
Что такое машинное обучение? | Oracle СНГ
Определение машинного обучения
Машинное обучение (ML) — это направление искусственного интеллекта (ИИ), сосредоточенное на создании систем, которые обучаются и развиваются на основе получаемых ими данных. Искусственный интеллект — это широкий термин, который включает в себя компьютерные системы, имитирующие человеческий интеллект. Машинное обучение и ИИ часто идут бок о бок, и термины иногда используются взаимозаменяемо, но, строго говоря, это не одно и то же. Разница состоит в том, что машинное обучение всегда подразумевает использование ИИ, однако ИИ не всегда подразумевает машинное обучение.
Сегодня компьютеры работают бок о бок с человеком. Каждый раз, когда мы пользуемся банковскими услугами, делаем покупки в Интернете или общаемся в соцсетях, алгоритмы машинного обучения помогают сделать это взаимодействие удобнее, эффективнее и безопаснее. Машинное обучение и связанные с ним технологии быстро развиваются: их сегодняшние возможности только вершина айсберга.
Узнайте больше о решении машинного обучения
Типы машинного обучения: два подхода к обучению
В основе машинного обучения лежат алгоритмы. Сегодня используются два основных типа алгоритмов машинного обучения: контролируемое обучение и самостоятельное обучение. Разница заключается в способе изучения данных для последующего прогнозирования.
| Машинное обучение под контролем | Обучение под контролем используется чаще всего. В этом случае исследователь данных выступает в качестве наставника, демонстрируя, какие результаты должен получить алгоритм. Как ребенок учится различать фрукты, запоминая рисунки в книге, так алгоритм практикуется на специальным образом маркированных наборах данных с преопределенными результатами. Для этого типа обучения используются такие алгоритмы, как линейная и логистическая регрессия, мультиклассовая классификация и метод опорных векторов. |
| Самостоятельное машинное обучение | Самостоятельное обучение подразумевает большую независимость: компьютер учится распознавать сложные процессы и алгоритмы без постоянного контроля со стороны человека. Такой тип обучения подразумевает отсутствие маркировки данных и конкретных предопределенных результатов. Такой тип обучения подразумевает отсутствие маркировки данных и конкретных предопределенных результатов.Если развивать аналогию с ребенком, самостоятельное обучение предполагает, что ребенок сам учится распознавать фрукты, сравнивая цвета и формы, вместо того чтобы запоминать их названия под руководством учителя. Он должен учиться находить сходство между изображениями, упорядочивать их по группам и придумывать обозначения для каждого. Для этого типа обучения используются такие алгоритмы, как кластеризация методом k-средних, анализ основных и независимых компонентов и ассоциативные правила. |
| Выбор подхода | Какой подход лучше всего соответствует Вашим потребностям? Ответ зависит от структуры и объема данных и сценария использования. Машинное обучение уже с успехом применяется в разнообразных отраслях с различными бизнес-целями и сценариями использования, включая:
|

Машинное обучение и разработчики
Приступая к работе с машинным обучением, разработчики будут полагаться на свои знания в области статистики, теории вероятностей и математического анализа, чтобы успешно создавать модели, способные обучаться с течением времени. При наличии у разработчиков необходимых навыков в этих областях не должно быть проблем с изучением инструментов, используемых многими другими разработчиками для обучения современных алгоритмов ML. Разработчики также могут принимать решения о том, будут их алгоритмы контролируемыми или нет. Разработчик может принимать решения и заранее настраивать модель в проекте, а затем разрешать модели учиться без участия разработчиков.
Часто трудно провести границу между разработчиком и исследователем данных. Иногда разработчики синтезируют данные из модели машинного обучения, а исследователи данных участвуют в разработке решений для конечного пользователя. Сотрудничество между этими двумя дисциплинами может повышать ценность и полезность проектов машинного обучения.
Бизнес-цель машинного обучения — моделирование жизненного цикла заказчика
Моделирование значения цикла обслуживания заказчика очень важно не только для компаний, занимающихся продажами через Интернет, но и организаций из других отраслей. В этом сценарии применения машинное обучение используется для определения, изучения и удержания наиболее ценных заказчиков. Модели оценки дают возможность проанализировать большие объемы данных о потребителях и определить заказчиков, приносящих наибольший доход, являющихся наиболее активными поклонниками бренда и сочетающих в себе эти две характеристики.
Модели значения цикла обслуживания заказчика особенно эффективны для прогнозирования будущей прибыли, которую отдельный заказчик принесет за определенный период в будущем. Эти сведения помогают концентрировать маркетинговые усилия на потребителях, приносящих наибольшую выгоду, поощряя их чаще взаимодействовать с брендом. Модели значения цикла обслуживания заказчика также повышают эффективность таргетирования, а значит, привлечения новых ценных заказчиков.
Моделирование оттока заказчиков с помощью машинного обучения
Привлечение новых заказчиков требует больших финансовых и временных затрат, чем поддержание уровня удовлетворенности и лояльности уже существующих. Моделирование помогает определить заказчиков, которые могут уйти, и причины их ухода.
Эффективная модель использует алгоритмы машинного обучения, чтобы оценить и ранжировать все факторы: от показателей риска для отдельных заказчиков до причин оттока. Полученные результаты играют важную роль при разработке стратегии удержания.
Углубленный анализ причин оттока заказчиков полезен при разработке систем скидок, кампаний по электронной почте и других маркетинговых мероприятий по удержанию ценных заказчиков.
Сегодня потребители имеют доступ к беспрецедентно широкому ассортименту товаров и услуг, а специальные средства дают возможность мгновенно сравнивать цены. Динамическое ценообразование или, как его еще называют, цена спроса помогает не отставать от рыночных тенденций. Оно дает возможность устанавливать цены на товары в зависимости от уровня интереса со стороны целевой аудитории, спроса на момент совершения покупки и участия покупателя в маркетинговой кампании.
Оно дает возможность устанавливать цены на товары в зависимости от уровня интереса со стороны целевой аудитории, спроса на момент совершения покупки и участия покупателя в маркетинговой кампании.
Такой гибкий подход требует хорошо продуманной стратегии машинного обучения и больших объемов данных о готовности покупателей заплатить установленную цену в зависимости от ситуации. Модели динамического ценообразования не просты в разработке, однако авиакомпании и транспортные службы успешно используют их для повышения прибыли.
Бизнес-цель машинного обучения — целевые заказчики с сегментацией
Секрет успешного маркетинга в том, чтобы предложить покупателю наиболее подходящий продукт в наиболее подходящий момент. Еще недавно маркетологам приходилось полагаться на собственную интуицию при распределении заказчиков по сегментам для таргетированного маркетинга.
Сегодня машинное обучение позволяет исследователям данных использовать алгоритмы кластеризации и классификации, чтобы распределить покупателей на отдельные группы на основе определенных вариаций. по тем или иным характеристикам, таким как демография, поведение на сайте и предпочтения. Сопоставление этих характеристик с алгоритмами поведения помогает разрабатывать точные специализированные маркетинговые кампании, которые более эффективно способствуют повышению продаж по сравнению с кампаниями общей направленности.
по тем или иным характеристикам, таким как демография, поведение на сайте и предпочтения. Сопоставление этих характеристик с алгоритмами поведения помогает разрабатывать точные специализированные маркетинговые кампании, которые более эффективно способствуют повышению продаж по сравнению с кампаниями общей направленности.
По мере накопления данных и усложнения алгоритмов растет эффективность персонализации, что помогает компании с почти абсолютной точностью определить свой идеальный сегмент покупателей.
