
Что такое Web Archive и как им пользоваться
2 июня 2020 Ликбез Технологии
Сервис пригодится, если нужно будет просмотреть неработающую или удалённую веб-страницу.
Что такое Web Archive
В 1996 году американский предприниматель и активист Брюстер Кейл основал некоммерческую организацию Internet Archive («Архив интернета»). С тех пор она создаёт и хранит копии сайтов, а также книг, изображений и другого контента, который публикуется на открытых ресурсах Сети. Таким образом учредитель намерен сберечь международное культурное наследие.
Архив пополняют боты, сканирующие веб. Им помогают сотрудники и партнёры организации, среди которых множество библиотек и университетов. Кроме того, любой пользователь может загружать контент на серверы через официальный сайт организации. Содержимое архива доступно здесь же — бесплатно и для всех желающих.
Web Archive, также известный как Wayback Machine («Машина времени»), — это один из разделов на сайте Internet Archive. Здесь можно добавить новые или просмотреть уже загруженные копии веб-страниц.
Здесь можно добавить новые или просмотреть уже загруженные копии веб-страниц.
Боты периодически обновляют данные. Но каждая очередная копия страницы не перезаписывает предыдущую, а сохраняется отдельно с указанием даты добавления. Поэтому с помощью Internet Archive можно посмотреть, как со временем менялись дизайн и наполнение выбранного сайта.
Копия сайта Google, созданная 3 декабря 2000 годаБолее того, сохранённые копии остаются доступными, даже если оригинал исчезает из Сети. По этой причине Web Archive часто используют, чтобы просмотреть опубликованную информацию, которую пытаются стереть, или получить доступ к старым и уже неработающим сайтам.
