
Как написать текст, который понравится поисковикам
Технологии поискового маркетинга
Разработчики поисковых систем обращают наше внимание на то, что необходимо писать тексты для людей — полезные, интересные, информативные. И это не только слова: алгоритмы Panda и «Баден-Баден» не щадят страницы со слабым контентом и вытесняют их далеко за пределы ТОПа.
Что есть некачественный контент?
На этот вопрос мы постарались найти ответ в анализе последствий введения нового фильтра Яндекса.
Наряду с такими признаками, как
- чрезмерный объем,
- плохая читабельность и
- смещение текста из видимой зоны, о низком качестве контента говорит
- неестественность языковых конструкций.
Именно об этом — качестве изложения — мы поговорим в новой статье и разберемся, при чем тут LSI-фразы и как с ними работать.
Что такое LSI
LSI-копирайтинг (LSI — аббревиатура от latent semantic indexing, что в переводе с английского языка означает «латентное семантическое индексирование») — методика написания и подачи текстового материала, повышающая его релевантность при анализе синонимов, слов, сопутствующих ключевому запросу, а также содержания и смысла текста поисковой системой.
Термин LSI стал звучать в профессиональной лексике оптимизаторов с запуском Google алгоритма Panda («Панда»). Но наиболее пристальное внимание ему стали уделять после прорыва поисковика в области семантического поиска и запуска алгоритма Hummingbird («Колибри»). Поисковая машина начала оценивать релевантность контента не столько на основании вхождения ключевого слова, сколько по степени смыслового соответствия текста исходному запросу. Над реализацией аналогичного подхода сейчас трудится и Яндекс.
Робот не просто цепляется за ключи как якоря, а сканирует и анализирует все содержание (контекст), что делает его оценку близкой к оценке человека.
В связи с этим закономерно появились термины LSI-фразы и LSI-копирайтинг. Они подразумевают расширение основного запроса, а именно: поиск его синонимов и сопутствующих тематических слов (латентных, то есть неочевидных ключей) и написание на их основе качественного материала.
Вместо расчета плотности и тошноты в дело вступает осмысленный подход, в основе которого лежит семантический анализ.
Цель этих действий — дать пользователю наиболее полный ответ на запрос, представить предметный текст в удобочитаемом виде.
Чем отличается LSI-текст от SEO-текста
Рассмотрим на примерах разницу между SEO-текстами и текстами, в которых учитывается LSI. Зададим в Яндексе запрос «купить эллиптический тренажер» и посмотрим на уровень качества контента сайтов с разных позиций.
На рис. 1 — описание раздела каталога интернет-магазина за пределами ТОП50. Мы видим изобилие основного ключа (12 раз в коротком тексте!). Копирайтер в точности подогнал текст под указанные запросы, отведя информативности и удобочитаемости второстепенное значение.
 Рис. 1. Пример классического SEO-текста, заточенного под ключевой запрос
Рис. 1. Пример классического SEO-текста, заточенного под ключевой запросНа рис. 2 — текст магазина из ТОП10, претендующий называться естественным и информативным. Единственное замечание касается врезки о сервисных услугах с целью добавить на страницу ряд коммерческих ключей: «доступные цены», «большой выбор», «гарантии», «скидки», «доставка» и т. д. В данном контексте эта информация не несет полезной нагрузки.
 Рис. 2. Пример естественного текста, ориентированного на людей
Рис. 2. Пример естественного текста, ориентированного на людейТекст из второго примера являет собой не просто набор слов, а смысловую единицу. Если скрыть в нем основной ключевой запрос «купить эллиптический тренажер», смысл не потеряется и из контекста мы поймем, о чем идет речь. Попробуйте сделать то же самое с текстом из первого примера — можно подставить любой другой вид тренажера и ничего не изменится, что говорит о шаблонном формате контента.
Далее рассмотрим, как построить основу (найти ядро запросов) для создания качественного релевантного текста, обогащенного LSI-лексикой.
Как найти слова для LSI-ядра
Начнем с того, что LSI-фразы условно можно разбить на две категории: синонимичные и сопутствующие (связанные тематикой с основным запросом). Первая группа слов позволяет избежать многочисленных повторов ключа, вторая — раскрыть тему текста. Можно предположить, что это будут НЧ-запросы, но это не совсем верно. LSI-фразы связаны по значению с основным запросом, и в их числе могут быть разные по частотности слова и словосочетания.
В нашем примере с эллиптическими тренажерами синонимами основного ключа могут быть:
- эллипс,
- эллипсоид,
- эллипсоидный,
- орбитрек.
Дополняющие тематические слова:
- беговая дорожка,
- степпер,
- кардиотренажер,
- велотренажер,
- лыжи,
- спортивное оборудование,
- домашний,
- профессиональный,
- для пресса,
- для похудения,
- для ходьбы,
- для спины,
- складной,
- магнитный,
- купить тренажер,
- цена,
- магазин и так далее.
Вопрос в том, как собрать это ядро запросов. Рассмотрим несколько бесплатных способов.
1. Поисковые подсказки
Изучаем актуальный поисковый спрос в рамках искомого запроса. Яндекс выдает десять поисковых подсказок, Google — всего три.
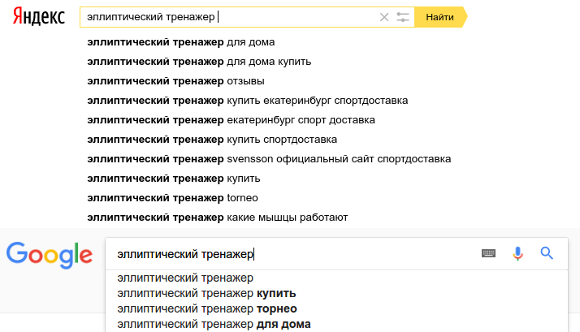 Рис. 3
Рис. 32. «Яндекс.Вордстат»
Находим «Запросы, похожие на …» в правой колонке сервиса «Вордстат» (рис.4).
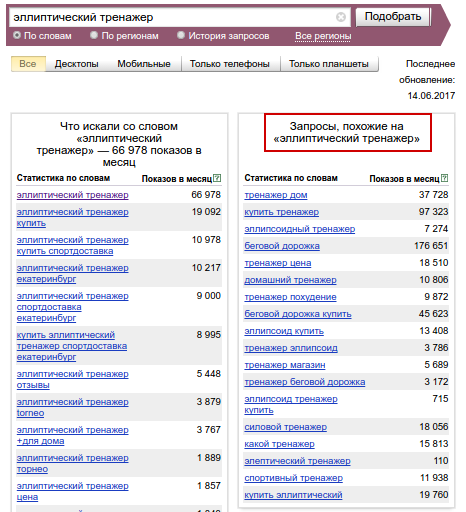 Рис. 4
Рис. 43. «Вместе с этим ищут»
Смотрим на рекомендации Яндекса и Google, основанные на других интересах людей в рамках искомого запроса. Блок располагается в нижней части страницы с результатами поисковой выдачи (рис. 5).
 Рис. 5
Рис. 54. Тексты сниппетов в ТОП10
Ранее для поиска дополнительных слов можно было использовать поисковые подсветки Яндекса (выделенные слова в сниппетах наряду с искомым запросом). Однако сейчас в подсветках ничего кроме региона найти не удастся (рис. 6).
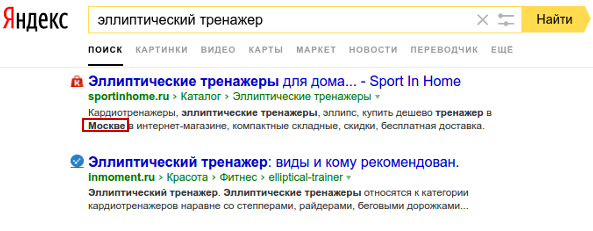 Рис. 6
Рис. 6Так как подсветки более не помогают, можно использовать другой вариант работы со сниппетами — просмотреть тексты в ТОП10 и выделить наиболее часто встречающиеся слова. Важное примечание: для анализа следует брать сниппеты некоммерческих сайтов, если продвигаемый сайт является коммерческим, и наоборот (рис. 7).
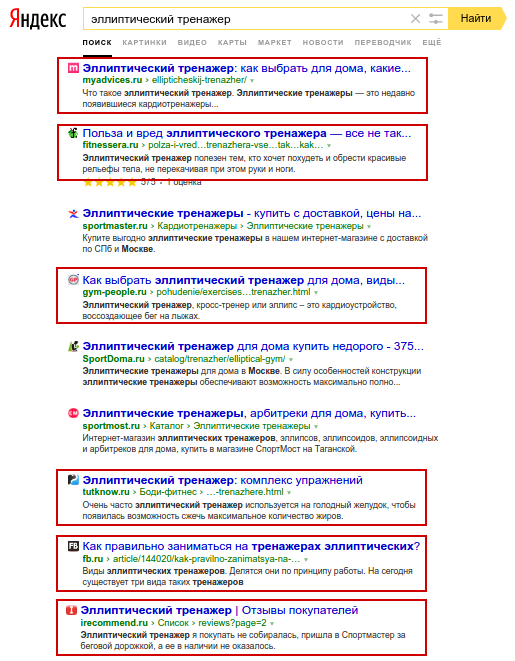 Рис. 7
Рис. 75. Генератор семантического ядра SeoPult
По сути этот инструмент агрегирует все перечисленные выше способы и исключает рутину. Указав основной запрос в ячейке и нажав кнопку «Семантика», вы за секунды получите список из нескольких десятков LSI-фраз (рис. 8). В их числе будут и синонимы, и расширяющие тематику слова. Фразы можно разбить на составляющие и брать для текста однословные запросы во избежание повторов ключа. Подборщик доступен в модуле контекстной рекламы на шаге 2, блок «Ручной подбор слов».
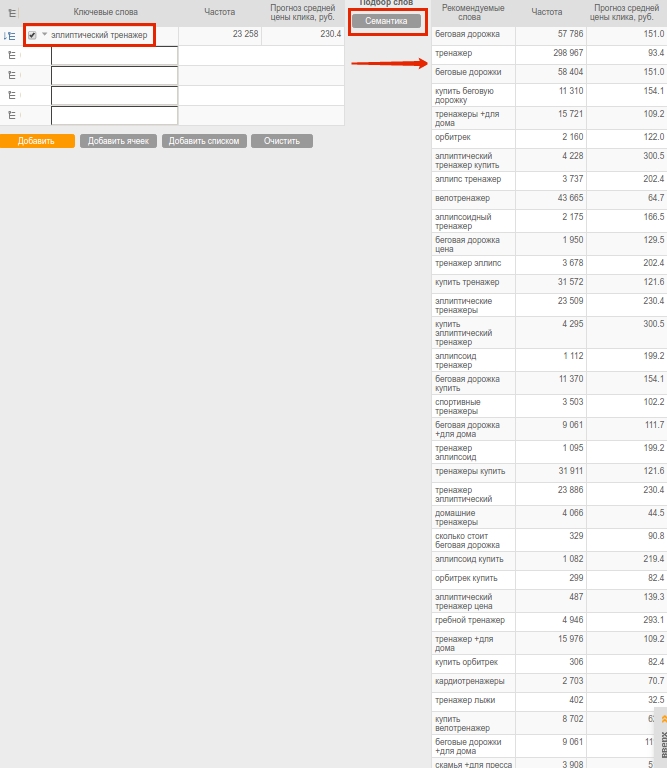 Рис. 8
Рис. 8В результате проведенной работы вы соберете довольно широкое LSI-ядро, однако далеко не все слова будут необходимы для конкретного текста. Нужно исходить из задачи и оставлять только те запросы, которые удовлетворят требованиям. Например, описание для раздела каталога магазина и информационная статья о выборе тренажера будут иметь разное назначение и отличный набор фраз.
Найденные LSI-запросы можно использовать не только для написания новых текстов, но и коррекции существующих. После очередного текстового апдейта поисковых машин вполне вероятно, что обновленный контент появится в выдаче по дополненным ключам.
Применяй с умом
Написание текстов на основе LSI-фраз — метод рабочий, но тем не менее не решающий проблему качества контента. Можно собрать богатую семантику для насыщенной и полезной статьи, но применить ее так, что текст невозможно будет читать.
Пример на рисунке ниже является тому подтверждением.

