Использование метатега robots | Блог Google Search Central
Прошло много времени с тех пор, как мы опубликовали эту запись в блоге. Часть информации может быть устаревшей (например, некоторые изображения могут отсутствовать, а некоторые ссылки уже не работают).Вторник, 6 марта 2007 г.
Недавно Дэнни Салливан поднял хорошие вопросы о том, как поисковые системы обрабатывают метатеги. Вот несколько ответов о том, как мы обрабатываем эти теги в Google.
Несколько значений содержимого
Мы рекомендуем размещать все значения содержимого в одном метатеге. Это позволяет легко находить метатеги. читать и снижает вероятность конфликтов. Например:
Если страница содержит несколько метатегов одного типа, мы объединим значения содержимого. Например, мы будем интерпретировать
аналогично:
Если значения содержимого конфликтуют, мы будем использовать наиболее строгие. Итак, если на странице есть эти метатеги:
Итак, если на странице есть эти метатеги:
Мы будем подчиняться значению noindex .
Ненужные значения содержимого
По умолчанию робот Googlebot индексирует страницу и переходит по ссылкам на нее. Так что нет необходимости помечать страницы
со значениями содержимого индекс или следует за .
Направление метатега robots специально для робота Googlebot
Чтобы предоставить инструкции для всех поисковых систем, установите метаимя на роботов . К
предоставьте инструкции только для робота Googlebot, установите метаимя Googlebot . Если хочешь
предоставлять разные инструкции для разных поисковых систем (например, если вы хотите
поисковая система индексирует страницу, но не другую), лучше всего использовать определенный метатег для каждого
поисковую систему, а не использовать общий метатег robots в сочетании с конкретным. Ты можешь найти
список ботов на robotstxt.org.
Если хочешь
предоставлять разные инструкции для разных поисковых систем (например, если вы хотите
поисковая система индексирует страницу, но не другую), лучше всего использовать определенный метатег для каждого
поисковую систему, а не использовать общий метатег robots в сочетании с конкретным. Ты можешь найти
список ботов на robotstxt.org.
Корпус и проставка
Робот Google понимает любую комбинацию строчных и прописных букв. Таким образом, каждый из этих метатегов интерпретируется точно так же:
Если у вас есть несколько значений содержимого, вы должны поставить запятую между ними, но не имеет значения, если вы также включаете пробелы. Таким образом, следующие метатеги интерпретируются одинаково:
 txt file and robots meta tags»> Если вы используете и файл robots.txt, и метатеги robots
txt file and robots meta tags»> Если вы используете и файл robots.txt, и метатеги robotsЕсли инструкции robots.txt и метатега для страницы конфликтуют, Googlebot следует наиболее ограничительный. Более конкретно:
- Если вы заблокируете страницу с помощью файла robots.txt, робот Googlebot никогда не просканирует страницу и никогда не прочитает метатеги на странице.
- Если вы разрешите страницу с файлом robots.txt, но заблокируете ее от индексации с помощью метатега, робот Googlebot получит доступ к странице, прочитает метатег и впоследствии не проиндексирует ее.
Действительные значения содержания метаданных robots
Googlebot интерпретирует следующие значения метатегов robots:
-
noindex: предотвращает включение страницы в индекс. -
nofollow: запрещает роботу Googlebot переходить по любым ссылкам на странице. (Обратите внимание, что это
отличается от атрибута nofollow уровня ссылки
(Обратите внимание, что это
отличается от атрибута nofollow уровня ссылки , который не позволяет роботу Googlebot по отдельной ссылке.) -
без архива: запрещает кэшированную копию этой страницы быть доступной в поиске полученные результаты. -
nosnippet: предотвращает появление описания под страницей в поиске результатов, а также предотвращает кеширование страницы. -
noodp: блокирует Описание проекта Open Directory страница от использования в описании, которое появляется под страницей в результатах поиска. -
нет: эквивалентноnoindex, nofollow.
