
Канонический адрес страницы — Вебмастер. Справка
Если на сайте есть страница, доступная по нескольким адресам, а также страницы с одинаковым или схожим содержимым, робот Яндекса может посчитать их дублями. Тогда он объединит страницы в группу дублей и выберет для показа в результатах поиска только одну из них — наиболее информативную и релевантную поисковым запросам. Такая страница называется канонической.
Вы можете указать роботу страницу, предпочитаемую для показа в результатах поиска, с помощью атрибута rel=»canonical». Также вы можете указать канонический адрес, если хотите изменить адрес сайта — с префиксом www или без него, протоколом HTTP или HTTPS.Внимание. Робот Яндекса воспринимает указание на канонический адрес как рекомендацию и может проигнорировать его в нескольких случаях.- Как указать канонический адрес страницы
- Как изменить адрес сайта с помощью канонического адреса
- Случаи, когда канонический адрес не учитывается
- Вопросы и ответы
Добавьте канонический адрес страницы с помощью атрибута rel=»canonical» одним из способов:
Например, страница доступна по двум адресам: www.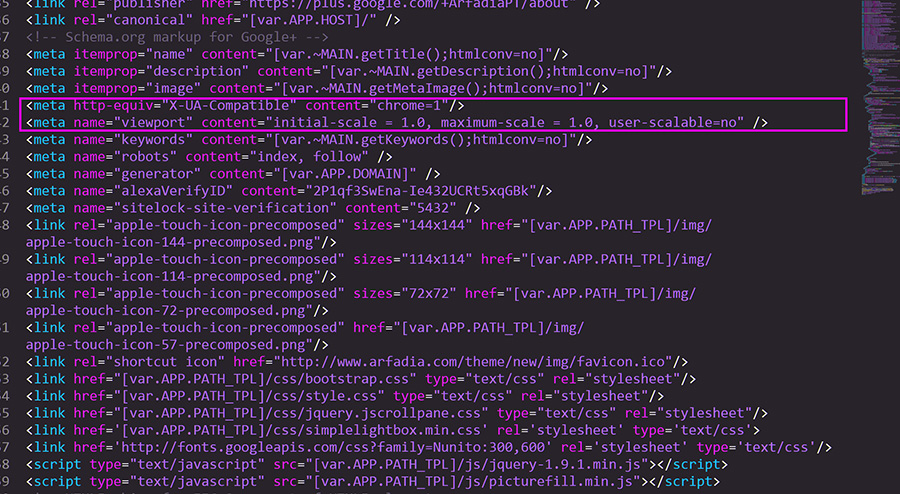 example.com/pages?id==2 и www.example.com/blog.
example.com/pages?id==2 и www.example.com/blog.
Если предпочитаемый адрес — /blog, добавьте в HTML-код страницы /pages?id=2 элемент link:
<link rel="canonical" href="http://www.example.com/blog"/>Link: <http://www.example.com/offer/file.pdf>; rel="canonical"Примечание. Указывайте канонический адрес в пределах одного домена. В качестве канонического адреса задавайте абсолютный путь, например http://example.com/blog/.
Страница, на которой размещен атрибут rel=»canonical» с адресом другой страницы, считается неканонической.Робот узнает об изменениях при обходе сайта. Если канонический адрес указан верно и робот не проигнорировал указание, неканоническая страница пропадет из результатов поиска. Убедиться в том, что страница удалена из поиска, можно в Вебмастере на странице (блок Исключённые страницы).
Робот игнорирует указания, если содержимое канонической страницы значительно отличается от содержимого неканонической. В этом случае в поиске может участвовать неканоническая страница. Чтобы проверить это, перейдите на страницу .
Чтобы исключить из поиска неканоническую страницу, адрес которой содержит GET-параметры или метки (UTM, from и т. д.), добавьте директиву Clean-param в файл robots.txt. В другом случае используйте директиву Disallow.
Вы можете указать канонический адрес, если хотите изменить адрес сайта:
Робот воспримет канонический адрес как редирект на новое главное зеркало и объединит две версии сайта в одну группу. Для этого в HTML-код или в HTTP-заголовок каждой страницы старого сайта добавьте ссылку на аналогичную страницу нового с атрибутом rel=»canonical». Например, вы меняете адрес http://example.com на https://example.com. На странице http://example.com/main/ нужно указать:
<link rel="canonical" href="https://example.com/main"/>Если атрибут будет указывать на другую страницу, робот может посчитать это различием в структуре сайтов. В таком случае переезд будет невозможен.
При смене адреса убедитесь, что контент старого и нового сайтов совпадает. Подробнее см. инструкцию по переезду.
Примечание. Если атрибут добавлен только на отдельные страницы, он не будет указывать на главное зеркало.
Робот Яндекса не учтет канонический адрес, если:
- На момент обхода неканонические страницы более полно отвечают на запрос пользователя, и их контент существенно отличается от канонических. Если вы уверены, что такие страницы не будут полезны пользователям в поиске, запретите индексирование в файле robots.txt.
- Канонический адрес недоступен для робота — перенаправляет на другую страницу или закрыт от индексирования. Это значит, что он не сможет участвовать в поиске. Тогда вместо канонического адреса может участвовать неканонический, если он доступен для робота.
В качестве канонического адреса указан URL в другом домене или поддомене.
Указано несколько канонических адресов.
Указана цепочка канонических адресов. Например, для адреса example.com/1 каноническим адресом является example.com/2, в то время как для адреса example.com/2 указан канонический адрес example.com/3.
- Атрибут rel=»canonical» указывает на страницу, на которой размещен. Это ошибка?
Если страница была исключена из поиска как неканоническая, значит, в ее HTML-коде или HTTP-заголовке робот нашел атрибут rel=»canonical» с указанием на канонический адрес. Удалите это указание и проверьте, что индексирование страницы, которую вы хотите вернуть в поиск, не запрещено.
как указывать атрибут правильно и зачем он нужен
Главное об атрибуте rel = «canonical”: что это такое, зачем и где указывать, какие ошибки часто допускают оптимизаторы.
Разбираемся, что нужно знать оптимизатору о работе с каноническими тегами. Материал для начинающих или тех, кто хочет освежить знания в памяти.
Что такое rel canonical и для чего он нужен
Одинаковый контент на разных страницах — плохо, за это следуют санкции. Но есть случаи, когда дубли оправданы. К примеру, одна и та же страница может входить в несколько категорий, один и тот же сайт может быть доступен с www и без, а еще в каталогах товаров есть сортировка и фильтрация.
Страницы могут быть не полностью одинаковыми. К примеру, на одной включен фильтр товаров по сезона, а на другой — сортировка по цене. Тем не менее, от включенных фильтров уникальными они не станут.
Фильтр в каталоге сайта www.asos.comВ таких случаях нужно указывать, какой вариант страницы роботу считать основным, то есть каноническим, а какие дублями. Для этого придумали канонический тег — rel = «canonical», он решает проблему дублирования контента.
Каноническая страница — это основной URL. Атрибут rel = «canonical» добавляют на страницы-дубли и в нем указывают адрес канонической страницы, чтобы дать боту знать, какую страницу они повторяют.
Зачем указывать основную версию страницы?
Причины указывать canonical:
избежать санкций поисковиков за дублирование контента;
корректно передавать ссылочный вес на нужную версию сайта и страницы;
из контента, доступного по нескольким URL, выбрать страницу, которая будет получать все сигналы и показываться в выдаче;
не тратить краулинговый бюджет на дубли.
Краткая информация о канонических URL из первых уст есть в справке Google и Яндекса.
Например, есть страница, доступная по трем адресам:
site.ru/page?id=123
site.ru/blog/category/tema
site.ru/blog/tema
Допустим, мы хотим, чтобы страница site.ru/blog/category/tema ранжировалась в выдаче, получала весь положенный ей ссылочный вес и другие сигналы — считалась канонической.
Тогда эту страницу мы не трогаем, в коде страниц дублей site.ru/page?id=123 и site.ru/blog/tema указываем ее как каноническую. В коды дублей мы добавляем такую строчку:
<link rel="canonical" href="http://site.ru/blog/category/tema"/>Неканонические страницы не попадут в индекс?
Страницы, отмеченные как неканонические, все равно могут попасть в выдачу. Яндекс отмечает:
«Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом».
В Вебмастере у всех страниц появилась пометка «каноническая», «неканоническая» и «каноническая страница не указана». Вы можно посмотреть неканонические страницы, попавшие в выдачу, для этого откройте «Страницы в поиске» и ищите строчки с пометкой «Неканоническая».
Неканоническая страница в выдачеGoogle тоже заявляет, что система признает указанный канонический URL, но не всегда, поскольку тег canonical — рекомендация, а не приказ к действию. Если неканоническая покажется ему релевантнее, она и появится в выдаче.
Но если сеошник указывает этот атрибут, уменьшается риск, что Google сам определит основной не ту версию страницы.
Канонические страницы все равно появляются в поиске чаще и имеют приоритет при показе в выдаче, а ошибки с настройкой canonical могут привести к проблемам в индексировании страниц. Разберем все варианты, когда нужно использовать канонический тег.
Когда нужно прописывать канонический тег
Используйте canonical, когда одинаковый контент доступен по разным URL. Когда дублирующиеся URL создаются системой, фактически сам контент не дублируется — разные URL обслуживают одно содержимое. Тем не менее, это дубли, канонический тег стоит указать. Разберем разные случаи.
Дублирование страниц
Дублирующиеся страницы с похожим содержанием, которые генерируются CMS. Они бывают на всех сайтах интернет-магазинов, где можно настраивать параметры выбора товара. Ссылки для навигации по каталогу, сортировка товаров, фильтрация, ссылки с UTM-метками для отслеживания, другие страницы с GET-параметрами в URL.
К примеру, если в каталоге есть несколько позиций одного дивана, отличающиеся только цветом обивки, можно выбрать самый популярный вариант и указать его каноническим. Все варианты диванов будут доступны пользователям, но ссылочный вес и другие сигналы будут идти на страницу с основным вариантом.
Другой вариант — страница товара подходит сразу под несколько категорий, так что образовываются множественные URL одного предмета. Решение такое же: выбрать популярную в качестве основной и указать ее на остальных дублирующих страницах в rel = «canonical».
Страницы пагинации
Переключение страниц в каталоге рождает дубли. Иногда для всех страниц пагинации указывают первую страницу в качестве канонической — это советуют не делать, потому что тогда проиндексируется только первая страница.
Вариант 1
Если на странице есть «Показать все», страница со всеми вариантами и будет канонической. На каждой из страниц пагинации укажите ее в атрибуте rel = «canonical».
Например, для страницы https://site.ru/category1/page-2 нужно прописать канонический URL:
<link rel="canonical" href="http://site.ru/category1/show-all">Вариант 2
Если «Показать все» нет, для каждой страницы пагинации советуют указывать эти же страницы как канонические.
Например, на странице https://site.ru/category1/page2 нужно указать каноническую ссылку:
<link rel="canonical" href="http://site.ru/category1/page2">Вариант 3
Есть и другое мнение: если указать canonical страницы саму на себя, все страницы пагинации пойдут в выдачу. Если вы считаете, что плохо, если у разных URL с отличающимся контентом будут одинаковые Title и Description, то не делайте так.