Важно осмысленно подходить к тому, что вы пишите — не нужно превращать текст в бессвязный набор предложений.
Необходимо:
- выделить наиболее релевантные ключи для конкретного материала,
- уместно вписать их в контекст,
- грамотно структурировать информацию,
- использовать приемы визуализации (заголовки, списки, абзацы, графику и проч.),
- изложить материал простым и доступным аудитории языком с соблюдением правил русского языка.
Помните, что ключи можно использовать не только в теле текста, но также в заголовке (Title) и описании страницы (Description), заголовках h2 и подзаголовках.
Только при комплексной оптимизации и регулярном создание новых страниц сайта с тематическим контентом можно рассчитывать на внимание читателей и расположение поисковых машин. В реализации этой задачи вам помогут профессиональные копирайтеры и редакторы.
© Николай Коноплянников, руководитель SeoPult.TV автоматизированной рекламной системы SeoPult
fortress-design.com
Все про LSI-тексты: подходы, инструменты, лучшие статьи
Апдейт поста: добавила блок информации про интересный бесплатный сервис Арсенкина по парсингу тегов h2-H6 по конкурентам из ТОП-10 Яндекса или своего произвольного списка URL. Это в пункте «Инструменты LSI».
LSI — тема старая, но именно сейчас она обретает новое дыхание в связи с последними тенденциями в изменениях алгоритмов ранжирования поисковых систем.
LSI-копирайтинг становится мощнейшим SEO-трендом 2017 года. И я считаю, каждый, кто связан с продвижением сайтов, или создает свой сайт любого типа, или оказывает услуги по написанию текстов, должен в обязательном порядке изучить эту тему «от и до» и применять.
Еще в 2010 году на Хабрахабре писали:
«Сегодня я расскажу об одном из подходов, которым активно пользуются поисковые гиганты и который звучит чем-то вроде мантры для SEO aka поисковых оптимизаторов. Этот подход называет латентно-семантический анализ (LSA), он же латентно-семантическое индексирование (LSI)«.
Прошло 7 лет..
Тема, конечно, поднималась тут и там у SEO-блогеров и в докладах на конференциях, но пока это было малочисленно. Началось все с изменением алгоритмов Гугла. А с приходом новых алгоритмов Яндекса — Баден-Бадена и Королева, про LSI заговорили все.

Сод
seoandme.ru
LSI ключевые слова: что это такое, как собрать и использовать в SEO
Что такое LSI?
LSI ключевые слова (Latent Semantic Indexing) — ключевые слова, семантически связанные с основным, фокусным ключевым словом. Являются частью алгоритма LSA, который расшифровывается как «латентно-семантический анализ». LSA появился в 1988 году в США благодаря инженерам, применившим его для индексирования текстов и представления баз данных. Позже данный метод использовался для анализа знаний школьников в США.
Многие считают, что LSI-слова — это только синонимы. На самом деле, это любые ключевые слова, которые появляются в результатах поиска вместе с заданным ключевым словом, потому что имеют один и тот же смысл. Например, «apple» и «itunes» являются ключевыми словами LSI, поскольку имеют один и тот же контекст и часто встречаются вместе. Таким образом LSI ключевые слова можно поделить на два вида:
- синонимические (sLSI)
- релевантные (rLSI)
Латентно-семантическое индексирование (LSI) — семантический алгоритм, который индексирует и находит тематически связанные фразы и слова, формируя таким образом своеобразный “хвост запросов” или, как их еще называют, лонгриды. LSI алгоритм лежит в основе современных поисковиков. Робот анализирует веб-страницы и определяет те слова, которые наиболее часто употребляются вместе на веб-страницах. Это и есть LSI ключи.

