
Что такое LSI копирайтинг, тексты и запросы: на примерах
Пожалуй, каждый копирайтер, который пишет тексты для поискового продвижения (SEO), хоть раз слышал понятие LSI копирайтинг. Или LSI тексты. Если не слышал – тоже неплохо, потому что сегодня получит ударную порцию новой информации и сможет спокойно прибавить 20-30% к своему гонорару.
По хорошему, о латентно-семантическом индексировании (именно так расшифровывается аббревиатура) есть целая статья в Википедии, но написана она слишком научно и без примеров. Поэтому я решил сделать простую, понятную, доступную и наглядную статью-руководство о том, что такое LSI тексты, и как их правильно писать. Другими словами, я хочу сегодня поделиться с Вами прикладной информацией которую можно сразу применять на практике и получать результат. Готовы? Тогда устраивайтесь поудобнее, мы начинаем!
Что такое LSI копирайтинг
На заре 2000-х годов поисковые системы (Google, Yandex) и др. работали не так как сейчас. Они анализировали, насколько страница сайта соответствует запросу пользователя, считая количество вхождений ключевых слов. В результате оптимизаторы “накачивали” ключевиками тексты, под завязку. А для пущей убедительности еще и выделяли их полужирным шрифтом. Такие материалы читать было нереально, зато они неплохо ранжировались (занимали лидирующие места) в поисковой выдаче.

Пример переоптимизированного текста, который на заре 2000-х ранжировался хорошо, а теперь гарантированно попадает под фильтр.
Со временем поисковые системы стали более совершенными. Они научились анализировать интент (намерение пользователя, причину, по которой он вводит тот или иной запрос) и подбирать страницы с ответом, исходя из типа запроса: коммерческие (когда человек хочет что-то купить) и информационные (когда хочет что-то узнать). Для информационных запросов как раз и был внедрен принцип анализа текста на базе скрытого или латентно-семантического индексирования (Latent Semantic Indexing) или, проще говоря, LSI.
Суть принципа: поисковые системы, анализируя тексты на сайте, принимают во внимание не только ключевые слова (так называемое, семантическое ядро), но и сопутствующие по смыслу слова, которые раскрывают тему (так называемое, тематическое ядро): синонимы, ассоциации, гипонимы, гиперонимы, смежные понятия и пр. Чем больше и насыщеннее тематическое ядро, тем более ценным выглядит текст для поисковых систем и тем выше он ранжируется. Вот почему многие SEO-специалисты, когда дают авторам техническое задание (ТЗ), указывают не только ключи, но и тематический словарь – те самые сопутствующие слова для активации LSI-фактора.
Давайте рассмотрим на наглядном примере. Представьте, что у Вас есть высокочастотный (ВЧ) запрос “гольф”. И Вы пишете статью. Исходя из одного только запроса поисковая система не может понять, о чем Вы пишете: то ли об игре, то ли о машине, то ли о длинном носке. Поэтому робот при индексации начнет анализировать окружающий текст (его тематическое ядро). Например, если оно у нас будет как на рисунке ниже, то сразу станет понятно, о чем речь.

Пример тематического (LSI) ядра для запроса «гольф».
То же самое справедливо и для более предметных ключевых слов. Когда пользователь вводит запрос “правила игры в гольф”, один из весомых факторов ранжирования – проработанное тематическое ядро, чтобы дать человеку исчерпывающий ответ на его вопрос, сократив время поиска нужной информации до минимума.
Другими словами, направление LSI копирайтинга строится на том, чтобы писать тексты под запросы, добавляя в них максимальное количество “близких” по смыслу (тематических) слов (прорабатывать ассоциативное ядро, чтобы оно было лучше, чем у конкурентов).
“Хвостовые” LSI запросы
Главная причина, по которой в поисковом продвижении активно используются LSI тексты – не только ранжирование страниц по основным запросам. Есть еще одна тонкость, которая обеспечивает отдельным сайтам до 50% дополнительного трафика (аудитории из поисковых систем). И эта тонкость называется “хвостовые запросы”.
Хвостовые запросы – это длинные запросы, которые, как правило, вводят от силы 1-2 раза в месяц. Или еще реже: раз в 2-3 месяца. Например: “Какой ноутбук лучше для копирайтера: Asus, Dell, Lenovo или MacBook и почему”. Да, да, есть даже такие запросы, и они не показываются в инструментах Яндекс.Вордстат и Google Keyword Planner. Хвостовыми они называются потому что их окончание включает много слов (а-ля хвост) из тематического ядра.
А теперь представьте, что есть две статьи. Обе оптимизированы под запрос: “Какой ноутбук лучше для копирайтера”. Но одна описывает линейку Acer, MSI, Xiaomi и HP, а другая – модели из хвоста запроса. Как Вы считаете, которая из статей будет выше в выдаче по предложенному выше “хвосту”? Естественно, что при прочих равных условиях – вторая.
Главная сила хвостовых запросов в том, что их очень много: сотни, тысячи, десятки тысяч в месяц. И, само собой, под каждый в отдельности оптимизировать или, как еще говорят, “затачивать” страницу нет смысла. Но! Чем более проработанное у Вас тематическое ядро, тем больше хвостовых запросов Вы захватываете автоматически, а значит, тем больше людей можете привести на свой сайт. Вот она, истинная сила LSI копирайтинга: получать аудиторию даже тогда, когда по основным запросам бешеная конкуренция.
К слову, если Вы посмотрите на реалии SEO продвижения, то заметите, что начинающие оптимизаторы на пару с копирайтерами всеми силами пытаются “заточить” страницу под основные ключи. Однако в случае, когда проект новый или у запросов высокая конкуренция, это нецелесообразно, поскольку так можно ждать результатов хоть до корейской Пасхи.
Вот почему продвинутые оптимизаторы и копирайтеры для решения подобных задач делают упор на низкочастотные ключевые слова (которые запрашивают до 500-700 раз в месяц), LSI-продвижение и “хвостовые” запросы. Так можно получить первые результаты уже через 2-3 недели и развить сайт гораздо быстрее. Но главное: копирайтер может сам продвигать так свой сайт или блог, даже без помощи SEO-специалиста.
LSI тексты и SEO-копирайтинг
И здесь я должен сделать очень важное уточнение: LSI тексты – это не замена SEO-копирайтингу. Это лишь один из его атрибутов в реалиях современного поискового продвижения. Да, когда Вы умеете составлять тематическое ядро – это хорошее подспорье, и в ряде случаев Вы сможете собирать “хвостовой” трафик по низкочастотным запросам без конкуренции. Но для достижения максимального эффекта при решении задачи, основы SEO нужно знать обязательно.

Связь SEO и LSI копирайтинга.
Благо, сейчас есть хорошие бесплатные курсы в открытом доступе на YouTube. К слову, ссылку на один из них я даю в 13 уроке своего собственного открытого курса “Копирайтинг с нуля за 30 дней”: SEO и LSI-адаптация текста. Посмотрите.
Как писать LSI тексты (на примерах)
Процесс написания текста (чаще всего, статьи) с учетом фактора латентного семантического индексирования немного отличается от процесса написания обычной статьи (которую я описывал в предыдущей публикации). И главное отличие в том, что перед разработкой текста Вы продумываете тематическое ядро. Это очень важно, поскольку от него будут напрямую зависеть и LSI-фактор, и количество “хвостовых” ключей.
Чтобы это сделать, я сейчас покажу Вам очень простую, но мощную технику. Эта техника базируется на методике ассоциативного мышления, и ее можно применять не только в копирайтинге, но и в нейминге, разработке слоганов, а также в решении ряда других, более сложных задач. В качестве наглядной иллюстрации я возьму эту статью. Именно эту, которую Вы сейчас читаете — про ЛСИ копирайтинг. Кстати, русскоязычная аббревиатура в предыдущем предложении – одно из слов тематического словаря. Впрочем, обо все по порядку.
1. Создание ассоциативного ядра (LSI-ядра) первого порядка
Тематическое или, как его еще называют, ассоциативное ядро создается не сразу, а поэтапно. На первом этапе мы берем локальное семантическое ядро (список ключевых слов) для текста и выписываем его. Либо сводим в интеллект-карту. Так будет гораздо проще и нагляднее в дальнейшем.