В таком случае не нужно проставлять canonical, а лучше закрыть страницы пагинации в noindex, follow и использовать dissalow в robots для /page. Это значит, что индексировать нельзя, а переходить по ссылкам можно.
<meta name="robots" content="noindex, follow"/>Напомним, что noindex подходит только для Яндекса.
HTTPS, HTTP, www
Один сайт может быть доступен по трем вариантам: http://site.ru и http://www.site.ru и https://www.site.ru. Но поисковые системы будут рассматривать все три как наборы отдельных страниц, если не указать canonical. Из-за чего могут быть проблемы со сканированием и индексацией сайта.
Мобильный URL
Google уже давно переходит на Mobile-First Indexing, то есть при индексировании он ориентируется на мобильную версию сайта.
Представитель Google Джон Мюллер рассказал, что делать с каноническим тегом в этих условиях.
Если у вас есть мобильная версия сайта m.site.ru, обычно у нее указывают rel = «canonical», ведущий на десктопную. А для десктопной используют тег rel=alternate, ведущий на мобильную. Если вы сделали так, ничего менять не надо. Бот распознает мобильную версию как каноническую, даже если в коде канонической указана десктопная. Если и в Sitemap.xml также, то тоже можно не трогать.
URL страны
Бывает, что для конкретной страны у сайта есть несколько версий с разными URL. При этом язык один и контент одинаковый с несущественными отличиями. Тогда нужно выбрать каноническую и сделать отсылки к ней на всех дублях.
Но если речь идет о разных языковых версиях, нужно использовать hreflang, чтобы поисковики выдавали отдельные результаты. Атрибут hreflang нужен для указания дополнительных URL с аналогичным или похожим содержимым на других языках или для отдельных регионов.
Из-за перехода Google на Mobile-First Indexing, нужно правильно настроить hreflang. Десктопные hreflang-теги должны ссылаться на десктопные URL, мобильные — соответственно на мобильные URL. И редиректить пользователей на нужную версию в зависимости от устройства.
Верхний и нижний регистр
Поисковик может посчитать разными два адреса, написанные в разном регистре. При назначении URL система должна применять только нижний регистр, чтобы одни и те же ссылки были действительно одинаковыми.
Материал по теме:
Htaccess для перенаправления верхнего регистра на нижний
Итак, с помощью rel = «canonical» можно указать поисковику, какую страницу считать основной и главной среди дублей, чтобы сканировать ее, индексировать, показывать в выдаче и направлять на нее ссылочный вес. Разберемся, как настраивать тег.
Как настроить canonical правильно: 6 способов указать основной URL
Для использования канонического тега нужно выбрать среди дублей основной URL, вписать его в атрибут:
<link rel="canonical" href="http://site.ru/page/">и добавить ко всем неосновным страницам.
Для добавления есть несколько способов:
С помощью плагина CMS
Большинство CMS имеют встроенную функцию или плагины, которые позволяют автоматизировать настройку канонического URL.
К примеру:
настроить canonical на WordPress можно с помощью плагина Yoast SEO;
в OpenCart в настройках товара можно задать SEO URL;
в Joomla версии от 3 и выше можно включить функцию SEF. Тогда в код технических страниц вида /index.php?option добавится атрибут rel = «canonical» с указанием основной страницы с ЧПУ.
Для примера подробнее рассмотрим WordPress как самую популярную CMS среди наших подписчиков.
Настройка canonical WordPress
Все просто: установите плагин Yoast SEO, чтобы канонические теги добавлялись автоматически.
Настроить теги для конкретной страницы можно в разделе «Дополнительно» («Advanced»), там нужно указать основной URL:
Настройка канонического тега WordPressYoast SEO делает так, что если на странице появляется noindex или nofollow, тег canonical пропадает, чтобы не было проблем с представлением сайта в выдаче.
Если вы не используете CMS и не можете реализовать канонический тег плагинами, можно сделать все иначе.
Прописать между тегами любой HTML-страницы
Основной способ — прописать rel = «canonical» в секцию < head > любой страницы-копии.
Например, если для страницы https://site.ru/*utm_content= канонической будет https://site.ru/, на страницу https://site.ru/*utm_content= нужно добавить код:
<link rel="canonical" href="http://site.ru/">В заголовке HTTP
У PDF и других не HTML документов нет секции < head >, так что использовать предыдущий способ не получится. Если у вас есть доступ к настройкам сервера, можно указать канонический тег в заголовке HTTP с использованием .htaccess или PHP.
При запросе дублирующего файла сервер должен отдавать ссылку на оригинальный файл:
<link: <http: site.ru="" guide.pdf>;="" rel="canonical"></http:></http:></http:></http:>К примеру, вы составили руководство, выложили его в блог и отдельно оформили в PDF-файл для скачивания, который разместили в подкаталоге http://site.ru/blog/*. HTTP-заголовок для этого руководства в PDF может выглядеть так:
HTTP/1.1 200 OK
Content-Type: application/pdf
Link: <http://site.ru/blog/canonical-tags/>; rel="canonical"
С другими страницами так тоже можно.
В файле Sitemap
Поисковики по умолчанию думают обо всех ссылках в XML-файле как о канонических. У Google есть требование включать в Карту сайта только канонические адреса страниц. Но Карта не свод правил для поисковых ботов, а список рекомендаций, который поисковики могут проигнорировать.
Материал по теме:
Как составить Sitemap
Через 301 редирект
Отвести трафик и ссылочный вес от дублей к канонической страницы можно с помощью 301 редиректа. Этот способ можно использовать, если сайт, к примеру, доступен по нескольким адресам:
https://site.ru/
http://site.ru/
http://www.site.ru/
https://www.site.ru/
Можно выбрать в качестве основного https://site.ru/, а со всех остальных настроить перенаправление.
Материал по теме:
Как настроить 301 редирект самостоятельно
Дополнительный сигнал — ссылки
Представитель Google Джон Мюллер в этом видео перечислял все сигналы, которые поисковик использует для определения канонического адреса.
К примеру, между адресами HTTPS и HTTP Google выберет HTTPS, а еще он может предпочесть привлекательный с его точки зрения URL. В числе сигналов каноникализации числятся ссылки с одной страницы на другую. Если вы указали канонической одну страницу, а по совокупности факторов другая кажется поисковику более подходящей, он не будет вас слушать.
Неправильной настройкой можно навредить индексированию страниц. Разберем несколько типичных ошибок оптимизаторов.
Неправильно указан canonical: популярные ошибки настройки
Использование нескольких канонических ссылок для одной страницы
Для одной страницы нужно указать один канонический адрес. Если указано несколько, бот либо проигнорирует страницу вообще, либо примет к сведению первый указанный URL.
Проверяйте, как плагин CMS реализует canonical, иногда из-за неправильной настройки он может указывать несколько адресов.
Настройка разных канонических URL одной странице
Похожий пункт, но речь идет не о нескольких канонических адресах для одной страницы, а в о разных, указанных разными способами.
Если вы используете несколько способов указать канонический тег, например, в HTTP-заголовке и в секции < head >, ссылка на основную страницу должна быть одна и та же.
Настройка цепочки канонических URL
Бот не будет учитывать канонический адрес, если для страницы, которую вы указали основной, настроена какая-то своя основная страница. Например, для адреса site.ru/1 канонической ссылкой указана site.ru/2, а для нее указана site.ru/3.
Размещение rel = «canonical» не в секции head
Тег rel = «canonical» должен находиться только в секции < head >. Если указать его в < body > документа, боты его проигнорируют. Или даже могут проигнорировать всю страницу.
Лучше перепроверить: даже если вы поставили canonical ближе к началу документа, секция < head > может закрыться раньше, например, из-за вставок JavaScript, контейнеров < iframe > или незакрытых парных тегов. Тогда canonical окажется за пределами < head > в секции < body >.
Указание первой страницы пагинации как канонической
Если для всех страниц пагинации канонической указать первую, бот не проиндексирует остальные. Выше мы писали, как лучше сделать, есть три варианта:
сделать канонической страницу «Показать все», если она есть;
для каждой страницы поставить ее же URL в качестве канонической, если нет общей страницы.
Но если вы считаете, что наличие всех страниц пагинации в выдаче плохо повлияет из-за повторяющихся Title и Description, не ставьте канонический тег вообще и закройте их для индексации. Используйте noindex, follow для страниц пагинации и для /page укажите disallow в файле robots. Такая настройка означает, что индексировать нельзя, а переходить по ссылкам можно.
Использование канонических URL вместо 301 редиректа
Тег canonical и 301 редирект кажутся похожими — перенаправляют бота на основную страницу. Но не стоит использовать canonical вместо редиректа. Редирект переводит весь трафик на один URL, а при использовании rel = «canonical» страница откроется, будет активной и сможет получать трафик, но не появится в индексе.
Выбор главной как канонической для всех страниц
Ошибкой будет указать главную страницу в качестве канонической для всего сайта. Боты могут проигнорировать все страницы, кроме главной.
Закрытие канонической страницы от индексирования
Если канонический URL закрыт от индексирования или по другой причине недоступен для поискового бота, он не сможет участвовать в формировании выдачи. В этом случае бот возьмет доступный неканонический URL.
Как проверить canonical
Проверить, для каких страниц вы настроили canonical и какие канонические страницы указали, можно с помощью сервиса Screaming Frog SEO Spider.
Результаты проверки страниц краулеромУзнать, какую страницу Google считает основной для конкретного URL, можно через инструмент проверки URL.
Проверить, как поступил Яндекс, можно в Вебмастере: если вы верно указали каноническую страницу, дубли пропадут из поиска. Посмотрите страницу «Индексирование» — «Страницы в поиске». Если страницу исключили из результатов, она будет в блоке «Исключённые страницы».
Проверка наличия дубля в выдачеРассказывайте, о каких необходимых вариантах использования canonical мы забыли, и какие еще ошибки настройки вы встречали в своей практике!
Rel Canonical или Noindex? Что лучше использовать для закрытия дублирующих страниц?
Чтобы избежать дублирования контента и некачественных страниц при индексации, веб-мастера обычно предпочитают устанавливать теги noindex, nofollow, иногда rel = canonical, а иногда и все вместе. Так как же все таки правильней ?
Теги canonical и noindex в Google
Джон Мюллер (John Mueller) на одной из встреч в Google Webmaster Central рассказал, что поисковик Google при определении качества сайта использует только те страницы, которые разрешены для индексации. То есть, страницы закрыты через теги noindex учитываться не будут, именно поэтому Джон рекомендовал веб-мастерам вместо тега «noindex» использовать rel = canonical для страниц с дублирующим контентом.
При использовании тега noindex все сигналы, связанные с дублирующейся страницей, теряются и не передаются при учете качества сайта в целом. Канонический тег позволяет передать все сигналы с дублирующей страницы, на каноническую.
В случае если Вы будете использовать оба тега одновременно (noindex, nofollow, и rel = canonical), это может привести к непредсказуемым последствиям, так как они совершенно противоречат друг-другу и не могут использоваться вместе. По этому вопросу Джон Мюллер ответил:
Общее правило заключается в том, что сигналы передаются и объединены с канонизацией. Когда Google видит два похожих URL адреса с вашего сайта и вы чётко нам указываете на то, какой из них вы предпочитаете, мы попытаемся их объединить и будем учитывать только один (обычно более весомый) URL. Редиректы, rel=canonical, внутренние и внешние ссылки, sitemaps, hrflang и так далее — всё это говорит нам о ваших предпочтениях и чем больше вы их настроите, тем больше мы будем следовать им и использовать их для выбора канонического адреса (пересылая при этом все сигналы на выбранную страницу).