 (Обратите внимание, что это
отличается от атрибута nofollow уровня ссылки
(Обратите внимание, что это
отличается от атрибута nofollow уровня ссылки Слово о значении содержания
нет Как определено
robotstxt. org,
следующее направление означает
org,
следующее направление означает noindex, nofollow .
Однако некоторые веб-мастера используют этот тег, чтобы указать отсутствие ограничений для роботов и непреднамеренно заблокировать все поисковые системы из их контента.
Обновление: Для получения дополнительной информации см. Документация по метатегу robots.Руководство по тегам Meta Robots (Простое руководство)
Содержание
Метатег robots считается одним из основных тегов SEO для аудита ваших страниц! В конце концов, ваша страница помечена метатегом робота «noindex», например, независимо от того, насколько ценным, полным и практичным является ваш контент, он не будет отображаться в Google.
Название кажется сложным, но мне верится. Эту цель гораздо проще проверить и понять, чем кажется.
Эту цель гораздо проще проверить и понять, чем кажется.
В этом контексте мы намерены рассказать вам немного больше о метатеге робота, о том, как его использовать, и о наиболее распространенных командах, которые вы можете использовать, чтобы иметь больший контроль над индексацией ваших страниц в Google! В конце мы дадим вам несколько советов, как не злоупотреблять метатегом и в каких случаях вы можете применять каждую команду.
Что такое тег Meta Robots?
Директивы для роботов — это простые фрагменты кода, которые добавляются на ваш веб-сайт, чтобы направлять роботов, таких как Google, при сканировании и индексировании содержимого вашего веб-сайта. Мета робота является частью этой директивы и представляет собой HTML-код, добавляемый в заголовок страниц, как показано выше! Помимо него, есть еще один файл под названием Robots.txt, который представляет собой файл, добавляемый в корень сайта для связи с роботами поисковых систем.
Разница между ними в том, что первая — тема этого поста — служит для управления индексацией вашего контента в Google и других поисковых системах. Второй контролирует отслеживание, то есть то, к какому контенту веб-сайта вы разрешаете доступ роботам. Оба очень растеряны. Ведь у них похожее название и схожие цели. Но не заблуждайтесь, его особенности разные.
Второй контролирует отслеживание, то есть то, к какому контенту веб-сайта вы разрешаете доступ роботам. Оба очень растеряны. Ведь у них похожее название и схожие цели. Но не заблуждайтесь, его особенности разные.
Файл robots.txt может предотвратить индексацию URL-адреса просто потому, что Google не может получить доступ к его содержимому, но это не означает, что он заблокирован от появления в результатах. Если у вас на сайте есть ссылка на него, например, он может быть проиндексирован «случайно». Цель этого файла — не дать Google тратить время на бесполезные страницы вашего сайта, избежать проблем со сканированием и позволить Google сосредоточиться на том, что действительно важно! Метатег робота напрямую определяет, как и будет ли отображаться ваша страница в результатах поиска.
«Как» и «Если»
Что вы подразумеваете под «как» и «если»? Давай выясним.
Как?
С помощью метароботов вы можете, например, контролировать размер, в котором Google должен отображать ваши изображения в таких местах, как Google Discover.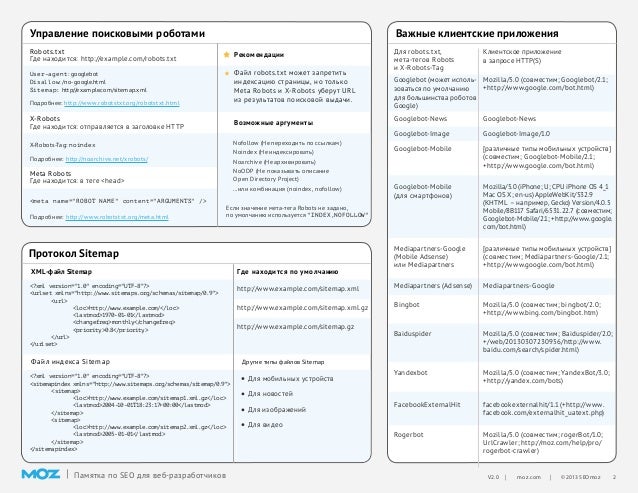 Вы также можете заблокировать отображение своих страниц в избранных фрагментах и другие возможности.