Локальное семантическое ядро для этой статьи.
Например, для этой статьи семантическое ядро состоит из четырех основных запросов. Есть еще второстепенные, но я их здесь не указывал, чтобы было проще. Буду потом смотреть, какие позиции они обеспечат материалу в поисковой выдаче.
Далее, к каждому ключевому слову (или набору ключевых слов, если их много) мы создаем облако ассоциаций, синонимов, гипонимов, гиперонимов и других связанных слов. Это, так называемые, LSI запросы первого порядка. Если у Вас получилось достаточно слов, и тематика не особо конкурентная, то на этом можно и остановиться.

LSI слова первого порядка.
Если запросы похожи, как в данном случае, то тематические ядра будут во многом совпадать. Тогда лучше сгруппировать ключевые слова, чтобы сэкономить время и избавить себя от лишней работы.
2. Создание тематического ядра второго порядка
У нас есть LSI-запросы первого порядка. Далее, мы берем каждое из этих слов и делаем для них свои ассоциативные мини-ядра. Например, для ассоциации SEO у нас получится вот такой фрагмент мини-ядра. Если будут слова, которые пересекаются с ядром первого порядка — не страшно.
Важно: ядро второго порядка должно быть прямо или косвенно связано с ядром первого, т.е. если Вы будете включать все слова, которые относятся к SEO, но не имеют связи с копирайтингом, толку будет немного.

Тематическое ядро второго порядка.
При составлении таких ассоциативных ядер большую роль играет словарный запас и здравый смысл. Программным способом их определить не так просто. Вроде как есть системы, но они либо сложные и платные (Just Magic), либо примитивные (Pixel Tools), либо далеки от совершенства и уступают методу ассоциативного мышления (Ultimate Keyword Hunter). По хорошему, здесь нужно подключать нейронные сети. А поскольку мощности требуются большие, как таковых онлайн сервисов для подбора LSI слов на базе нейросетей пока нет. Поэтому в LSI копирайтинге чем выше уровень эрудиции и начитанности автора — тем лучше.
3. Добавление LSI фраз
Для большинства задач первых двух пунктов хватает за глаза. Но мы-то легких путей не ищем, а потому усилим стратегию и составим из ассоциативного ядра набор дополнительных устойчивых словосочетаний (LSI фразы), которые используются в естественной речи.
К слову, этот пункт я добавил в статью по совету своего друга, SEO-специалиста, Антона Шабана. Он в свое время написал несколько классных статей для моего блога: о том, как написать SEO-текст правильно и об 11 инструментах копирайтера для продвижения.
Фрагмент облака ассоциативных фраз у нас выглядит вот так.

Фрагмент облака LSI фраз.
4. Пишем LSI текст с учетом всех ядер
Итак, у нас есть семантическое и тематическое ядра. Теперь выбираем формат статьи, создаем структуру и пишем текст. О том, какие форматы статей бывают, я рассказываю в этом видеоуроке. О том, как разработать структуру статьи, я рассказывал в предыдущей публикации.
Структура у меня получилась следующая:
- Заголовок
- Вводный абзац с постановкой задачи
- Блок о том, что такое LSI копирайтинг, слова, тексты и запросы
- Блок о “хвостовых” запросах
- Модуль о связи латентно-семантического индексирования и поискового продвижения (SEO)
- Методика написания LSIтекста
- Ассоциативное ядро первого порядка
- Тематическое ядро второго порядка
- Ассоциативные фразы
- Структура и сам текст
- Наглядный результат на примере текущей статьи
Чтобы получить максимальный эффект, я распределяю LSI слова и фразы равномерно по всему тексту.
Результат (пример LSI статьи)
В этой статье главное удобство в том, что Вы видите результат сейчас прямо перед собой. Сама статья — это показательный пример того, как писать LSI текст. Другой вопрос, насколько эффективно она будет ранжироваться. Об этом я узнаю спустя какое-то время. И расскажу Вам. Во всяком случае, в остальных материалах я использую такой же подход, и свои 4000 посещений в сутки блог имеет.