С другой стороны, noindex и disallow в robots.txt не являются признаками канонизации. Т.е. их наличие на странице не говорит нам, что вы хотите чтобы она сочеталась с какой-либо другой и что её сигналы нужно перенаправить. Disallow в robots.txt нам труднее понять, потому что мы даже не знаем соответствует ли указанная в нём страница чему-либо ещё на вашем сайте, есть ли похожие страницы, поэтому мы не можем использовать данный файл для канонизации, если бы захотели.
Отсюда следует: вы не должны смешивать noindex и rel=canonical так как для нас это очень противоречивая информация. Обычно мы выбираем rel=canonical и используем его поверх noindex, поэтому в любое время, когда вы полагаетесь на интерпретацию компьютерным скриптом (ботом), вы уменьшаете вес вашего входа (а SEO — во многом сводится на тем, чтобы указать боту ваши предпочтения).
Яндекс
Поисковая система Яндекс также распознает и учитывает оба тега, но комментариев от представителей Яндекса по вопросу можно ли использовать оба тега одновременно я не нашел. Но логически понятно, если теги распознаются также как и в Google, правила их использования должны быть теже.
Бороться с дублированием контента на сайте Яндекс также рекомендует в большей с помощью тега rel=cannonical, о чем есть небольшая заметка с примерами в блоге Платона Щукина https://yandex.ru/blog/platon/2878
Дублированный контент [SEO 2021] — Moz
Что такое дублированный контент?
Дублированный контент — это контент, который появляется в Интернете более чем в одном месте. Это «единое место» определяется как местоположение с уникальным адресом веб-сайта (URL). Таким образом, если одно и то же содержание отображается более чем на одном веб-адресе, у вас есть дублированный контент.
Хотя технически это и не является штрафом, дублированный контент все же может иногда влиять на рейтинг в поисковых системах. Когда существует несколько частей, как это называет Google, «в значительной степени похожего» контента в более чем одном месте в Интернете, поисковым системам может быть сложно решить, какая версия более релевантна данному поисковому запросу.
Почему важно дублировать контент?
Для поисковых системДублированный контент может представлять три основных проблемы для поисковых систем:
Они не знают, какую версию (и) включить / исключить из их индексов.
Они не знают, следует ли направлять метрики ссылок (доверие, авторитет, якорный текст, равенство ссылок и т. Д.) На одну страницу или сохранять их разделенными между несколькими версиями.
Они не знают, какие версии ранжировать по результатам запроса.
При наличии дублированного контента владельцы сайтов могут понести рейтинг и потерять трафик. Эти потери часто происходят из-за двух основных проблем:
Чтобы обеспечить наилучшее качество поиска, поисковые системы редко показывают несколько версий одного и того же контента, и поэтому вынуждены выбирать, какая версия с наибольшей вероятностью будет лучшим результатом. Это уменьшает видимость каждого дубликатов.
Доля ссылок может быть еще больше разбавлена, потому что другим сайтам также придется выбирать между дубликатами.вместо всех входящих ссылок, указывающих на один фрагмент контента, они ссылаются на несколько частей, распределяя ссылочный вес между дубликатами. Поскольку входящие ссылки являются фактором ранжирования, это может повлиять на видимость части контента при поиске.
Чистый результат? Часть контента не достигает такой видимости при поиске, как в противном случае.
Как возникают проблемы с дублированием контента?
В подавляющем большинстве случаев владельцы веб-сайтов намеренно, не создают дублированный контент.Но это не значит, что этого нет. На самом деле, по некоторым оценкам, до 29% Интернета — это дублированный контент!
Давайте рассмотрим некоторые из наиболее распространенных способов непреднамеренного создания дублированного контента:
1. Варианты URL
Параметры URL, такие как отслеживание кликов и некоторый код аналитики, могут вызывать проблемы с дублированным контентом. Это может быть проблемой, вызванной не только самими параметрами, но и порядком, в котором эти параметры появляются в самом URL-адресе.
Например:
Точно так же идентификаторы сеанса являются обычным создателем дублированного контента. Это происходит, когда каждому пользователю, посещающему веб-сайт, назначается другой идентификатор сеанса, который хранится в URL-адресе.
Удобные для печати версии содержимого также могут вызывать проблемы с дублированием содержимого при индексировании нескольких версий страниц.
Один из уроков здесь состоит в том, что, когда это возможно, часто полезно избегать добавления параметров URL или альтернативных версий URL (информация, которую они содержат, обычно может передаваться через скрипты).
2. HTTP против HTTPS или WWW против страниц без WWW
Если ваш сайт имеет разные версии на «www.site.com» и «site.com» (с префиксом «www» и без него), и один и тот же контент живет в обеих версиях, вы фактически создали дубликаты каждой из этих страниц. То же самое относится к сайтам, которые поддерживают версии как по адресу http: //, так и по адресу https: //. Если обе версии страницы активны и видны поисковым системам, вы можете столкнуться с проблемой дублирования контента.
3. Зачищенное или скопированное содержимое
Содержимое включает не только сообщения в блогах или редакционные материалы, но и страницы с информацией о продуктах.Скреперы, повторно публикующие контент вашего блога на своих сайтах, могут быть более привычным источником дублированного контента, но есть общая проблема и для сайтов электронной коммерции: информация о продукте. Если на многих разных веб-сайтах продаются одни и те же товары, и все они используют описания этих товаров производителем, идентичный контент оказывается в нескольких местах в Интернете.
Как исправить проблемы с дублированным контентом
Устранение проблем с дублированным контентом сводится к одной и той же центральной идее: определение того, какой из дубликатов является «правильным».
Всякий раз, когда контент на сайте можно найти по нескольким URL-адресам, он должен быть канонизирован для поисковых систем. Давайте рассмотрим три основных способа сделать это: с помощью перенаправления 301 на правильный URL, атрибута rel = canonical или с помощью инструмента обработки параметров в Google Search Console.
301 редирект
Во многих случаях лучший способ борьбы с дублированием контента — это настроить 301 редирект с «дублированной» страницы на исходную страницу контента.
Когда несколько страниц с потенциалом для хорошего ранжирования объединяются в одну страницу, они не только перестают конкурировать друг с другом; они также создают более сильный сигнал актуальности и популярности в целом.Это положительно повлияет на способность «правильной» страницы занимать высокий рейтинг.
Rel = «canonical»
Другой вариант работы с дублированным содержимым — использование атрибута rel = canonical. Это сообщает поисковым системам, что данная страница должна рассматриваться как копия указанного URL, и все ссылки, показатели контента и «рейтинг», которые поисковые системы применяют к этой странице, должны фактически быть зачислены на указанный URL.
Атрибут rel = «canonical» является частью заголовка HTML веб-страницы и выглядит следующим образом:
Общий формат:
... [другой код, который может быть в заголовке HTML вашего документа] ... ...[другой код, который может быть в заголовке HTML вашего документа]. ..
Атрибут rel = canonical должен быть добавлен в заголовок HTML каждой дублированной версии страницы, при этом часть «URL-адрес ОРИГИНАЛЬНОЙ СТРАНИЦЫ» выше заменена ссылкой на исходную (каноническую) страницу. (Убедитесь, что вы сохраняете кавычки.) Атрибут передает примерно такое же количество ссылок (рейтинг), что и перенаправление 301, и, поскольку он реализован на уровне страницы (а не на сервере), часто требуется меньше времени для разработки. осуществлять.
Ниже приведен пример того, как канонический атрибут выглядит в действии:
Использование MozBar для идентификации канонических атрибутов.
Здесь мы видим, что BuzzFeed использует атрибуты rel = canonical, чтобы приспособить их использование параметров URL (в данном случае отслеживания кликов). Несмотря на то, что эта страница доступна по двум URL-адресам, атрибут rel = canonical гарантирует, что все показатели ссылочного капитала и контента присваиваются исходной странице (/ no-one-does-this-anymore).
Meta Robots Noindex
Один метатег, который может быть особенно полезен при работе с дублированным контентом, — это мета-роботы, когда он используется со значениями «noindex, follow». Обычно называемый Meta Noindex, Follow и технически известный как content = «noindex, follow», этот метатег роботов может быть добавлен в заголовок HTML каждой отдельной страницы, которая должна быть исключена из индекса поисковой системы.
Общий формат:
... [другой код, который может быть в заголовке HTML вашего документа]... ... [другой код, который может быть в заголовке HTML вашего документа] ...
Метатег robots позволяет поисковым системам сканировать ссылки на странице, но не позволяет им включать эти ссылки в свои индексы. Важно, чтобы дублированную страницу можно было сканировать, даже если вы говорите Google не индексировать ее, потому что Google явно предостерегает от ограничения доступа для сканирования дублированного контента на вашем веб-сайте. (Поисковые системы любят видеть все, если вы допустили ошибку в коде.Это позволяет им сделать [вероятно, автоматизированный] «вызов для суждения» в других неоднозначных ситуациях.)
Использование мета-роботов — особенно хорошее решение для проблем с дублированием контента, связанных с разбивкой на страницы.
Предпочитаемый домен и обработка параметров в Google Search Console
Google Search Console позволяет вам установить предпочтительный домен вашего сайта (например, http://yoursite.com вместо http://www.yoursite.com) и указать, следует ли Робот Googlebot должен по-разному сканировать различные параметры URL (обработка параметров).
В зависимости от структуры вашего URL-адреса и причины проблем с дублированным контентом решение может быть найдено путем настройки предпочитаемого домена или обработки параметров (или и того, и другого!).
Главный недостаток использования обработки параметров в качестве основного метода работы с дублированным контентом заключается в том, что вносимые вами изменения работают только для Google. Любые правила, введенные с помощью Google Search Console, не повлияют на то, как Bing или сканеры любой другой поисковой системы интерпретируют ваш сайт; вам нужно будет использовать инструменты для веб-мастеров для других поисковых систем в дополнение к настройке параметров в Search Console.
Дополнительные методы работы с дублирующимся контентом
Поддержание единообразия при размещении внутренних ссылок по всему веб-сайту. Например, если веб-мастер определяет, что канонической версией домена является www.example.com/, то все внутренние ссылки должны вести на http: // www. example.co … вместо http: // example.com/pa … (обратите внимание на отсутствие www).
При распространении содержимого убедитесь, что веб-сайт синдикации добавляет обратную ссылку на исходное содержимое, а не на вариант URL.(Для получения дополнительной информации ознакомьтесь с нашим выпуском Whiteboard Friday о работе с дублированным контентом.)
Чтобы добавить дополнительную защиту от парсеров контента, крадущих SEO-кредитование вашего контента, разумно добавить самореферентную rel = canonical ссылку на ваш существующие страницы. Это канонический атрибут, указывающий на URL-адрес, на котором он уже находится, цель которого — помешать усилиям некоторых парсеров.
Самостоятельная ссылка rel = canonical: URL-адрес, указанный в теге rel = canonical, совпадает с URL-адресом текущей страницы.