Читайте также: Текстовый Анализатор SEO
LSI и поисковые алгоритмы
Массовый интерес к LSI пришел после того, как Яндекс анонсировал алгоритм “Палех”, который находил слова по cмыслу, используя нейронные связи. Таким образом, копирайтеры стали писать уже не просто SEO-оптимизированные тексты, основанные на технической составляющей (например, плотность кл. слов, тошнота и т.д.), а высококачественные и полезные LSI-тексты, которые содержат все логические “оттенки” основного самого частотного ключевого слова (маркерного запроса) и охватывают весь его ассоциативный ряд, за счет чего полностью удовлетворяют запрос пользователя. Для поисковика, конечно же, LSI является очень ценным. Со временем у Яндекс появился алгоритм
“Королев” — это следующий алгоритм на основе нейронных связей. А в Google в 2013-м появился “Колибри” (Hummingbird) — начиная с этого момента Google начал лучше обрабатывать запросы на естественном языке.
Читайте также: Как правильно парсить подсказки
Как парсить LSI ключи?
Поисковики поняли, что LSI наиболее точно нацелены на интент и удовлетворяют запрос пользователя и начали выводить их в подсказках в поле поиска, после заданного ключевого слова:


Читайте также: Чистка семантического ядра
Поисковые подсказки Google и Яндекс зависят от региона пользователя и дают разные результаты, так как имеют различия в алгоритмах. Но все они содержат LSI ключевые слова, а поэтому являются обязательным источником семантики при составлении семантического ядра онлайн. Подробнее о том, как формируются подсказки в Яндекс — тут.
Подсказки обновляются не реже одного раза в день, хорошо показывают текущие тренды и с разных сторон «покрывают» запрос пользователя, в разы повышают релевантность текста и благодаря этому позволяют получить страницам дополнительный трафик.
Собрать подсказки, включающие LSI, можно с помощью функционала Сбор поисковых подсказок:

Инструмент позволяет за считанные минуты собрать подсказки сразу из нескольких ПС — не только Яндекс и Google, но и даже подсказки Youtube:

Отмечу, что парсер также собирает блоки «Вместе ищут» и «Похожие запросы»:


На выходе, все подсказки вы получите в одном итоговом Excel-отчете. Собранные LSI ключевые слова полезно использовать во всех текстовых зонах страницы: Title, h2-h3, Description, Анкорах, Фрагментах, ALT изображений и т.д.
Выводы
LSI копирайтинг однозначно наиболее эффективный метод продвижения информационных сайтов, за LSI будущее алгоритмов ранжирования Яндекс и Google, которые продолжают внедрять принципы LSA/LSI.
Итак, подытожим, что даст нам использование LSI:
- с LSI вы сможете избавиться от переспама (например, «Баден-Баден») и воды, задать нужный ритм в тексте — он будет содержательным, пользователь найдет то, что искал;
- видимость и позиции вашего сайта будут улучшаться по ряду низко- и высокочастотных запросов (LSI лонгриды будут усиливать основное ключевое слово, то есть высокочастотный маркерный запрос), страница будет отображаться в результатах поиска как для вашего основного ключевого слова, так и для всех его “хвостов”.
- вы будете получать стабильный трафик по LSI-оптимизированным страницам;
- благодаря релевантности, которую внесут LSI-ключи — поведенческие факторы будут улучшаться, а процент отказов уменьшится. В итоге вырастет траст вашего сайта, вместе с такими показателями как ИКС и PageRank, сайт с большей вероятностью попадет в ТОП;
Благодаря LSI, ваш текст будет полностью целостным и органичным, отвечающий на запрос пользователя, а значит и требованиям поисковика.
Если у вас есть свои советы по SEO или замечания — пишите нам на электронную почту: support@rush-analytics.ru. Также рекомендуем воспользоваться автоматической кластеризацией запросов в Rush Analytics.
Интересно прочитать:
Как составить мета теги
Парсер Wordstat
www.rush-analytics.ru
LSI копирайтинг — что это такое? Секреты написания LSI-текстов для сайтов, как собрать ЛСИ запросы?
Уникальная технология, которая позволяет вывести сайт в ТОП, или очередное модное увлечение в мире SEO? Давайте разберемся, что такое LSI-копирайтинг. Чем он отличается от стандартного подхода к написанию текстов и нужно ли использовать данную технику на своих сайтах? Чтобы картина была полной, начнем с основ.
Содержание статьи:
Как работают LSA-алгоритмы (латентно-семантического анализа)?
Первые LSA-алгоритмы (латентно-семантический анализ) были запатентованы в 1988 году. Данная технология позволяет машинам лучше понимать смысл текста за счет анализа слов и фраз, которые используются в тексте, и поиска связи между ними.
Например, если в тексте находятся слова «Рено», «автомобиль», «колеса», «привод», «разгон», «характеристики» – компьютер понимает, что текст посвящен автомобилям Рено. Если вместе со словом «Рено» в тексте используются слова «основатель», «Луи», «человек», «промышленник», то статья написана об одном из основателей компании Рено – Луи Рено.
Благодаря латентно-семантическому анализу современные поисковые системы могут выводить в выдаче страницы сайтов, которые отвечают на запрос пользователя, но при этом не содержат самого запроса в тексте
.В целом LSI-анализ текстов помогает Яндексу или Google решать следующие задачи:
- Более точно определять смысл текста.
- Находить документы, которые отвечают на запрос пользователя, но не содержат ключевых слов из запроса.
- Оценивать контент с точки зрения полноты ответа на запрос пользователя.
Поскольку LSI-алгоритмы влияют на позиции страниц в поиске, SEO-специалисты заинтересованы в улучшении контента на своих сайтах. Добиться этого позволяет ЛСИ-копирайтинг – относительно новый подход к созданию текстов для сайтов.
LSI-копирайтинг — что это такое простыми словами?
LSI-копирайтинг – это технология написания текстов, содержащих синонимы и дополнительные ключевые фразы, которые связаны с продвигаемым запросом. Она позволяет повысить релевантность страницы запросу.
Помимо чисто технического добавления ключевых слов и LSI-фраз в текст, необходимо уделять внимание качеству контента и полноте раскрытия темы.
LSI-тексты | SEO-тексты | |
Цель текста | Максимально подробно ответить на запросы пользователя. | Написать текст с нужными ключевыми словами и определенным числом вхождений. |
Основные задачи | Полнота раскрытия темы, наличие LSI-фраз. | Достижение определенной плотности ключевых слов. |
Насколько аккуратно вписаны ключевые слова в текст | Важно, чтобы ключевые слова не привлекали к себе внимания. | Не важно, лишь бы нужные фразы находились в тексте. |
Оформление статьи | Очень важно. | Менее важно. |
Метрики | Показатель отказов, время на странице, наличие LSI-фраз в тексте, уникальность информации (в смысловом понимании). | Плотность ключевых слов, тошнота, уникальность (в техническом понимании). |
Размер текста | Как правило, больше. | Как правило, меньше. |
Требования к LSI-тексту
- Текст должен максимально полно отвечать на запрос пользователя. Нужно, чтобы в тексте была основная информация, которая может интересовать пользователя по данной теме.
- Текст должен содержать синонимы и ключевые слова, связанные с продвигаемым запросом. Как собрать такие фразы, будет сказано ниже.
- Четкая и логичная структура текста.
- Качественное оформление. Желательно наличие в тексте таблиц, списков, графиков, фотографий.
- Желательно наличие в тексте уникальной информации, данных, которых ранее не было в сети Интернет.
Как собрать ключевые запросы по технике LSI?
LSI-запросы – это слова и фразы, по которым поисковые системы могут лучше понять смысл текста. Они подразделяются на две группы:
- Синонимы слов, входящих в запросы из семантического ядра.
- Дополнительные ключевые фразы, которые связаны с ключами из семантического ядра. Например, для запроса «LSI» такими ЛСИ-запросами могут быть слова «тексты», «копирайтинг».
Мы разобрались, что такое LSI ключевые слова. Давайте посмотрим, в каких источниках их можно найти?
1. Словарь синонимов
Используйте специальные словари, чтобы найти синонимы слов из ключевых запросов. Аккуратно пользуйтесь этой информацией, чтобы не добавлять в тексты устаревшие слова или не подходящие по контексту синонимы.
2. Подсказки в поисковых системах
При вводе запроса в строку поиска автоматически выводятся поисковые подсказки. Они могут содержать дополнительные ключевые слова, которые стоит добавить в текст. Посмотрите подсказки в Яндексе и Google и выпишите те, которые соответствуют теме вашего текста:
3. Просмотр запросов из блока «Вместе с … ищут»
В нижней части результатов поиска содержится блок, в котором перечислены запросы, которые ищут вместе с заданной фразой. В данном блоке могут находиться LSI-слова. Например, на скриншоте ниже видно, что вместе с запросом «lsi копирайтинг» ищут информацию о Баден-Бадене (алгоритм Яндекса), SEO-копирайтинге, Istio.com (популярный сервис).
4. Правая колонка Wordstat
В правой колонке находятся фразы, которые, по мнению Wordstat, похожи на заданный запрос. В данной колонке могут находиться LSI-ключевые фразы.
Не нужно выписывать все слова, которые вы нашли в подсказках, Wordstat и других источниках. Достаточно выписать самые подходящие, которые позволят более глубоко раскрыть тему. Обратите внимание, что в подсказках и Wordstat могут встречаться фразы, которые совершенно не связаны с темой вашей статьи. Такие фразы необходимо отсеивать.
Как писать LSI-тексты для сайтов?
- Соберите семантическое ядро для текста.
- Подготовьте список подходящих для статьи LSI-слов из подсказок, блока «Вместе с … ищут» и правой колонки Wordstat.
- Добавьте в ТЗ список LSI-слов из п. 2. Попросите копирайтера использовать слова из этого списка в тексте. Не перегибайте палку, требуя использовать большое число слов в небольшом тексте. Вы можете получить нечитабельный контент, перегруженный ключевыми словами и LSI-фразами.
- На основе собранного семантического ядра и LSI-слов определите план текста. Структура должна быть такой, чтобы ключевые слова вписывались аккуратно и незаметно для читателя и были равномерно распределены по всему тексту.
- Напишите текст по ТЗ или поручите работу копирайтеру.
- Добавьте текст в инструмент Оригинальные тексты, после чего сверстайте на сайте.
Советы из видео ниже помогут вам легко написать любой текст и решить проблему чистого листа:
Где заказать LSI-тексты для сайта?
Технически процесс написания LSI-текста мало чем отличается от обычного копирайтинга. Написать статью с определенными словами и фразами – не проблема для многих людей.
Однако в случае ЛСИ-копирайтинга важно качество текста в плане его содержания и полноты раскрытия темы. Поэтому в качестве копирайтера лучше выбирать специалиста, имеющего опыт работы или образование в нужной сфере (текст о стройке пишет строитель, про автомобили – автомеханик, про языки – лингвист). Тогда в тексте не будет явных ляпов, и может быть уникальная информация, передающая опыт автора в данной сфере.
Рассмотрим варианты, где можно заказать LSI-копирайтинг:
1. Биржи копирайтинга
Объединяют массу фрилансеров. Например, на бирже Etxt.ru зарегистрировано более 1 млн. исполнителей. Рассмотрим плюсы и минусы заказа текстов через биржу:
Плюсы | Минусы |
|
|
2. Агентства копирайтинга
Услуги по написанию LSI-текстов могут оказывать студии и агентства. Например, такая услуга имеется в компании 1PS.ru и ряде других компаний.
Плюсы | Минусы |
|
|
Каталоги копирайтеров, форумы, сообщества
Найти авторов можно через каталоги, форумы и сообщества в социальных сетях. В ряде каталогов отдельно выделяются копирайтеры, журналисты, рерайтеры.
Плюсы | Минусы |
|
|
LSI-копирайтинг – это не волшебная палочка, которая может вытянуть проект в ТОП. Важно понимать, что помимо текстовых факторов, поисковые системы учитывают множество других параметров сайта и его окружения. Однако качество контента играет важную роль. При прочих равных условиях сайт с хорошими текстами, подробно раскрывающими тему, обойдет в поиске конкурента с низким качеством контента.
И самое важное: если вы хотите получить качественный текст, не экономьте на копирайтерах. Труд человека, способного разобраться в теме и сделать интересную статью, не может стоит дешево. Даже фрилансеру нужно что-то есть, платить за квартиру и содержать семью.
adblogger.ru
LSI в SEO: раскладываем по полочкам. Как использовать тематические слова эффективно
Автор Алексей Трудов На чтение 14 мин. Просмотров 255 Опубликовано
Вот уже несколько лет LSI-копирайтинг (использование в SEO-текстах «слов, задающих тематику») остается крайне модной тенденцией. За это время здравая в основе идея успела обрасти мифами и чересчур смелыми трактовками.
Выжимка: что оптимизаторы и копирайтеры думают о LSI
Если читать подряд все, что написано по теме, то вырисовываются следующие тезисы.
- Аббревиатура расшифровывается как latent semantic indexing — скрытое семантическое индексирование.
- Текст для продвижения должен включать тематичные слова, а не только ключевые.
- К LSI-словам относятся а) синонимы основного ключевика б) слова, которые характеризуют и дополняют основной ключевик в) другие слова, имеющие отношение к теме статьи.
- LSI — это специальный новый алгоритм поисковиков против плохих SEO-текстов, «новая эра в копирайтинге».
- Также алгоритм нужен чтобы отличать тексты по смыслу. Например, чтобы разделить описание фильма «Тачки» от характеристик садового инвентаря.
- А еще LSI-текст должен иметь структуру, быть написанным простым языком, иметь приятный ритм, правильно распределять ключевые слова и тематичные расширения. Информация должна быть подана на уровне эксперта без грамматических и орфографических ошибок.
- Чтобы найти LSI, можно использовать подсказки поисковой системы, подсветки на выдаче, анализ текстов конкурентов (и сервисы, которые все это автоматизируют).
- Кое-где даже проскакивают заголовки «LSI убило SEO!» (ссылка, которую я автоматически вставляю после очередных похорон моей профессии).
Я только что сэкономил вам несколько часов на перелопачивание десятков статей по теме. Теперь попробуем разобраться, что тут правда, а что миф. А главное — как можно использовать это знание на практике.
Что такое LSI на самом деле?
Вот краткий и академически точный ответ:
LSI — сингулярное разложение терм-документной матрицы.
Это видео стало сеошным мемом — нагромождение терминологии вызывает смех. На мой взгляд, довольно странно бояться незнакомых терминов, если под рукой есть Google. Чтобы разобраться в матчасти на бытовом уровне, не надо быть профессором.
Например, можете почитать статью «Тематическое моделирование текстов на естественном языке» (авторы Антон Коршунов, Андрей Гомзин), она раскрывает эту и несколько смежных тем на весьма доступном уровне. Приведу несколько ключевых цитат.
Сначала о важности метода:
Зачастую документы, релевантные запросу с точки зрения пользователя, не содержали терминов из запроса и поэтому не отображались в результатах поиска (проблема синонимии). С другой стороны, большое количество документов, слабо или вовсе не соответствующих запросу, показывались пользователю только потому, что содержали термины из запроса (проблема полисемии).
В 1988 г. Dumais et al предложили метод латентно-семантического индексирования (latent semantic indexing, LSI), призванный повысить эффективность работы информационно-поисковых систем путём проецирования документов и терминов в пространство более низкой размерности, которое содержит семантические концепции исходного набора документов.
А теперь о том, как он реализуется.
Исходная точка — это терм-документная матрица:
Элементы этой матрицы содержат веса терминов в документах, назначенные с помощью выбранной весовой функции. В качестве примера можно рассмотреть самый простой вариант такой матрицы, в которой вес термина равен 1, если он встретился в документе (независимо от количества появлений),и 0 если не встретился.
d1-d6 — документы, в первом столбце — термины
Легко видеть, что некоторые термины встречаются вместе в одном документе а другие — нет. Поисковые системы обладают базой текстов, которая в полной мере отражает особенности естественного языка. Это позволяет создавать огромные терм-документные матрицы и на их основе делать достоверные выводы о взаимосвязях между словами и принадлежности текстов к той или иной тематике.