Вы также можете заблокировать отображение своих страниц в избранных фрагментах и другие возможности.
Если
С директивным индексом или без индекса — позвольте мне объяснить каждый из них лучше — вы можете контролировать, может ли Google показывать вашу страницу в поисковой выдаче или нет!
Объяснение имен и директив мета-роботов
Разобьем стандартный код мета-роботов на части, чтобы вы могли лучше понять, как он работает:
Поле «имя», несмотря на то, что оно часто отображается как «роботы», можно изменить, чтобы направлена на конкретных роботов, в частных случаях, таких как:
name="Googlebot-Image"
Поле "контент" - это то место, где происходит волшебство цели робота... Вам необходимо ознакомиться с каждым из политики, которые можно добавить для достижения цели. Узнайте сейчас, каковы основные директивы для управления роботом Google:
Примечание: примечательно, что эти директивы не являются эксклюзивными и могут работать вместе, разделяя запятыми, например: «index , nofollow» — в этом случае мы разрешили индексацию страницы, но ее ссылки не могут отслеживаться для Google.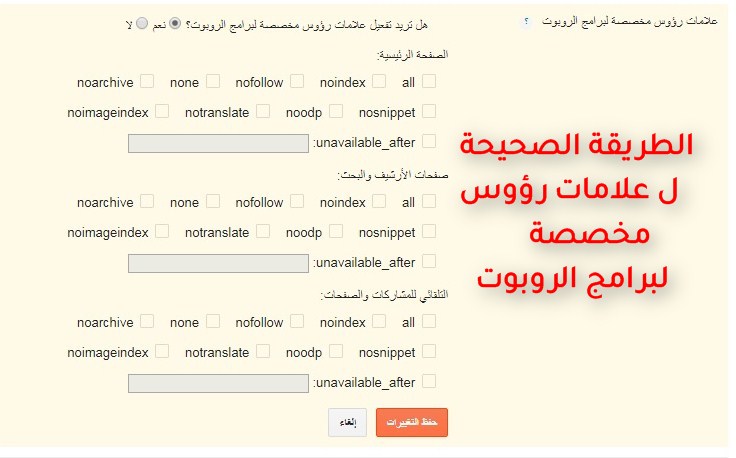
Все
Это значение политики по умолчанию: индексировать, следовать.
Другими словами, по умолчанию, если у вас ничего не заполнено в мете, роботы считают, что страница может быть проиндексирована и переходить по ее ссылкам! Не нужно использовать это: meta name="robots" content="all"
Noindex
Знаменитые мета-роботы noindex . Это одна из самых важных директив, так как она определяет, может ли ваша страница быть проиндексирована в Google или нет. В этом случае — noindex — вы блокируете отображение своей страницы в результатах поиска Google и других поисковых систем. meta name="robots" content="noindex"
Nofollow
Предотвращает отслеживание (доступ) роботами ссылок, присутствующих на странице. Так, например, если вы добавите эту директиву в этот пост, все ссылки, которые вы в ней разместили, не будут отслеживаться Google, когда вы зайдете сюда.
meta name="robots" content="nofollow"
None
Комбинирует noindex и nofollow (эквивалентно добавлению: "noindex,nofollow"). То есть с этой директивой Google не может индексировать или переходить по ссылкам на странице. meta name="robots" content="none"
То есть с этой директивой Google не может индексировать или переходить по ссылкам на странице. meta name="robots" content="none"
Noarchive
Эта политика запрещает Google отображать кэшированную ссылку в результатах поиска.
Что такое кэш?
Это хранилище информации, где, в случае с Google, страницы сохраняются в хранилище Google, чтобы пользователи имели к нему быстрый доступ, даже если оно не работает.