Пример LSI статьи.
Если материалы будут занимать высокие позиции в поисковой выдаче и привлекать трафик — хорошо. Не будут — значит нужно пересмотреть LSI запросы, изучить еще раз конкурентов и “пересобрать” текст. Плюс, поработать над поведенческими факторами, о которых я также буду рассказывать в одной из следующих статей.
Попробуйте применить эти советы на практике, и я убежден: у Вас все получится!
Искренне Ваш, Даниил Шардаков.
shard-copywriting.ru
LSI-копирайтинг: принципы, инструменты, рекомендации по составлению текстов
 Эволюция поисковых систем предъявляет новые требования к написанию текстов для сайта. SEO-копирайтинг уходит в прошлое, на смену приходит LSI-копирайтинг. Подробно рассказываем, что это и как работает.
Эволюция поисковых систем предъявляет новые требования к написанию текстов для сайта. SEO-копирайтинг уходит в прошлое, на смену приходит LSI-копирайтинг. Подробно рассказываем, что это и как работает.Задача поисковых систем — найти информацию, которая наиболее точно отвечает запросам пользователя. Для этого машины должны были научиться распознавать смысл на основе содержания, а не только по отдельным «маякам» — поисковым запросам.
Классическая схема «запрос-документ» стала неактуальной из-за заспамленности большинства тематик. Поэтому ей на смену пришли алгоритмы латентного семантического анализа, а затем нейросети. В ответ специалисты SEO стали внедрять LSI-копирайтинг.
Термин
LSI-копирайтинг — метод написания текстов на основе анализа синонимов поискового запроса и сопутствующих ключевых слов.
Цель — повышение релевантности, полезности, актуальности и достоверности материала. LSI-копирайтинг помогает поисковым системам лучше понимать смысл и содержание текста. В результате сайт может попасть на первые страницы выдачи, даже имея минимальное количество ключевых слов.
На практике это значит, что в тексте необходимо использовать синонимы основного запроса, сопутствующие ключевые слова и дополнительные фразы из смежных тематик. Это позволит полностью охватить и раскрыть тему. Такой контент оценят и пользователи, и поисковые системы.
История
В 1988 latent semantic analysis (LSA) получил патент U.S. Patent 4,839,853. Создатели метода — группа инженеров-исследователей: Скотт Дирвестер, Сьюзен Дюмэ, Джордж Фурнаш, Ричард Харшман, Томас Ландауэр, Карен Lochbaum и Линн Стритер.
Первоначально LSA применяли для выявления семантической структуры и автоматического индексирования текста. Затем — для построения когнитивных моделей и представления баз знаний. В США метод использовался для проверки качества обучающих методик и знаний школьников.
Суть метода
LSA, латентный семантический анализ — способ обработки информации на естественном языке. Он анализирует связь между коллекциями документов и терминами, которые в них встречаются. Латентный семантический анализ сопоставляет запросы и документы согласно тематике. Это позволяет выявлять скрытые ассоциативные и семантические связи.
LSI — аббревиатура от latent semantic indexing, с английского — латентное семантическое индексирование. Это способ использования LSA в области поиска информации.
Проще говоря, LSA позволяет машинам понимать смысл и содержание документа. А при ранжировании уравнивает «веса» разных по написанию, но близких по смыслу слов. Таким образом структурируются синонимы и запросы схожей тематики.
Основа системы — терм-документная матрица, разбор которой и является LSA. Терм-документная матрица представляет собой таблицу, в которой совмещаются «термы» (слова, фразы, термины) и документы. Строки соответствуют документам, а столбцы — терминам. Число обозначает количество пересечений.
|
Документ 1 |
Документ 2 |
Документ 3 |
Документ 4 |
Документ 5 |
Документ 6 | |
|
Корабль |
1 |
0 |
0 |
0 |
0 |
0 |
|
Лодка |
0 |
1 |
0 |
0 |
0 |
0 |
|
Океан |
1 |
1 |
0 |
0 |
0 |
0 |
|
Вояж |
1 |
0 |
0 |
1 |
1 |
0 |
|
Путешествие |
0 |
0 |
0 |
1 |
0 |
1 |
Процесс семантического анализа подобен работе простейшей нейросети — машина ищет пересечения связи между двумя слоями данных. Матрица описывает частоту, с которой встречаются термины в коллекциях документов.
LSI в алгоритмах поисковых систем
Первое упоминание LSA в поисковых системах связано с алгоритмом Panda от Google. Обновление ставило себе цель — найти и снизить количество контента низкого качества, который был создан с целью манипуляции поисковой выдачей. Алгоритм был запущен в феврале 2011, а уже в 2012 году появились первые упоминания об LSI-копирайтинге.
Окончательно новые требования к качеству текстов сформировались к 2013 году. В это время Google запустил новый алгоритм — Hummingbird («Колибри»). Главное отличие нового алгоритма — поиск стал понимать поисковые запросы разговорного типа. Google научился отыскивать нужные документы, исходя из семантических связей, а не просто по запросам.
Яндекс подхватил эстафету в ноябре 2016 года — запустил алгоритм «Палех». Его задача — распознавать низкочастотные и сложные запросы из «длинного хвоста». То есть понимать запросы в разговорном ключе. Общая масса таких запросов составляет порядка 40% от объема текста.
Для работы алгоритма были использованы нейросети и машинное обучение. Подробнее о механике и принципах работы алгоритма можно прочитать в блоге Яндекса на Хабрахабре. Введение в работу «Палеха» подогрело интерес к LSI-текстам в русскоязычном интернете.
Весной 2017 года Яндекс вводит «Баден-Баден» — новый алгоритм определения текстов, которые перенасыщены ключевыми словами. Тысячи сайтов попадают под фильтр и понижаются в выдаче, условием возврата трафика называется отказ от SEO-текстов.
Осенью 2017 Яндекс запускает «Королев» — алгоритм поиска на основе нейросетей. По заявлению Яндекса, алгоритм «…сопоставляет смысл запросов и веб-страниц…». Новый алгоритм работает на нейросетях, но при этом не отменяет LSI, а усиливает сложившиеся тенденции. Теперь писать SEO-тексты нет никакого смысла — вместо ТОПа можно получить фильтр за переоптимизацию.
Отличие LSI от SEO-копирайтинга
Для удобства используем сравнительную таблицу
|
Отличия |
SEO-тексты |
LSI-тексты |
|
Цель |
Написать текст с нужными ключевыми словами и определенным числом вхождений |
Полностью удовлетворить запрос пользователя |
|
Задача |
Вписать ключевые слова с определенной плотностью и расположением |
Охватить весь спектр ассоциативных связей, рассмотреть проблему со всех сторон |
|
Нахождение ключевых слов в тексте |
В заголовках, в первом абзаце, выше по тексту |
Не важно |
|
Оформление статьи |
Непринципиально |
Необходимо |
|
Способы оценки качества текста |
Техническая уникальность, плотность вхождений, частота использования слов на определенный объем текста |
Смысловая уникальность, полезность, удовлетворенность пользователя |
|
Объем текста |
От 2000 знаков с пробелами |
Столько, сколько нужно для раскрытия темы. На практике 5000–10 000 знаков и больше. |
Как видим, основное отличие — отход от чисто технических параметров текста к здравому смыслу: пользе, удобству читаемости. Можно сказать, что это эволюция SEO-копирайтинга — материалы создаются для людей, а не для роботов.
Это результат того, что теперь поисковые машины оценивают релевантность контента по смыслу. Учитывается контекст, уместность, семантические варианты запросов и их окружение. Вкупе с поведенческими факторами это позволяет оценивать качество текста и потребности читателей.
Преимущества и недостатки
Преимущества
Те, кто сумел приспособиться к новым требованиям поисковых систем, получают определенные преимущества.
- Увеличивается семантическое ядро. Все LSI-фразы — это дополнительные, низкочастотные ключи по той же тематике.
- Увеличивается «длинный хвост» запросов и трафик. Используйте сопутствующие запросы и получите посетителей по широкому спектру редких ключевых слов.
- Улучшаются поведенческие факторы. Объемная, полезная статья захватит больше читательского внимания и времени. Даже просто на то, чтобы пробежаться по заголовкам и разобраться, понадобится время.
- Вырастет количество социальных сигналов и естественных ссылок. Полезным материалом делятся, о нем рассказывают, сохраняют у себя на страницах, чтобы использовать в будущем.
- Вырастут позиции в поиске по высокочастотным фразам. «Длинный хвост» запросов подтянет за собой конкурентные ключевые слова, в этом ему помогут поведенческие и социальные факторы.
- Сайт не попадет под фильтр. Все современные алгоритмы нацелены на отсев бесполезных текстов, заточенных под роботов. Использование принципов LSI-копирайтинга позволит избежать подобной ситуации.
- Проще структурировать сайт. Если раньше приходилось создавать несколько страниц для охвата синонимов или сопутствующих запросов, то теперь можно создать одну страницу.
LSI-копирайтинг требует серьезного вложения труда как SEO-специалиста, так и копирайтера. Но этот труд окупится сторицей. Вы получите стабильное нахождение в ТОПе и внимание пользователей.
Недостатки
Несмотря на вышесказанное, LSI — не панацея и имеет ряд недостатков:
- Модель работает на допущении, что у слова есть всего одно значение.
- Текст рассматривается просто как набор слов, взаимосвязи и порядок игнорируются.
- Смысл текста не всегда может быть дословным, не учитывается сарказм, ирония, иносказания и т.п.
- Часть данных теряется в любом случае. Это происходит, потому что сингулярное разложение позволяет работать только с самыми значимыми данными терм-документной матрицы.
Однако даже с подобными недостатками метод LSI превосходит существовавшие прежде методы индексации. А использование нейросетей позволяет обучать поисковые машины еще быстрее и эффективнее.
Требования к LSI-текстам
К современным материалам предъявляются определенные требования.
- Польза и достоверность. Нужно раскрыть тему — текст должен давать пользователю полноценный ответ.
- Насыщенность LSI-фразами и наличие поисковых запросов. Нужно использовать ключевые слова, дополнительные слова из тематики и сопутствующие запросы.
- Простота изложения. Стиль и терминология подбираются таким образом, чтобы текст был понятен рядовому пользователю.
- Структура. Четкая структура и иерархия упрощают усвоение материала, читатель получает возможность «просканировать» документ и понять о чем речь с первого взгляда.
- Ритм текста. Рекомендуется чередовать длинные и короткие предложения. Это создает определенную динамику, которая увлекает читателя.
- Грамотность и достоверность информации. Не должно быть фактических и грамматических ошибок. Недостоверность определит пользователь, а ошибки — поисковые системы. И те, и другие сделают вывод о низком качестве текста.
Подведем итог. Существует спрос на качественные тексты экспертного уровня. Они должны обладать дополнительной ценностью для пользователей и поисковых машин, а не только содержать в себе ключевые слова.
Как создать LSI-текст
Этапы работы:
- Собрать семантическое ядро из основных запросов.
- Подобрать LSI-фразы — сопутствующие запросы и дополнительные слова из тематики.
- Составить техзадание для копирайтера. Упор делать на качество текста, а не вхождения тех или иных слов. Плотность, тошнота, частота вхождения и прочие технические параметры текста не важны. Важнее, чтобы тема была раскрыта.
- Готовый текст используйте для создания плана страницы — решите, как лучше использовать визуальный контент.
LSI-ключи
Различают два вида ключей:
- Релевантные — слова из тематики главного ключа, которые дополняют и уточняют его. Также сюда относятся фразы, которые имеют прямое отношение к теме статьи. Наличие таких фраз в статье позволяет понять, насколько тема раскрыта.
- Синонимичные — синонимы основного запроса. На них делается упор при базовой оптимизации текста. Это позволяет не создавать дополнительных страниц и привлекать отраслевой трафик на одну страницу.
LSI-запросы можно использовать:
- В анкорах входящих ссылок.
- В заключении или вступлении статьи.
- В окружающем тексте обратных и входящих ссылок.
- В названиях изображения, подписях и ALT.
- В заголовках и метатегах.
Важно не переусердствовать и не забывать об основном запросе. Достаточно единственного упоминания в тексте.
Инструменты для сбора LSI-фраз
На данный момент существует достаточное количество способов подобрать LSI-фразы.
Подсказки поисковых систем
В Яндексе можно подобрать слова, если применять разные вариации написания.