С сервисом можно работать через сайт и официальное приложение Wayback Machine для iOS и Android.
Сейчас читают 🔥
- Как скачать видео с YouTube на любое устройство
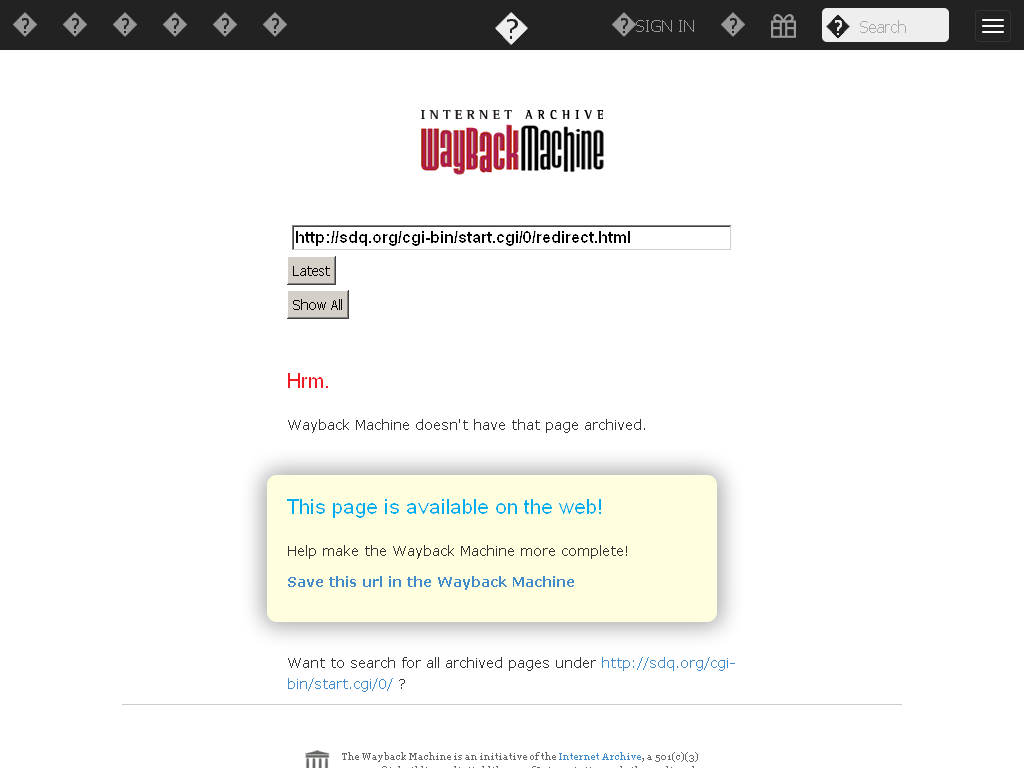
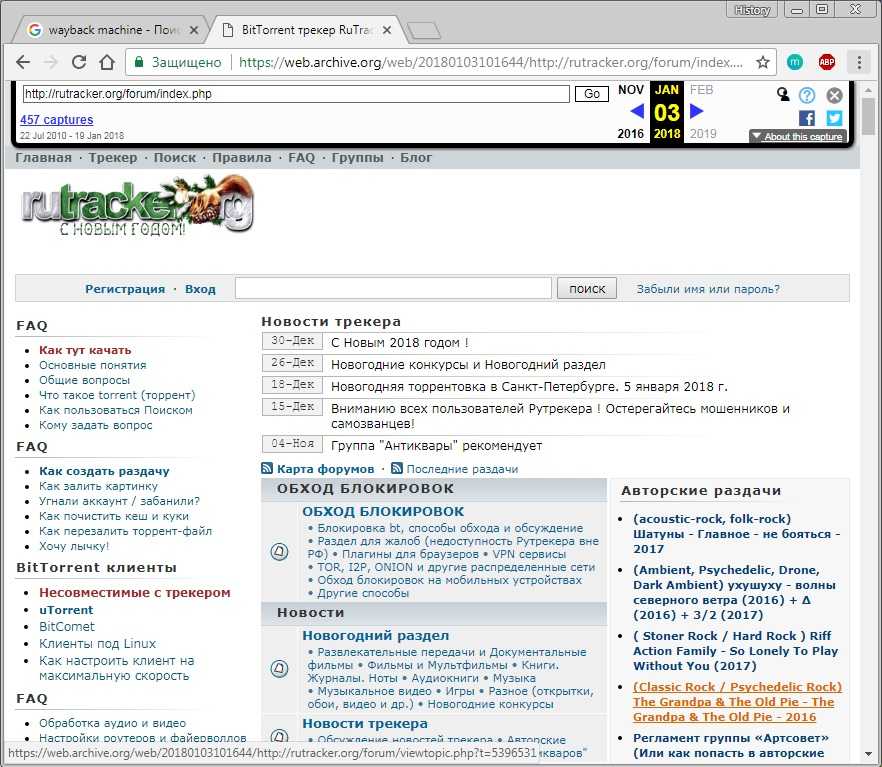
Как посмотреть архивные копии страницы в Web Archive
Откройте сайт Web Archive или приложение сервиса. Если используете последнее, сразу после запуска создайте аккаунт.
Если используете последнее, сразу после запуска создайте аккаунт.
Вставьте ссылку на нужную страницу и нажмите Enter (на сайте) или Overview of All Archives (в приложении).
Пролистайте календарь, чтобы найти подходящие копии. Дни, в которые бот создавал дубликаты страницы, отмечены кружками.
Нажмите на подходящую дату, чтобы просмотреть архивную копию.
Сайт также позволяет сравнивать две копии. Для этого на странице с календарём нажмите Changes, отметьте две даты и кликните Compare.
В результате Web Archive отобразит копии рядом и выделит несовпадения.
Как удалить копии ваших страниц из Web Archive или запретить их добавление
Если вы не желаете, чтобы копии вашего ресурса были в архиве, сообщите об этом администрации Internet Archive. Согласно официальной справке, для этого нужно отправить письмо на ящик [email protected], указав ссылку на свой сайт.
Скорее всего, вас попросят доказать факт владения ресурсом и объяснить причину удаления или запрета на добавление в архив. И да, писать лучше на английском.
И да, писать лучше на английском.