Однако огромный размер хорош только в плане статистической достоверности. Напрямую работать с матрицей, которая получена из миллиардов текстов, невозможно, так как требует слишком больших машинных ресурсов. Вот тут и нужно сингулярное разложение — математическая операция, которая позволяет упростить терм-документную матрицу, выделив из нее только самые значимые тенденции. Это и есть «проекция в пространство более низкой размерности, которое содержит семантические концепции исходного набора документов».
(С матчастью практически закончили, дальше пойдет ближе к практике. Если интересуют детали — обратитесь к статье на habrahabr, где разобран простой рабочий пример и показаны этапы разложения).
Для нас больше всего важна последняя цитата, которая поясняет конечную цель всех этих процедур с точки зрения поисковой системы:
Для задач информационного поиска запрос пользователя рассматривается как набор терминов, который проецируется в семантическое пространство, после чего полученное представление сравнивается с представлениями документов в коллекции.
Именно так и можно найти документ, который релевантен по смыслу, хотя и не содержит ключевых слов запроса, то есть не обладает текстовой релевантностью в классическом понимании.
А еще поисковик может сравнить представление текста конкретной страницы с эталонными документами конкретной тематики. Если они будут сильно различаться — это серьезный сигнал о том, что с текстом что-то не так.
Например, типичный SEO-текст образца 2008 года состоит из «воды» и специально вставленных ключевых слов. «Вода» в нашем семантическом пространстве будет толкать текст к документам общей тематики, а ключевые слова — наоборот к конкретной теме. Это несоответствие не так сложно выявить.
Недостатки LSI как метода оценки смысла текста
Даже после поверхностного знакомства с методом, вы обязательно заметите, что LSI — это не магия, а всего лишь методика анализа текстов. Более того, она имеет ряд недостатков и упрощений:
- Текст в этом методе рассматривается просто как «мешок слов». Игнорируется их порядок и взаимосвязи в предложении.
- Считается, что слово имеет единственное значение.
- Смысл естественного текста не обязательно совпадает со значением набора слов. Иносказание, ирония, подтекст таким образом не распознаются.
- Сингулярное разложение позволяет работать только с самыми значимыми составляющими исходной матрицы. Часть данных при этом все равно теряется.
Почему я заостряю на этом внимание? Потому что теперь мы видим полную картину и наконец можем сделать несколько важных промежуточных выводов. Вернемся к началу статьи и трезво посмотрим на распространенные убеждения. Итак.
Что нужно понимать, приступая к LSI-копирайтингу
Во-первых, не стоит думать, что LSI — это волшебная таблетка.
Совершенно очевидно, что поисковые системы используют множество методик для определения «спамности» или «полезности» текста. Скрытое семантическое индексирование не универсально, у него есть недостатки. Поисковики безусловно знают о них и применяют LSI в комплексе с другими факторами. Например, огромное количество данных о качестве текста дают поведенческие метрики.
Так что просто натыкать в водянистый текст тематичных слов — не лучшая стратегия в долгосрочной перспективе.
Во-вторых, нет смысла приравнивать написание хороших текстов к LSI-копирайтингу.
А именно это и происходит. Вот скриншот из Википедии о LSI-копирайтинге:
Зачем присобачивать принципы, известные со времен этак Гомера, к одной узкой методике?
В-третьих, LSI в чистом виде — история в первую очередь про «угадывание» смысла запроса, классификацию документов по темам и фильтрацию спама, и только во вторую — про ранжирование.
Недавно делал конспект докладов об устройстве Яндекса. Там есть очень показательный момент. Александр Сафронов рассказывает о направлениях по лингвистике для улучшения качества поиска. В том числе о синонимах и о связанных расширениях, уточнениях, похожих запросах. То и другое принято объединять под ярлыком «LSI». Но!
Распознавание синонимов — это в большей степени «боль» самой поисковой системы. Там понимают, что текст может быть качественным и релевантным, даже не включая все варианты. Например страница с вхождением «купить» может прилично ранжироваться по ключам «покупка», «приобрести» и так далее.
А вот про расширения запроса Александр Сафронов четко говорит:
Скорее всего, релевантный документ, помимо слов запроса, будет содержать эти дополнительные слова (если он действительно хорошо отвечает на запрос пользователя).
Пример дополнительных слов:
Заметьте, кстати, что здесь мы видим связи не только между отдельными словами. Поэтому очевидно, что для выделения расширений используется другая методика, а не LSI.
Второй нюанс в том, что базой для их получения является не только коллекция текстов, но и поисковые запросы. Их использование — это возможность для поисковика искать связи не по формальным критериям (встречаются ли в одном тексте или нет). Вариант: анализ связей между группой запросов, которую задал один пользователь в короткий промежуток времени (разумеется, с объединением данных по миллионам пользователей).
В-четвертых, для нахождения LSI требуются алгоритмы, работающие с довольно большим объемом текста.
Самый простой и часто предлагаемый путь — парсить подсветки Яндекса — и всегда работал не очень хорошо, давая очень скудный спектр слов, сейчас вообще малоактуален.
В-пятых, слова, которые предлагают сервисы, не являются результатом «настоящего» LSI, с которым работают поисковые системы (дальше эта оговорка упускается для краткости и как дань сложившимся понятиям).
Пункт прямо следует из предыдущего. Очевидно, что сервисы не имеют всех возможностей поисковика. Или, по крайней мере, не знают, на какой коллекции документов он определяет закономерности для себя. Тем не менее, связанную лексику сервисы могут генерировать неплохо. Для получения адекватного списка нужно как минимум работать с текстами из ТОПа по запросу (и лучше ТОП-50, а не ТОП-10). При этом, разумеется, тексты в ТОПе должны быть достаточно высокого качества. По низкочастотным запросам не всегда удается набрать достаточную базу.
Как правильно готовить LSI-тексты?
Ну вот мы и добрались до главного.
Если вы внимательно читали предыдущую часть, то могли задаться вопросом — а надо ли вообще этим заморачиваться? Ведь:
- Метод не идеален, имеет множество ограничений.
- Поисковики явно используют куда более сложные алгоритмы.
- Для получения адекватного списка нужна хорошая выборка данных, которую не всегда просто получить.
- Сами слова, задающие тематику, важны в первую очередь для защиты от фильтров. Конкретно в ранжировании помогают скорее не классические LSI-слова, а расширения из поисковых запросов.
- Писать тексты с LSI — значит дополнительно напрягать копирайтера. Иначе говоря — отвлекать его внимание от других важных элементов текста и оплачивать труд по более дорогой ставке. А еще — подсказывать путь, как можно написать статью внешне качественно.
- При этом все равно есть риск получить водянистый текст с кое-как вставленными терминами.
Я считаю, что мода на LSI (как и в случае большинства трендов) в значительной мере подогрета искусственно. Это в первую очередь способ позиционировать свои услуги по написанию текстов как более качественные либо продвинуть сервис по поиску тематичных слов. По крайней мере, у меня сложилось именно такое впечатление после чтения англоязычных материалов.
При этом зарубежные SEO-шники не особо утруждают себя поиском доказательств. Скриншот типичной статьи с советами по SEO:
(Привет всем, кто любит повторять мантру, что, дескать, интернет-маркетинг в России отстает на 3 года. В русскоязычных материалах я в целом видел более критичное отношение к теме, а сервисы в Рунете позиционируют свои услуги куда более аккуратно, не выдавая за волшебную кнопку. Впрочем, это субъективное наблюдение, чисто личные впечатления. Возможно, мне попались не те статьи. На Западе их очень много.)
Однако! Несмотря на все минусы, использовать LSI можно и нужно. Требуется только делать это эффективно и учитывать приведенный выше перечень проблем.
Мой вариант использования LSI
Схема очень простая.
1. Получаем список тематичных слов для каждой темы, которую планируем отдать копирайтеру. Сохраняем их леммы. Можно использовать бесплатный сервис Александра Арсёнкина: https://arsenkin.ru/tools/sp/ или платные текстовые анализаторы (убедитесь только, что они не ограничиваются парсингом подстветок)
2. Однако в ТЗ копирайтеру слова НЕ указываем. Главная задача — получить от него адекватный, решающий задачи пользователя текст. Именно на это и должен быть акцент.
3. Полученные на проверку тексты прогоняем через лемматизатор (тоже есть у Арсёнкина: https://arsenkin.ru/tools/lemma/) и сравниваем со списком LSI-лемм из первого этапа. Для быстрого сравнения списков можно использовать, например: https://bez-bubna.com/free/compare.php
4. Если значительной части LSI-лемм в тексте нет — смотрим его внимательнее. Возможно, с качеством текста что-то не в порядке. Если все хорошо и статья дает нормальный ответ на запрос — вставляем слова и публикуем. Если же есть проблемы — отправляем на доработку. Снова требуем сделать хорошо, а не просто добавить терминов.
В чем соль?
Во-первых, мы не смущаем копирайтера лишними требованиями.
Во-вторых, получаем полу-автоматический критерий для отбраковки плохих статей. Нормальный, человеческий текст будет содержать много LSI без всяких напоминаний. Если, конечно, тематичные слова были собраны корректно.
В-третьих, экономим собственное время на разбор LSI. Просто так выгрузить из сервиса слова и отдать на внедрение не получится. В них все равно будет попадать термины из смежных тематик (и не только: ошибок может быть много). Если давать LSI в ТЗ — придется чистить все результаты. Если использовать по моей схеме — только некоторые.
Завершающий этап: усиливаем текст новыми расширениями
После публикации текста нужно подождать пару месяцев, пока накопится статистика по переходам на него, а затем переработать контент, учитывая реальные запросы пользователей.
Выше я цитировал доклад сотрудника Яндекса, из которого следует, что наиболее эффективный путь получения дополнительных тематичных слов — работа с поисковыми запросами. Именно на основе этой идеи реализован инструмент по дополнительной оптимизации страниц в моем сервисе https://bez-bubna.com/ (точнее, его часть).
Общий принцип очень прост: смотрим состав поисковых запросов, сравниваем с текстом на странице и находим леммы, которые отсутствуют в тексте, но часто встречаются в запросах. Почему это работает?
Забудем о докладе Яндекса. Допустим даже влияния на продвижение основного ключа (главная функция LSI) слова из запросов не имеют. Тогда они способствуют продвижению по множеству низкочастотных запросов, которые немыслимо предусмотреть на этапе написания. Особая прелесть здесь в том, что можно исправить недостаточно эффективное семантическое ядро, быстро расширить семантику страницы.
Кроме того, поисковый спрос нестабилен. Появляются новые запросы, под которые еще очень мало контента в Интернете. Используя сервис, вы имеете шанс поймать эти перспективные ключи с малой конкуренцией и сделать контент более актуальным.
Вот пример — скриншот анализа моего поста об охвате записи ВК:
Метод эффективен даже в самом топорном исполнении — см. эксперимент по автоматической вставке ключей. На практике же требуется не просто впихивать новые расширения, но и добавлять контент (или по-новому расставлять акценты), чтобы страница давала адекватный ответ на эти новые запросы.
То есть: проработка страницы с помощью инструмента выходит за рамки простой текстовой оптимизации. Это работа сразу по нескольким фронтам, настоящее повышение качества контента. Это окупается (см. кейс с расчетом рентабельности: в нем не только вырос трафик, но и снизился процент отказов).
Короткие выводы для тех, кто пролистал, не читая
- LSI — один из современных подходов к анализу текстов. Имеет ряд ограничений и недостатков, это не единственный метод, который используют поисковые системы.
- Анализ связанной лексики наиболее эффективен в определении малоценных «водянистых» текстов и нахождении документов, которые могут соответствовать потребностям пользователя, хотя и не содержат ключевых слов, которые он ввел. Важность LSI как такового для ранжирования страниц с ненулевой текстовой релевантностью сомнительна.
- Использовать списки LSI-слов, которые генерируют разные сервисы, лучше всего на этапе приема работ для быстрой оценки и дополнительной оптимизации. В ТЗ же стоить включать более близкие к реальности критерии качества текста.
- Завершающий этап работы со страницей — усиление контента с помощью расширения семантики и проработки в плане интересов пользователя, которые не были приняты в расчет в начале (исходная точка — реальная статистика по запросам, которые давали трафик на страницу). На данный момент единственный публичный инструмент для автоматизации этого этапа есть в сервисе https://bez-bubna.com/.
Мы уже давно ежемесячно даем от 1000 ТЗ по статьям. И с тех пор, как внедрили более активную работу по проработке подзаголовков + LSI, изменились две вещи:
1. С появлением списка LSI из 20-60 тематических слов — копирайтера можно дополнительно заряжать на более качественный материал.
Копирайтеру сложнее написать бред, если надо обязательно упомянуть слова, повышающие ценность и информативность статьи.
(Однажды клиент пришел с текстом по теме «насморк», в котором не было слова «сопли» — копирайтеру все показалось нормальным, а клиент не был спецом по ТЗ).
Часто копирайтеры слепо пишут в рамках ключей, которые им дают. LSI частично решает эту проблему.
2. Более детальная проработка ТЗ в итоге дала качественные результаты: средние позиции по статьям, средний показатель привлечения дополнительного трафа по микроНЧ, средняя посещаемость — все выросло.
В итоге — даже если отдельный параметр LSI имеет небольшую абсолютную величину, то как доп.фактор, который конкуренты не используют — он может быть существенным и давать хороший результат.
Тем более, времени занимает немного.
Не вижу причин не юзать.
Подпишитесь на рассылку новостей. Никакого спама!
Email*
Подписаться
madcats.ru
что это и как их писать (структура и принцип написания на примерах)
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