Бизнес-цель машинного обучения — использовать возможности классификации изображений
Помимо розничной торговли, финансовых услуг и интернет-продаж, машинное обучение может использоваться в самых различных сценариях. Оно весьма эффективно применяется в научной, энергетической и строительной отраслях, а также в здравоохранении. Например, алгоритмы машинного обучения можно использовать в классификации образов для присвоения меток из предопределенного набора категорий образам входящих данных. Это дает возможность создавать трехмерные строительные планы на основе двухмерных чертежей, упрощать присвоение тегов фотографиям в соцсетях, дополнять постановку диагнозов и т. д.
Это дает возможность создавать трехмерные строительные планы на основе двухмерных чертежей, упрощать присвоение тегов фотографиям в соцсетях, дополнять постановку диагнозов и т. д.
Методы глубокого изучения, такие как нейросети, часто используются для классификации образов. Они хорошо определяют наиболее важные характеристики изображения даже при наличии вторичных факторов. Например, нейросети различают ракурс, уровень освещения, масштаб или помехи и могут корректировать характеристики изображения, чтобы обеспечить максимально качественный результат.
Разработка рекомендаций.
Системы рекомендаций играют большую роль в перекрестных и сопутствующих продажах, а также в обеспечении качественного обслуживания.
Netflix оценивает выгоду от своей системы рекомендаций в 1 млрд долларов в год, и эта система по заявлениям Amazon, дает возможность ежегодно увеличивать прибыль на 20–35 %.
Системы рекомендаций используют алгоритмы машинного обучения, чтобы обработать большие объемы данных и определить, понравится ли потребителю тот или иной товар или содержание.
Сценарии использования машинного обучения
Машинное обучение используется в самых разных бизнес-сценариях. Но за счет чего оно обеспечивает конкурентные преимущества? Одной из наиболее ценных возможностей машинного обучения является ускоренное принятие решений и сокращение сроков окупаемости за счет автоматизации. Это становится возможным благодаря повышению прозрачности бизнеса и улучшению качества взаимодействия.
«Обычно вся проблема кроется в отсутствии сотрудничества, — говорит Рич Клейтон (Rich Clayton), вице-президент по стратегии продукции Oracle Analytics. — Добавление машинного обучения в Oracle Analytics Cloud помогает лучше организовать работу, создавая, обучая и внедряя модели данных. Это инструмент для сотрудничества, ценность которого состоит в том, что оно ускоряет процессы и помогает отдельным бизнес-подразделениям работать вместе и создавать более качественные модели».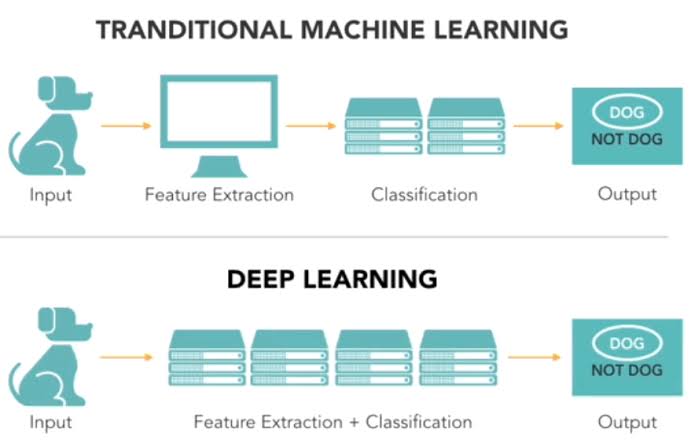
Например, финансовым отделам приходится регулярно выполнять анализ отклонений между прогнозируемыми и фактическими показателями. Эта задача не требует высоких интеллектуальных способностей и может быть поручена ИИ.
«За счет внедрения машинного обучения сотрудники финансового отдела могут работать быстрее и эффективнее, так как компьютер берет на себя рутинные обязанности», — поясняет Клейтон.
Эффективность прогнозирования
Одной из наиболее ценных возможностей машинного обучения является прогнозирование. Раньше решения в бизнесе принимались исходя из результатов за прошлые периоды. Сегодня машинное обучение использует сложные аналитические инструменты для прогнозирования. Вместо того чтобы полагаться на устаревшие данные, компании могут принимать решения в упреждающем формате.
Например, благодаря своевременному ТО производственные, энергетические и другие промышленные компании могут перехватывать инициативу и обеспечивать оптимизацию и надежность рабочих процессов. В нефтяной промышленности машинное обучение может определить, какие из сотен буровых вышек вот-вот выйдут из строя, и заранее уведомить сотрудников ремонтной службы. Такой подход не только способствует повышению производительности, но и продлевает операционные сроки и снижает уровень износа оборудования. Также это помогает снизить риск возникновения несчастных случаев, уберечь владельцев от претензий и повысить показатели соответствия нормативам.
В нефтяной промышленности машинное обучение может определить, какие из сотен буровых вышек вот-вот выйдут из строя, и заранее уведомить сотрудников ремонтной службы. Такой подход не только способствует повышению производительности, но и продлевает операционные сроки и снижает уровень износа оборудования. Также это помогает снизить риск возникновения несчастных случаев, уберечь владельцев от претензий и повысить показатели соответствия нормативам.
Преимущества предиктивного обслуживания распространяются в том числе на управление товарными запасами и организацию труда. Внедрение предиктивного ТО дает возможность избежать незапланированных простоев, более точно прогнозировать потребность в закупке запчастей и проведении ремонтных работ и сократить капиталовложения и операционные расходы.
Потенциал машинного обучения
Машинное обучение помогает извлекать добавочную стоимость из огромных объемов данных, доступных сегодня компаниям. Однако неэффективные процессы могут помешать компании реализовать его полный потенциал.
Чтобы машинное обучение приносило пользу компании, необходима комплексная платформа, которая упростит выполнение операций и развертывание масштабных моделей. Правильно подобранное решение помогает компании централизовать всю работу по data science на единой платформе для совместной работы и оптимизировать использование инструментов, платформ и инфраструктуры с открытым исходным кодом, а также управление ими.
Полезные материалы по Data Science и машинному обучению, которые помогут пройти сквозь джунгли из терминов / Хабр
Привет, Хабр! Меня зовут Ефим, я MLOps-инженер в Selectel. В прошлом был автоматизатором, ML-инженером, дата-аналитиком и дата-инженером — и уже несколько лет падаю в пропасть машинного обучения и Data Science. Это буквально необъятная сфера, в которой почти нет ориентиров. Основная проблема в том, что разделов математики довольно много и все они, на первый взгляд, нужны в том же машинном обучении.В этой статье делюсь полезными материалами, которые помогут найти и заполнить теоретические и практические проблемы и основательно подойти к своему профессиональному развитию. Добро пожаловать под кат!
Добро пожаловать под кат!
Используйте навигацию, если не хотите читать текст полностью:
→ Почему машинное обучение — это сложно
→ Нейронные сети
→ Выстраиваем работу с ML
→ Машинное обучение
→ Основы статистики, все части
→ Анализ данных в R, все части
→ Введение в математический анализ
→ Теория вероятностей — наука о случайности, все части
→ Курсы и гайды на Kaggle
→ Платформа DataCamp
→ Платформа Dataquest
→ Платформа Jovian
→ Канал StatQuest with Josh Starmer
→ Блог Machine Learning Mastery
Почему машинное обучение — это сложно
Для начала хотелось бы напомнить, почему одним курсом по машинному обучению и Data Science не обойтись.
Сфер применения машинного обучения много: от рекомендательных движков в музыкальных приложениях, до оценки благонадежности кредитуемого (aka задача кредитного скоринга). Спрос на специалистов, разбирающихся в предметной области и способных грамотно применять методы ML, постоянно растет.
В начале пути кажется, что создать собственный сервис просто: в сети есть открытые высокоуровневые библиотеки вроде PyTorch, TensorFlow, ONNX и других инструментов. Тем не менее, в силу специфики области возникает огромное количество вопросов. И даже понимание «основ» машинного обучения не избавляет от подводных камней — а их может быть много. Постараюсь это показать.