Как добавить копию страницы в Web Archive
Чтобы не дожидаться, пока бот найдёт и сохранит нужную вам страницу, можете добавить её вручную.
Если используете сайт, перейдите в специальный подраздел. Вставьте ссылку на сохраняемую страницу и нажмите Save Page. Отметьте пункт Save error pages, если хотите, чтобы система архивировала в том числе страницы, которые не открываются из-за ошибок.
Если используете приложение, вставьте ссылку на нужную страницу и нажмите Archive Page Now.
Для быстрого добавления страниц можно также использовать расширения для десктопных браузеров. После установки достаточно открыть в браузере нужную ссылку, нажать на кнопку плагина и выбрать Save Page Now.
Загрузить
Цена: Бесплатно
Загрузить
Цена: Бесплатно
Загрузить
Цена: 0
Загрузить
Цена: Бесплатно
Читайте также 🌐🖥🌐
- Как на Android сделать резервную копию данных в Google Drive
- Что такое кража цифровой личности и как защитить свои данные в интернете
- 6 причин не сохранять пароли в браузере
- Как восстановить файлы в Excel, если вы забыли их сохранить
- 10 лучших программ для восстановления данных с жёсткого диска
Веб-архив сайтов: как пользоваться Internet Archive Wayback Machine
В цифровом мире, которым является Глобальная сеть, машина времени вполне реальна. Более того, она давно существует и позволяет всем желающим вернуться в те самые «старые добрые» времена, когда солнце было ярче, а трава зеленее.
Более того, она давно существует и позволяет всем желающим вернуться в те самые «старые добрые» времена, когда солнце было ярче, а трава зеленее.
Найти сервис, предоставляющий доступ к старым версиям современных сайтов все желающие могут просто перейдя по ссылке. Казалось бы, для чего нужен ресурс, хранящий на своих серверах полноценный архив Глобальной сети? Но причин для этого есть множество:
-
Это просто интересно с точки зрения рядового пользователя – многим любопытно вернуться к тому самому старому дизайну привычных сайтов, который много лет назад радовал глаз и казался родным и близким. Те изменения, которые претерпевают с годами все популярные ресурсы в интернете, вызывает массу споров и критики. И, как результат, совершенно естественное желание ещё раз вернуться к классическим версиям, крепко засевшим в памяти.
-
Ведение архивов позволяет восстановить доступ к утерянной информации.
 Сайты закрываются и пропадают, вместе со всем, размещённым на них, контентом. Поэтому иногда может быть критически важным восстановить доступ к старой информации. Также ряд вебмастеров, владеющих собственной интеллектуальной собственностью в Глобальной сети, не ведут самостоятельно архивы. И в случаях повреждения баз данных, могут рассчитывать лишь на централизованные источники бекапов.
Сайты закрываются и пропадают, вместе со всем, размещённым на них, контентом. Поэтому иногда может быть критически важным восстановить доступ к старой информации. Также ряд вебмастеров, владеющих собственной интеллектуальной собственностью в Глобальной сети, не ведут самостоятельно архивы. И в случаях повреждения баз данных, могут рассчитывать лишь на централизованные источники бекапов.
-
Возможность проведения сравнительного анализа состава наиболее важных ресурсов интернета позволяет делать далекоидущие выводы и прогнозы. Не менее ощутимые результаты приносят подобные анализы собственных ресурсов. Проследите их прогресс и те дивиденды, которые он принёс вместе с собой.
 Сайты закрываются и пропадают, вместе со всем, размещённым на них, контентом. Поэтому иногда может быть критически важным восстановить доступ к старой информации. Также ряд вебмастеров, владеющих собственной интеллектуальной собственностью в Глобальной сети, не ведут самостоятельно архивы. И в случаях повреждения баз данных, могут рассчитывать лишь на централизованные источники бекапов.
Сайты закрываются и пропадают, вместе со всем, размещённым на них, контентом. Поэтому иногда может быть критически важным восстановить доступ к старой информации. Также ряд вебмастеров, владеющих собственной интеллектуальной собственностью в Глобальной сети, не ведут самостоятельно архивы. И в случаях повреждения баз данных, могут рассчитывать лишь на централизованные источники бекапов.