Хотя не все парсеры будут переносить полный HTML-код своего исходного материала, некоторые сделают это. Для тех, кто это делает, самодостаточный тег rel = canonical гарантирует, что версия вашего сайта будет считаться «оригинальной» частью контента.
Продолжайте учиться
Приложите свои навыки к работе
Сканирование сайта Moz Pro может помочь выявить дублирующийся контент на сайте. Попробовать >>
Канонический метатег | Adobe Commerce 2.4 Руководство пользователя
Некоторые поисковые системы наказывают веб-сайты, у которых несколько URL-адресов указывают на одно и то же содержание.Канонический метатег сообщает поисковым системам, какую страницу индексировать, если несколько URL-адресов имеют идентичный или очень похожий контент. Использование канонического метатега может улучшить рейтинг вашего сайта и общее количество просмотров страниц. Канонический метатег размещается в блоке страницы продукта или категории. Он предоставляет ссылку на ваш предпочтительный URL, поэтому поисковые системы придадут ему больший вес.
Пример 1. Путь к категории создает повторяющиеся URL-адреса
Например, если ваш каталог настроен на включение пути категории в URL-адреса продуктов, ваш магазин будет генерировать несколько URL-адресов, указывающих на одну и ту же страницу продукта.
1
2
http://mystore.com/gear/bags/driven-backpack.html
http://mystore.com/driven-backpack.html
Пример 2: Полный URL страницы категории
Когда канонические метатеги для категорий включены, страница категории вашего магазина включает канонический URL-адрес для полного URL-адреса категории:
1
http: // mystore.com / gear / сумки /
Пример 3: Полный URL страницы продукта
Когда канонические метатеги для продуктов включены, страница продукта включает канонический URL-адрес для имени домена / URL-адреса продукта, поскольку ключи URL-адреса продукта глобально уникальны.
1
http://mystore.com/driven-backpack.html
Если вы также включите путь категории в URL-адреса продуктов, канонический URL-адрес останется ключом-домена / URL-адреса продукта.Однако к продукту также можно получить доступ, используя его полный URL-адрес, который включает категорию. Например, если URL-ключ продукта — managed-backpack и назначен категории Снаряжение> Сумки, доступ к продукту можно получить с помощью любого URL-адреса.
Вы можете избежать штрафных санкций со стороны поисковых систем, исключив категорию из URL-адреса или используя канонический метатег для указания поисковым системам индексации по продукту или категории. Рекомендуется включить канонические метатеги как для категорий, так и для продуктов.
На боковой панели Admin перейдите в Магазины > Настройки > Конфигурация .
На левой панели разверните Каталог и выберите под ним Каталог .
Разверните раздел Search Engine Optimization .
Чтобы изменить какие-либо значения полей, необходимо сначала снять флажок Использовать системное значение после каждого поля.
Поисковая оптимизация
Если вы хотите, чтобы поисковые системы индексировали только страницы категорий, используя полный путь к категории, выполните следующие действия:
Если вы хотите, чтобы поисковые системы индексировали страницы продуктов только с использованием формата имени домена / ключа URL-адреса продукта, выполните следующие действия:
По завершении нажмите «Сохранить конфигурацию».
Что такое канонический URL-адрес? Как освоить Rel = Canonical Tag
Канонический URL — это предпочтительная версия веб-страницы.Он появляется в небольшом фрагменте кода на странице, который сообщает поисковым системам, как сканировать страницу и оценивать важность контента. Если один и тот же контент находится на разных URL-адресах, использование этого кода, называемого тегом rel = canonical, поможет поисковым роботам лучше понять, какой контент важен, решить проблемы с дублированным контентом, повысить рейтинг этого контента и в конечном итоге может привести на ваш сайт больше клиентов.
Чтобы показать вам, как использовать канонический URL, оставшаяся часть этого поста будет охватывать:
Что такое канонический URL?
Канонический элемент ссылки или канонический тег находится в заголовке HTML веб-страницы и сообщает поисковым системам, существует ли более важная версия страницы.Канонический тег имеет следующий вид: rel = ”canonical”.
Например, эта строка HTML-кода сообщает поисковым системам, что URL «https://shoestore.org» является исходной версией страницы, на которой встречается этот тег:
Тег важен, потому что поисковые системы регулярно сканируют веб-сайты в поисках информации, которая помогает им решить, как ранжировать страницы и сообщения. Если поисковый робот находит две страницы с одинаковым содержанием, он не знает, как их ранжировать. Нажми и твитни! .Он не может решить, какая страница должна быть ранжирована, поэтому две страницы поглощают ранжирующий потенциал другой. В результате не исключено, что ни один из элементов SEO-контента не будет ранжироваться.
Канонический URL-адрес должен быть настроен, если у вас есть две страницы с одинаковым содержанием на вашем сайте или если у вас есть контент на вашем сайте, который также используется на другом сайте. Вы можете использовать канонический тег, чтобы указать Google на исходный контент и убедиться, что первая часть получает все преимущества и преимущества SEO.
Этот тег был введен в 2009 году, когда Google работал с Microsoft (Bing) и Yahoo над достижением консенсуса в отношении принятия канонических условий.Хотя эта статья, скорее всего, будет посвящена использованию канонических символов для помощи сканерам Google, знайте, что подавляющее большинство поисковых систем принимают эти теги.
Почему Rel = Canonical подходит для SEO?
Проще говоря, дублированный контент сбивает поисковые системы с толку. Когда поисковые системы просматривают несколько страниц с одинаковым содержанием и не получают четких сигналов оптимизации ключевых слов, они:
- Не знаю, какую часть присвоить баллу
- Не знаю, что проиндексировать
- Не знаю, какие страницы должны иметь рейтинг
Тег rel = canonical разъясняет это, помогает поисковым системам понимать контент, предотвращает игнорирование страницы и повышает шансы на то, что контент будет ранжирован.
Используйте теги rel = canonical, чтобы прояснить повторяющийся контент, помочь поисковым системам понять контент и повысить шансы на то, что ваш контент будет ранжирован. Нажмите, чтобы твитнутьКогда-то ходили разговоры о том, что дублирование контента может привести к штрафам за поиск, снижению всего рейтинга веб-сайта или полному удалению его из поисковой выдачи. Однако сейчас многие оптимизаторы считают, что реального наказания нет.
Google не наказывает веб-сайты за дублированный контент; он просто отфильтровывает повторяющиеся результаты, чтобы улучшить работу и соответствовать поисковому запросу.
Несмотря на все ваши усилия, вполне вероятно, что у вас есть дублированный контент на вашем веб-сайте или что другие веб-сайты, возможно, взяли ваш контент и продублировали его на своих страницах. По оценкам экспертов, до 29% всего контента в сети дублируется.
Но вы можете легко решить эти проблемы и получить долгосрочные результаты SEO, используя передовые методы относительного канонического URL и зная, когда использовать этот тег.
Когда использовать канонический URL-адрес? (5 относительных канонических примеров)
Вот несколько относительных канонических примеров, которые показывают, когда вам следует использовать этот тег для выявления дублированного контента и соответствия лучшим практикам для SEO.
при повторной публикации существующего контента
Если у вас есть веб-сайт, который является частью франшизы или национальной организации, вы можете делиться заявлениями, пресс-релизами и даже контентом блога, изначально опубликованным на основном национальном веб-сайте. Вместо того, чтобы просто ссылаться на исходный контент и надеяться, что посетители сайта переходят по нему, вы можете опубликовать контент на своем собственном сайте. Это дублированный контент, которому нужен канонический тег. Вы можете использовать канонический URL, чтобы направлять поисковые роботы к исходному сообщению, чтобы оно не выглядело так, как будто вы копируете страницу.
Когда вы распространяете контент блога
Одна из ваших маркетинговых стратегий может включать распространение вашего существующего контента на других веб-сайтах. Распространение блогов помогает вам расширить узнаваемость вашего бренда и охват, в то время как издатель получает контент для своих страниц. Однако синдицированный контент означает, что ваши слова теперь распространяются в Интернете на нескольких страницах. Без канонических URL-адресов поисковые роботы могут не знать, какой контент появился первым и чему отдать приоритет. К счастью, многие блоги, распространяющие контент, знают, что нужно создавать канонические URL, чтобы не подвергать риску SEO или поисковую выдачу брендов, с которыми они работают.
Когда вы A / B тестируете разные страницы
A / B-тестирование — это стратегия, которую используют маркетологи, чтобы увидеть, какие элементы на странице работают лучше всего. Вы можете протестировать мелкие детали, такие как цвет различных кнопок, или большие изменения, такие как макет страницы или контент. В некоторых случаях Google мог сканировать обе страницы и не понимать, какую из них индексировать как исходную. Канонические URL-адреса служат путеводителем по исходному содержанию.
При использовании нескольких вариантов URL (часто на сайтах электронной торговли)
Канонические URL-адреса часто используются для веб-сайтов электронной коммерции, которые устанавливают разные иерархии и URL-адреса по мере изменения своих сайтов.На веб-сайте электронной коммерции может быть категория, посвященная обуви, с перечнем товаров, а затем изменить иерархию, чтобы разделить категорию на женскую и мужскую обувь или сандалии и кроссовки. Это означает, что URL-адреса для этих страниц продуктов меняются, даже если сами страницы остаются прежними. В результате получается два URL-адреса с одинаковым содержанием. Канонические URL-адреса являются частью передового опыта SEO в электронной коммерции, который направляет поисковые системы на верхние страницы.
Если на вашем сайте есть непреднамеренное дублирование контента
Как упоминалось ранее, у вас может быть дублированный контент на вашем веб-сайте, о котором вы даже не подозреваете. Нажми и твитни! .Существуют десятки ситуаций, которые могут привести к непреднамеренному дублированию контента. Вот несколько наиболее частых причин:
- У вашего сайта отдельные версии HTTP и HTTPS или WWW и не WWW страниц
- Другой сайт скопировал и повторно опубликовал ваш контент
- Метаописания и заголовки SEO одинаковы для нескольких страниц
- Существуют технические проблемы, такие как проблемы с разбивкой на страницы или несколько версий печатаемых и текстовых страниц
Поскольку выявить технические проблемы с дублированным контентом на вашем сайте может быть сложно, для поиска проблем следует использовать средство проверки дублированного контента.Инструмент SEO Audit Tool от Alexa может помочь вам найти скрытые проблемы с повторяющимся контентом, о которых вы, возможно, не подозреваете.
канонических URL и 301 редирект: в чем разница?
В некоторых случаях вам может потребоваться настроить перенаправление 301 вместо канонического URL. Редирект 301 автоматически отправляет посетителей сайта на новый URL-адрес, когда они нажимают на старую ссылку. В подавляющем большинстве случаев вы будете использовать переадресацию 301, если вы объединяете контент в свои архивы или обновляете свой URL-адрес или веб-страницу.Однако, если вы по-прежнему хотите, чтобы люди получали доступ к странице, даже если контент дублируется, вам понадобится канонический URL-адрес.
канонических URL по сравнению с метатегами роботов Noindex: что лучше?
Другой способ решить проблемы с дублированным контентом — это в первую очередь заблокировать сканирование страницы поисковыми системами. С помощью метатега SEO и метатега robots вы можете указать поисковым системам не сканировать ваши страницы, что может показаться быстрым решением. В большинстве случаев, однако, чем больше страниц Google сможет просканировать на вашем веб-сайте, тем лучше.Поэтому обычно лучше использовать noindex для страниц, для которых вы не собираетесь ранжировать или привлекать трафик.