Представьте ситуацию. Вы — начинающий специалист. И вам нужно некое портфолио, чтобы продемонстрировать потенциальному работодателю свои навыки и знания. Кроме того, их нужно где-то приобрести и поддерживать в актуальном состоянии.
Вы решили, что будете разрабатывать свой ML-сервис для распознавания лиц. Допустим, он будет построен на базе сверточных нейронных сетей и вы уже разобрались с формальной постановкой задачи (подозреваю, что там некоторым образом всплывут термины вроде Face Recognition и Face Identification). Предположим, что вы даже уже определились с выбором нужных инструментов — например Python, PyTorch и PyTorch Lighting. Какие вопросы могут возникнуть?
Какие вопросы могут возникнуть?
- Есть ли примеры кода для выбранных задач, или нужно будет имплементировать архитектуру сети с нуля?
- Если примеры кода есть, достаточно ли будет Transfer Learning или придется прикручивать Fine Tuning для моделей?
- В случае Fine Tuning какой набор данных нужен для создания проекта?
- Если своих данных нет, откуда их можно взять?
- Как разработать кастомную функцию потерь или функцию активации?
- Можно ли как-то осознанно выбрать гиперпараметры модели?
- На что вообще эти гиперпараметры влияют, есть ли рамки для каждого из них?
- Что делать, если возникла ошибка с размерностью входного слоя?
- Как имплементировать SOTA-архитектуру?
- Как интерпретировать полученные результаты?
 Например, есть параметр momentum. Это один из гиперпараметров, применяемых в обучении нейронной сети с использованием одной из вариаций стохастического градиентного спуска Adam (Adaptive Moment estimation). Чтобы просто понять, зачем этот параметр там нужен, нужно как минимум знать, что такое градиент. Это предполагает знание элементов математического анализа и концепции взвешенной суммы.
Например, есть параметр momentum. Это один из гиперпараметров, применяемых в обучении нейронной сети с использованием одной из вариаций стохастического градиентного спуска Adam (Adaptive Moment estimation). Чтобы просто понять, зачем этот параметр там нужен, нужно как минимум знать, что такое градиент. Это предполагает знание элементов математического анализа и концепции взвешенной суммы.Машинное обучение — это о математике
Давайте разберем один из сценариев в прошлом разделе: начинающему ML-инженеру нужно самостоятельно имплементировать SOTA-архитектуру на готовом фреймворке.В рамках задачи разработчику нужно будет самостоятельно расписать все слои SOTA и понять, как они между собой связаны — а это уже, как минимум, линейная алгебра и, возможно, тензорный анализ. На этом пункте многие скажут: «Очевидно, что ML-инженер должен знать эти дисциплины» — и будут правы.
Теория без практики мертва, но практика без теории слепа. Неважно, как вы изучаете: сверху вниз или снизу вверх, от общего к частному или от частного к общему — важно найти для себя некую точку баланса. Вот, как взаимосвязи в Data Science вижу я:
Вот, как взаимосвязи в Data Science вижу я:
Введение в Data Science и машинное обучение
Хороший курс для тех, кто только-только начинает вливаться в Data Science и машинное обучение. Простой, без академического снобизма и тонны громоздких терминов.
Лектор Анатолий Карпов рассказывает о наиболее популярных и надежных инструментах, которые применяют в различных компаниях при решении коммерческих задач. При этом в курсе есть достаточный минимум погружения в технические детали. Для меня этот курс был полезен тем, что помог структурировать уже имеющиеся знания и посмотреть на знакомые технологии под другим углом.
Источник → курс доступен по ссылке.
Нейронные сети
Этот курс дает возможность разобраться в устройстве оптимизаторов и даже написать свою версию. В курсе хорошо преподнесены вводные по линейной алгебре и имплементация метода обратного распространения ошибки на NumPy.
Курс особенно полезен для тех, у кого есть «база», новичкам его рекомендовать не могу.
Источник → изучайте нейронные сети по ссылке.
Выстраиваем работу с ML
Недавно мы с коллегами запустили курс «Выстраиваем работу с ML». В нем собрали полезные материалы для компаний, которые внедряют машинное обучение в рабочие процессы. Подробно рассмотрели концепцию MLOps — дисциплину, направленную на унификацию процессов разработки и развертывания ML-систем. Также рассмотрели отдельные инструменты для работы с ML-моделями и подробно осветили понятие платформы обработки данных.Источник → узнайте больше о ML по ссылке.
Машинное обучение
Это исключительно вводный курс, который скорее заинтересует, чем сделает из вас специалиста. Бережно и аккуратно рассказывает о базовых сущностях, которые лежат в основе математического аппарата машинного обучения. Поэтому курс особенно полезен для специалистов смежных направлений — например, техническим писателям.

Источник → курс доступен по ссылке.
Основы статистики, все части
Один из лучших курсов для «осторожного» погружения в работу статистических критериев, теорию формирования выборок и прочего.
Лектор Анатолий Карпов объясняет, из чего состоит критерий Стьюдента, в чем смысл центральной предельной теоремы, зачем нужно A/B-тестирование и другие вещи. Я бы сказал, этот курс полезен всем, потому что учит трезво оценивать реальность, осмыслять происходящие в ней события и случайные процессы.
Источник → первая часть доступна по ссылке.
Во второй части курса «Основы статистики» уже больше критериев и деталей.
Источник → вторая часть доступна по ссылке.
Третья часть курса еще сильнее погружает в вопросы линейной регрессии. Обсуждаются мультиколлинеарность, гетероскедастичность и другие проблемы, с которыми можно столкнуться в процессе построения регрессионных и классификационных моделей.
Источник → третья часть доступна по ссылке.
Анализ данных в R, все части
Говоря о курсах по основам статистики, имеет смысл упомянуть и курс по анализу данных в R. Поскольку все примеры, иллюстрирующие идеи и концепции из статистики, демонстрируются именно на этом языке.
Первая часть курса не распыляется и покрывает только часть тем — знакомство с синтаксисом, работу с датасетами и их визуализацию. Но этого вполне достаточно, чтобы влиться в язык и погрузиться в более сложные темы вроде RSpark.
Источник → первая часть доступна по ссылке.
Вторая часть логически развивает материал первой. В ней более пристально расписаны способы, как шерудить данные (преимущественно табличные), отрисовывать их и строить отчеты с помощью R Markdown.
Трудно сказать, насколько вам пригодится материал из этой части. Но если вы решили, что тематика языка R вам близка, то с помощью курса можете закрепить полученные знания.
Источник → вторая часть доступна по ссылке.
Введение в математический анализ
Не проходил курс полностью, но есть одна вещь, из-за которой готов его рекомендовать — это задачи.
 Почти в самом начале наткнулся на пример, который вогнал меня в ступор.
Решил задачу только со 117 попытки. 🥲 Не делайте так: лучше пропускать подобные задачи и идти по курсу дальше. Это позволит изучить его до конца и лучше понять, где используются пределы в машинном обучении.
Почти в самом начале наткнулся на пример, который вогнал меня в ступор.
Решил задачу только со 117 попытки. 🥲 Не делайте так: лучше пропускать подобные задачи и идти по курсу дальше. Это позволит изучить его до конца и лучше понять, где используются пределы в машинном обучении.Источник → проходите курс по ссылке.
Теория вероятностей — наука о случайности, все части
Этот курс оставил дыру в моем сердце… Я выполнил верно практически все задания, но стоило дать слабину на единственном разделе — и прощай, пройденный на 100% курс. Так или иначе, первая часть очень достойная и подойдет даже тем, кто уже знаком с теорией вероятностей.