В Google ситуация сходная.

Блоки «Вместе с..» и «… часто ищут»


Статистика запросов Яндекс и Google
У обоих «поисковиков» есть собственная статистика ключевых слов. Для подбора LSI-фраз можно воспользоваться ими. Это бесплатно, но долго. В Яндексе — это сервис Вордстат, а в Google — Google Keyword Planner. В последнем работать можно только из аккаунта Google AdWords.


Pixel Tools
Сервис доступен после регистрации. Нам нужен раздел «ТЗ для копирайтера». Вбиваем запрос и получаем тематические слова. В разы быстрее, чем при ручном сборе из поиска, но требует оплаты.

Схожие возможности имеют Megaindex и Serpstat. Оба сервиса платные.
Arsenkin Tools
Набор бесплатных инструментов для работы SEO-специалиста от arsenkin.ru. По нашей теме предлагает сразу два сервиса: «Парсинг подсветок Яндекса» и «Парсинг тегов h2–H6». Первый поможет подобрать сопутствующие запросы, второй — проанализировать структуру и распределение «ключей» конкурентов.

Ubersuggest tool
Для глубокой проработки LSI-фраз рекомендуем воспользоваться сервисом Ubersuggest tool. Сервис довольно прост в использовании и выдает довольно много вариантов дополнительных слов.

Видеогайд по инструментам для сбора LSI-фраз от Сергея Кокшарова
Создание структуры
Скелет любой статьи — структура. Именно она позволяет с первого взгляда оценить качество. Текст должен иметь иерархию и подчиняться внутренней логике. Части статьи не должны противоречить друг другу.
- Статья должна содержать заголовки и подзаголовки, маркированные списки и таблицы. Если это страница сайта, то стоит предусмотреть расположение отдельных элементов: кнопок, форм заказа, фотографий.
- Заголовок должен отражать основную идею материала, заголовки второго уровня — развивать тему в различных аспектах. Подзаголовки и заголовки третьего уровня указывают на частности или какие-то подробности.
- Заголовок и абзацы образуют, так называемые блоки. В каждом блоке может быть несколько абзацев. Абзац содержит от трех до шести строк и раскрывает одну определенную мысль. Короткие абзацы создают ощущение легкого, динамичного текста.
- Иерархию заголовков можно создать, опираясь на ключевые слова. Их нужно сгруппировать по смыслу. В статье идите от общего к частному — получится четкое и логичное повествование.
Обычно высокочастотные запросы касаются общей информации. Группа среднечастотников даст возможность глубже раскрыть тему. А низкочастотники позволят охватить нюансы, которые интересны пользователям.
Пример проработки структуры статьи

Постановка технического задания
Техническое задание стоит оформлять так, чтобы у копирайтера не возникало вопросов. Опишите требования максимально подробно и четко. Чем лучше вы подготовитесь, тем меньше придется переделывать. И учтите, что для LSI-копирайтинга требуются специалисты более высокого уровня. Идеально, если копирайтер имеет личный опыт в описываемой тематике.
Пример ТЗ

Набор лемматизированных слов

Выбор исполнителя
Есть несколько подходов к написанию хорошего LSI-текста:
- Обратиться к эксперту, попросить рассмотреть тему со всех сторон, рассказать о нюансах. Таким образом, LSI-фразы уже будут в тексте, либо их можно будет аккуратно добавить.
- Дать задание копирайтеру. Попросить вписать основные запросы в статье и заголовках, а сопутствующие запросы использовать для раскрытия темы.
- Другой вариант — дать копирайтеру основные ключи, а сами LSI-фразы добавить, когда текст будет написан.
- Заказать в агентстве. Вам не придется собирать техническое задание, копирайтеры в агентстве работают по обкатанным схемам — их не придется обучать или переделывать работу.
Сравнение LSI и SEO-текста
Пример текста с включением LSI-фраз. Это часть большого текста для страницы сайта. Рассматриваются все виды съемной тонировки. Отмечаются особенности каждого вида.

Пример классического SEO-текста. Проставлено несколько необходимых вхождений с определенной плотностью. Пространство между ключевыми словами заполнено общими, ничего не значащими фразами. Имитация информативного текста.

Частые вопросы по LSI
Если вы что-то не поняли или у вас возникли вопросы, посмотрите видео с Сергеем Кокшаровым. В ролике он отвечает на вопросы SEO-специалистов.
Вопросы-ответы от Сергея Кокшарова
Выводы
Иногда поднимается вопрос о целесообразности подбора LSI-фраз, ведь по логике, достаточно написать текст экспертного уровня. Но здесь не все так просто — невозможно всего лишь «прикинуть» в голове весь спектр сопутствующих слов. Поисковые системы анализируют огромные базы данных, без их статистики ключевых слов вы наверняка что-нибудь упустите.
Основная задача LSI — фильтрация спама и распознавание смысла текста. Непосредственно на ранжирование она влияет опосредованно. Но в условиях жесткой конкуренции необходимо прорабатывать сайт полностью. Поскольку иногда именно мелочи могут дать решающее преимущество.
LSI-копирайтинг — не идеальный метод, но имеет ряд преимуществ: позволяет не попасть под текстовые фильтры и улучшить старые материалы. Переработка текстов дает возможность вывести сайт из-под санкций и увеличить посещаемость сайта.
Латентный семантический анализ и индексирование — явление уже свершившееся. Более того, поисковые системы уже подключили к своей работе нейросети и машинное обучение. Логическим продолжением такой эволюции будет искусственный интеллект в информационном поиске.
www.seonews.ru
что это, преимущества, как найти и применить в тексте