Как настроить канонический URL
Теперь, когда вы понимаете, почему вы хотите использовать канонический тег и как он может вам помочь, пришло время добавить этот тег на ваш собственный сайт. Есть несколько способов сделать это в зависимости от плагинов, которые вы используете, и вашего уровня комфорта при добавлении кода на ваш сайт.
Хотя есть много способов выбрать лучший способ добавления канонического тега, важно, чтобы вы придерживались единого формата на своем веб-сайте. Нажми и твитни! .Если к страницам имеют доступ несколько человек, они могут добавлять теги по-разному, что может привести к еще большим проблемам с поисковой оптимизацией.
Добавить канонические URL-адреса с помощью Yoast
Yoast SEO — один из самых популярных плагинов SEO для WordPress, простой и легкий инструмент для добавления канонических тегов. Если у вас есть сайт WordPress, установите бесплатный плагин и легко добавьте канонический тег через страницу редактирования или раздел публикации. Это идеальный вариант, если вы не хотите касаться кода или технических элементов своей страницы.
Добавить канонические URL-адреса с помощью внутреннего кода
Без специального плагина, который предлагает канонические ссылки (или если вы просто не хотите использовать его для этой цели), вы можете добавить теги rel = canonical на свой сайт с помощью небольших фрагментов кода. Вы можете разместить код в заголовке своей страницы, чтобы установить канонический URL, как только сканеры попадают на вашу страницу:
Если вы не знакомы с настройкой кода заголовка на своей странице WordPress, вы можете следовать этому руководству, чтобы убедиться, что вы правильно применили код.
Добавить канонические изображения с помощью Диспетчера тегов Google
Если на вашем веб-сайте несколько тегов, вы можете управлять ими с помощью Диспетчера тегов Google. Это позволяет активировать один тег при загрузке страницы вместо десятков, повышая скорость и упрощая устранение проблем. У Moz есть подробное руководство по управлению тегами rel = canonical через GTM. Вы можете использовать этот инструмент для установки различных параметров того, что можно сканировать, а что следует игнорировать.
Найдите повторяющееся содержимое и добавьте канонические URL-адреса
Настройка канонического URL-адреса — это быстрый способ исправить проблемы SEO, связанные с дублированием контента на вашем сайте. Нажми и твитни! .Используйте средство проверки канонических URL-адресов, чтобы найти и исправить проблемы с дублирующимся контентом на вашем сайте, чтобы убедиться, что ваш контент оптимизирован для привлечения поисковых роботов и правильного взаимодействия с ними.
Чтобы получить доступ к проверке дублированного контента Alexa, которая является лишь частью нашего подробного отчета об аудите сайта SEO, подпишитесь на бесплатную пробную версию нашего Расширенного плана сегодня.
Google и логотип Google являются зарегистрированными товарными знаками Google LLC, используемыми с разрешения.
Технический SEO-трек: влияние мета-канонических тегов
Технический SEO — одна из ключевых областей воздействия на SEO.Наряду с другими приоритетными областями, такими как создание качественного контента и локализация, установление тематических ссылок, измерение и отчетность, коммуникация с заинтересованными сторонами, он играет решающую роль. Сосредоточение внимания на технических инициативах SEO помогает обеспечить хорошее позиционирование веб-сайта как для поисковых роботов, так и для посетителей сайта. При работе над техническим SEO мы уделяем внимание таким областям, как архитектура / структура сайта, соглашение об именах страниц / папок (URL), элементы навигации, настройка CMS, макет и кодирование шаблона страницы, индексирование и геотаргетинг и так далее.
Следуя жизненному циклу проекта SEO, мы определяем возможности технического усовершенствования, проводим анализ воздействия проекта и представляем POV, внедряем изменения, измеряем результаты и предлагаем следующие шаги на основе данных. В этом блоге мы рассмотрим правильную реализацию метаканонических тегов и анализ, который помог проверить влияние изменений на SEO сайта.
Присмотритесь к мета-каноническому тегу. Мета-канонические теги — рекомендуемые теги для сайтов как передовая практика SEO, представленная несколько лет назад, которая помогает Google и другим поисковым системам лучше понять, какие страницы содержат исходный контент.Этот простой элемент кода помогает повысить авторитетность контента и релевантность входящих ссылок для канонической страницы и обеспечивает более сильные сигналы ранжирования вашего контента. Реализовать мета-канонический тег очень просто: фрагмент кода следует поместить в раздел
. канонической страницы, а также на страницах с дублированным контентом на сайте (если у вас есть дубликаты — в первую очередь вам следует избегать дублирования контента).SEO-дружественные системы управления корпоративным контентом, такие как Adobe Experience Manager, позволяют легко реализовать метаканонические теги на всех страницах, развернутых с помощью CMS. Однако бывают случаи, когда небольшие веб-ресурсы не размещаются в CMS. В таких случаях нам необходимо проверить и обеспечить правильную реализацию метаканонических тегов.
Пример использования: измерение воздействия правильно настроенных метаканонических тегов. Давайте рассмотрим случай, когда небольшой веб-сайт изначально запускался с неправильно реализованными метаканоническими тегами.Определив возможность улучшения и внедрив правильные теги, мы измерили влияние корректировки, изучив данные о показах и кликах, посещениях SEO и рейтинге канонических URL-адресов в Google.
Измерение видимости канонических URL-адресов и кликов Мы можем легко измерить влияние на количество показов (имея в виду, сколько раз канонические URL-адреса присутствовали в результатах поиска) и кликов (когда пользователи нажимали на эти URL-адреса), просмотрев в отчете «Поисковый запрос» в Инструментах Google для веб-мастеров.
Влияние на рейтинг SEO Платформа BrightEdge SEO предоставляет отчеты, которые позволяют нам легко определять влияние реализации метаканонических тегов на ранжирование правильных канонических URL-адресов в поисковой выдаче. Детализированная отчетность, предоставляемая BrightEdge, позволяет нам отслеживать повышение рейтинга небрендовых, а также брендированных ключевых слов.
Несмотря на то, что готовая диаграмма отчета о запросах Google ясно показывает улучшение количества показов, нам необходимо экспортировать данные на лист и построить график показов и ряды данных о кликах на первичной и вторичной осях, чтобы лучше увидеть влияние на клики.Краткое замечание о падении в течение 4 и 5 недель после внедрения — было связано с сезонностью.
Измерение посещений при поисковой оптимизации Данные с платформы Adobe Analytics также подтверждают улучшение посещаемости при поисковой оптимизации (опять же, обратите внимание на спад — это связано с сезонностью).
Заключительные мысли В целом, этот эксперимент, проверяющий влияние метаканонических объявлений, показал значительное положительное влияние на: 1) показы, 2) количество ранжированных ключевых слов, 3) рейтинг ключевых слов и 4) посетителей.Менеджеры по SEO должны сосредоточиться на обсуждаемых здесь метаканонических тегах, чтобы улучшить SEO.
полное справочное руководство по их использованию
Коротко о каноническом URL
Элемент ссылки rel = "canonical" , часто называемый каноническим URL-адресом, является мощным инструментом для борьбы с проблемами дублирования контента, когда существует несколько вариантов (более или менее) одной и той же страницы.
По сути, он позволяет вам указать, какой вариант страницы является каноническим: вариант, который вы хотите, чтобы отображались в поисковых системах.
При реализации канонических URL-адресов помните о следующих передовых методах:
- Используйте абсолютные URL-адреса, включая домен и протокол.
- Определите только один канонический URL на странице.
- Определите канонический URL-адрес в разделе
- Укажите на индексируемую страницу.
Что такое канонический URL?
Элемент ссылки rel = "canonical" , часто называемый каноническим URL-адресом, представляет собой элемент HTML, который помогает предотвратить дублирование контента, информируя поисковые системы о предпочтении одного документа над другими идентичными или похожими документами.Когда на странице A есть канонический элемент ссылки, указывающий на страницу B, вы говорите, что страница A была канонизирована как .
Канонизация — это процесс, в котором предпочтительная версия страницы выбирается по сравнению с несколькими другими версиями.
Синонимы к слову канонический URL
Хотя их значение отличается, для обозначения канонического URL часто используются следующие термины: канонический тег, каноническая ссылка, rel canonical или rel = "canonical" .Для простоты, когда мы ссылаемся на канонический элемент HTML, мы назовем его каноническим URL-адресом .
Зачем нужен канонический URL?
С каноническим URL-адресом вы можете предотвратить дублирование контента как внутри, так и за пределами. Внутренний дублированный контент происходит в пределах вашего веб-сайта . Внешний дублированный контент возникает, когда существуют повторяющиеся или очень похожие страницы на разных доменах .
Канонические URL-адреса предотвращают проблемы с дублированием контента
Канонический URL сообщает Google, Bing и Yahoo, какие страницы показывать и какие страницы скрывать на страницах результатов поисковой системы.Хотя поисковые системы могут игнорировать канонический URL-адрес, это дает вам как владельцу веб-сайта больше контроля над его присутствием в Интернете.
Как выглядит канонический URL?
Ваши посетители не увидят канонический URL-адрес при посещении вашего веб-сайта. Канонический URL-адрес может быть определен в источнике страницы или в заголовке HTTP.
Источник страницы
Канонический URL-адрес должен находиться в разделе источника страницы.Для нашей домашней страницы канонический URL-адрес выглядит следующим образом:
Заголовок HTTP
Определение канонического URL-адреса в заголовке HTTP часто используется, когда вам нужно установить канонический URL-адрес для документа, отличного от HTML, например PDF.
В заголовке HTTP это выглядит следующим образом:
HTTP / 1.1 200 ОК
Сервер: nginx
Дата: Чт, 28 апреля 2016 г., 11:54:25 GMT
Тип содержимого: приложение / pdf
Длина содержимого: 23629
Последнее изменение: пт, 29 апр 2016, 17:47:17 GMT
Ссылка: ; rel = "canonical" Возможный сценарий, в котором вам нужно будет использовать заголовок HTTP для определения канонического URL-адреса для документа, отличного от HTML, — это когда контент предлагается как в виде обычной страницы (документ HTML), так и в виде PDF-файла. (документ не в формате HTML).
Обратите внимание: в настоящее время только Google (открывается в новой вкладке) поддерживает определение канонического URL-адреса с помощью заголовка HTTP. Для изображений Google не поддерживает (открывается в новой вкладке) канонические изображения, определенные через заголовок HTTP.
Предотвращение проблем с каноническими URL-адресами
Не позволяйте ошибкам, связанным с каноническими URL, отрицательно влиять на эффективность SEO. Контролируйте свой сайт с ContentKing и получайте оповещения в режиме реального времени.
Когда использовать канонический URL?
Нет никакого мыслимого сценария, в котором было бы плохой идеей включать канонический URL. Google, Bing и Yahoo в значительной степени полагаются на канонический URL-адрес, чтобы понять, какие страницы показывать, а какие скрывать на страницах результатов поисковой системы. Канонический URL-адрес может ссылаться на себя или на другую страницу.
Канонический URL, ссылающийся на себя
Если есть только одна версия страницы, убедитесь, что канонический URL ссылается на себя.