LSI тексты – это текстовый материал на тематику ключа, в котором помимо основного СЯ используются синонимы, иные словоформы, фразы, подходящие по смыслу и соответствующие центральной теме.
Только мы научились влиять на поисковую выдачу через SEO-тексты, как поисковые системы изменили свои алгоритмы. Теперь просто наполнить материал ключевиками недостаточно. Вернее, это даже чревато понижением рейтинга в выдаче за переспам. Google и Яндекс взяли курс на максимальную релевантность, и теперь оценивают не плотность ключевых слов, а соответствие текста основной его тематике, а также глубину ее раскрытия.
Пояснить разницу можно на простом примере. Техническое задание для оптимизированного текста выглядит как перечень ключевых слов, которые надо вписать в текст в четко указанной форме. Такой подход запутывал поисковые системы и не позволял им до конца понять, о чем конкретно текст. Например, ключевое слово «тачки», «купить тачки», «железные тачки», «тачки Москва» — о чем этот текст? О фильме, автомобилях или садовом инвентаре?
Семантическое ядро LSI текста значительно шире, и предполагает использование максимального количества слов, которые указывают на основную тематику. Если «тачки» — это о фильме, то в перечне ключевых слов обязательно будут также «билеты», «смотреть», «мультик», «кинотеатр», «премьера».
Что такое LSI
Аббревиатура LSI расшифровывается как «латентно-семантический индекс». Его предназначение – лучше понимать тексты. Термин появился после того, как Google заявил о борьбе за релевантную выдачу и запустил новые алгоритмы Панда и Колибри. Их цель – понять полностью контекст страницы. О контексте поисковой робот судит по набору слов, используемых в материале. Например, если в статье упоминаются слова «дорожка», «кардиотренажер», «спорт», «бег», то поисковая система может сделать вывод, что речь идет о спорте, а конкретно – беговой дорожке.
Как писать LSI тексты
Работа над LSI текстом не отличается от принципов написания авторского. У него должно быть название, разделы, подразделы, списки, если тема их предполагает. Отличия заключаются лишь в формировании семантического ядра. Оно значительно шире, чем у стандартного SEO-текста, поэтому объемы LSI материалов значительно больше.
Невозможно написать качественный текст, используя в нем максимальное количество тематических и околотематических слов, объемом 2 тыс. знаков. Поэтому LSI тексты чаще всего – это так называемые лонгриды на 8–10 тыс. знаков. Это условие повышает стоимость подготовки такой работы, но ее ценность и результативность для бизнеса также вырастает в разы.
Структура LSI текста
У LSI текста всегда есть структура, последовательность и плавность изложения, попытка рассмотреть основной предмет рассказа с разных сторон и дать максимум релевантной информации. Чтобы сделать текст лучше, чем у конкурентов, надо проанализировать поисковую выдачу. Для этого достаточно ввести запрос и просмотреть первые пять ссылок.
Обратите внимание на объем текста, стиль написания, насколько полно изложена информация по теме, затем создайте собственный LSI текст, стараясь сделать его лучше, чем у конкурентов. Но ни в коем случае не заимствуйте чужой. Поисковые системы за это не похвалят, а только понизят вас в выдаче. Требования уникальности к LSI тексту такие же, как и к любому другому в сети.
Как искать LSI запросы
Самое важное в процессе работы над LSI текстом – формирование семантического ядра. Это сложный процесс, так как недостаточно просто взять и собрать ключевые слова. Их надо максимально расширить с помощью синонимов и словоформ. Для этого придется прибегнуть к анализу запросов.
Как анализировать запросы читателей
Для этого используйте поисковые системы Google и Яндекс. Введите в строку ключевое слово и посмотрите на выпадающие подсказки. В них находятся запросы, подобные вашему, по которым люди ищут схожую информацию в сети. Обращайте внимание на список «вместе с этим часто ищут». Его можно найти внизу первой страницы Google и Яндекс. Выбирайте из этих списков то, что подходит для вашего будущего текста.
Как анализировать другие сайты
Введите ключевое слово и зайдите на первые пять страниц, которые показывает вам поисковая система в органической выдаче (без значка «реклама»). Критично оцените их, прочитайте текст и унесите с собой самое лучшее. Это может быть идея, структура, полезная информация. Но она нужна вам не для того, чтобы разместить на своем сайте, а для создания более качественного материала.
Как анализировать статистику
Если вы когда-либо запускали контекстную рекламу, просмотрите список поисковых запросов, по которым вас находили пользователи. Там можно найти много эффективных слов, которые органично дополнят ваше семантическое ядро.
Используйте и другие инструменты. Например, у Яндекса есть сервис Wordstat, который помогает в работе по сбору семантики. У Google есть такой же инструмент в рекламном кабинете Adwords под названием Google Planner. Полезными будут и дополнительные сервисы: Pixel Tool, Megaindex, Soovle.
В чем явные преимущества LSI текста
- Этот подход позволяет создавать тексты согласно последним требованиям поисковых систем, что ведет за собой все связанные преимущества. Сайту больше доверяют поисковые роботы, повышают его в органической выдаче. Соответственно, вы получаете больше посетителей, которые тоже остаются довольными.
- LSI текст всегда более информативный. Он раскрывает тему полностью, а значит – чаще отвечает потребностям человека в информации. В результате у вашего сайта уменьшается показатель отказов, улучшаются поведенческие факторы. Благодаря этому вы зарабатываете дополнительные плюсы в глазах поисковых роботов.
- Еще одно преимущество – повышение конкурентоспособности. Страница будет ранжироваться по большему количеству запросов, что приведет к большему охвату пользователей, которые используют в поиске не столь популярные слова. В долгосрочной перспективе LSI текст выигрывает, так как становится более сложно обогнать его по такому большому количеству запросов.
semantica.in
Как вывести сайт в топ при помощи скрытой семантики (LSI)
LSI (latent semantic indexing) – скрытое семантическое индексирование. Скрытая семантика позволяет определить релевантность документа ключевому запросу. Не ищите научное описание данного метода. Оно довольно сложное и не представляет особой важности в данном случае.
Проще говоря, LSI-метод указывает на то, что теперь поисковики смотрят не только на наличие в тексте ключевого слова, но и анализируют его окружение. А это окружение, в свою очередь, должно быть в непосредственной связи с ключевым словом. Таким образом, упоминая LSI, мы подразумеваем набор слов и словосочетаний внутри одной темы, которые также называют LSI-ключами (LSI keywords).
В тексте должны присутствовать слова, релевантные основному ключу (rLSI). Чем их больше, тем лучше, так как по ним, согласно методике, можно судить, насколько полно раскрыта заданная тема.
Вторая категория LSI-ключей – синонимы основного ключевого запроса (sLSI), которые также можно и даже нужно использовать, чтобы не только разнообразить текст, но и способствовать его продвижению.
Чтобы не запутаться окончательно в определениях, перейдем к примерам.
Бывает так, что по одному запросу в интернете можно найти страницы совершенно разной направленности. Например, вам нужна информация о фильме «Такси», но поиск не понимает, о чем речь, и предлагает список компаний, предоставляющих услуги по перевозке.
Как же тогда поисковик отличает эти два понятия?
Робот поисковой машины сканирует содержание страницы, выявляя отличительные определения по каждой теме:
- Такси – заказать, машина, стоимость, услуги и т. д.
- Такси – фильм, комедия, режиссер, актерский состав и т. д.
Скрытая семантика также позволяет не допустить в топ выдачи страницы с упоминанием ключевой фразы, если ее окружение не является релевантным. При вводе словосочетания «заказать пиццу» поисковик не будет предлагать пользователю, к примеру, посты в блогах, где эта фраза упомянута вскользь, а контекст не соответствует тематике. Даже если запись в блоге посвящена пиццам, она вряд ли попадет в топ. В данном случае слово «заказать» связано со словами «интернет-магазин», «купить» и т. д. Следовательно, предпочтение поисковик будет отдавать именно магазинам.
Так с помощью LSI поисковые системы ведут нас прямо к цели – мы хотим купить пиццу, а не прочитать о ней.
Как выглядят LSI-ключи в поиске
Прежде всего, это поисковые подсказки, которые указывают на слова, которые могут относиться к указанному запросу.