Где хранится история интернета?
Архив интернета – это самостоятельная некоммерческая организация. Она была основана в 1996 году в Сан-Франциско. Именно американский программист Брюстер Кейл решил вести учёт всей информации, накапливающейся в Глобальной сети.
Этот архив хранит не просто старые версии сайтов. Он регулярно сканирует интернет и сохраняет различные версии ресурсов, ведя историю их изменений. Помимо сайтов, здесь можно найти аудиокниги, различные видео и даже программное обеспечение.
В 2001 году владельцы Архива интернета разработали и саму машину времени – Wayback Machine. Инструмент занимается сканированием основной части открытой Сети и предоставляет доступ в интернет прошлого.
Книга и надпись History
Её используют не только для того, чтобы ностальгировать о прошлом, но находят ей практическое применение. Таким образом, например, можно возвращать к жизни старый контент. Он мог выпасть из поля зрения поисковых систем после удаления родительского сайта. Так что публикация таких статей зачастую рассматривается, как написание нового и уникального контента.
Помимо машины времени, разработчики Архива интернета дали жизнь и другим сервисам:
-
Open Library – или открытая библиотека.
Она хранит множество цифровых изданий и предоставляет к ним доступ сроком на две недели совершенно бесплатно.
-
Archive it – полноценная служба архивирования. Она помогает физическим и юридическим лицам с созданием и обработкой цифровых архивов. Благодаря подобным программным решениям, вы можете создавать собственные библиотеки ключевых бекапов личной интеллектуальной собственности.
 Она хранит множество цифровых изданий и предоставляет к ним доступ сроком на две недели совершенно бесплатно.
Она хранит множество цифровых изданий и предоставляет к ним доступ сроком на две недели совершенно бесплатно.
Технически Архив интернета основан на принципе зеркальных сайтов. То есть создаёт несколько собственных резервных копий на различных серверах. Они размещаются по всему свету и не могут быть выведены из строя одновременно.
Что такое веб-архив?
В широком смысле, веб-архив – это база данных с сохранёнными версиями страниц Глобальной сети. То есть владелец сайта может самостоятельно скопировать нужные страницы и отправить их на хранение в веб-архив.
Для самостоятельного сохранения внешнего вида интернета на определённый момент времени, веб-архивы используют поисковых роботов, активно перемещающихся по просторам Глобальной сети.
Благодаря таким сервисам, любой желающий может отправиться на пару десятков лет назад и посмотреть, как именно выглядели сайты того времени. Насколько они отличаются от современных аналогов и были ли действительно лучше.
Ведь на самом деле большинство изменений связаны с прогрессом и оптимизацией, а вовсе не вводятся для того, чтобы вас позлить. Дизайн меняется в угоду упрощению и эргономичности.
Сегодня наиболее важным параметром для любого ресурса является скорость его загрузки, а значит объёмные программируемые элементы просто недопустимы.
Самые посещаемые сайты могут похвастаться не одной сотней тысяч различных точек сохранения. Это говорит о важности фиксирования информации во всём её многообразии и изменении.
Воспринимая Глобальную сеть, как живой организм, который растёт и развивается, веб-архивы предстают в роли биологов, ведущих научные исследования.
Зачем нужен web archive и как его можно использовать?
Визуализация архива
Вариантов применения веб-архивов более чем достаточно. Хотя, с точки зрения рядового пользователя, не создающего самостоятельно контент в Глобальной сети, области применения подобных инструментов могут казаться и не столь очевидными:
-
Поиск старой или утерянной информации – зачастую, интересный контент может быть похоронен под тяжестью поисковой выдачи. Далеко не всегда те сайты, которые кажутся интересными и достойными вашего внимания, пользуются спросом большинства пользователей. В итоге они начинают застаиваться, терять свою актуальность и попросту вылетать из индекса. Дабы освежить в памяти понравившиеся статьи или ознакомиться с теми, которые ускользнули от вашего внимания, можно воспользоваться веб-архивом. Он может сохранять и видео, размещаемые на популярных площадках. Срок жизни у видеоконтента ощутимо меньше, в сравнении с текстовым.