Политика кэширования может быть реализована на вашем сайте независимо от Google, поэтому эта политика может быть полезна на сайтах, которые предпочитают отображать свои версии кэшированных страниц. meta name="robots" content="noarchive" указывает Google не отображать фрагмент текста или превью видео в результатах поиска.
Nosnippet
Например, он запрещает Google отображать метаописания ваших страниц в результатах поиска.
meta name="robots" content="nosnippet"
Unavailable_After: [дата/время]
ПОСЛЕДНИЕ ПОСТЫ
Если вы планируете начать онлайн-бизнес, вы должны осознать, что вам необходимо изучить веб-дизайн. Даже если вы не опытный...
Даже если вы не опытный...
Высокий рейтинг в результатах поиска необходим, если вы являетесь владельцем онлайн-бизнеса, веб-сайта или блога и хотите показать свое присутствие в Интернете. Вы ...
Позволяет установить ограничение по дате/времени, когда страница может быть проиндексирована в Google.
После установленной даты страница больше не может отображаться в результатах поиска (полезно, например, для целевых страниц для временных выпусков):
meta name=”robots” content=”unavailable_after: 2021-06-05″
Как проверить цель робота
Необходимое время: 30 минут.
Вот шаги для проверки цели робота
- Перейдите на страницу
Вы можете перейти на страницу, которую хотите проверить, и нажать CTRL + U, затем CTRL + F и выполнить поиск «роботы», чтобы увидеть если и как тег появляется на странице.
- Использование расширений
Вы можете использовать расширения Chrome для SEO, такие как SEO META, в 1 КЛИК.
- Подтвердить
Для проверки в масштабе идеально использовать инструмент отслеживания, такой как Screaming Frog.

Как внедрить метатег Robots?
Это очень простая разметка HTML для добавления в заголовок страниц, как в примере:
Название страницы <ссылка rel="canonical" href="url" />
Чтобы реализовать это, добавьте его с помощью приведенного выше шаблона на все страницы, которые вы хотите проиндексировать так, как Google считает нужным для пользователей! Но как это сделать? Ответ таков: это действительно зависит. Это зависит от вашей CMS! У многих он уже установлен по умолчанию. Другие нет. Вы должны проверить, есть ли она, и понять с разработчиком, как он может добавить разметку в HTML-код страниц или самостоятельно.
Что такое X-Robots-Tag?
Индексацией управляет не только метатег robots. Существует еще один, называемый X-Robots-Tag, который имеет ту же функцию и директивы. Разница только в форме реализации. В то время как метатег — это разметка в HTML-коде страницы, X-Robots-Tag — это HTTP-ответ, такой как перенаправление 301, отправляемый сервером веб-сайта.
Это полезно в некоторых конкретных случаях, в основном для блокировки индексации файлов, таких как PDF-файлы или изображения, например.
Процесс проверки X-Robots-Tag немного отличается, так как вы должны увидеть ответ HTTP со страницы.
Вы можете использовать кричащую лягушку, чтобы проверить масштаб. Для быстрой проверки на странице нужно использовать некоторые расширения Chrome.
7 Варианты использования тега Meta Robots
Узнайте, как использовать этот тег с примерами наиболее распространенных случаев, когда он полезен:
- Не индексировать страницы, не представляющие ценности для пользователя: если страница не имеет особого смысла для пользователя, вы можете добавить тег noindex.
- Тестовые страницы: вы можете использовать метаданные robots noindex, чтобы предотвратить индексацию страниц с нового сайта, который все еще тестируется, вместо ваших старых, и Google считает их дублирующим контентом.
- Запретить отображение страниц входа и администрирования в Google
- Страницы оформления заказа и страницы благодарности: их появление в Google не имеет особого смысла, так как это может запутать пользователей
- Страницы внутреннего поиска: это ОЧЕНЬ важно. Страницы внутреннего поиска/поиска обычно плохо индексируются в Google. Это потому, что они, как правило, являются страницами без контента и считаются неактуальными! Кроме того, вы можете непреднамеренно появиться в Google по нежелательным запросам, если не заблокируете индексацию этих страниц.