Если прокрутить страницу поисковой выдачи «Яндекса» или Google, можно увидеть блок рекомендаций, содержащий набор LSI-фраз.

Вы наверняка догадываетесь, что это далеко не все варианты слов, которые связаны с основным запросом или являются его синонимами. О том, как собрать более полный список, поговорим позже.
Что представляет собой LSI-текст
Итак, мы выяснили, где найти релевантные ключи. Теперь нужно понять, как использовать их при написании контента.
К примеру, нужно продвинуть страницу по запросу «надувной бассейн».
Проанализируем рекомендации поисковых систем.


Для сравнения приведу два описания для каталога надувных бассейнов. Одно из них представляет собой типичный водянистый текст, которыми грешат многие сайты, а другое (тоже не без воды) разбавлено LSI-словами из приведенных скриншотов.


Разумеется, это не идеальный пример описания. Но по нему можно понять, как работать с LSI-ключами.
Наличие синонимов и релевантных терминов и фраз в статье позволяет пользователям находить ее по самым разным запросам. Таким образом, вы можете привлекать на сайт больше трафика.
Часто статьи, написанные с помощью методики скрытого семантического индексирования сравнивают с экспертными. Человек, разбирающийся в теме, подготовит материал, охватывающий всевозможные нюансы, то бишь и все необходимые слова для привлечения трафика использует.
Но это не всегда так.
Не каждый специалист будет задействовать всю необходимую лексику (он использует одни слова, а пользователь при поиске может использовать совершенно другие). К тому же, по некоторым запросам в выдаче уже столько хорошего контента, что конкурировать становится сложно и приходится обращать внимание на каждую мелочь.
Поэтому во многих случаях возникает необходимость прибегать к сбору LSI-слов и анализу материалов конкурентов. Главное – не увлекаться, пытаясь обхитрить поисковую систему. Текст должен оставаться информативным, а не представлять собой плотную массу LSI-ключей.
Использование LSI-фраз в тексте (в том числе заголовке и описании) является одним из 200 факторов ранжирования в Google. Но заметьте – одним из. Метод латентно-семантического индексирования не решит всех проблем. Но исключать его из зоны внимания – большая ошибка. Особенно в условиях нынешней конкуренции.
Да и «Яндекс» во всем подражает «Гуглу». По крайней мере, пытается.
LSI и «Яндекс»
«Яндекс», как и Google, непрестанно совершенствует свои алгоритмы. Последним его изобретением стал «Баден-Баден», разработанный с целью фильтрации сайтов, использующих переспам ключевых слов. Оптимизаторы пытаются по максимуму напичкать ими тексты, чтобы оказаться на первых позициях страницы выдачи. Особенно это касается коммерческих сайтов. «Да кто эти описания читает?» – мысль, которая усыпляет бдительность многих вебмастеров.
Неудивительно, что «Баден-Баден» взбудоражил сообщество оптимизаторов. Тем, кто руководствовался позицией «и так сойдет», пришлось несладко. Разумеется, среди них много несогласных с полученными санкциями. В некоторых случаях алгоритм действительно способен дать осечку, особенно на первых порах. Однако если почитать ветку форума оптимизаторов, где «Баден-Баден» стал одной из горячих тем, можно наткнуться на некоторые забавные изречения.

