно хотите, чтобы поисковые системы следили и сканировали.
Исторически SEO-специалисты также выборочно использовали nofollow-ссылки, чтобы направить внутренний PageRank на более важные страницы.
Теги nofollow можно добавить в одном из двух мест:
- страницы (для nofollow всех ссылок на этой странице):
- Код ссылки (для перехода по отдельной ссылке):
 html» rel=»nofollow»>пример страницы
html» rel=»nofollow»>пример страницы
Nofollow не препятствует полному сканированию связанной страницы; это просто предотвращает его сканирование по этой конкретной ссылке. Наши собственные и другие тесты показали, что Google не будет сканировать URL-адрес, найденный по ссылке nofollow.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница появляется в карте сайта, страница может по-прежнему отображаться в результатах поиска. Точно так же, если это URL-адрес, о котором поисковые системы уже знают, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и ввел два новых атрибута ссылки, а именно:
- rel=»sponsored» — атрибут спонсируемый должен использоваться для идентификации ссылок, предназначенных для рекламных целей, где спонсорство и компенсационные соглашения существуют.
- rel=»ugc» — в качестве атрибута пользовательского контента это значение рекомендуется для ссылок на сайтах с пользовательским контентом, например, сообщения на форуме и комментарии в блогах.
Кроме того, все ссылки, помеченные как nofollow, спонсируемые или UGC, теперь рассматриваются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как это использовалось ранее для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, в котором также рассказывается об их влиянии, а также о экспертных выводах.
Что такое noindex, nofollow?
Как упоминалось выше, добавление тега nofollow на страницу не предотвратит ее сканирование. Чтобы предотвратить индексацию URL-адреса, вам также понадобится тег noindex. Это позволит Google просканировать страницу, но она не появится в индексе. Чтобы запретить Google полностью сканировать страницу, вы должны запретить это через robots.txt.
Другие директивы, которые нужно знать: канонические теги, нумерация страниц и hreflang
Существуют и другие способы указать Google и другим поисковым системам, как обрабатывать URL-адреса — их тоже стоит знать! Ознакомьтесь с приведенными ниже ресурсами, чтобы узнать больше.
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать. Канонизированные (т.е. вторичные страницы, направляющие поисковые системы на основную версию) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на настольные.
- Разбивка на страницы группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента относятся к какому региону, чтобы они могли расставить приоритеты для правильной версии для каждой аудитории. Все эти версии останутся в индексе.
Сколько времени вы должны потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны эффективность сканирования и бюджет сканирования для SEO. Хотя общепринятой практикой является запрет и неиндексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Хотя общепринятой практикой является запрет и неиндексирование страниц, которые не приносят пользы поисковым системам или пользователям (например, внутренний код, который используется только для работы сайта, или некоторые типы дублированного контента), решение о том, следует ли скрывать отдельных страниц, вероятно, не лучшее использование времени и усилий. Если нет особой причины скрывать страницу от поисковых систем, обычно лучше оставить решение за ними.
Проверка ваших директив с помощью Lumar
Поиск всех неиндексируемых страниц с помощью LumarОтчет о неиндексируемых страницах включает сведения обо всех страницах с неиндексируемым статусом. Вы можете увидеть их общее количество, а также разбивку правил, которые заставляют их классифицироваться как неиндексируемые:
Отсюда погрузитесь в отдельные отчеты, чтобы убедиться, что правильные правила применяются к правильные URL-адреса.
Индексация > Страницы без индекса
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, заголовке HTTP или файле robots. txt.
txt.
Индексация > Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за правила запрета в файле robots.txt.
Протестируйте новый файл robots.txt с помощью Lumar
Используйте функцию перезаписи robots.txt Lumar в дополнительных настройках, чтобы заменить текущий файл пользовательским.
При следующем запуске сканирования существующий файл robots.txt будет перезаписан новыми правилами. Это позволяет вам убедиться, что нужные URL-адреса запрещены, прежде чем внедрять изменения на действующий сайт.
Для получения дополнительной информации прочитайте наше руководство по управлению изменениями robots.txt с помощью Lumar.
Дополнительные технические учебные ресурсы по SEO
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации о noindex, nofollow и запрете на управление сканированием и индексированием вашего сайта.
Вы можете больше узнать об этих темах в нашей Технической SEO-библиотеке, а если вы хотите узнать, как проводить технический SEO-аудит, прочтите наше руководство. У нас также есть большой выбор регулярно обновляемых электронных книг по техническим темам SEO, которые помогут вам быть в курсе последних обновлений Google и передовых методов SEO.
* Примечание. Это сообщение было обновлено 26 августа 2022 г.
Сэм Марсден
SEO и контент-менеджер
Сэм Марсден — бывший менеджер Lumar по поисковой оптимизации и контенту, а в настоящее время — руководитель отдела SEO в Busuu. Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых изданий, таких как Search Engine Journal и State of Digital.