-
Восстановление собственных ресурсов, в случае поломок – причин для нарушения корректной работы собственных ресурсов бывает огромное множество. Связаны они могут быть не только с ошибками владельцев, но и с неполадками на арендуемом сервере. Поэтому подстраховаться и сохранить резервные копии в альтернативном архиве бывает очень полезно.
-
Получение уникального контента – некоторые очень предприимчивые вебмастеры собирают большие объёмы уникального текста из архивов. Это позволяет зарабатывать на органическом трафике.
-
Анализ точек роста сайта – сравнение показателей прошлой и текущей версий сайта открывает доступ к большому объёму полезный данных. Например, проследите поведенческие факторы, после смены элементов навигации. Оцените, как аудитория справляется с изменениями, и стоят ли они того.
Может быть выгоднее вернуть старый интерфейс в угоду эффективности и удобства посетителей.
-
Собирайте информацию из веб-архивов перед покупкой доменов. Проследите, каким было содержание в прошлом, и оцените имидж адреса до того, как решитесь потратить на него свои деньги. Крайне актуально при покупке дорогих доменов. Будет неприятно, если вы купите один из них, а окажется, что он давно скомпрометирован и находится под фильтрами большинства поисковых систем.
-
Современные дизайнеры и верстальщики могут почерпнуть немало полезной информации из веб-архивов. Ведь там хранится настоящая галерея искусства прошлых лет. Проследите эволюцию основных трендов, касающихся оформления и оснащения популярных сайтов.

 Может быть выгоднее вернуть старый интерфейс в угоду эффективности и удобства посетителей.
Может быть выгоднее вернуть старый интерфейс в угоду эффективности и удобства посетителей.
Как просмотреть старые версии сайтов на Wayback Machine?
Принцип работы поиска веб-архивов, в общем-то, не должен вызывать особых вопросов:
- Для начала отправляйтесь на сайт веб-архива: https://web. archive.org.
-
В открывшемся окне найдите строку поиска и введите адрес интересующего вас ресурса. Если вы не знаете точного домена, просто попробуйте поиск по ключевым словам. Он позволяет поработать с привычной выдачей, содержащей сайты, сохранённые ботами.
-
После того, как вы нашли нужный вам сайт и перешли в соответствующее окно, перед вами откроется информация о количестве сохранений и времени каждого из них. Здесь же располагается и временная шкала по годам. Проверить наличие актуальной версии можно на каждый день с момента открытия веб-архива. Разумеется, далеко не все сайты обладают резервными копиями прямо в каждый день. но чёрный график, располагающийся над временной шкалой, демонстрирует количество сохранений в те или иные периоды.
-
В календаре могут присутствовать отметки разного цвета.
-
После клика на кружок, которым отмечен нужный день, вы сможете выбрать версию. В один день бывает несколько сохранений, особенно если тогда происходили ключевые изменения в структуре ресурса. Все ссылки, проставленные в восстановленной версии страницы, будут активными и приведут вас туда, куда и должны были в тот момент, когда существовала сохранённая версия. Но некоторые элементы дизайна и изображения могут оказаться потерянными
 archive.org.
archive.org. Скриншот строки ввода url на Wayback Mashine
Скриншот календаря версий в Wayback Mashine

Скриншот версии сайта 2010 года в Wayback Mashine
Как посмотреть архив сайта в Google?
Самая популярная в мире поисковая система обладает собственными возможностями по работе с сохранёнными версиями сайтов, находящихся в органической выдаче. Найти кешированную страницу можно прямо из результатов выдачи. Для этого перейдите к нужной строке и нажмите на изображение небольшой стрелки, расположенной рядом с URL-адресом целевой страницы. После нажатия на эту стрелку, вы увидите выпадающее меню с пунктом: «Сохранённая копия».