Источник → первая часть доступна по ссылке.
Вторая часть гораздо интересней и без шуток. Она погружает читателя в борелевскую сигма-алгебру, процессы Бернулли и Пуассона, многомерные и условные непрерывные распределения. Надо ли изучать эти темы на старте? Точно нет. Стоит ли отложить этот курс и вернуться к нему позже? Да, безусловно!
Это по-настоящему полезный курс: машинное обучение буквально «сквозит» условными распределениями и понимание этой математической конструкции может сильно помочь в освоении сложного материала.
Источник → вторая часть доступна по ссылке.
Курсы и гайды на Kaggle
С пониманием таких вещей как permutation importance, partial dependence, SHapley Additive exPlanations (SHAP) и другим мне помог именно курс на Kaggle — Machine Learning Explainability.
Все курсы Kaggle встроены в интерфейс платформы, сопровождаются листингами с кодом и подробными комментариями. После теоретического блока можно поэкспериментировать с кодом, что достаточно удобно.
Источник → все курсы и гайды доступны по ссылке.
Платформа DataCamp
Платформа напоминает что-то вроде судоку или сканворда. Практическая польза от этой платформы в том, что можно набить руку на написании однотипных блоков кода. Так, можно запомнить, например, как считать абсолютную разницу двух столбцов в библиотеке Pandas или критерий Стьюдента в SciPy. Можно ли всё это сделать без подобной платформы? Конечно. Но если у вас есть желание обернуть это все в околоигровую форму, можно воспользоваться подобной платформой.

Источник → в «судоку» можно поиграть по ссылке.
Платформа Dataquest
Это примерно такой же сканворд, как и DataCamp. Но значительная часть курсов на Dataquest платная. Можно, конечно, идти по программе курса и просто гуглить материалы самостоятельно, но тогда вы лишите себя главного плюса этой платформы — визуализации результатов и прокаченных навыков. Другой вопрос, а нужно ли оно вам?
Источник → курсы доступны по ссылке.
Платформа Jovian
Уже довольно сложно найти что-то новое или оригинальное в экспоненциально возрастающем количестве курсов. Если вы хотите найти гайд по конкретной теме, попробуйте это сделать на Jovian. Это хорошая платформа-обучалка с акцентом в сторону Jupyter Notebook. Мне особенно приглянулись курсы по Deep Learning, Machine Learning и Natural Language Processing. Большая часть материалов на Jovian бесплатна.
Источник → подключайтесь по ссылке.
Канал StatQuest with Josh Starmer
В своё время я получил массу удовольствия от просмотра видео на канале StatQuest with Josh Starmer.
 Автор классно объясняет математические модели и методы — например, как работают случайные леса, логистическая регрессия, статистические тесты и другое. Особенно рекомендую видео о том, что там BAM!!!
Автор классно объясняет математические модели и методы — например, как работают случайные леса, логистическая регрессия, статистические тесты и другое. Особенно рекомендую видео о том, что там BAM!!!Источник → на канал можно попасть по этой ссылке.
Возможно, эти тексты тоже вас заинтересуют:→ Бот из машины. Как инженеру сократить время на диагностику дисков
→ Знакомство с частотными фильтрами. Часть 1: как спроектировать и немного схитрить
→ 5 полезных и просто занимательных проектов на Raspberry Pi начала весны 2023 года
Блог Machine Learning Mastery
В этом блоге можно найти массу примеров кода с разными фреймворками и полезные статьи. Довольно интересный материал, на который я недавно наткнулся, посвящен Loss-функциям в PyTorch. Рекомендую курс тем, кто хочет узнать больше деталей из привычной разработки нейронных сетей.Источник → читайте блог по ссылке.
Заключение
Как вы поняли, образовательных ресурсов много.
 И чтобы стать специалистом, нужно основательно подойти к их изучению, а также следить за новыми технологиями в мире машинного обучения и Data Science. Кстати, с последним мы помогаем в нашем Telegram-сообществе «MLечный путь». Там мы публикуем еженедельные дайджесты по DataOps и MLOps, обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также обмениваемся опытом. Присоединяйтесь к более 700 специалистам, развивающим ML- и Data-направления в российских и зарубежных компаниях.
И чтобы стать специалистом, нужно основательно подойти к их изучению, а также следить за новыми технологиями в мире машинного обучения и Data Science. Кстати, с последним мы помогаем в нашем Telegram-сообществе «MLечный путь». Там мы публикуем еженедельные дайджесты по DataOps и MLOps, обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также обмениваемся опытом. Присоединяйтесь к более 700 специалистам, развивающим ML- и Data-направления в российских и зарубежных компаниях.А какие источники для погружения в Data Science и ML знаете вы? Поделитесь своими вариантами в комментариях.
Машинное обучение: что это такое и почему это важно
Что это такое и почему это важно
Машинное обучение — это метод анализа данных, который автоматизирует построение аналитической модели. Это направление искусственного интеллекта, основанное на идее, что системы могут учиться на данных, выявлять закономерности и принимать решения с минимальным вмешательством человека.
Эволюция машинного обучения
Благодаря новым вычислительным технологиям машинное обучение сегодня не похоже на машинное обучение прошлого. Он родился из распознавания образов и теории о том, что компьютеры могут учиться, не будучи запрограммированными для выполнения определенных задач; исследователи, интересующиеся искусственным интеллектом, хотели узнать, могут ли компьютеры учиться на данных. Итеративный аспект машинного обучения важен, потому что по мере того, как модели подвергаются воздействию новых данных, они могут независимо адаптироваться. Они учатся на предыдущих вычислениях, чтобы производить надежные, воспроизводимые решения и результаты. Это не новая наука, но она получила новый импульс.
Хотя многие алгоритмы машинного обучения существуют уже давно, возможность автоматически применять сложные математические вычисления к большим данным — снова и снова, все быстрее и быстрее — появилась недавно. Вот несколько широко разрекламированных примеров приложений машинного обучения, с которыми вы, возможно, знакомы:
- Широко разрекламированный самоуправляемый автомобиль Google? Суть машинного обучения.

- Онлайн-рекомендации, такие как Amazon и Netflix? Приложения машинного обучения для повседневной жизни.
- Знаете, что клиенты говорят о вас в Твиттере? Машинное обучение в сочетании с созданием лингвистических правил.
- Обнаружение мошенничества? Одно из наиболее очевидных и важных применений в современном мире.

Машинное обучение и искусственный интеллект
В то время как искусственный интеллект (ИИ) — это широкая наука о том, как имитировать человеческие способности, машинное обучение — это особое подмножество ИИ, которое обучает машину тому, как учиться. Посмотрите это видео, чтобы лучше понять взаимосвязь между ИИ и машинным обучением. Вы увидите, как работают эти две технологии, с полезными примерами и несколькими забавными замечаниями.
Почему важно машинное обучение?
Возрождение интереса к машинному обучению связано с теми же факторами, которые сделали интеллектуальный анализ данных и байесовский анализ более популярными, чем когда-либо. Такие вещи, как растущие объемы и разнообразие доступных данных, более дешевая и мощная вычислительная обработка и доступное хранение данных.
Такие вещи, как растущие объемы и разнообразие доступных данных, более дешевая и мощная вычислительная обработка и доступное хранение данных.
Все это означает, что можно быстро и автоматически создавать модели, способные анализировать большие и сложные данные и получать более быстрые и точные результаты даже в очень больших масштабах. И, создавая точные модели, у организации больше шансов выявить выгодные возможности или избежать неизвестных рисков.
Что требуется для создания хороших систем машинного обучения?
- Возможности подготовки данных.
- Алгоритмы – базовые и расширенные.
- Автоматизация и итерационные процессы.
- Масштабируемость.
- Моделирование ансамбля.
Знаете ли вы?