Это в основном говорит поисковым системам: «Я единственная версия этой страницы, и только я должен быть проиндексирован».
Канонический URL-адрес, указывающий на другую страницу
Если существует несколько версий страницы, убедитесь, что канонический URL ссылается на страницу, которую вы предпочитаете индексировать поисковыми системами.
Распространенные случаи, когда канонические URL-адреса устраняют проблемы с дублированным контентом:
- Когда в URL используются параметры запроса.
- Когда страницы немного отличаются, обычно их называют почти дубликатами.
- Когда намеренно создано несколько версий страницы.
Параметры запроса в URL
В зависимости от структуры URL-адреса веб-сайта URL-адреса иногда содержат параметры запроса. Параметры запроса в URL используются для запроса определенного контента.
Возьмем к примеру:
www.example.com/shoes/nike?lang=uk&id=101
- Переменная
lang = ukуказывает, что язык запрошенной страницы — английский (Великобритания). - Переменная
id = 101указывает, что должна быть запрошена страница с номером 101. - Между переменными есть символы
и, которые указывают, что вам нужна английская (Великобритания) версия страницы 101.
Хотя параметры запроса удобны, URL-адреса, содержащие параметры запроса, трудны для чтения и легко создать дублированный контент. URL www.example.com/shoes/nike?id=101&lang=uk запрашивает ту же страницу, что и www.example.com/shoes/nike?lang=uk&id=101 , но страницы имеют другой URL. Такую форму дублирования контента можно легко исправить с помощью канонического URL.
Немного разные страницы (почти дубликаты)
Когда страницы немного отличаются, мы часто называем их «почти дублирующимися страницами» или «почти дубликатами». Хорошим примером почти повторяющихся страниц являются сайты электронной коммерции, где продается обувь. Представьте, что у вас есть обувь Nike Air Max 38 размера, которая доступна в красном, синем и черном цветах.При выборе другого цвета URL-адрес изменяется, но 99% содержимого страницы остается прежним.
- Общие Nike Air Max размер 38:
www.example.com/shoes/nike/men-38/ - General Nike Air Max 38, красный цвет:
www.example.com/shoes/nike/men-38-red/ - General Nike Air Max 38 размер синего цвета:
www.example.com/shoes/nike/men-38-blue/ - General Nike Air Max 38 размер, черный:
www.example.com/shoes/nike/men-38-black/
Поскольку содержание этих четырех страниц очень похоже, имеет смысл использовать канонический URL с www.example.com/shoes/nike/men-38-red/ , www.example.com/shoes/nike/men-38-blue/ и www.example.com/shoes/nike/men-38- черный / указывает на www.example.com/shoes/nike/men-38/ .
Намеренно создано несколько версий страницы
Может быть много причин для преднамеренного создания нескольких версий страницы. Приведу два примера:
- Персонализированные лендинги для кампаний
- Запуск тестов оптимизации коэффициента конверсии, в которых вы тестируете три версии одной и той же страницы, которые по сути имеют одинаковое содержание.
Если существует несколько версий страницы, не забудьте указать канонический URL-адрес на предпочтительную версию, которую вы хотите проиндексировать. Когда канонический URL-адрес ссылается на другой URL-адрес, поисковым системам сообщается:
«Есть несколько версий моей страницы, которые либо идентичны, либо очень похожи. Чтобы убедиться, что ваш индекс аккуратный и чистый, обязательно проиндексируйте страницу, на которую я ссылаюсь»
Полезные ресурсы
Рекомендации по использованию целевой страницы (открывается в новой вкладке)
Отдельные настольные и мобильные страницы
Если у вас есть отдельные страницы для компьютеров и мобильных устройств, вы должны использовать канонический URL-адрес и альтернативный URL-адрес, чтобы сообщить поисковым системам связь между этими страницами.
На данный момент Google — единственная поисковая система, которая поддерживает эту конкретную реализацию.
Поговорим о реализации:
Используйте атрибут mobile для передачи мобильной версии страницы.
Настольный
В настольной версии страницы канонический URL и альтернативный URL в разделе выглядят следующим образом:
Мобильный
На мобильной версии страницы канонический URL в разделе выглядит следующим образом:
Таким образом поисковые системы показывают мобильную версию страницы для мобильных устройств и версию страницы для настольных компьютеров.
Междоменный канонический
Канонический URL-адрес может использоваться для предотвращения дублирования контента в случаях, когда проблемы с дублированным контентом выходят за рамки одного веб-сайта.Когда контент публикуется на нескольких страницах, на нескольких доменах можно использовать междоменный канонический URL-адрес, чтобы сигнализировать поисковым системам, какую версию страницы следует проиндексировать.
Объединение ненужных страниц с редиректами
Если нет необходимости в существовании нескольких версий страницы, лучше всего перенаправить избыточные страницы на предпочтительную версию. Примеры, в которых переадресация — лучший способ справиться с несколькими версиями страниц:
- Страница доступна по протоколам HTTP и HTTPS.
- Страница доступна через несколько доменов (
www.example1.com,www.example2.com,www.example3.com) или субдоменов (www.example.com,www2.example.com,www3.example.com), и это не служит цели.
Обратите внимание, что если вы используете перенаправления в приведенных выше примерах, рекомендуется по-прежнему также использовать канонический URL. Если ваши перенаправления перестают работать, у вас все еще есть канонический URL-адрес, чтобы предотвратить проблемы с индексированием.
Правильно ли настроены ваши канонические URL-адреса?
Узнавайте, отправляете ли вы смешанные сигналы индексации, и будьте предупреждены о проблемах с каноническими URL-адресами в режиме реального времени с ContentKing.
Каковы лучшие практики в отношении канонических URL-адресов?
Канонический URL — это очень мощный инструмент в наборе инструментов веб-мастера. При работе с каноническими URL-адресами жизненно важно придерживаться приведенных ниже рекомендаций, чтобы предотвратить проблемы с индексированием:
- Используйте абсолютные URL-адреса — не может быть никаких сомнений относительно страницы, которую должна проиндексировать поисковая система.Используйте полный URL-адрес, включая протокол (HTTP или HTTPS), субдомен и домен.
- Один канонический URL на странице — всегда должен быть только один канонический URL на странице.
- Размещение в
- Укажите на индексируемую страницу. — канонический URL-адрес должен указывать на индексируемую страницу.
- Включите только предпочтительную версию страницы в карту сайта XML .
Использовать абсолютные URL-адреса
Мы должны использовать только абсолютные URL-адреса в качестве канонических URL-адресов. Возьмем, например:
Если этот URL-адрес является каноническим, то точное местоположение URL-адреса не вызывает сомнений. .
Теперь сравните канонический URL-адрес выше с неоднозначным URL-адресом ниже:
Некоторые веб-серверы по умолчанию настроены неправильно, что делает каждую страницу вашего веб-сайта доступной через все домены и поддомены.Это вызывает огромное количество дублированного контента, которого вы всегда должны избегать.
Использование абсолютных URL-адресов в качестве канонических URL-адресов предотвращает возникновение подобных проблем с дублированием содержимого.
Один канонический URL на странице
Всегда должен быть только один канонический URL на странице. Если определено более одного канонического URL, поисковые системы могут запутаться. Google заявил (открывается в новой вкладке), что они просто выберут один из канонических URL-адресов и проигнорируют другие, когда они встретят несколько канонических URL-адресов на одной странице.Хотя мы не уверены, как Bing и Yahoo обрабатывают несколько канонических URL-адресов на странице, они рекомендуют использовать только один канонический URL-адрес на странице.
Размещение в
— раздел Канонический URL-адрес всегда следует размещать в разделе вашей страницы. Если канонический URL-адрес не помещен в раздел , поисковые системы не смогут его найти и обработать. В свою очередь, это может привести к возникновению проблем с дублированием контента.
Ссылка на индексируемую страницу
Канонический URL-адрес всегда должен указывать на индексируемую страницу. Поисковые системы могут запутаться, когда канонический URL-адрес ссылается на страницу, которая перенаправлена 301 или сама канонизирована.
Включить только предпочтительную версию в карту сайта XML
Все страницы, включенные в вашу карту сайта XML, должны индексироваться поисковыми системами. Поэтому важно, чтобы в случае, если у вас есть несколько версий страницы, вы включали только предпочтительную версию страницы в свою карту сайта XML.
Управляйте каноническими URL-адресами
Найдите проблемы с каноническими URL-адресами и найдите URL-адреса, которые необходимо канонизировать!
Каковы ограничения канонического URL?
Хотя канонические URL-адреса являются отличным инструментом в наборе инструментов веб-мастеров, они также имеют свои ограничения.
Консолидация ссылочного авторитета только частично
Давайте рассмотрим пример: на странице A есть действительно мощные обратные ссылки. Страница A ссылается на страницу B как на каноническую.Поисковые системы, скорее всего, проиндексируют страницу B и оставят страницу A вне своего индекса.
Каждая ссылка передает некоторые полномочия, называемые полномочиями связи. Авторитет ссылки, который передается на страницу A через мощные обратные ссылки, равен , только частично, передается на страницу B. Мы говорим, что только частично, , потому что это серая область, о которой поисковые системы не очень ясно. Нет исследований, показывающих, что канонический URL-адрес передает все полномочия ссылки. Вдобавок к этому был введен канонический URL-адрес, чтобы сообщать поисковым системам, какие страницы отображать и какие страницы скрывать.Поэтому наша позиция по этой теме такова: канонический URL-адрес не полностью передает авторитет ссылки.
Мэтт Каттс из Google сказал, что «на самом деле нет большой разницы между ними [301 редирект и канонический URL]».
Если вы хотите передать как можно больше ссылок, мы советуем вам использовать 301 редирект.
Канонические URL-адреса не предотвращают проблем с оптимизацией сканирования
канонических URL-адресов предназначены для устранения проблем с дублированием содержимого. Канонический URL-адрес сообщает поисковым системам, какие страницы нужно индексировать, но не сообщает поисковым системам, какие страницы сканировать .Это важное различие.
Когда поисковые системы не тратят свое время на сканирование полезных и важных страниц, мы говорим о проблемах оптимизации сканирования. Существует множество причин, по которым поисковые системы не сканируют полезные и важные страницы. Поисковые системы могут попасть в бесконечные циклы переадресации, тратить много времени на сканирование страниц, которые вы не хотите индексировать в первую очередь, или продолжать попадать в тупики на вашем веб-сайте (страницы без ссылок на другие страницы).Это бесполезная трата, особенно с учетом того, что поисковые системы имеют так называемый «краулинговый бюджет» (время, отведенное на сканирование сайта) для каждого сайта. Robots.txt можно использовать для предотвращения проблем с оптимизацией сканирования.
Часто задаваемые вопросы о каноническом URL
- Передают ли канонические URL-адреса какой-либо авторитет ссылки?
- Могу ли я заставить поисковые системы использовать мой канонический URL?
- Канонический URL лучше, чем 301 редирект?
- Могу ли я испортить свой веб-сайт каноническими URL-адресами?
- Все ли поисковые системы поддерживают канонический URL?
- Как поисковые системы обрабатывают несколько канонических URL-адресов на одной странице?
- Предотвращает ли сканирование страниц канонический URL?
- Следует ли использовать канонические URL-адреса для страниц с разбивкой на страницы?