Найти кешированную страницу можно прямо из результатов выдачи. Для этого перейдите к нужной строке и нажмите на изображение небольшой стрелки, расположенной рядом с URL-адресом целевой страницы. После нажатия на эту стрелку, вы увидите выпадающее меню с пунктом: «Сохранённая копия».
Где посмотреть сохраненную версию страницы сайта в Google
Возможности Google, как веб-архива, очень ограничены. Потому что доступ вы сможете получить только к последней актуальной версии сайта. Это делается только для того, чтобы предоставить возможность получить необходимую информацию в условиях недоступности сервера, на котором размещается ресурс.
Фактически, сохранённая страница добавляется в архив Google в тот момент, когда поисковый бот её посещает. Так что версия может быть и месячной давности.
Как посмотреть копию сайта на определённую дату?
Различных инструментов, позволяющих получить доступ к сохранённой версии сайта, сегодня достаточно. Правда не все они предполагают возможность выбора различных точек сохранения. Большинство позволяет обращаться только к последней актуальной версии. Наиболее популярные из них следующие:
Правда не все они предполагают возможность выбора различных точек сохранения. Большинство позволяет обращаться только к последней актуальной версии. Наиболее популярные из них следующие:
-
Internet Archive – https://archive.org. Именно он содержит исчерпывающую и максимально подробную историю развития Глобальной сети. Доступность просматривать сайты в любой точке сохранения открывает широкие возможности для изучения контента. Самая настоящая машина времени для интернета.
-
Собственный кэш поисковых систем – и Google, и Яндекс предоставляют возможность просматривать последние сохранённые версии страниц, находящихся в органической выдаче. Если сайт попал в индекс, значит вы сможете отыскать доступную версию всех его проиндексированных страниц.
-
Попробуйте обратиться к необычным поисковикам, вроде Baidu – этот азиатский ресурс сканирует отечественный и западный сегменты Глобальной сети достаточно редко.
Поэтому, если вы хотите получить доступ к недавно заблокированным страницам, поиск сохранённых версий в этом поисковике – вполне актуальное решение.
-
CashedView.com – специализированая поисковая система, которая работает только с сохранёнными версиями сайтов. На фоне востребованности веб-архивов, появилось несколько подобных ресурсов. В качестве аналога можно рассмотреть, например, cashedpages.com. Подобные варианты придутся как нельзя кстати, если вас интересуют только недоступные или неактуальные версии страниц.
-
Внутренний кэш браузера – он работает с теми страницами, которые вы уже посещали. Сохраняя их в файлах cookies, он может намного быстрее загружать нужную информацию, при повторных посещениях. Но никто не запрещает вам восстанавливать сохранённые данные. Для этого просто введите в адресной строке своего браузера начало URL адреса в виде:
Google Chrome – chrome://cache
Opera – opera://cache
Mozilla Firefox – about:cache
 Поэтому, если вы хотите получить доступ к недавно заблокированным страницам, поиск сохранённых версий в этом поисковике – вполне актуальное решение.
Поэтому, если вы хотите получить доступ к недавно заблокированным страницам, поиск сохранённых версий в этом поисковике – вполне актуальное решение.