- В машинном обучении цель называется меткой.
- В статистике цель называется зависимой переменной.
- Переменная в статистике называется функцией в машинном обучении.
- Преобразование в статистике называется созданием признаков в машинном обучении.

Машинное обучение в современном мире
Используя алгоритмы для построения моделей, выявляющих связи, организации могут принимать более эффективные решения без вмешательства человека. Узнайте больше о технологиях, которые формируют мир, в котором мы живем.
Возможности и проблемы машинного обучения в бизнесе
В этом информационном документе O’Reilly представлено практическое руководство по внедрению приложений машинного обучения в вашей организации.
Прочитать информационный документ
Расширьте свой набор навыков
Получите подробные инструкции и бесплатный доступ к программному обеспечению SAS для развития навыков машинного обучения. Курсы включают: 14 часов учебного времени, 90 дней бесплатного доступа к программному обеспечению в облаке, гибкий формат электронного обучения, не требующий навыков программирования.
Курсы машинного обучения
Изменит ли машинное обучение вашу организацию?
В этом отчете Harvard Business Review Insight Center рассматривается, как машинное обучение изменит компании и то, как мы ими управляем.
Загрузить отчет
Применение машинного обучения к Интернету вещей
Машинное обучение можно использовать для достижения более высоких уровней эффективности, особенно применительно к Интернету вещей. В этой статье исследуется тема.
Прочитайте статью об IoT
Кто им пользуется?
Большинство отраслей, работающих с большими объемами данных, признали ценность технологии машинного обучения. Получая информацию из этих данных — часто в режиме реального времени — организации могут работать более эффективно или получать преимущество перед конкурентами.
Финансовые услуги
Банки и другие предприятия финансовой отрасли используют технологию машинного обучения для двух основных целей: выявления важных сведений в данных и предотвращения мошенничества. Эти идеи могут определить инвестиционные возможности или помочь инвесторам узнать, когда торговать. Интеллектуальный анализ данных также может идентифицировать клиентов с профилями высокого риска или использовать кибернаблюдение для выявления предупредительных признаков мошенничества.
Правительство
Правительственные учреждения, такие как общественная безопасность и коммунальные службы, особенно нуждаются в машинном обучении, поскольку у них есть несколько источников данных, которые можно использовать для анализа. Например, анализ данных датчиков позволяет определить способы повышения эффективности и экономии средств. Машинное обучение также может помочь обнаружить мошенничество и свести к минимуму кражу личных данных.
Здравоохранение
Машинное обучение — быстрорастущая тенденция в сфере здравоохранения благодаря появлению носимых устройств и датчиков, которые могут использовать данные для оценки состояния здоровья пациента в режиме реального времени. Эта технология также может помочь медицинским экспертам анализировать данные для выявления тенденций или тревожных сигналов, которые могут привести к улучшению диагностики и лечения.
Розничная торговля
Веб-сайты, предлагающие товары, которые могут вам понравиться на основе предыдущих покупок, используют машинное обучение для анализа вашей истории покупок. Ритейлеры полагаются на машинное обучение для сбора данных, их анализа и использования для персонализации покупательского опыта, проведения маркетинговых кампаний, оптимизации цен, планирования товаров и получения информации о клиентах.
Ритейлеры полагаются на машинное обучение для сбора данных, их анализа и использования для персонализации покупательского опыта, проведения маркетинговых кампаний, оптимизации цен, планирования товаров и получения информации о клиентах.
Нефть и газ
Поиск новых источников энергии. Анализ полезных ископаемых в земле. Прогнозирование отказа датчика нефтеперерабатывающего завода. Оптимизация распределения масла, чтобы сделать его более эффективным и экономичным. Количество вариантов использования машинного обучения для этой отрасли огромно и продолжает расти.
Транспорт
Анализ данных для выявления закономерностей и тенденций является ключом к транспортной отрасли, которая полагается на повышение эффективности маршрутов и прогнозирование потенциальных проблем для повышения прибыльности. Аспекты анализа данных и моделирования машинного обучения являются важными инструментами для компаний доставки, общественного транспорта и других транспортных организаций.
Узнайте больше об отраслях, использующих эту технологию
Как это работает
Чтобы получить максимальную отдачу от машинного обучения, вы должны знать, как сочетать лучшие алгоритмы с правильными инструментами и процессами. SAS сочетает в себе богатое, сложное наследие в области статистики и интеллектуального анализа данных с новыми архитектурными достижениями, чтобы ваши модели работали максимально быстро — даже в огромных корпоративных средах.
Алгоритмы : Графические пользовательские интерфейсы SAS помогают создавать модели машинного обучения и реализовывать итеративный процесс машинного обучения. Вам не нужно быть продвинутым статистиком. Наш обширный набор алгоритмов машинного обучения поможет вам быстро извлечь выгоду из ваших больших данных и включен во многие продукты SAS. Алгоритмы машинного обучения SAS включают:
| Нейронные сети | |
Деревья решений | |
Случайные леса | |
Ассоциации и обнаружение последовательностей | |
Повышение градиента и бэггинг | |
Метод опорных векторов | |
Отображение ближайших соседей | |
Кластеризация k-средних | |
Самоорганизующиеся карты |
| Методы оптимизации локального поиска (например, генетические алгоритмы) | |
Максимизация ожидания | |
Сплайны многомерной адаптивной регрессии | |
Байесовские сети | |
Оценка плотности ядра | |
Анализ главных компонентов | |
Разложение по сингулярным числам | |
Модели гауссовской смеси | |
Построение правил последовательного покрытия |
Инструменты и процессы : Как мы уже знаем, дело не только в алгоритмах. В конечном счете, секрет получения максимальной отдачи от ваших больших данных заключается в сочетании лучших алгоритмов для поставленной задачи с:
В конечном счете, секрет получения максимальной отдачи от ваших больших данных заключается в сочетании лучших алгоритмов для поставленной задачи с:
| Комплексное качество данных и управление ими | |
| Графические интерфейсы для построения моделей и потоков процессов | |
| Интерактивное исследование данных и визуализация результатов моделирования | |
| Сравнение различных моделей машинного обучения для быстрого определения лучшей |
| Автоматизированная оценка модели ансамбля для выявления лучших исполнителей | |
| Простое развертывание модели для быстрого получения воспроизводимых и надежных результатов | |
| Комплексная интегрированная платформа для автоматизации процесса преобразования данных в решения |
Вам нужны базовые рекомендации по тому, какой алгоритм машинного обучения для чего использовать? Этот блог Хуэй Ли, специалиста по данным в SAS, содержит удобную шпаргалку.

Подробнее по этой теме
- Аналитика борется с бедствием торговли людьмиЖертвы торговли людьми окружают нас повсюду. От принудительного труда до секс-бизнеса, современное рабство процветает в тени. Узнайте, почему организации обращаются к ИИ и аналитике больших данных, чтобы раскрыть эти преступления и изменить будущие траектории.
- Viking трансформирует свою стратегию аналитики с помощью SAS® Viya® на AzureViking полностью использует облачную аналитику, чтобы оставаться конкурентоспособными и удовлетворять потребности клиентов. Цифровая трансформация ритейлера предназначена для оптимизации процессов и повышения лояльности клиентов и доходов по всем каналам.
- Инфраструктура общественного здравоохранения остро нуждается в модернизацииУчреждения общественного здравоохранения должны гибко реагировать на длительные кризисы в области здравоохранения и острые чрезвычайные ситуации – от стихийных бедствий, таких как ураганы, до таких событий, как пандемия. Чтобы быть готовым, инфраструктура общественного здравоохранения должна быть модернизирована для поддержки подключения, обмена данными в реальном времени, аналитики и визуализации.