После таких умозаключений как-то перестаешь думать о том, что «Баден-Баден» – очередная попытка «Яндекса» загнать как можно больше компаний в «Директ». А это, кстати, крайне популярная среди вебмастеров точка зрения.
Поэтому смотреть в сторону LSI-копирайтинга можно и нужно, если вы продвигаетесь в «Яндексе». Использование синонимов и фраз, имеющих непосредственное отношение к ключевому запросу, позволит разнообразить ваш текст и снизить вероятность попадания под фильтр. К тому же, одни и те же фразы утомляют в процессе чтения.
Как копирайтерам и оптимизаторам работать с LSI
LSI-копирайтинг в Рунете появился относительно недавно. Иногда складывается ощущение, что пока еще не все понимают, что это и для чего нужно. Услуги по написанию LSI-статей предлагают наиболее продвинутые копирайтеры, что неудивительно, ибо для написания подобных материалов нужны определенные знания и опыт. На биржах и форумах оптимизаторов по-прежнему преобладает SEO-копирайтинг, как правило, без привязки к LSI.
Почему LSI-копирайтинг менее популярен:
- Высокая стоимость. Лонгриды – удовольствие не из дешевых. Если учитывать, какое количество времени занимает написание статьи с использованием всех релевантных слов, то можно понять, откуда такие цены.
- Не всегда можно найти эксперта или хорошего копирайтера, способного по-настоящему погрузиться с головой в тему и не вылезать из нее до тех пор, пока на выходе не получится первоклассный материал, достойный топа. Если с автором вам не повезет, на правки и доработки статьи может уйти не один день.
Чтобы оптимизатору объяснить все свои «хотелки» автору, придется написать довольно объемное ТЗ. Копирайтеры, специализирующиеся на LSI-текстах, способны самостоятельно собрать список необходимых слов и на их основании написать качественный материал.
В реальности же у многих оптимизаторов уходит немало времени на то, чтобы найти оптимальный баланс между стоимостью и качеством материала. Кто-то сразу пойдет к специалистам, а кто-то захочет снизить затраты и будет обучать биржевого юнца основам LSI. Во втором случае возникнет несколько вопросов:
- Сколько на это потребуется времени?
- Получится ли в итоге добиться желаемого результата?
- А сам оптимизатор понимает, что такое LSI?
В любом случае, написание LSI-текста начинается со сбора необходимых слов. Для этого можно воспользоваться некоторыми полезными онлайн-сервисами.
Сервисы для сбора LSI-фраз
Прежде всего, помимо самой страницы поиска (как было показано ранее) для получения информации можно использовать сервисы статистики «Яндекса» и «Гугла».
Wordstat
Переходим по адресу wordstat.yandex.ru, вводим запрос и смотрим варианты в правой колонке. Это и есть LSI-фразы.

Google Adwords
Заходим в аккаунт Google Adwords (если его нет – регистрируемся), выбираем меню «инструменты», а далее переходим в планировщик ключевых слов.

Теперь вводим основной запрос и добавляем его в минус-слова, тем самым исключая из вариантов, которые хотим видеть.

Далее открываем вкладку «Варианты ключевых слов» и прокручиваем страницу – вот и очередной список полезных для продвижения слов.
«ПиксельТулс»
Чтобы воспользоваться возможностями данного сервиса, необходимо перейти по адресу tools.pixelplus.ru и зарегистрироваться. После подтверждения электронного адреса перейдите в личный кабинет и выберите «ТЗ на SEO-копирайтинг».



Анализ текстов от MegaIndex
Инструмент от MegaIndex анализирует тексты страниц, находящихся в топе выдачи по заданному ключевому слову/фразе. В результате анализа мы получаем не только список LSI-однословников, но и статистику по использованию каждого из них на страницах топовых конкурентов.


Довольно важный показатель в таблице – уровень соответствия страницы запросу (TF*IDF). Если конкуренция в нише высокая, можно ориентироваться на показатели конкурентов при написании контента.
Необходимо также учитывать, что перечисленные инструменты не идеальны. Старайтесь внимательно изучать предложенные ими LSI-ключи и отбрасывать наименее релевантные. Иначе можно получить на выходе бредотекст.
Рекомендации к написанию LSI-текстов
При написании контента делайте упор на полноту информации. Но не стремитесь написать больше знаков – стремитесь максимально раскрыть тему и при этом донести свои мысли в наиболее понятной и краткой форме.
Опирайтесь на релевантные ключи и синонимы, но не злоупотребляйте ими. Текст должен быть естественным.
LSI-ключи следует использовать:
- в теле статьи,
- в заголовках,
- в качестве анкора для ссылок,
- в заголовках, тегах alt изображений, а также в названиях самих файлов.
Споры по поводу метода
В сети (особенно в русскоязычном сегменте) можно встретить самые разные мнения по поводу методики латентно-семантического индексирования. Кто-то пишет, что давно ее использует и доволен результатом. Кто-то, напротив, считает, что не стоит заморачиваться с этим, так как результаты непредсказуемы. Можно потратить деньги впустую, в то время как конкуренты со своими переспамленными текстами будут ранжироваться выше.
Здесь снова стоит напомнить, что не все зависит от одних лишь текстов. Факторов ранжирования огромное множество. В конце концов, чтобы принять решение о том, на какую позицию поместить вашу статью, поисковики анализируют в том числе и поведение пользователей на сайте.
Даже экспертная статья, приносящая пользу, может быть оформлена так, что поведенческие факторы намекнут ПС о том, что данный сайт стоит держать как можно дальше от начала выдачи. Или он будет напичкан горой рекламы, которая не только раздражает пользователей, но и снижает скорость загрузки сайта. А если юзер открыл статью со своего слабого старенького ноутбука, она будет виснуть при каждой прокрутке, что также приведет к закрытию страницы. Можно продолжать приводить примеры бесконечно.
В защиту же можно привести довольно веский аргумент. Использование LSI-ключей обосновано в том числе и логически. По-настоящему качественный текст должен максимально раскрывать тему. О том, насколько она раскрыта, как уже было сказано, можно судить по наличию релевантных основному запросу слов. Синонимы обычно используются, чтобы не повторяться в терминах и разнообразить предложения. На выходе получаем статью экспертного уровня, которую приятно читать – то, что нужно пользователю.
Что касается личного опыта, могу сказать, что LSI оказался для меня действенным способом продвижения информационного сайта с очень ограниченным бюджетом. Причем, в тот момент, когда я писала статьи, я даже не подозревала, что задействую LSI-ключи.
Что я делала:
- Выбирала тему статьи и подбирала под нее соответствующий запрос с помощью Wordstat.
- Набирала запрос в поиске и смотрела варианты – поисковые подсказки. Это давало мне больше идей для статьи.
- Обращала внимание на похожие запросы внизу выдачи под «Вместе с… ищут». Это также давало больше идей по теме. К тому же в некоторых случаях данные фразы могут существенно расширить словарный запас, так как копирайтерам часто приходится писать на незнакомую тему.
- Писала текст, учитывая все каноны современного SEO – структура, заголовки, прописанные теги и так далее.
Получилось так, что одна статья, для которой я по максимуму задействовала похожие запросы, до сих пор приносит больше трафика, чем любая другая на моем сайте. При этом варианты запросов самые разные.

Пожалуй, это одна из немногих страниц сайта, которая занимает одинаково высокие позиции как в «Гугле», так и в «Яндексе».
Выводы
Текст, привлекательный для поисковых машин, становится ближе к тексту, привлекательному для человека. Применение метода скрытого семантического анализа в поиске информации – еще один шаг навстречу запросам пользователей.
Будем надеяться, что со временем верхушки выдачи будут занимать только по-настоящему качественные статьи, дающие наиболее конкретную и полную информацию, которые интересно читать не только обывателям, но и специалистам.
kak-vyvesti-sayt-v-top-pri-pomoshchi-skrytoy-semantiki-lsitexterra.ru