1.🖇️ Передают ли канонические URL-адреса какие-либо ссылки?
Мы подозреваем, что при канонизации URL передается некоторый авторитет ссылки.
Как написано в разделе «Консолидация авторитета ссылки только частично», мы не можем с уверенностью сказать, передает ли канонический URL авторитет ссылки. Что мы действительно знаем, так это то, что канонический URL-адрес не предназначен для передачи полномочий ссылки, это то, для чего нужны редиректы 301.
2. ⚙️ Могу ли я заставить поисковые системы использовать мой канонический URL?
Нет, канонический URL — это совет, а не директива для поисковых систем.
3. ➡️ Канонический URL лучше, чем 301 редирект?
Канонический URL и 301 редирект — это два совершенно разных способа достижения цели.
Канонический URL-адрес используется, когда все версии страницы должны быть доступны для посетителей, но только одна из них должна индексироваться поисковыми системами.
Перенаправление 301 перенаправляет посетителей и поисковые системы с одного URL на другой. Перенаправленный URL-адрес недоступен для посетителей или поисковых систем.
4.⚠️ Могу ли я испортить свой сайт каноническими URL-адресами?
При неправильном использовании канонические URL-адреса могут вызвать серьезные проблемы при индексировании вашего веб-сайта.
Например, представьте, что по какой-то причине все ваши страницы имеют канонические значения для домашней страницы. Поскольку канонический URL-адрес является сильным сигналом для поисковых систем, они, скорее всего, обработают его и деиндексируют канонические страницы.
Несмотря на то, что вы должны быть осторожны с каноническими URL-адресами, мы настоятельно рекомендуем вам использовать их, чтобы сообщить поисковым системам, какие страницы индексировать и какие страницы скрывать.
5. 🤔 Все ли поисковые системы поддерживают канонический URL?
Мы знаем, что Google, Bing и Yahoo поддерживают канонический URL.
Яндекс и Baidu, похоже, также поддерживают канонический URL. Для DuckDuckGo непонятно.
6. 🙌 Как поисковые системы обрабатывают несколько канонических URL-адресов на одной странице?
Google заявил, что они будут полностью игнорировать элементы канонических URL-адресов, если на одной странице есть несколько канонических URL-адресов.
Непонятно, как другие поисковые системы справляются с этим, хотя мы настоятельно рекомендуем использовать только один канонический URL на странице.
7. 🛑 Предотвращает ли сканирование страниц канонический URL?
Нет, это не так. Поисковые системы по-прежнему будут сканировать ваши страницы, независимо от того, установлен ли канонический URL-адрес, указывающий на другой URL-адрес. Канонический URL-адрес — это просто сильный сигнал для поисковых систем относительно предпочтительной страницы, которая должна отображаться на страницах результатов поисковой системы. Также см. Канонические URL-адреса не предотвращают проблем с оптимизацией сканирования.
8. 🗒️ Следует ли использовать канонические URL-адреса для страниц с разбивкой на страницы?
Обычно рекомендуется не использовать канонический URL-адрес для страниц с разбивкой на страницы, поскольку страницы с разбивкой на страницы часто не показывают одинаковое содержимое.Вместо этого рекомендуется использовать элементы ссылки rel = "next" и rel = "prev" . Это лучший способ объяснить поисковым системам, что страницы с разбивкой на страницы на самом деле представляют собой серию страниц, которые следуют логической последовательности.
Вы, , можете использовать канонический URL-адрес для страницы с разбивкой на страницы, но только если у вас есть страница «Просмотреть все», которая загружается быстро. В этом случае вы ссылаетесь на страницу «Просмотреть все» на всех страницах с разбивкой на страницы как канонический URL-адрес. Подробные инструкции см. В документации Google по разбивке на страницы (открывается в новой вкладке).
Часто задаваемые вопросы
Введение в канонический тег для новичков
Отслеживаете ли вы позиции своего ключевого слова в рейтинге?
Попробуйте unamo seo бесплатно
ПОДПИСАТЬСЯ
Канонический тег поддерживается основными поисковыми системами с начала 2009 года, но, несмотря на преимущества, которые он предлагает как операторам сайтов, так и пользователям, многие операторы сайтов еще не реализовали его. Такое нежелание часто можно объяснить отсутствием знаний о теге, его назначении и реализации.
В этой статье мы рассмотрим все три, а также несколько типичных ошибок, допущенных при реализации тега.
Что такое канонический тег?
Канонический тег предназначен для дублирования содержимого и предпочтительного содержимого. Довольно необычное слово, но этимологически уместное. Он происходит от канона , который первоначально относился к библейским или светским правилам и законам, стандарту для суждения. Позднее он использовался для обозначения произведений писателя, признанных аутентичными.
Это последнее значение относится к Интернету, поисковой оптимизации и поисковым системам; помощь поисковым системам в определении исходной страницы по отношению к дублированному контенту.
Существует множество законных причин для дублирования контента, особенно когда речь идет о URL-адресах, сгенерированных системой. К ним относятся:
- Несколько URL-адресов — особенно на сайтах электронной коммерции, где URL-адреса создаются с помощью параметров фильтрации по цене, цвету, рейтингу и т. Д.
- URL-адреса идентификатора сеанса — автоматически генерируются вашей системой.То же самое относится к URL-адресам отслеживания, ссылкам на хлебные крошки, версиям для печати и постоянным ссылкам в определенных CMS.
- HTTP, HTTPS и WWW — поисковые системы видят http://www.mydomain.com, http://mydomain.com и https://www.mydomain.com как отдельные страницы и будут сканировать (и, возможно, индексировать ) их как таковые.
- Case — пользователи и большинство браузеров одинаково воспринимают верхний и нижний регистр, причем оба они в значительной степени взаимозаменяемы. То же самое не всегда верно для поисковых систем, поэтому, если ваш веб-сайт смешивает регистр в именах файлов и структуре папок, вам необходимо использовать канонический тег.
- URL-адрес для мобильных устройств — при использовании специального URL-адреса (обычно m.mydomain.com) для мобильной версии вашего веб-сайта.
- URL страны — при использовании нескольких URL-адресов для конкретной страны содержимое в основном остается тем же, с небольшими отличиями. Это не применяется, если язык другой, и в этом случае вы хотите, чтобы поисковые системы возвращали отдельные результаты.
В большинстве случаев контент фактически не дублируется; это несколько URL-адресов, обслуживающих один и тот же контент.Истинное дублирование — это когда фактический контент появляется на нескольких уникальных URL-адресах (www.mydomain.com по сравнению с www.someotherdomain.co), часто в результате синдикации контента.
Канонический тег должен использоваться во всех этих случаях, чтобы сообщить поисковым системам, какой из них является исходным контентом, а также какой URL следует сканировать, индексировать и возвращать в поисковой выдаче.
Использование канонического тега не является обязательным, и Мэтт Каттс ранее заявлял, что дублирующийся контент редко приводит к штрафу, если только он не является спамом или не используется для манипулирования рейтингом.Google в основном игнорирует дублированный контент, чтобы не загромождать поисковую выдачу одними и теми же результатами с разных URL-адресов, и если он не дает штраф , вы можете понести более низкий общий рейтинг для всего дублированного контента.
Как правильно использовать канонический тег
Первое, что нужно сделать при использовании канонического тега, — это решить, какой URL-адрес является предпочтительным, а затем добавить следующую пометку в раздел предпочтительного URL-адреса и всех его вариантов:
ПРИМЕЧАНИЕ: допустимы как относительные, так и абсолютные пути.
Хорошая новость заключается в том, что большинство CMS имеют это встроенное или, по крайней мере, имеют плагины, которые автоматизируют большую часть процесса. Если вы не используете CMS, Google (и другие поисковые системы) упростили управление определенными процессами, в том числе:
Если ваш сайт обслуживает один и тот же контент как на http , так и на https , и независимо от того, включен ли www или нет, вы можете рассмотреть возможность установки предпочтительного домена с помощью Инструментов для веб-мастеров или 301 редиректа.
Распространенные ошибки при реализации канонического тега
Установка домашней страницы в качестве предпочтительного URL-адреса
Бывают случаи, когда ваша домашняя страница будет предпочтительным URL-адресом, но не во многих случаях. Если все ваши канонические страницы указывают на вашу домашнюю страницу, вы рискуете, что ни одна из ваших страниц, кроме вашего индекса, не будет просканирована и проиндексирована поисковыми системами.
Использование нескольких канонических ссылок
Каждая страница должна иметь только одну каноническую ссылку, указанную в, в противном случае они будут игнорировать все .Это может произойти без вашего ведома из-за неправильной реализации плагина SEO или неправильно отредактированной темы / шаблона.
Размещение rel = canonical в
Как и в случае с несколькими каноническими ссылками, если ваша каноническая ссылка появляется где угодно, но не имеет значения, она просто игнорируется. В идеале он должен появиться в вашем разделе как можно раньше, чтобы избежать проблем с синтаксическим анализом.
Использование канонических ссылок в результатах с разбивкой на страницы
SEO может немного усложниться, когда дело доходит до разделения контента на несколько страниц, хотя иногда это необходимо.
При этом рекомендуется использовать теги rel = prev и rel = next вместо rel = canonical , чтобы обеспечить индексацию каждой страницы. В качестве альтернативы, если вы также консолидировали контент на одной странице «Просмотреть все», вы можете вместо этого добавить rel = canonical на эту страницу.
Использование канонических ссылок в избранных статьях
Если ваш сайт содержит регулярно обновляемую «избранную статью» или «избранный продукт», вам следует избегать использования тега rel = canonical специально на этой странице.Невыполнение этого или неправильная реализация может привести к тому, что эта страница будет проигнорирована и не будет отображаться в результатах поиска.
Использование канонических ссылок вместо перенаправления 301
Хотя на первый взгляд функциональность канонической ссылки во многом схожа с функциональностью редиректа 301, с точки зрения показателей это не так. Хотя оба они говорят поисковым системам обрабатывать несколько страниц (или URL-адресов) как одну страницу, 301 перенаправляет весь трафик на определенный URL-адрес, а канонический тег — нет.
Если структура вашего сайта изменилась, то предпочтительным вариантом является переадресация 301, так как она также исправит закладок. Если на вашем сайте дублированный контент, но вам необходимо измерить трафик до каждого URL-адреса , используйте каноническую ссылку в интересах поисковых систем.
Заключение
Несмотря на то, что штраф за дублированный контент маловероятен, поисковые системы, индексирующие весь ваш дублированный контент, влияют на релевантность их результатов, а также могут повлиять на ранжирование ваших страниц; в конечном итоге влияя на посещаемость вашего сайта и доход.Однако канонические теги — это не волшебная палочка, которая автоматически улучшит видимость ваших сайтов, во всяком случае, их неправильная реализация может повлиять на ваш общий рейтинг.
Если вы еще не внедрили канонические теги на свой сайт, вы должны сначала тщательно рассмотреть фактическую потребность (есть ли у вас дублированный контент или несколько URL-адресов, указывающих на один и тот же контент?), Прежде чем составлять стратегию реализации, и на каких страницах. Если вы уже ввели канонические теги, может быть полезно пересмотреть реализацию, чтобы убедиться, что все сделано правильно, и что вы не скрываете какие-либо страницы, которые следует проиндексировать.