LSI (Latent Semantic Indexing, “скрытое семантическое индексирование” или “индексация скрытого смысла”) – это добавление в текст статьи релевантных, тематических и сопутствующих ключевому запросу слов, формирующих тему, на которую пишется контент.
Что такое LSI слова?
LSI слова – это ключевые слова, связанные с основным ключом семантически. Они являются неотъемлемым элементом алгоритма LSA, то есть латентно-семантического анализа, который американские инженеры использовали еще в 1988 году для индексирования текстов и отображения баз данных. Затем его стали применять с целью анализа знаний американских школьников.
Многие вебмастера ошибочно полагают, что LSI словами являются лишь синонимы к основным ключевым фразам. Но в качестве них выступают любые ключевики, отображающиеся в результатах выдачи рядом с ключевым запросом, указанным в строке поиска, потому что у них аналогичный контекст.
Что такое LSI копирайтинг?
LSI копирайтинг – это способ написания текстового материала, направленный на увеличение релевантности страницы при анализе поисковиком синонимов и сопутствующих фраз ключевику, а также смысла текста и его подачи. Данный метод копирайтинга убеждает поисковых роботов в актуальности, ценности и достоверности статьи, что способствует ее поднятию в первую десятку поиска Google и Яндекса.
Принцип LSI копирайтинга заключается в том, что поисковые системы в процессе анализа текстов на сайте, помимо ключей, формирующих семантическое ядро, учитывают еще сопутствующие слова и похожие друг на друга по смыслу, раскрывающие тематику статьи.
Ассоциативное ядро формируют синонимы, гипонимы, гиперонимы, смежные термины и понятия, ассоциации и прочие слова. И чем оно масштабнее, тем материал может быть ценнее для поисковиков, соответственно страница с таким контентом должна ранжироваться выше.
В связи с этим многие сеошники, составляя технические задания для копирайтеров, указывают в них не только ключи, но и LSI-слова, которые нужно применить в тексте.
Чтобы было понятнее, приведу пример. Возьмем высокочастотный запрос “гольф”. Вам нужно написать статью. Если затачивать ее лишь под один ключевой запрос, поисковой машине будет трудно разобраться, о чем идет речь: о машине, длинном носке, игре или свитере.
Чтобы разобраться, поисковый робот в ходе индексации занимается анализом тематического ядра, то есть текста, окружающего основной ключ. И если в тематическом облаке будут содержаться сопутствующие ключу слова, то поисковик быстро поймет, о чем статья.
webmasterie.ru
LSI-копирайтинг – тренд ближайшего времени
В марте 2014 года Google начал шифровать абсолютно все поисковые запросы. Теперь в Google Analytics вместо поисковой фразы, по которой было совершенно n-нное количество визитов на сайт, мы увидим два слова: not provided. Напомним, Яндекс в декабре 2013 года – вместе с анонсом об отмене ссылочного ранжирования – также начал шифровать текст поисковой фразы в заголовке Referer у части поисковых запросов. Мы предполагаем, что рано или поздно это произойдет со всеми запросами. Причем, скорее рано, чем поздно.
Резюмируя, можно сказать: ситуация такова, что уже в ближайшее время с прежней ясностью понимать, какие запросы в тематике генерят переходы, уже будет нельзя – это можно будет только прогнозировать.
Основной вывод для владельцев сайтов и сеошников? Продвижение по позициям окончательно отменяется. Остается только одно достоверное мерило результативности – поисковый трафик.