- ИТ-директор SAS: почему лидеры должны развивать любознательность в 2021 г. В связи с изменениями, с которыми мы все сталкиваемся в этом году, ИТ-директорам следует рассчитывать на то, что любознательность сыграет решающую роль в том, как мы собираемся решать стоящие перед ними задачи. С момента появления COVID-19 наша ИТ-организация полагалась на любопытство — это сильное желание исследовать, учиться, узнавать — для подпитки необходимых срочных изменений. И именно любопытство позволит нам удовлетворить потребности будущего труда после пандемии.
 Цифровая трансформация ритейлера предназначена для оптимизации процессов и повышения лояльности клиентов и доходов по всем каналам.
Цифровая трансформация ритейлера предназначена для оптимизации процессов и повышения лояльности клиентов и доходов по всем каналам. В связи с изменениями, с которыми мы все сталкиваемся в этом году, ИТ-директорам следует рассчитывать на то, что любознательность сыграет решающую роль в том, как мы собираемся решать стоящие перед ними задачи. С момента появления COVID-19 наша ИТ-организация полагалась на любопытство — это сильное желание исследовать, учиться, узнавать — для подпитки необходимых срочных изменений. И именно любопытство позволит нам удовлетворить потребности будущего труда после пандемии.
В связи с изменениями, с которыми мы все сталкиваемся в этом году, ИТ-директорам следует рассчитывать на то, что любознательность сыграет решающую роль в том, как мы собираемся решать стоящие перед ними задачи. С момента появления COVID-19 наша ИТ-организация полагалась на любопытство — это сильное желание исследовать, учиться, узнавать — для подпитки необходимых срочных изменений. И именно любопытство позволит нам удовлетворить потребности будущего труда после пандемии.Какие существуют популярные методы машинного обучения?
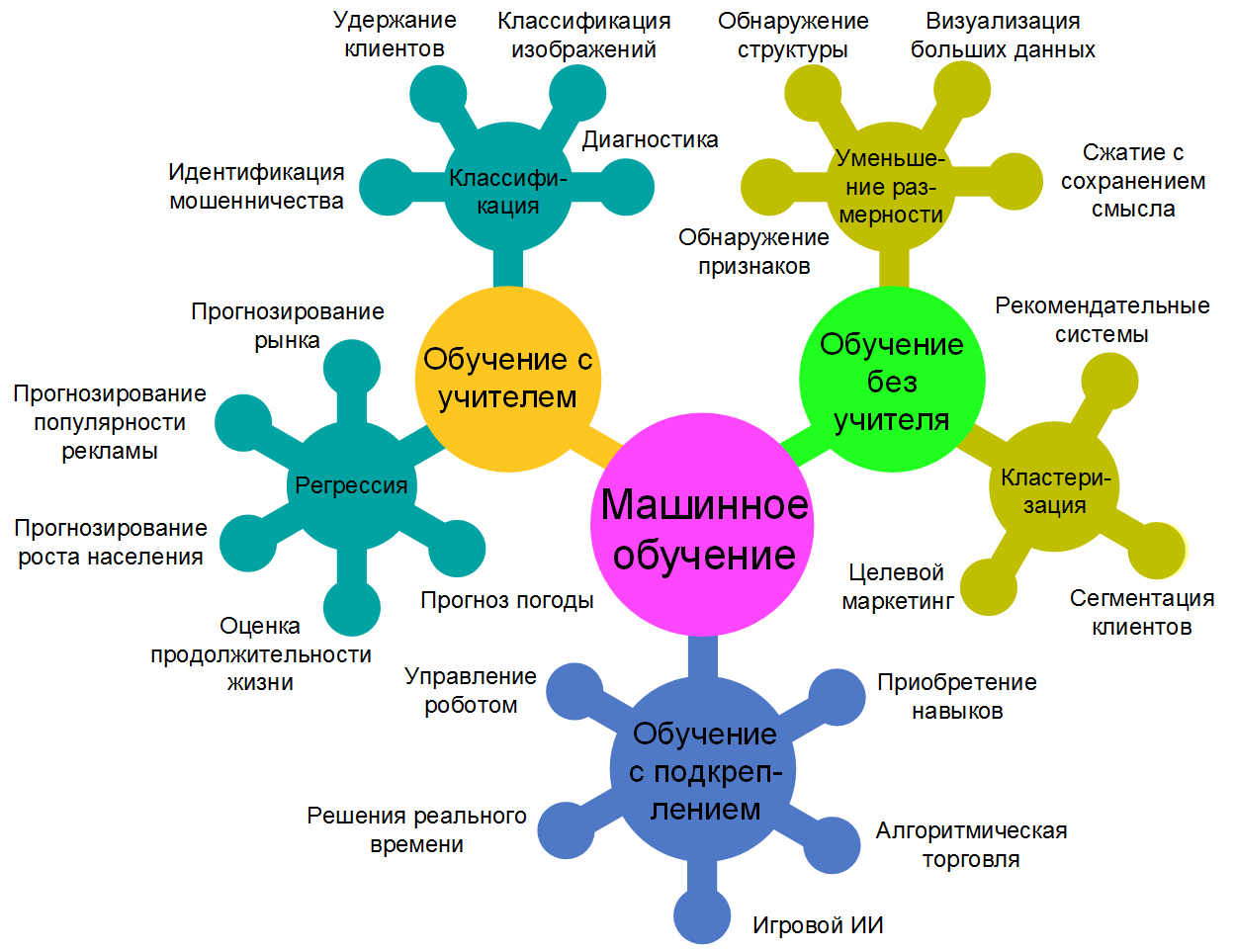
Двумя наиболее широко распространенными методами машинного обучения являются контролируемое обучение и неконтролируемое обучение , но существуют и другие методы машинного обучения. Вот обзор самых популярных типов.
Обучение под наблюдением Алгоритмы обучаются с использованием помеченных примеров, таких как входные данные, для которых известен желаемый результат. Например, элемент оборудования может иметь точки данных, помеченные либо «F» (сбой), либо «R» (работает). Алгоритм обучения получает набор входных данных вместе с соответствующими правильными выходными данными, и алгоритм обучается, сравнивая свои фактические выходные данные с правильными выходными данными, чтобы найти ошибки. Затем он соответствующим образом модифицирует модель. С помощью таких методов, как классификация, регрессия, прогнозирование и повышение градиента, контролируемое обучение использует шаблоны для прогнозирования значений метки на дополнительных немаркированных данных. Обучение с учителем обычно используется в приложениях, где исторические данные предсказывают вероятные будущие события. Например, он может предвидеть, когда транзакции по кредитным картам могут быть мошенническими или какой страховой клиент может подать иск.
Например, элемент оборудования может иметь точки данных, помеченные либо «F» (сбой), либо «R» (работает). Алгоритм обучения получает набор входных данных вместе с соответствующими правильными выходными данными, и алгоритм обучается, сравнивая свои фактические выходные данные с правильными выходными данными, чтобы найти ошибки. Затем он соответствующим образом модифицирует модель. С помощью таких методов, как классификация, регрессия, прогнозирование и повышение градиента, контролируемое обучение использует шаблоны для прогнозирования значений метки на дополнительных немаркированных данных. Обучение с учителем обычно используется в приложениях, где исторические данные предсказывают вероятные будущие события. Например, он может предвидеть, когда транзакции по кредитным картам могут быть мошенническими или какой страховой клиент может подать иск.
Обучение без учителя используется для данных, которые не имеют исторических меток. Системе не говорят «правильный ответ». Алгоритм должен выяснить, что показывается. Цель состоит в том, чтобы изучить данные и найти внутри некоторую структуру. Неконтролируемое обучение хорошо работает с транзакционными данными. Например, он может идентифицировать сегменты клиентов с похожими характеристиками, с которыми затем можно обращаться одинаково в маркетинговых кампаниях. Или он может найти основные атрибуты, которые отделяют потребительские сегменты друг от друга. Популярные методы включают самоорганизующиеся карты, отображение ближайших соседей, кластеризацию k-средних и разложение по сингулярным значениям. Эти алгоритмы также используются для сегментации текстовых тем, рекомендации элементов и выявления выбросов данных.