Интернет-архив: Wayback Machine
- О
- Блог
- Проекты
- Помощь
- Пожертвовать Значок пожертвованияИллюстрация в форме сердца
- Контакт
- Работа
- Волонтер
- Люди
| Найти этот URL | Некоторые полезные советы и подсказки | ||
| между этими датами (необязательно) | МесяцЯнварьФевральМартАпрельМайИюньИюльАвгустСентябрьОктябрьНоябрьДекабрьДень12345678910111213141516171819202122232425262728293031Год 20102009200820072006200 5200420032002200120001999199819971996 | ||
| МесяцЯнварьФевральМартАпрельМайИюньИюльАвгустСентябрьОктябрьНоябрьДекабрьДень12345678910111213141516171819202122232425262728293031Год 201020092008200720062005200420032002200120001999199819971996 |
| URL-адрес, соответствующий | Получить страницу, которая наиболее точно соответствует критериям поиска | |
Список всех страниц, соответствующих критериям поиска | ||
| Псевдонимы | Объединение псевдонимов (результаты поиска для yahoo. | |
Показывать псевдонимы отдельно (поиск yahoo.com выведет список www.yahoo.com отдельно) | ||
Не показывать псевдонимы (поиск yahoo.com не покажет www.yahoo.com) | ||
| перенаправлений | Скрыть редиректы (в результатах поиска мы не будем отображать страницы, которые перенаправляют на другие страницы) | |
Пометить редиректы (в результатах поиска мы будем отмечать все страницы, которые перенаправляют на другую страницу с помощью ‘r’) | ||
Показывать редиректы (в результатах поиска мы будем отображать страницы этот редирект) | ||
| Типы файлов | Все типы Изображений Аудио видео Бинарный Текст PDF | Будут отображаться только файлы указанного типа |
| Дубликаты | Показать дубликаты (если у нас есть 20 одинаковых версий страницы в этот же день все покажем) |
 com, www.yahoo.com
и yahoo.com/index.html будут объединены)
com, www.yahoo.com
и yahoo.com/index.html будут объединены)Расширенные подсказки и советы по поиску URL-адресов
Есть
ряд простых запросов на основе URL для проведения расширенного поиска
на документах в Wayback Machine. Для проведения этих продвинутых
Поиск, просто введите следующие URL-адреса в местоположении вашего браузера
или адресную строку.
Для проведения этих продвинутых
Поиск, просто введите следующие URL-адреса в местоположении вашего браузера
или адресную строку.
Получение самой последней заархивированной копии определенного URL-адреса
https://web.archive.org/web/http://www.cnet.com
, где «http://www.cnet.com» является целевым URL. Этот запрос возвращает последнее заархивированное версию этого целевого URL в архиве.
Извлечение архивная копия определенного URL-адреса с указанной даты
https://web.archive.org/web/20011007203917/http://www.cnet.com
Это возвращает конкретный документ, URL-адрес которого соответствует целевому URL-адресу и чей дата архива наиболее точно соответствует дате, указанной в формат ГГГГММДДччммсс. В приведенном выше примере возвращается www.cnet.com. заархивировано 7 октября 2001 г.
Дата нет необходимости указывать второй. Использование усеченной даты вернет заархивированную страницу, которая наиболее точно соответствует среднему значение указанной даты.
Пример усечения до года
https://web.archive.org/web/2000/http://www.cnet.comЭто возвращает документ, URL которого точно соответствует http://www.cnet.com и чья архивная дата наиболее точно соответствует 1 июля 2000 г. 1 — середина года или «среднее значение» 2000 года).
Пример усечения до года и месяца
https://web.archive.org/web/200010/http://www.cnet.comЭто возвращает документ, URL которого точно соответствует http://www.cnet.com и чья архивная дата наиболее точно соответствует 15 октября 2000 г. 15 число — середина октября или «среднее значение» октября 2000 г.).
 , 20:39 и 17 секунд.
, 20:39 и 17 секунд.Поиск для всех копий определенного URL-адреса, заархивированных за определенный период времени
https://web.
Это возвращает все копии определенного целевого URL (например, http://www.cnet.com) которые были заархивированы, начиная с даты, указанной в формат ГГГГММДДччммсс. В приведенном выше примере это возвращает список всех всех заархивированных версий www.cnet.com, заархивированных в Сентябрь 2001 г.
 archive.org/web/200109*/http://www.cnet.com
archive.org/web/200109*/http://www.cnet.comПоиск для всех URL-адресов сайта, заархивированных за определенный период времени
https://web.archive.org/web/200109*/http://www.cnet.com*
Это возвращает все URL-адреса, начинающиеся с http://www.cnet.com, которые были заархивированы в сентябре 2001 г.