Что такое LSI-копирайтинг
Что вообще означают все эти печальные для SEO (и обнадеживающие для тех, кто занимается продвижением с помощью контент-маркетинга) новости? Похоже, поисковые гиганты нацелились на планомерное истребление всех оставшихся в поисковом маркетинге элементов классического SEO. Это последовательно проводимая политика максимального нивелирования манипулятивных действий со стороны оптимизаторов.
Если не известно, по каким запросам ваш сайт получает трафик, то на основании чего делать вывод об эффективности того или иного продвигаемого ключа/поисковой фразы? Есть такое суждение: если мы забудем о поисковых запросах, оставим попытки отследить, каким запросам должна быть релевантна та или иная страница сайта, то релевантность в итоге на странице будет «размыта». Но на самом деле все не так. Все честно: о чем вы выпишите на странице – тому она и релевантна.
Тут важно понять, что релевантность – это уже давно не плотность ключа на странице. И мы понимаем, о чем говорим. Мы сами много лет назад разработали скрипт оценки плотности ключа на основании сайтов, находящихся в ТОП-20 поисковой выдачи по тому или иному запросу. И, в общем-то, с 2010-го мы уже им не пользуемся сами 🙂 – это просто ни к чему. Релеватность больше не касается фраз-маячков, вписанных в текстовый контент, релевантность во времена семантического поиска касается смысла, содержания.
Тренд ближайших нескольких лет – это так называемый LSI-копирайтинг.
С аббревиатурой LSI все более менее понятно: это латентно-семантическое индексирование (latent semantic indexing), метод индексирования скрытой семантики – семантики, меняющей значение в зависимости от контекста. Именно благодаря LSI поисковики учатся понимать естественный язык запросов.
В ответ на движение поисковиков в сторону семантического поиска возник так называемый LSI-копирайтинг. LSI-копирайтинг в ближайшие два-три года отменит seo-копирайтинг полностью.
Как меняется понятие «релевантность» с совершенствованием семантического поиска
Что мы подразумеваем под seo-копирайтингом? Работа с текстом на основании перечня вписываемых ключей и плотности их вписывания. Почему он будет существовать еще ближайшие два-три года? Вовсе не потому, что вписывание ключей сегодня эффективно. Просто инертность рынка огромна, именно поэтому работа с текстом по плотности ключей будет какое-то время еще жить.
Вписывание ключей (seo-копирайтинг) не актуален, не эффективен и даже вреден уже года два как. Все началось в 2011-м – с алгоритма Panda, крупнейшего по значимости в истории обновлений алгоритмов Google. Основное, что говорят о Panda: этот алгоритм был нацелен на борьбу с некачественными текстами. Но это не совсем так. На самом деле Panda оценивал взаимодействие пользователя с сайтом, еще точнее – степень его вовлеченности при просмотре содержимого веб-страницы. Очевидно, что текстовый контент играет огромную роль при формировании мнения посетителя о странице. И с этой точки зрения правомочно говорить, что Panda – это начало серьезной борьбы с некачественными текстами (хотя сводить все это обновление к одному только качеству текста, конечно, неправильно). После введения этого алгоритма выдача Google очистилась от огромного количества текстовых ферм и сайтов, на которых тексты явно были созданы ради вписывания ключей, а не для людей.
Но, по большому счету, настоящий прорыв в области семантического поиска произошел с введением в 2013 году алгоритма Hummingbird (Колибри). С этого момента началась истинная история LSI-копирайтинга.
Hummingbird был представлен на пресс-конференции, посвященной 15-летию Google. Тогда руководитель направления по разработке поисковой системы Амит Смит отметил, что Humminbird – самое серьезное с 2001 года обновление. С его введением начался период обработки поисковых запросов не столько по ключам, сколько по смыслу. Как заявили в Google, это нововведение – ответ на то, что люди начали реже вводить в строку поиска лаконичные запросы, содержащие ключевые фразы, и все чаще стали использовать при поиске «естественные» запросы – просто фразы разговорной речи, довольно часто сложные и длинные. Hummingbird «умел» обрабатывать такие запросы.
Таким образом, сегодня имеет смысл говорить о «релевантности смыслов», а не о «релевантности слов-маячков» на странице, что является серьезным эволюционным шагом в семантическом поиске.
Фактически речь идет о том, что поиск стремится «прочесть» и «пересказать» текст своими словами – а это – ни больше, ни меньше – заявка на искусственный интеллект. Пока, правда, ни один робот не прошел этот «текст для первоклассников», но эволюция в этом направлении идет впечатляющими темпами.
К чему все идет?
Сразу вспоминается, насколько серьезно Google в последнее время начал фокусироваться на разработках, связанных с созданием искусственного интеллекта. В январе 2014-го Ларри Пейдж лично курировал приобретение компанией Google лондонской фирмы DeepMind Technologies, ориентированной на создание алгоритмов глубокого машинного обучения, с использованием наработок в области нейробиологии.
А незадолго до этого поисковый гигант купил Boston Dynamics – всемирно известную инженерную компанию, разрабатывающую, пожалуй, самых продвинутых роботов на этой планете.
Одна из военных разработок Boston Dynamics — BigDog. Предназначен для перемещения на местности, где не может передвигаться обычный транспорт. Длина робота — 0,91 м, высота — 0,76 м, вес —110 кг.
Google ориентирован на глубокое обучение и, вероятно, на создание умного машинного «мозга». Более того, в компании создана комиссия по этике, которая будет наблюдать за тем, чтобы разработка искусственного интеллекта шла в «правильном» с точки зрения общепринятых гуманных норм направлении.
После этого, какой остается шанс, что Google оставит возможность производить хоть какие-то манипулятивные воздействия на выдачу? Никакого.
Смысл в том, что чем больше вы будете думать об интересах людей (вашей аудитории) и чем меньше о том, как за счет несовершенств поисковика можно накрутить трафик, – тем легче вам будет расти и получать лояльную аудиторию. Создавайте контент для людей, улучшайте сайты, чтобы посетителям было удобно ими пользоваться. Оптимизация кончилась, остался чистой воды маркетинг в Сети. Думайте о том, что нужно вашей ЦА, и давайте ей это – что еще тут можно сказать?
Ну и специально для тех, кто сомневается в том, что технологическая сингулярность будет достигнута. Посмотрите на видео ниже. И после такого вы все еще сомневаетесь?
Базовые движения этого робота заданы алгоритмом. Но он сам принимает решение, какие движения использовать – в зависимости от типа звучащей музыки и ритма.
Читайте также:
lsi-kopirayting-trend-blizhayshego-vremenitexterra.ru
Статья о LSI-копирайтинге: материалы блога 1PS
Представим, что вы читаете статью о выборе масла для двигателя. И вдруг замечаете в тексте слова «купить губную помаду». Перед вами устаревший, но пока используемый метод SEO. Когда ключи добавляют в тексты, не подходящие по теме.
Позже стали стараться употреблять прямое вхождение ключей. Что тоже уже относится к олдскульному SEO, хотя в некоторых тематиках до сих пор работает.
На данный момент чаще используют другой метод – следят за технической уникальностью, количеством вхождений ключевых слов, спамностью текста и т.п.
Но и этот привычный способ продвижения уходит в прошлое и передает эстафету инновационному LSI-копирайтингу.
LSI-копирайтинг – что за фрукт?
Начнем с LSI или latent semantic indexing. В переводе на русский – «латентное семантическое индексирование». В переводе на более понятный язык – метод индексирования, благодаря которому поисковые роботы Яндекс и Гугл могут обращать внимание на общий смысл текста, а не только на уникальность и насыщенность ключевыми словами.
Например, вы ввели в строку поиска «LSI-копирайтинг». Робот найдет множество страниц со сходными терминами и аббревиатурами, названиями организаций. Но в результатах выдачи на первых местах будут качественные статьи про SEO и LSI-тексты. Все остальное – на последних страницах.
Теперь перейдем к LSI-копирайтингу – это написание текстов, основанных на технологии скрытого семантического индексирования. То есть таких текстов, в которых важно не наличие ключевого слова, а содержание.
Разница между традиционным SEO-копирайтингом и инновационным LSI-копирайтингом в нескольких словах:
SEO-копирайтинг
- Написание текста на основании списка ключевых слов, с обязательным их вхождением в теги, заголовки, первые абзацы и т.п.
- Работа с плотностью ключевых слов в тексте.
- Работа с технической уникальностью.
LSI-копирайтинг
- Написание текста на основании списка ключевых слов, с упором на смысл, а не на вхождение этих ключей.
- Добавление в текст слов, которые связаны с основными запросами.
- Работа над полезностью и смысловой уникальностью материала.
Когда поисковые роботы стали применять LSI?
Латентно-семантический анализ запатентовали в далеком 1988 году. Однако поисковые системы начали постепенно внедрять LSI примерно 5 лет назад.
В 2011 Google стал использовать поисковый алгоритм Панда. Его цель – борьба с текстами плохого качества. Панда оценивает взаимодействие пользователя с сайтом – уровень вовлеченности человека при изучении определенной страницы.
При формировании мнения человека о странице основную роль играет текст. Поэтому при введении Панды выдача избавилась от кучи сайтов с некачественным контентом – публикациями, которые были созданы не для людей, а для вписывания ключевых слов.
В 2013 Google внедрил алгоритм Колибри. С этого момента поисковые запросы обрабатываются не только по ключам, но и по смыслу. Однако это не конец – в 2016 процесс поиска усовершенствовали, ввели сигнал ранжирования RankBrain, своего рода искусственный интеллект, который должен уметь понимать не отдельно смысл каждого слова и даже не общего содержания, а суть всей фразы целиком.
Нововведение связано с тем, что люди начали вводить в строку поиска лаконичные запросы с ключами, а также стали использовать «естественные» запросы – фразы из разговорной речи, порой длинные и сложные.
Схожая ситуация наблюдается и в Яндексе. В ноябре 2016 года Яндекс порадовал нас алгоритмом Палех. Из-за чего интерес к написанию LSI-текстов резко возрос.
Поисковики все сильнее обращают внимание на содержание, а не на технические показатели (наличие ключей, количество вхождений и т.д.). Теперь нужно говорить не только о «релевантности слов-маячков», но и о «релевантности смыслов». Что является последней тенденцией в семантическом поиске.
Яркий пример того, как поисковики работают сейчас: попробуйте ввести в строку поиска «фильм про парня который слышал женские мысли».
В первой десятке результатов выдачи будут такие страницы, в заголовке, а где-то и в содержании которых нет этого ключа:

Как писать тексты сегодня?
-
Раскройте суть ключевых слов и избегайте нетематических запросов. Когда закончите статью, спросите себя: если я введу ключ в поисковую строку, подойдет ли мой текст в качестве лучшего ответа?
Небольшая хитрость: используйте технику «Небоскреба». Находите самый интересный материал и создавайте более совершенный текст.
- Но, к сожалению, пока поисковики понимают суть не всех запросов, однако стремительно развиваются в этом направлении. Поэтому для лучшего результата, мы в случаях, когда это необходимо, сочетаем оба метода. И пока не получается отказаться насовсем от традиционной модели написания текстов. Тем не менее, при любых условиях во главу угла ставим смысл, а не вхождение ключей. Главное, чтобы читателям материал нравился. При необходимости слегка колдуем над оптимизацией, без ущерба для пользователя, но в угоду поисковикам.
- Не забывайте отслеживать результат, если статья не попадает в ТОП, ее лучше «допилить», начав со смысла – какие-то моменты развернуть чуть подробнее, добавить картинок, провести исследование. Материал на самом деле должен лучше других отвечать на запрос пользователя.
-
Включите в семантическое ядро страницы не только основные запросы, но и дополнительные ключевые слова. Они помогут поисковым роботом лучше понять смысл текста, поэтому обеспечат большие шансы на привлечение трафика на сайт.
Для поиска LSI-фраз есть как минимум 3 простых и бесплатных способа:
-
поисковые подсказки – проанализируйте спрос пользователей

-
Яндекс.Вордстат – смотрите на колонку «Что искали со словом»
-
рекомендации поисковиков – обратите внимание на конец первой страницы результатов поисковой выдачи
-
- Самое главное – вникайте в тему, пишите уникальные, полезные и интересные тексты. Такие, которые вы сами прочли бы с удовольствием.