Цель состоит в том, чтобы изучить данные и найти внутри некоторую структуру. Неконтролируемое обучение хорошо работает с транзакционными данными. Например, он может идентифицировать сегменты клиентов с похожими характеристиками, с которыми затем можно обращаться одинаково в маркетинговых кампаниях. Или он может найти основные атрибуты, которые отделяют потребительские сегменты друг от друга. Популярные методы включают самоорганизующиеся карты, отображение ближайших соседей, кластеризацию k-средних и разложение по сингулярным значениям. Эти алгоритмы также используются для сегментации текстовых тем, рекомендации элементов и выявления выбросов данных.
Обучение с полуучителем используется для тех же приложений, что и обучение с учителем. Но для обучения он использует как размеченные, так и неразмеченные данные — обычно небольшое количество размеченных данных с большим объемом неразмеченных данных (поскольку неразмеченные данные дешевле и требуют меньше усилий для получения). Этот тип обучения можно использовать с такими методами, как классификация, регрессия и предсказание. Полууправляемое обучение полезно, когда затраты, связанные с маркировкой, слишком высоки, чтобы обеспечить полностью маркированный процесс обучения. Ранние примеры этого включают идентификацию лица человека на веб-камере.
Этот тип обучения можно использовать с такими методами, как классификация, регрессия и предсказание. Полууправляемое обучение полезно, когда затраты, связанные с маркировкой, слишком высоки, чтобы обеспечить полностью маркированный процесс обучения. Ранние примеры этого включают идентификацию лица человека на веб-камере.
Обучение с подкреплением часто используется для робототехники, игр и навигации. При обучении с подкреплением алгоритм методом проб и ошибок определяет, какие действия приносят наибольшее вознаграждение. Этот тип обучения состоит из трех основных компонентов: агент (ученик или лицо, принимающее решения), среда (все, с чем взаимодействует агент) и действия (что агент может делать). Цель агента состоит в том, чтобы выбрать действия, которые максимизируют ожидаемое вознаграждение за заданный промежуток времени. Агент достигнет цели намного быстрее, если будет следовать хорошей политике. Таким образом, цель обучения с подкреплением состоит в том, чтобы изучить наилучшую политику.
Люди обычно могут создавать одну или две хорошие модели в неделю; машинное обучение может создавать тысячи моделей в неделю.
Томас Х. Дэвенпорт , лидер мнений в области аналитики
выдержка из The Wall Street Journal
В чем разница между интеллектуальным анализом данных, машинным обучением и глубоким обучением?
Хотя все эти методы преследуют одну и ту же цель — извлечение информации, закономерностей и взаимосвязей, которые можно использовать для принятия решений, — у них разные подходы и возможности.
Интеллектуальный анализ данных
Интеллектуальный анализ данных можно рассматривать как надмножество множества различных методов извлечения информации из данных. Это может включать традиционные статистические методы и машинное обучение. Интеллектуальный анализ данных применяет методы из многих различных областей для выявления ранее неизвестных закономерностей в данных. Это может включать статистические алгоритмы, машинное обучение, текстовую аналитику, анализ временных рядов и другие области аналитики. Интеллектуальный анализ данных также включает изучение и практику хранения данных и манипулирования ими.
Интеллектуальный анализ данных также включает изучение и практику хранения данных и манипулирования ими.
Машинное обучение
Основное отличие машинного обучения состоит в том, что, как и в статистических моделях, цель состоит в том, чтобы понять структуру данных — подогнать теоретические распределения к хорошо изученным данным. Таким образом, в статистических моделях за моделью стоит теория, которая математически доказана, но для этого требуется, чтобы данные также соответствовали определенным сильным предположениям. Машинное обучение развилось на основе способности использовать компьютеры для изучения структуры данных, даже если у нас нет теории о том, как эта структура выглядит. Тест для модели машинного обучения — это ошибка проверки новых данных, а не теоретический тест, подтверждающий нулевую гипотезу. Поскольку машинное обучение часто использует итеративный подход для изучения данных, обучение можно легко автоматизировать. Проходы выполняются по данным до тех пор, пока не будет найден надежный шаблон.
Проходы выполняются по данным до тех пор, пока не будет найден надежный шаблон.
Глубокое обучение
Глубокое обучение сочетает в себе достижения в области вычислительной мощности и специальные типы нейронных сетей для изучения сложных закономерностей в больших объемах данных. Методы глубокого обучения в настоящее время являются современными для идентификации объектов на изображениях и слов в звуках. Исследователи теперь стремятся применить эти успехи в распознавании образов к более сложным задачам, таким как автоматический языковой перевод, медицинские диагнозы и множество других важных социальных и деловых проблем.
Машинное обучение под наблюдением: курс регрессии и классификации (DeepLearning.AI)
Об этом курсе
2 532 581 недавних просмотров питон используя популярные библиотеки машинного обучения NumPy и scikit-learn.
• Создавайте и обучайте модели машинного обучения с учителем для задач прогнозирования и бинарной классификации, включая линейную регрессию и логистическую регрессию. Специализация по машинному обучению — это базовая онлайн-программа, созданная в сотрудничестве между DeepLearning.AI и Stanford Online. В этой удобной для начинающих программе вы изучите основы машинного обучения и узнаете, как использовать эти методы для создания реальных приложений ИИ.
Эту специализацию преподает Эндрю Нг, провидец ИИ, который руководил критическими исследованиями в Стэнфордском университете и новаторскими работами в Google Brain, Baidu и Landing.AI по продвижению области ИИ.
Эта специализация из трех курсов представляет собой обновленную и расширенную версию новаторского курса Эндрю по машинному обучению с рейтингом 4,9.из 5, и с момента его запуска в 2012 году его посетили более 4,8 миллиона человек.
Он представляет собой широкое введение в современное машинное обучение, включая обучение с учителем (множественная линейная регрессия, логистическая регрессия, нейронные сети и деревья решений), обучение без учителя (кластеризация, уменьшение размерности, рекомендательные системы) и некоторые из лучших практик, используемых в Silicon.
Специализация по машинному обучению — это базовая онлайн-программа, созданная в сотрудничестве между DeepLearning.AI и Stanford Online. В этой удобной для начинающих программе вы изучите основы машинного обучения и узнаете, как использовать эти методы для создания реальных приложений ИИ.
Эту специализацию преподает Эндрю Нг, провидец ИИ, который руководил критическими исследованиями в Стэнфордском университете и новаторскими работами в Google Brain, Baidu и Landing.AI по продвижению области ИИ.
Эта специализация из трех курсов представляет собой обновленную и расширенную версию новаторского курса Эндрю по машинному обучению с рейтингом 4,9.из 5, и с момента его запуска в 2012 году его посетили более 4,8 миллиона человек.
Он представляет собой широкое введение в современное машинное обучение, включая обучение с учителем (множественная линейная регрессия, логистическая регрессия, нейронные сети и деревья решений), обучение без учителя (кластеризация, уменьшение размерности, рекомендательные системы) и некоторые из лучших практик, используемых в Silicon. Valley за инновации в области искусственного интеллекта и машинного обучения (оценка и настройка моделей, использование подхода, ориентированного на данные, для повышения производительности и т. д.).
К концу этой специализации вы овладеете ключевыми понятиями и получите практические ноу-хау, чтобы быстро и эффективно применять машинное обучение для решения сложных реальных задач. Если вы хотите заняться искусственным интеллектом или построить карьеру в области машинного обучения, лучше всего начать с новой специализации по машинному обучению.