Директивы Noindex и Nofollow
Директивы Noindex и Nofollow
Содержание индекса Облако релевантности Coveo Разработчик Системный администратор Документация по продукту
В этой статье
- Добавление специальных директив Coveo
- Игнорировать директивы
- Что дальше?
В код веб-страницы можно добавить директивы, чтобы указать роботам, как индексировать содержимое страницы.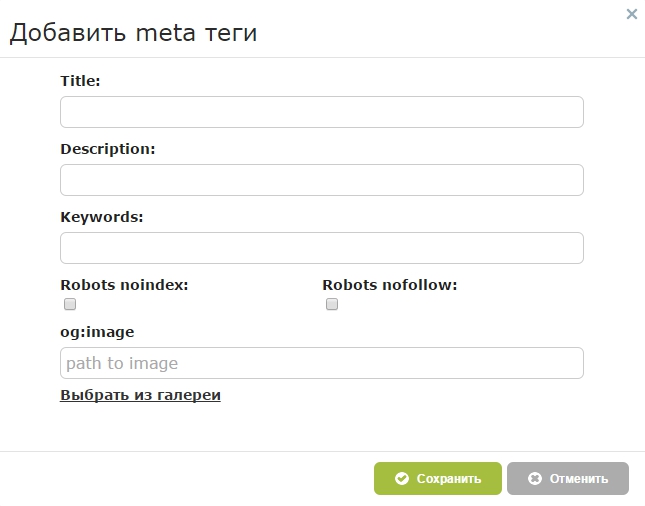 В частности, директива
В частности, директива noindex предписывает сканерам не индексировать страницу, а директива nofollow запрещает им переходить по ссылкам на странице (см. спецификации метатега Robots и HTTP-заголовка X-Robots-Tag).
При индексировании содержимого веб-источника сканер Coveo может либо следовать, либо игнорировать эти директивы (см. Добавление или редактирование веб-источника).
При индексировании содержимого веб-сайта сканер Coveo учитывает следующие директивы.
Эти директивы не чувствительны к регистру и могут появляться либо в мета-теге HTML-страницы , либо в HTTP-заголовке X-Robots-Tag .
| Директива | Инструкция |
|---|---|
| Роботам запрещено индексировать содержимое этой страницы. |
| Роботам запрещено переходить по ссылкам на этой странице. Пример Роботы не перейдут по этой ссылке: |
| Не индексируйте содержимое этой страницы и не переходите по ее ссылкам.
Эта директива эквивалентна |
| Роботам разрешено индексировать страницу и переходить по ее ссылкам. Это директива по умолчанию. |
 Однако, если в атрибуте
Однако, если в атрибуте Как правило, если не указано иное, эти директивы применяются ко всем роботам. Однако, если вы хотите, чтобы краулер Coveo соблюдал другие правила, у вас есть два варианта:
Если вы являетесь владельцем веб-сайта, который вы хотите сделать доступным для поиска, вы можете добавить специальные директивы Coveo в код, которому будет следовать сканер Coveo (см.
Добавление директив Coveo).Если вы не можете редактировать код веб-сайта, вы можете настроить свой веб-источник так, чтобы он игнорировал директивы
noindexиnofollow(см. Игнорировать директивы).
 Добавление директив Coveo).
Добавление директив Coveo).Добавить специальные директивы Coveo
Если вы являетесь владельцем веб-сайта, который вы хотите сделать доступным для поиска, вы можете добавить директивы индексации в код своей страницы, чтобы указать, какие элементы (т. е. страницы веб-сайта) разрешено сканировать роботам.
Мета-директивы с name="robots" и директивы заголовка ответа HTTP без указания имени искателя применяются ко всем искателям.
Однако если вы хотите, чтобы некоторые директивы применялись только к сканеру Coveo, вы можете использовать свойство name , чтобы указать coveobot .
В результате всякий раз, когда ваша страница содержит директивы, специально адресованные сканеру Coveo, сканер следует этим инструкциям и игнорирует общие директивы для всех роботов.
Примеры
Со следующим метатегом страницы всем роботам запрещено индексировать страницу и переходить по ссылкам в ней, кроме краулера
coveobot:При следующем HTTP-заголовке X-Robots-Tag всем роботам запрещено индексировать страницу и переходить по ссылкам в ней, кроме краулера
coveobot:HTTP/1.1 200 ОК Дата: Пн, 29апрель 2019 г., 15:08:11 по Гринвичу (…) X-Robots-Tag: nofollow, noindex, coveobot: все (…)
Игнорировать директивы
В качестве альтернативы, особенно если вы не являетесь владельцем веб-сайта, который вы хотите сделать доступным для поиска, вы можете указать сканеру Coveo игнорировать директивы веб-сайта.
Для этого на панели «Добавить/редактировать веб-источник» в разделе «Настройки сканирования» снимите соответствующий флажок (см.