Измерьте свои усилия по поисковой оптимизации и улучшите свой бизнес прямо сейчас!
Попробуйте unamo seo бесплатно
регистрация
Какие они и почему они важны? — Front End Development (2021)
SEO важен для каждого веб-сайта, и интернет-магазин не исключение. Канонические URL-адреса играют решающую роль в обеспечении того, чтобы веб-сайт вашего клиента не подвергался наказанию со стороны поисковых систем, а поисковая оптимизация была сильной. Они следят за тем, чтобы поисковые системы не запутались, когда разные URL-адреса указывают на одно и то же содержание или веб-страницу, и могут помочь сообщить, какие URL-адреса имеют идентичное или очень похожее содержание.
Если вы уже знакомы с каноническими URL-адресами или никогда раньше не видели термин rel = "canonical" , эта статья раскрывает детали, которые вам необходимо знать, чтобы интернет-магазин вашего клиента стал полностью поисковая система оптимизирована. Давайте нырнем.
Развивайте свой бизнес с помощью партнерской программы Shopify
Предлагаете ли вы услуги веб-дизайна и разработки или хотите создавать приложения для Shopify App Store, партнерская программа Shopify поможет вам добиться успеха.Присоединяйтесь бесплатно и получите доступ к возможностям распределения доходов, средам предварительной версии для разработчиков и образовательным ресурсам.
ПодписатьсяТак что же такое канонический URL?
Канонический URL — это элемент ссылки HTML с атрибутом rel = "canonical" (также известный как канонический тег), находящийся в элементе веб-страницы вашего клиента. Он указывает поисковым системам их предпочтительный URL. Это означает, что элемент канонического URL сообщает Google и другим поисковым системам о необходимости сканирования веб-сайта и о том, по какому URL следует индексировать содержание этой конкретной страницы.Это важно, потому что URL-адреса могут иметь вариации, основанные на множестве факторов, но отображать одинаковый или похожий контент. Спецификация была запущена в апреле 2012 года и была описана в RFC 6596.
«Это означает, что канонический элемент URL сообщает Google и другим поисковым системам о необходимости сканирования веб-сайта и о том, по какому URL следует проиндексировать содержание этой конкретной страницы».
Возьмем, к примеру, следующие URL:
fancytshirts.com www.fancytshirts.com
https: // m.fancytshirts.com
https://amp.fancytshirts.com
https://fancytshirts.com?ref=twitter
Каждый URL-адрес относится к одному и тому же содержимому домашней страницы моего модного веб-сайта с футболками, однако сами URL-адреса немного отличаются. Это может быть проблемой для поисковых систем, поскольку сама система не обязательно знает, какая страница должна быть источником правды, и может просто выбрать канонический URL-адрес алгоритмически за вас.
Другими словами, если у вас есть веб-страница, доступная по нескольким URL-адресам, или разные страницы с похожим содержанием (т.е. отдельные версии для мобильных и настольных компьютеров), вы должны указать поисковой системе, какой URL-адрес является официальным (каноническим) для этой страницы.
Почему канонические URL имеют значение?
1. Они помогают указать, какой URL-адрес вы хотите, чтобы люди видели в результатах поиска.
Вы могли бы предпочесть, чтобы люди переходили на вашу страницу с информацией о синих футболках через:
https://www.fancytshirts.com/tshirts/blue/bluetshirt.html
Вместо:
https: // fancytshirts.ru / футболки / спортивная одежда? gclid = ABCD
Использование канонических символов может помочь вам сохранить «чистоту».
2. Они упрощают отслеживание показателей для одного продукта / темы.
Когда существует множество URL-адресов, становится труднее получить консолидированные метрики для определенного фрагмента контента. Канонические URL-адреса помогают упростить работу и упорядочить ее, особенно когда дело доходит до отчетов о производительности вашему клиенту.
3. Они объединяют сигналы ссылок для похожих или повторяющихся страниц и управляют синдицированным контентом.
канонических URL-адресов помогают поисковым системам объединять информацию, имеющуюся у них для отдельных URL-адресов (например, ссылки на них), в единый авторитетный URL-адрес.Кроме того, если вы объединяете свой контент для публикации в других доменах, канонические URL-адреса помогают консолидировать рейтинг страницы с вашим предпочтительным URL-адресом. Другими словами, похожий или повторяющийся контент на веб-сайтах не должен конкурировать за трафик / рейтинг в поисковых системах.
«Если вы распространяете свой контент для публикации в других доменах, канонические URL-адреса помогают консолидировать рейтинг страницы с вашим предпочтительным URL-адресом».
Объект
canonical_url В Shopify объект canonical_url возвращает канонический URL-адрес для текущей страницы.Канонический URL-адрес — это URL-адрес страницы по умолчанию с удаленными параметрами URL-адреса. Его можно вывести так:
{{canonical_url}}
Для продуктов и вариантов Shopify канонический URL-адрес — это страница продукта по умолчанию без выбранной коллекции или варианта.
Например, товар в коллекции с выбранным вариантом может выглядеть примерно так:
https://fancytshirts.com/collections/classics/products/classic-t?variant=17287731270
Вывод canonical_url для этой страницы будет:
https: // fancytshirts.com / products / classic-t
Для конкретных случаев использования вы можете создавать собственные канонические URL-адреса для страниц или сообщений блога с помощью операторов if, основанных на различных шаблонах в вашей теме и с использованием настроек темы. Обычно это требуется только в том случае, если вы выполняете причудливую маскировку URL-адресов.
Вам также может понравиться: Введение в параметры темы.
Рекомендации по поисковой оптимизации и лучшие практики для канонических URL-адресов
Различные способы канонизации нескольких URL-адресов
Сосредоточение внимания на канонических URL-адресах в первую очередь подпадает под категорию SEO на странице, а не вне страницы (хотя вы должны где-то отслеживать свою общую стратегию перенаправления).Помимо использования rel = "canonical" , существует несколько способов канонизировать URL-адреса. В большинстве случаев rel = "canonical" является рекомендуемым способом объединения дублированного контента для поисковых систем, однако есть несколько других способов канонизации, которые следует рассмотреть.
1. Используйте 301 редирект
301 редирект — это код статуса, который сообщает Google или другим поисковым системам, что вы хотите создать постоянное перенаправление с одного URL на другой. Редирект 301 отправляет посетителей и поисковые системы на другой URL-адрес, отличный от того, который они изначально запрашивали в своем браузере или нажимали на странице результатов поиска.Эти перенаправления также связывают различные URL-адреса вместе, так что поисковые системы ранжируют все адреса на основе полномочий домена из входящих ссылок.
Вам также может понравиться: Как совместить SEO и оплачиваемую социальную работу для увеличения трафика и доходов.
2. Используйте пассивные параметры в Google Search Console
В консоли поиска Google вы можете найти возможность установить параметры URL после подтверждения вашего веб-сайта. Это дает вам возможность указать Google, какие параметры вы хотели бы считать пассивными.Это означает, что вы можете сказать Google: «Каждый раз, когда вы видите этот параметр URL, относитесь к нему так, как будто его не существует». Есть отличное руководство о том, как установить пассивные параметры с помощью инструмента параметров URL в Google Search Console.
«Это означает, что вы можете сказать Google:» Каждый раз, когда вы видите этот параметр URL, относитесь к нему так, как будто его не существует «».
3. Используйте хэши местоположения
Также известный как идентификаторы фрагментов, URL-адрес фрагмента — это URL-адрес с # в конце, который указывает конкретный раздел на странице (обычно происходит переход к идентификатору, который соответствует имени идентификатора фрагмента).В URL-адресе может существовать хэш, и Google вместе с другими поисковыми системами будет рассматривать его как единый URL-адрес. Это означает, что перескочивший контент не будет оцениваться по-другому и, следовательно, по-разному индексироваться. По сути, он будет канонизирован по тому же URL.
Вам также могут понравиться: 5 простых отчетов Google Analytics, которые вы должны создать для каждого клиента.
О чем следует помнить или чего избегать
р.Играя с поисковой оптимизацией и канонизацией, важно полностью понимать, как это влияет на поисковый рейтинг.Они могут быть как хорошими, так и плохими, но, чтобы избежать плохих моментов, я собрал несколько вещей, о которых следует помнить при использовании канонических URL.
1. Канонический URL или 301 редирект?
Shopify создает для вас автоматические перенаправления (например, в сообщениях в блогах), когда вы меняете URL-адрес уже опубликованного сообщения на новый URL-адрес. Однако сделать выбор между переадресацией 301 или установкой канонического URL-адреса иногда бывает непросто. По словам эксперта по SEO Йоста де Валка из Yoast: «Если нет технических причин не выполнять перенаправление, вы всегда должны выполнять перенаправление.Если вы не можете выполнить перенаправление, потому что это может нарушить работу пользователя или создать другие проблемы, установите канонический URL ».
Если нет технических причин для отказа от перенаправления, вы всегда должны выполнять перенаправление. Если вы не можете перенаправить, потому что это нарушит взаимодействие с пользователем или создаст другие проблемы, установите канонический URL-адрес.
Joost de Valk, Йоаст
Если вы хотите создать ручную переадресацию для определенных страниц в Shopify, вы можете следовать этому удобному руководству из нашей документации.
2. Не блокируйте сканирование определенных URL-адресов Google
Вы можете использовать robots.txt , чтобы указать Google, какие страницы запрещать, в основном, какие сканировать, а какие нет.
Однако это проблематично, когда дело доходит до дублирования контента. Это связано с тем, что вы, по сути, говорите Google не смотреть на конкретную страницу, поэтому робот Googlebot не сканирует и не индексирует страницу вообще, что означает, что любые сигналы ранжирования, которые могла иметь эта страница (хотя и дублированный контент), могли способствовать исходный источник, если указан канонический URL.Это означает, что вы упускаете сигналы взаимодействия, сигналы контента и все, что могло бы способствовать повышению рейтинга Google.
Следовательно, не запрещайте Google сканировать определенные URL-адреса в случае дублирования контента. Об этом позаботится настройка правильных канонических URL-адресов, и Google будет знать, на какие страницы смотреть.
3. Не удаляйте только неканонические версии 🙅
Кроме того, когда дело доходит до дублированного контента, иногда возникает склонность «очистить» и удалить или удалить старые сообщения, продукты и т. Д.Проблема заключается в том, что иногда этот контент был связан или упоминался в других местах.
Например, кто-то мог сохранить продукт в Pinterest и больше не сможет получить к нему доступ после удаления. Решение здесь — вместо этого перенаправить на новую страницу, продукт и т. Д., Которые должны быть доступны для потенциальных клиентов. Единственный случай, когда рекомендуется полностью удалять страницы без переадресации, — это если они были созданы по ошибке, были очень новыми или вообще не имели трафика.
На случай, если вы случайно удалили старый контент, убедитесь, что вы настроили свой клиент со страницей с ошибкой 404, которая улучшает взаимодействие с пользователем (UX), а не портит его. Некоторые из лучших страниц 404 запоминаются, потому что в них хорошо сочетается юмор и сильный UX.
канонических URL для всех!
SEO важен для каждого веб-сайта, и использование канонических URL-адресов может помочь лучше информировать поисковые системы о том, какие URL-адреса имеют идентичный или очень похожий контент.