Valley за инновации в области искусственного интеллекта и машинного обучения (оценка и настройка моделей, использование подхода, ориентированного на данные, для повышения производительности и т. д.).
К концу этой специализации вы овладеете ключевыми понятиями и получите практические ноу-хау, чтобы быстро и эффективно применять машинное обучение для решения сложных реальных задач. Если вы хотите заняться искусственным интеллектом или построить карьеру в области машинного обучения, лучше всего начать с новой специализации по машинному обучению.
Гибкие сроки
Сброс сроков в соответствии с вашим графиком.
Общий сертификатОбщий сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните сразу и учитесь по собственному графику.
СпециализацияКурс 1 из 3 в
Специализация по машинному обучению
Начальный уровеньНачальный уровень
Базовое кодирование (для циклов, функций, операторов if/else) и математика на уровне средней школы (арифметика, алгебра)
Будут объяснены другие математические понятия
Часов на выполнение Прибл.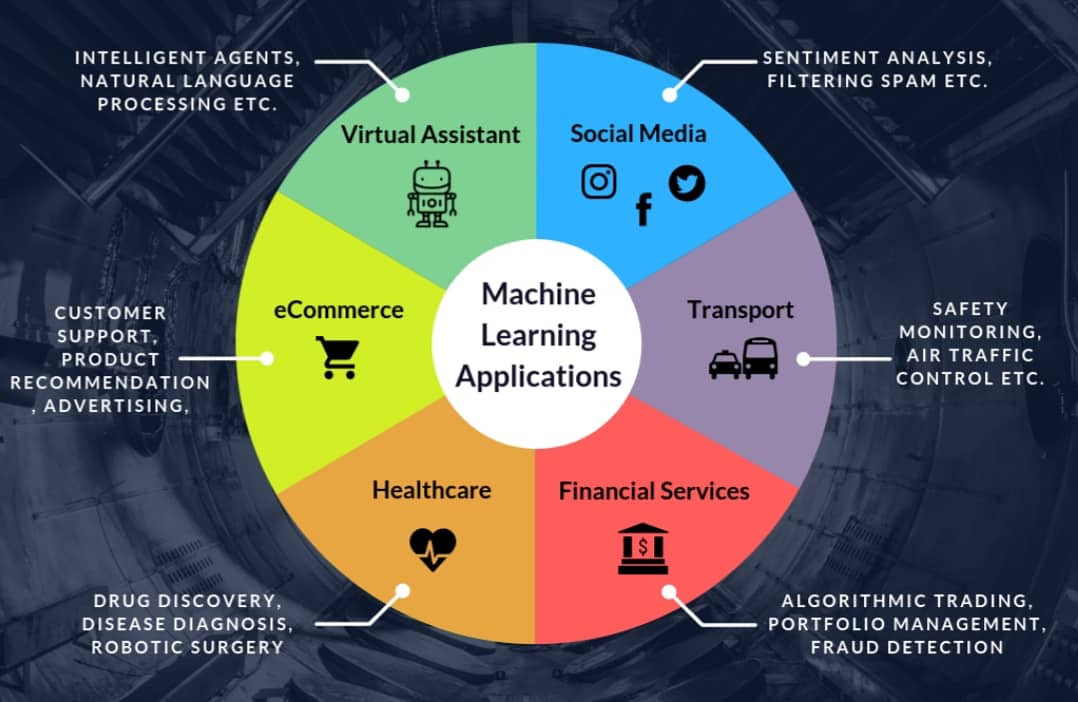 33 часа на выполнение
33 часа на выполнение
Английский
Субтитры: английский
Чему вы научитесь
Навыки, которые вы приобретете
- Регуляризация во избежание переобучения
- Градиентный спуск 9 0016 Обучение с учителем
- Линейная регрессия
- Логистическая регрессия для Классификация
Гибкие сроки
Сбросить сроки в соответствии с вашим расписанием.
Общий сертификатОбщий сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните сразу и учитесь по собственному графику.
СпециализацияКурс 1 из 3 в
Специализация по машинному обучению
Начальный уровеньНачальный уровень
Базовое кодирование (для циклов, функций, операторов if/else) и математика на уровне средней школы (арифметика, алгебра)
Будут объяснены другие математические понятия
Часов на выполнениеПрибл. 33 часа
Доступные языкиАнглийский
Субтитры: английский
Инструкторы
Эндрю Нг
Top Instructor
Instructor 9000 2 Основатель DeepLearning. AI и соучредитель Coursera 6 410 988 Учащиеся 38 Курсы
AI и соучредитель Coursera 6 410 988 Учащиеся 38 КурсыЭдди Шью
Архитектор учебного планаМенеджер по учебным программам, DeepLearning.AI
544,327 Учащиеся 14 КурсыАарти Багул
Top Instructor
9 0028 Инженер по учебным программам 340,712 Учащиеся 3 КурсыДжефф Ладвиг
Ведущий инструктор
Инженер по учебным программамDeepLearning.AI
340 712 Учащиеся 3 КурсыПредложено
DeepLearning.AI
DeepLearning.AI — компания, занимающаяся образовательными технологиями, которая развивает глобальное сообщество специалистов по искусственному интеллекту.

Stanford University
Leland Stanford Junior University, обычно называемый Стэнфордским университетом или Стэнфордом, является американским частным исследовательским университетом, расположенным в Стэнфорде, Калифорния, на территории кампуса площадью 8 180 акров (3310 га) недалеко от Пало-Альто, Калифорния, США. .
Отзывы
4.9
Заполненная ЗвездаЗаполненная ЗвездаЗаполненная ЗвездаЗаполненная Звезда 2197 отзывов5 звезд
91,89%
900 174 звезды
7,08%
3 звезды
0,58%
2 звезды
0,19%
1 звезда
0,23%
ЛУЧШИЕ ОТЗЫВЫ ОТ МАШИННОГО ОБУЧЕНИЯ С УПРАВЛЕНИЕМ: РЕГРЕССИЯ И КЛАССИФИКАЦИЯ
Заполненная звездаЗаполненная звездаЗаполненная звездаЗаполненная звездаЗаполненная звездаот MPS 11 сентября 2022 г.
Все в порядке. Я многому научился на этом первом курсе специализации. Спасибо Coursera за такой хороший и прекрасный курс по финансовой помощи. Я очень благодарен им.
Я очень благодарен им.
от AM 17 июля 2022 г.
Это лучший курс по контролируемому машинному обучению!
Эндрю Нг Сэр, как всегда, имеет такие важные и сложные концепции контролируемого машинного обучения с такой легкостью и отличными примерами, просто потрясающе!
Filled StarFilled StarFilled StarFilled StarFilled Starот ME 21 июля 2022 г.
Этот курс помог мне познакомиться с концепцией машинного обучения. Это отличная возможность изучить алгоритмы машинного обучения для всех, кто имеет базовые знания в области математики и статистики.
Filled StarFilled StarFilled StarFilled StarFilled Starот FAM 25 мая 2023 г.
Курс был чрезвычайно удобен для начинающих и прост в освоении, понравилась учебная программа, много узнал о различных алгоритмах машинного обучения, таких как линейная и логистическая регрессия, и в целом был отличным опытом. .
Просмотреть все отзывыО специализации по машинному обучению
Специализация по машинному обучению — это базовая онлайн-программа, созданная в сотрудничестве между DeepLearning. AI и Stanford Online. Эта программа для начинающих научит вас основам машинного обучения и тому, как использовать эти методы для создания реальных приложений ИИ.
AI и Stanford Online. Эта программа для начинающих научит вас основам машинного обучения и тому, как использовать эти методы для создания реальных приложений ИИ.