Wayback Machine в App Store
Описание
Архивируйте веб-страницы и твиты в Wayback Machine!
Чтобы заархивировать веб-страницы или твиты, просто «Поделитесь» ими с этим приложением.
Из Safari — выберите значок «Поделиться» в нижней части экрана, затем выберите это приложение «Wayback Machine».
В приложении Twitter выберите значок «v» в правом верхнем углу твитов, выберите «Поделиться твитами через…», затем выберите это приложение «Wayback Machine».
Но сначала вы должны добавить это приложение в функцию «Поделиться» вашего устройства iOS, выбрав значок «Поделиться» (стрелка вверх в нижней части Safari), затем нажав кнопку «…» (Дополнительно) и, наконец, добавив это приложение.
После того, как вы заархивировали свои веб-страницы или твиты, вы можете с уверенностью делиться их URL-адресами Wayback Machine через Twitter, Facebook, электронную почту и т. д., зная, что они будут там десятилетиями.
Пожалуйста, присылайте сообщения об ошибках, вопросы и предложения по адресу [email protected]
Версия 2.9.5
Исправлена ошибка входа, чтобы вы могли архивировать с помощью расширения «Общий доступ», а также улучшено оповещение о ходе выполнения.
Рейтинги и обзоры
131 Рейтинг
Разочарование
В некотором смысле это лучше, чем использование Wayback Machine в Safari, но во многих других отношениях это приложение является чрезвычайно ограничивающим.
Например, невозможно перейти назад, если щелкнуть ссылку.
Нет опции обновления, которая по какой-то причине является ключевой в Wayback.
Я поддерживаю и жертвую Интернет-архиву, но это приложение не готово к выпуску.
Одна вещь, которую они сделали очень хорошо, — это обзор на основе времени. Я думаю, что это очень хорошо продумано и реализовано.
1, не требуется вход в систему для основного использования
2, добавьте в браузер больше элементов управления, включая навигацию, перезагрузку и создание закладок
Спасибо за разработку этого приложения.
 Если бы приложение делало две вещи, в моем понимании оно было бы 5 звезд:
Если бы приложение делало две вещи, в моем понимании оно было бы 5 звезд:5 ⭐️ потенциал, но…🤔 обновите пожалуйста‼️
У Архива достаточно талантливых поклонников, чтобы улучшить два приложения ИА. Улучшить их давно пора.
Всем нравится Интернет-архив и те невероятные усилия, которые вложены в его создание. Это незаменимо для студентов и любителей знаний во всем мире. Это значительно расширяет доступ к знаниям и отпугивает лжецов правдой первоисточников. Это явно труд любви. Спасибо!
Пришло время повысить уровень ваших двух приложений, время сделать их первоклассными. Брюстер: пожалуйста, подключитесь к своим волонтерским ресурсам.
 *Прочитайте критические отзывы*, отнеситесь к ним серьезно и обновите❗️
*Прочитайте критические отзывы*, отнеситесь к ним серьезно и обновите❗️Хороший! Но некоторые вопросы
Мне действительно нравится это приложение, но я бы хотел, чтобы вы могли просто ввести название веб-страницы или просто выполнить поиск по любому слову вместо того, чтобы просто вводить URL-адрес. Но больше всего я хотел бы исправить то, чтобы для перехода на предыдущую страницу был свайп назад или стрелка назад, потому что это мучительно, когда приходится щелкать X или щелкать что-то еще, что откроет другую страницу. Кроме того, это отличное архивное приложение
Разработчик, Internet Archive, указал, что политика конфиденциальности приложения может включать обработку данных, как описано ниже. Для получения дополнительной информации см. политику конфиденциальности разработчика.
Данные, связанные с вами
Следующие данные могут быть собраны и связаны с вашей личностью:
- Контактная информация
- Пользовательский контент
- Идентификаторы
Данные, не связанные с вами
Могут быть собраны следующие данные, но они не связаны с вашей личностью:
Методы обеспечения конфиденциальности могут различаться, например, в зависимости от используемых вами функций или вашего возраста.