P.S. Мы пишем именно такие тексты. Заказать их можно здесь.
1ps.ru
Что такое LSI-копирайтинг? Понятный ответ здесь
Если вы – начинающий автор, то в современном жёстком и даже жестоком (шутка) мире текстописания вам обязательно надо иметь представление о том, что такое LSI-копирайтинг.
Я постараюсь сильно не умничать и рассказать на предельно понятном уровне не о термине, как о том, как писать тексты по LSI.
Немного о происхождении термина LSI копирайтинг и что он означает
Итак, что такое LSI копирайтинг? Как несложно догадаться, LSI – это аббревиатура английского словосочетания, которое на русский можно перевести как «скрытый смысловой анализ». Анализ качества текста происходит не только по уже устаревшей «прямой» релевантности, то есть по точным вхождениям ключевых слов, как было в эпоху становления SEO. Большое значение уделяется общему смыслу, словарному разнообразию и экспертного уровня материала заданной тематики.
Калькированный перевод аббревиатуры LSI в Википедии, который и переводом-то назвать сложно, называет технологию LSI копирайтинга технологией написания текстов с «латентным семантическим индексированием» . Ужас какой, ни одного русского слова в русском якобы переводе.
Появление LSI копирайтинга принято отождествлять с разработкой специалистами из Google нового поискового механизма, который получил название Панда и вышел в 2011, кажется, году. Он стал предъявлять к фундаментальным принципам написания сетевых публикаций иные требования, что незамедлительно сказалось на результатах поисковой выдачи. Что же именно произошло с поисковыми алгоритмами?
Как писать тексты по правилам LSI-копирайтинга?
Как сказал один из руководителей отдела поисковых разработок Яндекса, теперь поисковая машина может вывести в топ даже те тексты, где главный ключевой вопрос не встречается вовсе. Вот это – основная и наиболее четко сформулированная мысль создания текстов по LSI.
Если раньше поисковики учитывали в основном прямые, потом еще и разбавленные запросы, то теперь они все больше и больше анализируют общий смысл и качество текста. Лично мне лет с десять назад приходилось писать для ссылочного продвижения невообразимую чепуху – например, в текст про экструзию кукурузы надо было впихнуть ссылку «подставка под телевизор». Это реальный пример из моей профессиональной жизни. Так вот, LSI – это не усложнение задачи копирайтера, это его спасение в борьбе за смысл, логику материала и чистоту языка, который должен оставаться великим и могучим. Потому что теперь такие бессмысленные ссылки и тексты – табу, причем жёсткое.
Еще раз попытаюсь сформулировать суть LSI-копирайтинга: теперь писать надо не «под ключи», а «про ключи». Если предстоит написать текст на страницу, рекламирующую производство мебели в Новгороде по низким ценам, то весь текст должен быть «пропитан» именно этой темой, а не какими-то точными ключами. Как этого достичь? Привожу главные факторы написания качественных публикаций по «элэсай» — новостей, разделов сайта и любых других:
- Стараемся пропитывать текст профессиональной терминологией, для чего необходимо погружаться в тему каждой создаваемой публикации. Если речь, например, идет о деревянном строении, то писать текст исключительно про «красивый деревянный дом, купить который вы можете в нашей компании» — уже не вариант. Надо написать текст про сруб, оцилиндрованное бревно, брус профилированный и клеёный (именно так, через «ё»), про рубку в «теплый угол» и в «ласточкин хвост», про мауэрлат и стропильную систему. А уже только потом, словно на десерт, в тексте должно быть классическое сео- ключи и продавалки наподобие «купить, «недорого», «в Городе N» и так далее.
- Используем синонимы. Простейший пример – в материал, который вы сейчас читаете. Помимо слов «LSI», «текст» и «копирайтинг», которым и посвящена статья, здесь есть и «элэсай», и «материал», и «публикация», и «статья», и «контент», и даже «латентное семантическое индексирование», о как.
- Делаем структурные тексты. Уделяйте большое внимание оформлению – абзацы, заголовки, подзаголовки, списки. И чтобы каждый из элементов опять же был «пропитан» тематикой статьи.
- Маниакально следим за грамотностью. Опять же пример из реальной практики. На рубеже тысячелетий, то есть добрых полтора-два десятка лет назад, при написании текстов умышленно использовались наиболее типичные опечатки и ошибки, которые делали пользователи при вводе поисковых запросов. Сейчас поисковик благополучно сам исправляет ошибки юзеров и выдает ему правильные ответы. А сайты, которые пишут с ошибками, быстро и серьезно пессимизирует. Причем даже за пунктуационные ошибки, которые многими и за ошибки-то не признаются. Предлагаю запомнить мой слоган: грамотность – главнейший SEO-оптимизатор XXI века.
- Стараемся НЕ использовать «математику» при написании текстов – об этом мы еще также поговорим отдельно. Да, разумеется, любой поисковый алгоритм – это математический анализ контента. НО! Эта «математика» направляет все свои силы на то, чтобы приблизиться к литературе!
Да, используется проверка по Ципфу, спам, водность и прочие параметры. Но опять же – в погоне за качественным контентом алгоритм поиска поменяется, а русский язык – нет. Поэтому не язык должен подстраиваться под алгоритмы, а алгоритмы – под язык. И никак иначе. И именно это сейчас происходит. Поэтому я не беру в работу заказы, где написано «вода 5, спам 20, главред 10». Заказчики просто сами не понимают, что в итоге получат нечитаемый, сухой и нерелевантный бред.
А еще хуже – это роботизированные и совершенно идиотские (уж простите) задания – к этому тексту надо дописать 1234 символа и вставить слово «топор» 9 раз. Бегите от такой работы, как черт от ладана – это пример не копирайтинга по технологии LSI, а прямого пути в Баден-Баден и другие неприятные места. В прочем, это исключительно мое личное мнение. Надеюсь, дать ответ на вопрос, что такое LSI копирайтинг, у меня получилось.
И напоминаем, что вы всегда можете не только почитать познавательные публикации, но и заказать тексты для своего сайта.
==Если вам нравятся наши публикации – заходите также и на канал Лаборатории Контента в Яндекс.Дзене и поощряйте тексты лайками и репостами!
Искренне ваш,
Александр Алмис.
Читайте также:
xn—-jtbhhd0asebdc5i.xn--p1ai
что это такое, как влияет на SEO с примерами
Делаем вашу страницу интересной и стимулируем подписчиков почаще заглядывать к вам на страницу или на сайт за покупками

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
![]()
LSI-копирайтинг – это тексты, слова и словосочетания в которых взаимосвязаны и соответствуют выбранной теме.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA

Это читабельные статьи, написанные по заданным ключам. При этом они несут полезную информацию.
Предположим, вы ищите материалы по SEO-продвижению. Для этого вводите в Google соответствующий запрос. При этом вы хотите найти контент, который максимально полно раскроет ответы на волнующие вас вопросы.
Вы жмете кнопку «Поиск». При этом поисковый робот начинает перебирать все статьи по вашему запросу. Он смотрит не только на то, чтобы в тексте была заданная фраза, но и на слова, которые ее окружают. В процессе анализа он нашел 2 публикации на вашу тему.
В одной речь идет именно о том, о чем вы спрашивали, а во второй — данная фраза упомянута случайно, а сам пост о детских игрушках. Алгоритмы робота помогли ему это выяснить и, желая дать вам наиболее полезный контент, он поставил эту публикацию в конец. А пост про SEO он вынес повыше в поисковой выдачи.
Конечно, он оперирует не 2-я статьями, а сотнями тысяч. При этом похожим образом сравнивает их все и так формирует выдачу. Поэтому теперь на ТОП-позициях оказываются сайты, на которых расположены полезные для читателей тексты, с минимальным содержанием «воды» и рассуждений на смежные темы.
LSI-копирайтинг: что это и как его использовать
Данное направление копирайтинга появилось в ответ на ужесточение алгоритмов формирования выдачи. Именно LSI-индексирование помогало поисковым машинам оценивать соответствие текста заданному запросу.
Поэтому публикации ни о чем с тонной ключей перестали выводить сайты в ТОП. Теперь нужен контент с максимальной концентрацией полезности и с использованием LSI-фраз. Они «объясняют» роботам, о чем ваш текст, и то ли ищет пользователь.
Интересно, что чем больше в статье таких словосочетаний, тем очевиднее — ваш материал подходит по введенному запросу. При этом пост уникален, в нем нет переспама и другие слова сочетаются по смыслу с данными фразами.
Поисковые роботы научились узнавать”синонимы и омонимы. Например, есть слово «тачки», которое пользователь вводит в поиск. И не понятно, что именно ему нужно, ведь это может быть:
- Мультик.
- Автомобиль.
- Садовый инвентарь.
Поэтому машина смотрит и на другие слова в фразе, анализирует, выбрали ли вы что-то из предлагаемых вариантов. В первую очередь даются варианты с мультиком. Если это не то, вы даже можете пожаловаться на неподходящие варианты.
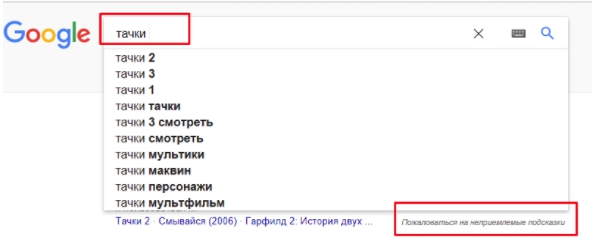
Когда начнете вводить второе слово, система предложит новые подсказки. При этом фразы, которые были в первом случае, исчезли из списка. Среди них вы сможете выбрать ту, которая нужна.
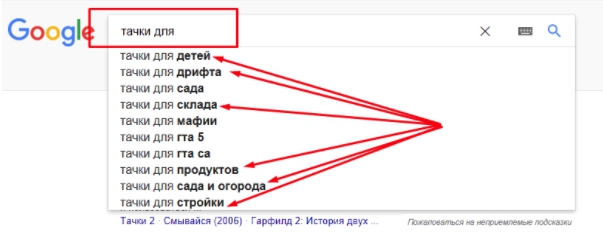
Как система оценивает публикации на вашем сайте, чтобы показать или не показать его в выдаче по вводимому ключу:
- Если у вас размещена рецензия на мультик, наверняка, в ней есть такие LSI-слова: «герои» , «мультфильм» , «озвучка» и т.д.
- Когда вы публикуете материалы о машинах и периодически называете их тачками, скорее всего, вы использовали и такие слова: «подвеска», «тюнинг», «купить» и пр.
- На сайтах о садовых принадлежностях могли употребляться фразы «двухколесные», «инвентарь», «тележка».
Получается, в запросе и в тексте для системы есть подсказки, которые она сопоставляет, анализирует и на их основе формирует выдачу. Именно LSI-слова помогают ей понимать контекст и оценивать полезность материала для пользователя.
Как найти такие слова, которые подскажут системе, что вы имеете ввиду? Один из способов — изучить варианты запросов, которые вводят пользователи. Все люди разные и одну и ту же информацию они могут искать, используя разные формулировки.
LSI-копирайтинг и SEO
LSI-копирайтинг помогает сайту оказаться на высоких позициях выдачи. То есть способствует SEO благодаря насыщению статьи словами по теме запроса.
Подобрать такие тематические фразы можно, если использовать:
- Подсветки. Это синонимы, указатели места, смежные слова по теме. К последним относятся формулировки наподобие «купить», «продать», «заказать». Но таких слов наберется до 10 штук — на большую и полезную статью не растянешь. Поэтому такой способ малоэффективен, и его используют редко.
- Частотный словарь ТОПа. Это варианты, которые предлагает поисковик, исходя из того, что по вашей теме ищут люди. Важно понимать, сколько раз встречалась та или иная формулировка. Если фраза вводилась часто и на многих сайтах, значит, она больше остальных соответствует вашей теме.
- Анализ всей коллекции документов поисковика. Если нужно изучить всю коллекцию поисковых запросов по выбранной теме, используйте Wordstat.yandex.ru. Плюс изучите несколько сотен позиций текстов в поисковой выдаче. Это поможет понять, какие слова и фразы чаще всего встречаются в материалах по вашей теме. Особое внимание обращайте на качественные статьи, которые вам показались ценными и полезными.
LSI-копирайтинг полезен для SEO-продвижения. Ведь для таких текстов не нужно делать прямое вхождение ключа. Система поймет, что вы имели ввиду по контексту, другим фразам, построению предложений.
LSI-копирайтинг: чем еще может быть полезен
При формировании списка LSI-ключей, специалист изучает много разносторонней информации и получает возможность наиболее полно раскрыть тему. Результат — качественный текст, который нравится и людям, и поисковым роботам.
Такой контент привлечет больше трафика на сайт за счет:
- Доверия — чем подробнее статья, тем лучше разобрался в теме человек, который ее писал. Он использовал много LSI-слов — поисковые роботы высоко это оценили.
- Уменьшения числа отказов — система поняла, о чем ваш пост, и показывает его только целевым пользователям. Они не уходят с сайта быстро, потому что получают то, что искали.
- Увеличения времени пребывания на сайте — людям нужно больше времени, чтобы изучить полезный и увлекательный контент.
- Более качественного ранжирования — много LSI-слов, значит, сайт ранжируется по большему количеству запросов, а не только по главной фразе.
- Уменьшения конкуренции по ключевым запросам — использование синонимов помогает формировать более конкретные, но менее частотные запросы. По ним мало кто продвигается — вам легче попасть в ТОП.
- Уменьшения спама — тошность текста падает за счет разбавления основных ключей.
- Увеличения числа обратных ссылок — на ваш увлекательный контент охотнее ссылаются другие ресурсы.
- Снижения вероятности санкций — вы не насыщаете тексты ключами, поэтому они защищены от спама. Поисковым роботам вы нравитесь.
Это только список очевидных выгод. А что LSI-копирайтинг дает в долгосрочной перспективе? Рост узнаваемости как эксперта и в конце-концов увеличение продаж.
Даже если до сегодняшнего дня вы ничего не знали об LSI-копирайтинге, но до этого сосредотачивались только на создании детальных и качественных статей, знайте — вы в теме. Продолжайте радовать читателей ценным контентом, только теперь с полным пониманием того, с помощью каких слов его преподносить.
semantica.in